Month: April 2021
Global Enterprise Data Management Market 2020 Recovering From Covid-19 Outbreak | Know …

MMS • RSS
Posted on mongodb google news. Visit mongodb google news

The Enterprise Data Management Market on-Surgical Fat Reduction marketis globally one of the leading markets involving innovative techniques development and extremely categorized sector. After a thorough investigation conducted over the industries under Enterprise Data Management market, the market report delivers in-depth information, based on the data related to export and import along with the ongoing industry trends in the global market. The report deeply observes the competitive structure of the Enterprise Data Management market worldwide. The Enterprise Data Management market report comprises the detailed summary of the various firms, manufacturers, organizations, and other competitive players ( Mindtree, Accenture, Goldensource, Phasic Systems Inc., Innovative Systems Inc., Informatica, Liasion Technologies, SAS Institute Inc., Solix technologies Inc., SyncForce, Jade Global, Cambridge Semantics Inc., SAP SE, IBM Corporation, Teradata Corporation, Cognizant, Symantec Corporation, Oracle Corporation, Intel Security, Stibo, Primitive Logic, Mulesoft, MongoDB. ) that hold major count over the global market in terms of demand, sales, and revenue by providing reliable products and services to the customers worldwide.
Get a Free Sample Report, Please [email protected] https://www.syndicatemarketresearch.com/sample/enterprise-data-management-market
The global Enterprise Data Management market report renders notable information about the Enterprise Data Management market by fragmenting the market into various segments. The global Enterprise Data Management market report delivers a comprehensive overview of the market’s global development including its features and forecast. It requires deep research studies and analytical power to understand the technology, ideas, methodologies, and theories involved in understanding the market.
Leading Manufacturers Analysis in Global Enterprise Data Management Market 2020:
Mindtree, Accenture, Goldensource, Phasic Systems Inc., Innovative Systems Inc., Informatica, Liasion Technologies, SAS Institute Inc., Solix technologies Inc., SyncForce, Jade Global, Cambridge Semantics Inc., SAP SE, IBM Corporation, Teradata Corporation, Cognizant, Symantec Corporation, Oracle Corporation, Intel Security, Stibo, Primitive Logic, Mulesoft, MongoDB.
Furthermore, the report presents complete analytical studies about the limitation and growth factors. The report provides a detailed summary of the Enterprise Data Management market’s current innovations and approaches, overall parameters, and specifications. The report also gives a complete study of the economic fluctuations in terms of supply and demand.
Based on Product Types report divided into
On-Cloud, On-Premise
Based on Applications/End-users report divided into
Energy and Utilities, BFSI (Banking, Financial Services and Insurance), Government, Healthcare, IT and Telecom, Transportation and Logistics, Retail, Manufacturing
To Know More About the Enterprise Data Management Market Report, Do Inquiry Here https://www.syndicatemarketresearch.com/inquiry/enterprise-data-management-market
Apart from this, the report includes the Enterprise Data Management market study based on geographical and regional location. Geographical Segmentation, On the basis of region, North America (United States, Canada), South America (Argentina, Chile, Brazil, etc.), Asia-Pacific (India, China, Japan, Singapore, Korea, etc.), Europe (UK, France, Germany, Italy, etc.), the Middle East & Africa (GCC Countries, South Africa, etc.) and the Rest of the world.
Key Points of Enterprise Data Management Market:
- CAGR of the Enterprise Data Management market during the forecast period 2020-2026.
- Forecasts on future industry trends and changes in customer behavior.
- Accurate information on factors that will help in the growth of the market during the next six years.
- Outlook of the market size and its contribution to the parent market.
- The growth and current status of the market in the COVID-19 Pandemic Situation.
- Analysis of the competitive landscape of the market and detailed information on the vendors.
- A comprehensive description of the factors that will challenge the growth of market vendors.
The Enterprise Data Management global report indicates the status of the industry and regional and global basis with the help of graphs, diagrams, and figures to make it easy and better understandable.
The Enterprise Data Management Report Supports the Facts Below:
Industry Historical Demand Trends and Future Development Study – Enterprise Data Management Market Investors will make their business decisions based on historical and projected performance of the market Enterprise Data Management in terms of growth trends, revenue contribution, and Enterprise Data Management market growth rate. The report offers Enterprise Data Management industry analysis from 2016 to 2019, according to categories such as product type, applications/end-users and regions.
Market Drivers, Limits and Opportunities – The market is deeply evaluated by a current market situation such as market growth factors and constraints. In addition, here we can discuss the latest industry news and its impact on the Enterprise Data Management business.
Industry Chain Analysis – The study of industry chain structure incorporates details related to supplier’s and buyer’s information. Furthermore, the report classifies the top manufacturers of Enterprise Data Management business based on their production base, cost structure, Enterprise Data Management production process, spending on raw materials and labor outlay.
Future Project Expediency – The Enterprise Data Management market report includes a detailed explanation about the past and present trends of the market has been following along with its future analysis that may concern with the Enterprise Data Management market growth.
You Can Browse Complete Report Here with TOC in a Single Click https://www.syndicatemarketresearch.com/market-analysis/enterprise-data-management-market.html
Note – To provide a more accurate market forecast, all our reports will be updated prior to delivery considering the impact of COVID-19.
(If you have any special requirements, please let us know and we will report to you as you wish.)
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Almir Vuk
Article originally posted on InfoQ. Visit InfoQ

ASP.NET Core in .NET 6 Preview 3 brings a lot of nice features to explore and one of them is the usage of Blazor components inside of desktop, WPF and Win Forms, applications via BlazorWebView control.
Hybrid apps are something that will be supported and emphasized with .NET 6. That will be accomplished using BlazorWebView. Support for building cross-platform hybrid desktop apps means you can write some of the UI parts of an app using web technologies while also leveraging native device capabilities of that platform and OS.
In .NET 6 Preview 3, BlazorWebView control is introduced for WPF and Windows Forms apps. Using BlazorWebView the developer is enabled to embed some of the Blazor functionality inside of the existing Windows desktop app which is based on the .NET 6. This hybrid approach allows the development team to combine existing WPF or Windows Forms desktop apps to modernize them and upgrade them with web-based parts using BlazorWebView embedding while keeping the core functionality and APIs of a desktop app.
In order to start using BlazorWebView controls, WebView2 Runtime needs to be installed.
The next steps to include Blazor functionality to an existing Windows Forms app are to update the Windows Forms app to target .NET 6 along with an update of the SDK used in the app’s project file to Microsoft.NET.Sdk.Razor.
With adding a package reference to Microsoft.AspNetCore.Components.WebView.WindowsForms the access to the WebView component is granted.
After adding the HTML and CSS files into wwwroot the Copy to Output Directory property of wwwroot needs to be set to Copy if newer.
Existing Blazor component can be rendered using BlazorWebView, with the following code snippet:
var serviceCollection = new ServiceCollection();
serviceCollection.AddBlazorWebView();
var blazor = new BlazorWebView()
{
Dock = DockStyle.Fill,
HostPage = "wwwroot/index.html",
Services = serviceCollection.BuildServiceProvider(),
};
blazor.RootComponents.Add<Counter>("#app");
Controls.Add(blazor);
The difference between adding BlazorWebView usage in the WPF app is with the reference to Microsoft.AspNetCore.Components.WebView.Wpf (url: https://nuget.org/packages/Microsoft.AspNetCore.Components.WebView.Wpf), and its usage in XAML control with set up the service provider as a static resource in the XAML code-behind.
