Month: February 2018

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: The Magic Quadrant for Advanced Analytic and ML Platforms is just out and there are some big changes in the leaderboard. Not only are there some surprising upgrades but some equally notable long falls.
The Gartner Magic Quadrant for Advanced Analytic and ML Platforms came out on February 22nd and there are some big changes in the leaderboard. Not only are there some surprising upgrades (Alteryx, KNIME, H20.ai) but some equally notable long falls for traditional players (IBM, Dataiku, and Teradata).
Blue dots are 2018, gray dots 2017.
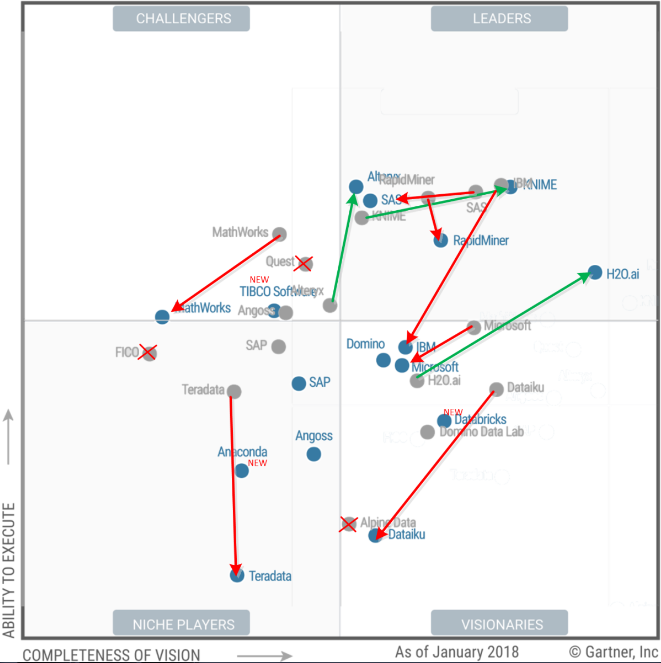
For those of you keeping track Gartner split this field in 2017 so that “Advanced Analytic & Machine Learning Platforms” (Machine Learning added just this year) is separate from “Business Intelligence and Analytic Platforms”. There’s significant overlap in the players appearing in both including SAS, IBM, Microsoft, SAP, Alteryx, and a number of others. Additionally you’ll find all the data viz offerings there like Tableau and Qlik.
From a data science perspective though we want to keep our eye on the Advanced Analytics platforms. In prior years the changes had been much more incremental. This year’s big moves seem out of character, so we dived into the detail to see if the scoring had changed or if the nature of the offerings was the key.
Has the Scoring Changed?
We read the 2018 and 2017 reports side-by-side looking for any major changes in scoring that might explain these moves. We didn’t find any. The scoring criteria and eligibility for each year remain essentially unchanged.
Of course raters are always influenced by changes in the market and such impacts can be subtle. In the narrative explanation of markets and capabilities we found only a few hints at how scoring might have been impacted.
New Emphasis on Integrated Machine Learning
We all want our platforms and their components to operate seamlessly. Last year the criteria was perhaps a bit looser with Gartner looking for “reasonably interoperable” components. This year there is much more emphasis on a fully integrated pipeline from accessing and analyzing data through to operationalizing models and managing content.
Machine Learning is a Key Component – AI Gets Noticed but Not Scored
It was important that ML capability be either included in the platform or easily accessed through open source libraries. To their credit, Gartner does not fall into the linguistic trap of conflating Machine Learning with AI. They define the capabilities they are looking for as including “support for modern machine-learning approaches like ensemble techniques (boosting, bagging and random forests) and deep learning”.
They acknowledge the hype around AI but draw a relatively firm boundary between AI and ML, with ML as an enabler of AI. Note for example that deep learning was included above. I’m sure we’re only a year or two away from seeing more specific requirements around AI finding their way into this score.
Automated ML
Gartner is looking for features that facilitate some portion of the process like feature generation or hyperparameter tuning. Many packages contain some limited forms of these.
While some of the majors like SAS and SPSS have introduced more and more automation into their platforms, none of the pure-play AML platforms are yet included. DataRobot gets honorable mention as does Amazon (presumably referring to their new SageMaker offering). I expect within one or two years at least one pure play AML platform will make this list.
Acquisition and Consolidations
Particularly among challengers, adding capability through acquisition continues to be a key strategy though none of these seemed to move the needle much in this year.
Notable acquisitions called out by Gartner for this review include DataRobot’s acquisition of Nutonian, Progress’ acquisition of DataRPM, and TIBCO Software’s acquisition of Statistica (from Quest Software) and Alpine Data.
Several of these consolidations had the impact of taking previously ranked players off the table presumably providing room for new competitors to be ranked.
Big Winners and Losers
So if the difference is not in the scoring it must be in the detail of the offerings. The three that really caught our eye were the rise of Alteryx and H20.ai into the Leaders box and the rapid descent of IBM out.
Alteryx
From its roots in data blending and prep, Alteryx has continuously added to its on-board modeling and machine learning capabilities. In 2017 it acquired Yhat that rounded out its capabilities in model deployment and management. Then, thanks to the capital infusion from its 2017 IPO it upped its game in customer acquisition.
