Month: October 2018

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Here are a few off-the-beaten-path problems at the intersection of computer science (algorithms), probability, statistical science, set theory, and number theory. While they can easily be understood by beginners, finding a full solution to some of them is not easy, and some of the simple but deep questions below won’t be answered for a long time, if ever, even by the best mathematicians living today. In some sense, this is the opposite of classroom exercises, as there is no sure path that lead to full solutions. I offer partial solutions and directions, to help solve these problems.

Mathematical tessellation artwork
1. A Special Number
Here we try to construct an irrational number x that has 50% of zero’s, and 50% of one’s, in its binary representation (digits in base 2.) To this day, no one knows whether any classic mathematical constant (Pi, e, log 2, SQRT(2) and so on) has such a uniform distribution of 0 and 1 in base 2, or any other base. The number is constructed as follows. Let us denote as S(n) the set of strictly positive integers that are divisible by p(1) or p(2) or … or p(n) where the p(k)’s are prime numbers to be determined later. We formally define x as the limit, when n tends to infinity, of x(n), with

The prime numbers p(1), p(2) and so on, are chosen such that x has 50% zero’s, and 50% one’s, in its base 2 representation. Which prime numbers we should choose is a relatively easy problem, achieved using a version of the greedy algorithm as follows:
- p(1) can not be 2 (why?) and the smallest value it can possibly be is p(1) = 3. Let’s pick p(1) = 3. Now, one third of the digits of x(1) are equal to 1.
- p(2) = 5 works. So let’s pick p(2) = 5. Now the proportion of 1 in the digits of x(2), is 7/15 still lower than 50%.
- p(3) = 7 does not work because x(3) would have more than 50% of its digits equal to 0. The smallest prime to choose next is p(3) = 17. With this choice, the proportion of 1 in the digits of x(3), is 0.498039216.
- The smallest next prime that works, is p(4) = 257. With this choice, the proportion of 1 in the digits of x(4), is 0.49999237.
Now we have an algorithm to find the p(k)’s. It is easy to prove (see here) that the proportion of 1 in x(n), denoted as r(n), is equal to

Note that this formula is correct only if the p(k)’s have no common divisors (why?), thus our focus is on prime numbers only. The fact that the above product, if taken over all prime numbers rather than those that we picked, is diverging, actually guarantees that we can grow our list of primes indefinitely, and at the limit as n tends to infinity, r(n) tends to 50%, as desired. Also note that for any fixed value of n, x(n) is a rational number and can be computed explicitly.
Questions
- Can you find the first 10 values of p(n)? What about the first 50 values? (you will need high precision computing for that)
- Is the number x constructed here, rational or not?
- Compute the first 10 decimals (in base 10) of x.
- Compute the exact values of x(n) up to n = 5.
- Provide an asymptotic formula for p(k) — this article might help you find the answer.
- Is the digit distribution of x truly random?
The answer to the last question is no. The digits exhibit strong auto-correlations, by construction. It is also easy to prove that x is not a normal number, since sequences of digits such as “100001” never appear in its base 2 representation.
2. Another Special Number
Again, the purpose here is to construct an irrational number x between 0 and 1, with the same proportion of digits equal either to 1 or 0, in base 2. I could call it the infinite mirror number, and it is built as follows, using some kind of mirror principle:
- The first digit is 0.
- First 2 digits: 0 | 1
- First 4 digits: 0, 1 | 1, 0
- First 8 digits: 0, 1, 1, 0 | 1, 0, 0, 1
- First 16 digits: 0, 1, 1, 0, 1, 0, 0, 1 | 1, 0, 0, 1, 0, 1, 1, 0
- And so on.
Can you guess the pattern? Solution: at each iteration, concatenate two strings of digits: the one from the previous iteration, together with the one from the previous iteration with 1 replaced by 0 and zero replaced by 1. This leads to the following recursion, starting with x(1) = 0:

