Month: June 2025

MMS • Sergio De Simone

Google has announced the integration of Gemini in Android Studio’s Agent Mode into the latest canary release of Android Studio, Android Studio Narwhal preview. According to Google, the new Agent Mode is designed to handle multi-step development tasks that span across several files.
Agent Mode takes Gemini integration in Android Studio a step forward by going beyond what was previously possible through simple chat interactions. Specifically, Agent Mode uses the entire project as context, not just the contents of the chat window. Its deeper integration with the IDE also allows it to directly modify the project, rather than merely suggesting code snippets to copy and paste. Most importantly, it can execute multi-step tasks.
With Agent Mode, you can describe a complex goal in natural language — from generating unit tests to complex refactors — and the agent formulates an execution plan that can span multiple files in your project and executes under your direction.
Examples of tasks you can ask Agent Mode to perform include building a project and fixing all errors, extracting hardcoded strings and migrating them to strings.xml, adding support for dark mode to an existing application, and more.
The agent carries out requested tasks step by step, allowing developers to review the changes. If they’re not satisfied, they can provide feedback and ask the agent to provide a new solution based on it until the result meets their expectations.
Agent Mode can interact with external tools via the Model Context Protocol (MCP), for example to create a pull request directly from Android Studio, or use any of the MCP servers currently available. The initial implementation of MCP support in this preview is partial, as only the stdio transport is available, with support for Streamable HTTP transport planned for a future release, along with external context resources, and prompt templates.
Agent Mode can be used with the Gemini’s free tier, which supports a limited context window though. Alternatively, you can use a one million tokens window by upgrading to Gemini 2.5 Pro.
Google highlights that Agent Mode is especially useful for routine, time-consuming tasks, helping free up developers’ time for more creative work. This could be seen as a subtle way to set expectation right about what this tool can bring to a developer’s workflow, or a hint at the most appropriate way to use it day to day.
As this is still a preview release, it’s expected that not all features will work flawlessly in every scenario. Early adopters of Gemini in Android Studio’s Agent Mode have reported several shortcomings, including issues seemingly related to the tool’s inability to run external tools to access source files or modify them. Google is aware of these issues and is actively working to address them.
MMS • RSS
Diversified Trust Co increased its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 117.8% during the 1st quarter, according to its most recent Form 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 15,071 shares of the company’s stock after acquiring an additional 8,152 shares during the period. Diversified Trust Co’s holdings in MongoDB were worth $2,643,000 at the end of the most recent reporting period.
Several other hedge funds have also bought and sold shares of the business. Robeco Institutional Asset Management B.V. boosted its stake in MongoDB by 13.2% during the first quarter. Robeco Institutional Asset Management B.V. now owns 19,449 shares of the company’s stock worth $3,411,000 after acquiring an additional 2,270 shares in the last quarter. WoodTrust Financial Corp lifted its stake in shares of MongoDB by 21.2% in the first quarter. WoodTrust Financial Corp now owns 5,150 shares of the company’s stock worth $903,000 after buying an additional 900 shares in the last quarter. Oppenheimer Asset Management Inc. lifted its stake in shares of MongoDB by 41.9% in the first quarter. Oppenheimer Asset Management Inc. now owns 7,058 shares of the company’s stock worth $1,238,000 after buying an additional 2,085 shares in the last quarter. TrueMark Investments LLC lifted its stake in shares of MongoDB by 14.0% in the first quarter. TrueMark Investments LLC now owns 6,419 shares of the company’s stock worth $1,126,000 after buying an additional 790 shares in the last quarter. Finally, Cambridge Investment Research Advisors Inc. lifted its stake in shares of MongoDB by 4.0% in the first quarter. Cambridge Investment Research Advisors Inc. now owns 7,748 shares of the company’s stock worth $1,359,000 after buying an additional 298 shares in the last quarter. Institutional investors own 89.29% of the company’s stock.
MongoDB Trading Up 0.3%
NASDAQ MDB traded up $0.72 on Friday, hitting $209.92. 3,106,432 shares of the company traded hands, compared to its average volume of 1,960,037. The company has a market capitalization of $17.15 billion, a price-to-earnings ratio of -184.14 and a beta of 1.39. The business’s 50 day moving average price is $190.83 and its 200-day moving average price is $216.65. MongoDB, Inc. has a 52-week low of $140.78 and a 52-week high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, beating the consensus estimate of $0.65 by $0.35. The company had revenue of $549.01 million for the quarter, compared to the consensus estimate of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. MongoDB’s quarterly revenue was up 21.8% compared to the same quarter last year. During the same period in the previous year, the business earned $0.51 earnings per share. As a group, sell-side analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Analysts Set New Price Targets
MDB has been the topic of several analyst reports. Cantor Fitzgerald upped their target price on shares of MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a research note on Thursday, June 5th. Barclays upped their target price on shares of MongoDB from $252.00 to $270.00 and gave the stock an “overweight” rating in a research note on Thursday, June 5th. Wells Fargo & Company downgraded shares of MongoDB from an “overweight” rating to an “equal weight” rating and dropped their target price for the stock from $365.00 to $225.00 in a research note on Thursday, March 6th. Bank of America upped their target price on shares of MongoDB from $215.00 to $275.00 and gave the stock a “buy” rating in a research note on Thursday, June 5th. Finally, Oppenheimer dropped their target price on shares of MongoDB from $400.00 to $330.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Eight research analysts have rated the stock with a hold rating, twenty-five have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to MarketBeat.com, the company currently has a consensus rating of “Moderate Buy” and a consensus target price of $282.47.
