Month: February 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Artificial intelligence has been fascinating to the human imagination since the term was first used by the first science fiction writers.
The roots of the concept of “artificial intelligence” must be sought deep in the ancient world, where folklore, legends and myths in almost every culture spoke of artificially created creatures endowed with supernatural intelligence, consciousness or other human qualities. The only factor uniting the myths of the whole world is that artificial intelligence was always created by a man so passionate about his work that his brainchild went beyond the boundaries of matter and turned into life, sometimes surpassing man.
Blockchain Phenomenon
Now we are standing at the crossroads of history, where two progressive technologies are beginning to merge and produce an absolutely new phenomenon. At first glance, the apparent antithesis of AI, the blockchain technology, exploded on the global technology arena as progress in technological constraints; a revolution that announced the creation of completely new industries and new perspectives.
Blockchain technology has completely changed our perception of Internet capabilities, has increased the speed of operations. Sending transactions has become more transparent and efficient. Combining these factors has opened up new business opportunities and increased profitability, as cryptocurrency miners created completely new markets.
Where the average user finds a financial bubble, most see the blockchain and cryptocurrency duality as a whole, although in reality they are interrelated in a completely different way. Technology has a huge untapped potential that needs to be mastered. At its core, the blockchain technology can cause big changes in our daily life, eliminating many professions and making it almost impossible to delay banking operations.
Companies see the potential of blockchain technologies and have already begun to introduce it into their business processes and models, optimizing many routine tasks, which made it possible to switch valuable human resources to more important problems. Many of the blockchain companies now enjoy the benefits of this technology.
The benefits are enormous, and the AI has already started its transition to the blockchain, becoming one. An example is a project such as Neuromation which trades datasets for companies to improve their own neural networks. Such projects allow blockchain companies to bring trade, services, and product development to a new level of quality and efficiency at much lower prices.
Artificial Intelligence In Action
There are already several working projects on the market in which the blockchain technology and AI are connected. Using available data in the blockchain, AI helps financial markets by analyzing types of loan products based on consumption and loan patterns. The AI takes this information from the blockchain and finds a correlation that could be missed by standard analytic methods. It is no secret that AI extracts most of the information from the Internet and other available sources – such as open databases and companies’ own archives. Also, this information is available for purchase on the Internet.
An example of such a solution, built on the merger of AI and the blockchain is GraphGrail AI built on the basis of natural language processing technologies with the marketplace of decentralized applications.
This platform is designed to analyze a large amount of textual data and solves the problem of extracting information based on deep learning technologies, neural networks, and machine learning. The project has great potential in the banking sector, the biotechnology and medicine market, security and compliance.
The number of branches of this technology in the modern world is very large, as it allows you to predict events based on a deep analysis of a large amount of information that constantly passes through the Internet and other resources. In essence, it is an intelligent information retrieval tool with an immense amount of applications. It is quite possible to realize the transparency of conducting transactions in the marketplace with regard to quality control for the input parameters, since The GraphGrail AI token is a calculation unit within the platform’s ecosystem, allowing payments to be made without intermediaries.
Application Graph
Real examples of the use of the GraphGrail AI model are not so far from their algorithms based on smart blockchain contracts. They may seem confusing but are widely used in everyday life. Creating independent applications implemented on the platform architecture allows the development of truly intelligent AI designs capable of integration into neural networks with elements of machine learning. In fact, they will not be designs that are so different from those that are present in films and video games. The difference will be that the designs created by GraphGrail AI are smart enough to learn from the information entered by people and to use the acquired skills.
An example is a chatbot application built on the platform of GraphGrail AI. Such chatbot can learn from customers based on their requests and correlate the necessary answers with a constantly evolving database that can learn from input parameters and human experience, and thus maximizing the resources and the efficiency of the application, as well as the satisfaction of the customer which results in actual transactions.
This service may also be useful to other blockchain companies since it can be used by smart contracts to verify compliance with external conditions. Such conditions can be virtually tied to any real objects in the world – people, companies and their interactions. Mergers and acquisitions, credit and accounting will also use smart contracts — for example, to check risks and audits in a reasonable amount of time. Lawyers can start creating standard smart contracts instead of the traditional contracts that they are used to. Artificial intelligence provides solution to many business problems. Developers can provider solutions adapted to their particular business through AI designer (for example, Wix, Unity, or Microsoft Azure).
Author Bio:
Melissa Crooks is Content Writer who writes for Hyperlink InfoSystem, a mobile app development company in New York, USA and India that holds the best team of skilled and expert app developers. She is a versatile tech writer and loves exploring latest technology trends, entrepreneur and startup column. She also writes for top app development companies.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Below is an extract of a 10-page cheat sheet about data science, compiled by Maverick Lin. This cheatsheet is currently a reference in data science that covers basic concepts in probability, statistics, statistical learning, machine learning, deep learning, big data frameworks and SQL. The cheatsheet is loosely based off of The Data Science Design Manual by Steven S. Skiena and An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani. Inspired by William Chen’s The Only Probability Cheatsheet You’ll Ever Need, located here.
Full cheat sheet available here as a PDF document. Originally posted here. The screenshot below is an extract.

For related cheat cheats (machine learning, deep learning and so on) follow this link.
DSC Resources
- Book and Resources for DSC Members
- New Perspectives on Statistical Distributions and Deep Learning
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions
MongoDB, Inc. Announces Date of Fourth Quarter and Full Year Fiscal 2019 Earnings Call
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
NEW YORK, Feb. 26, 2019 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB), the leading modern, general purpose database platform, today announced it will report its financial results for the fourth quarter and full year ended January 31, 2019, after the U.S. financial markets close on Wednesday, March 13, 2019.
![]()
In conjunction with this announcement, MongoDB will host a conference call on Wednesday, March 13, 2019, at 5:00 p.m. (Eastern Time) to discuss the Company’s financial results and business outlook. A live webcast of the call will be available on the “Investor Relations” page of the Company’s website at http://investors.mongodb.com. To access the call by phone, dial 866-548-4713 (domestic) or 323-794-2093 (international). A replay of this conference call will be available for a limited time at 844-512-2921 (domestic) or 412-317-6671 (international) using conference ID 1923915. A replay of the webcast will also be available for a limited time at http://investors.mongodb.com.
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 8,300 customers in over 100 countries. The MongoDB database platform has been downloaded over 45 million times and there have been more than one million MongoDB University registrations.
Investor Relations
Brian Denyeau
ICR for MongoDB
646-277-1251
ir@mongodb.com
Media Relations
Mark Wheeler
MongoDB, North America
866-237-8815 x7186
communications@mongodb.com
![]() View original content to download multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-announces-date-of-fourth-quarter-and-full-year-fiscal-2019-earnings-call-300801531.html
View original content to download multimedia:http://www.prnewswire.com/news-releases/mongodb-inc-announces-date-of-fourth-quarter-and-full-year-fiscal-2019-earnings-call-300801531.html
SOURCE MongoDB
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The European Union recently launched a bug bounty program for critical infrastructure projects, offering financial compensation to anyone who finds and reports a new security flaw.
