Month: June 2018


MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
At the JAFAC conference in Auckland, New Zealand, Snapper CEO Miki Szikszai gave a talk about how the company overcome some of the challenges of growing their technical team in an environment of perceived skills shortage. Their approach of employing teams of graduates and giving them real customer facing work to do rather than interspersing them into existing teams has resulted in better retention, higher quality work and higher engagement among the graduates and has enabled the more experienced people to become coaches and mentors where they share their knowledge freely to the benefit of the company and the teams.
Snapper is a ticketing technology company based in Wellington, New Zealand, selling their products and services around the world. He started by giving an overview of who Snapper are and where their technology is in use.
He explained that the company had been growing steadily and was struggling to find people with the requisite skillsets. They were looking for people with a specific set of skills, which he called a unicorn hunt. They wanted people with skills in:
- Smart cards
- Databases
- Backend systems
- Integration
- Mobile development
- Innovation
- Teamwork
They rapidly discovered that this combination of skills was very rare globally and not available in New Zealand. They then decided that an alternate approach to employing some unicorns would be to grow their own by taking on graduates. They opened up a few graduate roles and put them into the teams, to learn through osmosis. This was an abject failure – the company was under pressure to deliver product to the market so the senior people were reluctant to take time to teach as it’s quicker just to do it myself. This resulted in the seniors seeing the graduates as incompetent and only giving them menial tasks to do, and the graduates were resentful that the promised opportunities to work on new technologies were not coming to fruition. The graduate program ended unhappily.
They continued looking but were generally struggling to find the people they needed, which reinforced the belief that there was a significant skills shortage in New Zealand.
In 2014, CTO Norman Comerford was invited to teach some classes in Agile Development at Victoria University of Wellington and he came back astounded at the way the teams in the class were collaborating and working together. He identified that the real skills they needed were not the technology competencies rather they were:
- Teamwork and collaboration
- Problem solving
- Innovation
- Resilience
- Empathy
Everything else can be taught. Norman saw these skills being evidenced by the teams at the university. This prompted them to change the approach and relook at a graduate program, not taking on individuals and interspersing them into existing teams, rather they took on a whole team of graduates, gave them meaningful, customer facing work, and paid them well. They expected and encouraged a high standard of work and gave the senior developers the role of coach for the team.
The results were impressive – the team needed to learn some of the tech skills, but had strong problem solving and collaboration skills and were eager to learn the needed technologies. The senior people who provided coaching felt empowered and were encouraged by guiding and growing the competencies of the graduate.
They have now made the program a permanent fixture of the Snapper way of working. Each summer they take on one or two teams of students who are going into their final year of university , these interns spend the summer working full-time in the company, and continue working part time while studying in their final year. After they graduate some of the former students come into a three-year graduate employee programme where the goal is to accelerate their career progression, where they should be able to walk into a high quality intermediate role at Snapper or elsewhere. They are aiming to generate a pipeline of people who come in, grow their skills while contributing to the company and then can move on to roles in other organisations, thus spreading the skills and extending their knowledge.
He said that a benefit of the programme has been a significant increase in diversity as these graduates come from very varied backgrounds. He is explicit that:
We are not looking for the best coders, we’re looking for the best team workers
Since starting the program Snapper has doubled their team size and see the growth potential as being truly limitless, and they are putting experienced people into the wider New Zealand technical workforce.
Sandy Mamoli recently spoke about the Snapper migration to holacracy, that talk was reported on in this InfoQ article.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
A new transportation system that enables people to live and work anywhere, networking through an app to share stories and get ideas that change your company, and high-speed internet through space to connect people everywhere on the planet; these are sparkling disruptions which were presented at the Spark the Change conference.
Spark the Change Paris 2018 was held in Paris, France, on June 26:
We bring series of inspirational talks from people who already went through a positive change before, and are keen to share their learnings.
The conference talks covered three themes:
- Sparkling Disruptions
- Building Tomorrow’s Company
- Unleashing People’s Talent
InfoQ is covering this event with articles, summaries, and Q&As. This article summarizes the talks on sparkling disruptions.
The first talk at Spark the Change Paris was by Dirk Ahlborn, CEO and founder of Hyperloop Transportation Technologies. He spoke about bringing disruptive innovation that enables people “to live and work anywhere” to the traditional transportation industry.
Hyperloop is developing a new transportation system, based on tubes that create a low-pressure environment in which capsules can move fast using less energy. The idea for this kind of transportation system was described in a whitepaper by Elon Musk, CEO and founder of Tesla and SpaceX. Musk handed the concept to the public and Hyperloop decided to pick up this challenge.
