Month: May 2021
Operational Database Management Market to Witness Huge Growth by 2028 | Oracle, IBM, Neo …

MMS • RSS
Posted on mongodb google news. Visit mongodb google news
A new research study from JCMR with title Global Operational Database Management Market Research Report 2029 provides an in-depth assessment of the Operational Database Management including key market trends, upcoming technologies, industry drivers, challenges, regulatory policies & strategies. The research study provides forecasts for Operational Database Management investments till 2029.
The report does include most recent post-pandemic market survey on Operational Database Management Market.
Competition Analysis : Oracle, IBM, Neo Technologies, MariaDB Corporation, Datastax, MongoDB, Microsoft, InterSystems, MarkLogic, SAP, Aerospike
Request Free PDF Sample Report @: jcmarketresearch.com/report-details/1326500/sample
Commonly Asked Questions:
- At what rate is the market projected to grow
The year-over-year growth for 2020 is estimated at XX% and the incremental growth of the market is anticipated to be $xxx million.
Get Up to 40 % Discount on Enterprise Copy & Customization Available for Following Regions & Country: North America, South & Central America, Middle East & Africa, Europe, Asia-Pacific
- Who are the top players in the market?
Oracle, IBM, Neo Technologies, MariaDB Corporation, Datastax, MongoDB, Microsoft, InterSystems, MarkLogic, SAP, Aerospike
- What are the key market drivers and challenges?
The demand for strengthening ASW capabilities is one of the major factors driving the market.
- How big is the North America market?
The North America region will contribute XX% of the market share
Enquiry for segment purchase@ jcmarketresearch.com/report-details/1326500/enquiry
This customized report will also help clients keep up with new product launches in direct & indirect COVID-19 related markets, upcoming vaccines and pipeline analysis, and significant developments in vendor operations and government regulations
Geographical Analysis:
• North America: United States, Canada, and Mexico.
• South & Central America: Argentina, Chile, and Brazil.
• Middle East & Africa: Saudi Arabia, UAE, Turkey, Egypt and South Africa.
• Europe: UK, France, Italy, Germany, Spain, and Russia.
• Asia-Pacific: India, China, Japan, South Korea, Indonesia, Singapore, and Australia.
Market Analysis by Types: [Type]
Market Analysis by Applications: [Application]
Some of the Points cover in Global Operational Database Management Market Research Report is:
Chapter 1: Overview of Global Operational Database Management Market (2013-2025)
• Definition
• Specifications
• Classification
• Applications
• Regions
Chapter 2: Market Competition by Players/Suppliers 2013 and 2018
• Manufacturing Cost Structure
• Raw Material and Suppliers
• Manufacturing Process
• Industry Chain Structure
Chapter 3: Sales (Volume) and Revenue (Value) by Region (2013-2018)
• Sales
• Revenue and market share
Chapter 4, 5 and 6: Global Operational Database Management Market by Type, Application & Players/Suppliers Profiles (2013-2018)
• Market Share by Type & Application
• Growth Rate by Type & Application
• Drivers and Opportunities
• Company Basic Information
Continue……………
Note: Please Share Your Budget on Call/Mail We will try to Reach your Requirement @ Phone: +1 (925) 478-7203 / Email: sales@jcmarketresearch.com
Find more research reports on Operational Database Management Industry. By JC Market Research.
Thanks for reading this article; you can also get individual chapter wise section or region wise report version like North America, Europe or Asia.
About Author:
JCMR global research and market intelligence consulting organization is uniquely positioned to not only identify growth opportunities but to also empower and inspire you to create visionary growth strategies for futures, enabled by our extraordinary depth and breadth of thought leadership, research, tools, events and experience that assist you for making goals into a reality. Our understanding of the interplay between industry convergence, Mega Trends, technologies and market trends provides our clients with new business models and expansion opportunities. We are focused on identifying the “Accurate Forecast” in every industry we cover so our clients can reap the benefits of being early market entrants and can accomplish their “Goals & Objectives”.
Contact Us: https://jcmarketresearch.com/contact-us
JCMARKETRESEARCH
Mark Baxter (Head of Business Development)
Phone: +1 (925) 478-7203
Email: sales@jcmarketresearch.com
Connect with us at – LinkedIn
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Olimpiu Pop
Article originally posted on InfoQ. Visit InfoQ
According to the 2020 Java InfoQ Trends Report, Quarkus has grown in popularity, moving quickly into the Early Adopters space. The framework that calls itself supersonic, subatomic Java, has added more features to facilitate the development and operation of software applications. In the 17 months since the release of Quarkus 1.0, its built-in development mode has added state preserving hot deploy and redeploy features and now targets to add yet another feature inspired by Ruby. Quarkus 2.0 will provide developers the ability to run tests in a continuous manner every time a class is modified. This feature promises to run smoothly behind the scenes, notifying the developer if new code will break any tests.
InfoQ spoke to Stuart Douglas, senior principal engineer at Red Hat, for a deeper understanding of this promising feature.
InfoQ: What was the motivation for implementing continuous testing? What benefits do you think it will bring to the development process?
Stuart Douglas: It actually came about because of a question on the mailing list from a developer who primarily develops in Ruby, but was trying out Java. He said he loved the Quarkus live reload in quarkus:dev mode, but was disappointed that running tests were so slow in comparison, and pointed out that scripting language developers often use continuous testing.
I must admit my initial reaction was just “that’s just how it is in Java,” but after I slept on it, I realised that we actually had all the building blocks we needed in Quarkus to do our own continuous testing; all we really needed was to write a JUnit test runner and wire everything together.
From a developer’s point of view, this gives you almost instant feedback on changes that you make. As soon as you save your code, the tests run and you can see if your changes were effective. We use a very targeted approach to running tests, so we only run tests that your change might affect, and the result is a super quick feedback cycle that is like nothing I have ever experienced with Java. I actually feel disappointed that I can’t use it when working on Quarkus itself.
From the beginning, developer experience has been one of our main focuses in Quarkus, and this takes it to the next level. Because this is integrated into the core of Quarkus, every user has access to it out-of-the-box. This feature also does not bloat the resulting Quarkus application as none of the testing code ends up in your final application. This means that we can create lightweight cloud-focused applications while still providing a great developer experience.
InfoQ: This new feature is currently part of Quarkus’s alpha release. When will Quarkus 2.0 be available? Do you anticipate any changes before the GA release?
Stuart Douglas: At this stage, we are looking at mid-June.
At the moment, we are trying to get as much feedback as possible from the community, and have already made some changes based on the feedback we have received. I don’t expect the core functionality to change much between now and the release, but the more feedback we receive, the more likely we will be able to iron out any issues. There is still some work to be done on how we present the results, both in the console and the dev UI, so this will likely be the most user-visible change between now and the final release.
InfoQ: Are there any known limitations of continuous testing?
Stuart Douglas: I guess the biggest limitation is that it needs to run all the tests on startup in order to know which tests to run when code changes. So if you have a huge test suite, this may be an issue. There are things we can do to mitigate this, such as caching this information between launches, so this will likely improve in future releases.
InfoQ: Are you happy with the outcome so far? Would you implement anything differently?
Stuart Douglas: I think it is working better than I hoped when I first started experimenting. There will no doubt be improvements as time goes on, but I am really happy with the core architecture.
InfoQ: Can you give us an overview about its implementation details? Is there anything that you are particularly proud of?
Stuart Douglas: The first challenge when testing is enabled is to actually resolve the test artifacts and build a ClassLoader that can load the classes. When you are running your app normally, things like JUnit are not present, so we need to manually resolve them. This is relatively complex and needs to be done for both Maven and Gradle. But luckily, we already had code that we use to resolve the build time part of our extensions.
Next, we need to discover the tests, because development mode already tracked the current workspace to deal with changes that just required adding some additional metadata to our existing workspace model. Using this metadata, we can discover the user’s test classes and load them into our new ClassLoader. When we load the tests and application classes, we actually perform some bytecode transformations that allow us to track when methods are invoked. This is how we know which tests touch their corresponding classes.
The next thing we needed was a way to run the tests, which is the only bit that is completely new. This involved writing a JUnit runner, which I had not looked at before, but the API is really quite nice so the implementation is straightforward. When we run the tests on startup, we use the transformation mentioned above to track which tests use the application classes.
The three items above are all you need to actually run the tests, but we also need a way to rerun tests upon code change. Development mode already has support for detecting changed files and automatically compiling them, so we just had to modify this to handle tests as well. When source files are changed, we automatically compile them and look at the class usage data we gathered from our first test run. From this, we can figure out every test that uses the modified classes, and automatically run them, while not running any tests that are not relevant.
Out of all of this, the test runner is the only completely new part. Everything else is just an enhancement of a feature we already had. The bit I am most proud of is the way it can trace exactly which tests are affected by code. Without this, you would not accurately know which tests to run after a change.
InfoQ: Is continuous testing automatically enabled when development mode is enabled?
Stuart Douglas: It’s automatically available, but you need to press a key to enable it. This can be changed via configuration, so you can configure Quarkus to always use continuous testing. Quarkus provides several key bindings to control continuous testing, so you can quickly pause/resume testing, rerun tests, etc.
We are also providing a quarkus:test command that will only run the tests and not launch development mode. This gives users more flexibility. For example, if you are just doing test-driven development, you may only care about running the tests.
Targeted for a GA release in mid-June, Quarkus 2.0 brings, among other features, the ability to continuously run tests while code is written. Similar to the continuous deploy functionality added in Quarkus 1.11, continuous testing provides developers with quick feedback for modified code, promising to quickly detect any issues and potentially fix them. Part of Quarkus’s development mode runs out-of-the box allowing changes to be made via configuration. Even though still in alpha, only the UI side of the reporting tool will most-likely be affected with the core functionality remaining the same. More details on continuous testing may be found in Douglas’s YouTube video. Developers are encouraged to experiment with this new feature before the GA release.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Organizations in every industry are leveraging data and analytics to overcome roadblocks on the path to innovation and progress, plan for the future, and position their organization to competitive advantage.
The entire enterprise must become more connected than ever before for expertise to come together to drive a shared vision for innovative change. This means transitioning away from legacy systems and adopting a modern approach to business processes and operations, and data and analytics.
Ronald van Loon is an SAP partner, and as an industry analyst and insider for over twenty years, has an opportunity to further investigate the challenges emerging in the unified data and analytics domain.
To get the most value from data, businesses need to strengthen their data culture, and this continues to be an evasive objective for numerous organizations. With so many new systems, processes, and individual ways of thinking and working, creating a connected data ecosystem can be complex.
But with a unified data management and analytics solution, the world of business and IT can unite to drive data initiatives forward, enhance productivity, and overcome the unique challenges that are inherent to business and IT.
Data and Analytics Complexities Grow
Data is unquestionably increasing in value, but it’s simultaneously growing in complexity. Organizations have to tackle this complexity in order to benefit from the potential value of data. But traditional approaches to database, data warehousing, and analytics can take years of development and deployment before they produce any benefits, and even then, companies can face limitations when pertaining to real-time analytics, complex data sets, and data streaming.
Businesses are also reporting that they’re grappling with advancing and managing data as a business asset, driving a data culture, accelerating innovation via data, and using data and analytics to compete. 29.2% of businesses report having accomplished transformational business results, 30% report having built a meaningful data strategy, and only 24% believe their company was data-driven this last year.
A few of the primary challenges impeding analytics progress include:
- Lack of a strong analytics strategy, which may encompass under-utilized technologies, failing to set manageable goals that can provide quantifiable value, or lack of interaction and agility across data, IT, and business.
