Month: July 2022
Java News Roundup: JDK 19 in RDP2, Oracle Critical Patch Update, TornadoVM on M1, Grails CVE

MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for July 18th, 2022, features news from Oracle, JDK 18, JDK 19, JDK 20, Spring Boot and Spring Security milestone and point releases, Spring for GraphQL 1.0.1, Liberica JDK updates, Quarkus 2.10.3, CVE in Grails, JobRunr 5.1.6, JReleaser maintenance, Apache Tomcat 9.0.65 and 10.1.0-M17, Tornado VM on Apple M1 and the JBNC conference.
Oracle
As part of Oracle’s Critical Patch Update for July 2022, Oracle has released versions 18.0.1.1, 17.0.3.1, 11.0.15.1, 8u333 and 7u343 of Oracle Java SE. More details may be found in the release notes for JDK 18, JDK 17, JDK 11, JDK 8 and JDK 7.
JDK 18
Concurrent with Oracle’s Critical Patch Update, JDK 18.0.2 has been released with minor updates and removal of the alternate ThreadLocal class implementation of the current() and callAs() methods within the Subject class. However, support for the default implementation has been maintained. Further details on this release may be found in the release notes.
JDK 19
As per the JDK 19 release schedule, Mark Reinhold, chief architect, Java Platform Group at Oracle, formally declared that JDK 19 has entered Rampdown Phase Two to signal continued stabilization for the GA release in September. Critical bugs, such as regressions or serious functionality issues, may be addressed, but must be approved via the Fix-Request process.
The final set of seven (7) features for JDK 19 release will include:
Build 32 of the JDK 19 early-access builds was made available this past week, featuring updates from Build 31 that include fixes to various issues. More details may be found in the release notes.
JDK 20
Build 7 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 6 that include fixes to various issues. Release notes are not yet available.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
Spring Boot 2.7.2 has been released featuring bug fixes, improvements in documentation and dependency upgrades such as: Spring Framework 5.3.22, Spring Data 2021.2.2, Spring GraphQL 1.0.1, Tomcat 9.0.65, Micrometer 1.9.2, Reactor 2020.0.21 and MariaDB 3.0.6. Further details on this release may be found in the release notes.
Spring Boot 2.6.10 has been released featuring bug fixes, improvements in documentation and dependency upgrades such as: Spring Framework 5.3.22, Spring Data 2021.1.6, Jetty Reactive HTTPClient 1.1.12, Hibernate 5.6.10.Final, Micrometer 1.8.8, Netty 4.1.79.Final and Reactor 2020.0.21. More details on this release may be found in the release notes.
On the road to Spring Boot 3.0, the fourth milestone release has been made available to provide support for: the new Java Client in Elasticsearch; Flyway 9; and Hibernate 6.1. Further details on this release may be found in the release notes.
Spring Security 5.8.0-M1 and 6.0.0-M6 have been released featuring: a new setDeferredContext() method in the SecurityContextHolder class to support lazy access to a SecurityContext lookup; support for the SecurityContextHolderStrategy interface to eliminate race conditions when there are multiple application contexts; support for the AuthorizationManager interface to delay a lookup up of the Authentication (such as Supplier<Authentication>) vs a direct Authentication lookup; and provide an alternative for MD5 hashing in the Remember-Me token. There were numerous breaking changes in version 6.0.0-M6. More details on these releases may be found in the release notes for version 5.8.0-M1 and version 6.0.0-M6.
Spring for GraphQL 1.0.1 has been released featuring: improved handling when a source/parent is expected and is null; support for resolving exceptions from a GraphQL subscription; and a new default limit on the DEFAULT_AUTO_GROW_COLLECTION_LIMIT field within the DataBinder class. This version also ships with Spring Boot 2.7.2 and a dependency upgrade to GraphQL Java 18.2. Further details on this release may be found in the release notes.
Liberica JDK
Also concurrent with Oracle’s Critical Patch Update for July 2022, BellSoft has released patches for versions 17.0.3.1.1, 11.0.15.1.1 and 8u341 of Liberica JDK, their downstream distribution of OpenJDK. In addition, PSU versions 18.0.2, 17.0.4, 11.0.16, and 8u342 containing non-critical fixes have also been released.
Quarkus
Quarkus 2.10.3.Final has been released to address CVE-2022-2466, a vulnerability discovered in the SmallRye GraphQL server extension in which server requests were not properly terminated. This vulnerability only affects the 2.10.x release train. Developers are encouraged to upgrade to this latest release. More details on this release may be found in the release notes.
Grails Framework
The Micronaut Foundation has identified a remote code execution vulnerability in the Grails Framework that has been documented as CVE-2022-35912. This allows an attacker to “remotely execute malicious code within a Grails application runtime by issuing a specially crafted web request that grants the attacker access to the class loader.”
This attack exploits a portion of data binding capability within Grails. Versions 5.2.1, 5.1.9, 4.1.1 and 3.3.15 have been patched to protect against this vulnerability.
JobRunr
Ronald Dehuysser, founder and primary developer of JobRunr, a utility to perform background processing in Java, has released version 5.1.6 with support for Micrometer Metrics that now exposes recurring jobs and number of background job servers.
JReleaser
An early-access release of JReleaser, a Java utility that streamlines creating project releases, has been made available featuring a fix to an issue in Gradle where a property wasn’t properly checked before accessing it.
Apache Tomcat
The Apache Software Foundation has provided milestone and point releases for Apache Tomcat.
Tomcat 9.0.65 available features: a fix for CVE-2022-34305, a low severity XSS vulnerability in the Form authentication example; support for repeatable builds; and an update of the packaged version of the Tomcat Native Library to 1.2.35 that includes Windows binaries built with OpenSSL 1.1.1q. Further details on this release may be found in the changelog.
Apache Tomcat 10.1.0-M17 (beta) available features: an update of the packaged version of the Tomcat Native Library to 2.0.1 that includes Windows binaries built with OpenSSL 3.0.5; support for repeatable builds; and an update of the experimental Panama modules with support for OpenSSL 3.0+. Apache Tomcat 10.1.0-M17 is an alpha milestone release to provide developers with early access to the new features in Apache Tomcat 10.1 release train. More details on this release may be found in the changelog.
TornadoVM
TornadoVM, an open-source software technology company, has announced that developers may still install TornadoVM on the Apple M1 architecture despite Apple having deprecated OpenCL.
JBCNConf
JBCNConf 2022 was held at the International Barcelona Convention Center in Barcelona, Spain this past week featuring many speakers from the Java community who presented talks and workshops.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

When Apple adopted their new ARM-based CPUs collectively dubbed Apple Silicon, it made all existing Linux distributions incompatible with its most recent hardware. This is changing thanks to the hard work of the Asahi Linux team, that recently introduced preliminary support for Apple M1 Ultra and M2 CPUs.
The new release follows closely the first alpha made available last March for M1, M1 Pro, and M1 Max machines. Being alpha, that release did not support all features you usually take for granted in a kernel, including GPU, Bluetooth, HDMI, Touch Bar, and others.
The new release, besides adding support for more recent CPUs, also removes some of those limitations. Most notably, the latest Asahi kernel includes a working Bluetooth driver:
Thankfully, while the PCIe transport is new, the HCI interface that runs on top is standard, so once the core initialization and data transfer parts of the driver started working, most Bluetooth features did too. The driver does not need to concern itself with any of those details, it just shuffles data to/from the device.
Unfortunately, the current Bluetooth implementation does not coexist perfectly with 2.4 GHz Wi-Fi, so you should either disable Wi-Fi or use a 5 GHz network.
The addition of the Bluetooth driver provided the playground to test what the Asahi team calls “seamless upgrade”, i.e., the possibility for users to upgrade their kernels without incurring in complex reconfiguration. In fact, adding Bluetooth support implied modifying a number of different components of the kernel, including the device tree, the installer, and so on. Thanks to the “seamless upgrade” approach, existing users will only need to upgrade their packages and reboot to have Bluetooth working.
As to support for the new M2 chip, according to the Asahi team, it took a relatively short time to get a minimal system running on the M2, with support for the keyboard and trackpad requiring some additional effort. Actually, the initial 12-hour reverse-engineering marathon that led to the minimal system running can be watched on YouTube. This result confirms the team’s expectations that extending support to new CPUs Apple is going to introduce will not require so much of an effort as the initial work required to support the M1 chip. However, M2 support is currently only at a very experimental stage. For example, the Asahi team does not guarantee that installing new releases for the M2 will not require reinstalling everything from scratch.
As a final note, the Asahi team also reported progress on the GPU support front, thanks to Asahi Lina‘s work. At the moment, a prototype driver is available that is able to run graphics applications and benchmarks, passing 94% of the dEQP-GLES2 test suite, but the stack is still too experimental to be included in the release. Asahi Lina’s reverse-engineering sessions can also be watched on YouTube.
MMS • Nora Jones
Article originally posted on InfoQ. Visit InfoQ

Transcript
Jones: This talk is about creating a Production Readiness Review, about how it relates to incidents and psychological safety. I’m going to focus on the care you put behind Production Readiness Review process, and what should and should not go into that process. My name is Nora Jones. I’ve seen orgs from the frontlines as a software engineer, as an SRE, as a manager, and now as I’m running my own organization. In 2017, I keynoted at AWS re:Invent to an audience of around 50,000 people about the benefits of chaos engineering and helping make you more production ready at jet.com, now Walmart, and at Netflix. Most recently, I started my own company called Jeli, based on a need I saw for the importance and value to your whole business about a post-incident review. I also saw the barrier to getting folks to work on that. I started Jeli because of this. I also started an online community called Learning from Incidents in Software.
Outline
I’m going to spend a lot of time talking about context. A lot of what we learn in incident reviews and incident processes can actually be related to Production Readiness Reviews, and checklists, and processes themselves as well. I’m going to spend the first half building a case on why you need to spend time cultivating and sharing the context behind a PRR process in your organization with everyone there. Then, in the second half, I’m going to give you tangible ways to do that.
Creating a Repeatable PRR Process
Few services begin their lifecycle enjoying SRE support. We learned this actually from chapter 34 of the Google SRE textbook. You’re likely spending time creating this process or iterating and changing the existing process you have because you had an incident or an untoward outcome. As much as you try to or not, you might end up being quite reactive towards this. It’s ok, PRRs are usually fueled by this fact that there’s been an incident or that there’s been surprises that have happened recently that says, ok, we as an organization need to get a little bit more aligned on what it means to release a piece of software. We have to spend time figuring out how those surprises happen first by doing post-incident review, by looking at past incidents that may have contributed towards untoward outcome, and even past experiences.
What Are Your Business Goals, and Where Is Your Organization At?
Before you start creating this process, you have a very important question you need to answer for yourself, if you’re involved in creating this process. Where is your organization at? What are your current business goals? The process outlined in the Google SRE book is not going to be relevant for a startup. The Production Readiness process that a startup uses isn’t going to be recommended for a larger organization as well. I’m going to take this to a super high level and assume there’s two different types of orgs: your post-IPO org, and your pre-IPO org. In your pre-IPO org, you might care a lot about getting stuff released quickly, whether or not people are using the product. What it means to be production ready there is going to be quite different from when you have an actual stable service that you need to stay up all the time. Keep that in mind before you actually get started on this.
