Category: Uncategorized
Uno Platform 6.0 and Uno Platform Studio Released with Major Performance and Tooling Enhancements

MMS • Almir Vuk

The Uno Platform team has announced the general availability of Uno Platform 6.0 and Uno Platform Studio, introducing a broad set of enhancements aimed at improving developer productivity and cross-platform performance.
As stated in an official blog post, Uno Platform Studio is built on top of the open-source Uno Platform, and it delivers an easier development workflow for developers to build and ship .NET applications more efficiently using a single codebase.
One of the major highlights is Hot Design, a runtime visual designer now reaching general availability. Hot Design allows developers to pause a running application, visually edit the UI, and resume the session without restarting. This approach differs from traditional WYSIWYG tools by offering live editing of complex UIs directly within the application.
Uno Platform 6.0 introduces support for a unified Skia-based rendering engine across all platforms — including iOS, Android, WebAssembly, Windows, macOS, and Linux — running alongside existing native implementations. This approach, as explained, brings consistent, high-performance rendering using hardware acceleration across devices, while still allowing native rendering paths where applicable.
Regarding the performance and improvements, the team stated the following:
Uno Platform 6.0 is the best and the fastest Uno Platform yet, which now comes with a new unified rendering engine which provides massive improvements on app startup times, and hyper-performance on UI rendering – up to 75% smaller footprint, 60% faster startup, 30% less memory and 45X faster to run.
According to the Uno team, startup times have improved significantly. The official blog post stated the tests on an iPhone 13, which showed a drop from 1.5 seconds to 0.49 seconds. The rendering engine also reduces application footprint by up to 75%, improves startup speed by 60%, lowers memory usage by 30%, and boosts execution speed up to 45 times.
Additionally, the release introduces support for new components and features. A cross-platform MediaPlayerElement is now available, enabling video playback across all platforms using platform-specific backends such as libvlc and native players. WebView2, which allows navigation to web content and integration with JavaScript, is now supported on all targets, including a new GTK4-based implementation for Linux.
Significant progress was also made on application size and deployment optimizations. The Windows backend now supports a Win32 implementation instead of WPF, allowing for full IL trimming and reducing the size of self-contained apps by 100 MB. Combined with new XAML and resources trimming support for iOS and desktop targets, blank app sizes have been, as reported, reduced by 74% on Windows and 21% on iOS. These reductions also lead to a 35% improvement in build times when using ahead-of-time (AOT) compilation.
With this release, the team also introduced a new Uno.WinRT package, which exposes a wide range of non-UI cross-platform APIs for filesystem access, sensors, media handling, and hardware devices. By separating UI and non-UI capabilities, developers can now build libraries that rely solely on runtime features without including UI dependencies, simplifying cross-platform targeting and reducing package overhead.
As stated by the Uno team, the platform remains open source and free under the Apache 2.0 license. Core features, including development tools and critical components like DataGrid and WebView2, are guaranteed to stay open. Premium tooling, such as Uno Platform Studio, provides optional commercial support and enhancements while sustaining the development model.
Other changes in this release include improvements to Automated App Packaging, deprecation of UWP support, enhanced tooling integration, and more.
For interested readers, full release notes detailing all updates and changes are available on the official Uno Platform website.
MMS • RSS

On May 16, 2025, Barclays analyst Raimo Lenschow maintained an “Overweight” rating on MongoDB (MDB, Financial) while lowering the price target. The new price target is set at USD 252.00, a decrease from the previous price target of USD 280.00. This adjustment represents a 10% reduction in the price target for MDB shares.
This decision reflects a cautious outlook from Barclays, despite maintaining the same rating for MongoDB. Investors in MongoDB (MDB, Financial) should note this updated price target as it factors into their investment strategies.
MMS • RSS
Nicholas Investment Partners LP lowered its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 99.5% in the fourth quarter, according to the company in its most recent Form 13F filing with the Securities and Exchange Commission. The fund owned 8,373 shares of the company’s stock after selling 1,691,627 shares during the period. Nicholas Investment Partners LP’s holdings in MongoDB were worth $1,949,000 at the end of the most recent reporting period.
Several other hedge funds also recently modified their holdings of the company. Strategic Investment Solutions Inc. IL acquired a new stake in MongoDB during the 4th quarter valued at approximately $29,000. NCP Inc. acquired a new position in shares of MongoDB in the fourth quarter worth $35,000. Coppell Advisory Solutions LLC raised its holdings in MongoDB by 364.0% in the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after acquiring an additional 182 shares during the period. Smartleaf Asset Management LLC increased its stake in MongoDB by 56.8% during the fourth quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after acquiring an additional 134 shares during the period. Finally, Manchester Capital Management LLC increased its holdings in shares of MongoDB by 57.4% during the fourth quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock worth $89,000 after buying an additional 140 shares in the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
Insider Transactions at MongoDB
In other MongoDB news, CEO Dev Ittycheria sold 8,335 shares of the firm’s stock in a transaction dated Wednesday, February 26th. The shares were sold at an average price of $267.48, for a total value of $2,229,445.80. Following the completion of the sale, the chief executive officer now owns 217,294 shares in the company, valued at approximately $58,121,799.12. This trade represents a 3.69% decrease in their position. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this hyperlink. Also, Director Dwight A. Merriman sold 885 shares of the business’s stock in a transaction dated Tuesday, February 18th. The shares were sold at an average price of $292.05, for a total value of $258,464.25. Following the completion of the transaction, the director now directly owns 83,845 shares of the company’s stock, valued at approximately $24,486,932.25. The trade was a 1.04% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 34,423 shares of company stock worth $7,148,369 in the last 90 days. 3.60% of the stock is owned by insiders.
Wall Street Analysts Forecast Growth
A number of equities analysts have issued reports on the company. China Renaissance started coverage on MongoDB in a report on Tuesday, January 21st. They set a “buy” rating and a $351.00 target price for the company. Needham & Company LLC decreased their target price on MongoDB from $415.00 to $270.00 and set a “buy” rating on the stock in a report on Thursday, March 6th. Piper Sandler lowered their price objective on MongoDB from $280.00 to $200.00 and set an “overweight” rating on the stock in a research report on Wednesday, April 23rd. Truist Financial reduced their price target on MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research report on Monday, March 31st. Finally, Canaccord Genuity Group cut their target price on MongoDB from $385.00 to $320.00 and set a “buy” rating for the company in a research note on Thursday, March 6th. Eight research analysts have rated the stock with a hold rating, twenty-four have given a buy rating and one has issued a strong buy rating to the company’s stock. According to data from MarketBeat.com, the company has an average rating of “Moderate Buy” and a consensus price target of $294.78.
View Our Latest Research Report on MDB
MongoDB Price Performance
Shares of NASDAQ MDB opened at $195.90 on Wednesday. MongoDB, Inc. has a 12 month low of $140.78 and a 12 month high of $379.06. The company has a 50-day simple moving average of $174.62 and a 200-day simple moving average of $241.04. The company has a market cap of $15.90 billion, a PE ratio of -71.50 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The firm had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same period in the prior year, the business earned $0.86 EPS. On average, analysts anticipate that MongoDB, Inc. will post -1.78 EPS for the current year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Recommended Stories
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

If a company’s CEO, COO, and CFO were all selling shares of their stock, would you want to know? MarketBeat just compiled its list of the twelve stocks that corporate insiders are abandoning. Complete the form below to see which companies made the list.