- Unbalanced analytics programs that don’t account for diverse user needs as well as enterprise-wide standards, which can result in inefficiency and prevent analytics from being scaled.
- Insufficient data governance and data hygiene that impacts data accessibility and often leads to data silos.
- Myriad data sources, overlap, and obscurity due to the adoption of new processes and systems throughout numerous layers of the organization.
- Legacy analytics initiatives that hinder organizations from developing, deploying, and scaling advanced analytics due to deficient features for collaboration, and limited artificial intelligence (AI), machine learning (ML), and big data capabilities.
Companies can be further challenged in infusing data into the very DNA of their decision-making processes rather than just understanding or discussing the importance of including it. Ultimately, this puts a damper on creativity, curiosity, and an enterprise-wide data mindset that fosters dynamic, smart innovation across products and services.
Business leaders need to approach data and analytics investments as an accelerant to ongoing business requirements, develop analytics capabilities according to relevant use cases and business problems, and build upon this foundation by strategically implementing new tools, technologies, and solutions.
Business and IT Unified Data Management and Analytics Challenges
As data is one of the most powerful and critical assets an organization has, it must be available, accessible, and able to be leveraged by every user across the entire value chain. Business users have to be able to ask questions and get answers from their data and rely on it as a pillar of decision-making. This extends to both IT and business lines, though these two areas have distinctive roles, responsibilities, and purposes.
If business and IT can work together and share their knowledge and experience when it comes to data, progress can be optimized across the enterprise. But business and IT have their own set of unified data management and analytics challenges that they face that they need to overcome.
Business challenges:
- Trusted Data: Lacking quality data, outdated data, or duplicate data.
- Self-service: Overly complex systems and processes create barriers for business units who need simplified methods to get to the data that they need to make decisions.
- Ease of use: Having the capabilities to work independently and access the data that they want without contacting and/or burdening IT teams.
IT challenges:
- Hybrid Systems: Working on premise or in the cloud can be time consuming and overly complex.
- Heterogeneous Data: Siloed data from multiple sources is too spread out.
- Security and Governance: The evolving landscape of security, privacy and regulatory environments are becoming complicated.
When business and IT teams can’t effectively use data, they can’t work freely, make confident decisions, and leverage artificial intelligence (AI) and machine learning (ML) to help them transform data into solutions and meet the demands of evolving consumer behaviors, rapid transformation, and technological enabled workspaces.
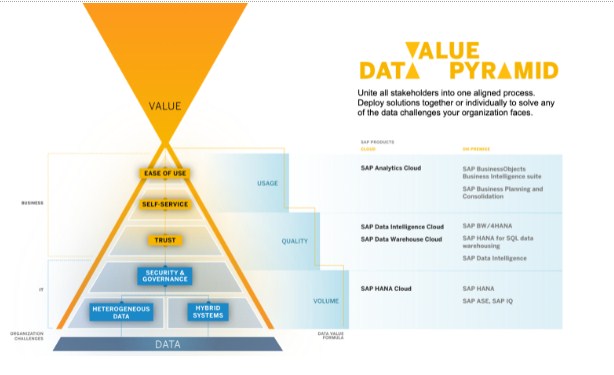
An Answer to Business and IT Challenges
Organizations need flexibility, agility, and connectivity in order to enhance collaboration and use data-driven insights to drive intelligent solutions forward. With a unified data management and analytics strategy, organizations can overcome the common challenges that business and IT are facing across industries.
SAP Unified Data and Analytics connects business and IT professionals and improves end-to-end data management to simplify data environments and help organizations grasp and maximize the true value of their data to its fullest potential.
In order to develop a unified data ecosystem, organizations are moving to cloud database as-a-service solutions, using an intelligent platform like the SAP Business Technology Platform that connects disjointed data from IoT, cloud and big data, creating a single source of truth. This helps businesses resolve data trust challenges and simplify IT disparate data and hybrid system complexities. At the same time, IT can better focus their attention on governance and model data in secure spaces. Data and workloads essentially become more integrated and connected, which helps business and IT better collaborate.
With intelligent cloud solutions, like SAP HANA Cloud, SAP Data Warehouse Cloud, SAP Data Intelligence Cloud, and SAP Analytics Cloud, organizations can choose what data to keep on premise and which to keep in the cloud, scaling as needed, migrating legacy systems where necessary, and start the process of building a modern infrastructure. Organizations can give data purpose with SAP Unified Data and Analytics.
An intelligent platform is going to simplify data accessibility for business teams while simultaneously providing visualizations and dashboards. This brings real-time data insights to life, enabling business teams to establish a meaningful connection to their insights, which solves the previously discussed decision-making and accessibility challenges.
Unified Data Management and Analytics Optimization
Eliminating unified data management and analytics challenges ensures that organizations are able to deploy their forecasts, contextualize data and analytics, and share insights across business and IT to continuously grow and innovate.
To learn more and stay current with the latest data and analytics trends and information, you can visit the executive corner industry pages with a focus on retail, public sector, or consumer packaged goods on saphanajourney.com or sign up for the SAP Data Defined: Monthly Bytes newsletter.
MMS • Gunnar Morling
Article originally posted on InfoQ. Visit InfoQ
Transcript
Morling: I’m going to tell you how I built a search for my weblog. Why is this interesting? I think it’s interesting, because this cost me 4 cents for 10K requests. Really, I don’t even have too many requests. Essentially, it cost me nothing. This is possible because I chose a serverless implementation approach for this. This is running on AWS Lambda, using their serverless technology. Actually, you can take a look at it right now. You can go to my weblog at morling.dev, and there, you have the search control in the upper right-hand side. If you put some search text in there, it will search my website, and really, this talk is about how this is implemented using serverless technology.
There should be three key takeaways in this talk for you. First of all, I am going to discuss why I think serverless is a good solution for this particular problem. Secondly, I’m going to talk about how you can implement serverless applications using Quarkus, which is a development stack for building cloud native applications. Lastly, I’m going to touch on a practical matter, this is cost control. How can we prevent a denial-of-wallet attack?
Mythbusters – Serverless Edition
Also, I hope I can debunk some common misconceptions and myths in the course of this talk. A while ago, I did this little tweetstorm, which I called Mythbusters, serverless edition. I was trying to address a few common misconceptions I hear again and again. Things like you couldn’t use Java for implementing serverless just because of the longer time it might take to start up, or things like, there’s automatically always something like a vendor lock-in if you go serverless. I hope I can convince you that those things, actually, are not true, and how they are not true.
Background
I work as a software engineer at Red Hat, where I am focusing on the Debezium project. Debezium is a tool, an open source platform for change data capture. If you’re curious what this is, and what you can do with it, I would very much recommend you check out the talk I did at QCon San Francisco, last year, which you can watch on infoq.com. I’m involved with a few other projects, such as Quarkus. This is actually the technical foundation of the search feature.
What Is Serverless?
To bring everybody on the same page, let’s just briefly discuss the definition of serverless. What is this actually, again? You can read it yourself. This is a definition by the Cloud Native Computing Foundation, CNCF. Essentially, they say, it’s a computing model which describes how you build and run applications without having to think about provisioning or managing servers yourself. Somebody else, in my case, this would be AWS, is taking care of this. Also, there’s this notion that this is executed, scaled, and built on-demand. This means if there is no workload, no requests are coming in, everything is scaled to zero, and you don’t have to pay anything for this at all. Then if there’s a spike in load, tons of requests are coming in at the same time, it will automatically scale out. It will be able to serve this load. All this happens automatically for you without you having to think about how this actually works too much.
Why Serverless For My Use Case?
Why did I think this is a good use case for my weblog? This is a static site, which runs on GitHub Pages. It’s just a set of static HTML files. This means those dynamic functionalities like search, you can’t really do this there. You need to have something more dynamic. I didn’t feel like using an external service like the custom Google search, because I wanted to have control over how this is printed and how results are shown, and so on. I wanted to do it myself. At the same time, I didn’t feel like using a traditional application server stack and things like that, because it would mean, I need to install an operating system, something like an app server. I need to keep this up to date, install all the patches, security fixes, and so on. I just felt I didn’t want to have to do this. I felt I would like to have some hands-off experience. Really, going serverless for me means there’s a smaller attack surface. I just need to focus on my actual implementation of my app. This is the code I’m dealing with, and this is what I need to keep up to date. Then, all the environment, all the server infrastructure, somebody else is taking care of that. It’s more secure for me.
Then there’s this matter of a lower cost factor. I just have a very low volume of load. This means in serverless, I will get away with just a few cents, or maybe nothing at all to pay. That’s pretty cool. Then, don’t be fooled, it doesn’t mean that serverless always would be a cheaper solution. If you have like a high constant base level of load, you might be better off looking into alternative approaches, but really, for this particular use case, serverless is very cost effective. Finally, it was, for me, a learning experience. I really wanted to learn how I can implement something running a Lambda. Using Quarkus, how could I actually go about this and solve this particular problem I had for my website?
Solution Overview – System Architecture
Let’s take a look into how this actually looks like. This is the overview. The static pages are served from GitHub Pages. I’m using Hugo, which is a static site generator. This produces HTML, which then is served while on GitHub Pages. If a search request comes in, so if you go to this little text control, you put some query there, this actually will invoke the API gateway, which runs on AWS. This is done via some AJAX request. It goes to the API gateway, which then routes the request back to the actual serverless implementation, which is running on AWS Lambda. In terms of implementation, this is using Apache Lucene as the search query or as the search engine implementation. This is using Quarkus as the development stack. Finally, this all runs with GraalVM native binary, so this means there’s no JVM involved. It runs as native code. This is because it gets very fast to start up that way, much faster than I could do it on the JVM. In terms of a serverless cold start user experience, this is exactly what I’m after.
Indexing and Searching
The question, of course, is how do I actually index my data in my blog post? Hugo provides me some help there. It can generate a JSON file, which contains essentially just the text of my blog post. You can see it here on the right-hand side. This is a nicely processable data structure with all the contents, the tags, publication date, all those kinds of attributes. This is the basis for my search service. I do have one trick, actually, I index everything at build time. If I do a change to my weblog like a new post, I also need to update this search service. Really, this makes it a bit more secure for me. My actual application runtime, it’s immutable. It is just read only. This means there’s no way you could write it, which is just more secure. Also, for my use case, I don’t update this content too often, this is just fine. Then, if I actually do it also to rebuild this application and that way benefit from an immutable application image.
In terms of the search engine itself, this is using Apache Lucene. Really, this is the go-to standard search engine, search library in Java. That’s what you’re looking at. It’s driving things like Elasticsearch, or also Solr. You also can use it as a library, which is what I’m doing here, to test all the things like word stemming, so you can look for certain words in different word forms, plural, singular, different verb forms, and so on. There’s result highlighting. You can see this on the website, the results are nicely highlighted. You actually see some context with your query match, and things like that. Also, there’s other advanced search features like fuzzy search, or proximity search. Also, really, this is why I didn’t feel like implementing this using JavaScript on the client side, because such a mature library such as Lucene provides all this for me, ready to use.
Serverless Apps with Quarkus – Lambda Request Handler
Let’s spend some time and think about how we actually can implement such a search or such a serverless application using the Quarkus stack. There’s different ways and I will explain just briefly how you could do this, and then also why or when you would choose which one of those three approaches. The first one would be, you just could use the Lambda Request Handler to implement the Request Handler interface, which you already might know if you have been working with Lambda on Java before. You can just use the Lambda SDK, implement this. Then Quarkus makes this for your usable on the JVM, but also in a native binary via GraalVM. That would be the first option.
Funqy
The second option would be what’s called Funqy. This is actually very interesting. It’s a dedicated function as a service framework, which is part of the Quarkus umbrella. Really, the idea there is to provide you with a very easy to use programming experience, which then targets different function as a service environments. You could use this with AWS Lambda, but you also could use it with Google Cloud Functions, Azure functions, and things like that. The idea there is you just define a single method here, which takes the parameters of the function as a method parameter to input. Then it just returns something. It’s a plain Java method. Funqy takes care of mapping this to Lambda and all those kinds of execution environments. That’s Funqy.
Lambda with Vert.x Web, Servlet, or RESTEasy
The last option you have for implementing a serverless application with Quarkus would be just to use your traditional web stack, so you can use things like Vert.x, maybe just in Servlets or RESTEasy, JAX-RS, things like that. Actually, that’s what I went for here. There, if you ever have done some REST development using Java, this will look very familiar to you. Here I’m using JAX-RS. I use all those annotations like @GET, @Produces, and so on. Really, this is my classic way how I would implement this. Then Quarkus actually takes care of mapping the Lambda invocation in the right way, so this web endpoint for me gets invoked.
When to Use What?
When would I use which one of those three approaches? I would go for the Request Handler approach, really, either if I had existing code, maybe I already have an existing application, and now I would like to move this over to Quarkus or maybe a native binary, then I would use this. Or, if I really needed to use specific APIs from the Lambda environment, then I would use this. Otherwise, I would not really go for that, because it really means I am now limited, I’m locked into this environment, and moving somewhere else would be rather tricky. I would use Funqy if I would get away with it. It really is a very basic function-based approach. This means it just maps simple GET and POST requests for me. I couldn’t, for instance, do something like an HTTP delete. Really, if this is enough for me, then I would go for this. Back when I built this, Funqy was just not as far as it is by now, maybe I would have gone for it. Actually, back then, I went for the web stack because this gives me the full flexibility. Maybe I use things like HTTP headers, cache control, all those attributes, content negotiation. I can do this using a web stack like JAX-RS. This is why I went for that. I felt I just would like to have this flexibility. Also, this makes it very portable.
Building for Lambda vs. K8s/Knative
Actually, what I can do now is Quarkus builds a Lambda function .zip file for me, which gets deployed to the Lambda environment. Really, I can just easily build this for other environments, just by matter of configuration. Let’s say I would like to run this on Kubernetes, or Knative, which is the container based serverless approach. I just can use this because I already have a portable web application. What I did in my project release, I put this dependency, the quarkus-amazon-lambda-http dependency, I put this into a separate Maven profile. Now either I enable this profile and then I build my project, my search for being executed via AWS Lambda, or I don’t build it with this profile. I just disable the profile. Then I just build a regular JAR, an executable JAR. I can very easily put this into a container image using tools like GIMP maybe. Then I could put it to Kubernetes, Knative, and all those services, which would interact with plain Linux container images. I have no login at all, I’m just very portable here.
Cold Starts – A Dish Best Served Fast
Let’s talk about cold starts, because this is the biggest concern around serverless. This means if a request comes in, it could be this application has been scaled to zero before. In my case, this would be very likely because I don’t have a high load. This means in all likelihood, if you go there, it won’t be running and it must be starting up very quickly so that the user doesn’t have to wait there for a long time. Quarkus helps a lot with the startup times, because what it does is it has this notion of a compile time boot. It does many things, which your traditional stack would do at application startup time, like scanning the classpath for dependencies or entities, things like that. Quarkus does all those things already at build time. Then, essentially, bytecode gets recorded, which describes this information, and it gets baked into the application. It just makes it faster to start up on the JVM. Really, if you want to go to the next level and have a startup in terms of milliseconds, then you would look at native binaries via GraalVM. Quarkus makes this very easy for you to do this.
Then, you’re looking at startup times in the range of milliseconds. Let’s say on my local laptop, this search would give me a time to first response. The time between startup and first result of below 50 milliseconds. That’s definitely very acceptable. In the Lambda environment, it depends a bit on how much resources you have assigned. You would look maybe at 200 or 300 milliseconds. Still, it’s acceptable. It gives you an instantaneous feel so that the user doesn’t have to feel that they need to wait for the cold start here.
Native Binaries via GraalVM
There’s a challenge with native binaries and GraalVM. You cannot just use all the tools and tricks you did in your Java application in a native binary. There are things like reflection, method handles, calling code via the Java native interface. You cannot really do this just as easily, because GraalVM does lots of optimizations. It does things like dead code elimination, so it analyzes your application. Then if you don’t use a specific method, or constructor, this would not be part of the native binary and then it couldn’t be used. That’s why reflection just cannot be used out of the box. Instead, you need to announce, you need to configure which archetypes you are going to reflect on. This is why if you take such a library as Apache Lucene, you just cannot take it and it would run out of the box in the native binary. In all likelihood, you need to do some preparation or steps for that. Quarkus comes with a set of extensions there. The idea is, for a very large range of popular dependencies, Quarkus enables their usage in GraalVM native binaries, so things like Kafka clients, Hibernate, Vert.x, Camel, MicroProfile, Prometheus, and so on. There are Quarkus extensions for that. Then this means you just add the right extension to your project. Then all this configuration will be made for you, and you can use this in a native binary.
No Quarkus Extension for Lucene Yet
In my case, for Apache Lucene, there was no Quarkus extension for this yet. This meant I was a bit on my own. Really, it’s not too hard. Essentially, it’s a bit of a matter of trial and error. You give it a try, you see how far you go into native binary, and then you can react to that. Just to give you one example, in Lucene, there’s what’s called the attribute factory, which is a factory which instantiates those attribute classes, which are essentially like metadata attributes of an index. This attribute factory uses method handle to instantiate those types. Actually, in this case, it cannot be used. There’s different ways method handles can be used in this particular one. It is not yet supported by GraalVM native binaries. What did I do? I created what’s called a substitution. GraalVM and the native binary creation allows you to substitute specific classes. In that case, I just provided my own version of that attribute factory, where I just use plain method calls to instantiate those attribute types. This class is used instead of the original one, and this problem is solved for me. Then I have this extension. This still is quite specific to my use case. Ideally, I would make this a bit more generic and then others who also would like to use Lucene would be able to use this as part of the Quarkus extending ecosystem.
Leveraging Interaction Patterns
There’s more we can do. We can go to a native binary and optimize the cold start times. Also, we can improve the situation further just by observing how this actually is going to be used. In this case, I figured, if a user is putting the mouse pointer into this text input field, in all likelihood, just shortly thereafter, they are going to execute a search. This is what I’m leveraging. If you look closely here at the network tool in my browser, what I actually do is, as soon as you put the cursor to this text input, it already will send a request to the back-end. This will actually take care of starting up the environment if it wasn’t started before. Now this means if a second later, or two seconds later, you actually submit your query, you will already hit a started up environment, and you don’t even perceive the cold startup delay at all. This is one way we can further improve this.
Cost Control – How to Prevent Denial-of-Wallet Attacks
Lastly, I would like to talk about this matter of cost control. The problem there is, this is a private project for me. It’s a side effort. I don’t have an operations team which would be running and monitoring this for me 24/7, which means I really want to be sure there isn’t such a thing as a denial-of-wallet attack. This means somebody just comes to the search, invokes it again and again. As with the serverless, which means I pay per use, potentially, I would be in for a bad surprise, and I would have to pay for many requests, which I don’t really want, of course. The question is, how can I avoid this? There’s a few measures you can do to make this really safe. The first thing to do is put an API usage plan in place. You can see it here a bit on the screenshot, you can do things like saying, “I would like to just have 50K requests per month. If it goes beyond that, no more requests are accepted.” That way, no more request will be billed. There’s a problem with that. This is what’s called the CORS preflight request. If you have an AJAX based integration into a website, as I have it, this means the browser will send this preflight request, and there you cannot have any custom headers. This means I cannot parse the API key, which in turn means I cannot use this API usage plan. Those CORS preflight requests, they still are unlimited. I cannot really limit them.
Budget Circuit Breaker
This is why I put in place what I would call a budget circuit breaker. Essentially, the idea there is to just have another Lambda, and this one essentially reacts to a budget alert. I have a budget alert set up which triggers if I reach a specific amount of spending on AWS. If this alert triggers, then this Lambda gets invoked. What it does is it spins down the rate limit and the burst limit of the API. This means zero requests per second are allowed, once this actually has kicked in, which means I wouldn’t be charged for any more requests coming in. There’s just one more problem with that, and this is, this all is asynchronous. This could mean it could take a few hours even until this circuit breaker really kicks in, and still during that time, somebody could still be invoking those CORS preflight requests lots of times. That’s why I put throttling in place, so just to rate limit the number of requests. In my case, this is a private page. I don’t need more than maybe 100, or maybe just 50 concurrent requests, and this would be plenty. I can just further limit down the speed of how quickly this would pile up. Really, to be ultimately safe, in the end, I put all of this behind CloudFlare Service Workers. There, they have a very good free tier, essentially, which allows me to handle all the CORS requests over there. Then if it goes beyond their free limit, it will just be cut off. In my case, I’m just fine with that. This is not business critical for me. I’m just fine to shut it down after 100K requests per day, and then it would cost me nothing at all. That way, I’m really safe. If I sit on a plane or I’m on holiday, I would not be at risk that this gets out of control.
Lessons learned
I definitely sense there was quite a steep learning curve with Lambda. There are things like IAM, Identity and Access Management, I found this is a really tricky beast. It’s hard to understand the minimum set of permissions you need. It takes you quite some time to figure this out. Actually, there’s a correlation between how much RAM you have assigned and then how much CPU cycles you would get. Actually, I would get away with 128 megabytes of RAM for my search there. Really, I have assigned 512, because that way I get more CPU shares, and just the end to end latency is a bit lower, requests are served quicker. That’s another interesting thing to keep in mind. More RAM doesn’t necessarily mean it’s better. Might not be worth it.
Then, really, with all the learning, I found Quarkus helps me a lot. As we have seen, it avoids this lock-in, so I’m not bound to Lambda specific interface. I can implement my serverless feature in different ways just using a regular web stack such as JAX-RS. Then there’s other things that, for instance, creates templates for SAM. That’s this Serverless Application Model, which is another tool from the Lambda ecosystem, which makes it quite easy for me to deploy such a serverless application. I can generate this actually. I can go to code.quarkus.io, and I just add write dependencies to this, or the Lambda dependency, and then this will generate a scaffolding for a new project for me.
This already contains templates for the SAM tool for me. I’m just two commands away from deploying this to Lambda and have it running. Finally, really, for me the most important takeaway, because this is a personal side project, you definitely should think about how you prevent those denial-of-wallet attacks.
If you come back to those myths and misconceptions, I hope I could convince you that you definitely can use Java via GraalVM native binaries. Cold starts are not a problem, really. Also, it doesn’t mean lock-in. There’s a very good portability story here. You just could move this functionality to other clouds or just even to Kubernetes or Knative, and you wouldn’t have any login at all. Those myths, I hope I could bust them.
