Month: August 2022

MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

The open source vulnerability scanner Trivy has been recently extended to support cloud security posture management (CSPM) capabilities. While initially available only for AWS, Trivy will soon get support for other cloud providers, says Aqua Security.
Trivy is a scanner for vulnerabilities in Kubernetes images, file systems, and Git repositories. Additionally, it can detect configuration issues and hard-coded secrets. The new feature adds an aws command to the trivy CLI which enables scanning live AWS accounts for all the checks defined in the AWS CIS 1.2 benchmarks.
For example, according to the AWS CIS benchmark, a properly configured cloud system should avoid using the root user, ensure multi-factor authentication is enabled for IAM users, make sure that credentials unused for 90 days or longer are disabled, and many more. For each of those checks, a remediation procedure is also defined in the standard.
The first step to use trivy with a live AWS account is authentication, followed by a scan. You can scan all resources in your default zone, as well as resources in a specific region or select a specific service. Additionally, you can filter scan results based on their severity:
$ aws configure
$ trivy aws
$ trivy aws --region=us-west-1
$ trivy aws --service=s3 --region=eu-east-1
$ trivy aws --severity=MEDIUM
The tool also supports several output formats including text tables, JSON, sarif, cosign-vuln, GitHub, and others. Furthermore, Trivy will cache its result for a configurable amount of time to allow you to inspect them without having to run the scan again.
Previous to the new release, Trivy could be used to scan the static configuration files of an AWS services, but not a live AWS account.
Interestingly, Aqua Security offers a paid CSPM SaaS enabling multi-cloud security posture management across AWS, Azure, Google Cloud, and Oracle Cloud. This solution is based on the open-source tool CloudSploit, which Aqua Security acquired in 2019. While the fact that CloudSploit has not been updated since August 2020 could lead to believe that Aqua Security is sunsetting it in favor of integrating its functionality into Trivy, the company has not disclosed any specifics about the relationship between the two tools.
Cloud security posture management helps organizations discover and remediate security risks, misuse, and misconfigurations in public clouds, with a specific focus on multi-cloud environments. Traced back to Gartner, CSPM is a moniker for a number of distinct approaches and practices to cloud security including risk assessment, incident response, compliance monitoring, configuration monitoring, and others.
MMS • Juan Fumero
Article originally posted on InfoQ. Visit InfoQ

Transcript
Fumero: Heterogeneous devices such as CPUs are present in almost every computing system today. For example, mobile devices contains a multi-core CPU plus an integrated GPU. Laptops usually contains two GPUs, one that is integrated into the main CPU, and one that is dedicated, usually for gaming. Even data centers are also integrating devices such as FPGAs. All of these devices help to increase performance, and run more efficient workloads. Heterogeneous devices are here, and are here to stay. Programmers of current and future computing system need to handle execution on a wide and diverse set of computing devices. However, many of the parallel programming frameworks for these devices are based on C and C++ programming language, and so expanding execution from other the languages such as Java is almost absent. That’s why we introduced TornadoVM. TornadoVM is a high performance computing platform for JVM. Java developers can benefit from execution on GPUs, FPGAs, multi-core, in an automatic manner. I will focus on programmability and how developers can use TornadoVM to accelerate their applications.
Background
I’m Juan Fumero. A research fellow at the University of Manchester. I’m the lead developer and architect of the TornadoVM project.
Outline
I’m going to talk about the following topics. I’m going to introduce some terminology, and I’m going to motivate the project a bit further. Then I’m going to dive in into the programmability. TornadoVM has currently two ways of programming, or two APIs. One is called Loop Parallel API, and the second is called Parallel Kernel API. We will explain each of them and I will show you some performance results. Then, I will explain how Tornado translates from the Java code to the actual parallel hardware, how Tornado maps the application to parallel hardware. Finally, I will show how TornadoVM is being piloted in industry, with some use cases.
Fast Path to GPUs and FPGAs
The question is how to access heterogeneous hardware right now. At the bottom, I show different hardware: CPUs, GPUs, FPGAs. At the top level, I show different high level programming languages. We will stay with Java, but similar situation applies for all the programming languages. If you choose Java, Java is executing on top of a virtual machine, and OpenJDK is an implementation of the virtual machine, but also GraalVM, Corretto, JDK, all of them work in a similar way. Essentially, the application is translated from the Java source code to bytecode. Then the VM executes the bytecode. If the application is executed frequently, the VM can optimize the code by compiling the methods that run frequently into optimized machine code only for CPU. However, if you want to access heterogeneous devices, such as GPUs, or FPGAs, you have to do it through a JNI library or JNI call. Essentially, the programmer has to import a library and make use of that library through a JNI call. In fact, the programmer might have an optimized application for one particular GPU, but if the application of the GPU changes, he might have to redo it again, or might have to retune some parameters. This happens also with different vendors of FPGAs, or different models even of GPUs. There is no full JIT that works in the same way that works for CPU. In the sense that it can frequently execute methods or frequently execute code and get optimized code for that architecture. There is no such thing for heterogeneous devices. That’s where TornadoVM sits. That’s the place of TornadoVM. TornadoVM works in combination with an existing JDK. TornadoVM is a plugin to JDK that allow us to run applications on heterogeneous hardware. That’s what we propose.
Hardware Characteristics and Parallelism
Let’s introduce some terminology I need. There are three different architectures here, one CPU, and a GPU, and an FPGA. Each architecture is optimized for different type of workloads. For example, CPUs are really optimized for low latency applications, while GPUs are really optimized for high throughput. FPGAs is a mixture between them. You can get very low latency and very high throughput. The FPGA, the way it works is that it’s physically wiring your application into hardware. You have exactly the pieces you need to run the application, in hardware. That’s why you can get very low latency. You can get higher throughput just by replicating units. I want to map these architectures to existing type of parallelism. In the literature, you can find three main types of parallelism, task parallelization, data parallelization, and pipeline parallelization. CPUs are quite optimized for task parallelization. Any of these architecture actually can use any type of parallelism. Let’s say that CPUs are quite optimized for task parallelization, meaning that each core can run different tasks. In contrast, GPUs are quite optimized for running data parallelization, meaning that the code you’re going to run is the same, the functions you’re going to run is the same, but take in different inputs. That’s where data parallelization comes from. Then you have FPGAs that are quite suitable for representing pipeline parallelization. In fact, with some instructions, you can enable a destruction level pipeline of instructions. That’s a very good target. Ideally, we want a framework that can express different type of parallelism to maximize performance for each type of device. I will show how TornadoVM does it.
TornadoVM Overview
I’m going to explain TornadoVM. TornadoVM is a plugin to JDK that allows Java developers to execute programs on heterogeneous hardware, fully automatic. It has an optimized JIT compiler, and it’s specialized for different types of hardware. The code that is generated for GPUs is different from the code generated for FPGAs or multi-core. Tornado can run also on multi-core systems. TornadoVM can also perform task migration between architectures, between devices. For example, TornadoVM can run the application on a GPU for a while, and later on migrate the execution without restarting the application to another GPU, or FPGA, while multi-core, back and forth. TornadoVM, the way it’s programmed is fully hardware agnostic. The input application, the source code of the application to be executed on heterogeneous hardware is the same for running on GPUs, CPUs, and FPGAs. TornadoVM can run with multiple JDK vendors, can run with OpenJDK, GraalVM, Red Hat Mandrel, Amazon Corretto, and Windows JDK. It’s open source. It’s available on GitHub. If you want, you can explore on GitHub.
