Month: November 2022
Omni Faces 4.0 Changes Minimal Dependency to Java 11, While Removing Deprecated Classes

MMS • Olimpiu Pop
Article originally posted on InfoQ. Visit InfoQ

Almost five years since its previous major release, OmniFaces 4.0 has been released after a long series of milestones that included a “Jakartified version of 3.14 with a couple of breaking changes” following the release of Jakarta EE 10. Besides the minimum requirements and breaking changes, new utility methods have been added and omnifaces.js is now sourced by Typescript rather than vanilla JavaScript.
The biggest considered advantage of the change to TypeScript is its ability to transpile the exact same source code to an older EcmaScript version such as ES5 or even ES3 for ancient web browsers. The intent is to do the same for Jakarta Faces’ own faces.js. Targeted at ES5, omnifaces.js is compatible with all major web browsers.
OmniFaces 4.0 is compatible with the Jakarta Faces 4.0 and Jakarta Faces 3.0 specifications from Jakarta EE 10 and Jakarta EE 9.1, respectively, with the minimum required version of Java 11. The Components#addFacesScriptResource() method was added for component library authors who’d like to be compatible with both Faces 3.0 and 4.0. It will allow the component developer to support both Faces 3.0 jakarta.faces:jsf.js and Faces 4.0 jakarta.faces:faces.js as resource dependencies. The method exists because it is technically not possible to use a variable as an attribute of an annotation such as @ResourceDependency.
Besides the increase in the minimal version of Java, other minimum dependencies have changed as well: Java 11, Jakarta Server Faces 3.0, Jakarta Expression Language 4.0, Jakarta Servlet 5.0, Jakarta Contexts and Dependency Injection 3.0, Jakarta RESTful Web Services 2.0 and Jakarta Bean Validation 3.0. In other words, OmniFaces 4.0 is not backwards compatible with previous versions of these dependencies because of the compiler-incompatible rename of the javax.* package to the jakarta.* package.
In the current version, everything that had been marked under the @Deprecated annotation in version 3.x has been physically removed. For instance: the tag ; and the WebXml.INSTANCE enumeration has been replaced with the WebXml.instance() and FacesConfigXml.instance() methods.
The built-in managed beans, #{now} and #{startup}, will now return an instance of the Temporal interface rather than the Java Date class. The framework still supports the time property, as in #{now.time} and #{startup.time}, in a backwards-compatible manner. Additionally, it provides two new convenience properties: instant and zonedDateTime as in #{now.instant}, #{now.zonedDateTime}, #{startup.instant} and #{startup.zonedDateTime}.
The Callback interfaces, dating back to Java 1.7, which had replacements available in Java 1.8, are now annotated under @Deprecated. For example, Callback.Void has been replaced by Runnable, Callback.Returning has been replaced by Supplier, Callback.WithArgument has been replaced by Consumer and Callback.ReturningWithArgument has been replaced by Function. Utility methods in Components and Events have been adjusted to use the new types.
Even if the changes in OmniFaces 4.0 are not that revolutionary, this has been a long-awaited version after the stretched milestone releases. Having a more current minimum dependency and changing to TypeScript, might provide interesting options to component builders relying on it.
Java News Roundup: WildFly 27, Spring Release Candidates, JEPs for JDK 20, Project Reactor
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for November 7th, 2022 features news from OpenJDK, JDK 20, OpenSSL CVEs, Build 20-loom+20-40, Spring Framework 6.0-RC4, Spring Boot 3.0-RC2, Spring Security 6.0-RC2, Spring Cloud 2021.0.5, WildFly 27, WildFly Bootable JAR 8.1, Quarkus 2.14.0 and 2.13.4, Project Reactor 2022.0, Micrometer Metrics 1.10 and Tracing 1.0, JHipster Lite 0.22.0 and Camel Quarkus 2.14 and 2.13.1.
OpenJDK
JEP 432, Record Patterns (Second Preview), was promoted from Candidate to Proposed to Target status for JDK 20. This JEP updates since JEP 405, Record Patterns (Preview), to include: added support for inference of type arguments of generic record patterns; added support for record patterns to appear in the header of an enhanced for statement; and remove support for named record patterns.
JEP 433, Pattern Matching for switch (Fourth Preview), was promoted from Candidate to Proposed to Target status for JDK 20. This JEP updates since JEP 427, Pattern Matching for switch (Third Preview), to include: a simplified grammar for switch labels; and inference of type arguments for generic type patterns and record patterns is now supported in switch expressions and statements along with the other constructs that support patterns.
The next step in a long history of addressing the inherently unsafe stop() and stop(Throwable) methods defined in the Thread and ThreadGroup classes , has been defined in JDK-8289610, Degrade Thread.stop. This proposes to degrade the stop() method in the Thread class to unconditionally throw an UnsupportedOperationException and deprecate the ThreadDeath class for removal. This will require updates to section 11.1.3 of the Java Language Specification and section 2.10 of the Java Virtual Machine Specification where asynchronous exceptions are defined.
JDK 20
Build 23 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 22 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20, developers are encouraged to report bugs via the Java Bug Database.
OpenSSL
OpenSSL, a commercial-grade, full-featured toolkit for general-purpose cryptography and secure communication project, has published two Common Vulnerabilities and Exposures (CVE) reports that affect OpenSSL versions 3.0.0 through 3.0.6 that may lead to a Denial of Service or Remote Code Execution.
CVE-2022-3602, X.509 Email Address 4-byte Buffer Overflow, would allow an attacker to use a specifically crafted email address that can overflow four bytes on the stack.
CVE-2022-3786, X.509 Email Address Variable Length Buffer Overflow, would allow an attacker to create a buffer overflow caused by a malicious email address abusing an arbitrary number of bytes containing the “.” character (decimal 46) on the stack.
BellSoft has reported that OpenJDK distributions, that include Liberica JDK, are not affected by these vulnerabilities as they use their own implementation of TLS. Developers are encouraged to upgrade to OpenSSL version 3.0.7.
Project Loom
Build 20-loom+20-40 of the Project Loom early-access builds was made available to the Java community and is based on Build 22 of JDK 20 early-access builds. This build also includes a snapshot of the ScopedValue API, currently being developed in JEP 429, Scoped Values (Incubator). It is important to note that JEP 429, originally named Extent-Local Variables (Incubator), was renamed in mid-October 2022.
Spring Framework
The fourth release candidate of Spring Framework 6.0.0 ships with new features such as: support for the Jakarta WebSocket 2.1 specification; introduce the DataFieldMaxValueIncrementer interface for SQL Server sequences; and introduce a variant of the findAllAnnotationsOnBean() method on the ListableBeanFactory interface for maintenance and potential reuse in retrieving annotations. There were also dependency upgrades to Micrometer 1.10.0, Micrometer Context Propagation 1.0.0 and Jackson 2.14.0. More details on this release may be found in the release notes.
The second release candidate of Spring Boot 3.0.0 features changes to /actuator endpoints and dependency upgrades to Jakarta EE specifications such as: Jakarta Persistence 3.1, Jakarta Servlet 6.0.0, Jakarta WebSocket 2.1, Jakarta Annotations 2.1, Jakarta JSON Binding 3.0, and Jakarta JSON Processing 2.1. Further details on this release may be found in the release notes.
The second release candidate of Spring Security 6.0.0 delivers: a new addFilter() method to the SpringTestContext class which allows a Spring Security test to specify a filter; the createDefaultAssertionValidator() method in the OpenSaml4AuthenticationProvider class should make it easier to add static parameters for the ValidationContext class; and numerous improvements in documentation. More details on this release may be found in the release notes.
Spring Cloud 2021.0.5, codenamed Jubilee, has been released featuring upgrades to the sub-projects such as: Spring Cloud Kubernetes 2.1.5, Spring Cloud Config 3.1.5, Spring Cloud Function 3.2.8, Spring Cloud Config 3.1.5 andSpring Cloud Openfeign 3.1.5. Further details on this release may be found in the release notes.
Red Hat
Red Hat has provided major and point releases to WildFly and Quarkus.
The release of WildFly 27 delivers support for Jakarta EE 10, MicroProfile 5.0, JDK 11 and JDK 17. There are also dependency upgrades to Hibernate ORM 6.1, Hibernate Search 6.1, Infinispan 14, JGroups 5.2, RESTEasy 6.2 and Weld 5. WildFly 27 is a compatible implementation for Jakarta EE 10 having passed the TCKs in the Platform, Web and Core profiles. Jakarta EE 8 and Jakarta EE 9.1 will no longer be supported. InfoQ will follow up with a more detailed news story.
WildFly Bootable JAR 8.1 has been released featuring support for JDK 11, examples having been upgraded to use Jakarta EE 10, and a remote dev-watch. More details on Bootable JAR may be found in the documentation.
Red Hat has released Quarkus 2.14.0.Final that ships with: support for Jandex 3, the class and annotation indexer; new Redis commands that support JSON, graph and probabilistic data structures; and caching annotations for Infinispan. Further details on this release may be found in the changelog.
Red Hat has also released Quarkus 2.13.4.Final featuring: a minimum version of GraalVM 22.3; dependency upgrades to JReleaser 1.3.0 and Mockito 4.8.1; and improvements such as support programmatic multipart/form-data responses. More details on this release may be found in the changelog.
On the road to Quarkus 3.0, Red Hat plans to support: Jakarta EE 10; MicroProfile 6.0; Hibernate ORM 6.0; HTTP/3; improved virtual threads and structured concurrency support based on their initial integration; a new gRPC server; and a revamped Dev UI. InfoQ will follow up with a more detailed news story.
Project Reactor
Project Reactor 2022.0.0 has been released featuring upgrades to subprojects: Reactor Core 3.5.0, Reactor Addons 3.5.0, Reactor Pool 1.0.0, Reactor Netty 1.1.0, Reactor Kafka 1.3.13 and Reactor Kotlin Extensions 1.2.0.
Micrometer
The release of Micrometer Metrics 1.10.0 features support for: Jetty 11; creating instances of the KeyValues class from any iterable; Kotlin Coroutines, allow for different metric prefixes in the StackdriverMeterRegistry class; and a message supplier in the WarnThenDebugLogger class to reduce String instance creation when the debug level is not enabled.
The release of Micrometer Tracing 1.0.0 features: establishing the Context Propagation library as a compile-time dependency to avoid explicitly having to define it in the classpath; support for RemoteServiceAddress in Sender/Receiver contexts; a handler that allows tracing data available for metrics; and setting an error status on an OpenTelemetery span when recording an exception.
JHipster Lite
JHipster Lite 0.22.0 has been released featuring an upgrade to Spring Boot 3.0, a new PostgreSQL dialect module; a refactor of the AsyncSpringLiquibaseTest class; fix the dependency declaration of the database drivers and developer tools; and remove the JPA properties that do not alter defaults.
Apache Software Foundation
Maintaining alignment with Quarkus, version 2.14.0 of Camel Quarkus was released that aligns with Camel 3.19.0 and Quarkus 2.14.0.Final. It delivers full support for new extensions, CloudEvents and Knative, and brings JVM support to the DSL Modeline. Further details on this release may be found in the list of issues.
Similarly, Camel Quarkus 2.13.1 was released that ships with Camel 3.18.3, Quarkus 2.13.3.Final and several bug fixes.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Meta has been at work to port their Android codebase from Java to Kotlin. In the process, they have learned a number of lessons of general interest and developed a few useful approaches, explains Meta engineer Omer Strulovich.
Meta’s decision to adopt Kotlin for their Android apps was motivated by Kotlin advantages over Java, including nullability and functional programming support, shorter code, and the possibility of creating domain specific languages. It was also clear to Kotlin engineers that they had to port to Kotlin as much of their Java codebase as possible, mostly to prevent Java null pointers from creeping into the Kotlin codebase and to reduce the remaining Java code requiring maintenance. This was no easy task and required quite some investigation at start.
A first obstacle Meta engineers had to overcome came from several internal optimization tools in use at Meta that did not work properly with Kotlin. For example, Meta had to update the ReDex Android bytecode optimizer and the lexer component of syntax highlighter Pygments, and built a Kotlin symbol processing (KSP) API, used to create Kotlin compiler plugins.
On the front of code conversion proper, Meta engineers opted to use Kotlin official converter J2K, available as a compiler plugin. This worked quite well except for a number of specific frameworks, including JUnit, for which the tool lacks sufficient knowledge to be able to produce correct conversions.
We have found many instances of these small fixes. Some are easy to do (such as replacing isEmpty), some require research to figure out the first time (as in the case of JUnit rules), and a few are workarounds for actual J2K bugs that can result in anything from a build error to different runtime behavior.
The right approach to handle this cases consisted in a three-step pipeline to first prepare Java code, then automatically run J2K in a headless Android Studio instance, and finally postprocess the generated files to apply all required refactoring and fixes. Meta has open sourced a number of those refactorings to help other developers to accomplish the same tasks.
These automations do not resolve all the problems, but we are able to prioritize the most common ones. We run our conversion script (aptly named Kotlinator) on modules, prioritizing active and simpler modules first. We then observe the resulting commit: Does it compile? Does it pass our continuous integration smoothly? If it does, we commit it. And if not, we look at the issues and devise new automatic refactors to fix them.
Thanks to this approach, Meta has been able to port over 10 million lines of Kotlin code, allowing thus the majority of Meta Android engineers to switch to Kotlin for their daily tasks. The process also confirmed a number of expected outcomes, including shorter generated code and unchanged execution speed. On the negative side, though, Kotlin compiler proved significantly slower than Java’s. This opened up a new front for optimization by using KSP for annotation processing and improving Java stub generation and compile times, which is still an ongoing effort.
Do not miss the original article about Meta’s journey to adopt Kotlin if you are interested in the full detail.
Kubecost Open Sources OpenCost: An Open Source Standard for Kubernetes Cost Monitoring
MMS • Mostafa Radwan
Article originally posted on InfoQ. Visit InfoQ

Kubecost recently open sourced OpenCost, an open source cost standard for Kubernetes workloads. OpenCost enables teams to operate with a single model for real-time monitoring, measuring, and managing Kubernetes costs across different environments.
OpenCost introduces a new specification and an implementation to monitor and manage the costs in Kubernetes environments above version 1.8.
InfoQ sat with Webb Brown, CEO of Kubecost, at KubeCon+CloudNativeCon NA 2022 and talked about OpenCost, its relevance to developers, and the state of Kubernetes cost management.
InfoQ: Can you tell us more about OpenCost and its significance?
Webb Brown: We’ve come together with a group of contributors to build the first open standard or open spec for Kubernetes or container-based cost allocation and cost monitoring. We’ve worked with teams at Red Hat, AWS, Google, New Relic, and others. We open sourced it earlier this year and contributed it to the CNCF. OpenCost was accepted by CNCF and is a sandbox project.
We think this is so important because there’s no agreed-upon common language or definition for determining the cost of a namespace or a pod or a deployment, ..etc. We see a growth in the amount of support with this community-built standard to converge on one set of common definitions.
Today, We have a growing number of integrations. We just had the fourth integration launch this week and have a lot more in the works. It’s been amazing to see the community come together and see this as a commonly agreed-upon definition.
InfoQ: What OpenCost enables for this ecosystem and what integrations are delivering for end-users?
Webb Brown: We see cost metrics going to a lot of different products whether it is Grafana or other FinOps platforms such as Vantage which recently launched OpenCost cost monitoring support for EKS.
