Month: March 2025

MMS • RSS
Posted on mongodb google news. Visit mongodb google news

AI game is changing.
The chip guys, like Nvidia, they had their moment. The first AI wave? They rode it high.
But guess what? That ride’s over. Nvidia’s been flatlining since June 2024.
Remember the internet boom? Everyone thought Cisco and Intel were the kings, right? Wrong. The real money was made by the companies that actually used the internet to build something new: e-commerce, search engines, social media.
And it’s the same deal with AI. The chipmakers? They’re yesterday’s news. The real winners? They’re the robotics companies, the ones building the robots we only dreamed about before.
We’re talking AI 2.0. The first wave was about the chips, this one’s about the robots. Robots that can do your chores, robots that can work in factories, robots that will change everything. Labor shortages? Gone. Industries revolutionized? You bet.
This isn’t some far-off fantasy, it’s happening right now. And there’s one company, a robotics company, that’s leading the charge. They’ve got the cutting-edge tech, they’re ahead of the curve, and they’re dirt cheap right now. We’re talking potential 100x returns in the next few years. You snooze, you lose.
Here’s the catch (it’s a good one): To uncover this sleeping giant, you’ll need our exclusive intel.
We want to make sure none of our valued readers miss out on this groundbreaking opportunity!
That’s why we’re slashing the price of our Premium Readership Newsletter by a whopping 70%.
For a ridiculously low price of just $29.99, you can unlock a year’s worth of in-depth investment research and exclusive insights – that’s less than a single restaurant meal!
Here’s why this is a deal you can’t afford to pass up:
• Access to our Detailed Report on this Game-Changing AI Stock: Our in-depth report dives deep into our #1 AI stock’s groundbreaking technology and massive growth potential.
• 11 New Issues of Our Premium Readership Newsletter: You will also receive 11 new issues and at least one new stock pick per month from our monthly newsletter’s portfolio over the next 12 months. These stocks are handpicked by our research director, Dr. Inan Dogan.
• One free upcoming issue of our 70+ page Quarterly Newsletter: A value of $149
• Bonus Reports: Premium access to members-only fund manager video interviews
• Ad-Free Browsing: Enjoy a year of investment research free from distracting banner and pop-up ads, allowing you to focus on uncovering the next big opportunity.
• 30-Day Money-Back Guarantee: If you’re not absolutely satisfied with our service, we’ll provide a full refund within 30 days, no questions asked.
Space is Limited! Only 1000 spots are available for this exclusive offer. Don’t let this chance slip away – subscribe to our Premium Readership Newsletter today and unlock the potential for a life-changing investment.
Here’s what to do next:
1. Head over to our website and subscribe to our Premium Readership Newsletter for just $29.99.
2. Enjoy a year of ad-free browsing, exclusive access to our in-depth report on the revolutionary AI company, and the upcoming issues of our Premium Readership Newsletter over the next 12 months.
3. Sit back, relax, and know that you’re backed by our ironclad 30-day money-back guarantee.
Don’t miss out on this incredible opportunity! Subscribe now and take control of your AI investment future!
No worries about auto-renewals! Our 30-Day Money-Back Guarantee applies whether you’re joining us for the first time or renewing your subscription a year later!
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
MongoDB’s MDB short percent of float has risen 8.76% since its last report. The company recently reported that it has 2.12 million shares sold short, which is 2.73% of all regular shares that are available for trading. Based on its trading volume, it would take traders 1.67 days to cover their short positions on average.
Why Short Interest Matters
Short interest is the number of shares that have been sold short but have not yet been covered or closed out. Short selling is when a trader sells shares of a company they do not own, with the hope that the price will fall. Traders make money from short selling if the price of the stock falls and they lose if it rises.
Short interest is important to track because it can act as an indicator of market sentiment towards a particular stock. An increase in short interest can signal that investors have become more bearish, while a decrease in short interest can signal they have become more bullish.
See Also: List of the most shorted stocks
MongoDB Short Interest Graph (3 Months)
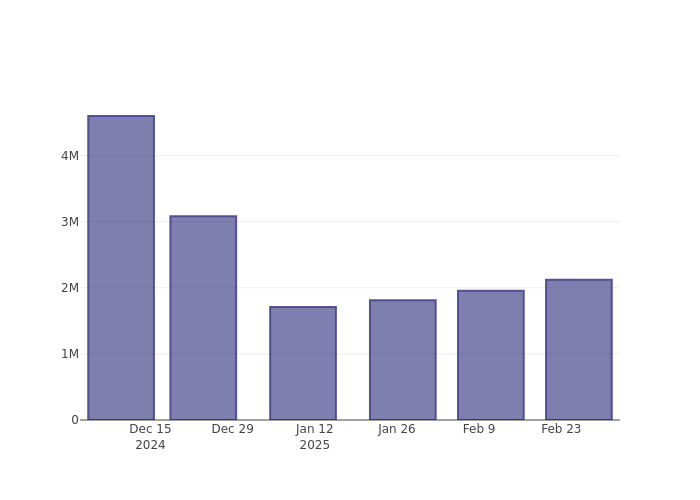
As you can see from the chart above the percentage of shares that are sold short for MongoDB has grown since its last report. This does not mean that the stock is going to fall in the near-term but traders should be aware that more shares are being shorted.
Comparing MongoDB’s Short Interest Against Its Peers
Peer comparison is a popular technique amongst analysts and investors for gauging how well a company is performing. A company’s peer is another company that has similar characteristics to it, such as industry, size, age, and financial structure. You can find a company’s peer group by reading its 10-K, proxy filing, or by doing your own similarity analysis.
According to Benzinga Pro, MongoDB’s peer group average for short interest as a percentage of float is 7.11%, which means the company has less short interest than most of its peers.
Did you know that increasing short interest can actually be bullish for a stock? This post by Benzinga Money explains how you can profit from it.
This article was generated by Benzinga’s automated content engine and was reviewed by an editor.
Market News and Data brought to you by Benzinga APIs
© 2025 Benzinga.com. Benzinga does not provide investment advice. All rights reserved.
Article originally posted on mongodb google news. Visit mongodb google news
ByteDance Launches New AI Coding Tool Trae with DeepSeek R1 and Claude 3.7 Sonnet Free For All Users
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ

ByteDance, the Chinese owner of TikTok, recently launched Trae, a new AI-powered code editor that offers unlimited free access to DeepSeek R1 and Claude 3.7 Sonnet large language models. Trae has both an international and domestic version, supports Visual Studio Code plug-ins, and competes with an increasing line of AI code editors (e.g., Cursor, Windsurf, PearAI, Replit).
Trae has two primary modes: the Builder mode, and the Chat mode. The Builder mode supports zero-to-one application development. In this mode, developers provide natural language specifications to Trae, which builds an application from the ground up, creating files and folders with the implementing code.
The Chat mode analyzes existing code, answers questions, provides suggestions and delivers real-time recommendations and code completions within the editor.
Trae’s domestic version targets Chinese developers, is equipped with Doubao-1.5-pro, an AI reasoning model matching Claude 3.5 Sonnet on several benchmarks, and lets users switch between the full-fledged DeepSeek R1 and V3 models. Trae’s international version recently made Claude 3.7 Sonnet available for use.
