Month: August 2022

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Google has a global network of 34 regions and 103 availability zones, bringing its Cloud services to customers in over 200 countries and territories worldwide. Recently, the company announced that it would expand its presence to three new cloud regions in Malaysia, Thailand, and New Zealand – on top of six other regions previously announced coming to Berlin, Dammam, Doha, Mexico, Tel Aviv, and Turin.
According to a Google Cloud blog post by Google Cloud’s Asia-Pacific vice president Karan Bajwa, the rationale behind the expansions is that data from IDC projects that total spending on cloud services in APAC (excluding Japan) will reach $282 billion by 2025. In addition, another research report cited in the post is from a 2021 survey from Information Services Group, which states that cloud services account for more than 84% of APAC’s IT and business services spending in Q3 2021, the most significant percentage of any region.
Bajwa also explains in the blog post that new cloud regions emerge as demand for digital services grows. Cloud adoption is increasing across industries in these markets, particularly in telecommunications, manufacturing, financial services, and retail.
A Google Cloud region is a specific geographic location where customers can deploy cloud resources in the context of cloud computing. At the very least, all Google Cloud regions provide services such as Compute Engine, Google Kubernetes Engine, Cloud Storage, Persistent Disk, CloudSQL, Virtual Private Cloud, Key Management System, Cloud Identity, and Secret Manager. Additional products are typically available within six months of the launch of a new region.
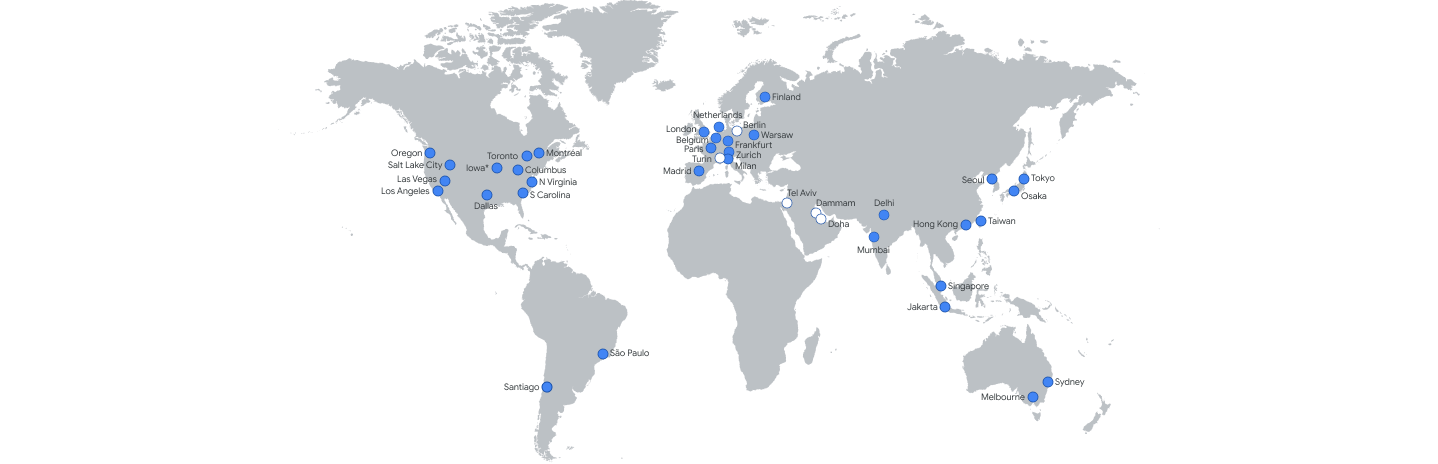
Source: https://cloud.google.com/about/locations
Google is currently trailing behind the other public cloud vendors Amazon Web Services and Microsoft Azure. According to IT market research Synergy Research Group, AWS leads with 34 percent of the global market share, followed by Microsoft at 21, and then Google at 10 percent. Combined, the three public cloud vendors are also the most significant spenders when it comes to building new data centers. For example, in 2022 only, Google intends to invest $9.5 billion in data centers and U.S. offices.
Simon Merrick, a DevOps/Cloud engineer at Trade Me, welcomes the cloud providers in New Zealand in a tweet:
And there you have it. @GoogleCloud_ANZ joining @awscloud and @Azure in opening datacenters in NZ.
Finally, Google Cloud is expected to have 14 cloud regions across the entire APAC region by the end of the year, compared to AWS’ 13 regions, three of which are planned in India, Australia, and New Zealand. Furthermore, Alibaba currently has 21 cloud regions, with no new regions announced this year. In the APAC region, Oracle, Microsoft, and IBM are expected to have 9, 17, and 7 cloud regions, respectively.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ
We can make good decisions with speed when we limit the cognitive load on any one person or team. Observability can help to increase delivery speed, by providing information to developers that helps them to make decisions quickly.
Jessica Kerr spoke about applying observability for speed and flow of delivery at QCon London 2022 and QCon Plus May 2022.
There’s only so much each person can hold in their head, as Kerr explained:
When the code is changing, there’s only so much a person can keep up with. When new people are joining, only so quickly can they load all this custom knowledge in.
When developers are making decisions, it helps to have information readily available, Kerr mentioned. This information should answer questions like “Who calls this service?” “How long does this function run?” “What values does this field hold?” “How many times do we hit the database, and for what?”
Kerr explained how developers can use distributed traces:
Distributed traces tell a story about each request. See who called whom. See what happened concurrently and what waited. See where the performance bottleneck is. Traces provide thousands of stories of individual requests moving through the software.
With thousands of stories, how do you find the one you want to look at? Kerr mentioned that querying over the traces helps with that: search for one that is slow, or one for a particular grumpy customer, or one that failed with a certain error message:
Then when I make a change to the code, I add new spans to the trace or attributes to the spans. I can see the new results locally, in test, and in production. I can be confident it’s working. And I can get satisfaction from knowing it’s useful to customers!
InfoQ interviewed Jessica Kerr about dealing with cognitive load and how observability can be an asset.
InfoQ: How does cognitive load limit the ability of teams?
Jessica Kerr: Our job as software developers isn’t typing. It is making decisions: what to change, where to change it, what to change it to, where else to look, what to name it all. When we make informed decisions, then rework is rare. When we don’t have enough knowledge of the system to know everywhere to look, then our decisions become bugs. We circle back again and again.
As we add capabilities, every feature request comes with the unstated requirement “… and everything else still works.” All that adds up to a lot to know.
To work smoothly, to have fast flow, we need most of that knowledge at our fingertips. Not “Let me google that again” and “Maybe if we search all the codebases we can find a reference to this.” We need instead “I understand how this works” or “I know who to ask about this.”
InfoQ: How can observability in software become an asset to organizing teams?
