Month: December 2018

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Many incidents happen during or right after the release argues Charity Majors, ceo at Honeycomb. She believes that stronger ownership of the deployment process by developers will ensure it is executed regularly and reduce risk. Fear of the release pipeline will lead developers to ship less which in turn increases the risk and impact of delivering new code. She argues for strong investment in the tooling, high observability during and after release, and small, frequent releases as a way of minimizing impact caused by shipping new code.
According to Majors, if releasing is risky or highly impactful then you need to make fixing that a priority. In the short-term, she recommends tracking failure frequency and cause then running post mortems on those failures. This will provide you with areas where you can invest in making your pipeline more resilient. You can also perform your deployments in the morning, during business hours, when everyone is available and fresh.
To begin to drive long-term improvements, the project needs an owner. As Majors notes, “if it doesn’t have an owner, it will never improve.” Companies can signal the importance of this project by making one of their best engineers the owner of these improvements. Majors puts forward that deploy software is often “a technical backwater, an accumulation of crufty scripts and glue code, forked gems and interns’ earnest attempts”. In her view, deploy software is the most important code you have and should be treated as such. This resonates with Alek Sharma, technical writer at CircleCI, who believes that DevOps is based on the argument that “code isn’t really serving its purpose until it’s been delivered”.
Majors then suggests that the developer who merges the code must also be the one who deploys the code. To ensure this is possible, she states that all developers must be software owners who:
1. Write code
2. Can deploy and roll back their own code
3. Are able to debug their own issues in prod (via instrumentation, not ssh)
Software ownership, according to Majors, is the natural end state of DevOps. It will help to shorten feedback loops and ensure that the developer with the most context of the change is ready to assist if the deployment goes poorly. This leads to better software and a better experience for customers. She goes on to state that a developer should not be promoted to a senior position if they do not know how to deploy and debug, in production, their own code.
However, Serhat Can, tech evangelist at Atlassian, suggests that if the release requires human approval, then the on-call team should perform the release. They can then follow up with the developers to have them perform their post-release checks. Developers should ensure it is easy for the on-call team to see the latest issues that could arise from the release.
The goal of these improvements is not to eliminate failure. As Majors notes, “distributed systems are never “up”; they exist in a constant state of partially degraded service. Accept failure, design for resiliency, protect and shrink the critical path.” Instead, the focus should be to enable shipping of small changes frequently and to exercise the process enough that failures become non-events since they are routine and non-impactful. From here you can begin to use the failures as learning opportunities.
Majors then introduces the concept of Observability Driven Development. Christine Yen, cpo at Honeycomb, describes this as “using production data to inform what, when, and how you develop, feature flag, and release system functionality”. She recommends incorporating the nouns that are used during development, such as build IDs, feature flags, or customer IDs, directly into your observability tooling. This will facilitate connecting the data to the change that introduced the failure. As Majors notes, “the quality of code is not knowable before it hits production”, therefore outfitting your code with the appropriate instrumentation before it ships will assist with debugging the changes in production.
While it may be true that most incidents happen just after a release, as Majors concludes having a strong culture of ownership can help reduce the frequency and impact of these incidents. Having developers that can debug their own code in production will improve their ownership over their releases. According to Majors, greater ownership over the release process will encourage developers to ship more frequently, resulting in higher quality, smaller releases.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
2018 has been a very interesting year for Java, as we discussed in InfoQ’s roundup of the year.
As we move into 2019, let’s take a look at some of the things to watch in the New Year in Java and related technologies, and have some fun by trying to predict what might happen.
DISCLAIMER: These are merely personal predictions by the author, and not official statements or roadmaps of any kind, from Oracle, InfoQ or anyone else.
Java 11 starts to see small, but significant adoption
This might be the least controversial prediction on this list. Java 9 and 10 saw virtually no deployment to production. Many teams seem to be waiting for a post-8 LTS release to arrive, and now that it’s here, a small but steady adoption of Java 11 will begin to appear.
A big driver for this adoption will be microservices and containerized applications, both of which are significantly easier with Java 11 than Java 8. Greenfield deployments of brand-new apps will be the obvious place for teams to begin adopting Java 11.
Prediction: Java 11 is roughly 10% of the overall reported Java production installations at the end of 2019.
No large-scale porting of existing applications from 8 to 11
Until now, the Java upgrade path for applications was fairly clean. Moving from 6 to 7 or from 7 to 8 was, in almost all cases, totally painless. The same cannot be said for the 8 to 11 upgrade – significant work is usually necessary to move a non-trivial application onto the new version.
Very few application groups have the resources to undertake a port, a rearchitect and a full retest of their applications just to stay on the current version of Java. As a result, I do not expect to widespread porting of Java 8 applications to Java 11, without some other compelling external reason to do so.
Prediction: No specific quantifiable prediction.
No analogue of the Python 2 / Python 3 divide
Much has been said about the possibility that with the advent of modular Java, the ecosystem will fragment along the lines of the Python 2 / Python 3 split experienced by that community.
I do not expect this to occur for several reasons – but the main one is that Java 11 is not a fundamentally different language, at a syntactic or a semantic level. Python syntax and the meaning of key datatypes (e.g. Unicode strings or longs) does change between versions, so library and application authors must consciously choose which language version is being targeted, and this choice pervades the entire ecosystem on a per-project basis.
In the Java case, on the other hand, it is the choice of the application owner whether to embrace modularity or not; and the choice of the library developer as to whether to deploy as modules, and if so, which fallbacks to offer to Java 8 applications. The workaday Java programmer continues much as before, and programs in basically the same language whether the project they are working on is targeting Java 8 or 11.
Prediction: No specific quantifiable prediction.
Continued Gradual Adoption of Graal
For those projects which have moved to Java 11, interest is likely to grow in the Graal project. This includes the next-generation JIT compiler, which may reach (or even surpass) the C2 compiler (aka -server) for Java 11 in 2019.
That Graal-JIT will, sooner or later, surpass C2 seems obvious – Graal’s design (especially the fact that it is implemented in Java) means that it is relatively easy for the Graal team to implement any new optimization that could be implemented in C2.
The umbrella term “Graal” also includes Oracle’s semi-open GraalVM project for polyglot runtimes. However, it is important to note that Graal-JIT is only available for Java 11 and up, whereas GraalVM only covers Java 8.
Therefore, the user community for Graal may well form two disjoint groups – one focused on performance of Java 11 applications, and one focused on polyglot apps leveraging the Java 8 ecosystem.
Predictions:
- 30-40% of Java 11 applications are using Graal-JIT in their Java 11 production deployments
- Making Graal the default JIT compiler is seriously discussed for Java 13 but ultimately not implemented
- GraalVM production deployments remain rare, but are increasingly being experimented with by application teams.
OpenJDK becomes the market leader for Java runtimes
Oracle are ending their ownership of the OpenJDK 8 project, and Red Hat have offered to take over as leaders. The same may well be true of the OpenJDK 11 project, as that project will be relinquished by Oracle when Java 12 is released.
Many developers miss the fact that Oracle’s LTS offerings are only for paying customers, so in the future the only free-as-in-beer support offerings for Java 8 (and 11, once Java 12 is released) will come from non-Oracle organizations, such as Red Hat, Amazon, Azul Systems and the multi vendor, community-driven AdoptOpenJDK project.
With no further free updates to OracleJDK being made available to the community, then I expect to see a rapid transition to OpenJDK as the production platform of choice for Java applications.
The good news is that for serverside applications (& increasingly for desktop Java apps as well), OpenJDK is a drop-in replacement for Oracle’s JDK.