To investigate if it would be feasible, Hyperloop explored the economics of public transportation. Many metro systems are heavily subsidized by governments, said Ahlborn. The Hyperloop system will be fully sustainable based on solar powered. The aim is to keep the operational costs as low as possible.
The technology that Hyperloop will use was already there when they started. Hyperloop has built their company differently, by collaborating with partners that are knowledgeable in vacuum tubes, lightweight materials, transportation systems, etc. Ahlborn explained that they are building a platform to bring partners together. With digitalization, doing everything online, they can keep costs low.
They started with 100 people in the feasibility study, and are growing fast. Now there are 800 people working for Hyperloop. They select people who are eager to do this and want to go on this mission. As a CEO of a company, knowing that people will show up to work even if you have no money in the bank is amazing – it shows they believe in the project, said Ahlborn. A trend that he mentioned is that more and more people will be working for multiple companies, either getting paid with salaries or with stock.
Question everything, the way we work, but also have fun, was Alhborn’s closing statement.
Next, Ludovic Huraux, CEO and founder of Shapr, spoke about the power of serendipity and networking.
Serendipity is the art of finding something great without looking for it, said Huraux. It’s about being curious and open to new things and people.
He suggested scheduling an hour for luck each week. When you meet someone new, don’t set any expectations, said Huraux. Think about what you can give and be useful and generous. You never know what will happen, he said.
Earlier InfoQ interviewed Huraux about the power of serendipity and networking, and asked him about cultural differences when it comes to networking:
Huraux: I have definitely discovered that people in the US are a bit more open to the idea of networking. In the New York specifically, it doesn’t take a lot of convincing to get a professional to join Shapr and grab coffee with someone new, since that is already part of the mindset. However, I have definitely seen a shift in Paris in the last few years, and I think people are starting to get more comfortable with the idea of meeting for coffee with someone new!
A conversation with someone who works in a completely different field can spark the idea that changes your company. Meeting new people can give an outside perspective on your projects and help to look at them in new ways; it gets you out of your own head, argued Huraux.
Serendipity is an attitude, a mindset. Huraux called it a lifestyle where people are open to meeting one another and helping each other out. Everyone has a story; if you say hello you can be part of it, he stated.
The last talk on sparkling disruptions was by Christophe de Hauwer, chief development officer at SES. He spoke about digital disruption through space.
The space economy is growing due to the increasing demand for connectivity. SES Satellites is a satellite operator that offers end-to-end solutions for video and networks. De Hauwer gave the example of airplanes: more and more airlines are offering WiFi on their flights. This often still is expensive for the passengers, but as the costs go down it will become more common.
Historically, projects in space were done by large government organizations, but now this is changing as smaller companies have begun executing those projects. These days there are also many investments in startups doing space projects, said De Hauwer.
Satellites are becoming fully digitized. This innovation lowers their weight, and the digital technology also needs less space. These developments are changing the type of services that are possible, said De Hauwer, it provides flexibility and it’s lowering the costs of existing services.
High-speed access to the internet is still limited. In developed countries, 84.40% has access to the internet of which 24% is high-speed access. In developing countries, only 42.90% has access with 8% of them having a high-speed connection. Satellites can provide high-speed access everywhere on the planet.
Future articles on Spark the Change will explore talks about the conference themes Building Tomorrow’s Company and Unleashing People’s Talent.
Article: Cats, Qubits, and Teleportation: The Spooky World of Quantum Computation (Part One)
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Twenty years ago, quantum computers were purely theoretical, and existed only on whiteboards and in academic papers. Now, quantum computers are available for hire on the cloud.
- Light travels around in discrete lumps (particles) of energy, but these lumps have many of the properties of a wave, such as a frequency and the ability to interfere with one another.
- As well as position and momentum, all quantum wave-particle-things have a third property, spin. Although any measured spin will be either totally-up or totally-down, the measurement has a chance of being either up or down. That is, until the measurement is made, the spin is both up and down. This is known as superposition.
- The final piece of quantum weirdness comes when pairs (or groups) of quantum things have some shared properties. This ‘entanglement’ has been achieved between electrons located 1.3 km away from each other.
- The smallest unit of quantum information theory is a qubit, which can also be 0 or 1. Unlike a classical bit, a qubit can also be a combination of the states 0 and 1.
