Month: April 2021

MMS • Nishant Bhajaria
Article originally posted on InfoQ. Visit InfoQ

Subscribe on:
Transcript
Shane Hastie: Hello, folks. Before we get into today’s podcast, I wanted to share with you the details of our upcoming QCon Plus virtual event. Taking place, this May 17 to 28. Qcon Plus focuses on emerging software trends and practices from the world’s most innovative software professionals. All 16 tracks are curated by domain experts to help you focus on the topics that matter right now in software development. Tracks include leading full-cycle engineering teams, modern data pipeline and continuous delivery, workflows and platforms. You’ll learn new ideas and insights from over 80 software practitioners at innovator and early adopter companies. Spaced over two weeks at a few hours per day, experienced technical talks, real-time interactive sessions, asynchronous learning, and optional workshops to help you validate your software roadmap. If you’re a senior software engineer, architect, or team lead, and want to take your technical learning and personal development to a whole new level this year, join us at QCon Plus this May 17 to 28. Visit qcon.plus for more information.
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. I’m sitting down with Nishant Bhajaria. Nishant is the head of privacy engineering and architecture for Uber. Nishant, welcome back, in fact. It’s nearly a year since we last caught up, what’s been happening?
Nishant Bhajaria: Well, besides the obvious, the pandemic, I’ve been working on more courses on LinkedIn Learning, where I teach people on security, privacy, how to build careers, interview for jobs, and also build teams that are inclusive. So, there’s a bunch of coursework happening on that front and it’s been even more involved because now, I can record those at home. So, that’s been keeping me busy. There’s obviously my day job, which I enjoy a lot. And then, I’m writing a book on privacy, which is a book towards engineers program managers, executives, people in media, anybody who wants to understand how privacy works. How do you protect data better? How do you move away from just the first principles? Ethics, aspects of the conversation and actually instrument and build some of the tooling behind the scenes. Writing, teaching, doing your day job keeps you pretty busy. And then, of course, there’s time for dog walks and just hoping to get that vaccine in which, hopefully, I will have had by the time this makes it to the internet.
Shane Hastie: Indeed, it’s been a crazy time all around the world. We’ve just recently published the InfoQ culture & methods trends report, and the shift to remote, of course, was the biggest impact on organizational culture. One of the topics we did touch on in that trends report was, in fact, what’s happening in terms of ethics and engineering. So, maybe we can delve first into that, privacy and ethics. What’s the state of play and are we getting better? Are we getting worse?
Nishant Bhajaria: Well, it’s interesting. We are trying to find a number where the numerator is changing because people are getting better. People are building more tools. There’s more of an industry coming up. As you know, there’s a lot of VC money flowing towards privacy tooling. There’s a lot of people getting into the field. There’s a lot of regulations coming in and hopefully, getting better on that front, as well. But it’s also getting more complex because people’s business models are changing. There’s more confusion about changes in the industry. People’s work habits are changing because of COVID. There’s healthcare data moving around, as well.
Nishant Bhajaria: Because of the improvements being cancelled out by the changes, I think, we’re largely in a state of homeostasis where the more things change, the more they remain the same. What I’m hearing from the industry across the board is we don’t know where to start. We don’t know how to measure success. We don’t know how to train people better. We don’t know how to make sure that we’re moving in the right direction. How do we measure? If you cannot measure improvement, you cannot be certain that improvement is taking place. So, it’s a two-faced answer here. One, things are getting better, but second, it’s hard to ascertain because so much is also changing in the industry, right now.
Shane Hastie: So, if we were to start, and try, and figure out a way to measure, where would we start? What would be the numerator for that baseline?
Nishant Bhajaria: I think the numerator for that baseline would be ensuring that there is some level of organizational consistency and tooling. Shane, when you and I talked last time, we agreed on the fundamental principle that executive sponsorship needs to be geared towards ethics and culture to make sure that we do the right thing in the company. Yes. You agree upon that. Everybody goes home. They get their t-shirts and they tell each other how wonderful ethically they are. But then, there comes a time to make the right choices. How do you make sure that the tools get built? Tools to delete data. Tools to detect data when data should not be collected. Tools to ensure that you don’t share data with unscrupulous actors. Tools to make sure that you understand who has access to what in the company. And that’s where the choices have to be made because people now have to make some trade-offs.
Nishant Bhajaria: You have gotten accustomed to engineers having access to everything. You have the ability to monetize data without any restraint. And now, you’re going to have to be taking some of that stuff away from engineers and the business leaders. How do you build the tooling for that? Where does the resourcing come from? Is it a centralized team? When that team builds resources, how do you make sure that people adopt that tooling? It’s a bit like you are putting a sticker on your fridge saying that, “Inside here are desserts. Do not eat them while their desserts are inside.” Who puts the sticker? Who enforces the obedience of the person living in the house? I feel like that’s where the confusion is. And that’s what motivated me to write this book that I’m talking about here because I feel it gives people the tooling to get started and help people understand the trade-offs as to what happens if you don’t build the tooling right, and what happens if you don’t get that started early on. That’s kind of what I’m picking up across the board from the industry.
Shane Hastie: If I am a leader in an organization and I want to improve our privacy practices and approaches, you said people don’t know where to start. Where would you start?
Nishant Bhajaria: Well, I would start early in the ingestion pipeline. So, one of my favorite diagrams that I talked about when the topic of security, governance, or privacy comes up is think of a funnel and place it horizontally, and the narrow end on the left-hand side, and the broad end on the right-hand side. And as data enters the funnel, more people access it. People infer things from the data. They join that data to other data in the company. They connect it to other data they had previously. They infer things from it. They build MN models based on it. Because of that, the TLDR is, and I know I’m kind of repeating myself a little bit, as you move left to right in the funnel, the data size grows. So, the longer you delay any sort of tooling, the more data you’re dealing with. You might be dealing with duplicative data.
Nishant Bhajaria: You might be dealing with data that is redundant, that is not high quality. So, you are now paying more to store data you may not need, and data which, if used, gives you the wrong answers. But somehow, this phenomenon of data envy, where you feel like you should have all this data because it might be useful down the road, makes your job much harder downstream. Because your ability to delete that data, obfuscate it, protect it, encrypt it, manage access to it. All of that is reduced because you are deluged by the volume of data. So, I would start as early in the process as possible.
Nishant Bhajaria: I would start at the point of ingest and say, “Here’s what’s entered the system. We have an understanding of what it is, what it means, what to do with it”, and make several smaller decisions early in the process, rather than making that one big decision downstream. Because when we delay that one big decision, we keep delaying that one big decision. And the delays get longer, the decision gets bigger, the stakes get higher and we ended up not making a decision until somebody makes that decision for us. Either by passing a law that is not easy to comply with or a breach that is hard to contain. I would recommend putting in place governance tooling as early in the pipeline as possible.
Shane Hastie: How do we balance the need to generate insight and provide customer service, provide better products, with these privacy concerns?
Nishant Bhajaria: I would say… Let me try and phrase the question a little bit and you can set me straight if I didn’t understand it right. Are we suggesting that these privacy concerns are not fixable? Are we saying that it’s endemic to how the products get built? I just want to make sure I understand your question correctly.
Shane Hastie: I picture myself in that leadership position, I want the benefit of being able to see all of that data, get the insights. But I also want to do what is right by my customers from a privacy perspective. So, it feels to me like there’s a trade-off, a difficult balance here.
Nishant Bhajaria: Then, there is and that’s kind of what I was getting at. Which I feel like, when you look at it through that lens, it almost feels like every product is going to have some privacy concerns. And the challenge, Shane, is that the shadow IT world where engineering development has become so decentralized. And because of that desensitized, means that the volume of data is so high, the unstructured nature of data, but you don’t actually know what is in those blobs of data until the right person accesses it, means that it is very hard to know exactly what you have and why you have it. It’s a bit like you have to look inside to know what’s inside by the time it’s already in the house, and you don’t know exactly how to get it out the door. So, my recommendation tends to be build early detection models. Ask people, who needs this data. Understand from a lineage perspective, how this data ended up flowing downstream.
Nishant Bhajaria: Here’s where you can benefit from the legacy that you have built up in the company. You have all of this past history of data, where you have tech debt, which is what is known as the old technical data that you have. Understand how did it get into the system. Who collected it? Who used it? How long was it kept of? And performing an analysis, it’s a bit like going to the doctor and getting an MRI done, or an annual physical done. It won’t cure you right away, but at least you’ll know which numbers are off. And then, you know what to cut back on. And gradually, the old debt will also age out, or you need to know how to delete it better, but you need to understand what you have been doing wrong. It’s a bit like, and I hate to use the analogy of alcoholism, but somebody told me a while ago, they have a psychology degree.
Nishant Bhajaria: They said that one reason why people who are alcoholics are afraid to give up their addiction is because there’s a moment when you stop drinking and you are sober, and then you realize what you look like and all the damage you’ve done, and you are afraid of that moment of reconciliation and facing up to your mistakes, or your weaknesses, or whatever, call it what you will. And that fear is what keeps people from stopping. And they keep going on that destructive path. Data collection is sort of consuming alcohol. You are intoxicated by this volume of data because it tastes so good and the money is so great. And I feel like that’s what stops people from doing the right thing because they’re afraid of what that pause is going to mean. “The other guy’s going to stop, as well, or is it just us? Or will it break all the systems that depend upon this unmitigated flow of data?”
Nishant BhajariaMy advice is intercept data early on. Identify what it is. Tag it so you know exactly what the risk it entails. How it maps, say, a law like GDPR, or CCP or CPR, or what have you. And embed into the data decisions about what it means to have that data. So, who should access it for how long? Could you share this data with somebody else? So, as an example, if you are collecting data about people’s shopping behaviors, to run and give them an ad, it may make sense to collect some data in a way to surface an ad right away because you want them to make a purchase right away. It makes sense. That’s how the internet works. But if you are sharing that data with an outside vendor, to give them an ad the next day, you might want to anonymize that data so that maybe, you key-off of some other ID, which you can be used to give them that ad in specific environments where they have agreed to be served data that was collected from them before.
Nishant Bhajaria: There are these trade-offs where, how you collect data, what you use it for when you use it for, how identifiable that data is, you can only make these sorts of decisions if you intercept that data early on. Again, I’m going to bring back my horizontal funnel. If you make this decision further down the funnel, at which point the volume of data has grown, your ability to detect data has shrunk. And therefore, the error rate has gone up, significantly, and that’s where laziness takes over. “Will it go? We’ll do it later on.” And that data then remains in your system. It gets copied to 50 other places. It gets shared accidentally to some other vendor, and then they suffered a breach. And then, you ended up getting fined. Your customer stopped trusting you. And then, everybody wakes up downstream saying, “Oh, my goodness. How did this happen?” Well, the mistake was made several steps before, and it’s almost impossible to reverse engineer and fix it after the fact. So, if that makes sense there.
Shane Hastie: We have so many sources of data today. There’s everything we’re carrying around with us. There are all of the apps, all of our devices, desktop, laptop. My smart light bulb knows things about me. There is this plethora of this lake of data. How can I, putting this on the other end, how can I, as a consumer, start to feel comfortable that people are using my data well? But I want the benefit of being able to tell my smart light bulb to turn on when I walk into the room.
Nishant Bhajaria: Yeah. And that’s where there is an interesting dichotomy, Shane. It’s like Abraham Lincoln basically said that, “Democracy is the worst form of government, except for the rest.” And technology is the same thing. We can dislike tech companies all we want to, but at the end of the day, there is a back and forth here. The data fuels the products. The products then produce more data, which then produce other products, and back and forth it goes. Where I think people need to be careful is, at some point, when you collect data to… For example, if I’m collecting your data to make an appliance that’s responsive to your needs at immediate notice, there is a definitive expectation where you provide me data that is tied to your needs, that is tied to a specific timeframe. What happens if that data then gets used for something completely different? If you consent to let your data be used for that product to be adaptable for your needs, what happens when that data then gets used to market other things to you?
Nishant Bhajaria: What happens when that data then gets sold to another vendor, that then builds a website or a quiz marketed to you, that then gets used to collect even more data. So, now you see how… Data is a bit like energy, it never completely disappears. It just keeps regenerating. How do you ensure that what is collected gets used for its intended purpose? How do you make sure that it is deleted on time? How do you make sure that there is trust on that front? Or in this case, I may collect your data that was mapped for your usage if you will, but then I can aggregate the behaviors that you demonstrated but disconnect those behaviors from your ID. So, I will not know that it’s Shane Hastie’s data, but I will know that somebody in their forties or thirties who lives in the ANZACs, uses their home appliance at this time of the day and have specific things done.
Nishant Bhajaria: And that enables me to build behavioral profiles of users like you, and build better products and invest better, right? That’s okay, theoretically speaking it, as long as I’m protecting your privacy but also fueling my business. But those decisions are only possible if you understand exactly what the privacy implications are of the data usage. For example, I can disconnect your ID, but can I also disconnect your IP address? If you live in a big city, say, Auckland, or Napier, or Dunedin, well, there’s a ton of people who live there, maybe I don’t identify you. But what if you live in a small town like Elko, Nevada, where maybe very few people live. So, there identifying of your data means, it’s as good as identifying you. So, there are trade-offs that have to be made based on location, as well. So, those sorts of decisions need to be made and it requires some level of early intervention.
Shane Hastie: Tell us a bit more about the book. What’s in it? Why should I buy it?
Nishant Bhajaria: I think, you should buy it because it helps you how to build privacy into your company. It’s one of those things where the longest leap, at this point, is between what gets discussed in privacy, in the media, and actually doing it right within your company, in a way that is responsible, scalable, transparent, and credible. The gap between the sentiment and the action is really wide. And it is not helped by us moving so quickly from, “Oh, my goodness. Who cares about privacy?” This was four or five years ago. It’s on the press every single day. Company after company, politician after politician wants to talk about this. But sometimes, to me, for those of us that have been in this field for a while, it feels like a bit of a feeding frenzy where it’s like, I’m not sure how many people actually know what it takes to build some of these tools or the trade-offs that need to get made, or how do you get executive buy-in. There’s a rhythm to it.
Nishant Bhajaria: There’s a strategy to it where you build a little bit, you show outcomes, you demonstrate that the business can still function. You can protect customers and actually have a value proposition and also do the right thing for privacy. And then, you use that when to get more buy-in, and you get that buy-in and build more products. There’s a sequence to it, but it takes time for those results to show up. So, this book will help you build tooling, that will help you understand data governance, that will connect all the new stories. For example, the New York Times had this pretty detailed report, back in late 2019, about how President Trump and his entourage were detected as they were traveling in Florida, where he played golf at Mar-a-Lago. He had a meal with the Japanese Prime Minister, and then he came back for the fundraiser. And the reason that happened is because somebody in his entourage had a smartphone with an app that was broadcasting location data.
