Month: September 2018

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Difference between Data Science and Web Development
Investments are essential for individuals and businesses. They reduce the risk in our lives and act as a cushion when needed. As far as businesses are concerned, investments are not only financial but also those of its employees, namely the creation of teams and the creation of images. There is a quote from Warren Buffet that says, “Someone is sitting in the shade today because someone planted a tree a long time ago.” True to this quote, companies must invest today to harvest the fruits of tomorrow. Taking into account recent trends, we will discuss two types of data: data science and web development. Investments are essential for individuals and businesses.
They reduce the risk in our lives and act as a cushion when needed. As far as businesses are concerned, investments are not only financial but also those of its employees, namely the creation of teams and the creation of images. There is a quote from Warren Buffet that says, “Someone is sitting in the shade today because someone planted a tree a long time ago.” True to this quote, companies must invest today to harvest the fruits of tomorrow. Taking into account recent trends, we will discuss two types of data: data science and web development.
Data science is interdisciplinary science if data analysis uses statistics, algorithm construction, and technology. With the recent trends in Data Science such as machine learning and artificial intelligence, more and more companies want to invest in a Data Science team to better understand their data and make sound decisions. Web development is the creation of a website for the internet or intranet. Since a website is the face of a business, it is necessary for businesses to invest one. In addition, Web development companies need to match their skills to future trends as companies become more e-commerce and e-learning oriented. This, in turn, is a determining factor for setting up Data Science teams in companies.
- Data Science involves analyzing data using specialized skills and technologies, while web development involves creating a website for the internet or intranet using business details, customer requirements and technical skills.
- Data Science is a relatively new concept introduced in 2008 while web development has existed since 1999.
- Python is used by both data specialists and web developers. However, in Data Science, it is used to analyze data while in Web development it is used to create a website.
- Data Science uses coding on a large scale, but also includes other elements, while the entire web development is based on coding.
- There are statistics involved in data science whereas in Web development statistics are not useful.
- Data scientists attempt to answer questions about the business at the end of the analysis, while php web developers try to meet the customer’s needs when creating a website.
- Data Science depends on the availability of data, while Web development relies on close interaction with the customer to understand the needs and obtain the required information.
- Data Science’s budget is high, but it is fixed while the budget for Web development keeps changing with the changing needs and additional features.
Similarities between these scientists and web developers:
You must write codes. You must work closely with customers. You must present these are the top three things that people tend to avoid when working as data specialists or web developers. However, each career you choose will end up having to complete all the tasks if you want to be good at your job.
From a financial point of view, they also have enormous potential. We will never run out of data and the demand for websites will not diminish. From the point of view of the task, data specialists solve optimization problems in different fields. While creating websites helps people convey their message to their target audience. Instead of choosing one or the other, why not both? You can perform tasks, analyzes, and at the same time generate data products, such as interactive dashboard and workflow automation.
Web developers vs. data scientists: Who rules the Python world?
The combination of data analysis and machine learning is hardly relevant, but the fact that web development and data analysis/machine learning overlap is certainly interesting.
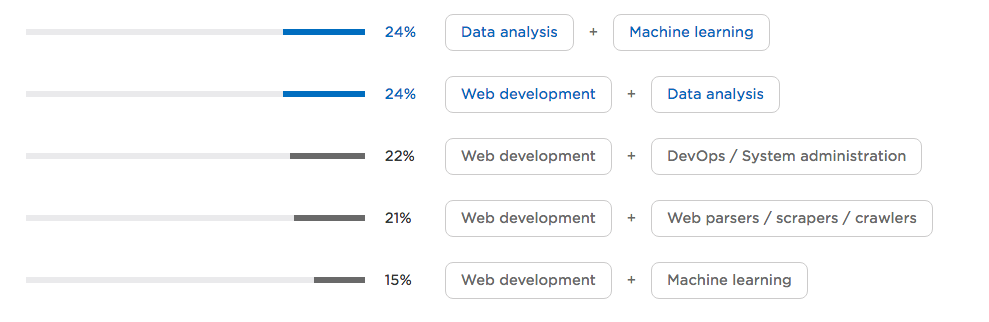
It’s fair to say that Python is everywhere we go, from DevOps to machine learning and data science. Stack Overflow seems to agree – according to some calculations done last year, Python is the fastest growing programming language. We chatted with David Robinson, the data specialist at Stack Overflow, about the growth of Python and we learned that it came from the tremendous expansion of data science and machine learning.
Conclusion Data Science VS Web Development
Careers are built on the passion, drive, skills, and opportunities that a person possesses. In the case of the comparison between data science and web development, both are fashionable and offer students, professionals, and more experienced professionals many areas to learn. Data Scientists need to have a good understanding of statistics and computer science. By combining this with the large data available to different vertical markets, Data Scientists have the ability to explore different data sets and help businesses predict their data for valuable information.
Originally posted by https://www.techtiq.co.uk
Payara Foundation Releases Payara Server and Payara Micro 5.183 Featuring MicroProfile 2.0 Support
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The Payara Foundation has recently released version 5.183 of Payara Server and Payara Micro with a host of new features, upgrades, and bug fixes including full support for MicroProfile 2.0 and Java EE 8. New features include: updates to MicroProfile APIs and the Admin Console; support for the OpenID specification; and a new application deployment descriptor schema.
First introduced in 2014, Payara was based on the open-source edition of GlassFish 4.1 while it was still maintained by Oracle. Payara has strived to provide outstanding customer support by being open-source, small/simple/powerful and compatible with major cloud platforms.
Payara release streams, introduced in 2017, define customer-focused release schedules. The community stream, available to all Payara users, is the normal quarterly release that includes new features, updates, and bug fixes. For Payara customers, the features stream contains monthly patches to the quarterly releases and the stability stream adds more frequent patches for improved stability and consistency.