By the time most of us reach adulthood, we know a few basic truths. Cats cannot be simultaneously alive and dead. Objects at opposite ends of the universe can’t affect each other. Computers operate on 0s and 1s, and that’s the most fundamental unit of information. The premise of quantum computation is that these truths are partially wrong. Don’t worry, the cat part is mostly right, at least for actual cats, and nothing can travel faster than light.
Twenty years ago, quantum computers were purely theoretical, and existed only on whiteboards and in academic papers. It was unclear whether one would ever be implemented. Ten years ago, the implementation of quantum computers was underway, but a genuinely useful quantum computer was still a distant prospect. Now, quantum computers are available for hire on the cloud. Businesses, academic institutions, and government labs are racing to be the first to announce a quantum computer which can solve problems too difficult for conventional computation.
But what is it which makes a quantum computer so powerful? What kind of problems is a quantum computer useful for? How do modern quantum computers actually work? Will all our computers be quantum computers in the future?
Introduction to quantum mechanics
Quantum mechanics was developed at the beginning of the twentieth century, as physicists began studying smaller and smaller particles. In order to explain what they were observing experimentally, they had to devise new models. In the nineteenth century, observation of refraction and interference had led to a general consensus in the scientific community that light was a wave (a bit like a wave in a swimming pool, or a sound wave in air). Increasingly sophisticated experiments had also revealed that atoms had a planet-like internal structure, with a dense core of protons and neutrons, surrounded by orbiting electrons.
Quantisation
The wave understanding of light was shaken up by the need to explain two experimental phenomena; the way very hot objects glow (thermal radiation), and the way that shining a light on metal releases electricity (the photoelectric effect). ‘Normal’ physics models did a lousy job of predicting how much high-frequency light would be emitted by a hot object. Max Planck discovered that if the radiant energy were treated as discrete lumps, theory could be made to match reality. When he published his work, his intention wasn’t to make a bold statement about the nature of reality. He assumed that that all he had discovered was a useful mathematical trick.
Einstein took things further in his explanation of the photoelectric effect. He demonstrated that the photoelectric effect could be neatly explained if light were considered to be a particle as well as a wave. That is, light travels around in discrete lumps of energy, but these lumps have many of the properties of a wave, such as a frequency and the ability to interfere with one another. If you find this confusing, you should! We’re all familiar with particles (like sand), and waves (like we see on a beach), but there’s no sensible analogy we can make to understand something which is simultaneously sand and a wave.
The situation for matter isn’t much better. Although electrons do orbit a proton nucleus, these orbits aren’t like planetary orbits; instead, they’re like rungs on a ladder (“quantisation”). Electrons are only allowed to jump between the rungs, and can never occupy the space in between. “But how”, you may ask, “do they get from one rung to another without traversing the space in between?” Many distinguished physicists have asked the exact same question, and the general scientific consensus seems to be resigned acceptance that we may never find a satisfying interpretation of quantum jumps.
Wave-particle duality
But there’s more – just as light is both a wave and a particle, even matter – solid, sensible, un-wavey matter – is actually both a wave and a particle. It’s been experimentally observed that electrons and molecules will diffract and interfere with one another. This is known as wave-particle duality, and it applies to both matter and light. It’s part of a broader theoretical framework which asserts that matter and light – despite seeming entirely distinct – are broadly related. (Einstein’s famous equation, E = mc2 , is a continuation of this idea, and expresses how light and matter can be changed into one another.)
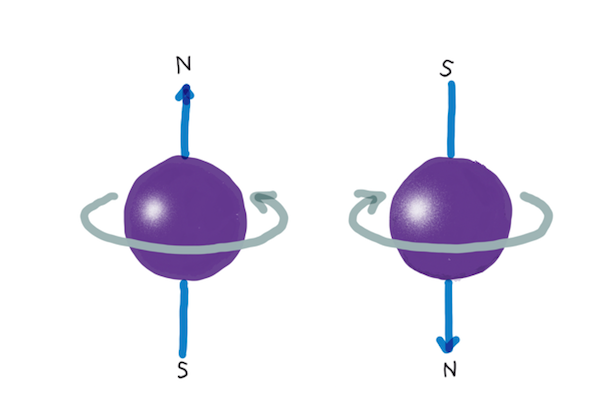
Spin
As well as position and momentum, all quantum wave-particle-things have a third property, spin. Spin was first observed when particles deflected in a magnetic field, as if they themselves were magnets. In the classical world, this would happen when charged objects spun, so the original experimenters called what they observed spin. Although it’s sort of analogous to angular momentum, quantum spin has to be considered a metaphor. If quantum particles were actually spinning (and were actually particles), their surface would have to move faster than the speed of light to achieve the observed magnetic effects.