We have seen lots of adoption and gotten positive feedback. There’s a lot more we want to do. I think that’s just representative of what open source allows us to do. We have lots of integrations and data and we’re ready to take it to new and exciting places.
InfoQ: What is the state of Kubernetes cost management today and where do you think we are heading?
Webb Brown: I think it’s helpful to go over the history. When we started the Kubecost open source project in 2019, more than 90% of the teams we surveyed reported not having accurate cost visibility into Kubernetes clusters.
Last year, CNCF did a study and that number was about 70%. Today we think we’re closer to 50%. Now We see more and more teams have visibility, whereas again, a year or two ago, most teams were in a black box. Today, I think it is about giving teams accurate and real-time cost visibility on all their infrastructure.
Now we’re moving into what we believe is phase two, In which, we have this great visibility, how do we make sure that we are running infrastructure efficiently? How do we optimize for the right balance of performance, reliability, and cost with applications and organizational goals in mind?
That is super exciting for us. Again, we think about cost as an important metric on its own, but one that’s deeply tied to all these other things. We are seeing more and more teams enter that phase two and we are working closely with thousands of them at this point.
InfoQ: Are there any plans to integrate with other cloud providers or vendors?
Webb Brown: Today, we have support for AWS, Azure, and GCP, as well as on-prem clusters and air-gapped environments. We plan to add support for a couple of other cloud providers soon. I believe support for Alibaba is going to be next and I expect it will be available this year. And we’re in talks with a handful of other vendors to support OpenCost as well as Kubecost.
InfoQ: You recently announced that Kubecost is going to be free for unlimited clusters, Can you tell us more about that?
Webb Brown: When we started Kubecost, soon after leaving Google five years ago, we expected that the number of clusters for a small team would tend to be pretty small, three, four, or maybe fewer. That number of clusters has grown way faster than we expected. What we saw were small teams that were saying we’ve twenty-five clusters.
We thought KubeCost’s original free product that could be installed on one cluster would be sufficient for small teams. Recently, we’ve decided we want to bring our product free to an unlimited number of clusters so that teams of all shapes and sizes can get cost visibility and management solutions.
Kubecost builds real-time cost monitoring and management tools for Kubernetes. OpenCost is a vendor-neutral open source project for measuring and allocating infrastructure and container costs.
Users can get started with Kubecost for unlimited individual clusters free of charge through the company’s website.
MMS • Andrew Lau
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Hey, folks. Before starting today’s podcast, I wanted to share that QCon Plus, our online software development conference, returns from November 30 to December 8. Learn from senior software leaders at early adopter companies, as they share their real world technical and leadership experiences, to help you adopt the right patterns and practices. Learn more at qconplus.com. We hope to see you there.
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I have the privilege of sitting down, across many miles, with Andrew Lau. Andrew, you are the CEO of Jellyfish, and probably a good starting point is, who’s Andrew, and what’s Jellyfish?
Introductions [00:51]
Andrew Lau: Shane, thank you for having me here. It’s great to talk to you and your community, and thanks for letting us share my story around. Okay, so who am I? Gee. So, I’m hailing from Cambridge, Massachusetts, right across the water from Boston. I’m actually a Bay Area, California native, who’s been in the more volatile weather for the last 25 years.
But to know me, I was trained as a software engineer, I came to the East Coast of the US for school, and I had no intention of staying. It wasn’t the cold winters that I sought, but life happened, is the actual answer. Transit engineer… Put my finger, almost by accident, into the startup scene. Met my current co-founders of Jellyfish 22 years ago, and I can talk to that in a second. But that’s what actually got me to both be in the startup scene, and stay here, geographically, where I am.
And so, I’ve gone on the journey from being an engineering manager, learning how to do pre-sales, pro services, engineering management, to find myself running big engineering teams, to eventually, entrepreneuring, and finding my way, and growing teams and businesses along the way. I probably wear multiple hats in life, doing all those things. And for fun, to know me personally, gee, I play tennis. And the last few years, a lot of people have been baking bread. I’ve been working on my, well prior life I was a barbecue judge, so I’ve actually been working on my Texas brisket game. So some people have been sitting at home watching bread rise. I’ve been sitting at home watching my smoker run. So that’s knowing me a little bit on this.
And to your second question, what is Jellyfish? Well, Jellyfish is a software company, five years old. Jellyfish makes an engineering management platform to really help leaders of engineering teams kind of help their teams get more successful and connected to the business.
We’ve been really lucky and during the last few years and I say that lucky in the sense that, look, it’s been a hard few years for all of us and I come here today with empathy. Shane, I hope you and your family are doing well. I hope listeners, your families are as well. It’s just been a tumultuous last few years, but the silver lining for us is just the growth that we’ve seen. We were just a handful of people before the pre Covid times and today we’re almost couple hundred. And so that change has been really a positive part of it, but it’s also been hectic, amazing and crazy to get the chance to work with such amazing people along the way.
Shane Hastie: An interesting background there and definitely we’ll probably delve into some of those things, but let’s start with something that came out of Jellyfish is this state of engineering management report. Tell us a little bit about that.
State of Engineering Management Report [03:25]
Andrew Lau: So, we have this unique seat from where we’re sitting where we have the privilege, and I say privilege, by working with hundreds of companies, the leading edge, the upper echelon of teams that are really defining the way that we do engineering at scale as an industry. And we have the privilege of working and helping with them and learning from them. But also that because of this we actually can see trends move through the actual teams, right?. And because of this earlier this spring, we put out an annual report, a state of engineering management and we’re really able to get a feel of what’s changing in these teams and what’s relevant along the way. And so those are… That really is the nature of our report and it’s because we’re sitting in this place where we can actually see what’s actually happening across the teams.
Shane Hastie: You can see what happens across the teams. So what are some of those insights? What are the things that you were seeing in this report?
Andrew Lau: Shane, with the state of engineering manage report, we actually look across the hundreds of companies we’re actually talking to, which allows us to see how hundreds of thousands of engineers are doing their work. And in doing so, we can actually see the trends in the world of engineering management leadership. And so the things that are actually in that report tie into how we can look at data driven teams actually outpace like data deficient teams, those that actually are focusing on innovation, quality and speed to market. Those are all areas where we actually can see the correlation moving that those actually focus on those things can actually accelerate those pieces.
If you cared a lot about making sure you invest in innovation, we can see how teams that actually focus on that are able to drive that up. We actually see teams that actually are focused on quality and actually how the implications of quality. Where poor quality actually influences the amount of time being spent actually repairing and maintaining and how you can actually manage that going forward once you start looking at it.
And the last area that I would actually say is actually even things are speed to market. So the time it takes from the time you conceive something to the time you actually can get it out there and you can see how teams, when they actually start looking at this data and how they behave differently across there. The report’s available, you’re welcome to actually pull it and take a look. A lot of great insights there. And I think part of it is because it’s a sampling of being able to see what trends play out in these kind of contemporary organizations that are really are driving the way forward for all of us. And so we’re privileged to actually get a chance to actually both see that and learn from these folks marching forward.
Shane Hastie: So what does it really mean to be data driven as an engineering manager today?
What does being data driven really mean? [05:57]
Andrew Lau: Great question. So, look, I grew up as an engineer, eventually made my way to engineering management. I would say that in my experience, a lot of it is what makes one successful. Well you get the knows of what’s actually happening on your team. You get the knows of when things are stuck, who actually needs help when a project’s actually in trouble and how can you actually nudge it forward. You also find out the knows of actually what’s happening from the business side and what they need.
I actually think after years of that, those are the things that you instinctually learn, which is great. However, I think instinct alone often isn’t sufficient because a few things at scale as you get bigger, as your team gets bigger, instinct alone can be dangerous. And look, we all know we’re wrong sometimes. We have gut feels. We have a quick read. I think we should feel that muscle. I think that’s an asset for all of us.
But sometimes you should also double check with data in that stuff. And I think especially in this day and age, I think we have to be careful of actually not realizing that we might actually have biases if we’re not careful. We all think we know who the best engineer is that helps save these projects. But sometimes we should lift the covers a little bit and realize is someone’s stuck? Are they not able to get through something because the PR’s are not getting helped? Is someone not actually getting the actual ramp up that they actually need?
And so when I come back to data driven, I think I’m going to paraphrase it wrong, but there’s an old analogy which is you can’t improve what you don’t measure, right? And I think data is part of your tool belt.
So what do we all bring as leaders? We bring, well we’re in technology space. We bring our technology chops forward and our own experiences when we’re actually doing it. We bring our own war stories and experiences that we’ve been through on the good days and the bad days and team members and friends that have had done well or actually hit walls. We bring all those with us. Those who alone are the kind of historical tool belts. I think what we should bring forward too is actually bring some data to validate your gut feel and assumptions along the way. Because in some ways as we scale, all of us… Data brings that kind of the bionic tool belt to help us make decisions better, right? Either because it validates that your gut is actually right or sometimes when we’re lost in not knowing where our team is needing help to bring kind of insight into figuring out, hey where should we turn? Where should we actually dive into? Or actually where should we actually correct the business? Because it doesn’t understand what’s actually happening.
And so to me data is actually just part of contemporary leadership, which is because we’re awash in it, we actually have to integrate in the way that we do things today. So that’s what data driven means to me.
Shane Hastie: You make the point there that we are awash in data making sense of those floods.
Making sense of the floods of data available to us [08:35]
Andrew Lau: Yeah, I was talking to someone recently, we have KPIs, we have all the KPIs, all the KPIs. We have all the data and I’m like well if you have all the data, the problem is then you almost have nothing because we’re so awash in it today, right? It’s easy to say you have all the data. I think it’s actually important to figure out what it is to look at. And I think when you actually think about this actually you should…
The area that we all can help each other on is actually understanding what to look at. Because today you could open any charting package, you could open any data stream, we’re awash in it and the question is what do you pay attention to? And I think for us there’s a few things. We’ve learned from some experienced individuals, people that we work with that like which things they pay attention to and we aim to actually make those data streams more accessible to those that are actually earlier in their pathway that don’t know those things.
We also are able to look at the corpus of all the things that are happening and kind of bring some data science to actually highlight what what’s correlating in these different factors, which things are actually the pieces that actually you should pay attention to. And so when I think about our role in this and all of our roles, it’s not that we need more data for data’s sake. We need to figure out which data pieces we should be looking at, which things we need to actually refine and which things we actually need to focus on. And then last bit is to make it easy to get to .but I think that’s the journey that we’re all on together to actually evolve this industry forward
Shane Hastie: As an engineering manager, which are the data gems, the things that really can help me understand what’s going on with my team and how do we make this data safe?
Andrew Lau: Okay, so my turn to actually turn the tables, Shane. What does safe mean to you? Because I feel like that’s a leading question. I want to make sure I get from you what safe means to you? ‘Cause you’re teaching us here,
Shane Hastie: How do we use the data in a way that the insights are useful and the people who the data is from have trust that it’s being used in a way that’s not going to be used against me. We go back to the 1940’s and before. W. Edwards Deming give a manager a numeric target and he will meet it even if it means killing the organization to do so.
Andrew Lau: You’re right. I would say a couple things to that. So this is fun by the way. Look, I think we can be terrible leaders with or without data. I’ll start with there first. So it is not because of data that actually makes us terrible leaders. And I actually think of this first and foremost when we think about leadership, core leadership, data’s an enabler, data’s not the thing.
Good leadership is not dependent on data [11:08]
I often talk about, before we talk about anything when it comes to data, we as a leader we need to talk about culture. And culture can be this soft, squishy word. Sometimes you can talk about enduring, it’s the unwritten rules. But I think when it comes to technology teams, it’s like actually culture actually implies what matters to us. And when I say us as a team, us as people delivering and you actually phrased it as against, I mean look frankly any company that actually is talking about against probably isn’t in the right place anyways because why are we all here at the companies we’re at? I don’t know anybody that actually wants their company to fail or at least I hope not.
So when I look at this, it’s all about making sure that if there is conflict it’s because we’re not understanding each other. We’re not rowing in the same direction proverbially.
The importance of alignment and clarity of purpose [11:57]
And so go back to culture. I actually think the most important part in leadership is to make clear what we care about and why. When I see disagreements actually happening and technology companies. I first started, is there a misalignment and lack of understanding because who the hell actually wants to sink their ship? I don’t know, that’s a crazy person in my view. More than likely I look at this and I see teams where the interns are working hard, jamming late into the night on a legacy code base fixing bugs of something they didn’t even make. And all the while the business is screaming, why isn’t this new feature delivered because we promised it yesterday.
Okay, well let me pause on that part of it. There’s a fundamental misalignment there. These guys and gals are staying late at night fixing a piece of software they didn’t actually fix. The business is yelling about delivering this other thing. Both of those are valuable for the company clearly, but somehow both parties doesn’t know what the other one wants and why. They’re not actually having a conversation. And so back to culture, I think it’s important to actually align on what matters to us. So Shane, you and I, we could care like, hey we need to just get things on the floor out as fast as possible. We might care about lead time and velocity like nobody’s business because all we want is get stuff out there. That’s all that matters. So if that were the case then I would say we should agree on that and we should actually make sure that we’re on the same page around why lead time and velocity of things that we actually look at and we care about.
Okay, it could be that you and I are like, hey we really got to spend time on innovation, this new thing. We need to put away everything else we’re doing. We need to agree on that. And so we should make sure that we’re protecting our time to work on those things. And so we should measure to make sure what else are we doing and let’s make sure we get it off the plate.
We should have this conversation first before we talk about any data because you’re right, we are awash with data in the world and data can take you many places if you don’t talk where you’re going first, right? It is but a tool to accomplish what you’re doing. I come back to it’s part of your Swiss army knife. It’s part of what you do once you’ve decided as a team, as a leader where you want to go. It is not magic on its own but I think it’s actually just a superpower to enhance what you’re already going in.
Shane Hastie: Shifting gear a tiny bit. Looking back at your career, you’ve gone from as you said, engineer to engineering manager to business person to entrepreneur. What’s that journey and what are the different perspectives that you take at each step in that journey?
The journey to engineering manager and entrepreneur [14:27]
Andrew Lau: I appreciate you asking because you and I were kibitzing a second ago about the languages we all started in. I started with C and you said you’re a COBOL guy, right? And so both of these things are probably lost annals of time. I don’t even know if any of my team members today actually can even talk about a Malik or a Calic anymore in these things. But who knows? I did start as an engineer. I was a systems engineer. I lived in kind of network stacks and the good old days of making sure my memory was free and rolled out. And look, I really enjoyed those days. Probably if I find some moment of retirement that probably is the life of me that can go back to that kind of hands on bit of it. I think that there’s something cathartic about actually working there in that way.
But I actually then eventually moved on to engineering management and I found that role just different. I actually think that when people go into engineering management, I think people think that’s a step forward. I don’t think it’s a step forward for everybody. I think there are times when it’s not fun and I actually look at this like, I’m a dad now of two girls and I kind of think of actually management as parenting. You don’t know you’re going to love it till you’re in it. We can intellectualize it all day long but you have to learn whether you find derivative satisfaction in leading others or when you’re coding yourself, you make a thing, you do a thing in that part of it. And so you kind of learn your way through that.
And then as I kind of progressed in my career, I learned around kind of large scale management, more executive management and I learned that the tillage of actually needing how to translate to business people that actually don’t understand how engineering actually works and that actually becomes the role.
