Month: June 2018

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Microsoft has announced that the .NET Core 2.0 will be considered “end of life” and thus no longer supported as of October 1, 2018. .NET Core 2.0 is considered a non-LTS release, and as such Microsoft only commits its support for three months after a successor has been released. In this case, with .NET Core 2.1 having been released May 31, .NET Core 2.0’s end has come.
Astute readers will note that October is more than three months from May 31. The reason for this increased lifespan is due to a critical bug that is affecting some users who are attempting to upgrade from .NET Core 2.0 to .NET Core 2.1. The issue is an application crashing exception (“System.BadImageFormatException”) that can occur when the “AppDynamics.Agent.Windows” package is part of a web application. Microsoft has reproduced the issue and agrees that it is a blocking item. As such a fix for this bug will be released in the .NET Core August 2018 update. Microsoft’s goal is for the users affected by the bug to then have approximately six weeks to then upgrade to .NET Core 2.1.
Microsoft .NET Core developer Noah Falk has provided additional details on the matter, observing that fixing this bug increased the severity of an additional known issue that will also be fixed. Preview builds will be available shortly for those looking to confirm the fix on their systems prior to the release of the official update.
As Microsoft’s Rich Lander notes, .NET Core 2.1 will be a long-term support release (LTS) so developers on older platforms should plan to upgrade to it as soon as possible. Upgrade instructions for migrations to .NET Core 2.1 and ASP.NET Core 2.1 are available now and it makes sense to start making preparations now.
If you’re interested in digging deeper into Microsoft’s support policy for .NET Core, they have prepared a detail document explaining the differences between a regular release and one considered LTS. Related to this is a full list of operating systems supported by .NET Core.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Many project failures are the result of a project going over schedule and over budget. Estimating up-front can help avoid unrealistic commitments at the outset.
- Top-down, scope-based estimation, before detailed planning, is more effective than bottom-up sizing and “guesstimates.”
- Top-down estimation tools can help establish realistic project boundaries, both when projects are in the initial planning stages and as they progress. This is key for setting expectations and keeping stakeholders happy.
- Overstaffing to achieve schedule compression is expensive and often ineffective. Project managers can use top-down estimation to visualize appropriate staffing and resource demands for their portfolios.
- When projects change (as they inevitably will) due to stakeholder demands or unforeseen circumstances, project managers should reforecast to update the schedule.
Everyone is familiar with the term “prior planning prevents poor performance,” so why is it so difficult for companies to live by this maxim? Perhaps because we are accustomed to living our lives by the phrase “move fast and get the job done.”
The problem, of course, is that moving too fast can indeed lead to things breaking – and that can cause big problems for software projects. Under pressure from up above, project managers might be inclined to forgo estimation and up-front planning in favor of jumping in with both feet. But I know all too well from over 30 years of software project management experience that a project that is rushed into development is one that is likely doomed to fail.
Back in the 1980’s, Kodak sought to diversify their film development business with software-driven document imaging solutions. The company spent over a year and a half investing millions of dollars and significant human resource hours building their system before they asked me for a project estimate. That estimate showed they had another two years and a lot more money to go. If the company had estimated up-front they may have been able to better assess the time to market and ROI opportunities. Instead, the entire thing was scuttled – a waste of valuable time and resources.
A colleague of mine once shared a similar sad story with me. He told me of a Christmas holiday, several years ago, when a customer asked him to provide a series of 22 estimates right before he went on break. They disagreed with his data driven estimations and decided to go their own way. Their project ended up failing due to unreasonable expectations and timeframes. They ended up coming back to him to do the work properly. Merry Christmas, indeed!
Today, companies are making the same errors. One organization recently undertook a large and intensive software development project. They ramped up to over 100 developers, but, because of internal pressure and an insanely short and unrealistic schedule, decided to forgo system integration testing. By not having a mechanism to assess the quality impacts, and rushing development, they ended up missing a lot of system defects and are now in the process of re-evaluating and starting from scratch.
Thankfully, there is no reason for history to continue to repeat itself. By focusing on what notto do, project managers can avoid the pitfalls that lead to cost and time overruns and deliver solutions that create true value.
Do NOT skip estimation and rush to detailed planning – estimate from the top down.
Any sort of planning is better than no planning at all – but top down estimation provides valuable input to the detailed planning process.
In my experience, I have found that setting unrealistic expectations is the primary cause of project failure. Developing accurate projections is a core competency that many organizations simply have not gotten very good at doing.
Part of the reason is because they tend to use traditional scoping processes to estimate the size of their projects, which can often lead to inaccurate projections. Traditionally, when project managers map out the scope of their projects, they do so from the bottom up. Managers ask individual team members to estimate how many hours they think they will work on a specific activities, and base their schedules on these “guestimates.” Unfortunately, this process is missing one key ingredient: facts. According to research based on QSM’s database of completed projects, two thirds of companies fail to compare planned performance to actual historical performance of similar projects, which could give teams a better indication of the time, effort, and money it will take to complete their work. Their best guesses result in missed deadlines, cost overruns, unhappy customers, and disenfranchised developers.
Taking a top-down, scope-based estimation approach at the onset of a project is a much more effective strategy. By using data from similar projects, managers can get an accurate representation of what it will take to complete their work and deliver a finished, working product. Right from the beginning they will have a comprehensive idea of how much functionality their project will have and be able to allocate resources accordingly.
Top-down estimation tools can help establish realistic project boundaries, both when projects are in the initial planning stages and as they progress. For example, a project manager might already have a team of 10 developers working on a five-month release cadence cycle. Throughout the course of this work, the simulation software may reveal a backlog refinement showing approximately 100 story points that need to be completed.
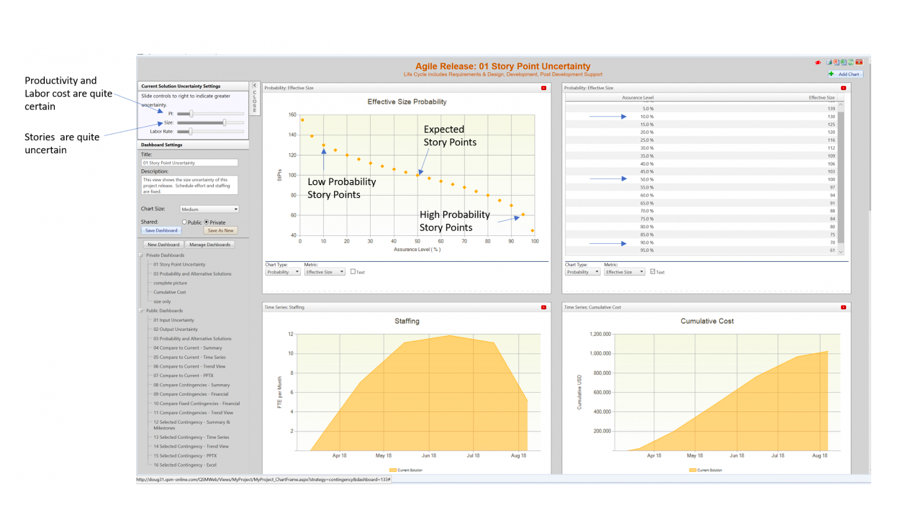
Further analysis shows that, while the initial estimates for team productivity and labor costs are spot on, new capabilities may not be able to added within the proposed schedule. Since that schedule is fixed, the project manager needs to focus on adjusting product features and capabilities to meet stakeholders’ expectations. They can use their simulation software to measure the probability of whether or not they will be able to achieve all 100 story points. Perhaps 80 are more realistic, or maybe 70. Whatever the number is, that is the number stakeholders can expect, at minimum.