You probably won’t be surprised to hear that spin is quantised. (This makes it even less like angular momentum, if you’re keeping track.) There are only two possible values for an individual particle’s spin, up and down. The fact that it only has two values makes spin a pleasing property for storing quantum information, which we’ll come back to later. Spin is also convenient for quantum information because things sit still while their spin is changed. Changing momentum or position, on the other hand, would be much less tidy. It would require the internals of a computer to be constantly racing around while accelerating and decelerating.
Superposition
With only two values to choose from, quantum spin could be a boring property. Things get more lively, though, because of one of the strangest quantum phenomena – superposition. Although any measured spin will be either totally-up or totally-down, the measurement has a chance of being either up or down. That is, until the measurement is made, the spin is both up and down. How much up and how much down is in the mix determines the chances of an up measurement or a down measurement. The same is true for other observables, like position or momentum. This is known as superposition. When a measurement is made, the state converges on a single point. (The mechanism of this convergence is still a subject of scientific debate, known as the measurement problem.)
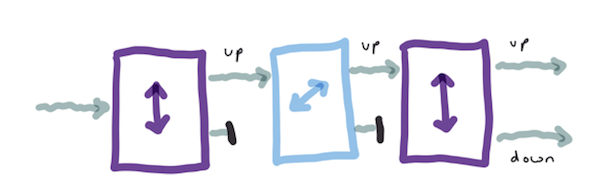
Since a superposed state can’t be directly observed, why would we think particles are in a superposed state? Superposition follows, at a mathematical level, from wave-particle duality. The first evidence for it is that some measurements give apparently random results. Randomness on its own isn’t evidence that states were superposed immediately before the measurement was done, but there are stronger experiments. Quantum spin was first observed by passing a stream of hot atoms through a magnetic box, and seeing that the atoms deflected into two neat streams (spin up and spin down). If only one of the streams (say, spin up) is passed through a second box, with the field oriented in the same direction, the stream won’t split again. This isn’t surprising; we filtered for spin up, and then we measured the spin again, and it stays spin up. If the second box is rotated, so that the magnetic field is ninety degrees to the first one, the spin is being measured on a different axis, and since we didn’t filter on that axis, the stream will again split into two. What happens if a third box is added, with the field oriented in the original direction? The particle stream has already been filtered to only include those with spin up, but the stream will split. Having its spin measured on a different axis undoes the filtering. Another way of saying that is that the middle box, with the rotated field, put the atoms back into a superposed state. (As well as showing superposition, this experiment shows Heisenberg’s uncertainty principle; if we know the spin in one direction, we erase our knowledge of the spin in the other direction.)
Quantum theories are counter-intuitive, because we all know that’s not how the world works. The theories were even unsettling to the scientists who developed them, who struggled with their strange implications. Einstein hated the idea that the world was fundamentally non-deterministic, which led to his famous pronouncement that ‘God does not play dice.’ Schrödinger hoped his later theoretical work would eliminate what he called ‘the quantum jump nonsense’ and expressed regret at ever having contributed to quantum theory..
In order to show how absurd superposition was, Schrödinger devised a thought experiment, in which a cat was isolated from the outside world in a box. Also in the box was a radioactive rock, a bottle of cyanide, and a geiger counter wired to a hammer, which would smash the bottle if any radioactivity was detected. The emission of particles from a radioactive source (radioactivity) is a probabilistic event, which cannot be predicted ahead of time. If a particle was emitted, the poison would be released, killing the occupants of the box. Quantum theory says that until a measurement was made, the decaying particle would be in both a decayed and non-decayed state. This means the famous cat would be simultaneously alive and dead until someone looked in the box see if the cat had survived (“the measurement”). While everyone agreed with Schrödinger that cats clearly should not be both alive and dead, no one could deny that superposition was the theory which best fit the experimental evidence. This created an interesting challenge – how could a theory be both accurate, and totally absurd?

Schrödinger’s cat stayed a thought experiment for two reasons. The first is that it seemed impossible to actually conduct the experiment; no experimenter could know what state the cat was in except by observing it, and the measurement of the cat’s health was the very action that would trigger a quantum collapse. The second reason is that it’s unethical for physicists to shut cats in boxes and probabilistically poison them.