TornadoVM System Stack
Let me show an overview of the system stack of TornadoVM. At the top level, we have an API. This is because TornadoVM exploits parallelism, it doesn’t detect parallelization. Tornado needs a way to identify where the parallel coordinates are located in the source code. That’s done through an API. I have an example of the API here in the slide. Don’t worry about the details, because I will show, step by step, how to build an application for TornadoVM. In a sense, what TornadoVM provides is tasks. Each task is a method. Tornado compiles at the method level, same as JDK, or JVM, compiles from the method level, to efficient code for GPUs and FPGAs. To indicate where the parallelism is, apart from the method level, it also provides some annotations. In fact, Tornado provides two annotations, @Parallel, and @Reduce. Here I show an example with @Parallel.
With Tornado, you can also create a group of methods, which means a group of tasks that are going to be compiled together in one compilation unit, and that’s what we call Task-Schedule. An example of a Task-Schedule is here. We have a Task-Schedule, we give it a name. Then we have a set of tasks. In this case, just one task. You can have as many as you want. Don’t worry about the rest of the details, because we will go through an example. That’s at the API level. Then we have the TornadoVM engine, which takes the input expressions from the bytecode level and automatically generate code for different architectures. Right now, Tornado has two backends, generate code for OpenCL and CUDA. It has two backends. The user can select which one to use, or sometimes Tornado can just pick one best to choose and run there.
Example – Blur Filter
For the rest of the presentation, I’m going to focus on the API level. We will discuss how TornadoVM can be used to accelerate Java applications. I’m going to start with an example, I’m going to use the blur filter. The blur filter is a filter for photography. Essentially, you have a picture and you want to make a blur effect in that picture. All the examples I show in this presentation are available on GitHub, so check out the code, and follow the code along with the explanation here.
Blur Filter Performance
Before going into the details of how it’s programed, I want to show you performance of this application running on a heterogeneous hardware. Here I show four different implementations. The first one, the red using parallel streams, so it’s going to run on CPU, and the implementation is using streams, Java streams. There is no GPU underneath. There is nothing. It’s just Java with parallel streams. The number represent the speed-up against Java sequential, so the higher the better. I run this on my laptop. I have 16 cores on my laptop, and the speed I get is 11.4. It’s quite good. It’s not linear, but quite close. If I run this with Tornado on a multi-core, I can get better speed-up. Still, I’m using 16 cores, but I get 17x performance compared to Java. This is because Tornado generates OpenCL for CPU. OpenCL is very good at vectorizing code. It’s using vector units. Maybe those vector units are not easily accessible, when you compile from Java streams. That’s why you can get a better performance. If we run the application on integrated graphics, we can get up to 19x performance. If we run the application on the GPU I have on my laptop, we can get up to 340x performance. It’s quite high. I now run the image. It’s an image of 5K pixels by 4K pixels. I think it is pretty standard for any camera nowadays. If we compare the speed-ups we get against the parallel version of the Java streams, which is what you can get right now in Java, we can get up to 30 times faster if we run on the GPU.
Blur Filter (Sequential)
How is this implemented? The blur filter has the following pattern. It has two loops to iterate over the x axis of the picture and the y axis of the picture, so x and y coordinates. Then you apply the filter. For the specific of the filter, just check the code online. It’s basically a map operator. For every pixel, I apply a filter, a function. This is data parallelization, essentially, because every pixel can be computed independently of any other pixel. The first thing to do in Tornado is to annotate the code.
Blur Filter – Defining Data Parallelism
As I say, because the pixel can be computed in parallel, what we do is to add annotation @Parallel for these two loops. Meaning that we tell Tornado, these two loops can be fully computed in parallel, and we have two level of parallelization here, to the kernel or to the parallel loop. In fact, this is quite common on GPUs. In contrast with CPU architectures, which we have one level of parallelization, we have 10 threads, 16 threads, or 50 threads. On GPUs, we can define 2D level of parallelization, even 3D level of parallelization. It’s because GPUs are mostly created for rendering graphics, and graphics are image of pixels, x pixels, and y pixels. The first thing to do is to annotate the code. By annotating the code, we define the data parallelization.
Blur Filter – Defining the Task Parallelism
The second thing is to define the tasks. Because this is a picture, we can split the task in three channels. The picture is represented with three channels, RGB: red, blue, green. What we’re going to do is to compute each of the channels in parallel, red channel, green channel, and blue channel. For that, we need to create three tasks. We have a TaskSchedule. It’s an object that Tornado provides. You need to provide a name for the object, a name for the TaskSchedule. In this case, we say blur filter, could be any other name. Then you define which data you want to copy in. Meaning that Tornado is expecting to play with this data, that’s because usually GPUs, CPUs, and FPGAs, they don’t share memory. We need a way to tell Tornado which memory, which regions you want to copy in the device and copy out. That’s done through the StreamIn and the StreamOut.
Then you have a set of tasks, tasks for red filter, tasks for the green channel, and tasks for the blue channel. The tasks are defined as follows. You parse a name, and this is useful because in the terminology, you want to launch task, you can say these tasks run on one device, this task runs on another device. You can refer that by the name. Then the second parameter is a function pointer or method pointer, essentially, the first is the class.method. We want to accelerate the method inside this class called blurFilter. The rest are the normal parameters for the method call. In fact, the signature of the method was 6 parameters, and those are the parameters expressed here as in any other method call. Then we call execute. Once we call execute, it will run in parallel on the device.
How TornadoVM Launches Java Kernels on Parallel Hardware
How TornadoVM selects the threads to run because the Java application is single thread, we just annotate sequential code with parallel annotations. What is happening is the following. When this call executes, so in our case will be filter.execute, it will start optimizing the code. It will compile the code from an intermediate representation. Tornado extends Graal, so the optimization happens in the intermediate representation level. It will optimize the code, and then will translate from the optimized code to efficient PTX or OpenCL code. Then it will call execute. When it call execute, it will launch hundreds or thousands of threads. How does Tornado know how many threads to run? It depends with the input application. Remember our kernel, the blur filter, we have two parallel loops, and each loop iterates over the dimensions of the image. X dimension and y dimension of the image. Tornado gets this information because it compiles at runtime, and create a grid of threads. It’s going to launch 2D grid of threads with the number of pixels in the x axis and the number of pixels in the y axis. Then it will compute the filter. Each pixel will be mapped to one thread.
Enabling Pipeline Parallelism
Let me talk about how Tornado enables pipeline parallelization. We talk about task parallelization, we can define many tasks to run, and data parallelization. Each task is a data parallel problem. TornadoVM can also enable pipeline parallelization. This is done especially on FPGA. When we select an FPGA to run, or when Tornado selects the FPGA to run, it will automatically insert information in the generated code to pipeline instructions. By using this strategy, we can increase performance 2x over the previous parallel code. It’s quite good.
