Author: Raul Salas

MMS • Raul Salas
Notice data integrity is the top challenge for data professionals
Top 10 Challenges to Practicing #DataScience at Work
Dirty data
Lack of DS talent
Company politics
Lack of clear question
Data inaccessible
Results not used
Explaining data science
Privacy
Lack of funds
Cannot afford data science team
https://t.co/rS90mFrBrd pic.twitter.com/o35LHCWDEc— Bob E. Hayes (@bobehayes) July 9, 2018
MMS • Raul Salas
Chinese AI beats doctors in diagnosing brain tumors! AI is getting better, but not here in America!
An artificial intelligence system called BioMind has managed to defeated a team comprised of 15 of China’s top doctors by a margin of two to one. The Next Web reports the details: When diagnosing brain tumors, BioMind was correct 87 percent of the time, compared to 66 percent by the medical professionals. The AI also only took 15 minutes to diagnose the 225 cases, while doctors took 30. In regards to predicting brain hematoma expansion, BioMind was victorious again, as it was correct in 83 percent of cases, with humans managing only 63 percent. Researchers trained the AI by feeding it thousands upon thousands of images from Beijing Tiantan Hospital’s archives. This has made it as good at diagnosing neurological diseases as senior doctors, as it has a 90 percent accuracy rate.
\
MMS • Raul Salas
 Data Science is a big buzzword currently. However, what does it really mean? Does anyone truly understand the complexity of the concepts, libraries, and even the underlying architecture and what it means for society, their careers, and businesses? Other countries are in a AI arms race, educating their populations and growing their AI workforce, but for AI to truly grow, it needs to be democratized so that everyone can use it’s power. This graphic explains AI in an easy to understand format and is a good reference guide as well.
Data Science is a big buzzword currently. However, what does it really mean? Does anyone truly understand the complexity of the concepts, libraries, and even the underlying architecture and what it means for society, their careers, and businesses? Other countries are in a AI arms race, educating their populations and growing their AI workforce, but for AI to truly grow, it needs to be democratized so that everyone can use it’s power. This graphic explains AI in an easy to understand format and is a good reference guide as well.
#AI needs further demystification and democratization: https://t.co/zNhdsy8UGB #abdsc #xAI #GDPR #AIethics #DataEthics #BigData #DataScience #DataScientists #MachineLearning #DeepLearning #DAIFE
Source for graphic: https://t.co/DLLKEFTdr1 pic.twitter.com/VbS3dnAN0W
— Kirk Borne (@KirkDBorne) July 9, 2018
MMS • Raul Salas

Ever wonder what happens in an Internet minute? Now that we are in 2018, I thought it would be good timing to discuss the state of internet activity in 2017. All these internet interactions generate a massive amount of data and is contributing to the growing demand for Big Data professionals.
What’s interesting to note is Google’s lack of dominance in Internet Activity. Once a stalwart, Google is now being matched by activity from Facebook, Snapchat, and twitter combined!
Notice the new entry for 2017 is the Alexa interactions. There are currently 50 Alexa’s shipped per minute, expect this number to skyrocket considering record Amazon Alexa sales this Christmas! Interactions with AWS Voice endpoints will skyrocket as well with the introduction of the Alexa Marketplace. In addition, this past November Amazon launched Alexa for Business product line as well (https://www.youtube.com/watch?v=ViB3XhsTLuo). This will propel Amazon interactions and data growth as well.
What does all this mean for Big Data? It means growth of data will continue to be strong and outstrip organization’s ability to make effective use of the data. At the same time, Machine learning and Artificial Intelligence will also be consuming data at very high rates. 2018 may be the year that organizations start to put emphasis on the quality of data as well as the triage/prioritization of data in their data warehouses.
MMS • Raul Salas

This is a quick blogpost from notes that i have gathered over time. There may be situations where support staff might be restricted from logging directly into a Mongodb instance. But there may also be a requirement for support staff to get information on the status of Mongodb environments, especially users of the Community version of Mongodb. These commands could also be run via a shell script as well that would allow a sysadmin to automate these commands into a daily routine.
You can quickly obtain information by executing the following commands:
mongo –port –username <username> –password <password> –authenticationDatabase admin –eval “mongo command”
Of course you will need to add the required authentication parameters relevant to your installation.
Obtaining host information – you can execute the mongo shell command along with some configuration options such as database, authenticatioen, and the –eval command followed by the actual mongo command you want to execute. The command is broken into the following parameters:
I setup a quick test environment, so no need to use any authentication parameters, but you can see how to execute the command and the associated output. You can see the version along with the host as well as os information.
$ mongo –eval “db.hostInfo()”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
{
“system” : {
“currentTime” : ISODate(“2017-10-23T20:50:43.959Z”),
“hostname” : “MacBook.local”,
“cpuAddrSize” : 64,
“memSizeMB” : 16384,
“numCores” : 8,
“cpuArch” : “x86_64”,
“numaEnabled” : false
},
“os” : {
“type” : “Darwin”,
“name” : “Mac OS X”,
“version” : “16.7.0”
},
“extra” : {
“versionString” : “Darwin Kernel Version 16.7.0: T4”,
“alwaysFullSync” : 0,
“nfsAsync” : 0,
“model” : “MacBook,3”,
“physicalCores” : 4,
“cpuFrequencyMHz” : 2900,
“cpuString” : “Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz”,
“cpuFeatures” : “FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX SMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16C SYSCALL XD 1GBPAGE EM64T LAHF LZCNT PREFETCHW RDTSCP TSCI”,
“pageSize” : 4096,
“scheduler” : “multiq”
},
“ok” : 1
}
Now, you would like to see what databases reside on this particular host with the listDatabases command.
$ mongo –eval “printjson(db.adminCommand( { listDatabases: 1 } ))”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.4.9
{
“databases” : [
{
“name” : “admin”,
“sizeOnDisk” : 49152,
“empty” : false
},
{
“name” : “local”,
“sizeOnDisk” : 65536,
“empty” : false
},
{
“name” : “test_db”,
“sizeOnDisk” : 65536,
“empty” : false
}
],
“totalSize” : 180224,
“ok” : 1
}
If you would like to see the collections within the database test_db, you can issue the following command to get a list of collections in json format.
$ mongo test_db –eval “printjson(db.getCollectionNames())”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
[ “cities”, “names” ]
That’s a quick overview of what can be done at the command line. For a more comprehensive list of commands, you can use the db.help() option to get a list of commands
As you can see it’s pretty comprehensive and is valuable for a sys admin and/or database administrator to get a quick picture of your Mongodb environment.
$ mongo test_db –eval “db.help()”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
DB methods:
db.adminCommand(nameOrDocument) – switches to ‘admin’ db, and runs command [ just calls db.runCommand(…) ]
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : …, capped : …, max : … } )
db.createView(name, viewOn, [ { $operator: {…}}, … ], { viewOptions } )
db.createUser(userDocument)
db.currentOp() displays currently executing operations in the db
db.dropDatabase()
db.eval() – deprecated
db.fsyncLock() flush data to disk and lock server for backups
db.fsyncUnlock() unlocks server following a db.fsyncLock()
db.getCollection(cname) same as db[‘cname’] or db.cname
db.getCollectionInfos([filter]) – returns a list that contains the names and options of the db’s collections
db.getCollectionNames()
db.getLastError() – just returns the err msg string
db.getLastErrorObj() – return full status object
db.getLogComponents()
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow queries on a replication slave server
db.getName()
db.getPrevError()
db.getProfilingLevel() – deprecated
db.getProfilingStatus() – returns if profiling is on and slow threshold
db.getReplicationInfo()
db.getSiblingDB(name) get the db at the same server as this one
db.getWriteConcern() – returns the write concern used for any operations on this db, inherited from server object if set
db.hostInfo() get details about the server’s host
db.isMaster() check replica primary status
db.killOp(opid) kills the current operation in the db
db.listCommands() lists all the db commands
db.loadServerScripts() loads all the scripts in db.system.js
db.logout()
db.printCollectionStats()
db.printReplicationInfo()
db.printShardingStatus()
db.printSlaveReplicationInfo()
db.dropUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into { cmdObj : 1 }
db.serverStatus()
db.setLogLevel(level,<component>)
db.setProfilingLevel(level,<slowms>) 0=off 1=slow 2=all
db.setWriteConcern( <write concern doc> ) – sets the write concern for writes to the db
db.unsetWriteConcern( <write concern doc> ) – unsets the write concern for writes to the db
db.setVerboseShell(flag) display extra information in shell output
db.shutdownServer()
db.stats()
db.version() current version of the server
Command line execution of Mongodb commands allows support staff to quickly obtain information on the Mongodb environment without running the risk of accidentally causing disruption of service
RAUL SALAS Raul@mobilemonitoringsolutions.com
MMS • Raul Salas
![]()
Graph databases like Neo4j have been making waves in the tech world recently, but your probably asking ”What the heck is a graph database?” and to top it off, your boss just told you that the development team wants to start using NEO4j graph database and you will need to install a High Availability cluster and administer it!
This will be somewhat of a quick start guide for the Enterprise version of Neo4J High Availability Cluster version to get it up and running quickly and get your project moving along. We will highlight a multi-instance install on a single laptop, However, these configuration files will be valuable in installing a high availability Neo4J cluster on 3 separate physical machines.
Step 1 – Download the enterprise server release from the following link
http://neo4j.com/download/other-releases/#releases
Step2 – Copy the download compressed file and install in 3 separate directories that effectively creates 3 instances.
Step 3 – Configure neo4j.conf file in each instance directory. (at the end of this blog post are the config files listed just as you will you them in your environment). Here are the most important areas of the Neo4j.conf modifications for each instance
dbms.backup.enabled=true
dbms.backup.address=127.0.0.1:6362
dbms.connector.bolt.address=127.0.0.1:7687
dbms.connector.http.address=127.0.0.1:7474
dbms.connector.https.address=127.0.0.1:7473
dbms.mode=HA
ha.server_id=1
ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
ha.host.coordination=127.0.0.1:5001
ha.host.data=127.0.0.1:6001
Step 4 – Start up each Neo4j instance with the following commands
(Macintosh version) /Install directory instance1/bin/Neo4j
/Install directory instance2/bin/Neo4j
/Install directory instance3/bin/Neoj
You should see the following output on startup
Starting Neo4j.
Started neo4j (pid 1788). It is available at http://127.0.0.1:7476/
This HA instance will be operational once it has joined the cluster.
See /neo4j-enterprise-3.3.1_instance3/logs/neo4j.log for current status.
Step 5 – Startup Neo4J web based admin console in your Browser
- HTTP
- http://127.0.0.1:7474 (instance one, HTTP)
- http://127.0.0.1:7475 (instance two, HTTP)
- http://127.0.0.1:7475 (instance three, HTTP)
Step 6 – You will need to change the password for the neo4j user on startup
Step 7 – View the status of your cluster on the monitoring and metrics page of the Neo4J administration console
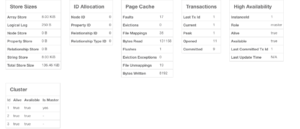
That’s a brief run through of how to install a multi instance cluster on your local machine! Again the config files are listed below for each instance!
