Month: November 2022

MMS • Srini Penchikala
Article originally posted on InfoQ. Visit InfoQ
Argo, a CNCF project, helps engineers to use Kubernetes covering many use cases from GitOps-based continuous deployment to event-based workflow automation. It can also be used to create an end-to-end DevOps platform. Alexander Matyushentsev from Akuity and Leonardo Luz Almeida from Intuit, maintainers of CNCF project, spoke last week at KubeCon CloudNativeCon North America 2022 Conference about how to build a production-grade Argo-based DevOps platform using Argoproj framework and best patterns on scaling it to support large enterprise needs.
Matyushentsev and Almeida started the presentation with a DevOps approach based on production tickets vs Gitops. They discussed how to get a Change Request (CR) in production approved, which is typically a workflow process. Argocd can be interfaced with your own Git provider to integrate the CI/CD and DevOps processes into the software development lifecycle. They discussed two approaches for managing the Git repos: Centralized Repo vs Individual Repo.
Centralized repo is where the application code and manifest files are maintained in the same repository. This makes it easier to store and track the source code and configuration files together but it suffers from a harder authentication model and a complex overal CI process. Individual repo approach offers the advantage of a simpler or no CI process, easier authentication model between Dev and Ops teams, and cleaner history. But one of the downsides is its decentralized nature which requires additional management effort.
They discussed how to generate Kubernetes manifest files using the Kustomize tool. You can leverage the overlay concept supported by the tool to manage the differences between Dev, Stage, and Production environments.
Argo framework also supports multi-tenancy that helps to manage the hierarchy and dependencies between different aspects of software development like projects, applications and teams. They also showed how to setup single sign-on (SSO) using the OIDC protocol supported by Argo CD. It works out of the box with OIDC-compatible provides like Auth0, Okta, and Azure IDP.
For authorization and access control requirements, Argo CD uses role based access model (RBAC) powered by Casbin framework. Casbin offers flexible configuration and allows to define groups with arbitrary set of permissions.
Projects in Argo CD provide the multi-tenancy capability based on a logical grouping for applications. It allows to define boundaries and isolate teams from each other. We can connect SSO and RBAC settings which helps to integrate authentication and authorization to get an unified security model. Matyushentsev and Almeida demonstrated a project setup by showing the details using an example YAML file.
They said Pull Requests (PRs) can replace the traditional support tickets in the CI/CD process. Store Argo CD configuration in a Git repo and use Argo CD to self-apply Git changes. Application developers can self-onboard via PRs and platform admin users can review the changes and either approve or reject PRs. No need for separate tickets and offline approvals to deploy changes. Git also has the advantage of having no database dependencies, so it’s relatively isolated and easier to install and configure in terms of deployments and dependency management.
The speakers concluded the presentation by showing an Argo CD control plane demo application and walked throught the details of installation and configuration of Argo CD, how to onboard a team with multi-tenancy setup, and how to define cluster level resources like cluster role, role binding etc.
For more information on this and other sessions, check out KubeCon NA 2022 conference’s main website.
MMS • Vivian Hu
Article originally posted on InfoQ. Visit InfoQ
The Cloud-native Wasm day at KubeCon + CloudNativeCon has become the go-to place for Wasm (short for WebAssembly) aficionados to gather and plot the future of the ecosystem. The focus of Cloud Native Wasm Day at KubeCon 2022 in Detroit is developer tooling for server-side WebAssembly.
Wasm was originally developed as a secure sandbox for the web browser. In recent years, it has found many applications on the server-side as a secure, lightweight, fast, and portable alternative to VMs and Linux containers (LXCs).
The event featured well-known companies such as Docker, Microsoft, VMWare, Fastly, Red Hat, and Cisco, as well as startups such as Fermyon, Second State, SingleStore, Cosmonic, and Suborbital.
Docker+Wasm
At the event, Docker announced Docker+Wasm technical preview in partnership with CNCF’s Wasm runtime WasmEdge. Docker CTO Justin Cormack shared how Wasm fits into Docker’s vision of supporting multiple types of containers. Then, Chris Crone from Docker and Michael Yuan from Second State presented how to build, run, and share Wasm apps using the Docker toolchain.
The demo app in Docker+Wasm, based on WasmEdge and provided by Second State, is a database-driven web application written in Rust and compiled into Wasm to run inside WasmEdge. The entire application can be built in containers (eg, a container with a pre-configured Rust dev environment) and deployed side by side with containers (eg, a container with a MySQL database) with a single “docker compose up”command.
Component model
Within the community, there are many efforts to improve Wasm to make it easier for companies like Docker to build tools for Wasm. The consensus effort is the component model for Wasm. Luke Wagner from Fastly gave an excellent talk on the design and progress of the component model, which would dramatically improve Wasm module’s reusability and composability. It will better access from one Wasm module to other modules and systems, including the operating system APIs (eg, networking). Major Wasm runtimes such as WasmEdge and Wasmtime are already committed to supporting and implementing the component model proposal.
While the Wasm component model is still a work in progress, the community is already using part of the spec. Brooks Townsend from Cosmonic gave a talk demonstrating practical examples of Wasm components that can migrate across clouds and devices using wasmCloud. Then Taylor Thomas discussed what component model applications could look like in the real world.
The Wasm component model defines new ways to manage and interact with Wasm modules. Bailey Hayes of Cosmonic and Kyle Brown from SingleStore, presented warg, a cryptographically verifiable and transparent registry for Wasm components. It could enable Wasm component modules to achieve new software supply chain security levels.
Programming languages
Programming language support is a crucial part of developer tooling. Several talks on Wasm day are about supporting new programming languages in Wasm.
Daniel Lopez Ridruejo and Rafael Fernandez Lopez from VMWare Office of CTO and Wasm Labs demonstrated the mod_wasm project. It is an Apache module that runs PHP applications in Wasm. The project has already advanced enough to run complex PHP applications such as WordPress.
Joel Dice from Fermyon explained how to run Java applications in Wasm. It is still early, as there is no support for GC in Wasm. But short-lived Java programs can already run without GC.
Christian Heimes from Red Hat discussed the current support for Python in Wasm runtimes. The CPython project can be compiled into Wasm, which allows a diverse set of Python applications to run on Wasm both in the browser and on the server!
Ivan Towlson from Fermyon discussed new features in the .NET runtime for Wasm that allows C# programs to better interoperate with C programs.
Embedded functions
A common use case for Wasm is for developers to create extensions for established software products or platforms.
The SingleStore presentation from Carl Sverre demonstrated how developers could use the Wasm runtime embedded in SingleStore’s cloud database to customize data processing through UDFs. By leveraging the built-in AI capabilities provided by SingleStore, developers can create sophisticated video games on that database platform!
Guba Sandor and Dubas Adam from Cisco presented a Wasm-based plugin system for the Envoy Proxy that is specifically designed for customizing logging data pipelines.
Cloud services
Finally, for developers, the easiest way to deploy Wasm functions is to have someone else manage the infrastructure for users. Several choices from startups are in this area in the cloud native Wasm day.
Fermyon launched the Fermyon Cloud service that lets developers simply turn a GitHub repo into a serverless microservice. The Fermyon Cloud fetches source code from the GitHub repo, builds it into Wasm bytecode, runs it on demand, and connects HTTP input and output to it.
Cosmonic launched a PaaS that enables developers to create, compose, run, and scale Wasm modules across clouds to accomplish complex workflows.
Suborbital showed a cloud-based extension engine for SaaS. It allows Wasm functions to be embedded into SaaS products as a more secure, faster, and more powerful alternative to web APIs.
Second State previewed flows.network, a serverless function platform for SaaS. Flow functions can be triggered by SaaS webhook events and send output to another SaaS API. It enables Wasm-based SaaS connectors (like Zapier but with code) and automated bots (eg, GitHub bots or chatbots).
MMS • Nicole Stanton
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Hey folks. Before starting today’s podcast, I wanted to share that QCon Plus, our online software development conference, returns from November 30 to December 8. Learn from senior software leaders at early adopter companies as they share their real-world technical and leadership experiences to help you adopt the right patterns and practices. Learn more at qconplus.com. We hope to see you there.
Good day folks. This is Shane Hastie for the Impact View Engineering Culture podcast. Today I’m sitting down across the miles with Nicole Stanton from Uplevel. Nicole, welcome. Thanks for taking the time to talk to us today.
Nicole Stanton: Yes, thanks so much for having me.
Shane Hastie: Probably a good starting point. Tell us a little bit about who’s Nicole and who’s Uplevel.
Introductions [00:49]
Nicole Stanton: Yes, absolutely. Uplevel is an engineering insights firm. We take insights from different data sources that engineers use every day, like Calendar, Git, Slack and Jira and we compile all of those into insights that hopefully help them with context switching. We have a lot of meeting insights on how long their meetings are and how that can be affecting their workday. We do always on metric, which is really interesting because that can help to lead to indicating burnout for different developers depending on how their days are going and if they’re working out of hours are not. And we measure deep work as well. So do your engineers have time to work? And we compile all of those insights together with different operational metrics as well so you can see if the work is getting done well. Ultimately, it’s a company that we believe if you put people first it will result in good work.
Shane Hastie: And yourself. How did you get to where you are there?
Nicole Stanton: I am a designer. I am a lead designer at the startup. I was employee number 9, three and a half years ago. We’ve recently gone through series A funding and we’re quite a bit bigger now. I had never worked in a startup before. This is my first startup. It was definitely a bit of a jump as far as career shifts, but I’ve been really enjoying it and leading the design team and growing brand and marketing as well as product within the company.
Shane Hastie: That means you’re working very closely with these engineers and working on the design for the product itself. What are some of your insights about working with engineers?
Insights on working with engineers [02:17]
Nicole Stanton: I have always throughout my career found a way to work with engineers because I love doing so. I think that they’re just a very intelligent bunch. This project is really fun because our core user is engineers and so to be able to really look to them for insights and try out different designs and get their input on that, they’re a very intelligent bunch and it’s really great to work with them so closely.
Shane Hastie: One of the things that brought us together today is Uplevel is doing an experiment. Is it still an experiment, but it’s shifted to a four-day work week?
Starting with a four-day work week experiment [02:53]
Nicole Stanton: Yes, we implemented that in January. End of last year, we started by bringing up the idea and doing our research. We did a lot of research into different articles that talked about it and just the science behind it and a couple of other things and decided, well, this is an experiment we would like to try, for many reasons. Each of the department leads kind of led some initiatives within the department to define what success would look there before implementing it. And then we started the experiment at the beginning of the new year. The experiment itself went for about three months where it was, let’s see if this is working. And then after that we decided it was working so well, we just implemented it as how the company runs.
Shane Hastie: Now it’s beyond the experiment, it is, this is how we do things here. I’d like to go right back to the experiment. What prompted that and what were some of the success measures that you were looking at?
Nicole Stanton: We were looking at wanting to make sure that work was still getting done. That was a big one. We wanted to make sure that people didn’t feel burnt out. We’re in the business of telling people if their workers are burnt out and so for ours to be burnt out would be definitely a big red flag for discontinuing the experiment. We were also looking at just general feelings of, do you feel you are getting your work done? Do you feel you were growing in your career? Things of that nature. So we did, not only looking at hard metrics but doing a lot of surveys to help get a pulse on what was happening.
Shane Hastie: And how was the experiment accepted? What were the different viewpoints towards it?
The result was higher productivity and more work getting done [04:26]
Nicole Stanton: It was a 100% buy-in by the company. I think the only person who was a little bit skeptical of it still at the end was our CEO and that’s just because he felt the need to work a lot more than the rest of us. But overwhelmingly, I think that we felt that in fact we were getting more work done. The development team specifically and the product team, one of the things that we kept doing that I think a lot of teams run into is we would overanalyze our decisions and we would almost get into a decision paralysis where we would just cycle and cycle and cycle and then just build whatever it had when we really needed to build something and then we would cycle on that and it was just this process that we would really get stuck in. And, the four day work week forced us to make decisions faster and then once we kind of had that cadence going, it was like, oh, this is really working well for our team and we ended up improving our productivity with the four day work week, which feels very counterintuitive.
Shane Hastie: So obviously turning the experiment into the way of working, what have been the challenges there?
Meetings were the biggest challenge [05:29]
Nicole Stanton: I think that one of the big challenges was meetings. Seems like an obvious one, especially depending on your role in the company and what you’re doing, just trying to find time to meet could be very difficult with limited hours in order to do that. The other thing again was I think just maintaining the appropriate amount of work for the sprint and we still kept the same amount as we did before we started the experiment but not over-indexing and making sure we do really good sprint planning so that we can be on top of making sure things get done.
Shane Hastie: What has the overall benefit been to the organization and to the teams and individuals?
Measurable benefits [06:07]
Nicole Stanton: I think general employee contentment has gone up quite a bit. Having that extra day. I also feel like focus has been something that has really been a part of things moving forward. For me personally, having that extra day, I stay way more focused because I know that I have just four days to make sure that I’m getting everything finished and wrapped up. And then I have two kids and they’re in school usually on Fridays. And to have that time for just me to making sure that I can do other things and I can book my appointments, I can exercise, I can get outside, I can do all these other things and have a little bit more me time made me much more present for my family for the weekend because I wasn’t trying to do all of those things at once.
I think we had some other employees that also really loved having that time. One of our developer managers, he has a side business of brewing Makgeolli, which is a traditional Korean rice alcohol and so he would use his Fridays to continue his side business there. Our customer service manager, her name is Lauren, she loved having a true day off. She has a small baby right now and she said with that time off… she described the weekend as being she would be really anxious on Sunday about making sure she was prepared for Monday and then she would start fretting being anxious on Sunday, on Saturday and having a Friday actually made it so she could enjoy some time off with her family.
Shane Hastie: Does everyone have the same day? So the work week is Monday to Thursday?