Understanding When to Use this API
Let me explain the pros and cons of using this style of API. As an advantage, this API based on annotations, allows the user to annotate sequential code. The user has to reason about sequential code, provide a sequential implementation, and then think about where to parallelize in the loop. In one way, this is fast for development, because if I have existing Java code, sequential code, I can just add annotations and get a parallel code. This API is very suitable for non-expert users. You don’t need to know GPU compute. You don’t need to know the hardware to run there. It doesn’t require the user to have that knowledge. As a limitation, this API, the loop annotation API, we call it parallel loop API, is limited in the number of patterns to run. We can run the typical map application, which is the filter. For each pixel, you compute a function, that’s the map pattern. Other patterns like scan or complex stencil, is hard to get from this API. Also, this API doesn’t allow the developer to have control over the hardware. It’s totally agnostic. Some developers need that control. Also, if you have an existing OpenCL and CUDA code, and you want to port it to Java, it might be hard. To solve these limitations, we introduce a second API that we call the parallel kernel API. I will explain how the API looks like.
Blur Filter Using the Kernel API
Let’s go back to our previous example, the blur filter. We have two parallel loops that we iterate over the x dimension and y dimension of the image, and compute the filter. We can translate this to our second API. Instead of having two loops, we will have implicit parallelism by introducing a context. The context is a Tornado object that the user can use. That object will give you access to the thread identifier for each dimension. For the x axis, we can get the information through context.globalIdx, and for the y axis, we can get information from the context.globalIdy. Then we compute the filter as usual. This is closer, if you’re familiar with CUDA and OpenCL, with those programming models. In fact, you might think about 2D grid, and then to identify in a unique way a thread, you just need to access to that thread in particular through x position and y position. Then you do your computation as usual.
Tuning the Amount of Threads to Run
How do we know the threads to run in this case? We need something else. Before, remember that Tornado will analyze the expressions at runtime, and will get the threads at runtime. That’s fully transparent for the user. In this case, the threads are not set. The user needs to set up that for us. In this particular example, because it’s a 2D grid, the user can create a 2D grid called worker 2D, and parses the x threads to run in the x dimension, and the y threads to run in the y dimension. Then it will set up the name of the function with that workerGrid. Then when the user calls execute, it will need to parse the grid. That’s the only difference you need to know. Through the Kernel Parallel API, the user, apart from manipulating at the thread level, can access local memory. For example, GPUs have different memories, global memory, local memory, present memory, so the user can program that memory, or can even synchronize a block of threads. It’s very close to what you might find with CUDA and OpenCL.
Strengths of TornadoVM
If we have this API that is coming from CUDA and OpenCL, why do we want to use Java, instead of having the application in OpenCL and PTX, or CUDA and PTX? TornadoVM also has other strengths, for example, live task migration, or code optimization, so we specialize the code depending on architecture. Also, it will run on FPGA. The workflow to run on FPGA is fully transparent, fully integrated with Tornado. Meaning that you can use your favorite IDE, for example IntelliJ, Eclipse, or any other editor, and you can just run on the FPGA if you have it. It can also be deployed easily on Amazon instances, for example, on cloud deployment. You will get that for free by porting that code into Java and TornadoVM.
Performance
I’m going to show some performance results because Tornado can be used for more than just applying filters for photography. In fact, it can be used for other types of applications. For example, for FinTech, or math simulations like the Monte Carlo or Black-Scholes that we see here. It can be used for computer vision applications, for physics simulation, for signal processing, and so on. Here I show a graph. The x axis shows different types of applications, and different implementations for running on the multi-core. The implementation is the same, it is different executions for different devices. The blue represents the multi-core. The green represents the FPGA. The violet, purple one represents the execution on GPU. The bars represent speed-ups. Again, Java sequentials, so the higher the better. As we can see for some applications running on the FPGA, it’s not worth it, so you don’t get any speed-up. For other types of applications like physics simulation, or signal processing, it’s very good at it. You can achieve very high speed-ups, for example, for signal processing, or physics simulation, you can get thousands of speed-ups compared to Java. These results are taken from one publication that we have. If you’re interested, just check out our website. It’s listed there.
TornadoVM Being Piloted in Industry
I’ll show how TornadoVM is being piloted in industry. I show two different use cases here, that we are working on. One with Neurocom Company in Luxembourg. They run natural language processing algorithm. So far what they have achieved is 30x performance by running their hierarchical clustering algorithms on GPUs. We have another use case, in this case, from Spark Works Company, a company based in Ireland. What they do is they have information from IoT devices, they want to post-process that information. They use a very powerful GPU, GPU100, to do the post-processing. They can get up to 460x performance compared to Java, which is quite good.
Remarks & Resources
TornadoVM is open source. It’s available on GitHub. You can download it. You can contribute if you want to. You can make suggestions. We are open to suggestions from the community. In fact, some of the features I have been talking about are coming from the community. We also have Docker images. You can run Tornado with Docker. It’s very easy, assuming you have the driver already installed. It’s just pull and run, essentially. There is a team behind TornadoVM. This is not created by just one person. This is an academic project. We are in academia. We are interested in collaborations, either academic collaborations or industry collaboration.
Takeaways
I have shown that heterogeneous devices are now pretty much in almost every computing system. There is no escape. Programmers of current computing systems as well as future computing system need to handle somehow, with the complexity of having a wide and diverse set of devices, such as GPUs, FPGAs, or any other hardware that is coming. Along with that, I have shown a strategy, a proposal to program those devices through TornadoVM. TornadoVM can be seen as a platform, high performance computing platform for Java and JVM that works in combination with existing JDKs. For example, with OpenJDK. We have discussed an application, for example, the blur filter. I have shown two different ways of implementing a blur filter, one using the parallel loop API that is well suited for non-experts in parallel computing. The parallel Kernel API that is suitable for people or developers that know CUDA and OpenCL already, and want to pour existing code into Tornado.
Why Debugging Is Tricky
Debugging is very tricky, because if anyone has been experimenting with GPU compute, and FPGA, debugging is a very frustrating task. What TornadoVM can do right now is logging information, can give you the compilation time. Meaning Tornado can compile from Java bytecode to OpenCL or PTX. We time those times, meaning from Java bytecode, using Graal compiler to the PTX, and then a second step of compilation is from the PTX or OpenCL via the driver, to actual binary. I can give you that. As well as data transfer time, for example, how much time does it take to send data back and forth? How much actual compute time it takes, along with how many threads Tornado runs on the actual platform, decide what to do with your application. All this information can be enabled with the profile option in Tornado. It’s not fully debugged, so you cannot do this by step by step execution on a GPU, as far as I know. I don’t know if there is any project on that. I think it’s complicated because you usually have thousands of threads running on that platform. What you usually do is to have a small set of threads to run on there, and then debug the application from that point. That’s one step.
The second step is that we can speed the code that Tornado generates. Meaning that I want to see what Tornado generates with OpenCL code, and then I can debug it myself. This is especially useful on FPGAs, because FPGA world is another area. Related to that with the debugging, we also have a debug mode for FPGA. The FPGAs will add a lot of extra overhead in the creation of the application, debugging and run. Usually, compilation on FPGA takes two or three hours of compiling that code. This is because if we generate OpenCL, that’s what OpenCL driver gives us. Tornado can run with the debug option and is fully integrated with the low level tools. For example, if we’re using the Intel FPGA with Intel tools, you can run your debug mode from your IntelliJ editor, for example, or whatever editor you use. Just run debug and you simulate that application on FPGA. It’s not running actually on FPGA, it’s running on your host. It’s a quick try that what Tornado generates can actually run on FPGA. That’s one thing on feedback.