Earlier my career I used to think that oh, you get into these roles and then you get to tell people what to do. Well you know, don’t tell anyone what to do actually in reality. You spend a lot of time bridging is the role and you’re trying to connect the dots and making two pieces actually fit together.
And then entrepreneuring on the other side, on the pure business side, having been through the other journey, I’m actually seeing that, look, there are business implications in this stuff and I empathize with not understanding on the other side. And I guess the benefit of going through all those journeys is I get to look at my other self and actually realize I didn’t actually understand the perspective from the other side of the table at the time. And I try the best I can to realize, to speak to myself back then to understand two sides of it. This is what I need from the other side of the table.And I think to me that’s actually, I joke with my engineer leader either the best job or the worst job. The worst job is that I know the challenges he’s facing and I could tell him, did you do this? Did you didn’t do that? Okay, I know I can be a pain in the ass.
On the flip side, I come here with empathy on it and I understand that your stereotypical business CEO is a pain in the butt yelling this, this, this. And at the very least I try to come back and I should contextualize it. Hey, this is the why. This is what I saw when I was in that seat the other side and I empathize with you. It is a thing but this is a business reality and our job together is to connect those pieces, right?
And I think at the same time I look back to my old engineer self and I would say, hey, there were days that I hated too. I hated working on somebody else’s code that was horrible and then we needed to ship a date on this thing and I hated time commitments that someone else made. But at the same time with that empathy I can actually say, well if a time commitment was made it was because of this and this is why the business needs this and if we don’t do this, this is what’s actually happening and dear engineer tell me what else could we actually do differently to make sure that we get this or tell me what’s going to give. And the engineer that’s stuck late at night working on bugs, I see you and I understand that sucks and that wasn’t your code and that’s not your fault. And so please bring it up to me because the business would rather actually have you working on new features and great things.
So surface that for me so that we can actually talk about what we can actually put away so you can get to those other things. I think that to me being in all these seats has actually helped me actually see the other side. And I hope and you can go connect with my engineering team to figure out, am I the good or bad version of me? But I try to show up to actually figure out can I speak in a way that I actually can bridge both sides of it. At least to both contextualize why I’m saying what I’m saying and try to elicit what’s holding us back from doing those things. And I think being in multiple seats helps us see the constraints of each party along the way.
Shane Hastie: Thank you for that. So culture. It’s a wide ranging term. With Jellyfish with the organizations that you have been a part of and being a founder for, how do you define the culture and maintain the culture?
Understanding culture [18:54]
Andrew Lau: First of all, culture’s a hard word to define. You called it out. On the worst of times people think of it as foosball tables and yoga balls. That’s not culture. We can actually talk about the artifacts and outcomes that it is the unwritten rules. It’s the fabric that holds us together. These are analogies but they’re not actually defining it. So if you ever find a way to describe to me culture in succinct words, Shane, please email me and teach me how to talk about it.
I take it for granted that culture’s vividly important. It is not the foosball tables and yoga balls. I think that’s a media cleansed way of what culture actually is. I actually think of it as the way that we behave. It’s the norms that we actually do things. I do like that it’s the unwritten rules. So we don’t actually have lots of process. It’s process without process. It’s the values, it’s all of those things.
I do think it’s really important. It’s what keeps high performing teams heading in the same direction without a lot of direction and berating. And I actually think that I am definitely a student of it more than anything I know it’s what kept me at companies over time saying that we actually have to develop. So to me personal philosophy, I don’t think culture can be mandated. And we’re definitely in the middle of learning this over the last couple years. So maybe we were actually have a handful of people. Maybe you could pretend that one could mandate culture like dear team, have fun, right? Okay, well guess what? That doesn’t work. Last I checked, no one has fun when you say to have fun. And this is extra true actually at the couple hundred people that we’re actually at now. And so the other thing to recognize that culture can be stagnant, it actually has to evolve because the thing that’s stuck in the past is never going to come with a new team. And teams have to own their culture. And so for me philosophically, culture has to be refreshed and built by the teams. It can’t be proclaimed. It actually has to be organically developed at the team level. And my role in this is to actually shepherd it, to nudge it to be the guardrails. I can tamp down things that are bad but I can still click a fire in things that are good but the kernel of it actually has to start on the team first.
Leadership’s role is to spot things that are good and give them fuel [20:52]
And so my role in this is to guide to spot things that are good and give it fuel. And fuel can be attention, time could be money, encouragement, teaching. Those are all things that I look for because I actually think that’s the most important part of actually that culture does evolve. Culture is present and culture is owned by the team themselves, not proclaimed from somebody from far away.
And so to make it super tangible, I’ll tell a silly story. Really early on in the company someone came in and I don’t know if you’ve ever seen, there’s a YouTube show called Hot Ones about eating chicken wings. And I know this is going to take your podcast in funny directions here, but it’s about chicken wings. And I remember a woman, I’m not going to out her ’cause she’s awesome. She just joined the team and she came to work one day. She’s like, I saw this thing about the show of Hot Ones. I think we should do it at work. And then the conversation was like, no I don’t think we should, I don’t think I’m going to do any work. I think you should do this. What I didn’t mean by that is, it is not like it’s on her, it’s actually it’s about her. And so the encouragement was actually like you should do it.
And so behind the scenes, yes we make sure that we’re buying the hot sauces. We make sure we’re picking up the wings at the grocery store for her and Falafels in her case because she’s vegetarian too and we make sure that she’s sending out the emails to nudge people to show up and to remind them. But she shows up and she throws this amazing party. Everyone had a great time, burnt their faces off, remembers it for years to come. And she did this amazing and trivia. But the key part is it’s about her. It’s about that culture. It’s about the initiative there. And that’s a very minor, silly story. It’s about chicken wings but it’s actually about how we play a role, all of us and actually encouraging each other to bring it forward, to be yourself and to bring it to the team and let it blossom in that way. And I know most of your content on your podcast is actually about engineering and teams and that stuff and we’re talking about chicken wings. But I actually think culture is a big part of what we do as leaders and teams. That’s the way we think about it at our house.
Shane Hastie: Another part of culture is rituals. How do we define build and allow these rituals to be positive experiences for our teams?
Rituals as a part of culture [22:56]
Andrew Lau: I think rituals go part of culture. It’s part of the lore of being there, part of why you’re there. It also makes you feel at home, makes you feel part of the team. It’s part of the identity along the way. I think they are important. And I go back to my matching point around culture, which is I think they evolve organically.
Rituals are almost the best things that we remember from our past that we keep doing forward. I think can’t pre-think a ritual before it actually happens. So you can’t proclaim culture from on high, it doesn’t work. Rituals are the things that happen to survive because people like them. I’ll share a fun story. One of our rituals at our team is that if you look from the outside you would say, oh you guys do an all meeting every Thursday at 4:00 PM. I was like, yeah, we kind of do but we don’t call it that. It has a strange name. It’s called demos. Okay, you’re like demos, what is that?
So it’s an outgrowth. It’s an outgrowth of when we were under 10 people, we used to sit around a big red table. We were probably seven folks we’re all working on different things and we’d sit around a table and we used to demonstrate what we’re actually working on with each other just every Thursday. So we sit down, sit around table, grab a beer maybe and just pass the screen share around and just show what we’re actually working on. And back then it was probably more about code, more about product. And that evolved as we grew too as we actually added a sales team, a finance team, marketing team. And it evolved to being something that we actually, I took turns sharing what are we doing in different departments. I remember actually saying, hey, here’s a new legal contract we actually showed and my co-founder, David, used to make fun of me. You just showed a word document that doesn’t count. But it was actually good.
People actually found value in actually learning what each of us actually working on. And there are times when the world is tough that we take a moment to actually share that hey, here’s our bank account balance, we’re going to be okay team. But either way it became a thing that we rotated. And so we still continue that ritual today at 200 people and we now go department to department and we actually pass the mic and each week we describe what we’re actually working on. And for my turn when I get to do it, we still have tradition which is every board meeting we do, which is every quarter. We then run the Thursday after a board meeting. We run the same slides with the whole team and for two reasons. One because I believe it’s deeply aligning to actually understand what we’re marching towards and why as a team. We execute better for it.
But also back to the term culture. I think we have a culture of curiosity in our team. We have a culture of actually curiosity, especially around entrepreneurship. Not everybody wants to be an entrepreneur tomorrow, but they’re all really curious about it. And so we’re there to demystify what actually happens. When I was earlier in my career, it’s like what happens in these boards? It’s really scary, complicated. It’s not. We have to approve things. We have to legal stamp things. But it is I think valuable to actually unfurl those things. And so that’s an example of a ritual that we took from when we were smaller to when we’re actually bigger because people still wanted it. We still check in every Thursday. It’s like, do you still want this? We still keep doing that, right? You made me think of recently I’ve been unfurling, where did this ritual come from?
And so my co-founders and I met 23 years ago. They hired me in 1999 and I realized that this whole demos concept actually goes back to a thing we used to do. That ritual back at that company we used to call dogs and demos. We would do hot dogs and demos, same concept. And I realized that that actually concept itself was actually born in a company that I was actually with when I crossed paths. My co-founder, Dave, in 1999 called Inc. to me, which became Yahoo’s search when they used to demos on a monthly basis, similar thing, grab a beer and watch a demo.
And I learned as I pulled that thread, that ritual actually goes all the way back to the mid nineties to SGI. So silicon graphics, so Shane, you and I can date ourselves that we can nod at each other and actually know what SGI was. Those were the super coolest workstations back in the day. It is super cool to, for me to actually realize that these rituals do carry on from generation to generation just because when things work, you keep doing them right? And we learn from that part of it. And that’s how rituals actually established because we propagate forward what worked. And you can’t proclaim that beforehand. You have to do it post facto.
Shane Hastie: Andrew, some really interesting conversations and great stuff here. If people want to continue the conversation, where do they find you?
Andrew Lau: Well, you can find me on LinkedIn. You can find me on Twitter. I guess the handles amlau, A-M-L-A-U and please come check us out jellyfish.co. We’re hiring. Anyone actually that has contributions around culture or metrics or thinking of engineering leadership and how that actually makes a dent in the world. We’d love to meet and trade notes. We’re here as students of all of us and love to learn from you. So, Shane would love the chance to actually meet some of your crew here and really appreciate you having us here.
Shane Hastie: Thank you so much.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS recently introduced Amazon EventBridge Scheduler, a new capability in Amazon EventBridge that allows organizations to create, run, and manage scheduled tasks at scale.
Amazon EventBridge is a serverless event bus that allows AWS services, Software-as-a-Service (SaaS), and custom applications to communicate with each other using events. Since its inception, the scheduler is the latest addition to the service, which has received several updates, such as the schema registry and event replay.
Marcia Villalba, a senior developer advocate for Amazon Web Services, explains in an AWS Compute blog post:
With EventBridge Scheduler, you can schedule one-time or recurrently tens of millions of tasks across many AWS services without provisioning or managing the underlying infrastructure.
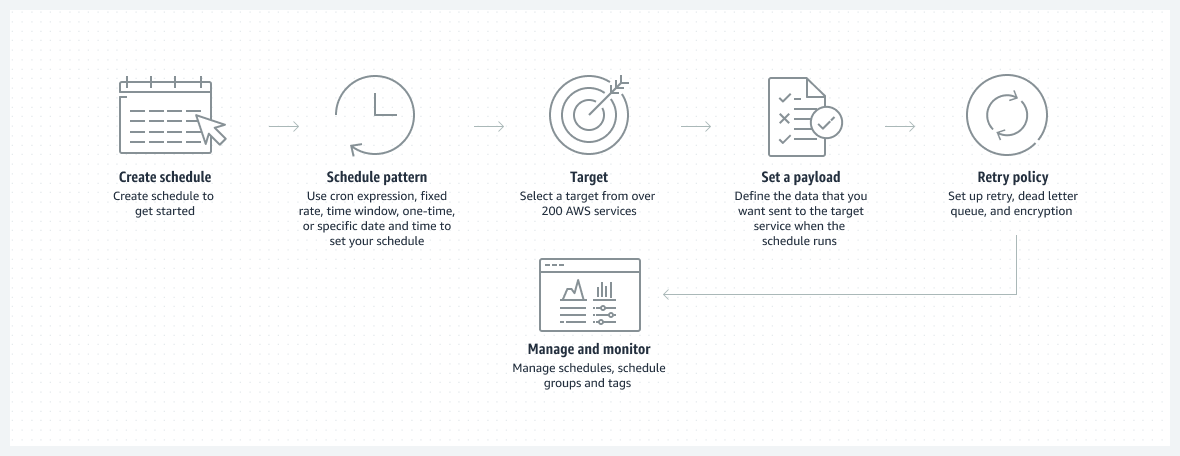
Source: https://aws.amazon.com/eventbridge/scheduler/
Developers can create schedules using the AWS CLI that specify when events and actions are triggered to automate IT and business processes and provide scheduling capabilities within their applications. EventBridge Scheduler allows developers to configure schedules with a minimum granularity of one minute.
Yan Cui, an AWS serverless hero, tweeted:
It’s great to finally see an ad-hoc scheduling service in AWS. My only nitpick is that it’s granular to the minute, not an issue in most cases, though.
The capability provides at least once event delivery to targets, and you can create schedules that adjust to different delivery patterns by setting the window of delivery, the number of retries, the time for the event to be retained, and the dead letter queue (DLQ). An example is:
$ aws scheduler create-schedule --name SendEmailOnce
--schedule-expression "at(2022-11-01T11:00:00)"
--schedule-expression-timezone "Europe/Helsinki"
--flexible-time-window "{"Mode": "OFF"}"
--target "{"Arn": "arn:aws:sns:us-east-1:xxx:test-chronos-send-email", "RoleArn": " arn:aws:iam::xxxx:role/sam_scheduler_role" }"
More specifics on the configuration are available in the user guide.
Developers in the past have used other means. A respondent in a Reddit thread mentions:
I was already using AWS Rules for a scheduler, but this scheduler they’ve made doesn’t seem like it can do everything that the rules can.
However, Mustafa Akın, an AWS community builder, expressed in a tweet:
I have waited for this service a long time. Many of us had to write custom schedulers because of this, we use SQS with time delays, it works but not ideal. Now we can delete some code and rejoice in peace.
Yet received a response from Zafer Gençkaya, an engineering manager, OpsGenie at Atlassian, stating:
One more lovely vendor-lock use case- that’s we have been waiting for for so long. It makes lots of backend logics redundant! I’d love to see exact-once delivery support, too — of course with additional fee.
Amazon EventBridge Scheduler is currently generally available in the following AWS Regions: US East (N. Virginia), US West (Oregon), US East (Ohio), Europe (Ireland), Europe (Frankfurt), Europe (Stockholm), Asia Pacific (Sydney), Asia Pacific (Tokyo), and Asia Pacific (Singapore). Pricing details of the service are available on the pricing page.
MMS • Audun Fauchald Strand Truls Jorgensen
Article originally posted on InfoQ. Visit InfoQ
Transcript
Strand: Autonomy is the cornerstone of team based work. Teams should include all the competence and all the capabilities they need to solve the problems they own. When they have that, they should have the freedom and trust to make the decisions about their domain, without asking others for permission. We work at NAV, the largest bureaucracy in Norway. When you’re that big, it’s also valuable to have alignment across these teams. Most things should be done in mostly the same way.
