Month: November 2018

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The TypeScript team has released version 3.2 of TypeScript, improving support for various metaprogramming patterns and Object spread and rest on generic types. The release also includes BigInt support for environments which support this stage 3 ECMAScript proposal.
TypeScript 3.2 adds stricter type checking for bind, call, and apply, one of the critical pieces towards full support for variadic kinds. TypeScript program manager Daniel Rosenwasser explains the importance of these additional type checks:
In JavaScript, bind, call, and apply are methods on functions that allow us to do things like bind this and partially apply arguments, call functions with a different value for this, and call functions with an array for their arguments.
TypeScript could not previously strictly check these functions and each of bind, call, and apply were typed to accept any number of arguments and return the any type. Two earlier features support the necessary abstractions to type bind, call, and apply accurately:
thisparameter types (TypeScript 2.0)- Modeling parameter lists with tuple types (TypeScript 3.0)
The TypeScript 3.2 release introduces a new flag, strictBindCallApply, which adds two new global types for declaring stricter versions of signatures for bind, call, and apply:
CallableFunction– methods on callable objectsNewableFunction– methods on constructable but not callable objects
The TypeScript team expects this feature to help catch bugs when using sophisticated metaprogramming, or simple patterns like binding methods within class instances.
Object spread and rest are two widely adopted features from ES2015 which are supported by most of TypeScript, but until this release was not available for generic types.
In the case of spread, TypeScript had no way of expressing the return type from the generic type, so there was no mechanism to express two unknown types getting spread into a new one. TypeScript 3.2 now allows object spreads for generics, and models this functionality using intersection types.
For object rest, instead of creating a new object with some extra/overridden properties, rest creates a new object lacking some specified properties. However, after iterating through many ideas, the TypeScript team realized that the existing Pick and Exclude helper types provide the ability to perform an object rest on a generic type.
BigInt support is near complete and is expected to be part of the ES2019 standard. BigInts allow the handling of arbitrarily large integers. TypeScript 3.2 adds type-checking for BigInts and emits BigInt literals for environments with BigInt support via the TypeScript esnext target.
Because BigInts introduce different behavior for mathematical operators, the TypeScript team has no immediate plans to provide down-leveling support for environments without BigInt support. Today, this means that BigInt support only works for Node.js 11+, Chrome 67+, and browsers based on similar versions of Chromium. Firefox, Safari, and Edge all report working on BigInt implementations.
Other improvements to TypeScript 3.2 include:
- Allowing non-unit types in union discriminants
- Supporting Object.defineProperty property assignments in JavaScript
- Supporting the printing of an implied configuration object to the console with
--showConfig - Improving the formatting and indentation for lists and chained calls
- Scaffolding local
@typespackages withdts-gen - Adding intermediate
unknowntype assertions - Adding missing
newkeyword
Review the TypeScript roadmap for full details of these and other changes in the TypeScript 3.2 release.
Work has already begun on TypeScript 3.3, with Partial type argument inference being the first planned feature. This change would allow _ to appear in type argument lists as a placeholder for locations for type inference to occur, allowing users to override a variable in a list of defaults without explicitly providing the rest, or allowing inference of a type variable from another one.
The other major feature on the TypeScript roadmap which may appear for TypeScript 3.3 is alignment with recent changes to the ES decorators proposal.
TypeScript is open source software available under the Apache 2 license. Contributions and feedback are encouraged via the TypeScript GitHub project and should follow the TypeScript contribution guidelines and Microsoft open source code of conduct.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
At the recent Large Installation System Administration (LISA) 2018 Conference, Sherry Xiao, Production Engineer at Instagram, explained how their team split Instagram’s services across datacenters in the US and Europe. They achieved data locality in their stateful services – Cassandra and TAO – by using new and modified tools from Facebook’s engineering team.
Facebook acquired Instagram in 2012, and the latter migrated to Facebook’s infrastructure. Instagram’s infrastructure was only in the US, whereas Facebook’s datacenters were in both the US and Europe. Instagram’s stack consists primarily of Django, Cassandra, the TAO distributed data store, Memcached and Celery async jobs. They had to split their services between US and EU datacenters to solve data storage space constraints. High latency from Cassandra quorum calls, partitioning the dataset for data locality, failover within the EU region and master-replica synchronization for TAO were the challenges the team had to overcome to make the split.