Nishant Bhajaria: Journalists sitting at the New York Times headquarters were tracking the most protected human being on the planet because somebody in his entourage had a smartphone that was broadcasting location data. Find that great information, but what does that mean in terms of tooling? What does that mean in terms of data deletion? What does that mean in terms of sound data governance? How do I review my products better before they get shipped out the door and start collecting a ton of data? How do you instrument those things? How do you hire people? How do you train people? How do you build the UI? How do you build a back-end databases? What are the trade offs? Now, this book is interesting for me, and I’m always be an interested party cause I wrote it, but it has enough learnings from my past where I tell people, “Here are the patterns you need to observe.”
Nishant Bhajaria: It is not overly prescriptive, where it doesn’t tie itself to a specific set of technologies, but it’s instructive enough where you can read it and understand what to do and what not to do, and apply it to your unique circumstance. What makes privacy challenging, Shane, is that everybody’s tech stack is just a bit different. Everybody’s business lines are just a bit different. So, how do you take a book and apply it to all of these different skills in different domains? Because remember everybody builds products differently in the company. People have different release cycles, different code teams, et cetera.
Nishant Bhajaria: They don’t often talk to each other. For privacy, we’re going to have to stitch these alliances together. So, this book will help you provide the context. One last example I’ll give is, countries that are great, I believe, are democracies because democracies have hardware and software. They have hardware that is, they have armies, they have good business systems, they have civic institutions. And they have good software that is, they have communities, they have infrastructure, they have educational institutions, laws and truth, values that we respect. Privacy requires both hardware and software. Privacy requires tooling and organizational alignment. And this book provides both. It’s like democratizing privacy in a way that is actionable.
Shane Hastie: What are the trends? We spoke right at the beginning about ethics, and you said, “We’re getting better.” But the challenges are getting greater, so we’re sort of sitting in the middle. What are the trends that you’re seeing that we need to consider when we look forward for the next 6, 12, 18 months? I
Nishant Bhajaria: I think trends are interesting. And I predicted a year ago, today, actually the 5th of March 2020. And I told my friend that COVID was going to be a two-day story, and that did not wear very well. So, I’m a little humble when it comes to broadcasting the future. But I do know more about privacy and security, and software, and business than I do about medicine. So, maybe I should stick to my domain of expertise. So, my trend, when it comes to privacy, my prediction is we’re going to see a great deal of splintering. My hope would be to have some sort of, catch-all, federal legislation in the US that provides clarity on exactly what privacy means. How do you apply it? How do you build it? Things like that. What, instead, we’re probably going to see, several state level laws, different interpretations of those laws at maybe, the local or federal level. We’re going to see a lot of confusion and what’s going to happen, as a result, is there’s going to be tons of vendors.
Nishant Bhajaria: We’re already seeing vendors, some specializing in consent. Some specializing in data governance. Some specializing in data detection, and protection, and encryption. And we’re going to see this patchwork model where you will have on the one hand, more awareness, more tooling, more regulations, which has this feeling of having what airport security because you feel if all these folks are watching us, surely the bad folks won’t get on the plane. On the flip side, it’s going to be very hard to measure because when you have so much siloing of the efforts that happen, it’s going to be very hard to judge the effectiveness of how well is the user being protected.
Nishant Bhajaria: You’re going to see maybe, breaches or privacy harms would become big news stories, which is going to be used as evidence that nothing is working. Or you’re going to see this long period of no activity, where people are going to think they’re okay, all these laws are working because we’re not seeing all these bad stories in the press anymore, but you might still be making mistakes. So, we’re going to see a lot of false positives and false negatives. That’s kind of my somewhat, not very optimistic narrative for the future.
Shane Hastie: How do we turn that around? How do we turn that into a more positive story?
Nishant Bhajaria: I think how we turn that into a more positive story is by ensuring that companies invest early in privacy. And I have made the case in the book that you can invest in privacy early and make a very affirmative use case to improve your relationship with the customer. When you delete data, you end up with less data, but you have more of the data you actually care about, which means fewer queries, fewer burn cycles, fewer copies of bad data. And as a result, you have a better end outcome. You spend less money storing data you don’t need. One of my friends who does PR in privacy and security, she’s very sharp, she tells me that the best way to protect data is to not have it. So, if you have data that’s sitting in your warehouse or sitting in your Cassandra storage, expecting to be used later on, you are also spending money to protect that data.
Nishant Bhajaria: You’re spending money, managing encryption keys, access control algorithms to protect it, et cetera. If you delete that data soon or obfuscate it, you are not spending as much money protecting it. So, the case I’m making is, you lean in a little bit early, you spend the money early on, and as a result, the investment you have downstream ended up getting better. You have better products. You end up saving money, downstream. You have less security risks. You have less of this worry as to something bad will happen. So, I would say, don’t wait for the government to tell you what to do. We all know what the right way to do this. There’s tooling examples in the book. There’s other examples out there. Use it, make those investments early, and then use the regulations of this world as a floor, not a ceiling.
Shane Hastie: One of the things that you spoke about was shifting to the left, earlier on, before stuff comes into that inverted funnel of yours. One of the potential challenges I see there, or is it a challenge? How do our small autonomous two-pizza teams we’re working on, things further on the right of the pipe, how do they shift themselves to the left?
Nishant Bhajaria: I think honestly, for some team, Shane, it’s going to be very hard to shift further to the left. So, I would say we need to look at governance much more broadly. Governance, historically, is this catch-all term, which basically seems to mean that we’re going to do the right thing. We want to check these boxes. “Did you check this feature? I checked it. It’s great.” But my advice to companies is let’s come up with a way to catalog this data early on in the process. What that means is let’s assume you are a company that collects data about people’s shopping habits. You basically have a user profile. You collect data about them, for example, their home address, and you use that data for two purposes. Again, we’re going to be very over-simplistic here. You collect that data to ship products to them, but you also use that address to do some research.
Nishant Bhajaria: That is, what are people in the zip code doing? What kind of products are they buying? When do they buy them? How much do they click on ads? What operating system are they using on their smartphones? Things like that. Because that tells you a lot about purchasing patterns. Now, these teams downstream that you speak of could serve two purposes. They could either serve a fulfillment purpose. In which case, they are shipping stuff to people that they bought and paid for. In which case, they need to have access to the full address because you can’t ship something to my house unless you know exactly where I live. But if you are using my purchasing habits to make inferences about what I might like to buy in the future. So, as an example, if I bought a new leash or a new coat for my dog, you could infer that maybe I’ve got a new pet and maybe, two weeks down the road, I’ll need pet food. Four weeks down the road, I might need pet supplies.
Nishant Bhajaria: Six weeks down the road, I might need medical refills. Those sorts of inferences you might do, not just on me, but for a whole bunch of other users. So, when these downstream teams get that data, you might want to anonymize my address, my email address. Obfuscate my home address, as well. Maybe, round off some decimal points from my IP address. So, you can call it a bigger circle and get more data, analyze more information, but not aim it towards me. So, I would say apply tags to the data that says, “Home address underscore single use, underscore user purchase.” If I see that tag, I know that this data is very granular. It has a human being’s specific home address. I should only use it to ship something. But if I’m doing analysis, maybe I should let this data go or delete it.
Nishant Bhajaria: On the other hand, you could come up with a separate tag that says, “Home address, underscore obfuscated, underscore three decimal points. What that means is, it does not have my home address, it only has my IP address, but only has three decimal points, which means it probably covers four or five blocks, which means you can get more quality analysis by getting more correct data in terms of covering more use cases, but not identify a specific person. So, you have now achieved two goals. You have achieved better data protection for me, from a privacy perspective, and enable the fact that you are now looking at data much more holistically and getting better outcomes. But the only way these downstream teams will be able to make those decisions is if the people who collect the data upstream, apply those tags to the data. So, you need better connections between these upstream and downstream teams.
Nishant Bhajaria: I would say, rather than the downstream teams moving them further to the left, I would say have them talk to the people, the people who collect the data. The collectors need to talk to the consumers. The collectors no longer get to say, “I collected it. It’s not my responsibility to protect it.” That’s historically, been the position on a lot of companies. No more of that. And the consumers can no longer say that, “We’re not responsible for what gets collected. We’re just going to use what we use.” No, these folks need to talk to each other. And the people who collect the data need to know how it gets used. And the people who use the data need to know how it gets collected. That bridge is going to be very critical. I’m okay with people living in your islands, but let’s have some bridges in between.
Shane Hastie: Those bridges are sometimes hard to build.
Nishant Bhajaria: Yeah, it cost money.
Shane Hastie: I’m going to go beyond money. There’s a culture shift here, isn’t there?
Nishant Bhajaria: It is. That’s one of those things where the volume of data sometimes, wipes away the significance of it. I was talking to a friend of mine the other day, and she was complaining about a specific politician who lies a lot. And she said that this guy lies so much, his lies almost don’t matter. And there’s sort of a truth to it. Where if you lie so much, people stop believing you and it almost doesn’t matter anymore. So, what happens? The parallel I’m drawing here is that the data that is collected is so voluminous that people forget how important that data is for individual users, because there are so many users in this case. When you have privacy rights being violated for so many users, an individual user often is forgotten. My push from a cultural perspective is that the people who collect the data are just as invested as the people who use it.
Nishant Bhajaria: Because what happens is, if you end up with data being collected incorrectly, and somebody has to go and delete the data, all those changes have to be made pretty quickly. They have to be made pretty suddenly. And now everybody’s impacted. The people who collected correctly, and the people who collected incorrectly. The people who use it wisely, and the people who use it unwisely. The people who manage the data platforms. The people who manage the microservices. The people who manage the hive storage. The people who run the queries. The people who do the audits. I wouldn’t want to be the engineer, whose cavalier behavior towards data, causes so much churn downstream. So, the culture change here is I could do 50 correct things, but the one wrong thing I do could be so disruptive towards the company’s reputation towards the end user. So, why not do the right thing at the get-go?
Nishant Bhajaria: Because just as I wouldn’t like it, if somebody else disrupts me, I wouldn’t want to be the one disrupting somebody else. So, the culture change is about doing the right thing in a way that doesn’t just benefit you, it benefits everyone else. And I feel like this has to come from the top. It’s like innovation initiative always starts bottom up, but culture has to start from the top down. If you see senior executives in the company, senior leadership leaning in and saying, “Let’s do the right thing from a privacy perspective. Investing in it and then making the hard choices and making sure that the wrong stuff doesn’t ship out the door, unimpeded.” Those choices send a message. And I think, the cultural choice is important. And that’s why I was leaning into the money aspect, because I usually try to make the argument with money first, because you make the money argument to get people’s attention.
Nishant Bhajaria: And then, you make the cultural argument. In some cases I made the cultural argument for it literally, varies on a case by case basis. But for people like me, that have been in the privacy field for a long time, we’re just accustomed to making the financial argument because so much of our early career was spent not knowing where the cultural argument would go. We’ve had more success with the money argument, but my encouragement where people would be, to lean in both on the money argument and the cultural argument because you don’t know exactly who the person on the other side of the table is and what’s going to sell better.
Shane Hastie: You said the book’s coming. It’s called Privacy by Design. It’s coming from Manning. Where can people find it, and where can they find you?
Nishant Bhajaria: The book’s title is Privacy by Design, and it’s on manning.com. If you go to manning.com and enter my name, or if you just Google my name, it’s one of the earliest links that comes up. It’s going to be released later on this fall. You can find me on LinkedIn. And just reach out to me on LinkedIn, I’d be happy to provide you a link. It’s already doing pretty well on pre-sales because there’s a significant level of interest based on people who are struggling to do the right thing. What I’m seeing, Shane, is that there’s a lot of interest among the engineering population, because these are folks who need to actually handle the data correctly from a privacy perspective. But there’s also a lot of interests at the executive level because they routinely get hit with these fines, these budget requests, these headcount requests. So, they need to understand why exactly they’re spending all this money, and what the cost of not spending it would be.
Nishant Bhajaria: I’m also seeing a lot of uptake from the media industry. There’s a lot of interest among the journalist community. People want to understand exactly what happens behind the scenes. What are the trade-offs from a privacy perspective? I’m seeing a lot of uptake there, as well. I would say, I would not want people to think of this book as being only for the executives, or only for the engineers. It’s for literally anybody who wants to get started in this field. There’s material in it that’s fairly at the beginners level. There’s material in it for people that are much further along, and then there’s stuff in it for people that are much more advanced. So, it’s manning.com/privacybydesign. That’s the link for the book.
Shane Hastie: Nishant, thanks ever so much. It’s been good to catch up.
Nishant Bhajaria: Definitely. Thank you so much Shane, again, for having me.
Mentioned
Validate your software roadmap by learning the trends, best practices, and solutions applied by the world’s most innovative software professionals. Deep-dive
with over 80 software leaders to help you learn what should be on your radar.
Discover the 16 software topics curated by domain experts. Join over 1500 of
your peers at QCon Plus this May 17-28.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

SPARQL is a powerful language for working with RDF triples. However, SPARQL can also be difficult to work with, so much so that it often is not utilized anywhere near as often for its advanced capabilities, which include aggregating content, building URIs, and similar uses. This is the second piece in my exploration of OntoText’s GraphDB database, but many of these techniques can be applied with other triple stores as well.
Tip 1. OPTIONAL and Coalesce()
These two keywords tend to be used together because they take both advantage of the Null value. In the simplest case, you can take advantage of coalesce to provide you with a default value. For instance, suppose that you have an article that may have an associated primary image, which is an image that is frequently used for generating thumbnails for social media. If the property exists, use it to retrieve the URL, but if it doesn’t, use a default image URL instead.
# Turtle
article:_MyFirstArticle
a class:_Article;
article:hasTitle “My Article With Image”^^xsd:string;
article:hasPrimaryImage “path/to/primaryImage.jpg”^^xsd:anyURI;
.
article:_MyFirstArticle
a class:_Article;
article:hasTitle “My Article Without Image”^^xsd:string;
.
With SPARQL, the OPTIONAL statement will evaluate a triple expression, but if no value is found to match that query then rather than eliminating the triple from the result set, SPARQL will set any unmatched variables to the value null. The coalesce statement can then query the variable, and if the value returned is null, will offer a replacement:
#SPARQL
select ?articleTitle ?articleImageURL where {
?article a class:_Article.