Nicole Stanton: Yes. We have a lot of US holidays that fall on Mondays and on those particular weeks where we have a Monday holiday, we’re starting to implement trainings on Friday. So, that’s kind of how we’re handling that. But no more than a four day work week each week.
Shane Hastie: How do you handle things like customer support on a Friday?
Nicole Stanton: We always have a customer support person on call so they’ll be hooked up and be available and that rotates on who that is. But unfortunately, being in tech, there’s no way to get around that even on the weekends.
Shane Hastie: What are your peers in the industry looking at you and saying, what are your customers looking at you and saying?
Customer feedback [08:16]
Nicole Stanton: Our customer engagement has been pretty good. Most of them definitely respect it. There is that side on customer service where occasionally customer service will have to take a call on a Friday. For the most point, those customers really do respect the four-day work week and they also asked a lot of questions I think we even have one customer who started to look at their individual teams doing something similar, especially in development. Most of our clients are very large and so for it to be a company-wide thing might be more difficult, but within their own teams.
Shane Hastie: Did you explore or let some teams do it and others not, as part of the experiment or was it a whole, a total switch?
Nicole Stanton: We talked about it. We are so small as a startup, there are so many people that are working almost like Swiss army knives to some extent. And so it would be really difficult for some teams to do it and some teams not to, which is why we implemented it totally throughout the company. That’s to be said, sales in general I believe will sometimes work on Fridays because they just have a different cadence and it’s a different type of role.
Shane Hastie: How do we keep that fair?
Nicole Stanton: If a salesperson chooses to work on a Friday, which most of the time they’re on commission, that is their choice and they know that the team is not available. So that’s one of the ways we’ve implemented that.
Shane Hastie: They don’t get to take a Monday or a Wednesday?
Nicole Stanton: The company has a policy also that there is unlimited PTO and I know a lot of companies have done that anyway and so if you want to work a Friday and take a Monday off, that is totally your prerogative.
Shane Hastie: Unlimited PTO, sounds like a wonderful thing. My experience has been that people take less time off.
Unlimited paid time off [09:56]
Nicole Stanton: That was our founder’s huge worry with having unlimited PTO. They actually wrote it into our benefits handbook that in order to get some of the benefits… like, we have a couple of different benefits that are getting a personal stipend for a hobby as well as money to increase your training and you don’t have access to those unless you take at least two weeks off every year. So, that’s how they handled not falling into a culture that was about not taking time off with that role.
Shane Hastie: It sounds so wonderful to be just able to take that time and yet we need to do things to encourage people to do so. This is the engineering culture podcast. What are some of the other interesting elements of the Uplevel culture?
Exploring the Uplevel culture [10:40]
Nicole Stanton: I can say that it’s a really fun place to work because ultimately what we’re trying to build is something that helps to encourage companies to take care of their workforce and to protect that culture and to increase employee satisfaction at work. And part of that is doing lots of experiments in the company itself. So not only have the four-day work week and the unlimited PTO, the company itself, it really does tend to walk the talk. Every Wednesday at lunch, we have a… over Zoom now because about 50% of our company is in Seattle and the rest of it is kind of distributed among the states and we will have Wednesday games and that will include the CEO, as well as the VP of Marketing and all of the leaders and everyone, shows up and we will play code names most of the time, which is pretty fun.
And we’ll divide into teams and there’s a lot of trash talking and there are always prizes for winning teams, which is really fun. One of the popular ones that our CEO likes to do is the winning team will get dinner for their families and things like that, which is just, it’s awesome. It’s great to be a part of that. And, really just promoting good culture, good discussion, good relationships among all of us. And I think in general because of that, it’s fostered a group of people that just authentically care about our mission and want to push the startup across the line of being successful.
Shane Hastie: How is that culture going to be maintained as the company grows?
Maintaining culture as the organization grows [12:14]
Nicole Stanton: We have had a lot of discussions about that. We just recently hired our first HR people and culture person as part of our team and that is her sole job. And so, one of the things we’re constantly doing is, we are taking temperature checks, we’re constantly trying to get employee feedback. I think that as the designer, I’m going to say that I feel like having a strong brand also helps with that, especially with what we’re trying to do. So definitely putting words to that brand mission and making sure that people are aware and on board and are still working towards a goal, I think really helps to maintain the culture as well.
Shane Hastie: I’m not sure whether you have access to this. What are you seeing from the data that your customers are getting that this very detailed information about how their teams are working? Do you get any insights from that?
Insights from customer data 13:07
Nicole Stanton: The data and insights that we collect from our customers, we always are looking at it from the point of view of benefiting the developer. And so we are always asking questions, does this feel safe if somebody else saw this, are we comparing developers? A lot of our competitors, they’ll have charts on, is your developer elite, normal or are they… they actually rank developers based on their data and we are very far away from all of that. So our insights really are very geared towards what information can we give you to help the developer and help the manager to manage those developers better.
So no specifics. Even our always-on metric, we want to be careful that it’s not trying to inspire a culture of hey, if you are on all the time, that means you’re working more and that’s better. We’re very much promoting the idea that that’s a bad thing. So we do get concerns over privacy often with our data and most of the time when our customers are in our product and see how we’re displaying things and the care we’ve taken to really protect that developer, most of those concerns dissipate.
Shane Hastie: Yes, the temptation would certainly be there to try and use this data to drive performance.
Nicole Stanton: Yes, we are strong believers in using data for good instead of evil.
Shane Hastie: Thinking back to the four-day work week, how has that impacted your… I’m going to make an assumption that it’s been positive, but your ability to hire good people? And you mentioned that you’ve got people at least half the team remote now.
Four-day week as an attractor for great people [14:50]
Nicole Stanton: Yes, we have gotten a huge influx on all of our job openings when we went into the four-day work week. We have posted those jobs to a couple of different websites that are promoting the four-day work week and that’ll also help us to get candidates. Ultimately, when candidates see that we do the four-day work week, we get a lot of applicants
Shane Hastie: Nicole, you mentioned that you are a distributor team, you’ve got some people in Seattle and the rest spread across the states, how frequently do people actually come together? And those who are in Seattle, do you have a single office where they come every day, or is it the horrible hybrid or how do you do that?
Nicole Stanton: We do have a shared office that we use on Mondays, so anybody in Seattle can come in on Mondays to work together and a lot of people will. That of course is optional for where your comfort level is because we’re all from different walks of life with different medical needs and everything else. It’s very much whatever you feel safe doing. With the distributed teams, we have everyone fly in every other month and we will do a week of being in person for those that are comfortable and being in person. And me specifically, we have product dinners, but different departments will do different dinners and things to reconnect as well as brainstorms and things during the day while we’re in person to kind of reset and to reengage and to also just meet all of our coworkers and things that tend to gel so much better in person. We do have Zoom options and remote options for those who don’t want to come in to that space.
Shane Hastie: What else do you do to maintain that culture?
Nicole Stanton: So during those every other month, kind of everybody meetups in the city, we will have usually one big dinner. We’ve done ax throwing before with everyone. Our last big party and we’re actually probably getting a little too big for this to be the case anymore, but one of our coworkers lives on a lake and we took over her backyard and just threw a wonderful day gathering for the summer, in which case, of course, we’re a very competitive bunch. We all separated out into teams and played an Olympics game that involved some paddle boarding and some flip cup and some other things that we can compete against each other with, which is always fun.