Resources
This talk, essentially, is a condensed version of a blog post, which you can find on my blog. There, you can read up in all detail about all those things which I’ve been talking about. Also, all this is open source, so you can just take this and put it to your own blog, to your own site, if you want to. Feel free to do it. It is Apache licensed. Then if you would like to know more about Quarkus, which is driving all this, go to quarkus.io. Lastly, I have this blog post I found by this engineer, Harish, which was very helpful for me to implement the budget circuit breaker. Definitely check this out, too.
See more presentations with transcripts
What is the Market's View on Mongodb Inc (MDB) Stock's Price and Volume Trends Friday?
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Overall market sentiment has been high on Mongodb Inc (MDB) stock lately. MDB receives a Bullish rating from InvestorsObserver’s Stock Sentiment Indicator.

Mongodb Inc has a Bullish sentiment reading. Find out what this means for you and get the rest of the rankings on MDB!
What is Stock Sentiment?
In investing, sentiment generally means whether or not a given security is in favor with investors. It is typically a pretty short-term metric that relies entirely on technical analysis. That means it doesn’t incorporate anything to do with the health or profitability of the underlying company.
Sentiment is how investors, or the market, feels about a stock. There are lots of ways to measure sentiment. At the core, sentiment is pretty easy to understand. If a stock is going up, investors must be bullish, while if it is going down, sentiment is bearish.
InvestorsObserver’s Sentiment Indicator looks at price trends over the past week and also considers changes in volume. Increasing volume can mean a trend is getting stronger, while decreasing volume can mean a trend is nearing a conclusion.
For stocks that have options, our system also considers the balance between calls, which are often bets that the price will go up, and puts, which are frequently bets that the price will fall.
What’s Happening With MDB Stock Today?
Mongodb Inc (MDB) stock is trading at $295.94 as of 12:01 PM on Friday, May 28, a rise of $4.30, or 1.47% from the previous closing price of $291.64. The stock has traded between $291.26 and $298.31 so far today. Volume today is below average. So far 122,302 shares have traded compared to average volume of 640,134 shares.
To see InvestorsObserver‘s Sentiment Score for Mongodb Inc click here.
More About Mongodb Inc
Founded in 2007, MongoDB is a document-oriented database with nearly 25,000 paying customers and well past 1.5 million free users. MongoDB provides both licenses as well as subscriptions as a service for its NoSQL database. MongoDB’s database is compatible with all major programming languages and is capable of being deployed for a variety of use cases.
Click Here to get the full Stock Score Report on Mongodb Inc (MDB) Stock.
Article originally posted on mongodb google news. Visit mongodb google news
NoSQL Databases Software Market Innovative Strategy by 2028 | MongoDB, Amazon, ArangoDB …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
JCMR recently broadcasted a new study in its database that highlights the in-depth market analysis with future prospects of NoSQL Databases Software market. The study covers significant data which makes the research document a handy resource for managers, industry executives and other key people get ready-to-access and self analyzed study along with graphs and tables to help understand market trends, drivers and market challenges. Some of the key players mentioned in this research are MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis
Get Access to Free sample Report PDF @ jcmarketresearch.com/report-details/1326836/sample
COVID-19 Impact on Global NoSQL Databases Software Market
COVID-19 is an infectious disease caused by the most recently discovered novel corona virus. Largely unknown before the outbreak began in Wuhan (China) in December 2019, COVID-19 has moved from a regional crisis to a global pandemic in just a matter of a few weeks.
In addition, production and supply chain delays were also witnessed during the second quarter which poised a challenge to the NoSQL Databases Software market, since end-user industries were still not operating at their full capacity.
Enquire for customization in Report @ jcmarketresearch.com/report-details/1326836/enquiry
What are the market’s problems in NoSQL Databases Software?
Changing regulatory landscapes, operational barriers, and the emergence of alternative technologies are all impacting the NoSQL Databases Software industry.
What are the various types of NoSQL Databases Software Market?
Based on type, the NoSQL Databases Software market is divided into [Type]. In 2021, the segment held the largest share.
Who are the top key players in the NoSQL Databases Software market?
MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis
Who are the key end-users of the NoSQL Databases Software market?
The NoSQL Databases Software market is divided into [Application] other end users.
Which region is the most profitable for the NoSQL Databases Software market?
The emerging economies in the Asia Pacific region will be the lucrative markets for NoSQL Databases Software products. .
What is the current size of the NoSQL Databases Software market?
The current market size of global NoSQL Databases Software market is estimated to be USD XX in 2021.
Get Discount instant FLAT40% Discount on full Report @ jcmarketresearch.com/report-details/1326836/discount
North America is the region’s largest market for NoSQL Databases Software.
North America includes countries such as the US, Canada, and Mexico. North America is the second-largest consumer and producer of electricity, after Asia Pacific. The US and Canada, which are among the largest consumers in this region as well as globally, constitute the largest share of the NoSQL Databases Software market.
Secondary Research:
This research study made extensive use of secondary sources, directories, and databases such as Hoover’s, Bloomberg BusinessWeek, Factiva, and OneSource to identify and collect information useful for a technical, market-oriented, and commercial study of the global portable generator market. Other secondary sources included company annual reports, press releases, and investor presentations, white papers, certified publications, articles by recognized authors, manufacturer associations, trade directories, and databases.
Primary Research:
Various sources from both the supply and demand sides were interviewed during the primary research process to obtain qualitative and quantitative information for this report. Primary sources included industry experts from the core and related industries, as well as preferred suppliers, manufacturers, distributors, technology developers, researchers, and organizations from all segments of the value chain of this industry. To obtain and verify critical qualitative and quantitative information, in-depth interviews were conducted with a variety of primary respondents, including key industry participants, subject-matter experts, C-level executives of key market players, and industry consultants.
Estimation of Market Size
The total size of the NoSQL Databases Software market was estimated and validated using both top-down and bottom-up approaches. These methods were also widely used to estimate the size of various market sub segments. The following research methodologies were used to estimate market size:
Extensive secondary research was used to identify the industry’s key players.
The revenues generated by the market’s leading players in molecular diagnostics have been determined through primary and secondary research.
All percentage shares, splits, and breakdowns were calculated using secondary sources and confirmed using primary sources.
TABLE OF CONTENTS OF NoSQL Databases Software Market Report
1 INTRODUCTION
1.1 study objectives
1.2 definition
1.3 inclusions & exclusions
1.4 market scope
1.5 years considered
1.6 currency
1.7 limitations
1.8 stakeholders
1.9 summary of changes
2 RESEARCH METHODOLOGY
2.1 research data
2.2 market breakdown and data triangulation
2.3 scope
2.4 impact of covid-19 on industry
2.5 market size estimation
3 EXECUTIVE SUMMARY
4 PREMIUM INSIGHTS
4.1 attractive opportunities in NoSQL Databases Software market
4.2 NoSQL Databases Software market, by region
4.3 NoSQL Databases Software market in North America, by end user & country
4.4 NoSQL Databases Software market, by application
4.5 NoSQL Databases Software market, by end user
5 MARKET OVERVIEW
5.1 introduction
5.2 covid-19 health assessment
5.3 road to recovery
5.4 covid-19 economic assessment
5.5 market dynamics
5.6 trends
5.7 market map
5.8 average pricing of NoSQL Databases Software
5.9 trade statistics
5.8 value chain analysis
5.9 technology analysis
5.10 tariff and regulatory landscape
5.11 NoSQL Databases Software: patent analysis
5.14 porter’s five forces analysis
6 NoSQL Databases Software MARKET, BY APPLICATION
6.1 Introduction
6.2 Emergency
6.3 Prime/Continuous
7 NoSQL Databases Software MARKET, BY END USER
7.1 Introduction
7.2 Residential
7.3 Commercial
7.4 Industrial
8 GEOGRAPHIC ANALYSIS
8.1 Introduction
8.2 North America
8.3 Asia Pacific
8.4 Europe
8.5 Middle East & Africa
8.6 South America
9 COMPETITIVE LANDSCAPE
9.1 Key Players Strategies
9.2 Market Share Analysis Of Top Five Players
9.3 Market Evaluation Framework
9.4 Revenue Analysis Of Top Five Market Players
9.5 Company Evaluation Quadrant
9.6 Competitive Leadership Mapping Of Start-Ups
9.7 Competitive Scenario
10 COMPANY PROFILES
10.1 Major Players
10.2 Startup/Sme Players
11 APPENDIX
11.1 Insights Of Industry Experts
11.2 Discussion Guide
11.3 Knowledge Store
11.4 Available Customizations
11.5 Related Reports
11.6 Author Details
Buy instant copy of this research report @ jcmarketresearch.com/checkout/1326836
Find more research reports on NoSQL Databases Software Industry. By JC Market Research.
About Author:
JCMR global research and market intelligence consulting organization is uniquely positioned to not only identify growth opportunities but to also empower and inspire you to create visionary growth strategies for futures, enabled by our extraordinary depth and breadth of thought leadership, research, tools, events and experience that assist you for making goals into a reality. Our understanding of the interplay between industry convergence, Mega Trends, technologies and market trends provides our clients with new business models and expansion opportunities. We are focused on identifying the “Accurate Forecast” in every industry we cover so our clients can reap the benefits of being early market entrants and can accomplish their “Goals & Objectives”.
Contact Us: https://jcmarketresearch.com/contact-us
JCMARKETRESEARCH
Mark Baxter (Head of Business Development)
Phone: +1 (925) 478-7203
Email: sales@jcmarketresearch.com
Connect with us at – LinkedIn
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

In a world of GPT-3 AI-generated content, are writers even needed? In a recent business experiment, I set out to answer this question.
If you’re wondering, who am I to tell you anything about GPT-3 AI? Well, I’m Lillian Pierson, and I help data professionals become world-class data leaders and entrepreneurs – to date I’ve trained over 1 million data professionals on the topics of data science and AI. I’m a data scientist turned data entrepreneur, and I’ve been testing out GPT-3 AI for about 3 months now in my data business, Data-Mania.
As a data entrepreneur, I spend a TON of my time, energy, and financial resources on creating content. From podcast episodes to YouTube scripts, to emails and social media posts, content creation eats up a huge chunk of my week.
So when I heard about GPT-3 AI copy services, I was curious to know: would this be a useful tool in my business?
Would I be able to 10x my content production rates? Replace freelance writers?
Rather than simply buying into the online hype, I wanted to conduct my own research – and today, I want to share it with you. Whether you’re a data entrepreneur, data professional, or simply a fellow data geek who LOVES reading about the smartest AI companies, read on to get the full scoop on GPT-3 AI and how I believe it will shape the content writing industry.
In this article, we’ll cover:
- What is GPT-3 AI?
- The pros of GPT-3
- The cons of GPT-3
- 3 guidelines to use GPT-3 while maintaining brand integrity
- Will GPT-3 change the content writing industry?
Let’s get started.
What is GPT-3 AI?
First of all, what is GPT-3 AI? GPT-3 is a model for human-like language production written in Python. It uses large amounts of texts crawled from the web to create similar, but unique content. Since it was developed by OpenAI and released for public use in June of 2020, there have been TONS of data entrepreneurs creating SAS products that run off of GPT-3.
Some of the most common GPT-3 AI content services are Copy.ai and WriteSonic. I conducted my experiment using Writesonic.
Pros of GPT-3 AI
Alright, let’s start with the good.
1. Great for Product Descriptions
During my experiment, I have to say I was genuinely impressed by the product description snippets I was able to create using Write Sonic’s GPT-3 AI service.
All I needed to do was input the name of my product (in this case, it was my free Data Superhero Quiz) as well as add product info such as features and benefits. All I did was copy and paste some bullet points from my sales page and I was good to go.