?article article:hasTitle ?title.
optional {
?article article:hasPrimaryImage ?imageURL.
}
bind(coalesce(?imageURL,”path/to/defaultImage.jpg”^^xs:anyURI) as ?articleImageURL)
}
This in turn will generate a tuple that looks something like the following:
|
articleTitle |
articleImageURL |
|
My Article With Image |
path/to/primaryImage.jpg |
|
My Article Without Image |
path/to/defaultImage.jpg |
Coalesce takes an unlimited sequence of items and returns the first item that does not return a null value. As such you can use it to create a chain of precedence, with the most desired property appearing first, the second most desired after that and so forth, all the way to a (possible) default value at the end.
You can also use this to create a (somewhat kludgy) sweep of all items out a fixed number of steps:
# SPARQL
select ?s0 ?s1 ?s2 ?s3 ?s4 ?o ?hops where {
values ?s1 {my:_StartingPoint}
bind(0 as ?hops0)
?s1 ?p1 ?s2.
filter(!bound(?p1))
bind(1 as ?hops1)
optional {
?s2 ?p2 ?s3.
filter(!bound(?p2))
bind(2 as ?hops2)
optional {
?s3 ?p3 ?s4.
filter(!bound(?p3))
bind(3 as ?hops3)
optional {
?s4 ?p4 ?o.
filter(!bound(?p4))
bind(4 as ?hops4)
}
}
}
bind(coalesce(?hops4,?hops3,?hops2,?hops1,?hops) as ?hops)
}
The bound() function evaluates a variable and returns true() if the variable has been defined and false() otherwise, while the ! operator is the not operator – it flips the value of a Boolean from true to false and vice-versa. Note that if the filter expression evaluates to false(), this will terminate the particular scope. A bind() function will cause a variable to be bound, but so will a triple expression … UNLESS that triple expression is within an OPTIONAL block and nothing is matched.
This approach is flexible but potentially slow and memory intensive, as it will reach out to everything with four hops of the initial node. The filter statements act to limit this: if you have a pattern node-null-null, then this should indicate that the object is also a leaf node, so no more needs to be processed. (This can be generalized, as will be shown below, if you’re in a transitive closure situation).
Tip 2. EXISTS and NOT EXISTS
The EXISTS and NOT EXISTS keywords can be extraordinarily useful, but they can also bog down performance dramatically is used incorrectly. Unlike most operators in SPARQL, these two actually work upon sets of triples, returning true or false values respectively if the triples in question exist. For instance, if none of ?s, ?p or ?o have been established yet: the expression:
# SPARQL
filter(NOT EXISTS {?s ?p ?o})
WILL cause your server to keel over and die. You are, in effect, telling your server to return all triples that don’t currently exist in your system, and while this will usually be caught by your server engine’s exception handler, this is not something you want to test.
However, if you do have at least one of the variables pinned down by the time this expression is called, these two expressions aren’t quite so bad. For starters, you can use EXISTS and NOT EXISTS within bind expressions. For example, suppose that you wanted to identify any orphaned link, where an object in a statement does not have a corresponding link to a subject in another statement:
# SPARQL
select ?o ?isOrphan where {
?s ?p ?o.
filter(!(isLiteral(?o))
bind(!(EXISTS {?o ?p1 ?o2)) as ?isOrphan)
}
In this particular case, only those statements in which the final term is not a literal (meaning those for which the object is either an IRI or a blank node) will be evaluated, The bind statement then looks for the first statement in which the ?o node is a subject in some other statement, the EXISTS keyword then returns true if at least one statement is found, while the ! operator inverts the value. Note that EXISTS only needs to find one statement to be true, while NOT EXISTS has to check the whole database to make sure that nothing exists. This is equivalent to the any and all keywords in other languages. In general, it is FAR faster to use EXISTS this way than to use NOT EXISTS.
Tip 3. Nested IF statements as Switches (And Why You Don’t Really Need Them)
The SPARQL if() statement is similar to the Javascript condition?trueExpression:falseExpression operator, in that it returns a different value based upon whether the condition is true or false. While the expressions are typically literals, there’s nothing stopping you from using object IRIs, which can in turn link to different configurations. For instance, consider the following Turtle:
#Turtle
petConfig:_Dog a class:_PetConfig;
petConfig:hasPetType petType:_Dog;
petConfig:hasSound “Woof”;
.
petConfig:_Cat a class:_PetConfig;
petConfig:hasPetType petType:_Cat;
petConfig:hasSound “Meow”;
.
petConfig:_Bird a class:_PetConfig;
petConfig:hasPetType petType:_Bird;
petConfig:hasSound “Tweet”;
.
pet:_Tiger pet:says “Meow”.
pet:_Fido pet:says “Woof”.
pet:_Budger pet:says “Tweet”.
You can then make use of the if() statement to retrieve the configuration:
# SPARQL
select ?pet ?petSound ?petType where {
values (?pet ?petSound) {(pet:_Tiger “Meow”)}
bind(if(?petSound=’Woof’,petType:_Dog,
?petSound=’Meow’,petType:_Cat,
?petSound=’Tweet’,petType:_Bird,
()) as ?petType)
}
where the expression () returns a null value.
Of course, you can also use a simple bit of Sparql to infer this without the need for the if s#tatement:
# SPARQL
select ?pet ?petSound ?petType where {
values (?pet ?petSound) {(pet:_Tiger “Meow”)}
?petConfig petConfig:hasSound ?petSound.
?petConfig petConfig:hasPetType ?petType.
}
with the results:
|
?pet |
?petSound |
?petType |
|
pet:_Tiger |
“Meow” |
petType:_Cat |
As a general rule of thumb, the more that you can encode as rules within the graph, the less that you need to rely on if or switch statements and the more robust your logic will be. For instance, while a dogs and cats express themselves in different ways most of the time, both of them can growl:
#Turtle
petConfig:_Dog a class:_PetConfig;
petConfig:hasPetType petType:_Dog;
petConfig:hasSound “Woof”,”Growl”,”Whine”;
.
petConfig:_Cat a class:_PetConfig;
petConfig:hasPetType petType:_Cat;
petConfig:hasSound “Meow”,”Growl”,”Purr”;
.
|
?pet |
?petSound |
?petType |
|
pet:_Tiger |
“Growl” |
petType:_Cat |
|
Pet:_Fido |
“Growl” |
petType:_Dog |
In this case, the switch statement would break, as Growl is not in the options, but the direct use of SPARQL works just fine.
Tip 4. Unspooling Sequences
Sequences, items that are in a specific order, are fairly easy to create with SPARQL but surprisingly there are few explanations for how to build them . . . or query them. Creating a sequence in Turtle involves putting a list of items in between parenthesis as part of an object. For instance, suppose that you have a book that consists of a preface, five numbered chapters, and an epilogue. This would be expressed in Turtle as:
#Turtle
book:_StormCrow book:hasChapter (chapter:_Prologue chapter:_Chapter1 chapter:_Chapter2 chapter:_Chapter3
chapter:_Chapter4 chapter:_Chapter5 chapter:_Epilogue);
Note that there are no commas between each chapter.
Now, there is a little magic that Turtle parsers do in the background when parsing such sequences. They actually convert the above structure into a string with blank nodes, using the three URIs rdf:first, rdf:rest and rdf:nil. Internally, the above statement looks considerably different:
# Turtle
book:_StormCrow book:hasChapter _:b1.
_:b1 rdf:first chapter:_Prologue.
_:b1 rdf:rest _:b2.
_:b2 rdf:first chapter:_Chapter1.
_:b2 rdf:rest _:b3.
_:b3 rdf:first chapter:_Chapter2.
_:b3 rdf:rest _:b4.
_:b4 rdf:first chapter:_Chapter3.
_:b4 rdf:rest _:b5.
_:b5 rdf:first chapter:_Chapter4.
_:b5 rdf:rest _:b6.
_:b6 rdf:first chapter:_Chapter5.
_:b6 rdf:rest _:b7.
_:b7 rdf:first chapter:_Epilogue.
_:b7 rdf:rest rdf:nil.
While this looks daunting, programmers might recognize this as being a very basic linked list, whether rdf:first points to an item in the list, and rdf:rest points to the next position in the list. The first blank node, _:b1, is then a pointer to the linked list itself. The rdf:nil is actually a system defined URI that translates into a null value, just like the empty sequence (). In fact, the empty sequence in SPARQL is in fact the same thing as a linked list with no items and a terminating rdf:nil.
Since you don’t know how long the list is likely to be (it may have one item, or thousands) building a query to retrieve the chapters in their original order would seem to be hopeless. Fortunately, this is where transitive closure and property paths come into play. Assume that each chapter has a property called chapter:hasTitle (a subproperty of rdfs:label). Then to retrieve the names of the chapters in order for a given book, you’d do the following:
# SPARQL
select ?chapterTitle where {
values ?book {book:_StormCrow}
?book rdf:rest*/rdf:first ?chapter.
?chapter chapter:hasTitle ?chapterTitle.
}
That’s it. The output, then, is what you’d expect for a sequence of chapters:
|
pointsTo |
|
chapter:_Prologue |
|
chapter:_Chapter1 |
|
chapter:_Chapter2 |
|
chapter:_Chapter3 |
|
rdf:nil |
The property path rdf:rest*/rdf:first requires a bit of parsing to understand what is happening here. property* indicates that, from the subject, the rdf:rest path is traversed zero times, one time, two times, and so forth until it finally hits rdf:nil. Traversing zero times may seem a bit counterintuitive, but it means simply that you treat the subject as an item in the traversal path. At the end of each path, the rdf:first link is then traversed to get to the item in question (here, each chapter in turn. You can see this broken down in the following table:
|
path |
pointsTo |
|
rdf:first |
chapter:_Prologue |
|
rdf:rest/ rdf:rest/rdf:first |
chapter:_Chapter1 |
|
rdf:rest/r rdf:rest/ rdf:rest/df:first |
chapter:_Chapter2 |
|
rdf:rest/ rdf:rest/ rdf:rest/ rdf:rest/rdf:first |
chapter:_Chapter3 |
|
rdf:rest/ rdf:rest/ rdf:rest/ rdf:rest/rdf:rest |
rdf:nil |
If you don’t want to include the initial subject in the sequence, then use rdf:rest+/rdf:first where the * and + have the same meaning as you may be familiar with in regular expressions, zero or more and one or more respectively.
This ability to traverse multiple repeating paths is one example of transitive closure. Transitive closures play a major role in inferential analysis and can easily take up a whole article in its own right, but for now, it’s just worth remembering the ur example – unspooling sequences.
The ability to create sequences in TURTLE (and use them in SPARQL) makes a lot of things that would otherwise be difficult if not impossible to do surprisingly easy.
As a simple example, suppose that you wanted to find where a given chapter is in a library of books. The following SPARQL illustrates this idea:
# SPARQL
select ?book where {
values ?searchChapter {?chapter:_Prologue}
?book a class:_book.
?book rdf:rest*/rdf:first ?chapter.
filter(?chapter=?searchChapter)
}
This is important for a number of reasons. In publishing in particular there’s a tendency to want to deconstruct larger works (such as books) into smaller ones (chapters), in such a way that the same chapter can be utilized by multiple books. The sequence of these chapters may vary considerably from one work to the next, but if the sequence is bound to the book and the chapters are then referenced there’s no need for the chapters to have knowledge about its neighbors. This same design pattern occurs throughout data modeling, and this ability to maintain sequences of multiply utilized components makes distributed programming considerably easier.
Tip 5. Utilizing Aggregates
I work a lot with Microsoft Excel documents when developing semantic solutions, and since Excel will automatically open up CSV files, using SPARQL to generate spreadsheets SHOULD be a no brainer.
However, there are times where things can get a bit more complex. For instance, suppose that I have a list of books and chapters as above, and would like for each book to list it’s chapters in a single cell. Ordinarily, if you just use the ?chapterTitle property as given above, you’ll get one line for each chapter, which is not what’s wanted here:
# SPARQL
select ?bookTitle ?chapterTitle where {
values ?searchChapter {?chapter:_Prologue}
?book a class:_book.
?book rdf:rest*/rdf:first ?chapter.
?chapter chapter:hasTitle ?chapterTitle.
?book book:hasTitle ?bookTitle.
}
This is where aggregates come into play, and where you can tear your hair out if you don’t know the Ninja Secrets. To make this happen, you need to use subqueries. A subquery is a query within another query that calculates output that can then be pushed up to the calling query, and it usually involves working with aggregates – query functions that combine several items together in some way.
One of the big aggregate workhorses (and one that is surprisingly poorly documented) is the concat_group() function. This function will take a set of URIs, literals or both and combine them into a single string. This is roughly analogous to the Javascript join() function or the XQuery string-join() function. So, to create a comma separated list of chapter names, you’d end up with a SPARQL script that looks something like this:
# SPARQL
select ?bookTitle ?chapterList ?chapterCount where {
?book a class:_book.
?book book:hasTitle ?bookTitle.
{{
select ?book
(group_concat(?chapterTitle;separator=”n”) as ?chapterList)
(count(?chapterTitle) as ?chapterCount) where {
?book rdf:rest*/rdf:first ?chapter.
?chapter chapter:hasTitle ?chapterTitle.
} group by ?book
}}
}
The magic happens in the inner select, but it requires that the SELECT statement includes any variable that is passed into it (here ?book) and that the same variable is echoed in the GROUP BY statement after the body of the subquery.
Once these variables are “locked down”, then the aggregate functions should work as expected. The first argument of the group_concat function is the variable to be made into a list. After this, you can have multiple optional parameters that control the output of the list, with the separator being the one most commonly used. Other parameters can include ROW_LIMIT, PRE (for Prefix string), SUFFIX, MAX_LENGTH (for string output) and the Booleans VALUE_SERIALIZE and DELIMIT_BLANKS, each separated by a semi-colon. Implementations may vary depending upon vendor, so these should be tested.
Note that this combination can give a lot of latitude. For instance, the expression:
# SPARQL
group_concat(?chapterTitle;separator=”</li><li>”;pre=”<ul><li>”;suffix=”</li></ul>”)
will generate an HTML list sequence, and similar structures can be used to generate tables and other constructs. Similarly, it should be possible to generate JSON content from SPARQL through the intelligent use of aggregates, though that’s grist for another article.