MMS • RSS

Friday, May 16, 2025
<!–
–>
Fee-free purchases, easy 1:1 redemption, PYUSD stablecoin adoption to increase and new payment use cases are set to drive innovation as PayPal and Coinbase expand their partnership enhancing digital currency utility for consumers, enterprises, and institutions.
PayPal Holdings, Inc. and Coinbase Global, Inc. have announced an expansion of their partnership aimed at increasing the adoption, distribution, and utilization of the PayPal USD (PYUSD) stablecoin. This collaboration is set to provide value for consumers, enterprises, and institutions as they continue to utilize digital currencies across platforms and borders with the stability of regulated USD-denominated crypto-native assets.
PYUSD stablecoin adoption to increase with new partnership by PayPal and Coinbase
Alex Chriss, President and CEO of PayPal, stated, “For years, we’ve worked with Coinbase to enable a best-in-class integration to provide a simple, familiar way for PayPal users to fund crypto purchases on Coinbase. Our objectives aligned further as we deployed PYUSD in combination with our payments expertise, enabling greater commerce applications. We are excited to drive new, exciting, and innovative use cases together with Coinbase and the entire cryptocurrency community, putting PYUSD at the center and driving further utility and adoption for digital currencies among developers, customers, and other users.”
The expanded partnership will grant Coinbase’s millions of customers direct access to PYUSD while also providing the thousands of institutions already utilizing crypto increased utility with PYUSD. Key details of the collaboration include:
- 1:1 PYUSD to USD conversions: Coinbase users will now have the ability to buy, sell, and trade PYUSD without incurring platform fees. Additionally, users will be able to redeem PYUSD 1:1 for US dollars directly on Coinbase platforms.
- Payments-related activities: The two companies are committed to working together on a range of innovations that will accelerate the adoption and utility of stablecoin-based solutions for global money movement and management, with a particular focus on commerce.
- DeFi exploration: Coinbase and PayPal will explore new use cases for PYUSD within DeFi and onchain platforms.
Brian Armstrong, CEO of Coinbase, expressed enthusiasm about the collaboration, stating, “We’re excited to be partnering with PayPal. Their more than 430 million consumer and merchant accounts offer an unprecedented opportunity to increase stablecoin adoption globally.”
This agreement builds on the previous collaboration announced in 2021, which enabled Coinbase users to link their PayPal accounts for immediate and direct funding of purchases on Coinbase, as well as making fiat currency withdrawals from Coinbase.

Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- – Exclusive content from leaders in the industry
- – Q&A articles from industry leaders
- – Tips and tricks from the most successful developers weekly
- – Monthly issues, including all 90+ back-issues since 2012
- – Event discounts and early-bird signups
- – Gain insight from top achievers in the app store
- – Learn what tools to use, what SDK’s to use, and more
Subscribe here
MMS • RSS

Friday, May 16, 2025
<!–
–>
With over 30 years of leadership experience in software and cloud businesses, including roles at NetApp, McAfee, and FireEye, MongoDB names Mike Berry CFO, positioning the company for strategic growth and innovation in the technology sector.
MongoDB, Inc. has announced the appointment of Mike Berry as Chief Financial Officer, effective May 27, 2025. In his new role, Berry will oversee MongoDB’s accounting, financial planning and analysis (FP&A), treasury, and investor relations functions. Additionally, he will collaborate with other senior executives to establish and execute the company’s long-term strategic and financial goals.
Leadership background and industry expertise: MongoDB names Mike Berry CFO
Mike Berry joins MongoDB after serving as Chief Financial Officer at NetApp for five years. A veteran in the technology sector, Berry has held CFO roles at numerous prominent companies, including McAfee, FireEye, Informatica, IO, SolarWinds, and i2 Technologies. With over three decades of experience in software and cloud businesses, Berry is recognized for his strategic leadership and his ability to drive sustainable, profitable growth.
Dev Ittycheria, President and CEO of MongoDB, expressed confidence in Berry’s appointment, stating, “Mike’s unique combination of strategic, operational, and financial expertise makes him a valuable addition to the MongoDB leadership team. His experience with consumption models and his successful track record of scaling businesses to $5 billion in revenue align perfectly with our vision for the future.”
Ittycheria also emphasized the importance of Berry’s experience as MongoDB continues to support customers who are in the early stages of leveraging Generative AI (GenAI) for modernizing legacy applications and creating new solutions.
Mike Berry’s perspective on joining MongoDB
Mike Berry conveyed his enthusiasm about joining the company, noting, “MongoDB’s impressive record of innovation and its leadership in a strategic software market present substantial growth opportunities. While I had not planned to take on another CFO role after retiring from NetApp, the chance to work with a company of MongoDB’s caliber was exceptionally compelling. I look forward to contributing to the company’s continued success and creating long-term value for customers, shareholders, and employees.”
Upcoming financial results announcement
MongoDB will announce its first-quarter financial results for fiscal year 2026 on June 4, 2025, after the U.S. financial markets close. The results will cover the three months ended April 30, 2025. A conference call will take place on the same day at 5:00 p.m. Eastern Time, during which the company’s financial performance and business outlook will be discussed.
Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- – Exclusive content from leaders in the industry
- – Q&A articles from industry leaders
- – Tips and tricks from the most successful developers weekly
- – Monthly issues, including all 90+ back-issues since 2012
- – Event discounts and early-bird signups
- – Gain insight from top achievers in the app store
- – Learn what tools to use, what SDK’s to use, and more
Subscribe here
MMS • Roland Meertens Steef-Jan Wiggers

Transcript
Roland Meertens: I think a lot of people here understand that nowadays you can go above and beyond to show yourself, to showcase your skills whenever you’re searching for a new job. I think a lot of people realize that if you want to get a job, it can be important to already showcase yourself before you start job hunting. A lot of people here at QCon aspire a great career in tech, and they are very open to doing something extra besides your work. I think it’s also important to optimize the efforts to actually gain something back. Very often, people ask me, can you share your experiences? Yes, people tend to want to hear experiences of what people do in their spare time to get some more visibility on themselves. Hopefully that’s what you’re searching for.
Steef-Jan Wiggers: I’m Steef-Jan. I’m a principal consultant for a company called Team Rockstars IT. That’s a company that was founded 10 years ago. I joined recently because they said they want to do some consultancy. I figured, why not just try something new in my career? Previously, I was an architect, engineer. I’d done all that stuff. I wanted to try something different, like going to customers, do some pre-sales, and also thought leadership. That’s why I chose to work for this company. I’m also doing stuff of art. I’m active within InfoQ. I’m lead editor for Cloud News. On top of that, I’m also what’s called a Microsoft MVP.
Roland Meertens: I’m Roland Roland Meertens. I’m working at Wayve. It’s a company which makes self-driving cars. At InfoQ, I am an editor. I’m hosting the generally AI podcast. In this talk, we’re going to share our experience with social media.
Basically, what are we getting out of LinkedIn? What tips and tricks are we using to get some reach? We’re also going to talk about our blog posts. I think we both have a personal blog. We both have a personal website. One of us is a Microsoft MVP, which is a really cool title. We’re also talking about, can you build an online course? If there’s other things people have questions about, I think we both tried a lot in our spare time to get some extra reach. Also, we’re going to explain to you how to contribute to InfoQ. We can tell you how you can contribute to InfoQ articles, InfoQ news, how you can start your own podcast and maybe even speak at QCon.
Social Media
Let’s start with social media. I think the number one social medium, if you want to present yourself professionally, is LinkedIn. How many people are following you on LinkedIn?