<Window x:Class="WpfApp1.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:WpfApp1"
xmlns:blazor="clr-namespace:Microsoft.AspNetCore.Components.WebView.Wpf;assembly=Microsoft.AspNetCore.Components.WebView.Wpf"
mc:Ignorable="d"
Title="MainWindow" Height="450" Width="800">
<Grid>
<blazor:BlazorWebView HostPage="wwwroot/index.html" Services="{StaticResource services}">
<blazor:BlazorWebView.RootComponents>
<blazor:RootComponent Selector="#app" ComponentType="{x:Type local:Counter}" />
</blazor:BlazorWebView.RootComponents>
</blazor:BlazorWebView>
</Grid>
</Window>
var serviceCollection = new ServiceCollection();
serviceCollection.AddBlazorWebView();
Resources.Add("services", serviceCollection.BuildServiceProvider());
Issues with Razor component types not being visible in the project can be resolved by the usage of an empty partial class for the component.
Other noticeable updates and releases about ASP.NET Core updates in .NET 6 Preview 3 are: smaller SignalR, Blazor Server, and MessagePack scripts, how to enable Redis profiling session, HTTP/3 endpoint TLS configuration, .NET Hot Reload support, Razor compiler no longer produces a separate Views assembly, Shadow-copying in IIS, Vcpkg port for SignalR C++ client, reduced memory footprint for idle TLS connections, remove slabs from the SlabMemoryPool. About Blazor WebView and other releases, you can read more on the announcement written by Daniel Roth.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Allow us to perceive the necessity for and significance of database sharding with the assistance of an instance.
Assume there’s a database assortment (with no sharding) of 50,000 workers working in a reputed Multi-Nationwide Firm. The corporate maintains a database document of all of the freshers and skilled workers in a single database.
Your activity is to entry a profile of an worker from the 50000-employee database. With out sharding the database, discovering the end result will take numerous time and effort. The search sample will comply with a step-by-step strategy and wish 50,000 transactions to show the small print of a single piece of knowledge you’re in search of within the database.
Going again to the identical instance, we now divide the overall variety of workers into sub-divisions akin to freshers, skilled, job-profile, and different sections to make the search simpler. For example, if there are a complete of 15000 Software program-Builders working within the firm, and also you need the small print of a selected developer, then the database will look solely into the 15000 sub-divisions as an alternative of trying by way of your entire database.
1. Spot the distinction?
The database on the second situation seems to be extra organized, simplified, and clear after database sharding. Proper? That’s the place database sharding comes into the image. The thought behind database sharding is to simplify the duty into smaller divisions to reuse the information in a tech-savvy and environment friendly manner. Technically, database sharding streamlines the looking course of and makes an attempt to search out the search merchandise from the checklist within the first go, thus saving time.
2. What’s Sharding?
Database sharding is an information distribution course of and shops a single knowledge set into a number of databases. The aim of database distribution is to reinforce the scalability of functions. Sharding is a wonderful technique to hold the information secure throughout completely different assets. In MongoDB, database sharding is achievable by breaking down large knowledge units into sub-divided knowledge units throughout a number of MongoDB cases.
Consideration: MongoDB makes use of database sharding for deployment assist, particularly when there are high-volume knowledge units which can be comparatively elevated throughput operations. It’s also necessary to notice that every shard is an unbiased database, and all of the shards include a single native database.
three. Sharded Cluster
Sharded Cluster is a gaggle of MongoDB cases. In easy phrases, these are a set of nodes that comprise MongoDB deployment. A sharded cluster has three essential elements:
- A Shard: A shard is a single MongoDB occasion that holds a subset of the sharded knowledge. Every shard could be a reproduction set or a single mongos occasion.
- Config server: Config servers retailer the metadata for a sharded cluster. It consists of the set of chunks on the person shard and in addition the vary defining the chunks.
- Mongos cases: Mongos cases cache the information and route learn and write operations to the appropriate shards. Furthermore, additionally they replace the cache when metadata adjustments for the cluster.
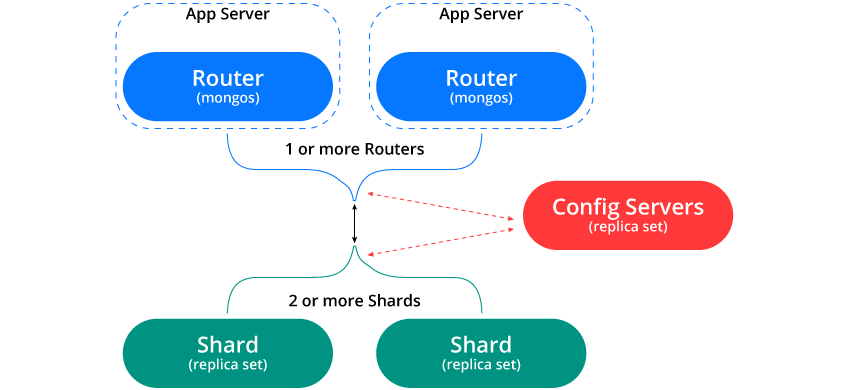
four. Shard Keys
On sharding a MongoDB dataset, a shard secret’s mechanically created by default. The shard key will be within the type of an listed subject or listed compound fields that will probably be used to distribute the information among the many shards. Typically, the “shard key” is used to distribute the MongoDB assortment’s paperwork throughout all of the shards, the place the important thing consists of a single subject or a number of fields in each doc.
MongoDB divides the vary of shard key values into non-overlapping ranges of shard key values, the place each vary is linked with a bit. Particularly, MongoDB tries to interrupt down chunks in an excellent style among the many completely different shards current within the cluster.
A shard key can be utilized to distribute knowledge within the following
5. Balancer and Even Chunk Distribution
The balancer is a course of that holds the accountability of distributing the chunks evenly among the many completely different shards. There’s a stability specifier for every cluster that handles the chunk distribution. The stability specifier handle operating the first job and even distributing chunks throughout all shards evenly. The method of this kind of chunk distribution carried out evenly is popularly referred to as even chunk distribution.
6. Benefits of Sharding
The elemental thought behind database sharding is to interrupt advanced knowledge into subparts for simple accessibility anytime, anyplace. Take a look at some great benefits of sharding a database:
1. Elevated Storage capability
In database sharding, when knowledge will get distributed throughout the shards within the cluster, every shard comprises a subset of the overall knowledge within the cluster. On growing the information quantity, the extra shards develop which results in increasing the cluster storage capability.
2. Excessive Availability
With an unsharded database, an outage in a single database shard has the caliber to deteriorate your entire utility and loosen its performance and even cease. Nevertheless, with a sharded database, if there may be full unavailability of a number of shard replicas, only some components of the appliance or web site are unavailable to some customers. Nevertheless, the opposite shards proceed their operation with none concern.
three. Learn/write
In MongoDB, the learn and write workloads are simply distributed throughout the shards within the sharded cluster. It permits every shard to course of a subset of the cluster operation. Each the learn and write efficiency will be instantly scaled horizontally throughout the cluster by growing the shard rely.
four. Facilitates horizontal scaling
Another reason programmers love database sharding is that it facilitates horizontal scaling (additionally famend as scaling out). Meaning it permits to have parallel backends and perform duties concurrently with no trouble. Whether or not the main focus is on writing or studying operations, scaling out can add an enormous benefit to reinforce the efficiency and in addition remove complexities.
