Month: October 2022
Podcast: The Collaborative Culture and Developer Experience in the Redis Open Source Community

MMS • Yiftach Shoolman
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today, I’m sitting down with if Yiftach Shoolman. Yiftach is the co-founder and CTO of Redis. Today I’m in Australia and he’s in Israel. Yiftach, welcome. Thank you for taking the time to talk to us today.
Yiftach Shoolman: Great to talk with you, Shane. You pronounce my name correctly. Thank you.
Shane Hastie: Thank you very much. So let’s start. Tell us about your background.
Introductions [00:48]
Yiftach Shoolman: Okay, so I’m a veteran in the high tech area. I started my career early in 1990, and did ADSL system in order to accelerate the broadband. So everything in my career is somehow related to performance and then I realized that after the broadband become adopted, I realized that this is no more the bottleneck. The bottleneck is inside at the centre. I started my first company named Crescendo Networks that does, I would say, application acceleration plus balance capability at the front end of web servers and actually accelerate web servers. This company was eventually sold to a F5 in 2008 and one of the board member in Crescendo was Ofer Bengal, my co-founder in Redis. Back then we realized that after we solved the bottleneck at the front end of the data centre, the web server, the application server, we realized that the main bottleneck inside where the data is, which is the database, and this is where we started to think about Redis. At that time that was early 2010.
We started a company in 2011. There was a technology called Memcached which is an open source that does cashing for databases and we found a lot of holes in the Memcached. For instance, every time you scale it you lose data or it doesn’t have replication, et cetera. We thought “What is the best way to solve all these walls at the technology level?” Then we realized that there is a new project which is getting momentum. It is called Redis. It has replication built in. Back then it didn’t have scaling capabilities but we managed to solve it somehow and then we created the Redis Company. Back then it was different name. It was called Garantia Data and we offered Memcached while the backend was the Redis infrastructure. Now when we launched the service and it was the first database as a service ever, I think, in the middle of 2012, all of a sudden people were asking us, “Okay, Memcached is great but what about Redis?”
We said to ourself, “The entire infrastructure is Redis. Let’s also open the interface of Redis and offer two services.” So we did it early 2013. We offered Redis as a service and Memcached as a service. It took us one year to understand that the market wants Redis, not anymore Memcached and this is the story I would say. Few years afterwards we asked Salvatore Sanfilippo who is the creator of Redis open source to join forces and to work for Redis Company because we believe it’ll help the community and to grow Redis. He accepted the offer and became part of our team, is still part of our team. Redis as a company, in addition to us contributing to the open source, the majority of the contributions coming from our employees, we also have a commercial product, Redis as a service by Redis the company. It is called Redis Enterprise Cloud as well as the Redis Enterprise Software that people can deploy on-prem.
Few words about the company, we are almost 800 employee distributed across multiple geo regions and of course continue in supporting the open source in a friendly open manner. We’ve well defined committee that is composed from people from registered company, a lady from AWS named Madelyn and a guy from Alibaba, Zhao Zhao and freed two leaders of the open source are from Redis, Yossi and Oran and another guy Itamar is also from Redis, so like five people, the committee of the open source in addition to all the commercial products that we have. But we are able to talk about developer culture. So I’ll let you ask the questions.
Shane Hastie: Thank you. So how do you build a collaborative culture that both supports the open source community but also does bring the for-profit motive of a commercial enterprise?
Supporting open-source and commercial needs [05:08]
Yiftach Shoolman: So let’s start with giving you some numbers. I cannot expose our commercial numbers because we are private company, but just for our audience to know. Redis is downloaded more than 5 million time a day. If you combine all the download alternative like going to register and downloading the code, launching dock here with Redis, et cetera, this is MOS and all the other databases together. Amazing, this is because of many two reasons. First, Redis is very simple to work with. Second, it solves a real problem. You cannot practically guarantee any real time application without using Redis, whether use it as a cache or whether use it as your primary database. We as a commercial company of many, many customers, were using it as a primary database. On our cloud service metrics that I can share with you, we have over 1.6 million databases that were launched, which is a huge number of course, all the public clouds like AWS, GCP and Azure.
This is just to show the popularity of Redis. We tried and I think so far we didn’t try it to be able to make the core of Redis completely open source BSD so people can use it everywhere, even create a competitive product to our commercial offering which you can see that all the large CSP cloud service provider provide ready as a service, which is fine. We are competing with them. We think we are better, but it’s up to the user to decide. This is a huge community of users but also contributors. If you look at the number of active contributors to Redis, they think it is close to 1000. I think we discuss it well in our conversation prior to the recording, just for everyone to understand what it means to manage an open source. It’s not just go to GitHub and open source it and people can contribute whatever they like.
When you manage a critical component such as Redis which is the core reason for your real time performance, you just cannot allow any PR out there to be accepted. First, some of the PR are not relevant to the roadmap of the border. Some of them need to be rewritten because they may expose to security breach or they may contain bugs, et cetera. Someone needs to mentor everyone who is contributing and we allocate our best people to do that, which is a huge work. It’s a huge work. Think about the group of your best engineers on a daily basis looking at the PRs the community guys are providing. They’re viewing them, providing comment and then making sure that this can be part of the next version of Redis.
By doing so, we believe that we increase the popularity of Redis, increase the usage of Redis and increase the ambition of developers to develop, to contribute to Redis because people would like to be a contributor to Redis because it’s very populated, well written, it’s a great technology and you want to publish in your LinkedIn profile or whenever you go to an interview that you are a contributor to such a great success. So this is how we do it.
Source Available licenses [08:17]
You ask on the commercial side. There are some capabilities that we keep only on the commercial license that we provide with Redis Enterprise. I think by 2018 we were the first company launched what is called Source Available License, which is a new version I would say of open-source software. It allows you the freedom to change it, to use it for yourself without contributing back, et cetera but it doesn’t allow you to create a competitive commercial product to Redis the company. We did it only on certain component of the open source, not the core, on the modules that extend the Redis capabilities to new use cases like Search and document with JSON and Graph and TimeSeries and even vector similarity search and AI. We put this under the source available license so people can use it for free in the open source wherever they want, but if you want to create a commercial product, we say you cannot use our code for that. This is how we monetize. We have the free deals of licensing, open source, source available and closed source.
Shane Hastie: You described putting your best engineers onto reviewing the open source, managing the pull request and so forth. How do you nurture and build that community and how do you, I want to say incentivize, motivate your teams?
Nurturing the community and motivating contributors [09:45]
Yiftach Shoolman: Yeah, great question. I think it is out to maintain, to be able to be successful for such a long time. If you look at the history of Redis, almost any other database out there used to pitch against Redis because the other databases found that Redis is so popular and can solve a lot of the problems that their commercial product was designed for. It actually put a risk on their business.
I think the magic of Redis with this large community of user is that we don’t stop innovating. We don’t stop contributing code and we build an architecture that allows people to extend it for their own use cases. By the way, like I mentioned with the modules that we decided to commercialize and at least the company, Redis, whenever we hire developers, we tell them, “Listen guys, if you find a problem that you think it is meaningful and you want to create a product out of it, the Redis platform is the right platform for you. Just do it and if we find it attractive in the market and we see good reaction from customers and community, we’ll support you. We’ll create a team around you. You will live it, et cetera.
As a result of this, we created a lot of very good ideas and product like this Search, JSON, the Graph, the IimeSeries, the Probabilistic, the AI. All these were created by the developers who found real problems and this is what we do internally. I know that there are other companies who are doing it internally for their own use cases based on the open source so these provide it as a platform. It’s a core platform, open core that allows you to extend it with your own core and you can decide whether you want this core to be open source, source available or closed source even. The platform allows you to do that. If it was a very closed platform, limited capabilities without any contribution from outside, et cetera, there are open sources like this, the adoption would’ve been very, very limited.
Shane Hastie: And you talk about hiring developers, how do you build great teams?
Building great teams [11:56]
Yiftach Shoolman: Great question. I think culturewise, first of all, in term of where to hire engineers, we don’t care. If there is someone that wants to work for us as a company or with us, the partner of our team, if we find a match between his desires and what we need anywhere in any place in the world so we are completely distributed. On the other end, we would like to maintain the culture of Redis which is humble design, humble people. I would say simple design but very, very unique in the way it was written, very clear, well documented. This is how we want our developers to react. Be very clear. Be very transparent. Expose the things that bother you and be very precise in how you document the issues that you encounter with. I think if we manage to maintain this culture for a very long time… I forgot to mention what I mentioned before, be innovative if you find the problems that you think it is a real problem.
Redis was designed when it started 2009. It is almost 13 years ago. The technology world has changed dramatically. The basic design of Redis is great like simple, shared-nothing architecture, scale horizontally and vertically as you want with multi processes, not multi-threaded, et cetera. Again, shared-nothing architecture but if for instance there is a problem that can only be solved with multi-threaded, this is fine. Let’s sync together how we can change the architecture of Redis and allow it to scale also horizontally. Okay, this is just one example.
If there are other, for instance, Redis is written in C and if someone wants to extend Redis with other capabilities with modules and it wants to use Rust because Rust is becoming very popular, it runs as fast as C almost, but it protects you from memory leak and under memory corruption bug, we provide a way to do it. You can do it. You can extend the code with fast functionality to solve any problem you want. The code will continue to be written in C, but you want the extension to be with Rust or other language like Python or Java or whatever or Go, go ahead and do that.
So this diversity I would say of programming languages that can support the core is very good for Redis. In addition, I would say there is a huge ecosystem that the community built around clients like clients that utilize the capabilities of Redis and are integrated part of any applications that people are developing today.
There are 200 different clients for Redis. Someone can say, “Listen this is too much.” I can agree with that as well. This is why for our customer we recommended I would say full set of clients across the different languages that we maintain together with the community. We guarantee that the bugs are fixed, et cetera. On the other end, if someone find is that what we provide is not good enough and you want to do something with other language, et cetera or just want to innovate something, go ahead and do that. We will support you by promoting it in the developer side of Redis, redis.io. If it is good, you will pick up stars very, very nicely and you will see adoption.
There are multiple examples in which people created additions to Redis, not only on the core server but also on the client side or on the ecosystem. This became a very popular open source software and some of them are also maintained commercially. They provide open source client for some language with commercial supports that they provide and they created a small business around it. Some of them even created bigger business world, which is good. This is how open source should work.
Shane Hastie: So looking back over the last 12 years and beyond, what are the significant changes that you have seen in the challenges that developers face?
The evolving challenges developers face [16:04]
Yiftach Shoolman: I think no question. The first, the foremost is the cloud. Today’s are developers who start developing in the clouds. They don’t even put the code on the laptop. I still think this is the minority, but the new wave of developers will go to some of the developer platform out there and start developing immediately in the cloud that was not there before, so this is one thing.
Second, they think from the database perspective, it is no more relational. In fact, if you look at the trends in the market, the number of new applications that are developed with relational databases declines. More and more applications are now starting new model data models that are provided by the No-SQL of the world or the multi-model of the world, like key-value document, graph, time series with search capabilities, et cetera. Unstructured data can scale linearly without all the restrictions of schema, et cetera. This is another trend.
The third trend, I would say, it’s real time. A lot of application need the real time speed today and real time has two areas, I would say. First I think the more significant one is how fast you access the data and this is where Redis shine. As a general concept, we want all the operation complex or simple and ready to build in less than a millisecond speed because otherwise you just break the real time experience of the end user. This is just one part. The other part is how far the application is being deployed from the end user because if for instance, the application works great and inside the data centre the experience is less than 50 millisecond which include the application and the database and everything in between, but your distance from your application is 200 millisecond, you will not get the written experience.
And I think the trends that we see today specifically by the cloud provider but also by a CDN vendor, is that they try to develop a lot of edge data centre and data centre across the regions worldwide in order to be closer as possible to the user because if you think on next generation applications, the ways will be deployed is completely globally between that hour and that hour, the majority of the user will be from Europe. Let’s build the clusters there. With Kubernetes it’s easy to do that because you can scale it very nicely and then shrinking down doing the night time and scale out your cluster in South America because this is where the users are there. But applications cannot work without data and the data needs to be real time, so Redis is used in these use cases and it should be globally deployed, et cetera. This is a sync game. Another trend that we see today in the market.
We mentioned cloud, we mentioned the multi-model, we mentioned the real time, we mentioned the globally distributed need. Last but not least, you will ask it, async AI will be a component of every application stack soon if not now. Whether this is features for feature store, feature stories, a way for you to enrich your data before you do the influencing of AI, use the store in order to add more information to the data, receive from the user in order to be more accurate in your AI results or whether this is vector similarity search which also supported by Redis. Just to make sure that we align with this definition, so vector allows you to put the entire context about the user in a vector and almost every application needs it in addition to the regular data about the user.
I don’t know your hobbies or things that related to context, what you like, what you prefer, et cetera. You can do recommendation engine. You can do a lot of stuff with this. Eventually if you look at the next generation of profile of user in any database, they will have the regular stuff like where do you live, your age, your height, and then a vector about yourself, which any application will decide how to formulate the vector. Then if you would like to see user with similar capabilities, you will look for vector similarity search inside your database. I truly believe this is a huge trend in next generation application and the way databases should be built.
Shane Hastie: I can hear screams about privacy and how do we do this ethically.
Privacy challenges from vector data [20:40]
Yiftach Shoolman: You’re right. It’s a good question to ask. How do you do it without exposing privacy? It’s a challenge. I totally agree it’s a challenge. By the way, from our perspective at Redis, we don’t really deal with that because it’s up to the application to decide which vectors they put in the database but once they put it there, we will make sure that if you would like to find similar users based on vector which is no one can read vectors. It’s a floating point, it’s coded. No one can understand from it anything about the user unless you wrote the application. I think in term of privacy, this is more secure than any other characteristics that you put on the user but based on the fact that the vector is there and under all the privacy compliance, et cetera, you can search for similar vectors in Redis very, very fast. This is what I’m trying to say.
Shane Hastie: On leadership perspective, how do you grow good leaders in technology teams?
Growing leaders in technology teams [21:42]
Yiftach Shoolman: As a technology company, we always have these guys in the technologies that want to be great managers and there is another type of people who want to be great technologists. They less want to manage others. They want to invest deeper in the technology and be a kind of architect. As a company we allow people to grow on both direction. It’s up to them to decide whether they want to be manager that mean less closer to the code, probably in some cases less closer to the technology, to the day-to-day technology, not in general and the other wants to continue doing it but less managing people. We allow people to grow on both parts and I think other companies are doing it as well, but we always want, even if you select to be a manager in the technology, we want you to be closer to the technology in order to take the right decisions.
I mean it’s a different space. It changes so quickly. One of the things that differentiate I think software programming than any other profession out there is the gap between great developers, I would say mediocre developer, not the poor one can be 100 time in execution. This is why we would like to hire great developers. We understand that. To manage these people, sometimes you need to be flexible because they are smart at their own perspective, not only on the code and technology but what is going on in the world. How we can be better citizen in our countries and in the world in general. By the way, the spirit of the open source is exactly that. It’s exactly that. Contribute to other. It’s not only yours. People can take it and do something else. Encourage people to do other use cases, not the things that you thought about only.
You should have this culture to accept these people because even if they grow… I don’t know in the morning, to run for four hours and they start. They work at 11:00 AM and they work until 5:00 PM but they’re excellent in what they do. The deliveries that they can provide is huge, huge, huge benefit to the companies that they work for. This is why we try not to put limitations there. I think our leaders, our managers, of course you need to stand behind the milestones and the promises, et cetera. One of the ways to do it is to be able to accept that some of your employees are exceptional and they work differently and you cannot use the same boundaries to everyone. This is a thing that we are taking care of.
Shane Hastie: Looking back over the last couple of years, there are industry statistics out there that developer experience hasn’t been great. Burnout figures are at 80 plus percent, the great resignation, all of these things happening, mental health being a challenge and general developer experience. How do we make these people’s lives better?
Supporting teams through developer experience [24:46]
Yiftach Shoolman: I think it’s a great question in here. I think also you will find out different answer from different people because eventually a great developer experience allows you to write your code even without writing code. You would agree like low code, you don’t need to do anything. Just few clicks here, few clicks there, no compilation, click the button, it is running in the cloud. I have an application. Not all developers want to work like this. Some of them want to understand what is running behind the scene, what is the overhead associated with the fact that you abstract so many things for me and they want to deep dive and understand the details in order to create faster application, better application or paper so I think you always need to give this balance. One of the thing, and by the way, I didn’t mention it when you asked me about the trends, and I think at least at the database space, there is what is called today a serverless concept.
I must say, and you ask me not to do it, but I’ll do it, that we started with this concept in 2011 when we started the company. We said, “Why should developer when it comes to the cloud, know about instances, know about cluster, know about everything that the outer world that is going there.” If you look at the number of instances that each cloud provider provides today, these are a hundred and every year there is a new generation, etc. Why should as a developer, I should care about it. The only thing I care about when I access the database are two things. How many operations per second I would like to make and what is the memory limit or the dataset size that I would like to work with? You was a database provider should challenge me according to the combination of both, how many operation, what is the side of my data set?
If I run more operation, you should be smart. The database as a service, you should be smart to scale out or scale in the cluster and eventually charge me according to the actual uses that I use. We invested, we started with it as I mentioned earlier, we don’t want the customer to deal with no cluster, how many CPUs, et cetera, care about your Redis and we will charge you only for the amount of request that you use and the memories that you use. This is becoming very popular. We are not the only one who provide serverless solution today and it makes the developer experience very easy because you just have an end point. You do whatever you want and eventually if needed you will be charged for a few dollar a month, so maybe more depending on your usage. That said, the other developers really like to fill the other way even if it is VM, even if it’s Docker to fill the software, to load it, to understand exactly how it uses the CPU, et cetera.
As a company, we also provide them a way to work with our software and do that and of course, they can take the source available element and do it themself. I think we are trying, I would say, to give a lot of options for developers across the spectrum not only serverless, but if someone wants more details, go manage it yourself. Understand what is running behind the scene. We will help you to run it better.
Shane Hastie: Yiftach, thank you very very much, some really interesting concepts there and some good advice. If people want to continue the conversation, where do they find you?
Yiftach Shoolman: So you can find me on Twitter, I’m @yiftachsh or you can of course find me on LinkedIn. Look for Yiftach Shoolman. Look for Redis. If you want to start developing with Redis, go to redis.io or redis.com. You will find a lot of material about this great technology and this is it.
Shane Hastie: Thank you so much. Thank
Yiftach Shoolman: Thank you. It was great talking with you Shane.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
During the recent Ignite conference, Microsoft announced Azure Cosmos DB for PostgreSQL, a new generally available (GA) service to build cloud-native relational applications. It is a distributed relational database offering with the scale, flexibility, and performance of Azure Cosmos DB.
Azure Cosmos DB is a fully managed NoSQL database with various APIs targeted at NoSQL workloads, including native NoSQL and compatible APIs. With the support of PostgreSQL, the service now supports relational and NoSQL workloads. Moreover, the company states that Azure is the first cloud platform to support both relational and NoSQL options on the same service.
The PostgreSQL support includes all the native capabilities that come with PostgreSQL, including rich JSON support, powerful indexing, extensive datatypes, and full-text search. Next to being built on open-source Postgres, Microsoft enabled distributed query execution using the Citus open-source extension. Furthermore, the company also stated in a developer blog post that as PostgreSQL releases new versions, it will make those versions available to its users within two weeks.
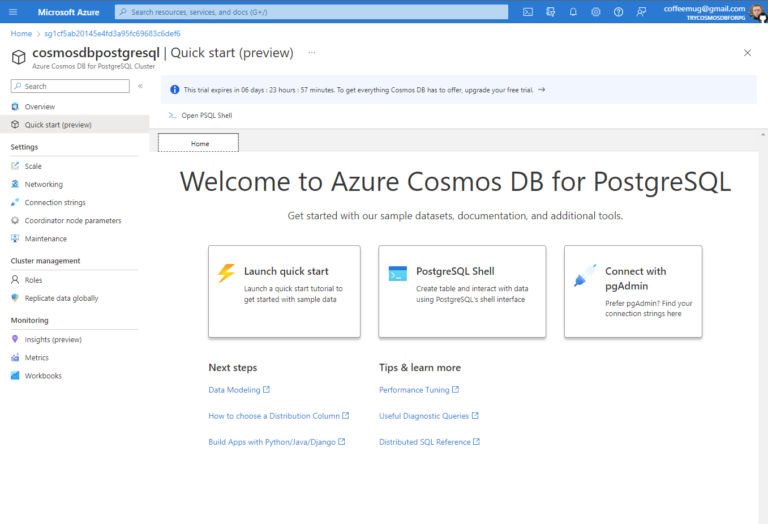
Source: https://devblogs.microsoft.com/cosmosdb/distributed-postgresql-comes-to-azure-cosmos-db/
Developers can start building apps on a single node cluster the same way they would with PostgreSQL. Moreover, when the app’s scalability and performance requirements grow, it can seamlessly scale to multiple nodes by transparently distributing their tables. A difference compared to Azure Database for PostgreSQL, which Jay Gordon, a Microsoft Azure Cosmos DB senior program manager, explains in a tweet:
#AzureCosmosDB for #PostgreSQL is a distributed scale-out cluster architecture that enables customers to scale a @PostgreSQL workload to run across multiple machines. Azure Database for PostgreSQL is a single-node architecture.
In addition, the product team behind Cosmos DB tweeted:
We are offering multiple relational DB options for our users across a number of Database services. Our Azure Cosmos DB offering gives you PostgreSQL extensions and support for code you may already be using with PostgreSQL.
And lastly, Charles Feddersen, a principal group program manager of Azure Cosmos DB at Microsoft, said in a Microsoft Mechanics video:
By introducing distributed Postgres in Cosmos DB, we’re now making it easier for you to build highly scalable, cloud-native apps using NoSQL and relational capabilities within a single managed service.
More service details are available through the documentation landing page, and guidance is provided in a series of YouTube videos. Furthermore, the pricing details of Azure Cosmos DB are available on the pricing page.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
During the recent Ignite Conference, Microsoft announced the public preview of Azure Deployment Environments. This managed service enables dev teams to quickly spin up app infrastructure with project-based templates to establish consistency and best practices while maximizing security, compliance, and cost-efficiency.
Setting up environments for applications that require multiple services and subscriptions in Azure can be challenging due to compliance, security, and possible long lead time to have it ready. Yet, with Azure Deployment Environments, organizations can eliminate the complexities of setting up and deploying environments, according to the company, which released the service in a private preview earlier this year.
Organizations can preconfigure a set of Infrastructure as Code templates with policies and subscriptions. These templates are built as ARM (and eventually Terraform and Bicep) files and kept in source control repositories with versioning, access control, and pull request processes. Furthermore, through Azure RBAC and Azure AD security authentication, organizations can establish comprehensive access controls for environments by the project- and user types. And finally, resource mappings ensure that environments are deployed to the correct Azure subscription, allowing for accurate cost tracking across the organization.
In a Tech Community blog post, Sagar Chandra Reddy Lankala, a senior product manager at Microsoft, explains:
By defining environment types for different stages of development, organizations make it easy for developers to deploy environments not only with the right services and resources, but also with the right security and governance policies already applied to the environment, making it easier for developers to focus on their code instead of their infrastructure.
Environments can be deployed manually through a custom developer portal, CLI, or pipelines.
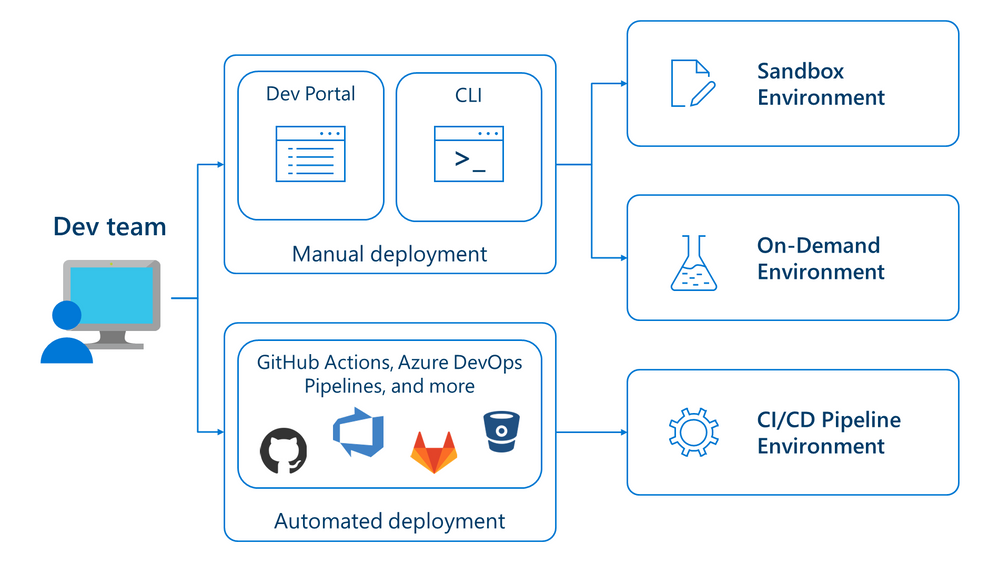
Azure Deployment Environments are an addition to the existing services, such as CodeSpaces and Microsoft Dev Box the company made available earlier to enhance developer productivity and coding environments. CodeSpaces allows developers to get a VM with VSCode quickly, and similarly, with Microsoft Dev Box, they can get an entire preconfigured developer workstation in the cloud.
Amanda Silver, CVP of the Product Developer Division at Microsoft, tweeted:
Minimize environment setup time and maximize environment security and compliance with Azure Deployment Environments. Now in public preview! Game changer for platform engineering teams.
More details of Azure Deployment Environments are available on the documentation landing page. Pricing-wise, the service is free during the preview period, and customers will only be charged for other Azure resources like compute storage and networking created in environments.
MMS • Daniel Mangum
Article originally posted on InfoQ. Visit InfoQ