Entanglement
The final piece of quantum weirdness comes when pairs (or groups) of quantum things have some shared properties. For example, if a pair of photons is generated by splitting a photon, the total spin of the pair has to be the same as the spin of the donor photon. So far, so good, except that if superpositions are involved, the measured state is only determined at the point of measurement. Once the state of one photon is known, we know exactly what the state of the other photon has to be. That means, when one half of the pair is measured, its state collapses, and the state of the other photon also collapses at the exact same moment.
Einstein had famously stated that information could not travel faster than light, and so he was understandably offended by what he described as ‘spooky action at a distance’. Things, he felt, should not be able to affect each other’s state instantaneously over great distances. In order to resolve this problem, physicists came up with a ‘hidden variable’ theory – their hypothesis was that even though the states seemed random, some unmeasurable extra property was set at the point of creation, which meant that measurement outcomes were always predetermined, and there was no distressing faster-than-light effect. It seems like a hidden variable theory should be difficult to disprove (by definition; the variable is hidden). However, thirty years after hidden variables were first proposed, John Bell did some clever maths which demonstrated that if measurements were done along different axes, a world with hidden variables would be statistically distinguishable from one without them. Later experiments on entangled pairs have consistently supported the ‘no hidden variables’ outcome.
What kind of distances does entanglement ‘work’ for? Particles can be entangled even when they’re far apart, which makes the correlations and apparent action at a distance even more startling. Chinese researchers have managed to send entangled photons from space to earth, a distance of 1,200 km. What about physical particles? Entanglement has been achieved between electrons located 1.3 km away from each other. What’s extra-impressive with the electron experiment is that the entanglement was ‘transmitted’ to the electrons by entangling them with photons and then sending the photons to get entangled with one another. After this was done, the states of the electrons were random, but perfectly correlated. Spookiness is apparently a transmissable condition.
Consciousness, multiple universes, and decoherence
Once it was agreed that quantum physics explained things very well, scientists turned their attention to a different question; if the world was quantum, why did it seem so classical? What was it about measurement that destroyed superpositions? One theory is that it observation by a conscious being is the key feature of a measurement (that is, the cat is both alive and dead until the box is opened and an experimenter peeks in).
Another theory is that a superposition never actually collapses – instead, each ‘alternative’ carries on in its own world. That is, measurement isn’t a collapse; it’s a branching. This branching process is continuous, and leads to a multiplicity of worlds. These theories have also been combined, with the idea being that when a measurement happens, two universes are created; in each universe, the conscious mind of the experimenter sees a new, internally consistent, reality. Instead of many-worlds, there are many-minds. The (somewhat tautological) reasoning is that since we never perceive something as being in two different states, consciousness is incapable of perceiving something as being in multiple states, and so a given observer has many distinct experiences as they interact with a superposed state.
These theories are intriguing, and include some appealingly familiar themes from science fiction. Sadly, they are of limited scientific value, because they’re impossible to either prove or disprove. The measurement problem is still controversial, but there is a growing scientific consensus that a phenomenon known as decoherence is a significant part of the reason why superpositions collapse. More precisely, there is no ‘collapse’, only a very rapid decoherence as superposed quantum states interact with their environment. The larger the system, the more rapid the decoherence. For example, even in a hard vacuum, interaction with sunlight would cause a dust mote to decohere in 10 microseconds, and a superposed kitten in 10 nanoseconds. (Why a kitten? Schrödinger’s kitten is smaller than Schrödinger’s cat!) It doesn’t make much sense, even as a thought experiment, to ask whether a kitten in a vacuum is alive or dead, since kittens need to breathe. With a breathable atmosphere present, kitten-decoherence would be effectively instantaneous, taking only 10 -26seconds.
The more macroscopic a system is, the more environment there is, and so the greater the effect of decoherence. Even apparently isolated systems decohere, because perfect isolation is impossible; the environment will always cause some noise. Decoherence interaction can be mathematically modelled, although the calculations are complex. Probably because of this complexity, decoherence theory was only proposed in 1991, long after the other foundations of quantum mechanics.
Quantum information theory
Quantum information theory deals with how information behaves in a quantum system. Just as the smallest unit of classical information theory is a bit, which can be 0 or 1, the smallest unit of quantum information theory is a qubit, which can also be 0 or 1. A spin is a physically convenient representation of a qubit, so up spin down is 0, and down spin is 1. Light polarization can also be used, using horizontal for 0 and vertical for 1. We sometimes represent qubits as arrows, so 0 is down and 1 is up.
