Category: Database

MMS • RSS
Article originally posted on Database Journal – Daily Database Management & Administration News and Tutorials. Visit Database Journal – Daily Database Management & Administration News and Tutorials
Deployment of cloud-based technologies introduces a wide range of challenges; however, few of them are scrutinized to the same extent as security. When analyzing security-related challenges, it is important to note that they encompass several distinct but interrelated technologies, including authentication and authorization, network isolation, as well as data integrity and confidentiality. In addition, when dealing with data services, it is also necessary to distinguish between the data plane, facilitating access to the underlying content and the management plane, which allows for delegation of administrative tasks. In this article, we will explore how these concepts apply to the Azure Cosmos DB offering.
The first line of defense when controlling data plane access to Cosmos DB is implemented by leveraging the IP address-based network filtering at the account level. By default, this filtering is disabled, effectively allowing network connectivity from any location. Once you enable it, all inbound traffic is blocked unless you explicitly permit it. When using the Azure portal, there are four configuration options that represent different connection types:
- Add my current IP – this option provides a convenient method to allow connectivity from the public IP address representing your computer. This can be a computer residing in any location with Internet connectivity, including on-premises datacenters and Azure virtual networks.
- IP (SINGLE IPV4 OR CIDR RANGE) – this option allows you to specify any Internet-based IP address or an IP address range in the Classless Inter-Domain Routing notation.
- Exceptions (Allow access to Azure Services) – this is a checkbox (enabled by default) that controls connectivity from Azure PaaS services, such as Azure Stream Analytics, Azure Functions, and Azure App Service that are capable of interacting directly with Cosmos DB.
- Exceptions (Allow access to Azure portal) – this is a checkbox (enabled by default) that controls connectivity to Cosmos DB directly from the Azure portal via such portal-based data management interfaces as Data Explorer.
If you decide to manage a firewall programmatically (for example, by using Azure PowerShell, Azure CLI, or REST API), then you can accomplish this by modifying the ipRangeFilter property of the object representing a target Cosmos DB account. In such case, you will need to provide specific IP addresses or IP address ranges:
- Exceptions (Allow access to Azure Services) is represented by the IP address 0.0.0.0.
- Exceptions (Allow access to Azure portal) – is represented by the IP addresses 104.42.195.92,40.76.54.131,52.176.6.30,52.169.50.45,52.187.184.26 for Azure public (the portals for US Gov, as well as Germany and China national clouds are represented by their respective, unique IP addresses).
Following establishing a successful network connection, incoming requests are subject to authentication and authorization. To implement them, Cosmos DB relies on several complementing security mechanisms. The first of them involves the use of account-specific, autogenerated master keys. Each account includes two master keys, which provide full control of its entire content. In addition, each account also includes a pair of read-only keys, which grant the ability to carry out read-only operations (with the exception of reading permissions of account resources). Having two master (and two read-only) keys allows you to regenerate each key independently of the other one in the same pair, facilitating key rotation while at the same time, providing uninterrupted access to users and applications.
The use of master keys should be limited to scenarios that require full privileges to the content of an account. For more granular access, you should use resource tokens. Resource tokens provide user-based permissions to individual account resources, including collections, documents, attachments, stored procedures, triggers, and user-defined functions. They are auto-generated when a database user is granted permissions to a resource and re-generated in response to a request referencing that permission. By default, they are valid for one hour, with the maximum timespan of five hours.
Resource tokens are typically employed in scenarios that implement the valet key pattern (for details, refer to its architectural overview on Microsoft Docs). This pattern involves a middle-tier service that serves as the authentication and authorization broker between a client and a back-end service (which in our case, corresponds to the target Cosmos DB account). The mid-tier service has full access to the account based on the knowledge of one of the two master keys. The mid-tier service is also responsible for authenticating the client (for example, by using Azure Active Directory). Once the client successfully authenticates, the mid-tier service requests a resource token associated with the authenticated user from the Cosmos DB account and relays the token back to the client. At that point, the client can use the token to access Cosmos DB resources directly. This continues until the token expires, resulting in the 401 exception. In response, the client contacts the middle-tier service again, which in turn initiates the request for a new resource token.
