Month: April 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Everything you need to know about a top algorithm in Machine Learning

In the beginning, learning Machine Learning (ML) can be intimidating. Terms like “Gradient Descent”, “Latent Dirichlet Allocation” or “Convolutional Layer” can scare lots of people. But there are friendly ways of getting into the discipline, and I think starting with Decision Trees is a wise decision.
Decision Trees (DTs) are probably one of the most useful supervised learningalgorithms out there. As opposed to unsupervised learning (where there is no output variable to guide the learning process and data is explored by algorithms to find patterns), in supervised learning your existing data is already labelled and you know which behaviour you want to predict in the new data you obtain. This is the type of algorithms that autonomous cars use to recognize pedestrians and objects, or organizations exploit to estimate customers lifetime value and their churn rates.
In a way, supervised learning is like learning with a teacher, and then apply that knowledge to new data.
DTs are ML algorithms that progressively divide data sets into smaller data groups based on a descriptive feature, until they reach sets that are small enough to be described by some label. They require that you have data that is labelled (tagged with one or more labels, like the plant name in pictures of plants), so they try to label new data based on that knowledge.
DTs algorithms are perfect to solve classification (where machines sort data into classes, like whether an email is spam or not) and regression (where machines predict values, like a property price) problems. Regression Trees are used when the dependent variable is continuous or quantitative (e.g. if we want to estimate the probability that a customer will default on a loan), and Classification Trees are used when the dependent variable is categorical or qualitative (e.g. if we want to estimate the blood type of a person).
The importance of DTs relies on the fact that they have lots of applications in the real world. Being one of the mostly used algorithms in ML, they are applied to different functionalities in several industries:
- DTs are being used in the healthcare industry to improve the screening of positive cases in the early detection of cognitive impairment, and also to identify the main risk factors of developing some type of dementia in the future.
- Sophia, the robot that was made a citizen of Saudi Arabia, uses DTs algorithms to chat with humans. In fact, chatbots that use these algorithms are already bringing benefits in industries like health insuranceby gathering data from customers through the application of innovative surveys and friendly chats. Google recently acquired Onward, a company that uses DTs to develop chatbots that are exceptionally functional in delivering world-class customer care, and Amazon is investing in the same direction to guide customers quickly to a path of resolution.
- It is possible to predict the most likely causes of forest disturbances, like wildfire, logging of tree plantations, large or small scale agriculture, and urbanization by training DTs to recognize different causes of forest lossfrom satellite imagery. DTs and satellite imagery are also used in agriculture to classify different crop types and identify their phenological stages.
- DTs are great tools to perform sentiment analysis of texts, and identify the emotions behind them. Sentiment analysis is a powerful technique that can help organizations to learn about customers choices and their decision drivers.
- In environmental sciences, DTs can help to determine the best strategy for dealing with invasive species, ranging from eradication to containment, and mitigation of spread.
- DTs are also used to improve financial fraud detection. The MIT showed that it could significantly improve the performance of alternative ML models by using DTs that were trained with several sources of raw data to find patterns of transactions and credit cards that match cases of fraud.
DTs are extremely popular for a variety of reasons, being their interpretability probably their most important advantage. They can be trained very fast and are easy to understand, which opens their possibilities to frontiers far beyond scientific walls. Nowadays, DTs are very popular in business environments and their usage is also expanding to civil areas, where some applications are raising big concerns.
The firm Sesame Credit (a company affiliated with Alibaba) uses DTs and other algorithms to engine a system of social evaluation, taking into consideration various factors such as the punctuality with which bills are paid and other online activities. The benefits of a good “Sesame score” in China range from a higher visibility on dating sites to skipping the waiting line if you need to see a doctor. Actually, after the chinese government announced it will apply its so-called social credit system to flights and trains and stop people who have committed misdeeds from taking such transport for up to a year, there is a concern that the system will end up creating a massive “ML-backed Big Brother”.
The Basics
In the movie Bandersnatch (a stand-alone Black Mirror episode from Netflix), the viewer can interactively choose different narrative paths and reach different story lines and endings. There is a complex set of decisions hidden behind the movie storytelling that lets the audience move in a kind of Choose Your Own Adventure mode, for which Netflix had to work out a way of loading multiple versions of each scene while presenting it in a simple way. In practice, what Netflix producers did was to segment the movie and set different branch points for the viewer to move through, and come up with different results. In other words, this is just like building a DT.
DTs are composed of nodes, branches and leafs. Each node represents an attribute (or feature), each branch represents a rule (or decision), and eachleaf represents an outcome. The depth of a Tree is defined by the number of levels, not including the root node.
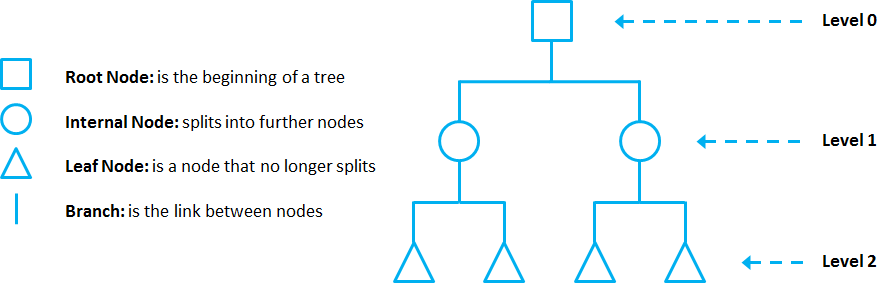
In this example, a DT of 2 levels.
DTs apply a top-down approach to data, so that given a data set, they try to group and label observations that are similar between them, and look for the best rules that split the observations that are dissimilar between them until they reach certain degree of similarity.
They use a layered splitting process, where at each layer they try to split the data into two or more groups, so that data that fall into the same group are most similar to each other (homogeneity), and groups are as different as possible from each other (heterogeneity).
The splitting can be binary (which splits each node into at most two sub-groups, and tries to find the optimal partitioning), or multiway (which splits each node into multiple sub-groups, using as many partitions as existing distinct values). In practice, it is usual to see DTs with binary splits, but it’s important to know that multiway splitting has some advantages. Multiway splits exhaust all information in a nominal attribute, which means that an attribute rarely appears more than once in any path from the root to the leaf, which make DTs easier to comprehend. In fact, it could happen that the best way to split data might be to find a set of intervals for a given feature, and then split that data up into several groups based on those intervals.
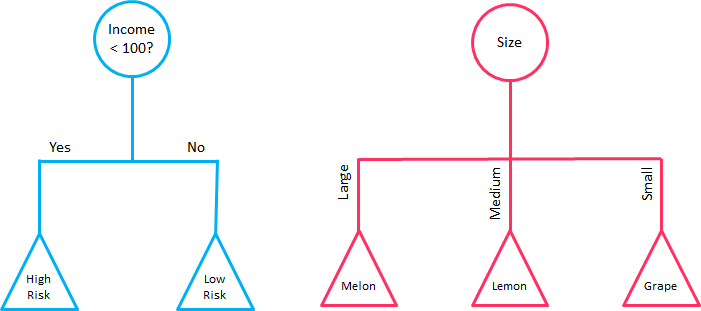
On the left hand side, a DT with binary splitting, as opposed to a DT with multiway splitting on the right.
In bidimensional terms (using only 2 variables), DTs partition the data universe into a set of rectangles, and fit a model in each one of those rectangles. They are simple yet powerful, and a great tool for data scientists.
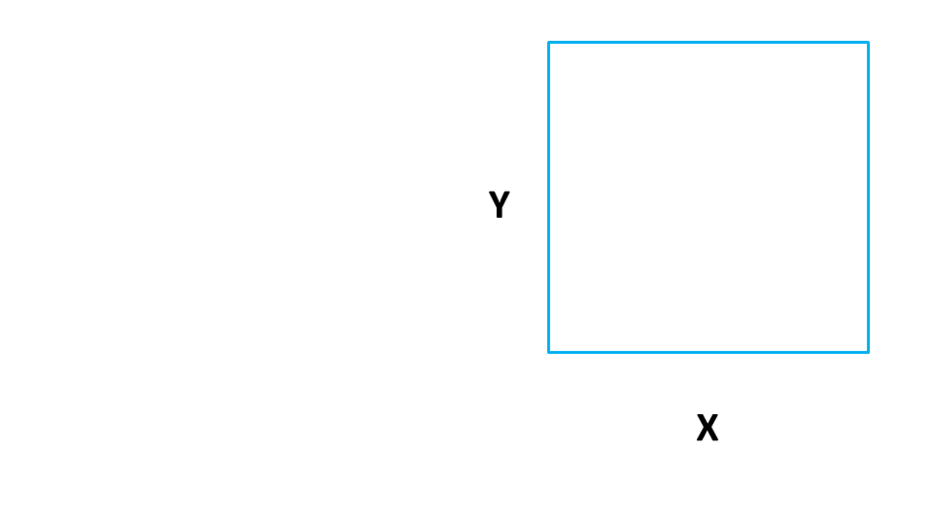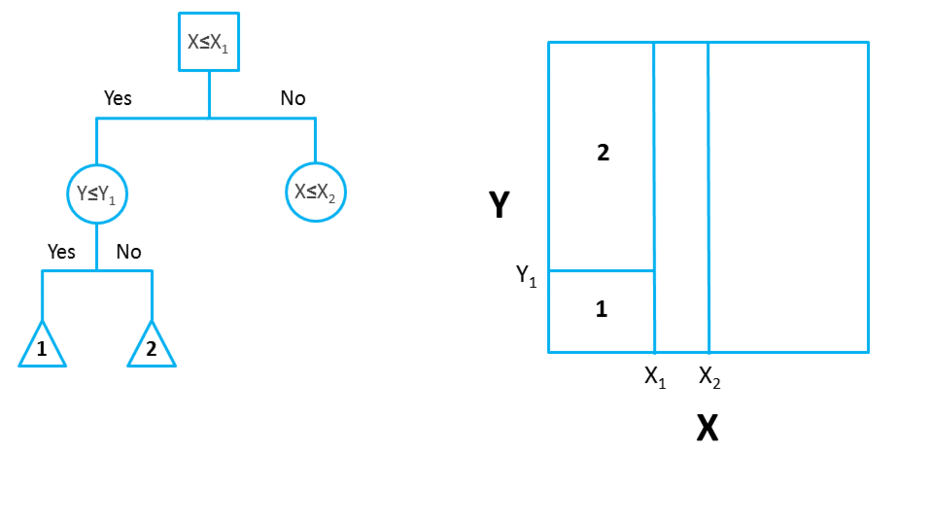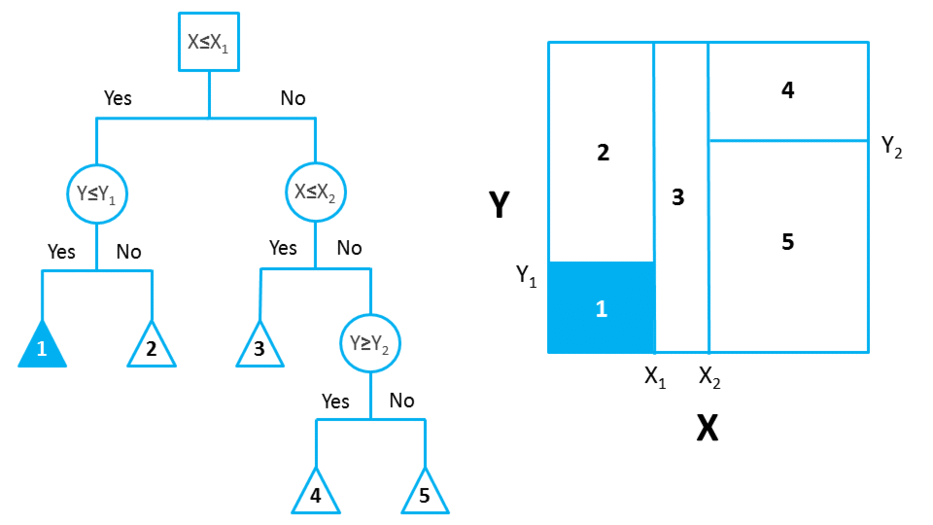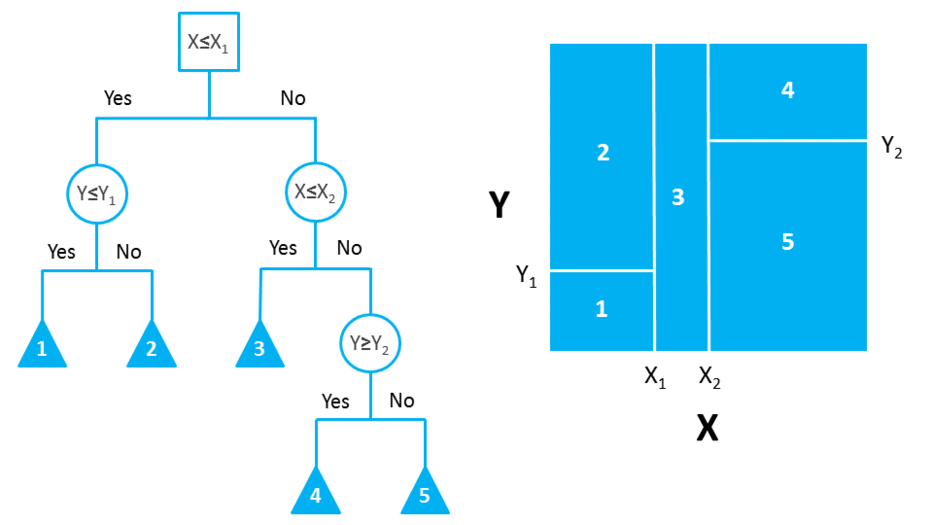
Right figure shows the partition of the bidimensional data space produced by the DT on the left (binary split). In practice, however, DTs use numerous variables (usually more than 2).
Each node in the DT acts as a test case for some condition, and each branch descending from that node corresponds to one of the possible answers to that test case.
Prune that Tree
As the number of splits in DTs increase, their complexity rises. In general, simpler DTs are preferred over super complex ones, since they are easier to understand and they are less likely to fall into overfitting.
Overfitting refers to a model that learns the training data(the data it uses to learn) so well that it has problems to generalize to new (unseen) data.
In other words, the model learns the detail and noise (irrelevant information or randomness in a dataset) in the training data to the extent that it negatively impacts the performance of the model on new data. This means that the noise or random fluctuations in the training data is picked up and learned as concepts by the model.

While the black line fits the data well, the green line is overfitting
Under this condition, your model works perfectly well with the data you provide upfront, but when you expose that same model to new data, it breaks down. It’s unable to repeat its highly detailed performance.
So, how do you avoid overfitting in DTs? You need to exclude branches that fit data too specifically. You want a DT that can generalize and work well on new data, even though this may imply losing precision on the training data. It’s always better to avoid a DT model that learns and repeats specific details like a parrot, and try to develop one that has the power and flexibility to have a decent performance on new data you provide to it.
Pruning is a technique used to deal with overfitting, that reduces the size of DTs by removing sections of the Tree that provide little predictive or classification power.
The goal of this procedure is to reduce complexity and gain better accuracy by reducing the effects of overfitting and removing sections of the DT that may be based on noisy or erroneous data. There are two different strategies to perform pruning on DTs:
- Pre-prune: When you stop growing DT branches when information becomes unreliable.
- Post-prune: When you take a fully grown DT and then remove leaf nodes only if it results in a better model performance. This way, you stop removing nodes when no further improvements can be made.
Example of an unpruned DT, as taken from DataCamp
In summary, a big DT that correctly classifies or predicts every example of the training data might not be as good as a smaller one that does not fit all the training data perfectly.
Main DTs algorithms
Now you may ask yourself: how do DTs know which features to select and how to split the data? To understand that, we need to get into some details.
All DTs perform basically the same task: they examine all the attributes of the dataset to find the ones that give the best possible result by splitting the data into subgroups. They perform this task recursively by splitting subgroups into smaller and smaller units until the Tree is finished (stopped by certain criteria).
This decision of making splits heavily affects the Tree’s accuracy and performance, and for that decision, DTs can use different algorithms that differ in the possible structure of the Tree (e.g. the number of splits per node), the criteria on how to perform the splits, and when to stop splitting.
So, how can we define which attributes to split, when and how to split them? To answer this question, we must review the main DTs algorithms:
CHAID
The Chi-squared Automatic Interaction Detection (CHAID) is one of the oldest DT algorithms methods that produces multiway DTs (splits can have more than two branches) suitable for classification and regression tasks. When building Classification Trees (where the dependent variable is categorical in nature), CHAID relies on the Chi-square independence tests to determine the best split at each step. Chi-square tests check if there is a relationship between two variables, and are applied at each stage of the DT to ensure that each branch is significantly associated with a statistically significant predictor of the response variable.
In other words, it chooses the independent variable that has the strongest interaction with the dependent variable.
Additionally, categories of each predictor are merged if they are not significantly different between each other, with respect to the dependent variable. In the case of Regression Trees (where the dependent variable is continuous), CHAID relies on F-tests (instead of Chi-square tests) to calculate the difference between two population means. If the F-test is significant, a new partition (child node) is created (which means that the partition is statistically different from the parent node). On the other hand, if the result of the F-test between target means is not significant, the categories are merged into a single node.
CHAID does not replace missing values and handles them as a single class which may merge with another class if appropriate. It also produces DTs that tend to be wider rather than deeper (multiway characteristic), which may be unrealistically short and hard to relate to real business conditions. Additionally, it has no pruning function.
Although not the most powerful (in terms of detecting the smallest possible differences) or fastest DT algorithm out there, CHAID is easy to manage, flexible and can be very useful.
You can find an implementation of CHAID with R in this link
CART
CART is a DT algorithm that produces binary Classification or RegressionTrees, depending on whether the dependent (or target) variable is categorical or numeric, respectively. It handles data in its raw form (no preprocessing needed), and can use the same variables more than once in different parts of the same DT, which may uncover complex interdependencies between sets of variables.
In the case of Classification Trees, CART algorithm uses a metric called Gini Impurity to create decision points for classification tasks. Gini Impurity gives an idea of how fine a split is (a measure of a node’s “purity”), by how mixed the classes are in the two groups created by the split. When all observations belong to the same label, there’s a perfect classification and a Gini Impurity value of 0 (minimum value). On the other hand, when all observations are equally distributed among different labels, we face the worst case split result and a Gini Impurity value of 1 (maximum value).
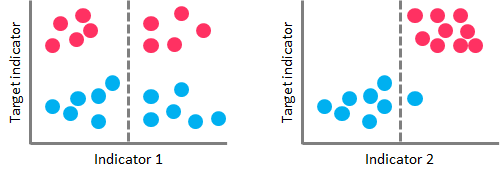
On the left-hand side, a high Gini Impurity value leads to a poor splitting performance. On the right-hand side, a low Gini Impurity value performs a nearly perfect splitting
In the case of Regression Trees, CART algorithm looks for splits that minimize the Least Square Deviation (LSD), choosing the partitions that minimize the result over all possible options. The LSD (sometimes referred as “variance reduction”) metric minimizes the sum of the squared distances (or deviations) between the observed values and the predicted values. The difference between the predicted and observed values is called “residual”, which means that LSD chooses the parameter estimates so that the sum of the squared residuals is minimized.
LSD is well suited for metric data and has the ability to correctly capture more information about the quality of the split than other algorithms.
The idea behind CART algorithm is to produce a sequence of DTs, each of which is a candidate to be the “optimal Tree”. This optimal Tree is identified by evaluating the performance of every Tree through testing (using new data, which the DT has never seen before) or performing cross-validation(dividing the dataset into “k” number of folds, and perform testings on each fold).
CART doesn’t use an internal performance measure for Tree selection. Instead, DTs performances are always measured through testing or via cross-validation, and the Tree selection proceeds only after this evaluation has been done.
ID3
The Iterative Dichotomiser 3 (ID3) is a DT algorithm that is mainly used to produce Classification Trees. Since it hasn’t proved to be so effective building Regression Trees in its raw data, ID3 is mostly used for classification tasks (although some techniques such as building numerical intervals can improve its performance on Regression Trees).
ID3 splits data attributes (dichotomizes) to find the most dominant features, performing this process iteratively to select the DT nodes in a top-down approach.
For the splitting process, ID3 uses the Information Gain metric to select the most useful attributes for classification. Information Gain is a concept extracted from Information Theory, that refers to the decrease in the level of randomness in a set of data: basically it measures how much “information” a feature gives us about a class. ID3 will always try to maximize this metric, which means that the attribute with the highest Information Gain will split first.
Information Gain is directly linked to the concept of Entropy, which is the measure of the amount of uncertainty or randomness in the data. Entropy values range from 0 (when all members belong to the same class or the sample is completely homogeneous) to 1 (when there is perfect randomness or unpredictability, or the sample is equally divided).
You can think it this way: if you want to make an unbiased coin toss, there is complete randomness or an Entropy value of 1 (“heads” and “tails” are equally like, with a probability of 0.5 each). On the other hand, if you make a coin toss, with for example a coin that has “tails” on both sides, randomness is removed from the event and the Entropy value is 0 (probability of getting “tails” will jump to 1, and probability of “heads” will drop to 0).
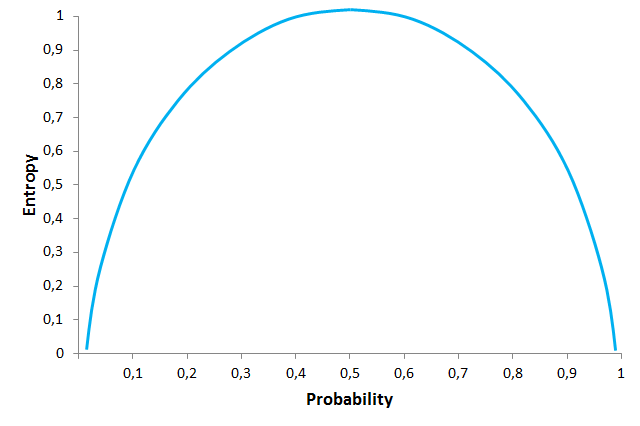
In this graph you can see the relationship between Entropy and the probability of different coin tosses. At the highest level of Entropy, the probability of getting “tails” is equal to the one of getting “heads” (0.5 each), and we face complete uncertainty. Entropy is directly linked to the probability of an event. Example taken from The Null Pointer Exception
This is important because Information Gain is the decrease in Entropy, and the attribute that yields the largest Information Gain is chosen for the DT node.
But ID3 has some disadvantages: it can’t handle numeric attributes nor missing values, which can represent serious limitations.
C4.5
C4.5 is the successor of ID3 and represents an improvement in several aspects. C4.5 can handle both continuous and categorical data, making it suitable to generate Regression and Classification Trees. Additionally, it can deal with missing values by ignoring instances that include non-existing data.
Unlike ID3 (which uses Information Gain as splitting criteria), C4.5 uses Gain Ratio for its splitting process. Gain Ratio is a modification of the Information Gain concept that reduces the bias on DTs with huge amount of branches, by taking into account the number and size of the branches when choosing an attribute. Since Information Gain shows an unfair favoritism towards attributes with many outcomes, Gain Ratio corrects this trend by considering the intrinsic information of each split (it basically “normalizes” the Information Gain by using a split information value). This way, the attribute with the maximum Gain Ratio is selected as the splitting attribute.
Additionally, C4.5 includes a technique called windowing, which was originally developed to overcome the memory limitations of earlier computers. Windowing means that the algorithm randomly selects a subset of the training data (called a “window”) and builds a DT from that selection. This DT is then used to classify the remaining training data, and if it performs a correct classification, the DT is finished. Otherwise, all the misclassified data points are added to the windows, and the cycle repeats until every instance in the training set is correctly classified by the current DT. This technique generally results in DTs that are more accurate than those produced by the standard process due to the use of randomization, since it captures all the “rare” instances together with sufficient “ordinary” cases.
Another capability of C4.5 is that it can prune DTs.
C4.5’s pruning method is based on estimating the error rate of every internal node, and replacing it with a leaf node if the estimated error of the leaf is lower. In simple terms, if the algorithm estimates that the DT will be more accurate if the “children” of a node are deleted and that node is made a leaf node, then C4.5 will delete those children.
The latest version of this algorithm is called C5.0, which was released under proprietary license and presents some improvements over C4.5 like:
- Improved speed: C5.0 is significantly faster than C4.5 (by several orders of magnitude).
- Memory usage: C5.0 is more memory efficient than C4.5.
- Variable misclassification costs: in C4.5 all errors are treated as equal, but in practical applications some classification errors are more serious than others. C5.0 allows to define separate cost for each predicted/actual class pair.
- Smaller decision trees: C5.0 gets similar results to C4.5 with considerably smaller DTs.
- Additional data types: C5.0 can work with dates, times, and allows values to be noted as “not applicable”.
- Winnowing: C5.0 can automatically winnow the attributes before a classifier is constructed, discarding those that may be unhelpful or seem irrelevant.
You can find a comparison between C4.5 and C5.0 here
The dark side of the Tree
Surely DTs have lots of advantages. Because of their simplicity and the fact that they are easy to understand and implement, they are widely used for different solutions in a large number of industries. But you also need to be aware of its disadvantages.
DTs tend to overfit on their training data, making them perform badly if data previously shown to them doesn’t match to what they are shown later.
They also suffer from high variance, which means that a small change in the data can result in a very different set of splits, making interpretation somewhat complex. They suffer from an inherent instability, since due to their hierarchical nature, the effect of an error in the top splits propagate down to all of the splits below.
In Classification Trees, the consequences of misclassifying observations are more serious in some classes than others. For example, it is probably worse to predict that a person will not have a heart attack when he/she actually will, than vice versa. This problem is mitigated in algorithms like C5.0, but remains as a serious issue in others.
DTs can also create biased Trees if some classes dominate over others. This is a problem in unbalanced datasets (where different classes in the dataset have different number of observations), in which case it is recommended to balance de dataset prior to building the DT.
In the case of Regression Trees, DTs can only predict within the range of values they created based on the data they saw before, which means that they have boundaries on the values they can produce.
At each level, DTs look for the best possible split so that they optimize the corresponding splitting criteria.
But DTs splitting algorithms can’t see far beyond the current level in which they are operating (they are “greedy”), which means that they look for a locally optimal and not a globally optimal at each step.
DTs algorithms grow Trees one node at a time according to some splitting criteria and don’t implement any backtracking technique.
The power of the crowd
But here are the good news: there are different strategies to overcome these drawbacks. Ensemble methods combine several DTs to improve the performance of single DTs, and are a great resource to get over the problems already described. The idea is to train multiple models using the same learning algorithm to achieve superior results.
Probably the 2 most common techniques to perform ensemble DTs are Bagging and Boosting.
Bagging (or Bootstrap Aggregation) is used when the goal is to reduce the variance of a DT. Variance relates to the fact that DTs can be quite unstable because small variations in the data might result in a completely different Tree being generated. So, the idea of Bagging is to solve this issue by creating in parallel random subsets of data (from the training data), where any observation has the same probability to appear in a new subset data. Next, each collection of subset data is used to train DTs, resulting in an ensemble of different DTs. Finally, an average of all predictions of those different DTs is used, which produces a more robust performance than single DTs. Random Forest is an extension over Bagging, which takes one extra step: in addition to taking the random subset of data, it also takes a random selection of features rather than using all features to grow DTs.
Boosting is another technique that creates a collection of predictors to reduce the variance of a DT, but with a different approach. It uses a sequential method where it fits consecutive DTS, and at every step, tries to reduce the errors from the prior Tree. With Boosting techniques, each classifier is trained on data, taking into account the previous classifier success. After each training step, the weights are redistributed based on the previous performance. This way, misclassified data increases its weights to emphasize the most difficult cases, so that subsequent DTs will focus on them during their training stage and improve their accuracy. Unlike Bagging, in Boosting the observations are weighted and therefore some of them will take part in the new subsets of data more often. As a result of this process, the combination of the whole sets improves the performance of DTs.
Within Boosting, there are several alternatives to determine the weights to use in the training and classification steps (e.g. Gradient Boost, XGBoost, AdaBoost, and others).
You can find a description of similarities and differences between both techniques here
Interested in these topics? Follow me on Linkedin or Twitter
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
A complete guide to K-means clustering algorithm

Let’s say you want to classify hundreds (or thousands) of documents based on their content and topics, or you wish to group together different images for some reason. Or what’s even more, let’s think you have that same data already classified but you want to challenge that labeling. You want to know if that data categorization makes sense or not, or can be improved.
Well, my advice is that you cluster your data. Information is often darkened by noise and redundancy, and grouping data into clusters (clustering) with similar features is an efficient way to bring some light on.
Clustering is a technique widely used to find groups of observations (called clusters) that share similar characteristics. This process is not driven by a specific purpose, which means you don’t have to specifically tell your algorithm how to group those observations since it does it on its own (groups are formed organically). The result is that observations (or data points) in the same group are more similar between them than other observations in another group. The goal is to obtain data points in the same group as similar as possible, and data points in different groups as dissimilar as possible.
Extremely well fitted for exploratory analysis, K-means is perfect for getting to know your data and providing insights on almost all datatypes. Whether it is an image, a figure or a piece of text, K-means is so flexible it can take almost everything.
One of the rockstars in unsupervised learning
Clustering (including K-means clustering) is an unsupervised learning technique used for data classification.
Unsupervised learning means there is no output variable to guide the learning process (no this or that, no right or wrong) and data is explored by algorithms to find patterns. We only observe the features but have no established measurements of the outcomes since we want to find them out.
As opposed to supervised learning where your existing data is already labeled and you know which behaviour you want to determine in the new data youobtain, unsupervised learning techniques don’t use labelled data and the algorithms are left to themselves to discover structures in the data.
Within the universe of clustering techniques, K-means is probably one of the mostly known and frequently used. K-means uses an iterative refinement method to produce its final clustering based on the number of clusters defined by the user (represented by the variable K) and the dataset. For example, if you set K equal to 3 then your dataset will be grouped in 3 clusters, if you set K equal to 4 you will group the data in 4 clusters, and so on.
K-means starts off with arbitrarily chosen data points as proposed means of the data groups, and iteratively recalculates new means in order to converge to a final clustering of the data points.
But how does the algorithm decide how to group the data if you are just providing a value (K)? When you define the value of K you are actually telling the algorithm how many means or centroids you want (if you set K=3 you create 3 means or centroids, which accounts for 3 clusters). A centroid is a data point that represents the center of the cluster (the mean), and it might not necessarily be a member of the dataset.
This is how the algorithm works:
- K centroids are created randomly (based on the predefined value of K)
- K-means allocates every data point in the dataset to the nearest centroid (minimizing Euclidean distances between them), meaning that a data point is considered to be in a particular cluster if it is closer to that cluster’s centroid than any other centroid
- Then K-means recalculates the centroids by taking the mean of all data points assigned to that centroid’s cluster, hence reducing the total intra-cluster variance in relation to the previous step. The “means” in the K-means refers to averaging the data and finding the new centroid
- The algorithm iterates between steps 2 and 3 until some criteria is met (e.g. the sum of distances between the data points and their corresponding centroid is minimized, a maximum number of iterations is reached, no changes in centroids value or no data points change clusters)
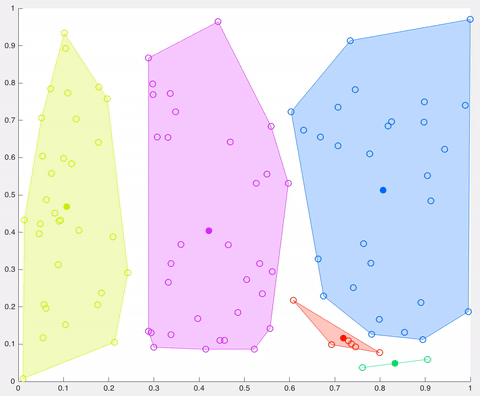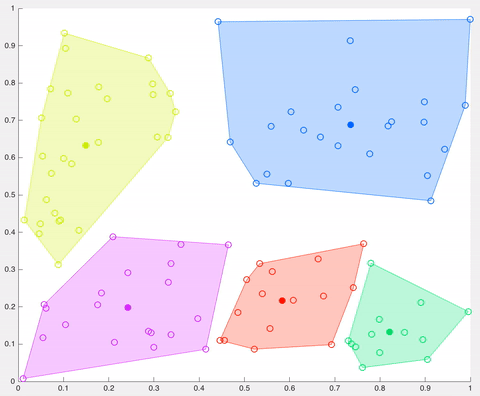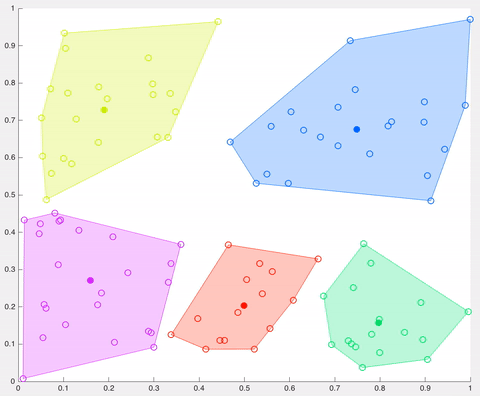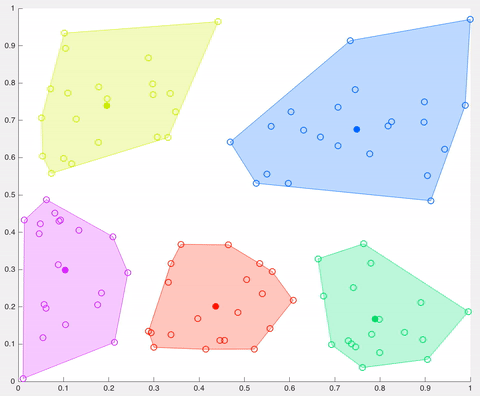
In this example, after 5 iterations the calculated centroids remain the same, and data points are not switching clusters anymore (the algorithm converges). Here, each centroid is shown as a dark coloured data point. Source: http://ai.stanford.edu
The initial result of running this algorithm may not be the best possible outcome and rerunning it with different randomized starting centroids might provide a better performance (different initial objects may produce different clustering results). For this reason, it’s a common practice to run the algorithm multiple times with different starting points and evaluate different initiation methods (e.g. Forgy or Kaufman approaches).
But another question arises: how do you know the correct value of K, or how many centroids to create? There is no universal answer for this, and although the optimal number of centroids or clusters is not known a priori, different approaches exist to try to estimate it. One commonly used approach is testing different numbers of clusters and measure the resulting sum of squared errors, choosing the K value at which an increase will cause a very small decrease in the error sum, while a decrease will sharply increase the error sum. This point that defines the optimal number of clusters is known as the “elbow point”, and can be used as a visual measure to find the best pick for the value of K.
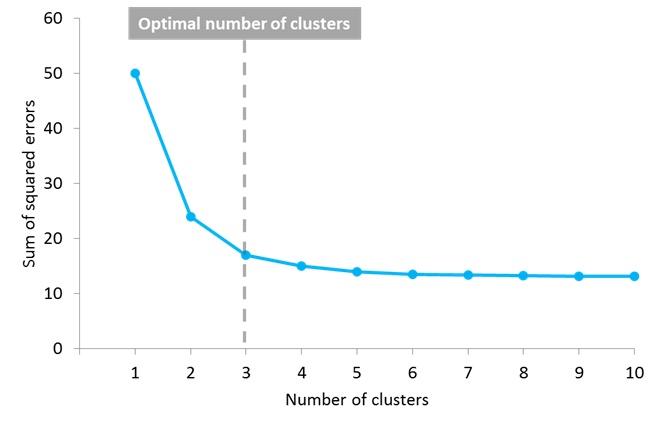
In this example, the elbow point is located in 3 clusters
K-means is a must-have in your data science toolkit, and there are several reasons for this. First of all it’s easy to implement and brings an efficient performance. After all, you need to define just one parameter (the value of K) to see the results. It is also fast and works really well with large datasets, making it capable of dealing with the current huge volumes of data. It’s soflexible that it can be used with pretty much any datatype and its results are easy to interpret and more explainable than other algorithms. Furthermore, the algorithm is so popular that you may find use cases and implementations in almost any discipline.
But everything has a downside
Nevertheless, K-means presents some disadvantages. The first one is that you need to define the number of clusters, and this decision can seriously affect the results. Also, as the location of the initial centroids is random, results may not be comparable and show lack of consistency. K-means produces clusters with uniform sizes (each cluster with roughly an equal quantity of observations), even though the data might behave in a different way, and it’s very sensitive to outliers and noisy data. Additionally, it assumes that data points in each cluster are modeled as located within a sphere around that cluster centroid (spherical limitation), but when this condition (or any of the previous ones) is violated, the algorithm can behave in non-intuitive ways.
Example 1
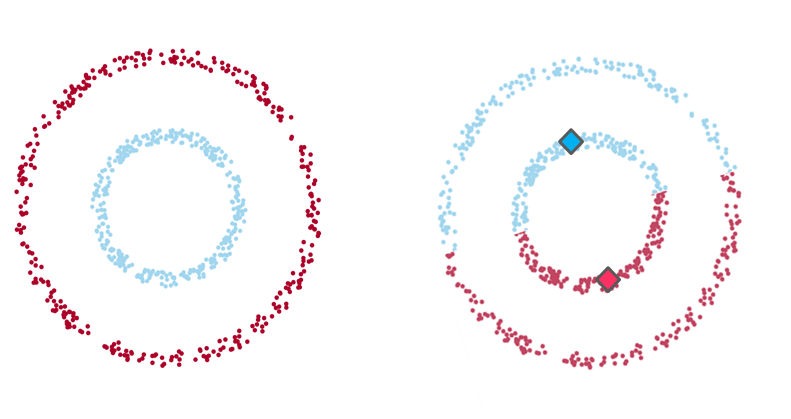
Example 1: On the left-hand side the intuitive clustering of the data, with a clear separation between two groups of data points (in the shape of one small ring surrounded by a larger one). On the right-hand side, the same data points clustered by K-means algorithm (with a K value of 2), where each centroid is represented with a diamond shape. As you see, the algorithm fails to identify the intuitive clustering.
Example 2
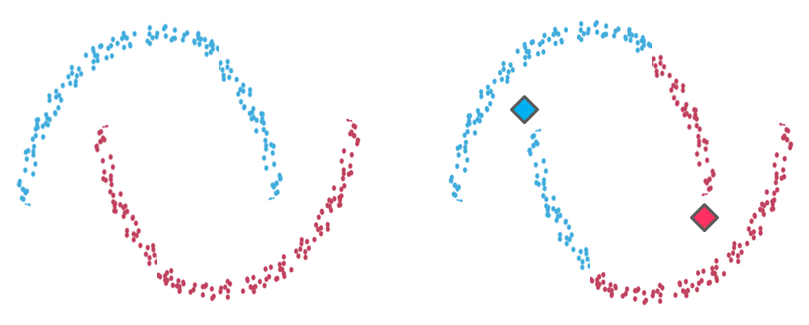
Example 2: On the left-hand side the clustering of two recognizable data groups. On the right-hand side, the result of K-means clustering over the same data points does not fit the intuitive clustering. As in the case of example 1, K-means created partitions that don’t reflect what we visually identify due to the algorithm’s spherical limitation. It tries to find centroids with neat spheres of data around them, and performs badly as the cluster’s geometric shape deviates from a sphere.

Example 3
Example 3: Once again, on the left-hand side there are two clear clusters (one small and tight data group and another larger and dispersed one) which K-means fails to identify (right-hand side). Here, in an attempt to balance the intra-cluster distances between both data groups and generate clusters with uniform sizes, the algorithm blends both data groups and creates 2 artificial clusters that don’t represent the dataset.
It’s interesting to see that K-means doesn’t allow data points that are far away from each other to share the same cluster, no matter how obvious the relation between these data points might be.
What to do now?
The thing is real life data is almost always complex, disorganized and noisy. Situations in the real world rarely reflect clear conditions in which to apply these type of algorithms right out of the shelf. In the case of K-means algorithm it will be expected that at least one of its assumptions gets violated, so we need not only to identify this, but to know what to do in such case.
The good news is that there are alternatives, and deficiencies can be corrected. For example, converting data to polar coordinates can solve the spherical limitation we described in example 1. You may also consider using other types of clustering algorithms if you find serious limitations. Possible approaches would be to use density-based or hierarchical-based algorithms, which fix some of K-means limitations (but have their own limitations).
In summary, K-means is a wonderful algorithm with lots of potential uses, so versatile it can be used for almost any kind of data grouping. But there is never a free lunch: you need to be aware of its assumptions and the way it operates if you don’t want to get guided to wrong results.
Interested in these topics? Follow me on Linkedin or Twitter
Teaching the Computer to Play the Chrome Dinosaur Game With TensorFlow.js Machine Learning Library
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Fritz’s HeartBeat Medium publication recently issued an article by Aayush Arora which shows how Google’s machine learning TensorFlow.js library can be leveraged in the browser to teach the computer to play the Chrome Dinosaur Game.
The Chrome Dinosaur Game (sometimes called the T-Rex Game) appeared five years ago in a Chrome browser when a user would try and visit a website while disconnected from the Internet. The Chrome Dinosaur Game is a simple infinite runner, in which a player may have to jump over cacti, and dodge underneath obstacles. Controls are basic: pushing the space bar translates into a jump, and the down arrow into ducking. The goal is to survive for as long as possible, and a timer measures how long the player manages to sift through obstacles:
The chosen set of features, given the nature of the game, is the speed of the game, the width of the oncoming obstacle and its’ distance from the player’s T-Rex. The computer will learn to map those three variables to outputs from which one of two decisions can be taken: jump or don’t jump (Note that the original version of the game also allows the dinosaur to crouch, which is not modelized here in the decision list). The computer will learn by trial and errors, gathering training data every time it fails at the game, then restarting the game with the accumulated experience.
Tensorflow.js is used as a machine learning library. TensorFlow’s tutorials identify the following steps for a machine learning implementation:
- load, format and visualize the input data
- define the model architecture
- prepare the data for training
- train the model
- make predictions
In this particular example, we start with no training data, so the first step is essentially empty. For the second step, Arora uses a neural network, based on a sequential model, with an input and output layer, both with a sigmoid activation function. The first layer includes the three predictive variables previously mentioned: game speed, width of oncoming obstacle, and distance from the T-Rex. The first layer computes 6 units which serve as an input for the second and final layer. The final layer has two outputs, whose values correspond respectively to the probability of jumping or not jumping:
import * as tf from '@tensorflow/tfjs';
dino.model = tf.sequential();
dino.model.add(tf.layers.dense({
inputShape:[3],
activation:'sigmoid',
units:6
}))
dino.model.add(tf.layers.dense({
inputShape:[6],
activation:'sigmoid',
units:2
}))
The third step involves converting input data into tensors which TensorFlow.js can handle:
dino.model.fit(
tf.tensor2d(dino.training.inputs),
tf.tensor2d(dino.training.labels)
);
No shuffling is implemented in the third step, as we incrementally add inputs to an initially empty training set, each time the computer fails at the game. Normalization is realized here by having the output values in the training set between 0 and 1. As a matter of fact, when the T-Rex fails at avoiding an obstacle, the corresponding input triple (game speed, width of oncoming obstacle, and distance from T-Rex) is mapped to either [1, 0] or [0, 1], which encodes the outputs of the second layer. If the T-Rex was jumping and failed at evading the obstacle, then the appropriate decision was to not jump: [1, 0]. Conversely, if the T-Rex was not jumping, and met with an obstacle, the appropriate decision was to jump: [0, 1].
As a fourth step, when training data is made available, the model is trained with a meanSquaredError loss function and the Adam optimizer with a learning rate of 0.1 (the Adam optimizer is quite effective in practice and requires no configuration):
dino.model.compile({
loss:'meanSquaredError',
optimizer: tf.train.adam(0.1)
})
The fifth step occurs during a game repetition: as the game proceeds, and new values of the input triple are computed, predictions are run and jump/no jump decisions are taken, when it makes sense to take them (e.g. when the T-Rex is not busy jumping):
if (!dino.jumping) {
let action = 0;
const prediction = dino.model.predict(tf.tensor2d([convertStateToVector(state)]));
const predictionPromise = prediction.data();
predictionPromise.then((result) => {
if (result[1] > result[0]) {
action = 1;
dino.lastJumpingState = state;
} else {
dino.lastRunningState = state;
}
resolve(action);
});
Fritz is a machine learning platform for iOS and Android developers. TensorFlow.js is open source software available under the MIT license. Contributions and feedback are encouraged via TensorFlow’s GitHub project and should follow TensorFlow’s contribution guidelines.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
HashiCorp has released version 0.9 of Nomad, their distributed scheduler platform. This release includes enhancements to the scheduling features that determine how Nomad places applications across the infrastructure. The other major release is the groundwork for a plugin-based feature strategy to enable easier integrations with a number of technologies.
The enhancements to the scheduling features allow for additional methodologies for instructing Nomad on how to handle job placement decisions. By default, Nomad uses bin packing when making decision on job placement. Bin packing attempts to maximize the usage of resources on a set of client nodes before moving onto additional nodes. This has the advantage of typically smaller fleets and better cost savings.
With this release, a new spread stanza has been added to permit specifying a distribution for jobs based on a specific attribute or client metadata. This includes attributes such as datacenter, availability zone, or physical datacenter racks. The spread stanza allows for specification of a distribution ratio across a set of target values for a specified attribute:
spread {
attribute = “${node.dc}”
weight = 20
target “us-east1” {
percent = 50
}
target “us-east2” {
percent = 30
}
target “us-west1” {
percent = 20
}
}
In the above example, the spread stanza will tell the Nomad scheduler to attempt to distribute 50% of the workload into us-east1, 30% into us-east2, and the remaining 20% into us-west1. As the spread scores are combined with other scoring factors, such as bin packing, the end result may not align exactly to the defined stanza. Nomad treats spread criteria as a soft preference, meaning even if no nodes match the given criteria the placement will still be successful. A job or task can have multiple spread criteria with a weight parameter used to describe the relative preference between them.
Similar to the new spread stanza, an affinity stanza has been added that permits expressing a preference for a given workload based on the runtime state of the environment. This new stanza allows for assigning a preference for job placement based on any node property that is available to Nomad clients. This is in contrast to the constraint stanza which outright restricts the set of eligible nodes.
job "docs" {
# Prefer nodes in the us-west1 datacenter
affinity {
attribute = "${node.datacenter}"
value = "us-west1"
weight = 100
}
group "example" {
# Prefer the "r1" rack
affinity {
attribute = "${meta.rack}"
value = "r1"
weight = 50
}
task "server" {
# Prefer nodes where "my_custom_value" is greater than 5
affinity {
attribute = "${meta.my_custom_value}"
operator = ">"
value = "3"
weight = 50
}
}
}
}
In this example there is a strong affinity at the job level for the us-west1 datacenter. At the group level it will prefer the r1 rack while at the task level a preference for nodes where my_custom_value is greater than five is expressed.
Affinity scores can be negative, known as an anti-affinity, and will express a preference to not use that node based on the provided attribute. As with the spread stanza, the weight property can be used to assign relative priority over a series of stanzas.
This release also includes a new feature allowing for system jobs to displace lower priority workloads. Preemption allows for Nomad to kill allocations in order to place higher priority jobs when resources are limited. In version 0.9 support for system jobs was added, support for service and batch jobs is scheduled for a future Enterprise release.
The Nomad client was refactored in this release to enable plugin-based support for Task Driver Plugins and Device Plugins. The task driver subsystem allows support for a range of workload types and provides drivers for tasks like deployment automation and automatic secret injection. With this release, external plugin support was added allowing for external contributions by the community. The LXC task driver plugin was externalized and provides an example of how the new plugin system works.
Also included in this release is a new device plugin system that allows support for specialized hardware devices like GPUs, TPUs, and FPGAs. This new plugin system enables the Nomad client to detect a device, determine its capabilities, and make it available to the scheduler. The Nomad 0.9 release includes a native Nvidia CPU device plugin to allow support for these devices.
For more details and additional features included in this release, please review the official announcement on the HashiCorp blog. The CHANGELOG provides the full list of changes in the release. The open source version of Nomad is available free for download.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Microsoft announced the release of .NET for Apache Spark, adding new high-performance C# and F# language bindings to the big-data computation engine.
At the recent Spark + AI summit, Microsoft announced the preview release of .NET for Apache Spark. Apache Spark is written in Scala, and so has always had native support for that language. It has also long had API bindings for Java, as well as popular data-science languages Python and R. The new language bindings for C# and F# are written on a new Spark interop layer. In tests on the TPC-H benchmark, .NET performance was comparable to other languages, and in some cases was “2x faster than Python.”
Developers can reuse existing .NET Standard compatible code and libraries, and “can access all aspects of Apache Spark including Spark SQL, DataFrames, Streaming, MLLib.” Cloud developers can deploy .NET for Apache Spark in Microsoft’s Azure using Azure HDInsight and Azure Databricks, or in Amazon Web Services using Amazon EMR Spark and AWS Databricks.
Running .NET apps on Spark requires installation of the Microsoft.Spark.Worker binaries as well as a JDK and the standard Apache Spark binaries. Developing an app requires installation of the Microsoft.Spark nuget package. The Microsoft devs have submitted Spark Project Improvement Proposals (SPIPs) to include the C# language extension and a generic interop layer in Spark itself. However, Sean Owen, an Apache Spark committer, commented that it would be “highly unlikely” that the work would be merged into Spark.
Commenters on Hacker News contrasted .NET for Apache Spark with pre-cursor project Mobius, which has provided C# support on Apache Spark since 2016, pointing out several improvements. First, Mobius was written using Mono, an older open-source version of the .NET framework, whereas .NET for Apache Spark uses .NET Core, which provides better cross-platform support and performance improvements. Further, Mobius only supports versions of Spark up to 2.0; the latest version of Spark is up to 2.4. Finally, .NET for Apache Spark has incorporated many lessons-learned and user feedback from Mobius.
One commenter pointed out that while the new .NET library performs as well as or better than the other languages:
“[P]erformance is not the only thing – there is also ability to debug issues. For this you still need to dig into Apache core which is in Scala.”
The .NET for Apache Spark roadmap lists several improvements to the project already underway, including support for Apache Spark 3.0, support for .NET Core 3.0 vectorization, and VS Code support. .NET for Apache Spark source code is available on Github.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

R studio
Data structures
You’ve probably used many (if not all) of them before, but you may not have thought deeply about how they are interrelated. In this brief overview, I’ll show you how they fit together as a whole. If you need more details, you can find them in R’s documentation.
R’s base data structures can be organised by their dimensionality (1d, 2d, or nd) and whether they’re homogeneous (all contents must be of the same type) or heterogeneous (the contents can be of different types). This gives rise to the five data types most often used in data analysis:
Homogeneous: Atomic vector (1d), Matrix(2d), Array(nd)
Heterogeneous: List, Data frame
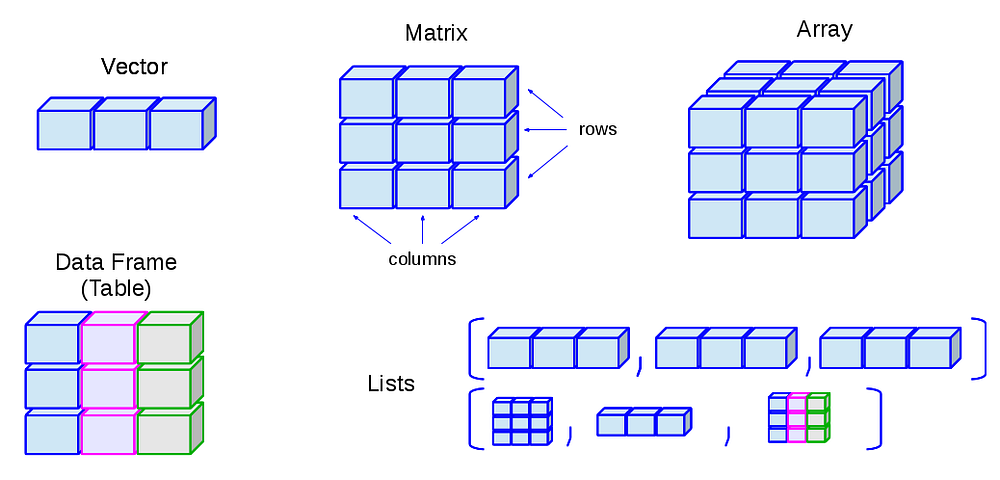
Hacker Noon
Almost all other objects are built upon these foundations. In the OO field guide you’ll see how more complicated objects are built of these simple pieces. Note that R has no 0-dimensional, or scalar types. Individual numbers or strings, which you might think would be scalars, are actually vectors of length one.
Given an object, the best way to understand what data structures it’s composed of is to use str(). str() is short for structure and it gives a compact, human readable description of any R data structure.
Almost all other objects are built upon these foundations. In the OO field guide you’ll see how more complicated objects are built of these simple pieces. Note that R has no 0-dimensional, or scalar types. Individual numbers or strings, which you might think would be scalars, are actually vectors of length one.
Given an object, the best way to understand what data structures it’s composed of is to use str(). str() is short for structure and it gives a compact, human readable description of any R data structure.
Vectors
The basic data structure in R is the vector. Vectors come in two flavours: atomic vectors and lists. They have three common properties:
- Type,
typeof(), what it is. - Length,
length(), how many elements it contains. - Attributes,
attributes(), additional arbitrary metadata.
They differ in the types of their elements: all elements of an atomic vector must be the same type, whereas the elements of a list can have different types.
NB: is.vector() does not test if an object is a vector. Instead it returns TRUEonly if the object is a vector with no attributes apart from names. Use is.atomic(x) || is.list(x) to test if an object is actually a vector.
Atomic vectors
There are four common types of atomic vectors that I’ll discuss in detail: logical, integer, double (often called numeric), and character. There are two rare types that I will not discuss further: complex and raw.
Atomic vectors are usually created with c(), short for combine:
dbl_var <- c(1, 2.5, 4.5)
# With the L suffix, you get an integer rather than a double
int_var <- c(1L, 6L, 10L)
# Use TRUE and FALSE (or T and F) to create logical vectors
log_var <- c(TRUE, FALSE, T, F)
chr_var <- c("these are", "some strings")Atomic vectors are always flat, even if you nest c()’s:
c(1, c(2, c(3, 4)))## [1] 1 2 3 4# the same as
c(1, 2, 3, 4)## [1] 1 2 3 4Missing values are specified with NA, which is a logical vector of length 1. NAwill always be coerced to the correct type if used inside c(), or you can create NAs of a specific type with NA_real_ (a double vector), NA_integer_ and NA_character_.
Types and tests
Given a vector, you can determine its type with typeof(), or check if it’s a specific type with an “is” function: is.character(), is.double(), is.integer(), is.logical(), or, more generally, is.atomic().
int_var <- c(1L, 6L, 10L)
typeof(int_var)## [1] "integer"is.integer(int_var)## [1] TRUEis.atomic(int_var)## [1] TRUEdbl_var <- c(1, 2.5, 4.5)
typeof(dbl_var)## [1] "double"is.double(dbl_var)## [1] TRUEis.atomic(dbl_var)## [1] TRUENB: is.numeric() is a general test for the “numberliness” of a vector and returns TRUE for both integer and double vectors. It is not a specific test for double vectors, which are often called numeric.
is.numeric(int_var)## [1] TRUEis.numeric(dbl_var)## [1] TRUECoercion
All elements of an atomic vector must be the same type, so when you attempt to combine different types they will be coerced to the most flexible type. Types from least to most flexible are: logical, integer, double, and character.
For example, combining a character and an integer yields a character:
str(c("a", 1))## chr [1:2] "a" "1"Remember the difference between atomic vector and list in R for not messing up when in projects
When a logical vector is coerced to an integer or double, TRUE becomes 1 and FALSE becomes 0. This is very useful in conjunction with sum() and mean()
x <- c(FALSE, FALSE, TRUE)
as.numeric(x)## [1] 0 0 1# Total number of TRUEs
sum(x)## [1] 1# Proportion that are TRUE
mean(x)## [1] 0.3333333
Coercion often happens automatically. Most mathematical functions (+, log, abs, etc.) will coerce to a double or integer, and most logical operations (&, |, any, etc) will coerce to a logical. You will usually get a warning message if the coercion might lose information. If confusion is likely, explicitly coerce with as.character(), as.double(), as.integer(), or as.logical().
Lists
Lists are different from atomic vectors because their elements can be of any type, including lists. You construct lists by using list() instead of c():
x <- list(1:3, "a", c(TRUE, FALSE, TRUE), c(2.3, 5.9))
str(x)## List of 4
## $ : int [1:3] 1 2 3
## $ : chr "a"
## $ : logi [1:3] TRUE FALSE TRUE
## $ : num [1:2] 2.3 5.9Lists are sometimes called recursive vectors, because a list can contain other lists. This makes them fundamentally different from atomic vectors.
x <- list(list(list(list())))
str(x)## List of 1
## $ :List of 1
## ..$ :List of 1
## .. ..$ : list()is.recursive(x)## [1] TRUEc() will combine several lists into one. If given a combination of atomic vectors and lists, c() will coerce the vectors to lists before combining them. Compare the results of list() and c():
x <- list(list(1, 2), c(3, 4))
y <- c(list(1, 2), c(3, 4))
str(x)## List of 2
## $ :List of 2
## ..$ : num 1
## ..$ : num 2
## $ : num [1:2] 3 4str(y)## List of 4
## $ : num 1
## $ : num 2
## $ : num 3
## $ : num 4The typeof() a list is list. You can test for a list with is.list() and coerce to a list with as.list(). You can turn a list into an atomic vector with unlist(). If the elements of a list have different types, unlist() uses the same coercion rules as c().
Lists are used to build up many of the more complicated data structures in R. For example, both data frames (described in data frames) and linear models objects (as produced by lm()) are lists:
is.list(mtcars)## [1] TRUEmod <- lm(mpg ~ wt, data = mtcars)
is.list(mod)## [1] TRUEAttributes
All objects can have arbitrary additional attributes, used to store metadata about the object. Attributes can be thought of as a named list (with unique names). Attributes can be accessed individually with attr() or all at once (as a list) with attributes().
y <- 1:10
attr(y, "my_attribute") <- "This is a vector"
attr(y, "my_attribute")## [1] "This is a vector"str(attributes(y))## List of 1
## $ my_attribute: chr "This is a vector"The structure() function returns a new object with modified attributes:
structure(1:10, my_attribute = "This is a vector")## [1] 1 2 3 4 5 6 7 8 9 10
## attr(,"my_attribute")
## [1] "This is a vector"By default, most attributes are lost when modifying a vector:
attributes(y[1])## NULLattributes(sum(y))## NULLFactors
One important use of attributes is to define factors. A factor is a vector that can contain only predefined values, and is used to store categorical data. Factors are built on top of integer vectors using two attributes: the class, “factor”, which makes them behave differently from regular integer vectors, and the levels, which defines the set of allowed values.
x <- factor(c("a", "b", "b", "a"))
x## [1] a b b a
## Levels: a bclass(x)## [1] "factor"levels(x)## [1] "a" "b"# You can't use values that are not in the levels
x[2] <- "c"## Warning in `[<-.factor`(`*tmp*`, 2, value = "c"): invalid factor level, NA
## generatedx## [1] a <NA> b a
## Levels: a b# NB: you can't combine factors
c(factor("a"), factor("b"))## [1] 1 1Factors are useful when you know the possible values a variable may take, even if you don’t see all values in a given dataset. Using a factor instead of a character vector makes it obvious when some groups contain no observations:
sex_char <- c("m", "m", "m")
sex_factor <- factor(sex_char, levels = c("m", "f"))
table(sex_char)## sex_char
## m
## 3table(sex_factor)## sex_factor
## m f
## 3 0Sometimes when a data frame is read directly from a file, a column you’d thought would produce a numeric vector instead produces a factor. This is caused by a non-numeric value in the column, often a missing value encoded in a special way like . or -. To remedy the situation, coerce the vector from a factor to a character vector, and then from a character to a double vector. (Be sure to check for missing values after this process.) Of course, a much better plan is to discover what caused the problem in the first place and fix that; using the na.strings argument to read.csv() is often a good place to start.
# Reading in "text" instead of from a file here:
z <- read.csv(text = "valuen12n1n.n9")
typeof(z$value)## [1] "integer"as.double(z$value)## [1] 3 2 1 4# Oops, that's not right: 3 2 1 4 are the levels of a factor,
# not the values we read in!
class(z$value)## [1] "factor"# We can fix it now:
as.double(as.character(z$value))## Warning: NAs introduced by coercion## [1] 12 1 NA 9Unfortunately, most data loading functions in R automatically convert character vectors to factors. This is suboptimal, because there’s no way for those functions to know the set of all possible levels or their optimal order. Instead, use the argument stringsAsFactors = FALSE to suppress this behaviour, and then manually convert character vectors to factors using your knowledge of the data. A global option, options(stringsAsFactors = FALSE), is available to control this behaviour, but I don’t recommend using it. Changing a global option may have unexpected consequences when combined with other code (either from packages, or code that you’re source()ing), and global options make code harder to understand because they increase the number of lines you need to read to understand how a single line of code will behave.
While factors look (and often behave) like character vectors, they are actually integers. Be careful when treating them like strings. Some string methods (like gsub() and grepl()) will coerce factors to strings, while others (like nchar()) will throw an error, and still others (like c()) will use the underlying integer values. For this reason, it’s usually best to explicitly convert factors to character vectors if you need string-like behaviour. In early versions of R, there was a memory advantage to using factors instead of character vectors, but this is no longer the case.
Matrices and arrays
Adding a dim attribute to an atomic vector allows it to behave like a multi-dimensional array. A special case of the array is the matrix, which has two dimensions. Matrices are used commonly as part of the mathematical machinery of statistics. Arrays are much rarer, but worth being aware of.
Matrices and arrays are created with matrix() and array(), or by using the assignment form of dim():
# Two scalar arguments to specify rows and columns
a <- matrix(1:6, ncol = 3, nrow = 2)
# One vector argument to describe all dimensions
b <- array(1:12, c(2, 3, 2))# You can also modify an object in place by setting dim()
c <- 1:6
dim(c) <- c(3, 2)
c## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6dim(c) <- c(2, 3)
c## [,1] [,2] [,3]and
## [1,] 1 3 5
## [2,] 2 4 6length()names()have high-dimensional generalisations:
length()generalises tonrow()andncol()for matrices, anddim()for arrays.names()generalises torownames()andcolnames()for matrices, anddimnames(), a list of character vectors, for arrays.
length(a)## [1] 6nrow(a)## [1] 2ncol(a)## [1] 3rownames(a) <- c("A", "B")
colnames(a) <- c("a", "b", "c")
a## a b c
## A 1 3 5
## B 2 4 6length(b)## [1] 12dim(b)## [1] 2 3 2dimnames(b) <- list(c("one", "two"), c("a", "b", "c"), c("A", "B"))
b## , , A
##
## a b c
## one 1 3 5
## two 2 4 6
##
## , , B
##
## a b c
## one 7 9 11
## two 8 10 12c() generalises to cbind() and rbind() for matrices, and to abind()(provided by the abind package) for arrays. You can transpose a matrix with t(); the generalised equivalent for arrays is aperm().