The above script also illustrates how a count function has piggy-backed on the same subquery, in this case using the COUNT() function.
It’s worth mentioning the spif:buildString() function (part of the SPIN Function library that is supported by a number of vendors) which accepts a string template and a comma-separated list of parameters. The function then replaces each instance of “{?1}”,”{?2}”, etc. with the parameter at that position (the template string being the zeroeth value). So a very simple report from above may be written as
# SPARQL
bind(spif:buildString(“Book ‘{$1}’ has {$2} chapters.”,?bookTitle,?chapterCount) as ?report)
which will create the following ?report string:
Book ‘Storm Crow’ has 7 chapters.
This templating capability can be very useful, as templates can themselves be stored as resource strings, with the following Turtle:
#Turtle
reportTemplate:_BookReport
a class:_ReportTemplate;
reportTemplate:hasTemplateString “Book ‘{$1}’ has {$2} chapters.”^^xsd:string;
.
This can then be referenced elsewhere:
#SPARQL
select ?report where {
?book a class:_book.
?book book:hasTitle ?bookTitle.
{{
select ?book
(group_concat(?chapterTitle;separator=”n”) as ?chapterList)
(count(?chapterTitle) as ?chapterCount) where {
?book rdf:rest*/rdf:first ?chapter.
?chapter chapter:hasTitle ?chapterTitle.
} group by ?book
}}
reportTemplate:_BookReport reportTemplate:hasTemplateString ?reportStr.
bind(spif:buildString(?reportStr,?bookTitle,?chapterCount) as ?report).
}
With output looking something like the following:
|
report |
|
Book ‘Storm Crow’ has 7 chapters. |
|
Book “The Scent of Rain” has 25 chapters. |
|
Book “Raven Song” has 18 chapters. |
This can be extended to HTML-generated content as well, illustrating how SPARQL can be used to drive a basic content management system.
Tip 6. SPARQL Analytics and Extensions
There is a tendency among programmers new to RDF to want to treat a triple store the same way that they would a SQL database – use it to retrieve content into a form like JSON and then do the processing elsewhere. However, SPARQL is versatile enough that it can be used to do basic (and not so basic) analytics all on its own.
For instance, consider the use case where you have items in a financial transaction, where the items may be subject to one of three different types of taxes, based upon specific item details. This can be modeled as follows:
# Turtle
item:_CanOfOil
a class:_Item;
item:hasPrice 5.95;
item:hasTaxType taxType:_NonFoodGrocery;
.
item:_BoxOfRice
a class:_Item;
item:hasPrice 3.95;
item:hasTaxType taxType:_FoodGrocery;
.
item:_BagOfApples
a class:_Item;
item:hasPrice 2.95;
item:hasTaxType taxType:_FoodGrocery;
.
item:_BottleOfBooze
a class:_Item;
item:hasPrice 8.95;
item:hasTaxType taxType:_Alcohol;
.
taxType:_NonFoodGrocery
a class:_TaxType;
taxType:hasRate 0.08;
.
taxType:_FoodGrocery
a class:_TaxType;
taxType:hasRate 0.065;
.
taxType:_Alcohol
a class:_TaxType;
taxType:hasRate 0.14;
.
order:_ord123
a class:_Order;
order:hasItems (item:_CanOfOil item:_BoxofRice item:_BagOfApples item:_BottleOfBooze);
.
This is a fairly common real world scenario, and the logic for handling this in a traditional language, while not complex, is still not trivial to determine a total price. In SPARQL, you can again make use of aggregate functions to do things like get the total cost:
#SPARQL
select ?order ?totalCost where {
values ?order {order:_ord123}
{{
select ?order (sum(?itemTotalCost) as ?totalCost) where {
?order order:hasItems ?itemList.
?itemList rdf:rest*/rdf:first ?item.
?item item:hasPrice ?itemCost.
?item item:hasTaxType ?taxType.
?taxType taxType:hasRate ?taxRate.
bind(?itemCost * (1 + ?taxRate) as ?itemTotalCost)
}
group by ?order
}}
}
While this is a simple example, weighted cost sum equations tend to make up the bulk of all analytics operations. Extending this to incorporate other factors such as discounts is also easy to do in situ, with the following additions to the model:
# Turtle
discount:_MemorialDaySale
a class:_Discount;
discount:hasRate 0.20;
discount:appliesToItem item:_CanOfOil item:_BottleOfBooze;
discount:hasStartDate 2021-05-28;
discount:hasEndDate 2021-05-31;
.
This extends the SPARQL query out a bit, but not dramatically:
# SPARQL
select ?order ?totalCost where {
values ?order {order:_ord123}
{{
select ?order(sum(?itemTotalCost) as ?totalCost) where {
?order order:hasItems ?itemList.
?itemList rdf:rest*/rdf:first ?item.
?item item:hasPrice ?itemCost.
?item item:hasTaxType ?taxType.
?taxType taxType:hasRate ?taxRate.
optional {
?discount discount:appliesToItem ?item.
?discount discount:hasRate ?DiscountRate.
?discount discount:hasStartDate ?discountStartDate.
?discount discount:hasEndDate ?discountEndDate.
filter(now() >= ?discountStartDate and ?discountEndDate >= now())
}
bind(coalesce(?DiscountRate,0) as ?discountRate)
bind(?itemCost*(1 – ?discountRate)*(1 + ?taxRate) as ?itemTotalCost)
}
}}
}
In this particular case, taxes are required, but discounts are optional. Also note that the discount price is only applicable around Memorial Day weekend, with the filter set up in such a way that ?DiscountRate would be null at any other time. The conditional logic required to support this externally would be getting pretty hairy at this point, but the SPARQL rules extend it with aplomb.
There is a lesson worth extracting here: use the data model to store contextual information, rather than relying upon outside algorithms. It’s straightforward to add another discount period (a sale, in essence) and with not much more work you can even have multiple overlapping sales apply on the same item.
Summary
The secret to all of this: these aren’t really Ninja secrets. SPARQL, while not perfect, is nonetheless a powerful and expressive language that can work well when dealing with a number of different use cases. By introducing sequences, optional statements, coalesce, templates, aggregates and existential statements, a good SPARQL developer can dramatically reduce the amount of code that needs to be written outside of the database. Moreover, by taking advantage of the fact that in RDF everything can be a pointer, complex business rules can be applied within the database itself without a significant overhead (which is not true of SQL stored procedures).
So, get out the throwing stars and stealthy foot gloves: It’s SPARQL time!
Kurt Cagle is the community editor for Data Science Central, and the editor of The Cagle Report.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ
In response to the recent surge in cryptocurrency mining attacks, GitHub has changed how pull requests from public forks are handled in GitHub Actions to prevent abuse.
As the CEO of DevOps platform LayerCI, Colin Chartier, explained in a recent article,
As the market capitalization of cryptocurrency surged from $190 billion in January of 2020 to $2 trillion in April of 2021, it’s become profitable for bad actors to make a full time job of attacking the free tiers of platform-as-a-service providers.
Chartier describes how an attacker can abuse GitHub Actions cron feature to create new commits every hour with the aim to mine cryptocurrencies.
Because developers can run arbitrary code on our servers, they often violate our terms of service to run cryptocurrency miners as a “build step” for their websites.
According to Chartier, one strategy to reduce the chances of being detected that is becoming popular is using a headless browser for these attacks.
As a result of this, major providers of free-tiered CI platforms, including GitLab and TraviCI, announced restrictions to their free offerings to prevent abuse.
Given this context, GitHub has announced two changes to pull request handling to make it harder for attackers to trigger the execution of mining code on upstream repositories by simply submitting a pull request.
This […] has a negative impact on repository owners whose legitimate pull requests and accounts may be blocked as a result of this activity.
As a first measure, upstream repositories will not be held responsible for abusive attacks triggered by forked repos.
Our enforcement will be directed at the account hosting the fork and not the account associated with the upstream repository.
In addition to this, when a contributor submits a pull request for the first time, manual approval from a repository collaborator with write access will be required before a GitHub Action can be run.
Based on conversations with several maintainers, we feel this step is a good balance between manual approval and existing automated workflows. This will be the default setting and, as of now, there is no way to opt out of the behavior.
GitHub also stated this approach could be made more flexible in the future, if it impacts negatively maintainers.
While GitHub strategy could work for the time being, according to Chartier it is likely that attacks will become more sophisticated and will circumvent any measures. In his rather pessimistic view, only abandoning computationally expensive proof-of-concept mining could preserve CI platforms free tiers.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
The stock of MongoDB (NAS:MDB, 30-year Financials) gives every indication of being modestly overvalued, according to GuruFocus Value calculation. GuruFocus Value is GuruFocus’ estimate of the fair value at which the stock should be traded. It is calculated based on the historical multiples that the stock has traded at, the past business growth and analyst estimates of future business performance. If the price of a stock is significantly above the GF Value Line, it is overvalued and its future return is likely to be poor. On the other hand, if it is significantly below the GF Value Line, its future return will likely be higher. At its current price of $296.8099 per share and the market cap of $18.2 billion, MongoDB stock gives every indication of being modestly overvalued. GF Value for MongoDB is shown in the chart below.

Because MongoDB is relatively overvalued, the long-term return of its stock is likely to be lower than its business growth, which averaged 12.7% over the past three years and is estimated to grow 28.67% annually over the next three to five years.
Link: These companies may deliever higher future returns at reduced risk.
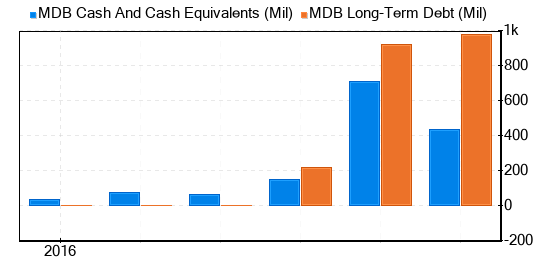
Since investing in companies with low financial strength could result in permanent capital loss, investors must carefully review a company’s financial strength before deciding whether to buy shares. Looking at the cash-to-debt ratio and interest coverage can give a good initial perspective on the company’s financial strength. MongoDB has a cash-to-debt ratio of 0.98, which ranks worse than 70% of the companies in Software industry. Based on this, GuruFocus ranks MongoDB’s financial strength as 4 out of 10, suggesting poor balance sheet. This is the debt and cash of MongoDB over the past years:
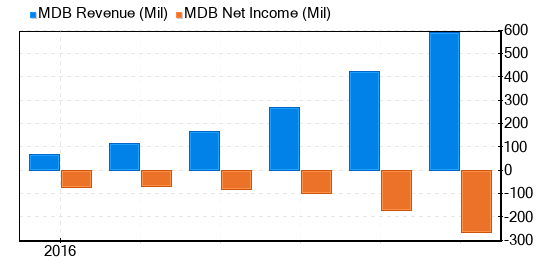
It is less risky to invest in profitable companies, especially those with consistent profitability over long term. A company with high profit margins is usually a safer investment than those with low profit margins. MongoDB has been profitable 0 over the past 10 years. Over the past twelve months, the company had a revenue of $590.4 million and loss of $4.51 a share. Its operating margin is -35.45%, which ranks worse than 82% of the companies in Software industry. Overall, the profitability of MongoDB is ranked 2 out of 10, which indicates poor profitability. This is the revenue and net income of MongoDB over the past years:
Growth is probably one of the most important factors in the valuation of a company. GuruFocus’ research has found that growth is closely correlated with the long-term performance of a company’s stock. If a company’s business is growing, the company usually creates value for its shareholders, especially if the growth is profitable. Likewise, if a company’s revenue and earnings are declining, the value of the company will decrease. MongoDB’s 3-year average revenue growth rate is better than 66% of the companies in Software industry. MongoDB’s 3-year average EBITDA growth rate is 2.5%, which ranks worse than 67% of the companies in Software industry.
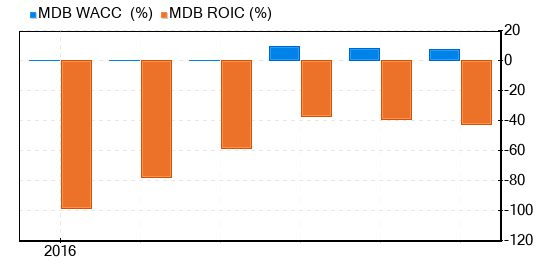
Another way to evaluate a company’s profitability is to compare its return on invested capital (ROIC) to its weighted cost of capital (WACC). Return on invested capital (ROIC) measures how well a company generates cash flow relative to the capital it has invested in its business. The weighted average cost of capital (WACC) is the rate that a company is expected to pay on average to all its security holders to finance its assets. If the ROIC is higher than the WACC, it indicates that the company is creating value for shareholders. Over the past 12 months, MongoDB’s ROIC was -44.27, while its WACC came in at 7.78. The historical ROIC vs WACC comparison of MongoDB is shown below:
In summary, the stock of MongoDB (NAS:MDB, 30-year Financials) shows every sign of being modestly overvalued. The company’s financial condition is poor and its profitability is poor. Its growth ranks worse than 67% of the companies in Software industry. To learn more about MongoDB stock, you can check out its 30-year Financials here.
To find out the high quality companies that may deliever above average returns, please check out GuruFocus High Quality Low Capex Screener.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Joe Gray
Article originally posted on InfoQ. Visit InfoQ

Transcript
Voitova: Joe Gray is a Senior OSINT Specialist at QOMPLX, and Principal OSINT Instructor at the OSINTion. The topic of our session is phishing, social engineering, and OSINT, especially right now during the pandemic.
Can you tell us a little bit about your background?
Gray: I’m very passionate about all things dealing with the human aspect of security, notably OSINT and social engineering. Specifically, within social engineering, the psychological perspectives as it relates to getting people to do things they probably shouldn’t. The proper ways to actually reinforce the learning as opposed to standing behind a pulpit and pontificating, “Thou shalt not do this,” I like to be very transparent as to why something is a bad decision. With regards to OSINT, honestly, OSINT is probably one of the biggest threats that we deal with right now, because it is something that exists en masse due to social media. Then from one country to another and one location to another, just the perspective of information being a commodity, being something that is sold, that has a financial value. Because people have social media, and we are all stuck at home, bored out of our minds, there’s an uptick of people, on one hand, sharing a lot of what I like to call casseroles and cat videos. Basically, pictures of their food and pictures of their pets, things along those lines. For someone who is seeking to do harm, that is something that we can use to manipulate. If we’re doing it in a malicious sense, I use the term manipulation. If we’re doing it as part of a Pen test or a red team engagement, I prefer to use the term influence, because if you look at the dictionary definitions, they’re really the same. If you look at definitions from psychological bodies of knowledge, like the American Psychological Association, manipulation has a certain level of malice associated with it that influenced us not.