Alteryx’ vision has always been an easy to use platform allowing LOB managers and citizen data scientists to participate. Gartner also reports very high customer satisfaction.
Last year Gartner described this as a ‘land and expand’ strategy moving customers from self-service data acquisition all the way over to predictive analytics. This win has been more like a Super Bowl competitor working their way up field with good offense and defense. Now they’ve made the jump into the ranks of top contenders.
H2O.ai
H2O.ai moved from visionary to leader based on improvements in their offering and execution. This is a coder’s platform and won’t appeal to LOB or CDS audiences. However, thanks to being mostly open source they’ve acquired a reputation as thought leaders and innovators in the ML and deep learning communities.
While a code-centric platform does not immediately bring to mind ease of use, the Deep Water module offers a deep learning front end that abstracts away the back end details of TensorFlow and other DL packages. They also may be on the verge of creating a truly easy to use DL front end which they’ve dubbed ‘Driverless AI’. They also boast a best-in-class Spark integration.
Their open source business model in which practically everything can be downloaded for free has historically crimped their revenue which continues to rely largely on subscription based technical support. However, Gartner reports H2O.ai has 100,000 data scientist users and a strong partner group including Angoss, IBM, Intel, RapidMiner, and TIBCO, which along with its strong technical position makes it revenue prospect stronger.
IBM
Just last year IBM pulled ahead of SAS as the enthroned leader of all the vendors in this segment. This year saw a pretty remarkable downgrade on ability to execute and also on completeness of vision. Even so, with its huge built in customer base it continues to command 9.5% of the market in this segment.
Comparing last year’s analysis with this year’s, it seems that IBM has just gotten ahead of itself in too many new offerings. The core Gartner rating remains based on the solid SPSS product but notes that it seems dated and expensive to some customer. Going back to 2015 IBM had expanded the Watson brand which used to be exclusive to its famous Question Answering Machine to cover, confusingly, a greatly expanded group of analytic products. Then in 2016 IBM doubled down on the confusion by introducing their DSx (Data Science Experience) platform as a separate offering primarily aimed at open source coders.
The customers that Gartner surveyed in 2017 for this year’s rating just couldn’t figure it out. Too many offerings got in the way of support and customer satisfaction, though Gartner looked past the lack of integration to give some extra points for vision.
IBM could easily bounce back if they clear up this multi-headed approach, show us how it’s supposed to be integrated into one offering, and then provide the support to make the transition. Better luck next year.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
Large Collection of Neural Nets, Numpy, Pandas, Matplotlib, Scikit and ML Cheat Sheets
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This collection covers much more than the topics listed in the title. I also features Azure, Python, Tensorflow, data visualization, and many other cheat sheets. Additional cheat sheets can be found here and here. Below is a screenshot (extract from the data visualization cheat sheet.)

The one below is rather interesting too, but the source is unknown, and anywhere it was posted, it is unreadable. This is the best rendering after 30 minutes of work:

The full list can be found here or here. It covers the following topics:
- Big-O Algorithm Cheat Sheet: http://bigocheatsheet.com/
- Bokeh Cheat Sheet: https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Python_Bokeh_Cheat_Sheet.pdf
- Data Science Cheat Sheet: https://www.datacamp.com/community/tutorials/python-data-science-cheat-sheet-basics
- Data Wrangling Cheat Sheet: https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf
- Data Wrangling: https://en.wikipedia.org/wiki/Data_wrangling
- Ggplot Cheat Sheet: https://www.rstudio.com/wp-content/uploads/2015/03/ggplot2-cheatsheet.pdf
- Keras Cheat Sheet: https://www.datacamp.com/community/blog/keras-cheat-sheet#gs.DRKeNMs
- Keras: https://en.wikipedia.org/wiki/Keras
- Machine Learning Cheat Sheet: https://www.datasciencecentral.com/profiles/blogs/the-making-of-a-cheatsheet-emoji-edition
- Machine Learning Cheat Sheet: https://docs.microsoft.com/en-in/azure/machine-learning/machine-learning-algorithm-cheat-sheet
- ML Cheat Sheet:: http://peekaboo-vision.blogspot.com/2013/01/machine-learning-cheat-sheet-for-scikit.html
- Matplotlib Cheat Sheet: https://www.datacamp.com/community/blog/python-matplotlib-cheat-sheet#gs.uEKySpY
- Matpotlib: https://en.wikipedia.org/wiki/Matplotlib
- Neural Networks Cheat Sheet: http://www.asimovinstitute.org/neural-network-zoo/
- Neural Networks Graph Cheat Sheet: http://www.asimovinstitute.org/blog/
- Neural Networks: https://www.quora.com/Where-can-find-a-cheat-sheet-for-neural-network
- Numpy Cheat Sheet: https://www.datacamp.com/community/blog/python-numpy-cheat-sheet#gs.AK5ZBgE
- NumPy: https://en.wikipedia.org/wiki/NumPy
- Pandas Cheat Sheet: https://www.datacamp.com/community/blog/python-pandas-cheat-sheet#gs.oundfxM
- Pandas: https://en.wikipedia.org/wiki/Pandas_(software)
- Pandas Cheat Sheet: https://www.datacamp.com/community/blog/pandas-cheat-sheet-python#gs.HPFoRIc
- Pyspark Cheat Sheet: https://www.datacamp.com/community/blog/pyspark-cheat-sheet-python#gs.L=J1zxQ
- Scikit Cheat Sheet: https://www.datacamp.com/community/blog/scikit-learn-cheat-sheet
- Scikit-learn: https://en.wikipedia.org/wiki/Scikit-learn
- Scikit-learn Cheat Sheet: http://peekaboo-vision.blogspot.com/2013/01/machine-learning-cheat-sheet-for-scikit.html
- Scipy Cheat Sheet: https://www.datacamp.com/community/blog/python-scipy-cheat-sheet#gs.JDSg3OI
- SciPy: https://en.wikipedia.org/wiki/SciPy
- TesorFlow Cheat Sheet: https://www.altoros.com/tensorflow-cheat-sheet.html
- Tensor Flow: https://en.wikipedia.org/wiki/TensorFlow
Other DSC Resources
- Invitation to Join Data Science Central
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, Feb. 22, 2018 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB), the leading modern, general purpose database platform, today announced that its Chief Financial Officer, Michael Gordon, will present at the Morgan Stanley Technology, Media and Telecom Conference in San Francisco.