Raul Salas Raul@mobilemonitoringsolutions.com
———————neo4j config files—————- ————————————-
————————— instance 1 neo4j.conf —————————————-
#*****************************************************************
# Neo4j configuration
#
# For more details and a complete list of settings, please see
# https://neo4j.com/docs/operations-manual/current/reference/configuration-settings/
#*****************************************************************
# The name of the database to mount
#dbms.active_database=graph.db
# Paths of directories in the installation.
#dbms.directories.data=data
#dbms.directories.plugins=plugins
#dbms.directories.certificates=certificates
#dbms.directories.logs=logs
#dbms.directories.lib=lib
#dbms.directories.run=run
#dbms.directories.metrics=metrics
# This setting constrains all `LOAD CSV` import files to be under the `import` directory. Remove or comment it out to
# allow files to be loaded from anywhere in the filesystem; this introduces possible security problems. See the
# `LOAD CSV` section of the manual for details.
dbms.directories.import=import
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
#dbms.security.auth_enabled=false
# Enable this to be able to upgrade a store from an older version.
#dbms.allow_upgrade=true
# Java Heap Size: by default the Java heap size is dynamically
# calculated based on available system resources.
# Uncomment these lines to set specific initial and maximum
# heap size.
#dbms.memory.heap.initial_size=512m
#dbms.memory.heap.max_size=512m
# The amount of memory to use for mapping the store files, in bytes (or
# kilobytes with the ‘k’ suffix, megabytes with ‘m’ and gigabytes with ‘g’).
# If Neo4j is running on a dedicated server, then it is generally recommended
# to leave about 2-4 gigabytes for the operating system, give the JVM enough
# heap to hold all your transaction state and query context, and then leave the
# rest for the page cache.
# The default page cache memory assumes the machine is dedicated to running
# Neo4j, and is heuristically set to 50% of RAM minus the max Java heap size.
#dbms.memory.pagecache.size=10g
# Enable online backups to be taken from this database.
dbms.backup.enabled=true
# By default the backup service will only listen on localhost.
# To enable remote backups you will have to bind to an external
# network interface (e.g. 0.0.0.0 for all interfaces).
dbms.backup.address=127.0.0.1:6362
#*****************************************************************
# Network connector configuration
#*****************************************************************
# With default configuration Neo4j only accepts local connections.
# To accept non-local connections, uncomment this line:
#dbms.connectors.default_listen_address=0.0.0.0
# You can also choose a specific network interface, and configure a non-default
# port for each connector, by setting their individual listen_address.
# The address at which this server can be reached by its clients. This may be the server’s IP address or DNS name, or
# it may be the address of a reverse proxy which sits in front of the server. This setting may be overridden for
# individual connectors below.
#dbms.connectors.default_advertised_address=localhost
# You can also choose a specific advertised hostname or IP address, and
# configure an advertised port for each connector, by setting their
# individual advertised_address.
# Bolt connector
dbms.connector.bolt.enabled=true
#dbms.connector.bolt.tls_level=OPTIONAL
dbms.connector.bolt.listen_address=127.0.0.1:7687
# HTTP Connector. There must be exactly one HTTP connector.
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=127.0.0.1:7474
# HTTPS Connector. There can be zero or one HTTPS connectors.
dbms.connector.https.enabled=true
dbms.connector.https.listen_address=127.0.0.1:7473
# Number of Neo4j worker threads.
#dbms.threads.worker_count=
#*****************************************************************
# SSL system configuration
#*****************************************************************
# Names of the SSL policies to be used for the respective components.
# The legacy policy is a special policy which is not defined in
# the policy configuration section, but rather derives from
# dbms.directories.certificates and associated files
# (by default: neo4j.key and neo4j.cert). Its use will be deprecated.
# The policies to be used for connectors.
#
# N.B: Note that a connector must be configured to support/require
# SSL/TLS for the policy to actually be utilized.
#
# see: dbms.connector.*.tls_level
#bolt.ssl_policy=legacy
#https.ssl_policy=legacy
# For a causal cluster the configuring of a policy mandates its use.
#causal_clustering.ssl_policy=
#*****************************************************************
# SSL policy configuration
#*****************************************************************
# Each policy is configured under a separate namespace, e.g.
# dbms.ssl.policy.<policyname>.*
#
# The example settings below are for a new policy named ‘default’.
# The base directory for cryptographic objects. Each policy will by
# default look for its associated objects (keys, certificates, …)
# under the base directory.
#
# Every such setting can be overriden using a full path to
# the respective object, but every policy will by default look
# for cryptographic objects in its base location.
#
# Mandatory setting
#dbms.ssl.policy.default.base_directory=certificates/default
# Allows the generation of a fresh private key and a self-signed
# certificate if none are found in the expected locations. It is
# recommended to turn this off again after keys have been generated.
#
# Keys should in general be generated and distributed offline
# by a trusted certificate authority (CA) and not by utilizing
# this mode.
#dbms.ssl.policy.default.allow_key_generation=false
# Enabling this makes it so that this policy ignores the contents
# of the trusted_dir and simply resorts to trusting everything.
#
# Use of this mode is discouraged. It would offer encryption but no security.
#dbms.ssl.policy.default.trust_all=false
# The private key for the default SSL policy. By default a file
# named private.key is expected under the base directory of the policy.
# It is mandatory that a key can be found or generated.
#dbms.ssl.policy.default.private_key=
# The private key for the default SSL policy. By default a file
# named public.crt is expected under the base directory of the policy.
# It is mandatory that a certificate can be found or generated.
#dbms.ssl.policy.default.public_certificate=
# The certificates of trusted parties. By default a directory named
# ‘trusted’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#
# To enforce client authentication client_auth must be set to ‘require’!
#dbms.ssl.policy.default.trusted_dir=
# Certificate Revocation Lists (CRLs). By default a directory named
# ‘revoked’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#dbms.ssl.policy.default.revoked_dir=
# Client authentication setting. Values: none, optional, require
# The default is to require client authentication.
#
# Servers are always authenticated unless explicitly overridden
# using the trust_all setting. In a mutual authentication setup this
# should be kept at the default of require and trusted certificates
# must be installed in the trusted_dir.
#dbms.ssl.policy.default.client_auth=require
# A comma-separated list of allowed TLS versions.
# By default TLSv1, TLSv1.1 and TLSv1.2 are allowed.
#dbms.ssl.policy.default.tls_versions=
# A comma-separated list of allowed ciphers.
# The default ciphers are the defaults of the JVM platform.
#dbms.ssl.policy.default.ciphers=
#*****************************************************************
# Logging configuration
#*****************************************************************
# To enable HTTP logging, uncomment this line
#dbms.logs.http.enabled=true
# Number of HTTP logs to keep.
#dbms.logs.http.rotation.keep_number=5
# Size of each HTTP log that is kept.
#dbms.logs.http.rotation.size=20m
# To enable GC Logging, uncomment this line
#dbms.logs.gc.enabled=true
# GC Logging Options
# see http://docs.oracle.com/cd/E19957-01/819-0084-10/pt_tuningjava.html#wp57013 for more information.
#dbms.logs.gc.options=-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintPromotionFailure -XX:+PrintTenuringDistribution
# Number of GC logs to keep.
#dbms.logs.gc.rotation.keep_number=5
# Size of each GC log that is kept.
#dbms.logs.gc.rotation.size=20m
# Size threshold for rotation of the debug log. If set to zero then no rotation will occur. Accepts a binary suffix “k”,
# “m” or “g”.
#dbms.logs.debug.rotation.size=20m
# Maximum number of history files for the internal log.
#dbms.logs.debug.rotation.keep_number=7
# Log executed queries that takes longer than the configured threshold. Enable by uncommenting this line.
#dbms.logs.query.enabled=true
# If the execution of query takes more time than this threshold, the query is logged. If set to zero then all queries
# are logged.
#dbms.logs.query.threshold=0
# The file size in bytes at which the query log will auto-rotate. If set to zero then no rotation will occur. Accepts a
# binary suffix “k”, “m” or “g”.
#dbms.logs.query.rotation.size=20m
# Maximum number of history files for the query log.
#dbms.logs.query.rotation.keep_number=7
# Include parameters for the executed queries being logged (this is enabled by default).
#dbms.logs.query.parameter_logging_enabled=true
# Uncomment this line to include detailed time information for the executed queries being logged:
#dbms.logs.query.time_logging_enabled=true
# Uncomment this line to include bytes allocated by the executed queries being logged:
#dbms.logs.query.allocation_logging_enabled=true
# Uncomment this line to include page hits and page faults information for the executed queries being logged:
#dbms.logs.query.page_logging_enabled=true
# The security log is always enabled when `dbms.security.auth_enabled=true`, and resides in `logs/security.log`.
# Log level for the security log. One of DEBUG, INFO, WARN and ERROR.
#dbms.logs.security.level=INFO
# Threshold for rotation of the security log.
#dbms.logs.security.rotation.size=20m
# Minimum time interval after last rotation of the security log before it may be rotated again.
#dbms.logs.security.rotation.delay=300s
# Maximum number of history files for the security log.
#dbms.logs.security.rotation.keep_number=7
#*****************************************************************
# Causal Clustering Configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in Causal Clustering mode.
# See the Causal Clustering documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# CORE – Core member of the cluster, part of the consensus quorum.
# READ_REPLICA – Read replica in the cluster, an eventually-consistent read-only instance of the database.
# To operate this Neo4j instance in Causal Clustering mode as a core member, uncomment this line:
#dbms.mode=CORE
# Expected number of Core machines in the cluster.
#causal_clustering.expected_core_cluster_size=3
# A comma-separated list of the address and port for which to reach all other members of the cluster. It must be in the
# host:port format. For each machine in the cluster, the address will usually be the public ip address of that machine.
# The port will be the value used in the setting “causal_clustering.discovery_listen_address”.
#causal_clustering.initial_discovery_members=localhost:5000,localhost:5001,localhost:5002
# Host and port to bind the cluster member discovery management communication.
# This is the setting to add to the collection of address in causal_clustering.initial_core_cluster_members.
# Use 0.0.0.0 to bind to any network interface on the machine. If you want to only use a specific interface
# (such as a private ip address on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.discovery_listen_address=:5000
# Network interface and port for the transaction shipping server to listen on. If you want to allow for
# messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.transaction_listen_address=:6000
# Network interface and port for the RAFT server to listen on. If you want to allow for messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.raft_listen_address=:7000
# List a set of names for groups to which this server should belong. This
# is a comma-separated list and names should only use alphanumericals
# and underscore. This can be used to identify groups of servers in the
# configuration for load balancing and replication policies.
#
# The main intention for this is to group servers, but it is possible to specify
# a unique identifier here as well which might be useful for troubleshooting
# or other special purposes.
#causal_clustering.server_groups=
#*****************************************************************
# Causal Clustering Load Balancing
#*****************************************************************
# N.B: Read the online documentation for a thorough explanation!
# Selects the load balancing plugin that shall be enabled.
#causal_clustering.load_balancing.plugin=server_policies
####### Examples for “server_policies” plugin #######
# Will select all available servers as the default policy, which is the
# policy used when the client does not specify a policy preference. The
# default configuration for the default policy is all().
#causal_clustering.load_balancing.config.server_policies.default=all()
# Will select servers in groups ‘group1’ or ‘group2’ under the default policy.
#causal_clustering.load_balancing.config.server_policies.default=groups(group1,group2)
# Slightly more advanced example:
# Will select servers in ‘group1’, ‘group2’ or ‘group3’, but only if there are at least 2.
# This policy will be exposed under the name of ‘mypolicy’.
#causal_clustering.load_balancing.config.server_policies.mypolicy=groups(group1,group2,group3) -> min(2)
# Below will create an even more advanced policy named ‘regionA’ consisting of several rules
# yielding the following behaviour:
#
# select servers in regionA, if at least 2 are available
# otherwise: select servers in regionA and regionB, if at least 2 are available
# otherwise: select all servers
#
# The intention is to create a policy for a particular region which prefers
# a certain set of local servers, but which will fallback to other regions
# or all available servers as required.
#
# N.B: The following configuration uses the line-continuation character \
# which allows you to construct an easily readable rule set spanning
# several lines.
#
#causal_clustering.load_balancing.config.server_policies.policyA=\
#groups(regionA) -> min(2);\
#groups(regionA,regionB) -> min(2);
# Note that implicitly the last fallback is to always consider all() servers,
# but this can be prevented by specifying a halt() as the last rule.
#
#causal_clustering.load_balancing.config.server_policies.regionA_only=\
#groups(regionA);\
#halt();
#*****************************************************************
# Causal Clustering Additional Configuration Options
#*****************************************************************
# The following settings are used less frequently.
# If you don’t know what these are, you don’t need to change these from their default values.
# Address and port that this machine advertises that it’s RAFT server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.raft_advertised_address=:7000
# Address and port that this machine advertises that it’s transaction shipping server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.transaction_advertised_address=:6000