Questions and Answers
Beckwith: Recently, I was looking at an OpenCL stack, and there were some differences that I found out based on the operating system and the enablement that happens, right from the underlying hardware architecture up to the OS. Have you found TornadoVM to generate a different optimized stack depending on the OS and the underlying hardware architecture?
Fumero: In fact, it depends even the driver we use, on the same operating system. I can tell you of an example we had a few months back. What Tornado does inside is a bit complicated. It’s not only about the full JIT, it’s also managing data buffers for you. Essentially, the code that is generated by the architecture is different. One of the things we do for reductions, when you have a reduction it’s a special case when you run in parallel. A reduction means that you have a list of values and you want to reduce all of them to scalar values. This is fully data dependent. To run the next iteration you need to complete the previous one. There’s an algorithm to make this in parallel. To make this in parallel you need to play with workgroups, in the GPU world. Meaning, I split my problem into small problems, and because those block of threads is a subset of the whole iteration space, can share memory, but sharing memory on GPUs is not coherent. You need to insert values. We had this a few months back that we have these reductions working. Then in one platform, Intel, actually, it didn’t work. It was because one of the drivers they put something that Tornado didn’t realize, then the next version we have to [inaudible 00:35:13], then Tornado can pick up and magically reductions continue working again. Yes, even the same platform with the same OS, it’s just different driver implementation. You can get different behaviors. Usually not. Usually, you get the same thing. Actually, we cross-validated between them, so we have a full unit test suite. We run it in different architecture. We run it on Intel integrated graphics, Intel CPU, NVIDIA GPUs. We run a subset on FPGAs as well. We cross-validated that everything is going well.
Beckwith: It’s very smart to build it on top of OpenCL, and CUDA, and everything. I like the idea of cross-validation and unit testing as well.
Fumero: You can have the AoT, so you can run Java code, and then compile the code ahead of time. You can even make your own modifications. If you’re an expert in OpenCL, or CUDA, you can just throw your new modifications, new optimizations, and then pre-compile it and run it in TornadoVM. That’s fully integrated. For TornadoVM, I just save compilation time, and that’s all. On FPGAs, it’s more complicated, because this is long term. Especially, we design this ahead of time because of the FPGA workgroup. The way we usually go for the FPGA is that we first do debugging mode. We try on CPU, on your local host. Then we do the full JIT mode. You have your application. You run it. Then you wait two hours to get your binary. If you’re running on a server that runs on the application for months, or years, within two hours, it’s fine. As soon as the application is ready, Tornado will switch devices. For many users, they want instant performance, so for that, you can plug in your FPGA, your bitstream, which is the configuration file for actual architecture for the FPGA. We can get that binary directly from the OS.
See more presentations with transcripts
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
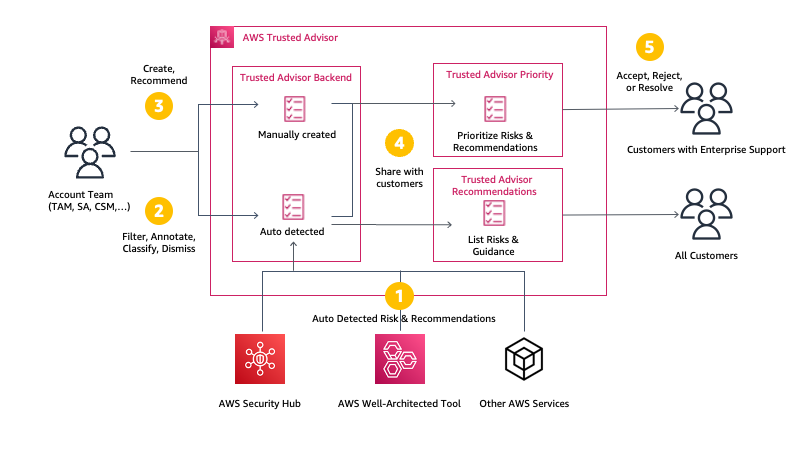
Recently, AWS announced the general availability of a new capability for their Trusted Advisor service with Trusted Advisor Priority, allowing Enterprise Support customers prioritized and context-driven recommendations manually curated by the AWS account team based on their knowledge of the customer’s environment and the machine-generated checks from AWS Services.
AWS Trusted Advisor is a service that continuously analyzes customers’ AWS accounts and provides recommendations to help them follow AWS best practices and Well-Architected guidelines. The service currently implements over 200 checks in five categories: cost optimization, performance, security, fault tolerance, and service limits. Depending on the level of support (AWS Basic Support, AWS Developer Support, AWS Business Support, or AWS Enterprise Support), customers either have access to core security and service limits checks, or access to all checks.
With the Priority capability, Enterprise Support customers have a prioritized view of critical risks, which shows prioritized, contextual recommendations and actionable insights based on the business outcomes. In addition, it also surfaces risks proactively identified by the customers’ AWS account team to alert and address critical cloud risks stemming from deviations from AWS best practices.
The capability was in preview earlier this year. The GA release now includes new features such as allowing delegation of Trusted Advisor Priority admin rights to up to five AWS Organizations member accounts, sending daily or weekly email digests to alternate contacts in the account, and allowing customers to set IAM access policies for Trusted Advisor Priority.
Sébastien Stormacq, a principal developer advocate at Amazon Web Services, explains in an AWS news blog post:
Trusted Advisor uses multiple sources to define the priorities. On one side, it uses signals from other AWS services, such as AWS Compute Optimizer, Amazon GuardDuty, or VPC Flow Logs. On the other side, it uses context manually curated by your AWS account team (Account Manager, Technical Account Manager, Solutions Architect, Customer Solutions Manager, and others) and the knowledge they have about your production accounts, business-critical applications, and critical workloads.
Source: https://aws.amazon.com/blogs/aws/aws-trusted-advisor-new-priority-capability/
Other public cloud providers, such as Microsoft, offer similar services as AWS Trusted Advisor. Microsoft’s Azure Advisor analyzes customers’ configurations and usage telemetry and offers personalized, actionable recommendations to help customers optimize their Azure resources for reliability, security, operational excellence, performance, and cost. The recommendations stem from the Azure Well-Architected Framework.
AWS Trusted Advisor Priority is available in all commercial AWS Regions where Trusted Advisor is available, except the two AWS Regions in China. It is available at no additional cost for Enterprise Support customers.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Several other large investors have also made changes to their positions in MDB. Norges Bank acquired a new position in MongoDB during the 4th quarter worth about $277,934,000. TD Asset Management Inc. lifted its position in MongoDB by 153.9% during the 4th quarter. TD Asset Management Inc. now owns 525,000 shares of the company’s stock worth $277,909,000 after buying an additional 318,259 shares in the last quarter. Jennison Associates LLC acquired a new position in MongoDB during the 1st quarter worth about $113,395,000. Fiera Capital Corp lifted its position in MongoDB by 79.7% during the 1st quarter. Fiera Capital Corp now owns 146,670 shares of the company’s stock worth $65,062,000 after buying an additional 65,043 shares in the last quarter. Finally, Geode Capital Management LLC lifted its position in MongoDB by 7.1% during the 4th quarter. Geode Capital Management LLC now owns 864,250 shares of the company’s stock worth $456,904,000 after buying an additional 56,940 shares in the last quarter. Institutional investors own 88.70% of the company’s stock.