Don’t Take Production Readiness Reviews from Other Orgs as a Blueprint
I really don’t want folks to take these Production Readiness Reviews from other organizations as a blueprint, it should be unique to you. I’ll explain the impetus behind this. It can be actually in fact problematic to your organization to just copy this. We actually as a tech industry received the idea of Production Readiness Reviews from other industries. It started with aviation, and it worked really well for them. Then it went to healthcare. Healthcare decided, checklists are working very well in aviation, we should have checklists in healthcare. I want to share a quote from a late doctor that studied system safety in hospitals, because I believe it’s actually relevant to us as a software industry as well. We’re later to the game here, from these highly regulated industries that have these Production Readiness Review processes.
This is from Robert L. Wears book, “Still Not Safe,” highly recommend. He says, “Many patient safety programs today are naive transfers of an intervention of something successful elsewhere, like a checklist. It’s lacking the important contextual understanding to reproduce the mechanisms that led to its success in the first place.” I state this because we have a danger as a software industry of getting into this as well. This SRE checklist may have worked exactly at Google, but context matters. You need to make sure the checklists you’re developing has context. You need to know the why behind each item. You need to make sure your coworkers understand and inform that as well.
Five Monkeys Experiment
This leads me to the most important question of my talk, do you know the history of why your current Production Readiness Review process was introduced, and do new hires? I hesitated a bit putting the story in because there’s problematic connotations behind it and problematic practices behind it. I don’t want anyone to think that I’m relating organizations to monkeys. I opted to share this story because I think it illustrates the point I’m trying to make about psychological safety. There are hallmarks of this in this particular case. Going to the case in 1966, researchers at University of Wisconsin-Madison, studied monkeys. They put five monkeys in an environment as part of an experiment, and in the middle of the cage was a ladder with bananas on it at the top. Every time a monkey tried to climb the ladder, they would get sprayed with icy water. When other monkeys saw other monkeys try to climb on the ladder, they would help stop them. Eventually, the researchers started replacing the monkeys that they had sprayed with icy water with monkeys that hadn’t been a part of this experiment before. Until there was a group of monkeys in the middle that had never been sprayed with icy water.
I bring up the story because it captures a pervasive theme in many organizational cultures, if they don’t have psychological safety, to do the things that we’re always told that’s the way it’s been done without questioning or revisiting the reasoning behind it. Even long after that reason ceases to exist. It’s actually a really good measurement of psychological safety in the organization. Are we blindly following lists and procedures even when we are feeling that we need to question the context behind them? Have you been a new hire at an organization where you think, this doesn’t quite make much sense, but you don’t feel comfortable saying the thing yet? That’s an important measurement for leaders in organizations as well. Are folks asking you questions? Are folks asking each other questions about why certain things are happening? Because again, it might not be relevant anymore.
Giving, and Getting Context
My hope is at this point that I’ve convinced you that you need context. You need to understand context. You need to be constantly giving context. How do I give or get it? We spoke earlier about the fact that the Production Readiness Review process might be coming into play, because the organization has had a lot of recent incidents. Maybe they’re having a lot of them, maybe they’ve just had a string of bad ones recently. I know Laura Nolan was actually talking about firefighting, and what’s happening a lot when you feel like you’re firefighting a lot of incidents in an organization. As you’re trying to introduce this process, people might be very busy in the middle of it, too. It’s important to take the time and space to actually put some care into this process.
Psychological Safety
Let’s go back to increasing psychological safety for a second. Amy Edmondson is a professor at Harvard Business School, and she has a lot of amazing work on psychological safety in organizations. Do we say that we have a uniformly high level of competence in our organizations that I can say what I’m actually thinking about this release? What I’m actually thinking about this Production Readiness Review. If you can, that’s indicative of high psychological safety, which will make your team more effective. It will make your Production Readiness Review way more effective as well. I’m curious also, how many different answers you get on what’s important to a release. Different people are holding different contexts from marketing, to engineering, to PR. Does it feel safe to speak up about this? Do we know why the PRR is happening? Do we feel comfortable asking about it? Do we know who’s driving it and why?
Hearing Different Perspectives When Creating PRRs is Important
I want to share a quick screenshot from Jeli. We’re an incident analysis platform, but some of this stuff can be applied towards Production Readiness Reviews as well. This is a list of different people that may have participated in an incident. Hearing different perspectives, when creating the Production Readiness Review process is really important. We want to make sure it’s not just the person that’s pushing the button that says, this is release now, this is ready to go. We want to make sure that we’re capturing all the perspectives. One of the things we like to do internally at my organization, is put our releases in an individual Slack channel, so that we can analyze afterwards, who was involved, from who was observing the channel, to who was participating in it. That way, we can capture the different perspectives about what this release means to them, so that we ensure that we’re capturing every party. This is a significant amount of work.
Law of Requisite Variety
I want to talk about the law of requisite variety. What I’m basically trying to say here is that the care that you put into the Production Readiness Review process should match the importance of that particular release as well. This law basically says, informally and practically, that in order to deal properly with the diversity of problems that the world throws at you, you need to have a repertoire of responses, which is at least as nuanced as the problems you face. I’ll share a quick image from a consultancy that does some of this work. It’s shaped between problems and responses over here. I want you to imagine this left-hand column problem equaling the release itself that we’re talking about in that moment, and the right-hand column response equaling the PRR process. When we look at responses here, in relation to creating a PRR process, this is what we mean. Any control system that you have must be at least as complex as the system that governs. The system that governs here is the release, and the governing system is the PRR process. This is how it actually should match.
I want to also share this equation related to some of that as well. We know context is important, but disseminating that context is also really important. We spend a lot of time being reactive in organizations and reacting to errors going down. I really like this equation from cognitive psychologist who studies organizations as well, Gary Klein. In order to improve performance, in order to improve the value of these releases and how good they are, it’s a combination of both error reduction and insight generation. The insight generation piece is the context. It’s how much we’re talking to everyone. It’s how much they’re contributing to the situation. Yet, we as a software industry focus a lot on the error reduction portion. We’re missing the mark on improving our performance, and actually creating high performing teams internally.
How to Get Ready To Make a Production Ready Review
Before writing the PRR review, you should get introspective about looking at incidents, and talking to the necessary parties and teams impacted by this release. Getting ready to make a production ready review. How do we do that? When creating or iterating your PRR process, consistency might be important, you might not be iterating this every time and starting anew, but you should at least retrospect it a little bit. Before writing the PRR process, I actually recommend that you have held retrospectives for incidents or previous releases that have surprised you or even gone well in various ways with the necessary parties, without doing the PRR review yourself as an SRE in a vacuum.
Again, I want you to write down the context on what inspired this PRR process. Keep those receipts. Were there specific incidents or releases that didn’t go as planned? The person in charge of writing this PRR should also acknowledge their role in this. That also indicates psychological safety. Even if you’re not a manager or leading the organization in some way, but you’re in charge of the PRR, there’s a power dynamic there. Acknowledging that, as the creator of that will help make the parties around you that are contributing to it feel safer. It’s important to get context from these teams outside of SRE on what it means to be production ready. What does that mean for marketing? What does that mean for product? What does that mean for software? What does that mean for leadership? What does that mean for ICs? Then, do you have areas to capture feedback about this particular release?
Components of a Strong Retrospective Process
Myself, and a lot of my colleagues at Jeli have spent our careers studying introspection and incident reviews. We’ve spent a lot of time creating what it means to have a strong retrospective process. I want to relate this to PRRs. There’s a lot of components that we can lift and shift from a strong retrospective process to a PRR process. We want to first identify some of the data. We want to analyze that data. Where’s our data coming from? We want to interview the necessary parties. We want to talk to and have cognitive interviews from the folks participating in the release in some way. We want to then calibrate and share what we’ve found with them, involve them in the process, co-design it together. We want to meet with each other and share our different nuances of the event and different takes. Then we want to report on it and disseminate it out.
Every organization has different needs, strengths, limitations, and goals for their Production Readiness Review process. Take what steps make sense to you. People that are doing the PRR process also probably have constraints on how much time they can spend on it. They probably have other responsibilities, especially if it’s a smaller organization. Different releases are going to have differing levels in terms of the time and care spent on that Production Readiness Review. Fundamentally, you can learn from all of these, but realistically we know that orgs are balancing tradeoffs between time spent in development and operations versus time spent in learning and sharing context with each other.
Identify
You may want to look at multiple things that are informing the PRR, like incidents. This might be like a quick example of three incidents that had various releases associated with them that may have not gone as planned. If you can look at those together and annotate as a group, the different ways that you were talking about these incidents, and the different ways that impacted releases of various parties, you’re going to get a lot more value out of it. You can see here that, we’re seeing the nuances of this particular release and how it impacted the organization. People are tagging when stuff is happening, and people are commenting questions that they have about the particular release and how it might have gone awry. This can then inform the Production Readiness Review process in the future, which might be a pretty awesome action item of an incident.
If you’re creating or revising your PRR, you can identify previous incidents to find the opportunities and people to inform that PRR. You want to interview colleagues and have a cognitive style of interviewing. You can take things from the SDD briefing guide to look at how we interview people and how we talk to our colleagues. We want to find out like what their understanding of the PRR is. What’s important to them? What feels confusing, or ambiguous, or unclear? What they believe they know about the PRR that their colleagues don’t. Talking to them individually will help reveal this too. What scares them about this release? A premortem of sorts. These things can help make your readiness review ready to catch something before it has a failure or unintended consequences.
Earlier, we talked about checklists potentially becoming almost dangerous because it’s a box checking exercise without context. You’re going into these events trying to understand what things were happening beyond your knowledge. That’s why we incorporate the different perspectives of our colleagues. I’m sharing this again, a particular Slack channel related to a release, finding all of the necessary parties. If all the groups impacted aren’t talking, that’s also something to dig into first. We can see a few people were just observing the situation. Did you talk to everyone that was impacted by this in some way, even if they were just lurking or observing? Make it explicitly clear to people that you’re talking to, what the expectation is when you’re talking to them, what their participation or role is in informing your Production Readiness Review.
Incidents are Catalysts
I related this to incidents before, and I want to tie that back. Incidents are a catalyst to understanding how your org is structured in theory, versus how it’s structured in practice. It’s one of the only times that rules go out the window, because everyone’s doing what they can to stop the bleeding as quickly as possible. Surfacing that delta between what you thought was going to happen and what actually happened, should and can inform your PRR process in a really beneficial way. I would strongly recommend tying incidents to it. This incident, or the past incidents are catalysts to showing you what your organization is good at, and what needs improvement in your PRR processes. Where were deltas in people’s mental models in the situation, especially between teams? Use your colleagues. Leverage them. Collaborate, talk. In this distributed world that we have with the pandemic where everyone is remote, this is even more important, as I’m sure folks have realized. Use previous incidents and releases to inform your PRR process, and then rinse, wash, repeat each release.
How to Know There’s Improvement
How do you know if it’s working? How do we know if we’re improving? We’re not going to get to zero incidents, obviously, but maybe our releases feel smoother. Maybe we’re feeling more alignment with our colleagues. Maybe we’re feeling comfortable speaking up. More folks might be participating in the PRR process. More folks feel comfortable questioning the why behind different pieces of the review. If you’re not seeing that in the beginning, that’s usually indicative that there’s more to dig into. People know where to get context on the PRR. Folks feel more confident in releases. Teams are collaborating more in this process beyond just SRE doing it in a vacuum. There’s a better understanding of the shared incident, the shared definition of production ready.
Questions and Answers
Sombra: There have been a few themes there, is there anything that you would like to mirror or echo?
