Month: June 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Let me start off with a few common assumptions about the subject of this write up “Four Powerful People Skills For Data Scientists”, and my take on each of them based on my experience and observations.
1. Common Assumption: People skills are just “fluffy” soft skills
Soft skills are often referred to as “the fluffy stuff”. People skills in particular, top the list of fluffiness, in many people’s perception.
Observation: People skills can be characterized as a set of hard, tangible skills which require significant learning and training effort.
2. Common Assumption: Data Scientists have poor people skills
In a corporate environment, data scientists are labeled as “the geeks” or “the incomprehensive ones” or “the guys living in an ivory tower,” all of which are rather friendly characterizations.
Observation: Data Scientists are amongst those groups of professionals with the highest potential to develop people skills – unknowingly.
3. Common Assumption: People skills are somehow deceptive
People skills are quite frequently perceived as manipulative and, by the way: “I am not a sales guy anyway, and I have no intention whatsoever to become one.”
Observation: First, every business and public institution is operated by people. People skills are not the sole domain of sales and HR. Second, people skills are not so much about seducing people to buy things they don’t want, as to handle challenging and complex situations with other people.
Why should you invest in people skills?
Because it pays off, literally.
I have seen businesses thrive based on people skills, including my own. On the other hand, I have witnessed companies generating millions of USD in losses or opportunity costs due to lack of people skills on their teams.
Over the last 25 years, I have worked in different companies on four continents. My collection of Four Powerful People Skills is based both on my experience as well as on observations.

Source: Wikipedia
Let’s get started.
1. User Experience (UX) Skills
Whenever dealing with people and businesses, you need to understand their experience reality. The proverbial pain points are part of everyone’s experience reality, but usually, people are not suffering and in pain all the time. Hence, asking your customers, partners, colleagues about pain points will give you just a limited view on the reality they are dealing with on a daily basis. You can (and you should) gain insights by asking lots of questions, but this route has its limitations. Not everyone will tell you everything they know. That’s not because they are secretive. Most of the time, people leave out many important nuances in response to your questions because they seem to be just too obvious to them to even mention it to you. It’s by far more effective to immerse yourself into someone else, quite literally, and walk in their shoes for a while.
Example: At the time of writing this article, I am taking rig truck driving lessons, as well as excavators and forklift operator training. My company is growing its business with commercial and military vehicle manufacturers. Will I ever make money driving trucks? No (although, admittedly, it’s a hell lot of fun). We are providing data science services. However, our User Experience Skills help us understand the people on the ground. Ultimately, every data science project has an impact on the people in the first front line of business. Understand the people you build and design for, directly or indirectly. Gain a holistic, contextual understanding of your work. It always pays off.
Advice: Launch a User Experience Team
If your business is catering to fast food restaurant chains, someone on your team should flip burgers for at least a couple days. Commercial vehicles? Someone should get a truck driving license. Logistics? Somebody should work in a logistics center for a while. Don’t offload these tasks to the lowest ranking employees on your team. First, because you will not act upon their learnings. Second, because you have to set a signal: “We take customer centricity to a whole new level.” The higher up in the hierarchy the person getting his hands dirty, the higher the impact.
Your company does not support these efforts? Do it anyways. Invest your own time and money if possible.
2. Communication Skills
Over the last 10 years, I have been working with people from at least 30 different countries. The biggest challenge? Literally, in many cases, people do not understand each other. We are living in a globalized world, and it’s quite common to work on projects with teams distributed across multiple countries such as Spain, France, Italy, the UK, India, China, and the USA. In such a multicultural case, you might assume that you all speak English on your team. However, you are faced with seven different English dialects: Spanish English, French English, Italian English, British English, Indian English, Chinese English and US (Texan for example) English. Each dialect sounds almost like a distinct language.
I have seen companies losing business opportunities worth millions of USD, just because nobody could understand the other party’s distinct English dialect.
Advice: Invest in accent reduction training. Speak slowly and clearly
You should take this advice very seriously (more so than any other advice in this article). Nobody will tell you bluntly that you are hard to understand, because it would be considered as impolite. As a result, you might repeat the same mistakes over, and over again, losing time, money and motivation. If you are a French company catering to customers in the US, or a Texan company working with business partners in China or vice versa, you can surely make one assumption right from the start: The other party will hardly understand what you are saying. This is a huge problem for many businesses and organizations. Accent reduction training can get you on the track, tapping into business opportunities that otherwise might get lost once and forever.
The same goes for fast talkers. Some people even pride themselves to talk fast (because they have so much valuable knowledge to share). In fact, they overrun their audience. If you are this type of person: Hit the brakes hard. Really, really hard. Speaking slowly and clearly will be painful and inconvenient for you in the beginning. However, your audience will benefit from understanding what you actually say. Don’t just hit the brakes ones. Make it a habit each and every time you open your mouth (it’s hard to overcome the habit of fast mumbling, I am speaking from my own experience here).
Your company does not support these efforts? Do it anyways. There are many great courses out there available for free on YouTube.
3. Behavioral Science Skills
I recently stumbled upon a meme stating something along the lines of: “We can all agree that people skills are more difficult than nuclear physics.” In fact, human behaviors are very complex and ambiguous. You should always stay away from simplistic explanations. Whenever someone starts a sentence with: “Humans behave in such ways, because …” you can be sure, that they don’t.
A few years ago, I started asking myself: “Why do humans behave the way they do under certain conditions?” For example: “Why do some people thrive under pressure while others collapse?” “Why do some businesses embrace innovation, while others resist any change?” Or: “Why do some businesses survive and others die?”
I started searching for answers in (business) psychology, and over time, I drifted towards human behavioral biology, molecular biology, and neuroscience amongst others. Having no formal STEM education whatsoever, I am faced with severe limits on the amount and depth of knowledge I am able to acquire and absorb. Nonetheless, the insights I gained over the years, opened my mind. I lost interest in simplistic answers in the quest for an explanation of human behaviors. Instead, I learned to look from different angles: One and the same behavior might be interpreted in different ways, even within one and the same discipline.
This set of skills take time to acquire, but it’s the most rewarding one intellectually. By comparison, Communication Skills beats all other people skills listed here by far, in terms of an ROI (return on investment). Nonetheless, the other skills in this article shouldn’t be ignored.
Examples: There are two complementary ways to get your feet wet with Behavioral Science Skills. A) Read a lot. B) Observe a lot. Let me give you a couple of examples from my reading list:
“48 Laws of Power” by Robert Greene
This book is rather a collection of 48 anecdotes than laws. However, they offer some excellent explanation of how people in power reason, feel and act. Some consider this book to be pure evil, as it outlines deceptive and manipulative techniques used by those in power. I recommend reading this book with a healthy distance to the subject (so does the author, as he confessed in one of his interviews). This book helped me navigate through various difficult encounters with those in power.
“Human Behavioral Biology” by Robert Sapolsky
This series of 25 lectures at Stanford University (you can find them on YouTube) is a must-watch for everyone who wants to dive into the subject of human behavioral biology. Each lecture is approx. 60-90 minutes long, and this series does not assume any prior knowledge of this subject. As Robert Sapolsky states in the first lecture, everybody should learn about it.
“The Unthinkable: Who Survives When Disasters Strikes – And Why” by Amanda Ripley
Based on countless interviews with survivors and subject matter experts, Amanda Ripley outlines three distinct phases people go through when disasters strike (denial, deliberation, and decisive action) and how they feel, think and act in each of those phases. This book helped me better understand my own potential behaviors in the event of a disaster. But also, I discovered surprising parallels to how businesses respond when their markets face disruption. Think, Kodak, PanAm, Blackberry, and Nokia as some of the prominent examples. After all, businesses are made of people.
Obviously, these are just a few items on my list. I deliberately picked those three which could not be more different from each other, just to give you an idea of the spectrum.
Advice: Launch a book club at your company
Many outstandingly successful companies have internal book clubs (such as for example Tableau, which was recently acquired by Salesforce for more than 15 billion USD), and they benefit greatly from the shared learning experience. They become smarter as a company, they promote a meritocratic culture and they become more valuable.
Your company does not support these efforts? Do it anyways. Gather a bunch of people you enjoy spending time with, and start your own informal book club.
4. Time Management Skills
You need to learn to manage other people’s calendars. Sometimes it feels like being another person’s personal assistant, but here’s the deal: Most people are bombarded with information, their attention spans become shorter and shorter. To make things worse, the wide-spread, excessive usage of social media chops up people’s attention span even more. The co-founder of Facebook, Sean Parker, goes even as far as claiming that his former company destroys the very fabric of our society.
Example: Whenever dealing with customers, partners, and employees, I think thoroughly through their calendar: “What is the next step? When should we meet and talk?” I send them meeting invites, I send them reminders, and new invites when they miss their appointments, I keep track of progress and think through each and every step. Being someone else’s nanny is tough at times: Nobody pays you directly for that effort, it’s frustrating when people break their commitments, and after all, they are grown-ups, right? They should do it by themselves! But they don’t. Being able to get people to commit and holding them accountable can literally save your business and your career.
Advice: Organize time management training
These training should be delivered by office managers and secretaries, not by self-proclaimed time management gurus. Secretaries deal with a difficult clientele (top executives) and they know how to keep them on track in good times and in bad times. They are the real super nannies, and you should become one, too, if you want to get things done when dealing with other people (close a sale, finish a project, get a raise, etc.).
