Month: August 2022

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently, AWS announced a new feature, Fine-Grained Visual Embedding, for its cloud-scale business intelligence (BI) service Amazon QuickSight allowing customers to embed individual visualizations from Amazon QuickSight dashboards in high-traffic webpages and applications.
With Amazon QuickSight, customers can seamlessly integrate interactive dashboards, natural language querying (NLQ), or the entire BI-authoring experience into their applications –making data-informed decisions easier for their end users. The new Fine-Grained Visual Embedding feature will allow them to embed any visuals from dashboards into their applications.
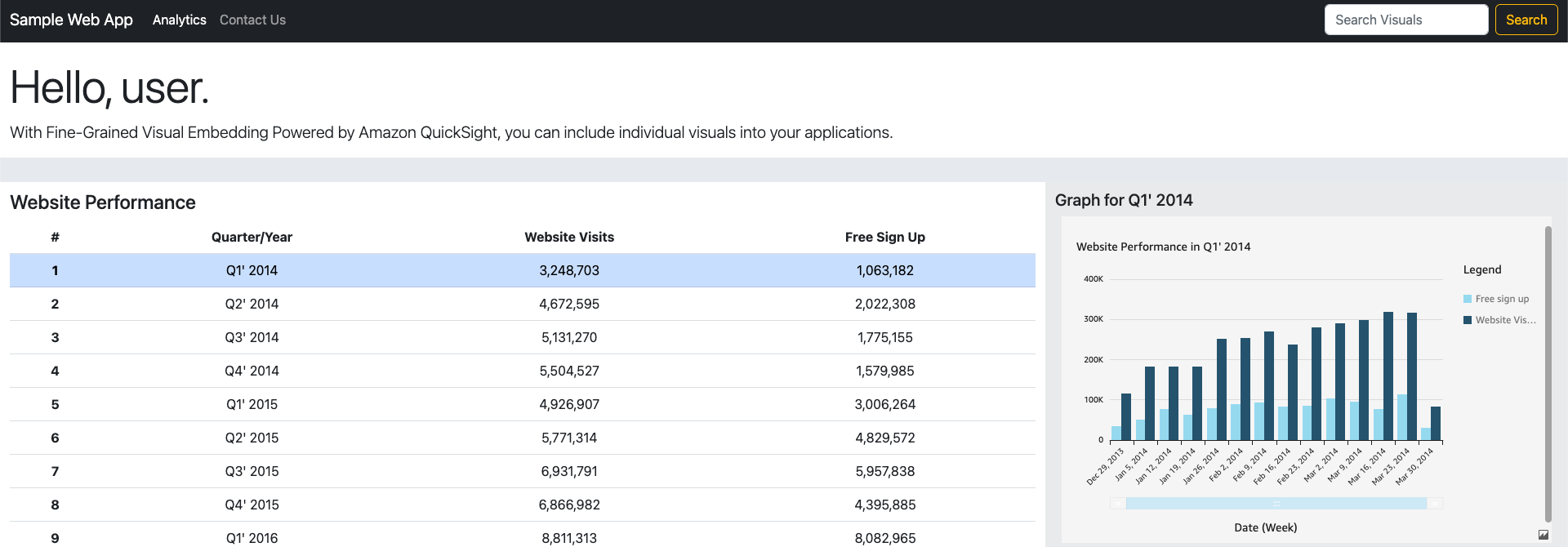
Source: https://aws.amazon.com/blogs/aws/new-fine-grained-visual-embedding-powered-by-amazon-quicksight/
If visuals are updated or source data changes, embedded visuals are automatically updated, and as website traffic grows, they are automatically scaled. Data access is secured by row-level security that ensures users can only access their own data.
There are two ways for users to leverage the Fine-Grained Visual Embedding: either by the so-called 1-Click Embedding, or QuickSight APIs to generate the embed URL. 1-Click Embedding is intended for nontechnical users to generate embed code that can be inserted directly into internal portals or public sites. In contrast, ISVs and developers can embed rich visuals in their applications using the APIs.
For 1-Click Embedding, there are two types: 1-Click Enterprise Embedding, which allows users to enable access to the dashboard with registered users in their account, and public embedding, where users can allow access to the dashboards for anyone.
In addition to 1 Click Embedding, users can perform visual embedding through the API – using the AWS CLI or SDK to call the API GenerateEmbedUrlForAnonymousUser (embedding visuals in an application for users without provisioning them in Amazon QuickSight) or GenerateEmbedUrlForRegisteredUser (embedding visuals in an application for users that are provisioned in Amazon QuickSight). When calling the API, users will have to pass the Dashboard, Sheet, and Visual IDs, which are available in the menu section for the selected visual.
{
'DashboardId':'',
'SheetId':'',
'VisualId':''
}
Tracy Daugherty, general manager of Amazon QuickSight at AWS, told InfoQ:
Customers love that Amazon QuickSight makes it easy to perform and share advanced analytics without data science or infrastructure management expertise. With Fine-Grained Visual Embedding Powered by Amazon QuickSight, we are now making it even easier for customers to deliver powerful insights to users where they need them the most—from high-traffic webpages and applications to internal portals—with the simple click of a button.
Currently, the Fine-Grained Visual Embedding feature is available in Amazon QuickSight Enterprise Edition in all supported regions. Furthermore, pricing details of Amazon QuickSight are available on the pricing page.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

When the team that maintains the gov.uk website faced the issue of updating their old and outdated jQuery dependency, they decided instead to get rid of it altogether. Among other benefits, they achieved a not negligible performance improvement and, in the process, created a migration guide for other developers to tap into.
As senior developer Andy Sellick explained, the project was born as a side-project to remove tech debt and legacy code, but it eventually brought benefits in both performance and security alongside with reducing maintenance complexity.
From a developer perspective removing jQuery has been a long but worthwhile process. Rewriting our code has taught us a lot about it and we’ve expanded and improved our tests. In many places we’ve been able to restructure and improve our code, and in some cases remove scripts that were no longer needed.
The task was a large one, with over 200 scripts spread across multiple applications and pages, plus their corresponding tests. On the positive side, each script could be rewritten as an isolated piece of work, which made contributions much easier across the whole organization. This made it possible, for example, for backend developers to get involved in the process and speed it up.
The team also realized the task had not to be an “all or nothing” endeavor to turn out successful. Indeed, where specific applications used jQuery in more complex and larger scripts, the team decided to give them their own jQuery dependency to avoid slowing down progress while still ensuring most of the website would be migrated.
Speaking of the benefits the migration brought, security is a clear winner, since gov.uk was stuck on seriously outdated jQuery 1.12.4. Furthermore, the migration got rid of a major maintenance problem in itself.
The team summarized several performance improvements they got in a second article, addressing thus some of the initial criticism. This seemed to focus mostly on the argument that jQuery has a negligible size in the context of modern network speeds and caching. On the contrary, while jQuery is indeed only 32 Kb in size, head of frontend development Matt Hobbs stressed the fact that JavaScript libraries are render-blocking resources. This means they have a significant impact on the time it takes for a page to fully render in addition to sheer page load times, with an improvement of 17% and 8% respectively. Additionally, the time required for the web pages to become interactive also improved by 17%. The benefits are even greater for visitors using slower devices or experiencing adverse network conditions, as Hobbs detailed in a Twitter thread that is a great example of how to measure web performance.
As mentioned, the gov.uk team also created a specific guide to remove jQuery from an existing JavaScript codebase, including a list of common issues and hints at how to deal with syntactic and standard library differences.
MMS • Renato Losio Kristi Perreault Luca Bianchi Flo Pachinger Tim
Article originally posted on InfoQ. Visit InfoQ
Prologue
Renato Losio: In this session, we are going to be chatting about building applications from edge to cloud, so understand as well what we mean by edge and what we mean by from edge to cloud.
Before introducing today’s panelists, just a couple of minutes to just clarify what we mean by building applications from edge to cloud. Edge computing has added a new option basically, in the last few years, delivering data processing, analysis, storage close to the end users. We’ll let our experts define what we mean by close to the end user, what the advantages are. Let’s see as well what we mean by from edge to cloud. Data is no longer confined to a data center or to a bucket in a specific region, but it’s just generating large quantity at the edge, even ever growing amounts and processed and stored in the cloud. Cloud providers, not only the big cloud providers, but many other ones as well, extended their infrastructure as a service to more locations, more entry points, integrate different options that offer new options at the edge that’s as well increased the complexity and the choice for developers and for a project. We’re going to discuss the benefits and limitation of edge technologies. We look at really, how can we adopt them in our real life project?
Background, and Journey through the Edge
My name is Renato Losio. I’m a Principal Cloud Architect at Funambol. I’m an InfoQ editor. I’m joined by four industry experts at least that have experience on the edge side. That is definitely not my field. I’d like to give each one of you the opportunity to introduce yourself and share about your own journey or your own expertise on the edge part, and why you feel that is important. I will start with just basically asking, give a couple of sentences to say who you are, and where you’re coming from in this journey to edge.
Luca Bianchi: I am Luca Bianchi. I’m CTO of Neosperience, which is an Italian based company focused on product development and helping companies build great products. During my career, I had to face a number of challenges of companies needed to push the data back from the cloud to the edge. We started with the marketing domain where data needed to be reached at the edge. Then in recent years, I started focusing into healthcare or security for machine learning. I am quite in the middle of the journey to the edge. I don’t know which part is behind and which part is in front of me, but I have enough scars about that.
Tim Suchanek: It’s a dear topic to me, as I’m spending my full time working on this topic. I’m Tim, CTO of Stellate. We founded the company last year to make it easier to cache GraphQL at the edge. While it’s great to bring the whole application to the edge, there’s a lot happening in order to make it possible for maybe older applications but also new applications to benefit from the edge we’re building at Stellate, so that you can cache at the edge. That’s what we’re doing.
Flo Pachinger: I’m Flo. I’m a Developer Advocate at Cisco. I’m pretty sure this is my topic, with edge compute, because I did already some IoT projects, specifically for edge compute, like in the manufacturing space a lot in Germany. We had a lot of challenges already there, how to connect and then get the data in an aggregated or in a better form, basically, to the cloud. Yes, also work on some computer vision stuff.
Kristi Perreault: My name is Kristi Perreault. I am a Principal Software Engineer at Liberty Mutual Insurance and an AWS serverless hero. I work in the serverless DevOps space at Liberty Mutual. We’re pretty heavy on the cloud computing side of this journey. I definitely know that there are some folks working on the edge still. I’ve also had some personal experience in doing so in my own projects with some IoT, some robotics, some cloud computing.
The Main Benefits and Use Cases of the Edge
Losio: I will say that from your introduction, you are almost completely a different industry and experience. It’s quite obvious that edge technology is not just one sector. It’s not just machine learning. It’s not just IoT. It’s not just finance or whatever. It is helping in very different areas. More data is now collected and processed at the edge and used in very different technologies and location, what do you see as the main benefits and use cases? What are the use cases maybe we don’t talk about?
Pachinger: From my experience, it comes basically down to latency, and to have some compute or time directly at the edge. You have critical compute tasks of what you can do, and what needs to be computed at the edge. A classic example would be, like I had a robot arm demo and challenge on our last event, and basically, it requires real time communication. It was a C++ interface, and you need to move the robot arm around. If the latency was really high, or 500 milliseconds, like we’re talking about, like not 2 seconds, we’re talking about really low milliseconds, then you can’t do this. This application can’t be in the cloud, so it really needs to be on-prem there. Especially in the manufacturing space, with connecting the machines, just like having telemetry data, collecting telemetry data, safety requirement, of course, that the machine is shutting off, like this kind of logic there. This is something you had to have something at the edge there. Especially in what I see is in the manufacturing space, in utilities, in oil and gas, and these kinds of industries, this is remote places. You need edge compute there, because the latency or the way to travel to another compute node is just too far away.
Suchanek: Maybe before I dive into that, I want to quickly talk about the term edge. I think that with edge, it’s just easy to quickly define. One thing is that in the edge industry, for example, CDN providers, which just have hundreds of locations around the planet, the edge meant the edge of the network, meaning where they have the presence. The edge can also go a step further, as Flo already alluded to ML applications. In a sense, if you want to, you could define what Tesla does with GPUs in the cars, as edge as well. If you go that far, you could also say that every browser is an edge. I’m not sure if we want to go that far, but for coming a bit into the applications that we see, so for sure, when you’re in the API space, it’s quite useful to do certain things at the edge that you don’t do at your central server. Just because it’s separate infrastructure, it’s already a big advantage.
For example, we are building a rate limiting product right now. The fact that it doesn’t even have to hit my server, and I can protect the origin server, it doesn’t even have to hit it. That is a big advantage. We can dive into architecture later more, but I definitely see more a hybrid approach. I have not yet seen really large scale applications that are from scratch written at the edge. They’re slowly coming. You basically need all the capabilities that you have in the central cloud at the edge, and they’re slowly coming. From our side, what we do is that we make it easy to cache GraphQL responses at the edge. GraphQL is an API protocol that Facebook came up with a few years ago. It’s, in a sense, an alternative to REST. The advantage of GraphQL is that it has a very clear set of boundaries and like a specification, how every request and response can look like, and so you can build more general tooling. That’s why we built the caching. Because now with GraphQL, when you know the schema of a GraphQL server, you can do smart things and invalidate, because reads and writes are separated in GraphQL. That’s how we utilize it. Without GraphQL, the edge caching there from APIs is a bit cumbersome, more cumbersome, and now that is a new opportunity how we are utilizing it.
Losio: Actually as well, I gave it for granted what edge is, but actually different people might consider edge very different scenario. I was even thinking, maybe because I’m really cloud oriented, for me edge was really a point of presence of the cloud provider, but actually it’s not necessarily even that. Actually, even those ones keep growing.
Limits of Cloud Providers Adding Zones and Functionality Closer to End Users
What is, for example, your point of view in where we are going as well with the cloud? It’s obvious that all the providers are adding zones, are adding new functionality closer to the end user. Where do we see that limit? Is that just a latency point, or there’s some other advantages?
Bianchi: I think that there are a number of advantages not only based on the latency value, which is a big point. We had a project in which our customer needed to manage vehicles on the highways and provide feedback on the vehicles while people were driving. They had very high latency constraints. Usually, I also see that when you enter in the machine learning domain, you basically had constraints related to bandwidth. Basically, I have the opportunity to work on the video processing applications, in which if you process the video stream using machine learning model, or at the edge, and here, we need to explain what we mean by at the edge because you can be directly on the camera, or maybe you can be in a data center close to the camera. It is a number of different things, but you are definitely at the edge, then you’re bringing out from the stream only the insights. You’re already using the bandwidth needs. This is one thing.
The other thing, especially important for the healthcare domain, but not only for the healthcare domain is about data locality. Because sometimes you cannot afford to shift peoples’ data for regulatory reasons or privacy reasons, you cannot shift data out from the legal boundaries of the owner. With machine learning at the edge, you can deploy the model directly from the cloud. You can train the model, you can manage everything in the cloud, and then deploy the model at the edge, then process the data and extract all the anonymized or insights from the edge.
Developer Perspective on Cloud Latency
Losio: You actually already mentioned a good point that is just not simply a problem of latency. I don’t know if you have any specific example as well. In your case, you mentioned that you work a lot on the cloud side as well as a team with some on the edge side. From a developer perspective, does anything change? I’m always this cool person that I’m playing with the cloud. If I’m coming from a developer side, probably the only thing I think are, ok, edge is maybe something new but until now, I always had to think about the latency of my request or the response time or whatever of my API that I was developing. Do I need, as a developer in the cloud, to think about that, or is that something for someone else?
Perreault: Yes. I like that Tim took a step back here and actually thought about edge as different definitions too, because I definitely have a different viewpoint than the folks here. We’re all insurance, we’re financial data. We’re not really using things that are hardware or machine based. When I think of edge, I just think of it in the traditional definition of having your compute and your processing really close to your data and your data storage. I think that we do that in a hybrid mix with the on-prem that we still have, as well as our cloud computing and things. In terms of a developer, I always think it’s just important that you should understand every step of that process, even just at a very basic level, in terms of things like vocabulary is changing all the time, things become buzzwords and overused, and those kinds of things. I think it’s important to know what edge is. Maybe not even just the traditional definition or anything, but how that helps you and your company.
We’ve hit on latency a lot, but one thing that our company is concerned with is cost. That’s something that we’re going to be thinking of in terms of edge computing and your cloud solutions as well. That’s something that you should be thinking of as a developer, too, because you want to make sure that you’re building applications that are really well architected right now, is a big focus for us. That involves all of those pillars of security, of cost, and of performance and reliability.
The Cost of Edge Compute
Losio: That’s an interesting point of view. I never thought about the cost part. Are you basically suggesting that doing it at the edge is cheaper because the data doesn’t have to go around the world? Or it is actually more expensive because I’m paying for data centers that the cloud is, I’m not saying taking advantage of this scenario, but maybe the local zone is a bit more expensive than a data center far away?
Perreault: I think it depends on what you’re doing and what you’re working on. I think that that’s what I mean when I say like, you just got to be educated on all the different options, because in some cases, it might be cheaper for you to go to the edge than it is to keep all of that up in the cloud, and do all of the processing, all of the data, and you’re worried about performance and things. It might be cheaper in that aspect to do it for edge. It really depends on your use case, how much data you’re processing, what you’re working on, and how many other services or things you’re interacting with. Then I think of, in the cloud, there’s almost edge computing in a way. If you’re going multi-region, or cross account, or doing different availability zones, that might not be optimized. It might help from a security perspective, and it might help from a data backup perspective, but it’s not going to help from a cost perspective. Just different things to think about, I think, in terms of insurance and financial lens.
Pachinger: We did a calculation there. It’s completely true, it really depends on the use case. One example of what we did is like, especially at the remote places, where we placed an industrial router there, we did actually edge compute on this industrial router, which interconnectivity was 3G and 4G. You can definitely see if you don’t compute this at the edge, then you have costs at the cellular level, like with the service provider there. Plus, you have also cost at AWS or like also at the public cloud provider. You had double the cost there. There, we did the calculation, and yes, without any surprise, it was like, go for edge compute. That’s a no-brainer. Yes, it really depends on accessibility. Like, is it remote? How much can we leverage actually classic like internet or cable and extend what we have there? This was the use case, and then it was clearly go for edge compute.