Check Out Our Latest Report on MongoDB
Insider Transactions at MongoDB
In other news, CFO Srdjan Tanjga sold 525 shares of the stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $90,961.50. Following the completion of the sale, the chief financial officer now directly owns 6,406 shares of the company’s stock, valued at $1,109,903.56. This represents a 7.57% decrease in their ownership of the stock. The sale was disclosed in a document filed with the SEC, which is available at this hyperlink. Also, CAO Thomas Bull sold 301 shares of the stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the sale, the chief accounting officer now directly owns 14,598 shares of the company’s stock, valued at approximately $2,529,103.50. This trade represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold a total of 51,202 shares of company stock valued at $10,576,696 over the last three months. Corporate insiders own 3.10% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Today, we are inviting you to take a free peek at our proprietary, exclusive, and up-to-the-minute list of 20 stocks that Wall Street’s top analysts hate.
Many of these appear to have good fundamentals and might seem like okay investments, but something is wrong. Analysts smell something seriously rotten about these companies. These are true “Strong Sell” stocks.
MMS • Matt Foster
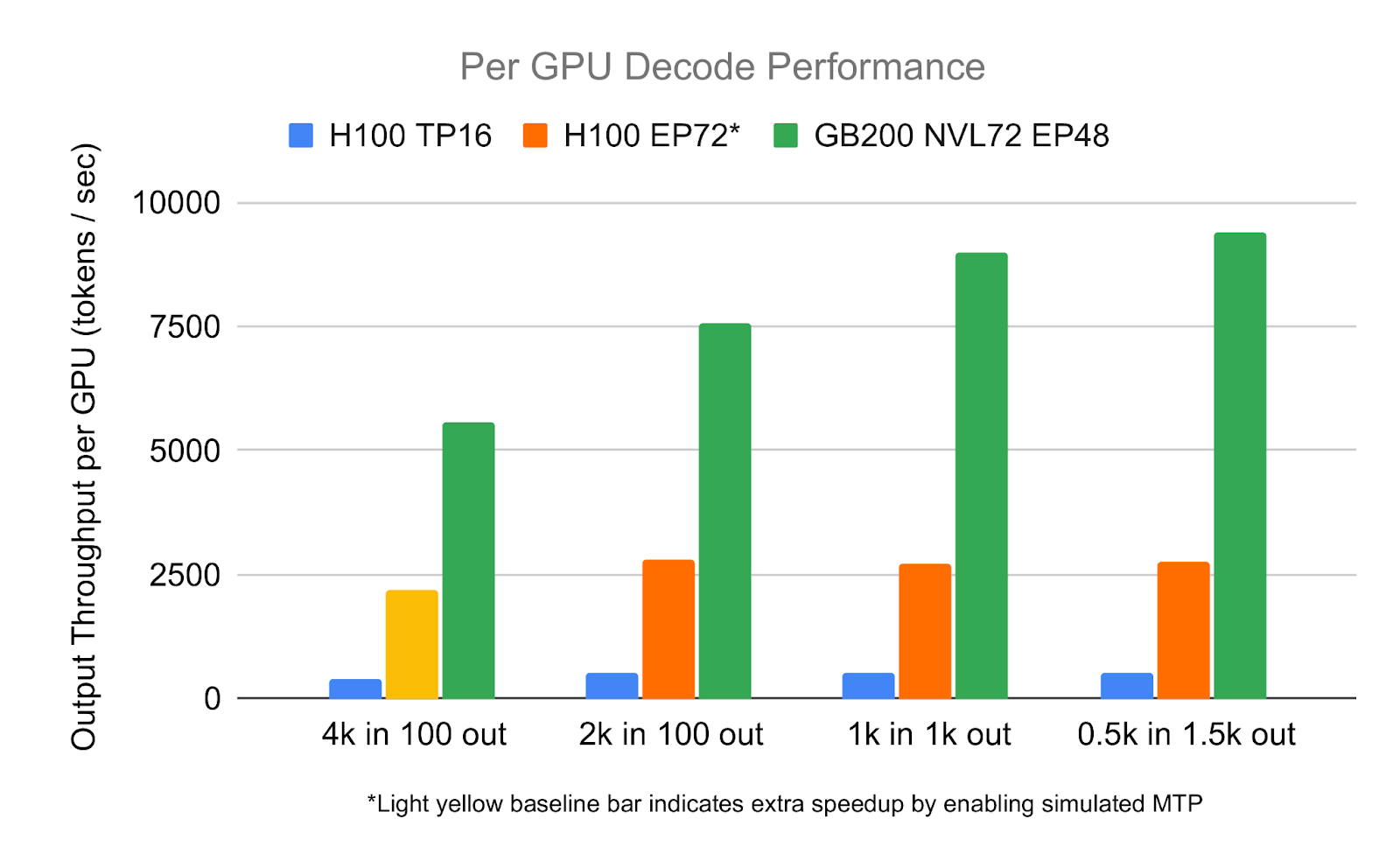
In collaboration with NVIDIA, researchers from SGLang have published early benchmarks of the GB200 (Grace Blackwell) NVL72 system, showing up to a 2.7× increase in LLM inference throughput compared to the H100 on the DeepSeek-V2 671B model.
The uplift is attributed to a suite of software optimizations built for the Blackwell architecture, including FP8-optimized matrix multiplication, accelerated attention kernels, and high-speed token routing over NVLink. These enhancements were integrated into the SGLang runtime to fully exploit GB200’s dense multi-GPU fabric and unified memory model.
NVIDIA’s GB200 NVL72 is positioned as a general-purpose platform for large-scale AI, spanning both training and inference. This benchmark, focused solely on inference, offers an early look at how the system performs under realistic load—before broader workloads like multi-trillion parameter training or multimodal serving are publicly tested.
In decoding benchmarks using a 2,000-token prompt, SGLang achieved 7,583 tokens per second per GPU—a 2.7× improvement over H100 HGX systems on the same workload. This level of throughput enables faster responses for large-context inputs and high concurrency, such as technical document summarization, codebase-aware AI assistants, and enterprise-scale retrieval-augmented generation (RAG). It also reduces the number of GPUs required to serve large models interactively, improving both latency and cost efficiency at scale.
The benchmark was conducted using DeepSeek-V2, a 671-billion parameter, decoder-only large language model. Released by DeepSeek, the model follows a Mixture-of-Experts (MoE) design—activating ~21B parameters per token (≈ 9% of the total)—meaning only a fraction of the parameters are used during inference.
This architecture presents a realistic performance challenge: token routing between experts stresses inter-GPU communication, while the large model size and long prompt lengths place sustained pressure on GPU memory.
To achieve the reported speedup, the SGLang team integrated a series of Blackwell-specific optimizations into their runtime. These include DeepGEMM, a high-performance FP8 matrix multiplication library designed to exploit Blackwell’s new UMMA (Unified Matrix Multiplication Accelerator) instructions; FlashInfer FMHA (Fused Multi-Head Attention), a rewritten fused attention kernel optimized for the DeepSeek model’s prefill phase; and DeepEP, a communication library that efficiently shuffles tokens between routed experts using direct NVLink memory mapping.
The team also employed CUTLASS MLA (Multi-Head Latent Attention), a latent-attention kernel tuned for Blackwell’s memory hierarchy, and Mooncake, a custom transfer engine for disaggregated key-value (KV) cache movement.
Collectively, these components formed a software path that minimized compute, memory, and communication overhead during SGLang’s large-scale multi-GPU inference experiments.
The authors note that while the benchmark demonstrates significant gains in decoding throughput, several areas remain under-optimized. In particular, the prefill stage has yet to be fully tuned, and many kernels do not yet saturate the GB200’s memory bandwidth or compute capacity. Communication and compute are also not fully overlapped, leaving further efficiency gains on the table.
Future work will focus on closing these gaps, with plans to optimize prefill latency and improve memory utilization and latency.
MMS • RSS
![]() Asset Management One Co. Ltd. trimmed its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 5.3% during the 1st quarter, according to the company in its most recent 13F filing with the Securities and Exchange Commission (SEC). The fund owned 38,280 shares of the company’s stock after selling 2,127 shares during the quarter. Asset Management One Co. Ltd.’s holdings in MongoDB were worth $6,726,000 as of its most recent filing with the Securities and Exchange Commission (SEC).
Asset Management One Co. Ltd. trimmed its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 5.3% during the 1st quarter, according to the company in its most recent 13F filing with the Securities and Exchange Commission (SEC). The fund owned 38,280 shares of the company’s stock after selling 2,127 shares during the quarter. Asset Management One Co. Ltd.’s holdings in MongoDB were worth $6,726,000 as of its most recent filing with the Securities and Exchange Commission (SEC).
Several other institutional investors and hedge funds have also bought and sold shares of the stock. Strategic Investment Solutions Inc. IL bought a new stake in shares of MongoDB in the 4th quarter worth approximately $29,000. Coppell Advisory Solutions LLC grew its position in shares of MongoDB by 364.0% in the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after buying an additional 182 shares during the last quarter. Smartleaf Asset Management LLC grew its position in shares of MongoDB by 56.8% in the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after buying an additional 134 shares during the last quarter. J.Safra Asset Management Corp grew its position in shares of MongoDB by 72.0% in the 4th quarter. J.Safra Asset Management Corp now owns 387 shares of the company’s stock worth $91,000 after buying an additional 162 shares during the last quarter. Finally, Aster Capital Management DIFC Ltd bought a new stake in shares of MongoDB in the 4th quarter worth approximately $97,000. 89.29% of the stock is currently owned by institutional investors.