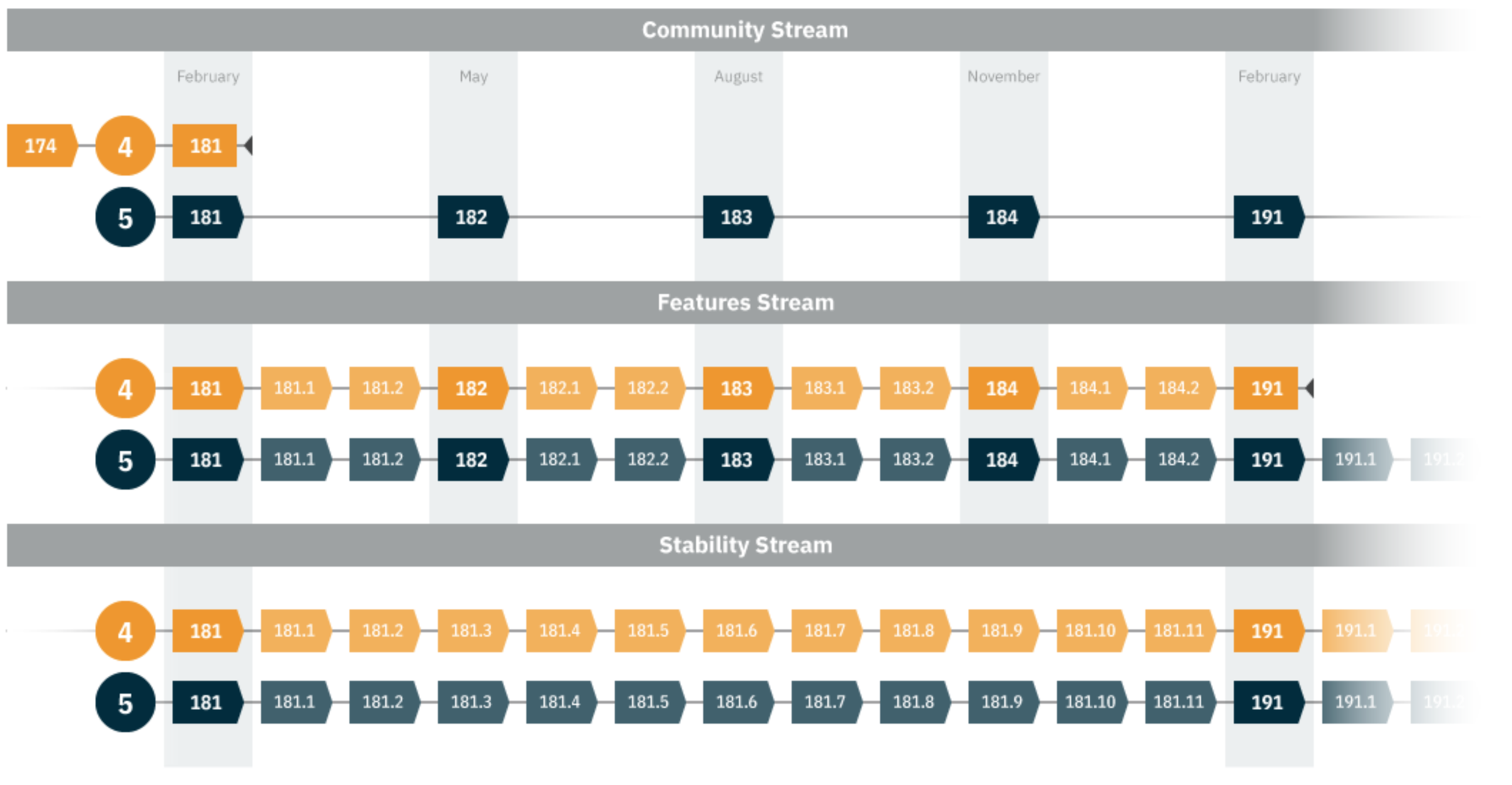
Payara 5.183 is the third quarter release for 2018. At the beginning of the year, Steve Milledge, founder and director at Payara, discussed Payara’s plans for 2018. He stated that version 5.183 would focus on reactive and asynchronous. In particular:
For the 183 release due August we are focusing on expanding our support for reactive and asynchronous programming styles. Ideas at the moment are:
- Ensuring Java EE APIs can be used from Lambdas, Completable Futures, Collections parallel stream operations
- Support Lambdas as Message Listeners
- Support CDI beans as Message Listeners
- Add enhanced CDI support with
@Asynch;@Pooled;@ClusterScoped;@ServerScoped- Deployable Concurrency Resources
In addition we are targeting MicroProfile 2.0 for the 5.183 release although depending on what the MicroProfile project does this may come earlier.
MicroProfile Updates
To be aligned with the MicroProfile 2.0 specification, Payara provided updates to existing implementations of APIs OpenAPI and REST Client and new implementations of APIs Fault Tolerance, Config, Open Tracing and JWT-Auth.
Fault Tolerance 1.1
Fault Tolerance was updated to include integration with the Metrics and Config APIs. Multiple metrics can be collected and exposed to provide data such as which methods wrapped around a @FaultTolerance annotation were executed, the status of any triggered circuit breakers, the number of retries, the number of failures, etc. Also, parameters, using a specific configuration key format, can be provided within @FaultTolerance annotations, classes or methods.
Config 1.3
To complement the URL class, Payara added support for the URI class by introducing new methods to convert a string into a URI class or any other class containing a constructor that accepts a string. This will allow configuration values to be converted to any class that is constructed with a string.
A new mapping rule was also added to allow for easier conversion of environmental variables containing an underscore to configuration keys.
Open Tracing 1.1
Open Tracing 1.1 is now aligned with the latest Open Tracing specification that offers Java APIs to collect tracing information. Also included is a tag to indicate which component provided the trace.
JWT-Auth 1.1
JWT-Auth was updated to include integration with Config. Originally implemented in the early days of Payara, JWT-Auth public keys were supported, but not portable. Using Config, public keys can now be specified containing the contents of the public key or the location where the key resides.
REST Client 1.1
REST Client, originally implemented in version 5.182, has been updated to include asynchronous support for calling REST services. It is now possible to create methods that return an instance of CompletionStage that can be asynchronously followed with another thread.
