Month: November 2018


MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
If you thought Amazon Web Services (AWS) might run out of services to launch, this year’s re:Invent put that fear to rest. At the recently concluded event, AWS shared a flurry of announcements across a range of categories. re:Invent rarely has a “theme” for its announcements. But there was heavy attention on machine learning, databases, hybrid cloud, and account management.
Let’s start with compute-related announcements. AWS released a pair of new virtual machine instance types. The EC2 A1 instance feature ARM-based processors and are suitable for Linux workloads. If you need virtual machines with up to 100Gbps of network bandwidth, the new C5n instances are now available. EC2 users who want to scale quickly without warming up new VMs can now hibernate a running (Amazon Linux) instance and wake it up when needed. Users only pay for storage and Elastic IPs when a VM is in a hibernated state. AWS also shared their intent to build a hybrid computing experience. Not available until later in 2019, AWS Outposts are intended to bring AWS services and infrastructure to any data center. Details are scant, but expect more information in the coming months.
Serverless computing got a boost at re:Invent. AWS announced Lambda Layers which gives developers up to five packages to inject into a given function at runtime. This promotes component sharing and keeps the core function package as small as possible. Lambda users also get access to custom runtimes that opens up the option to use languages like C++ an Rust for functions. For Lambda functions serving up HTTP(S) requests, you can now use the Application Load Balancer. The function-oriented workflow service, AWS Step Functions, also got a refresh with new integrations to services like DynamoDB, AWS Batch, Amazon SQS, and Amazon SageMaker. Finally, AWS announced Firecracker, an open source virtualization technology based on KVM that’s used by Lambda for sandboxing functions.
Next, let’s look at the networking-related announcements. AWS introduced a global traffic router called AWS Global Accelerator. This service uses static Anycast IP addresses as an entry point and routes TCP or UDP requests through the AWS global network based on characteristics like geography, application health, and custom weighting rules. The new AWS Transit Gateway service makes it possible to use a single gateway for connecting Virtual Private Clouds (VPCs) to on-premises networks. This gets customers away from point-to-point connectivity and into a hub-and-spoke architecture. Service meshes are a hot topic nowadays, and AWS App Mesh is Amazon’s answer. This beta service uses the Envoy proxy (and an AWS control plane instead of Istio) to improve control flow and observability of microservices. As a related service, AWS Cloud Map provides service discovery by tracking application components and helping developers discover services at runtime.
Storage services is where AWS got its start years ago, and they continue to evolve their offerings today. S3 is the AWS object storage service, and it received a few key updates. First, it got Intelligent Tiering. Today, S3 users choose among storage classes based on how frequently they need to access their data. With Intelligent Tiering, users have a new storage class that monitors access patterns and moves infrequently-accessed objects to a cheaper tier. S3 also now has a preview feature (S3 Batch Operations) that simplifies bulk operations against objects in S3. AWS also added the ability to “lock” an object during a customer-defined period to support data retention requirements. For those working with the file system versus object storage, AWS offered a pair of relevant announcements. Amazon FSx for Lustre offers a managed, distributed file system for compute-intensive workloads. And, Amazon FSx for Windows File Server delivers a managed Windows file system for workloads that need file storage. It supports the SMB protocol, Windows NTFS and Active Directory integration. For those looking to move chunks of data from on-premises to Amazon S3 or Elastic File System, the new AWS DataSync is available now.
As a related topic, let’s review the database and analytics-driven announcements from re:Invent. AWS offered a pair of key updates to their NoSQL database, DynamoDB. First, DynamoDB Transactions offer ACID-compliant transactions across multiple tables in a given AWS region. Secondly, DynamoDB On-demand is a new pricing model that doesn’t require up-front capacity planning, while still offering all the standard DynamoDB features. Their relational database, Amazon Aurora, got a new geo-replication feature called Amazon Aurora Global Database. This applies to the MySQL variant of Aurora, and creates read replicas that can quickly be promoted to a primary in the case of a regional outage. AWS also announced an upcoming preview of Amazon Timestream, a time-series database with no infrastructure management requirements. The new Amazon Quantum Ledger Database (QLDB) is a managed ledger database that offers an immutable log. It complements the upcoming preview of Amazon Managed Blockchain where the blockchain network activity can be replicated into QLDB.
Regarding data analytics, AWS Lake Formation (not yet in preview) is for creating S3-based data lakes from a variety of data sources. Another preview service is ML Insights for Amazon QuickSight which offers things like anomaly detection and forecasting. For data processing, AWS announced Amazon Managed Streaming for Kafka (in preview) where developers can get managed Kafka clusters (including Zookeeper clusters).
Besides the services named above, AWS launched a handful of other application-oriented capabilities. For container-based deployments, users can leverage AWS CodeDeploy for blue/green deployments to minimize downtime. The AWS Transfer for SFTP offers a highly available managed service for getting data into Amazon S3 buckets. The set of people excited about managed SFTP and those excited about robotics probably has little overlap, but the latter group now has AWS RoboMaker for developing, simulating, and deploying robotic apps at scale. Finally, Amazon Personalize (in preview) uses machine learning to give developers a capability to build and consume recommendation models.
Internet-of-Things was also highlighted at re:Invent this year with a series of preview services. AWS IoT Events is a managed service for detecting and responding to events from IoT sensors and apps. It detects events across thousands of sensor types. The AWS IoT Things Graph lets developers visually connect devices and services to create IoT apps. It includes pre-built models for popular device types, or you can build your own custom model. And AWS IoT SiteWise is designed to work with industrial equipment. Your on-premises industrial data goes through a gateway and is stored in AWS for analysis.