Insider Activity at MongoDB
In other news, Director Hope F. Cochran sold 1,175 shares of the firm’s stock in a transaction that occurred on Tuesday, April 1st. The stock was sold at an average price of $174.69, for a total value of $205,260.75. Following the completion of the sale, the director now directly owns 19,333 shares of the company’s stock, valued at $3,377,281.77. This trade represents a 5.73% decrease in their position. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available at this link. Also, CEO Dev Ittycheria sold 25,005 shares of the firm’s stock in a transaction that occurred on Thursday, June 5th. The shares were sold at an average price of $234.00, for a total value of $5,851,170.00. Following the completion of the sale, the chief executive officer now directly owns 256,974 shares of the company’s stock, valued at $60,131,916. The trade was a 8.87% decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last three months, insiders sold 51,202 shares of company stock valued at $10,576,696. Insiders own 3.10% of the company’s stock.
MongoDB Stock Up 0.3%
<!—->
NASDAQ MDB opened at $209.92 on Friday. The firm has a market cap of $17.15 billion, a price-to-earnings ratio of -184.14 and a beta of 1.39. The business has a 50-day moving average price of $190.83 and a 200-day moving average price of $217.14. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The firm had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The business’s quarterly revenue was up 21.8% compared to the same quarter last year. During the same quarter in the prior year, the company posted $0.51 earnings per share. Research analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analyst Upgrades and Downgrades
A number of brokerages have recently weighed in on MDB. Cantor Fitzgerald lifted their price objective on MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a research report on Thursday, June 5th. Citigroup lowered their target price on MongoDB from $430.00 to $330.00 and set a “buy” rating for the company in a research note on Tuesday, April 1st. Stifel Nicolaus lowered their target price on MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research note on Friday, April 11th. Morgan Stanley lowered their target price on MongoDB from $315.00 to $235.00 and set an “overweight” rating for the company in a research note on Wednesday, April 16th. Finally, Scotiabank raised their target price on MongoDB from $160.00 to $230.00 and gave the company a “sector perform” rating in a research note on Thursday, June 5th. Eight equities research analysts have rated the stock with a hold rating, twenty-five have issued a buy rating and one has assigned a strong buy rating to the company’s stock. According to MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and a consensus price target of $282.47.
Check Out Our Latest Stock Analysis on MDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
Aljian Capital Management LLC increased its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 76.1% in the first quarter, according to the company in its most recent filing with the Securities and Exchange Commission. The firm owned 4,501 shares of the company’s stock after purchasing an additional 1,945 shares during the period. Aljian Capital Management LLC’s holdings in MongoDB were worth $789,000 as of its most recent filing with the Securities and Exchange Commission.
A number of other institutional investors have also recently added to or reduced their stakes in MDB. IFP Advisors Inc boosted its position in MongoDB by 54.3% in the 4th quarter. IFP Advisors Inc now owns 1,632 shares of the company’s stock valued at $380,000 after buying an additional 574 shares during the last quarter. Amalgamated Bank boosted its position in MongoDB by 1.9% in the 4th quarter. Amalgamated Bank now owns 4,713 shares of the company’s stock valued at $1,097,000 after buying an additional 89 shares during the last quarter. Mn Services Vermogensbeheer B.V. boosted its position in MongoDB by 1.8% in the 4th quarter. Mn Services Vermogensbeheer B.V. now owns 28,100 shares of the company’s stock valued at $6,542,000 after buying an additional 500 shares during the last quarter. Oppenheimer & Co. Inc. boosted its position in MongoDB by 93.4% in the 4th quarter. Oppenheimer & Co. Inc. now owns 9,193 shares of the company’s stock valued at $2,140,000 after buying an additional 4,440 shares during the last quarter. Finally, Proficio Capital Partners LLC purchased a new position in MongoDB in the 4th quarter valued at about $10,135,000. 89.29% of the stock is owned by hedge funds and other institutional investors.
Insider Buying and Selling
In related news, Director Hope F. Cochran sold 1,175 shares of the firm’s stock in a transaction that occurred on Tuesday, April 1st. The shares were sold at an average price of $174.69, for a total value of $205,260.75. Following the completion of the transaction, the director now owns 19,333 shares of the company’s stock, valued at approximately $3,377,281.77. This trade represents a 5.73% decrease in their position. The transaction was disclosed in a document filed with the SEC, which is accessible through this hyperlink. Also, insider Cedric Pech sold 1,690 shares of the firm’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $292,809.40. Following the completion of the transaction, the insider now directly owns 57,634 shares of the company’s stock, valued at $9,985,666.84. This represents a 2.85% decrease in their position. The disclosure for this sale can be found here. Over the last ninety days, insiders sold 51,202 shares of company stock worth $10,576,696. Corporate insiders own 3.10% of the company’s stock.