Steef-Jan Wiggers: About 4,000, I think.
Roland Meertens: I’m also around 4,000, 4,500. I personally think this is a nice amount, as in, I’m not a prime influencer. I think it helps me to connect with people in technology which are relevant for me. There are people in the world of self-driving cars who are following me and thus know me. What I hope to achieve is that whenever I go to an interview, people already know me or have seen my face, because that’s a massive difference. If people know that you have the knowledge required to do the job, and they know you’re often talking about that, then I think people will be more lenient towards you in interviews, rather than they have to assess from scratch whether you’re good.
For LinkedIn, I sometimes see people get started by posting more on LinkedIn. There’s a couple of things I sometimes see people do wrong or, in my opinion, not get the most out of it. One is that I see a lot of people who are just plain boring. They will only post something like, I’ve just got this new job, or I’ve just got this new promotion, or I followed this online course. I’m like, it’s nice, great that you posted. For me, it really seems to help if I relate content to myself as a person. That sounds very vain, but I really notice that whenever I give insights which relate to me, that people pick it up more, than that I say, this is a new industry insight, which is also frustrating. Sometimes we write really nice articles with really interesting research, and then nobody posts it.
Steef-Jan Wiggers: I wanted to ask first, before I share my experience, who uses LinkedIn, posts something, like they’ve changed jobs or all that stuff on LinkedIn? I do it myself as well. Sometimes I’m saying, I’m working for a new client, or at least for a new employer. I’ve done it once recently. Otherwise, I usually tend to not to. Sometimes you can say, I’ve given this certification, which also can be a bit boring. Even personal stuff you can share, if you want to. You see that too. I’m not sure if you should or shouldn’t. I’ve done it.
My wife passed away, so I did put that on LinkedIn, but it’s more like because I want to get rid of her account because it doesn’t make sense. You could do something like that. You don’t have to. Predominantly, I use LinkedIn just to post stuff that I’ve blogged or predominantly when I bring out InfoQ news just to amplify the fact or getting bigger reach of what I’ve written. It’s something I do quite regularly. Then my company uses LinkedIn a lot as well to promote their events and stuff, so you see that happening too.
Roland Meertens: Also, about relating it to yourself as a person, I would also be mindful that you’re not making it too personal. Sometimes I see people post, I’m going on holiday. I’m like, this is not very interesting content. That makes me lose trust in that person. The one thing which is good is that you can meet a lot of interesting people through LinkedIn. If you go to a conference, sometimes people come to you and they say, I’ve already known you from following you on this platform. It can be a good way to introduce yourself to others if you already know them. Sometimes people reach out, they ask you to drink some coffee at a conference. It’s a great way to meet more people. Again, we will show you a couple of examples in the next slide about how this helped us as a person to connect more. What about Twitter, Bluesky, Mastodon, or YouTube, Instagram, TikTok, do you have any of those?
Steef-Jan Wiggers: I actually have Twitter, but I tend to shift more to Bluesky. Whoever uses Bluesky as well? I’ve got both. I’m leaning more towards Bluesky than really using Twitter because everyone’s shifting away because Elon Musk is doing some weird stuff. I’m not using Mastodon that much. You can use YouTube. I don’t leverage YouTube that much. I’ve created some videos and put them online, but I’m not really interested in creating a following. I just had a few talks that I found interesting and I thought it was a really good way of just putting it on YouTube. There are also platforms where you can present back in the Corona days, that also straight away streamed into YouTube. Instagram is more personal. Sometimes I run. I just put it on Instagram, that’s it. That’s more a personal thing. I don’t think you should use it for business purposes, at least in my view. TikTok, yes, that’s something for kids.
Roland Meertens: We’re directly going into this. Sometimes you do see people and also developers who are posting or doing YouTube streams or other things like that. Personally, I have a feeling that if you want to be popular on a short message platform like Twitter or Bluesky, you have to post a lot of interesting insights on a daily basis, which can be very difficult to do. Or at least for me, that was not something which I thought was sustainable. The problem with something like YouTube and Instagram or TikTok is that you very quickly become more an influencer than a developer. Also building up an audience is going to be incredibly hard. If you have to start from zero, you get very little views. It’s very difficult to refine that art, in my experience.
Talking about LinkedIn, last time people asked me, do you have some concrete examples of where LinkedIn helped you? One thing which I thought was funny is that I looked at how I got a couple of the jobs in my career. For one of the jobs, basically someone reached out to me on June 8, 2020, just after a company I was working at was acquired. They said, how’s this transition going? I said, only one week in, it’s looking good.
One week later, it was not that good anymore. I just said, how are you doing? He said, here’s my WhatsApp. This is something which is really nice. Because before I even needed a new job, this person already reached out and asked me how I was doing just purely out of interest, because we met at a conference and he knew that I was active on LinkedIn and was posting a lot of insights.
Also, fun fact here is that I managed to skip the last interview at this company because the CEO saw that I generated enough interesting content that they were comfortable that I had the right skills to do the job. They moved to an offer way faster due to a very small amount or a minimum amount of public presence. The other thing is this. This is, for example, someone who is a recruiter at Wayve. She reached out to me a couple of years ago, just asked me, how are you doing? I wasn’t interested in a job at the time, but that way she already knew me. You can also proactively reach out to people who know you.
For example, Adam, he’s also recruiting at the company I work at right now. He and I met each other because he reached out, because he liked the blog I was writing. A couple of years later, when I actually became interested in working at this company, he already knew me. I also reached out to him at some point because he was working at Meta and I bought an Oculus Quest. I was like, “You want to play this together? Like want to try this out together?” In that sense, I think these are some concrete examples where blogging, LinkedIning, writing articles online have really helped me personally in my career.
Steef-Jan Wiggers: I could of course show you similar examples, but yes, it definitely helps you reach out to, let’s say people that are on stage here and talking. When I do some research, and I do some write-ups in some of the presentations here, then I can reach out through LinkedIn. You would wonder, why not sending an email? Email is possible, but I see that they tend to react more swiftly on LinkedIn than they do through emails. The downside of LinkedIn, one way is, yes, if you get recognized then you get a lot of recruiters on your tail that are asking for you to join their company, even though you just switched the company, they don’t care, they just keep shooting. That’s one of the downfalls. The other thing is, you can easily reach out to people like also this example.
Blog Posts and Personal Websites
Then we have something like blog posts. Who blogs? Who still uses? Personal or just sharing your knowledge? That’s how I started too. I used something like blogspot.co. That’s, I think, a predecessor to WordPress, which I started creating a blog post around a message broker called BizTalk Server. That’s back in the day when there was not a cloud yet or the cloud was upcoming, but I was doing on-prem stuff. I just found some stuff out and I was like, this is pretty cool to just write about it and add some pictures or diagrams or that kind of stuff, and push that forward.
Like what you see here too, there were some numbers, there were some followers, but getting really dedicated reporters. Initially, I had a lot of them because BizTalk was still proficient and available. When the cloud came up and you have your shift towards the cloud, you did see that the people became less interested in this particular part of technology. I started another blog and then I call it Cloud Perspective. I think I’m being relevant again. The numbers went up a bit. It’s a lot of effort put in, and you’re not sure if you get the traffic, depends. Then also you’re now also battling with AI because you can generate quite some interesting content through that too.