To complement the URL class, Payara added support to set an instance of URI class as a parameter using Config when injecting a RestClient interface. Application-specific URI/sURLs are specified as a configuration key in the microprofile-config.properties file as shown below:
org.redlich.payara.RestClientApp/mp-rest/url=http://localhost:8080/restapp
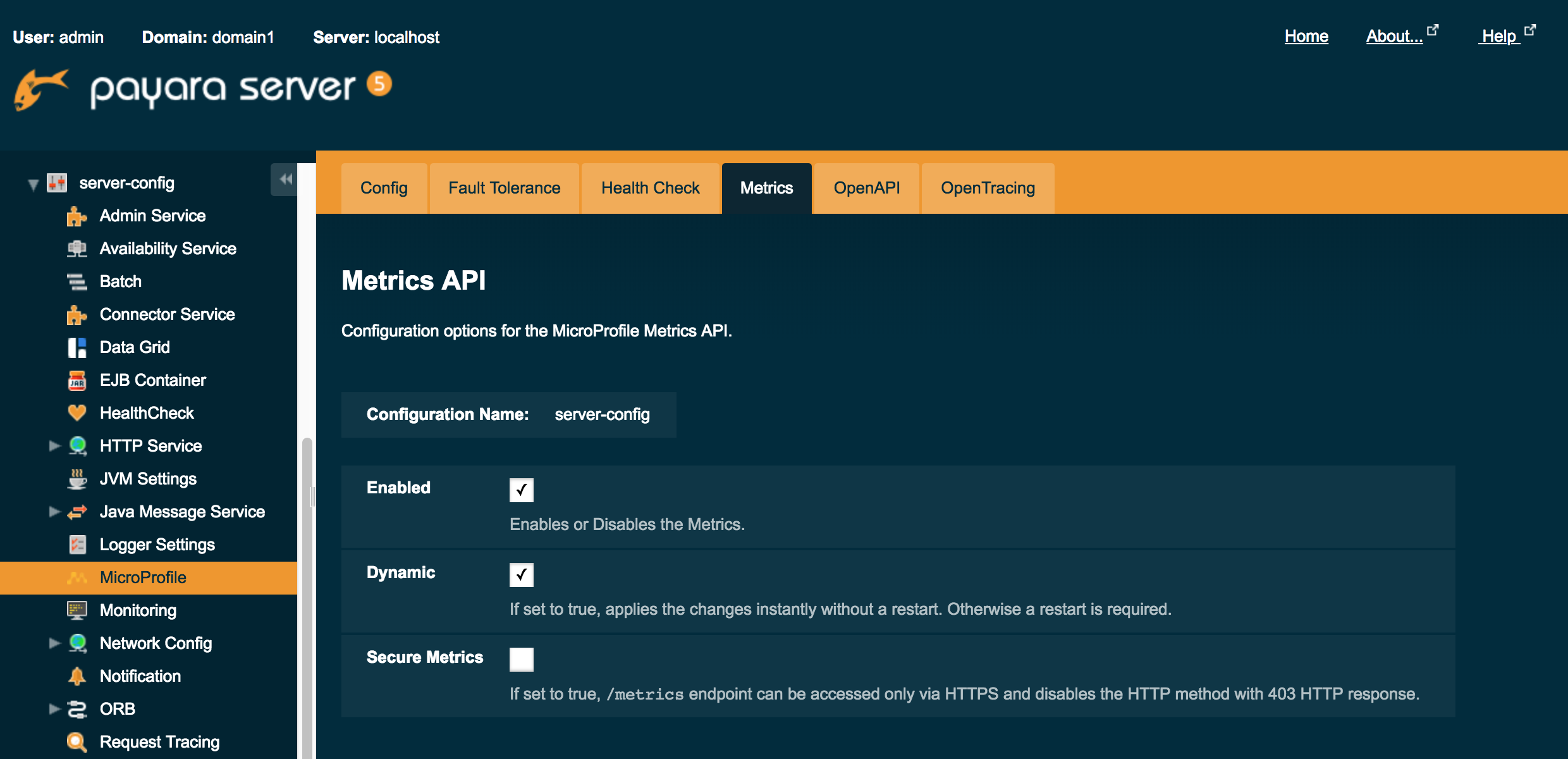
Admin Console
Enhancements to the Payara Server admin console include a new MicroProfile settings page for each server instance. As shown below, there are a multitude of property settings for the various MicroProfile APIs.
Also, based on customer feedback, the list of server configuration options that were once unordered are now listed in alphabetical order.
OpenID Connect
With the introduction of support for the OAuth 2.0 protocol in version 5.182, Payara now supports OpenID Connect, a security mechanism layered on top of OAuth, in version 5.183. OpenID Connect implements the OpenID specification, but as stated in the OpenID Connect documentation:
OpenID Connect performs many of the same tasks as OpenID 2.0, but does so in a way that is API-friendly, and usable by native and mobile applications. OpenID Connect defines optional mechanisms for robust signing and encryption. Whereas integration of OAuth 1.0a and OpenID 2.0 required an extension, in OpenID Connect, OAuth 2.0 capabilities are integrated with the protocol itself.
Resources
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
What is K Means Clustering?
Clustering means grouping things which are similar or have features in common and so is the purpose of k-means clustering. K-means clustering is an unsupervised machine learning algorithm for clustering ‘n’ observations into ‘k’ clusters where k is predefined or user-defined constant. The main idea is to define k centroids, one for each cluster.
The K Means algorithm involves:
- Choosing the number of clusters “k”.
- Randomly assign each point to a cluster.
- Until clusters stop changing, repeat the following:
- For each cluster, compute the cluster centroid by taking the mean vector of points in the cluster.
- Assign each data point to the cluster for which the centroid is the closest.
Two things are very important in K means, the first is to scale the variables before clustering the data, and second is to look at a scatter plot or a data table to estimate the number of cluster centers to set for the k parameter in the model.
Choosing the optimal K value:
One way of choosing the k value is to use the elbow method. First, you compute the sum of squared error (SSE) for some values of k. SSE is the sum of the squared distance between each member of the cluster and its centroid. If you plot k against the SSE, you will see that the error decreases with increasing k. This is because as the number of clusters increases, the error should be smaller and therefore, distortion should be smaller. The idea of the elbow method is to choose the k value at which the SSE decreases significantly.
Applications of K-Means Clustering:
k-means can be applied to data that has a smaller number of dimensions, is numeric, and is continuous. such as document clustering, identifying crime-prone areas, customer segmentation, insurance fraud detection, public transport data analysis, clustering of IT alerts…etc.
Also read: How to Utilize K Means Clustering model for unsupervised ML problems?
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The webhint project provides an open source linting tool to check for issues with accessibility, performance, and security. The creation of websites and web apps has an increasing number of details to perfect, and webhint strives to help developers remember these details.
webhint is available as either a CLI tool or as an online scanner. The quickest way to get started with webhint is with the online scanner, which requires a public facing URL to run a report and get insights about an application.
To use webhint within the development workflow, install it via npm:
npm install hint
As is the case with most feature-rich tools, webhint has many configuration choices and options. The project recently added an initialization CLI command to ease the creation of a webhint configuration:
npm create hintrc
When webhint is run to test an application, it can run in one of three environments: jsdom, Chrome, or Edge. The latter two options leverage the Chrome DevTools protocol, while the former option allows for a quick but more limited round of checks in a Node.js environment without a browser.
Numerous hints may get checked for an application. For example, the http-compression hint performs several requests for each resource within an application, specifying different headers, and checking and validating the content that gets returned.
In support of Progressive Web Apps (PWA), webhint analyzes the web manifest file to check its accuracy and settings.
The webhint tool can also verify that the server-side for an application is returning the correct content-type for a resource.
The project recently added a CSS parser, including a PostCSS abstract syntax tree.
Parser support is also available for TypeScript, Babel, and Webpack. The Webpack integration offers guidance for better tree shaking to improve application performance. The TypeScript and Babel integration checks against list of browsers specified within the webhint configuration to determine which version of JavaScript should get output by these transpilers.
webhint is an open source project, part of the JS Foundation, available under the Apache 2 license. Beyond the source code for the webhint parser, the online scanner source code is also available. Contributions are welcome via GitHub.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Google announced it is bringing code search with the newly revamped Cloud Source Repositories in beta availability. The overhaul of the service means an entirely new user interface and semantic code search capabilities.
The beta available Cloud Source Repositories is according to the announcement powered by the same underlying code search infrastructure that Google engineers perform their code searches on every day. Furthermore, code search in Cloud Source Repositories also uses the same document indexing and retrieval technologies that Google uses for their Search. Hence, this service can improve developer productivity, whether the code resides in Cloud Source Repositories or a developer mirrors their code from the cloud versions of GitHub or Bitbucket.
