Month: May 2019

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Calin: Hello, everyone, and thank you very much for having me here, first of all, because I’ve been upgraded to this massive room because of the interest that has been registered so I wasn’t expecting this so I’m both humbled and grateful for all of you to come here.
Imagine that you are the systems engineer at the fintech and you have worked on the infrastructure of a payment services provider product for more than a year and within half an hour into a planned penetration test, your whole production cluster gets compromised. We are talking about firewall rules being bypassed and we’re talking about Google Cloud services that you shouldn’t have access to also being bypassed.
In a day and age in which no security control is completely impenetrable, I am here today to talk to you about our hurdles as a financial-regulated institution and some of the things we’ve learned and what you can take away as well.
So who am I? I am Ana Calin and I am the systems engineer in that little story I was telling you about and I work for Paybase.
The things I’m going to cover today. First of all, I’m going to give you a tiny bit of context as who is Paybase and what we do, then we’ll look at the things we’ve achieved so far and some of our tech stacks, so not the complete tech stack but some of it, then I’ll give you proper details about this compromise that I keep on talking about. Some of the things you can take away from security and resilience point of view and then challenges we’ve encountered on our road to compliance, specifically PCI DSS compliance and challenges we’ve managed to avoid specifically because of our cloud native setup.
Paybase
Paybase is an API-driven payments services provider. Our business model is B2B, so business to business, and our customers are marketplaces, gig/sharing economies, cryptocurrencies or, in more general terms, any businesses that connect a buyer with the seller. Our offering is very important because platform businesses, such as the ones I just mentioned, face a very tough challenge. Not only do they have to solve very complex technical issues, they also now, with the updated regulation, have to either become a regulated payments institution themselves or they have to integrate with a third party. The current solutions, well, they are very costly and they are very inflexible, so we came up with a product that is less expensive, very flexible, and also less complex. In other words, we just make regulation easier for our customers.
What We Have Achieved so Far
We are under two years old, one and a half, about the same thing. We have built our own processing platform from scratch, completely cloud native and with more than 90% open source software and we’re currently onboarding our first seven clients and we are in no shortage of demand. We are FCA authorized, we have an electronic money institution license and in 2017, we have received an Innovate UK grant worth 700,000 pounds in order to democratize eMoney infrastructure for startups and SMEs.
We are also PCI DSS Level 1 compliant, this is the highest level of compliance and in my opinion, having worked directly with it, it’s a huge achievement given that the current state of this standard is one that most very large institutions that need to comply choose to actually pay annual fines rather than become compliant. This makes sense financially to them because of the technical complexity of their systems, the technical debt and many of them because of the hundreds of legacy applications that they are still running.
Some fun facts about PCI DSS. Between 2012 and 2017, there has been a 167% increase in companies that have become compliant and yet in 2017, more than 80% of the businesses that should be compliant remain non-compliant.
Our Tech Stack
We follow a microservices-based infrastructure but our actual application is a distributed monolith that is separated by entities and the reason why we do this is because that way, we get flexibility in how we separate concerns and we scale. We have built everything on top of Google Cloud Platform and the reason why we chose Google Cloud is because at the time, we needed a Kubernetes-managed service and Google Cloud had the best offering and if I am to give my own personal opinion, I still think that, from a Kubernetes-managed-service point of view, they still have the best offering in the market today.
Our infrastructure is built with Terraform as infrastructure as code and our applications are deployed with Kubernetes wrapped around in Helm. From an observability stack, which is really important, just in general to have a good view of what’s happening into your cluster, we use EFK, so Elasticsearch, Fluentd, and Kibana for low collection and Prometheus and Grafana for metric aggregation. If you are thinking, “Why do we need the different observability stacks?” first of all, although they are complementary to each other, they give us different things. EFK gives us events about errors and what happen in the application and Prometheus and Grafana give us metrics, so for example, the error rate of a service, the CPU usage, whether a service is up or down.
From an actual application point of view, we have more than 50 microservices. Our application is written mainly in JavaScript but we use Protobuf as an interface definition language so that in the event we decide that we want to rewrite parts of our application into a more pragmatic language, then Protobuf, gRPC in this case, would give us that, so we’re not locked into our choice of programming language.
The communication between services is done synchronously via gRPC with HTTP/2 as a transport layer and we also use NSQ as a distributed messaging broker which helps us synchronously process event messaging.
Details about the Compromise
Now that you know a bit of our tech stack I’m going to tell you a bit about our compromise, what happened. First of all, a bit of context. This happened in the scope of a planned internal infrastructure penetration test, this happened in our production cluster, but at the time, the production cluster wasn’t actively used by customers. The pentester, let’s call him Mark because, well, that’s his actual name, had access to a privilege container within the cluster, so it wasn’t a 100% complete compromise from the outside.
There were a few weak links. First of all, GKE, so Kubernetes managed service from Google Cloud comes insecure by default or it came at the end of last year. What do I mean by insecure by default? If you are to provision a cluster, you would get the compute engine scope with the cluster, you would get the compute engine default service account and you would get legacy metadata endpoints enabled. The compute engine scope refers to an OAuth scope, so an access scope that allows different Google Cloud services to talk to each other. In this case, GKE speaking to GCE and it was a read/write access.
I’m going to be naughty and I’m going to take the blame and put it on someone else, in this case, Terraform. The first bit on the screen, it’s a part of the documentation taken yesterday from how to provision a container cluster with Terraform. As you can read, it says, “The following scopes are necessary to ensure the current functionality of the cluster.” and the very first one is compute/read/write, which is this engine scope that I’m talking about. I can tell you that this is a complete lie, ever since we did that penetration test, we realized that you don’t need this, we took it out and our clusters are functioning just right.
Compute engine service account. When you provision a cluster in GKE, if you don’t specify a specific service account, it uses the default service account associated with your project. You might think that this is not necessarily a problem, well, it’s a big problem because this service account is associated with the editor role in Google Cloud Platform, which has a lot of permissions. I’m going to talk to you about the legacy metadata endpoints in a second.
Metadata Endpoints
My next point was about queueing the metadata endpoints, so within Google Cloud you can queue the metadata endpoints of a node and if this is enabled, this gives you details about the Kubernetes API as the kubelet. What that means is that if you run this particular command or just the kubelet you will be able to get access to certain secrets that that relate to Kubernetes API from within any pod or node within a GKE cluster and from there on, well, the world is your oyster.
What can you do to disable this? First of all, a very quick disclaimer. The latest version of GKE, so 1.12, which is the very current one, comes with this metadata endpoint disabled, but if you’re not on that version, you can disable it either by building your cluster with gcloud CLI and specifying the metadata disable legacy endpoint flag or you can do it in Terraform by adding that following workload metadata config block into your note config block. The result, it should be something like this and I’ve added some resources for you guys if you have GCP and you want to check this particular issue at the very end.
The weak link, number two, Tiller is the server side component of Helm. If you read the documentation of Helm, it says that you should never provision Helm or Tiller in a production cluster with all of the default options. We did this and we said we were going to change it later on, but when it came to the penetration test, we decided to live life on the edge and live it on and see how far a penetration tester can go. The default options means that Tiller comes with mTLS disabled, it performs no authentication by default and this is all very bad because Tiller has permissions that it can create any Kubernetes API resource in the cluster, so it can do anything or remove anything.
How would you go about getting access to Tiller from a non-privileged pod? I have taken a random cluster that has Tiller installed and I have deployed fluentd in a pod in a different namespace than the kube-systems namespace that the Tiller lives. It also has the Helm client installed, so can see that the very first command is Helm version, and this gives me nothing, but if I telnet directly, the address of Tiller and the port then all of a sudden I’m connected to Tiller and, well, I can do everything I want from here.
What can you do in terms of mitigations? Ideally, you would enable mTLS or run Tillerless Tiller, but if you are unable to do that, you should at the very minimum bind Tiller to local host so that it only listens for requests that come from the pod IP that it lives in and the result, it should look like this bit here.re, so unable to connect to remote host.
Security and Resilience
Let’s have a look at some of the security and resilience notes that we learned and we picked up along the way. A secure Kubernetes cluster should, at the minimum, use a dedicated service account with minimal permissions. Here, I’m not talking about service account in the context of Kubernetes but service account in the context of GKE. If I am to translate this to an Azure world that’s called the service principle.