Background
Jørgensen: My name is Truls, and the guy that just started talking is Audun. We are principal engineers at NAV. We have been working here for five and six years. Both of us have been working as software developers for over 15 years. Maybe it’s because of that, or maybe it’s because we are often seen together, colleagues tend to compare us to Statler and Waldorf, the silly old Muppets on the balcony of The Muppet Show.
Strand: Here we are, we are programmers working in IT. In this talk, we’re going to talk about how we achieved alignment in the technology dimension. We think that the tools, techniques we’ve used can be useful for others in other dimensions as well.
Jørgensen: Let’s start with a really short introduction of NAV. It’s Norwegian Labor and Welfare Administration. We got 20,000 employees across the country, making it the largest bureaucracy in Norway. The mission for NAV is to assist people back into work. We also provide benefits to Norwegians from before they are born until after they’re dead. In total, it sums up to one-third of the state budget.
IT at NAV (Norwegian Labor and Welfare Administration)
Let’s talk about IT at NAV. Since NAV was established in 2006, IT was always slow. By slow, I’m talking four huge coordinated releases a year slow. As you know, slow means risky. By risky, I mean 103,000 development hours in a single release risky. It doesn’t get more risky than that. That has changed. That changed in 2016, and what a change that has been. Instead of releasing four times a year, we now release over 1300 times per week. This has been a massive transformation. This transformation is the context for this talk. This graph is saying something about speed, but perhaps not much on flow. We have more graphs for you.
What happened in 2016, was that we got a new CTO, and he insisted that NAV should reclaim technical ownership, and start to insource. As you see, this graph correlates with the previous one. NAV used to think of IT as a support function, and as a consequence, NAV didn’t have any in-house developers at all. Instead, NAV tended to lean on consultants to get that boring IT stuff done. In fact, I started as the very first developer back in 2016. Today, we have almost 450 internal developers. We think it’s worth making a point there. If you want to optimize for speed and fast flow, you must leave behind the mindset that IT is a support function. In order to succeed with the digitalization, NAV had to consider IT as a core domain. This third graph shows a very similar curve, so absolutely no surprise at all. We didn’t have any product teams at all before 2016. We used to be organizing projects, but today teams are considered the most important part of our organization, and by Conway’s Law, the architecture.
What We Left Behind
Strand: These changes mean that we have left something behind. Basically, before 2016, NAV was organized by function. That is organized by function where each function is specialized and solves a very specific task. Such a design yields a busy organization but the flow suffers because of all the internal handovers. An organization that optimizes for flow should further aim to reduce the handovers and need to accept the cost of duplicating functions, reducing the handover risk by domain instead in the cross-functional teams.
What We Adopt and Prefer
Jørgensen: What we adopt and prefer when optimizing for fast flow. That’s really the topic for the rest of this talk. As we have seen, we have adopted a team first mindset at NAV, but as we shall see, the surrounding organization struggles to figure out how we can set those teams up for success. While high performing cross-functional teams demand autonomy, it is also valuable for NAV to have alignment across these teams, but getting alignment in the age of autonomy, that’s pretty hard work. We have come up with some techniques to achieve that alignment that we’re going to share with you. First, let us start with the teams and why they demand autonomy in NAV. As we have seen, we have over 100 teams, and each team is playing a part directly or indirectly in the lives of the people of Norway.
Strand: We have one team working on the unemployment benefit, another with the parent key benefits. We have teams owning and coding the front page on nav.no, and the application platform that everything runs on. One team we worked a lot with lately is a team behind the sickness benefit. This doesn’t really translate to relevant English, but the team is called team Bamble. Bamble is an island off the west coast of Norway, and one of the central team members of the team comes from that island. That’s why they chose that name. Team Bamble is a proper interdisciplinary team. There’s programmers, legal experts, communication experts, and designers, and other kinds of members. They’re mature, having worked again for a few years, having practiced continuous learning for a long period of time. In theory, they know everything they need to know to figure out how to do this, how to solve all the problems that need to be solved to create a system that automates the full chapter of Norwegian law, controlling the payment of the sickness benefit to our users.
Jørgensen: People come to this team with different perspectives, with different voices. One voice, the developer voice suggests that the most important thing the team should deliver is a sustainable system. Because the system are modeling an important part of a welfare state that is constantly changing. The software we create should be adaptive to change. Another voice argues that the most important thing the team should deliver is a system that makes the case handling more efficient. Then we have a third voice that wants the team to focus on a more user friendly service for the sick. Finally, the fourth voice claiming that the most important thing that the team could do is to create a system that does a better job with compliance than the old system for sickness benefit. Coming to think of it, all of these voices make sense. Ideally, we want all of those perspectives implemented in the new system. These voices don’t always form a beautiful choir. When push comes to shove, which perspective wins, which voice is the loudest? To top it off, when the team funding comes from one of the voices alone, that makes it even harder to balance their perspectives. Getting their perspectives is really important.
Let’s run quick examples on why. Providing support for the sick. That’s nothing new. The previous system is over 40 years old and tailored for a human caseworker. This new system is instead tailored for computers, and aims to do a fully automated calculation of the benefits. In some ways, this is where the human brain meets the machine. It’s also where theory meets practice. Coming to think about it, the rule set is the theory, but those rules has been put to test by caseworkers for over 40 years. That raises some really interesting questions, such as the practice has in some cases served as a Band-Aid for inconsistencies in the rule set. How do we transform that practice to a new system? Also, during that time, different practices throughout the country has emerged. Which of those practices should be considered to be the correct one? What does that mean for the practices that we now consider wrong? These are indeed complex questions to answer. It doesn’t matter how good you are in Kotlin. In order to be able to come up with answers to these kinds of questions, the team must be cross-functional: developers, designers, compliance experts, and legal experts must work together.
Strand: With all these people in the team, the team requires autonomy to function well. The essence of what Truls just said is that this is basically the job, but NAV wants to automate the sickness benefit. This is what this means. Navigating a long line of problems without a clear solution, but many different forces trying to shape the solution to the problem. This isn’t really about how fast a programmer you are or how fast the team can produce code. It’s about how fast the team can learn about the problems and the forces affecting them. Trying to find solutions that are sustainable, understandable, legal, and sound technical. For the team to be able to do that they need to work together over time. They need trust and psychological safety, and good relationships between the team members. Seldom has this quote by our hero, Alberto Brandolini, been more correct, “Software development is a learning process, working code is a side effect.” After thinking about this for a little while, if you believe this code, how does that affect how you work? What’s important if learning is more important than creating code? How should you change how you work? You need to put structures in place outside of teams as well as inside, that help the teams to learn as efficiently as possible. In such a team, with all these different team members from all these different departments, each team brings a different perspective to the table. The departments need to find ways to structure the learnings being done in the teams, and finding ways to get this knowledge back into all the teams that work at NAV.
The Surrounding Organization
Jørgensen: Let’s talk about the surrounding organization. We had just briefly touched upon it. Remember those graphs earlier? What does the organization behind this change look like? Cross-functional teams demand not only autonomy, but they need that the surrounding organization operate as support. That is not how it really is at NAV. NAV is not just a system of teams. NAV is also Norway’s largest bureaucracy, and we have two competing organization designs. Both are struggling to find a way to coexist. There’s obviously a lot of tension between the cross-functional teams, and the traditional hierarchy, which is very much alive. Everyone agrees to some extent that cross-functional problems are best solved in cross-functional teams. In order to be responsible, teams need autonomy. Empowering the teams means that the different departments such as the IT department, legal, and the benefit departments are losing influence. Everybody wants to go to heaven, but nobody really wants to die. In NAV, changing the formal organization to be a better fit for a system of teams is a really long running process. We cannot sit and wait it out, although this process is currently running. This is the reality. We have over 100 teams that is deploying to production all the time, and they are cross-functional, and they are competent. We have also this large bureaucracy surrounding those teams struggling with the question, what could the departments do to set the teams up for success? Now we will discuss what IT at NAV has done to set the teams up for success to increase the speed and flow.
Alignment in the Age of Autonomy
Strand: We really think that the other departments both in NAV and maybe even other places, can learn from what we have done. First, we need to talk a little bit about how alignment and autonomy comes together. Most of you have probably seen this drawing. It’s from one of our software development process heroes, Henrik Kniberg. There’s always a Kniberg drawing to visualize the concept you want to explain to someone else. It’s easy from seeing this drawing where you want to be. It’s a quadrant so we want to be in the upper right-hand quadrant, also there’s a green circle showing the desired place to be. What is Kniberg saying here? He’s saying that you need teams that have a clear understanding of what problems to solve, and the constraints and opportunities to connect it to that problem. You also want to give the teams a large amount of freedom on how to solve this problem. This is very easy to say, we need aligned autonomy, but getting there isn’t necessarily as easy as just saying those words. How do you get there? What do you do differently tomorrow to get closer to the desired state and the best working? You really need a plan. You need people to work on the measures of that plan. Now we’re going to talk about our measures, what our plan looked like. I probably like to say that we planned all the history before we started. We have tried things and we’ve tried to keep doing what worked and stopped doing things that didn’t work.
Jørgensen: Something that didn’t work was NAV’s strategy for getting alignment in the years before 2016. That used to be, to write principles on the company wiki. In the age of autonomy, that’s some crazy definition of done. You will write that principle on the wiki and then you can get frustrated over lazy employees not following what you just wrote. We have seen this strong indication of sloppy leadership repeating at several organizations, not just NAV. The message is the same. This isn’t good enough. If you aim for speed and fast flow in your organization, writing stuff on the company wiki is not enough, if you want to direct the flow somewhere. Alignment in the age of autonomy needs another approach. You need to find each team and talk with them with respect for their autonomy. Make the team want to do it, and provide helpful guidance along the way. Always adapt it to their context and their abilities, and be aware to not exceed their cognitive capacity. You do this for each team.
Strand: What you’re saying is you can just put this principle on the company wiki and then we’ll be done.
Jørgensen: I guess we are done. No, we should discuss some examples instead. First, we will discuss two descriptive techniques, and then two normative techniques that we have seen work good together.
Descriptive Technique – The Technology Radar
Strand: The most basic technique that we have is the technology radar. This is an internal technology radar just for NAV. We want the teams at NAV to use this to share the technologies they’ve tried, and the conclusions or the learnings they’ve made from those choices. The radar has traditional categories, just like the Thoughtworks radar, of assess, trial, adopt, and hold, and also another one called disputed. It’s implemented with a simple Slack channel, where anyone can make suggestions and attribute the discussions, and add that up in a database to show the conclusions and the data for what happened. If you really want to summarize our strategy with the technology radar in a tabloid way, you can say that when it comes to technology, everything is loud, as long as you broadcast your choices to the organization. This is basically our implementation of that principle.
It’s sometimes misunderstood as a list of allowed technologies. We think it is a curated list of the technologies used. We have a small group of editors that collect the suggestions and moderate the discussions. Sometimes the discussions are basically as good as the conclusions. One of my hobbies at NAV is to, for instance, say that we need Gradle in adopt and Maven in hold, or the other way around, just to observe all the interesting discussion that comes afterwards. Or maybe just say something about the Spring Framework, it works the same way. Basically, our radar shows the breadth of the technology landscape, but it also gives teams insight into what other teams are doing. This insight has a real effect on alignment. Because when one team can see what another team does, it’s easier for them to choose the same thing if the first team is happy with what they’ve been doing.
At the same time, this radar is very descriptive. It doesn’t have any normal development. It doesn’t say what’s allowed and not. That has a really interesting and helpful side effect of reducing or maybe even removing shadow IT. Because when teams can publish the choices they made without being yelled at for doing something illegal, it’s much easier for them to say what they have, and there’s no reason to hide choices that I think others will not like. All in all, this has been a really good thing for NAV. Sometimes the radar isn’t enough, we need to go into more depth on the topic.
Descriptive Technique – Weekly Technical Demo
Jørgensen: For this, we have the weekly technical deep dive. The weekly technical deep dive started small, back when we were less than 20 in-house developers. Now this arena serves as a weekly technical pulse throughout the organization, perhaps even more so during the pandemic. We’re now using Zoom, and it attracts over 400 people each Tuesday, and the recipe, that’s still the same. One team takes the mic and presents something they’re working on, something they’re proud of to all the other teams. The weekly demo is as the technology radar a descriptive technique for creating alignment. It’s really efficient for spreading good ideas across teams. It’s relatively low effort. It needs a dedicated and motivated group of people to arrange this every week. It’s low effort, but really high impact. That group is doing an incredible important job. They’re really changing the culture at NAV towards more openness, and more kindness, and more curiosity, and more learning each week. These are two descriptive techniques, time to discuss some more normative ones. This is the technical direction presentation, and we should spend a little more time on this one.
Technical Direction
Strand: This presentation is basically a complement to the more descriptive techniques that we talked about already. For those, the goal was to create more transparency and more discussion. With this presentation, technical direction, we want to be more normative and say what we as principal engineers believe to be the best way forward with different teams. This is perhaps a little more concrete things we do during [inaudible 00:22:21]. We spend a lot of time between the teams writing the architecture layer and translating between the layers. We also make it a target to spend some time coding in teams. Doing that makes it possible for us to aggregate and refine the experiences that teams have, as an input to our presentation. We also try to talk to and learn from other organizations, and have learnt a lot from people outside NAV as well.
Jørgensen: The presentation itself is a big Miro board, and each team gets their own copy of this, meaning that there are now over 100 copies of this somewhere. We usually start by telling why this presentation exists, and why we need a technical direction in NAV. It’s basically the gist of what we have been talking about so far, starting with this graph. Then we move on to tell each team our plan. We have held this presentation for over 100 times now. It is in Norwegian. The presentation exists to serve as a discussion material for each team. If the team needs some time after this session to think, we are more than happy to come back to discuss more. We can also provide training material for each topic and provide courses or time with subject matter experts, if the team wants. If the team wants part, it’s really important, because this is pull, not push.
Strand: NAV is very heterogeneous. We have teams with mostly new code, they’ve written all by themselves. We have teams that maintains almost 40-year-old code. It’s quite challenging to create a document or an opinion even that’s relevant for all of these different teams. Something that’s been a part of the solution from the beginning for some teams requires an incredible effort and is almost impossible to implement for other teams. Our way around this has been to try to describe what we want to happen as arrows. What should the teams move away from and what should they move towards? Then we can use that set of arrows as a background for discussion with the teams. Do they need to start to move away from the left side or should they aim to get all the way to the right side? Also, by being concrete and talking about what the team should stop doing, it makes it much more useful for the teams. It’s easier for people like us to create a list of good things, but actually saying what’s bad and what we want the team to stop doing is more difficult, but also more helpful for the teams.
Jørgensen: There are four categories of topics. It is data driven, culture, techniques, and sociotechnical.
Data Driven
Strand: NAV has a really unique position when it comes to data. We have so much data about our users but we still have a great potential in how we actually use this data. We want to become more data driven, both in how the teams work and operate, but also in the products and services we provide to our users. To achieve this, we need to think differently when it comes to data. How can we keep sharing data between our large product areas in NAV without creating the tight coupling that makes it impossible for teams to change independently? We are basically saying that sharing of data between teams should be done using streams instead of APIs or even the database. For analytical data, we are heavily influenced by the data mesh concept by Zhamak Dehghani. We have created a new data platform, and try to encourage teams to see analytical data as a product instead of a byproduct of the application they own.
Culture
Jørgensen: We consider the team to be the most important component in our system architecture. The culture category is also really important. As Audun mentioned on the technology radar part, we don’t want technology choices to lay in the shadows, we want transparency, and we want openness. We challenge the teams to try pair programming for internal knowledge sharing in order to not be dependent on the most experienced developers. Our point is that the whole team should benefit from knowledge sharing, even the most experienced developers. This is just our suggestion, and the team can come up with other ways to achieve that knowledge sharing goal, which is really the outcome. Also, we code in the open after great inspiration from Anna Shipman and government of UK. The last arrow is about sustainability. We have left a project mindset behind, and now we think that our projects are never done. Therefore, we shouldn’t race to a finish line that does not exist. Instead we should pace ourselves for the long run, and do health checks in the teams on a regular basis.
Techniques
Strand: Now we come to more technical part. What techniques should be adopted to move forward as teams? Topically, this is quite broad ranging, from how to use Git, to how to use the cloud. The common theme is probably to increase the speed of development. We want teams to move away from feature branches and shared test environments, and toward trunk based development and isolated end-to-end tests. It’s also really important for NAV to maintain technical quality, and keep the technical debt under control. We say that teams should spend at least 25% of their capacity to work protecting quality. This is the minimum. If you need to increase the quality you need to spend more than 25%. Lastly, we’re moving to the cloud. We have multi-cloud and have done lots of security enhancements to be able to do that migration. We want to have security champions in every team, and we want to distribute the responsibility of security out to the teams that have more hands-on knowledge about what is going on.
Sociotechnical
Jørgensen: The last category is sociotechnical. That’s a large one. First off, we tend to stress the point that we have a legacy that we should be proud of. NAV was established in 2006, but that was really a merge of three existing agencies. We have legacy software that has served the welfare state for over 40 years. We should think of that legacy code with respect, and as the code that won. It didn’t get deleted, because it worked. That said, our legacy applications are system centric, and not suitable for a sociotechnical approach where we build teams to take on a problem and a solution to that problem. The sociotechnical approach has huge impacts on an organization. The team should be responsible for a full vertical, and a horizontal, convenient layered responsibility does not work. Also, teams should have a known way of interacting with each other in a team API. Teams should be categorized. Team topologies helps us establish a common vocabulary for naming those categories. The last two arrows are huge arrows, and essentially saying that Norway needs to rethink how public sector software is financed. These are long running processes and a way over what a team can decide. We have included them here for an aligned understanding of the larger picture, which is also important for the team to understand.
This is what we call the technical direction in NAV. The main thing is perhaps not the contents on each arrow, but more on the Meta level. We spend time on why this matters, and we are open about our plan. We discuss each and every arrow with each and every team. We communicate with each team by approaching them, using our trainers and walk the floors in the organization, and establish a really short feedback loop along the way. That allows us to tap into what works and what doesn’t, and not least, which pain points exists in several teams. When we see those pain points, we have some teams that just love to tackle pain points that other teams have.
Golden Path Platform
Strand: There is actually even a more powerful force system of alignment in terms of walking around talking to teams and respecting their autonomy. This powerful force is what Spotify called the Golden Path Platform. We have multiple such platforms at NAV. We have our design system and a data platform, and our application platform called NAIS. It is open source, and you can learn about it at nais.io. All of these platforms have one thing in common, they strive to make it as easy as possible to do the right thing. We try to avoid the stick and focus on building an incredible carrot instead. By doing this, we hope to find the right balance between the innovative creativity of autonomous teams and the large scale efficiency of alignment. Most teams will find the best for the Golden Path, but from time to time, there will be teams that see that there are better alternatives for them. Sometimes that team will strike gold. They will find a better way of doing a thing and more teams will start doing it the same way, and we’ll incorporate that as part of the platform. Thus these internal platforms need to have a proper product mindset and treat their internal users as their customers in the same way as other software teams treat their users. They need to talk a lot to their users and understand the needs. The point of NAV isn’t to have a great platform, but to provide good services and good product to our users, inhabitants to Norway. This is important to always remember for a platform team. They are there for the streamlined teams not for themselves.
CAKE Driven Development
We even created our own buzzword, for NAIS and now also for the data platform, we’ve used some really innovative new techniques to pull the teams onto the platforms. If we can replace the question, do I want to really write my old JBoss application [inaudible 00:34:12] stateless application running in Docker on Kubernetes, with the question, do I want cake? We have seen that we have even more success with making teams take that first step into the future. We went out to all the teams and we said that every team will get a cake, and by this we mean a proper delicious chocolate cake when their first app is running in production. Of course, we weren’t that sinister. We made all the teams that got a cake take a picture, and we posted that in our Slack channel. Then the other teams saw that more teams migrated and wanted to be part of this cool gang, and of course they wanted cake. They knew that they could ask other teams, and we built a community around these migrations. We saw that most of the support questions in our Slack channel about NAIS was answered by other users instead of the team making the platform, and that is what we got out of cake.
Jørgensen: It was not just cake. The first movers to NAIS got their own very limited edition of hoodies. Later we expanded the catalogs, created more hipster merch, such as socks with the NAV logo. This works not just into tricking people into using a platform but to build a community and a pride of working for NAV. Now, our cutest cats are using that merch and making that community feeling even stronger. That’s cake driven development.
Recap
We think it’s time to wrap up returning to the question, what do we adopt and prefer when optimizing for speed and fast slow in NAV? We have adopted a team-first mindset. That mindset has allowed us to go much faster than we used to. We have discussed why high performing cross-functional teams demand autonomy. In a large organization with over 100 such teams, speed and fast flow needs a direction. That direction must be understood by the teams. When they do, you are in the upper right quadrant of the Henrik Kniberg quadrant. It’s easy to agree that aligned autonomy is desirable, but to actually get there is hard work. Our approach to achieve alignment in the age of autonomy is to interact with each team, respecting the team autonomy, and make the team understand why they should change something, and provide helpful guidance along the way. Always adapt it to their context and their abilities, and be cautious to not exceed their cognitive capacity.
Strand: Teams is basically our most valuable asset. In fact, it’s the most important component in our systems architecture as well. In order to optimize for speed and fast flow, the surrounding organization should do their best to set those teams up for success, as we’ve shown you how we have managed to achieve that.
Jørgensen: We have shown you some techniques that we use to set the teams up for speed and fast flow. The internal tech radar and the weekly deep dives are descriptive techniques. They’re used for knowledge sharing, to move technology choices out of the shadows. These techniques need a buy-in from the teams and some people that convert the process over time.
Strand: Then we have the normative part that complements the descriptive, a refined aggregated line of thought being both strategic and concrete. The trick lies in the communication. You won’t get [inaudible 00:38:12], you have to get into your shoes. You walk two floors and talk to the teams about a team’s context and the problems on their level, and understand they also have other problems, and other forces working them, and value their autonomy when it comes to that. We really need to respect that autonomy.
Jørgensen: The strongest form of alignment is achieved in a common platform. By talking to all the teams, the short feedback loop allows us to identify the common pain points. We can bring those pain points to a platform team, such as the application platform team, or design system team, or data platform team. The platform teams should make it easy to do the right thing, and also sweet because everybody loves cake.
Strand: That is how we got alignment in the age of autonomy.
Questions and Answers
Skelton: Looking back at the work you’ve done over the years, how do you feel about all the stuff that’s happened?
Strand: I think the whole journey has been incredible, basically. The fact that we’ve been able to go from no developers to 400 developers, and everything is just great. I still think we need to really deliver. The problems we’re trying to solve are so big. It takes time to deliver the actual results, but we managed to get all the correct pieces in place to be able to do that, I think.
Skelton: If another organization wanted to take some ideas from what you’ve shared, where would you advise them to start? Let’s say they’re a big organization, maybe it’s a government department in another country, or maybe it’s a large insurance company, something like this, where there’s quite a lot of bureaucracy. What things would you suggest they start with?
Jørgensen: It turns out there, there’s a lot of places that are trying to do that also in Norway right now. I think what happened at NAV was that we got this new CIO back in 2016. He articulated a vision for what we could be and what we should be. He told that story, in and out of the organization, and made the organization believe it. At the same time, there’s also this movement, bottom-up as well. Audun and me, also worked there. We were squishing the middle management. We were really trying to disrupt from both top-bottom and bottom-up. I think that’s necessary.
Strand: I also think that you need autonomy before you need alignment, you need teams having flow, and then you need to add the alignment to make sure you can scale it up. If you start with alignment, I’m not really sure you get anywhere you need to. You need to have fast moving teams. That’s the main priority. Then you have to get the problem of all the teams running in different directions and try to solve that, but you have to wait for that problem to occur, I think.
Skelton: Maybe bring just enough autonomy back with all of these separate followers so that there’s some coherence, rather than saying the most important thing is alignment and everyone doing things in the same way. Because that leads off in a different direction. If we had all the time in the world, then that approach could work, but we’re thinking about fast flow, we’re thinking about the need to get things done really quickly, so we have to use approaches which feel radically different from what we might have done.
Strand: Definitely, for us, we come from such a large and old organization, you have to go through 11 sometimes to reach 7.
Jørgensen: Also, from the first graph that’s showing us this huge increase in deployment frequency, if we drill down to per week, you’ll see that there’s quite a high jump in the middle of 2019. What you’ll learn there is that, that’s because we removed the last part of the central coordination with deployments.
Skelton: Kind of release management, something like this.
Jørgensen: Yes. That was really just a click of a button that we just removed. That has huge impacts on the deployment frequency. Replacing bureaucracy with trust, that helps flow.
Skelton: You also need to take the time to build that trust and build that shared understanding of why it’s now fine to have that automated, we can’t just go straight there. That takes some time.
How do you convince senior technical leaders to create and support these different approaches? I’ve been having a problem getting alignment, how do you convince the technical leaders? What things have you tried that seemed to work well?
Strand: I think the whole presentation is about that. We tried to work it from several different angles. We really tried not to be the guy who makes every decision, but we want the teams to do it by themselves, the radar and the demo. We also want our voice to be heard. We’re really focusing on them hearing that just as an opinion. It’s not us just because we’re principals, everybody has to do what we say. This is a suggestion. This is a direction we think it’s good, but we understand that some of the teams have not come to it, at least not right away. It’s ok for them to talk back, basically. We need to figure out what’s the best way. It’s difficult. Every time they don’t listen to us, I struggle a bit, but I think it’s better in the long run.
Jørgensen: We think of the technical direction as a discussion material with each team. Around each year, we do an iteration of that presentation to be updated from new learnings and insights. Then we basically talk to the teams again. We are constantly talking to the teams and listening to them as well. There’s not us only getting our meanings true, but just getting that feedback loop. That’s probably the most important thing.
See more presentations with transcripts
MMS • Roksolana Diachuk
Article originally posted on InfoQ. Visit InfoQ

Transcript
Diachuk: I’m Roksolana. I work as a big data developer at Captify, and also, I’m the Diversity Inclusion Ambassador there. I’ve been lead of Women Who Code Kyiv community in Ukraine. Also, I often speak at conferences and various meetups.
Outline
I’m going to talk about AdTech as a sphere in the domain, to give a better understanding of the concept, of the things I’ve been working on. Then I’ll move specifically to the data pipelines in the context of AdTech. I’ll give lots of practical examples, more on the architectural level of which pipelines are used in its AdTech, how they are built. There’ll be a whole section about historical data reprocessing. Then we’ll draw some conclusions out of it.
AdTech
First of all, talking about AdTech. AdTech or advertising technology, it’s like advertising on steroids, as people call it, because it means that usually in advertising we want to sell something. We want to find the right consumers or customers to sell it to them. While in AdTech, a specific set of technologies is used to basically deliver the right content at the right time and to the right consumers. With the help of these technologies that gather some context and better understanding of the users, it’s possible to build better pipelines in terms of performance.
What Captify Does
What does Captify do in terms of AdTech? Captify is the largest independent holder of user search data outside of Google. We collect, categorize search events from users in real time. We have billions of consumers. This data actually feeds our campaigns and helps to build advertising campaigns in a more efficient manner. We have this main product, which is called SENSE. It’s a so-called search intent platform. This platform allows users to manage their campaigns, figure out the performance of their campaigns and efficiency, and also use the concept of audiences. Having been able to gather search data, we categorize the users on the various audiences they belong to. Therefore, the advertisers will be able to sell the product in a more targeted manner to specific users they’re interested in.
Data Pipelines in AdTech
Talking about the data pipelines, we have various pipelines to the search needs of various teams. For example, there is a reporting pipeline. In any company, there are some reports in the end of the month, quarter or year. Search reports are built on top of specific volumes of the data, and therefore, most of the cases require the latest technologies behind them. Another pipeline is around insights. Captify has this concept of insight, which gives a better understanding of what’s happening in the market currently, in terms of the current trends from the user searches, like what the users are searching for more this month. These insights and tailored insights for each of the customers helps to build more efficient advertising campaigns. The concept of classification of the data, gathering the insights, delivering them to the teams is also built using big data technologies. Data costs attribution pipeline is a whole topic. In general, it’s like more one of the financial pipelines. It’s an important one in terms of the way we use our data and the way we figure out whether our data is efficient or not. Another pipeline is around building users audiences. There is a pipeline which classifies users into these various audiences. There are separate sets of pipelines that actually pushes data to our customers. This is also like a set of various pipelines. Just in general, all kinds of data processing, collection, storage is also built using modern data pipelines.
Reporting
Talking about reporting first, I’m going to cover, not all of the pipelines that I mentioned, only a set of those because some of them just require more time to look into it. They are more complex. You’re going to discover more, some challenges around those pipelines, and the way they work right now, and possible future improvements. Talking about reporting. As a concept, reporting is quite simple. We have some data provider that shares the data with us. We need to ingest this data, transform it in some way, and upload it to some storage system. A storage system can be very different. It can be a query engine, or something like HDFS or S3, depends on the needs. How it looks like at Captify is just a more simplified version, or a bird-like view. We have Amazon S3 storage, where our customers push the data in various formats, CSV, parquet, and protobuf are the most common ones. We process these formats using Spark. There are some details we’re seeing that happen behind the scenes, so we’re going to look into it in more details. First of all, reading the data from Amazon S3, we don’t just read the data with Spark, we use our own build library on top of Amazon S3 client called S3 Lister, which lists the files and filters out the parses if we don’t need to read, usually in terms of the time. For example, you will read the data over a month or a week, but you won’t have to read the data for the whole year, in most of the cases.
Another detail is around actually reading the data with Spark. We need to enforce some schema, because for reporting, some expectations are set for us by the consumer teams regarding the way the data is going to look like. There is another important part, which is around parsing the dates. The data is sent in very different formats, but we are applying partitioning of the data by the date in the end of the Spark pipeline. Therefore, we rely a lot on the information regarding the timestamps, first of all, when we want to list the data and filter it out. As you can imagine, these algorithms should be adjusted to different data formats. Also for partitioning of the data in the end, so we have some generalized format that we want to see, which is usually the date, time, and hour. We can partition by these dates. The issue is that sometimes we get the data where we can read these timestamps within the files, which is the usual expected way, like the timestamp the copy file. Sometimes we do get the data where the dates are hidden in the parse names or some directory names, which can be challenging at times to actually adjust each of the Spark jobs to read the data specifically and partition it the way we would expect to.
Another part of the pipeline is actual data loading. As soon as we roll this Spark job we just read the files and set up a format, we need to upload the data to Impala which is a query engine built on top of HDFS. What happens behind the scenes here? Again, we enforce the schema that is expected by the analytics team that provides this definition. There are some caveats around uploading the data to Impala. First of all, when we have a fresh data provider and we need to make the first upload, a fresh upload, we may have very different volumes of the data. For example, the partner started to push the data a few months ago, so we already have two or three months, or it’s very fresh, like only a few days. The thing is that the job running from the fresh upload and scheduled one is a bit different, especially in terms of resources. The scheduled uploads can run a few times a day for example, and you would gather a few hours of data or one day of data at once. While with a fresh upload, you need to run it over a month of data, or even a year sometimes. Therefore, these uploads are different by the resources used and they can be different by the approach to filter now the time periods. In some jobs, we have the mechanisms to figure out whether we already uploaded this data or not. With a fresh upload, there are some steps to figure out that actually there is no data yet, therefore we need to upload it from the beginning of time.
Another thing around Impala was minor data handling. As you noticed, I put both HDFS and S3 behind Impala here, although Impala is built on top of HDFS by default, because we use so-called mechanism of hot-cold storage for some of the data feeds. Usually, the data feeds is saved in our storage system for 30 months for reporting needs, and therefore, usually you would query one month of the data. Very rarely you would query the whole year. Therefore, we have this concept of hot and cold data. We read the data from HDFS, which is hot data, it can be a few days or months tops. S3 stores the data as so-called cold data, which is much older than one month, in such a way queries that want to check recent data run fast on HDFS, and they are the most recent ones. In terms of storage capacity and cost, it’s a more effective way to store less data on HDFS. Queries that run over longer periods of time are more time expensive, but they are rare, and therefore it’s ok to have this data move to S3. Also, new feeds are also pushed to S3 just for the reasons of moving to a safer storage system.
Reporting Challenges
Talking about challenges. First of all, is around diverse data types. There are different approaches to reading different files. For example, if CSV and parquet are not very much different, the protobuf files will be a completely different story and different formats of the fields, some expectations in terms of more or less a unified schema. Therefore, sometimes there are some challenges around setting up specific columns or even specific files. Another interesting challenge around time dependency. As I said, we need to parse dates, we need to partition the data by the date as well. Therefore, there is a lot of dependency on the data, which is a time nature. Therefore, there can be issues with parsing out the data with the file names, digging it out with the files, changing the format from Unix timestamp, for example to a date, and all of that.
Another challenge is around external data storage. I mentioned this mechanism of hot and cold data, and why it can cause issues with metadata is because S3 tables for Impala are not native. Therefore, it’s necessary to create them as external. How it works, is that Impala can discover the data as its own, like this is the data in my table. Impala won’t be able to delete this data, or have something like that, more destructive nature. For example, it’s safer that if you accidentally delete something in Impala, then the data is still safe on S3, or even if you did it on purpose, and then you can rediscover some of the partitions. Also, there can be issues with discovery of the partitions. Time from time we have some errors when Impala suddenly loses some of the partitions although they are physically on S3. Sometimes the mechanism of external tables in Impala specifically is not completely clear. Another challenge is around being able to connect with the end users. Another team sets up the expectations around the way the data is going to look like. Also, they can have some expectations in terms of performance of the queries, how often they want to run these queries and how long they want these queries to run. Therefore, we as a team should support this need and be in constant loop with them, so each time we upload some new data, we have to get feedback from them that the data is the right format. That everything looks as expected.
Data Costs Attribution
Another interesting pipeline is called data costs attribution. It’s more on the financial side of things, but it’s a very important pipeline because it’s part of this advertising nature. We are going to dig deeper into it. From an engineering standpoint, we have log level data, the data about user events, as we call it. User events is the reaction of the user to the ad. Their reaction can be different. For example, it can be impression, click, conversion, as we call them. Therefore, we have a log of those events, like how each of the users reacted to this ad. The specific time when it happened, and all the information around it, like what exactly did the user see, like specific ads, whether it’s part of the campaign, and all of that. The next part is the ingestor module, which actually reads this data. We have actually three pipelines for our three data providers of the attribution pipeline, and therefore we ingest the data differently for each of the providers, similarly to the way I described for reporting.
With this data, there is another module which actually maps the data to the expected format. The expected format is, again, provided by the analytics team. This module is important, because we have way too many fields in the initial log level data. It’s actually a log, and therefore we can have like 300 columns there, or something like that, and we don’t need all of that. Therefore, a mapper helps to filter out all of this data and set up the format that we actually expect to see. Another module is transformer. Transformer actually is the core of attribution. This is where the attribution itself is happening. Another module is data costs calculator. It’s a financial pipeline, and therefore the data costs are calculated up to some transformations, and the result is saved to the database. How it looks like, from very far beyond, because basically, we have some Amazon S3, we have files there, we run Spark jobs, save the information to HDFS. In the process, we refer to some PostgreSQL tables. This is how the attribution looks like. Obviously, as I mentioned, a set of those modules, they are all parts of the various Spark jobs, and some of them only one Spark job. Therefore, a lot of things are happening behind the scenes.
First of all, in order to understand how attribution works, let’s look into the data source. We have Amazon S3 with two kinds of data sources or files. One of them is called standard feed, and another is segment feed. Standard feed is the actual log level data that we get from the user events. This is a concept of standard feed in advertising, so it’s not something that we invented. Second feed is a feed of audiences that we classified. We store them on S3 as well. Therefore, we can refer to this data, it’s more like internal nature of this data that is generated by some other teams. What happens is that we have information about user events in standard feed, and we have information about audiences in segment feed. We need to find a way to join two of those feeds to figure out actually that the users that clicked on the ad, for example, are actually the same users that we targeted from the segments. We have some campaign running, and, for example, we want to advertise some toys for pets. Therefore, we will target the segments of dog lovers or cat lovers. Those are the people that usually search for some stuff around pets. Therefore, we need to figure out that actually we’re targeting those users in the first place, whether they got into our log of events or not. That’s the core of attribution. Why it’s important, because each of the events is not free for us. It’s provided by the data providers and therefore we need to pay for the events that actually work for us, the events that we expected to see from the users from specific segments.
The attribution data source also in terms of structure looks like this: we have impressions, clicks, and conversions. It’s in this one because the attribution itself is based on the impressions being the initial events, because usually clicks and conversions happen only after impressions. Therefore, even in terms of processing, we start to transform first impressions, we generate results first for the impressions. Only then we can run attribution for both clicks and conversions. What happens in the pipeline? We have Amazon S3. Again, we use this S3 Lister client that helps to list only specific files of the period. There is this ingestion module, which is a Spark job. This module reads different kinds of files, sets up some more like unified schema, and that’s it. We get to the mapping. We filter all the columns, only the ones that we expect to see in the final result. There is a part where we refer to our PostgreSQL database. It’s important because in order to make some conclusions around the kinds of data that we get from the data providers, we need to match it with our internal data about campaigns and users. Basically, for the same campaign, we can have two kinds of IDs, the IDs provided by the data provider, the way they refer to this campaign, and our internal IDs that we call Captify ID. That’s why we need to build some mappings between external IDs and internal IDs, and add up some additional information about the campaigns from the database that we have, from our SENSE tool basically. You can see that everything is connected here.
The next part is around transformation. That’s exactly where the join of the feeds happen, the segment feed and standard feed. The join happens on the inclusion rule. Basically, during the mapping stage, we gathered some information about the segments that is stored in our database, and those segments are assigned to specific campaign. We can figure out that actually, this is a segment that we targeted. Let’s look into the segment feed and see that actually those are the same, so just the join happens there. There is a data costs calculator. There are just lots of financial formulas in terms of the data costs over different periods of time. It’s also a Spark job. The result is saved on HDFS.
Data Costs Attribution Challenges
Talking about challenges. First of all, the attribution pipeline is heavy in terms of resources. It generates large volumes of the data. You can imagine processing log level data where we can have information about the users, like every millisecond. Therefore, there’s a lot of data and we need to join it also with segment feed. The result can be quite huge with all the calculated formulas. It’s complicated in terms of performance. It’s hard to actually pinpoint the failures with the structure because there are some business rules built in into the way some of the mappings work, for example. Therefore, sometimes you need to dig deeper to figure out what actually triggered the result. For example, some data costs are not calculated the way they should, or we don’t get the data for some of the campaigns. Another challenge is around historical data reprocessing. In general, it’s usually applied to this pipeline, because it’s critical in terms of business side of things. It’s an interesting use case. Also, it has large data volumes, and therefore it can be a challenge to reprocess even small periods of time.
Historical Data Reprocessing
Now let’s move to historical data reprocessing. Usually, when you think of reprocessing of historical data, you can imagine that we have data that is stored over, for example, a year or months, whatever the period is. In terms of business use cases, why would you need to actually reprocess this same data that you already processed? Let’s imagine the case when business teams figure out that there is something off with the data over a specific period of time. For example, at the end of March, they figure out that actually there was some issue that happened at the beginning of March, and therefore all of the data over this period of time, which is a month, is not correct. It’s not corrupted fully, but it’s not correct. Therefore, it’s bad for their reporting. They want to present proper numbers, and they don’t want to recalculate it manually, therefore, for these external business teams it’s important to see the correct data, and see the issue fixed, is there for that period of time, or in general for the future. Business rules changes is always a complicated process, because it can influence a lot of things, different pipelines that may seem not connected in the beginning. Also, it can trigger some issues in the future if you didn’t research this change properly.
We have the attribution pipeline that I discussed previously, and we write the data from the Spark job to HDFS, usually in parquet format. We need to reprocess this data, and how it’s going to look like. There is a mechanism built in attribution for reprocessing. Usually, when we just process the data for the usual attribution we run, we set up the config called the feed period. We want to process the data over some period of time. Usually, it’s a small period, like it can be a few days, like three, five days. We also set up a period for segment feed to merge them only in some period of time, like current days, for example, again. In reprocessing, it’s a bit different, you also would like to set up a start date just for safety reasons. For example, on 29th of March, I figure out that there is an issue on the 2nd of March. Obviously, you won’t be able to fix the issue on 29th of March, you will still need some time to pick the issue, to test it, to deploy it, to talk to business teams for them to confirm it. Therefore, it’s better to set up a start date just in case you’ll have to run it over a bigger or smaller period of time. Then the period itself is chosen in such a way that you just take the current day, minus the feed period, which is 30 days. The files are filtered by these dates, starting from the minimum time. Therefore, with such a mechanism, it’s possible to go back in time, take some period of time and rerun the new business rules on top of that.
Talking about safety in terms of different versions of the code. How it’s usually achieved is by setting so-called fixed version, so we have production version. It’s stable. Yes, it produces incorrect data, but for now it’s stable. The data is usually partially incorrect, therefore there is at least something for the end users. They need this data every day. There is another version of the same pipeline, which is a reprocessed one, so production version takes the latest stable version that we had and run it. Reprocessed version is going to run a new set of business rules that we set up. Both of them save the data to HDFS, but different directories. The structure of directories looks like this: impressions, clicks, and conversions. First of all, we process impressions, and therefore we can then either process just impressions, and we trigger the pipeline to rerun the clicks and conversions, or we process both of them, but usually impressions takes the longest.
How it works is that we ran our production version, it’s still running. We ran our reprocessing version. Then we just replace the directories, obviously, with the backup in such a way that new directories move to the old place. We can run reprocessed version only on impressions, and that’s why we will just drop clicks and conversion from production version and set up impressions of the needed period of time. In this case, it’s very important not to mix up something and set up the proper period of time for the directories we are going to reprocess. They are processed on the hourly basis, that’s why sometimes it’s better to take a bigger period to replace the directory, than a smaller one. There is a reporting pipeline that runs on top of attribution. I didn’t mention it before, because it’s just the same as all the other reporting pipelines. The data is taken from HDFS, Spark job just runs and saves it to Impala. Then we have some tables. When we want to have Impala tables, we would like to, in the same manner as with directories, just drop the partitions that are incorrect and set up and we run the pipeline to get us a result, reprocessed tables. Reprocessed means that it’s just different result with the new business case. With Impala, it’s not very complicated. Again, this external storage, it will be necessary to drop the data on S3 as well.
There is also a way to check the reporting before actually running it in production. Same as before. I’ve shown the various versions that we switch to. Here, we can still run production version, and save the result for March, for example, the full month, or only a few days, just to have this check running to another table. Then the team from the business can check out this data and say that, yes, the business rule is correct, you got it right. You can run it in production. That’s also an option, depending on how critical the business rule change is.
Future with Delta Lake
Talking about the future, this is one of the ways we do that, having various scripts. Some of the steps are not really automated, and therefore, there can be a lot of challenges around automating it and making the right thing basically, especially if it’s something like very critical and important that should be done, like [inaudible 00:32:06]. One of the things that we considered is using Delta Lake. There are quite a lot of features from Delta Lake that can be used for various Spark jobs pipelines. I chose here, three of those that would help this specific pipeline, first of all, is schema enforcement. Just because schema is important for all the reporting pipelines. It’s important for end users, and therefore it’s good that something like Delta Lake can allow to enforce the schema, and more importantly, keep the changes of the schema and see how it changes over time. As I mentioned, especially with reprocessing, when the data can change over time, because of some business rule change. It’s great to be able to see these changes in the data log as Delta Lake allow us to do so. Also, another feature which would be useful is time traveling. Again, just looking back into the data, figuring out at which point for example something went wrong, maybe some issue creeps in. Or just being able to analyze the changes and figure out what worked in the past and what didn’t.
We’re already on that path. What we were able to do is convert some parquet files to Delta files, as well as all of the Spark table use. Some of the pipelines are already writing data to Delta format, and they already have a log which keeps track of the changes. Therefore, the plan is to move as many pipelines as possible to the same manner and to be able to track those changes and leverage the nature of Delta Lake, which allow us to do so. Another challenge in the future for us is being able to actually reprocess the data using Delta Lake, for example, Vacuum technology. In case of seeing that some data is not working for us or some data is corrupted, or it has issues, that would make sense to be able to just remove it, in the same case as we did with reprocessing and see how it works with rerunning the pipeline and generating new data, and again, being able to see the versions of the data.
Challenges around Reprocessing
Talking about general challenges around reprocessing, the one that I didn’t mention before is computing resources. I already talked about huge data volumes for attribution pipeline. Therefore, we usually need quite a lot of computing resources when you want to reprocess some period of time. As an example, a week of data, or less than a week, can be like 2, 3 terabytes for one of the pipelines, which is a lot if you want to reprocess a month. Therefore, a lot of resources are needed for this reprocessing pipelines, and it takes time. If it’s critical for the business, the speed is also critical, as they would expect to see the result as fast as possible.
Another challenge is around complexity of the pipeline itself. There are some different steps that should be done very precisely. Some errors in one of the steps of the pipeline can affect the way you would solve this issue. Precise steps means that if you fail on some of those, the cost can be high, because of all of the above mentioned challenges, you will need to reprocess the data again. I had this case, for example, which was not nice, especially because of the critical nature of the pipeline and expectations of other teams to get the result as fast as possible.