Your company does not support these efforts? Do it anyways. Invest your own time and money if possible.
Why should you do all this?
Because most other people won’t.
Most people will ignore this advice. They will find excuses why they can’t (such as: “My company does not support these efforts!”). That’s is good for you, if you take the advice above seriously. If you run a business, you can put yourself ahead of your competition with reasonable learning and training effort. Likewise, if you are a data scientist in a large corporation, and you want to have a great career, the Four Powerful People Skills For Data Scientists will certainly help.
In any case, I wish you the very best!
I run a data science & data literacy consultancy, and we cater to large companies in Europe and the US. You have questions I didn’t answer in my write-up, or you want to share your experiences? Please leave a comment or reach out to me via email rafael@knuthconcepts.com or LinkedIn. Thank you!
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Ramani: I’m going to go through what I think might be a familiar experience for some of you. The year is 2010, this is PacFeed, PacFeed is a newly created independent digital media company. PacFeed is most known for its list of goals, like “21 Ways to Lose a Ghost.” The technical team is small, only one to two developers, and they work on the website, and the source code is stored in a monolithic repository.
A couple years later, PacFeed grows to support other types of media content, like video. It’s now known for producing viral videos, a lot of them about cats. With its growth into different types of content, PacFeed’s technical team has tripled in size over the years to be able to support a content team. Adding more business logic to PacFeed has become cumbersome as growth continues. Deploying any change, big or small, requires so much coordination between developers, it can be comparable to anarchy. Something needs to change, so they turn to microservices.
PacFeed has split out into multiple microservices that make up different parts of the system, and interact with each other in different ways. PacFeed grows to support even more types of media content. They’re now known for their award winning investigative journalism team and their brands, like Tasty, videos to make cooking more accessible.
With this media expansion, PacFeed’s technical team grows. Its responsibility is to make sure that content is accessible and discoverable across a wide variety of platforms, from PacBook, to PacTube, to its own PacFeed platform. With the move to a microservice architecture, it’s easier to build these services, which is great.
Then there becomes a necessity to create internal tools for employees, and tech, and other parts of the business organization, to aid their workflows. With the creation of internal tools introduces a new question, “How do we secure our services so that only employees who are authorized to access tools can access them?” Today, that’s what I’d like to talk to you about.
My name is Shraya, and I work at BuzzFeed, which might have a few similarities to the problems that PacFeed had. I work as a software engineer on security infrastructure tools, one tool that I worked on is something that we used to solve the problem of securing internal services.
I’m going to start off with some background on our infrastructure and the evolution of auth at BuzzFeed. I’ll go through the different types of auth that we considered, and what we initially went with before we started to feel some scaling problems. This evolution ultimately led us to build our own solution to securing services called SSO. I’m going to go through the different parts of SSO, and what the user experience looks like, then, SSO is recently open sourced, so finally I’d like to talk a little bit about that and why and how we ended up going through an open source process and I’m going to talk a little bit about how we maintain the project.
Infrastructure Goals
Let’s start with how we have historically approached auth at BuzzFeed, and the auth infrastructure problems we have faced as we continue to grow into the organization that we are today. BuzzFeed reached a point where it was apparent that it would need to be able to build fast to be able to support its business growth. In order to do so, we invested time in building scalable infrastructure. The first big improvement to our infrastructure was the introduction to a homegrown tool to standardize the way we deploy and test our services, called Rig.
This is what Rig looks like, Rig is a platform our engineers use that creates an opinionated workflow for creating, deploying, and testing services. It leverages containerization and is built on Docker and Amazon ECS. A user can change the source code to the monorepo on GitHub, and then a Docker image is built and stored in Amazon ECR, and then the service with the built image can be deployed from a separate UI that we call Deploy UI, onstage in-production environments.
Having Rig made creating new applications easy, and allows developers to be able to focus more of their efforts on actually developing software. Rig was developed with some goals in mind, and these same goals have influenced the way we write much of our infrastructure and develop our tools. We want the tools we create to provide consistency across the org. Having consistency allows for a unified developer workflow that we can document, and makes it easy to onboard new developers, and makes it easy for mobility across teams.
From an operational standpoint, we want our infrastructure engineers to have a simple experience, automating as much of the workflow as possible. From a security standpoint, we want access control to our infrastructure to be as granular as possible, so that only those who need access have access. Lastly, we want the experience for developers using these tools to be as pleasant as possible.
Going through our goals with Rig, we get consistency in our deployment workflow across all services, managing and operating this infrastructure becomes much easier because it’s all automated. We have granular access control because we have different keyrings and permissions on deploying services. Lastly, developers are happier because they can deploy their code themselves and get built and tested results faster, and be more productive overall.
With Rig, we were able to build even faster. Here’s a bit of a breakdown of the current state of our tech ecosystem. We have around 600 services that are deployed on Rig, and they can be broken down into a few different categories, 250 UI services, 150 API services and 150 message queue reader services for publishing and consuming messages.
Let’s focus on these 250 UI services, these are front end internal tools, like a UI for deploying services or a tool for video producers to be able to upload and edit their videos. This means that they need to be secured, which brings us back to this question, “How do we secure our services?” Well, we considered a few auth options against our infrastructure goals, with the ideal solution being something that would check all of these boxes.
The first option that seemed like it would be a reasonable choice was a VPN. Many organizations have their employees connect to a VPN to be able to access whatever services they need within the private network. In terms of infrastructure goals, a VPN didn’t seem like the best option. A VPN may provide consistency in our infrastructure, but I’m also sure many of us know how annoying it is to always have to connect to a VPN, let alone have to set up, and maintain, and monitor the infrastructure for one. We’d also still need to have an additional solution to granular access control, as a VPN would not give that to us on its own.
Another option was to punt on coming up with a way to secure our services, and allow service owners to bake that into their applications however they might see fit. This inconsistency was something that we did not want. From a security observability perspective, we would have no insight into how secure our services were. There could be granular access control, but that would be up to the service owners. Instead of solving the problem with one solution, every developer would need to relearn how to solve this authentication problem over and over again.
Identity Aware Proxy
Our last option that we considered was something called an Identity-Aware Proxy. This comes from Google’s BeyondCorp philosophy based on the principles of zero trust network. What are all these things, you may ask? Well, let’s go back almost a decade ago, to early 2010 again, where Sneaky Panda, the Elderwood Gang, and the Beijing Group are suspects in a series of cyber-attacks dubbed Operation Aurora. These attacks compromised the networks of 30 companies, including Yahoo, Adobe, Morgan Stanley, and Google to steal their data. Google was actually the only company to disclose the breach in a blog post released in January of 2010.
As an interesting aside to this, they mentioned in their blog post that they had evidence to suggest that the attack was to access the Gmail accounts of Chinese activists, this is actually what led them to cease their operations in China.
Why is this relevant? Well, this event was the impetus for an industry wide shift on our approach to security, moving from a model of relying purely on a very secure perimeter to a more distributed and granular form of security. It was during this time that the philosophy of zero trust networks came to be.
Basically, Sneaky Panda were able to figure out a way to get past the perimeter in this network, either because of an unreliable VPN provider, or stealing Pacman’s credentials, or a poor encryption algorithm on a security protocol. The whole network would be vulnerable to attack once Sneaky Panda got through. This is what zero trust networks aimed to prevent, based on these three tenets.
First, network locality is not sufficient for deciding trust in a network. The network is always assumed to be hostile, and external and internal threats exist on the network at all times. Second, every device, user, and network flow should be authenticated and authorized, meaning granular access control. Lastly, policies must be dynamic and calculated from as many sources of data as possible. Having good monitoring and flexibility in the system is important.
Using this philosophy, Google created their BeyondCorp philosophy, which is defined in a white paper that was written in December of 2014. From this white paper came the concept of an Identity-Aware Proxy, which is considered a building block towards a BeyondCorp architecture model.
The purpose of an Identity-Aware Proxy is to shift authentication and access control to be something that’s based on the user, rather than on what network the user is in, and doing this by having the proxy service sit between the user and the upstream. It uses a third party provider, like Google, to authenticate and authorize the user trying to log into the service.
With this kind of model, if Sneaky Panda gets into the network, he still can’t really get access to any service within the network secured by this Identity-Aware Proxy, without maybe having the user’s credentials and MFA. With granular access control, if Sneaky Panda gets Pacman’s credentials and MFA, then only those services that Pacman had access to would be vulnerable. Hopefully, critical services that have admin access would be protected and inaccessible to Sneaky Panda.
This was everything that we wanted, consistent, easy to maintain, granular access control, low developer setup overhead. Now we just needed to figure out which one to use, like any good developer, we looked to open source. The implementation we ended up using is a Go binary from Bitly called Oauth2_proxy. Every service would have an auth proxy service in front of it, which runs the Oauth2_proxy binary with the appropriate configurations.
Scaling Problems
This was great for a while, when we only had a few user-facing services, but we soon started to question its scalability as more user-facing services, therefore more auth proxy services, were created. We started to see more and more scaling problems, felt all around. To start, the users accessing the services behind Oauth2_proxy would have a frustrating experience. Many of our users use multiple tools in our microservice ecosystem. For example, a video producer might use one tool to upload and package their videos, another one to see when they’d be published to the appropriate platforms, another one to get metrics on how the performance of the video did.
This was not only frustrating for users, because they’d have to click through and sign into every new service. It also enforced bad security practices, as users would blindly click through all the auth proxies without actually checking that they’re using their credentials for the correct service.