Transcript
Mangum: My name is Dan Mangum. I’m a Crossplane maintainer. I’m a staff software engineer at Upbound, which is the company behind the initial launch of the Crossplane project, which is now a CNCF incubating project. I’m going to be talking to you about Kubernetes as a foundation for infrastructure control planes. I’m going to cheat a little bit, I did put an asterisk on infrastructure, because we’re going to be talking about control planes in general. It’s going to expand a little bit beyond infrastructure specifically. That is going to serve as a great use case for control planes here.
Outline
When I give talks, I like to be really specific about what we’re going to cover, so you can know if there’s going to be value for you in this talk. I usually go through three stages, motivation. That’s going to be, what is a control plane, and why do I need one? Then explanation. Why Kubernetes as a foundation. That’s the title of our talk here. Why does Kubernetes serve as a good foundation for building control planes on top of? Then finally, inspiration. Where do I start? Now that I’ve heard about what control planes are, why Kubernetes is useful for them, how do I actually go about implementing one within my organization with some tangible steps?
What Is a Control Plane?
What is a control plane? In the Crossplane community, we like to describe a control plane as follows, a declarative orchestration API for really anything. We’re going to be specifically talking about two use cases for control planes. The first one is infrastructure. Infrastructure is likely the entry point that many folks have had to a declarative orchestration API. What does that look like? The most common use case is with the large cloud providers, so AWS, Azure, and GCP. There’s countless others. Essentially, what you’re doing is you’re telling them, I would like this state to be a reality. It’s a database to exist or a VM to exist, or something like that. They are reconciling that and making sure that that is a state that’s actually reflected, and then giving you access to that. You don’t actually worry about the implementation details or the imperative steps to make that state a reality. There’s also a bunch of other platforms that offer maybe specialized offerings, or something that has a niche take on what a product offering should look like. Here we have examples of bare metal, we have specific databases, we have a message bus solution, and also CDN. There’s a lot of smaller cloud providers and platforms that you may also use within your organization.
The other type of control plane that you may be familiar with, and is used as a declarative orchestration API is for applications. What are the platforms that offer declarative orchestration APIs for applications? Once again, the large cloud providers have higher level primitives that give you the ability to declare that you want an application to run. Whether that’s Lambda on AWS, or Cloud Run on GCP. These are higher level abstractions that they’ve chosen and defined for you, that you can interact with to be able to run an application and perhaps consume some of that infrastructure that you provisioned. There’s also layer-2 versions of this for applications as well. Examples here include static site generators, runtimes like Deno or something, and a quite interesting platform like Fly.io that puts your app close to users. These are basically opinionated offerings for application control planes, where you’re telling them you want an application to run, and they’re taking care of making that happen.
Why Do I Need a Control Plane?
Why do I need a control plane? We’ve already made the case that you have a control plane. These various platforms, I would hazard a guess that most people have had some exposure or are currently using at least one of these product offerings. Let’s take it for granted that you do have a control plane. The other part we need to focus on is I, or maybe we, what are the attributes about us that make us good candidates for a control plane? QCon likes to call its attendees and speakers, practitioners. I like to use a term similar to that, builders. In my mind, within an organization, there’s a spectrum between two types of builders. One is platform, and the other is product. On the platform side, you have builders who are building the thing that builds the thing. They’re giving you a foundation that the product folks build on top of to actually create the business value that the organization is interested in. When we talk about these two types of personas, we frequently view it as a split down the middle. There’s a single interface where platform teams give a set of APIs or a set of access to product folks. In some organizations that may look like a ticketing system. In a more mature DevOps organization, there may be some self-service workflow for product engineers.
In reality, the spectrum looks a lot more like this. There’s folks that exist at various parts of this. You may have someone in the marketing team, for instance, who wants to create a static site, and they have no interest in the underlying infrastructure. They’re very far to the product side. You may have someone who is a developer who knows a lot about databases, and wants to tune all the parameters. Furthermore, you may have an organization that grows and evolves over time. This is something I’m personally experiencing, working at a startup that’s growing rather quickly. We’ve gone from having a small number of engineers to many different teams of engineers, and our spectrum and where developers on the product and platform side sit on that, has changed quite a bit over time. Those abstractions that you may be getting from those cloud providers or platforms that you’re using may not fit your organization in perpetuity.
Control Plane Ownership
We said that you already have a control plane. What’s the issue? You just don’t own it yet. All of these control planes that you’re using are owned by someone else. Why do they have really great businesses around them? Why would you want to actually have some ownership over your control plane? Before we get into the benefits of ownership, I want to make it very clear that I’m not saying that we shouldn’t use these platforms. Folks at AWS, and GCP, and Azure, and all of those other layer-2 offerings, they’ve done a lot of work to give you very compelling offerings, and remove a lot of the operational burden that you would otherwise have to have yourself. We absolutely want to take advantage of all that work and the great products that they offer, but we want to bring that ownership within your organization.
Benefits to Control Plane Ownership
Let’s get to the benefits. The first one is inspection, or owning the pipe. I’ve heard this used when folks are referring to AWS. I like to use Cloudflare actually as a great example of this. It’s a business that’s built on having all of the traffic of the internet flow through it, and being able to build incredible products on top of that. You as an organization currently probably have someone else who has the inspection on your pipe. That may be AWS, for instance. They can give you additional product offerings. They can see how you’re using the product. They can grow and change it over time. If you move beyond a single platform, you lose the insight and you may not be the priority of the person who owns a pipe that you’re currently using. When you have that inspection, you can actually understand how folks within your organization are using infrastructure, deploying it, consuming it. Everything goes through a central place, even if you’re using multiple different platforms.
The next is access management. I know folks who are familiar with IAM on AWS or really any other platform, know how important this is and how complicated it can be. From a control plane perspective that sits in front of these platforms, you have a single entry point for all actors. You’re not saying anymore, I want to give permission for a single developer to AWS, even if you’re giving them the ability to create a database on AWS. We’ll actually define a higher level concept that even if it maps one to one as an abstraction on top of a concrete implementation, you’re going to have a single entry point where you can define all access for users, no matter what resources they’re accessing behind the scenes.
Next is the right abstractions. Unless you’re the largest customer of a cloud platform, you are not going to be the priority. There may be really great abstractions that they offer you. For instance, in my approximation, Lambda on AWS has been very successful, lots of folks are building great products on top of it. However, if your need for abstraction changes, and maybe your spectrum between platform and product folks evolves over time, you need to be able to change the different knobs, and maybe even for a specific project offer a different abstraction to developers, and not be locked into whatever another platform defines as the best for you.
The last one is evolution. Your organization is not going to be stagnant, and so the API that you present to developers may change over time. Your business needs may change over time, so the implementations behind the API of your control plane can also evolve over time without the developers actually even needing to know.
Why Kubernetes as a Foundation?
We’ve given some motivation for why you would need a control plane within an organization. We’re going to make that really concrete here by looking at an explanation of why Kubernetes serves as a strong foundation for a control plane. Really, what I’m talking about here is the Kubernetes API. Kubernetes has come about as a de facto container orchestration API. In reality, it’s really just an API for orchestrating anything. Some may even refer to it as a distributed systems framework. When I gave this presentation at QCon in London, I referred to it as the POSIX for distributed systems. While that may have some different abstractions than something like an operating system, it is critical to start to think about Kubernetes and distributed systems as something we program just like the things that an operating system offers us, the APIs it gives us. What Kubernetes allows us to do is extend APIs and offer our own. Let’s get into how that actually works.
Functional Requirements of a Control Plane
What are the functional requirements for a control plane? Then let’s try to map those back to what Kubernetes gives us. First up is reliable. I don’t mean that this is an assertion that a pod never restarts or something like that. What I’m saying is we can’t tolerate unexpected deletion of critical infrastructure. If you’re using ephemeral workloads on a container orchestration platform, this isn’t as big of a deal. You can stand for nodes to be lost, and that sort of thing. We can still stand for that to happen when dealing with infrastructure. What we can’t have happen is for the control plane to arbitrarily go and delete some of that infrastructure. We can withstand it not reconciling it for a period of time.
The next is scalable, so you have more value at higher adoption of a control plane. We talked about that inspection and the value that you get from that. You must be able to scale to meet the increased load that comes from having higher adoption within your organization, because that higher adoption is what brings the real value to your control plane. The next is extendable. I’ve already mentioned how Kubernetes does this a little bit, and we’ll go into the technical details. You must be able to evolve that API over time to match your evolving organization. It needs to be active and responsive to change. We’re not just saying that we want this to exist, and after it exists, we’re done. We’re going to have requirements that are changing over time. Our state that we desire is going to evolve over time. There’s also going to be external factors that impact that. I said earlier that we don’t want to give up all of the great work that those cloud providers and platforms have done, so we want to take advantage of those. You may have a rogue developer come in and edit a database outside of your control plane, which you don’t want to do, because that’s going outside of the pipe. Or you may just have an outage from the underlying infrastructure, and you want to know about that. You need a control plane that constantly reconciles your state, and make sure what’s represented externally to the cluster matches the state that you’ve put inside of it.
If you’ve seen this before, it’s because I took most of these directly from the Kubernetes website. These are the qualities that Kubernetes says it provides for container orchestration. It also offers them for really any other distributed system you want to build on top. There’s a number of others that we’re not going to talk specifically about, but are also useful. One is secrets management, which is useful when you need to connect to these external cloud providers, as well as potentially manage connection details to infrastructure you provision. There’s network primitives. There’s access control, which we touched on a little bit already. Last and certainly not least, is a thriving open source ecosystem. You have a foundation that if you need to actually change the foundation itself, you can go in and be a part of driving change. You can have a temporary fork where you have your own changes. You can actually be part of making it a sustainable project over time, which lots of organizations as well as individuals do today.
You Can Get a Kubernetes
Last on the list of things that is really useful for Kubernetes, is what we like to say, you can get a Kubernetes. What I mean by this is Kubernetes is available. There is a way to consume Kubernetes that will fit your organization. In fact, there’s 60-plus distributions listed on the CNCF website that you can use on your own infrastructure, you can run yourself, or pay a vendor to do it for you. There’s 50-plus managed services where you can actually just get the API without worrying about any of the underlying infrastructure. Kubernetes, despite what platforms you use, is going to be there for you, and you can always consume upstream as well.
What’s Missing?
What’s missing from this picture? If Kubernetes gives us everything that we need, why do we need to build on top of it? There’s two things that Kubernetes is missing out on, and I like to describe them as primitives and abstraction mechanisms. Kubernetes does offer quite a few primitives. You’ve probably heard of pods, deployments, ingress. There’s lots of different primitives that make it very easy to run containerized workloads. What we need to do is actually start to take external APIs and represent them in the Kubernetes cluster. For example, an AWS EC2 instance, we want to be able to create a VM on AWS alongside something like a pod or a deployment, or maybe just in a vacuum. There’s also things outside of infrastructure, though. At Upbound, we’re experimenting with onboarding employees by actually creating an employee abstraction. We’ll talk about how we do that. That is backed by things like a GitHub team that automatically make sure an employee is part of a GitHub organization. There can also be higher level abstractions, like a Vercel deployment that you may want to create from your Kubernetes cluster for something like an index.js site.
The other side is abstraction mechanisms. How do I compose those primitives in a way that makes sense for my organization? Within your organization, you may have a concept of a database, which is really just an API that you define that has the configuration power that you want to give to developers. That may map to something like an RDS instance, or a GCP Cloud SQL instance. What you offer to developers is your own abstraction, meaning you as a platform team have the power to swap out implementations behind the scenes. I already mentioned, the use for an employee, and a website maps a Vercel deployment. The point is, you can define how this maps to concrete infrastructure, and you can actually change it without changing the API that you give to developers within the organization. Lastly, is how do I manage the lifecycle of these primitives and abstraction mechanisms within the cluster? I’m going to potentially need multiple control planes. I’m going to need to be able to install them reliably. I might even want to share them with other organizations.
Crossplane – The Control Plane Tool Chain
I believe Crossplane is the way to go to add these abstractions on top of Kubernetes, and build control planes using the powerful foundation that it gives us. If you’re one of the Crossplaners, it’s essentially the control plane tool chain. It takes those primitives from Kubernetes and it gives you nice tooling to be able to build your control plane on top of it by adding those primitives and abstraction mechanisms that you need. Let’s try and take a shot at actually mapping those things that we said are missing from Kubernetes to concepts that Crossplane offers.
Primitives – Providers
First up is providers. They map to primitives that we want to add to the cluster. Provider brings external API entities into your Kubernetes cluster as new resource types. Kubernetes allows you to do this via custom resource definitions, which are actually instances of objects you create in the cluster that define a schema for a new type. The easiest way to conceptualize this is thinking of a REST API and adding a new endpoint to it. After you add a new endpoint in a REST API, you need some business logic to actually handle taking action when someone creates updates or deletes at that endpoint. A provider brings along that logic that knows how to respond to state change and drift in those types that you’ve added to the cluster. For example, if you add an RDS instance to the cluster, you need a controller that knows how to respond to the create, update, or delete of an RDS instance within your Kubernetes cluster.
The important part here is that these are packaged up as an OCI image for ease of distribution and consumption. All of these things are possible without doing this, but taking the OCI image path for being able to distribute these means that they are readily available. OCI images have become ubiquitous within organizations, and every cloud provider has their own registry solution as well. These are really easy to share and consume. You can also compose the packages themselves, which providers is one type of Crossplane package, and start to build a control plane hierarchy out of these packages, which we’ll talk a little bit in when we get to composition.
Abstraction Mechanisms – Composition
Abstraction mechanisms are this kind of second thing that we said we’re missing from Kubernetes. Crossplane offers abstraction mechanisms via composition. Composition allows you to define abstract types that can be satisfied by one or more implementations. This is done via a composite resource definition. This is different from the custom resource definition that Kubernetes offers. Crossplane brings along a composite resource definition. The composite resource definition, or as we like to call an XRD, as opposed to the Kubernetes CRD. The XRD allows you to define a schema just like a CRD, but it doesn’t have a specific controller that watches it. Instead, it has a generic controller, which we call the composition engine, which takes instances of the type defined by the XRD and maps them to composition types. A composition takes those primitives, and basically tells you how the input on the XRD maps to the primitives behind the scenes.
Let’s take an example, and we’ll keep using that same one that’s come up a number of times in this talk, a database. In your organization, you have a database abstraction. Really, the only fields a developer needs to care about, let’s say, are the size of the database, and the region that it’s deployed in. On your XRD, you define those two fields, and you might have some constraints on the values that could be provided to them. Then you author, let’s say, three compositions here. One is for AWS, one is for GCP, and one is for Azure. On the AWS one, let’s say you have some subnets, a DB subnet group and an RDS instance. On the GCP one, you have, let’s say a network and a Cloud SQL instance. On Azure, you have something like a resource group, and an Azure SQL instance. When a developer creates a database, it may be satisfied by any one of these compositions, which will result in the actual primitives getting rendered and eventually reconciled by the controllers. Then the relevant state gets propagated back to the developer in a way that is only applicable to what they care about. They care about that their database is provisioned. They don’t care about if there is a DB subnet group and a DB behind the scenes.
These are actually also packaged as OCI images, that’s the second type of Crossplane package. A really powerful ability you have with these packages is to say what you depend on. You can reference other images as dependencies, which means that if you install a configuration package with the XRD and compositions that we just talked about, you can declare dependencies on the AWS, GCP, and Azure providers, and Crossplane will make sure those are present. If not, will install them for you with appropriate versions within the constraints that you define. This allows you to start to build a DAG of packages that define your control plane and make it really easy to define a consistent API and also build them from various modular components.
Making this a little more concrete, I know this is difficult to see. If you want this example it’s from the actual Crossplane documentation. Here we’re on the left side defining an XRD that is very similar to the one that I just described. This one just takes a storage size. On the right side, we’re defining a Postgres instance implementation that is just an RDS instance that maps that storage size to the allocated storage field in the AWS API. Something that’s really important here is that we strive and always do have high fidelity representations of the external API. That means that if you use the AWS REST API, and there’s a field that’s available for you, you’re going to see it represented in the same way as a Kubernetes object in the cluster. This is a nice abstraction here, but it’s quite simplistic, you’ll see there’s something like the public accessible field is set to true, which basically means it’s public of the internet. Not a common production use case.
Without actually changing the XRD or the API that the developer is going to interact with, we can have a much more complex example. This example here is creating a VPC, three subnets, a DB subnet group, some firewall rules, and the RDS instance, which is a much more robust deployment setup here. The developer doesn’t have to take on this increased complexity. This really goes to show that you may have lots of different implementations for an abstraction, whether on the same platform or on multiple, and you can, just like you do in programming, define interfaces, and then implementations of that interface. Because what we’re doing here is programming the Kubernetes API and building a distributed system, building a control plane on top of it.
This is what the actual thing the developer created would look like. They could as it’s a Kubernetes object, include it in something like a Helm chart, or Kustomize, or whatever your tooling of choice is for creating Kubernetes objects. They can specify not only their configuration that’s exposed to them, but potentially allow them to select the actual composition that matches to it based on schemes that you’ve defined, such as a provider and VPC fields here. They can also define where the connection secret gets written to. Here, they’re writing it to a Kubernetes secret called db-conn. We also allow for writing to External Secret Stores, like Vault, or KMS, or things like that. Really, you get to choose what the developer has access to, and they get a simple API without having to worry about all the details behind the scenes.
Where to Start
Where do I start? How do we get to this inspiration? There’s two different options. One is pick a primitive. You can take a commonly used infrastructure primitive that you use in your architecture, maybe it’s a database we’ve been talking about, maybe it’s a Redis Cache, maybe it’s a network. Everyone has things that have to communicate over the network. If you identify the provider that supplies it, and go and install that provider, without actually moving to the abstraction mechanisms, you can create the instances of those types directly. You can create your RDS instance directly, or your Memcached instance directly, and include that in your Kubernetes manifest, and have that deployed and managed by Crossplane.
The next option is picking an abstraction. This is the more advanced case that we just walked through. You can choose a commonly used pattern in your architecture, you can author an XRD with the required configurable attributes. You can author compositions for the set of primitives that support it, or maybe multiple sets of primitives that support it. You can specify those dependencies. You can build and publish your configuration, and then install your configuration. Crossplane is going to make sure all those dependencies are present in the cluster. The last step then is just creating an instance, like that Postgres database we saw.
These are some of the examples of some of the abstractions that the community has created. Some of these are really great examples here. Platform-ref-multi-k8s, for example, allows you to go ahead and create a cluster that’s backed by either GKE, EKS, or AKS. There’s lots of different options already. I hope this serves as inspiration as well, because you can actually take these and publish these publicly for other folks to install, just like you would go and install your npm package. Maybe that’s not everyone’s favorite example, but install your favorite library from GitHub. You can start to actually install modules for building your control plane via Crossplane packages, and you can create high level abstractions on top of them. You can create different implementations, but you don’t have to reinvent the wheel every time you want to bring along an abstraction. A great example we’ve seen folks do with this is create things like a standard library for a cloud provider. For example, if there is some common configuration that is always used for AWS, someone can create an abstraction in front of an RDS instance that basically has same defaults. Then folks who want to consume RDS instances without worrying about setting those same defaults themselves can just have the ones exposed to them that make sense.
Questions and Answers
Reisz: This is one of those projects that got me really excited. I always think about like Joe Beda, one of the founders of Kubernetes, talking about defining like a cloud operating model, self-service, elastic, and API driven. I think Crossplane proves that definition of building a platform on top of a platform. I think it’s so impressive. When people look at this, talk about the providers that are out there and talk about the community. Obviously, people that are getting started are dependent at least initially on the community that’s out there. Hopefully always. What’s that look like? How are you seeing people adopting this?
Mangum: The Crossplane community is made up of core Crossplane, which is the engine which provides the package manager and composition, which allows you to create those abstractions. Then from a provider perspective, those are all their individual projects with their own maintainers, but they’re part of the Crossplane community. In practice, over time, there’s been a huge emphasis on the large cloud providers, as you might expect, for either AWS, GCP, Azure, Alibaba. Those are more mature providers. However, about five months ago or so, the Crossplane community came up with some new tooling called Terrajet, which essentially takes Terraform providers for which there’s already a rich ecosystem, and generates Crossplane providers from the logic that they offer. That allowed us and the community to have a large increase in the coverage of all clouds. At this point, it’s, number one, very easy to find the provider that already exists that has full coverage. Number two, if it doesn’t exist to actually just generate your own. We’ve actually seen an explosion of folks coming in generating new providers, and in some cases putting their own spin on it to make it fit their use case, and then publishing that for other folks to do some.
Reisz: You already got all these Terraform scripts that are out there. Is it a problem to be able to use those? It’s not Greenfield. We have to deal with what already exists. What’s that look like?
Mangum: Having the cloud native ecosystem in the cloud in general exist for quite a while, almost no one who comes to Crossplane is coming in with a Greenfield thing. There’s always some legacy infrastructure. There’s a couple of different migration patterns, and there’s two kind of really important concepts. One is just taking control of resources that already exist on a cloud provider. That’s fairly straightforward to do. Cloud providers always have a concept of identity of any entity in their information architecture. If you have a database, for instance, the cloud may allow you to name that deterministically, or it may be non-deterministic, where you create the thing and they give you back a unique identifier, which you use to check in on it. Crossplane uses a feature called the external-name, which is an annotation you put on all of your resources, or if you’re creating a fresh one, Crossplane will put it on there automatically. That basically says, this is the unique identifier of this resource on whatever cloud or whatever platform it actually exists on. As long as you have those unique identifiers, let’s say like a VPC ID or something like that, you could just create your resource with that external-name already there. The first thing the provider will do is go and say, does this already exist? If it does, it’ll just reconcile from that point forward. It won’t create something new. That’s how you can take control of resources on a cloud provider.
If you have Terraform scripts and that sort of thing, there are a couple of different migration patterns. A very simple one, but one we don’t recommend long term is we actually have a provider Terraform, where you can essentially put your Terraform script into a Kubernetes manifest, and it’ll run Terraform for you, so give you that active reconciliation. There’s also some tooling to translate Terraform HCL into YAML, to be more native in Crossplane’s world.
Reisz: What are you all thinking out there, putting these XRDs, putting these CRDs onto Kubernetes clusters to maintain on and off-cluster resources. I’m curious, the questions that everybody has out there in the audience. For me, like the operator pattern is so popular with Kubernetes, and applying it on and off-cluster just seems so powerful to me. This is one of the reasons why I’m so excited about the project and the work that you all are doing.
Mangum: One of the benefits of that model is just the standardization on the Kubernetes API. One thing we like to point out, I’m sure folks are familiar with policy engines like Kyverno, or OPA, or that sort of thing, as well as like GitOps tooling, like Argo, or Flux, because everything is a Kubernetes manifest, you actually get to just integrate with all of those tools more or less for free. That’s a really great benefit of that standardization as well.
Reisz: Talk about security and state, particularly off-cluster. On-cluster is one thing, you have access to the Kubernetes API. You can understand what’s happening there. What about off-cluster? Is that like a lot of polling, what does that look like? How do you think about both managing state and also security when you’re off-cluster?
Mangum: Generally, we talk about security through configuration. Setting up security in a way where you’re creating a type system that doesn’t allow for a developer to access something they’re not supposed to. That can look like never actually giving developers access to AWS credentials, for example. You actually just give them Kubernetes access, kind of that like single access control plane I was talking about, and they interact through that. There’s never any direct interaction with AWS. The platform isn’t in charge of interacting with AWS.
In terms of how we actually get state about the external resources and report on them, there is no restriction on how a provider can be implemented. In theory, let’s say that some cloud provider offered some eventing API on resources, you could write a provider that consumed that. Frequently, that’s not an option, so we do use polling. In that case, what we really try to do is offer the most granular configuration you need to poll at a rate that is within your API rate limits, and also matches the criticality of that resource. For instance, in a dev environment, you may say, I just want you to check in on it once a day. It’s not critical infrastructure, I don’t need you to be taking action that often. If it’s production, maybe you want it more frequently.
Reisz: What do you want people to leave this talk with?
Mangum: I really encourage folks to go in and try authoring their own API abstractions. Think about the interface that you would like to have. If you could design your own Heroku or your own layer-2 cloud provider, what would that look like to you? Look at the docs for inspiration, and then think about writing your own API, maybe mapping that to some managed resources from cloud providers. Then offering that to developers in your organization to consume.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Developed at Fox-IT, part of NCC Group, Dissect is a recently open-sourced toolset that aims to enable incident response on thousands of systems at a time by analyzing large volumes of forensic data at high speed, says Fox-IT.
Dissect comprises various parsers and file formats implementations that power its target-query and target-shell tools, providing access to forensic artifacts, such as Runkeys, Prefetch files, Windows Event Logs, etc. Using Dissect you can, for example, build an incident timeline based on event logs, identify anomalies in services, perform incident response, and more.
Before being open-sourced, Dissect has been used for over 10 years at Fox-IT for a number of large organizations. This explains its focus on analyzing complex IT infrastructures:
Incident response increasingly involves large, complex and hybrid IT infrastructures that must be carefully examined for so-called Indicators of Compromise (IOCs). At the same time, victims of an attack need to find out as quickly as possible what exactly happened and what actions should be taken in response.
At its core, Dissect is built on top of several abstractions, including containers, volumes, filesystems, and OSes. This layered architecture, where each layer can operate independently from the others, provides the foundations for analysis plugins, which include OS-specific plugins such as Windows event logs or Linux bash, as well as more generic ones, like browser history or filesystem timelining.
An important detail is that, by default, we only target the “known locations” of artifacts. That means that we don’t try to parse every file on a disk, but instead only look for data in the known or configured locations.
Dissect’s main benefits, according to Fox-IT, are speed, which makes it possible to reduce data acquisition that previously required two weeks down to an hour, and flexibility, which makes it almost data format and OS-agnostic. Dissect aims indeed to simplify the task of accessing a container, extracting files, and use a specific tool to parse them for forensic evidence by providing a unique tool covering all of these usages.
Dissect workhorse is the already mentioned target-query tool, which makes it possible to retrieve information from a target, including basic attributes like its hostname, OS, users, as well as more in-depth information like file caches, registry, shellbags, runkeys, USB devices, and more. If you prefer a more interactive approach, you can use target-shell which is able to launch a shell running on your target to quickly browse an image or access some Python API provides by Dissect.
Dissect can be installed running pip install dissect or run using Docker. If you want to have some data to play around with, you can use NIST Hacking case images.
Presentation: Project Loom: Revolution in Java Concurrency or Obscure Implementation Detail?
MMS • Tomasz Nurkiewicz
Article originally posted on InfoQ. Visit InfoQ

