Month: December 2019

MMS • K Jonas
Article originally posted on InfoQ. Visit InfoQ
Dec 10th 2019, cloud native software company Solo.io released WebAssembly Hub, a service for building, deploying, sharing, and discovering WebAssembly extensions for the Envoy proxy. Extending Envoy with filters can provide customizations such as TLS inspection, TCP proxying, and HTTP request and response manipulation. The Solo.io team’s goal for the WebAssembly Hub is to remove barriers for developing and sharing Envoy filters and enable users to configure and extend their service mesh.
According to Solo.io founder and CEO Idit Levine:
At Solo.io, we believe that extending the functionality of your service mesh should be simple and secure, this is why we’re excited about integrating Wasm with Envoy Proxy. We built the WebAssembly Hub to help end users develop extensions and consume them.
The WebAssembly Hub is an image registry for WebAssembly (abbreviated Wasm) extensions for Envoy, which are created and added to the hub. WebAssembly extensions can be built with any of the supported languages, such as C, Go, and .NET. Wasm is currently supported by the service mesh Istio, Solo.io’s Gloo Enterprise, and the Envoy Proxy itself. Other Envoy-based service meshes are expected to offer Wasm support in the near future.
Users can create extensions, such as routing rules, written in any Wasm supported language. Extensions are made available on the WebAssembly Hub and usable with Envoy service meshes with the Solo.io CLI wasme. After writing an extension, users push the extension to the WebAssembly Hub registry with wasme. The extension can then be deployed to a Envoy environment by configuring the service to load the module from the WebAssembly Hub registry.
Extensions can be shared as modules by adding them to the catalog with wasme, which creates a pull request against the wasme Github repository. The PR will be reviewed by the WebAssembly Hub team and included in the catalog if accepted. Users can also explore and search for extensions on the WebAssembly Hub website. Current modules include the templating engine Inja Transformation, AWS Lambda authentication and routing, and a REST to SOAP translation tool. The WebAssembly Hub also provides the configuration updates needed to add an extension to Envoy-based products.
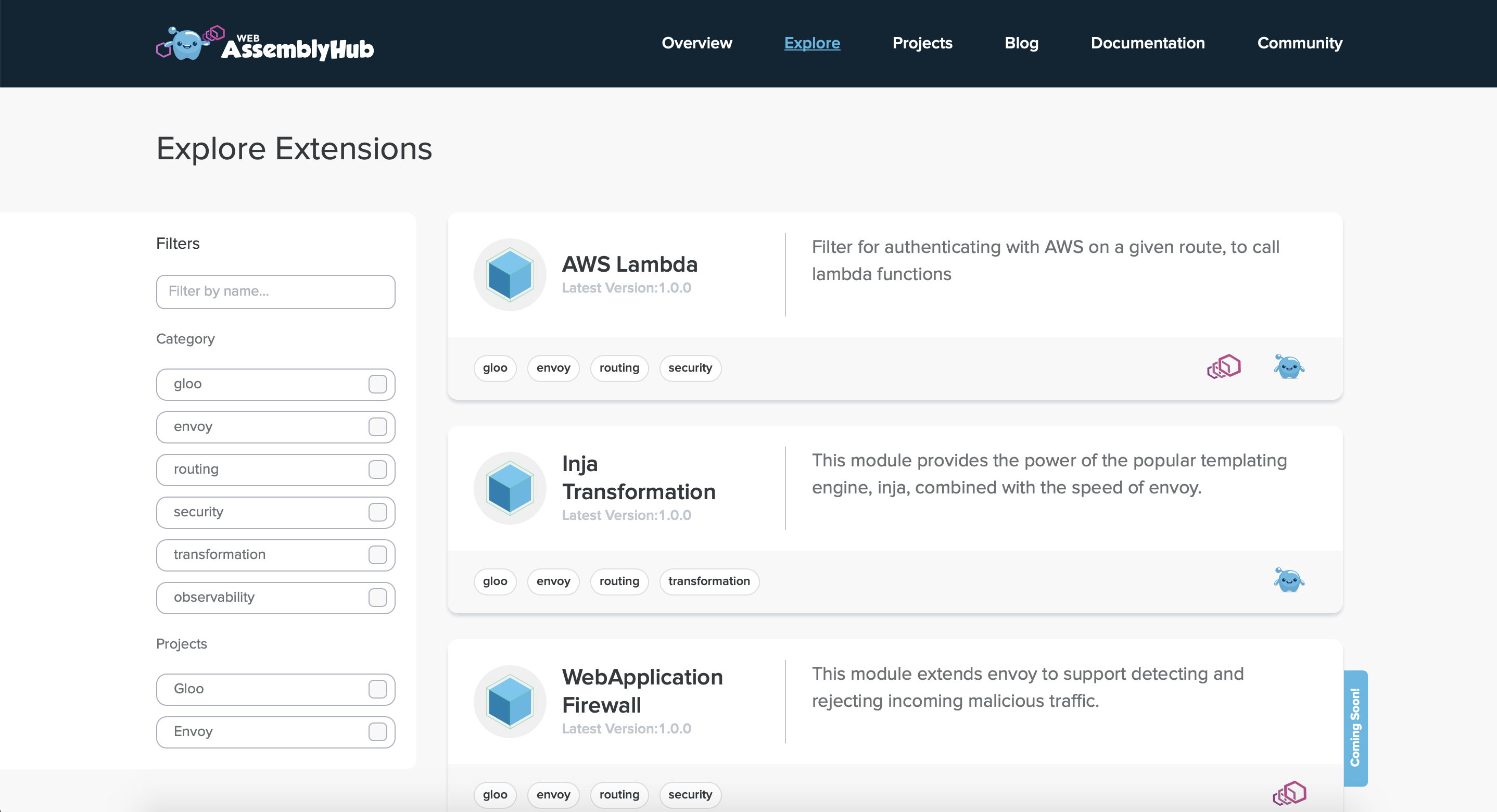
WebAssembly Hub Search, from the Solo.io blog
Solo.io selected Wasm for extending Envoy due to its speed and ability to dynamically add or modify extensions without needing to stop an Envoy process or recompile. Additionally, the Wasm community has developed compiler support for many popular languages. The Wasm extensions do not make changes directly to Envoy itself, which provides isolation to ensure if an extension crashes, Envoy is not negatively impacted. Solo.io’s recent release of the Envoy-based API gateway, Gloo, also includes built-in support for Wasm. With this feature, Wasm extensions can be built and deployed to both Envoy and Gloo.
Learn more and browse the available extensions at the WebAssembly Hub. To get started with creating extensions, visit the Solo.io documentation.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Things at work that make us smile or laugh can improve team cohesion, productivity and organisational performance. Fun can’t be forced, but it can be fostered, said Holly Cummins at FlowCon France 2019, where she spoke about the importance of fun in the workplace.
Cummins presented three steps to achieving fun. What she calls step 0 is an implied prerequisite, which is to stop prohibiting fun. Step 1, removing un-fun things, is often a double win, as Cummins explained:
Usually, people hate tasks because they know they don’t add value. So eliminating waste, busy-work, and repetitive tasks increases efficiency but also makes our workplaces more fun.
Step 2 is having fun, where the right kind of fun will depend a lot on who is having the fun. Cummins mentioned that there may not be a one-fun-fits-all recipe:
I personally advocate for fun-with-exercise (like ping pong), since exercise breaks improve brain function. However, having a giggle, playing a game, or watching something funny are all great.
Cummins explained how programming and fun are related to each other:
Programming is fun! Well, I should qualify that. On bad days, when nothing works, or where there’s lots of tedious graft, programming maybe isn’t so fun. But at its best, programming is really fun – there are puzzles, and then when we figure the puzzle out, there’s the reward of working code. And we get to make stuff! Programming has a creative aspect and a logical aspect, so it’s satisfying in multiple ways.
Agile is about eliminating waste and shortening feedback cycles, Cummins said. She mentioned that work which everyone knows is useless drains fun from a workplace, so eliminating overhead and heavy paperwork is a win for both people and productivity. Cummins also mentioned SRE, where a primary goal is to eliminate toil:
Toil is those repetitive, manual, un-fun tasks which eat staff time. This makes being on an SRE team way more pleasant than one doing traditional ops.
Feedback is also important, as Cummins explained. Tighter feedback cycles give us a better chance of delivering the right thing, and they also improve job satisfaction. “Nobody likes doing work and having it go into the void – we want to know if we’re doing well and see a positive impact from our efforts,” Cummins said. “Ultimately, what we want is to see people using the things we made.”
Fun isn’t about what people are doing, it’s about how they’re feeling. Cummins mentioned that managers shouldn’t try to enforce fun, but they can create a culture where fun can flourish. The first step is ensuring the team knows fun is tolerated, so that people aren’t afraid to laugh or play. Managers can set an example by having fun themselves.
InfoQ interviewed Holly Cummins, worldwide development leader, IBM Garage, after her talk at FlowCon France 2019.
InfoQ: How would you define fun at work?
Holly Cummins: I find it most useful to define fun by example. Fun is things that feel good, that make us smile or laugh (this is called “positive affect” by fun geeks). Things that are fun include exploration, play, puzzles, games, and jokes. For a young child, exploration might be playing with a rattle. For a developer, it might be making a computer say Hello World, in Go, in a container, on Kubernetes. A child’s puzzle might be a Rubik’s cube, whereas an adult puzzle might be figuring out why the Go program is generating a big stack trace!
InfoQ: What makes fun so important?
Cummins: There’s a lot of evidence that fun defuses tensions, improves team cohesion, and reduces sick leave. What’s more surprising is that fun also improves productivity and organisational performance. This is true even if the fun is really trivial. People shown a comedy video before taking a test scored 12% higher on the test than those who went in cold.
InfoQ: How can we measure fun?
Cummins: The best way to destroy fun is to measure it. That doesn’t mean fun can’t be quantified – people whose job it is to research fun do that all the time. My favourite academic measurement of fun is the “funtinuum”. However, if we try to institutionalise and operationalise fun by defining fun metrics … it’s not going to create a fun environment. I heard a sad story of an office party where management took attendance, to make sure all staff were having the mandated fun. That’s just so obviously counter-productive.
InfoQ: What should not be done when you want people to have fun??
Cummins: I used to think there were two steps in achieving fun; the first step was to eliminate un-fun things, and then once that was done, fun could be added. However, once people started telling me their stories about fun, I realised there’s actually an implied prerequisite, which is to stop prohibiting fun. This should be obvious, but apparently it’s not. I’ve been told sad stories about HR prohibiting people from sending out emails to share cakes, or management telling distributed teams that they couldn’t play Doom as an after-hours team-building exercise. The (frankly mystifying) mandate was that if they were in the office after 5:30 they had to be doing work. Someone even told me their project manager once caught them looking happy and said, “Why are you smiling? Work isn’t a place to be happy!”
InfoQ: How can gamification and play help us?
Cummins: Games and play are both excellent ways to learn. We sometimes use the terms interchangeably, but games have a goal and rules, whereas play is unstructured and is done for its own sake. Gamification has an obvious appeal to management, since its goals and rules can be aligned to the broader organisational goals. I know of one team that managed to churn through ten years of technical debt, create a thousand new automated tests, and eliminate hundreds of SonarQube issues by running a competition. What I find fascinating is that the prize wasn’t big – it was just a free lunch! StackOverflow is another example where gamifying the support forum model hugely improved the quality of both questions and answers. StackOverflow doesn’t even have a material prize at all, but people still want to win. Rewarding good answers with points was so effective that all StackOverflow’s predecessors have more or less vanished. It’s more subtle, but velocity tracking is also a form of gamification – teams want to see that number go up, so they will push to try and claim one more point before the end of the sprint.
The benefit of play is harder to quantify, but it’s still important. Play in the workplace often manifests itself as quirkiness in the design of internal tools, or easter eggs in products. These quirks can delight both the users and the developers who create them. Play is also what we do when we’re learning something new. Play is often a precursor to innovation; we find new ideas when we explore the boundary between what we know how to do and what we don’t. One of my favourite quotes is from John Cohn, an IBM Fellow famous for his IoT gadgets and rainbow-dyed lab coat. He says, “You must take the time to play to be creative.”
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

Adrian Cockcroft, VP cloud architecture strategy at AWS, recently shared his thoughts on how to produce resilient systems that operate successfully in spite of the presence of failures. He covers five tools: concentrating on rapid detection and response, System Theoretic Process Analysis (STPA), lineage driven fault detection, no Single Point of Failure (SPOF) principle, and risk prioritization. At the recent QCon San Francisco event, he also shared what he considers are good cloud resilience patterns for building with a continuous resilience mindset.
Cockcroft indicates that there are many possible failure modes within a given system, with each testing a different aspect of resilience. However, he feels that of particular note are incidents where the system fails silently and components that fail infrequently. He states:
The system needs to maintain a safety margin that is capable of absorbing failure via defense in depth, and failure modes need to be prioritized to take care of the most likely and highest impact risks.
He continues that adopting a “learning organization, disaster recovery testing, game days, and chaos engineering tools are all important components of a continuously resilient system.” Ryan Kitchens, senior site reliability engineer at Netflix, shared that the Netflix team leverages these techniques to ensure the team is prepared to prevent and respond to incidents.
The first technique that Cockcroft recommends is ensuring rapid detection and response. In the event that a failure occurs, quick detection is vital to ensure a prompt resolution. He indicates that engineers should understand the delay built into their observability systems and ensure that some critical metrics are collected at one second intervals. He stresses the importance of measuring the mean time to repair (MTTR) but also stresses the importance of finding a way to track prevented incidents. As Kitchens notes “we need to start realizing that the other side of why things went wrong is understanding how things go right.”
His second technique involves working with the system constraints that need to be satisfied to maintain safe operation. Cockcroft recommends using the System Theoretic Process Analysis (STPA) approach as described in Engineering a Safer World by Nancy G. Leveson. STPA is based on a functional control diagram of the system with safety constraints and requirements identified for each component in the design. Commonly, the control pattern is divided into three layers: a business function, a control system that manages the business function, and the human operators that monitor the control system. This approach emphasizes the connections between the components and how they can be affected by failures.
Lineage driven fault detection is the third technique that Cockcroft suggests. This approach starts with the most important business driven functions of the system and follows the value chain that is invoked when that function is working as intended. Cockcroft explains that this is “effectively a top-down approach to failure mode analysis, and it avoids the trap of getting bogged down in all the possible things that could go wrong using a bottom-up approach.”
The fourth technique is to ensure that the system does not contain any single points of failure. Cockcroft recommends that high resiliency systems should have three ways to succeed, and leverage quorum based algorithms. He notes that “when there’s three ways to succeed, we still have two ways to succeed when a failure is present, and if data is corrupted, we can tell which of the three is the odd one out.”