Jones: I think one of the points I wanted to stress is there is a huge psychological safety component to being able to ask questions behind certain rules and procedures that just feel normal in your organization. I understand that not every organization has that. I think it starts with your colleagues, like trying to cultivate that relationship with your colleagues. Because, ultimately, there are a lot more individual contributors than there are managers. I think at that point, the managers can’t ignore some of those questions. It doesn’t need to be combative. It can just be inquisitive. Say, before each release, you need to get three code reviewers. You’ve never really questioned it before, but you’re like, why three? Why from this particular team? Can you give me some history on that? You as the engineer, having history on that particular nuanced rule will help you in the future and will actually help that release. Because it’s helping you collaborate with your colleagues and actually understand your organizational context a bit more.
Sombra: We were talking about Production Readiness Reviews, and the opinion of Laura was that the teams that own or they are subject matter experts should own the process. What is your opinion whenever multiple teams own a specific piece of software?
Jones: I feel like that’s always the case. It’s very rare that one team has owned the entire release, and it’s affected no one else. This is actually a mindset shift that we have to do as SREs, I think a lot of the time, it’s like, my service was impacted the most, so I should own the release process for this. What does that impact mean? If that incident hit the news, have you talked to your PR team, like about the release process? Have you talked to your customer support people? I don’t quite know what it means to be the team that’s most directly impacted. I get a lot of us are writing the software that contributes greatly to these. What I’m advocating for is that we co-design this process with the colleagues that might also be impacted in this situation. One of the ways you can do that is check who’s lurking in your Slack channels and incident? They might not be saying anything, but they’re there. Check who’s anomalous for that, and chat with them. Because I think it ultimately benefits you as an SRE to know what to prepare for when you’re writing the software, when you’re releasing it, when you’re designing it.
Sombra: Have you found in terms of dissemination of information in humans, what is a good way to bring back the findings of an incident analysis to the team, if they’re not in charge of doing that analysis?
Jones: It’s really hard, but it’s so necessary. I feel like so often in organizations we write incident reviews, or we write release documents, as a checkbox item, rather than a means of helping everyone understand and develop an understanding together. I think it starts with shifting the impetus of writing these documents. It’s not to emotionally feel good and close a box and feel like we’re doing a thing. It’s like, to collaborate. I think every organization is a little bit different. I think some organizations really leverage Zooms. They might feel like they have a lot of Zoom meetings, especially in this remote world. Then some organizations might shy away from Zoom meetings, and dive more into documentation world.
I’ve honestly been a part of organizations that have been either/or, where we’ll have to have a Zoom meeting to get people to even read the document. Then, on other organizations, if someone’s requesting a Zoom meeting, you’re like, why don’t you just send me a document? It’s like one way or the other. I would encourage you to think about where your organization leans, and whatever you can do to get people to talk to you about how they feel about some of the line items and how it impacts them. I think too often we just write these documents or write these reviews in a vacuum, and we’re assuming people are reading them, but are we actually tracking that? Are we actually tracking their engagement with it? Are we actually going and talking to them afterwards, or are they just blindly following the process? We’re happy because that means that it’s good.
Sombra: You said that multiple people should answer their PRR, but you get multiple perspectives, and a different level of experience. For example, a junior engineer will respond differently than a senior engineer would, and the team sees that the junior engineer has a different response. How do you stand the multiple contributors? How do you coalesce the voices of multiple contributors at different levels of experience?
Jones: At some point, there is going to need to be a directly responsible individual. A lot of the time it’s the SRE, or the most used software team. They’re going to have to put a line in the sand. Not everyone’s going to be happy. I think focusing less on people’s opinions, and more on people understanding each other is really helpful. Like, here are the different perspectives involved in the situation. I really love this question about the junior engineer versus senior engineer. Because I would encourage the senior engineer in that situation, to ask more questions of the junior engineer on why they’re feeling a certain way, and help give them the context, because that’s going to be data for you and yourself. Because this junior engineer is going to be pushing code, and if they don’t quite understand some of the release processes and the context that goes behind them, it might indicate to you that you need to partner with them a little bit more. It should be revealing, actually, in a number of ways. I would leverage that as data. It would help level up the junior engineer in the team itself. I think involving them in the process without necessarily having them dictate the process is going to be really helpful for their growth and also the organization’s growth in general.
Sombra: That is an assumption that this junior engineer would have a substandard opinion. There are some cases in which your junior engineer will tell you that something is wack in your system, and that’s definitely a voice that you want.
Jones: All of our mental models are incorrect, whether I’m a senior engineer, whether I’m the CEO, whether I’m head of marketing. We all have different mental models, and they’re all partial and incomplete. I think your job as the person putting together that PRR document, is to surface the data points between all these mental models so that we can derive a thing that all of us can understand and use as a way to collaborate.
I’m curious if you gave your current PRR process to people in other teams and ask them why they thought we were doing each thing as an organization. I’m curious what answers you would get, because I think that would be data for you as the author yourself. Not asking if they understand it, but asking them why they think each line item exists. If they give you a lot of different answers, I think that’s homework for you to do yourself, to put more context in there.
Sombra: PRRs, if they are service specific. Also, how do you leverage one when handling incidents?
Jones: I don’t think a PRR needs to be created for every service. I think there should be an overarching release process that’s good for the organization to do as a whole. I think individual services might want to own their own release processes too, like before we integrate this with other systems, or before we deploy it to prod, not necessarily the organization releases it to customers. We might want to have our own release process too. I think that’s up to each individual team. In the service deployment situation, if it’s just about your service and your team deploying to prod, I would make sure you include all your team members in that, especially the junior engineers. I would actually have them, if you do have a psychologically safe organization, share their context first so that it’s not checkered by some of the senior engineers’ context. It really requires you to have a safe space for them to do that.
I would also look at some of your downstream services, too, if you have the time to incorporate some of those thoughts on your releases, and how your releases in the past have impacted them. Any internal incidents that you may have been a part of, too. Lots of different nuances for lots of different situations. Primarily, in my talk, I was talking about the overall Production Readiness Review of like, we’re deploying a particular release right now.
Sombra: In the time continuum, you would have this as a precursor from going out. Then just like if there’s an incident, you will do a different process to analyze that incident and pick it back into the PRR.
Jones: Exactly.
Sombra: I was asking Laura, if there is any tooling that she preferred or that she gravitates towards when implementing a PRR. Is there anything that you have found that is helpful in order to start laying out the process from the mechanics?
Jones: I think the most important piece is that you choose a tool that is inherently collaborative. By that I mean, you can see people’s names that are writing things in there. You can surface things from your colleagues. I would strongly advocate for your PRR to not necessarily be in like GitHub or GitLab, or something that is inherently in a readme file that might not get updated that much. Maybe yours do. I would encourage it to be in some format where you can keep this document living, and encourage people to ask questions after certain releases. Question whether or not the PRR process worked for us.
I’ve certainly been in organizations where we’ve been a bit too reactive to incidents. With every incident that went awry, we would add a line item to our PRR process. Definitely don’t do that, because then you end up with this PRR process that’s just monstrous and you’re not actually understanding the underlying mechanisms that led to that individual thing you’re adding being present to begin with. I think a lot of this is about asking your colleagues questions, and having those questions be public in this living document. It can be Google Docs. It can be Notion. I am biased because I started the tool that did some of these things. We have a lot of collaboration components in Jeli as well, more focused towards incidents. There’s a lot of tools. The most important thing is that it’s collaborative and that it’s living.
Sombra: Since we’re also talking about the environmental and human aspects of PRRs, what organizations or what stakeholders are we normally forgetting that could extract value from this document? Do you have an intuition or an opinion?
Jones: Are you asking about the consumers of this document, like who it’s going to be most useful for?
Sombra: We tend to see things from an engineering lens, but are there any stakeholders? For example, product would come to mind. If you’ll never ship anything, because the PRR is 200 lines or 200 pages long, that has an implication or at least has a signal for the business.
Jones: Totally. I would be very scared if it was 200 pages long.
Sombra: Obviously, it’s an exaggeration.
Jones: I think there’s a more nuanced version that needs to exist for engineers and for your team. I think it should be based off of the higher level version. It should all be feeding into a thing that everyone can grok onto, and that product can understand, that marketing can understand, so that you have that high level mechanism, and everything’s trickling down to a more nuanced view from there. Because if you’re having separate things, that’s when silos start to exist. Especially in the remote world that we’re in now, I’m seeing so many more organizations exist even more in silos than they normally have been. Over sharing and over communicating and over asking, like, Inés, what did you actually think of this particular line item? Because you’ve been involved in an incident like this in the past, not like a pain, as this does sound good, but actually getting into the specifics of it and making Inés feel safe to answer that question from me.
Sombra: This is actually reinforcing your previous point where if you put it in GitHub, like other areas of your organization may not have access or permissions to be able to see it. The access and discoverability of the document itself gets cut.
Jones: What do you do if you have a question on a readme in GitHub, you can’t comment on it. You go and ping your best friend in Slack and you’re like, do you know what this thing means? It’s not in a public channel, and so you’re in your silos again. They might have an incomplete view of what it means. They’ll probably have an opinion like, yes, I don’t get that either, but we just do it anyway. It’s important to encourage an organization that’s asking these questions in public. I know a lot of the folks in this audience are senior engineers. I think what you need to do is demonstrate that vulnerability, so that other people in your organization follow.
Sombra: I think this is very insightful. It’s like, we just tend to think about systems, but we forget the people, and then they’re made with people.
Jones: The people are part of these systems. We tend to just think of them as just software, but it’s like we’re missing this whole piece of the system, if we don’t take the time to understand the people component too. We’re not trained a lot in that as software engineers. It might seem like, this is the easy part, but it’s actually just as complex. Understanding both of these worlds and combining them together is going to be so important for the organization’s success onboarding new hires, keeping employees there. All of these feeds into these things.
See more presentations with transcripts
MMS • Kolton Andrus Laura Nolan Ines Sombra
Article originally posted on InfoQ. Visit InfoQ

Transcript
Reisz: We’re going to continue the discussion about running production systems.
All of our panelists have released software, they’ve all carried the pager. At least in my mind, they come from three different personas in software. Laura Nolan is a senior SRE at Slack. She’s a frequent contributor to conferences like SREcon, and QCon. She’s on the steering committee for SREcon. She’s published quite a bit, all on the topic of SRE, even contributed to a bunch of books, including one that I have right here on my desk, a chapter here on this. We’ve got Ines Sombra, who’s an engineering leader at Fastly. She’s got many of the teams that are powering their CDNs or edge compute software. Then we’ve got Kolton Andrus. Kolton is the CEO of Gremlin. Kolton was one of the engineers at the heart of building the chaos engineering capability at Netflix, before he went on to found Gremlin, a company that does something very similar that brings a platform to other companies.
All of them, we’ve got engineering, we’ve got SRE, and we’ve got a chaos engineer here. What we’re going to do is have a discussion. They’re not just going to stay in those lanes, but we have them from those areas, at least, to continue the discussion about SRE.
What Is Production Readiness?
When you think about production readiness, I’d like to know what comes to mind so we can frame the conversation. What do you think about when we talk about production readiness?
Nolan: To me, there’s a bunch of aspects to this. I think that one of the most important things about production readiness for me is that it is very difficult to reduce it down to just a color by the numbers checklist. I think that one of the most important things is that the owning team, the team that’s going to have the skin in the game, is going to be carrying the pager, whether that’s the dev team, or whether it’s an SRE team. I think the most important thing is that that team, which is presumably the team that knows that system best, is going to really take the time to engage and think deeply about how can that system fail? What is the best thing that that system can do in various situations like overload, like dealing with partial infrastructure failures, that sort of thing?