You can test if an object is a matrix or array using is.matrix() and is.array(), or by looking at the length of the dim(). as.matrix() and as.array() make it easy to turn an existing vector into a matrix or array.
Vectors are not the only 1-dimensional data structure. You can have matrices with a single row or single column, or arrays with a single dimension. They may print similarly, but will behave differently. The differences aren’t too important, but it’s useful to know they exist in case you get strange output from a function (tapply() is a frequent offender). As always, use str() to reveal the differences.
str(1:3) # 1d vector## int [1:3] 1 2 3str(matrix(1:3, ncol = 1)) # column vector## int [1:3, 1] 1 2 3str(matrix(1:3, nrow = 1)) # row vector## int [1, 1:3] 1 2 3str(array(1:3, 3)) # "array" vector## int [1:3(1d)] 1 2 3Data frames
A data frame is the most common way of storing data in R, and if used systematically makes data analysis easier. Under the hood, a data frame is a list of equal-length vectors. This makes it a 2-dimensional structure, so it shares properties of both the matrix and the list. This means that a data frame has names(), colnames(), and rownames(), although names()and colnames() are the same thing. The length() of a data frame is the length of the underlying list and so is the same as ncol(); nrow() gives the number of rows.
As described in subsetting, you can subset a data frame like a 1d structure (where it behaves like a list), or a 2d structure (where it behaves like a matrix).
Creation
You create a data frame using data.frame(), which takes named vectors as input:
df <- data.frame(x = 1:3, y = c("a", "b", "c"))
str(df)## 'data.frame': 3 obs. of 2 variables:
## $ x: int 1 2 3
## $ y: Factor w/ 3 levels "a","b","c": 1 2 3Beware data.frame()’s default behaviour which turns strings into factors. Use stringsAsFactors = FALSE to suppress this behaviour:
df <- data.frame(
x = 1:3,
y = c("a", "b", "c"),
stringsAsFactors = FALSE)
str(df)Testing and coercion
Because a data.frame is an S3 class, its type reflects the underlying vector used to build it: the list. To check if an object is a data frame, use class() or test explicitly with is.data.frame():
typeof(df)## [1] "list"class(df)## [1] "data.frame"is.data.frame(df)## [1] TRUECombining data frames
You can combine data frames using cbind() and rbind():
cbind(df, data.frame(z = 3:1))## x y z
## 1 1 a 3
## 2 2 b 2
## 3 3 c 1rbind(df, data.frame(x = 10, y = "z"))## x y
## 1 1 a
## 2 2 b
## 3 3 c
## 4 10 zWhen combining column-wise, the number of rows must match, but row names are ignored. When combining row-wise, both the number and names of columns must match. Use plyr::rbind.fill() to combine data frames that don’t have the same columns.
It’s a common mistake to try and create a data frame by cbind()ing vectors together. This doesn’t work because cbind() will create a matrix unless one of the arguments is already a data frame. Instead use data.frame() directly:
bad <- data.frame(cbind(a = 1:2, b = c("a", "b")))
str(bad)## 'data.frame': 2 obs. of 2 variables:
## $ a: Factor w/ 2 levels "1","2": 1 2
## $ b: Factor w/ 2 levels "a","b": 1 2good <- data.frame(a = 1:2, b = c("a", "b"),
stringsAsFactors = FALSE)
str(good)## 'data.frame': 2 obs. of 2 variables:
## $ a: int 1 2
## $ b: chr "a" "b"Exercises
- What are the six types of atomic vector? How does a list differ from an atomic vector?
- What makes
is.vector()andis.numeric()fundamentally different tois.list()andis.character()? - Test your knowledge of vector coercion rules by predicting the output of the following uses of
c():
c(1, FALSE)
c("a", 1)
c(list(1), "a")
c(TRUE, 1L)4.Why do you need to use unlist() to convert a list to an atomic vector? Why doesn’t as.vector() work?
5. Why is 1 == "1" true? Why is -1 < FALSE true? Why is "one" < 2 false?
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
This year roadmap for Rust was the result of an open call for blog posts from the community to set out major priorities for the language development throughout 2019, including reshaping the governance model, bringing to light new language features, and improving the compiler.
Whereas Rust 2018 roadmap centered around productivity, this year’s theme is maturity. Productivity has in fact a lot in common with maturity. Testament to this is the overlap between portions of the 2018 and 2019 roadmaps, which goes well beyond the inevitable inclusion of features that were planned for 2018 and could not make it into the language, such as is the case for async/await. This does not mean, however, that the Rust team could not deliver on its 2018 roadmap. Quite the opposite, if you take a look at the number of improvements that were released across 2018 on the language and standard library front, for the compiler, and documentation.
Speaking of the language, what the Rust core team has on its plans is finishing up a number of features that have been already worked on and are at some maturity level but are not finished yet. Examples are support for async/await, const generics, generic associated types, and specialization.
On the compiler front, a major goal for rustc is improving raw compilation times and code generation. This will be pursued through a number of strategies, including parallelizing rustc and introducing new MIR optimization. The Rust team will also extract parts of rustc into libraries with the aim to make it easier to understand and maintain, as well as moving towards a Rust specification. To improve integration with IDEs, there is an ongoing effort to build the Rust Language Server 2.0.
Another big area of improvements will be cargo, Rust package manager, which recently got support for alternative registries. In 2019, cargo should get plugins, better support for cross compilation, and a number of features already in the works, such as offline mode, improving profiles and more.
As a final note, it is worth noting a new effort to reshape governance, i.e. the way the Rust community interacts and contributes to the language and its ecosystem development. In particular, this includes the work of a new Governance working group aimed to improve policies and procedures across the whole Rust project. In a Hacker News thread, Rust core team member Steve Klabnik, who recently left Mozilla out of a number of reasons but will not stop contributing to Rust, made clear this is by no means a shift towards a committee-like model for the evolution of the language. Instead, the core team will remain in charge of the language and will ensure the rest of the teams work in a coherent way.
If you want to know all the details concerning Rust 2019 roadmap, do not miss the official RFC.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
The Data Science Method (DSM) – Pre-processing and Training Data Development
This is the fourth article in a series about how to take your data science projects to the next level by using a methodological approach similar to the scientific method coined the Data Science Method. This article is focused on the pre-processing of model development dataset and training data development. If you missed the previous article(s) in this series, you can go to the beginning here, or click on each step title below to read a specific step in the process.
The Data Science Method
- Problem Identification
- Data Collection, Organization, and Definitions
- Exploratory Data Analysis
- Pre-processing and Training Data Development
- Fit Models with Training Data Set
- Review Model Outcomes — Iterate over additional models as needed.
- Identify the Final Model
- Apply the Model to the Complete Data Set
- Review the Results — Share your findings
- Finalize Code and Documentation

Pre-processing is the concept of standardizing your model development dataset. This is applied in situations where you have differences in the magnitude of numeric features and situations where you have categorical and continuous variables. This would also be the juncture where other numeric translation would be applied to meet some scientific assumptions about the feature, such as accounting for atmospheric attenuation in satellite imagery data.
Here are the general steps in pre-processing and training data development:
- Create dummy or indicator features for categorical variables
- Standardize the magnitude of numeric features
- Split into testing and training datasets
- Apply scaler to the testing set
- Create dummy or indicator features for categorical variables
Although some machine learning algorithms can interpret multi-level categorical variables, many machine learning models cannot handle categorical variables unless they are converted to dummy variables. I hate that term, ‘dummy variables’. Specifically, the variable is converted into a series of boolean variables for each level of a categorical feature. I first learned this concept as an indicator variable, as it indicates the presence or absence of something. For example, below we have the vehicle data set with three categorical columns; specifically, Manufacturer, Model, and vehicle type. We need to create an indicator column of each level of the manufacturer.
dfo=df.select_dtypes(include=[‘object’]) # select object type columns
df = pd.concat([df.drop(dfo, axis=1), pd.get_dummies(dfo)], axis=1)
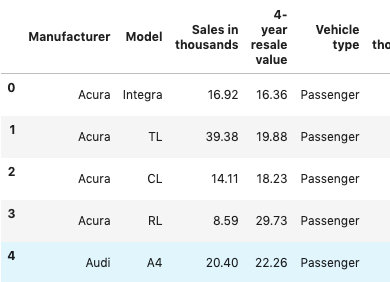
An original data frame with categorical features
First, we select all the columns that are categorical which are those with the data type = ‘object’, creating a data frame subset named ‘dfo’. Next, we concatenate the original data frame df while dropping those columns selected in the dfo, df.drop(dfo,axis=1), with the pandas.get_dummies(dfo)command, creating only indicator columns for the selected object data type columns and collating it with other numeric data frame columns.
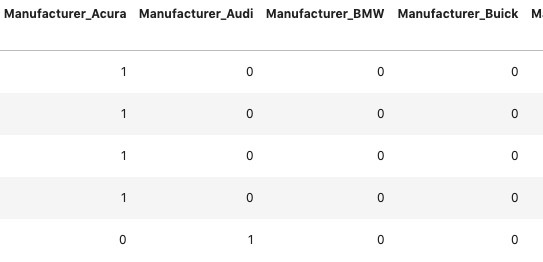
Dummies now added to the data frame with column name such as ‘Manufacturer_’
We perform this conversion regardless of the type of machine learning model we plan on developing because it allows a standardized data set for model development and further data manipulation should our planned approach not provide excellent results in the first pass. Pre-processing is the concept of standardizing your model development dataset.
2. Standardize the magnitude of numeric features
This is applied in situations where you have differences in the magnitude of numeric features. This would also be the juncture where other numeric translation would be applied to meet some scientific assumptions about the feature, such as accounting for atmospheric attenuation in satellite imagery data. However, you do not pass your dummy aka indicator features to the scaler; they do not need to be scaled as they as are boolean representations of categorical features.
Many machine learning algorithms objective functions are based on the assumption that the variables have mean of zero and have variance in the same order of magnitude of one, think L1 and L2 regularization. If the development features are not standardized then the larger magnitude features may dominate the objective function and further may spuriously reduce the impact of other features in the model.
Here is an example, the below data is also from the automobile sales dataset. You can see from the distribution plots for each feature that they vary in magnitude.