And wow! With the click on a button, I had ten high-quality product descriptions to pull from. The service was even suggesting some features and benefits I hadn’t even thought of.
2. Unique and Anonymous
A big pro to using GPT-3 AI content is that everything it spits out is completely unique. There’s no need to worry about plagiarized content. Also, the service is totally anonymous – no one will know you’re using AI so there’s no need to worry about being judged.
3. Good ROI on Your Time and Money
After reviewing the product descriptions created by Writesonic, I have to admit I liked them a lot better than the ones I’d written myself. Considering the fact they’d taken me a good 10-20 minutes to write, PLUS I’d purchased templates for $50 to speed up the process of writing them, the GPT-3 AI content is clearly better value. I had dozens of descriptions within just 30 seconds.
Overall, if you are looking for a tool to help you quickly and easily create short content snippets (i.e. product descriptions!) you should definitely add a tool like Copy.ai or Writesonic to your toolbox.
Cons of GPT-3 AI
While I had some successes with GPT-3 AI, I also had some total failures.
1. Lacks context
Unfortunately, GPT-3 is not great at generating content if it doesn’t have the context directly from you.
I tried playing around with its article writing mode, which is still in beta.
Essentially, you give it an outline and an introduction, and then it returns the entire article with all of the body copy.
While technically the information may be factually correct, it lacks context. It won’t have the context needed for YOUR particular audience, so it won’t be intelligible.
Information without context about WHY it matters to your customers is useless. They need to know why they should care and how what you’re sharing will actually have an impact on their life. Without that, you’re simply producing content for the sake of content, and adding to the noise.
2. In some cases, it gets things wrong.
While in some cases the information might be garbled and lacking context, in other instances, the content GPT-3 AI provides could be flat out wrong. GPT-3 AI will lack the nuances about your industry that come naturally to you.
For example, when I was using Writesonic’s article mode, one of the headings was “What are the obligations of a Data Processor?”
However, the body copy that GPT-3 produced did NOT correlate with the appropriate heading. Rather than telling me the obligations of a Data Processor, it gave me content about the role of a Data Protection Officer.
It brought up a totally different point. And while it may be related, if you had actually used this content on the web, it would’ve reduced your credibility and put your brand in a bad light.
In short, I would straight up AVOID GPT-3 AI for article-writing or long-form content. You could potentially use it as a research tool, to help you uncover relevant topics you may not have thought of, but always be sure to dig deeper into those topics and not rely on what GPT-3 gives you.
3 Guidelines To Make the Most of GPT-3
Here are three recommendations and safety guidelines for you to use in order to make sure that you’re protecting your brand integrity and the quality of the content you produce when working with GPT-3.
1. Review GPT-3 AI Content Carefully
GPT-3 is going to create a TON of content for you. It’s up to you to pick and choose what is valuable, and to make sure everything is factually correct and appropriate.
2. Add Personalization
Whatever content that GPT-3 gives you, you need to improve on it, add to it and personalize it for your brand. You know your customers better than anyone else. I recommend seeing GPT-3 as more of a content research tool than as something to produce finished copy.

3. Add Context
No one on this planet needs more random information. What we need is meaning and context. So while the creators of GPT-3 are correct in saying it produces ‘human-like text, it’s not able to add the context readers need in order to create meaning in their lives.
Content without context doesn’t compel readers to take action based on what they’ve read – all it does is overwhelm them. Information for the sake of information simply adds to the noise – which is something all of us online content creators should be trying to avoid at all costs
4. Listen to All Content Aloud
And last, but not least, rule number four is to listen to your end text aloud.
You want to make sure that whatever content GPT-3 AI spits out, you’re listening to out loud so you can make sure it’s conversational and flows nicely. It’ll also be an opportunity to double-check everything is factually correct.
My favorite tool to do this is a TTS reader.
By following these guidelines, you’ll be able to ensure that you can safely increase your content production WITHOUT harming your brand’s reputation.
Will GPT-3 change the game for writers?
After reviewing the results from my business experiment, I STILL believe that there is a need for highly skilled content writers. However, the rise of GPT-3 AI demonstrates how AI is certainly changing the content marketing landscape.
While I do believe GPT-3 may replace low-level, unskilled writers (who, let’s be real, probably shouldn’t be pursuing writing in the first place) businesses will continue to require writers who can deliver nuance, context, and meaning to their customers.
At best, GPT-3 will become a tool that helps smart writers speed up their writing process and make their lives easier. They may use GPT-3 content as a starting point from which they can create highly personalized and meaningful content.
At worst, the web could become flooded with GPT-3 AI generated that only adds noise to the already crowded internet, significantly contributing to the overwhelm people are already experiencing when trying to find high-value information online.
In order to create long-form, meaningful content, GPT-3 AI content tools still have a long way to go, but they show promise as a tool to speed up businesses’ content workflows.
About the Author
Mentor to World-Class Data Leaders and Entrepreneurs, CEO of Data-Mania
Lillian Pierson, P.E. helps data professionals transform into world-class data leaders and entrepreneurs. To date she’s educated over 1 Million data professionals on AI. She’s also been delivering strategic plans since 2008, for organizations as large as the US Navy, National Geographic, and Saudi Aramco.
Get the Data Entrepreneur’s Toolkit (free)
If you love learning about this GPT-3 tool, then you’re also going to love our FREE Data Entrepreneur’s Toolkit – it’s designed to help data professionals who want to start an online business and hit 6-figures in less than a year.
It’s our favorite 32 tools & processes (that we use), which includes:
- Marketing & Sales Automation Tools, so you can generate leads and sales – even in your sleeping hours
- Business Process Automation Tools, so you have more time to chill offline, and relax.
- Essential Data Startup Processes, so you feel confident knowing you’re doing the right things to build a data business that’s both profitable and scalable.
Trending: Real-Time Analytics Market Growth Analysis, Recent Trends and Regional Forecast …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

LOS ANGELES, United States: QY Research offers an overarching research and analysis-based study on, “Global Real-Time Analytics Market Report, History and Forecast 2016-2027, Breakdown Data by Companies, Key Regions, Types and Application“. This report offers an insightful take on the drivers and restraints present in the market. Real-Time Analytics data reports also provide a 5 year pre-historic and forecast for the sector and include data on socio-economic data of global. Key stakeholders can consider statistics, tables & figures mentioned in this report for strategic planning which lead to success of the organization. It sheds light on strategic production, revenue, and consumption trends for players to improve sales and growth in the global Real-Time Analytics Market. Here, it focuses on the recent developments, sales, market value, production, gross margin, and other significant factors of the business of the major players operating in the global Real-Time Analytics Market. Players can use the accurate market facts and figures and statistical studies provided in the report to understand the current and future growth of the global Real-Time Analytics market.
This report includes assessment of various drivers, government policies, technological innovations, upcoming technologies, opportunities, market risks, restrains, market barriers, challenges, trends, competitive landscape, and segments which gives an exact picture of the growth of the global Real-Time Analytics market.
| Top Companies/Manufacturers: | Microsoft, SAP, Oracle, IBM, Informatica, Amdocs, Infosys, Google, Impetus Technologies, MongoDB |
| Market Segment by Product Type: | Processing in Memory In-Database Analytics Data Warehouse Appliances In-Memory Analytics Massively Parallel Programming |
| Market Segment by Application: | BFSI Manufacturing Media and Entertainment Government Retail and Wholesale Military Warehouses Scientific Analysis |
Get PDF Sample Copy of the Report Real-Time Analytics market
https://www.qyresearch.com/sample-form/form/3170257/global-real-time-analytics-market
Do You Have Any Question Or Specific Requirement? Ask to Our Industry Expert:
https://www.qyresearch.com/customize-request/form/3170257/global-real-time-analytics-market
Competitive Landscape
Competitor analysis is one of the best sections of the report that compares the progress of leading players based on crucial parameters, including market share, new developments, global reach, local competition, price, and production. From the nature of competition to future changes in the vendor landscape, the report provides in-depth analysis of the competition in the global Real-Time Analytics market.
Key questions answered in the report:
- What is the growth potential of the Real-Time Analytics market?
- Which product segment will grab a lion’s share?
- Which regional market will emerge as a frontrunner in the coming years?
- Which application segment will grow at a robust rate?
- What are the growth opportunities that may emerge in the Interactive Patient Engagement Systems industry in the years to come?
- What are the key challenges that the global Real-Time Analytics market may face in the future?
- Which are the leading companies in the global Real-Time Analytics market?
- Which are the key trends positively impacting the market growth?
- Which are the growth strategies considered by the players to sustain hold in the global Real-Time Analytics market
Table of Contents
1 Market Overview of Real-Time Analytics
1.1 Real-Time Analytics Market Overview
1.1.1 Real-Time Analytics Product Scope
1.1.2 Real-Time Analytics Market Status and Outlook
1.2 Global Real-Time Analytics Market Size Overview by Region 2016 VS 2021VS 2027
1.3 Global Real-Time Analytics Market Size by Region (2016-2027)
1.4 Global Real-Time Analytics Historic Market Size by Region (2016-2021)
1.5 Global Real-Time Analytics Market Size Forecast by Region (2022-2027)
1.6 Key Regions, Real-Time Analytics Market Size (2016-2027)
1.6.1 North America Real-Time Analytics Market Size (2016-2027)
1.6.2 Europe Real-Time Analytics Market Size (2016-2027)
1.6.3 Asia-Pacific Real-Time Analytics Market Size (2016-2027)
1.6.4 Latin America Real-Time Analytics Market Size (2016-2027)
1.6.5 Middle East & Africa Real-Time Analytics Market Size (2016-2027) 2 Real-Time Analytics Market Overview by Type
2.1 Global Real-Time Analytics Market Size by Type: 2016 VS 2021 VS 2027
2.2 Global Real-Time Analytics Historic Market Size by Type (2016-2021)
2.3 Global Real-Time Analytics Forecasted Market Size by Type (2022-2027)
2.4 Processing in Memory
2.5 In-Database Analytics
2.6 Data Warehouse Appliances
2.7 In-Memory Analytics
2.8 Massively Parallel Programming 3 Real-Time Analytics Market Overview by Application
3.1 Global Real-Time Analytics Market Size by Application: 2016 VS 2021 VS 2027
3.2 Global Real-Time Analytics Historic Market Size by Application (2016-2021)
3.3 Global Real-Time Analytics Forecasted Market Size by Application (2022-2027)
3.4 BFSI
3.5 Manufacturing
3.6 Media and Entertainment
3.7 Government
3.8 Retail and Wholesale
3.9 Military
3.10 Warehouses
3.11 Scientific Analysis 4 Real-Time Analytics Competition Analysis by Players
4.1 Global Real-Time Analytics Market Size by Players (2016-2021)
4.2 Global Top Players by Company Type (Tier 1, Tier 2 and Tier 3) & (based on the Revenue in Real-Time Analytics as of 2020)
4.3 Date of Key Players Enter into Real-Time Analytics Market
4.4 Global Top Players Real-Time Analytics Headquarters and Area Served
4.5 Key Players Real-Time Analytics Product Solution and Service
4.6 Competitive Status
4.6.1 Real-Time Analytics Market Concentration Rate
4.6.2 Mergers & Acquisitions, Expansion Plans 5 Company (Top Players) Profiles and Key Data
5.1 Microsoft
5.1.1 Microsoft Profile
5.1.2 Microsoft Main Business
5.1.3 Microsoft Real-Time Analytics Products, Services and Solutions
5.1.4 Microsoft Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.1.5 Microsoft Recent Developments
5.2 SAP
5.2.1 SAP Profile
5.2.2 SAP Main Business
5.2.3 SAP Real-Time Analytics Products, Services and Solutions
5.2.4 SAP Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.2.5 SAP Recent Developments
5.3 Oracle
5.3.1 Oracle Profile
5.3.2 Oracle Main Business
5.3.3 Oracle Real-Time Analytics Products, Services and Solutions
5.3.4 Oracle Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.3.5 IBM Recent Developments
5.4 IBM
5.4.1 IBM Profile
5.4.2 IBM Main Business
5.4.3 IBM Real-Time Analytics Products, Services and Solutions
5.4.4 IBM Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.4.5 IBM Recent Developments
5.5 Informatica
5.5.1 Informatica Profile
5.5.2 Informatica Main Business
5.5.3 Informatica Real-Time Analytics Products, Services and Solutions
5.5.4 Informatica Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.5.5 Informatica Recent Developments
5.6 Amdocs
5.6.1 Amdocs Profile
5.6.2 Amdocs Main Business
5.6.3 Amdocs Real-Time Analytics Products, Services and Solutions
5.6.4 Amdocs Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.6.5 Amdocs Recent Developments
5.7 Infosys
5.7.1 Infosys Profile
5.7.2 Infosys Main Business
5.7.3 Infosys Real-Time Analytics Products, Services and Solutions
5.7.4 Infosys Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.7.5 Infosys Recent Developments
5.8 Google
5.8.1 Google Profile
5.8.2 Google Main Business
5.8.3 Google Real-Time Analytics Products, Services and Solutions
5.8.4 Google Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.8.5 Google Recent Developments
5.9 Impetus Technologies
5.9.1 Impetus Technologies Profile
5.9.2 Impetus Technologies Main Business
5.9.3 Impetus Technologies Real-Time Analytics Products, Services and Solutions
5.9.4 Impetus Technologies Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.9.5 Impetus Technologies Recent Developments