Kerr: As leaders of teams, we can use observability. An important input to team management is error budgets and service level objectives. Observability in the software lets us count the percentage of incoming requests that are succeeding fast enough, and check that against our agreed-upon service level.
For instance, maybe our checkout service is expected to return within 900 milliseconds, 99% of the time over any 30-day period. That leaves 1% as an error budget. When our service is meeting that objective with no sweat, the team can keep working on features, and try stuff like reducing capacity. When that error budget is almost gone, it’s time to direct the team’s effort toward reliability instead.
New Microsoft Defender Products: Threat Intelligence and External Attack Surface Management
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Microsoft recently announced two security products: Microsoft Defender Threat Intelligence and Microsoft Defender External Attack Surface Management. These new products are driven by their acquisition of RiskIQ just over one year ago.
Microsoft acquired RiskIQ, a global threat intelligence and attack surface management leader, to assist their shared customers in developing a more comprehensive view of global threats to their businesses, better understanding vulnerable internet-facing assets, and developing world-class threat intelligence.
With Microsoft Defender Threat Intelligence (TI), customers will have direct access to real-time data and Microsoft’s unmatched signals to hunt for threats across their environments proactively. It uses built-in AI and machine learning capabilities to uncover the attacker or threat and the elements of their malicious infrastructure.
Vasu Jakkal, corporate vice president, Security, Compliance, Identity, and Management, explained in a Microsoft Security blog post:
This depth of threat intelligence is created from the security research teams formerly at RiskIQ with Microsoft’s nation-state tracking team, Microsoft Threat Intelligence Center (MSTIC), and the Microsoft 365 Defender security research teams. The volume, scale, and depth of intelligence are designed to empower security operations centers (SOCs) to understand the specific threats their organization faces, harden their security posture accordingly, and enhance the detection capabilities of Microsoft Sentinel and the family of Microsoft Defender products.
Nathan McNulty, a senior Microsoft cyber security solutions architect at Patriot, tweeted:
My honest take so far is that we already have similar data sets in other solutions, but that doesn’t mean the service isn’t worth it. Plenty of folks aren’t familiar with other tools, and this might fit into their workflow better. Better TI never hurts 🙂
The other new product, Microsoft Defender External Attack Surface Management (EASM), allows customers to discover unknown and unmanaged resources visible and accessible from the internet, essentially the same view an attacker has when selecting a target. The product scans the internet and its connections daily and builds a complete catalogue of a customer’s environment, discovering internet-facing resources, even the agentless and unmanaged assets. In addition, it offers continuous monitoring without needing agents or credentials and prioritizes new vulnerabilities.
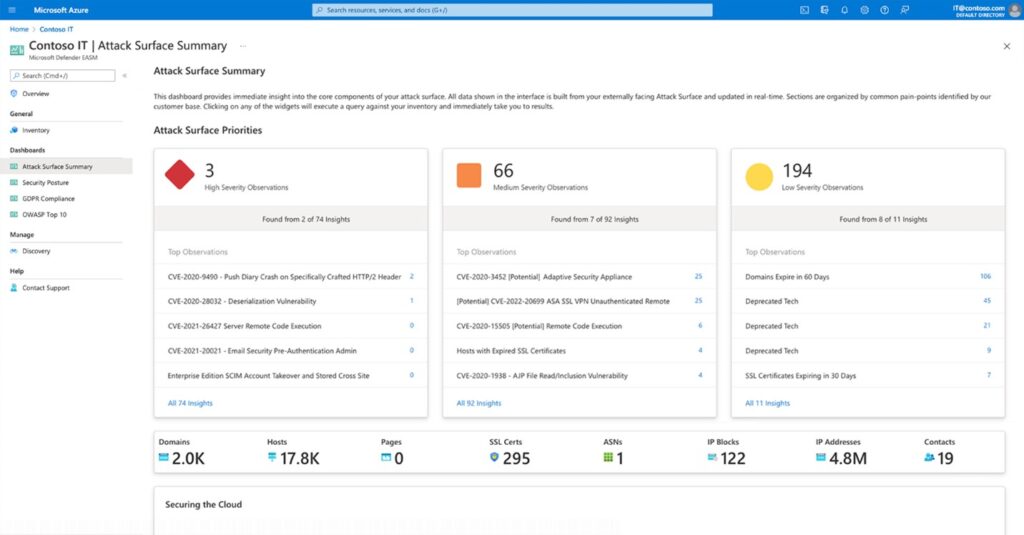
EASM can be set up via the Portal within an approved region. By default, customers can have a 30-day trial before they get billed for any asset. The product uses the following assets for the billing – IP, Domains, and Host. More details on pricing are on the pricing page.
In addition to the release of the two new security products, Microsoft also announced the new Microsoft Sentinel solution for SAP, allowing customers to now monitor, detect, and respond to SAP alerts, such as privilege escalation and suspicious downloads, all from their cloud-native SIEM.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

To help users understand where a back gesture will land them in an Android app, Google has introduced a new predictive back gesture. The new feature allows the user to decide whether they want to complete the gesture or not by showing an animated preview of the gesture outcome. It is available in the last Android 13 beta for developers to start experimenting with it and prepare the migration.
Gesture controls where added to Android 10 as a extension to the button-based design used for back actions. While they represented a powerful enhancement to Android user experience, the variety of actions the new paradigm supported could be hard to handle. In particular, Google says, users have expressed a preference for knowing where a back gesture will take them before they complete it.
The new predictive back gesture will not be available to users in the upcoming Android 13 release. Instead, Google is giving developers plenty of time to adapt their apps and adopt the new API. Failing that, Google says, users will experience a broken back gesture navigation. In fact, alongside with the introduction of the new API, Google will remove the deprecated KeyEvent.KEYCODE_BACK event and the onBackPressed method used in Activity and Dialog.
Google offers developers support to make the migration easier through the latest AndroidX Activity 1.6.0-alpha05 release. Non-AndroidX based apps will have to tap directly into the platform API, instead.
In the simplest case, that is when an app uses default back navigation, developers are only required to opt in to the new mechanism by adding android:enableOnBackInvokedCallback="true" to your AndroidManifest.xml.
For apps that handle by themselves the back action to provide a customized experience through OnBackPressedDispatcher, developers will also ensure they use AndroidX Activity 1.6.0-alpha05 for the predictive back gesture to work seamlessly.
On the other end, apps still using the old back gesture mechanism will need to update to AndroidX’s OnBackPressedDispatcher and implement OnBackPressedCallback as shown in the following snippet:
val onBackPressedCallback = object: OnBackPressedCallback(true) {
override fun handleOnBackPressed() {
// Your business logic to handle the back pressed event
}
}
requireActivity().onBackPressedDispatcher
.addCallback(onBackPressedCallback)
The OnBackPressedCallback can be disabled by setting onBackPressedCallback.isEnabled when an app has no defined behaviour for the back gesture.