The control plane security protection of Cosmos DB leverages Role Based Access Control (RBAC), which is part of the Azure core platform functionality. RBAC involves the use of pre-defined and custom roles that determine the list of actions that a role holder is allowed to carry out. Implementing it requires designating an Azure Active Directory user, group, or service principal that will become the role holder and specifying the scope (a subscription, resource group, or an individual resource, such as a Cosmos DB account) in which the role assignment will take effect. Cosmos DB-specific built-in RBAC roles include only DocumentDB Account Contributor and Cosmos DB Account Reader, but you have the option of creating custom roles if needed (for details regarding this process, refer to Microsoft Docs).
This concludes our introduction to Cosmos DB security. In upcoming articles published on this forum, we will explore user and permission management in more detail.
MMS • Raul Salas

This is a quick blogpost from notes that i have gathered over time. There may be situations where support staff might be restricted from logging directly into a Mongodb instance. But there may also be a requirement for support staff to get information on the status of Mongodb environments, especially users of the Community version of Mongodb. These commands could also be run via a shell script as well that would allow a sysadmin to automate these commands into a daily routine.
You can quickly obtain information by executing the following commands:
mongo –port –username <username> –password <password> –authenticationDatabase admin –eval “mongo command”
Of course you will need to add the required authentication parameters relevant to your installation.
Obtaining host information – you can execute the mongo shell command along with some configuration options such as database, authenticatioen, and the –eval command followed by the actual mongo command you want to execute. The command is broken into the following parameters:
I setup a quick test environment, so no need to use any authentication parameters, but you can see how to execute the command and the associated output. You can see the version along with the host as well as os information.
$ mongo –eval “db.hostInfo()”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
{
“system” : {
“currentTime” : ISODate(“2017-10-23T20:50:43.959Z”),
“hostname” : “MacBook.local”,
“cpuAddrSize” : 64,
“memSizeMB” : 16384,
“numCores” : 8,
“cpuArch” : “x86_64”,
“numaEnabled” : false
},
“os” : {
“type” : “Darwin”,
“name” : “Mac OS X”,
“version” : “16.7.0”
},
“extra” : {
“versionString” : “Darwin Kernel Version 16.7.0: T4”,
“alwaysFullSync” : 0,
“nfsAsync” : 0,
“model” : “MacBook,3”,
“physicalCores” : 4,
“cpuFrequencyMHz” : 2900,
“cpuString” : “Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz”,
“cpuFeatures” : “FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX SMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16C SYSCALL XD 1GBPAGE EM64T LAHF LZCNT PREFETCHW RDTSCP TSCI”,
“pageSize” : 4096,
“scheduler” : “multiq”
},
“ok” : 1
}
Now, you would like to see what databases reside on this particular host with the listDatabases command.
$ mongo –eval “printjson(db.adminCommand( { listDatabases: 1 } ))”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.4.9
{
“databases” : [
{
“name” : “admin”,
“sizeOnDisk” : 49152,
“empty” : false
},
{
“name” : “local”,
“sizeOnDisk” : 65536,
“empty” : false
},
{
“name” : “test_db”,
“sizeOnDisk” : 65536,
“empty” : false
}
],
“totalSize” : 180224,
“ok” : 1
}
If you would like to see the collections within the database test_db, you can issue the following command to get a list of collections in json format.
$ mongo test_db –eval “printjson(db.getCollectionNames())”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
[ “cities”, “names” ]
That’s a quick overview of what can be done at the command line. For a more comprehensive list of commands, you can use the db.help() option to get a list of commands
As you can see it’s pretty comprehensive and is valuable for a sys admin and/or database administrator to get a quick picture of your Mongodb environment.