That is,

The number x, defined as the limit of x(n) as n tends to infinity, share a few properties with the number discussed in the first problem:
- x(n) is always a rational number, easy to compute exactly.
- The proportion of digits of x, equal to 0 in base 2, is 50% by construction.
- The number x is not normal: the sequence of digits “111” never appears in its binary expansion.
Is x is a rational number? I could not find any period in the first few hundred digits of x in base 2; it makes me think that this number is probably irrational. Can you compute the first 10 decimals of x, in base 10?
Finally, the digit 0 (in base 2) appears in the following positions:
1, 4, 6, 7, 10, 11, 13, 16, 18, 19, 21, 24, 25, 28, 30, 31, 34, 35, 37, 40, 41, 44, 46, 47, 49, 52, 54, 55, 58, 59, 61, 64, 66, 67, 69, 72, 73, 76, 78, 79, 81, 84, 86, 87, 90, 91, 93, 96, 97, 100, 102, 103, 106, 107, 109, 112, 114, 115, 117, 120, 121, 124, 126, 127, …
Do you see any patterns in that sequence?
Another number with digits uniformly distributed, although in base 10, is the Champernowne constant, defined as 0.12345678910111213… That number is even normal. Yet unlike Pi or SQRT(2), it fails many tests of randomness, see the section “failing the gap test” in chapter 4 in my book. Rather than using the concept of normal number, a better definition of a number with “random digits” is to use my concept of “good seed” (discussed in the same book) which takes into account the joint distribution of all the digits, not just some marginals. Note that for some numbers, the distribution of the digits does not even exist. See chapter 10 in the same book for an example.
3. Representing Sets by Numbers or Functions
Here we try to characterize a set of strictly positive integer numbers by a real number, or a set of real numbers by a function.
If S is a set of strictly positive integers, one might characterize S by the number f(S) = x, defined as follows: However, this approach has some drawbacks: for instance, f({1}) = f({2,3,4,5,6,…}) = 1/2. In short, all finite sets have a number representation that is also matched by an infinite set. How can we walk around this issue? If instead of using the representation using the base 2 system as above, we use the logistic map representation (see chapter 10 in my book), would this solve the issue? That is, in the logistic map numeration system, where digits are also equal to either 0 or 1, can two different sets be represented by the same number?
However, this approach has some drawbacks: for instance, f({1}) = f({2,3,4,5,6,…}) = 1/2. In short, all finite sets have a number representation that is also matched by an infinite set. How can we walk around this issue? If instead of using the representation using the base 2 system as above, we use the logistic map representation (see chapter 10 in my book), would this solve the issue? That is, in the logistic map numeration system, where digits are also equal to either 0 or 1, can two different sets be represented by the same number?
Let’s turn now to sets consisting of real numbers. But first, let’s mention that there is enough real numbers in [0, 1] to characterize all sets consisting only of integer numbers: in short, in principle, there is a one-to-one mapping between sets of integers, and real numbers. Unfortunately, there isn’t enough real numbers to characterize all sets of real numbers, thus we can not uniquely characterize a set of real numbers, by a real number. However there is enough real-valued functions to characterize all of them uniquely. See this article for an introduction on the subject.
The first idea that comes to my mind, to characterize a measurable bounded set S of real numbers, is to use the characteristic function of a uniform distribution on S. Two different sets will have two different characteristic functions. It is not difficult to generalize this concept to unbounded sets, but how can you generalize it to non measurable sets? Also, many characteristic functions won’t represent a set; for instance, in this framework, no set can have the characteristic function of a Gaussian distribution. By contrast, for sets of strictly positive integer numbers, any real number in [0, 1] clearly represents a specific set. How to go around this issue?
Another interesting issue is to study how operations on sets (union, intersection, hyper-logarithm, and so on) look like when applied to the number or real-valued function that characterize them.
The next tricky question of course, is how to represent sets of real-valued functions, by a mathematical object. There isn’t enough characteristic functions, by far, to uniquely characterize these sets. Operators, a branch of functional analysis, might fit the bill. These are functions whose argument is a function itself, such as the integral or derivative operators.
Related Articles
- One Trillion Random Digits
- Curious Mathematical Problem
- Another Off-the-beaten-path Data Science Problem
- Two More Math Problems: Continued Fractions, Nested Square Roots, D…
- Mathematical Olympiads for Undergrad Students
- Difficult Probability Problem: Distribution of Digits in Rogue Systems
- Little Stochastic Geometry Problem: Random Circles
- Paradox Regarding Random (Normal) Numbers
- Curious Mathematical Object: Hyperlogarithms
- 88 percent of all integers have a factor under 100
- Fractional Exponentials – Dataset to Benchmark Statistical Tests
- Two Beautiful Mathematical Results – Part 2
- Two Beautiful Mathematical Results
- Four Interesting Math Problems
- Number Theory: Nice Generalization of the Waring Conjecture
- Fascinating Chaotic Sequences with Cool Applications
- Representation of Numbers with Incredibly Fast Converging Fractions
- Yet Another Interesting Math Problem – The Collatz Conjecture
- Simple Proof of the Prime Number Theorem
- Factoring Massive Numbers: Machine Learning Approach
- Representation of Numbers as Infinite Products
- A Beautiful Probability Theorem
- Fascinating Facts and Conjectures about Primes and Other Special Nu…
- Three Original Math and Proba Challenges, with Tutorial
For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn, or visit my old web page here.
DSC Resources
- Invitation to Join Data Science Central
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Data Mining
There is an important distinction related to data mining. First the difference between mining the data to find patterns and build models, and second using the results of data mining. Data Mining results inform the data mining process itself.
The CRISP data mining process
Cross-industry standard process for data mining, known as CRISP-DM, is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model and breaks the process of data mining into six major process.