Machine learning was clearly an area of focus for AWS at this year’s event. Amazon kicked off the week by announcing that their own “Machine Learning University” would be available to any developer. Then, AWS kicked off a series of announcements related to AI/ML services, particularly around Amazon SageMaker. The new SageMaker Ground Truth capability helps you label datasets used to train machine learning systems. Options for labeling include automation via active learning, or Amazon Mechanical Turk for human intervention. SageMaker Neo is a new feature that makes it possible to train machine learning models once, and run them anywhere in the cloud or edge. This supports a variety of frameworks (e.g. TensorFlow, PyTorch) and hardware architectures (e.g. ARM, Intel). For data scientists with limited data sets for training and an interest in reinforced learning, there’s now SageMaker RL. And you can also now use Git repos to store SageMaker notebooks. Additional ML announcements included the preview of Amazon Textract for optical character recognition (OCR) and Amazon Elastic Inference which lets you add GPU acceleration to any EC2 (and SageMaker) instance. Finally, AWS announced a new “machine learning” category of products (representing algorithm and model packages) in the AWS marketplace.
The last category of announcements relates to account management and best practices. AWS Control Tower (in preview) makes it easier to set up multi-account AWS environments with blueprints to deploy components in a secure fashion. The AWS Security Hub, also in Preview, gives you a centralized view of security alerts across accounts, as well as constant checks of your service configurations. If you struggle with managing all the commercial software licenses used in your account, the AWS License Manager is designed to help. And if companies want to limit the catalog of add-on services available to users, the AWS Private Marketplace should add value. Finally, the AWS Well-Architected Tool offers a self-service experience for reviewing AWS workloads to see if they match best practices.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Hashicorp has released new features to better integrate Consul, a service mesh and KV store, with Kubernetes. These features include support for installing Consul on Kubernetes using an official Helm Chart, autosyncing of Kubernetes services with Consul, auto-join for external Consul agents to join a Kubernetes cluster, support for Envoy, and injectors so Pods can be secured with Connect. These new features can be used to facilitate cross-cluster communication between Kubernetes cluster or within heterogeneous workloads and environments.
As part of this integration, Hashicorp is focused on enhancing instead of replacing Kubernetes. They are utilizing the core Kubernetes workflow components such as Services, ConfigMaps, and Secrets by building on top of these core primitives. This allows for features such as Consul catalog sync to convert external services into first-class Kubernetes services.
Consul now has an official Helm Chart for installation in Kubernetes, allowing for a full Consul setup within minutes. This setup can be either a server cluster, client agents, or both.
After cloning and checking out the latest tagged release, you can install the chart using
$ helm install .
This will install a three-node, fully bootstrapped server cluster with a Consul agent running on each Kubernetes node. You can then view the Consul UI by forwarding port 8500 from a server pod
$ kubectl port-forward consul-server-0 8500:8500
The Helm Chart is fully configurable and allows you to disable components, change the image, expose the UI service, configure resource and storage classes. For more details, please review the full list of configurable options. By adjusting the configuration, you can deploy a client-only cluster which is useful if your Consul servers are run outside of a Kubernetes cluster, as shown in the example configuration below:
global:
enabled: false
client:
enabled: true
join:
- "provider=aws tag_key=... tag_value=..."
The join configuration will use the cloud auto-join to discover and join pre-existing Consul server agents.
The auto-join feature has been enhanced to utilize the Kubernetes API to discover pods running Consul agents. This is instead of using static IP addresses or DNS to facilitate the join.
Consul will authenticate with Kubernetes using the standard kubeconfig file used for authenticating with kubectl. It will search in the standard locations for this file. Once connected, you can instruct Consul to auto-join based on tags:
$ consul agent -retry-join 'provider=k8s label_selector="app=consul,component=server"'
This command will ask the agent to query Kubernetes for pods with the tags app=consul and component=server. Consul will retry this command periodically if no pods are found. This can be used by agents running outside of the Kubernetes cluster.
Kubernetes services now have automatic syncing to the Consul catalog. Consul users can discover these services via Consul DNS or the HTTP APIs. This uses standard Kubernetes tooling to register the services, meaning if they are moved to a new pod or scaled, the Consul catalog will remain up to date. This also allows non-Kubernetes workloads to connect to Kubernetes services through Consul.
Currently this syncing process only includes NodePort services, LoadBalancer services, and services with an external IP set. An example of a standard LoadBalancer service configuration:
apiVersion: v1
kind: Service
metadata:
name: consul-ui
spec:
ports:
- name: http
port: 80
targetPort: 8500
selector
app: consul
component: server
release: consul
type: LoadBalancer
Once this is run, you can query the service from outside of Kubernetes:
# From outside of Kubernetes
$ dig consul-ui.service.consul.
;; QUESTION SECTION:
;consul-ui.service.consul. IN A
;; ANSWER SECTION:
consul-ui.service.consul. 0 IN A 35.225.88.75
;; ADDITIONAL SECTION:
consul-ui.service.consul. 0 IN TXT "external-source=kubernetes"
To help identify them in the Consul UI, externally registered services are marked with a Kubernetes icon
Finally, Consul services can be registered into first-class Kubernetes services. This allows Kubernetes users to connect to them via Kubernetes APIs. It does however, require that Consul DNS be configured with Kubernetes.This syncing process can be run via the Helm Chart:
syncCatalog:
enabled: true
Additional options are available for deeper configuration. This functionality is also open-source and part of of the consul-k8s project.There are now native Kubernetes injectors to allow you to secure your pods with Connect. Connect enables secure service-to-service communication with automatic TLS encryption and identity-based authentication. With this, a Connect sidecar running Envoy (a proxy for Connect) can be automatically injected into pods, making the Kubernetes configuration automatic. If the pod is properly annotated, Envoy is auto-configured, started, and able to both accept and establish connections via Connect. Here is an example Redis server with Connect configured for inbound traffic:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
annotations:
"consul.hashicorp.com/connect-inject": "true"
spec:
containers:
- name: redis
image: "redis:4.0-alpine3.8"
args: [ "--port", "6379" ]
ports:
- containerPort: 6379
name: tcp
We can then configure a Redis UI to talk to Redis over Connect. The UI will be configured to talk to a localhost port to connect through the proxy. The injector will also inject any necessary environment variables into the container.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-ui
spec:
replicas: 1
selector:
matchLabels:
app: redis-ui
template:
metadata:
labels:
app: redis-ui
annotations:
"consul.hashicorp.com/connect-inject": "true"
"consul.hashicorp.com/connect-service-upstreams": "redis:1234"
spec:
containers:
- name: redis-ui
image: rediscommander/redis-commander
env:
- name: REDIS_HOSTS
value: "local:127.0.0.1:1234"
- name: K8S_SIGTERM
value: "1"
ports:
- name: http
containerPort: 8081
The Kubernetes Connect injector can be run using the Helm Chart. Every client agent will need gRPC enabled for the Envoy proxies.
connectInject:
enabled: true
client:
grpc: true
These new features simplify the process of running Consul on Kubernetes. As well, with the auto-join and syncing features, Hashicorp believes this simplifies running in environments that integrate with non-Kubernetes workloads. In addition to these new features, work is being done to integrate Terraform and Vault with Kubernetes, with release planned in the next few months.
Presentation: If You Don’t Know Where You’re Going, It Doesn’t Matter How Fast You Get There

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Work on the next major version of Google’s language has already begun with around 120 open proposals candidate to be reviewed for Go 2, writes Google engineer Robert Griesemer. Google also intends to make the Go 2 process much more community-driven.
The existing proposals are mostly the results of the process Google used to manage Go evolution. In short, whenever a proposal was submitted that did not satisfy Go 1 compatibility guarantees, the proposal was postponed and labeled Go 2. Now, the Go team has started categorizing the proposals and rejecting all those that appear out of the scope of Go or not actionable. The proposals that will survive this review process are the ones that have a chance to influence the language and its standard library. As InfoQ already reported, two major themes for Go 2 are generics and better error handling. The rest of possible new features, though, will have to balance in that there are already millions of Go programmer and large code bases. This makes the process that will lead to Go 2 significantly different than the process that led to Go 1.0. The risk here, according to the Go team, is splitting up the community if the new language does not arise from an inclusive process where each change is carefully chosen.
To prevent this risk, Google is implementing a new proposal evaluation process. Until now, all change proposals were evaluated by a committee of senior Go team members. From now on, the Go team will submit the proposals they deem interesting to the community. Based on community feedback, the Go team will then decide what changes to implement. Within the bounds of Go three-month development cycle, both the Go team and the community at large will experiment with the new features and provide additional feedback, which will inform the final decision whether to ship the new feature or not.
Additionally, the process that will lead to Go 2 will be an incremental process where features are added to Go 1 releases. In fact, the Go team has already selected a few Go 2 proposals that are candidate for inclusion in Go 1.13, the next planned release for Go. Thos are adding support for Unicode identifiers, adding binary integer literals, and improving shift expressions.
Now it’s the time for the community to provide their feedback. If they pass this screening, the features listed above should make it into the language by Feb 1, 2019. From that moment the Go team and the community will have a chance to experiment with the new features and decide whether to keep or abandon them.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- ASP.NET Core has a built-in distributed caching interface.
- Performance, shared data, and durability are the primary benefits of distributed caching.
- Couchbase Server is a memory-first database that is great for use as a distributed cache.
- NuGet packages make it easy to add Couchbase Server to your application.
- Using the “IDistrubutedCache” interface abstracts away the details and makes it easy to interact with cache in your ASP.NET Core controllers.
With the release of .NET Core 2.0, Microsoft has the next major version of the general purpose, modular, cross-platform and open source platform that was initially released in 2016. .NET Core has been created to have many of the APIs that are available in the current release of .NET Framework. It was initially created to allow for the next generation of ASP.NET solutions but now drives and is the basis for many other scenarios including IoT, cloud and next generation mobile solutions. In this second series covering .NET Core, we will explore some more the benefits of .NET Core and how it can benefit not only traditional .NET developers but all technologists that need to bring robust, performant and economical solutions to market.
Caching can help improve the performance of an ASP.NET Core application. Distributed caching is helpful when working with an ASP.NET application that’s deployed to a server farm or scalable cloud environment. Microsoft documentation contains examples of doing this with SQL Server or Redis, but in this post,I’ll show you an alternative. Couchbase Server is a distributed database with a memory-first (or optionally memory-only) storage architecture that makes it ideal for caching. Unlike Redis, it has a suite of richer capabilities that you can use later on as your use cases and your product expands. But for this blog post, I’m going to focus on it’s caching capabilities and integration with ASP.NET Core. You can follow along with all the code samples on Github.
Benefits of distributed caching
- Performance. A cache stores data in RAM for quick and easy retrieval. It will often be faster to retrieve data from this cache, rather than use the original sourceevery time.
- Shared cache data. If you are using a multi-server deployment for your ASP.NET Core application, a load balancer could direct your user to any one of your ASP.NET Core servers. If the cached data is on the web servers themselves, then you need to turn on sticky sessions to make sure that user is always directedto the same ASP.NET Core server. Thiscan lead to uneven loads and other networking issues – see this Stack Overflow answer for more details).
- Durability. If an ASP.NET Core web server goes down or you need to restart it for any reason, this won’t affect your cached data. It will still be in the distributed cache after the restart.
No matter which tool you use as a distributed cache (Couchbase, Redis, or SQL Server), ASP.NET Core provides a consistent interface for any caching technology you wish to use.
Installing Couchbase
The first step is to get the distributed cache server running. Choose the installation method that’s most convenient for you. You can use Docker or a cloud provider, or you can install it on your local machine (which is what I did for this blog post). It’s a free download, and you can use the free Couchbase Community edition. (The Enterprise Edition is also free and unlimited for pre-productionuse, but I’ll be using the Community edition in this blog post).
When you install Couchbase, you’ll open up your web browser and go through a short wizard. The default settings are fine for this blog post.
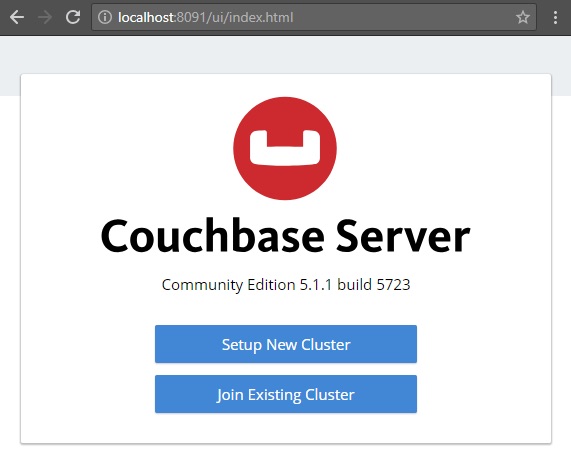
Once you’ve installed Couchbase, create a “bucket”. This is where you will store your cached data. I called my bucket “infoqcache”. I created an “Ephemeral” bucket (which is a memory-only option). You can also use a “Couchbase” bucket (which will store the data in memory first and persist to disk asynchronously).
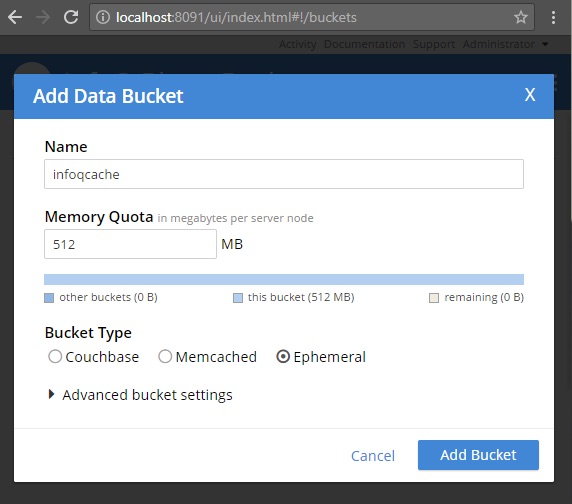
The last step of setting up Couchbase is security. Add a Couchbase user with appropriate permissions to that bucket. I called my user “infoq” and gave it a password of “password” (please use something stronger in production!). In the Enterprise edition, there are a lot of roles to choose from, but for this simple use case we don’t need them. “Bucket Full Access” for infoqcacheis enough.
Make sure you’ve completed all these installation steps before moving on to ASP.NET Core. Here are the steps with links to more detailed documentation.
- Install Couchbase (Follow the instructions on the downloads page)
- Setup Couchbase (Explore the Server Configuration)
- Created a bucket (Creating a Bucket)
- Created a user with permission to the bucket. (Creating and Managing Users with the UI)
Create a new ASP.NET Core Application
I’m going to create a sample ASP.NET Core API application to show the distributed caching capabilities of ASP.NET Core. Thiswill be a small, simple application with two endpoints.
I’m using Visual Studio 2017. From there, I select File→New→Web→ASP.NET Core Web Application.
The next step is to select what kind of ASP.NET Core project template to use. I’m using a bare-bones “API” with no authentication and no Docker support.
This project has a ValuesController.cs file. I’m going to replace most of the code in this class with my own code. Here is the first endpoint that I will create. It doesn’t use any caching and has a Thread.Sleepto simulate high-latency data access (imagine replacing that Thread.Sleep with a call to a slow web-service or a complex database query).
[Route("api/get")]
public string Get()
{
// generate a new string
var myString = Guid.NewGuid() + " " + DateTime.Now;
// wait 5 seconds (simulate a slow operation)
Thread.Sleep(5000);
// return this value
return myString;
}
Start that website (Ctrl+F5 in Visual Studio). You can use a tool like Postman to interact with the endpoint. But for this example, a browser is good enough. In my sample project, the site will launch to localhost:64921, and I configured the endpoint with a route of api/get. So, in a browser I go to localhost:64921/api/get:
Thisa trivial example, but it shows that this endpoint is a) getting some unique string value, and b) taking a long time to do it. Every time you refresh will be at least a 5-secondwait. Thiswould be a great place to introduce caching to improve latency and performance.
We now have an ASP.NET Core application that needs caching and a Couchbase Server instance that wants to help out. Let’s get them to work together.
The first step is to install a package from NuGet. You can use the NuGet UI to search for Couchbase.Extensions.Caching, or you can run this command in the Package Manager Console: Install-Package Couchbase.Extensions.Caching -Version 1.0.1. This is an open-source project, and the full source code is available on Github.
NuGet will install all the packages you need for your ASP.NET Core application to talk to Couchbase Server and to integrate with ASP.NET Core’s built-in distributed caching capabilities.
Now open up the Startup.cs file in the project. You will need to add some setup code to the ConfigureServices method here.
services.AddCouchbase(opt =>
{
opt.Servers = new List<Uri>
{
new Uri("http://localhost:8091")
};
opt.Username = "infoq";
opt.Password = "password";
});
services.AddDistributedCouchbaseCache("infoqcache", opt => { });
(I also added using Couchbase.Extensions.Caching; and using Couchbase.Extensions.DependencyInjection; at the top of the file, but I use ReSharper to identify and add those for me automatically).
In the above code, AddCouchbase and AddDistributedCouchbaseCache are extension methods that add to the built-in ASP.NET Core IServiceCollection interface.
With AddCouchbase, I’m telling ASP.NET Core how to connect to Couchbase, giving it the user/password I mentioned earlier in the post.
With AddDistributedCouchbaseCache, I’m telling ASP.NET Core how to use Couchbase as a distributed cache, specifying the name of the bucket I mentioned earlier in the post.
Documentation for this extension is available on Github. Don’t forget to add cleanup/tear downcode in the ConfigureServicesmethod.
Now that we’ve configured ASP.NET Core to know how to cache let’s put it to use in a simple example.
The simplest thing we can do with distributed caching is to injectit into the ValuesControllerand usean IDistributedCachedirectly.
First, add IDistributedCacheas a parameter to the constructor.
public ValuesController(IDistributedCachecache)
{
_cache = cache;
}
Since we already configured the distributed cache in Startup.cs, ASP.NET Coreknows how to set this parameter (using dependency injection). Now,_cacheis available in ValuesController to get/set values in the cache. I wrote another endpoint called GetUsingCache. This will be just like the Get endpoint earlier, except it will use caching. After the first call, it will store the value and subsequent calls will no longer reach the Thread.Sleep.
[Route("api/getfast")]
public string GetUsingCache()
{
// is the string already in the cache?
var myString = _cache.GetString("CachedString1");
if (myString == null)
{
// string is NOT in the cache
// generate a new string
myString = Guid.NewGuid() + " " + DateTime.Now;
// wait 5 seconds (simulate a slow operation)
Thread.Sleep(5000);
// put the string in the cache
_cache.SetString("CachedString1", myString);
// cache only for 5 minutes
/*
_cache.SetString("CachedString1", myString,
new DistributedCacheEntryOptions { SlidingExpiration = TimeSpan.FromMinutes(5)});
*/
}
return myString;
}
The first request to /api/getfast will still be slowbut refresh the page, andthe next requestwill pull from the cache. Switch back to the Couchbase console, click “Buckets” in the menu, and you’ll see that the “infoqcache” bucket now has 1 item.
One important thing to point out in ValuesController is that none if it is directly coupled to any Couchbase library. It all depends on the ASP.NET Core libraries. This commoninterface gives you the ability to use Couchbase distributed caching any place else that uses the standard Microsoft ASP.NET Core libraries. Also, it’s all encapsulated behind the IDistributedCacheinterface, which makes it easier for you to write tests.
In the above example, the cached data will live in the cache indefinitely. But you can also specify an expiration for the cache. In the below example, the endpoint will cache data for 5 minutes (on a sliding expiration).
_cache.SetString("CachedString1", myString,
new DistributedCacheEntryOptions { SlidingExpiration = TimeSpan.FromMinutes(5)});
Summary
ASP.NET Core can work hand-in-hand with Couchbase Server for distributed caching. ASP.NET Core’s standard distributed cache interface makes it easy for you start working with the cache. Next, get your ASP.NET Core distributed applications up to speed with caching.
If you have questions or comments about the Couchbase.Extensions.Caching project, make sure to check out the GitHub repository or the Couchbase .NET SDK forums.
About the Author
Matthew D. Groves is a guy who loves to code. It doesn’t matter if it’s C#, jQuery, or PHP: he’ll submit pull requests for anything. He has been coding professionally ever since he wrote a QuickBASIC point-of-sale app for his parent’s pizza shop back in the 90s. He currently works as a Developer Advocate for Couchbase. He is the author of AOP in .NET (published by Manning), and is also a Microsoft MVP.
With the release of .NET Core 2.0, Microsoft has the next major version of the general purpose, modular, cross-platform and open source platform that was initially released in 2016. .NET Core has been created to have many of the APIs that are available in the current release of .NET Framework. It was initially created to allow for the next generation of ASP.NET solutions but now drives and is the basis for many other scenarios including IoT, cloud and next generation mobile solutions. In this second series covering .NET Core, we will explore some more the benefits of .NET Core and how it can benefit not only traditional .NET developers but all technologists that need to bring robust, performant and economical solutions to market.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Mozilla strives to make WebAssembly as fast as possible. In recent versions of Firefox, calls between JavaScript and WebAssembly are now faster than non-inlined JavaScript to JavaScript function calls. Mozilla also is looking beyond an MVP state to make WebAssembly more useful for building applications.
Recently, Mozilla has optimized calls between the JavaScript and WebAssembly and also has made calls from WebAssembly to built-ins faster. Two classes of improvements led to these results: reducing bookkeeping, by eliminating unnecessary work to organize stack frames, and cutting out intermediaries, by taking the direct path between functions.
One scenario in Firefox where JavaScript to JavaScript remains faster than JavaScript to WebAssembly is inlined functions, where function calls the same function repeatedly, because the compiler copies that function into the calling function.
Mozilla also looks at the future of WebAssembly by looking at the sets of features needed to make WebAssembly viable. The MVP features for WebAssembly are considered complete:
- Compile target
- Fast execution
- Compact
- Linear memory
For WebAssembly to provide support for heavyweight desktop application developers, more features are needed:
- Threading – a proposal based on SharedArrayBuffers
- SIMD (single instruction multiple data) – under active development
- 64-bit addressing – planning
- Streaming compilation – in Firefox, active development by other browsers
- Implicit HTTP caching – under active development
For standard web development, the features needed include:
- Fast calls between JS and WebAssembly – complete in Firefox, active development by other browsers
- Fast and easy data exchange – several different proposals under active discussion
- ES module integration – proposal evolving, initial implementations under active development
- Toolchain integration – in progress
- Backwards compatibility – wasm2js tool
To meet the needs of JavaScript frameworks and compile-to-JavaScript languages, WebAssembly has further requirements:
- Garbage collection – two proposals under discussion
- Exception handling – early research and development phase
- Debugging – rough support in some browser debugging tools
- Tail calls – proposal under discussion
WebAssembly beyond the browser introduces even more requirements:
- Portable interface – proposal under discussion
- Standardized runtime – a few early projects under development
WebAssembly is just past its minimum viable product phase, and the specification and implementation are under very active discussion and development. To learn more about the present and future of WebAssembly, a highly informative introduction from mozilla is available, WebAssembly’s post-MVP future: A cartoon skill tree.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In a recent blog post, Amazon announced they made Auto Scaling for EC2 instances more powerful with the addition of a predictive scaling feature. Furthermore, with this new feature, customers can create a scaling plan without the need to tweak autoscaling over time manually.
In the past in 2009, Amazon added scaling capabilities such as Auto Scaling, and Elastic Load Balancing to EC2 instances to respond to rapid changes in demand. Going forward with the evolution of machine learning in the cloud, Amazon today adds well-trained models to predict customers’ expected traffic and EC2 usage. This addition is the predictive scaling feature, allowing customers to switch to it on. Jeff Barr, chief evangelist for AWS, stated in the blog post:
The model needs at least one day’s of historical data to start making predictions; it is re-evaluated every 24 hours to create a forecast for the next 48 hours.
The predictions will be based on the customer’s usage and from millions of data points from tens of thousands of EC2 instances with different runtimes by Amazon itself. Moreover, Amazon uses these data points to build a sophisticated Recurrent Neural Network (RNN) that can, for example, predict the average CPU utilization of the EC2 fleet.
Customers can enable predictive scaling by using a three-step wizard process to choose the resources that they want to observe and scale. The first step is opening the Auto Scaling Console, and search for scalable resources. Next, select an EC2 Auto Scaling group, assign the group a name, pick a scaling strategy, and leave both Enable predictive scaling and Enable dynamic scaling.
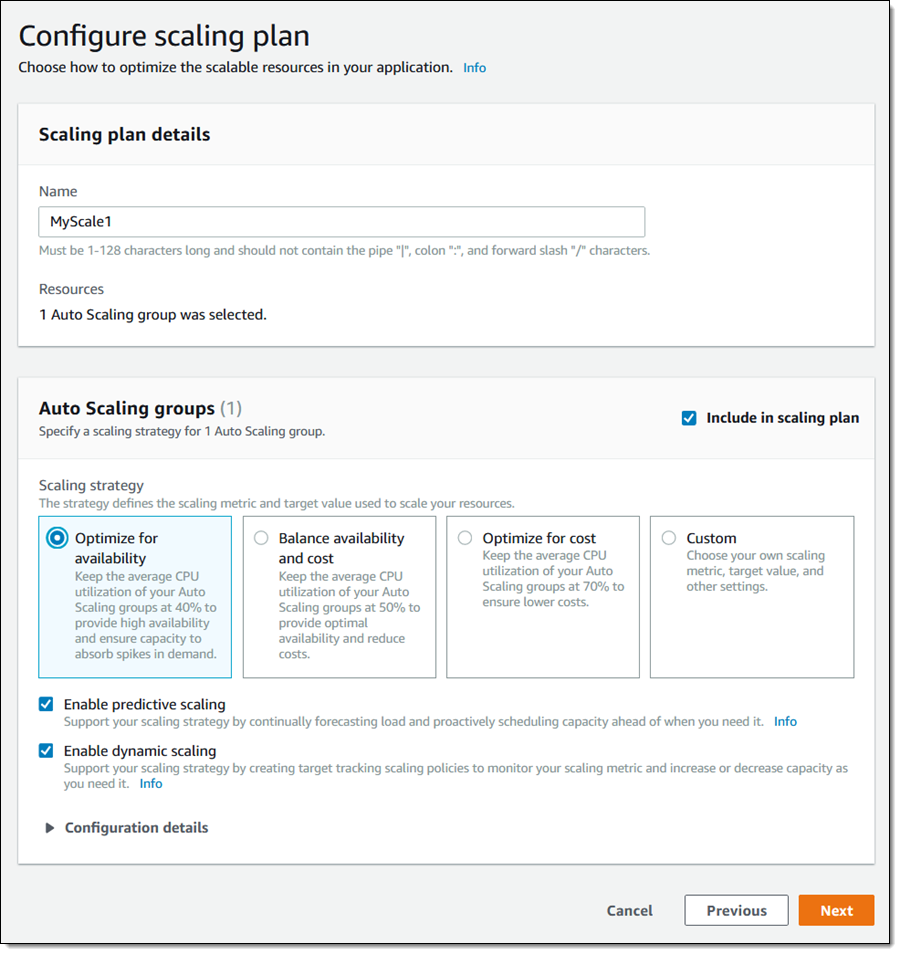
Source: https://aws.amazon.com/blogs/aws/new-predictive-scaling-for-ec2-powered-by-machine-learning/
Barr explains in the blog that Predictive scaling works by forecasting load and scheduling minimum capacity; dynamic scaling uses target tracking to adjust a designated CloudWatch metric to a specific target. Furthermore, both models work well together because of the scheduled minimum capacity already set by predictive scaling. The forecast can be on one of the three pre-chosen metrics or custom metrics as customers can fine-tune the predictive scaling to their own needs. Finally, the plan is ready, and the learning and prediction process can begin. Through the console, customers can observe the forecast on the chosen metrics.
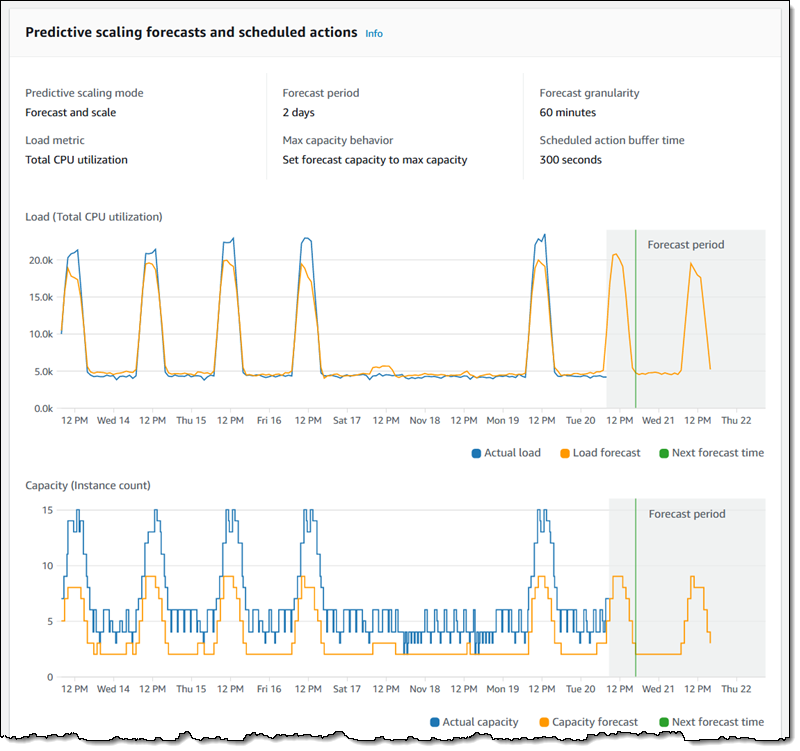
Source: https://aws.amazon.com/blogs/aws/new-predictive-scaling-for-ec2-powered-by-machine-learning/
According to Barr, there are a few considerations about predictive scaling:
- Timing – Once the initial set of predictions have been made and the scaling plans are in place, the plans are updated daily, and forecasts are made for the following two days.
- Cost – You can use predictive scaling at no charge, and may even reduce your AWS charges.