There is no guesswork involved; everything is based on proven data points. Therefore, the estimate is far more accurate than those derived from traditional estimation. Teams can set accurate expectations, leading to satisfied customers and less pressure on development teams to deliver solutions in unmanageable timeframes.
Do NOT react to impending deadlines by overstaffing.
To use yet another cliché, it is a fact that “too many cooks spoil the broth,” and yet the first thing that many project managers do when faced with mounting deadlines is to staff up their projects. The theory is, the more people, the faster we will get it done.
Of course, this almost never goes well. More often than not, adding more resources to a project creates more complexity and increases the chances for mistakes. More people lead to miscommunication, which can increase defects and cause rework. Indeed, more people usually leads to more — not less – time being spent on a project.
Project managers can use top-down estimation to visualize appropriate staffing and resource demands for their portfolios. These estimates can be broken down by both initiative and month, over the course of a specific period of time. They can even break out staff by spending rates and compare them to budget constraints to ensure that those people will be appropriate for a particular project, or match up with their organization’s current and future capacity needs. Here is an example of how this may look over time.

Do NOT be a slave to your plan.
Prior planning does not mean that teams cannot change course throughout development. Despite best-laid plans, most projects will inevitably encounter some unknown factors or re-prioritization during their lifespan. Perhaps management will ask for new features to be added, or team members will be moved onto different, more mission critical tasks.
While uncertainties can crop up at any time, they can be factored into the top-down planning process, thus mitigating their potential impact, as evidenced by our earlier example of the project that might not hit 100 story points. Incorporating this uncertainty upfront can help avoid sudden changes early on.
There may still be fluctuations throughout the course of development, most driven by changing stakeholder demands. For example, customers may demand new features to meet changing market dynamics. These requests will, inevitably, have a direct impact on development, and teams need to be ready to adjust while still managing as close as possible to their initial commitments.
Unfortunately, many organizations do not know how to adjust when these unanticipated bumps in the road come up, but estimates can easily fluctuate (hence the name “estimates”), and reforecasting can take place to accommodate changing needs and dynamics. Priorities can be shifted or removed completely to accommodate new work demands. Scopes can be refined to provide stakeholders with updated and realistic schedules to keep things on track. It is a living process that plays well with organizations’ drive toward agile development.
As with anything else, communication is critical to this entire process. Stakeholders can see numbers on a screen and take them as gospel, even if those numbers can fluctuate during the course of development. Right at the outset, project managers must be able to effectively let their stakeholders know that the estimates they develop are subject to change based on a number of factors (ironically, most of them driven by stakeholder demands).
However, they must also communicate that the estimates are the best possible representations of a project’s scope at a given point in time – the beginning. They and their teams will work toward delivering the required capabilities on time, on budget and, most importantly, with the expected functionality.
In the end, the most important thing to do is learn from past mistakes. That does not just mean comparing current projects to past efforts. It means learning from the likes of Kodak and other organizations that have taken some wrong steps. By planning things at the outset – and not adhering to traditional norms – project managers and development teams have a better chance to deliver software that delivers value to customers with the desired quality without running over schedule or breaking budgets.
About the Author
 Lawrence H. Putnam, Jr. is co-CEO of QSM, a leader in software process improvement and systems development estimation. Larry’s primary area of responsibility is to oversee the strategic direction of QSM’s products business. This includes meeting revenue goals, strategic product direction, customer care and research. Larry has over 25 years of experience in software measurement, estimating and project control. He joined QSM in 1987 and has worked in every aspect of the business, including business development, customer support, professional services and now executive management.
Lawrence H. Putnam, Jr. is co-CEO of QSM, a leader in software process improvement and systems development estimation. Larry’s primary area of responsibility is to oversee the strategic direction of QSM’s products business. This includes meeting revenue goals, strategic product direction, customer care and research. Larry has over 25 years of experience in software measurement, estimating and project control. He joined QSM in 1987 and has worked in every aspect of the business, including business development, customer support, professional services and now executive management.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Chatbots are becoming more critical to developers in their daily lives – from understanding how the technology operates, to creating better code. Developers tend to have a natural curiosity about bots and the tech behind it. Artificial intelligence tools exist to address emotional intelligence with chatbots in conversational interfaces.
Anamita Guha, product manager at IBM Watson, spoke about designing conversational interfaces at Spark the Change France 2018. InfoQ is covering this event with articles, summaries and Q&As.
InfoQ spoke with Guha about how chatbots can support developers in their daily work, how developers feel about chatbots, what it takes to design a chatbot that deals with emotions, and what the future will bring in conversational interfaces.
InfoQ: Where do chatbots fit into the developer’s platforms and tools, and how can they support developers in their daily work?
Anamita Guha: Chatbots can be used in a variety of ways to support developers: documentation (use it like an index); personal assistant (develop chatbots with a schedule to eliminate users’ daily routine); and ultimately, make lives easier by automating systems. Developers are all about efficiency and will hack together code motivated by making their lives and everyone’s around them easier. I know developers who have created bots to generate powerpoint status decks for executives. Cases like this help to free up their time to work on bigger problems.
Many use artificial intelligence (AI) and bots to automate all sorts of tasks and alerts like code deployments and testing. Additionally, when working in large, distributed teams, developers can see when an item is being pushed, merged, or edited by someone else, allowing more efficiency in development, collaboration and accuracy, and ultimately better code.
InfoQ: How do developers feel about chatbots?
Guha: Chatbots are seen to be emerging tech, and a lot of companies are in the hype: “We need a bot, and we need it now”. Since 2015, the bot landscape has quadrupled, which means developers are realizing more than ever that chatbot development is important to learn as soon as possible.
Developers fall on a wide spectrum of emotion when it comes to chatbots, depending on who the developer is and what the bot is used for. In general, most developers want to stay ahead of the curve when it comes to development so they can stay relevant in such an evolving industry. This fosters a natural curiosity about bots and the tech behind it. In terms of using bots, I’ve found developers will use bots only if it is useful to them. This includes web-based bots, as well as voicebots like Alexa and Google Home.
From start-ups to SMBs to enterprises, developers are facing similar challenges; it is hard to always find a business justification to the executive team on why a bot might be necessary, or even required. Simultaneously, the leadership team is trying to balance their need to evolve as an organization by leveraging new technologies like bots.
For these reasons and more, we are now at an inflection point. For more than a decade since the Apple store’s inception, everyone wanted to build an app, but now, people want to build a bot. Today, bots are even becoming the gateway for kids to get into coding and the first step in development – and ultimately to get involved in technology. Bots are becoming more and more pervasive and multi-modal.
InfoQ: What does it take to design a chatbot?
Guha: I approach chatbots and their design the same way I do a product, by asking the following questions: what problem does it solve, who is our target user, and why should they care? To answer the questions successfully, it is imperative to first understand the use case, where it will live, and the demographic of the users. This is because it influences the conversation design. For example, when designing a conversational chatbot on Facebook used by teens, you could use emojis, whereas an Alexa skill for banking transactions would use direct and simple verbiage.
It’s also important to note that bots, like the evolution of human communication, are evolving. Learn from how users are interacting with your bot, and iterate!
InfoQ: How can you make a chatbot that knows how to deal with feelings?
Guha: Various AI tools can help you address emotional intelligence. For instance, the empathy suite at IBM helps users see how someone is feeling based on how they are typing. Different words can give a certain tone or vibe, and one can respond accordingly.