MongoDB Price Performance
Shares of MongoDB stock traded up $0.72 on Friday, hitting $209.92. The company had a trading volume of 3,106,432 shares, compared to its average volume of 1,960,037. The business has a 50-day simple moving average of $190.83 and a 200-day simple moving average of $217.14. The company has a market cap of $17.15 billion, a PE ratio of -184.14 and a beta of 1.39. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The firm had revenue of $549.01 million during the quarter, compared to analysts’ expectations of $527.49 million. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The firm’s revenue for the quarter was up 21.8% compared to the same quarter last year. During the same period last year, the firm posted $0.51 earnings per share. On average, equities research analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Wall Street Analysts Forecast Growth
A number of equities analysts have weighed in on MDB shares. Truist Financial decreased their price objective on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a research report on Monday, March 31st. The Goldman Sachs Group reduced their price target on shares of MongoDB from $390.00 to $335.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Macquarie reaffirmed a “neutral” rating and set a $230.00 price target (up previously from $215.00) on shares of MongoDB in a research report on Friday, June 6th. Bank of America increased their price target on shares of MongoDB from $215.00 to $275.00 and gave the stock a “buy” rating in a research report on Thursday, June 5th. Finally, Rosenblatt Securities reduced their price target on shares of MongoDB from $305.00 to $290.00 and set a “buy” rating on the stock in a research report on Thursday, June 5th. Eight equities research analysts have rated the stock with a hold rating, twenty-five have given a buy rating and one has issued a strong buy rating to the company. According to data from MarketBeat.com, MongoDB presently has a consensus rating of “Moderate Buy” and a consensus target price of $282.47.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Nuclear energy stocks are roaring. It’s the hottest energy sector of the year. Cameco Corp, Paladin Energy, and BWX Technologies were all up more than 40% in 2024. The biggest market moves could still be ahead of us, and there are seven nuclear energy stocks that could rise much higher in the next several months. To unlock these tickers, enter your email address below.
MMS • RSS
Asset Management One Co. Ltd. trimmed its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 5.3% during the 1st quarter, according to the company in its most recent 13F filing with the Securities and Exchange Commission (SEC). The fund owned 38,280 shares of the company’s stock after selling 2,127 shares during the quarter. Asset Management One Co. Ltd.’s holdings in MongoDB were worth $6,726,000 as of its most recent filing with the Securities and Exchange Commission (SEC).
Several other institutional investors and hedge funds have also bought and sold shares of the stock. Strategic Investment Solutions Inc. IL bought a new stake in shares of MongoDB in the 4th quarter worth approximately $29,000. Coppell Advisory Solutions LLC grew its position in shares of MongoDB by 364.0% in the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after buying an additional 182 shares during the last quarter. Smartleaf Asset Management LLC grew its position in shares of MongoDB by 56.8% in the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after buying an additional 134 shares during the last quarter. J.Safra Asset Management Corp grew its position in shares of MongoDB by 72.0% in the 4th quarter. J.Safra Asset Management Corp now owns 387 shares of the company’s stock worth $91,000 after buying an additional 162 shares during the last quarter. Finally, Aster Capital Management DIFC Ltd bought a new stake in shares of MongoDB in the 4th quarter worth approximately $97,000. 89.29% of the stock is currently owned by institutional investors.
Insider Activity at MongoDB
In other news, Director Hope F. Cochran sold 1,175 shares of the firm’s stock in a transaction that occurred on Tuesday, April 1st. The stock was sold at an average price of $174.69, for a total value of $205,260.75. Following the completion of the sale, the director now directly owns 19,333 shares of the company’s stock, valued at $3,377,281.77. This trade represents a 5.73% decrease in their position. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available at this link. Also, CEO Dev Ittycheria sold 25,005 shares of the firm’s stock in a transaction that occurred on Thursday, June 5th. The shares were sold at an average price of $234.00, for a total value of $5,851,170.00. Following the completion of the sale, the chief executive officer now directly owns 256,974 shares of the company’s stock, valued at $60,131,916. The trade was a 8.87% decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last three months, insiders sold 51,202 shares of company stock valued at $10,576,696. Insiders own 3.10% of the company’s stock.
MongoDB Stock Up 0.3%
NASDAQ MDB opened at $209.92 on Friday. The firm has a market cap of $17.15 billion, a price-to-earnings ratio of -184.14 and a beta of 1.39. The business has a 50-day moving average price of $190.83 and a 200-day moving average price of $217.14. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The firm had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The business’s quarterly revenue was up 21.8% compared to the same quarter last year. During the same quarter in the prior year, the company posted $0.51 earnings per share. Research analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analyst Upgrades and Downgrades
A number of brokerages have recently weighed in on MDB. Cantor Fitzgerald lifted their price objective on MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a research report on Thursday, June 5th. Citigroup lowered their target price on MongoDB from $430.00 to $330.00 and set a “buy” rating for the company in a research note on Tuesday, April 1st. Stifel Nicolaus lowered their target price on MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research note on Friday, April 11th. Morgan Stanley lowered their target price on MongoDB from $315.00 to $235.00 and set an “overweight” rating for the company in a research note on Wednesday, April 16th. Finally, Scotiabank raised their target price on MongoDB from $160.00 to $230.00 and gave the company a “sector perform” rating in a research note on Thursday, June 5th. Eight equities research analysts have rated the stock with a hold rating, twenty-five have issued a buy rating and one has assigned a strong buy rating to the company’s stock. According to MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and a consensus price target of $282.47.