If an app cannot update to AndroidX, for whatever reason, Google is providing a path forward exposing the lower-level OnBackInvokedCallback API. In this case, apps will need to implement an onBackInvoked method to leverage their previous onBackPressed logic and to get a chance to react to the back action once the user completes it. Additionally, they will need to unregister the OnBackInvokedCallback to prevent broken behaviour.
Once developers have updated their apps to the new predictive back gesture mechanism, they will be able to test it by enabling a specific developer option available in Android 13 beta 4 under Settings > System > Developer options.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Researchers from Meta AI and Stanford University have developed a metric for pruning AI datasets which improves training scalability from a power-law to exponential-decay. The metric uses self-supervised learning and performs comparably to existing metrics which require more compute power.
The metric and experiments were described in a paper published on arXiv. Although the performance of large AI models has been shown to scale with dataset size, this scaling follows a power-law relationship, such that increasing performance by a few percentage points may require an order-of-magnitude more data samples. Using statistical mechanics, the researchers showed that by properly pruning the dataset, performance can scale via an exponential-decay relationship. Since existing pruning techniques either perform poorly or else are compute-intensive, the team developed a new technique that uses a self-supervised AI model that can estimate a pruning metric with less computation. According to senior researcher Surya Ganguli:
Overall this work suggests that our current ML practice of collecting large amounts of random data is highly inefficient, leading to huge redundancy in the data, which we show mathematically is the origin of very slow, unsustainable power law scaling of error with dataset size.
In 2020, OpenAI published their research on trends in the accuracy of neural language models trained with different architectures, number of parameters, computing cycles, and dataset sizes. The key finding was that model performance, particularly the training loss value, exhibits a power-law relationship with each of three scale factors: number of model parameters, the size of the training dataset, and the amount of compute power used in training. This power-law relationship means that, holding compute and parameters constant, improvements in performance require large amounts of additional data; for example, according to the Meta team, “an additional 2 billion pre-training data points (starting from 1 billion) leads to an accuracy gain on ImageNet of a few percentage points.”
An exponential-decay relationship, by contrast, would require less additional data to achieve a similar performance improvement. The Meta team began by developing a theoretical model of performance improvement from data pruning using statistical mechanics. The key operation is to determine the margin of each training example, which indicates whether the example is “easy” (large margin) or “hard” (smaller margin). The researchers found that the best pruning strategy depends on the initial dataset size: for small datasets, it was best to keep the easy examples, whereas for larger datasets, keeping harder examples was better. The team also found that as initial dataset size increases, pruning more examples from the dataset is required to achieve an exponential-decay in performance
However, the best existing metrics for dataset pruning required a substantial amount of compute power as well as labeled datasets, making them impractical for pruning training datasets for large foundation models, which are trained on unlabeled datasets. To solve this, the Meta researchers developed a “simple, scalable, self-supervised pruning metric.” To compute the metric, the team used k-means clustering on an embedding space from a pre-trained model. The pruning metric for each dataset example is its distance from the nearest cluster centroid. Using this metric, the researchers could train a model using only 75% of the ImageNet dataset, “without accuracy loss.”
Ari Morcos, a member of the Meta research team, joined a Reddit discussion about the work, answering several users’ questions. In response to a question about the need to train a separate model to compute the pruning metric, Morcos replied:
One of the ideas we propose at the end of the paper is the idea of “foundation datasets”, which would be assembled over many trainings, and then could be used to broadly pre-train. In this case, the cost of finding the foundation data would be amortized over all the future pre-trainings.
The investigation of scaling laws for AI training is an active research topic. In 2020, InfoQ covered OpenAI’s original paper which outlined scaling laws for language models. More recently, researchers from Google and DeepMind investigated the scaling properties of different model architectures, finding that the “scaling coefficient differs greatly” depending on the architecture, and that some model architectures do not scale at all.
MMS • Rick Spencer
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Developer burnout has always been a concern, and it will continue to be even as the way we work has changed.
- In this new era of work, organizations need to embrace online social intelligence.
- Tech leadership is by definition a technical job, but it is also a people-centric job.
- Mastering asynchronous communication is vital as teams become more distributed.
- The phrase “work-life balance” has become somewhat cliche, but it’s a concept that needs to be embraced to help dev teams avoid burnout.
For obvious reasons, the developer workforce has become increasingly distributed over the past two-plus years, and that has contributed to new levels of stress. Conditions continue to evolve, but work still needs to be done. With this backdrop, what can IT leaders do to prepare for the future of software development that gives teams the tools and resources they need to keep individual developers happy, productive and as stress-free as possible?
As the new post-COVID norm defines itself, a good number of developers have embraced working remotely in either co-working spaces or their home offices. They’ve grown to avoid the distractions that can arise and achieve better work-life balance, while also maintaining or even improving productivity.
On the flip side, there is still a minority of those who feel working in a traditional office setting with shared workspaces brings the best out of developer teams, and this setup certainly has its advantages. But businesses are finding it harder and harder to justify continuing to spend on real estate and leases when the trend in the workforce clearly points to a distributed model.
All of this said, developer burnout has always been a concern, and it will continue to be even as the way we work has changed. Fatigue and burnout appear in any line of work, so the key for leaders is to find ways to help their teams avoid – or at least minimize – work-related stress in a way that supports evolving work styles.
Embracing Online Social Intelligence
In this new era of work, it’s imperative for team members – from the CEO down – to have the ability to “read the virtual room” and have an understanding of what developers are thinking and feeling based on the tone and content of online interactions and conversations. Whether it’s Slack, Zoom, Teams or any other collaboration tool, it’s not the same as communicating face-to-face with someone who’s literally sitting at the same table.
It’s possible to teach leaders the skills necessary to manage effectively in this environment, but we’re also seeing a rise of new and emerging leaders that are thriving because they place a priority on empathy and personal connections, even when most of the communication that takes place with their team members is digital. Paying attention to online social cues can help leaders determine if and when team members are stretching themselves too thin.
Make no mistake, modern communication tools have helped make work more productive and efficient. But the best leaders are those who are able to analyze behavior on these tools so they can offer team members support when it’s needed most. Some ways managers can do this include:
- Regular one-on-one meetings: These meetings are important for getting a sense of the motivation and morale of the team. If the leaders are feeling beaten down, defeated, or hopeless, they should also assume that these attitudes are flowing down to the team. Alternatively, if leaders that are working well together, have high morale and are highly motivated, most likely the rest of the team is as well.
