Month: November 2017

MMS • Raul Salas
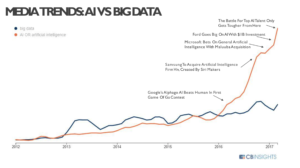
CB Insights analysis of media mentions of Artificial Intelligence and Big Data shows the hype curve for Artificial Intelligence taking off while mentions of Big Data are also starting to increase steadily.
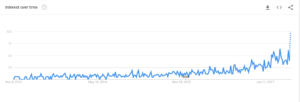
A global google insights search term analysis uncovered some interesting keyword searches that offers some insight into the convergence of big data and Machine learning as well as what country is dominating the keyword searches.
The first search term I analyzed was “Big data AI”. A recent spike in search terminology as expected.
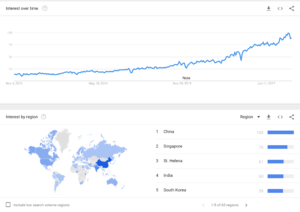
A deeper dive into search analysis the keyword term “Machine Learning”, A subset of Artificial Intelligence was used. What surprised me what that China was on the top of the list in number of searches. I was expecting to see the United States or even Europe at a much higher ranking.
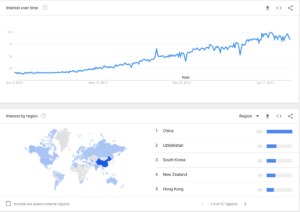
Search Term analysis of key components of Big Data NoSQL databases used in Machine Learning was performed to gain a deeper understanding. The second chart is the search term “Apache Spark” Spark is an advanced, Big Data in-memory Apache Spark computing database engine delivering 100x the performance of Hadoop Artificial Intelligence and Machine Learning workloads. Spark is now being used in conjunction with popular Data Science libraries such as Mlib. Once again, China is the top ranked country for the search term.
Another surprising search term ranking where China was #1 was “Mongodb” Another Big Data NoSQL database used in Machine Learning. I certainly was expecting Mongodb’s country search term top ranking to be the United States, especially since it was founded in New York City!
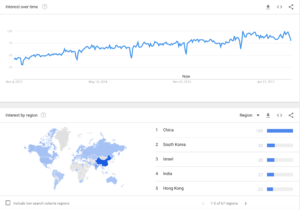
What’s interesting is that China appears to be in the lead in the Big Data and Machine Learning fields. This is certainly not a good sign for the United States in maintaining it’s technology lead needed for economic and military dominance. Currently, China is pushing for an unmanned police station entirely powered by Artificial Intelligence. http://www.siliconrepublic.com/machines/wuhan-police-station-ai-face-scanners There needs to be a renewed focus on STEM education in High Schools and Universities in the United States on the scale of the Manned Moon NASA projects of the 1960s.
Author: Raul Salas Raul@Mobilemonitoringsolutions.com
MMS • Raul Salas
ClustrixDB (www.clustrix.com) created an interesting graphic depicting the future of the relational and NoSQL database platforms. The graphic was interesting and great topic to expand on.
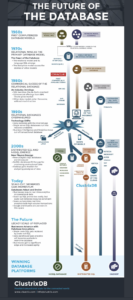
So in order to talk about the future, we first need to talk about the past and present. In the past, there were traditional relational database vendors such as Microsoft and Oracle. These databases were the workhorse of Corporate America as they provided support for banking, finance, and other corporate support activities. Then came the rise of the internet, Mobile, Cloud, and Social media in the early 2000s. This trend resulted in a large growth of unstructured data that resided outside of the corporate firewall. New database technologies such as NoSQL rose to the meet the demand of high volume and velocity data growth. NoSQL databases such as Mongodb, Cassandra, and Hadoop focus on unstructured data processing. While the Relational database platforms focus on traditional structured transactions and single server hardware hosted environments.
It is important to note that in the past 5 years licensing costs for both Oracle and Microsoft database products have increased dramatically. While NoSQL Open source products can be utilized at a much lower price point on a subscription basis or community Open Source versions in a free unsupported mode. NoSQL products such as Hadoop have industry low storage cost price points that show a really positive return on investment, especially housing large amounts of data for data lakes for example. Another trend happening now is that Developers are driving the database adoption trends, not database administrators. This is an important new trend that will drive marketing and business strategies now and for the future both for database vendors as well as their customers.
Today, NoSQL scale-out databases are becoming popular as Machine Learning and Artificial Intelligence become mainstream. The data requirements for this new technology require scale out across commodity hardware that can handle real-time analytics for say self-driving cars or a fully automated manufacturing plant. This is where companies like Google’s Spanner and Clustrix come into play and are pioneers in this space. This technology is a high cost solution, but is an answer to the resource constraints of existing technology.
In the future, Hadoop will remain a player in the batch processing data warehouse/data lake space. While traditional relational database players such as Microsoft and Oracle create new analytics products that are distributed in nature. The database industry could shake out into three distinct areas: NoSQL, Distributed SQL and Hadoop, Single Node traditional SQL will either morph into or get replaced by scale-out SQL as well as existing data warehouse analytics features will become real-time.
A good example of this trend is now happening with Cloudera Hadoop/Spark integration in the new Lambda Architecture which combines real-time processing with Spark and Machine Learning libraries such as mahout and sending data for batch processing in the Hadoop ecosystem and integration. Businesses are already seeing significant competitive edge with predictive analytics and personalization implementing the Lambda architecture.
Raul Salas raul@mobilemonitoringsolutions.com
MMS • Raul Salas

Sort Memory errors in Mongodb and how to resolve them!
So you installed Mongodb and everything seems to be humming along for months and then all of the sudden your application comes to a grinding halt because of the following strange error your receiving from Mongodb:
OperationFailed: Sort operation used more than the maximum 33,554,432 bytes of RAM. Add an index, or specify a smaller limit.’ on server
This error is caused by Mongodb engine exceeding memory capacity limits on sorting when Mongodb cannot use an index. The default memory limit for sorting data is 32 MB. A good first step would be to optimize the query with the explain query parameter, However, to get your application online quickly there is a quick fix for this issue. The default parameter for an internal system parameter called “InternalQueryExecMaxBlockSortBytes” will need to be modified. Let’s verify what the parameters are now on this particular Mongodb instance
db.adminCommand({getParameter: ‘*’})
This will return a large document with the internalQueryExecMaxBlockingSortBytes the value of 33,554,432 bytes (33 MB). So now let’s increase this parameter to 134,217,728 bytes (134 MB) by executing the following command:
db.adminCommand({“setParameter”:1,”internalQueryExecMaxBlockingSortBytes”:134,217,728})
Now execute your query to see if the error goes away! You may need to increase the parameter if your query continues to fail. It would be nice if Mongodb included a metric to monitor this parameter’s usage in a future release.
Update for Mongodb 4.0:
$sort and Memory Restrictions
The $sort stage has a limit of 100 megabytes of RAM. By default, if the stage exceeds this limit, $sort will produce an error. To allow for the handling of large datasets, set the allowDiskUse option to true to enable $sort operations to write to temporary files. See the allowDiskUse option in db.collection.aggregate() method and the aggregate command for details.
Raul Salas
Raul@mobilemonitoringsolutions.com