5.10 MongoDB
5.10.1 MongoDB Profile
5.10.2 MongoDB Main Business
5.10.3 MongoDB Real-Time Analytics Products, Services and Solutions
5.10.4 MongoDB Real-Time Analytics Revenue (US$ Million) & (2016-2021)
5.10.5 MongoDB Recent Developments 6 North America
6.1 North America Real-Time Analytics Market Size by Country (2016-2027)
6.2 United States
6.3 Canada 7 Europe
7.1 Europe Real-Time Analytics Market Size by Country (2016-2027)
7.2 Germany
7.3 France
7.4 U.K.
7.5 Italy
7.6 Russia
7.7 Nordic
7.8 Rest of Europe 8 Asia-Pacific
8.1 Asia-Pacific Real-Time Analytics Market Size by Region (2016-2027)
8.2 China
8.3 Japan
8.4 South Korea
8.5 Southeast Asia
8.6 India
8.7 Australia
8.8 Rest of Asia-Pacific 9 Latin America
9.1 Latin America Real-Time Analytics Market Size by Country (2016-2027)
9.2 Mexico
9.3 Brazil
9.4 Rest of Latin America 10 Middle East & Africa
10.1 Middle East & Africa Real-Time Analytics Market Size by Country (2016-2027)
10.2 Turkey
10.3 Saudi Arabia
10.4 UAE
10.5 Rest of Middle East & Africa 11 Real-Time Analytics Market Dynamics
11.1 Real-Time Analytics Industry Trends
11.2 Real-Time Analytics Market Drivers
11.3 Real-Time Analytics Market Challenges
11.4 Real-Time Analytics Market Restraints 12 Research Finding /Conclusion 13 Methodology and Data Source
13.1 Methodology/Research Approach
13.1.1 Research Programs/Design
13.1.2 Market Size Estimation
13.1.3 Market Breakdown and Data Triangulation
13.2 Data Source
13.2.1 Secondary Sources
13.2.2 Primary Sources
13.3 Disclaimer
13.4 Author List
About Us:
QYResearch always pursuits high product quality with the belief that quality is the soul of business. Through years of effort and supports from huge number of customer supports, QYResearch consulting group has accumulated creative design methods on many high-quality markets investigation and research team with rich experience. Today, QYResearch has become the brand of quality assurance in consulting industry.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
LOS ANGELES, United States: QY Research offers an overarching research and analysis-based study on, “Global Data Management System (DBMS) Market Report, History and Forecast 2016-2027, Breakdown Data by Companies, Key Regions, Types and Application“. This report offers an insightful take on the drivers and restraints present in the market. Data Management System (DBMS) data reports also provide a 5 year pre-historic and forecast for the sector and include data on socio-economic data of global. Key stakeholders can consider statistics, tables & figures mentioned in this report for strategic planning which lead to success of the organization. It sheds light on strategic production, revenue, and consumption trends for players to improve sales and growth in the global Data Management System (DBMS) Market. Here, it focuses on the recent developments, sales, market value, production, gross margin, and other significant factors of the business of the major players operating in the global Data Management System (DBMS) Market. Players can use the accurate market facts and figures and statistical studies provided in the report to understand the current and future growth of the global Data Management System (DBMS) market.
This report includes assessment of various drivers, government policies, technological innovations, upcoming technologies, opportunities, market risks, restrains, market barriers, challenges, trends, competitive landscape, and segments which gives an exact picture of the growth of the global Data Management System (DBMS) market.
| Top Companies/Manufacturers: | Actian, Teradata, BMC Software, Broadcom, Couchbase Server, Embarcadero Technologies, EnterpriseDB Software Solution, MongoDB, HP, Oracle, IBM, InterSystems, Microsoft, Neo Technology, Pitney Bowes, Bradmark Technologies, MarkLogic, SAP, TIBCO, Vision Solutions, VoltDB |
| Market Segment by Product Type: | Relational Non-Relational |
| Market Segment by Application: | Banking & Financial Government Hospitality Healthcare and Life Sciences Education Media & Entertainment Professional Service Telecom & IT |
Get PDF Sample Copy of the Report Data Management System (DBMS) market
https://www.qyresearch.com/sample-form/form/3169988/global-data-management-system-dbms-market
Do You Have Any Question Or Specific Requirement? Ask to Our Industry Expert:
https://www.qyresearch.com/customize-request/form/3169988/global-data-management-system-dbms-market
Competitive Landscape
Competitor analysis is one of the best sections of the report that compares the progress of leading players based on crucial parameters, including market share, new developments, global reach, local competition, price, and production. From the nature of competition to future changes in the vendor landscape, the report provides in-depth analysis of the competition in the global Data Management System (DBMS) market.
Key questions answered in the report:
- What is the growth potential of the Data Management System (DBMS) market?
- Which product segment will grab a lion’s share?
- Which regional market will emerge as a frontrunner in the coming years?
- Which application segment will grow at a robust rate?
- What are the growth opportunities that may emerge in the Interactive Patient Engagement Systems industry in the years to come?
- What are the key challenges that the global Data Management System (DBMS) market may face in the future?
- Which are the leading companies in the global Data Management System (DBMS) market?
- Which are the key trends positively impacting the market growth?
- Which are the growth strategies considered by the players to sustain hold in the global Data Management System (DBMS) market
Table of Contents
1 Market Overview of Data Management System (DBMS)
1.1 Data Management System (DBMS) Market Overview
1.1.1 Data Management System (DBMS) Product Scope
1.1.2 Data Management System (DBMS) Market Status and Outlook
1.2 Global Data Management System (DBMS) Market Size Overview by Region 2016 VS 2021VS 2027
1.3 Global Data Management System (DBMS) Market Size by Region (2016-2027)
1.4 Global Data Management System (DBMS) Historic Market Size by Region (2016-2021)
1.5 Global Data Management System (DBMS) Market Size Forecast by Region (2022-2027)
1.6 Key Regions, Data Management System (DBMS) Market Size (2016-2027)
1.6.1 North America Data Management System (DBMS) Market Size (2016-2027)
1.6.2 Europe Data Management System (DBMS) Market Size (2016-2027)
1.6.3 Asia-Pacific Data Management System (DBMS) Market Size (2016-2027)
1.6.4 Latin America Data Management System (DBMS) Market Size (2016-2027)
1.6.5 Middle East & Africa Data Management System (DBMS) Market Size (2016-2027) 2 Data Management System (DBMS) Market Overview by Type
2.1 Global Data Management System (DBMS) Market Size by Type: 2016 VS 2021 VS 2027
2.2 Global Data Management System (DBMS) Historic Market Size by Type (2016-2021)
2.3 Global Data Management System (DBMS) Forecasted Market Size by Type (2022-2027)
2.4 Relational
2.5 Non-Relational 3 Data Management System (DBMS) Market Overview by Application
3.1 Global Data Management System (DBMS) Market Size by Application: 2016 VS 2021 VS 2027
3.2 Global Data Management System (DBMS) Historic Market Size by Application (2016-2021)
3.3 Global Data Management System (DBMS) Forecasted Market Size by Application (2022-2027)
3.4 Banking & Financial
3.5 Government
3.6 Hospitality
3.7 Healthcare and Life Sciences
3.8 Education
3.9 Media & Entertainment
3.10 Professional Service
3.11 Telecom & IT 4 Data Management System (DBMS) Competition Analysis by Players
4.1 Global Data Management System (DBMS) Market Size by Players (2016-2021)
4.2 Global Top Players by Company Type (Tier 1, Tier 2 and Tier 3) & (based on the Revenue in Data Management System (DBMS) as of 2020)
4.3 Date of Key Players Enter into Data Management System (DBMS) Market
4.4 Global Top Players Data Management System (DBMS) Headquarters and Area Served
4.5 Key Players Data Management System (DBMS) Product Solution and Service
4.6 Competitive Status
4.6.1 Data Management System (DBMS) Market Concentration Rate
4.6.2 Mergers & Acquisitions, Expansion Plans 5 Company (Top Players) Profiles and Key Data
5.1 Actian
5.1.1 Actian Profile
5.1.2 Actian Main Business
5.1.3 Actian Data Management System (DBMS) Products, Services and Solutions
5.1.4 Actian Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.1.5 Actian Recent Developments
5.2 Teradata
5.2.1 Teradata Profile
5.2.2 Teradata Main Business
5.2.3 Teradata Data Management System (DBMS) Products, Services and Solutions
5.2.4 Teradata Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.2.5 Teradata Recent Developments
5.3 BMC Software
5.3.1 BMC Software Profile
5.3.2 BMC Software Main Business
5.3.3 BMC Software Data Management System (DBMS) Products, Services and Solutions
5.3.4 BMC Software Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.3.5 Broadcom Recent Developments
5.4 Broadcom
5.4.1 Broadcom Profile
5.4.2 Broadcom Main Business
5.4.3 Broadcom Data Management System (DBMS) Products, Services and Solutions
5.4.4 Broadcom Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.4.5 Broadcom Recent Developments
5.5 Couchbase Server
5.5.1 Couchbase Server Profile
5.5.2 Couchbase Server Main Business
5.5.3 Couchbase Server Data Management System (DBMS) Products, Services and Solutions
5.5.4 Couchbase Server Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.5.5 Couchbase Server Recent Developments
5.6 Embarcadero Technologies
5.6.1 Embarcadero Technologies Profile
5.6.2 Embarcadero Technologies Main Business
5.6.3 Embarcadero Technologies Data Management System (DBMS) Products, Services and Solutions
5.6.4 Embarcadero Technologies Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.6.5 Embarcadero Technologies Recent Developments
5.7 EnterpriseDB Software Solution
5.7.1 EnterpriseDB Software Solution Profile
5.7.2 EnterpriseDB Software Solution Main Business
5.7.3 EnterpriseDB Software Solution Data Management System (DBMS) Products, Services and Solutions
5.7.4 EnterpriseDB Software Solution Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.7.5 EnterpriseDB Software Solution Recent Developments
5.8 MongoDB
5.8.1 MongoDB Profile
5.8.2 MongoDB Main Business
5.8.3 MongoDB Data Management System (DBMS) Products, Services and Solutions
5.8.4 MongoDB Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.8.5 MongoDB Recent Developments
5.9 HP
5.9.1 HP Profile
5.9.2 HP Main Business
5.9.3 HP Data Management System (DBMS) Products, Services and Solutions
5.9.4 HP Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.9.5 HP Recent Developments
5.10 Oracle
5.10.1 Oracle Profile
5.10.2 Oracle Main Business
5.10.3 Oracle Data Management System (DBMS) Products, Services and Solutions
5.10.4 Oracle Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.10.5 Oracle Recent Developments
5.11 IBM
5.11.1 IBM Profile
5.11.2 IBM Main Business
5.11.3 IBM Data Management System (DBMS) Products, Services and Solutions
5.11.4 IBM Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.11.5 IBM Recent Developments
5.12 InterSystems
5.12.1 InterSystems Profile
5.12.2 InterSystems Main Business
5.12.3 InterSystems Data Management System (DBMS) Products, Services and Solutions
5.12.4 InterSystems Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.12.5 InterSystems Recent Developments
5.13 Microsoft
5.13.1 Microsoft Profile
5.13.2 Microsoft Main Business
5.13.3 Microsoft Data Management System (DBMS) Products, Services and Solutions
5.13.4 Microsoft Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.13.5 Microsoft Recent Developments
5.14 Neo Technology
5.14.1 Neo Technology Profile
5.14.2 Neo Technology Main Business