# The time limit within which a new leader election will occur if no messages from the current leader are received.
# Larger values allow for more stable leaders at the expense of longer unavailability times in case of leader
# failures.
#causal_clustering.leader_election_timeout=7s
# The time limit allowed for a new member to attempt to update its data to match the rest of the cluster.
#causal_clustering.join_catch_up_timeout=10m
# The size of the batch for streaming entries to other machines while trying to catch up another machine.
#causal_clustering.catchup_batch_size=64
# When to pause sending entries to other machines and allow them to catch up.
#causal_clustering.log_shipping_max_lag=256
# Raft log pruning frequncy.
#causal_clustering.raft_log_pruning_frequency=10m
# The size to allow the raft log to grow before rotating.
#causal_clustering.raft_log_rotation_size=250M
### The following setting is relevant for Edge servers only.
# The interval of pulling updates from Core servers.
#causal_clustering.pull_interval=1s
# For how long should drivers cache the discovery data from
# the dbms.cluster.routing.getServers() procedure. Defaults to 300s.
#causal_clustering.cluster_routing_ttl=300s
#*****************************************************************
# HA configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in High Availability mode.
# See the High Availability documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# HA – High Availability
# SINGLE – Single mode, default.
# To run in High Availability mode uncomment this line:
dbms.mode=HA
# ha.server_id is the number of each instance in the HA cluster. It should be
# an integer (e.g. 1), and should be unique for each cluster instance.
ha.server_id=1
# ha.initial_hosts is a comma-separated list (without spaces) of the host:port
# where the ha.host.coordination of all instances will be listening. Typically
# this will be the same for all cluster instances.
ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
# IP and port for this instance to listen on, for communicating cluster status
# information with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.coordination=127.0.0.1:5001
# IP and port for this instance to listen on, for communicating transaction
# data with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.data=127.0.0.1:6001
# The interval, in seconds, at which slaves will pull updates from the master. You must comment out
# the option to disable periodic pulling of updates.
ha.pull_interval=10
# Amount of slaves the master will try to push a transaction to upon commit
# (default is 1). The master will optimistically continue and not fail the
# transaction even if it fails to reach the push factor. Setting this to 0 will
# increase write performance when writing through master but could potentially
# lead to branched data (or loss of transaction) if the master goes down.
#ha.tx_push_factor=1
# Strategy the master will use when pushing data to slaves (if the push factor
# is greater than 0). There are three options available “fixed_ascending” (default),
# “fixed_descending” or “round_robin”. Fixed strategies will start by pushing to
# slaves ordered by server id (accordingly with qualifier) and are useful when
# planning for a stable fail-over based on ids.
#ha.tx_push_strategy=fixed_ascending
# Policy for how to handle branched data.
#ha.branched_data_policy=keep_all
# How often heartbeat messages should be sent. Defaults to ha.default_timeout.
#ha.heartbeat_interval=5s
# How long to wait for heartbeats from other instances before marking them as suspects for failure.
# This value reflects considerations of network latency, expected duration of garbage collection pauses
# and other factors that can delay message sending and processing. Larger values will result in more
# stable masters but also will result in longer waits before a failover in case of master failure.
# This value should not be set to less than twice the ha.heartbeat_interval value otherwise there is a high
# risk of frequent master switches and possibly branched data occurrence.
#ha.heartbeat_timeout=40s
# If you are using a load-balancer that doesn’t support HTTP Auth, you may need to turn off authentication for the
# HA HTTP status endpoint by uncommenting the following line.
#dbms.security.ha_status_auth_enabled=false
# Whether this instance should only participate as slave in cluster. If set to
# true, it will never be elected as master.
#ha.slave_only=false
#********************************************************************
# Security Configuration
#********************************************************************
# The authentication and authorization provider that contains both users and roles.
# This can be one of the built-in `native` or `ldap` auth providers,
# or it can be an externally provided plugin, with a custom name prefixed by `plugin`,
# i.e. `plugin-<AUTH_PROVIDER_NAME>`.
#dbms.security.auth_provider=native
# The time to live (TTL) for cached authentication and authorization info when using
# external auth providers (LDAP or plugin). Setting the TTL to 0 will
# disable auth caching.
#dbms.security.auth_cache_ttl=10m
# The maximum capacity for authentication and authorization caches (respectively).
#dbms.security.auth_cache_max_capacity=10000
# Set to log successful authentication events to the security log.
# If this is set to `false` only failed authentication events will be logged, which
# could be useful if you find that the successful events spam the logs too much,
# and you do not require full auditing capability.
#dbms.security.log_successful_authentication=true
#================================================
# LDAP Auth Provider Configuration
#================================================
# URL of LDAP server to use for authentication and authorization.
# The format of the setting is `<protocol>://<hostname>:<port>`, where hostname is the only required field.
# The supported values for protocol are `ldap` (default) and `ldaps`.
# The default port for `ldap` is 389 and for `ldaps` 636.
# For example: `ldaps://ldap.example.com:10389`.
#
# NOTE: You may want to consider using STARTTLS (`dbms.security.ldap.use_starttls`) instead of LDAPS
# for secure connections, in which case the correct protocol is `ldap`.
#dbms.security.ldap.host=localhost
# Use secure communication with the LDAP server using opportunistic TLS.
# First an initial insecure connection will be made with the LDAP server, and then a STARTTLS command
# will be issued to negotiate an upgrade of the connection to TLS before initiating authentication.
#dbms.security.ldap.use_starttls=false
# The LDAP referral behavior when creating a connection. This is one of `follow`, `ignore` or `throw`.
# `follow` automatically follows any referrals
# `ignore` ignores any referrals
# `throw` throws an exception, which will lead to authentication failure
#dbms.security.ldap.referral=follow
# The timeout for establishing an LDAP connection. If a connection with the LDAP server cannot be
# established within the given time the attempt is aborted.
# A value of 0 means to use the network protocol’s (i.e., TCP’s) timeout value.
#dbms.security.ldap.connection_timeout=30s
# The timeout for an LDAP read request (i.e. search). If the LDAP server does not respond within
# the given time the request will be aborted. A value of 0 means wait for a response indefinitely.
#dbms.security.ldap.read_timeout=30s
#———————————-
# LDAP Authentication Configuration
#———————————-
# LDAP authentication mechanism. This is one of `simple` or a SASL mechanism supported by JNDI,
# for example `DIGEST-MD5`. `simple` is basic username
# and password authentication and SASL is used for more advanced mechanisms. See RFC 2251 LDAPv3
# documentation for more details.
#dbms.security.ldap.authentication.mechanism=simple
# LDAP user DN template. An LDAP object is referenced by its distinguished name (DN), and a user DN is
# an LDAP fully-qualified unique user identifier. This setting is used to generate an LDAP DN that
# conforms with the LDAP directory’s schema from the user principal that is submitted with the
# authentication token when logging in.
# The special token {0} is a placeholder where the user principal will be substituted into the DN string.
#dbms.security.ldap.authentication.user_dn_template=uid={0},ou=users,dc=example,dc=com
# Determines if the result of authentication via the LDAP server should be cached or not.
# Caching is used to limit the number of LDAP requests that have to be made over the network
# for users that have already been authenticated successfully. A user can be authenticated against
# an existing cache entry (instead of via an LDAP server) as long as it is alive
# (see `dbms.security.auth_cache_ttl`).
# An important consequence of setting this to `true` is that
# Neo4j then needs to cache a hashed version of the credentials in order to perform credentials
# matching. This hashing is done using a cryptographic hash function together with a random salt.
# Preferably a conscious decision should be made if this method is considered acceptable by
# the security standards of the organization in which this Neo4j instance is deployed.
#dbms.security.ldap.authentication.cache_enabled=true
#———————————-
# LDAP Authorization Configuration
#———————————-
# Authorization is performed by searching the directory for the groups that
# the user is a member of, and then map those groups to Neo4j roles.
# Perform LDAP search for authorization info using a system account instead of the user’s own account.
#
# If this is set to `false` (default), the search for group membership will be performed
# directly after authentication using the LDAP context bound with the user’s own account.
# The mapped roles will be cached for the duration of `dbms.security.auth_cache_ttl`,
# and then expire, requiring re-authentication. To avoid frequently having to re-authenticate
# sessions you may want to set a relatively long auth cache expiration time together with this option.
# NOTE: This option will only work if the users are permitted to search for their
# own group membership attributes in the directory.
#
# If this is set to `true`, the search will be performed using a special system account user
# with read access to all the users in the directory.
# You need to specify the username and password using the settings
# `dbms.security.ldap.authorization.system_username` and
# `dbms.security.ldap.authorization.system_password` with this option.
# Note that this account only needs read access to the relevant parts of the LDAP directory
# and does not need to have access rights to Neo4j, or any other systems.
#dbms.security.ldap.authorization.use_system_account=false
# An LDAP system account username to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
# Note that the `dbms.security.ldap.authentication.user_dn_template` will not be applied to this username,
# so you may have to specify a full DN.
#dbms.security.ldap.authorization.system_username=
# An LDAP system account password to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
#dbms.security.ldap.authorization.system_password=
# The name of the base object or named context to search for user objects when LDAP authorization is enabled.
# A common case is that this matches the last part of `dbms.security.ldap.authentication.user_dn_template`.
#dbms.security.ldap.authorization.user_search_base=ou=users,dc=example,dc=com
# The LDAP search filter to search for a user principal when LDAP authorization is
# enabled. The filter should contain the placeholder token {0} which will be substituted for the
# user principal.
#dbms.security.ldap.authorization.user_search_filter=(&(objectClass=*)(uid={0}))
# A list of attribute names on a user object that contains groups to be used for mapping to roles
# when LDAP authorization is enabled.
#dbms.security.ldap.authorization.group_membership_attributes=memberOf
# An authorization mapping from LDAP group names to Neo4j role names.
# The map should be formatted as a semicolon separated list of key-value pairs, where the
# key is the LDAP group name and the value is a comma separated list of corresponding role names.
# For example: group1=role1;group2=role2;group3=role3,role4,role5
#
# You could also use whitespaces and quotes around group names to make this mapping more readable,
# for example: dbms.security.ldap.authorization.group_to_role_mapping=\
# “cn=Neo4j Read Only,cn=users,dc=example,dc=com” = reader; \
# “cn=Neo4j Read-Write,cn=users,dc=example,dc=com” = publisher; \
# “cn=Neo4j Schema Manager,cn=users,dc=example,dc=com” = architect; \
# “cn=Neo4j Administrator,cn=users,dc=example,dc=com” = admin
#dbms.security.ldap.authorization.group_to_role_mapping=
#*****************************************************************
# Miscellaneous configuration
#*****************************************************************
# Enable this to specify a parser other than the default one.
#cypher.default_language_version=3.0
# Determines if Cypher will allow using file URLs when loading data using
# `LOAD CSV`. Setting this value to `false` will cause Neo4j to fail `LOAD CSV`
# clauses that load data from the file system.
#dbms.security.allow_csv_import_from_file_urls=true
# Retention policy for transaction logs needed to perform recovery and backups.
#dbms.tx_log.rotation.retention_policy=7 days
# Limit the number of IOs the background checkpoint process will consume per second.
# This setting is advisory, is ignored in Neo4j Community Edition, and is followed to
# best effort in Enterprise Edition.
# An IO is in this case a 8 KiB (mostly sequential) write. Limiting the write IO in
# this way will leave more bandwidth in the IO subsystem to service random-read IOs,
# which is important for the response time of queries when the database cannot fit
# entirely in memory. The only drawback of this setting is that longer checkpoint times
# may lead to slightly longer recovery times in case of a database or system crash.
# A lower number means lower IO pressure, and consequently longer checkpoint times.
# The configuration can also be commented out to remove the limitation entirely, and
# let the checkpointer flush data as fast as the hardware will go.
# Set this to -1 to disable the IOPS limit.
# dbms.checkpoint.iops.limit=300
# Enable a remote shell server which Neo4j Shell clients can log in to.
#dbms.shell.enabled=true
# The network interface IP the shell will listen on (use 0.0.0.0 for all interfaces).
#dbms.shell.host=127.0.0.1
# The port the shell will listen on, default is 1337.
#dbms.shell.port=1337
# Only allow read operations from this Neo4j instance. This mode still requires
# write access to the directory for lock purposes.
#dbms.read_only=false
# Comma separated list of JAX-RS packages containing JAX-RS resources, one
# package name for each mountpoint. The listed package names will be loaded
# under the mountpoints specified. Uncomment this line to mount the
# org.neo4j.examples.server.unmanaged.HelloWorldResource.java from
# neo4j-server-examples under /examples/unmanaged, resulting in a final URL of
# http://localhost:7474/examples/unmanaged/helloworld/{nodeId}
#dbms.unmanaged_extension_classes=org.neo4j.examples.server.unmanaged=/examples/unmanaged
# Specified comma separated list of id types (like node or relationship) that should be reused.
# When some type is specified database will try to reuse corresponding ids as soon as it will be safe to do so.
# Currently only ‘node’ and ‘relationship’ types are supported.
# This settings is ignored in Neo4j Community Edition.
#dbms.ids.reuse.types.override=node,relationship
#********************************************************************
# JVM Parameters
#********************************************************************
# G1GC generally strikes a good balance between throughput and tail
# latency, without too much tuning.
dbms.jvm.additional=-XX:+UseG1GC
# Have common exceptions keep producing stack traces, so they can be
# debugged regardless of how often logs are rotated.
dbms.jvm.additional=-XX:-OmitStackTraceInFastThrow
# Make sure that `initmemory` is not only allocated, but committed to
# the process, before starting the database. This reduces memory
# fragmentation, increasing the effectiveness of transparent huge
# pages. It also reduces the possibility of seeing performance drop
# due to heap-growing GC events, where a decrease in available page
# cache leads to an increase in mean IO response time.
# Try reducing the heap memory, if this flag degrades performance.
dbms.jvm.additional=-XX:+AlwaysPreTouch
# Trust that non-static final fields are really final.
# This allows more optimizations and improves overall performance.
# NOTE: Disable this if you use embedded mode, or have extensions or dependencies that may use reflection or
# serialization to change the value of final fields!
dbms.jvm.additional=-XX:+UnlockExperimentalVMOptions
dbms.jvm.additional=-XX:+TrustFinalNonStaticFields
# Disable explicit garbage collection, which is occasionally invoked by the JDK itself.
dbms.jvm.additional=-XX:+DisableExplicitGC
# Remote JMX monitoring, uncomment and adjust the following lines as needed. Absolute paths to jmx.access and
# jmx.password files are required.
# Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords,
# the shipped configuration contains only a read only role called ‘monitor’ with password ‘Neo4j’.
# For more details, see: http://download.oracle.com/javase/8/docs/technotes/guides/management/agent.html
# On Unix based systems the jmx.password file needs to be owned by the user that will run the server,
# and have permissions set to 0600.
# For details on setting these file permissions on Windows see:
# http://docs.oracle.com/javase/8/docs/technotes/guides/management/security-windows.html
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.port=3637
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.authenticate=true
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.ssl=false
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.password.file=/absolute/path/to/conf/jmx.password
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.access.file=/absolute/path/to/conf/jmx.access
# Some systems cannot discover host name automatically, and need this line configured:
#dbms.jvm.additional=-Djava.rmi.server.hostname=$THE_NEO4J_SERVER_HOSTNAME
# Expand Diffie Hellman (DH) key size from default 1024 to 2048 for DH-RSA cipher suites used in server TLS handshakes.
# This is to protect the server from any potential passive eavesdropping.
dbms.jvm.additional=-Djdk.tls.ephemeralDHKeySize=2048
#********************************************************************
# Wrapper Windows NT/2000/XP Service Properties
#********************************************************************
# WARNING – Do not modify any of these properties when an application
# using this configuration file has been installed as a service.
# Please uninstall the service before modifying this section. The
# service can then be reinstalled.
# Name of the service
dbms.windows_service_name=neo4j
#********************************************************************
# Other Neo4j system properties
#********************************************************************
dbms.jvm.additional=-Dunsupported.dbms.udc.source=tarball
—————————— neofj.conf instance 2 ——————————————–
#*****************************************************************
# Neo4j configuration
#
# For more details and a complete list of settings, please see
# https://neo4j.com/docs/operations-manual/current/reference/configuration-settings/
#*****************************************************************
# The name of the database to mount
#dbms.active_database=graph.db
# Paths of directories in the installation.
#dbms.directories.data=data
#dbms.directories.plugins=pluginsbolt
#dbms.directories.certificates=certificates
#dbms.directories.logs=logs
#dbms.directories.lib=lib
#dbms.directories.run=run
#dbms.directories.metrics=metrics
# This setting constrains all `LOAD CSV` import files to be under the `import` directory. Remove or comment it out to
# allow files to be loaded from anywhere in the filesystem; this introduces possible security problems. See the
# `LOAD CSV` section of the manual for details.
dbms.directories.import=import
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
#dbms.security.auth_enabled=false
# Enable this to be able to upgrade a store from an older version.
#dbms.allow_upgrade=true
# Java Heap Size: by default the Java heap size is dynamically
# calculated based on available system resources.
# Uncomment these lines to set specific initial and maximum
# heap size.
#dbms.memory.heap.initial_size=512m
#dbms.memory.heap.max_size=512m
# The amount of memory to use for mapping the store files, in bytes (or
# kilobytes with the ‘k’ suffix, megabytes with ‘m’ and gigabytes with ‘g’).
# If Neo4j is running on a dedicated server, then it is generally recommended
# to leave about 2-4 gigabytes for the operating system, give the JVM enough
# heap to hold all your transaction state and query context, and then leave the
# rest for the page cache.
# The default page cache memory assumes the machine is dedicated to running
# Neo4j, and is heuristically set to 50% of RAM minus the max Java heap size.
#dbms.memory.pagecache.size=10g
# Enable online backups to be taken from this database.
dbms.backup.enabled=true
# By default the backup service will only listen on localhost.
# To enable remote backups you will have to bind to an external
# network interface (e.g. 0.0.0.0 for all interfaces).
dbms.backup.address=127.0.0.1:6363
#*****************************************************************
# Network connector configuration
#*****************************************************************
# With default configuration Neo4j only accepts local connections.
# To accept non-local connections, uncomment this line:
#dbms.connectors.default_listen_address=0.0.0.0
# You can also choose a specific network interface, and configure a non-default
# port for each connector, by setting their individual listen_address.
# The address at which this server can be reached by its clients. This may be the server’s IP address or DNS name, or
# it may be the address of a reverse proxy which sits in front of the server. This setting may be overridden for
# individual connectors below.
#dbms.connectors.default_advertised_address=localhost
# You can also choose a specific advertised hostname or IP address, and
# configure an advertised port for each connector, by setting their
# individual advertised_address.
# Bolt connector
dbms.connector.bolt.enabled=true
#dbms.connector.bolt.tls_level=OPTIONAL
dbms.connector.bolt.listen_address=127.0.0.1:7688
# HTTP Connector. There must be exactly one HTTP connector.
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=127.0.0.1:7475
# HTTPS Connector. There can be zero or one HTTPS connectors.
dbms.connector.https.enabled=true
dbms.connector.https.listen_address=127.0.0.1:7573
# Number of Neo4j worker threads.
#dbms.threads.worker_count=
#*****************************************************************
# SSL system configuration
#*****************************************************************
# Names of the SSL policies to be used for the respective components.
# The legacy policy is a special policy which is not defined in
# the policy configuration section, but rather derives from
# dbms.directories.certificates and associated files
# (by default: neo4j.key and neo4j.cert). Its use will be deprecated.
# The policies to be used for connectors.
#
# N.B: Note that a connector must be configured to support/require
# SSL/TLS for the policy to actually be utilized.
#
# see: dbms.connector.*.tls_level
#bolt.ssl_policy=legacy
#https.ssl_policy=legacy
# For a causal cluster the configuring of a policy mandates its use.
#causal_clustering.ssl_policy=
#*****************************************************************
# SSL policy configuration
#*****************************************************************
# Each policy is configured under a separate namespace, e.g.
# dbms.ssl.policy.<policyname>.*
#
# The example settings below are for a new policy named ‘default’.
# The base directory for cryptographic objects. Each policy will by
# default look for its associated objects (keys, certificates, …)
# under the base directory.
#
# Every such setting can be overriden using a full path to
# the respective object, but every policy will by default look
# for cryptographic objects in its base location.
#
# Mandatory setting
#dbms.ssl.policy.default.base_directory=certificates/default
# Allows the generation of a fresh private key and a self-signed
# certificate if none are found in the expected locations. It is
# recommended to turn this off again after keys have been generated.
#
# Keys should in general be generated and distributed offline
# by a trusted certificate authority (CA) and not by utilizing
# this mode.
#dbms.ssl.policy.default.allow_key_generation=false
# Enabling this makes it so that this policy ignores the contents
# of the trusted_dir and simply resorts to trusting everything.
#
# Use of this mode is discouraged. It would offer encryption but no security.
#dbms.ssl.policy.default.trust_all=false
# The private key for the default SSL policy. By default a file
# named private.key is expected under the base directory of the policy.
# It is mandatory that a key can be found or generated.
#dbms.ssl.policy.default.private_key=
# The private key for the default SSL policy. By default a file
# named public.crt is expected under the base directory of the policy.
# It is mandatory that a certificate can be found or generated.
#dbms.ssl.policy.default.public_certificate=
# The certificates of trusted parties. By default a directory named
# ‘trusted’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#
# To enforce client authentication client_auth must be set to ‘require’!
#dbms.ssl.policy.default.trusted_dir=
# Certificate Revocation Lists (CRLs). By default a directory named
# ‘revoked’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#dbms.ssl.policy.default.revoked_dir=
# Client authentication setting. Values: none, optional, require
# The default is to require client authentication.
#
# Servers are always authenticated unless explicitly overridden
# using the trust_all setting. In a mutual authentication setup this
# should be kept at the default of require and trusted certificates
# must be installed in the trusted_dir.
#dbms.ssl.policy.default.client_auth=require
# A comma-separated list of allowed TLS versions.
# By default TLSv1, TLSv1.1 and TLSv1.2 are allowed.
#dbms.ssl.policy.default.tls_versions=
# A comma-separated list of allowed ciphers.
# The default ciphers are the defaults of the JVM platform.
#dbms.ssl.policy.default.ciphers=
#*****************************************************************
# Logging configuration
#*****************************************************************
# To enable HTTP logging, uncomment this line
#dbms.logs.http.enabled=true
# Number of HTTP logs to keep.
#dbms.logs.http.rotation.keep_number=5
# Size of each HTTP log that is kept.
#dbms.logs.http.rotation.size=20m
# To enable GC Logging, uncomment this line
#dbms.logs.gc.enabled=true
# GC Logging Options
# see http://docs.oracle.com/cd/E19957-01/819-0084-10/pt_tuningjava.html#wp57013 for more information.
#dbms.logs.gc.options=-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintPromotionFailure -XX:+PrintTenuringDistribution
# Number of GC logs to keep.
#dbms.logs.gc.rotation.keep_number=5
# Size of each GC log that is kept.
#dbms.logs.gc.rotation.size=20m
# Size threshold for rotation of the debug log. If set to zero then no rotation will occur. Accepts a binary suffix “k”,
# “m” or “g”.
#dbms.logs.debug.rotation.size=20m
# Maximum number of history files for the internal log.
#dbms.logs.debug.rotation.keep_number=7
# Log executed queries that takes longer than the configured threshold. Enable by uncommenting this line.
#dbms.logs.query.enabled=true
# If the execution of query takes more time than this threshold, the query is logged. If set to zero then all queries
# are logged.
#dbms.logs.query.threshold=0
# The file size in bytes at which the query log will auto-rotate. If set to zero then no rotation will occur. Accepts a
# binary suffix “k”, “m” or “g”.
#dbms.logs.query.rotation.size=20m
# Maximum number of history files for the query log.
#dbms.logs.query.rotation.keep_number=7
# Include parameters for the executed queries being logged (this is enabled by default).
#dbms.logs.query.parameter_logging_enabled=true
# Uncomment this line to include detailed time information for the executed queries being logged:
#dbms.logs.query.time_logging_enabled=true
# Uncomment this line to include bytes allocated by the executed queries being logged:
#dbms.logs.query.allocation_logging_enabled=true
# Uncomment this line to include page hits and page faults information for the executed queries being logged:
#dbms.logs.query.page_logging_enabled=true
# The security log is always enabled when `dbms.security.auth_enabled=true`, and resides in `logs/security.log`.
# Log level for the security log. One of DEBUG, INFO, WARN and ERROR.
#dbms.logs.security.level=INFO
# Threshold for rotation of the security log.
#dbms.logs.security.rotation.size=20m
# Minimum time interval after last rotation of the security log before it may be rotated again.
#dbms.logs.security.rotation.delay=300s
# Maximum number of history files for the security log.
#dbms.logs.security.rotation.keep_number=7
#*****************************************************************
# Causal Clustering Configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in Causal Clustering mode.
# See the Causal Clustering documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# CORE – Core member of the cluster, part of the consensus quorum.
# READ_REPLICA – Read replica in the cluster, an eventually-consistent read-only instance of the database.
# To operate this Neo4j instance in Causal Clustering mode as a core member, uncomment this line:
#dbms.mode=CORE
# Expected number of Core machines in the cluster.
#causal_clustering.expected_core_cluster_size=3
# A comma-separated list of the address and port for which to reach all other members of the cluster. It must be in the
# host:port format. For each machine in the cluster, the address will usually be the public ip address of that machine.
# The port will be the value used in the setting “causal_clustering.discovery_listen_address”.
#causal_clustering.initial_discovery_members=localhost:5000,localhost:5001,localhost:5002
# Host and port to bind the cluster member discovery management communication.
# This is the setting to add to the collection of address in causal_clustering.initial_core_cluster_members.
# Use 0.0.0.0 to bind to any network interface on the machine. If you want to only use a specific interface
# (such as a private ip address on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.discovery_listen_address=:5000
# Network interface and port for the transaction shipping server to listen on. If you want to allow for
# messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.transaction_listen_address=:6000
# Network interface and port for the RAFT server to listen on. If you want to allow for messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.raft_listen_address=:7000
# List a set of names for groups to which this server should belong. This
# is a comma-separated list and names should only use alphanumericals
# and underscore. This can be used to identify groups of servers in the
# configuration for load balancing and replication policies.
#
# The main intention for this is to group servers, but it is possible to specify
# a unique identifier here as well which might be useful for troubleshooting
# or other special purposes.
#causal_clustering.server_groups=
#*****************************************************************
# Causal Clustering Load Balancing
#*****************************************************************
# N.B: Read the online documentation for a thorough explanation!
# Selects the load balancing plugin that shall be enabled.
#causal_clustering.load_balancing.plugin=server_policies
####### Examples for “server_policies” plugin #######
# Will select all available servers as the default policy, which is the
# policy used when the client does not specify a policy preference. The
# default configuration for the default policy is all().
#causal_clustering.load_balancing.config.server_policies.default=all()
# Will select servers in groups ‘group1’ or ‘group2’ under the default policy.
#causal_clustering.load_balancing.config.server_policies.default=groups(group1,group2)
# Slightly more advanced example:
# Will select servers in ‘group1’, ‘group2’ or ‘group3’, but only if there are at least 2.
# This policy will be exposed under the name of ‘mypolicy’.
#causal_clustering.load_balancing.config.server_policies.mypolicy=groups(group1,group2,group3) -> min(2)
# Below will create an even more advanced policy named ‘regionA’ consisting of several rules
# yielding the following behaviour:
#
# select servers in regionA, if at least 2 are available
# otherwise: select servers in regionA and regionB, if at least 2 are available
# otherwise: select all servers
#
# The intention is to create a policy for a particular region which prefers
# a certain set of local servers, but which will fallback to other regions
# or all available servers as required.
#
# N.B: The following configuration uses the line-continuation character \
# which allows you to construct an easily readable rule set spanning
# several lines.
#
#causal_clustering.load_balancing.config.server_policies.policyA=\
#groups(regionA) -> min(2);\
#groups(regionA,regionB) -> min(2);
# Note that implicitly the last fallback is to always consider all() servers,
# but this can be prevented by specifying a halt() as the last rule.
#
#causal_clustering.load_balancing.config.server_policies.regionA_only=\
#groups(regionA);\
#halt();
#*****************************************************************
# Causal Clustering Additional Configuration Options
#*****************************************************************
# The following settings are used less frequently.
# If you don’t know what these are, you don’t need to change these from their default values.
# Address and port that this machine advertises that it’s RAFT server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.raft_advertised_address=:7000
# Address and port that this machine advertises that it’s transaction shipping server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.transaction_advertised_address=:6000
