Month: January 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

I had an interesting discussion with one of my son’s friends at a neighborhood gathering over the holidays. He’s just reached the halfway point of a Chicago-area Masters in Analytics program and wanted to pick my brain on the state of the discipline.
Of the four major program foci of business, data, computation, and algorithms, he acknowledged he liked computation best, with Python in the lead against R and SAS for his attention. I was impressed with his understanding of Python, especially given that he’d had no programming experience outside Excel before starting the curriculum.
After a while, we got to chatting about NumPy and Pandas, the workhorses of Python data programming. My son’s friend was using Pandas a bit now, but hadn’t been exposed to NumPy per se. And while he noted the productivity benefits of working with such libraries, I don’t think he quite appreciated the magnitude of relief provided for day-to-day data programming challenges. He seemed smitten with the power he’d discovered with core Python. Actually, he sounded a lot like me when I was first exposed to Pandas almost 10 years ago — and when I first saw R as a SAS programmer back in 2000. As our conversation progressed, I just smiled, fully confident his admiration would grow over time.
Our discussion did whet my appetite for the vanilla Python data programming I’ve done in the past. So I just had to dig up some code I’d written “BP” — before Pandas. Following a pretty exhaustive search, I found scripts from 2010. The topic was stock market performance. The work stream entailed wrangling CSV files from the investment benchmark company Russell FTSE website pertaining to the performance of its many market indexes. Just about all the work was completed using core Python libraries and simple data structures lists and dictionaries.
As I modernized the old code a bit, my appreciation for Pandas/NumPy did nothing but grow. Much more looping-like code in vanilla Python. And, alas, lists aren’t dataframes. On the other hand, with Pandas: Array orientation/functions? Check. Routinized missing data handling? Check. Tables/dataframes as core data structures? Check. Handling complex input files? Check. Powerful query capability? Check. Easy updating/variable creation? Check. Joins and group by? Check. Et al.? Check.
For the analysis that follows, I focus on performance of the Russell 3000 index, a competitor to the S&P 500 and Wilshire 5000 for “measuring the market”. I first download two files — a year-to-date and a history, that provide final 3000 daily index levels starting in 2005. Attributes include index name, date, level without dividends reinvested, and level with dividends reinvested.
Once the file data are in memory, they’re munged and combined into a single Python multi-variable list. The combined data are then sorted by date, at which point duplicates are deleted. After that, I compute daily percent change variables from the index levels, ultimately producing index performance statistics. At the end I write the list to a CSV file.
My take? Even though the code here is no more than intermediate-level, data programming in Python without Pandas seems antediluvian now. The array orientations of both Pandas and NumPy make this work so much simpler than the looping idioms of vanilla Python. Indeed, even though I programmed with Fortran, PL/I, and C in the past, I’ve become quite lazy in the past few years.
This is the first of three blogs pretty much doing the same tasks with the Russell 3000 data. The second uses NumPy, and the final, Pandas.
The technology used for the three articles revolves on JupyterLab 0.32.1, Anaconda Python 3.6.5, NumPy 1.14.3, and Pandas 0.23.0.
Read the remainder of the blog here.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Amazon Web Services Open Data (AWSOD) and Amazon Sustainability (AS) are working together to make sustainability datasets available on the AWS Simple Storage Service (S3), and they are removing the undifferentiated heavy lifting by pre-processing the datasets for optimal retrieval. Sustainable datasets are commonly from satellites, geological studies, weather radars, maps, agricultural studies, atmospheric studies, government, and many other sources.
On December 10, 2018, AWSOD and AS teams released the first group of datasets. These datasets add a new category of data to the existing AWS Open Data datasets. While these sustainability datasets have been previously publicly available, AWS is improving the ease of access to the datasets, for example, separating large archive files into smaller addressable chunks that can be retrieved independently. AWS uses Simple Storage Service (S3) for storage with buckets set to public accessibility. Simple Notification Services (SNS) are used to notify consumers of new data, and CloudFront is used in a few cases to make data available via application programming interfaces for faster retrieval.
To further stimulate usage of the new datasets, AWS is working with the Group on Earth Observations (GEO) to grant $1.5 million in cloud credits to gain insights about the planet.
AWS provides documentation for using the sustainability open datasets and tags for searching the datasets. The dataset “Africa Soil Information Service (AfSIS) Soil Chemistry” can be used as a starting point to learn about applying machine learning to open data with a walkthrough Jupyter notebook. Third-party contributors to the community of individuals using open datasets are publishing blogs with walkthroughs on how to use the public datasets. Walkthroughs include:
Additionally, AWS has customers that are successfully doing work in the cloud to support sustainability practices, including:
Sebastian Fritsch, who works on data analytics for agriculture, participated in a Q&A with AWS about the usage of satellite datasets and was asked “Were there any highlights for you?” he answered: “Being able to scale up data products from a relatively small pilot region up to global availability just by changing a few lines of code is a highlight for us.”
Before the release of the sustainability datasets, AWS Global Open Data Lead Jed Sundwall spoke about continuously learning to improve how AWS stages petabytes of open data. AWS is adding a variety of indexes to the open datasets to increase the ease of access including external indexes, file naming, and internal indexes. AWS staff are observing a community coming together, and they realize they can gauge the success of the datasets by the mechanisms the community builds to process those datasets. Lastly, AWS has a well-defined program for covering the cost and allowing new contributors to make their public datasets available through AWS.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Kubernetes is experiencing phenomenal growth since it solves specific pain points with respect to application portability and deployment.
- Kubernetes is already a reality in eliminating vendor lock-in and enabling cloud portability with the choice of offerings on the different clouds.
- Although Kubernetes is already established in multiple clouds, multi-cloud means more than that.
- The application and distributed system patterns that render itself to multi-cloud including some examples and case studies.
- How the Kubernetes community is coming together to address the challenges related to multi-cloud.
At the recently concluded “sold-out” Kubecon+CloudNativeCon 2018 conference at Seattle, attended by about 8500 attendees, many of the multiple Kubernetes services offered by the major cloud providers were discussed right from the opening keynote to the many technical sessions.
Although the variety of cloud providers have the respective Kubernetes offerings, with each cloud trying to distinguish their offerings around complementary services, the goal for the Kubernetes community is for application portability across the Kubernetes offerings. However in reality, can a single application or solution span these multiple clouds, or does multi-cloud simply mean the organizational reality of dealing with multiple clouds?
InfoQ caught up with experts in the field at Kubecon 2018 in Seattle: Dr. Lew Tucker, former cloud CTO at Cisco, Dr. Sheng Liang, CEO of Rancher Labs, Marco Palladino, CTO of Kong and Janet Kuo, Kubecon+CloudNativeCon 2018 co-chair and software engineer at Google about the multi-cloud aspects of Kubernetes and the challenges that remain.
The panelists start off by discussing the growth of the Kubernetes community, and how it has enabled application development and deployment in the cloud. They talk about what multi-cloud means and the synergies with the Kubernetes platform and community.
They discuss some distributed system patterns that render themselves suitable for multi-cloud, including some existing projects and case studies layered around Kubernetes.
Finally, the panelists identify some of the challenges that remain to be addressed by the Kubernetes community in order to make multi-cloud a reality, including the potential roadmap for the project to address some of the challenges.
InfoQ: Let’s talk about the Kubernetes community in general, and the recently concluded Kubecon 2018 in particular. As folks being involved with the community and the conference right from its inception, what reasons do you attribute to the growth and how does it affect developers and architects in particular going forward?
Lew Tucker: It’s true – Kubernetes is seeing amazing growth and expansion of the developer and user communities. As an open source orchestration system for containers, it’s clear that Kubernetes makes it easier for developers to build and deploy applications with resiliency and scalability, while providing portability across multiple cloud platforms. As the first project to graduate from the Cloud Native Computing Foundation, it is quickly becoming the de-facto platform for cloud native apps.
Sheng Liang: Kubernetes became popular because it solved an important problem really well: how to run applications reliably. It is the best container orchestrator, cluster manager, and scheduler out there. The best technology combined with a very well-run open source community made Kubernetes unstoppable.
Marco Palladino: The growth of Kubernetes cannot be explained without taking into consideration very disruptive industry trends that transformed the way we build and scale software: microservices and the rise of containers. As businesses kept innovating to find new ways of scaling their applications and their teams, they discovered that decoupling and distributing both the software and the organization would provide a better framework to ultimately enable their business to also grow exponentially over time. Large teams and large monolithic applications were, therefore, decoupled — and distributed — into smaller components. While a few companies originally led this transformation a long time ago (Amazon, Netflix and so on) and built their own tooling to enable their success, every other large enterprise organization lacked both the will, the know-how and the R&D capacity to also approach a similar transition. With the mainstream adoption of containers (Docker in 2013) and the emergence of platforms like Kubernetes (in 2014) shortly after, every enterprise in the world could now approach the microservices transition by leveraging a new, easy-to-use self-service ecosystem. Kubernetes, therefore, became the enabler not just to a specific way of running and deploying software, but also to an architectural modernization that organizations were previously cautious to adopt because of lack of tooling, which was now accessible to them. It cannot be ignored that Docker and Kubernetes, and most of the ecosystem surrounding these platforms, are open source — to understand the Kubernetes adoption, we must also understand the decisional shift of enterprise software adoption from being top-down (like SOA, driven by vendors) to being bottom-up (driven by developers). As a result of these Industry trends, that in turn further fed into Kubernetes adoption, developers and architects now can leverage a large ecosystem of self-service open source technologies that’s unprecedented compared to even half a decade ago.
Janet Kuo: One of the key reasons is that Kubernetes has a very strong community — it is made up of a diverse set of end users, contributors, and service providers. The end users don’t choose Kubernetes because they love container technology or Kubernetes, they choose Kubernetes because it solves their problems and allows them to move faster. Kubernetes is also one of the largest and one of the most active open source projects, with contributors from around the globe. This is because there’s no concentration of power in Kubernetes, and that encourages collaboration and innovation regardless of whether or not someone works on Kubernetes as part of their job or as a hobby. Lastly, most of the world’s major cloud providers and IT service providers have adopted Kubernetes as their default solution for container orchestration. This network effect make Kubernetes grow exponentially.
InfoQ: Some of us can recount the Java days that eliminated vendor lock in. Kubernetes has a similar mission where vendors seem to cooperate on standards and compete on implementations. Eliminating vendor lock in might be good overall. However, what does cloud portability or multi-cloud mean, and does it even matter to the customer (keeping aside Kubernetes)?
Tucker: Layers of abstraction are typically made to hide the complexity of underlying layers, and as they become platforms, they also provide a degree of portability between systems.
In the early Java days, we talked about the promise of “write once, and run anywhere” reducing or eliminating the traditional operating system lock-in associated with either Unix, or Windows. The degree to which this was realized often required careful coding, but the value was clear. Now with competing public cloud vendors, we have a similar situation. The underlying cloud platforms are different, but Docker containers and Kubernetes provides a layer of abstraction and high degree of portability across clouds. In a way this forces cloud providers to compete on the services offered. Users then get to decide how much lock-in they can live in order to take advantage of the vendor specific services. As we move more and more towards service-based architectures, it’s expected that this kind of natural vendor lock-in will become the norm.
Liang: While eliminating cloud lock-in might be important for some customers, I do not believe a product aimed solely at cloud portability can be successful. Many other factors, including agility, reliability, scalability, and security are often more important. These are precisely some of the capabilities delivered by Kubernetes. I believe Kubernetes will end up being an effective cloud portability layer, and it achieves cloud portability almost as an side-effect, sort of like how the browser achieved device portability.
Palladino: Multi-cloud is often being approached from the point of view of a conscious top-down decision made by the organization as part of a long-term strategy and roadmap. However, the reality is much more pragmatic. Large enterprise organizations really are the aggregation of a large variety of teams, agendas, strategies and products that happen to be part of the same complex “multi-cellular” organism. Multi-cloud within an organization is bound to happen simply because each different team/product inevitably makes different decisions on how to build their software, especially in an era of software development where developers are leading, bottom-up, all the major technological decisions and experimentations. Those teams that are very close to the end-user and to the business are going to adopt whatever technology (and cloud) better allows them to achieve their goals and ultimately scale the business. The traditional Central IT — far from the end-users and from the business but closer to the teams — will then need to adapt to a new hybrid reality that’s being developed beneath them as we speak. Corporate acquisitions over time of products and teams that are already using different clouds will also lead to an even more distributed and decoupled multi-cloud organization. Multi-cloud is happening not necessarily because the organization wants to, but because it has to. Containers and Kubernetes — by being extremely portable — are therefore, a good technological answer to these pragmatic requirements. They offer a way to run software among different cloud vendors (and bare-metal) with semi-standardized packaging and deployment flows, thus reducing operational fragmentation.
Kuo: Cloud portability and multi-cloud gives users the freedom to choose best-fit solutions for different applications for different situations based on business needs. Multi-cloud also enables more levels of redundancy. By adding redundancy, users achieve more flexibility to build with the best technology, and also helps them optimize operations and stay competitive.
InfoQ: Kubernetes distributions and offerings on different clouds will try to differentiate their respective offerings, which seems the natural course of “Co-opetition”. What are the pitfalls that the Kubernetes community should avoid, based on your past experiences with similar communities?
Tucker: It’s natural to expect that different vendors will want to differentiate their respective offerings in order to compete in the market. The most important thing for the Kubernetes community is to remain true to its open source principles and put vendor or infrastructure based differences behind standard interfaces to keep the platform from fragmenting into proprietary variants. Public interfaces, such the device plugin framework (for things such as GPUs) and CNI (Container Networking Interface) isolate infrastructure specific difference behind a common API, allowing vendors to compete on implementation while offering a common layer. Vendors today also differentiate in how they provide managed Kubernetes. This sits outside the platform, leaving the Kubernetes API intact which still leaves it up the user whether or not they wish to adopt a vendors management framework in their deployment model.
Liang: The user community should avoid using features that make their application only work with a specific Kubernetes distro. It is easy to stand up Kubernetes clusters from a variety of providers now. After creating the YAML files or Helm charts to deploy your application on your distro of choice, you should also try the same YAML files or Helm charts on GKE or EKS clusters.
Palladino: The community should be wary of any cloud vendor hinting at an “Embrace, Extend, Extinguish” strategy that will in the long term fragment Kubernetes and the community and pave the road for a new platform “to rule them all.”
Kuo: Fragmentation is what the Kubernetes community should work together on to avoid. Otherwise, end users cannot get consistent behavior in different platforms and lose the portability and the freedom to choose – which brought them to Kubernetes in the first place. To address this need first identified by Google, the Kubernetes community has invested heavily in conformance, which ensures that every service provider’s version of Kubernetes supports the required APIs and give end users consistent behavior.
InfoQ: Can you mention some no-brainer distributed system or application patterns that make it a shoe in for multi-cloud Kubernetes? Is it microservices?
Tucker: Microservice-based architectures are a natural fit with Kubernetes. But when breaking apart monolithic apps into a set of individual services, we’ve now brought in the complexity of a distributed system that relies on communication between its parts. This is not something that every application developer is prepared to take on. Service meshes, such as Istio, seem like a natural complement for Kubernetes. They off-load many networking and traffic management functions, freeing up the app developer from having to worry about service authentication, encryption, key exchange, traffic management, and others while providing uniform monitoring and visibility.
Liang: While microservices obviously fit multi-cloud Kubernetes, legacy deployment architecture fits as well. For example, some of our customers deploy multi-cloud Kubernetes for the purpose of disaster recovery. Failure of the application in one cloud does not impact the functioning of the same app in another cloud. Another use case is geographic replication. Some of our customers deploy the same application across many different regions in multiple clouds for the purpose of geographic proximity.
Palladino: Microservices is a pattern that adds a significant premium on our architecture requirements because it leads to more moving parts and more networking operations across the board — managing a monolith is a O(1) problem, while managing microservices is a O(n) problem. Kubernetes has been a very successful platform for managing microservices, since it provides useful primitives that can be leveraged to automate a large variety of operations that in turn remove some — if not most — of that “microservices premium” from the equation. The emergence of API platforms tightly integrated with those Kubernetes primitives — like sidecar and ingress proxies — are also making it easier to build network intensive, decoupled and distributed architectures. With that said, any application can benefit from running on top of Kubernetes, including monoliths. By having Kubernetes running as the underlying abstraction layer on top of multiple cloud vendors, teams can now consolidate operational concerns — like distributing and deploying their applications — across the board without having to worry about the specifics of each cloud provider.
Kuo: Microservices is one of the best-known patterns. Sidecar pattern is also critical for modern applications to integrate functionalities like logging, monitoring, and networking into the applications. Proxy pattern is also useful for simplifying application developers’ lives so that it’s much easier to write and test their applications, without needing to handle network communication between microservices, and this is commonly used by service mesh solutions, like Istio.
InfoQ: What does the emerging Service Mesh pattern do to enable multi-cloud platform implementation (if any)?
Tucker: I believe Kubernetes-based apps based on a microservices and service mesh architecture will likely become more prevalent as the technology matures. The natural next step is for a service mesh to connect multiple kubernetes clusters running on different clouds. A multi-cloud service mesh would make it much easier for developers to move towards stitching together the very best components and services from different providers into a single application or service.
Liang: The emerging service mesh pattern adds a lot of value for multi-cloud Kubernetes deployment. When we deploy multiple Kubernetes clusters in multiple clouds, the same Istio service mesh can span these clusters, providing unified visibility and control for the application.
Palladino: Transitioning to microservices translates to an heavier use of networking across the services that we are trying to connect. As we all know the network is implicitly unreliable and cannot be trusted, even within the private organization’s network. Service Mesh is a pattern that attempts to make our inherently unreliable network reliable again by providing functionalities (usually deployed in a sidecar proxy running alongside our services) that enable reliable service-to-service communication (like routing, circuit breakers, health checks, and so on). In my experience working with large enterprise organizations implementing service mesh across their products, the pattern can help with multi-cloud implementations by helping routing workloads across different regions and data-centers, and enforcing secure communication between the services across different clouds and regions.
Kuo: Container orchestration is not enough for running distributed applications. Users need tools to manage those microservices and their policies, and they want those policies to be decoupled from services so that policies can be updated independent of the services. This is where service mesh technology come into play. The service mesh pattern is platform independent, so a service mesh can be built between clouds and across hybrid infrastructures. There are already several open-source service mesh solutions available today. One of the most popular open-source service mesh solutions is Istio. Istio offers visibility and security for distributed services, and ensures a decoupling between development and operations. As with Kubernetes, users can run Isio anywhere they see fit.
InfoQ: Vendors and customers usually follow the money trail. Can you talk specifically about customer success stories or case studies where Kubernetes and/or multi-cloud matters?
Liang: Rancher 2.0 has received tremendous market success precisely because it is capable of managing multiple Kubernetes clusters across multiple clouds. A multinational media company, uses Rancher 2.0 to stand up and manage Kubernetes clusters in AWS, Azure, and their in-house vSphere clusters. Their IT department is able to control which application is deployed on which cloud depending on its compliance needs. In another case, Goldwind, the 3rd largest wind turbine manufacturer in the world, uses Rancher 2.0 to manage multiple Kubernetes clusters in the central data center and in hundreds of edge locations where wind turbines are installed.
Palladino: I have had the pleasure of working very closely with large enterprise organizations and seeing the pragmatic challenges that these organizations are trying to overcome. In particular, one large enterprise customer of Kong decided to move to multi-cloud on top of Kubernetes due to the large number of acquisitions executed over the past few years by the organization. Each acquisition would bring new teams, products and architectures under the management of the parent organization, and over time, you can imagine how hard it became to grow existing teams within the organization with so much fragmentation. Therefore, the organization decided to standardize how applications are being packaged (with Docker) and executed (with Kubernetes) in an effort to simplify ops across all the teams. Although sometimes very similar, different cloud vendors actually offer a different set of services with different quality and support, and it turns out that some clouds are better than others when it comes to certain use cases. As a result, many applications running within the organization also ran on different clouds depending on the services they implemented, and the company was already a multi-cloud reality by the time they decided to adopt Kubernetes. In order to keep the latency low between the applications and the specific services that those products implemented from each cloud vendor, they also decided to start a multi-cloud Kubernetes cluster. It wasn’t by any means a simple task, but the cost of keeping things fragmented was higher than the cost of modernizing their architecture to better scale it in the long-term. In a large enterprise, it’s all about scalability — not just technical but also organizational and operational.
Kuo: There are a wide variety of customer success stories covered in Kubernetes case studies. My favorite is actually one of the oldest — the one about how Pokemon Go (a mobile game that went viral right after it’s release) runs on top of Kubernetes, which allowed game developers to deploy live changes while serving millions of players around the world. People were surprised and excited to see a real use case of large scale, production Kubernetes clusters. Today, we’ve learned about so many more Kubernetes customer success stories — such as the ones we just heard from Uber and Airbnb on KubeCon keynote stage. Diverse and exciting use cases are now the norm within the community.
InfoQ: From a single project or solution viewpoint, is it even feasible for the different components or services to reside in multiple clouds? What are the major technical challenges (if any) that need to be solved before Kubernetes is truly multi-cloud?
Tucker: Yes. Work on a dedicated federation API apart from the Kubernetes API is already in progress ( see on Kubernetes and on GitHub). This approach is not limited to clusters residing at the same cloud provider. But, it’s still very early days and many of the pragmatic issues beyond the obvious ones such as increased latency and different cloud service APIs are still under discussion.
Liang: Yes it is. Many Rancher customers implement this deployment model. We are developing a number of new features in Rancher to improve multi-cloud experience. 1) A mechanism to orchestrate applications deployed in multiple clusters that reside in multiple clouds. 2) Integration with global load balancers and DNS servers to redirect traffic. 3) A mechanism to tunnel network traffic between pods in different clusters. 4) A mechanism to replicate storage across multiple clusters.
Palladino: Federation across multiple Kubernetes clusters, a control plane API that can help run multiple clusters and security (users and policies). Synchronizing resources across multiple clusters is also a challenge, as well as observability across the board. Some of these problems can be fixed by adopting third-party integrations and solutions, but it would be nice if Kubernetes provided more out-of-the box support in this direction. There is already an alpha version of an experimental federation API for Kubernetes, but it’s unfortunately not mature enough to be used in production (with known issues).
Thinking of a multi-cloud Kubernetes is akin to thinking of managing separate Kubernetes clusters at the same time. The whole release lifecycle (packaging, distributing, testing and so on) needs to be applied and synced across all the clusters (or a few of them based on configurable conditions), while having at the same time a centralized plane to monitor the status of operations across the entire system. Both application and user security also become more challenging across multiple clusters. At runtime, we may want to enforce multi-region routing (for failover) between one cluster and another, which also means introducing more technology (and data plane overhead) in order to manage those use cases. All of the functionality that we normally use in a single cluster, like CI/CD, security, auditing, application monitoring and alerting, has to be re-thought in a multi cluster, multi-cloud environment — not just operationally but also organizationally.
Kuo: Kubernetes already does a good job of abstracting underlying infrastructure layer so that cloud provider services, such as networking and storage, are simply resources in Kubernetes. However, users still face a lot of friction when running Kubernetes in multi-cloud. Technical challenges include connectivity between different regions and clouds, disaster discovery, logging and monitoring, need to be solved. We need to provide better tooling to make the user experience seamless and the community is dedicated to providing those resources.
InfoQ: Please keep this brief but can you talk about some products or technologies that may not be mainstream yet, but might help obviate some of the issues that we’ve been talking about so far and makes development and deployment on multi-cloud easier?
Liang: Our flagship product, Rancher, is designed specifically to manage multiple Kubernetes clusters across multiple clouds
Palladino: Open-source products like Kong can help in consolidating security, observability and traffic control for our services across multi-cloud deployments, by providing a hybrid control plane that can integrate with different platforms and architectures, and by enabling large legacy applications to be decoupled and distributed in the first place. Open-source ecosystems, like CNCF, also provide a wide variety of tooling that help developers and architects navigate the new challenges of multi-cloud and hybrid architectures that the Enterprise will inevitably have to deal with (Monoliths, SOA, Microservices and Serverless). It’s very important that – as the scale of our systems increase – we avoid fragmentation of critical functions (like security) by leveraging existing technologies instead of reinventing the wheel. And open-source, once again, is leading this trend by increasing developer productivity, while at the same time creating business value for the entire organization.
Kuo: One of the common patterns I see is to manage everything using Kubernetes API. To do this, you most likely need to customize Kubernetes APIs, such as using Kubernetes CustomResourceDefinition. A number of technologies built around Kubernetes, such as Istio, rely heavily on this feature. Kubernetes developers are improving the custom Kubernetes APIs feature, to make it easier to build new tools for development and deployment on multi-cloud.
InfoQ: Final Question. Summing up, where do you see the Kubernetes community headed, and how important is multi-cloud in defining the roadmap? Any other random thoughts about Kubernetes and Kubecon that developers and architects should care about?
Tucker: Most user surveys show that companies use more than a single cloud vendor and often include both public and private clouds. So multi-cloud is simply a fact. Kubernetes, therefore provides an important common platform for application portability across clouds. The history of computing, however, shows that we continually build up layers of abstraction. When we therefore look at multi-cloud, it may be that other “platforms” such as serverless or a pure services-based architecture built on top of kubernetes might be where we are really headed.
Liang:. Multi-cloud started as a wonderful side benefit of Kubernetes. I believe multi-cloud is now a core requirement when people plan for Kubernetes deployment. The community is working in a number of areas to improve multi-cloud support: Kubernetes conformance, SIG multi-cluster, and Federation. I’m extremely excited about where all these efforts are headed. I encourage all of you to take a look at these projects if you are interested in multi-cloud support for Kubernetes.
Palladino: Kubernetes and containers enabled entire organizations to modernize their architectures and scale their businesses. As such, Kubernetes is well-positioned to be the future of infrastructure for any modern workload. As more and more developers and organizations deploy Kubernetes in production, the more mature the platform will become to address a larger set of workloads running in different configurations, including multi-cloud. Multi-cloud is a real and pragmatic topic that every organization should plan for in order to continue being successful as the number of products and teams — with very unique requirements and environments — keeps growing over time. Like a multicellular organism, the modern enterprise will have to adapt to a multi-cloud world in order to keep building scalable and efficient applications that ultimately deliver business value to their end users.
Kuo: The Kubernetes community has a special interest group for cloud providers to ensure that the Kubernetes ecosystem is evolving in a way that’s neutral to all cloud providers. I’ve already seen many Kubernetes users choose Kubernetes for the benefit of multi-cloud. I envision that more enterprise users will join the Kubernetes community for that very same reason.
Conclusion
Panelists talk about their own personal experience with the Kubernetes community and how it’s enabling cloud development and deployment. All panelists conclude that Kubernetes is already a reality in eliminating vendor lock-in and enabling cloud portability with the choice of offerings on the different clouds. However, they also recognize that multi-cloud means more than a common platform on multiple clouds.
The panelists talk of the pragmatic approach of the Kubernetes community to be able to solve specific pain points related to application development and deployment in a true open source fashion and community manner. This community approach is unlikely to fall into the danger of “embrace and extend” that has been the bane of many projects in the past.
Finally, panelists talk about application patterns, like Service Mesh, Istio and so on, in the context of some examples that require Kubernetes and its roadmap to evolve to be truly multi-cloud.
About the Panelists
 Lew Tucker Former VP/CTO at Cisco Systems and served on the board of directors of the Cloud Native Computing, OpenStack, and Cloud Foundry Foundations. He has more than 30 years of experience in the high-tech industry, ranging from distributed systems and artificial intelligence to software development and parallel system architecture. Prior to Cisco, Tucker was VP/CTO Cloud Computing at Sun Microsystems where he led the development of the Sun Cloud platform. He was also a member of the JavaSoft executive team, launched java.sun.com, and helped to bring Java into the developer ecosystem. Tucker moved into technology following a career in Neurobiology at Cornell University Medical school and has a Ph.D. in computer science.
Lew Tucker Former VP/CTO at Cisco Systems and served on the board of directors of the Cloud Native Computing, OpenStack, and Cloud Foundry Foundations. He has more than 30 years of experience in the high-tech industry, ranging from distributed systems and artificial intelligence to software development and parallel system architecture. Prior to Cisco, Tucker was VP/CTO Cloud Computing at Sun Microsystems where he led the development of the Sun Cloud platform. He was also a member of the JavaSoft executive team, launched java.sun.com, and helped to bring Java into the developer ecosystem. Tucker moved into technology following a career in Neurobiology at Cornell University Medical school and has a Ph.D. in computer science.
 Marco Palladino is an inventor, software developer and Internet entrepreneur based in San Francisco. As the CTO and co-founder of Kong, he is Kong’s co-author, responsible for the design and delivery of the company’s products, while also providing technical thought leadership around APIs and microservices within both Kong and the external software community. Prior to Kong, Marco co-founded Mashape in 2010, which became the largest API marketplaceand was acquired by RapidAPI in 2017.
Marco Palladino is an inventor, software developer and Internet entrepreneur based in San Francisco. As the CTO and co-founder of Kong, he is Kong’s co-author, responsible for the design and delivery of the company’s products, while also providing technical thought leadership around APIs and microservices within both Kong and the external software community. Prior to Kong, Marco co-founded Mashape in 2010, which became the largest API marketplaceand was acquired by RapidAPI in 2017.
 Janet Kuo is a software engineer for Google Cloud. She has been a Kubernetes project maintainer since 2015. She currently serves as co-chair of KubeCon + CloudNativeCon.
Janet Kuo is a software engineer for Google Cloud. She has been a Kubernetes project maintainer since 2015. She currently serves as co-chair of KubeCon + CloudNativeCon.
 Sheng Liang is co-founder and CEO of Rancher Labs. Rancher develops a container management platform that helps organizations adopt Kubernetes. Previously Sheng Liang was CTO of Cloud Platform at Citrix and CEO and founder of Cloud.com (acquired by Citrix.)
Sheng Liang is co-founder and CEO of Rancher Labs. Rancher develops a container management platform that helps organizations adopt Kubernetes. Previously Sheng Liang was CTO of Cloud Platform at Citrix and CEO and founder of Cloud.com (acquired by Citrix.)
Machine Learning for Transactional Analytics: Customer Life time Value v/s Acquisition Cost
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Understanding customer transactional behaviour pays well for any business. With the tsunami of start ups in recent times and the immense money flow in businesses, customers find lucrative offers from companies for acquisition, retention & referrals strategies. Understanding transactional behaviour of a customer has become even more complex with the invent of new business houses everyday. Although, with the rise of powerful machines, one can easily manage working with TBs of data, complexity of business economics has made this behavioural analysis far more difficult.
Collecting and analysing your business data on all aspects such as acquisition cost, operational cost, base profit, revenue growth, referrals etc can help in providing the lifecycle profit patterns from a customer. But it does not help in solving many business questions such as
What is the actual value of a new customer in Dollars worth today?
How much money business can spend to acquire a new customer?
Lets take an example to understand it more intuitively. Firstly, to estimate the value of a new customer, we have to know the annual profit patterns or cash flow patterns if cash flow pattern differs from profit pattern from a customer. Secondly, we need to figure out how many years customer stay with your business?
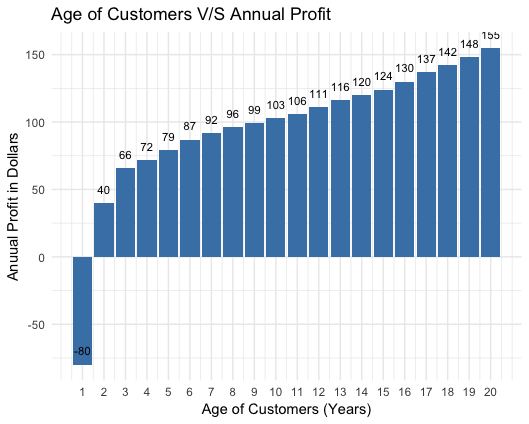
The figure above shows a customer profits for an imaginary firm based on all factors mentioned earlier. Customer value keeps on increasing with the time for which customer stays with the company. Customer who stays 2 yrs will generate $26 of profit ($80 acquisition cost balanced in first 3 years profits $40 & $66. If customer stays for 5 years, will generate $264 in total (-$80+$40+$66+$72+$79+$87). But the differences in customer value is very large. For same calculations if done for 10 years, customers will generate net worth $760.
It would not be wise to spend $760 today for a customer who will stay with company for 10 years as the profit generated in future would not be equivalent to $760 today. We need to apply discount computing to take it to present value. Using a standard 15 percent discount rate will make $760 to $304. (To get net present value of first year profit, therefore divide $40 by 1.15, for next year divide $66 by 1.15 and so on). So For a customer who will stay with company for 10 years, one can pay up to $304 on acquisition costs. Now we know how to calculate value of customer based on life expectancy of customer.
Customer Lifetime calculations
The next question is what is expected duration of a customer to stay with company. To answer this, we have to find out retention rates for a customer. It is a fact that retention rates vary among customers based on age, profession, gender, acquisition source & may be more than dozen variables. Simplest way to calculate average customer stay time is to calculate overall defection rate and invert the fraction. First count the number of customers who defect over a period of several months, then annualise this number to get a fraction of customer base to begin with. e.g. you lose 50 customer out of 1000 customer over three months. This works to 200 customer a year, or 1/5 of all customers. Then we need to invert this number, it will become 5. So now we can say, on an average, a customer stays with company for 5 years. In percentage terms defection rate for customer is 20%.
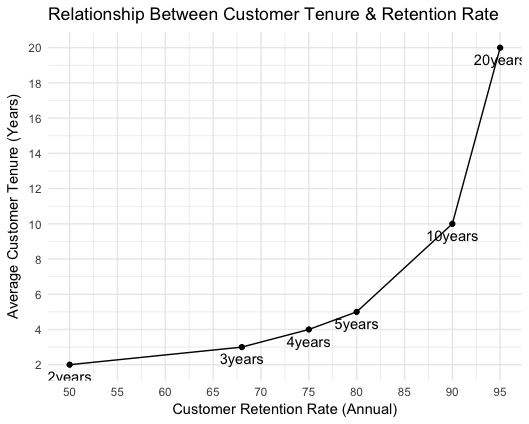
Lifetime Calculation Improvements
To estimate customer cash flow accurately, we need to refine the above mentioned calculations. Firstly, we have assumed defection rates are constant throughout the customer life cycles. In real life, such is never the case; defection rates are very much higher than average in early years and much more lower later on. Taking averages may lead to over or under estimating the profit numbers. Additionally one more refinement we need to make to calculate the true value of customer. Instead of trying to calculate the value of single, average, static customer at a single moment, we need to think in terms of annual classes of customers at different point in their life cycle. In real world, company acquire new users each year. some of them defect early, others may stay for years. But company invest money in the entire set of customers. So, to get the present value of average customer, we must study each group separately over time.
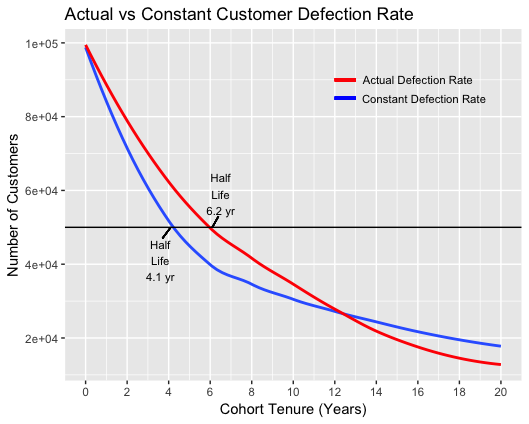
Lets take a scenario as shown in above image, where 100,000 new customers enter at time zero. Company invested $80 at time zero making it to total $80*100,000= $8 million for whole set of customers. By end of year 1, 22% customers defected, only 78% left, to pay back invested 8 million. By year 5, more than half people defected. To get present value of customer, we will estimate the set of cash flow people generate till the time they defect. Earlier in blog, we get current value of customer at $304. At constant rate of defection of 10%, we may be dangerously wrong in deciding the money to be invested in customer acquisition whereas the actual defection rate shown in above image make this number to only $ 172 from $304. Imagine company spending $200 on new customer based on earlier calculated values. It would be completely lose making venture.
Machine learning Scope
In above calculations, we tried to approximate the customer life time value & corrected ourselves initially from $ 760 to $172. It still contains assumptions of same cohort transactional behaviour. Every individual behave in a distinct way. When we plan targeting a customer based on machine learning based marketing campaign then why not to calculate Customer life time value for every unique customer. Based on certain pre-defined variables, one can easily predict life time value of a customer & can strategise accordingly.
One can also add that every organisation is getting more and more transactional data every day making it difficult to manage especially, in the presence of numerous acquisition dependent variables, to get the accurate accounting numbers. Moreover, the transactional behaviour of customers have also been largely influenced by various offers, incentives from cash burning start ups. By making use of RFM ( Recency-Frequency-Monetary)- “magical marketing triangle” with advanced statistical methods considering customer irregular transactional behaviour, can help in creating a probabilistic machine learning model to do wonders to business economic predictability.
This article has been originally published here
DataToBiz connects businesses to data and excels in cutting-edge ML technologies in order to solve most of the simple and trivial problems of business owners with the help of data. Feel free to Contact
Podcast: Megan Cartwright on Building a Machine Learning MVP at an Early Stage Startup
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Today on the InfoQ Podcast, Wes speaks with ThirdLove’s Megan Cartwright. Megan is the Director of Data Science for the personalized bra company. In the podcast, Megan first discusses why their customers need a more personal experience and how their using technology to help. She focuses quite a bit of time in the podcast discussing how the team got to an early MVP and then how they did the same for getting to an early machine learning MVP for product recommendations. In this later part, she discusses decisions they made on what data to use, how to get the solution into production quickly, how to update/train new models, and where they needed help. It’s a real early stage startup story of a lean team leveraging machine learning to get to a practical recommendations solution in a very short timeframe.
Key Takeaways
- The experience for women selecting bras is poor experience characterized by awkward fitting experiences and an often uncomfortable product that may not even fit correctly. ThirdLove is a company built to serve this market.
- ThirdLove took a lean approach to develop their architecture. It’s built with the Parse backend. The leveraged Shopify to build the site. The company’s first recommender system used a rules engine embedded into the front end. After that, they moved to a machine learning MVP with a Python recommender service that used a Random Forest algorithm in SciKit-Learn.
- Despite having the data for 10 million surveys, the first algorithms only need about 100K records to be trained. The takeaway is you don’t have to have huge amounts of data to get started with machine learning.
- To initially deploy their ML solution, ThirdLove first shadowed all traffic through the algorithm and then compared it to what was being output by the rules engine. Using this along with information on the full customer order lifecycle, they validated the ML solution worked correctly and outperformed the rules engine.
- ThirdLove’s machine learning story shows that you move towards a machine learning solution quickly by leveraging your own network and using tools that may already familiar to your team.
Show notes will follow shortly
About QCon
QCon is a practitioner-driven conference designed for technical team leads, architects, and project managers who influence software innovation in their teams. QCon takes place 7 times per year in London, New York, San Francisco, Sao Paolo, Beijing & Shanghai. QCon London is at its 13th Edition and will take place Mar 4-6, 2019. 140+ expert practitioner speakers, 1500+ attendees and 18 tracks will cover topics driving the evolution of software development today. Visit qconlondon.com to get more details.
More about our podcasts
You can keep up-to-date with the podcasts via our RSS Feed, and they are available via SoundCloud and iTunes. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The Pure attribute was added to .NET in version 4 as part of the Code Contracts initiative. The idea was that Pure and other attributes/functions in the System.Diagnostics.Contracts namespace would be used to decorate classes and methods throughout .NET’s Base Class Library (BCL).
Once that was done, the Code Contracts tooling could be used to perform advanced analysis and bug detection. However, the Code Contracts project failed. While there were several reasons for this, some of the more compelling ones include:
- The syntax was verbose, requiring full lines where developers would prefer to use attributes.
- The contracts were not exposed via reflection, eliminating the possibility for 3rd party tooling.
- The contracts were not exposed XML docs, meaning they could not be automatically included in documentation.
- When a contract was violated for any reason, the application crashed immediately with no chance for logging or corrective action
- The tooling was outside the normal compilation path, requiring additional steps and making the use of build servers more difficult.
Since the end of the Code Contracts project, the Roslyn analyzers have taken over as the static analysis tool of choice. Roslyn analyzers are part of the normal VB/C# compiler pipeline, so their use doesn’t add any complexity to the build process.
This leaves the question, “What to do with the code contract attributes?” Dan Moseley of Microsoft reports, “We don’t use or enforce those and generally have been removing contract annotations.”
Andrew Arnott, another Microsoft employee, counters with the idea that the Pure attribute specifically could still be of use,
But [Pure] is useful because one can write analyzers that will flag a warning when a [Pure] method is executed without doing anything with the result.
The basic idea behind this is any method marked as Pure should never have side effects. Its only purpose is to return a value. If it returns a value, and that value is subsequently ignored, then there was no reason to call the method in the first place. Therefore, the warning would always indicate a mistake.
And that’s what should happen. If you are using Microsoft.CodeQuality.Analyzers, then rule CA1806 will warn you about ignoring the results of a Pure method. But there are two catches:
First, it cannot warn you if a method is improperly marked as Pure. That capability is theoretically possible, as Pure methods should only read from other pure methods.
Secondly, you must include the compiler constant “CONTRACTS_FULL”. The Pure attribute itself is marked with a Conditional attribute. This means that without the aforementioned compiler constant, the Pure attribute will be stripped away from your compiled code. This actually happened to some methods in .NET’s immutable collections library.
InfoQ Asks: What other Code Contracts features would you like to see in modern .NET development?
Introducing Hyperledger Grid, a Framework for Building Distributed Supply Chain Solutions
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In a recent Hyperledger blog post, a new project has been announced called Hyperledger Grid. Grid is a framework for integrating distributed ledger technology (DLT) solutions with enterprise business systems for the supply chain industry. The project consists of reference architectures, common data models and smart contracts, all based-upon open standards and industry best practices.
Supply chain is often brought up when debating the opportunity of blockchain solutions. Well documented use cases include Seafood tracking, Food safety, Pharmaceutical safety and authenticity and Asset maintenance. Since there is established interest in leveraging distributed ledgers across these industries and verticals, the Hyperledger Grid project focuses-on accelerating the development of these solutions through shared capabilities.
The Hyperledger project is known for its blockchain-related tools and platforms. However, the Grid project has made it clear that it is not a blockchain or application:
Hyperledger Grid is a framework. It’s not a blockchain and it’s not an application. Grid is an ecosystem of technologies, frameworks, and libraries that work together, letting application developers make the choice as to which components are most appropriate for their industry or market model.
Hyperledger projects are industry agnostic and are designed to be flexible. Since many enterprise business systems and markets are relatively mature, Grid seeks to integrate with these solutions with other emerging technologies like blockchains, smart contracts and identity providers.
A key component in bridging traditional enterprise systems with other emerging technologies is Sabre:
The initial linkage between Grid and other elements in the stack will be via Sabre, a WebAssembly (WASM) Smart Contract engine. By adopting this approach, Grid asserts the strategic importance of WASM and provides a clear interface for integration with platforms inside and outside of Hyperledger. It is our hope and expectation that WASM and Sabre become a de facto Hyperledger standard.
The initial implementation of Grid is focused on: providing reference implementations of supply chain specific data types, data model and common business logic represented as smart contracts. These artifacts will be constructed based-on existing open standards and best practices. The Grid project will then demonstrate how to combine components from the Hyperledger stack into a single business solution. Some of the scenarios that Grid will be focusing on in the future include Asset transformation, Asset exchange and Asset tracking.
The primary contributors of this project include Cargill, Intel and Bitwise IO. In a recent press release, Cargill vice president, Keith Narr explained why they decided to get involved in the Grid project:
Hyperledger Grid is another way to help make food and agricultural supply chains more inclusive – creating new markets for farmers and developing economies. With our wide set of food and agricultural supply chain data, Cargill is leading the industry to work together and improve traceability, trade, food safety, nutrition, farmer livelihoods and more. Hyperledger Grid provides an ecosystem of reusable, open-source digital tools that developers can work with to build products, prototypes and applications that address supply-chain use cases, including traceability, food safety, trade settlement and more.
For additional information on Hyperledger Grid, the project proposal has been published and their code repository is available on GitHub.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Looking back to our article Top 10 Technology Trends of 2018 we can say that we were preparing you for the upcoming changes related to aspects of security, changes provoked by the AI in business operations, extensive application of blockchains, further development of the Internet of Things (IoT), growing of NLP, etc. Some of these statements have been implemented in 2018, yet some will remain topical in 2019 as well. Only one factor remains stable – development. There is no doubt, the technologies will continue to develop, improve and upgrade to fit their purposes better.
Primarily smart data technologies were actively applied only by huge enterprises and corporations. Today, big data has become available to a wide range of small businesses and companies. Both big enterprises and small companies tend to rely on big data in the questions of the intelligent business insights in their decision-making.
The ever-growing stream of data may also present a challenge to businesspeople. The prediction of changes in the role of big data and technologies is even more difficult. Thus, our top technology trends of 2019 are to serve a comprehensible roadmap for you.
1. Data security will reinforce its positions
The range of threads is enormous; therefore the discussion of the cybersecurity related issues will continue. The consumers have a growing awareness of the value of their information. Consequently, they become even more interested in the way how it will be used. Governments are actively planning, developing and adopting regulations on cybersecurity in this regard. Due to some cases of violation of the General Data Protection Regulation (GDPR) and loud scandals concerning Google and Facebook the application of enforcement measures is expected in 2019.
Moreover, we believe that cybersecurity will become more intelligence-driven in the upcoming year. Intelligence may become the only solution to the fast, automated attacks. Machine learning is called upon to play a crucial role in providing this intelligence. The AI-powered smart machines are expected to become more independent in the decision-making process. Probably, it will help companies to be one step ahead of the hacker, to predict attacks and define possible sore points.
2. Internet of Things will deliver new opportunities
It is quite evident that IoT is now being used by the companies representing all spheres of human activity. Moreover, the companies and businesspeople get even more interested in the practical implementation of smart technological solutions rather than in theoretical development. The attributes like “connected”, “smart” or “intelligent” are now added to all technologies and solutions developed for various industries.
According to some specialists, it is yet not the time to regard the IoT as something done. Undoubtedly the changes brought by the IoT are only under development. In 2019 the IoT capabilities are expected to shift to automating and augmenting how people experience the connected world. It will most probably result in a more unstructured landscape of a wide variety of dynamically meshed things and services.
3. Automation continues to be game-changing
The automation has entered in different industries, won a dominant position and acquired a good reputation. Undoubtedly, 2019 will bring progress, upgrade, and prosperity to robotic automation.
Autonomous things like drones, robots and autonomous vehicles are rapidly developed along with AI solutions. We expect a shift from the stand-alone things to complex systems of intelligent autonomous things. With the development of the AI technologies, autonomous things get more and more brains to interact and establish interrelations within complex systems. Thus, self-driven cars are capable of images recognition and geolocation tracking for making routes, voice recognition to follow the commands and various other technologies to provide convenience and comfort to people.
The RPA, or robotic process automation, is no longer a one-day technology. Nowadays it proved to be a technology changing the businesses. In 2019, the number of attended robots, those working alongside humans, is going to grow even more significant. In additions, the RPA in the public sector will rise, and governments will discover new opportunities with RPA.
4. AR is expected to overcome VR
For the 2018 year it was common to consider VR (virtual reality software) to be the most significant achievement of our generation. However, the situation has dramatically changed. VR proved to have a limited range of application among the companies and the customers. Therefore, the experts forecast the overcoming of VR by the AR (augmented reality software) soon.
The AR technologies will continue to be profitable for enterprise software development. In 2019, AR will become more common for mobile devices. Unlike VR, it does not require headsets. Therefore the AR’s ability to be deployed on mobile phones and tablets is far more robust.
Also, it is expected that AR will change the spheres of marketing and advertising in the upcoming year. AR provides a completely personal experience. Thus customers’ engagement is skyrocketing. A consistent communication channel for direct dialogue between the customer and provider will be ensured using the AR developments. Probably, AR will also reinforce its position in the area of manufacturing. Industrial AR platforms help the manufacturers to visualize data sets and provide assistance in jobs related to physical labor. It is predicted that AR software will become a key to the transformation of this sphere.
5. Connected clouds will shift to hybrid cloud solutions
The majority of companies now rely on cloud computing. Therefore, the consumption of cloud services is going to grow over in 2019. Gartner predicts that the cloud computing market will reach $200 billion.
The range of cloud solutions and delivery models is getting bigger and bigger. This fact makes cloud services more adaptable in different areas of activity. Hybrid cloud solutions will be winning popularity among companies. However, they will also present a challenge for some companies. The majority of IT service providers think that hybrid cloud solutions help to speed up service delivery. This is a crucial milestone. At first, cloud solution was regarded as a way to avoid building vast IT infrastructures from scratch and in such a way to reduce costs. Shortly these solutions will bring more flexibility and the abilities to react fast and even more efficiently to the rapidly changing market conditions. A new view on the cloud solutions adoption will be developed by the industries. So, we expect 2019 to be the year of hybrid and multi-cloud solutions for business.
6. Personalization will result in the rise of adaptive devices
Actually we are the witnesses of the immense evolution of AI-powered chatbot technology. Starting with simple routine tasks, chatbots are now actively turning into AI assistants. Customers got used to them very fasts and now cannot even imagine dealing with some issues without AI assistance.
Moreover, personalization will be represented not only due to the purposeful user commands for different devices but also in the devices themselves. Thus, they will be able to adapt themselves to the individual needs of the owner after a certain period, even without any commands on his part. This technology has become rather sophisticated. Thus the majority of customers cannot even guess whether they communicate with a person or with a chatbot.
Due to the excellent operation of Apple’s Siri, Amazon’s Alexa, people started to rely more on AI assistants in daily routine. What is expected in 2019 is that even more advanced assistants will appear and take responsibility for more complex dealings. With the help of the improved speech recognition techniques, the AI assistance will get a chance to provide you with a far more personalized experience. Perhaps you will find yourself speaking, communicating, and giving tasks to your refrigerator or lamp, as well as letting your car build the best routes and drive you there shortly.
7. Reinforcement learning and new architectures of neural networks will revolutionize prediction
The key idea of the neural networks is to create millions of active interconnections within computer brains to provide it with multiple opportunities to perform tasks and learn from them. A primary neural network usually consists of millions of artificial neurons. They proved to learn from image, text, audio data very efficiently. It is expected that due to the new theory applying the principle of an information bottleneck the deep neural networks will forget noisy data, yet to preserve the information what this data represents. Thus, the neural networks become more and more alike to the neurons of human beings.
Reinforcement learning (RL) in its turn is a form of neural network that usually learns from its environment with the help of observation, actions, and rewards. Reinforcement learning has not been widely applied in various industries due to the existence of some obstacles and complications. The following facts may explain it: RL involves more complex algorithms and less mature tools and requires accurate simulations of the real-world environment. However, the potential capabilities of RL proved to be enormous. It can easily solve traditional neural networks problems. These are the three main problems: the absence of training data, the lack of training data, and the high cost of training data. These factors make reinforcement learning a good method for solving sequential decision-making problems that are common in game playing, financial markets, and robotics.
Most likely reinforcement learning will become one of the most significant trends in 2019. Due to the successes of DeepMind’s, AlphaZero and OpenAI’s Dota bot, a lot of companies are now actively investing in the development of reinforcement learning platforms. These platforms will considerably increase the opportunities of the companies. Moreover, there is a whole generation of data scientists who regard RL as a means to revolutionize prediction. Therefore the implementation of RL will find a vast amount of use cases in various industries.
8. Energy efficiency and sustainable development remain core goals for humanity
The matters of energy sources and their efficient use exponentially increase their popularity every year. There is a whole range of factors that will influence the energy market in 2019.
First of all, efficient energy management demands more insights into energy usage. Therefore, smart tools are to be widely applied here. The new regulations will come into effect in 2019. Also, we expect the strengthening of interconnection between technologies and energy. Integrated platforms and smart data solutions will bring their benefits both to the energy producers and energy consumers.

Sustainability continues to be a core goal for every single company. And as a last but not least, a growth on the energy storage market is expected in 2019. Get ready for the more common use of portable energy sources and GaN (gallium-nitride) solutions for efficient use and storage of residential and commercial energy.
9. Upgrading humans becomes real
2019 promises to become a year of AI technologies application in healthcare and medicine. People will face with a chance to get new opportunities, physical and mental capabilities they could not even dream of before. Humans will get a chance to modify, improve and continually upgrade their abilities and minds.
AI applications are capable to accelerate and improve the accuracy of diagnosis. Machine learning algorithms will be used to explore the biological and chemical interactions of drugs. Telemedicine will also improve healthcare by making it easier for patients to communicate with doctors. It will provide better opportunities for treating and monitoring chronic diseases 24/7.
Also, biomedical electronics will take the stage. The digital technologies are to broaden the sphere of their competence in providing assistance doctors and mitigating the stressful situations. Bionics and biomedical electronics will introduce new solutions for people with handicaps or those suffering from severe illnesses or some injuries. Nowadays, prosthetics are being developed extremely fast. New light and reliable materials, 3D printing technologies and smart algorithms allow building highly-functional prosthesis.
10. Smart spaces will continue growing into smart cities
During the last several decades the way people live, work and interact has been considerably changed. The focus of human life has shifted from nature to technologies. Rapid development of science, industrial revolution and constant development of new technologies largely influenced on the way people live. The life is speeding up. Nowadays, the borderline between virtual and physical blurs. The technology became an essential part of our daily life. Thus, there evolves the need to create spaces where technologies and physical environment will successfully coexist.
Smart space is a physical or digital environment where people and AI-powered technological solution can efficiently interact. Because technologies have entered our daily life, smart space is going to win its popularity in the upcoming year. Smart spaces take individual technologies and combine them into collaborative and interactive environments. The growing popularity of smart spaces reflects in the appearance of smart cities, digital workplaces, smart homes and companies.
Conclusion
Technologies are now in the center of attention for all industries. We expect 2019 to become a year of new use cases and possibilities. We will witness new changes and feel the benefits of machine learning and AI development.
We compiled a list of trends that in opinion of our experts are the most probable. Hopefully, these trends will bring us only positive and valuable results. This list is always open to your suggestions. Please, feel free to express your ideas in the comment section below.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The latest Xcode 10.2 beta release includes support for Swift 5. In addition to bringing new features at the language and tooling level, this new release produces smaller binary packages for iOS 12.2 by not including the Swift runtime in the app bundle.
The possibility of not packaging a runtime within app bundles is a direct consequence of Swift 5 ABI stability, a feature that has been on Swift’s horizon since Swift 3. Besides shrinking app sizes, ABI stability will also enable binary frameworks that are not tied to the compiler used to build them and that are binary-compatible with multiple, including future Swift versions. According to the Swift ABI stability roadmap, all major tasks that were required to implement ABI stability are now complete, except for writing up the relevant technical specifications. Those include type metadata, calling conventions, and data layout.
On the language front, this beta introduces a number of new features:
- You can now call types annotated with the new
@dynamicallyCallableattribute as if they were functions, in a similar way tooperator()in C++ and Python callable objects. For example, you can write:@dynamicCallable struct ToyCallable { func dynamicallyCall(withArguments: [Int]) {} func dynamicallyCall(withKeywordArguments: KeyValuePairs<String, Int>) {} } let x = ToyCallable() x(1, 2, 3)Along with the
@dynamicMemberLookupintroduced in Swift 4.2,@dynamicallyCallableaims to extend interoperability with dynamic languages like Python, JavaScript, Perl, and Ruby. For example, if you have a Python class:# Python class: class Dog: def __init__(self, name): self.name = name self.tricks = [] # creates a new empty list for each `Dog` def add_trick(self, trick): self.tricks.append(trick)you could import it in Swift using an interoperability layer and call its method in a more natural way:
// import DogModule.Dog as Dog let Dog = Python.import("DogModule.Dog") let dog = Dog("Brianna") // in Swift 4.2, this would be let dog = Dog.call(with: "Brianna") dog.add_trick("Roll over") // in Swift 4.2, this would be dog.add_trick.call(with: "Roll over") let dog2 = Dog("Kaylee").add_trick("snore") // in Swift 4.2, this would be Dog.call(with: "Kaylee").add_trick.call(with: "snore") - Keypaths in Swift 5 support the
.selfsyntax to refer to the entire input value:let id = Int.self var x = 2 print(x[keyPath: id]) // Prints "2" x[keyPath: id] = 3 print(x[keyPath: id]) // Prints "3" - If you apply
try?to an optional type you will get a flattened optional, instead of a nested optional:// x is Bar?? in Swift 4.2 and Bar? in Swift 5 let x = try? foo?.makeBar() // dict is [String: Any]?? in Swift 4.2, [String: Any]? in Swift 5 let dict = try? JSONSerialization.jsonObject(with: data) as? [String: Any] - The new
ExpressibleByStringInterpolationprotocol, which supersedes_ExpressibleByStringInterpolation, improves string interpolation performance, efficiency, and clarity.
Several of Swift 5 new language features are not backward compatible and require to update Swift 4.2 code. While Xcode 10.2 remains in beta, you will want to make sure your Swift code remains compatible with Xcode 10.1, which is the only Xcode version that can be used to submit apps to the App Store. You can do this using conditional compilation, like in this example:
#if compiler(<5)
// Swift 4.2 version
#else
// Swift 5 version
#endif
Additionally, it is worth noting that Xcode 10.2 removes support for Swift 3, so you better migrate your Swift 3 code to Swift 4.2 using Xcode 10.1 before moving to Xcode 10.2.
This is just a short introduction of the most significant changes in Swift 5, which also includes features added to the Swift Standard Library and the Swift Package Manager, and improvements to the compiler. If you are interested in the full detail, do not miss the official announcement. You can download Xcode 10.2, and the related iOS SDK 12.2, available to any registered developer, from Apple download page.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Guest blog by Igor Bobriakov.
First days after celebration of the New Year is the time when looking back we can analyze our actions, promises and draw conclusions whether our predictions and expectations came true. As 2018 came to its end, it is perfect time to analyze it and to set trends for the next year. The amount of data generated every minute is enormous. Therefore new approaches, techniques, and solutions have been developed.
Looking back to our article Top 10 Technology Trends of 2018 we can say that we were preparing you for the upcoming changes related to aspects of security, changes provoked by the AI in business operations, extensive application of blockchains, further development of the Internet of Things (IoT), growing of NLP, etc. Some of these statements have been implemented in 2018, yet some will remain topical in 2019 as well. Only one factor remains stable — development. There is no doubt, the technologies will continue to develop, improve and upgrade to fit their purposes better.
Primarily smart data technologies were actively applied only by huge enterprises and corporations. Today, big data has become available to a wide range of small businesses and companies. Both big enterprises and small companies tend to rely on big data in the questions of the intelligent business insights in their decision-making.
The ever-growing stream of data may also present a challenge to businesspeople. The prediction of changes in the role of big data and technologies is even more difficult. Thus, our top technology trends of 2019 are to serve a comprehensible roadmap for you.
1. Data security will reinforce its positions
The range of threads is enormous; therefore the discussion of the cybersecurity related issues will continue. The consumers have a growing awareness of the value of their information. Consequently, they become even more interested in the way how it will be used. Governments are actively planning, developing and adopting regulations on cybersecurity in this regard. Due to some cases of violation of the General Data Protection Regulation (GDPR) and loud scandals concerning Google and Facebook the application of enforcement measures is expected in 2019.
Moreover, we believe that cybersecurity will become more intelligence-driven in the upcoming year. Intelligence may become the only solution to the fast, automated attacks. Machine learning is called upon to play a crucial role in providing this intelligence. The AI-powered smart machines are expected to become more independent in the decision-making process. Probably, it will help companies to be one step ahead of the hacker, to predict attacks and define possible sore points.
2. Internet of Things will deliver new opportunities
It is quite evident that IoT is now being used by the companies representing all spheres of human activity. Moreover, the companies and businesspeople get even more interested in the practical implementation of smart technological solutions rather than in theoretical development. The attributes like “connected”, “smart” or “intelligent” are now added to all technologies and solutions developed for various industries.
According to some specialists, it is yet not the time to regard the IoT as something done. Undoubtedly the changes brought by the IoT are only under development. In 2019 the IoT capabilities are expected to shift to automating and augmenting how people experience the connected world. It will most probably result in a more unstructured landscape of a wide variety of dynamically meshed things and services.
3. Automation continues to be game-changing
The automation has entered in different industries, won a dominant position and acquired a good reputation. Undoubtedly, 2019 will bring progress, upgrade, and prosperity to robotic automation.
Autonomous things like drones, robots and autonomous vehicles are rapidly developed along with AI solutions. We expect a shift from the stand-alone things to complex systems of intelligent autonomous things. With the development of the AI technologies, autonomous things get more and more brains to interact and establish interrelations within complex systems. Thus, self-driven cars are capable of images recognition and geolocation tracking for making routes, voice recognition to follow the commands and various other technologies to provide convenience and comfort to people.
The RPA, or robotic process automation, is no longer a one-day technology. Nowadays it proved to be a technology changing the businesses. In 2019, the number of attended robots, those working alongside humans, is going to grow even more significant. In additions, the RPA in the public sector will rise, and governments will discover new opportunities with RPA.
4. AR is expected to overcome VR

For the 2018 year it was common to consider VR (virtual reality software) to be the most significant achievement of our generation. However, the situation has dramatically changed. VR proved to have a limited range of application among the companies and the customers. Therefore, the experts forecast the overcoming of VR by the AR (augmented reality software) soon.
The AR technologies will continue to be profitable for enterprise software development. In 2019, AR will become more common for mobile devices. Unlike VR, it does not require headsets. Therefore the AR’s ability to be deployed on mobile phones and tablets is far more robust.
Also, it is expected that AR will change the spheres of marketing and advertising in the upcoming year. AR provides a completely personal experience. Thus customers’ engagement is skyrocketing. A consistent communication channel for direct dialogue between the customer and provider will be ensured using the AR developments. Probably, AR will also reinforce its position in the area of manufacturing. Industrial AR platforms help the manufacturers to visualize data sets and provide assistance in jobs related to physical labor. It is predicted that AR software will become a key to the transformation of this sphere.
5. Connected clouds will shift to hybrid cloud solutions
The majority of companies now rely on cloud computing. Therefore, the consumption of cloud services is going to grow over in 2019. Gartner predictsthat the cloud computing market will reach $200 billion.
The range of cloud solutions and delivery models is getting bigger and bigger. This fact makes cloud services more adaptable in different areas of activity. Hybrid cloud solutions will be winning popularity among companies. However, they will also present a challenge for some companies. The majority of IT service providers think that hybrid cloud solutions help to speed up service delivery. This is a crucial milestone. At first, cloud solution was regarded as a way to avoid building vast IT infrastructures from scratch and in such a way to reduce costs. Shortly these solutions will bring more flexibility and the abilities to react fast and even more efficiently to the rapidly changing market conditions. A new view on the cloud solutions adoption will be developed by the industries. So, we expect 2019 to be the year of hybrid and multi-cloud solutions for business.
6. Personalization will result in the rise of adaptive devices
Actually we are the witnesses of the immense evolution of AI-powered chatbot technology. Starting with simple routine tasks, chatbots are now actively turning into AI assistants. Customers got used to them very fasts and now cannot even imagine dealing with some issues without AI assistance.
Moreover, personalization will be represented not only due to the purposeful user commands for different devices but also in the devices themselves. Thus, they will be able to adapt themselves to the individual needs of the owner after a certain period, even without any commands on his part. This technology has become rather sophisticated. Thus the majority of customers cannot even guess whether they communicate with a person or with a chatbot.
Due to the excellent operation of Apple’s Siri, Amazon’s Alexa, people started to rely more on AI assistants in daily routine. What is expected in 2019 is that even more advanced assistants will appear and take responsibility for more complex dealings. With the help of the improved speech recognition techniques, the AI assistance will get a chance to provide you with a far more personalized experience. Perhaps you will find yourself speaking, communicating, and giving tasks to your refrigerator or lamp, as well as letting your car build the best routes and drive you there shortly.
7. Reinforcement learning and new architectures of neural networks will revolutionize prediction
The key idea of the neural networks is to create millions of active interconnections within computer brains to provide it with multiple opportunities to perform tasks and learn from them. A primary neural network usually consists of millions of artificial neurons. They proved to learn from image, text, audio data very efficiently. It is expected that due to the new theory applying the principle of an information bottleneck the deep neural networks will forget noisy data, yet to preserve the information what this data represents. Thus, the neural networks become more and more alike to the neurons of human beings.
Reinforcement learning (RL) in its turn is a form of neural network that usually learns from its environment with the help of observation, actions, and rewards. Reinforcement learning has not been widely applied in various industries due to the existence of some obstacles and complications. The following facts may explain it: RL involves more complex algorithms and less mature tools and requires accurate simulations of the real-world environment. However, the potential capabilities of RL proved to be enormous. It can easily solve traditional neural networks problems. These are the three main problems: the absence of training data, the lack of training data, and the high cost of training data. These factors make reinforcement learning a good method for solving sequential decision-making problems that are common in game playing, financial markets, and robotics.
Most likely reinforcement learning will become one of the most significant trends in 2019. Due to the successes of DeepMind’s, AlphaZero and OpenAI’sDota bot, a lot of companies are now actively investing in the development of reinforcement learning platforms. These platforms will considerably increase the opportunities of the companies. Moreover, there is a whole generation of data scientists who regard RL as a means to revolutionize prediction. Therefore the implementation of RL will find a vast amount of use cases in various industries.
8. Energy efficiency and sustainable development remain core goals for humanity
The matters of energy sources and their efficient use exponentially increase their popularity every year. There is a whole range of factors that will influence the energy market in 2019.
First of all, efficient energy management demands more insights into energy usage. Therefore, smart tools are to be widely applied here. The new regulations will come into effect in 2019. Also, we expect the strengthening of interconnection between technologies and energy. Integrated platforms and smart data solutions will bring their benefits both to the energy producers and energy consumers.

Sustainability continues to be a core goal for every single company. And as a last but not least, a growth on the energy storage market is expected in 2019. Get ready for the more common use of portable energy sources and GaN (gallium-nitride) solutions for efficient use and storage of residential and commercial energy.
9. Upgrading humans becomes real
2019 promises to become a year of AI technologies application in healthcare and medicine. People will face with a chance to get new opportunities, physical and mental capabilities they could not even dream of before. Humans will get a chance to modify, improve and continually upgrade their abilities and minds.
AI applications are capable to accelerate and improve accuracy of diagnosis. Machine learning algorithms will be used to explore the biological and chemical interactions of drugs. Telemedicine will also improve healthcare by making it easier for patients to communicate with doctors. It will provide better opportunities for treating and monitoring chronic diseases 24/7.
Also, biomedical electronics will take the stage. The digital technologies are to broaden the sphere of their competence in providing assistance doctors and mitigating the stressful situations. Bionics and biomedical electronics will introduce new solutions for people with handicaps or those suffering from severe illnesses or some injuries. Nowadays, prosthetics are being developed extremely fast. New light and reliable materials, 3D printing technologies and smart algorithms allow building highly-functional prosthesis.
10. Smart spaces will continue growing into smart cities
During the last several decades the way people live, work and interact has been considerably changed. The focus of human life has shifted from nature to technologies. Rapid development of science, industrial revolution and constant development of new technologies largely influenced on the way people live. The life is speeding up. Nowadays, the borderline between virtual and physical blurs. The technology became an essential part of our daily life. Thus, there evolves the need to create spaces where technologies and physical environment will successfully coexist.
Smart space is a physical or digital environment where people and AI-powered technological solution can efficiently interact. Because technologies have entered our daily life, smart space is going to win its popularity in the upcoming year. Smart spaces take individual technologies and combine them into collaborative and interactive environments. The growing popularity of smart spaces reflects in the appearance of smart cities, digital workplaces, smart homes and companies.
Conclusion
Technologies are now in the center of attention for all industries. We expect 2019 to become a year of new use cases and possibilities. We will witness new changes and feel the benefits of machine learning and AI development.
We compiled a list of trends that in opinion of our experts are the most probable. Hopefully, these trends will bring us only positive and valuable results. This list is always open to your suggestions. Please, feel free to express your ideas in the comment section below.
Originally published in activewizards.com
DSC Resources
- Book and Resources for DSC Members
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions