Month: June 2018


MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
A new side-channel vulnerability affecting Intel processors, known as TLBleed, can leak information by snooping on Translation Look-aside Buffers (TLBs), writes VUsec security researcher Ben Gras.
Gras, who will present his accomplishment at next Blackhat 2018 conference, claims he could extract encryption keys used by GPG:
Our TLBleed exploit successfully leaks a 256-bit EdDSA key from libgcrypt (used in e.g. GPG) with a 98% success rate after just a single observation of signing operation on a co-resident hyperthread and just 17 seconds of analysis time.
TLBs are a kind of cache that is used to speed up translation of frequently used virtual addresses into physical memory. TLBleed shows a way for a hyperthread to access information belonging to another hyperthread running on the same core by using TLBs to detect when valuable information is available in the CPU registers. This vulnerability is not related to Spectre and Meltdown, both of which exploits speculative execution glitches to leak information from the CPU cache.
What is most concerning about this vulnerability is the fact it uses data accesses and not the code path being executed, which means existing protections for already known side-channel attacks may be not effective against TLBleed. Indeed, Gras mentions a second attack based on TLBleed that can leak bits from the recent libgcrypt version that included a side-channel resistant RSA implementation. This second type of attack leverages machine learning techniques to be more effective. writing for The Register, Chris Williams, who had access to a white paper by Gras and others, explained that the team used a classifier to identify the execution of sensitive operations, including cryptographic operations, based on TLB latencies.
Intel will not address this vulnerability, arguing that a program that correctly guards itself against other kinds of side-channel attacks, e.g., by making its patterns of data access look the same both when using cryptographic keys and when not, will also be immune to TLBleed. While acknowledging this, Gras maintains that there are very few programs that are so perfectly written as to prevent side-channel attacks, as the leakage of RSA keys from libgcrypt shows.
This is not the stance taken by OpenBSD maintainers, who decided to disable the use of simultaneous multi-threading (SMT) for Intel processors:
Since many modern machines no longer provide the ability to disable Hyper-threading in the BIOS setup, provide a way to disable the use of additional processor threads in our scheduler. And since we suspect there are serious risks, we disable them by default.
OpenBSD will extend this policy to other CPUs and other architectures in the future.
A less intrusive OS-level mitigations to TLBleed would be preventing the concurrent execution of two threads belonging to different processes on the same core, which is not always a trivial change to the OS scheduler, though.
It is not yet clear whether other vendors will do anything to address TLBleed at the OS level or if Cloud providers will offer the possibility to prevent two different virtual machines from sharing the same core. InfoQ will continue reporting as new information will become available.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Microsoft Edge now supports the recently ratified W3C WebDriver recommendation, making it easier to automate unit and functional tests with Edge. Edge WebDriver is also now an Edge Feature on Demand, providing automatic WebDriver updates for each release of Edge.
Numerous versions of the WebDriver protocol have been created over the years, originating in the Selenium project before moving to the W3C for standardization. For JavaScript testing, several libraries including Intern and WebDriver.io help normalize the testing differences across browsers. With the W3C WebDriver protocol reaching recommendation status, hopefully, the inconsistencies in testing across browsers diminish over time.
Another major challenge with cross-browser testing is keeping each version of WebDriver up to date for each browser release. Previously WebDriver instances were developed by third-parties and were often out of sync with new versions of browsers. More recently, browser vendors have taken ownership of their WebDriver implementations.
This release of WebDriver for Edge introduces several improvements for testing on Edge.
The Actions API provides low-level input into the browser via action sequences, allowing developers to test more complex scenarios via mouse and keyboard input. New testing commands include support for getting timeouts, getting and setting the window dimensions, and getting the property of an element. Additionally, many bugs, edge cases, and inconsistencies with other WebDriver implementations got fixed in this release.
It is also possible to test Progressive Web Apps (PWAs) with Edge WebDriver, as well as out of process WebViews, which allow for embedding a web browser view into a native Windows 10 application. These changes make it easier to test all forms of Edge-based web applications.
To use Edge and WebDriver today, within Edge developers should enable Developer Mode by opening the Settings app and go to “Update & Security”, “For developers”, and select “Developer Mode”. Developer Mode automatically installs the appropriate version of WebDriver. With this change to providing WebDriver as a Feature on Demand, Microsoft will no longer provide standalone downloads for Microsoft Edge WebDriver going forward for current and future versions of Edge.
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, N.Y., June 26, 2018 — MongoDB, Inc. (“MongoDB”) (Nasdaq: MDB), the leading modern, general purpose database platform, today announced the pricing of $250 million aggregate principal amount of 0.75% convertible senior notes due 2024 in a private placement to qualified institutional buyers pursuant to Rule 144A under the Securities Act of 1933, as amended (the “Securities Act”). The aggregate principal amount of the offering was increased from the previously announced offering size of $200 million. MongoDB also granted the initial purchasers of the notes an option to purchase up to an additional $50 million principal amount of notes. The sale of the notes is expected to close on June 28, 2018, subject to customary closing conditions.
The notes will be general unsecured obligations of MongoDB and will accrue interest payable semiannually in arrears on June 15 and December 15 of each year, beginning on December 15, 2018, at a rate of 0.75% per year. The notes will mature on June 15, 2024, unless earlier converted, repurchased or redeemed. The initial conversion rate will be 14.6738 shares of MongoDB’s Class A common stock per $1,000 principal amount of notes (equivalent to an initial conversion price of approximately $68.15 per share). The initial conversion price of the notes represents a premium of approximately 27.50% over the last reported sale price of MongoDB’s Class A common stock on June 25, 2018. The notes will be convertible into cash, shares of MongoDB’s Class A common stock or a combination of cash and shares of MongoDB’s Class A common stock, at MongoDB’s election.
MongoDB may redeem the notes, at its option, on or after June 20, 2021, if the last reported sale price of MongoDB’s Class A common stock has been at least 130% of the conversion price then in effect for at least 20 trading days (whether or not consecutive) during any 30 consecutive trading day period (including the last trading day of such period) ending on the date on which we provide notice of redemption at a redemption price equal to 100% of the principal amount of the notes to be redeemed, plus accrued and unpaid interest to, but excluding, the redemption date.
MongoDB estimates that the net proceeds from the offering will be approximately $241.8 million (or $290.4 million if the initial purchasers exercise their option to purchase additional notes in full), after deducting the initial purchasers’ discount and estimated offering expenses payable by MongoDB. MongoDB intends to use a portion of the net proceeds from the offering to pay the cost of the capped call transactions described below. MongoDB intends to use the remainder of the net proceeds for working capital and other general corporate purposes.
In connection with the pricing of the notes, MongoDB entered into capped call transactions with one or more of the initial purchasers and/or their respective affiliates or other financial institutions (the “option counterparties”). The capped call transactions are expected generally to reduce potential dilution to MongoDB’s Class A common stock upon any conversion of notes, with such reduction subject to a cap initially equal to $106.90 (which represents a premium of approximately 100% over the last reported sale price of MongoDB’s Class A common stock on June 25, 2018). If the initial purchasers exercise their option to purchase additional notes, MongoDB expects to enter into additional capped call transactions with the option counterparties.
MongoDB expects that, in connection with establishing their initial hedges of the capped call transactions, the option counterparties or their respective affiliates may enter into various derivative transactions with respect to MongoDB’s Class A common stock and/or purchase shares of MongoDB’s Class A common stock concurrently with or shortly after the pricing of the notes. This activity could increase (or reduce the size of any decrease in) the market price of MongoDB’s Class A common stock or the notes at that time.
In addition, MongoDB expects that the option counterparties or their respective affiliates may modify their hedge positions by entering into or unwinding various derivatives with respect to MongoDB’s Class A common stock and/or purchasing or selling MongoDB’s Class A common stock or other securities of MongoDB in secondary market transactions following the pricing of the notes and prior to the maturity of the notes (and are likely to do so on each exercise date for the capped call transactions). This activity could also cause or avoid an increase or a decrease in the market price of MongoDB’s Class A common stock or the notes, and to the extent the activity occurs during any observation period related to a conversion of notes, this could affect the number of shares and value of the consideration that a noteholder will receive upon conversion of its notes.
Neither the notes, nor any shares of MongoDB’s Class A common stock issuable upon conversion of the notes, have been registered under the Securities Act or any state securities laws, and unless so registered, may not be offered or sold in the United States absent registration or an applicable exemption from, or in a transaction not subject to, the registration requirements of the Securities Act and other applicable securities laws.
This press release is neither an offer to sell nor a solicitation of an offer to buy any securities, nor shall it constitute an offer, solicitation or sale of the securities in any jurisdiction in which such offer, solicitation or sale would be unlawful prior to the registration or qualification under the securities laws of any such jurisdiction.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 6,600 customers in over 100 countries. The MongoDB database platform has been downloaded over 35 million times and there have been more than 850,000 MongoDB University registrations.
Investor Relations Contact:
Brian Denyeau
ICR for MongoDB
646-277-1251
Media Relations Contact:
MongoDB
866-237-8815 x7186
communications@mongodb.com
Forward-Looking Statements
This press release contains “forward-looking statements” within the meaning of federal securities laws, including statements concerning the expected closing of the offering and the anticipated use of proceeds from the offering. Forward-looking statements include all statements contained in this press release that are not historical facts and such statements are, in some cases, identified by words such as “anticipate,” “believe,” “continue,” “could,” “estimate,” “expect,” “intend,” “may,” “plan,” “project,” “will,” “would” or the negative or plural of these words or similar expressions or variations. These forward-looking statements are based on the information currently available to us and on assumptions we have made. Actual results may differ materially from those described in the forward-looking statements and are subject to a variety of assumptions, uncertainties, risks and factors that are beyond our control including, without limitation: market risks, trends and conditions; and those risks detailed from time-to-time under the caption “Risk Factors” and elsewhere in our Securities and Exchange Commission filings and reports, including our Quarterly Report on Form 10-Q filed on June 7, 2018, as well as future filings and reports by us. Except as required by law, we undertake no duty or obligation to update any forward-looking statements contained in this release as a result of new information, future events, changes in expectations or otherwise.
Article: App Architecture, iOS Application Design Patterns in Swift Review and Author Q&A
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The book tries to give a gradual introduction to each covered architecture starting from a general description of their features, then going into a more detailed discussion.
- The architecture of an application defines how it integrates different services, such as event handling, network and file services, graphics and window management, and more.
- Covered architectures go from the ubiquitous Model-View-Controller to a few more experimental ones, such as the Elm architecture.
- The key differentiator between architectures is the way they handle state representation and change.
App Architecture, iOS Application Design Patterns in Swift by Chris Eidhof, Matt Gallagher, and Florian Kugler presents a number of architectures for iOS and Swift applications, from the ubiquitous Model-View-Controller to a few more experimental ones. The book is accompanied by a set of videos that are available as a separate purchase and add a live-coding dimension to the book content.
The architecture of an application defines how it integrates different services, such as event handling, network and file services, graphics and window management, and more. The book targets both experienced and novice iOS app developers by providing ground-up explanations for all relevant concepts, including for example why model and view are such fundamental concepts. Furthermore, the book tries to give a gradual introduction to each covered architecture starting from a general description of their features, then going into a more detailed discussion.
The first architecture presented is the well-known Model-View-Controller (MVC), which is standard in Cocoa and aims to decouple the internal representation of information (model) from the ways it is transformed (controller) and presented to the user (view).
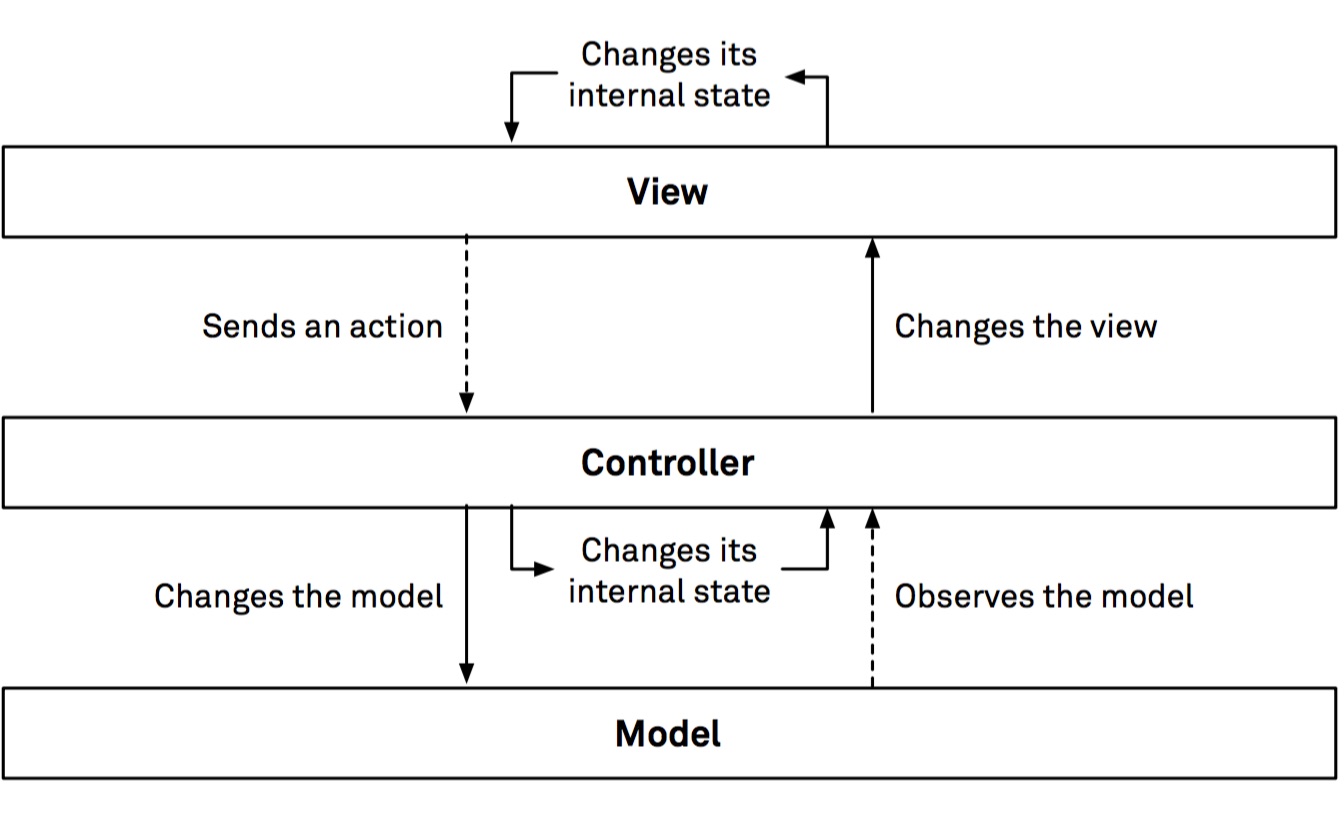
The second architecture, Model-View-ViewModel+Coordinator (MVVM-C), is a variation of MVC that stresses the importance of having multiple view-models, one for each view, and a coordinator in charge of dealing with transitioning from a view to another.
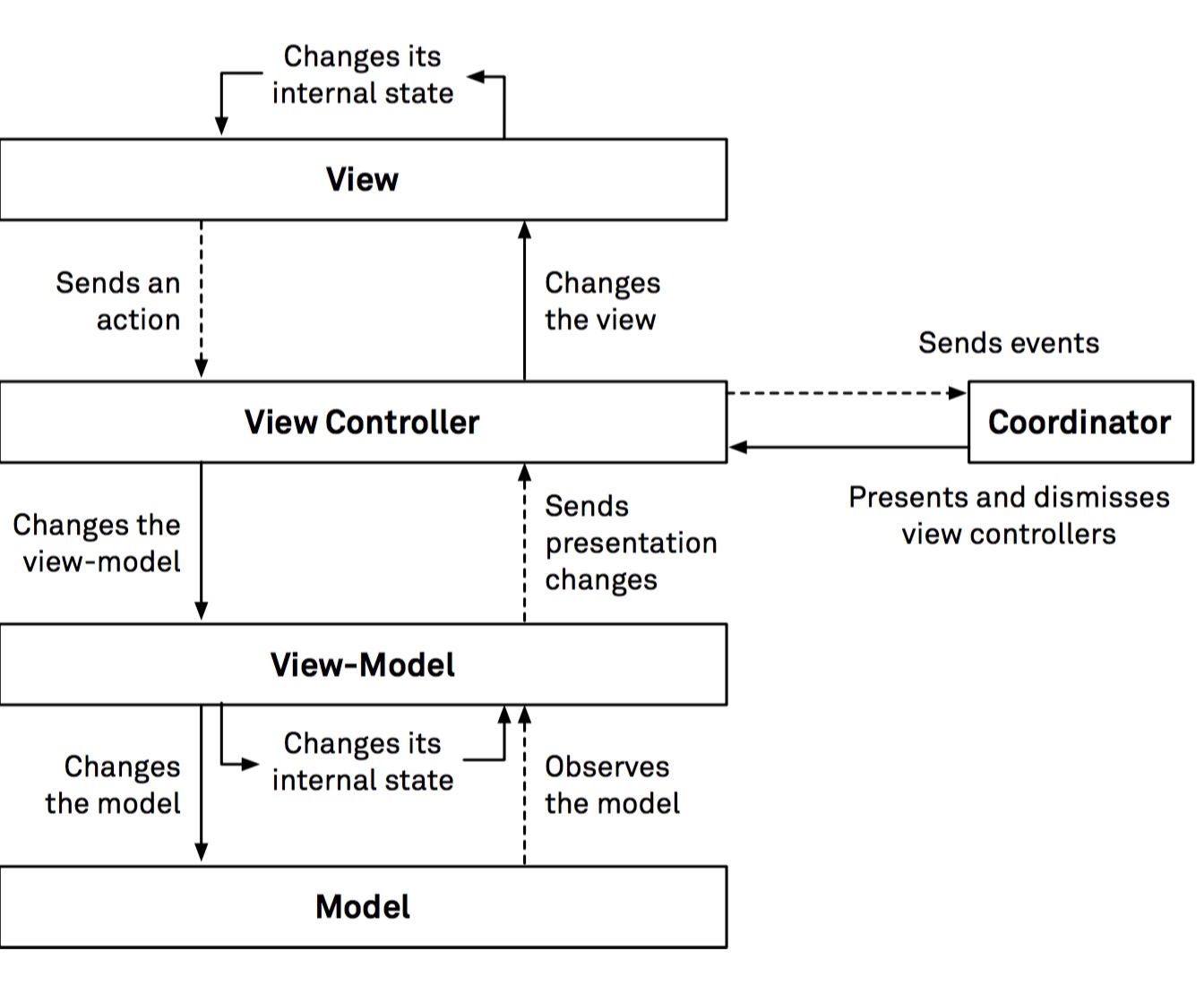
The next architecture presented, Model-View-Controller+ViewState (MVC-S), is a more experimental one, based on property observation and aiming to streamline view state management and to make it more manageable by explicitly encoding each view state change in a view state object. This makes the data flow through your app more unidirectional in comparison with MVC, where it is usual that views store part of their state and are taken as a source of truth regarding their state. On the other hand, in MVC-S, the view state is the source of truth regarding the view state.
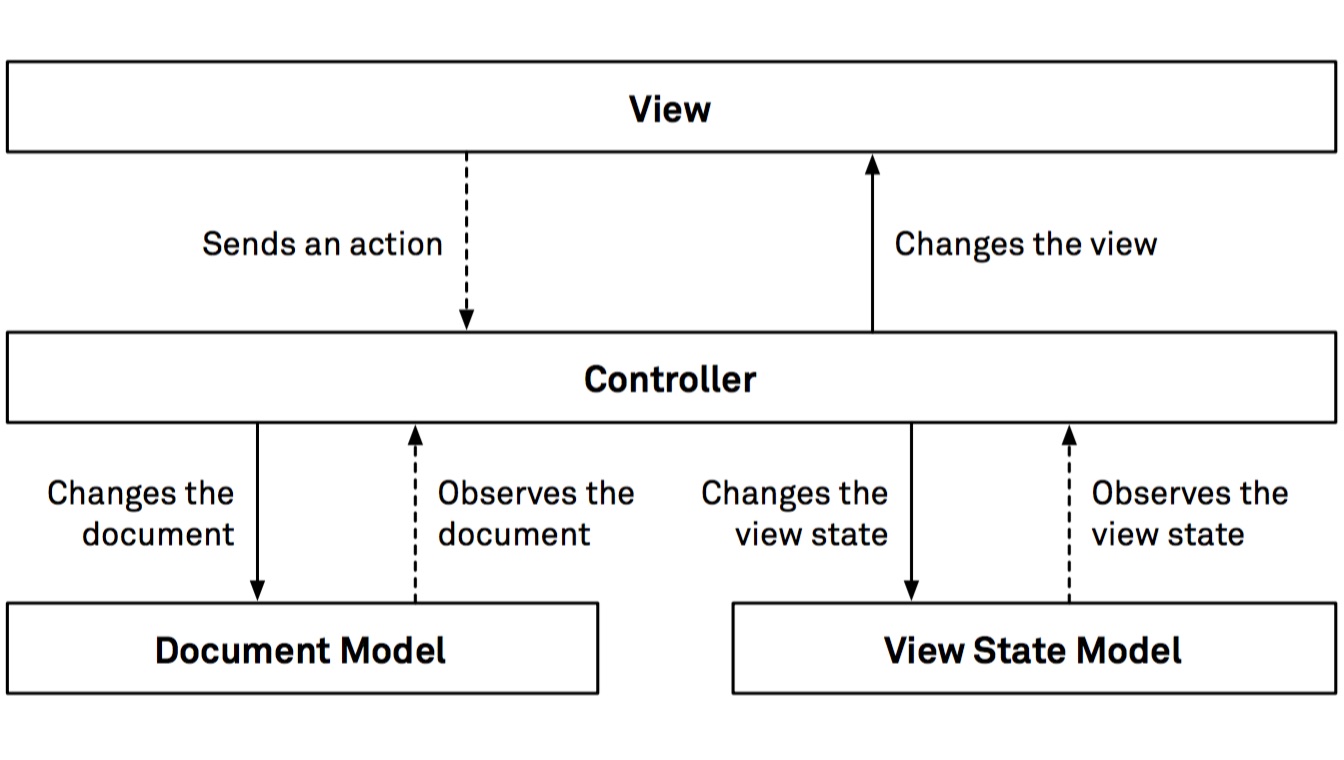
The fourth architecture presented, ModelAdapter-ViewBinder (MAVB), is another experimental pattern that fully leverages the idea of bindings, which lie at the foundations of Cocoa. In MAVB, you construct view binders instead of views and only deal with state in model adapters. A view binder wraps a view class and exposes a static list of bindings that affect the underlying view.
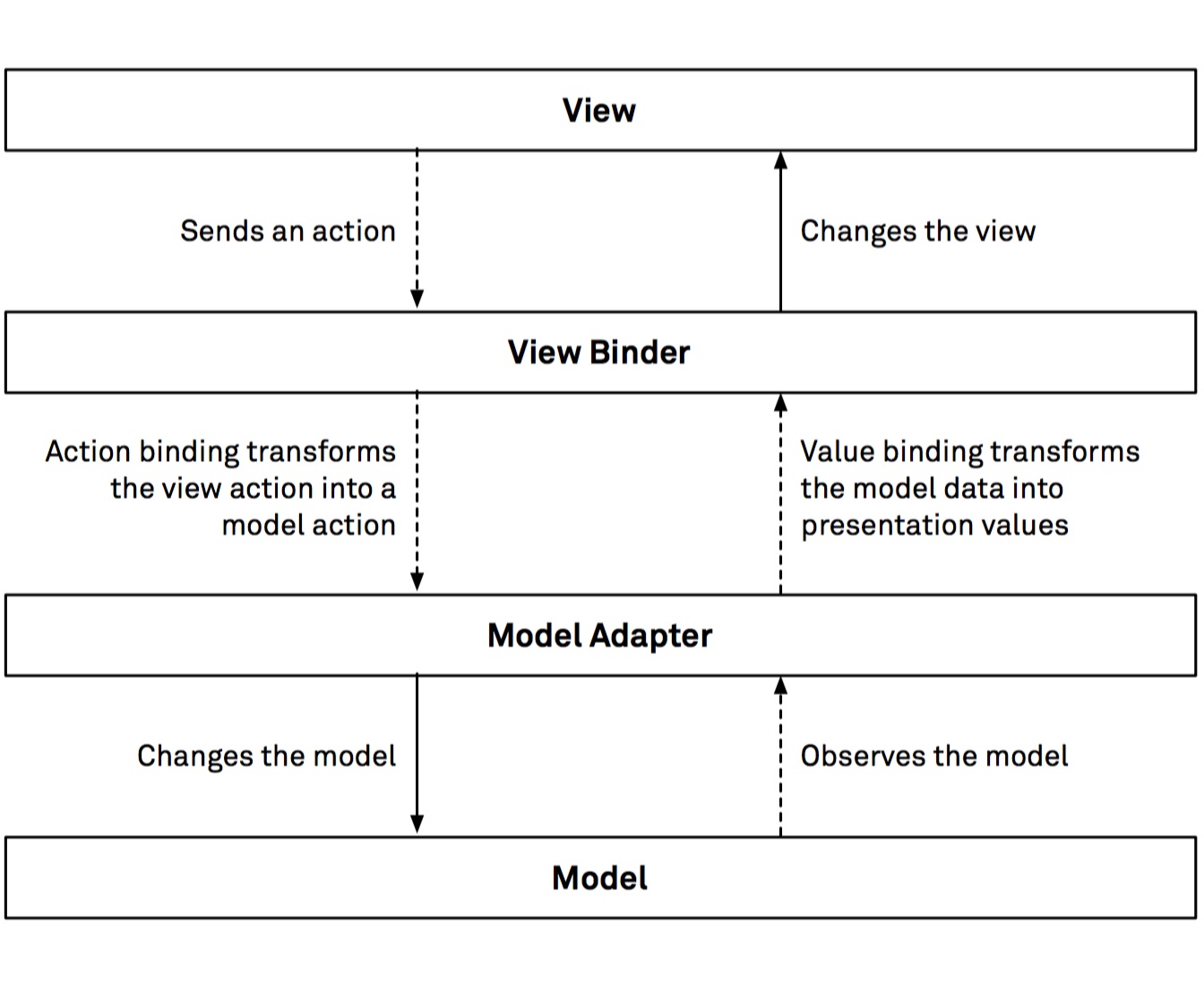
Finally, the book presents the Elm architecture (TEA) in the context of an iOS app, which is a more radical departure from MVC. The basic idea in TEA is encoding both model and view state in a single object, then change the app state by sending events to this object, and update the view through a virtual view hierarchy, which is derived from the state object. The appeal of this approach lies in the fact that the code that generate the view can be a pure function that computes the view hierarchy without any side effects.

The book describes the main features of each architecture and their pros and cons by implementing in five different ways a reference application that is able to record and play back voice notes. The reference application strikes a balance between complexity and simplicity to provide the right amount of information to the reader.
As mentioned, the book authors have recorded a collection of videos to accompany the book and that can be purchased separately. The videos offer over 8 hours of in-depth discussion covering all six architectural patterns, showing how to add a new feature to each of the five versions of the recording app, and going through the whole process of implementing a simple app for each of the covered architectures.
InfoQ has taken the chance to speak with Chris Eidhof, Matt Gallagher, and Florian Kugler to learn more about their book.
Could you summarize your background and your experience with iOS app architectures?
Chris Eidhof: Ever since the release of the first public SDK, I’ve been developing apps for iOS, first in Objective-C and later in Swift. I’ve seen very different kinds of architectures with both clean and messy code bases. Before writing code for iOS, I was deeply into functional programming. Today, I have large functional code bases, as well as large object-oriented code bases (and everything in between!).
Matt Gallagher: I’ve been writing iOS apps professionally since the App Store was unveiled in 2008. Prior to that, I was a professional Mac developer. Over the last decade I’ve written iOS apps in many different styles, with many different teams, using many different architectures. I’ve written nearly 200 articles on Mac and iOS development on cocoawithlove.com
Florian Kugler: I’ve been working on the iOS and macOS platforms for the last six years, and on various other platforms before that. Application architecture is a concern that always has been part of my work, although more on an implicit level until I started to work on this book.
What makes this book necessary? What gap does it fill?
CE: UIKit is designed for MVC. However, outside of the iOS world, people have been writing apps in very different architectures, such as MVVM (on Windows), or React (on the web). We want to give an overview of the different architectures, as well as a thorough description of how these architectures work, what their philosophy is, and what they look like at the code level.
MG: In the first 5 years of iOS, I feel that programmers were mostly trying to keep up with iOS itself, doing anything they could to get things working. Quality, maintainability and good architecture were secondary considerations.
In the last 5 years, people have started to realise that an “anything goes” approach leads to code being thrown out every few years, and it might be better to start with a clear, maintainable approach. To do this, you need a better understanding of architecture, so you can continuously refactor to address limitations and maintain the code.
FK: Application architecture is often a topic where people have very strong opinions about the “best” way of doing things. We wanted to take a more neutral look at a wide variety of design patterns, because we believe that the same problem can be solved in many different ways with different trade-offs. We don’t want to sell you on one particular pattern, but present the similarities and differences of various patterns, from the conceptual level all the way down to the implementation details.
In your book you describe five different architectures. Besides the standard MVC and its variant MVVM-C, you also consider three more experimental architectures. Can you explain where those originated and how you chose them?
CE: We wanted to show ideas from different architectures used outside of the iOS world. For example, The Elm Architecture is centered around view state, and uses a virtual view hierarchy to describe how to translate the view state into a view hierarchy. It needs quite a bit of infrastructure, but the resulting application code is very small.
MVC+ViewState takes the idea of centralized view state, and applies it to MVC. It does not have a virtual view hierarchy, but works with regular MVC components.
MG: I’ve been working on ModelAdapter-ViewBinder (MAVB) for a long time. I first started experimenting with some of its ideas in 2015. The premise started with defining everything about an object — in particular, views — on construction, instead of through mutable property changes, method overloads and delegates. These require a huge amount of knowledge about the implicit behavior of UIKit objects and it’s too easy to conflict with this implicit behavior, or your own behavior, or otherwise make mistakes. Reactive bindings, and encapsulating all state in model-adapters, flowed very naturally from the idea of configuring all behaviours on construction. Through this, the CwlView library and the MAVB was born.
I showed the CwlViews library to Chris Eidhof when we were both at the Playgrounds conference in 2017. The code was still a mess at that point, but it led to us discussing application architectures and eventually led to the book.
MVC+ViewState was an effort I started during the writing of the book to bring some of the ideas from The Elm Architecture and MAVB back to MVC. I consider it a teaching architecture; it shows how view-state can take a more major role — particularly around navigation — without requiring any functional programming or abstract ideas like reducers.
FK: We chose the experimental design patterns primarily because we found them to be sufficiently different from the more common patterns: they stretch your comfort zone while still being instructive and providing applicable lessons.
In broad terms, when should a developer stick with one of the two more traditional architectures and when should they check into one of the experimental ones? Do the experimental architecture fill a niche or are they as general as MVC?
CE: In a production code base, we wouldn’t recommend using an experimental technique for something as big as an architecture. That said, it is definitely possible to write production apps using any of these architectures. We believe it is important to really understand these architectures first, and choose which architecture you want second.
For each architecture, we have described lessons in the book that you can bring to other architectures. For example, we show how you can use coordinators with MVC, or how you can build a declarative view hierarchy (similar to TEA or MAVB) for parts of an existing app.
MG: Given that UIKit/AppKit are built to expect an MVC approach — and most sample code you find will also be MVC — I think most people should start with MVC. If you’re writing code with novice programmers, you should stick with MVC. Experience is probably the best guide: if you’ve written projects in the past that suffered from issues, try something new and see if you can address those issues. There are different flavors of MVC including with ViewState, MVVM in minimal, no-Rx, and full-Rx; if you want to try something more experimental you can fully test out our TEA or MAVB approaches, or simply take lessons from them.
As for whether the experimental architectures are niche, or otherwise limited, the only significant limitation is that Chris’ Elm implementation and my CwlViews implementation doesn’t cover all of UIKit. The patterns themselves are robust and scalable. If you’re prepared to add additional framework functionality as needed, these approaches will scale and handle all common scenarios.
FK: The experimental architectures are as general as MVC, but they come with the usual trade-offs when deviating from the mainstream on a certain platform: you have to build and maintain the necessary framework code yourself, there are less resources out there, and there’s a steeper learning curve for new developers in your team. You should definitely try out experimental patterns on a small scale before committing to them on a large project; you need to evaluate if you have a sufficiently good reason to incur the costs of deviating from the norm.
Could you shortly summarize the strengths and shortcomings of each of the architectures you present?
MG: MVC is simple and works well with Apple’s frameworks but requires significant vigilance to maintain data dependencies, and it requires skill to keep classes small and modular.
MVVM-C maintains data dependencies well, especially presentation dependencies, but some people find RxSwift confusing. Navigation logic and interaction logic are not as well covered in the pattern as presentation logic.
MVC+ViewState is almost as simple as MVC and handles navigation in a very elegant way. However, it requires a lot of observation functions, and it doesn’t include default tools for managing complex observing callbacks.
MAVB is syntactically efficient and has a clear story for all data ownership and dependencies. However, if you find Rx transformations difficult to read, it’s going to be terse and confusing.
The Elm Architecture describes an entire program through value types and a small set of transformations — it’s very simple to reason about. However, it is highly framework dependent and the framework we used is very rough, implementing only what is required for our program, and its implementation is likely to be a bottleneck until a robust, widely used framework becomes established.
FK: MVC has very little overhead and gives you a lot of freedom to make your own implementation choices, which is its weakness at the same time: you have to fill in the gaps and be disciplined to keep your project maintainable.
MVVM-C encourages you to think about your program in terms of data transformation from the model to the view and provides an easily testable interface to your view data. On the flip side, MVVM projects often require you to understand a reactive programming library.
In The Elm Architecture you describe your views declaratively based on the current state of the application. This eliminates a lot of glue code and the possibility for mistakes that come with a mutable view hierarchy. However, TEA requires a framework wrapping UIKit that has to be maintained, and animations are a non-trivial problem to solve.
The ModelAdapter-View Bindings architecture has a striking resonance with one fundamental Cocoa concept: bindings. Bindings are also a feature that is greatly supported by a language like Objective-C. Generally speaking, do you see any differences across the architectures you cover from the point of view of which language the app is written in?
MG: All the features of Cocoa Bindings could be implemented in Swift using Swift key paths and protocols. The difference in Swift, compared to Cocoa, is that you must declare the protocol conformance at compile time, instead of blindly sending messages and hoping they’ll work at runtime. It’s a little more code but the reliability saving is worth the effort.
Ultimately, I think people used Objective-C’s dynamic message send and dynamic class construction because they could, and not because there was no other way. It produced a few ‘cute tricks’ but the reliability cost was real, which is why Swift has chosen to drop support for the most dynamic features.
FK: In theory, all architectures could be implemented in either Objective-C and Swift. However, Swift’s support for value types (structs and enums) is of great help when implementing more functional patterns like the Elm Architecture, and unidirectional data flow patterns in general.
Has the introduction of Swift shifted the architectural paradigms for iOS app development?
CE: Absolutely, yes. Features like structs, enums, and Swift’s type system enable us to write code in a very different style. For example, an architecture like Elm would be very impractical in Objective-C. At the same time, higher-order functions are more common in Swift (by now, everyone uses methods like
mapandfilter). This makes the barrier for libraries such as RxSwift or ReactiveSwift much lower.MG: Yes, without doubt. Swift has a much more sophisticated type system, and it can create more compile-time guarantees. The compiler can prove more of your program’s validity, but only if your architecture is written to encode inter-component behaviors in the interfaces between components.
It’s a complicated way of saying that generics and composition over inheritance are improving reliability and reusability.
Of the architectures you decided not to cover in the book, what are the most promising in your opinion?
CE: The instant feedback of interpreted languages like JavaScript make a technique such as React Native very interesting. However, we decided to focus the book on Swift.
MG: I think a minimal MVVM (using Swift key path observing) is a light-weight, easy to understand architecture. It doesn’t solve a huge number of problems compared to MVC but it does solves some, and when talking about the book to lots of programmers it’s clear that reactive programming is a big sticking point for many; they’d rather something lighter.
Short of starting off developing a new app, what is the best way for developers to begin experimenting with any of the more experimental architectures you present?
CE: The book comes with a lot of sample code. Throughout the book we show the Recordings sample app, and we wrote this app in all of the different architectures. You can quickly get started with an architecture when you add a new feature to the sample app.
Another great way is to take an existing app and rewrite part of it in a new architecture. By working in a domain you know, you can focus solely on the code.
MG: The book offers many “Lessons” at the end of each chapter, which focus on taking the ideas of that chapter’s major pattern and applying them to small components, usually within an MVC app.
FK: Often you can experiment with different patterns in parts of an existing app, like a settings screen or something similar that’s relatively independent. Additionally, you can take ideas from other patterns and apply them within the frame of you current architecture.
Choosing the right architecture is usually a key factor in determining the overall success of an app (including factors such as development model, performance, time to market, etc.). What should developers take into account to maximize their project’s chances of success when choosing the right architecture?
CE: The more familiar you are with an architecture, the easier it will be for you to write correct, clean, and maintainable code. However, some architectures really help to eliminate common problems, such as observation, or dealing with view-state. We believe you should understand the different architectures, and then look at how they would work in your context. For example, whether your team enjoys object-oriented programming or functional programming can make a big impact on deciding which architecture to use.
We don’t believe any of the described architectures is “best” or “worst”. Instead, we think you should evaluate for yourself.
MG: The best architecture is the one that your team wants to work on. Find out what your team likes and let people have fun.
FK: I’d argue that social factors mostly outweigh the technical ones in terms of the “best” architecture for a certain project. Experience with a certain pattern, general skill level, and personal preferences amongst many other factors play an important role in making a good choice.
Finally, a word about your decision to create a series of companion videos to the book. What was your goal with them? What value do they provide and to which audience?
CE: The videos are really quite different from the book. In the book, we can give an overview of the architectures, describe the ideas and code, and give a lot of background information. The videos show what it’s like to work in each architecture. For example, we add a mini-player feature to the recordings app, once for each architecture, and we need to touch almost every part of the code base to build this.
MG: Chris and Florian made a compelling case. I’d never previously recorded videos except for conference talks. We wanted to work on some more “interactive” ideas, relative to the book which is inherently static. The result was a number of refactoring videos. I also developed an “8 patterns in a single file” idea; I wanted to try and distill a number of patterns down to their most basic core, and touch on some patterns that we didn’t cover in the book. I think it worked out really well!
To read more about the book and the videos, or to buy them, visit objc.io.
 Chris Eidhof is one of the objc.io co-founders, and host of Swift Talk. He also co-authored the Functional Swift and Advanced Swift books. Before, he wrote apps such as Deckset and Scenery.
Chris Eidhof is one of the objc.io co-founders, and host of Swift Talk. He also co-authored the Functional Swift and Advanced Swift books. Before, he wrote apps such as Deckset and Scenery.
 Matt Gallagher works as a software developer and consultant based in Melbourne, Australia; both independently and through his streaming media technologies company Zqueue.
Matt Gallagher works as a software developer and consultant based in Melbourne, Australia; both independently and through his streaming media technologies company Zqueue.
 Florian Kugler is one of the objc.io co-founders. He worked on Mac Apps like Deckset, co-authored the Functional Swift and Core Data books, and hosts the weekly Swift Talk video series.
Florian Kugler is one of the objc.io co-founders. He worked on Mac Apps like Deckset, co-authored the Functional Swift and Core Data books, and hosts the weekly Swift Talk video series.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Last week, IBM announced a significant expansion of their cloud capabilities and an increase of the presence of availability zones across the globe. The announcements show the substantial investments IBM makes to compete with Amazon, Microsoft, and Google in the cloud services market.
An IBM Availability Zone is an isolated location within an IBM Cloud Region with independent power, cooling, and networking – and IBM will launch 18 of these zones in North America, Europe, and Asia-Pacific – to further increase the geographical expansion of their cloud footprint. Aki Duvver, IBM’s vice-president of Worldwide Cloud Offering and Product Management, said in an eWeek article on the expansion:
We’re increasingly finding that we have to be where our clients reside—we have to meet our customers where their data sits. Eighty-five percent of our customers’ data sits on-premises today, and much of that data is moving to the cloud over time.
IBM further announced that it would bring more services into their Cloud regions and availability zones ranging from infrastructure to data to serverless to AI capabilities. In a blog post about the expansion of IBM Availability Zones in the six global regions – Andrew Hately, VP, DE and chief architect IBM Watson and Cloud Platform, said:
The most exciting aspect of this new region/availability zone architecture is that it provides an even more robust infrastructure foundation for the new offerings we’ll be delivering on a continuous basis in the future. By abstracting physical locations and providing additional underlying redundancy, we’re able to roll out new capabilities like Virtual Private Cloud networking (which was also announced in beta today) for IaaS services.
With Availability zones, IBM Cloud customers will have another benefit. They can deploy multizone Kubernetes clusters across the availability zone using the IBM Cloud Kubernetes Service. Furthermore, these Kubernetes clusters now also feature worker pools – a collection of worker nodes, which the Kubernetes cluster can distribute across the Availability Zones.
The driver for increasing the number of the availability zones is also a result of the General Data Protection Regulation (GDPR), enacted by the European Union on May 25. Moreover, the regulation will impact multinationals with a presence in the EU, as they will be forced to keep and maintain business data within individual data centers inside the home-country boundaries of specific nations – and be able to prove this upon inspection. In the same eWeek article on the expansion Alki Duvver said on privacy regulations:
We have to meet the MNC customers with the data privacy requirements that are in-country. In addition to GDPR, for example, in Germany, we have the federal C5 Attestation, which is around cloud computing compliance controls catalog and information security.
In an earlier news item, InfoQ reported on the general availability of Availability Zones in Azure, while both Amazon and Google have had availability zones for some time now and are more spread across the globe. IBM steps in with their expansion of availability zones to support their customers like ExxonMobil, Bausch + Lomb, Crédit Mutuel and Westpac – pushing their workloads to the IBM Cloud. Faiyaz Shahpurwala, general manager, IBM Cloud, stated in the blog post that customers could expect more:
This is just a part of our continued investments into the IBM cloud strategy. There is much more to come as we deliver new offerings and enhancements to intelligently and securely guide our customers through their journey to the cloud.
Distributed Messaging Framework Apache Pulsar 2.0 Supports Schema Registry and Topic Compaction
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The latest version of open-source distributed pub-sub messaging framework Apache Pulsar enables companies to move “beyond batch” by acting on data in motion. Streamlio recently announced the availability of Apache Pulsar 2.0.1 streaming messaging solution. The new version supports Pulsar Functions, Schema Registry and Topic Compaction.
Other features in the new release include:
- Upgrade of Apache BookKeeper to version 4.7
- Performance improvements
- Compatibility with pre-2.0 releases of Pulsar
Pulsar Functions: This stream-native processing capability was first announced as a preview feature earlier this year. Pulsar Functions are lightweight compute processes that can be used to apply transformations and analytics directly to data as it flows through Pulsar, without requiring external systems or add-ons. Functions are executed each time a message is published to the input topic.
Schema Registry: The Schema Registry simplifies development of data-driven applications by providing developers the ability to define and validate the structure and integrity of data flowing through Pulsar. It supports a built-in registry that enables clients to upload data schemas on a per-topic basis. Those schemas dictate which data types are recognized as valid for that topic. The schema registry is currently available only for the Java client.
Topic Compaction: This is a new enhancement to Pulsar in coordination with the Apache Bookkeeper solution for streaming data storage that improves performance. Topic compaction is a process that runs in the Pulsar broker to build a snapshot of the latest value for each key in a topic. The topic compaction process reads through the backlog of the topic, retaining only the latest message for each key in a compacted backlog. It is non-destructive so the original backlog is still available for the users who need it. Users can control when Topic Compaction occurs by triggering it manually via a REST endpoint.
InfoQ spoke with Matteo Merli, the co-founder of Streamlio and the architect and lead developer of Pulsar while at Yahoo, about Pulsar framework and its product roadmap.
InfoQ: How does Pulsar compare with other messaging frameworks?
Matteo Merli: Like a number of other frameworks, Pulsar provides distributed messaging capabilities accessible by a variety of clients. Pulsar differentiates itself with capabilities that make it possible to keep up with the requirements of modern data-driven applications and analytics without the cost and complexity of alternatives. More specifically, those capabilities include better throughput and latency, scalability, stream-native function processing, and support for both publish-subscribe messaging and message queuing, multi-datacenter replication, security and resource management.
InfoQ: What is the Pulsar product roadmap and upcoming features?
Merli: As an open source project, the roadmap for Apache Pulsar is shaped by the Pulsar community of contributors and users. Current development work that is expected to release soon includes support for additional access interfaces, an expanded set of connectors to data sources and repositories, enhancements to provide multi-tier storage capabilities, an expanded set of supported schema formats.
The Pulsar team released the 2.0.1 version last week which includes fixes to Python packages on PyPI and REST APIs provided by Pulsar proxy. For more information on the new release, check out the release notes on Pulsar’s website.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: As advanced analytics and data science have matured into must-have skills, data science groups within large companies have themselves become much larger. This has led to some unique problems and solutions that you’ll want to consider as your own DS group grows larger.

It seems like only two or three years ago you wouldn’t have had to ask this question. Unless you were Google, Amazon, or an equally big player your data science teams were small, maybe in the range of 3 to 12, and were still trying to find their place in your organization.
Fast forward to today and it’s not unusual to find teams of 20 or 40 or even more and that’s a game changer. It’s no longer like Cheers where everyone knows your name. In larger organizations more order, organization, and process becomes necessary.
The large analytic platform providers clearly understand this. I’m thinking IBM, Microsoft, SAS, Alteryx and similar. Over the last year or so there’s been an increasing focus on elephant hunting, slang I’m sure you’ll recognize for trying to get a foothold where the big teams live.
Here are some topics and questions that seem to arise as common ground from trying to manage larger DS orgs.
You’re Going to Want to Standardize on a Process Which Probably Means Standardizing on a Platform
If you’ve got 40 people in a data science team that implies a large number of projects and as a result a large number of models or product features to keep track of and maintain. You can’t have everyone freelancing in tools and project structure or you’ll never keep up.
As you’ve approached this scale you probably tried to adhere to a common process such as CRISP-DM and may even have written some internal standards about how that’s implemented. Another common situation is for a DS group to have coalesced around a comprehensive platform.
Take Alteryx for example that enables the process from data blending through modeling. You’re all using the platform so it’s easy to communicate where you are in a modeling project and there can be project-by-project discussion of when and if, for example, you’re going to use custom code as opposed to the built-in tools.
That will get you part of the way there and some will be happy with this semi-formal level of formalization. However, the lessons we take from the project management process and application development disciplines like Agile are that more organization can be better and doesn’t necessarily bog things down.
Recently both IBM and Microsoft have created offerings to template this level of organization for you in hopes of getting you to focus on their DS and cloud offerings. IBM has the Data Science Experience and Watson Studio. Microsoft introduced the Team Data Science Process.
Some Examples from the Microsoft Team Data Science Process (TDSP)
Of the ‘systems’ we were able to identify, the Microsoft TDSP seems to be the most comprehensive, literally defining project steps and individual roles and responsibilities. TDSP includes:
- A data science lifecycle definition (high level project plan description).
- A standardized project structured (including even sample templates for things like project charters and reports).
- A list and description of the required infrastructure and resources.
- Tools and utilities for project execution (the Microsoft offerings this platform is intended to promote).
The high level process diagram is not all that different from CRISP-DM but easy to use when describing the steps. 
Going down one more level, the TDSP even lays out specific roles and responsibilities for each common DS role including Solution Architect, Project Manager, Project Lead, and Data Scientists. 
The entire package is quite comprehensive and detailed. If you haven’t addressed this level of detail for your organization this would be a good starting point.
Maintaining Data Pipelines
Another common pain point in larger DS organizations is acquiring and maintaining data pipelines. Probably as your organization grew this was originally assigned to junior data scientists. As you grew you realized this wasn’t a good use of resources.
Over the last two or three years the separate discipline of Data Engineer has emerged as a formal and separate supporting role for the data science process. There are a great many specialized skills in maintaining data pipelines ranging from MDM to more technical skills like creating data lakes or creating instances of Spark.
It’s an open conversation in each organization whether this task falls under the data science group or IT. It will depend on how many of these folks you need and whether they are dedicated to these data science tasks, and of course some internal politics.
However, as data science increasingly becomes a team sport played by specialists this function is your major connection to IT and needs to be clearly defined and agreed.
Managing the Incoming Project Pipeline
Looking from the data science team upward to your internal customers, many data scientists find that more than a third of their time is spent meeting with LOB managers to define and vet new projects and then to report progress.
This is also a process that will benefit from some formalization starting with an agreement at the executive level of how the benefit of various projects is to be calculated.
Some organizations are requiring an initial estimate of dollar benefit before undertaking new projects. This no doubt leads to some pretty optimistic projections from LOB managers but it’s important in establishing a project charter to quantify the goals.
Like any good project, this step leading up to the project charter should also include the measures and threshold values that will be used for determining customer acceptance. Yes these may be subject to some revision once you get underway, but it’s important to put a stake in the ground so you can manage the priority of incoming projects.
Educating Internal Customers
When we think of the training needs of a DS group we often think just of what skills our data scientists need to do their work. However, there is also a requirement to educate your customers in what they can and can’t expect, and what the process of engaging with you will look like.
Some organizations take a minimalist approach to this providing say scheduled quarterly one-hour briefings and perhaps some written material for managers wanting to be educated.
Some take a more comprehensive approach of using each project win as a briefing opportunity to tell their story not only to their specific internal customer but in shortened form to other potential LOB customers. This serves as basic education for those that haven’t yet engaged with you, and continuing education about your expanding capabilities as your group becomes more successful.
Internal education of your data science team is just as important and much more under your direct control. Aside from the obvious opportunities for juniors to learn from seniors by participating directly in projects, some of the comprehensive platforms like the IBM Watson Studio have very specifically designed-in instructional materials and resources across a wide variety of DS topics.
Keeping the Creative Momentum
As organizations grow, there is a temptation to view the DS group as just another service provider. LOB managers define problems to be solved and the DS group delivers. Begins to sound a lot like order taking.
The truth will continue to be that as your data scientists keep abreast of what’s evolving in our profession, your group is best positioned to suggest creative solutions to problems that may not yet have even been identified.
There’s a temptation to divide every organization into just two levels of strategic development. Either you are in that exciting and less well defined period of figuring out how data and analytics will create competitive advantage, or you have passed over into the refinement phase where improvements are more incremental.
As the lead or influencer in a large DS organization it’s important to maintain that creative input to the organization. No organization is permanently in the initial stage or permanently in the incremental improvement phase. It would be good practice to carve out a specific amount of time and effort to gather the best knowledge and ideas from your DS team, and have a method of floating these up to the LOB and executive levels.
No one in the company will ever know more about data science and what it can do than your group. Don’t become order takers.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
Uncategorized
Podcast: Pooja Brown on Building Great Engineering Cultures
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In this podcast Shane Hastie, Lead Editor for Culture & Methods, spoke with Pooja Brown, VP of Engineering at Docusign about building great engineering culture.
Key Takeaways
- Great culture comes when people are aligned with the organisation’s mission
- There are ways to bring the voice of the customer to the ears of the team and doing so creates empathy and results in better products
- Transparency and openness around what matters to the company helps ensure people align with those goals
- Every engineer is responsible for ensuring that the code they write is reliable, available and secure
- Fairness and transparency are key to great culture
- Being a people manager requires technical knowledge for credibility but is not about providing technical leadership; many people confuse the two
Subscribe on iTunes
![]()
RSS Feed
![]()
Soundcloud
Sponsored by
Ocado Technology: This podcast is brought to you by Ocado Technology, a division of the Ocado Group. Ocado Technology builds the software and systems powering Ocado.com, the world’s largest online-only grocery retailer. We’ve been disrupting the grocery industry for over fifteen years using the cloud, robotics, AI, and IoT. Find out more and check out career opportunities here.
- 0:40 Introductions
- 1:32 Why digital signature technology matters
- 2:42 To have a great culture you need to be a part of the mission statement
- 3:32 The importance of truly being customer focused
- 3:48 An example of how Docusign are focusing on real customer experiences
- 4:46 How to open channels to enable engineers to really hear the voice of the customer
- 5:12 The “three-in-a-box” model that Docusign uses to ensure teams hear directly from their customers in order to build empathy and understanding
- 5:42 Ways in which Docusign ensures that the engineering teams hear from their customers
- 6:08 The closer you can get the person writing the code to the real customer problem the faster and more effectively the problem will be addressed
- 6:32 The importance of transparency around what matters to the company
- 6:57 Every engineer is responsible for ensuring that the code they write is reliable, available and secure
- 7:59 The value of providing a framework for career growth in an organisation
- 8:27 It’s important to build a fair culture where people understand why decisions are made, even if they don’t agree with them they can see how a decision was made
- 8:36 Make sure that people understand the expectations for each role and each level in the role across the whole organisation
- 8:52 This transparency, including salary transparency, removes fear from within and between teams
- 9:27 How Docusign give everyone a Global Impact Day in which people volunteer their time at the company’s expense for causes that matter to them
- 9:40 Pooja and some of her team going to the Glide Memorial Church to help out in a soup kitchen
- 10:48 Being clear about career progression structures that doesn’t confuse management and technical leadership
- 11:00 Being a people manager is a hard role to be successful at in a software company
- 11:12 Being a people manager requires technical knowledge for credibility but is not about providing technical leadership; many people confuse the two
- 12:25 The way Docusign supports people who move into a people management role
- 12:48 The best way to build technical leadership is through an apprentice model
- 13:03 Ways that Docusign provides guidance and support for people building their technical competencies
- 14:05 The experience of the Docusign team at QCon
- 16:03 The number of women leaders on the Docusign team
- 16:15 Approaches to actively promote and help build women’s careers
- 16:31 Writing job descriptions so they are truly gender neutral
Mentioned:
About QCon
QCon is a practitioner-driven conference designed for technical team leads, architects, and project managers who influence software innovation in their teams. QCon takes place 7 times per year in London, New York, San Francisco, Sao Paolo, Beijing & Shanghai. QCon New York is at its 7th Edition and will take place Jun 27-29, 2018. 100+ expert practitioner speakers, 800+ attendees and 15 tracks will cover topics driving the evolution of software development today. Visit to qconnewyork.com get more details.
More about our podcasts
You can keep up to date with the podcasts via our RSS Feed, and they are available via SoundCloud and iTunes. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The creation of software diagrams has been scaled back as a result of the shift to agile methodologies. When diagrams are created, they are often confusing and unclear.
- The C4 model consists of a hierarchical set of software architecture diagrams for context, containers, components, and code.
- The hierarchy of the C4 diagrams provides different levels of abstraction, each of which is relevant to a different audience.
- Avoid ambiguity in your diagrams by including a sufficient amount of text as well as a key/legend for the notation you use.
Software architecture diagrams are a fantastic way to communicate how you are planning to build a software system (up-front design) or how an existing software system works (retrospective documentation, knowledge sharing, and learning).
However, it’s very likely that the majority of the software architecture diagrams you’ve seen are a confused mess of boxes and lines. An unfortunate and unintended side effect of the Manifesto for Agile Software Development is that many teams have stopped or scaled back their diagramming and documentation efforts, including the use of UML.
These same teams now tend to rely on ad hoc diagrams that they draw on a whiteboard or put together using general-purpose diagramming tools such as Microsoft Visio. Ionut Balosin last year wrote “The Art of Crafting Architectural Diagrams“, which describes a number of common problems with doing this, related to incomprehensible notations and unclear semantics.
(Click on the image to enlarge it)
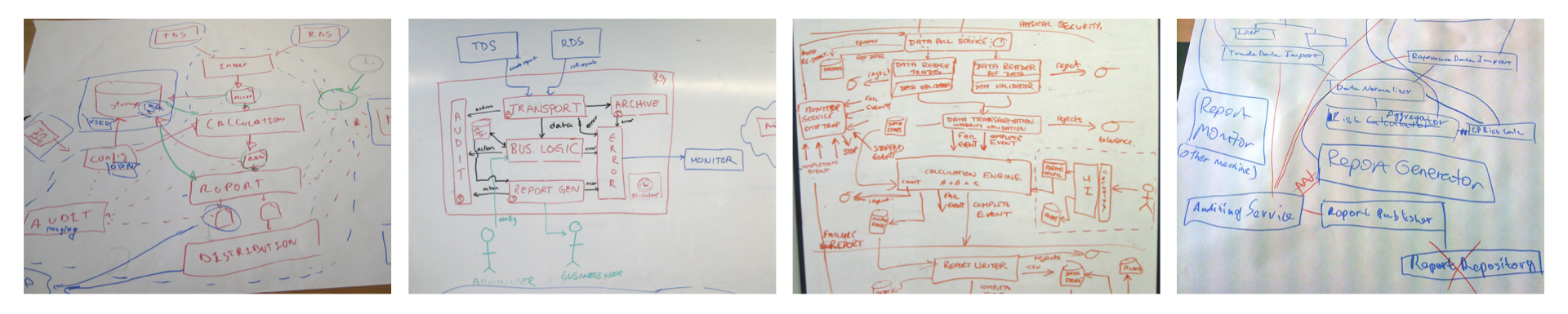
Ambiguous software architecture diagrams lead to misunderstanding, which can slow a good team down. In our industry, we really should be striving to create better software architecture diagrams. After years of building software myself and working with teams around the world, I’ve created something I call the “C4 model”. C4 stands for context, containers, components, and code — a set of hierarchical diagrams that you can use to describe your software architecture at different zoom levels, each useful for different audiences. Think of it as Google Maps for your code.
(Click on the image to enlarge it)

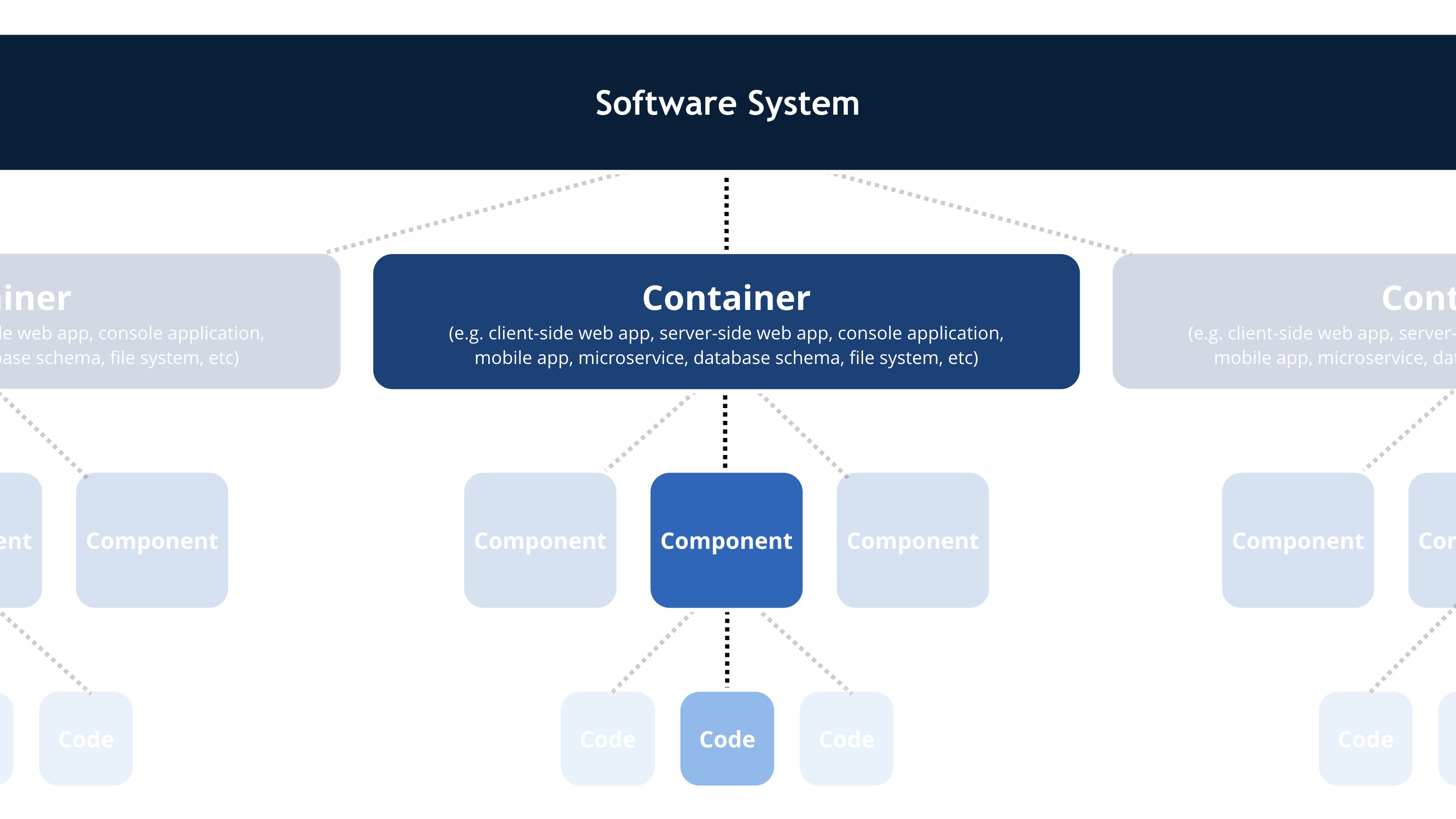
To create these maps of your code, you first need a common set of abstractions to create a ubiquitous language to use to describe the static structure of a software system. The C4 model considers the static structures of a software system in terms of containers (applications, data stores, microservices, etc.), components, and code. It also considers the people who use the software systems that we build.
(Click on the image to enlarge it)
Level 1: System context diagram
Level 1, a system context diagram, shows the software system you are building and how it fits into the world in terms of the people who use it and the other software systems it interacts with. Here is an example of a system context diagram that describes an Internet banking system that you may be building:
(Click on the image to enlarge it)
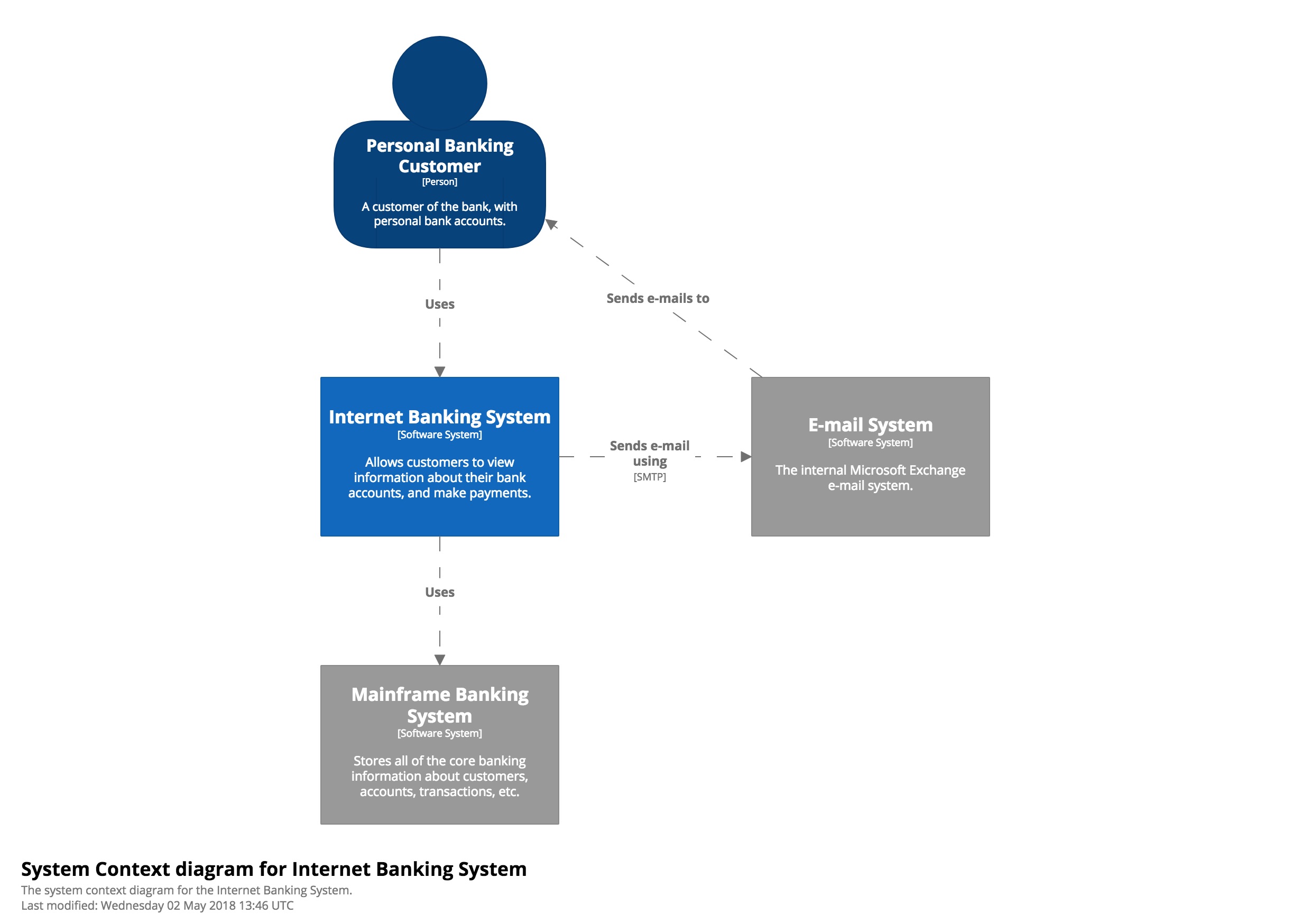
Personal customers of the bank use the Internet banking system to view information about their bank accounts and to make payments. The Internet banking system uses the bank’s existing mainframe banking system to do this, and uses the bank’s existing e-mail system to send e-mail to customers. Colour coding in the diagram indicates which software systems already exist (the grey boxes) and those to be built (blue).
Level 2: Container diagram
Level 2, a container diagram, zooms into the software system, and shows the containers (applications, data stores, microservices, etc.) that make up that software system. Technology decisions are also a key part of this diagram. Below is a sample container diagram for the Internet banking system. It shows that the Internet banking system (the dashed box) is made up of five containers: a server-side web application, a client-side single-page application, a mobile app, a server-side API application, and a database.
(Click on the image to enlarge it)
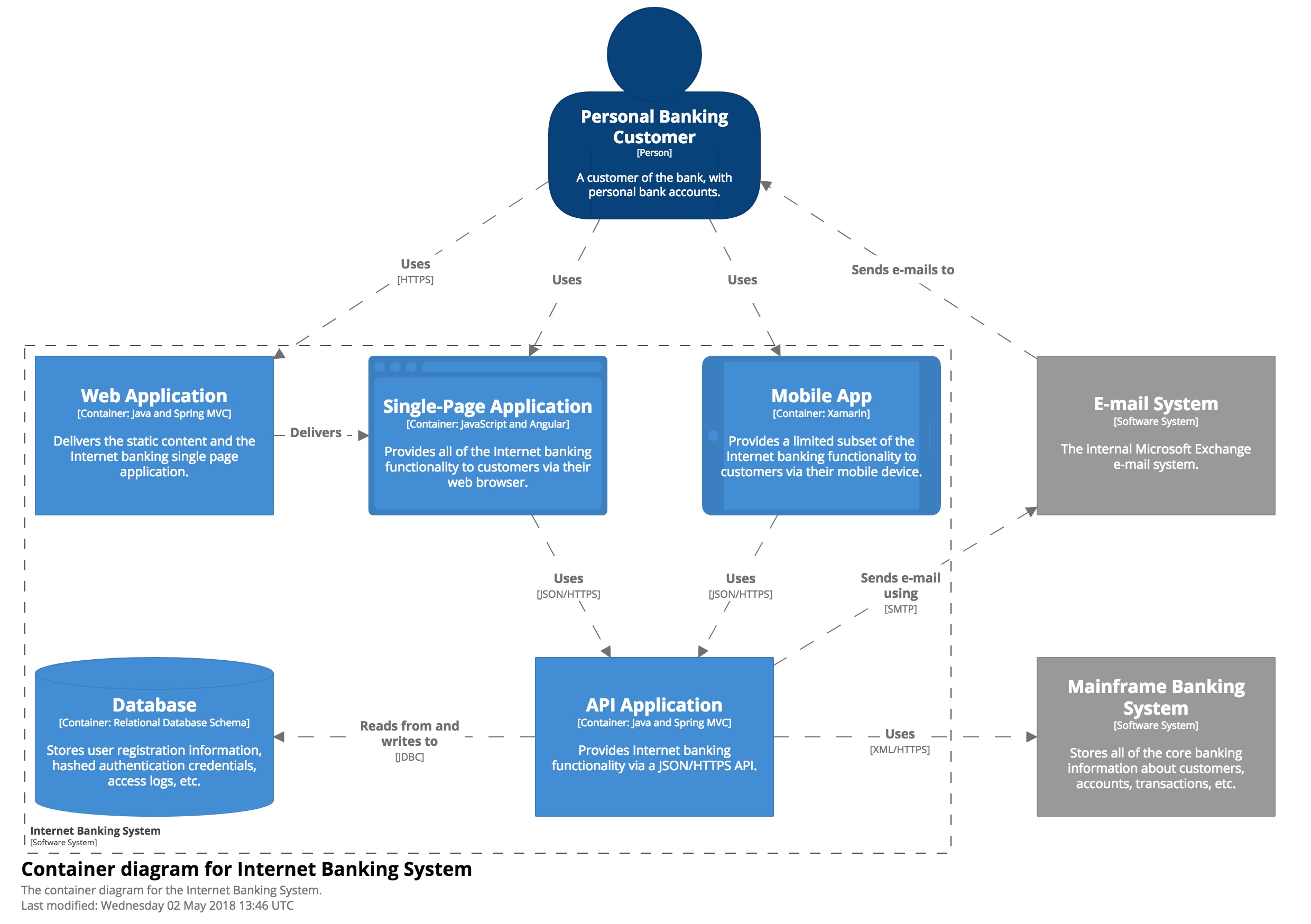
The web application is a Java/Spring MVC web application that simply serves static content (HTML, CSS, and JavaScript), including the content that makes up the single-page application. The single-page application is an Angular application that runs in the customer’s web browser, providing all of the Internet banking features. Alternatively, customers can use the cross-platform Xamarin mobile app to access a subset of the Internet banking functionality. Both the single-page application and mobile app use a JSON/HTTPS API, which another Java/Spring MVC application running on the server side provides. The API application gets user information from the database (a relational-database schema). The API application also communicates with the existing mainframe banking system, using a proprietary XML/HTTPS interface, to get information about bank accounts or make transactions. The API application also uses the existing e-mail system if it needs to send e-mail to customers.
Level 3: Component diagram
Level 3, a component diagram, zooms into an individual container to show the components inside it. These components should map to real abstractions (e.g., a grouping of code) in your codebase. Here is a sample component diagram for the fictional Internet banking system that shows some (rather than all) of the components within the API application.
(Click on the image to enlarge it)

Two Spring MVC Rest Controllers provide access points for the JSON/HTTPS API, with each controller subsequently using other components to access data from the database and mainframe banking system.
Level 4: Code
Finally, if you really want or need to, you can zoom into an individual component to show how that component is implemented. This is a sample (and partial) UML class diagram for the fictional Internet banking system that, showing the code elements (interfaces and classes) that make up the MainframeBankingSystemFacade component.
(Click on the image to enlarge it)

It shows that the component is made up of a number of classes, with the implementation details directly reflecting the code. I wouldn’t necessarily recommend creating diagrams at this level of detail, especially when you can obtain them on demand from most IDEs.
Notation
The C4 model doesn’t prescribe any particular notation, and what you see in these sample diagrams is a simple notation that works well on whiteboards, paper, sticky notes, index cards, and a variety of diagramming tools. You can use UML as your notation, too, with the appropriate use of packages, components, and stereotypes. Regardless of the notation that you use, I would recommend that every element includes a name, the element type (i.e., “Person”, “Software System”, “Container”, or “Component”), a technology choice (if appropriate), and some descriptive text. It might seem unusual to include so much text in a diagram, but this additional text removes much of ambiguity typically seen on software architecture diagrams.
Make sure that you have a key/legend to describe any notation that you’re using, even if it’s obvious to you. This should cover colours, shapes, acronyms, line styles, borders, sizing, etc. Your notation should ideally remain consistent across each level of detail. Here is the diagram key/legend for the container diagram shown previously.
(Click on the image to enlarge it)

Finally, don’t forget about the diagram title, which should appear on every diagram to unambiguously describe each diagram’s type and scope (e.g., “System context diagram for Internet banking system”).
More information
The C4 model is a simple way to communicate software architecture at different levels of abstraction, so that you can tell different stories to different audiences. It’s also a way to introduce (often, reintroduce) some rigour and lightweight modelling to software development teams. See c4model.com for more information about the C4 model, as well as supplementary diagrams (runtime and deployment), examples, a notation checklist, FAQs, videos from conference talks, and tooling options.
About the Author
 Simon Brown is an independent consultant specialising in software architecture, and the author of “Software Architecture for Developers” (a developer-friendly guide to software architecture, technical leadership and the balance with agility). He is also the creator of the C4 software architecture model, which is a simple approach to creating maps of your code. Simon is a regular speaker at international software development conferences and travels the world to help organisations visualise and document their software architecture.
Simon Brown is an independent consultant specialising in software architecture, and the author of “Software Architecture for Developers” (a developer-friendly guide to software architecture, technical leadership and the balance with agility). He is also the creator of the C4 software architecture model, which is a simple approach to creating maps of your code. Simon is a regular speaker at international software development conferences and travels the world to help organisations visualise and document their software architecture.