Developers and operators also felt scaling problems. For developers creating a new service, the process of adding auth meant copying over this boilerplate Oauth2_proxy template and modifying config values. To most developers, what these configurations meant was confusing and completely opaque to them. Then maintaining these Oauth2_proxy services was a frustrating experience as well.
For example, there was a critical security fix for Oauth2_proxy, and that meant updating our service in every single Oauth2_proxy service, and graphing our code base for every single Oauth2_proxy service. This was not only tedious for the engineers maintaining the services, it also created a larger surface area for the potential of an attack.
Also, Oauth2_proxy did not have any metrics tracking baked into it, so debugging an issue like that critical security fix was not easy since we had no visibility into that part of our system. Adding that visibility would be tedious, because it meant changing it in every single Oauth2_proxy service. We were hoping that our next solution would be able to improve our infrastructure.
With that we realized that even though we got consistency and granular access control, doing anything with the Oauth2_proxy service was a pain. We decided that we wanted to build something new. When coming up with our new solution, we did not want to stray too far from what we already had. We decided to use the logic of Oauth2_proxy to create what we like to call the SS-Octopus or SSO, a single sign on version of Oauth2 proxy.
What Is SSO?
What is SSO? Well, this is SSO, is an implementation of an established standard protocol called the CAS Protocol, which stands for Centralized Authentication Service. It consists of a CAS server, which is responsible for authenticating users and granting access to the services, and a CAS client which protects the service and uses the CAS server to retrieve the identity of the user. SSO has these two binaries, sso-auth is the CAS server, and sso-proxy is the CAS client.
This is a sample auth flow, I’m going to go into a little bit more detail of all the different parts of this flow now. First, there’s sso-proxy, it acts as an Identity-Aware Proxy for the upstreams, sitting between them and the user. It stores a short-lived session cookie that refreshes every minute or so with sso-auth, and this whole refresh process is done behind the scenes.
Then there’s sso-auth, which acts as the auth provider for sso-proxy, and it uses a third party provider like Google to authenticate the user, and stores the user identity information in a long-lived session cookie that lasts about 15 days. When this session cookie expires, the user is redirected to a sign in page, and then must sign in with Google again.
This is because the third party auth provider is the source of truth on information about the user. It provides the user identity information to sso-auth, which then in turn provides the user information to sso-proxy. We use Google as our provider, and we’re working with the community to support other providers, like GitHub and, often, Azure AD.
Then there are the upstreams, and these are the services that are secured by SSO. They’re defined in a YAML file, because we wanted to get on the YAML bandwagon as well. Developers can add their services into this shared file, which starts off with a mapping from the internal service address to sso-proxy’s address. Then we have other options like allowed groups, which allows for group space authorization or request time outs. They can also setup overrides for addresses to allow for a better user experience, that a user could just go to pac-land.com instead of having to go to pac-land.sso.pac-world.io, in this example.
This is the new experience for someone logging into two services. As a service that I use all the time, in this example, I’m logging into our Deploy UI service to begin with and get directed to log in with Google. After signing in with Google, I get directed to the Deploy UI page, and then can go ahead and deploy some services.
Now, say, I want to check my service that I just deployed, I’m going to open a tab and go to Httpbin, which is a sample service that we have behind SSO. This time, I immediately get redirected to Httpbin. Sso-proxy refreshes every minute, so if my account were to get hacked by Sneaky Panda, by the time I leave the stage, it could be locked down, and nor I or Sneaky Panda would be able to access either service.
Having SSO in production checks all the boxes for our infrastructure goals. With centralized auth, operating our infrastructure is a much simpler streamlined process. Rather than having to maintain hundreds of individual auth proxies, our infrastructure engineers only to focus on one code base and have those changes be reflected in all of our services. This has made it easier for bug fixes and to be able to add better monitoring and metrics tracking, and to generally audit all of our services that we have secured by SSO, without having to graph for days and days.
Open Source? Why?
That that’s a little bit of SSO, it’s been in production for a few years, and we have hundreds of services behind it. After a couple of years of having this in production, we made a decision to open source. This decision was not taken lightly, open sourcing security is scary, you don’t want to be giving away the keys to your kingdom. We realized that open sourcing SSO shows the lock to our kingdom without actually giving away the keys. Still, we had many justifications to make before open sourcing SSO.
First, SSO was born out of an open source project, and so it only seemed natural to give back to the community. We understood, from talking to folks in similar roles at other companies, that the need for centralized auth was a common problem among platform engineering teams. We learned that many teams had built their own solution internally, because there was no ideal open source solution. We hoped to work together in the open to tackle this. We also knew empirically that Oauth2_proxy, from which SSO was originally forked, has a large and active community of users. We felt confident that it would achieve similar traction with SSO.
Finally, we believed that granting access to our code base would improve our security practices, I’m about to discuss in the next section about how we did this. Security encompasses a variety of risk factors that you can’t really prepare for. We know that it’s really difficult to get right, we hoped that this transparency would shine a light on our security footprint.
Open Source? How?
When thinking about how we’re going to execute this open source, we made sure to consider what would make an open source project successful, and what we could do to mitigate the risks surrounding open sourcing a significant piece of our security infrastructure.
To start, we made sure that we had significant and substantial documentation to make getting started with SSO as easy as possible. We focused a lot of our efforts on a quickstart guide to lessen the barrier of entry for users to use the project. We think that having this quickstart guide was a major part in its success for getting people to start contributing and using SSO.
Another thing that we decided was important to do was to change the name of our project, the original name was COAP, for Centralized Oauth Proxy, and we didn’t think this was a suitable name, and there are two reasons for this name change. First, we wanted it a step away from this acronym, because we wanted the name of this tool to be something that was inclusive of all communities that might want to use an open source tool. We also thought that for the future of the project, we wanted to expand past Oauth, and so rebranding would allow us to do that.
I started by polling engineering on naming suggestions, and got some really interesting ones, Soap, Cap, this is what happens when you don’t really ask a marketing team, you just ask a bunch of engineers to come up with names. We ended up going with something simple and self defining, SSO, because it seemed like the right thing to do.
In addition to these refactoring and documentation changes, when beginning the open source process, we had larger conversations around what risks we were going to be taking by open sourcing SSO, and what we could do to mitigate these risks. We decided to take a three pronged approach to auditing the security of our project.
One tool that we take advantage of, for many different parts of our code base, is a third party bug bounty program called HackerOne. It allows us to pay for security vulnerabilities found by security experts. Since the start of having SSO in production, we have been using HackerOne for SSO. Before open sourcing, we contacted a few known hackers who we worked with, and gave them access to the code to see if they could find any vulnerabilities by having the two side by side. We also hired a third party consultant to pen-test SSO and provide code review.
We vetted a few companies based on cost and process, and we decided on one that worked for us, and gave them access to the code base for a one-week review. While nothing significant came up from this, we were happy that we had the peace of mind of getting this review done.
Lastly, we have an in-house security consultant who did an architectural review of SSO, and actually found something interesting in the way we encrypt our session states and cookies.
Some background, we encrypt our session states, which contain the user email, access and refresh tokens generated by the third party provider, and we store this encrypted session state in cookies on sso-auth and on sso-proxy, which is what powers this whole auth flow. We previously used AES-GCM encryption, but our security architecture consultant informed us that this type of encryption is not resistant to an attack called a nonce-reuse misuse attack. If a nonce, a number used once, is reused, the XORs of the plaintext messages are leaked, so Sneaky Panda can see your token and hijack your auth session. Not good.
There is a different type of encryption, called AES-SIV, that has nonce-reuse misuse resistance. Ciphers with this type of resistance don’t fail catastrophically when the nonce is reused. The only information that’s leaked when the same nonce is used twice under the same key is just the cipher text, rather than the plaintext. We ended up going with an open source package called Miscreant that implements a AES-SIV. This was a great learning experience on security best practices for our team, and made us feel more confident going forward with the open source.
After going after going through this security audit process, we felt more prepared. Beyond preparedness, understanding that security is never completely done, was crucial. Our team has a learning and growth mindset about all of our work. This includes acknowledging that unknown unknowns exist, and that we’re going to have to continuously adapt. Nothing is ever 100% guaranteed to be secure, but careful planning, good communication, and clear expectations allowed us to assuage our initial fears.
Then we finally open sourced SSO, and it went really well, we are really proud of it and everyone who’s worked on it. The open source process has been really beneficial for us. While it often seems like open sourcing an internal security project involves more risk than reward, we’ve had an incredibly powerful and positive experience overall.
Maintaining SSO
After the open source happened, we recognized that there was a lot of work to be done maintaining this project, and we made this a priority for our team. To make maintaining SSO sustainable, we took a few approaches, first, we created a maintainers working group that meets once a week. It’s made up of people from the infer teams, other stakeholders, those who are just interested in learning Golang, and those who are just interested in contributing to SSO. In our meetings, we discuss all of the issues and pull requests that come in during that week. Sometimes we also do knowledge shares on new and existing features.
From this working group, we also came up with an on-call rotation that rotates through the members of the group, and we established internal SLAs for responding to the issues in the PRs. During that time that we established those SLAs, we also made sure to have an external contributing doc with guidelines on how to contribute to the repository.