Certainly, there are particular areas that are going to come up again, that teams are going to need to be prompted to think about. One of the most obvious being, how to deal with recovery and failure. Monitoring and understanding the system is a huge area always. How to deal with scaling and constraints and bottlenecks and limits, because all systems have those. How do we deal with load shedding and overload is always a huge area. Then data is another big issue. How do you safeguard your data? How do you know that you can restore from somewhere? How do you deal with ongoing work? In Google, we call this toil, so work of turning up new regions and turning things down, work of onboarding new customers, that sort of thing. How do you ensure that that doesn’t scale as the system grows and overwhelm the team? That tends to be what I think about in terms of production readiness.
Reisz: Prompts, things to think about, not necessarily a checklist that you’re going down.
Sombra: When it comes to production readiness, I translate it into just like operational excellence. Then, for me, it signals to like how uncomfortable or nervous a team is around their own service. It is like, are we scared to deploy it? Are we scared to just even look at it? For me, it’s just like I signal it to health, and how many pages do we get? Are we burning out on on-call? Is the person that is going on-call just feeling that they have to hate their lives. Then just like, is it stressful? For me, it’s just more about like, production readiness equals feelings. When we feel ok, then basically we’re doing things right. That’s where my mind goes immediately.
Andrus: There’s a lot that I agree with here. I’m a big believer of skin in the game, that if you feel the pain of your decisions that you’ll choose to optimize it in a way. You touched on another important point, Ines, on the confidence and the pain. We want people to feel a little bit of friction, and to know that their work is making their lives better. We don’t want to punish them and have them feel overwhelmed or have them feel a lot of stress about that. I’ve been to so many company parties with a laptop in my bag. That’s not the fun part of the job. It might be one of the battle scars you get to talk about later. I think a lot of it comes down to, to me, production readiness is how well do you understand your system? We always have teams and people that are changing. Day one on a new team is like, draw me the system. Tell me what we depend upon. Tell me what you think is important. I think a lot of it comes down to that understanding, and so when we have a good understanding of the monitoring and what it means.
I’ve been part of teams that had 500 alerts, and we cleaned that down to 50. The start of that exercise was, does anyone know what these do? The answer was no, but don’t touch them, because they might be important. If you understand that, you can make much better decisions and tradeoffs. Of course, I’ll throw that chaos engineering angle in. One of the ways you understand it is you see how the system behaves in good times and in bad. You go through some of these, you have some opportunities to practice them so you understand how that system might respond. To me, it’s about mitigating risk. A lot of what we do in reliability I’ve come to learn or feel has a lot to learn from security, in that a lot of what we’re doing is mitigating risk and building confidence in our systems.
Reisz: Nora Jones talked about context, understanding the context of why we’re doing different things on there. I think that totally makes sense.
Having Org Support and Skin in the Game
Sombra: I do want to point one thing out, whenever we say that skin in the game is a factor. Yes, but that’s not the end all, and be all. It also requires organizational support, because a team can be burning. Unless you leave them space to go and fix it, then the skin in the game just helps you only so far, the environmental support for it. If you’re lucky to be in an operationally conscious company, then you will have the opportunity to go and make the resilience a focus of your application. It requires us as leaders to make sure that we also understand it and it is part of our OS. We’re like, is it secure? Is it reliable? Then it just becomes a core design and operating principle for the teams and the management here as well.
Reisz: What do you mean by that, Ines? You space to go fix at Slack? What do you mean specifically to go fix it?
Sombra: A manager needs to pair. If you have a team with 500 alerts, it takes time to winnow them down, understand them, and then just even test them. If you never give them the time, then you’re going to have a team with 500 alerts that continues to burn and continues to just churn through people. The people alone are not enough. You have to have support.
Nolan: Most definitely. I agree with that so much. One of the big precepts of the way that SRE in the early years of Google was, and I think this is not the case in the industry, but there was a very big emphasis that most SRE teams supported a number of services. There was always an idea that you could hand a service back to the developers if they wouldn’t cooperate in getting things prioritized as needed. Of course, sometimes you would have problems in the wider environment, but that idea that almost SRE by consent was this very big thing that teams would just have burning things piled on them until the team circled the drain.
Consulting vs. Ownership Model for SRE (Right or Wrong Approach)
Reisz: Laura, in your talk, you talked about the consulting versus ownership model for SRE. Is there a wrong or right approach?
Nolan: I don’t think either are wrong or right. I think they both have a different set of tradeoffs, like everything else in engineering. Having a dedicated SRE team is extremely expensive, I think, as many organizations have noticed. You need to set up a substantially sized team of people for it to be sustainable. I know we’re all thinking about burnout at this stage of the pandemic, and the whole idea of The Great Resignation, people leaving. In order for a team to be sustainable service owners, in my view, they need to be a minimum of eight people. Otherwise, you just end up with people on-call too frequently having too much impact on your life. That’s an expensive thing. A team is also limited in the number of different things it can really engage with, in a deep way. Because human brains are only so large, and if you’re going to be on-call for something, you need to understand it pretty well. There’s no point in just putting people on-call to be pager bookies with a runbook that they apply in response to a page. That’s good engineering, and it’s not good SRE or operations practice. You need a set of services that really justifies that investment.
What’s true to say is, a lot of organizations don’t have a set of services where it makes sense to dedicate eight staff purely to reliability and availability type goals. Where do you go? That’s where your consulting or your embedded model makes sense, where you have people who bring specifically production expertise. It’s not going to be a team of people who are dedicated to production that are going to own and do nothing but reliability, but you’ll have one person embedded on a team whose job is to spread that awareness and help raise the standards, the operational excellence of the whole team. That’s where the consulting model or the embedded model makes sense, I think.
Distribution of Chaos Engineers among Teams
Reisz: Imagine we can’t have chaos engineers on every single team. How do you think about this question?
Andrus: I’ve lived on both sides of the coin. When I was at Amazon, we were on the team that was in charge of being that consulting arm. That gives you the latitude and the freedom to work on tooling, to do education and advocacy, to have that holistic view of the system. To see those reoccurring issues that are coming across multiple teams. At Netflix we’re on the platform team in the line of fire. It was a different set of criteria. I appreciated the great operations folks we had across the company that helped us that were working on some similar projects. We saw a different set of problems that we were motivated to go fix ourselves. I think that’s a unique skill set. If you have that skill set on your team, and somebody’s passionate about it, having them invest the time to go make the operations better and teach the team itself works very well. If you have a bunch of engineers that maybe don’t have as much operational experience, just telling them they’re on-call may start them on the journey and give them some path to learn, but isn’t really setting them up for success.
It’s funny, we talked about management a little bit and cost a little bit. As a CEO now, that’s a little bit more my world. To me, I think we underappreciate the time and effort that goes into reliability as a whole. Ines’s point that management needs to make space for that and needs to make time for it and invest in it, is something that hits home for me. I heard a story secondhand of somebody that was having a conversation about reliability, and said, how much are you spending on security? The answer was like, all the money in the world. He was like, how much are you spending on reliability? Like nothing in comparison, and not a great answer there. It is like, do you have more system stability issues from security incidents, or availability outages? The conversation was over at that point.
I think framing it in a way that helps our leadership think about this in terms that they understand and how to prioritize and quantify it. That’s the other tricky part is that, how do you know how valuable the outage that didn’t occur was? I’ve been picking on Facebook for the last couple of conversations I’ve had on this. Imagine you could go back in time, and imagine you could find and fix an issue that would have prevented that large outage that was estimated to be $66 million. I almost guarantee you cannot convince anyone that it was that valuable of a fix, but it was in hindsight. How do we help folks understand the value of the work that we do, knowing that sometimes it is super paramount, and sometimes it might not ever matter?
Understanding Value of Work Done
Reisz: How do you help people understand the value of the work that’s being done?
Sombra: I think it’s hard. We don’t reason through risk very well. It’s just hard. People are not used to that. I think there’s a cultural element too, where if you glorify the firefighting, you’re going to be creating a culture where you, like the team said, never have an incident, just get under-looked, no matter how many heroics you do. If you go and then always grease the squeaky wheel, then you’re going to be creating this problem too. Granted, all of our houses are made out of glass, so I’m not going to pick on anyone. I can tell you that there’s not going to be a single solution, they carry nuance. Then we’re not very good with nuance, because it’s just hard.
I do have a point about Laura’s embedded versus consulting model. I’m a fan of having my own embedded SREs. I deal with the data pipelines. I lived in a world where we have an entire organization that I depend on, but depending on your failure domain and depending on your subject matter expertise, I like having both. A centralized team where I can go for core components that are going to have attention, and they’re going to have care, and then just also being able to leverage them, and then just make sure that my roadmap is something that I can control.
The Centralized Tooling Team
Nolan: That’s almost a fourth model where you have the centralized tooling team. That’s not really what I think of as an SRE team. I think of an SRE team as a team that owns a particular service, deals with deployment, deals with all the day-to-day operation stuff, is on-call for it, and really more deeply engaged with the engineering roadmap as well. I know that not many organizations actually have that.
Andrus: It’s a great clarification, and I’m glad you brought it up. Because a lot of folks think, yes, we have a centralized team and they own our chaos engineering tooling, and our monitoring tooling, and our logging, and we’re done.
Nolan: We’re not done.
Sombra: I’m actually missing the nuance, because what you’re saying is just like you would have a team, or for example, services, but you’re talking about applications that are not necessarily core services, for example, a CI and CD pipeline.
Nolan: For years, I was an SRE on a team that we run a bunch of big data pipelines, and that was what we did. We didn’t build centralized tooling for Google. We built tooling and we did work on that particular set of pipelines. You’ve got to be quite a large organization to fall into that.
Sombra: We could consider that in my scope as an embedded SRE. These people that are only just thinking about that, and then just we go to the other centralized as foundational core pieces. Also, it’s difficult to reason to your point, Wes, is because we’re using these terms very differently and contextually they mean things in different organizations. First, calibrate on the meaning, and after that, we’re like, yes, we’re doing the same thing.
Teaching Incident Response
Reisz: How do you teach incident response? Laura, I actually held up this book. I’m pointing to chapter 20 here. How might you suggest on some things to help people learn incident response and bring that into the organization.
Nolan: I want to build a card game to teach people incident response, and I keep meaning to open source it and never quite getting time to. The pandemic came along, and you think I would have time, but then I started doing a master’s degree like an idiot. Teaching it, I think it’s always important to have fun when you’re teaching something. I think it’s important to be practical and hands-on. I don’t believe in long talks where people are just sitting there doing nothing for a long period of time. I always like to simulate things. Perhaps you can run an incident around some of your chaos testing. I’ll talk a little bit about what to do during an incident and what to do after an incident. You’re right, before an incident, everyone needs to know what the process is that you’re going to follow during an incident and get a chance to practice it. Keep it consistent. Keep it simple.
Then, during an incident, the key thing is to follow that process. One of the most important things is to have a place where people go, that they know that they can communicate about an ongoing incident. Have a way for people to find what’s going on and join an incident. Have someone who’s in charge of that incident, and the operational aspects of that incident. Dealing with people that are coming along, asking questions, dealing with updates, and communication with stakeholders. Dealing with pulling people into the incident that they need to be in there. Use the operational person, the incident commander to insulate people who are doing the hands-on technical, hands-on keyboard work of debugging and fixing that incident. People really complicate the whole incident management thing, and they go, firefighters. Really, it’s about having a system that people know, and insulating the people who are doing the hands-on work from being distracted by other things. Having someone who keeps that 360-degree view of what’s going on, making sure that you’re not spending time down in the weeds, and forgetting something important off to the side, like maybe that after six hours people need to eat. Hopefully, you don’t have too many six-hour incidents, but they do occur.
Then afterwards, the most important thing is to look at what happened and learn. Looking for patterns and what’s going on with incidents, like understanding particular incidents in depth what happened, particularly the very impactful ones, or the ones that might hint at bigger risks, the near misses, and looking for things that are happening again.
Andrus: It’s interesting. I could agree with most of what Laura says, and just say, move on. There’s how you prepare people. I think investing in giving people time for training, and there’s lots of different learning styles. Shadowing was effective for me, being able to watch what other people did. This is a perfect use case for chaos engineering. You should go out and you should run some mock exercises, blind and not blind. There’s the set of, tell everyone you’re going to do it so they have time to prepare, and they’re aware, and go do it. Make sure it goes smoothly in dev, or staging, or whatever. Then there’s the blind one, the, ok, we’ve got an advance team. We’re going to run an incident and what we really want to test there is not the system, but the people and the processes. Does someone get paged? Do they know where the runbook is, the dashboards? Do they know where to go find the logs? Do they have access to the right system? Can they log in and debug it? Just going through that exercise I think is worthwhile for someone that’s joined a team.
Being the call leader, that’s the other one that Laura talked about there. That’s an interesting role, because there’s lots of ways to do it. Having a clear process, a clear chain of command, maybe not the most popular terminology. It’s a benefit to the folks that are on the call, you need someone that’s willing to make a call. It’s tricky to make a call, and you will never have complete information. You have to exercise judgment and do your best. That’s scary. You need someone that’s willing to do that as part of the exercise. I also agree pretty heavily with, that person is really managing status updates, letting folks know where time and attention is being done, managing the changes that are happening. The experts of the systems are each independently going debugging, diagnosing, and then reporting back what they’re learning.
Reisz: What’s incident response look like at Fastly?
Sombra: How do you teach it? I agree with both Laura and Kolton, a designated coordinator is really helpful. It’s helpful to also have a function, if you already have incident command as a thing that your company does, then it’s great, because you can rely on those folks to teach it to others. Since, apparently, I woke up with my management hat as opposed to my data hat, I will tell you that a critical thing is to make sure that your incident team is staffed appropriately. Because if they don’t have time, if they’re going from incident to incident that they don’t have time to teach it or develop curriculum, then it’s just really hard to be able to just spread that knowledge across.
Incident Response at Fastly
What does it look like? We have a team that deals with incidents. They’re actually rolling out this training as we go along. Then I like to hear great things. A technical writer, at some point, is helpful to have in your organizational evolution, because how do you convey knowledge in a way that sticks, and how do you educate folks, becomes much more of a concern, because I want to be able to build these competencies.
A Centralized, Consistent Tooling that Covers Security
Reisz: Are you aware of anything out there that offers a centralized mostly consistent tooling capability that covers security?
Sombra: Centralization is hard, the larger you are, and expensive.
A Chaos Engineering Approach to Evaluate AppSec Postures
Reisz: Is there a chaos engineering like approach for companies to evaluate application security postures? From a security standpoint, can chaos engineering be used to actually test your defense in depth?
Andrus: Yes, chaos engineering is a methodology where by which you go out and you cause unexpected or fail things to happen to see what the response and the result is with the system. That can be leveraged in many ways to do it. When I first started talking about chaos engineering, everyone just said, “Pentesting, that’s what you do? We need that.” I think there’s a world where pentesting is super valuable. It’s a different set of problems. I think there’s a lot we can learn from security and how we articulate and quantify and talk about the risk of our systems. Security has to deal with the defender’s dilemma in a different way. The people may be acting maliciously. You have things coming from the outside, you can’t trust anything. I think we actually have a slightly easier mandate in the reliability space, that, in general, people are acting with best intentions. We’re looking for unexpected side effects and consequences that could cause issues. The way you approach that is just much different. The whole social engineering side isn’t really as applicable, or maybe that’s what incident management looks like.
Nolan: We might care about overload and DDoS type attacks, but yes, you’re right, by and large, we’re dealing with entropy and chaos, and not malice, which is nice.
Andrus: That’s a good point. One of the most powerful tools in chaos engineering is changing the network, because we can simulate a dependency or an internal or third-party thing failing, and so you can go in and modify the network, then obviously, there’s a lot of security potential implications there.
Nolan: You’re quite right. One of the great things about doing that testing is you can simulate slow overloaded networks, which are always worse than something being hacked.
Burnout in SRE
Reisz: I want to talk about burnout. Why is burnout a topic that we talk a lot about or seems to come up a lot about when we’re talking about SRE?
Nolan: Burnout in a team is a vicious cycle. It’s a self-fulfilling prophecy. It’s something that gets worse unless you intervene. From a systems perspective, that’s something that we hate in SRE. The mechanism here is a team is overloaded. It’s not able to get itself into a better position, for whatever reason. Maybe it’s dealing with a bunch of complicated systems that it doesn’t fully understand or whatever else, or has 500 alerts. Teams that are in that position, they’ll tend to find that people will get burnt out, will go somewhere else, leaving fewer people with expertise in the system, trying to manage the existing set of problems. It gets worse and it spirals. The most burnt out or the most on fire teams that I’ve ever seen have been ones that have been trapped in that cycle where all the experienced people burnt out and left. Left a bunch of mostly newbies who are struggling to manage the fires and also get up to speed with the system. Having a team that’s burned out, it’s very hard to recover from. You have to really intervene. That’s why we have to care about it, just from a sheer human perspective of, we don’t want to feed the machines with human blood, to use a memorable phrase from my friend Todd Underwood. It’s a bad thing to do to people and to our organizations and our services.
Burnout Monitoring, and Prevention
Reisz: How do you watch for and get ahead of burnout.
Sombra: I think it’s important because it’s a thing that is often overlooked, and then it results on things that are not optimal from a decision making perspective, from a roadmap ability to follow, from an operational reliability. How do I watch out? I tend to look for signals that let me to believe whether the team is getting burned out or not, like on-call, how many pages you’ve gotten? At the beginning of any team that I manage, or even the teams in my organization, I’m like, I want us reviewing all of the alerts that have fired every single planning meeting every week. I want to know, it’s like, were they actionable, or were they not actionable? Is it a downstream dependency that is just causing us to get paged for something that we can’t really do anything about? To your point of the network, the network is gnarly. The closer you are to it, the more unhappy you’re going to be. If there are things that are just completely paging you, you get tired, like you don’t have infinite amount of energy. Conservation and application of that is something that becomes part of running a system. This is a factor of your applications too.
Andrus: I don’t want to sound like, kids, get off my lawn. When I was early in my career, folks didn’t want to be in operations because it was painful, and it sucked. We’ve been through this last decade where SRE is cool. It’s the new hotness. I don’t say that because that’s a problem. It’s important to recognize this isn’t a new problem. I think this is something that’s been around and it’s something that comes, and it probably comes in cycles, depending on your team or your company. It’s always a concern when it comes to operating our systems and doing a good job.
What you just described Ines was the first thing I thought of when Wes brought this up. I owned a tool for a short time at Amazon that was the pager pain tool. It tracked teams that were getting paged too much, and people that were getting paged too much. It went up to the SVP level, because we knew that that impacted happiness and retention and people’s ability to get quality work done. I think actually, we were talking about ways to help quantify things for management. This is quantifying the negative, similar to quantifying outages, but quantifying that pager pain helps us to have a good understanding. If we see teams that are in trouble, teams that are in the red on that, we should absolutely intervene and make it better, as opposed to just hoping that it improves over time, because it won’t.
Nolan: I fully agree with what you both said about pager frequency and the number of pages. I also want to call out the fact that we need to be careful about how frequently people are on-call as well, like literally how many minutes on-call they are. You can get to a point if you’re on-call too much, it just feels like you’re under house arrest. If you’re on-call for something where you might need to jump on a big Zoom call if something goes down, or where you might need to be at your hands on keyboard within 10 minutes, you’re really limited on what you can do in your life. I think that matters as well.
Staffing a Team Appropriately
Sombra: On your point about staffing a team appropriately, it’s completely 100% the way to address that. Like your size of eight is great, if you have eight. Even four is great, because at this point you have a person being on-call every week.
Nolan: Four is survivable, but eight is sustainable I think.
Reisz: What’s the math behind eight, why eight?
Nolan: With eight people you could be on-call for a week, every two months. You got a lot of time to do engineering work. You got enough people around. You can get cover if it’s on vacation. You don’t have to constantly be on-call for holidays and Christmases.
Sombra: Use that flexibility to tier as well.
Reisz: Someone is screaming at their screen right now that we don’t have eight people on our teams, how in the world are we going to deal with a problem like that? How do you answer them?
Andrus: Find a buddy team.
Nolan: I know a lot of teams that don’t have eight people on them. I’m describing something that I think should be the goal for most teams. A team that I was on, for example, in fact, we had two teams that were running somewhat related services, and that were both too small to really be sustainable, we were looking two rotations of three people, and we merged those teams. Because it makes sense, technically, because there’s an awful lot of shared concerns. It made sense in terms of a more sustainable rotation for both sides of the team. Things like that can happen.
Organizationally, I think a lot of organizations optimize for very small, very siloed specialized teams. I think in terms of sustainability, it can be better to go a little bit bigger. Yes, everyone has to care about the slightly bigger, more complex set of services. That’s the tradeoff. If it means that six or seven weeks out of eight, you can go for a swim in the evening, that’s a really nice thing in terms of can people spend 20, 30 years in this career? Which I was like, I can spend 30 years in a career if I’m on-call once every two months. Can I do it if I’m on-call once every three weeks? I probably can’t.
Sombra: Another to that eight number is that it requires a tremendous amount of funding as well, if you don’t have it, to Laura’s point, it’s like you do that. For example, I also don’t have everyone in my organization that has a team that is staffed that large. That is a very large team. I think also, like in my mind, every time I think about that, my mind goes to one particular person that is a subject matter expert of one particular data pipeline that is 100% critical. Then right now, I live and breathe trying to get this person a partner and a pair. Then at this point, you just pitch in as an organization with a greater group, so you try to make it a we problem as well.
Reisz: I like that, make it a, we problem.
Key Takeaways
I want to give each of you to give your one big point. One of your big one takeaway that you’d like everybody to take away from this panel. What do you want people to take away?
Andrus: There’s a couple of phrases I hear a lot of people say, when I have an opportunity to educate, one of them is, how do you quantify the value of your work to management? How do you help them understand that a boring system doesn’t come for free, and that’s what you want? I talk to a lot of less mature organizations that are earlier in their journey, and I hear a lot of, we have enough chaos. That’s always a frustrating one to me, because that’s the perception that chaos engineering is to cause chaos. This is a problem with the name. It’s a bit of a misnomer. We’re here to remove chaos from the system. We’re here to understand it and make it more boring. When people say we’re not quite ready yet, to me, that’s like saying, I’m going to lose 10 pounds before I start going to the gym. The only way to get ready is to go out and start doing it. That’s where that practitioner’s skin in the game opinion that I have is, the best way to learn in many cases is find safe ways to mitigate it. We don’t want to cause an outage, but get out there and get your hands dirty in the system, so that you really understand how it works. I think there’s a lot of value in the academic exercise of what the system looks like. The devil is always in the details. It’s always some thread pool you didn’t know about, some timeout that wasn’t tuned correctly. Some property that got flipped globally that no one was expecting. It’s these things that aren’t going to show up on your whiteboard that are going to cause you outages.
Nolan: I will follow on directly from that point. I think one of the questions that we didn’t quite get time to talk about was, how should SREs and engineers engage with each other? What’s the engagement model? What I would say to that is, we need to remember that SREs are engineers. If your SREs are only doing Ops work and reactive work, they’re not doing engineering, that’s one of the things that will head you towards burnout. I think one of the best ways to describe what it is that SREs do, engineering-wise, if we don’t do feature engineering work, is we do the engineering that makes the system boring. What makes your system exciting right now, make it way more boring. One of the things that worry you about your system, what keeps you up at night, what risks do your team know are there, engineer those out of your systems. That’s what we do.