Check Out Our Latest Stock Analysis on MDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s list of ten stocks that are set to soar in Summer 2025, despite the threat of tariffs and other economic uncertainty. These ten stocks are incredibly resilient and are likely to thrive in any economic environment.
MMS • RSS
MongoDB (MDB) has long been the poster child of the cloud software boom, with its Atlas database-as-a-service platform powering everything from e-commerce to AI-driven analytics. Yet today, the company sits at a crossroads: its stock is buoyed by a near-unanimous “Strong Buy” consensus from Wall Street analysts, while quantitative models like the Zacks Rank suggest caution. The question isn’t whether MongoDB remains a leader in its space—it does—but whether its current valuation can sustain the optimism baked into its average brokerage recommendation (ABR) of 1.54, or if investors should heed the whispers of decelerating growth.

The Brokerage Bull Case: A Numbers Game
The ABR of 1.54—derived from 24 “Strong Buy” ratings out of 35 total—paints MongoDB as a buy-and-hold darling. Analysts cite its 22% year-over-year revenue growth in Q1, improving gross margins (now 72%), and the rollout of Atlas Vector Search, its AI-native database tool. Citigroup’s recent $350 price target (up from $300 in 2024) and Piper Sandler’s $350 call reflect this optimism. These firms argue that MongoDB’s shift to a subscription-based model, alongside its dominance in the $80 billion database market, positions it to weather macroeconomic headwinds.
But dig deeper, and the narrative falters. Brokerage recommendations are not neutral signals. Firms with underwriting relationships to MongoDB—or exposure to its ecosystem—are incentivized to maintain positive ratings. TheStreet’s analysis of MDB’s analyst coverage reveals that 60% of firms covering the stock also ranked among its top institutional shareholders in 2024. Such conflicts of interest, while legal, cast doubt on the objectivity of the ABR.
The Zacks Reality Check: Earnings Math Matters
Enter the Zacks Rank #2 (Buy), a quantitative model that tracks earnings estimate revisions. While the rank is bullish, the methodology underscores a critical point: MongoDB’s consensus estimate for 2025 has only risen 15.8% in the past month, to $3.03 per share. That may sound positive, but it pales compared to the 30-40% upward revisions seen in prior high-growth quarters.
The disconnect? MongoDB’s growth is decelerating. While 22% revenue growth is robust, it’s down from 34% in 2023 and 57% in 2022. Meanwhile, the Zacks model’s four factors—earnings momentum, earnings surprises, upward revisions, and industry rank—now place MDB in the top 20% of stocks, but not the top 10%. For a stock trading at a price-to-sales (P/S) ratio of 8.8x, versus its historical peak of 12.2x, this suggests investors are already pricing in a slowdown.
The Elephant in the Room: Valuation and Macro Risks
MongoDB’s valuation remains a sticking point. At $280.36 (the current consensus target), MDB would trade at a P/S of 10.5x—still elevated relative to peers like Snowflake (SNOW, P/S 4.2x) or Datadog (DDOG, P/S 6.1x). Even if MongoDB’s AI integration (Atlas Vector Search) drives new use cases, the company’s reliance on enterprise IT budgets poses risks. A prolonged macro slowdown could delay cloud spending, squeezing both margins and growth rates.
The Zacks Rank’s #2 Buy rating also carries a caveat: it’s a short-term signal. The model’s historical performance shows that stocks with high Zacks Rank scores often underperform over 12-18 months if their growth decelerates. For MongoDB, the question isn’t whether it can grow—it’s whether it can grow enough to justify its valuation.
Investment Thesis: Hold Until the Fog Lifts
MongoDB’s story isn’t over. Its Atlas platform retains a 50% market share in cloud databases, and AI tools like Vector Search could unlock new revenue streams. Yet investors must navigate a tension: the ABR’s exuberance versus the Zacks Rank’s tempered view.
The path forward is clear. Use the Zacks model to validate broker calls: if upward revisions to MongoDB’s earnings estimates accelerate beyond 15.8% in the next quarter, the stock could justify its current price. But if growth continues to slow—and the P/S ratio remains above 8x—MDB becomes a prime candidate for profit-taking. For now, the data suggests a Hold rating.
In an era where data-driven signals often clash with Wall Street’s narrative, MongoDB’s journey is a masterclass in balancing hype with hard numbers. Investors would be wise to let the latter lead.