As we are seeing right now, because everyone’s cooped up at home, there’s the uptick of all of that. Then there’s also the uptick of misinformation and disinformation that is being shared at great scale, partially because of the U.S. election and partially just because it’s a day that ends in y.
Security Risks from Social Media
Voitova: Let’s imagine I’m an engineer, I work in a huge company. I’m sitting here working from home, so you’re saying that when I’m sharing a picture of my food to some social media, to Instagram or to Twitter, this might be a security risk for my organization?
Gray: Absolutely. Because right now we have a lot of people who are sharing how much they love or loathe their employer because of things their employer is doing or allowing them to do while working in the pandemic. As a byproduct, I probably could have already found that information out via LinkedIn. It’s a lot easier to find it via Facebook during these times. The other thing is because a lot of people are not in the office and they’re working from home, that means that they have their phones at easier disposal, which means that they may find themselves on social media more frequently. Then, using food as an example, if I see someone sharing food quite frequently, and I notice it’s a particular type of food, or it is something associated with a particular diet, say, keto or paleo, or something like that, that in itself I could use as part of a phishing engagement to be able to gain unauthorized access. Quite honestly, I could just offer you some recipes, and the recipe might actually be a legitimate recipe, but there may be some special ingredients that you don’t necessarily see, per se, in the form of malware or other technical exploitation.
Creating Phishing Emails
Voitova: Let’s talk about that. I’m sharing some pictures of food. Based on my preferences, you can build targeted phishing emails, or phishing messages to target me as an employee in a company, to trigger me to go to some link, to some malicious site that looks like a recipe site. What next? Before we jump in into what will happen next, can you give me some real life examples of such phishing emails, something unusual? Because I’m sure everyone knows how a phishing email looks like, usually they look like a phishing email, like spam. You’re talking about some sophisticated crafted emails, can you give some more examples how you can use different things to build this?
Gray: From the perspective of phishing, whenever I do those types of engagements, we’ll just say, for example, I’m contracted to do a phishing engagement, and I have 10 billable hours of time to do the phishing. The way I would break that time up, in all honesty, is I would automatically scrape one hour off the top for reporting, no matter what. Then probably of the nine hours remaining, at least two-thirds of those would be used collecting OSINT about the organization and the employees of the organization. Then the remaining two hours would be spent building the actual infrastructure, because really, it’s not that hard. When I do phishing, I tend to use two distinct domains whenever I send the phish. I have a piece of software that I use to clone websites, and I make modifications to them, altering things like from POST to GET so that I can steal things via the URL and write it to an Apache log as opposed to having to stand up a database on the backside. I will stand up that infrastructure. I will send everything, and I just wait.
What makes my approach very unique in that regard, as opposed to what I would consider commodity phishing, which would be phishing en masse from exploit kits, because, for example, when I first got into social engineering back in 2016, I was working on a PhD. I never finished it. We were told to identify a problem within our specific discipline, mine being security, and try to identify a solution. At the time, Locky was all the rage. Part of Locky’s exploit kit, it would automatically phish people to propagate. That was a big problem. Then, secondly, I had to use purely academic resources. By using social engineering, I was able to not only use technology journals, but I was able to use psychology and sociology journals. That’s an example for that.
Fast forward to the actual execution and how I would go about doing it. When I say I use two domains, the way I do it is I host the actual web infrastructure on a cheap 88 cent domain, something like a .tech, a .info, something like that. It doesn’t have to be anything fancy, unless the organization is blocking those cheap domains. Even if they’re blocking those, there’s others that you can come across. The domain that I actually send the phish from will be a more legitimate domain. I’m a huge fan of squatting. I’ll buy the .us or .co.uk to their .com. That’s my typical approach. Then I will typically use something like G Suite or O365 to send it. To take it a step further, I will go as far as to set up a Sender Policy Framework, SPF, DomainKeys Identified Mail, and Domain Message Authentication Reporting Conformance, DMARC, which are all email reputation and security protocols. I will set those up because it will make my sending domain look more legitimate. That’s on the technical side.
On the non-technical side, I’m going to go digging through Instagram, Facebook, LinkedIn, public filings, historical DNS stuff. I’m going to use websites that marketing and sales professionals use to get leads lists to build my list. Furthermore, the things that I tend to look for, I try to find out what they call their employees. An example of that would be Walmart. Walmart and Kroger both call their employees, associates. Disney calls their employees, cast members. Nucor calls their employees, teammates. Verizon Media calls their security team, The Paranoids.
Where to Learn Industry-Specific Phishing Lingo
Voitova: How do you learn these terms? Where do you read about that?
Gray: Honestly, it’s typically via the career site, or HR blogs, or it’s typically something within the actual website. Because, think about it, if I were phishing Disney, and I called their employees, employees instead of cast members, that’s game over right out the gate. Going back to a scenario based upon something Christina put in the chat about a 20% coupon on your next keto meal delivery. Using food as an example, what I might do is I might try to find out who your employer’s HR vendor is, like ADP or TriNet. I’ll find out who that vendor is. I’ll find a way to spoof them. Spoof is a bad term. I don’t like to use the term spoofing because of the prevalence of SPF and DKIM and DMARC these days. Spoofing is not as effective. It tends to get caught a lot faster.
I would squat something associated with that domain. I would send an email to those targeted employees and say, “Your employer has partnered with us for this and that, and as a byproduct, we have frequently set up a partnership with this organization, ketomealstogo.coffee. As a byproduct, because you are an employee or a cast member of your company, you get an introductory 40% discount and 20% discount all along. We have set up single sign-on for this, please input your company credentials.” I’m going to go as far as to get a high resolution logo to put there. I’m going to make this look as official as possible. I’m going to make every effort that I can to convince you that not only does your employer know that this is happening, but also that the HR vendor or whatever platform is aware of as well, using those hi-res logos. Because I’m telling you it’s single sign-on, I am now able to steal your corporate credentials.
Phishing Trigger
Voitova: As a trigger, you would use something you learn about this employee’s like food preferences. Then you would add something that people do, especially people working in large companies like HR company, like some contractors, or something, like security department, help desk, some part of the entity, and basically create the email with some savings. Like, register right now and you will get some savings, some money back, or special program because you’re an employee, so put your credentials to have this discount.
Gray: Exactly. Any person who’s worked for a company that uses someone like ADP as their HR information system, knows the exact emails I’m talking about. You already get spammed and bombarded from the platform giving you all of these deals. This is just exploiting that capability. Honestly, a lot of this is made possible via OSINT. That’s why I tend to spend 60% to 70% of my time in such an engagement doing the OSINT analysis, because I want to know specific phrases associated with a company. At the same time, I want to be able to speak intelligently to it with those phrases. In the past, I was able to get access to the CFO of an organization, assigned a personal computer. It belonged to the company, but it was assigned to the CFO. I accompanied a voice phish. I spoofed a number and called him, and fed him a whole line of stuff using the most important phrase within social engineering, of, can you please help me? To get him to click the link. Once he clicked the link, I had embedded some malicious code to go alongside what it was that I was working on. Because this person was in the C-suite of the company, he had local administrator, which then allowed me to escalate my privileges and take over the entire domain internally.
The Most Effective Phishing Method
Voitova: What is more effective from your perspective, to send written email or to call, to have this influence using voice?
Gray: I tend to like to do both, to be honest, because if someone expects an email, they’re more apt to act upon it. If you can have the conversation with them, you can make them expect it. Obviously, for companies of varying sizes, like if you’re dealing with a company that has 100 employees, it’s a lot easier to call those employees and grease the skids about the incoming email. Whereas if you’re dealing with a multinational company with half a million employees-plus, you’re not really going to be afforded that luxury. The best thing to do in that perspective would probably be to assess employees using OSINT. The stereotypical employee that I would tend to look at for that would be someone in line that doesn’t really employ access controls on social media. You can tell that if they see it, they share it. They post it. They believe it. It’s on the internet, it must be true. That gullible employee, that’s who I’m going to tend to look for. Even within those gullible employees, I’m going to try to triage to find employees in sensitive roles, like HR, accounting, or security, or even help desk, someone that may have elevated access or access to something that may be lucrative to a criminal.
Weak Links in Phishing Attacks
Voitova: The weakest link are people that share a lot, that engage a lot in social media, and at the same time, have some privileges in their organization.
Gray: I look at the organizational perspective of it. Obviously, some roles within an organization mandate the use of social media, sales, marketing, HR specifically. I won’t target someone’s personal account. I will never try to phish someone on their personal Facebook or Instagram. That’s not to say that I will not read everything that they’ve posted and use it against them. With that, you tend to have varying types of people. You have some that are adamant that they won’t use social media. You have the ones that are more judicious with their use of social media. They won’t be as active about talking about work, it’s all personal stuff. There’s a group I’m in online, and we came up with personality types about the various members of the group. Personality type number 17 is the chronic oversharer. For that, I’m always on the lookout for number 17s, because they tend to tell me things that I can’t find any other way. There’s no public filing that’s going to tell me this. There’s no technology implementation that I can find via DNS. I’m not going to be able to do my favorite trick and put in the company’s headquarter address on Instagram. I’m not going to be able to look and see the posts there to find out what is hanging out there. It’s something that you typically find via happenstance. If we think about, prior to the social media era, it’s the reason why foreign countries would send spies to bars in Washington, D.C., in the Northern Virginia area, because they could overhear conversations about work. Basically, social media takes the necessity of a bar out of that equation.
Social Engineering Attacks Exploiting the COVID-19 Pandemic
Voitova: You can read all of these things. We have actually a question regarding the pandemic. Have you produced or come across any social engineering attacks that have taken advantage of the current situation of increased anxiety in media, all the things going on right now, especially, with those personality types, especially with those number 17s? Have you noticed something, like their behavior changed maybe?
Gray: I’ve seen a lot of intelligence about attacks taking advantage of it. Me, personally, I’ve not been doing much active social engineering in the past few months. In that regard, I personally haven’t. Even if I were, I don’t think I would particularly use COVID as a ruse, because it’s just too much of a hot button topic. I do understand that the malicious actors, the bad folks will, because they don’t always play by the rules, obviously. That’s something that I personally wouldn’t do. There is a whole swath of information related to adversaries and attackers using that particular vector. Same thing right now with the election. Me, personally, no.
The Work from Home Exploit
Voitova: Now I see that for some people, the election and the pandemic can be a trigger. It also means that it can be like a background, because of a lot of people working from home, because we start receiving all these things. From my perspective, people become less cautious and they’re easier to manipulate, especially from the calls. Someone will call me and say, “I’m from your IT department. We want to help you with VPN,” these kind of things.
Gray: Absolutely. That’s a very viable thing. Honestly, I don’t think using COVID in particular is a useful tactic with that. You could still use the way we work from home. You could still use that. That being said, that’s not to say that I can’t exploit the workflow, because at the end of the day, my philosophy with security is, sure, finding technology flaws, that’s a very awesome thing to do. The real meat and potatoes of doing anything security related is to find the flaws in the processes. If I can find a process flaw, that’s more powerful than any technology flaw that I can exploit. Solely on the fact of, we have IDS as we have SIMs, we have all sorts of technology sensors to find technical exploitation. You don’t really have those types of sensors to watch for when the technology or the process itself as defined by the company is broken. You typically don’t find those things out until something goes wrong. If I know that it is common for someone from the help desk to call and assist people in setting up their VPNs, or that you use multi-factor authentication, like Duo. If I know that you have to provide a six digit code to be able to talk to a help desk, I’ll ask for the code. It doesn’t matter what code you give me, it’s going to work. You can tell me 123456, and for that one I might actually question you. It would have to seem like it would actually be something generated from the app. At the end of the day, that’s something that I would totally go for if I know that there’s a specific process in place, and I can replicate part of that process. Absolutely.
That’s something that I’ve used via Instagram in the past. I found where employee ID numbers are printed on company badges, and I found the company badges on Instagram. Whenever I call someone, I come up with my own employee ID number. The specific use case I’m thinking of was during Derbycon 2017, when I won the Social Engineering Capture the Flag. I was calling a large publicly traded company in Kentucky, and they asked for my employee ID. I threw in a random letter. The letter I gave them was A. They were like, “There are no letters in your employee ID number.” I was like, “I’m sorry, let me put my glasses on. I’m sorry, that’s a 4.” I was able to test the waters with that. In using that ambiguity, it works really well to your favor for that.
The Employee ID Number Phishing Vector
Voitova: This is great, because literally A looks like a 4. You tricked those people?
Gray: Exactly. The thing is, when you’re dealing with employee ID numbers, you don’t know if it’s going to be A through Z, or not. I tend to stick only with A through F. The only numbers that I really play with in terms of making those claims might be 0, 1, 2, 4, with 2, I might claim it’s a Z. I don’t really use 2 that much, I use 0, 1, 4 more often than not, so I could say it’s either I, L, A, or O. Doing something along those lines, it works really well. It was all because it was posted to Instagram. When I surveil a company, the first thing I do is I get their physical address for headquarters. I immediately type in that address on Instagram, and I see what people have posted. Inevitably, you’ve got that new employee that is super excited. They’ve just started their new job. It’s like, “New job workflow, look at my badge.” Obviously, this is not a legit badge, except for I am the state password inspector. They’ll post that to Instagram, and now I know that state password inspectors have badges that look like that, or Stark Industries badges look like that, or ININTECH. Any of these fake badges. Fsociety, they have their own badges. Granted, these are all satire fake badges that someone made for me at conferences, but for me to go get a picture off Instagram and go and get a badge printed for it, that’s not hard.
Using Company Dress Code as a Security Exploit
Another thing, back when I used to do physical Pen tests, and I would try to sneak into a place, I would always try to find out what their company dress code and uniforms look like. Obviously, I’m not going to go sneaking into any companies right now with a Mohawk. In the past, I would go to thrift stores like Goodwill and buy up old t-shirts, polos, and button ups for companies. Because, where I live, there’s one particular trash company that pretty much serves all companies in the area. If you show up in a white pickup truck with a yellow and green logo on the side, and a green polo shirt with a yellow font on it, you’re probably going to be able to convince them that you at least need to look at the dumpster. With that, you can either use that to pivot to gain access to the building, or you can steal a few bags of trash and take it off-site for further analysis that way.