A secure Kubernetes cluster should also use minimal scopes, so least privilege principle. It should use network policies, and network policies are useful for restricting access towards certain pods that run in a more privileged mode. or it should use Istio with authorization rules enabled and the authorization rules, if they are set up properly, achieve the same thing as network policies. It should also provide some pod security policies, and these are useful for not allowing any pods that don’t meet certain criteria to be built within your cluster, so in the event an attacker get into your cluster, they can only deploy pods with certain criteria. You should use scanned images because using untrusted image it’s counterintuitive and you don’t want to install vulnerabilities within your cluster without knowing. You should always have RBAC enabled, a note on RBAC. GKE, AKS and EKS, they all come with RBAC enabled today but AKS only had RBAC enabled recently so you should look into this if you don’t have RBAC.
A resilient Kubernetes cluster should- here we’re talking about resilience rather than security- first of all, be architected with failure and elasticity in mind by default. In other words, no matter what you’re building, always assume that it’s going to fail or someone is going to break it. You should have a stable observability stack so you get visibility into what’s happening and you should be testing your clusters with a tool such as Chaos Engineering.
I know that Chaos Engineering can be very intimidating for most us, I personally was intimidated as well by it, but after I played with it, and it’s just a matter of running that particular command on the screen to actually install it in a cluster, it’s really easy. It’s a great way of testing how resilient your applications are, especially if you are running JVM-based beasts such as Elasticsearch. This particular command says install chaoskube which is a flavor of Chaos Engineering and make it run every 15 minutes, so every 15 minutes, a random pod into your cluster will be killed. You don’t necessarily have to install it straight away into your production cluster, start with other clusters, see what the behavior is and move on from there.
Challenges
The last part of my talk is mostly around challenges in terms of compliance, please come and talk to me after if you’ve had similar challenges or if you are looking at moving towards the same direction.
Challenge number one, as a PCI compliant payment services provider with many types of databases, I want to be able to query data sets in a secure and database agnostic manner so that engineers and customers can use it easily and so that we are not prone to injections.
This particular challenge has two different points to it. Especially when you’re using more than one type of databases, you want to make it easy for your customers, especially if you are API driven, to be able to query your data sets, so this is about customer experience. The second part of it is about security, so PCI DSS requirement number 6.5.1 requires you to make sure that your applications are not vulnerable to any injection flaws whether they are SQL or any other types.
“So how did we approach this?” I hear you say. Meet PQL. PQL is domain specific language that our head of engineering wrote, it is inspired by SQL. It is injection resistant because it doesn’t allow for mutative syntax, it is database agnostic and it adheres to logical operator precedence. How it looks? This is an example of how it can look, the way we’ve achieved this was through syntactical analysis so by parsing tokenized input into AST and through lexical analysis.
Challenge number two. As a PCI compliant payment services provider, I am required to implement only one primary function per server to prevent functions that require different security levels from coexisting onto the same server and this is requirement 2.2.1 of PCI DSS. This was a difficult one because we don’t have any servers. Yes, Google Cloud has some servers that we use through association, but we don’t really have any servers, we run everything in containers and note that the actual standard doesn’t even say anything about virtual machines, never mind containers.
The way we approached this was by trying to understand what the requirement is and the requirement is prevent functions that require different security levels from coexisting into the same space otherwise from accessing each other.
We said that we’re going to think that the server equals a deployable unit, so a pod or a container and in that case, we meet the requirement because we’re using network policies which restrict traffic between the different services and we’re using other bits of security as well. We’re also using pod security policies to make sure that only pods that are allowed, that meet certain criteria can come into the cluster and a very important one, we’re using only internal, trusted and approved images and scanned as well and I’ll come back to the scanning in a second.
Those were specific challenges, some examples, this is not an exhausted list but those were challenges that we had to think outside the box. Now let’s look at challenges that we actually didn’t have to deal with because of our setup.
As a PCI compliant payment services provider, I am required to remove all test data and accounts from system components before the system becomes active or goes into production, this is requirement 6.4.4. and it makes sense to have this requirement.
The normal way of organizations splitting their Google Cloud infrastructure- I’ve taken Google Cloud as an example but this sort of applies to other cloud providers- it’s by having one massive organization and then you’d have a project and under that project you’d have all of the services and companies like AWS actually suggest that you should have accounts or two different accounts, one for billing and one for the rest of the things you are doing. If you are to do this, then you can split your environments within a GKE cluster at the namespace level, so you’d have a production namespace, you would have a quality insurance namespace, and a staging namespace all living within the same cluster, then you’d be able to access all of the different services.
From a PCI DSS point of view, you have the concept of a cardholder data environment, which basically is the scope of the audit that you have to perform. If you are to do it this way then your scope would be everything within the VPC, but we did it in a different way.
This is the way in which we split our environments, for each environment, we have a specific project and then we have a few extra projects for the more important things that we need to do. For example, we have a dedicated project for our image repo, we have a dedicated project for out Terraform state, and we have one for our backups, this is very important from PCI but also from a compromise. From PCI point of view, it’s important because we managed to reduce the scope to just the GKE cluster within the production project, and from a compromise point of view, because most of the compromise happened with that compute engine default service account that only had editor role within the project, so yes, it managed to bypass our firewall rules, yes, it managed to get access to the buckets within the production project. It didn’t manage to get access to our image repo, it didn’t manage to get access to our backups or any of the other environments, so from that point of view, it was quite contained.
What do you get from this? You get an increased security, you get separation of concerns, get a reduction of the scope and of course easier to organize RBAC. I’m not saying that by doing this, you won’t be able to get it as secure, I’m sure you will, but it’s going to take much more work.
Removal test data and accounts from system components before the account goes live. This actually doesn’t apply to us because the test data would only ever be in all of the other environments, never in the production environment to begin with.
Challenge number four that we’ve avoided. As a PCI compliant payment services provider, I am required to perform quarterly internal vulnerability scans, address vulnerabilities and perform risk scans to verify all high-risk vulnerabilities are resolved in accordance with the entity’s vulnerability ranking and this is requirement 11.2.1.
This is a very interesting one. First of all, random comment, that’s just the image that I liked so I decided to put it there because it’s my talk, but this particular challenge is about interpretation. When you are running everything within containers, you don’t really have the concept of internal infrastructure or unless you’re going to say, “Well, the way to meet this is by doing very frequent penetration tests,” which is not necessarily viable to any organization. What we said is that we make sure that all of the images that ever reach our cluster have been scanned and no image that hasn’t been scanned or hasn’t passed certain vulnerability ranking requirements will ever get into our cluster.
I’ve made a diagram. When a developer pushes code into GitHub, some integration tests run, and if those integration tests have passed then an image build starts and if the image build has been successful then there’s another step that inherits from the tag of the first image and takes that image and it scans everything in it. If the scan passes, so it doesn’t have any vulnerabilities higher than low, then the initial image, it’s retrieved and then it’s successfully pushed into GCR. If the image scan doesn’t pass, then the build is failed and our developers have no other way of getting that code into an environment. That’s a way of dealing with it.
I hear you ask, “Well, yes. But what if you find a vulnerability that wasn’t there three months ago when you last updated your image?”. This is both a proactive and a reactive measure. That doesn’t happen because we deploy multiple times a day and because we are running a monolith. Every time any change into our code happens, a new image is pushed and all of our services, although they have different configurations, they will always be running on the same image. From a database and other application point of view, we ensure on a regular basis to check our images and also update versions and so on.
Summary
Security is not a point in time but an ongoing journey, a never-ending ongoing journey and that’s important to keep in mind. All of the things that we’ve done, that doesn’t mean that we’re all of a sudden secure, it just means we are more secure. We should all think of security as a way to make it really hard for attackers to get in so that they have to use so many resources that they won’t bother rather than, “Yes, we’re secure. We can sleep quietly at night.” You can never sleep at night in this job.
You can use open source software and achieve a good level of security. It’s just a certain amount of work but it can be done, we like a challenge because we’re all engineers. I want to leave you with the fact that we really need to challenge the PCI DSS status quo. It’s really hard for different organizations to become compliant, especially organizations that are not in the fintech environment and that can sometimes make them fail to reach market.
For us, specifically, it was really hard to become compliant because one of the things that we dealt with was the educational process that we had to undertake. Our auditor initially said that he had knowledge of containers and Google Cloud services and it turned out that he didn’t that much so we spent a lot of time educating him and this shouldn’t be our job. This should be the people who are training the QSAs to do their job.
If you have a similar setup or if you’re looking to go into this direction, please come and talk to me and hopefully together we can find a way to challenge PCI DSS and make it better for everyone. I have, as I promised, some resources if you are interested to read or check your clusters and I will make sure to make the slides available.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Hawkins: Thank you for coming, I’ve got a treat for you today. Perhaps not everyone can get to every single session in my FinTech track, I’m disappointed, but I realize it’s a reality. What I’ve done now is I’ve gathered together someone from each of our sessions today to answer some of the most difficult questions that you might have about operating in a regulated industry, operating in an industry where security and resilience are paramount when you deal with customer data, etc.
The way we’re going to run this is I’m going to ask the questions to start with because I’m nicer than you look and that will make them feel more comfortable. After 10-15 minutes, I’ll pass over to the audience if you’ve got any questions, and you can start asking nice questions to our panelists today. Before we get going, I’m going to ask them each to introduce themselves, explain who they are, who they work for, how regulation impacts their day job or their company. After that, I’ll launch into a few questions and if and it’s quite likely, I don’t ask something that you’re interested in, then you will get a chance to throw your question at them after a little while.
Introduction
Maude: My name is Jason Maude, and I am the head of technology advocacy at Starling Bank. Starling Bank is a licensed bank, so we are quite heavily regulated.
Calin: I’m Ana Calin. I’m a Systems Engineer at Paybase and Paybase is a payment services provider, we also have loads of regulation, we have to regulate with PCI DSS. We’re FCA authorized and there’s others as well.
Quinn: I am Carolyne Quinn, working for the enterprise blockchain firm, R3. Many of our customers are banks and insurance companies and they are heavily regulated but the regulation is still a work in progress a little bit for blockchain, and we do engage with the FCA a lot. We have a regulatory team but the regulation itself is still being worked out at the moment.
Patel: My name Suhail Patel. I am a platform engineer at Monzo Bank, we are also a fully licensed bank and we are very heavily regulated.
Jones: My name is Will Jones. I work at Habito, we’re a mortgage brokerage and sort of online mortgage platform, so we’re also directly authorized and regulated by the FCA for procedures such as advice we give to customers about getting mortgages and things like that.
Safety of DevOps in the Financial Industry
Hawkins: Suppose I’m a regulator or an auditor or maybe even just a traditional CIO, so I know that the way to make it hard for people to make mistakes or hard for the bad guy to get in, is to make it hard for anyone to do anything. To that purpose, I have a dev team, I have an ops team, and nothing gets to production except via the ops team and preferably nothing gets to production ever, because that’s the safest way. I hear your companies don’t operate like this. I’m a bit concerned that you might be ignoring some of the segregation of responsibility in various types of audit scenarios. Is it safe to do DevOps in the financial industry? Jason [Maude], do you want to start?
Maude: I would not only say that it is safe, I would say that it is safer than doing it the other way. Obviously, the safest way of developing code is not to do it. If you don’t develop code, if you don’t release anything else ever then you won’t introduce any bugs. Hopefully, no one else will do that as well and then we can all go home. Given that people are going to want to keep developing, the safer way of doing things is to early release often, try and release every day at least. The reason that that is safer is because then each of your releases is quite small, whenever you get a bug or a flaw in your code, you need to look through your code to find where the flaw is. If you’re releasing a day’s worth of code, that’s much easier than if you’re releasing three months worth of code, because three months worth of code is going to take a whole huge lot more reading to get through and find the bug. There’s also the possibility of bugs, two things which work independently, but don’t work together, causing a bug and that’s much more likely in three months worth of code. I’d say that from everyone, from the point of view of the safety of the customer, it is much safer to release code early, release code often.
Calin: I also agree with what Jason said, from a Kubernetes world point of view and microservices, if you are using Kubernetes and that’s how you deploy your services, you have the option of adding in your deployment manifests rolling updates, which means that every time you make a change to an update, every time you change your image, the old pod will only be killed once the new pod passed all of the health checks. If it doesn’t work, then you still have something healthy that was never killed, to begin with. It depends on how you’re doing it, but, yes, it can be very safe.
Patel: I agree with both Jason and Ana. As Sarah alluded too this morning, you know, releasing a large, a massive release means that you have to have an ops team and as someone who would probably be in that position, that’s not something that I want to be worrying about day to day, running other people’s code and managing their release cycles. An ops team usually is far smaller than general engineering. They don’t have the capacity to go through every single change line by line and figure out if this is going to be impacting users or what the global impact is going to be. If you have a much faster, more frequent release cycle that’s empowered by engineers who are working on the product on a day to day basis it means that they are much more confident with their smaller scope changes, releasing them into production and understanding the failure scenarios.
Availability of Developers with Appropriate Skills
Hawkins: I remember a couple of years ago when we were starting Starling Bank and talking to the FCA and trying to persuade them that we could run entirely in the cloud. One of the things they were concerned about wasn’t resilience or privacy or security or anything, it was a key man dependencies and the availability of skills. The FCA were rather scared about us going with AWS, believe it or not, because they thought skills weren’t available out there. I think they’re probably a little bit better educated now, but there’s a point there, isn’t’ there? We all know that development is 90% copying and pasting off Stack Overflow and the Stack Overflow support for say Java where there’s 9.3 million developers is bit deeper than it is with Haskell, for instance. The point generalizes to Monzo using Cassandra, maybe or people who are looking to build their business on R3 Corda. How can you answer those sorts of challenges from regulators or other people about availability of skills, should you get into trouble?
Jones: I think in the early days of the business, as I alluded to my talk, like recruiting for specific sales sketch is always a challenge and I think when you’re just starting out as well, the bar you should have for hiring is incredibly high regardless of the technologies you’re picking and to some degree the technologies they factor into it, but you’re just looking for brilliant engineers, whoever you can get your hands on to get something bootstrapped and off the ground. Then I’m inclined to think that once you get past that initial wave and you’re actually building something credible and your product market fit has been ascertained and you’re building a scalable business at the point basically, which the regulator considers you a serious entity and is looking to engage with you on a much deeper level, then the set of skills, effectively the regulator’s, the key skills you’re looking for are necessarily language specific, because now you have a set of more general problems like scaling a business, building disaster, recovery, and fault tolerance. Yes, the language you pick for those is important but I feel like some of these more architectural concerns that you’re not going to find a Stack Overflow answer on, you know, how do you split the monolith up into 40 microservices, 12 months, unless that answer does exist, in which case, send me the link. There is this kind of gap period in the middle where you might have a skill shortage, but I think you can mitigate it, especially if you are building like distributed applications using microservices. You can play cards, like the polyglot card and so if you reach a point where you can’t find the skills, then you might have to make a hard choice and pick a new stack, but at least you’ve architected the system in a manner that lets you make those choices, whereas if you’re favoring more traditional approach, building a monolith that you don’t have a massive velocity in terms of releases and enabling you to change it, then you’re probably going to run into those problems at some point, and you’re not prepared to adapt. Most of these traditional challenges is all about time to release and time to adapt and those are the problems you should be solving. Hopefully, those problems are independent, the tools you pick, and if you solve them, they should enable you to adapt to any kind of challenge the regulator might bring in that regard.
Patel: If we look at a lot of legacy banks, they’re having the same challenges, they want to hire COBOL and mainframe developers, which are equally hard to find in the market, maybe even more so than Cassandra and Kubernetes engineers nowadays. We believe in hiring just engineers who are good at particular technologies and by leveraging technology that we are using, leveraging a modern stack, we actually have a larger pool of people that we can tap into because these are exciting technologies that are in the market right now. People who are coming out of university, the next wave of engineers, are getting really excited about these technologies and they’re being adopted by a lot of major platforms like AWS, and Google Cloud Platform which brings even more credibility into the market. I don’t see AWS releasing a mainframe product anytime soon.
Hawkins: Carolyne [Quinn], do you want to say why a bank would think that R3 Corda is a safe bet?
Quin: Just a bit of context, we developed our software about two-three years ago, so it’s very new and we have to work very hard to get people comfortable with using us, so, we run a lot of meetups. We have about three or four people on the developer relations team, who go around the world training people how to use Corda and getting them comfortable with the software and what it does. I’m running Corda trials where people can use our software for six weeks in different use cases, we have one running at the moment in like selling houses basically, we’ve loads of real estate brokers and banks all involved in that.
It’s similar for developers who have worked on other blockchain softwares, they may be familiar, a lot of it is written in Java. It’s also written in Kotlin and many people aren’t familiar with that either but we hire people all the time who don’t know Kotlin or they learn it on the job, apparently it’s quite easy to learn. In summary, we’re working hard all around the world, we just did one in Poland, we did one in India last week, doing meetups and helping developers get excited about Corda which is an open source technology.
Keeping up with the Novelties
Hawkins: I’ve got a question which I’ll throw to Ana [Calin] first. Kubernetes moves pretty fast, so there’s new versions all the time, new things, Istio, Envoy, Ambassador, all these sorts of things. Doesn’t that introduce a bit of an overhead of keeping up? There used to be this idea that you never run the zero of anything, because it’s just a bit too new. It might have some bugs, it might have some problems. Do you still consider things like that or do you just take what comes along?
Catalin: Very good question. Well, there’s two points to this, first of all, you don’t just go ahead and deploy a new version of something into production out of the blue. You first take it through multiple environments and that’s when deployment and continuous delivery come into place. We do keep up with most of the newest versions, it hasn’t always worked out and when it hasn’t we just rolled back. Because we do deploy multiple times a day, it’s quite easy to do that.
Hawkins: Is there a risk that you might back the wrong horse at any point here? You might adopt something very new, and get stuck with it and find out a little bit further down the line that you can’t get out of it?
Calin: That hasn’t been that case, I can’t imagine a situation in which we couldn’t get out of a certain technology. It hasn’t happened, but we do roll back and forth and then, sometimes we wait for new technology to become more mature before we use it again. We have a lot of flexibility in terms of playing around with tools.
Jones: In terms of being locked into a specific technology there’s two stances that I have on that. One angle is someone like a massive vendor like AWS, you’ve got to strike a balance of exploiting the vendor as harnessing all the stuff they can offer you, and weighing that up against locking how likely or desperately are you trying to ensure that you can deploy to multiple clouds. There are certain environments to which they may be required from an especially tight regulatory environment, even in our environment which is quite tightly regulated, it’s not required. It can be worth evaluating the tradeoff and I think in lots of cases it is worth leaning into someone like AWS especially at a point in the business where you’re focusing on growth that could be really valuable.
In terms of locking into a particular technology like Kube, it’s getting harder and harder because as the practice evolves, and people build tools like Kubernetes they’re being built by engineers that appreciate the challenges of lock in. If you look at Kubernetes a lot of the API and the way it’s designed, it’s designed so that you can minimize the points that we should join to it. If you look at things like exposing configuration through volumes, the only thing you’re going to have to couple yourself to then is a file system, which is something you can pull Kubernetes out from without disrupting the app. These days more and more frameworks and libraries and stuff like that is being built in a way that makes it easier for you to couple than not necessarily old, but a previous wave of technologies, frameworks that shall not be named, that you’ve already baked into the framework. These days it feels like a lot more things are built in that way that you can sit on top of them without necessarily setting roots into them.
Open Banking
Hawkins: Let’s talk about open banking. Jason [Maude], maybe you take this one first. There’s some spectacularly sensitive data that’s being flown around here. From someone’s bank balance, you can determine all sorts of personal details or from the bank statement, you can determine all sorts of personal details. People are now giving access to third parties to access that data via my banking APIs. Monzo and Starling both offer such APIs, Paybase are in that game as well, and Habito are in the starting marketplace so on one side of it and then, Carolyne [Quinn] of course. All three are working with a lot of banks that are in this too. How can we do that safely? Is it not just too risky to have this data flying around all over the place?
Maude: Yes, we can do it safely. To give a brief answer to this, there has always been a need to share such banking data and previously what happened in the old days is that you used to print out your bank statement on a piece of paper and then go and show it to the mortgage broker or whoever in order to say “Well here’s what I’m earning,” and to provide that proof. Then that moved on to the advanced technology of giving someone another organization, your login details for your internet banking and allowing them to go in and screen scrape all your data off a browser and hope that they didn’t also authorize a £10,000 payment to themselves at the same time.
Open banking is hopefully a step up above both of those things, in that you can now choose what data you share. You can say, “I want to share my balance with these other third party, but not my transaction history”, or “I want to share my transaction history, but not my personal data, not my name and address“.
The ability to segregate this down and say “I want to share this bit of data but not that bit of data” makes this much more secure rather than less because with just the printout you could lose it or they could just take data from it by writing it down that you don’t know, or with the screen scraping they could do goodness knows what. The only other option is to not share banking data at all, which unfortunately doesn’t fly when the other third party with whom you want to share the data needs to make financial decisions about you. We could abandon the mortgage market, but Will [Jones] might be sad if that happened.
Patel: In terms of open banking, just to add to that having the control to be able to revoke your data is equally as important. If you give an organization access to your web portal to do screen scraping, you have no idea about what they’ve done with their data and how often they access it and how long they’re going to continue to have access for. Most people don’t realize that when you give that kind of access, you lose protections from your bank because you’ve essentially authorized the third party and given them your username and password, which is their method of authentication. Open banking just by via regulation provides you a better insight into how often these organizations are extracting your data and how are they using it, and what pieces of data they have access to, which is incredibly important, and something that you didn’t have with the previous methods.
Questions and Answers
Participant 1: You all operate software delivery processes within a regulated environment. Are there any elements of those processes you would choose not to do if they were optional to you?
Patel: A lot of our software delivery processes go into change management, so ensuring that all changes we make are forward-looking, but reversible. If we need to adapt for failure, if we ship a bad release, we can reverse that decision in a matter of minutes. Just thinking about security, from those two standpoints, even if we weren’t in a regulated environment, those are two really nice properties to have in any software organization to be able to ship software securely and also to be able to have the reversibility. Those things would continue even in a non-regulated environment.
Calin: I have a very specific example. PCI DSS asks for organizations to check their firewall rules every three months or every six months. What that means is you have to gather as a team in a room and say, “Do we still want this firewall rules?” We’ve written them using infrastructure as code, we’ve restricted them as much as possible, we know they won’t change unless we change them. Everything is change controlled, everything can be tracked, we have full audit and still, we have to do this. In my opinion, very silly thing, so, I would remove that.
Maude: I would say I probably wouldn’t remove much that’s significant about our software deployment procedures. A lot of it is about finding ways that you can fulfill the regulations in an imaginative manner. For example we use things like ChatOps, we use Slack for people to gain permission in a four-eyes manner to initiate a deployment to production. That allows us to fulfill regulatory requirements around having having oversight of this, having an audit log, making sure that we can control things, but it doesn’t require us to sign bits of paper or have a giant filing cabinet somewhere. I think it’s about finding ways of fulfilling the regulations in a way that does not block you which is definitely possible.
Participant 2: I want to get back to the key man thing quickly because I think that’s kind of an interesting angle there. With microservices, we’ve decoupled the monolith so that an individual flaw, as we heard in the keynote this morning, doesn’t mean a total outage, it means that like compartmentalize outage, which is definitely better from a risk standpoint. There’s still kind of an implicit assumption in the key man thing that the expertise on the product is locked in the minds of like a small number of individuals. I’m wondering if it might be possible to convince a regulator that with a microservices architecture, it’s actually the sort of API contracts of the microservices that are really the important thing to understand and then it might be less important to actually have a key man understanding of that since it can be better defined. Do you think that’s possible? How you might go about convincing someone who’s not a software engineer that that’s true?
Maude: Briefly that could be possible. I still think that you’re not going to be able to remove the need for a human to understand what the contract means and how the underlying implementation works. You’re going to have to have some sort of rotation between the various teams working on the various microservices so that you can spread knowledge out and not have it concentrated in one or two individuals who may leave.
Jones: This ties a bit to the last question actually which is, it’s easy to paint the regulator as a Boogeyman. Habito is broadly aligned, in this case they’re arguing the key man thing from a risk perspective, we definitely share that opinion. You always want to mitigate stuff like that with documentation, but there’s other ways to look at it. If you’re onboarding a new engineer, I think this probably ties into what you’re saying. It’s good to have strong contracts and have them documented. You probably still want some high level documentation to just optimize your onboarding process that you can get new engineers up to speed as quickly as possible.
From a business point of view, that’s selfishly, you’re solving a very real problem, which is how can I grow my engineering team effectively. They’re just viewing that problem for a different angle, which is what if your engineering team shrinks drastically? It ties into the previous question as well, what would I remove from my deployment process? Probably nothing, because the things I put in that process are there to mitigate risk which is exactly all the regulator’s asking me to do to a degree.
Participant 3: I’d like to ask the panel how important is it that professionals like yourselves and others in more traditional regulated industries need to update their education and language use when talking about regulation? To give you an example, I still get loads of due diligence questionnaires, because a lot of our clients are regulated, which asks about the location, my data center, the fire risk assessment you’ve done on it, loads of other examples and I waste hours of my life trying to explain what an AWS regional, a multi-availability zone is to people who haven’t got a clue about this. What sources of education can you recommend to them to update their knowledge about how modern software development works?
Patel: From our perspective, that’s going to be a losing battle. If you’re looking for like one specific recommendation of technology, we’ve been quite fortunate in that there have been, there has been a big influx in these startup banks in the regulated market. They’ve all used common infrastructure and modern software development practices, so not going for the waterfall and having an operations manager and doing a big bang release.
We’ve been quite fortunate in bending the rules a little bit, but that’s not to say that we’ve been doing anything, like insecure or invalid or unjustified. Sometimes the regulator’s impressed with how far we’ve thought about these things, compared to other like traditional banks, when you look at their answers and when you look at our answers, and how we architect for failure, for example, and resiliency. By tying ourselves into these providers, these vendors like AWS and tying us into these technologies which are open and not closed source allows us to tap into broader communities and discuss these with other companies rather than being locked in to something internal which we need to spend hours and hours explaining to regulators.
Calin: We also had a similar problem recently when we got our PCI DSS compliance. Part of it was training the auditor of how containers work and there was a lot of back and forth, a lot of days spent of trying to explain why this is secure enough based on what the requirement asks if I’m touching upon it on my talk as well. We haven’t figured that out from a PCI DSS point of view. I agree that it’s a problem. That is going to be my call of action, so let’s talk after.
Maude: If you send me the name and email address of who creates these forms, I would be happy to talk to them about what an AWS region is and what and availability zone is and so on in order to try and convince them that what is the fire risk in a place that I don’t know where it is, is not a question that you can sensibly answer.
Hawkins: There’s something in the AWS terms and conditions which say they can throw you off in 30 days, which is 30 days to re-implement your platform on another cloud provide. Do financial institutions really sign those Ts and Cs?
Maude: Yes, we have to, as part of the regulation for us, we have to be able to show that we have tested being on a different cloud provider, a cloud provider, other than AWS, by testing what is meant by that in the regulation is we have a document that says we can do it, and how we would do it, not that we actually have tried to test it in the software engineering sense. It would be possible, it would be difficult, but it’s something that we’re going to have to concentrate on more and more as financial institutions the ability to not be tied down to a single cloud provider.
Participant 4: I was going to comment on that because it seems that the European regulators these days are focusing more and more on the concept of an exit strategy from a given outsourcing partner, so, how would you comment on the kind of the dilemma between the need for moving fast using cloud services to make this someone else’s problem going in using the maximum abstraction layer or the cloud services to be most efficient towards being kind of agnostic when it comes to cloud services, to cater for the exit strategy concerns from their regulators.
Maude: I would say so you have to weigh out the risks. If a financial institution was told by AWS get out, or if they were told by AWS, your price is going to be doubled, tripled in 30 days’ time, then that would be a big problem. The question is, how likely is that problem? I would say not very likely. It’s trying to weigh out the that sort of black swan high impact low probability risk and saying how much effort do we have to put towards mitigating that and you have to balance that off with all the other risks.
Quinn: Just to give an alternative perspective, we’ve recently launched a blockchain network, which is called Corda Network. We work exclusively with businesses rather than individuals and some of the businesses have been a little bit reluctant to be locked into our blockchain network. It’s the same points, they don’t want to be reliant on one provider. If a lot of their data is then associated with our blockchain network, how would they leave? So, we’ve set up an independent foundation, especially for that, because we’re such an early business. This is a way to show that the governance is not with R3 which is our company, that it’s with a completely separate legal entity and that participants can vote for and stand for the boards. Just to provide an alternative perspective on the same problem.
Patel: In terms of development and exit strategies I think in this particular instance, the regulator might be seen as a Boogeyman. It just makes good business sense to have an exit strategy, should you be kicked off, it could happen, AWS could start becoming unreliable, for example. They could be having major issues, they might not have enough capacity to satisfy your needs, having an exit strategy makes good business sense in general. From a software engineering perspective, building abstractions, so that you’re not tied into one vendor is, is an important strategic decision as well. Investing in those frameworks and tooling and libraries and education, being locked into like one vendor’s primary database, for example, picking on open source technologies. A lot of cloud providers provide the same technology just rebranded differently, Google has its Cloud SQL product, Amazon has its Aurora and RDS products, they are functionally equivalent. It’s pretty easy to migrate from one to the other, so if you build your abstractions, loosely coupled, it could be fairly easy to move, and having a good exit strategy makes sense.
Participant 5: Hello, I’m ex AWS. I would think they would probably argue quite strongly that they are not functionally equivalent, as far as when they talk about various different things, but that’s just an aside. I was just going to ask about how you would think about infrastructure as code, how that comes under your consideration in terms of regulation. I know it’s a slightly forward-thinking concept, but infrastructure as code is going to become more and more important and how it’s going to become more important in the future and how it’s going to essentially take over from code in a lot of the areas, so we’re going to code less and infrastructure more in a sense.
Patel: I don’t think I agree with the premise that you’re going to code less and have infrastructure as code more. The way I see it is, if you look at how things were done in prior to a lot of these tools, which allow you to specify infrastructure as code were coming out, things like Terraform, things like CloudFormation, a lot of people were essentially just spinning up EC2 boxes and AWS products by hand. What you ended up with is just an estate, a jungle, where you had zero control about who was talking to what and where, and when, and how and making it reproducible was an absolute nightmare.
What infrastructure as code has allowed people to do is to essentially modularize and templatize this, your whole infrastructure, your whole estate. What you can do is you can say is “Okay, I want another copy of this,” in another AWS region and you can have an exact copy of that spun up, barring a few modifications. Another thing that infrastructure with code allows you to do is version control which is very important. To be able to show incremental improvements to see who made what decision where and when, and how things have changed. That’s pretty important from a regulatory standpoint, being able to show how things have changed over time and also being able to show line by line, exactly how your estate is set out, is pretty important as well.
It’s been a far-reaching benefit of infrastructure as code, rather than spinning things up by hand, but I don’t think it’s a full replacement for code. There is going to be software developed, stuff that infrastructure doesn’t fully solve. I don’t think it’s going to be a full replacement for code, maybe different kinds of code is going to be written.
Calin: I also agree that I don’t think it’s going to be a full replacement for code, but from a regulatory perspective, infrastructure as code helps with compliance a lot, because one of audit questions you get is, when was this changed? Show me how it was done. There are two big steps, first of all, you show the configuration, the Terraform configuration. Second, you look at the Terraform state and say, “Well, it was done at this time it was done by this person and it’s with this version.” From that point of view, it makes regulation easier.
Moderator: So always answer your auditor by starting off giving the features out of Git, and then see what remains.
Participant 6: going back to the stuff you talked about, be able to roll back your releases. Obviously, you can’t roll back a release if it deleted a bunch of data, so, you’re going to lean heavily on immutable data. What technologies and tooling have you found useful in making sure you have an immutable set of data that you can fall back on?
Jones: I actually have the opposite problem. We have an event log, which is immutables for the largest part, which means that if you deploy a new release, it’s not going to delete anything, but it might write some new data that an old release doesn’t understand. That problem I think it’s really hard to deal with because rolling back just never becomes an option, because, sure, you’ve still got your old container up and running, but if you flip your DNS back to it, then it’s going to crash because there’s a load of data that it doesn’t understand. Back to one of my earlier points, the only solution we found effective is just increasing wherever possible the velocity in which you can fail forward. How do you mitigate and move on from that? The problem is broadly solvable, but it probably requires a wider cultural change.
We’ve not yet really baked in, which is you only deploy changes that are perfectly forward and backward compatible. Personally, I haven’t spent enough time sort of weighing up the tradeoffs of that. On the one hand, you gain immense flexibility, you can automate pretty much all forms of canary rollouts, for instance, but on the other hand, maybe it costs you development time and mental engagement because you have a lot of optional fields or in every case, you have to account for whether or not a piece of data is there. It’s not a shift we’ve made yet, but in general, yeah, we’re just kind of clumsy falling forward as fast as possible is something we found better luck with when you do have immutable data.
Calin: I think we found quite a good solution to this. We have our services that perform all of the actions that our API has to do and then, we have our databases and our services are deploy these Kubernetes deployments which are stateless, and all of the databases, they maintain a quorum, and they are deployed at StatefulSets. What that means is, you have a volume attached to the pod and if that pod dies, or you kill it, the data stays there and it waits for a new pod with the same kind hostname to come up, so the data doesn’t move.
The other thing that helps with this is in the event that you do corrupt your data, is taking backups, so take backups as often as you can, we do them every half an hour so that if you do end up losing any data, you lose the minimum amount that you can afford. That’s a good way of doing it. That’s how we’ve been doing it. If one of the new changes to any of our services is not good enough, and it fails, then it will never become healthy in the first place, so, we shouldn’t touch any of the data.