This is our contributing guide, it includes a link to the code of conduct, step by step instructions on how to get started. Our goal is to figure out ways to lessen the barrier for entry to be able to contribute and use SSO. We try to be clear about what we will and will not accept on issues in PRs, and try our best to lean towards an optimistic merging policy.
This term was coined by Peter Hinton’s, and essentially says that it’s better to accept and merge all pull requests that come in in a timely manner. This can be difficult, especially when maintaining a critical piece of our security infrastructure. We tend to fall somewhere in the middle of that, and a rigid merging policy, or a pessimistic merging policy, because we want to make sure that contributors know that they’re making a difference by contributing, which will hopefully encourage them to continue to do so.
Maintaining an open source project is a lot of work, and required us to invest time and energy in approaches to make it sustainable. In the end, knowing that the work that we put into maintaining the project has made people’s lives even a little bit better is worth it.
That’s a little bit about how we approach our security infrastructure and why and how we ended up building an open source solution for microservice auth at BuzzFeed. With the SS-Octopus, PacFeed is able to have a centralized solution to microservice auth, following best infrastructure practices and making sure that only authorized users can access the tools that they need to.
If you’d like to try out SSO, it’s there. We work on actively maintaining it, and we would love any feedback in the form of issues or pull requests.
Questions and Answers
Participant 1: After centralizing all the authorization you have before distributed, did you face any issues with any latency in the request or something?
Ramani: No, not really, Oauth2 proxy and SSO have the same mechanism, so there wasn’t really any latency, because the cookie session is stored in the client and then in sso-auth, it’s the same flow, even though they’re just cookies that are encrypted and stored in the headers.
Participant 1: From what I saw there, you are specifying all the permission stuff in a YAML file. Do you have any way to make the checks dynamic or something?
Ramani: That’s something that actually we’ve gotten some requests for in issues, and something that we haven’t really been able to prioritize, but would love to have people contribute.
Participant 2: Could you elaborate a little bit on what made you select CAS as your authentication protocol in contrast to the others, Summer, or ATC, or whatever?
Ramani: Yes, I think it was because it worked the best with the with our existing Oauth2 proxy solution. When we were developing it, we wanted something that wouldn’t be too out of what we already had going on. We did consider other options, but I think that was a big draw to even to push people to justify us to build our own solution.
Moderator: Just to clarify something, you showed the administration, how you configure the service for the upstreams, when you manage which users have access to that. Is that now like a Google Group management for the emails? Because you just showed the emails, I wanted to make sure.
Ramani: Yes, there’s group-based authorization, we manage that using the Google Admin API. We’ve also been getting a lot of requests for on having just email based authorization in the YAML file itself. That’s something that we’ve been discussing, and I think we’ve had some pull requests open up for that, but we’re trying to get that in.
Participant 3: Assuming that Sneaky Panda is already on your network, how do you stop them directly accessing any of the internal services without going through the proxy?
Ramani: If you don’t have the Oauth proxy, how do you…?
Participant 3: I assume that the Oauth proxy is external facing, and then it’s redirecting internally to those services. If they were already on your network, why can’t they just directly connect to those services?
Ramani: Because we have IAM rules on our tasks, we have everything in our infrastructure also secure, we have additional security in our infrastructure, in addition.
Moderator: I think if I can take a crack at it, the challenge is you can isolate a network inside. I mean, you can prevent anybody accessing it, but you can’t prevent anybody accessing it because you need your developers to access it. The challenge is, “Ok, now you need to open it up,” and the natural motion is to say, “Ok, I’ll just open it up so that a privileged machine, like a developer’s machine, will just be able to SSH into it,” and that’s when you get in trouble.
What this does is it says, “Ok, the systems don’t open up to any network” They don’t care about network access, these are the upstream that are protected. They allow access through a specific form of authorization, and that form of authorization is, in turn, authorized or not through this proxy. If you compromise the developer’s machine, if they haven’t logged in with their two-factor auth and all of the components, they wouldn’t have access, similarly, a malicious attacker who compromised that developer’s machine wouldn’t either.
The network segregation is already past network segregation, it’s already its own network, and the question is, “Who can access that network?” It’s not about the service being compromised, it’s about the developer accessing the system being compromised.
Participant 3: Ok, so the access token is getting forwarded on to the actual internal service, and that’s where the authorization is happening.
Moderator: Yes, I think so. Maybe we can do another update.
Participant 4: Once you add this repository of open source, did you find it expensive to maintain, considering you might have to go back to someone like HackerOne to see the progress that I made with all the contributions, if you go back and find out from them if they’re still compliant with good security practices?
Ramani: Because we use HackerOne for a lot of different parts of our organization, we haven’t really seen an uptick in HackerOne reports being opened up after open sourcing SSO. Yes, who knows? Maybe we’ll get a security issue at some point in time, we haven’t really had any cost upticks after open sourcing SSO.
Moderator: Maybe I’ll add that HackerOne is free for open source, so in this case, BuzzFeed was also a solution. I think BuzzFeed uses HackerOne premium internally. If you have an open source project, I don’t know if they’re here or not, but I believe that they’re free, or at least there is some scheme for them to be free in open source.
Participant 5: How do you actually protect flows that don’t involve external users, that is service-to-service communications?
Ramani: For our service-to-service communications, we don’t use SSO. We actually have an internal API gateway that we use. This is mostly just for user facing services that employees can access the UI services that they need to.
Moderator: I’d say, probably the leader in the open source society is Envoy Proxy, maybe it’s part of Istio, that is the one that’s most discussed, I haven’t had experience with it.
What other popular, like you mentioned Rig and SSO, what other sort of top open source projects do you consume that you want to share about, that you’ve published?
Ramani: Rig isn’t open sourced yet, but maybe one day. This is actually the first big open source project that BuzzFeed’s released, we have some Android libraries that we’ve open sourced in the past. I think we’re trying to use the same model to open source some of our storage infrastructure applications, actually, Felicia works on that stuff.
Participant 6: Thanks for the talk, first of all. I wanted just to ask about one point, when you mentioned, regarding the Oauth2, where the proxy had to be set up manually for each application. How does it work with SSO? Is it like a single key, handwritten?
Ramani: Yes, instead of having to add all this boilerplate code, we have just a shared YAML file, if a service is created it can add just like a blob of YAML that will have it configured and ready to use with SSO.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Work continues on nullable refence types for C# 8, revealing edge cases that need to be addressed before the final release and new opportunities for reducing the amount of boilerplate developers have to write.
Here are some of the open questions for nullable reference types:
- Which takes precedence,
MaybeNullorNotNull? - Should
AllowNullandNotNullbe allowed on value types? - Should
!change top level nullability when there was no warning? - Should ref arguments always be assumed to be assigned to?
- Which conversions should preserve the nullable state of members?
- Should we support
var?, and if so, what are the open issues? - Along those lines, would we allow
var? (x, y) = ...deconstructions? - Should we permit (or forbid)
typeof(string?), given that we can never honor the nullable annotation? - When we compute a nullable annotation in flow analysis, should we use the context?
- Should the result of a dynamic invocation be treated as non-null, as it is generally outside the scope of static analysis?
Other questions have been answered. Here are some of the highlights that may affect how code is written.
- The nullability of a conditional invocation (
x?.F()) is always nullable. - Throw statements and throw expressions yield a warning when their operand may be null.
- No nullability warnings in unreachable code.
- The nullability of anonymous types are part of its inferred signature.
Declarative Argument Null Checks
One of the holes in nullable reference types is they are merely a suggestion as far as the compiler is concerned. Even if you mark a parameter as non-nullable, there is nothing to stop someone from accidentally passing in a null, especially when using reflection or dynamic. Which means you still need to add a null argument check at the beginning of your function.
With the Simplified parameter null validation, you’ll be able to tell the compiler it should create the null check for you. Two versions of the syntax have been proposed.
void Insert(string s!)
void Insert(string! s)
In both cases the bang operator (!) is used, either on the type name or the parameter name. The argument for the first version is it is an implementation detail of the function and not part of the method signature. The argument for the second version is it is more consistent with the nullable version (void Insert(string? s)) and perhaps it should be of the method signature. This is significant because if it’s part of the signature, then it can be applied to interface methods as well. And this then opens up questions about inheritance and overriding methods.
Another question is how it will be implemented. Options include:
- C# emits the check inline in IL
- C# emits a call to a helper method in IL
- C# just emits a tag, allowing the JIT process to decide how to perform the check
Another question is what happens when the type is nullable (int?) but the null check is desired. If supported, this may result in an contradiction in the signature (void Insert(int?! i)).
Not yet discussed is using an attribute ([NotNull]) instead of custom syntax. While more verbose, it would set a precedent for other forms of declarative parameter checking.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
A bounded context is a defined part of software where particular terms, definitions and rules apply in a consistent way, Eric Evans explained in his keynote at DDD Europe earlier this year. A canonical context has a refined model and an expressive ubiquitous language with unambiguous definitions. But a description of a system that looks so tidy is, for him, very suspicious. None of the large software systems he has been involved in have been anywhere near that tidy. In a recently published presentation, he describes different kinds of bounded contexts, including some that involve microservices.
Evans, a thought leader in DDD and author of the seminal book Domain-Driven Design, notes that the bounded context as a concept has drawn increasing interest from the community over the years, but is still an area where there is more to be done. One confusion that Evans sometimes notices in teams is differentiating between bounded contexts and subdomains. In an ideal world they coincide, but in reality they are often misaligned. He uses an example of a bank structured around cash accounts and credit cards. These two subdomains in the banking domain are also bounded contexts. After reorganising the business around business accounts and personal accounts, there are now two other subdomains, but the bounded contexts stay the same, which means they are now misaligned with the new subdomains. This often results in two teams having to work in the same bounded contexts with an increasing risk of ending up with a big ball of mud.
