Month: February 2020

MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ
Google has released Android 11 as a preview for developers, who can now adapt their apps to the upcoming Android release and provide early feedback to help Google improve the release robustness. Android 11 includes indeed many behavioural changes that could affect existing apps, as well as new feature and API and new privacy options.
Android 11 will support a number of new APIs for media management, connectivity, data sharing, machine learning, and more.
The MediaStore API supports now performing batch operation on media files, including granting write access to files, creating “favorite” files, and trash files or delete them immediately. Apps can also use raw paths to access files to simplify working with third-party libraries. To improve debug performance, developers can load GLES and Vulkan graphics layers into native application code.
The new ResourceLoader and ResourceProvider APIs enable apps to extend the way resources are searched and loaded. This is intended for custom asset loading, e.g. using a specific directory instead of the application APK. Additionally, C/C++ developers will be able to decode image directly using the NDK ImageDecoder API.
Machine learning support is another area where Android 11 brings new features, specifically adding support for TensorFlow Lite’s new quantization scheme, new ML controls for QoS, and streamlined data management across components to reduce data redundancy. Biometrics support is also extended with the new `BiometricManager.Authenticators interface.
Android 11 also introduces several changes to privacy, which include scoped storage enforcement, background location access, and a new one-time permission model that should make it easier for users to grant access to location, microphone, and camera in a single step.
All privacy changes listed above affect existing apps and Google explicitly requires developers to check their apps are compatible with them. But Android 11 introduces a few other behavioural changes that could have an impact on existing apps. For example, the JobScheduler API enforces now call limits to identify potential performance issues; furthermore, when the user denies twice a spcecific permission, then the OS assumes that means “don’t ask again”; and last but not least, the ACTION_MANAGE_OVERLAY_PERMISSION now always brings up the top-level Settings screen, whereas it used to bring the user to an app-specific screen.
The number of changes brought by Android 11 is too long to be fully covered here, so do not miss the official documentation for full detail. Also keep in mind that Android 11 development is not completed yet and Google plans to share new preview versions over the coming months.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

NGINX announced the release of versions 1.13 and 1.14 of NGINX Unit, its open-source web and application server. These releases include support for reverse proxying and address-based routing by both the connected client’s IP address and the target address of the request.
NGINX Unit is able to run web applications in multiple language versions simultaneously. Languages supported include Go, Perl, PHP, Python, Node.JS, Java, and Ruby. The server does not rely on a static configuration file, instead allowing for configuration via a REST API using JSON. Configuration is stored in memory allowing for changes to happen without a restart.
With these latest releases, NGINX Unit now offers support for reverse proxying. A reverse proxy sits in front of the web servers and forwards client requests to those servers. The new proxy option has been added to the general routing framework and allows for proxying of requests to a specified address. At this time, the proxy address configuration has support for IPv4, IPv6, and Unix socket addresses.
For example, the routes object below will proxy the request to 127.0.0.1:8000 in the event that the incoming request matches the match condition:
{
"routes": [
{
"match": {
"host": "v1.example.com"
},
"action": {
"proxy": "http://127.0.0.1:8000"
}
}
]
}
The proxy option joins the previously added pass and share actions for deciding how to route traffic. The pass option, added in version 1.8.0, allows for internal routing of traffic by either passing requests to an application or a route. Internal routing is beneficial in cases where certain requests should be handled by separate applications, such as incorrect requests being passed off to a seperate application for handling to minimize impact on the main application.
The share action, added in version 1.11.0, allows for the sharing of static files. This includes support for encoded symbols in URIs, a number of built-in MiME types, and the ability to add additional types.
Address based routing was added with the 1.14 release. It enables address matching against two new match options: source and destination. The source match option allows for matching based on the connected client’s IP address, while the destination option matches the target address of the request.
Also with this release, the routing engine can now match address values against IPv4- and IPv6-based patterns and arrays of patterns. These patterns can be wildcards with port numbers, exact addresses, or CIDR notation. In the example below, requests with a source an address that matches the CIDR notation will provide access to the resources within the share path.
{
"routes": [
{
"match": {
"source": [
"10.0.0.0/8",
"10.0.0.0/7:1000",
"10.0.0.0/32:8080-8090"
]
},
"action": {
"share": "/www/data/static/"
}
}
]
}
If the /www/data/static/ directory has the following structure:
/www/data/static/
├── stylesheet.css
├── html
│ └──index.html
└── js files
└──page.js
Then a request such as curl 10.0.0.168:1000/html/index.html will serve the index.html file.
Artem Konev, Senior Technical Writer for F5 Networks, indicates that future releases of NGINX Unit should include round-robin load balancing, rootfs support to further enhance application isolation, improved logic for handling static assets, and memory performance improvements.
NGINX Unit is available for download on GitHub. Support for NGINX Unit is provided with NGINX Plus. For more details on changes in the release, please review the NGINX Unit changelog.
MMS • Uday Tatiraju
Article originally posted on InfoQ. Visit InfoQ

Github shipped an updated version of good first issues feature which uses a combination of both a machine learning (ML) model that identifies easy issues, and a hand curated list of issues that have been labeled “easy” by project maintainers. New and seasoned open source contributors can use this feature to find and tackle easy issues in a project.
In order to eliminate the challenging and tedious task of labelling and building a training set for a supervised ML model, Github has opted to use a weakly supervised model. The process starts by automatically inferring labels for hundreds of thousands of candidate samples from existing issues across Github repositories. Multiple criteria are used to filter out potentially negative training samples. These criteria include matching against a 300 odd curated list of labels, issues that were closed by a pull request submitted by a new contributor, and issues that were closed by pull requests that had tiny diffs in a single file. Further processing is done to remove duplicate issues and to split the samples into training, validation, and test sets across repositories.
At the moment, Github is using preprocessed issue titles and bodies that are one-hot encoded as features to train the model. TensorFlow framework was chosen to implement the model. The common practise of regularization along with additional text data augmentation and early stopping techniques are used to train the model.
To rank and present good first issues to the user, the model is run to classify all open issues. If the probability score of the classifier for an issue is above a designated threshold, the issue, along with its probability score, is added to the bucket of issues slated for recommendation. Next, all open issues with labels that match any of the curated list of labels are inserted to the same bucket. These label based issues are assigned higher scores. Finally, all issues in the bucket are ranked based on their scores with a penalty based on issue age.
Currently, Github trains the model and runs inference on open issues offline. The machine learning pipeline is scheduled and managed using Argo workflows.
Compared to the first release of good first issues feature back in May 2019, Github saw the percent of recommended repositories that have easy issues increase from 40 percent to 70 percent. Moreover, the burden on project maintainers to triage and label open issues has been reduced.
In the future, Github plans to improve the issue recommendations by iterating on the training data and the ML model. In addition, project maintainers will be provided with an interface to enable or remove machine learning based recommendations.
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ
Endre Simo, senior software developer and open-source contributor to a few popular image-processing projects, ported the Pigo face-detection library from Go to browsers with WebAssembly. The port illustrates the performance potential of WebAssembly today to run heavy-weight desktop applications in a browser context. InfoQ interviewed Simo on the benefits of the port and the technical challenges encountered. Answers have been edited for clarity.
InfoQ: You have authored or contributed to a number of open-source projects, mostly tackling image processing and image generation problems. Triangle, for instance, for the most artistic people among developers, takes an image and converts it to computer-generated art using Delaunay triangulation. Caire resizes images in a way that respects the main content of the image.
 |
 |
What brought you to machine learning and live face detection?
Endre Simo: I have a long-time interest in face detection and optical flow in general, which, in turn, awoke a researcher and data-analyst side in me. Because in the last couple of years I was pretty much involved in image processing, computer vision and all this sort of things and since I am also an active contributor in the Go community, I thought that it was the proper time to undertake a project bringing about something which the Go programmers were really missing: a very lightweight, platform-agnostic, pure Go face-detection library, which does not require any third-party dependency. At the time when I started to think about the idea of developing a face-detection library in Go, the only existing library for face-detection and optical flow targeting the Go language was GoCV, a Go (C++) binding for OpenCV, but many can acknowledge that working with OpenCV is sometimes daunting, since it requires a lot of dependencies and there are major differences between versions which could break existing code.
InfoQ: BSD-licensed OpenCV also provides facial recognition capabilities and wrappers for a number of other languages, including JavaScript. What drove you to write Pigo, what features does it provide and what differentiates it from OpenCV?
Simo: First of all, I do not really like wrappers or bindings around an existing library, even though it might help in some circumstances to interoperate with some low-level code (like C for example) without the need to reimplement the code base in the targeted language. Let me explain why:
- first of all it forces you to dig deeper into the library own architecture in order to transpose it to the desired language and
- second, which is more important, it costs you with slower build times since it needs to transpose a C code to the targeted language. Not to mention that the deployment is getting way more complicated and you can forget about a single static binary file like it is the case with the Go binaries.
So the major takeaway in my decision to start working on a simple computer vision library suitable specifically for face-detection was the huge time needed by GoCV at the first compilation. The Pigo face-detection library (which by the way is based on the Object Detection with Pixel Intensity Comparisons Organized in Decision Trees paper) is very lightweight, it has zero dependencies, exposes a very simple and elegant API, and more importantly is very fast, since there is no need for image preprocessing prior to detection. One of the most important features of Go is the generation of cross-build executables. Being a library 100% developed in Go thus means that it is very easy to upload the binary file to small platforms like Raspberry Pi, where space constraints are important. This is not the case with OpenCV (GoCV) which requires a lot of resources and produces slower build times.
In terms of features it might not cover all the functionalities of OpenCV since the latter is a huge library with a big amount of functions included for numerical analysis and geometrical transformations, but Pigo does very well what it has been purposed to, i.e. detecting faces. The first version of the library could only do face detection but during the development new features have been added like pupils/eyes detection and facial landmark points detection. My desire is to develop it even further and have it do gesture recognition. This will be a major takeaway and also a heavy task since it implies to work with pre-trained data adapted to the binary data structure required by the library, or to put it otherwise to train a data set which is adaptable to the data structure of a binary cascade classification.
InfoQ: Why porting Pigo to WebAssembly?
Simo: The idea of porting Pigo to WebAssembly originated from the simple fact that the Go ecosystem has missing terribly a well-founded and generally available library for accessing the webcam. The only library I found targeted the Linux environment only, which obviously was not an option. So in order to prove the library real-time face-detection capabilities, I opted to create the demos in Python and communicate with the Go code (the detection part has been written in Go) through shared object (.so) libraries. I did not obtain the desired results, the frame rates were pretty bad, so I thought that I will try integrating/porting to WebAssembly.
InfoQ: Can you tell us about the process and technical challenges of porting Pigo to WebAssembly? How easy is it to port a Go program to Wasm?
Simo: Porting Pigo to WebAssembly was a delightful experience. The implementation went smoothly without any major drawbacks. This is probably due to the well written
syscall/jsGo API. Possibly, the only thing which you need to be aware if you are working with thesyscallAPI is that the JavaScript callback functions should always be invoked inside a goroutine, otherwise you are getting a deadlock. However, if you have enough experience with Go’s concurrency mechanism, that shouldn’t pose any problems. Another aspect is related to how you should invoke the Javascript functions as Go functions, since thesyscall/jspackage has been developed I think having the Javascript coder in mind. In the end, this is only a matter of acquaintance.
Another important aspect a Wasm integrator should keep in mind is that as WebAssembly runs in the browser, it is no longer possible to access a file from the persistent storage. This means that the only option for accessing the files required by an application is through somehttpcalls supported by the JavaScript language, like thefetchmethod. This can be considered a drawback since it imposes some kind of limitations. First, you need to have an internet connection for accessing some external assets. Second, it could introduce some latency between the request and response. It is much faster to access a file located on the running system than to access a file through a web connection. This can pose noticeable problems (memory consumption in particular) when you have to deal with a lot of external assets: either you load all the assets prior to running the application, or you need to fetch the new assets on the fly – which can suspend the application ocasionally.
InfoQ: What performance improvements did you notice, if any?
Simo: The Wasm integration has proved that the library is capable of real-time face detection. The registered time frames were well above 50 FPS, which was not the case with the Python integration. I notified some small drops in FPS when I enabled the facial landmark points detection functions, but this is somehow obvious since it needs to run the same detection algorithm over the 15 facial points in total.
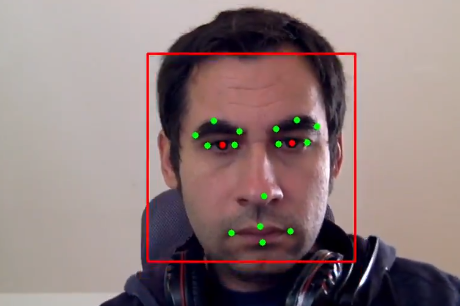
[Example of facial landmarks detection as performed by Pigo]
InfoQ: You now have face detection running in the browser. How do you see that being used in connection with other web applications?
Simo: Running a non-JavaScript face detection library in the web browser gives you a lot of satisfaction not because it is running in the browser, since there are many other face-detection libraries targeting the Javascript language, but because you know that it was specifically designed for the Go community. That means someone familiar with the Go language can pick up the implementation details and understand the API more easily. The Wasm port of the library is a proof of concept that Go libraries could be easily transposed to WebAssembly. I see a tremendous potential in this port because it opens the door to a lot of creative development. Furthermore, I’ve presented a few possible use cases as Python demos (I might transpose them to Wasm at some time), for example a Snapchat-like face masquerade, face blurring, blink and talk detection, face triangulation etc. I have also integrated it into Caire, where it has been used to avoid face deformation on images with dense content. With the face detection activated, the algorithm tries to avoid cropping the pixels inside the detected faces, retaining the face zone unaltered.
InfoQ: How long did it take you to have a working wasm port? Did you enjoy the experience? Do you encourage developers to target WebAssembly today or do you assess that it wiser to wait for the technology to mature (in bundle size, features, tooling, ecosystem, etc.)?
Simo: Since I worked on the Wasm implementation part-time, I haven’t really counted how many hours it took to have a working solution, but it went pretty smooth. I really encourage developers to target WebAssembly because it has a great potential and it’s getting to have a wide adoption among many programmers. Many languages already offer support for WebAssembly, so I think it will have a bright feature in the following years, considering that WASI (WebAssembly System Interface) which is a subgroup of Wasm is also getting the interest of systems programmers.
MMS • Brittany Postnikoff
Article originally posted on InfoQ. Visit InfoQ

In this podcast, Daniel Bryant sat down with Brittany Postnikoff, a computer systems analyst specialising on the topics of robotics, embedded systems, and human-robot interaction. Topics discussed included: the rise of robotics and human-robot interaction within modern life, the security and privacy risks of robots used within this context, and the potential for robots to be used to socially engineer people.
Key Takeaways
- Physical robots are becoming increasingly common in everyday life, for example, offering directions in airports, cleaning the floor in peoples’ homes, and acting as toys for children.
- People often imbue these robots with human qualities, and they trust the authority granted to a robot.
- Social engineering can involve the psychological manipulation of people into performing actions or divulging confidential information. This can be stereotyped by the traditional “con”.
- As people are interacting with robots in a more human-like way, this can mean that robots can be used for social engineering.
- A key takeaway for creators of robots and the associated software is the need to develop a deeper awareness of security and privacy issues.
- Software included within robots should be patched to the latest version, and any data that is being stored or transmitted should be encrypted.
- Creators should also take care when thinking about the human-robot UX, and explore the potential for unintended consequences if the robot is co-opted into doing bad things.