# The time limit within which a new leader election will occur if no messages from the current leader are received.
# Larger values allow for more stable leaders at the expense of longer unavailability times in case of leader
# failures.
#causal_clustering.leader_election_timeout=7s
# The time limit allowed for a new member to attempt to update its data to match the rest of the cluster.
#causal_clustering.join_catch_up_timeout=10m
# The size of the batch for streaming entries to other machines while trying to catch up another machine.
#causal_clustering.catchup_batch_size=64
# When to pause sending entries to other machines and allow them to catch up.
#causal_clustering.log_shipping_max_lag=256
# Raft log pruning frequncy.
#causal_clustering.raft_log_pruning_frequency=10m
# The size to allow the raft log to grow before rotating.
#causal_clustering.raft_log_rotation_size=250M
### The following setting is relevant for Edge servers only.
# The interval of pulling updates from Core servers.
#causal_clustering.pull_interval=1s
# For how long should drivers cache the discovery data from
# the dbms.cluster.routing.getServers() procedure. Defaults to 300s.
#causal_clustering.cluster_routing_ttl=300s
#*****************************************************************
# HA configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in High Availability mode.
# See the High Availability documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# HA – High Availability
# SINGLE – Single mode, default.
# To run in High Availability mode uncomment this line:
dbms.mode=HA
# ha.server_id is the number of each instance in the HA cluster. It should be
# an integer (e.g. 1), and should be unique for each cluster instance.
ha.server_id=2
# ha.initial_hosts is a comma-separated list (without spaces) of the host:port
# where the ha.host.coordination of all instances will be listening. Typically
# this will be the same for all cluster instances.
ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
# IP and port for this instance to listen on, for communicating cluster status
# information with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.coordination=127.0.0.1:5002
# IP and port for this instance to listen on, for communicating transaction
# data with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.data=127.0.0.1:6002
# The interval, in seconds, at which slaves will pull updates from the master. You must comment out
# the option to disable periodic pulling of updates.
ha.pull_interval=10
# Amount of slaves the master will try to push a transaction to upon commit
# (default is 1). The master will optimistically continue and not fail the
# transaction even if it fails to reach the push factor. Setting this to 0 will
# increase write performance when writing through master but could potentially
# lead to branched data (or loss of transaction) if the master goes down.
#ha.tx_push_factor=1
# Strategy the master will use when pushing data to slaves (if the push factor
# is greater than 0). There are three options available “fixed_ascending” (default),
# “fixed_descending” or “round_robin”. Fixed strategies will start by pushing to
# slaves ordered by server id (accordingly with qualifier) and are useful when
# planning for a stable fail-over based on ids.
#ha.tx_push_strategy=fixed_ascending
# Policy for how to handle branched data.
#ha.branched_data_policy=keep_all
# How often heartbeat messages should be sent. Defaults to ha.default_timeout.
#ha.heartbeat_interval=5s
# How long to wait for heartbeats from other instances before marking them as suspects for failure.
# This value reflects considerations of network latency, expected duration of garbage collection pauses
# and other factors that can delay message sending and processing. Larger values will result in more
# stable masters but also will result in longer waits before a failover in case of master failure.
# This value should not be set to less than twice the ha.heartbeat_interval value otherwise there is a high
# risk of frequent master switches and possibly branched data occurrence.
#ha.heartbeat_timeout=40s
# If you are using a load-balancer that doesn’t support HTTP Auth, you may need to turn off authentication for the
# HA HTTP status endpoint by uncommenting the following line.
#dbms.security.ha_status_auth_enabled=false
# Whether this instance should only participate as slave in cluster. If set to
# true, it will never be elected as master.
#ha.slave_only=false
#********************************************************************
# Security Configuration
#********************************************************************
# The authentication and authorization provider that contains both users and roles.
# This can be one of the built-in `native` or `ldap` auth providers,
# or it can be an externally provided plugin, with a custom name prefixed by `plugin`,
# i.e. `plugin-<AUTH_PROVIDER_NAME>`.
#dbms.security.auth_provider=native
# The time to live (TTL) for cached authentication and authorization info when using
# external auth providers (LDAP or plugin). Setting the TTL to 0 will
# disable auth caching.
#dbms.security.auth_cache_ttl=10m
# The maximum capacity for authentication and authorization caches (respectively).
#dbms.security.auth_cache_max_capacity=10000
# Set to log successful authentication events to the security log.
# If this is set to `false` only failed authentication events will be logged, which
# could be useful if you find that the successful events spam the logs too much,
# and you do not require full auditing capability.
#dbms.security.log_successful_authentication=true
#================================================
# LDAP Auth Provider Configuration
#================================================
# URL of LDAP server to use for authentication and authorization.
# The format of the setting is `<protocol>://<hostname>:<port>`, where hostname is the only required field.
# The supported values for protocol are `ldap` (default) and `ldaps`.
# The default port for `ldap` is 389 and for `ldaps` 636.
# For example: `ldaps://ldap.example.com:10389`.
#
# NOTE: You may want to consider using STARTTLS (`dbms.security.ldap.use_starttls`) instead of LDAPS
# for secure connections, in which case the correct protocol is `ldap`.
#dbms.security.ldap.host=localhost
# Use secure communication with the LDAP server using opportunistic TLS.
# First an initial insecure connection will be made with the LDAP server, and then a STARTTLS command
# will be issued to negotiate an upgrade of the connection to TLS before initiating authentication.
#dbms.security.ldap.use_starttls=false
# The LDAP referral behavior when creating a connection. This is one of `follow`, `ignore` or `throw`.
# `follow` automatically follows any referrals
# `ignore` ignores any referrals
# `throw` throws an exception, which will lead to authentication failure
#dbms.security.ldap.referral=follow
# The timeout for establishing an LDAP connection. If a connection with the LDAP server cannot be
# established within the given time the attempt is aborted.
# A value of 0 means to use the network protocol’s (i.e., TCP’s) timeout value.
#dbms.security.ldap.connection_timeout=30s
# The timeout for an LDAP read request (i.e. search). If the LDAP server does not respond within
# the given time the request will be aborted. A value of 0 means wait for a response indefinitely.
#dbms.security.ldap.read_timeout=30s
#———————————-
# LDAP Authentication Configuration
#———————————-
# LDAP authentication mechanism. This is one of `simple` or a SASL mechanism supported by JNDI,
# for example `DIGEST-MD5`. `simple` is basic username
# and password authentication and SASL is used for more advanced mechanisms. See RFC 2251 LDAPv3
# documentation for more details.
#dbms.security.ldap.authentication.mechanism=simple
# LDAP user DN template. An LDAP object is referenced by its distinguished name (DN), and a user DN is
# an LDAP fully-qualified unique user identifier. This setting is used to generate an LDAP DN that
# conforms with the LDAP directory’s schema from the user principal that is submitted with the
# authentication token when logging in.
# The special token {0} is a placeholder where the user principal will be substituted into the DN string.
#dbms.security.ldap.authentication.user_dn_template=uid={0},ou=users,dc=example,dc=com
# Determines if the result of authentication via the LDAP server should be cached or not.
# Caching is used to limit the number of LDAP requests that have to be made over the network
# for users that have already been authenticated successfully. A user can be authenticated against
# an existing cache entry (instead of via an LDAP server) as long as it is alive
# (see `dbms.security.auth_cache_ttl`).
# An important consequence of setting this to `true` is that
# Neo4j then needs to cache a hashed version of the credentials in order to perform credentials
# matching. This hashing is done using a cryptographic hash function together with a random salt.
# Preferably a conscious decision should be made if this method is considered acceptable by
# the security standards of the organization in which this Neo4j instance is deployed.
#dbms.security.ldap.authentication.cache_enabled=true
#———————————-
# LDAP Authorization Configuration
#———————————-
# Authorization is performed by searching the directory for the groups that
# the user is a member of, and then map those groups to Neo4j roles.
# Perform LDAP search for authorization info using a system account instead of the user’s own account.
#
# If this is set to `false` (default), the search for group membership will be performed
# directly after authentication using the LDAP context bound with the user’s own account.
# The mapped roles will be cached for the duration of `dbms.security.auth_cache_ttl`,
# and then expire, requiring re-authentication. To avoid frequently having to re-authenticate
# sessions you may want to set a relatively long auth cache expiration time together with this option.
# NOTE: This option will only work if the users are permitted to search for their
# own group membership attributes in the directory.
#
# If this is set to `true`, the search will be performed using a special system account user
# with read access to all the users in the directory.
# You need to specify the username and password using the settings
# `dbms.security.ldap.authorization.system_username` and
# `dbms.security.ldap.authorization.system_password` with this option.
# Note that this account only needs read access to the relevant parts of the LDAP directory
# and does not need to have access rights to Neo4j, or any other systems.
#dbms.security.ldap.authorization.use_system_account=false
# An LDAP system account username to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
# Note that the `dbms.security.ldap.authentication.user_dn_template` will not be applied to this username,
# so you may have to specify a full DN.
#dbms.security.ldap.authorization.system_username=
# An LDAP system account password to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
#dbms.security.ldap.authorization.system_password=
# The name of the base object or named context to search for user objects when LDAP authorization is enabled.
# A common case is that this matches the last part of `dbms.security.ldap.authentication.user_dn_template`.
#dbms.security.ldap.authorization.user_search_base=ou=users,dc=example,dc=com
# The LDAP search filter to search for a user principal when LDAP authorization is
# enabled. The filter should contain the placeholder token {0} which will be substituted for the
# user principal.
#dbms.security.ldap.authorization.user_search_filter=(&(objectClass=*)(uid={0}))
# A list of attribute names on a user object that contains groups to be used for mapping to roles
# when LDAP authorization is enabled.
#dbms.security.ldap.authorization.group_membership_attributes=memberOf
# An authorization mapping from LDAP group names to Neo4j role names.
# The map should be formatted as a semicolon separated list of key-value pairs, where the
# key is the LDAP group name and the value is a comma separated list of corresponding role names.
# For example: group1=role1;group2=role2;group3=role3,role4,role5
#
# You could also use whitespaces and quotes around group names to make this mapping more readable,
# for example: dbms.security.ldap.authorization.group_to_role_mapping=\
# “cn=Neo4j Read Only,cn=users,dc=example,dc=com” = reader; \
# “cn=Neo4j Read-Write,cn=users,dc=example,dc=com” = publisher; \
# “cn=Neo4j Schema Manager,cn=users,dc=example,dc=com” = architect; \
# “cn=Neo4j Administrator,cn=users,dc=example,dc=com” = admin
#dbms.security.ldap.authorization.group_to_role_mapping=
#*****************************************************************
# Miscellaneous configuration
#*****************************************************************
# Enable this to specify a parser other than the default one.
#cypher.default_language_version=3.0
# Determines if Cypher will allow using file URLs when loading data using
# `LOAD CSV`. Setting this value to `false` will cause Neo4j to fail `LOAD CSV`
# clauses that load data from the file system.
#dbms.security.allow_csv_import_from_file_urls=true
# Retention policy for transaction logs needed to perform recovery and backups.
#dbms.tx_log.rotation.retention_policy=7 days
# Limit the number of IOs the background checkpoint process will consume per second.
# This setting is advisory, is ignored in Neo4j Community Edition, and is followed to
# best effort in Enterprise Edition.
# An IO is in this case a 8 KiB (mostly sequential) write. Limiting the write IO in
# this way will leave more bandwidth in the IO subsystem to service random-read IOs,
# which is important for the response time of queries when the database cannot fit
# entirely in memory. The only drawback of this setting is that longer checkpoint times
# may lead to slightly longer recovery times in case of a database or system crash.
# A lower number means lower IO pressure, and consequently longer checkpoint times.
# The configuration can also be commented out to remove the limitation entirely, and
# let the checkpointer flush data as fast as the hardware will go.
# Set this to -1 to disable the IOPS limit.
# dbms.checkpoint.iops.limit=300
# Enable a remote shell server which Neo4j Shell clients can log in to.
#dbms.shell.enabled=true
# The network interface IP the shell will listen on (use 0.0.0.0 for all interfaces).
#dbms.shell.host=127.0.0.1
# The port the shell will listen on, default is 1337.
#dbms.shell.port=1337
# Only allow read operations from this Neo4j instance. This mode still requires
# write access to the directory for lock purposes.
#dbms.read_only=false
# Comma separated list of JAX-RS packages containing JAX-RS resources, one
# package name for each mountpoint. The listed package names will be loaded
# under the mountpoints specified. Uncomment this line to mount the
# org.neo4j.examples.server.unmanaged.HelloWorldResource.java from
# neo4j-server-examples under /examples/unmanaged, resulting in a final URL of
# http://localhost:7474/examples/unmanaged/helloworld/{nodeId}
#dbms.unmanaged_extension_classes=org.neo4j.examples.server.unmanaged=/examples/unmanaged