Losio: That’s actually a good point, because I remember not a while ago that I saw, for the very first time in my life, I had one of those Snowcone devices that you borrow from the cloud provider with a lot of storage. There was as well some computing on the machine, I was like, are we just going to do any computing on the machine? Then I realized that actually there are use cases, maybe they’re not my use case, but there’s really benefit, because maybe that box is going to travel for two weeks before going back, so you can take advantage of that, but as well that not necessarily when you hire with the connection, it might be that cheap to do it in any other way.
Regulatory Compliance and Edge Compute
In that sense, do we see a compliance rule as well? I was thinking about the finance world, but not just that one, Luca mentioned the data has to stay in a specific country. Do we see that as well as the edge problem, or is it entirely different more legal problem, or whatever? I don’t know if you have a shared view on that one. As you said, the edge can be many things. I remember actually, you really considered that as part of the edge as well.
Suchanek: I think when it comes to data compliance, I just have to quote our lawyers when we talked about GDPR, because a bunch of customers are asking about it. The lawyer said, only God knows if it’s GDPR compliant. The thing is that it’s really tough with GDPR compliance. It’s not like with other compliances like SOC 2 where you can just actually do an audit and you’re done. It’s a bit more complicated than that. The irony is that, for us, at least in caching, there were customers asking for caching something only in a specific region. It turns out that’s not needed. What I mean by that is, if I do a request from Europe, then usually we only cache in Europe. If I do the request from wherever, then we cache there apparently. According to our lawyers, that is enough for GDPR compliance. What some users were asking is to say, we never cache outside of Europe, even though I as a European citizen am traveling outside of the EU. That is my knowledge now. It’s a confusing field. All the bigger enterprise customers we have, their legal team then comes and talks to our legal team, and that needs to be figured out. I think there’s still a lot happening there to realize these things.
Perreault: Tim, if I can elaborate on that, too. Obviously, compliance is huge for us. We’re dealing with credit card numbers. We’re dealing with quotes and claims and insurance data and all that PPI. It’s a huge concern of ours. You hit on a really good point where we’re also global, so we have contractors everywhere. Something that you have to think about is when you’re caching this data it’s different in the U.S. where I live versus our Ireland office, or our contractors out in India, or some of those things. There is like a fear there. With on-prem, those boundaries are less blurry, but when you start thinking hybrid cloud, and there’s a fear of going to the cloud, and what does this look like, and what is security? How do we answer those questions? It’s not a one-size-fits-all solution, depending on what you’re doing.
Edge Tech and Hybrid Cloud
Losio: You just mentioned actually hybrid cloud. I was wondering if there’s any specific challenge or specific differences when we think about edge technology and hybrid scenario. Because, if I understand, there are two aspects, one you mentioned before, is I might have something a bit, not because I don’t want to go to the public cloud, but because I need the data next door, and next door is not the big cloud provider, whoever it is, Microsoft, Google, Amazon, whatever else, is not there. Probably, if I’m in Iceland, maybe I need to do it different with a local provider or whatever. I was wondering as well in terms of paradigm there’s still a very big difference between hybrid, or if everything is hybrid at the end, the moment you start to talk about edge?
Pachinger: From that perspective, it’s very interesting, because hybrid is, again, a definition case, from what we see is that you leverage several clouds there. Usually, what we see is that the majority of customers are hybrid cloud users, they’re using several clouds there. I think it’s not wrong to say that hybrid in a way also extends to the edge, to any specific data center or to any other service provider what we see there. There again, coming back to Tim’s suggestions, going back and say, we need to define as well where the edge is. Usually, I go through the Linux Foundation Edge Consortium or organization. They released a really cool white paper there, where everything is included. They say, this is basically a specific edge category for embedded hardware. This is more for the service provider. This is more for like using rack servers. It depends also a bit on the hardware, of course, where the edge is defined. As you said, it definitely fits to a hybrid cloud strategy there. It all comes down to the hardware, and also from the definitions, I usually tend to step back on how to define it and more to like, what does it do. We can be more clear on the things there.
Suchanek: Maybe about what you said Flo. I liked that point with like, where’s the boundary? I think that in a sense, you could argue that it’s a blurry line. The thing is that if you have one location, let’s say you use AWS, I think they already support over 40, 50 locations, if you take their local zones, Wavelength zones. Then, ok, one location is not actually edge, so then we take two, also not edge. When is it edge, 10, 20, 30, 40, 50? That’s the thing, and you just have multiple locations. You for sure need to put something in front. They, for example, have the Global Accelerator product, or you can use Route 53 for IP based routing or something like that. After all, I think as soon as you have a certain amount of locations, you probably can talk about edge. All those locations could basically run everything that a cloud can run. You can also check that out for AWS, specifically. I don’t have any affiliation with them, but we use it. You can check out for certain locations. They, for example, support the whole offering, than maybe in a small edge location, how they call it, less of the offering. After all, you have the cloud in a region, and then you just have many of those, and then you can call it edge in a sense. It’s blurry for me at least.
Bianchi: It’s blurry, but I think that there is quite a big difference between the edge computing, which is under the cloud provider domain. Basically, AWS, or whatever has the full control on the edge location, so it is simpler. If you need to deploy Lambda at edge, just to give you an example, it’s much more simpler. It’s not straightforward as deploying a Lambda directly on a given region, but it’s simpler. If you need to deploy something on an edge device, which is located within a company boundary, you have to face a number of complexities related to integration, to network security, and a lot of stuff that makes things a lot harder.
The Future of Edge Technology
Losio: I was wondering when you mentioned as well before about the use case for the edge technology. I was wondering if there is a new use case. If I think about where we were 10 years ago, 10 years ago there was really no edge, where at least. We were just talking maybe about a bit of caching for some, I’m thinking about Amazon maybe there was a bit there, before a load balancer you could use CloudFront. That was probably already there at the beginning. Five years ago, started some service at the edge, now it’s a very big topic. I was wondering in 5 years or 10 years, where’s the direction? Just new areas where we’re going to use edge technology or simply edge technology will become the norm and almost transparent to the service.
Suchanek: I think that’s an interesting one, let’s look into the future. I think that more is moving to the edge. Let’s assume we want to move a whole application to the edge, what would need to happen on a technical level without any centralized data storage anymore? We would for sure need to solve data, the easy part. Compute is not that challenging. Compute at the edge we got already. Data is the challenge. What options do we have there? Caching is one option. We still have maybe five, six main regions where we have our databases and they are replicated or sharded. The other option is that at the edge we could be sharding by user. Only the user data is stored there, that could be an option. What is obviously not scaling is that we would take terabytes of data to everything in edge location and replicate it 200 times. That’s not scaling. We would need to come up with some better solutions there, how to distribute the data. Then there are many approaches right now like FaunaDB, and whatever you’ve got.
I think the solutions are still quite early. I think there’s a saying that you shouldn’t trust any database that’s younger than five years. We’ll need to wait a bit for all the databases that just came out, before we use them in production for edge related things. Cloudflare released the SQLite approach. Also Fly does that where they stream between the SQLite and saving them, that still won’t give you strong consistency, it will only give you eventual consistency, meaning, if I do a write and a read directly after, I might see old data. That’s a tradeoff.
Losio: It’ll be an interesting tradeoff, because I wonder if it will be [inaudible 00:30:54] application that will accept that as a tradeoff knowing the importance of the milliseconds becoming small or smaller in that case.
Suchanek: I would be curious to hear Kristi’s view on that, because I think there are a bunch of applications that can accept that tradeoff of eventual consistency.
Losio: Probably finance is not one of the main areas.
Suchanek: Probably not.
Perreault: Again, it depends. Actually, the one thing that keeps like playing in my mind when you were talking about this was, it’s not new, but new to me, and what we’re exploring is more of like content delivery networks too. Because we’re a lot of frontend applications, so we have to serve up web pages and that’s how we gather our data. That’s one thing that is top of mind that I’m thinking of for edge locations, and for using computing on the edge. I think that there’s going to be a lot of that in terms of networking. Yes, to your point, financial data, insurance data, credit cards, that stuff, that’s going to be really hard to work around with the edge. Especially that brings in the compliance issue a lot too. Every country and globally, there’s different laws, there’s different policies, even by states here, too, it’s different. I know our process for working with California is completely different than working with Ohio. I think some of those, it’s going to be interesting. I wish I did have that glass ball to see who comes up with that solution and what that looks like. I think we’re interested in that. Right now, we’re all bought in on cloud and we’re headed that way. Hopefully, we’ll see how multi-region, and cross account, and all of that works out.
Pachinger: For me, what I see right now, maybe early adopter phase, or a bit of maturity level. A good appliance is computer vision, so where we have GPUs at the edge, and thinking about that’s nano, like in this super small size there. You can do a lot with cameras, with image detection. A classic example would be with vehicles there to detect something. Then persons, of course. We have lots of use cases where like, does the person actually wear their face mask or not, so to see? Again, in the GDPR, it’s like, are we actually violating the privacy of the user? It depends, of course, where you can deploy the cameras there. I think in the machine learning level, inference at the edge. This is still a bit early, but I see already some applications there. I think they will definitely grow and increase in that area.
Use Cases for ML at the Edge
Losio: Do you see any other use case increasing for machine learning at the edge?
Bianchi: I think that in the next three to five years, a lot of machine learning workflows will be pushed to the edge due to the fact that a number of specialized devices are coming, which is a good thing. On the other hand, I don’t think that right now we have a sufficient level of abstraction from the device. When you are deploying machine learning on the device, you still need to understand what is under your hardware, what kind of GPUs you’re using, what instruction set is supported? We have great tools, but they are evolving quickly. I don’t think that now we can abstract away from the hardware complexity. Hopefully, within the next five years we will be there and we will be able to take a machine learning model, cross compile it for the given whatever hardware, and then deploy that to the hardware. We are not yet there.
Suchanek: I think that the ML use case that has been mentioned, that makes total sense. Also, we will still see more use cases coming as we have compute as a general, let’s say, primitive available now with something like Cloudflare Workers. I think people are still looking for these use cases. I just want to mention one big one that I haven’t heard, which is A/B testing. There’s a whole industry around that. There’s, for example, LaunchDarkly, which is a startup basically just built on that, where at the edge, you make the decision, where I send the actual request routing, generally. That’s the big one. Anything that is right now, for example, the HTTP gateway, or API gateway from AWS, all these things, I think, are perfect candidates to run at the edge, so you can decide where the actual request goes.
The Open Standards and Risk of Vendor Lock-In at the Edge
Losio: As you mentioned, as well, some services from Cloudflare and AWS. One topic that usually when we think about edge technology in general [inaudible 00:36:00], all exciting new services, new products at the edge, not at the edge, is, what are the standards, what are open standards, what is the risk of a vendor lock-in, also, if I think in 5 years, 10 years?
Pachinger: It’s always a challenge, because we see this actually in the cloud providers as well there, that the more you develop your application towards one cloud, of course, they try to leverage it or say, ok, let’s be cloud native, or like, let’s go in this direction and make it easy for all cloud providers. I think at the edge it will be similar. However, we are leveraging a lot of like open source container technologies like containerization. I think it will stay at this level. Containerization is I think the way to go to. Then we have K3s, for example, as a really cool solution there. Then, classic like a hypervisor, maybe an embedded hypervisor, but nothing super big. Depending again on what edge we’re talking about, but talking about like the classic edge, or the smart device edge, or the constrained device edge there, this is where I see containerization there. Also, I think, with containerization, you can have it in this category. Then you can also have it in a data center in a rack server, for example. I think this is very important to have it open, to have no lock-in there, no vendor lock-in. This is of course very important. It’s like a lot of users, they like this. This would be from a software perspective there.
Losio: Do you see that as an issue in your experience? If I understand well, you’re very much an AWS focused company.
Perreault: Yes. Actually, I did want to add on to what Flo said, because I do agree. I think that one of the things that I really like about working at Liberty Mutual is that we are very open to whatever tools you want to use, whatever providers, whatever way you want to go, we are very much AWS driven and focused. We do have Azure support. We do have Google Cloud Support. There are folks that go to those ways. We do have some folks in the machine learning space or processing large amounts of data and data analytics that might prefer Azure and some of the tools that they have over there, over AWS. We also use containerization. That’s a great kind of half step from on-prem to cloud. That’s one that folks reference. We also use Kubernetes, Docker, Fargate, it’s all across the board.
With a really large company, the idea of vendor lock-in is a little different, because once we’re bought into something we’re bought in, and then it’s a long process to move, and to take that stuff out. We have about 3000 developers, 5000 people working in tech, and we’re 110 years old, so there’s a lot of data. We’re always acquiring new companies and things too. We’ve inherited some of their vendor lock-in or some of their tooling to bring that in and modernize, or to even go in that direction, if that’s a better solution. The idea of vendor lock-in is interesting, because we have what feels like every vendor all the time, and it hasn’t been too much of an issue. It’s just a matter of we’re going to be bought in on AWS, and like most of our expertise is there. If you choose to do something else, you’re more than welcome to, but some of that learning curve might be a little harsher and steeper for you.
The Roles Arising from Edge Compute
Losio: I was actually wondering, thinking about our audience, as well about developers and software engineers, how do you approach the cloud in the long term, from the cloud to be maybe a cloud architect, cloud engineer, whatever, to be an edge expert? Do you see the need of edge experts? Is it going to be a specialty somehow? We’re going to have a new title, maybe it already exists, edge engineer, I have no idea. Or you see as kind of, from a software developer point of view, almost transparent that it’s just ok, you deal with it, and someone else deals with the location of your data, Tim, from the graph point of view?
Suchanek: I think that we probably would not need new job descriptions there. There are a few things unique to the edge, for example, interconnectivity, but usually, as Luca also mentioned earlier, the abstractions that you get these days are so good, that I can “just write a function and upload it” and the providers usually take care of it. Then rather advanced scenario, I might have to know about that, but then we’re in distributed systems anyway. I think, generally, with these JavaScript interfaces that are available these days, Cloudflare Worker, and so on, Deno also has an edge product, you don’t really need to be that specialized.
I also want to add one thing regarding vendor lock-in. There is an important initiative happening right now called WinterCG. Where basically all the major edge compute providers came together and said, let’s agree on a minimum API that we want to support.
Losio: I’ll ask Luca if he shares the same view, that we don’t need special developers.
Bianchi: I don’t agree with Tim, because we are seeing that in some domain especially related to machine learning, people are naturally specializing into bringing models down to the edge. For instance, we are using AWS Panorama, and it requires a lot of effort. Some people of my team had to study and specialize into compiling the models directly for the hardware. Maybe in the future, the abstraction will be more mature, so we’ll be able to have the same developer develop the same thing for the edge and for the cloud. Actually, I think that some effort is required.
Losio: If I simplify a bit what you said, it’s basically, if you develop a Lambda function, probably you don’t care where we deploy it. Maybe you can deploy it at the edge or you deploy it at a standard region or whatever. If you deploy a machine learning model, and it depends really a lot on the hardware, then if the hardware at the edge is different like Panorama or whatever, then you have a different challenge.
Bianchi: Yes. Exactly.
Pachinger: It depends also maybe on the industry there. A classic example is like IT/OT conversion, where OT, operation technology from manufacturing context, they would like to integrate more with cloud providers, with the classic IT. From like layer 1 network perspective, up to layer 7, of course, to the application perspective, collect data, again, also leverage machine learning there and gather the data to the cloud. This is exactly where, of course, like a specific knowledge is important. How do the machines operate? What are the network requirements? In this way, there’s definitely expertise needed. If you talk about, I can just use the Lambda, I can just use some cloud native technologies there, I don’t care about the specifics at the edge, then like, not everybody, but in a way, a classic standard cloud developer or developer can definitely handle that.
See more presentations with transcripts
MMS • Shawn Swyx Wang
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Welcome to the InfoQ podcast [00:04]
Daniel Bryant: Hello, and welcome to the InfoQ podcast. I’m Daniel Bryant, head of Developer Relations at Ambassador Labs and News Manager here at InfoQ. Today I have the pleasure of sitting down with Shawn Wang, Head of Developer Experience at Airbyte. Shawn also goes by the name Swyx on the internet, that’s Swyx, and I’ve been following his work for a number of years.
His recent blog post entitled “The End of Localhost, explored local development environments and the potential move to remote developments”. And this caused quite a stir in the developer communities. I wanted to chat to him more and explore the topic in more depth.
In this episode of the podcast, we cover everything from the topic of local development environments to the exploration of hybrid and remote development. And of course, the future of IDEs.
Introductions [00:42]
Let’s get started. Hello, Swyx, and welcome to the InfoQ podcast. Thanks for joining us today.
Shawn “Swyx” Wang: Thank you for having me. I’m excited to chat.
Daniel Bryant: Could you briefly introduce yourself for the listeners, please?
Shawn “Swyx” Wang: My name is Shawn, I also go by Swyx. I’ve done a number of roles since joining tech. I used to be a trader here in London actually, where I’m recording right now, but I pivoted to tech not too long ago.
And I’ve worked at Netlify, Two Sigma, AWS, Temporal, and I’m currently at Airbyte. Basically just working on developer relations and developer experience, always working for a developer tools company. And on the side, I do some blogging, which is why I’m here.
Could you set the scene for writing your recent blog post “The End of Localhost: All the Cloud’s a Staging Environment, and All the Laptops Merely Clients?” [01:17]
Daniel Bryant: Perfect. Yes, that’s why I’ve been following you for many years, for your blogs. And I think you and I have led similar paths. I mean, I haven’t done the trading, but we’ve led similar paths in the software space. We could talk for hours on developer experience, developer relations, many things.
But in particular, I was really interested by your recent blog post, The End of Localhost. And that’s what we’re going to frame the podcast around today. I think so many great insights for folks from all different angles, whether you’re a developer, an operator, or whatever your persona is. So for folks who haven’t read the blog post, could you summarize perhaps the core premise of why you put together what was called, The End of Localhost: All the Cloud’s a Staging Environment, and All the Laptops Merely Clients? Great title.
Shawn “Swyx” Wang: I have a little bit of pretend Shakespeare literature bent around me. So if I can see a reference, an opportunity to squeeze it in, I will.
The premise of this, let me just start at the inciting incidents. I have been basically skeptic of the cloud development environments for the past few years. I’ve seen the rise of CodeSandbox, I’ve seen the rise of GitHub Codespaces. And I’m like, Yes, good for small things like testing stuff out, but you’ll never do anything serious in these. And then I started to see people like Guillermo Rauch from Vercel saying he no longer codes on a laptop, he just has an iPad. And that starts to really shift my gears.
But the inciting incident for this particular blog post where I was really starting to take it seriously, was Sam Lambert, who’s the CEO of PlanetScale, saying that PlanetScale doesn’t believe in localhost on a podcast. I don’t remember which podcast it was, I think it was Cloudcast or something like that? I put a link in the blog post. But for a dev tools company to come out and say that they don’t care about localhost is a bolder statement than I think most people realize, because for most people a proper development experience must include a local clone of whatever the cloud environment is doing so you can run things locally without network access.
And this is exactly what I worked on at Netlify. I worked on Netlify Dev, which is a local proxy that compiles Netlify’s routing services down to the CLI. At AWS we spend a lot of time building the AWS Amplify CLI, which does clone a few things. It’s not a complete clone because it’s very hard to clone AWS down to the local environment and that’s where you start to see the issues. And mostly what is Docker Compose, but a way to locally clone your production cluster onto your local desktop. And you can see it’s not a very high fidelity local clone, particularly as you start to use more and more cloud services.
And so the assertion is that this is a temporary phenomenon. This is not the end state of things, because all that we have to do and where every single cloud environment is trending, is that you should have branches. It should be cheap to spin them up and spin them down. You should not treat them like pets. You should treat them like cattle, which means if you want to spin something up for a few seconds, go ahead. It doesn’t cost much. You can do it without a second thought. And so why are you wasting any time maintaining the differences or debugging differences between dev and prod when you can just have multiple prods and just swap between them?
So that is the premise of the debate. That was a personal journey that took a few years. And I sort of wrote it up in a tweet. And I was like, I want to get people’s opinions. I know this will be slightly controversial, but I was very taken aback by how strongly opinion was. Obviously devs have very strong feelings about their development environment. And obviously it’s the main tool of our trade, so of course, but it really split ways in terms of whether or not people use significant cloud services or they don’t use significant cloud services or they don’t see much benefit, and whether or not people have experienced the pain with maintaining different environments.
So one of my favorite lines, I really love this phase from Bob Metcalfe, was quoted by Marc Andreessen. The browser reduced operating systems to a poorly debugged set of drivers. The browser is essentially a better operating system for apps than the operating system itself, because it’s a much easier application delivery mechanism. So if the cloud is doing the same thing to dev environments, then the cloud will reduce the dev machine to a poorly maintained set of environment mocks. We’ll never have full fidelity to the production environment just because we don’t have secrets or we don’t have the right networking setup. We don’t have to write data in place. And so anytime spent debugging dev and prod differences is time wasted as long as you can get cloud good enough. So let’s go get cloud good enough.
What’s the benefit of a dev environment being able to travel with you? [05:29]
Daniel Bryant: Perfect. That’s a great intro. And there’s so much to break down. I encourage listeners to read the full blog post and I’ll definitely link it in the show notes because it’s a fantastic read, straight up. I read it about 10 times now and I take away different things every time. It is a monster blog post, it’s fantastic.
But a few things caught my eye and I’d love to dive into them for the listeners in a bit more detail. You’ve touched on a little bit there, but the ultimate developer wishlist stood out for me, as in like, what do we want as developers? I think back to my days, many Java development, did a bit JavaScript, did do a bit GoNow. And three things really stood out to me and I’d like to work through them and get your opinion on them now.
The first one, and you hinted at that with the iPad development, but you said your personal dev environment travels with you no matter which device you use. And obviously there’s GitHub Codespaces, GitPod, doc and dev environments. There’s a bunch of tools out there. I’d love for you to break that down for us. What’s the benefit of that dev environment traveling with you, the stop/start maybe of the dev environments? I’d love to hear your thoughts of why that was a wishlist item.
Shawn “Swyx” Wang: Oh, preface this with why I like to start with the wishlist, why I started this blog post with a wishlist. So some people might go directly into what remote dev environment is. But I like to start from the problems rather than the solutions, because solutions will come and go, but the problems remain. And as long as we can set a long term goal of what we actually want in an ideal world, we can kind of work our way backwards, to how we get there. And so that’s why I started with this wishlist. And I think the dev environment traveling with you is kind of a luxury, but also it’s a productivity thing. Like all your bash aliases, all your CLIs that you always use. If you use a different version of, I don’t know, like what is trendy these days? Like FZF or all these sort of command line utilities that you know of, but are not fully distributed yet, but you just want to use it everywhere you go with you.
Like my favorite is Z, the little command line called Z, that remembers every folder you’ve been in and does a sort of frequency matching so that you can just jump back and forth between folders, just by typing a partial match of the folder name. Like all those little utilities that increase your productivity, you want to have them everywhere that you code. And sometimes you don’t have access to your machine, whether you’re traveling or using a coworker’s laptop or you’re, quote unquote, SSH’ing into a remote environment. And you’re trying to debug something and you just don’t have the utilities that you’re used to. So now you spend some time writing lower level scripts that you would have put together in a macro, in a previous environment. So it just takes so much time to set up and people have built all sorts of tooling for this.
I think Spotify’s Backstage maybe comes to mind. Netflix also has a sort of boots shopping tool that they use internally, all sorts of companies have this company dev environment. But then there’s also an element of personalization that makes your dev experience yours, rather than the one that’s prescribed to you by some company or your employer. And I think that is an ideal that we try to reach. We may not ever reach that because it’s hard to basically teleport the whole machine regardless of any hardware. But I think we have enough generic tools and interfaces that we could possibly do 90% of that to work. One device or one tool that has made significant progress, that you did mention, was actually, VS Code implemented Settings Sync. It actually used to be a user land plug in that would post your settings to a GIST and then you’d have to download the GIST and do all sorts of funky gymnastics, but VS Code just built it in and it just works. And it downloads the extensions that you always use so you get your intelligent suggestions and it just works.
And I think that is something that is improving developer productivity as they move machines. So I think it’s a luxury, maybe on the scale of things it’s not as important as the other stuff, but I just chucked it in there because there’s some things that, if you pick the right solution, you get a bunch of these for free together.
Can you dive into the motivations and reality of being about to spin up a dev environment on-demand? [09:04]
Daniel Bryant: Let’s dive into the second item I pulled up. It is any apps environmental dependencies, everything from an HTTPS certificate to a sanitized sandbox fork of production databases are immediately available to any teammate ramping up to contribute any feature – no docs, no runbook. And I can totally, I haven’t done a bunch of microservice work, empathize with this. Not only is like TLS cert’s an issue, but even other services, databases, this I think is a big one. I’d like to get your take on this wishlist item.
Shawn “Swyx” Wang: So first of all, I appreciate that you called it the TLS cert. Because I actually debated whether I should say TLS cert or HTTP cert and I settled on HTTPS because that’s the thing that most people see. But it’s always confusing to have two names for that process. I’m a guy who, I care about docs. I think it’s a mark of a good developer to write docs and to write runbooks. At the same time I know that people ignore them, or people skip steps, or they are badly written and you just can’t quite follow them. And that’s also very frustrating. And ultimately the best docs is the docs you don’t have to read. And that is a product level improvement that you kind of have to make there. But I do see that a lot of the cloud providers and cloud setups that are out there are trending towards this place, where again, this is an outcome of treating your environment like cattle, not pets.
All these should be commoditized things and immediately available. It should not be like one of these forks or one of these certs per developer or per organization or per team or per feature. You should have multiple of these. You should have 10 of these simultaneously running if you want to. And why not? So that’s why I said any teammate ramping up to contribute any feature. You should be able to work on multiple features at the same time and not have any conflicts between them and to have a relatively high fidelity fork of whatever you have in production. And something I mentioned about the sanitized fork of the production database also matters a lot. There’s just some companies are working on this, which is protecting PII information. And I think these are difficult problems, but they’re not unsolvable problems. And there are companies working on this.
And it’s easy to see a future in which some standardized version of this is essentially solved. It will never be solved forever because data is complex and heterogenous and difficult. But on some level we can probably have some version of this future where environments are truly disposable, truly ephemeral, truly just high fidelity as possible. And I don’t think there’s that much of a difference from doing that. I don’t think whatever improvements we can make in Localhost cannot match that. Whatever we do in production, being able to thwart that is always going to be a superior alternative. I’m trying to express something, but I don’t have the words for it. Like something to code gains. The word that comes to mind is a substrate. In environment to code against, you want to have a high validity environment to code against as much as possible to your production rather than making it easy to run locally. And that’s, I think, what we achieve with this vision.
Daniel Bryant: Yes, I love it. And it brought back some memories. I remember IT did a bunch of Ruby on Rails and we had some really old services running on an old version of Ruby. And I had to use RBM locally to manage my machine of different versions of Ruby, different dependencies, like GEM. The bundles were a nightmare. And then the other day I fired up GITPod, just a name check GI Bob. And I was working on two branches in two different browser tabs of the same project. And I was like, whoa, that was a little bit of … And I’m sure you can do this with other remote dev experiences, not just GITPod, but that blew my mind, to fiddling around with RBM, all my local tools, to having two environments in two separate tabs on the same machine. I was like, that’s amazing, right?
Shawn “Swyx” Wang: To me it’s just really about all these things that can be commoditized, you should never have to worry about it. It should just be a part of the workflow as ubiquitous is GIT. GIT is forking code and whatever this cloud thing is, this cloud development is, it’s just forking your environment. And I think that’s a very expansive vision and that papers over a lot of infrastructural work that needs to be done, but it’s going to be done because in terms of vision, that is the best way. The alternative is leave things as the status quo and it is not super productive.
Maybe one more thing I’ll offer, and this is something I’ve been thinking about a lot, which is I’ve been talking to the Deno guys, Ryan Dahl, and the people working on Deno Deploy and also the Cloudflare people, CloudFlare workers and workers for platforms, and essentially there’s an intermediate tier that’s emerging between clients and server. And that is serverless, client server serverless. And the serverless functions are kind of an ephemeral tier of compute that are easily forkable, that are trusted, but Sandbox in a way that you can run untrusted code on it. It’s just a very interesting environment where you can get very, very close to production-level infrastructure in a fork.
So I feel like there’s a very strong empathy in the service movement with this movement, which is, it should be able to spin up these environments easily. And obviously the easiest one to spin up is compute but then now that trend is moving to databases. And I think more and more of the infrastructure primitives should become serverless, air-quote serverless, in that way, where it’s cheap and easy to spin things up.
What is your opinion on using local emulators of remote services for testing? [13:50]
Daniel Bryant: I remember, myself, I’ve played around with AWS Lamda and the SAM environment and I was using LocalStack to emulate some of the things. And for some use cases, it worked really well. And for other use cases, to your point, the emulators really showed they were emulators.
Shawn “Swyx” Wang: They’re always going to trail behind. These guys have put a lot of work into it, but it’s kind of a losing battle or a Sisyphean battle is the Greek metaphor I would use. That you’re always going to trail behind and maybe you should just stop trying.
Do you think it is currently possible to scale from coding an MVP app in your bedroom to a Unicorn within a matter of weeks? [14:14]
Daniel Bryant: I think that it’s great. We can first dive into that a bit more in a minute because Yes, I totally get it. I totally get it. The final wishlist item I wanted to pick up on, because I think it frames the rest of the discussion perfectly. Because I think this is maybe a bit controversial, but I think it’s great.
You said, you can scale up MVP to Unicorn in weeks using one of the serverless or new Heroku-like platforms with off payments, databases, communication handled by world class SAS teams. And that’s the vision, going from one person in their bedroom to a multi Unicorn, right? Do you really think that’s possible?
Shawn “Swyx” Wang: I think that’s possible. I think that should be possible, that there’s something that we want to get infrastructure to a point of doing, but I respect that not everyone will want this actually. I think you should have the option to have it. You should have the technologies available to you if you want it. But at the same time, large companies will always want to have their own platform by which you run everything through. So I view the world of SAS and all these sort of infrastructure as a service companies, I view them as net additions.
You could roll it yourself. You would take a long while, you would rediscover all the foot guns that everyone else has discovered ahead of you and you would take a lot more time, but you would have full control of it. So there is some level at which it makes sense to make that bargain of, I will give over control to someone who knows more than me, I’ll pay them money, I’ll exchange fixed costs up front for variable costs that I know is higher in the long run, but total cost of ownership is lower. I’ll do all those trade offs for my size and until such time as I need to bring it in-house, I will bring it in-house. But I think these are net additions. I think that is a positive. We just have to be very clear about what actual primitives are additive to us and what are just really very thin combinations of other primitives that we should probably just bring in-house anyway, because they don’t add that much value.
It’s one of those difficult things to really make a judgment of because as someone who’s not a domain expert, it’s always very easy to under appreciate like, oh, you’re just a crond service, why do I need you? And then figure out how unreliable crond skill can be. So I think it does take some experience. I don’t necessarily think that this is the biggest point for me, but I do think that this is a litmus test of how good cloud services are and if we’re not there yet, maybe we should go build what’s missing. And to me, as someone who’s into dev tools in the startups, I’m always looking for the negative space where the existing set of solutions are not well addressed yet.
Can you walk us through some local development environments and developer experiences that you’ve encountered? [16:31]
Daniel Bryant: I love it. I’m the same, working in tools face as well. That totally makes sense, looking for the gaps, looking for the things to join it all together. Love that, love that.
Let’s move on a little bit now because you’ve got some great points I wanted to look into there. I was really curious to dive into existing solutions already out there. The next bit of the blog, you said, hey, Google, FAANGs, already do a bunch of this stuff and you and I were talking off mic. We know not everyone’s in Netflix, we know not everyone’s in Google, but often they can show us where the future might be, or there’s something interesting there. So my general experience, when I chat to people, when I chat to a lot of folks in this space, they don’t know how other companies develop.
It’s not a thing developers talk about. They talk about architecture, but they don’t necessarily talk about local dev setup. So I’d love for you to give us a bit of insight into what have you seen as you’ve looked around at dev environments, you looked at Google, you mentioned Slack, you mentioned a bunch of other folks in the blog post. I’d love to get your take on where is the vanguard, if you like? Where are they in terms of local or not local dev experience?
Shawn “Swyx” Wang: I want to preface this with, I haven’t actually worked at any of these companies that I’m about to mention. The only big co I worked at is Amazon. And Amazon did not have a, we had one but we didn’t really use it internally. I think it was, I forget the name of it. Cloud Nine?
Daniel Bryant: Oh Yes, I know it. It got acquired, right?
Shawn “Swyx” Wang: But we didn’t really use it internally for anything development wise. But anyway, so the list I had and by the way, this is one part of how I blog, which is, I’ll tweet out the rough direction I want it to go. And then if you have enough of a relationship with your readers, they’ll contribute examples to you. So I didn’t know all this when I started out, but Google, Facebook, Etsy, Tesla, Palantir, Shopify, Slack and GitHub, all chimed in with their versions of whatever the FM or workspace cloud development environment is. And at some point in their lifespan, and some of them have talked about it publicly and some of them have not. Like Tesla was not public about this, but apparently, I got one tweet that said for vehicle OS development, they moved from local to cloud because it was too expensive to run locally.
At some point it makes sense for those people, especially if they have a lot of proprietary infrastructure, if they want to restrict what their developers do or they want to provide tools that cannot be provided locally, all those things are worthwhile investments for them. And I just think it’s really interesting. So I’m very much of the opinion that we should not cargo cult, which is, oh, Netflix did it. Netflix is successful therefore doing cloud development environments makes you successful. That’s kind of not the way to think about this because that is the path to madness. But the way I look at technology innovation diffusion is that it usually starts at the big players and then it trickles down.
And so what I pay attention to is, when people leave, I have a few friends at Facebook, I have a few friends at Shopify, when people leave, what do they miss? And so the Facebookers talk about Facebook on Demand and Facebook, local dev doesn’t exist. And that is just such a stark contrast that is immediately compelling. But that’s one thing. The second thing that you want to look out for is, does it still make sense at the individual level? Is this something that you only do because you have a team of 10,000 people? Or does it make sense for three people? Does it make sense for one person? And I think this concept of cloud development environments or end of Localhost, I think it applies for one person as well because I want to work on multiple things at the same time.
So in other words, right now, there’s a lot of investment in proprietary tooling at the big co’s because they can afford it. Eventually, some of these people will leave. Actually some of them are, I have a list them at the end of the post, and then work on spreading this technology to everyone else. So that’s kind of how innovation works. It starts proprietary and then it gets productized and commoditized. And I think that we’re in the middle of seeing this happen.
Are you a fan of Wardley Maps? [19:58]
Daniel Bryant: Perfect. Are you a fan of Wardley Maps? Sorry, I’m just thinking of all the things you mentioned there.
Shawn “Swyx” Wang: Yes.
Daniel Bryant: I love Simon’s work and you can literally see things going, there was that genesis to product, then commodity. Have you tried to map out, at all, the dev tooling space?
Shawn “Swyx” Wang: Oh dear. I have one. I actually have a separate post called, The Four and a Half Kinds of Developer Platforms. And my map looks very different from Wardley mapping. I think Wardley Maps do play a lot of significance in my thinking. The problem is they tend to look like conspiracy theory maps, the always sunny in Philadelphia meme. And I’m like, this is going to make people laugh at you rather than come along with you.
So I tend to keep my dimensionality simple, two by two matrices or some kind of heroes’ journey type of storytelling. But Yes, I look at things in terms of money spent, the way that industries move together or separately. So what I have is, four and half kinds of platforms would be application platforms, infrastructure platforms, developer platforms, which is the one we’re talking about today, and then the fourth one would be data platforms.
Daniel Bryant: Oh, interesting.