As we can see in the process diagram, the entire process is an exploration of the data through iteration. Let’s discuss this steps now.
Business Understanding
First of all, it is necessary to understand the problem to be solved. This may seem obvious, but recasting the problem and designing a solution is the usual process. As seen in the diagram this is shown by cycles within a cycle. At this stage the analyst’s creativity plays an important role.
As we seen in Part 1 there are powerful tools to solve a particular problem. Therefore, the design team should think carefully about the problem to be solved and about the use scenarios. This itself is one of the most important fundamental principles of data science.
Data Understanding
It is important to understand the strengths and limitation from the available raw material, from which the solution will be built. The data comprise contains different information, which can be historical data, customers data, marketing data or transactional data, from a database. The costs of data is also very important, cause some will be free and others require effort to obtain it. The estimate of the cost and benefits of each data source should therefore be made.
Data Preparation
The next step is data preparation. Usually raw data is not in a format that can be directly used to perform data analysis. Most platforms require data to be in a form different from how the data are provided. In very simple terms, most platforms require data to be in a matrix form with the variables being in different columns and rows representing various observations. Data can be available in a structured, semi-structured, and unstructured form. A significant effort is needed to align semi-structured and unstructured data into a usable form.
One very general and important concern during data preparation is to beware of “leaks”
(Kaufman 2012 – Leaking in data mining: Formulation, detection, and avoidance. ACM Transaction on Knowledge Discovery from Data (TKDD)) If you interested you can read it here:
Modeling
The next step is to put the data to work and build a model. The output of modeling is some sort of model or pattern capturing regularities(trends) in the data. It is important to know some sorts of techniques and algorithms that exist. Models vary in terms of complexity and can range from simple univariate linear regression models to complex machine learning algorithms.
Evaluation
The purpose of the evaluation stage is to assess the results and to gain confidence of valid and reliable data. It also serves to help ensure that the model satisfies the original business goals. The primary goal of data science for business is to support decision making, and solve the business problem. In the evaluation stage even if a model passes, there may be other considerations that make it impractical. The results includes both quantitative and qualitative assessments, so it must be think of the comprehensibility of the model. Finally, a comprehensive evaluation framework is important. For further studies have a look here:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4932655/
Deployment
In the deployment stage the results of data mining are put into real use. Many times, the models have to be corrected and new variables added or removed to enhance the performance. The clearest cases of deployment involve implementing a predictive model in some information system or business process. Additionally, the mining techniques themselves are deployed (for example targeting online advertisements).
Regardless of whether deployment is successful, the process returns to the Business Understanding phase. The process of data mining leads to great insights, so a second iteration can improve the solution. However, there are adjustment all the time, so you can go back from each stage to the prior one.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Introduction
Artificial Intelligence is growing at a rapid pace in the last decade. You have seen it all unfold before your eyes. From self-driving cars to Google Brain, artificial intelligence has been at the centre of these amazing huge-impact projects.
Artificial Intelligence (AI) made headlines recently when people started reporting that Alexa was laughing unexpectedly. Those news reports led to the usual jokes about computers taking over the world, but there’s nothing funny about considering AI as a career field. Just the fact that five out of six Americans use AI services in one form or another every day proves that this is a viable career option
Why AI?
Well, there can be many reasons for students selecting this as their career track or professionals changing their career track towards AI. Let us have a look at some of the points on discussing why AI!
- Interesting and Exciting
AI offers applications in those domains which are challenging as well as exciting. Driverless cars, human behaviour prediction, chatbots etc are just a few examples, to begin with. - High Demand and Value
Lately, there has been a huge demand in the industry for the data scientists and AI specialists which has resulted in more jobs and higher value given at workplace - Well Paid
With high demand and loads of work to be done, this field is one of the well-paid career choices currently. In the era, when jobs were reducing and the market was saturating, AI has emerged as one of the most well-paid jobs
If you still have thoughts on why one should choose AI as their career then my answer will be as clear as the thought that “If you do not want AI to take your job, you have to take up AI”!
Level 0: Setting up the ground
If maths(too much) does not intimidate and furthermore you love to code, you can then only start looking at AI as your career. If you do enjoy optimizing algorithms and playing with maths or are passionate about it, Kudos! Level 0 is cleared and you are ready to start a career in AI.
Level 1: Treading into AI
At this stage, one should cover the basics first and when I say basics, it does not imply to get the knowledge of 4–5 concepts but indeed a lot of them(Quite a lot of them)
Cover Linear Algebra, Statistics, and Probability Math is the first and foremost thing you need to cover. Start from the basics of math covering vectors, matrices, and their transformations. Then proceed to understand dimensionality, statistics and different statistical tests like z-test, chi-square tests etc. After this, you should focus on the concepts of probability like Bayes Theorem etc. Maths is the foundation step of understanding and building those complex AI algorithms which are making our life simpler!
- Select a programming language
After learning and being profound in the basic maths, you need to select a programing language. I would rather suggest that you take up one or maximum two programming languages and understand it in depth. One can select from R, Python or even JAVA! Always remember, a programing language is just to make your life simpler and is not something which defines you. We can start with Python because it is abstract and provides a lot of libraries to work with. R is also evolving very fast so we can consider that too or else go with JAVA. (Only if we have a good CS background!) - Understand data structures
Try to understand the data structure i.e. how you can design a system for solving problems involving data. It will help you in designing a system which is accurate and optimized. AI is more about reaching an accurate and optimized result. Learn about the Stacks, linked lists, dictionaries and other data structures that your selected programing language has to offer. - Understand Regression in complete detail
Well, this is one advice you will get from everyone. Regression is the basic implementation of maths which you have learned so far. It depicts how this knowledge can be used to make predictions in real-life applications. Having a strong grasp over regression will help you greatly in understanding the basics of machine learning. This will prepare you well for your AI career. - Move on to understand different Machine Learning models and their working
After learning regression, one should get their hands dirty with other legacy machine learning algorithms like Decision Trees, SVM, KNN, Random Forests etc. You should implement them over different problems in day to day life. One should know the working math behind every algorithm. Well, this may initially be little tough, but once you get going everything will fall in its place. Aim to be a master in AI and not just any random practitioner! - Understand the problems that machine learning solves
You should understand the use cases of different machine learning algorithms. Focus on why a certain algorithm fits one case more than the other. Then only then you will be able to appreciate the mathematical concepts which help in making any algorithm more suitable to a particular business need or a use case. Machine learning is itself divided into 3 broad categories i.e. Supervised Learning, Unsupervised Learning, and Reinforcement Learning. One needs to be better than average in all the 3 cases before you can actually step into the world of Deep Learning!
Level 2: Moving deeper into AI
This is level 2 of your journey/struggle to be an AI specialist. At this level, we deal with moving into Deep Learning but only when you have mastered the legacy of machine learning!
- Understanding Neural Networks
A neural network is a type of machine learning which models itself after the human brain. This creates an artificial neural network that via an algorithm allows the computer to learn by incorporating new data. At this stage, you need to start your deep learning by understanding neural networks in great detail. You need to understand how these networks are intelligent and make decisions. Neural nets are the backbone of AI and you need to learn it thoroughly! - Unrolling the maths behind neural networks
Neural networks are typically organized in layers. Layers are made up of a number of interconnected ‘nodes’ which contain an ‘activation function’. Patterns are presented to the network via the ‘input layer’, which communicates to one or more ‘hidden layers’ where the actual processing is done via a system of weighted ‘connections’. The hidden layers then link to an ‘output layer’ where the answer is output. You need to learn about the maths which happens in the backend of it. Learn about weights, activation functions, loss reduction, backpropagation, gradient descent approach etc. These are some of the basic mathematical keywords used in neural networks. Having a strong knowledge of them will enable you to design your own networks. You will also actually understand from where and how neural network borrows its intelligence! It’s all maths mate.. all maths! - Mastering different types of neural networks
As we did in ML, that we learned regression first and then moved onto the other ML algos, same is the case here. Since you have learned all about basic neural networks, you are ready to explore the different types of neural networks which are suited for different use cases. Underlying maths may remain the same, the difference may lie in few modifications here and there and pre-processing of the data. Different types of Neural nets include Multilayer perceptrons, Recurrent Neural Nets, Convolutional Neural Nets, LSTMS etc. - Understanding AI in different domains like NLP and Intelligent Systems
With knowledge of different neural networks, you are now better equipped to master the application of these networks to different applications in Business. You may need to build a driverless car module or a human-like chatbot or even an intelligent system which can interact with its surrounding and self-learn to carry out tasks. Different use cases require different approaches and different knowledge. Surely you can not master every field in AI as it is a very large field indeed hence I will suggest you pick up a single field in AI say Natural Language processing and work on getting the depth in that field. Once your knowledge has a good depth, then only you should think of expanding your knowledge across different domains. - Getting familiar with the basics of Big Data
Although, acquiring the knowledge of Big Data is not a mandatory task but I will suggest you equip yourself with basics of Big Data because all your AI systems will be handling Big Data only and it will be a good plus to have basics of Big Data knowledge as it will help you in making more optimized and realistic algorithms.
Level 3: Mastering AI
This is the final stage where you have to go all guns blazing and is the point where you need to learn less but apply more whatever you have learned till now!
- Mastering Optimisation Techniques
Level 1 and 2 focus on achieving accuracy in your work but now we have to talk about optimizing it. Deep learning algorithms consume a lot of resources of the system and you need to optimize every part of it. Optimization algorithms help us to minimize (or maximize) an Objective function (another name for Error function) E(x) which is simply a mathematical function dependent on the Model’s internal learnable parameters. The internal parameters of a Model play a very important role in efficiently and effectively training a Model and produce accurate results. This is why we use various Optimization strategies and algorithms to update and calculate appropriate and optimum values of such model’s parameters which influence our Model’s learning process and the output of a Model. - Taking part in competitions
You should actually take part in hackathons and data science competitions on kaggle as it will enhance your knowledge more and will give you more opportunities to implement your knowledge. - Publishing and Reading lot of Research Papers