![]()
The MongoDB presentation is scheduled for Thursday, March 1, 2018, at 9:35 a.m. Pacific Time. A live webcast of the presentation will be available on the Events page of the MongoDB investor relations website at https://investors.mongodb.com/events-and-presentations/events. A replay of the webcast will also be available for a limited time.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 4,900 customers in over 90 countries. The MongoDB database platform has been downloaded over 30 million times and there have been more than 700,000 MongoDB University registrations.
Investor Relations
Brian Denyeau
ICR
646-277-1251
ir@mongodb.com
Media Relations
MongoDB
866-237-8815 x7186
communications@mongodb.com
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-to-present-at-the-morgan-stanley-technology-media–telecom-conference-300603071.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-to-present-at-the-morgan-stanley-technology-media–telecom-conference-300603071.html
SOURCE MongoDB, Inc.
Off the Beaten Path – HTM-based Strong AI Beats RNNs and CNNs at Prediction and Anomaly Detection
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: This is the second in our “Off the Beaten Path” series looking at innovators in machine learning who have elected strategies and methods outside of the mainstream. In this article we look at Numenta’s unique approach to scalar prediction and anomaly detection based on their own brain research.
 Numenta, the machine intelligence company founded in 2005 by Jeff Hawkins of Palm Pilot fame might well be the poster child for ‘off the beaten path’. More a research laboratory than commercial venture, Hawkins has been pursuing a strong-AI model of computation that will at once directly model the human brain, and as a result be a general purpose solution to all types of machine learning problems.
Numenta, the machine intelligence company founded in 2005 by Jeff Hawkins of Palm Pilot fame might well be the poster child for ‘off the beaten path’. More a research laboratory than commercial venture, Hawkins has been pursuing a strong-AI model of computation that will at once directly model the human brain, and as a result be a general purpose solution to all types of machine learning problems.
After swimming against the tide of the ‘narrow’ or ‘weak’ AI approaches represented by deep learning’s CNNs and RNN/LSTMs his bet is starting to pay off. There are now benchmarked studies showing that Numenta’s strong AI computational approach can outperform CNN/RNN based deep learning (which Hawkins characterizes as ‘classic’ AI) at scalar predictions (future values of things like commodity, energy, or stock prices) and at anomaly detection.
How Is It Different from Current Deep Learning
The ‘strong AI’ approach pursued by Numenta relies on computational models drawn directly from the brain’s own architecture.
‘Weak AI’ by contrast, represented by the full panoply of deep neural nets, acknowledges that it is only suggestive of true brain function, but it gets results.
We are all aware of the successes in image, video, text, and speech analysis that CNNs and RNN/LSTMs have achieved and that is their primary defense. They work. They give good commercial results. But we are also beginning to recognize their weaknesses: large training sets, susceptibility to noise, long training times, complex setup, inability to adapt to changing data, and time invariance that begin to show us where the limits of their development will lead us.
Numenta’s computational approach has a few similarities to these and many unique contributions that require those of us involved in deep learning to consider a wholly different computational paradigm.
Hierarchical Temporal Memory (HTM)
It would take several articles of this length to do justice to the methods introduced by Numenta. Here are the highlights.
 HTM and Time: Hawkins uses the term Hierarchical Temporal Memory (HTM) to describe his overall approach. The first key to understanding is that HTM relies on data that streams over time. Quoting from previous interviews, Hawkins says,
HTM and Time: Hawkins uses the term Hierarchical Temporal Memory (HTM) to describe his overall approach. The first key to understanding is that HTM relies on data that streams over time. Quoting from previous interviews, Hawkins says,
“The brain does two things: it does inference, which is recognizing patterns, and it does behavior, which is generating patterns or generating motor behavior. Ninety-nine percent of inference is time-based – language, audition, touch – it’s all time-based. You can’t understand touch without moving your hand. The order in which patterns occur is very important.”