Then the other thing is, does your company support blogging? Because who blogs for his or her company? There’s a few people out there that do that as well. That’s another way that I found out is companies also started to do blogs, and then that really got a little bit of a challenge because you also have your own personal blog. Where do you put that content? I also geared too much to put blog posts more for my company than for myself.
Roland Meertens: Especially, Medium and Substack is extremely easy to set up, but it’s very difficult to get dedicated readership. Because if you have to start from scratch, you have to get some attention from somewhere. In practice, that means posting to the Y Combinator news sites or posting on Reddit. I always personally struggled creating a new blog from scratch because if you don’t have any traction yet, getting the initial readers is hard. Especially dedicated readers. It is one thing to have one blog post explode once, but getting people back and back to your website over time is very difficult.
Especially with ChatGPT, I think on the one hand, people are reading less blog posts because ChatGPT will just answer any question you have. Also, it allows people to create these low effort blog posts. I would definitely say, don’t be like one of those people who just pumps out article after article, but try to find a new niche in the market where you are the true experts. Because if you have a completely new insight which no AI has picked up yet, that’s when people start finding you and that’s when people start seeing you as a person to keep in mind.
As you said, if your company supports blogging, you can actually take work you already do on a daily basis, put it out on the web. Sometimes they even pay you for it. That can be nice. In my experience, this can be very helpful in any future interviews or whenever you’re talking with other people to prove that you have some experience in an area. I sometimes take some of the blog posts I’ve written for a company and show them to people to say, this is the insight you want. You could basically do it on the company time.
Personal websites, they are harder to set up, but I do think they showcase even more dedication to putting yourself out there. In my case, I’ve got this website called, Pinch of Intelligence, which I set up 10 years ago. I’m not using it a lot lately. It’s even harder to get dedicated readers. I don’t think anyone here has this as their homepage. You shouldn’t. What is nice is that you can get complete freedom of what you post about. If you are having a blog or if you are having some personal brand online, it’s always nice if you consistently post about the same thing over and again, such that people know you as the cloud person. Overall, it’s just a good personal portfolio. Whenever I’m interviewing people and I see they have a personal website, I always take a look because it’s just interesting to see what they are spending their spare time on. Downside is that if your website or if a blog post becomes popular on any of the other websites, like Y Combinator news or Reddit, your website will go down. That’s a shame.
Being a Microsoft MVP (Community Recognition)
Steef-Jan Wiggers: I like to talk a bit about being recognized within a certain community. Microsoft, in this case, brings out a recognition which is called Microsoft Value Professional, which is awarded to people that provide value. It’s not about being the smartest or so. That could be in other, let’s say, communities.
Back in the day, you had an Oracle Ace and someone who’s really into Oracle and knew a lot about it, that was being basically awarded with the Ace award from fellow forum leaders or users, basically. Microsoft has this program called MVP. I think they started this about 30 years ago through forums, but then they just expanded it through the people that stand out during presentations or blogs. Who else is an MVP? You have similar things like AWS. AWS has AWS Heroes. Any AWS Heroes? We have one in InfoQ, which is Renato, who has been awarded through AWS for being a hero. There are others. There’s things like a Java Champion. Even at a company called Databricks, they have these programs called Databricks MVP. There are multiple companies like Microsoft that award you with these awards.
In case of an MVP, it’s a yearly renewal. They weigh you in if you’re still valuable for them. I’ve been valuable for 15 years, apparently, so still going strong. One of the things as an MVP, you be on stage. Before I was an MVP, I was not on stage because I hated to be in the center of attention. Back when I was a young kid, you had to do a presentation at school. I hated that. I wanted to hide and I wanted to be under here because I didn’t want to do it. Once I became an MVP, I thought, maybe I should overcome that fear and just start going on stage and then present, so what I’m doing today.
Fifteen years ago, I’m not so sure if I would stand this quiet and talking to you and addressing you. I’ll be more like this. This is something that I’ve done. If you’re an engineer and you want to get out of your comfort zone, or maybe you want to address people live like this instead of a blog, but really face people and want to share it, then, yes, being on stage is a thing. I started doing this 15 years ago and now I’m enjoying it. Back in the day, I hated it. I had stage fright. I couldn’t sleep a day before and all that stuff. It really helped me in expressing the way I am today. I’m a pretty introverted person, then, all of a sudden, you’re facing people and maybe talking even about some personal stuff. That’s different.
Roland Meertens: In terms of being on stage, I think the big value you can get out of being on the stage, and especially if you’re talking about actual professional work instead of personal brands, I think you can really establish yourself as an expert. Talking at places like QCon helps a lot because then you have an audience of experts in the field of software engineering. Getting gigs at QCon often requires that people already know you as someone who has this experience, has this knowledge, and can talk about their work in an interesting way. For me, it helped me a lot to also get my knowledge out and also think about what do I actually want to say, what do I actually want to do. I can definitely recommend doing that. Also, even getting there can require a certain amount of personal brand building before you get invited regularly to speak at conferences.
Steef-Jan Wiggers: That’s true. Yes, once you get recognized, and they do ask you. In 2010 it was more like user groups, they got invited and became something like a call for papers, or they do curation like they do at InfoQ. There’s an option that you either submit a real good talk, you get elected, or they find you because you stand out in your field. My predominant field is enterprise integration. I’m more like a backend guy, while you’re more an artificial, machine learning, cool stuff guy.
Building an Online Course
Roland Meertens: The other thing which people sometimes ask me is, should I build an online course? The big benefits of publishing a course is that if you do it in the early days of a framework, you can be the go-to person for that framework. In my case, I once published a course on TensorFlow when TensorFlow was very new. What’s really nice is if you can get this published because the publisher can support you. In my case, they did all the video editing. I really hate video editing. They did a lot of preparation, they do all the selling, they do all the marketing.
The downside is that most publishers will probably do a spray and pray thing where they hire 20 people to make a course about this new framework. Then you just hope that your course is working the best and that’s when they start promoting you more. I do sometimes get questions in interviews whenever I’m applying for a new job on, how much do you know about this thing, from 1 to 5, where 5 is someone who wrote a course about this? Then you can just say, I actually wrote a course about this. It’s again another way to establish yourself as an expert in an interview. You can get a bit of money from this, but often they prepay you something and your course never makes anything anymore. It’s a very large time investment, that’s a big downside. It takes a lot of time to create something which is good. Then you just hope that it benefits you in the long run.
Steef-Jan Wiggers: I created a course, but it was more like in person than something online. I think if you create a course or if you have blog posts or something, it becomes tangible and you can refer to it definitely in an interview.
What Is InfoQ?
Let’s switch to InfoQ. InfoQ, a daughter company from C4Media: so, you got QCon on one side, you got InfoQ the other side. The sister website of QCon is InfoQ. That’s who we work for. It’s a platform that you have podcasts, you have news articles, you have news items. We both are more into news items writing while you’re more predominantly in podcasts. That’s another type of content that’s being published on this platform. It’s done by practitioners focusing on a part of the hype cycles, predominantly early adopters of any innovative stuff. Looking ahead in time instead of writing a lot about what’s already established or what’s proven. Although sometimes we do write about stuff that is proven. For instance, stuff around serverless is still pretty popular. There was a great talk about Octopus and the energy market where they also leverage serverless. It’s not always about the latest and greatest in new technology. We of course focus heavily on it, but sometimes we do write about other stuff. That’s what we do at InfoQ.