Prediction: Over 50% of both Java 8 and Java 11 production runtimes are using OpenJDK rather than Oracle JDK, at the end of 2019.
Release of Java 12
Java 12 is feature-frozen and is due to be released in March 2019. Barring a major incident, it is hard to see that this will not ship on time.
It is not a long-term support release, and is unlikely to see wide adoption (just as Java 9 and 10 were not widely adopted).
Prediction: Java 12 releases on time, and has rounding-error production deployments at the end of 2019.
Release of Java 13
Java 13 is due to be released in September 2019. No details are available of any features currently targeted at this release.
As with Java 12, it is a feature release, not an LTS release. Accordingly, there is no reason at this time to suppose that it will not ship on time. Equally, it is unlikely to see wide adoption, with teams instead focusing on moving Java 11 into production.
Prediction: Java 13 releases on time, and has rounding-error production deployments at the end of 2019.
Value Types Does Not Ship as Preview in Java 13
Value Types are the effort to bring a third type of fundamental value to the JVM, alongside primitive types and object references. The concept can be thought of as relaxing some of the rules of the Java type system, allowing composite data structures more similar to C structs, without the baggage, while retaining full Java type safety.
Brian Goetz, the Java language architect, uses the phrase: “codes like a class, works like an int” to describe how he envisages a typical developer will use the value types feature, once it has finally been delivered.
There has been sustained, continued progress towards value types, but as of the end of 2018, only experimental, very early-access, experts-only alpha prototypes have ever been produced.
This is not surprising – value types are one of the most fundamental and deep-rooted changes to the Java platform that have ever made.
The complexity and the ambition of this feature, and the corresponding sheer amount of engineering work necessary make it very unlikely that this will be delivered, even in an initial form in 2019.
Prediction: No form of Value Types is included, even as a Preview Feature in Java 13.
Initial Version of Match Expressions Ships as Preview in Java 13
Switch expressions are a prerequisite for match expressions. Without an expression form present in syntax, it is impossible to deploy match expressions within the Java language. Indeed, without match expressions, there is very little point in introducing switch expressions at all.
Accordingly, I expect standardized switch expressions to be followed swiftly by simple forms of match expressions. The feature is likely to be limited to type matches only initially, with no destructuring or other advanced features.
Prediction: An initial, limited form of Match Expressions is included as a Preview Feature in Java 13.
Modest Growth of Kotlin
The Kotlin language from JetBrains has attracted increasing interest from developers in recent years. In particular in the Android space there has been an explosion, and a dominance of Kotlin for new projects on Android.
However, no comparable explosion has occurred in server-side Java, the traditional heartland for JVM languages. In 2019, I see continued gradual adoption of Kotlin, but not a flurry of projects / teams moving to it. There will be several high-profile projects that are publicly using Kotlin to build upon.
Prediction: Kotlin will continue to win fans in the core Java community, but will not break through, and will remain smaller than the Scala ecosystem.
Business As Usual
The above highlights some of the changes at the bleeding edges of Java. However, in the rest of the Java world (the hinterland of Java) then it will be another year of more of the same. Java’s IDEs, libraries and the rest of the ecosystem will basically continue on the same trajectory.
Java’s solid position and momentum within the industry will continue to carry it forward without any major upsets.
Prediction: No specific quantifiable prediction.
Google Updates Cloud Spanner: Query Introspection, New Regions, and New Multi-Region Configurations
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In a recent blog post, Google announced a few enhancements for Cloud Spanner – a globally distributed NewSQL database. Based on customer requests Google updated the service with query introspection improvements, new region availability, and new multi-region configurations.
With Google Cloud Spanner customers can use a Cloud database service that combines the benefits of a relational database structure with non-relational horizontal scale. Furthermore, the service provides customers with high-performance transactions and strong consistency across rows, regions, and continents with a 99.999% availability SLA, no planned downtime, and enterprise-grade security. Moreover, with an increase in availability in more regions Cloud Spanner further improves performance as customers will have an option to host the database service in the same region as their application stack.
In the blog post, Deepti Srivastava, Product Manager, Cloud Spanner stated:
To help meet that goal, we recently announced the availability of Cloud Spanner in Hong Kong as part of the GCP region launch. Additionally, we have added Cloud Spanner availability to seven other GCP regions this year, bringing the total region availability to 14 (out of 18) GCP regions. New regions added this year are South Carolina, Singapore, Netherlands, Montreal, Mumbai, Northern Virginia, and Los Angeles. Our plan is for Cloud Spanner to be available in all new GCP regions moving forward.
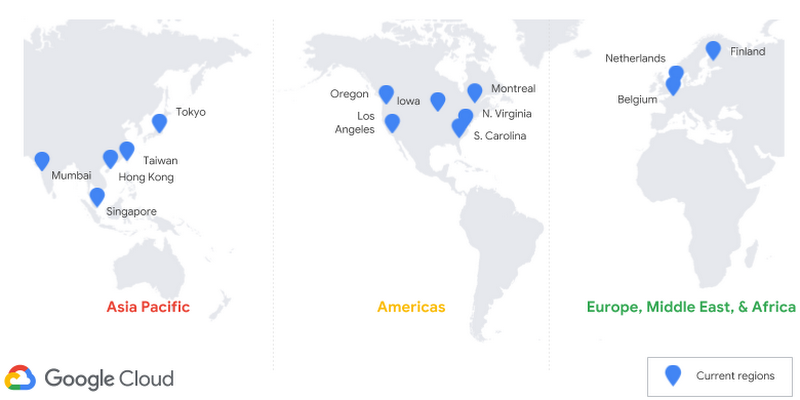
Next, for more availability of Cloud Spanner in more regions, Google is also adding two new multi-region configurations. Multi-region configurations, GA since November of last year, provides customers with a more straightforward development model, improved availability, and reduced read latency. The new multi-region configurations are:
- nam6: multi-region coverage within the United States
- eur3: multi-region coverage within the European Union
Lastly, Google added a query introspection capability to provide customers with better visibility into frequent and expensive queries running on Cloud Spanner. They can according to the blog post view, inspect, and debug the most common and most resource-consuming Cloud Spanner SQL queries that are executed on a database. Furthermore, Srivastava stated:
This information is useful both during schema and query design, as well as for production debugging—users can see which queries need to be optimized to improve performance and resource consumption. Optimizing queries that use significant amounts of database resources is a way to reduce operational costs and improve general system latencies.
For more details about the pricing of Cloud Spanner see the pricing page.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Performance tuning in Java is an experimental science.
- There are no magic “go faster” command-line switches for the JVM.
- There are no “tips and tricks” to make Java run faster.
- The execution speed of Java code is highly dynamic and fundamentally depends on the underlying JVM.
- The behavior of JIT-compiled code is significantly more important than the interpreter itself.
- This book offers both theory and practice on how to performance tune in Java.
- This is a comprehensive book that represents a tutorial for beginners and a reference for experienced Java performance tuning practitioners.
Optimizing Java, released in May 2018, is a comprehensive in-depth look at performance tuning in the Java programming language written by Java industry experts, Ben Evans, James Gough and Chris Newland.
The book hits the ground running where the authors thoroughly define Java optimization and performance in the opening chapter. They explain why Java performance tuning may have been incorrectly applied throughout the lifespan of most applications. It is important to note:
The execution speed of Java code is highly dynamic and fundamentally depends on the underlying Java Virtual Machine. An old piece of Java code may well execute faster on a more recent JVM, even without recompiling the Java source code.