5. Speedier question response
Everytime you submit a question on an unsharded database, it seems to be for the searched question in all of the rows and columns of the desk till it finds the searched question. For low-volume knowledge, it could look insignificant, nevertheless it turns into problematic with a high-volume database. In contrast to the unsharded database, the sharded database distributes the database into sub-sections the place queries need to go to fewer rows, and the outcomes are thus fast and environment friendly.
7. Sharded and Non-Sharded Collections
A database assortment will not be all the time uniform. Meaning the database can have a mix of each sharded in addition to unsharded collections of knowledge.
Sharded Assortment: A set of knowledge which can be damaged down within the cluster and are properly partitioned known as a sharded assortment.
Non-Sharded Assortment: The database assortment saved on a major shard (the shard carrying all of the un-sharded assortment) is named a non-sharded assortment.
eight. Connecting to a Sharded Cluster
For connecting to a sharded cluster, it is advisable hook up with the sharded router utilizing the mongos course of. Meaning it’s important to be a part of the mongos router with collections (sharded and unsharded) within the sharded cluster. By no means make the error of connecting to each particular person shard for performing learn and write operations.
9. Sharding Technique
For the distribution of knowledge throughout the shared clusters, the MongoDB sharding follows the next methods:
- Hash-based Sharding
- Vary based mostly Sharding
- Listing-based Sharding
- Geo-based Sharding
10. Hash-based Sharding
Hash-based database sharding is also called key-based sharding. Right here values are taken from newly registered knowledge into the database and plugged into the hash perform. Key-value, or we are able to name it the hash worth, is the shard ID that determines the situation of incoming or the registered knowledge. Ensure to maintain the values on the hash perform in a sequential association in order that there isn’t a mismatch of worth and the shard.
11. Vary-based sharding
Ranged sharding includes knowledge distribution based mostly on the ranges of the given shard values. For example, there’s a assortment of knowledge storing the stock particulars the merchandise will get positioned based mostly on the amount of knowledge availability. The largest downside of range-based sharding is that it wants a lookup desk for studying and write queries, so it could retard the appliance efficiency.
12. Listing-based Sharding
Listing-based sharding is a sharding technique used to take care of a document of shard knowledge. There’s a lookup desk (additionally known as location service), the place it shops the sharded key and tracks all the information entries. Utilizing the shard and key pair, the shopper engine takes session from the situation service after which switches to a selected shard to proceed for additional work.
13. Geo-based Sharding
Geo-based sharding is similar to that of range-based database sharding, with the one distinction that queries listed here are geographically based mostly. The information procession is down with a shard that corresponds to the person area underneath the vary of 100 miles. The proper instance is Tinder, a courting app that makes use of Geo-Based mostly sharding to maintain balancing the manufacturing load of the geo-shards.
14. Concerns Earlier than Sharding
The perks of knowledge sharding could impress you. Nevertheless, there are various components that want consideration, else you will have to pay the worth of knowledge loss or injury. There are a couple of issues it’s essential to deal with earlier than continuing with the database sharding:
- Earlier than database sharding, be mindful completely different points like planning, execution, and upkeep. Ensure to have a chicken’s-eye view of all of the sharded cluster infrastructure necessities and complexities concerned.
- Be cautious when coping with knowledge assortment, particularly with the sharded database assortment. Thoughts you, after you have shared a database assortment, there isn’t a technique to undo it. Merely put, MongoDB doesn’t allow unsharding after sharding database assortment.
- The selection of Shard key you make for sharding performs a big position in cluster habits, total effectivity, and efficiency. Ensure to examine the cardinality, frequency, and monotonicity of the shard key correctly. Don’t miss to examine the shard key limitation.
- Operational necessities and restrictions of database sharding are additionally exhausting to disregard.
15. Zones in Sharded Clusters
Earlier than we dive into the MongoDB zone, allow us to deal with understanding a zone.
A gaggle of shards with a selected set of tags is usually referred to as a zone. MongoDB zones out there in shading permit distributing chunks based mostly on chunks throughout shards. All of the work, learn and write documentation inside a zone is finished on shards matching the zone. When creating sharded knowledge zones within the sharded clusters, you possibly can hyperlink a number of shards within the cluster. Better of all, you possibly can freely affiliate a shard with any variety of zones. Simply needless to say each time there’s a balanced cluster, migration of chunks in MongoDB takes place such that solely these shards related to the zone get migrated, lined by the zone.
Consideration: MongoDB routes reads and writes falling right into a zone vary solely to these shards contained in the sharded cluster zone. Shard zones are simply manageable. All the fundamental operations like making a zone layer, including or eliminating shard from the zone, or overviewing current zones are potential.
16. Collations in Sharding
A gaggle of transactions belonging to a single shard is named collations. It consists of a transaction checklist and a collation header. The collation header includes info submitted to the principle chain, and the transaction checklist is the sequence of transactions.
Attempt utilizing the shard Assortment command together with the collation: choice to shard a group with a default collation.
1. Change Streams
It turns into troublesome for functions to answer sudden adjustments.
From the upgraded MongoDB model three.6, change streams allow functions to simplify the real-time knowledge adjustments by leveraging MongoDB functionalities. Meaning functions can get knowledge accessibility with out the price of tailing the operations log. Change streams include sturdy and dynamic options like the overall ordering that permits functions to obtain adjustments sequentially as utilized to the database.
2. Transactions
The organized manner of representing the change of state is named transactions. Ideally, there are 4 properties known as ACID:
- Atomic – The general transaction will get dedicated, or there isn’t a transaction in any respect.
- Constant – The database have to be constant earlier than and after the transaction.
- Remoted – No-one will get to see any a part of the transaction till it’s dedicated.
- Sturdy – Even when there’s a system failure or a restart, there isn’t a change on the saved knowledge.
MongoDB helps multi-document transactions. The MongoDB model helps four.zero, multi-document transactions on reproduction units, whereas the upgraded Mongo model four.2, helps multi-document transactions on reproduction units and the sharded clusters.
Wrapping Up
Database sharding facilitates horizontal scaling and is a more practical technique to pace up operational effectivity. Apart from, sharding databases simplify the data-management and upkeep procedures. Maybe, not all databases assist database sharding. Worst of all, the sharded database can not get unsharded. The largest concern comes when coping with advanced knowledge, particularly when there’s a knowledge pull from a number of assets. Watch out and attentive, and bear in mind the listed issues talked about above. As a delicate reminder, database sharding will solely flip to your benefit if you understand to make use of them successfully. In any other case, if not achieved the appropriate manner, you would possibly corrupt tables and even result in knowledge loss.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

The Latest Released NoSQL market study has evaluated the future growth potential of Global NoSQL market and provides information and useful stats on market structure, size and trends. The report is intended to provide cutting-edge market intelligence and strategic insights to help decision makers take sound investment decisions and identify potential gaps and growth opportunities. Besides, the report also identifies and analyses changing dynamics, emerging trends along with essential drivers, challenges, opportunities and restraints in NoSQL market.
The business intelligence report of NoSQL market is a compilation of the key factors overseeing industry growth with respect to the competitive landscape and geographical outlook. Moreover, the report elaborates on the challenges prevailing the industry while also offering insights into opportunities that will aid business growth in micro markets. Additionally, case studies depicting the impact of COVID-19 pandemic on the industry are included, to impart a better understanding of this business vertical.
Overview of COVID-19 impact analysis:
- Impact of COVID-19 on global markets along with their economic condition.
- Observed variations in demand share and supply trends of the industry.
- Short term & long-term outlook of COVID-19 pandemic on market growth.