Conclusions
First of all, I think that AdTech is an exciting domain for big data stack, that there are a lot of things that can be done and improved in the domain, and a lot of interesting tasks in general. Secondly, that there are various approaches to the way we would usually work with data to the way we build data pipelines. Therefore, the ones that I’ve shown are not an example of the way you would do things in your company. Obviously, it differs from one company to another. It’s more like an example of how we do it at Captify, and the way we are trying to improve it in the future. Another important conclusion that I think that there is always room for improvement and the parts we’re learning. It’s not like your pipelines which are stable just should stay the same way, you can always improve them by adding some new tech, just in general, analyzing what doesn’t work, or works for you, and refactoring the code, changing something, and all of that.
Questions and Answers
Polak: People asked specifically about the attribution pipeline, how does this implementation influence other teams?
Diachuk: Current implementation mostly influences other teams in terms of the delivery of the results of the pipeline. We’re actually using to understand, in my case, it’s mostly like analytics team that run queries on top of the data that they will get the result of some period of time, because the pipeline is quite heavy. Therefore, it’s more around their estimates and expectations. Also, current architectural pipeline allows different teams to differently access the data at various points of the pipeline, like accessing the results as parquet files or within the query engine to actually query the tables in such a way they distribute the load a little bit, and they can look at the data in the most convenient way for them.
Polak: How are you handling duplicated data sent from a data provider, if that’s something that you’re handling?
Diachuk: Here we have some caching mechanisms for different data feeds. Usually the mechanism needs to identify first, what’s uniqueness criteria. In most level data cases, when we have user events, we can rely on something like the timings event, because it’s millisecond granularity and IDs of the users or IDs of the actual event. Such fields help to deduplicate that. Also, we have more complex feeds, which depend on one another, like talking about attribution pipeline, one of the data providers supplying like four separate feeds that we then merge in the way each event goes up to one another. There should be a specific direction. The deduplication there happens on multiple stages. The first one joining one field with another, for example, events from the videos. Another one is, after we’ve joined video events with impressions, we’re going to clicks and conversions that I’ve shown. There we can have additional deduplication for the events, which happened after that.
Polak: Data duplication is known to be always one of the challenges in the data space.
You mentioned working with Delta Lake specifically, and using it for multiple scenarios such as schema validation. Do you see any other improvement possibilities of tech stack aside from Delta Lake?
Diachuk: Yes. Currently, there is general direction within my company to move slightly to Databricks’ platform, so there’s going to be some changes within the whole pipeline in terms of maybe using some Databricks services. Another big push is around implementing the data mesh concept. Therefore, we are currently working on identifying different criteria on the data, like gold standard, silver, and all those levels. Therefore, we are currently working on pushing the data on different stages so that we would have raw data, more aggregated transformed data, and clean data. Therefore, we’re implementing that with the help of both Delta Lake and just our internal tools. We are also looking into different query engines to have better performance out of those, because Impala is no longer serving our needs and users usually run too heavy queries. Therefore, we’re looking into other options as well.
Polak: How do you monitor the healthiness of all your cloud ingestion pipelines part?
Diachuk: We did build our own monitoring tools using Prometheus and Grafana, so we have dashboards. In terms of the metrics, I can share that we get those on different stages of the pipeline. First, trying to figure out that we actually get the data from our data provider, and that it’s not late in terms of time, because usually there is a schedule. Also then figuring out whether we actually process the data, and the issue is not in the final application. We usually rely on these Prometheus alerts and dashboards that we build in Grafana for that.
Polak: When you think about current or future challenges in the business domain that you work at, what are the challenges for data products in AdTech?
Diachuk: The biggest challenge is about data privacy, with the banning of the cookies in multiple browsers, and multiple companies in AdTech are now trying to build their own cookieless solution. My company as well is doing that. The main challenge here is to actually identify the users without relying on cookies and without knowing more of the users but more relying on the context of these users, like what they’re interested in, gathering information about them, but without actually knowing who they are. It’s the biggest challenge both for big data because the pipelines should be built, and storage systems. For data scientists as well, because they need to actually build this algorithm and identify the context of the users, and figure out that at least users are actually the ones we are interested in, from the beginning.
Polak: It reminds me when GDPR compliances just started. There was a lot of changes that companies in architecture need to take in order to enable GDPR. Still, even today, some companies are still going through that journey, because there’s no one solution for these things. It’s really interesting to see how the world is going to adapt and how you are going to adapt the architecture and the processes to enable a cookieless world.
See more presentations with transcripts
MMS • Dragan Stepanovic
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Pull Request-based async code reviews are a prevailing way of reviewing code in our industry
- When feedback is invited only after making a lot of changes, it becomes very difficult for both the PR reviewer(s) and the author to course-correct and build in quality
- Delays are an inherent property of asynchronous reviews, and they increase PR batch transaction cost
- With small Pull Requests, we lose throughput if we review them asynchronously because delays in communication start dominating PR lead time
- Co-creation patterns, Pair and Mob Programming enable continuous code review which enables both high throughput and high quality
Decades ago, open-source software gave us the ability for anyone in the world to contribute to a codebase of a public project. Contributors could be on different ends of the world, in vastly different time zones, not even knowing each other’s names for that matter. A contributor to the project comes up with an idea for improvement, makes a change, and raises a Pull Request (PR) for that change. Then, the owner of the project gets to review the change and decide, when it suits them, if they’d like to integrate the proposed change or not.
Fast-forward many years later, Pull Requests and asynchronous ways of working are the dominant ways in which developers in product development teams review each other’s work. But, we have to be very wary of adopting solutions from contexts that don’t necessarily optimize for the same things that product development teams do in their day-to-day work.
This article dives into the throughput and quality of the async code review process, which are very important dimensions to optimize for in product development teams. It also explains why co-creation patterns – Pair and Mob programming – as an alternative way of working are able to optimize for both of those dimensions, instead of needing to trade off between them.
Async code reviews
In most of the teams I have had the chance to work with or observe, developers work individually on their own work items. At the start, that sounds like a sensible idea, but too often we forget how much integration we have with other people in the team. After all, we’re not part of the same team for no reason, right? Code reviews are one of these integration points where developers try to use code review as a means to building in quality and getting human judgement, before pushing the work downstream until it eventually reaches production.
The way it goes is that once a developer thinks they are done with coding, they invite other team members to review their work. This is nowadays, typically done by raising a Pull Request and inviting others for a review. But, because reviewers are busy with their own work items and a plethora of other things happening in the team, they are not able to react immediately. So, while the author is waiting for a review, they also want to feel productive, thus they start working on something else instead of twiddling their thumbs and waiting for a review.

Figure 1 – PR-based async code review
Eventually, when reviewer(s) become available and provide feedback on the PR and/or ask for changes, the author of the PR is then not available because they are busy with something else. This delayed ping-pong communication can extend over several days/weeks and a couple of iterations, until the author and reviewer(s) converge on a solution they are both satisfied with and which gets merged into the main branch.
Study on async code reviews
A good share of teams I had the chance to coach and advise in my career were at some point curious to try out ways of working that were different from async code reviews. One thing they were not sure about was how they were currently performing and what kind of metrics would help them understand that.
Also, having a background in eXtreme Programming (XP), Lean, and the Theory of Constraints, there were some metrics I was curious to see in the async code reviews world, so I decided to do a study. It started small but turned out to be a fairly extensive one, where I analyzed over 40,000 PRs from more than 40 very active repositories of product development teams doing PR-based async code reviews.
Over the course of the study, a couple of systemic insights jumped out at me. From personal and anecdotal experience, some of them I expected to see, but some of them were quite a surprise.
Big Pull Requests inhibit the ability to build in the quality
The bigger the PR, the more likely it will suffer from the so-called “LGTM syndrome”. If the PR is big, reviewers have way less incentive to build in the quality. It takes them a long time to review, lots of back and forth with the author, dragging for many days/weeks while the pressure for delivery piles up. It’s already too late and very difficult to course-correct at the point when work reaches the reviewer(s). They often tend to give up on the ability to steer the work, merely comment “LGTM” (Looks Good To Me), and approve the PR, hoping to build in quality later. That, of course, rarely happens.
Even when reviewers want to invest time, energy, and patience in reviewing big PRs, if the author makes a lot of changes before asking for feedback, and if they went astray at one point (the likeliness for that grows with the amount of work) it is emotionally very painful to divorce from the solution they went with. Sunk cost fallacy kicks in, and it’s very difficult to counteract it.
All of these points are the experience we mostly share across the industry, but it was interesting to see it in the data, as well.
Here, we have a scatter plot, where each dot represents a merged PR. On the X-axis, we have PR size in lines of code changed and on the Y-axis we see engagement per size (number of comments per 100 lines of code). This data set is just one example, but it’s important to emphasize that this behavior was visible across all the other analyzed data sets.

Figure 2 – Engagement per size by size scatter plot
As we increase the size of the PR, we get to see less engagement per size. We have a process to help us build in quality that is based on feedback and inviting human judgement, but if the system incentives constrain our ability to get the feedback, that also means we are less likely to build in quality. So, we end up introducing delays, at the cost of not being able to build in quality. It’s a lose-lose if you ask me.
There are additional reasons why big PRs affect our ability to build in quality that were not part of the study, but are worth mentioning here.
Context tends to decay with delayed feedback, which means it’s more likely for reviewer(s) to struggle in understanding the reasoning and context behind a certain author’s decisions. That makes it less likely for reviewers to contribute to the quality of the work.
Because they bundle a bunch of changes together, big PRs are more likely to cause a problem in production, which means they are more likely to cause a significant amount of rework. From my experience, the likelihood of rework grows exponentially with the number of changes introduced at once.
When the issue in production occurs, it also takes us longer to troubleshoot the problem and find the needle in the haystack that caused it. The loss of context, as a second-order effect of too many changes introduced at once, is another thing that contributes to a longer time to troubleshoot, as well.
Benefits of small Pull Requests
It’s been a long time now since our industry has understood the value of small batches from Lean. Smaller PRs take less time to write, which means we get feedback sooner, and we are able to detect earlier if we went astray. It’s also easier for reviewers to find 10 minutes of their time to review a small PR than having to find a couple of hours in their schedule to review a big PR. This makes it more likely that a PR will be reviewed sooner.
Also, since reviewers get invited for feedback sooner, we get to see more engagement on smaller PRs than on bigger ones. When they are able to provide feedback early, reviewers have a sense of being able to contribute to the quality. Small PRs are also less risky to deploy than big PRs, since fewer things can go wrong with a smaller change.
Furthermore, if something goes wrong, it’s easier to pinpoint the change that introduced the problem, which means we’re able to detect and resolve the incident sooner. All of these things positively contribute to all four key DORA metrics:
- Deployment Frequency – How often an organization successfully releases to production
- Lead Time for Changes – The amount of time it takes a commit to get into production
- Change Failure Rate – The percentage of deployments causing a failure in production
- Time to Restore Service – How long it takes an organization to recover from a failure in production
Small Pull Requests reviewed asynchronously have lower throughput
One of the surprising insights from the study that I didn’t expect, and that was persistent across all datasets, was around visualizing PR wait time per size, by size.
PR wait or queue time represents the time that PR spends in the queue, not being worked on, waiting for someone’s attention; e.g., waiting for a review from the reviewer(s), waiting for the author to respond to comments, or to make a change requested by the reviewer(s), waiting to get merged after the approval, etc.

Figure 3 – Wait time per size, by size
As we can see from this scatter plot, as we decrease the size of a PR, teams doing async code reviews incurred exponentially longer wait times per PR size. That exponentially longer wait time also translates to an exponentially higher perceived cost of code review per size as we make PRs smaller.
One of the reasons wait time per size dominates on the smaller PR size of the spectrum is that the engagement per size on smaller PRs is higher, as we saw on the engagement per size scatter plot. The cost of delays and latency that are incurred with the async communication grows exponentially as we reduce the size of a PR.
An important thing to have in mind is that as we incur more wait time per PR size, we incur more waste per PR, leading to more cumulative waste in our system of work. So, as we keep reducing PR size, we exponentially constrain our ability to push changes through the system of work.
That point was also supported by looking at the average PR flow efficiency.
The flow efficiency metric represents the time spent working on an item as a percentage of the item’s lead time.


The lower the flow efficiency, the more waste in the system and the less efficient the process is, and vice versa.

Figure 4 – Average flow efficiency by size
As you can see, as we reduce the size of a PR, flow efficiency at one point takes a nosedive. This means it takes us way longer cumulative lead time to push the same amount of code through the system if we split it into multiple smaller PRs, compared to when we do it in a single big PR. As we incur more wait time in the process, the denominator of the flow efficiency goes up, causing flow efficiency to drop, lead times to go up, and the throughput to go down.
So, with the async way of working, we’re forced to make a trade-off between losing quality (big PRs) and losing throughput (small PRs).
Interestingly, teams intuitively start feeling this pain as they reduce PR size beyond the point where wait time starts dominating PR lead time.
Inventory in the system expands until it matches the transaction cost
In Lean manufacturing, a concept called batch transaction cost describes the cost of sending a batch of work to the next stage of processing. In knowledge work, that cost could be in real terms (e.g., dollar value), and/or perceived ones, and there could be multiple factors contributing to it. The reason this concept is very important is that the higher the transaction cost of a stage of processing, the more inventory we pile up in front of that stage to compensate for the cost of transferring a batch.
Here’s an example from the real world. If the shipping cost from an e-commerce site is, say, $3, most often you’re not going to order an item that costs $1, right? You’ll typically batch it with some other items in the basket before ordering. On the other hand, when the shipping cost is very low or even free (think Amazon Prime), ordering low-price items becomes economically sound.
Also, compared to batching items over time in the basket before ordering, you’ll be ordering items exactly when you need them instead of only when the basket value is high enough to justify the shipping costs. That means that items will also arrive sooner, one by one, instead of all but the last item in the batch waiting for the last one. The flow of items increases.
A general point here, applicable to product development, is that any effort to get things out of the door sooner must involve reducing the transaction cost in the system, otherwise, we start batching the inventory throughout the system of work. That in turn delays delivery, feedback, and learnings that we get from our customers and production system, which means our learning cadence decelerates. Once our learning cadence decelerates, we become risk-averse and tend to go with more conservative solutions because the system is signalling that the cost of learning is high. That’s the way the economics of our system of work inhibits our capability to innovate because trying out riskier ideas becomes economically way less viable. Just asking people to be more risk-averse and innovative doesn’t make sense if the incentive structure of the system is pushing strongly against it. The behavior that we see is governed by the system, so if we want to see different behavior, we need to work on the system.
Now, when we talk about the transaction cost, delays in the system are also one type of it, and thus incentivize actors to increase the batch size to compensate for it.
If a delivery from your favorite online clothing store takes one week, and you want to try out multiple things before deciding which one you’ll keep, you’ll probably order all options and sizes you’re considering. On the contrary, if it’s same-day delivery you’ll probably order way fewer items, possibly just one, try it out, see if it fits, and only then order the next option if it doesn’t.
The same thing happens with a slow-running test suite. If it takes me 20 minutes to run the tests, I’m not going to run them after every line of code change I make. Incurring that much overhead so often doesn’t make any economic sense, so I’ll run the tests less often, which means introducing more changes to the system before getting feedback. That makes me slide back into bigger batches, which, as mentioned, brings its own set of problems that we want to avoid.