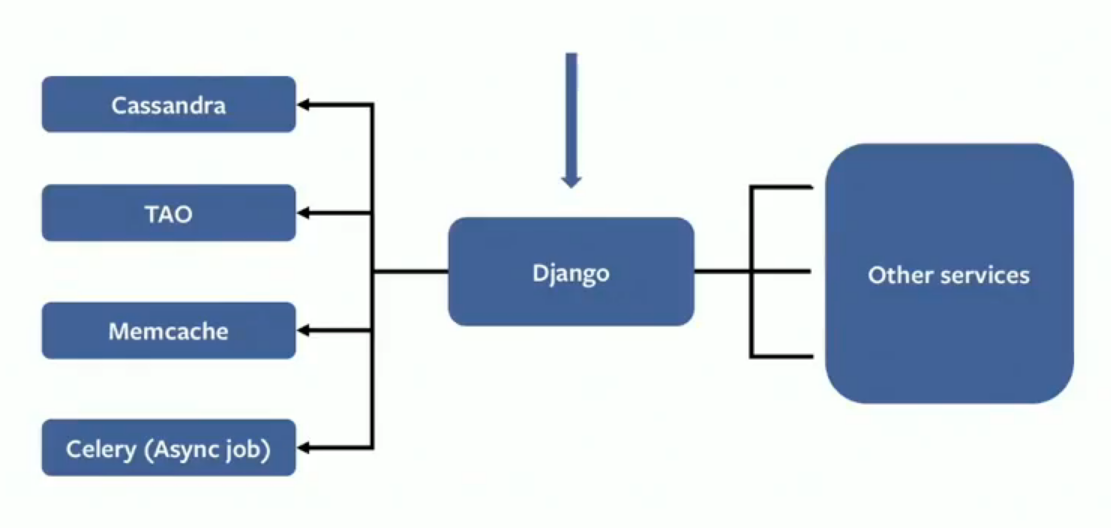
Image Courtesy – https://www.youtube.com/watch?v=2GInt9E3vrU
Instagram uses Cassandra as a general key value storage service. They moved it from AWS to Facebook’s own datacenters with other components. Cassandra uses a quorum of replicas across datacenters for both read and write consistency. Maintaining copies of the data in European datacenters would have led to a waste of storage, and quorum requests to travel across the ocean, which was inadvisable due to high latency. The Instagram team instead partitioned the data so that US users had their data in the 5 US datacenters, and EU users in the 3 EU datacenters, using a tool called Akkio. Akkio is a data placement tool built by Facebook that can optimize data retrieval. It does this by grouping data into logical sets that are then stored in the datacenters closest to the end users that access them frequently. Akkio, says Xiao, “tracks the access patterns of end users and triggers the data migration”.
This architecture absolves the need to store copies of all data in each datacenter. The US and EU DCs could operate independently, and quorum requests could stay on the same continent. Instagram also used the Social Hash partitioner to route requests to the correct buckets, especially for accounts with a high number of followers.
TAO is Facebook’s storage for the social graph used by Instagram also. In sharded mode, TAO has a single master per shard. Writes are forwarded only to the master – which runs in the US datacenters – and replicas are read-only. The team modified TAO so that it could write to the region-local master in the EU, avoiding the cross-Atlantic call. Why is Akkio not used here? “TAO has a different data model compared to Cassandra”, explains Xiao, “where most of the use cases are keyed by user id, and the data belongs to the user itself”. In contrast, media objects handled by TAO can be accessed by users all over the globe, and thus Akkio cannot do an optimal placement for the data based on locality.
The final architecture resulted in a stateless Django tier in front, backed by a partitioned Cassandra and TAO writing to local master nodes. The migration entailed a change in the disaster recovery (DR) planning as cross-ocean DR was not possible due to latency as well as different data sets. Each region was capable of handling the load from a failed datacenter by keeping a 20% headroom in each datacenter, according to Xiao.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
 There is a library called threading in Python and it uses threads (rather than just processes) to implement parallelism. This may be surprising news if you know about the Python’s Global Interpreter Lock, or GIL, but it actually works well for certain instances without violating the GIL. And this is all done without any overhead — simply define functions that make I/O requests and the system will handle the rest.
There is a library called threading in Python and it uses threads (rather than just processes) to implement parallelism. This may be surprising news if you know about the Python’s Global Interpreter Lock, or GIL, but it actually works well for certain instances without violating the GIL. And this is all done without any overhead — simply define functions that make I/O requests and the system will handle the rest.
Global Interpreter Lock
The Global Interpreter Lock reduces the usefulness of threads in Python (more precisely CPython) by allowing only one native thread to execute at a time. This made implementing Python easier to implement in the (usually thread-unsafe) C libraries and can increase the execution speed of single-threaded programs. However, it remains controvertial because it prevents true lightweight parallelism. You can achieve parallelism, but it requires using multi-processing, which is implemented by the eponymous library multiprocessing. Instead of spinning up threads, this library uses processes, which bypasses the GIL.
It may appear that the GIL would kill Python multithreading but not quite. In general, there are two main use cases for multithreading:
- To take advantage of multiple cores on a single machine
- To take advantage of I/O latency to process other threads
In general, we cannot benefit from (1) with threading but we can benefit from (2).
MultiProcessing
The general threading library is fairly low-level but it turns out that multiprocessing wraps this in multiprocessing.pool.ThreadPool, which conveniently takes on the same interface as multiprocessing.pool.Pool.
One benefit of using threading is that it avoids pickling. Multi-processing relies on pickling objects in memory to send to other processes. For example, if the timed decorator did not wraps the wrapper function it returned, then CPython would be able to pickle our functions request_func and selenium_func and hence these could not be multi-processed. In contrast, the threading library, even through multiprocessing.pool.ThreadPool works just fine. Multiprocessing also requires more ram and startup overhead.
Analysis
We analyze the highly I/O dependent task of making 100 URL requests for random wikipedia pages. We compare:
We run each of these requests in three ways and measure the time required for each fetch:
- In serial
- In parallel in a
threadingpool with 10 threads - In parallel in a
multiprocessingpool with 10 threads
Each request is timed and we compare the results.
Results
Firstly, the per-thread running time for requests is obviously lower than for selenium, as the latter requires spinning up a new process to run a PhantomJS headless browser. It’s also interesting to notice that the individual threads (particularly selenium threads) run faster in serial than in parallel, which is the typical bandwidth vs. latency tradeoff.
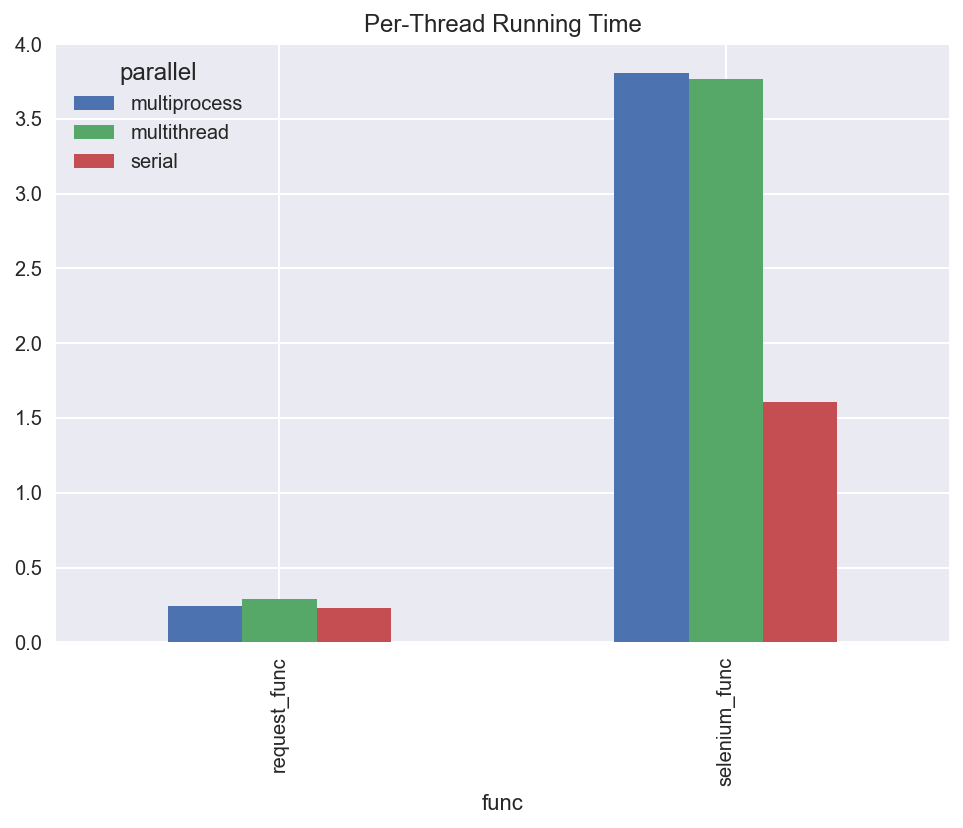
In particular, selenium threads are more than twice as slow, problably because of resource contention with 10 selenium processes spinning up at once.
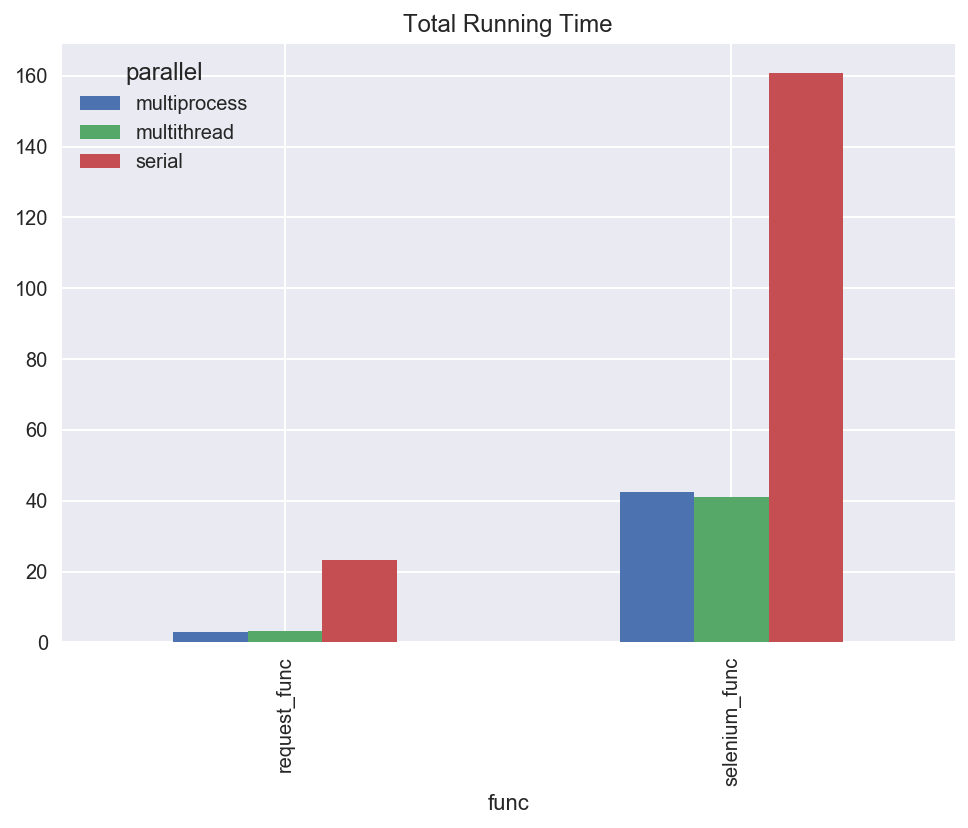
Likewise, all threads run roughly 4 times faster for selenium requests and roughly 8 times faster for requests requests when multithreaded compared with serial.
Conclusion
There was no significant performance difference between using threading vs multiprocessing. The performance between multithreading and multiprocessing are extremely similar and the exact performance details are likely to depend on your specific application. Threading through multiprocessing.pool.ThreadPool is really easy, or at least as easy as using the multiprocessing.pool.Pool interface — simply define your I/O workloads as a function and use the ThreadPool to run them in parallel.
Improvements welcome! Please submit a pull request to our github.
Michael Li is founder and CEO at The Data Incubator. The company offers curriculum based on feedback from corporate and government partners about the technologies they are using and learning, for masters and PhDs.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Our world is fuelled by information, today more than ever before. Social media, technology, the internet at large – all of these contribute to a curious society who will not tolerate a knowledge gap, especially when it comes to business and government. The amount of data online is staggering, and if unlocked, could contribute to a more efficient, responsive and effective society, spurring on economic growth and unleashing limitless potential.
A Global Picture of Open Datasets
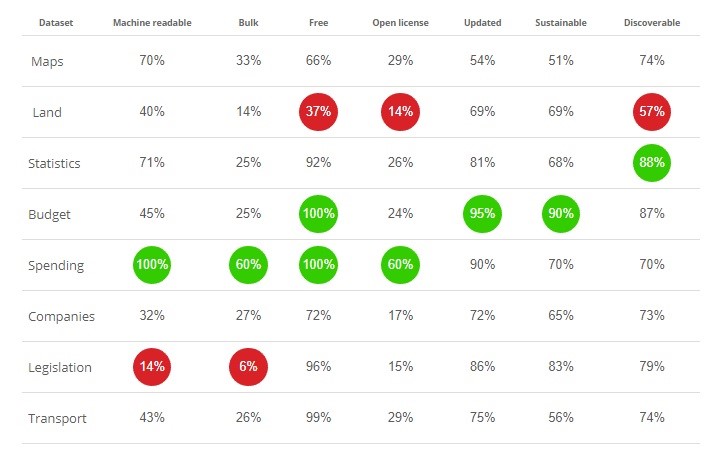
Across studies of more than 115 countries, open data in some form or another is available in 97%. However, this statistic may paint a rosier picture than is actually the case. Only 74% of the datasets are up to date, and only 24% of it can be accessed and downloaded without a license. A little over half of the data available can be accessed in a reusable way, making 47% impossible to utilize for further study or comparability. Below you can see some of the common barriers to access for open data around the world, and how they compare between categories.
Let’s look a little closer to home, at the statistics for open data within the US. Looking at a map of all the States, the comprehensiveness of their key datasets shows an uneven knowledge-base. While some States like Colorado score A+ in a category like Companies, (the register of all corporations that exist within the State) others like California are scored F. This score is brought down by similar factors to the worldwide data, such as the datasets being incomplete, unverifiable, in-comparable, and with licensing restrictions.
It’s also important to recognize that individual cities may be more inclined to share open data, creating laws and initiatives to push the transparency and comprehensiveness of key datasets. Washington DC for example have evidence of their intention to begin publishing open datasets of city operational metrics in the District of Columbia as far back as 2006, while Connecticut mandated a state-wide open data portal in 2014. In cities without state-wide policies in place, the open data available may be skewed towards a smaller number of districts.
Understanding the Comparability of Open Data
The very nature of a lot of the datasets in use means that comparability is always going to be a tough nut to crack. For example, on issues like crime or healthcare, there are too many variables between States to reliably compare data and make intelligent conclusions. On the contrary however, some data will be easily compared across States – such as open data on inspections or permits, which are widely speaking similar from place to place and require municipal inspectors to adhere to national laws on compliance and health and safety.
Within a category, there is no set standard for how to organize and discover open data – which leads to some confusion when it comes to utilizing even comprehensive sources of key datasets. For example, in Kansas City, Missouri the open data regarding building permits is broken down by years and geographic location. This would force a researcher to comb through several disparate datasets to get a good understanding of the topic as a whole. In general, our researchers have found little correlation if any between quality and quantity of open data across the USA, with some States like Boston containing a limited number of datasets, and yet still covering a wide variety of topics. Others may have a huge amount of data, but as it is disorganized or incomplete – the value of this data is questionable.
Apertio: Cutting Through the Noise
Apert.io is the first global database and search engine for open data, starting with the US, and constantly expanding its reach. It has the largest coverage in the world, with more than 2000 open data sites included, which together hold trillions of records. From a single point of access, data that was historically out of reach for the masses is now discoverable, available and easy to access.
With in-data search, Apert.io is ahead of the competition, uncovering the insights within the data, rather than relying on publisher’s classifications – many of which are incomplete or inaccurate. In this way, our data is both comprehensive and comparable, allowing users to find the data that truly addresses their needs. Data analysts can quickly and accurately find the information they’re looking for, while data publishers can get a true benchmark of their peers’ data publications in terms of both quantity and quality.
Uncovering the hidden gems of open data shouldn’t be held back by issues of comprehensiveness or comparability, and at Apert.io – we’re leading the way.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
TDD is more than a technique; it’s a whole style of programming, an integrated system of related behaviors and ideas. The five premises of TDD provide a ring in which we operate, they are the air that a TDD’er breathes.
GeePaw Hill, a software coach, spoke about five underplayed premises of TDD at eXperience Agile 2018. InfoQ is covering this conference with Q&As, summaries, and articles.
The five premises of test-driven development (TDD) form the kind of fundament under which almost all TDD proceeds, said Hill. They are really what is binding us into this test-driven approach in the first place.
The five premises that Hill presented were:
- The Money Premise — We’re in this for the money.
- The Judgment Premise — We’ll rely on individuals making local decisions.
- The Correlation Premise — Internal quality *is* productivity.
- The Chaining Premise — We’ll test mostly in very small parts.
- The Steering Premise — Tests & testability are first-class design participants.
When you are inside TDD these premises are invisible but still they are extremely important, argued Hill. You have to keep them in mind when doing TDD.
The money premise is about where the money is. TDD is not about testing, improving quality, or craftsmanship. The aim of TDD is to ship more value faster, said Hill, we’re in this for the money.
The judgment premise implies that we are totally depending on individual humans using individual judgment. Software is doing the same thing every time, but the same is not true for humans, argued Hill. TDD is not an algorithm for coding; you have to take decisions when you are doing TDD.
The correlation premise says that internal quality and productivity are correlated. They have a direct relationship, go up together and go down together, said Hill, as they both depend on things like skills and domain knowledge. Keeping your code in good shape is not optional, argued Hill.
The chaining premise tells us that the way to test the chain is by testing each individual link in that chain. Programs are broken down in smaller parts; you have to do the testing on those parts. Testing the whole chain is expensive, it’s difficult to write the tests and maintain them, but testing the links is the cheapest way that will cover the most ground, said Hill.
The steering premise says that tests and testability are first class participants in design. If you don’t have a testable design, you don’t have a design, argued Hill. You are constantly questioning how to test this, and how it has been tested so far, all the way through from the very first line of code to the very last line of code that you write. You must change your design to make it as easy as possible to test, he said.
When you do TDD the premises will play a role during the work. They are invisible, the air you breathe, argued Hill.
InfoQ spoke with GeePaw Hill after his talk.
InfoQ: What’s makes it so important to know the TDD premises?
GeePaw Hill: If we’re unaware of these premises, we can talk ourselves into some pretty serious foot-shooting behavior. For each of these, I could give an example, but let’s take the correlation premise.
TDD’ers are obsessed with the internal quality of their code, because they know it’s directly and immediately correlated with their productivity. Folks who don’t know that are prone to see work affecting the internal quality as “cleaning”, a word I avoid assiduously. No matter how important one thinks it is to wash the dishes, the simple truth is that you can eat off dirty dishes for a long time and come to no harm. You can delay on the cleaning, because right now what you need is food, not cleaner plates. You want more food now, so you skip washing the dishes “just this once”.
But what if not washing the dishes meant that you would immediately have less food now? Internal quality isn’t cleanliness because it’s a major factor in production, not a nice-to-have; the negative productivity effect of a poor factoring, a bad name, a long delay between the introduction of a variable and its initialization, is immediate. A person who understands the correlation premise never sees internal code quality as optional.
InfoQ: How can we improve our TDD skills?
Hill: TDD is often seen as a simple technique, but the argument of the premises is that it really is a whole style of programming, not a new tacked-on mechanic, but an integrated system of related behaviors and ideas. People who are skilled in karate are called karetekas, and in judo they’re called judoka. Going from the old-school styles to the modern synthesis is somewhat like going from being a kareteka to a judoka. It involves lots of different muscles, different movements, different ideas.
That having been said, there are really the same old things we have to do to get any rich skill:
- find a quiet safe place to open your mind to it.
- read around and study.
- practice practice practice.
There are teachers and mentors, and they can help you do all three of these things, but they can’t do them for you. As with all complex learning endeavors, there is no royal road to TDD.



MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Visual Studio Code October 2018 release, numbered 1.29, introduces a number of significant new features, while confirming Visual Studio Code trend as the most used text editor in the JavaScript ecosystem.
Below are some of the most significant improvements in version 1.29:
-
Search: your regular expression can now span over multiple lines by including the
ncharacter. Additionally, regex searches now support backreferences and lookahed, with lookbehind planned for a future release. Lookahead allows you to build regexes that match, for example, HTML tags opening and closing:<([a-z]*)></1>(?=<)will match<body></body>. Additionally, the newsearch.useReplacePreviewsetting allows developers to disable the preview diff that appear when doing search/replace operation. -
Debugging: to improve call stack readability, it is now possible to collapse all stack frames not referring to user code, such as external code, skipped files, etc. Additionally, each debug session shows now its output in a separate debug console, which help to distinguish which message comes from where. Traces can now be styled when debugging Node.js or Chrome.
-
Workbench: macOS Mojave dark mode is now better supported along with full screen. The new
workbench.editor.highlightModifiedTabsallows to highlight files that need to be saved through a thick top border of the corresponding editor tab. Additionally, the newbreadcrumbs.symbolSortOrdersetting controls whether symbols in the Breadcrumb picker are ordered or not. -
Terminal: when you create a split terminal, you can now control whether it inherits the current working directory of its parent terminal using the
terminal.integrated.splitCwdsetting (inherited, only available on macOS), starts with the workspace root (workspaceRoot), or uses the initial working directory of its parent (initial). Additionally,cmd-backspaceon macOS will delete the whole line from the start to the current insertion point.
Visual Studio Code 1.29 includes support for TypeScript 3.1.4 and improves support for other languages, including CSS, Markdown, etc.
On a related note, minor version 1.29.1 of Visual Studio Code has already been released to fix a number of bugs.
As mentioned, the latest “State of JavaScript” survey shows that Visual Studio Code popularity is increasing ever more abd sets it firmly above Sublime Text and Vim.
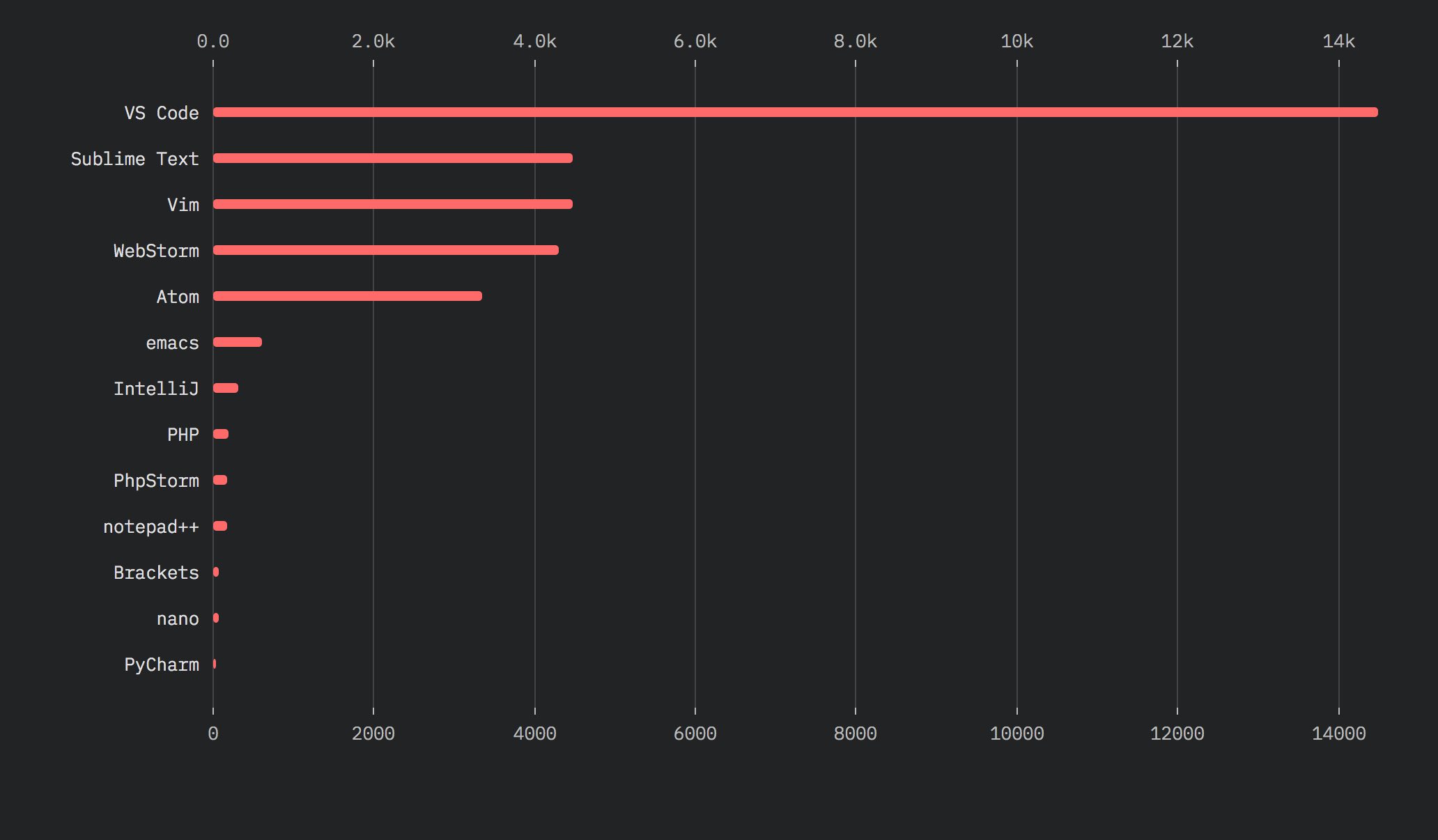
(Image from 2018.stateofjs.com)
There are many more new features in Visual Studio Code 1.29 that we cannot cover here, so do not miss the official announcement for full detail.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
The third annual University of San Francisco (USF) MBA class Golden State Warriors analytics exercise provided an opportunity to test the students’ ability to “Think Like a Data Scientist” with respect to identifying and quantifying variables that might be better predictors of performance for the Golden State Warriors professional basketball team. This was also an opportunity to test and fine-tune the Hypothesis Development Canvas, and boy was that an eye-opener for me. The Hypothesis Development Canvas works, but I need to do a better job of explaining how to use it properly. Here are just a few of my learnings from the USF exercise:
- The Hypothesis is a “Business Outcomes” hypothesis (versus a statistical hypothesis). Consequently, the Hypothesis needs to clearly articulate what it is that the students are trying to prove or improve with their data science project.And the business hypothesis must be actionable with clear impact on the generated Business Value. For example, “Winning the upcoming games while reducing player ‘wear-and-tear’” for GS Warriors exercise.
- KPI’s and Metrics. Need to spend more time on identifying the KPI’s against which success and progress will be measured, and then understanding the business and operational ramifications of the under-performance and over-performance of those KPI’s. For example, what are the metrics that can be used to measure reducing player wear-and-tear? Examples could include minutes played per game, minutes played consequently, consecutive minutes of rest, number of games of rest (Did Not Play).
- Business Value.This should tie directly to how proving out the business hypothesis impacts the finances, operations and customers, such as increased revenues, increased profits, and improve customer satisfaction. This should be the basis for creating an ROI calculation and should tie to some of the metrics against which we are going to measure success.
- These are the risks are associated with the costs of False Positives and False Negatives; that is, the costs associated with the analytic model being wrong.Sample risks could be resting key players too much or not enough that has short-term impact on winning games and longer-term impacts on player injuries.
Okay, so we’ll continue to test and continue to refine the Hypothesis Development Canvas. Oh, the life of a Data Scientist…
Golden State Warriors Exercise
Scenario: You have been hired by Golden State Warriors to review in-game performance data to quantify metrics that predict the keys to the Warriors victories in upcoming games against the Brooklyn Nets (10/28) and the Chicago Bulls (10/29).
Purpose: Apply “Thinking Like a Data Scientist” approach to identify and quantify variables that might be better predictors of in-game performance. In particular, track how much time the team spends doing the following:
- Setting up a simple analytic environment
- Gathering and preparing data
- Exploring the data using simple data visualization techniques
- Creating and testing composite metrics (scores) by grouping and transforming base metrics
- Creating a score or analytic model that supports your recommendations
Keys to Success:
- Analytic results must be insightful and actionable (recommendations)
- Describe and defend your analytic process
Check out Figure 1 which summarizes the results of the “Golden State Warriors Data Analytics Exercise” 2017 class exercise, and actually provides the first indication that we could create a document to guide our “Think Like a Data Scientist” process.
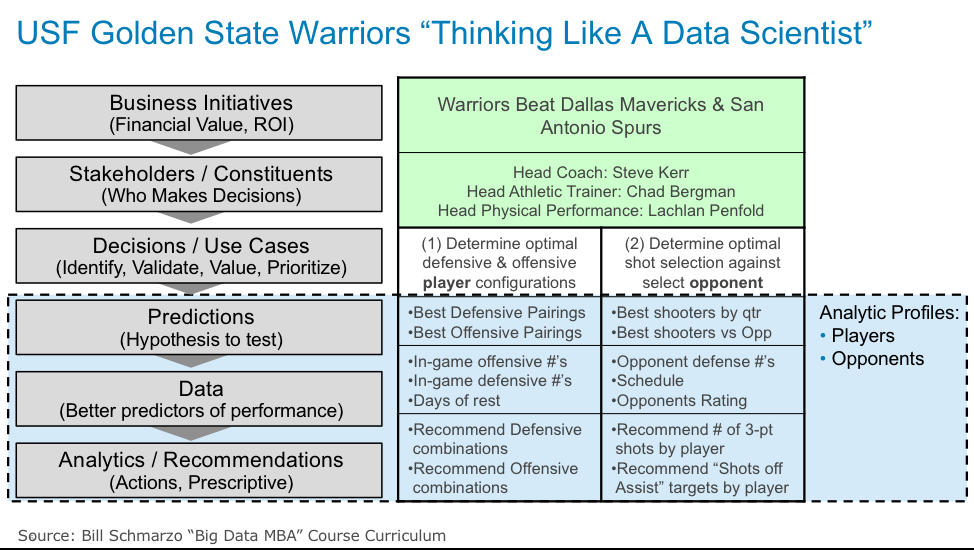
Figure 1: 2017 Golden State Warriors Results
Student Examples
All of the teams got it this year, which was an improvement over previous years when there was a team or two that struggled with the assignment. I’ve provided just three examples below due to keep the blog concise, but each of the teams did outstanding work.
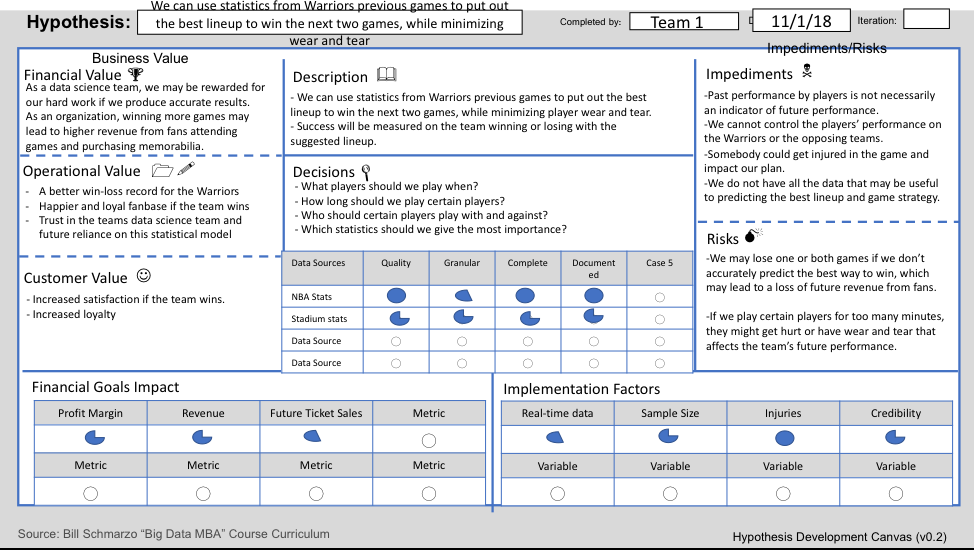


And finally, my version of the Golden State Warrior Exercise Hypothesis Development Canvas:

Bonus: External Contribution
As a bonus contribution, Alex ChandyCEO 2DA Analytics, took up the challenge and contributed the Hypothesis Development Canvas below concerning “Lowering Inventory Costs”.
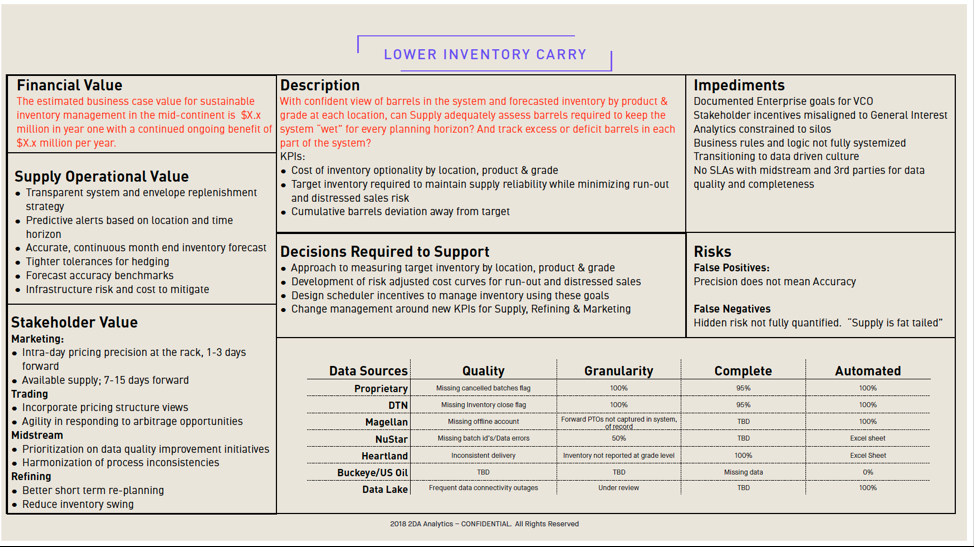
Thanks Alex for being a part of our learning experience! I love the level of detail he put into the canvas, and I in particular, greatly appreciate his willingness to share his work with everyone else. Working together, we can share, learn and improve.
Isn’t that the real promise of social media?
I encourage the students to include their work in their portfolios as they look for jobs after graduation! Each and every one of them would make for an excellent hire – smart, resourceful, hard-working – and they know how to deliver results.
Congratulations Big Data MBA class of 2018!

Members of the University of San Francisco 2018 Big Data MBA Class: Kavleen Batra, Chotika Chansereewat, Philip Chukwueke, Soumil Milan Doshi, Richard Fianza, Meredith Hursh, Mary-Ann Kubal, Colin Lau, Kelly Menold, Robert Mills, Hao Nguyen, Sahar Padash, Poranas Promsookt, Monica Rin, Lauren Ross, Felix Ruess, Mimoza Selmani, Hewotte Theodros, Thuy Tran, Minh Vu.