- Resources – We are launching with support for EC2 instances, and plan to support other AWS resource types over time.
- Applicability – Predictive scaling is a great match for websites and applications that undergo periodic traffic spikes. It is not designed to help in situations where spikes in load are not cyclic or predictable.
- Long-Term Baseline – Predictive scaling maintains the minimum capacity based on historical demand; this ensures that any gaps in the metrics won’t cause an inadvertent scale-in.
The predictive scaling feature for EC2 instances will be available initially in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Singapore) regions. For more details on EC2 Auto Scaling pricing, see the pricing page.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
“Java by Comparison; Become a Java Craftsman in 70 Examples” is an excellent book. To describe it in one sentence: It teaches you how to write better and clearer Java code.
Who is this book for?
I like that the authors set expectations for the book by saying you should be able to code Fizz Buzz in less than 15 minutes. It’s a lot more specific than just saying one should know how to program.
The authors struck a good balance in covering multiple audiences. The book manages to be useful for:
- New developers – Most examples are understandable by a programmer who just knows the basics. Even when using an API that a new programmer might not know, it is still clear why the improved version is better.
- New Java developers transitioning from another language – The examples focus on common idioms. This helps map knowledge from the other language and also helps the developer realize when they are carrying idioms from the other language.
- Mid-level Java developers – Most of the examples are still useful to a developer who would like to write better code. Since each example is independent, it is easy to skim past the ones that the developer knows and go straight to the other parts. It’s also good for learning JUnit 5 and Java 8 best practices in a clear/concise way.
- Experienced developers – It’s easy to forget that not everyone knows as much as you do. This book is an excellent way to remember to write code that is easily understandable to everyone on the team. It’s also helpful to keep handy during code reviews to show teammates. After all, you didn’t make up these ideas on clean code; they are well recognized!
What is the format?
The majority of the book uses a two page format which is convenient in a physical book or two page view in an e-book reader. Just make sure your screen is large enough to view two pages at once. Trying to read this on a Kindle seems like it would be a frustrating experience!
The two page format is not the one you might have seen from another publisher. This one is designed for comparing code. The top left page has the “before” code. The top right page has the improved code. This is an easy format for comparing. It’s also helpful in seeing that the improved code is often shorter/cleaner.
The important differences in the code snippets are supposed to be highlighted. However, in the print copy, the highlighting is medium gray (on a light gray background.) By contrast, the Java keywords are in black bolded and the rest of the code is in black.
This had the effect of me needing to train myself to “tune out” the keywords and focus on the gray text. It took me a few pages to get there so wasn’t a big problem. There was a reference to green so I imagine the e-book uses actual colors. At least the printed book isn’t a problem for the colorblind as there is only one color involved!
The bottom/remainder both pages describe the differences, why they are important and various other pointers. Which brings us to another formatting oddity. When code is used within the text sections, it was in a narrower font than the text. I’m used to the opposite. Some of the examples even contain bonus tips like how to avoid null pointers.
What version of Java is covered?
The book primarily targets Java 8. There were great examples with lambdas, streams and optionals. I even learned that the Collections class has a frequency method. That’s definitely something that could make my code shorter!
There’s a reference to a number of APIs in Java 9, which is fun. One of tips had a suggestion for documenting modules for Java 9. Overall, Java 8 is a logical choice that will keep the book current for a long time. The APIs introduced in Java 9/10/11 aren’t used in the space of examples used in the book.
How are the examples?
The examples cover a variety of topics. Many were refactorings for writing shorter and easier to read code. Some were functional like not using BigDecimal for monetary amounts. (Thank you!) I also really like seeing the JUnit 5 parameterized test in there. I liked the tip that gave a template for writing good comments.
Is the book all examples?
Mostly. The first 8 chapters cover the 70 examples. The ninth and final chapter covers other good development practices. I’m glad Jenkins and SonarQube got a shout out in there. I also enjoyed seeing libraries referenced like jGiven (a BDD library for Java) and junit-quickcheck (for property-based testing).
Finally, it was great to see the caveat that it is important for an actual person to look at static analysis rules to see if they apply.
Overall impressions
I enjoyed reading this book and definitely recommend it. It’s written in an easy to read style with both short and fun examples. I was definitely skeptical when reading the back cover and seeing the broad range of skills that this book was targeting. However, it is true: this book really is useful for more than just novices. Happy reading!
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
With the release of Java 11, the transition of Java into an OpenJDK-first project is finally complete. The days of most Java installations using the proprietary OracleJDK binaries are at an end. This increased focus on Open and Free Java naturally brings the contributions of companies other than Oracle into greater prominence. InfoQ recently spoke with Rich Sharples, Senior Director of Product Management for Middleware at Red Hat, to discuss OpenJDK and Red Hat’s involvement with it.
InfoQ: Red Hat have been a contributor to OpenJDK since the very earliest days. Can you speak to your history with the project?
Sharples: Red Hat announced a broad contributor agreement with Sun Microsystems on November 5, 2007. This agreement covered the participation of Red Hat engineers in all Sun-led open source projects. As part of this, Red Hat signed Sun’s OpenJDK Community TCK License Agreement, becoming the first major software vendor to do so. Red Hat also committed to sharing its developers’ contributions with Sun to create the OpenJDK community and foster innovation. Red Hat is one of the largest contributors to OpenJDK after Oracle.
By doing this, Red Hat has deepened its participation in the Java ecosystem, which was significant after its acquisition of JBoss in the previous year. In 2009, Sun was acquired by Oracle and the relationship that had developed between Sun and Red Hat was continued under Oracle.
Since joining the OpenJDK project in 2007, Red Hat has continued contributing in the upstream OpenJDK community, as well as packaging and supporting OpenJDK with Red Hat Enterprise Linux. For example, Red Hat assumed leadership of OpenJDK 6 in 2013 (and supported it until 2016) and took over stewardship of OpenJDK 7 in 2015. Andrew Haley explains more about our stewardship in this post on the Red Hat Developer Blog.
OpenJDK 6 was packaged and supported in Red Hat Enterprise Linux 5, 6, and 7, as was OpenJDK 7. OpenJDK 8 is supported in Red Hat Enterprise Linux 6 and 7. OpenJDK 11 is supported in Red Hat Enterprise Linux 7.6. In addition to providing support across a range of Red Hat Enterprise Linux versions, we have consistently provided lifecycle support for our OpenJDK distributions.
The lifecycle for OpenJDK 7 has recently been extended to June 2020, and the lifecycle for OpenJDK 8 has been extended to June 2023 with the intent of providing users with sufficient time to migrate workloads to OpenJDK 11.
In addition to distributing and providing lifecycle support for OpenJDK on Red Hat Enterprise Linux, Red Hat’s open source Java middleware products support OpenJDK for Red Hat Enterprise Linux, enabling users to get a full stack support from the operating system through to application services from a single vendor, and other Red Hat products internally run on OpenJDK. We are a leader in offering support to customers worldwide that rely on open source to run their production workloads.
InfoQ: Let’s talk about the current state of play. As it stands right now, how many engineers at Red Hat are working on OpenJDK (both full-time and part-time)? What areas are they working on?
Sharples: As a policy we don’t publicize Red Hat’s investment in particular projects.
The lead Engineer of Red Hat’s Java Platform team Andrew Haley has been a member of the OpenJDK Governing Board for many years and is also the lead of the AArch64-port projects. Additionally, Andrew is also the lead of the JDK 7 project and intends to apply for leadership of OpenJDK 8 and 11 after Oracle EOLs them.
InfoQ: To talk about specific technologies – which areas do you think Red Hat has contributed the most to? What are the technical components where Red Hat’s leadership has been strongest?
Sharples: Red Hat started, wrote much of, and leads the 64-bit ARMv8 port, AArch64 for OpenJDK, and helped move it into the upstream OpenJDK project. Currently, we’re working with the OpenJDK community on a new ultra-low pause time Garbage Collector named Shenandoah that’s outside the OpenJDK mainline now – but fully supported in Red Hat Enterprise Linux 7. The work is targeted to enter mainline in OpenJDK 12.
InfoQ: The current state of garbage collection in OpenJDK is very interesting. For example, as of JDK 11, G1 is finally reaching full maturity as a collector. Red Hat obviously have the Shenandoah collector, while Oracle have been working on ZGC. Can you comment on Red Hat’s approach to participation in the GC space, especially as regards G1? How would you compare and contrast Shenandoah and ZGC? Would you like to give an estimate as to when Red Hat think that Shenandoah will be a plausible choice for a production collector?
Sharples: Our main area of participation continues to remain Shenandoah GC at this time. Additionally, a very significant (although not user-visible) collaboration is happening in the development of Hotspot’s GC interface, in which Red Hat is actively participating.
GC code used to be spread around a lot of Hotspot code, but it’s now very well separated, both from Hotspot’s core and each GC from every other. Shenandoah shares some code with G1, which lead to a couple of improvements and bug fixes there too. Notably, G1 has adopted a few features which originally appeared in Shenandoah first, for example multi-threaded full-GC and, very recently, heap uncommit on idle.
ZGC and Shenandoah are very similar in their goals (reduce pause times on large heaps). However they follow a very different implementation strategy — Shenandoah uses Brooks Pointers, whereas ZGC uses colored pointers and multiple-memory-mappings.
ZGC is often better in terms of throughput and pause-times. However, Shenandoah has better ergonomics, which means that it can practically operate better in difficult conditions like almost-full heap or allocation bursts. ZGC cannot (by design) use compressed oops, which means that it has a disadvantage on medium-sized (<32GB) heaps. Furthermore, even though it’s never been a goal, Shenandoah operates very well on small heaps, making it an ideal GC for applications that may grow in size, but are not guaranteed to do so.
Shenandoah is already offered as a production choice as part of RHEL >= 7.5’s JDK-8u distribution, and to our knowledge, it is already used as such. We’re currently working on getting Shenandoah into upstream in JDK12. When it lands there, it’ll be an experimental feature. We cannot say at this time when the experimental flag will be removed in upstream OpenJDK distribution.
InfoQ: Obviously, one of the big news pieces recently has been the news that Red Hat are to be acquired. How will this change the position of Red Hat relative to OpenJDK?
Sharples: We cannot say anything additional about IBM. Please refer back to our press release and our blog post from Jim Whitehurst.
InfoQ: What do you think the most exciting parts of OpenJDK (and the wider Java / JVM ecosystem) are right now? Which technologies and new developments do you think are the ones that our readers should pay the closest attention to in the next 12-18 months?
Sharples: Java has to move beyond its sweet spot as a scalable language runtime for large-scale business critical applications and better compete with lighter, nimbler languages and runtimes – especially in cloud-native environments where memory footprint and latency are very sensitive.
What’s exciting to note is that the Java community continues to innovate at the JVM level. Among other things, Graal and Substrate VM recognize that the average lifespan of a running JVM is significantly shorter in a container and devops environment. Monolithic applications ran on the JVM for months at a time, containerized microservices in a continuous delivery environment may run for days or hours, and in the serverless world they may run for (milli)seconds.
It’s important to note that it’s not just the JVM that has become exciting (again), but the broader Java ecosystem is keeping pace. Along with optimizing the JVM itself and the continuous introduction of new lightweight and nimble runtimes like Thorntail, there are projects like Eclipse MicroProfile and its specifications that help bring Java EE developers who have traditionally written monolithic applications to the world of lightweight microservices.
Red Hat, with tools like the Fabic8 Maven Plugin and Spring Cloud Kubernetes, has been leading the way for developing Java applications that are native to Kubernetes, Istio, and OpenShift. This greatly simplifies the microservices architecture that only a couple of years ago required many standalone infrastructure services that had to be managed individually. The Java ecosystem as a whole continues to move forward at a rapid pace.
We’re also thinking about new chip architectures (like ARM and GPUs) for specialized workloads such as AI and Machine Learning as well as new elements of the cloud architecture such as edge devices, gateways, mobile devices and wearables.
InfoQ: Any other comments for our readers?
Sharples: The interest in Java has never been greater and the future of Java has never been brighter.