Shawn “Swyx” Wang: So people working on data engineering. And I feel like web developers historically underestimate the amount of data engineering that is going on. And that has been the biggest blind side for me in just catching up in all of them. And the final half platform is the platform of platforms that eventually emerges at all of these companies. So particularly things like logging. You will need to log all the things and feed information from one place to the other, building off-end and obviously the singletons in the company that naturally emerge because they need to be the central store of all data, all information that is relevant to them. It’s an open question. So I used to work at Temporal. It’s an open question whether workflow engines count as a platform of platforms because they are used in both infrastructure and applications. And I think maybe that is something that should not be encouraged. Maybe we should have separate engines for those of them, because it’s very tricky to commingle these resources together. But yes, I think it’s an emerging area of debate for me, but I have mapped it out and that’s the TL;DR.
What feedback have you received on your blog post? Are developers ready to give up localhost yet? [21:59]
Daniel Bryant: That’s awesome. And that’s another podcast we can bring you in for, is to cover those platforms because that sounds fascinating. I’ll definitely be checking that blog later on. So I know we’re sort of coming close-ish to time. I want to leave a bit of a gap here. You and I talked before about addressing the feedback you’ve got from this post, both the good feedback and the negative feedback. Because to your point earlier, that some folks really do love their local dev environments. They do treat them like pets and I’ve been there in the past, so I would love to get your take now on the feedback you’ve got when you put the tweets out there, you put the blog out there. Was it predominantly good feedback you got, predominantly bad? I’d love your take on it.
Shawn “Swyx” Wang: I think it’s interesting. The thought leader types love it, and then the anonymous types don’t. If I could sum up the reactions …
Daniel Bryant: That’s awesome.
Shawn “Swyx” Wang: … it does trend to that way because I notice that the people that were positive, Jonno Duggan, Erik Bernhardson, Kelsey Hightower, Danny Ramos, Simon Willison, Paul Biggar, Patrick McKenzie. I can say these names and I don’t have to introduce them. They’re thought leader types. All of them were positive. And then the people I would have to introduce, or I don’t even know their bio, they were saying things like, you can pry my Localhost from my cold dead hands. This is the final step in the road to the inescapable surveillance dystopia. General purpose computation on your own machine is probably going to be illegal in 20 years. It will be our greatest accomplishment if we can liberate even 1% of humanity from this soul stifling metaverse. So really cutting, really brutal. But even that last comment was agreeing, saying, this is probably inevitable, we just don’t like it.
And I think there’s two questions. One is, should you like it? And two is, is it inevitable, whether or not you like it? So I think the two levels to debate, maybe the second level is just, who knows? Who knows if it’s actually inevitable, only history can tell. All we’re doing here is we’re observing some trends. Everything is trending in one direction. Maybe it’ll continue, maybe not. Should we like it? That is the bigger question. And I think it’s reasonable to want more control. It’s always reasonable to want privacy. And I think that’s why this tweet or this post did well on Hacker News in terms of up votes, but the comments just tore it to shreds.
Daniel Bryant: Brutal. Yes.
Shawn “Swyx” Wang: Because Hacker News, out of all the communities, loves privacy, loves open source, hates proprietary services. So I think that is entirely reasonable. And then the other thing to point out is, if you are a thought leader type, you probably work for a large vendor or you are a founder. So you are trying to provide proprietary services. And so you have a vested interest in encouraging people that, hey, the cloud will not harm you or the cloud is a TCO win or whatever the choice of terminology you favor. It’s really up to you what your value system is. I think that my north star is, am I more productive and how much time am I spending on things I don’t really want to spend time on, it’s just incidental complexity? And what kind of apps do I want to develop? And my universe of apps is increasingly more infrastructure centric, more data driven than other types of apps.
If you’re just the front end dev, you take markdown, you transform into HTML and then, that’s about it, then go ahead, be my guest. You can do everything Localhost. Go code on your planes, go code in your mountain cabins, I don’t care. But if you use any sort of significant cloud services, you will not be able to mock some percentage of them. And even if you deploy significant cluster services, you can’t run that on your local machine. And so there’s just a lot of reasons where you’re just running into issues with development. And I think for the vast majority of people trying to make money, doing big things with technology, that’s what they’ll be concerned about. So I’m focused there.
Is there anything else we haven’t covered that you really want to point listeners to and focus on in the blog post [25:21]
Daniel Bryant: So we’re getting to the end of our time here, but I wanted to ask if there is anything else we haven’t covered that you really want to point listeners to and focus on in the blog post?
Shawn “Swyx” Wang: There is one more nuance between the inner loop and outer loop where the cloud has basically already eaten the dev outer loop. So now we’re just talking about whether the cloud is eating the dev inner loop. So I encourage you to read more on the blog post there.
Daniel Bryant: So the inner and outer dev loop is super interesting and probably that’s a whole podcast we can do in the future. So Yes, because I’ve done a lot of thinking in that space as well. And that’s been a fantastic tour de force of the potential end of Localhost. Fantastic. If folks want to find out more, where’s the best way to engage with you, Swyx? On Twitter, LinkedIn, via your DX Tips site? Let the folks know.
Shawn “Swyx” Wang: Actually, intentionally, I don’t have a LinkedIn. This has been a sticking point for recruiters because they’re like, we need to hire people onto your team and people want to look you up. So I said, basically, try not to do CRUD data entry for a $26 billion company that turns on and sells your information. Literally, that’s all they do. You hate Google and Facebook doing that, so why are you doing it for free on LinkedIn? Anyway, so you can reach out to me on Twitter or DX Tips. DX Tip is the new, dedicated blog that I spun out for my writing. I’m hoping for it to be maybe a baby InfoQ.
Daniel Bryant: Ah, interesting, interesting competition.
Shawn “Swyx” Wang: I don’t have inhibition. I needed to split out my personal reflections from my professional reflections. And I thought that there was enough of an audience that I could do a dedicated one. I was more inspired by CSS-Tricks. So Yes, sorry. To cut a long story short, you can reach out to me there.
Thank you for joining us today! [26:46]
Daniel Bryant: This has been awesome. It’s been a great chat we’ve got in the can here. And thank you very much for your time.
Shawn “Swyx” Wang: Thanks so much, Daniel. It was a pleasure.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Matthew Scullion
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I’m sitting down literally across the world from Matthew Scullion. Matthew is the CEO of Matillion who do data stuff in the cloud. Matthew, welcome. Thanks for taking the time to talk to us today.
Introductions [00:25]
Matthew Scullion: Shane, it is such a pleasure to be here. Thanks for having us on the podcast. And you’re right, data stuff. We should perhaps get into that.
Shane Hastie: I look forward to talking about some of this data stuff. But before we get into that, probably a good starting point is, tell me a little bit about yourself. What’s your background? What brought you to where you are today?
Oh gosh, okay. Well, as you said, Shane, Matthew Scullion. I’m CEO and co-founder of a software company called Matillion. I hail from Manchester, UK. So, that’s a long way away from you at the moment. It’s nice to have the world connected in this way. I’ve spent my whole career in software, really. I got started very young. I don’t know why, but I’m a little embarrassed about this now. I got involved in my first software startup when I was, I think, 17 years old, back in late nineties, on the run-up to the millennium bug and also, importantly, as the internet was just starting to revolutionize business. And I’ve been working around B2B enterprise infrastructure software ever since.
And then, just over 10 years ago, I was lucky to co-found Matillion. We’re an ISV, which means a software company. So, you’re right, we do data stuff. We’re not a solutions companies, so we don’t go in and deliver finished projects for companies. Rather, we make the technologies that customers and solution providers use to deliver data projects. And we founded that company in Manchester in 2011. Just myself, my co-founder Ed Thompson, our CTO at the time, and we were shortly thereafter joined by another co-founder, Peter McCord. Today, the company’s international. About 1500 customers around the world, mostly, in revenue terms certainly, large enterprise customers spread across well over 40 different countries, and about 600 Matillioners. Roughly half R and D, building out the platform, and half running the business and looking after our clients and things like that. I’m trying to think if there’s anything else at all interesting to say about me, Shane. I am, outside of work, lucky to be surrounded by beautiful ladies, my wife and my two daughters. And so, between those two things, Matillion and my family, that’s most of the interesting stuff to say about me, I think.
Shane Hastie: Wonderful. Thank you. So, the reason we got together to talk about this was a survey that you did looking at what’s happening in the data employment field, the data job markets, and in the use of business data. So, what were the interesting things that came out of that survey?
Surveying Data Teams [03:01]
Matthew Scullion: Thanks very much for asking about that, Shane. And you’re quite right, we did do a survey, and it was a survey of our own customers. We’re lucky to have quite a lot of large enterprise customers that use our technology. I mean, there’s hundreds of them. Western Union, Sony, Slack, National Grid, Peet’s Coffee, Cisco. It’s a long list of big companies that use Matillion software to make their data useful. And so, we can talk to those companies, and also ones that aren’t yet Matillion customers, about what they’ve got going on in data, wider in their enterprise architecture, and in fact, with their teams and their employment situations, to make sure we are doing the right things to make their lives better, I suppose. And we had some hypotheses based on our own experience. We have a large R and D team here at Matillion, and we had observations about what’s going on in the engineering talent market, of course, but also feedback from our customers and partners about why they use our technology and what they’ve got going on around data.
Our hypothesis, Shane, and the reason that Matillion exists as a company, really is, as I know, certainly you and probably every listener to this podcast will have noticed, data has become a pretty big deal, right? As we like to say, it’s the new commodity, the new oil, and every aspect of how we work, live and play today is being changed, we hope for the better, with the application of data. It’s happening now, everywhere, and really quickly. We can talk, if you want, about some of the reasons for that, but let’s just bank that for now. You’ve got this worldwide race to put data to work. And of course, what that means is there’s a constraint, or set of constraints, and many of those constraints are around people. Whilst we all like to talk about and think about the things that data can do for us, helping us understand and serve our companies’ customers better is one of the reasons why companies put data to work. Streamlining business processes, improving products, increasingly data becoming the products.
All these things are what organizations are trying to do, and we do that with analytics and data visualization, artificial intelligence and machine learning. But what’s spoken about a lot less is that before you can do any of that stuff, before you can build the core dashboard that informs an area of the business, what to do next with a high level of fidelity, before you can coach the AI model to help your business become smarter and more efficient, you have to make data useful. You have to refine it, a little bit like iron ore into steel. The world is awash with data, but data doesn’t start off useful in its raw state. It’s not born in a way where you can put it to work in analytics, AI, or machine learning. You have to refine it. And the world’s ability to do that refinement is highly constrained. The ways that we do it are quite primitive and slow. They’re the purview of a small number of highly skilled people.
Our thesis was that every organization would like to be able to do more analytics, AI and ML projects, but they have this kink in the hose pipe. There’s size nine boots stood on the hose pipe of useful data coming through, and we thought was lightly causing stress and constraint within enterprise data teams. So we did this survey to ask and to say, “Is it true? Do you struggle in this area?” And the answer was very much yes, Shane, and we got some really interesting feedback from that.
Shane Hastie: And what was that feedback?
60% of the work in data analytics is sourcing and preparing the data [06:42]
Matthew Scullion: So, we targeted the survey on a couple of areas. And first of all, we’re saying, “Well, look, this part of making data useful in order to unlock AI machine learning and analytics projects. It may well be constrained, but is it a big deal? How much of your time on a use case like that do you spend trying to do that sort of stuff?” And this, really, is the heart of the answer I think. If you’re not involved in this space, you might not realize. Typically it’s about 60%, according to this and previous survey results. 60% of the work of delivering an analytics, AI and machine learning use case isn’t in building the dashboard, isn’t in the data scientist defining and coaching the model. Isn’t in the fun stuff, therefore, Shane. The stuff that we think about and use. Rather it’s in the loading, joining together, refinement and embellishment of the data to take it from its raw material state, buried in source systems into something ready to be used in analytics.
Friction in the data analytics value stream is driving people away
So, any time a company is thinking about delivering a data use case, they have to think about, the majority of the work is going to be in refining the data to make it useful. And so, we then asked for more information about what that was like, and the survey results were pretty clear. 75% of the data teams that we surveyed, at least, reported to us that the ways that they were doing that were slowing them down, mostly because they were either using outdated technology to do that, pre-cloud technology repurposed to a post-cloud world, and that was slowing this down. Or because they were doing it in granular ways. The cloud, I think many of us think it’s quite mainstream, and it is, right? It is pretty mainstream. But it’s still quite early in this once-in-a-generation tectonic change in the way that we deliver enterprise infrastructure technology. It’s still quite early. And normally in technology revolutions, we start off doing things in quite manual ways. We code them at a fairly low level.
So, 75% of data teams believe that the ways that they’re doing migration of data, data integration and maintenance, are costing their organizations both time, productivity and money. And that constraint also makes their lives less pleasant personally as they otherwise could be. Around 50% of our user respondents in this survey revealed this unpleasant picture, Shane, to be honest, of constant pressure and stress that comes with dealing with inefficient data integration. To put it simply, the business wants, needs and is asking for more than they’re capable of delivering, and that leads to 50% of these people feeding back that they feel under constant pressure and stress, experiencing burnout, and actually, this means that data professionals in such teams are looking for new roles and looking to go to areas with more manageable work-life balances.
So, yeah, it’s an interesting correlation between the desire of all organizations, really, to make themselves better using data, the boot on the hose pipe slowing down our ability to doing that, meaning that data professionals are maxed out and unable to keep up the demand. And that, in turn, therefore, leading to stress and difficulty in attracting and retaining talent into teams. Does that all make sense?
Shane Hastie: It does indeed. And, certainly, if I think back to my experience, the projects that were the toughest, it was generally pretty easy to get the software product built, but then to do the data integration or the data conversions as we did so often back then, and making that old data usable again, were very stressful and not fun. That’s still the case.
Data preparation and conversion is getting harder not easier [10:43]
Matthew Scullion: It’s still the case and worse to an order of magnitude because we have so many systems now. Separately, we also did a survey, probably need to work on a more interesting way of introducing that term, don’t I, Shane? But we talk to our clients all the time. And another data point we have is that in our enterprise customers, our larger businesses – so, this is typically businesses with, say, a revenue of 500 million US dollars or above. The average number of systems that they want to get data out of and put it to work in analytics projects, the average number is just north of a thousand different systems. Now, that’s not in a single use case, but it is across the organization. And each of those systems, of course, has got dozens or hundreds, in many cases thousands of data elements inside it. You look at a system like SAP, I think it has 80,000 different entities inside, and that would count as one system on my list of a thousand.
And in today’s world, even a company like Matillion, we’re a 600-person company. We have hundreds of modern SaaS applications that we use, and I’d be fairly willing to bet that we have a couple of ones being created every day. So, the challenge is becoming harder and harder. And at the other side of the equation, the hunger, the need to deliver data projects much, much more acute, as we race to change every aspect of how we work, live and play, for the better, using data. Organizations that can figure out an agile, productive, maintainable way of doing this at pace have a huge competitive advantage. It really is something that can be driven at the engineering and enterprise architecture and IT leadership level, because the decisions that we make there can give the business agility and speed as well as making people’s lives better in the way that we do it.
Shane Hastie: Let’s drill into this. What are some of the big decisions that organizations need to make at that level to support this, to make using data easier?
Architecture and data management policies need to change to make data more interoperable [12:44]
Matthew Scullion: Yeah, so I’m very much focused, as we’ve discussed already, on this part of using data, the making it useful. The refining it from iron ore into steel, before you then turn that steel into a bridge or ship or a building, right? So, in terms of building the dashboards or doing the data science, that’s not really my bag. But the bit that we focus on, which is the majority of the work, like I mentioned earlier, is getting the data into one place, the de-normalizing, flattening and joining together of that data. The embellishing it with metrics to make a single version of the truth, and make it useful. And then, the making sure that process happens fast enough, reliably, at scale, and can be maintained over time. That’s the bit that I focus in. So, I’m answering your question, Shane, through that lens, and in my belief, at least, to focus on that bit, because it’s not the bit that we think about, but it’s the majority of the work.
First of all, perhaps it would be useful to talk about how we typically do that today in the cloud, and people have been doing this stuff for 30 years, right? So, what’s accelerating the rate at which data is used and needs to be used is the cloud. The cloud’s provided this platform where we can, almost at the speed of thought, create limitlessly scalable data platforms and derive competitive advantage that improves the lives of our downstream customers. Once you’ve created that latent capacity, people want to use it, and therefore you have to use it. So, the number of data projects and the speed at which we can do them today, massively up and to the right because of the cloud. And then, we’ve spoken already about all the different source systems that have got your iron ore buried in.
So, in the cloud today, people typically do, for the most part, one of two different main ways to make data useful, to do data integration, to refine it from iron ore into steel. So, the first thing that they do, and this is very common in new technology, is that they make data useful in a very engineering-centric way. Great thing about coding, as you and I know well, is that you can do anything in code, right? And so, we do, particularly earlier technology markets. We hand code making data useful. And there’s nothing wrong with that, and in some use cases, it’s, in fact, the right way to do it. There’s a range of different technologies that we can do, we might be doing it in SQL or DBT. We might be doing it using Spark and Pi Spark. We might even be coding in Java or whatever. But we’re using engineering skills to do this work. And that’s great, because A, we don’t need any other software to do it. B, engineers can do anything. It’s very precise.
But it does have a couple of major drawbacks when we are faced with the need to innovate with data in every aspect of how we work, live and play. And drawback number one is it’s the purview of a small number of people, comparatively, right? Engineering resources in almost every organization are scarce. And particularly in larger organizations, companies with many hundreds or many thousands of team members, the per capita headcount of engineers in a business that’s got 10,000 people, most of whom make movies or earth-moving equipment or sell drugs or whatever it is. It’s low, right? We’re a precious resource, us engineers. And because we’ve got this huge amount of work to do in data integration, we become a bottleneck.
The second thing is data integration just changes all the time. Any time I’ve ever seen someone use a dashboard, read a report, they’re like, “That’s great, and now I have another question.” And that means the data integration that supports that data use case immediately needs updating. So, you don’t just build something once, it’s permanently evolving. And so, at a personal level for the engineer, unless they want to sit there and maintain that data integration program forever, we need to think about that, and it’s not a one and done thing. And so, that then causes a problem because we have to ramp new skills onto the project. People don’t want to do that forever. They want to move on to different companies, different use cases, and sorry, if they don’t, ultimately they’ll probably move on to a different company because they’re bored. And as an organization, we need the ability to ramp new skills on there, and that’s difficult in code, because you’ve got to go and learn what someone else coded.
Pre-cloud tools and techniques do not work in the modern cloud-based environment
So, in the post-cloud world, in this early new mega trend, comparatively speaking, one of the ways that we make data useful is by hand-coding it, in effect. And that’s great because we can do it with precision, and engineers can do anything, but the downside is it’s the least productive way to do it. It’s the purview of a small number of valuable, but scarce people, and it’s hard to maintain in the long term. Now, the other way that people do this is that they use data integration technology that solves some of those problems, but that was built for the pre-cloud world. And that’s the other side of the coin that people face. They’re like, “Okay, well I don’t want to code this stuff. I learned this 20 years ago with my on-premise data warehouse and my on-premise data integration technology. I need this stuff to be maintainable. I need a wider audience of people to be able to participate. I’ll use my existing enterprise data integration technology, ETL technology, to do that.”
That’s a great approach, apart from the fact that pre-cloud technology isn’t architected to make best use of the modern cloud, public cloud platforms and hyperscalers likes AWS Azure and Google Cloud, nor the modern cloud data platforms like Snowflake, Databricks, Amazon Redshift, Google BigQuery, et al. And so, in that situation, you’ve gone to all the trouble of buying a Blu-ray player, but you’re watching it through a standard definition television, right? You’re using the modern underlying technology, but the way you’re accessing it is out of date. Architecturally, the way that we do things in the cloud is just different to how we did it with on-premises technology, and therefore it’s hard to square that circle.
It’s for these two reasons that today, many organizations struggle to make data useful fast enough, and why, in turn, therefore, that they’re in this lose-lose situation of the engineers are either stressed out and burnt out and stuck on projects that they want to move on from, or bored because they’re doing low-level data enrichment for weeks, months, or years, and not being able to get off it, as the business’ insatiable demand for useful data never goes away and they can’t keep up. Or, because they’re unable to serve the needs of the business and to change every aspect of how we work, live and play with data. Or honestly, Shane, probably both. It’s probably both of those things.
So our view, and this is why Matillion exists, is that you can square this circle. You can make data useful with productivity, and the way that you do it is by putting a technology layer in place, specifically designed to talk to these problems. And if that technology layer is going to be successful, we think it needs to have a couple of things that it exhibits. The first one is it needs to solve for this skills problem, and do that by making it essentially easier whilst not dumbing it down, and by making it easier, making a wider audience of people able to participate in making data useful. Now, we do that in Matillion by making our technology low-code, no-code, code optional. Matillion’s platform is a visual data integration platform, so you can dive in and visually load, transform, synchronize and orchestrate data.
That low-code, no-code environments can make a single engineer far more productive, but perhaps as, if not more importantly, it means it’s not just high-end engineers that can do this work. It can also be done by data professionals, maybe ETL guys, BI people, data scientists. Even tech-savvy business analyst, financiers and marketers. Anyone that understands what a row and a column is can pretty much use technology like Matillion. And the other thing that the low-code, no-code user experience really helps with is managing skills on projects. You can ramp someone onto a project that’s already been up and running much more easily, because you can understand what’s going on, because it’s a diagram. You can drop into something a year after it was last touched and make changes to it much, much more easily because it’s low-code, no-code.
Now, the average engineer, Shane, in my experience, often is skeptical about visual 4GL or low-code, no-code engineering, and I understand the reasons why. We’ve all tried to use these tools before. But, in the case of data, at least, it can be done. It’s a technically hard problem, it’s one that we’ve spent the last seven, eight years perfecting, but you can build a visual environment that creates the high-quality push down ELT instruction set to the underlying cloud data platform as well, if not perhaps even better than we could by hand, and certainly far faster. That pure ELT architecture, which means that we get the underlying cloud data platform to do the work of transforming data, giving us scalability and performance in our data integrations. That’s really important, and that can be done, and that’s certainly what we’ve done at Matillion.
The skills challenges are most apparent in large organisations
The other criteria I’ll just touch on quickly. The people that suffer with this skills challenge the most are larger businesses. Smaller businesses that are really putting data to work tend to be either technology businesses or technology-enabled businesses, which probably means they’re younger and therefore have fewer source systems with data in. A higher percentage of their team are engineering team members. They’re more digitally native. And so, the problem’s slightly less pronounced for that kind of tech startup style company. But if you’re a global 8,000, manufacturing, retail, life sciences, public sector, financial services, whatever type company, then your primary business is doing something else, and this is something that you need to do as a part of it. The problem for you is super acute.
And so, the second criteria that a technology that’s going to solve this problem has to have is it has to work well for the enterprise, and that’s the other thing that Matillion does. So, we’re data integration for the cloud and for the enterprise, and that means that we scale to very large use cases and have all the right security and permissions technology. But it’s also things like auditability, maintainability, integration to software development life-cycle management, and code repositories and all that sort of good stuff, so that you can treat data integration in the same way that you treat building software, with proper, agile processes, proper DevOps, or as we call them in the data space, data-ops processes, in use behind the scenes.
These challenges are not new – the industry has faced them with each technology shift
So, that’s the challenge. And finally, if you don’t mind me rounding out on this point, Shane, it’s like, we’ve all lived through this before. Nothing’s new in IT. The example I always go back to is one from, I was going to say the beginning of my career. I’d be exaggerating my age slightly there, actually. It’s more like it’s from the beginning of my life. But the PC revolution is something I always think about. When PCs first came in, the people that used them were enthusiasts and engineers because they arrived in a box of components that you had to solder together. And then, you had to write code to make them do anything. And that’s the same with every technology revolution. And that’s where we’re up to with data today. And then later, visual operating systems, abstracted the backend complexity of the hardware and underlying software, and allowed a wider audience for people to get involved, and then, suddenly, everyone in the world use PCs. And now, we don’t really think about PCs anymore. It’s just a screen in our pocket or our laptop bag.
That’s what will and is happening with data. We’ve been in the solder it together and write code stage, but we will never be able to keep up with the world’s insatiable need and desire to make data useful by doing it that way. We have to get more people into the pass rush, and that’s certainly what we and Matillion are trying to do, which suits everyone. It means engineers can focus on the unique problems that only they can solve. It means business people closer to the business problems can self-serve, and in a democratized way, make the data useful that they need to understand their customers better and drive business improvement.
Shane Hastie: Some really interesting stuff in there. Just coming around a little bit, this is the Engineering Culture podcast. In our conversations before we started recording, you mentioned that Matillion has a strong culture, and that you do quite a lot to maintain and support that. What’s needed to build and maintain a great culture in an engineering-centric organization?
Maintaining a collaborative culture [25:44]
Matthew Scullion: Thanks for asking about that, Shane, and you’re right. People that are unlucky enough to get cornered by me at cocktail parties will know that I like to do nothing more than bang on about culture. It’s important to me. I believe that it’s important to any organization trying to be high performance and change the world like, certainly, we are here in Matillion. I often say a line when I’m talking to the company, that the most important thing in Matillion, and I have to be careful with this one, because it could be misinterpreted. The most important thing in Matillion, it’s not even our product platform, which is so important to us and our customers. It’s not our shiny investors. Matillion was lucky to become a unicorn stage company last year, I think we’ve raised about 300 million bucks in venture capital so far from some of the most prestigious investors in the world, who we value greatly, but they’re not the most important thing.
It’s not even, Shane, now this is the bit I have to be careful saying, it’s not even our customers in a way. We only exist to make the lives of our customers better. But the most important thing at Matillion is our team, because it’s our team that make those customers’ lives better, that build those products, that attract those investors. The team in any organization is the most important thing, in my opinion. And teams live in a culture. And if that culture’s good, then that team will perform better, and ultimately do a better job at delighting its customers, building its products, whatever they do. So, we really believe that at Matillion. We always have, actually. The very first thing that I did on the first day of Matillion, all the way back in January of 2011, which seems like a long, long time ago now, is I wrote down the Matillion values. There’s six of them today. I don’t think I had six on the first day. I think I embellished the list of it afterwards. But we wrote down the Matillion values, these values being the foundations that this culture sits on top of.
If we talk to engineering culture specifically, I’ve either been an engineer or been working with or managing engineers my whole career. So, 25 years now, I suppose, managing or being in engineering management. And the things that I think are the case about engineering culture is, first of all, engineering is fundamentally a creative business. We invent new, fun stuff every day. And so, thing number one that you’ve got to do for engineers is keep it interesting, right? There’s got to be interesting, stimulating work to do. This is partly what we heard in that data survey a few minutes ago, right? If you’re making data useful through code, might be interesting for the first few days, but for the next five years, maintaining it’s not very interesting. It gets boring, stressful, and you churn out the company. You’ve got to keep engineers stimulated, give them technically interesting problems.
But also, and this next one applies to all parts of the organization. You’ve got to give them a culture, you’ve got to give each other a culture, where we can do our best work. Where we’re intellectually safe to do our best work. Where we treat each other with integrity and kindness. Where we are all aligned to delivering on shared goals, where we all know what those same shared goals are ,and where we trust each other in a particular way. That particular way of trusting each other, it’s trusting that we have the same shared goal, because that means if you say to me, “Hey, Matthew, I think you are approaching this in the wrong way,” then I know that you’re only saying that to me because you have the same shared goal as I do. And therefore, I’m happy that you’re saying it to me. In fact, if you didn’t say it to me, you’d be helping me fail.
So, trust in shared goals, the kind of intellectual safety born from respect and integrity. And then, finally, the interest and stimulation. To me, those are all central to providing a resonant culture for perhaps all team members in an organization, but certainly engineers to work in. We think it’s a huge competitive advantage to have a strong, healthy culture. We think it’s the advantage that’s allowed us, in part, but materially so, to be well on the way to building a consequential, generational organization that’s making the world’s data useful. Yes, as you can tell, it’s something I feel very passionate about.
Shane Hastie: Thank you very much. A lot of good stuff there. If people want to continue the conversation, where do they find you?
Matthew Scullion: Well, me personally, you can find me on Twitter, @MatthewScullion. On LinkedIn, just hit Matthew Scullion Matillion, you’ll find me on there. Company-wise, please do go ahead and visit us at matillion.com. All our software is very easy to consume. It’s all cloud-native, so you can try it out free of charge, click it and launch it in a few minutes, and we’d love to see you there. And Shane, it’s been such a pleasure being on the podcast today. Thank you for having me.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Virtual Machine Threat Detection in Google Security Command Center Now Generally Available
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Google Cloud recently announced the general availability (GA) of Virtual Machine Threat Detection (VMTD) as a built-in service in Security Command Center Premium, which can detect if hackers attempt to mine cryptocurrency in a company’s cloud environment.
The capability of the Security Command Center is a part of the vision the company has regarding invisible security. Earlier, VMTD was released in public preview and received adoption from users around the world, according to the company. Moreover, since the service’s initial release, the company has added several new features like more frequent scanning across many instances.
Customers can easily enable VTMD by checking a box in their Security Command Center Premium settings. Subsequently, the service can detect if the customers’ cloud environment contains malware that hijacks infrastructure resources to mine cryptocurrency. Furthermore, the service provides technical information about the malware to help administrators block it.
VM Threat Detection is built into Google Cloud’s hypervisor, a secure platform that creates and manages all Compute Engine VMs. Under the hood, the service scans enabled Compute Engine projects and VM instances to detect unwanted applications, such as cryptocurrency mining software running in VMs. And the analysis engine ingests metadata from VM guest memory and writes findings to Security Command Center.
VMTD does not rely on software agents to detect malware compared to traditional cybersecurity products. Attackers cannot disable it; unlike agents, they potentially can. Furthermore, setup is less time-consuming, considering when there are a large number of instances.
In a Google Cloud blog post, the company intends to expand VMTD to cover more cybersecurity use cases in the future. Timothy Peacock, a senior product manager, stated:
In the future, we plan on further improving VMTD’s understanding of Linux kernels to detect additional advanced attacks and report live telemetry to our customers. With its unique position as an outside-the-instance observer, VMTD can detect rootkits and bootkits, attacks that tamper with kernel integrity, and otherwise blind the kernel and traditional endpoint detection and response technology (EDR) to their presence.
Lastly, the pricing details of the Security Command Center are available on the pricing page, and more details are on the documentation landing page.
MMS • Doris Xin
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Automating the ML pipeline could put machine learning into the hands of more people, including those who do not have years of data science training and a data center at their disposal. Unfortunately, true end-to-end automation is not yet available.
- AutoML is currently most frequently used in hyperparameter tuning and model selection. The failure of AutoML to be end-to-end can actually cut into the efficiency improvements; moving aspects of the project between platforms and processes is time-consuming, risks mistakes, and takes up the mindshare of the operator.
- AutoML systems should seek to balance human control with automation: focusing on the best opportunities for automation and allowing for humans to perform the parts that are most suited for humans. By combining the manual and automated strategies, practitioners can increase confidence and trust in the final product.
- The collaboration between humans and automation tooling can be better than either one working alone. By combining the manual and automated strategies, practitioners can increase confidence and trust in the final product.
- ML practitioners are the most open to the automation of the mechanical engineering tasks, such as data pipeline building, model serving, and model monitoring, involved in ML operations (MLOps). The focus of AutoML should be on these tasks since they are high-leverage and their automation has a much lower chance of introducing bias.
The current conversation about automated machine learning (AutoML) is a blend of hope and frustration.
Automation to improve machine learning projects comes from a noble goal. By streamlining development, ML projects can be put in the hands of more people, including those who do not have years of data science training and a data center at their disposal.
End-to-end automation, while it may be promised by some providers, is not available yet. There are capabilities in AutoML, particularly in modeling tasks, that practitioners from novice to advanced data scientists are using today to enhance their work. However, seeing how automation and human operators interact, it may never be optimal for most data science projects to completely automate the process. In addition, AutoML tools struggle to address fairness, explainability, and bias—arguably the central issue in artificial intelligence (AI) and ML today. AutoML systems should emphasize ways to decrease the amount of time data engineers and ML practitioners spend on mechanistic tasks and interact well with practitioners of different skill levels.
Along with my colleagues Eva Yiwei Wu, Doris Jung-Lin Lee, Niloufar Salehi, and Aditya Parameswaran, I presented a paper at the ACM CHI Conference on Human Factors in Computer Systems studying how AutoML fits into machine workflows. The paper details an in-depth qualitative study of sixteen AutoML users ranging from hobbyists to industry researchers across a diverse set of domains.
Questions asked aimed to uncover their experiences working with and without AutoML tools and their perceptions of AutoML tools so that we could ultimately gain a better understanding of AutoML user needs; AutoML tool strengths / weaknesses; and insights into the respective roles of the human developer and automation in ML development.
The many faces of AutoML
The idea of automating some elements of a machine learning project is sensible. Many data scientists have had the dream of democratizing data science through an easy-to-use process that puts those capabilities in more hands. Today’s AutoML solutions fall into three categories: cloud provider solutions, commercial platforms, and open source projects.
Cloud provider solutions
The hosted compute resources of Google Cloud AutoML, Microsoft Azure Automated ML, and Amazon SageMaker Autopilot provide all the familiar benefits of cloud solutions: integration with the cloud data ecosystem for more end-to-end support, pay-as-you-go pricing models, low barrier to entry, and no infrastructure concerns. They also bring with them common cloud service frustrations a project may face: lack of customizability, vendor lock-in, and an opaque process. They all offer no-code solutions that appeal to the citizen scientist or innovator. But for the more advanced user, the lack of transparency is problematic for many scenarios; as of this writing, only Amazon SageMaker Autopilot allows the user to export code and intermediate results. Many users find themselves frustrated by the lack of control over model selection and limited visibility into the models utilized.
It is a familiar story with the Google, Amazon, and Microsoft solutions in other categories; cloud products seek to provide as much of an end-to-end solution as possible and an easy-to-use experience. The design tradeoff is low visibility and less customization options. For example, Google AutoML only provides the final model; it fails to yield the training code or any intermediate results during training. Microsoft Azure gives much more information about the training process itself, but it does not give the code for the training models.
{kind=link}
Commercial platforms
The most frequently discussed commercial AutoML products are DataRobot and H20 Driverless AI. The companies behind these products are seeking to provide end-to-end AI and ML platforms for business users as well as data scientists, particularly those using on-premises compute. They focus on operationalizing the model: launching the application or data results for use.
Open source projects
There are a lot of open source projects in the machine learning space. Some of the more well-known are Auto-sklearn, AutoKeras, and TPOT. The open source process allows for the best of data science and development to come together. However, they are often lacking in post-processing deployment help that is a primary focus of commercial platforms.
What AutoML brings to a project
Those we surveyed had frustrations, but they were still able to use AutoML tools to make their work more fruitful. In particular, AutoML tools are used in the modeling tasks. Although most AutoML providers stated that their product is “end-to-end,” the pre-processing and post-processing phases are not greatly impacted by AutoML.
The data collection, data tagging, and data wrangling of pre-processing are still tedious, manual processes. There are utilities that provide some time savings and aid in simple feature engineering, but overall, most practitioners do not make use of AutoML as they prepare data.
In post-processing, AutoML offerings have some deployment capabilities. But Deployment is famously a problematic interaction between MLOps and DevOps in need of automation. Take for example one of the most common post-processing tasks: generating reports and sharing results. While cloud-hosted AutoML tools are able to auto-generate reports and visualizations, our findings show that users are still adopting manual approaches to modify default reports. The second most common post-processing task is deploying models. Automated deployment was only afforded to users of hosted AutoML tools and limitations still existed for security or end user experience considerations.
The failure of AutoML to be end-to-end can actually cut into the efficiency improvements; moving aspects of the project between platforms and processes is time-consuming, risks mistakes, and takes up the mindshare of the operator.
AutoML is most frequently and enthusiastically used in hyperparameter tuning and model selection.
Hyperparameter tuning and model selection
When possible configurations quickly explode to billions, as they do in hyperparameters for many projects, automation is a welcome aid. AutoML tools can try possibilities and score them to accelerate the process and improve outcomes. This was the first AutoML feature to become available. Perhaps its maturity is why it is so popular. Eleven of the 16 users we interviewed used AutoML hyperparameter-tuning capabilities.
Improving key foundations of the modeling phase saves a lot of time. Users did find that the AutoML solution could not be completely left alone to the task. This is a theme with AutoML features; knowledge gained from the human’s prior experience and the ability to understand context can, if the user interface allows, eliminate some dead ends. By limiting the scope of the AutoML process, a human significantly reduces the cost of the step.
AutoML assistance to model selection can aid the experienced ML practitioner in overcoming their own assumptions by quickly testing other models. One practitioner in our survey called the AutoML model selection process “the no assumptions approach” that overcame their own familiarity and preferences.
AutoML for model selection is a more efficient way of developing and testing models. It also improves, though perhaps not dramatically, the effectiveness of model development.
The potential drawback is that, left unchecked, the model selection is very resource heavy – encompassing ingesting, transforming, and validating data distributions data. It is essential to identify models that are not viable for deployment or valuable compute resources are wasted and can thus lead to crashing pipelines. Many AutoML tools don’t understand the resources available to them which causes system failures. The human operator can pare down the possible models. But this practice does fly in the face of the idea of overcoming operator assumptions. The scientist or operator has an important role to play discerning what experiments are worth providing the AutoML system and what are a waste of time.
Informing manual development
Despite any marketing or names that suggest an AutoML platform is automatic, that is not what users experience. There is nothing entirely push-button, and the human operator is still called upon to make decisions. However, the tool and the human working together can be better than either one working alone.
By combining the manual and automated strategies, practitioners can increase confidence and trust in the final product. Practitioners shared that running the automated process validated that they were on the right track. They also like to use it for rapid prototyping. It works the other way as well; by performing a manual process in parallel with the AutoML process, practitioners have built trust in their AutoML pipeline by showing that its results are akin to a manual effort.
Reproducibility
Data scientists do tend to be somewhat artisanal. Since an automated process can be reproduced and can standardize code, organizations can have a more enduring repository of ML and AI projects even as staff turns over. New models can be created more rapidly, and teams can compare models in an apples-to-apples format.
In context: The big questions of responsible AI
At this point in the growth of AI, all practitioners should be considering bias and fairness. It is an ethical and social impetus. Documenting efforts to minimize bias is important in building trust with clients, users, and the public.
The key concept of explainability is how we as practitioners earn user trust. While AutoML providers are making efforts of their own to build in anti-bias process and explainability, there is a long way to go. They have not effectively addressed explainability. Being able to reveal the model and identify the source of suspect outcomes helps build trust and, should there be a problem, identify a repair. Simply having a human involved does not assure that there is no bias. However, without visibility, the likelihood of bias grows. Transparency mechanisms like visualization increase user understanding and trust in AutoML, but it does not suffice for trust and understanding between humans and the tool-built model. Humans need agency to establish the level of understanding to trust AutoML.
In our interviews, we discovered that practitioners switch to completely manual development to have the user agency, interpretability, and trust expected for projects.
Human-automation partnership
A contemporary end-to-end AutoML system is by necessity highly complex. Its users come from different backgrounds and have diverse goals but are all likely doing difficult work under a lot of pressure. AutoML can be a significant force multiplier for ML projects, as we learned in our interviews.
While the term “automated ML” might imply a push-button, one-stop-shop nature, ML practitioners are valuable contributors and supervisors to AutoML. Humans improve the efficiency, effectiveness and safety of AutoML tools by instructing, advising and safeguarding them. With this in mind, the research study also identified guidelines to consider for successful human-automation partnerships:
- Focus on automating the parts of the process that consume valuable data engineering time. Currently there are only 2.5 data engineer job applicants for every data engineer position (compare this to 4.76 candidates per data scientist job listing or 10.8 candidates per web developer job listing according to DICE 2020 Tech Job Report); there is much demand and little supply for this skill set.
- Establish trust with users as well as agency for those users. When AutoML systems deprive users of visibility and control, those systems cannot be a part of real-world uses where they can have an impact.
- Develop user experience and user interfaces that adapt for user proficiency. The trend for AutoML systems is to develop more capabilities for novice and low-code users. Although some users have the ability to export raw model-training code, it is often a distraction from their workflow, leading to wasted time exploring low-impact code. Further, when novices are afforded the option to see raw model-training code it requires them to self-select the appropriate modality (information and customizability provided to the user). Matching expert users with the “novice modality” causes frustration due to lack of control. In the other direction, novices get distracted by things they don’t understand.
- Provide an interactive, multi-touch exploration for more advanced users. Iteration is the habitual and necessary work style of ML practitioners, and the tool should aid in the process rather than interrupt it.
- Let the platform be a translator and shared truth for varied stakeholders. The conversations between business users and ML practitioners would greatly benefit from a platform and shared vocabulary. Providing a trusted space for conversation would remove that burden that frequently falls to the ML engineers.
AutoML systems should seek to balance human control with automation: focusing on the best opportunities for automation and allowing for humans to perform the parts that are most suited for humans: using contextual awareness and domain expertise.
Is AutoML ready?
As a collection of tools, AutoML capabilities have proven value but need to be vetted more thoroughly. Segments of these products can help the data scientist improve outcomes and efficiencies. AutoML can provide rapid prototyping. Citizen scientists, innovators, and organizations with fewer resources can employ machine learning. However, there is not an effective end-to-end AutoML solution available now.
Are we focusing on the right things in the automation of ML today? Should it be hyperparameter tuning or data engineering? Are the expectations appropriate?
In our survey, we found that practitioners are much more open to automating the mechanical parts of ML development and deployment to accelerate the iteration speed for ML models. However, AutoML systems seem to focus on the processes over which the users want to have the most agency. The issues around bias in particular suggest that AutoML providers and practitioners should be aware of the deficiencies of AutoML for model development.
The tasks that are more amenable to automation are involved in machine learning operations (MLOps). They include tasks such as data pipeline building, model serving, and model monitoring. What’s different about these tasks is that they help the users build models rather than remove the user from the model building process (which, as we noted earlier, is bad for transparency and bias reasons).
MLOps is a nascent field that requires repetitive engineering work and uses tooling and procedures that are relatively ill-defined. With a talent shortage for data engineering (on average, it takes 18 months to fill a job position), MLOps represents a tremendous opportunity for automation and standardization.
So rather than focus on AutoML, the future of automation for ML and AI rests in the ability for us to realize the potential of AutoMLOps.
Java News Roundup: JReleaser 1.2, Spring Batch, PrimeFaces, Quarkus, JobRunr, Apache Beam
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

It was very quiet for Java news during the week of August 22nd, 2022 featuring news from JDK 19, JDK 20, Spring Batch 5.0.0-M5, Quarkus 2.11.3, JReleaser 1.2.0, PrimeFaces 12.0.0-M3, JobRunr 5.1.8, Apache Beam 2.14.0 and Apache Johnzon 1.2.19.
JDK 19
JDK 19 remains in its release candidate phase with the anticipated GA release on September 20, 2022. The release notes include links to documents such as the complete API specification and an annotated API specification comparing the differences between JDK 18 (Build 36) and JDK 19 (Build 36). InfoQ will follow-up with a more detailed news story.
JDK 20
Build 12 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 11 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
After a very busy previous week, it was a very quiet week for the Spring team.
On the road to Spring Batch 5.0.0, the fifth milestone release was made available with updates that include: removing the autowiring of jobs in JobLauncherTestUtils class; a migration to JUnit Jupiter; and improvements in documentation. This release also features dependency upgrades to Spring Framework 6.0.0-M5, Spring Data 2022.0.0-M5, Spring Integration 6.0.0-M4, Spring AMQP 3.0.0-M3, Spring for Apache Kafka 3.0.0-M5, Micrometer 1.10.0-M4 and Hibernate 6.1.2.Final. And finally, Spring Batch 5.0.0-M5 introduces two deprecations, namely: the Hibernate ItemReader and ItemWriter interfaces for cursor/paging are now deprecated in favor of using the ones based on the Jakarta Persistence specification; and the AssertFile utility class was also deprecated due to the discovery of two static methods in JUnit that provide the same functionality. More details on this release may be found in the release notes.
Quarkus
Red Hat has released Quarkus 2.11.3.Final that ships with a comprehensive fix for CVE-2022-2466, a vulnerability discovered in the SmallRye GraphQL server extension in which server requests were not properly terminated. There were also dependency upgrades to mariadb-java-client 3.0.7, postgresql 42.4.1 and 42.4.2 and mysql-connector-java 8.0.30. Further details on this release may be found in the release notes.
JReleaser
Version 1.2.0 of JReleaser, a Java utility that streamlines creating project releases, has been made available featuring: support for Flatpak as a packager; allow basedir to be a named template; allow a message file, with each line as a separate message and to skip empty/blank lines, on Twitter via Twitter4J; an option to configure unused custom launchers as it was discovered via the logs that the -add-launcher argument was not being passed. There were also numerous dependency upgrades such as: jsonschema 4.26.0, github-api 1.308, slf4j 2.0.0, aws-java-sdk 1.12.270 and 1.12.290 and jsoup 1.15.3. More details on this release may be found in the changelog.
PrimeFaces
On the road to PrimeFaces 12.0.0, the third release candidate has been made available featuring: a fix for the AutoComplete component not working on Apache MyFaces; a new showMinMaxRange attribute to allow navigation past min/max dates with a default value of true; and a new showSelectAll attribute to the DataTable component to display the “select all checkbox” inside the column’s header. Further details may be found in the list of issues.
JobRunr
Ronald Dehuysser, founder and primary developer of JobRunr, a utility to perform background processing in Java, has released version 5.1.8 that features the ability to turn off metrics for background job servers.
Apache Software Foundation
Apache Beam 2.41.0 has been released featuring numerous bug fixes and support for the KV class for the Python RunInference transform for Java. More details on this release may be found in the release notes and a more in-depth introduction to Apache Beam may be found in this InfoQ technical article.
Version 1.2.19 of Apache Johnzon, a project that fully implements the JSR 353, Java API for JSON Processing (JSON-P), and JSR 367, Java API for JSON Binding (JSON-B) specifications, has been released featuring: basic support of enumerations in the PojoGenerator class; adding JSON-Schema to onEnum callback; ensure an import of JsonbProperty when enumerations use it; and expose the toJavaName() method to subclasses in the PojoGenerator class. Further details on this release may be found in the changelog.
MMS • Karsten Silz James Ward
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Java is still a great language, but Kotlin is a faster-developing, incremental alternative, while Scala takes Functional Programming to some extremes.
- James prefers languages that let him write more correct code through a high level of validation at compile time.
- Through Scala, James found programming paradigms and experiences that have altered his way of thinking.
- Default mutability in Java is a “trillion-dollar mistake” because it makes it hard to reason about what the code does.
- Project Loom’s approach is a game-changer because it removes the cognitive overload of reactive programming.
James Ward is a Java Champion and Kotlin Product Manager at Google. He hosts the “Happy Path Programming” podcast with Bruce “Thinking in Java” Eckel. In one episode, Eckel spoke of “people who are still trapped in the Java world.” Ward agreed and called default mutability in Java the “trillion-dollar mistake” (referencing the “billion-dollar mistake” of NullPointerExceptions). InfoQ got curious about this Java champions’ view on Java and asked Ward some questions. Here are the answers.
InfoQ: What is the role of the Kotlin Product Manager at Google? What are your day-to-day responsibilities?
Ward: There are two sides to the Kotlin PM job. I work with our Android teams and JetBrains on Kotlin language improvements and growth. I also work with many engineering teams within Google to help make their server-side and Android migrations from Java to Kotlin successful.
InfoQ: What is the state of JVM languages in 2022?
Ward: I began using the Java programming language 25 years ago and think it is still a great language. But I’ve also been able to work with more modern JVM languages over the past ten years, including Scala and Kotlin. Scala is great for developers wanting to take Functional Programming to some extremes. Kotlin is more of an incremental step for existing Java developers having good support for some Functional paradigms like immutability and sum types but lacking some of the “Monadic” features that Scala has. Both Kotlin and Scala have great interoperability with Java, enabling ecosystem sharing. JVM developers have many options for great languages and a lot of tooling overlap (build tools, IDEs, production/introspection tools, etc.). It is great that on the JVM, in one large ecosystem, there is such a spectrum of language options.
InfoQ: How much JVM back-end development happens in Kotlin these days? And how do you think Kotlin could become more popular there?
Ward: Overall, the Kotlin share of JVM servers is fairly small, but it is growing quickly. Google, for example, has seen significant growth in the use of Kotlin for server-side development. Developers who’ve either switched from Java or come from other languages report they are very satisfied with the experience. Null safety, coroutines, and expressiveness are often noted as important reasons why Kotlin is more productive and fun to work with.
Kotlin will definitely continue to grow on the server-side. Spring, Quarkus, and Micronaut have done quite a bit of work to make their Kotlin experiences great (such as coroutine interoperability for Reactive). Enterprises generally move pretty slowly with new technologies. Still, for many the move to Kotlin (on the JVM) is a much less risky and disruptive change than moving to Rust (for example). Also, Kotlin’s interoperability with Java helps code migrations to be incremental instead of rewrites. Many teams I’ve worked with just add new code in Kotlin to an existing Java codebase.
InfoQ: How do the JVM languages stack up against other programming languages, especially in the cloud? Python and JavaScript are more popular than Java in Google searches and have more questions on Stack Overflow.
Ward: If I were designing a programming language, I’d aim to have fewer searches and questions asked about my language. 😉 Having been a programmer for over 30 years, I tend more towards languages that enable me to write more “correct” code that is testable and reusable. I don’t like surprises in production, and I want to be able to refactor without fear. Having a compiler that can perform a high level of validation on my program is an essential feature. Sure I might not be able to write raw code as fast as others, but I do write code that is pretty unlikely to have bugs in production. If you consider fixing production bugs as part of the development cycle, then using modern languages on the JVM likely provides the highest productivity possible for many problem domains.
InfoQ: GraalVM produces native Java applications that start faster and use less memory. How will this affect the competitive position of JVM languages in the cloud?
Ward: Startup and memory overhead have definitely hindered the adoption of JVM technologies in some problem spaces (serverless, CLIs, Kubernetes operators, etc.). GraalVM Native Image, Kotlin/Native, and Scala Native help take these languages to places where typically interpreted or native languages used to be a better fit. Now we can have our cake (fast startup and minimal memory overhead) and eat it too (modern high-level languages). I recently created a server with the Kotlin Ktor library, which I can run on the JVM or compile to native with both Kotlin/Native and GraalVM Native Image. In the native case, the startup time was about 2 ms, the memory usage was 11 MB, and the binary was compacted down to 700 KB. For many use cases, we no longer need to make tradeoffs between native and modern/high-level languages.
InfoQ: What makes Scala so appealing to you?
Ward: Scala has a long learning curve. After over ten years with the language, I still feel like a novice. Which is great for me because I love learning new programming languages and enjoy the challenge. I also have really bought into many of the principles of Functional Programming but have not yet followed those all the way to Haskell, so Scala is a good place to be somewhat comfortable with JVM-based FP. I’m currently writing a book with Bruce Eckel and Bill Frasure about Effect Oriented Programming in Scala 3 and ZIO 2. Functional Effects represent a concept that makes a significant difference to the quality of software we create but isn’t well supported yet in Java or Kotlin. There are many reasons to choose Java or Kotlin, but concepts like Effects are not on that list.
InfoQ: For which applications or problems is Scala a perfect fit? Where is it not?
Ward: Many factors determine technology fit. I’ve worked on projects recently where team structure implied that Java and Spring Boot were the best fit for the environment. One of the most significant factors to “fit” is the technology the team wants to use. I think this aligns with my Kotlin PM job goals which revolve around helping make Kotlin a technology that developers want to use.
InfoQ: JetBrains claims Kotlin is a “better Java,” but Java is still 5-12 times as popular. Where do you see Kotlin’s role today? And what will its role be in the future?
Ward: The Java language has evolved over time. But as the language architect (Brian Goetz) describes — it has a “last mover advantage,” which in many cases is the right choice. If startups live by the slogan “move fast and break things,” then enterprises live by the slogan “move slowly and break nothing,” which is pretty consistent with how the Java language has evolved over the past 20 years or so. For me, I like to move faster than typical enterprise organizations enable (due to compliance, security, regulatory, and other reasons). So yeah, Kotlin is in some ways a “better Java,” but “better” for me may not be “better” for everyone, and that is OK. The JVM and Android support both Java and Kotlin — and that is a good thing.
InfoQ: In episode 51 of your Happy Path Programming podcast, Bruce Eckel spoke of “people who are still trapped in the Java world” (around 33:15). You agreed. Please explain to our readers why you and Bruce feel this way.
Ward: 25 years ago, I wrote my Java like I wrote my Perl. Bruce’s “Thinking in Java” transformed how I thought about programming. Now both Bruce and I have found programming paradigms and experiences that have had the same effect, totally altering the way we think about things. Bruce and I have not experienced these disruptions through Java (the language) but through other languages. I believe what Bruce and I were highlighting in that episode was not a knock against Java (the language) but a hope that programmers continually learn and find ways to grow, just as both Bruce and I have.
InfoQ: As described by Tony Hoare, NullPointerExceptions are the “billion-dollar mistake.” Null safety in a language is the fix. Kotlin has it, and Dart and Swift even have sound null safety. Java doesn’t have it and doesn’t seem to get null safety anytime soon. Why do you think that is?
Ward: In Java, EVERYTHING that is not a primitive value is nullable. And it would require a massive overhaul of the whole language and standard library to change that. Many modern languages have a foundational principle that nullability should be expressed through the type system. It is just very hard or impossible to bolt on later. As described earlier, I aim to write programs that are more verifiably correct at compile time, and explicit nullability is one way I do that. One of the reasons I don’t use the Java language much anymore is because expressing nullability in a compiler-verified way is tough.
InfoQ: You said that adding null safety is “very hard or impossible to bolt on later.” Google’s Dart accomplished this by adding null safety for applications and libraries seven years after version 1.0. 😉 Anyhow, what’s your advice to Java developers who want to have fewer NullPointerExceptions?
Ward: The hard part isn’t the language feature. It is all the APIs. According to the type system, everything in the Java standard library and most everything in the Java library ecosystem is nullable. For null safety to be useful and not gigantically annoying to deal with, all underlying types must correctly express their nullability. This is the change that is very hard or impossible to make.
InfoQ: In the same “Happy Path Programming” episode, you called default mutability in Java the “trillion-dollar mistake” (around 35:05). Please elaborate on why you think that is.
Ward: I’ve been bitten too many times with production issues where it was very hard to figure out the cause because I was unable to “reason” about the code in question. You see this when people post the “what does this code do” kind of puzzler on Twitter. Most of the time, it is a puzzler because the mutability makes it so my simple brain can’t reason about what is happening. You never see people posting the same kinds of challenges in a purely immutable form because immutable values and pure functions are something my brain can comprehend. I’m certain that the more of our programs can be pure functions and values, the fewer bugs there will be in what we build.
InfoQ: How much do you think tool support (such as IDEs and build tools) matters for the success of a programming language?
Ward: I used to write a lot of code without the help of an IDE (vim — fight me, please), but now the IDE is an essential part of my productivity. One reason I love programming languages with great type systems is that the IDE provides much better hints as I write code. When I have to write code in dynamic languages, I wonder how anyone ever does anything without a million reference API lookups because I can’t do anything without my IDE dot-completing all the options.
InfoQ: Talking about tools: Visual Studio Code had 14 million users in February 2021 and was the second-most loved IDE in Stack Overflow’s “2022 Developer Survey” (neovim was number one). Let’s assume that Visual Studio Code becomes the default free IDE for all developers, supporting all relevant programming languages and frameworks. How would that change software development?
Ward: VS Code is a great tool and, for many developers, has been a huge step forward from “Sublime Text,” vim, or emacs. But for me, it is still significantly less helpful than IntelliJ (for JVM stuff), especially when it comes to refactoring. So I don’t use it much, but I get that it very well may be the best code editor that developers have used (assuming they haven’t used all of them).
InfoQ: Compilers reveal code errors. Static analyzers, such as Error Prone, Spotbugs, or PMD, show even more errors, including the dreaded NullPointerExceptions. Why aren’t these static analyzers more widely used then?
Ward: Generally, I like to keep my toolchain as condensed as possible. Whether for performance, simplicity, or collaborative reasons, I prefer to put as much validation logic as possible into something the compiler can validate (i.e., the type system). To me, linters and static code analysis tools are a sign of something that should just be validated in the compiler. Still, likely, there are language constraints preventing that. These tools are good for improving code quality but also a strong signal to language designers of what they should be trying to move from meta-programming to just programming.
InfoQ: You said you “prefer to put as much validation logic as possible into something the compiler can validate.” The Java compiler doesn’t validate null safety, empty else branches, and such. But static analyzers like Google’s Error Prone do. How do you see the benefits of adding these analyzers to Java versus the downsides of complicating your toolchain?
Ward: Linters and other static code analysis tools express limitations with the type system and compiler checks. These limitations will always exist, so the tools won’t go away anytime soon. But hopefully, they help programming models and compilers to evolve, covering more of the possible foot guns over time.
InfoQ: Google’s cross-platform UI framework Flutter takes less than a second to compile a change and update the application. Why is compiling and updating JVM applications still so slow by comparison?
Ward: The more a compiler does to validate the correctness of something, the longer it will take. I don’t know any way around that. I can do zero-compilation on something, run it in production, then get runtime errors as a result. That is not the way I want to develop software. So to me, judgments of compile time have to be balanced with compiler value. However, I do often run Java, Kotlin, and Scala compilers incrementally with hot-reload in under a second (thank you, good caching). This debate needs to shift to “how long does it take to get to correct or bug-free” instead of “how long does it take to get something with an indeterminate amount of broken to production.”
InfoQ: In my Spring Boot project, frequent class reloading failures negate my fast compilation speed. And with regards to your “get something with an indeterminate amount of broken to production” comment: I think compilation complexity for Dart (the language in Flutter) may be in the ballpark of Java. Still, Flutter recompiles and redeploys on mobile in one second most of the time. Most Java projects don’t. Now Flutter owns its whole toolchain (language, compiler, runtime, framework, and build tool). Java doesn’t (e.g., build tool and application framework). For developer productivity, how important is it that JVM languages own their whole toolchains?
Ward: Nothing is preventing similar inner-dev cycle times on the JVM from being that fast. A new Android Studio feature called Live Edit almost instantly updates the UI for Jetpack Compose apps, based on a code change, in an emulator, or on a device. Play Framework had sub-second server reloads on the JVM a decade ago, using some fancy classloader tricks. The challenge is mostly around investing the engineering time to make that experience fast and great. But for some reason, that hasn’t been a huge priority in the JVM ecosystem. For server frameworks, Quarkus has done the best job optimizing this, and I’m sure there is more they could still do.
InfoQ: How would you define and measure the success of a programming language? For instance, you could say Scala is successful because it made functional programming more mainstream. You could also argue that Scala isn’t successful anymore because it lost the #2 JVM language spot to Kotlin.
Ward: Goals matter, and everyone has different goals. For me, it is about value alignment. I really appreciate that the Flix programming language wrote down its goals/principles.
Flix is an incredibly successful programming language because it has done an amazing job executing its goals. If Flix set a goal to have 10 million active developers, they’d definitely be failing on that one (but I’d still like it because I agree with the principles of the language). Liking a language is different from the success of a language. As a Kotlin PM, one of my goals for the language is to make it easier for developers to build correct software (i.e., fewer production bugs). The language has already been shown to reduce Android app crashes by 20%, which is a big success. I’d like to take this further and continue to help reduce app and server-side errors with language and tooling improvements.
InfoQ: The history of software development is a history of increased levels of abstractions. But innovations like object-orientation and functional programming are more than 50 years old. How do you think the abstraction level has increased in the last 20 years? And how do you see it rising in the next 20 years?
Ward: Until recently, many of the ideas from Functional Programming were siloed into technologies for math nerds (of which I aspire to be someday). Now thanks to Scala (and others), we are beginning to see a fusion of OO and FP that makes FP accessible to the masses who may not be math nerds. This fusion will continue to play out for a while, helping to make our code more testable and reusable. Kotlin is a great example of that, being a bridge for many OO Java developers into “lite-FP,” which doesn’t require a degree in Category Theory. The next phase of this transition will include embracing the idea of “Effects” (separating pure functions from the small parts that talk to the external world / aren’t referentially transparent). Many new programming languages already have this concept built-in: Flix, Unison, Roc, etc. Beyond effects, one concept we will likely see emerge is something like Datalog — a query language built into the general purpose language. I first saw this idea with Linq, then with Flix. Queries are a pretty universal need, whether for databases, lenses (updating immutable data structures), GraphQL, etc. So having an integrated and compiler-verified way to write queries is a significant advantage.
InfoQ: Which programming language has evolved the best?
Ward: This definitely depends on the definition of “best.” If we consider this from a purely academic perspective, I think by many orders of magnitude, Scala has been the recipient of more Ph.D. research than any language I know. Many of the Scala language features end up in other languages, which is great for everyone. Python has done an amazing job of being a generally approachable language. I heard that many data-oriented professionals can’t solve most of the typical programming challenges but can write the Python code that represents a complex mathematical algorithm or processes a massive data set using libraries like Pandas, NumPy, etc. Kotlin is a modern language with Java interop and multiplatform capability. So what is “best” depends on many factors.
InfoQ: Which upcoming feature of any JVM language excites you the most?
Ward: On the JVM side, Loom is game-changing. For most Java / JVM developers, “Reactive” has been a good idea but not worth the cognitive and complexity overhead. Kotlin Coroutines enabled a similar idea of zero-cognitive cost for async operations that appear imperative. Yet, for many JVM developers, Reactive will likely remain a “nice-to-have” feature until Loom is available in their organization. Given that timeframe, many developers on the JVM will use concurrency abstractions like Kotlin Coroutines and Scala ZIO Effects on JDK 8 before then. Given the challenges with the Loom timeframe, and the current availability of alternatives, I have to say the upcoming feature I’m most excited about in any JVM language is Scala’s braceless syntax which is half there in Scala 3.0 and may reach completion in Scala 3.3. I love how little visual noise there is in my code relative to the problem I’m solving for. I know it seems silly that just removing the braces can have such an impact. But Python shows us that cognitive overhead may generally be the highest cost in most organizations. The hardest/most costly part of writing a correct program is not the text to bytecode/machine code transformation. It is the cost of correctly representing and reading human ideas in a form that computers can understand. It seems silly, but the braces in most code distract my brain from the human intent of the code.
InfoQ: If you could make one change to each JVM language, what would those changes be?
Ward: Java: There are a lot of changes I’d love to make, and that sounds like an indictment. But it isn’t because on the JVM, you can either choose another language or accept that things move slowly, and that is good. If I had to pick one thing to change, it’d probably be better support for immutability. Default mutability is a recipe for non-deterministic programs.
Kotlin: When I program in Kotlin, the thing I most miss from Scala is a nice syntax for monadic chaining (called “do notation” in Haskell and a for comprehension in Scala). Like Kotlin coroutines, it makes code seem imperative when really it is chained function calls. I have no idea how that kind of thing should be added to Kotlin, but if done right, I think it’d be awesome.
Scala: The hardest thing about Scala is that there are many ways to do roughly the same thing. For example, there are at least three ways in Scala 3 to do something that is basically a Sum Type (sealed, enum, and logical OR). I don’t know how you ever take things away in a programming language. Still, Scala complexity is a problem, and having many ways to do most things is a problem for the language.
InfoQ: COBOL is more than 60 years old and still in active use. Do you think developers will still write new Java applications when Java turns 60 in 2056?
Ward: For sure! Java is a critical part of so many of the systems we use every day. It is not going away, and with slow but progressive enhancements, it continues to improve (unlike COBOL). The larger Java ecosystem (including Kotlin, Scala, Clojure, Groovy, etc.) also continues to grow. As a whole, it is likely the largest developer ecosystem in the world. New JVM languages continue to emerge like Flix, showing that the innovation cycle isn’t stopping anytime soon. Innovative and game-changing technologies like Testcontainers, GraalVM, and Kalix continue to emerge from the Java ecosystem, illustrating the strength to continue growing and improving for another 35 years (at least).
InfoQ: Please share your closing thoughts on JVM languages in 2022.
Ward: It is an exciting time to work with Java, Kotlin, and Scala! The tools and languages enable the highest developer productivity I’ve ever experienced. From phones to servers, Java technologies are behind the vast majority of critical systems we use every day. And for me, it is so nice to get to pick from many different languages on one platform.
InfoQ: James, we thank you for this interview.
Wrap-Up
Ward explained the podcast remarks well: When Eckel spoke of “people who are still trapped in the Java world,” he was referring to developers using what he and James see as old paradigms in Java, such as procedural and object-oriented programming. In contrast, Eckel and Ward have embraced functional programming concepts in Scala that are not available in the Java language. And mutable code makes it harder for Ward to reason about that code and eventually produces more bugs, unlike pure functions and values that are immutable.
MMS • Phillipa Avery
Article originally posted on InfoQ. Visit InfoQ

Transcript
Avery: Welcome to Scaling the North Star of Developer Experience. We’re going to be talking about what it would take to grow a business through the different stages of business growth, and how we can change ways of looking at developer experience during those different growth stages.
Who am I? My name is Phillipa Avery. I’m an engineering manager of the Java platform here at Netflix. I’ve been at Netflix for about eight years now. Prior to Netflix, I was in academia. I did work for the government, as well as doing some small work in startups and medium-size companies. I’m taking a lot of the experience that I have gained from those companies and applying that to this presentation to say what it is that we should apply in terms of tradeoffs, and how we should measure those tradeoffs for different aspects of developer experience as a business grows. I’ll be going through the different stages of the business growth that I’ll be focusing, and what those specific tradeoffs are that we’re going to be looking at. As well as going through some examples of how those tradeoffs have been applied with different processes for developer experience.
Stages of Business Growth
Let’s start with talking about what the different stages of business growth are. We have a focus of hydras or different heads representing the different types of business growth that we have. When we start, we have a startup, which is focusing on a single thing, we’re trying to get something out the door quickly. We have a baby that’s coming out to try and really achieve one single thing, and achieve it well for the audience that we’re trying to target. Then as we move into the growth stage, where we actually take what we have that we’ve learned from the startup, and we start to apply it to a bigger audience and we get more learnings. We might start branching out into different aspects of the business domain that we’re focusing on.
Once we’ve gone past the growth stage, we really start moving into maturity, where we actually know what we’ve done well. We know what we’re trying to achieve. We know the target audience that we’re trying to actually work on and make sure that they are getting the best product that we can achieve for them. We’re going to have different conflicting business prioritizations and different business needs. That is really represented in this maturity phase where we actually have to look really closely at what the different tradeoffs are, and make very key decisions. Which leads into the final stage, which is renewal or decline, which is more of an optional stage. You can actually continue to grow at maturity, with some pros and cons. With the renewal or decline phase, you really need to make decisions as to whether you’re going to put all your bets in one particular aspect, whether you’re going to kill off one aspect of the business. Maybe grow in a different aspect of the business and start branching out and start seeing different changes and complexities grow as you’re starting to branch out into different aspects.
Tradeoff Focus
With those business growth stages, the next thing we’re going to look at is the tradeoff. There are many tradeoffs which you need to look at when you’re talking about business growth. Specifically for developer experience, we’re going to be focusing on the tradeoffs of velocity versus stability. This is generally a scenario where if you need velocity, you will have to lose out in stability, and vice versa. The velocity means that you are moving fast and you’re more prone to make mistakes, hence the loss of stability. If you are more stable and having to take things slower or making sure that you are making less mistakes, you would generally lose on being able to move quickly and highly constructively.
Startup
How do these apply to the different business stages that we have? Let’s look at our baby hydra here with a higher weight on velocity. When we’re doing a startup, we’re really focused on getting some quick reads from the audience and getting a fast turnover to make decisions as to where we’re going to focus on our product. We really need to have a very high velocity to get our product out the door with changes as quickly as possible. We will lose out on stability for that. That’s ok, because we don’t have a large target audience base at this point. We’re really trying to focus on experimentation and product development, rather than we’re focusing on making sure that the product that we have is stable for the user base.
Growth
After the startup phase, where we’re really iterating quickly and trying to do more of a proof of concept rather than a stable product, then we start moving into our growth phase. This is where we actually start having different aspects of the business start to compete as we’re looking at, where we’re going to put our money, where we’re going to put our favoritism of what we’re focusing on. We might see a change in velocity and stability as a result. We have a larger user base now that we need to make sure we’re maintaining experience for the users and creating a more stable product. Given that, we will probably see a drop in velocity to some degree, as we’re starting to focus more on our stability and our resilience story around the growth of the business that we are currently seeing move out of a startup and baby phase, into a teenage phase.
Maturity
Once we reach maturity, this is where we have some really interesting questions on tradeoffs, where we have a number of branching areas that we could focus on and areas that we could experiment with. We might actually even start branching out into different business domains. We really need to find a great balance between velocity and stability. If we focus too much on stability at this point, we lose our ability to make choices and move and continue to adapt to the market that’s out there. We really need to make sure we’re finding ways to maintain the velocity as well. This is where a lot of the developer experience will come into play. If we are bogging down our developers with their stability requirements and stating that they don’t have to push or do any changes due to the fact that it will break the service, then we’re actually reducing our ability to innovate and create velocity around that. We really need to make sure that we are focusing on finding that balance, both in terms of the business requirements, but also in terms of the technologies that we’re providing to our developers, to allow them to continue to keep developing with this balance happening.
Renewal or Decline
Finally, we move into renewal or decline. It’s hard to represent using an icon. Essentially, we are looking at more of an up and down here where you might see different areas of the business experiencing a high degree of velocity, and others are going more into maintenance mode entirely, where they will completely focus on stability. They don’t want to make any changes to that particular type of the business. It might be fading out, or it might just be perfectly good and we’re not looking to innovate in that area anymore. It’s just an existing customer base that will continue. We want to make sure it has the least amount of changes needing to happen. You might focus mainly on security. Whereas other areas of the business, you really need to keep cutting edge. You need to make sure that you’re providing a developer experience which is moving forward quickly.
Choice of IDE
Let’s go through some of the examples of how we apply this at Netflix and the choices that we’ve made over the years. We’re going to start with a really simple use case, which is choice of IDE. When I first started at Netflix, everyone could have whatever IDE they wanted. We had a mix of Vim versus Emacs, which of course Vim wins. Then we had Eclipse and IntelliJ. You name it, we had almost every IDE that you have available, including Visual Basic at some point as well. I have seen that. What we found was that this actually really worked well for our startup scenario when we had a very small amount of engineers coding their code base without having to make changes to other people’s code bases as much. There was no real need for consistency of IDE at that point in time. As we grew, we found that having a recommended version of IDE was the right balance. By recommended version, we actually chose IntelliJ to say, this is the one which we will support. This is the one we’ll provide licensing for. This is the one which going forward if we’re going to create things like plugins, there’ll be plugins for this particular IDE. At some point, we probably will need to make the choice of actually saying, and this is now the only IDE which you should be able to use if we start bringing other aspects in that we don’t currently have. These are the sorts of things which we’re looking at when we decide the tradeoffs again, velocity versus stability for our IDE choice.
Monorepo vs. Multi-repo
Next we’re going to talk about monorepo versus multi-repo. Netflix has a multi-repo, we use library version management very extensively. We made the decision early on not to do monorepo, and it has a lot of tradeoffs in terms of velocity versus stability. This is actually one of the tradeoffs where we’re continuing to lean on velocity and having a higher propagation speed, rather than leaning on stability, where we’re going to have less breaking changes, potentially blocking different services from being able to release their application. When we have a release that happens from the libraries owner’s perspective, they’re able to release their library and it will go out into the environment, and through our CI/CD process, it’ll slowly get picked up by the different consuming services. Those consuming services, 90% of them are probably going to pick up that library without any issue.
We have a bunch of version management and dependency graph management that happens from the customer perspective, in order to make sure that we’re locking different dependencies to reduce the variables of what they’re picking up. It still has a large degree of complexity and a large degree of failure. For those 10%, for example, of services that have trouble when they’re picking it up due to conflicts in dependency management, particularly when we have transitive dependencies potentially locking some things, they are pretty gnarly to try and fix. We spend a lot of our support time looking at that, which we wouldn’t have to if we had a monorepo. The downside to that is it could actually block being able to release if you’re not able to get through those 10% of services quickly enough to release. By having our multi-repo or having our dependency publication, we can then also publish it for the services that need it quickly and make them focus on plugging it in really quickly. It gives us more flexibility of choice.
Of course, with any service like this, you all have to have a high degree of CI/CD. Specifically with monorepo, you really need to invest in your integration testing story. That is something that we have not done particularly well and we really need to focus on getting that done right, either for monorepo or for multi-repo. With monorepo, it is particularly important to have that story correct. The other approach, which we actually do have some degree of is hybrid approach, where you have different aspects of the business, which will have a monorepo versus other aspects of the business which will continue to have a multi-repo. We are focusing on this. It can be hard to find aspects which are self-contained enough to be able to create a monorepo on their own, but they do exist. There might be a very well informed reason as to why you have it for one aspect and not have it for others. This aspect might be contained enough that the velocity is not actually significantly impacted, versus a very large monorepo for an entire organization where you do have impact from velocity versus having a more stable release cycle.
Build vs. Buy
Next, we’re going to talk about build versus buy. When we have the aspect of the choice of whether we’re going to create something in-house, or whether we’re going to purchase or use open source products that are available externally, a lot of the time, what we’ll focus on is, can this actually achieve what I need it to do? Probably, if you’ve actually been trying to make this choice, there is going to be some small things which won’t match up to what it is that you’re looking at, that is available to purchase, or utilize in open source. Will it give me some degree of customization or tailoring? You have to make that choice as to whether it’s worth doing that customization or tailoring where even possible with the choices of buy versus building the entire thing in-house.
One of the mistakes that people often make is to say, it’s free, essentially, as once I’ve purchased it, that’s the cost, or once I’ve used open source, that’s the cost. Then I continue to keep rolling it in. In order to use open source, you’ve got to remember that you’re actually maintaining and you’ve got to have a great relationship with the open source community, or else you’re going to end up branching, and you’re going to end up having to maintain your own product anyway. Which means you’ve got to be highly active and engaged with all of the requests that come in for different needs and requirements with different business use cases from other people who are also using the same product. You need to try and make sure that you’re influencing as well as contributing back to the open source repository. Same with if you’re buying something, you need to talk to your vendor, and make sure that the needs of the company are being met with the product and the future direction of the product. Which is going to cost money either in terms of asking the vendor to do something, or in terms of your engineering time to make sure you’re on top of the open source community.
That in itself is going to outweigh the support costs of choosing build versus buy. The real choice comes down to the scope of the problem. If it’s something which is going to be a quick maintain, like build scenario, then you might choose to build and maintain that in-house. I think the learning curve of anyone who comes on board is pretty easy, because it’s a small scoped product that you’ve created. If it gets to a larger scope with branching complexity. At that point, you might be better off leaning into saying, there is going to be complexity that we have to manage anyway. We might as well take advantage of the open source or buy alternative, in order to make sure that we are on top of what the current community outside of our company is, so that we are keeping up to date in cutting edge. Additionally, it actually helps expand your knowledge base as you start bringing in people outside of your company that are really pushing on what you assume to be true, given what you are experiencing inside of your company. Having the scope of the problem increase, actually, you might lean more on wanting to buy at that point, far more than build.
The Blooming Hydra
Finally, we’re going to talk about the blooming hydra area. Abstract, but once you start growing your business, and you start growing into different areas of the business, now again, you’re going to have different needs and requirements. You might have completely different aspects of the business that have different needs. For example, when talking about Netflix, we talk about what we refer to as our streaming need, which is our product for streaming. We might have the actual content, which is one different business aspect, versus the UI, which is another one, versus the actual playback itself, and what it takes to stream the content. That is what we call our streaming side. Then we have our studio side, which is all the technology around what it takes to actually produce the content, and record, and have the whole studio production side of things. They have completely different needs. We have developers across the company which are working on these, usually in isolation, but there are some degrees of leverage that we could apply from the lower services of developer experience here.
The key thing comes down to whether we’re looking at generalization of a particular aspect of developer experience, and how much complexity you’re going to introduce by needing to make sure a single product is going to encompass the needs of all of these use cases. Here, we’re going to apply the principle of KISS, of Keep It Simple Stupid. Try and make sure that you’re not over-generalizing, and that you are not making peace with a higher degree of complexity. If you start finding that you are needing to really slow down to the point of decision paralysis, because the amount of things that you will need to include and change will actually have repercussions across board. At that point, it might be better to actually separate these products even though you have redundancy, and even though there might be engineering redundancy or support. You’re going to have a degree of velocity that will be able to be maintained specific for different use cases.
That’s that tradeoff in terms of generalization or complexity. Do we want to have a single support system for the entire product across all of these different use cases, or do we want to have what we call redundant localized developer experience? Where we have a local team specifically supporting potentially the exact same technology but in a different way for this particular use case, and the same with this use case, and the same with this use case. In this case, redundancy might actually help in terms of velocity. Then you need to look at what the cost of what it is that you’re saving for being able to quickly cycle and not have so much complexity, versus the redundant engineering headcount or areas that we might potentially be able to leverage if we put into a smaller centralized group.
Stop, Look, and Listen
Finally, stop, look and listen. In Australia we have this song, which is, “Stop, look, and listen, before you cross the road.” It’s been many years, and it’s still stuck in my head. This is a reminder, this song stick in your head, stop, look, and listen before moving on down the road. Any time that you are making the decision to move down and to bring in a different type of developer experience, bring in a different type of process around developer experience, remember to apply these principles. Firstly, apply agile thinking. Where we’re used to applying agile thinking to when we create software development, we also should be applying it to the decision making around developer experience. How we’re going to say if we can quickly roll back this decision that we’re making. Let’s just move forward and try it. Let’s take the learnings, let’s change directions if need be. Don’t get stuck on decision paralysis. Should we do this? What’s the long-term repercussions? Take that into mind. Take it all in and then make a decision and try it in the smallest possible way. Take that agile thinking and apply it in every single time you make it, whether it’s in a single domain, multiple domains. Try it, move forward. Take the learnings, change directions, or keep going if it’s showing it’s the right way to do it.
Part of this is also to avoid sunken fallacy cost. Doing these small iterations of agile decision making and agile development for a developer experience will lose money. It probably will, but in the long run, you are actually going to have a better experience and a better product. Same as what we do with agile thinking in software development. There is going to be a cost. Don’t think of it as the sunken cost. That is perfectly ok to have some loss here. Keep moving, keep the momentum moving forward. Make sure that we are balancing again that stability versus velocity in our decision making process.
Make sure we are actually budgeting for that reevaluation improvement. Every time that we make that decision to say, ok, we’re going to not do this anymore. That’s actually something we need to budget for. It’s not just something that we can just push off to the side and forget. Tech debt isn’t an additional budget, it’s something that we should include in our budget, when we’re actually making decisions to say, we’re not going to do this anymore. We are going to move down a different path. Next, make sure that you are building insight on developer experience from the get-go. This shouldn’t be an afterthought. Every time that you create something which is for developers, create measurable, quantitative metrics inside a product, where you’re measuring how they use it, how often they’re using it, what their workflow is that they’re using it for. Even if there are only a few uses built in, as they come, you will really want this metrics analysis in order to decide what the decision for how to move forward with this product should be.
Part of the pitfalls that you need to watch out for are, again, this growing fragmentation across this user base. If it’s deliberate, make sure that you’re accounting for that as to what it is that you will and won’t support as part of that fragmentation. If it’s not deliberate, then make sure that you are reaching out to people and showing them what the repercussions of having this fragmentation are. When you’re making choices, make sure that you’re again trying to use these measurement insights that you’ve built in, and that you are looking at the qualitative and quantitative balance, and not just listening to the loudest voice in the room. As a developer experience inside a company, it’s really easy to be swayed by loudest voice in the room, because people know you, they know where you sit. They can come talk to you. They can come ask for what they need from you. You will be very eager to try and solve their experience for them because they’re right there and you can talk to them and get quick feedback. That might not be the best thing that you can actually focus on at this point in time, it might not be the highest leverage of what you can really achieve. By having that balance away, you can actually say, ok, this request is really important for this particular person. However, we have these quantitative metrics which show that this change will actually affect others adversely, or potentially isn’t the best thing that we could actually focus on at this point. It will help you make better decisions going forward.
Hydras FTW (For the Win)
Hydras for the win. Really, we want to make sure that we are saying that there are different businesses at different stages, and will require different needs. If you take anything from this talk, please take the key thing that change is not a scary thing. If we make a bad decision, it can be costly, but it usually means that we can recover from it in some degree by making a choice going forward. If we continue to keep pushing down the same path, then we can have issues as well. Make sure that we are actually saying that we are going to change with the idea of velocity versus stability. We might say a particular aspect of the business might not change, and we’re ok with letting that go into maintenance mode. Overall, we need to make sure that we are creating a velocity aspect in some area of the business, that we are continuing to improve and that we are continuing to keep challenging ourselves as to how we really provide a developer experience that enables them to have a high degree of velocity in different aspects. We’re not trying to solve for world peace, although sometimes it may seem like we are in terms of the complexities that we’re dealing with. Essentially, this is a solvable problem. This is something that we can get through. Make sure that we are looking at the metrics. Make sure that we are looking at the tradeoffs. Ultimately, make the choice, be agile, move through with it, and continue to evaluate at regular points in time.
Questions and Answers
Kerr: You talked a lot about the most important point being you can change your mind. What’s something that you all implemented for developer experience that you changed your mind on?
Avery: We’re constantly changing our minds. Actually, let’s talk about something which we haven’t changed our mind on yet but we’re constantly reevaluating. If we go to the IDE choice as an example, we were talking about how we have this non-single choice. We haven’t actually said we’re going to dictate that this is the IDE that you have to use. At some point, and I missed this out in here, we might have to say, we’re going to do a specific type of IDE which a lot of companies you’ll find use what we call remote IDE versus local IDE. Remote IDE is where you essentially will have a centralized website, which you do all of your development on. You don’t do any of your development by pulling down your code locally onto your laptop, it’s all done remotely. We’ve made the choice to do local development, but we are actually continuing to evaluate whether we’re going to do remote development, because it does have a lot of benefits that you could get from having that centralized control, as well as having the exact same hardware that you would have when you do your deployment. We are constantly evaluating, we’re currently doing it at the moment, what the pros and cons are, and whether the business value for implementing that infrastructure is actually worth making the changes to migrate everyone over from having the local development to the remote development.
Kerr: Do you have some people doing remote development now?
Avery: We have people that experiment with it. Ultimately, though, that is an investment in infrastructure, more so, especially when we’re talking about trying to get the networking as close as possible to developers. Having essentially the distributed system which we have all of our production services, need to be as close to the developer as possible, literally, as in regional, close to the developer. We, at the moment, have three main regions that we work on, and trying to get it closer so that the actual interaction cost over the wire is as quick as possible, is the main thing that we would need.
Kerr: Getting the responsiveness that we get naturally from local development?
Avery: Exactly.
Kerr: Some decisions don’t feel like ones you’d want to change your mind about, like we have a monorepo and it’s not going well, but the pain of splitting back out again, we feel stuck. Have you experienced anything similar like that?
Avery: Yes, 100%. I think the monorepo is one of the trickier ones, because as you grow, rolling that back actually gets harder. What you can do is you can start breaking it up. That hybrid approach is actually an interesting one, which you can take and start saying, ok, we’re going to say that this is a monorepo, and we’re going to have the right degree of CI/CD around this monorepo. Now we’re actually going to start pulling in more use cases into that monorepo. You can do a split approach. Think of it as Roman riding almost, where you basically have the old and the new at the same time. The Roman riding is where you have two horses, one is a fresh horse, one is the horse that you’ve been riding, and you switch the horses. You essentially will have the old business value, which is not in the monorepo, but you will have a new business value, which is in its monorepo. Then you can actually start pulling use cases, and repositories start getting rewritten. I’m a big fan of constantly rewriting code, if it’s still being used, and constantly making sure that you are evaluating the way that you are doing business requirements in your code. Part of that is rewriting it and seeing if we can actually create a new microservice of it. As you’re doing that and you’re creating a new repository, you then start putting that into the monorepo, if that’s the choice that you’ve decided to go forward with.
Kerr: Bit by bit. It seems like it would be easier to go into a monorepo than out, but still you can focus on the areas that you’re working on. Domain driven design has some good pieces about that.
Do you have a single mandated issue tracker?
Avery: We do not. We majority use Jira. There are a bunch of other use cases.
Kerr: You use the same Jira, or do people like flex it because I know Jira is not just one thing?
Avery: Individual teams will have their own Jira projects, and each team chooses how to use it, and they choose their workflow. My team in particular has projects and boards for each product that we own. Therefore, if you want to have a ticket for a particular product, you will go and make a ticket inside that particular project.
Kerr: How do you source requirements from your engineering teams for the developer platform, if that’s a thing you do?
Avery: Yes, we do. I like to have what I call both inreach and outreach. Inreach is really easy. You’re sitting there, that’s that loudest voice in the room. People will come to you and they’ll say, this is what I want. It’s easy to react to. It’s easy to obtain, because you just sit back and let it come to you. Especially when you’re really busy and under water, it potentially is the easiest way to get customer feedback. Doing the outreach balances that off. By outreach, I’m talking about going out and speaking to users, planned. Saying, we’re going to target each aspect of the business and we’re going to talk to them independently. We’re going to make sure that we’re getting surveys from our user base. Try to get a good representation, not just the people that are the ones you talk to the most. You want to make sure that you’re doing outreach to the people that you actually don’t talk to the most.
You want to make sure that you are setting up different ways of achieving this. Some of them is through having communications, we use Slack, to having the Slack support. We have office hours as well, which is that inreach then again. We have constant, we call them roadshows, where we go to the different teams, and we actually say, these are what we give to you. This is the how you use it. We have education where we actually will go out and seek to make sure that there is best practices being applied to the products which we are providing to people. As well as that survey. The surveys can be hit or miss. You really need to try and make sure that they are as small as possible, and that you’re not doing them too much, because then people will start getting burnt out by them. Once a quarter, we have one big one that will go out to different targeted user bases and get that information.
Kerr: It’s almost like you have a little miniature company with marketing and customer success and documentation.
Avery: Yes, 100%. I think that as you scale, that’s really important because, otherwise, the fragmentation I was talking about in terms of how different people are using not just the different technologies, but also your technology in different ways. You might provide them a product and you don’t anticipate the way that people will use that product all the time. Suddenly, they’ll come back with a support request, and you’re like, I had no idea that that was how you were using that. Then you have to try and figure out that tradeoff. If you can reduce that fragmentation simply through education and understanding prior to that happening, how people are using it, you can get on top of it and try and have a more consistent experience overall.
Kerr: How does Netflix’s culture affect developer experience?
Avery: A lot of people have heard the freedom responsibility aspect of Netflix. Freedom responsibility is essentially trying to say that people should have the freedom to make the choices that they want to make specific to their business needs. As long as they are responsible for those choices, in terms of the cost of those responsibilities and how that will affect the company’s bottom line. Especially as a centralized platform team, this can hit pretty hard because that fragmentation of what people are using and then wanting to come back and get support for it can actually increase if there is no dictating to say we only support this one specific thing. IDE choice is an example of this, where you might have people that are using Eclipse or are using VB and come in and say, I need support on this. We’re like, we don’t have the capacity. We don’t have the bandwidth, and we don’t have the knowledge of how to support that particular type of product.
It has pros and cons. What we try to do as a centralized business is be very clear on the responsibility aspect. We don’t tell people, you’re not allowed to do this. We say, if you choose to do this, here is what you are responsible for, and here’s what the repercussions of making that choice could be going down the road. We have what we call paved path and off paved path. Paved path is our well supported products. We ask people to stay on paved path, because it will help us to actually support them going forward. If you choose to go off paved path, here’s what the actual repercussions are, especially if you move to a different team in the company or you move on.
Kerr: What’s an example of the paved path?
Avery: One of my teams is the framework team at Netflix for backend microservices. We use Spring Boot for that. It is a Java based product, and we support Java for our backend services, a majority. If someone decides to go and create a product in Go, for example, because there is a perfectly good business use case for creating it in Go versus Java, we will educate them and talk through the repercussions of that in terms of support down the road. If they make the decision, ultimately, that this is the best thing for that particular use case, that is up to them.
Kerr: What are the Java teams getting that the people who write it in Go are responsible for themselves?
Avery: What is the support?
Kerr: Yes.
Avery: The Netflix ecosystem, for example, we have a bunch of metrics integrations which are in-house. We have some really good metrics tools to be able to have operations of your service in production, traffic insights, tracing, real time metrics, and that’s written in Java. The integration is written in Java, the API is in Java.
Kerr: You get this insight into what’s happening in production just naturally if you use Java and integrate with the other tools.
Avery: We have a bunch of different ecosystem, what we call ecosystem integrations, metrics is one of them. There are a lot of others. Even our security is written primarily for Java. We do have polyglot solutions now, so that security does need the ability to be able to have it regardless if it’s in Java or not, but it’s not as paved path supported and easily integratable.
Kerr: Developers in Go would need to find their own way to output metrics, and get those into whatever frontend.
Avery: Potentially even rewrite the libraries that will be interacting with the ways of doing that.
Kerr: Because they do need to mesh with the Netflix ecosystem, but that’s not going to be done. It’s not going to be trivial.
Avery: Then that rewritten component that they’ve had to rewrite in Go, they need to maintain that and support that going forward. If they move on and go to a different team or a different company, someone else has to be trained in how that was rewritten. As opposed to a centralized team owning and maintaining it, and having that constant iteration of new learning curves, being up to date with the current status quo.
See more presentations with transcripts