Voitova: They won’t be suspicious because this is how people usually look like, so it’s expected.
Gray: Using the dumpster analogy, if you say that if I can’t inspect your dumpster, we may not be able to pick up your trash. They are going to let you inspect that dumpster because the worst thing that can happen to them is the trash to pile up.
How to protect from targeted Phishing Emails
Voitova: You provide some motivation. You basically push people to agree. Let’s talk about defenses, because I imagine that if I got an email from HR department, like email that you send me, I can fall into. I’m not sure if I will see single sign-on, I might be suspicious on this tab, but still, I might provide some information. If you are an employee and the company, how will you protect from especially these targeted phishing emails?
Gray: First and foremost, buy up all of the adjacent domains that are possible. It can get pricey, but if you have the .com, the .us, the .net, the .org, you might want to go ahead and buy up as many of the others as you can. Obviously, that’s going to do some protection on the inside, in terms of squatting from that, but that necessarily doesn’t protect you from someone squatting as your vendors. The biggest thing, honestly, is training and awareness. If someone comes across something phishy, I would expect them to hop on the phone and make a phone call and say, “I just got this email, it’s coming from such and such. I’m not so sure about it. Can you please verify this? I know you didn’t send it but it came from ADP. Can you call out to ADP and verify this?” During the verification, if someone calls you, implement some necessity of urgency. Just be like, “I’m sorry, I’ve got to jump on another call.
Can I call you back as soon as the call is over?” Because my power only lasts as long as I can keep you on the phone. If you have a reason to hang up, then you are either going to have to call me back, and if I’ve spoofed a number, it’s not going to work. Or, I’m going to have to try to call you back. Whenever people use that response for me, I tend to have to tiptoe and tap dance to find an excuse or a time to call them back. That makes it more difficult as well.
Also, from a company perspective, I cannot evangelize multi-factor authentication enough. I know a lot of people like to hate on SMS, text based multi-factor. While it is not my favorite, it’s better than nothing. Then I would follow that with the applications like Duo and Google Authenticator, stuff like that, followed by the physical RSA token type things. Then my most favorite, honestly, is the YubiKey UTF hardware token, because with that, you actually have to physically have the token in hand and be able to push the sensors on it to make it work. That creates a problem in and of itself, because of the fact if you lose it, you’re out. You have to make that consideration and have your workarounds for that.
The other thing from a personal perspective as well as a company perspective, I don’t agree with companies telling employees what they can and cannot post, in general. What I do like for companies to do is to say, this is an example of something that is appropriate to be posted, this is something that’s inappropriate to be posted. Obviously, we want you to paint us in the best light possible. If you’re having a bad day, and you need to vent, all that we ask is that you button up your access controls and don’t post things publicly. When I was director of IT security a few years ago, for a company, I knew that there were things that I was going to implement that employees were going to hate. I knew that they were going to go home, they were going to hop on Facebook, and they were going to complain about it. I told them, I’m not the person that’s going to tell you not to do that. It’s not within my role. Honestly, you have every right to do so. The only thing I ask is that you set the access controls away from public, make it friends or connections only. At the time, friends of friends was a thing, so you could do this as well but you don’t know who’s there. I always like to use the whole toothpaste analogy. Once you squeeze it out, you can’t put it back in the tube. The part that you can get back in the tube, it’s not going to be the same. You’ll never get it all back in there.
This is something I talk about in my OPSEC courses, encrypted messaging apps and encrypted emails like ProtonMail, that’s all the rage right now. That works for a particular vector in terms of sophisticated adversaries and governments spying on your stuff. The thing people fail to realize is once the information is decrypted and on someone else’s device, nothing is stopping them from taking screenshots, from transcribing it, from taking pictures or screen recordings. There are so many ways that I can gather that information and still make it go public. The same exists for anything, because I might post something in haste and I may accidentally have the wrong access controls for it. It may be set to public. That could be that very moment that an adversary is surveilling my site, and they see it, and they take a screenshot of it. Even though I’ve deleted it, it’s still there.
Summary
Voitova: As a company, the things you can do to prevent phishing, or at least to protect as much as you can. You can buy domains, so phishers won’t buy those domains. You can implement a lot of security awareness training, and especially awareness training regarding phishing, with examples, with these public posts, how they can be used and misused. You can implement MFA rules. Please implement MFA everywhere. Basically, you can teach your employees if they see something suspicious, if they receive some suspicious email, call to the department, or IT department, or security department, and say that it happened and ask them to verify the source.
Gray: Another thing with that is set up an internal email address, like phishingatyourdomain.com. Encourage people, “If you’re in doubt about this, forward this email to phishing at, and we will analyze it, and if it’s a legit phish, we may reward you with something like a Starbucks gift card or a $5 Amazon gift card or something. It’s not going to happen every time you report one, but from time to time, we will reward those, if it is a legitimate thing.” Then that way, number one, everybody knows exactly where to report it to, because if people don’t know where to report, or they fear that they’re going to get in trouble if they click on something, or report, they’re not going to do it. I don’t want to fall down this rabbit hole, because there’s a lot of rabbit holes that one could fall down on this, specifically.
I have an entire talk about phishing metrics and what actually matters. Whenever I do phishing engagements, I don’t really care how many people open it, or how many people click it. Obviously, I care more about people clicking it than I do opening it. The thing that I care most about would be how many people actually report it, because that gives an organization an idea of how much time between an event occurring do they have to respond to something before bad things happen.
See more presentations with transcripts
MMS • Lena Reinhard
Article originally posted on InfoQ. Visit InfoQ
Transcript
Reinhard: I want to share with you key lessons that I’ve learned from building and leading organizations through times of change, uncertainty, and fast growth, and talk about what engineering teams need from leaders right now. Let’s talk about right now. Where are you at in this moment? This has been a year for all of us, including for our teams, and many people have gone through difficult times of great hardship. A human core need is choice. We want to have control and autonomy over important parts of our world. We want to be able to make decisions about things that matter to us. The key aim of our brain is survival, and its protective mechanisms keep us alive. They got us to where we are at today. In times like these, what we can control in our environments and lives becomes limited, and with that, one of our core needs is threatened. This leads to increasing unease and stress for many of us and for many people in our teams and organizations. I want to show you frameworks to get out of our brain’s desire to focus on what’s now, and help you support your teams effectively.
Leadership Horizons
To get us started, I want to look at leadership horizons. The human brain is programmed to narrow its focus in the face of a threat. That’s an evolutionary survival mechanism, which is designed for self-protection. The trap is that our field of vision becomes really restricted to the immediate foreground. As leaders, we need to navigate different horizons at all times, though. I want to pull us out of this perspective in the immediate foreground, and think about different operating horizons. Specifically, when I say horizons, I mean different views between the present and the day-to-day, the short-term, midterm, the longer term, and then the vision that’s far out. As horizons, I also think they refer to different levels of ambiguity, from the very concrete, to the more blurry, strategic, and visionary view. Especially, in times of change, we need to be able to navigate those different views and layers. We need to actively manage the present while also anticipating what’s next week, next month, next year, to prepare our organizations and teams for changes ahead. This requires active work from us in times of change, and is foundational for leading. Like in a landscape, all of those layers are intertwined. Of course, they’re not separate. I want to focus on reviewing the foundations, as well as the present and the big picture, and how we lead our teams through all those. I want to give those to you as frameworks to orient yourself around.
Foundations – Managing Yourself
Let’s start with foundations. I believe one of the most crucial leadership skills is managing ourselves. It starts with managing our thoughts. Our thoughts have huge impact on the people around us in our teams. Our perspectives, our biases, they influence our decisions, and ultimately, our leadership. Self-reflection is a really crucial skill, also when it comes to managing our brain’s responses to change. Another aspect is managing our energy. I think that’s even more important than managing our time. Managing our energy means managing what in a day-to-day drains us and energizes us. We can look at our calendars, sit down and identify what are the meetings and conversations that I get excited about, that energize me and others that may drain me. Then use that as a foundation to balance how we structure our work time.
Of course, managing our time is also an important factor. It’s really important to ruthlessly prioritize. Always be clear on what the most important thing is that you could be focusing on. Part of that are self-organization skills as well. How you manage priorities. How you stay organized, and have your to-do list under control. I know that the latter part is sometimes really hard. Managing ourselves also means managing our operational horizons. Always making time for strategic thinking, even if it’s sometimes really difficult. I sit down every morning for 10 to 15 minutes when I start my workday and think on strategic topics, strategic questions and how they relate to the present work in my organization. It also means always making sure that you understand goals, the bigger picture, the vision, and maintain that connection every single day. Self-management is foundational for our success as leaders. Part of it is also understanding what we need as well as the people around you.
Human Core Needs
This is the BICEPS model of human core needs, which was coined by the performance coach and trainer, Paloma Medina. It’s based on research on what motivates and drives human beings, and their behaviors. The core needs are belonging, being close to close-minded people. Improvement, like learning and growing. Also, choice for control or autonomy. We also seek equalities of fairness in decisions, but also want to feel that our ability to contribute is fair. Then there’s predictability or certainty, safety, stability. The last part is significance or status, so being appreciated and having our work being visible. When these core needs aren’t met, we move into fight or flight mode, which renders us ineffective and means we’re not able to do our best work. Our job as leaders is to understand what matters to everyone on our teams, what motivates, drives them and what they need.
High-Performing Team Needs
You may all have heard the research on high performing teams already. These five key factors that make teams high performing. There’s psychological safety, believing that we won’t be rejected. That we feel free to express work relevant thoughts and feelings to others. There’s dependability, so teammates reliably completing quality work on time. Structure and clarity. Also, meaning, finding a sense of purpose in our work or the output. Then feeling that our work has an impact. You’ve probably heard of this model already. I have great news for you because it’s all connected. The research on high-performing teams shows how meeting human core needs has impact at the team level. These needs always need to be balanced, and not everything is equally important to everyone at all times. That means that a key foundation for our work as leaders is understanding the needs of the people around us. Even more so in a time like this when those needs may be changing as people’s life circumstances change frequently.
Teams Need Leaders Who Understand Their Needs
The best tool we have as leaders in our toolkit is asking good questions, listening, observing, and taking note of what motivates our teammates. That’s the basis for us to do our work well. I can tell you a lot about leadership tools, but I don’t know you or your teammates, and what you need in this moment may vary. Your best tool are good questions and genuine curiosity.
Teams Need Strong Relationships
Another foundation are strong relationships, and they have a lot to do with understanding our teammates’ needs. Strong and trustful relationships between team members on our teams are the basis of psychological safety and high performance. They make learning, growth, and strong feedback culture possible. I believe that maintaining strong connections is now even more important than it’s ever been. For our distributed teams at CircleCI, we’ve always had structures to help our teammates build those relationships. For example, regular pair programming, but also fireside chats, some standups or standdowns even, engineering talks and engineering book club, department-wide meetings or mentoring program.
Foundations’ Review
We talked about managing ourselves. Reflecting and managing our behaviors and thought patterns. Then asking good questions to help us understand core needs in our teammates. With that, also laying the foundation for high performing teams, and helping our teammates build relationships.
The Big Picture
Let’s look at the big picture next. Big Picture meaning strategy, vision, direction, higher level context. Team missions are also a part of the big picture, anything that describes the long term view. I want to start there, because the big picture is crucial for anything we do in the present. It needs to be our guidepost, our goal, our lighthouse, and impact our steps that we take and the direction we move in every single day. I believe the big picture also means long term or strategic investments in team and our leadership strategies. I want to start with those at first.
Teams Need Leadership at all Levels
One of our biggest task as leaders is to bring up people with and around us. I’ve been saying for many years that I believe organizations need leadership at all levels, to carry our organizations forward and help us succeed, especially distributed teams. I think management and leadership are distinct skill sets. A definition that I really like is that management is about coping with complexity. It brings order and predictability. Whereas leadership, by contrast, is about coping with ambiguity and change. This skill, specifically, is really needed at all levels in organizations. The first step we can take to foster leadership at all levels, is when we lead through context instead of control. Focus on sharing direction, vision, and bigger picture, and values with our teams. There’s a couple reasons for that. First of all, there’s a lot of power in meaning, and knowing where people are having an impact can be a great motivator and also help with alignment. This helps, for example, by helping engineers understand how their work contributes to the bigger picture, to longer term business goals, how it helps users or how it helps other teams. Part of that is also helping teams navigate ambiguity. Making sure they understand the abstract but also the practical implications of a vision on their work. We can help people do that by approaching it deliberately and coaching them through handling different levels of ambiguity.
Leading through context also means empowering people to do the right thing. I believe that context is one of the most important things that we need to do as leaders. It’s a crucial part of our jobs. Some examples for how I aim to demonstrate at least the skill in my work right now. I send a weekly email to my management team, with an overview of important context in the organization’s topics that are going on and events that are happening around us. I also regularly send summaries of important conversations that I have to my staff. In department-wide meetings, we communicate big picture, longer term vision, and strategy for us.
The second aspect on fostering leadership at all levels is focusing on values, principles, and outcomes, specifically when we’re setting expectations. Then entrusting employees with autonomy. Focusing on outcomes and impact instead of micromanaging is a really important way in sharing ownership and distributing responsibilities. One approach that we’ve been using for a while to do that are OKRs. They are outcome focused, and they encourage teams to think about the best ways to achieve those outcomes instead of prescribing approaches, and entrusting people with achieving those, again, in alignment with values.
Another aspect to foster leadership at all levels is distributing ownership, specifically starting by reducing dependencies and just looking at your own work, and asking yourself, where am I as a single point of failure? What decisions cannot be made if I’m not around? Distributing ownership fosters autonomy. Frameworks like architectural decision records, but also clear roles and responsibilities really help with that. The context setting also fosters distributed decision making and ownership. It means not having everything run through us and having control, but instead sharing key information with people and trusting them to make the best decision based on that context.
Teams Need a Strong Connection to the Big Picture
I also want to talk about maintaining a strong connection to the big picture. First of all, all of us continuously need that. Check in with yourself every day and make sure that you understand the longer term view. I also know that this big picture or strategy isn’t always around, especially in fast growing companies or in startups. It’s your job to help get to that. If there is no strategy or the big picture isn’t clear to you, start with that and work with the other leaders around you to build that big picture. Also, make sure to maintain that connection with the big picture for others. Make sure that the people around you are clear on strategy and vision to help with the autonomy. Be relentless about communicating strategy and vision to others. Set yourself reminders, for example, monthly. Check in with your team. Ask whether they understand, or which aspects of it are unclear to them. I think there’s no such thing as too much communication on strategy.
