Month: March 2019

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Kenthapadi: Thank you all for coming on the last day of the main conference. I’m going to start with a few stories. Let’s go back almost two decades. This was when the insurance commission at Massachusetts had decided to make the anonymous medical records available for various research purposes. Back then, there was a grad student at MIT named Latonya Sweeney. So what she did was she got hold of the voter roll at Cambridge for about $20 and joined the two data sets, the anonymized health records and the voter roll, not on attributes that we would expect, not on attributes like name or Social Security Number because these are now present in the anonymous data, but on attributes such as zip code, date of birth, and gender. With this, she was able to identify the health records of the Governor of Massachusetts.
It turns out that this was not an isolated incident. Later research has shown that around two-thirds of people in the United States are uniquely identifiable based on a combination of these attributes, specifically like zip code, date of birth, and gender. So this kind of illustrates that when we make any data available, we have to not only think in terms of what is there and that data set, but also think in terms of, what other external information someone might make use of to join with the data set?
Let’s go forward nearly 10 years. Then came the Netflix challenge. Many of you might remember this. This was in 2006 when Netflix decided to make available the anonymized movie ratings of around 500,000 Netflix users. So this is about 10% of their users. This data set had about 200 ratings per user. This was great. It was very well-intentioned. It was to see if we can improve the algorithms for predicting what movies might users like. But what happened was there were two researchers from the University of Texas who joined the Netflix Prize challenge data set with the public data set from IMDB. These are like publicly rated movies on IMDB. By joining these two data sets, they were able to associate identity with some of the anonymized movie ratings.
This, again, worked in a similar fashion. On the left side, we have the anonymized Netflix data. On the right side, we have the public but incomplete IMDB data. The difference is that in the public data sets if you take Alice, she’s likely to acknowledge watching movies that she’s comfortable saying in public. But in the Netflix data, she might have also rated some movies that might have been sensitive or she may not want others to know about it. The intention of the join was that if you think of all possible movies, it’s intrinsically high dimensional. So the movie records of each person, especially when combined with the ratings, becomes almost like a signature for a person. So that was the information which was a used for this attack.
As a result of the attack, the researchers were able to associate identity with many of the records. Just to give an example. If, say, there’s a hypothetical user who we know has watched these movies, it can reveal a lot about the political, religious, or other social beliefs. So I hope, from these two examples, I have convinced you that it’s very important to think of privacy, and it is important to think of ways in which the attackers might use the data in ways that you may not have imagined when you reveal the data set initially.
Let’s go forward another decade. This is a roughly about a year back. This is a very interesting work called Gender Shades. This is by two researchers who wanted to see how good is face recognition software for different groups of populations. Specifically, they wanted to understand whether the accuracy of face recognition is the same for men and women, or is it the same across the skin tone? What they observed was that the commercially available face recognition software had higher accuracy for men and higher accuracy for light-skinned individuals. In particular, when we take the combination, they observed a significant difference in accuracy between light-skinned men and dark-skinned women.
For example, they observed that the error rates for dark-skinned women were as much as 20% to 34%. So this, again, highlights that it’s not enough for us as maybe Machine Learning practitioners and data-driven system builders to just develop models, but also think of how accurate these models are for different populations.
Algorithmic Bias
If you take this message broadly, there have been lots of studies showing that when it comes to Machine Learning and the AI systems there, there are a lot of ethical challenges. This is partly because we know that there are inherent biases in different parts of society, and these biases can get reflected in the training data. So more often than not, many models are trained on training data, which is derived from human judgments. Either these can be explicit human judgments, or these can be implicit human judgments in the follow up for user feedback. The reality is that there are a lot of biases when it comes to such human judgments.
One of the challenges with the AI and Machine Learning models is that they might reflect these biases in the models and sometimes can even potentially amplify such biases. So there is so much work and awareness around these issues of late that there are even popular books written on this topic. I would encourage all of you to take a look at some of these books, like “Weapons of Math Destruction,” which go into such challenges across almost all applications that we can think of.
So if there is one message that I would love you to take out of this talk, is that we should think of privacy, or transparency, or fairness by design when we build products. Instead of leaving them as afterthought, we should think of them upfront when we design AI and Machine Learning models. For the rest of the talk, I’m going to give you a very brief overview of what we do at LinkedIn and then describe a few case studies that highlight how we are approaching privacy and fairness at LinkedIn.
AI at LinkedIn
As many of you might know, our LinkedIn has the vision of creating economic opportunities for every member of the global workforce. Our mission is more about, how do we connect the world’s professionals to make them more productive and successful? Towards this mission as well as vision, we have built what we call the Economic Graph. This is a graph which contains over half a billion LinkedIn members, around 26 million companies, 15 million jobs, 50,000 skills, and so forth, and all the connections and the relationships between these different entities.
It so happens that if you look at almost all applications on LinkedIn, the Machine Learning or AI is one of the key underpinnings, because the power of LinkedIn or even the essence of all the applications is that they’re data-driven and no wonder that we are heavy users of AI within LinkedIn. For example, we have several petabytes of data which are being processed either offline or near line every day. If you look at all the different Machine Learning models, we have several billions of parameters which need to be learned periodically from the data. At any point in time, we have about 200 A/B Machine Learning experiments happening every week, and so forth.
Given what the message I was trying to convey earlier and given the scale at which we operate, it is natural that we need to take dimensions like privacy and fairness seriously. In fact, my role at LinkedIn is to lead our efforts for fairness, privacy, and related aspects of transparency, explainability across all our products. I’m going to describe two of the case studies with respect to privacy.
Analytics & Reporting Products at LinkedIn
The first one is around how we address privacy when it comes to analytics at LinkedIn. The second one is about privacy in the context of a large crowdsourced platform that we built called LinkedIn Salary. So let’s start with the first one. So, this is the analytics platform at LinkedIn. It so happens that whenever there is a product that we have at LinkedIn, there is usually an associated analytics dimension. For example, to LinkedIn’s members, we provide analytics on the profile views. Similarly, when they post some content, articles or posts on LinkedIn, we provide analytics in terms of who viewed that content and how the demographic distribution of the viewers is in terms of titles, companies, and so forth. Similarly, when advertisers advertise on LinkedIn, we provide them analytics on who are the LinkedIn members who viewed these ads, or clicked on the ads, and so forth.
Given this and for all of this, the analytics provides demographics of the members that engage with the product. One of the nice or interesting aspects of analytics applications is that unlike arbitrary queries, unlike our usual, say, database or a sequel applications for the kinds of analytics applications I described, they admit queries of very specific type. Quite often, this involves querying for the number of member actions for some settings such as ads and for a specified time period, and also along with the demographic breakdowns in terms of titles, companies, company sizes, industries, and so forth.
So we can kind of abstract these types of queries in the following template. We want to select the number of, say, actions from your table which contains some statistics type and some entity for a given time range and for certain choices of the demographic attributes. For example, we can think of the table as corresponding to the clicks on a given ad. The attribute value could be that we want all the senior directors who clicked on this ad.
You might wonder, this is all being provided in aggregate, what are the privacy concerns? It happens that we want to ensure that an attacker cannot infer whether a member performed some action from this reported analytics. So, for example, due to various regulations and our member-first policy, we don’t want an advertiser to know which members clicked on an ad. We don’t want for anyone to figure out which member clicked on an article.
And for this, we assume that the attackers might have a lot of auxiliary knowledge. For instance, they can have knowledge of various attributes associated with the target member. This can be obtained from the public LinkedIn profile. We can know the title of the member, or which schools they went to, which companies they worked at, and so forth. We also make a strong assumption that the attacker might also know about others who perform similar actions. This can be achieved in several ways. One way might be that the attacker might create a small number of fake accounts, and the fake accounts might resemble the target member, and the attacker has control over how the fake accounts respond to, say, the ads.
Possible Privacy Attacks
Let me give you an example of potential privacy attacks in this setting. Let’s say that an advertiser wants to or target all the senior directors in the U.S. who happened to have studied at Cornell. This criteria in itself matches several thousands of LinkedIn members, and hence, it will be over any minimum targeting thresholds that we have. But the moment we consider the demographic break down by, say, company, such as we are looking at all the members who meet this criteria but who are from a given company, this constraint may end up matching just one person.
Even though we targeted all the senior directors in the U.S. who went to Cornell, the moment we consider any one company, the number of such people might be just one. And now by revealing the statistics at the company level, it’s possible for us to know whether that person clicked on the ad or not. So our initial thought was, what if we require, say, minimum reporting thresholds such as we don’t report unless maybe at least a 15 people clicked on the ad for any dimension, right?
But then the problem is that, as I mentioned before, the attacker can create fake profiles. By observing, let’s say, if this threshold is 10, the attacker can create 9 fake profiles. And if we reveal the statistics, then the attacker can know that this real member indeed clicked on the ad. This assumes that the attacker creates 9 fake profiles and has all those fake profiles clicked on the ad. In principle, this approach can hold even if the threshold is much larger, just that it makes attacks of this kind harder to execute.
Similarly, if you think of other mechanisms such as maybe round and report in increments of 10 and so forth, so even those don’t work. We can easily construct Cornell cases as well by observing the reporter’s statistics. Well, over time, the attacker can maybe be able to figure out who clicked on that. So all this suggests that we need rigorous techniques to preserve member privacy. As part of these techniques, we may not want to reveal the exact accounts.
Key Product Desiderata
This is as far as the privacy concerned. At the same time, we should remember that the very goal of this product is to provide sufficient utility and coverage from the product perspective. So, of course, we could have achieved privacy by not showing any statistics, but that’s not going to help with the analytics product. So we want to provide as many analytics combinations as possible for as many demographic combinations and as many different types of actions as possible.
So that’s one of the requirements from the product perspective. We also have requirements along the consistency of what we show. Say, if we’re computing the true count and reporting the true counts, we don’t have to worry about this. Because if, let’s say, the same query is repeated over time, we know that we will get the same answer because we’re asking, what is the number of clicks on this ad for the month of September? So that’s not going to change, whether I issue the query now or in future.
But the moment we decide not to reveal the true answer and maybe potentially obfuscate or add noise, these kind of requirements may not hold anymore. Similarly, there are several other types of consistency that we might want, so I won’t be going into each of this in the interest of time. To summarize, we can think of the problem as, how do we compute robust and reliable analytics in a manner that preserves member privacy and at the same time provides sufficient coverage, utility, and consistency for the product?
Differential Privacy
Here is where I’m going to take a segue into this notion called differential privacy. This is a notion that has been developed over roughly the last 10 to 15 years. Here, the model is that, let’s say, there is a database shown on the left side in red. On the right side is an analyst who is interested in issuing some queries and learning the answers to those queries. In between the database and the analyst is a curator who decides how to respond to the questions of the analyst.
Let’s, as a thought experiment, consider two worlds. One world is original data. The other world is the same as the original data, but it does not contain, say, one person’s data. Let’s say that the blue world here contains my data, and the red world does not contain my data. Everything else is the same. Yes. If we can’t guarantee that from what we give to the analyst, the analyst cannot determine which of the two worlds we are in, that gives a very strong intuitive guarantee on my privacy. This means that irrespective of which world we are from, we are using in reality that the analysts or the attacker cannot determine which of the two was used. This, in particular, means that the attacker gains very little information about my private data, and this gives us, intuitively, a strong guarantee on my privacy.
In terms of if there is a way to formalize this, so this is called differential privacy. It intuitively requires that if you take two databases which just differ in one individual or one record, the distribution of the curator’s output should be about the same with respect to both. I’m not going to go into the mathematical definition, but you can kind of think of this as a definition with some parameter. There’s a parameter, epsilon, here which kind of quantifies the information leakage. The smaller the epsilon, the better it is for the purposes of privacy.
This might all sound abstract because I’m talking about this thought experiment, which does not exist in reality. In reality, either my data is there in the database or it’s not there in the database. But, again, remember that this is just for the purpose of understanding this definition. In practice, this definition can be achieved by adding a small amount of random noise. Formally, you can add noise from what is known as the Laplace distribution, such that the more sensitive the query is, the more noise you add. By sensitivity, we mean the extent to which the function changes if one person’s record is added or removed from the data set.
Intuitively, if you think of, say, something like counting, we know that if you remove just one person, the accounts are going to maybe change at most by one. It has very low sensitivity. Whereas some other queries, such as if you think of all people’s salaries, the sensitivity might be quite large, because if one person earns a disproportionately large amount, that can affect the output of the function.
Again, the takeaway here is that there are ways to instantiate this definition in practice. Over years these techniques have been developed more and more, and they have evolved from being in the research domain to being in practice. In fact, it so happens that all of us, in some way or other, have used differential privacy. Differential privacy today is deployed as part of Google’s Chrome browser. It’s deployed as part of iVoice from apple. It’s deployed as part of ad analytics at LinkedIn. We all have used techniques or differential privacy without perhaps knowing that this is being applied.
PriPeARL: a Framework for Privacy-Preserving Analytics
Going back to our setting, so the way we make use of differential privacy is as follows. First, as I said earlier, we want consistency. In particular, if the same query is issued again and again, we want to ensure that the results don’t change. The way we do this by creating a pseudo-random noise. We don’t generate noise at every instance when the query is asked. Instead, we determine this noise based on the query parameters. Specifically, we take all the parameters of the query, which are shown on the left side, then we compute cryptographic hash based on these parameters, and then normalize that into, say, a zero-one range and then map that to the suitable distribution.
This way, in this manner, we can show that we can generate the noise which looks random, but it’s determined in a manner which is kind of deterministic. Then we compare the true count for the analytics and add this random-looking noise. The noisy count that results is what we reveal then to advertisers. So as I mentioned just now, this satisfies the property that if you repeat the same query, you’re going to get the same result. It’s good for consistency. It’s also good from the perspective that you cannot perform an averaging attack. You cannot keep issuing the same query again and again, and maybe average out the noise and that way get a good sense of what is the true answer.
There are also various other types of consistency that we have to handle, such as consistency for top queries, or consistency across time ranges, and so forth. I will refer you to our paper for more details, or I will be happy to talk offline after the talk. This is implemented as part of our analytics pipeline. Here, in this architecture, the ports to the left are what we can think of as offline or nearline components. Based on the various tracking events such as the impressions, clicks, and so forth, these are directed to an offline analytics computation pipeline, which operates on, say, a daily basis, as well as an online or nearline analytics for getting the analytics in the last few hours. And output of these are fed to Pinot, which is our scalable online analytics platform.
To the right side is what happens online. Let’s say that either through our analytics web interface or through the associated APIs, we get a query for, say, the statistics about some ad campaign. As part of this query, we go and retrieve the true answer from this Pinot store. At the same time, we also compute this noise in the manner that I described earlier. Then the privacy mechanism takes both of these into account and applies various consistency checks and then returns the noisy count back to the advertiser. In this manner, we ensure that member privacy is preserved. And at the same time, we can have balance between various conflicting requirements such as coverage and a consistency of the data.
Lessons Learned from Deployment
This has been deployed within LinkedIn for more than one year. There are a lot of the lessons we learned during this process. For example, we learned about the need for balancing semantic consistency versus just adding maybe unbiased and unbounded noise. For example, let’s say, if you draw noise from such a distribution, the noise can be sometimes positive, and sometimes it can be negative. Let’s say the true count is maybe five clicks. And if our noise happens to be, say, negative seven, we don’t want to report, five plus negative seven, negative two, as the answer. That doesn’t look intuitive, and people might think that there is a bug in the system. So we had to balance between adding such unbiased noise, versus ensuring that it looks consistent and meaningful from the product perspective.
Similarly, there are a few other lessons we learned such as, even though for the purposes of privacy it’s enough for us to reveal such noisy counts. We still suppressed when these counts were very small. Because of the fact that we’re adding noise, the small counts may not be meaningful anymore. In fact, in the very first place, we don’t want anyone to make inferences based on a very small number of clicks. Those are not statistically meaningful. In particular, once we add such noise, we would like to not show such small counts. So this is something we added to the product.
The final most important lesson for us was that in the process of scaling this to various applications, we had to make not only the tools available, we had to kind of abstract out the relevant components, realize that these are not just specific to, say, other analytics, but applicable across various other analytics applications as well. We not only built those tools, but also built, as I stated, tutorials, how-to tutorials, and so forth. That helps for increasing the chances of adoption of such tools. So that’s something that I think most of you can resonate with. If you’re building something which is initially built for one vertical application, but then you realize that it’s horizontally applicable, then it’s important to not only have the tools, but also have sufficient documentation and convince and talk about why this is important, and make the tools easier for our options so that we can then scale for various applications.
In summary, in this framework, we address various challenges such as privacy of users, product coverage, data consistency, and so forth. There are a lot of interesting challenges here such as, instead of adding the same amount of noise for, say, impressions and clicks, can we trade off in a certain manner? Can we think of this as an optimization? Maybe we might want to add more noise, say, to impressions, and less noise to clicks. So there a lot of interesting challenges that we can think of in this setting. Let me acknowledge that this is a joint effort with lots of different people from several different teams.