There are a number of performance metrics defined and used in this book:
- Throughput – the rate of work a system or subsystem can perform.
- Latency – the time required to process a single transaction and observe a result.
- Capacity – the number of units of work, such as transactions that can be simultaneously running in a system. This is related to throughput.
- Utilization – a CPU should be busy doing work rather than be idle.
- Efficiency – calculated as throughput divided by utilization.
- Scalability – a measure of the change in throughput as resources are added.
- Degradation – an observed change in latency and/or throughput as a function of an increased load on a system.
A number of performance tuning antipatterns have plagued developers over the years. These have derived possibly due to boredom, resume padding, lack of understanding, or an attempt to find solutions for non-existent problems. The authors define some of these antipatterns and debunk the myths associated with them.
There are plenty of practical heuristics and code-level techniques, but the authors warn that these may do more harm than good if not properly applied. Readers are encouraged to fully understand performance tuning concepts before experimenting with any code or applying advanced command-line parameters that invoke garbage collectors and JVM parameters. There are also plenty of code examples that demonstrate the concepts.
Relevant performance tuning topics include how code is executed on the JVM, garbage collection, hardware and operating systems, benchmarking and statistics, and profiling. The authors conclude the book with a chapter on Java 9 and beyond.
Evans and Newland spoke to InfoQ for insights on their experiences, learnings and obstacles on authoring this book.
InfoQ: What inspired you to co-author this book?
Ben Evans: I had the original idea, and I knew I wanted to write with a co-author. James and I are old friends, and he’d helped with “Java in a Nutshell” so I knew that we could write well together, so he was a natural choice.
The book was in development when we felt we wanted to dive deeper into JIT compilation and cover some of the tools in the space. I’d previously worked with Chris and was really impressed with his JITWatch tool, so we asked him to join us towards the end of the project.
Chris Newland: For the past five years I’ve worked on an open-source project called JITWatch which is a tool for helping Java developers understand the compilation decisions made at runtime by the JVM. I’ve given a few presentations about the JVM’s JIT compilers but felt that it would be useful for Java developers if there was a book that explained how the technology works.
InfoQ: Did you have a specific target audience in mind as you wrote this book?
Evans: Intermediate to advanced Java developers that want to do performance analysis well, using sound methods and not by guesswork. A secondary audience includes those developers that want to dig deeper into the JVM and understand how it really works, in terms of bytecode, garbage collection and JIT compilation.
Newland: I think we tried to make the book accessible for developers of all levels and there are plenty of examples to illustrate the points we are making. There are parts of the book aimed at mid-level to senior developers who are looking to gain a deep understanding of JVM performance.
InfoQ: While every aspect of Java performance in this book is important, is there a topic that is most important for readers to fully understand?
Evans: That there are no magic spells or “tips and tricks”. Performance is not the same as software development – instead it is its own set of skills and it can be best thought of as a separate discipline.
That discipline is data-driven – it is about the collection and interpretation of observable data. There are difficulties about collecting, analysing and understanding the data and the behaviour of an entire application is totally different to the behaviour of a small amount of toy code or tiny benchmark.
Or, as our friend Kirk Pepperdine always likes to say: “Measure, don’t guess.”
Newland: I think the most important idea to take from the book is that everything your program does has a cost, be it allocating new objects, invoking methods, or executing algorithms. In order to improve program performance, you must first understand how to reliably measure it and only then are you ready to begin experimenting with the different performance improvement techniques.
InfoQ: How will Java performance be affected, if at all, with the new Java SE release cycle especially in terms of new features (such as the new var reserved type introduced in Java 10) and improvements in garbage collection?
Evans: One of the things that the book tries to teach is an understanding of what features are potentially performance-affecting. Things like Java’s generics or the new var reserved type name are purely compile-time language features – they only really exist while javac is crunching your code. As a result, they have no runtime impact at all!
Garbage collection, on the other hand, is something that affects every Java program. It is a very deep and complex subject, and often badly misunderstood by programmers. For example, I often see it asserted (on certain online forums) that “garbage collection is very wasteful compared to manual memory management or reference counting” – usually without any evidence whatsoever, and almost always without any evidence beyond a trivial benchmark that appeals to a specific edge case.
In reality, modern GC algorithms are extremely efficient and quite wonderful pieces of software. They are also extraordinarily general purpose – as they must remain effective over the whole range of Java workloads. This constraint means that it can take a long time for a GC algorithm to really become fully battle-tested and truly production-quality.
In the Java world, backwards compatibility and lack of regressions – including performance regressions – is taken very seriously. For example, in the Parallel collector (which was the default until Java 9), a bare minimum of work is done by the JVM when allocating new memory. As that work contributes to the observed runtime of your application threads, this keeps program execution as fast as possible. The trade-off for that (there are always trade-offs) is more work that needs to be done by the collector during a stop-the-world (STW) pause.
Now, in Java 9, the default collector becomes G1. This collector needs to do more work at allocation time, so the observed runtime of application code can increase just because of the change in collection algorithm.
For most applications, the increase in time required for this allocation will be very small, in fact small enough that application owners won’t notice. However, some applications, due to the size and topology of their live object graph are badly affected.
Recent releases of G1 have definitely helped reduce the number of applications that are negatively affected, but I still run across applications where moving from Parallel to G1 is not a straightforward process. Things like this mean that garbage collection is still a field that requires some careful attention when thinking about performance.
So the new advances in GC – the ongoing maturation of G1 as well as new collectors, such as ZGC and Shenandoah, are starting to come to the attention of developers – are definitely a live topic once again for people that care about the performance of their applications.
Newland: The new release cadence allows for a more incremental approach to performance improvements. Rather than waiting 2+ years for major new features, we are seeing more experimental collectors like ZGC and Epsilon along with a steady stream of improvements to the core libraries such as String and Collection performance.
InfoQ: Are there plans for updated editions of this book, if necessary?
Evans: I think that over time, there would definitely be scope for a 2nd edition, assuming that the folks at O’Reilly would like to publish one! The big areas that I think would drive that new edition would be:
First, the arrival of new GC choices into the mainstream – which we’ve already talked about above.
Second, the whole story around new compilation technology – the Graal JIT compiler is, I think, a bigger deal than many developers realize right now. The work being done to bring private linkage, i.e., jlink custom runtime images, and also ahead-of-time (AOT) compilation to Java is huge, especially for people who want to do microservices and cloud with the architectural changes (including a focus on app startup time) that come with that. Those changes to Java’s compilation technologies will inevitably have a major impact on the performance story.
Third, there’s a goal that (Java language architect) Brian Goetz refers to as “To align JVM memory layout behavior with the cost model of modern hardware.” This is all the Project Valhalla work (including value types) but also the folks looking at vectorization and GPU-based compute. This area – not just value types but so many other pieces of the puzzle – will have a large impact on the way that we build Java/JVM applications and, of course, on their performance.
Newland: I think Graal is a very exciting new JVM technology and as its adoption grows it would be useful to cover it in the book.
InfoQ: What are your current responsibilities, that is, what do you do on a day-to-day basis?
Evans: I’m a Director at jClarity, a Java performance company that I founded with Kirk Pepperdine and Martijn Verburg a few years ago. When I’m not busy there, I also have my own private consulting, research and teaching practice. The aim of that business is to help clients tackle their performance and architecture problems and help grow their developer teams. I’m always happy to hear from people who I might be able to help – ben@kathik.co.uk.
I spend some time helping with a charity called Global Code that runs coding summer schools for young software engineers and entrepreneurs in West Africa. I also do some interim/consulting CTO work, as well as a fair amount of speaking and writing, including of course, running the Java/JVM content track at InfoQ.