# Specified comma separated list of id types (like node or relationship) that should be reused.
# When some type is specified database will try to reuse corresponding ids as soon as it will be safe to do so.
# Currently only ‘node’ and ‘relationship’ types are supported.
# This settings is ignored in Neo4j Community Edition.
#dbms.ids.reuse.types.override=node,relationship
#********************************************************************
# JVM Parameters
#********************************************************************
# G1GC generally strikes a good balance between throughput and tail
# latency, without too much tuning.
dbms.jvm.additional=-XX:+UseG1GC
# Have common exceptions keep producing stack traces, so they can be
# debugged regardless of how often logs are rotated.
dbms.jvm.additional=-XX:-OmitStackTraceInFastThrow
# Make sure that `initmemory` is not only allocated, but committed to
# the process, before starting the database. This reduces memory
# fragmentation, increasing the effectiveness of transparent huge
# pages. It also reduces the possibility of seeing performance drop
# due to heap-growing GC events, where a decrease in available page
# cache leads to an increase in mean IO response time.
# Try reducing the heap memory, if this flag degrades performance.
dbms.jvm.additional=-XX:+AlwaysPreTouch
# Trust that non-static final fields are really final.
# This allows more optimizations and improves overall performance.
# NOTE: Disable this if you use embedded mode, or have extensions or dependencies that may use reflection or
# serialization to change the value of final fields!
dbms.jvm.additional=-XX:+UnlockExperimentalVMOptions
dbms.jvm.additional=-XX:+TrustFinalNonStaticFields
# Disable explicit garbage collection, which is occasionally invoked by the JDK itself.
dbms.jvm.additional=-XX:+DisableExplicitGC
# Remote JMX monitoring, uncomment and adjust the following lines as needed. Absolute paths to jmx.access and
# jmx.password files are required.
# Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords,
# the shipped configuration contains only a read only role called ‘monitor’ with password ‘Neo4j’.
# For more details, see: http://download.oracle.com/javase/8/docs/technotes/guides/management/agent.html
# On Unix based systems the jmx.password file needs to be owned by the user that will run the server,
# and have permissions set to 0600.
# For details on setting these file permissions on Windows see:
# http://docs.oracle.com/javase/8/docs/technotes/guides/management/security-windows.html
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.port=3637
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.authenticate=true
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.ssl=false
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.password.file=/absolute/path/to/conf/jmx.password
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.access.file=/absolute/path/to/conf/jmx.access
# Some systems cannot discover host name automatically, and need this line configured:
#dbms.jvm.additional=-Djava.rmi.server.hostname=$THE_NEO4J_SERVER_HOSTNAME
# Expand Diffie Hellman (DH) key size from default 1024 to 2048 for DH-RSA cipher suites used in server TLS handshakes.
# This is to protect the server from any potential passive eavesdropping.
dbms.jvm.additional=-Djdk.tls.ephemeralDHKeySize=2048
#********************************************************************
# Wrapper Windows NT/2000/XP Service Properties
#********************************************************************
# WARNING – Do not modify any of these properties when an application
# using this configuration file has been installed as a service.
# Please uninstall the service before modifying this section. The
# service can then be reinstalled.
# Name of the service
dbms.windows_service_name=neo4j
#********************************************************************
# Other Neo4j system properties
#********************************************************************
dbms.jvm.additional=-Dunsupported.dbms.udc.source=tarball
——————- neo4j.conf instance 3 ———————————————
#*****************************************************************
# Neo4j configuration
#
# For more details and a complete list of settings, please see
# https://neo4j.com/docs/operations-manual/current/reference/configuration-settings/
#*****************************************************************
# The name of the database to mount
#dbms.active_database=graph.db
# Paths of directories in the installation.
#dbms.directories.data=data
#dbms.directories.plugins=plugins
#dbms.directories.certificates=certificates
#dbms.directories.logs=logs
#dbms.directories.lib=lib
#dbms.directories.run=run
#dbms.directories.metrics=metrics
# This setting constrains all `LOAD CSV` import files to be under the `import` directory. Remove or comment it out to
# allow files to be loaded from anywhere in the filesystem; this introduces possible security problems. See the
# `LOAD CSV` section of the manual for details.
dbms.directories.import=import
# Whether requests to Neo4j are authenticated.
# To disable authentication, uncomment this line
#dbms.security.auth_enabled=false
# Enable this to be able to upgrade a store from an older version.
#dbms.allow_upgrade=true
# Java Heap Size: by default the Java heap size is dynamically
# calculated based on available system resources.
# Uncomment these lines to set specific initial and maximum
# heap size.
#dbms.memory.heap.initial_size=512m
#dbms.memory.heap.max_size=512m
# The amount of memory to use for mapping the store files, in bytes (or
# kilobytes with the ‘k’ suffix, megabytes with ‘m’ and gigabytes with ‘g’).
# If Neo4j is running on a dedicated server, then it is generally recommended
# to leave about 2-4 gigabytes for the operating system, give the JVM enough
# heap to hold all your transaction state and query context, and then leave the
# rest for the page cache.
# The default page cache memory assumes the machine is dedicated to running
# Neo4j, and is heuristically set to 50% of RAM minus the max Java heap size.
#dbms.memory.pagecache.size=10g
# Enable online backups to be taken from this database.
dbms.backup.enabled=true
# By default the backup service will only listen on localhost.
# To enable remote backups you will have to bind to an external
# network interface (e.g. 0.0.0.0 for all interfaces).
dbms.backup.address=127.0.0.1:6364
#*****************************************************************
# Network connector configuration
#*****************************************************************
# With default configuration Neo4j only accepts local connections.
# To accept non-local connections, uncomment this line:
#dbms.connectors.default_listen_address=0.0.0.0
# You can also choose a specific network interface, and configure a non-default
# port for each connector, by setting their individual listen_address.
# The address at which this server can be reached by its clients. This may be the server’s IP address or DNS name, or
# it may be the address of a reverse proxy which sits in front of the server. This setting may be overridden for
# individual connectors below.
#dbms.connectors.default_advertised_address=localhost
# You can also choose a specific advertised hostname or IP address, and
# configure an advertised port for each connector, by setting their
# individual advertised_address.
# Bolt connector
dbms.connector.bolt.enabled=true
#dbms.connector.bolt.tls_level=OPTIONAL
dbms.connector.bolt.listen_address=127.0.0.1:7689
# HTTP Connector. There must be exactly one HTTP connector.
dbms.connector.http.enabled=true
dbms.connector.http.listen_address=127.0.0.1:7476
# HTTPS Connector. There can be zero or one HTTPS connectors.
dbms.connector.https.enabled=true
dbms.connector.https.listen_address=127.0.0.1:7673
# Number of Neo4j worker threads.
#dbms.threads.worker_count=
#*****************************************************************
# SSL system configuration
#*****************************************************************
# Names of the SSL policies to be used for the respective components.
# The legacy policy is a special policy which is not defined in
# the policy configuration section, but rather derives from
# dbms.directories.certificates and associated files
# (by default: neo4j.key and neo4j.cert). Its use will be deprecated.
# The policies to be used for connectors.
#
# N.B: Note that a connector must be configured to support/require
# SSL/TLS for the policy to actually be utilized.
#
# see: dbms.connector.*.tls_level
#bolt.ssl_policy=legacy
#https.ssl_policy=legacy
# For a causal cluster the configuring of a policy mandates its use.
#causal_clustering.ssl_policy=
#*****************************************************************
# SSL policy configuration
#*****************************************************************
# Each policy is configured under a separate namespace, e.g.
# dbms.ssl.policy.<policyname>.*
#
# The example settings below are for a new policy named ‘default’.
# The base directory for cryptographic objects. Each policy will by
# default look for its associated objects (keys, certificates, …)
# under the base directory.
#
# Every such setting can be overriden using a full path to
# the respective object, but every policy will by default look
# for cryptographic objects in its base location.
#
# Mandatory setting
#dbms.ssl.policy.default.base_directory=certificates/default
# Allows the generation of a fresh private key and a self-signed
# certificate if none are found in the expected locations. It is
# recommended to turn this off again after keys have been generated.
#
# Keys should in general be generated and distributed offline
# by a trusted certificate authority (CA) and not by utilizing
# this mode.
#dbms.ssl.policy.default.allow_key_generation=false
# Enabling this makes it so that this policy ignores the contents
# of the trusted_dir and simply resorts to trusting everything.
#
# Use of this mode is discouraged. It would offer encryption but no security.
#dbms.ssl.policy.default.trust_all=false
# The private key for the default SSL policy. By default a file
# named private.key is expected under the base directory of the policy.
# It is mandatory that a key can be found or generated.
#dbms.ssl.policy.default.private_key=
# The private key for the default SSL policy. By default a file
# named public.crt is expected under the base directory of the policy.
# It is mandatory that a certificate can be found or generated.
#dbms.ssl.policy.default.public_certificate=
# The certificates of trusted parties. By default a directory named
# ‘trusted’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#
# To enforce client authentication client_auth must be set to ‘require’!
#dbms.ssl.policy.default.trusted_dir=
# Certificate Revocation Lists (CRLs). By default a directory named
# ‘revoked’ is expected under the base directory of the policy. It is
# mandatory to create the directory so that it exists, because it cannot
# be auto-created (for security purposes).
#dbms.ssl.policy.default.revoked_dir=
# Client authentication setting. Values: none, optional, require
# The default is to require client authentication.
#
# Servers are always authenticated unless explicitly overridden
# using the trust_all setting. In a mutual authentication setup this
# should be kept at the default of require and trusted certificates
# must be installed in the trusted_dir.
#dbms.ssl.policy.default.client_auth=require
# A comma-separated list of allowed TLS versions.
# By default TLSv1, TLSv1.1 and TLSv1.2 are allowed.
#dbms.ssl.policy.default.tls_versions=
# A comma-separated list of allowed ciphers.
# The default ciphers are the defaults of the JVM platform.
#dbms.ssl.policy.default.ciphers=
#*****************************************************************
# Logging configuration
#*****************************************************************
# To enable HTTP logging, uncomment this line
#dbms.logs.http.enabled=true
# Number of HTTP logs to keep.
#dbms.logs.http.rotation.keep_number=5
# Size of each HTTP log that is kept.
#dbms.logs.http.rotation.size=20m
# To enable GC Logging, uncomment this line
#dbms.logs.gc.enabled=true
# GC Logging Options
# see http://docs.oracle.com/cd/E19957-01/819-0084-10/pt_tuningjava.html#wp57013 for more information.
#dbms.logs.gc.options=-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintPromotionFailure -XX:+PrintTenuringDistribution
# Number of GC logs to keep.
#dbms.logs.gc.rotation.keep_number=5
# Size of each GC log that is kept.
#dbms.logs.gc.rotation.size=20m
# Size threshold for rotation of the debug log. If set to zero then no rotation will occur. Accepts a binary suffix “k”,
# “m” or “g”.
#dbms.logs.debug.rotation.size=20m
# Maximum number of history files for the internal log.
#dbms.logs.debug.rotation.keep_number=7
# Log executed queries that takes longer than the configured threshold. Enable by uncommenting this line.
#dbms.logs.query.enabled=true
# If the execution of query takes more time than this threshold, the query is logged. If set to zero then all queries
# are logged.
#dbms.logs.query.threshold=0
# The file size in bytes at which the query log will auto-rotate. If set to zero then no rotation will occur. Accepts a
# binary suffix “k”, “m” or “g”.
#dbms.logs.query.rotation.size=20m
# Maximum number of history files for the query log.
#dbms.logs.query.rotation.keep_number=7
# Include parameters for the executed queries being logged (this is enabled by default).
#dbms.logs.query.parameter_logging_enabled=true
# Uncomment this line to include detailed time information for the executed queries being logged:
#dbms.logs.query.time_logging_enabled=true
# Uncomment this line to include bytes allocated by the executed queries being logged:
#dbms.logs.query.allocation_logging_enabled=true
# Uncomment this line to include page hits and page faults information for the executed queries being logged:
#dbms.logs.query.page_logging_enabled=true
# The security log is always enabled when `dbms.security.auth_enabled=true`, and resides in `logs/security.log`.
# Log level for the security log. One of DEBUG, INFO, WARN and ERROR.
#dbms.logs.security.level=INFO
# Threshold for rotation of the security log.
#dbms.logs.security.rotation.size=20m
# Minimum time interval after last rotation of the security log before it may be rotated again.
#dbms.logs.security.rotation.delay=300s
# Maximum number of history files for the security log.
#dbms.logs.security.rotation.keep_number=7
#*****************************************************************
# Causal Clustering Configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in Causal Clustering mode.
# See the Causal Clustering documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# CORE – Core member of the cluster, part of the consensus quorum.
# READ_REPLICA – Read replica in the cluster, an eventually-consistent read-only instance of the database.
# To operate this Neo4j instance in Causal Clustering mode as a core member, uncomment this line:
#dbms.mode=CORE
# Expected number of Core machines in the cluster.
#causal_clustering.expected_core_cluster_size=3
# A comma-separated list of the address and port for which to reach all other members of the cluster. It must be in the
# host:port format. For each machine in the cluster, the address will usually be the public ip address of that machine.
# The port will be the value used in the setting “causal_clustering.discovery_listen_address”.
#causal_clustering.initial_discovery_members=localhost:5000,localhost:5001,localhost:5002
# Host and port to bind the cluster member discovery management communication.
# This is the setting to add to the collection of address in causal_clustering.initial_core_cluster_members.
# Use 0.0.0.0 to bind to any network interface on the machine. If you want to only use a specific interface
# (such as a private ip address on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.discovery_listen_address=:5000
# Network interface and port for the transaction shipping server to listen on. If you want to allow for
# messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.transaction_listen_address=:6000
# Network interface and port for the RAFT server to listen on. If you want to allow for messages to be read from
# any network on this machine, us 0.0.0.0. If you want to constrain communication to a specific network address
# (such as a private ip on AWS, for example) then use that ip address instead.
# If you don’t know what value to use here, use this machines ip address.
#causal_clustering.raft_listen_address=:7000
# List a set of names for groups to which this server should belong. This
# is a comma-separated list and names should only use alphanumericals
# and underscore. This can be used to identify groups of servers in the
# configuration for load balancing and replication policies.
#
# The main intention for this is to group servers, but it is possible to specify
# a unique identifier here as well which might be useful for troubleshooting
# or other special purposes.
#causal_clustering.server_groups=
#*****************************************************************
# Causal Clustering Load Balancing
#*****************************************************************
# N.B: Read the online documentation for a thorough explanation!
# Selects the load balancing plugin that shall be enabled.
#causal_clustering.load_balancing.plugin=server_policies
####### Examples for “server_policies” plugin #######
# Will select all available servers as the default policy, which is the
# policy used when the client does not specify a policy preference. The
# default configuration for the default policy is all().
#causal_clustering.load_balancing.config.server_policies.default=all()