Wall Street Analyst Weigh In
A number of research analysts have issued reports on MDB shares. Stifel Nicolaus cut their target price on shares of MongoDB from $425.00 to $340.00 in a research report on Thursday, June 2nd. William Blair restated an “outperform” rating on shares of MongoDB in a research report on Tuesday, May 24th. Credit Suisse Group cut their target price on shares of MongoDB from $650.00 to $500.00 and set an “outperform” rating on the stock in a research report on Thursday, June 2nd. Robert W. Baird started coverage on shares of MongoDB in a research report on Tuesday, July 12th. They set an “outperform” rating and a $360.00 target price on the stock. Finally, Barclays upped their target price on shares of MongoDB from $338.00 to $438.00 and gave the company an “overweight” rating in a research report on Tuesday, August 16th. One research analyst has rated the stock with a sell rating and seventeen have given a buy rating to the company’s stock. According to data from MarketBeat, the company presently has an average rating of “Moderate Buy” and a consensus price target of $414.78.
Insider Buying and Selling
In related news, CTO Mark Porter sold 1,520 shares of the stock in a transaction that occurred on Tuesday, August 2nd. The stock was sold at an average price of $325.00, for a total transaction of $494,000.00. Following the completion of the sale, the chief technology officer now directly owns 29,121 shares of the company’s stock, valued at approximately $9,464,325. The transaction was disclosed in a document filed with the SEC, which is available through the SEC website. In other news, CTO Mark Porter sold 1,520 shares of the firm’s stock in a transaction that occurred on Tuesday, August 2nd. The shares were sold at an average price of $325.00, for a total transaction of $494,000.00. Following the completion of the transaction, the chief technology officer now directly owns 29,121 shares of the company’s stock, valued at approximately $9,464,325. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available through this hyperlink. Also, Director Dwight A. Merriman sold 14,090 shares of the firm’s stock in a transaction that occurred on Monday, August 1st. The stock was sold at an average price of $312.06, for a total transaction of $4,396,925.40. Following the transaction, the director now directly owns 1,322,954 shares of the company’s stock, valued at $412,841,025.24. The disclosure for this sale can be found here. In the last three months, insiders sold 43,795 shares of company stock valued at $12,357,981. 5.70% of the stock is owned by corporate insiders.
MongoDB Price Performance
NASDAQ MDB opened at $353.57 on Friday. The business has a 50 day simple moving average of $314.31 and a 200 day simple moving average of $333.46. MongoDB, Inc. has a 52-week low of $213.39 and a 52-week high of $590.00. The company has a debt-to-equity ratio of 1.69, a quick ratio of 4.16 and a current ratio of 4.16. The stock has a market cap of $24.08 billion, a price-to-earnings ratio of -73.05 and a beta of 0.96.
MongoDB (NASDAQ:MDB – Get Rating) last posted its earnings results on Wednesday, June 1st. The company reported ($1.15) earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of ($1.34) by $0.19. MongoDB had a negative return on equity of 45.56% and a negative net margin of 32.75%. The business had revenue of $285.45 million during the quarter, compared to analysts’ expectations of $267.10 million. During the same period in the prior year, the business earned ($0.98) EPS. MongoDB’s revenue for the quarter was up 57.1% compared to the same quarter last year. Analysts anticipate that MongoDB, Inc. will post -5.08 earnings per share for the current fiscal year.
MongoDB Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Several other institutional investors have also recently made changes to their positions in MDB. Confluence Wealth Services Inc. purchased a new stake in shares of MongoDB in the fourth quarter worth $25,000. Bank of New Hampshire purchased a new stake in shares of MongoDB in the first quarter worth $25,000. Covestor Ltd purchased a new stake in shares of MongoDB in the fourth quarter worth $43,000. Cullen Frost Bankers Inc. purchased a new stake in shares of MongoDB in the first quarter worth $44,000. Finally, Tcwp LLC purchased a new stake in shares of MongoDB in the first quarter worth $52,000. Hedge funds and other institutional investors own 88.70% of the company’s stock.
Insiders Place Their Bets
In other news, CRO Cedric Pech sold 350 shares of MongoDB stock in a transaction that occurred on Tuesday, July 5th. The shares were sold at an average price of $264.46, for a total transaction of $92,561.00. Following the completion of the transaction, the executive now directly owns 45,785 shares in the company, valued at $12,108,301.10. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through the SEC website. In other news, CRO Cedric Pech sold 350 shares of MongoDB stock in a transaction that occurred on Tuesday, July 5th. The shares were sold at an average price of $264.46, for a total transaction of $92,561.00. Following the completion of the transaction, the executive now directly owns 45,785 shares in the company, valued at $12,108,301.10. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through the SEC website. Also, Director Dwight A. Merriman sold 3,000 shares of MongoDB stock in a transaction that occurred on Wednesday, June 1st. The shares were sold at an average price of $251.74, for a total transaction of $755,220.00. Following the transaction, the director now owns 544,896 shares of the company’s stock, valued at $137,172,119.04. The disclosure for this sale can be found here. Insiders sold 43,795 shares of company stock worth $12,357,981 over the last three months. Company insiders own 5.70% of the company’s stock.
Analysts Set New Price Targets
A number of equities research analysts recently issued reports on MDB shares. UBS Group increased their price objective on MongoDB from $315.00 to $345.00 and gave the stock a “buy” rating in a research report on Wednesday, June 8th. Citigroup increased their target price on MongoDB from $425.00 to $450.00 in a research note on Monday, August 22nd. Piper Sandler reduced their target price on MongoDB from $430.00 to $375.00 and set an “overweight” rating on the stock in a research note on Monday, July 18th. Needham & Company LLC increased their target price on MongoDB from $310.00 to $350.00 and gave the company a “buy” rating in a research note on Friday, June 10th. Finally, Robert W. Baird assumed coverage on MongoDB in a research note on Tuesday, July 12th. They issued an “outperform” rating and a $360.00 target price on the stock. One equities research analyst has rated the stock with a sell rating and seventeen have assigned a buy rating to the company. Based on data from MarketBeat, the company has an average rating of “Moderate Buy” and a consensus target price of $414.78.
MongoDB Stock Performance
Shares of MDB opened at $353.57 on Friday. The company has a debt-to-equity ratio of 1.69, a current ratio of 4.16 and a quick ratio of 4.16. MongoDB, Inc. has a one year low of $213.39 and a one year high of $590.00. The company has a 50-day simple moving average of $314.31 and a two-hundred day simple moving average of $333.46. The firm has a market capitalization of $24.08 billion, a PE ratio of -73.05 and a beta of 0.96.
MongoDB (NASDAQ:MDB – Get Rating) last issued its quarterly earnings data on Wednesday, June 1st. The company reported ($1.15) EPS for the quarter, topping the consensus estimate of ($1.34) by $0.19. MongoDB had a negative net margin of 32.75% and a negative return on equity of 45.56%. The business had revenue of $285.45 million during the quarter, compared to analyst estimates of $267.10 million. During the same period last year, the business posted ($0.98) earnings per share. MongoDB’s quarterly revenue was up 57.1% compared to the same quarter last year. On average, analysts anticipate that MongoDB, Inc. will post -5.08 EPS for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Get Rating).
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Analyst Ratings Changes
Several analysts have recently commented on MDB shares. Redburn Partners started coverage on shares of MongoDB in a research report on Wednesday, June 29th. They set a “sell” rating and a $190.00 price objective for the company. Robert W. Baird assumed coverage on shares of MongoDB in a report on Tuesday, July 12th. They set an “outperform” rating and a $360.00 price objective on the stock. Oppenheimer dropped their price objective on shares of MongoDB from $490.00 to $400.00 and set an “outperform” rating on the stock in a report on Thursday, June 2nd. Canaccord Genuity Group dropped their price objective on shares of MongoDB from $400.00 to $300.00 in a report on Thursday, June 2nd. Finally, Barclays raised their price objective on MongoDB from $338.00 to $438.00 and gave the company an “overweight” rating in a research note on Tuesday, August 16th. One analyst has rated the stock with a sell rating and seventeen have assigned a buy rating to the company. According to MarketBeat.com, MongoDB currently has an average rating of “Moderate Buy” and an average price target of $414.78.
MongoDB Stock Down 2.8 %
The company has a quick ratio of 4.16, a current ratio of 4.16 and a debt-to-equity ratio of 1.69. The company has a market capitalization of $24.08 billion, a PE ratio of -73.05 and a beta of 0.96. The stock has a 50-day moving average of $314.31 and a 200 day moving average of $333.46.
MongoDB (NASDAQ:MDB – Get Rating) last issued its quarterly earnings results on Wednesday, June 1st. The company reported ($1.15) earnings per share for the quarter, topping analysts’ consensus estimates of ($1.34) by $0.19. The company had revenue of $285.45 million for the quarter, compared to the consensus estimate of $267.10 million. MongoDB had a negative net margin of 32.75% and a negative return on equity of 45.56%. The firm’s quarterly revenue was up 57.1% on a year-over-year basis. During the same period in the previous year, the firm earned ($0.98) EPS. Sell-side analysts anticipate that MongoDB, Inc. will post -5.08 EPS for the current year.
Insider Transactions at MongoDB
In other news, CRO Cedric Pech sold 350 shares of the company’s stock in a transaction on Tuesday, July 5th. The stock was sold at an average price of $264.46, for a total transaction of $92,561.00. Following the transaction, the executive now owns 45,785 shares of the company’s stock, valued at approximately $12,108,301.10. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this link. In other news, CRO Cedric Pech sold 350 shares of the company’s stock in a transaction on Tuesday, July 5th. The stock was sold at an average price of $264.46, for a total transaction of $92,561.00. Following the transaction, the executive now owns 45,785 shares of the company’s stock, valued at approximately $12,108,301.10. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this link. Also, CEO Dev Ittycheria sold 4,991 shares of the company’s stock in a transaction on Tuesday, July 5th. The shares were sold at an average price of $264.45, for a total value of $1,319,869.95. Following the transaction, the chief executive officer now directly owns 199,753 shares in the company, valued at approximately $52,824,680.85. The disclosure for this sale can be found here. Insiders sold a total of 43,795 shares of company stock worth $12,357,981 in the last quarter. Insiders own 5.70% of the company’s stock.
Institutional Investors Weigh In On MongoDB
A number of hedge funds and other institutional investors have recently bought and sold shares of the business. Norges Bank bought a new position in shares of MongoDB in the fourth quarter valued at approximately $277,934,000. Renaissance Technologies LLC grew its stake in MongoDB by 833.6% during the second quarter. Renaissance Technologies LLC now owns 520,000 shares of the company’s stock valued at $134,940,000 after acquiring an additional 464,300 shares in the last quarter. TD Asset Management Inc. grew its stake in MongoDB by 153.9% during the fourth quarter. TD Asset Management Inc. now owns 525,000 shares of the company’s stock valued at $277,909,000 after acquiring an additional 318,259 shares in the last quarter. Voya Investment Management LLC grew its stake in MongoDB by 905.0% during the second quarter. Voya Investment Management LLC now owns 346,477 shares of the company’s stock valued at $89,911,000 after acquiring an additional 312,003 shares in the last quarter. Finally, Jennison Associates LLC purchased a new position in MongoDB during the first quarter valued at approximately $113,395,000. Institutional investors own 88.70% of the company’s stock.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Analyst Upgrades and Downgrades
Several research analysts have issued reports on MDB shares. Mizuho lifted their target price on shares of MongoDB from $270.00 to $390.00 and gave the stock a “buy” rating in a report on Wednesday, August 17th. Citigroup boosted their price objective on shares of MongoDB from $425.00 to $450.00 in a report on Monday, August 22nd. Robert W. Baird began coverage on shares of MongoDB in a report on Tuesday, July 12th. They issued an “outperform” rating and a $360.00 price objective for the company. Canaccord Genuity Group decreased their price objective on shares of MongoDB from $400.00 to $300.00 in a report on Thursday, June 2nd. Finally, Piper Sandler dropped their price objective on MongoDB from $430.00 to $375.00 and set an “overweight” rating on the stock in a research report on Monday, July 18th. One research analyst has rated the stock with a sell rating and seventeen have issued a buy rating to the company. According to MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and a consensus price target of $414.78.
MongoDB Stock Performance
The company has a debt-to-equity ratio of 1.69, a current ratio of 4.16 and a quick ratio of 4.16. The business has a 50-day simple moving average of $314.31 and a 200 day simple moving average of $333.46. The firm has a market cap of $24.08 billion, a PE ratio of -73.05 and a beta of 0.96.
Want More Great Investing Ideas?
MongoDB (NASDAQ:MDB – Get Rating) last issued its quarterly earnings results on Wednesday, June 1st. The company reported ($1.15) EPS for the quarter, topping analysts’ consensus estimates of ($1.34) by $0.19. MongoDB had a negative return on equity of 45.56% and a negative net margin of 32.75%. The business had revenue of $285.45 million during the quarter, compared to analysts’ expectations of $267.10 million. During the same quarter in the prior year, the business posted ($0.98) earnings per share. The business’s quarterly revenue was up 57.1% on a year-over-year basis. Equities research analysts forecast that MongoDB, Inc. will post -5.08 EPS for the current year.
Insider Buying and Selling at MongoDB
In other MongoDB news, Director Dwight A. Merriman sold 3,000 shares of the stock in a transaction on Wednesday, June 1st. The stock was sold at an average price of $251.74, for a total value of $755,220.00. Following the completion of the sale, the director now owns 544,896 shares in the company, valued at approximately $137,172,119.04. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available at this link. In related news, Director Dwight A. Merriman sold 3,000 shares of the business’s stock in a transaction that occurred on Wednesday, June 1st. The stock was sold at an average price of $251.74, for a total value of $755,220.00. Following the transaction, the director now directly owns 544,896 shares of the company’s stock, valued at approximately $137,172,119.04. The transaction was disclosed in a legal filing with the SEC, which can be accessed through the SEC website. Also, CEO Dev Ittycheria sold 4,991 shares of the business’s stock in a transaction that occurred on Tuesday, July 5th. The stock was sold at an average price of $264.45, for a total value of $1,319,869.95. Following the completion of the transaction, the chief executive officer now directly owns 199,753 shares in the company, valued at $52,824,680.85. The disclosure for this sale can be found here. Insiders have sold 43,795 shares of company stock valued at $12,357,981 over the last 90 days. 5.70% of the stock is currently owned by corporate insiders.