It’s written predominantly by people that are also engineers or architects that are really the doers. Although I am a consultant, but I still do a lot. Yes, they called me a principal consultant, but I’m somewhere in between. I still do stuff that is relevant for the audience of InfoQ. There are tons of stuff we produce weekly, monthly. There’s people like us editors that write stuff, but there’s also people that contribute in ways of articles. Sometimes I get an article that I review and then that’s also being published.
What We Do at InfoQ
Roland Meertens: This is what we do at InfoQ. Personally, I’ve been an editor since 2017. Lately, I’m not writing a lot of articles anymore, but I just started a new podcast recently about AI. The other thing I do is participate in AI, machine learning trends report. That’s something which we do every year at InfoQ, where we get together with a couple of experts and talk about what are the latest and greatest trends. That is content which gets watched a lot. That’s also something which in terms of personal branding can really help you establish yourself.
Steef-Jan Wiggers: We started around the same time. I do mostly news items. I progressed from being a junior editor all the way up to a senior level in a couple of years. I’m also now basically managing the Cloud Queue. That’s what I do. Also, review articles that come in, predominantly the cloud related articles, because there’s all sets of articles, because basically InfoQ has all these buckets or queues. You have the AI, ML, which you’re working in. Cloud, that’s me. You got architecture. You got culture. You got DevOps. There’s different queues and also different set of content that we’re creating. I’m doing news items in the cloud and I review articles of cloud. It doesn’t mean that there’s only cloud articles.
There are also other types of articles that are also being reviewed, but then through editors that are more versed in that particular space. Also, like Roland Roland Meertens, there’s trend reports. There’s a great one on architecture. That’s one of the main ones. That also gets a lot of attention. Then, there are some sub-trend reports around cloud and DevOps, AI, machine learning, and so forth. That’s what we do, but there’s multiple people, multiple editors, a lot of people also in the background also that are organizing this event. There’s a lot of people behind the screens as well. We also have people behind the screen helping us out in getting the content out.
Direct Benefits, with InfoQ
Roland Meertens: There’s quite a couple of direct benefits of writing for InfoQ compared to the other things we talked about before. One of the downsides I always see when you’re starting your own personal blog or whenever you’re starting out being more active on LinkedIn or starting a new YouTube channel, whatever, is just the amount of audience. I already said, normally you’re hoping that people on Reddit, on Y Combinator news, they pick up your news. The big benefit of InfoQ is the amount of audience. If you publish something on infoq.com, the content is immediately on the front page. You immediately have these 700,000 viewers, which are potentially clicking your article. If you put something on Reddit, it always ends up in the new category, which means that basically only the couple of really dedicated readers are assessing whether your article is worth seeing. That’s a big benefit.
The other thing which I personally really like is the feedback on what and how you write. Whenever I write something for my personal blog, or whenever I do something, like post something on LinkedIn, I personally have one friend who always critiques me and says, this article could be better written this way or that way, but that’s very rare. Becoming better in crafting your own personal brand, becoming a better technical writer is something which doesn’t come for free or doesn’t come automatically. That’s something where I think working with or for QCon and writing an article or writing a news item is very valuable. First of all, Daniel will read your article and give feedback. We also have, for example, a professor in English literature who can critique your article. That’s very daunting, but that actually makes you better. That’s also one of the few moments in writing content that I got feedback on, how can you make this better? How can you improve this? How can you make this more interesting for other people?
Steef-Jan Wiggers: The other benefit is that you explore a lot of technology. I’m predominantly working in Azure because I’m a Microsoft MVP. However, I also get to look into what technology AWS offers and Google. If I talk to customers, I can also relate to the fact that other cloud platforms have similar type of services. That makes me, in some way, maybe a better consultant or engineer that I also know a bit more about the other platforms. The other thing that helped me personally, because I started to learn more about other platforms when I started doing integration work, why I had to connect Azure to Google, for instance. If I didn’t know what Google was at all, or at least the cloud platform, that would have been a very daunting task.
Basically, because I was doing all this work for InfoQ, I started to learn more about other clouds too. Also, a little bit about AI, ML, and there’s other stuff that’s really interesting when you’re working for InfoQ, or at least while you’re doing stuff for InfoQ, the article writing and such. The other thing which I really like is attending conferences. Going to San Francisco and attend a conference on that side is also interesting. You get to learn people from Silicon Valley, which you usually don’t because they tend not to come here, and vice versa. It’s interesting in ways of networking. That’s another benefit. That’s the thumbs up.
Roland Meertens: The big benefit of attending conferences is you can attend QCon, I think, for free as an editor. Not sure what the rules are, but we are here. We got invited. Also, if you go to other conferences and you say, I’m writing for InfoQ, often they will give you a free ticket. This doesn’t go for all conferences. I think that the AWS conference doesn’t do this. A lot of the conferences or the events, I ask, can I come to your conference, not pay entry, but I will write an article about it. Often, they just said, yes, you’re free to come. That’s good.
Also, InfoQ pays you something for content. I personally always use this to invest in podcasting, buying books to learn more about AI and machine learning. It can be a benefit. If you set up your own personal website, I’m bleeding money on that, bleeding money on server costs. For InfoQ, you actually get something back. InfoQ is especially looking for .NET, Web Dev, and Cloud Editors. There’s an email for that, editors@infoq.com.
How InfoQ Works
Steef-Jan Wiggers: They adopt this chasm book, what they’re leaning towards, and taking the principles of it. They’re really focusing on the innovators and early adopter space, because that’s where we write content around. This is also where a lot of cloud platforms and other companies are pushing content and saying, this is a new service. An interesting thing, for instance, quantum computing. You see that all these big cloud providers now say, I’ve got this chip. Microsoft’s got Majorana 1. Google has Willow. I think AWS, they all have these funny names, called Ocelot. That’s one of the things. This is, of course, something that’s now in its infancy, but it’s progressing, just an example. It’s an example of what we’re focusing on too. It’s basically those first two areas. Not to say that we don’t cover anything beyond the chasm, which is early or late majority, but the real focus is where we are going to be in a couple years’ time. This is one of the things that we do. That’s the content we focus on.
Then, it’s geared towards a certain target audience. That’s engineers, architects, those people that are really working with the technology. Could also be maybe interesting for consultants even to when they talk to customers, because they’re following what’s on this website, “This is where things are going”. Predominantly, we’re using or looking at the engineers, developers, DevOps engineers, architects, and so forth. Also, the number here is two-thirds, identify themselves as architects.
Roland Meertens: Also, just coming back to the point of, how can you use this for your own personal brand? How can you use this for your own personality, your own online presence? I personally sometimes feel a bit bad because I’m writing about something which is completely new and nobody is interested in it. I think I gave a talk at a QCon where like five people showed up about how great ChatGPT and large language models were. I was like, nobody is interested in this. You see that a couple of years later, suddenly this becomes the predominant technology. You can be known for one of the people who was already talking about this in the early days. Even if you think, this is new technology, I’m not sure if people are even interested in it, and you get low reader numbers. If you persist, you will become the person who is known as one of the predominant people in this industry and in this area.
How does InfoQ work? One of the things you can do is just approach us. There’s more people who are wearing an InfoQ shirt. If you’re interested in blogging for them, as I said, I think it helps a lot. You can also add us on LinkedIn and ask us questions. There’s a couple of things which I can recommend if you want to start doing this. One is writing a long-form article. I made a tiny URL for this. If you’re writing a long-form article, InfoQ already connects you with an editor who will give feedback on both your writing and your content and the way you should style your content.
I know a lot of people who didn’t have a lot of time to become a permanent editor, but they wrote one or two articles, have gotten a lot of feedback on their writing. Whenever I’m looking at someone’s article, sometimes I say, this is specifically very interesting: write more about this, write less about that. It really helps you to develop this writing muscle. You can also become an InfoQ editor immediately. There’s an infoq.com, write for InfoQ.
I created a special form about how to join the InfoQ editors. There’s basically now a form where you can leave your email, write your full name, your LinkedIn profile, hopefully you already have one. You have to say what kind of person you are and what queue you would like to join. There’s an inspiring quote by Thomas Betts who has 50 podcasts and 100 articles reviewed. Your article can be reviewed by Thomas Betts. I think it’s very easy to sign up and try this out.
Conclusion
Steef-Jan Wiggers: Usually, I’m doing technical talks and stuff and now I’m doing something also out of my comfort zone because this is talking about some personal stuff and how I build my brand and becoming a little bit more visible than back in the old days when I don’t want to be visible at all. Still, sometimes it does feel awkward to get the recognition because you’re standing here and then you’re talking about stuff that is different than talking about integration, Azure Logic Apps, messaging. I feel totally comfortable about that. This is something that’s different.
Questions and Answers
Participant 1: Could you think about the tradeoff between your public profile and companies that forbids to have a public profile? Me as an engineer, I have either the ability to make a profile, to be publicly available, to be famous and everything, or I can go to some company that pays quite a lot, but forbids to have a public profile.
Roland Meertens: You mean that your personal profile might clash with the profile of your company?
Participant 1: No, more about like secrecy and you are not allowed to make some public talks and all this stuff.
Roland Meertens: It’s always difficult. Because your company says that you are absolutely the best and you are sitting there thinking, our tech stack is a joke. You can’t publish that, of course. That’s indeed difficult. I tend to walk around this a bit by writing about things our company has nothing to do with, but which are still relevant to engineering. Like if you’re working at a dating app, maybe you can write about how you can do scalability for something, but then using a technology which you are not using. That’s something I sometimes do.
Again, try to work with the company to see how you can integrate into their messaging. This can happen automatically if you’re working on a high visibility project. That’s also something to try to steer your career towards is, can you volunteer to be on something which you know will be published and which you know will be online later? My relationship with the people at companies I worked at who are responsible for PR is always a bit so-so. Sometimes they really appreciate that I do something, and then sometimes they scream in my face, being like, “Why did you publish this? You were not allowed to”. Get a good relationship with those people, is basically what I want to say, because, often, if you have a good relationship, they can make your slides better for a presentation. You can get a massive boost by getting way better slides, way better tips on how to give a presentation.
Also, if you have a good personal relationship with them, they will forgive you that you didn’t hand in the slides two weeks ahead of your presentation. That’s the things I would do. That’s the nice thing about personal blog posts is you can always blog about a thing you do in your spare time. It takes, of course, your spare time.
Participant 2: If you were starting from zero again, how would you take advantage of the opportunities that a conference presents to advance your career?
Roland Meertens: If you’re starting absolutely from zero?
Participant 2: Yes, if you suddenly had zero LinkedIn followers, for example, and you wanted to build your network. I’m sure you’re approached at conferences now, so you’re not doing the approaching maybe, but if it was the opposite, how would you take advantage of what a conference allows you to do?
Roland Meertens: I think it really depends on what kind of person you are. I noticed that there are some people, especially politicians, who tend to just chat for five minutes with everyone and then hand out their business cards. This is why I’m also quite fine. I know I’m not the biggest LinkedIn influencer with my 4,000 followers. I know that all of the people I’m connected with, I have a bit of a personal relationship with. I would personally rather chat for an hour with people and really get to know them, really get to understand what their tech stack is about, really get to understand what synergies you can have, rather than that you try to spray and pray and get to be known by everyone.
Especially if you’re further on in your career, you start noticing that everyone is always working at all the same companies. Being known by the small amount of people which really matter, and who are going to interview you at some point, or who are going to refer you to that cool job at one of the big FAANG companies or something, I think that is more important than trying to reach as many people as possible.
Steef-Jan Wiggers: Yes, quality over quantity.
Participant 3: If I am not mistaken, you both have like a full-time job, and the InfoQ, the stuff you do on LinkedIn, your blog post, you do on your free time. How much time would you say it takes you, like every week or something? Do you have tips on how to manage that properly?
Steef-Jan Wiggers: I have five kids now, because I met someone. She has two kids, I have three. I also now have three dogs. It’s a lot of time. Then, I have not a full-time job though. I started working 36 hours, because I did start to notice that I couldn’t do it all besides my job. You have to think about evenings. I don’t know what your personal situation is, but let’s say you do have kids or not. If you have kids, then, yes, you have to find a time when they’re sleeping, when they’re young. When they’re getting older, they have their own ways. Then the things that you do in life as well, besides like sports, or to friends. You have to find some balance. I usually do it early in the mornings. I just try to find a spot to do this because you do have control over your time, to start creating content or prep for a presentation.
In general, yes, you do find time, but it requires some type of dedication. You have to find a thin line between where you want to prioritize your time to. Don’t forget that the path that I’ve taken personally took about 15, 20 years. When I started my career, I’d done nothing, like only work. At some point I started doing a little bit of blogging and then I just progressed. It’s over those years that I spent time. It’s hard to answer because it’s like going like this with your personal time and find the right time. Sometimes the ideas come, after jet lag, I get awake and I’m like, this is interesting. Even then you can take the time. Although I’m not sure if that’s good for you, you’re getting more tired.
Roland Meertens: For me, it also comes and goes a bit. Like for InfoQ itself, I’m quite happy that they are very flexible with that. I shouldn’t say that, but because they don’t want you to be flexible and to write every week. For me, it comes and goes. Sometimes I have ideas and I say, can I start this new podcast series? They allow me to. What I also try to do is at some point in my career, but this is already five, six years ago, is I try to build some consistency where I thought I want to have one interesting LinkedIn post every week. Let me think about what I can post this week, which would make it interesting.
Can I already build up some content for the future? This can be about, I’m going to attend this conference and this is what I’m talking about. I’m attending this conference, this is what I learned. I’m doing this thing in my spare time, take a look at the first results. If you see it as a thing you try to do on a weekly or a frequent cadence, then not only do a lot of those platforms reward that, but you also get into the mindset of, this is interesting, maybe I can put this on my personal content calendar. I’m not doing this anymore. I’m just posting things as they come and go. It can be good to get into the habit initially when you’re starting to build up the start of your personal brand.
See more presentations with transcripts
MMS • RSS
Barclays has revised its price target for MongoDB (MDB, Financial), lowering it from $280 to $252, while maintaining an Overweight rating on the stock. This adjustment comes as part of the firm’s expectations for the company’s first-quarter earnings. Despite anticipating strong Q1 results, Barclays suggests that the guidance may be cautious, which could influence stock positioning. The overall market for off-cycle software is expected to reflect trends seen in on-cycle counterparts. Barclays continues to show interest in companies that are currently out of favor, such as Salesforce and Workday, while also noting the potential in Intuit. Investors are advised to consider positioning carefully as the earnings season unfolds.