Subscribe on:
Show Notes
Could you introduce yourself? –
- 01:05 My name is Brittany Postnikoff, or Straithe on Twitter
- 01:10 My current work is researching whether robots can social-engineer people, how they can do it, and what sort of defences we can put in place against those attacks.
Could you provide an overview of your “Robot social engineering” QCon New York 2019 talk? –
- 01:35 Some of the key themes of the talk include talking about how people interact with robots on a social level.
- 01:45 A lot of the research that has been done on human-robots interactions are things like robots holding authority over people, especially if the robot looks to have been given authority.
- 02:05 For example, when we do experiments, there’s usually a researcher in the room, and you generally trust the researcher.
- 02:15 What would happen is the researcher that would explain that the robot is going to say how the work needs to be performed, and the participant needs to listen.
- 02:30 In that case, the researcher is delegating authority to the robot, and people will interact with it appropriately.
- 02:40 I also talked about empathy for robots, whether they can bribe humans and similar experiments.
- 02:55 I introduced social engineering, and talked about robot social engineering attacks that I can see happening soon.
Robots are becoming prevalent within our society – can you give any examples? –
- 03:10 The robots in my talk are very much physical robots – nothing like a Twitter bot that you might interact with.
- 03:20 Roombas are usually the base case when I’m talking about robot social engineering.
- 03:25 There are also robots in airports that help navigating between gates.
- 03:40 There are robots in stores helping to sell things; one called Pepper that helps sells cellphones in malls.
Can you share how security, privacy and ethics differ in the domain of robotics? –
- 04:00 One of my favourite phrases: bugs and vulnerabilities become walking, talking vulnerabilities.
- 04:15 The aspect of physical embodiment that makes the domain of robotics interesting.
- 04:25 If you have a camera or microphone in one of your rooms, and you want to have a private conversation that’s not listened to by Amazon or Google, you might go to another room.
- 04:40 If you have a robot, and a malicious actor has worked their way into that robot, then it could follow you to a new room – all of a sudden there’s new privacy and security issues.
- 04:50 If a malicious person can get into your robot, they have eyes and ears into your home in places that they shouldn’t.
- 05:00 Having a camera that can move into a child’s room or bedroom – you might not notice it if it’s your robot and you’re used to it moving around all the time.
- 05:10 People don’t understand that when a malicious actor takes over your robot, it’s usually indistinguishable from when the robot is acting on its own.
How can we encourage engineers to think about security and privacy when they are designing these kinds of systems? –
- 05:30 I think a big part of it is awareness, which is why I like giving this talk and exposing people to this topic.
- 05:40 If you don’t know that certain attacks can happen, or certain design decisions make these kind of attacks more likely, why would you defend against it?
- 05:50 Building a culture of more security and privacy is something I try and do with these talks.
Are blackbox ML and AI algorithms helping or hindering what’s going on in robotics? –
- 06:20 My research typically avoids things ML and AI, because when you do social robotics work, there’s a concept called Wizard-of-Oz-ing.
- 06:30 It’s like in the movie, when you don’t know until the last moment that (spoiler alert) there’s a man behind the curtain controlling everything.
- 06:40 We use that in research as well, because it’s been shown that people can’t tell the difference between an autonomous robot that is acting on its own, and one that is being controlled by someone.
- 06:55 The important part of my research is the physicality of the robots, so how they gesture or look at people.
- 07:05 If it’s two feet tall, do you interact with it differently if it’s six feet tall?
- 07:10 So we spoof the ML and AI because results show they’ll interact with it the same way whether someone is controlling it or not if they perceive the robot to be capable of interacting on its own.
Can you introduce the topics of social engineering? –
- 07:40 It is a term that is used by the security community, but other terms that people might be familiar with are things like scams, conmen etc.
- 07:55 One of my favourite examples is from the early 2000s, when there was a gentleman who bought large amounts of cheap wine and rebottled it as more expensive types of wine (or relabelled it).
- 08:30 He did the rebottling, but it wasn’t enough – he had to convince people that the wine he had was worth buying.
- 08:45 He had tailor-made suits and fancy cars – he lived the lifestyle of someone who would own expensive bottles of wine – and had a background story prepared.
- 09:10 All that blends into one technique called ‘pretexting’ – there’s information gathering, knowing what you want to talk about, and why.
- 09:30 A lot of it is interpersonal playing on people’s cognitive dissonance between what they expect and what is real.
- 09:40 People often suspend their disbelief if people are believable.
How can robots be used for social engineering? –
- 09:50 Robots have different social abilities that they can use; empathy, authority, bribing, building a trust relationship, and these are a lot of the same things used in social engineering.
- 10:05 Robots can use these techniques is the same way.
- 10:10 We had robots build rapport with people, build a story about how the robot really liked working in the lab but was feeling sick lately and have a virus.
- 10:30 If you watch the video you can see the participants having empathy towards the robot and how bad they felt for it when it was sick.
- 10:40 The robot would say things like: “the experimenters are going to come and reset me – oh no!” and because it was an experiment, the researchers would do that.
- 10:50 People were visibility upset when that happen.
- 10:55 This is the kind of scammers rely on when there’s been a big disaster; con people will be asking for donations to this charity or saying that they’ve lost their home.
- 11:05 There have been experiments where robots have been pan-handling to get money – and people were thinking that the robot needs a home too.
- 11:15 It’s amazing how similar we are treating robots who are able to move as similar to humans.
- 11:20 My goal for the next few years is to try and recreate social engineering experiments but with robots instead.
How do engineers in general mitigate some of the risks you have mentioned? –
- 11:50 You can put security on the robots.
- 11:55 A lot of the robots I have interacted with have had dismal security.
- 12:05 The server software is from 2008, a beta version, has had no updates – and there’s dozens of open CVEs on it – and they are broken when you buy the robot.
- 12:20 That’s something to think about – make sure you can update the software, and someone is checking the security of robots in their home.
- 12:35 One robot I was playing with has a very usable portal when you go to the robot’s web server.
- 12:45 A lot of the robots have their own servers on them.
- 12:50 You can log in, but a lot of people don’t change the default password, so it is easy to get in.
- 12:55 It was easy for me to get in and make the robot do dangerous things.
- 13:00 It’s important to let users know or help them do proper set up.
- 13:10 Engineers could develop processes for people to do the proper set up and change passwords.
What can I do, as a user, to educate myself on these risks? –
- 13:30 Awareness is a good place to start; For example, I like to put my Roomba in a closet when it’s done.
- 13:35 That way, if someone was able to get control of it, they couldn’t do much because it was in a closet.
- 13:40 A lot of Roomba-like robots are now being sold as home guards, and they have 1080 HD cameras on them, and see if anyone is home or when they were there last.
- 14:00 If you have vacations on public calendars in your home, and a controlled robot can see that – it’s a great time to case your home.
- 14:15 By putting the robot in a closet, at least you are protecting yourself from some of those things.
- 14:20 It’s always a good step to reset passwords for all of your devices when you get something new.
- 14:25 Trying to run updates whenever you can is also a good idea.
- 14:30 Specifically when it comes to robot social engineering, if the robot is in your space, there are things you can do to contain it.
- 14:40 If the robot is in a public space, it’s not great to try and contain it because you can get in trouble for messing with someone else’s property.
- 14:50 If you have robots wandering around taking pictures of people’s faces or number-plates, people can be uncomfortable with that.
- 15:00 Having a way to obscure your face can be useful too.
What is the state of interaction between academia and industry? –
- 15:15 As far as I know, I am one of two people in the world looking at this topic, and the first to actively write about joining social engineering and robots together that I can find.
- 15:30 There are small overlaps with other places because this is so inter-disciplinary; academia and industry are doing well on collaboration and interacting with robots.
- 15:45 Interaction between robots has been adopted by industry and is being researched by academia – that space is going well.
- 15:50 Security and robots in general are going quite well – companies are showing up and presenting at conferences, so there is overlap between those spaces.
- 16:05 I haven’t seen as much overlap between academia and industry; I’ve tried to talk to some companies, and they’re not as concerned with things that may happen.
- 16:15 I think it will take an act of attack for things to happen before people start paying attention.
- 16:25 When it comes to robot social engineering specifically, it’s a very new space and I’m looking forward to seeing what will happen.
- 17:05 Because my topic is so inter-disciplinary, there are different groups who have different thoughts about how it should be done.
- 17:15 I feel that it makes my research stronger, because there are so many differing opinions and lack of understanding between groups.
- 17:25 I see my research as being an opportunity to be able to bring multiple groups together and give a nexus to talk in social situations that we otherwise might not have.
What do you think the future is for robotics and software engineering from a sci-fi perspective? –
- 18:00 I don’t think it has to be either software or hardware driven.
- 18:05 That’s one thing that usually gets me in sci-fi; there’s usually only focus on one technology where multiple vulnerabilities probably exist in the same space.
- 18:15 Star wars does it well; you have multiple different types of robots, throughout the whole franchise, who do a variety of different things.
- 18:25 If you look at C3P0, he’s pretty terrible at walking but is very smart.
- 18:30 Then you have R2D2, who doesn’t talk much – there’s some inflection in the voice which gives personality but his communication skills aren’t on the same par as C3P0.
- 18:45 R2D2 is great for flying around in space, using tools specifically.
- 18:55 Then you have some of the newer robots which are fantastic ninja fighters, which are obviously very good at movement, so I think Star Wars has that flexibility.
- 19:05 At the same time, there’s so many different formats for sharing information and processing data, in the Star Wars universe too.
- 19:15 When you think about Matrix, Snowcrash, Westworld, iRobot – there’s probably examples from each one of those things that we’re going to go towards in the future.
- 19:30 That’s one way that industry affects academia is that there’s so much effort people put in to create their robots that they grew up with in movies and make them real.
- 19:45 Star Trek has inspired so much technology since its initial release; it’s a feedback loop, for sure, where our imagination inspires what’s happening in tech.
What’s the best way to learn more about robotics or your topic? –
- 20:15 A lot of what I do is social robots, and less about robotics – if you had me in a room with a lot of roboticists, we wouldn’t have much to talk about other than design of outward appearance.
- 20:30 For hard robotics, it’s a lot of maths – so taking a lot of maths classes; learning how to use ROS, the Robot Operating System; getting experienced with hardware boards.
- 20:45 There’s a lot of books by “No Starch Press” which would help there.
- 20:50 Going to conferences and attending different workshops is helpful too – there’s a few conferences I go to that have workshops that bring you up to base level.
- 21:00 For university courses, trying a human computer interaction course is very helpful because it teaches you how people interact with machines like phones.
- 21:15 A lot of those principles can also be applied to robots.
- 21:20 I would recommend a robotics course if you wanted to get into physical and electrical robot design.
- 21:35 For human computer interaction there’s only a few schools that offer those courses, so choose one of them.
- 21:40 I always recommend an ethics course – take as many of these as you can.
What’s the best way to follow your work? –
About QCon
QCon is a practitioner-driven conference designed for technical team leads, architects, and project managers who influence software innovation in their teams. QCon takes place 8 times per year in London, New York, Munich, San Francisco, Sao Paolo, Beijing, Guangzhou & Shanghai. QCon London is at its 14th Edition and will take place Mar 2-5, 2020. 140+ expert practitioner speakers, 1600+ attendees and 18 tracks will cover topics driving the evolution of software development today. Visit qconlondon.com to get more details.
More about our podcasts
You can keep up-to-date with the podcasts via our RSS Feed, and they are available via SoundCloud, Apple Podcasts, Spotify, Overcast and the Google Podcast. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
MMS • Helen Beal
Article originally posted on InfoQ. Visit InfoQ

Algorithmia, an AI model management automation platform for data scientists and machine learning (ML) engineers, now integrates with GitHub.
The new integration integrates machine learning initiatives into organisations’s DevOps lifecycles. Users can access centralised code repository capabilities such as portability, compliance and security. The integration follows DevOps best practices for managing machine learning models in production with the goal of shortening time-to-value for data science initiatives.
Algorithmia’s company history began with an AI algorithm marketplace for data scientists and ML engineers to find and share pre-trained models and utility functions. Launched in 2017, the Algorithmia platform uses a serverless AI layer for scaled deployment of machine and deep learning models. There is also an enterprise offering for those wanting to deploy, iterate, and scale their models on their own stack or Algorithmia’s managed cloud.
GitHub brings together a developers community to discover, share and build software and is a major repository for software developers and data science teams. By integrating with GitHub, Algorithmia enables data science deployment processes to follow the same software development lifecycle (SDLC) organisations already use, via an integration. With this Algorithmia-GitHub integration, users can store their code on GitHub and deploy it directly to Algorithmia and Algorithmia Enterprise. This means that teams working on ML can participate in their organisation’s software development lifecycle (SDLC) and multiple users can contribute and collaborate on a centralised code base, ensuring code quality with best practices like code reviews through pull requests and issue tracking. Users can also take advantage of GitHub’s governance applications around dependency management to reduce the risk of their models utilising package versions with deprecated features.
InfoQ asked Algorithmia CEO, Diego Oppenheimer to tell us more about the new integration.
InfoQ: Why are teams increasingly looking to machine learning as part of their applications?
Oppenheimer: As enterprises accumulate vast amounts of data, the ability to manually process it rapidly becomes infeasible. The rate at which machine learning models can produce actionable outputs is exponentially greater than traditional applications. A healthy elastic machine learning lifecycle requires little overhead, which could cut down on expensive headcount. As companies grow in size, workflow can become siloed (across departments, offices, continents, etc). A centralised ML repository helps with cross-company alignment. As a use case example: Instantaneous customer service or product function is a requisite for any business. If a customer has a negative experience, they are unlikely to continue doing business with you. To that end, ML opens doors to instantaneous, repeatable, scalable service features to ensure positive customer experience, and models can iterate quickly, meaning improvements can happen in far less time than going through a traditional review and update process.
InfoQ: Why would people want to use Algorithmia?
Oppenheimer: Algorithmia seeks to empower every organisation to achieve its full potential through the use of AI and machine learning. Algorithmia focuses on ML model deployment, serving, and management elements of the ML lifecycle. Users can connect any of their data sources, orchestration engines, and step functions to deploy their models from all major frameworks, languages, platforms, and tools. Algorithmia Enterprise offers custom, centralised model repositories for all stages of the MLOps and management lifecycle, enabling data management, ML deployment, model management, and operations teams to work concurrently on the same project without affecting business operations. Data scientists are not DevOps experts, and DevOps engineers are not data scientists. Time is wasted when a data scientist is tasked to build and manage complex infrastructure, make crucial decisions on how to scale ML deployments efficiently and securely, and all without incurring excessive costs. Algorithmia Enterprise customers don’t have to worry about wasting resources getting to deployment. We make it easy for both teams to work together.
InfoQ: Do you see data scientists and ML engineers regularly embedded into product teams? Or are software engineers in these teams upskilling to these roles?
Oppenheimer: The short answer is yes, data scientists and ML engineers are regularly embedded into product teams, though the configuration of teams is still in early stages so it’s not yet a definitive migratory pattern. The most successful ML teams are ones directly tied to a product or business unit because of how direct the impact can be. We see more and more centres of excellence in data science and ML in which ML teams are assigned to a product for a period of time to develop capabilities.
InfoQ: Will you also be announcing a GitLab integration?