Transcript
Nurkiewicz: I’d like to talk about Project Loom, a very new and exciting initiative that will land eventually in the Java Virtual Machine. Most importantly, I would like to briefly explain whether it’s going to be a revolution in the way we write concurrent software, or maybe it’s just some implementation detail that’s going to be important for framework or library developers, but we won’t really see it in real life. The first question is, what is Project Loom? The question I give you in the subtitle is whether it’s going to be a revolution or just an obscure implementation detail. My name is Tomasz Nurkiewicz.
Outline
First of all, we would like to understand how we can create millions of threads using Project Loom. This is an overstatement. In general, this will be possible with Project Loom. As you probably know, these days, it’s only possible to create hundreds, maybe thousands of threads, definitely not millions. This is what Project Loom unlocks in the Java Virtual Machine. This is mainly possible by allowing you to block and sleep everywhere, without paying too much attention to it. Blocking, sleeping, or any other locking mechanisms were typically quite expensive, in terms of the number of threads we could create. These days, it’s probably going to be very safe and easy. The last but the most important question is, how is it going to impact us developers? Is it actually so worthwhile, or maybe it’s just something that is buried deeply in the virtual machine, and it’s not really that much needed?
User Threads and Kernel Threads
Before we actually explain, what is Project Loom, we must understand what is a thread in Java? I know it sounds really basic, but it turns out there’s much more into it. First of all, a thread in Java is called a user thread. Essentially, what we do is that we just create an object of type thread, we parse in a piece of code. When we start such a thread here on line two, this thread will run somewhere in the background. The virtual machine will make sure that our current flow of execution can continue, but this separate thread actually runs somewhere. At this point in time, we have two separate execution paths running at the same time, concurrently. The last line is joining. It essentially means that we are waiting for this background task to finish. This is not typically what we do. Typically, we want two things to run concurrently.
This is a user thread, but there’s also the concept of a kernel thread. A kernel thread is something that is actually scheduled by your operating system. I will stick to Linux, because that’s probably what you use in production. With the Linux operating system, when you start a kernel thread, it is actually the operating system’s responsibility to make sure all kernel threads can run concurrently, and that they are nicely sharing system resources like memory and CPU. For example, when a kernel thread runs for too long, it will be preempted so that other threads can take over. It more or less voluntarily can give up the CPU and other threads may use that CPU. It’s much easier when you have multiple CPUs, but most of the time, this is almost always the case, you will never have as many CPUs as many kernel threads are running. There has to be some coordination mechanism. This mechanism happens in the operating system level.
User threads and kernel threads aren’t actually the same thing. User threads are created by the JVM every time you say newthread.start. Kernel threads are created and managed by the kernel. That’s obvious. This is not the same thing. In the very prehistoric days, in the very beginning of the Java platform, there used to be this mechanism called the many-to-one model. In the many-to-one model. The JVM was actually creating user threads, so every time you set newthread.start, a JVM was creating a new user thread. However, these threads, all of them were actually mapped to a single kernel thread, meaning that the JVM was only utilizing a single thread in your operating system. It was doing all the scheduling, so making sure your user threads are effectively using the CPU. All of this was done inside the JVM. The JVM from the outside was only using a single kernel thread, which means only a single CPU. Internally, it was doing all this back and forth switching between threads, also known as context switching, it was doing it for ourselves.
There was also this rather obscure many-to-many model, in which case you had multiple user threads, typically a smaller number of kernel threads, and the JVM was doing mapping between all of these. However, luckily, the Java Virtual Machine engineers realized that there’s not much point in duplicating the scheduling mechanism, because the operating system like Linux already has all the facilities to share CPUs and threads with each other. They came up with a one-to-one model. With that model, every single time you create a user thread in your JVM, it actually creates a kernel thread. There is one-to-one mapping, which means effectively, if you create 100 threads, in the JVM you create 100 kernel resources, 100 kernel threads that are managed by the kernel itself. This has some other interesting side effects. For example, thread priorities in the JVM are effectively ignored, because the priorities are actually handled by the operating system, and you cannot do much about them.
It turns out that user threads are actually kernel threads these days. To prove that that’s the case, just check, for example, jstack utility that shows you the stack trace of your JVM. Besides the actual stack, it actually shows quite a few interesting properties of your threads. For example, it shows you the thread ID and so-called native ID. It turns out, these IDs are actually known by the operating system. If you know the operating system’s utility called top, which is a built in one, it has a switch -H. With the H switch, it actually shows individual threads rather than processes. This might be a little bit surprising. After all, why does this top utility that was supposed to be showing which processes are consuming your CPU, why does it have a switch to show you the actual threads? It doesn’t seem to make much sense.
However, it turns out, first of all, it’s very easy with that tool to show you the actual Java threads. Rather than showing a single Java process, you see all Java threads in the output. More importantly, you can actually see, what is the amount of CPU consumed by each and every of these threads? This is useful. Why is that the case? Does it mean that Linux has some special support for Java? Definitely not. Because it turns out that not only user threads on your JVM are seen as kernel threads by your operating system. On newer Java versions, even thread names are visible to your Linux operating system. Even more interestingly, from the kernel point of view, there is no such thing as a thread versus process. Actually, all of these are called tasks. This is just a basic unit of scheduling in the operating system. The only difference between them is just a single flag, when you’re creating a thread rather than a process. When you’re creating a new thread, it shares the same memory with the parent thread. When you’re creating a new process, it does not. It’s just a matter of a single bit when choosing between them. From the operating system’s perspective, every time you create a Java thread, you are creating a kernel thread, which is, in some sense you’re actually creating a new process. This may actually give you some overview like how heavyweight Java threads actually are.
First of all, they are Kernel resources. More importantly, every thread you create in your Java Virtual Machine consumes more or less around 1 megabyte of memory, and it’s outside of heap. No matter how much heap you allocate, you have to factor out the extra memory consumed by your threads. This is actually a significant cost, every time you create a thread, that’s why we have thread pools. That’s why we were taught not to create too many threads on your JVM, because the context switching and memory consumption will kill us.
Project Loom – Goal
This is where Project Loom shines. This is still work in progress, so everything can change. I’m just giving you a brief overview of how this project looks like. Essentially, the goal of the project is to allow creating millions of threads. This is an advertising talk, because you probably won’t create as many. Technically, it is possible, and I can run millions of threads on this particular laptop. How is it achieved? First of all, there’s this concept of a virtual thread. A virtual thread is very lightweight, it’s cheap, and it’s a user thread. By lightweight, I mean you can really allocate millions of them without using too much memory. There’s a virtual thread. Secondly, there’s also a carrier thread. A carrier thread is the real one, it’s the kernel one that’s actually running your virtual threads. Of course, the bottom line is that you can run a lot of virtual threads sharing the same carrier thread. In some sense, it’s like an implementation of an actor system where we have millions of actors using a small pool of threads. All of this can be achieved using a so-called continuation. Continuation is a programming construct that was put into the JVM, at the very heart of the JVM. There are actually similar concepts in different languages. Continuation, the software construct is the thing that allows multiple virtual threads to seamlessly run on very few carrier threads, the ones that are actually operated by your Linux system.
Virtual Threads
I will not go into the API too much because it’s subject to change. As you can see, it’s actually fairly simple. You essentially say Thread.startVirtualThread, as opposed to new thread or starting a platform thread. A platform thread is your old typical user threads, that’s actually a kernel thread, but we’re talking about virtual threads here. We can create a thread from scratch. You can create it using a builder method, whatever. You can also create a very weird ExecutorService. This ExecutorService doesn’t actually pull threads. Typically, ExecutorService has a pool of threads that can be reused in case of new VirtualThreadExecutor, it creates a new virtual thread every time you submit a task. It’s not really a thread pool, per se. You can also create a ThreadFactory if you need it in some API, but this ThreadFactory just creates virtual threads. That’s very simple API.
The API is not the important part, I would like you to actually understand what happens underneath, and what impact may it have on your code bases. A virtual thread is essentially a continuation plus scheduler. A scheduler is a pool of physical called carrier threads that are running your virtual threads. Typically, a scheduler is just a fork join pool with a handful of threads. You don’t need more than one to four, maybe eight carrier threads, because they use the CPU very effectively. Every time a virtual thread no longer needs a CPU, it will just give up the scheduler, it will no longer use a thread from that scheduler, and another virtual thread will kick in. That’s the first mechanism. How does the virtual thread and the scheduler know that the virtual thread no longer needs a scheduler?
This is where continuations come into play. This is a fairly convoluted explanation. Essentially, a continuation is a piece of code that can suspend itself at any moment in time and then it can be resumed later on, typically on a different thread. You can freeze your piece of code, and then you can unlock it, or you can unhibernate it, you can wake it up on a different moment in time, and preferably even on a different thread. This is a software construct that’s built into the JVM, or that will be built into the JVM.
Pseudo-code
Let’s look into a very simple pseudo-code here. This is a main function that calls foo, then foo calls bar. There’s nothing really exciting here, except from the fact that the foo function is wrapped in a continuation. Wrapping up a function in a continuation doesn’t really run that function, it just wraps a Lambda expression, nothing specific to see here. However, if I now run the continuation, so if I call run on that object, I will go into foo function, and it will continue running. It runs the first line, and then goes to bar method, it goes to bar function, it continues running. Then on line 16, something really exciting and interesting happens. The function bar voluntarily says it would like to suspend itself. The code says that it no longer wishes to run for some bizarre reason, it no longer wishes to use the CPU, the carrier thread. What happens now is that we jump directly back to line four, as if it was an exception of some kind. We jump to line four, we continue running. The continuation is suspended. Then we move on, and in line five, we run the continuation once again. Will it run the foo function once more? Not really, it will jump straight to line 17, which essentially means we are continuing from the place we left off. This is really surprising. Also, it means we can take any piece of code, it could be running a loop, it could be doing some recursive function, whatever, and we can all the time and every time we want, we can suspend it, and then bring it back to life. This is the foundation of Project Loom. Continuations are actually useful, even without multi-threading.
Thread Sleep
Continuations that you see in here are actually quite common in different languages. You have coroutines or goroutines, in languages like Kotlin and Go. You have async/await in JavaScript. You have generators in Python, or fibers in Ruby. All of these are actually very similar concepts, which are finally brought into the JVM. What difference does it make? Let’s see how thread sleep is implemented. It used to be simply a function that just blocks your current thread so that it still exists on your operating system. However, it no longer runs, so it will be woken up by your operating system. A new version that takes advantage of virtual threads, notice that if you’re currently running a virtual thread, a different piece of code is run.
This piece of code is quite interesting, because what it does is it calls yield function. It suspends itself. It voluntarily says that it no longer wishes to run because we asked that thread to sleep. That’s interesting. Why is that? Before we actually yield, we schedule unparking. Unparking or waking up means basically, that we would like ourselves to be woken up after a certain period of time. Before we put ourselves to sleep, we are scheduling an alarm clock. This scheduling will wake us up. It will continue running our thread, it will continue running our continuation after a certain time passes by. In between calling the sleep function and actually being woken up, our virtual thread no longer consumes the CPU. At this point, the carrier thread is free to run another virtual thread. Technically, you can have millions of virtual threads that are sleeping without really paying that much in terms of the memory consumption.
Hello, world!
This is our Hello World. This is overblown, because everyone says millions of threads and I keep saying that as well. That’s the piece of code that you can run even right now. You can download Project Loom with Java 18 or Java 19, if you’re cutting edge at the moment, and just see how it works. There is a count variable. If you put 1 million, it will actually start 1 million threads, and your laptop will not melt and your system will not hang, it will simply just create these millions of threads. As you already know, there is no magic here. Because what actually happens is that we created 1 million virtual threads, which are not kernel threads, so we are not spamming our operating system with millions of kernel threads. The only thing these kernel threads are doing is actually just scheduling, or going to sleep, but before they do it, they schedule themselves to be woken up after a certain time. Technically, this particular example could easily be implemented with just a scheduled ExecutorService, having a bunch of threads and 1 million tasks submitted to that executor. There is not much difference. As you can see, there is no magic here. It’s just that the API finally allows us to build in a much different, much easier way.
Carrier Thread
Here’s another code snippet of the carrier threads. The API may change, but the thing I wanted to show you is that every time you create a virtual thread, you’re actually allowed to define a carrierExecutor. In our case, I just create an executor with just one thread. Even with just a single thread, single carriers, or single kernel thread, you can run millions of threads as long as they don’t consume the CPU all the time. Because, after all, Project Loom will not magically scale your CPU so that it can perform more work. It’s just a different API, it’s just a different way of defining tasks that for most of the time are not doing much. They are sleeping blocked on a synchronization mechanism, or waiting on I/O. There’s no magic here. It’s just a different way of performing or developing software.
Structured Concurrency
There’s also a different algorithm or a different initiative coming as part of Project Loom called structured concurrency. It’s actually fairly simple. There’s not much to say here. Essentially, it allows us to create an ExecutorService that waits for all tasks that were submitted to it in a try with resources block. This is just a minor addition to the API, and it may change.
Tasks, Not Threads
The reason I’m so excited about Project Loom is that finally, we do not have to think about threads. When you’re building a server, when you’re building a web application, when you’re building an IoT device, whatever, you no longer have to think about pooling threads, about queues in front of a thread pool. At this point, all you have to do is just creating threads every single time you want to. It works as long as these threads are not doing too much work. Because otherwise, you just need more hardware. There’s nothing special here. If you have a ton of threads that are not doing much, they’re just waiting for data to arrive, or they are just locked on a synchronization mechanism waiting for a semaphore or CountDownLatch, whatever, then Project Loom works really well. We no longer have to think about this low level abstraction of a thread, we can now simply create a thread every time for every time we have a business use case for that. There is no leaky abstraction of expensive threads because they are no longer expensive. As you can probably tell, it’s fairly easy to implement an actor system like Akka using virtual threads, because essentially what you do is you create a new actor, which is backed by a virtual thread. There is no extra level of complexity that arises from the fact that a large number of actors has to share a small number of threads.
Use Cases