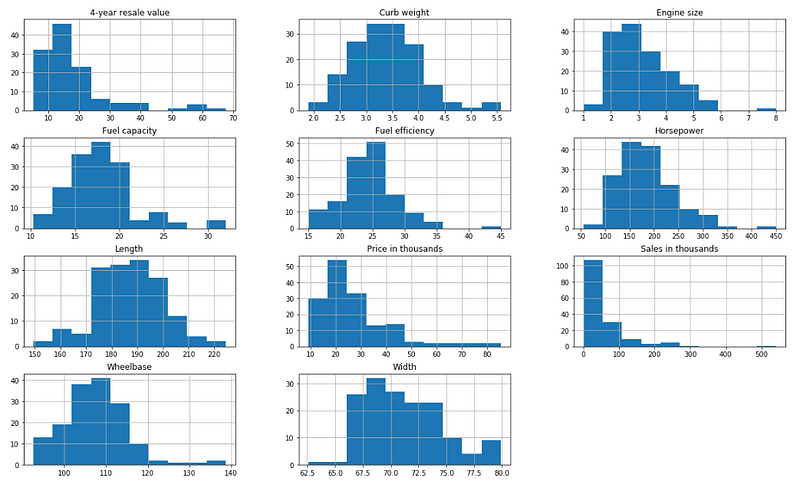
Numeric Features of differing magnitudes
When applying a scaler transformation we must save the scaler and apply the same transformation to the testing data subset. Therefore we apply it in two steps, first defining the scaler based on the mean and standard deviation of the training data and then applying that scaler to each the training and testing sets.
3. Split the data into training and testing subsets
Implementing a data subset approach with a train and test split with a 70/30 or 80/20 split is the general rule for an effective holdout test data for model validation. Review the code snippet and the other considerations below on splitting the model development data set into training and testing subsets.
4. Apply the standard scaler to the testing set
Before applying the scaler we split our dataset into training and testing dataset subsets so we can have a blind hold out sample in the testing set for model evaluation. It would also be appropriate to apply the standard data scaler to the entire data set and then split into test and train subsets afterward. It’s a matter of preference as to which comes first, just ensure the same adjustments applied to the training data are also carried through on the testing data.
from sklearn.model_selection import train_test_split
df=df.dropna()
X=df.drop([‘4-year resale value’], axis=1)
y=df[[‘4-year resale value’]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
from sklearn import preprocessing
import numpy as np
scaler = preprocessing.StandardScaler().fit(X_train)
X_scaled=scaler.transform(X_train)
X_test_sc=scaler.transform(X_test)
Other Considerations in training data development
If you have time series data be sure to consider how to appropriately split your data into training and testing data for your optimal model outcome. Most likely you’re looking to forecast, and your testing subset should probably consist of the time most recent to the expected forecast or for the same period in a different year, or something logical for your particular data.
Additionally, if your data needs to be stratified during the testing and training data split, such as in our example if we considered European carmakers to be different strata then American carmakers we would have included the argument stratify=country in the train_test_split command.
In upcoming articles, I’ll cover machine learning model fitting and model review. Stay in touch by following me on Medium or Twitter. To receive updates about the Data Science Method or Data Science Professional Development Sign up here.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: Communicating with your Board of Directors about AI/ML is different from conversations with top operating executive. It’s increasingly likely your Board will want to know more and planning that communication in advance will make your presentation more successful.

Whether this comes in the form of being summoned to discuss and explain, or whether you, along with your CEO decide to proactively communicate, it will pay to consider in advance what that communication should include and what the message should be.
This will not be the same as addressing senior operating management and it’s important to start with understanding what your Board of Directors does and doesn’t do.
The Job of the Board
From an objective standpoint, for-profit Boards have a fiduciary responsibility to shareholders that requires two major types of activity, one advisory and the other oversight. In brief, that would typically include the following:
- Hire and compensate the CEO.
- Approve the corporate strategy.
- Test the business model. Monitor the company’s products, services, and programs.
- Approve the budget and major asset purchases.
- Ensure adequate resources.
- Ensure the integrity of published financial statements.
- Protect the company’s assets and reputation.
- Ensure the company complies with laws and regulations.
- Represent the shareholders and ensure actions of the company are designed to protect and drive shareholder value.
The most important issue here is that the Board does not formulate the strategy or manage the company. Neither do they direct what technologies or business models should be adopted.
Their role is fundamentally a conservative one, to review the work of others and protect the interests of the shareholders.
On a subjective basis, while Board members may be very senior in their experience of your and other industries, they may not be as well informed as you and senior management on new technologies and how to exploit them.
Second, their meetings are relatively short and infrequent, so unless specifically asked it’s unlikely you’ll get more than two hours to make your case, and even that may be generous. The best case may be that there is a standing committee of the Board for technology, but these are relatively uncommon.
In short, how do you keep your message relatively short but sufficiently deep to create understanding. What topics should you cover?
Education
I would argue that this conversation actually requires two separate sessions, first one to educate Board members about what AI/ML is and what it can do, and a second more substantive conversation about whether the company’s approach to utilizing AI/ML is correct.
While the education session will clearly cover many basics that don’t need to be detailed here, it should include these topics:
- AI/ML consists of several distinct technologies, not all of which are as ready for commercial adoption as others.
- ML scoring models and forecasting models are a mature technology.
- IoT and edge computing applications are mature.
- Parts of NLP such as chatbots are rapidly maturing and can be confidently implemented.
- Most image processing or image classification applications remain bleeding edge and their implementation risks remain substantial.
- Really cutting edge technologies like GANS or reinforcement learning are simply not ready for prime time.
- Despite the popular press, AI/ML is not yet the new electricity. It is another in a long string of technological advancements that need to be embraced. However, just as with all previous technologies, it is the way the organization deals with its implementation that determines what value will be realized.
- Any implementation of AI/ML is dependent on the existence of suitable data. Acquiring and maintaining that data has implications for cost and for the IT organization that need to be figured into all plans.
Organizing the Strategic Conversation
In this conversation I suggest you think like a Board member and divide this into two broad topics along the lines they might think of it:
- How do we make sure we get value from our AI/ML investments?
- What risks do we need to be aware of and how can they be mitigated?
The Value Conversation
The first thing to understand, is that unless your company is one of the very few true leaders in adoption, neither your Board or your management will be thinking outside of the current business model. The question on their minds will be how to use these tools to improve current operations. If you need a refresher look back at our conversation that differentiates ‘AI Inside’ or ‘Applied AI’. That list of opportunities should include at least these:
- Operational efficiency (including IoT opportunities and robotic process automation).
- Business expansion. Discovering new offerings or better channels through the use of more data and better analytics.
- Enhanced customer experience.
- Better more efficient marketing.
- Better pricing.
Just as important as Applied AI is the potential for evolving wholly new business models around data services and platform strategies. This will be a dramatic diversion from typical thinking about your company’s business model and its ability to hold off future competitors.
This is as much a part of the ‘risk’ conversation as it is a part of the ‘value’ conversation. If your competitors beat you to a platform strategy you might find your company just another commodity supplier in someone else’s AI/ML platform ecosystem.
The Risk Conversation
To repeat, AI/ML leaves your company open to be outflanked by competitors, especially in the area of platform strategies.
Separate from this however are two relatively operational risks.
- There is significant operation risk from piecemeal implementation. It would be extremely common for your company to already be using AI/ML in many pockets throughout the organization.
Like CRMs and ERPs before this, the failure to create a central standardized approach and strategy will almost surely lead to greater pain later.
As those individual applications of AI/ML become increasingly important to the operation of their business units, they are likely to have been based on different analytical platforms, programming languages, and data sources and feeds. When the time comes that the case for standardization becomes overwhelming, the cost of tearing these out and starting over will be extremely high.
Best to start now with agreement on an overall AI/ML strategy, standardized platforms, and methods of data governance. This also supports best use of financial and human assets.
- Second is a question already frequently asked at the Board level. What is the risk of a data breach or unintended inclusion of bias into an important operating model? Both of these are actually pretty likely and the importance of the risk will depend on your industry. If you are in a heavily regulated industry like finance or healthcare, or if you hold a dominant position of trust with a large number of individual users (social media) it will be best to start thinking about your response now.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 1.5 million times.
He can be reached at:
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In a recent press release, Salesforce announced additions to their Einstein platform that bring Artficial Intelligence (AI) solutions to Salesforce developers and admins using a low code, point and click configuration-based experience. The recent additions to the platform include Einstein Translation that allows for the language translation of a Salesforce object or field and Einstein Optical Character Recognition (OCR) which uses computer vision technology to detect and extract objects from documents. In addition, Salesforce has added mechanisms to prevent its AI capabilities from embedding bias within its machine learning models.
Salesforce customers generate more than 6 billion predictions everyday using Einstein AI capabilities. However, using these AI capabilities does not require extensive data science expertise. Salesforce wants to enable business users to be more productive by leveraging intelligent insights generated by the platform:
Companies must continue to accelerate and expand their use of AI to remain competitive, but each has unique processes, data and use cases that require customized AI. With a global shortage of data scientists necessary to build these tailored AI solutions, Salesforce has been bridging the skills gap by empowering Salesforce developers and admins with “point and click” solutions and low-code services in the Einstein platform.
Einstein Translation is one of the new capabilities added to the Einstein platform and allows developers or admins to setup automatic translation of any Salesforce object of field. A use case that Salesforce has identified for this technology is translating inbound customer enquiries to the native language of the customer support agent who is available to service the request.
The other new capability introduced is Einstein Optical Character Recognition which is able to analyze documents and extract contextual information of the object using computer vision. This technology can be used to enable a sales rep to scan a prospect’s business card, extract the text from the business card image and then load it into Salesforce.
Embedding AI into Salesforce applications is nothing new for the company. Last year, Salesforce introduced Einstein Prediction Builder, which will predict the outcome of any Salesforce field or object and predict a future outcome, such as what is the likelihood of this customer paying their next invoice.
As AI becomes more prevalent, so have concerns about its use in society. Recently, the European Union published Ethics guidelines for trustworthy AI which includes the following:
- Lawful – AI should respect applicable laws and regulations
- Ethical – Respecting ethical principles and values
- Robust – Both from a technical perspective while taking into account its social environment
Salesforce has also made a commitment to democratized and trusted AI and recently issued the following statement:
The implications of AI are unlike those posed by other technologies because of the pace of disruption it will bring and the levels of uncertainty around its potential impact. Salesforce recognizes that it is not enough to just make AI accessible; every developer, admin and end user of AI must also be empowered to use AI in a transparent, responsible and accountable way. As AI technology continues to change and evolve, Salesforce commits to upholding its number one value of trust and delivering the tools and understanding necessary to identify and mitigate harmful AI bias.
As a result of this commitment, Salesforce also announced features that provide explanations about “why” a prediction is being made. Salesforce wants to avoid bias influencing predictions and allows administrators to exclude race or gender biases through alerts when a harmful bias has been detected within a dataset.
John Ball, an evp and general manager at Salesforce, explains why it is important to develop AI capabilities that can be trusted:
Our mission goes beyond just making the technology more accessible, we are committed to democratizing AI that people can trust and use appropriately.
For more information on how Salesforce addresses AI bias, please refer to their blog post.