Month: October 2024

MMS • RSS
Posted on mongodb google news. Visit mongodb google news
MongoDB, Inc. (NASDAQ:MDB – Get Free Report)’s stock price rose 4.9% during mid-day trading on Wednesday . The company traded as high as $273.33 and last traded at $272.17. Approximately 667,942 shares traded hands during mid-day trading, a decline of 54% from the average daily volume of 1,446,957 shares. The stock had previously closed at $259.46.
Analyst Ratings Changes
MDB has been the topic of a number of research analyst reports. Piper Sandler raised their target price on MongoDB from $300.00 to $335.00 and gave the company an “overweight” rating in a report on Friday, August 30th. Stifel Nicolaus raised their price target on shares of MongoDB from $300.00 to $325.00 and gave the stock a “buy” rating in a research report on Friday, August 30th. DA Davidson boosted their price target on MongoDB from $265.00 to $330.00 and gave the company a “buy” rating in a research note on Friday, August 30th. Wells Fargo & Company upped their target price on MongoDB from $300.00 to $350.00 and gave the company an “overweight” rating in a research note on Friday, August 30th. Finally, Bank of America boosted their price target on shares of MongoDB from $300.00 to $350.00 and gave the company a “buy” rating in a report on Friday, August 30th. One analyst has rated the stock with a sell rating, five have issued a hold rating and twenty have issued a buy rating to the stock. Based on data from MarketBeat, MongoDB has a consensus rating of “Moderate Buy” and a consensus price target of $337.56.
MongoDB Stock Performance
The business’s fifty day moving average price is $262.41 and its 200-day moving average price is $288.60. The stock has a market capitalization of $20.21 billion, a PE ratio of -97.92 and a beta of 1.15. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Thursday, August 29th. The company reported $0.70 EPS for the quarter, topping the consensus estimate of $0.49 by $0.21. The company had revenue of $478.11 million during the quarter, compared to analyst estimates of $465.03 million. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. MongoDB’s revenue was up 12.8% on a year-over-year basis. During the same quarter in the previous year, the firm earned ($0.63) earnings per share. As a group, equities research analysts expect that MongoDB, Inc. will post -2.44 EPS for the current year.
Insider Transactions at MongoDB
In other news, Director Dwight A. Merriman sold 2,000 shares of the stock in a transaction on Friday, August 2nd. The stock was sold at an average price of $231.00, for a total transaction of $462,000.00. Following the transaction, the director now directly owns 1,140,006 shares of the company’s stock, valued at $263,341,386. This represents a 0.00 % decrease in their position. The transaction was disclosed in a filing with the Securities & Exchange Commission, which is available through this link. In other news, Director Dwight A. Merriman sold 2,000 shares of the company’s stock in a transaction that occurred on Friday, August 2nd. The stock was sold at an average price of $231.00, for a total transaction of $462,000.00. Following the sale, the director now directly owns 1,140,006 shares of the company’s stock, valued at $263,341,386. This represents a 0.00 % decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available at the SEC website. Also, CRO Cedric Pech sold 302 shares of the stock in a transaction dated Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total transaction of $77,387.50. Following the completion of the transaction, the executive now directly owns 33,440 shares of the company’s stock, valued at approximately $8,569,000. The trade was a 0.00 % decrease in their position. The disclosure for this sale can be found here. In the last quarter, insiders sold 15,896 shares of company stock valued at $4,187,260. Corporate insiders own 3.60% of the company’s stock.
Institutional Investors Weigh In On MongoDB
Several hedge funds have recently added to or reduced their stakes in the business. Vanguard Group Inc. lifted its position in MongoDB by 1.0% in the first quarter. Vanguard Group Inc. now owns 6,910,761 shares of the company’s stock valued at $2,478,475,000 after buying an additional 68,348 shares during the last quarter. Jennison Associates LLC boosted its stake in MongoDB by 14.3% during the 1st quarter. Jennison Associates LLC now owns 4,408,424 shares of the company’s stock worth $1,581,037,000 after purchasing an additional 551,567 shares during the period. Swedbank AB raised its stake in MongoDB by 156.3% during the 2nd quarter. Swedbank AB now owns 656,993 shares of the company’s stock valued at $164,222,000 after acquiring an additional 400,705 shares during the last quarter. Champlain Investment Partners LLC raised its holdings in MongoDB by 22.4% during the first quarter. Champlain Investment Partners LLC now owns 550,684 shares of the company’s stock worth $197,497,000 after purchasing an additional 100,725 shares in the last quarter. Finally, Clearbridge Investments LLC increased its holdings in MongoDB by 109.0% in the first quarter. Clearbridge Investments LLC now owns 445,084 shares of the company’s stock valued at $159,625,000 after buying an additional 232,101 shares in the last quarter. 89.29% of the stock is owned by hedge funds and other institutional investors.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Market downturns give many investors pause, and for good reason. Wondering how to offset this risk? Click the link below to learn more about using beta to protect yourself.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Rafiq Gemmail
Article originally posted on InfoQ. Visit InfoQ
Jesse Anderson, managing director of the Big Data Institute and author of Data Teams, recently published the latest findings from his annual Data Teams Survey of 81 data leaders and engineers across a range of enterprise types. The 2024 survey shows a slow adoption of LLMs by data teams, a neutral impact from remote work, and an overall decline in the perception of delivered value. The survey also calls out that data-operations capabilities are missing from half of the respondents.
The Data Teams Survey’s analysis emphasised the importance of spreading skills and cognitive load in the data domain across teams with data science, engineering, and operations capabilities. Anderson wrote that while data science and engineering teams are well-represented, “operations teams are lacking in half of the respondents.” Further, he also highlighted inconsistencies in how data teams tend to define the role of operations engineers, with only 20% aligning on a definition which covers systems engineering skills. He wrote:
The individual contributors must meet the criteria and definitions to represent the job title. We see well-represented responses for data scientists and data engineers with operations lagging.
Anderson also published another article looking at the evolution of results from Data Teams Surveys between 2020 and 2024, in which he commented on the methodologies and practices used by data teams. Anderson wrote that over time he’s seen a “decline in DataOps and an increase in teams not using a methodology” of any kind. Anderson wrote that “choosing a methodology is still essential” for successful teams.
Commenting on differentiators between high and low-value teams, Anderson wrote that high performers followed “more best practices.” The survey showed that these practices include engineering norms such as unit testing, close business collaboration, picking the right technologies, and having appropriate cross-functional skills.
A recent episode of the Data Engineering Podcast discussed the need for increased engineering and operational rigour in data teams with Petr Janda, founder of Synq.io. He started Synq, a data operations reliability and observability platform, following his experience with data teams that measured incident recovery times in weeks, compared to hours for other engineering teams. Janda talked about the need for incident resolution processes which factor in a granular, data specific, impact on stakeholders and downstream systems. Calling out missing processes, he said:
Everyone was focusing on the problem of detecting issues … So once we detect that a certain table is missing data or that a certain test is now failing because some business validation is not met, what happens afterwards? What is the workflow from the perspective of finding the right team to deal with that issue, and assessing the impact on the company? Is this even an issue we have to deal with right now, or is that something that can wait and be dealt with later?
Anderson also reviewed participants’ responses to questions about their teams’ delivery of value to the business. Looking back over previous surveys, he observed a downward trend that he said, “should give everyone in the industry pause.” Anderson noted that many respondents “highlighted a disconnect between data teams and business needs.” This was attributed to insufficient “domain knowledge” and issues with “communicating data value to stakeholders.” Anderson wrote:
I’ve been seeing this lower value creation trend anecdotally, and now we see it in the data. For a nascent industry like data teams, we should gradually increase the amount of value created or, at a minimum, stay the same. This downward trend has been troubling me for some time … It is concerning to me that there wasn’t an increase in value creation over three years.”
On the subject of remote work, the survey shows that the majority of respondents indicate that remote work has not impacted their team’s productivity. The survey also showed a slow and shallow adoption of LLMs, with only 12% of surveyed teams using LLMs for data processing, which he described as their “ideal” use case. After accounting for 24% of teams not using LLMs at all, Anderson explained that the remainder primarily use them “for code generation, ideation or copy creation, and code debugging.”
Janda concluded by reflecting on his hope that data teams would become more embedded into organisations’ operational radar, rather than “seeing data as this thing on the side.” He also called out the need for more cross-functional skills on data teams, saying:
I hope to see a lot more teams being cross-functional in the way I remember we removed boundaries between frontend and backend and infra teams, by creating cross-functional units.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

|
Listen to this story |
What is Database Market?
The database market encompasses the industry focused on developing, distributing, and managing database management systems (DBMS) related services. The market includes various types of databases, such as relational (RDBMS), NoSQL, NewSQL, and cloud databases. Key players in database market include Oracle, Microsoft, AWS, and MongoDB, with demand driven by the exponential growth of data, big data analytics, and the shift toward cloud-based solutions for scalability and flexibility.
MMS • Edin Kapic
Article originally posted on InfoQ. Visit InfoQ

The Uno Platform has unveiled its latest update, version 5.4, packed with over 290 new features and enhancements. As part of this update, the team has prioritised addressing concerns raised by enterprise clients, alongside improving the overall performance of applications built on the Uno Platform.
Uno platform is an alternative UI platform for building multi-device applications in C# and XAML. It was launched in 2018, after years of internal use by a Canadian company nventive. It allows developers to write applications for Windows, iOS, Android, WebAssembly, macOS and Linux. It is released under Apache 2.0 open-source license on GitHub.
A key focus of the 5.4 release is performance, with significant improvements aimed at making apps run faster and more efficiently. The Uno team reduced memory allocations by 15% on the DependencyObject in event arguments that are used in many app operations. This reduction directly impacts apps with large visual trees, resulting in smoother performance and a better user experience. Also, by optimising the critical code paths of DependencyObject, the team has alleviated the load on the garbage collector part of the framework.
Among the features of this release, the introduction of markup IRootObjectProvider support stands out. This addition allows developers to create more dynamic and context-aware markup extensions by allowing the extension to traverse the visual object tree of the XAML page where the extension is used. Markup extensions are ways to extend the capabilities of XAML, allowing for more sophisticated and reusable code.
For developers ready to upgrade to Uno Platform 5.4, a detailed migration guide has been provided.
In response to feedback from both enterprise clients and the broader community, the 5.4 release includes several notable enhancements aimed at making the platform more robust and accessible. Among these improvements are:
- The addition of new automation peers for better accessibility support, enabling a more inclusive user experience.
- Improved scaling detection for Linux X11 systems, enhancing cross-platform performance.
- GIF support for Skia Desktop
- AppWindow API that provide greater control over app windows, including functionality to move, resize, and toggle window visibility.
The full list of changes for the 5.4 release is available on the UNO GitHub account.
According to .NET developers’ discussions on social media, the main advantage of the Uno platform over MAUI or Xamarin is being the only cross-platform .NET framework to support writing WebAssembly and Linux applications in C# and XAML.
Podcast: Generally AI – Season 2 – Episode 2: Fantastic Algorithms and Where to Find Them
MMS • Anthony Alford Roland Meertens
Article originally posted on InfoQ. Visit InfoQ
Transcript
Roland Meertens: Welcome to Generally AI season two, episode two. As a fun fact to get started with, I discovered last week that Edsger W. Dijkstra invented his shortest path algorithm in 20 minutes, on a terrace of a cafe in the Netherlands, and he was wondering what the shortest path is from Rotterdam to Groningen, and apparently he didn’t even use a pencil and paper when inventing it. And he says that that helped him avoid all the avoidable complexities, and I think that taking 20 minutes to think about a solution seems acceptable for a LeetCode code problem like this. What do you think?
Anthony Alford: I feel like most of my candidates are not in the same class as the esteemed professor, but yes, why not?
Roland Meertens: I think so too. The other fun fact I have for you, by the way, is that when he started publishing his algorithms, for the first five years, he didn’t use a machine. So basically he and the other researchers would just look at the algorithm for a super long time to convince them that it was correct and would work. So that’s a good unit test, I guess.
Anthony Alford: That’s a good code review, anyway. So there’s a similar anecdote, but I think it was a different guy who said, “I have not tested this code. I’ve merely proved it correct”.
Roland Meertens: Well, that’s the other thing: there wasn’t a notion yet of proof of correctness for algorithms. And at some point he had a call for algorithms for a conference, and so many people submitted algorithms he could find a counter case for, that he just told these mathematicians, or logicians, or whatever it was at the time before computer science was computer science. He basically told them, “You have to submit your algorithm and a proof of correctness”, and apparently immediately someone submitted that and then he knew it was correct.
Anthony Alford: Nice.
Roland Meertens: I will tell you one last other fun fact. The shortest sub-spanning tree algorithm was initially invented to save copper wire on a big electric panel because you want to ground all the points to the same place.
Anthony Alford: Oh.
Roland Meertens: So you want to find the shortest amount of copper which helps with that.
Anthony Alford: That’s amazing. It’s funny how much all this hearkens back to the hardware world.
Roland Meertens: Yes, but then, at that time, these algorithms make sense.
Anthony Alford: Yes. So I don’t have a fun fact so much as a fun anecdote, and this was a blog post from a very long time ago, where a mathematician noticed that mathematicians who were specialists in algebra ate their corn on the cob one way, and the ones from analysis ate theirs in a different way.
Roland Meertens: Interesting.
Anthony Alford: With eating corn on the cob, you can basically go-
Roland Meertens: Left to right
Anthony Alford: … raster pattern, and the other way is to go around the whole thing and then move, and then go around the whole thing. And so the algebraists eat in the raster pattern and the analysts eat in spirals.
Roland Meertens: Interesting.
Anthony Alford: Nobody’s sure what that means or how general it is, but it seemed to hold true for most of the people this guy polled.
Roland Meertens: Nice. Interesting. I will also, by the way, send you the link to the interview in which Edsger Dijkstra said this.
Where Do Algorithms Come From? [03:27]
Roland Meertens: Welcome to Generally AI season two, episode two, where I, Roland Meertens, will be discussing our favorite algorithms with Anthony Alford.
Anthony Alford: Hey, Roland. Well, it’s interesting. We started out with the fun facts about algorithms, and I’ve spent the last few weeks trying to think, what is my favorite algorithm?
Roland Meertens: What is your favorite algorithm?
Anthony Alford: Well, before I get to that, I started thinking, as I do, where do algorithms come from? The answer may surprise you. Do you have a guess where algorithms come from?
Roland Meertens: I don’t know, but I have a pretty good sense of “algo-rhythm”.
Anthony Alford: Nice. Well, algorithms come from Uzbekistan.
Let me explain. In the land that is today known as Uzbekistan, there’s a region called Khwarazm, and this was a long time ago, the home of a man named Muhammad ibn Musa al-Khwarizmi. Actually, that’s what al-Khwarizmi means, it’s someone from Khwarazm.
Roland Meertens: No way.
Anthony Alford: Right? Surprise. By the way, as an aside, this is what we call a toponymic surname, a surname that comes from a place name.
Roland Meertens: Ah.
Anthony Alford: Fun fact. Anyway, today, we usually just refer to this man as al-Khwarizmi. He was born approximately the year 780, and in about the year 820, he was appointed as an astronomer and the head of the House of Wisdom in the city of Baghdad.
There was a lot going on at the House of Wisdom back then. This was during a cultural golden age. The house was a library, an academy, a research center. Scholars were translating ancient Greek texts as well as doing a lot of original work. And some of the work that al-Khwarizmi did was he wrote a book. He wrote it in Arabic, of course, a book about how to do calculations using the Hindu numerals.
As you no doubt know, ancient people like the Greeks and Romans, didn’t have the place value number system that we use today. They used letters for numbers. For example, Roman numerals for one, 10, 100, 1000, those are all different letters from the alphabet.
Roland Meertens: Yes.
Anthony Alford: Whereas we just use a number one, the numeral one, and we add zeros. They didn’t have zeros.
Roland Meertens: Who did not have zeros? The Greeks and the Romans?
Anthony Alford: Anybody.
Roland Meertens: Nobody had zeros.
Anthony Alford: Somebody had to invent the zero.
Roland Meertens: Once someone did extremely poorly on a math test, they had to invent a new number to grade them.
Anthony Alford: You’re cracking me up. It’s like that Happy Gilmore sketch. Anyway, somewhere between the first and fourth centuries, our modern numeral system was invented in India, and it spread to the Islamic world, and eventually to Al-Khwarizmi. And he wrote a very influential book on how to use these numerals and the positional system to do arithmetic. And even today, we still call these numerals, Hindu-Arabic.
Roland Meertens: Yes.
Anthony Alford: Sadly, his original text is lost, but it was translated into Latin. And in the process, Al-Khwarizmi’s name was Latinized, variously to Algorismi, Algorismus, Algoritmi, and the translation of his book was called Algoritmi de Numero Indorum, or in English, Al-Khwarizmi on the Hindu Art of Reckoning. So spoiler alert, our word algorithm comes from the name, Al-Khwarizmi. So I’m sure many of you listeners knew that. I’m sure you knew that too, Roland, but-
Roland Meertens: I did not know this. So I really enjoyed this fun fact.
Anthony Alford: Right, so that’s where the word comes from. Now, a brief digression, when we talk about an algorithm, what does that mean? And Wikipedia says, “It’s a finite sequence of mathematically rigorous instructions, typically used to solve a class of specific problems or perform a computation”.
Roland Meertens: Seems fair, yes.
Anthony Alford: Yes. So the first algorithms that most of us learn as young students are those for doing basic arithmetic: addition and subtraction. And that’s what Al-Khwarizmi’s book was, a book of algorithms. Originally, his Latinized name, Algorismus, became synonymous with the number system and the technique of doing arithmetic with this system was actually called algorism.
Roland Meertens: Is it like there’s algorithm and algebra, right? So that is not going from the same thing.
Anthony Alford: You’re getting ahead of me.
Roland Meertens: Okay, I’m speed running this podcast.
Anthony Alford: Foreshadowing. Yes, actually, we will talk about algebra. They’re both Arabic words, right?
Roland Meertens: Yes.
Anthony Alford: The al, the same word in alchemy and alcohol. A lot of words that start with al-
Roland Meertens: Are Arabic.
Anthony Alford: … are actually Arabic in origin, yes.
Roland Meertens: Okay.
Fibonacci and the Algorismists [08:19]
Anthony Alford: Anyway, as I said earlier, his work was translated into Latin. It was introduced to the West about the 12th century, but it didn’t really take the Western world by storm at first. It was probably known only to a few intellectuals. So what did help to popularize it was a 13th century book called Liber Abaci. It was written in the year 1202 by Leonardo of Pisa.
Roland Meertens: Oh.
Anthony Alford: There’s another toponymic surname. He’s better known to us today as Fibonacci.
Roland Meertens: Oh, interesting.
Anthony Alford: Actually, Fibonacci is short for Filius Bonacci, which means the son of Bonacci. And we would call that a patronymic surname. So-
Roland Meertens: We just became a word fun facts podcast.
Anthony Alford: Well, I love etymology. Well, it’s good he’s got that alias, because when I think of Leonardo and Pisa, I think about Leonardo da Vinci dropping cannonballs off the tower of Pisa. [Ed: this was Galileo, not Da Vinci].
Roland Meertens: Yes. So there were more intellectuals in Pisa.
Anthony Alford: Yes. Well, he was much later. And by the way, da Vinci is another toponymic surname, but I digress. Back to Fibonacci’s book, Liber Abaci. The title is a little confusing, at least to those of us who don’t speak Latin, and I’m one of those, because it sounds like it might be a book about how to use an abacus. In fact, it describes methods of doing calculation without an abacus, but with using that Hindu numeral system. So it’s actually instructions on how to use al-Khwarizmi’s algorithms.
Roland Meertens: So at this point in time, these people already adopted the Arabic number system, or were people still using the Roman number system?
Anthony Alford: So this book was what started the adoption of those numerals in the West.
Roland Meertens: Yes, because of the easy algorithms for addition and subtraction.
Anthony Alford: But it didn’t take over completely, and according to Wikipedia, again, for centuries after this book, the people who followed it were called the algorismists, but there were also people who were called abacists, who were the traditionalists. They had that abacus, you could take it from my cold dead hands, attitude.
Roland Meertens: Yes. If you are a listener who is still holding out, please, please contact us. We will want to interview you.
Anthony Alford: Yes. Well, again, a digression, for those of you who have read the book by Richard Feynman, Surely You’re Joking, Mr. Feynman!
Roland Meertens: Yes, great book.
Anthony Alford: Doesn’t he have a scene where he’s going head-to-head with an abacus guy, doing calculations.
Roland Meertens: Yes, indeed, indeed.
Anthony Alford: The abacus guy could beat him on some stuff, but then Feynman was a Nobel Prize-winning physicist. It would be hard to beat him in some math problems, I think.
Roland Meertens: Yes, I think the thing is that someone, there was indeed an abacus salesman, which at that time is a thing because there’s no calculator yet. So you have abacus salesmen, which I think is already the first amazing thing. And then someone in a cafe starts giving their mathematics problems, and before calculators, people would be really good at simplifying the problems, right?
Anthony Alford: Yes.
Roland Meertens: So he just knows how to simplify the things, and then it’s quicker than the person who is just moving all these beads around.
Anthony Alford: I wonder if he got to use a slide rule or something like that.
Roland Meertens: No. So he was just doing it in his head.
Anthony Alford: He was just doing it in his head.
Roland Meertens: Yes.
Anthony Alford: Amazing. So that’s the power of the Algorismus algorism.
Roland Meertens: Yes. yes, indeed.
Algorithms for the Fibonacci Sequence [11:47]
Anthony Alford: All right, well, so back to Fibonacci. Of course, he’s probably most famous for that sequence that’s named after him, where the next number in the sequence is the sum of the previous two. So 1, 2, 3, 5, 8, 13.
Roland Meertens: Yes.
Anthony Alford: So if your story points are 13 or more, you probably need to break that story up…
Roland Meertens: Yes. This person did not invent the story points, but he did invent the numbering system.
Anthony Alford: So calculating the nth number in that sequence, that’s often a favorite way for instructors in programming to demonstrate recursion, because you can write a very neat little recursive function that, given an input n, it will return the nth number in the sequence.
And I think it’s probably a pretty popular software interview question. Now, that’s probably a controversial topic on Reddit, or Hacker News, or something like that, but I think there are some nice things about it.
For example, the common recursive implementation gives you a platform to talk about complexity of that algorithm, right? By the way, do you know the complexity of the recursive Fibonacci calculation?
Roland Meertens: We talked about algorithms for this in a previous podcast.
Anthony Alford: Did we?
Roland Meertens: Yes, in the previous season, because I think we also found that there’s numerical ways to approach it because you have to calculate a previous number.
Anthony Alford: It’s exponential. Actually, it turns out the complexity is the Fibonacci number.
Roland Meertens: Oh, okay.
Anthony Alford: So anyway, and then you could talk about, well, how do you speed it up? And the answer is you can use memoization.
Roland Meertens: Yes.
Anthony Alford: Spoiler alert, I’m going to call this my favorite algorithm, right?
Roland Meertens: Yes.
Anthony Alford: So there’s non-recursive implementations, such as iteratively calculating it, but my favorite way is to use the golden ratio.
Roland Meertens: Oh.
Anthony Alford: And in mathematics, the golden ratio: two quantities are in the golden ratio if their ratio to each other is the same as the ratio of their sum to the bigger of the two. So three to five should be in approximately the same ratio as five is to eight and so forth. So that golden ratio is approximately 1.618.
You can calculate the closed form of it and it’s one plus the square root of five over two. And then the square root of five is 2.236, approximately. So you can approximate the nth Fibonacci number by taking that golden ratio, 1.618, raising it to the nth power and then dividing by the square root of five.
Roland Meertens: Yes, and it gives you an approximation, right? It’s not exact.
Anthony Alford: It’s not exact. You just basically round, but the error is very small.
Roland Meertens: Oh, interesting. How big is the error then?
Anthony Alford: It’s less than 0.01, I think, once you get past the fourth or fifth Fibonacci number.
Roland Meertens: Fantastic.
Al-Khwarizmi and Algebra [14:38]
Anthony Alford: So that’s my favorite algorithm, but as they say on TV, “Wait, there’s more”. I want to make an AI connection, and you spoiled this for me. So besides his work with the number system, Al-Khwarizmi wrote another book. The English title is The Compendious Book on Calculation by Completion and Balancing, which sounds like something that might be found in the Hogwarts library.
Roland Meertens: Yes.
Anthony Alford: But anyway, this introduced systematic methods for solving linear and quadratic equations. So the Arabic title of this book, which I am not going to try to read, but it contains the word, al-jabr, which is the part about restoring broken parts. And that is where we get the word algebra.
Roland Meertens: So it was the same person, it was the person named Algorithmus who also gave us the word, algebra.
Anthony Alford: Yes, that’s correct.
Roland Meertens: Interesting.
Anthony Alford: Yes, and his approach involved standard operations. So you might say, he had algorithms for doing algebra. We have him to thank for algorithms, for the decimal system and algebra. And so the AI connection is, of course, linear algebra.
Roland Meertens: Yes.
Anthony Alford: … that’s the foundation of neural networks.
Roland Meertens: The people in the House of Knowledge must love the current AI hype.
Anthony Alford: Yes. They’re well past the… What is it, the “trough of despair?” I forget.
Roland Meertens: Yes, indeed, indeed.
Anthony Alford: So that is my favorite algorithm. Actually, I have the Fibonacci sequence and also Algorism himself.
Roland Meertens: Yes, your favorite algorithm is Mr. Algorithm himself.
Anthony Alford: That’s right.
Roland Meertens: I love the approximate Fibonacci algorithm.
Anthony Alford: I forgot we’d talked about that, but-
Roland Meertens: Well, we mentioned it, but we never really explained it, so I really like it.
Probabilistic Counting [17:19]
Roland Meertens: All right, so from my side, I really like that you took an algorithm to approximate the Fibonacci sequence because I want to talk with you about probabilistic counting.
Anthony Alford: That sounds like fun.
Roland Meertens: It is fun. Probabilistic counting sounds like something which shouldn’t exist because either you count it or you don’t. But sometimes you want to have a reasonable estimate that is good enough, like in the case of the Fibonacci sequence. And the thing I want to do today is I want to talk about an algorithm, but I also want to talk about how I modified it a bit.
So the thing is that whenever I visit a conference, I talk to a lot of people, but I always wonder how many unique people did I talk to? Because sometimes you talk to the same person again, and maybe you already forgot them.
So I came up with an approach to this problem, but I first want to talk about the algorithm which inspired this. And that is that if you are a website, like Reddit or YouTube, and you want to know how many unique people visited your website or listened to your podcast.
And it is possible that someone listens to the same podcast twice. Maybe people started listening to this and now they dropped out during the break, and they come back later, and you don’t want to count them all as unique listeners, right? You don’t want to say that we have, I don’t know how many thousand listeners, whereas actually it’s half of them. So you don’t want to double count.
Anthony Alford: Maybe you do and maybe you don’t.
Roland Meertens: Yes, depending on how good you want to feel, you do or you don’t. And also, in this case, for our podcast, I don’t really care about the exact number. I do want to know a rough estimate.
Anthony Alford: Right.
Roland Meertens: And the naive way to solve this problem is that every time someone listens to our podcast, we add a name to a list, and then we turn that into a set, removing all the duplicates. Then we just count the cardinality of the sets. So we count the number of people in the sets, and that will take a lot of compute, and that will have a lot of memory. Hopefully we need a lot of memory to count all the listeners.
Anthony Alford: For this podcast, absolutely. We’re going to need several terabytes.
HyperLogLog [19:48]
Roland Meertens: If you have more than five people. So the algorithm which people have there is called HyperLogLog and does probabilistic counting. Do you know HyperLogLog?
Anthony Alford: I’ve heard of it, so obviously I’m interested in the etymology. Can you explain the name?
Roland Meertens: Oh, so I think at some point someone made an algorithm called HyperLog, and then people improved and called it HyperLogLog. And I think there’s even HyperLogLog++.
Anthony Alford: Oh my goodness.
Roland Meertens: At some point, I was on a holiday in Portugal and I started reading all these papers, but this was five years ago, so I forgot the intricate details.
Anthony Alford: Interesting.
Roland Meertens: But yes, so it’s probabilistic counting. So it’s not actually counting, but you’re using probabilities to estimate the count of the size of a set.
Anthony Alford: Got it.
Roland Meertens: And in the case of our website, imagine we have a website. Actually, the Reddit blog is how I first found this algorithm, because they are using this to estimate things. And the approach is as follows: imagine that each person who is browsing Reddit has a unique ID and that’s somehow encoded by their browser IP, I don’t know, hardware.
So everybody has a unique thing to them. So we can track them on Reddit. So if they visit the same post twice, they have the same unique name. And for ease, let’s just say it’s their name, right? So their computer’s named Anthony or Roland. So what you do is you can take the hash of that number. So you take the ID someone has, you take a hash of that number, and I’m not going to explain what a hash function is, but this hash, when viewing it as a binary number, has an equal probability of a one or a zero in each location.
Anthony Alford: Oh, interesting.
Roland Meertens: Hopefully. If you have a good hash function it’s equally likely that if you look at the binary representation, there’s a one or zero in each response.
Anthony Alford: Got it.
Roland Meertens: Now, the interesting thing is that you can treat this hash, this 0, 1, 0, 1, 1, 0, 1, you can treat this as a dice roll or you can treat it as consecutive coin flips. So if you do this, you can start counting the number of leading zeros.
And for example, if you have a number, there’s a one in two chance that your hash starts with one leading zero, and a one in four chance you have two leading zeros. And one in eight that you have three leading zeros, and you can see where this going. If you see that someone has eight leading zeros, the chance was one in 256, and 16 leading zeros, you only have a chance of one in 65,536.
Anthony Alford: Buy a lottery ticket.
Roland Meertens: Yes, so the nice thing is that, as a website, the only thing you have to keep count of is the maximum number of leading zeros which you saw someone have.
Anthony Alford: Oh.
Roland Meertens: So if you had a lot of people visit your website, you don’t know exactly how much, but you do know that you saw someone with eight leading zeros, you’ve had 256 people. The mathematical expectation is that 256 people listen to your podcast.
Anthony Alford: That’s cool.
Roland Meertens: If you just saw all these numbers flip by, right? And you saw, at some point, someone with 16 leading zeros, you expect that to have been around 65,536 people.
Anthony Alford: Right.
Roland Meertens: Yes, so the only memory you need is one number. You only need four bits, or eight bits, or whatever, how many people you expect.
Anthony Alford: Well heck, let’s go 32.
Roland Meertens: Yes. You only need 32 bits to count an estimate of the number of people.
Anthony Alford: So are you going to tell us about how much the error band is there?
Roland Meertens: Yes, and this is also where algorithms like, I think, this the idea of something like HyperLog. I’m not entirely sure which algorithm introduces what concept, but you could also of course take a look at what’s the number of leading zeros for different hash functions. What’s the number of leading zeros at different places in the same hash?
So what you can start doing is you can start making buckets. So you take the first four zeros and then have different buckets, and then you count the rest of leading zeros for the rest of the number. And that way you can already get way better approximations, and you can take the harmonic mean of these numbers to guess-
Anthony Alford: Not the golden mean?
Roland Meertens: It’s not the golden ratio.
Anthony Alford: The golden ratio.
Roland Meertens: No, it’s the harmonic mean. I will also admit that I don’t know exactly what all the possible mathematical means are. So you can use different tricks to get to better approximations of these numbers.
Anthony Alford: That’s pretty cool. I really love that. Just counting the number of zeros, super simple. And it’s probably not extremely accurate, but like you said, is it good enough? Might be.
Roland Meertens: For just giving someone a quick estimate of how well their post is doing, it’s probably good enough. And as I said, the error band is lower, as you add more of these buckets, then you start having a larger memory footprint, but your memory footprint is still insanely small for counting millions of people.
Anthony Alford: Yes, exactly. So it sounds like you need a couple of things. One, you need a way to uniquely identify each person, and then you need one or more hash functions that meet this criterion that they’re balanced like that.
Roland Meertens: Well, yes, so you need one. I think Bloom filters work on the, it’s some kind of structure for your data. There’s again, probabilistic, where you can check whether an element is in your Bloom filter by using multiple hash functions.
Anthony Alford: Gotcha.
Roland Meertens: In this case, you would just assume that you have one and that that gives you a probabilistic one or zero for all the numbers.
Anthony Alford: Okay.
Roland Meertens: Nice. So not all the hash functions work, right? But some do.
Anthony Alford: Right, well, we could probably do, we probably won’t, but we could do an entire episode on the different types of hash functions.
Roland Meertens: That sounds like something for the next season.
Anthony Alford: What’s your favorite hash function?
Roland Meertens: I really don’t know. I spent a lot of time trying to explain the concept of a hash function to non-technical people, and I have not found a good way to do it. So if you have one and find one, if you find the way to explain a hash function to non-technical people, please let me know.
Anthony Alford: I don’t think I’ve ever had the need. I guess you can maybe do it, it’s for a product manager.
Roland Meertens: As you can see, I’m a lot of fun at parties, but I also like to go to parties and I ask people what their favorite algorithm is.
Anthony Alford: What do you get for answers?
Roland Meertens: Well, I always tell them about HyperLogLog.
Anthony Alford: Oh, okay.
Roland Meertens: But someone last week told me they liked a stable matching algorithm.
Anthony Alford: Okay.
Roland Meertens: Which is a way of making pairs of people using preferences, where both people want to go for a different preference.
Anthony Alford: Okay.
Counting Conference Encounters [27:00]
Roland Meertens: Long story. Anyways, coming back to my original question.
Anthony Alford: Yes, please.
Roland Meertens: How many people did I talk to at a conference? What I figured is that, instead of remembering every name, I can simply remember the alphabetically lowest name and then afterwards I can look at the probability someone has that name or alphabetically lower, and see what the estimated people is which I needed to talk to find someone named like that.
So if I go to a conference and I talk to one person, when you’re sorting all the possible names and the number of people who were born in the UK, there’s a 50% chance that their name is lower than the name Keith.
Anthony Alford: Really?
Roland Meertens: Yes, but only 25% is alphabetically lower than Divian. So I downloaded the data set of baby names from 1996 till 2021, which I will also put in the show notes. At the 12 and a half percentile, so one eighth chance, is the name Babukar. And then if we have that again, we get to the name Alvin.
So I figured this is a great way of, you only have to remember one name, then you look it up in your data set of baby names, and then you can have an estimate of how many people you talk to. And I think you can improve it by remembering alphabetically the lowest name for each letter, if you’re talking to a lot of people, and then you take the harmonic mean, and then you have a better estimate for how many people you talk to.
Anthony Alford: So what was your number?
Roland Meertens: I never do this. I always think it would be fun to try this with a crowd, but just asking in the crowd, what is the alphabetically lowest name you all have? So maybe if we ever do QCon live.
Anthony Alford: Well, I was going to say, at your next party you should do that.
Roland Meertens: Yes, so you can estimate the cardinality of your party.
Anthony Alford: So you have to have ground truth. I was going to say, I would just do like they do voting in some countries where I make everybody I talk to, I would dip their finger and paint and then I would know if I talked to them again.
Roland Meertens: I’m mostly wondering if I start estimating cardinality of my parties, I can soon count it on the one hand. So I don’t even need my abacus.
Anthony Alford: Put a turnstile at the door.
Roland Meertens: Yes, indeed.
Anthony Alford: That’s pretty fun. I love that algorithm.
Words of Wisdom [29:36]
Roland Meertens: Thanks. It’s my favorite algorithm. Words of wisdom, did you learn anything recently? Did you dive into something?
Anthony Alford: Just Al-Khwarizmi and the House of Wisdom. Definitely a lot of interesting scholarship there.
Roland Meertens: Yes, are there other famous things which have come out of the House of Wisdom?
Anthony Alford: I think Al-Khwarizmi did some work on astronomy. So he did some catalogs of stars and things like that.
Roland Meertens: Yes, interesting. Did he also ever treat it as a clock, like we discussed in one episode last season?
Anthony Alford: That I do not know.
Roland Meertens: Because I have seen more people referencing using Jupiter as a clock. So it’s getting more and more settled in my brain that this used to be a normal way of counting time.
Anthony Alford: Interesting.
Roland Meertens: Yes.
Anthony Alford: We’re on Jupiter time.
Roland Meertens: Well, I don’t know, and to what extent people kept track of that. Methods of keeping and tracking time really intrigue me somehow. The one thing which I learned last week, a couple of days ago, at night, at some moment I couldn’t sleep anymore because I had to answer the following question. You know that the eyesight of an eagle is way better than that of a human, right? Like four to eight times better.
Anthony Alford: Right.
Roland Meertens: How do they measure this?
Anthony Alford: They have the eagle read off the eye chart? I don’t know.
Roland Meertens: Yes. It used its wing to indicate, it’s pointing left, pointing up, pointing right.
Anthony Alford: You’re going to tell me.
Roland Meertens: Well, yes, indeed. So I spent a bit of time trying to figure this out when I should have gone to bed. So I was thinking, how do they do this? Can they mathematically calculate this? Is there something intrinsic to the eye where you can treat it as a lens and you can do something with that? Or do they do an eye test? But then how do they do this?
I have gone quite far. So what I figured out they do is they have a long tunnel and they teach the eagle that they put something on the specific screen. So if a screen has a specific pattern, it can fly through the tunnel and land on that screen. So the pattern could be, I don’t know, let’s just assume that the pattern would be a photo of a mouse. I don’t know what the actual pattern is. Maybe they do something else.
Let’s say that the eagle flies through a tunnel, there’s two screens at the end. One screen shows a mouse, the other screen shows a fire truck. If it lands on top of the screen with the mouse, it gets the treats, it gets food.
And what they do is that they have the eagle fly through the tunnel towards the screens, and then they show different sizes of this pattern on the screen. And then they look at when the eagle starts deviating towards the correct screen, and then they know that at that distance they have perceived the pattern correctly.
Anthony Alford: Okay, whereas a person has to get a lot closer before they get their treat.
Roland Meertens: Well, yes, we can easily communicate with a human and ask them to name letters.
Anthony Alford: I definitely want them to use grad students in this experiment, to make them work for treats.
Roland Meertens: Yes, so what I tried to do, after I found this, I thought, “I really want to see how they conduct such an eye test for eagles, and if there’s something which they do regularly”. I could not find this on YouTube. So that’s my other request for listeners. If you know someone who is conducting eye tests on eagles, please reach out to us and send us a video. I’m very interested in this.
Anthony Alford: So we can estimate how many people know this by: we figure out the name of the person who emails us…
Roland Meertens: Yes, if you now listen to this podcast, and so sometimes I think, “Oh, I know more about this than the podcast maker. Should I email them? No, they probably get a lot of emails”. Don’t be like that. Please do send us an email. I really want to see this, and I will put a link to the webpage where I learned about this in the show notes.
Anthony Alford: I may have to go spend the rest of my evening looking that up.
Roland Meertens: Please tell me what you find. If you find a video, that’s what I would love to see. If I can conduct an eye test on any kind of different animals, I would love to see that.
Conclusion [33:45]
Roland Meertens: Thank you very much for listening to this episode, and if you like this podcast, please tell your friends about it. Share it with the world. Thank you Anthony for joining again.
Anthony Alford: It was a lot of fun. I learned a lot.
Roland Meertens: Perfect.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Sanctuary Advisors LLC bought a new stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) in the second quarter, according to the company in its most recent Form 13F filing with the Securities and Exchange Commission (SEC). The institutional investor bought 7,442 shares of the company’s stock, valued at approximately $1,860,000.
Other hedge funds and other institutional investors have also made changes to their positions in the company. Raleigh Capital Management Inc. raised its holdings in MongoDB by 24.7% in the 4th quarter. Raleigh Capital Management Inc. now owns 182 shares of the company’s stock valued at $74,000 after acquiring an additional 36 shares during the last quarter. Advisors Asset Management Inc. increased its holdings in shares of MongoDB by 12.9% in the first quarter. Advisors Asset Management Inc. now owns 324 shares of the company’s stock valued at $116,000 after purchasing an additional 37 shares during the last quarter. Atria Investments Inc lifted its position in MongoDB by 1.2% during the first quarter. Atria Investments Inc now owns 3,259 shares of the company’s stock worth $1,169,000 after buying an additional 39 shares in the last quarter. Taylor Frigon Capital Management LLC boosted its stake in MongoDB by 0.4% during the second quarter. Taylor Frigon Capital Management LLC now owns 9,903 shares of the company’s stock worth $2,475,000 after buying an additional 42 shares during the last quarter. Finally, Fifth Third Bancorp grew its holdings in MongoDB by 7.6% in the 2nd quarter. Fifth Third Bancorp now owns 620 shares of the company’s stock valued at $155,000 after buying an additional 44 shares in the last quarter. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Insider Transactions at MongoDB
In related news, CEO Dev Ittycheria sold 3,556 shares of the stock in a transaction on Wednesday, October 2nd. The stock was sold at an average price of $256.25, for a total value of $911,225.00. Following the transaction, the chief executive officer now owns 219,875 shares of the company’s stock, valued at $56,342,968.75. This represents a 0.00 % decrease in their ownership of the stock. The transaction was disclosed in a filing with the SEC, which is available through this hyperlink. In related news, CRO Cedric Pech sold 302 shares of MongoDB stock in a transaction on Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total transaction of $77,387.50. Following the sale, the executive now directly owns 33,440 shares in the company, valued at $8,569,000. This trade represents a 0.00 % decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available through the SEC website. Also, CEO Dev Ittycheria sold 3,556 shares of the company’s stock in a transaction on Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total transaction of $911,225.00. Following the completion of the transaction, the chief executive officer now owns 219,875 shares of the company’s stock, valued at $56,342,968.75. This represents a 0.00 % decrease in their position. The disclosure for this sale can be found here. In the last three months, insiders sold 15,896 shares of company stock valued at $4,187,260. Insiders own 3.60% of the company’s stock.
MongoDB Price Performance
Shares of NASDAQ MDB opened at $259.46 on Wednesday. The stock’s 50-day moving average is $262.41 and its two-hundred day moving average is $288.60. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03. The company has a market cap of $19.03 billion, a price-to-earnings ratio of -92.33 and a beta of 1.15. MongoDB, Inc. has a 1-year low of $212.74 and a 1-year high of $509.62.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Thursday, August 29th. The company reported $0.70 earnings per share for the quarter, topping analysts’ consensus estimates of $0.49 by $0.21. MongoDB had a negative net margin of 12.08% and a negative return on equity of 15.06%. The firm had revenue of $478.11 million for the quarter, compared to analyst estimates of $465.03 million. During the same period in the prior year, the firm earned ($0.63) earnings per share. The business’s quarterly revenue was up 12.8% compared to the same quarter last year. Analysts forecast that MongoDB, Inc. will post -2.44 EPS for the current fiscal year.
Analysts Set New Price Targets
Several research analysts have recently weighed in on the stock. Mizuho boosted their price target on shares of MongoDB from $250.00 to $275.00 and gave the company a “neutral” rating in a research report on Friday, August 30th. DA Davidson increased their price target on shares of MongoDB from $265.00 to $330.00 and gave the company a “buy” rating in a research note on Friday, August 30th. Morgan Stanley upped their price objective on MongoDB from $320.00 to $340.00 and gave the company an “overweight” rating in a report on Friday, August 30th. Oppenheimer raised their target price on MongoDB from $300.00 to $350.00 and gave the stock an “outperform” rating in a research note on Friday, August 30th. Finally, Wells Fargo & Company upped their price target on MongoDB from $300.00 to $350.00 and gave the company an “overweight” rating in a research note on Friday, August 30th. One research analyst has rated the stock with a sell rating, five have assigned a hold rating and twenty have issued a buy rating to the company’s stock. According to data from MarketBeat.com, the company presently has an average rating of “Moderate Buy” and a consensus target price of $337.56.
View Our Latest Analysis on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Click the link below and we’ll send you MarketBeat’s list of the 10 best stocks to own in 2024 and why they should be in your portfolio.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Shaaf Syed
Article originally posted on InfoQ. Visit InfoQ

Python 3.13, the latest major release of the Python programming language is now available. It introduces a revamped interactive interpreter with streamlined features like multi-line editing, enabling users to edit code blocks efficiently by retrieving the entire context with a single key press. Furthermore, Python 3.13 allows for the experimental disabling of the Global Interpreter Lock (GIL), alongside the introduction of a Just-in-Time (JIT) compiler, enhancing performance though still in an experimental phase. Lastly, the update removes several outdated modules and introduces a random.
A new interactive interpreter
Python 3.13 introduces a new interactive interpreter with exciting features, starting with multi-line editing. Previously, pressing the up key would navigate through previous commands line by line, making it challenging to edit multi-line structures like classes or functions. With Python 3.13, pressing up retrieves the entire block of code and recognizes the context, which allows for easier and more efficient editing. Furthermore, by pressing F3, users can enable paste mode and insert chunks of code, including support for multi-line.
In previous versions, users had to type functions like help(), exit(), and quit(). With the new interactive interpreter, users can now just type help or F1, allowing them to browse the Python documentation, including modules. Similarly, for exit() and quit(), just typing the words exit or quit will quit the interactive interpreter. This is a common complaint from programmers new to REPL(Read-Eval-Print Loop) or interactive interpreters.
Developers can now also clear the screen using the clear command in the interpreter. Previous versions of the interpreter did not have this command, and developers had to resort to terminal configurations to achieve this behavior. Lastly, the new color prompts and tracebacks also aid in better usability for the developers.
Free-threaded
It is now possible to disable the Global Interpreter Lock (GIL), an experimental feature disabled by default. The free-threaded mode needs different binaries, e.g., python3.13t. In simplified terms, GIL is a mutex (lock) that controls the Python interpreter. It provides thread safety but also means that only one thread can be in an execution state at a time.
GIL makes many types of parallelism difficult, such as neural networks and reinforcement learning or scientific and numerical calculations where parallelism using CPU and GPU is necessary. Contention issues cause conflicts with a Single-threaded model. Free-threaded mode allows applications to consume all the underlying CPU cores by providing a multi-threading programming model.
Python has been great for single-threaded applications. However, modern languages like Java, Go, and Rust all provide a model for multi-threading, making comprehensive use of the underlying hardware. GIL has provided thread safety for Python applications, e.g. using C libraries. However, removing GIL has been challenging, with failed attempts and broken integration into C extensions. Developers are used to using the Single-threaded model for applications, and disabling GIL can cause unexpected behavior.
The Just-in-Time Compiler
An experimental JIT (Just-in-time) compiler is now part of the main branch in Python. However, in Python 3.13, it is turned off by default. It is not part of the default build configuration and will likely stay that way in the foreseeable future. Users can enable JIT while building CPython by specifying the following flag.
--enable-experimental-jit
The Python team has been adding enhancements in this direction for some time. For example, The Specializing Adaptive Interpreter introduced in Python 3.11 (PEP 659) would rewrite the bytecode instructions in place with type-specialized versions as the program ran. The JIT, however, is a leap toward a much more comprehensive array of performance enhancements.
This experimental JIT uses copy-and-patch compilation, which is a fast compilation algorithm for high-level languages and bytecode. A fast compilation technique that is capable of lowering both high-level languages and low-level bytecode programs to binary code by stitching together code from an extensive library of binary implementation variants. Haoran Xu, Fredrik Kjolstad describe the approach in-depth in this paper.
The current interpreter and JIT are both generated from the same specification, thereby ensuring backward compatibility. According to PEP 744, any observable differences in testing were mostly bugs due to micro-op translation or optimization stages. Furthermore, the JIT is currently developed for all Tier 1 platforms, some Tier 2 platforms, and one Tier 3 platform. The JIT is a move away from how CPython executes Python code. The performance of the JIT is similar to the existing specializing interpreter, while it does bring some overhead, for example, build time dependencies and memory consumption.
Other updates
Python 3.13 removes several modules (PEP 594), and soft deprecates tools like optparse and getopt, and introduces new restrictions on certain built-in functionalities, particularly in C-based libraries.Python 3.13 also introduces a CLI feature for random. Users can now generate random words from a list of words or sentences or generate random floats, decimals, or integer values, by calling the random function as follows.
# random words from a sentence or list of words
python -m random this is a test
python -m random --choice this is a test
# random integers between 1 and 100
python -m random 100
python -m random --integer 100
# random floating-point numbers
python -m random 100.00
python -m random --float 100
The behavior of locals has also changed in Python 3.13. It now returns an independent snapshot of the local variables and values without affecting any future calls within the same scope. Previously locals() was inconsistent and leading to bugs. This change brings more consistency and helps developers during the debugging process. this change affects locals() and globals() in exec and eval.
def locals_test_func()
x = 10
locals()["x"] = 13
return x
Python 3.13 introduces significant changes that enhance the developer experience. Improvements like the interactive interpreter, along with experimental features like free-threaded and the JIT compiler, promise a more robust and dynamic programming experience. The experimental disabling of GIL enables current libraries and frameworks to adjust and make changes for future releases.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Today, Amazon ElastiCache announces support for Valkey version 7.2 with Serverless priced 33% lower and self-designed (node-based) clusters priced 20% lower than other supported engines. With ElastiCache Serverless for Valkey, customers can create a cache in under a minute and get started as low as $6/month. Valkey is an open source, high performance, key-value datastore stewarded by Linux Foundation backed by 40+ companies. Valkey is a drop in replacement of Redis OSS, developed by long standing Redis OSS contributors and maintainers, and has seen rapid adoption since project inception in March 2024. AWS is actively contributing to the Valkey project. With this launch, customers can benefit from a fully managed experience built on open-source technology while taking advantage of the 13+ years of operational excellence, security, and reliability that ElastiCache provides.
In today’s post, we provide you an overview of ElastiCache for Valkey, its benefits, and how you can upgrade your ElastiCache for Redis OSS cache to ElastiCache for Valkey cache.
Overview of ElastiCache for Valkey
Amazon ElastiCache is a fully managed, Valkey-, Memcached-, and Redis OSS- compatible caching service that delivers real-time, cost-optimized performance for modern applications. ElastiCache scales to millions of operations per second with microsecond response time, and offers enterprise-grade security and reliability. With ElastiCache for Valkey, you can choose between self-designed (node-based) clusters and serverless caching deployment options. You can leverage features like automatic scaling, high availability with multi-AZ deployments, and cross-Region replication, ensuring business continuity and disaster recovery. By offering Valkey as a managed service through ElastiCache, AWS enables customers to benefit from its extensive capabilities without the operational overhead of managing Valkey themselves.
ElastiCache for Valkey offers the following benefits:
- Lower pricing: You can further optimize costs on ElastiCache Serverless for Valkey with 33% reduced price, and 90% lower minimum data storage of 100 MB starting as low as $6 per month. On ElastiCache for Valkey self-designed (node-based) clusters, you can benefit from up to 20% lower cost compared to other engines. Additionally, ElastiCache supports size flexibility for reserved nodes within an instance family and AWS Region. If you are using ElastiCache reserved nodes, when you switch from ElastiCache for Redis OSS to ElastiCache for Valkey, you retain your existing discounted reserved node rates across all node sizes within the same family and also get more value out of your reserved nodes discount.
- Operational excellence: ElastiCache for Valkey provides a fully managed experience built on open-source technology while leveraging the security, operational excellence, 99.99% availability, and reliability from AWS.
- Performance: Customers choose ElastiCache to power some of their most performance-sensitive, real-time applications. It can provide microseconds read and write latency and can scale to 500 million requests per second (RPS) on single self-designed (node-based) cluster.
- API compatibility: ElastiCache for Valkey is compatible with Redis OSS APIs and data formats and customers can migrate their applications without needing to rewrite code or make changes to their architecture.
- Zero-downtime migrations: Existing users of ElastiCache for Redis OSS can quickly upgrade to ElastiCache for Valkey with zero downtime.
- Continuous innovation: The commitment from AWS to support Valkey ensures that customers are not only adopting a stable solution but also one that is poised for future growth and innovation. As the Valkey community continues to develop and enhance the project, AWS customers will benefit from ongoing improvements and new features that keep their applications competitive. AWS is also actively contributing to Valkey and you can read more about that on Amazon ElastiCache and Amazon MemoryDB announce support for Valkey.
Solution Overview
You can get started with Amazon ElastiCache for Valkey with just a few steps:
- Create a ElastiCache Serverless for Valkey cache.
- Create an Amazon Elastic Compute Cloud (Amazon EC2) instance.
- Download and set up the valkey-cli utility.
- Connect to the cache from an application.
We walk through these steps in the following sections. Then we demonstrate performing basic operations on the database. We also discuss how to upgrade from ElastiCache for Redis OSS to ElastiCache for Valkey.
Creating an ElastiCache Serverless for Valkey cache
You can create an ElastiCache Serverless for Valkey cache using the AWS Management Console, AWS Command Line Interface (AWS CLI), or ElastiCache API. The following code is an example of creating a ElastiCache Serverless for Valkey cache using the AWS CLI. Ensure that your CLI version is up-to-date to use Valkey resources in ElastiCache.
This creates an ElastiCache Serverless for Valkey cache in your default VPC and uses the default security group.
You can verify the status of ElastiCache Serverless cache creation using the describe-serverless-caches command.
Setting up EC2 for connecting to an ElastiCache Serverless for Valkey cache
ElastiCache can be accessed through an Amazon Elastic Compute Cloud (Amazon EC2) instance either in the same Amazon Virtual Private Cloud (Amazon VPC) or from an EC2 instance in a different Amazon VPC using VPC peering.
Create an EC2 instance using Getting started with EC2. ElastiCache Serverless for Valkey cache uses both ports 6379 and port 6380. To successfully connect and execute Valkey commands from your EC2 instance, your security group must allow access to these ports as needed.
Downloading and setting up valkey-cli
Connect to your EC2 instance and download valkey-cli utility by running the following commands.
For detailed instructions on using valkey-cli to connect and execute commands against Valkey engine, see the valkey-cli documentation. It’s important to build support for TLS when installing valkey-cli. ElastiCache Serverless for Valkey caches are only accessible when TLS is enabled.
Connecting to Valkey cache for reading and writing
To connect to ElastiCache Serverless for Valkey cache, obtain the endpoint for your new serverless cache using the describe-serverless-caches AWS CLI command. You will find two endpoints.
Connect to ElastiCache Serverless for Valkey cache using the valkey-cli utility.
- -h = hostname
- -p = port
- -c = cluster mode
- –tls = TLS Enabled clusters
Now, you’re ready to execute basic GET and SET operations against ElastiCache Serverless for Valkey cache. The following is an example of a HSET operation to create a HASH object in Valkey. Valkey hashes are data structures used to store collections of field-value pairs. Hashes are useful when you need to represent objects or store related data in a single entity, such as a user profile with multiple attributes (for example, name, age and email).
This creates a Hash object car:1 with attributes such as make, model, year, engine, horsepower, transmission, and price.
Now, you can retrieve individual or all field value pairs using the HMGET or HGETALL operation.
Upgrade from ElastiCache for Redis OSS to ElastiCache for Valkey
If you’re an existing user of ElastiCache for Redis OSS, you can quickly upgrade to ElastiCache for Valkey with zero downtime. The following example shows an existing ElastiCache for Redis OSS cache ready to be upgraded to ElastiCache for Valkey cache.
- Initiate the upgrade process in the ElastiCache Console by choosing Redis OSS caches from the navigation pane, and then choosing Modify.
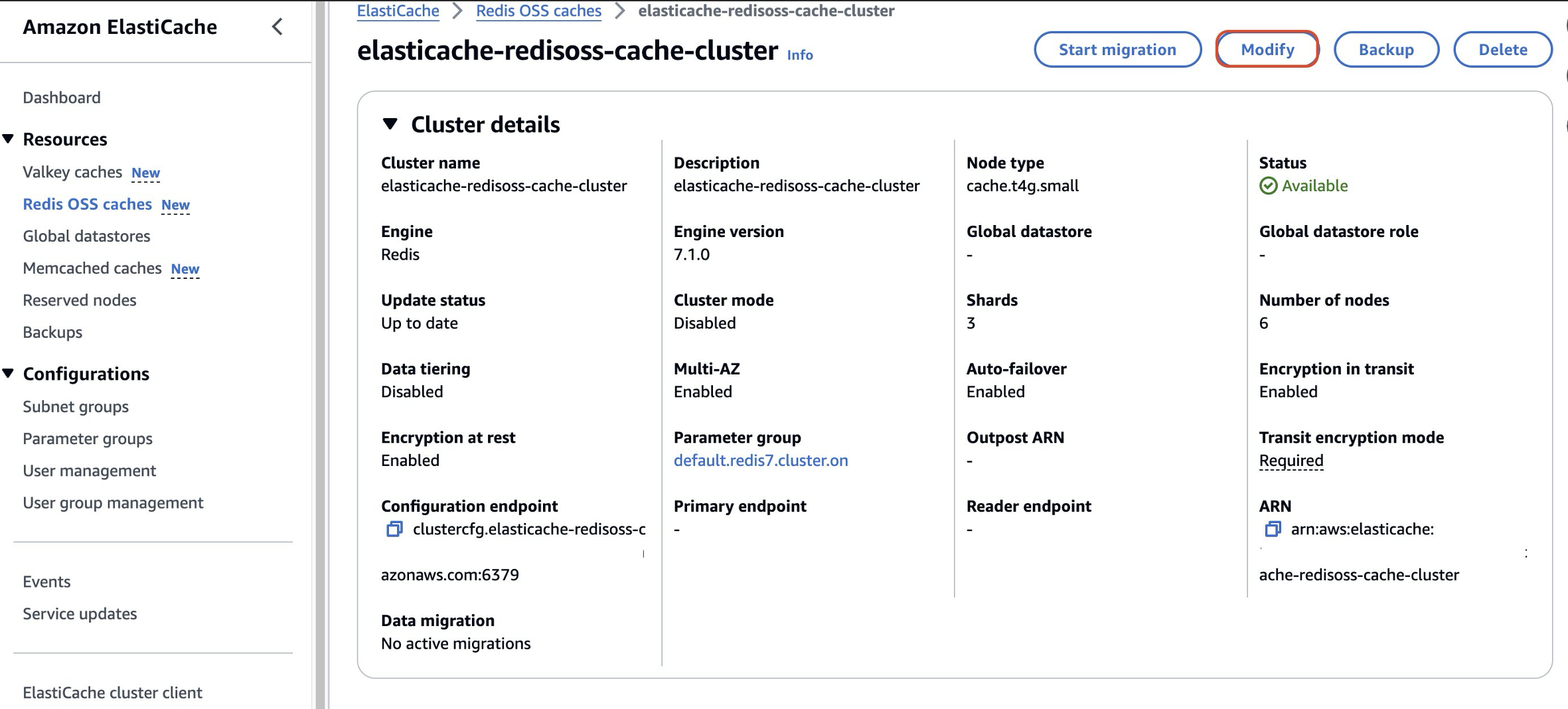
- In the Modify ElastiCache window, under Cluster settings, you will see multiple Engine options, including Redis OSS and Valkey. Select Valkey as the engine option and choose Preview Changes
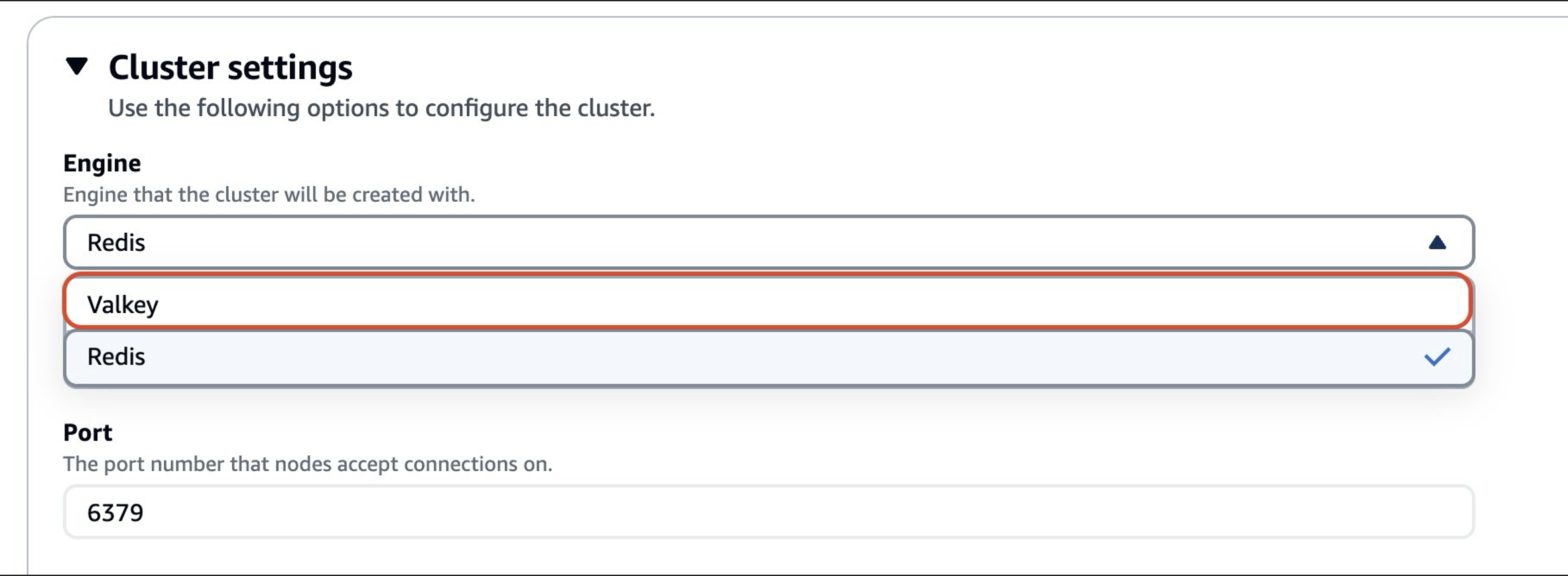
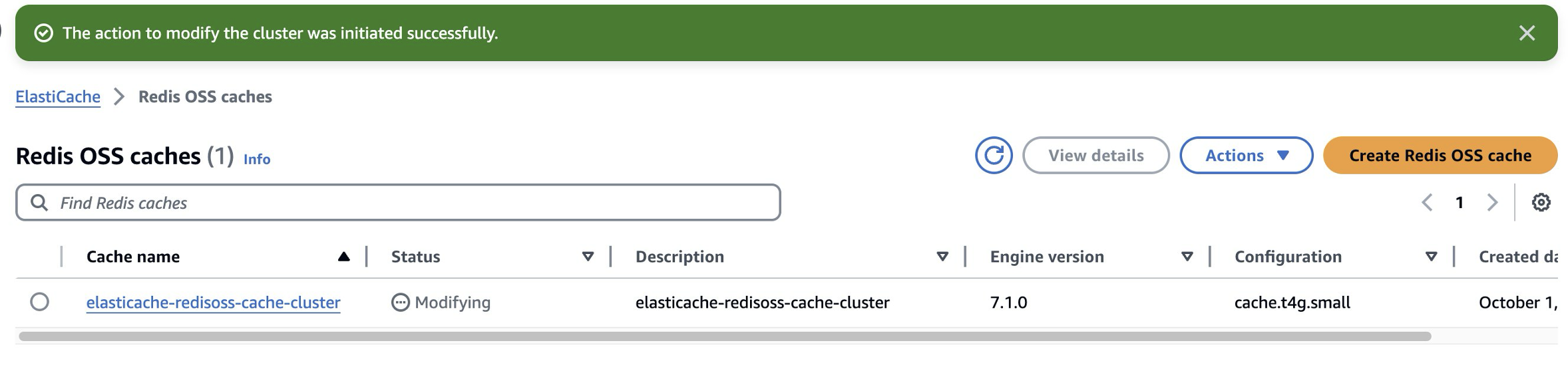
- The next screen shows a summary of modifications. Select Yes under Apply Immediately to confirm your engine change from Redis OSS to Valkey, and then choose Modify. A notification The action to modify the cluster was initiated successfully will appear after selecting Modify.
- Your existing ElastiCache for Redis OSS cache will have a status of “Modifying”.
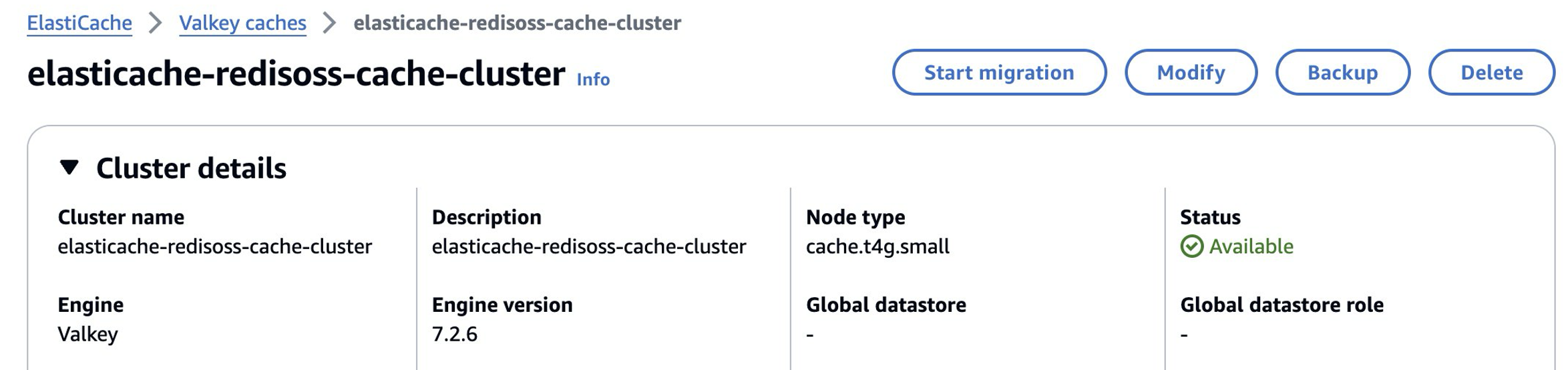
- Upon successful upgrade, elasticache-redisoss-cache-cluster no longer appears under Redis OSS caches. Instead, appears under Valkey caches.

- With minimal application disruption, you have now upgraded your engine from Redis OSS to Valkey.
Cleanup
To maintain the principle of least privilege and avoid incurring future charges, delete the resources you created as part of this post. Delete the ElastiCache cluster (see deleting a cluster for more information) and EC2 instance (delete-instance)
Conclusion
In this post, we showed you how to create an ElastiCache for Valkey cache, how to setup Elastic Compute Cloud (EC2) instance for connecting to an ElastiCache Serverless for Valkey cache, and how to connect to ElastiCache Serverless for Valkey cache for reading and writing. We also saw an example of upgrading from ElastiCache for Redis OSS cache to ElastiCache for Valkey cache.
The addition of Valkey support to Amazon ElastiCache represents a significant step forward in the commitment at AWS to providing robust, open-source solutions for your database applications. If you’re not already signed up, you can choose Get started on the ElastiCache page and complete the sign-up process. After you sign up, see the ElastiCache documentation, which includes the Getting Started guides for Amazon ElastiCache for Valkey. After you have familiarized yourself with ElastiCache for Valkey, you can create a serverless cluster within minutes by using the ElastiCache console, AWS CLI or ElastiCache API.
About the authors
 Madelyn Olson is a maintainer of the Valkey project and a Principal Software Development Engineer at Amazon ElastiCache and Amazon MemoryDB, focusing on building secure and highly reliable features for the Valkey engine. In her free time she enjoys taking in the natural beauty of the pacific northwest with long hikes and serene bike rides.
Madelyn Olson is a maintainer of the Valkey project and a Principal Software Development Engineer at Amazon ElastiCache and Amazon MemoryDB, focusing on building secure and highly reliable features for the Valkey engine. In her free time she enjoys taking in the natural beauty of the pacific northwest with long hikes and serene bike rides.
 Goumi Viswanathan is a Senior Product Manager in the Amazon In-Memory Databases team. She has over 12 years of product experience and is focused on leading cross functional teams delivering database solutions. Outside of work, she enjoys traveling and spending time outdoors.
Goumi Viswanathan is a Senior Product Manager in the Amazon In-Memory Databases team. She has over 12 years of product experience and is focused on leading cross functional teams delivering database solutions. Outside of work, she enjoys traveling and spending time outdoors.
 Siva Karuturi is a Worldwide Specialist Solutions Architect for In-Memory Databases based out of Dallas, TX. Siva specializes in various database technologies (both Relational & NoSQL) and has been helping customers implement complex architectures and providing leadership for In-Memory Database & analytics solutions including cloud computing, governance, security, architecture, high availability, disaster recovery and performance enhancements. Off work, he likes traveling and tasting various cuisines Anthony Bourdain style!
Siva Karuturi is a Worldwide Specialist Solutions Architect for In-Memory Databases based out of Dallas, TX. Siva specializes in various database technologies (both Relational & NoSQL) and has been helping customers implement complex architectures and providing leadership for In-Memory Database & analytics solutions including cloud computing, governance, security, architecture, high availability, disaster recovery and performance enhancements. Off work, he likes traveling and tasting various cuisines Anthony Bourdain style!
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
<!–
 Join us free for the Data Summit Connect 2021 virtual event!
Join us free for the Data Summit Connect 2021 virtual event!
We have a limited number of free passes for our White Paper readers.
Claim yours now when you register using code WP21.
–>

With MongoDB Performance Tuning, Percona reaffirms its commitment to open source. We believe in making database management more straightforward, more efficient, and accessible to everyone. By sharing our expertise through this guide, we aim to help you enhance your database and application performance, ensuring that your MongoDB deployments run smoothly and efficiently.
So, dive in and prepare to unlock the full potential of MongoDB!
Download PDF
Article originally posted on mongodb google news. Visit mongodb google news
MONGODB ALERT: Bragar Eagel & Squire, P.C. is Investigating MongoDB, Inc. on Behalf of
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

NEW YORK, Oct. 08, 2024 (GLOBE NEWSWIRE) — Bragar Eagel & Squire, P.C., a nationally recognized shareholder rights law firm, is investigating potential claims against MongoDB, Inc. (NASDAQ: MDB) on behalf of long-term stockholders following a class action complaint that was filed against MongoDB on July 9, 2024 with a Class Period from August 31, 2023 to May 30, 2024. Our investigation concerns whether the board of directors of MongoDB have breached their fiduciary duties to the company.
Article originally posted on mongodb google news. Visit mongodb google news