Request Sample Copy of this Report @ https://www.business-newsupdate.com/request-sample/91444
A snapshot of the regional landscape:
- As per the study, the regional landscape of the NoSQL market is fragmented into North America, Europe, Asia-Pacific, Middle East and Africa, South America.
- Performance of each regional market is analyzed with respect to the projected growth rate over the forecast duration.
- Insights into the sales generated, revenue accrued, and growth rate registered major regional contributors are included.
Other highlights from the NoSQL market report:
- The competitive gamut of the NoSQL market is defined by leading players like IBM Cloudant,MongoDB,Aerospike,MapR Technologies,Couchbase,MarkLogic,Basho Technologies,Neo4j,MongoLab,Google,SAP,AranogoDB,Microsoft,Apache,DataStax,RavenDB,Oracle,Amazon Web Services,Redis,CloudDB andMarkLogic.
- Crucial details regarding manufactured products, company profile, production patterns and market remuneration, are given.
- The research entails information pertaining to the individual market share held by each major company, along with their gross margins and pricing patterns.
- The product landscape of the NoSQL market is comprised of Key-Value Store,Document Databases,Column Based Stores andGraph Database.
- Minutiae regarding revenue aspects as well as volume predictions of each product segment is provided.
- Pivotal information such as market share, growth rate, and production patterns of each product type over the forecast timeframe are documented.
- The report fragments the application spectrum of the NoSQL market into Retail,Online gaming,IT,Social network development,Web applications management,Government,BFSI,Healthcare,Education,Others, ,Geographically, the detailed analysis of production, trade of the following countries is covered in Chapter 4.2, 5: ,United States ,Europe ,China ,Japan andIndia.
- The report examines the market share for each application while predicting the growth rate for the forecast period.
- The study also enumerates the competition trends and provides a comprehensive analytical review of the industry supply chain.
- The report assesses market dynamics by conducting Porter’s five forces analysis and SWOT analysis to determine the feasibility of a new project.
Key points of the market study:
- Comprehensive analytical overview of the current NoSQL market scenario and market dynamics.
- Holistic outlook comprising of internal and external factors including product development strategies
- A thorough analysis of the impact of COVID-19 on the NoSQL market
- Competitive player’s sustenance as a result of adaptive techniques
- Vulnerability of the market dealt with incorporation of sustainable and innovative ideas
- Detailed product insight via the product portfolio, product requirements and relevant specificities
- Fluctuating customer behavior amidst the fast-changing global trends
- Geographic analysis specifying the largest market share holder and the potential market spaces.
Reasons for buying this report:
- It offers an analysis of changing competitive scenario.
- For making informed decisions in the businesses, it offers analytical data with strategic planning methodologies.
- It offers seven-year assessment of NoSQL Market.
- It helps in understanding the major key product segments.
- Researchers throw light on the dynamics of the market such as drivers, restraints, trends, and opportunities.
- It offers regional analysis of NoSQL Market along with business profiles of several stakeholders.
- It offers massive data about trending factors that will influence the progress of the NoSQL Market.
Request Customization on This Report @ https://www.business-newsupdate.com/request-for-customization/91444
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Database choice performs a big function in total product improvement. How seamlessly you may edit, replace, retrieve or delete is determined by the database you select. Of the 2 database sorts – non-relational and relational databases, it’s essential to select the perfect match based mostly in your particular person wants. You’ll have most likely heard about probably the most in-demand database MongoDB, which is a NoSQL and a highly regarded doc database. On this article, we try to the touch upon the explanations for the elevated reputation of MongoDB.
MongoDB, a document-based NoSQL database, is a schema-less database with compelling traits and salient options that permits customers to question knowledge in probably the most easy and tech-savvy manner. The database supported with JSON-style storage allows customers to control and entry knowledge with no hassles.
With greater than 15 million downloads, MongoDB has change into probably the most most popular database and is utilized by programmers globally. Carry on studying to know extra about MongoDB, its benefits, why to make use of it, and the place it may be used.
Benefits of MongoDB over RDBMS
MongoDB NoSQL databases and relational databases differ in some ways. Not solely is MongoDB easy-to-use, however it additionally helps wonderful scaling choices. Furthermore, the efficiency capabilities of MongoDB are unbeatable in comparison with different databases.
Sounds awe-inspiring? There are different distinctive and unparalleled options and built-in functionalities that make MongoDB probably the most most popular alternative amongst builders. Allow us to check out a few of the benefits of utilizing MongoDB over RDBMS.
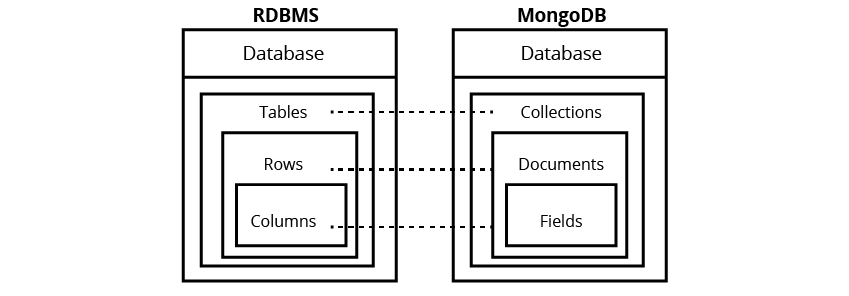
MongoDB is schema-less: In relational databases, we should create tables, schemas, and relations to determine and manage the info. However, MongoDB is a schema-less database that doesn’t require the creation of tables and different inflexible, pre-defined schema. As a doc database, MongoDB shops all of the information in a single assortment.
MongoDB has no joins: In RDBMS, connecting two or extra tables is difficult because it requires utilizing joins. MongoDB has no advanced joins, and altering the doc construction in MongoDB is straightforward, permitting us to attach different paperwork with no problem.
No major key set-up: When utilizing RDBMS, establishing a major key’s mandatory. In MongoDB, there isn’t a have to explicitly create a major key. The NoSQL database affords an _id area, created by default, with each doc. This created area acts as a major key. The reserved _id area serves as the first key in MongoDB, and it have to be a singular worth. You will need to be aware that if there isn’t a set as much as the _id area, MongoDB fills it with “MongoDB Id Object” robotically.
MongoDB Makes use of CAP Theorem: RDBMS focuses on ACID properties by way of Atomicity, Consistency, Isolation, and Sturdiness. However, MongoDB makes use of CAP theorem Consistency, Availability, and Partition tolerance for database distributions.
What makes MongoDB a lot in-demand?
Are you aware why MongoDB is turning into a favorite alternative amongst builders? Its wonderful capabilities are listed under:
Versatile doc schemas
Utilizing Structured Question Language databases, each time there’s an try to insert info, declaration and affirmation of a desk schema are mandatory. MongoDB, being a doc database, holds completely different paperwork in a single assortment. Merely put, MongoDB permits the storage of a number of objects in a unified manner, with a distinct set of fields. Versatile doc schemas provide nice benefits when engaged on advanced knowledge or dealing with real-time knowledge.
Code-native knowledge entry
Getting the info within the Object is usually not straightforward. In a lot of the databases, you’ll most likely need to leverage Object Relational Mappers to get this work executed. MongoDB saves you from utilizing heavy wrappers and permits you to retailer and entry knowledge in the simplest manner. Merely put, you may have code-native knowledge entry from any programming language like dictionaries in Python, associative arrays in JavaScript, and Maps in Java.