Wall Street Analysts Forecast
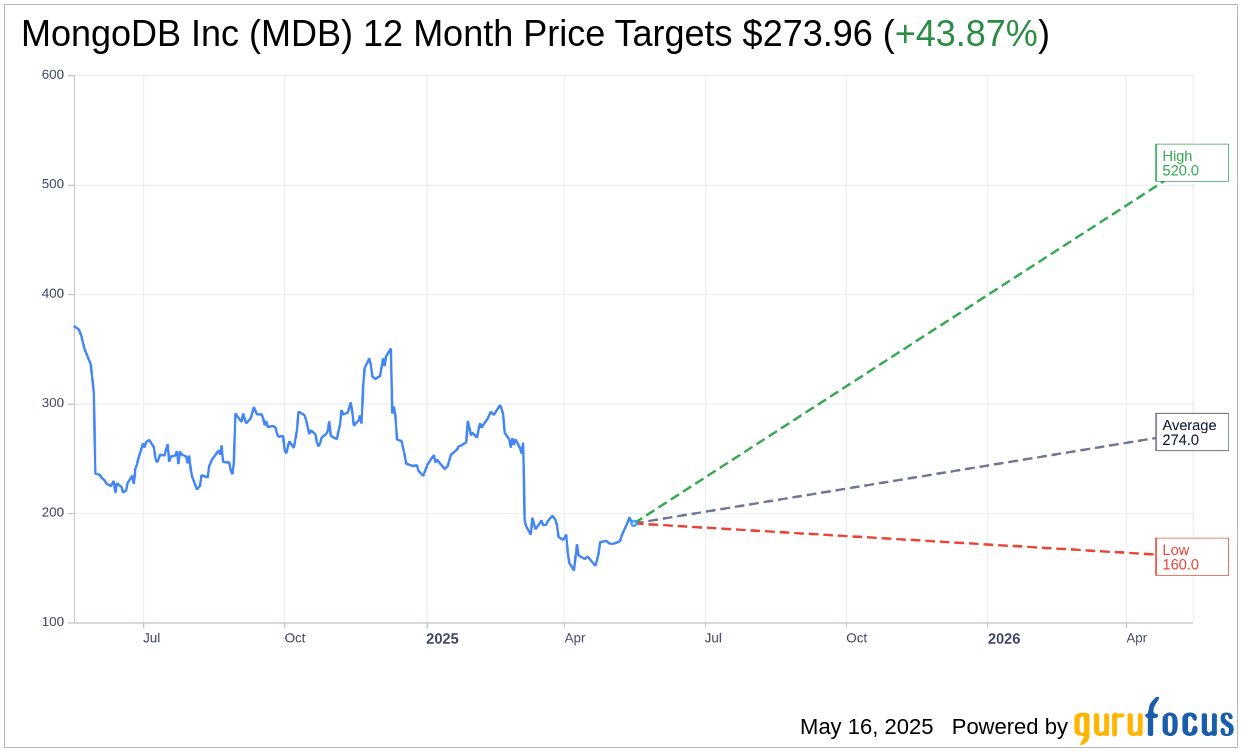
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $273.96 with a high estimate of $520.00 and a low estimate of $160.00. The average target implies an
upside of 43.87%
from the current price of $190.43. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 38 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $438.57, suggesting a
upside
of 130.31% from the current price of $190.425. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: March 05, 2025
- Total Revenue: $548.4 million, a 20% year-over-year increase.
- Atlas Revenue: Grew 24% year-over-year, representing 71% of total revenue.
- Non-GAAP Operating Income: $112.5 million, with a 21% operating margin.
- Net Income: $108.4 million or $1.28 per share.
- Customer Count: Over 54,500 customers, with over 7,500 direct sales customers.
- Gross Margin: 75%, down from 77% in the previous year.
- Free Cash Flow: $22.9 million for the quarter.
- Cash and Cash Equivalents: $2.3 billion, with a debt-free balance sheet.
- Fiscal Year 2026 Revenue Guidance: $2.24 billion to $2.28 billion.
- Fiscal Year 2026 Non-GAAP Operating Income Guidance: $210 million to $230 million.
- Fiscal Year 2026 Non-GAAP Net Income Per Share Guidance: $2.44 to $2.62.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 20% year-over-year revenue increase, surpassing the high end of their guidance.
- Atlas revenue grew 24% year over year, now representing 71% of total revenue.
- The company achieved a non-GAAP operating income of $112.5 million, resulting in a 21% non-GAAP operating margin.
- MongoDB Inc (MDB) ended the quarter with over 54,500 customers, indicating strong customer growth.
- The company is optimistic about the long-term opportunity in AI, particularly with the acquisition of Voyage AI to enhance AI application trustworthiness.
Negative Points
- Non-Atlas business is expected to be a headwind in fiscal ’26 due to fewer multi-year deals and a shift of workloads to Atlas.
- Operating margin guidance for fiscal ’26 is lower at 10%, down from 15% in fiscal ’25, due to reduced multi-year license revenue and increased R&D investments.
- The company anticipates a high-single-digit decline in non-Atlas subscription revenue for the year.
- MongoDB Inc (MDB) expects only modest incremental revenue growth from AI in fiscal ’26 as enterprises are still developing AI skills.
- The company faces challenges in modernizing legacy applications, which is a complex and resource-intensive process.
MMS • RSS

Mid-cap stocks often strike the right balance between having proven business models and market opportunities that can support $100 billion corporations. However, they face intense competition from scaled industry giants and can be disrupted by new innovative players vying for a slice of the pie.
This is precisely where StockStory comes in – we do the heavy lifting to identify companies with solid fundamentals so you can invest with confidence. Keeping that in mind, here are two mid-cap stocks with massive growth potential and one that may have trouble.
Market Cap: $11.05 billion
Headquartered in Ohio, Lincoln Electric (NASDAQ:LECO) manufactures and sells welding equipment for various industries.
Why Are We Cautious About LECO?
-
Organic revenue growth fell short of our benchmarks over the past two years and implies it may need to improve its products, pricing, or go-to-market strategy
-
Projected sales growth of 2.1% for the next 12 months suggests sluggish demand
-
Earnings growth underperformed the sector average over the last two years as its EPS grew by just 5.4% annually
Lincoln Electric’s stock price of $197.92 implies a valuation ratio of 21x forward P/E. Dive into our free research report to see why there are better opportunities than LECO.
Market Cap: $15.47 billion
Started in 2007 by the team behind Google’s ad platform, DoubleClick, MongoDB offers database-as-a-service that helps companies store large volumes of semi-structured data.
Why Are We Fans of MDB?
-
ARR trends over the last year show it’s maintaining a steady flow of long-term contracts that contribute positively to its revenue predictability
-
High switching costs and customer loyalty are evident in its net revenue retention rate of 119%
-
Free cash flow margin is anticipated to expand by 5.1 percentage points over the next year, providing additional flexibility for investments and share buybacks/dividends
At $190.20 per share, MongoDB trades at 7.1x forward price-to-sales. Is now the time to initiate a position? See for yourself in our in-depth research report, it’s free.
Market Cap: $27.32 billion
Operating under multiple brands like Orkin and HomeTeam Pest Defense, Rollins (NYSE:ROL) provides pest and wildlife control services to residential and commercial customers.
Why Will ROL Beat the Market?
-
Impressive 11.9% annual revenue growth over the last two years indicates it’s winning market share this cycle
-
Offerings are difficult to replicate at scale and result in a best-in-class gross margin of 52.1%
-
ROL is a free cash flow machine with the flexibility to invest in growth initiatives or return capital to shareholders
Rollins is trading at $56.37 per share, or 49x forward P/E. Is now a good time to buy? Find out in our full research report, it’s free.