Shane Hastie: A culture insights company providing feedback to organizations, bringing that learning into your own organization, walking the talk and the four day work week. What’s next?
Growing the company [17:20]
Nicole Stanton: I think at this point we are really looking at growing with going through series A, which has been great. Our customer service team has been growing like crazy as well as our sales team, which is pretty exciting. We currently have a great experience for developers and for developer managers. We are also looking at rounding out that experience for executives within our product so that as an executive you can see stats on teams. Again, not to compare but to look at why work might not be getting done, whether that’s a team not having enough time to do that work because they’re in too many meetings or there’s too much context switching, which is another one of my favorite insights.
So context switching is when a developer has too many different types of work on their plate, it’s really hard for them to find time to work on those things because the ramp up and ramp down from those different items adds time to their calendar.
Shane Hastie: Nicole, thanks very much for taking the time to talk to us today. If people want to continue the conversation, where do they find you?
Nicole Stanton: Absolutely. Uplevelteam.com is the best way to connect with our company. We have a blog there, which we like to post different articles where we’re interviewing our developers on different things, different insights on how to cut down on your meetings and increase your deep work, things like that. And then we also have a LinkedIn and a Twitter account to follow.
Shane Hastie: Wonderful. Thank you so much.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Alen Genzic
Article originally posted on InfoQ. Visit InfoQ

Microsoft released ASP.NET Core 7 Release Candidate 2, the final release candidate for .NET 7 on October 11th. This release includes improvements to output caching, further improvements to the dynamic authentication in Blazor feature introduced in RC1 and experimental WebAssembly multithreading support using Web Workers.
This version of ASP.NET introduces a new vary-by option and improves the OutputCachePolicyBuilder API.
In previous versions of .NET, the output cache would always vary by the host name, meaning output caches for host names pointing to the same application would be duplicated by default. The SetVaryByHost option now gives developers the ability to disable this feature:
builder.Services.AddOutputCache(options =>
{
options.AddBasePolicy(builder => builder.SetVaryByHost(false));
}
The OutputCachePolicyBuilder now includes the option to instantiate an empty policy, not including the default policies, allowing you to customise your output cache from the ground up.
Blazor Dynamic authentication is improved by enabling developers to view detailed logs by adding this LogLevel to their configuration:
"Logging": {
"LogLevel": {
"Microsoft.AspNetCore.Components.WebAssembly.Authentication": "Debug"
}
}
The WebAssembly wasm-experimental workload allows the use of multithreaded code by leveraging Web Workers.
Developers can now install the wasm-experimental workload and add the WasmEnableThreads property to the project file to enable the use of threading in their WebAssembly code. This feature is still in the experimental phase and Microsoft does not recommend using it in production. The full release of this feature is planned for .NET 8.
Microsoft principal engineer Aleksey Kliger’s GitHub repository contains a comprehensive example of the new Web Workers multithreading feature.
This final release candidate for .NET 7 before its official launch in November can be downloaded from the official site. Microsoft’s official announcement mentions that this release is suitable for use in production environments as well. The use of .NET 7.0 on Windows requires the Visual Studio 17.4 latest preview. On macOS, it needs the latest version of Visual Studio for Mac. The latest version of the C# Extension includes support for .NET 7 and C# 11 for Visual Studio code users.
Other notable features already available or confirmed to be in the official .NET 7 release coming in November include rate limiting, Generic Math, and regular-expression improvements. Further improvements planned for the full ASP.NET 7 release are available in the ASP.NET 7 roadmap. Additional features still under consideration for .NET 7 can be seen in the .NET 7 Planning GitHub milestone.
Note that the .NET 7 release is a Standard Support version of .NET, with support available for 18 months after release. The next Long-Term Support version will be .NET 8, with support times of 36 months. More information on this can be seen in the Support Lifecycle document.
With this release come new updates to the previous LTS versions. Version 6 upgrades to version 6.0.10 and version 3.1 upgrades to version 3.1.30.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Introduced in OpenSSL 3.0 in September 2021 and affecting all successive versions up to and including OpenSSL 3.0.6, the two recently patched vulnerabilities are caused by buffer overruns in X.509 certificate verification.
Both CVE-2022-3786 and CVE-2022-3602 describe two buffer overflow issues in an X.509 email address verification, leading to the possibility of a denial of service attack for the former, and of a remote code execution attack for the latter.
The vulnerabilities require either a CA to have signed the malicious certificate or the application to ignore a failed certificate validation, which makes an exploit unlikely, though. For this reason, CVE-2022-3602 severity was downgraded from “critical” to “high” after an initial assessment.
While downgrading CVE-2022-3602 reduced somewhat the impact of the announcement, it is still true that OpenSSL is a key component for the security of the Web and, as it became evident after Heartbleed was discovered in 2014, patching it is a major undertaking. In fact, a report by Internet intelligence company Shodan revealed that over 80,000 devices where still vulnerable to Heartbleed six years after its disclosure.
The initial classification of CVE-2022-3602 as critical caused many worries in the community, but, as Dan Lorenc, co-creator of the cryptographic signing provider Sygstore and co-founder of supply chain security startup Chainguard, remarked, the fact that during almost a decade this was the first critical vulnerability reinforces the idea that open source code is at least as secure as proprietary, closed source code.
This vulnerability will likely lead to many discussions around the perceived unsustainability and insecurity of open source, but the facts remain that major, well-funded vendors see bugs like this at a much higher rate. […] We should instead focus on building secure software that has the tooling necessary to make remediation faster and more seamless by rooting it in secure by default measures.
Another reason for concern came from the early announcement of the vulnerabilities, one week in advance on the patch being available, which could have allowed attackers to look for ways to exploit them before the patch was released. This is in compliance with OpenSSL policy, aimed to provide a date for users to get ready to patch, though. Sonatype co-founder and CTO Brian Fox further explained to InfoQ that talking publicly about such issues has a beneficial effect:
I think it can only have helped to drive awareness which should lead to faster patching. In fact, in our recent State of the Software Supply Chain report, we have data that clearly indicates the more widely publicized a vulnerability is, the faster people respond.
Sentry head of open source Chad Whitacre brought the focus on the importance for companies to contribute to make open source projects financially viable:
A lot of companies have stepped up to the plate since [Heartbleed] to finance the community-supported open source projects we all depend on, but there are still a lot of companies sitting on the sidelines.
As a final remark, it is important to understand that the discovery of vulnerabilities will never end. As Fox summarizes it, “after you patch, prepare for the next vulnerability.” The focus should be directed towards being able to respond and patch immediately.
Here you can find a list of affected distributions that will require a patch.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Companies nowadays are looking for ways to cultivate a product mindset. While the idea of cultivating a “product mindset” allows us to focus primarily on ourselves, actually transforming our organizations often means changing our behavior to focus on our customers and how we work together to serve them, Matt LeMay said at Better Ways 2022 where he spoke about the myth of a product mindset.