Hedge Funds Weigh In On MongoDB
Several institutional investors have recently bought and sold shares of MDB. Confluence Wealth Services Inc. purchased a new position in shares of MongoDB in the fourth quarter valued at $25,000. Bank of New Hampshire purchased a new stake in shares of MongoDB during the 1st quarter valued at about $25,000. John W. Brooker & Co. CPAs purchased a new stake in shares of MongoDB during the 2nd quarter valued at about $26,000. Prentice Wealth Management LLC purchased a new stake in shares of MongoDB during the 2nd quarter valued at about $26,000. Finally, Venture Visionary Partners LLC purchased a new stake in shares of MongoDB during the 2nd quarter valued at about $28,000. 88.70% of the stock is owned by hedge funds and other institutional investors.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
- Get a free copy of the StockNews.com research report on MongoDB (MDB)
- Why This Dip in Advanced Auto Parts May be an Opportunity
- MarketBeat: Week in Review 8/22 – 8/26
- Institutional Buying Put A Bottom In Marvell Technology
- Dell Stock Retreats On Weaker Sales, Falls Into Value Terrirtory
- 3 Reasons Dollar General’s Rally Has Legs
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

The price of MongoDB Inc. (NASDAQ: MDB) closed at 363.74 in the last session, up 7.42% from day before closing price of $338.60. In other words, the price has increased by $+25.14 from its previous closing price. On the day, 1427512 shares were traded. MDB reached its highest trading level at $365.53 during the session, while it also had its lowest trading level at $353.07.
3 Tiny Stocks Primed to Explode
The world’s greatest investor — Warren Buffett — has a simple formula for making big money in the markets. He buys up valuable assets when they are very cheap. For stock market investors that means buying up cheap small cap stocks like these with huge upside potential.
We’ve set up an alert service to help smart investors take full advantage of the small cap stocks primed for big returns.
Click here for full details and to join for free.
Sponsored
Ratios:
We take a closer look at MDB’s different ratios to gain a better understanding of the stock. For the most recent quarter (mrq), Quick Ratio is recorded 4.20 and its Current Ratio is at 4.20. In the meantime, Its Debt-to-Equity ratio is 1.77 whereas as Long-Term Debt/Eq ratio is at 1.76.
Upgrades & Downgrades
In addition, analysts’ ratings and any changes thereto give investors an idea of the stock’s future direction. In the most recent recommendation for this company, Robert W. Baird on July 13, 2022, initiated with a Outperform rating and assigned the stock a target price of $360.
On June 29, 2022, Redburn started tracking the stock assigning a Sell rating and target price of $190.
Needham reiterated its Buy rating for the stock on June 10, 2022, while the target price for the stock was revised from $310 to $350.
Insider Transactions:
An investor can also benefit from insider trades by learning what management is thinking about the future direction of stock prices. A recent insider transaction in this stock occurred on Aug 02 when Porter Mark sold 1,520 shares for $325.00 per share. The transaction valued at 494,000 led to the insider holds 29,121 shares of the business.
MERRIMAN DWIGHT A sold 1,000 shares of MDB for $310,679 on Aug 01. The Director now owns 540,896 shares after completing the transaction at $310.68 per share. On Aug 01, another insider, MERRIMAN DWIGHT A, who serves as the Director of the company, sold 14,090 shares for $312.06 each. As a result, the insider received 4,396,867 and left with 1,322,954 shares of the company.
Valuation Measures:
For the stock, the TTM Price-to-Sale (P/S) ratio is 26.58 while its Price-to-Book (P/B) ratio in mrq is 36.59.
Stock Price History:
Over the past 52 weeks, MDB has reached a high of $590.00, while it has fallen to a 52-week low of $213.39. The 50-Day Moving Average of the stock is 311.64, while the 200-Day Moving Average is calculated to be 377.79.
Shares Statistics:
According to the various share statistics, MDB traded on average about 1.53M shares per day over the past 3-months and 936.31k shares per day over the past 10 days. A total of 67.71M shares are outstanding, with a floating share count of 65.61M. Insiders hold about 2.70% of the company’s shares, while institutions hold 92.90% stake in the company. Shares short for MDB as of Jul 14, 2022 were 3.87M with a Short Ratio of 2.32, compared to 4.34M on Jun 14, 2022. Therefore, it implies a Short% of Shares Outstanding of 5.69% and a Short% of Float of 6.63%.
Earnings Estimates
The company has 18 analysts who recommend its stock at the moment. On average, analysts expect EPS of $-0.28 for the current quarter, with a high estimate of $-0.21 and a low estimate of $-0.32, while EPS last year was $-0.24. The consensus estimate for the next quarter is $-0.14, with high estimates of $0.02 and low estimates of $-0.32.
Analysts are recommending an EPS of between $0.08 and $-0.43 for the fiscal current year, implying an average EPS of $-0.21. EPS for the following year is $0.23, with 21 analysts recommending between $0.87 and $-0.07.
Revenue Estimates
A total of 21 analysts have provided revenue estimates for MDB’s current fiscal year. The highest revenue estimate was $1.25B, while the lowest revenue estimate was $1.17B, resulting in an average revenue estimate of $1.19B. In the same quarter a year ago, actual revenue was $873.78M, up 36.40% from the average estimate. Based on 21 analysts’ estimates, the company’s revenue will be $1.55B in the next fiscal year. The high estimate is $1.68B and the low estimate is $1.48B. The average revenue growth estimate for next year is up 30.20% from the average revenue estimate for this year.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Someone with a lot of money to spend has taken a bearish stance on MongoDB MDB.
And retail traders should know.
We noticed this today when the big position showed up on publicly available options history that we track here at Benzinga.
Whether this is an institution or just a wealthy individual, we don’t know. But when something this big happens with MDB, it often means somebody knows something is about to happen.
So how do we know what this whale just did?
Today, Benzinga‘s options scanner spotted 10 uncommon options trades for MongoDB.
This isn’t normal.
The overall sentiment of these big-money traders is split between 30% bullish and 70%, bearish.