Participant 7: We have now discussed the regulation, mostly with respect to the cloudification and deploying to the cloud, but if I look at other advancements of the FinTech without deploying concerns or things like using blockchain or possibly paying with cryptocurrencies or all kinds of new payment providers or third parties that collect your data and are not may be fully authorized, like banks. Do you think the cost of these more regulation is needed or less regulation than today? Do you think, for example, that today’s regulation is sufficient or is completely insufficient? There should be much more in a different way. What do you think?
Quinn: I can speak from our company’s perspective. We don’t have a cryptocurrency in our company at all, it’s just the underlying blockchain or distributed ledger technology. We’re not like, there’s no regulation specifically in the U.K, like we’re working with the FDA laws and they’re issuing guidance, but we’re not regulated in the same way that anyone else on this panel is. It’s still a lot of the regulation is emerging, that’s just some context setting.
It’s almost like a philosophical question, like do you think it’s effective to have more regulation or less? Do you have to have the right incentives rather than regulation? And what promotes the right behavior, basically? I think more guidance is certainly needed in the cryptocurrency space, and where a lot of people may have lost money and it’s a bit of a Wild West atmosphere, at least in the last couple of years. At least in our company, all of our clients are really heavily regulated, so no one can engage on our network without dealing with financial regulation that exists in many different countries around the world. Although we’re not heavily regulated, anyone who uses our software is, so, kind of a second degree of regulation there. In summary, I think more guidance on regulation is needed around cryptocurrencies, for sure.
Maude: Moving on from cryptocurrencies where I completely agree, I think that the regulatory environment does need to work harder in some ways to catch up with all the new technologies, the new way of banking, the new way of doing financial services. We had to give an example, Starling Bank along with all the other regulated banks had to recently publish data that allowed people coming on online to compare ourselves, the Starling Bank with other banks to see who was better. There were some fairly simple questions there like, how long does it take to open a bank account? How long does it take to get a debit card? How long does it take to replace your debit card if you lose it?
With Starling Bank, if you lose your debit card, you can go into the app, cancel the card, order a replacement, get a virtual replacement instantly and then provision it to your mobile wallet, so, how long does it take to get the card? No time at all, but they want to know about the physical card because for them, they are thinking “no, a debit card is a physical piece of plastic that you hold”, so, you have to take into account postage times.
The regulatory book, by the way for defining all the terms that were necessary to understand this was this thick, and this is designed to produce data that an average customer off the street can just go on to a website and download very easily. There’s going to have to be a lot of paradigm shift thinking in the minds of regulators, as we heard earlier with the form about the data center in order to try and apply this regulation, so there’s definitely work needed there to keep up.
Participant 8: I think we’re all fairly familiar with PCI DSS and encryption and masking of PAN data and credit card data, but when it comes to GDPR PII data, there seems to be varying opinion on the interpretation of the GDPR regulations around whether that data should be encrypted in transit and at rest or not.
Calin: Well, there’s one argument to be made, which is just because you’ve encrypted data that doesn’t mean that you’re doing everything else in a secure manner. Under GDPR you’re not obliged to encrypt data exactly because of this, but under all of the other regulation, you should encrypt the data and if you want any security you should do. In my opinion, GDPR is very vague and it’s written in such a way that almost everyone can turn it around and say, “Well, I think I can do it this way.” , but not everyone will agree with me, that’s just my opinion.
Maude: There’s also the question when you actually sit down with GDPR and try and decide what is personal data, it actually becomes harder than you’d think. I could give out a postcode right now, technically, that’s personal data, but if I just read out a random postcode, you’ve no idea whose personal data it is or who it relates to. Me just reading out a random postcode does not violate any sort of data regulation, if I start reading out that postcode, along with someone’s name and date of birth and so on, then in a combination that becomes very much personal data that you do not want to leak. Oftentimes, it’s not about specifically the data fields, but it’s about the connections between those fields and whether you’re revealing the whole picture as it were, of someone’s personal profile.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
GitHub has announced a number of new features aimed to help developers secure their code, including the ability to create PRs for any dependencies needing an update to include security fixes, integration with WhiteSource data for better vulnerability assessment, dependency insights, and more.
GitHub security-related features revolve around vulnerability alerts, which were introduced in 2017 to alert developers about any known vulnerability found among their projects’ dependencies. According to GitHub’s own data, although more than 27 million security alerts were generated since then, patching has been often a slow process:
While security vulnerability alerts provide users with the information to secure their projects, industry data shows that more than 70 percent of vulnerabilities remain unpatched after 30 days, and many can take as much as a year to patch.
GitHub figure matches well with analysis from other vendors that highlighted a number of action points for the open-source community to improve on their security-related practices.
In an effort to make it easier for project maintainers to patch their code quickly, GitHub integrated with Dependabot, which they have just acquired and made freely available. Dependabot, originally available in the GitHub marketplace as a paid service, is able to scan a project’s dependencies for any vulnerabilities and automatically open PRs for each of them. This will allow maintainers to fix security vulnerabilities by simply merging those PRs.
Furtermore, to help enterprise project maintainers to promptly audit their project dependencies and exposure to any new vulnerability, GitHub launched Dependency Insights. Dependency insights leverage GitHub dependency graph to provide developers an overview of their project dependency status, including any open security advisory, the possibility of listing and inspecting a project’s dependencies, and so on.
Another new feature in GitHub meant to provide developers with more data about any discovered vulnerabilities, is GitHub security alerts integration with open source security platform WhiteSource. According to GitHub, this will broaden the current coverage of potential vulnerabilities that the platform is able to detect and help developers prioritize, remediate, and report about vulnerabilities.
As a final note, to improve communication among maintainers of a project when they need to exchange information and discuss any found vulnerabilities, GitHub now offers a private workspace, called maintainer security advisories to make that possible without leaking sensitive information to hackers. Additionally, it is now possible to explicitly set up a security policy associated with a project so contributors know what they are supposed to do to responsibly report a vulnerability.
Experiences Going from Event-Driven to Event Sourcing: Fangel and Ingerslev at MicroCPH
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
As many other start-ups, Lunar Way started with a monolithic Rails backend application but shortly after going live three years ago, for organisational and technical reasons, a decision was made to start a migration towards a microservices architecture. This led to an event-driven microservices backend consisting of about 75 microservices, with asynchronous message passing as their main communication pattern.
At the recent MicroCPH 2019 conference in Copenhagen, Thomas Bøgh Fangel and Emil Krog Ingerslev, both from Lunar Way, a fintech company providing banking services though a smartphone, described how along this microservices journey they found out that their platform had some inherent problems. Last year, therefore, they decided to move to event sourcing in order to solve these problems and get consistency guarantees within the platform. In their presentation they discuss four problems they encounted and how they solved them using event sourcing and event streams.
Consistency problem
Their first problem was a consistency problem. When a service is making a change in its database, an event should also be published on the message queue. But if the service crashed directly after the database update, no event was published — a zero-or-more message delivery. This led to a consistency problem which neither the event producer, nor the consumer, was aware of. This also led to strange support cases which they often fixed by resending events or by manually updating the data in the consuming service.
A solution to this is to make the state change and message publishing in one atomic operation. Their take on this was to use event sourcing where each event also represents the state change, which makes it inherently atomic. Ingerslev points out though, that this is an event internal to the service, and thus needs to be published. By reading each event, publish it and then store a cursor pointing to the event; they can guarantee that all events are published externally. If the service crashes and restarts, it will continue publishing events, starting with the event the cursor points at – at least once delivery.
Adding a new service
Their next problem was adding a new service. Before starting, the service will need data from upstream services, but reading events suffers from the previous consistency problem. The solution is again event sourcing with an ordered event stream, that has the possibility of redelivery. By adding an API on top of an event stream, they enabled a consumer to read all events of a specific type from the very beginning. The internal events are an implementation detail; it’s about how a service stores its state, which shouldn’t be exposed. Instead, they create integration events that are a projection of internal events, and these are the events a consumer reads.
Self-healing
The third challenge was broken services. A service receives events, but if an event is lost for some reason, the consumer service is unaware of this and ends up in an inconsistent state. To solve this, the consumer needs to know when an event is missing and be able to get it redelivered. The solution with redelivery of events works here as well, with the added functionality of redelivery from any point in the event stream, not just the beginning. The same technique with a cursor is also used here: when the consumer knows the last event received and the order of events, it can detect if the next event is out of order. A problem is that a missing event is not detected until a new event arrives, but this can be mitigated by regularly asking upstream services for events after the last one indicated by the cursor.
Change
The last topic was about change. A service may change on the inside, but should still avoid breaking communication with other services or require big bang migrations of several services. In their first implementation they had a consensus among developers that only additive changes should be made to the events. When they had to change the structure in an event, they also had to make coordinated migrations of all services involved. In the new solution based on event sourcing, they are using integration events. There is only one event stream inside a service, but it’s possible to have multiple projections, each with its own integration event stream. By adding a new projection based on an evolution of the data model, consumers can later start to read the new integration stream and the new projection. This way a migration can be done without coordination between service deployments.
Ingerslev summarizes by pointing out that event sourcing libraries are not commonly available. This led them to build their own framework, which was quite expensive. He notes that introducing a new service design paradigm in all teams is hard and takes time, but emphasizes that the event sourcing patterns they’ve used are very composable and easy to improve. Fangel concludes by pointing out one pattern that emerged during their work. They went from a painful situation with special or manual handling of specific cases, to a normal mode of operation of a service, and this made it possible for the developers to focus on what’s most important — the business domain.
Most presentations at the conference were recorded and will be available over the coming months.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
R-squared measures how well your data fits a regression line. More specifically, it’s how much variation in the response variable your linear model explains. it is expressed as a percentage (0 to 100%). The percentage is problem specific, so you can’t compare R-squared across different situations; You can use it to compare different models for one specific set of data.
R-squared is also influenced by the number of observations: 0.80 R-squared on 100 observations doesn’t mean the same thing as 0.80 R-squared on 1,000 observations. One way around this is to compute R-squared on multiple sub-samples with 100 observations, then compute its median. That way, you can compare an R-squared on (say) 1,000 observations, with one on 100 observations
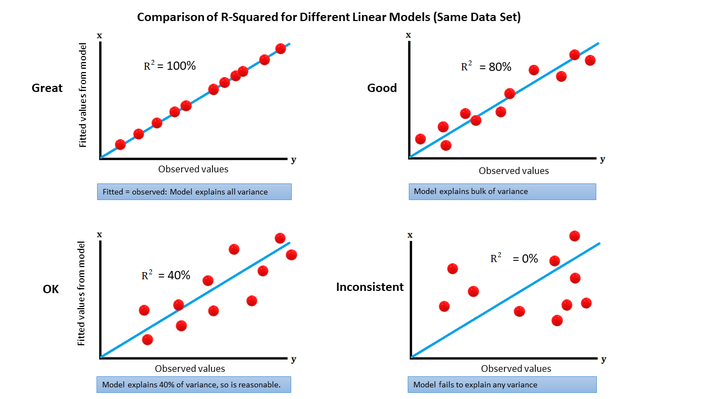
For more statistical concepts explained in one picture, follow this link.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The Electron team recently announced the release of version 4 and version 5 of Electron. Electron maintains an aggressive release cycle to stay current with the latest updates from Chromium, V8, and Node.js. Significant updates in these versions include better control over remotes and requests, and an in-progress initiative to update Electron’s callback-based APIs to use promises.
Electron aims to provide a rapidly stabilizing and improved platform for building desktop apps with Node.js, Chrome, and other modern web development APIs. Electron 4 updates its major dependencies to Chromium version 73.0.3683.119, Node.js version 12.0.0, and V8 JavaScript engine version 7.3.492.27.
Many of Electron’s APIs were created before ECMAScript standardized promises. The ongoing initiative to move Electron’s callback-based APIs to leverage promises is well underway, and covers a wide range of electron features from tracing to cookies.
To provide developers with an additional level of control over application security, Electron 4 adds the ability to disable the remote module, the mechanism to access main process modules from the renderer process, for BrowserWindow and webview tags.
Electron 4 also adds the ability to filter remote.require() / remote.getGlobal() requests for use cases when applications do not want to disable the remote module altogether, but seek additional control over which modules can get required via remote.require.
Version 5 extends this additional remote filtering control by introducing new remote events to allow remote.getBuiltin, remote.getCurrentWindow, remote.getCurrentWebContents and <webview>.getWebContents to also be filterable.
Electron 4 WebContents instances include a new method, setBackgroundThrottling(allowed), for enabling or disabling throttling of timers and animations when a page gets moved to the background.
Version 5 of Electron includes a new process.getProcessMemoryInfo function to get memory usage statistics about the current process. Additionally, the BrowserWindow supports the management of multiple BrowserViews within a single BrowserWindow.
Complete lists of breaking changes and bug fixes in Electron 4 and 5 are available in release notes:
Additionally, with the updates to the Chromium, V8, and Node.js dependencies, numerous additional JavaScript and web standards improvements are now part of Electron. Highlights of recent changes are available in the relevant release notes:
Numerous improvements are already underway for Electron 6 and progress may be viewed with the Electron releases summary. With this and future releases, Electron continues to improve on its powerful platform for building desktop applications with web technologies.
Electron also has an App Feedback Program to allow developers to provide early testing and feedback during the beta release cycle. For the 3.0 release, the Electron team thanks Atlassian, Atom, Microsoft Teams, Oculus, OpenFin, Slack, Symphony, VS Code, and other program members for their assistance.
Electron is available via the MIT open source license. Contributions are welcome via the Electron GitHub organization and should follow Electron’s contribution guidelines and code of conduct.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Over the past few years, microservices have evolved from an innovator-only architecture to a practice used to some degree at most companies. However, scaling up from a proof-of-concept project to a production-grade, enterprise-scale software platform built on microservices requires serious planning, dedication and time. The companies that have invested heavily in creating stable microservices architectures have learned many lessons on overcoming the challenges involved in operating complex, distributed systems.
Free download
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Data analytics organisation, Splunk, recently released Splunk Connected Experiences which delivers insights through augmented reality, mobile devices like Apple TV, and mobile applications. They also released Splunk Business Flow which enables business operations professionals to gain insights across their customer journeys and business processes.
Connected Experiences includes Splunk Cloud Gateway which provides a secure cloud service with end-to-end encryption that allows for mobile engagement when the Splunk Enterprise app for Mobile is installed. Splunk Mobile provides Splunk Enterprise users with actionable alerts and mobile-friendly dashboards on their mobile devices through the Splunk Mobile App. Alerts provide users with the option to take an action directly versus having to log into another system. Dashboards are embedded in related alerts and available on mobile devices including access to dashboards via Apple Watch. The Splunk Mobile App for iPhone and Apple Watch is downloadable through the App Store.
Splunk TV is a native Apple TV app that allows customers to securely view Splunk dashboards on any peripheral device instead of dedicated PCs. The Splunk TV app is available from the App Store on Apple TV.
Splunk Augmented Reality (AR) provides direct access to the Splunk dashboard by scanning a QR code or NFC tag that is pasted to a specific server rack, or any real-world object, with a mobile device. Splunk AR is available through the Splunk Mobile App, and can be used in multiple environments, such as IT and server logs or equipment health data that could affect plant downtime.
For customers that are voice (Splunk Natural Language Search) enabled, this app also allows users to talk to Splunk via the mobile app and have live results spoken back. The Splunk AR App for iPhone and iPad available to download through the App Store.
Splunk Business Flow is aimed at business operations professionals responsible for overseeing business processes and ensuring positive customer experiences. It’s a process mining solution for the discovery of bottlenecks that might threaten business performance. It also helps identify improvement opportunities. Users can correlate data from multiple data systems to discover their end-to-end business processes. Users can explore variances and problems with an exploration and visualisation interface and investigate the potential root causes behind business process issues to improve efficiencies. Andre Pietsch, product owner at Otto Group, said:
As a large European retailer processing millions of customer transactions per hour, getting visibility into Otto’s most critical and most heterogeneous digital processes is very challenging and time-consuming today. Using Splunk Business Flow, we can get immediate visibility of our data and can enable our business to easily access and understand how to increase our conversion rates and decrease our cycle times.
Splunk further expanded its artificial intelligence and machine learning capabilities to deliver a modern IT Operations suite that includes infrastructure monitoring, service monitoring, automation, AIOps and incident response. The suite enables both infrastructure and operations teams gather context around an incident with the hope of improved resolutions times.
Splunk’s new monitoring suite for modern IT Ops includes new versions of Splunk IT Service Intelligence 4.2, Splunk App for Infrastructure 1.3 (which is now included with Splunk ITSI), and integrations with Splunk VictorOps and Splunk Phantom. These releases deliver predictive analytics, service intelligence, event management, operations automation and IT infrastructure monitoring. Splunk Enterprise Security 5.3, Splunk User Behavior Analytics 4.3 and Splunk Phantom 4.2, customers can use their security-relevant data to manage threat detection and operations, investigate internal and external threats and automate their security operations centres.
Google Kubernetes Engine Enhancements: Upgrade Channels, Windows Container Support and Stackdriver
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
At the recent KubeCon EU in Barcelona, Google announced that it will offer three new release channels for its Google Kubernetes Engine (GKE): Rapid, Regular, and Stable. With these channels, Google Cloud Platform (GCP) users can choose whether they want the freshest release or the most stable one — or quickly evaluate the latest updates in a development environment.
Google will first introduce the Rapid channel in alpha, which allows users to subscribe and get early access to the latest Kubernetes version. Each release will then matures to the Regular channel, and finally to the Stable channel. Each channel will have a different release cadence and purpose:
- Google updates the Rapid channel weekly, and includes an array of new features that may still be in beta testing. Moreover, the channel is aimed at developers who want to test the latest features, and aren’t too concerned about the impact that unresolved issues may have on their workloads.
- Next, the Regular channel will push out upgrades every few weeks, including features and versions of applications that have passed the internal testing process within Google. However, users can still encounter issues in their deployments because of lack of (historical) external test data.
- Finally, with the Stable channel, where stability and performance are essential, upgrades take place every few months, and each updated version has passed internal validation, as well as extensive observation of feature performance within working clusters.
In a blog post about the latest enhancements to GKE, Aparna Sinha, director product management for Kubernetes and Anthos at Google, wrote:
We’ll offer three channels; Rapid, Regular, and Stable, each with different version maturity and stability, so you can subscribe your cluster to an update stream that matches your risk tolerance and business requirements.
With the release of the Rapid channel, Google is also bringing early support for Windows Containers to GKE (Kubernetes 1.14.0) and offers support for Windows Server Containers in June, which will allow users to deploy and manage Windows Containers alongside Linux-based containers within the same cluster. In a recent TheNewStack article about the latest GKE enhancements, Sinha said:
We have a lot of customers who are interested in running their windows based applications on Kubernetes, and you can imagine, many have an application that’s running on the Windows operating system.
Note that Microsoft recently also announced Windows Server containers support in Azure Kubernetes Service (AKS) for the latest versions, Kubernetes 1.13.5 and 1.14.0.
In addition to the release channels and Windows support for GKE, Google also announced the general availability of Stackdriver Kubernetes Engine Monitoring. With this tool, users can monitor and log data from GKE, as well as Kubernetes deployments in other clouds and on-premises infrastructure.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Introduction
In a world where we generate data at an extremely fast rate, the correct analysis of the data and providing useful and meaningful results at the right time can provide helpful solutions for many domains dealing with data products. We can apply this in Health Care and Finance to Media, Retail, Travel Services and etc. some solid examples include Netflix providing personalized recommendations at real-time, Amazon tracking your interaction with different products on its platform and providing related products immediately, or any business that needs to stream a large amount of data at real-time and implement different analysis on it.
One of the amazing frameworks that can handle big data in real-time and perform different analysis, is Apache Spark. In this blog, we are going to use spark streaming to process high-velocity data at scale. We will be using Kafka to ingest data into our Spark code
What is Spark?
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workloads in a respective system, it reduces the management burden of maintaining separate tools.
What is Spark Streaming?
Spark Streaming is an extension of the core Spark API that enables high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or TCP sockets and processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to file systems, databases, and live dashboards. Since Spark Streaming is built on top of Spark, users can apply Spark’s in-built machine learning algorithms (MLlib), and graph processing algorithms (GraphX) on data streams. Compared to other streaming projects, Spark Streaming has the following features and benefits:
- Ease of Use: Spark Streaming brings Spark’s language-integrated API to stream processing, letting users write streaming applications the same way as batch jobs, in Java, Python and Scala.
- Fault Tolerance: Spark Streaming is able to detect and recover from data loss mid-stream due to node or process failure.
How Does Spark Streaming Work?
Spark Streaming processes a continuous stream of data by dividing the stream into micro-batches called a Discretized Stream or DStream. DStream is an API provided by Spark Streaming that creates and processes micro-batches. DStream is nothing but a sequence of RDDs processed on Spark’s core execution engine like any other RDD. It can be created from any streaming source such as Flume or Kafka.
Difference Between Spark Streaming and Spark Structured Streaming
Spark Streaming is based on DStream. A DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset. Spark Streaming has the following problems.
Difficult — it was not simple to built streaming pipelines supporting delivery policies: exactly once guarantee, handling data arrival in late or fault tolerance. Sure, all of them were implementable but they needed some extra work from the part of programmers.
Inconsistent — API used to generate batch processing (RDD, Dataset) was different than the API of streaming processing (DStream). Sure, nothing blocker to code but it’s always simpler (maintenance cost especially) to deal with at least abstractions as possible.
Spark Structured Streaming be understood as an unbounded table, growing with new incoming data, i.e. can be thought as stream processing built on Spark SQL.
More concretely, structured streaming brought some new concepts to Spark.
Exactly-once guarantee — structured streaming focuses on that concept. It means that data is processed only once and output doesn’t contain duplicates.
Event time — one of the observed problems with DStream streaming was processing order, i.e the case when data generated earlier was processed after later generated data. Structured streaming handles this problem with a concept called event time that, under some conditions, allows to correctly aggregate late data in processing pipelines.
sink, Result Table, output mode and watermark are other features of spark structured-streaming.
Implementation Goal
In this blog, we will try to find the word count present in the sentences. The major point here will be that this time sentences will not be present in a text file. Sentences will come through a live stream as flowing data points. We will be counting the words present in the flowing data. Data, in this case, is not stationary but constantly moving. It is also known as high-velocity data. We will be calculating word count on the fly in this case! We will be using Kafka to move data as a live stream. Spark has different connectors available to connect with data streams like Kafka
Word Count Example Using Kafka
There are few steps which we need to perform in order to find word count from data flowing in through Kafka.
The initialization of Spark and Kafka Connector
Our main task is to create an entry point for our application. We also need to set up and initialise Spark Streaming in the environment. This is done through the following code
|
1
2
|
val sparkConf = new SparkConf().setAppName(“DirectKafkaWordCount”)
val ssc = new StreamingContext(sparkConf, Seconds(2))
|
Since we have Spark Streaming initialised, we need to connect our application with Kafka to receive the flowing data. Spark has inbuilt connectors available to connect your application with different messaging queues. We need to put information here like a topic name from where we want to consume data. We need to define bootstrap servers where our Kafka topic resides. Once we provide all the required information, we will establish a connection to Kafka using the createDirectStream function. You can find the implementation below
|
1
2
3
4
5
6
7
8
9
10
|
val topicsSet = topics.split(“,”).toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG –> brokers,
ConsumerConfig.GROUP_ID_CONFIG –> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG –> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG –> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
|
Using Map and Reduce to get the word count
Now, we need to process the sentences. We need to map through all the sentences as and when we receive them through Kafka. Upon receiving them, we will split the sentences into the words by using the split function. Now we need to calculate the word count. We can do this by using the map and reduce function available with Spark. For every word, we will create a key containing index as word and it’s value as 1. The key will look something like this <’word’, 1>. After that, we will group all the tuples using the common key and sum up all the values present for the given key. This will, in turn, return us the word count for a given specific word. You can have a look at the implementation for the same below
|
1
2
3
4
|
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(” “))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
|
Finally, the processing will not start unless you invoke the start function with the spark streaming instance. Also, remember that you need to wait for the shutdown command and keep your code running to receive data through live stream. For this, we use the awaitTermination method. You can implement the above logic through the following two lines
|
1
2
|
ssc.start()
ssc.awaitTermination()
|
Full Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
package org.apache.spark.examples.streaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(s“”“
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <groupId> is a consumer group name to consume from topics
| <topics> is a list of one or more kafka topics to consume from
|
““”.stripMargin)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName(“DirectKafkaWordCount”)
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(“,”).toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG –> brokers,
ConsumerConfig.GROUP_ID_CONFIG –> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG –> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG –> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(” “))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
|
Summary
Earlier, as Hadoop have high latency that is not right for near real-time processing needs. In most cases, we use Hadoop for batch processing while used Storm for stream processing. It leads to an increase in code size, a number of bugs to fix, development effort, and causes other issues, which makes the difference between Big data Hadoop and Apache Spark.
Ultimately, Spark Streaming fixed all those issues. It provides the scalable, efficient, resilient, and integrated system. This model offers both execution and unified programming for batch and streaming. Although there is a major reason for its rapid adoption, is the unification of distinct data processing capabilities. It becomes a hot cake for developers to use a single framework to attain all the processing needs. In addition, through Spark SQL streaming data can combine with static data sources.
If you want to read more about data science, you can read our blogs here