The bug bounty is offered as part of FOSSA, the “Free and Open Source Software Audit” project. The FOSSA list includes two notable Java projects: Apache Tomcat and Kafka. Other projects, such as KeePass, are available now.
The bounty program is paying up to €25,000 for exceptional bugs with a total fund of approximately €851,000 payable to those who find the bugs. Participation is open worldwide for most projects, although some programs are private bounties. Full details are available through the European Commission bounty list.
Each project will patch any security issues located during the bounty period. Application developers using projects featured in FOSSA or other code, should apply basic Software Composition Analysis tools. Similar to the GitHub security graph alerts, developers can use tools such as Dependency Check, Dependabot, or Contrast Community Edition to monitor their projects for vulnerable components. Without this detection, developers may be left using vulnerable versions of these libraries after security issues have been patched.
Duo Security’s Fahmida Rashid has offered a counter-piece to FOSSA, “Open Source Software Needs Funding, Not Bug Bounty Programs.” This analysis primarily calls out the role of unpaid maintainers with an existing backlog of unfixed issues. Without funds for open source maintenance, issues may simply be added to the backlog. In this end, FOSSA offers a possible 20% bonus for an accepted and committed fix. One startup, Tidelift, is helping to fund maintenance of open source projects with a similar financial amount.
A related recent financial analysis by Trail of Bits indicates that most participants engage in bug bounties as a side-hustle. Top performers specialize in select bugs and earn between $16,000 and $34,000 per year depending on the program. BugCrowd’s statistics from 2019 indicate that the average time spent is between 6 to 10 hours per week, however this number may not align with what it takes to be a top performer.
Developers can participate in the FOSSA bounty programs by joining HackerOne and/or Intigriti/Deloitte to enter the bounty.
Other notable bug bounty programs include:
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The first stable release of Linaria, a zero-runtime CSS-in-JS library, is now available to developers. Linaria provides a new API to facilitate using it with React and aims for a better developer experience and build integration.
Linaria adds the styled tag to its existing css tag. The styled tag creates a React component with a parameterized styling.
import { styled } from 'linaria/react';
// Create a styled component
const Button = styled.a`
display: inline-block;
border-radius: 3px;
padding: 0.5rem 0;
margin: 0.5rem 1rem;
width: 11rem;
background: transparent;
color: white;
border: 2px solid white;
`
render(
<Button
href="https://github.com/callstack/linaria"
target="_blank"
rel="noopener"
primary
>
GitHub
</Button>
)
Linaria’s tags follow the ES2015 tagged template literal syntax. Template literals are string literals allowing embedded expressions. Tagged templates allow parsing template literals with a function. In the previous code example, display: inline-blockstyled.astyled.a`display: inline-block` is a tagged template literal. Developers may write template literals with a syntax following standard CSS or with an object style syntax.
Additionally, the styled tag supports dynamic styling through interpolation of a function within a template literal.
const Title = styled.h1`
color: ${props => (props.primary ? 'tomato' : 'black')};
`;
The Title React component will adjust its color to tomato or black based on its primary props.
Dynamic styling is however not supported by older browsers such as Internet Explorer as it relies on CSS custom properties (also known as CSS variables). CSS custom properties are supported by modern browsers.
Linaria 1.0 ships with a new Command Line Interface (CLI) to extract the CSS content from the JavaScript source. The following command will extract the CSS from the component and screen directories into the styles directory.
npx linaria -o styles src/component/**/*.js src/screens/**/*.js
Linaria 1.0 also comes with a new Rollup plugin, enabling developers to build with Rollup as an alternative to existing Webpack support. This release also improves its support for the stylelint processor. While previous Linaria releases only supported the Stylis CSS preprocessor, Linaria now allows developers to use any CSS preprocessor, such as Sass, or custom PostCSS syntaxes. Linaria also accepts a configuration file (linaria.config.js)`.Importantly, Linaria supports CSS source maps for a streamlined debugging experience.
CSS-in-JS refers to a pattern where CSS is composed using JavaScript instead of defined in external CSS files. Two sub-patterns coexist. Runtime CSS-in-JS libraries, such as Emotion or Styled-components, dynamically modify styles at runtime, for instance by injecting style tags into the document. Zero-runtime CSS-in-JS is a pattern which promotes extracting all the CSS at build time. Linaria and Astroturf are primary proponents of that pattern.
Linaria is an open source project available under the MIT license. Contributions are welcome via the Linaria GitHub project and should follow the Linaria code of conduct and contributions guidelines.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The Hyperscript Tagged Markup (HTM) library, which proposes an alternative to JSX, released its second major iteration. HTM 2.0 is a rewrite that is faster and smaller than HTM 1.x, has a syntax closer to JSX, and now supports Server-Side Rendering (SSR). With HTM 2.0, developers may enjoy simplified React/Preact workflows for modern browsers.
HTM 2.0 contributors have optimized for performance and size. The release notes explain:
HTM is now 20 times faster, 10% smaller, has 20% faster caching, runs anywhere (native SSR!). The Babel plugin got an overhaul too! It’s 1-2 orders of magnitude faster, and no longer requires JSDOM (…).
HTM also ships with a prebuilt, optimized bundle of htm with preact. The library’s authors explain:
The original goal for htm was to create a wrapper around Preact that felt natural for use untranspiled in the browser. I wanted to use Virtual DOM, but I wanted to eschew build tooling and use ES Modules directly.
HTM 2.0 strives to deliver a syntax closer to JSX, building on HTM’s primary goal of developer-friendliness, as detailed by the library’s authors.
HTM 2.0 tag template syntax mostly mirrors that of JSX. It features spread properties (<div ...${props}>), self-closing tags: (<div />), components (<${Foo}>, where Foo is a component reference), and boolean attributes (<div draggable />). HTM 2.0 syntax is also similar to alternative templating syntaxes hyperHMTL and lit-html.
Luciano Mammino, a developer who successfully used HTM for quick prototyping with Preact, comments:
I will also use
htm, a library that can be easily integrated with Preact to define DOM elements in a very expressive and react-like way (like JSX), without having to use transpilers like Babel.
HTM relies on standard JavaScript’s Tagged Templates, which are natively implemented in all modern browsers. With HTM (see html template tag in following example), developers can describe DOM trees in render functions, with a syntax similar to that of JSX:
render(props, state) {
return html`
<div class="container mt-5">
<div class="row justify-content-center">
<div class="col">
<h1>Hello from your new App</h1>
<div>
${state.loading &&
html`
<p> Loading time from server...</p>
`} ${state.time &&
html`
<p>⏱ Time from server: <i>${state.time}</i></p>
`}
</div>
<hr />
</div>
</div>
</div>
`
}
The HTM module must be used in connection with a HyperScript function:
import htm from 'htm';
function h(type, props, ...children) {
return { type, props, children };
}
const html = htm.bind(h);
console.log( html`<h1 id=hello>Hello world!</h1>` );
// {
// type: 'h1',
// props: { id: 'hello' },
// children: ['Hello world!']