With Cloud Source Repositories developers have the benefit of leveraging the Google Search technology for their code base search – using a single query over all owned repositories either mirrored or added to Cloud Source Repositories. Furthermore, Cloud Source Repositories take identity and access management (IAM) permissions into account and do not show any code to developers who do not have access to view it. Also, Cloud Source Repositories support RE2 regular expressions in search patterns, allowing developers to perform complex search queries.
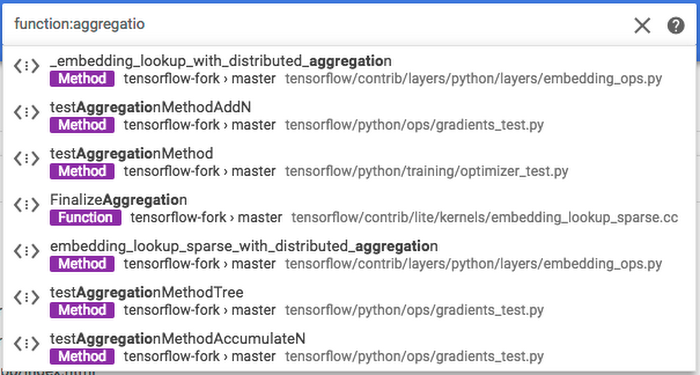
When a developer submits a search query in code search, that query goes to a root machine and sharded to hundreds of leaf machines. The query processing involves matching by file names, classes, functions and other symbols, and matching of the context and the namespace of the symbols. Note that search works across all languages. However, the semantic understanding of sources which enhances search is limited to Java, JavaScript, Go, C++, Python, TypeScript and Proto files.
Furthermore, if developers use a regular expression, then the code search runs an optimized algorithm to find potential matches for the regular expression quickly. Subsequently, it refines the results against the full regular expression to find the actual matches. Russell Wolf, product manager, said in a Hacker News thread on the announcement of Cloud Source Repositories in beta:
The more code you have, the more benefit you get from having fast search tools across your entire code base that can perform complex semantic and regular expression queries. Even with smaller codebases, I find it the fastest way to find the code I need.
Developers can try Cloud Source Repositories through the Google Cloud Platform (GCP) free trial and free tier. Furthermore, developers can create a new empty repository or mirror their code from the cloud version of GitHub or Bitbucket.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- There is no one-size-fits-all approach to being agile, or to scaling Scrum
- Lean and Agile are different things, but are great partners
- You can be lean without being agile, and you can be agile without being lean
- Executives must be fully engaged and part of the process
- Understanding complexity and multi-team systems is critical for success
Toyota Connected uses Scrum combined with the Toyota Production System to deliver Lean Production, enabling teams to deliver rapid PDCA cycles. Scrum of Scrums, Meta Scrum, and the chief product owner, are some of the approaches used to scale Scrum for multiple teams and products. Agility is not the goal. It’s a result, an outcome.
Nigel Thurlow, chief of Agile at Toyota Connected, will talk about “Scrum The Toyota Way” at eXperience Agile 2018. This conference will be held in Lisbon, Portugal, on October 1 – 2.
InfoQ will be covering eXperience Agile with Q&As, summaries, and articles. This year’s conference theme, “Improving Through People,” is described below:
Discover the latest cutting-edge Agile practices by top industry leaders from around the world. eXperience Agile is more than just another Agile conference. This is an event that will highlight the most revolutionary applications of Agile being used today.
InfoQ interviewed Thurlow about how the DNA of Toyota connects to Scrum and agile, the challenges that Toyota Connected is dealing with, how they apply agile and what they have learned, the role of the product owner, how the C Suite fits into the agile world, and how Scrum and agile relate to the Toyota Production System and Lean Production.
InfoQ: What’s the DNA of Toyota and how does that connect to Scrum and agile?
Nigel Thurlow: Everybody at Toyota understands the customer-first promise and the founding principles of TPS and the Toyota Way. When we discuss the value of embracing new technology and the digital world, we always have our DNA giving us the reasons why we need to do it: our customers.
Customer First was first coined in 1946 by the first president of Toyota Motor Sales Japan, Shotaro Kamiya, and is the principle of considering the need and desires of the customer when determining direction and strategy. Simply stated, it’s delivering the highest quality, in the shortest lead time, for the lowest cost.
Scrum is a framework to enable teams to deliver rapid PDCA cycles, where value is prioritized for the customer, and non value added work is eliminated. It’s important to note that Scrum does not make you lean, and being lean does not mean you are doing great Scrum.
Agility is a result or outcome, and is not the goal. Scrum is one way to help achieve that, in fact it’s the best way to codify PDCA I’ve worked with. Everyone knows what PDCA is, but no one actually knows how long a PDCA cycle should last for. What we are trying to do with Scrum is shorten that cycle. The cycle to inspect customer feedback (check) and to adapt to that feedback (act). I sometimes refer to this as PDIA, Plan, Do, Inspect, Adapt.
Just as Scrum does not make you Lean, being Lean does not mean you are Agile. You can be Lean without being Agile, and you can be Agile without being Lean. They are different, yet very complementary concepts. We want to be Lean, delivering the flow of value the most efficient way possible, but we also want to be Agile by being able to respond rapidly to changes in customer or market demand, or responding to unknown events quickly.
InfoQ: What are the challenges that Toyota Connected is dealing with?
Thurlow: Toyota Connected (TC) was established as an agile startup to help Toyota respond rapidly to the changing connected-car technology space. We are not just talking about self-aware cars, but about providing a wide array of connected services to vehicle owners to serve their mobility needs. That’s the vision of Toyota’s President, Akio Toyoda, which we try to execute by leveraging the digital tools at our disposal — from Artificial Intelligence to the Internet of Things — enabling us to build the future of connected vehicle technologies.
We are working in an ever-fast changing world where time to market is no longer measured in years, but often in months, and soon even shorter durations. As the ability to upgrade cars in real-time becomes an everyday occurrence, as well as the increasing levels of live data vehicles are now able to stream, we have to be able to deliver the benefits and capabilities our customers seek. Whether that’s helping an insurance company set rates through accurate and meaningful driver scoring, or being able to correct an operational problem with an over the air update, to creating mobility options like the Hui car-sharing service in Honolulu in partnership with Servco Pacific Inc, and to integrating Amazon’s Alexa into Toyota vehicles and studying advancements in data science and AI.
InfoQ: How does Toyota Connected apply agile?
Thurlow: We practice and teach Toyota Production System (Lean) and Toyota Way principles, but we are also an agile company by design. TC was setup to behave like a startup, but with the stability and funding of a global corporation. We create an office environment for great engineering and technical excellence, that allows teams to thrive in a creative and open way.
Our small (typically five to six people) collaborative teams sit very closely together in open-space offices, with obeya rooms, visual management and andon displays all around them. Whilst we use electronic tools, we teach and encourage visual management to enable transparency and openness and to enable real-time discussions at the gemba with leadership and key stakeholders.
We are focused on creating flow efficiency through eliminating bottlenecks and impediments to deliver value faster to the customer. This involves studying multi-team science, something we have partnered with the University of North Texas to study, and conducting many experiments to define the repeatable patterns in many contexts to enable agility across the organization. We are currently working on a number of scholarly white papers for publication in the coming months to share this learning with the agile world.
A example of Multi Team Systems is Scrum of Scrums and Meta Scrum. We define these as behavioral patterns, and it is through observing them we can identify what works and what struggles. We can then experiment by adjusting the process and see the effect on the behavior. As we refine these team interactions, we iterate and document them as patterns, both positive and negative.
Another example is the idea of creating a SoSM (Scrum of Scrums Master) and making them accountable for the release of the joint team’s effort. We find that this creates a command and control leadership style, as we now have a single person ‘telling’ the teams to deliver. This dampens the collaboration between teams as they are now being measured and held accountable by a proxy manager.
We recognize that simply making a group of people use Scrum does not create a great team, and when we involve multiple teams we find the challenges are amplified. Changing behaviors and teaching team skills is essential.
Cynefin enables us to understand complex adaptive systems, and teams are indeed complex with many unpredictable behaviors. It’s important to understand that it is task interdependence that determines if you need a team, and not people in a reporting structure who are necessarily a team, despite what the organization chart might say. If individuals need to work consistently with other individuals to deliver something, then we consider them interdependent and we form a team, irrespective of reporting lines. Those people work interdependently, adaptively and dynamically towards a shared & valued goal.
Studying the work of David Snowden with the professors at UNT, we are starting to define behavioral markers that teams can self identify against and then self correct against, together with close coaching and support from the team’s Scrum Master.
We are defining what agility means to Toyota as a global corporation. We have taken a lot of industry knowledge and we are giving back to the community by trying to find synergies between TPS/Lean and the agile world. We have recently launched a public offering called Scrum the Toyota Way, for example, and after successful beta tests we are now planning a wider public availability of this training. We continue to learn new things and evolve as our understanding of this world deepens.
InfoQ: What have you learned?
Thurlow: We have learned that agility is hard, really hard. There is also no such thing as an agile transformation. You fundamentally have to change your operating model, and undertake an organizational transformation to achieve the agility you desire. Scrum is but one item in the toolbox to help you do this. You also need a sense of urgency. If the C Suite don’t see a compelling reason to change, chances are you’ll actually make things worse by messing with the current condition, and the resistance to change will be overwhelming, with no mandate to actually achieve that change.
I’ve also realized that not everyone needs to be agile! If you’re shipping concrete slabs you probably don’t need to do that in two-week sprints, as the need to change rapidly is not there. Sure, Scrum will give you a planning cadence, but Scrum was intended to work in complex domains and with complex systems. These are areas where a linear approach and fixed thinking are not effective.
If you are working in a domain that is fixed and varies little, then agility may not be as important as being Lean. Optimizing the efficiency of product flow may be much more beneficial. If however, you are working in a fast changing ever evolving market, then agility is crucial. Remember, you can be lean and not agile, and you can be agile and not lean. I’d suggest that agility plus lean is a winning combination. You could say that Agility is delivering the right thing, and Lean is delivering the thing right.
InfoQ: How successful is Scrum for you?
Thurlow: If you are a one team one product startup, Scrum is very simple to apply, and very effective. If you put a group of highly talented individuals together in a room and provide the motivation and the challenge, they’ll create great things. Scrum is highly effective at shortening the PDCA cycle and delivering rapid results, by enabling rapid response to change, a key agile tenet.
Scale that to one team with many products and the product backlog becomes a team backlog. Prioritization now becomes much more challenging as many stakeholders vie for the number one spot. Making that team backlog visible to leadership is critical to enable real-time discussion and prioritization. And when I say visible, I mean on a physical board across a giant wall or a series of whiteboards stitched together. This is precisely what we are doing at Toyota Connected.
Scale that to many teams on the same product, and certain patterns become useful; patterns to enable higher level backlog and product management. It’s here we start to use Meta Scrum for the management of backlog, as well as Scrum of Scrums for the management of delivery across multiple interdependent teams. The coordination of multiple dependencies between teams and products is amplified and so the need to find pragmatic techniques to coordinate that collaboration is essential.
When you scale that to many teams on many products, the complexity scales exponentially. Now throw in numerous dependencies, and constraints, whether that’s multiple partners or vendors, or built in constraints within a global corporation, and agility becomes far more complex to achieve. The concepts are the same, the tools are the same, but the context alters everything. This is where organizational design and the operating model have to change and evolve.
We have clearly recognized that there is no one-size-fits-all scaling framework. Frameworks are context agnostic, but at scale context is everything. Patterns, techniques, experiments, and empowered teamwork are all essential, but there is no silver bullet, not yet anyway.
InfoQ: How crucial is the role of product owner?
Thurlow: The product owner role is critical to the success of a Scrum team, but is also the most challenging to get right. The Scrum Guide notion of the team doing the heavy lifting on creating the backlog is not workable in practice at scale. Developers do not always possess the skills or desire to be the owners of a product backlog, even if the PO is still accountable. Being able to sell and market a product, as well as do the business analysis side of the role requires certain disciplines that are not plentiful in highly technical engineers, nor is it the best use of their skills and talents. If that role does exist or evolves within the team, then the team effectively become a product owner anyway. Of course, this depends on the way you define Product Ownership, and the bigger picture of Product Management.
Various scaling approaches attempt to remedy this through various means, but we have come to realize that we need a clear product owner in that role, and that while the role is singularly accountable, the role of product ownership is an activity that involves many people. A single team concept does not scale without adaptation and without immense discipline, and such discipline is hard to achieve in a large corporation.
Through the study of the product owner role, we have realized that we needed to codify the actual work of creating the backlog. Afterall, we need the backlog for the team to work on, and for the team to refine. Therefore we created an activity called Product Backlog Development.
Product Backlog Development is the act of creating Product Backlog Items. This is an ongoing process in which the Product Owner together with any required stakeholders create Product Backlog Items. Required stakeholders may include; Customers, Subject Matter Experts, System Users, Business Representatives and support from any group necessary to help the Product Owner develop backlog items. During Product Backlog Development the product vision, strategy and roadmap are created, reviewed and revised. Product Backlog Development occurs every Sprint.
It may seem simple, and probably others would argue not needed as the Scrum Guide defines this anyway, albeit less explicitly, but what we have found is that it does not define it well enough, so we simply did.
We do of course promote and enable open and effective communication between the teams and the actual customers, but often we found that the product owner being actively engaged is more effective day-to-day, especially where we have time zones, language, and technological limitations. We also use the chief product owner concept when we have many teams working on the same product. The chief product owner enables effective communication between many teams and a customer, as well as working with other product owners to ensure everyone is aligned and focused on the highest priorities.
InfoQ: How does the C Suite fit into the agile world?