A Mature productive context is producing value, but probably built on concepts in the core domain that are outdated. An important question to ask is how misaligned its core domain is, when compared to the current view of the core domain, and how much this is constraining the evolvement of the business. Too much misalignment can lead to a demand in transforming the existing context, but in Evans’ experience, they often don’t transform so well. Changing the basic assumptions of software often means that it ends up broken; he therefore recommends against doing so.
Other types of contexts Evans describes include Quaint context, an old context which still does useful work, but maybe is implemented using old fashioned technology and not aligned with the current vision of the domain, and Generic subdomain context together with Generic Off the Shelf (OTS) context, which address an important generic subdomain in a conventional way that other contexts must conform to. He also describes and compares Generalist Context with Specialist Context.
Evans believes that microservices is the biggest opportunity, but also the biggest risk we have had for a long time. What we should be most interested in is the capabilities they give us to fulfil the needs of the business we are working with, but he also warns against the bandwagon effect. One problem he sees is that many believe that a microservice is a bounded context, but he thinks that’s an oversimplification. He instead sees four kinds of contexts involving microservices.
The first is Service Internal, describing how a service works. For Evans, this is the type people think about when they say that a microservice is a bounded context. Here a service is isolated from other services and handled by an autonomous team. This fits his definition of a bounded context, but he notes that it’s not enough. Using only this type, we would end up with services that don’t know how to talk to each other.
The second is API of Service, describing communication with other services. One challenge here is how teams design and adapt to different APIs. Data-flow direction could determine development dependency with consumers always conforming to an upstream data flow, but Evans think there are alternatives. Highly influential groups may create an API that other groups must conform to, for example with authorities, where you commonly must adapt to their APIs irrespective of the direction data is flowing.
The third is Cluster of codesigned services. When several services are designed to work with each other to accomplish something, they together form a bounded context. Evans notes that the internals of the individual services can be quite different with models different from the model used in the API.
The final type is Interchange Context. Evans points out that the interaction between services also must be modelled. The model in this context describe the messages and definitions to use when services interact with other services. He notes that there are no services in this context; it’s all about messages, schemas and protocols.
Exposed Legacy Asset can be useful when we want a legacy system to participate in a microservices environment. One way is to create an interface that looks like a microservice and interacts with other microservices, but internally interacts with a legacy system. This keeps us from corrupting the new microservices built, but it also keeps us from having to change the legacy system; they are often fragile and can be corrupted and even turned into a big ball of mud.
Evans concludes by trying to define what DDD really is. A challenge is how tightly should DDD be defined. A definition should share a common vision and language, but should also be flexible to allow for innovation and improvement. The community is important, but it must be an honest community open to the possibility of being wrong when the result isn’t as expected. He also thinks we should try to clarify the limits of applicability of DDD; all software projects should not be done with DDD. He summarizes by defining DDD as a set of guiding principles: focus on the core domain, explore models in a creative collaboration, and speak a ubiquitous language within a bounded context. His final words were:
Let’s practice DDD together, shake it up and renew.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- We constantly experience the three kinds of empathy – cognitive, emotional and empathic concern – but it’s cognitive empathy that companies and leaders refer to when they are talking about being more empathetic at work
- The best way to start expressing or showing empathy to others is through your communication
- Highly collaborative teams are empathic because they embrace varying perspectives, value unique ideas, and give each other the space to speak freely and openly
- To overcome the barriers of empathy at work, leaders and employees alike must immediately acknowledge the failure and do their best to course correct
- To engage empathy in difficult situations, one must be patient, garner perspective, and focus on connecting with their listener to further their relationship in a positive way
The book Empathy at Work by Sharon Steed explores the role empathy plays in team communication and interaction, and provides tools to help people become better empaths in difficult situations. It describes the steps we can take in order to show empathy daily and contribute to a healthy, collaborative, positive work culture.
InfoQ readers can read Empathy at Work online by signing up for an O’Reilly membership (free, no credit card required).
InfoQ interviewed Steed about the importance of empathy for people working in agile teams, what we can do to become more empathic, the qualities that empathetic companies have, how speaking with intention can make our communication more empathic, why allowing some autonomy can be incredibly empathetic, how leaders can deal with empathy failures, and how we can develop an empathic mindset.
InfoQ: Why did you write this book?
Sharon Steed: I was actually approached by the people at O’Reilly Media to write something about empathy in corporate environments. I spoke at Velocity in New York in October of 2018, and they liked my talk topic and suggested I create some content for them. I’ve been speaking about individual empathy, empathy at work, and empathy on teams for several years now, so I had a good idea of the kind of ebook I wanted to write. I’ve also done a course with LinkedIn on empathy and communication, so saying yes was easy since I’d had some experience creating this caliber of content.
Once I started to actually outline and write, that “why” question came up again a few times. I wanted to write this particular piece so that professionals could have a go-to source of how to engage empathy in corporate settings. There are so many great works out there by people talking about communication, collaboration, emotional intelligence and other similar topics, and of course Brené Brown’s work on vulnerability and empathy is massively impactful and groundbreaking in so many beautiful ways. I think that empathy in a professional context, however, is still a thing that hasn’t been explored nearly as much as other “soft skills.” I wrote this book to essentially start the conversation around this topic to a much broader audience than I usually get to engage with.
Speaking is wonderful because I get to be face-to-face with people from all walks of life, but a talk can only get so far into the world. The internet helps some with recorded talks being posted online. Even then, however, I can’t connect with audiences who aren’t physically there. This ebook allows me to spread my message and work in a much larger way, and that continues to be a very exciting thing.
InfoQ: For whom is the book intended?
Steed: I’d like to think this is a book that could help everyone! If you are a living, breathing human being, you most likely have several daily interactions with other humans. And to truly optimize those interactions, you must engage empathy in a meaningful way.
With that said, I intended this book to be for those working on teams at companies. Specifically, I wanted this book to help people in management roles. Being a people manager is an incredibly difficult job; it’s almost like two, maybe even three, jobs at once. You have to manage down to your team and make sure that each member is not only producing at minimum a satisfactory level. You must also manage up to your own direct superior and satisfy their directives and expectations. Finally, you have to complete the tasks of your own specific job title.
When I was writing this book, I was thinking specifically about these individuals. In most of my talks, I have a section on culture and how to improve a culture through engaging empathy. I firmly believe that true company change starts top-down, spreads from the bottom, but is implemented in earnest from the middle. Managers are the most influential group in almost any company because they are consistently engaging with the widest range of people in the building. If managers can become better empaths, a true cultural shift can happen and feeling inside of any company will be a more positive one.
InfoQ: How do you define empathy?
Steed: There are several definitions and types of empathy that all circle around the same general idea, and then there is my own specific definition for me personally in my own day-to-day life. I’ll start with the dictionary and academic definitions, and then round it out with my own paradigm.
If you look up empathy in a dictionary, it’ll say something to the effect of, “The feeling to understand or share the feelings of another person.” Empathy is essentially attempting to feel what the other person is feeling in the sincerest possible way in order to better understand them. Researchers and academics have defined several different types of empathy, but the three main ones most talked about are emotional empathy, cognitive empathy and empathic concern.
Emotional empathy is inherent in us; when we see someone laughing, we smile. When we see someone crying, we feel sad. Cognitive empathy is understanding what a person is thinking or feeling; this one is often referred to as “perspective taking” because we are actively engaged in attempting to “get” where the person is coming from. Empathic concern is being so moved by what another person is going through that we are empowered to act. The majority of the time when people are talking about empathy, they are referring to empathic concern.
These definitions of empathy are all accurate and informative. But a big point that I always try to make is that empathy is a verb; it’s a muscle that must be worked consistently for any real change to occur. That’s why everyone’s definition of what empathy is in their own lives is going to be a little bit different. We all feel understand in a different way, so each person truly has to define what empathy looks and feels like for themselves. For me, it’s allowing me to finish my thoughts. I’m a stutterer, and it sometimes takes me a bit to get a word or a thought out. Although someone may know what I’m going to say, I need them to allow me to say it. That is showing me empathy. I always encourage my clients and audiences to define empathy on their own terms.
InfoQ: How important is empathy for people working in agile teams?
Steed: Some of my favorite events to speak at are agile-focused ones, in part because they already get it. Why? Because the agile manifesto and approach to work is already inherently empathetic. Things like providing a supportive environment; trusting people to get the job done; reflecting on how to be more effective; and adjusting and tuning an individual’s or team’s behavior if something isn’t working within the system are all incredibly empathetic actions. Let’s break this down.
Supportive environments are those that allow for everyone to thrive in the exact capacity that makes each individual successful. What does that mean? It means that everyone understands and accepts that just because one person finds success in a specific way, it doesn’t mean that any other individual will use that same approach. Supportive environments are those where every team member meets their coworkers at whatever level they are at without bias or judgement.
Trust is imperative to any successful endeavor. If teams don’t trust each other – both interdepartmentally or internally as a unit – there is no way a company can truly achieve the goals they set out for themselves. Trust is empathetic because it lends itself to understanding. When you trust someone, a few things are happening. First, you are taking the things they say at face value. There’s no questioning ideas or methods, there’s just encouragement and giving them the space to work. Second, there is a sense of understanding among the team; you give people the benefit of the doubt because you know you don’t have all the answers and that others might be better equipped to deal with a specific problem than you are.