This will also vary depending on the medium the bot manifests in. If it is a text-based bot, consider word choice and sentence structure – or a voice bot: tone, voice, and inflection. Additionally, a virtual assistant or entity bot in AR/VR is wired with eye tracking and can pick up on body language, so be sure to research technologies to help you find the right tool that will empower to build the emotionally intelligent bot.
InfoQ: What will the future bring us in conversational interfaces for platforms and tools?
Guha: In the future, I think everything will be a conversational interface. For example, you will be able to instruct anything, from your phone to your watch to your car, to perform an activity, and they will all have a working memory of the task. We already live in a world where transactions are done through biometrics like eye tracking or fingerprints. As these futuristic notions come together, they will ultimately allow developers and technologists who are building this future to obtain a larger digital footprint on someone and eventually personalize how one lives.
InfoQ: IBM started the initiative Call for Code which aims to support innovation and technology for good. Can you elaborate?
Guha: Recently, there has been a wave of AI and intelligent technologies that seem to be driving a greater emphasis on the use of technology to create social good. While the tech industry has somewhat of a reputation for being self-serving and capitalistic, I think everyone’s cognizant that they want to give back — even if they don’t necessarily know how.
One way IBM is addressing this is through the Call for Code. Natural disasters have been growing in severity and frequency over the past decade. While we cannot stop them from happening, we can use technology to lessen their impact. We’re encouraging developers worldwide to use their skills and our technology to help solve the problems natural disasters create.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Who are our Data Quality Heroes?
Lemahieu W., vanden Broucke S., Baesens B.
This article is based upon our upcoming book Principles of Database Management: The Practical Guide to Storing, Managing and Analyzing Big and Small Data, www.pdbmbook.com See also our corresponding YouTube channel with free video lectures.
Data management entails the proper management of data as well as the corresponding data definitions or metadata. It aims at ensuring that (meta-) data is of good quality and thus a key resource for effective and efficient managerial decision making. Data quality (DQ) is often defined as ‘fitness for use,’ which implies the relative nature of the concept. Data that is of acceptable quality in one decision context may be perceived to be of poor quality in another decision context, even by the same business user. For instance, the extent to which data is required to be complete for accounting tasks may not be required for analytical sales prediction tasks. Data quality determines the intrinsic value of the data to the business. Information technology only serves as a magnifier for this intrinsic value. Hence, high-quality data combined with effective technology is a great asset, but poor quality data combined with effective technology is an equally great liability. This is sometimes also referred to as the GIGO, or Garbage In, Garbage Out principle, stating that bad data results into bad decisions, even with the best technology available. Decisions made based on useless data have cost companies billions of dollars. A popular example of this is the address of a customer. It is estimated that approximately 10% of customers change their address on a yearly basis. Obsolete customer addresses can have substantial consequences for mail order companies, package delivery providers or government services.
Poor DQ impacts organizations in many ways. At the operational level, it has an impact on customer satisfaction, increases operational expenses, and will lead to lowered employee job satisfaction. Similarly, at the strategic level, it affects the quality of the decision-making process. The magnitude of DQ problems is continuously being exacerbated by the exponential increase in the size of databases. This certainly qualifies data quality management as one of the most important business challenges in today’s data based economy.
Organizations are hiring various data management related job profiles to ensure high data quality and transforming data into actual business value. In what follows, we review the information architect, database designer, data owner, data steward, database administrator and data scientist. Depending upon the size of the database and the company, multiple profiles may be merged into one job description.
The information architect (also called information analyst) is responsible for designing the conceptual data model, preferably in dialogue with the business users. He/she bridges the gap between the business processes and the IT environment and closely collaborates with the database designer who may assist in choosing the type of conceptual data model (e.g. EER or UML) and the database modeling tool. A good conceptual data model is a key requirement for storing high quality data in terms of data accuracy and data completeness.
The database designer translates the conceptual data model into a logical and internal data model. He/she also assists the application developers in defining the views of the external data model as such contributing to data security. To facilitate future maintenance of the database applications, the database designer should define company-wide uniform naming conventions when creating the various data models which enforces data consistency.
Every data field in every database in the organization should be owned by a data owner, who is in the authority to ultimately decide on the access to, and usage of, the data. The data owner could be the original producer of the data, one of its consumers, or a third party. The data owner should be able to fill in or update its value which implies that the data owner has knowledge about the meaning of the field and has access to the current correct value (e.g. by contacting a customer, by looking into a file, etc.). Data owners can be requested by data stewards (see below) to check or complete the value of a field, as such correcting a data quality issue.
Data stewards are the DQ experts in charge of ensuring the quality of both the actual business data and the corresponding metadata. They assess DQ by performing extensive and regular data quality checks. These checks involve, amongst other evaluation steps, the application or calculation of data quality indicators and metrics for the most relevant DQ dimensions. Clearly, they are also in charge of taking initiative and to further act upon the results of these assessments. A first type of action to be taken is the application of corrective measures. However, data stewards are not in charge of correcting data themselves, as this is typically the responsibility of the data owner. The second type of action to be taken upon the results of the data quality assessment involves a deeper investigation into the root causes of the data quality issues that were detected. Understanding these causes may allow designing preventive measures that aim at eradicating data quality problems. Preventive measures may include modifications to the operational information systems where the data originate from (e.g., making fields mandatory, providing drop-down lists of possible values, rationalizing the interface, etc.). Also, values entered in the system may immediately be checked for validity against predefined integrity rules and the user may be requested to correct the data if these rules are violated. For instance, a corporate tax portal may require employees to be identified based upon their social security number, which can be checked in real-time by contacting the social security number database. Implementing such preventive measures obviously requires the close involvement of the IT department in charge of the application. Overall, preventing erroneous data from entering the system is often more cost-efficient than correcting errors afterward. However, care should be taken not to slow down critical processes because of non-essential data quality issues in the input data.
The database administrator (DBA) is responsible for the implementation and monitoring of the database. Example activities include: installing and upgrading the DBMS software, backup and recovery management, performance tuning and monitoring, memory management, replication management, security and authorization, etc. A DBA closely collaborates with network and system managers. He/she also interacts with database designers to reduce operational management costs and guarantee agreed upon service levels (e.g. response times and throughput rates). The DBA can contribute to data availability and accessibility, two other key data quality dimensions.
Data scientist is a relatively new job profile within the context of data management. He/she is responsible for analyzing data using state-of-the-art analytical techniques to provide new insights into e.g. customer behavior. A data scientist has a multidisciplinary profile combining ICT skills (e.g., programming) with quantitative modeling (e.g., statistics), business understanding, communication, and creativity. A good data scientist should possess sound programming skills in such languages as Java, R, Python, SAS, etc. The programming language itself is not that important, as long as the data scientist is familiar with the basic concepts of programming and knows how to use these to automate repetitive tasks or perform specific routines. Obviously, a data scientist should have a thorough background in statistics, machine learning and/or quantitative modeling. Essentially, data science is a technical exercise. There is often a huge gap between the analytical models and business users. To bridge this gap, communication and visualization facilities are key. A data scientist should know how to represent analytical models, accompanying statistics and reports in user-friendly ways by using traffic-light approaches, OLAP (on-line analytical processing) facilities, If-then business rules, etc. A data scientist needs creativity on at least two levels. On a technical level it is important to be creative with regard to data selection, data transformation and cleaning. The steps of the standard analytical process must be adapted to each specific application and the “right guess” could often make a big difference. Second, analytics is a fast-evolving field. New problems, technologies and corresponding challenges pop up on an ongoing basis. It is important that a data scientist keep up with these new evolutions and technologies and has enough creativity to see how they can yield new business opportunities. It is no surprise that these data scientist are hard to find in today’s job market. However, data scientists contribute to the generation of new data and/or insights, which could leverage new strategic business opportunities.
To conclude, ensuring high quality data is multidisciplinary exercise combining various skills. In this article we reviewed the following data management job profiles from a data quality perspective: information architect, database designer, data owner, data steward, database administrator and data scientist.
For more information, we are happy to refer to our book Principles of Database Management: The Practical Guide to Storing, Managing and Analyzing Big and Small Data, www.pdbmbook.com and YouTube channel.
About the Authors
Wilfried Lemahieu is a professor at KU Leuven, Faculty of Economics and Business, where he also holds the position of Dean. His teaching, for which he was awarded a ‘best teacher recognition’ includes Database Management, Enterprise Information Management and Management Informatics. His research focuses on big data storage and integration, data quality, business process management and service-oriented architectures. In this context, he collaborates extensively with a variety of industry partners, both local and international. His research is published in renowned international journals and he is a frequent lecturer for both academic and industry audiences. See feb.kuleuven.be/wilfried.lemahieu for further details.
Bart Baesens is a professor of Big Data and Analytics at KU Leuven (Belgium) and a lecturer at the University of Southampton (United Kingdom). He has done extensive research on Big Data & Analytics and Credit Risk Modeling. He wrote more than 200 scientific papers some of which have been published in well-known international journals and presented at international top conferences. He received various best paper and best speaker awards. Bart is the author of 8 books: Credit Risk Management: Basic Concepts (Oxford University Press, 2009), Analytics in a Big Data World (Wiley, 2014), Beginning Java Programming (Wiley, 2015), Fraud Analytics using Descriptive, Predictive and Social Network Techniques (Wiley, 2015), Credit Risk Analytics (Wiley, 2016), Profit-Driven Business Analytics (Wiley, 2017), Practical Web Scraping for Data Science (Apress, 2018) and Principles of Database Management (Cambridge University Press, 2018). He sold more than 20.000 copies of these books worldwide, some of which have been translated in Chinese, Russian and Korean. His research is summarized at www.dataminingapps.com.
Seppe vanden Broucke works as an assistant professor at the Faculty of Economics and Business, KU Leuven, Belgium. His research interests include business data mining and analytics, machine learning, process management and process mining. His work has been published in well-known international journals and presented at top conferences. He is also author of the book Beginning Java Programming (Wiley, 2015) of which more than 4000 copies were sold and which was also translated in Russian. Seppe’s teaching includes Advanced Analytics, Big Data and Information Management courses. He also frequently teaches for industry and business audiences. See seppe.net for further details.

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This article was written by Lauren Brunk.
The data scientist was deemed the “sexiest job of the 21st century.” The Harvard Business Review reasons that this “hybrid of data hacker, analyst, communicator and trusted adviser” is a rare combination of skills, worth a high paycheck.
Too good to be true? Yes, according to Forbes. Turns out, data scientists spend most of their time (up to 79%!) on the part of their job they hate most.

The Demand for Data Scientists:
Thousands of companies across a myriad of industries are hiring data scientists, likened to the “quants” of Wall Street in the 1980s and 1990s for their exclusive abilities to understand and interpret data, a kind of secret weapon for doing better business, as depicted in The Big Short.
But with a supply of just over 11,000 data scientists and a rapidly growing demand, the competition among employers to secure this role is steep. The U.S. Bureau of Labor Statistics projects that demand will be 50-60% higher than supply by 2018. And McKinsey predicts that by 2018, the United States alone will face a shortage of 1.5 million analysts and managers who know how to use big data to make decisions.
Companies who don’t hire a data scientist now might not be able to find one at all.
The Role of a Data Scientist:
Once an organization has a data scientist, however, what then? How do they cultivate an environment that maximizes that person’s skills and makes them want to stay?
Consider first what an average data scientist does all day:
- Builds training sets (3% of the time)
- Cleans and organizes data (60%)
- Collects data sets (19%)
- Mines for data patterns (9%)
- Refines algorithms (4%)
- Other (5%)
Here’s where we see just how un-sexy the role has become, because an overwhelming majority of data scientists agree that collecting data sets and cleaning and organizing them is their least favorite part of the job. Worse, collecting and organizing data has absolutely nothing to do with insights; it’s simply data preparation. It takes a high level of skill to do, but it’s not data science.
Companies could free their data scientists to spend up to 79% more of their time on analysis by having someone else prepare the data. Not only would companies derive more value from every extra moment spent on insights, but they would enable their data scientists to do what they love.
Data preparation, therefore, should be applied to the correct role—data engineer.
The Role of A Data Engineer:
To read the rest of this article, click here. To read more DSC articles involving data engineers and data science, click on the links.
DSC Resources
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
MongoDB Expands its Leadership as the Modern, General Purpose Database Platform With New Product Announcements
MMS • RSS
NEW YORK, June 27, 2018 /PRNewswire/ — MongoDB, Inc. (Nasdaq: MDB), the leading, modern general database platform, made several major product announcements today that expand on its leadership in the database market.

Nearly every company is focused on using software for a competitive advantage. MongoDB has become a strategic database platform that enables this competitive advantage for thousands of customers around the world. Customers choose MongoDB for three key reasons:
- MongoDB offers the best way to work with data due to the ease, flexibility, performance and versatility of the document model;
- The native distributed capabilities of MongoDB make it easy for customers to intelligently place data where they need it for high availability, scalability, locality, regulatory and other key business requirements;
- Customers have the freedom to run MongoDB anywhere, from on-premise to consuming MongoDB as a service in the public cloud.
Today’s announcements strengthen each of these pillars and further expand MongoDB’s leadership as the obvious choice for all modern applications.
“Every business today is focused on digital transformation, which is all about leveraging modern digital technologies to drive superior business performance, but this is far easier said than done,” said Dev Ittycheria, President & CEO, MongoDB. “With the product announcements made today, MongoDB not only provides a compelling database platform for the most sophisticated use cases, but also extends the power of MongoDB to a mobile database and a new serverless platform. This is a massive step for the industry that will enable customers to dramatically accelerate their ability to use software and data to create a sustainable competitive advantage.”
MongoDB is the best way to work with data
The release of MongoDB 4.0 is highlighted by the general availability of multi-document ACID transactions, making it even easier to address a complete range of use cases on MongoDB. By providing a consistent view of data across replica sets and enforcing all-or-nothing execution to maintain data integrity, MongoDB transactions will be very familiar to developers already accustomed to working with transactions in legacy relational databases.
“Coinbase’s mission is to create an open financial system for the world. MongoDB’s technology is enabling us to scale globally and we’re looking forward to partnering with the company along our journey to become the most compliant, reliable and trusted crypto-trading platform in the world,” said Niall O’Higgins, Engineering Manager, Coinbase. “The addition of multi-document ACID transactions has the potential to greatly speed our engineering workflow.”
MongoDB also announced the general availability of MongoDB Stitch, the company’s new serverless platform, which facilitates the rapid development of mobile and web applications. The services provided in Stitch give developers unparalleled access to database functionality while providing the robust security and privacy controls expected in today’s environment.
MongoDB Stitch today offers four key services to help customers get applications to market faster while reducing operational costs:
- Stitch QueryAnywhere is a service that exposes the full power of the document model and the MongoDB query language directly to application developers building mobile and web applications. This is done through a powerful rules engine that also lets customers define security policies at a fine-grained level to ensure sophisticated controls for data access are in place.
- Stitch Functions allow developers to run JavaScript functions in Stitch’s serverless environment, allowing them to easily create secure APIs and to build integrations with microservices and server-side logic. Functions also enable integration with popular cloud services such as Slack and Twilio, enriching apps with a single method call to Stitch.
- Stitch Triggers are real-time notifications that automatically invoke functions in response to changes in the database, taking actions as they happen in applications, other services, or the database itself. These can be used to initiate other database operations, push data to other systems or send messages to end-users, such as SMS or emails.
- Stitch Mobile Sync (beta) automatically synchronizes data between documents stored locally in the newly announced MongoDB Mobile and the backend database. MongoDB Mobile allows developers to have the full power of MongoDB on mobile devices locally. Combined with Stitch Mobile Sync, they can easily make sure data is synchronized and up to date in real-time across mobile devices and the backend database.
“MongoDB has always been about giving developers technology that helps them build faster,” said Eliot Horowitz, CTO and cofounder, MongoDB. “MongoDB Stitch brings our core strengths—the document model, the power of distributed databases, and the ability to run on any platform—to your app in a way we’ve never done before. Stitch is serverless, MongoDB-style: it eliminates much of the tedious boilerplate so many apps require to get off the ground and keeps you focused on the work that matters.”
Acxiom, the data foundation for the world’s best marketers, uses MongoDB to build next-generation data environment solutions for Fortune 100 brands across various industries leveraging its proprietary Unified Data Layer framework—an open, trusted data framework for the modern enterprise—that powers a connected martech and ad-tech ecosystem. Over the past year, Acxiom has also been using MongoDB Stitch to re-platform its Real-time Operational Data Store to a scalable cloud-first approach.
“Stitch has been fantastic for us. We’ve cut the time to develop an API for our customers in half, and by combining MongoDB Atlas and Stitch, our teams now have more time to solve business problems versus focusing on the management or operational overhead,” said Chris Lanaux, vice president of product and engineering at Acxiom. “That combination has become a key part of our cutting-edge cloud architecture, helping us design, build and manage omnichannel solutions that power exceptional consumer experiences.”
Intelligently put data where it’s needed
As properly handling data becomes a critical imperative for businesses in every industry, organizations have to be far more thoughtful about where their data lives—whether to meet strict regulatory requirements such as GDPR or to provide a low-latency user experience. Furthermore, as regulatory policies and business requirements change, organizations need to be able to adapt quickly to new requirements without any downtime.
Today, MongoDB announced Global Clusters in Atlas, which allow customers to easily create sophisticated policies to carefully position data for geographically distributed applications. By dynamically configuring these policies, customers can ensure that data is distributed and isolated within specific geographic boundaries. Similarly, by using Global Clusters, relevant data can be moved with the click of a button close to end-users for worldwide, low-latency performance. Traditionally, orchestrating these kinds of sophisticated data policies with legacy databases was incredibly challenging if not impossible for most companies. This breakthrough capability enables organizations of any size to easily serve customers around the world while seamlessly and securely managing their data globally.
Freedom to run anywhere
MongoDB Mobile, announced in beta today, extends the freedom MongoDB gives users to run anywhere. Users now have the full power of MongoDB, all the way out to the edge of the network on IoT assets, as well as iOS and Android devices.
MongoDB Mobile, a new mobile database, allows developers to build faster and more responsive applications, enabling real-time, automatic syncing between data held on the device and the backend database. Previously, this could only be achieved by installing an alternative or feature-limited database within the mobile application which resulted in extra management, complicated syncing and reduced functionality.
“One of the most important and universal trends in modern software application development is a focus on value, specifically where developers can add value versus where they are merely reimplementing common scaffolding,” said Stephen O’Grady, Principal Analyst with RedMonk. “Platforms that understand this are responding by automating and abstracting undifferentiated work away from those developing software, allowing them to focus on the application itself. MongoDB’s Mobile and Stitch offerings are examples of precisely this trend at work.”
MongoDB 4.0’s new MongoDB Kubernetes Operator (Beta) supports provisioning stateful, distributed database clusters, coordinating orchestration between Kubernetes and MongoDB Ops Manager. Adding to the previous Cloud Foundry integration, support for Kubernetes gives customers the freedom to take advantage of on-premise, hybrid and public cloud infrastructure.
MongoDB Atlas is giving users more choice by extending the Atlas Free Tier to Google Cloud Platform, in partnership with Google. This allows the growing developer community relying on GCP services to build their applications using fully-managed MongoDB with no cost of entry. The Atlas Free Tier offers 512 MB of storage and is ideal for prototyping and early development.
In addition, the company announced a number of sophisticated new security features for Atlas, such as encryption key management, LDAP integration, and database-level auditing, to offer the most security conscious organizations more control over their data. Furthermore, MongoDB Atlas now enables covered entities and their business associates to use a secure Atlas environment to process, maintain, and store protected health information, under an executed Business Associate Agreement with MongoDB, Inc., for those organizations subject to the requirements of the Health Insurance Portability and Accountability Act of 1996 (HIPAA).
Further resources
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 6,600 customers in more than 100 countries. The MongoDB database platform has been downloaded over 40 million times and there have been more than 850,000 MongoDB University registrations.
Media Relations
MongoDB
866-237-8815 x7186
communications@mongodb.com
![]()
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-expands-its-leadership-as-the-modern-general-purpose-database-platform-with-new-product-announcements-300673148.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-expands-its-leadership-as-the-modern-general-purpose-database-platform-with-new-product-announcements-300673148.html
SOURCE MongoDB, Inc.
MongoDB Expands its Leadership as the Modern, General Purpose Database Platform With New Product Announcements
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, June 27, 2018 /PRNewswire/ — MongoDB, Inc. (Nasdaq: MDB), the leading, modern general database platform, made several major product announcements today that expand on its leadership in the database market.
Nearly every company is focused on using software for a competitive advantage. MongoDB has become a strategic database platform that enables this competitive advantage for thousands of customers around the world. Customers choose MongoDB for three key reasons:
- MongoDB offers the best way to work with data due to the ease, flexibility, performance and versatility of the document model;
- The native distributed capabilities of MongoDB make it easy for customers to intelligently place data where they need it for high availability, scalability, locality, regulatory and other key business requirements;
- Customers have the freedom to run MongoDB anywhere, from on-premise to consuming MongoDB as a service in the public cloud.
Today’s announcements strengthen each of these pillars and further expand MongoDB’s leadership as the obvious choice for all modern applications.
“Every business today is focused on digital transformation, which is all about leveraging modern digital technologies to drive superior business performance, but this is far easier said than done,” said Dev Ittycheria, President & CEO, MongoDB. “With the product announcements made today, MongoDB not only provides a compelling database platform for the most sophisticated use cases, but also extends the power of MongoDB to a mobile database and a new serverless platform. This is a massive step for the industry that will enable customers to dramatically accelerate their ability to use software and data to create a sustainable competitive advantage.”
MongoDB is the best way to work with data
The release of MongoDB 4.0 is highlighted by the general availability of multi-document ACID transactions, making it even easier to address a complete range of use cases on MongoDB. By providing a consistent view of data across replica sets and enforcing all-or-nothing execution to maintain data integrity, MongoDB transactions will be very familiar to developers already accustomed to working with transactions in legacy relational databases.
“Coinbase’s mission is to create an open financial system for the world. MongoDB’s technology is enabling us to scale globally and we’re looking forward to partnering with the company along our journey to become the most compliant, reliable and trusted crypto-trading platform in the world,” said Niall O’Higgins, Engineering Manager, Coinbase. “The addition of multi-document ACID transactions has the potential to greatly speed our engineering workflow.”
MongoDB also announced the general availability of MongoDB Stitch, the company’s new serverless platform, which facilitates the rapid development of mobile and web applications. The services provided in Stitch give developers unparalleled access to database functionality while providing the robust security and privacy controls expected in today’s environment.
MongoDB Stitch today offers four key services to help customers get applications to market faster while reducing operational costs:
- Stitch QueryAnywhere is a service that exposes the full power of the document model and the MongoDB query language directly to application developers building mobile and web applications. This is done through a powerful rules engine that also lets customers define security policies at a fine-grained level to ensure sophisticated controls for data access are in place.
- Stitch Functions allow developers to run JavaScript functions in Stitch’s serverless environment, allowing them to easily create secure APIs and to build integrations with microservices and server-side logic. Functions also enable integration with popular cloud services such as Slack and Twilio, enriching apps with a single method call to Stitch.
- Stitch Triggers are real-time notifications that automatically invoke functions in response to changes in the database, taking actions as they happen in applications, other services, or the database itself. These can be used to initiate other database operations, push data to other systems or send messages to end-users, such as SMS or emails.
- Stitch Mobile Sync (beta) automatically synchronizes data between documents stored locally in the newly announced MongoDB Mobile and the backend database. MongoDB Mobile allows developers to have the full power of MongoDB on mobile devices locally. Combined with Stitch Mobile Sync, they can easily make sure data is synchronized and up to date in real-time across mobile devices and the backend database.
“MongoDB has always been about giving developers technology that helps them build faster,” said Eliot Horowitz, CTO and cofounder, MongoDB. “MongoDB Stitch brings our core strengths—the document model, the power of distributed databases, and the ability to run on any platform—to your app in a way we’ve never done before. Stitch is serverless, MongoDB-style: it eliminates much of the tedious boilerplate so many apps require to get off the ground and keeps you focused on the work that matters.”
Acxiom, the data foundation for the world’s best marketers, uses MongoDB to build next-generation data environment solutions for Fortune 100 brands across various industries leveraging its proprietary Unified Data Layer framework—an open, trusted data framework for the modern enterprise—that powers a connected martech and ad-tech ecosystem. Over the past year, Acxiom has also been using MongoDB Stitch to re-platform its Real-time Operational Data Store to a scalable cloud-first approach.
“Stitch has been fantastic for us. We’ve cut the time to develop an API for our customers in half, and by combining MongoDB Atlas and Stitch, our teams now have more time to solve business problems versus focusing on the management or operational overhead,” said Chris Lanaux, vice president of product and engineering at Acxiom. “That combination has become a key part of our cutting-edge cloud architecture, helping us design, build and manage omnichannel solutions that power exceptional consumer experiences.”
Intelligently put data where it’s needed
As properly handling data becomes a critical imperative for businesses in every industry, organizations have to be far more thoughtful about where their data lives—whether to meet strict regulatory requirements such as GDPR or to provide a low-latency user experience. Furthermore, as regulatory policies and business requirements change, organizations need to be able to adapt quickly to new requirements without any downtime.
Today, MongoDB announced Global Clusters in Atlas, which allow customers to easily create sophisticated policies to carefully position data for geographically distributed applications. By dynamically configuring these policies, customers can ensure that data is distributed and isolated within specific geographic boundaries. Similarly, by using Global Clusters, relevant data can be moved with the click of a button close to end-users for worldwide, low-latency performance. Traditionally, orchestrating these kinds of sophisticated data policies with legacy databases was incredibly challenging if not impossible for most companies. This breakthrough capability enables organizations of any size to easily serve customers around the world while seamlessly and securely managing their data globally.
Freedom to run anywhere
MongoDB Mobile, announced in beta today, extends the freedom MongoDB gives users to run anywhere. Users now have the full power of MongoDB, all the way out to the edge of the network on IoT assets, as well as iOS and Android devices.
MongoDB Mobile, a new mobile database, allows developers to build faster and more responsive applications, enabling real-time, automatic syncing between data held on the device and the backend database. Previously, this could only be achieved by installing an alternative or feature-limited database within the mobile application which resulted in extra management, complicated syncing and reduced functionality.
“One of the most important and universal trends in modern software application development is a focus on value, specifically where developers can add value versus where they are merely reimplementing common scaffolding,” said Stephen O’Grady, Principal Analyst with RedMonk. “Platforms that understand this are responding by automating and abstracting undifferentiated work away from those developing software, allowing them to focus on the application itself. MongoDB’s Mobile and Stitch offerings are examples of precisely this trend at work.”
MongoDB 4.0’s new MongoDB Kubernetes Operator (Beta) supports provisioning stateful, distributed database clusters, coordinating orchestration between Kubernetes and MongoDB Ops Manager. Adding to the previous Cloud Foundry integration, support for Kubernetes gives customers the freedom to take advantage of on-premise, hybrid and public cloud infrastructure.
MongoDB Atlas is giving users more choice by extending the Atlas Free Tier to Google Cloud Platform, in partnership with Google. This allows the growing developer community relying on GCP services to build their applications using fully-managed MongoDB with no cost of entry. The Atlas Free Tier offers 512 MB of storage and is ideal for prototyping and early development.
In addition, the company announced a number of sophisticated new security features for Atlas, such as encryption key management, LDAP integration, and database-level auditing, to offer the most security conscious organizations more control over their data. Furthermore, MongoDB Atlas now enables covered entities and their business associates to use a secure Atlas environment to process, maintain, and store protected health information, under an executed Business Associate Agreement with MongoDB, Inc., for those organizations subject to the requirements of the Health Insurance Portability and Accountability Act of 1996 (HIPAA).
Further resources
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 6,600 customers in more than 100 countries. The MongoDB database platform has been downloaded over 40 million times and there have been more than 850,000 MongoDB University registrations.
Media Relations
MongoDB
866-237-8815 x7186
communications@mongodb.com
![]()
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-expands-its-leadership-as-the-modern-general-purpose-database-platform-with-new-product-announcements-300673148.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-expands-its-leadership-as-the-modern-general-purpose-database-platform-with-new-product-announcements-300673148.html
SOURCE MongoDB, Inc.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Google has released a client library to make it easy for developers to use Google Cloud IoT Core from Android Things devices. Developers can connect to the IoT Core MQTT bridge, authenticate a device, publish device telemetry, subscribe to configuration changes, and handle errors and network outages.
Cloud IoT Core is a fully managed service on Google Cloud Platform that allows developers to securely connect, manage, and ingest data from globally dispersed devices. Cloud IoT Core, in combination with other services from Google Cloud Platform, provides a solution for collecting, processing, analyzing, and visualizing IoT data in real time. Furthermore, Android Things is designed to support data collection for telemetry, powerful computer vision, audio processing, and machine learning applications.
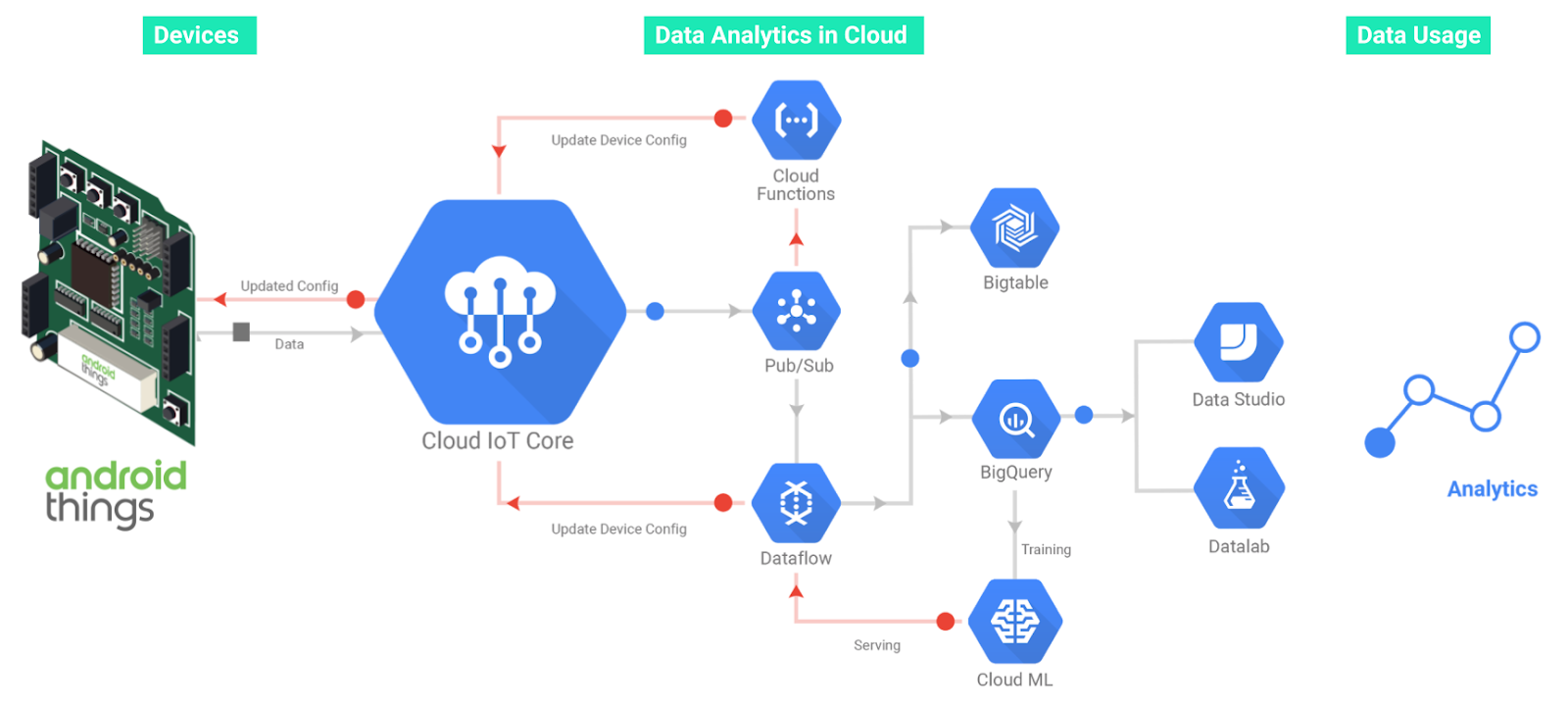
The Cloud IoT Core client library provides abstractions for every Cloud IoT Core function, such as publishing telemetry events, device state, and receiving device configuration from Cloud IoT Core.
The Cloud IoT Core keeps track of approved devices through a device registry, and each device uses a public key to authenticate with the server. For authentication with Cloud IoT Core, the client library supports both RSA and ECC keys, and implements JSON Web Tokens (JWTs).
Devices can publish their telemetry data to one or more buckets by issuing a PUBLISH message through the MQTT connection. Messages must be published to an MQTT topic in the following format:
/devices/{device-id}/events
Using Cloud IoT Core, developers can monitor the state of each connected device. Device state updates are usually triggered by a change to the device, for example a configuration update from Cloud IoT Core, or a change from an external source, such as a firmware update. Device state is published to an MQTT topic using the format:
/devices/<device_id>/state
Developers can control a device by sending it a device configuration from Cloud IoT Core. The data can be in any format, such as binary data, text, JSON, or serialized protocol buffers. It is important to note than a device is not guaranteed to receive every configuration update; if there are many updates released in a short period of time, devices may not receive intermediate versions.
To get started with the Cloud IoT Core client library, add the following to the build.gradle file in your Android Things project:
implementation 'com.google.android.things:cloud-iot-core:1.0.0'
The following Kotlin example demonstrates how to create a new configuration and client based on an existent project:
var configuration = IotCoreConfiguration.Builder().
.setProjectId("my-gcp-project")
.setRegistry("my-device-registry", "us-central1")
.setDeviceId("my-device-id")
.setKeyPair(keyPairObject)
.build()
var iotCoreClient = IotCoreClient.Builder()
.setIotCoreConfiguration(configuration)
.setOnConfigurationListener(onConfigurationListener)
.setConnectionCallback(connectionCallback)
.build()
iotCoreClient.connect()
The following Kotlin examples show how to publish telemetry information or device state:
private fun publishTelemetry(temperature: Float, humidity: Float) {
// payload is an arbitrary, application-specific array of bytes
val examplePayload = """{
|"temperature" : $temperature,
|"humidity": $humidity
|}""".trimMargin().toByteArray()
val event = TelemetryEvent(examplePayload, topicSubpath, TelemetryEvent.QOS_AT_LEAST_ONCE)
iotCoreClient.publishTelemetry(event)
}
private fun publishDeviceState(telemetryFrequency: Int, enabledSensors: Array<string>) {
// payload is an arbitrary, application-specific array of bytes
val examplePayload = """{
|"telemetryFrequency": $telemetryFrequency,
|"enabledSensors": ${enabledSensors.contentToString()}
|}""".trimMargin().toByteArray()
iotCoreClient.publishDeviceState(examplePayload)
}
Google also provided a sample that shows how to implement a sensor hub on Android Things, collecting sensor data from connected sensors and publishing them to a Google Cloud IoT topic.
More information on Cloud IoT Core is available on the Cloud IoT Core page, official documentation, and Google’s IoT Developers community.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The three core strategies for managing failure in a microservices architecture are proactive testing, mitigation, and rapid response.
- If you have a small number of microservices or a shallow topology, consider delaying adoption of a service mesh, and evaluate alternative strategies for failure management.
- If you are deploying a service mesh, be prepared to invest ongoing effort in integrating the mesh into your software development lifecycle.
App Architecture, iOS Application Design Patterns in Swift Review and Author Q&A
Service meshes such as Istio, Linkerd, and Cilium are gaining increased visibility as companies adopt microservice architectures. The arguments for a service mesh are compelling: full-stack observability, transparent security, systems resilience, and more. But is a service mesh really the right solution for your cloud native application? This article examines when a service mesh makes sense and when it might not.
Microservices, done right, let you move faster
In today’s world, time to market is a fundamental competitive advantage. Responding quickly to market forces and customer feedback is crucial to building a winning business. Microservices is a powerful paradigm to accelerate your software agility and velocity workflow. By empowering different software teams to simultaneously work on different parts of an application, decision making is decentralized.
Decentralized decision making has two important consequences. First, software teams can make locally optimal decisions on architecture, release, testing, and so forth, instead of relying on a globally optimal standard. The most common example of this type of decision is release: instead of orchestrating a single monolithic application release, each team has its own release vehicle. The second consequence is that decision making can happen more quickly, as the number of communication hops between the software teams and centralized functions such as operations, architecture, and so forth is reduced.
Microservices aren’t free — they introduce new failure modes
Adopting microservices has far-reaching implications for your organization, process, and architecture. In this article, we’ll focus on one of the key architectural shifts — namely, microservices is a distributed system. In a microservices-based application, business logic is distributed between multiple services that communicate with each other via the network. A distributed system has many more failure modes, as highlighted in the fallacies of distributed computing.
Given these failure modes, it’s crucial to have an architecture and process that prevent small failures from becoming big failures. When you’re going fast, failures are inevitable, e.g., bugs will be introduced as services are updated, services will crash under load, and so forth.
As your application grows in complexity, the need for failure management grows more acute. When an application consists of a handful of microservices, failures tend to be easier to isolate and troubleshoot. As your application grows to tens or hundreds of microservices, with different, geographically distributed teams, your failure management systems need to scale with your application.
Managing failure
There are three basic strategies for managing failure: proactive testing, mitigation, and rapid response.
- Proactive testing. Implementing processes and systems to test your application and services so that failure is identified early and often. Classical “quality assurance” (QA) is included within this category, and although traditional test teams focused on pre-release testing, this frequently now extends to testing in production.
- Mitigation. Implement strategies to reduce the impact of any given failure. For example, load balancing between multiple instances of a service can insure that if a single instance fails, the overall service can still respond.
- Rapid response. Implement processes and systems to rapidly identify and address a given failure.
Service meshes
When a service fails, there is an impact on its upstream and downstream services. The impact of a failed service can be greatly mitigated by properly managing the communication between services. This is where a service mesh comes in.
A service mesh manages service-level (i.e., Layer 7) communication. Service meshes provide powerful primitives that can be used for all three failure management strategies. Service meshes implement:
- Dynamic routing, which can be used for different release and testing strategies such as canary routing, traffic shadowing, or blue/green deployments.
- Resilience, which mitigate the impact of failures through strategies such as circuit breaking and rate limiting
- Observability, which help improve response time by collecting metrics and adding context (e.g., tracing data) to service-to-service communication
Service meshes add these features in a way that’s largely transparent to application developers. However, as we’ll see shortly, there are some nuances to this notion of transparency.
Will a service mesh help me build software faster?
In deciding whether or not a service mesh makes sense for you and your organization, start by asking yourself two questions.
- How complex is your service topology?
- How will you integrate a service mesh into your software development lifecycle?
Your service topology
Typically, an organization will start with a single microservice that connects with an existing monolithic application. In this situation, the benefits of the service mesh are somewhat limited. If the microservice fails, identifying the failure is straightforward. The blast radius of a single microservice failure is inherently limited. Incremental releases can also likely be accomplished through your existing infrastructure such as Kubernetes or your API Gateway.
As your service topology grows in complexity, however, the benefits of a service mesh start to accumulate. The key constraint to consider is the depth of your service call chain. If you have a shallow topology, where your monolith directly calls a dozen microservices, the benefits of a service mesh are still fairly limited. As you introduce more service-to-service communication where service A calls service B which calls service C, a service mesh becomes more important.
Integrating your service mesh into your SDLC
A service mesh is designed to be transparent to the actual services that run on the mesh. One way to think about a service mesh is that it’s a richer L7 network. No code changes are required for a service to run on a service mesh.
However, deploying a service mesh does not automatically accelerate your software velocity and agility. You have to integrate the service mesh into your development processes. We’ll explore this in more detail in the next section.
Implementing failure management strategies as part of your SDLC
A service mesh provides powerful primitives for failure management, but alternatives to service meshes exist. In this section, we’ll walk through each of the failure management strategies, and discuss how the apply to your SDLC.
Proactive testing
Testing strategies for a microservices application should be as real-world as possible. Given the complexity of a multi-service application, contemporary testing strategies emphasize testing in production (or with production data).
A service mesh enables testing in production by controlling the flow of L7 traffic to services. For example, a service mesh can route 1% of traffic to v1.1 of a service, and 99% of traffic to v1.0 (a canary deployment). These capabilities are exposed through declarative routing rules (e.g., linkerd dtab or Istio routing rules).
A service mesh is not the only way to proactively test. Other complementary strategies include using your container scheduler such as Kubernetes to do a rolling update, an API Gateway that can canary deploy, or chaos engineering.
With all of these strategies, the question of who manages the testing workflow becomes apparent. In a service mesh, the routing rules could be centrally managed by the same team that manages the mesh. However, this likely won’t scale, as individual service author(s) presumably will want to control when and how they roll out new versions of their services. So if service authors manage the routing rules, how do you educate them on what they can and can’t do? How do you manage conflicting routing rules?
Mitigation
A service can fail for a variety of reasons: a code bug, insufficient resources, hardware failure. Limiting the blast radius of a failed service is important so that your overall application continues operating, albeit in a degraded state.
A service mesh mitigates the impact of a failure by implementing resilience patterns such as load balancing, circuit breakers, and rate limiting on service-to-service communication. For example, a service that is under heavy load can be rate limited so that some responses are still processed, without causing the entire service to collapse under load.
Other strategies for mitigating failure include using smart RPC libraries (e.g., Hystrix) or relying on your container scheduler. A container scheduler such as Kubernetes supports health checking, auto scaling, and dynamic routing around services that are not responding to health checks.
These mitigation strategies are most effective when they are appropriately configured for a given service. For example, different services can handle different volumes of requests, necessitating different rate limits. How do policies such as rate limits get set? Netflix has implemented some automated configuration algorithms for setting these values. Other approaches would be to expose these capabilities to service authors, who can configure the services correctly.
Observability
Failures are inevitable. Implementing observability — spanning monitoring, alerting/visualization, distributed tracing, and logging — is critical to minimizing the response time to a given failure.
A service mesh automatically collects detailed metrics on service-to-service communication, including data on throughput, latency, and availability. In addition, service meshes can inject the necessary headers to support distributed tracing. Note that these headers still need to be propagated by the service itself.
Other approaches for collecting similar metrics include using monitoring agents, collecting metrics via statsd, and implementing tracing through libraries (e.g., the Jaeger instrumentation libraries).
An important component of observability is exposing the alerting and visualization to your service authors. Collecting metrics is only the first step, and thinking how your service authors will create alerts and visualizations that are appropriate for the given service is important to closing the observability loop.
It’s all about the workflow!
The mechanics of deploying a service mesh are straightforward. However, as the preceding discussion hopefully makes clear, the application of a service mesh to your workflow is more complicated. The key to successfully adopting a service mesh is to recognize that a mesh impacts your development processes, and be prepared to invest in integrating the mesh into those processes. There is no one right way to integrate the mesh into your processes, and best practices are still emerging.
About the Author
 Richard Li is a veteran of several successful high-technology startups. Previously, Richard was VP, Product & Strategy at Duo Security. Prior to Duo, Richard was VP, Strategy & Corporate Development at Rapid7. Richard also led the creation of the original product management organization at Rapid7. Richard has also held a number of leadership positions in sales, marketing, and engineering at Red Hat. H
Richard Li is a veteran of several successful high-technology startups. Previously, Richard was VP, Product & Strategy at Duo Security. Prior to Duo, Richard was VP, Strategy & Corporate Development at Rapid7. Richard also led the creation of the original product management organization at Rapid7. Richard has also held a number of leadership positions in sales, marketing, and engineering at Red Hat. H