Let me give a quick flavor of the second application, which is the tool, LinkedIn Salary. This is a tool where we provide insights on how the salary is distributed for different occupations and regions. For example, from this product, we can learn about the salaries for, say, user experience designers in the Bay Area, and we provide the median salary, the 10th and 90th percentiles, and the various different types of compensation, the distribution in terms of the histogram from what we have obtained, how the salary varies by title, by region, and so forth. This is all based on a massive crowdsourcing that we have been performing by collecting salaries from LinkedIn members with their consent.
This is how we collected salary from LinkedIn members. For example, Charlotte here has the option to provide her base salary as well as her various types of compensation. And once a member submits their salary, and once we have enough data, we get back to the members with the insights for their corresponding professions. Today, this product has been launched in several countries, and it makes use of salary data points obtained from several millions of LinkedIn members.
Data Privacy Challenges
What I want to highlight today, though, is that there are a lot of privacy challenges when it comes to how we designed this product. Salary is one of the most sensitive attributes that we have on the LinkedIn platform, and we had two related goals when designing this product. We wanted to minimize the risk of inferring any one individual’s compensation from this aggregated insights. The second related goal was we wanted to protect against worst-case scenarios, such as a data breach. We wanted to ensure that there’s no single point of failure in our system.
These were achieved by a combination of several different techniques such as encryption, access control, de-identification, aggregation, and so forth. I would refer you to take a look at this paper and associated talk slides for more details. But let me just give you an example to illustrate how this is done at a very high level. Let’s say that Charlotte provided her salary as a user experience designer at Google, and then we associate the key relevant attributes of the member along with the salary that Charlotte has provided. For example, this might include her title, region, company, years of experience and so forth, along with the salary, which is, let’s say, 100K. Then we form cohorts from this original data. So these cohorts can be thought of as, say, salaries for all user experience designers in San Francisco Bay Area. This can also be by, say, UX designers who are in the internet industry or UX designers who work at Google in Bay Area with some years of experience and so forth.
At first, it might seem that it’s enough to do this and make this data available for our offline analysis but turns out that, in this example, this may not be the case. But if you take, say, the queries such as [inaudible 00:35:28] at Slack, we know that at any point, there is just one person who is civil at the company. And from such de-identified data, we might still be able to infer that person’s identity and their salary.
So because of that, we required that there needs to be at least a minimum number of data points from each cohort before that data is even available to us as Machine Learning researchers to process offline. This is the data that we use to perform the modeling and compute the statistical insights, which are then displayed back in the product. Again, there is a very detailed architecture and system design that involves different encryptions, decryptions ensuring that there is no single point of failure, and so forth. Again, in the interest of time, I’m not going to discuss the specifics.
Fairness in AI at LinkedIn
Let me just jump to the last part of the talk, which is about, how do we look at fairness in Machine Learning systems? As far as this is concerned, our guiding principle has been what we call “Diversity by Design.” By this, we mean that we are not creating, say, a separate product for diversity, but we are integrating diversity as part of our existing products. In fact, you might ask, “Why diversity?” A lot of research has shown that diversity is tied with the culture of a company, as well as financial performance. In LinkedIn’s own studies, we have found that around 80% of the LinkedIn customers want diversity for improving the company culture, and around 60% think that it’s correlated with the financial performance. There are also studies in Academia as well as by [inaudible 00:37:37] which show this correlation within diversity and financial performance.
If you look at LinkedIn, the notion of diversity happens in various settings. For example, if you look at the talent products that we have at LinkedIn, there are several different ways in which people might use these products. So we have integrated diversity as part of three stages. The first is planning. This is when a company wants to decide which are the skills that they want to look for, which are the regions where people with those skills are present? How does diversity appear across the industry? How does diversity appear at the current company in different disciplines? And so forth. So this is the planning stage. The second stage is when it comes to the actual hiring and sourcing of candidates. And the third one is, once we have employees, how do we ensure that we train avoiding bias, and unconscious bias, and so forth.
LinkedIn recently announced products across all three stages of this talent pipeline. I’m going to mostly focus on the second part, but let me just give you a feel for what we mean by the first part. This is the planning stage, and LinkedIn has a product recently launched called LinkedIn Talent Insights. With this product, we can not only know the skill distribution for our different regions or for different professions and so forth, but we have integrated diversity insights as part of this. Specifically, the LinkedIn customers can understand, what is the gender representation of their workforce, and how does that compare with the peer companies in the industry? Which are the sub-teams that have the biggest room for improvement? These insights can help your company to set realistic goals with respect to diversity, and also decide how they want to prioritize various diversity efforts.
Let’s say that, through this tool, your company has determined that, for certain skills or certain titles, this is the available diversity in terms of the talent supply pool. Then the natural next question is, how can the recruiters or hiring managers at the company reach out to this talent? That is where our LinkedIn Recruiter tool comes in. This is a tool which allows a recruiter to search for different skills, titles, locations, and so forth, and they get to see a list of candidates who are good matches for the search query. Our goal is to maximize the mutual interest between the recruiter and the candidate.
What we have done here is we have ensured that these results are representative of the underline talent pool. By this, we mean that, let’s say, for this query such as the UX designers, or product designers, interaction designers, let’s say that the underlying talent pool is about 40% women and 60% men. What we are ensuring is that, even in our top results, the top page of results, we are reflecting the distribution that is present in the underlying talent pool. You might ask, “What is the intuition for such representativeness?” The intuition is that ideally, we would like similar distribution for, say, gender, or age, or other attributes for both the top line results, as well as all the candidates that qualify for that search request.
This, in particular, means that we would like to have the same proportion of members with any given attribute value across both these sets. This is grounded in a notion called equal opportunity. There are very interesting papers, both from computer science, as well as from the law profession, and so forth, around this notion. This is our underlying intuition, and how do we convert this intuition into an algorithm?
This is done in two steps. First, as part of our algorithm, which re-ranks the results to ensure representativeness, we first determine, what is their desired proportion with respect to an attribute of interests, such as gender for a given search request? That’s the first part. The second part is, how do we compute your Fairness-aware ranking of a given size?
Let’s go into the first part. The first part is based on this intuition that I mentioned earlier. So for a given search request, we retrieve all the members that meet that criteria. We call that as the set of members that qualify for the search request. Then from these members, we determined the distribution with respect to the attribute of interest, in this case, the distribution with respect to gender. So that’s how we get the desired proportions for the attribute of interest. Let me just remark that there may be other ways of getting such desired distributions. For example, this can be obtained based on certain legal mandates or even voluntary commitments of companies and so forth.
Once we have the desired distribution, the algorithm works as follows. We first get the set of potential candidates that match the query and then partition them into different buckets. For example, in the case of gender, we partition them into the bucket for whom the gender has been inferred as male, the female, and the cases where we were not able to infer the gender. And then within each bucket, we rank the candidates based on the score from the underlying Machine Learning model. Then we aggregate or merge this rank lists where we ensure the representativeness requirements.
When we perform the merging, we ensure that the candidates, at any position, whether it’s top 10 or top 25, top 50, and so forth, the distribution of candidates represents the distribution in the underlying talent pool. At the same time, it takes into account as much as possible ensuring that the highest scored candidates are selected. There is a detailed architecture in the design, how we achieve this as part of our recruiters’ search pipeline. Again, in the interest of time, I’m going to skip this and defer you to the engineering blog post that we published a few weeks back.
As a result of this, therefore, we ensure that over 95% of all searches on LinkedIn Recruiter are representative of the underlying talent pool. We also then perform the A/B Tests to see whether there is any impact on various business metrics. The interesting aspect is that we were able to achieve this representativeness without any impact on the business metrics. We observed no significant change in the business metrics, such as whether candidates are responding to messages or emails from the recruiters. Now, this approach has been ramped to all users of LinkedIn Recruiter tool worldwide.
Reflections
Let me just conclude the talk with the two takeaways. The first takeaway, as I mentioned earlier, is that we need to think of the privacy and fairness from the beginning. We need to think of them as part of our design, rather than thinking of them as an afterthought. I’m hoping that from the few case studies that I described, I have conveyed a sense of the challenges associated with ensuring this.
In particular, one of the challenges is that privacy or fairness are not just technical problems. These are not problems that, say, software engineers or computer scientists can go and determine. These are problems which have a socio-technical dimension, which means that we have to collaborate and reach consensus with all the stakeholders. This includes the product teams, the legal teams, the PR engineering, the AI teams, as well as, in our instance, even reaching out to LinkedIn members and customers, and building the consensus from all the stakeholders. That is very, very important when we consider dimensions like fairness, transparency, and privacy. With that, let me conclude. Here are some references that have more details on this topic.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Recently open-sourced by Cloudfare, Wrangler is a set of CLI tools to build, preview, and publish Cloudfare Workers written in Rust and compiled to WebAssembly.
Wrangler aims to provide an end-to-end experience for developers to be able to write their serverless functions in Rust and deploy and run them on Cloudfare Workers after translating them into WebAssembly. The WebAssembly compilation step is hidden behind Wrangler CLI.
To experiment with Wrangler, you can install it using cargo executing cargo install wrangler. The general structure of a project generated by Wrangler includes a src directory where Rust code is stored, a worker directory containing a worker.js from where Rust-generated code can be pulled in, and a couple of metadata files. Wrangler has three main commands: build, preview, and publish. The build command will compile all Rust code to WebAssembly, while the preview command will allow you to run your function on Cloudfare infrastructure. At the moment, though, it is not possible to preview a function locally, but, at least, previewing a function on Cloudfare infrastructure does not require a Cloudfare account.
Your Rust code is written as usual: you can bring in any external dependencies specifying it in you Cargo.toml file ans you use wasm_bindgen to improve the communication between wasm and JS by enabling the use of strings, objects, classes and so on. For example, you could have this simple Rust file:
use wasm_bindgen::prelude::*;
extern "C" {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet(name: &str) -> String{
&format!("Hello, {}!", name);
}
This code can be imported and executed in the worker.js file using the following syntax:
const { greet } = wasm_bindgen;
await wasm_bindgen(wasm)
const output = greet('Worker')
Cloudfare plans to add more commands to Wrangler, including support for linting, testing, benchmarking, and size profiling.
Cloudfare Workers are serverless functions written in JavaScript that can be run in any of Cloudfare’s edge locations that are scattered across the world. According to Cloudfare, thanks to the proximity of their edge locations to end users, Workers improve performance by reducing network latency. Cloudfare Workers use the V8 JavaScript engine to run your code, but they do not use Node.js, instead relying on their own implementation of a number of APIs to improve efficiency and safety.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Introduction to topic model:
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body.
In topic modeling, a topic is defined by a cluster of words with each word in the cluster having a probability of occurrence for the given topic, and different topics have their respective clusters of words along with corresponding probabilities. Different topics may share some words and a document can have more than one topic associated with it.
Overall, we can say topic modeling is an unsupervised machine learning way to organize text (or image or DNA, etc.) information such that related pieces of text can be identified.
Architecture of topics :
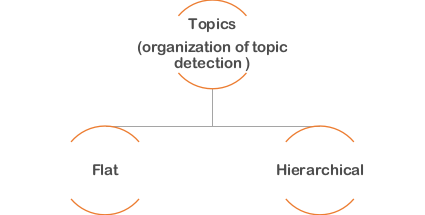
Figure1. Architecture of topics
Figure 1. Shows the organization of topics. Topics comes in two forms, a flat and a hierarchical. In the other word, there are two methods for topic detection (topic model) a flat and a hierarchical.
The flat topic models means, these topic models and their extensions can only find topics in a flat structure, but fail to discover the hierarchical relationship among topics. Such a drawback can limit the application of topic models since many applications need and have inherent hierarchical topic structures, such as the categories hierarchy in Web pages , aspects hierarchy in reviews and research topics hierarchy in academia community . In a topic hierarchy, the topics near the root have more general semantics, and the topics close to leaves have more specific semantics.
Topic model approach:
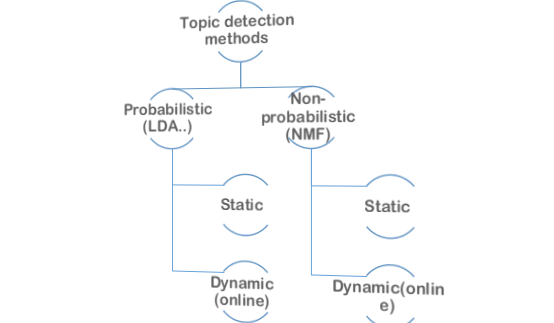
figure 2 topic modeling approach
A popular topic modeling approaches are illustrated in figure 2.
These approaches could be divided into two categories, i.e., probabilistic methods and non-probabilistic methods. Probabilistic methods usually model topics as latent factors, and assume that the joint probability of the words and the documents could be described by the mixture of the conditional probabilities over the latent factors i.e., LDA and HDP. On the contrary, non-probabilistic methods usually use NMF and dictionary learning to uncover the low-rank structures using matrix factorization.NMF methods extends matrix factorization based methods to find the topics in the text stream. All the above mentioned methods are static topic detection methods and cannot handle the topic evolving process in the temporal dimension. Thus, various extensions of these methods have been proposed to handle this issue.
Reference:
Xu, Y., Yin, J., Huang, J., & Yin, Y. (2018). Hierarchical topic modeling with automatic knowledge mining. Expert Systems with Applications, 103, 106-117.
Chen, J., Zhu, J., Lu, J., & Liu, S. (2018). Scalable training of hierarchical topic models. Proceedings of the VLDB Endowment, 11(7), 826-839.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Monday newsletter published by Data Science Central. Previous editions can be found here. The contribution flagged with a + is our selection for the picture of the week. To subscribe, follow this link.
Featured Resources and Technical Contributions
- A Healthcare Problem in Need of a Data Analytics Solution
- Kafka Monitoring with Prometheus, Telegraf, and Grafana
- The significance of Interaction Plots in Statistics
- Choosing from Popular Python Web Frameworks
- How do I learn AI using Python?
- Ensemble Methods in One Picture +
- Advanced cross-validation tips for time series
- SVMs in One Picture
- News: Data Science Competition with $1 Million in Prizes
- All About Using Jupyter Notebooks and Google Colab
Featured Articles and Forum Questions
- Educating for AI – one of the most critical problems in AI
- Using the Digital Transformation Journey Workbook to Deliver “Smart” Spaces
- News: Microsoft Joins $250 Million Funding in DataBricks
- Now that We’ve Got AI What do We do with It?
- The importance of Alternative Data in Credit Risk Management
- Best Practices for Implementing ML in an Organization
- IoT – Transforms the world to Smart Planet with Smart Machines
- Data Science: What to Expect in 2019
- How TensorFlow is helping in maintaining Road Safety
- Why Is It Time for Your Company to Invest in Cloud ERP?
- Using anomaly detection to detect and fix price errors
Picture of the Week
View full diagram in article marked with a +
To make sure you keep getting these emails, please add mail@newsletter.datasciencecentral.com to your address book or whitelist us. To subscribe, click here. Follow us: Twitter | Facebook.
Hire a Data Scientist | Search DSC | Find a Job | Post a Blog | Ask a Question
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Maude: My name is Jason Maude and I am a senior engineer at Starling Bank. What I want to talk to you about today is Starling’s Bank’s journey, how we built Starling Bank, and the architecture behind it. I particularly want to address a point that was raised in the very first keynote of this conference. The idea that this trade off between reliability on the one hand, and speed of delivery on the other, is a false dichotomy. It’s a false choice. The top companies, the top players in this game are not making that choice, they are going for both. They’re trying to improve both their reliability and their speed of delivery. I only want to talk through how you can do that, what sort of architecture you can implement in order to achieve that goal. I also want to explain why we chose Java at Starling Bank as our language of choice to do this, and why that decision helped us implement this architecture that we wanted.
The Problem with Banking
So first up, I’m going to talk about banking. What is the problem with banking? Banking IT has proven itself somewhat resistant to changes in the software industry. Does anybody work in banking here or financial services? Is that fair to say, do you think? Yes, it’s slightly slower, slightly more conservative? This is a quote from Mark Zuckerberg, and it was for a time the unofficial motto of Facebook, before they changed it to something much less catchy. The idea behind it was not, “Let’s introduce bugs. Let’s have as many bugs as possible.” The idea behind it was that sometimes you have to develop and ship code fast. All the time you have to develop and ship code fast. The reason behind that is that you want to learn, you want to learn quickly.
Sometimes learning is achieved through failure and that failure means that you have to cope with bugs, bugs get introduced. So you break things. You learn through that. And that learning helps you deliver better software. It allows you to deliver software that your customers really want. This sort of epitomizes the culture we’re moving towards, or have moved towards. This sort of fail fast, learn stuff, continuous delivery culture. Brilliant. So, why don’t banking and financial services, why don’t they fully embrace that culture?
Here’s a quote from Harry Potter, and Gringotts is the bank in Harry Potter. This quote epitomizes the essence, the core of banking. Banking is about trust. If I go and put my money in the bank, I want to know that it’s going to be there. I want to know that it’s not going to be stolen by any child wizards, and I want to know that I can reliably go and get that money when I need to and take it out. I need to be able to reliably know that I can make a payment and that payment will go out to the other bank that I want to send the money to, and that payment will happen once, it won’t happen twice. I won’t drain my account by sending out all my money, and I won’t not send out the payment and then get charged late fees or have people shouting at me down the phone because I haven’t paid them.