- Break a negativity cycle: A lot of developers find themselves from time to time dwelling on negative thoughts. This is oftentimes a matter of living in the future, but in a bad way. “If such and such goes wrong, then …” and we see individuals spinning out long internal yarns about how to respond to that non-existent situation.
- Prioritize feedback: Everyone deserves constant feedback. No one should be surprised by any aspect of their annual performance review (either positive or negative). In fact, I’ve always found continuous feedback to be more effective than annual review in terms of keeping a team engaged and ensuring everyone is invested in a common goal. I would much rather see tools that help me ensure that engineering managers and directors are giving coaching and feedback on at least a weekly basis, rather than suffer the backlog of work and the build-up of anxiety around a yearly review.
- Identify the right management style: We too often forget that every person needs something different from their direct manager in order to perform their best. Leaders need to figure out what each one of their reports needs – some people need a collaborator, some need a mentor, some need a taskmaster, while some have inherent problems with authority, and therefore need very special handling. It is important to note that the kind of manager someone needs for optimal performance may not be the kind of manager that someone wants or prefers. It’s important to figure this out and even ask people on your team what they want as well.
- Remember that transparency leads to trust: Something that I prioritize as a manager is spending time sharing what I’m working on. This not only helps engineers understand the context in which I am working (and what I am worried about), but it also helps to humanize my side of the relationship, which for some people is important for building trust.
Over time, as leaders develop stronger relationships with their teammates, they get better at identifying when a report might need more support, a break, etc. That’s why it’s important to remember that though technical leadership is a technical job, really, at the end of the day, it is also a people-centric job.
Perfecting Asynchronous Communication
With so many teams distributed globally, they need to take advantage of the sliver of time when meetings can take place within “normal” working hours for all – essentially in the morning for those on the West Coast and later afternoon in Europe. This gives developers significant chunks of time for uninterrupted work, while also keeping the communication flow going using the organization’s preferred collaboration tools.
Developers crave longer stretches of work time with no interruptions from meetings. During these times they can focus intently on writing code, building applications, or turn their attention to any other problem-solving that might pop up. This can have a two-pronged effect by boosting productivity across the organization while also increasing team morale. We all feel valuable when we’re able to take the time necessary to solve more complex problems. The work is much more rewarding and engaging, and that shouldn’t be overlooked. In fact, it’s a large part of what keeps people from changing jobs or even careers.
Having fewer formal meetings is nice, but communication and collaboration still need to take place for developers to do their jobs effectively. This is where mastering asynchronous communication comes in. It’s becoming more vital as teams become more distributed. Here is a quick breakdown of how synchronous and asynchronous communication differ:
- Synchronous communication. This takes place among team members who are in close geographic proximity, such as the same city, state or time zone. It’s easier for these teams to quickly organize one-off meetings to sort out issues, even if it’s via Zoom or Teams. In the developer world, these teams typically share responsibilities for the same sets of code and often work together in real-time. One of the main challenges they face is accurately capturing the rationale behind their design and/or logic in a way that’s searchable and shareable.
- Asynchronous communication. This type of communication is sharply on the rise as teams are increasingly formed across states, time zones and continents. Since it’s virtually impossible for these teams to routinely jump on a quick call when necessary, they need asynchronous methods and tools that keep important information flowing in a searchable way, with assignments clearly communicated and documented. The challenge here is breaking down the natural siloes that appear when teams are distributed around the world. Effective asynchronous communication allows developers to work independently but with full visibility. When done correctly, this method prevents bottlenecks, keeps the code flowing smoothly, and limits unnecessary stress that can lead to burnout.
Each of these communication methods can be both effective and productive, but asynchronous communication is often newer to most. Implementing best practices and evolving them over time keep teams on the same page, which ultimately limits frustrations.
One effective approach that works for us at InfluxData is holding a daily company-wide ‘stand up’ meeting to create a sense of unity at a company where the team is fully remote and distributed all around the world. Every employee joins this 10-minute Zoom meeting, and we share announcements and updates from the different divisions of our business, give employee shout-outs or recognize work anniversaries. Standup has helped our company maintain its strong culture throughout the pandemic while keeping our distributed team engaged, connected and invested in our common goal.
Taking Work-Life Balance Seriously
The phrase “work-life balance” has become somewhat cliche as our work and home lives have blended, but it’s a concept that needs to be embraced to help dev teams avoid burnout. Separating home and office lives are largely a thing of the past, but it’s still important for developers to completely disconnect from the job when they’re not “at work.”
At the dawn of the pandemic, when teams were largely forced to work from home, many tried to still maintain a significant separation from home while “at” work, even if this was in perception only via the latest office-like Zoom backgrounds. As we all got more comfortable with this reality, however, it became much more common for team members to open up where home life is concerned. We all now know the names and ages (and probably more) of our teammates’ kids and pets, and in some cases, this has helped teams bond on a more personal level.
Taking it a step further, many developers now include day-to-day family responsibilities into their workdays. Quick breaks to feed the family, walk the dog or pick up the kids from school are quite common. This applies to self-care as well, such as a short walk or jog around the neighborhood or an online yoga class to break up the day. In my experience, the new culture of remote work has made developers both happier and healthier – a main reason why many are reluctant (and flat-out resist) the return to pre-pandemic office days.
Company culture plays an integral role in helping team members maintain their health and happiness. Business leaders and organizations as a whole need to respect a healthy work-life balance for their teams, because doing so is a win-win proposition. Employees win because they’re happier and more productive, and businesses win because they’re able to retain their top talent in what has become the most competitive job market in recent memory.
The Bottom Line
Ultimately, as the way developers work continues to evolve, so too should healthy tactics and habits that can minimize stress and help save team members from completely burning out. Winning organizations will be those who devise a plan and refine it over time to meet developers’ needs. This is not only a good business strategy – it’s a good human strategy.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

The growing number of organizations creating and deploying machine learning solutions raises concerns as to their intrinsic security, argues the NCC Group in a recent whitepaper.
The NCC Group’s whitepaper provides a classification of attacks that may be carried through against machine learning systems, including examples based on popular libraries such as SciKit-Learn, Keras, PyTorch and TensorFlow platforms.
Although the various mechanisms that allow this are to some extent documented, we contend that the security implications of this behaviour are not well-understood in the broader ML community.
According to the NCC Groups, ML systems are subject to specific forms of attacks in addition to more traditional attacks that may attempt to exploit infrastructure or applications bugs, or other kind of issues.
A first vector of risk is associated to the fact that many ML models contain code that is executed when the model is loaded or when a particular condition is met, such as a given output class is predicted. This means an attacker may craft a model containing malicious code and have it executed to a variety of aims, including leaking sensitive information, installing malware, produce output errors, and so on. Hence:
Downloaded models should be treated in the same way as downloaded code; the supply chain should be verified, the content should be cryptographically signed, and the models should be scanned for malware if possible.