Research — Implement — Innovate — Test. Keep repeating this cycle by reading on a lot of research papers related to AI. This will help you in understanding how you can just not be a practitioner but be an thrive to be an innovator. AI is still nascent and needs masters who can innovate and bring revolution to this field. - Tweaking maths to roll out your own algorithms
Innovation needs a lot of research and knowledge. This is the final place where you want yourself to be to actually fiddle with the maths which powers this entire AI. Once you are able to master this art, you will be one step away in bringing a revolution!
Conclusion
Mastering AI is not something one can achieve in a short time. AI requires hard work, persistence, consistency, patience and a lot of knowledge indeed! It may be one of the hottest jobs in the industry currently. Being a practitioner or enthusiast in AI is not difficult but if you are looking at the being a master at this, one has to be as good as those who created it! It takes years and skill to be a master at anything and same is the case with AI. If you are motivated, nothing can stop you in this entire world. ( Not even an AI :P)
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The Babel 7 release includes many significant changes and improvements including support for TypeScript transpilation and a better approach to managing ES.Next proposals.
The Babel and TypeScript teams collaborated to get Babel to parse and transform type syntax with @babel/preset-typescript. Babel already includes support for Flow, and the goal of the Babel team is to support tools that enable JavaScript users to take advantage of gradual typing. TypeScript program manager Daniel Rosenwasser explains the motivation and benefits for the Babel-TypeScript collaboration:
Over a year ago, we set out to find what the biggest difficulties users were running into with TypeScript, and we found that a common theme among Babel users was that trying to get TypeScript set up was just too hard. The reasons often varied, but for a lot of developers, rewiring a build that’s already working can be a daunting task.
While the TypeScript compiler is still the preferred way to build TypeScript, Babel can handle compiling/transpiling, but Babel does not have built-in type-checking. This integration allows Babel users to get the typo and error checking benefits of TypeScript.
TC39, the working group that defines the annual updates to the JavaScript language, creates numerous proposals for consideration following a stage process where Stage 4 signifies inclusion in the language. Babel 7 changes the default behavior to require users to explicitly opt-in to any feature earlier than version 4 with the aim of preventing users from inadvertently relying on features which are not yet final.
A full list of TC39 proposals supported by Babel is available at babel/proposals.
Significant improvements to the approach to configuration with Babel get made with version 7, including the introduction of babel.config.js. This new configuration file is optional and is not intended as a full replacement for .babelrc, but is expected to be useful in some instances such as different compilation options for development and production environments.
According to Babel maintainer Henry Zhu,
*.js configuration files are fairly common in the JavaScript ecosystem. ESLint and Webpack both allow for .eslintrc.js and webpack.config.js configuration files, respectively.
One caveat to note is that babel.config.js has a different configuration resolution than .babelrc. The new configuration file always resolves the configuration from that file whereas .babelrc would lookup from each file upward until it found a config. This addition makes it possible to take advantage of selective configuration with overrides.
There are challenges on efficiently publishing ES2015+ packages and also consuming and compiling these packages. Babel configuration now allows for applications requiring different compilation configurations for tests, client-side source code, and server-side code to skip the need to create a new .babelrc file per directory.
Babel 7 also adds experimental support for automatic polyfilling for features like Promises and Symbols in environments lacking these features natively. Rather than importing entire polyfills, Babel 7 aims only to import the polyfills used in the codebase.
Better module targeting, caller metadata for Babel transforms, JSX support, a babel-upgrade tool, and much more gets added with Babel 7.
There are several breaking changes to be aware of when upgrading to Babel 7:
- Remove support for Node.js prior to version 6
- Switch to using the @babel namespace with scoped packages to prevent confusion with what is an official Babel package.
- Remove yearly presets, replace with @babel/preset-env
- Replace stage proposal resets with opt-in for individual TC39 proposals
- Any TC39 proposal plugin is now -proposal instead of -transform
- Introduce a peerDependency on @babel/core for certain user-facing packages (e.g. babel-loader, @babel/cli, etc)
In looking towards the future of Babel beyond version 7, Zhu remarks:
Babel is inherently tied to what it compiles: JavaScript. As long as there are new additions to propose/work on there is work to be done there. That includes the time/effort to implement and maintain the syntax even before it becomes “stable.” We care about the whole process: the upgrade path, education of new features, teaching of standards/language design, ease of use, and integration with other projects.
For example, the Babel team has been working on support for the revised Decorators proposal which gets included in version 7.1. The revised proposal is significantly different than the previous proposal and adds many more features. The TypeScript roadmap also includes plans to implement the revised ES Decorator proposal.
Other new Babel features under development include minification, plugin orders, better validation/errors, using Babel asynchronously, and much more. See the Babel roadmap for more details.
Babel is available under the MIT open source license. Contributions are welcome via the Babel GitHub organization and should follow Babel’s contribution guidelines and code of conduct. Donations to support the project may also be made via Open Collective.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Management systems from the last century so not work in the modern age
- There is a significant “management tax” in the current organisation structures which slows down innovation
- The pace of change and the demand for more humanistic workplaces means organisations need to change the way they are structured and led
- When these changes are made the results are amazing in terms of employee engagement, customer satisfaction and profitability
- There are skills and techniques which leaders can learn to achieve these outcomes
In their new book From Hierarchy to High Performance, Doug Kirkpatrick, Bill Sanders, Dawna Jones, Ozlem Brooke Erol, Josh Levine, Sue Bingham and Anna McGrath provide a series of essays designed to help “Unleash the Hidden Superpowers of Ordinary People to Realize Extraordinary Results”.
The premise of the book is that the management structures and employee engagement systems that most organizations apply are not (may never have really been) relevant and useful for the 21st century. The pace of change and the expectations of people for meaningful work and humanistic workplaces mean that businesses must change the way they deal with their people and when they do so the results are amazing terms of customer and employee satisfaction, profitability and sustainability.
InfoQ spoke to Doug Kirkpatrick (as a representative of the authors) about the book. An extract from the book can be downloaded from here and the book can be purchased from here.
InfoQ: Why did you write this book – what is the underlying problem or challenge you are addressing by doing so?
Doug Kirkpatrick: As a father and career coach to two millennial daughters, I’ve seen through their eyes the human toll of working in an environment that sucks. Why do we even tolerate work environments riven by power trips, ego, toxic behaviors, and dysfunctional cultures? How can we create workplaces that are generative, vibrant, creative and life-affirming? A small percentage of organizations have created those kinds of workplaces. Most organizations won’t change unless and until they’re faced with an existential crisis. Can we nudge workplaces to transform, not because they’re in crisis but because it’s better for their business and the people who work there? That’s the challenge we’re trying to address.
InfoQ: Who it the book for? How do you ensure you are not just preaching to the converted?
Kirkpatrick: The book is for leaders who are in a position to initiate transformational change and would like some guidance in their decision-making process mixed with a bit of inspiration. I would say that it’s also for anyone working in an organization who finds themselves intrigued by the title and wants to learn more in the hope that we can generate some “heat” from the bottom layers of hierarchies by forcing people at the top to confront some tough questions, like “why do we have four layers of management in a ten-person office?”. That’s a real situation that I recently encountered, by the way.
InfoQ: The title of the book indicates that hierarchy is somehow bad or prevents high performance – why is that the case, and what is the alternative?
Kirkpatrick: Hierarchy isn’t, per se, “bad”. It’s just costly when applied to human organizations as the primary method of organizing. Our vision is for organizations that are heterarchies or networks, where command-and-control and the iron fist of authority is restricted and everyone is respected and given a voice. It’s entirely possible for heterarchies and networks to have people form nested hierarchies within them. It’s just that such arrangements are voluntary, not imposed by someone in power, and can be undone when the participants decide that the arrangement no longer serves their interest or the interest of the organization. Hierarchies are also extremely costly. Gary Hamel writes eloquently about the “management tax”, or the direct and indirect cost of bureaucracy, which he estimates at about $3 trillion USD per year. The management tax shows up in miscommunication between layers of the bureaucracy, unnecessary permission steps for activities, and hiring managers-of-others for people who are perfectly capable of managing themselves. Since management is the least efficient activity of any organization, why create cumbersome, complex structures to exponentially grow the inefficiency?
InfoQ: Why should organisations care about humanistic work practices and higher purpose – isn’t the purpose of a business to make money?
Kirkpatrick: I would argue that the purpose of a business has neverbeen to make money. Any businessperson who thinks like that should seriously consider doing something else with their life. The purpose of a business is to fulfill human economic needs, and do so sustainably in a way that creates more value for customers than it destroys in consuming resources to create that value (also known as “profit”). It’s really not rocket science: there are only eight basic human economic needs and always have been: food, clothing, shelter, communication, transportation, entertainment, personal security and health care. Every business that has ever existed or ever will exist is about fulfilling one or more of those human needs or creating productive assets for those who directly fulfill those needs. You either play the game of work well and do so sustainably (i.e., at a profit) or not (at a loss)—one or the other over some relevant time period. That’s the purpose of a business—sustainably fulfilling human needs, which is a very noble thing to do when done humanely with great respect and care for people: employees, customers, suppliers, community members and all other stakeholders. If business is all about fulfilling human needs, why would anyone want to be part of an organization that does so with blatant disregard for human dignity? Profit is actually a means (providing the condition of sustainability) to an end (fulfilling human needs), not the end itself.
InfoQ: What are some of the practices that need to be stopped and are there alternates to them in the high performing organizations?
Kirkpatrick: So many practices need to be stopped that it would be hard to catalog them in a few short paragraphs.
I would start with using different language. We need to replace our dehumanizing, industrial age vocabulary with language that reflects deep respect for people. Once we acknowledge the humanity of people in our language (and by extension in our work cultures), we will start to see other dehumanizing practices like traditional performance reviews transform or disappear.
Here are some examples of language that needs to change, and soon:
Human Resources (see also: HR). In the 1980s, organizations replaced the old concept of a “personnel department” with the new, improved concept of a “human resources department”. Management saw the term “personnel” as overly supportive of workers in the brave new world of reengineering. As journalist Cliff Weathers noted, new efficiency technologies called for a new generation of panopticonic overseers aligned with management to keep workers (resources) on track.
A copy machine is a resource. A forklift is a resource. A parking lot is a resource. People aren’t resources. Henry Mintzberg said it best: “A resource is a thing. I am a human being. I am not a human resource.”
Our People (see also: My People, Your People, His People, Her People, Your People, Their People, Its People). Perhaps we should reserve possessive pronouns for things (not people) that can actually be possessed?
Empowerment. Empowerment programs usually involve someone with power lending his or her power to someone with less power. The problem with this scenario is that what has been loaned can be repossessed at any time. People either have power to do certain things or they don’t. Revokable empowerment is an unsustainable oxymoron.
Employee (see also: Employees). Dictionary.com defines employee as “a person working for another person or business firm for pay”. In an era of talent wars, when robot managers are now giving orders to humans, that definition doesn’t seem very motivating. Not coincidentally, this usage sprang up in the mid-1800s, right around the advent of the Industrial Age. Much of American labor jurisprudence reflects this glaring dichotomy between superiors and ‘inferiors”. The legal doctrine of respondeat superior, for example, is derived from the common law of masters and servants. Would a truthful job description labeled “servant” attract millennials to a rigid command-and-control business hierarchy? Not likely.
Direct Reports (see also: Indirect Reports). More lazy language that reinforces the artificial distinction between superiors and inferiors. Exactly when did people consent to become “reports”?
Boss. Conveys the devaluing notion that one person has all the answers, and merely needs to issue orders to inferiors to get the work done.
Headcount. Apparently, it’s not important to know whether a person’s entire body is engaged at work.
FTEs: Where bosses exile fellow human beings to a nameless, soulless, acronymic existence.
Driving Engagement: Out on the range, where people are cattle. Git along, little dogies!
Blue-Collar vs. White-Collar: An industrial-age labor law distinction between people who work with their hands and “professionals”. Since the so-called “blue-collar” workers I’m familiar with have high-paying roles with elevated cognitive content (industrial electro-mechanics often create ladder logic programming for PLCs, for example), this absurd and arbitrary distinction needs to soon become extinct, like the dinosaurs.
Start with language, and other practices will follow.
InfoQ: A common situation we have seen is that a company embarks on a “transformation”, bringing in new ideas and new ways of working and spends lots of money on a change program to implement the new practices, yet a couple of years later all that has changed is the labels and language people use, none of the anticipated benefits and culture shifts have happened. Why is this the case and what can be done to prevent this cycle from happening?
Kirkpatrick: Gary Hamel says two things are needed for meaningful, effective transformation: 1) leaders need to be willing to give up power and 2) organizations need to cohere around simple, clear principles. That resonates with me, coming from my Morning Star background where there was zero command authority and the entire governance of the enterprise was based on two core principles. Because every situation is different, it’s hard to generalize about reasons for failure in change management. Deep, sustainable change is dependent on both mindset (culture) and systems (ways of working). If companies are stuck, then the failure lies in one or the other of those domains, or both. What does the change project post-mortem disclose?
One of the reasons I like organizing around simple, clear principles is that they are easy to understand. If you embrace the principle of not using force or coercion, for example, then the corollaries are zero command authority and no power to unilaterally fire or discipline. Since command authority is binary (you either have it or you don’t), it’s pretty easy to detect violations and deal with them. A nice benefit of adopting that principle is that you develop stronger leaders. Command authority causes leadership muscles to atrophy, it leads to laziness and power-mongering. When you develop your leadership muscles (because command authority is not an option) using influence, trust, communication, respect and persuasion, you become a stronger leader.
InfoQ: As technical influencers and technical leaders what are some concrete things that the InfoQ readers can do to help bring these changes into their own organizations?
Kirkpatrick: Start a book club around the future of work with your leadership team and find two or three books to work through in a six-month period. Find which lessons resonate and which don’t. Theorize an experiment (on your own or with a consultant) that allows you to demonstrate transformative change in all (if you’re small) or part of your organization. Make sure the change is big enough to be noticeable and attract interest but beware of creating chaos or disorientation. If you’re experimenting in a small part of a larger organization, make sure that you satisfy the informational and other needs of the larger domain but still honor your original transformative intent.
About the Book Authors
 Bill Sanders is a business transformation and process innovation expert. He drives organizations to execute on innovative strategy using their existing strengths and unlocking latent potential. Using his proven and holistic approach, Bill rapidly bridges the gap between strategy and execution by identifying the misalignments between strategy, goals, process and execution, and then designing elegant solutions that close those gaps, accelerating growth, profitability and innovation.
Bill Sanders is a business transformation and process innovation expert. He drives organizations to execute on innovative strategy using their existing strengths and unlocking latent potential. Using his proven and holistic approach, Bill rapidly bridges the gap between strategy and execution by identifying the misalignments between strategy, goals, process and execution, and then designing elegant solutions that close those gaps, accelerating growth, profitability and innovation.
 Dawna Jones specializes in releasing imperceptible blocks to personal leadership and company transformation while advancing decision-making skills and mindset to lead in complex fast-moving environments. Dawna’s insights enable you to perceive the sub-surface influences so you can collectively adapt fast with less stress in the midst of chaotic transformation.
Dawna Jones specializes in releasing imperceptible blocks to personal leadership and company transformation while advancing decision-making skills and mindset to lead in complex fast-moving environments. Dawna’s insights enable you to perceive the sub-surface influences so you can collectively adapt fast with less stress in the midst of chaotic transformation.
 Ozlem Brooke Erol worked at IBM for 11 years and held positions as VP of Sales and Marketing in a few others. She started her first business www.yourbestlifeinc.com helping individuals step into a more meaningful and fulfilling life by using their gifts and passion. She is still doing career coaching to make sure more people are aligned with what they do at work and be more fulfilled.
Ozlem Brooke Erol worked at IBM for 11 years and held positions as VP of Sales and Marketing in a few others. She started her first business www.yourbestlifeinc.com helping individuals step into a more meaningful and fulfilling life by using their gifts and passion. She is still doing career coaching to make sure more people are aligned with what they do at work and be more fulfilled.
 Josh Levine is an educator, designer, and best-selling author, but above all, he is on a mission to help organizations design a culture advantage. His new book Great Mondays: How to Design a Company Culture Employees Love presents the framework and tools business leaders need to understand, design, and manage their own culture.
Josh Levine is an educator, designer, and best-selling author, but above all, he is on a mission to help organizations design a culture advantage. His new book Great Mondays: How to Design a Company Culture Employees Love presents the framework and tools business leaders need to understand, design, and manage their own culture.
 Sue Bingham is the co-author of Creating the High Performance Workplace: It’s Not Complicated to Develop a Culture of Commitment and the founder of HPWP Group. Having been at the forefront of creating positive change in the workplace for more than 35 years, Sue is widely recognized as an expert in helping successful leaders achieve impactful, lasting change in their behavior and in their organizations.
Sue Bingham is the co-author of Creating the High Performance Workplace: It’s Not Complicated to Develop a Culture of Commitment and the founder of HPWP Group. Having been at the forefront of creating positive change in the workplace for more than 35 years, Sue is widely recognized as an expert in helping successful leaders achieve impactful, lasting change in their behavior and in their organizations.
 Doug Kirkpatrick is an organizational change consultant, TEDx and keynote speaker, executive coach, author, and educator. He is a regular contributor to the Huffington Post blog on Great Work Cultures and the author of “Beyond Empowerment: The Age of the Self-Managed Organization.” As a partner in NuFocus Strategic Group, an international consulting firm, he leads organizational change and education initiatives around the world.
Doug Kirkpatrick is an organizational change consultant, TEDx and keynote speaker, executive coach, author, and educator. He is a regular contributor to the Huffington Post blog on Great Work Cultures and the author of “Beyond Empowerment: The Age of the Self-Managed Organization.” As a partner in NuFocus Strategic Group, an international consulting firm, he leads organizational change and education initiatives around the world.
 Anna McGrath, for the past 15 years, has used her vibrant people skills to help organizations–from traditional hierarchies to bleeding-edge start-ups–become smarter and healthier in both business and culture. She has built a reputation as a coach who embodies love, authenticity, and humor while advising leaders that are open to learning. And now that she’s at Godfrey Dadich Partners, Anna aims to continue her work both internally and externally with new and existing clients.
Anna McGrath, for the past 15 years, has used her vibrant people skills to help organizations–from traditional hierarchies to bleeding-edge start-ups–become smarter and healthier in both business and culture. She has built a reputation as a coach who embodies love, authenticity, and humor while advising leaders that are open to learning. And now that she’s at Godfrey Dadich Partners, Anna aims to continue her work both internally and externally with new and existing clients.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Alibaba Cloud, the cloud computing arm of Alibaba Group, announced the opening of two new availability zones in the United Kingdom. With the addition of these new availability zones, Alibaba is increasing its presence in the EMEA region.
The new availability zones increase the Alibaba Cloud’s footprint in EMEA to three locations: Frankfurt, Dubai, and now London. The expansion of zones is an answer to the increasing demand from customers for Alibaba Cloud services in the EMEA region. Customers in this region can now benefit from an increase in the availability of Alibaba Cloud services and better disaster recovery capabilities. Furthermore, the new data centers offer a wide range of Alibaba Cloud product lines, including Elastic Computing, Storage, Database, Network, Application Services and Big Data Analytics.
The addition of the new data centres increases the number of availability zones to 52 in 19 regions around the world. Yeming Wang, general manager of Alibaba Cloud EMEA, said in the announcement blog post:
Our expansion into the United Kingdom, and by extension into Europe, is in direct response to the rapidly increasing demands we have seen for local facilities within the region. Using AI-powered and data-driven technology, our latest data centres will offer customers complete access to our wide range of cloud services from machine learning capabilities to predictive data analytics – ensuring that we continue to offer an unparalleled level of service.
According to a Bloomberg article about the new data centers in the UK, Alibaba is moving toward the EMEA region because of the increasing tensions between the US and China and to enhance its success outside of China.
With Alibaba expanding the number of availability zones it starts competing more with other public cloud providers, who also expanded their number of availability zones in the last 12 months. IBM for instance, announced in June, an expansion of their availability zones across the globe. Furthermore, Microsoft announced in April, new availability zones in France and Central US Government Iowa (Central US) regions. Lastly, Amazon at the end of last year added a new region in Paris including availability zones.
Alibaba cloud is currently fifth in the world rankings of cloud computing solutions firms by market share. According to citya.m. article, research from Synergy revealed that Amazon Web Services is first and Microsoft is second, while Google and IBM take third and fourth place respectively.
| Cloud Provider | Regions | Availability Zones |
|---|---|---|
| Amazon | 19 | 56 |
| Microsoft | 54 | 15 |
| 18 | 55 | |
| IBM | 6 | 18 |
| Alibaba | 19 | 52 |
The cloud market is growing with the increase of data centres, Tony Lock, distinguished analyst and director of engagement from Freeform Dynamics, said in the same announcement blog post:
Today, with planning, global enterprises and organisations of all sizes are able to make informed and strategic decisions about their cloud investments. Together, cloud solution maturity and customer experience are leading to the popularity of a multi-cloud approach to services, which, in turn, is encouraging providers to look carefully at their own points of distinction. The arrival of Alibaba Cloud into Europe is an important milestone, not only for the company, but for the market by providing another significant world-wide cloud option for businesses in the EMEA region.

Big Data as a Service, get easily running a Cloudera Quickstart Image with Dockers in GCP
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
It’s not a secret that containers technology (popularly known as dockers) is becoming one of the top choices in software projects [1], but What about data projects/clusters? Many companies and projects have intentions to take advantages of it. Some examples are Cloudera [2] and the apache-spark-on-k8s project [3], personally, I suggest if you want more information as what exactly is called “Big Data as a Service” to check the last Strata Data Conference [4] of Anant Chintamaneni and Nanda Vijaydev (BlueData).
In this article, I will guide you with simple steps in order to get a Cloudera Quickstart Images v5.13 running remotely in a Google Cloud instance. Well, get the job done!
Prerequisites
1. Have a Google Cloud account (Just log in with your Gmail and automatically get $300 of credit for one year) [5]
2. Create a new project
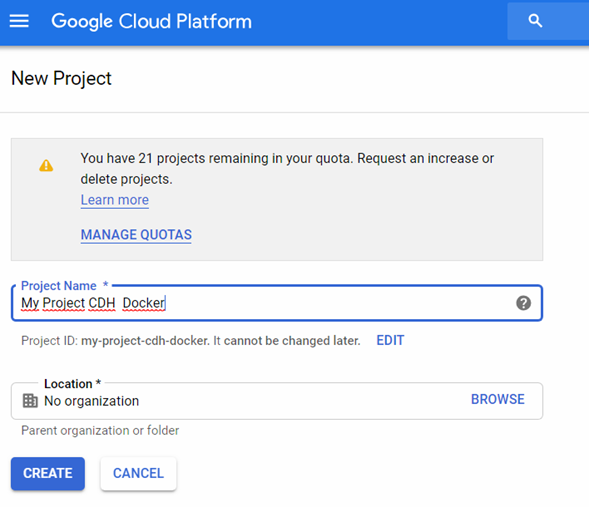 Let’s start
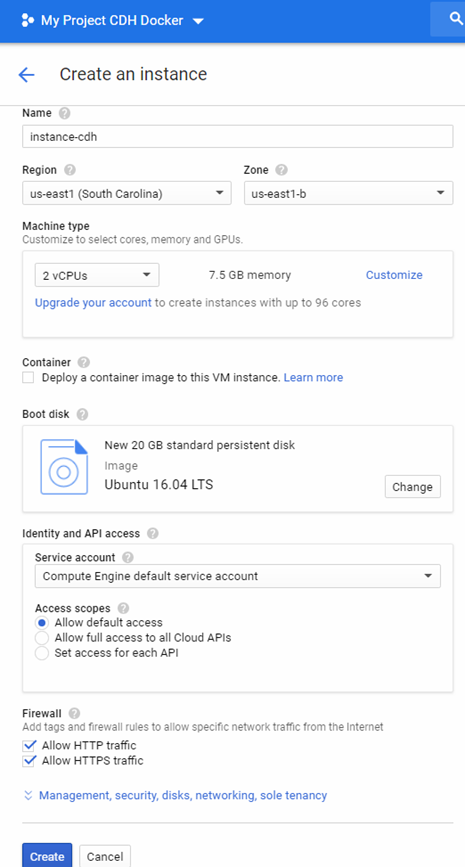
Let’s start- First, create a VM instance

2. Define basic tech specs (important to allow HTTP y HTTPS traffic)
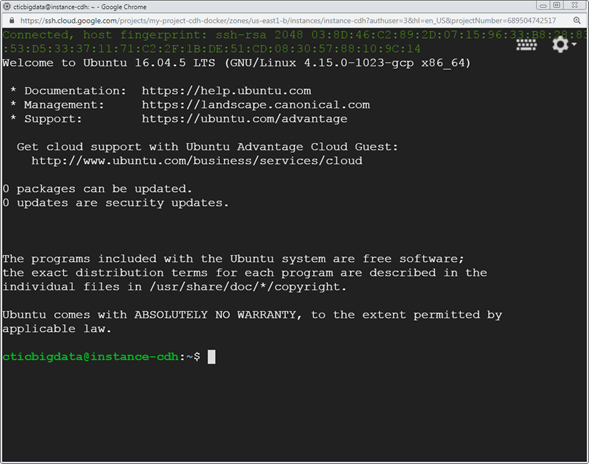
3. Connect using SSH
4. Install docker
curl -sSL https://get.docker.com/ | sh
5. Update the package database with the Docker package
sudo apt-get update
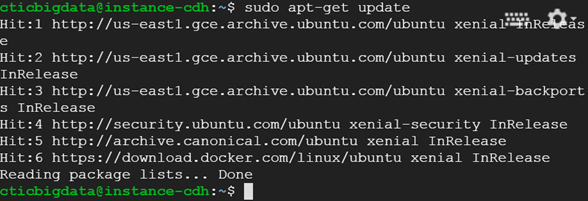
6. Get the Cloudera Quickstart Image
sudo wget https://downloads.cloudera.com/demo_vm/docker/cloudera-quickstart-vm-5.13.0-0-beta-docker.tar.gz

7. Extract the tar file
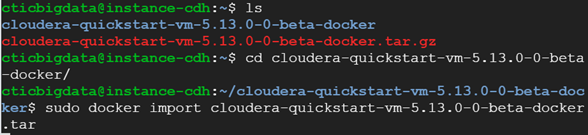
tar xzf cloudera-quickstart-vm-*-docker.tar.gz

8. Import the docker *maybe you could run out of space, in that case, remove the tar.gz file an re-run the import
sudo docker import cloudera-quickstart-vm-5.13.0–0-beta-docker.tar
9. Check the container image ID
sudo docker images

10. Run the container
sudo docker run --hostname=quickstart.cloudera --privileged=true -t -i -p 8777:8888 -p 7190:7180 -p 90:80 b46c7719892d /usr/bin/docker-quickstart

Let’s do some explanation about the parameters [7]
· sudo docker run: main command to start the docker
· — hostname: Pseudo-distributed configuration assumes this hostname
· — privileged=true: Required for HBase, MySQL-backed Hive metastore, Hue, Oozie, Sentry and Cloudera Manager
· -t: Allocate a pseudoterminal. Once services are started, a Bash shell takes over. This switch starts a terminal emulator to run the services.
· -i: If you want to use the terminal, either immediately or connect to the terminal later.
· -p 8777:8888: Map the Hue port in the guest to another port on the host.
· b46c7719892d: Docker images ID obtained from step 9
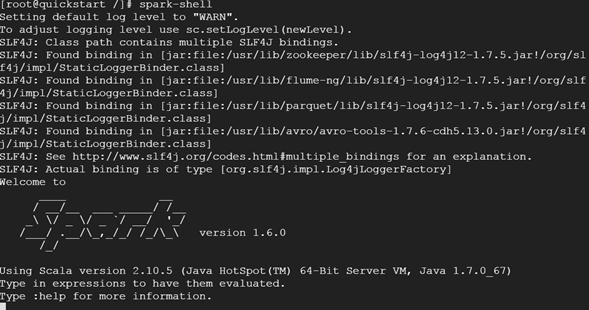
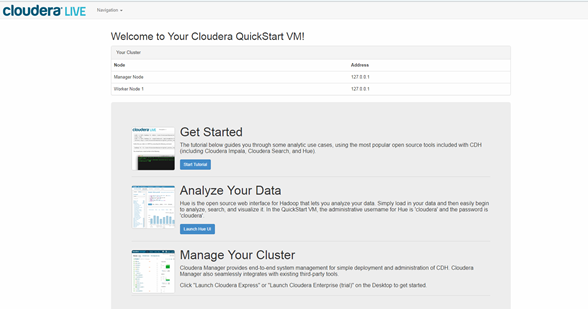
11. Test the services
Spark
Hive

HBase

Hue (port 8777)**
- *In order to access first you have to allow the ports you defined in step 10. For security try to open just those ports, in the image I opened all.
User and password cloudera

Hue UI!
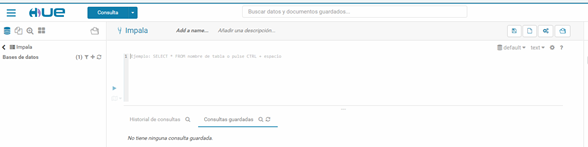
Cloudera running (port 90)
11. Exit the container
Just type Ctrl+d

Go further
You can run in the background with this code, because if you do not pass the -d flag to docker run your terminal automatically attaches to the container
sudo docker run --hostname=quickstart.cloudera --privileged=true -t -i -p 8777:8888 -p 7190:7180 -p 90:80 b46c7719892d /usr/bin/docker-quickstart -d
If you want to reconnect to the shell (to stop just type Ctrl+d)
sudo docker ps 256e31278a92
sudo docker attach 256e31278a92
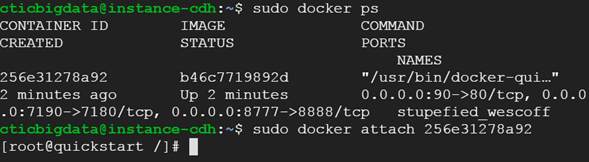
Conclusion
In this article, I show how easy is to start using the Cloudera Quickstart Image using dockers.
See you in the next article! Happy Learning!
Code:
antoniocachuan/cloudera-quickstart-dockers
Useful information for the article about setting a cloudera quickstart images with docker …github.com
Useful information for the article about setting a cloudera quickstart images with docker …github.com
Links:
[1] https://www.theserverside.com/feature/The-benefits-of-container-development-with-Docker
[2] http://community.cloudera.com/t5/CDH-Manual-Installation/CDH-on-Kubernetes/td-p/64772
[3] https://github.com/apache-spark-on-k8s/spark
[4] https://conferences.oreilly.com/strata/strata-ny-2018/public/schedule/detail/69534
[6] https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-16-04
[7] https://www.cloudera.com/documentation/enterprise/5-6-x/topics/quickstart_docker_container.html