$ mongo test_db –eval “db.help()”
MongoDB shell version v3.4.9
connecting to: mongodb://127.0.0.1:27017/test_db
MongoDB server version: 3.4.9
DB methods:
db.adminCommand(nameOrDocument) – switches to ‘admin’ db, and runs command [ just calls db.runCommand(…) ]
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : …, capped : …, max : … } )
db.createView(name, viewOn, [ { $operator: {…}}, … ], { viewOptions } )
db.createUser(userDocument)
db.currentOp() displays currently executing operations in the db
db.dropDatabase()
db.eval() – deprecated
db.fsyncLock() flush data to disk and lock server for backups
db.fsyncUnlock() unlocks server following a db.fsyncLock()
db.getCollection(cname) same as db[‘cname’] or db.cname
db.getCollectionInfos([filter]) – returns a list that contains the names and options of the db’s collections
db.getCollectionNames()
db.getLastError() – just returns the err msg string
db.getLastErrorObj() – return full status object
db.getLogComponents()
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow queries on a replication slave server
db.getName()
db.getPrevError()
db.getProfilingLevel() – deprecated
db.getProfilingStatus() – returns if profiling is on and slow threshold
db.getReplicationInfo()
db.getSiblingDB(name) get the db at the same server as this one
db.getWriteConcern() – returns the write concern used for any operations on this db, inherited from server object if set
db.hostInfo() get details about the server’s host
db.isMaster() check replica primary status
db.killOp(opid) kills the current operation in the db
db.listCommands() lists all the db commands
db.loadServerScripts() loads all the scripts in db.system.js
db.logout()
db.printCollectionStats()
db.printReplicationInfo()
db.printShardingStatus()
db.printSlaveReplicationInfo()
db.dropUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into { cmdObj : 1 }
db.serverStatus()
db.setLogLevel(level,<component>)
db.setProfilingLevel(level,<slowms>) 0=off 1=slow 2=all
db.setWriteConcern( <write concern doc> ) – sets the write concern for writes to the db
db.unsetWriteConcern( <write concern doc> ) – unsets the write concern for writes to the db
db.setVerboseShell(flag) display extra information in shell output
db.shutdownServer()
db.stats()
db.version() current version of the server
Command line execution of Mongodb commands allows support staff to quickly obtain information on the Mongodb environment without running the risk of accidentally causing disruption of service
RAUL SALAS Raul@mobilemonitoringsolutions.com
MMS • Raul Salas
ClustrixDB (www.clustrix.com) created an interesting graphic depicting the future of the relational and NoSQL database platforms. The graphic was interesting and great topic to expand on.
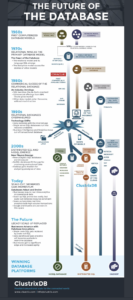
So in order to talk about the future, we first need to talk about the past and present. In the past, there were traditional relational database vendors such as Microsoft and Oracle. These databases were the workhorse of Corporate America as they provided support for banking, finance, and other corporate support activities. Then came the rise of the internet, Mobile, Cloud, and Social media in the early 2000s. This trend resulted in a large growth of unstructured data that resided outside of the corporate firewall. New database technologies such as NoSQL rose to the meet the demand of high volume and velocity data growth. NoSQL databases such as Mongodb, Cassandra, and Hadoop focus on unstructured data processing. While the Relational database platforms focus on traditional structured transactions and single server hardware hosted environments.
It is important to note that in the past 5 years licensing costs for both Oracle and Microsoft database products have increased dramatically. While NoSQL Open source products can be utilized at a much lower price point on a subscription basis or community Open Source versions in a free unsupported mode. NoSQL products such as Hadoop have industry low storage cost price points that show a really positive return on investment, especially housing large amounts of data for data lakes for example. Another trend happening now is that Developers are driving the database adoption trends, not database administrators. This is an important new trend that will drive marketing and business strategies now and for the future both for database vendors as well as their customers.
Today, NoSQL scale-out databases are becoming popular as Machine Learning and Artificial Intelligence become mainstream. The data requirements for this new technology require scale out across commodity hardware that can handle real-time analytics for say self-driving cars or a fully automated manufacturing plant. This is where companies like Google’s Spanner and Clustrix come into play and are pioneers in this space. This technology is a high cost solution, but is an answer to the resource constraints of existing technology.
In the future, Hadoop will remain a player in the batch processing data warehouse/data lake space. While traditional relational database players such as Microsoft and Oracle create new analytics products that are distributed in nature. The database industry could shake out into three distinct areas: NoSQL, Distributed SQL and Hadoop, Single Node traditional SQL will either morph into or get replaced by scale-out SQL as well as existing data warehouse analytics features will become real-time.
A good example of this trend is now happening with Cloudera Hadoop/Spark integration in the new Lambda Architecture which combines real-time processing with Spark and Machine Learning libraries such as mahout and sending data for batch processing in the Hadoop ecosystem and integration. Businesses are already seeing significant competitive edge with predictive analytics and personalization implementing the Lambda architecture.
Raul Salas raul@mobilemonitoringsolutions.com
MMS • Raul Salas
Sort Memory errors in Mongodb and how to resolve them!
So you installed Mongodb and everything seems to be humming along for months and then all of the sudden your application comes to a grinding halt because of the following strange error your receiving from Mongodb:
OperationFailed: Sort operation used more than the maximum 33,554,432 bytes of RAM. Add an index, or specify a smaller limit.’ on server
This error is caused by Mongodb engine exceeding memory capacity limits on sorting when Mongodb cannot use an index. The default memory limit for sorting data is 32 MB. A good first step would be to optimize the query with the explain query parameter, However, to get your application online quickly there is a quick fix for this issue. The default parameter for an internal system parameter called “InternalQueryExecMaxBlockSortBytes” will need to be modified. Let’s verify what the parameters are now on this particular Mongodb instance
db.adminCommand({getParameter: ‘*’})
This will return a large document with the internalQueryExecMaxBlockingSortBytes the value of 33,554,432 bytes (33 MB). So now let’s increase this parameter to 134,217,728 bytes (134 MB) by executing the following command:
db.adminCommand({“setParameter”:1,”internalQueryExecMaxBlockingSortBytes”:134,217,728})
Now execute your query to see if the error goes away! You may need to increase the parameter if your query continues to fail. It would be nice if Mongodb included a metric to monitor this parameter’s usage in a future release.
Update for Mongodb 4.0:
$sort and Memory Restrictions
The $sort stage has a limit of 100 megabytes of RAM. By default, if the stage exceeds this limit, $sort will produce an error. To allow for the handling of large datasets, set the allowDiskUse option to true to enable $sort operations to write to temporary files. See the allowDiskUse option in db.collection.aggregate() method and the aggregate command for details.
Raul Salas
Raul@mobilemonitoringsolutions.com
MMS • Raul Salas
coun·ter·cul·ture
ˈkoun(t)ərˌkəlCHər/
noun
noun: counter-culture
- a way of life and set of attitudes opposed to or at variance with the prevailing social norm.
“the idealists of the 60s counterculture”
Yesterday, NoSQL vendor Mongodb (MDB) went public and now has a $1.5 billion dollar valuation! A pretty good IPO for a company that many database industry insiders said would fail. Mongodb is a good example of how a technology driven counter-culture can remake an entire industry!
Many people do not even know about NoSQL technology, yet it’s impact is in our daily lives, everything from Netflix to Facebook to Amazon, NoSQL drives many of the Social media features used by everyone in the modern economy.
In some ways, NoSQL in 2017 is still considered counter-culture due to many corporations third party vendors not jumping on the NoSQL platform for their products. This is slowly changing as software vendors like Sitecore Content Management software packages are requiring Mongodb as a backend for their personalization features, forcing some fortune 500 companies to implement NoSQL in their environments.
Since the 1980s, relational database technology by Microsoft and Oracle basically ruled the market place. This was intentional, since the relational database model reflected the business models between 1970-2005. Sometime during the late 2000s, social media, the rise of Open Source software, cloud services, smart phones, and cheap commodity servers started to be common and business models changed along with the new social media technology.
To meet the needs of social media, a new generation of databases called NoSQL were being created in the Open Source world that more accurately matched the new business models being created as well as the appetite for speed of unstructured information from various sources.
NoSQL databases such as Mongodb were shunned by many Database professionals as novelties. This mode of thinking was perpetuated by the major relational database vendors. In addition, Many Database administrators who spent most of their career becoming experts in relational database platforms were hesitant to embrace the NoSQL platforms. DBAs main criticism of NoSQL database platforms was that they did not support transactions. When in fact, Relational Databases did not reflect the new data and business models of social media, machine learning, and personalization era. Social Media is probably as revolutionary as the invention of the printing press and society and businesses are adapting to this new form of communication.
In the future, Artificial intelligence will also make a comeback as Open Source NoSQL’s ability to handle unstructured data from multiple sources in Real-Time makes AI reality. Self-Driving cars, Website Personalization, factory automation, machine learning algorithms running various business units will all use Open Source NoSQL database platforms.
Raul Salas
Raul@mobilemonitoringsolutions.com