// }
The HyperScript h function can be customized for server-side rendering to render HTML strings instead of virtual DOM trees. Developers can use HTM anywhere they can use JSX.
HTM 2.0 is ready for production use. HTM is available under the Apache 2.0 open source license. Contributions and feedback may be provided via the htm GitHub project.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
According to the World Economic Forum, the global manufacturing sector could be one of the sectors most influenced by the latest technological trends like AI, machine learning and IoT – collectively termed Industry 4.0 – with great potential for disruption and transformation if these technologies are employed intelligently.
While AI has proven to be one of the most broadly disruptive technologies of the digital revolution, it best maximizes its potential when deployed in conjunction with two augmentative domains – robotics and Internet of Everything (IoE).
Robotics has become an integral part of the manufacturing sector over the past two decades and the finesse, complexity, and sophistication of robotic tasks have been significantly enhanced via AI. Tasks which were previously relegated to the human domain due to complexity and labor constraints are now routinely completed by robots.
As for IOE, the ease of deployment and advanced capabilities of sensors allow for the universalization of AI in the manufacturing sector. Because sensors collect data continuously and can be placed nearly anywhere, manufacturers can expect to increase productivity, connectivity, and scalability as IOE becomes more engrained in the sector.
The question for manufacturers remains, wherein the operation is AI most applicable? We will outline a list of 15 use cases across seven segments.
Predictive and Preventive Maintenance
A top area in maintenance is the area of data-driven maintenance enabling the transformation of maintenance in manufacturing from reactive to preventive maintenance powered by AI enabled predictive capability. A whopping $647 billion is lost globally each year in industrial asset downtime, per the International Society of Automation (Source: https://www.isa.org/standards-publications/isa-publications/intech-magazine/2013/feb/automation-it-predictive-maintenance-embraces-analytics/ ). Role of sensors and IOT enabled devices to enable real-time information feed to AI engines is key. IOT when applied as sensors in an industrial setting often termed as IIOT Industrial IOT. This works in conjunction with AI to achieve the desired results.
AI has the potential to drive the regime towards enhanced uptime reducing downtime via different possibilities:
Use Case 1: Real-Time Alert of Wear, Tear, Fault, or Breakdown – Warning signals of potential breakdown by AI, it could even look ahead for fatigue
Use Case 2: Lifetime Prediction: Using AI to accurately predict Time to Live for Assets like Machinery improving overall life of machinery and assets
Use Case 3: AI to enable more informed asset maintenance schedule triggering a focused repair and MRO schedule optimizing overall effort, cost, and quality across assets.
Enhancing Robots Effectiveness
While currently, robots are quite mainstream in automating manufacturing shop floors presence of AI can enhance the role of robots by better task handling
Use Case 4: Enhanced effectiveness of robots in form of powerful software to enable robots to take on complex tasks. Not just complexity but also the versatility of tasks enhanced by AI
Use Case 5: Role of AI in better human-robot interaction to enable more effective utilization of robots is key. Cobots are emerging as potential enablers in this area.
Manufacturing supply chain
The overall manufacturing industry is heavily dependent upon the accompanying supply chain effectiveness for overall productivity and efficiency. AI combined with IOT has tremendous potential
Some identifiable use cases are as below:
Use Case 6: Real-time tracking of supply vehicles helps in better utilization of logistics fleet thereby optimizing overall production schedule
Use case 7: Better data-driven AI-based approach to analyzing inventory and thereby using it to lower inventory costs can be a great cost saver for manufacturers.
Use case 8: Shipping and Delivery Lead Time can not only be accurately predicted, but it is also optimized via application of AI algorithms
Design Disruption
AI has an element of technology which has enabled take on roles of creative tasks like art music etc. A related use case in the context of manufacturing is appearing more and more real.
Use Case 9. Use of AI-based generative design is being used by large design houses like auto manufacturers. airplane manufacturers etc enabling creative machine or part or asset designs not limited by human designers.
Quality Management and Improvement
Several data-driven initiatives are now becoming mainstream in manufacturing processes, most prominent of them being in the area of quality management and improvement.
Use Case 10. Quality process improvement. AI can enable understand limitations, shortcomings, or deficiencies of current as manufacturing quality processes and using AI applied on quality data several improvement opportunities can be harnessed.
Use Case 11: Using complex AI like computer vision to explore defects in produced items can be a great way to ensure product quality.
Digital Twin
A recent initiative spanning several sectors of manufacturing is the idea of digital twin where there is an equivalent mapped equivalent of a process in reality. AI role is such a digital twin areas below.
Use Case 12: Idea of such a digital twin is to understand and simulate how the process flows occur and identify what if scenarios via AI. AI thus enables the realization of potential implications of the process
Use Case 13: Exception Management: In conventional workflows, exceptions are usually routed to humans to take care of the same. In an AI wired process such processes could be automated and straight through actions could be taken by programs rather than humans
Use Case 14: Testing of design and manufacturing feasibility of items can be carried out intelligent simulations.
Mass Customization and N=1
In the world of data driven product management, a key application of AI will be in terms of understanding customers closely.
Use Case 15: Understanding customers closely and designing, manufacturing and testing products with a high level of customization. This leads to change of models of design and manufacturing also to include flexible ways of catering to all diverse products. Example of BTO models falls in this.
So we can safely now say AI is here to disrupt the manufacturing industry in conjunction with Robotics and IOT like technologies ushering in the broadly accepted term of Industry 4.0
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: Adoption of AI/ML by larger companies has more than doubled since last year according to these survey results from McKinsey and Stanford’s Human-Centered AI Institute. This new data gives us a much better idea of which global regions and which industries are adopting which AI/ML techniques.

Still, trying to point a finger at any particular company and determine to what extent they’re using AI/ML, what types they’re using, and in what functions remains pretty much a crap shoot.
The best data we’ve seen so far shows that between 1/5th and 1/3rd of larger companies are implementing AI/ML ‘at scale’, meaning they’re putting on a full court press to use this as a competitive differentiator. Does that mean that roughly 75% of companies are getting left behind? And what about mid-size companies?
Now we have some new data sources that are both a little more current (surveys in 2018) and a little more granular. For this we have to thank the good folks at McKinsey for their AI Adoption Survey, and the folks at Stanford’s Human-Centered AI Institute who for the last few years have been publishing the encyclopedic ‘AI Index’. The 2018 AI Index brings together stats from a huge variety of sources including this McKinsey study to let us see the progress of AI along its many axes.
The Top Line
- 47% say their companies have embedded at least one AI capability in their business processes. That’s up from 20% in the 2017 study giving some evidence that the expected 6X growth over the next four or five years is attainable.
- Another 30% said they were piloting AI.
- But only 21% said AI was embedded in several parts of their business indicating a piece meal approach to adoption instead of a coherent AI strategy.
- 58% said that less than 10% of their companies’ overall spend on digital technologies was going to AI but 71% indicated that those expenditure will grow.