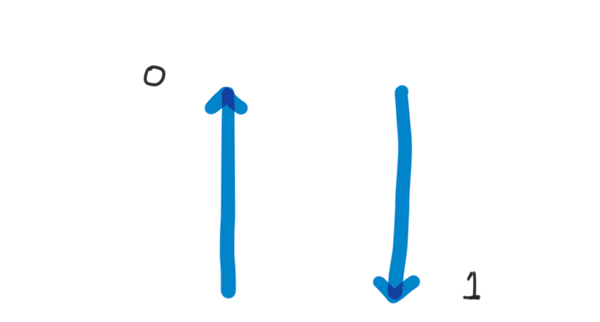
Unlike a classical bit, a qubit can also be a combination of the states 0 and 1. This superposition is represented as a point on a sphere. The reason it’s a point on a sphere, rather than just a probability between 0 and 1, is that the superposed state has two dimensions, and is represented as a two-dimensional matrix. When measured, a qubit will collapse down to a classical ‘0’ or ‘1’ state, but all operations before that measurement – including multi-qubit-gates – are performed on the more complex quantum state.
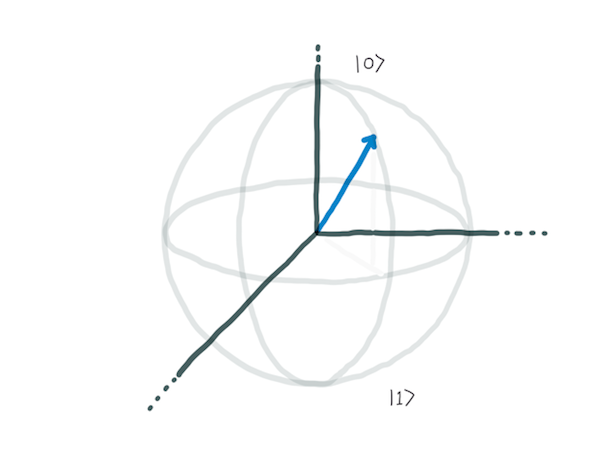
A classical single-bit logic gate flips the state of the bit a (a NOT operation). A quantum NOT gate represents a 180 degree rotation, but many other operations on a sphere are possible. For example, a 90 degree rotation on a ‘0’ puts the qubit into a state where it’s a superposition of ‘0’ and ‘1’ (with an additional twizzle around the axis, this is called a ‘Hadamard gate’). Other operations change the angular position (twisting the sphere around).
One thing the qubit model doesn’t really capture, at least not visually, is the notion of entanglement. Multi-qubit gates are able to create entanglement between qubits, and also to disentangle them. A controlled-NOT operation (analogous to an exclusive-OR) is usually used for this purpose – or, perhaps more accurately, entanglement is a side-effect of a quantum controlled-NOT gate. Entanglement has big implications for the computation capability of the system.

It’s generally agreed that entanglement is key to the speedup of a quantum computer. Because entanglement involves correlations between states, an entangled state cannot just be written as the product of two independent states. Thinking in terms of matrices, an entangled state’s matrix cannot be factored into two smaller matrices. That irreduce-ability means entangled states cannot be efficiently simulated on a classical computer. It was, in fact, the computational complexity of simulating large quantum systems on a classical computer which led to the realisation that quantum computers might have superior computational capability.
In part 2 of this series, we’ll look more at computational complexity, and explain how and why some quantum algorithms have much lower computational complexity than their classical equivalents.
About the Author
 Holly Cummins is a full-stack developer, and cloud computing technical lead. She is also a frequent speaker, Java Champion, and author of Enterprise OSGi in Action. Holly holds a DPhil (PhD) in Quantum Computation from the University of Oxford.
Holly Cummins is a full-stack developer, and cloud computing technical lead. She is also a frequent speaker, Java Champion, and author of Enterprise OSGi in Action. Holly holds a DPhil (PhD) in Quantum Computation from the University of Oxford.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Support for the Git wire Protocol version 2 is now available in the latest official version of the Git client, Git 2.18, along with other new features aimed at improving performance and UI.
Git protocol version 2 (v2) was merged a couple of weeks ago to Git’s master branch, shortly before core team member Brandon Williams announced it publicly. Git’s wire protocol defines how Git client and server communicate to carry through clone, fetch, and push operations. This new version aims to improve performance and is better suited for future improvements, according to Williams.
The main motivation for the new protocol was to enable server side filtering of references (branches and tags).