Sombra: My main takeaway, too, is that we tend to think about it in terms where it’s fancy. If you’re a large company, you do all of this. It’s not necessarily about fancy, it’s about processes that you can do even if you’re not at the scale of a Google or a Netflix, or all of the people that are just rolling out with the monikers that we tend to use a few years later. I think that these things are important. It’s just like being able to just reason, fund, invest in the things that give you confidence. The last point is that you’re not done. This is not a thing that is ever finished. Understand that, incorporate this, and then just live through that. It’s a process of continuous iteration, continuous improvement. There’s not a box to check. If you approach it with a box to check then you’re always going to be surprised. You’re going to be reactive. You’re going to burn your team. You’re never finished. Go to the gym every day.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

At Alexa Live 2022, Amazon announced new APIs and SDKs for Alexa skill developers, including the Alexa Ambient Home Dev Kit, the Alexa Connect Kit SDK for Matter, Universal Device Commands, and more.
The Alexa Ambient Home Dev Kit is a collection of APIs and services aimed to provide a unified experience to Alexa users. The first five APIs in the Kit are Home State, which include support for learning about customers’ preferences for sleep, time, dinner, and so on; Safety & Security, which extends Alexa Guard‘s capabilities leveraging sound event detection, such as smoke alarms, etc; Credentials, aimed to simplify credential input; Device and Group Organization, and Multi-admin Simple Setup for Matter.
The Alexa Connect Kit SDK for Matter extends Alexa Connect Kit to Matter-compatible devices. Alexa Connect Kit (ACK) is a service that aims to make it easier to integrate Alexa within other products. Instead of writing an Alexa skill, managing a cloud server, etc., to integrate Alexa capabilities into a new product, you can integrate an ACK hardware module in your product that will provide Alexa capabilities. The Alexa Connect Kit SDK for Matter brings the benefits of ACK to devices supporting the Matter Wi-Fi connectivity standard, supporting cloud connectivity, over-the-air updates, and more.
Universal Device Commands (UDCs) and Agent Transfers (ATs) are directed to device makers that aim to simplify interaction when multiple voice services are available on the same device. With UDCs, customers may utter a command using any wake word recognized by any compatible voice service and have their command executed by the corresponding service. Using ATs, instead, voice services will be able to transfer any customer request they cannot fulfill to a different voice service.
As a final note, Amazon introduced the Alexa Voice Service SDK 3.0, which combines the Alexa Smart Screen SDK and the AVS Device SDK. While this new SDK does not bring any new features in themselves, it can make it easier for device makers to support Alexa in their products thanks to unified templates and configuration.
There is much more to Alexa features announced at Alexa Live 2022 than what can be covered here, including new monetization options for developers through the Alexa Shopping Kit and Alexa Skill SDK, so do not miss the official round-up for the full detail.
MMS • Jerome Petazzoni
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Running stateful workloads on Kubernetes used to be challenging, but the technology has matured. Today, up to 90% of companies believe that Kubernetes is ready for production data workloads
- OpenEBS provides storage for stateful applications running on Kubernetes; including dynamic local persistent volumes or replicated volumes using various “data engines”
- Local PV data engines provide excellent performance but at the risk of data loss due to node failure
- For replicated engines, there are three options available: Jiva, cStor, and Mayastor. Each engine supports different use cases and needs
- OpenEBS can address a wide range of applications, from casual testing and experimentation to high-performance production workloads
When I deliver a Kubernetes training, one chapter invariably comes at the end of the training and never earlier. It’s the chapter about stateful sets and persistent storage – in other words, running stateful workloads in Kubernetes. While running stateful workloads on Kubernetes used to be a no-go, up to 90% of companies now believe that K8s is ready for data. The last lab of that chapter involves running a PostgreSQL benchmark (that keeps writing to disk) in a pod, and then breaking the node that runs that pod and showing various mechanisms involved in failover (such as taint-based evictions). Historically, I’ve been using Portworx for that demo. Recently, I decided to give OpenEBS a shot.
In this post, I’ll give you my first impressions of OpenEBS: how it works, how to get started with it, and what I like about it.
OpenEBS provides storage for stateful applications running on Kubernetes; including dynamic local persistent volumes (like the Rancher local path provisioner) or replicated volumes using various “data engines”. Similarly to Prometheus, which can be deployed on a Raspberry Pi to monitor the temperature of your beer or sourdough cultures in your basement, but also scaled up to monitor hundreds of thousands of servers, OpenEBS can be used for simple projects, quick demos, but also large clusters with sophisticated storage needs.
OpenEBS supports many different “data engines”, and that can be a bit overwhelming at first. But these data engines are precisely what makes OpenEBS so versatile. There are “local PV” engines that typically require little or no configuration, offer good performance, but exist on a single node and become unavailable if that node goes down. And there are replicated engines that offer resilience against node failures. Some of these replicated engines are super easy to set up, but the ones offering the best performance and features will take a bit more work.
Let’s start with a quick review of all these data engines. The following is not a replacement for the excellent OpenEBS documentation; but instead is my way of explaining these concepts.
Local PV data engines
Persistent Volumes using one of the “local PV” engines are not replicated across multiple nodes. OpenEBS will use the node’s local storage. Multiple variants of local PV engines are available. It can use local directories (used as HostPath volumes), existing block devices (disks, partitions, or otherwise), raw files (ZFS file systems enabling advanced features like snapshots and clones), or Linux LVM volumes (in which case OpenEBS works similarly to TopoLVM).
The obvious downside of the local PV data engines is that a node failure will cause the volumes on that node to be unavailable; and if the node is lost, so is the data that was on that node. However, these engines feature excellent performance: since there is no overhead on the data path, read/write throughput will be the same as if we were using the storage directly, without containers. Another advantage is that the host path local PV works out of the box – without requiring any extra configuration – when installing OpenEBS, similarly to the Rancher local path provisioner. Extremely convenient when I need a storage class “right now” for a quick test!
Replicated engines
OpenEBS also offers multiple replicated engines: Jiva, cStor, and Mayastor. I’ll be honest, I was quite confused by this at first: why do we need not one, not two, but three replicated engines? Let’s find out!
Jiva engine
The Jiva engine is the simplest one. Its main advantage is that it doesn’t require any extra configuration. Like the host path local PV engine, the Jiva engine works out of the box when installing OpenEBS. It provides strong data replication. With the default settings, each time we provision a Jiva volume, three storage pods will be created, using a scheduling placement constraint to ensure that they get placed on different nodes. That way, a single node outage won’t take out more than one volume replica at a time. The Jiva engine is simple to operate, but it lacks the advanced features of other engines (such as snapshots, clones, or adding capacity on the fly) and OpenEBS docs mention that Jiva is suitable when “capacity requirements are small” (such as below 50 GB). In other words, that’s fantastic for testing, labs, or demos, but maybe not for that giant production database.
cStor engine
Next on the list is the cStor engine. That one brings us the extra features mentioned earlier (snapshots, clones, and adding capacity on the fly) but it requires a bit more work to get it going. Namely, you need to involve the NDM, the Node Disk Manager component of OpenEBS, and you need to tell it which available block devices you want to use. This means that you should have some free partitions (or even entire disks) to allocate to cStor.
If you don’t have any extra disk or partition available, you may be able to use loop devices instead. However, since loop devices carry a significant performance overhead, you might as well use the Jiva provisioner instead in that case, because it will achieve similar results but will be much easier to set up.
Mayastor engine
Finally, there is the Mayastor engine. It is designed to work tightly with NVMe (Non-Volatile Memory express) disks and protocols (it can still use non-NVMe disks, though). I was wondering why that was a big deal, so I did a little bit of digging.
In old storage systems, you could only send one command at a time: read this block, or write that block. Then you had to wait until the command was completed before you could submit another one. Later, it became possible to submit multiple commands, and let the disk reorder them to execute them faster; for instance, to reduce the number of head seeks using an elevator algorithm. In the late 90s, the ATA-4 standard introduced TCQ (Tagged Command Queuing) to the ATA spec. This was considerably improved, later, by NCQ (Native Command Queuing) with SATA disks. SCSI disks had command queuing for a longer time, which is also why they were more expensive and more likely to be found in high-end servers and storage systems.
Over time, the queuing systems evolved a lot. The first standards allowed queuing a few dozens of commands in a single queue; now we’re talking about thousands of commands in thousands of queues. This makes multicore systems more efficient, since queues can be bound to specific cores and reduce contention. We can now have priorities between queues as well, which can ensure fair access to the disk between queues. This is great for virtualized workloads, to make sure that one VM doesn’t starve the others. And importantly, NVMe also optimizes CPU usage related to disk access, because it’s designed to require less back-and-forths between the OS and the disk controller. While there are certainly many other features in NVMe, this queuing business alone makes a great deal of a difference; and I understand why Mayastor would be relevant to folks who want to design storage systems with the highest performance.
If you want help to figure out which engine is best for your needs, you’re not alone; and the OpenEBS documentation has an excellent page about this.
Container attached storage
Another interesting thing in OpenEBS is the concept of CAS, or Container Attached Storage. The wording made me raise an eyebrow at first. Is that some marketing gimmick? Not quite.
When using the Jiva replicated engine, I noticed that for each Jiva volume, I would get 4 pods and a service:
- a “controller” pod (with “-ctrl-” in its name)
- three “data replica” pods (with “-rep-” in its name)
- a service exposing (over different ports): an iSCSI target, a Prometheus metrics endpoint, and an API server
This is interesting because it mimics what you get when you deploy a SAN: multiple disks (the data replica pods) and a controller (to interface between a storage protocol like iSCSI and the disks themselves). These components are materialized by containers and pods, and the storage is actually in the containers, so the term “container attached storage” makes a lot of sense (note that the storage doesn’t necessarily use copy-on-write container storage; in my setup, by default, it’s using a hostPath volume; however this is configurable).
I mentioned iSCSI above. I found it reassuring that OpenEBS was using iSCSI with cStor, because it’s a solid, tested protocol widely used in the storage industry. This means that OpenEBS doesn’t require a custom kernel module or anything like that. I believe that it does, however, require some userland tools to be installed on the nodes. I say “I believe” because on my Ubuntu test nodes with a very barebones cloud image, I didn’t need to install or configure anything extra anyway.
After this quick tour of OpenEBS, the most important question is: does it fit my needs? I found that its wide range of options meant that it could handle pretty much anything I would throw at it. For training, development environments, and even modest staging platforms, when I need a turnkey dynamic persistent volume provisioner, the local PV engines work great. If I want to withstand node failures, I can leverage the Jiva engine. And finally, if I want both high availability and performance, all I have to do is invest a minimal amount of time and effort to set up the cStor engine (or Mayastor if I have some fancy NVMe devices and want to stretch their performance to the max). Being both a teacher and a consultant, I appreciate that I can use the same toolbox in the classroom and for my clients’ production workloads.
MMS • Phillipa Avery
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- The balance between stability and velocity will change over time, with newer companies emphasizing velocity over stability, and valuing stability more as the product matures.
- A unified centrally supported technical stack can help provide agile development with stable support processes, allowing a company to scale quickly without trading velocity or stability.
- The decision to support a technology centrally should be an ongoing process, taking into account the cost effectiveness and business impact of the support needs.
- Large business decisions like monolith vs multi-repo, or build vs buy, will be key choices with long lasting repercussions. It’s important to analyze the needs of the company and make the choice based on what the company values regarding agility, stability and ongoing development cost.