Website aibase.com claims that access to Claude is free and unlimited:
ByteDance, through its AI programming software Trae, is making Claude 3.7 Sonnet, the world’s first “hybrid reasoning model,” freely available to all users. As revealed in a post by X user @geekshellio this morning (06:24 PST): “ByteDance Trae is making a big move! Claude3.7 is now available for unlimited free use!”
Trae’s privacy policy states that, while codebase files are stored locally on the user’s devices, Trae will temporarily upload to their servers to compute embeddings. Upon completion, all plaintext code would be permanently deleted but the embeddings and associated metadata would be kept. Additionally, the policy makes it clear that it collects any information (including any code snippets) that the user chooses to input. The user’s personal information may be stored on a server located outside of the user’s country of residence, with servers located in the United States, Singapore, and Malaysia.
Importantly, the policy states that “certain entities within our corporate group […] process Information You Provide, Automatically Collected Information, and Information From Other Sources for us, as necessary to provide functions such as storage, content delivery, security, research and development, analytics, online payments, customer and technical support, and content moderation.” It thus remains possible that the embeddings computed from the temporary uploaded user files are shared with the unspecified entities of the corporate group.
The latter point is relevant for companies or users who have high requirements in terms of privacy, intellectual property, or security. Libraries such as vec2text allow recovering the original text from its corresponding embeddings. The library’s authors explained a year ago in a talk titled Text Embeddings Reveal (Almost) As Much As Text that 92% of most short texts (inferior to 32 tokens) can be reconstructed with perfect accuracy. While the accuracy of reconstruction drops with the length of text, the reconstructed text still often leaks valid portions of the original text. Assessing and mitigating text embedding inversion is a current topic of research.
Trae is a fork of Microsoft’s popular open-source IDE and text editor Visual Studio Code. As such, most, if not all, of Visual Studio Code plugins can be reused in Trae. As part of the initial setup, users can import their existing Visual Studio Code plugins and settings.
One Reddit user noted:
I feel like this would’ve been better as a VSCode extension. Copilot, Q, Gemini, all were able to take this approach. Also, VSCode isn’t considered a full IDE and adding some AI features isn’t enough to change that. It seems like they forked VS Code just for the ability to say they “created an IDE” in the same way other projects fork Chromium to “build a browser”.
Another user answered as follows:
Nah the extension API is pretty limited. Copilot uses proprietary APIs not available to extensions.
If you really want an integrated experience, and not just a sidebar UI, you need to go the same route as Cursor and fork Code-OSS (the MIT-licensed part of VS Code, analogous to Chromium for Chrome)
Another developer mentioned enjoying the coding experience:
It’s surprisingly very good. The AI responses are very good, and it’s free to use. They don’t charge anything for claude-3.5-sonnet. I also love its UI even though they totally copied JetBrains Fleet’s UI.
Trae is available on both Macs and PCs. Developers can refer to the online documentation for support.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Shares of MongoDB Inc MDB rose in early trading on Tuesday, ahead of its fourth-quarter results to be reported on Wednesday, March 5.
The company is likely to report in-line or marginally better fourth-quarter results and guide to subscription revenue growth of around 18% for fiscal 2026, according to Rosenblatt Securities.
The MongoDB Analyst: Analyst Blair Abernethy reaffirmed a Buy rating and price target of $350.
The MongoDB Thesis: The company is likely to report quarterly total revenue of $517 million, slightly short of the consensus, while coming in-line with the guidance range, Abernethy said in the note.
Check out other analyst stock ratings.
“We expect Mongo’s Subscriptions Revenue to grow 13% Y/Y to $502m (97% of Total Revenue) and Services Revenue to $15m (growth of 15% Y/Y),” Abernethy added.
MongoDB could report earnings of 67 cents per share, beating consensus of 66 cents per share, the analyst stated.
“We believe the enterprise database spending environment, legacy application migrations, and next generation AI application development activity in Q4 have remained relatively stable drivers for Mongo,” he wrote.
“We continue to watch Mongo’s Cloud-based Atlas adoption as it generates most of its revenue and growth from consumption charges for Atlas.”
MDB Price Action: Shares of MongoDB had declined by 4.33% to $247.80 at the time of publication on Tuesday.
Read More: Market Momentum: 3 Stocks Poised for Significant Breakouts
Photo: Shutterstock
Don’t miss a beat on the share market. Get real-time updates on top stock movers and trading ideas on Benzinga India Telegram channel.
© 2025 Benzinga.com. Benzinga does not provide investment advice. All rights reserved.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Database software company MongoDB (MDB) will be reporting earnings tomorrow after the bell. Here’s what investors should know.
MongoDB beat analysts’ revenue expectations by 6.4% last quarter, reporting revenues of $529.4 million, up 22.3% year on year. It was a very strong quarter for the company, with a solid beat of analysts’ billings estimates and EPS guidance for next quarter exceeding analysts’ expectations. It added 125 enterprise customers paying more than $100,000 annually to reach a total of 2,314.
Is MongoDB a buy or sell going into earnings? Read our full analysis here, it’s free.
This quarter, analysts are expecting MongoDB’s revenue to grow 13.3% year on year to $519.1 million, slowing from the 26.8% increase it recorded in the same quarter last year. Adjusted earnings are expected to come in at $0.67 per share.
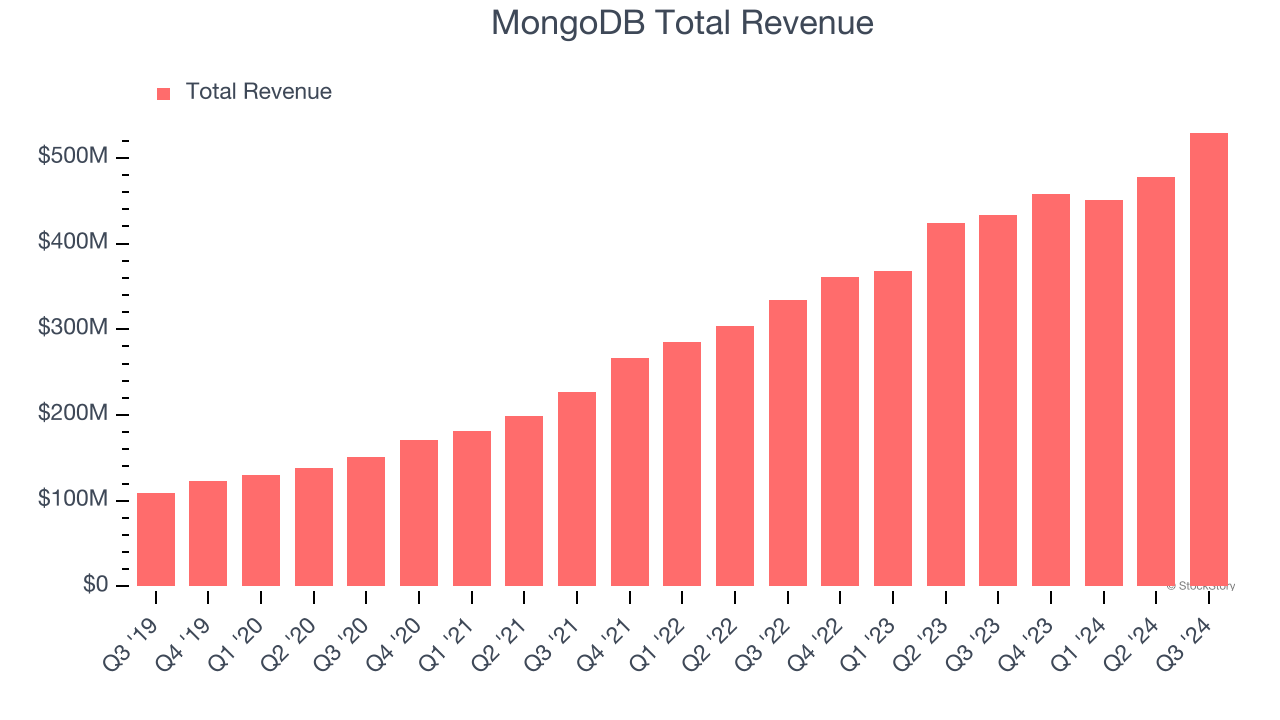
Analysts covering the company have generally reconfirmed their estimates over the last 30 days, suggesting they anticipate the business to stay the course heading into earnings. MongoDB has missed Wall Street’s revenue estimates three times over the last two years.