So the ‘memory’ element of HTM is how the brain differently interprets or relates each sequential input, also called ‘sequence memory’.
By contrast, conventional deep learning uses static data and is therefore time invariant. Even RNN/LSTMs that process speech, which is time based, actually do so on static datasets.
Sparse Distributed Representations (SDRs): Each momentary input to the brain, for example from the eye or from touch is understood to be some subset of all the available neurons in that sensor (eye, ear, finger) firing and forwarding that signal upward to other neurons for processing.
Since not all the available neurons fire for each input, the signal sent forward can be seen as a Sparse Distributed Representation (SDR) of those that have fired (the 1s in the binary representation) versus the hundreds or thousands that have not (the 0s in the binary representation). We know from research that on average only about 2% of neurons fire with any given event giving meaning to the term ‘sparse’.
SDRs lend themselves to vector arrays and because they are sparse have the interesting characteristics that they can be extensively compressed without losing meaning and are very resistant to noise and false positives.
By comparison, deep neural nets fire all neurons in each layer, or at least those that have reached the impulse threshold. This is an acknowledged drawback by current researchers in moving DNNs much beyond where they are today.
Learning is Continuous and Unsupervised: Like CNNs and RNNs this is a feature generating system that learns from unlabeled data.
When we look at diagrams of CNNs and RNNs they are typically shown as multiple (deep) layers of neurons which decrease in pyramidal fashion as the signal progresses. Presumably discovering features in this self-constricting architecture down to the final classifying layer.
HTM architecture by contrast is simply columnar with columns of computational neurons passing the information on to upward layers in which pattern discovery and recognition occurs organically by the comparison of one SDR (a single time signal) to the others in the signal train.
HTM has the characteristic that it discovers these patterns very rapidly, with as few as on the order of 1,000 SDR observations. This compares with the hundreds of thousands or millions of observations necessary to train CNNs or RNNs.
Also the pattern recognition is unsupervised and can recognize and generalize about changes in the pattern based on changing inputs as soon as they occur. This results in a system that not only trains remarkably quickly but also is self-learning, adaptive, and not confused by changes in the data or by noise.
Numenta offers a deep library of explanatory papers and YouTube videos for those wanting to experiment hands-on.
Where Does HTM Excel
HTM has for many years been a work in progress. That has recently changed. Numenta has published several peer reviewed performance papers and established benchmarking in areas of its strength that highlight its superiority over traditional DNNs and other ML methods on particular types of problems.
In general, Numenta says that the current state of its technology represented by its open source project NuPIC (Numenta Platform for Intelligent Computing) currently excels in three areas:
Anomaly Detection in streaming data. For example:
- Highlighting anomalies in the behavior of moving objects, such as tracking a fleet’s movements on a truck by truck basis using geospatial data.
- Understanding if human behavior is normal or abnormal on a securities trading floor.
- Predicting failure in a complex machine based on data from many sensors.
Scalar Predictions, for example:
- Predicting energy usage for a utility on a customer by customer basis.
- Predicting New York City taxi passenger demand 2 ½ hours in advance based on a public data stream provided by the New York City Transportation Authority.
Highly Accurate Semantic Search on static and streaming data (these examples are from Corticol.Io a Numenta commercial partner using the SDR concept but not NuPICS).
- Automate extraction of key information from contracts and other legal documents.
- Quickly find similar cases to efficiently solve support requests.
- Extract topics from different data sources (e.g. emails, social media) and determine customers’ intent.
- Terrorism Prevention: Monitor all social media messages alluding to terrorist activity even if they don’t use known keywords.
- Reputation Management: Track all social media posts mentioning a business area or product type without having to type hundreds of keywords.
Two Specific Examples of Performance Better Than DNNs
Taxi Demand Forecast
In this project, the objective was to predict the demand for New York City taxi service 2 ½ hours in advance based on a public data stream provided by the New York City Transportation Authority. This was based on historical streaming data at 30 minutes intervals using the previous 1,000, 3,000, or 6,000 observations as the basis for the forward projection 5 periods (2 ½ hours) in advance. The study (which you can see here) compared ARIMA, TDNN, and LSTM to the HTM method where HTM demonstrated the lowest error rate.

Machine Failure Prediction (Anomaly)
The objective of this test was to compare two of the most popular anomaly detection routines (Twitter ADVec and Etsy Skyline) against HTM in a machine failure scenario. In this type of IoT application it’s important that the analytics detect all the anomalies present, detect them as far before occurrence as possible, trigger no false alarms (false positives), and work with real time data. A full description of the study can be found here.
The results showed that the Numenta HTM outperformed the other methods by a significant margin. 
Even more significantly, as noted in the caption below, the Numenta HTM method identified the potential failure a full 3 hours before the other techniques.

You can find other benchmark studies on the Numenta site.
The Path Forward
Several things are worthy of note here since as we mentioned earlier the Numenta HTM platform is still a work in progress.
Commercialization
Numenta’s business model currently calls for it to be the center of a commercial ecosystem while retaining its primary research focus. Currently Numenta has two commercially licensed partners, Corticol.Io which focuses on streaming text and semantic interpretation. The second is Grok (Grokstream.com) which has adapted the NuPIC core platform for anomaly detection in all types of IT operational scenarios. The core NuPICs platform is open source if you’re motivated to experiment with potential commercial applications.