In the world of async code reviews, if it takes me 10 minutes to make a change and 2 hours to get a review, the wait-to-work time ratio for this change is 120/10=12. In other words, we have a flow efficiency of only 7.7% and the work is waiting 92.3% of its lead time! The system is signalling a high cost of code review, which incentivizes actors in the system to ask for it less often, which means making more changes before asking for it, which means going back into bigger PRs. A process that expensive will never incentivize making small changes, which means refactoring and incremental development in small steps become less likely. Corollary, teams having lower latency in their process and lower wait-to-work time ratio have higher chances of keeping their codebase healthy and keeping it responsive to change by enabling a continuous flow of small improvements that compound over time.
To put it in another way, if there are delays in the process (and they are inherent to the async way of working) I can always find you a batch size small enough for which flow efficiency is so bad that it doesn’t make economic sense to have a batch size that small. This, in turn, incentivizes us to go back into bigger batches.
While you may ignore economics, it won’t ignore you. — Don Reinertsen
Another issue with delays and the async way of working is that they make it more likely for people to pull in more things, increasing Work in Process (WIP) inventory and context-switching. We saw it with Ema and Luka in “Figure 1 – PR-based async code review”. While Ema was waiting for Luka to review, she figured she could start working on something else. Per Little’s Law, the average cycle time is directly proportional to the average Work in Process and inversely proportional to the average throughput. That means that pulling in more work, as Ema did while she was waiting, increases delays, which makes cycle times go up and throughput go down.

When we work individually and review code asynchronously, WIP is often way higher than we think. If we have 4 people in a team, and they work individually, we might think we have 4 things in progress. But when there are delays in the system, and we rely on getting feedback from other people, as we do with code reviews, it’s very likely that we end up with at least twice as much WIP. Ema pulling more work while she’s waiting happens to everyone else on the team because they also need to wait for the review of their respective PRs. So we end up with 8 things in progress. In my experience, it’s not surprising to see teams having WIP equivalent to a couple of multiples of the number of people in the team.

Figure 5 – High WIP invites even more WIP Causal Loop Diagram
At the same time, ironically, if you were to ask Ema and others on the team, they’d probably say that they felt quite productive during this time. One of the most important lessons from Systems Thinking is that systems often deteriorate not in spite of but because of our efforts to improve them. The most intuitive solutions often tend to be far from the ones that help with shifting the system towards a more desirable state.
A general point here is that the second-order effect of high WIP is that it reinforces itself. The more WIP we have in the system, the less responsive it becomes, the longer the wait times and delays, and that, in turn, incentivizes even higher WIP because people pull in more stuff as they need to wait. Humans are great at piling up inventory and increasing WIP when they face delays.
Co-creation patterns
The conclusion of the study I did was that in order not to exponentially lose throughput as we reduce the average size of a PR, the author, and reviewer(s) need to react exponentially faster to each other’s request. And that eventually leads us to synchronous, continuous code reviews and co-creation patterns.
Co-creation patterns, Pair and Mob Programming are ways of working where we work together on the same thing, at the same time. We start together, work together, and finish together. Pair Programming1 is a technique where a pair of developers works on the same thing, while Mob Programming2 is more focused on having all the skills in the session necessary to get the feature into customers’ hands. Depending on the feature at hand, that might involve only developers, but also other skills (design, product, content…).
The idea is to move people to the problem, instead of moving the problem to the people; the latter involves splitting the problem and giving each person a piece of that problem to solve individually, and then trying to reassemble the whole piece afterward. When we swarm on the problem, as a byproduct, we have fewer delays in the interactions, which means a shorter lead time to get our work into customers’ hands. Think about it: when there’s an outage in production, how do we go about it? Typically, all the people needed to resolve the issue jump on a call and work together to resolve it.
The reason we’re working in this way is that we want to resolve the issue sooner, so we can reduce the time to recover and thus minimize the impact. But the important insight is that we can use the same way of working to minimize the lead time to deliver. That, in turn, accelerates the learning cadence that helps us cut solutions that don’t work sooner, and thus maximizes the throughput of the value of the team.
Eli Goldratt, the founder of the Theory of Constraints, had a lot to say about emergencies being a great learning opportunity. The rules used during emergencies violate our standard rules and challenge unquestioned assumptions, but we rarely ask ourselves if our “special rules” should actually be our standard rules.
Also, the incentive structure that we get as a byproduct of co-creation is also very different from the typical “You Burn, I’ll Scrape” approach. Instead of having an undertone of “an author and a critic”, we have people together building and being responsible for making it work.
…our system of make-and-inspect, which if applied to making toast would be expressed: ‘You burn, I’ll scrape. — W. Edwards Deming
One of the typical arguments I hear in favor of PRs and async code reviews is: “Code should be reviewed by someone who was not involved in the process of building”. But, from my experience, the delayed and out-of-context review is actually a disadvantage, not an advantage of this process.
What guarantees that the same person providing an out-of-context and delayed review wouldn’t provide the same or better feedback if they were providing it as the code was being written? It’s a hard and probably impossible thing to measure, but from my experience, more context, less delay in the process, and faster communication contribute to higher quality, more timely, and cheaper to integrate feedback. I’m guessing that’s also the reason I observed that teams co-creating had at least an order of magnitude less rework, including fewer bugs and problems in production.
BOTH throughput AND quality
I know it sounds utopian, but we can actually both have our cake and eat it too. We can both have high throughput and high quality. It also wouldn’t be the first time to discover that that’s possible, since the DORA research showed that stability and throughput have an AND instead of OR relationship. Instead of having either throughput or stability, we have either both throughput and stability, or neither of those.
The way that co-creation patterns change the economics of the system is that with Pair and Mob Programming review delays and wait times are, by design, essentially non-existent. As someone is physically or virtually sitting next to me, working on the same thing I am, they are able to provide continuous code review with every atomic change I make in the code, and vice versa. The process itself guarantees the availability of actors, which is necessary in order to have an immediate code review and consequently not lose throughput with smaller PRs.
Figure 6 – Reducing transaction cost drives the smaller optimal batch size
Featured animation: Kelly Albrecht
Effectively, in Lean terms, we’re able to minimize the transaction cost because we’re minimizing the cost of code review, enabling even smaller batches, and increasing the flow through the system. The size of a PR effectively becomes a minimal, atomic change that could be as low as 1 line of code.
When we have immediate availability and free cost of code review, I’m able to get more timely, more frequent, and richer feedback (it’s verbal, immediate, and in the context). This is crucial in order to build in quality, but, as a byproduct, it also reduces the amount of rework. The reason is that when we go down the wrong route we avoid straying away for a long time since the course correction happens sooner, and that leads to more time left for value-added work and, thus, higher productivity. We reach a state of quality-enabled speed.
Another advantage that is often missed is that working together doesn’t only minimize the wait time. Typically, it also reduces the processing/work time, because other people often have an idea of how to do something in a faster way, which means the processing time goes down as well. That, in turn, translates into even shorter lead times and higher throughput.
When we have fast course correction, enabled by continuous code review, we also tend to counteract the sunk cost fallacy and falling in love with the solution. The only thing I have to lose is a minimal change that I just made. I can deal with that far better than having to discard a week’s worth of effort. Thus, we make it more likely to build in quality.
Besides that, and contrary to async code reviews, as a byproduct of working together on the same thing at the same time we reduce Work In Process, which accelerates the flow of work through the system. As mentioned, async work that needs to integrate makes us prone to pulling in even more work, which makes things even worse. In the case of a team of 4 people, when they work individually, they can easily end up with twice as much WIP. In the case of Pair Programming, they’d have a WIP of 2, which is 4 times less! With Mob Programming, WIP is even less. That’s an opportunity for a huge reduction in WIP that is hard to leave on the table.
Common misconceptions
Having said all this, I don’t think that everyone should do Pair/Mob programming all the time- this is a common misconception that I hear from people sceptical about these practices.
The point is, I think that when it comes to the way of working, we as an industry have wrong defaults in place, where most of the time everyone works individually. Most teams operate as N teams of 1 person, instead of 1 team of N persons.
The pandemic seems to have contributed to this, as well. From its onset, as the whole industry went remote, for some reason we’ve put an equals sign between being remote and async work. These two ideas are orthogonal to each other. We can both work remotely and co-create, so we keep the above-stated benefits of working together, while also having the flexibility of working from home.
A question I also often get is: “How is co-creation allowing for flexibility of individual schedules that we get with async work?” There are teams that want to try out Pair Programming, but they bump into the problem of having slippages in individual schedules and pairing partners not being available when needed. That’s an important crossroad where teams usually take a wrong turn and go async. The need to go async at that point is feedback about something. It’s feedback about the low flow resiliency with the given schedules. Instead of going async, we can consider increasing the resilience of the group by having more people in the session. That allows for more overlap in the schedules while keeping the flow efficiency high and getting things out of the door sooner. Mob programming especially provides that resiliency, and people can drop out and come back as they need. It’s not that everyone needs to be there all the time. That was never the idea.
Now, if you have a team whose team members are in very distant time zones and there’s not much overlap between team members during the work day, I’d question that team composition decision instead of jumping into the async wagon. Regardless of this whole topic, I’d expect a team to be composed of team members with enough overlap in working hours. The definition of enough may vary, but from my experience, at least 5 hours of overlap is a good target to aim for.
Interestingly, the way it also plays out in practice is that flexibility in individual schedules coupled with high resiliency of the group can actually be an advantage. Typically, as with in-office work, some people like to start their day sooner and some later. People that start sooner start working on the work item, then the rest of the people join, and then the group of people that ends their working day later wrap it up for the day. Since we’ve worked on the item for longer hours during the day, we’ll probably get it done sooner, while people keep their flexible individual schedules. It can be a win-win situation.
In a world where unfortunately most people only have had experience working alone, learning to work together is a new skill that takes time and patience to acquire. I remember attending Woody Zuill’s workshop on Mob Programming. Out of three days of the workshop, he spent the first whole day having people practice working together, contributing in a timely manner, and treating each other with kindness, consideration, and respect. Those principles are ground rules for working together. To be honest, at that time it seemed a bit superfluous to spend so much time on this topic. But over the years, as I started observing and working with more and more teams trying to co-create, it became obvious why being intentional about these principles and skills is so important.
It’s very important to have proper guidance and coaching for the teams that want to embark on the journey of co-creation, especially if no one from the group has prior experience with it. Otherwise, teams might end up evaluating a technique thinking they were doing Pair or Mob programming, while in reality, they were doing something very much different. People hijacking the keyboard, individuals dominating conversations, too long or non-existent rotations, people being disengaged and zoning out, etc. were never part of the co-creation idea, yet, that’s what I often get to see in the teams saying “This is not for us”. And they are right. But, first, we need to make sure we’re evaluating a technique we think we’re evaluating. Investing time in learning more about these practices and getting proper support helps us with that.
Another essential point is that working together bubbles up latent problems in the team very fast. When we work individually, by design there’s not much interaction between people, so potential issues tend to be way less visible and way more delayed. Once the issue of having difficulties working together in a team becomes obvious, there’s often a tendency to think “co-creation is not for us”. That might be the case, but only if addressing the problems in the team surfaced by a particular technique is not something we’re after. The technique is just a mirror of the underlying team dynamics. We get to choose what we do with that feedback, but, ultimately, we can’t blame a technique for the issues that exist without it anyway.
Nevertheless, working together should not be forced upon anyone. After all, you might give it a shot and find it’s really not your cup of tea. Everyone should try to find the environment that meets their needs best. Hopefully, that moves us closer to a state where more people find joy in their work.
Summary
Reducing PR size in async code reviews will only get you so far. There’s a point where a smaller PR size becomes economically unviable, and we have to make a trade-off between throughput and quality. Moving from async code reviews to pairing on code review, to doing work itself together (Pair/Mob Programming) is a progression that lots of teams in our industry might benefit from experimenting with.
There are lots of other benefits3 why teams might consider giving it a try, and from my experience it’s a way of working that has brought so much joy and productivity to teams I have had a chance to do it with, that I believe it’s a competitive advantage and capability for teams and companies that get to adopt it.
References
MMS • Shane Hastie
Article originally posted on InfoQ. Visit InfoQ

At the recent QCon San Francisco conference, Katherine Jarmul, Privacy Activist and Principal Data Scientist at Thoughtworks, gave a talk on unravelling techno-solutionism, in which she explored the inherent bias in AI training datasets, the tendency to assume that there will be a technical solution to almost any problem and that those technical solutions will be beneficial for mankind. She discussed ways to identify techno-solutionism and posed questions for technologists to consider when building products.
She started by discussing how the training datasets used in AI systems have biases inserted based on the tags allocated to them by the people who perform the tagging. Large numbers of taggers who are among the lowest paid in the tech industry. To illustrate the point she showed a photograph of a man and a woman having a conversation, which was tagged as a worker is being scolded by her boss in a stern lecture and a hot, blond girl getting criticized by her boss. The image had no indication that either of these descriptions was true, and yet the tagging goes into the database to train AI systems.
She defined techno-solutionism as a naïve belief that any problem can be solved by applying a magic technology box and that the application of technology will change society for the better. Techno-solutionism treats technology advancement as inherently good. She used the example of the first written formula for gun-powder which was discovered in the 9th Century in China while researching the elixir of life. Is the technology good, neutral of bad?
The reality is that almost any technical advance has benefits and harms. Often the benefits and harms are unevenly distributed – one group may reap most or all of the benefits while others receives all or most of the harm.
She pointed out that the computer industry is one where techno-solutionism is rife, and she traced the thinking to the early mythology of Silicon Valley, and even further back to the California Mentality of the early settlers who had an attitude of we can overcome challenges, better ourselves and change the terrain. In Silicon Valley this has emerged as the belief that one good idea can change the world, and make you rich.
She quoted Joseph Weizenbaum, who built what is regarded as the first AI system, as saying that computer technology has, from the very beginning, been
a fundamentally conservative force, that entrenched existing hierarchies and power dynamics, which otherwise might have had to be changed
This conservatism has meant that societal change has been impeded and the benefits of technological advancement have accrued disproportionately to a small proportion of humanity.
She gave pointers on how to spot techno-solutionism in action. If you find yourself making any of these statements think carefully about the wide impact of what you are working on:
- I’m optimizing a metric that someone made up
- Everyone agrees on how awesome everything will be
- If only we had _______ it would solve everything
- Mythology speak: revolutionise, change, progress
- People who bring up potential issues are excluded
- I haven’t tested a non-technical solution to the problem
She then gave five specific lessons that technologists need to take into account when building products:
1) Contextualize the technology
Ask what came before this technology, what would happen if it was never discovered, what would we do without this technology?
2) Research the impact, not just the technology
Look at the potential impact of the technology in the short, medium and long term. Look wide to identify who and what may be impacted and explore the knock-on impacts
3) Make space for, and learn from, those who know
Identify the people, communities and groups who are impacted and listen to them. Make sure you communicate their voices and if you are in a position of privilege use that privilege to let other voices be heard.
4) Recognize system change and speak it plainly
Use language wisely and with forethought. She used an example of “revolutionize” e-commerce used to describe a small change to a way of interacting online. Exaggeration and hyperbole are often used to obfuscate the impact of change on disadvantaged communities.
5) Fight about justice, not just about architectures
She spoke about researchers fired from Google for exposing the bias in their algorithms. Lend your voice to those who have been silenced.
She then spoke about her own decision to focus on data privacy as an area where she has a passion for change and can make a difference.
She ended with a series of questions for the audience to ponder:
- What could you be doing if you weren’t building what you are now?
- What could you change if you focused on the change, not the technology?
- What if we took collective responsibility for the future of the world instead of the future of technology?