5.14.3 Neo Technology Data Management System (DBMS) Products, Services and Solutions
5.14.4 Neo Technology Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.14.5 Neo Technology Recent Developments
5.15 Pitney Bowes
5.15.1 Pitney Bowes Profile
5.15.2 Pitney Bowes Main Business
5.15.3 Pitney Bowes Data Management System (DBMS) Products, Services and Solutions
5.15.4 Pitney Bowes Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.15.5 Pitney Bowes Recent Developments
5.16 Bradmark Technologies
5.16.1 Bradmark Technologies Profile
5.16.2 Bradmark Technologies Main Business
5.16.3 Bradmark Technologies Data Management System (DBMS) Products, Services and Solutions
5.16.4 Bradmark Technologies Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.16.5 Bradmark Technologies Recent Developments
5.17 MarkLogic
5.17.1 MarkLogic Profile
5.17.2 MarkLogic Main Business
5.17.3 MarkLogic Data Management System (DBMS) Products, Services and Solutions
5.17.4 MarkLogic Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.17.5 MarkLogic Recent Developments
5.18 SAP
5.18.1 SAP Profile
5.18.2 SAP Main Business
5.18.3 SAP Data Management System (DBMS) Products, Services and Solutions
5.18.4 SAP Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.18.5 SAP Recent Developments
5.19 TIBCO
5.19.1 TIBCO Profile
5.19.2 TIBCO Main Business
5.19.3 TIBCO Data Management System (DBMS) Products, Services and Solutions
5.19.4 TIBCO Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.19.5 TIBCO Recent Developments
5.20 Vision Solutions
5.20.1 Vision Solutions Profile
5.20.2 Vision Solutions Main Business
5.20.3 Vision Solutions Data Management System (DBMS) Products, Services and Solutions
5.20.4 Vision Solutions Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.20.5 Vision Solutions Recent Developments
5.21 VoltDB
5.21.1 VoltDB Profile
5.21.2 VoltDB Main Business
5.21.3 VoltDB Data Management System (DBMS) Products, Services and Solutions
5.21.4 VoltDB Data Management System (DBMS) Revenue (US$ Million) & (2016-2021)
5.21.5 VoltDB Recent Developments 6 North America
6.1 North America Data Management System (DBMS) Market Size by Country (2016-2027)
6.2 United States
6.3 Canada 7 Europe
7.1 Europe Data Management System (DBMS) Market Size by Country (2016-2027)
7.2 Germany
7.3 France
7.4 U.K.
7.5 Italy
7.6 Russia
7.7 Nordic
7.8 Rest of Europe 8 Asia-Pacific
8.1 Asia-Pacific Data Management System (DBMS) Market Size by Region (2016-2027)
8.2 China
8.3 Japan
8.4 South Korea
8.5 Southeast Asia
8.6 India
8.7 Australia
8.8 Rest of Asia-Pacific 9 Latin America
9.1 Latin America Data Management System (DBMS) Market Size by Country (2016-2027)
9.2 Mexico
9.3 Brazil
9.4 Rest of Latin America 10 Middle East & Africa
10.1 Middle East & Africa Data Management System (DBMS) Market Size by Country (2016-2027)
10.2 Turkey
10.3 Saudi Arabia
10.4 UAE
10.5 Rest of Middle East & Africa 11 Data Management System (DBMS) Market Dynamics
11.1 Data Management System (DBMS) Industry Trends
11.2 Data Management System (DBMS) Market Drivers
11.3 Data Management System (DBMS) Market Challenges
11.4 Data Management System (DBMS) Market Restraints 12 Research Finding /Conclusion 13 Methodology and Data Source
13.1 Methodology/Research Approach
13.1.1 Research Programs/Design
13.1.2 Market Size Estimation
13.1.3 Market Breakdown and Data Triangulation
13.2 Data Source
13.2.1 Secondary Sources
13.2.2 Primary Sources
13.3 Disclaimer
13.4 Author List
About Us:
QYResearch always pursuits high product quality with the belief that quality is the soul of business. Through years of effort and supports from huge number of customer supports, QYResearch consulting group has accumulated creative design methods on many high-quality markets investigation and research team with rich experience. Today, QYResearch has become the brand of quality assurance in consulting industry.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Paul Bakker Kavitha Srinivasan
Article originally posted on InfoQ. Visit InfoQ

Transcript
Bakker: My name is Paul.
Srinivasan: I’m Kavitha.
Bakker: We’re both part of the developer experience team at Netflix. We’re going to talk about how we use developer experience to really drive your large architectural migration.
How It Started
Before we go into all the details of what we did, and what we learned from it, we do have to give a little bit of context how we got involved, and why we did what we did. In the space of show production, there’s a lot of people involved in producing a show. Netflix produces many shows. To support these efforts, we have many in-house built apps to keep track of all the things. At one point in time, the architecture that we used for this is that we had many different microservices, each responsible for part of the data. These microservices would typically expose their data using a gRPC endpoint, and in some cases, REST. From the perspective of devices, we wanted to have one single API, specifically a single GraphQL API with a single schema. The way to accomplish that is that we added a GraphQL server API in front of those microservices.
It is an architecture that many companies use, and that is generally something that works out very well. Also, for us, it worked out quite well for quite a while. At some point, we did start to see limitations in this architecture. It had a lot to do with the scale we were doing things in, and number of teams involved. Every change that was made in these back-end services, specifically, like adding new data to the schema, so new fields to the schema, all these changes will also require a code change from the team managing the GraphQL server API, because they had to add code to do a new gRPC call, to get the data. Then add it to the schema, so that this would be exposed in the GraphQL schema for the devices. The fact that this team had to do that manual work, meant that they were a bit of a blocker basically, for all the changes that were being made. Just because of the sheer number of things involved, that just became a bottleneck by itself.
Another problem with this approach is that the device teams, the user interface developers, and the back-end teams responsible for the data are quite disconnected from each other, because we have this team sitting in the middle that actually takes care of the GraphQL schema. We didn’t have a lot of natural collaboration going on between the device teams and the back-end teams, to really collaborate on a schema that works best for everyone.
Apollo Federation
Srinivasan: Right along this time, Apollo came up with a Federation spec. It described how we can split a single shared graph across many different services, each owning a portion of the graph. We call these, Domain Graph Services, or DGSs, in this architecture. Let’s say for example, you have a type, movie, that’s owned by a movie DGS. It defines the movie ID and title field. Now you have another service called the review service that wants to extend this movie type by adding another field called reviews, and provides the data for it. You can have an incoming GraphQL query that goes to the gateway. The gateway is configured so it knows it needs to talk to the movies’ DGS and the reviews’ DGS in order to fulfill the query, get the data, and send the response back. That’s how Federation works at a very high level.
This solved the big problem with the bottleneck for us, because now the gateway has no business logic. All it does is routes requests, and reaches out to the appropriate services. All the schema collaboration is now being done by the back-end and the front-end teams, and any changes related to it. The gateway is completely oblivious to this process.
To learn more about Federation, check out this talk by Jennifer and Stephen on how Netflix scales its API with GraphQL Federation.
How to Onboard 30 Teams on New Technology
Bakker: With this new architecture in mind, we envisioned that it would increase the rate of change that we could make and increase the rate of innovation that we could go after. However, this new architecture also meant new challenges, and we introduced a completely new problem. Because so far the back-end service teams that we had, and at the time we had about 30 teams involved, they only had to expose a gRPC endpoint. It’s something they were already very familiar in doing. They weren’t too concerned about a GraphQL schema or how the data would look like in a GraphQL endpoint. We weren’t worried about GraphQL in the first place. It wasn’t really something that they needed to think about, because another team was taking care of that. With this new architecture, we did require those teams to all onboard on this new technology and this new architecture. They would now be responsible for owning part of the schema, which means also the schema design that comes with it, and be responsible for writing the code to actually implement a GraphQL endpoint. On top of that, GraphQL was a very new technology when we look at back-end development, because we didn’t have a lot of GraphQL going on in the company in back-end microservices at the time. The question that we were facing is, how do we get 30 teams excited about onboarding all this new technology and this new architecture, while it does imply a lot of extra, new work for them?
When You Give a Developer Carrots
Srinivasan: The answer to that is providing developers with lots of incentives by way of a great developer experience. You want your developers to be happy, and you want to spark developer joy. How do you go about doing that? First and foremost, is the ease of onboarding. In our case, we had a mix of developers who were already familiar with GraphQL, and many who were not. Added to that, you have Federation, which is a completely new concept to introduce. You want your users to focus on the business logic, and not so much on the wire up and the setup details.
Next, you want to give your users a familiar ecosystem to work with. At Netflix, we have a whole slew of tools that we use for debugging, tracing, and logging. We wanted to make sure we provide tight integration so users can use the tools that they are already familiar with during this migration. The third aspect is consistency. You want to try to make all the code look the same. You can easily enforce best practices as a result. It also makes it much easier when it comes to debugging, and sharing what you’ve learned with other teams. This also fosters more collective learning for patterns, and you’re not reinventing the wheel so much. You want to build a strong sense of community, and this makes the journey much more exciting for everyone involved.
The Paved Path for Back-end Services
Bakker: Looking a little bit at how back-end development is typically done at Netflix, we have what we call the paved path. The paved path is the easiest and best reported way to get things done. As an example, looking at this picture, it might be a little bit more exciting and more fun to go off the road and climb these boulders, and find your way around them. It’s definitely more efficient to just follow the paved path and get to your destination. Very similar, we have the paved path for back-end development. Back-end development at Netflix is standardized on Java. We use Spring Boot. On top of Spring Boot, we have built many integrations such as distributed tracing and distributed metrics and logging. We have integrations with security systems to do authorization and authentication. We have a host of different IPC clients to do gRPC and REST. Also, server implementations to do gRPC and REST. Know that there is no GraphQL here because GraphQL really wasn’t something that we were using a lot within the company when looking at back-end server development.
Set Up a GraphQL Service
Srinivasan: How do you go about setting up a GraphQL service? First of all, you want to initialize your Spring Boot app. Then you have to create a schema, which is the API that you want your service to expose. Then you write a data fetcher, to return data in response to requests. Then you need to build your schema for the parser. Then lastly, you want to set up your HTTP endpoint to respond to /GraphQL queries.
Bakker: Let’s look at an example and see how that actually would look like in code. The example that we will look at is implementing a schema. It’s a very simple schema. We have a query type defined, and on the query we have one field that we can query for, which is hello. It has enabled arguments and it will return as a message, as a string. If you want to implement this in Spring Boot using GraphQL Java, the code looks like this. It’s a working example and it’s quite a bit of code, so we are not going to look at the details of this code. The important detail that I want to point out here is that there’s only a single line of business logic on this slide. All the other code is just setup code. It is boilerplate. Obviously, this would be code that every team would have to refigure out, and write. An important detail here is that this code although it’s a working example, is really a naive implementation. It’s really not thinking about error handling. It is really just taking care of the more simplistic happy path. Doing this in a more production-ready way, there’s quite a bit of code to write. It will be code that every team would have to reinvent and get writes, if it would not provide anything else.
Srinivasan: You have the happy path, but now you want to add authorization. You want to add tracing, logging, metrics. You want to add error handling, custom exception handling, and so on. All of this is just repeated boilerplate code that users can easily do away with and not have to write each time in each of their services.
The Domain Graph Service Framework (DGS)
Bakker: Very clearly, we could do much better here. Early on in this architectural migration, we decided to invest in a Domain Graph Service framework, or DGS. The DGS framework is really GraphQL integration for Spring Boot Netflix. The Netflix part in that is also important. It’s not just about general Spring Boot usage, but it is also about integrating with all the different components that we already have at Netflix. This framework uses GraphQL Java internally. GraphQL Java is a pre-built, maintained open source library that really takes care of the lower level details for doing GraphQL in Java.
Let’s take a look at how the DGS framework looks like. The same code example that we have seen previously would just look like this code, using the DGS framework. You immediately see, it’s a lot less code. It looks like a lot more declarative. In a familiar Spring Boot fashion, we use annotations for a lot of things. We use @DgsComponent to mark the component as being a class for the framework. We use @DgsData to say, this method is actually providing a data fetcher for a specific field in our schema. In this example it’s the hello field that we had specified. We have integration with things like @Secured to get authentication, or authorization on a field level out of the box. This integrates with the Netflix implementation of these security concerns. What’s left is really just a business logic that the developer should be concerned about. Then there’s all sorts of conveniences to, for example, easily get input arguments using this @InputArgument annotation. It really makes your code really nice and concise, and most of all, that’s really focused.
A huge benefit that we get out of this is that there’s a lot of consistency between code bases. There were initially about 30 teams that needed to be onboarded on this new architecture. We have less than a handful of developers in the developer experience team. That’s the team that’s helping out all these teams, and help them whenever problems come up, and get things going. With that ratio, it is really important for us that if a developer comes to us with a question on, for example, our select channel, that we can go into their code repository and quickly understand how it’s all fitting together, and really focus on the code that might be problematic. We get that because of this consistency, because all our code bases are structured in a very similar way, we can really quickly point out the code that we actually need to look at.
Another benefit that we’re not seeing in this code, but that we are getting for free is that we get a lot of integrations with existing Netflix systems. For example, this code example integrates with distributed logging, distributed tracing, and distributed metrics. There’s no setup required at all for a developer. There’s all those working out of the box.
Testing
Srinivasan: Next, let’s talk about testing. Testing can have a big impact on developer velocity. With the framework, we were able to provide a nice, easy way to eliminate any setup code and just focus on the business logic that you want to test. In this case, the GraphQL query. The rest of the test setup purely involves any validation steps you want to add. On top of this, we also make it really easy to construct your GraphQL query string. We’ve not shown it here for the sake of simplicity, but we provide a nice type-safe way to construct your GraphQL query string, as opposed to manually handcrafting it, which can be quite painful. Not only this, this just talks about testing your local DGS. This has to operate in a federated system, which has many moving parts. We also offer our developers many easy ways to test manually, end-to-end, their queries in a federated setup.
Schema Management
Bakker: These are just some examples of what we did at the coding level, the way developers run their code. Being in a federated architecture, there’s many more parts that are required. One of the things to really think about is schema management, because each team is managing their own part of the schema, analyzed to come together. Looking at the broader GraphQL community outside of Netflix, Apollo has some really good tooling that helps with things like schema management. We actively collaborate with Apollo on both the Federation specification, but also the tooling around this to make developer’s life easier.
However, because we have so many existing systems within Netflix, and we wanted to deeply integrate with these systems, we decided to build this tooling ourselves. What you get with this tooling is really the one-stop shop for everything around your DGS and your schema. You get schema efficiency. You get statistics on how your schema and the fields in your schema are being used and used by who. There’s integrations with build pipelines, and distributed tracing, and metrics, and logging, and all these things. This really becomes the one place to find all your information and manage your schema and your DGS.
Tracing and Logging
Srinivasan: Then comes tracing and logging in this distributed architecture. As you can see, we have our tool here. This is a custom in-house tool that developers have already been using. With the DGS framework, we were able to integrate with this existing tool and make this available for all developers who have migrated onto this new architecture. This tool shows the request fanout pattern. As you can see, it comes in, the gateway is now forwarding it to many different DGSs, which in turn can go ahead and talk to other back-end services. All of this is captured in this view. It’s all color coded, so you can see yellows for warnings, and red for errors. It also has the correlated request logs on the left-hand panel. We’re able to get correlated logs, because in the DGS framework, we ship all the logs to Elasticsearch clusters, and we’re able to view all the relevant pieces of information in just this one view. Edgar also allows us to drill down and analyze performance. At every stage of the processing of the request, you can see how much time it took, all the way down to your data fetchers.
To learn more about observability at Netflix, please check out Elizabeth Carretto’s talk.
Documentation
Bakker: Another very key aspect of developer experience, and so many of you spend a lot of energy on, is getting really great documentation. We have about 30 teams as part of this migration, and you have less than a handful of developer experience developers. How can we scale supporting that many number of teams and developers? Documentation is really key there, we believe. It is really critical that developers can easily get started themselves, can learn about the more advanced use cases by themselves, and for the most part, find solutions to problems they might run into themselves as well. The documentation is just really the key part there.
Learnings – Which Path to Pave?
Srinivasan: So far, we talked about the DGS framework that we built, and the several tools that we developed in order to make a smooth developer experience. For the remainder of the talk, we’ll focus on the learnings from this journey. Starting off with, which experience do you want to build out or which path do you want to pave? In our case, we started really small with a very narrow set of users, a very narrow use case as well. To begin with, all we wanted to do was reduce boilerplate code. Starting with GraphQL Java, we wanted to add more features to it, but make sure that we don’t take away anything. In order to do that, we needed to provide escape hatches at the right places, so developers still have access to all the low-level features in GraphQL Java, in the event that we didn’t already support it in the framework. This was in the initial phases.
Then, as we moved along, and as the adoption started growing, we heard about more feature requests, and we incorporated a lot more features along the way. Now, gradually, we’re up to a point where we have almost 30-plus teams who have onboarded onto this new architecture, all using our framework and tools. Not only that, we also have users that have nothing to do with Federation. They’re not part of this migration, but they’re also using our tools and the framework to just be able to easily start up a GraphQL service.
Bakker: Especially early on in this migration, we had to figure out what to show for and what features to add exactly, because the way this works is that the teams actually implementing these DGSs, started at the same time, as we as the developer experience team started talking about, maybe we should do a framework, and we should have built all these tools. Prioritization was really important, what to do first. That’s early on with the teams that are actually doing the implementation work. The developer experience folks embedded with these teams, and were part of basically the first DGSs that were built. That way we got a really deep understanding of what problems to solve, what needed smoothening out. It also just built developer empathy.
Later on in the process, we adopted this philosophy that we never say no. Of course, there’s a lot of subtlety to that. Essentially, there are many ways to say yes. What we mean by this is that we always prioritize the users first. Of course, we have the bigger features that we are working on, and things that we want to get out in the framework. Whenever a developer comes to us with a question, and that can be a bug report, but it can also be a feature request, and in many cases, they have some idea how to improve their developer experience. The easy thing to do would be to create a Jira, put it on your backlog, and come back to it a few weeks later whenever you have time.
Instead of doing that, what we do is we basically try to interact with these users right away. That means coming up with a design, basically, of whatever we need to do together with them. Then go and implement these features when possible, just the same day or the next day. With having that really short feedback cycle, we get a lot of benefits. First of all, our users, they feel like you’re actually listening to them. Not just listening to them, but they get immediate benefits from being a user of the framework, because they have this idea on how they can improve their own work. Instead of having to put in the time to actually implement those features in the infrastructure, they talk to us, and they basically get it for free. The benefit for us, obviously, is that we get really good feedback, and we know what to focus on, because that’s what our users need. This does slow down the work on bigger features a little bit, but that is a trade-off that worked out really well for us.
Engage With Your Users
Srinivasan: Finally, you want to engage with your users continuously. We have a support channel on Slack, where we almost hear from our users on a daily basis, whether it be feature requests, or requests for bug fixes, and sometimes even design discussions with a narrow focus set of users. We also do surveys to glean general patterns of how our tools are being used, and how effective they are across different types of users. We also found user interviews to be extremely effective, regardless of where you are in this process. Just targeted, small focused groups of users to learn about the workflows and general needs, can go a long way in informing your priorities and even figuring out what the next new experience to build out would be.
The Risk of Reinventing the Wheel
Bakker: This migration has been a huge success story for us. That is a success story that has been going on for about a year now. We also want to give you a little bit of a word of warning. That is, before you dive into building all these custom tooling and frameworks yourself, there is definitely a risk of trying to reinvent the wheel. The first thing that you really have to think about hard is that, can I actually do a better job than whatever is available in open source or the market? Because, especially at Netflix, where we have a really strong culture of freedom and responsibility, and it stretches also to technology choices, a team is free to choose a technology they think they can do the best job fit. Which means, if they think they can do a better job using some open source tool instead of using the tooling we provide, they’re free to do so. They will actually go out and do that. We have to make sure that the users see the benefits of using the tooling that we provide, and are actually doing a better job than they would otherwise do, because they have these things available.
Something else that we put a lot of extra time and thought in, is how do we contribute back to the wider GraphQL community? How do we also learn from the wider GraphQL community? Concretely, what we’re doing is we’re collaborating very closely with Apollo. This is collaboration on the Federation spec, but also lots of in-depth discussions about how tooling should work and in which ways tooling can help making the developer experience better. This way, hopefully, others can learn from us, but we’re also learning from how other companies are solving some problems that we might be facing. Definitely make sure that you give these things thought as well.
Srinivasan: We’d like to leave you with a famous quote by Winston Churchill, “A pessimist sees the difficulty in every opportunity, and an optimist sees the opportunity in every difficulty”.
See more presentations with transcripts