Image and Text Classification
A notable absence from the current list of capabilities is image and text classification. There are no current plans for Numenta to develop image classification from static data since that is not on the critical path defined by streaming data. It’s worth noting that others have demonstrated the use of HTM as a superior technique for image classification not using the NuPICs platform.
Near Term Innovation
In my conversation with Christy Maver, Numenta’s VP of Marketing she expressed that they are confident that they will have a fairly complete framework for how the neocortex works within the timeframe of perhaps a year. This last push is in the area of sensorimotor integration that would be the core concept in applying the HTM architecture to robotics.
For commercial development, the focus will be on partners to license the IP. Even IBM established a Cortical Research Center a few years back staffed with about 100 researchers to examine the Numenta HTM approach. Like so many others now trying to advance AI by more closely modeling the brain, IBM, like Intel and others has moved off in the direction of specialty chips that fall in the category on neuromorphic or spiking chips. Brainchip out of Irvine already has a spiking neuromorphic chip in commercial use. As Maver alluded, there may be a silicon representation of Numenta’s HTM in the future.
Other articles in this series:
Off the Beaten path – Using Deep Forests to Outperform CNNs and RNNs
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
MongoDB, Inc. Announces Date of Fourth Quarter and Full Year Fiscal 2018 Earnings Call
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, Feb. 13, 2018 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB), the leading modern, general purpose database platform, today announced it will report its financial results for the fourth quarter and full year ended January 31, 2018, after the U.S. financial markets close on Tuesday, March 13, 2018.
![]()
In conjunction with this announcement, MongoDB will host a conference call on Tuesday, March 13, 2018, at 5:00 p.m. (Eastern Time) to discuss the Company’s financial results and business outlook. A live webcast of the call will be available on the “Investor Relations” page of the Company’s website at http://investors.mongodb.com. To access the call by phone, dial 800-239-9838 (domestic) or 323-794-2551 (international). A replay of this conference call will be available for a limited time at 844-512-2921 (domestic) or 412-317-6671 (international) using conference ID 5850950. A replay of the webcast will also be available for a limited time at http://investors.mongodb.com.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 4,900 customers in over 90 countries. The MongoDB database platform has been downloaded over 30 million times and there have been more than 700,000 MongoDB University registrations.
Investor Relations
Brian Denyeau
ICR for MongoDB
646-277-1251
ir@mongodb.com
Media Relations
MongoDB, North America
866-237-8815 x7186
communications@mongodb.com
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-announces-date-of-fourth-quarter-and-full-year-fiscal-2018-earnings-call-300598094.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-announces-date-of-fourth-quarter-and-full-year-fiscal-2018-earnings-call-300598094.html
SOURCE MongoDB
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: How about a deep learning technique based on decision trees that outperforms CNNs and RNNs, runs on your ordinary desktop, and trains with relatively small datasets. This could be a major disruptor for AI.
 Suppose I told you that there is an algorithm that regularly beats the performance of CNNs and RNNs at image and text classification.
Suppose I told you that there is an algorithm that regularly beats the performance of CNNs and RNNs at image and text classification.
- That requires only a fraction of the training data.
- That you can run on your desktop CPU device without need for GPUs.
- That trains just as rapidly and in many cases even more rapidly and lends itself to distributed processing.
- That has far fewer hyperparameters and performs well on the default settings.
- And relies on easily understood random forests instead of completely opaque deep neural nets.
Well there is one just announced by researchers Zhi-Hua Zhou and Ji Feng of the National Key Lab for Novel Software Technology, Nanjing University, Nanjing, China. And it’s called gcForest.
State of the Art
This is the first installment in a series of “Off the Beaten Path” articles that will focus on methods that advance data science that are off the mainstream of development.
Mainstream in AI for image and text classification is clearly in deep neural nets (DNNs), specifically Convolutional Neural Nets (CNNs), Recurrent Neural Nets (RNNs), and Long/Short Term Memory Nets (LSTM). The reason is simple. These were the first techniques shown to work effectively on these featureless problems and we were completely delighted to have tools that work.
Thousands of data scientists are at this moment reskilling to be able to operate these DNN variants. The cloud giants are piling in because of the extreme compute capacity required to make them work which will rely on their mega-clouds of high performance specialty GPM chips. And many hundreds if not thousands of AI startups, not to mention established companies, are racing to commercialize these new capabilities in AI. Why these? Because they work.
Importantly, not only have they been proven to work in a research environment but they are sufficiently stable to be ready for commercialization.
The downsides however are well knows. They rely on extremely large datasets of labeled data that for many problems may never be physically or economically available. They require very long training times on expensive GPU machines. The long training time is exacerbated because there are also a very large number of hyperparameters which are not altogether well understood and require multiple attempts to get right. It is still true that some of these models fail to train at all losing all the value of the time and money invested.
Combine this with the estimate that there are perhaps only 22,000 individuals worldwide who are skilled in this area, most employed by the tech giants. The result is that many potentially valuable AI problems simply are not being addressed.
Off the Beaten Path
To some extent we’ve been mesmerized by DNNs and their success. Most planning and development capital is pouring into AI solutions based on where DNNs are today or where they will be incrementally improved in a year or two.