Newland: I work in market data, using Java and the JVM to process stock market information in real-time. The programs I write tend to have a small number of performance-critical regions where an understanding of the JVM is essential.
About the Book Authors
Ben Evans is an author, speaker, consultant and educator. He is co-founder of jClarity, a startup that delivers performance tools & services to help development & ops teams. He helps to organize the London Java Community and serves on the Java Community Process Executive Committee, helping define standards for the Java ecosystem. He is a Java Champion, JavaOne Rockstar Speaker and a Java Editor at InfoQ. Ben travels frequently and speaks regularly, all over the world. Follow Ben on Twitter @kittylyst.
James Gough has worked extensively with financial systems where performance and accuracy have been essential for the correct processing of trades. He has a very pragmatic approach to building software and experience of working with hundreds of developers to help improve their understanding of performance and concurrency issues over the last few years. Follow James on Twitter @Jim__Gough.
Chris Newland has been working with Java since 1999 when he started his career using the language to implement intelligent agent systems. He is now a senior developer and team lead at ADVFN using Java to process stock market data in real time. Chris is the inventor of JITWatch, an open-source visualiser for understanding the Just-In-Time (JIT) compilation decisions made by the HotSpot JVM. He is a keen JavaFX supporter and runs a community OpenJFX build server at chriswhocodes.com. Follow Chris on Twitter @chriswhocodes.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In a recent blog post, Facebook announced they have open-sourced PyText, a modeling framework, used in natural language processing (NLP) systems. PyText is a library built upon PyTorch and improves the effectiveness of promoting experimentation projects to large-scale production deployments.
PyText offers several advantages when building NLP applications over traditional approaches. Ahmed Aly Hegazy, a software engineer at Facebook, provided the following benefits:
PyText provides a simplified workflow which enables faster experimentation. This occurs through access to a rich set of prebuilt model architectures and utilities for text processing and vocabulary management to facilitate large-scale deployment. In addition, the ability to harness the PyTorch ecosystem, including prebuilt models and tools created by researchers and engineers in the NLP community also provides opportunities.
NLP systems facilitate human to computer interactions through natural language and the use of artificial intelligence. Facebook leverages natural language processing in many of their services including Messenger and their video conferencing device called Portal.
Facebook has been able to reduce time to market for many of their own features, as a result of using PyText, Aly Hegazy explains:
At Facebook, we’ve used this framework to take NLP models from idea to full implementation in just days, instead of weeks or months, and to deploy complex models that rely on multitask learning.
Historically, natural language processing frameworks have struggled addressing the needs of both research, or experimentation, projects and production workloads. Aly Hegazy attributes many of the challenges associated to:
NLP systems can require creating, training, and testing dozens of models, and which use an inherently dynamic structure. Research-oriented frameworks can provide an easy, eager-execution interface that speeds the process of writing advanced and dynamic models, but they also suffer from increased latency and memory use in production.
PyText is able to avoid many of these research project-to-production challenges as it is built on top of PyTorch 1.0 which accelerates the path from research to production. Facebook has been able to demonstrate PyText’s capabilities at scale as it is used in more than a billion daily predictions while meeting Facebook’s stringent latency requirements. An example of how Facebook uses PyText is in Portal as it is used to interpret commands from users. When a user instructs Portal to “call my dad”, PyText is able to use semantic parsing to understand the relationship between the user and the person they are trying to call.
PyText complements Facebook’s other NLP investments, including integration with fastText, a text classification library. It is also able to improve DeepText, a text understanding engine, by providing semantic parsing and implementing multitask learning models that cannot be built using DeepText.
The benefits that Facebook has accrued by using PyText go beyond time-to-market efficiencies and extend to improved accuracy. Aly Hegazy explains:
We have used PyText to iterate quickly on incremental improvements to Portal’s NLP models, such as ensembling, conditional random fields, and a conflated model for all domains. This has improved the accuracy of our models for our core domains by 5 percent to 10 percent. We also used PyText’s support for distributed training to reduce training time by 3-5x for Portal.
The PyText framework is available on GitHub and includes pretrained models and tutorials for training and deploying PyText models at scale.

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Monday newsletter published by Data Science Central. Previous editions can be found here. The contribution flagged with a + is our selection for the picture of the week. To subscribe, follow this link.
Featured Resources and Technical Contributions
- Announcement: Winner of the Data Science Central Competition
- Comparison of the Top Speech Processing APIs
- Data Science, Common Stocks and V&V
- Predicting the demise of retail bookstores: a time series forecasting
- The lxml Package and xpath Expressions for Web Scraping
- Google Data Studio in 10 minutes: Step-by-Step Guide
- New Book: Architects of Intelligence
- Text Summarization and Sentiment Analysis: Novel Approach
- How to Visualize a Decision Tree from a Random Forest in Python – using Scikit-Learn
- Question: Transitioning to Data Science from Aerospace Engineering
- Sentiment Analysis of Amazon Customer Reviews with Visualizations
- Steps to Learn Python for Data Science
- 5 Minute Analysis: Getting the Whole Picture of Retail Sales
- 30 Things I learned Organizing South East Asia’s Largest Datathon
Featured Articles
- Why You Should be a Data Science Generalist – and How to Become One
- In a World of AI Delirium, Data is the Source of Business Value
- Developing a Data Science College Curriculum with Infographics
- Why I agree with Geoff Hinton: Explainable AI is overhyped by media
- How Airlines & Hotels Profit From Your Data +
- Introduction to Relational Data Logistics
- So You Think You Can Be A Data Scientist?
- What will make “Data” work in 2019?
- Excellent visualization – A who’s who guide to the Marvel Cinematic Universe
- ML approach to strategic market research and segmentation
- How can firms save time and cost with Deep learning
- How Virtual Assistants are Changing the Rules of Business
- Make the best use of Google Chrome with these amazing extensions
Picture of the Week
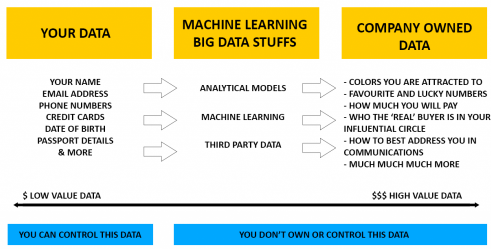
Source for picture: contribution marked with a +
To make sure you keep getting these emails, please add mail@newsletter.datasciencecentral.com to your address book or whitelist us. To subscribe, click here.
Hire a Data Scientist | Search DSC | Find a Job | Post a Blog | Ask a Question
Uncategorized
Forward and Reverse Containment Logic – Introduction to Relational Data Logistics
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
The question of how to structure or arrange data in order to gain worthwhile insights is quite different from the issue of what data to include or how it should be analyzed. I often find myself preoccupied with structure and organization. In part, this is because of my belief that unique logistics can lead to different types of insights. Popular these days to the point of gaining industry dominance is holding data as large tables. If we peer into the code for the application handling the tables, in all likelihood bytes are being moved to and from many different locations in memory and files. In my line of work, data is often transferred between different tables. This sometimes occurs manually – if cut-and-paste can be described as manual. Why not get a machine to do it? I am certainly not opposed to the suggestion. Then it would be a machine moving data between tables. It is important to note that something, somebody, or both must handle the data logistics. It just so happens that when a computer does the job, the logistics are preset in code. When I handle the logistics manually, it can be shaped on the fly. When people think about this movement of data, I believe they tend to focus on the movement itself rather than the logic behind it. I suggest that data logistics – or perhaps just logistics more generally – is more about the reasoning behind the structure – the structure giving rise to movement.
