Month: January 2022

MMS • RSS
Posted on mongodb google news. Visit mongodb google news
(VIANEWS) – The NASDAQ ended the session with MongoDB (MDB) jumping 7.86% to $402.36 on Monday while NASDAQ jumped 2.56% to $14,122.85.
Volume
Today’s last reported volume for MongoDB is 967619, 6.52% below its average volume of 1035110.
MongoDB’s last close was $373.05, 36.77% below its 52-week high of $590.00.
The company’s growth estimates for the current quarter and the next is a negative 19.4% and a negative 3%, respectively.
MongoDB’s Revenue

Year-on-year quarterly revenue growth grew by 43.7%, now sitting on 702.16M for the twelve trailing months.
Stock Price Classification
According to the stochastic oscillator, a useful indicator of overbought and oversold conditions,
MongoDB’s stock is considered to be oversold (<=20).
MongoDB’s Stock Yearly Top and Bottom Value
MongoDB’s stock is valued at $402.36 at 18:13 EST, way under its 52-week high of $590.00 and way above its 52-week low of $238.01.
MongoDB’s Moving Average
MongoDB’s worth is way below its 50-day moving average of $509.44 and above its 200-day moving average of $389.11.
More news about MongoDB (MDB).
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

A recently disclosed vulnerability affecting the PolKit component has been present on several Linux distributions for over 12 years. The vulnerability is easily exploited, says Bharat Jogi, Director of the Qualys Research Team that discovered it, and allows any unprivileged user to gain full root privileges on a vulnerable host.
PolKit provides a mechanism to enable non-privileged processes to communicate with privileged ones and to allow users to use it to execute commands with root privileges with the command pkexec. This latter functionality is similar in nature to the more widespread sudo.
Qualys security researchers have been able to independently verify the vulnerability, develop an exploit, and obtain full root privileges on default installations of Ubuntu, Debian, Fedora, and CentOS. Other Linux distributions are likely vulnerable and probably exploitable.
At the root of the vulnerability is a memory corruption issue in the way pkexec handles its command line arguments. Specifically, when it is run with no arguments, which means argc is 0, a part of its main function will enable an out-of-bounds write which under given conditions will overwrite its next contiguous memory. This happens to be envp[0], meaning one can easily inject a malicious environment variable into pkexec‘s environment.
Qualys did not disclose code that exploits the vulnerability, but since the vulnerability is so easy to exploit, public exploits have become available online in less than a day from the disclosure.
The vulnerability is not exploitable remotely and requires having physical access to a system. Qualys demonstrated how PwnKit can be exploited by user nobody, which has not privileges at all, on a fully-patched Linux distro.
The fact that PwnKit is not remotely exploitable triggered a few comments on Reddit tending to downplay its relevance. In fact, while it is true that PwnKit alone will not be enough to take control of a remote system, it is known that attackers usually exploit several vulnerabilities in a row, called a vulnerability chain, to eventually gain control of a system. This means all affected systems should be patched as soon as possible.
On the good side of things, a temporary mitigation is available that is really trivial to apply and consists of removing the SUID-bit from pkexec running:
chmod 0755 /usr/bin/pkexec
Unfortunately, it is not always easy to check if a patched version has been installed. If you have automatic security updates enabled on your system, chances are you system has been already patched. Otherwise, you should check your distribution’s security advisory or the changelog of the currently installed polkit package on your system.
Alternatively, Qualys itself makes a tool, Qualys VMDR, used to identify critical vulnerabilities, including PwnKit. If you prefer using open-source vulnerability detector Falco, security firm Sysdig has released a rule to configure Falco to detect PwnKit.
In addition to Linux-based distributions, the vulnerability might also affect other UNIX-like operating systems where Polkit is available, says Jogi. The researchers at Qualys did not investigate their exploitability, though, except for OpenBSD, which is not vulnerable due to the kernel refusing to execve() a program if argc is 0.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
(VIANEWS) – Shares of MongoDB (NASDAQ: MDB) rose 5.37% to $393.08 at 10:39 EST on Monday, following the last session’s upward trend. NASDAQ is rising 1.76% to $14,012.66, following the last session’s upward trend. This seems, up to now, an all-around up trend exchanging session today.
MongoDB’s last close was $373.05, 36.77% under its 52-week high of $590.00.
Volume
Today’s last reported volume for MongoDB is 194385 which is 81.22% below its average volume of 1035114.
The company’s growth estimates for the ongoing quarter and the next is a negative 19.4% and a negative 3%, respectively.
MongoDB’s Revenue
Year-on-year quarterly revenue growth grew by 43.7%, now sitting on 702.16M for the twelve trailing months.
Volatility
MongoDB’s last week, last month’s, and last quarter’s current intraday variation average was a negative 1.51%, a negative 3.01%, and a positive 3.95%, respectively.
MongoDB’s highest amplitude of average volatility was 3.96% (last week), 4.23% (last month), and 3.95% (last quarter), respectively.
Stock Price Classification
According to the stochastic oscillator, a useful indicator of overbought and oversold conditions,
MongoDB’s stock is considered to be oversold (<=20).
MongoDB’s Stock Yearly Top and Bottom Value
MongoDB’s stock is valued at $393.08 at 10:39 EST, way below its 52-week high of $590.00 and way higher than its 52-week low of $238.01.
MongoDB’s Moving Average
MongoDB’s worth is way below its 50-day moving average of $509.44 and above its 200-day moving average of $389.11.
More news about MongoDB (MDB).
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
A whale with a lot of money to spend has taken a noticeably bearish stance on MongoDB.
Looking at options history for MongoDB MDB we detected 10 strange trades.
If we consider the specifics of each trade, it is accurate to state that 40% of the investors opened trades with bullish expectations and 60% with bearish.
[LIVE NOW ON YOUTUBE] Click Here to Watch a FREE MASTERCLASS on the Ultimate Bear Market Survival Guide with Matt Maley! (register to get the recording if you cannot attend LIVE)
From the overall spotted trades, 2 are puts, for a total amount of $61,160 and 8, calls, for a total amount of $310,418.
What’s The Price Target?
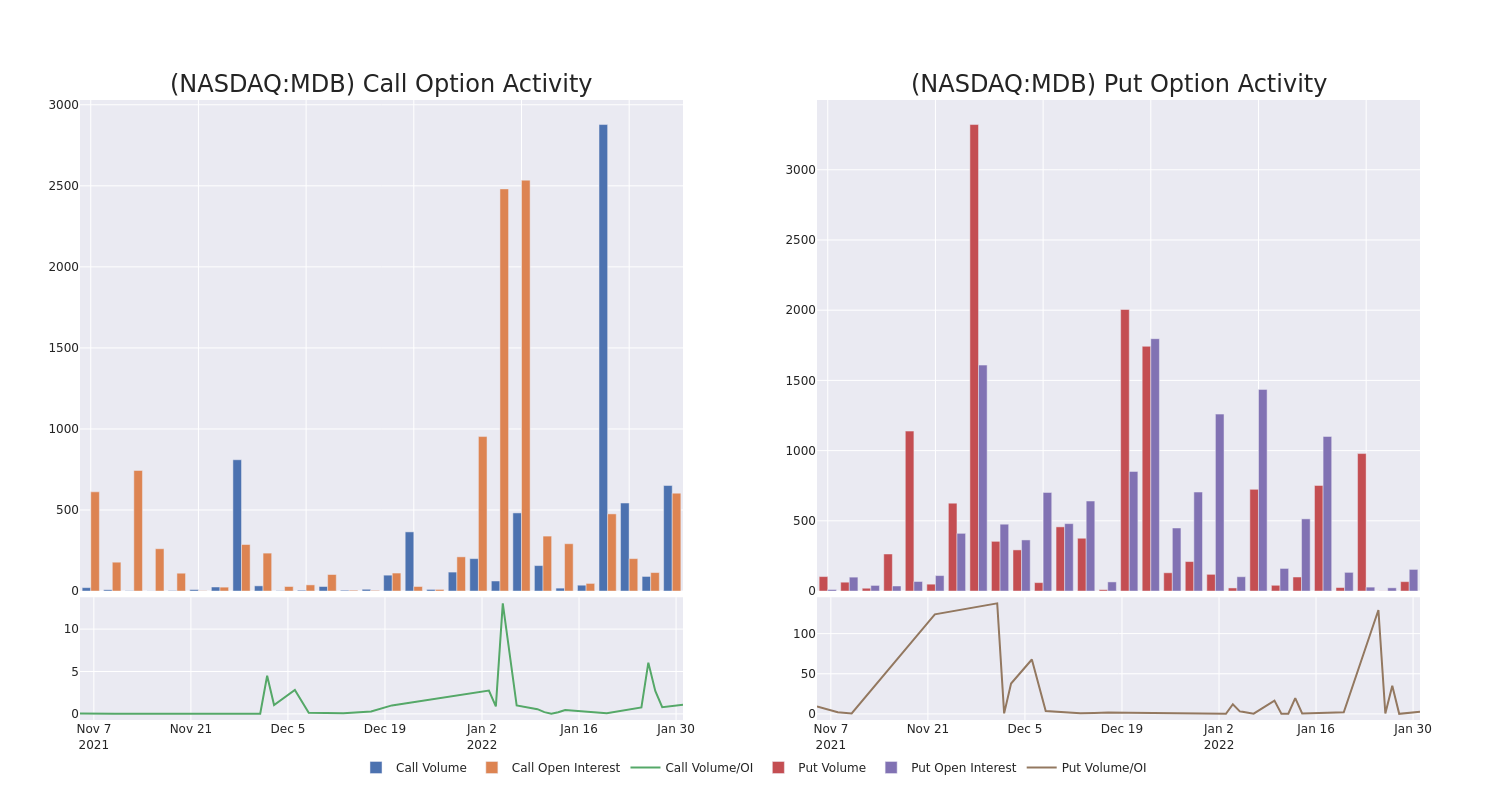
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $360.0 to $450.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $360.0 to $450.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | CALL | SWEEP | BULLISH | 02/04/22 | $410.00 | $51.7K | 81 | 97 |
| MDB | CALL | SWEEP | BEARISH | 02/04/22 | $420.00 | $48.0K | 39 | 114 |
| MDB | CALL | TRADE | BULLISH | 05/20/22 | $450.00 | $42.2K | 46 | 17 |
| MDB | CALL | SWEEP | BEARISH | 02/04/22 | $410.00 | $42.2K | 81 | 203 |
| MDB | PUT | SWEEP | BULLISH | 02/11/22 | $395.00 | $36.0K | 12 | 29 |
Where Is MongoDB Standing Right Now?
- With a volume of 1,185,779, the price of MDB is up 8.59% at $405.11.
- RSI indicators hint that the underlying stock is currently neutral between overbought and oversold.
- Next earnings are expected to be released in 36 days.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you are already an options trader or would like to get started, head on over to Benzinga Pro. Benzinga Pro gives you up-to-date news and analytics to empower your investing and trading strategy.
Article originally posted on mongodb google news. Visit mongodb google news
Cloud-based Database Market: Amazon Web Services, MongoDB, Google, Microsoft, Oracle …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Introduction and Scope
The Cloud-based Database market research analysis covers ideas, classifications, implementations, industry chain structure, and a basic review of the area. The exact investigation of Cloud-based Database implementations utilized in market analysis. The report emphasizes significant segment characteristics such as increasing US dollar demand by end-user segments and business size, as well as adjustments in the target market. It also gives data on the volume and significance of several Cloud-based Database sub-segments of the corporate field. Cost and implementation methods, as well as growth objectives and recommendations, are frequently discussed in the research.
Vendor Landscape and Profiling:
Amazon Web Services
MongoDB
Google
Microsoft
Oracle
IBM
Cassandra
Rackspace Hosting
Couchbase
Salesforce
SAP
Tencent
Alibaba
Teradata
We Have Recent Updates of Cloud-based Database Market in Sample [email protected] https://www.orbisresearch.com/contacts/request-sample/4395226?utm_source=PL
The Cloud-based Database industry insight report discusses the present state of the market, development prospects, future forecasts, key industries, and major suppliers. The most current market research also offers insight into the business climate of the Cloud-based Database market, which is largely characterized by rivalry, revenue creation, and production capabilities. The study contains each company’s pricing approach, gross margins, market share, and volume generated. It also maintains a record of all participants’ distribution networks and operational locations, allowing them to access them. The study provides a thorough view of the Cloud-based Database market by segmenting it by product, end-users, and different important geographies. Based on current and future trends, demand in all of these market segments is expected to grow during the projected period.
Market Segmentation: Cloud-based Database Market
Product-based Segmentation:
SQL Database
NoSQL Database
Application-based Segmentation:
Small and Medium Business
Large Enterprises
Purchase Cloud-based Database Market Report at @ https://www.orbisresearch.com/reports/index/global-cloud-based-database-market-growth-status-and-outlook-2020-2025?utm_source=PL
The Cloud-based Database evaluation provides a comprehensive overview of the forecast period. The research investigates the relevant trends, growth drivers, and divisions of the target market. The influence of several variables such as market trends, growth drivers, constraints, threats, and opportunities is highlighted in the industry. External variables such as risks and opportunities exist in the Cloud-based Database market, which has basic drivers and weaknesses.
Regional Assessment and Segment Diversification.
– North America (U.S., Canada, Mexico)
– Europe (U.K., France, Germany, Spain, Italy, Central & Eastern Europe, CIS)
– Asia Pacific (China, Japan, South Korea, ASEAN, India, Rest of Asia Pacific)
– Latin America (Brazil, Rest of L.A.)
– Middle East and Africa (Turkey, GCC, Rest of Middle East)
The Cloud-based Database study dives into the different demand, constraint, and incentive variables that are expected to affect market growth during the forecasted timeframe. The study examines industry competitiveness as well as a comprehensive examination of Porter’s Five Forces to assist customers in determining the economic climate of significant Cloud-based Database industry vendors.
Report Highlights
• The report includes country-wise growth projections of the Cloud-based Database industry in the next five years.
• Region wise Cloud-based Database products or services demand data.
• Regional insights on the Cloud-based Database market.
• Market share insights.
• Application and product insights including the revenue in terms of USD million from the year 2015 to 2025.
• Supply and demand side analytics are provided in the report.
• Value chain analysis and stakeholder analysis is provided in the study.
• The report covers the major geographic regions including Eastern Europe, Western Europe, North America, Middle East, Africa, and Asia Pacific.
Make an enquiry before purchase @ https://www.orbisresearch.com/contacts/enquiry-before-buying/4395226?utm_source=PL
Customers will utilize the study’s industry competition analysis and SWOT analysis model comparison to forecast the strategic role of major Cloud-based Database company suppliers. The research study will focus on trends and prominent developments that will play a significant influence in the Cloud-based Database industry’s growth during the predicted timeframe. This study has an impact on supply and demand predictions, volume, revenue, import/export usage, investment, and gross margins. Customers would have a range of alternatives for improving their profits, according to a newly published poll that is a Cloud-based Database market research assessment.
About Us:
adroitmarketresearch (https://adroitmarketresearch.com/) is a single point aid for all your market research requirements. We have vast database of reports from the leading publishers and authors across the globe. We specialize in delivering customized reports as per the requirements of our clients. We have complete information about our publishers and hence are sure about the accuracy of the industries and verticals of their specialization. This helps our clients to map their needs and we produce the perfect required market research study for our clients.
Contact Us:
Hector Costello
Senior Manager Client Engagements
4144N Central Expressway,
Suite 600, Dallas,
Texas 75204, U.S.A.
Phone No.: USA: +1 (972)-362-8199 | IND: +91 895 659 5155
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Rags Srinivas
Article originally posted on InfoQ. Visit InfoQ
SUSE announced Rancher Desktop 1.0.0 for containers recently. It includes the latest K3S version (v1.23.3 at the time of writing) by default but also provides the ability to pick and choose a version of K3S. The container runtime is containerd by default, although dockerd (moby) is the other option.
InfoQ caught up with Matthew Farina, Software Architect at SUSE about Rancher Desktop 1.0.0.
He talks about the challenges of Kubernetes and container management on the desktop and how it influenced the design and evolution of the Rancher Desktop. He also adds technical details of the product and its overlaps vis-a-vis the Docker desktop.
InfoQ: What’s the background and motivation for Rancher Desktop? Can you talk about it’s recent evolution from 0.6, 0.7 to 1.0.0?
Farina: At SUSE, we want to make the experience simple and easy for developing and preparing applications to run in Kubernetes. When we first looked at the current landscape for running Kubernetes locally, we found two challenges. First, many different versions of Kubernetes are used in production. With the changes in each minor release of Kubernetes, the version you use matters. Second, running Kubernetes locally can take a bit of knowledge. Those who are focused on applications often don’t have the time to learn about running local Kubernetes. Spending a lot of time to run Kubernetes takes away from time on their applications, which reduces velocity. Rob Pike, one of the creators of Go and UTF-8, once noted that “Simplicity is the art of hiding complexity.” We wanted to create a desktop app that would simplify the experience of running Kubernetes by hiding the complexity of running it and making the controls to configure Kubernetes more discoverable.
Making the controls to configure Kubernetes more discoverable is what led us to develop a graphical user interface. Discovering your options in a GUI is easier than at the command line.
Dealing with multiple versions is more complicated than just being able to locally run the same version of Kubernetes as you do in production. This is because of the way Kubernetes changes between minor releases, and therefore it’s useful to test how your applications handle Kubernetes being upgraded. I’ve personally run into challenges when a Kubernetes upgrade caused my application to become unstable or stop working. One of the aspects we built into Rancher Desktop is the ability to change version to a newer version and have it upgrade the environment while keeping your workloads. This can help you test how their applications handle Kubernetes being upgraded.
Once people started running Rancher Desktop, we learned more about their needs when preparing applications to run in Kubernetes. One of those was the need to build, run, and try out their containers without pushing them to or pulling them from a registry. To do all of this without a registry, while making them available to Kubernetes, meant the same container runtime Kubernetes is using needs to be used to build and run the containers outside of it. This led to us incorporating more tools and we ended up with nerdctl, a subproject of containerd.
While using nerdctl we learned that there were gaps between it and the Docker CLI. The nerdctl developers are doing a great job closing the gap between it and the Docker CLI but there is still a gap. To fill that gap, we provided the option to use dockerd, provided from the Moby project, along with the Docker CLI. Users now have a choice between nerdctl and the Docker CLI when using Rancher Desktop.
A second area of growth is in the platforms Rancher Desktop is available for. It all started on macOS using the Intel architecture. From there we added support for Windows, Linux, and Apple Silicon. Each of these environments has their own nuances and differences. For example, on Windows we use the Windows Subsystem for Linux. This enables Rancher Desktop to provide Kubernetes to even Windows Home users without any additional software needing to be installed.
InfoQ: The obvious next question. How does this compare to the Docker Desktop? Is Rancher Desktop meant to supplant Docker desktop?
Farina: When we started the development of Rancher Desktop, our goal wasn’t aimed at creating a candidate to supplant Docker Desktop. Instead, we focused on improving the experience of running Kubernetes locally and Docker Desktop focuses on containerizing applications. And, Docker has spent years working on Docker Desktop to make it great at containerizing applications.
As we added container features to build, push, and pull images and run containers to Rancher Desktop to support Kubernetes app developers, Rancher Desktop started to overlap with Docker Desktop in terms of capabilities.
InfoQ: As the name implies, is this tool only for the Desktop? Or, does it also help in multi-cloud Kubernetes deployment, given Rancher’s multi-cloud history?
Farina: Rancher Desktop provides local Kubernetes and container management. It’s designed to complement Rancher, which enables you to manage multiple Kubernetes clusters across any infrastructure. With Rancher Desktop you can locally develop, prepare, and test your workloads and applications that you will run in your test and production clusters. Rancher Desktop is for those who develop and prepare applications to run in Kubernetes.
InfoQ: From the github repo, this tool is primarily written in typescript. Why typescript when many of the newer infrastructure tools are being written in Go? Can you provide some inner workings details?
Farina: From the beginning, we knew we wanted Rancher Desktop to be cross platform and have a simple and easy to use user interface. The most popular open source tool to build cross platform user interfaces is Electron which leads you to write in JavaScript or a language that transpiles to it.
JavaScript was the origin language Rancher Desktop was written in. Over time we realized we wanted some of the benefits TypeScript offered, such as type safety, and made the transition.
From Electron, subprocesses are run that include code written in other languages such as Go. These parts of the code include agents to ensure port forwarding from the virtual machine to the host works, that tools such as nerdctl on the host can communicate into the virtual machine where Kubernetes and the container runtime are running, and more. Then there are the open-source projects Rancher Desktop is built upon. These include projects like k3s and lima that are written in Go.
InfoQ: What’s the future and roadmap for Rancher Desktop? Anything else to add?
Farina: SUSE will continue with active development of Rancher Desktop and we have some exciting features in development, including user interface improvements for Kubernetes users in the future.
The top level project provides more information on the project and the docs goes into details including details and usage of nerdctl which is the Docker-compatible CLI for containerd.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

The Operational Database Management Systems (OPDBMS) Software market report is a perfect foundation for people looking out for a comprehensive study and analysis of the Operational Database Management Systems (OPDBMS) Software market. This report contains a diverse study and information that will help you understand your niche and concentrate of key market channels in the regional and global market for Operational Database Management Systems (OPDBMS) Software. To understand competition and take actions based on your key strengths you will be presented with the size of the market, demand in the current and future years, supply chain information, trading concerns, competitive analysis and the prices along with vendor information. The report also has insights about key market players, applications of Operational Database Management Systems (OPDBMS) Software, its type, trends and overall market share.
To set your business plan into action based on our detailed report, you will also be provided with complete and accurate prediction along with future projected figures. This will provide a broad picture of the market and help in devising solutions to leverage the key profitable elements and get clarity of the market to make strategic plans. The data present in the report is curated from different publications in our archive along with numerous reputed paid databases. Additionally, the data is collated with the help of dealers, raw material suppliers, and customers to ensure that the final output covers every minute detail regarding the Operational Database Management Systems (OPDBMS) Software market, thus making it a perfect tool for serious buyers of this study.
Operational Database Management Systems (OPDBMS) Software Market: Competition Landscape
The Operational Database Management Systems (OPDBMS) Software market report includes information on the product launches, sustainability, and prospects of leading vendors including: (IBM, SQLite, MongoDB, Microsoft, RavenDB, MarkLogic, SAP, InterSystems, EnterpriseOB, Oracle, MariaDB, Amazon Web Services(AWS), DataStax, ArangoDB, Google, Couchbase, Redis Labs)
Click the link to get a free Sample Copy of the Report @ https://crediblemarkets.com/sample-request/operational-database-management-systems-opdbms-software-market-193524?utm_source=AkshayT&utm_medium=SatPR
Operational Database Management Systems (OPDBMS) Software Market: Segmentation
By Types:
Cloud-based
On-premises
By Applications:
Relational Database Management
Nonrelational Database Management
Operational Database Management Systems (OPDBMS) Software Market: Regional Analysis
All the regional segmentation has been studied based on recent and future trends, and the market is forecasted throughout the prediction period. The countries covered in the regional analysis of the Global Operational Database Management Systems (OPDBMS) Software market report are U.S., Canada, and Mexico in North America, Germany, France, U.K., Russia, Italy, Spain, Turkey, Netherlands, Switzerland, Belgium, and Rest of Europe in Europe, Singapore, Malaysia, Australia, Thailand, Indonesia, Philippines, China, Japan, India, South Korea, Rest of Asia-Pacific (APAC) in the Asia-Pacific (APAC), Saudi Arabia, U.A.E, South Africa, Egypt, Israel, Rest of Middle East and Africa (MEA) as a part of Middle East and Africa (MEA), and Argentina, Brazil, and Rest of South America as part of South America.
Key Benefits of the report:
- This study presents the analytical depiction of the global Operational Database Management Systems (OPDBMS) Software industry along with the current trends and future estimations to determine the imminent investment pockets.
- The report presents information related to key drivers, restraints, and opportunities along with detailed analysis of the global Operational Database Management Systems (OPDBMS) Software market share.
- The current market is quantitatively analyzed from 2021 to 2028 to highlight the global Operational Database Management Systems (OPDBMS) Software market growth scenario.
- Porter’s five forces analysis illustrates the potency of buyers & suppliers in the market.
- The report provides a detailed global Operational Database Management Systems (OPDBMS) Software market analysis based on competitive intensity and how the competition will take shape in the coming years.
Direct Purchase this Market Research Report Now @ https://crediblemarkets.com/reports/purchase/operational-database-management-systems-opdbms-software-market-193524?license_type=single_user;utm_source=AkshayT&utm_medium=SatPR
Major Points Covered in TOC:
Market Overview: It incorporates six sections, research scope, significant makers covered, market fragments by type, Operational Database Management Systems (OPDBMS) Software market portions by application, study goals, and years considered.
Market Landscape: Here, the opposition in the Worldwide Operational Database Management Systems (OPDBMS) Software Market is dissected, by value, income, deals, and piece of the pie by organization, market rate, cutthroat circumstances Landscape, and most recent patterns, consolidation, development, obtaining, and portions of the overall industry of top organizations.
Profiles of Manufacturers: Here, driving players of the worldwide Operational Database Management Systems (OPDBMS) Software market are considered dependent on deals region, key items, net edge, income, cost, and creation.
Market Status and Outlook by Region: In this segment, the report examines about net edge, deals, income, creation, portion of the overall industry, CAGR, and market size by locale. Here, the worldwide Operational Database Management Systems (OPDBMS) Software Market is profoundly examined based on areas and nations like North America, Europe, China, India, Japan, and the MEA.
Application or End User: This segment of the exploration study shows how extraordinary end-client/application sections add to the worldwide Operational Database Management Systems (OPDBMS) Software Market.
Market Forecast: Production Side: In this piece of the report, the creators have zeroed in on creation and creation esteem conjecture, key makers gauge, and creation and creation esteem estimate by type.
Research Findings and Conclusion: This is one of the last segments of the report where the discoveries of the investigators and the finish of the exploration study are given.
Key questions answered in the report:
- What will the market development pace of Operational Database Management Systems (OPDBMS) Software market?
- What are the key factors driving the Global Operational Database Management Systems (OPDBMS) Software market?
- Who are the key manufacturers in market space?
- What are the market openings, market hazard and market outline of the market?
- What are sales, revenue, and price analysis of top manufacturers of Operational Database Management Systems (OPDBMS) Software market?
- Who are the distributors, traders, and dealers of Operational Database Management Systems (OPDBMS) Software market?
- What are the Operational Database Management Systems (OPDBMS) Software market opportunities and threats faced by the vendors in the Global Operational Database Management Systems (OPDBMS) Software industries?
- What are deals, income, and value examination by types and utilizations of the market?
- What are deals, income, and value examination by areas of enterprises?
About US
Credible Markets is a new-age market research company with a firm grip on the pulse of global markets. Credible Markets has emerged as a dependable source for the market research needs of businesses within a quick time span. We have collaborated with leading publishers of market intelligence and the coverage of our reports reserve spans all the key industry verticals and thousands of micro markets. The massive repository allows our clients to pick from recently published reports from a range of publishers that also provide extensive regional and country-wise analysis. Moreover, pre-booked research reports are among our top offerings.
The collection of market intelligence reports is regularly updated to offer visitors ready access to the most recent market insights. We provide round-the-clock support to help you repurpose search parameters and thereby avail a complete range of reserved reports. After all, it is all about helping you reach an informed strategic decision about purchasing the right report that caters to all your market research demands.
Contact Us
Credible Markets Analytics
99 Wall Street 2124 New York, NY 10005
Email: [email protected]
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
![]() Vident Investment Advisory LLC reduced its holdings in MongoDB, Inc. (NASDAQ:MDB) by 36.2% during the third quarter, Holdings Channel.com reports. The fund owned 2,904 shares of the company’s stock after selling 1,646 shares during the quarter. Vident Investment Advisory LLC’s holdings in MongoDB were worth $1,369,000 at the end of the most recent reporting period.
Vident Investment Advisory LLC reduced its holdings in MongoDB, Inc. (NASDAQ:MDB) by 36.2% during the third quarter, Holdings Channel.com reports. The fund owned 2,904 shares of the company’s stock after selling 1,646 shares during the quarter. Vident Investment Advisory LLC’s holdings in MongoDB were worth $1,369,000 at the end of the most recent reporting period.
A number of other hedge funds and other institutional investors have also made changes to their positions in MDB. Truist Financial Corp boosted its holdings in shares of MongoDB by 22.4% in the 3rd quarter. Truist Financial Corp now owns 3,026 shares of the company’s stock worth $1,427,000 after purchasing an additional 553 shares in the last quarter. Moody Lynn & Lieberson LLC purchased a new position in shares of MongoDB in the 3rd quarter worth about $2,954,000. Caas Capital Management LP purchased a new position in shares of MongoDB in the 2nd quarter worth about $65,542,000. BOKF NA purchased a new position in shares of MongoDB in the 3rd quarter worth about $1,099,000. Finally, Marshall Wace North America L.P. boosted its holdings in shares of MongoDB by 72.5% in the 2nd quarter. Marshall Wace North America L.P. now owns 28,928 shares of the company’s stock worth $10,457,000 after purchasing an additional 12,160 shares in the last quarter. Institutional investors and hedge funds own 87.90% of the company’s stock.
MDB has been the subject of a number of research reports. Barclays cut their price objective on MongoDB from $590.00 to $556.00 in a report on Wednesday, January 12th. Stifel Nicolaus increased their target price on MongoDB from $495.00 to $550.00 and gave the company a “buy” rating in a report on Tuesday, December 7th. Needham & Company LLC increased their target price on MongoDB from $534.00 to $626.00 and gave the company a “buy” rating in a report on Tuesday, December 7th. Piper Sandler increased their target price on MongoDB from $525.00 to $585.00 and gave the company an “overweight” rating in a report on Tuesday, December 7th. Finally, increased their target price on MongoDB from $475.00 to $560.00 and gave the company a “buy” rating in a report on Tuesday, December 7th. They noted that the move was a valuation call. Four research analysts have rated the stock with a hold rating and twelve have assigned a buy rating to the stock. Based on data from MarketBeat.com, the stock presently has a consensus rating of “Buy” and a consensus price target of $542.13.
In other MongoDB news, Director Dwight A. Merriman sold 3,000 shares of MongoDB stock in a transaction on Wednesday, December 1st. The stock was sold at an average price of $487.81, for a total value of $1,463,430.00. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available at this hyperlink. Also, insider Thomas Bull sold 2,500 shares of MongoDB stock in a transaction on Wednesday, December 15th. The stock was sold at an average price of $492.13, for a total value of $1,230,325.00. The disclosure for this sale can be found here. In the last ninety days, insiders have sold 111,506 shares of company stock valued at $54,323,150. 7.40% of the stock is owned by corporate insiders.
NASDAQ MDB opened at $373.05 on Monday. MongoDB, Inc. has a fifty-two week low of $238.01 and a fifty-two week high of $590.00. The stock has a market cap of $24.90 billion, a P/E ratio of -78.87 and a beta of 0.65. The stock has a 50 day simple moving average of $467.86 and a two-hundred day simple moving average of $457.10. The company has a debt-to-equity ratio of 1.71, a quick ratio of 4.75 and a current ratio of 4.75.
MongoDB (NASDAQ:MDB) last announced its earnings results on Monday, December 6th. The company reported ($0.11) earnings per share (EPS) for the quarter, topping the consensus estimate of ($0.38) by $0.27. MongoDB had a negative return on equity of 101.71% and a negative net margin of 38.32%. The firm had revenue of $226.89 million during the quarter, compared to analyst estimates of $205.18 million. During the same quarter in the prior year, the company earned ($0.98) EPS. The business’s revenue was up 50.5% compared to the same quarter last year. Sell-side analysts predict that MongoDB, Inc. will post -4.56 earnings per share for the current year.
About MongoDB
MongoDB, Inc engages in the development and provision of a general purpose database platform. The firm’s products include MongoDB Enterprise Advanced, MongoDB Atlas and Community Server. It also offers professional services including consulting and training. The company was founded by Eliot Horowitz, Dwight A.
Featured Article: Compound Interest
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB).

Want More Great Investing Ideas?
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
“
NoSQL Market research is an intelligence report with meticulous efforts undertaken to study the right and valuable information. The data which has been looked upon is done considering both, the existing top players and the upcoming competitors. Business strategies of the key players and the new entering market industries are studied in detail. Well explained SWOT analysis, revenue share and contact information are shared in this report analysis. It also provides market information in terms of development and its capacities.
Get Sample Copy of this report with latest Industry Trend and COVID-19 Impact @: https://www.a2zmarketresearch.com/sample-request/574811
Some of the Top companies Influencing in this Market includes:
SAP, MarkLogic, IBM Cloudant, MongoDB, Redis, MongoLab, Amazon Web Services, Basho Technologies, Google, MapR Technologies, Couchbase, AranogoDB, DataStax, Aerospike, Apache, CloudDB, MarkLogic, Oracle, RavenDB, Neo4j, Microsoft.
Various factors are responsible for the market’s growth trajectory, which are studied at length in the report. In addition, the report lists down the restraints that are posing threat to the global NoSQL market. This report is a consolidation of primary and secondary research, which provides market size, share, dynamics, and forecast for various segments and sub-segments considering the macro and micro environmental factors. It also gauges the bargaining power of suppliers and buyers, threat from new entrants and product substitute, and the degree of competition prevailing in the market.
Global NoSQL Market Segmentation:
Market Segmentation: By Type
Key-Value Store, Document Databases, Column Based Stores, Graph Database
Market Segmentation: By Application
Retail, Online gaming, IT, Social network development, Web applications management, Government, BFSI, Healthcare, Education, Others
Global NoSQL Market research report offers:
- Market definition of the global NoSQL market along with the analysis of different influencing factors like drivers, restraints, and opportunities.
- Extensive research on the competitive landscape of global NoSQL
- Identification and analysis of micro and macro factors that are and will effect on the growth of the market.
- A comprehensive list of key market players operating in the global NoSQL market.
- Analysis of the different market segments such as type, size, applications, and end-users.
- It offers a descriptive analysis of demand-supply chaining in the global NoSQL market.
- Statistical analysis of some significant economics facts
- Figures, charts, graphs, pictures to describe the market clearly.
Get Up to 30% Discount on the first purchase of this report @: https://www.a2zmarketresearch.com/discount/574811
Regions Covered in the Global NoSQL Market Report 2020:
• The Middle East and Africa (GCC Countries and Egypt)
• North America (the United States, Mexico, and Canada)
• South America (Brazil etc.)
• Europe (Turkey, Germany, Russia UK, Italy, France, etc.)
• Asia-Pacific (Vietnam, China, Malaysia, Japan, Philippines, Korea, Thailand, India, Indonesia, and Australia)
The cost analysis of the Global NoSQL Market has been performed while keeping in view manufacturing expenses, labor cost, and raw materials and their market concentration rate, suppliers, and price trend. Other factors such as Supply chain, downstream buyers, and sourcing strategy have been assessed to provide a complete and in-depth view of the market. Buyers of the report will also be exposed to a study on market positioning with factors such as target client, brand strategy, and price strategy taken into consideration.
Key questions answered in the report include:
- What will be the market size and the growth rate by the end of the forecast period?
- What are the key NoSQL Market trends impacting the growth of the market?
- What are the potential growth opportunities and threats faced by the leading competitors in the market?
- What are the key outcomes of Porter’s five forces analysis and the SWOT analysis of the key players functioning in the global NoSQL Market?
- This report gives all the information regarding industry Overview, analysis and revenue of this market.
- What are the market opportunities and threats faced by the vendors in the global NoSQL market?
Table of Contents
Global NoSQL Market Research Report 2021 – 2028
Chapter 1 NoSQL Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global NoSQL Market Forecast
Buy Exclusive Report: https://www.a2zmarketresearch.com/checkout
If you have any special requirements, please let us know and we will offer you the report as you want.
About A2Z Market Research:
The A2Z Market Research library provides syndication reports from market researchers around the world. Ready-to-buy syndication Market research studies will help you find the most relevant business intelligence.
Our Research Analyst Provides business insights and market research reports for large and small businesses.
The company helps clients build business policies and grow in that market area. A2Z Market Research is not only interested in industry reports dealing with telecommunications, healthcare, pharmaceuticals, financial services, energy, technology, real estate, logistics, F & B, media, etc. but also your company data, country profiles, trends, information and analysis on the sector of your interest.
Contact Us:
Roger Smith
1887 WHITNEY MESA DR HENDERSON, NV 89014
+1 775 237 4147
Related Reports:
NoSQL market, NoSQL market research, NoSQL market report, NoSQL Market comprehensive report”
Podcast: Liz Rice on Programming the Linux Kernel with eBPF, Cilium and Service Meshes
MMS • Liz Rice
Article originally posted on InfoQ. Visit InfoQ

Subscribe on:
Transcript
Introductions [00:36]
Charles Humble: Hello and welcome to the The InfoQ Podcast, I’m Charles Humble, one of the co-hosts of the show, and editor-in-chief of Cloud Native consultancy firm Container Solutions. My guest this week is Liz Rice. Liz is Chief Opensource Officer with cloud native networking and security specialists Isovalent, creators of the Cilium eBPF based networking project. She is also the chair of the CNCF’s Technical Oversight Committee, and is the author of Container Security, a book published by O’Riley. For today’s podcast, the focus is on eBPF, we’ll explore what it is, how it works under the hood and what you can and can’t do with it. We’ll also talk a little bit about the Cilium project. Liz, welcome to The InfoQ Podcast.
Liz Rice: Hi, thanks for having me.
What does the Linux kernel actually do? [01:22]
Charles Humble: I thought a good place to start would be with a couple of definitions, because I think some of our listeners might not be that familiar with some of what we’re going to talk about, and it’s maybe an obvious thing to start with, but could you just briefly describe what it is that the Linux kernel actually does?
Liz Rice: Yeah, I think it’s really important to level set that because eBPF allows us to run custom programs in the kernel, but if you’re not completely familiar with what the kernel is, that doesn’t make a lot of sense. And I think the kernel is one of those things that a lot of developers, a lot of engineers take for granted, and they know, maybe, that there’s a thing called user space and a thing called the kernel, but maybe after that, it starts getting little bit wishy-washy. I certainly remember not having a clear understanding of that in the past.
So what does the kernel do for us? The kernel is the part of the operating system that lets applications do things with hardware. So every time we want to write something to the screen, or get something from the network, or maybe read something from a file, even accessing memory, it all involves hardware. And you can’t from user space, where our application’s run, you can’t directly access that hardware.
We use the kernel to do it on our behalf and the kernel is privileged and able to get at the hardware for us. So our applications, every time they want to do one of these things like read from a file, they have to make what’s called a system call, and that’s the interface where our application is saying, please read a number of bytes from a file, for example. And most of the time, we’re not really aware of that because the programming languages that we use day to day give us higher level abstractions, so we don’t really need to get involved with the syscalls, typically, for most developers. But it’s good to know, good to have an understanding of that.
Charles Humble: And then in a cloud native context, it’s perhaps worth of saying as well that there is only the one kernel, so regardless of whether you’re running with virtual machines or with bare metal, however many applications you are running, they are all sharing that same privileged kernel.
Liz Rice: And that kernel is doing all of the communication between the underlying hardware and the applications running on it.
eBPF stands for extended Berkeley Packet Filter. What’s a packet filter? [03:45]
Charles Humble: While we’re doing this level setting, we should also mention something else. So eBPF stands for extended Berkeley Packet Filter. What’s a packet filter?
Liz Rice: Yeah, it’s a great question. I quite often say that eBPF initials don’t necessarily help us understand very much about what eBPF is today, but it really reflects the history.
So, packet filtering is this idea that if you have network traffic flowing in or out of your computer, you might want to look at individual packets, maybe do something interesting with individual packets, a lot of energy in networking, a lot of the time people are debugging networking issues, and in order to do that, you might need to filter out and look at just the traffic going to a particular destination, for example. This idea of filtering is that you’ve got this enormous stream of packets, but you can just look at the ones you are interested in. So initially, the idea of Berkeley Packet Filtering was to be able to specify what kinds of packets you’re interested in, perhaps by looking at the address, and you’d get a copy of those packets that you could then examine and use for debugging purposes without having to wade through this enormous stream of everything that’s happening on the machine.
Charles Humble: And then, in order to do the actual packet filtering, what is it that we have?
Liz Rice: We have a little bit of code that says, “Does this packet match my filter?” And kernel developers started to think, well, this is like a little, almost like a little virtual machine here. What if we could do more powerful things with these programs that we are running to look at network packets? What if we could run them in other contexts, not just looking at a network packet, but maybe some other operations that the kernel’s doing.
What is the extended bit? [05:38]
Charles Humble: Right, and that’s how you get to the extended bit. It’s again, perhaps worth saying the original Berkeley Packet Filter itself is quite old, in tech terms. The first release was 1992. It’s the original packet filter from BSD. So what is the extended bit? What does the “e” bit add?
Liz Rice: At one level, extended just means we’re going to use this concept of running custom programs somewhere in the kernel. It also, I think in that bucket of things that gets… Differentiates what we might call eBPF from BPF, there was a change to the kind of instruction set that was used for writing those eBPF programs, and there was also the introduction of a thing called maps.
Charles Humble: What are they?
Liz Rice: Maps are data structures that you can share between different BPF programs or between a BPF program and user space, so it’s how we can communicate information between an application and the eBPF programs that is interested in. So for example, if you’re getting observability data from an eBPF program that’s running in the kernel, it’s going to throw the data, maybe all the events that you want to observe, it’s going to throw that information into a map and the user space application can read the data out of the map at a later point. So yeah, maps, instruction sets and the variety of different places that we can hook programs in. I think that really characterizes what makes the “e” of eBPF.
Maps give you a way of handling state. Are there different types of maps? [07:10]
Charles Humble: Right, yes. And then the maps, of course, give you a way of handling state, which is interesting. Are there different types of maps?
Liz Rice: There’s a variety of different types of map, but they’re essentially all key value stores, and you can write into them from user space and from kernel space, and you can read from them in user space and kernel space. So you can use them to transfer information between the two, you can also share them between different BPF programs. So you might have one BPF program attached to one event and another BPF program attached to a different event, perhaps at two different points in the networking stack, and you can share information between those two programs using a map. So you might, for example, correlate knowledge of the networking end points between programs that attach at the socket layer, which is as close as it can be to the application and another program acting at the XDP layer, which is as close as it can be to the network interface.
Is eBPF analogous to JavaScript in the browser or Lua in a gaming engine? [08:10]
Charles Humble: When we think about a programming language inside another environment, I might think about, say Lua in a gaming engine, or maybe JavaScript in a web browser. Are those useful points of comparison, do you think?
Liz Rice: Actually, they really are. There’s a chap called Brendan Gregg who did a lot of the pioneering work for using eBPF for observability, and I believe it’s quote from him that describes… It says that eBPF is to the kernel as JavaScript is to HTML. It makes it programmable and it allows you to do dynamic changes to what… In the JavaScript world, you would have a static webpage, suddenly it becomes dynamic. We have this programmable ability and that’s a nice analogy for eBPF in the kernel.
What’s the underlying motivation for this?[08:59]
Charles Humble: What’s the underlying motivation for this? Linux is open source, so couldn’t you just get the changes you need into the kernel if you need them?
Liz Rice: I think there’s a couple of angles to this. One is, Linux is enormous and very complicated. I think it’s 30 million-odd lines of code in the Linux kernel, so if you want to make a change to it, it’s not going to be a trivial undertaking, and you are going to have to deal with convincing the whole community that a change that you want to make is appropriate and that it’s going to be useful for the Linux community as a whole. And maybe you want to do something really bespoke, and that wouldn’t necessarily be useful for everybody. So it might not be appropriate to accept a change that you might want to make for a specific purpose into the general purpose Linux kernel.
Liz Rice: Even if you convince everyone that your change is a really good idea, you would make the change and it might get accepted. Maybe you are a super fast programmer and it takes virtually no time to get that code written and get it accepted into the kernel, but then there is this huge delay between code being added to the mainstream Linux kernel repos, and actually being run in production.
It literally takes years. You don’t just download the kernel onto your machine. You’ll typically take a Linux distribution like RHEL, or Ubuntu, or Arch, or Alpine, or whatever. And those distributions are packaging up stable releases of the kernel, but quite often, and they’re years old. They’re often using time to convince themselves of the stability of those versions of the kernel. The latest RHEL release… I’m trying to remember, I think it’s using a kernel that’s from 2017 or 2018, I think 2018. We can check on that. So it’s three to four years between code making it into a kernel release and actually being included in the distribution that you might run in an enterprise environment. So you probably don’t want to wait three or four years for your change to the kernel.
Yeah, if we can just load it dynamically, we don’t even have to reboot the machine, you can literally just load a program into the kernel dynamically, and that can be amazing for running custom codes, for making custom behaviors and also for security mitigations. There’s a really great example of the idea of a packet of death.
What’s a packet of death? [11:33]
Charles Humble: What’s a packet of death?
Liz Rice: If you have a kernel vulnerability that, for whatever reason, isn’t able to handle a particularly crafted network packet, perhaps there’s a length field that is incorrectly set up and the kernel, through vulnerability, maybe doesn’t handle that correctly and reads off the end of the buffer or something like that.
And with eBPF there have been at least one case of this, where to mitigate a packet of death vulnerability, you can just have an eBPF program distribute that immediately, load it into production environments, and you are immediately no longer vulnerable to the packet of death that would have otherwise crashed your production machines. Literally in a matter of minutes, rather than waiting for a security patch, can mitigate this kind of security issue. I think that’s a really powerful example of how eBPF can be really useful from a security patching perspective.
How does the verifier work in eBPF? [12:32]
Charles Humble: It’s an interesting thing that you bring up a security angle, because obviously, if I’m running custom code in kernel space, there’s not a lot I can’t do. There are an awful lot of things I could do as a malicious actor in a system once I’ve got code loaded there. So how does the verifier work in eBPF? How safe is it? How secure is it?
Liz Rice: When you load a BPF program into the kernel, it goes through a step called verification. And this is checking that the program is safe to run. It’s got to be safe from the perspective of not crashing, so it’s going to analyze the program and make sure that it’s going to run to completion, that it’s not doing any null pointer de-references. When you are writing programs, you have to explicitly check every single pointer to make sure that it’s not null before you de-reference it, otherwise the verifier will reject your program.
And you are also limited in what you’re allowed to do in terms of accessing memory, and in order to get information about the kernel, there are a set of, what are called BPF helper functions. So for example, if you want to find out the current time or the current process ID, you’d use a helper function to do that, and depending on the context in which you are running a BPF program, you are allowed to use a different set of helper functions. You wouldn’t be allowed to access helper function related to a network packet if you weren’t in the context or processing a network packet, for example. And these helper functions make sure that you are only accessing memory, that the particular process related to this function is allowed to access. So that helps from a security point of view, ensure that one application can’t use BPF to read data from another application’s process, for example.
So that BPF verification process is very strict, can be quite a challenge to get your BPF programs to pass the verification step, but its one of the, I guess, arts of programming for eBPF, but it’s an extremely powerful way of sandboxing what your different BPF programs can do. That said, BPF programs are very powerful and a correct BPF program could still be written by a malicious user or loaded by a malicious user to do something that might be totally legitimate in one scenario and completely malicious in another. So for example, if I let you load a packet filter into my running system, you can start looking at all my network traffic. That’s not necessarily what I want you to be able to do. You could be sending it off to a different network destination. So you no more allow someone to run BPF code than you would allow them to have root access to your machine, it’s something that comes with great privilege and great responsibility.
There are quite a lot of other non-network use cases that you can use eBPF for, right? [15:35]
Charles Humble: We’ve hinted at this already, but we should probably make it explicit, just because I think the name is slightly confusing. So this isn’t purely about networking, there are quite a lot of other non-network use cases that you can use eBPF for, right? Things like tracing, profiling, security and so on.
Liz Rice: Absolutely, it’s a really great point, and there’s been a lot of useful observability. I mentioned Brendan Gregg and the work that he did, and does at Netflix. He and others have built this huge array of tools that allow you to inspect what’s going on and measure what going on in… You mention it, across the kernel, there will be a tool to measure it, looking at what files are being opened, looking at the speed of IO. There’s dozens of these little command line tools that you can run to get data about how your system is performing. Really, really powerful and show the breadth of what you can can do from an observability perspective.
And then if we start thinking about observing what’s happening in a running system, we can look at what an application’s doing. I mentioned the idea of observing what files are being opened, and you could use that from a security perspective. You can say, well, is this file that this application’s looking at, is that legitimate? For example. Another really great example of security use of BPF is seccomp.
Charles Humble: Okay, so the word seccomp is a contraction of secure computing, or secure computing mode, and that’s the Linux kernel feature that allows you to restrict the actions available within a running container via profiles. How does that work in this context?
Liz Rice: You associate a seccomp profile with an application to say this application is allowed to run this set of system calls. So we mentioned syscalls before this, this interface between user space and the kernel. And occasionally there are system calls that it doesn’t make sense for many applications to have access to.
Charles Humble: Can you give an example?
Liz Rice: Very few applications that you’re running day to day should be able to change the system time on your platform. You want that system time to be fixed and known. So a lot of seccomp profiles would disallow the setting of time on the machine, so seccomp is a really commonly used use of BPF, that a lot of people don’t realize is actually using BPF to do it.
But you can take that a lot further and we can write eBPF code to, not just look at system calls, but look at a much broader range of events. There’s some really great work being done around the Linux security module interface. So it’s called BPF LSM, this is the interface within the kernel that tools like AppArmor use to police whether or not operations are permissible or not, from a security perspective. You have a security profile, and with BPF LSM, we can make those profiles much more dynamic. We can be a lot more driven by the context of the application. And so, I think there’s going to be some really powerful tools built on BPF LSM, and those are not just about observing whether or not behavior is good or bad, but they can actually prevent, for example, I’m not going to let this application access that file above and beyond what the file permissions would permit.
eBPF has two distinct classes of user – end users and kernel developers [19:04]
Charles Humble: There’s an interesting thing here, which I think is worth just pulling out and making explicit. When I think about eBPF, I think about people writing custom code to run in the container, in the kernel, in production. But actually, probably a more common use case, like the seccomp example we were just talking about, is something more like an end user, someone who’s deploying a pre-written eBPF program in order to modify the behavior of a Linux kernel in some way.
Liz Rice: Yeah, I think for most users, they will find it quite challenging to write BPF programs. Now, personally, I’m someone who loves to get involved, write some code to really understand how things work, and I know enough to know that I can write some basic BPF code, but I can rapidly get to the point where you are dealing with Linux kernel structures and events that happen in the context of the kernel, so you quite quickly need some knowledge about how the kernel’s operating, and that’s pretty in depth knowledge which most of us don’t have.
Although I’m really quite excited about getting in there and looking at eBPF code to understand it, the reality of it is that, for most of us, that’s an intellectual exercise rather than something we’d really want to build. I think the use of eBPF as a platform, it’s going to be based on people using tools, using projects, using products that are already written, and perhaps they can define particular profiles that are using eBPF to implement that tool.
Cilium would be a really great example of that. So, Cilium is a networking project, it’s known as a Kubernetes CNI, although it can be used for networking in non-Kubernetes environments as well. And as an example of a profile, for example, Cilium can enforce networking security profiles, and you would write your profile in terms of what IP addresses or even domain names a particular application is allowed to access. Cilium can convert that into eBPF programs that enforce that profile, so you don’t have to know about the eBPF code in order to use that security profile.
Do you write eBPF programs as bytecode, or do you write it in some high level language and then compile it across? [21:22]
Charles Humble: I want to come back to Cilium in a second, actually, but before we go there, if you to write programs for eBPF, obviously the underlying format is bytecode. It looks a bit like x86 assembly maybe, or perhaps Java bytecode, if people are familiar with that, but how do you actually write it? Do you write it as bytecode, or do you write it in some high level language and then compile it across?
Liz Rice: There are people who do write bytecode directly, I’m not one of them. So you have to have compiler support to compile to the BPF bytecode, and today, that compiler support is available in Clang. If you want to write code in C and, more recently, you can also compile Rust code to BPF targets. So those are your limited choices for writing the code that’s going to run, actually within the kernel itself.
There are certainly circumstances where you really just want to write the BPF code and then you can use, there are things like bpftool, which is a general purpose, you can do quite a lot of things with bpftool, but one of the things you can do is load programs into the kernel. So you would necessarily have to write your own user space code, but most of the time we do want to write something in user space as well, that’s going to perhaps configure the eBPF code, perhaps get information out of that BPF program.
So we’re often going to be writing, not just the kernel code, but also some user space code, and there’s a much broader range of support for different languages that there are libraries for Go, there are libraries for Python, Rust, there’s a framework called BCC, which supports C and Python and Lua, to my recollection. So yeah, you have a lot more choice for your user space language than you do for the code that eventually becomes the bytecode.
How does my eBPF program actually hook into the kernel? [23:10]
Charles Humble: And then, how does my eBPF program actually hook into the kernel? Are there predefined hook points that I have, or how does that work?
Liz Rice: You’ve actually got a huge range of places that you can hook your BPF programs too. There’s what’s called kprobes and kretprobes, which are the entry point and exit point from any kernel function, so if you know the name of the function, you can hook into it.
You can also hook to any trace points. Some of those trace points are well defined and not going to change from one kernel version to the next, other trace points might move around, so you maybe have to know what you’re doing a little bit.
There are events like network events, so the arrival of a network packet, that takes me to a thing called XTP, which I think is just brilliant. So XDP stands for Express Data Path, and the idea of this was, well, if we’ve got network packets arriving from an external network, they’re coming through a network interface card, and then they get to the kernel, we want to look at those packets as quickly as possible. Maybe we want to run a program that’s going to drop packets, so the earlier we can drop them, the less work had to be done to handle that packet. So the idea of XDP was, well, wouldn’t it be cool if we didn’t even have to get that packet as far as the kernel? What if the network interface card could handle it for us? So XDP is a type of eBPF program that you can run on the network. Not all cards support it, not all network drivers support it, but it’s a really nice concept, I think, that you could offload or program to run, actually on different piece of hardware.
What’s the overhead like if I’m running an eBPF program in my kernel? [24:49]
Charles Humble: That’s really cool, actually. I love things like that. What’s the overhead like if I’m running an eBPF program in my kernel?
Liz Rice: This is one of those questions that comes up and I always feel like, well, it’s as long as a piece of string. I could write a pathologically poor eBPF program and attach it to every single possible event, and you would definitely notice the difference, but typically, performance is excellent, and in a lot of cases, what your eBPF program is doing on an individual event basis is very small. Maybe we’re looking at a network packet and dropping it, or saying, no, send this one over here. Maybe not doing a lot per event, but doing that event millions of times. It’s typically going to run very quickly, because it’s running in the kernel, there’s no context switch between kernel and user space. For example, if we can handle that event entirely within the kernel, dropping network packets, being a really great example of something that, if you don’t have to transition to user space, that’s going to be way more performant. So typically, eBPF tooling is dramatically more performant than the equivalent in user space because we can avoid these transitions.
How do Cilium and eBPF relate to each other? [26:07]
Charles Humble: You mentioned Cilium earlier, so changing tack slightly, let’s talk about Cilium a little bit. So how do Cilium and eBPF relate to each other?
Liz Rice: I think this is something that, maybe it’s not always obvious to people when they see Cilium, the project. The people who created the Cilium project were involved in the early days of eBPF as well, people like Thomas Graf and Daniel Borkmann, who were working on networking in the kernel, and still do, and specifically looking at eBPF in the kernel and realizing how powerful this could be for networking, for the ability to sidestep some of the things like IP tables, which as your IP tables grow, they become less performant, particularly in an environment like Kubernetes, where your pods are coming up and down all the time, which means your IP address is coming up and down all the time, which means if you are using IP tables, you have to rewrite those tables all the time and they’re not designed to make small changes related to one endpoint.
So, Thomas and Daniel and others had realized that this was a really great opportunity for eBPF to rationalize the way that networking could work. So Cilium has its roots in networking. It does go hand in hand with eBPF development because some of the Cilium maintainers are also making changes in the kernel, the kernel maintainers as well. So we can see the development of Cilium and eBPF stepping up together over time.
Liz Rice: But today, Cilium is primarily known, I think, for networking, but also providing a bunch of observability and security features as well, that are sometimes less well known. We have a component called Hubble that gives you really great network flow visibility, so you can see where traffic is flowing within your network and within Kubernetes identities, because it’s aware of the pods of services or the Kubernetes identity information is known by Cilium, so we can very easily show you, not just that this packet went from IP address A to IP address B, but also what Kubernetes entities were involved in that network flow.
And also security, I mentioned network policy earlier. There’s also some really interesting work that we’ve been experimenting with. Let’s say an application makes a network connection, we know what Kubernetes entity was involved, but we also know what process was involved and we can use that information to find out, well, what was the executable that was running at the time, and was that an expected executable? Did we expect that executable to be opening that network connection. Does this look like a cryptocurrency miner, for example, do we expect a pod to run for the days and then suddenly start creating network connections, or is that perhaps a sign that the pod has been compromised in some way? So combining the network information with some knowledge about what the application is that’s running, can provide some really powerful higher level runtime security tooling as well.
Why is Cilium a good solution to the problem that service mesh is trying to solve? [29:15]
Charles Humble: Now Google announced that they were using Cilium for a new data plane for GKE, and I know that you’ve also now introduced a beta for eBPF based service mesh as part of Cilium 1.11, so can you talk a little bit about that? I’m presuming there’s some efficiency gains there, as against the conventional sidecar proxy model that we typically use, but can you talk a little bit about that? Why is Cilium a good solution to the problem that service mesh is trying to solve?
Liz Rice: Yeah, so different people’s interpretation of what service mesh is varies from one person to the next, but if we look at some of the individual capabilities of service meshes, well, one thing it’s doing is, it’s load balancing traffic. Here are three different versions of the same application, but we’re going to canary test between these three different versions, for example. That’s load balancing, it’s a network function that we already had in Cilium. Getting observability into traffic—Observability is a big part, I think, of people expect from a service mesh. For some time, Cilium has worked with the Envoy Proxy. We have observability at layer three, four within Cilium itself, and then we can also use Envoy to get observability at layer seven, so that kind of observability angle was already almost there, things like identity awareness, Cilium is already identity aware.
TLS termination and Ingress capabilities, we were already at like, well, we’ve got kind of 90% of what people expect a service mesh to be, how do we take it that last step? So what we’re doing in this beta is really saying, well, here is Cilium as the data plane for your service mesh, how do users want to configure that? What’s the control plane, what’s the management interface that people want to use to configure that?
And I think one of the reasons why it’s really, really compelling is, we talked before about how eBPF allows you to avoid these transitions between kernel and user space, and if you look at the path that a network packet takes when you’re using a sidecar model service mesh, which is the model that service meshes have all used thus far, every single pod’s got its own sidecar, so if we imagine traffic flowing between two different pods, a network packet has to go through the networking stack on the kernel, up to the proxy that’s in user space, in the sidecar, back down into the kernel to be then rooted to the application. And if it’s coming from the application to another application pod, it’s going to do that transition into the sidecar as it leaves one pod, and then again as it enters another pod. So we’ve transitioned that packet in and out of the kernel endless times.
And because Cilium is inherently involved in the networking at either end of the pod, we don’t have to keep passing it backwards and forwards through these user space proxies. We can have a single instance of the proxy running on the kernel and take that network packet straight from one pod, through the kernel, to that proxy, proxy can decide what to do with it, and then it transitions into the kernel just that one more time. So the early indications, performance wise, are really, really good. I think that was what we expected to see because of the greater… Well, much fewer transition points, and it’s good to see that’s actually turning out to be true.
Charles Humble: It’s working out in practice. Yeah, that’s excellent.
Liz Rice: Yes.
What else is new and exciting for you in Cilium 1.11? [33:02]
Charles Humble: Cilium 1.11 came out in December of last year, what else is new and exciting for you in that release?
Liz Rice: I think I mentioned that Cilium is not exclusively used in Kubernetes environments, and a lot of the additional features that we’ve been working on over the last couple of releases have been enabling, particularly, large scale networks to use Cilium, either in a combined Kubernetes and BGP environment, or perhaps in a standalone networking environment.
So some of the interesting things involve, what if you’ve got two different Kubernetes clusters running in different data centers and you own the BGP connection between the two, so we can enable Cilium, understanding the endpoints of the IP address management at either end of that and advertising it across your BGP network. So some of these, more on-prem, high scale capabilities that some of our users have really been asking for.
Where is a good place for listeners to learn more? [33:59]
Charles Humble: That’s fantastic. If listeners want to go and learn more about either eBPF or Cilium, where is a good place for them to go and maybe get started?
Liz Rice: If they want to look at web pages, cilium.io and ebpf.io are a great place to start. If they want to find knowledgeable people and communicate with them, there is a really great eBPF and Cilium Slack community. I mentioned before about how Cilium and eBPF had grown together in lockstep, and that’s really why the Slack community covers both eBPF and Cilium, we have this history of both the eBPF implementation and the Cilium implementation community there.
It’s a really great community and there’s a lot of helpful people, if you want to come and ask questions and learn about eBPF. Maybe I’ll also mention, myself and my colleague, Duffie Cooley, host a weekly, we call it eBPF and Cilium Office Hours, which loosely stands for ECHO, so on Fridays you can come and join us on YouTube. We explore lots of topics related to eBPF tooling and Cilium and that whole world, and we very much welcome people coming and getting involved, chatting with us, asking us questions, particularly on the livestream.
Charles Humble: Fantastic, and I’ll make sure that all of those links are included in the show notes for this episode when it appears on infoq.com. Liz, thank you so much for joining me this week on The InfoQ Podcast.
Liz Rice: My absolute pleasure, thanks for having me.
Mentioned
QCon brings together the world’s most innovative senior software engineers across multiple domains to share their real-world implementation of emerging trends and practices.
Find practical inspiration (not product pitches) from software leaders deep in the trenches creating software, scaling architectures and fine-tuning their technical leadership
to help you make the right decisions. Save your spot now!
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.