Thurlow: Executive and senior leadership engagement is key once you start to scale the number of products, or the number of teams. At Toyota Connected we scale the role of product owner to the executive level and we conduct an Executive Meta Scrum monthly to review enterprise progress, ensure alignment to vision and strategy, and to make critical prioritization decisions.
We also have an Executive Action Team (EAT) where the same senior executives meet frequently to review impediments (blocking issues) and self assign them for resolution. This means the EAT behaves like a Scrum team, pulling impediments from a backlog and executing work to resolve them. In larger more complex multi vendor or multi affiliate product delivery, we may also have an intermediate Leadership Action Team (LAT) to resolve impediments or to take more rapid action before it is escalated to the EAT.
If you don’t have this engagement, you will find the ability to change direction or priority quickly is diminished, and with it your agility and perhaps your competitiveness.
Executive engagement is also needed to tackle the silos that exist in large companies and organizations. It’s a challenge to eliminate the silos that evolve and protect their existence. This makes value stream design long and painful, and as Peter Drucker once said, “any innovation in a corporation will stimulate the corporate immune system to create antibodies that destroy it.” To truly transform an organization we must optimize the system for the flow of value, and this means looking at the whole system, and changing the whole system, if that is what is needed.
We must stop doing agile and start enabling flow and shortening the feedback loops. Then we will become agile.
InfoQ: Toyota is known for the Toyota Production System and Lean Production. How does Scrum and agile relate to this?
Thurlow: Scrum, the predominant agile framework, was based on the Toyota Production System (what many refer to as lean, a term coined by the authors of the book, “The Machine that Changed the World,” the first major publication on how Toyota manufactures products) and, as I was recently told by Kent Schwaber, on DuPont’s influence to adopt an empirical planning approach. In fact, Scrum is simply an empirical planning approach, with rapid feedback loops built in to enable certain behavioral characteristics in a team. It is PDCA codified with time boxed steps.
How long should planning, doing, checking and acting last? And what is actually happening in each of these phases? Scrum codified this, providing discipline around PDCA.
TPS/Lean is the gold standard for lean product development. Codifying PDCA using Scrum is providing a mechanism through which we can improve our responsiveness to change, and to constantly inspect and adapt the value we are delivering to our customers.
However, agile isn’t saving lean and lean isn’t saving agile; the agile movement is enabling companies that are already lean or may wish to be lean to make decisions faster. We are using frameworks like Scrum and tools coming out of the Toyota Production System to enable business agility, thus developing the ability to respond more quickly to market trends. “Agility is not the goal. It’s a result or an outcome”.
InfoQ: If InfoQ readers want to learn more about Scrum The Toyota Way, where can they go?
Thurlow: Right now we are testing a number of public classes. We have just held two beta classes and will be holding two more public classes, one in Portlandand one in Dallas. We are also sponsoring Agile Camp. The event in Dallas is in final preparation and will soon be announced on various social media platforms by Agile Camp.
We also offer a 100% discount for our military veterans and serving members of law enforcement so they can attend and learn new skills for re-entry into the jobs market and help them serve the public more effectively.
About the Interviewee
 Nigel Thurlow is an Organizational Theorist, Continuous Improvement Leader, Agile and Scrum Expert, and The Chief of Agile at Toyota Connected. He is an internationally recognized industry expert on Lean and Agile approaches and is leveraging the power of The Toyota Production System and The Toyota Way to enhance and develop Agility in Lean Product Development.
Nigel Thurlow is an Organizational Theorist, Continuous Improvement Leader, Agile and Scrum Expert, and The Chief of Agile at Toyota Connected. He is an internationally recognized industry expert on Lean and Agile approaches and is leveraging the power of The Toyota Production System and The Toyota Way to enhance and develop Agility in Lean Product Development.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Spring has released two versions of their Web Services project at the same time: version 3.0.4.RELEASE as the main branch of development, and version 2.4.3.RELEASE for maintenance. Both versions have been upgraded to run on Spring Framework 5.1.0 and to support Java 11.
Spring Web Services (Spring-WS) is a product of the Spring community focused on creating document-driven Web services. It aims to facilitate contract-first SOAP service development, allowing for the creation of flexible web services using one of the many ways to manipulate XML payloads.
The most notable improvement in the new Spring Web Services versions is support for Java 11. Since Java 9, a number of key Java EE packages such as core XML and SOAP-based packages, had their visibility reduced, and in Java 11, these packages have been removed altogether. Thus, to use Spring Web Services on Java 9+, developers can no longer depend on the JDK providing key XML and SOAP-based libraries.
A new Java 11 profile, which contains the extra dependencies that developers must add to their own build file, has been added to the Spring Web Services build file. Developers should add the dependencies to their build file when using Java 11. The following is a snippet of the build.xml with the dependencies needed for Java 11 on version 3.0.4.RELEASE:
<dependencies>
<dependency>
<groupId>com.sun.xml.ws</groupId>
<artifactId>jaxws-ri</artifactId>
<version>2.3.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.jvnet.staxex</groupId>
<artifactId>stax-ex</artifactId>
<version>1.7.8</version>
</dependency>
<dependency>
<groupId>com.sun.xml.messaging.saaj</groupId>
<artifactId>saaj-impl</artifactId>
<version>1.3.28</version>
</dependency>
<dependency>
<groupId>javax.xml.soap</groupId>
<artifactId>javax.xml.soap-api</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>javax.xml.ws</groupId>
<artifactId>jaxws-api</artifactId>
<version>2.3.0</version>
</dependency>
Developers who still use Spring Web Services 2.4.3.RELEASE will not have problems using Java 11. This version just uses a slightly older version of the SOAP API (1.3.8). The following is a snippet of the build.xml with the dependencies needed for Java 11 on version 2.4.3.RELEASE:
<dependencies>
<dependency>
<groupId>com.sun.xml.ws</groupId>
<artifactId>jaxws-ri</artifactId>
<version>2.3.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.jvnet.staxex</groupId>
<artifactId>stax-ex</artifactId>
<version>1.7.8</version>
</dependency>
<dependency>
<groupId>com.sun.xml.messaging.saaj</groupId>
<artifactId>saaj-impl</artifactId>
<version>1.3.28</version>
</dependency>
<dependency>
<groupId>javax.xml.soap</groupId>
<artifactId>javax.xml.soap-api</artifactId>
<version>1.3.8</version>
</dependency>
<dependency>
<groupId>javax.xml.ws</groupId>
<artifactId>jaxws-api</artifactId>
<version>2.3.0</version>
</dependency>
Both Spring Web Services versions bring a series of bug fixes and improvements beyond the common Java 11 support, such as:
- SaajSoapMessage created with default (empty) SoapEnvelope (SWS-1018)
- SimpleXsdSchema not initialized property produces NullPointerException (SWS-1036)
- Resolve version conflicts of third party libraries (SWS-1030)
- Ehcache – OWASP Dependency Check issues (SWS-1033)
Features specific to Spring Web Services 3.0.4.RELEASE are:
- Make SimpleXsdSchema give a more productive error message (SWS-1037)
- Polish documentation, a set of small corrections on the documentation, such as a wrong reference to Gradle Wrapper instead of Maven Wrapper, broken links, etc. (SWS-1038)
- Upgrade to latest version of Spring (SWS-1039)
Spring Web Services artifacts are staged on maven central and http://repo.spring.io/. There is also an example on Spring GitHub repo demonstrating how to use Spring Web Services with Spring Boot.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

TensorFlow 1.x Deep Learning Cookbook
By Antonio Gulli, Amita Kapoor
Take the next step in implementing various common and not-so-common neural networks with Tensorflow 1.x
In this book, you will learn how to efficiently use TensorFlow, Google’s open source framework for deep learning. You will implement different deep learning networks such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Deep Q-learning Networks (DQNs), and Generative Adversarial Networks (GANs) with easy to follow independent recipes. You will learn how to make Keras as backend with TensorFlow.