How should a computer spell checker program work? Personally, I would create a data file (a.k.a. dictionary) containing a list of correctly spelled words. I would scan the specimen document and compare each word to the contents of the data file. For added speed, I might divide the data file either by first letter or first two letters; so then it isn’t necessary to scan the entire data file to check spelling. I would store the current position of the specimen scan in case the user decides to temporarily suspend the process – although the speed of the CPU might mitigate the need. It is certainly necessary to make the program check for user input on a separate thread so the user can split CPU resources. A secondary data file should be created in case the user wants to add words. The primary data file needs to be protected in case the user wants to revert back to the original. So although no movement of data has occurred, nonetheless I can reason through the structure of the enabling system. Data logistics for me is the art of anticipation, accommodation, and enablement.
In my day-to-day work activities, the analytics that I do goes towards addressing business challenges, obstacles, and situations. Although I can achieve high levels of granularity, generally speaking I monitor phenomena at an aggregate level. Because of this predisposition towards aggregate analysis, the structure of the data tends to be fairly simple: it is normally stored as tables. Compare this to the problems faced by a field investigator who might attempt to solve a murder case using the data available on site. I understand the idea of trying to address this and other types of problems using an almost actuarial approach or as business concern. But a field investigator does not play the role of social researcher or operations manager. Aggregate analysis is not particularly helpful. This person needs to use the specific facts at hand to solve the case. Venturing far from the facts can make the findings easier to question during court proceedings; more importantly, it can interfere with case resolution. A data logistician should recognize the need for data to retain the structural details of the narrative from witnesses and from multifarious resources such as surveillance relating specifically to the case.
Using Structure to Hold Relational Details
I developed Neural Logic, as it is currently described in this blog, over a couple of days. I only needed a bit more than an hour to create the prototype interpreter. However, I spent a couple of nights reasoning out the logistics – in my head – in bed as I tried to sleep. Neural Logic is not a programming language but a method of scripting relationships in data. At the core of this methodology is “forward and reverse containment logic.” Assume there is “Don Philip” and “cat” – and it is necessary to retain the relationship that Don Philip owns the cat. Forward containment can be expressed simply as Don Philip>own>cat. The cat exists (its concept is contained) only in relation to what Don Philip owns. Reverse containment differs in that the left is subsumed by the right: e.g. (Jake>kill>cat)<for<fun. This is the basic structure – subject to further development, of course.
Why would anyone want to retain the relational details of data? An algorithm can be used to search for relational similarities and peculiarities. For example, 15-year-old Jake killed a cat for fun. This might be useful in the assessment of whether 51-year-old Jake has the capacity to kill anything. If the relational details are not stored, the unstructured text buried in some police records might render the past event relatively inaccessible. Possibly the person who designed the database was mostly concerned about incident categories rather than narrative details – i.e. had a more businesslike perspective on the data generated by case investigators. Personally, I would use a combination of standard text, keywords, categories, and relational code to describe noteworthy events. Below I provide some lines of relational code using Neural Logic. Notice that several people own cats. Nothing in the code indicates that they own the same cat or that the type of ownership is the same, just to be clear. Sameness can be expressed by using a shared unique reference: e.g. [1] for apartment; otherwise, sameness cannot be assumed.
The interesting part is in asking the questions. We might want to know who on the database owns a cat. We can pose the question as follows: “l/?> own>cat”. More precisely, on the left side of the expression being analyzed, what element of data precedes “own>cat”? Forward containment suggests that the owner is immediately to the left. I offer a number of other questions the results of which I will discuss individually.
On the runtime screen – a.k.a. “DOS box” or “DOS prompt” (since the program is running on Windows XP), notice that the interpreter didn’t have answers to a few questions. This is because I asked some questions that the interpreter didn’t have data to answer. Why? Because ((Don Philip>ask>questions)<for<output)<for<diagnostics. By the way, I use verbs in the third-person present tense: hence, I use “ask” rather than “asks.” I am still working on some of the specifics of implementation.
Question 1
Question:l/?> Expression:own>cat
… Response:Don Philip
… Response:Jill
… Response:James
In the above, the question is who or what owns a cat. The datafile contains three explicit incidents of cat ownership. Although it is true that Jake killed a cat, this does not necessarily mean that the cat belonged to him. Hence, Jake does not appear on the list.
Question 2
Question:l/?< Expression:for<fun
… Response:Jake>kill>cat
… Response:Jude>brush>cat
Because containment is reversed, the implications of searching for a left-side construct means that the left is subsumed by the right: i.e. the left does not cause the right but rather belongs to the right. The left of the expression is what is done for fun – not who is having fun. The datafile suggests that Jake killed a cat for fun. Jude brushes a cat for fun. These are probably not the same cats. There isn’t enough information to be definitive. How is tense determined? The tense is always present tense. In terms of how the time of the event is determined, that can be included in the narrative.
Question 3
Question:r/in<? Expression:feed>cat
… Response:apartment[1]
The question is not about who feeds cats. Rather, when a cat is fed, where does the feeding occur? Jude is the only person in the data feeding a cat; this occurred in an apartment. The apartment belongs to John. But Jude feeds the cat for Gwen; and he is compensated for doing so. We therefore have the opportunity for further investigation – the relationship between Gwen and John and between Jude and John – given that Jude has access to an apartment that belongs neither to Gwen nor Jude.
Question 4
Question:r/on<? Expression:feed>cat
… Response: Um, not sure … “feed cat on”
There isn’t enough data. The question is about the details to the right of a forward containment expression. But the question involves reverse containment. This takes some thought, of course.
Question 5
Question:r/in<? Expression:brush>dog
… Response: Um, not sure … “brush dog in”
There isn’t any data about a dog being brushed.
Question 6
Question:l/?> Expression:kill
… Response:Jake
In the above, the question isn’t who or what was killed – but who or what did the killing. The datafile indicates that Jake killed a cat. (I want to reassure readers that no cats or other animals were harmed or injured in the production of this blog. A cat was used as reference as opposed to a human purely by chance. In terms of why anything had to be killed, I wanted to spotlight the possible use of relational data to solve homicide cases. I point out that “dead cat” is used in other contexts – e.g. “dead cat bounce” when a stock recovers suddenly after a freefall only to continue dropping shortly thereafter.)
In case anybody is interested, I don’t have any pets. But if I could have a pet, I would like a donkey that could haul coconuts. Behold the hard-working creature below that I would be proud to have as a pet.
(Don Philip>want>donkey[1])<as<pet
donkey[1]<is<hard-working
Those with a good sense of linguistics might point out . . .
Don Philip>want>(donkey[1]<as<pet)
After all, the relationship doesn’t exist to be subsumed under pet. The alternative above would actually result in the same answer although I indeed recognize the need to accommodate different relational structures.
Speaking of hard-working, I want to point out that since Neural Logic was only deployed recently, in all likelihood it will radically change. I am merely sharing its early development. I believe it represents a worthwhile conversation piece. In terms of how this scripting format differs from codified narrative, I would say that Neural Logic allows for expression that is highly quotidian in nature and unlikely to be quantified – whereas codified narrative is still designed for analytic interpretation – e.g. the comparing the “odour of data.” Neural Logic code is not meant to ever progress to that level. Still, there are certainly some potential overlaps in application. Codified narrative is structured by the narrative itself. Neural Logic code is structured by the relationships within the narrative, which might not be well expressed by the storyline itself. The storyline can get quite distorted in order to focus on the relationship between elements. So the main difference is that codified narrative follows the unfolding of events; relational code follows the invocation of relationships.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Cost is no longer the constraint on Product Management; execution is.