Reflecting on how to be more effective and then adjusting as needed is a real cornerstone of empathy in my opinion. Something I say in my talks is that you (the audience) will fail at this, probably multiple times a day. I struggle with it all the time! But the most important thing is to get back right back at it as quickly as possible. Regroup, take a deep breath, and then try again. You see, reflecting on how something went and examining behaviors that worked and didn’t are useful on agile teams because it is literally an agile action. Being adaptable and being thoughtful are empathetic actions as well.
InfoQ: What can we all do to become more empathic?
Steed: Empathy is going to be a bit different for everyone because all of us have different wants and needs. Empathy is also much easier when we are dealing with people who we identify with or who we care about. So though it is always useful, empathy is most imperative when we are in a situation with a person we don’t identify with or we are in a difficult/uncomfortable interaction.
With that in mind, one thing I always tell people to always remind yourself that you most likely do not have the full context of a situation. This means, quite literally, that you don’t know everything. You only know what you see and what you are told, then from there you create your opinion. Your opinion on the situation is not a fact; your opinion is your view – your perspective – of what’s going on. And your perspective doesn’t take into account the various moving parts of the situation as a whole and all of the individuals involved.
So being empathetic in most situations where empathy is vital is reminding yourself that you have no idea what’s going on in this person’s life and what may be affecting their mood at work. So always approach every situation with a good amount of patience. Patience is the key to both not taking anything too personally and also to keeping the true goal of the interaction in mind.
Another thing we can do to be more empathetic is to be mindful of who we are speaking to at all times. So many of the people I work with feel that they aren’t strong communicators. I think many of us have some sort of insecurity around the way we communicate with others, especially our coworkers. And it’s understandable; we live in a time in which the standards of how we must treat each other are incredibly high. Everyone wants to be (and absolutely should be) treated fairly, spoken to with respect, and dealt with in a professional way. The problem is that all of those things mean something different to every single person. When I say to be mindful, I mean take this human being you are speaking to into account during the conversation; treat them not the way you want to be treated, but they way they want and need to be treated. That single behavior will make an enormous difference in how others respond to you.
InfoQ: What qualities do empathetic companies have?
Steed: Every company is different, just as every team, department and individual is different. What works for one company is not going to work for another. This is why every leadership team needs to prioritize defining empathy (both as individuals and as entities as a whole) before they can create a system that works for them in engaging empathy.
With that said, there are a few characteristics that most empathetic companies have. One is transparency. The vast majority of workers understand that not all information is available to them, and that many of the important things going on behind the scenes are on a need-to-know basis. However there are ways for companies to let their employees in a little. The example I give in the book is how Buffer publishes everyone’s salaries and the formula behind it. Obviously not every company can or should do that, but this kind of transparency helps trust and security thrive.
Another global characteristic is that everyone is given the space to speak their mind (within reason) and, as a result, everyone feels heard. New managers especially may feel the need to rule with an iron fist or to immediately exert the power of their team. Allowing their direct reports to express themselves when they have concerns or just a unique take on an old idea, however, really lends itself to a more open culture and one that is rooted in trust and autonomy.
InfoQ: How does speaking with intention make our communication more empathic?
Steed: Something I say both to my clients and in my talks is to “speak with intention first, for impact second.” This means that we should speak with the end goal of the interaction in mind and then use impact to help both drive home our point and to further foster a connection with the individual with whom we are speaking.
Think about the last time you got upset with someone at work or a conversation went from benign to heated. What was your gut reaction? Maybe it was to raise your voice; speak sarcastically; insult the person’s ideas; or to give negative and aggressive body language cues (i.e. crossing your arms, eye rolls, etc.). When we get into situations where we feel we are being attached or disrespected, the first thing to go negative is our communication. We get defensive (because we are hurt and upset) so we then speak in a tone and with language that showcases those feelings. This can devolve incredibly quickly into an argument, a destroyed relationship and – most importantly for those at work – a fractured team.
Instead of approaching the conversation with the end goal in mind, we are now in “fight mode.” We speak for impact first with the intention of hurting the other person the way they just hurt us. That’s why prioritizing intention over impact is empathetic; we are making the foundation of our message (and, therefore, our thoughts) solution-oriented. We have a goal to keep in mind, and we know that our words are going to either help achieve that goal or make that goal that much harder to achieve.
We have a goal to keep in mind, and we know that our words are going to either help reach that goal or make that goal much more difficult to achieve.
You mentioned in the book that allowing some autonomy can be incredibly empathetic. Can you elaborate?
Steed: Allowing autonomy really goes back to trust. Managers and leaders who trust their employees are going to give those employees “long leashes,” so to speak. I realize that this won’t work on every team. But it’s important that everyone is given a chance to at least work in a way that best suits their style. Autonomy is more than just about allowing people to do whatever they want when they want. It’s allowing people to think about problems in different and unusual ways. It’s giving space for people to work through issues on their own and then engaging their thought processes to see how they think and where they end up. In short, allowing people to be a bit autonomous on your team is empathetic because you are giving others the time and energy to work thought things at a pace and capacity that works best for them.
Many teams have rules and specific ways things are done, and that makes sense. No one wants to fix something that works perfectly well as it is currently. However, allowing for some autonomy gives employees some space to figure things out on their own terms. And the result of doing that is a team and workforce that feels included in the company in a much greater capacity. This is empathetic because now everyone feels understood. And understanding is truly the cornerstone of empathy.
InfoQ: How can leaders deal with empathy failures?
Steed: I’m a huge fan of people taking real, sincere responsibility for the things that they do wrong. Think about it: how often do people really apologize for a misstep and then immediately try to course correct? It is miserable to admit when we are at fault, and even worse to have to figure out how to make things right. When leaders fail, it can be especially difficult for a few reasons. First, everyone sees it; everyone knows when you’ve failed and everyone can then, as a result, judge you. Second, your failure could potentially have a major impact on the team or company.
When we take this same reasoning and results to failures of empathy, the aftermath can be quite overwhelming. Everyone wants to feel heard and valued. When we fail at empathy, we risk making people feel insignificant and unimportant. That’s why when we fail, we should immediately acknowledge the misstep and then reinforce to whomever we are speaking with that they are, indeed, a valuable part of the team and that their ideas and feelings matter. I know this sounds very “soft” and mushy, but it really goes back to one thing (and it’s a thing that those in the agile community really value): humanity.
We’re not dealing with difficult coworkers; bosses who are never happy; direct reports who can’t follow directions; or leadership that doesn’t seem to care about their teams. We’re dealing with human beings, and humans have lives, feelings and complex emotions that can’t be turned off when we’re in the office. That’s why it’s so important for leaders to constantly remind themselves that when they fail at empathy – because they will, without a doubt, fail at it – that they immediately confront that failure and try to re-engage when emotions are more level. Also, it helps if there is some sort of system in place for when empathy fails.
InfoQ: What’s your suggestion for developing an empathy mindset?
Steed: I’m constantly championing empathy as a verb so people can truly engage empathy on a daily basis on their teams. However, I get that empathy is a very abstract concept; it’s not something that you can give a few simple directives for and then just go do. You have to put considerable thought into what empathy is going to look and feel like for you and your team.
There are, however, a few constants when attempting to get into an empathy mindset. This isn’t necessarily a guide or a process; it’s more so a few things you’ll absolutely have to consider (and become quite good at) in order to truly engage empathy in difficult situations.
The first thing is patience. We do not live in a culture where patience is valued or tolerated. We are constantly bombarded with stuff: current events, terrible news, cute puppy gifs, funny memes, and a host of other things. We are a “right now” culture and if we have to wait for something? We definitely do NOT want it. However patience is truly the foundation of an empathy mindset. Patience helps us calm down and see the situation from its basic level: an interaction with an actual end goal.
The next thing you need to have is perspective. The two things that I do when I need to get perspective is to first, repeat what was just said to me. Often times, we don’t hear what was said to us; we hear our opinion of what was said. When we are repeating or rephrasing what was said to us, we are doing our best to eliminate bias and to get clarity. The second is to focus on understanding. This goes back to reminding ourselves that we do not have the full context of the situation from the other person’s perspective. Understanding is reiterating to ourselves that because we don’t have the full picture, we should be slow to anger and put all of our energy into hearing the other person out.
Finally, we need to focus on truly connecting with the person we are addressing. When we’re in a heated situation, we lose sight that this exact conversation is the one that will springboard all future interactions. So we need to take care to maintain and further the relationship. An empathy mindset basically comes down to that: engaging in the necessary behaviors that allow relationships with your coworkers to flourish.
About the Author
Sharon Steed is an international keynote speaker, author and founder of Communilogue, a corporate empathy and communications consultancy. She has spoken at companies and conferences from various industries in 15 countries spanning four continents on improving team communication and collaboration through engaging empathy; vulnerability as a professional asset; and has given a TEDx talk on empowering insecurities. An author and course instructor for O’Reilly Media, Inc., her live online training “Empathy at Work” is held continuously throughout the year and her eBook Empathy at Work is available in the O’Reilly library; and her course “Communicating with Empathy” is available on LinkedIn.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
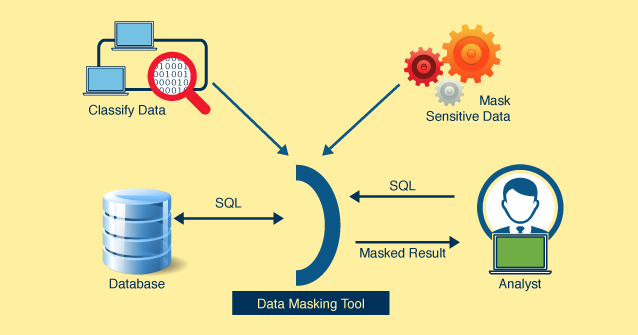
In this digital age, the threats against an organization’s data are massive and the consequences of a breach are extremely devastating for a business. So it has become important to consider various factors when it comes to secure databases.
Our world is on a huge risk of data theft and a few months ago, Facebook data breach news proved this. One interesting fact is that almost 80% of the confidential information in a business organization resides in a non-production environment that is used by the testers, developers and other professionals. Just a single and small breach can damage the reputation of company in the market.
Giant tech companies like Facebook has become the poster child of data misuse. If the organization is small, then such problems can be tackled but when it comes to organizations that hold the keys to a huge amount of data creates huge risk.
It is no surprise that safeguarding confidential business and customer information has become more important than ever. Companies are more focusing on product development and neglecting privacy issues. A famous movement DevSecOps are helping to raise an issue like sensitive data security. But more than that, it is very important to ensure that data security and privacy always stay at top of the mind.
How Data Masking is related to the Security of a Business Organization?
The business organization must implement security controls through their normal software testing tools so that only certain authorized individuals can access particular data. We are discussing some effective data masking strategies for business organizations. By following these techniques, organizations can make their “data securing strategy” more practical and effective:
- Try to maintain integrity: There must be consistently masked data- even for the data derived from multiple uniform sources, so that relationship between values is preserved after the data is transformed.
- Masked data must be delivered quickly: Although the data is constantly changing and the makeup of non-production takes some time, the companies need to continuously mask and deliver the masked data.
- An End-to-end approach is necessary: Simply applying masking strategies is not enough! Company should make sure to look for the end to end approach too to identify the sensitive data and their accessibility to their clients.
Data Masking and Security
Few reasons that enterprise businesses should use data masking:
- To protect sensitive data from third party vendors: The sharing of information with third-party is mandatory but certain data must be kept confidential.
- The error of Operator: Big organizations trust their insiders to make good decisions, but data theft is often a result of operator error and businesses can safeguard themselves with data masking.
The Indian lab of IBM has brought out a new solution to protect against theft of sensitive data from call centres. They have developed a technology named AudioZapper for the solution in the global marketplace that addressed complete security concerns of a call center. IBM Solutions offers required protection of confidential data such as credit card numbers, PIN, and other social security numbers from getting into wrong hands.
You may like to get more information on Protect confidential data with Static Data Masking by CA Technologies
Availability of Data masking software
There are some effective data masking software which are available in the market that gives businesses everything they need to continuously protect sensitive information. They provide a reliable masking solution with a variety of predefined algorithms. With a single software solution, you get various services like creating masking data and then efficiently delivering to its concerned users. The best thing about this software is they deliver amazing services in affordable charges.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

The sports digital transformation is upon us, and the world of sports is about to be disrupted through the technology at play. In the words of the most decorated Olympian to step on the podium:
“You can’t put a limit on anything. The more you dream, the farther you get.”
-Michael Phelps
The field of sports has advanced by leaps and bounds over the last decade. By looking at sports from a commercial perspective, we can tell just how much the world of sports has benefited from globalization and all that is happening in the tech world. The sports ecosystem—from the right holders to the broadcasters, the technology platforms, the partners to the providers—is ready for a disruption. Sporting events from across the world are now popularly broadcasted through different media to give an immersive experience to end users. The sports industry now generates some amazing figures, which demonstrates that it is at the tipping point of something great. New applications are tearing down the barriers that we once had for sports and are taking fan experiences to a whole other level.
With technologies like IoT, Big Data Analytics, AR, VR, AI, and the Cloud, there is no reason why we shouldn’t believe that the sports viewing experience will be totally revamped a year or two down the line.
It is believed that the North American Sports Market, which is one of the most popular with the most domestic viewers, will have a worth of over $78.5 billion by 2021. The same North American market for sports was worth well under $53.5 billion during the year 2012. Hence, we have seen a rapid increase of almost 47 percent during the last 10 years.
These figures aren’t just from one market, either. If we look at other markets including Europe, Africa, Asia, India, and Australia, we can see different figures and increases that lead to a lot of optimism for the future. The figures from today’s sports market are all but indicating that the next biggest opportunity in broadcasted sports is upon us now. It is the right moment for broadcasters to jump on the sports digital transformation bandwagon and cash in on the prospects that are on offer within this market.
Ronald van Loon is a Tata Communications Partner with access to a wealth of research published by the Tata Group. This research has revealed some startling prospects for the sports digital transformation, and Ronald cannot wait to share this information with you.
How to Monetize
Whenever the question of accepting the Sports Digital Transformation arises, organizations want to know just how they can monetize the gains on offer here.
Opportunities
There are numerous opportunities for broadcasters and organizers to look at when it comes to incorporating the digital transformation within the sports viewing experience. These opportunities include the following:
Focusing on the Fans
It is best for you to focus on the fans and to give them a viewing experience that is unparalleled by any other. Fans across the globe want to remain in the thick of things and do not want to feel left out of the whole process.
You should focus your campaign on the fans so that they know they are in the limelight and are being valued by the franchise.
Stats suggest that many viewers today are casual viewers and may not follow the action live and on a consistent basis. This research just shows the potential for broadcasters when it comes to turning over these casual viewers into permanent viewers. Once the interest of these viewers is increased, the broadcaster will be able to achieve a greater permanent audience..
“We’re at an inflection point, and must weigh up the value of reach versus quality of engagement. Just trying to maximise reach is not a viable long-term strategy. Attracting younger audiences can be a challenge due to the constraints of traditional golfing formats in terms of the time and duration of events. Innovative new formats such as GolfSixes are helping the European Tour appeal to a broader demographic beyond our traditional fan base. Digital is the biggest opportunity we have to reach a new audience,” mentioned Tom Sammes, who is the Senior Strategy Manager at the European Tour.
Immersive Experience
With Virtual Reality and Augmented Reality technologies taking center stage, it is best for broadcasters to incorporate these technologies within their offerings as well. Broadcasters that promise an immersive viewing experience with AR and VR technologies will dominate sports broadcasting in the future.
Challenges
While there are multiple opportunities to explore, broadcasters also face numerous challenges in completely revolutionizing today’s sports broadcasting sphere.
Attracting Younger Generations
No sport in the world wouldn’t want to grow their existing audiences. Every sport would want to have a larger audience size, and preferably a younger audience because of how much they are attracted to the sport and the competitiveness on offer.
“Any business that wants to grow has to attract new audiences rather than continue to go back to its existing audiences. “We want to align with our customers’ passion points and recognize that we are going to have fewer direct touchpoints and face-to-face interactions with them. One of the important things with partnerships is you can engage with that audience around their passion points. When that all comes together it’s perfect. And, if you can engage new audiences as part of that, clearly that enables you to achieve a growth objective as a business,” mentions Tricia Weener, who is also the Global Head of Partnerships at HSBC.
Getting the right young audience is the first of many challenges for broadcasters and the sport itself.
Anytime, Anywhere
In the era of personalized content, the average sports consumer wants to watch the game on their own schedule. Fans want to be able to view their favorite sports on the go, without any issues whatsoever.
“All viewers, but especially younger viewers, expect to watch content any time, on any screen, and be able to pause, rewind or watch highlights. Our platform is popular among younger viewers who do not want to pay subscription fees or be tied to a device. They want the freedom to watch and pay as they go,” says Parnwell from Dazn.
Fast Development of Technologies
Technologies around us are rapidly growing, and broadcasters are forced to think of ways to incorporate them in the mix on the go. This will present an increasing challenge for organizations going in the future.
The Impact of Technologies on Monetization
It has been found that AI systems can help with choosing the right cameras on the go. Viewers want to be able to see the right content through the right cameras, and AI can help accomplish that.
Both IoT and AI have multiple applications in sports that can monitor and improve employee fitness on the go. Players can understand their strengths and weaknesses, and work to improve them.
Organizers can also use both these technologies to boost interactivity levels in viewers around the globe. “Sponsors are attracted by digital interaction, and most brand partnerships will include incremental digital activations. For F1, digital is a tool to drive our marketing objectives for fan engagement, as well as a platform for business evolution. In five years’ time, we want the digital fan experience to be frictionless. The digital and media ecosystem should make it easy to be an F1 fan,” believes Frank Arthofer from Formula 1.
What Can Broadcasters Learn?
Broadcasters need to know just how they can make the sport more impressive and exciting for young audiences. Fans of all ages can become customers; broadcasters can help improve their revenue streams by incorporating technology and monetizing the trends here.
You can read more about Tata’s research in this regard by clicking here.

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
According to Facebook, PyRobot will allow developers to get up and running with a robot quickly thanks to it providing a higher-level abstraction on top of the robot operating system (ROS).
Similarly named as PyTorch, Facebook machine learning framework for Python, PyRobot will play a similar role to PyTorch in the arena of robot programming, Facebook scientists Abhinav Gupta and Saurabh Gupta say.