# Will select servers in groups ‘group1’ or ‘group2’ under the default policy.
#causal_clustering.load_balancing.config.server_policies.default=groups(group1,group2)
# Slightly more advanced example:
# Will select servers in ‘group1’, ‘group2’ or ‘group3’, but only if there are at least 2.
# This policy will be exposed under the name of ‘mypolicy’.
#causal_clustering.load_balancing.config.server_policies.mypolicy=groups(group1,group2,group3) -> min(2)
# Below will create an even more advanced policy named ‘regionA’ consisting of several rules
# yielding the following behaviour:
#
# select servers in regionA, if at least 2 are available
# otherwise: select servers in regionA and regionB, if at least 2 are available
# otherwise: select all servers
#
# The intention is to create a policy for a particular region which prefers
# a certain set of local servers, but which will fallback to other regions
# or all available servers as required.
#
# N.B: The following configuration uses the line-continuation character \
# which allows you to construct an easily readable rule set spanning
# several lines.
#
#causal_clustering.load_balancing.config.server_policies.policyA=\
#groups(regionA) -> min(2);\
#groups(regionA,regionB) -> min(2);
# Note that implicitly the last fallback is to always consider all() servers,
# but this can be prevented by specifying a halt() as the last rule.
#
#causal_clustering.load_balancing.config.server_policies.regionA_only=\
#groups(regionA);\
#halt();
#*****************************************************************
# Causal Clustering Additional Configuration Options
#*****************************************************************
# The following settings are used less frequently.
# If you don’t know what these are, you don’t need to change these from their default values.
# Address and port that this machine advertises that it’s RAFT server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.raft_advertised_address=:7000
# Address and port that this machine advertises that it’s transaction shipping server is listening at. Should be a
# specific network address. If you are unsure about what value to use here, use this machine’s ip address.
#causal_clustering.transaction_advertised_address=:6000
# The time limit within which a new leader election will occur if no messages from the current leader are received.
# Larger values allow for more stable leaders at the expense of longer unavailability times in case of leader
# failures.
#causal_clustering.leader_election_timeout=7s
# The time limit allowed for a new member to attempt to update its data to match the rest of the cluster.
#causal_clustering.join_catch_up_timeout=10m
# The size of the batch for streaming entries to other machines while trying to catch up another machine.
#causal_clustering.catchup_batch_size=64
# When to pause sending entries to other machines and allow them to catch up.
#causal_clustering.log_shipping_max_lag=256
# Raft log pruning frequncy.
#causal_clustering.raft_log_pruning_frequency=10m
# The size to allow the raft log to grow before rotating.
#causal_clustering.raft_log_rotation_size=250M
### The following setting is relevant for Edge servers only.
# The interval of pulling updates from Core servers.
#causal_clustering.pull_interval=1s
# For how long should drivers cache the discovery data from
# the dbms.cluster.routing.getServers() procedure. Defaults to 300s.
#causal_clustering.cluster_routing_ttl=300s
#*****************************************************************
# HA configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in High Availability mode.
# See the High Availability documentation at https://neo4j.com/docs/ for details.
# Database mode
# Allowed values:
# HA – High Availability
# SINGLE – Single mode, default.
# To run in High Availability mode uncomment this line:
dbms.mode=HA
# ha.server_id is the number of each instance in the HA cluster. It should be
# an integer (e.g. 1), and should be unique for each cluster instance.
ha.server_id=3
# ha.initial_hosts is a comma-separated list (without spaces) of the host:port
# where the ha.host.coordination of all instances will be listening. Typically
# this will be the same for all cluster instances.
ha.initial_hosts=127.0.0.1:5001,127.0.0.1:5002,127.0.0.1:5003
# IP and port for this instance to listen on, for communicating cluster status
# information with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.coordination=127.0.0.1:5003
# IP and port for this instance to listen on, for communicating transaction
# data with other instances (also see ha.initial_hosts). The IP
# must be the configured IP address for one of the local interfaces.
ha.host.data=127.0.0.1:6003
# The interval, in seconds, at which slaves will pull updates from the master. You must comment out
# the option to disable periodic pulling of updates.
ha.pull_interval=10
# Amount of slaves the master will try to push a transaction to upon commit
# (default is 1). The master will optimistically continue and not fail the
# transaction even if it fails to reach the push factor. Setting this to 0 will
# increase write performance when writing through master but could potentially
# lead to branched data (or loss of transaction) if the master goes down.
#ha.tx_push_factor=1
# Strategy the master will use when pushing data to slaves (if the push factor
# is greater than 0). There are three options available “fixed_ascending” (default),
# “fixed_descending” or “round_robin”. Fixed strategies will start by pushing to
# slaves ordered by server id (accordingly with qualifier) and are useful when
# planning for a stable fail-over based on ids.
#ha.tx_push_strategy=fixed_ascending
# Policy for how to handle branched data.
#ha.branched_data_policy=keep_all
# How often heartbeat messages should be sent. Defaults to ha.default_timeout.
#ha.heartbeat_interval=5s
# How long to wait for heartbeats from other instances before marking them as suspects for failure.
# This value reflects considerations of network latency, expected duration of garbage collection pauses
# and other factors that can delay message sending and processing. Larger values will result in more
# stable masters but also will result in longer waits before a failover in case of master failure.
# This value should not be set to less than twice the ha.heartbeat_interval value otherwise there is a high
# risk of frequent master switches and possibly branched data occurrence.
#ha.heartbeat_timeout=40s
# If you are using a load-balancer that doesn’t support HTTP Auth, you may need to turn off authentication for the
# HA HTTP status endpoint by uncommenting the following line.
#dbms.security.ha_status_auth_enabled=false
# Whether this instance should only participate as slave in cluster. If set to
# true, it will never be elected as master.
#ha.slave_only=false
#********************************************************************
# Security Configuration
#********************************************************************
# The authentication and authorization provider that contains both users and roles.
# This can be one of the built-in `native` or `ldap` auth providers,
# or it can be an externally provided plugin, with a custom name prefixed by `plugin`,
# i.e. `plugin-<AUTH_PROVIDER_NAME>`.
#dbms.security.auth_provider=native
# The time to live (TTL) for cached authentication and authorization info when using
# external auth providers (LDAP or plugin). Setting the TTL to 0 will
# disable auth caching.
#dbms.security.auth_cache_ttl=10m
# The maximum capacity for authentication and authorization caches (respectively).
#dbms.security.auth_cache_max_capacity=10000
# Set to log successful authentication events to the security log.
# If this is set to `false` only failed authentication events will be logged, which
# could be useful if you find that the successful events spam the logs too much,
# and you do not require full auditing capability.
#dbms.security.log_successful_authentication=true
#================================================
# LDAP Auth Provider Configuration
#================================================
# URL of LDAP server to use for authentication and authorization.
# The format of the setting is `<protocol>://<hostname>:<port>`, where hostname is the only required field.
# The supported values for protocol are `ldap` (default) and `ldaps`.
# The default port for `ldap` is 389 and for `ldaps` 636.
# For example: `ldaps://ldap.example.com:10389`.
#
# NOTE: You may want to consider using STARTTLS (`dbms.security.ldap.use_starttls`) instead of LDAPS
# for secure connections, in which case the correct protocol is `ldap`.
#dbms.security.ldap.host=localhost
# Use secure communication with the LDAP server using opportunistic TLS.
# First an initial insecure connection will be made with the LDAP server, and then a STARTTLS command
# will be issued to negotiate an upgrade of the connection to TLS before initiating authentication.
#dbms.security.ldap.use_starttls=false
# The LDAP referral behavior when creating a connection. This is one of `follow`, `ignore` or `throw`.
# `follow` automatically follows any referrals
# `ignore` ignores any referrals
# `throw` throws an exception, which will lead to authentication failure
#dbms.security.ldap.referral=follow
# The timeout for establishing an LDAP connection. If a connection with the LDAP server cannot be
# established within the given time the attempt is aborted.
# A value of 0 means to use the network protocol’s (i.e., TCP’s) timeout value.
#dbms.security.ldap.connection_timeout=30s
# The timeout for an LDAP read request (i.e. search). If the LDAP server does not respond within
# the given time the request will be aborted. A value of 0 means wait for a response indefinitely.
#dbms.security.ldap.read_timeout=30s
#———————————-
# LDAP Authentication Configuration
#———————————-
# LDAP authentication mechanism. This is one of `simple` or a SASL mechanism supported by JNDI,
# for example `DIGEST-MD5`. `simple` is basic username
# and password authentication and SASL is used for more advanced mechanisms. See RFC 2251 LDAPv3
# documentation for more details.
#dbms.security.ldap.authentication.mechanism=simple
# LDAP user DN template. An LDAP object is referenced by its distinguished name (DN), and a user DN is
# an LDAP fully-qualified unique user identifier. This setting is used to generate an LDAP DN that
# conforms with the LDAP directory’s schema from the user principal that is submitted with the
# authentication token when logging in.
# The special token {0} is a placeholder where the user principal will be substituted into the DN string.
#dbms.security.ldap.authentication.user_dn_template=uid={0},ou=users,dc=example,dc=com
# Determines if the result of authentication via the LDAP server should be cached or not.
# Caching is used to limit the number of LDAP requests that have to be made over the network
# for users that have already been authenticated successfully. A user can be authenticated against
# an existing cache entry (instead of via an LDAP server) as long as it is alive
# (see `dbms.security.auth_cache_ttl`).
# An important consequence of setting this to `true` is that
# Neo4j then needs to cache a hashed version of the credentials in order to perform credentials
# matching. This hashing is done using a cryptographic hash function together with a random salt.
# Preferably a conscious decision should be made if this method is considered acceptable by
# the security standards of the organization in which this Neo4j instance is deployed.
#dbms.security.ldap.authentication.cache_enabled=true
#———————————-
# LDAP Authorization Configuration
#———————————-
# Authorization is performed by searching the directory for the groups that
# the user is a member of, and then map those groups to Neo4j roles.
# Perform LDAP search for authorization info using a system account instead of the user’s own account.
#
# If this is set to `false` (default), the search for group membership will be performed
# directly after authentication using the LDAP context bound with the user’s own account.
# The mapped roles will be cached for the duration of `dbms.security.auth_cache_ttl`,
# and then expire, requiring re-authentication. To avoid frequently having to re-authenticate
# sessions you may want to set a relatively long auth cache expiration time together with this option.
# NOTE: This option will only work if the users are permitted to search for their
# own group membership attributes in the directory.
#
# If this is set to `true`, the search will be performed using a special system account user
# with read access to all the users in the directory.
# You need to specify the username and password using the settings
# `dbms.security.ldap.authorization.system_username` and
# `dbms.security.ldap.authorization.system_password` with this option.
# Note that this account only needs read access to the relevant parts of the LDAP directory
# and does not need to have access rights to Neo4j, or any other systems.
#dbms.security.ldap.authorization.use_system_account=false
# An LDAP system account username to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
# Note that the `dbms.security.ldap.authentication.user_dn_template` will not be applied to this username,
# so you may have to specify a full DN.
#dbms.security.ldap.authorization.system_username=
# An LDAP system account password to use for authorization searches when
# `dbms.security.ldap.authorization.use_system_account` is `true`.
#dbms.security.ldap.authorization.system_password=
# The name of the base object or named context to search for user objects when LDAP authorization is enabled.
# A common case is that this matches the last part of `dbms.security.ldap.authentication.user_dn_template`.
#dbms.security.ldap.authorization.user_search_base=ou=users,dc=example,dc=com
# The LDAP search filter to search for a user principal when LDAP authorization is
# enabled. The filter should contain the placeholder token {0} which will be substituted for the
# user principal.
#dbms.security.ldap.authorization.user_search_filter=(&(objectClass=*)(uid={0}))
# A list of attribute names on a user object that contains groups to be used for mapping to roles
# when LDAP authorization is enabled.
#dbms.security.ldap.authorization.group_membership_attributes=memberOf
# An authorization mapping from LDAP group names to Neo4j role names.
# The map should be formatted as a semicolon separated list of key-value pairs, where the
# key is the LDAP group name and the value is a comma separated list of corresponding role names.
# For example: group1=role1;group2=role2;group3=role3,role4,role5
#
# You could also use whitespaces and quotes around group names to make this mapping more readable,
# for example: dbms.security.ldap.authorization.group_to_role_mapping=\
# “cn=Neo4j Read Only,cn=users,dc=example,dc=com” = reader; \
# “cn=Neo4j Read-Write,cn=users,dc=example,dc=com” = publisher; \
# “cn=Neo4j Schema Manager,cn=users,dc=example,dc=com” = architect; \
# “cn=Neo4j Administrator,cn=users,dc=example,dc=com” = admin
#dbms.security.ldap.authorization.group_to_role_mapping=
#*****************************************************************
# Miscellaneous configuration
#*****************************************************************
# Enable this to specify a parser other than the default one.
#cypher.default_language_version=3.0
# Determines if Cypher will allow using file URLs when loading data using
# `LOAD CSV`. Setting this value to `false` will cause Neo4j to fail `LOAD CSV`
# clauses that load data from the file system.
#dbms.security.allow_csv_import_from_file_urls=true
# Retention policy for transaction logs needed to perform recovery and backups.
#dbms.tx_log.rotation.retention_policy=7 days
# Limit the number of IOs the background checkpoint process will consume per second.
# This setting is advisory, is ignored in Neo4j Community Edition, and is followed to
# best effort in Enterprise Edition.
# An IO is in this case a 8 KiB (mostly sequential) write. Limiting the write IO in
# this way will leave more bandwidth in the IO subsystem to service random-read IOs,
# which is important for the response time of queries when the database cannot fit
# entirely in memory. The only drawback of this setting is that longer checkpoint times
# may lead to slightly longer recovery times in case of a database or system crash.
# A lower number means lower IO pressure, and consequently longer checkpoint times.
# The configuration can also be commented out to remove the limitation entirely, and
# let the checkpointer flush data as fast as the hardware will go.
# Set this to -1 to disable the IOPS limit.
# dbms.checkpoint.iops.limit=300
# Enable a remote shell server which Neo4j Shell clients can log in to.
#dbms.shell.enabled=true
# The network interface IP the shell will listen on (use 0.0.0.0 for all interfaces).
#dbms.shell.host=127.0.0.1
# The port the shell will listen on, default is 1337.
#dbms.shell.port=1337
# Only allow read operations from this Neo4j instance. This mode still requires
# write access to the directory for lock purposes.
#dbms.read_only=false
# Comma separated list of JAX-RS packages containing JAX-RS resources, one
# package name for each mountpoint. The listed package names will be loaded
# under the mountpoints specified. Uncomment this line to mount the
# org.neo4j.examples.server.unmanaged.HelloWorldResource.java from
# neo4j-server-examples under /examples/unmanaged, resulting in a final URL of
# http://localhost:7474/examples/unmanaged/helloworld/{nodeId}
#dbms.unmanaged_extension_classes=org.neo4j.examples.server.unmanaged=/examples/unmanaged
# Specified comma separated list of id types (like node or relationship) that should be reused.
# When some type is specified database will try to reuse corresponding ids as soon as it will be safe to do so.
# Currently only ‘node’ and ‘relationship’ types are supported.
# This settings is ignored in Neo4j Community Edition.
#dbms.ids.reuse.types.override=node,relationship
#********************************************************************
# JVM Parameters
#********************************************************************
# G1GC generally strikes a good balance between throughput and tail
# latency, without too much tuning.
dbms.jvm.additional=-XX:+UseG1GC
# Have common exceptions keep producing stack traces, so they can be
# debugged regardless of how often logs are rotated.
dbms.jvm.additional=-XX:-OmitStackTraceInFastThrow
# Make sure that `initmemory` is not only allocated, but committed to
# the process, before starting the database. This reduces memory
# fragmentation, increasing the effectiveness of transparent huge
# pages. It also reduces the possibility of seeing performance drop
# due to heap-growing GC events, where a decrease in available page
# cache leads to an increase in mean IO response time.
# Try reducing the heap memory, if this flag degrades performance.
dbms.jvm.additional=-XX:+AlwaysPreTouch
# Trust that non-static final fields are really final.
# This allows more optimizations and improves overall performance.
# NOTE: Disable this if you use embedded mode, or have extensions or dependencies that may use reflection or
# serialization to change the value of final fields!
dbms.jvm.additional=-XX:+UnlockExperimentalVMOptions
dbms.jvm.additional=-XX:+TrustFinalNonStaticFields
# Disable explicit garbage collection, which is occasionally invoked by the JDK itself.
dbms.jvm.additional=-XX:+DisableExplicitGC
# Remote JMX monitoring, uncomment and adjust the following lines as needed. Absolute paths to jmx.access and
# jmx.password files are required.
# Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords,
# the shipped configuration contains only a read only role called ‘monitor’ with password ‘Neo4j’.
# For more details, see: http://download.oracle.com/javase/8/docs/technotes/guides/management/agent.html
# On Unix based systems the jmx.password file needs to be owned by the user that will run the server,
# and have permissions set to 0600.
# For details on setting these file permissions on Windows see:
# http://docs.oracle.com/javase/8/docs/technotes/guides/management/security-windows.html
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.port=3637
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.authenticate=true
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.ssl=false
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.password.file=/absolute/path/to/conf/jmx.password
#dbms.jvm.additional=-Dcom.sun.management.jmxremote.access.file=/absolute/path/to/conf/jmx.access
# Some systems cannot discover host name automatically, and need this line configured:
#dbms.jvm.additional=-Djava.rmi.server.hostname=$THE_NEO4J_SERVER_HOSTNAME
# Expand Diffie Hellman (DH) key size from default 1024 to 2048 for DH-RSA cipher suites used in server TLS handshakes.
# This is to protect the server from any potential passive eavesdropping.
dbms.jvm.additional=-Djdk.tls.ephemeralDHKeySize=2048
#********************************************************************
# Wrapper Windows NT/2000/XP Service Properties
#********************************************************************
# WARNING – Do not modify any of these properties when an application
# using this configuration file has been installed as a service.
# Please uninstall the service before modifying this section. The
# service can then be reinstalled.
# Name of the service
dbms.windows_service_name=neo4j
#********************************************************************
# Other Neo4j system properties
#********************************************************************
dbms.jvm.additional=-Dunsupported.dbms.udc.source=tarball
MMS • Raul Salas
CB Insights analysis of media mentions of Artificial Intelligence and Big Data shows the hype curve for Artificial Intelligence taking off while mentions of Big Data are also starting to increase steadily.
A global google insights search term analysis uncovered some interesting keyword searches that offers some insight into the convergence of big data and Machine learning as well as what country is dominating the keyword searches.
The first search term I analyzed was “Big data AI”. A recent spike in search terminology as expected.
A deeper dive into search analysis the keyword term “Machine Learning”, A subset of Artificial Intelligence was used. What surprised me what that China was on the top of the list in number of searches. I was expecting to see the United States or even Europe at a much higher ranking.
Search Term analysis of key components of Big Data NoSQL databases used in Machine Learning was performed to gain a deeper understanding. The second chart is the search term “Apache Spark” Spark is an advanced, Big Data in-memory Apache Spark computing database engine delivering 100x the performance of Hadoop Artificial Intelligence and Machine Learning workloads. Spark is now being used in conjunction with popular Data Science libraries such as Mlib. Once again, China is the top ranked country for the search term.
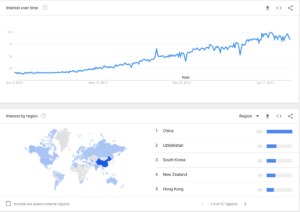
Another surprising search term ranking where China was #1 was “Mongodb” Another Big Data NoSQL database used in Machine Learning. I certainly was expecting Mongodb’s country search term top ranking to be the United States, especially since it was founded in New York City!
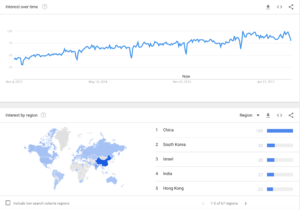
What’s interesting is that China appears to be in the lead in the Big Data and Machine Learning fields. This is certainly not a good sign for the United States in maintaining it’s technology lead needed for economic and military dominance. Currently, China is pushing for an unmanned police station entirely powered by Artificial Intelligence. http://www.siliconrepublic.com/machines/wuhan-police-station-ai-face-scanners There needs to be a renewed focus on STEM education in High Schools and Universities in the United States on the scale of the Manned Moon NASA projects of the 1960s.
Author: Raul Salas Raul@Mobilemonitoringsolutions.com
MMS • Raul Salas
ClustrixDB (www.clustrix.com) created an interesting graphic depicting the future of the relational and NoSQL database platforms. The graphic was interesting and great topic to expand on.
So in order to talk about the future, we first need to talk about the past and present. In the past, there were traditional relational database vendors such as Microsoft and Oracle. These databases were the workhorse of Corporate America as they provided support for banking, finance, and other corporate support activities. Then came the rise of the internet, Mobile, Cloud, and Social media in the early 2000s. This trend resulted in a large growth of unstructured data that resided outside of the corporate firewall. New database technologies such as NoSQL rose to the meet the demand of high volume and velocity data growth. NoSQL databases such as Mongodb, Cassandra, and Hadoop focus on unstructured data processing. While the Relational database platforms focus on traditional structured transactions and single server hardware hosted environments.
It is important to note that in the past 5 years licensing costs for both Oracle and Microsoft database products have increased dramatically. While NoSQL Open source products can be utilized at a much lower price point on a subscription basis or community Open Source versions in a free unsupported mode. NoSQL products such as Hadoop have industry low storage cost price points that show a really positive return on investment, especially housing large amounts of data for data lakes for example. Another trend happening now is that Developers are driving the database adoption trends, not database administrators. This is an important new trend that will drive marketing and business strategies now and for the future both for database vendors as well as their customers.
Today, NoSQL scale-out databases are becoming popular as Machine Learning and Artificial Intelligence become mainstream. The data requirements for this new technology require scale out across commodity hardware that can handle real-time analytics for say self-driving cars or a fully automated manufacturing plant. This is where companies like Google’s Spanner and Clustrix come into play and are pioneers in this space. This technology is a high cost solution, but is an answer to the resource constraints of existing technology.
In the future, Hadoop will remain a player in the batch processing data warehouse/data lake space. While traditional relational database players such as Microsoft and Oracle create new analytics products that are distributed in nature. The database industry could shake out into three distinct areas: NoSQL, Distributed SQL and Hadoop, Single Node traditional SQL will either morph into or get replaced by scale-out SQL as well as existing data warehouse analytics features will become real-time.
A good example of this trend is now happening with Cloudera Hadoop/Spark integration in the new Lambda Architecture which combines real-time processing with Spark and Machine Learning libraries such as mahout and sending data for batch processing in the Hadoop ecosystem and integration. Businesses are already seeing significant competitive edge with predictive analytics and personalization implementing the Lambda architecture.
Raul Salas raul@mobilemonitoringsolutions.com
MMS • Raul Salas
Sort Memory errors in Mongodb and how to resolve them!
So you installed Mongodb and everything seems to be humming along for months and then all of the sudden your application comes to a grinding halt because of the following strange error your receiving from Mongodb:
OperationFailed: Sort operation used more than the maximum 33,554,432 bytes of RAM. Add an index, or specify a smaller limit.’ on server
This error is caused by Mongodb engine exceeding memory capacity limits on sorting when Mongodb cannot use an index. The default memory limit for sorting data is 32 MB. A good first step would be to optimize the query with the explain query parameter, However, to get your application online quickly there is a quick fix for this issue. The default parameter for an internal system parameter called “InternalQueryExecMaxBlockSortBytes” will need to be modified. Let’s verify what the parameters are now on this particular Mongodb instance
db.adminCommand({getParameter: ‘*’})
This will return a large document with the internalQueryExecMaxBlockingSortBytes the value of 33,554,432 bytes (33 MB). So now let’s increase this parameter to 134,217,728 bytes (134 MB) by executing the following command:
db.adminCommand({“setParameter”:1,”internalQueryExecMaxBlockingSortBytes”:134,217,728})
Now execute your query to see if the error goes away! You may need to increase the parameter if your query continues to fail. It would be nice if Mongodb included a metric to monitor this parameter’s usage in a future release.
Update for Mongodb 4.0:
$sort and Memory Restrictions
The $sort stage has a limit of 100 megabytes of RAM. By default, if the stage exceeds this limit, $sort will produce an error. To allow for the handling of large datasets, set the allowDiskUse option to true to enable $sort operations to write to temporary files. See the allowDiskUse option in db.collection.aggregate() method and the aggregate command for details.
Raul Salas
Raul@mobilemonitoringsolutions.com
MMS • Raul Salas
coun·ter·cul·ture
ˈkoun(t)ərˌkəlCHər/
noun
noun: counter-culture
- a way of life and set of attitudes opposed to or at variance with the prevailing social norm.
“the idealists of the 60s counterculture”
Yesterday, NoSQL vendor Mongodb (MDB) went public and now has a $1.5 billion dollar valuation! A pretty good IPO for a company that many database industry insiders said would fail. Mongodb is a good example of how a technology driven counter-culture can remake an entire industry!
Many people do not even know about NoSQL technology, yet it’s impact is in our daily lives, everything from Netflix to Facebook to Amazon, NoSQL drives many of the Social media features used by everyone in the modern economy.
In some ways, NoSQL in 2017 is still considered counter-culture due to many corporations third party vendors not jumping on the NoSQL platform for their products. This is slowly changing as software vendors like Sitecore Content Management software packages are requiring Mongodb as a backend for their personalization features, forcing some fortune 500 companies to implement NoSQL in their environments.
Since the 1980s, relational database technology by Microsoft and Oracle basically ruled the market place. This was intentional, since the relational database model reflected the business models between 1970-2005. Sometime during the late 2000s, social media, the rise of Open Source software, cloud services, smart phones, and cheap commodity servers started to be common and business models changed along with the new social media technology.
To meet the needs of social media, a new generation of databases called NoSQL were being created in the Open Source world that more accurately matched the new business models being created as well as the appetite for speed of unstructured information from various sources.
NoSQL databases such as Mongodb were shunned by many Database professionals as novelties. This mode of thinking was perpetuated by the major relational database vendors. In addition, Many Database administrators who spent most of their career becoming experts in relational database platforms were hesitant to embrace the NoSQL platforms. DBAs main criticism of NoSQL database platforms was that they did not support transactions. When in fact, Relational Databases did not reflect the new data and business models of social media, machine learning, and personalization era. Social Media is probably as revolutionary as the invention of the printing press and society and businesses are adapting to this new form of communication.
In the future, Artificial intelligence will also make a comeback as Open Source NoSQL’s ability to handle unstructured data from multiple sources in Real-Time makes AI reality. Self-Driving cars, Website Personalization, factory automation, machine learning algorithms running various business units will all use Open Source NoSQL database platforms.
Raul Salas
Raul@mobilemonitoringsolutions.com