What AI/ML Applications are Being Used in What Processes?
The following charts are drawn from both reports but are all based on the McKinsey survey data from February 2018 and represents the responses of 2,135 participants globally. In each chart the values in bars are the percentage of respondents who indicated they utilize the particular technique in at least one area of their business. The underlying data also indicates where each technique is being used more widely if you want to drill down.
Techniques Adopted by Region
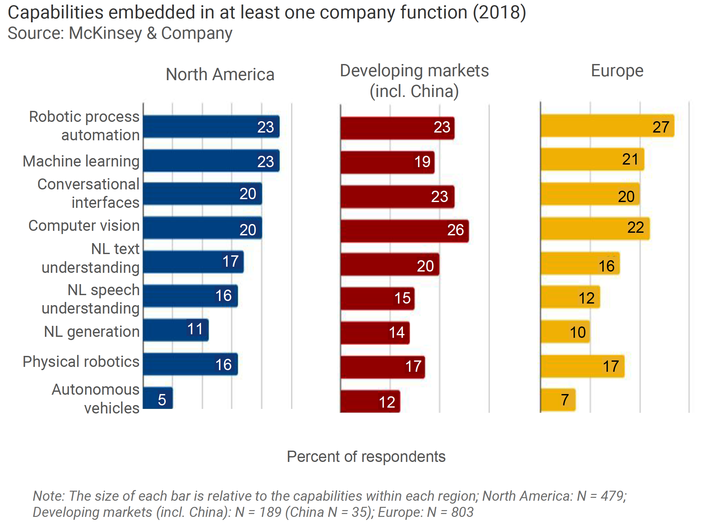
Data for other regions appears in the source reports with surprising similarity in adoption rates and techniques.
What Business Processes Are Seeing the Biggest Impacts?
As expected at this stage of adoption, projects appear to be selected based on their expected business value, and that value varies significantly by industry.
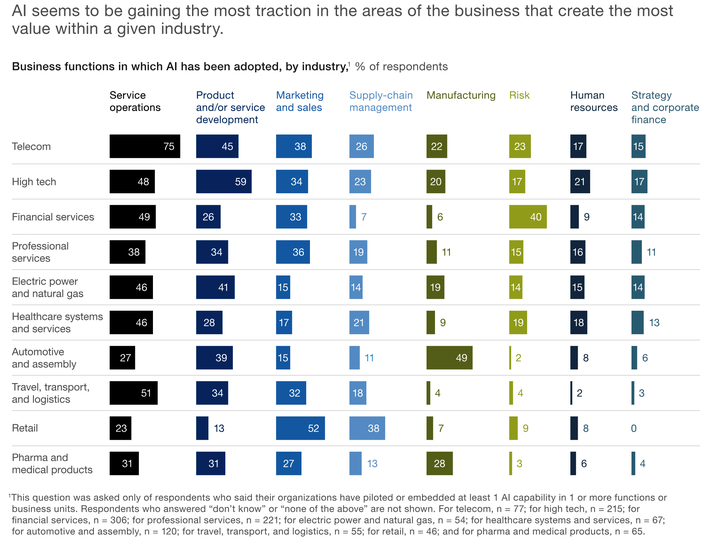
There are other fairly obvious correlations in the data. For example,
- Autonomous vehicle AI is of greatest importance in the automotive industry.
- Physical robotics is most important in manufacturing.
- Techniques enhancing risk mitigation are most important in financial services.
Factors Holding Back Adoption
Three of the top four reasons holding back adoption are all related to leadership and the lack of an AI strategy. Again this shows that this stage of adoption seems to be driven by targets of opportunity rather than a well-planned organizational commitment.
The second of four reasons is familiar to all of us, the difficulty in hiring or developing the talent necessary to drive these projects.
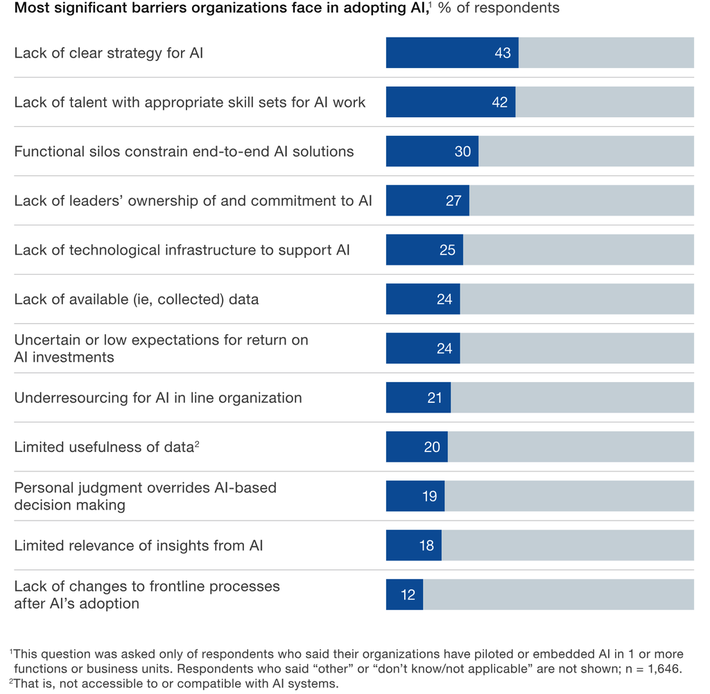
How Much Can We Rely on this Data?
McKinsey and the folks at Stanford’s Human-Centered AI Institute are top notch thought leaders in trying to quantify adoption. Still, before relying on these seemingly precise values in your decision making, it’s best to remember the potential pitfalls in all types of surveying.
- The 2,135 respondents represent only about 10% of the 20,466 people invited to respond. This introduces a significant ‘self-selection’ bias as those most open to or experienced with AI are most likely to have responded.
- Those invited were all registered users of McKinsey.com. Once again, those using this excellent resource are self-identifying as being receptive to new techniques like AI. Also, while the size of the respondent’s companies is not part of the analysis it seems likely that these folks are from larger companies.
- Finally, especially in larger companies, the ability of any one person to know the full scope of adoption of AI in all aspects in the organization is limited to that individual’s knowledge. Respondents included executives who might be expected to have broad knowledge, but also managers and individual performers whose knowledge may not be so broad.
The study unfortunately doesn’t show how many different techniques are being used in a single company. For example, if a large company uses a chatbot somewhere in their business are we really going to give them credit for AI adoption? This probably isn’t the case but the study doesn’t resolve the question.
I’m always on the lookout for any competent quantitative measures of adoption. Across large and medium size organizations that are the most likely adopters I suspect these survey results come in on the high end of reality but any insight is valuable.
Other articles by Bill Vorhies
About the author: Bill is a Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Analyzing campaign efficiency with Pivot Billions
Managing data just keeps getting tougher. The more we think we’ve gotten a handle on our data the more it grows and becomes too large for our existing analyses.
This issue became very clear to me after I undertook the task of trying to understand the effectiveness of ad campaigns using SiteCatalyst weblogs. Seeing as I’d analyzed weblogs before I didn’t think this would be much of an issue. The twist: the weblogs contained over 2 Billion rows!
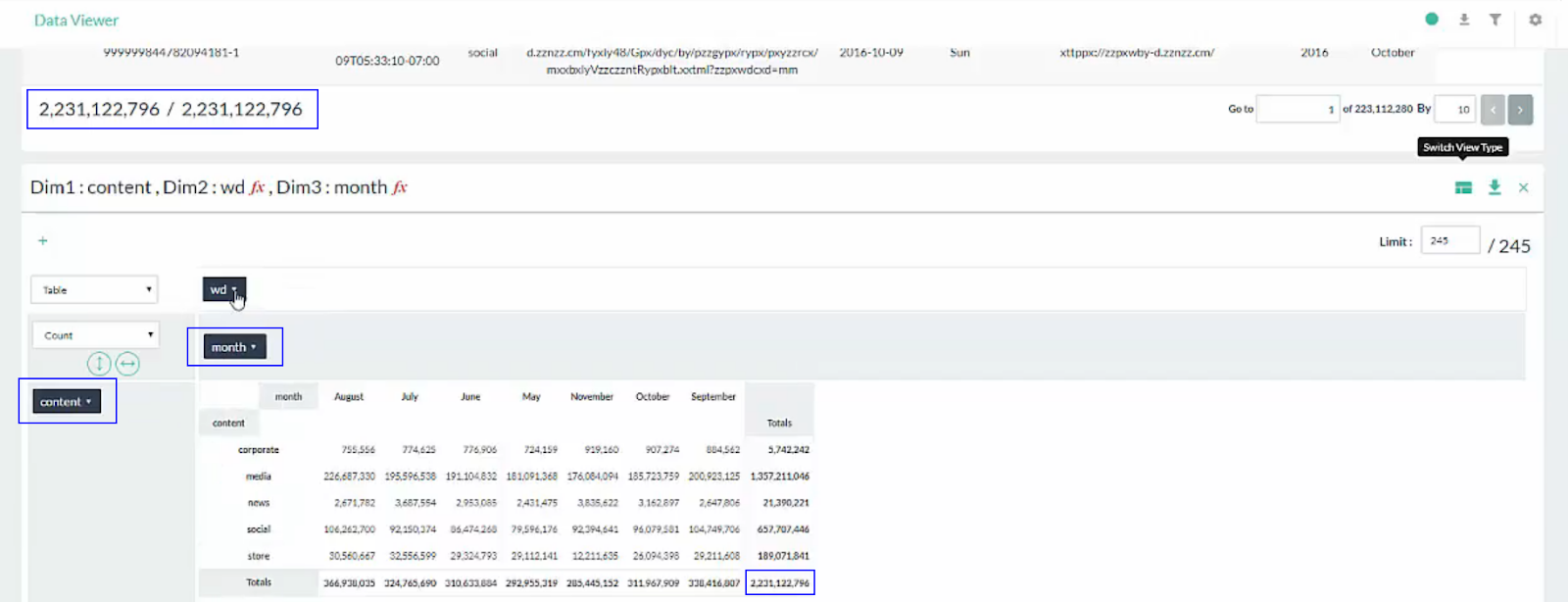
I decided to use Pivot Billions to analyze the data due to its scalability to handle massive datasets. Then came the fun part. Taking the over 2 Billion rows of data, Pivot Billions loaded them into 500 Amazon c4.large instances in a matter of minutes. Then I started to explore the data using Pivot Billions’ reorganization and transformation features. I was mainly interested in how the ad campaigns had worked throughout the data so I used Pivot Billions’ column creation function to quickly extract the month and weekday from my date column (took about 4 seconds). Then I did my first pivot.
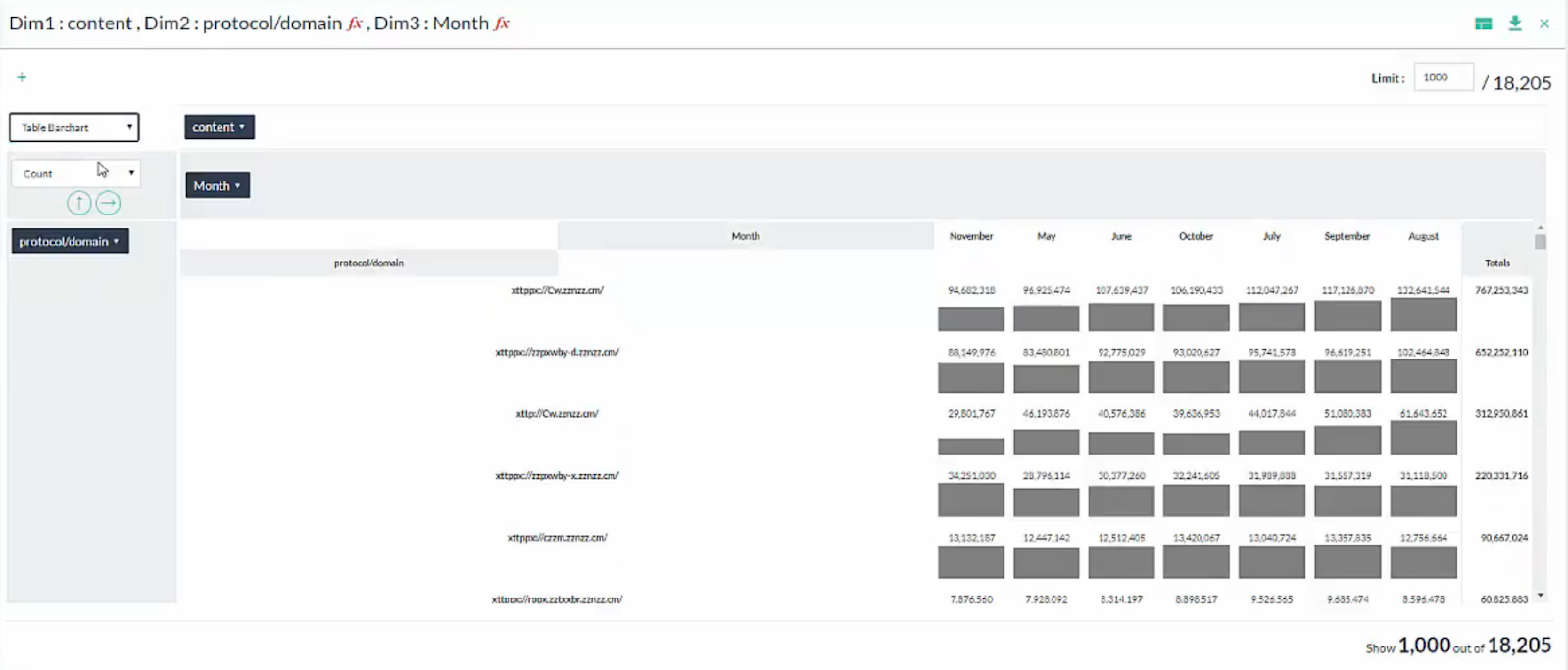
All of my data was rearranged into a view by content type, month, and weekday. I was now able to interactively explore the distribution of my data by each of the combinations of these features. I wanted a quick overview of how each of the content types drove traffic each month so I viewed the content and month columns’ data as a Table in Pivot Billions’ PivotView.
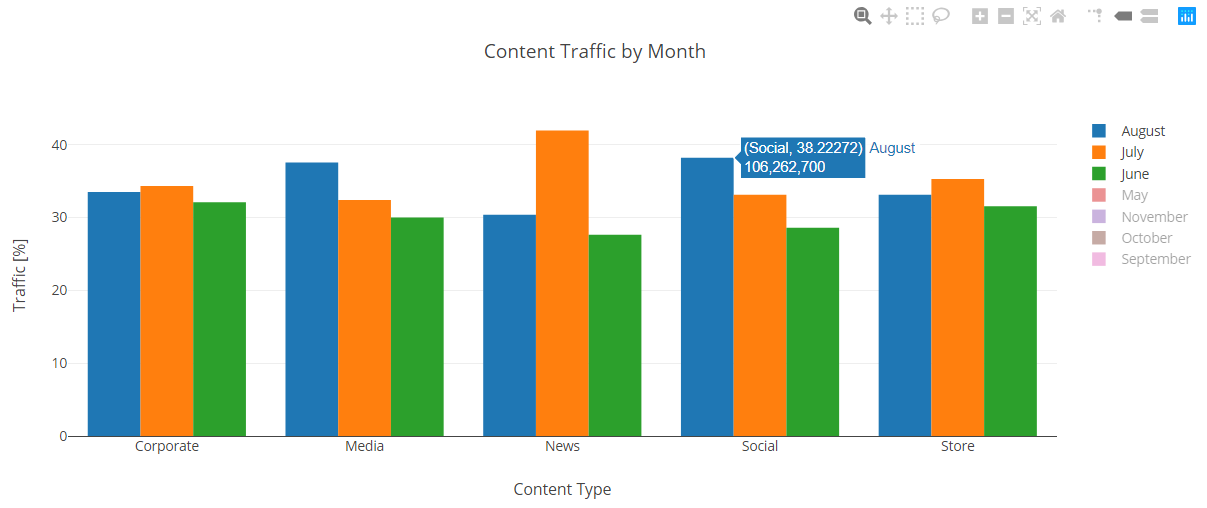
This was a nice summary of my data but I wanted a more visual representation. I viewed the data as a Bar Graph so I could compare the content types and months more easily.
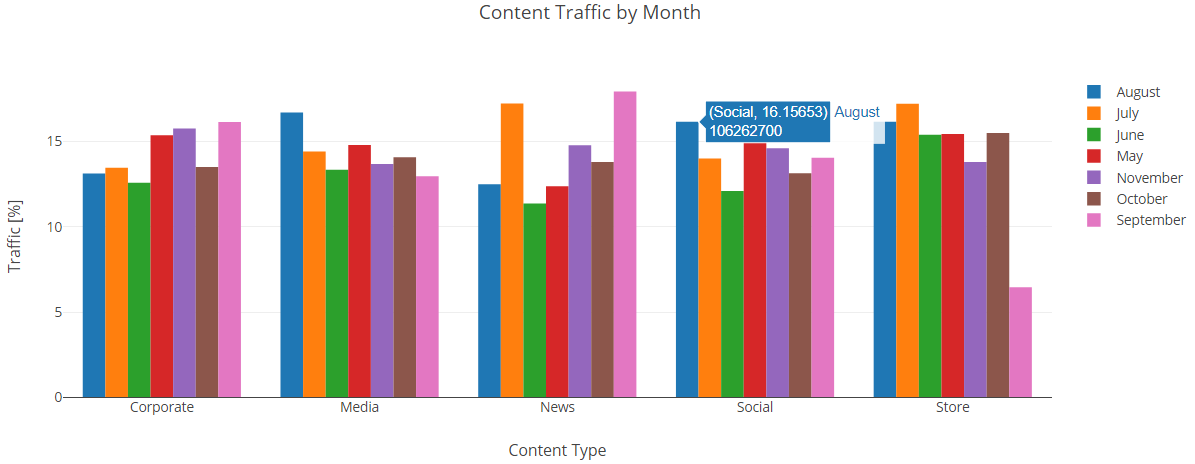
From this overview it appears that the traffic to the site experienced a significant jump during August for the Social and Media content categories. Focusing on the summer months, we can more clearly see the effect.
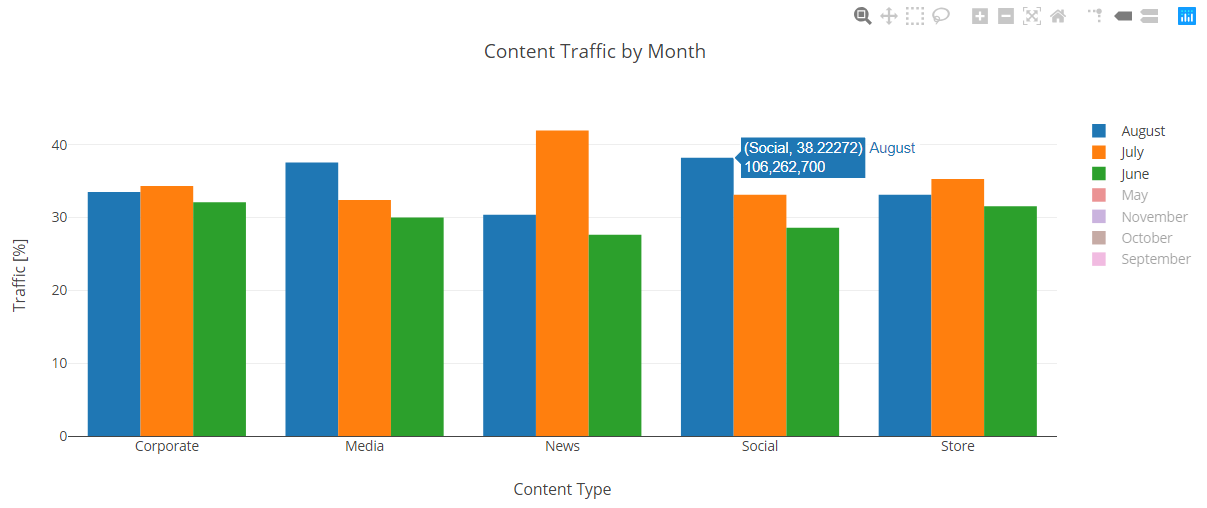
The Media and Social content categories saw an average 6% jump in traffic in August over the summer months. Seeing as these categories were already by far the best traffic generators this was pretty impressive.
Now I wanted to understand what caused this jump (and hopefully how to repeat it). My first guess was that this jump could correspond to the End-of-the-Summer campaign that was running at the start of each week (Monday) in August so I decided to dive a little deeper. By now viewing the data as a Table Barchart in Pivot Billions’ PivotView, dragging the weekday feature into my PivotView, and deselecting the other days of the week from the weekday feature, I was able to quickly visualize my data’s month-to-month Monday traffic.
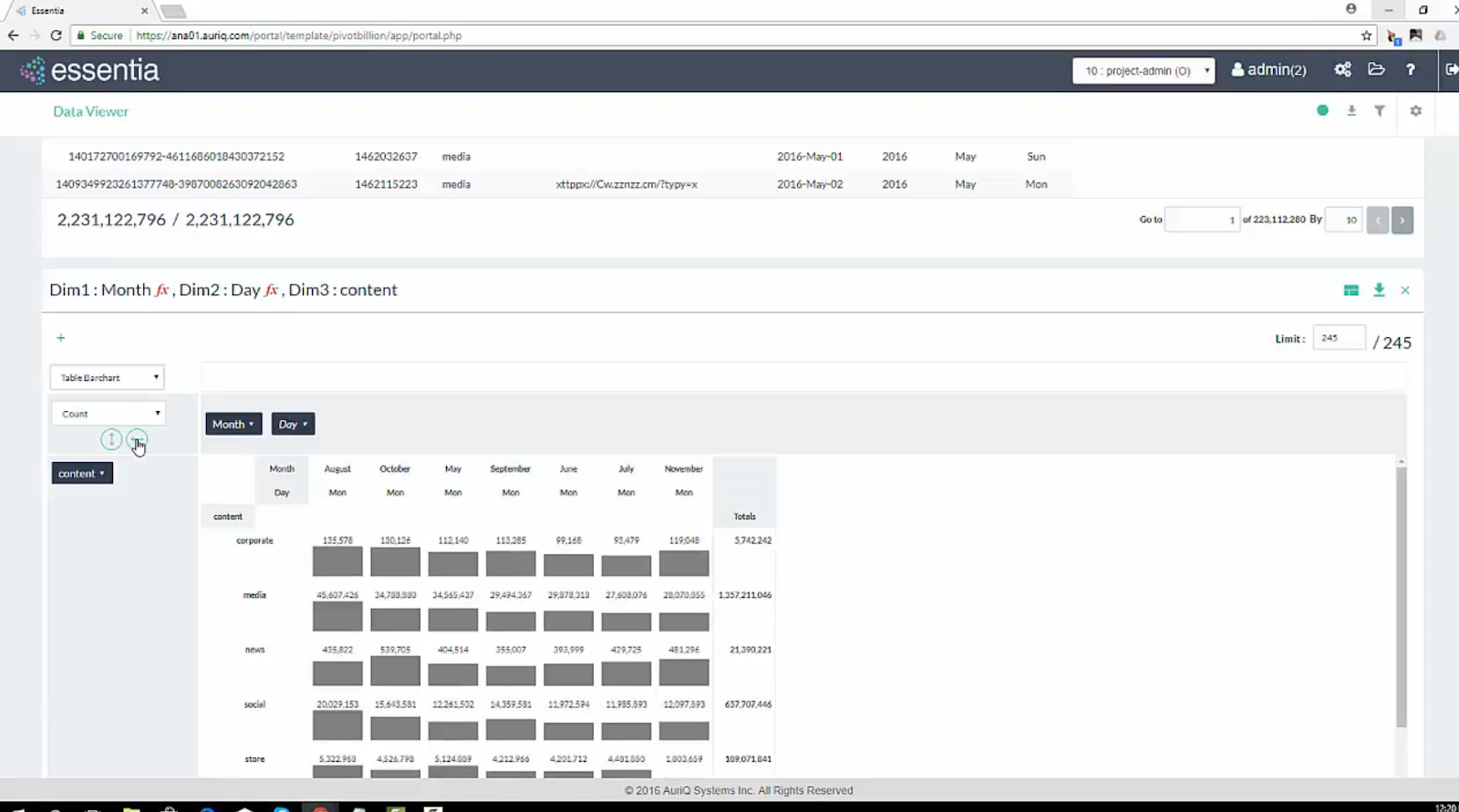
Mondays in August did indeed see a large increase in Social and Media traffic, approximately 50% of the total August jump. This made it more likely that the End-of-Summer ad campaign was at least partially responsible for the increased traffic but I wanted a more complete view. After re-selecting the other days of the week I was able to see a more detailed view of how the ad campaign tracked with potential customers throughout the week.
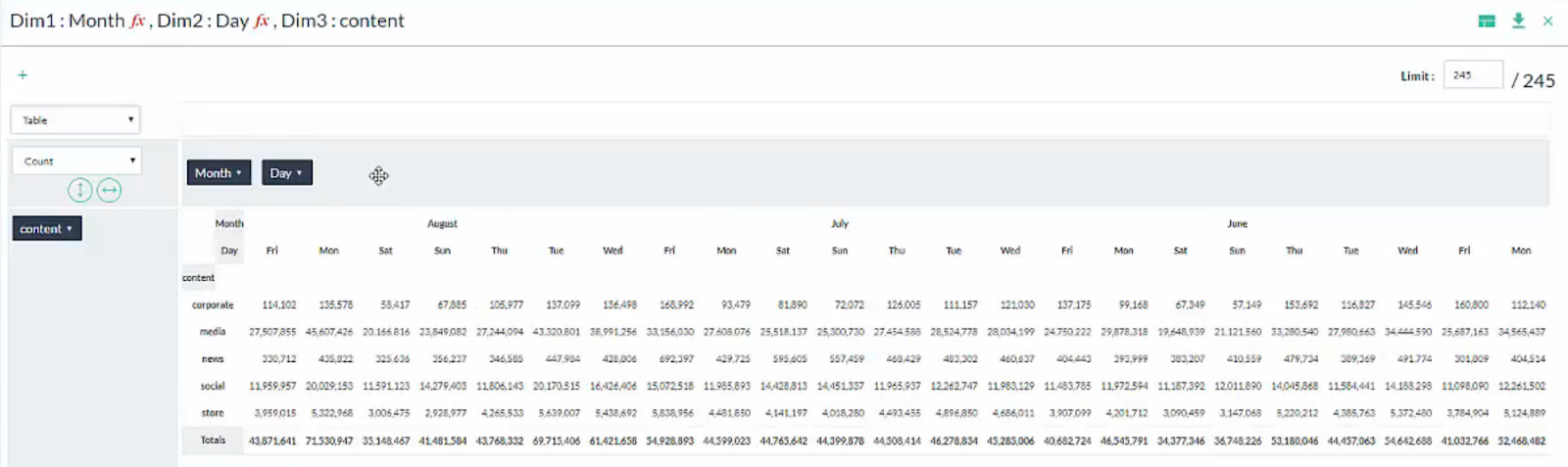
It was now clear that the traffic had a very noticeable spike from social and media sources on Mondays in August, followed by high but declining traffic on Tuesdays and Wednesdays. This was not seen earlier in the summer since the campaign had not started. It is reasonable to conclude that the End-of-Summer ad campaign had a significant effect on social and media traffic.
This is already fairly useful information but really I’d like to drill down into the ad campaign and see which sites were driving the most traffic. I quickly pivoted my data again, this time by protocol/domain and month so I could get a closer view. Viewing the pivoted data as a Table Barchart again and sorting the data so the sites and months with the highest traffic were at the top and at the right, I was able get a detailed look at the best performing sites and which of them had the highest impact from the ad campaign.
Note: The protocol/domain data has been anonymized for this post.
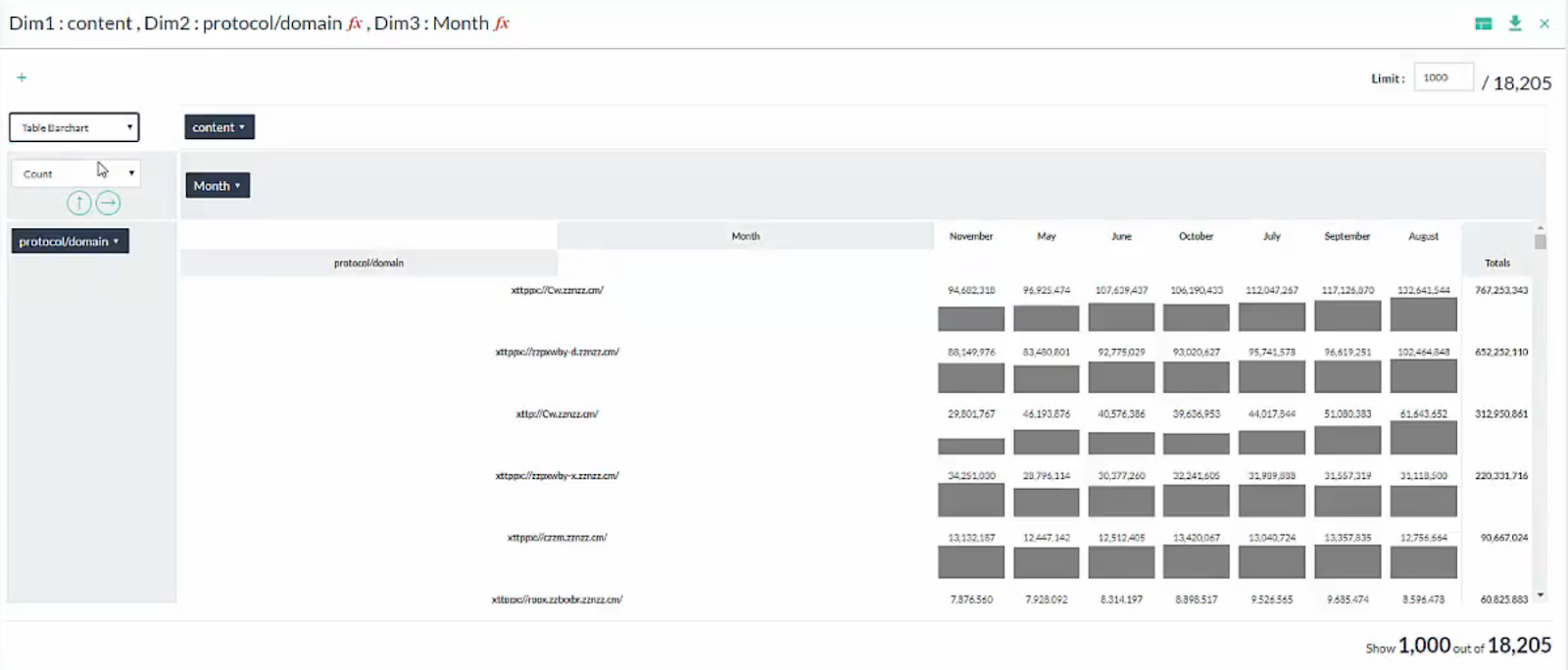
It’s clear that some sites had much higher impacts from the ad campaign than others. Even amongst the five highest performing sites, two weren’t affected by the ad campaign, one had a moderate improvement, and two others had sizable increases. The highest performing site saw an over 17% increase in traffic from the ad campaign and the third highest performing site saw a nearly 50% gain! Now that I know the types of ad campaigns that are most effective and have a full list of sites that they are most effective on, this analysis will be helpful in improving the ROI of future ad campaigns and making sure the investments are spent in the right places.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Imperva has publicly released the source code to Domain Directory Controller (DDC), a Java library that simplifies common Active Directory integrations.
Unlike Java’s base LdapContext, this library builds on top of Apache Directory LDAP to simplify work such as managing primary/secondary server connections, query pagination, and automatic reconnection attempts. The library is designed to support organizations of any size, including advanced cases where there are multiple Active Directory servers and no cross-forest trust.
DDC also provides an abstraction API over top of the LDAP query syntax. This API provides an enumeration of Active Directory fields, giving developers an easy and statically-typed way of building working queries. This query syntax is more legible in code:
Sentence nameAndDepSentence = queryAssembler
.addPhrase(FieldType.FIRST_NAME, PhraseOperator.EQUAL,"Gabriel")
.addPhrase(FieldType.DEPARTMENT, PhraseOperator.EQUAL,"IT")
.closeSentence(SentenceOperator.AND);
Sentence countrySentence = queryAssembler
.addPhrase(FieldType.COUNTRY, PhraseOperator.EQUAL,"Italy")
.closeSentence();
Sentence finalSentence = queryAssembler
.addSentence(nameAndDepSentence)
.addSentence(countrySentence)
.closeSentence(SentenceOperator.OR);
The alternative LDAP query without DDC would look like this:
(&(&(co=Italy)(department=IT)(division=Security))(|(givenName=Gabriel)(givenName=Noam)))
“Every enterprise IT group is looking to reduce the identity stores used by applications. The most common are Active Directory, LDAP and Kerberos.” explains Darren Mar-Elia, a 14-time Microsoft MVP and head of product for Semperis.
A lack of a consistent API to leverage AD caused its own issues and often resulted in sub-optimal use of AD and brittleness for the application. This open source AD library is a great help to those organizations that are looking for a standardized way of integrating their applications into AD in a consistent and secure manner.
The query API also takes steps to mitigate security concerns of LDAP queries, such as LDAP injection, which would otherwise let remote attackers control lookups through String concatenation.
One common activity in Active Directory is user/group resolution. Group membership is often used to determine if a user should have access to an asset or permission within an application. As organizations grow, this membership becomes complicated as a user’s permissions becomes a mix of direct grants, roles, and nested recursive groups. DDC simplifies this otherwise complicated lookup, through the ddc-service isMemberOf method. Application developers can use this for fine-grained access control to determine authorization, after performing authentication through common frameworks like Spring Security or Apache Shiro.
Domain Directory Controller was created by Gabriel Beyo, principal engineer, and is available under an Apache 2 license.