The NCC Group claims to have successfully exploited this kind of vulnerability for many popular libraries, including Python pickle files, SciKit-Learn pickles, PyTorch pickles and state dictionaries, TensorFlow Server and several others.
Another family of attacks are adversarial perturbation attacks, where an attacker may craft an input that causes the ML system to return results of their choice. Several methods for this have been described in literature, such as crafting an input to maximize confidence in any given class or a specific class, or to minimize confidence in any given class. This approach could be used to tamper with authentication systems, content filters, and so on.
The NCC Group’s whitepaper also provides a reference implementation of a simple hill climbing algorithm to demonstrate adversarial perturbation by adding noise to the pixels of an image:
We add random noise to the image until confidence increases. We then use the perturbed image as our new base image. When we add noise, we start by adding noise to 5% of the pixels in the image, and decrease that proportion if this was unsuccessful.
Other kinds of well-known attacks include membership inference attacks, which enable telling if an input was part of the model training set; model inversion attacks, which allow attacker to gather sensitive data in the training set; and data poisoning backdoor attacks, which consist in inserting specific items into the training data of a system to cause it to respond in some pre-defined way.
As mentioned, the whitepaper provides a comprehensive taxonomy of machine learning attacks, including possible mitigation, as well as a review of more traditional security issues that were found in many machine learning systems. Make sure you read it to get the full detail.
MMS • Dean Guida
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Introductions [00:05]
Good day, folks. This is Shane Hastie from the InfoQ Engineering Culture podcast. Today, I’m sitting down with Dean Guida. Dean, welcome. Thanks for taking the time to talk to us today.
Dean Guida: Yes, absolutely. Really great to be here.
Shane Hastie: So you are the founder of Infragistics. So probably a useful starting point is, who’s Dean and who’s Infragistics?
Dean Guida: I started off as a software developer, freelance consultant, and got an engineering degree. And I founded Infragistics 33 years ago and we build UI and UX tools for professional developers that are building enterprise apps, commercial apps. And we really focus in on simplicity and beauty.
And so we have a whole set of UI frameworks for mobile, web, desktop, data visualization grids, everything to build all the different UI patterns in your application. And we also have a lot of design-to-code tools that help designers and developers do that handoff.
So design systems that work in your favorite prototyping tool, whether it’s Adobe XD, Sketch or Figma. So you have this whole design language. And then we can then prototype that, bring that into a code generator and generate production code for that with components.
So we’re really big in the software space. So our biggest segment is software companies, and then after that it’s financial services.
But we sell to every industry and we’ve recently, which I think is going to be beneficial as we talk about teams today, we recently introduced a product called Slingshot, which is a business tool that is a digital workplace that connects everyone that you work with with everything, data analytics, project, task management, content, chat, all in one simple and beautiful experience.
Shane Hastie: Strong technical background, building tools for technologists, our audience are technologists, what’s different about running a company of technologists? Maybe it’s not different, but as a founder, as a CEO, what do you need to take care of to make sure that your teams are well looked after?
The value in diversity [02:07]
Dean Guida: Really, the foundation is people, and we actually intentionally built our teams and our company across many different cultures. So we’re in six different regions around the world. And we actually did that to have diversity of thinking.
So when you have people from different cultures and different points of view, and we want to build software and do build software for the world, that’s one thing we purposely did. So early on in my career, I would always hire people just like me, think like me, act like me. And everyone got along, but we always solved the problem the same way.
And when you have diversity of thinking, someone could be going to the right and then thinking differently, making you go left, and then you build on that idea. So that’s just kind of one technique we’ve done. But at the center of any company and certainly software companies is people and really designing the physical, the processes, the environment, the culture that really allows people to be creative and work together.
Shane Hastie: Culture is such a wide term. I use a subtle definition from Johanna Rothman, culture is the reality of the lowest common denominator that management accepts in an organization. What is culture?
What is culture? [03:18]
Dean Guida: I don’t really like that definition. Culture to me is how you act and behave and get work done and work with each other. So that’s culture to me. And culture has to be just like designing software, caring about the experience, culture has to be thought of in a very design experience way. And so we do a lot of things.
I’ll keep some of my answers short, but even comes down to the physical space that you want to create this, or at least we do, want to create this warm and welcoming environment. Because we want people to feel at ease, to be creative, to be relaxed.
And then when we meet, we have food at the table. And again, everything to just kind of be relaxed and create this environment where people can do their best work, not feel that pressure.
And then another technique is really just creating as leaders and as people that you hire, always wanting to help somebody and having a safe space where people can ask for help, people can express ideas that may be silly and nobody disregards that. Because that’s the best way to solve problems, not get stuck on problems too long when someone else can help and really leverage the whole team in building the best software and delighting your customer.
Shane Hastie: How do you create that safety?
Dean Guida: Well-.
Shane Hastie: Psychological safety is probably one of the most talked about terms lately. But I’m skeptical because a lot of organizations give it lip service, but I see less than safe things happening on the ground. How do you make sure.
Dean Guida: Yes.
Shane Hastie: That you build that safety in?
Ways to build safety into the culture [04:47]
Dean Guida: First, it starts with hiring so that you look for people that are lifelong learners, curious and open to other ideas. So you try and hire those attributes in the beginning, certainly with skills in the areas you may need. And the second is leadership.
What’s critical is all your indirect leaders and your direct leaders need to demonstrate that openness to other ideas, not shooting down ideas, not making people feel silly for asking a question. And so it starts with really by example, with your leaders and indirect leaders.
And then something that I always do is I’m always very conscious to have everyone participate. So if we’re in a meeting and we’re talking and someone is not expressing their point of view, I always like to call them, ask for their point of view.
And that does a couple thing. One, they could actually really disagree with everything and they’re being silent, which is a horrible thing. You want them to speak up their point of view and maybe they’re right, maybe they’re wrong or maybe it’s somewhere in the middle, until you’re just drawing out open conversation.
But a lot of it is with leadership. I mean, when people kind of come in to your organization, they’re sensing what’s the norm here, how do we behave. And the outcome you want is, “Oh, I felt really comfortable here. People were very helpful.” And so it starts with leadership.
Shane Hastie: How do you build those skills in leaders?
Leadership by example [06:07]
Dean Guida: You demonstrate it. And when leaders, and we all do it, misbehave, that you talk to them one on one outside of anyone. And I learned this technique, situation, behavior, impact. And so you really say, “Hey, here was the situation. You were over talking everyone in the meeting and the behavior was, no one could really express themselves.
And the impact was it shut down conversation.” So it, which people can relate more to feedback when you tell them the situation, behavior, impact. And then you just pause and you let them speak. And it’s not a confrontational thing. It’s just kind of giving feedback.