The market surged in 2024 and reached record highs after Donald Trump’s presidential victory in November, but questions about new economic policies are adding much uncertainty for 2025.
While the crowd speculates what might happen next, we’re homing in on the companies that can succeed regardless of the political or macroeconomic environment. Put yourself in the driver’s seat and build a durable portfolio by checking out our Top 5 Strong Momentum Stocks for this week. This is a curated list of our High Quality stocks that have generated a market-beating return of 176% over the last five years.
Stocks that made our list in 2020 include now familiar names such as Nvidia (+1,545% between March 2020 and March 2025) as well as under-the-radar businesses like the once-small-cap company Exlservice (+354% five-year return). Find your next big winner with StockStory today for free.
MMS • RSS
Cresset Asset Management LLC cut its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 47.2% during the 4th quarter, according to the company in its most recent filing with the Securities & Exchange Commission. The fund owned 2,838 shares of the company’s stock after selling 2,533 shares during the quarter. Cresset Asset Management LLC’s holdings in MongoDB were worth $661,000 at the end of the most recent quarter.
Other hedge funds have also recently bought and sold shares of the company. Strategic Investment Solutions Inc. IL bought a new stake in shares of MongoDB during the 4th quarter worth about $29,000. NCP Inc. bought a new stake in shares of MongoDB during the 4th quarter worth about $35,000. Coppell Advisory Solutions LLC raised its position in shares of MongoDB by 364.0% during the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after buying an additional 182 shares in the last quarter. Smartleaf Asset Management LLC raised its position in shares of MongoDB by 56.8% during the 4th quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock worth $87,000 after buying an additional 134 shares in the last quarter. Finally, Manchester Capital Management LLC raised its position in shares of MongoDB by 57.4% during the 4th quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock worth $89,000 after buying an additional 140 shares in the last quarter. 89.29% of the stock is currently owned by institutional investors.
MongoDB Stock Performance
Shares of MDB opened at $195.90 on Wednesday. The company’s 50 day moving average price is $174.62 and its 200 day moving average price is $241.04. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $379.06. The company has a market capitalization of $15.90 billion, a PE ratio of -71.50 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The company had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same period in the previous year, the firm posted $0.86 earnings per share. On average, equities analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Analysts Set New Price Targets
A number of analysts have commented on MDB shares. Royal Bank of Canada dropped their price target on shares of MongoDB from $400.00 to $320.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Mizuho lowered their price objective on shares of MongoDB from $250.00 to $190.00 and set a “neutral” rating on the stock in a research note on Tuesday, April 15th. Cantor Fitzgerald assumed coverage on shares of MongoDB in a research note on Wednesday, March 5th. They issued an “overweight” rating and a $344.00 price objective on the stock. Wedbush lowered their price objective on shares of MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Finally, Daiwa America raised shares of MongoDB to a “strong-buy” rating in a research note on Tuesday, April 1st. Eight equities research analysts have rated the stock with a hold rating, twenty-four have assigned a buy rating and one has issued a strong buy rating to the stock. According to data from MarketBeat, the company has an average rating of “Moderate Buy” and an average price target of $294.78.
Get Our Latest Report on MongoDB
Insider Buying and Selling at MongoDB
In other MongoDB news, CEO Dev Ittycheria sold 18,512 shares of MongoDB stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $3,207,389.12. Following the completion of the sale, the chief executive officer now directly owns 268,948 shares in the company, valued at $46,597,930.48. The trade was a 6.44% decrease in their ownership of the stock. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which is available through the SEC website. Also, CFO Srdjan Tanjga sold 525 shares of MongoDB stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $90,961.50. Following the completion of the sale, the chief financial officer now owns 6,406 shares of the company’s stock, valued at $1,109,903.56. This trade represents a 7.57% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold 34,423 shares of company stock worth $7,148,369 over the last ninety days. 3.60% of the stock is currently owned by insiders.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s list of seven stocks and why their long-term outlooks are very promising.
MMS • RSS
Mercer Global Advisors Inc. ADV decreased its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 52.4% in the 4th quarter, according to the company in its most recent disclosure with the SEC. The institutional investor owned 2,008 shares of the company’s stock after selling 2,213 shares during the quarter. Mercer Global Advisors Inc. ADV’s holdings in MongoDB were worth $467,000 as of its most recent filing with the SEC.
Several other institutional investors have also bought and sold shares of MDB. Caisse DE Depot ET Placement DU Quebec grew its holdings in shares of MongoDB by 196.0% in the 4th quarter. Caisse DE Depot ET Placement DU Quebec now owns 44,103 shares of the company’s stock worth $10,268,000 after acquiring an additional 29,203 shares during the last quarter. Utah Retirement Systems grew its stake in MongoDB by 1.7% in the fourth quarter. Utah Retirement Systems now owns 11,840 shares of the company’s stock valued at $2,756,000 after purchasing an additional 200 shares in the last quarter. AQR Capital Management LLC increased its position in MongoDB by 92.1% in the 4th quarter. AQR Capital Management LLC now owns 37,126 shares of the company’s stock worth $8,643,000 after purchasing an additional 17,802 shares during the last quarter. Lido Advisors LLC raised its position in MongoDB by 74.8% during the fourth quarter. Lido Advisors LLC now owns 1,208 shares of the company’s stock valued at $281,000 after acquiring an additional 517 shares in the last quarter. Finally, Northern Trust Corp increased its stake in shares of MongoDB by 6.4% during the 4th quarter. Northern Trust Corp now owns 468,010 shares of the company’s stock worth $108,957,000 after purchasing an additional 27,981 shares during the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Stock Up 2.2%
NASDAQ:MDB opened at $195.90 on Wednesday. The firm’s fifty day simple moving average is $174.62 and its 200 day simple moving average is $241.04. The stock has a market cap of $15.90 billion, a P/E ratio of -71.50 and a beta of 1.49. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $379.06.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same quarter last year, the firm posted $0.86 EPS. On average, analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analysts Set New Price Targets
MDB has been the topic of a number of recent analyst reports. Citigroup dropped their price objective on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research note on Tuesday, April 1st. Redburn Atlantic upgraded shares of MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 target price on the stock in a research report on Thursday, April 17th. Morgan Stanley dropped their target price on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating for the company in a research report on Wednesday, April 16th. Oppenheimer dropped their price objective on MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a report on Thursday, March 6th. Finally, Canaccord Genuity Group reduced their price target on MongoDB from $385.00 to $320.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Eight analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has given a strong buy rating to the company. According to MarketBeat, MongoDB currently has an average rating of “Moderate Buy” and a consensus target price of $294.78.
Read Our Latest Analysis on MongoDB
Insider Buying and Selling
In related news, CEO Dev Ittycheria sold 18,512 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $3,207,389.12. Following the transaction, the chief executive officer now owns 268,948 shares in the company, valued at $46,597,930.48. This represents a 6.44% decrease in their ownership of the stock. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at the SEC website. Also, Director Dwight A. Merriman sold 885 shares of MongoDB stock in a transaction on Tuesday, February 18th. The stock was sold at an average price of $292.05, for a total value of $258,464.25. Following the completion of the sale, the director now directly owns 83,845 shares of the company’s stock, valued at $24,486,932.25. The trade was a 1.04% decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 34,423 shares of company stock worth $7,148,369 in the last quarter. Corporate insiders own 3.60% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Market downturns give many investors pause, and for good reason. Wondering how to offset this risk? Enter your email address to learn more about using beta to protect your portfolio.