PyRobot will make it easier for the research community to use robotics data sets, algorithm implementations, and models, and also help them set benchmarks, compare their work, and build on each others’ results.
Facebook scientists claim PyRobot can bring down the time required to set up a robot from days to just a few hours. What makes things even harder in robot programming is that supporting multiple robots usually adds a significant complexity. Indeed, it is not easy to port code for one robot platform to another due to differences in API and available abstractions. Therefore, one of the goals of PyRobot is providing cross-robot abstractions, so you only need to import the right robot class from PyRobot while leaving the rest of your code unchanged to target a specific robot:
from pyrobot import Robot
robot = Robot('locobot')
target_joints = [
[0.400, 0.721, -0.471, -1.4, 0.920],
[-0.675, 0, 0.23, 1, -0.70]
]
robot.arm.go_home()
for join in target_joints :
robot.arm.set_joint_positions(joint, plan=False)
robot.arm.go_home()
One big advantage of this approach, say Facebook scientists, is that you can develop your robot application using low-cost robots such as LoCoBot, without locking yourself in. This would make it more affordable to deploy a fleet of robots that will operate and learn in parallel and allow you to improve your solution.
PyRobot provides abstractions to control joint position, velocity, and torque, for path planning, forward and inverse motion, and more. Currently, PyRobot supports two robot platforms: LoCoBot and Sawyer, with more coming. Foreseeably, PyRobot success and adoption will largely depend on how well Facebook and the PyRobot community will work to extend the number of supported robot platforms. Next on Facebook roadmap is Universal Robots, but Facebook is already calling for the participation of the research community to provide support for more hardware.
PyRobot approach to cross-robot development is different to that fostered by, e.g., H-ROS SoM, a modularity stack meant to be embedded inside modular robots so they provide the same programmable interface.
It is worth noting that both Amazon and Microsoft recently announced support for ROS in some of their products. Amazon introduced AWS RoboMaker, which is a cloud-service to develop, test, and deploy ROS-based applications, while Microsoft is working on integrating ROS into Windows 10. In fact, both solutions address a different set of concerns than PyRobot’s and should be not confused with the latter.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
When one looks at the amazing roster of talks for most data science conferences what you don’t see is a lot of discussion on how to leverage object storage. On some level you would expect to — ultimately if you want to run your Spark or Presto job on peta-scale data sets and have it be available to your applications in the public or private cloud — this would be the logical storage architecture.
While logical, there has been a catch, at least historically, and that is object storage wasn’t performant enough to actually make running Spark jobs feasible. With the advent of a modern, cloud native approaches that changes and the implications for the Apache Spark™ community are pretty significant.
At the heart of this change is the extension of the S3 API to include SQL query capabilities, S3 Select. With S3 Select, users can execute queries directly on their objects, returning just the relevant subset, instead of having to download the whole object — significantly more efficient than the regular method of retrieving the entire object store.
MinIO has pioneered S3 compatible object storage. MinIO’s implementation of the S3 Select API matches the native features while offering better resource utilization when it comes to executing Spark jobs. These advancements deliver orders of magnitude performance improvements across a range of frequently used queries.
Using Apache Spark with S3 Select
With the MinIO S3 Select API, applications can offload query jobs to the MinIO server itself, resulting in significant speedups for the analytic workflow.
By pushing down possible queries to MinIO, and then loading only the relevant subset of the object to memory for further analysis, Spark SQL runs faster, consumes less network resources, uses less compute/memory resources and allows more Spark jobs to be run concurrently.
The implementation of Apache Spark with S3 Select works as a Spark data source, implemented via DataFrame interface. At a very high level, Spark and S3 Select convert incoming filters into SQL S3 Select statements. It then sends these queries to MinIO. As MinIO responds with data subset based on Select query, Apache Spark makes it available as a DataFrame for further operations. As with any DataFrame, this data can now be consumed by any other Apache Spark library e.g. Spark MLlib, Spark Streaming and others.
Presently, MinIO’s implementation of S3 Select and Apache Spark supports JSON, CSV and Parquet file formats for query pushdowns. Apache Spark and S3 Select can be integrated via spark-shell, pyspark, spark-submit etc. One can also add it as Maven dependency, sbt-spark-package or a jar import.
MinIO has, like all of its software, open sourced this code. It can be found here for further inspection.
High-Speed Query Processing
To provide a sense of the performance, MinIO ran the TestDFSIO benchmark on 8 nodes and compared that with similar performance from AWS S3 itself. The average overall read IO was 17.5 GB/Sec for MinIO vs 10.3 GB/Sec for AWS S3. While MinIO was 70% faster (and likely even faster on a true apples to apples comparison) the biggest takeaway for the reader should be that both systems have completely redefined the performance standards associated with object storage.
Needless to say, this performance gap versus AWS S3 will increase as you scale the number of nodes available to MinIO.
This performance extends to writes as well, with both Minio and AWS S3 posting average overall write IO’s of 2.92 GB/Sec and 2.94 GB/Sec respectively. Again, the differences between MinIO and AWS S3 are less material than the overall performance.
What this means for the Apache Spark community is that object storage is now in play for Spark jobs that require high performance and scalability.
AWS S3 provides that in the public cloud. MinIO provides that in the private cloud.
One advantage of going the private cloud route with Minio is that the private cloud offers more opportunity to tune the hardware to the specific use case. This means NVMe drives, Optane memory and 100 GbE network. This will offer at least an order of magnitude performance improvements over the public cloud numbers listed above.
Learning More
As noted, MinIO’s code is open source and available here. We had the only talk on the subject at Spark + AI Summit and have made the slides available here. If you want to learn more, you can reach out to us on hello@min.io. or you can always interact with us on our Slack Channel.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
OVERVIEW & PURPOSE
Before we dive deep into the topic let’s ask a few questions to yourself and start diving into it as deep as you want to…!!!
- What it is?
- Why it came into existence?
- Where it was used?
- What are the results we achieve using this?
- How we can implement this?
Coming to the journey of this blog that it was a continuous series of six blogs that we are going to discuss about the Facial Recognition in a Feynman Learning Technique, Using CNN and Open CV with Python. Moreover, we need to know brief about the topic.
Technologies Used: Open CV (open source Computer Vision Library) and CNN (Convolutional Neural Networks) Algorithm.
Programming Language used: Python
What it is actually?
Let’s suppose two people met at some place at some time on some day…(First Meet)
Person 1: Good morning sir….
Person 2: Good morning. Thanks, May I know, are you?
Person 1: By the way I’m Kiran new to this apartment.
Person 2: Okay!
Same persons met again after a week – (Next Meet)
Person 1: Hi sir! How are you?
Person 2: Hello, I’m Fine Thanks and What about You?
In the first meet the person came to identify him with some unique identity and then stored in his memory. Where in the second meet he directly recognized the person and greeted him.
This is the same way Face recognizing system is an AI Model that will get trained and will function as a Human in Recognizing the Person. This is happened with series of training of the model and then use. This system led to procure to many applications. Today we are going to dive into the Chapter where to use? And Why it came into existence?
In Technical Terms:
A facial recognition system is a technology capable of identifying or verifying a person from a digital image or a video frame from a video source. There are multiple methods in which facial recognition systems work, but in general, they work by comparing selected facial features from given image with faces within a database. It is also described as a Biometric Artificial Intelligence based application that can uniquely identify a person by analyzing patterns based on the person’s facial textures and shapes. Face Recognition System
Facial Recognition Technology has become a part of Security these days , its applications become enormous in distinct Fields. It will be the world’s most used AI technology by 2022.Most of the Applications used this and derived many use cases in the industry , the growth is increasing day by day.
Attendance Management System:
- Using this AI Technology People maintain the Attendance records of the employees by identifying the faces in front of the system and matches with the image available in the database to keep their attendance record.
- As face recognition technology is one of the least intrusive and fast-growing biometric technologies, it works by identification of People faces using the most unique characteristics of their faces. Say goodbye to proxy Attendance management. Student Attendance Management System
Driver Monitoring System:
- The Subaru facial recognition system (Driver Monitoring System), called Driver Focus, stands as the first such biometric platform in the compact SUV segment, Subaru says. Driver Focus aims to reduce the estimated 1,000 injuries per day in the United States that involve distracted driving. The feature will come standard on Forrester’s Touring models, the most expensive Forrester model. Driver Monitoring System
- This system monitors the driver’s facial expressions and controls the speed of the engine and stops when the driver is tired.
Security Systems:
- Companies are fed up with remembering the traditional passwords for accessing, they were training deep learning algorithms to recognize fraud detection, and reduce the need of remembering passwords, and to improve the ability to distinguish between a human face and a photograph.
- Gender, age, Liveliness and anti-spoof Detection got included.
Emotion Detecting System:
It’s an Emotion recognition system that which is derived from the face recognition. It identifies the Human emotion and feeling with the expressions on the face. This also came into existence with many applications
Let’s check few applications where emotion is a key part of the System:
- Buying goods from a shop, whether customer is satisfied or not? We can find this with his facial movements and expressions. Most liked goods can be filtered.
- Eating in some restaurants finding the expressions of people whether they are delight full or not? Restaurant Owner can expect the sales of food and improve the order regarding their expressions.
- Employee Emotion detection, If the emotion is like frustrated and sad let the system give him a break and make a stress-free environment.
By-Kranthikiran Diddi