But just as there were no successful or practical DNNs just 5 to 7 years ago, there is nothing to say that the way forward is dependent on current technology. The history of data science is rife with disruptive methods and technologies. There is no reason to believe that those won’t continue to occur. gcForest may be just such a disruptor.
gcForest in Concept
gcForest (multi-Grained Cascade Forest) is a decision tree ensemble approach in which the cascade structure of deep nets is retained but where the opaque edges and node neurons are replaced by groups of random forests paired with completely-random tree forests. In this case, typically two of each for a total of four in each cascade layer.
Image and text problems are categorized as ‘feature learning’ or ‘representation learning’ problems where features are neither predefined nor engineered as in traditional ML problems. And the basic rule in these feature discovery problems is to go deep, using multiple layers each of which learns relevant features of the data in order to classify them. Hence the multi-layer structure so familiar with DNNs is retained.
All the images and references in this article are from the original research report which can be found here.

Figure 1: Illustration of the cascade forest structure. Suppose each level of the cascade consists of two random forests (black) and two completely-random tree forests (blue). Suppose there are three classes to predict; thus, each forest will output a three-dimensional class vector, which is then concatenated for re-representation of the original input.
By using both random forests and completely-random tree forests the authors gain the advantage of diversity. Each forest contains 500 completely random trees allowed to split until each leaf node contains only the same class of instances making the growth self-limiting and adaptive, unlike the fixed and large depth required by DNNs.
The estimated class distribution forms a class vector which is then concatenated with the original feature vector to be the input of the next level cascade. Not dissimilar from CNNs.
The final model is a cascade of cascade forests. The final prediction is obtained by aggregating the class vectors and selecting the class with the highest maximum score.
The Multi-Grained Feature
The multi-grained feature refers to the use of a sliding window to scan raw features. Combining multiple size sliding windows (varying the grain) becomes a hyperparameter that can improve performance.

Figure 4: The overall procedure of gcForest. Suppose there are three classes to predict, raw features are 400-dim, and three sizes of sliding windows are used.
Replaces both CNNs and RNNs
As a bonus gcForest works well with either sequence data or image-style data.

Figure 3: Illustration of feature re-representation using sliding window scanning. Suppose there are three classes, raw features are 400-dim, and sliding window is 100-dim.
Reported Accuracy
To achieve accurate comparisons the authors held many variables constant between the two approaches and performance might have been improved with more tuning. Here are just a few of the reported performance results on several different standard reference sets.
 Image Categorization: The MNIST dataset [LeCun et al., 1998] contains 60,000 images of size 28 by 28 for training (and validating), and 10,000 images for testing.
Image Categorization: The MNIST dataset [LeCun et al., 1998] contains 60,000 images of size 28 by 28 for training (and validating), and 10,000 images for testing.
 Face Recognition: The ORL dataset [Samaria and Harter, 1994] contains 400 gray-scale facial images taken from 40 persons. We compare it with a CNN consisting of 2 conv-layers with 32 feature maps of 3 × 3 kernel, and each conv-layer has a 2 × 2 maxpooling layer followed. We randomly choose 5/7/9 images per person for training, and report the test performance on the remaining images.
Face Recognition: The ORL dataset [Samaria and Harter, 1994] contains 400 gray-scale facial images taken from 40 persons. We compare it with a CNN consisting of 2 conv-layers with 32 feature maps of 3 × 3 kernel, and each conv-layer has a 2 × 2 maxpooling layer followed. We randomly choose 5/7/9 images per person for training, and report the test performance on the remaining images.
 Hand Movement Recognition: The sEMG dataset [Sapsanis et al., 2013] consists of 1,800 records each belonging to one of six hand movements, i.e., spherical, tip, palmar, lateral, cylindrical and hook. This is a time-series dataset, where EMG sensors capture 500 features per second and each record associated with 3,000 features. In addition to an MLP with input-1,024-512-output structure, we also evaluate a recurrent neural network, LSTM [Gers et al., 2001] with 128 hidden units and sequence length of 6 (500-dim input vector per second).
Hand Movement Recognition: The sEMG dataset [Sapsanis et al., 2013] consists of 1,800 records each belonging to one of six hand movements, i.e., spherical, tip, palmar, lateral, cylindrical and hook. This is a time-series dataset, where EMG sensors capture 500 features per second and each record associated with 3,000 features. In addition to an MLP with input-1,024-512-output structure, we also evaluate a recurrent neural network, LSTM [Gers et al., 2001] with 128 hidden units and sequence length of 6 (500-dim input vector per second).
The authors show a variety of other test results.
Other Benefits
The run times on standard CPU machines are quite acceptable especially as compared to comparable times on GPU machines. In one of the above tests the gcForest ran 40 minutes compared to the MLP version which required 78 minutes.
Perhaps the biggest unseen advantage is that the number of hyperparameters is very much less that on a DNN. In fact DNN research is hampered because comparing two separate runs with different hyperparameters so fundamentally changes the learning process that researchers are unable to accurately compare them. In this case the default hyperparameters on gcForest run acceptably across a wide range of data types, though tuning in these cases will significantly approve performance.