Looking at MongoDB’s peers in the data storage segment, some have already reported their Q4 results, giving us a hint as to what we can expect. Snowflake delivered year-on-year revenue growth of 27.4%, beating analysts’ expectations by 3%, and Commvault Systems reported revenues up 21.1%, topping estimates by 6.9%. Snowflake traded up 4.6% following the results while Commvault Systems was down 7.5%.
Read our full analysis of Snowflake’s results here and Commvault Systems’s results here.
When a company has more cash than it knows what to do with, buying back its own shares can make a lot of sense–as long as the price is right. Luckily, we’ve found one, a low-priced stock that is gushing free cash flow AND buying back shares. Click here to claim your Special Free Report on a fallen angel growth story that is already recovering from a setback.
This article contains syndicated content. We have not reviewed, approved, or endorsed the content, and may receive compensation for placement of the content on this site. For more information please view the Barchart Disclosure Policy here.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Rosenblatt Securities restated their buy rating on shares of MongoDB (NASDAQ:MDB – Free Report) in a report released on Tuesday,Benzinga reports. Rosenblatt Securities currently has a $350.00 price target on the stock.
A number of other research firms also recently issued reports on MDB. Scotiabank reduced their price target on shares of MongoDB from $350.00 to $275.00 and set a “sector perform” rating on the stock in a research report on Tuesday, January 21st. Canaccord Genuity Group lifted their price objective on shares of MongoDB from $325.00 to $385.00 and gave the company a “buy” rating in a research report on Wednesday, December 11th. Robert W. Baird boosted their price target on shares of MongoDB from $380.00 to $390.00 and gave the stock an “outperform” rating in a research report on Tuesday, December 10th. Guggenheim upgraded shares of MongoDB from a “neutral” rating to a “buy” rating and set a $300.00 price target on the stock in a research report on Monday, January 6th. Finally, China Renaissance initiated coverage on shares of MongoDB in a research report on Tuesday, January 21st. They set a “buy” rating and a $351.00 price target on the stock. One research analyst has rated the stock with a sell rating, five have given a hold rating, twenty-three have given a buy rating and two have issued a strong buy rating to the stock. According to data from MarketBeat.com, MongoDB has an average rating of “Moderate Buy” and a consensus price target of $361.83.
Get Our Latest Research Report on MongoDB
MongoDB Trading Down 1.8 %
MDB stock traded down $4.64 during mid-day trading on Tuesday, hitting $254.38. 1,684,121 shares of the company were exchanged, compared to its average volume of 1,598,739. The company has a market capitalization of $18.94 billion, a PE ratio of -92.84 and a beta of 1.28. MongoDB has a twelve month low of $212.74 and a twelve month high of $428.91. The firm has a fifty day simple moving average of $263.28 and a 200 day simple moving average of $275.36.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Monday, December 9th. The company reported $1.16 earnings per share for the quarter, topping the consensus estimate of $0.68 by $0.48. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The company had revenue of $529.40 million during the quarter, compared to analyst estimates of $497.39 million. During the same period last year, the business earned $0.96 EPS. The firm’s revenue for the quarter was up 22.3% compared to the same quarter last year. As a group, sell-side analysts anticipate that MongoDB will post -1.78 earnings per share for the current year.
Insider Buying and Selling at MongoDB
In other news, CAO Thomas Bull sold 1,000 shares of the business’s stock in a transaction dated Monday, December 9th. The stock was sold at an average price of $355.92, for a total transaction of $355,920.00. Following the sale, the chief accounting officer now directly owns 15,068 shares in the company, valued at approximately $5,363,002.56. The trade was a 6.22 % decrease in their ownership of the stock. The transaction was disclosed in a document filed with the SEC, which is accessible through the SEC website. Also, CEO Dev Ittycheria sold 8,335 shares of MongoDB stock in a transaction that occurred on Wednesday, February 26th. The stock was sold at an average price of $267.48, for a total value of $2,229,445.80. Following the completion of the transaction, the chief executive officer now directly owns 217,294 shares in the company, valued at approximately $58,121,799.12. This represents a 3.69 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 47,314 shares of company stock worth $12,525,863 over the last 90 days. Insiders own 3.60% of the company’s stock.
Hedge Funds Weigh In On MongoDB
Several institutional investors have recently added to or reduced their stakes in the business. Strategic Investment Solutions Inc. IL bought a new stake in shares of MongoDB during the fourth quarter valued at approximately $29,000. Hilltop National Bank grew its holdings in MongoDB by 47.2% during the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after buying an additional 42 shares in the last quarter. NCP Inc. bought a new stake in MongoDB during the fourth quarter worth $35,000. Brooklyn Investment Group bought a new stake in MongoDB during the third quarter worth $36,000. Finally, Continuum Advisory LLC grew its holdings in MongoDB by 621.1% during the third quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock worth $40,000 after buying an additional 118 shares in the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering what the next stocks will be that hit it big, with solid fundamentals? Enter your email address to see which stocks MarketBeat analysts could become the next blockbuster growth stocks.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
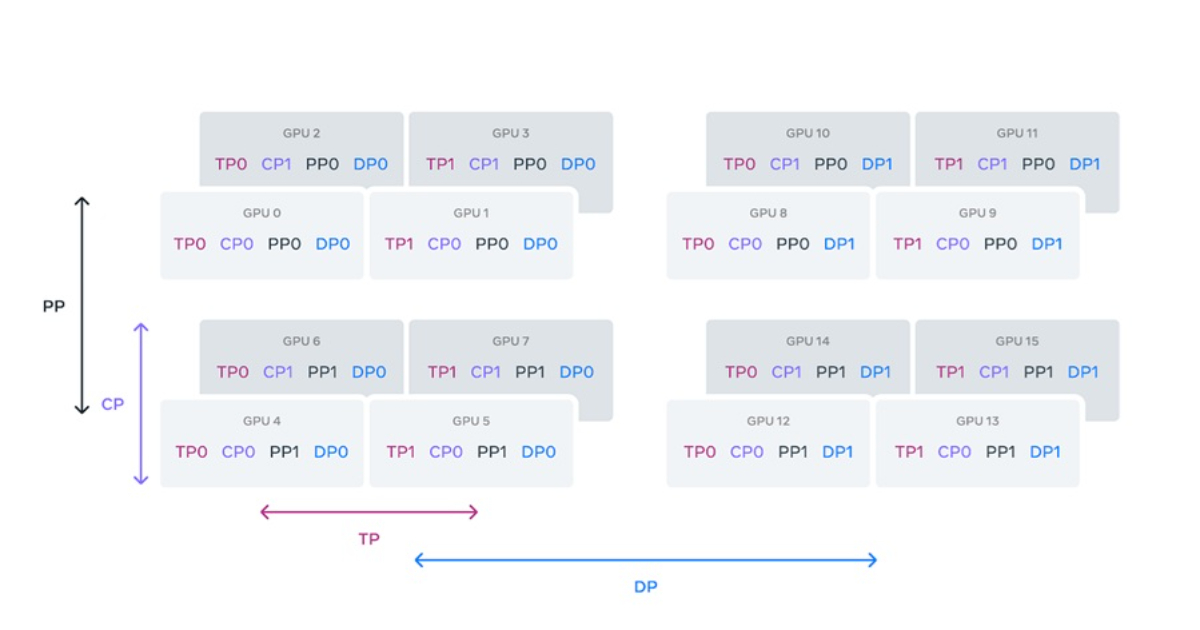
Hugging Face has published the Ultra-Scale Playbook: Training LLMs on GPU Clusters, an open-source guide that provides a detailed exploration of the methodologies and technologies involved in training LLMs across GPU clusters. The playbook is based on over 4000 scaling experiments conducted using up to 512 GPUs, with a focus on optimizing throughput, GPU utilization, and training efficiency. It aims to provide practical guidance for researchers and engineers working on large-scale model training, offering reproducible benchmarks, implementation details, and performance optimizations.
The guide covers various parallelism strategies essential for scaling LLM training. Data parallelism (DP) enables multiple GPUs to process different batches of data simultaneously, while tensor parallelism (TP) distributes the model’s weights across GPUs to balance memory usage and computation. Pipeline parallelism (PP) splits the model into segments distributed across GPUs, allowing different parts of the model to be processed concurrently. Context parallelism (CP) is also explored as an emerging technique to improve scalability.
Memory management is another key topic in the playbook, addressing challenges such as memory constraints and optimization techniques. Activation recomputation is introduced as a method to reduce memory consumption by recalculating intermediate activations when needed rather than storing them. Gradient accumulation is highlighted as a way to achieve larger effective batch sizes without exceeding memory limits, improving training stability and efficiency. These techniques are essential for training LLMs that exceed the memory capacity of individual GPUs.
The playbook also provides extensive benchmarking insights, demonstrating the importance of empirical testing in optimizing training configurations. By testing various setups to determine the best balance between batch size, model architecture, and the number of GPUs used. Effective benchmarking helps refine training speed, resource allocation, and computational efficiency, which are crucial for large-scale training.
Communication overhead between GPUs is another factor influencing training efficiency. The playbook discusses methods for reducing idle GPU time by overlapping communication with computation, such as using all-reduce operations during the backward pass. Strategies for optimizing network bandwidth and minimizing synchronization delays are also explored to improve overall training performance.
Posts about the playbook reflect a wave of excitement and appreciation for this open-source guide, Leandro von Werra, head of researcher at Hugging Face, who announced the playbook shared:
Learn how to train your own DeepSeek-V3 model using 5D parallelism, ZeRO, fast kernels, compute/comm overlap and bottlenecks with theory, interactive plots and 4000+ scaling experiments and audio!
And AI developer Denis Redozubov posted:
There are some very cool bits like a widget calculating a memory breakdown of the transformer model
Finally, the playbook also touches on future directions in LLM training, anticipating advancements in hardware and software that will continue to shape the field. Research into optimizing communication, reducing memory overhead, and refining parallelism techniques is expected to drive further improvements in scalability and efficiency.
Presentation: Practical Benchmarking: How To Detect Performance Changes in Noisy Results
MMS • Matt Fleming
Article originally posted on InfoQ. Visit InfoQ

Transcript
Fleming: Who can see a face in this image? What about this one of Danish electrical sockets? This one of some birds? That’s weird, we all know there’s no actual faces in these images, but then all of you will pretty much put your hands up and said you could see that. It turns out, the human brains are constantly searching and scanning for faces all of the time, and this particular phenomenon is called pareidolia. This is the tendency for your perception to try and attach meaning to the things that it sees. Your brain is constantly looking for signal in noisy images, noisy scenes, and things like that. I think that as performance engineers, we have a very similar problem.
Anybody that’s spent any time looking at performance charts, it’s constantly searching for performance changes, regressions, optimizations in the data. Just like your eyes can be tricked when you’re looking for faces, and you’ll see faces in things where there are no faces, we constantly get tripped up by this, and we see regressions where they don’t exist. This is a time series. Your eyes are probably drawn to the spike there. That’s like an interesting data point. I’m not quite sure what’s going on there. It would depend on the test and the system and a bunch of other factors, but I’m sure tell you now that this is noise and not repeatable. It’s a total fluke of the system. This actual data point could have come from absolutely anywhere.
Unlike with the faces in the images, we don’t have millions of years of evolution to quickly filter this out. We don’t know within an instant that there’s no actual face there. This takes much more critical reasoning. It’s much harder to be disciplined and teach yourself that actually you need to do something else. You can’t just eyeball the charts. You wouldn’t ever want to sacrifice this ability. Though your eyes can lie to you, they can trick you into thinking you see things that don’t exist, you still want that ability to look across a crowded restaurant and see an old colleague, an old friend. You wouldn’t give up that for anything in the world. By the same token, your eyes, your intuition, and your pattern matching capabilities are incredibly valuable if we look at performance data.
Background
This talk is going to cover noise and benchmarking. We’ll look at, what is the origin of noise? How do we define it? How do we measure it? If we can ever truly eliminate it? Also, the meat of the talk is going to be, how do you deal with noise in your performance data?
I’m co-founder and CTO at Nyrkiö. I used to be a Linux Kernel maintainer for a number of years. I’ve been a part of performance teams for various companies around the world. I’ve written a couple of research papers on automated distributed systems testing and performance testing. There’s a big caveat with this whole talk, which is that I’m not a mathematician. I have friends that are mathematicians, but everything in here I’ve approached from having a benchmarking issue and trying to find the mathematics to analyze it, to find solutions to the problems. I don’t recommend you do that. It’s incredibly time consuming and laborious. Just steal everything out of this talk.
What is Noise, and How Can We Measure It?
If we’re going to talk about noise, which we are for the rest of the presentation, we need some working definition. I really like this one from Nate Silver’s, The Signal and The Noise, which is, “I use noise to mean random patterns that might easily be mistaken for signals”. I think this captures quite well the problem I talked about with pareidolia, which is seeing things that aren’t there. Because crucially, what we do as performance engineers is we will make decisions based on our analysis of the data. If we make decisions based on bad data, we’ll get bad decisions.
This is incomplete, I think, for our purposes, because I personally talk about results being noisy, like there’s a lot of noise in these results. These are noisy results. I don’t think this fully covers that, because when we talk about noisy results, what we’re really talking about is variation in the results. What I mean by this is, if your results have a wide range of values or are widespread or a dispersion, then that can make analyzing the data much more tricky. This is great, because variation is a mathematical concept, which means we can use math to solve these problems and to work with this data.
You’re all pretty familiar with standard deviation. One of the measures of dispersion or spreading results that I really like is coefficient of variation, which is just the standard deviation over the mean, times 100. It’s quite simple to calculate. NumPy has got functions for calculating this. Crucially, because you’re normalizing over the mean, you get a percentage, which I personally found is quite intuitive for describing how noisy results are. You can say like the throughput of this benchmark is 50,000 RPS plus or minus 5%, and because it’s normalized over the mean, it allows you to compare across different runs of tests as well, which is quite helpful. Anybody who’s spent any time in Ops has probably seen this mean and the denominator, and is freaking out a little bit.
We all know that means are pulled either side by outliers, by the max and the min, and it’s not what you would call a robust measure of dispersion. What this means is, you can assume, for a normal distribution, that the statistically significant values fall within a certain range of the mean, and anything outside of that is unlikely. It’s a good way to detect performance changes, because if you have a very unlikely by this distribution value all the way over here, there’s probably something going on there that warrants analysis.
This distribution, if you are familiar with it, this is the normal distribution. Unfortunately, many results, many benchmarks and datasets don’t actually follow this distribution. We need something that’s more robust. We need a non-parametric test. Because if you have a cache and you have a fast path and a slow path, you get a bimodal distribution, so you get two of these. If you have many services and you have a fanout in a microservice architecture, and you’re hitting many services for your request, you’ll get a long tail in latency, which, again, doesn’t follow this shape.
We need something that doesn’t rely on the mean. For that, I quite like the interquartile range, if for no other reason than when you’re doing benchmark runs, and you’re collecting metrics, usually you’re collecting percentiles for something. I know I do for latencies. The IQR is just you take the 75th percentile and subtract the 25th and that’s it. It’s a really straightforward measure of dispersion around the middle half. It ignores outliers, or if you flip it around, it’s a good way to detect outliers, because you’re ignoring the things on the outer edges. It doesn’t suffer from that skew that you get with the mean.
If for some reason you want to include all the data, because remember, this is a measure of the middle half of your dataset. It measures things around the median, and ignores the outliers. It is simple to calculate, but maybe you want something more all-encompassing, slightly more complex, but still a really good, robust measure is the median absolute deviation. It is more complex, so I’m going to describe it.
Me as a non-mathematician, this is scary. You measure the distance of each of the data points from the median. You just subtract the median from it, basically. You get a new set of data points, and then solve them, and then you find the median again. It’s like two levels of median. What that ends up doing is you get a much more stable measure of dispersion because you focus on these medians. It is more complicated, but it uses all the data points. Depending on what your performance results look like, this may be a more accurate, useful measure.
Where Does Noise Come From, and Why Can’t You Escape It?
At least now we have some way to measure noise in our system. Since we can measure noise in the benchmarks, maybe we want to look at where it comes from. Maybe we’d want to do something like minimize the noise in a test. There’s a few places where, in my experience, noise come from, and it pays to be aware of them, because, unfortunately, the answer to this question is absolutely everywhere. The reason for that is because of the non-determinism in modern systems. What’s interesting about this is a lot of the places where you get non-determinism, and what I mean by that is this is usually in relation to the execution order of something, like you can’t guarantee the exact sequence of events happens the same way every time. The reason we have this usually is for better peak performance.
If you think of caches or sharing of resources, things like that, where if things are idle, you try and use that resource efficiently, that leads to non-determinism, because it depends on the load on the system. It depends exactly what’s happening. It depends on the events before it. This is the source of a lot of the problems in benchmarking. Crucially, in modern systems, it’s fundamental. No one’s going to sacrifice this peak performance, not usually anyway for more stable results. We have to have ways of dealing with this. In my experience, the number one place, and it still trips me up, like at least once every three or four months, the number one place that benchmark result instability comes from for CPU bound benchmarks is the CPU frequency changing.
In modern CPUs, the clock speed of a CPU is related to the power that it draws. The higher the frequency, the more power it draws. What modern operating systems will do is they will crank down the frequency to save power. This makes sense if you have a light load in the system, but during benchmarking, usually, there are periods where we have a very heavy load in the system. What the operating system will do, unless you tune it, is it will start off as a low frequency, and then once the OS notices that there’s a high load in the system, will gradually start cranking up the frequency. This isn’t instantaneous. It does take some time.
Unfortunately, for us as performance engineers, it’s an indeterminate amount of time every time you do it. There’s no guarantee it will happen exactly the same way every time at the same point in the test. This creates random fluctuations in your charts and your metrics. If you are lucky enough to be running benchmarks on bare metal machines, and you own the hardware, you can lock the frequency. Linux in particular has CPU frequency drivers, and you can pin the frequency to a specific value and basically get around this whole problem. If you run benchmarks in the cloud where maybe you don’t have permissions to do that, then this is going to be an issue for you.
Here’s a little example of this. I had a REST API based benchmark running in a public GitHub runner, and measured the CPU frequency during the benchmark run. You can see, hopefully, it bouncing around as the benchmark runs in relation to the load and exactly what’s going on. As you might imagine, this produces really unstable results. Crucially, they’re unstable in different ways on different runs. If you run the same thing twice, you get different amounts of noise, which is really problematic, if you’re trying to do things like figure out whether the software change you just introduced, introduced performance change. It makes it very difficult to do that.
The takeaway from this is, don’t run benchmarks in GitHub runners. Garbage collection is another source of noise in benchmark results. I know things are much better recently, like with recent versions of Java, for example. You can tune this. It’s amazing how many times this catches out people, particularly for older versions. I was running a throughput-based benchmark on Apache Cassandra, which is written in Java, and saw these dips in the throughput, and figured out these dips are actually related to garbage collection cycles, but they line up pretty well. I’m sure many of you are still running a Java 11, maybe, Java 8? These are still problems. I know things are better in more recent versions. Maybe the last one to cover, just generally, is resource contention is also a major source of noise.
In particular, as a former kernel maintainer, I often think about resource contention at the lock level, like locks that are contended. It scales up to distributed systems and microservice and things like that, so you can have services that contend on specific endpoints in different microservices. The really nefarious thing about this one is that while you measure the CPU time or the request latency for your particular benchmark, resource contention often happens because of totally unrelated entities accessing the resource. It’s almost like a hidden cost. This can make it really tricky to eliminate that noise and try and get useful results.
One solution to all these problems with like, where does noise come from, and maybe the metrics we’re using are flawed somehow, is, I’ve heard people advocate for proxy metrics. Proxy metrics are actually pretty good. They do help in certain situations. When I say proxy metric, I mean you’re measuring something that the user doesn’t care about, but you do. Which is a crass way of saying, you’re measuring something that has no visible user impact but makes your life easier as a developer, or a performance engineer, or somebody who is responsible for the performance of software.
A good example of this would be like instruction per cycle, maybe allocations, things like that. There is no one obvious way to do it, no one clear way to do it. There’s no winner. There’s no silver bullet. Proxy metrics also suffer from problems. Here’s a C++ microbenchmark for a Kafka compatible streaming application. There’s the time series, so you’ve got the benchmarks being run, after every commit for a couple of months or so. You can see with your eyes these two bands of values. There’s like a high one, ran about 1.35 million, and there’s a low one with about 1.2 million. This chart does actually illustrate why you wouldn’t ever want to completely give up your ability to eyeball charts, because it’s a bad idea to do it initially. I don’t believe in eyeballing charts to find regressions.
If you use other methods that we’ll talk about later to find regressions as part of the analysis, this is really powerful, because everyone I imagine figures out it’s a bit weird. It’s either noisy or there’s something off with the results. What I would hope to have seen, assuming no performance change, is just like a really stable line somewhere. This is a proxy metric, because what we’re actually measuring in this chart is instruction counts for each of the runs. You run the benchmark and you count how many instructions that took. It looks like there’s two values. What I found out on some analysis was that if you run the AWS m5d.12xlarge instance, in the fine print of the documentation, it says you will either get a Skylake or you will get a Cascade Lake. This explains why we have two bands of values.
If you get a Cascade Lake, you use more instructions for the exact same code. If you use a Skylake you use less instructions. I never found out why. I just found out this. One thing to do with eyeballing charts is your choice of visualization is also really important, because maybe you can see the bounding there. I don’t think it’s completely obvious, like you could probably have a good guess that this looks like two different values. If you did something like a scatter plot, then it looks a lot more obvious. You see this banding. Having the right visualization tool is also really important. This is the problem with proxy metrics, or at least one of the dangers to be aware of, is this is a different metric for the exact same runs on the same hardware.
For each of the runs, we measure instructions, and we measure request latency in nanoseconds. The problem with proxy metrics is that they are proxy metrics, and they don’t measure something your user cares about. Your user probably cares about time. Proxy metrics usually are something that’s not time-based allocations or instructions. The user doesn’t care which microarchitecture run. They don’t see that difference. It’s completely missing from this chart. Proxy metrics can be good, but they are not without some rough edges.
We talked a lot about the nature of noise and how to measure it. I like to have this mental model of the different kinds of performance tests you can run. Microbenchmarks will be analogous to unit tests, something very small. The surface area of the thing you’re testing is very minor. Maybe it’s one function, maybe it’s a couple of instructions, but definitely no I/O, something very small. As you scale up the scope of the thing you’re testing, you go to benchmarks. Then, end-to-end tests really should be representative of what your users see. I’m talking like full-blown server and client architectures. Maybe you use a staging environment, but it should be totally representative of the things your users and customers are doing.
Each of these types of microbenchmarks has within it an intrinsic amount of noise because it’s linked to the scope of the test. As you broaden the scope and you go from microbenchmark to benchmark to end-to-end test, the amount of stuff you’re testing is bigger and the sources of noise gets bigger too. What I found is usually the microbenchmark can be tuned and pushed to have a minimum amount of noise. It’s true that microbenchmarks are sometimes more susceptible to noise because you’re measuring a very small thing on very small scales.
Things like cache alignment really show up here, but you tend to have more control over cache placement with microbenchmarks so you can squeeze out the noise. It’s less so the end-to-end test side of the spectrum. That’s actually a worthwhile tradeoff, because while you can minimize noise for the end-to-end tests, I’ve seen InfoQ talks from the financial training folks, they minimize object allocation in Java in the fast path. All that’s really good. Crucially, end-to-end tests should match whatever noise your users are seeing. If you’re going to do it in your test, you need to do it in production too, otherwise, it’s not truly representative.
Detecting Performance Changes in Noisy Data
Let’s talk a little bit about detecting changes in performance data, particularly since hopefully I’ve convinced you that some amount of noise is going to be there. You can’t really escape it. You can tune things, but you’re going to find noise. Hopefully I’ve convinced you why you wouldn’t do this as a first step. Just don’t do this. It’s good for a subsequent analysis. You don’t do this initially. It’s too easy for you to find false positives. It’s time consuming. It’s super boring, I found, like just staring at charts every morning. There are better things to do with your time. Don’t do this. The next step up is probably thresholds. We talked about measures of noise.
Maybe you’re thinking, I could use that measure of noise, maybe multiply by a fudge factor, and anything outside of that is a potential regression. That’s definitely one way to do it. It’s certainly better than eyeballing things. You’re using a bit of statistics there. I have found that thresholds tend to balloon. If you have a system that works well and you’re getting value from it, you have a threshold per test.
Sometimes you’ll expand to per metric per test, sometimes per metric per test per release. It very quickly explodes and gets out of hand. These all require a certain amount of tuning as well, particularly if you can imagine, you have a huge shift in the performance, because you implement an optimization. That’s a good change. Maybe you have to go and tweak all the thresholds. Or, if you reduce the noise, maybe you’ve got to go and tweak the thresholds too. It’s better than eyeballing it. It’s still not quite there yet. This is just a copy of the graph from before that shows how you maybe could use the thresholds. The three-sigma rule is a good rule for normally distributed data. If it’s three times the standard deviation, that’s probably an unlikely value. Maybe that’s performance change. Again, you can do this, and I know systems that do do this. I think SAP wrote a paper on this many years ago. They tend to be quite high overhead for the developer.
I’m going to talk now about change point detection, which was a new way to me when I learned about it a few years ago. I’ll cover what it is, and then cover a little bit the backstory and some of the details. Change point detection works really well. For that situation I described with the threshold, it doesn’t work so well. If you have a step change in performance, this is a benchmark over time, so some time series data that measures throughput. It going up is good, you’re getting more performance out of the system. You have this problem that maybe you want to tweak the thresholds as the performance is changing, because these are good changes.
Change point detection basically sidesteps that, because what change point detection will do is it will find the places in a distribution or a time series where there are fundamental shifts in the underlying distribution, which, for us, is a fancy of saying it finds performance changes basically in your metrics. You can guess maybe where there would be some here. To me, these look like change points here. You have a persistent and fundamental shift in the performance of this metric. Change point detection, as a general concept, has been around for decades. It’s used in biomedical research. It’s used in financial trading, fraud detection, a whole bunch of stuff. It’s only in the last 5 years or so, that it’s been used for software performance.
I first learned about it from a paper from MongoDB, which was done in 2020. It’s actually how I came to meet my co-founder. This was, I think, the paper that introduced it to a lot of people. Then a few years later, in 2023, me and some other colleagues from DataStax wrote a follow-up paper where we basically improved on the first paper. Now it’s used in a bunch of different companies. It’s used in different products. It’s really starting to, I think, gain traction as a useful tool in your toolbox for measuring performance and detecting changes. Because the field is so old and vast, there are many algorithms, and there was no way I could possibly cover them all. What I will do is I’m going to focus on E-divisive because that’s the one that’s used in the Mongo paper and then the paper that I co-wrote. What I will provide is a general framework for thinking about change point algorithms.
In pretty much all the change point algorithms, there is basically three components to the algorithms or the process. You need some method for moving through the time series and finding things to compare. Then you need a method to do the comparison. Then, what you need is a final third method to basically make some determination on the things you found. What this looks like is, the search and the comparison work hand in hand, and they will go through the time series trying to find candidate change points. These things look like change points, but it doesn’t make a determination whether they actually are change points. That happens in the filter function. What you’re looking for is statistically significant changes in the distribution.
You have these three functions, and then the way you implement all of them is varied. The search one, you can use pretty much any technique you use for the search algorithm. You can do sliding windows side by side, then move through the time series, and you’re comparing the things in the window. You can do top-down, where you take your time series, and just basically split it into chunks, and then compare the chunks. Bottom-up is essentially the reverse of that, where you start with chunks and merge them together. E-divisive, for the search one, has the top-down. It’s a bisection-based strategy. I’ve covered a couple times this idea about the distribution of your data, whether it’s non-normal or non-parametric. Non-parametric, is you don’t assume any properties of the underlying distribution, which for a non-normal distribution, is pretty handy. If you know your data is normal, probably not, but maybe it is, you can use standard MLE type stuff.
For the non-parametric things, you can make further choices in implementation based on whether you have multiple metrics or a single metric. You can find all these on Wikipedia, basically. You can use any of these mathematical concepts for comparing distributions or comparing samples from distributions. The filter is the final step. Again, it takes into account the nature of the data. You can use like a Student T-test, which is actually how Hunter works, the paper that I co-wrote. Or, you can do some permutation-based things. There’s a bunch of other stuff that you can do. The point here is basically, for the comparison and for the filter, you need to take into account the shape of your data, like what it actually looks like to get the best results.
I’m going to cover very briefly walking through the E-divisive algorithm. This is not supposed to be all-encompassing. These steps are pretty intricate. There’s some matrix mapping there, which I won’t go into. Hopefully, it just gives you an idea of how a top-down, non-parametric CPD algorithm would work. We start off with a one time series, and we find some place in the time series where we want to cut it into two chunks. Then we recursively go on the left and the right-hand side. Let’s take the right-hand side first, and just basically do the exact same steps again. We search, find candidate change points. Let’s say we find one on the right-hand side. Then we do the filter, is this a significant change? No, and it’s done. The filter method is used as a stopping criteria in a bisection-based algorithm.
Go to the left, chop that in half, and do the same thing, basically on the left-hand side of those little chunks there. Because the field is so vast, there are many frameworks, libraries, and projects that use CPD because it’s not just used for performance changes. It’s used for a whole range of different stuff. The single processing algorithms project is the one from MongoDB. It’s what they wrote for their paper in 2020. Ruptures is a Python library that’s got a vast collection of CPD algorithms. If you wanted to just try some out, that’s a really good one to get started with. You can plug your data in and go nuts. Perfolizer is created by Andrey Akinshin. It’s used in benchmark.net. Again, that’s got multiple CPD algorithms you can take a look at. Hunter is the open-source project for the paper I co-wrote, which is based on the MongoDB library, but uses Student’s T-test and gets more deterministic results.
Unfortunately, I’d like to say CPD is amazing, and you should use it no matter what, every time for everything. Of course, that’s not true, because of the way CPD works with these candidate change points, you need a certain amount of data points to decide whether there’s performance change or not. For Hunter, it’s between 4 and 7. What this means is, as new data points come in, you can have change points be calculated after the fact. You need to be able to handle this system where even though you’ve recorded your benchmark run and you’ve moved on, days later, maybe, you’ll get a performance change notification. I found this works really well. CPD in general works really well as the backstop in a performance testing framework.
Maybe you have some faster, less precise measures of change, maybe using some of the measures of noise, using some of those tricks to find performance changes, and then CPD, as like the umpire, essentially in cricket, that’s right at the back, and with all the data, makes determinations across the whole data range about whether there’s a performance change. You need multiple data points to run these algorithms. Also, as compared with something like threshold-based techniques, where you’re using coefficient of variation or something, CPD is more computational expensive. It just is. The more data you have, the more metrics you have, the longer it takes to calculate this stuff.
Key Takeaways
Your brains are amazing. They are amazing pattern matchers. Sometimes we get tricked, and for performance charts in particular, it’s difficult to correct ourselves. You need to use some statistical tools, particularly because noise is inevitable, it’s everywhere. Even if you try and minimize it, there are limits to what you can do. CPD is a good tool to have in your toolbox for working with noisy benchmark data.
Questions and Answers
Participant 1: You said one of the drawbacks of CPD is that sometimes it takes days until you notice, because you need several data points. Do you know any way that I could detect performance change or regression immediately in a noisy environment, or is this completely hopeless?
Fleming: You can still detect performance changes in noisy environments immediately. It depends on the magnitude of the change. I have a lot of faith in CPD, and so I will do things like use alerts based on it, or alert the whole team. With detecting changes immediately in a PR, for example, I don’t put as many restrictions on it, I don’t block the PR. I don’t necessarily alert anybody, because it tends to be less reliable. You can do it, but if you have a really huge performance drop, you can catch that immediately. Depending on the noise and the magnitude of the change, that becomes more difficult. It’s easy for small changes to slip through. One of the nice things about CPD is it catches this death by a thousand cuts problem. You can totally do it.
Participant 2: In those examples that you showed, there was quite obvious cliffs of change. Over time on a project, there might be so many incremental, or such an incremental performance degradation, is there a risk that it might not be significant enough as a single data point to trigger an alert or a concern? If you take a step back and look at its journey over the last 12 months, actually, you’ve gone from something that was highly performant to now something that is the opposite.
Fleming: This is the death by a thousand cuts thing I alluded to. CPD, depending on the algorithm you pick, window size is the wrong thing, because there are window-based methods, but it alters the size of the distribution it looks at. We can go back over the whole data and see those soft, slow declines. It will flag a change point for those slow declines. Where it picks it, depends on the cleanliness of your data and things like that, but it’s certainly capable. I’ve seen it work where it definitely noticed this degradation, even though it was minor, over a long period of time. In the most extreme case, if you compared the one on the left-hand side and the right-hand side, you would see that they were different. That’s all that’s really required for CPD, is just this ability to pick some size of distribution and compare the two. It should still catch that.
Participant 3: You were talking about the problem of detecting changes quickly at the front edge. Is there an opportunity to use CPD with different parameters to detect that change rapidly, or does that become almost like an anti-pattern in a way?
Fleming: One of the things that I like, and Hunter actually has a way to do this, is you can use CPD to find the most recent stable region of a time series. One of the problems that other methods have, if you’re trying to basically use the whole time series, is things get washed out as things change. With CPD, you can say, give me the most recent change point, from that point to the end, do you get a stable region. Then that, used in combination with basically any kind of statistical test, actually is really powerful.
Participant 4: Have you got any views on how you can make performance engineering a concern of regular developers?
Fleming: There’s a number of things that we could do. I’d like to see them differently. I’d like to see it taught a lot more. It seems to be one of those things that people have to grapple with by themselves, which works. That’s totally fine. I think as senior people in tech, we should be teaching this to more people. It is a skill. It’s totally learnable by everybody. I think that would help a lot. It’s just people who know what they’re doing, teaching other people. You could do like brown bag lunch talks, things like that.
I’ve done those at companies I’ve worked for, and they’re very well received, because most people haven’t had it explained in a comprehensive way. There’s a lot of value from these kinds of talks, where it’s condensed and there’s a narrative to it, and it’s thought through, rather than sending people blogposts, which are cool. There’s a difference, like sitting somebody down and walking them through an entire talk specifically for performance engineering. There’s education, I think is one.
I think having the stakeholders in projects agree up front about the performance characteristics of things would make this a concern for many teams. This is like NFRs and things like that, and pushing that conversation at the start. One of the things that I’ve done for one of the distributed systems projects I worked on, we were adding a new feature, we were adding consistency to an eventually consistent database. At the front, I got people to agree on what the expected performance characteristics were, and then implement performance tests at the start, so that I could show people the numbers. Numbers are really powerful. I think if you have that, that really helps. Then the third one is tying it to revenue. If you can show people how bad performance impacts revenue, everybody listens to that.
Participant 5: There was one bit where you had a choice to make in your functions about like, is it normally distributed? If it is, I’ll use a maximum likelihood estimator, otherwise, I’ll use something else. How do you test whether your distribution is normal or not?
Fleming: I’ve got two answers. The short one is, assume it’s not, and just don’t use any of the parametric methods. There are ways to test for normality, if you Google it. That’s what I do, I would just Google, normality test. There are ways you can test for it. It becomes cumbersome. It depends on the benchmark. It depends on the dataset. I think a lot of the time, it’s easier just to assume it’s not.
Participant 6: For people from a data science or analytics background, tests like these may come super naturally, as this goes. Have you had luck with collaborating with colleagues in the data science department, for instance, to work on how are these methods working on the monitoring of these systems?
Fleming: No, I haven’t. I would love to do something like that.
See more presentations with transcripts
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Alright, listen up, because the AI game is changing, and you don’t want to get left behind.
Yeah, the chip guys, like Nvidia, they had their moment. The first AI wave? They rode it high.
But guess what? That ride’s over. Nvidia’s been flatlining since June 2024.
Remember the internet boom? Everyone thought Cisco and Intel were the kings, right? Wrong. The real money was made by the companies that actually used the internet to build something new: e-commerce, search engines, social media.
And it’s the same deal with AI. The chipmakers? They’re yesterday’s news. The real winners? They’re the robotics companies, the ones building the robots we only dreamed about before.
We’re talking AI 2.0. The first wave was about the chips, this one’s about the robots. Robots that can do your chores, robots that can work in factories, robots that will change everything. Labor shortages? Gone. Industries revolutionized? You bet.
This isn’t some far-off fantasy, it’s happening right now. And there’s one company, a robotics company, that’s leading the charge. They’ve got the cutting-edge tech, they’re ahead of the curve, and they’re dirt cheap right now. We’re talking potential 100x returns in the next few years. You snooze, you lose.
Here’s the catch (it’s a good one): To uncover this sleeping giant, you’ll need our exclusive intel.
We want to make sure none of our valued readers miss out on this groundbreaking opportunity!
That’s why we’re slashing the price of our Premium Readership Newsletter by a whopping 70%.
For a ridiculously low price of just $29.99, you can unlock a year’s worth of in-depth investment research and exclusive insights – that’s less than a single restaurant meal!
Here’s why this is a deal you can’t afford to pass up:
• Access to our Detailed Report on this Game-Changing AI Stock: Our in-depth report dives deep into our #1 AI stock’s groundbreaking technology and massive growth potential.
• 11 New Issues of Our Premium Readership Newsletter: You will also receive 11 new issues and at least one new stock pick per month from our monthly newsletter’s portfolio over the next 12 months. These stocks are handpicked by our research director, Dr. Inan Dogan.
• One free upcoming issue of our 70+ page Quarterly Newsletter: A value of $149
• Bonus Reports: Premium access to members-only fund manager video interviews
• Ad-Free Browsing: Enjoy a year of investment research free from distracting banner and pop-up ads, allowing you to focus on uncovering the next big opportunity.
• 30-Day Money-Back Guarantee: If you’re not absolutely satisfied with our service, we’ll provide a full refund within 30 days, no questions asked.
Space is Limited! Only 1000 spots are available for this exclusive offer. Don’t let this chance slip away – subscribe to our Premium Readership Newsletter today and unlock the potential for a life-changing investment.
Here’s what to do next:
1. Head over to our website and subscribe to our Premium Readership Newsletter for just $29.99.
2. Enjoy a year of ad-free browsing, exclusive access to our in-depth report on the revolutionary AI company, and the upcoming issues of our Premium Readership Newsletter over the next 12 months.
3. Sit back, relax, and know that you’re backed by our ironclad 30-day money-back guarantee.
Don’t miss out on this incredible opportunity! Subscribe now and take control of your AI investment future!
No worries about auto-renewals! Our 30-Day Money-Back Guarantee applies whether you’re joining us for the first time or renewing your subscription a year later!
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

Microsoft has recently launched Azure AI Foundry Labs, a hub designed to bring the latest AI research and experiments to developers, startups, and enterprises. The company started this to bridge the gap between groundbreaking research and real-world applications, enabling developers to explore new possibilities.
Azure AI Foundry Labs offers a range of new assets and experimental research projects that empower developers to create prototypes for new technologies. Among the notable projects are Aurora, a large-scale atmospheric model providing high-resolution weather forecasts and air pollution predictions; MatterSim, a deep learning model for atomistic simulations; and TamGen, a generative AI model for drug design using a GPT-like chemical language model for target-aware molecule generation and refinement.
The Labs also feature ExACT, an open-source project that enables agents to learn from past interactions and dynamically improve search efficiency. Magentic-One is a multi-agent system built on the AutoGen framework that solves complex problems by orchestrating multiple agents. Additionally, OmniParser v2, a vision-based module, converts UI into structured elements, enhancing agents’ action generation.
The company writes in an AI and Machine Learning blog post:
Developers can create prototypes using experimental research in Azure AI Foundry Labs, collaborate with researchers and engineering teams by sharing feedback, and help speed up the time to market for some of the most promising technologies.
Lastly, one of the most recent additions to Azure AI Foundry Labs is BioEmu-1, introduced by Microsoft Research. This deep-learning model is designed to predict the range of structural conformations that proteins can adopt. Another one is Magma, a multimodal foundation model designed to understand and act in digital and physical environments.
In a LinkedIn post of Satya Nadella, John C. Hockinson, an AI & Automation Leader, commented:
AI innovation is moving fast, and Azure AI Foundry Labs is putting cutting-edge research directly into the hands of developers. Access to experimental models and breakthroughs means faster iteration, real-world testing, and accelerated AI adoption.
And similar responses on X where Microsoft MVP John Cook tweeted:
Massive move! Giving devs direct access to cutting-edge AI research is how real innovation happens.
Microsoft is not alone in the hyperscale cloud market with AI exploration for developers through Azure AI Foundry Labs. Competing companies like Google and AWS have also launched similar services.
Google, for instance, has Google Labs, which gives developers access to the latest AI innovations, including Project Astra, Project Mariner, and NotebookLM. Project Astra is a research prototype that explores the potential capabilities of a universal AI assistant, while Project Mariner investigates the future of human-agent interaction, specifically through web browsers. On the other hand, AWS offers PartyRock, a mostly free, low-code tool designed for building generative AI applications. This tool features a new app search function and allows document processing integration into applications.