Change-friendly design
Many programmers have the behavior of bringing down the location or utility for customizing knowledge. With MongoDB, there isn’t a have to convey the location down as a result of the modifications or customizations supplied utilizing MongoDB are spectacular. Any time you have to change the schema, you’ll not need to lose beneficial downtime. MongoDB permits customers so as to add new knowledge anytime, anyplace – with none disturbance in its operational processes.
Highly effective querying and analytics
The truth that there are not any advanced joins in MongoDB additionally provides as much as an amazing benefit. Which means MongoDB permits knowledge accessibility seamlessly with out the necessity to make joins. MongoDB is aware of attain into paperwork when performing queries. The MongoDB Question Language (MQL) helps highly effective dynamic question on paperwork facilitating deep queries. Above all, the doc database permits accessing advanced knowledge merely utilizing one-line of JSON-like code.
Simple horizontal scale-out
MongoDB facilitates horizontal scaling with the assistance of database sharding. Because the knowledge is structured horizontally, it turns into straightforward to unfold it throughout completely different servers and entry it in a simplified manner. You’ll be able to create clusters utilizing real-time replications and shard high-volume knowledge to maintain efficiency.
Harness the potential of database sharding to distribute the database into a number of clusters. With database sharding, you’ll get an elevated storage capability and likewise quicken the question response charge.
Warning Bell: When sharding a database, remember that after you have accomplished the sharding, you can not unshard it at any value.
Why Use MongoDB?
Now that you’ve got noticed the primary variations between MongoDB and NoSQL databases, you might need understood the perks of utilizing MongoDB. Listed below are a couple of compelling causes to make use of MongoDB over different databases.
Extremely versatile – Being a Non-Structured Question Language, there isn’t a have to create tables when working with MongoDB. Consequently, there’s an considerable diploma of versatility in storing, managing, and accessing knowledge. Versatility provides an amazing benefit when storing large and uncategorized knowledge.
Spectacular Pace – One of many causes for the excessive demand for MongoDB is its velocity. As there isn’t a have to create a desk or schema, the database velocity is spectacular. Utilizing MongoDB, the CRUD (Creating, Studying, Updating, Deleting) velocity is quicker than different databases. A MongoDB question is 100 occasions faster, permitting customers to index their search within the speediest time.
Simply Accessible – Another excuse for utilizing MongoDB is that it helps nearly all the most important programming languages C, C++, C#, Java, Node.js, Perl, PHP, Python, Ruby, Scala, and lots of extra. Additionally, MongoDB has wonderful community-supported drivers for low well-liked programming languages too. You can too host MongoDB on its cloud service, MongoDB Atlas, which affords each a community-driven open supply and a premium Enterprise Version.
Simple-to-Use
If you happen to occur to be a JavaScript developer, you’ll fall in love with the doc database; MongoDB. In comparison with different databases, MongoDB is straightforward to make use of. Even a beginner can perceive the database and use it effectively with no problem. As MongoDB shops every file to the Binary JSON, it turns into tremendous straightforward to make use of the database, particularly in case you are utilizing JavaScript libraries like Node.js, React, or Categorical.js within the backend.
The place to Use MongoDB?
MongoDB is a wonderful alternative for net functions the place there’s little to no consumer interplay. Not like a relational database, the place there’s a have to retailer info throughout a number of tables and even create joins, MongoDB saves the additional duties and does it implicitly. Utilizing MongoDB, you may retailer consumer info in probably the most unified manner. Consequently, there can be a single question to a single assortment, and the front-end can take care of enhancing the info.
Integrating Huge-Knowledge – If your online business entails a pool of incoming knowledge from completely different sources, MongoDB will show to be very useful. When different databases have failed, MongoDB comes up with distinctive capabilities to retailer and combine large knowledge seamlessly. The one-document database supplies sturdy capabilities to retailer a considerable amount of various knowledge in probably the most simplified manner.
Defining Advanced-Knowledge – MongoDB permits embedded paperwork (additionally known as Nested Paperwork) to outline nested constructions. Nested paperwork are paperwork the place a doc is current inside a doc. It’s useful when a one-to-many relationship exists between paperwork. Better of all, MongoDB helps specialised knowledge codecs like geospatial format, that end in a resilient repository that is still unbroken even after edits.
In a nutshell, you need to use MongoDB for the next:
- Blogs and content material administration
- E-commerce product catalog
- Consumer knowledge administration
- For real-time analytics and high-speed logging, and excessive scalability
- Configuration administration
- To keep up Geospatial knowledge
- Cell and social networking websites
Consideration: You will need to be aware that MongoDB isn’t the fitting alternative for a strong transactional system or locations the place the info mannequin is upfront. Additionally, it’s a poor resolution to leverage MongoDB for tightly coupled methods. Maybe, Structured Question Language would be the proper match!
Conclusion
MongoDB is a strong database with wonderful capabilities and stands out in-built features. Right now, IT sectors, e-commerce, banking, logistics, and lots of others are managing their knowledge circulation utilizing MongoDB. Multi-national firms like Bosch, Uber, Accenture, Barclays, to call a couple of, use MongoDB for storing the uncategorized knowledge in probably the most refined manner.
In case you are on the lookout for probably the most environment friendly database to retailer and entry knowledge seamlessly, there isn’t a higher choice than MongoDB. Though the efficiency evaluation of MongoDB is exceptionally excellent, maybe there isn’t a transaction assist, and certainly the database makes use of very excessive reminiscence for storage. Nevertheless, the putting options you get for utilizing MongoDB shouldn’t be sacrificed for the high-memory value.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Source for picture: here
The first part of this list was published here. These are articles that I wrote in the last few years. The whole series will feature articles related to the following aspects of machine learning:
- Mathematics, simulations, benchmarking algorithms based on synthetic data (in short, experimental data science)
- Opinions, for instance about the value of a PhD in our field, or the use of some techniques
- Methods, principles, rules of thumb, recipes, tricks
- Business analytics
- Core Techniques
My articles are always written in simple English and accessible to professionals with typically one year of calculus or statistical training, at the undergraduate level. They are geared towards people who use data but are interesting in gaining more practical analytical experience. Managers and decision makers are part of my intended audience. The style is compact, geared towards people who do not have a lot of free time.
Despite these restrictions, state-of-the-art, of-the-beaten-path results as well as machine learning trade secrets and research material are frequently shared. References to more advanced literature (from myself and other authors) is provided for those who want to dig deeper in the interested topics discussed.
1. Machine Learning Tricks, Recipes and Statistical Models
These articles focus on techniques that have wide applications or that are otherwise fundamental or seminal in nature.
- One Trillion Random Digits
- New Perspective on the Central Limit Theorem and Statistical Testing
- Simple Solution to Feature Selection Problems
- Scale-Invariant Clustering and Regression
- Deep Dive into Polynomial Regression and Overfitting
- Stochastic Processes and New Tests of Randomness – Application to Cool Number Theory Problem
- A Simple Introduction to Complex Stochastic Processes – Part 2
- A Simple Introduction to Complex Stochastic Processes
- High Precision Computing: Benchmark, Examples, and Tutorial
- Logistic Map, Chaos, Randomness and Quantum Algorithms
- Graph Theory: Six Degrees of Separation Problem
- Interesting Problem for Serious Geeks: Self-correcting Random Walks
- 9 Off-the-beaten-path Statistical Science Topics with Interesting Applications
- Data Science Method to Discover Large Prime Numbers
- Nice Generalization of the K-NN Clustering Algorithm – Also Useful for Data Reduction
- How to Detect if Numbers are Random or Not
- How and Why: Decorrelate Time Series
- Distribution of Arrival Times of Extreme Events
- Why Zipf’s law explains so many big data and physics phenomenons
2. Free books
- Statistics: New Foundations, Toolbox, and Machine Learning Recipes
Available here. In about 300 pages and 28 chapters it covers many new topics, offering a fresh perspective on the subject, including rules of thumb and recipes that are easy to automate or integrate in black-box systems, as well as new model-free, data-driven foundations to statistical science and predictive analytics. The approach focuses on robust techniques; it is bottom-up (from applications to theory), in contrast to the traditional top-down approach.
The material is accessible to practitioners with a one-year college-level exposure to statistics and probability. The compact and tutorial style, featuring many applications with numerous illustrations, is aimed at practitioners, researchers, and executives in various quantitative fields.
- Applied Stochastic Processes
Available here. Full title: Applied Stochastic Processes, Chaos Modeling, and Probabilistic Properties of Numeration Systems (104 pages, 16 chapters.) This book is intended for professionals in data science, computer science, operations research, statistics, machine learning, big data, and mathematics. In 100 pages, it covers many new topics, offering a fresh perspective on the subject.
It is accessible to practitioners with a two-year college-level exposure to statistics and probability. The compact and tutorial style, featuring many applications (Blockchain, quantum algorithms, HPC, random number generation, cryptography, Fintech, web crawling, statistical testing) with numerous illustrations, is aimed at practitioners, researchers and executives in various quantitative fields.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). He recently opened Paris Restaurant, in Anacortes. You can access Vincent’s articles and books, here.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Mongita, a lightweight embedded document database that implements a commonly-used subset of the MongoDB/PyMongo interface, has been announced. The open source Python library is intended to be useful to Python developers who want to use JSON files but don’t want the overhead of a MongoDB server.
Mongita can be configured to store its documents either on disk or in memory. The main developer, Scott Rogowski, says Mongita is a good alternative to SQLite for embedded applications when a document database makes more sense than a relational one.

He also suggests Mongita would be good for unit testing:
“Mocking PyMongo/MongoDB is a pain. Worse, mocking can hide real bugs. By monkey-patching PyMongo with Mongita, unit tests can be more faithful while remaining isolated.”
Mongita implements a commonly-used subset of the PyMongo API, meaning that projects could be started with Mongita and upgraded to MongoDB if and when they get large enough to warrant the move. The library is embedded and self contained, doesn’t need a server and doesn’t start a process.
In terms of performance, Rogowski says Mongita is within an order of magnitude of MongoDB and Sqlite in 10k document benchmarks, and is well tested, with 100% test coverage and more test code than library code.
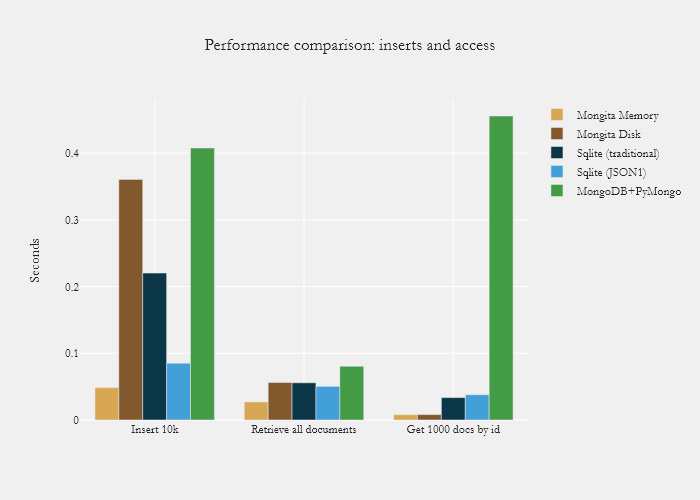
Another advantage of Mongita is its limited dependencies, as it will run anywhere that Python runs. The only dependencies are pymongo (for bson) and sortedcontainers (for faster indexes). Mongita also offers experimental thread-safety, avoiding race conditions by isolating certain document modification operations.
Rogowski isn’t advocating Mongita for all uses, saying it should be avoided in situations that need a traditional server/client configuration as it isn’t process-safe, so if you have multiple clients it should be avoided.
It is also limited in the commands it implements, concentrating on the most commonly used subset, so isn’t suitable when MongoDB’s less common commands are needed. Robowski says the goal is to eventually implement most of MongoDB, but t will take some time to get there.
Performance is another consideration; while Mongita has comparable performance to MongoDB and SQLite for common operations, Robowski admits it’s possible you’ll find bottlenecks – especially with uncommon operations.
More Information
Related Articles
Studio3T MongoDB GUI Adds Migration
MongoDB Atlas Adds MultiCloud Cluster Support
MongoDB Improves Query Language
MongoDB 4.0 Gets Multi-Doc ACID Support
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.


Comments
or email your comment to: comments@i-programmer.info
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Jonathan Allen
Article originally posted on InfoQ. Visit InfoQ

Continuing our series on the over 100 API changes in .NET 6, we look at extensions to the LINQ library.
Indexing Operations on IEnumerable<T>
Originally one of the distinguishing characteristics of IEnumerable<T> versus IList<T> was the latter supported indexed operations such as retrieving the 5th element in the collection. The idea was that only collections that supported fast index operations (at or near O(1)) would implement IList<T>. In theory you would never even try to perform indexed operations on an IEnumerable<T> because it would be assumed to be slow.
With the introduction of LINQ, many of those assumptions faded. Extension methods such as Enumerable.Count() and Enumerable.ElementAt() made it possible to treat any enumerable collection as if it had a known count and fast indexing, even if it really just counted every element.
These three new extension methods continue that trend.
public static TSource ElementAt<TSource>(this IEnumerable<TSource> source, Index index);
public static TSource ElementAtOrDefault<TSource>(this IEnumerable<TSource> source, Index index);
public static IEnumerable<TSource> Take<TSource>(this IEnumerable<TSource> source, Range range);
The Range type refers the new fairly new C# range syntax. For example,
var elements = source2.Take(range: 10..^10)
Counting Operations on IEnumerable<T>
When one calls .Count() on an IEnumerable<T>, two things happen. First, the LINQ library tries to cast it to an interface that exposes a Count property. If it can’t do that, then it iterates through the entire sequence, counting the items as it goes.
For large collections, this counting can be very expensive. If an IQueryable is involved, say for a database query, it could conceivably take minutes or longer to get the count. So developers have asked for a “safe” counting function. This function would check for a fast Count property, and if can’t find one then it would return nothing. This new function is defined as:
public static bool TryGetNonEnumeratedCount(this IEnumerable<T> source, out int count);
The long name, TryGetNonEnumeratedCount, is a bit of hint to the developer that they are doing something odd. Ideally, any API that returns a list would return either a strongly named collection (e.g. CustomerCollection), a high performance List<T>, or a higher level interface such as IList<T> or IReadOnlyList<T>. Doing any of these would eliminate the need for TryGetNonEnumeratedCount, but sometimes the developer doesn’t have control over the API they are calling.
Three-way Zip Extension Method
The Zip extension method combines two sequences by enumerating both simultaneously. For example, if you had the list 1, 2, 3 and the list A, B, C, then the resulting sequence would be (1, A), (2, B), (3, C).