Oppenheimer: Algorithmia’s source code management (SCM) system provides flexibility and options for ML practitioners. We have created a flexible architecture that allows for the integration of other SCMs in the future. Our latest integration with GitHub opens doors for a lot of models sitting in GitHub repositories to go directly into production. Algorithmia will be releasing other integrations in upcoming product releases.
InfoQ: What are the most common ML patterns you see today?
Oppenheimer: Data science teams are rapidly growing across all industries as companies rush to get ahead of the AI/ML curve. Top business use cases for machine learning are models to reduce costs, models to generate customer insights, and models that improve customer experience. Most ML-minded companies are within the first year of model development and only 9 percent of organisations rate themselves as having sophisticated ML programs. Half of companies doing ML spend between 8 and 90 days deploying one model. For companies with tens or hundreds of models, this timeline can drastically delay ROI. The biggest challenges reported during ML development are with scaling models up, model versioning and reproducibility, and getting organisational alignment on end goals. AI and ML budgets are growing across all industries, with financial services, manufacturing, and IT leading the charge of increasing their budgets by 26-50 percent. Determining what constitutes ML success varies by job role. Executives and C-level directors deem a return on investment the key success indicator according to our latest State of Enterprise Machine Learning Report.
InfoQ: Are there any particular industries that are leading adoption in this space?
Oppenheimer: We see ML growth across all industries, with ML market growth from $7.3bn in 2020 to $30.6bn in 2024 [43% CAGR] according to Forbes. However, the financial, manufacturing, and IT sectors do seem to be leading the way with increased budgets, well-defined use cases, and models in deployment.
InfoQ: What is your vision for your company in the next 12 to 24 months?
Oppenheimer: Algorithmia is focused on enabling organisations to take advantage of ML and AI to improve their businesses. AI is the most significant technological advancement in our lifetime and it will quickly become a core part of almost every business in the same way that the internet played a huge transformational role since their inception. Our organisation is focused on solving the last mile to delivering these capabilities to line-of-business applications in a scalable and manageable way. Integration with current organisational software development lifecycles and IT infrastructure is key so we will continue building and delivering flexibility at the pace that technology is advancing. We aim to partner with data science, DevOps, product, and executive team to reduce the time to market and allow them to create a competitive advantage with their ML investments.
The GitHub integration is now available to algorithmia.com public users and for existing Algorithmia Enterprise customers. The 2020 State of Enterprise Machine Learning Report is available here.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcripts
Vidstedt: I’m Mikael Vidstedt. I work for Oracle, and I run the JVM team, and I’ve been working with JVMs my whole career.
Stoodley: I’m Mark Stoodley, I work for IBM. I am also the project lead for Eclipse OpenJ9, which is another open-source Java virtual machine. I’ve also spent my whole career working on JVMs, but primarily in the JIT compiler area.
Tene: I’m Gil Tene. I’m the CTO at Azul Systems, where we make Zing and Zulu, which are JVMs. I have been working on JVMs, not for my whole career, just the last 19 years.
Kumar: I’m Anil Kumar from Intel Corporation. I can say I’ve been working at on the JVMs for the last 17 or 18 years, but not in the way these guys on the left side are talking. I’m more in showcasing how good they are. I also chair the committee at SPEC which made the OSGjava benchmark. If you heard about SPECjbb2005, SPECjbb2015, SPECjvm, SPECjEnterprise, they all had come out of the company Monica [Beckwith] and I have worked on. Anything related to how to improve these benchmarks better, how you can use them or what issue you see, perfectly happy to answer those things. We are working on a new one, so if you have any suggestions…
Kuksenko: I am Sergey Kuksenko. I am from Oracle, from Java performance team. My job is making Java JDK, JVM, whatever is faster, probably for the last 15 years.
GC and C4
Moderator: One of the things that we have in common in this panel is startup and JVM futures and responsiveness. Everybody has contributed in some way or form to improving the responsiveness of your application if it runs on the JVM. If you have any questions in that field, with respect to, say, futures, then I think talking to Mark [Stoodley] about that would be a good option, or you can just start talking to Gil [Tene] as well, where he can tell you everything about LTS, MTS, and anything in between. There’s an interesting thing that I wanted to mention about ZGC and as well as C4. Maybe you want to talk about C4. Do you want to start talking about C4 and how it changed the landscape for garbage collectors?
Tene: I did a talk yesterday about garbage collection in general. I’ve been doing talks about garbage collection for almost 10 years now. The talk I did yesterday was actually a sponsored talk, but I like to put just educational stuff in those talks too. I used to do a GC talk that was very popular. I stopped doing it four or five years ago, because I got sick of doing it, because it’s the only talk anybody wanted me to do. The way the talk started is I was trying to explain to the world what C4 is, and it turned out that you needed to educate people on what GC is and how it works. We basically ended up with a one-hour introduction to GC, and that’s popular. What I really like in the updated thing is, when I went back and looked at what I used to talk about and how we talk about it now, I used to explain how GCs work right now and how this cool, different way of doing it that’s solving new problems, that is needed, which is C4 and Zing, does its thing and how it’s very different and how I’m surprised we were the only ones doing it.
Yesterday I was able to segment the talk differently and talk about the legacy collectors that still stopped the world and the fact that all future collectors in Java are going to be concurrent compacting collectors. There are three different implementations racing for that crown now. I expect there to be three more, probably. I wouldn’t be surprised if there’s a lot of academic thing. There’s finally a recognition that concurrent compaction is the only way forward for Java to keep actually having the same GC in the next decade. It should have been for this decade, but I’ll take next decade. C4 probably is the first real one that did that. We’ve been shipping it for nine years. We did a full academic peer review paper on it in 2011. It is a fundamental algorithm for how to do it, but there’s probably 10 other ways to skin the cat. The cat is concurrent compaction. Everybody needs to skin it.
Vidstedt: I think you’re absolutely right. I think the insight has been that, for the longest time, throughput was basically the metric. That’s what we wanted Java to be really fast on the throughput side, and then, maybe 10, 15 years ago was when we started realizing that, “Yes, we’ve done a lot of that.” It’s not like we can sit back and just relax and not work on it, but I will say that the obvious next step there was to make everything concurrent and get those pause-times down to zero. Yes, lots of cool stuff happening in that area.
Stoodley: That’s actually a broader trend, I think, across all JVMs. Throughput did use to be the only thing that people really were focused in carrying about. The other metrics like responsiveness, like startup time, like memory footprint, and all of these kinds of metrics are all now coming to the floor, and everybody’s carrying about a lot of different things. It introduces a lot of interesting challenges in JVMs, and how do you balance what you do against all of those metrics, how do you understand, how do you capture what it is that the person running a Java application wants from their JVM in terms of footprint, in terms of startup, in terms of throughput, in terms of responsiveness, etc. It’s a very interesting time to be a JVM developer, I think.
Tene: I think the reason you’ve heard how many years we’re all at it is because it’s very interesting to work on JVMs.
Different Implementations of Compacting Concurrent Collectors
Participant 1: In the same way that the legacy collectors let your split and try it off between latency and throughput, I was curious see what the panel thinks about the different implementations of compacting concurrent collectors these days and how you would say they’re differentiating themselves in their runtime profiles? For a little bit of context, I’ve been using Java for 20 years. I haven’t been on the JVM side. I’ve been on the other side. I’ve been causing problems for you guys for 20 years. By the way, not everyone’s just interested in the GC talks. We did coordinate in the mission talks. That was remarkable. I was just curious to see if you could reflect on that, how do you see the different collectors differentiating themselves in that low cost, time, low latency space.
Tene: It’s hard to tell you. I think they’re still very evolving, and where they were aligned and whether there will differentiation on throughput versus responsiveness is still a question. I think there are multiple possible implementations that all could be good at both latency and throughput, that all myth about you have to trade them off, it’s false. There’s simple math that shows a concurrent collector will beat a stop-the-world collector on efficiency. There is no trade-off. Forget about the trade-off. There are implementation choices and focuses, for example, memory elasticity, focusing on small footprint versus large, is fragmentation a problem or not, which battles do you want to pick and compare it. We might find that there’s some rounded way of handling all of them, or maybe there’s specialization. I think there’s a lot for us to learn going forward.
For example, for us, with Zing, we probably started from the high performance, high throughput, low latency world, and we’ve been slowing coming towards the small. Today, you can run it in containers with a couple cores and a couple gigabytes in it. It’s great. For us, 200-megabyte seems really, really small, like tiny. Then you have these guys, they’re starting there and actually trying to compact from there. Those are very different concerns. I don’t know exactly what line, size of heap, size of footprint, maybe even throughput the crossovers are. They’re not architectural. They’re more about the focus of that implementation. I think that over the next three, four, five years, we’re going to see multiple implementations evolving, and they’ll either have an excellence in one field or wide breadth or whatever it is. Obviously, I think that the one we have now in production is the best, but I fully expect to sit here with a panel of five other guys comparing what we do well.
Stoodley: I would agree with that. I think, for us, it’s still early days. We’re still building out our technologies in this area. There’s still a lot to do just to get to state of the art in the area. There’s lots of interesting things to do, and we’ll see what it looks like when we get there. In the end, how successful we’ll be and whether there will be differentiation is going to come down to people like yourselves asking us questions and showing us examples, giving us things to prove how well it works or how well it doesn’t work. That will drive how well-developed these things are going forward. We need your help.
Realising New Features
Participant 2: Can I ask a follow-up question? When are we going to deprecate or take out CMS and G1 from the options?
Vidstedt: I have good news for you. Eight hours ago, I think, now, approximately, CMS was finally actually removed from the mainline codebase.
Tene: This is for 15 or 14?
Vidstedt: We never promise anything in terms of releases, but this is mainline JDK. The next release that comes out is 14, in March. That much I can say.
Participant 2: [inaudible 00:11:54]
Vidstedt: The reason why I’m hesitating here is that the only time to tell when a feature actually is either shipped or not in the release is when the release has likely been made. We can always change our minds. Basically, I will say that this is unlikely for CMS, but if people come around and say, “Hey, CMS, what’s actually the greatest thing since sliced bread?” On top of that, we’re willing to help maintain it because that’s the challenge for us.
Tene: That one’s the big one. Ok, all you guys, let’s say it great. Are you going to maintain it?
Vidstedt: Exactly. We’re not hesitating that to our use cases where CMS is very great but the fact is that it has a very high maintenance cost associated with it. That’s the reason why we’ve looked at deprecating and now finally removing it. Again, you’ll know on March, whichever day it is, if it’s in 14 or not, but, I’d bet on it not being there.
Tene: The other part of that question was the really interesting one. When are we going to deprecate G1?
Vidstedt: I think this is back to how things are evolving over time. What I know about myself is that I’m lousy in predicting the future. What we typically do is we listen to people that come around, and they say “We have this product and it’s not working as well as we want it to,” be it that on the throughput side or on the pause-time side, or I’m not as efficient as I could, or footprint, as Gil [Tene] mentioned. All of those things, those help drive us. We make educated guesses, obviously, but in the end, we do need the help from you figuring out what the next steps really are. G1 may, at some point, well be deprecated. I’m actually hoping that it will be, because that means that we’re innovating and creating new things. Much like CMS was brilliant when it was introduced 20 years ago or so, it has served its purpose, and now we’re looking into the future.
Tene: Let me make a prediction, and then we’ll look at the recording in the future. I want people to remember that yes, I’m that Zing guy and C4 and all that, but we also make Zulu, which is straight OpenJDK with all the collectors that are in it, including CMS that’s about to go away. I think G1 is a fine collector in Zulu. It’s probably the best collector in the Zulu thing, especially in Java 11 and above, as you’ve said. I think it’s around for a while. If I had to predict, I think we’ll see maturation of the concurrent compacting collector that can handle throughput with full generational capability in OpenJDK somewhere in the next three to five years to a point where it handles the stuff, it’s not experimental, maybe not default yet but can take it. At that point, you’re going to have this overlap period between that and existing default one, which is G1. I think that will last for another five-plus years, at least, before any kind of deprecation. If I had to guess, G1’s not going away for at least a decade, probably 15 years. If it goes away in 15 years, we’ll have really good things to replace it with.
Vidstedt: Exactly. Thanks for saying that. We try to be at least very responsible when it comes to deprecating and removing things, because we, again, realize that old things have value in their respective context, let’s say. CMS, for example, I remember the first time I mentioned that we were going to deprecate it. It was back in 2011 at JavaOne. I know that people had been talking about it before, but that was the first time I told people in public. Then we actually deprecated it in, I want to say 2000-something, a few years ago. We’ve given people some amount of, at least, heads up that it’s going away. We like to think that the G1 collector is a good replacement, and there are other alternatives coming as well. We do spend significant time on removing things. We realized that that comes with a cost as well.
Stoodley: Interestingly, in OpenJ9, we have not been removing collectors so much. We do have some legacy collectors that are from 15 years ago, things called optavgpause, which nobody really believes that it actually does optimize for average pause anymore. Our default collector is a generational concurrent similar to what CMS is, and we’ve kept that. We have a region-based GC. It’s called Balanced. We are working on pause-less GC. The irony is not lost on me that I have to pause while saying pause-less, because it’s very different than saying pauseless. Anyway, we have all of these things. one of the interesting features about OpenJ9 is we build the same source code base into every JDK release. JDK 8, 11, and 13 right now, all have the same version of OpenJ9 in them, in their most recent J9 release. Deprecating some of the things like GC policies are a little bit harder for us, but, on the plus side, it forces us to keep investing in those things and making sure they work really well in providing lots of options for people, depending on what it is that they want from their collector.
Tene: Actually, picking up on what you just said, the same JVM across the releases, we do the same on our Zing product. The same exact JVM is going for Java 7, 8, 9, 11, 13. HotSpot had this at some point. For a very short period of time, it was actually our domain thing, the HotSpot Express release model, which I personally really like. I really liked having a JVM that can be used across multiples. There’s goodness about the cool good things that have worked on for Java 14 bringing speed to Java 11 and that stuff. I would love to see a transition, a way to do that again, and it does have this little “deprecation is harder” problem, but only at the JVM level, not at the class library level. HotSpot Express, I think, was a great idea in the OpenJDK world. I don’t know what you think about it.
Vidstedt: I think there are definitely pros and cons. Obviously, you can get more of the investment and the innovation that is happening in mainline or more recent releases, let’s say, all the way to the old releases as well. What I think we found was that it came into existence at a time where JDKs were not actually being shipped. JDK 7 was effectively stalled for I think it was 5.5 years or something like that. We needed to get the innovation into people’s hands, so, therefore, we had to deliver the JVM into the only existing release at the time, which was JDK 6. Once the JDK started coming more rapidly and more predictively, I’m going to say that the reason for backporting things was less of an issue, let’s say, and also, the cost again of making sure that everything works. There’s a lot of testing and stuff that needs to happen to make sure that the new innovation not only works on the mainline version but on all the other versions in the past as well. There are trade-offs, some are good, are more challenging.
Tene: I would say that the community benefit that I would most put on this is time-to-market for performance improvement. As it stands today, you invest usually in the latest. They just get better. The GCs get better. The runtime gets better, whatever it is. Lots of things get better, but then those better things are only available as people transition and adopt. When we’re able to bring them to the current dominant version, you get a two-year time-to-market improvement. It’s exactly the same thing, but people get to use it for real a couple of years earlier. That’s really, I think, what’s driving us in the product, and probably you guys have been in the same way. I’d love to see the community pipeline do that too, so Java 11 and 13 could benefit from the work on 15 and 17 at the performance side.
Stoodley: It’s also from platform angle too so improvements in platforms. Containers weren’t really a thing when JDK 8 came out, but they become the thing now. If most of the ecosystem is still stuck on JDK 8, as a lot of the stats say, then it forces you to backport a whole bunch of stuff, and it’s extra work to do that backporting in order to bring that support for modern platforms into the place where everyone is. From our perspective, it’s just an easier way to provide that support for modern platforms, modern paradigms that would otherwise have to take a change in API perhaps. You have to jump the modularity bound, the hurdle, or whatever it is that’s holding you back from moving from 8 to 11. That’s getting easier and easier for a variety of reasons, and the advantage of doing that is getting greater and greater. Don’t think that I’m trying to discourage anyone from upgrading to the latest version of the JDK. I want people running all modern stuff. I recognize that it’s a reality for a lot of our customers, certainly from an IBM standpoint and stakeholders from the point of view of our open-source project. It’s just the reality that they’re on JDK 8. If we want to address their immediate requirements, JDK 8 is where you have to deliver it.
Vidstedt: This is not going to be a huge dataset, I guess, but how many people in here have tried something after 8, so 9 and later? For how many did that work?
Participant 3: We’re running 11. We’re running a custom build of 11 in production with an experimental collector. It’s a small sample set, highly biased.
Vidstedt: Ok. Out of curiosity, what happened? Ok, didn’t work.
Tene: Actually, when I look around, I start with that question, “How many have tried,” and then I say, “How many have tried in production?” Ok. How many are in production? Same number, good. How many don’t have aid in production anymore? There you go. That’s a great trend, by the way, because across our customer base for Zulu, for example, which we’ve been tracking for a while. In the last two months, we’ve started seeing people convert their entire production to running on 11. Running on 11 doesn’t mean coding to 11. It means running on 11. Because that’s the first step. I’m very encouraged to see that in real things. We have the first people that are doing that across large deployments, and I think that’s a great sign. Thank you, because you’re the one who makes it good for everybody else, because you end up with a custom build.
Challenges in Migrating
Participant 4: I was just going to share that the challenges for us getting from 8 to 9 was actually the ecosystem. The code didn’t compile, but that was just Java 9’s modules. I completely understand the reason why modules exist. I totally understand the ability to deprecate and removing things. Used it, loved it, many years ago. Can’t believe it’s still in the JDK. Our biggest challenge was literally just getting the module system working from 8 to 9. We couldn’t migrate because the ecosystem wasn’t there. We had to wait for ByteBuddy, for example, to get up on to 9. Going from 9 to 10 and 10 to 11 was literally IntelliJ migrate to the next language version. I have lots of challenges doing that. I tried going from 8 to 11. That was a complete abject failure. It was just so complicated to get there. Went 8 to 9, got everything working on 8 to 9, and then just went 9 to 10 and 10 to 11. 9 to 10, 10 to 11 was like a day’s work, 8 to 9 was about 3 months, because we had to wait for the ecosystem. It was simply not possible, but that was a long time ago.
Tene: I think your experience is probably not going to be the typical, because a lot of the ecosystem took a while, and it went straight to 11. As a result, you won’t have it on 9. There’s a bunch of people that are doing it now rather than when you did it. The 9 and 10 might actually be harder to jumping to 11 because there’s things that only started supporting in 11. For most people, I think we’re going to see a jump straight from 8 to 11. They’re both out there.
Participant 4: Yes, we started our 11 migration basically the day that 11 was out, and we tried to migrate. We’re very early.
Vidstedt: I think what we’re also seeing is that the release cadence that we introduced started with 9, but 10 was obviously the first one that then came out 6 months later. It takes time to go to 9, to some extent. There are a few things that you do need to adjust. ByteBuddy is a good example of that. What I think we saw was that the ecosystem then caught on to the release cadence and realized that there isn’t a whole lot of work moving between releases. As a matter of fact, what we’re seeing more now is that older relevant libraries and frameworks are proactively looking at mainline changes and making sure that once the releases do come out, it may not be the first day, but it’s at least not all that long after the release that they ship support versions. I think it’s going to be easier for people to upgrade going forward, not just because the big change really was between 8 and 9, but also because the libraries are more active in keeping up.
Tene: I like to ask the people for support and voice, and a good example of one that I’d like to voice, please move faster, is Gradle. I really wish Gradle was 13-ready the day 13 came out, and I’ll ask them to do it when 14 comes out so it’ll be ahead of time. Please, wherever it is that you can put your voice to issues and stuff, make it heard.
Efficiency of GCs
Kumar: After one question on the part of you guys talking a lot on the GC side, one of the trend we start seeing is many of them deploying in the container, and the next part, in the interaction with the customer, I’m seeing the use of the function as a service. That use case I wanted to check, is anyone of you here planning to deploy that yet? Because I do see some use. When that will happen, I don’t think right now the GCs are considering that case of just being up 500 milliseconds.
Stoodley: Epsilon GC is built for exactly that use case.
Tene: Don’t do GC, because there’s no point, because we’re going to be deprecating.
Kuksenko: It wasn’t built for that use case, it was a different purpose, but it’s extensively used for that.
Stoodley: It works well there.
Kuksenko: I’d rather say, it doesn’t work well.
Tene: It does nothing, which is exactly what you need to do for 500 milliseconds. It does not work very well, yes.
Kumar: Any thoughts about adding those testing for what GC might be good for function as a service situations? The reason I’m asking this is that 10, 15 years ago, when the Java came [inaudible 00:27:55], people were seeing the same issue where it’s C-program, you get the same reputability, it takes that many microseconds to do Java. It can be anywhere from one millisecond to one minute. Function as a service, when in the cloud, people are looking for the guarantees, what is your variability for that function within that range. I feel, right now, the GC will be in trouble at the rate we saw [inaudible 00:28:20].
Tene: I think we’re measuring the wrong things, honestly, and I think that as we evolve, the benchmarks were going to need to follow with the actual uses will play. If you look at function as a service right now, there’s a lot of really cool things out there, but the fundamental difference is between measuring the zero-to-one and the one-to-many behaviors. Actual function as a service deployments out there, the real practical ones are all one-to-many. None of them are zero-to-one. There are experiments of people playing with. Maybe soon, we can get to a practical zero-to-one thing, but measuring zero-to-one is not where it is, because it takes five seconds to get a function as a service started. It’s not about the GC, it’s not about the 500 milliseconds, microseconds, or whatever it is. The reason nobody will stick around for just 500 milliseconds is it costs you 5 seconds to start the damn thing.
Now, over time, we might get that down, and the infrastructure might get that down. It might start being interesting. I fundamentally believe that for function as a service to be real, it’s not about short-lived, it’s about elastic start and stop when you need to. The ability to go to zero is very useful, so the speed from zero is very important, but it’s actually the long-lasting throughput of a function that is elastic that matters. Looking at the transition from start to first operation is important, and then how quickly do you get quick is the next one, and then how fast are you once you’ve been around for a while. Most function as a service will be running for hours, repeating the same function and the same thing very efficiently. Or, to say it in a very web-centric way, we’re not going to see CGI-bin functions around for a long time. CGI-bin is inefficient. Some of you are old enough to know what I’m talking about. We’re not going to see the same things. The reason we have servlet engines is because CGI-bin is not a practical way to run, and I wish the Hadoop people knew that too.
The behaviors that we’re seeing now that I think are really intriguing is that the AOT/quickstart/decide what to perform first at the edge, the eventual optimization in the trade-off between those, can you do this and that, rather than this or that. Then GC within this is the smallest concern for me, because I think the JIT compilers and the code quality are much more dramatic, and the CPU spent on them at the start, which you guys do some interesting stuff around, I think is very important. GCs, they can adapt pretty quickly. We probably are seeing just weird nobody planned for these cases, but it’s very easy to work them out of the way. They don’t have a fundamental problem in the first two seconds, and all we have to do is just tweak around the heuristics so that it will get out of the way. It’s the JIT compilers and the code quality that’ll dominate, I think.
Kumar: The other cases I’m seeing, like the health care or others where you could have a large image or a directory comes in, they want to shut it down. They don’t want the warm instant something due to security and other things. You have that in your heap or something where you don’t end up doing the GC immediately. You can’t imagine to analyze and GC, and so you’re not there in the responsiveness.
Tene: You see that people want to shut it down because it’s wasteful, but that’s after it’s been up and doing nothing for minutes, I think.
Vidstedt: I completely agree with you. The time to warm or whatever we want to call it is a thing and a lot of that is JIT compilation and getting the performance cold in there. The other thing is class loading and initialization in general. I think that the trend we’re seeing and we’ve been working on is attacking that in two different ways. The first one is by offloading more of that computation, if you so will, to before you actually start up the instance. With JDK 9 and the model system, we also introduced the concept of link time. Using J-Link, you can create something ahead of time before you actually start up the instance where you can bake in some of the state or precompute some of that state so that you don’t have to do it at startup. That’s one way of doing that. Then, we’re also working on language and library level optimizations and improvements that can help make more of that stuff happen, let’s say, ahead of time, like statically compute things instead of having to execute it at runtime.
Tene: OpenJDK 12 and 13 have made great strides in just things like class-data sharing that I think it’s cut it in half.
Vidstedt: Yes. I know, it’s been pretty impressive. We have spent a lot of time. We have especially one guy in Stockholm who spends like 24 hours a day working on just getting one small thing at a time improved when it comes to startups. He picks something for the day or the week and just goes at it. CDS has been improving a couple of different ways, both on the simplicity side. It’s actually, class-data sharing, for those of you who don’t know it, is basically taking the class metadata. This is not the cold itself, but it’s like all the fields and bytecodes, all the rest of the metadata around classes. Storing that off is something that looks very much like a shared library. Instead of loading the classes JAR files or whatever at startup, you can just map in the shared library, and you have all the relevant data in there.
Simplicity in the sense that it’s been there for quite a while since JDK 5 if I remember correctly, but it’s always been too hard to use. We’ve improved on how you can use it. It isn’t always basically start up the VM and the archive will get created and mapped in next time. The other thing is that we’ve improved on what goes into it, both more sharing, more computations stored in the archive. Also, we’ve started adding some of the objects on the Java heap bin there as well. More and more stuff is going into the archive itself. I think what we’ve seen is that the improvements – I’m forgetting the numbers right now. We’ve talked about this at Oracle Code One earlier this year – the startup time for Hello World and Hello Lambda and other small applications has been improved. It’s not a magnitude, but it’s significant improvements, let’s say.
Kuksenko: I have to add that we work with startup from thought areas. We have AOT right now. We finally did CDS, class data sharing, not for all JDK class, but it’s possible to use it for your application class-data.
Tene: AppCDS.
Kuksenko: AppCDS is our second option. The third option, class and mainland, some of the guys pass through all static initialization of our class libraries using stuff. Nobody cares when JVM started. People cared when the domain is finally executed, but we have to pass all of that static initialization before. It was also reduced.
Tene: The one unfortunate name here is called class data sharing because the initial thing was how desktops don’t have to have multiple copies of this. We probably should call it something like class computation preloading. It’s saving us all the class loading time, all the parsing, all the verification, all the computation of just taking those classes and putting their memory in the right format and initializing stuff. It’s the sharing part, that’s the bit.
Vidstedt: I agree. We’re selling the wrong part of the value at this point. You’re right.
Stoodley: We got caught by that too, because we introduced shared classes cache in Java 5. It’s true that it did share classes when we introduced that technology, but very quickly, after Java 6, we started storing it ahead of time, compiled code in there, and now we’re starting profile data in there and other metadata and hints and all kinds of goodness that dramatically improved the startup time of the JDK, of applications running on the JDK, even if you have big Java EE apps. It’s sharing all of that stuff or storing all of that stuff and making it faster to start things up.
Tene: I think that’s where we’re going to see a lot more improvement and investment too. I think the whole CDS, AppCDS, whatever we call it going forward, and all the other things, like stored profiles, we know how to trigger the JITs already, we don’t have to learn on the back of 10,000 operations before we do them, that stuff. We call that ReadyNow. You guys have a different thing for this. We have JIT stashes or compile caches or whatever we call them. I think they all fall into the same category, and the way to think of the category is we care about how quickly a JVM starts and jumps into fast code. We’re winding this big rubber band, then we store our curled up rubber band with the JVM so it could go, “Poof,” and it starts. That’s what this CDS thing is and all the other things we’re going to throw into it over time, but it’s all about being ready to run really quick. The idea would be we have a mapped file, we jump into the middle of it, and we’re fast. That’s what we all want, but we want to do this and stay Java.
Java as a Top Choice for Function as a Service
Kumar: I think the second part of that one is, ok, we showed that it could be fast, it could be pretty responsive. I have been in Intel and other customers across many environments, not just Java. When it comes to function as a service, which is a rising case in the cloud, I don’t see that Java is still at the top choice. I see Python, I see Node.js, and other languages. Is there anything at the programming level being done so people see Java as the top choice for the function as a service?
Stoodley: Do you think that choice is being made because of performance concerns or because of what they’re trying to do in those functions?
Kumar: What they’re trying to do and how easy it is to be able to set up and do those things.
Tene: I think that function as a service is a rapidly evolving world, and I’ve seen people try to build everything in it. It seems to be very good for Glue right now, for things like occasional event things, not event streaming, but handle triggers, handle conditions. It’s very good for that. Then, when you start running your entire streaming flow through it, you find out a lot. I think that when you do, that’s where you’re going to end up wanting Java. You could do Java, you could probably do, I don’t know, C++ or Rust. Once you start running those things, what matters is not how quickly it starts, it’s how it performs.
Right now, within the runtime languages, within the ones where you can actually state and GC and all that stuff and don’t have to worry about the stuff yourself, Java dramatically outperforms everything else. There’s a reason most infrastructure, Cassandra, Elastic, Solr, or Kafka is in Java, on a JVM. It’s because when it actually comes down to how much you get out of the machine, that dramatically outperforms a Python or a JavaScript or a Ruby. There’s great ways to get stuff off the ground if you don’t care how fast they run, but if you start actually using a lot of it, you’re going to put something that uses the metal well. C++ uses metal well and Rust uses the metal well. You could write in those. Go is somewhere in between, but Java dramatically outstrips Go in performance right now, for example.
Vidstedt: The other thing we have with Java, I’d like to think at least, is the serviceability and observability and debugging aspects of it. It executes quickly, but if something isn’t working as well as you’d expect, you have all these ways for looking into what’s actually going on. That’s much harder with C++, for example.
Tene: It’s got an ecosystem that’s been around for 20 years and isn’t NPM.
Stoodley: Checkmark, not NPM.
Participant 4: That’s why we’re on the JVM for our use case because it’s like a Toyota Camry. You can go to the shop, buy a new indicator bulb, and plug it in. I can get a Thai tokenizer or a Chinese tokenizer and plug it into Java. It’s open source, it’s on GitHub. The ecosystem is inside.
Stoodley: The other thing is that the runtime is engineered to scale well across a wide variety of machines. No matter how much iron you throw at it, it can scale from mainframes down to little small devices. You don’t have to think about that. In other languages, you have to think hard about that in order to get that degree of scalability, and it’s work, and it’s hard.
Participant 5: Why Java is faster than Go?
Tene: Because it has a JIT. Period. It’s that simple. Go as a language doesn’t have any limitations like that. It’s just Go the runtime and the choices they have right now that they’ve made. If Go could have a compacting collector, Go could have a fully multitier JIT if you want to, and people have with using LLVM backends for Go. Right now, if you run in Go, you’re running an AOT nonspeculative optimized piece of code, there’s no way that thing could compete with speculative optimizations in a JIT. That’s it.
Vidstedt: Another way of phrasing it is, we have man-centuries, if not millenniums, behind us on the Java side, just the investment from multiple companies for 25 years or so. Just the fact that we’ve been around for much longer, but yes, that is obviously our secret, but not so secret weapon in the end.
Stoodley: I have a slide at the beginning of my talk later today that shows all of the different investment that just companies have made in building JIT compilers, AOT compilers, caching JIT compilers, now JIT servers, all kinds of investment. Like you say, it’s definitely hundreds and it may be thousands of person-years of effort that have gone into building all of that stuff. Now, they’re not all still around, but we’ve learned from all of those exercises, and it doesn’t even count all of the academic work that’s gone into building these things and making them better and enhancing them. I mean, the Java ecosystem is super rich in the investments that we’ve made in compilation technologies. It’s pretty amazing actually.
More Data Scientist Working on Java?
Participant 6: Do we have any plan for Java to support more data scientists to work, like machine learning?
Tene: We had this nice panel at Oracle. One of the things that I’d pointed out is there’s a bunch of libraries in Java that target this. The main bug that they have is the name. They just need to name themselves JPandas, and everybody would then know what it is. Then they’ll know that Java has stuff that does AI. As long as they insist on naming it other things other than those cool names everybody knows.
Vidstedt: I’ll mention two things. I think we’re running out of time. I’ll mention Project Panama is where we’re doing a lot of the exploration and the innovation and implementation stuff, let’s say, around how we can make machine learning come closer to Java. It is a multistep story from the lowest level leverage in the vectorized instructions, in the CPU in a better way, and also make use of already existing machine learning libraries that exist today. I’m sure that a lot of people are using Python for machine learning. The library in the back end is not actually Python it’s like some native code. It’s just that the front end is Python. We want to enable that same use case on the Java side. We can interact with the library using Java code in a better way.
Participant 7: Is it in a timeline?
Vidstedt: I never promise timelines. Keep track of Panama, There’s a lot of cool stuff happening there right now. There were presentations at JVM, I think we had one this year. Keep your eyes open.
Stoodley: There’s lots of interesting research work going around doing Auto SIMD, Auto GPU in the Java ecosystem. We have some projects even with OpenJ9 that are looking at Auto GPU usage. I think it’s coming, it’s just not quite there production-ready.
Tene: I think what you see on on our side, we’re making the JVMs and JDKs. We tend to look at the low level parts, how do you get good vector libraries and optimize ways to pass across library paths and all that. The actual ecosystem gap I think is at the top, the approachable library APIs for people who just want to ride to this stuff, and they’re never going to ride to the levels we just talked about. They’re going to ride to whatever JPandas is going to be. What we need is for people to go build JPandas, and it’s not us, because it’s an ecosystem item.
Stoodley: Once it gets built, then it’s up to us to make it fast and make it work really well.
Participant 8: I think that would happen really quickly after something like Panama.
Tene: People can do it now. There’s nothing holding them back. Panama will allow you to do it faster, faster meaning performance faster, but it’s not about performance. It’s about approachability.
Stoodley: Usability.
Participant 9: Maybe in the broader ecosystem, which is consistent. From our use case, it’s absolutely about performance and not about approachability.
Tene: Ok, fair.
Participant 10: There was a talk yesterday from Google about moving TensorFlow to Swift. After the talk, I asked why they’re not planning to use a JVM language like Kotlin instead of Swift, which are very similar. The claim was that the fact that the JVM has a garbage collection is a limitation in the machine learning world, and they prefer Swift because it is reference counting instead. What’s your point?
Tene: I think that’s a religious argument, not a technical one.
Participant 10: I thought so.
Kuksenko: I’d rather say that just reference counting because he had to know the garbage collector does [inaudible 00:46:54].
Tene: Precisely, yes. A much less efficient garbage collector, that’s what it is, yes.
See more presentations with transcripts
MMS • Katharina Probst
Article originally posted on InfoQ. Visit InfoQ

Transcript
Probst: I am really excited about sharing with you some other way of thinking about what ownership means and hopefully send you home with some food for thought.
Let’s start with something that seems completely unrelated. Let’s start with this. You go to a website, probably happens once in a while, and it’s not working. You, as the customer, have no idea what’s going on behind the scenes there. What is going on behind the scenes, in this example, is what I would call the classic incident in three acts, and many of us have seen this kind of incident, I bet.
It starts with the system, and for whatever reason, that system catches on fire. Probably not physically, but it catches on fire. Maybe somebody pushed some bad code, or it got overloaded, or somebody caught a cable in the data center, or something bad happened. For whatever reason, it catches on fire. Of course, because we live in a world of microservices, this system does not live on its own. There’s another system that really needs this system that just caught on fire. What happens in this other system, as I’m sure many of you have seen, some metric that indicates health of that system goes through the roof. Requests stack up, latencies go through the roof, it runs out of memory. Then, here’s your third act. This is you, as the customer, wanting to get to that webpage, and it’s not working.
We’ve all seen this. Why is this relevant? I’ll tell you why this is relevant to ownership after I introduce myself. My name is Katharina Probst. Confusingly, I go by Katharine. You can find me on LinkedIn and various other social media.
Ownership in Distributed Systems
I want to start by getting you to think a little bit about how we define ownership in distributed systems before we talk about people and teams. Let’s think about this a little bit. Many of us live in this world, where we have many different systems that interact with each other. There are probably services that, together, form a larger system that provides some kind of functionality to the user. How do we actually define ownership in such systems, and what are the expectations one system has on another? Let’s explore that a little bit.
If you have two systems that need to talk to each other, you need to be incredibly explicit about how they talk to each other. One system needs to say, “Ok, if you need something from me, if you need, in this case, a list of phone numbers from me, you need to send me exactly this kind of request with exactly this kind of data and input, and I will return you exactly that. I will give you back a list of phone numbers, and each phone number has a, say, number in it and a name in it.” The owners of these two systems get together, and they talk in great depth about what exactly is the API between those two systems.
Then, when these two systems are actually running together, there’s agreed-upon status codes that they exchange often. Hopefully, when this first system sends a request to this other system, that other system returns a “200 OK” along with the response. That’s hopefully the vast majority of cases. It returns a “200 OK.” The system that was calling knows exactly what that means. It knows, “Ok, things went well,” and that the response is not garbage, and I can expect to find the list of phone numbers, in this case. That’s great.
There are other status codes as well. There is the “You’ve come to the wrong place.” That’s the 301. There is the “I have no idea what you’re talking about.” That’s the 404. There is, “I am a teapot.” That’s 418, I looked it up. There are various other very clearly agreed-upon status codes that these two systems have, and they each know what it means. Another status code that I put up here is 503 – Service Unavailable. Another thing that happens that is best practice when two systems talk to each other is that, if my system up here calls this other system and this other system is having a bad time or is going through a rough patch, the best practice is for it to fail quickly. Fail fast. Then, the caller knows, “Ok, I cannot expect an answer right now.” Then there are best practices around what to do with that. Maybe you retry with backoff, maybe serve a fallback, maybe do something, maybe make your users more or less happy even if you can’t get them exactly what they need. There are very clear protocols that we follow.
What are one service’s expectations from another? We talked about clean APIs, articulate what you can and cannot do. We talked about status codes, articulate exactly what your caller should do next. It should be clear what to do next. Also, fail fast. Those are just some of the ideas that we, as a community, as an industry, have developed around how systems talk to each other.
We also have developed a lot of best practices around what to do with failure modes. We’re very careful not to have a single point of failure. If you heard Aaron’s [Blohowiak] talk this morning, he talked about how Netflix runs in three regions so that there isn’t a single point of failure. We always want to make sure that there isn’t just one server or one zone or one region that handles any one specific thing, ideally. We have best practices around what to do when a lot of requests come in. A system cannot always say yes to a request. At some point, it needs to throttle or it needs to say, “I can’t do any more.” Then we have very good practices, again, around communications. Fail fast, let your caller know what’s going on. Communicate clearly where you are.
Those are some of the things that we, again, as a community, have developed around how systems interact with each other. It’s not all about what to do when a request comes in. There’s sort of this meta thing here, which is that we, as the owners of these services, spend a lot of time thinking about how is this going to scale. How much traffic is my system going to have to handle in one or two years? What’s going to happen when we have that kind of traffic? Probably, we need to do some work to make it be able to handle that kind of traffic. What do we need to do to set ourselves up for success?
The key insight here is that if we think ahead, and we actually spend the time preparing ourselves for the future, we can actually prevent some of the reactive work from happening. One of the examples here is precompute some stuff. “There is this request that always takes me forever, and I need to do a bunch of work. How about I precompute it and cache it somewhere?” That then protects your system from having to do all that work repeatedly. Those are some of the patterns that we’ve developed.
Ownership in Human Systems
The thesis that I bring here to this talk is that humans are very different from machines. Ok, that’s not the thesis, we all know that. Human systems actually work in surprisingly similar ways sometimes. I want to draw an analogy between all the best practices and patterns that we’re seeing in distributed systems and our human systems and how we, as humans, interact and how we, as teams, can interact. If there’s nothing else you take away from this talk, I want you to think about, when you go back to your jobs, in your daily job, what are the best practices that we’ve learned from systems that we can actually apply to our teams and to our interactions as people? Let’s explore those ideas a little bit.
This is a blurred, image of my inbox. I have like 100,000 unread messages here. All of them are interesting to me. I’m never going to be able to read them all, but all of them are interesting to me. You see, up here, I have a bunch of updates that’s usually something like people leaving me comments and docs and things like that, and somebody’s pinging me on chat, some personal message. Then, helpfully, Gmail tells me, “You received this message five days ago. Are you going to do anything about it?” Then I have a system that doesn’t always scale, but I have a system where I star emails that I really need to do something about, like pay a bill. This is my personal inbox. My work inbox looks different. Not any better.
The point here is that I’m sure I’m not the only one, that sometimes feels like a system that is getting a lot of requests and a lot of stuff being put on my plate. I need to be able to answer the question, “How can I function in this environment and still provide to my co-workers what they need so they’re not blocked so they can do their jobs? What does my team need to do in order to make sure that other teams aren’t blocking, that we, as a company, can actually move forward productively?” Our human systems look something like this. They look very much like our distributed systems in a lot of cases. Basically, there’s a lot of people talking all to each other. This is probably not news to you, and your inbox probably doesn’t look very different from mine. Again, the question is, what do we do about it?
Option number one. Some days, I feel like all I’m capable of doing is saying, “418 I’m a teapot.” I like that status code, I really do. That’s not actually what I say. What I actually say sometimes, and I don’t know if you do this too, but sometimes I actually say, “I’m being DDoSed,” I have so many people wanting so much stuff from me, I sit down at my desk, and just the act of prioritizing it makes me throwing “out of memory” error. I’m literally DDoSed. That’s not a good state of being, and so I started thinking a lot about how can I apply some of the things in this analogy to distributed systems to my own work so that I can show great ownership and so my team can show great ownership. My 10-year-old son really loves Mondays. I don’t know why, but he will get up any day of the week and say it’s Monday. Sometimes he’ll get up on Thursday and say, “Today is the fourth Monday of the week.” Sometimes I feel that way too. Let’s do something about it.
If I think about this analogy again, what can I do to behave like a well-behaved system? When we have computer systems that misbehave, what do we do afterwards? We get together, we have a blameless postmortem meeting, and we talk about what have we learned and where do we need to put better APIs and things like that in place. Let’s do the same about our work. Let’s reflect a little bit on what we do. As we go through this and we go through this analogy, I’ll lay out a few goals that I have set for myself and for my team. Let’s talk a little bit about clean APIs.
One of the things that we want to be able to do is articulate what we can do and what we cannot do. Just like a system’s responsibility is to get whatever they need from their downstream systems, it is my responsibility to do the leg work to be able to handle a request. If somebody comes to me and asks me a question, and I’m actually the one who is going to answer this question, it’s my job to go and figure out who to talk to and what systems to dig into, and so forth. That is a clean instruction. The API is you ask me a question, I do the leg work, I figure it out, and I come back with the answer. Just like in a system, I would expect that system to go call its downstream systems rather than me having to call.
Similarly, status codes – what’s the equivalent of status codes with human interaction? Again, if you draw that analogy, my responses should give you a pretty clear indication of what to do next. I should be clear about, “Can I do it? Can I not do it? Can my team do it? What is the next step here?” Then, third, fail fast applies very much as well. You don’t want me to fail, I hope, but if I do, you probably want me to know right away.
Let’s dive in a little bit. Let’s talk a little bit more about clean APIs. What are your focus areas? What are my focus areas? What are the things that I want to focus on this quarter or this year, and what is it that I’m not going to focus on? If I have a clear articulation of what my team’s charter is and what my charter is, it makes it so much easier for people to know when to come to me for something. Being clear about what our priorities are, and also, that leads to the second thing, what our priorities aren’t right now in this quarter, is actually super helpful to the rest of the organization. Courtney [Hemphill] talked earlier a little bit about communication, how communication is key. If nobody knows what I’m doing, then that really doesn’t help anybody. Me disappearing into a corner for six months and then reappearing makes it very difficult for the rest of the organization to fit around that model.
Let’s talk a little bit about status codes. Let’s take a hypothetical example. My colleague comes to me and asks me, “Can you figure out why X is failing?” If all goes well, and for instance, it’s a quick thing, my colleague gets back a 200 OK, not really, but you get the idea, and I will say, “Definitely, here’s the problem. Here’s why X is failing,” and I’m able to answer their question. Hopefully, all goes well. That’s the 99.99% case. Everybody knows where they are and get what they need. In reality, what happens sometimes is, my colleague comes to me or my colleague sends me an email saying, “Can you help figure out why X is failing?” What do they get from me? First of all, nothing right away, because I’m probably behind on my email, like today, I was kind of busy with this track. So I’m behind on my email, and right now they don’t know anything.
Now, there are two scenarios. Scenario one is I’m actually working on it. I received their message, I’m doing my leg work, I’m looking at some dashboards, I’m looking at some systems, I’m talking to a bunch of people, but I haven’t told my colleague that. I’m working on it, but my colleague doesn’t know that right now. The other option is I’m not working on it, because they’re not the only one who wants something from me at that point in time. To my colleague, obviously, that looks the same, and I’m sure you’ve been in the same boat before with your colleagues and you have done that as well.
How does my colleague react, or how does my colleague even tell the difference? What would a system do? A system would retry after it times out. What’s the human equivalent of retrying? Ping. If you’ve ever gotten a ping, this is what this means. My colleague comes back and says, “Ping. Hi. Anybody there? Can you figure out why X is failing?” Of course, all these other people retry too. Then, we’re back in this DDoS situation, because everything stacks up. I catch on fire, hopefully not literally.
What do I take away from this? One of my goals is to be clear about where things are. I told you a little while ago, I have a few goals that I set that I learned from drawing this analogy. I’m nowhere near perfect on these goals, but this is something that I’m working on and that I talk with other people about.
The first goal is return 202 Accepted when I can do the work. I wouldn’t say, “202 Accepted,” although maybe I should. I will say, “Ok, I’ll do that, and I will get it to you by the end of the week.” That analogy actually works pretty nicely for teams as well. I don’t know about your teams, but my teams get a lot of requests saying, “We really need this feature. The world is going to end if we don’t get this feature. We really need all of this.” When they come to us and they say, “Can you build this feature?” or “Can you do this integration?” or whatever it is, we have to make a decision, and we have to make a decision and be very explicit about it. The other team needs to know where they stand. We should send them a 202 Accepted, “We’ll do and we’ll do it by the end of the quarter,” or we have to say we can’t do it.
Fail fast. I talked about 202 Accepted with an asterisk of when I can do it, and that’s actually really key, because I think all of us have a lot more things that they could be doing than they have time for. I think we need to be very clear as owners of our areas to be honest about what we can and cannot do and why. Getting back to my colleague and saying, “I get it, it’s important. I really do understand you need this, but I simply cannot humanly do it,” is an important skill. You have to be able to say, “I have these other priorities right now that are just more important than this specific request.” Being honest about that and saying, “No. Right now, I’m throttling and I cannot do this right now. Let’s talk about it in a week.”
I think one of the worst things that systems can do and I think humans can do is time out and then return a permanent redirect. Let’s say my colleague sends me an email, says, “Can you figure out why X is failing?” I do nothing. Probably, maybe I haven’t even really digested the email. I do nothing. Eventually, they ping me because I timed out. They ping me, and then I come back and I say, “I finally read your email. I’m not the right person to talk to. Go talk to this person over there.” That’s probably not great. Not a great experience. If that happens to me, I feel like I haven’t shown great ownership of my area, but also, just great ownership of the company. I haven’t unblocked my colleague and they just lost a whole bunch of time where, really, the right person to talk to is somewhere over there.
When we talked about systems, we also talked about failure modes and how to avoid them. The same thing happens in teams, and some of this is probably very familiar to you, and it applies. You want to make sure there’s no single point of failure. If all this stuff is on your plate and you’re the only one who can do it, you have work to do in making sure you’re not the single point of failure here. You need a deeper bench on your team. You need to make sure that other people can answer these questions and do this work as well.
What do systems do? They scale horizontally. What do teams do? They scale horizontally. Many of us spend a lot of time thinking about how can we get our teams to a place where multiple people can do any given task. If that one person is out for a vacation or wherever, other people are there, and the business continues, and nobody’s blocked. The same thing applies.
Don’t always say yes. We already talked about that a little bit. You can’t commit to everything, probably, so be clear about when you cannot say yes. If everything’s a P0, nothing is. Many of you feel that too. Goal number four is be very explicit and say yes when you can do it, or when I can do it. That means my utilization is down here in the lower levels, not up here. Be very clear when you can and cannot do it. Then, communicate. The more time I spend in this industry, the more I’ve become a really firm believer in communication, up, and down, and sideways, and everywhere. Through of the talks earlier today, this was touched upon as well and how it’s very important, not just to have good communication, but to be really thoughtful about what that communication is.
For instance, you might send status reports, but be very careful about how to send those status reports, because they need to be usable by the readers of those status reports. Otherwise, they’re not going to get anything out of it. You wasted time and they wasted time, and still, nobody knows what’s going on. I’ve read many status reports where I just read a page and I’d have no idea what it was talking about. It made perfect sense to the people who wrote it, but they’re kind of not the target audience. Let’s not write status reports that are not readable by other people outside the team. We think a lot about that and how can we just be very crisp and clear in our communication, and I think that’s really important, especially as you work on projects that involve multiple teams.
Then, the corollary is that you really kind of need to have a system. Develop that system, whatever works for you that’s for your internal tracking, making sure that you know what’s going on. Also, figuring out what works with other teams, what works with your management chain so that everybody is on the same page and in the loop and there are no surprises.
When I talked about systems, I talked a little bit about we think proactively. We want to think about where are we going to be in a year or two. Ideally, the same thing applies. It’s not all about reactive work. It’s not all about, requests come in, you handle them, and the work is done. It’s very much about, “What is the charter of my team a year from now? What do I need to scale myself to a year from now? What are the skills I need to develop to be able to do my job a year from now, or two years from now?” That’s really important, and I feel like we often don’t spend enough time on that, especially on the personal growth piece.
My theory is that we all say we’re so busy and we just don’t have any resources left to think about that. Whereas, when we design our systems, sometimes we have time to think about what will that system look like. I really think it’s important to think about also for our own personal development and personal growth. I do think that when we think ahead, and we do spend some time planning and developing ourselves for what lies ahead a year from now or two years from now, just like in systems, we can avoid some of the reactive work further down the road. If we develop tools so that people can answer questions more easily or if we scale out our org in a way that more people can handle the work and so forth, then that really helps us scale and prepare for the future.
Take-Aways
What are some of the takeaways here? The thing on the left, if there’s nothing else you take away from this talk, the one thing I want you to think about is this analogy. If you know me, I’m all about analogies, and sometimes I really take them too far. I feel like this one can go pretty far. Think about that in your daily work, how some of the best practices and patterns we’ve developed in distributed systems, how they apply to us. Then do less, but do it well. Just like systems, don’t do everything, don’t sign up for everything, but what you do sign up for, make an effort to do it really well and have a high SLO. If you say no, explain why, and be explicit about what else is more important right now and why it’s more important for the business. Communicate. I’m just going to bring home that point one more time. Communication is key. It’s important especially as we scale. If you don’t know what’s going on in some other team, you’re just going to drown them in more work, and it turns out, it’s probably not even them that need to be doing them. Then, minimize timeouts, which is part of communication. If you can’t do something, tell them fast.
Finally, as we head into the evening and close this talk, one of the things that I really want to take away for myself and that I want to share with you also is, just like distributed systems will eventually fail, we’ve learned that, we need to set ourselves up for failures. Eventually, distributed systems will fail. The same thing will happen with us. We can have all the systems and processes and good intentions in place, eventually, we will drop something. Apologies if you’re waiting for an email from me. Hopefully, it’ll happen at some point soon. I don’t expect perfection from myself in that regard. I strive for it, but I don’t expect it. It’s also very important that we apply that to others. We understand they’re under the same pressures as we are. We understand that they are also just trying their best, and they’re trying to be a good citizen and a good owner. Sometimes that means taking stuff off their plate. Sometimes that means saying, “I could ask this person to do something for me, but you know what, they’re overloaded, I know they are. It’ll take me 10 minutes longer than it would take them, I’ll just do it myself.” It can also mean that. That also helps us work together better as a company, I think.
Questions and Answers
Participant 1: The question that I had is that, usually, what bothers a lot is the context switching. Whenever someone asks me a question, that takes me off my work. Even if I say no, so I don’t have time, that takes me off work. Switching back to an original context, that takes a lot of work. Do you have a way of preventing them to ask the question the first time? “I’m busy right now, don’t bother me. After 3 p.m., you can call me,” or whatever.
Probst: Do you want me to take my distributed systems to the limit, that analogy?
Participant 1: Please do.
Probst: I’m going to need some time with that. The question was, how can I avoid distractions? I think there’s two aspects to this. One is avoid distractions in the moment, I actually now completely turn off notifications sometimes when I’m heads-down on something, because I know somebody will ping me or some email will come in. I get distracted super easily. People have been saying this for years, but it actually makes a huge difference when you turn off other notifications and you’re just, “I’m just going to read this document now for the next half hour.” That’s number one, tuning out the distractions.
That doesn’t solve the problem that you were posing, which is how do I prevent people from asking me in the first place. The way that I think about this is, I want to be clear about what people should come to me for and what is not something that people should come to me for, what is already documented, or what is another team’s charter or responsibility. Being very clear about that helps a little bit. Sometimes you still get lots of questions, and you redirect, and that’s fine. I think just being clear about that really helps.
Participant 1: How do you make yourself clear about that, just have a list of topics that people can ask you?
Probst: I do, actually. We have team charters, and we can always do better, but we can say, “This team does these things and is responsible for this system,” and so forth.
Participant 2: What happens when you have so much mail or so many requests? Because you want to fail fast or respond to every request. Sometimes it takes a while for you to read a request.
Probst: You have to triage, yes.
Participant 2: Really understand what is being requested before you can respond with, “I can do this,” or you have to ask someone else. Just processing these requests will take a significant amount of time. How do you deal with situations like this?
Probst: I don’t have all the answers. I can tell you what I do, or a few things that I do. Number one is I do spend time every day scanning through my emails and kind of triaging. The ones I can respond to quickly, I respond to quickly. The ones that take more work, I get back to later. They get a star. There are threads that are just very involved. I have actually, for instance, forwarded that thread to somebody who is already on it and said, “Look, this thread, I don’t have time to read and digest it, but it looks like you’re active on, so just pull me in if you need me.” Because maybe there’s some deep thing that’s being discussed, and I fully trust that person to figure that out, and I don’t need to be in it. I try not to let really important things stay on my plate for too long for that reason. It does take a lot of reactive time. It’s very true. I always have a list of things that I know I want to accomplish this week, like the more proactive stuff, and then email is separate. Email is like the more reactive stuff, typically.
Participant 3: As developers, we help each other, and I suppose we want to grow up with our team members. What if one of your team members is asking you for help, and after you provided your thoughts or pseudocode or solution, he or she even asked for more? Basically, they expect you to provide exactly the code.
Probst: I think there are also two aspects to this. One is, where do you draw the line in terms of how much time you’re willing to give to your teammates? We always talk about we help each other, and together we’re a more proactive team. Maybe one thing that can help is to think about where is that person on their journey of learning. Aaron [Blohowiak], this morning, talked about these levels of ownership, and is this person in a place where you just have to teach them and kind of bring them up these levels of ownership. Then they require more oversight or more time commitment, I guess, from the rest of the team. If that’s too heavily leaning on one person, then that could be a problem. I think it’s the manager’s or the team lead’s job to recognize this with input, obviously, and load balance better.
The second aspect of my thought is that something that I see happen quite a bit is that the people who show the greatest ownership, they care a lot, they’re very involved, they get all the stuff handed to them. We’re, “Oh my gosh, we have a problem. Who can handle it? This person over here can handle it, because they handle everything else. We know they’re going to do it really.” To me, that’s like a single point of failure problem. Then, it’s up to the team and the team lead and the manager to make sure that we can scale horizontally. We’re not always perfect with that, and people emerge as these single points of failure because they’re so great. This is an ongoing process of you recognize the problem, and then you scale out again, and you recognize the problem, and you scale out. If you’re having that problem personally, I would certainly talk to the manager about it. I wouldn’t consider that like an escalation. It’s just, “How do I do this? You expect me to do all this stuff, and now I’m spending all this time on this other person.” That’s what I would do.
Participant 4: You mentioned identifying single points of failure within teams. I’ve heard some exercises teams will apply to identify single points of failure. An example is they’ll identify a team member and have them be gone for the day and find out what things fail. Are there approaches that you have applied to find this effective? As you mentioned, it was kind of reactive, you may identify the problem once it happens, but is there anything you apply to identify that single point of failure?
Probst: That’s an excellent point, and it will just further my analogy, I love it. Everything I talked about here is reactive. What we do systems, we do failure testing and failure injection testing. Sending people away is a great example. Just send them away and see what happens, just like we do with chaos testing. I think I haven’t, to be honest, done too much of that, like send people away and let’s see what happens. I do think about sort of the hypothetical, of what would happen if this person weren’t here? What systems do we have that don’t have clear owners? It’s a huge red flag to me if some bug comes in and everybody’s, “Nobody really knows this code.” That’s a big red flag, so we need to do something about that. Just paying attention to these things before they blow up and become problems is the approach I’ve taken, although I really like your idea of failure injection testing. I might have to do that.
See more presentations with transcripts
MMS • Natalie Silvanovich
Article originally posted on InfoQ. Visit InfoQ

Transcript
Silvanovich: Today I’m going to give a talk entitled “Small is Beautiful, How to Improve Security by Maintaining Less Code.” I’m Natalie Silvanovich, and I’m on a team at Google called Project Zero. Project Zero’s goal is to reduce the number of zero-day vulnerabilities available to attackers in the wild. We do this from a user-focused perspective, so we look at all products, not just Google products.
Attack Surface Reduction
Most of our work consists of finding vulnerabilities in these products and reporting them so they’re no longer available to attackers because they’ve been fixed. Recently we filed our 1500th vulnerability, which is in the five years that our team has been around. In finding all of these vulnerabilities, we’ve noticed that a lot of these vulnerabilities have things in common. Specifically, a lot of them are due to needless attack surface.
The attack surface of a piece of software is basically everything that an attacker can manipulate, everything that an attacker could find bugs in, and obviously the less of this you have, the better. We’ve all heard the joke, it’s not a bug, it’s a feature. Bugs and features are intertwined I think in a more important way. Every bug started its life as a feature, and every feature introduces the risk of creating new bugs.
What attack surface reduction really is, is making sure that this tradeoff is worth it, because a lot of bugs we find are due to code that, this decision wasn’t made. It’s code that basically provides no benefit to users, and yet is there creating security risk. Specifically, what we’ve seen is unused features, old features, code sharing, third party code, and excessive SKUs and branching. That’s what I’ll talk about today.
Finally, I’m going to talk a little bit about privileged reduction and sandboxing. I don’t consider this to be a strictly attack surface reduction, but it’s something you can do if you aren’t able to reduce the attack surface.
Unused Features
To start off, I’ll talk bout unused features. This slide is, unfortunately, missing a cartoon. They wanted $15 per presentation to license it, and that’s too much. You have to pretend that I just said something really witty about product managers putting way too many features into products.
With unused features, all code has risk. All code risks introducing security problems and other bugs into your software, so it’s important to make sure this tradeoff is worth it. Obviously, if a feature isn’t used, it’s not. It’s important to get rid of these.
To start off with an example, JavaScript. Who here has written a few lines of JavaScript or at least complained about it? Most people in here. Now, who here has heard of this feature, array symbol species, the code in the middle? Show of hands. Has no one heard of this feature? I was going to ask if anyone had put it into serious software, but I guess clearly not if no one has even heard of it. What this feature does is, in JavaScript, you can do lots of things to an array. For example, you can slice an array. What that’ll do is it’ll make a subarray of the array. Then there’s this question. Let’s say you have a subclass of an array and do you slice it? Do you get an array back or do you get the subclass of the array back?
The JavaScript standard says, “Why don’t we do both?” There is array symbol species. This returns the constructor that is used to create the array that is [inaudible 00:04:11] by any function on an array. This is crazy, no one uses it, and I have a sarcastic point at the end. This was also very difficult to implement and introduced a large number of bugs.
Here’s a bug that I found that was due to array symbol species, and it is in Chakra, which means it was an Explorer Edge bug. Here’s the code that causes this bug. The way this works is, I’m a malicious person, I create a webpage containing this code and then I convince someone to visit the page and then that compromises their browser. Here is the code. You start off at the bottom, you’re creating the MyArray, and what’s important here is this is a mix type array. You’ve got objects and arrays and my name and numbers in there. Then you call filter on it. That’s the very bottom. What filter does to an array is it will run a test on every element of an array and then put that element into a new array if it passes. In this case, it always passes, so it should just copy the array into a new array.
Of course, it’s the subclass of an array, so you get to that question, is the thing it returns an array or a my array? Then you call array symbol species. Then this returns this class dummy, which returns this other array, which is actually what this array is going to be copied into.
This turns out, in the JavaScript engine, both being a type confusing bug, because the engine assumes that this is going to be a mix type array that it’s copying into, but it’s not, and this also ends up being a memory corruption vulnerability because this array is too short, so it also writes off the end of the memory. This is the actual code from the script engine. The interesting part is there’s the array species create, and then you can see that it basically just copies into it without checking anything.
This is just one of I think about 15 or even 20 vulnerabilities involving this array symbol species part of JavaScript that have been reported, which is problematic because I did a scan of the internet. I think there are roughly 150k pages that use this, which is not very much, especially if you consider that a lot of them are JavaScript tutorials. Also, this is from a marker in Chrome, you can add to Chrome basically a counter that for beta users will count how many times a feature is used, and based on that, 0.0015% of all page loads use array symbol species. This is minuscule. This is an example of a feature that I think is way more risk than the benefit it provides.
To give another example of a bug like this, this was recently filed by someone on my team, Jann Horn, and this is a bug in IP compression. This is part of the IP basic standard, and it allows IP packets to be compressed. On a Mac, there was a memory corruption vulnerability, and typically these types of vulnerabilities can allow an attacker to execute code in the context of the software where the bug is. Anyhow, this was in this IP comp feature which was hardly ever used if you look at traffic on the internet and broken on Mac OS, so it didn’t even work correctly. That meant it was very unlikely that any user is reusing it. They fixed it by just turning this off.
Those were two examples of unused features. You might wonder, why does this happen? Why do things like this stay in software? I have a quote from Tumblr on a picture of a boat to answer that, which is that in software, once you put a feature in, it can be very difficult to go back.
There’s ways you can deal with this. Lots of software will put in experimental features. For example, this is a flag from Chrome saying that this feature is experimental. They will often do this, and they do it in Firefox too, to just test if a feature gets uptake. Then they can take it back if it doesn’t and it turns out to be too risky. Of course, this doesn’t actually solve the problem that if you have that tiny number of users, if you remove the feature you might break people, but at least I guess those people have been warned. Something I find encouraging is I’ve started to see an increasing willingness among vendors to remove features where there’s that very low usage and tons of vulnerabilities. This is, for example, from the Blink mailing list, which is HTML for Chrome. They’re removing these HTML features because they have tiny usage, like 0.01% of all page views, and they caused just tons and tons of bugs. Here’s an example from Microsoft Office. In this case, they’re disabling one format that Microsoft Word can open, and once again it had this problem where there was just a tiny number of limited users and a huge number of bugs, so they just turned it off. Likewise, they disabled VBScript in Internet Explorer for the same reasons.
How do you avoid this problem? Base features on user need. That sounds silly, but it’s important to make sure that, especially if you know a feature is going to be really complex, really likely to have bugs, that there’s enough usage of it that it’s worth it. It’s also a good idea to track feature use in beta or production if it’s possible, because some of the worst situations I’ve seen is where companies have just thrown something out the door with no way to know if anyone’s using it, and then it becomes very difficult to take features back because you have no way to know who is using it, is it a large number, is it a very important customer, that sort of thing. Tracking is good here.
It’s also good to be willing and able to disable features. These are two different things. I’ve certainly encountered vendors who have told me, “We will never turn off a single feature if a single user is using it.” While this is an opinion, I think that it’s important to at least consider turning off features if they have very small usage if the cost of this is protecting all your customers. Like with the array symbol species, a very small number of people are actually using it, but the security impact actually affects everyone. Everyone could be tricked into visiting that malicious website, even if they never use any websites that legitimately use this feature.
It’s also important to be able to disable features. Occasionally I run into situations where vendors will want to turn stuff off. Then when they try they realize it’s too inextricably linked to other stuff. It’s just really difficult.
There’s a lot of cases for modular code, but security is one of them. To give an example, does everyone remember that bad FaceTime bug where someone could add someone to a group call and then if they added themselves again, it would just pick up that group call and then you could just hear on the other end? What Apple did temporarily was they turned group FaceTime off, which meant that people could still use FaceTime for a lot of things and not be subject to the bug. Imagine if they didn’t have modular code. Then they might have to take down all of FaceTime. This is how a modular code can help you. It means that, in an emergency, you can turn features off.
This is also, I think, from Tumblr. It’s never too late to do things differently, and palm trees.
Old Features
Even though we’ve seen a lot of bugs due to unused features, what’s more common is that there are features that were useful, but aren’t anymore. They fell slowly into disuse as things have become more modern.
This can lead to bugs because, to start off, you have the risk-benefit things. If there’s no users, it’s just all harm to your users due to the feature being enabled, but also this code can be higher risk. To start off, old code was also often written before what I would call the modern security environment, before we knew all the types of bugs that could cause security problems. Old code, it’s not uncommon that it will have bugs you wouldn’t expect to find these days in it. Also, the lack of attention to this code can make it higher risk. People aren’t going to notice necessarily if it has bad bugs in it.
Here’s an example of a bug due to old code. I found this vulnerability in Adobe Flash in 2017. It was a use after free, a dangling reference, like that Mac issue. I found out initially that it was a result of a hack made to Adobe Flash to load macromedia.com in 2003. Does that website still exist? No, and it hasn’t existed for many years and yet this hack kicked around. There was a vulnerability for 14 years. This is an example. Temporary hacks, if you don’t remove them, can introduce bugs that don’t need to be there.
Here’s another example, and this was also found by Jann Horn in Virtual Box. This is basically a virtual machine and its guest host escalation. It was a way to break out of the virtual machine. It had two root causes. One was that old code wasn’t fully removed and the other was that it was fixed in upstream but not downstream, and I’ll talk about that later.
Here’s the source of the bug. You’ll notice the most important part is to-do, remove this code, it’s no longer relevant. Unfortunately, this didn’t get to-done, and this remained a vulnerability for quite awhile. This is a case for prioritizing removing this codex because if you don’t remove code that’s unused, you’re risking vulnerabilities or other bugs will occur due to it.
Here’s another example. I found this bug recently in iMessage, and it’s Mac only. It’s a bug where you send an iMessage to another Mac and it causes memory corruption immediately with no user interaction. We actually exploited one issue like this so it can be used to get arbitrary code execution on another device without touching it. A very serious vulnerability.
This one occurred in deserializing a URL that was sent in that message, and it turned out on a Mac when you deserialize a URL, it can process a bookmark format from 2011, so eight years old. This was fixed by removing the ability to parse that format, but I think if it had been removed a bit earlier when this format wasn’t used anymore, we wouldn’t have found that bug.
What can you do? Yet another case for a tracking feature use, getting rid of the ones that are no longer used, if you can’t track feature used, sometimes it can be good to run a content stats. To give an example for browsers, there are some good ways to track if things are being used. Another good thing is to scan the internet and see what’s actually being used. That is almost as good of a statistic.
It’s also a good idea to compare usage to reported security issues. For example, I used to be on the Android security team and when people externally reported bugs, there were a few buckets of specific features that had a lot of bugs. Those can be good candidates to have their attack surface reduced or changed in some way.
It’s also a good idea to prune your code trees regularly. Look for code that hasn’t been modified in a while and figure out why. Figure out if anyone is still actually using it. It can also be helpful to refactor older code. This will reduce some of the risk of just code being less secure because people didn’t know as much about security back then.
Also, it’s important to make sure that all code has an owner. There’s two reasons for this. First, we definitely reported vulnerabilities where the code has no owner and it takes a really long time to fix because the vendor can’t figure out how to get the specific component fixed or who knows anything about it. That’s bad if someone like my team reports a vulnerability, but it’s even worse if this happens, there’s an attacker in the wild using this and you can’t find who knows anything about this and can fix it.
It’s also true that if every piece of code has an owner, there’s someone who wants to get rid of that code and no longer own it. That can hasten the deprecation process quite a bit.
Another thing that leads to unnecessary attack surface is code sharing, and there’s two sides here. On one hand, if you use code for multiple purchases too much, especially if the code is used for something that doesn’t have a lot of privileges and then something that is very security-sensitive, you can have this problem where someone will add in a feature for the less sensitive stuff and it will cause a huge security risk for the more sensitive stuff.
Sometimes code sharing can lead to extra attack surface, but on the flip side sometimes there are too many copies of a piece of code, and then it leads to stuff being difficult to maintain and risk of bugs not getting fixed.
Here’s an example of some bugs we filed a few years ago on the Samsung S6 Edge device. There were memory corruption issues due to image processing. You would download an image from the internet and it would hit this bug, and once again cause memory corruption. We found out it was due to bugs in a codec called QJpeg by a company called Quorum. Here is Quorum’s website, and you’ll notice they have a long and illustrious history that ends in 2008.
I thought this was a case of the unused code. Then I looked into it, and it turns out that this image decoder is actually used for one thing. When you start up your device and it sings and it has the carrier logo that it displays, it uses this codec. Nothing else. Unfortunately, the way this was implemented is it was just plonked into the Android image subsystem. Then it was available everywhere for images from the internet, images in the gallery, that sort of thing. This is an example of, they shared this code really broadly when it didn’t need to be. If they had just limited it to loading that one image on startup, this wouldn’t even be a security bug because if you have enough access to a device, you can swap out that image. You can already do a lot of stuff on that device. Now this code was moved so it was used to process stuff that’s completely untrusted off the internet, and that’s what caused the problem.
To give a flip side, this is a case of too many copies of code. When I was on the Android team, which was about five years ago now, there were many copies of the web view, which is the code that processes HTML and JavaScript on the Android devices and many features copied this code, and sometimes there would be bugs in all of the code and they would be fixed in one version but not in another. Every time there was a bug that was reported, there was so much work to fix because there were so many different versions.
One thing we did is we moved to a unified web view so that now the code can be updated in one place and it’s much easier to fix vulnerabilities.
Here’s another context issue, and this happened in some iMessage vulnerabilities that I reported recently. These ones actually work on iPhone and Mac, and we’ve exploited one of these. These are basically once again remote issues, don’t touch the target device and code execution. All of these bugs happened due to deserialization in iMessage. The problem was that there’s this class that’s used for deserialization basically everywhere on Mac and IOS systems, and one of their features is that when you decode a class like an array, it will also decode the subclass.
This is useful in a lot of contexts, especially local contexts. In the remote contexts, it was a lot of attack surfaces. It meant that you could deserialize all these classes that weren’t necessary, and basically all these bugs were in these subclasses.
Apple fixed these issues, but they also added a serialization mode where you could just decode the class and not the subclasses. If this had been reduced before we started looking for these bugs, we would have found zero bugs. All of these bugs would have been prevented by reducing the attack surface, which, specifically in the context of iMessage, didn’t add any features that were useful to users.
How do you prevent this? Make sure every attack surface supports only the needed features and be very careful about that situation where you have the code that is used for the low privileged context and the very sensitive context, because you need a way to make sure that people aren’t putting stuff into the component that’s not very sensitive, not realizing that it’s also being put into this very sensitive component. One easy way to do that is to split the code. There’s other ways like Code Review, but it’s important to think about.
Also, avoid multiple copies of the same library. This is a situation where you’re just creating more risk of bugs usually with no benefit to users.
Third-Party Code
Now I’m going to talk a little bit about third party code. Third-party code is a frequent cause of unnecessary attack surface. There’s lots of ways it can go wrong. It can be straight out misused, it can support extra features, it cannot be updated and it can interact with stuff in unexpected ways.
Let me give some examples of all of these. To start off, straight off misuse. This is a vulnerability that [inaudible 00:22:58] and I found in the FireEye Malware protection system. This is a device that will just sit on your network and scan stuff that’s coming in over the network and see whether it’s malicious, see whether it’s a known virus, that sort of thing. One thing that this will do is, if you send a JAR file over the network, it will decompile it and make sure that it’s safe. The way the system did it is they used a third-party library called Jode, and it will decompile the stuff on the network with it. We contacted the developer of this component and he told us, “You shouldn’t do that. It executes the code while it decompiles it.”
This vulnerability was pretty basic. We sent in the JAR that was decompiled using this feature, and yes, it did, in fact, execute our code in this appliance. Anyhow, this a situation of plug and play. Find the thing that does what you need, put it on without thinking about security, and that can lead to all sorts of security issues including stuff like this.
Now here’s an example of something being done right. Another risk with third-party software is it has all these features you don’t use, because third party software is never made exactly for your application. There’s always extra stuff in there. In this case, there was a memory corruption vulnerability in Linux, and it didn’t affect Android because Linux supports flags that you can use to turn off features. Android had actually set these flags.
This is good design from the Linux perspective in that they make it so that people who use Linux can turn different features off and it’s good design from the Android perspective because they actually made a point of turning off everything they weren’t using.
Here’s a more complicated example of isolating yourself from third party software. James Forshaw and my team worked with Adobe to do what he called win32Klcodkwon. The idea is that for a while there were vulnerabilities in Adobe Flash all the time. They would lead to arbitrary code execution in the context of the browser. To actually start accessing interesting data, you need to break out of the browser sandbox and access the OS.
A common way this was done on Windows was using an API called win32k. It was fairly old and had a lot of vulnerabilities in it. What James did is, on Windows there’s a way that you can compile a binary so that it can’t use win32k. He went through all of the flash source and removed everything that needed that API, replaced it with something different and then you could turn on this flag and compile it so that it couldn’t use win32k. Then, when there was a vulnerability, this API wouldn’t be accessible to the malicious code. This is an example of Adobe flash isolating itself from the OS, the third-party software that had a lot of vulnerabilities in it.
Another thing that happened is lack of updates. When I worked on Android, this was a common problem. There were a lot of things that had delays in updates, web view, media, Qualcomm, Linux. This is an ongoing problem and they’re still working on basically reducing the windows between bugs being found and then being updated on Android.
If you think about it this way, if you make some software, an attacker might want to put in a lot of effort to find a bug and attack your users. If you have a third party library in there that isn’t updated, that’s free. Why would they spend on it? They just get free bugs. It’s really important to make sure these libraries are up to date. Otherwise, you’re making the bar very low for an attacker in lots of situations.
When I was working on the Android stuff, someone said something to me that really rang true. He said, “What people need to know is that a puppy isn’t for Christmas, a puppy is forever.” When you think about third-party software, this is sort of the case. When you get it, it’s new and it’s exciting and it solves all of your problems and you love it, but you don’t always think about the lifetime of maintenance it will require.
If you think about it, when you integrate a third party component into your system, in some way you are inextricably tying the future of your product to the future of that product. Even if you remove it that’s an amount of effort you’re going to have to put in. There’s going to be changes you’re going to have to make. This isn’t a decision that you can make lightly. It’s a decision that you need to make really with a solid understanding of the cost of updating the software and reducing its features and all this attack surface stuff upfront.
What do you need to do with third-party software? It’s very important to track it and to have a process for using it. Some of the worse situations I’ve dealt with have been when people don’t even know they were using that component. Someone who’s no longer at the company put it in and no one knows it’s there. The way to prevent this is to make sure that you’re tracking it and that you have a process for use, that it’s not just one person making this decision, it’s something you’re doing as a team with an understanding of what’s going to be done to maintain it.
It’s important to trim unnecessary features from third-party libraries, and a lot of them support this. If you look at stuff, for example, that supports video decoding, they’ll often let you turn specific codecs off, turn specific features off. It’s a good idea to use these flags as much as possible and just get rid of everything you’re not using, because then if there’s bugs in it, those bugs won’t affect you.
Also, security update frequently. You don’t want to give attackers free bugs, so make sure you just squash them as soon as they’re found.
Excessive SKUs and Branching
Another thing that can lead to unnecessary attack surface is excessive SKUs and branching. A SKU is a stock keeping unit. That means if you make hardware every unique model you make has a SKU. This often corresponds to a unique software release.
By branches, I mean release branches. I don’t mean you branch your software and you develop for a while and then you merge it back in. That doesn’t really have security risk. When you split your branch into 10 branches and maintain them all, that increases the security risk quite a bit. It means that you basically increase your risk of introducing bugs when you’re patching stuff, and also it means it is now 10 times the effort to patch everything.
This is a page from a Dr. Seuss poem, “Too Many Daves”. It tells the tragic tale of Mrs. McCave, who made the timesaving yet shortsighted decision to name all her sons Dave, and yet now she has problems. She has her 27 sons running around and she can’t tell them apart. When she calls them, they don’t come. No one knows what she’s talking about. This is what will happen to you if you have too many SKUs.
I’m going to give some examples of vendors who had SKUing and branching problems. In this case, I’m going to anatomize the vendor because they told me this information in confidence.
We have vendor number one and vendor number one is a large software vendor. They make a lot of products. They make a lot of software and then a small amount of hardware. We found a bug that was in two products, a new product and an old product. When we got the fix back, it was in the new product and not the old product. I thought what had happened was that they just forgot to fix it in the old one. That’s actually a really something that happens with branching.
What actually happened is they said that this was pretty much a build issue. The way their tree works is they have the new one, it goes in, it merges, it merges, it gets to the old one, it merges, it mergers. Then it gets to these tiny hardware products. This broke the build. Then they start reverting and reverting, and then apparently they cut it at that point and that’s how this bug didn’t get fixed.
This is just an example of how you have these really complicated build processes. This increases the risk for a lot of different reasons that stuff doesn’t get fixed. Either you forget to put it in or it gets reverted accidentally or it breaks the build and to takes a lot of time to fix it. All sorts of bad things for having a really large number of branches.
Now I’m going to talk about vendor number two. I have to warn you, every time I give this talk five people come up to me and are like, “Am I vendor number two?” I just want to warn you, you are probably not vendor number two. Everyone thinks this. If you are, at least you’re in good company.
Vendor number two releases 365 SKUs per year, which is one device per day. They only make devices. They don’t make anything else. Once we found a vulnerability that affected all of their devices. We typically give vendors 90 days to fix a bug, and they couldn’t fix it in 90 days because imagine over three or four years you have 1000 devices to fix this on. That made it very slow.
Because of all of these, they couldn’t tell us a fix date and they certainly couldn’t synchronize the fix date. We asked them fix saturation. How long do you think it will be until about 50% of devices are fixed? They were just, “That’s inherently unknowable.” Which is true if you have 1000 SKUs.
This is just a case where SKUs get out of control. It’s really hard to do security updates. This company has recently started reducing the number of SKUs they have to solve this problem, although this is more challenging because they don’t have support periods. They also don’t really know when they’re going to be done, when they can stop supporting this really large number of SKUs because they have no way to know whether anyone’s using them or they don’t have a date where it’s ok to cut people off.
Here’s another example. This is Android related. If you’ve ever looked at the Android tree, they have a lot of branches and they have a lot of release branches that they maintain. What happened here is, there was a vulnerability in their main kernel branch that got fixed in 2017. This didn’t make it into the branch that is used to compile the pre-built kernel that gets put onto most Android devices.
This is a situation, too many branches and this fix didn’t make it to eh branch it needed to be in to get to all of the devices. Now, two years later, my team discovers that people are using this vulnerability in the wild. This is a worst-case scenario of having too many branches. You find this vulnerability, you fix it, it doesn’t make it into something, but attackers see it and then they’re able to use that bug basically until you realize your mistake and fix it everywhere.
How do you avoid this? Avoid branching, avoid SKUs. That’s easier said than done. What I’m really saying here is make sure you understand the costs of cutting a branch and maintaining it and of creating a SKU.
It’s not uncommon for companies to do this early on without appreciating the cost, and then regretting it later. It’s a good idea to have a document of support for everything. That means if you really mess this up, there’s a timeline, even if it’s really long, in which you can fix stuff. It’s also a good idea to robustly test every branch and product. It’s obviously better to not have that so many branches or SKUs, but in the worst-case scenario, if you can’t reduce them. If you have a system set up where every time you fix a vulnerability, you can test that it’s fixed on every branch. Then, if you fix a vulnerability you can also test that every branch still functions correctly, that’s a big head start on making it so that it’s actually possible to fix a vulnerability in every single branch and to do it quickly.
Sandboxing and Privilege Reduction
Now I’m going to talk a bit about privileged reduction in sandboxing. This isn’t really attack surface reduction, but this is what you can do if you have really risky and bug-prone code that you can’t get rid of, that it’s really hard to reduce the attack surface of. To start off, privileged reduction is basically just reducing the privileges of a process. It’s not uncommon for us to find stuff that can access stuff it doesn’t need, and this is fairly simple. If you can just figure out what stuff needs and reduce it, that’s protecting your users in the case, if there’s ever a bug.
There’s also sandboxing, and sandboxing is typically when you can’t just reduce the privileges. If something is both very risky and needs access to privileged stuff, then you can split it into different pieces and then use IPC to communicate between the pieces. That can allow you to reduce the risk to the risky code while still being able to access the stuff you need to do.
It makes existing vulnerabilities less sever, although often this will require splitting functionality, and especially with sandboxing, it’s not something that you can do without understanding your code. It requires you to have a clear risk analysis of all functionality in a piece of software. To sandbox effectively, you need to basically know what you have, know what’s high risk and know what you want to split out.
Also, sandboxing adds an upfront cost. It means that now, on an ongoing basis, you need to start evaluating stuff. What component does it go in, what risk does it pose and make sure that you’re not making your sandbox more weak every time you add something new in.
To give some examples, a few years ago there was a series of vulnerabilities in Android called Stagefright. These were image decoder issues. They were presented at Black Hat by JDoc and then many people found similar vulnerabilities.
At that time these image decoding libraries and media decoding libraries were just libraries. You would load them into your process and call them, and then they would have whatever privilege level your process had, which increased the risk. This was fixed by splitting out these libraries into their own service in Android and reducing the privileges of that, and then the library was just this stub that called into this service. This means that no matter where you called them from you would have low privileges. That protected the users somewhat in the case that there was a vulnerability in the service, though of course none of this stuff is perfect and there always still is some risk posed by vulnerabilities.
Here is a picture of the Chrome sandbox. This is just an example of sandboxing. The important part here is at the bottom you have the two renderer process. These are the high-risk code. They parse all the HTML, the JavaScript, that sort of thing, and renderer processes have vulnerabilities in them all the time. I don’t even want to count, but I would say every release cycle every month there are several vulnerabilities.
The rest of the system is protected because they use IPC to talk to the other components. Let’s say you access a file in a browser, you hit something, it goes through the renderer process. Then the renderer process communicates with this and says, “Grab me this file,” and then it’ll get the file back, and that means that the process itself doesn’t need to have access to that file and that this behavior can be restricted in some ways.
I want to warn you against jumping to sandboxing, though, by using a bit of an analogy here. I think in school we were all taught about the different ways to protect the environment – reduce, reuse, recycle. The most important one is reduce. If you don’t buy the thing, it definitely won’t hurt the environment. If you do have to buy the thing, if you use it as much as possible before buying another thing, that protects the environmental a bit.Then your worst option is to recycle. If you buy the thing, use it one and recycle it, it’s still worse for the environment than the other two.
I think this is very much true about sandboxing. You’re best to just get rid of the thing and then you should try to reduce its privileges, and then you should sandbox. I think people talk about sandboxing really frequently without exploring their other options. I think it’s something that’s very important to do, but it’s also important to consider whether you need the thing that you’re sandboxing in the first place as well.
Conclusions
In conclusion, there’s a lot of things you can do to reduce attack surface. You should consider the security impact of features and design and make sure you’re considering the security cost of the feature before adding it in. You should track feature use and remove old and unused features. Carefully consider third party code and keep it up to date, reduce SKUs and branches, have a support period for every product. Sandbox and reduce privileges in the case that you can’t just reduce serious attack surface entirely.
I’m going to end off with Smokey the Bear. Only you can reduce attack surface. I want you to think about the software you develop or the software you design or the team you manage, and think of one thing you can do to reduce attack surface. Attack surface isn’t all or nothing. Every little thing you can do to reduce it will reduce your product’s susceptibility to attackers. Let’s think about how we can all reduce attack surface and protect our users.
Questions and Answers
Moderator: I have a first question. If you were to prioritize the things, what would you do first and what would you do last?
Silvanovich: Yes, this is a tough one, and its also because these things have different costs. I think for the stuff I’ve looked at, the big wins are often removing the unused features. Sometimes that can be very easy, low cost. Also, the third-party code is a huge one, and that’s something I often see big wins in. Things like the reducing the SKUs, that’s hugely valuable, but it’s also hugely expensive and time-consuming often. I’d say maybe that one’s not as important, but it really depends on what you’re looking at.
Often when people start looking at attack surface, there’s a few things where they can tell right away as easy, big win, and then there’s things that are more expensive that they have to consider more closely.
Moderator: So usually, on security, it depends on the threat model.
Participant 1: Thanks for the great talk. I have a question. You say that we should carefully consider adding or importing dependencies on third party libraries. If we don’t, if we really need that feature, there is library that implements that and we need to choose, do I bring this guy, this thing, into my system or should I implement myself and risk it having a bug, which will cause a security failure?
Silvanovich: That’s a really good point and I actually forgot to say that. I’m not against third-party libraries. I think there are definitely situations where the risk of using the third party is less than the risk of running your own.
Some examples of this would be things like crypto image decoders, things where there’s really good mature solutions and your chance of writing a good one isn’t as high as what’s out there. I think where there tends to be more problems is the stuff that’s less well used or people who include it for a tiny thing from which the code is outsized.
,p> I think the way to balance this is if there’s a really good mature solution that does security updates and you’re committed to updating it, I think that’s usually better than writing your own software. It’s where you start getting into things with immature software, no security updates, not very many users, I think that’s when you should either spend a lot of time evaluating that solution or seriously consider writing your own.
Participant 2: You mentioned the point where you do not want to reuse the libraries in multiple places, but nowadays, having the [inaudible 00:45:06] it allows you to have it decentralized. You can download those plugins anywhere from the internet as well by just having [inaudible 00:45:17] plugins.
It solves a lot of purpose for the developer because you get, on the fly, a lot of libraries. It makes it easier for the development. How do you balance between these two things, where you were suggesting not to use the libraries in multiple places?
Silvanovich: For third-party libraries, I think it’s always just a matter of, are they suitable for your purpose? Are they mature enough? Are they better than what you can write? For that case, if you end up using it in two places, that’s not a big deal if you’ve evaluated it and you’re tracking new features and that sort of thing. I think the problem with the code-sharing happens more often with internal libraries.
Participant 2: I’m talking about internal, mainly.
Silvanovich: Yes. Your internal stuff. I think that you have to decide either do you split or do you go to the work of tracking, that it’s always going to be useful or all the purposes you’re using it on. There’s no right answer there, but it’s basically important to do one or the other. Most of the problems occur when people just share and then don’t think about, we have all of these competing needs based on everyone who’s using it, and we haven’t given any thought to how we reconcile them.
Participant 2: Adding to that, also, I feel there is a bureaucracy. We have a software division completely focused on creating libraries. That’s their main job. They want you to push all these [inaudible 00:46:51] used in all the business areas and so their core or their job streamline. How do [inaudible 00:47:02]
Silvanovich: I think there’s an opportunity there. If they really want you to use their libraries, then maybe they really want to make sure that their libraries are suited to the needs of everything they’re being used for. Maybe that’s an opportunity to put things like flags in or other ways to basically make sure that minimum features are used in security-sensitive context.
See more presentations with transcripts
MMS • Dylan Schiemann
Article originally posted on InfoQ. Visit InfoQ

The TypeScript team announced the release of TypeScript 3.8, which includes type-only imports and exports, private fields, and top-level await.
While the importing and exporting of types would often work because of import elision, ambiguity occurred when it was unclear if it was a type or value getting imported. Import statements that only contained imports used as types would get eliminated by TypeScript’s import elision. To work around these issues, TypeScript 3.8 adds a new syntax for importing and exporting types:
import type { SomeThing } from "./some-module.js";
export type { SomeThing };
The import type statement only imports declarations to use for type annotations and declarations and always gets fully erased during transpilation. The export type command only provides an export for type contexts, also getting erased from TypeScript’s output. When using import type to import a class, the class cannot get extended.
The TypeScript compiler introduces a new flag, importsNotUsedAsValues, to determine what happens to imports not used at run-time. The values for this flag, remove, preserve, or error, provide developers with more control over importing and exporting types.
The ECMAScript private fields proposal recently reached stage 3 due to significant efforts from Bloomberg and the TypeScript team.
Private fields start with a # character and get uniquely scoped to their containing class. TypeScript modifiers like public or private cannot get used on private fields. Private fields cannot get accessed or detected outside of the containing class.
Private fields are different than the TypeScript private keyword. As explained by Daniel Rosenwasser, program manager of the TypeScript team:
When it comes to properties, TypeScript’s private modifiers are fully erased – that means that while the data will be there, nothing is encoded in your JavaScript output about how the property was declared. At runtime, it acts entirely like a normal property. That means that when using the private keyword, privacy is only enforced at compile-time/design-time, and for JavaScript consumers, it’s entirely intent-based. The upside is that this sort of “soft privacy” can help your consumers temporarily work around not having access to some API, and works in any runtime. On the other hand, ECMAScript’s # privates are completely inaccessible outside of the class.
Note that TypeScript currently only supports private fields transpilation to ES6 and higher as the backward-compatible implementation leverages WeakMaps, whereas the private keyword works back to ES3.
ECMAScript 2020 adds export * syntax to expose all members of a module as a single member. Previously developers would need to use this syntax:
import * as utilities from "./utilities.js";
export { utilities };
With ECMAScript 2020 and TypeScript 3.8, this gets reduced to:
export * as utilities from "./utilities.js";
The introduction of promises in ES6 provided the foundation for better asynchronous handing in JavaScript, but has led to many additional features in the five years since its initial release, such as async/await. The latest addition is top-level await, which allows await at the top level of a module.
Top-level await is now also supported by TypeScript 3.7, though only can get transpiled to ES2017 and newer environments, and the modules support is esnext or system, as it requires an environment with ES module support.
TypeScript 3.8 now supports es2020 as a transpilation target and module option. This mode preserves the ES2020 features added in TypeScript 3.7 and 3.8.
The TypeScript 3.8 release improves its directory watching support and adds a new watchOptions compiler configuration field. These options give developers greater control over how directories and files get watched, improving performance and reliability in working with changes to node_modules.
The watchOptions field provides four new options: watchFile, watchDirectory, fallbackPolling, and synchronousWatchDirectory, each of which has several configuration options for how often to check files and directories.
The TypeScript 3.8 compiler also includes a new compiler performance optimization option, assumeChangesOnlyAffectDirectDependencies, which tells TypeScript only to recheck and rebuild files that have changed as well as files that directly import them.
With each TypeScript release, the compiler introduces breaking changes as its type checking capabilities improves. In TypeScript 3.8, the compiler adds stricter assignability checks to unions with index signatures.
In the TypeScript community, after two TSConf events in Seattle in 2018 and 2019, the first TSConf Japan and TSConf.eu events are occurring in February and March.
TypeScript is open source software available under the Apache 2 license. Contributions and feedback are encouraged via the TypeScript GitHub project and should follow the TypeScript contribution guidelines and Microsoft open-source code of conduct.