A few use cases that are actually insane these days, but they will be maybe useful to some people when Project Loom arrives. For example, let’s say you want to run something after eight hours, so you need a very simple scheduling mechanism. Doing it this way without Project Loom is actually just crazy. Creating a thread and then sleeping for eight hours, because for eight hours, you are consuming system resources, essentially for nothing. With Project Loom, this may be even a reasonable approach, because a virtual thread that sleeps consumes very little resources. You don’t pay this huge price of scheduling operating system resources and consuming operating system’s memory.
Another use case, let’s say you’re building a massive multiplayer game, or a very highly concurrent server, or a chat application like WhatsApp that needs to handle millions of connections, there is actually nothing wrong with creating a new thread per each player, per each connection, per each message even. Of course, there are some limits here, because we still have a limited amount of memory and CPU. Anyways, confront that with the typical way of building software where you had a limited worker pool in a servlet container like Tomcat, and you had to do all these fancy algorithms that are sharing this thread pool, and making sure it’s not exhausted, making sure you’re monitoring the queue. Now it’s easy, every time a new HTTP connection comes in, you just create a new virtual thread, as if nothing happens. This is how we were taught Java 20 years ago, then we realized it’s a poor practice. These days, it may actually be a valuable approach again.
Another example. Let’s say we want to download 10,000 images. With Project Loom, we simply start 10,000 threads, each thread per each image. That’s just it. Using the structured concurrency, it’s actually fairly simple. Once we reach the last line, it will wait for all images to download. This is really simple. Once again, confront that with your typical code, where you would have to create a thread pool, make sure it’s fine-tuned. There’s a caveat here. Notice that with a traditional thread pool, all you had to do was essentially just make sure that your thread pool is not too big, like 100 threads, 200 threads, 500, whatever. This was the natural limit of concurrency. You cannot download more than 100 images at once, if you have just 100 threads in your standard thread pool.
With this approach with Project Loom, notice that I’m actually starting as many concurrent connections, as many concurrent virtual threads, as many images there are. I personally don’t pay that much price for starting these threads because all they do is just like being blocked on I/O. In Project Loom, every blocking operation, so I/O like network typically, so waiting on a synchronization mechanism like semaphores, or sleeping, all these blocking operations are actually yielding, which means that they are voluntarily giving up a carrier thread. It’s absolutely fine to start 10,000 concurrent connections, because you won’t pay the price of 10,000 carrier or kernel threads, because these virtual threads will be hibernated anyway. Only when the data arrives, the JVM will wake up your virtual thread. In the meantime, you don’t pay the price. This is pretty cool. However, you just have to be aware of the fact that the kernel threads of your thread pools were actually just natural like limit to concurrency. Just blindly switching from platform threads, the old ones, to virtual threads will change the semantics of your application.
To make matters even worse, if you would like to use Project Loom directly, you will have to relearn all these low level structures like CountDownLatch or semaphore to actually do some synchronization or to actually do some throttling. This is not the path I would like to take. I would definitely like to see some high level frameworks that are actually taking advantage of Project Loom.
Problems and Limitations – Deep Stack
Do we have such frameworks and what problems and limitations can we reach here? Before we move on to some high level constructs, so first of all, if your threads, either platform or virtual ones have a very deep stack. This is your typical Spring Boot application, or any other framework like Quarkus, or whatever, if you put a lot of different technologies like adding security, aspect oriented programming, your stack trace will be very deep. With platform threads, the size of the stack trace is actually fixed. It’s like half a megabyte, 1 megabyte, and so on. With virtual threads, the stack trace can actually shrink and grow, and that’s why virtual threads are so inexpensive, especially in Hello World examples, where all what they do is just like sleeping most of the time, or incrementing a counter, or whatever. In real life, what you will get normally is actually, for example, a very deep stack with a lot of data. If you suspend such a virtual thread, you do have to keep that memory that holds all these stack lines somewhere. The cost of the virtual thread will actually approach the cost of the platform thread. Because after all, you do have to store the stack trace somewhere. Most of the time it’s going to be less expensive, you will use less memory, but it doesn’t mean that you can create millions of very complex threads that are doing a lot of work. It’s just an advertising gimmick. It doesn’t hold true for normal workloads. Keep that in mind. There’s no magic here.
Problems and Limitations – Preemption
Another thing that’s not yet handled is preemption, when you have a very CPU intensive task. Let’s say you have 4 CPU cores, and you create 4 platform threads, or 4 kernel threads that are doing very CPU intensive work, like crunching numbers, cryptography, hashing, compression, encoding, whatever. If you have 4 physical threads, or platform threads doing that, you’re essentially just maxing your CPU. If instead you create 4 virtual threads, you will basically do the same amount of work. It doesn’t mean that if you replace 4 virtual threads with 400 virtual threads, you will actually make your application faster, because after all, you do use the CPU. There’s not much hardware to do the actual work, but it gets worse. Because if you have a virtual thread that just keeps using the CPU, it will never voluntarily suspend itself, because it never reaches a blocking operation like sleeping, locking, waiting for I/O, and so on. In that case, it’s actually possible that you will only have a handful of virtual threads that never allow any other virtual threads to run, because they just keep using the CPU. That’s the problem that’s already handled by platform threads or kernel threads because they do support preemption, so stopping a thread in some arbitrary moment in time. It’s not yet supported with Project Loom. It may be one day, but it’s not yet the case.
Problems and Limitations – Unsupported APIs
There’s also a whole list of unsupported APIs. One of the main goals of Project Loom is to actually rewrite all the standard APIs. For example, socket API, or file API, or lock APIs, so lock support, semaphores, CountDownLatches. All of these APIs are sleep, which we already saw. All of these APIs need to be rewritten so that they play well with Project Loom. However, there’s a whole bunch of APIs, most importantly, the file API. I just learned that there’s some work happening. There’s a list of APIs that do not play well with Project Loom, so it’s easy to shoot yourself in the foot.
Problems and Limitations – Stack vs. Heap Memory
One more thing. With Project Loom, you no longer consume the so-called stack space. The virtual threads that are not running at the moment, which is technically called pinned, so they are not pinned to a carrier thread, but they are suspended. These virtual threads actually reside on heap, which means they are subject to garbage collection. In that case, it’s actually fairly easy to get into a situation where your garbage collector will have to do a lot of work, because you have a ton of virtual threads. You don’t pay the price of platform threads running and consuming memory, but you do get the extra price when it comes to garbage collection. The garbage collection may take significantly more time. This was actually an experiment done by the team behind Jetty. After switching to Project Loom as an experiment, they realized that the garbage collection was doing way more work. The stack traces were actually so deep under normal load, that it didn’t really bring that much value. That’s an important takeaway.
The Need for Reactive Programming
Another question is whether we still need reactive programming. If you think about it, we do have a very old class like RestTemplate, which is like this old school blocking HTTP client. With Project Loom, technically, you can start using RestTemplate again, and you can use it to, very efficiently, run multiple concurrent connections. Because RestTemplate underneath uses HTTP client from Apache, which uses sockets, and sockets are rewritten so that every time you block, or wait for reading or writing data, you are actually suspending your virtual thread. It seems like RestTemplate or any other blocking API is exciting again. At least that’s what we might think, you no longer need reactive programming and all these like WebFluxes, RxJavas, Reactors, and so on.
What Loom Addresses
Project Loom addresses just a tiny fraction of the problem, it addresses asynchronous programming. It makes asynchronous programming much easier. However, it doesn’t address quite a few other features that are supported by reactive programming, namely backpressure, change propagation, composability. These are all features or frameworks like Reactor, or Akka, or Akka streams, whatever, which are not addressed by Loom because Loom is actually quite low level. After all, it’s just a different way of creating threads.
When to Install New Java Versions
Should you just blindly install the new version of Java whenever it comes out and just switch to virtual threads? I think the answer is no, for quite a few reasons. First of all, the semantics of your application change. You no longer have this natural way of throttling because you have a limited number of threads. Also, the profile of your garbage collection will be much different. We have to take that into account.
When Project Loom Will be Available
When will Project Loom be available? It was supposed to be available in Java 17, we just got Java 18 and it’s still not there. Hopefully, it will be ready when it’s ready. Hopefully, we will live into that moment. I’m experimenting with Project Loom for quite some time already. It works. It sometimes crashes. It’s not vaporware, it actually exists.
Resources
I leave you with a few materials which I collected, more presentations and more articles that you might find interesting. Quite a few blog posts that explain the API a little bit more thoroughly. A few more critical or skeptic points of view, mainly around the fact that Project Loom won’t really change that much. It’s especially for the people who believe that we will no longer need reactive programming because we will all just write our code using plain Project Loom. Also, my personal opinion, that’s not going to be the case, we will still need some higher level abstraction.
Questions and Answers
Cummins: How do you debug it? Does it make it harder to debug? Does it make it easier to debug? What tooling support is there? Is there more tooling support coming?
Nurkiewicz: The answer is actually twofold. On one hand, it’s easier, because you no longer have to hop between threads so much, in reactive programming or asynchronous programming in general. What you typically do is that you have a limited number of threads, but you jump between threads very often, which means that stack traces are cut in between, so you don’t see the full picture. It gets a little bit convoluted, and frameworks like Reactor try to somehow reassemble the stack trace, taking into account that you are jumping between thread pools, or some asynchronous Netty threads. In that case, Loom makes it easier, because you can survive, you can make a whole request just in a single thread, because logically, you’re still on the same thread, this thread is being paused. It’s being unpinned, and pinned back to a carrier thread. When the exception arises, this exception will show the whole stack trace because you’re not jumping between threads. What you typically do is that when you want to do something asynchronous, you put it into a thread pool. Once you’re in a thread pool, you lose the original stack trace, you lose the original thread.
In case of Project Loom, you don’t offload your work into a separate thread pool, because whenever you’re blocked your virtual thread has very little cost. In some sense, it’s going to be easier. However, you will still be probably using multiple threads to handle a single request. That problem doesn’t really go away. In some cases, it will be easier but it’s not like an entirely better experience. On the other hand, you now have 10 times or 100 times more threads, which are all doing something. These aren’t really like Java threads. You won’t, for example, see them on a thread dump. This may change but that’s the case right now. You have to take that into account. When you’re doing a thread dump, which is probably one of the most valuable things you can get when troubleshooting your application, you won’t see virtual threads which are not running at the moment.
If you are doing the actual debugging, so you want to step over your code, you want to see, what are the variables? What is being called? What is sleeping or whatever? You can still do that. Because when your virtual thread runs, it’s a normal Java thread. It’s a normal platform thread because it uses carrier thread underneath. You don’t really need any special tools. However, you just have to remember on the back of your head, that there is something special happening there, that there is a whole variety of threads that you don’t see, because they are suspended. As far as JVM is concerned, they do not exist, because they are suspended. They’re just objects on heap, which is surprising.
Cummins: It’s hard to know which is worse, you have a million threads, and they don’t turn up in your heap thread dump, or you have a million threads and they do turn up in your heap dump.
Nurkiewicz: Actually, reactive is probably the worst here because you have million ongoing requests, for example, HTTP requests, and you don’t see them anywhere. Because with reactive, with truly asynchronous APIs, HTTP database, whatever, what happens is that you have a thread that makes a request, and then absolutely forgets about that request until it gets a response. A single thread handles hundreds of thousands of requests concurrently or truly concurrently. In that case, if you make a thread dump, it’s actually the worst of both worlds, because what you see is just a very few reactive threads like Netty, for example, which is typically used. These native threads are not actually doing any business logic, because most of the time, they are just waiting for data to be sent or received. Troubleshooting a reactive application using a thread dump is actually very counterproductive. In that case, virtual threads are actually helping a little bit, because at least you will see the running threads.
Cummins: It’s probably like a lot of things where when the implementation moves closer to our mental model, because nobody has a mental model of thread pools, they have a mental model of threads, and so then when you get those two closer together, it means that debugging is easier.
Nurkiewicz: I really love the quote by Cay Horstmann, that you’re no longer thinking about this low level abstraction of a thread pool, which is convoluted. You have a bunch of threads that are reused. There’s a queue, you’re submitting a task. It stands in a queue, it waits in that queue. You no longer have to think about it. You have a bunch of tasks that you need to run concurrently. You just run them, you just create a thread and get over it. That was the promise of actor systems like Akka, that when you have 100,000 connections, you create 100,000 actors, but actors reuse threads underneath, because that’s how JVM works at the moment. With virtual threads, you just create a new virtual thread per connection, per player, per message, whatever. It’s closer, surprisingly, to an Erlang model, where you were just starting new processes. Of course, it’s really far away from Erlang still, but it’s a little bit closer to that.
Cummins: Do you think we’re going to see a new world of problem reproduction ickiness, where some of us are on Java 19 and taking advantage of threads, and some of us are not. At the top level, it looks similar, but then once you go underneath the behavior is really fundamentally different. Then we get these non-reproducible things where it’s the timing dependency plus a different implementation means that we just spend all our time chasing weird threading variations.
Nurkiewicz: I can give you even a simpler example of when it can blow up. We used to rely on the fact that thread pool is the natural way of throttling tasks. When you have a thread pool of 20 threads, it means you will not run more than 20 tasks at the same time. If you just blindly replace ExecutorService with this virtual thread, ExecutorService, the one that doesn’t really pull any threads, it just starts them like crazy, you no longer have this throttling mechanism. If you naively refactor from Java 18 to Java 19, because Project Loom was already merged to project 19, to the master branch. If you just switch to Project Loom, you will be surprised, because suddenly, the level of concurrency that you achieve on your machine is way greater than you expected.
You might think that it’s actually fantastic because you’re handling more load. It also may mean that you are overloading your database, or you are overloading another service, and you haven’t changed much. You just changed a single line that changes the way threads are created rather than platform, then you move to the virtual threads. Suddenly, you have to rely on these low level CountDownLatches, semaphores, and so on. I barely remember how they work, and I will either have to relearn them or use some higher level mechanisms. This is probably where reactive programming or some higher level abstractions still come into play. From that perspective, I don’t believe Project Loom will revolutionize the way we develop software, or at least I hope it won’t. It will significantly change the way libraries or frameworks can be written so that we can take advantage of them.
See more presentations with transcripts
Venkat Subramaniam Brings a Contemporary Twist to GoF Design Patterns With Modern Java at Devoxx BE
MMS • Olimpiu Pop
Article originally posted on InfoQ. Visit InfoQ