The Big Picture Review
Leadership at all levels is a really important skill. Then, maintaining the connection with vision and strategy for ourselves and our teams at all times.
The Present
Next up, I want to talk about the present. The day-to-day work that we do with our teams in our organizations. Of course, our day-to-day work is deeply intertwined with the big picture, the longer term, as well as the foundations. In this section, I want to give you a few more practical tools for your day-to-day work with your teams.
Teams Need Alignment
First of all, let’s talk about alignment and how to maintain it. I think an important part of our work as leaders is to create communication patterns. Making sure that people know what communication to expect and where. All of us face a lot of information, and it’s important to know for people what to expect, where it helps them not miss it but also helps them be prepared. Just to give you one example, we have one specific channel, one email where we always communicate new hires to people. A different approach, it’s by our Slack channel where we communicate when new job posts are opening internally, or a channel for announcements that people can’t miss. Knowing what to expect also helps people navigate the huge amount of information they deal with every day and make sure that they don’t miss anything.
Another important part of communication is making sure that we always assume that people don’t know. Always assume that people don’t know and that they will have to hear something many times. When you’re tired of saying it, assume that 60% to 80% of people have actually heard it. There’s another rule to say everything seven times across different channels. You don’t probably actually have to say everything seven times, but I think it’s really good and it’s pretty safe guidance, especially in distributed teams. When you say things across different channels, you’re also making sure that people actually have a chance to process things or, again, that you’re not missing out. Relentlessly communicate vision and strategy. We’ve covered this but in the spirit of over-communicating intentionally, I’m saying it again to make the point.
Communication also always lands best when it’s tailored to what matters to people. People want to know what changes mean for them. We made a few hiring process changes a couple months ago. When conveying those to managers, we focused on increasing our ability to hire faster, more effectively, while also maintaining high standards and inclusivity. When we conveyed those things to the engineers in our team, we said the same things, but we also added how it was going to impact their involvement in interviews and their contributions. Whenever you communicate, always show clear feedback paths. It’s really important. We’ll talk later a little bit more how it helps with learning on teams.
Then, be a dolphin. This is an example by David Feeny, Emeritus Professor of Information Management at Oxford. Dolphins can only take in very small amounts of air, and as a result, they have to surface very frequently to breathe again, every 15 to 20 minutes. Whales, on the other hand, can take in large amounts of air and therefore stay submerged for up to 90 minutes depending on the whale type. Be a dolphin. It’s much better to pop your head out frequently to talk about little change instead of trying to make a big splash all at once and then disappearing back into the ocean again. Being a dolphin also helps avoid surprises, and also helps position you as a constant and a presence in your team, and helps you show up as a leader. Plus, it also means it helps you gather feedback much more frequently and iteratively. Then adapt as you go, leading to much higher quality results.
Teams Need Continuous Learning
Teams also need continuous learning. That’s an important pillar of high performance. It starts with embracing failure. When you make mistakes, be open about them and address what you’re doing to fix the middle, so what you’re putting in place to do better in the future. The way that we talk about failure as leaders has a huge impact on how we shape culture on our teams. That’s why blameless incident reviews are so important in treating failure as a learning opportunity. With that, the blamelessness specifically is a cornerstone of high performance in teams. I also like running experiments and basically asking teams to test hypotheses and then test them and see what they come up with and iterate from there again. This approach really helps keep changes small and much more digestible and manageable for teams. It also allows people to take ownership, which helps with leadership aspects.
One approach that I like taking is introducing changes as experiments, then running them for two weeks, four weeks, depending on what it is. Reviewing, doing a retrospective about them as a team, and then repeating. This approach also instills increased resilience on teams and ability to handle change. Then regularly reviewing lessons learned really helps with instilling that learning culture. Retrospectives specifically are a great tool to discuss how we can improve our human and technical systems as a team. Blameless incident reviews are a great tool to help us understand problems and drive towards solutions as a team in a way that fosters learning, and in a way that also helps us embrace failure and learn from it.
Teams Need Tools to Build Resilience
As change is a key aspect of our work as leaders, I think resilience is an important tool for us to focus on. When we support teams in times like these when we grow organizations, especially when they grow really fast, but then also as part of DevOps culture, change is really a key trait of our work as leaders. I want to show you two tools that I’ve used for helping teams navigate change and build resilience. The context that we talked about earlier, as well as helping teams understand their purpose, big picture connection, and small experiments are also all tools that help with resilience as well. The two ones I want to show you now is focusing on what we can change and treating change as loss.
This framework that you’re seeing here is a model adapted from Stephen Covey’s, 7 Habits of Highly Effective People. A key trait of resilient people is that they accept what they cannot change and focus their energy on what they can change. This model is designed in three circles, between what the team controls at the center, then what the team influences in the middle, and then the soup outside. The idea is to focus the team’s action where they can have direct action, or persuasive in recommending action. Instead of the part where their main action is in the response. Change situations I often use to dissect with teams what change I can drive. It’s also useful to help teams for how they respond to change, and for team discussions about that.
Another framework I really like is treating change as loss. Any change even when it’s clearly the right change to make, triggers feelings of loss: loss of control, pride, status, or loss of visibility and insight. If you ever tell people that they need to move their desk, even on their home office, you can see what changes we’re talking about there. The model that you can see here is the Bridges’ Transition Model. It’s focused on helping people discover, accept, and embrace a new situation. At first, it focuses on acknowledging an ending and helping people understand and deal with losses. The second part is the neutral zone, focused on realignments towards new patterns. Part three is starting something new. You can make successful changes by addressing the transition that people experience during change. Instead of pushing forward, focus on supporting people through the transition towards something new. Don’t start at the third part, but go through all changes. This helps tremendously. Don’t forget to celebrate wins as you’re moving into the new parts, and celebrate those wins early.
Review of the Present
In the present, we just looked at how continuous alignment helps teams stay connected, and how communication patterns that you use will impact the way that your teams are able to do that. We also looked at how learning culture is really useful for teams, especially in how we handle failure and how we talk about it. Then looked at tools to develop resilience, specifically treating change as loss and focusing on what teams can change.
Summary
Right now is a defining moment for leaders. We look today at how we can shape our leadership work to help our teams navigate that. We reviewed the foundations, navigating leadership horizons between managing the present but also the bigger picture, and helping people understand those. We also reviewed crucial leadership skills, like this navigation of horizons, and how we can manage our instincts in our brain when it wants to focus on only what’s right in front of us. We looked at human core needs and how it helps us to understand them, and how it helps us shape high performing teams by using questions as a leadership tool. We also looked at the present in our day-to-day work, specifically, alignment tools to build communication patterns using clear feedback paths and being a dolphin. Another part of the present is learning and continuously learning with our teams by using quick experiments, and by talking openly about failure without blame. We also looked at tools for resilience, like treating change as loss and focusing on what teams can change. Then, of course, the bigger picture, fostering leadership at all levels in our teams and always maintaining communication about vision and strategy, and making sure people understand those. We looked at what engineering teams need from leaders right now. With that, the question I want to ask you is, how are you going to show up for your teams as a leader right now?
See more presentations with transcripts
Database Servers Market Will Reflect Significant Growth Prospects of US$ Mn during 2021-2026 …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Latest research on Global Database Servers Market report covers forecast and analysis on a worldwide, regional and country level. The study provides historical information of 2016-2021 together with a forecast from 2021 to 2026 supported by both volume and revenue (USD million). The entire study covers the key drivers and restraints for the Database Servers market. this report included a special section on the Impact of COVID19. Also, Database Servers Market (By major Key Players, By Types, By Applications, and Leading Regions) Segments outlook, Business assessment, Competition scenario and Trends .The report also gives 360-degree overview of the competitive landscape of the industries.
Moreover, it offers highly accurate estimations on the CAGR, market share, and market size of key regions and countries. Players can use this study to explore untapped Database Servers markets to extend their reach and create sales opportunities.
Some of the key manufacturers operating in this market include: IBM, Oracle, Microsoft, MongoDB, Amazon, Dell, Redis Labs, SAP, SAS Institute, Pimcore GmbH, The PostgreSQL Global Development Group, TIBCO Software, Information Builders, NetApp, Profisee Group, ASG Technologies, Tealium, FUJITSU and More…
Download Free PDF Sample Copy of the Report(with covid 19 Impact Analysis): https://www.globmarketreports.com/request-sample/115479
Our Research Analyst implemented a Free PDF Sample Report copy as per your Research Requirement, also including impact analysis of COVID-19 on Database Servers Market Size
Database Servers market competitive landscape offers data information and details by companies. Its provides a complete analysis and precise statistics on revenue by the major players participants for the period 2021-2026. The report also illustrates minute details in the Database Servers market governing micro and macroeconomic factors that seem to have a dominant and long-term impact, directing the course of popular trends in the global Database Servers market.
Market Segment by Type, covers:
Relational Database Server
Time Series Database Server
Object Oriented Database Server
Navigational Database Server
Market split by Application, can be divided into:
Education
Financial Services
Healthcare
Government
Life Sciences/Manufacturing
etail/Utilities
Regions Covered in the Global Database Servers Market:
1. South America Database Servers Market Covers Colombia, Brazil, and Argentina.
2. North America Database Servers Market Covers Canada, United States, and Mexico.
3. Europe Database Servers Market Covers UK, France, Italy, Germany, and Russia.
4. The Middle East and Africa Database Servers Market Covers UAE, Saudi Arabia, Egypt, Nigeria, and South Africa.
5. Asia Pacific Database Servers Market Covers Korea, Japan, China, Southeast Asia, and India.
Years Considered to Estimate the Market Size:
History Year: 2015-2021
Base Year: 2021
Estimated Year: 2021
Forecast Year: 2021-2026
Get Chance of up to 50% Extra Discount@: https://www.globmarketreports.com/request-discount/115479
Reasons to buy:
- Procure strategically important competitor information, analysis, and insights to formulate effective R&D strategies.
- Recognize emerging players with potentially strong product portfolio and create effective counter-strategies to gain competitive advantage.
- Classify potential new clients or partners in the target demographic.
- Develop tactical initiatives by understanding the focus areas of leading companies.
- Plan mergers and acquisitions meritoriously by identifying Top Manufacturer.
- Formulate corrective measures for pipeline projects by understanding Database Servers pipeline depth.
- Develop and design in-licensing and out-licensing strategies by identifying prospective partners with the most attractive projects to enhance and expand business potential and Scope.
- Report will be updated with the latest data and delivered to you within 2-4 working days of order.
- Suitable for supporting your internal and external presentations with reliable high quality data and analysis.
- Create regional and country strategies on the basis of local data and analysis.
Some Major TOC Points:
- Chapter 1: Database Servers Market Overview, Product Overview, Market Segmentation, Market Overview of Regions, Market Dynamics, Limitations, Opportunities and Industry News and Policies.
- Chapter 2: Database Servers Industry Chain Analysis, Upstream Raw Material Suppliers, Major Players, Production Process Analysis, Cost Analysis, Market Channels, and Major Downstream Buyers.
- Chapter 3: Value Analysis, Production, Growth Rate and Price Analysis by Type of Database Servers.
- Chapter 4: Downstream Characteristics, Consumption and Market Share by Application of Database Servers.
- Chapter 5: Production Volume, Price, Gross Margin, and Revenue ($) of Database Servers by Regions.
- Chapter 6: Database Servers Production, Consumption, Export, and Import by Regions.
- Chapter 7: Database Servers Market Status and SWOT Analysis by Regions.
- Chapter 8: Competitive Landscape, Product Introduction, Company Profiles, Market Distribution Status by Players of Database Servers.
- Chapter 9: Database Servers Market Analysis and Forecast by Type and Application.
- Chapter 10: Database Servers Market Analysis and Forecast by Regions.
- Chapter 11: Database Servers Industry Characteristics, Key Factors, New Entrants SWOT Analysis, Investment Feasibility Analysis.
- Chapter 12: Database Servers Market Conclusion of the Whole Report.
- Continue…
For More Information with including full TOC: https://www.globmarketreports.com/industry-reports/115479/Database-Servers-market
Key highlights of the Database Servers Market report:
• Growth rate
• Renumeration prediction
• Consumption graph
• Market concentration ratio
• Secondary industry competitors
• Competitive structure
• Major restraints
• Market drivers
• Regional bifurcation
• Competitive hierarchy
• Current market tendencies
• Market concentration analysis
Customization of the Report: Glob Market Reports provides customization of reports as per your need. This report can be personalized to meet your requirements. Get in touch with our sales team, who will guarantee you to get a report that suits your necessities.
Get Customization of the Report@: https://www.globmarketreports.com/request-customization/115479
Contact Us:
Glob Market Reports
17224 S. Figueroa Street,
Gardena, California (CA) 90248, United States
Call: +1 915 229 3004 (U.S)
+44 7452 242832 (U.K)
Website: www.globmarketreports.com
Article originally posted on mongodb google news. Visit mongodb google news
Database Engines Market Will Reflect Significant Growth Prospects of US$ Mn during 2021-2026 …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Latest research on Global Database Engines Market report covers forecast and analysis on a worldwide, regional and country level. The study provides historical information of 2016-2021 together with a forecast from 2021 to 2026 supported by both volume and revenue (USD million). The entire study covers the key drivers and restraints for the Database Engines market. this report included a special section on the Impact of COVID19. Also, Database Engines Market (By major Key Players, By Types, By Applications, and Leading Regions) Segments outlook, Business assessment, Competition scenario and Trends .The report also gives 360-degree overview of the competitive landscape of the industries.
Moreover, it offers highly accurate estimations on the CAGR, market share, and market size of key regions and countries. Players can use this study to explore untapped Database Engines markets to extend their reach and create sales opportunities.
Some of the key manufacturers operating in this market include: Google, Oracle, Microsoft, MongoDB, IBM, Redis Labs, Percona, Facebook and More…
Download Free PDF Sample Copy of the Report(with covid 19 Impact Analysis): https://www.globmarketreports.com/request-sample/115478
Our Research Analyst implemented a Free PDF Sample Report copy as per your Research Requirement, also including impact analysis of COVID-19 on Database Engines Market Size
Database Engines market competitive landscape offers data information and details by companies. Its provides a complete analysis and precise statistics on revenue by the major players participants for the period 2021-2026. The report also illustrates minute details in the Database Engines market governing micro and macroeconomic factors that seem to have a dominant and long-term impact, directing the course of popular trends in the global Database Engines market.