With a problem-solution approach, you will understand how to implement different deep neural architectures to carry out complex tasks at work. You will learn the performance of different DNNs on some popularly used data sets such as MNIST, CIFAR-10, Youtube8m, and more. You will not only learn about the different mobile and embedded platforms supported by TensorFlow but also how to set up cloud platforms for deep learning applications. Get a sneak peek of TPU architecture and how they will affect DNN future.
By using crisp, no-nonsense recipes, you will become an expert in implementing deep learning techniques in growing real-world applications and research areas such as reinforcement learning, GANs, autoencoders and more.
What you will learn:
- Install TensorFlow and use it for CPU and GPU operations
- Implement DNNs and apply them to solve different AI-driven problems.
- Leverage different data sets such as MNIST, CIFAR-10, and Youtube8m with TensorFlow and learn how to access and use them in your code.
- Use TensorBoard to understand neural network architectures, optimize the learning process, and peek inside the neural network black box.
- Use different regression techniques for prediction and classification problems
- Build single and multilayer perceptrons in TensorFlow
- Implement CNN and RNN in TensorFlow, and use it to solve real-world use cases.
- Learn how restricted Boltzmann Machines can be used to recommend movies.
- Understand the implementation of Autoencoders and deep belief networks, and use them for emotion detection.
- Master the different reinforcement learning methods to implement game playing agents.
- GANs and their implementation using TensorFlow.
Click here to get the free eBook

Data Science Algorithms in a Week
By Dávid Natingga
Build strong foundation of machine learning algorithms In 7 days.
This book will address the problems related to accurate and efficient data classification and prediction. Over the course of 7 days, you will be introduced to seven algorithms, along with exercises that will help you learn different aspects of machine learning. You will see how to pre-cluster your data to optimize and classify it for large datasets. You will then find out how to predict data based on the existing trends in your datasets.
This book covers algorithms such as: k-Nearest Neighbors, Naive Bayes, Decision Trees, Random Forest, k-Means, Regression, and Time-series. On completion of the book, you will understand which machine learning algorithm to pick for clustering, classification, or regression and which is best suited for your problem.
What you will learn:
- Find out how to classify using Naive Bayes, Decision Trees, and Random Forest to achieve accuracy to solve complex problems
- Identify a data science problem correctly and devise an appropriate prediction solution using Regression and Time-series
- See how to cluster data using the k-Means algorithm
- Get to know how to implement the algorithms efficiently in the Python and R languages
Click here to get the free eBook

Mastering Machine Learning with R – Second Edition
By Cory Lesmeister
Master machine learning techniques with R to deliver insights in complex projects
In this book, you will explore, in depth, topics such as data mining, classification, clustering, regression, predictive modeling, anomaly detection, boosted trees with XGBOOST, and more. More than just knowing the outcome, you’ll understand how these concepts work and what they do.
With a slow learning curve on topics such as neural networks, you will explore deep learning, and more. By the end of this book, you will be able to perform machine learning with R in the cloud using AWS in various scenarios with different datasets.
What you will learn:
- Gain deep insights into the application of machine learning tools in the industry
- Manipulate data in R efficiently to prepare it for analysis
- Master the skill of recognizing techniques for effective visualization of data
- Understand why and how to create test and training data sets for analysis
- Master fundamental learning methods such as linear and logistic regression
- Comprehend advanced learning methods such as support vector machines
- Learn how to use R in a cloud service such as Amazon
Click here to get the free eBook

Optimizing Hadoop for MapReduce
By Khaled Tannir
This book is the perfect introduction to sophisticated concepts in MapReduce and will ensure you have the knowledge to optimize job performance. This is not an academic treatise; it’s an example-driven tutorial for the real world.
Starting with how MapReduce works and the factors that affect MapReduce performance, you will be given an overview of Hadoop metrics and several performance monitoring tools. Further on, you will explore performance counters that help you identify resource bottlenecks, check cluster health, and size your Hadoop cluster. You will also learn about optimizing map and reduce tasks by using Combiners and compression.
The book ends with best practices and recommendations on how to use your Hadoop cluster optimally.
What you will learn:
- Learn about the factors that affect MapReduce performance
- Utilize the Hadoop MapReduce performance counters to identify resource bottlenecks
- Size your Hadoop cluster’s nodes
- Set the number of mappers and reducers correctly
- Optimize mapper and reducer task throughput and code size using compression and Combiners
- Understand the various tuning properties and best practices to optimize clusters
Click here to get the free eBook.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Citizens can get the information and services they need more quickly because users’ needs are considered in government service design, and suppliers can work with the government in modern agile ways: these are two benefits resulting from the UK Government’s digital transformation. Having teams exposed directly to users motivates teams to make their products better.
James Stewart, partner at Public Digital, presented the UK Government’s digital transformation journey at Agile Summit Greece 2018. InfoQ is covering this event with summaries, articles, and Q&As.
The key to the digital transformation was in the “default” part of “digital by default”. Instead of online channels being an optional extra, we worked to put the culture, processes, practices, and technologies of the internet at the heart of how services are conceived and delivered, said Stewart, a massive change in how the UK government shapes policy, how it understands what citizens need, and how it measures its performance.
The UK government’s transformation raised the expectations among the public and civil servants of what a government can achieve when it works digitally, which may be the most lasting legacy in the UK and around the world, argued Stewart.
InfoQ interviewed Stewart about what it was that made the transformation a revolution, the main challenges they had and how they dealt with them, the benefits that the digital transformation delivered, and the lessons learned.
InfoQ: Your talk’s title mentions “Revolution NOT Evolution”. What was it that made it a revolution?
James Stewart: The title is taken from the 2010 review by Martha Lane-Fox that led to the creation of the Government Digital Service (GDS). The vision presented there was of shifting government to a service culture: one that put the needs of citizens above the bureaucratic structures, and one that embraced internet-era ways of working rather than the 19th century processes that shaped most modern governments.
InfoQ: What were the main challenges and how did you deal with them?