A mindset isn’t digital; it’s not something you have or you don’t have. LeMay stated that like many trendy concepts in business, “product mindset” is just vague and general enough for people to project onto their own often competing goals and assumptions.
Changing our behavior is hard and annoying. We like shiny new things that make us feel good about ourselves over actually changing our behavior in a meaningful way, LeMay said. If it wasn’t uncomfortable and annoying, we would have done it already, he commented.
LeMay mentioned three steps that people can take today to change:
- Talk to a customer
- Share something unfinished with your team
- Use simple descriptive language and stop obsessing over vague trendy nonsense like “product mindset”
LeMay mentioned what he called the first law of organizational gravity:
Individuals in an organization will avoid customer-facing work if it is not aligned with their day-to-day responsibilities and incentives.
If you want to be customer-centric, spend more time talking to your customers, LeMay recommended. He referred to Teresa Torres, who suggests that at a minimum you should have weekly touchpoints with customers.
Presenting finished polished fancy documents to our colleagues makes us feel better about ourselves, but it doesn’t bring value to our customers, LeMay said. He suggested that we should be brave enough to bring multiple customer perspectives into our work before it’s finished enough to be “impressive”.
LeMay said that arbitrary made-up goals that aren’t business or customer goals give us a dangerous artificial sense of control. He also mentioned that arbitrary made-up concepts like “product mindset” give us a way to feel really smart and good without doing uncomfortable and annoying things we actually need to do.
Instead of spending time on overcomplicated nonsense, we should focus on the good, the obvious, and the hard-to-actually-implement stuff, LeMay concluded.
InfoQ spoke with Matt LeMay about cultivating a product mindset:
InfoQ: How can we cultivate just enough product mindset to enable behavior change toward doing things that matter to customers?
Matt LeMay: When it comes to mindset vs. behavior, there’s kind of a chicken and egg question. Do we change our mindset in order to change our behavior? Or do we change our behavior in order to change our mindset?
One concept I find really helpful in thinking about all this is practice. If you want to get great at a sport or a musical instrument, you can debate “mindset” vs “behavior” all you want but, at the end of the day, not much is going to happen until you start practising. When it comes to new ways of working, I think this holds true as well. The sooner you can get out of theory and into practice, the more quickly you’re going to see material improvement. Theory (or “mindset”) can provide inspiration and guidance, but it’s never a substitute for actually doing the thing.
InfoQ: What can be done to make it less uncomfortable for people to connect with customers and find out what they need?
LeMay: This is a great question! I think the first step is to ask yourself: what exactly is making you uncomfortable?
Are you afraid that you’re going to look unprepared? For some people, having a script prepared is really helpful for talking to customers.
Are you afraid that you don’t know what you’re doing? For some people, sitting in on a few sessions led by a trained researcher can be really helpful.
Are you afraid that you’re already too far removed from your customer’s needs and behaviors? Maybe have a few informal conversations with people you know who use the product before conducting user research.
At the end of the day, though, you’ll probably never feel fully prepared to connect with customers. The challenge is to work through that discomfort and do it anyway.
MMS • Shane Hastie
Article originally posted on InfoQ. Visit InfoQ

Charity Majors, founder and CTO of Honeycomb.io, gave a talk at QCon San Francisco about the pendulum of being a senior engineer and a manager. She discussed the need for managers in technical teams to have engineering credibility and the value that comes from deliberately embracing both senior technologist and manager roles over your career, but not both at the same time.
She started by explaining that management is often seen as an alternate to progressing as an engineer, that technologists have to chose to move away from their technical focus if they want to advance in their career. She pointed to some assumptions that are often held about management roles:
- It is a one-way trip
- It is always a promotion
- You make a lot more money
- They should stop writing code
- It’s more prestigious than engineering
- It’s the only real option for career progression
- It’s the only way to have influence
- All managers want to be directors or VPs
- All managers would rather be writing code
- The best engineers make the best managers
She went on to debunk all of these assumptions and explain why the manager and the engineer roles are not incompatible.
She explained that a team deserves a manager who wants to be in the people leadership role, who can help develop people in their own growth. The manager needs to be genuinely interested in the process, sociotechnical systems and nurturing the careers of their team. A manager in a technical environment needs to have coding skills that are strong enough, fresh enough and modern enough to evaluate the work of the team and to resolve technical conflicts.
A technologist growing their career deserves to have career advancement, a role that is challenging, interesting and not a one way street. They need to be able to keep their technical skills relevant, while retaining options for the direction they want to move in. A career should be long and vared and become more enjoyable over time, not less so.
She said that in order to achieve this, technologists need to be able to build their technical skills, chose to move into a management role for a period of time and swap back to having a technical focus. Technologists and technical leaders need both skill sets to reach their full potential, and doing so makes them better technologists and better leaders.
She made the point that you don’t have to chose to be one or the other, but that you must chose one at a time. You cannot be both a deep technologist and manager at the same time. You need to deliberately step between these roles because the fundamental way work is done is different in each role:
Being a good engineer involves blocking out interruptions, focusing on learning and solving hard problems
Being a good manager involves being available to your team and interruptible, even being interrupt-driven
She made the strong point that you need to start on the engineering track first – build strong and deep technical skills. You don’t have to be the best engineer, but you do need experience, confidence and good judgement with enough years on the job that your skills won’t immediately atrophy.
She advised that when taking a management role, commit to it for a minimum of two years, but no more than five years if you want to retain the technical credibility. If you plan to swing back and forth, do so before your skills decay to the point you become unemployable.
Talking about the manager as team member, she said you need to keep your technical credibility, and one way to do that is to write some code. Ignore the oft-stated advice that managers should not write code. However, do not write code on the critical path, rather look for ways you can contribute in small and supporting roles. She suggested taking the on-call backup of first resort for support calls. It will give you insight into the quality of the code base, will let you see how the code is being maintained, and will be supporting the team in a very concrete way.
From an organisational perspective, it is important that moving into management is not seen as a promotion, so that moving back into engineering is not a demotion. Rather both shifts are clearly about career change.
She made the point that you can make the pendulum swing between technical leader and technologist a few times, but eventually you will come to a fork in the road where you need to chose moving into more senior management roles or remain at the technical coalface. Neither is necessarily better or worse than the other, and you have to make a deliberate, informed choice about which path will be better for you.
She gave some advice for senior leaders looking to establish a culture where moving between management and technology is accepted and seen as healthy requires:
- Don’t build a system where if people have to be a manager if they want to be in the loop or have a seat at the table
- Drain authoritarianism out of your hierarchy. Command-and-control management is toxic to any kind of creative flourishing
- Management is overhead, management is a support function. Visualise your hierarchy upside down; support system, not dominance
- If you’re not happy as a manager, don’t do it. Your sacrifice will only hurt yourself and those around you
- Build a long, healthy, flourishing career by leaning into curiosity, love of learning and surrounding yourself with amazing people
She ended by saying that Only you get to decide what is right for you.