- The Impact Driven Product is the most that we can build and deliver (under the existing constraints) that will help us learn fast and create the highest impact for both our customers and for our business.
- Key Business Outcomes help define what to build, who we are building for, and why.
- Minimum Viable Product is not a proof of concept, nor is it a full-fledged product. It was meant to be the smallest thing we can put together to answer a set of relevant questions.
- The valuable outcome of an estimation session is the set of conversations and interactions that happen around story details. It’s the second c of a user story, the “conversation”.
The book “Lean Product Management” by Mangalam Nandakumar is about finding the smartest way to build an Impact Driven Product that can deliver value to customers and meet business outcomes when operating under internal and external constraints.
A sample chapter on Key Business Outcomes is available for InfoQ readers.
InfoQ interviewed the author on the current challenges of Product Management, how an Impact Driven Product can help overcome at least some of them and how Key Business Outcomes can help you validate that you’re building the right thing, while the Minimum Viable Product approach may not be what you need to succeed; all of this under the minimum wasting conditions.
InfoQ: Why did you decide to write the book?
Mangalam Nandakumar: We’re witnessing a shift in how we build digital products. Technology innovations, markets dynamics and consumer behaviours are influencing product trends. We’re seeing new products that are disrupting old businesses in fascinating ways. But in product management, we still lean back on the traditional mindset bound purely by managing scope and meeting timelines.
It was about three years ago when I was running my startup that I first noticed how startups were struggling to take a product idea to market. All of these startups followed processes by the book, but failed to create any real business impact. What I mean is that they were building the wrong stuff, the right way. Business owners today understand the need to be Lean. Yet product managers are unsure about how to demonstrate product success. This is why I wanted to share my experiences and ideas. I hope that my book can influence a shift in perspective for product management. I hope it can be a guide for product teams to think in terms of impact and value creation.
InfoQ: For whom did you write the book?
Nandakumar: The book is ideal for product managers, and for anyone embarking on building a new product.
When starting on a new product, it can be quite hard to determine which product idea to pursue. Product managers need a clear process to identifying business value – especially when there are few or no users, unclear market conditions and fuzzy business goals. This book promises a systematic approach to solving this problem. So, startups founders, entrepreneurs, and intrapreneurs can benefit from this too.
InfoQ: Product Management is facing new challenges today. For instance, you said that “cost is no longer the constraint—execution is.”. Would you mind elaborate on that?
Nandakumar: Think about this. You’ve found a great solution to a pressing need in the market. You have the right technology to productize it. You may even have an early mover advantage. But you’re also at the risk of being outmaneuvered by competition or changing market scenarios. When you know you have a product that can create new channels of value that didn’t exist before, then you’re willing to place higher bets, and raise investments. Entrepreneurs realize that the value creation pie is not limited. It’s not a zero-sum game, where one person’s gain is another’s loss. However, what will hold you back is your ability to execute on that vision of value creation. If you can’t deliver on the promise of value, then you’re bound to fail as a business. This is why, I feel that product managers need to own value creation, and not just follow a plan. We’re no more bound by budgets. We’re only bound by our vision to create the most impact. How we execute on that vision is what will define us.
InfoQ: You mention that the book is about finding the smartest way to build an Impact Driven Product. Can you detail on that?
Nandakumar: I’ve noticed too often that people are obsessed with following processes to the tee. Or by their technology preferences. So much that they miss the forest for the trees. Technology leaders may sometimes get too caught up in “doing things the way they think it should be done” (which is not necessarily the right way). They seem reluctant to step out of their comfort zones. What happens because of this, is that teams spend considerable time, effort, money and resources building features that are not adding to the product’s impact. This is far from being smart, don’t you think?
When I say we need to find the smartest way to build products, I mean that we need to critically evaluate our implementation decisions in the light of how much impact we can create vs. what it will cost us. For instance, if there is a tool that will get us to 70% of our needs, at 10% of our costs (vs. if we build it in-house), why not buy? Yes, there will be trade-offs in the longer run, but it can help us validate the value proposition quickly. So, if we decide to throw away the feature because it had no takers, then we’ve done it at a really low cost. But if the feature turns out to be a hit, then we can invest in building it further. Pivot or persevere decisions aren’t limited to business models. Small pivots in product strategy must be factored into our plan. Smartness lies in how we let business outcomes and customer impact guide our strategy, and not the other way around.
InfoQ: Focusing on outcomes instead of outputs is quite a common line of thought in the Product Development discipline. What questions do you have in mind when it comes to discovering Key Business Outcomes?
Nandakumar: Customers really don’t care about how hard we worked. They don’t care whether we followed all our processes well. Or even if we followed any processes at all. They don’t care whether we had a consistent velocity every sprint. They don’t want to look at our burn-up/ burn-down charts. All they care about is how well our product meets their needs and aspirations. They’re always evaluating if the money/ time or mind-space they’re investing into our product is worth it. When they determine it’s not worth it, they will drop our product and move on. When we look at it this way, we realize that our operations, processes, and even culture should be channelized only towards creating impact. Don’t follow something because we’ve always done it this way. It goes back to what I said earlier about building the wrong things the right way. If our processes get in the way of delivering impact, we should mercilessly drop them.
The Key Business Outcomes depend on what aspects of growth, sustainability or impact we want to create. Identify metrics that tell us if we’re meeting those outcomes. Ask questions that help us evaluate if our proposed product value is higher than the customer expectations. The questions themselves depend on the specific context of our business and product.
InfoQ: How can they contribute to the success of a Product?
Nandakumar: Key Business Outcomes (KBO) is one of four aspects that influence the success of a product, along with customer value, execution plan and internal & external constraints. KBOs reflect the business intent, and the underlying value systems. They represent the DNA of our business, which influences what trade-offs we’re willing to make. They also tell us what aspects of growth, sustainability or impact we want to pursue. KBOs therefore directly or indirectly define the success metrics of the overall product, and its features.
InfoQ: Regarding tricks to finding the best solution, do you have some recipes to share?
Nandakumar: For this, we need to understand the relationship between technology and the business. Is technology an enabler to business or is technology the business itself? It is important to internalize the difference between these two roles that technology plays in our business. Once we have established that technology is a core differentiator or an enabler, only then can we explore the possible options available to us. Buy off the shelf tools, build in-house, or outsource are possible options. If our feature is an enabler and if our success metrics can be achieved by an off-the-shelf tool, then we should just proceed with finding the optimal tool. But the prerequisite to this is defining what success means to the product. If we’re unclear on what impact we hope to create, or what our hypothesis is even, then it’s difficult to evaluate our options.
InfoQ: What in your opinion is the importance of planning for a successful Product?
Nandakumar: Most of us have our own, fuzzy idea about the product’s success. But rarely do we get specific about what that success means. We end up with a plan that means different things to different people. Even more importantly, we don’t really plan for success. End-to-end product experience depends on how different departments/ functions work well together. Sales, marketing, technology, and customer support must align towards creating a delightful end-to-end experience for the customer. When we don’t share the same idea of success, and when we don’t plan for that success, then it manifests as broken product experiences for the customer.
InfoQ: Minimum Viable Product is often suggested as an approach to start small and fail fast. What are the missing parts that you’ve identified there?