The final technique that Cockcroft describes is risk prioritization. For this he recommends leveraging the ISO standard engineering technique of Failure Modes and Effects Analysis (FMEA). This technique involves list the potential failure modes and ranking the probability, severity, and observability of those failures on a 1 – 10 scale, with 1 being good. By multiplying those estimates together, each failure modes can be ranked based on its risk priority number (RPN) of between 1 and 1000. As an example, an extremely frequent, permanently impactful incident with low to zero observability would have an RPN of 1000.
In Cockcroft’s opinion, STPA allows for a top-down focus on control hazards while FMEA facilitates a bottom-up focus on prioritizing failure modes. He feels that STPA tends to produce better failure coverage than FMEA, especially in cases of human controller and user experience issues.
In his recent talk at QCon San Francisco, Cockcroft shared what he considers are good resilience practices for building cloud-based applications. This includes the previously mentioned rule of threes. He also noted that when performing a disaster recovery between regions the goal should be to fail from a region with smaller capacity to one with larger capacity. This helps ensure that the failover is not further impacted by insufficient capacity. Along the same lines, failing from a distant region to a closer, and hopefully lower latency, region can help ensure the failover is more successful.
He continued by stressing the importance of employing a “chaos first” mentality and noted that, while he was at Netflix, chaos monkey would be the first app introduced into a new region. This forced applications, and the teams that own them, to be prepared to handle failure from day one. Finally he shared his concept of continuous resilience, which he admits is a basic rebranding of chaos engineering in order to hopefully allow for less hesitation in applying the concept to production workloads. As continuous delivery needs test-driven development and canaries, Cockcroft posits that continuous resilience needs automation in both test and production. He stressed the importance of making failure mitigation into a well tested code path and process.
Cockcroft notes that while it isn’t possible to build a perfect system, these techniques can “focus attention on the biggest risks and minimize impact on successful operations.” As Charity Majors, CTO of honeycomb, notes
It will always be the engineer’s responsibility to understand the operational ramifications and failure models of what we’re building, auto-remediate the ones we can, fail gracefully where we can’t, and shift as much operational load to the providers whose core competency it is as humanly possible.
MMS • InfoQ.com
Article originally posted on InfoQ. Visit InfoQ
At InfoQ we are passionate about software. Our team of regular editors and contributors all have full-time jobs in the software industry, building software and managing software teams. Our mission is to facilitate the spread and change of innovation in professional software development. We do this through the content we publish online via InfoQ and a number of other platforms including YouTube, Apple News, Alexa, as well as in-person through the various QCon conferences we run around the world.
To help guide our content, groups of our editors meet regularly to discuss the global content strategy for InfoQ and the technology trends that significantly impact our industry. During these discussions, we consider the state of practice, emerging ideas and things we hear within our network and at meetups, conferences, analyst events, etc. We also take into account traffic patterns on the site and attendance at sessions at QCon and other industry conferences as well as, where possible, publicly accessible surveys, our own reader surveys and other data.
The output from these discussions is a series of topic graphs, based on a technology adoption curve, which we use to inform our content policy.
Free download
MMS • InfoQ.com
Article originally posted on InfoQ. Visit InfoQ
At InfoQ we are passionate about software. Our team of regular editors and contributors all have full-time jobs in the software industry, building software and managing software teams. Our mission is to facilitate the spread and change of innovation in professional software development. We do this through the content we publish online via InfoQ and a number of other platforms including YouTube, Apple News, Alexa, as well as in-person through the various QCon conferences we run around the world.
To help guide our content, groups of our editors meet regularly to discuss the global content strategy for InfoQ and the technology trends that significantly impact our industry. During these discussions, we consider the state of practice, emerging ideas and things we hear within our network and at meetups, conferences, analyst events, etc. We also take into account traffic patterns on the site and attendance at sessions at QCon and other industry conferences as well as, where possible, publicly accessible surveys, our own reader surveys and other data.
The output from these discussions is a series of topic graphs, based on a technology adoption curve, which we use to inform our content policy.
Free download
MMS • Abel Avram Wesley Resiz
Article originally posted on InfoQ. Visit InfoQ

Each November in San Francisco, 1,600 senior software engineers and architects transform the Hyatt Regency off Embarcadero into the epicenter of software. QCon San Francisco 2019, the 13th edition of the International Software Conference that visits the Bay Area annually, was no exception.
This year’s conference featured 177 speakers, track hosts, workshop presenters, and committee members. These are people like one of the foremost thinkers in the DevOps movement John Willis, CEO/Co-Founder of DarkLang Ellen Chisa, and VP Cloud Architecture Strategy @AWSCloud Adrian Cockcroft.
The conference kicked off with an opening keynote from Pat Helland. Pat is the principal software architect at Salesforce where he works on cloud-based, multi-tenant database systems. He is also legend in software when it comes working distributed systems. You may have read some of his past work in the ACM Queue including Immutability Changes Everything, Consistently Eventual, and Identity by Any Other Name.
Pat’s QCon San Francisco opening keynote was Mind Your State for Your State of Mind and considered how distinct application patterns have grown over time to leverage different types of distributed stores. The talk concluded with a set of actionable takeaways including “Different applications demand different behaviors from durable state.” So ask yourself, “Do you want it right (“read your writes”) or do you want it right now (bounded and fast SLA)?”
Over the following three days (and the additional two workshop days) there were tracks on building socially conscious software, including Alex Qin’s How Do We Heal?, understanding the software supply chain in today’s containerized world, including GitHub’s Nickolas Means’ Securing Software From the Supply Side and diving into the languages of infrastructure, with talks like Lachlan Evenson’s Helm 3: A Mariner’s Delight.
A personal highlight of mine came in the track I hosted (Living On The Edge: The World of Edge Compute From Device to Infrastructure Edge). Long time QCon attendee Vasily Vlasov of Netflix’s Cloud Gateway team, gave his first QCon talk, to rave reviews. It earned one of my top five recommendations of day 3.
After three intensive days chatting, discussing, and learning from some of today’s leading minds in software, it ended with the perfect closing keynote. Dr Pamela Gay is a senior scientist at the Planetary Science Institute where she’s mapping the surface of celestial objects. She’s part of the team that worked to find where they could land a spacecraft on a 500m wide asteroid tumbling through space. Her talk was about the limitations of AI and how science needs citizen scientists to crowdsource the massive amount of work involved. Her talk (and transcript) is available now on InfoQ. If you haven’t seen it yet, take 45 minutes and prepare to be inspired.
As always, some members of InfoQ’s team of practitioner-editors were present and wrote a number of posts about the event. Below we’ve summarized the key takeaways and highlights as blogged and tweeted by attendees. Over the course of the next several months, InfoQ will be publishing the majority of the conference sessions online.
Keynotes and Recommended Talks
Conference Chair’s Top Talks for Each Day
@QConSF: Looking for some talks to watch during your travels home from #QConSF? @wesreisz shares his recommendations from day 1 https://twitter.com/QConSF/status/1194300176438976512
@gunnarmorling: Wow, feeling really honoured to be listed in the #QConSF Day 2 viewing recommendations by @wesreisz; Thanks again to everybody for joining my session! https://twitter.com/gunnarmorling/status/1194738619094712320
@wesreisz: …and without further adieux, here are the QCon Day Three recommendations. If you attended, all the videos are available. If you didn’t make it to the conference, ping someone who did. They have about 50 shares each. http://infoq.com/conferences/qconsf2019… #QConSF https://twitter.com/wesreisz/status/1195122243954626562
Microcultures and Finding Your Place by Mike McGarr
Twitter feedback on this keynote included:
@shanehastie: #QConSF @SonOfGarr Cultures and microcultures matter and you can’t avoid it https://t.co/DdkqaQ6UKF
@shanehastie: #QConSF @SonOfGarr Culture has an immune system that resists change
@shanehastie: #QConSF @SonOfGarr Culture comes into existence when a single individual recruits at least one other and they create shared beliefs about why and how they are successful. The core values. behaviors are visible and reflective of the core values
@shanehastie: #QConSF @SonOfGarr The spectrum of behaviors that expose the culture. Tolerated or accepted behaviors expose the real culture. https://t.co/BuLvTGaCZa
@shanehastie: #QConSF @SonOfGarr Components of culture Culture is encapsulated in behaviors. https://t.co/LMCLNoCEnp
@danielbryantuk: Great start to @SonOfGarr’s #QConSF keynote about organizational culture, with a shout out to the book American Nations. “Culture surrounds us, and it determines and limits your strategy. You will be well placed to take time to understand your organization’s culture” https://t.co/p5tTqWmFow
@shanehastie: #QConSF @SonOfGarr When thinking about the culture you want to be part of, start by identifying the behaviors you want to experience
@bou_majeed: #QConSF day 3 keynote: in organizations: tools, process and people are visible while values and behavior are not!!
@shanehastie: #QConSF @SonOfGarr Three types of artifacts that are visible evidence culture. https://t.co/vvXSfT229E
@shanehastie: #QConSF @SonOfGarr Examples of language artifacts that indicate the explicit and consistent aspects of culture https://t.co/J8w51s6pNb
@shanehastie: #QConSF @SonOfGarr Dimensions of culture to understand https://t.co/UxWoPszo8Y
@shanehastie: #QConSF @SonOfGarr Interviewing for culture https://t.co/d5bnjyLpXI
@shanehastie: #QConSF @SonOfGarr The influence of founders on culture visible through the org chart https://t.co/ToAOdu5KrZ
@shanehastie: #QConSF @SonOfGarr Quote – the most important people for your culture are the ones who leave As a manager modeling behavior is the most important thing you can do https://t.co/7AYr0tTYv5
@shanehastie: #QConSF @SonOfGarr Microcultures come from the people leader in a team or area of the org. Microcultures can feel like working in completely different businesses https://t.co/NysXSmVcvW
@mary_grace: Microcultures spring up within companies from the C-suites down. If the leaders have unique enough leadership styles, a company can hit a point where each department feels like an entirely different company. @SonOfGarr #QConSF https://t.co/C8UD6Ijelc
@shanehastie: #QConSF @SonOfGarr Tools have an impact on culture too. Eg Java vs Ruby. Tools have communities that form around them and the beliefs of those communities seep into the organization. This can result in tensions between groups. https://t.co/ggOgikckYu
@PurposeCreator: Programming languages are a reflection of microcultures in an organization #QConSF https://t.co/WI91oRHs7x
@shanehastie: #QConSF @SonOfGarr Tools enable and constrain the behaviors of people in the organization Changing tools can cause behaviors to change https://t.co/B2j4Jrd8ff
@mary_grace: Tools enable and constrain behavior. They don’t solve every problem, but they can at times influence decisions and change behavior. @SonOfGarr #QConSF
Mind Your State for Your State of Mind by Pat Helland
Twitter feedback on this keynote included:
@danielbryantuk: Great fun listening to @PatHelland talk about state management in his #QConSF keynote This is really important for microservice-based systems https://t.co/ZxWurTHCeV
@danielbryantuk: “Transaction management with microservices can be challenging, outside of a single call to the data store. Microservices stink when it comes to session management” @PatHelland #QConSF https://t.co/Oqcgk1R4Y8
@ddoomen: Different problems need different solutions… #qconsf https://t.co/TM01aW1Aqs
@shanehastie: #QConSF @PatHelland key takeaways https://t.co/5JQgpzQmoo
When Machine Learning Can’t Replace the Human by Pamela Gay
Twitter feedback on this keynote included:
@shanehastie: #QConSF @starstryder The goal is to create a platform where the generation of knowledge is easier than it is today
@shanehastie: #QConSF @starstryder We initiate you to join us to create knowledge and understanding https://t.co/KdSNIsJ7jc
@SusanRMcIntosh: When Keats said he wants a love as constant as the star, he seemed to forget they explode @starStryder #QConSF
Architectures You’ve Always Wondered About
Secrets at Planet-Scale: Engineering the Internal Google KMS by Anvita Pandit
Steef-Jan Wiggers attended this session:
Anvita Pandit, senior developer at Google, explained Google’s internal Key Management System (KMS), which supports various Google services. This internal KMS manages the generation, distribution and rotation of cryptographic keys, and also handles other secret data. Moreover, the internal KMS supports various services on the Google Cloud Platform (GCP), including the Cloud KMS, and therefore this system needs to scale.