MMS • Bailey Hanna
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Having non-unified testing processes can expedite development, increase team autonomy, and better match the team’s need, but it can also create confusion, missed requirements and a sense of isolation among teams when not done right
- Individualized processes benefit not only the team implementing them, but also your customers, other development teams and your organization as a whole by increasing efficiency and quality
- Individual processes may not work for everyone. The context of your team and your product determines whether or not individualized processes are right for you. By understanding product/contractual requirements and your team’s skill set, you ensure that all needs are met while allowing for that increase in productivity
- By implementing processes in an iterative fashion, by reducing gaps in the current process, then by eliminating overhead in it, and finally by properly repeating these tasks on a regular cadence, you increase the likelihood of success and reduce the likelihood of negative repercussions
- Having practices in place such as communities of practice, a shadowing program, and up-to-date documentation, you can ensure that individual processes have a positive impact on your organization and reduce the risk of confusion or other negative impacts
Many people in the software industry – especially on the testing side of things – have often been asked, “So, what’s your testing process like at *insert company name here*?” People want to know what your processes are at your company; either out of genuine curiosity, a search to find a fit for their skills, or to find issues in it that they think you could solve by changing “just one thing”. But what happens when the answer is “It depends”?
Many organizations in the software industry have fallen into a state where they have set processes that are used across the organization and teams. There’s a specific approach to be taken to development, to testing, to deployment and more. But most of the time there is one set process for each “step” in the process. The issue with this is that every team is not the same, so why are their processes all the same?
In this article we’re going to explore what it can mean for teams to have individualized processes that are formed by the context of the work they are doing and of the team itself. What does it mean to have different processes? What can you gain (or lose) from this approach? How can you determine if they’re right for you? Where do you even start with attempting to move towards individual processes? And how do you set your organization up for success while moving away from a unified approach? These are all questions that we’ll be answering in the coming sections.
What exactly are individual team processes?
Individual team processes are processes that are specific to the context and the needs of a given team. Every team is unique; from the work that they are doing to the individuals who make that team up, there are contexts and skills that vary from any other team you have within an organization. Due to this, having one set of processes that every team needs to follow can be detrimental.
A clear example of this is a UI-focused team vs a backend-specific team. Those two teams have different requirements and different expected outcomes, so if they were to follow identical processes, there would likely be overhead that isn’t necessary or gaps being missed. The UI design team processes may have a step for designer review of new UI components, but that would just constantly get skipped by a backend team. Meanwhile, the backend team may have requirements on security testing for different types of attacks that would never apply to the UI team. By letting them define the processes which make sense for themselves, they can ensure they aren’t wasting time and they can focus on identifying their own gaps and improving their processes for their context.
It’s also important for these processes to have the ability to evolve over time. As priorities within a project change or the members who make up a team change, their processes may need to shift as well. By allowing teams the autonomy to control their processes,it enables them to review them regularly and make the necessary changes to ensure there are no gaps or tedious overhead slowing the team down. This ensures that the efficiency they have curated remains over time.
One thing that is important to note about individual team processes though is that they should never be completely unique. There will always be overlap between teams in certain areas. For example, every team likely has it in their development process that their code is reviewed by another team member. This is very likely an organizational requirement in most companies. So this is going to appear in every team’s process, which doesn’t mean that teams don’t have individual processes anymore; it just means that there are still some common aspects which are better for organizational alignment. It’s the addition and removal of non-required pieces to suit the context of the team that make it an individualized process.
What are the risks with this approach?
Although there are other risks to working with individual team processes, the biggest one is a lack of organizational alignment. For example, if you have teams who are so focused on having their own process and being completely unique that they try out a “new” test framework, but don’t share that information, you could have another team doing the same thing and doubling the effort it takes and sharing none of the lessons learned, challenges, tips and tricks, etc, to getting that framework up and running. It’s important to make sure teams understand that they have the ability to choose the processes that work best for them, but that they don’t have to be brand new processes. Learning from other teams and being able to leverage their insights and bringing on processes that have been tried and proven helps everyone, and can still fit the context of your team just as well as others, so without that alignment and sharing individual processes it easily becomes more detrimental than beneficial. We’ll explore ways to reduce this risk more in a later section as well.
Some of the other risks that are always worth considering are a potential lack of transparency into the processes, confusion on teams as you shift processes, increased ramp up time for inter-team moves, and difficulty in tracking audit requirements. Some of these risks are especially prevalent in companies with strict contractual obligations. For things like missing audit requirements, you can alway ensure those are present in all processes, similarly to how I mentioned requiring code reviews above. Most of the other risks also align back to the lack of alignment, and by ensuring that there is a good foundation for sharing information and discussion amongst teams, you can address those risks as well. Although they add to the work required to make individual processes work, it can still be done if that’s what the team is committed to.
What are the benefits of individual team processes?
The benefits that teams can see from introducing these context specific processes range from things like increased efficiency, which benefits the organization and customers, to an added sense of ownership for the individual contributors on a team, which benefits employee satisfaction and growth.
By letting teams have additional ownership and a say in the processes that make up their day-to-day, we usually see an improvement in the quality of the features being produced, increases in their efficiency, increased satisfaction with less frustration from processes which don’t align to their needs, new innovative approaches being taken in terms of tooling and frameworks since they can explore more easily within those processes and added flexibility to adjust to changes. This list is also not exhaustive. These are the common benefits that I’ve seen on almost every team that I’ve worked on with this approach, but some teams see their own benefits like increased communication within the team, better alignment on goals etc.
I think for me the biggest benefit that I see on teams, personally, is the reduction in friction around testing and quality conversations. When the requirements for testing and quality fit the context of the work the team is doing, then they are much more open to those processes. They can understand the why behind the approaches we take and it helps things to move much more smoothly. I’ve seen a very positive shift in the attitudes of the entire team to the testing processes when they are able to define the ones that make sense and work for them.
How would I know if individual team processes are right for my team?
Determining if individual processes are the right choice or the right fit for your team is a crucial step. No matter how interesting they may sound or how excited you may be to implement them, it is important to consider the current context of the organization and teams within it before you attempt moving to individual team processes. So, I’m actually going to start with some of the indicators of a potentially bad fit.
Some of the biggest indicators I have seen for individual team processes not working well in an organization are: having strict contractual obligations, having strict waterfall processes, having a very tightly coupled architecture, and already having issues with inter-team communication. The reason that these are the biggest red flags usually for teams is that when you have stricter processes and requirements, it can be easy for things to get missed as teams move to their own context-specific processes. Especially when there are already issues with communication within an organization, teams may not be aware of why certain aspects of processes need to stay in every team and they could remove them which can cause large scale consequences.
An example of this would be a company working with medical data files, based on government regulations. Very strict processes need to be followed for privacy concerns. Organizations with a tightly coupled architecture can also experience issues when teams are not in alignment on required processes or coverage, which again is made worse when there is a lack of communication. In order for teams with this setup to thrive with individual team processes, there needs to be a very healthy level of communication between all teams.