In the More arities for tuple returning zip extension method proposal, you will gain the ability to directly combine 3 sequences at once.
public static IEnumerable<(TFirst First, TSecond Second, TThird Third)> Zip<TFirst, TSecond, TThird>(this IEnumerable<TFirst> first, IEnumerable<TSecond> second, IEnumerable<TThird> third);
public static IQueryable<(TFirst First, TSecond Second, TThird Third)> Zip<TFirst, TSecond, TThird>(this IQueryable<TFirst> source1, IEnumerable<TSecond> source2, IEnumerable<TThird> source3);
Strictly speaking, this new version of Zip isn’t necessary as one could simply apply .Zip(…) multiple times. But the reviewers decided the three-sequence version happens often enough to justify including it in the library. Other arities such as 4 or 5 were rejected as not being common enough.
Note: The usual word arity (plural arities) means the number of arguments or operands taken by a function. In the Zip function extension method, the arity would be 3.
Batching Sequences
Often developers need to break up a sequence into discrete batches or chunks. For example, they may find that sending 100 rows to the database at a time offers better performance than sending one at a time or all of them at once.
While this code isn’t particularly difficult to write, it tends to be error prone. It’s really easy to make a mistake in the last batch if the item count isn’t evenly divisible by the batch size. So as a convenience, the Chunk extension method was added.
public static IEnumerable<T[]> Chunk(this IEnumerable<T> source, int size);
public static IQueryable<T[]> Chunk(this IQueryable<T> source, int size);
If you don’t want to wait for .NET 6, the open source library MoreLINQ includes this operation under the name Batch.
Note that in this feature, and the Zip extension method above, there is both a IEnumerable and IQueryable version. All new APIs that return an IEnumerable are required to include a matching IQueryable version. This prevents someone from changing a query into a normal sequence without realizing it.
Analyzer Checks
When the API itself can’t prevent developers from using code incorrectly, library authors are increasingly turning to analyzers. Some of these are built into the C# compiler, others are added via libraries such as NetAnalyzers (formally FXCop) and the 3rd party Roslynator.
The first of the new analyzers deals with the OfType<T> extension method. This filters an input sequence, only returning items of the indicated type T. If the input type cannot be cast to the output type, the current behavior is to just return an empty sequence. With the do not use OfType<T>() with impossible types proposal, the developer will instead get a compiler warning.
The use AsParallel() correctly proposal addresses the situation where someone calls AsParallel() and then immediately begins to enumerate the sequence. Though it isn’t obvious from the API, AsParallel() must appear before any operations that can be parallelized such as mapping and filtering. Again, this mistake would be reported as a compiler warning.
*By Operators
The *By operators refer to DistinctBy, ExceptBy, IntersectBy, UnionBy¸ MinBy, and MaxBy. For the first four, a keySelector is provided. This allows the comparison part of the operation to be performed on a subset of the value rather than the entire value. This can be used to improve performance or to provide custom behavior without losing the original value. An optional comparer may also be provided.
In the case of MinBy and MaxBy, a selector is provided instead of a keySelector. Again, an optional comparer may be provided. (For completeness, the Min and Max operators also accept an optional comparer now.)
public static IEnumerable<TSource> DistinctBy<TSource, TKey>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector);
public static IEnumerable<TSource> DistinctBy<TSource, TKey>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector, IEqualityComparer<TKey>? comparer);
public static IEnumerable<TSource> ExceptBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector);
public static IEnumerable<TSource> ExceptBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector, IEqualityComparer<TKey>? comparer);
public static IEnumerable<TSource> ExceptBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TKey> second, Func<TSource, TKey> keySelectorFirst);
public static IEnumerable<TSource> ExceptBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TKey> second, Func<TSource, TKey> keySelectorFirst, IEqualityComparer<TKey>? comparer);
public static IEnumerable<TSource> IntersectBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector);
public static IEnumerable<TSource> IntersectBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector, IEqualityComparer<TKey>? comparer);
public static IEnumerable<TSource> IntersectBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TKey> second, Func<TSource, TKey> keySelectorFirst);
public static IEnumerable<TSource> IntersectBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TKey> second, Func<TSource, TKey> keySelectorFirst, IEqualityComparer<TKey>? comparer);
public static IEnumerable<TSource> UnionBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector);
public static IEnumerable<TSource> UnionBy<TSource, TKey>(this IEnumerable<TSource> first, IEnumerable<TSource> second, Func<TSource, TKey> keySelector, IEqualityComparer<TKey>? comparer);
public static TSource MinBy<TSource, TResult>(this IEnumerable<TSource> source, Func<TSource, TResult> selector);
public static TSource MinBy<TSource, TResult>(this IEnumerable<TSource> source, Func<TSource, TResult> selector, IComparer<TResult>? comparer);
public static TSource MaxBy<TSource, TResult>(this IEnumerable<TSource> source, Func<TSource, TResult> selector);
public static TSource MaxBy<TSource, TResult>(this IEnumerable<TSource> source, Func<TSource, TResult> selector, IComparer<TResult>? comparer);
public static TResult Min<TSource, TResult>(this IEnumerable<TSource> source, IComparer<TResult>? comparer);
public static TResult Max<TSource, TResult>(this IEnumerable<TSource> source, IComparer<TResult>? comparer);
Each IEnumerable method has a matching IQueryable method with the same signature.
*OrDefault Enhancement
The *OrDefault operator variant is used to provide a default value when an empty enumeration is sent to the Single, First, or Last operator. In this feature, the default value returned can now be overridden.
public static TSource SingleOrDefault<TSource>(this IEnumerable<TSource> source, TSource defaultValue);
public static TSource SingleOrDefault<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate, TSource defaultValue);
public static TSource FirstOrDefault<TSource>(this IEnumerable<TSource> source, TSource defaultValue);
public static TSource FirstOrDefault<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate, TSource defaultValue);
public static TSource LastOrDefault<TSource>(this IEnumerable<TSource> source, TSource defaultValue);
public static TSource LastOrDefault<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate, TSource defaultValue);
Again, each IEnumerable method has a matching IQueryable method with the same signature.
For our previous reports in the series, see the links below:
This is the FIRST thing data science professionals should know about working with universities
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
If you wanted to recruit for “data science” talent at a university, where would go? Should you go to the College of Computing? Would it be in the College of Business? Is it in the Department of Mathematics? Statistics? Is there even a Department of Data Science?
There is more variation in the housing of data science than any other academic discipline on a university campus. Why the variation? And why should you care?
The answer to the first question – Why the variation? – may not be straightforward.