And if the dialogue goes on and on, back and forth, it’s just not even worth it at that point where you just say, “Okay, I gave you the feedback and I hope you think about it.” But it’s really you as a leader, making sure that when bad behavior creeps up, that you’re talking about it.
And it has huge business value, because when people are afraid to ask for help, a problem could take a day to solve or it could take a week to solve, if you don’t ask for help. And then just ideas and collaboration, always a team makes the best decision. No matter how smart an individual is or thinks they are, a team always makes the better decision.
Shane Hastie: That’s great. Thinking about teams making better decisions and giving leaders feedback, how do you help people who are moving into a leadership position for the first time?
Effective training is vital for new leaders [07:27]
Dean Guida: You really need to train them. I mean, whether it’s you or someone in your company or externally, it’s not fair for anyone to not give them any level of training. But it happens all the time. So what’s really important is one, is that we all think we communicate clearly, asking someone to do something, giving them a task.
And that’s one just really important learning is that you may think you’ve communicated clearly. Someone goes off and does the work and comes back and you’re disappointed. Now it could have been you didn’t communicate clearly.
So we teach this whole kind of communication style, which is okay, what, when, who, what’s your expected outcome. But then, actually whoever you’re communicating to should repeat back what they heard, what they’re going to do.
And then you should have that open dialogue like, “It’s okay to keep coming to me if you would like help or clarity on anything,” and have that. And so you’re building up that trust and communication. And then you teach people too, that things always happen.
If you’re an A player you’re usually getting bombarded with 20 tasks and you either work late, work long hours and achieve it all, or you communicate to those that are involved, “Hey, we have to prioritize these things because I can’t achieve all of this.”
So that communication of, “I’m blocked, I’m overloaded. We need to reset this” or “I need more information here” is critical, that open communication. And so that’s important.
And then the second, which is really also to the foundation of culture and creating that safe space is trust. You have to work so hard at building trust with your team. And trust is easily lost. So it’s a very fluid situation. So you’re always should be nurturing trust. And there’s a lot of ways to build trust.
But the first thing in building trust is just show up as yourself, be you, be authentic and share something personal and have meals with people. What we do on our executive team, we meet once a week, we kick every meeting off and we start off three or four minutes and just share something personal. And you can share whatever you want.
But I can’t tell you how much of a bond that creates. You start to really get to know the person as a human and that creates trust. And as a leader, always do what you say. That creates trust. As a leader, you can show emotion. I believe in emotion in the workplace. But you should have controlled emotion and just be real with people and be authentic.
And so those are some of the techniques to really create a well gelling team. But yes, be yourself, show up and be authentic and be real and don’t have any kind of work mask versus outside company mask and just be yourself.
Shane Hastie: So you’ve touched on it, that means it’s got to be safe within the organization to be my authentic self then. For many people that’s hard.
Showing up as your authentic self [10:08]
Dean Guida: Yes. I mean, there’s nuances there as well. You be yourself, but of course that doesn’t mean you’re doing something crazy and wild that you’d do on the weekend with your pals, but still be yourself. So of course, there’s nuances in how you behave.
Shane Hastie: It sounds to me like a lot of this came from the in-person culture and collaboration your organization has. We’ve shifted. We are now very, very remote. You mentioned being globally distributed, but we are more than globally distributed now. We are in remote teams. How is Infragistics handling the remote aspect, that shift to remote and what is hybrid?
Supporting the shift to remote work [10:50]
Dean Guida: If you’re a senior person or an experienced person, it’s a lot easier working remote and working from home. Where it’s really difficult is when you’re bringing on new people or more junior people. I mean, that is harder because they lose that benefit of just watching and observing and being around people that are experienced and skilled.
So that becomes more difficult. But we use Slingshot, so the product I talked about in the intro, which is a digital workplace. And everyone uses Agile in software development. But I also believe in Agile business teams and from a business perspective.
And so with Slingshot, it’s a digital workplace. Everyone checks in every morning, each team, whether they’re a business team or a product team, what did I do yesterday, what I’m doing today. And just that simple check in and transparency that’s kind of digital to asynchronous, it builds trust.
Because you know what everyone’s working on. You can see what their priorities are, because it’s what they’re working on. Or you can see whether it’s taking longer. And so getting rid of that uncertainty for managers. And a lot of times managers will just have possibly negative thoughts when they don’t know what’s going on.
That helps create trust and transparency. Then the other thing with Slingshot is that for each task, it’s all digital and you have threaded discussions right next to the task, which is so helpful. So it’s, “Okay, I need you to go design this experience for onboarding.”
Okay, great. Well, you can see all the threaded discussions of where what’s happening. If someone’s blocked, if there’s an issue. And so you don’t have to have status meetings around what’s going on, you’re seeing it right next to the task and all the content you need to achieve that right next to the task.
Slingshot’s is a very powerful tool that through the tool itself, you have this asynchronous communication without doing extra work and you get rid of all those horrible status meetings and someone micromanaging you because they want to know what’s going on and it happens more fluidly.
Shane Hastie: And what’s happening with your office space with this shift?
Changing the use of office space [12:44]
Dean Guida: We invested a lot of money in all our offices space, because we really believe in experience and having this really relaxed atmosphere. So our headquarters, we have a 75,000 square foot building in New Jersey. It’s kind of empty right now, I have to say.
So we surveyed. We’re in South America, we’re in Europe, we’re in Eastern Europe, we’re in Tokyo, we’re in New Jersey. We’re in all these locations. And pretty much consistently across every location, only a third of our team wants to come into the office.
And of the third of the team that wants to come in, it’s on demand or part-time or just around team events. So we left it up to our managers to define when they come in. And we also told our managers, “You can’t force anyone to come in as well, just because it’s this kind of new world where people have really enjoyed working from home.”
And so we’re going with that and just rolling with it. So we still have offices around the world. It’s funny. We have an office in Montevideo in Uruguay, they like to come in. And we have an office in Sofia, Bulgaria in Eastern Europe, they like to come in too.
There are different regions of the world people want to come in. Now it’s still only a third, but they want to come in. And it’s fluid too. Even myself and my own team, learn to be around people physically. So we’re not demanding it and we’re being flexible. And so our offices, some places are more populated than others.
Shane Hastie: So that fluidity and flexibility, how do you prevent it being chaos?
Embracing fluidity and flexibility without it becoming chaos [14:10]
Dean Guida: Well, what’s really important is, there’s all these pieces that contribute to culture. So one, everyone should understand what is the company trying to do, what’s their vision and purpose, that helps. Ours is creating simplicity and beauty and happiness in the world one app at a time.