But, now that I’ve talked about situations where individual processes may not be the best fit, how can you tell when they will be? The best indicators that individual processes are a great fit are: having autonomous and high functioning teams, having or moving towards a decoupled architecture, having teams who are frustrated by an inability to try new processes or by overhead, and having some teams who are already starting to do this.
I’m going to start by digging into that last point. In so many cases, teams are already doing this in some way. If there is an organization-wide process where certain aspects don’t apply to that team, they may already be telling new employees to just skip over that section. Or you hear them talking frequently about things that don’t apply to them. This means that the team is already moving toward defining their own processes, but without the ability to make it common practice. They’re already doing what they need to in order to identify overhead or gaps in the existing process and make the necessary changes to better suit their needs. This shows strongly how well they could benefit from having individual processes.
Going toward individual team processes
If you’ve been convinced to give individual team processes a try, I strongly suggest slowly working towards them. Trying to rush towards instantly letting every team define their own processes can cause some of the risks discussed before to present more readily. By slowly moving towards this approach, you can identify issues and address them as you work towards that goal.
The first step is to define the current process. By making sure that everything is well-defined, the current approach sets teams up to identify any gaps in those processes that they have or need to add in additional processes to fit their needs. Once the organization-wide process is defined, teams should review it and add to that strategy any extra steps needed to fill those identified gaps. Once that is completed teams should share those additions with other teams to see if they would benefit any other teams.
Once teams are comfortable with the organizational approach with their specializations, they can start to work on removing pieces. They can do this by reviewing the current team process again, but this time looking for any steps which do not meet the needs or the context of the team and removing them from the process. Once teams have identified these steps, they should share these changes with other teams to get feedback to ensure that these steps are not required by some contractual obligation that the team wasn’t aware of. At this point, teams have an individual team process which fits their context!
The last step for teams though is to start to review these processes on a regular basis. By reviewing them for both gaps and overhead regularly, the processes can continue to evolve as the team does. As requirements and the team members change reviews, ensure that everything is still aligned to the context. As always, if changes are being made in the process, those updates should then be shared outside of the team.
At that point, teams will be working with individualized team processes. From that point they should monitor for benefits that they are seeing from this approach and make sure that they are checking in with all teams regularly to ensure this approach is working and that all teams are still in alignment.
How can we set ourselves up for success?
Since we know that a lack of alignment and cohesion are the biggest risks to maintaining healthy individual processes, how can we tackle the risk early and set ourselves up for success? I generally break it down into three suggested approaches: documentation, shadowing and communities of practice.
Having up-to-date and comprehensible documentation of team processes is very important. Documentation not only allows other teams to learn about your processes, but it allows your team to verify that you are all on the same page about the processes you have defined. It’s important for the team to revisit this documentation on a regular basis to keep it up-to-date and accurate, to share updates when you make changes to your processes, and to ensure that it is in a publicly accessible spot for alignment amongst other teams.
Shadowing is a great way for other teams to get a more personal look into your processes and to understand whether or not they would be a good fit on their team. By having two individuals pair up and shadow one another as they work through the development and testing processes, you gain better insight into how those processes look in action and this can help to address any gaps that may exist in the documentation that should be recorded.
The last piece is to have communities of practice. These are usually an open forum where individuals are able to discuss topics around a given initiative. I like to break communities of practice down into role-specific communities. So there may be a community of practice for testing and quality, for example where teams can come to share ideas and information about those topics. These become an ideal location for teams to discuss their processes (development processes in a development community of practice, testing processes in a quality community of practice, etc.). They establish a safe space to discuss wins, challenges, tips, etc., and allow other teams to see if new processes being pioneered on other teams could work for their team’s context as well!
Although you could go with just one or two of these approaches, I have found that they are best used all together. They allow individuals to learn in the environment that suits them best. For example, some people learn best through reading, some through one-on-one conversation, and some enjoy a larger group setting for discussing these topics. By combining all three you are best set up for success!
So what does it all mean?
At the end of the day, there are many benefits to having teams working with processes that are defined by the context of their work and their team. But, like many things in life and the workplace, they also take work.
By allowing teams to create and establish practices that fit their context, you enable an increase in team autonomy, efficiency, and the quality of the work being produced. It allows for the processes and practices used on a team to grow as the team does, and enables teams to experiment and share more with other teams in the organization. Teams will also see a decrease in frustrating overhead or trying to adhere to requirements that just don’t make sense for what they do in their day-to-day. By putting in the work and allowing teams to take more control of their approaches, the teams, the organization and our customers benefit.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

Maven Central Search (mcs) is a command line tool to retrieve dependency coordinates from Maven Central. The tool uses Picocli for the command line interface and GraalVM to compile executable native images for macOS, Linux and Windows.
The wildcard search option displays all artifacts from Maven Central containing the provided argument in their name. The following example retrieves all artifacts, containing spring-boot-starter, including the date of the last release:
mcs search spring-boot-starter
Searching for spring-boot-starter...
Found 4626 results (showing 20)
Coordinates Last updated
=========== ============
org.teasoft:bee-spring-boot-starter 13 Sep 2022 at 12:40 (CEST)
com.infilos:relax-spring-boot-starter 13 Jun 2022 at 16:27 (CEST)
io.sreworks:tesla-spring-boot-starter 06 Jun 2022 at 10:01 (CEST)
com.seepine:spring-boot-starter-parent 05 Jun 2022 at 14:50 (CEST)
io.nats:nats-spring-boot-starter 25 May 2022 at 14:36 (CEST)
…
The coordinate search retrieves all artifacts for the provided coordinate:
mcs search org.springframework.boot:spring-boot-starter
Searching for org.springframework.boot:spring-boot-starter...
Found 170 results (showing 20)
Coordinates Last updated
=========== ============
org.springframework.boot:spring-boot-starter:2.7.5 20 Oct 2022 at 15:26 (CEST)
org.springframework.boot:spring-boot-starter:2.6.13 20 Oct 2022 at 11:56 (CEST)
org.springframework.boot:spring-boot-starter:2.7.4 22 Sep 2022 at 13:44 (CEST)
org.springframework.boot:spring-boot-starter:2.6.12 22 Sep 2022 at 11:32 (CEST)
org.springframework.boot:spring-boot-starter:2.7.3 18 Aug 2022 at 08:30 (CEST)
…
The pom.xml configuration is shown instead of a table whenever Maven Central returns exactly one result:
mcs search org.springframework.boot:spring-boot-starter:2.7.5
Searching for org.springframework.boot:spring-boot-starter:2.7.5...
org.springframework.boot
spring-boot-starter
2.7.5
All mcs commands support the -l argument to specify the maximum number of results:
mcs search -l 3 org.springframework.boot:spring-boot-starter
Searching for org.springframework.boot:spring-boot-starter...
Found 170 results (showing 3)
Coordinates Last updated
=========== ============
org.springframework.boot:spring-boot-starter:2.7.5 20 Oct 2022 at 15:26 (CEST)
org.springframework.boot:spring-boot-starter:2.6.13 20 Oct 2022 at 11:56 (CEST)
org.springframework.boot:spring-boot-starter:2.7.4 22 Sep 2022 at 13:44 (CEST)
Retrieving artifacts containing a specific class name is possible with class name search:
mcs class-search Joiners
Searching for artifacts containing Joiners...
Found 232 results (showing 20)
Coordinates Last updated
=========== ============
io.github.light0x00:to-be-graceful:0.0.2 23 Aug 2022 at 16:24 (CEST)
io.github.light0x00:to-be-graceful:0.0.1 20 Aug 2022 at 12:28 (CEST)
me.hao0:diablo-common:1.0.2 10 Oct 2016 at 15:57 (CEST)
…
Optionally the -f flag may be used to specify a fully classified class name:
mcs class-search -f org.optaplanner.core.api.score.stream.Joiners
Searching for artifacts containing org.optaplanner.core.api.score.stream.Joiners...
Found 106 results (showing 20)
Coordinates Last updated
=========== ============
org.optaplanner:optaplanner-core:7.65.0.Final 03 Feb 2022 at 19:54 (CET)
org.optaplanner:optaplanner-core-impl:8.29.0.Final 14 Oct 2022 at 14:17 (CEST)
org.optaplanner:optaplanner-core-impl:8.28.0.Final 26 Sep 2022 at 12:13 (CEST)
…
The command line interaction is built with Picocli, a one file Java framework which makes it easier to create command line applications. Picocli supports TAB completion, option parameters and subcommands. Applications using Picocli may be compiled ahead of time to a GraalVM native image which results in a single executable file.
mcs may be installed on macOS, Linux and Windows with the Homebrew, Snap, SDKMAN! and Chocolatey package managers. The release process of mcs is automated using JReleaser.
InfoQ spoke to Maarten Mulders, IT Architect at Info Support, Java Champion and the creator of mcs.
InfoQ: What was the inspiration to create the project?
Mulders: I read an article in the NLJUG “Java Magazine” by Julien Lengrand-Lambert about creating CLI’s with Kotlin and PicoCLI. It made me curious. Would it really be so easy? My fingers where itching, but I didn’t really have a goal yet. And just doing again what was written out in the article seemed boring to me. At the same time, I found myself often switching from my editor or command line to a web browser, only to visit search.maven.org for looking up exact Maven coordinates. Voilà, my use case was there. As I didn’t know much Kotlin back then, I decided to go with Java 17.
InfoQ: Which is your favorite feature of mcs?
Mulders: That would be the fact that if you have specified the exact coordinates of an artifact, mcs will output the
pom.xmlsnippet for you. I’m still contemplating if I could provide the snippet for more situations. For instance, when you specify agroupId+artifactIdtogether with a new command line flag such as--latest. But I haven’t quite made up my mind about that idea.
InfoQ: Can you already tell us something about upcoming features?
Mulders: I’ve already had (and rejected!) so many ideas! But one of the more interesting ideas that was proposed, quite a while ago by Benjamin Marwell, is to include a vulnerability score. I still have to dive a bit into the details. Most specifically, there seems to be an API provided by Sonatype for this purpose, but you can’t invoke it too often unless you create an account.
InfoQ: What do you like most about maintaining the project?
Mulders: I like the interactions with users of the tool, people telling me how useful it is to them. Also, I’ve had quite a few interesting conversations, both online and offline, about new features and whether/how they would fit in the tool. I should definitely include the fact that releasing the project is really a matter of two mouse clicks and a bit of patience. A few minutes later, the new version will be out, published through major distribution channels like SDKMAN!, Homebrew and Chocolatey. That deserves a shout-out to Andres Almiray – he gave me a lot of help in setting up JReleaser so that creating a new release is actually a fun thing to do, rather than a “fingers crossed” one.
Initially released in December 2021, mcs 0.2.3 is the latest version. More information about mcs can be found in the introduction blog.
MMS • Vivian Hu
Article originally posted on InfoQ. Visit InfoQ
In the Cloud native Wasm day event at KubeCon NA 2022, Docker announced Docker+Wasm technical preview in partnership with CNCF’s Wasm runtime WasmEdge. With a single command, docker compose up, Docker developers can instantly build, share, and run a complete Wasm application.
Wasm was originally developed as a secure sandbox for the web browser. In recent years, it has found many applications on the server-side, as a secure, lightweight, fast, and portable alternative to VMs and Linux containers (LXCs) — an area that was originally pioneered by Docker.
The standard demo app in Docker+Wasm, provided by Second State, is a database-driven web application with one WasmEdge “container” for the entire web service (microservice), and two Linux containers for supporting services — one for the MySQL database and one for NGINX to server the static HTML page for the frontend UI. The three containers run side by side in the same network and form a single application. The microservice is written in Rust and compiled into Wasm. It has a high-performance (non-blocking) HTTP server, an event handler (for the business logic on how to process HTTP requests), and a MySQL database client. The entire “containerized” microservice is only 3MB, compared to hundreds of MBs for the Linux containers for the database and NGINX.
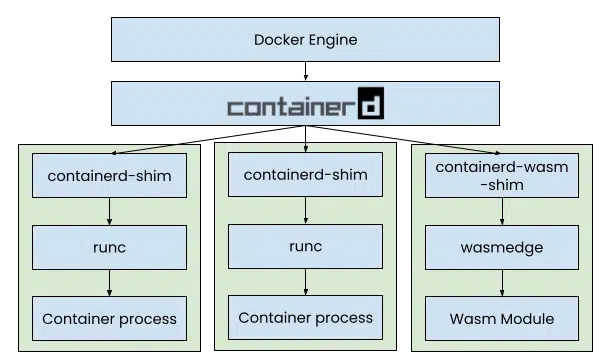
Source: Introducing the Docker+Wasm Technical Preview
Docker Compose not only runs those Wasm applications alongside containers but also builds the Rust source code into Wasm. Developers do not even need to install the Rust compiler toolchain since the entire build environment is also containerized by Docker. Docker + Wasm is a single tool that takes care of both building and running the Wasm applications.
As Docker started the container revolution that led to the cloud-native era, Docker’s commitment to supporting Wasm in a “multi-runtime” world is especially relevant.
The Docker+wasm announcement makes perfect sense. We no longer live in a single-runtime world: there are Linux containers, windows containers, and wasm containers. OCI can package them all, I should be able to build and run them all with @docker. — Solomon Hykes, co-founder of Docker.
The technologies behind Docker+Wasm were largely from the open-source community. For example, Docker relies on a containerd shim called runwasi, originally created by Microsoft’s DeisLabs, to start WasmEdge and execute the Wasm program.
The open-source work could go well beyond Docker. For example, the Red Hat team has integrated Wasm runtime support into OCI runtime crun. That enables the entire Kubernetes stack to support WasmEdge seamlessly apps. In fact, the Liquid Reply team has demonstrated Podman+Wasm using WasmEdge in the days leading up to the KubeCon event.
Other Wasm applications demonstrated at the KubeCon event include AI inference applications, Dapr-based microservices, and data processing functions in streaming pipelines. Now with Docker+Wasm, developers can easily build, share, and run these applications.