Implementing encryption at scale requires a highly available key management, which means 99.999% at Google. To achieve this, Google uses several strategies, as presented by Pandit:
- Best practices for change management and staged rollouts
- Minimize dependencies, and aggressively defend against their unavailability
- Isolate by region and client type
- Combine immutable keys and wrapping to achieve scale
- Provide a declarative API for key rotation
Building & Scaling High-Performing Teams
Mistakes and Discoveries While Cultivating Ownership by Aaron Blohowiak
Twitter feedback on this session included:
@charleshumble: Netflix culture – avoid rules, people over process, context not control, freedom and responsibility. Freedom and responsibility runs deep – it isn’t just a slogan – we hold you to account for the quality of your decision making. @aaronblohowiak #qconsf
@charleshumble: From the CEO down the hierarchy, responsibility at Netflix is delegated. Likewise from the CEO down the hierarchy, vision is refined. The job of the leadership is to narrow the scope; people close to the work can make the best decisions. @aaronblohowiak #qconsf
@charleshumble: The expectation for every employee at Netflix: Responsibility and follow-through, proactivity and anticipation. Great long-term decisions. @aaronblohowiak #qconsf
@charleshumble: What is ownership: A collection of beliefs, attitudes and behaviors. Ownership is not binary, it is a spectrum. @aaronblohowiak #QConSF
@charleshumble: Levels of ownership. We want to spend the minimum amount of time on levels 0-2 0) Demonstration 1) Oversight 2) Observation 3) Independent execution – very little management oversight. 4) Vision @aaronblohowiak #QConSF
@charleshumble: @aaronblohowiak A common mistake is not to be explicit about what level you are at – otherwise you and your report/peer can think you are at different levels. Also be explicit when there level changes. @aaronblohowiak #qconsf
@charleshumble: @aaronblohowiak If someone is stuck in an approval-seeking behavior pattern, they may just be waiting for permission to stop. @aaronblohowiak #qconsf
@charleshumble: @aaronblohowiak Even amazing people shouldn’t start at a high level because they don’t understand the current context. @aaronblohowiak #QConSF
@charleshumble: Someone asking don’t you trust me is the best signal, as a manager, that you are a crap manager. Ownership evolves. Not just over the course of relationships, but also over the course of projects. @aaronblohowiak #QConSF
@danielbryantuk: Great takeaways from @aaronblohowiak’s #QConSF talk about cultivating ownership I like the model of levels of where you and your manager think you’re working at, and how things can go wrong with this https://t.co/KGCorRr7cE
@danielbryantuk: “Given the right context and the freedom to do what’s best, people will make great decisions” @aaronblohowiak at #QConSF on Netflix’s freedom and responsibility culture https://t.co/Rg75X3hOZZ
@charleshumble: Firing someone is never easy, but if you have a team/corporate value, firing and hiring are where that value is expressed. @aaronblohowiak #QConSF
Passion, Grace, & Fire – The Elements of High Performance by Josh Evans
Twitter feedback on this session included:
@danielbryantuk: Ownership-oriented culture, and a look inside Netflix’s leadership principles, via @ZenTeknologist at #QConSF – extreme transparency – deep delegation – radical honesty – true accountability https://t.co/ouxscnmICi
@danielbryantuk: Seeking and working with fully formed adults at Netflix, via @ZenTeknologist at #QConSF “Average performance at Netflix results in a generous severance package” https://t.co/SiEnYMIZ7t
@danielbryantuk: A guest appearance from @philip_pfo in @ZenTeknologist’s #QConSF talk about leadership “The ability to delegate to someone who was willing to take complete ownership was essential to scale the team” https://t.co/NLDOt4GqYZ
@ddoomen: Good overview on how to align the passion and skills of people with the goals of your organization #QConSF https://t.co/KSEaryYFRo
@danielbryantuk: Deep questions and thinking points for your career journey as an individual and leader, via @ZenTeknologist at #QConSF https://t.co/a1PSOEcFIz
@marcofolio: Great session by @ZenTeknologist at #QConSF about building & maintaining an Ownership-Oriented Culture. Autonomy with Passion, Grace & Fire for fully formed Adults. https://t.co/0K60UvyJiq
The Focusing Illusion of Developer Productivity by Courtney Hemphill
Twitter feedback on this session included:
@alienelf: “People tend to get behind missions, rather than decrees” ~ @chemphill #QConSF https://t.co/PXCwowAJDJ
Ethics, Regulation, Risk, and Compliance
Ethics Landscape by Theo Schlossnagle
Twitter feedback on this session included:
@hbao: Ethics is a software engineer’s responsibility because you are building products that have wide social impacts. #QConSF @postwait https://t.co/hO4WTZPVjZ
Languages of Infrastructure
Automated Testing for Terraform, Docker, Packer, Kubernetes, and More by Yevgeniy Brikman
Steef-Jan Wiggers attended this session:
Key takeaways from the talk included the recommendation to use an appropriate mix of all testing techniques, such as static analysis, unit tests, integration tests, and end-to-end tests. As demonstrated through the use of a “testing pyramid”, he suggested creating many unit tests and static analysis tests, fewer integration tests, and only a handful of end-to-end tests. Ultimately, testing infrastructure code will establish confidence and get rid of the fear of deployment …
Brikman suggested that DevOps teams deploy less, leading to deployment only working 60% of the time. A better way of dealing with fear is to do automated tests, which raises confidence. As Brikman puts it, everyone knows how to write automated tests for application code, but how to test Terraform code that deploys infrastructure that works or Kubernetes code that ultimately deploys services is different …
An overview of several techniques to test infrastructure code was provided:
- Static Analysis
- Unit tests
- Integration tests
- End-to-end test
… Brikman recommends using all of the testing techniques available.
Living on the Edge: The World of Edge Compute from Device to Infrastructure Edge
Machine Learning on Mobile and Edge Devices With TensorFlow Lite by Daniel Situnayake
Steef-Jan Wiggers attended this session:
The key takeaways from this talk included understanding and getting started with TensorFlow Lite, and how to implement on-device machine learning on various devices – specifically microcontrollers – and optimizing the performance of machine learning models …
Situnayake … began the presentation by explaining what machine learning is. In a nutshell, he summarizes it as follows:
Traditionally a developer feeds rules and data into an application, which then output answers, while with machine learning the developer or data scientist feeds in the answers and data, and the output are rules that can be applied in the future.
He pointed out that the two main parts of machine learning are training and inference:
The inference is most useful to do on edge devices, while training usually takes a lot of power, memory and time; three things edge devices don’t have.
… Beyond mobile devices, TensorFlow Lite can work on things like Raspberry Pi (embedded Linux), edge TPUs (Hardware Accelerators), and microcontrollers, which allows for machine learning “on the edge”. With machine learning on the edge, developers may not have to worry about bandwidth, latency, privacy, security, and complexity. However, there are challenges, such as limited compute power, especially on the microcontroller, and limited memory and battery life. Yet, Situnayake said TensorFlow Lite mitigates some of these challenges, and allows developers to convert an existing machine learning model for use in TensorFlow Lite and deploy it on any device …
Lastly, Situnayake discussed making models perform well on the devices. TensorFlow offers tools and techniques for improving performance across various devices – varying from hardware accelerators to pruning technique.
Self-Driving Cars as Edge Computing Devices by Matt Ranney
Twitter feedback on this session included:
@danielbryantuk: The autonomous car as an edge device… Interesting insight from @mranney at #QConSF https://t.co/FTVPNDerXe
@wesreisz: Quick intro to vocabulary of robotics #uberatg @mranney #qconsf https://t.co/HD3zyoqKRt
@danielbryantuk: @FitzXyz @mranney yeah, I’ve found that “edge” is quite an overloaded term. This #QConSF track covers nearly all definitions of the edge: this tweet is more about edge devices/IoT, but there are also talks about the CDN/API gateway edge, too
@emballerini: How does one do end-to-end testing on self-driving cars? You build a 40-acre test track (among other things). Fascinating presentation by @mranney #QConSF https://t.co/cjtjU7RkgI
Microservices Patterns & Practices
Controlled Chaos: Taming Organic, Federated Growth of Microservices by Tobias Kunze
Twitter feedback on this session included:
@breckcs: Controlling the organic, federated growth of #microservices by @tkunze: going beyond #observability to #controllability. #QConSF https://t.co/1Ft9o2pOa2
@marcofolio: Those are some interesting stats by @tkunze ! The huge impact of one router failure, shared on #QConSF . Can we control this chaos within microservices? https://t.co/hx7IkKw9Sj
@ddoomen: A very good example of the operational complexity of a growing landscape of microservices #qconsf https://t.co/s1SBu6czjn
Managing Failure Modes in Microservice Architectures by Adrian Cockcroft
Twitter feedback on this session included:
@danielbryantuk: Fascinating insight into availability, safety, and security within modern systems, via @adrianco at #QConSF https://t.co/rz2OSzPtGc
@danielbryantuk: Great intro to observability, and a discussion of how the STPA Model from the book “Engineering a Safer World” relates to modern software systems, via @adrianco at #QConSF https://t.co/OIUmN1mpag
@danielbryantuk: Interesting intro to Failure Modes and Effects Analysis (FMEA) for web services and infrastructure, via @adrianco at #QConSF https://t.co/6jiulzGle0
Stateful Programming Models in Serverless Functions by Chris Gillum
Steef-Jan Wiggers attended this session:
He discussed two stateful programming models — workflow and actors — using Azure Functions, which is Microsoft’s implementation of serverless computing.
Gillum started by talking about Azure Functions, which are “serverless” by nature; the hosting environment supports autoscaling, and running functions are pay per use. Azure Functions are like AWS Lambda, Google Cloud Functions, or other Function as a Service (FaaS) platforms. However, the difference is the “bindings” abstraction, which decouples the code from the data source or destination. It is the central part of the programming model, and the concept allows for building more advanced programming models.
Next, Gillum pointed out the principles and best practices that apply for running functions like Lambda and Azure Functions:
- Functions must be stateless
- Functions must not call other functions
- Functions should do only one thing
… Gillum stated that the event sourcing allows Microsoft to support multiple languages, such as the combination of .NET and JavaScript….
Besides workflows, developers can also leverage the actor programming model in Durable Functions. Gillum said:
Actors will be a first-class concept in Durable Functions, alongside orchestrations. Customers will be able to use one or both of our stateful programming models in the same application, depending on their needs.
User & Device Identity for Microservices @ Netflix Scale by Satyajit Thadeshwar
Twitter feedback on this session included:
@danielbryantuk: How the Netflix login flow (and related systems) has evolved over the past year, via Satyajit at #QConSF “moving authentication to the edge has improved performance, coupling, and security” https://t.co/jWGF5S7B5O
Modern Data Architectures
Future of Data Engineering by Chris Riccomini
Twitter feedback on this session included:
@gwenshap: “we use terraform to manage Kafka topics and connectors. This topic has compaction policy, which is an exciting policy to have when you system evolves”. @criccomini at #QConSF
@gwenshap: #QConSF – @criccomini shares that WePay data infrastructure is based on Airflow, Kafka and BigQuery.
@gwenshap: “we use terraform to manage Kafka topics and connectors. This topic has compaction policy, which is an exciting policy to have when you system evolves”. @criccomini at #QConSF
Steef-Jan Wiggers attended this session:
Riccomini stated that his intention with this talk was to provide a survey of the current state of the art for data pipelines, ETL, and data warehousing, and to look forwards at where data engineering may be heading:
The two primary areas where I think we’re going are towards more real-time data pipelines and towards decentralized and automated data warehouse management.
…In his talk Riccomini provided an overview of the various stages of data engineering, from an initial “none” stage up to a “decentralization” stage:
- Stage 0: None
- Stage 1: Batch
- Stage 2: Realtime
- Stage 3: Integration
- Stage 4: Automation
- Stage 5: Decentralization
Each stage depends on the situation an organization is in, and has some challenges…
Riccomini said that WePay is at a particular stage – some companies are further ahead, and some behind, but these stages can help to build a roadmap…
Lastly, Riccomini went on to explain the final stage, “decentralization”, a stage in which an organization has a fully automated real-time data pipeline. However, the questions is, does it require one team to manage this? According to Riccomini, the answer is “no”, as he stated in the future multiple data warehouses will be able to be set up and managed by different teams. In his view, traditional data engineering will evolve from a more monolithic data warehouse to so-called “microwarehouses” where everyone manages their own data warehouse.
Taming Large State: Lessons From Building Stream Processing by Sonali Sharma, Shriya Arora
Twitter feedback on this session included:
@gwenshap: At Netflix, we are big on A/B testing. If someone has an idea, we try it immediately. And can’t wait for the results to arrive #qconsf @sonali_sh https://t.co/Z3wUKJAg9X
Optimizing Yourself: Human Skills for Individuals
Optimizing Yourself: Neurodiversity in Tech by Elizabeth Schneider
Susan McIntosh attended this session:
What’s your superpower? Elizabeth Schneider posed this question early in her talk on neurodiversity at QConSF 2019, as she explained to the audience how understanding her own neurodiversity gave her greater strength to work with others and deliver great work. However, she also had to recognize that she had weaknesses (kryptonite), and needed to recharge in an appropriate fortress of solitude, just like other superheroes…
As a programmer several years ago, Schneider came to understand that she communicated differently than others after her scrum master had the team do a quick self-evaluation on communication styles; most of the rest of the team was in a completely different quadrant than where Schneider found herself. This helped her recognize that she could learn how to adjust her communication style to fit the needs of others, and to ask for specific adjustments in how others communicated with her. She gave the example of having other in her team give her a cue (tapping on the wrist) when she got too excited about a specific topic.
Understanding the difference between empathy and sypmathy also helped Schneider improve her ability to communicate with her team. Referencing Brené Brown’s work on empathy, Schneider discussed how being able to “put yourself in someone’s shoes” has helped her better recognize the needs of the customer, the product owner, and other team members.
While communication and interactions with others is important to understand, Schneider also noted a couple of environmental changes that, while subtle, can improve productivity. Citing research on office temperature, Schneider notes that a small increase in the physical heat of an office can result in greatly improved cognitive function in women. Additionally, she encourages the use of “focus time” – four or more hours of uninterrupted time – where deep thinking can occur.
Practices of DevOps & Lean Thinking
Mapping the Evolution of Socio-Technical Systems by Cat Swetel
Twitter feedback on this session included:
@DivineOps: When #ticketmaster was born, computers were not obvious! That’s why computer is in the name! That’s how we ended up with a custom OS You have to recognize where you are on that evolution timeline @CatSwetel #QConSF https://t.co/LkjCY1mZTs
@charleshumble: Thinking about Wardley mapping. How do you treat a component. How does the rest of the industry treat the same component. @CatSwetel #QConSF https://t.co/nF1smPMVEf https://t.co/xuXGlyuMeq
@DivineOps: How do developers metabolize information? We write code! And the longer and the more code we write the more technical debt we end up with @CatSwetel #qconsf https://t.co/kYhe2m4m5j
@DivineOps: If #devops is just a #mindset, then we can all sit in a room, change their minds, and live happily ever after! I mean what’s wrong with you all not being able to implement it? Do you not want it badly enough?! @CatSwetel #QConSF https://t.co/gXeEqEanrM
@charleshumble: The map is not the thing. You must also construct the narrative. Likewise DevOps is not (just) a mindset. @CatSwetel #QConSF. (the quote in the photo is from 1952.) @CatSwetel #QConSF. https://t.co/hoG5BaaoCj
@charleshumble: Ticketmaster runs an emulated VAX. Why? It had 43 years of getting really good at its job. @CatSwetel #QConSF.