So we really believe in simplicity and beauty digitally of course, and helping companies through our tools and the apps we built to achieve that. Then everyone should kind of understand the objectives.
And so directionally when you know what your objectives are and your goals and you give people the autonomy to execute, you’ll actually get innovation, new ways to solve problems. But with giving goals and direction and using Slingshot, our digital workplace, it’s not chaotic.
There’s a false security of everyone being in one building that you know what everyone’s working on, everyone’s being productive and you’re working on the right things. A lot of CEOs and boards of directors and executives need that. They want that, but it’s a false security blanket.
And so these tools of where are we going? Objectively, what’s the outcome look like? And then using a digital workplace, whether it’s Slingshot or some other tools where you can really transparently see the collaboration, the tasks, the conversations, it really helps.
Shane Hastie: How do you encourage innovation?
Encouraging innovation [15:24]
Dean Guida: Again, it starts with that curiosity and continued learning. So I always work at trying to create this learning organization and data driven organization. So it’s like a foundation that we’re constantly working at. So you hire for it. We ask questions like, “What books did you read last year? What books are you reading now? Do you have personal professional goals improvement?” So just really trying to test for it. That’s one thing.
The second is really what we talked about already, which is just creating an environment where people feel safe to ask for help and to offer opinions and points of view.
And then the other is where you go and tell someone, it depends on the level of person and skill, but instead of being prescriptive on how to do something, you just tell them what you want the outcome. And that gives them the agency and autonomy and even intrinsic motivation to do it a different way, which is one form of innovation.
We have a big formal program around innovation where we put 50 million dollars in to nurture ideas that are not revenue generating. And we have a process for validating and then funding these ideas. So at every level, you can nurture innovation. It all comes back to culture and people.
Shane Hastie: Let’s dig a little bit into that 50 million dollars to do things that are not revenue generating. You mentioned there’s a process to pitch your idea. How does that work?
Internal funding for innovation [18:43]
Dean Guida: Anyone in the company can have a vision of a product or something that solves a problem, starts with that. And then we kind of teach them to express it in affirmations too, just like, “Here’s my vision of this product and the problem I’m solving.”
And then if we solve that problem and built that product, what would it look like? How would the world look? So actually visualize that. So that’s step one. And then step two is what is the addressable market? What market share can we win with that product and so that the investment and the chances of winning a reasonable share of market would justify the investment?
So it’s the idea, how to express the idea, then prototype it. And then we get feedback from a prototype after some market validation of addressable market. And then we’re just a big believer in feedback.
We a hundred percent believe in the design code and iterating and getting feedback before you code. So we prototype it, get feedback with other team members, with customers, with partners. And before a huge investment, just testing the reaction to it and getting that feedback. And then if it passes all those things, there’s five of us that make a decision.
Then we fund it and we fund it so that people can design and build the software. And most developers and designers know that once you have a customer base where you start selling something, you get stuck in the mud, it just takes longer to add value, due innovation.
And so it’s a really nice incubation period where there’s no pressure of revenue, no customers asking for these specific things. And you just get a longer runway to realize your vision of solving some problem. I think innovation and funding different ideas too, you have to be careful.
Because you don’t want to create a environment where… Like I’ve been asked, “Well, do you give them special stock compensation? Do you give them this special thing?” And it really excludes the people that are working on your core products that are generating the revenue that’s funding this.
So I’m very careful to appreciate everyone that’s working on our core products that are giving us the cash flow to do this. And we’re not making people have this special, they’re special because they’re doing innovation or R and D. No, they had a great idea. It’s market worthy, and so they’re doing that. But we try and treat and recognize all parts of the product team and organization, their contributions that’s enabling this.
Shane Hastie: One of the things that I’ve seen in organizations that sometimes gets in the way of collaboration is the way incentives have worked. We ask people to collaborate and work in cross-functional teams and then once a year we stack rank them against each other. How do you manage that?
Separating coaching and feedback from pay and rewards [19:17]
Dean Guida: Yes, that’s horrible. It has a lot to do with how you pay people and also how you coach people. So we’ve separated coaching and feedback. We don’t do annual reviews. And so what we do is we buy data every two years globally, because we want to pay people at fair market.
And then so at the 50 percentile and then for our A plus people, the 75 percentile. So we kind of want to know what market is to pay people fairly. And we have a whole coaching season that’s way off cycle. We give raises in January.
But our coaching cycle happens in the second quarter. And we stretch it out because different product teams have different needs of delivering product. And the coaching, we have a really kind of lightweight coaching process that we’ve evolved over the years. Because if it’s heavyweight, no one does it.
It’s unbelievable how you invest in coaching, but managers and even people that are getting coached don’t want to do it, even though we fund personal development plans. Because it’s more work. So we try to make it very lightweight to give feedback, areas for improvement.
And then we have three to four goals, everyone’s personal development goals, and we invest in it. So someone wants to learn data science or some ML algorithm, oh great, we’ll fund that. So separating pay from coaching and feedback is really critical. And then paying fairly, we always want to pay fairly and know what paying fairly means.
Shane Hastie: Dean, there’s some really interesting stuff there. If people want to continue the conversation, where do they find you?
Dean Guida: Our main website is Infragistics.com. That’s Infragistics.com. And then Slingshot is a freemium model. So people can go use it free forever. Three digital workspaces are free, so they could find that. It’s native in Apple, Android, web, and desktop and macOS. But if you go to slingshotapp.io, that’s the website for it.
So it’s slingshotapp.io. So it’s a great way to run hybrid and remote teams and work from home. And even if you’re all in the office, it just creates that trust, transparency and accountability. And there’s a deep analytics part to it too, which we hook into all kinds of SAAS systems and big data to make data driven decision.
Shane Hastie: Thank you so much.
Dean Guida: Thank you.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Java News Roundup: Extent-Local Variables, Payara Platform, Project Reactor, Ktor, Spring Web Flow
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for August 8th, 2022, features news from OpenJDK, JDK 19, JDK 20, Jakarta EE 10, Spring WebFlow 3.0.0-M1, Spring Tools 4.15.3, Payara Platform Enterprise 5.42.0, Quarkus 2.11.2, MicroStream 7.0.1-beta, Piranha 22.8.0, JobRunr 5.1.7, Eclipse Vert.x 4.3.3, Project Reactor 2022.0.0-M5, Ktor 2.1.0, Apache Camel 3.18.1 and KCDC Conference.
OpenJDK
JEP 429, Extent-Local Variables (Incubator), was promoted from its JEP Draft 8263012 to Candidate status. This incubating JEP, under the auspices of Project Loom, proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads.
InfoQ will follow up with a more detailed news story.
JDK 19
Build 35 of the JDK 19 early-access builds was made available this past week, featuring updates from Build 34 that include fixes to various issues. More details on this build may be found in the release notes.
JDK 20
Build 10 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 9 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
The Road to Jakarta EE 10
On the road to Jakarta EE 10, Ivar Grimstad, Jakarta EE developer advocate at the Eclipse Foundation, announced in his Hashtag Jakarta EE weekly blog that the ballot for the Core Profile of Jakarta EE 10 is now open until August 15. Eclipse GlassFish 7.0.0-M7 has passed the Jakarta EE Platform TCK and work continues on the TCK for Jakarta Concurrency 3.0 so that it can be included in the Jakarta EE 10 Web Profile.
Spring Framework
Four years since the last set of releases, the first milestone release of Spring Web Flow 3.0 has been made available. This release focuses on alignment with Spring Framework 6.0 and Jakarta EE and the Spring Web Flow samples have been updated accordingly. It was necessary to remove the Tile application from the samples in favor of the Thymeleaf Page Layout since Tile is not aligned with Jakarta EE. Also, Spring Faces is not included in the release due to its integration with JSF.
One week after the release of version 4.15.2, Spring Tools 4.15.3 has been released that ships with fixes such as: a Spring Boot Tools slow down; and copied files that hadn’t retained the copyright ownership. More details on this release may be found in the changelog.
Payara
Payara Platform Enterprise 5.42.0 has been released with a focus on addressing CVE-2021-37422, a zero-day vulnerability that affects web applications deployed in the default context root within all distributions of the Payara Platform. There were also five bug fixes, one improvement and one component upgrade. These fixes will also be included in the upcoming releases of Payara 6 Community (Alpha 4) and Payara Community Version 5.2022.3 during the week of August 15, 2022.
Quarkus
Red Hat has released Quarkus 2.11.2 in which the team is still struggling to find a comprehensive fix for CVE-2022-2466, a vulnerability discovered in the SmallRye GraphQL server extension in which server requests were not properly terminated. It was originally thought that this vulnerability only affects the 2.10.x release train. More details on this release may be found in the release notes.
MicroStream
MicroStream 7.0.1-beta has been released featuring enhancements to: validate channel folders against the configured channel count and throw a meaningful exception if there is a mismatch; and add a live object check to GC to ensure retaining of objects in storage when still live in the virtual machine.
Piranha
Piranha 22.8.0 has been released. Dubbed the “Hello, Expressly 5” edition for August 2022, this new release includes: fixing a number of code smells; a dependency upgrade to Eclipse Grizzly 4.0.0; enabling the TCK for the Jakarta Expression Language 5.0 specification; and fixing test errors in the the VirtualHttpServer class. More details on this release may be found in their documentation and issue tracker.
JobRunr
Ronald Dehuysser, founder and primary developer of JobRunr, a utility to perform background processing in Java, has released version 5.1.7 that ships with initial support for the Java Platform Module System and a fix for a double array parameter that was not supported in job methods since JobRunr 4.0.2.
Eclipse Vert.x
In response to a number of reported bugs found in version 4.3.2, Eclipse Vert.x 4.3.3 has been released featuring fixes to those bugs along with documenting deprecations and breaking changes. There is also initial support for the recently-released virtual threads incubation project. More details on this release may be found in the release notes.
Project Reactor
On the road to Project Reactor 2022.0.0 the fifth milestone release was made available featuring dependency upgrades to the reactor-core 3.5.0-M5, reactor-netty versions 1.1.0-M5 and 2.0.0-M1, and reactor-kafka 1.3.12 artifacts. There was also a realignment to milestone 5 with the reactor-pool 1.0.0-M5, reactor-addons 3.5.0-M5, and reactor-kotlin-extensions 1.2.0-M5 artifacts that remain unchanged.
Ktor
JetBrains has released Ktor 2.1.0, the asynchronous framework for creating microservices and web applications, that includes: a new command line tool for creating Ktor apps; support for Yeoman to generate scaffolding for a variety of projects; a new Gradle deployment plugin; and support for YAMLconfiguration.
Apache Camel
Apache Camel 3.18.1 has been released featuring 41 improvements and fixes to include: dependency upgrade to Spring Boot 2.7.2 and hadoop-common 3.3.3 module, the latter of which addresses CVE-2022-26612. More details on this release may be found in the release notes.
Kansas City Developer Conference
The Kansas City Developer Conference (KCDC) was held at the Kansas City Convention Center in Kansas City, Missouri this past week featuring many speakers from the Java community who presented talks and workshops.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS recently announced the general availability of license-included Visual Studio software on Amazon Elastic Cloud Compute (Amazon EC2) instances. Organizations can now pay a per-user subscription fee for fully compliant AWS-provided Visual Studio licenses.
Visual Studio is the integrated development environment (IDE) from Microsoft, and Amazon now provides preconfigured Amazon Machine Images (AMIs) of the latest Enterprise and Professional 2022 versions. With these AMIs, customers can launch on-demand Windows instances, including Visual Studio and Windows Server licenses, without long-term licensing commitments.
Channy Yun, a principal developer advocate for AWS, explains in an AWS news blog post:
You can launch EC2 instances using license-included AMIs, and multiple authorized users can connect to these EC2 instances using Remote Desktop software. Your administrator can authorize users centrally using AWS License Manager and AWS Managed Microsoft Active Directory (AD).
First, the administrators in an organization create an instance of AWS Managed Microsoft AD and allow AWS License Manager to onboard to it by accepting permission. Next, they can select a Visual Studio edition, add authorized users to the license of Visual Studio edition, perform the necessary administrative tasks using the AWS Command Line Interface (CLI) tools via AWS License Manager APIs, and launch a Windows instance with pre-configured Visual Studio software using the EC2 Console. And finally, after launching a Windows instance, they associate a user to the product in the Instances screen of the License Manager console.
Once administrators authorize end users and launch the instances, users can remotely connect to their Visual Studio instances using their AD account information shared by the administrator via Remote Desktop software.
Moly Sheets, a principal product manager – Technical, Spatial Computing, tweeted:
Game changer for complex remote workstation & QA environments.
Microsoft offers Visual Studio free through a community version – and professional and enterprise through licensing. Furthermore, through the Azure marketplace, customers can set up virtual machines with the community or enterprise edition of Visual 2022. According to the Microsoft documentation Visual Studio in a preconfigured Azure virtual machine is a quick, easy way to go from nothing to an up-and-running development environment.
License-included Visual Studio on Amazon EC2 is available in all AWS commercial and public Regions. Customers are billed per user for licenses of Visual Studio through a monthly subscription and per vCPU for license-included Windows Server instances on EC2. Furthermore, they can use On-Demand Instances, Reserved Instances, and Savings Plans pricing models for EC2 models.