Reliability and security and overall trust are big things in banking. This leads to a conservative culture. People don’t really want to change in case they break something, in case one of these payments doesn’t go out, in case they lose their trust and people withdraw their money and then the bank collapses. This conservatism leaks into the software engineering practices that many banks have. It means that for them, continuous delivery means once every three months and even then, “Whoa, slow down cowboy. You’re being a bit faster.” So this inherent conservatism, this inherent, “Let’s make sure that we release slowly, let’s make sure we don’t break anything,” that is often the experience of many people working with software, with banks or other financial institutions.
But at least it means that banks never suffer IT problems. I was worried that one was going to be a bit too dry, so I’m glad that you caught onto that. Let’s delve into one of the biggest problems that a bank has ever seen. This is a tale of banking woe from the United Kingdom. So it’s the 18th of July and a group of engineers are preparing to release an update to a batch job scheduler. This is a thing that takes jobs and schedules them. It says, “Right, now run this one, run this one, run this one.”
They prepared the release, they’ve tested the code, they’ve got all the sign off from 20 different layers of management, they’ve got their backup plan in place, and they release the code and they monitor it. They’re following good practices here, they’re not just trusting that everything will go right. They’ve released the code, they’re monitoring the code. They monitor it. It’s not going so well or it’s a bit too slow, there are too many failures. The error rate is slightly too high.
So what do they do? Next day, the 19th, they decide, “Let’s roll back. Let’s move the changes back to the previous version.” Great. And they roll back the code successfully. The database, however, is another story. They don’t manage to roll back the database successfully. So now, when the batch jobs starts for the 19th, you have the database at one version and the code at another, and these two versions aren’t compatible.
The batch job scheduler starts running jobs. Those jobs fail because the database is in the wrong place, and the batch job scheduler doesn’t care. It just keeps going and keeps chucking out jobs and says, “Run this one, run this one.” Some of those jobs, it turns out, were dependent on each other. One needed to complete successfully before the next one could run successfully. But merrily the system plowed along, churning up the data and causing no end of chaos. And so, it comes to the 20th of June and the system is in a nightmarish state. People’s mortgages have been calculated wrong, no one can get into their banking IT systems through the online web portal, customers are phoning up and shouting down the phone. It’s all a big nightmare.
The engineers have to desperately run around and try and reset everything and put everything back in place. But it takes them almost a month to correct the problems, during which time everything is in this chaotic state. So, if you move fast like Mark Zuckerberg, you’ll break things, and if you move slow like this bank or many other banks, you break things.
If you develop, you break things. You will break things if you develop code. And once you accept this fact, and once crucially you put this as part of your design philosophy and move it into your code, then you can start to eliminate this speed versus reliability dichotomy.
Who Are Starling Bank?
I’m now going to give you a brief introduction to who Starling Bank are. We describe ourselves as a tech start-up with a banking license. We’re a mobile-only bank in the UK, and by mobile-only bank, what we mean is that you can only access Starling Bank through your phone. You download an app onto your iPhone or Android device, you apply for a bank account through the app submitting all the data that you need, and then you get access to all your banking information through the app.
We’ve got all of the standard features that you would associate with a bank account. You have a debit card, you have the ability to pay money from your bank to other banks. We also have some features that are quite, we think innovative, quite new, fine-grained card control that allows you to turn your card off for particular interactions such as online payments, aggregated spending data so that you can see how much you spent at a particular merchant or how much you spent in a particular category every month. The ability to automatically provision your card from your app into GooglePay or ApplePay or any other virtual wallet.
We built this bank in a year. We started building in earnest in July, 2016, and by May, 2017, we were ready to launch ourselves publicly. We launched the apps and the public started downloading them and they liked them so much that come March 2018, we were awarded the best British Bank award at the British Bank Awards. The question is then how have we managed to deliver so quickly and deliver all of these features, not only the existing ones that banks have, but all these new ones, while at the same time maintaining this reliability that customers demand? Now I’m going to talk about how we have built our architecture to be reliable.
Self-Contained Systems
We work off the principle of self-contained systems, and you can read more about the design philosophy of self-contained systems at the web address there. Now, we don’t use all of the design philosophy there, but we use quite a lot of it, we base quite a lot of our design thinking on that. Now, self-contained systems are systems that are designed to handle one type of job. So in the context of a bank, those jobs might be, say, to handle cards and card payments, or to handle sending money to another bank or to maintain a list of the customers transactions, or to send notifications out to other people.
Now, these self-contained systems, I wouldn’t really describe them as microservices, I think they’re too big. We can have the how-big-is-a-microservice argument later. I would more describe them as micro lifts. They have their own database, which for us is running in an RDS instance in the cloud. They have their own logic and they have their own APIs, and their APIs can be connected from other self-contained systems or from the outside world.
Each of these self-contained systems for us runs in an easy two instance in AWS and we can have multiple of these spun up at any particular time. So if there’s a particular large number of card payments coming through, for example, we can spin up three, four, five, six, however many instances we need of that particular self-contained system. We at least have two of each running at all times for redundancy purposes. They each have their database they can connect to, and these self-contained systems can be accessed by each other via their APIs. They can also be accessed by the mobile apps and they can be accessed by our browser-based management portal, which is the management system written for the bank managers so that they can manage the bank. There are no startup dependencies between these things, and crucially there’s no distributed transactions either. So, there’s nothing to link these two things together or couple them together. All of these different services are running independently of one another.
Recovery in Distributed Architectures
So we have a cloud-based modern scalable architecture. How do we make it reliable? Recovery in distributed systems. The problem that the people running the batch scheduler found is that if you have a load of distributed systems talking to one another, and one of them happens to go wrong, then that problem can spread to the next one. The batch job scheduler can sit there and say, “I’d like to run this job please.” And the second system will go, “Fine, yes, I will run that job.” And it will create a data problem. It’ll process things incorrectly, store them in the database incorrectly, so it will create a problem. And then that problem could spread to a third system, or a fourth system.
In fact, the bug is very much like a virus. It can spread from system to system and you can find yourself in a situation where you have corrupted data all over the place. You have commands that you don’t really want to run all over the place. Fundamentally, this is happening because the systems, all of these different services you’re running, are too trusting. They accept without question that the commands they are being given are good to run. “Yes, sure. I’ll run that for you. No problem.” I’m obviously in the correct state, otherwise, you wouldn’t have asked me to run that.
But as we know, bugs can happen, things can break. So, the question then is how do we stop this wildfire or virus-like spread of a problem from one system to the next system in a scenario that becomes very difficult to unwind? We have invented an architectural philosophy around this, which we call LOASCTTDITTEO, or Lots Of Autonomous Services Continually Trying To Do Idempotent Things To Each Other. We like this because it just rolls off the tongue. No, so it’s obviously a bit too long, this one. We showed this to Adrian Cockcroft from AWS and he shortened it for us down to DITTO architecture, Do Idempotent Things To Others.
Who here is aware of what idempotency means, what the concept is? That’s good. For the benefit of those of you who don’t know, I’ll explain idempotency at least in the context that we’re using it. Idempotency means that if you try and run a command twice, the exact same command twice, the outcome is the same as if you ran it once. And indeed, if you run it three times or four times or end times, no matter how many times you run this same specific command, the outcome will be the same as if you run it once. This is a very important concept when it comes to building reliable software, especially in banking.
DITTO Architecture
DITTO architecture and its principles. The top core principle of DITTO architecture is this idea that everything you do, every command you run, every work item you process should be run at least once and at most once. Now, why didn’t I just say once rather than extending it out? The reason is because saying at least once and at most once gives you the two problems that you must tackle when trying to work out how to make a reliable system. When you were trying to run a command, you’ve got to make sure that it actually happens. So you’ve got to retry making that command until you’re sure that it has been a success. But you don’t want to retry it and have it happen again and again and again and again. It must be idempotent. You must be able to make sure that when you ask to make that payment, you only make it once. You don’t make it multiple times, even if there is a problem in your system.
The systems that we have, all of these self-contained systems, all of these services, are trying to work towards eventual consistency. So they receive instructions and they immediately store these instructions in the database. Then the database becomes the repository of what work must be done. The store, the list of what work has to be achieved, what payments have to be made, what cards have to be reissued, what addresses have to be changed, whatever the command is, whatever the piece of work that you need to do is, that is stored and logged in the database at first. And then from there you can try and catch up and make everything consistent and make sure that the processing that needs to be done to make this payment or issue the card or what have you, is correctly performed by all the systems that need to be involved.
Your smarts are in your services here, not in the pipes between them. The connection between the services has no queuing mechanism or no detection mechanism, they just pass the requests between services as they’re asked. All of the smarts to detect whether you are running something once or twice or whether you haven’t run it at all, are contained within the services which are continually, as I said, trying to catch themselves up to eventual consistency. As I mentioned before, there are no distributed transactions here in our system, so you have to anticipate that something could get halfway through and fail. If a particular command, a particular work item requires you to make changes in three different systems, you have to anticipate that at any particular stage this could fail and then the system will need to make sure that it can catch up, and make sure that it can reach that situation of eventual consistency. Above all, mistrust, suspicion, skepticism needs to be built into each of the services. “Have I already done this? Have I not done this at all?” It needs to check and re-check.
Now I’m going to go through an example of how this will work. So, the example I’m going to pick is someone needs to make a payment from their Starling Bank account to another bank account somewhere else. How would this work? They take their mobile phone and they say, “I’d like to make a payment to this bank account please, £20. Thank you. Go.” That request is then sent to customer, the customer service. That’s the service responsible for storing the balance and storing the transactions that the customer wants to make.
The customer service receives the request and the first thing it does is put that in the database. It does a little bit of validation beforehand just to make sure the customer has enough money to send that out. But it very quickly, as quickly as it possibly can, stores that in the database. And that is the synchronous bit. We try and reduce synchronicity to a minimum. The synchronous bit is taking it, validating it, putting it in the database, done. Then responding to the mobile and saying, “Thank you very much, 200 accepted. Tick.”
It then records the transaction, says, “Great,” reduces the balance as necessary, and then sends that payment off to the payment system. The payment system is there to communicate with the outside world, it’s there to connect to the faster payments network that we have in the UK, which allows us to send payments between different banks. It will say, “Hey, payment, please make this payment.” And payment will go, “Thank you very much. Store in the database, accepted,” and then payment will send it out to the payment network.
Payment then has to contact bank, and bank is what is the system that maintains the ledger and it has to record in the ledger that a payment has been sent out so that later when the faster payments network come to us with the bill and say, “Here’s the bill that you need to pay because we’ve made these payments on your behalf, that we will be able to reconcile that bill.” So bank takes the payment, stores it in the database, “200 accepted, thank you very much.” Then writes it into the ledger.
Now that is all a very nice and jolly and happy path, but what happens when things start to go wrong? This time we’re going to imagine things going wrong. So the customer comes along, they say, “I’d like to make a payment, please.” Customer accepts it, “200 accepted, thank you.” Stores it in the database, reduces the balance, records the transaction, and then it sends it off to payment and payment’s not there. The payment instances aren’t working, none of them are up. There’s a problem somewhere. So customer goes, “Ah, okay.” It doesn’t get a good response back, so what does it do?
Well, it’s got this work item. It waits for five minutes and then it tries again, and it sends that payment over to the payment service again, and then the payment service says, “Oh great, this time I’m here and I will accept it. Thank you very much, 202 accepted.” So this concept of being able to retry work items to making sure that you have actually done them by going, “Well, if I didn’t get a good response, I’ll wait five minutes and then try again,” provides the at least once component that we need.
Now let’s imagine that payment tries to send something to bank, because obviously, it needs to store the payment in the ledger. Payment sends the payment to bank and bank stores the payments in the ledger, and then tries to communicate back that it’s done this and the communication fails. Maybe the bank instance goes down before it’s had a chance to communicate back. Maybe the payment instance disappears before it has a chance to be responded to. Either way, there’s some breakdown in communication and bank actually does the work of putting this payment in the ledger, but that isn’t communicated back to payment.
So, following our catch-up retry problem, payment comes along and says, “All right. I’ll try it again five minutes later,” and it sends off the message to bank. Bank receives this payment and says, “Okay, I’ve got this. Let me just check to see if I’ve put this in the ledger already.” Goes off to the ledger, finds out it has put it in the ledger already. Now at this point, it doesn’t throw an exception. It doesn’t complain and shout and go, “Oh, there’s a problem.” It just goes, “Thank you very much, 200 accepted. I’ve done that for you. What you wanted to achieve, that this has gone into the ledger, has been achieved. Tick.” So that is the idempotency, that is the at most once.
Now, you’ll notice that all over this diagram and the previous one I’ve been putting UUID in brackets all over the place. UUID it is a unique identifier which for us is a 32-character hexadecimal string that we associate with everything, and I mean everything. Everything in our system gets a UUID, every card, every customer, every payment, every transaction, every notification, every ledger entry, everything gets a UUID. This UUID is passed around with the items. That is the key to making sure that idempotency is achieved, because the only sure-fire way you can guarantee that this is exactly the same command and I have processed this one already, is by having a UUID and so you can see the UUID and you can say, “Well, this UUID matches a UUID I already have in the database, I’m not going to do this again.” Idempotency.
Catch-up Processing
What does this look like when we implement it in code? What we have is two concepts here that I want to explain, which is the catch-up processor and the recoverable command. The Recoverable Command, the RC bit labeled there, is an idempotent command to do something, to make the payment, to send a new card out, to cancel the card, etc. That has built into it checks to make sure that the work item hasn’t already been processed, it receives a UUID, so it takes a UUID in and then interprets what that UUID is and what it means, but it makes sure that everything has a UUID associated with it. So everything in order to be processed has to have this UUID. Once it’s processed the item, if it processed it successfully, it stores that fact in the database and it goes, “Hey, database, I have processed this item successfully. Please mark this with a timestamp or similar marker to say this work item has been processed, do not try and process it to again.”
The catch-up processor is there to provide the retry function. So it is its job that runs every five minutes or one minute or 10 minutes, depending on what sort of cadence you need, and it will take up 1,000, 100, however many you need items from the database that need processing. It will farm those out to various different recoverable commands. We have a big ring buffer command bus which we will put work items on and then we have threads going around picking up those work items and processing them through the appropriate recoverable command.
If something goes wrong, if there’s a bug, what happens is that the recoverable command will not say that the work item is complete. The catch-up processor will come back in five minutes and try and re-process it. If it’s still a problem, it’ll keep processing it until it’s fixed, until the desired state has been achieved and then it will go tick. These catch-up processors help us continually work towards eventual consistency.
But Why Java?
Now I want to get down to – given this as the enterprise languages track – the reason that we chose Java for our enterprise. One of the benefits of Java at a tactical work item level is that exceptions are really noisy. You get a lot of noise, you can throw an exception, you can stop processing, you can bubble this exception up. That allows you to make sure that a work item will not be processed, that any further processing done on the work item, including marking it as complete in the database, will be stopped. This then becomes obvious to monitor, you can see what’s going on, and you can make sure that your system will carry on iterating over this item until it is complete.
At a more strategic level, we have a reliable ecosystem in Java. Java has a large user base, it has good tooling, many people who know it so it’s easy to hire for. And this provides us with a higher order reliability. We’re not just thinking now about reliability at the level of an individual payment. Customers don’t just want to know that single payments or transactions or their day-to-day banking will go through very well. They want to know that they won’t be called in a years’ time to be told that their bank has gone out of business and now they need to spend loads of time and go through mountains of paperwork, switching their bank account to another bank account. They need to know that this bank account will be here in a decade’s time, 15 years, 20 years, etc, etc. So choosing a language that is well supported in terms of its tooling, its user base and so on, is a very good consideration for an enterprise that is thinking long term, which banks have to.
It also means that we have easier integrations with legacy third parties. A lot of the trick with banking is allowing consumers to interface with systems that were designed 30, 40, 50 years ago, and removing that difficulty of interfacing with things that are written by transferring, fixed with disseminated text files to around about the system, which we have to do. Since Java provides us with an easy way of interfacing with all of those crazy more outdated systems, it becomes easier for us to offer our consumers an easy interface into the banking world.
The Benefits of DITTO Architecture
What are the benefits of this architecture? What are the things that we can do? What does this give us? Instance termination is safe. This is the key point about our architecture. So, if we feel an instance is in trouble either because something has gone wrong and it’s run out of memory, or if we think it’s under attack, or even if we just want to terminate it and bring up a new version, we can do so, safe in the knowledge that if it’s in the middle of processing anything that that work item will be re-picked up by a new instance and processed in an idempotent manner, processed in a manner that means that we don’t have a duplicate occurring, a duplicate payment or what have you.
When I say instance termination is safe, I don’t just mean the instances running code. I also mean the database instances. If a database instance goes out for some reason, alright, we’ll lose some functionality for while, but at least we won’t get into a position where we have that spreading bug problem because everything that comes along to that instance to do something, the first thing that the instance tries to do is save the work item in the database. And if the database isn’t there, then the service will just go, “500. I can’t save anything in the database. This is all broken. Go away and come back later.” So anything trying to contact it will be able to catch up by contacting it later through the catch-up processors and the retry functionality. That allows us to be a bank that does database upgrades in the middle of the day during office hours, which we do and have been doing recently.
It allows us to be a bank where continual delivery means slightly faster than once every three months. We can make sure that because we can kill instances at any time, we can take old versions out of service and bring new versions into service any time we choose without worrying about what it’s doing. Now, we don’t quite have continual delivery of production, we still get sign-off to go into production, but we are releasing to production at least once a day, if not twice, three, four, five times a day. This allows us to move much faster and deliver features much faster.
Traditional banking, or incumbent banking, I should say, works in this “bi-modal” manner. What that means is that they end up delivering their user interface, their apps and their web portals very fast, but their back end, that goes very much more slowly. You have this problem whereby you’re trying to deliver the user interface over a back end that may not support the features that you want to implement. It must be an interesting challenge to work in those banks where you have to iterate the user interface to deliver things over a back end that doesn’t really change. Whereas with us, our back end goes 10 times faster than our front end. So we’re actually in a position where if a new feature needs to be released, we can release the whole feature back front end all at once. Fantastic. We can deploy that and make sure that it goes into production, that feature gets out to customers as quickly as we can.
But you might be thinking we’re a regulated industry. Banking is a regulated industry in the UK as I’m sure it is here. What do the regulators say about this? Here’s an example. One of the things that the regulations say is when you do a release, you must let everyone know that a release is happening. Now, generally, banks will do that by sending out an email, but if we’re releasing every day, we don’t want to spam people with emails going, “There’s a release, there’s a release, there’s a release.” So what we do is we go into Slack and we post what we call the “rolling” giphy indicating that our production system is rolling. You can see various examples of our rolling here. This lets everyone know that the system is rolling. We’ve fulfilled our regulatory requirement. This has been signed off by auditors. They’re happy with this. They’re happy that we are fulfilling our requirements to let our employees know that there is a change in code coming along.
Oftentimes, people use regulation as an excuse. They say, “Ah no, can’t … Oh, we’d love to satisfy and delight our customers, but alas, regulation prevents us from doing so.” That’s a load of rubbish. Yes, it’s complete BS. This shows that regulators are happy with you delivering as long as you fulfill the spirit of what is intended you can deliver quickly to customers. You just have to think of an inventive way of fulfilling the spirit of the regulation.
What happens if something goes wrong? If something explodes, we have screens everywhere. These are screens showing Grafana graphs that we’ve created of various metrics, card payments going out, faster payments going out, exceptions happening. We’ve got these screens all throughout the office. So if something goes wrong, people will quickly, notice because these things are very visible and they’ll say, “Hang on a minute, what’s going on with all the exceptions coming out of such and such?” We can quickly look into it. And because we are happy with releasing on a very fast cadence, we can release a fix to that problem. It doesn’t require an emergency. “Oh God, we’ve got to release today. How on earth do we do that? Quick, get the VP of blah blah blah on the phone and this person and this person and the 20 other people we need to do the release.” We can just do the release. So we can fix bugs quickly.
We can also test this. Here’s our chat-ops killing of particular instances of things. Here’s me going into slack and saying, “I’d like to recycle all of the instances of this particular service, please. Take them all out of service one by one and bring up new ones.” That’s recycle. But I could also go “Kill. Kill all of the instances, bring them down.” The eagle-eyed amongst you might be able to see that that’s in demo. Yes, fine, testing and demo is okay, but in order to make sure that this is actually working, you need to test it in production.
We run chaos in production. We’re a bank, we run chaos engineering in production. We don’t run a lot of it. We don’t have a full Simian army going, we only have one little monkey who goes and kills instances, but he will kill instances in production. He will take instances of services down. Now, we do that fairly regularly. We don’t often take all instances of a particular service down at once, but on occasion, we have had to do that and we felt that that’s the most prudent thing to do in response to an emergency. And we can do all this because we’re happy that things will catch up.
The Future
I want to briefly talk about two topics regarding the future of where Starling is going, where this architecture is going. The first one is scale. We started hitting scale problems recently. One of the scale problems we’ve hit is the self DOS problem where we create a denial of service attack against ourselves by having one service pick up a work item, try and communicate with another service, “Hey, can you process this work item?” And that service goes, “Error.” Then five minutes later the first service goes, “Can you process this work item?” If there’s a large scale problem, it will be doing that with a thousand work items. Obviously, because the catch-up processors are run in each instance, it will be doing 2000 work items because there were two instances running a thousand work items. And if we’ve scaled this up too many instances, there’ll be end thousand work items coming across and which will all be being rejected. This will fill up the ring buffers, it can overheat the database of particular services. We found that happening.
So we’ve started instituting queue management where we’ve visualized all of this in our management application and we can go and we can pause particular catch-up processors. We can say, “Stop this. Pause this catch-up processor, it’s overheating the system. We need to go and fix it.” Then we can click play when we want to play it again and then it’ll catch up when we’re happy it’s being fixed. Also, we can pause or even delete, in a real emergency, particular work items. So we can say, “Stop this work item, it’s causing a problem. Let us fix it first.” That visualization helps us overcome that problem.
The second problem we have is race conditions. Obviously, we’ve got various different instances trying to go into the database and pick up work items through their catch-up processors. And if two instances both go and pick up the same work item, then the idempotency checks become very difficult because you can check whether that work item has been processed, but if two things are processing at the same time, then the idempotency checks will pass on both of them because the work item hasn’t been processed in either case. So this is a tricky situation where you could possibly get a duplicate because your idempotency checks get bypassed.
We’re thinking around how to fix that and we haven’t come up with a good solution yet, but we’re progressing towards an answer, which is maybe we need to separate out that work item processing. Maybe we could need to be more intelligent with how the catch-up processors pick up items out of the database and have that separated from the actual instances and the running of the particular work items. But we still want to maintain the smarts in the services, not in the pipes.
The other thing to say is about the future of the JVM, and the future of Java in general. We’re at the moment on Java 8 and we’re trying to upgrade to Java 10 and then hopefully to Java 11, which has the long term support with it. And we’re encountering a few problems, and those problems mainly relate to third-party libraries we use. We use third-party libraries and those third-party libraries use other third-party libraries, etc, etc, which use things in Java that in Java 8 are visible methods and classes that are visible, and they can go and get. In Java 9 when modularization was brought in, a load of that visibility disappeared. Now these third-party libraries have had to upgrade themselves. The third-party libraries that depend on them have to upgrade themselves, and so on and so on, in order to cope with this new world.
So we’re finding upgrading our system that we’re spending a lot of time upgrading, slowly finding versions of these libraries that work with later versions of Java. This takes a lot of effort. The question is, will Java maintain that reliability, that backwards compatibility, which gives Java a lot of its cache? Will it still be there? Can we still say it has backwards compatibility? Will it still maintain that in the future? I guess watch this space and come to the next talk for answers on that one.
Some Important Takeaways
Let me finish up with some important takeaways from this talk. First up, design software to be skeptical. I first put this down as designed software to be suspicious, and then I thought, “No wait, that doesn’t really scan, people might misinterpret that.” So design software to be skeptical to question what it is doing. Don’t just blindly accept that the command you have received is, “Yes, that must be good. Someone else must’ve checked that.” Check it yourself. Have your individual services mistrust what they are being handed by other services or by the outside world to check whether they’ve already been run, whether they have been run at all, whether they have been completed.
Give everything a UUID, all your work items, all your objects in the database everything everywhere must have a UUID if you are to implement an architecture like this, because that is the only way to guarantee that reliability that you need. It’s the only way to guarantee idempotency. Fire alarms are good. Having something that’s continually going off going, “There’s a problem here. There’s a problem here. There’s a problem here.” Yes, it might be annoying, but it allows you to quickly identify that there is a problem and help your cause and help fix it and help your customers, who presumably this error is affecting, get back on track.
And above all to end on a positive note, you can do anything that you can undo. If you are in a situation where there’s going to be a problem, something’s going to go wrong, which inevitably it will, and do you anticipate that and you build your system to cope with that, then you can deploy at speed. You can go at speed because if you make a bug, if you create a bug, if you create a problem which you inevitably will, then your system will be able to catch up and will be able to get itself into a good position and it won’t failover or fail your customers. If you do that, then you can break this dichotomy, this false choice between speed and reliability, and you can have both.
Questions & Answers
Participant 1: You mentioned that for every request the note will first write the request to the database before processing it. Do you have an idea of how much overhead this has, and how it affects the performance?
Maude: It certainly affects the performance a lot. In order to answer that question, we’d have to consider what would happen if we decided not to do that, and how it affects the performance. But if we decided not to do it, then I’m not sure we could run a banking system like this. So, in essence, it’s a cost that we have to pay at the moment. We have to be able to pay that cost. I think it does add quite a lot of load onto the system. And maybe if you don’t need a system as reliable as a banking system, you wouldn’t do it. But we haven’t tried to exactly measure what would happen if we take it away because then that would just completely wreck our systems. I’m afraid I can’t give you an exact answer on that one.
Participant 2: Just to clarify, I’m trying to understand the DITTO, this is a very interesting concept. If everything has to be idempotent and it seems that there is a constraint that the flow has to be only one direction. So, you cannot expect the second, you can only say, “Create it, accept it,” but you cannot wait, then it produces something that will be used by the caller.
Maude: I see what you mean. In a certain way, yes, you’re right. I think what you’re saying is that you can’t have something that goes “If service A call service B, then service B can’t hand back a fully formed, completed object to service A”. Yes, you are absolutely right about that. The only thing service B can hand back is a promise, essentially a UUID saying, “I promise to do this piece of work. I will do this piece of work for you. If you want to know how this piece of work is going, please enquire using the UUID you have provided.”
Generally speaking, most of the time in the happy path, things happen very quickly. So we don’t actually need to worry too much about that. The reason that we make it asynchronous, even though it appears synchronous to the human eye, in the happy path, is because in the sad path we need to have that asynchronicity so that we can catch up later and have that eventual consistency.
Participant 3: What if your retriable command just keeps failing forever? How do you deal with that?
Maude: We have people who are watching it during office hours. Everyone’s looking at those screens, as I said, screens with exceptions on them. If you get a particular work item that is failing consistently, what you see on those exception screens is a consistent pattern of normally two times because we’re running two instances every five minutes, there is an exception blip. People notice that and then go in and say, “What’s going on with this work item? How can we fix it?” and then release a problem. If there’s a problem that’s out of office hours, we have a rotation of a pager duty rotation to alert us to a serious problem is occurring and we need to go and fix it now, and then people will get up in the middle of the night and go and fix it. So, we don’t have any work or items that infinitely fail because we jump on the exceptions and correct them.
Participant 4: I’m wondering in your architecture, did you choose to use message queues in any of your workflows or maybe your retry logic? And if not, what was your rationale for avoiding that?
Maude: We didn’t choose to use message queues for anything. We chose to put all of the queuing and processing and retry logic in the services, the smarts in the service, not in the pipes. So we chose to use the database essentially, as our queue of work. The rationale behind that is that it’s then easy to kill an instance, bring it back up again, and still process those work items. You haven’t lost those work items. Maybe you lost their position in the command bus, the ring buffer, that’s having the recoverable commands farmed out to it, But it doesn’t matter because that recoverable, that ring buffer will refill with exactly the same commands because they’re all stored in the database and you can go and get them. So we felt that that was a more reliable way of processing basically.
Participant 5: Can a work item be partially finished?
Maude: Yes, absolutely, work items can definitely be partially finished. Every single service along the way has to check that it’s done their bit of the work item and that, if it needs to pass that work item onto another service, that pass on has been done. So, you need to build this retry catch-up processor logic in every service that needs to process that item.
Just before we go, I would like to say if you want to know more, please go and check out the Starling podcast where I host this and I get people from Starling Bank to come on and discuss various topics around how we built the bank from a technical point of view.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Woodruff: I’m really humbled to be here because it’s my first time at QCon. I know this is very senior, so be gentle with me. I want this to be a conversation. I always get a lot of good insights when I do this talk. So if people have ideas, please pass it along. I’ve had actually people do pull requests. All this source code that I do is all on GitHub. People have gone in and done pull requests and given me ideas. Hopefully, this is a two-way street. So we’re going to talk about ASP.NET Core 2.1 in terms of web APIs.
How I got started with building APIs was about seven, eight years ago. A few guys and I, we were Microsoft MVPs at the time and we were building an application for the MVP summit. We built an API in the back end, and we built a Windows Phone 7. If anyone remembers that platform, it was actually really fun to build the apps for it. No one used them. But at least it was really fun to build the apps. I really got a passion for building good APIs because I did build a very good API for that app. I started digging into learning more about HTTP and learning more about REST and learning more about data caching. So we’re going to really talk about stuff that I’ve learned over the last seven, eight years. Hopefully, it’ll hit a note with you guys.
Chris Woodruff, I am a developer advocate for JetBrains. I cover all of North America for .NET. I cover primarily ReSharper and Rider, Riders .NET Cross-Platform.NET IDE. So I’ll be using that tool. If you go, “Hey, what’s that IDE?” It’s Rider. At the end, if I have a couple people that I remember at the end, I’m going to give away a couple licenses to either ReSharper or Rider. It’s up to you what you want.
What Do You and I Do Wrong?
I always start this out with what you and I do wrong. It’s really what I did wrong. And I think I went over that a little bit in the beginning. I just started getting and started doing APIs without really thinking about them beforehand. And that can really get you in some trouble. Let’s talk about what we do wrong and maybe our teams, because maybe you’re more senior, but you have people that work for you that you have tasked to do certain jobs. They might do these things, so maybe you can go back and remind them not to do these things.
The first is the dreaded connecting your controller. This is all MVC pattern with ASP.NET Core. We’ve all seen the demos Microsoft has out. And they’re really good demos to learn. But you shouldn’t have a connection between your data access and your controllers. It’s like saying you should have all your code in one project. It’s probably not a good idea. The other one is the dreaded spaghetti code, or having lots of code in one place. I like to spread my code out into logical compartments, so one, it’s organized well, and it’s also testable. Now, at the end, I’ll talk about how I test my APIs in both unit testing and integration testing, which is a new testing technology that Microsoft came out with, with ASP.NET Core 2.0.
One thing that I always got burned in the beginning was coupling my domain knowledge to my data access on the way I build my APIs now. And really, I don’t connect anything up and I don’t couple anything. So my domain doesn’t care and doesn’t really know where the data is coming from, which is really important when I have to do testing and I have to bring in a new project that contains mock and maybe mock objects that I’m going to use to test my stuff. My domain objects don’t care.
Back eight years ago, I think we do more thinking about testing now. But who honestly didn’t really do a lot of testing seven, eight years ago? You can be honest. Not very many of us. And we’re learning. So before you start architecting your APIs, you really have to think about how you’re going to test them. I always say there are two ways that I test my APIs: internally with unit testing, and externally with integration testing, and we’ll look at that like I said in a little while.
What Does ASP.NET Core Help Us with?
Most of us or a good number of us were at the previous talk before lunch where they talked about the CLR and the CLR core. But here’s a question I’m going to ask you guys. So maybe you guys will get over food coma from lunch. Who uses ASP.NET Core? A good number, okay, awesome. Tell me what you guys like about ASP.NET Core and .NET core in general?
Participant: Portability.
Woodruff: Portability, so cross-platform. That’s awesome. So that way you can put it on any platform. You can put it in containers. You can use Docker. That’s awesome, anything else?
Participant: Templates.
Woodruff: Yes. That’s good, templates.
Participant: System.Web.
Woodruff: Oh, yes, the dreaded System.Web. I think Jared hit on that. When they build .NET Core, they really could allow that baggage go. That’s really awesome. There’s one thing that …
Participant: [inaudible 00:07:08]
Woodruff: Yes, that was a thing. When I started digging into .NET Core and ASP.NET Core, the thing that blew me away was dependency injection that was built in from the very start. I understood dependency injection in .NET framework, but man, it was difficult to use some of those third-party libraries and tools. I had a hell of a time sometimes using inject and stuff like that. Also, I had a hard time when I built those solutions. Maybe junior developers or developers that came in, they had a hard time understanding those projects and getting up to speed on them, because the code was sometimes a little convoluted, so to say. But I love how dependency injection was built in from the start. We’ll look at how they leverage that especially with testing and using multiple data access projects to do your solutions.
HTTP Quiz
I do another talk at places, like I’m doing it at VS Live in Orlando. I do a talk just on HTTP. I guess I’m kind of crazy. I love HTTP. I think anyone who builds Web APIs or APIs in general should at least understand some of the concepts of HTTP. We can call it REST, but you should just know some of the stuff. So I’m going to do a little quiz. Okay? To make you guys wake up and give me some talking. I’m going to give you a resource and I’m going to give you a verb and I’m going to give you the expected outcome of this HTTP request. And I want you to tell me what the response code’s going to be. Let’s see what you know. I have a resource called “Products,” and I’m going to use the Get verb, and the expected outcome is I get a list of all products that are in the system just through the API.
Participant: 200.
Woodruff: 200. That one’s simple. That was like a softball. Now I’m going to give products, but I’m going to give a parameter for it where the product color is green. And what do you think the response code for this is? 200 again. I can’t fool you guys. So it’s pretty easy. Now we’re going to get products and a post. See, now we’re getting different answers. I think it’s a 201, because 201 is created. Now, you may disagree with that because you may say, “Well, this 200 is more applicable.” I’m not saying you’re wrong. I’m just saying I want you to think about what you’re going to send back in your API through the HTTP response. Now I’m going to look for one specific product and it has a key of 81. What should I get back or what should I expect?
Participant: 200.
Woodruff: 200. Now I’m looking up something that doesn’t have a key in it.
Participant: 404.
Woodruff: That one’s simple. We all see 404 a lot and day-to-day, so not found. Now I’m going to do an update. Now I’m going to do a put on a product that has a key of 81. So we know 81 exists. What do you think the response code’s going to be?
Participant: 200.
Woodruff: I hear 200. I hear 204. Anyone think anything different than 200 or 204? So 204, no content. So why would it be no content? Anyone want to guess why I would do a 204 and have no content?
Particiant: You wanted to be more [inaudible 00:12:06].
Woodruff: Yes. I want my responses to be as small as possible, as tight as possible. I’ve already sent over that object. All I really need to know is it got updated. I’m going to go back. You got me on this one. Now I’m going to call that again with the same put right after. I saved it, and maybe 20 seconds later, I send another put over. You guys already saw the answer. So it’d be a 304 not modified, because it hasn’t been modified. I’m sending over the exact same payload, the same object. So, say if it’s JSON that I’m sending over or XML, and it matches, I want to communicate that to the consumer of that API, just say, “You know what? I didn’t do anything with it. It has been modified. But I’m at least acknowledging that I’m going to send something back to you.” The last one is deleting a resource. What do you guys think?
Participants: 204.
Woodruff: 204. Yes, no content, because if I’m deleting something, why would I send it back, right? All I really need to know is I’m going to send it back. This quiz was really supposed to make you think about how you want to communicate. I always say HTTP is the language of the internet. How we communicate with our APIs are very important.
I have this little workflow that I kind of figured out, I sat down and went through. It gives you this thing that says yes or no when you move through, and you can figure out what kind of response code that you want. I’m not going to go through all this. I really just put this up there. The slide deck will be available for you guys to download and take a look at. Actually, it’ll be up on the GitHub repository after this talk also. We build our APIs, but then we have to figure out how we’re also going to communicate using HTTP.
The other thing with .NET Core that’s really important in ASP.NET Core, is to really learn about asynchronous development. Now, we’re all senior, you probably all know this, but it is really important. I think at some point, .NET Core may not let you do synchronous programming anymore. It just may throw all that out and just go, “Everything has to be asynchronous.” So I’m going to hedge my bets and just do as much asynchronous development. I do that quite a bit, or I do it as much as I can in my project. So it’s just a reminder to do async, async/await. We do it a lot in the JavaScript side in our clients and the consumers of our Web API. So we should do it in our APIs also.
A Look at the Architecture
Let’s take a look at the architecture for my APIs. I have four parts to this. I have an API project. And each one of these blocks within the triangle is a project in the total .NET solution. So I have an API project. I have a domain. Why I put it in the center is because it’s kind of the linchpin for everything. And then I have data, and then I have tests. I always try to stress that tests are just as important of a project as any other project in my .NET solution, in my .NET Core solution.
Let’s look at some code. I have this and I’ve set this up, and hopefully everyone can see it. You can see that I have a number of different projects. Again, we have our API. We have our domain. We’ve got data. And then I have a number of different tests while I also have a project that contains my mock data. That’s important because I don’t ever want to test, do unit testing with production data. I have a really simple mock data project that we can look at. Then I have unit tests, which are xUnit. Then I also want to throw in low MS unit test just so people can see the difference between xUnit and MS unit.
So if I open up my API. We all know this, the new startup.cs, the Startup class. You’ll see that I have a lot of stuff. One suggestion I have is to keep this small and tight. Break out your configuration. Try to organize things a little better. That’s a little help. The other thing is I use Swagger. I don’t know if anyone else uses Swagger, but I’m going to show you how easy it is to set up Swagger in your Web API. All you really need is Swashbuckle.AspNetCore for your new NuGet packages. Iin your configure services, you just add that SwaggerGen. You can give it your title and the description and the version of the Swagger doc.
Then down here in your configure method, we’re going to use Use Swagger and then use Swagger UI. So, you can also see I’ve got some core stuff. I’m not going to go into cores. I’m not going to go into identity in this talk because those are pretty complicated subjects and I don’t have that much time. I’m going to run it just so I can prove that this actually runs and my Web API is functional. So you can see that just by doing that small amount of code, I get Swagger built in right from the start. Now, I do have the raw machine-readable swagger.json that I can have other libraries pull and create clients for me.
But just to prove that this is all working, let’s just go out and grab all the albums. So the database I’m using for this is called Chinook. Chinook was a test database, a demo database that Microsoft created a number of years ago, and it simulates an online music store. Why use this one? One, it’s a little smaller. And two, it’s not bicycle parts. North wind and venture works are pretty boring. They’re fine databases if you need something big. But for like these Web APIs, I just like something that has a little more interesting data. You can see that in here, if I increase, you can see that here’s an album for those about to rock. We salute you. That’s a AC/DC album, “Balls to the Wall,” another AC/DC. It’s a little interesting. Out on my GitHub repository, I do have a link to where you can get this database that you can use with the Web API project. So you can get everything to run this.
API Layer
Let’s go back and one, let’s take a look at and talk about the API project. So we looked at documenting your API. Let’s talk about the API layer. It’s really important. It’s the thing that kind of communicates and gets your HTTP requests and send backs and then it will send back the responses. I kind of equate it to, if you’re building ASP.NET MVC application, your UI should be thin and dumb. These controllers that I have in my API projects aren’t very complicated. They don’t have very much code to them because all I’m really doing is getting something, getting that request in, I send it back into my domain to be processed. I get something back. And based on what I get back, I’m going to send a certain kind of request or a certain kind of response code back from my API to the consumer. So, it doesn’t know anything about domain. It doesn’t know anything about the data access, which is really important.
The next one is I like to interact with my consumers using ViewModels. Now, I call them ViewModels. You can call them whatever you want. But they are not the entity models that are generated from entity framework core. Those are a good starting point. But I like to have a little more flexibility with my APIs so that if I had something that was different or maybe an object that I’m going to send back that was maybe a mash-up of two different entity models from entity framework, I can do that. In the beginning, when you’re first learning to build Web APIs, you basically will get entity models back, send them back, and you’ll send them out to the consumer. You’ll assume that that’s what you want back from your APIs.
But think about this example. I have albums and I have artists. When I send back albums, if I send back one or a set of albums, the album really is just an album ID, an album name, and it has an artist ID in there. So when I send that back, that doesn’t really give me all the information I really want to send back to the consumers. I want to send back the artist name with it. But if I send back from the API in a HTTP response only the entity model of an album, I’m locked in to just what is in that object based on the database table. So that’s why I think ahead and say, “You know what? I’m going to build out a bunch of ViewModels.” They may be 90% the same as my entity models, but at least if I have any changes down the road, I don’t have as much technical debt and I’m not going to have to change and cause a lot of issues in my projects. So just a thing to be aware of when you’re building your APIs.
Domain Layer
Domain layer. I’m going to go through this first and then we’ll take a look at the domain layer code. This contains my entity models. It’s containing my view models. In my domain project, I don’t have those entity models exist in my data projects because I want them in one single place. I want all my data projects – if they’re production data or mock data or another, maybe I have a SQL server project that I can get data out of a SQL server database, and maybe I have another one if I have to move over to MySQL or Postgres or Oracle – but by having the entity models in my domain, one, I’m keeping those in one place. I’m not having duplicate code running through my solution. And two, if someone comes in and develops a new data project to get data from a different database, they’ll know what the entity models are supposed to be.
My domain layer also contains all of my interfaces that my data repositories are going to adhere to. The thing with the dependency injection with .NET Core is it kind of forces you down the interface path, which is good because I didn’t do interfaces as much 10 years ago as I do now, AND I really suffered because of it. So all my interfaces, my contracts, are in my domain project because that’s where all of my data projects have to come and figure out how they have to implement. So they all work at the same level.
My domain layer uses dependency injection for all of the repository. We’ll take a look at how we do dependency injection real quick. Probably most of you guys already know, but for the few people that don’t, we’ll take a look at that in a second. Then I think of my domain layer as my supervisor. So my supervisor is an actual class that’s in my domain layer. It takes in view models on one side and will spit entity models out the other side and vice versa. It’s really where I do my conversions, I do my validation, I do any error checking. It is really where all of my work gets done in my solution, because I don’t want that done in the data access, because all my data access project should do is get data and push data back and forth from a data repository. My APIs don’t need to know any of that, even though you can decorate your controllers with attributes to do some kind of validation. I’ve mixed reviews on that. Sometimes I do it, sometimes I don’t. I’m moving against using those validation attributes in my controllers, and pushing everything into my domain so that those controllers stay as dumb as possible, as simple as possible.
Let’s take a look at my domain. Well, first, let’s take a look at how I do dependency injection, just so people know that have never seen dependency injection in ASP.NET Core. In here, I have a method called, “Configure Repositories.” That gets sent in the IServiceCollection from my startup class. In here, I’m just doing a bunch of AddScopes. So this is how we inject our data. I inject my data repositories into this project. You can see that it takes an interface and then it takes the class that implements that interface contract.
I showed you that because, well, one is there’s all my repository interfaces. These are pretty simple. It’s just a bunch of methods that simulate all the data access method. Basically, it simulates all the HTTP verbs that I want to do. So I can do my gets and my puts and my posts and my deletes. Then I can have multiple gets if I want to get all or get one, so pretty simple stuff, nothing that difficult. But my supervisor, you can see that this is broken up into multiple files. It is one big class, that I do partial classes, I do partial on, because it got too big and I wanted to have a little more control over it. But as you can see here, we have a number of private variables that represent each one of our data repositories that we injected into our startup. You can see that the way that we get those objects back out using dependency injection is by calling those and getting those through the constructors of classes.
This Chinook supervisor will go out, and in the dependency injection container, grab those objects out. The reason why we had to do the interface is because they have to be pulled out based on an interface type. So, I just want to make that clear. And then if I go down the album, you can see that my album stuff isn’t really that complicated either. I mean, this isn’t a complicated solution. I talked to a lot of people that aren’t as senior as all you guys. I kind of built this for the least common denominator developer out there. But at least it gets the discussion and gets the ideas across.
Now, we do have these converters. I built these converters just to show how we can convert between the view models and the entity models. Now you guys will say, “Well, why don’t you use something like AutoMapper?” Who uses AutoMapper? Awesome product. Jimmy Bogart is a smart dude, and I tell him that every time I see him. There is a ramp up time to understanding that product, and I didn’t want to throw that complicated product into this demo. Now, I may do a version of this with AutoMapper or I’m going to be doing another talk next year around fully domain driven development web APIs. So I’ll probably use AutoMapper with that.
But just know that these converters are just used to convert back and forth, because I didn’t want that code, that logic, to be in the supervisor so that I could at any time replace these converters with something else like AutoMapper. I’m always thinking about when I’m building my APIs and building my solutions, how to break out my code in small enough chunks because I’m not a really smart guy. I mean, you guys are probably a lot smarter than me. I’m just a poor kid from Flint, Michigan, that grew up in a trailer park. I had a professor in college that always said that. He had a Ph.D. in astrobiology, and he was a smart dude, but he was this poor kid from northern Michigan from the Upper Peninsula. And I kind of related to him. I grew up the first kid going to college in my family blue collar, auto workers. I try to keep things simple, because that’s kind of me. So that’s why I kind of break out this code into small enough chunks so I can come back six months later and understand my code again.
But in here, you can see that I have my entity. These are my entity models. These are my view models. So here’s album; this was generated using Entity Framework Core scaffolding-Db. You can see it’s a typical POCO object that represents an album from my database. It has album ID, title, artist ID. But if I take a look at the view model, I have an additional property for that artist name. Now, you could have something where there’s a person table and an address table, and a person can have multiple addresses. But there’s a primary address that’s set in that address table. But when you’re pushing a person out through your API, that person, you may go, “I want to have the primary address incorporated into that person class that goes out through my API.” So that reinforces why I’m using view models in addition to my entity models.
Data Layer
We will jump back in and do the last. So my data layer, pretty simple. It’s where all the heavy lifting for data happens. I have everything to find on interfaces. They’re based on my domain layer. Again, if I build and I do have two different data access projects in the solution, one production database, one mock data, but they all adhere to the same interfaces so that I can use dependency injection. My API and my domain don’t really know which is which.
When I run my tests, I dump in my mock data project into the dependency injection, and it gets used from the domain without knowing anything’s different. Then I use Entity Framework Core 2.1 to do all this. But you can use anything that is .NET standard 2.0. And I’ll probably lie. You guys heard Jared talk about what .NET standard is. It’s really a standard that encapsulates all the APIs that you can use in your projects. Last, I’ve talked about it, but I do have a mock-up from my data layer. I just threw my favorite form of data up on the screen, so it kind of ages me.
Caching
The other thing is, up to about three months ago, I didn’t have this section in this talk. So caching. It’s really important to think about caching way ahead. Before you even start building your APIs, you have to ask yourself, one, do you want to use caching? Two, what type of caching are you going to use? Because how you’re going to push out and how you’re going to use your API will give you a different caching story. There are three types of caching that we can use with Web API. We can use response caching, in-memory caching, and distributed caching.
Now, if I was building a Web API project, and this was going to exist on maybe one server inside my company, and it was going to be used for maybe a department application, and maybe 20 people were going to use this API or the applications that consume the API, I would probably use in-memory caching because it’s inside. You build it inside the code of your projects or of your solution. But if I was building this API to exist out in the cloud or in a data farm, in-memory caching would be awful to use because I want to have a caching story that caches across all the instances of my servers, of my Web API servers. That’s where I would use distributed caching.
But first, let’s take a look at response caching. Anyone use response caching in their Web APIs? The response caching is an HTTP 1.1 specification. Basically, it just says that if I set this attribute on my controller or action in my controller, that the consumer of that API can cache the information coming back for a certain duration of time. In this case, it would be 60 seconds. The response header that you would see if you took a look at that through Fiddler or Postman or something is you would see that cache control. And then there’s actually a response cache. There’s an attribute that says to enforce no caching if you did want to have explicit yes or no caching in there.
Response caching, if you’ve ever hit a API that has response caching, maybe you grab something in Chrome, and then a couple seconds later, if you call that API using a get verb, again, and it’s really fast, well, it’s because Chrome is built to understand and use response caching. So it actually stored that information inside of its internal memory, and then instead of going out to that API, it said, “Oh, this is cached. I’ll just grab it and give it back to you again.” If you do this, do this with the understanding that the consumers of your API don’t have to use the caching. You’re just saying, “If you want to cache this, cache it. If you don’t, you don’t,” but it’s up to the consumer to handle it.
In-memory caching. I probably don’t have a lot of time to go into this. If you scan through my solution, you’ll see where it is. Basically, you set it up in your startup, and then you can set it up to where you can push things into a cache in your data access and then get it back out so you don’t have to call the database. If you want to dig in more, there’s lots of documentation out on the MSDN site.
Now, distributed caching is more complicated. It’s an external cache that you set up in your solution. This just goes in a lot of technical details. But basically, what we’re doing is we’re going to be setting up maybe a Redis cache or we can set up a SQL server cache if we want that. And then if we’re out on the popular cloud platforms, each one has their own distributed caching product and service. So Azure has Redis Cache. Amazon has ElastiCache, and Google Cloud has Memcache. These are just different products that you can use. It’s kind of interesting.
A lot of people will say, “Well, why do you have SQL server cache if you’re getting your data from a SQL server database?” But your API may be getting data from a SQL server that is not in the same location, physical location. So maybe it’s 1,000, 2,000 different continent and you have a cache in a local SQL server that you can collect that data and keep it much closer to your API implementation and save on some latency and some performance.
Testing
Last thing, testing. I have two types of tests that I have in my solution. I have unit testing and integration testing. Unit testing, I’m not going to go into that. We should all pretty much know what unit testing is. Integration testing is for API endpoints. Anyone take a look at implementation, or I’m sorry, integration testing for Web API? It’s very cool. I want to take a look at it. You set it up very much like a unit test. If I open up my integration test, in here, I have this code and I have to have some NuGet packages set up in here. But you can take a look at that through my project. But you have to have these two namespaces, so Microsoft.AspCore.TestHost and .Hosting.
What this is, is I’m going to set up. In my constructor, I’m going to say I’m going to have a new test server that basically sets up a new web host builder that will use my startup in my API project. It uses whatever environment I want. In this case, I’m going to use the development environment. It gets this server. This is an actual little tiny web server that gets spun up that encapsulates your product, your API, the whole solution. And then I’m going to create a client based on that server. I’m going to store that in a private variable that I’m going to use in my test, so that client understands everything about the API and understands all the APIs. It understands the shape of what view models have to be sent and what comes out. It understands everything.
What I can do now is I can set up a test. For this, I’m going to say AlbumGetallTestAsync. I’m going to create a new HTTP request that’s based on the verb that I get sent into this attribute. And then I’m going to call album. So basically, this is a call to get all albums. Then I’m going to send that request into the client using a SendAsync. I have two ways that I can check to see if this test was done correctly. I can say response.ensuresuccessstatuscode, or I can explicitly, if I want to check to see if it’s a status code other than okay, other than a 200, I can do an assert.equal and then check the HTTP status code to whatever status code I want to the response.statuscode. So those are equal. You don’t have to do both of those. You can just do one or the other.
If you wanted to check, this is an AlbumGetTestAsync. This will send in a verb and an ID. It just tests to see if that one album is in the database or coming out of your API. So remember, these tests are done externally to your project, to your solution, where the unit tests are really done against internal objects within your solution.
Let’s wrap this up. I really appreciate you guys coming to this talk. If you guys have any questions, I’ll be around for the rest of the day. I’ll just be walking around. If you want to get the code for this, it’s out under my GitHub account, which is cwoodruff and you’ll find it under ChinookASPNETCoreAPINTier. And then I have an article that I wrote for InfoQ along this same subject. So there’s the bit.ly link for it. You can contact me through my email @JetBrains or you can follow me on Twitter. But I really appreciate you guys coming out and giving me some of your time. Hopefully, this was valuable.
Again, if you guys have any ideas, please come up and talk to me. The gentleman here that gave me the dependency injection, come on up afterwards and I’ll give you a license, and sure, Gabriel, because he was giving good feedback. And if you guys have any questions about just JetBrains in general or want to tell me anything about our products, good or bad, just come on up and talk to me. So that’s what I’m here for also. Thank you.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Brikman: Thank you all for coming. This is a talk, as John has mentioned, of the ugly layer beneath your microservices, all the infrastructure under the hood that it’s going to take to make them work and some of the lessons we learned. There’s not a great term for this. I’m just going to use the word DevOps, although it’s not super well-defined. And one of the things I want to share is a confession about DevOps to start the talk off.
Hey, there it is. There’s a limited range on this thing. So here’s the confession – the DevOps industry is very much in the stone ages, and I don’t say that to be mean or to insult anybody. I just mean, literally, we are still new to this. We have only been doing DevOps, at least as a term, for a few years. Still figuring out how to do it. But what’s scary about that is we’re being asked to build things that are very modern. We’re being asked to put together these amazing, cutting edge infrastructures, but I feel like the tooling we’re using to do it looks something like that.
Now, you wouldn’t know that if all you did was read blog posts, read the headlines, everything sounds really cutting edge. Half the talks here, half the blog posts out there, they’re going to be about, oh my God, Kurbernetes, and Docker, and microservices, and service meshes, and all these unbelievable things that sound really cutting edge. But for me as a developer, on a day to day basis, it doesn’t feel quite so cutting edge, right? That’s not what my day-to-day experience feels like. My day-to-day experience with DevOps feels a little more like that. You’re cooking pizza on an iron with a blow dryer. This is your hashtag for this talk, #thisisdevops. This is what it feels like.
Sometimes it feels more like that where you’re like, “Okay, I guess that works, but why are we doing it like this?” Nothing seems to fit together quite right. Everything’s just weirdly connected. What’s happening here? This is probably your company’s CI/CD pipeline. That’s what it looks like. So that’s what DevOps feels like to me. I feel like we don’t admit that often enough. We don’t admit the fact that building things for production is hard. It’s really hard. It actually takes a lot of work to go to production. It’s really stressful. It’s really time-consuming. We’ve worked with a whole bunch of companies and also had previous jobs, and the numbers we found look something like this.
If you are trying to deploy infrastructure for production use cases and you’re using a managed service, in other words, something that’s managed for you by a cloud provider like AWS or Azure, you should expect that before you’re ready to use that thing in production, you’re going to spend around two weeks. If you’re going to go build your own distributed system on top of that, go run a bunch of Node, or Ruby, or play apps, build your little microservices, you’re going to easily double that two to four weeks, if those things are stateless.
If they’re stateful, if it’s a distributed system that needs to write data to disk and not lose that data, now we go up in order of magnitude. Now to get to a production quality deployment of that, we’re talking two to four months for each of these distributed systems. So, if your team is thinking of adopting the ELK Stack or if you’re thinking of adopting Mongo DB or any of these large complicated systems, it’s going to take you months to operationalize them.
And then finally, the entire cloud architecture. You want to go build the entire thing, go to prod on AWS, Azure, Google Cloud, it’s six to 24 months. Six months, that’s your tiny little startup, and 24 months and up is much more realistic for larger companies. And these are best case scenarios. So this stuff takes a long time. As an industry, I don’t know that we talk about this enough. People like to come up here and tell you, “We win,” and not tell you that they spent three years working on that thing.
There are some things that are getting better in this industry, though. One of the ones that makes me personally very happy is this idea of managing more and more of our infrastructure as code. As opposed to managing manually by clicking around, we’re now managing more and more of our infrastructure as code. You’re seeing that across the Stack. We used to provision the infrastructure manually; now we have a lot of infrastructure as code tools. We used to configure servers manually’ now we have a lot of configuration management tools, and so on, and so forth.
All of this stuff is being managed as code. I think that’s a game changer. I think that’s hugely valuable because code gives you a tremendous number of benefits. Hopefully, if you’re developers, you believe in that. But, things like automation. Instead of deploying something manually over and over again, spending hours, you’ll let the computer do it. Computer is really good at doing the same thing over and over again. You get version control. So when something breaks, the entire history of your infrastructure is in a version control system, and you can just go look at the commit log to find out what changed.
You can code review those changes. You can’t code review somebody manually deploying something. You can write automated tests, which we’ll talk about a little later, for your infrastructure. Again, you can’t write automated tests if you do things by hand. Your code access documentation. So how your infrastructure works is captured in code rather than some CIS admins head. And you get code reuse, which means you can use a code that you’ve written earlier. You can use code written by others.
That’s kind of the genesis of this talk. I work at a company called Gruntwork, and we’ve built a reusable library of infrastructure code using a variety of technologies. We basically have these prebuilt solutions for a whole bunch of different types of infrastructure. Along the way, we’ve deployed this infrastructure for hundreds of companies, they’re using it in production, and it’s over 300,000 lines of code. This is actually a really old number, so it’s probably way over that at this stage. We’ve written a lot of infrastructure code. My goal in this talk is to share basically the things we got wrong, or to share the lessons we’ve learned along the way. It’s helpful as you go out there and you’re starting to use your microservices, as you’re starting to deploy all this stuff, you can benefit from some of these lessons, not make the same mistakes that we did.
I’m Yevgeniy Brikman, I go by the nickname, Jim. I’m one of the co-founders of Gruntwork, and the author of a couple of books, “Terraform: Up and Running” and “Hello, Startup,” both of which talk quite a bit about this DevOps stuff. If you’re interested in learning more, grab yourself a copy. Today, here are the things I’m going to chat with you about. The first thing I’ll do is I’ll give you guys the checklist. And what I mean by that is, we’re going to talk about why infrastructure work takes as long as it does. Then we’re going to talk about some of the tools that we use and the lessons from that. We’ll talk about how to build reusable infrastructure modules, how to test them, and how to release them. So it’s a good amount to cover. Let me get rolling. We’ll start by chatting about the checklist.
The Checklist
I’ve generally found that there’s really two groups of people. There’s the people that have gone through the process of deploying a whole bunch of infrastructure, have suffered the pain, have spent those six to 24 months and understand it, and then there’s the people who haven’t, who are newbies. When they see these numbers, when they see that it’s going to take them six to 24 months to get live for production infrastructure, they tend to look like that. “You got to be kidding me. It’s 2019, can’t possibly take that long.” You have a lot of overconfident engineers who are like, “Ah, maybe other people take that long. I’ll get this done in a couple of weeks.” No, you won’t. It’s just not going to happen. It’s going to take a long time if you’re doing it from scratch.
Now, the real question is, why? I’m sure many of you have experienced this. You expected to deploy this thing in a week, and it took you three months. So where did that time go? Why does this stuff take so long? I think there are really two main factors in the plan to this. The first one is something called “Yak shaving”. How many of you are familiar with this term? So, less than half the room. Okay. For the other half of you, you’re welcome. This is my gift to you today. This is one of my favorite terms, and I promise you, you will use this term after I introduce it to you. The other half of the room is smiling because you know why.
What is Yak shaving? Yak shaving is basically this long list of tasks that you do before the thing you actually wanted to do. The best explanation I’ve seen of this comes from Seth Godin’s blog, and he tells a little story like this. You get up one morning and you decide you’re going to wax your car. It’s going to be great. It’s going to be a fun Saturday morning. You go out to the backyard, you grab your hose, and the hose is broken. “Okay, no problem. I’ll go over to home depot. I’ll go buy a new hose.” You get in your car, you’re just about to head out and you remember, “Oh, to get to home depot, I have to go through a whole bunch of toll booths. I need an easy pass otherwise I’m going to be paying tolls all day long. So no problem, I’ll go grab the easy pass from my neighbor.”
You’re just about to head to your neighbor’s house when you remember, “Oh, wait, I borrowed pillows last week. I should return those otherwise he’s not going to give him the easy pass.” So you go find the pillows, and you find out all the Yak hair has fallen out of the pillows while you were borrowing them. The next thing you know, you’re at a zoo shaving a Yak, all so you can wax your car. That’s Yak shaving. If you’re a programmer, you know exactly what I’m talking about. You’ve run into this a thousand times. All you wanted to do was change the little button color on some part of your product, and for some reason, you’re over here dealing with some like TLS certificate issue, and then you’re fixing some CI/CD pipeline thing, and you seem to be moving backwards and sideways, rather than the direction you want to go. So, that’s Yak shaving.
I would argue that this, in the DevOps space, is incidental complexity. It’s basically the tools that we have, they’re all really tightly coupled. They’re not super well designed. Again, remember, we’re still in the Stone Age. We’re still learning how to do this. And so as a result, when you try to move one little piece that’s stuck to everything else and you seem to just get into these endless Yak shaves. So that’s reason number one.
Now, the second reason is what I would argue as the essential complexity of infrastructure. This is the part of the problem that’s actually real, that’s there that you have to solve, and I think most people aren’t aware of what most of it is. To share with you what we’ve learned in this space is I’m going to share with you guys what we call our production-grade infrastructure checklist. This is the checklist we go through when we’re building infrastructure that is meant to be used in production, infrastructure that you’re willing to bet your company on. Because if you’re going to go put your company’s data in some database, you want to know that it’s not going to lose it tomorrow and take your company out of business. So this is what I mean by production-grade.
Here’s the first part of the checklist, and this is the part that most people are very aware of. You want to deploy some piece of infrastructure, Kafka, ELK, microservices, whatever it is. You realize, “Okay, I’ve got to install some software. I have to configure it, tell it what port numbers to use, what paths to use on the hard drive. I have to get some infrastructure, provision it, might be virtual infrastructure in a cloud, and then I have to deploy that software across my infrastructure.” When you ask somebody to estimate how long it’ll take to deploy something, these are the things 99% of developers are thinking of. These are the obvious ones. But this is page one out of four, and the other three pages are just as important, and most people don’t take them into account when they’re doing their estimates. So here’s where the real pain comes in.
Let’s look at page two. Page two has things that I think most of you would agree are equally important. Things like security. How are you going to encrypt data and transit TLS certificates? How are you going to do authentication? Are you going to manage secrets, server hardening? Each of these things can be weeks of work. Monitoring for this new piece of infrastructure. What metrics are you gathering? What alerts is it going to trigger when those metrics are not where they should be? Logs. You’ve got to rotate them on disc. You’ve got to aggregate them to some central endpoint, backup and restore. Again, if you’re going to put some data in a database, you want to be confident that data isn’t going to disappear tomorrow. This stuff takes time. That’s two.
Let’s go look at page three. How about networking? Especially if you’re thinking about microservices here today, I know a lot of you have to think about how are we going to do service discovery and all the other things you’re doing with things like a service mesh. How do you handle IP addresses? How do you do all the subnets? How are you going to manage SSH access or VPN access to your infrastructure? These aren’t optional. You have to do these things, and this is where the time ends up going when you’re deploying a piece of infrastructure. You need to make it highly available, heard a lot about that today, scalability, performance.
Finally, page four, which most people do not get to, things like cost optimization. How do you make it so this thing doesn’t bankrupt your company? That seems pretty important. Documentation almost nobody gets to. What did you do? Why did you do it? And then automated testing. So, again, very few people get to this. They just don’t think of it. You think, how long is it going to take me to deploy something? You’re thinking of page one. Basically install, configure, deploy. I’m done. And you’re forgetting about three other pages of really important stuff.
Now, not every piece of infrastructure needs every single one of these items, but you need to most of them. So the takeaway here is when you go to build something in the future, when your boss says, “How long is it going to take you to deploy X?” Go through that checklist. Go through that checklist and make a very conscious decision that, “We will do end-to-end TLS”, or, “We won’t.” “We will think about SSH access,” or, “We won’t.” Figure those out. Make those explicit. Your time estimate will at least be directionally correct. You’ll still be off by quite a bit cause of Yak shaving, but at least you’ll be a little closer. So, hopefully, that checklist is useful. You can find a more complete version of it on the Gruntwork website, gruntwork.io. It’s in the footer. You can also just search for the production-readiness checklists. That’s a really complete version of this. Use it. We use it all the time. It’s really valuable.
Tools
Second item is we’ll chat a little bit about the tools that we use. Something that a lot of people ask is, what tools do we use to implement that checklist? I know what I need to do, how do I actually do it? I’ll go over the tools that we use, but something important to understand is that this is not a recommendation to you. You are going to have your own requirements, you’re going to have your own use cases. The reason I bring this up is a little bit different, and I’ll cover that in just a second. So, just to answer the question.
At Gruntwork, the tools that we use, we like things that let us manage our infrastructure as code, of course. We like things that are open source, things that have large communities, support multiple providers, multiple clouds, that have strong support for reuse and composition of the code. Composable pieces are important at the infrastructure layer as well. We’ll talk about that in a bit. We like tools that don’t require us to run other tools just to use those tools, and we like the idea of immutable infrastructure. We’ll cover all of that a little bit later.
The tools that we’re using as of today look something like this. At the basic layer, all of our general networking, load balancers, all the integrations with services, all the servers themselves, which are usually virtual servers, all of that we deploy and manage using Terraform, which lets us do it all as code using HDL as the language. On top of that, those servers are running some sort of virtual machine images. In Amazon, for example, those are Amazon machine images, and we define and manage those as code using Packer, another open-source tool that lets you manage things as code.
Now, some of those virtual machine images run some sort of Docker agent. That might be something to do with Kurbernetes, or ECS, or some other Docker cluster. So those servers form into a Docker cluster, and in that cluster, we’re going to run any of our Docker workloads, so all sorts of containers. Docker lets us define how to deploy and manage those services as code usually using something like a Docker file. Then the hidden layer under the hood that most people don’t tell you about, but it’s always there, is all of this stuff is glued together using a combination of – basically, this is our duct tape. Bash scripts, Go for binaries, Python scripts when we can use them – that’s the stack.
But here’s the thing. These are great tools. If you can use them, great. But that’s not really the takeaway here. The real takeaway here is that whatever toolset fits your company, whatever you end up picking isn’t going to be enough. You could pick the most perfect tools, or you could copy exactly what we did, or come up with something different, and it won’t matter at all unless you also change the behavior of your team and give them the time to learn these tools. So infrastructure-as-code is not useful just in and of itself. It only is useful when combined with a change in how your team works on a day-to-day basis.
I’ll give you a really simple example of where this is absolutely critical. Most of your team, if you’re not using infrastructure-as-code tools, it’s probably used to doing something like this. You need to make a change to the infrastructure. You do it manually and you do it directly. You SSH to a server, you connect to it, you run some command, I made the change that I needed to. Now, what we’re saying is when you introduce any of those tools, Chef, Puppet, Terraform, whatever it is, you’re saying that now we have this layer of indirection. Now to make a change, I have to go check out some code. I have to change the code, and then I have to run some tool or some process, and that’s the thing that’s going to change my infrastructure. That’s great, but the thing to remember is that these pieces in the middle, they take time to learn, to understand, to internalize. Not like five minutes of time, like weeks, months, potentially, for your team to get used to this. It takes much longer than doing it directly.
Here’s what’s going to happen. And if you don’t prevent this upfront, I guarantee this will happen no matter what tools you’re using. You’re going to have an outage. Something is going to go wrong. And now, your ops person, your DevOps, you’re CIS Admin, whoever it is, is going to have to make a choice. They can spend five minutes making a fix directly, and they know how to do that already, or they can spend two weeks or two months learning those tools. What are they going to choose during the outage? Pretty clearly, they’re going to make the change by hand.
What does that lead to? Well, it turns out, with infrastructure as code, if you’re making changes manually, then the code that you worked so hard on does not represent reality anymore. It does not match what’s actually deployed, what’s actually running. So, as a result, the next person that tries to use your code is going to get an error. Guess what they’re going to do? They’re going to say, “This infrastructure as code thing doesn’t work. I’m going to go back, and I’m going to make a change manually.” That’s going to screw over the next person, the next person. You might’ve spent three months writing the most amazing code, and in a week of outages, all of it becomes useless and no one’s using it.
That’s the problem because changing things by hand does not scale. If you’re a three-person company, sure. Well, do whatever you need to do. But as you grow, it does not scale to do things manually, whereas code does. So it’s worth the time to use these tools only if you can also afford the time to let everybody learn them, internalize them, make them part of their process. I’ll describe a little bit what that process looks like in just a second. But if you don’t do that, don’t bother with the tools. There’s no silver bullets. It’s not going to actually solve anything for you.
Modules
Third lesson we’ve learned as we wrote this huge library of code is how to build reusable nice modules. The motivation comes from the following. Most people when they start using infrastructure as code in any of these tools, they basically try to define all of their infrastructure in a single file or maybe a single set of files that are all deployed and managed together. So all of your environments, Devs, Stage, QA, Prod, everything defined in one place.
Now, this has a huge, huge number of downsides. For example, it’s going to run slower just because there’s more data to fetch, more data to update. It’s going to be harder to understand. Nobody can read 200,000 lines of Terraform and make any real sense of them. It’s going to be harder to review both to code review the changes to code review any kind of plan outputs that you get. It’s harder to test. We’ll talk about testing. Having all your infrastructure in one place basically makes testing impossible. Harder to reuse the code. To use the code also, you need to have administrative permissions. Since the code touches all of the infrastructure to run it at all, you need to have permissions to touch all of the infrastructure. Limits your concurrency. Also, if all of your environments are defined in one set of files, then a little typo anywhere will break everything. You’re working on making some silly change in stage and you take down Prod. So that’s a problem.
The argument that I want to make is that large modules, by that I mean like a large amount of infrastructure code in one place, are a bad idea. This is not a novel concept. At the end of the day, infrastructure as code, the important part here is, it’s still code. We know this in every other programming language. If you wrote, in Java, a single function that was 200,000 lines long, that probably wouldn’t get through your code review process. We know not to build gigantic amounts of code in one place, in every other language, in every other environment. But for some reason, when people go to infrastructure code, they assume that’s somehow different, and they forget all the practices that they’ve learned, and they shove everything into one place. So that’s a bad idea that is going to hurt almost immediately, and it’s only going to get worse as your company grows.
What you want to do is you do not want to build big modules. At the very least, to protect against the last issue I mentioned, the outages, you want to make sure that your environments are isolated from each other. That’s why you have separate environments. But even within an environment, you want to isolate the different pieces from each other. For example, if you have some code that deploys your VPCs, basically the network topology, or the subnets, the route tables, IP addressing, that’s probably code that you set up once, and you’re probably not going to touch it again for a really long time. But you probably also have code that deploys your microservices, your individual apps, and you might deploy those 10 times per day.
If both of those types of code live in one place, if they’re deployed together, if they’re managed together, then 10 times per day, you’re putting your entire VPC at risk of a silly typo, of a human error, of some just minor thing that can take down the entire network for your entire production site. That’s not a good thing to do. Generally speaking, because the cost of getting it wrong here is so high, you want to isolate different components of your infrastructure from each other as well, where a component is based on how often it’s deployed, if it’s deployed together, risk level rise. So, typically, your networking is separate from your data stores, is separate from your apps. That’s kind of the basic breakdown.
But that only fixes the issue of, “Well, I broke everything.” All the other issues would remain if that’s all you did. You still have to think about the fact that it runs slower. The fact that it’s harder to test, the fact that it’s harder to reuse the code. So really, the way I want you to think about your architecture when you’re working on infrastructure code is, if this is your architecture, you have all sorts of servers, and load balancers, databases, caches, cues, etc., then the way to think of this as infrastructure code is not, “I’m going to sit down and write.” The way to think about it is, “I’m going to go and create a bunch of standalone little modules for each of those pieces.” Just like in functional programming, you wouldn’t write one function. You write a bunch of individual little functions, each responsible for one thing and then you compose them altogether. That’s how you should think about infrastructure code as well. I call these modules. That seems to be the generic term in the infrastructure world, but really there are no different than functions. They take in some inputs, they produce some output, and you should be able to compose them together.
Typically, what that looks like is you start by breaking down your environments. So dev, stage, and prod live in separate folders. They’re separated from a code perspective. Within each environment, you have those different components. As I said, your networking layer separate from your database layer, separate from your app layer. Under the hood, those things are using reusable modules, basically functions, to implement them. So it’s not like those are copied and pasted. Under the hood, they’re using a shared library that you can build out, and that library itself should be made, again, from even simpler pieces. Again, there’s nothing new here that I’m telling you other than just whatever programming practices you would use in your Java code, in your scholar code, in your Python code. Use them in your infrastructure code as well. It’s still code. The same practices tend to apply.
I’ll show you a really quick example of what the infrastructure code can look like, just to build your intuition around this. The example I’ll look at really quickly here is there’s a set of modules that are open source for something called Vault, for deploying Vault on AWS. Vault is an open-source tool for storing secrets, things like database passwords, TLS certificates, all of that stuff, you need a secure way to store it. Vault is a nice open source solution, but it’s a reasonably complicated piece of infrastructure.
Vault itself is a distributed system, so we typically run three Vault servers. The recommended way to run it is with another system called Console, which is itself a distributed key-value store, and you typically run five of those servers. There are all sorts of networking things, TLS certs you have to worry about. So there’s a decent number of things to think through. You can look at this later on after the talk if you’re interested just to see an example of how you can build reusable code to do this.
I’ll show you the Vault code checked out here on my computer. I don’t know if you can read that. Maybe I’ll make the font a little bigger. Let’s try. That’s a little better. Well, over here, there are basically three main folders, examples, modules, and test. The rest of the stuff you can ignore. Examples, modules, test. So the modules folder is going to have the core implementation for Vault. The thing to notice here is there isn’t just one Vault module that deploys all of Vault, and all of Console, and all of those dependencies. It actually consists of a bunch of small submodules. In other words, basically smaller functions that get combined to make bigger ones. For example, here, there’s one module called Vault cluster. This happens to be Terraform code that deploys an autoscaling group and a launch configuration, basically a bunch of infrastructure to run a cluster of servers for Vault.
Now, that’s one module in here, and that’s all it does. Separate from that, we have another one, for example, to attach security group rules. These are essentially the firewall rules for what traffic can go in and out of Vault. That’s also a Terraform code, and it lives in a completely separate module. Even separate from that are other things like install Vault. This happens to be a Bash script that can install a specific version of Vault that you specify on a Linux server. As you can see, it’s a bunch of these separate orthogonal standalone pieces. Why? Why build it this way?
One thing that’s really important to understand is you get a lot more reuse out of it this way. I don’t mean just in some hypothetical, “You’re not going to need it” approach. I mean, even within a single company, if you’re running Vault in production, you’ll probably deploy it like that. Three Vault servers, maybe five Console servers, separate clusters scaled separately. But in your pre-production environments, you’re not going to do that. That’s really expensive. Why waste? You might run it all on a single cluster, might even run it on a single server.
If you write your code as one giant super module, it’s really hard to make it support both use cases, whereas if you build it out of these small individual Lego building blocks, you can compose them and combine them in many different combinations. I can use, for example, the firewall security group rules for Vault, and I can attach those to another module that deploys Console because they’re separate pieces, and I can combine them in different ways. So exactly like functional programming, nothing different here. It’s a different language than you might be used to.
We have a bunch of these standalone little pieces. Then in the examples folder, we show you the different ways to put them together. Think of it as executable documentation. We have an example in here of how to run a private Vault cluster. Under the hood, this thing is using some of those little sub-modules that I showed you earlier, and it’s combining them with some modules from another repo that run Console and a whole bunch of other stuff. It shows you one way to assemble these building blocks. There are also examples here of how to build, for example, a virtual machine image. This is using Packer. So, all sorts of examples of how to do this stuff.
Now, why bother writing all of this example code? Well, for one thing, this is documentation. This is good for your team to have access to. But the other really critical reason we always write this example code is the test folder. In here, we have automated tests. And the way we test our infrastructure code is we’re going to deploy those examples. The examples are how we’re going to test everything, which creates a really nice virtual cycle. We create a bunch of reusable code, we show you ways to put it together in the examples folder, and then we have tests that after every commit, ensure the examples do what they should, which means the underlying modules do what they should. I’ll show you what the test look like in just a minute, but that’s your basic folder structure of how to build reusable, composable modules of small pieces that each do one thing. UNIX philosophy says this, functional programming says this, you should do it in an infrastructure world as well.
We walked through these things. Let me skip forward. The key takeaway is, if you open up your code base for Chef, Puppet, Terraform, whatever tools you’re using, and you see one folder that has two million lines of code, that should be a huge red flag. That should be a code smell just like it would be in any other language. So small, reusable, composable pieces. We have a very large library of code, and this has been the route to success to build code that is actually reusable, testable, that you can code review, etc.
Tests
I mentioned testing a few times. Let me quickly talk about how that works. One of the things we’ve learned building up this library, even before we built this library, when we tried to use some of the open source things that are out there is that infrastructure code, in particular, rots very, very quickly. All of the underlying pieces are changing. All the cloud providers are changing and releasing things all the time. All the tools like Terraform and Chef, they’re changing all the time. Docker is changing all the time. This code doesn’t last very long before it starts to break down. So, really, this is just another way of saying that infrastructure code that does not have automated tests is broken.
I mean that both as a moral takeaway lesson for today, but I also mean that very literally. We have found every single time that we have written a nontrivial piece of infrastructure, tested it to the best of our ability manually, even sometimes run it in production, taking the time to go and write an automated test for it, has almost always revealed nontrivial bugs, things that we were missing until then. There is some sort of magic that when you take the time to automate a process, you discover all sorts of issues and things you didn’t realize before. In both bugs in your own code, which we have plenty of, but we found bugs in all of our dependencies too when deploying elastic search. We actually found several nontrivial bugs in elastic search because we had automated tests. We found many nontrivial bugs in AWS and Google cloud itself, and, of course, in Terraform, and in Docker, all the tools we’re using. I mean this very literally. If you have a pile of infrastructure code and some repo that doesn’t have tests, that code is broken. I absolutely guarantee it. It’s broken.
How do you test them? Well, for the general purpose languages, we more or less know how to test. We can run the code on localhost on your laptop, and you can write unit tests that mock outside dependencies and test your code in isolation. We more or less know how to do that. But what do you do for infrastructure code? Well, what makes testing infrastructure code pretty tricky is we don’t have localhost. If I write Terraform code to deploy an AWS VPC or Google Cloud VPC, I can’t run that on my own laptop. There’s no localhost equivalent for that.
I also can’t really do unit testing. Because if you think about what your infrastructure code is doing, most of what that code does is talk to the outside world. It talks to AWS, or Google Cloud, or Azure. If I try to mock the outside world, there’s nothing left. There’s nothing left to test. So I don’t really have local hosts. I don’t really have the unit testing. Really, the only testing you have left with infrastructure code is essentially what you would normally call integration testing, sometimes end-to-end testing. The test strategy is going to look like this. You’re going to deploy your infrastructure for real, you’re going to validate that it works the way you expect it to, and then you’re going to un-deploy it.
I’ll show you an example of this. The example that I’m showing you is written with the help of a tool called Terratest. This is an open-source library for writing tests in Go, and it helps you implement that pattern of bringing our infrastructure up, validate it, and then tear the infrastructure back down. Originally, we built it for Terraform, that’s why it has that name, but it now works with Packer, with Docker, with Kurbernetes, with Helm Charts, with AWS, with Google cloud, a whole bunch of different things. It’s actually a general purpose tool for integration testing, but the name has stuck. We’re not very good at naming things.
The Terratest philosophy is to basically ask the question, how would you have tested this thing manually? Let’s look, again, at that example of Vault. Here’s my Vault infrastructure. I wrote a pile of code to deploy this. How do I know it’s working? Well, probably the way I would test that it’s working is I would connect to each node, make sure it’s up, run some Vault commands on them, to initialize the Vault cluster, to unseal it. I’d probably store some data. I’d probably read the data back out. Basically, do a bunch of sanity checks that my infrastructure does what it says on the box.
The idea with Terratest is you’re going to implement exactly those same steps as code. That’s it. It’s not magic. It’s not easy necessarily, but it’s incredibly effective because what this is going to do is, you’re going to verify that your infrastructure actually does what it should after every single commit, rather than waiting until it hits production. Let’s look at an example for Vault. I mentioned that with Vault, we have all of this example code. Here’s this Vault cluster private example that has one particular way to use all our Vault modules. The test code for it lives in here. Vault cluster, private test. This is Go code that’s going to test that code. The test consists of essentially four, what we call stages. I’m not going to cover what the stages are, but basically four steps. The first two, if you notice, they use the Go keyword, defer. This is like a try-finally block. This is what you run at the end of the test. Really, the test starts over here.
The first thing we’re going to do is deploy the cluster. Then we’re going to validate the cluster, and then at the end of the test, we’re going to tear it down. So what’s the code actually doing? Deploying the cluster is a little pilot code that basically says, “Okay…”- and this was using a bunch of helpers built into Terratest – it says, “Okay, my example code or my real code lives in this folder. I want to pass certain variables to it that are good for test time.” Here we do a bunch of unique names and a bunch of other good practices for tests. “And then I’m basically just going to run Terraform init and Terraform apply to deploy this. I’m just running my code just like I would have done it manually using some helpers from Terratest.” Once that cluster is deployed, and all of those Terratest helpers will fail the test if there’s any error during deployment. Now I’m going to validate that Vault does what it should.
First, I’m going to initialize and unseal my cluster. The way to do that is basically what I described. We’re first going to wait for the cluster to boot up because we don’t know how long that’ll take. And that code is a retry loop that basically says, “Hey, ping each node on the cluster until it’s up and running,” because you don’t know exactly how long it will take. Yay, microservices, right? Everything’s eventually consistent. Then I’m going to initialize Vault. The way I do that is I’m going to run this command right here, vault operator init. This is exactly what you would’ve done manually. I’m going to do that by SSHing to the server and running that command, and there’s basically a one-liner in Terratest to SSH to something, execute a command. Then I’m going to unseal each of the nodes, which is basically just more SSH commands, the stem vault operator unseal, etc.
Hopefully, you got the idea. I am just implementing the steps I would have done manually as code. This code executes after every single commit to the Vault repo. And that’s going to give me a pretty good confidence that my infrastructure does what it should. I now know that if I’d made a commit to the Vault repo and it deployed, that that code can fire up a Vault cluster successfully, that I can initialize and unseal it, that I can store data in that cluster, and I can read that data back out. We have fancier tests that redeploy the cluster, that check for zero downtime deployments, that check all sorts of properties, but that’s the basic testing strategy.
If you’re not doing this, then you’re basically just doing it in production and letting your users find out when you have bugs, which sometimes you have to. I mean, to some extent, we all test in production, but you can get a tremendous amount of value by doing this sort of testing ahead of time. I walked through Terratest, and Terratests has a ton of helpers for working with all these different systems. Helpers for making HTTPs requests, helpers for SSHing, helpers for deploying a Helm Chart to Kurbernetes, etc. It’s just trying to give you a nice DSL for writing these tests.
So a couple of tips about tests. First of all, they’re going to create a lot of stuff. You’re constantly bringing up an entire Vault cluster. In fact, our automated tests to deploy all of those examples in different flavors, so every commit spends up something like 20 Vault clusters in our AWS accounts. What you don’t want to do is run those tests in production because it’s going to mess things up for you, but you don’t even want to run them in your existing staging or Dev accounts either. You actually want to create a completely isolated account just for automated testing. Then what you want to do in that account is run a tool- there’s cloud-nuke, there’s, I forget the name, Janet or monkey or something like that. There’s a bunch of tools that can basically blow away an entire account for you, and you’ll want to run that basically as a cron job. Because occasionally, tests will fail, occasionally they’ll leave resources behind due to a bug in the test, etc. So make sure to clean up your accounts.
The other thing that I’ll mention about testing is this classical test pyramid that you see for pretty much every language, where at the bottom you have your unit tests, then on top of that you have integration tests, and then on top, end-to-end tests. It’s a pyramid because the idea is you want to have more unit tests, smaller number of integration tests, very small number of end-to-end tests. Why? Because as you go up the pyramid, the cost of writing those tests, the brittleness of those tests, and how long those tests take to run goes up significantly. So it is to your advantage to try to catch as many bugs as you can as close to the bottom of the pyramid as you can. Now, you’re going to need all the test types. This is not to say one test type is better than another. You’re going to need all of them. But proportion wise, this is what you ideally have just because of the costs go up.