The GoF Design Patterns published back in 1998, qualifies as a classic of computer science as it is still being taught both in universities but also recommended as best practice in the industry. In his deep dive session from Devoxx, Venkat Subramaniam gave them a contemporary twist, by implementing Iterator, Strategy, Decorator or Factory Method with modern Java.
In the introduction of his talk, Venkat considers the book authors to be grandfathers of software development and their design patterns with grandma’s recipes: even if you have them, you will not be able to reproduce the dish. So, he considers that design patterns are phenomenal as a communication tool, but a disaster as a software design tool.
The following are usual patterns that we could meet in our day-to-day coding, which he made a bit more fluent all in his energetic and joyful manner.
The iterator pattern changed quite a lot due to Java’s embrace of functional programming. One of the biggest changes was the shift from an external iterator to an internal iterator, which came with Java’s functional API. With this change, you can evolve from using the verbose imperative style iteration
int count = 0;
for(var name: names) {
if(name.length() == 4) {
System.out.println(name.toUpperCase());
count++;
if(count == 2) {
break;
}
}
}
}
to the fluent functional iteration:
names.stream()
.filter(name -> name.length() == 4)
.map(String::toString)
.limit(2)
.forEach(System.out::println);
The limit(long) and takeWhile(Predicate<? super T>) (added in Java 9) are the functional equivalents of continue and break statements, the first one taking just a numerical limit, while the second using an expression.
Even if Java’s functional API is part of the JDK for almost a decade already, there are still common mistakes that linger in the code bases. The one that can make the results of iteration operations unpredictable(especially in parallel executions) is when the functional pipeline is *not* pure (it changes or depends on any state visible from the outside).
Lightweight strategy – where we want to vary a small part of an algorithm while keeping the rest of the algorithm the same. Historically, the pattern was implemented by having a method that takes a single method interface as a parameter that has multiple implementations for each of the strategies to be implemented. As strategies are often a single method or function. So, functional interfaces and lambdas work really well.
Even though anonymous classes represented an implementation mechanism, functional interfaces(Predicate<? super T> is a good candidate) or lambdas make the code a lot more fluent and easier to comprehend. In modern Java, Strategy is more of a feature than a pattern that requires significant effort to implement.
public class Sample {
public static int totalValues(List numbers) {
int total = 0;
for(var number: numbers) {
total += number;
}
return total;
}
public static int totalEvenValues(List numbers) {
int total = 0;
for(var number: numbers) {
if(number % 2 == 0) { total += number; }
}
return total;
}
public static int totalOddValues(List numbers) {
int total = 0;
for(var number: numbers) {
if(number % 2 != 0) { total += number; }
}
return total;
}
public static void main(String[] args) {
var numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(totalValues(numbers));
System.out.println(totalEvenValues(numbers));
System.out.println(totalOddValues(numbers));
}
}
The more modern take would be to use a lambda for the strategy:
import java.util.function.Predicate;
public class Sample {
public static int totalValues(List numbers,
Predicate selector) {
int total = 0;
for(var number: numbers) {
if(selector.test(number)) {
total += number;
}
}
return total;
}
public static boolean isOdd(int number) {
return number % 2 != 0;
}
public static void main(String[] args) {
var numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(totalValues(numbers, ignore -> true));
System.out.println(totalValues(numbers,
number -> number % 2 == 0));
System.out.println(totalValues(numbers, Sample::isOdd));
}
}
Factory method using default methods
In the introduction to the factory method implementation, Venkat stated the following:
What is the worst keyword in Java from the polymorphism point of view? […] Even though final, instanceof and static are good candidates for this, they are mininions. new is the mafia of all of them.
Multiple patterns (creational patterns), frameworks(Spring, Guice) or techniques were conceived in order to address the “evilness” of new, its lack of polymorphism support and its tight coupling. Inspired by Ruby’s polymorphic ability to create different objects based on context, Venkat proposes an implementation of the factory method pattern by using Java’s default keyword. This approach would allow one to make use of interfaces and very small implementing classes, making the code easier to follow.
import java.util.*;
interface Pet {}
class Dog implements Pet {}
class Cat implements Pet {}
interface Person {
Pet getPet();
default void play() {
System.out.println("playing with " + getPet());
}
}
class DogPerson implements Person {
private Dog dog = new Dog();
public Pet getPet() { return dog; }
}
class CatLover implements Person {
private Cat cat = new Cat();
public Pet getPet() { return cat; }
}
public class Sample {
public static void call(Person person) {
person.play();
}
public static void main(String[] args) {
call(new DogPerson());
call(new CatLover());
}
}
Decorator
Even if the decorator pattern is theoretically well-known by many programmers, few actually implemented it in practice. Probably the most infamous example of its implementation is the construction of io packages. Venkat proposes a different approach to this pattern, based on the functions composability: by using the identity function and andThen(Function ) he has the ability to build simple, fluent mechanisms that enhance the abilities of an object.
class Camera {
private Function filter;
public Camera(Function... filters) {
filter = Stream.of(filters)
.reduce(Function.identity(), Function::andThen);
}
public Color snap(Color input) {
return filter.apply(input);
}
}
public class Sample {
public static void print(Camera camera) {
System.out.println(camera.snap(new Color(125, 125, 125)));
}
public static void main(String[] args) {
print(new Camera());
print(new Camera(Color::brighter));
print(new Camera(Color::darker));
print(new Camera(Color::brighter, Color::darker));
}
}
Even if the patterns seem to be forever young, as Venkat Subramaniam mentioned during his talk: “Design patterns often kick in to fill the gaps of a programming language. The more powerful a language is, the less we talk about design patterns as these naturally become the features of the language.”
Together with the evolution of programming languages and of our experience evolve also the patterns as time goes on. Some of them are absorbed as features of the languages, others were deemed obsolete and others are easier to implement. Regardless of which category your favourite falls into, Venkat suggests using them as communication means and letting the code evolve towards them. Also, he recommends experimenting with multiple programming languages, as a way to make your coding more fluent.
Amazon EC2 Trn1 Instances for High Performance on Deep Learning Training Models Are Now Available
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

AWS announces general availability of Amazon EC2 Trn1 instances powered by AWS Trainium Chips. Trn1 instances deliver the highest performance on deep learning training of popular machine learning models on AWS, while offering up to 50% cost-to-train savings over comparable GPU-based instances.
AWS Trainium is the second-generation of machine learning chips that AWS purpose built for deep learning training. Each Amazon EC2 Trn1 instance deploys up to 16 AWS Trainium accelerators to deliver a high-performance, low-cost solution for deep learning training in the cloud.
Trn1 instances are the first Amazon EC2 instance to offer up to 800 Gbps of networking bandwidth, lower latency and 2x faster than the latest EC2 GPU-based instances, using the second generation of AWS’s Elastic Fabric Adapter network interface to improve scaling efficiency.
Trn1 instances also use AWS Neuron, the SDK for Trn1 instances, enables customers to get started with minimal code changes and is integrated into popular frameworks for machine learning like PyTorch and TensorFlow.
Trn1 instances are built on the AWS Nitro System, a collection of AWS-designed hardware and software innovations that streamline the delivery of isolated multi-tenancy, private networking, and fast local storage.
According to AWS, developers can run deep-learning training workloads on Trn1 instances using AWS Deep Learning AMIs, AWS Deep Learning Containers, or managed services such as Amazon Elastic Container Service, and AWS ParallelCluster, with support for Amazon Elastic Kubernetes Service, Amazon SageMaker, and soon AWS Batch.
As the computer-intensive workloads are increasing, the need for high-efficiency chips is growing dramatically. While Trainium can be compared to Google’s tensor processing units which are their AI training workloads hosted in Google Cloud Platform, the offerings are different at many levels.
It can also compete with some of the newly launched AI chips such as IBM Power10, which claims to be three times more efficient than the previous models of the POWER CPU series, or NVIDIA A100, which claims to offer 6x higher performance than NVIDIA’s previous-generation chips.
MMS • Zhou Jieguang
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- MLOps is a concept that enables data scientists and IT teams to collaborate and speed up model development and deployment by monitoring, validating, and managing machine learning models.
- In practice, the ML codes may only take a small part of the entire system, and the other related elements required are large and complex.
- Apache DolphinScheduler is adding a variety of machine learning-related task plugins to help data analysts and data scientists easily use DolphinScheduler.
- Although there are various types of MLOps systems, their core concepts are similar and can be roughly divided into four categories.
- In the future, Apache DolphinScheduler will divide the supported MLOps components into three modules, namely data management, modeling, and deployment.
MLOps, the operation of machine learning models, is a thoroughly studied concept among computer scientists.
Think of it as DevOps for machine learning, a concept that enables data scientists and IT teams to collaborate and speed up model development and deployment by monitoring, validating, and managing machine learning models.
MLOps expedite the process from experimenting and developing, deploying models to production, and performing quality control for the users.
In this article, I’ll discuss the following topics:
- New functions of MLOps introduced in Apache DolphinScheduler
- Machine learning tasks supported by Apache DolphinScheduler
- The usage of Jupyter components and MLflow components
- The Apache DolphinScheduler and MLOps integration plan
What is MLOps?