Out of all of the special options we uncovered, 7 are puts, for a total amount of $350,946, and 3 are calls, for a total amount of $252,706.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $250.0 to $400.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $250.0 to $400.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | CALL | SWEEP | BEARISH | 09/16/22 | $400.00 | $169.4K | 356 | 219 |
| MDB | PUT | SWEEP | NEUTRAL | 09/16/22 | $300.00 | $111.5K | 866 | 226 |
| MDB | PUT | TRADE | BULLISH | 01/20/23 | $250.00 | $59.4K | 1.3K | 30 |
| MDB | CALL | TRADE | BEARISH | 09/16/22 | $400.00 | $45.5K | 356 | 83 |
| MDB | PUT | TRADE | BEARISH | 11/18/22 | $350.00 | $42.9K | 56 | 40 |
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | CALL | SWEEP | BEARISH | 09/16/22 | $400.00 | $169.4K | 356 | 219 |
| MDB | PUT | SWEEP | NEUTRAL | 09/16/22 | $300.00 | $111.5K | 866 | 226 |
| MDB | PUT | TRADE | BULLISH | 01/20/23 | $250.00 | $59.4K | 1.3K | 30 |
| MDB | CALL | TRADE | BEARISH | 09/16/22 | $400.00 | $45.5K | 356 | 83 |
| MDB | PUT | TRADE | BEARISH | 11/18/22 | $350.00 | $42.9K | 56 | 40 |
Where Is MongoDB Standing Right Now?
- With a volume of 787,026, the price of MDB is down -2.24% at $355.6.
- RSI indicators hint that the underlying stock may be approaching overbought.
- Next earnings are expected to be released in 5 days.
What The Experts Say On MongoDB:
- Citigroup has decided to maintain their Buy rating on MongoDB, which currently sits at a price target of $450.
- Barclays has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $438.
- Mizuho has decided to maintain their Buy rating on MongoDB, which currently sits at a price target of $390.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.
Article originally posted on mongodb google news. Visit mongodb google news
Open Source Big Data Tools Market Major Strategies Adopted By Leading Market … – Spooool.ie
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Open Source Big Data Tools Market Report Coverage: Key Growth Factors & Challenges, Segmentation & Regional Outlook, Top Industry Trends & Opportunities, Competition Analysis, COVID-19 Impact Analysis & Projected Recovery, and Market Sizing & Forecast.
Latest launched research on Global Open Source Big Data Tools Market, it provides detailed analysis with presentable graphs, charts and tables. This report covers an in depth study of the Open Source Big Data Tools Market size, growth, and share, trends, consumption, segments, application and Forecast 2028. With qualitative and quantitative analysis, we help you with thorough and comprehensive research on the global Open Source Big Data Tools Market. This report has been prepared by experienced and knowledgeable market analysts and researchers. Each section of the research study is specially prepared to explore key aspects of the global Open Source Big Data Tools Market. Buyers of the report will have access to accurate PESTLE, SWOT and other types of analysis on the global Open Source Big Data Tools market. Moreover, it offers highly accurate estimations on the CAGR, market share, and market size of key regions and countries.
Major Key players profiled in the report include: MongoDB Inc., AQR Capital Management, Apache, RapidMiner, HPCC Systems, Neo4j?Inc., Atlas.ti, Qubole, Qualtrics, Pentaho, Cloudera, Google, GitHub, Kaggle, Greenplum and More…
Download Free Sample PDF including COVID19 Impact Analysis, full TOC, Tables and [email protected]
https://www.marketinforeports.com/Market-Reports/Request-Sample/480771
Don’t miss the trading opportunities on Open Source Big Data Tools Market. Talk to our analyst and gain key industry insights that will help your business grow as you create PDF sample reports.
Segmental Analysis:
The report has classified the global Open Source Big Data Tools market into segments including product type and application. Every segment is evaluated based on share and growth rate. Besides, the analysts have studied the potential regions that may prove rewarding for the Open Source Big Data Tools manufcaturers in the coming years. The regional analysis includes reliable predictions on value and volume, there by helping market players to gain deep insights into the overall Open Source Big Data Tools industry.
Market split by Type, can be divided into:
Language Big Data Tools
Data Collection Big Data Tools
Data Storage Class Big Data Tools
Data Analysis Big Data Tools
Market split by Application, can be divided into:
Bank
Manufacturing
Consultancy
Government
Share your budget and Get Exclusive Discount @
https://www.marketinforeports.com/Market-Reports/Request_discount/480771
The authors of the report have analyzed both developing and developed regions considered for the research and analysis of the global Open Source Big Data Tools market. The regional analysis section of the report provides an extensive research study on different regional and country-wise Open Source Big Data Tools industry to help players plan effective expansion strategies.
Regions Covered in the Global Open Source Big Data Tools Market:
• The Middle East and Africa (GCC Countries and Egypt)
• North America (the United States, Mexico, and Canada)
• South America (Brazil etc.)
• Europe (Turkey, Germany, Russia UK, Italy, France, etc.)
• Asia-Pacific (Vietnam, China, Malaysia, Japan, Philippines, Korea, Thailand, India, Indonesia, and Australia)
Years Considered to Estimate the Market Size:
History Year: 2015-2019
Base Year: 2019
Estimated Year: 2022
Forecast Year: 2022-2028
Detailed TOC of Open Source Big Data Tools Market Report 2022-2028:
Chapter 1: Open Source Big Data Tools Market Overview
Chapter 2: Economic Impact on Industry
Chapter 3: Market Competition by Manufacturers
Chapter 4: Production, Revenue (Value) by Region
Chapter 5: Supply (Production), Consumption, Export, Import by Regions
Chapter 6: Production, Revenue (Value), Price Trend by Type
Chapter 7: Market Analysis by Application
Chapter 8: Manufacturing Cost Analysis
Chapter 9: Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10: Marketing Strategy Analysis, Distributors/Traders
Chapter 11: Market Effect Factors Analysis
Chapter 12: Open Source Big Data Tools Market Forecast
Continued……
To learn more about the report, visit @ https://www.marketinforeports.com/Market-Reports/480771/open-source-big-data-tools-market
What market dynamics does this report cover?
The report shares key insights on:
- Current market size
- Market forecast
- Market opportunities
- Key drivers and restraints
- Regulatory scenario
- Industry trend
- New product approvals/launch
- Promotion and marketing initiatives
- Pricing analysis
- Competitive landscape
It helps companies make strategic decisions.
Does this report provide customization?
Customization helps organizations gain insight into specific market segments and areas of interest. Therefore, Market Info Reports provides customized report information according to business needs for strategic calls.
Get Customization of the [email protected]:
https://www.marketinforeports.com/Market-Reports/Request-Customization/480771/open-source-big-data-tools-market
Why Choose Market Info Reports?:
Market Info Reports Research delivers strategic market research reports, industry analysis, statistical surveys and forecast data on products and services, markets and companies. Our clientele ranges mix of global business leaders, government organizations, SME’s, individuals and Start-ups, top management consulting firms, universities, etc. Our library of 600,000 + reports targets high growth emerging markets in the USA, Europe Middle East, Africa, Asia Pacific covering industries like IT, Telecom, Chemical, Semiconductor, Healthcare, Pharmaceutical, Energy and Power, Manufacturing, Automotive and Transportation, Food and Beverages, etc. This large collection of insightful reports assists clients to stay ahead of time and competition. We help in business decision-making on aspects such as market entry strategies, market sizing, market share analysis, sales and revenue, technology trends, competitive analysis, product portfolio, and application analysis, etc.
Contact Us:
Market Info Reports
17224 S. Figueroa Street,
Gardena, California (CA) 90248, United States
Call: +1 915 229 3004 (U.S)
+44 7452 242832 (U.K)
Website: www.marketinforeports.com
Article originally posted on mongodb google news. Visit mongodb google news