With infrastructure code, it’s the same pyramid. The only slight gotcha is that we don’t have pure unit tests as we discussed. You can do some linting, you can do some static analysis. Maybe you can count that as almost a unit test, but we don’t really have pure unit testing. So, really, your unit test equivalent in the infrastructure world is to test individual modules. This is why having small little pieces is so advantageous, because you can run a test for an individual module pretty quickly and easily, whereas running a test for your entire infrastructure will take hours, and hours, and hours. So small individual modules, that’s a good thing. That’s the base of your pyramid.
Then the integration test equivalent is one layer up. That’s basically a bunch of modules combined together. Then finally at the top, that might be testing your entire infrastructure. That’s pretty rare because the time’s involved here, just to set the expectations for you correctly, look like this. Your unit tests in the infrastructural world take between one and 20 minutes typically. They’re not sub second, unfortunately. Integration tests can take from five to 60 minutes, and end-to-end tests, that depends completely on what your architecture looks like. That could take hours, and hours, and hours. So for your own sanity, you want to be as far down the pyramid as you can. This is another reason why small little building blocks are great because you can test those in isolation.
Key take away here, infrastructure code that does not have tests is broken. Go out there, write your tests, use whatever languages and libraries you prefer. But the way to test it is to actually deploy it and see if it works.
Releases
The final piece for the talk today that I’ll use to wrap up is just how you release all of this code, how you basically put everything together. Here’s what it’s going to look like. Hopefully, from now on, the next time your boss says, “Hey, go deploy X,” this is the process that you’re going to use. You’re going to start by going through a checklist because you want to make sure that when your boss asks you for an estimate, you actually know what it is that you need to build and you don’t forget critical things like data backups and restores. You’re then going to go write some code in whatever tools make sense for your team, and, hopefully, you’ve given your team the time to learn, and adapt, and internalize those tools. You’re going to write tests for that code that actually deploy the code to make sure it works. You’re then going to have somebody review each of your code changes, so metal pull request or merge request, and then you’re going to release a new version of your code, of your library.
And a version isn’t anything fancy. This can literally be a get to tag. But the point of a version is it’s a pointer to some immutable bit of code. “Here is my code to deploy microservice for version 1.0, and here’s 1.1, 1.2, and 1.3.” It’s some immutable little artifact. What you can do with that infrastructure code is now you can take your immutable artifact, and, first, you can deploy to some early pre-prod environments, to Dev or QA, and test it there. If it works well, you can take the same immutable artifact and deploy it in your next environment. You can promote it to staging. And since it’s the same code, it should work the same way. Then finally, promote it to prod.
The key takeaway – we went from that at the start of the talk with our pizza slice and iron cooking mechanism, to this where now we have small, reusable modules. We’ve gone through a checklist, we’ve written tests for them, we’ve code reviewed them, and we’re promoting them from environment to environment. That’s it. Thank you very much.
Questions & Answers
Participant 1: Thanks for that, it was great. I was curious about how are you guys managing your deployments of Terraform code for CI/CD pipeline? Are you automatically running Terraform, or are you running tests on top of that, or checks against the plans, etc.?
Brikman: CI/CD, the whole end-to-end pipeline is a pretty long discussion because a lot of it does tie into the specifics of each company. That’s why there are three million CI/CD tools out there, because you’re trying to implement your custom workflow. But the general structure to imagine in your head is, at the very basic layer, we start over here with the individual standalone modules, so like that Vault module that I showed you. That lives in its own repo, its own little universe. It’s just there, and you have example code and tests for it. Every commit there gets tested only if it passes the test to do, then release a new version of that code.
You have a whole bunch of these repos. You have one from Vault, you have one for your VPCs, one to deploy Kubernetes, etc, etc. Each of those is tested by itself. Those are your individual building blocks. Then over here you’re going to now assemble those into your particular infrastructure. So that might be a separate repo. Whether it lives in a separate repo or not isn’t actually critical, but I’m just going to explain it that way because it just mentally helps to separate them. In a separate repo, you’re now going to assemble your infrastructure using those modules. You’re going to take Vault over here, and you’re going to deploy in this VPC, and you’re going to run Kubernetes in this thing, and you’re going to connect it with the service discovery mechanism, etc.
That’s, again, more code that you write. Now, if those were your individual units that you are unit testing, this way to combine them is essentially the integration testing. So what you want to do, is in this repo, you’re going to run a test against it after every commit as well, or maybe nightly, depending how long those take. Now we’re getting into the larger chunks of infrastructure, so that’s a little slower.
If those tests pass, now you can release a new version of your infrastructure repo. Now you can take those versions, and finally, in our final repo, you deploy them to your actual live environments. You can take version 3.6 that pass tests in this repo, which is using 10 modules from those repos that also passed tests, and you’re going to deploy that to Dev. If it works well, you’re then going to deploy to staging. If that works well, you’re going to deploy that same version to production.
In those live environments, typically you’re not going to spin up the entire architecture from scratch. You could, but that probably takes hours and is brittle. So usually what most companies do is they just have some kind of smoke tests that runs against the already existing environment. So if you have a dev environment, you deployed version 3.6 of your microservice library in there, and you’re going to run smoke tests against that environment that’s already standing up and do a bunch of sanity checks. Can I talk to my service? Can I deploy a new version of it? Whatever you need to verify. Then you do the same thing in staging and production. And hopefully, by the time you’re in prod, the code has been tested across so many layers that you’re still going to have bugs. There are always going to be bugs, but it hopefully eliminates a lot of the sillier ones.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
TypeScript 3.4 Supports Incremental Builds and globalThis
The TypeScript team announces the release of TypeScript 3.4, including faster incremental builds, improvements for higher order type inference of generic functions, and support for ES.Next globalThis.
Over the past few years, the TypeScript has substantially improved the efficiency and ergonomics in expressing and inferring type definitions. The latest improvement in TypeScript 3.4 allows functions to infer types from other generic functions. Before this release, generic functions struggled to infer type when other generic functions get passed as their arguments and type information gets lost. As explained by TypeScript program manager Daniel Rosenwasser:
During type argument inference for a call to a generic function that returns a function type, TypeScript will, as appropriate, propagate type parameters from generic function arguments onto the resulting function type.
TypeScript 3.4 also improves the experience when working with read-only array-like types. Previously a type of ReadonlyArray was required, but this blocks usage of more common [] shorthand syntax during array definition. Now a readonly modifier gets provided before the array, e.g. readonly string[] to define a readonly array where each item is a string. Tuples also can use the readonly modifier, e.g. readonly [string, number].
In earlier versions of TypeScript, mapped types such as the Readonly utility type did not function on array and tuple types. In TypeScript 3.4, when using the readonly modifier on a mapped type, TypeScript automatically converts array-like types to their readonly analogs.
When developers declare mutable variables or properties, TypeScript typically widens values allowing for value assignment without defining an explicit type. The challenge, as explained by Rosenwasser:
JavaScript properties are mutable by default. This means that the language will often widen types undesirably, requiring explicit types in certain places. To solve this, TypeScript 3.4 introduces a new construct for literal values called
constassertions. Its syntax is a type assertion withconstin place of the type name (e.g.123 as const).
New literal expressions with const assertions allow TypeScript to signal that no literal types in that expression should have their type definition widened, object literals receive readonly properties, and array literals become readonly tuples.
One of the long-awaited additions to JavaScript is a standard for referencing the global context. Due to existing implementations with various libraries, it has taken several years to decide on a solution. TC39, the group, and process for defining future additions to JavaScript, have settled on globalThis which has now reached stage 3 support, the level at which the TypeScript waits before adding new features. globalThis provides a global context regardless of the environment in which an application exists.
To leverage globalThis, most applications today will need to use a globalThis polyfill to support older browsers and JavaScript engines. One result of this change is that the type of top-level this is now typed as typeof globalThis instead of any when working in the noImplicitAny mode of TypeScript. Developers wishing to avoid this change may use the noImplicitThis flag until they have time to update their usage of the global context.
To improve compilation times with TypeScript, TypeScript 3.4 adds a new --incremental flag which saves project graph information from the last compilation which gets used to detect the fastest way to type-check and emit changes to a project, reducing subsequent compile times. Rosenwasser explains the performance improvement by exploring the build types of Visual Studio Code:
For a project the size of Visual Studio Code, TypeScript’s new
--incrementalflag was able to reduce subsequent build times down to approximately a fifth of the original.
TypeScript 3.4 has some potentially breaking changes, all of which are consequences of using the new features. For example, if a codebase does not expect the propagation of generic type arguments, then it will need updates to compile without errors when using TypeScript 3.4.
The TypeScript team is already working on features for TypeScript 3.5, including a move from TSLint to ESLint and several language and compiler improvements including negated types.
The TypeScript community also announced the second TSConf event on October 11th with TypeScript founder Anders Hejlsberg delivering the keynote.
TypeScript is open source software available under the Apache 2 license. Contributions and feedback are encouraged via the TypeScript GitHub project and should follow the TypeScript contribution guidelines and Microsoft open source code of conduct.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Interaction plots are used to understand the behavior of one variable depends on the value of another variable. Interaction effects are analyzed in regression analysis, DOE (Design of Experiments) and ANOVA (Analysis of variance).
This blog will help you to understand the interaction plots and its effects, how to interpret them in statistical designs, and the problems you will face if you don’t include them in your statistical models. In any statistical study, whether it’s a product development, manufacturing process, simulation, health, testing and so on. Many variables can affect the expected outcome (Response). Changing/adjusting these variables can affect the outcome directly.
Interactions plots/effects in Regression equation:
- To determine if two variables are related in a linear fashion
- To understand the strength of the relationship
- To understand what happens to the value of Y when the value of X is increased by one unit
- To establish a prediction equation that will enable us to predict Y for any level of X
- Correlation is used to measure the linear relationship between two continuous variables (bi-variate data)
- Pearson correlation coefficient “r” will always fall between –1 and +1
- A correlation of –1 indicates a strong negative relationship, one factor increases the other decreases
- A correlation of +1 indicates a strong positive relationship, one factor increases so does the other
Interaction Plots/effects in Design of Experiments (DOE):
The analyze phase of DMAIC (Define Measure Analyse Improve and Control) process narrowed down the many inputs to a critical few, now it is necessary to determine the proper settings for the vital few inputs because:
- The vital few potentially have interactions
- The vital few will have preferred ranges to achieve optimal results
- Confirm cause and effect relationships among factors identified in analyze phase of DMAIC process (e.g. regression)
- Understanding the reason for an experiment can help in selecting the design and focusing the efforts of an experiment
Reasons for design of experimenting are:
- Problem Solving(Improving a process response)
- Optimizing(Highest yield or lowest customer complaints)
- Robustness(Constant response time)
- Screening(Further screening of the critical few to the vital few X’s)
Problem Solving:
- Eliminate defective products or services
- Reduce cycle time of handling transaction processes
Optimizing:
- Mathematical model is desired to move the process response
- Opportunity to meet differing customer requirements (specifications or VOC)
- Robust Design
- Provide consistent process or product performance
- Desensitize the output response(s) to input variable changes including NOISE variables
- Design processes knowing which input variables are difficult to maintain
Screening:
- Past process data is limited or statistical conclusions prevent effective characterization of critical factors in analyze phase
Interaction Plots/effects in Anova:
Analysis of Variance (ANOVA) is used to determine if there are differences in the mean in groups of continuous data.
Power of ANOVA is the ability to estimate and test interaction effects.
There are 2 ways - One way ANOVA and Two way ANOVA
- A one-way ANOVA is a type of statistical test that compares the variance in the group means within a sample whilst considering only one independent variable or factor.
- A two-way ANOVA is, like a one-way ANOVA, a hypothesis-based test. However, in the two-way ANOVA each sample is defined in two ways, and resulting put into two categorical groups.
Example of using Interaction plots in Anova:
The main effects plot by plotting the means for each value of a categorical variable. A line connects the points for each variable. Look at the line to determine whether a main effect is present for a categorical variable. Minitab also draws a reference line at the overall mean.
Interpret the line that connects the means as follows:
- When the line is horizontal (parallel to the x-axis), there is no main effect present. The response mean is the same across all factor levels.
- When the line is not horizontal, there is a main effect present. The response mean is not the same across all factor levels. The steeper the slope of the line, the greater the magnitude of the main effect.
Interaction plot example from ANOVA showing running time, type of marathon and strength
Interaction effects/plot Definition:
Interactions occur when variables act together to impact the output of the process. Interactions plots are constructed by plotting both variables together on the same graph. They take the form of the graph below. Note that in this graph, the relationship between variable “A” and Y changes as the level of variable “B” changes. When “B” is at its high (+) level, variable “A” has almost no effect on Y. When “B” is at its low (-) level, A has a strong effect on Y. The feature of interactions is non-parallelism between the two lines.
While the plots help you interpret the interaction effects, use a hypothesis test to determine whether the effect is statistically significant. Plots can display non-parallel lines that represent random sample error rather than an actual effect. P-values and hypothesis test help you sort out the real effects from the noise.
- Parallel lines: No interaction occurs.
- Nonparallel lines: An interaction occurs. The more nonparallel the lines are, the greater the strength of the interaction.
Examples of different interactions:
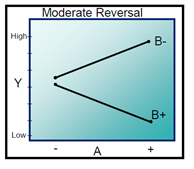
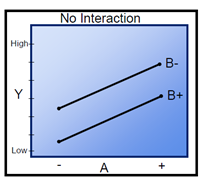
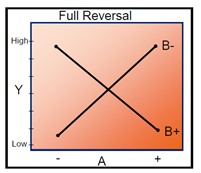
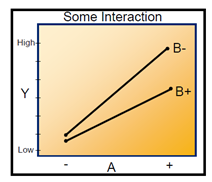
Real-time example - Running a Marathon:
If we want to plan to run a marathon within next one year we need to understand dependent and independent variables like age, shoe type, speed, wind, stamina, cardio strength, nutrition, weight, practice hours, coach, method, location and so on. This kind of effect is called the main effects. It will be less significant to assess only the main effects, by adjusting all these variables in a proper manner we can get the desired response that is completing a marathon run within the expected time.
Marathon running example. only representation On an interaction plot, parallel lines indicate that there is no interaction effect while different slopes suggest that interaction might be present.
Sample data

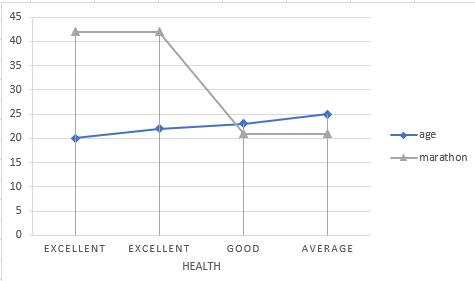
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Booking.com’s engineering team scaled their Graphite deployment from a small cluster to one that handles millions of metrics per second. Along the way, they modified and optimized Graphite‘s core components – carbon-relay, carbon-cache, and the rendering API.
Booking.com tracks both technical and business metrics in Graphite. They started using graphite in 2012, on a RAID 1+0 setup, which was also used for their databases, but it did not scale well for Graphite. They sharded the requests to distribute the traffic across storage nodes. However, this was hard to maintain and they switched to SSDs in a RAID 1 configuration.
The default carbon-relay, written in Python, ran into CPU bottlenecks and became a single point of failure. The team rewrote it in C, and also changed the deployment model so that each monitored host had a relay. This would send the metrics to endpoints in multiple datacenters backed by bigger relays and buffer data locally when there was a failure. To get around uneven balancing of metrics across servers, they implemented a consistent hashing algorithm. However, they continued to face issues with adding new storage nodes, used shell scripts to sync data between datacenters, and had to keep replacing SSDs (each lasted 12-18 months) due to the frequent writes (updates) made to disk. At some point in time, the team considered HBase, Riak and Cassandra for storage backends, but it’s unclear if they pursued those efforts. Other engineering teams have successfully utilized Cassandra as a scalable Graphite backend.
One of the optimizations the team did early on was carbonzipper, which could proxy requests from the web front end to a cluster of storage backends, according to Vladimir Smirnov, former System Administrator at Booking.com. Ultimately, the team had to replace the standard carbon cache and their rewritten relay with Golang based implementations. The go-carbon project is the current implementation of the graphite/carbon stack in Go.
Booking.com has a distributed “Event Graphite Processor” that generates graphite metrics from event streams, processing more than 500k events per second. Event streams are generated across the stack and stored in Riak. “Booking.com heavily uses graphs at every layer of its technical stack. A big portion of graphs are generated from events”, says Damien Krotkine, Senior Software Engineer and Ivan Paponov, Senior Software Developer, at Booking.com. Apart from events, various collectors and scripts collect metrics from Booking.com’s systems. Initially starting with collectd, they switched to Diamond, a Python based system metrics collector. Did they standardize on metric naming conventions? To an extent – they started by reserving sys.* (for system metrics) and user.* (for testing etc), and left everything else to the developers to determine the metric names they wanted to use.
Apart from capacity planning and troubleshooting, Booking.com uses Graphite to “correlate business trends with system, network and application level trends”. They use Grafana as the front-end for visualization.