- Being able to easily trial new centrally supported technology and fail fast if it doesn’t succeed is integral to growth.
An optimal Developer Experience will depend a lot on the company the developer is working for – taking into account the company’s values, culture and business drivers. As the company grows, what it values will shift to adapt to the growth, and in turn how a developer needs to create, deploy and maintain their code will change too. This article discusses why and when changes to developer needs will occur, how to get ahead of them, and how to adapt when these changes are necessary. I talk through some of the experiences myself and peers have had at Netflix, identifying some key learnings and examples we have gained over the years.
The impact of growth
The balance between velocity and stability changes over time as a company grows. When a company first starts its journey, they are iterating quickly and experimenting with different approaches. They often need to produce something quickly to test, and either scrap or extend the approach. This type of “prototyping” phase often doesn’t need an investment into stability, as failures will have a limited scope of impact.
As the user base of the product grows, however, there is a higher expectation of stability and cost effectiveness. This often results in a more cautious (and slower) approach to changes to the product, hence stability will affect the ability to maintain a higher velocity. This can be stemmed by putting into place a well founded and stable CI/CD system, which can create a level of trust that enables higher velocity. When developers trust that their changes will not break production systems, they are able to focus more on the velocity of innovation, and not spend excessive time on manual validation of changes made.
As the business grows, this level of trust in the release process is critical, and well-founded testing practices (such as the Testing Pyramid) will set the process up for success. Even with this in place though, a well-rounded CI/CD process will incur a hit to velocity through the validation process, and this will grow as the complexity of the overall product system grows.
To illustrate this point, over the years Netflix has introduced a number of validation steps to our standard CI/CD process, including library version dependency locking (to isolate failures for a particular library), automated integration and functional tests, and canary testing. Each of these stages can take a variable amount of time depending on the complexity of the service. If a service has many dependencies it will have more likelihood of one of those dependencies failing the build process and needing debugging. A service that is more functionally complex will have a larger testing footprint which will take longer to run, especially if more integration and functional tests are needed. When running a canary on a service that executes multiple types of traffic patterns (e.g. different devices, request types, data needs), a longer canary run is needed to eliminate noise and ensure coverage of all these patterns.
To remain flexible with the above needs, we lean into our microservice approach to create services with a decomposed functional footprint, allowing smaller dependency graphs, shorter testing times, and less noisy canaries. Additionally, we avoid blocking the release process without an easy override process. If a dependency version fails a build, it’s easy to roll back or lock to the previous version for the failing service. Test failures can be analyzed and fixed forward, ignored (and hopefully re-evaluated after), or modified depending on the changes made. Canary failures can be individually analyzed as to the cause and the developer can choose to move forward with the release (by-pass) as needed. The balance of velocity vs stability by CI/CD is ultimately decided by the service maintainers depending on their own comfort levels and the business impact.
Centralized vs local tools
At some point, a company may need to make a decision as to whether they will let developers individually choose and maintain the technology for their business needs, or provide a recommended (or mandated) technology which is then centrally supported by the company. The way I think about the choice between centralized vs local, is that centralized offerings enable a company to provide consistency across the entire product ecosystem. This can be consistent provisions of integrations (security, insights, resiliency, CI/CD etc), or best practices (architectures, patterns, dependency management etc). This centralized consistency can be very powerful from an entire business perspective, but might actually be detrimental for a particular use case. If you define a single solution that provides a consistent approach, there will almost always be a use case that needs a different approach to be successful with their business driver.
As an example, we specify Java with SpringBoot as our supported service tech stack. However, there are a number of use cases where data engineering will need to use python or Scala for their business needs. To further build on this example, we use Gradle extensively as our build tool, which works really well for our chosen tech stack, but for the developers using Scala, SBT might be a better fit. We then need to evaluate whether we want to enhance our Gradle offering for their use case, or allow (and support) the use of SBT for the Scala community.
Getting the right balance of understanding the decision weight of the centralized benefits vs the local business needs, and being able to evaluate the trade offs, is an ongoing process that is continually evolving. Understanding at what point a use case should be considered for centralized support should be evaluated by looking at the data – how many users are on the tech stack in question, what is the business impact (bottom dollar) of the workflow on the stack, how many people would it take to support the stack centrally? All these factors should be considered, and if there is sufficient prioritization and room for growth, then the tech stack should be moved to centralized support.
With Netflix’s culture promoting freedom and responsibility, we will often see developers make the decision to choose their own solutions for their use cases, and maintain the responsibility for this choice. This can be a great option for small use cases with low business impact. If there is a likelihood that the scale of impact will grow, however (more people start using the technology, or the impact of the use case is higher on the business), then this choice can be detrimental to the business long term – it can create a bottleneck in the ability to move quickly or scale if there is only one person supporting the technology, or if that person moves to a different project it can create tech debt with no one able to support the technology.
Given we can’t support all the use cases that would benefit from centralized support, we try to take a layered approach, where we provide decoupled components that can be used for different tech stacks with highly critical centralized needs – for example, security. These can be used (and managed) independently in a localized approach, but become more integrated and centrally managed the more you “buy in” to the entire supported ecosystem – what we refer to as the Paved Path. For the average developer it is much easier for them to use the paved path offerings and have all the centralized needs managed for them, while the more unique business cases have the option to self manage and choose their own path – with a clear expectation of responsibilities that come with that decision, such as extra developer time needed when something unsupported goes wrong, what the cost to migrate to the paved path in the future might be (if it becomes supported), and how easy it is to remove the technology from the ecosystem if it proves too costly.
To illustrate this decision process, often being on the paved path will require a migration of the service to the new technology. In some cases the disruption and cost of migrating a legacy service to a new technology is deemed lower upfront value than spending developer hours on the service only once things go wrong. We saw this in practice when we had the recent Log4Shell vulnerability and we needed to (repeatedly) upgrade the entire fleet’s log4j versions. For the services that were on the paved path, this was done entirely hand’s free for developers, and was completed within hours. For services that were mostly on the paved path, there were minimal interactions needed and turnover happened within a day. For services that were not on the paved path, there were multiple days worth of developer crunch time needed, with intensive debugging and multiple push cycles to complete. In the grand scheme however, this was still more cost effective with less business impact than migrating them to the paved path upfront.
Monorepo or multi-repo strategy
Unfortunately there is not a clear answer on how a company can decide between a monorepo or multi-repo strategy, as both approaches will have significant deficiencies as the product scales. The big difference that I can talk to is release velocity for a percentage of the product base. With a monorepo it is more difficult to target a release for a subset of the product (by design). For example, if you want to release a code change or new version (e.g. a new JDK version), it can be difficult for application owners to opt in to the change before others. Additionally, the monorepo can be significantly slower to release a new change, as it must pass validation for all the product before it is able to be released.
The Netflix multi-repo approach on the other hand provides a highly versatile and fast approach to releases – where a new library version is published and then picked up by consuming applications via automated dependency update CI/CD processes. This allows individual application owners to define the version of the code change that they wish to consume (for good and bad), and it is available for consumption immediately upon publication. This approach has a few critical downsides: dependency version management is incredibly complex, and the onus for debugging issues in the version resolution is on the consuming application (if you want to have a deeper understanding of how Netflix solves for this complexity, this presentation on Dependency Management at Scale using Nebula is a great resource diving into the details). If a service releases a new library, while it is perfectly viable for 99% of the population, there is often a small percentage of applications that have some transitive dependency issues that must be identified and resolved.
Long-term, we are moving towards a hybrid approach where we enable a multi-repo but mono release approach – singular repository library owners can release a new version, but must go through a centralized testing pipeline that builds and runs the library against their consumers. If the pipeline fails, the onus is on the library producer to decide what steps to take next to resolve the issue.
Convergence in technical stacks
Whenever a conversation happens on how to move an entire company to a consistent technical stack, you will likely hear the adage of “the carrot or the stick” – do you provide appealing new features and functionality (the carrot) that makes adhering to the paved path appealing enough that people self opt-in, or do you enforce developers to use paved path offerings (the stick)? At Netflix we try to lean towards the carrot approach, and keep the stick for a small set of high leverage and/or business impact needs.
Ideally, the carrot would always be the approach taken. Sometimes, however, a centralized approach might have benefits for specific use cases, but from the overall business perspective, it has high leverage. These cases will often not have much of a carrot for the individual developers, and can even add extra hurdles and complexity to their existing development workflows. In cases like this, we emphasize the responsibility to act to the benefit of the company, and provide clear reasons for why it is important. We try to reduce any extra burden to the best of our ability and demonstrate the benefits of the consistent approach as much as possible.
On rare occasions, we will provide a top-down approach to providing a consistent tech stack, where the priority of migrating to the new stack is dictated higher for an individual team than their other priorities. This usually happens for security reasons (such as the aforementioned Log4Shell case), or when the overall business benefits of a consistent tech stack outweigh the individual teams’ needs – for example the tail end of a migration where the cost of support for the remaining use cases is becoming too expensive to maintain.
Build vs buy
Let’s classify build vs buy as built entirely in-house, vs using an external offering. At Netflix, we like to lean towards Open Source (OS) when possible, and we both produce and consume a number of OS products.
When possible, we lean towards “buying”, with a preference for OS offerings. If we can find an OS project with high alignment to the requirements and a thriving community, that will become the most likely candidate. If however there are no OS offerings, or there are significant differences in functionality with existing projects, we will evaluate building in-house. In the case where there is a smaller functional need, we will usually build and maintain entirely in-house. In cases where the project is larger or has high leverage externally, we will consider releasing it as an OS project.
If you choose to go open source, regardless of whether you choose to publish your own OS project or use an external project – both options will have a developer cost. When publishing a project there is the cost of building the community around the product – code and feature reviews, meetups, alignment with internal usage. All these can add up fast, and often popular OS offerings need at least one developer working full time on the OS management. When using external offerings it is important to maintain a working relationship with the community – to contribute back to the product, and to influence the future directions and needs to align with internal usage. It can be a risk if the direction of the external product changes significantly from the company’s use, or the OS project is disbanded.
Developer experience over time
As the engineering organization grows with the scale of the company, consistency begins to matter more. Often at the smaller growth stages it’s likely that each developer will be working across multiple stacks and domains – they manage the entire stack. As that stack grows, the need to focus efforts on a specific part becomes clear, and it’s now multiple people working on that stack. As more people become involved in that workflow, and become more specialized in their specific part of the stack, there are increased opportunities to optimize the things they don’t need to care about – more centralized infrastructure, abstractions and tooling. Taking that over from a centralized perspective can then free them up to focus on their specific business needs, and a smaller group of people supporting these centralized components can serve a large number of business specific developers.
Additionally, as the company ages we need to accept that technology and requirements are constantly changing, and what might have failed in the past might now be the best viable solution. Part of this is setting up an attitude of failure being acceptable but contained – fail fast and try again. For example, we have long used a system of A/B testing to trial new features and requirements with the Netflix user base, and will often scrap features that are not deemed beneficial to the viewership. We will also come back later and retrial the feature if the product has evolved or the viewership needs have changed.
Another internal technical example of this is our Publisher Feedback feature, which was used to verify candidate library releases before release into our multi-repo ecosystem. For each candidate published, we would run all downstream consumers of a dependency with a configured acceptance test threshold and provide feedback to the library producer on failures caused by the candidate release, optionally automating gating of the release as part of the library build. Unfortunately, the difficulty of providing a build environment out-of-band from the regular CI workflow made it difficult to provide more than compilation level feedback on the “what-if”’ dependencies, and as we realized we weren’t going to pursue declarative CI using the same infrastructure as we’d originally planned, we had to reevaluate. We instead invested in pull-request based features via Rocket CI, which provides APIs, abstractions and features over our existing Jenkins infrastructure. This allowed us to invest in these new features while avoiding being coupled to the specifics of the Jenkins build environment.
My advice for engineering managers working in fast-growing companies is: don’t be afraid to try something new, even if it has failed before. Technology and requirements are constantly changing, and what might have failed in the past might now be the best viable solution.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Amazon recently announced the general availability (GA) of AWS Lambda Powertools TypeScript. The set of utilities for Node.js Lambda functions helps developers follow best practices for tracing, structured logging, and custom metrics.
AWS Lambda Powertools is an open-source library that provides a collection of utilities for AWS Lambda functions to make developers’ lives easier. The utility set focuses on implementing best practices such as structured logging, custom metrics, tracing, and more, as defined by the AWS Well-Architected Serverless Lens.
AWS Lambda Powertools supports the three most popular Lambda runtimes – Python, Java, and now Node.js, with the general availability release of AWS Lambda Powertools for TypeScript. The GA release is a follow-up of the beta release beginning of the year and receives the same features as the Python and Java versions in subsequent releases, as seen in the roadmap.
The GA release focuses on three observability features: distributed tracing (Tracer), structured logging (Logger), and asynchronous business and application metrics (Metrics) – each production is ready and provides the following benefits:
- The Tracer utility adds custom annotations and metadata during function invocation, which are then sent to AWS X-Ray. Developers can use annotations to search for and filter traces based on business or application contextual information such as product ID or cold start.
- The Logger utility adds contextual information to application logs. By structuring logs as JSON, developers can use Amazon CloudWatch Logs Insights to search for their structured data.
- And finally, the Metrics utility makes it easier to create complex high-cardinality application data. When developers include structured data with their metrics, they can search for it and perform additional analysis.
Ryan Toler, cloud architect at Trek10, stated in his recent blog post on AWS Lambda Powertools for TypeScript:
Think of each utility as a “power-up” for Lambda, adding a unique ability to help solve distinct challenges found in serverless applications.
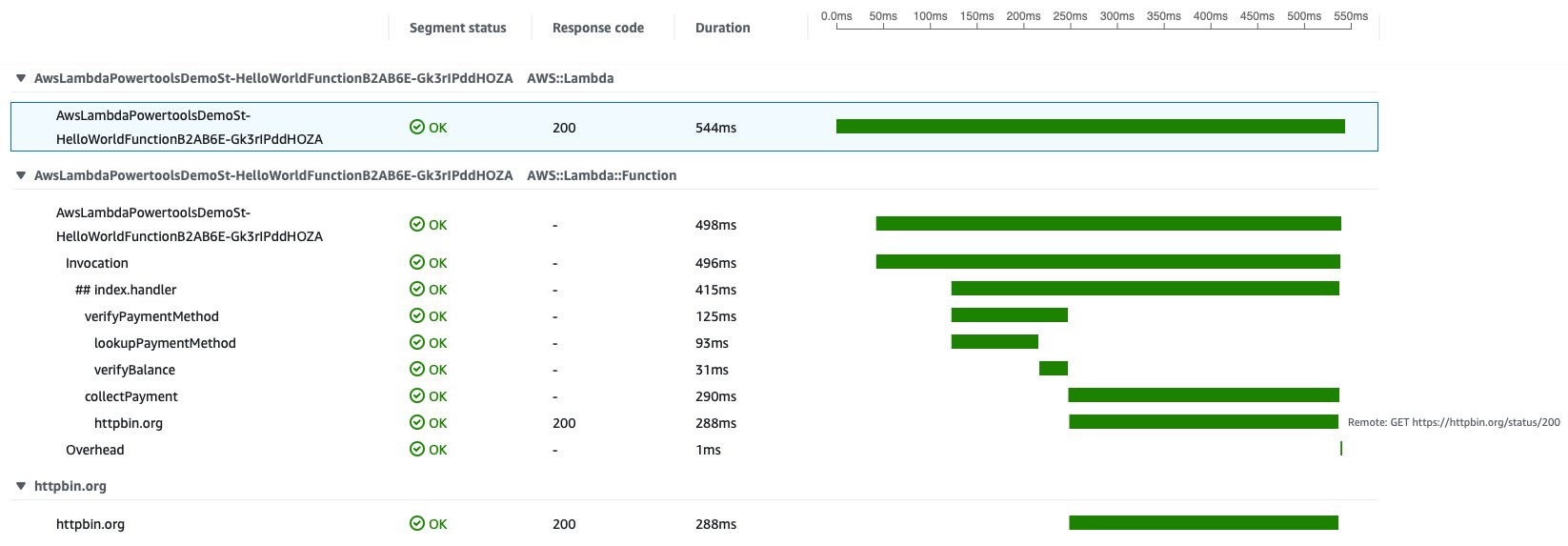
Sara Gerion, a senior solutions architect at AWS, concluded in an AWS Compute blog post:
AWS Lambda Powertools for TypeScript can help simplify, accelerate, and scale the adoption of serverless best practices within your team and across your organization. The library implements best practices recommended as part of the AWS Well-Architected Framework without you needing to write much custom code.
In addition, Eoin Shanaghy, CTO of fourTheorem, concludes in his blog post on AWS Lambda Powertools:
Adding the AWS Lambda Powertools to your application gives you a fast way to establish good practices in all of your serverless applications.
Lastly, the Node.js runtime in the AWS Lambda Powertools TypeScript is available in all AWS regions where Lambda is available.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ
In software development there are always things that we don’t know. We can take time to explore knowable unknowns, to learn them and get up to speed with them. To deal with unknowable unknowns, a solution is to be more experimental and hypothesis-driven in our development.
Kevlin Henney gave a keynote about Six Impossible Things at QCon London 2022 and at QCon Plus May 10-20, 2022.
The known knowns are our comfort zone — they’re the things we know we know, Henney said. We clearly have a bias towards thinking in the known knowns. Which is fine if you’re working in disciplines and domains in which everything about what you are going to do and how you are going to do is known in advance, Henney argued.
Software development is not rote repetition and it’s not manufacturing, as Henney explained:
The point of software development is to produce something that does not currently exist rather than repeat without variation something that does exist. By definition, that means there are always things we don’t know — whether it’s bugs, new technologies, new domains, new architectures, new requirements — because otherwise we are dealing with solved problems that we can just drag and drop.
Henney presented two different kinds of unknowns. The first of which is the known unknowns, which are the things we know we don’t know:
Known unknowns are the things we can list in advance that we need to know. If I don’t know about a particular framework we’re going to use, I know that I don’t know that. It’s not a surprise to me, so in theory I can account for needing some time and effort to learn it and get up to speed with it.
Unknown unknowns are the things we don’t know we don’t know, Henney mentioned. He gave an example:
An unknown unknown can be the architecture that everyone was so convinced would deliver sufficient performance is not even close to meeting expectations. We’re either going to spend more sprints trying to make it work — with no guarantee it ever will — or we’re going to ditch that approach to try another — or perhaps both!
Unknowable unknowns is the realm of assumptions, this is where the bugs live (and bite), where surprises derail our plans, Henney mentioned:
By unknowable here I mean that there is no process I can undertake to make them more known. They are only knowable when they happen and they cannot be forced.
A lot of what occupies time in software development comes from the things we didn’t know we didn’t know. This should encourage us to be more experimental and hypothesis-driven in our development rather than plan-driven, Henney suggested. Fixed plans are for known knowns.
InfoQ interviewed Kevlin Henney about knowable and unknowable unknowns and using roadmaps for product development.
InfoQ: What’s the difference between “unknown unknown” and “unknowable unknown”?
Kevlin Henney: I can prototype to determine feasibility or I can release incrementally to gain confidence in development and feedback on what is developed. I can intentionally put myself in the position that I will stumble across some of the unknown unknowns. But what about the things I cannot rearrange? Mostly, unknowable unknowns concern the future, which is intrinsically unknowable.
People often talk about prioritising requirements by business value. This is, according to our current understanding of physics, not possible. At best, you can prioritise requirements by estimated business value — and if you believe “estimates” and “actuals” are equivalent, well, that’s a different conversation we need to be having!
You can only discover unknowable unknowns as they happen, but you won’t be able to use that new knowledge in the past. The current pandemic is a good example of this. The pandemic disrupted everything, not just software development, but if we take the narrow context of software development, there is no planned or agile process that at the start of 2020 accounted for its effect on developers, companies, customers and so on. There was no development spike or incremental delivery that could have revealed the pandemic and its scale and longevity any sooner.
InfoQ: How do unknown unknowns impact the concept of using roadmaps for product development?
Henney: The roadmap metaphor is potentially a very effective visualisation. I say “potentially” because what we see is a significant disconnect between what roadmaps actually are and what normally get presented as product roadmaps. Anyone familiar with roadmaps knows they contain many roads. If you have a roadmap with only one road, you probably don’t need a map — at most, you need a simple itinerary. And what’s the itinerary? It’s a linear plan that assumes there is only one path into the future and, therefore, that the future is knowable. Good luck with that.
The real value of a roadmap is that it acknowledges there are different routes and different destinations. And as the future reveals itself day by day, month by month, some routes will be seen as better than others, new routes will be revealed and others will become closed. That sounds like product development in the real world.
MMS • Aditya Kulkarni
Article originally posted on InfoQ. Visit InfoQ

BLST Security recently released the latest version of its platform, enabling DevOps and Application Security teams to avoid API specification flaws. The BLST platform aims to help teams understand their APIs by creating an OpenAPI Specification table.
Business Logic Security Testing (BLST) Security has developed an end-point mapper that provides a graphical interface to developers. With the latest version, developers can upload any OpenAPI Specification (OAS) file and get access to the params table, end-point mapper, and misconfiguration checklists. For the developers using the platform, the aim is to make it easy to document the APIs. The online BLST mapper can help developers understand how their API works by looking at how their clients use it.
OpenAPI Specification is a standard, language-agnostic interface for describing, producing, consuming, and visualizing RESTful web services. Formerly known as Swagger Specification, when properly defined, a consumer can understand and interact with the remote service with a minimal amount of implementation logic. After the OAS file is uploaded BLST runs a series of checks on it and provides a detailed table describing the exact problem and the location to help faster resolution.
As observed by Cloudflare Radar team, API traffic was growing the fastest among all the traffic types, up by 21% between first week of February 2021 to the first week of December 2021. A study conducted by Marsh McLennan Cyber Risk Analytics Center on 117,000 cybersecurity incidents discovered that API insecurity was responsible for annual losses between $41 – 75 billion globally.
One of the twitter users and YouTuber Kunal Kushwaha took the notice of BLST Security by tweeting, “Why is API security necessary? How to secure business logic? Let’s look at the difference between APIs a few years ago and APIs nowadays, following up with ways to find vulnerabilities your API management misses with @BLSTSecurity“.
In other news, Daniel Kirsch, co-founder, Principal Analyst and Managing Director at TechStrong Research was quoted at TechStrong Con,
“The industry is starting to recognize the idea that this is a really important area — that the data and services that go across APIs are critical. What we’re seeing is that API security is falling in the cracks.”
In another session at TechStrong Con, Matt Tesauro, Distinguished Engineer, Noname Labs at Noname Security stated that tools need to understand how APIs write or talk to other APIs and it’s also possible to use the recorded traffic in the HTTP archives.
BLST Security has recently reached 400 stars on GitHub. Interested readers can follow the announcement on LinkedIn or follow the documentation here. BLST Security is on Discord as well as GitHub.