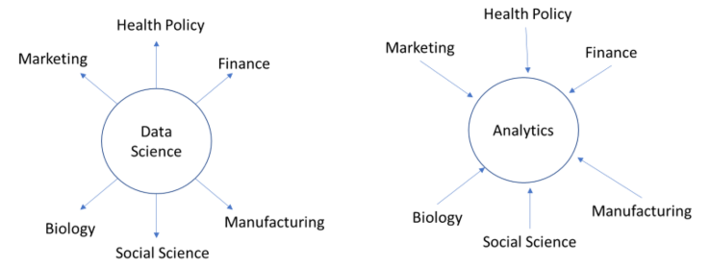
As in any organization, not all academic programs are a function of long-term, well-considered strategic planning – many analytics programs evolved at the intersection of resources, needs, and opportunity (and some noisy passionate faculty). As universities began to formally introduce data science programs around 2006, there was little consistency regarding where this new discipline should be housed. Given the “academic ancestry” of analytics and data science it is not surprising that there is variation of placement of programs across the academic landscape:
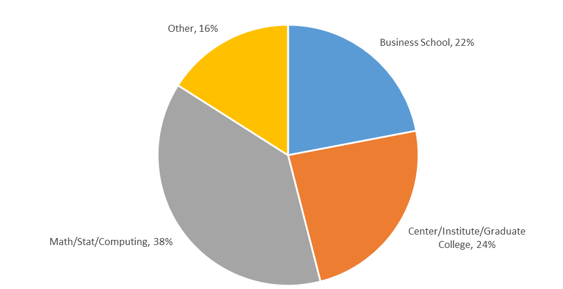
Exacerbating this, we do not yet have a universal consensus as to what set of competencies should be common to a data science curriculum – again largely due to its transdisciplinary foundations. The fields of computer science, mathematics, statistics, and almost every applied field (business, health care, engineering) have professional organizations and long-standing models for what constitutes competency in those fields. Data science has no standardization, no accreditation, and no certifying body. As a result, the “data science” curriculum may look very different at different universities – all issues that have contributed to the misalignment of expectations for both students and for hiring managers.
The second question (why should you care?) might be more relevant –
Generally, universities have approached the evolution of data science from one of two perspectives – as a discipline “spoke” (or series of electives) or as a discipline “hub” (as a major) as in the graphic above.
University programs that are “hubs” – reflecting the model above on the left – have likely been established as a “major” field of study. These programs are likely to be housed in a more computational college (e.g., Computing, Science, Statistics) or in a research unit (like a Center or Institute) and will focus on the “science of the data”. They tend to be less focused on the nuances of any individual area of application. Hub programs will (generally) allow (encourage) their students to take a series of electives in some application domain (i.e., students coming out of a hub program may go into Fintech, but they may also go into Healthcare – their major is “data”). Alternatively, programs that are “spokes” – reflecting the model above on the right – are more likely to be called “analytics” and are more frequently housed in colleges of business, medicine, and the humanities. Programs that are “spokes” are (generally) less focused on the computational requirements and are more aligned with applied domain-specific analytics. Students coming out of these programs will have stronger domain expertise and will better understand how to integrate results into the original business problem but may lack deep computational skills. Neither is “wrong” or “better” – the philosophical approaches are different.
Understanding more about where an analytics program is housed and whether analytics is treated as a “hub” or a “spoke” should inform and improve analytics professionals collaborative experiences with universities.
The book “Closing the Analytics Talent Gap” is available through Amazon and directly from the publisher CRC Press.
NoSQL Databases Software Market In-Depth Analysis including key players MongoDB, Amazon …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Los Angeles, United State, – including Q4 analysis The report named, Global NoSQL Databases Software Market has been added to the archive of market research studies by JCMR. The industry experts and researchers have offered reliable and precise analysis of the NoSQL Databases Software in view of numerous aspects such as growth factors, challenges, limitations, developments, trends, and growth opportunities. This report will surely act as a handy instrument for the market participants to develop effective strategies with an aim to reinforce their market positions. This report offers pin-point analysis of the changing dynamics and emerging trends in the Global NoSQL Databases Software Market.
Get PDF template of NoSQL Databases Software @jcmarketresearch.com/report-details/1290527/sample
Additionally, it provides a futuristic perspective on various factors that are likely to boost the Global NoSQL Databases Software Market growth in the years to come. Besides, authors of the report have shed light on the factors that may hamper the growth of the Global NoSQL Databases Software Market.
The report also helps in understanding the Global NoSQL Databases Software Market through key segments including application, product type, and end user. This analysis is based on various parameters such as CGAR, share, size, production, and consumption.
The leading industry experts have also scrutinized the Global NoSQL Databases Software Market from a geographical point of view, keeping in view the potential countries and their regions. Market participants can rely on the regional analysis provided by them to sustain revenues.
The report has also focused on the competitive landscape and the key strategies deployed by the market participants to strengthen their presence in the Global NoSQL Databases Software Market. This helps the competitors in taking well-versed business decisions by having overall insights of the market scenario. Leading players operating in the NoSQL Databases Software comprising , MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis are also profiled in the report.
What the Report has to Offer?
- NoSQL Databases Software Market Size Estimates: The report offers accurate and reliable estimation of the market size in terms of value and volume. Aspects such as production, distribution and supply chain, and revenue for the NoSQL Databases Software are also highlighted in the report
- NoSQL Databases Software Analysis on Market Trends: In this part, upcoming market trends and development have been scrutinized
- NoSQL Databases Software Growth Opportunities: The report here provides clients with the detailed information on the lucrative opportunities in the NoSQL Databases Software
- NoSQL Databases Software Regional Analysis: In this section, the clients will find comprehensive analysis of the potential regions and countries in the global NoSQL Databases Software
- NoSQL Databases Software Analysis on the Key Market Segments: The report focuses on the segments: end user, application, and product type and the key factors fuelling their growth
- NoSQL Databases Software Vendor Landscape: Competitive landscape provided in the report will help the companies to become better equipped to be able to make effective business decisions
Get Customized full NoSQL Databases Software Report in your Inbox within 24 hours @ jcmarketresearch.com/report-details/1290527/enquiry
How can the research study help your business?
(1) The information presented in the NoSQL Databases Software report helps your decision makers to become prudent and make the best business choices.
(2) The report enables you to see the future of the NoSQL Databases Software and accordingly take decisions that will be in the best interest of your business.
(3) It offers you a forward-looking perspective of the NoSQL Databases Software drivers and how you can secure significant market gains in the near future.
(4) It provides SWOT analysis of the NoSQL Databases Software along with useful graphics and detailed statistics providing quick information about the market’s overall progress throughout the forecast period.
(5) It also assesses the changing competitive dynamics of the NoSQL Databases Software using pin-point evaluation.
Get Special up to 40% Discount on full research report @ jcmarketresearch.com/report-details/1290527/discount
The report answers several questions about the Global NoSQL Databases Software Market includes:
What will be the market size of NoSQL Databases Software market in 2029?
What will be the NoSQL Databases Software growth rate in 2029?
Which key factors drive the market?
Who are the key market players for NoSQL Databases Software?
Which strategies are used by top players in the market?
What are the key market trends in NoSQL Databases Software?
Which trends and challenges will influence the growth of market?
Which barriers do the NoSQL Databases Software markets face?
What are the market opportunities for vendors and what are the threats faced by them?
What are the most important outcomes of the five forces analysis of the NoSQL Databases Software market?
Buy Instant Full Copy Global NoSQL Databases Software Report 2029 @ jcmarketresearch.com/checkout/1290527
Find more research reports on NoSQL Databases Software Industry. By JC Market Research.
About Author:
JCMR global research and market intelligence consulting organization is uniquely positioned to not only identify growth opportunities but to also empower and inspire you to create visionary growth strategies for futures, enabled by our extraordinary depth and breadth of thought leadership, research, tools, events and experience that assist you for making goals into a reality. Our understanding of the interplay between industry convergence, Mega Trends, technologies and market trends provides our clients with new business models and expansion opportunities. We are focused on identifying the “Accurate Forecast” in every industry we cover so our clients can reap the benefits of being early market entrants and can accomplish their “Goals & Objectives”.
Contact Us: https://jcmarketresearch.com/contact-us
Mark Baxter (Head of Business Development)
Phone: +1 (925) 478-7203
Email: sales@jcmarketresearch.com
Connect with us at – LinkedIn
Article originally posted on mongodb google news. Visit mongodb google news