Stewart: I worked in government for six years and the challenges kept changing as we went on. One of the biggest initially was learning to deal with the mythology that defined how many processes worked. In any organisation that’s been around for a while, ways of doing things build up and often disconnect from the reasons they were put in place. Things are cited as “rules” which are really just norms. We had to get really good at working out the difference, and on pushing back on some of those rules to get to the core principles.
For example, some people said that you couldn’t ask technical questions in interviews or deviate from a script if a candidate said something you wanted to dig into. That’s not the case, as long as you are confident that you’re giving every candidate an equal opportunity to prove themself, are consistent, and keep good records. We got really good at doing the research and pushing back so that we could change the practices without compromising the (often very sensible) principles.
As time went on, though, the bigger challenges revealed themselves in the funding, governance and power structures of government. You can get a certain way into providing better services, improving technology, introducing new skills without addressing those big parts of the system. But at a certain point you have to fix the systemic things if you want to really take advantage of internet-era ways of working. And that’s when you run into real resistance as you’re challenging the things people have spent entire careers defending. We got a certain distance with that and really successful common platforms like GOV.UK Pay and GOV.UK Notify are the evidence of that, but much deeper institutional reform is still needed.
In the InfoQ article Agile in the UK Government – An Insider Reveals All, Nick Tune mentioned that not assessing full end-to-end systems poses major challenges for the front end teams to deliver:
What shocks me the most about the conflicting digital and IT silos is that GDS don’t seem to assess any of the backend systems, in my experience. They expect digital teams building the websites to work in an agile way, focusing on users and open sourcing their code, but I never saw the same standards being applied to the internal IT teams who manage all of the backends. I know of one government project where the digital team couldn’t even add one extra textbox to their address fields, something users were complaining about, because the backend IT teams were too busy to make the change.
InfoQ: Which benefits did the UK Government’s digital transformation deliver?
Stewart: The headline is that it saved £4.1bn over three years, but the reality is that we achieved that by focusing on deeper benefits. Millions of people can get the information and services they need more quickly; there are teams across government who are equipped to what their users need and how and when they need it and to continually improve services; and there’s a whole new set of suppliers who can work with government in modern, agile ways.
Tune described in his InfoQ article what is done to assure that users’ needs get high attention:
IT projects in the UK government must follow an approved GDS format. During each phase of the lifecycle you have to personally demonstrate to GDS that your team has understood who your users are, what their needs are, and how the system you are building addresses those needs.
InfoQ: What lessons did you learn on your transformation journey?
Stewart: So many lessons! Some of my colleagues set out to document the higher level lessons. The result was an entire book — Digital Transformation at Scale: Why the Strategy Is Delivery — but there’s a huge amount more that couldn’t be included there.
But top of the list is the importance of remaining focused on your purpose and your users’ needs. As technologists and agilists we can too easily be drawn into improving technology or simplifying processes without stepping back and asking why we have those things in the first place, or if the change we’re making is the right one.
I’ve talked to a lot of teams in large organisations who have taken all the right steps in moving to agile but are still having trouble motivating their teams, and the missing piece is almost always being exposed directly to your users. Whether they’re end customers, or internal users, there’s nothing like seeing people use your products to motivate the team to make them better.
Beyond that, a thing I’ve spent a lot of time on recently is looking at the way finance works (or doesn’t) in a continuous delivery environment, the result of which was a paper for the AWS Institute – Budgeting for Change – writing that was yet another reminder of the importance of a genuinely inter-disciplinary approach. I worked with a public sector finance specialist and learned a huge amount in the process. Revolutionary change requires engaging with all angles of the way we do things, always with a team that can apply as broad as possible a range of perspectives and skills.
Earlier InfoQ publications explored how the UK government uses cloud computing, DevOps at the UK government, Agile in the UK government, open source development at the UK government, and DevOps at UK’s Department for Work and Pensions.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The adoption of Axon Framework is growing rapidly and recently hit one million downloads, Allard Buijze noted in his presentation at the recent Event-Driven Microservices Conference in Amsterdam, where he described the basic concepts, the history and future of Axon, a framework for systems based on DDD, event sourcing and CQRS.
Buijze started by noting that events are very special; they describe something that happened and are part of the history of a system. We can find problems from the past and we can set expectations on the future. For Buijze this is what drives the event sourcing practice – use your events, not just as a side effect, but as the source of truth in your applications.
Buijze also pointed that it’s important that a service is consuming its own events – this is essential in event sourcing. If your service is making decisions based on internal data, not on the events, you are not doing full event sourcing. You have an event driven architecture, but you cannot guarantee that the events are a true representation of what has happened in the service.
In Buijze’s experience there are a lot of microservices architectures based on entity services, and he calls this design technique noun-driven design. The idea is to find all the nouns in the documentation describing the new system, these will be the services, and all the verbs become the API calls. This technique will likely result in a distributed big ball of mud, with all services depending on each other. If one service goes down the whole system will be unusable.
Instead of starting with microservices Buijze wants us to start with a monolith. they are easier to deploy and refactor, although they are harder to scale, and he points out that we shouldn’t confuse a good monolith with a big ball of mud. The strategy he recommends is to start with the monolith but making sure there is a clearly defined structure inside. With time, when too many people have to work with the same parts of the code, then it’s time to extract some components, preferably without changing other parts. As time passes and needs arises, more and more components can be moved out.
To help in extracting components, location transparency is very important, and Buijze notes that the primary feature of Axon is not CQRS, it is location transparency between the components inside an application. If two components are not aware of their respective location, then you can change that location. It also means that you don’t have to know in which service a certain operation is – you just send a message and it will find its destination.
A component should neither be aware of nor make any assumptions about the location of components it interacts with
Events are important, but Buijze points out that there are three categories of messages that a component has reasons to send and emphasizes that an event is not the same thing as a message:
- An Event is when something has happened. They are distributed to all handlers and no results are returned.
- A Command is when you want the system to do something. They are routed to a single handler and return a result.
- A Query is when you want to know something. They return a result.
To support the promises of location transparency and work with these different types of messages, AxonHub was released in 2017, at last year’s conference. Buijze describes it as a messaging platform that understands the different type of messages, not the content, and is capable of routing the different types to the correct destinations. He notes that the ideas of the hub are comparable to the microservices concept of smart endpoints and dumb pipes even though the pipe in this case is aware of the message types.
Looking into the future, Buijze believes that the microservices evolution will continue, and he also believes that the way the Axon components work and communicate can be useful in a serverless environment. Their first step in this direction will be to provide a SaaS solution, but he also noted that they have more to learn and that there is more work to be done to be able to use a serverless environment efficiently.
Earlier this year the Axon team released AxonDB, a purpose-built event store. The store is used by AxonHub for storing events and because of that they have decided to merge these two products into Axon Server which was announced during the conference. The server is available both as open source and as an enterprise version.
The work on the next version of Axon, version 4, is ongoing and the first milestone was recently released. Product launch is planned for October 18.
Axon Framework is an open source product for the JVM platform, founded i 2009 by Allard Buijze. In July 2017 a separate company, AxonIQ, was founded to solely work with the Axon products.