Figure 1. MLOps is the set of practices at the intersection of Machine Learning, DevOps, and Data Engineering.
MLOps is the DevOps of the machine learning era. Its main function is to connect the model construction team with the business, operation, and maintenance team, and establish a standardized model development, deployment, and operation process so that corporations can grow businesses using machine learning capabilities. (refs)
In real production, the ML codes may only take a small part of the entire system, and the other related elements required are large and complex.

Figure 2. MLOps and ML tools landscape (v.1 January 2021)
Although there are various types of MLOps systems, their core concepts are similar and can be roughly divided into the following four categories:
- data management
- modeling
- deployment
- monitoring
DolphinScheduler is adding a variety of machine learning-related task plugins to help data analysts and data scientists to use DolphinScheduler.
- Supports scheduling and running ML tasks
- Supports user’s training tasks using various frameworks
- Supports scheduling and running mainstream MLOps
- Provides out-of-the-box mainstream MLOPs projects for users
- Supports orchestrating various modules in building ML platforms
- Applies different projects in different modules according to how the MLOps is matched with the task
ML Tasks Supported by Apache DolphinScheduler
Here is a current list of the supported task plugins:

Figure 3. The Current ML tasks supported by Apache DolphinScheduler
Jupyter Task Plugin
Jupyter Notebook is a web-based application for interactive computing. It can be applied to the whole process of computing: development, documentation, running code, and displaying results.
Papermill is a tool that can be parameterized and execute Jupyter Notebooks.

Figure 4. Jupyter Task Plugin
MLflow Task Plugin
MLflow is an excellent MLOps open source project for managing the life cycle of machine learning, including experimentation, reproducibility, deployment, and central model registration.

Figure 5. MLflow Task Plugin
OpenMLDB Task Plugin
OpenMLDB is an excellent open source machine learning database, providing a full-stack FeatureOps solution for production.
OpenMLDB task plugin is used to execute tasks on the OpenMLDB cluster.
Figure 7. OpenMLDB task plugin
You can configure conda environment variables in common.properties and create a conda environment for executing Jupyter Notebook, as shown here:

Figure 8. Create a conda environment
Call Jupyter task to run Notebook.
- Prepare a Jupyter Notebook
- Use DolphinScheduler to create a Jupyter task
- Run the workflow
The following is a Notebook for training a classification model using the SVM and iris datasets.
Notebook receives the following four parameters:
- experiment_name: TheExperiment name recorded at MLflow Service Center
- C: SVM parameter
- kernel: SVM parameter
- model_name: The name of the model registered to the MLflow Model Center

Figure 9. Train model notebook
Drag Jupyter components to canvas, and create a task, shown below.
The task will run Notebook: /home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm.ipynb, and save the result in the following route:
/home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm/03.ipynb
Set the runtime parameter C to “1.0,” and set the kernel to “linear,” The running conda environment is the kernel: “jupyter_test.”

Figure 10. The running conda environment is the kernel: “jupyter_test”
We can replicate two more identical tasks with different parameters. So we get three Jupyter tasks with different parameters, as follows:

Figure 11. 3 Jupyter tasks with different parameters
After the creation is complete, we can see our new workflow in the workflow definition (this workflow contains 3 Jupyter tasks). Once the workflow is running, you can click the task instance to check how each task is executed, and view the log of each task.

Figure 12. View the log of each task
Usage scenarios
- Data exploration and analysis
- Training models
- Regular online data monitoring
MLflow Component Usage
We can use MLflow task to train the model by following steps:
- Prepare a dataset
- Create MLflow training tasks with DolphinScheduler
- Run the workflow
An example of creating a workflow is as follows, including two MLflow tasks:

Figure 13. An example of creating a workflow
Task 1: Use SVM to train the iris classification model, and set the following parameters, in which the hyperparameter search space is used for parameter adjustment. If it is not filled in, the hyperparameters will not be searched.

Figure 14. Set parameters
Task 2: Use the AutoML method to train the model. Use flaml as the AutoML tool, and set the search time to 60 seconds, only allowing for using lgbm, xgboost as the estimator.

Figure 15. Details of the Executed task instances
Deploy tasks with MLflow
- Select the model version to deploy
- Use the DolphinScheduler created MLflow to deploy tasks
- Simple test interface
As mentioned above, we have registered some models in the MLflow Model Center, we can open 127.0.0.1:5000 to see the model versions.
Create a task for MLflow Models. Specify that the model is iris_model (production version), and the monitoring port is set to 7000.

Figure 16. Determine the model URI and monitoring port
 Figure 17. Specific running mechanism
Figure 17. Specific running mechanism

Figure 18. Test the Customizable running results
Automatic deployment after training the model, for example:
Using the workflow we created above (Jupyter training model, MLflow deployment model) as a sub-workflow, and connect them to form a new workflow.
Apache DolphinScheduler and MLOps Integration Plan

Figure 19. MLOps landscape of Apache DolphinScheduler
The above picture is a display diagram of machine learning-related tools and platforms. Apache DolphinScheduler will selectively support some of these tools and platforms that have a wide range of use and high value.
In the future, Apache DolphinScheduler will divide the supported MLOps components into three modules, namely data management, modeling, and deployment. The components involved are mainly DVC (Data Version Control), integrated Kubeflow modeling, and provide Seldon Core, BentoML, and Kubeflow, among other deployment tools to suit the needs of different scenarios.
How to integrate more tools so that Apache DolphinScheduler can better serve users is a topic that we contemplate in the long run. We welcome more partners who are interested in MLOps or open source to participate in the joint career.
MMS • Monica Beckwith Gil Tene Todd Montgomery
Article originally posted on InfoQ. Visit InfoQ

Transcript
Printezis: I’m Tony Printezis. I’ve been working on JVM garbage collection for way too long. I’m currently at the Twitter VM team.
Montgomery: I’m Todd Montgomery. The closest thing you could call me is a network hacker. I’ve been designing protocols and things like that for a very long time. That’s why I have the white beard. I’ve been around high performance networking and high performance systems for about that long as well.
Beckwith: I’m Monica. I’ve been working with OpenJDK for a long time now, even before it was OpenJDK, so during the Sun JDK days. I am currently the JVM architect at Microsoft.
Tene: I’m Gil Tene. I’ve been working on garbage collection almost as long as Tony. Tony’s paper on the CMS collector is one of the first garbage collection papers I read. That makes it more than 20-plus years now. I just worked in all kinds of different software engineering and system engineering parts, built operating systems and kernel things, and JVMs obviously at Azul. Accidentally built an application server in the ’90s. I played with a bunch of different things, that generally means I’ve made a lot of mistakes, I’ve learned from a few. Some of them are in the performance area. At Azul, I play with Java virtual machines, obviously, and some really cool performance stuff.
Java’s Just-in-Time (JIT) Compilation
Printezis: We’ll pick the topic for this panel, which is just-in-time compilation versus ahead-of-time compilation. Let’s maybe spend a couple minutes just to give a little background so everybody can understand what the difference between the different approaches are. Do you want to give a quick explanation of why Java has JIT compilation, and why it needs it, and how it works?
Beckwith: For the JVM to reach an optimal compilation ability with lots of compilation tricks such as inlining, or loop unrolling, there has to be some information that is provided, and many of the advanced optimizations or optimizers call this profile guided optimization. For the JVM, when we are thinking of the bytecode and we’re trying to get the bytecode to work on our hardware, be it x86-64 or ARM64. We want the execution to be in native code, because that’s what the hardware understands. That’s where the JVM comes in, and the JIT helps optimize when we have this series of opcodes that are coming out of the JVM, the JIT helps us optimize and give better performance. Performance that the underlying hardware understands and has the appropriate unit, such as the cache, or an offloading unit or anything like that. The JIT helps us with those optimizations.
GraalVM and AOT in OpenJDK
Printezis: Apparently, lots of people complain that JIT compilation always has to do work at the beginning, it doesn’t work very well. There was a couple of AOT solutions in Java, one that has been removed from OpenJDK. It was built in OpenJDK, and was removed. Then there is also GraalVM as well. Do you want to give an overview of GraalVM, AOT in OpenJDK?
Tene: Actually, I don’t like the terms AOT and JIT, because I think they’re weirdly named. In fact, both of them are named for what they don’t do. If you wanted to categorize them, a just-in-time compiler will take the bytecode, the code that you want to optimize, and optimize it for the machine at the time that it is needed that it’s used. It has the ability to optimize then. It has also the ability to optimize later to replace code with other code, which actually empowers a lot of optimizations that are pretty interesting. What a just-in-time compiler can’t do is compile ahead-of-time. What an ahead-of-time compiler does is it takes all the code and it compiles it to your binary before you ever run the program. It could do all that and avoid all the later work of doing this. What ahead-of-time compiler can’t do is compile just-in-time. The annoying thing is the choice. If you have to choose between them, I am definitely on the just-in-time side. I’ve got some strong arguments for why, because you just get faster code, period. It’s provable. The real question is, why do we have to choose?
Go and Ahead-of-Time Compilation
Printezis: Todd, you did mention in your presentation that you have been playing around with and using Go and Rust, that, as far as I understand, they both generate binaries. I know Rust is actually at a different level, a bit much lower level than Go and Java, of course. Any thoughts on why Go does pretty well with just basically an ahead-of-time compiler and doesn’t do any dynamic optimization?
Montgomery: I think that one thing that is glossed over, but I don’t think that you will gloss over or Monica would is the fact that Java is a little bit behind the OpenJDK, not other JDKs, or JVMs, in terms of the great amount of work that’s been done in things like LLVM for the last 15, 20 years. There is a lot of optimizations that are not available as easily, and most of those are ahead-of-time compilation. In essence, I think that there is a lot of stuff that you can get from ahead-of-time compilation and optimization. There are some things that really work well for certain types of systems. Go happens to be one, but C++ is a huge one, because you can do a lot of different metaprogramming that really makes a lot of the optimizations extremely effective. That’s where I think a lot of that sits, is there’s a lot of good stuff that’s in those cases.
I think to get the most out of it, you actually need both. I think that you can do ahead-of-time, a lot of different global optimizations that just make sense because we as humans can’t see everything and think of everything, but the compiler can see some things, and just make things more efficient overall. There’s still profile guided stuff that based on workload, based on what has happened, that is really great stuff. I think to get the most out of it, you need both. I don’t think you can get away with just one. I think you can use both and use it very effectively.
Printezis: I think Java maybe gets more benefit from just-in-time compilation, because basically everything is a virtual method essentially in it. Doing some runtime profiling can actually eliminate a lot of virtual method calls, inline more.
Tene: I think we shouldn’t confuse the implementation choices with the qualities of just-in-time or ahead-of-time. It’s absolutely true that with ahead-of-time compilation, people feel like they can afford to throw a lot more analysis power at the optimizations, and therefore lots of times people will say, this analysis we can do ahead-of-time. In reality, anything an ahead-of-time compiler can do a just-in-time compiler can do. It’s just a question of, can you afford doing? Do you want to spend the time while you’re running the program to also do that? That’s one direction.
The reverse is also true. If we just stopped this line between ahead-of-time and just-in-time, the fundamental benefit of a just-in-time compiler is it can replace code. The fact that you can replace code allows you to speculate and optimize, hopefully, rather than only for things you can prove, because you know that if it’s wrong, you can throw it away and replace it with other code that you can optimize. That ability to do late optimization enables faster code. This is true for all languages, Java is certainly one, but it’s true everywhere. If you could speculate that today is Tuesday, you can generate faster code for Tuesday. When Tuesday turns into Wednesday, you can throw away that code and generate fast code for Wednesday. That’s better than ahead-of-time.
Ahead-of-time compilers should be able to speculate if they knew that somebody could later replace the code. There’s no need to do all the analysis, we could do just-in-time, if we could do it ahead-of-time and retain the ability to later do additional just-in-time optimizations. Putting these two together actually could give you the best of both worlds. I can afford this because somebody else did it, or I did it well ahead-of-time. I can also allow myself and afford to do optimizations that it can only do if I can later replace the code if I was wrong.
JAOTC and the JVMCI Interface
Beckwith: We had this in HotSpot where we replaced, the first execution will go into AOT. Then of course it goes into C1 with full profile and everything. I wanted to go back to Todd. I’m asking questions, just because I wanted to understand, if you ever used I think it was in Java 9, Java 10, and I think 11 to 13 or 14, we had the privilege of using the JAOTC with the JVMCI interface. Did you ever use it? Were there any feedback that you would have, because I know you mentioned Java has these nuances.
Montgomery: Even from Java 8 to Java 9, there was a difference in terms of, it’s really difficult for when people are doing optimizations, specifically for Java, it’s been my experience that first get something to inline. That’s not always as easy as it might seem. Because that enables all the other optimizations. When doing that, things that go from Java 8 to Java 9 was a fairly big change in terms of stuff that used to be able to be inlined well, all of a sudden didn’t inline well, which then hindered other optimizations. When that is jarring, and I can think of one specific thing that I saw with that jump that was a little jarring. Then, several other things along the line of going from different Java versions. It’s really tough. Sometimes it just works. You upgrade a JVM, things are great. You get some performance improvements that you didn’t expect and everything’s fine. What typically happens though, 7 to 8 wasn’t too much of a jump in that direction. Eight to 9 was. Nine to 14, there’s been changes there that people have seen. I think you get to do that once. Then after that people are like, should we look at other languages besides Java? Because when it’s latency sensitive, and I think about this specifically, it’s really difficult for people to look at an upgrade and go, it’s worth us spending the time to upgrade, when they see regressions from the platform that they’re using.
I’ve seen some instances of that going from different versions. This does have an impact, I think, that people tend to not look at so much. That’s one of the reasons why I do know of several teams that they upgrade to a new version of the JDK extremely slowly. Some which will not move off Java 8 until they know every single thing about what a current version will do, and will even look at something like 17, and go, it’d be great if we had some of the things that are in 17, but it also is going to translate into lost money. That’s a real hard argument to say, you also probably make some money, so what does this look like? It’s hard to do that. It’s definitely visible from the number of clients that I look at in terms of this specifically in the trading space.
Tene: I think you raise an interesting point about the changes across versions. I spend a lot of time looking at these, and the reality is that you meet people that say, Java 11 or Java 17 now is much faster. Then they meet people that say, no, it’s much slower. Then they meet people that say, I can’t tell the difference. They’re all right. Every one of them is right, because there are some things that got faster, some things that got slower, and some things that didn’t change. Some of these are inherent to the JDK libraries themselves, a specific example like stack blocking, where there’s new APIs for stack blocking, they’re much better abstracted, but much slower. All the APIs for stack blocking are gone, so what are you going to do? There are counterexamples like stream APIs that got much faster in other under the hood implementations. Collection, if you’re going to HashMap, stuff like that got better. It varies as the platform goes along. Those aren’t actually JIT versus AOT, it’s just the code.
The fragility of the JIT compilation is another point that you raised. This is where I’ll raise my pet peeve, that version of Java in which implementation of a JVM you’re using to run it is not the same thing. It’s true that OpenJDK and so did the mainstream, took some step backs, and inlining is a specific sensitivity. If you look at the JIT compiler world out there beyond OpenJDK’s base ability to do C1 and C2, you have multiple strong JITs out there, including Azul’s Falcon JIT for our Prime platform. GraalVM has a JIT, OpenJ9 has a JIT. All of those vary in how they approach things. Both the GraalVM JIT and the LLVM based JIT that we use for Falcon, take a much more aggressive approach to optimization and inlining, which a JIT allows you to do because you can inline just in the paths you’ve profiled down and even speculatively. If you apply that, you get some pretty strong benefits. A lot of times, you can reduce that sensitivity of, yes, if it was above 35 bytecodes, did it get inlined or not? When you’re more aggressive in your inlining because you decide you can afford to throw more CPU and work at optimization, you blow through those kinds of limitations too. You inline what needs to be inlined. You inline what escape analysis helps with. You inline where you’re hot, even if it’s fat. Yes, all those things come at a cost, but if you just decide to spend the cost, you can get some really good speed out of it, even in a just-in-time compiler.
AOT Shortcomings
Beckwith: I agree with that. Gil, you mentioned about speculative optimizations. Speculative optimization and the risk with it. We can take the risk which is like, be on the aggressive side, or we can help the speculation by doing data dependency analysis or whatever. At Microsoft, we’re looking at escape analysis, because Gil mentioned LLVM and Graal. I think one of the advantages is the whole escape analysis and how we design the umbrella. How do we spread out with respect to that? That will help your inlining as well. My question was mostly that when we have this AOT trying to feed our profile guided and stuff like that, so basically, we don’t start into the interpreter, we just go into the AOT code. Were there any issues with respect to getting at least the libraries and everything like AOT’ed? That was my question was, did we have any shortcomings?
Tene: I actually clocked it a little bit. I actually think the approach that was there with the Java AOT was probably the healthier direction, as I said, you can AOT but later JIT. The reason that didn’t show a lot of value is because the AOT was fairly weak. The AOT only did C1 level optimization. C1 is very cheap, and you never keep that, you want the C2 costly optimization, or the stronger Falcon, or stronger GraalVM in each stuff later anyway. The AOT wasn’t offsetting any of the JIT stuff. All it was doing is helping come up a little quicker, and C1 is pretty quick. If you want C1 to kick in, lower your C1 compilation threshold, and then it’ll kick in.
The thing it was offsetting wasn’t much and it was doing it without a lot of performance for that code. It was a tight little tweak at the beginning, but it wasn’t replacing most of the JIT’ing. The cool thing is if you can actually optimize at the same level to JIT 1 with the same speculation to JIT 1, so that the JIT wouldn’t have to do it unless you are wrong. Then you effectively get ahead-of-time JIT’ing, if you’d like. Think of it as, one JVM already ran through this, already have the experience of all this. It tried, it guessed all kinds of stuff. It was wrong. It learned what was wrong, but it settled on speculatively optimizing a successful, fast piece of code. What if the next JVM that ran started with that, so this JVM ahead-of-times for that JVM, a JIT could AOT for future runs. A JIT could recover from a prior AOT speculating, which would allow the AOT to dramatically speculate just like a JIT does.
Beckwith: You think PGO and AOT. You think, get the profile information and that could give it AOT, and then get another AOT, which has this profile info. I agree.
Tene: Like I said, I hate AOT and JIT as terms, because all AOT means is not JIT, and all JIT means is not AOT. PGO, profile guided optimization, all JITs tend to do them and AOTs could PGO, no problem with that. Speculative optimization? JITs speculatively optimize. You can do speculative optimizations in AOTs if you also add things to the object code that let you capture what the speculation was. If you think about it, if I compile code that is only correct on Tuesday, in most current object code formats, I have no way to say this code is only correct on Tuesday. It’s fast, but when it turns into Wednesday, throw it away. There’s no way for me to put that in the object file. When you do add that, then an AOT could encode that. It could say, this is code for Tuesday, that’s code for Wednesday, that’s code for Thursday, they’re all faster, don’t run them on a Monday. Code replacement, deoptimization, and on-the-fly replacement of code as opposed to JIT’ing is the enabler for speculation. AOTs could speculate, and AOTs could PGO, if we just coordinate on the other side. Then a JIT turns into an AOT and AOT turns into a JIT. There’s no difference between them, and we’re in this Nirvana place and don’t have to argue anymore.
Escape Analysis
Montgomery: Monica, you mentioned escape analysis. I won’t even say it’s a love-hate relationship. It’s a hate-hate relationship, because I can’t rely on it at all. Statically, I can look at a piece of code that has inline, and I can tell visually if there’s no way it escapes, but somehow the escape analysis thinks that it does, which then blows other things up. I don’t necessarily think this is an AOT versus JIT type of thing. Some of the reasons that we don’t have things like stack allocation and other things in Java is because it should be something that gets optimized. I agree with that. However, in practice, for systems that want to rely on it, there’s no way that they can. It doesn’t, for me, seem to have much to do with AOT or JIT, when I can look at a piece of code, know that this is not going to escape, but yet, it will have the effect of escaping. It feels to me that that’s where a lot of things can fall down in JIT, is that, yes, a PGO type of situation where you can look at it, and no other way can something escape, but yet, there is more conservative approach taken, and it therefore does escape. Although, realistically, it can’t, because something else makes it so that it can’t be optimized.
That’s what a lot of the AOT work that’s done for the last decades has looked at, is, can we make this so that it is always optimized? It seems to me that a lot of times, we look at the JIT, specifically in Java, and say, it couldn’t optimize this because this chain of things that have to happen before that happens was broken by something else. Yet, an AOT analysis, which, I don’t know if it’s more thorough, or it’s just different, it’s looking at things from a different perspective. On the AOT side, there’s lots of things I can think of which can also defeat optimizations. What I’m thinking here is that escape analysis is one of those things, it’s always pointed at as being great, but in my experience is one of those things that I just wish it would just let me have stack allocation and go off and do something else with those cycles, instead of trying to analyze it.
Printezis: Won’t you get that with value types, basically, so we don’t have to worry about escape analysis that much?
Tene: Value types will only bite a tiny amount of that. I think this is colored by which implementations you use. Unfortunately, the C2 escape analysis has been pretty weak. It hasn’t moved much forward in the last several versions. Both GraalVM and Falcon have done a huge amount of work in escape analysis and have shown it to be very effective. I think there are two parts to this. One is, does escape analysis work or not? You could look at it and say, I can tell, but the compiler can’t tell, stupid compiler. Then just get a smarter compiler. Then separately, I think what you’re also pointing to is, regardless of whether it’s able to or not, there’s this feeling of fragility, where it worked yesterday, but as something changed and escape analysis doesn’t work anymore, for whatever reason. Something changed in its lower code, and it seems fragile, brittle, in that sense.
There’s this sense of predictability you get with an AOT because it did what it did, and it’s done and it’s not going to change. There’s that, whatever speed it has, it has. That’s something you could put as a check on the AOT side of, it’s going to run it multiple times on the same machine with no NUMA effects and all that, and you’ll probably get similar speeds. I think JITs can strive for that as well. It’s true that there’s a lot more sensitivity in the system, of everything works except that you loaded this class before that class, and that became too complicated, so give up or something. Sometimes it’ll work. Sometimes it won’t, and it gets that feeling.
I do want to highlight, escape analysis is very powerful. We’re not alone in showing that. Escape analysis combined with inlining is very powerful. Usually, escape analysis driven inline is very powerful. There’s one other part which is, there are the escape analysis where you could look and you say, there’s no way this could escape, so why isn’t it doing it? It really should be catching it. Then there are all these cool, partial or speculative escape analysis things that you could do where you say this could escape, but in the hot path it doesn’t, let’s version the code. The JIT will actually split the code, have a version that has escape analysis benefits, and if you’re lucky, 99% of the time you go there you get the speed. That way, it could escape. It’s a different version of the generated code.
Again, one of the powers of a JIT compiler is you can do that because you can survive the combinatorial mistakes. If you do deep inlining and cover all the paths, the problem explodes to be totally impractical with a year’s worth of optimization. If you only optimize the paths you believe happen and then survive the fact that you took other paths with the optimization mechanisms, then you can afford to do very aggressive escape analysis and inlining together. Both Falcon and GraalVM each show that. You see the amazing, like 30%, 40% improvements in linear speed as a result of these things now. They’re certainly paying off.
Beckwith: There are so many. During our investigation, and we’ve shared it on OpenJDK as well, we’ve seen certain optimization opportunities that we can bring to OpenJDK that are currently missing from OpenJDK. It’s exactly what you said, Todd and Gil. It’s the conservative approach versus a little more aggressive. Then partial escape analysis is another great, kind of like an aggressive approach as well. In OpenJDK, we’ve just scratched the surface of escape analysis. I think escape analysis was put in OpenJDK to show that it can be done, and now we just have to get it right. Maybe it took so many years, yes, but we’re getting there.
Tene: My take is, what we need in OpenJDK is a modern JIT compiler, so we can build all this in it. Really, we have a 23-year-old JIT compiler in HotSpot, which got us this far. It’s really hard to keep moving forward, which is why it tends to fall behind in some of the more modern and more aggressive optimization techniques. It’s not that it’s unable to do it, it’s really good, but enhancing it is slow. This is where you can look at multiple newer JITs out there. Obviously, our approach has been take LLVM, use it as a JIT. We contributed a lot to LLVM to make it usable as a JIT. We use it that way. GraalVM has the approach with the Graal JIT compiler, which is a more modern JIT compiler. OpenJ9 has its own. Also, there are projects within OpenJDK for future JDK stuff. We’ll see which optimizers we go in. Actually, we’re going to see more than one. Really, in my opinion, and this is based on some experience of trying to get it to do otherwise, it’s hard for us to enhance C2 with velocity to do these optimizations, which is why we invested in a different one. I think OpenJDK will eventually have a different JIT that will allow us to get a lot more of these optimizations into mainstream OpenJDK as well.
Printezis: At Twitter, a lot of our services will use Graal, and we have a lot of Scala code. We see a lot of benefit for several of our services using Graal versus C2. We did some looking into it and stuff, and we believe that a lot of the benefit is because of the better escape analysis that Graal has, at least for the versions which we also do right now, that we have tried.
Tene: We do a lot of testing with Finagle code which you guys created, and Scala based, and we do see regularly 15% to 25% performance improvements, driven strongly by escape analysis, vectorization. Auto-vectorization is amazing, but you need a JIT compiler that does it. Modern hardware has amazing vectorization capabilities that is built for more power and higher speed.
Printezis: The version of Graal we’re using, though, was doing actually a pretty poor job with any vectorization. It was not doing any vectorization. I don’t know whether they’ve published their vectorization code to the open source. I think it was proprietary.
Tene: We use the LLVM auto-vectorizer, which Intel and AMD and Arm all contribute the backends to, so the backends that match the hardware. We get to leverage other people’s work, which is pretty cool. Most of what we’ve done is massaged the Java semantics into it so it’ll get picked up. When you look at what modern vectorizers can do, which wasn’t around until about six, seven years ago, you can do vectorization of loops with ifs in them, and things like that, which would seem unnatural before, because vectors now have predicates on predicates on predicates. In fact, I recently tried to create code that can’t be vectorized, and it was hard. I had to step back and even I tried it vectorized. Then I had to think hard, what can I do that it can’t possibly vectorize? I had to come up with that, because everything I threw at it, it just picked up and used the vector instructions for it.
Montgomery: We’ve been here before where you and I, we work at it, we can’t break it but somebody else tries something that we didn’t think of, and all of a sudden, now it’s slow again. That’s a never-ending cycle.
Tene: You’re right. The fragility is there, but I actually don’t think the fragility is as much about the JIT as about the optimizers themselves, like if you change a line of code, whatever optimizer you have, you might have just gone outside the scope [inaudible 00:35:59], and it gives up on stuff it can do. JITs are probably a little more sensitive, because most stuff moves around, but an AOT compiler is just as sensitive to code change as a JIT is.
Montgomery: I’ve spent a lot of my career chasing down and going, I compiled this yesterday, and nothing changed. All of a sudden, now it won’t optimize this, what is going on? That is across both approaches. You try to minimize it, but it does happen. I totally agree on that.
Tene: What is different in terms of this is cache line alignment, and speculative optimization can do cache line alignment, because you run and your arrays happen to be aligned, and everything’s fine. Then the next run, though, malloc was off by 8 bytes, and they’re just not aligned. The code doesn’t work the same way. It’s just two runs, one after the other with the same code, AOT or not, different results.
Beneficial Examples of JIT and AOT Utilization
Printezis: Can you please give me some best example where the JIT and where AOT can be used, and they can be beneficial?
I would guess that most cases, for any application that runs for any non-trivial amount of time, it doesn’t run for like 5 seconds, so a JIT will work pretty well. The application will get more benefit of it. Maybe you can use some AOT in order to have a better starting point to save you for startup. Just for the long term, a JIT will do a much better job. I think there are some cases where it will make sense to just use AOT. If you want to implement something like ls in Java, you don’t necessarily want to bring up an entire JVM in order to look at some directories and then just say that’s it. I’m not picking on ls, just if you have a small utility that’s going to run for a very short period of time, I think, just generating a binary and AOT’ing everything, is going to be the right approach. I think that’s how I see it.
Montgomery: Actually, it’s not time related, but it’s also the same thing of if you’ve got something that’s totally compute bound, it’s just simply straight compute, then AOT is going to be the same as your JIT. The downside, though, to the JIT in that case, is that it has to wait and learn, so a startup delay. Again, that can be addressed with other things. It is a good point, though, that certain things don’t need to have the JIT and would react much better to AOT. That’s the minority of applications. Most applications, especially enterprise applications, for business and stuff like that, almost all of them are going to have way too much conditional load. The way that they work between times a day, and stuff like that, JIT is a much better approach, honestly, if you have to pick between the two.
Tene: If you’re going to do AOT, take a hard look at PGO for AOT. Because having AOT optimized, given actual profiles, it makes for much better optimizations. Even then, speculation is extremely [inaudible 00:39:43], data driven speculation. The belief that no number will be larger than 100, and the ability to optimize because that’s what you believe, is something you can’t do in an AOT unless you can later survive being wrong. Sometimes, you’ve got pure compute on entire spectrum data, and you’re going to do all the combinations. Lots of times, all you’re doing is processing U.S. English strings. U.S. English strings do fit in 8 bits. You can speculate that everything you’re ever going to see is that, and you’ll get better everything. An AOT just can’t deliver that, because that might run in China and it won’t work, where you can survive that. There are data driven optimization, speculative data value range driven optimizations, they’re just more powerful if you can survive getting them wrong and replacing the code. That’s fundamentally where JIT wins on speed. Where it fundamentally loses is, it takes a lot of effort to get the speed and all that, so tradeoffs. People tend to turn down the optimization capability because they don’t want to wait 20 minutes for speed. I do think there’s a hands-down, it wins if you can speculate. The real trick is, how do we get AOTs to speculate? I think we can.
See more presentations with transcripts