The code is not fully open source but can be had from the authors. The link for that request occurs in the original study.
We have all been waiting for DNNs to be sufficiently simplified that the average data scientist can have it on call in his tool chest. The cloud giants and many of the platform developers are working on this but a truly simplified version still seems very far away.
It may be that gcForest, though still in research, is the first step toward a DNN replacement that is fast, powerful, runs on your ordinary machine, trains with little data, and is easy for anyone with a decent understanding of decision trees to operate.
P.S. Be sure to note where this research was done, China.
Other articles in this series:
Off the Beaten Path – HTM-based Strong AI Beats RNNs and CNNs at Prediction and Anomaly Detection
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
MMS • RSS
NEW YORK, Feb. 8, 2018 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB), the leading modern, general purpose database platform, today announced that its Chief Financial Officer, Michael Gordon, will present at the Goldman Sachs Technology and Internet Conference in San Francisco.
![]()
The MongoDB presentation is scheduled for Wednesday, February 14, 2018, at 9:40 a.m. Pacific Time. A live webcast of the presentation will be available on the Events page of the MongoDB investor relations website at https://investors.mongodb.com/events-and-presentations/events. A replay of the webcast will also be available for a limited time.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 4,900 customers in over 90 countries. The MongoDB database platform has been downloaded over 30 million times and there have been more than 700,000 MongoDB University registrations.
Investor Relations
Brian Denyeau
ICR
646-277-1251
ir@mongodb.com
Media Relations
MongoDB
866-237-8815 x7186
communications@mongodb.com
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-to-present-at-goldman-sachs-technology-and-internet-conference-300596079.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-to-present-at-goldman-sachs-technology-and-internet-conference-300596079.html
SOURCE MongoDB, Inc.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: There are an increasing number of larger companies that have truly embraced advanced analytics and deploy fairly large numbers of data scientists. Many of these same companies are the one’s beginning to ask about using AI. Here are some observations and tips on the problems and opportunities associated with managing a larger data science function.
 We spend a lot of time looking inward at our profession of data science, studying new developments, looking for anomalies in our own practices, and spreading the word to other practitioners. But when we look outward to communicate about data science to others it’s different. Maybe you have this same experience but when I talk to new clients it’s often as not to educate them at a fairly basic level about what’s possible and what’s not.
We spend a lot of time looking inward at our profession of data science, studying new developments, looking for anomalies in our own practices, and spreading the word to other practitioners. But when we look outward to communicate about data science to others it’s different. Maybe you have this same experience but when I talk to new clients it’s often as not to educate them at a fairly basic level about what’s possible and what’s not.
The good news is that there’s now a third group: execs and managers in larger companies who have embraced advanced analytics and who try to keep up by reading, but are not formally trained. If these analytics managers are data scientists, all well and good. But as you move up the chain of command just a little bit you’ll soon find yourself talking to someone who may be an enthusiastic supporter but whose well intentioned self-education still leaves them short on some basic knowledge.
Who are these folks? Well Gartner says you’re a mid-size user if you have 6 to 12 data scientists and it takes more than 12 to be a larger user. And that’s not counting the dedicated data engineers, IT, and analysts also assigned to the task. So it’s certainly the large users and probably many of the mid-size users we’re addressing.
For a while I’ve been collecting what I call Cliff Notes for Managing Data Science to address this group. Here’s the first installment.
Do you really want an AI strategy?
 I’ll try to keep this short because this topic tends to set me off. The popular press and many of the platform and application vendors have started just recently calling everything in advanced analytics “Artificial Intelligence”. Not only is this not accurate it makes the conversation much more difficult.
I’ll try to keep this short because this topic tends to set me off. The popular press and many of the platform and application vendors have started just recently calling everything in advanced analytics “Artificial Intelligence”. Not only is this not accurate it makes the conversation much more difficult.
First of all if you’ve already got a dozen data scientists then you are firmly in the camp of machine learning / predictive analytics. Machine learning is much more mature and more broadly useful than just AI (which also uses a narrow group of machine learning techniques). So good for you. Keep up the good work. Just because it helps humans make decisions, what you have been doing so far is not AI.
Modern AI is the outcome of deep neural nets and reinforcement learning. AI involves recognition and response to text, voice, image, and video. It also encompasses automated and autonomous vehicles, game play, and the examination of ultra-large data sets to identify very rare events. This area is quite new and only the text, voice, image, and video capabilities are ready for commercial deployment.
Technically if you have deployed a chatbot anywhere in your organization you are utilizing AI. Chatbot input and sometimes output is based on NLU (natural language understanding) one of the good applications of deep learning. Chances are that if you do not have at least one chatbot today, you will have one within a year. Chatbots are a great way to engage with customers and save money. They are not whiz-bang solutions. This is what most of AI is going to look like when deployed.
By all means begin the conversation about where modern AI may be of value in your strategy but don’t oversell this yet. The real money is in what you’ve been doing right along with predictive and prescriptive analytics, IoT, and the other well developed machine learning technologies.
Should your data scientists be centralized or decentralized?
 There are two schools of thought here and the deciding factor is probably how many data scientists you have. One school of thought is that you should embed them closest to where the action is, in marketing, sales, finance, manufacture. You name it, every process can benefit from advanced analytics. They will learn the unique perspective, language, problems, and data of that process which will make them more effective.