This means the Git server does not need to send the client a list of all the references in the repository and have the client do the filtering. In large repositories, there can be a huge number of references, amounting to several MBs of data being transferred irrespective of the operation the client wants to carry through. When using v2, Git servers will filter references based on the required operation before sending the list back to the client. For example, says Williams, if you are updating a branch that is only a few commits behind its remote counterpart, or checking if your branch is up-to-date, transferring the whole list of references is just a waste of time and bandwidth. Indeed, based on Google’s internal use of v2, Williams states that accessing a large repository, such as Chrome’s, which contains over 500k branches and tags, may be up to three times faster compared to version 1. Additionally, the new protocol makes it easier to implement new features like ref-in-want and fetching and pushing symrefs.
Git clients using v2 will be still able to talk to older servers that do not support it. This happens thanks to a conscious design decision to use a side-channel to send the additional information required by v2. Older servers will simply ignore the side channel and respond with the full list of references.
To allow developers to select the protocol version they would like to use, Git now includes a new -c command line option, as in the following example:
git -c protocol.version=2 ls-remote
To make v2 the default, you can change Git configuration:
git config --global protocol.version=2
Another new feature in Git 2.18 aimed to improve performance is the serialized commit-graph. Basically, now Git can store the commit graph structure in a file along with some extra metadata to speed up graph walks. This is especially effective when listing and filtering commit history or computing merge bases. According to Derrick Stole, member of the team at Microsoft that implemented the feature, enabling it will provide a 75–99% speedup on such operations when run against large repos such as the Linux kernel’s or Git’s itself. Git commit graph is still experimental since a few Git features do not play well with the commit graph, such as shallow clones, replace-objects, and commit grafts. If you do not need them, you can enable the commit graph by running git config core.commitGraph true.
Read the full list of features in Git 2.18 in the official release notes.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Amazon announced a new feature with their API Gateway service that will provide customers with private API endpoints inside their Virtual Private Cloud (VPC). These API endpoints are only accessible from within the customers Amazon VPC using VPC Endpoints.
The API Gateway is a service in AWS enabling developers to create, publish, maintain, monitor, and secure APIs. Furthermore, Amazon manages the service and customers only have to pay for each API call and amount of data transferred out. However, for Private APIs, there is no data transfer out charges. Enterprises behind the API Gateway back their APIs with various backend technologies like AWS Lambda, Amazon EC2, Elastic Load Balancing products such as Application Load Balancers or Classic Load Balancers, Amazon DynamoDB, Amazon Kinesis, or any publicly available HTTPS-based endpoint.
Since the initial public release back in mid-July 2015, the API Gateway has evolved to its current version supporting private endpoints. Moreover, the private endpoints are, according to the blog post on the announcement, one of the missing pieces of the puzzle. Over the years Amazon added the following crucial features:
With the current API Gateway and its rich feature set, customers are now able to build public facing APIs with nearly any backend they want. Furthermore, with the addition of a private endpoints feature, customers can securely expose their REST APIs to other services and resources inside their VPC, or those connected via Direct Connect to their own data centers.
The AWS PrivateLink interface VPC Endpoints are the enabler for the API Gateway private endpoints, as they work by creating elastic network interfaces in subnets that users define inside their VPC. Subsequently, these network interfaces provide access to services running in other VPCs or AWS services like the AWS API Gateway. When users define their interface endpoints, they need to specify which service traffic should go through them.
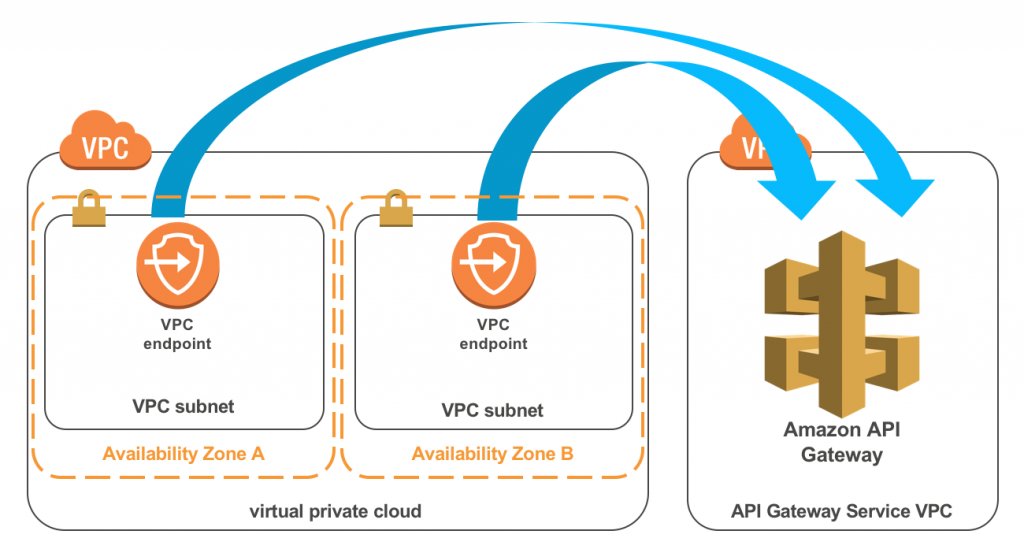
Source: https://aws.amazon.com/blogs/compute/introducing-amazon-api-gateway-private-endpoints/
The Amazon API Gateway is currently available in 16 AWS regions around the world, and pricing details are available on the pricing page. Furthermore, in-depth information about the Amazon API Gateway is accessible through its resources page.



MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
During recent years domain events are increasingly being discussed, but we should be discussing commands just as much, Martin Schimak explained at the recent DDD eXchange 2018 conference at Skills Matter, London, where he covered events, command and long-running services in a microservices world, and how process managers and similar tooling can help in running core business logic.
For Schimak, an independent consultant in Austria, the best thing about events is that they are facts representing something that already has happened. We are increasingly dealing with distributed systems, and with a local guarantee from within a service that something has happened we can add trust to an eventually consistent world. Events also help us decouple services and let us look at the past.
All the advantages of using events is one reason why event-driven architectures are increasingly popular, sometimes with a design that only relies on events for integrating services. This is a simplification that may be reasonable, but Schimak notes that it also creates some dangers. One example is a simple order process only consisting of order placed, payment received, goods fetched, and goods shipped events used by payment, inventory and shipment services. A simple change like fetching the goods before charging the customer will change the flow of messages which will require a change in all involved services, and this is for Schimak a coupling between services that is suboptimal.
Since events are just facts, they don’t trigger any action by themselves. When listening to events we instead need some form of policy that decides what should happen when a specific event is received. In a pure event-based system, this policy is always in the consuming service. With a command-based approach this policy might be placed in the event publishing service, but Schimak argues that often none of the services are a good fit. For him, a third option is to add a mediator that listens to specific events and decides about the following step.
With an order service added to the previous example, this service could listen to relevant events and send commands, thus coordinating the process when a customer places an order and later gets that order fulfilled. With the same change as in the example, now only the order service needs a change. Schimak notes that the logic running in this process commonly is business logic belonging to the core domain of the business.
For Schimak, commands are intents for something to happen in the future, and he defines two types of execution of a command:
- An atomic transaction execution, typically with an intent to change a model; an example is a place order command that leads to an order created and an order placed event published.
- A composite, long-running execution with an intent of a more business-level result, possibly needing several steps to be achieved. An example is the same place order command, but where the end result is an order fulfilled or order cancelled event.
In a request payment scenario, we should strive to achieve a valuable business result. A payment service would then publish events like payment received or payment cancelled. In Schimak’s experience we instead often expose problems that could be temporary, like failing credit card charging, and delegating to the client to deal with this. This means that we force a client to deal with the policy kind of problems that clearly are payment concerns – maybe a retry should be done later, potentially with new credit card data. If the client is an order service, it must besides handling orders also deal with payments, thus spreading the payment domain knowledge out of the payment service. This also increases the size and complexity of the order service.
Delegating our problems to our clients forces them to deal with the mitigation. They become god services.
Instead we should see payment as a long-running service dealing with all internal problems related to payment, and only publish events related to the end result – payment received or payment cancelled. Schimak emphasizes that this is not about creating a central coordinator to take care of the whole business, it’s more about a good API design that helps in protecting different bounded contexts from each other.
A common tool when working with long-running services is a Process Manager. Typical requirements for a process manager are the handling of time and timeouts, retries, and compensation when a process has failed. We can implement all this ourselves, but Schimak prefers to use a framework like Axon messaging and Saga management, or Lagom. He also suggests looking into using some form of business process execution engine, but emphasizes that the tooling must be lightweight and usable within a single service. Examples of open source process engine frameworks include Activiti, Camunda and Zeebee, (also from Camunda). In the serverless space, AWS has created Step Functions, and other cloud vendors are also moving in this direction.
Schimak’s personal experience with long-running services and business process engines includes several years of using Camunda in the order fulfilment process at Zalando. He has also together with Bernd Rücker from Camunda written two articles, Events, Flows and Long-Running Services: A Modern Approach to Workflow Automation and Know the Flow! Microservices and Event Choreographies on InfoQ.