Market Segment by Type, covers:
Storge Engine
Query Engine
Market split by Application, can be divided into:
Large Enterprises
Small and Medium Sized Enterprises
Private
Regions Covered in the Global Database Engines Market:
1. South America Database Engines Market Covers Colombia, Brazil, and Argentina.
2. North America Database Engines Market Covers Canada, United States, and Mexico.
3. Europe Database Engines Market Covers UK, France, Italy, Germany, and Russia.
4. The Middle East and Africa Database Engines Market Covers UAE, Saudi Arabia, Egypt, Nigeria, and South Africa.
5. Asia Pacific Database Engines Market Covers Korea, Japan, China, Southeast Asia, and India.
Years Considered to Estimate the Market Size:
History Year: 2015-2021
Base Year: 2021
Estimated Year: 2021
Forecast Year: 2021-2026
*Get Upto $1000 Flat Discount on All License Type@https://www.globmarketreports.com/request-discount/115478
Reasons to buy:
- Procure strategically important competitor information, analysis, and insights to formulate effective R&D strategies.
- Recognize emerging players with potentially strong product portfolio and create effective counter-strategies to gain competitive advantage.
- Classify potential new clients or partners in the target demographic.
- Develop tactical initiatives by understanding the focus areas of leading companies.
- Plan mergers and acquisitions meritoriously by identifying Top Manufacturer.
- Formulate corrective measures for pipeline projects by understanding Database Engines pipeline depth.
- Develop and design in-licensing and out-licensing strategies by identifying prospective partners with the most attractive projects to enhance and expand business potential and Scope.
- Report will be updated with the latest data and delivered to you within 2-4 working days of order.
- Suitable for supporting your internal and external presentations with reliable high quality data and analysis.
- Create regional and country strategies on the basis of local data and analysis.
Some Major TOC Points:
- Chapter 1: Database Engines Market Overview, Product Overview, Market Segmentation, Market Overview of Regions, Market Dynamics, Limitations, Opportunities and Industry News and Policies.
- Chapter 2: Database Engines Industry Chain Analysis, Upstream Raw Material Suppliers, Major Players, Production Process Analysis, Cost Analysis, Market Channels, and Major Downstream Buyers.
- Chapter 3: Value Analysis, Production, Growth Rate and Price Analysis by Type of Database Engines.
- Chapter 4: Downstream Characteristics, Consumption and Market Share by Application of Database Engines.
- Chapter 5: Production Volume, Price, Gross Margin, and Revenue ($) of Database Engines by Regions.
- Chapter 6: Database Engines Production, Consumption, Export, and Import by Regions.
- Chapter 7: Database Engines Market Status and SWOT Analysis by Regions.
- Chapter 8: Competitive Landscape, Product Introduction, Company Profiles, Market Distribution Status by Players of Database Engines.
- Chapter 9: Database Engines Market Analysis and Forecast by Type and Application.
- Chapter 10: Database Engines Market Analysis and Forecast by Regions.
- Chapter 11: Database Engines Industry Characteristics, Key Factors, New Entrants SWOT Analysis, Investment Feasibility Analysis.
- Chapter 12: Database Engines Market Conclusion of the Whole Report.
- Continue…
For More Information with including full TOC: https://www.globmarketreports.com/industry-reports/115478/Database-Engines-market
Key highlights of the Database Engines Market report:
• Growth rate
• Renumeration prediction
• Consumption graph
• Market concentration ratio
• Secondary industry competitors
• Competitive structure
• Major restraints
• Market drivers
• Regional bifurcation
• Competitive hierarchy
• Current market tendencies
• Market concentration analysis
Customization of the Report:Glob Market Reports provides customization of reports as per your need. This report can be personalized to meet your requirements. Get in touch with our sales team, who will guarantee you to get a report that suits your necessities.
Get Customization of the Report@ https://www.globmarketreports.com/request-customization/115478
Contact Us:
Glob Market Reports
17224 S. Figueroa Street,
Gardena, California (CA) 90248, United States
Call: +1 915 229 3004 (U.S)
+44 7452 242832 (U.K)
Website: www.globmarketreports.com
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ

Nikolas Burk, developer relations at Prisma — the database ORM — recently announced that all Prisma tools (Prisma Client, Prisma Studio, Prisma Migrate) are ready for production usage. Prisma Migrate graduated from preview this year and is now generally available.
Burk summarized the rationale behind the Prisma suite of tools as follows:
At Prisma, we found that the Node.js ecosystem — while becoming increasingly popular to build database-backed applications — does not provide modern tools for application developers to deal with these tasks [—data modeling, schema migrations, and writing database queries].
Application developers should care about data — not SQL.
As tools become more specialized, application developers should be able to focus on implementing value-adding features for their organizations instead of spending time plumbing together the layers of their application by writing glue code.
Prisma proposes three tools that cater to different remote data management aspects. The Prisma Client is an auto-generated and type-safe query builder that lets developers perform create, read, update and delete (CRUD) operations on an underlying database. Prisma Studio is a user interface application with which developers may visually explore and manipulate the contents of a database.
The newly generally available Prisma Migrate strives to streamline an iterative development process in which a database schema is modified together with the querying application. Daniel Normal, developer advocate at Prisma, summarizes the goal of Prisma Migrate as follows:
Today’s data-driven applications demand constant change. When working with a relational database, managing a continually evolving schema can be a challenge.
Prisma Migrate is a database schema migration tool that simplifies evolving the database schema in tandem with the application. […] Prisma Migrate treads the balance between productivity and control by automating the repetitive and error-prone aspects of writing database migrations while giving you the final say over how they are executed.
Prisma Migrate features a database schema DSL in which developers may express database entities and relationships between entities:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
birthdate DateTime @db.Date
activated Boolean @default(false)
}
The schema DSL is translated to SQL migration scripts:
CREATE TABLE "User" (
"id" SERIAL NOT NULL,
"email" TEXT NOT NULL,
"name" TEXT,
"birthdate" DATE NOT NULL,
"activated" BOOLEAN NOT NULL DEFAULT false,
PRIMARY KEY ("id")
);
CREATE UNIQUE INDEX "User.email_unique" ON "User"("email");
As the database schema evolves, Prisma Migrate generates a history of .sql migration files in a dedicated folder:
migrations/
└─ 20210313140442_init/
└─ migration.sql
└─ 20210313140442_added_job_title/
└─ migration.sql
While Prisma Migrate covers commonly occurring schema changes (e.g., adding fields), developers may need to customize the migration scripts to add code specific to a database vendor or provide for an unhandled use case. The Prisma Migrate documentation mentions a few examples: renaming a field, changing the types of field, or changing the direction of a one-to-one relationship.
Developers on Reddit have emphasized that while having an ORM abstraction sit between the database(s) and the application may be useful, they still in practice need to know about SQL and the specifics of the underlying database — in particular for query optimization and performance purposes. This led some developers to advocate bypassing the abstraction altogether. Burk argued back that the cases in which the ORM abstraction leaks are infrequent enough to significantly dent Prisma’s added value:
SQL is complex, it’s easy to shoot yourself in the foot with it, and its data model (relational data/tables) is far away from the one application developers have (nested data/objects) when working in JS/TS. Mapping relational data to objects incurs a mental as well as a practical cost!
[…] In the majority of cases (which for most apps are fairly straightforward CRUD operations) developers shouldn’t pay that cost. They should have an API that feels natural and makes them productive. That being said, for the 5% of queries that need certain optimizations, Prisma allows you to drop down to raw SQL and make sure your desired SQL statements are sent to the DB.
I see Prisma somewhat analogous to GraphQL on the frontend, where a similar claim could be: “Frontend developers should care about data, not REST endpoints”. GraphQL liberates frontend developers from thinking about where to get their data from and how to assemble it into the structures they need.
The Prisma-generated migration history can be version-controlled so that the changes of schema can be tracked together with the rest of the application under development. Prisma Migrate currently supports PostgreSQL, MySQL, SQLite, and SQL Server (in Preview).
A recent crop of frameworks and meta-frameworks have added Prisma to their stack. Redwood, a full-stack framework that seeks to bring the Ruby on Rails experience to JavaScript; Wasp, a web app DSL written in Haskell; and Blitz, a full-stack React Framework built on Next.js, are all using Prisma for their data layer.
The Prisma documentation is available online and contains a conceptual introduction accompanied by tutorials. Prisma is a company backed by venture capital that provides open-source software distributed under the Apache 2.0 license.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

NoSQL Software Market research report studies the market status, competition landscape, market size, share, growth rate, future trends, market drivers, opportunities, challenges
This report contains market size and forecasts of NoSQL Software in Global, including the following market information:
Global NoSQL Software Market Revenue, 2016-2021, 2022-2027, ($ millions)
Global top five companies in 2020 (%)
The global NoSQL Software market was valued at xx million in 2020 and is projected to reach US$ xx million by 2027, at a CAGR of xx% during the forecast period.
Research has surveyed the NoSQL Software companies, and industry experts on this industry, involving the revenue, demand, product type, recent developments and plans, industry trends, drivers, challenges, obstacles, and potential risks.
Download PDF Sample of NoSQL Software Market report @ https://www.themarketinsights.com/request-sample/124430
Total Market by Segment:
Global NoSQL Software Market, By Type, 2016-2021, 2022-2027 ($ millions)
Global NoSQL Software Market Segment Percentages, By Type, 2020 (%)
Cloud Based
Web Based
China NoSQL Software Market, By Application, 2016-2021, 2022-2027 ($ millions)
China NoSQL Software Market Segment Percentages, By Application, 2020 (%)
E-Commerce
Social Networking
Data Analytics
Data Storage
Others
Global NoSQL Software Market, By Region and Country, 2016-2021, 2022-2027 ($ Millions)
Global NoSQL Software Market Segment Percentages, By Region and Country, 2020 (%)
North America
US
Canada
Mexico
Europe
Germany
France
U.K.
Italy
Russia
Nordic Countries
Benelux
Rest of Europe
Asia
China
Japan
South Korea
Southeast Asia
India
Rest of Asia
South America
Brazil
Argentina
Rest of South America
Middle East & Africa
Turkey
Israel
Saudi Arabia
UAE
Rest of Middle East & Africa
Report Customization available as per requirements Request Customization@ https://www.themarketinsights.com/request-customization/124430
Competitor Analysis
The report also provides analysis of leading market participants including:
Total NoSQL Software Market Competitors Revenues in Global, by Players 2016-2021 (Estimated), ($ millions)
Total NoSQL Software Market Competitors Revenues Share in Global, by Players 2020 (%)
Further, the report presents profiles of competitors in the market, including the following:
MongoDB
Amazon
ArangoDB
Azure Cosmos DB
Couchbase
MarkLogic
RethinkDB
CouchDB
SQL-RD
OrientDB
RavenDB
Redis
Microsoft
To Check Discount @ https://www.themarketinsights.com/check-discount/124430
Table of ContentChapter One: Introduction to Research & Analysis Reports
Chapter Two: Global NoSQL Software Overall Market Size
Chapter Three: Company Landscape
Chapter Four: Market Sights by Product
Chapter Five: Sights by Application
Chapter Six: Sights by Region
Chapter Seven: Players Profiles
Chapter Eight: Conclusion
Chapter Nine: Appendix
9.1 Note
9.2 Examples of Clients
9.3 Disclaimer
</s
List of Table and Figure
Table 1. NoSQL Software Market Opportunities & Trends in Global Market
Table 2. NoSQL Software Market Drivers in Global Market
Table 3. NoSQL Software Market Restraints in Global Market
Table 4. Key Players of NoSQL Software in Global Market
Table 5. Top NoSQL Software Players in Global Market, Ranking by Revenue (2019)
Table 6. Global NoSQL Software Revenue by Companies, (US$, Mn), 2016-2021
Table 7. Global NoSQL Software Revenue Share by Companies, 2016-2021
Table 8. Global Companies NoSQL Software Product Type
Table 9. List of Global Tier 1 NoSQL Software Companies, Revenue (US$, Mn) in 2020 and Market Share
Table 10. List of Global Tier 2 and Tier 3 NoSQL Software Companies, Revenue (US$, Mn) in 2020 and Market Share
Table 11. By Type Global NoSQL Software Revenue, (US$, Mn), 2021 VS 2027
Table 12. By Type – NoSQL Software Revenue in Global (US$, Mn), 2016-2021
Table 13. By Type – NoSQL Software Revenue in Global (US$, Mn), 2022-2027
Table 14. By Application Global NoSQL Software Revenue, (US$, Mn), 2021 VS 2027
Table 15. By Application – NoSQL Software Revenue in Global (US$, Mn), 2016-2021
Table 16. By Application – NoSQL Software Revenue in Global (US$, Mn), 2022-2027
Table 17. By Region Global NoSQL Software Revenue, (US$, Mn), 2021 VS 2027
Table 18. By Region – Global NoSQL Software Revenue (US$, Mn), 2016-2021
Table 19. By Region – Global NoSQL Software Revenue (US$, Mn), 2022-2027
Table 20. By Country – North America NoSQL Software Revenue, (US$, Mn), 2016-2021
Table 21. By Country – North America NoSQL Software Revenue, (US$, Mn), 2022-2027
Table 22. By Country – Europe NoSQL Software Revenue, (US$, Mn), 2016-2021
Table 23. By Country – Europe NoSQL Software Revenue, (US$, Mn), 2022-2027
Table 24. By Region – Asia NoSQL Software Revenue, (US$, Mn), 2016-2021
continued…
About us.
The Market Insights is a sister company to SI Market research and The Market Insights is into reselling. The Market Insights is a company that is creating cutting edge, futuristic and informative reports in many different areas. Some of the most common areas where we generate reports are industry reports, country reports, company reports and everything in between. At The Market Insights, we give our clients the best reports that can be made in the market. Our reports are not only about market statistics, but they also contain a lot of information about new and niche company profiles. The companies that feature in our reports are pre-eminent. The database of the reports on market research is constantly updated by us. This database contains a broad variety of reports from the cardinal industries. Our clients have direct access online to our databases. This is done to ensure that the client is always provided with what they need. Based on these needs, we at The Market Insights also include insights from experts about the global industries, market trends as well as the products in the market. These resources that we prepare are also available on our database for our esteemed clients to use. It is our duty at The Market Insights to ensure that our clients find success in their endeavors and we do everything that we can to help make that possible.
Direct Contact
Jessica Joyal
+91-9284395731 | +91 9175986728
sales@themarketinsights.com
“