MMS • Almir Vuk

Earlier this month, Microsoft announced the release of .NET 10 Preview 5, delivering updates across multiple components, including ASP.NET Core, .NET MAUI, Windows Presentation Foundation (WPF), and Entity Framework Core. As reported, this preview introduces new features and improvements aimed at enhancing developer productivity, application observability, and customization.
Regarding ASP.NET Core, a new capability allows developers to configure custom security descriptors for HTTP.sys request queues via the RequestQueueSecurityDescriptor property in HttpSysOptions. As stated, this feature offers better control over access to request queues at the OS level.
Additionally, validation resolver APIs supporting Minimal APIs have been marked as experimental to allow future modifications, though the top-level AddValidation APIs remain stable.
OpenAPI generation has been improved with support for version 3.1. The release also extends metadata extraction from XML documentation, recognizing and tags for response descriptions.
Furthermore, the Blazor framework introduces a method for easier rendering of Not Found pages by specifying a NotFoundPage component in the router configuration. As mentioned in the release notes, this approach is prioritized over the older NotFound fragment and is now included in default project templates.
This content will be ignored because we have NotFoundPage defined.
Notable addition in the Preview 5 is the introduction of detailed metrics and tracing capabilities for Blazor apps. As noted, Metrics are published via dedicated meters for components, lifecycle events, and server circuits.
Tracing uses a new Microsoft.AspNetCore.Components activity source includes detailed instrumentation for navigation, event handling, and circuit lifecycles.
With a note that developers can enable these diagnostics by configuring OpenTelemetry to collect data from the corresponding sources and meters.
builder.Services.ConfigureOpenTelemetryMeterProvider(meterProvider =>
{
meterProvider.AddMeter("Microsoft.AspNetCore.Components");
meterProvider.AddMeter("Microsoft.AspNetCore.Components.Lifecycle");
meterProvider.AddMeter("Microsoft.AspNetCore.Components.Server.Circuits");
});
builder.Services.ConfigureOpenTelemetryTracerProvider(tracerProvider =>
{
tracerProvider.AddSource("Microsoft.AspNetCore.Components");
});
In <a href="http://.NET MAUI, support has been added for XAML Global and Implicit Namespaces. These features simplify markup by allowing developers to use controls without specifying multiple xmlns declarations. A new global namespace can include custom views, converters, and third-party libraries, enabling cleaner and more maintainable XAML.
Implicit namespaces can be activated through project properties, reducing the need for verbose declarations. However, Microsoft notes that tooling errors may occur while this feature remains in preview.
For more information on these features, David Ortinau, Principal Product Manager at Microsoft, has published a dedicated blog post covering the latest updates in .NET MAUI.
Another notable addition to .NET MAUI is the ability to intercept web requests in HybridWebView. This is now possible by handling the WebResourceRequested event, developers can alter or block requests, enabling scenarios such as injecting custom headers or serving local resources.
The update for .NET for Android and Apple platforms, such as iOS, macOS, and tvOS, primarily focuses on quality and stability improvements. Specific details are available in the respective GitHub repositories.
WPF introduces a shorthand syntax for Grid.RowDefinitions and Grid.ColumnDefinitions, making XAML as explained, more concise, and this will improve Hot Reload support.
Font and globalization enhancements include the addition of the simsun-extg font to improve rendering in East Asian languages. Also, the Fluent theme has been refined, addressing crashes and improving styling for RTL layouts. Performance gains were achieved by reducing memory allocations and removing unused code paths.
Lastly, Entity Framework Core 10 Preview 5 brings the ability to define custom names for default constraints, providing more control over database schema generation. Developers can now assign constraint names directly in model configuration or enable automatic naming for all default constraints using UseNamedDefaultConstraints.
For interested readers, full release notes with all updates, fixes, and known issues are available through Microsoft’s official documentation and GitHub repositories.
MMS • RSS
![]() Oppenheimer Asset Management Inc. grew its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 41.9% during the 1st quarter, according to its most recent 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 7,058 shares of the company’s stock after buying an additional 2,085 shares during the quarter. Oppenheimer Asset Management Inc.’s holdings in MongoDB were worth $1,238,000 at the end of the most recent reporting period.
Oppenheimer Asset Management Inc. grew its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 41.9% during the 1st quarter, according to its most recent 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 7,058 shares of the company’s stock after buying an additional 2,085 shares during the quarter. Oppenheimer Asset Management Inc.’s holdings in MongoDB were worth $1,238,000 at the end of the most recent reporting period.
Several other institutional investors and hedge funds have also recently added to or reduced their stakes in MDB. Strategic Investment Solutions Inc. IL acquired a new stake in MongoDB in the 4th quarter valued at about $29,000. Coppell Advisory Solutions LLC lifted its position in shares of MongoDB by 364.0% in the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after buying an additional 182 shares during the last quarter. Smartleaf Asset Management LLC boosted its stake in shares of MongoDB by 56.8% during the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after acquiring an additional 134 shares during the period. J.Safra Asset Management Corp boosted its stake in shares of MongoDB by 72.0% during the 4th quarter. J.Safra Asset Management Corp now owns 387 shares of the company’s stock worth $91,000 after acquiring an additional 162 shares during the period. Finally, Aster Capital Management DIFC Ltd bought a new stake in MongoDB in the 4th quarter valued at $97,000. 89.29% of the stock is owned by institutional investors.
MongoDB Trading Up 0.3%
Shares of MDB opened at $209.92 on Friday. The stock’s 50-day moving average price is $189.81 and its two-hundred day moving average price is $218.26. MongoDB, Inc. has a 12 month low of $140.78 and a 12 month high of $370.00. The company has a market capitalization of $17.15 billion, a PE ratio of -184.14 and a beta of 1.39.
<!—->
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The company had revenue of $549.01 million for the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The firm’s quarterly revenue was up 21.8% on a year-over-year basis. During the same period in the previous year, the firm earned $0.51 earnings per share. Equities research analysts predict that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Insiders Place Their Bets
In related news, Director Hope F. Cochran sold 1,175 shares of the company’s stock in a transaction that occurred on Tuesday, April 1st. The stock was sold at an average price of $174.69, for a total transaction of $205,260.75. Following the transaction, the director now directly owns 19,333 shares of the company’s stock, valued at approximately $3,377,281.77. This represents a 5.73% decrease in their position. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through the SEC website. Also, insider Cedric Pech sold 1,690 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total value of $292,809.40. Following the completion of the transaction, the insider now owns 57,634 shares in the company, valued at approximately $9,985,666.84. The trade was a 2.85% decrease in their position. The disclosure for this sale can be found here. In the last ninety days, insiders sold 51,202 shares of company stock worth $10,576,696. Company insiders own 3.10% of the company’s stock.
Wall Street Analyst Weigh In
Several brokerages have recently weighed in on MDB. William Blair reissued an “outperform” rating on shares of MongoDB in a research report on Thursday. Piper Sandler raised their price objective on shares of MongoDB from $200.00 to $275.00 and gave the stock an “overweight” rating in a research report on Thursday, June 5th. Redburn Atlantic raised MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 price target for the company in a report on Thursday, April 17th. Citigroup decreased their price objective on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a report on Tuesday, April 1st. Finally, Stifel Nicolaus dropped their target price on MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a report on Friday, April 11th. Eight equities research analysts have rated the stock with a hold rating, twenty-five have assigned a buy rating and one has given a strong buy rating to the company. According to data from MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and a consensus target price of $282.47.
Get Our Latest Research Report on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Robert Krzaczynski

The OWASP Foundation has officially introduced the AI Testing Guide (AITG), a new open-source initiative aimed at assisting organizations in the systematic testing and security of artificial intelligence systems. This guide, led by Matteo Meucci and Marco Morana, serves as a fundamental resource for developers, testers, risk officers, and cybersecurity professionals, promoting best practices in AI system security.
As AI technologies become embedded in critical industries—from finance and healthcare to national security—the need for structured, AI-specific testing has grown significantly. Unlike traditional software, AI systems introduce unique challenges, including non-deterministic behavior, data drift, adversarial attacks, and algorithmic bias. The AITG addresses these issues directly using methodologies derived from OWASP’s established practices, including the Web Security Testing Guide (WSTG) and the Mobile Security Testing Guide (MSTG).
The AI Testing Guide focuses on areas such as data-centric testing, fairness evaluation, adversarial robustness, privacy validation, and continuous model monitoring. It emphasizes the importance of reproducibility, ethical alignment, and risk mitigation, particularly in high-stakes applications.
Industry professionals have already voiced their support. Michael Tyler, an expert in enterprise security strategy, commented:
OWASP’s AITG is a true game-changer for AI security. As CISOs, we’ve wrestled with AI’s non-deterministic nature and silent data drift. This guide offers a structured path to secure, auditable AI, from prompt injection to continuous monitoring. A vital roadmap for responsible deployment!
Teddy Ramanakasina, an associate director specializing in cybersecurity and IT audit, added:
Great initiative! Structured AI testing is essential to align security, governance, and assurance. Happy to contribute from a risk and audit perspective — looking forward to engaging with the OWASP community.
Similarly, Soulaiman Hajjaj, a cloud and cybersecurity specialist, emphasized the critical need for such a framework:
Excellent initiative! This addresses a critical gap, as a massive number of organisations lack comprehensive AI security frameworks. Structured testing methodologies are non-negotiable for risk mitigation.”
The OWASP AI Testing Guide is designed to be both technology-agnostic and globally relevant, with a roadmap focused on continuous updates to keep pace with AI advancements. OWASP invites developers, researchers, red teamers, and ethical hackers to contribute via its official channels and Slack community.
The project is currently in Phase 1, with a public draft and GitHub repository now live. Community input is being actively encouraged to help refine the guide ahead of its first official release, scheduled for September 2025.