Nandakumar: Minimum Viable Product is the smallest thing that can validate the riskiest proposition, without running out of resources. But, a lot of us forget this intent of the MVP and focus on the terminologies. “Minimum” is a very relative term. But in our heads, we equate it to the smallest thing that we’re capable of building. It may not be market ready. MVP comes with a lot of context. It makes a lot of sense when we are experimenting with a new business model, testing the viability of a product idea / need, or establishing the viability of a technology. Now, if we’re launching a product in a saturated market where there are other players, we cannot afford to build the smallest possible thing and hope for it to succeed. Instead why don’t we try to maximize our chances for success or at least maximize our chances of learning? So, if we flip the MVP connotation to maximum valuable product, what would we build? That’s the basis for what I describe as the Impact Driven Product. At any given point, we should try to build the most that we can (under given constraints) that will help us to learn fast and create the highest impact for both our customers and for our business.
InfoQ: How would you include the end-user feedback to validate that you’re actually building the right product? Are the common end-users prepared to see an imperfect and under-construction product?
Nandakumar: End-users come in all shapes and sizes! Early adopters may be willing to pay for an imperfect product (with defects, bad user experience, feature poor etc.) if it still offers them a great solution to a pressing problem. But, in a market with rich competition, this may not work. Customers switch loyalties too quickly. Also, how we anticipated our customers to use/ value the product may not be how they actually use/ value it. So, if we don’t have our ears to the ground, we’re surely bound to miss the signals from the market. We may continue to invest in features that are more than perfect, but not really increasing the value proposition for our customers. Or we’re losing customers by not paying attention to the features that they value most. Or sometimes it’s pricing or messaging or other related aspects that’s costing us our customer base. How do we fix a problem that we don’t know exists? This is why end user feedback is critical. In my book, I have included a number of ways you can capture qualitative and quantitative end-user feedback. Tracking these against the desired KBOs over time will tell us if we’re building the right product.
InfoQ: Part three of the book is mostly about waste elimination. Can you describe the most typical sources of waste that you’d throw away whenever possible, and replace by other approaches?
Nandakumar: The essential aspect of Lean production is how to avoid waste while ensuring quality. When we apply the same construct to product management, it boils down to how we take product decisions and actions. Are we basing them on data or are we relying on opinions? Do we go with what we know today and commit to learning fast, or do we endlessly wait to gather evidence where there is none? Trying to be perfect with our estimations is another aspect of waste that I address in my book. Process waste happen when we choose perfection, efficiency and throughput over outcomes, collaboration and speed to market.
About the Book Author
 Mangalam Nandakumar has over 17 years of experience in product management and software delivery. She is an entrepreneur and has founded two startups. She has worked at Citigroup, Ocwen Financial Solutions, ThoughtWorks Technologies and RangDe.Org. She brings a vibrant perspective on product management due to her diverse experience having worked with startups, enterprises, non-profits, both in product companies and software consultancy organizations. She has a strong foundation in Agile and Lean methodologies. She has coached teams on their Agile transformation journeys.
Mangalam Nandakumar has over 17 years of experience in product management and software delivery. She is an entrepreneur and has founded two startups. She has worked at Citigroup, Ocwen Financial Solutions, ThoughtWorks Technologies and RangDe.Org. She brings a vibrant perspective on product management due to her diverse experience having worked with startups, enterprises, non-profits, both in product companies and software consultancy organizations. She has a strong foundation in Agile and Lean methodologies. She has coached teams on their Agile transformation journeys.
EnvoyCon 2018 Part One Summary: The Rise of Envoy, xDS APIs, and Square and Alibaba Adoption
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The inaugural EnvoyCon ran in Seattle, USA, alongside the KubeCon and CloudNativeCon events, and explored the past, present and future of the Envoy Proxy. Key takeaways from the first part of the day included: the success of Envoy has been driven by the rapid establishment of a (non commercial) community and the focus on technical qualities such as performance, extensibility and well-defined management APIs; many engineers and organisations are contributing to the open source Envoy code base, including Lyft, Google and Apple; and Square have deployed more than 2000 Envoy instances in production across 120 services, both on-premises and within the public cloud.
Matt Klein, “plumber and loaf balancer” (software engineer) at Lyft and creator of the Envoy Proxy, opened the day by talking about the creation of Envoy. The Lyft team created the proxy as an internal project in 2015 because none of the other proxies available at the time met all of their requirements for backend data store load balancing and service discovery, which was needed as the Lyft team moved from a monolithic application to a service-based system. The project was originally going to be called “Lyft Proxy” until the engineering teams desire for a “cooler” name forced him to look in a thesaurus under “proxy”.
Envoy was released as open source mid-way in 2016, and after rapid adoption by the wider community it became hosted as an “incubating project” by the Cloud Native Computing Foundation (CNCF). Along with Kubernetes, Envoy is the only project to have “graduated” from the CNCF, which indicates the level of maturity, breadth of contributors, and wide-scale adoption. Envoy has arguably become the “universal data plane API” for modern service meshes and edge gateways, with projects like Istio, Ambassador and Gloo providing control planes for this data plane proxy. In addition, although the original Envoy project is written in C++, the Ant Financial team have created SOFAMesh, a Go-based implementation of the Envoy APIs.

Klein shared his view that the success of Envoy is largely “down to the community” and their uptake, contributions and support. He also proposed that there are several other reasons for the rapid industry uptake of Envoy: there is no “premium” (commercial) version; decisions within the project are made upon the basis of “technology first”; and an ecosystem has been built that allows “differentiated success on top” (for example, in the control plane implementations). From a technical perspective, he believes that Envoy provides: performance, reliability, a modern codebase, extensibility, best in class observability, and a well-defined configuration API.
Harvey Tuch, staff software engineer at Google, was next to the stage, and he provided an overview of the contributions to Envoy. The largest contributors in regard to code and pull requests include Lyft, Google, Turbine Labs, Tetrate, Alibaba, IBM, Solo, Datawire, and Apple. Over the past two years the Envoy code base has grown from 20k lines of code to 100k+, but in 2018 the codebase was divided between “core” and “extensions” in order to make this more manageable.
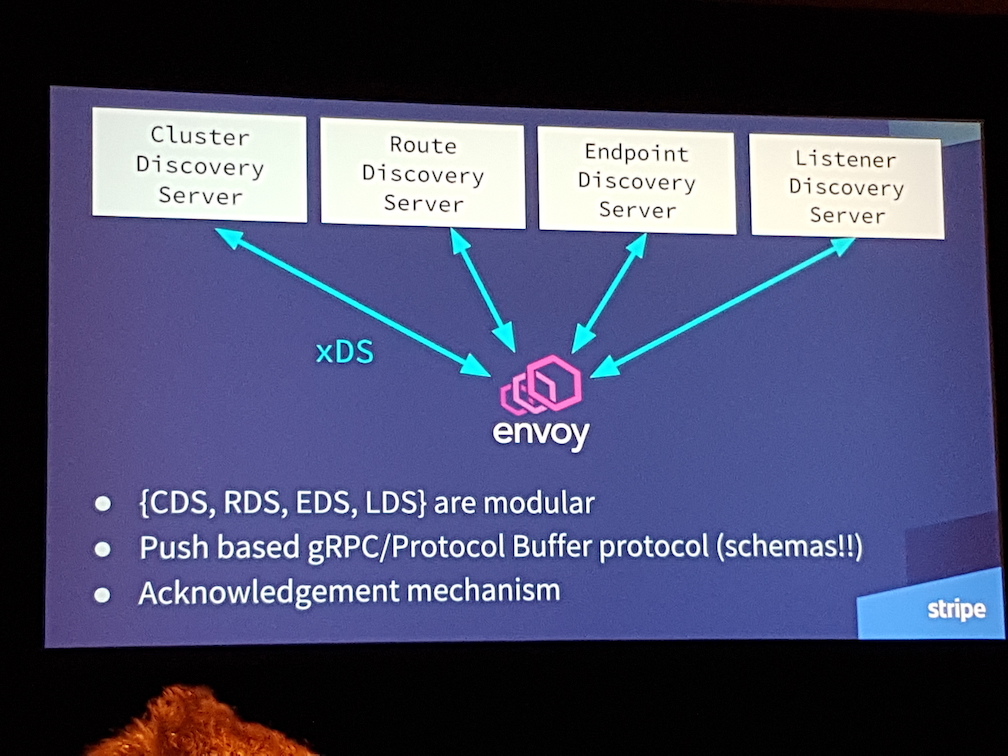
Isaac Diamond, software engineer at Stripe, provided an overview of the Envoy management “xDS” APIs that can be implemented by backend servers. These APIs cover, for example, the cluster discovery service (CDS), route discovery service (RDS), endpoint discovery service (EDS), and listener discovery service (LDS). All of these APIs offer eventual consistency and do not interact with each other. Potentially, many higher-level operations such as performing an A/B deployment of a service require the ordering of operations in order to prevent traffic being dropped, and accordingly the Aggregate Discovery Service (ADS) API is often used. The ADS API allows all other APIs to be marshalled over a single gRPC bidirectional stream from a single management server, which allows for deterministic sequencing of operations.
Next, Michael Puncel and Snow Pettersen, software engineers at Square, provided a tour of Envoy usage at Square. Envoy has been a core part of implementing a bespoke service mesh that is being deployed as the Square engineering team are migrating from a monolithic application to service-based system. The motivations for the migration include the simplification of the client/server libraries, distribution of load balancing responsibilities, and to abstract the infrastructure from application code. Square run their applications primarily on bare metal, with some workloads being run on public cloud. They have a “Kubernetes-like” deployment system, which orchestrates applications running on multi-tenanted hosts with no network namespacing but mutual TLS (mTLS) enforced between all applications.
The Envoy control plane implemented by the Square team was built upon the open source java-control-plane (rather than the often used go-control-plane), and makes extensive use of custom caching for identity access management (IAM) and service discovery.
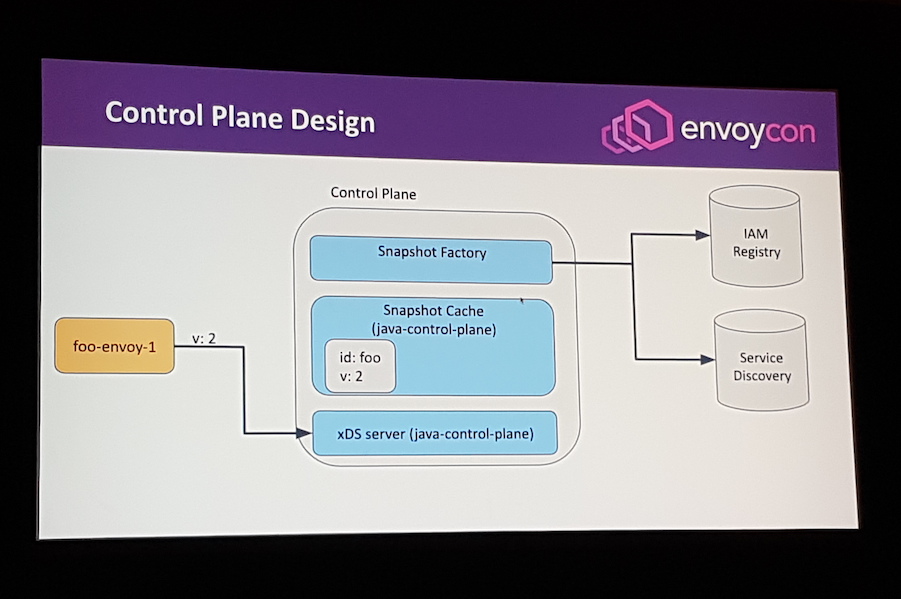
Puncel and Pettersen provided a detailed overview of how their team migrated from a virtual IP (VIP)-powered service discovery and routing solution to an Envoy-powered service mesh. They currently have implemented feature parity with the legacy system, and 2000 Envoy instances are deployed across 120 services, both on-premises and within the public cloud. They cautioned that although they had put a lot of thought and resources into the engineering of the control plane that interacts with Envoy, the “hardest part of rolling out a service mesh is the migration”, which involves communicating the benefits to engineers, providing training, and coordinating the deployment of the mesh.
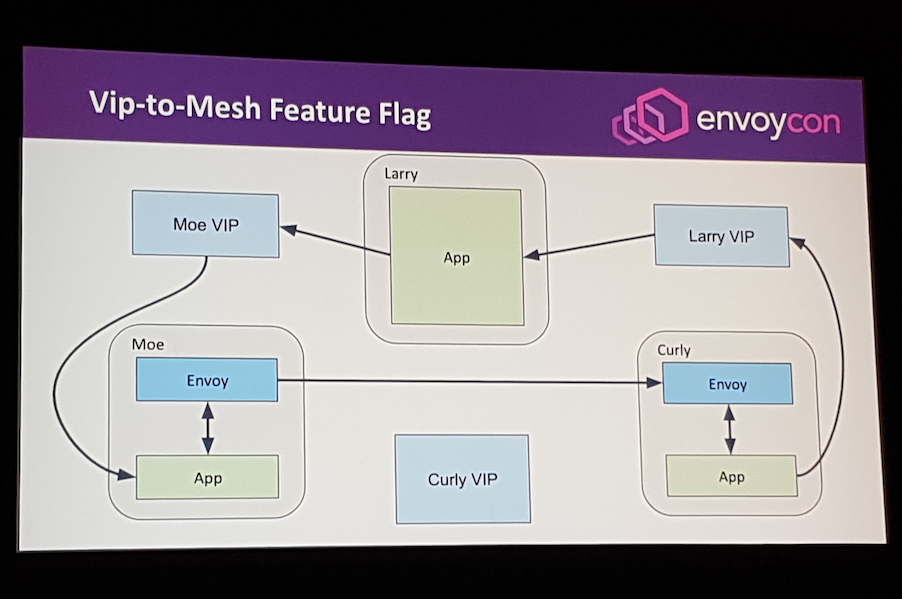
Future plans include finishing the migration to Envoy, migrating to Kubernetes for service orchestration, adding SPIFFE integration for security management, and replacing their current edge/forward proxy.
Andy Shi, developer advocate at Alibaba Group, was next to the stage and discussed how Alibaba are using Envoy to autoscale Java-based RPC microservices. He introduced Apache Dubbo, a Java RPC framework that has been released as open source by Alibaba — which is very popular within China — and RSocket, an application protocol providing reactive stream semantics, and talked about integration work between these technologies and Envoy and the Kubernetes Horizontal Pod Autoscaler. Several filters were created for Envoy that allowed for custom metrics from both Dubbo and RSocket to captured and sent to Prometheus, which in turn were used to drive autoscaling decisions, based on user traffic patterns and service interaction. Work is ongoing in this space, and Shi encouraged developers to prioritise observability in order to support operational understanding and automation of tasks such as autoscaling.
Slide decks of talks can be found on the EnvoyCon Sched page, and the recording of many of the presentations can be found on the CNCF YouTube channel.