There are two schools of thought here and the deciding factor is probably how many data scientists you have. One school of thought is that you should embed them closest to where the action is, in marketing, sales, finance, manufacture. You name it, every process can benefit from advanced analytics. They will learn the unique perspective, language, problems, and data of that process which will make them more effective.
On the other hand, the average data scientist has had that title only 2 ½ years. That just shows you how fast we’re starting to graduate new ones and how rapidly they’re getting snapped up. What it means is that you probably have a few relatively experienced data scientists who have been around the block and a larger number of juniors who are just getting started.
The juniors should have come with a very impressive set of technical skills and in theory can contribute to any data science problem. The reality is that the juniors and the seniors as well need to keep learning by experience, not to mention having time to catch up with the new techniques that are being introduced all the time. So the goal will be to have enough contact time between the seniors and the juniors so that everyone continues to develop.
If you’ve got a half-dozen with various experience levels working together that’s probably OK. However one interesting model is a hybrid that brings all your data scientists together on a fairly regular schedule so they can share experiences and learning.
Another possible implementation would be to have a few seniors deployed out in each end user organization with the juniors on rotating assignment to assist.
Spread them too thin and you won’t benefit from their growth. It may also cause them to leave for greener pastures.
Should every data science project have an ROI?
The further you go up the chain of command, the more senior management will say ‘of course, this is our most basic concept’. And that’s not necessarily bad but it needs to come with some balance.
It will be many years and perhaps never when you fully exploit all the data and all the analytics that will create competitive advantage. And many of those applications haven’t even been conceived today.
One type of financial discipline that is completely appropriate is pre-establishing time budgets or measures that tell you when the solution is good enough. This is particularly true in all types of customer behavior modeling.
If your data science team has a built in bias that is a potential weakness it is that they will always want to keep working to make those models better. Even if the time would be better spent on other data science projects. This scheduling discipline needs the understanding of exactly how the work is done and that most likely belongs to your Chief Data Scientist.
Incidentally, that Chief Data Scientist should also be regularly evaluating and recommending platforms and techniques to make the group more efficient, particularly in the fast emerging area of automated machine learning.
HOWEVER, there needs to be an opportunity for discovery. This is a little like an engineering lab where your data scientists need a little formally allocated time to ‘go in there and find something interesting’. Give them a little unstructured time to explore.
The most interesting phrase in science is not ‘Eureka’, but ‘that’s funny’ (Isaac Asimov).
Should you keep all that data or only what you need?
This question is very closely related to the one above about ROI. Our ordinary instinct is to keep only what we need. However there is a strong school of thought among data scientists that data is now so inexpensive to store that we should keep it all and figure out how to benefit from it later.
The opposite school starts with ‘what is the problem we are trying to solve’ and works backwards to the data necessary to achieve that. This is also the school that says when we have achieved X% accuracy to this question that is sufficient and any data not necessary to support that should be discarded.
Well the problem is that all that data that doesn’t appear to be predictive most assuredly contains pockets of outliers and pockets of really interesting new opportunities. You may not have the manpower to dig into it today, but that’s also why we argued for giving your data science team some self-directed time to ‘find something interesting’.
Storing new data in a cloud data lake where data scientists can explore it is ridiculously cheap (but not free). Where you need discipline is when you operationalize your new insight and it becomes mission critical. Then you need the full weight of good data management, provenance control, bias elimination, and the proverbial single definition of the truth.
What about Citizen Data Scientists and the democratization of analytics?

All data science projects are team efforts and those teams consists of data scientists, LOB SMEs, and probably some analysts and folks from IT. As these non-DS team members get more experience of course they become more valuable. Particularly they are increasingly able to restate business problems as data science problems that they can bring to the table.
What really scares me and should scare you too are statements in the press to the effect that AI and machine learning have become so user friendly that they are “only a little more complex than word processors or spreadsheets”, or “users no longer need to code”.
That may be very narrowly true but that does not mean you should ever begin a data science project without including an adequate number of formally trained data scientists.
It is true that our advanced analytic platforms are becoming easier to use. The benefit is that fewer data scientists can do the work that used to require many more. It does not mean that citizen data scientists, no matter how well intentioned, should be given control over these projects.
The slick visual user interfaces in many analytic applications hide many critical considerations that a DS will know and a CDS will not. The issues are much too long to list here but for example include false positive/false negative threshold cost tradeoffs, best algorithm selection, the creation of new features, hyperparameter adjustment of those algorithms, bias detection, and the list goes on. This is no self-driving car.
What we recommend is indeed getting those analysts and LOB managers deeply involved in the team process. That will allow them to spot new opportunities. If you want to empower your organizations start with actively educating for data literacy. Leave actually driving the data science to the data scientists.
Cybersecurity may be what forces your hand into true AI
Whether you are dealing with cybersecurity in-house or contracting out, this is the first place you should be sure that there is real AI at work. It turns out that the deep learning techniques at the core of modern AI are particularly good at spotting anomalies and threats. If you want to front load your AI strategy this is the best place to start. As the Marines say, don’t bring a knife to a gun fight.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at: