Month: June 2018
MongoDB Announces Proposed Private Offering of $200 Million of Convertible Senior Notes

MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, June 25, 2018 /PRNewswire/ — MongoDB, Inc. (“MongoDB”) (Nasdaq: MDB), the leading modern, general purpose database platform, today announced that it intends to offer, subject to market conditions and other factors, $200 million aggregate principal amount of convertible senior notes due 2024 in a private placement to qualified institutional buyers pursuant to Rule 144A under the Securities Act of 1933, as amended (the “Securities Act”). MongoDB also intends to grant the initial purchasers of the notes an option to purchase up to an additional $30 million principal amount of notes.
![]()
The notes will be general unsecured obligations of MongoDB and will accrue interest payable semiannually in arrears. The notes will be convertible into cash, shares of MongoDB’s Class A common stock or a combination of cash and shares of MongoDB’s Class A common stock, at MongoDB’s election. The interest rate, initial conversion rate, repurchase or redemption rights and other terms of the notes will be determined at the time of pricing of the offering.
MongoDB intends to use a portion of the net proceeds from the offering to pay the cost of the capped call transactions described below. MongoDB intends to use the remainder of the net proceeds for working capital and other general corporate purposes.
In connection with the pricing of the notes, MongoDB expects to enter into capped call transactions with one or more of the initial purchasers and/or their respective affiliates and/or other financial institutions (the “option counterparties”). The capped call transactions are expected generally to reduce potential dilution to MongoDB’s Class A common stock upon any conversion of notes, with such reduction subject to a cap. If the initial purchasers exercise their option to purchase additional notes, MongoDB expects to enter into additional capped call transactions with the option counterparties.
MongoDB expects that, in connection with establishing their initial hedges of the capped call transactions, the option counterparties or their respective affiliates may enter into various derivative transactions with respect to MongoDB’s Class A common stock and/or purchase shares of MongoDB’s Class A common stock concurrently with or shortly after the pricing of the notes. This activity could increase (or reduce the size of any decrease in) the market price of MongoDB’s Class A common stock or the notes at that time.
In addition, MongoDB expects that the option counterparties or their respective affiliates may modify their hedge positions by entering into or unwinding various derivatives with respect to MongoDB’s Class A common stock and/or purchasing or selling MongoDB’s Class A common stock or other securities of MongoDB in secondary market transactions following the pricing of the notes and prior to the maturity of the notes (and are likely to do so on each exercise date for the capped call transactions). This activity could also cause or avoid an increase or a decrease in the market price of MongoDB’s Class A common stock or the notes, and to the extent the activity occurs during any observation period related to a conversion of notes, this could affect the number of shares and value of the consideration that a noteholder will receive upon conversion of its notes.
Neither the notes, nor any shares of MongoDB’s Class A common stock issuable upon conversion of the notes, have been registered under the Securities Act or any state securities laws, and unless so registered, may not be offered or sold in the United States absent registration or an applicable exemption from, or in a transaction not subject to, the registration requirements of the Securities Act and other applicable securities laws.
This press release is neither an offer to sell nor a solicitation of an offer to buy any securities, nor shall it constitute an offer, solicitation or sale of the securities in any jurisdiction in which such offer, solicitation or sale would be unlawful prior to the registration or qualification under the securities laws of any such jurisdiction.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 6,600 customers in over 100 countries. The MongoDB database platform has been downloaded over 35 million times and there have been more than 850,000 MongoDB University registrations.
Investor Relations Contact:
Brian Denyeau
ICR for MongoDB
646-277-1251
ir@mongodb.com
Media Relations Contact:
MongoDB
866-237-8815 x7186
communications@mongodb.com
Forward-Looking Statements
This press release contains “forward-looking statements” within the meaning of federal securities laws, including statements concerning the proposed terms of the notes and the capped call transactions, the completion, timing and size of the proposed offering and capped call transactions and the anticipated use of proceeds from the offering. These forward-looking statements include all statements contained in this press release that are not historical facts and such statements are, in some cases, identified by words such as “anticipate,” “believe,” “continue,” “could,” “estimate,” “expect,” “intend,” “may,” “plan,” “project,” “will,” “would” or the negative or plural of these words or similar expressions or variations. Forward-looking statements are based on the information currently available to us and on assumptions we have made. Actual results may differ materially from those described in the forward-looking statements and are subject to a variety of assumptions, uncertainties, risks and factors that are beyond our control including, without limitation: market risks, trends and conditions; and those risks detailed from time-to-time under the caption “Risk Factors” and elsewhere in our Securities and Exchange Commission filings and reports, including our Quarterly Report on Form 10-Q filed on June 7, 2018, as well as future filings and reports by us. Except as required by law, we undertake no duty or obligation to update any forward-looking statements contained in this release as a result of new information, future events, changes in expectations or otherwise.
![]() View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-announces-proposed-private-offering-of-200-million-of-convertible-senior-notes-300671431.html
View original content with multimedia:http://www.prnewswire.com/news-releases/mongodb-announces-proposed-private-offering-of-200-million-of-convertible-senior-notes-300671431.html
SOURCE MongoDB, Inc.

Presentation: Distributed Tracing: Latency Analysis for Your Microservices Using Spring Cloud & Zipkin


MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The LinkedIn Engineering team have recently discussed their “LinkedOut” failure injection testing framework in more detail. This framework supports the generation of hypotheses about application and service resilience, and enables failure to be injected to a specific request via the LinkedIn LiX A/B testing framework or via data in a cookie. Failure scenarios that can be tested include errors, delays and timeouts. The LinkedOut project is part of the larger “Waterbear” initiative to encourage every team at LinkedIn to contribute to resilience engineering efforts.
Logan Rosen, Sr. Engineer, Site Reliability at LinkedIn, recently wrote “LinkedOut: A Request-Level Failure Injection Framework” on the LinkedIn Engineering blog. The post began by stating that in a complex, distributed technology stack, it is important to understand the points where things can go wrong and also to know how these failures might manifest themselves to end users. Engineers should assume that “Anything that can go wrong, will go wrong.”
There are many ways to inject failures into a distributed system, but the most fine-grained way to do it is at the request level. The Netflix chaos/resilience engineering team have previously discussed how they created the Failure Injection Testing (FIT) framework that eventually evolved into the Chaos Automation Platform (ChAP), which injected failure in just this way. Similarly the LinkedIn Site Reliability Engineering (SRE) team established the the Waterbear project in late 2017, which is an effort to help developers “hit resiliency problems head-on” by both replicating system failures and adjusting frameworks to handle failures gracefully and transparently. Out of this work emerged the LinkedOut failure injection testing framework which enables request-level failure injection.
At its core LinkedOut is a “disrupter” request filter in the organisation’s Rest.li stack, a Java framework that allows developers to easily create clients and servers that use a REST-style of communication. The open-source portion of this work can be found in the r2-disruptor and restli-disruptor modules within the project’s GitHub repository. LinkedOut is currently able to create three types of failures: error — the Rest.li framework has several default exceptions thrown when there are communication or data issues with the requested resource; delay — engineers can specify an amount of latency before the filter will pass the request downstream; and timeout — the filter waits for the timeout period specified.
Engineers use the LinkedOut framework to validate at development time that their code is robust. This validation is extended to production scenarios to provide external parties the confidence and evidence of robustness. There are two primary mechanisms to invoke the disruptor while limiting impact to the end-user experience. One of these is LiX, the LinkedIn framework for A/B testing and feature gating at LinkedIn, and the second is the Invocation Context (IC), a LinkedIn-specific, internal component of the Rest.li framework that allows keys and values to be passed into requests and propagated to all of the services involved in handling them.
LiX allows engineers to target failures on multiple levels, from an individual request for a single member to a percentage of all members for an entire downstream cluster.
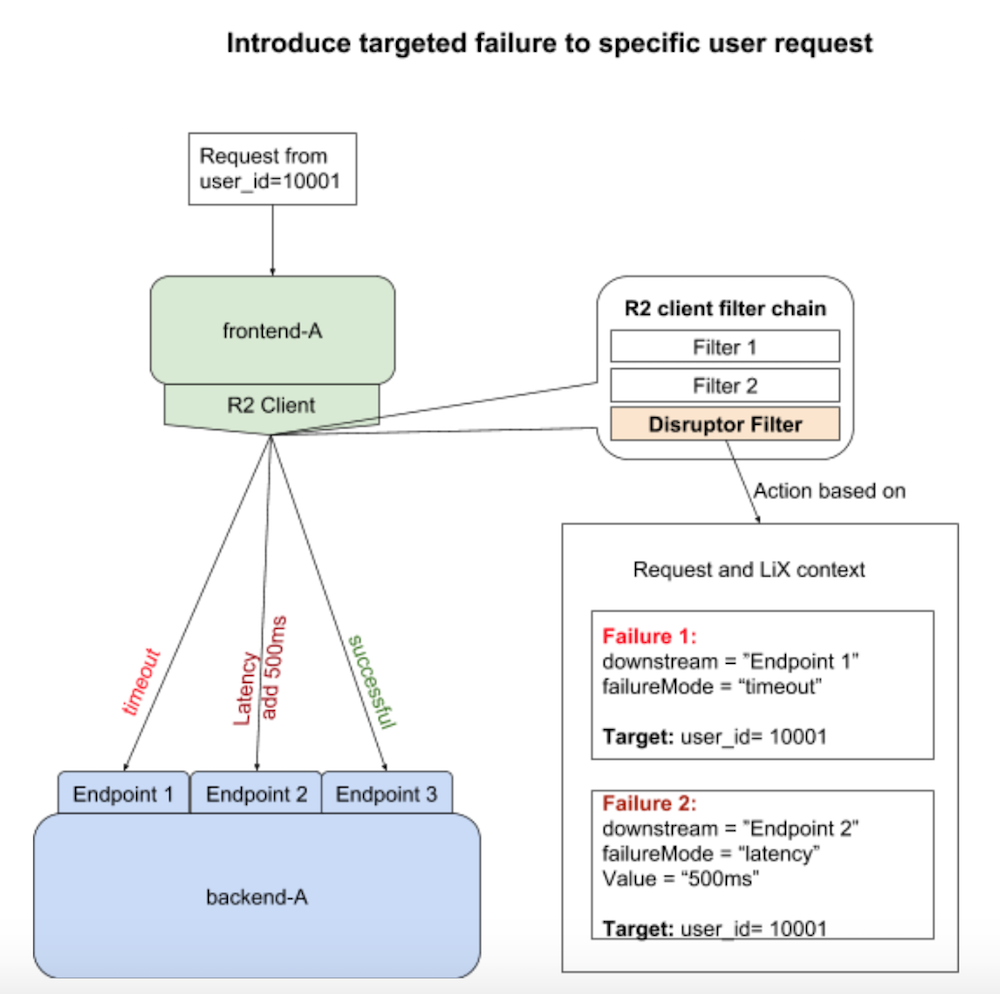 Introducing targeted failure with LinkedOut (image via the LinkedIn Engineering blog)
Introducing targeted failure with LinkedOut (image via the LinkedIn Engineering blog)
As the service call graph is large and complicated at LinkedIn — the latest home page depends on more than 550 different endpoints in its dependency tree — it is very difficult for engineers to ensure expected “graceful” degradation on the home page for every failure scenario involving this many endpoints. Therefore the SRE team created a service account (not associated with a real member) and gave it access to all of the LinkedIn products.
To automatically test web pages the team leverage an internal framework at LinkedIn that allows for Selenium testing at scale. They send commands to inject the disruption information into the invocation context (IC) via a cookie (which only functions on their internal network), authenticates the user, and then loads the URL defined in the test. The team considered several ways to determine success after injecting failures, but for the first iteration of the framework they decided to simply provide default matchers for “oops” (error) pages and blank pages. If the page loaded by Selenium matched one of these default patterns, they would consider the page to not have gracefully degraded.
When discussing lessons learned, Rosen discusses that the service accounts created did not always mirror real members’ experiences on LinkedIn. For example, an SRE created a test to check for graceful degradation on the Profile Views page, and initially every single downstream failure resulted in a test failure, meaning that the page returned an error. However, upon logging in as the test user the problem was revealed: because this test user had no connections on LinkedIn, and nobody was visiting its profile, the Profile Views page returned an error, even without any failures injected. The fix was to provide the associated data by viewing the test user’s profile, but it brought the issue to light that “test users aren’t always great representations of what people really see on LinkedIn.” The plan to avoid this in the future is to allow users of LinkedOut to provide their own test users, which they can pre-populate with data.
At LinkedIn the mechanism of triggering failures via feature targeting (flagging) is simple due to the maturity and power of the LiX experimentation framework. Engineers create a targeting experiment based on the failure parameters that they specify. Once the experiment is activated, the disruption filter picks up the change, via a LiX client, and fails the corresponding requests. Using LiX also allows an engineer to easily terminate failure plans (“within minutes”) that have gone wrong or are impacting end-users inappropriately.
The IC injection mechanism enables quick, one-off testing in the browser by specifying disruption data via a cookie. To discover the downstream services involved within the creation of a web page the engineers use a service within LinkedIn called “Call Tree” that consumes Kafka events produced by services when they handle requests and builds a corresponding call tree that show all the steps involved. Call Tree allows a grouping key to be set as a cookie within a request, which links together all the call trees it discovered for a given request. The SRE team built a Chrome extension that make the service discovery and IC fault injection easier for engineers performing these tests. Once the engineer selects failure modes for all applicable resources, the extension creates a disruption JSON blob for these failures, sets a cookie to inject it into the IC, and then refreshes the page with the failure applied.
Although the recent blog post focuses on the technical aspects of failure injection, a previous post “Resilience Engineering at LinkedIn with Project Waterbear” discusses the importance of establishing a supportive culture, focusing on the human-side of resilience testing, and ensuring that chaos tests are designed and run by following the scientific method and creating hypotheses.
At LinkedIn, SREs have been working cross-functionally with service owners and their teams on a project that was named “Waterbear” (after the nickname for the tardigrade, a notoriously resistant creature that can survive, among other places, in the vacuum of space). The post suggests that Waterbear should be thought of as providing “application resilience” as a service; SRE teams own the domain and the problem, and “measure, analyse, and provide best practices to help improve the resilience of each application for the application owners and engineering teams”. One of the core LinkedIn SRE values is, “attack the problem, not the person”, which in turn is a a reflection of the company values, “act like an owner” and “relationships matter”.
Knowing that an individual service owner won’t be shamed or verbally attacked when a problem occurs creates a much more positive environment for problem-solving. This also makes it easier for the SRE organization to influence the decision-making process throughout the engineering teams in order to make changes to shared infrastructure
The latter blog post concludes by stating that the development team and leadership team have been very supportive of Waterbear and LinkedOut.
As long as we have scientific approaches to validate our hypothesis against failure scenarios, the ability to limit the blast radius of failure, the capability to derive clear action items to improve system resilience, and can build proper tooling/systems to make running such tests extremely easy, every team at LinkedIn can contribute to resilience engineering efforts.
Additional information on LinkedOut can be found on the LinkedIn Engineering blog and the associated Rest.li GitHub repositories.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The lean startup Build-Measure-Learn feedback loop can be embraced into existing organizations providing benefits of fast validation of products and services;
- Agile and various other lean agile improvement schemes provide partial silo based optimization – that fails improving the organization as a whole;
- To be successful, we must articulate the lean agile engine and its relationship to the existing business management frameworks; the feedback loop between product or service development and the customer must be identified, silos have to be removed and impact based delivery metrics put in place;
- Inside out thinking is rampant in big organizations; however it is only through empathy and trial and failure that you can receive practical feedback from your customer, not by imposing the proposed solutions and hoping that they will resonate with the customers;
- The lean startup program transforms individuals’ traditional thinking to an iterative assumption-validation mindset – starting with business rather than engineering and removing software code from initial assumption validation!
The book The Pragmatist’s Guide to Corporate Lean Strategyby Michael Nirexplores how to practically adopt lean enterprise and lean startup concepts to turn your company into a lean agile enterprise promoting business agility. It provides examples from companies that have applied these concepts, describes the strategy, best practices, anti-patterns, and gives insights into lean and agile transformations.
InfoQ readers can download a sample of the book:
Cadence is King – Chapter from Pragmatist Guide to Corporate Lean Strategy.
InfoQ interviewed Nir about what makes it difficult for large organizations to focus on customers and how to overcome this, how large organizations can apply lean startup concepts, how organizations can apply a framework for adopting lean, and how to deal with the main challenges of lean agile transformations.
InfoQ: What made you decide to write this book?
Michael Nir: Last summer InfoQ interviewed me about Rethinking Lean Startup at a Big Corporate. At that time I was working with several clients rolling out lean startup and promoting business agility. At these transformations I encountered recurring anti patterns in how organizations, especially big ones, implement agile, lean, design thinking and then try to scale it all together. The culprit is not the specific method or approach; the underlying concepts are solid. Rather, it is orchestrating the overall strategy and achieving the business impact and value that is missing. Thus, Agile is relegated to software and product, Scrum tends to be even more local; Kanban is an OPS thing, DEVOPS uses jargon hardly any business person understands, Lean UX and design thinking never cross UX boundaries; Innovation labs and user centered design workshops are failing to integrate into product development, on top of which scaling efforts limit themselves as well to local optimization. In this wildly fragmented landscape it is difficult to truly impact the customer and create true business value. I find that lean startup provides the comprehensive holistic and overarching engine for value driven growth. It is the ultimate driver for business agility.
In the book, I share the good, the bad, and the ugly of enterprise-level adoption of lean startup practices (what we call a “lean corporation”). I provide step-by-step instructions specifically targeted to technologists in multiple roles. Building experience on Steve Blank and Eric Ries’ “lean startup” framework, this book takes these concepts to the next level by providing best practice guidelines, sharing “horror stories” and common anti-patterns in a fun and engaging way.
InfoQ: For whom is the book intended?
Nir: The book is intended for a broad audience – those in engineering, product development, technology and business management interested in strategy, business agility, lean management, execution, and emerging technologies. It takes a broad yet in depth view of contemporary advances in entrepreneurial management and leadership. It focuses on the organizational change necessary for enterprises facing market disruption.
I had some great endorsements for it already by well known individuals, together with blunt and harsh criticism from others, also well known individuals. Naturally I disliked the criticism, yet I have to agree that the book is not an introduction guide to agile, scrum or lean. I skip the basics and assume my smart readers are versed in many of the existing approaches to agile and lean, or can look these up on their own. My approach is sometimes associative, and I find it difficult to limit my writing to text book style writing. Hence, the book is intended for smart readers 🙂
InfoQ: What makes it difficult for large organizations to focus on customers?
Nir: First and foremost, they’ve been in business for years, they make money, and they are comfortable within the confines of the organization; they don’t feel the need to interact with a consumer. Going outside of the office and actually asking a customer what they want is something they just don’t do. The concept of gemba is foreign to them. Most of them are convinced that they are not allowed to do it, that it’s the job of others to interact with consumers. The same is true for developing solutions for internal consumers; the prevailing mindset is “it’s not our job to ask questions.”
Inside-out thinking is a recurring challenge for enterprises. For example, traditional insurance companies focus on making it hard for the consumer to receive their money when submitting a claim. This isn’t a specific hurdle but rather a mindset of the insurance company around which many of the internal automated processes are built. They make it hard to issue a claim, they make it difficult to get support on the status of the claim, they instill an internal mindset in which the consumer is dishonest, they follow through with slow response to consumer requests, they require paper and fax be used rather than email (blaming regulation); the list goes on and on.
The story about the VP of product at a big financial business who told me, “but I have a detailed survey of my customers” when explaining his decision to offer 11 web pages full of 121 product variants, never gets old.
Can it be any different? Check out what disruptor insurance providers are doing.
InfoQ: What can be done to overcome this?
Nir: Implementing outside-in thinking in these organizations is more than a well designed exercise in creating a persona – which is often how organizations start with human centric design – it’s a nice to have – but the wrong first step.
Rather, it is an ongoing battle to break free from the prevailing mindset of “the consumer is our enemy” and “there’s a zero sum game between us and the consumer” to embracing collaboration with the consumer. Having executives participate in sessions with real people as part of structuring the persona has a tremendous impact and leads to true empathy; the outside-in thinking usually follows.
In many cases, there is an assumption that people who create software and products know what their customers actually need. There are two problems with that: the first is assuming that there is a single homogenous customer type. There never is. There are multiple customers with conflicting demands and preferences, so it is important to identify their types and make decisions about who your customers actually are. Second, you can’t know what the customers need until you talk to them and ideally give them a prototype to try out and provide feedback on. Fall in love with the problem, not a solution. It is only through empathy and trial and failure that you can get practical feedback from your customer, not by imposing the proposed solutions and hoping that they will resonate with the customers.
InfoQ: How can large organizations apply lean startup concepts?
Nir: In the book, the first part is named: Five Lessons from Lean Startup Thinking. I detail the lessons I learned from application of Agile and Scrum,Scaled Agile, Lean startup, Design Thinking, Lean UX,DEVOPS, Four Disciplines of Execution and more.
The five lean startup lessons are:
- Start with the customer in mind
- Define and communicate the mission and vision
- Synthesize an integrative operating model
- Identify metrics that matter
- Pivot or persevere
When my team tried to implement these concepts we ran into the proverbial road blocks and developed work-arounds that I share in the book.
In my opinion the most important step for big organizations to succeed with applying lean enterprise concepts is by Synthesizing an integrative operating model, otherwise they will fail.
In fact, The organizations I helped create a lean enterprise engine already had a myriad of frameworks in place. Many were using agile as a delivery method, on top of which they implemented a scaled agile delivery to manage multiple delivery teams. In an internal system transformation at a Fortune 100 insurance company, they called their scaled agile delivery mechanism “the factory” and each delivery team used scrum to manage itself. At the same enterprise, they had UX experts and a Lean UX delivery team that had its own development resources. In addition, there was an ongoing DEVOPS effort to enable faster delivery of results across operations.
This familiar landscape exemplifies the well-known silos that impede the benefits that supposedly emerge from the various frameworks. I experienced agile and Lean UX initiatives that impacted parts of the organization without improving overall business outcomes. I knew that we had to take a different approach when creating a lean enterprise engine; otherwise it would become another failed improvement effort. The challenge we had was that lean startup discusses a vision of entrepreneurship but fails to provide a guiding framework of how to get there. Both books by Ries are visionary and insightful, yet they do not offer the valuable steps to getting the system up and running. Q&A with Infoq – Eric Ries The Startup Way.
We must identify the holistic delivery approach and where our various improvement initiatives fit in it!
To be successful, we must articulate the lean engine and its relationship to the existing frameworks.
The feedback loop between product or service development and the customer must be identified, silos have to be removed, and impact-based delivery metrics put in place.
Speaking of metrics – many agile transformations embrace team velocity as one of the three top metrics, and promise executives an ongoing improvement of velocity. One may ask why velocity is the wrong metric. Focusing on velocity as a metric is similar to focusing on output rate in production; it is a wrong metric to measure and celebrate. However since it is so easy to measure, organizations prefer to focus on it rather than explore leading metrics that are impactful.
InfoQ: How can we find out sooner if we should persevere or pivot with a new product?
Nir: Metrics, Metrics and metrics! See for example an interview with InfoQ about metrics for team – Conduct Objectives for High Performance Teams. All of us have been part of projects that have failed. My pet peeve is that someone will say at some point – at least we learned something.
It reminds me of the movie: Burn After Reading by the Coen brothers. The last scene shows a CIA executive asking his subordinate, “what have we learned from the debacle?”, to which he answers, “I don’t know”. The senior then says, “well we know not to do it again – but I don’t really know what we did…”
Always start by identifying what the behaviour or learning that you’re expecting is – define the assumption and the hypothesis; only then create the solution and offer it to customers – both internal and external- evidence based methods!
InfoQ: What can large organizations do to integrate a mechanism for pivoting into their operating model?
Nir: While startups can pivot themselves on a daily basis, in bigger businesses we learned we had to integrate the concept of the pivot into the operating model. We had to explain to the organization the accepted amount of pivots in a certain time frame; in other words, how many pivots were allowed in a given timeframe. We found that the concepts of a pivot were not necessarily foreign to the portfolio management team and the program management office.
Traditional product development frameworks introduce phase gates to support a GO/NO GO decision at various intervals of the development process. In practice though, these become mere administrative hurdles to overcome as the project or program progresses towards completion and the product is released to the market. Often the phase gates involve only a review of documentation, rather than evidence based feedback to a working model of the product.
This is where pivoting provides a different framework than the traditional phase gate approach.
The decision to pivot must be based on empirical validation evidence (relevant lead-impact metrics).
This evidence is collected from real consumers (representing the selected persona) who interact with a partial solution – an MVP. The MVP integrates important and uncertain assumptions that we identified enabling us to measure true alignment with our vision. These pivot decisions are in line with our vision and mission to deliver the right products and features that would delight our customers.
The framework brings together concepts from various schools of thought – thus it is crucial to Synthesize an Integrative Operating Model. Otherwise pivoting, which is at the heart of a successful lean enterprise implementation, will not be truly accepted as an option and will be viewed as a failure rather than as validated learning.
Make pivoting a celebrated event. Bigger organizations are reluctant to pivot and see a pivot as a threat. So lower the danger, reduce the impact, and demonstrate the benefits of the pivot.
InfoQ: Your book provides a framework for adopting lean. What does it look like?
Nir: I discuss five techniques to succeed, progress, and change, along with the implementation timeline:
- Define the mission
- Identify customer personas
- Implement the prototype MVP and program training
- Run experiments with customers to validate your hypotheses
- Pivot or persevere in a build-measure-learn cycle
I develop a daily schedule that includes the above five techniques to succeed and their focus in the implementation timeline of the first 30 days, the first 90 days, and the first 12 months.
While my initial approach was that of a framework-by-framework analysis of tools and techniques to succeed, I felt that synthesizing the information from the day-in-the-life perspective would provide a comprehensive map of the step-by-step plan for corporate lean strategy and execution. The day-in-the-life perspective also enables getting started faster and delivering results quicker.
Every chapter has a mapping of the activity and the time recommended spending on that activity.
For example during the first 30 days it is as below:
Activity
Time Spent
Comments
Define vision
50%
Collaborative vision definition
Identify customer personas
10%
Focus on outside-in point of view
Prototype MVP and program training
25%
Train executive leadership
Run experiments
10%
Prepare for experiments
Pivot or persevere
5%
Ideate potential pivots
InfoQ: How can organizations apply this framework?
Nir: Focus on getting business people in the room – that’s one of the things I like about the four disciplines of execution. If you want to change how an organization does business, it is not enough to have engineers practice Scrum; there has to be business buy in. It all connects to this amorphic idea of business agility. I already discussed it on rethinking lean startup in a big corporate. We found that having the PMO lead and support the effort makes lots of sense. This is another gainful insight – use existing common structures yet repurpose them.
Once you have business buy in, and in the same room, train them, get them to come up with ideas. I prefer conducting an executive workshop; however this could work with any team. Then have them break down the assumptions lurking their ideas. Next step, have them rank the ideas according to most important and most uncertain. Let them pick a risky and uncertain idea and identify the hypothesis behind the assumption. This is a tricky step where many need coaching; help them distinguish between an assumption and a hypothesis. Ask them how they might validate the hypothesis – they need to create a tangible test that can be quickly validated.
At this step, as we start the process, I ask them to validate without any software being written! Software is an enabler that isn’t necessary to validate business assumptions!
Sometimes we follow with a crazy five days MVP – similar to The Design Sprint concepts, however less UX oriented than what is proposed there.
The teams then proceed to create a Kanban board of their validation activities. We ask them to present their validations and pivots – similar to an agile demo – in 90 days. We grow the program organically, and we add development members into the teams. This is the opposite of how agile teams normally grow – where scaling is usually seen as growing organically from development; I believe that’s the main reason agile is limited in impact. Business agility has to be customer focused; it is not about having dev teams deliver faster.
InfoQ: What are the main challenges of agile transformation, and how can we deal with them?
Nir: That’s a great question! And one that I am often asked when speaking to various audiences.
There are several recurring patterns of challenges – they are all around vision, leadership and alignment.
So many companies are ’agile by name only’nowadays, where it is crucial to start with the basics – when you say agile what do you mean? What are you trying to achieve? What are you trying to solve? What is your vision for business agility – rather than creating merely agile engineering teams?
“Big bang” (full reorg), top-down, lean agile transformation fails to address the minds and hearts of middle managers who play an important role in any organization. Not building trust with this group is the first sign of failure for a lean agile coaching organization.
When you initiate a lean agile transformation, spend extra time on expectation setting.
Ensure that the roadmap of the lean agile transformation, including deliverables with related measurements and milestones, are defined as is the process to collect this data. Set regular data reviews and ensure that the format of the reports that you provide meets the expectations of your audience. Ideally, set up an automated report from a lifecycle management tool of your choice.
I mentioned that velocity of a team is a vanity metric that is not meaningful for the business because it reflects output – quantity rather than quality and business relevance, on top of which it is easy to game it. When you focus on velocity you also impede the breaking of silos – since you encourage teams to throw their work over the wall so to speak
Lastly – in my opinion – without feedback loops with customers, agile is as wasteful as waterfall; the only reason for adopting lean agile is to activate a fast-responsive feedback loops that enables data based decisions for product and service development.
About the author
 Michael Nir is a keynote speaker, best selling author and Lean Agile inspiration expert; known for his passion, creativity and innovation. The author of ten books on influence, consumer experience, and Agile project management, Nir delivers practical skills gained from eighteen years of experience leading change at global organizations in diverse industries.
Michael Nir is a keynote speaker, best selling author and Lean Agile inspiration expert; known for his passion, creativity and innovation. The author of ten books on influence, consumer experience, and Agile project management, Nir delivers practical skills gained from eighteen years of experience leading change at global organizations in diverse industries.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Facebook’s globe-spanning network consists of both wide-area backbone networks as well as edge Points-of-Presence, which support end-user facing requests and internal traffic, both of which have been growing at a rapid pace. To meet increased network provisioning and maintenance demands, the network engineering team built Vending Machine, a workflow framework that utilizes Zero Touch Provisioning (ZTP) methods to run code to perform any kind of configuration on network devices.
Zero Touch Provisioning (ZTP) is a mechanism by which network devices like switches can be configured from their factory-default state without any human intervention. Supported by many networking vendors, it involves the device sending a request on bootup, usually via DHCP, to fetch the location of a central server from which it can download and apply configuration. This process can subsequently involve automation tools like Chef and Puppet. Network devices that have been traditionally configured using the CLI by a human operator can be automatically setup. As switch vendors started supporting ZTP using DHCP, Facebook’s team worked with IP routers and optical equipment vendors to support similar features. The existing automation work that the Facebook team had done in DHCP-based auto-provisioning could then be reused.
Facebook has built network automation tools in the past, but most of its network provisioning and configuration was done via Method of Procedures (MOPs). MOPs were essentially documentation, like runbooks, that engineers had to follow. As increasing deployment demands led to hiring more engineers to run these MOPs, they became more complicated and error prone. Facebook’s original provisioning system had its roots in a console based system. Over the years, new roles, paths and platforms were added, which made the MOP based system harder to use. The framework called Vending Machine (VM) grew out of these needs. Vending Machine takes “a device role, location, and platform” as input and returns “a freshly provisioned network device, ready to deliver production traffic” as output, according to the article.
Facebook engineers describe the motivation behind building VM in a talk:
In response to a DHCPDISCOVER message, a device is given either a configuration file or a configuration script to execute on the network device. For the scripted option, how the script executes and what it’s capable of varies by each vendor (so far) and by network role. After configuring itself, the device will typically reboot. But in real life we have other things to do before releasing a device to production. We also have had interesting problems of not being able to generate configuration prior to physically installing a device – so if you don’t have configuration pre-generated, how do you respond to a DHCP request with a configuration file? This problem led us to develop a workflow automation system wrapped around ZTP.
According to the talk, Facebook had to make changes in its DHCP stack, which is based on ISC’s open source DHCP server while building VM. A special piece of Python code is downloaded on to the network device by standard ZTP methods, which becomes the starting point for a VM workflow. The Python agent downloads instructions, configuration, firmware and patches from the VM server to the network device, installs them, and sends the output log and exit status back to VM.
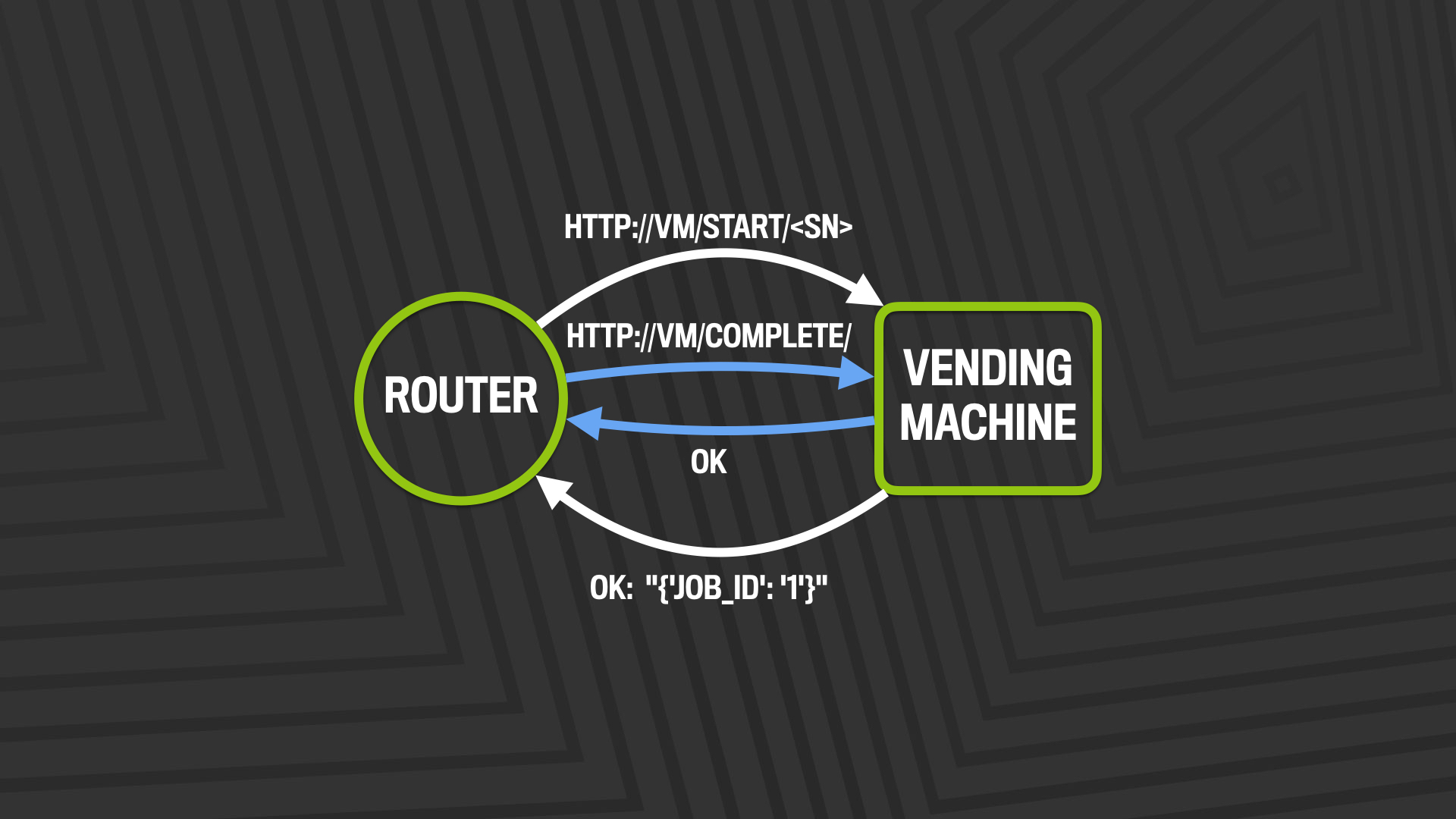
Image courtesy : https://code.facebook.com/posts/166812063987311/scaling-the-facebook-backbone-through-zero-touch-provisioning/
VM follows a workflow model where engineering teams could run code in any language in a series of standard steps. Failure of any step would result in requeuing of the step for future execution. Each step can consist of a standalone binary. It is worth noting that the steps can be written in any programming language. Gradually, the teams moved away from MOPs as more and more VM steps were developed to replace them. VM speeded up the provisioning process further by determining which steps were independent and running them in parallel.
VM’s future roadmap includes orchestration of groups of VM jobs, and fully automated rebuilds of planes in Facebook’s global network. VM is an example of the recent wave of DevOps principles being applied to networking.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
DataMelt computational platform for data analysis organized its Java documentation:
- Java API organized by topic: http://jwork.org/dmelt/api/
- Full Java API with links to source code: https://jwork.org/dmelt/javadoc/
- DataMelt examples: http://jwork.org/dmelt/code/
Uncategorized
Presentation: The Future of Blockchain
MMS • RSS
Bio
Paul Puey (CEO, Edge) Alex Bosworth (Director, DMG) Diego Espinosa (CEO, Linnia) Joshua Satten (Director, Wipro) Jessica Groopman (Industry Analyst, Kaleido Insights) – Moderator.
 Global Big Data Conference’s vendor agnostic Global Blockchain Conference is held on April 2nd, April 3rd, & April 4th 2018 on all industry verticals(Finance, Retail/E-Commerce/M-Commerce, Healthcare/Pharma/BioTech, Energy, Education, Insurance, Manufacturing, Telco, Auto, Hi-Tech, Media, Agriculture, Chemical, Government, Transportation etc.. ). It will be the largest vendor agnostic conference in Blockchain space. The Conference allows practitioners to discuss Blockchain through effective use of various techniques.
Global Big Data Conference’s vendor agnostic Global Blockchain Conference is held on April 2nd, April 3rd, & April 4th 2018 on all industry verticals(Finance, Retail/E-Commerce/M-Commerce, Healthcare/Pharma/BioTech, Energy, Education, Insurance, Manufacturing, Telco, Auto, Hi-Tech, Media, Agriculture, Chemical, Government, Transportation etc.. ). It will be the largest vendor agnostic conference in Blockchain space. The Conference allows practitioners to discuss Blockchain through effective use of various techniques.