@charleshumble: What happens to all the legacy code. How do we innovate responsibility? We are such a young industry, we are just getting started. @CatSwetel #QConSF
@DivineOps: You can tell that we are a young industry because we are measuring the age of our systems in months We have to stop sh!tting on things because they are old @CatSwetel #qconsf https://t.co/nZtfAyqsXU
@DivineOps: The map is _not_ the thing The map (just like code) becomes immediately outdated as soon as you create it The act of mapping is what makes our obstacles conspicuous @CatSwetel #QConSF https://t.co/OLv9EG3JD4
Production Readiness: Building Resilient Systems
Observability in the Development Process: Not Just for Ops Anymore by Christine Yen
Twitter feedback on this session included:
@danielbryantuk: “Observing our code in production is a form of testing. Throughout the software development process, we should be optimising for feedback: both in dev and prod” @cyen #QConSF https://t.co/JnD9DYg3SF
@danielbryantuk: “Fine-grained release mechanisms like feature flags are very useful, but you must have the ability to get fine-grained feedback from the changes in order to derive the full value” @cyen #QConSF https://t.co/6qq6YVERDx
@danielbryantuk: “Tools should speak my language. Hearing that CPU usage is high across a cluster doesn’t provide as much value as learning that the latency of an expensive API endpoint increased for an important customer after our latest deploy” @cyen #QConSF https://t.co/DduXFnILwf
@danielbryantuk: Nice takeaways from @cyen’s #QConSF talk about observability in the development process https://t.co/8jyPSuzs9q
Socially Conscious Software
Holistic EdTech & Diversity by Antoine Patton
Twitter feedback on this session included:
@haacked: Antoine Patton (founder of @unlockacademy) speaking about lack of access, money, and time as a barrier to marginalized people who want to learn to code. #QConSF https://t.co/W8zwHlz3HS
@alexqin: Wow Antoine Patton of @unlockacademy just facilitated a Diversity Design sprint for a room FULL of people to design education programs that solve tech’s lack of diversity at scale #QConSF I have never seen this done at a conference before https://t.co/vuTJI6piqQ
Impact Starts With You by Julia Nguyen
Twitter feedback on this session included:
@alexqin: We are worth more than our side hustles, our careers, our salaries @fleurchild #QConSF too real https://t.co/kZvoWFoVGy
@alexqin: It’s ok to take breaks it’s ok to leave things @fleurchild #QConSF https://t.co/rUUYcrvjHM
@alexqin: I come from a family of refugees and I carry the refugee mentality with me still. That I need to uplift my community. @fleurchild #QConSF https://t.co/5E4ASXdxMj
@alexqin: I don’t have to suffer in order to care @fleurchild #QConSF https://t.co/KsZsIKNhQu
Software Supply Chain
Shifting Left with Cloud Native CI/CD by Christie Wilson
Twitter feedback on this session included:
@sarah_shewell: Our systems are becoming more and more complex making configuration as code critical. We wouldn’t debug if we knew the answer. Debugging is learning. @bobcatwilson #QConSF https://t.co/yRAKQUwohS
@desbiens: Shifting left with cloud native CI/CD with @bobcatwilson using @tektoncd #QConSF https://t.co/uVAyd4AxIx
The Common Pitfalls of Cloud Native Software Supply Chains by Daniel Shapira
Twitter feedback on this session included:
@aysylu22: Excellent overview of security aspects of software supply chains by @Da5h_Solo. Some Qs to ask when ensuring secure supply chains: – can anyone access anything w/o authenticating? – what permissions do auth’d users have? – any sensitive info in commit/build history? #qconsf https://t.co/YSv1g8hPRJ
Trust, Safety & Security
Exploiting Common iOS Apps’ Vulnerabilities by Ivan Rodriguez
Twitter feedback on this session included:
@vixentael: Great start of security track at #QConSF! @ivRodriguezCA describes how he reverse engineered iOS apps and what typical vulnerabilities he found! Highly recommend to check his blog & github if you’re interested in RE: https://t.co/Fe3ZRRr0zB https://t.co/tPlanooz8n
@vixentael: App blindly opens URL received from server — okay, we will put a malicious link there! #qconsf @ivRodriguezCA https://t.co/7SoHJ1tovF
@vixentael: Remote MitM attack on vulnerable iOS apps Lucky it’s just a demo, otherwise I’d turn off my phone immediately … @ivRodriguezCA #QConSF https://t.co/cRsViwaICZ
@vixentael: Repeat after me: HTTPS is not enough! @SyntaxPolice #QConSF https://t.co/NHxeu98VvN
@vixentael: End-to-end encryption is useful not for chat applications. E2EE helps to protect data that’s ‘flying’ from server to server. @SyntaxPolice #QConSF https://t.co/yCLLFjv4fy
@vixentael: Crypto in web browser? Dream or reality? Depends on your threat model! #qconsf @SyntaxPolice https://t.co/H7xCSb6YuW
Reflecting on a Life Watching Movies and a Career in Security by Jason Chan
Twitter feedback on this session included:
@vixentael: Being in security team is hard: think about how much software we have now in our houses, in our cars, in mobile devices. @chanjbs is reflecting on modern security processes at #QConSF https://t.co/svAz8OzaQa
@vixentael: Questions to ask in your org: do you want to train your engineers as security experts, or to help them to build secure systems? @chanjbs at #QConSF https://t.co/A2zV42Xzwt
Security Culture: Why You Need One and How to Create It by Masha Sedova
Twitter feedback on this session included:
@vixentael: Security culture is part of the enterprise culture itself. If you try to build security culture that mismatches company’s culture, you will fail. People are driven on what kind of behavior is rewarded and what is punished. @modMasha at #QConSF https://t.co/odK0BXd3k9
@vixentael: Negative security culture appears when bad security decisions are not punished, and good security decisions are not enforced. Which kind of culture you have: Compliance, Process, Trust, Autonomy? @modMasha #QConSF https://t.co/88V7aDYxfE
@vixentael: Everyone has a security culture! @modMasha #QConSF https://t.co/jFX513YXxH
Small Is Beautiful: How to Improve Security by Maintaining Less Code by Natalie Silvanovich
Twitter feedback on this session included:
@vixentael: @natashenka #QConSF How to narrow down the attack surface? – remove old / unused code – keep an eye on shared code that you use often, one bug — problems everywhere – check/update dependencies! https://t.co/rSPt9tSomC
@vixentael: Chrome Sandbox is a huge system @natashenka at #QConSF https://t.co/WfxygJUKRP
Sponsored Solutions Track V
3 Common Pitfalls in Microservice Integration and How to Avoid Them by Niall Deehan
Twitter feedback on this session included:
@mary_grace: Failing fast is important but requires a good solution and a chance to try again. @NiallDeehan #QConSF
Unofficial Events
Women in Tech & Allies Breakfast (Co-Sponsored by Netflix) by Wade Davis
Susan McIntosh attended this session:
The Women in Tech & Allies breakfast at QCon San Francisco featured Wade Davis, the vice president of inclusion strategy and product at Netflix. Davis encouraged allies to “act in solidarity” with women, favoring this more collaborative, interactive phrase than the passive description of “ally.” He noted that the activity is not done after one event, but is rather daily action and interaction — he encouraged all to “show up every day” in the journey of understanding and supporting women in technology…
Davis recommended a handful of items: read books by women; amplify what they recommend by frequently attaching their name to their ideas in conversations; and dig into behavior with more specific questions (“What would cause you to get involved?” rather than “Why aren’t you involved?”).
Opinions about QCon
Impressions expressed on Twitter included:
@PurposeCreator: I appreciate the values that guide this conference. #QConSF !! https://t.co/bXF9SdtPHp
@bou_majeed: One #ux of badges is to use them for talks feedback #QConSF https://t.co/ehmqrGC0kn
@BettyJunod: Special thank you to @kcasella for organizing such an amazing event this morning at #QConSF A wonderful way to meet with folks at the conference and was brought to tears at times from a very powerful and thoughtful talk by @Wade_Davis28
@floydmarinescu: @QConSF goes the extra mile for attendees. One of the three levels of the conference venue has no windows. So what do we do? Living green wall, full spectrum day lighting, and huge plants. #qconcares #qcon #qconsf https://t.co/JSuD9mTIW0
@CatSwetel: Oh! I almost forgot to thank @botchagalupe for the *amazing* interpretive dance intro for my #qconsf talk. I’ve asked to be introduced through interpretive dance *many* times, but for some reason, people always think I’m joking.
@PurposeCreator: Thank you conference organizers for putting together a great learning experience at #qconsf https://t.co/CYWSPetT9W
@PurposeCreator: #QConSF superb job cultivating diversity, mastery, community!
Carl Chesser attended the conference:
This was my first time attending QCon, and I was really impressed with the quality of the conference. I have been a long time consumer of content on InfoQ, so it was great to be there in person and meet more practitioners that are working on interesting problems…
QCon is a conference which organizes its talks into specific tracks. Track hosts that have been identified as experts in that domain, then do the work of identifying speakers to talk in these tracks. This approach makes it very clean on how they have direct selection on the talks to ensure they fulfill the targeted track and the speakers are known for being good at public speaking. As a result, majority of the talks are well prepared and are conveyed in an effective way. The conference was held all within a single location, Hyatt Regency in San Francisco, which made the logistics for attendees quite convenient. It was easy to get to and from talks, allowing you more time to strike conversations with others, and lowering the stress of having to determine where do I need to go next…
While at the conference, I had the opportunity to connect and talk with many other engineers and practitioners. By being in San Francisco, I was able to reconnect with a couple former colleagues which made it a really valuable time. I then was able to connect with other speakers which I found extremely valuable. … Several times I found people some tie back to the Kansas City area (where I’m from) or work in the related industry (healthcare). By having my talk announced before the conference, I also had some other planned meetings with companies and start-ups to learn more about what they were trying to solve, and how it related to challenges we were facing at our company. Having these scheduled meetings were valuable to have additional conversations that I wouldn’t probably normally engage if I didn’t plan beforehand.
Takeaways
Takeaways from QCon London included:
@vixentael: Great security track today at #QConSF @QConSF! I’m so grateful to our speakers, they delivered amazing security talks ” deep, detailed, easy to understand Average rating for the track: 90% green! Also, you can ALREADY check slides online: https://t.co/Wch7ZyRQA2
@glamcoder: Thanks @QConSF for having me! That was an amazing experience and I’m so grateful for all the people who came to listen my talk. Love being part of such a great conference. And now it’s end and I’m looking forward to future opportunities. #QConSF https://t.co/xcQGxJt46D
@11329032: It was such an honor to speak @QConSF about the work that I do. This is a really impressive conference and I loved talking with and learning from other speakers
@JamesonL: Just finished up attending #QConSF and I had an amazing time. A great place to hear about the newest challenges Tech is facing… and more importantly, how we’re solving them!
@Yssybyl: Back home after #QConSF – had a great time as a speaker and learned a lot from the other talks. If a QCon is happening near you I’d recommend it, you won’t be disappointed!
@gunnarmorling: @mwessendorf @QConSF Thanks, Matthias; being at #QConSF was an outstanding experience, enjoyed every minute!
@ddoomen: I absolutely love the networking opportunities #qconsf offers. Lunches, open spaces, the long breaks, everything is designed to meet other people and exchange experiences and learnings across the world. https://t.co/N1HUdGjzXT
@bou_majeed: It was busy and enjoying week at #QConSF I learned a lot, had fun, and had opportunity to meet great people. Thanks to everyone who made this successful and perfect https://t.co/0Hd8Z0RcnP
Carl Chesser attended the conference:
It was a great experience being at QCon. I really enjoyed getting to meet and talk with other engineers and the talks within this conference were strong. I hope it works out to attend future QCon conferences, and I’m really thankful for the opportunity for speaking at this event.
Conclusion
InfoQ produces QCons in 8 cities around the globe (including our newest edition QCon Munich). Our focus on practitioner-driven content is reflected in each committee’s unique make up. The program committee of leading software engineers and leaders meets for 30 weeks to individually select each speaker at QCon. The next QCon is well underway and takes place in London March 2-6, 2020. We will return to San Francisco November 16-20 2020.
MMS • Abel Avram Wesley Resiz
Article originally posted on InfoQ. Visit InfoQ

Each November in San Francisco, 1,600 senior software engineers and architects transform the Hyatt Regency off Embarcadero into the epicenter of software. QCon San Francisco 2019, the 13th edition of the International Software Conference that visits the Bay Area annually, was no exception.
This year’s conference featured 177 speakers, track hosts, workshop presenters, and committee members. These are people like one of the foremost thinkers in the DevOps movement John Willis, CEO/Co-Founder of DarkLang Ellen Chisa, and VP Cloud Architecture Strategy @AWSCloud Adrian Cockcroft.
The conference kicked off with an opening keynote from Pat Helland. Pat is the principal software architect at Salesforce where he works on cloud-based, multi-tenant database systems. He is also legend in software when it comes working distributed systems. You may have read some of his past work in the ACM Queue including Immutability Changes Everything, Consistently Eventual, and Identity by Any Other Name.
Pat’s QCon San Francisco opening keynote was Mind Your State for Your State of Mind and considered how distinct application patterns have grown over time to leverage different types of distributed stores. The talk concluded with a set of actionable takeaways including “Different applications demand different behaviors from durable state.” So ask yourself, “Do you want it right (“read your writes”) or do you want it right now (bounded and fast SLA)?”
Over the following three days (and the additional two workshop days) there were tracks on building socially conscious software, including Alex Qin’s How Do We Heal?, understanding the software supply chain in today’s containerized world, including GitHub’s Nickolas Means’ Securing Software From the Supply Side and diving into the languages of infrastructure, with talks like Lachlan Evenson’s Helm 3: A Mariner’s Delight.
A personal highlight of mine came in the track I hosted (Living On The Edge: The World of Edge Compute From Device to Infrastructure Edge). Long time QCon attendee Vasily Vlasov of Netflix’s Cloud Gateway team, gave his first QCon talk, to rave reviews. It earned one of my top five recommendations of day 3.
After three intensive days chatting, discussing, and learning from some of today’s leading minds in software, it ended with the perfect closing keynote. Dr Pamela Gay is a senior scientist at the Planetary Science Institute where she’s mapping the surface of celestial objects. She’s part of the team that worked to find where they could land a spacecraft on a 500m wide asteroid tumbling through space. Her talk was about the limitations of AI and how science needs citizen scientists to crowdsource the massive amount of work involved. Her talk (and transcript) is available now on InfoQ. If you haven’t seen it yet, take 45 minutes and prepare to be inspired.
As always, some members of InfoQ’s team of practitioner-editors were present and wrote a number of posts about the event. Below we’ve summarized the key takeaways and highlights as blogged and tweeted by attendees. Over the course of the next several months, InfoQ will be publishing the majority of the conference sessions online.
Keynotes and Recommended Talks
Conference Chair’s Top Talks for Each Day
@QConSF: Looking for some talks to watch during your travels home from #QConSF? @wesreisz shares his recommendations from day 1 https://twitter.com/QConSF/status/1194300176438976512
@gunnarmorling: Wow, feeling really honoured to be listed in the #QConSF Day 2 viewing recommendations by @wesreisz; Thanks again to everybody for joining my session! https://twitter.com/gunnarmorling/status/1194738619094712320
@wesreisz: …and without further adieux, here are the QCon Day Three recommendations. If you attended, all the videos are available. If you didn’t make it to the conference, ping someone who did. They have about 50 shares each. http://infoq.com/conferences/qconsf2019… #QConSF https://twitter.com/wesreisz/status/1195122243954626562
Microcultures and Finding Your Place by Mike McGarr
Twitter feedback on this keynote included:
@shanehastie: #QConSF @SonOfGarr Cultures and microcultures matter and you can’t avoid it https://t.co/DdkqaQ6UKF
@shanehastie: #QConSF @SonOfGarr Culture has an immune system that resists change
@shanehastie: #QConSF @SonOfGarr Culture comes into existence when a single individual recruits at least one other and they create shared beliefs about why and how they are successful. The core values. behaviors are visible and reflective of the core values
@shanehastie: #QConSF @SonOfGarr The spectrum of behaviors that expose the culture. Tolerated or accepted behaviors expose the real culture. https://t.co/BuLvTGaCZa
@shanehastie: #QConSF @SonOfGarr Components of culture Culture is encapsulated in behaviors. https://t.co/LMCLNoCEnp
@danielbryantuk: Great start to @SonOfGarr’s #QConSF keynote about organizational culture, with a shout out to the book American Nations. “Culture surrounds us, and it determines and limits your strategy. You will be well placed to take time to understand your organization’s culture” https://t.co/p5tTqWmFow
@shanehastie: #QConSF @SonOfGarr When thinking about the culture you want to be part of, start by identifying the behaviors you want to experience
@bou_majeed: #QConSF day 3 keynote: in organizations: tools, process and people are visible while values and behavior are not!!
@shanehastie: #QConSF @SonOfGarr Three types of artifacts that are visible evidence culture. https://t.co/vvXSfT229E
@shanehastie: #QConSF @SonOfGarr Examples of language artifacts that indicate the explicit and consistent aspects of culture https://t.co/J8w51s6pNb
@shanehastie: #QConSF @SonOfGarr Dimensions of culture to understand https://t.co/UxWoPszo8Y
@shanehastie: #QConSF @SonOfGarr Interviewing for culture https://t.co/d5bnjyLpXI
@shanehastie: #QConSF @SonOfGarr The influence of founders on culture visible through the org chart https://t.co/ToAOdu5KrZ
@shanehastie: #QConSF @SonOfGarr Quote – the most important people for your culture are the ones who leave As a manager modeling behavior is the most important thing you can do https://t.co/7AYr0tTYv5
@shanehastie: #QConSF @SonOfGarr Microcultures come from the people leader in a team or area of the org. Microcultures can feel like working in completely different businesses https://t.co/NysXSmVcvW
@mary_grace: Microcultures spring up within companies from the C-suites down. If the leaders have unique enough leadership styles, a company can hit a point where each department feels like an entirely different company. @SonOfGarr #QConSF https://t.co/C8UD6Ijelc
@shanehastie: #QConSF @SonOfGarr Tools have an impact on culture too. Eg Java vs Ruby. Tools have communities that form around them and the beliefs of those communities seep into the organization. This can result in tensions between groups. https://t.co/ggOgikckYu
@PurposeCreator: Programming languages are a reflection of microcultures in an organization #QConSF https://t.co/WI91oRHs7x
@shanehastie: #QConSF @SonOfGarr Tools enable and constrain the behaviors of people in the organization Changing tools can cause behaviors to change https://t.co/B2j4Jrd8ff
@mary_grace: Tools enable and constrain behavior. They don’t solve every problem, but they can at times influence decisions and change behavior. @SonOfGarr #QConSF
Mind Your State for Your State of Mind by Pat Helland
Twitter feedback on this keynote included:
@danielbryantuk: Great fun listening to @PatHelland talk about state management in his #QConSF keynote This is really important for microservice-based systems https://t.co/ZxWurTHCeV
@danielbryantuk: “Transaction management with microservices can be challenging, outside of a single call to the data store. Microservices stink when it comes to session management” @PatHelland #QConSF https://t.co/Oqcgk1R4Y8
@ddoomen: Different problems need different solutions… #qconsf https://t.co/TM01aW1Aqs
@shanehastie: #QConSF @PatHelland key takeaways https://t.co/5JQgpzQmoo
When Machine Learning Can’t Replace the Human by Pamela Gay
Twitter feedback on this keynote included:
@shanehastie: #QConSF @starstryder The goal is to create a platform where the generation of knowledge is easier than it is today
@shanehastie: #QConSF @starstryder We initiate you to join us to create knowledge and understanding https://t.co/KdSNIsJ7jc
@SusanRMcIntosh: When Keats said he wants a love as constant as the star, he seemed to forget they explode @starStryder #QConSF
Architectures You’ve Always Wondered About
Secrets at Planet-Scale: Engineering the Internal Google KMS by Anvita Pandit
Steef-Jan Wiggers attended this session:
Anvita Pandit, senior developer at Google, explained Google’s internal Key Management System (KMS), which supports various Google services. This internal KMS manages the generation, distribution and rotation of cryptographic keys, and also handles other secret data. Moreover, the internal KMS supports various services on the Google Cloud Platform (GCP), including the Cloud KMS, and therefore this system needs to scale.
Implementing encryption at scale requires a highly available key management, which means 99.999% at Google. To achieve this, Google uses several strategies, as presented by Pandit:
- Best practices for change management and staged rollouts
- Minimize dependencies, and aggressively defend against their unavailability
- Isolate by region and client type
- Combine immutable keys and wrapping to achieve scale
- Provide a declarative API for key rotation
Building & Scaling High-Performing Teams
Mistakes and Discoveries While Cultivating Ownership by Aaron Blohowiak
Twitter feedback on this session included:
@charleshumble: Netflix culture – avoid rules, people over process, context not control, freedom and responsibility. Freedom and responsibility runs deep – it isn’t just a slogan – we hold you to account for the quality of your decision making. @aaronblohowiak #qconsf
@charleshumble: From the CEO down the hierarchy, responsibility at Netflix is delegated. Likewise from the CEO down the hierarchy, vision is refined. The job of the leadership is to narrow the scope; people close to the work can make the best decisions. @aaronblohowiak #qconsf
@charleshumble: The expectation for every employee at Netflix: Responsibility and follow-through, proactivity and anticipation. Great long-term decisions. @aaronblohowiak #qconsf
@charleshumble: What is ownership: A collection of beliefs, attitudes and behaviors. Ownership is not binary, it is a spectrum. @aaronblohowiak #QConSF
@charleshumble: Levels of ownership. We want to spend the minimum amount of time on levels 0-2 0) Demonstration 1) Oversight 2) Observation 3) Independent execution – very little management oversight. 4) Vision @aaronblohowiak #QConSF
@charleshumble: @aaronblohowiak A common mistake is not to be explicit about what level you are at – otherwise you and your report/peer can think you are at different levels. Also be explicit when there level changes. @aaronblohowiak #qconsf
@charleshumble: @aaronblohowiak If someone is stuck in an approval-seeking behavior pattern, they may just be waiting for permission to stop. @aaronblohowiak #qconsf
@charleshumble: @aaronblohowiak Even amazing people shouldn’t start at a high level because they don’t understand the current context. @aaronblohowiak #QConSF
@charleshumble: Someone asking don’t you trust me is the best signal, as a manager, that you are a crap manager. Ownership evolves. Not just over the course of relationships, but also over the course of projects. @aaronblohowiak #QConSF
@danielbryantuk: Great takeaways from @aaronblohowiak’s #QConSF talk about cultivating ownership I like the model of levels of where you and your manager think you’re working at, and how things can go wrong with this https://t.co/KGCorRr7cE
@danielbryantuk: “Given the right context and the freedom to do what’s best, people will make great decisions” @aaronblohowiak at #QConSF on Netflix’s freedom and responsibility culture https://t.co/Rg75X3hOZZ
@charleshumble: Firing someone is never easy, but if you have a team/corporate value, firing and hiring are where that value is expressed. @aaronblohowiak #QConSF
Passion, Grace, & Fire – The Elements of High Performance by Josh Evans
Twitter feedback on this session included:
@danielbryantuk: Ownership-oriented culture, and a look inside Netflix’s leadership principles, via @ZenTeknologist at #QConSF – extreme transparency – deep delegation – radical honesty – true accountability https://t.co/ouxscnmICi
@danielbryantuk: Seeking and working with fully formed adults at Netflix, via @ZenTeknologist at #QConSF “Average performance at Netflix results in a generous severance package” https://t.co/SiEnYMIZ7t
@danielbryantuk: A guest appearance from @philip_pfo in @ZenTeknologist’s #QConSF talk about leadership “The ability to delegate to someone who was willing to take complete ownership was essential to scale the team” https://t.co/NLDOt4GqYZ
@ddoomen: Good overview on how to align the passion and skills of people with the goals of your organization #QConSF https://t.co/KSEaryYFRo
@danielbryantuk: Deep questions and thinking points for your career journey as an individual and leader, via @ZenTeknologist at #QConSF https://t.co/a1PSOEcFIz
@marcofolio: Great session by @ZenTeknologist at #QConSF about building & maintaining an Ownership-Oriented Culture. Autonomy with Passion, Grace & Fire for fully formed Adults. https://t.co/0K60UvyJiq
The Focusing Illusion of Developer Productivity by Courtney Hemphill
Twitter feedback on this session included:
@alienelf: “People tend to get behind missions, rather than decrees” ~ @chemphill #QConSF https://t.co/PXCwowAJDJ
Ethics, Regulation, Risk, and Compliance
Ethics Landscape by Theo Schlossnagle
Twitter feedback on this session included:
@hbao: Ethics is a software engineer’s responsibility because you are building products that have wide social impacts. #QConSF @postwait https://t.co/hO4WTZPVjZ
Languages of Infrastructure
Automated Testing for Terraform, Docker, Packer, Kubernetes, and More by Yevgeniy Brikman
Steef-Jan Wiggers attended this session:
Key takeaways from the talk included the recommendation to use an appropriate mix of all testing techniques, such as static analysis, unit tests, integration tests, and end-to-end tests. As demonstrated through the use of a “testing pyramid”, he suggested creating many unit tests and static analysis tests, fewer integration tests, and only a handful of end-to-end tests. Ultimately, testing infrastructure code will establish confidence and get rid of the fear of deployment …
Brikman suggested that DevOps teams deploy less, leading to deployment only working 60% of the time. A better way of dealing with fear is to do automated tests, which raises confidence. As Brikman puts it, everyone knows how to write automated tests for application code, but how to test Terraform code that deploys infrastructure that works or Kubernetes code that ultimately deploys services is different …
An overview of several techniques to test infrastructure code was provided:
- Static Analysis
- Unit tests
- Integration tests
- End-to-end test
… Brikman recommends using all of the testing techniques available.
Living on the Edge: The World of Edge Compute from Device to Infrastructure Edge
Machine Learning on Mobile and Edge Devices With TensorFlow Lite by Daniel Situnayake
Steef-Jan Wiggers attended this session:
The key takeaways from this talk included understanding and getting started with TensorFlow Lite, and how to implement on-device machine learning on various devices – specifically microcontrollers – and optimizing the performance of machine learning models …
Situnayake … began the presentation by explaining what machine learning is. In a nutshell, he summarizes it as follows:
Traditionally a developer feeds rules and data into an application, which then output answers, while with machine learning the developer or data scientist feeds in the answers and data, and the output are rules that can be applied in the future.
He pointed out that the two main parts of machine learning are training and inference:
The inference is most useful to do on edge devices, while training usually takes a lot of power, memory and time; three things edge devices don’t have.
… Beyond mobile devices, TensorFlow Lite can work on things like Raspberry Pi (embedded Linux), edge TPUs (Hardware Accelerators), and microcontrollers, which allows for machine learning “on the edge”. With machine learning on the edge, developers may not have to worry about bandwidth, latency, privacy, security, and complexity. However, there are challenges, such as limited compute power, especially on the microcontroller, and limited memory and battery life. Yet, Situnayake said TensorFlow Lite mitigates some of these challenges, and allows developers to convert an existing machine learning model for use in TensorFlow Lite and deploy it on any device …
Lastly, Situnayake discussed making models perform well on the devices. TensorFlow offers tools and techniques for improving performance across various devices – varying from hardware accelerators to pruning technique.
Self-Driving Cars as Edge Computing Devices by Matt Ranney
Twitter feedback on this session included:
@danielbryantuk: The autonomous car as an edge device… Interesting insight from @mranney at #QConSF https://t.co/FTVPNDerXe
@wesreisz: Quick intro to vocabulary of robotics #uberatg @mranney #qconsf https://t.co/HD3zyoqKRt
@danielbryantuk: @FitzXyz @mranney yeah, I’ve found that “edge” is quite an overloaded term. This #QConSF track covers nearly all definitions of the edge: this tweet is more about edge devices/IoT, but there are also talks about the CDN/API gateway edge, too
@emballerini: How does one do end-to-end testing on self-driving cars? You build a 40-acre test track (among other things). Fascinating presentation by @mranney #QConSF https://t.co/cjtjU7RkgI
Microservices Patterns & Practices
Controlled Chaos: Taming Organic, Federated Growth of Microservices by Tobias Kunze
Twitter feedback on this session included:
@breckcs: Controlling the organic, federated growth of #microservices by @tkunze: going beyond #observability to #controllability. #QConSF https://t.co/1Ft9o2pOa2
@marcofolio: Those are some interesting stats by @tkunze ! The huge impact of one router failure, shared on #QConSF . Can we control this chaos within microservices? https://t.co/hx7IkKw9Sj
@ddoomen: A very good example of the operational complexity of a growing landscape of microservices #qconsf https://t.co/s1SBu6czjn
Managing Failure Modes in Microservice Architectures by Adrian Cockcroft
Twitter feedback on this session included:
@danielbryantuk: Fascinating insight into availability, safety, and security within modern systems, via @adrianco at #QConSF https://t.co/rz2OSzPtGc
@danielbryantuk: Great intro to observability, and a discussion of how the STPA Model from the book “Engineering a Safer World” relates to modern software systems, via @adrianco at #QConSF https://t.co/OIUmN1mpag
@danielbryantuk: Interesting intro to Failure Modes and Effects Analysis (FMEA) for web services and infrastructure, via @adrianco at #QConSF https://t.co/6jiulzGle0
Stateful Programming Models in Serverless Functions by Chris Gillum
Steef-Jan Wiggers attended this session:
He discussed two stateful programming models — workflow and actors — using Azure Functions, which is Microsoft’s implementation of serverless computing.
Gillum started by talking about Azure Functions, which are “serverless” by nature; the hosting environment supports autoscaling, and running functions are pay per use. Azure Functions are like AWS Lambda, Google Cloud Functions, or other Function as a Service (FaaS) platforms. However, the difference is the “bindings” abstraction, which decouples the code from the data source or destination. It is the central part of the programming model, and the concept allows for building more advanced programming models.
Next, Gillum pointed out the principles and best practices that apply for running functions like Lambda and Azure Functions:
- Functions must be stateless
- Functions must not call other functions
- Functions should do only one thing
… Gillum stated that the event sourcing allows Microsoft to support multiple languages, such as the combination of .NET and JavaScript….
Besides workflows, developers can also leverage the actor programming model in Durable Functions. Gillum said:
Actors will be a first-class concept in Durable Functions, alongside orchestrations. Customers will be able to use one or both of our stateful programming models in the same application, depending on their needs.
User & Device Identity for Microservices @ Netflix Scale by Satyajit Thadeshwar
Twitter feedback on this session included:
@danielbryantuk: How the Netflix login flow (and related systems) has evolved over the past year, via Satyajit at #QConSF “moving authentication to the edge has improved performance, coupling, and security” https://t.co/jWGF5S7B5O
Modern Data Architectures
Future of Data Engineering by Chris Riccomini
Twitter feedback on this session included:
@gwenshap: “we use terraform to manage Kafka topics and connectors. This topic has compaction policy, which is an exciting policy to have when you system evolves”. @criccomini at #QConSF
@gwenshap: #QConSF – @criccomini shares that WePay data infrastructure is based on Airflow, Kafka and BigQuery.
@gwenshap: “we use terraform to manage Kafka topics and connectors. This topic has compaction policy, which is an exciting policy to have when you system evolves”. @criccomini at #QConSF
Steef-Jan Wiggers attended this session:
Riccomini stated that his intention with this talk was to provide a survey of the current state of the art for data pipelines, ETL, and data warehousing, and to look forwards at where data engineering may be heading:
The two primary areas where I think we’re going are towards more real-time data pipelines and towards decentralized and automated data warehouse management.
…In his talk Riccomini provided an overview of the various stages of data engineering, from an initial “none” stage up to a “decentralization” stage:
- Stage 0: None
- Stage 1: Batch
- Stage 2: Realtime
- Stage 3: Integration
- Stage 4: Automation
- Stage 5: Decentralization
Each stage depends on the situation an organization is in, and has some challenges…
Riccomini said that WePay is at a particular stage – some companies are further ahead, and some behind, but these stages can help to build a roadmap…
Lastly, Riccomini went on to explain the final stage, “decentralization”, a stage in which an organization has a fully automated real-time data pipeline. However, the questions is, does it require one team to manage this? According to Riccomini, the answer is “no”, as he stated in the future multiple data warehouses will be able to be set up and managed by different teams. In his view, traditional data engineering will evolve from a more monolithic data warehouse to so-called “microwarehouses” where everyone manages their own data warehouse.
Taming Large State: Lessons From Building Stream Processing by Sonali Sharma, Shriya Arora
Twitter feedback on this session included:
@gwenshap: At Netflix, we are big on A/B testing. If someone has an idea, we try it immediately. And can’t wait for the results to arrive #qconsf @sonali_sh https://t.co/Z3wUKJAg9X
Optimizing Yourself: Human Skills for Individuals
Optimizing Yourself: Neurodiversity in Tech by Elizabeth Schneider
Susan McIntosh attended this session:
What’s your superpower? Elizabeth Schneider posed this question early in her talk on neurodiversity at QConSF 2019, as she explained to the audience how understanding her own neurodiversity gave her greater strength to work with others and deliver great work. However, she also had to recognize that she had weaknesses (kryptonite), and needed to recharge in an appropriate fortress of solitude, just like other superheroes…
As a programmer several years ago, Schneider came to understand that she communicated differently than others after her scrum master had the team do a quick self-evaluation on communication styles; most of the rest of the team was in a completely different quadrant than where Schneider found herself. This helped her recognize that she could learn how to adjust her communication style to fit the needs of others, and to ask for specific adjustments in how others communicated with her. She gave the example of having other in her team give her a cue (tapping on the wrist) when she got too excited about a specific topic.
Understanding the difference between empathy and sypmathy also helped Schneider improve her ability to communicate with her team. Referencing Brené Brown’s work on empathy, Schneider discussed how being able to “put yourself in someone’s shoes” has helped her better recognize the needs of the customer, the product owner, and other team members.
While communication and interactions with others is important to understand, Schneider also noted a couple of environmental changes that, while subtle, can improve productivity. Citing research on office temperature, Schneider notes that a small increase in the physical heat of an office can result in greatly improved cognitive function in women. Additionally, she encourages the use of “focus time” – four or more hours of uninterrupted time – where deep thinking can occur.
Practices of DevOps & Lean Thinking
Mapping the Evolution of Socio-Technical Systems by Cat Swetel
Twitter feedback on this session included:
@DivineOps: When #ticketmaster was born, computers were not obvious! That’s why computer is in the name! That’s how we ended up with a custom OS You have to recognize where you are on that evolution timeline @CatSwetel #QConSF https://t.co/LkjCY1mZTs
@charleshumble: Thinking about Wardley mapping. How do you treat a component. How does the rest of the industry treat the same component. @CatSwetel #QConSF https://t.co/nF1smPMVEf https://t.co/xuXGlyuMeq
@DivineOps: How do developers metabolize information? We write code! And the longer and the more code we write the more technical debt we end up with @CatSwetel #qconsf https://t.co/kYhe2m4m5j
@DivineOps: If #devops is just a #mindset, then we can all sit in a room, change their minds, and live happily ever after! I mean what’s wrong with you all not being able to implement it? Do you not want it badly enough?! @CatSwetel #QConSF https://t.co/gXeEqEanrM
@charleshumble: The map is not the thing. You must also construct the narrative. Likewise DevOps is not (just) a mindset. @CatSwetel #QConSF. (the quote in the photo is from 1952.) @CatSwetel #QConSF. https://t.co/hoG5BaaoCj
@charleshumble: Ticketmaster runs an emulated VAX. Why? It had 43 years of getting really good at its job. @CatSwetel #QConSF.
@charleshumble: What happens to all the legacy code. How do we innovate responsibility? We are such a young industry, we are just getting started. @CatSwetel #QConSF
@DivineOps: You can tell that we are a young industry because we are measuring the age of our systems in months We have to stop sh!tting on things because they are old @CatSwetel #qconsf https://t.co/nZtfAyqsXU
@DivineOps: The map is _not_ the thing The map (just like code) becomes immediately outdated as soon as you create it The act of mapping is what makes our obstacles conspicuous @CatSwetel #QConSF https://t.co/OLv9EG3JD4
Production Readiness: Building Resilient Systems
Observability in the Development Process: Not Just for Ops Anymore by Christine Yen
Twitter feedback on this session included:
@danielbryantuk: “Observing our code in production is a form of testing. Throughout the software development process, we should be optimising for feedback: both in dev and prod” @cyen #QConSF https://t.co/JnD9DYg3SF
@danielbryantuk: “Fine-grained release mechanisms like feature flags are very useful, but you must have the ability to get fine-grained feedback from the changes in order to derive the full value” @cyen #QConSF https://t.co/6qq6YVERDx
@danielbryantuk: “Tools should speak my language. Hearing that CPU usage is high across a cluster doesn’t provide as much value as learning that the latency of an expensive API endpoint increased for an important customer after our latest deploy” @cyen #QConSF https://t.co/DduXFnILwf
@danielbryantuk: Nice takeaways from @cyen’s #QConSF talk about observability in the development process https://t.co/8jyPSuzs9q
Socially Conscious Software
Holistic EdTech & Diversity by Antoine Patton
Twitter feedback on this session included:
@haacked: Antoine Patton (founder of @unlockacademy) speaking about lack of access, money, and time as a barrier to marginalized people who want to learn to code. #QConSF https://t.co/W8zwHlz3HS
@alexqin: Wow Antoine Patton of @unlockacademy just facilitated a Diversity Design sprint for a room FULL of people to design education programs that solve tech’s lack of diversity at scale #QConSF I have never seen this done at a conference before https://t.co/vuTJI6piqQ
Impact Starts With You by Julia Nguyen
Twitter feedback on this session included:
@alexqin: We are worth more than our side hustles, our careers, our salaries @fleurchild #QConSF too real https://t.co/kZvoWFoVGy
@alexqin: It’s ok to take breaks it’s ok to leave things @fleurchild #QConSF https://t.co/rUUYcrvjHM
@alexqin: I come from a family of refugees and I carry the refugee mentality with me still. That I need to uplift my community. @fleurchild #QConSF https://t.co/5E4ASXdxMj
@alexqin: I don’t have to suffer in order to care @fleurchild #QConSF https://t.co/KsZsIKNhQu
Software Supply Chain
Shifting Left with Cloud Native CI/CD by Christie Wilson
Twitter feedback on this session included:
@sarah_shewell: Our systems are becoming more and more complex making configuration as code critical. We wouldn’t debug if we knew the answer. Debugging is learning. @bobcatwilson #QConSF https://t.co/yRAKQUwohS
@desbiens: Shifting left with cloud native CI/CD with @bobcatwilson using @tektoncd #QConSF https://t.co/uVAyd4AxIx
The Common Pitfalls of Cloud Native Software Supply Chains by Daniel Shapira
Twitter feedback on this session included:
@aysylu22: Excellent overview of security aspects of software supply chains by @Da5h_Solo. Some Qs to ask when ensuring secure supply chains: – can anyone access anything w/o authenticating? – what permissions do auth’d users have? – any sensitive info in commit/build history? #qconsf https://t.co/YSv1g8hPRJ
Trust, Safety & Security
Exploiting Common iOS Apps’ Vulnerabilities by Ivan Rodriguez
Twitter feedback on this session included:
@vixentael: Great start of security track at #QConSF! @ivRodriguezCA describes how he reverse engineered iOS apps and what typical vulnerabilities he found! Highly recommend to check his blog & github if you’re interested in RE: https://t.co/Fe3ZRRr0zB https://t.co/tPlanooz8n
@vixentael: App blindly opens URL received from server — okay, we will put a malicious link there! #qconsf @ivRodriguezCA https://t.co/7SoHJ1tovF
@vixentael: Remote MitM attack on vulnerable iOS apps Lucky it’s just a demo, otherwise I’d turn off my phone immediately … @ivRodriguezCA #QConSF https://t.co/cRsViwaICZ
@vixentael: Repeat after me: HTTPS is not enough! @SyntaxPolice #QConSF https://t.co/NHxeu98VvN
@vixentael: End-to-end encryption is useful not for chat applications. E2EE helps to protect data that’s ‘flying’ from server to server. @SyntaxPolice #QConSF https://t.co/yCLLFjv4fy
@vixentael: Crypto in web browser? Dream or reality? Depends on your threat model! #qconsf @SyntaxPolice https://t.co/H7xCSb6YuW
Reflecting on a Life Watching Movies and a Career in Security by Jason Chan
Twitter feedback on this session included:
@vixentael: Being in security team is hard: think about how much software we have now in our houses, in our cars, in mobile devices. @chanjbs is reflecting on modern security processes at #QConSF https://t.co/svAz8OzaQa
@vixentael: Questions to ask in your org: do you want to train your engineers as security experts, or to help them to build secure systems? @chanjbs at #QConSF https://t.co/A2zV42Xzwt
Security Culture: Why You Need One and How to Create It by Masha Sedova
Twitter feedback on this session included:
@vixentael: Security culture is part of the enterprise culture itself. If you try to build security culture that mismatches company’s culture, you will fail. People are driven on what kind of behavior is rewarded and what is punished. @modMasha at #QConSF https://t.co/odK0BXd3k9
@vixentael: Negative security culture appears when bad security decisions are not punished, and good security decisions are not enforced. Which kind of culture you have: Compliance, Process, Trust, Autonomy? @modMasha #QConSF https://t.co/88V7aDYxfE
@vixentael: Everyone has a security culture! @modMasha #QConSF https://t.co/jFX513YXxH
Small Is Beautiful: How to Improve Security by Maintaining Less Code by Natalie Silvanovich
Twitter feedback on this session included:
@vixentael: @natashenka #QConSF How to narrow down the attack surface? – remove old / unused code – keep an eye on shared code that you use often, one bug — problems everywhere – check/update dependencies! https://t.co/rSPt9tSomC
@vixentael: Chrome Sandbox is a huge system @natashenka at #QConSF https://t.co/WfxygJUKRP
Sponsored Solutions Track V
3 Common Pitfalls in Microservice Integration and How to Avoid Them by Niall Deehan
Twitter feedback on this session included:
@mary_grace: Failing fast is important but requires a good solution and a chance to try again. @NiallDeehan #QConSF
Unofficial Events
Women in Tech & Allies Breakfast (Co-Sponsored by Netflix) by Wade Davis
Susan McIntosh attended this session:
The Women in Tech & Allies breakfast at QCon San Francisco featured Wade Davis, the vice president of inclusion strategy and product at Netflix. Davis encouraged allies to “act in solidarity” with women, favoring this more collaborative, interactive phrase than the passive description of “ally.” He noted that the activity is not done after one event, but is rather daily action and interaction — he encouraged all to “show up every day” in the journey of understanding and supporting women in technology…
Davis recommended a handful of items: read books by women; amplify what they recommend by frequently attaching their name to their ideas in conversations; and dig into behavior with more specific questions (“What would cause you to get involved?” rather than “Why aren’t you involved?”).
Opinions about QCon
Impressions expressed on Twitter included:
@PurposeCreator: I appreciate the values that guide this conference. #QConSF !! https://t.co/bXF9SdtPHp
@bou_majeed: One #ux of badges is to use them for talks feedback #QConSF https://t.co/ehmqrGC0kn
@BettyJunod: Special thank you to @kcasella for organizing such an amazing event this morning at #QConSF A wonderful way to meet with folks at the conference and was brought to tears at times from a very powerful and thoughtful talk by @Wade_Davis28
@floydmarinescu: @QConSF goes the extra mile for attendees. One of the three levels of the conference venue has no windows. So what do we do? Living green wall, full spectrum day lighting, and huge plants. #qconcares #qcon #qconsf https://t.co/JSuD9mTIW0
@CatSwetel: Oh! I almost forgot to thank @botchagalupe for the *amazing* interpretive dance intro for my #qconsf talk. I’ve asked to be introduced through interpretive dance *many* times, but for some reason, people always think I’m joking.
@PurposeCreator: Thank you conference organizers for putting together a great learning experience at #qconsf https://t.co/CYWSPetT9W
@PurposeCreator: #QConSF superb job cultivating diversity, mastery, community!
Carl Chesser attended the conference:
This was my first time attending QCon, and I was really impressed with the quality of the conference. I have been a long time consumer of content on InfoQ, so it was great to be there in person and meet more practitioners that are working on interesting problems…
QCon is a conference which organizes its talks into specific tracks. Track hosts that have been identified as experts in that domain, then do the work of identifying speakers to talk in these tracks. This approach makes it very clean on how they have direct selection on the talks to ensure they fulfill the targeted track and the speakers are known for being good at public speaking. As a result, majority of the talks are well prepared and are conveyed in an effective way. The conference was held all within a single location, Hyatt Regency in San Francisco, which made the logistics for attendees quite convenient. It was easy to get to and from talks, allowing you more time to strike conversations with others, and lowering the stress of having to determine where do I need to go next…
While at the conference, I had the opportunity to connect and talk with many other engineers and practitioners. By being in San Francisco, I was able to reconnect with a couple former colleagues which made it a really valuable time. I then was able to connect with other speakers which I found extremely valuable. … Several times I found people some tie back to the Kansas City area (where I’m from) or work in the related industry (healthcare). By having my talk announced before the conference, I also had some other planned meetings with companies and start-ups to learn more about what they were trying to solve, and how it related to challenges we were facing at our company. Having these scheduled meetings were valuable to have additional conversations that I wouldn’t probably normally engage if I didn’t plan beforehand.
Takeaways
Takeaways from QCon London included:
@vixentael: Great security track today at #QConSF @QConSF! I’m so grateful to our speakers, they delivered amazing security talks ” deep, detailed, easy to understand Average rating for the track: 90% green! Also, you can ALREADY check slides online: https://t.co/Wch7ZyRQA2
@glamcoder: Thanks @QConSF for having me! That was an amazing experience and I’m so grateful for all the people who came to listen my talk. Love being part of such a great conference. And now it’s end and I’m looking forward to future opportunities. #QConSF https://t.co/xcQGxJt46D
@11329032: It was such an honor to speak @QConSF about the work that I do. This is a really impressive conference and I loved talking with and learning from other speakers
@JamesonL: Just finished up attending #QConSF and I had an amazing time. A great place to hear about the newest challenges Tech is facing… and more importantly, how we’re solving them!
@Yssybyl: Back home after #QConSF – had a great time as a speaker and learned a lot from the other talks. If a QCon is happening near you I’d recommend it, you won’t be disappointed!
@gunnarmorling: @mwessendorf @QConSF Thanks, Matthias; being at #QConSF was an outstanding experience, enjoyed every minute!
@ddoomen: I absolutely love the networking opportunities #qconsf offers. Lunches, open spaces, the long breaks, everything is designed to meet other people and exchange experiences and learnings across the world. https://t.co/N1HUdGjzXT
@bou_majeed: It was busy and enjoying week at #QConSF I learned a lot, had fun, and had opportunity to meet great people. Thanks to everyone who made this successful and perfect https://t.co/0Hd8Z0RcnP
Carl Chesser attended the conference:
It was a great experience being at QCon. I really enjoyed getting to meet and talk with other engineers and the talks within this conference were strong. I hope it works out to attend future QCon conferences, and I’m really thankful for the opportunity for speaking at this event.
Conclusion
InfoQ produces QCons in 8 cities around the globe (including our newest edition QCon Munich). Our focus on practitioner-driven content is reflected in each committee’s unique make up. The program committee of leading software engineers and leaders meets for 30 weeks to individually select each speaker at QCon. The next QCon is well underway and takes place in London March 2-6, 2020. We will return to San Francisco November 16-20 2020.
MMS • Jan Stenberg
Article originally posted on InfoQ. Visit InfoQ

The new release of KSQL, an event streaming database for Apache Kafka, includes pull queries to allow for data to be read at a specific point in time using a SQL syntax, and Connector management that enables direct control and execution of connectors built to work with Kafka Connect. Since the Confluent team behind KSQL believes it’s an extra significant release, they have decided to rename the tool to ksqlDB. The goal for the tool is to provide one mental model for doing everything needed to build a complete streaming app using ksqlDB, which in turn only depends on Kafka.
ksqlDB is used for continuously transforming streams of data. It reads messages from Kafka topics and can filter, process, and react to these messages and create new derived topics. Materialized views can then be created over the created topics, views that are perpetually kept up-to-date as new events arrive. Until now ksqlDB has only been able to query continuous streams, which are called push queries because they push out a continuous stream of changes. With the new release, ksqlDB can also read current state of a materialized view using pull queries. These new queries can run with predictable low latency since the materialized views are updated incrementally as soon as new messages arrive.
With the new connector management and its built-in support for a range of connectors, it’s now possible to directly control and execute these connectors with ksqlDB, instead of creating separate solutions using Kafka, Connect, and KSQL to connect to external data sources. The motive for this feature is that the development team believes building applications around event streams was too complex. Instead, they want to achieve the same simplicity as when building applications using relational databases.
In a blog post, Jay Kreps, CEO of Confluent and one of the co-creators of Apache Kafka, describe the new features in more detail and why they are important in order to make event streaming a mainstream approach to application development. He thinks that providing a database built for streaming is a part in achieving that. He sees events as a first-class citizen in a modern development stack and believes that it must be as simple to build an event streaming application as building a REST service or CRUD application.
Internally, the ksqlDB architecture is based on a distributed commit log used to synchronize the data across nodes. To manage state, RocksDB is used to provide a local queryable storage on disk. A commit log is used to update the state in sequences and to provide failover across instances for high availability.
Kreps refers to a blog post by Martin Kleppmann: Turning the database inside-out with Apache Samza, and notes that Kafka provides the foundational ingredients for this kind of event-oriented model. He also points out that with the new functionality, ksqlDB can make this architectural pattern easier to implement.
In a short video, Tim Berglund from Confluent runs a demo describing old and new features of ksqlDB.
ksqlDB is owned and maintained by Confluent Inc. as part of its Confluent Platform and is licensed under the Confluent Community License. The code is available on GitHub.
MMS • Jan Stenberg
Article originally posted on InfoQ. Visit InfoQ

The new release of KSQL, an event streaming database for Apache Kafka, includes pull queries to allow for data to be read at a specific point in time using a SQL syntax, and Connector management that enables direct control and execution of connectors built to work with Kafka Connect. Since the Confluent team behind KSQL believes it’s an extra significant release, they have decided to rename the tool to ksqlDB. The goal for the tool is to provide one mental model for doing everything needed to build a complete streaming app using ksqlDB, which in turn only depends on Kafka.
ksqlDB is used for continuously transforming streams of data. It reads messages from Kafka topics and can filter, process, and react to these messages and create new derived topics. Materialized views can then be created over the created topics, views that are perpetually kept up-to-date as new events arrive. Until now ksqlDB has only been able to query continuous streams, which are called push queries because they push out a continuous stream of changes. With the new release, ksqlDB can also read current state of a materialized view using pull queries. These new queries can run with predictable low latency since the materialized views are updated incrementally as soon as new messages arrive.
With the new connector management and its built-in support for a range of connectors, it’s now possible to directly control and execute these connectors with ksqlDB, instead of creating separate solutions using Kafka, Connect, and KSQL to connect to external data sources. The motive for this feature is that the development team believes building applications around event streams was too complex. Instead, they want to achieve the same simplicity as when building applications using relational databases.
In a blog post, Jay Kreps, CEO of Confluent and one of the co-creators of Apache Kafka, describe the new features in more detail and why they are important in order to make event streaming a mainstream approach to application development. He thinks that providing a database built for streaming is a part in achieving that. He sees events as a first-class citizen in a modern development stack and believes that it must be as simple to build an event streaming application as building a REST service or CRUD application.
Internally, the ksqlDB architecture is based on a distributed commit log used to synchronize the data across nodes. To manage state, RocksDB is used to provide a local queryable storage on disk. A commit log is used to update the state in sequences and to provide failover across instances for high availability.
Kreps refers to a blog post by Martin Kleppmann: Turning the database inside-out with Apache Samza, and notes that Kafka provides the foundational ingredients for this kind of event-oriented model. He also points out that with the new functionality, ksqlDB can make this architectural pattern easier to implement.
In a short video, Tim Berglund from Confluent runs a demo describing old and new features of ksqlDB.
ksqlDB is owned and maintained by Confluent Inc. as part of its Confluent Platform and is licensed under the Confluent Community License. The code is available on GitHub.
MMS • Daniel Lemire
Article originally posted on InfoQ. Visit InfoQ

Transcript
Lemire: My name is Daniel Lemire, I’m from the University of Quebec, and I’m going to talk to you about Parsing JSON Really Quickly. I’m one of the authors of what might be the fastest JSON parser in the world, and so I’m going to try to tell you about the strategies we’ve used and give you some examples of the tricks that we’ve been building up to make this possible.
How Fast Can You Read a Large File?
I’m going to start with a relatively simple and naïve question to motivate my talk. If I give you a relatively large file, and I ask you to read it in software, and then I ask you what is your limit, are you limited by the performance of your disk, or are you limited by the performance of your processor? I would guess that most people would say that you’re strictly limited by your disk. I could reframe this same question by talking about network.
I would argue that the story is a little bit more complicated than people sometimes think. In preparing this talk, I just benchmarked the disk on my iMac, which is just a basic stupid iMac on my desk, on campus. My disk was rated at 2.2 gigabytes per second as a throughput. Of course, there are better disks out there and network adapters that are much faster also.
Let’s compare with how quickly we can do very naïve task using software. Let’s say, for example, that I take a relatively large text file, and I put it in memory. My memory is probably not going to be much of a bottleneck because I can read tens of gigabytes per second in memory easily. Let’s not worry about the memory, and let’s try to just go through the lines in my file and just add up their length. This is a stupid benchmark, but the point is, illustrate just about the simplest thing you could do with this sort of data.
If I benchmark it using a fairly standard CPU, I get a fraction of a gigabyte per second in speed. If I were to do the same thing, and my input was disk, I would be entirely CPU bound in this case, if the disk is all mine and the file is large enough. You can switch to C++, and again, I’m only using rather naïvely the standard APIs. In this case, at least in my test, I get slightly better, so I break the 1 gigabyte per second barrier and it’s basically the same silly test. My point here is not so much that I couldn’t do these things much faster, so certainly, whether you’re in Java, or in C++, you can certainly beat these numbers. Here I’m just trying to illustrate that if you’re writing just standard code, you’re probably going to have some trouble reaching gigabytes of data per second ingesting files.
Nobody here will say this, but some people could say, “It doesn’t matter because your processor or your core is going to get much faster next year or in two years.” That’s what people used to say in the ’90s. Now, of course, we all know that our cores are not getting much faster with each passing year. If we’re going to reach gigabytes per second processing data, we better have good software to do it.
JSON
Of course, nobody cares about parsing lines of text and counting their length in software, that’s kind of a silly problem, but people do care about things like JSON. I would assume that most people here have heard of JSON hopefully. It’s a fairly standard thing, it’s well established, it’s fairly simple. You have arrays, strings, numbers, it’s all glued together with some text. It’s all over the public APIs and so forth, and even entire systems are built around parsing JSON around.
What I hear a lot – not from everyone, but from enough people – is that they have all these cool AI stuff, but their servers are just spending all their time producing JSON and parsing JSON. I see a few people laughing so maybe this happens to you. It’s kind of silly if you think about it, but that’s life.
Here I’m going to focus on JSON parsing. It’s maybe important to define what I mean by JSON parsing because it could mean different things to different people. What I mean here is, you read all of the content, you check that is valid as per the specification, you check, for example, that the encoding is correct so you have proper strings. You parse the numbers, and you build some kind of tree data structure, so a document object model. Arguably, this is a little bit harder than parsing lines in a text file though it should be a little bit slower. How quickly can you go? If I pick what might be one of the very best JSON library in Java – Jackson – and if I use a pretty good benchmark file that I’ve picked up somewhere on the web, that I’m going to use throughout this talk – it’s twitter.json, was collected from the Twitter API, and it contains numbers, Unicode string and so forth. It’s a pretty good benchmark because it’s an all-around typical JSON file. I get that Jackson can ingest the JSON file at a fraction, about a third in my case – of course, the results will vary depending on your hardware and your software, but I post my source code – at about a third of a gigabyte per second, so we’re very far from maxing out our disk with a single core.
If we switch to C++, then a very good library is RapidJSON. If you’re coding in C++, and you’re processing JSON, and you want really good performance, and probably you know about RapidJSON, you do a little bit better. In this benchmark, you reach about two-third of a gigabyte per second. Again, you’re very far from maxing out the disk in this instance. The question is, can you do it? Can you parse JSON at gigabyte speeds? Of course, you can, otherwise it wouldn’t be much of a talk – no, I have a bit more to go.
We built this library, simdjson, that can achieve on this benchmark 2.4 gigabyte per second. It’s actually the only library that I know of that I can actually max out my disk. This means that on my test machine, roughly speaking – please don’t do any math here, just an order of magnitude – it’s about 1.5 cycles per input byte. This does not give you a lot of leeway, you cannot take each byte and start to think deeply about what to do with this byte and then switch to the next one, you only have 1.5 cycles per input byte. It’s a little bit better than it sounds because our superscalar processors can do many things in one cycle, at least when they’re not doing silly random access work in memory, or other notation. When you’re CPU bound, you can certainly beat one instruction per cycle, so this is a bit better than it sound.
Avoid Hard-to-Predict Branches
How did we do it? I’m going to cover a few basic strategies that probably most people here know, but I’m going to go a little bit more deeply in them, and then I’m going to show how we apply them. This was mentioned today, several times people talk about measuring mispredicted branches and so on. I’m going to go deeper into this, and actually say that you should really work hard to avoid hard-to-predict branches, and I’m going to work from an example.
Let’s say, for example, you’re trying to write random integers to an array. You do a silly loop and if your random integers are generated using a fast, state of the art, pseudo-random number generator, you might be able to do this task using about, say, three cycles per number generated. Let’s say you modify this job. This code here is silly but it’s just to illustrate my point. You say, “I’m going to do the same work, but I only want to write out odd numbers.” I do it in fully manner, I generate my random integer and then I check whether it’s odd. This is very fast, I only have to check the least significant bit, and if it is, I’m going to write it out.
If you’re a bit naïve about it, and if you’re doing textbook computer science, you might look at this and say, “It’s not necessarily any slower, it might even be faster than previous code because you’re not writing as much to the output array.” Actually, it’s massively slower because what’s happening here is that a modern processor rely on branch predictions. Each time the processor sees a branch, it tries to predict its output, several cycles ahead of time. Then it does the computation based on this prediction. If the prediction is false, then it needs to throw away all of this work, and start again back at the point where it mispredicted. I carefully design my silly benchmark so that it will be clearly very difficult for the processor to correctly predict the branch because it’s got a random number, and how can it predict whether it’s odd or not?
Thankfully, I can rewrite the same benchmark without a branch, and typically this is almost always possible. What I’m doing here is that – this is a typical trick – I’m always writing out a random integer to the array, but I only increment my index when the integer is odd. In this code, there’s no more branch; actually, there’s a branch due to the y loop, but inside the y loop, there’s no branch. I’ve basically transformed the problem with the branch into one where it’s just arithmetic, and the performance is back to nearly what it was originally.
What happens quite often is that when you make this point to people, they write a little benchmark, and then they say, “My code with branch is actually faster than your branchless code.” Here’s one scenario that might explain what happens. If I take my code with the branch, the one I showed you, the silly one, and by design, I’m using a pseudo-random number generator, this means that I can repeat the benchmark many times, but it’s always going to be the same random number. To try to fool the processor, I can say use a loop that has 2,000 iterations. If I do that, and I repeat and repeat always the iteration, and I plot the misprediction rate, initially, during the first iteration, I’ve got a 50% misprediction rate. Very quickly, the processor adapts and actually learn – and I’m not kidding – it learned the 2,000 predictions, and it can learn them pretty well. This example with my relatively old Skylake processor, it takes a really long time before it falls down to 1%, but you see after 50 trials, I’m down to 5%. If you use the new fancy AMD processors in the same time it falls down 0.1%. Apparently, there’s something about deep learning or whatever, neural networks; it’s not deep learning, but anyhow, it’s a very good branch predictor.
One problem is that it’s really hard to benchmark code with branches because processors do all sort of crazy things to fool you. Another fact that I’m now documenting here is that sometimes by adding a branch, you can worsen the branch prediction elsewhere. Basically, it can depend on your processor, but lots of processors predict branches based on history. The history of the branch is taken, and if you’re adding a branch, then this history gets more complicated to learn, and so it can worsen things, even if the new branch that you’ve introduced is predictable. Basically, branches can have bad effect and these bad effects are not so easy to measure.
Use Wide “Words”
I said earlier that I only have about 1.5 cycles per byte. This means I cannot go byte by byte when I process my input. I need to go with wide words, so maybe 64-bit boards, or when possible, I should be using SIMD instructions. SIMD instructions have been around for a long time, they go back to Pentium 4. They were first introduced as a motivation multimedia, sound for example. Now, people invoke machine learning and deep learning [inaudible 00:18:00] but it’s the same story.
What they do is that they add wider registers, so, the normal general-purpose registers are 64 bits on most processors, but then they add 128, 256-bit, and even 512-bit registers. They also add new fancy instructions, like really fast lookup tables. Basically, the story goes like this, your mobile phone, your iPhone for example, has NEON instruction, which use registered span under a 28 bit, the same as legacy x64 processors. The more recent processors you can buy now on your servers, use AVX and AVX2, so they use 256-bit registers. The fancy new processors from Intel go up to 512-bit. For our work for simdjson, we use the first three type of systems. We do not yet go to AVX 512. Part of it is that it’s not widespread yet.
For our new program for SIMD instructions, the approach that we’ve been using for simdjson is to use intrinsic function. These are special functions that call sometimes a very specific instruction that is specific to the processor you’re using. They’re higher-level APIs, higher-level function, so Swift, C++, you’ve got the Java vector API that is along these lines, we don’t use that. You can also rely on Compiler Magic, so you compile whether it’s in Java or C can take a loop, for example, and vectorize it; it’s like magic. You can use optimized functions, Java has some of them. Or, for example, when you’re using crypto library, then these guys typically write all of their code in assembly, which I don’t recommend because it gets a little bit difficult.
Avoid Memory/Object Allocation
Another trick – again, nothing revolutionary – is that you should avoid memory and object allocation as much as you can. In simdjson, we use what we call a tape. When you’re parsing the JSON document, everything gets written to one tape that’s reusable, so whenever we encounter a string, we don’t allocate memory for the string. Whenever we encounter a number, we don’t allocate memory for the number, everything gets written consecutively.
Measure the Performance
Another strategy that we use is that we measure the performance a lot. We do what I would call benchmark driven development. It might not be practical, but it’s fun. Here’s a plot of our performance on Twitter file on one specific machine over time. On the x-axis, you’ve got the commits and on y-axis, you’ve got throughput. Here I’m cheating a little bit because the y-axis does not start at zero, but I just wanted to show what it looks like. You can see we have these big jumps when someone finds a new, clever way to do things. What’s interesting is, in our first public release, we reached 2 gigabytes per second, and we thought we were pretty clever. Now we’re at 2.4, and I think we’re going to go higher. I’m planning to go to at least 2.5, if not more. Also, we use a performance test in our continuous integration. That’s a kind of worm in itself, but we try to basically detect commits that cause a major problem on one type of system very quickly.
This is almost an aside, but here is a point that I’m finding that I often have to do. If you’re doing CPU intensive work – I’m not talking about accessing data in RAM or something like that – if you’re doing processor intensive work, then you have to worry about the fact that, no matter what you think, your processor frequency is probably not constant. Especially, if you’re working on a nifty new laptop that’s thin, it’s probably not constant. If you want to measure performance seriously, then you probably don’t want to equate the time with the number of CPU cycles. This was mentioned today, you probably need to use performance counters from your CPU if you’re serious about it.
Example 1. UTF-8
Let me go into specific examples of what we do. One problem that we have when we want to parse JSON is that the input, at least on the web typically, is Unicode, so UTF-8, and we want to check that the bytes are actually UTF-8. UTF-8 is an extension of ASCII; this ASCII is valid UTF-8, but it adds extra code points that span 2, 3, or 4 bytes. If you want to write in Klingon, for example, you’re going to have to use more than 1 byte.
There are only about 1.1 million valid code points, everything else is garbage. Of course, you want to stop, you don’t want to ingest strings that are not valid, because then it’s going to end up in your database, and maybe even show on your website, and God knows what. You want to stop it right there. Typically, the way people validate Unicode is with code like this. This is not actual code, I took real code, and then I simplified it because it’s much longer, but basically it’s a bunch of branches. This works really fine if your input is ASCII because you’ve got one predictable branch and everything is fine, but the minute you start hitting Unicode, then you’ve got branch mispredictions all over. You can avoid the branch misprediction by using a finite state machine, but it’s complicated. You can do even better than this, you can use SIMD instructions, so you load 32 bytes of data, you use 20 magical instructions. Then you got no branch and no branch misprediction. I don’t have time to go into what these 20 something instructions are. Actually, I know of three different strategies that end up with the same instruction count, just about, but I’m just going to illustrate it.
For example, in UTF-8, in the standard Unicode that we see on the web, no byte value can be larger than 244. The way we check this – you could just do a comparison, but we like to just do a saturated subtraction. Basically, we take the byte value, and we subtract 244, and obviously, if the result is not zero, then you have a value that’s greater than 244. Otherwise, because of the saturation bit, it goes to zero. Saturation just means that it doesn’t wrap around, it goes to zero if it’s too small.
This can be written in code using one of these intrinsic functions I was talking to you about. This voids assembly but it’s super ugly. In this case, with this one function, I can check 32 bytes at once, so it’s really efficient, really fast. Then I could go on for about an hour to explain, everything else falls into place, but let me jump to the results. Compared to branching, if I have an input that’s random UTF-8, I’m about 20 times faster using SIMD instructions than I am with using branching, so, much better.
Example 2. Classifying characters
Let me work out here in our fun problem that’s more closely related to JSON. In JSON, we have what they call “Search all characters,” I think is the specification that calls them that, so the comma, the colon, the colon separates the key and values, and then the braces that differentiates between objects and arrays.
Then you have white-space, and basically, outside the strings, you cannot have much else. You have the atoms, you have the numbers, but the structure is given by these characters. You want to identify them, but you don’t want to identify them one by one, it’s too slow. We’re going to build a lookup table approach, so what do we do is we take each byte value, and we decompose it into two nibbles. A nibble is 4 byte, so the least significant 4 bits I’m going to call it the low nibble and the most significant 4 bits I’m going to call it a high nibble.
I’m going to use the fact that whether using ARM, or Intel, or AMD, you have fast instructions that can do table lookups as long as they’re relatively small. Let me give you an example of what these instructions are capable of. I start with an array of 4 bit value, so nibbles, and I create a lookup table. Here, for simplicity, my lookup table is just the numbers from 200 to 215, but this could be actually entirely random. Of course here, I could just add 200 to lookup, but I wanted something people could follow. What I want to do here as a task, I want to map zero to 200, 1 to 201 and so on. This task can be done in one instruction. It’s a really fast instruction on most processors.
That doesn’t give me the character classification I was talking about, but the recipe is actually quite simple. I need two lookups. I take all my low nibbles, and I look them up in one table. Then I take all my high nibbles and I look them up into another table, and then I do the bitwise AND between the two. Then I choose my lookup tables carefully, so that the comma ends up mapping to 1, the colon to 2, the brackets to 4, and the white-space characters to 8 and 16.
I’m going again to show you terrible, really ugly code, so in this case, it’s the implementation using ARM NEON with intrinsic functions. It looks really scary but it’s not. At the top, I basically defined my consonants which are my lookup table, so I’ve got two lookup tables. Then my five instructions are given below. The first two instructions identify the high and low nibbles. Then the instruction three and four are just lookups, and then last instructions, I do a bitwise AND. In five instructions, in this case, I can classify 16 characters without any branches whatsoever, it’s super fast.
Example 3. Detecting Escaped Characters
Here’s a fun one. You all know that if you want to put a quote inside a string, you need to escape it, which means that you have to add a backspace before it. That backspace itself also needs to be escaped, of course, so it’s “backspace, backspace.” if I’ve got “backspace, quote,” then it gets really confusing because it’s “backspace, backspace, backspace, quote,” and I could keep going. In practice, this means that you could get a JSON input that looks like this Can you tell where the string starts, where they end? You don’t know, so it’s really hard to figure out the structure from this.
There’s a trick actually. If you’ve got an odd number of backspace characters before a character, then this character is escaped. If you’ve got an even number, then you don’t need to worry because an even number of backslash characters are just going to be mapped back to a series of backslashes. Let me give you an example of how we go about it. I go back to my input string, I identify the backslashes, so I map them to a bit set. Everywhere I’ve got a backslash I put a one otherwise I’ve got zeros. Then I’m going to define two constants. You’ll see where I’m going with this, or maybe not, but it will be fun. I’ve got one constant where I put a one at every even index, so 0, 2 and so forth. Then finally, I have a constant where I’ve got one at every odd index, so one, three and so forth. Then I plug in this firmly at the very top, ok. I’m not going to explain it. A student of mine asked me, “How did you get that?” I said, “Lots of hard work.” You’ve got this formula here, you can just try it out at home, it’s fun.
This actually does the right thing. In this case, it will identify the fact that my quote character right there is escaped so it’s not actually a string delimiter quote. It sounds really painful, there’s lots of instructions there, but again, no branches whatsoever. If I remove the escape quotes, then the remaining quotes tell me where my strings are. I can just identify all my quotes, so I put a one where I’ve got a quote, and I don’t find my escape quotes. Then whatever remains are my string delimiter quotes. It’s important for me to identify where my quotes are when I’m parsing JSON because if I want the structure of the document, I need to be sure that I remove all the braces, the colons, and so on that are inside strings because they don’t count. I want to know where my strings are.
I do a little bit of mathematical magic here, so if I start with where my quotes are, and I want to turn this into a bitmap that indicates the inside of my quote, I can do a prefix XOR. I show it in the code, basically I shift by one, I XOR with the original, I take the result, I shift it by two, and I XOR again, and so forth. This looks a little bit expensive, but you can actually do this with one instruction on most processors. It’s a [inaudible 00:35:55], it’s used for cryptography so probably those of you who don’t do crypto don’t know about this instruction, but this can actually be really cheap. If you do this, you go from the location of the quote to the string regions. This means I can mask out any instructional character that is inside of a quote, again, without any branching.
If you follow all of my examples, if you put them together in your mind, you realize that the entire structure of the JSON document can be identified as a bitset – so with the ones and so forth – without any branch.
Example 4. Number Parsing Is Expensive
At this point, you’re going to have to go from the bitset to the locations of the onen. I’ve got a nice trick on how to do this, but let me jump ahead because the time is a bit short, but maybe I can come back to it later.
Another problem we have is that number parsing is surprisingly expensive. If you take some Java code that has to ingest data in text form, and you try to benchmark, the time spent parsing the floating-point numbers is totally crazy. I built a little benchmark, so I generated that random floating-point numbers and I just wrote them to a string in memory. Then I went back, and I tried to read back these floating-point numbers using a well-optimized C function, so a string to D. Then I reach the fantastic speed of 90 megabytes per second, so this certainly should be slower than yours as these, would hope so.
I’m basically spending 38 cycles per byte, and I have a total of 10 branch misses per floating-point number. This is not fun, and this is going to end up being a bottleneck. Basically, you have to use either a fast floating-point parsing library that someone wrote or, like we did, you write your own and you hope for the best.
I’m going to go back a little bit on my original strategy which said, “Let’s try to use wide words.” Again, you have the same problem. If you look at most code that parses numbers, you do it byte by byte, and this is, of course, not going to ever be super fast. I’m going to do some mathematical magic and I’m not going to explain the formula. This is a formula I actually came up with probably working late on a Saturday night. If you gave me eight ASCII characters or eight characters, I take it and I map it to a 64 bit integer, I just copy it over. Then I applied this little formula, then it’s going to give me true when my characters are specifically eight digits. Why is that important? Because very often the numbers that are expensive to parse are numbers that are made of lots of digits. Some people really like to throw in a lot of precision when they serialize their data and it is expensive to parse back. Very often you want to speculate, and say, “Ok, maybe here, I’ve got eight digits, and I want to be able to check it really quickly.” In this case, I’m able to use this format, it’s really cheap, only a few instructions, and I know right away whether I’ve eight digits. If I do, then I’ve got a function to sell to you.
This one I did not invent, I picked that up on the web somewhere, Stack Overflow probably. There’s credit for it in the source code. What you want to do is you take these eight digits, and you turn them into an integer. You don’t do it character by character, you actually do three multiplications and a few arithmetic functions, and that’s probably that’s the total sum of it. I’m not going to go into everything else we do for parsing, but this gives you an idea of the strategy.
Runtime Dispatch
When you write Java code or use Git, so forth, you often don’t have a problem where you don’t know about the hardware you’re running on. We are doing optimizations that are really low-level, that are specific to the hardware. We do some optimizations for processors that have 256-bit registers. Then, to support legacy hardware, we need to also have 128-bit registers. We basically need two functions for it as well. Then we support also ARM but that’s a little bit easier because [inaudible 00:42:27] is a little bit more stable. We have this support on Intel and AMD processors, we have to support two code paths. The way we do it is fairly standard. We basically build and compile two functions and then we do what they call runtime dispatch. The first time the parsing function is called it’s actually calling a special function that should be called only once. There’s concurrency involved, but I removed it from the code for simplicity. You check the feature of the CPU, and then you branch depending on the function you want to use.
Then you basically reassign the function pointer. The next time there’s not going to be any CPU checking, because you’re assuming that the person running your program is not switching the CPU under you, so you’re going to call the right function right away. I’ve known about runtime dispatch for a long time, and everyone says it’s super easy but then when you ask around you find out that few people have actually tried to implement it. When you try to implement it using portable code as much as possible, so it runs under Visual Studio, Clang, and GCC, we found it really hard to do. In part, it’s because there are bugs in some of these compilers, and there were no good model on how to do it.
One of our objectives was to have a single header library. We don’t know how people are going to build our code, so we don’t want to depend on the build system, we really want the code to do all of the work. For this reason, this was a little bit hard. Obviously, if you’re working in Java side then you don’t have to worry about that because someone else is worrying about it for you.
The simdjson is a free library, it’s available on GitHub. It’s a single header library, so it’s really easy to integrate, you can just plug it in your system. It’s relatively modern C++. One of my students says that it’s advanced C++. We support different hardware, so we support ARM. There’s a co-author that actually wrote a version for Swift that acts as a wrapper for our stuff, and it beats Apple’s parser. Then we support relatively old Intel and AMD processors.
It’s under an Apache license, there’s no patent because I’m poor and stupid. It’s used by reasonable people at Microsoft and Yandex. We have wrappers in Python, PHP, C#, Rust, JavaScript, Ruby, there are ports also very exciting. There are ports to Rust, so there’s a version that’s written entirely in Rust, but apparently the keyword unsafe was used. There’s an ongoing port to Go and there’s a C# port also. No, Java port, sadly, that’s missing.
We have an academic reference, it was published in the “VLDB Journal.” I’m going to end with some credits. Not all of them, but a lot of the clever, magical algorithms with really crazy formulas were designed by Geoff Langdale, who’s my primary co-author. Also, there’s lots of contributors as this is GitHub, we’re in 2019 so when you post something on the web, everyone comes to help you sometimes.
See more presentations with transcripts