Month: March 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Background
One of the hardest problem in AI is not technical
It is social
Specifically, it is the problem of “educating people for living and working in a world dominated by AI”
This blog is based on my talk and notes in panels at the world government summit where the future society at the Harvard Kennedy school runs a workshop on AI on behalf of HIS EXCELLENCY OMAR BIN SULTAN AL OLAMA – Minister of State for Artificial Intelligence – United Arab Emirates
I also spoke of these ideas in the Kings College Legal tech and emerging technologies conference in London
The problem is acknowledged by many. Most countries now have an AI policy expressed in considerable detail (AI policy details) and there is a lot at stake. However, its not only about threats – there are also many potential advantages
Educating for AI – Dimensions
Educating for AI chould be considered in terms of problems and opportunities:
- The Finland model finland’s grand AI experiment 1 percent
- Educating for disrupted job losses
- Technology hubs – Technion, cifar etc
- Retraining teachers
- Educating young people
- New systems of meritocracy – ex Kaggle
- Considering AI for augmentation – ex Cobots
- AI for competitive advantage
To elaborate these ideas below
Countries
- The finland experience (as above)
- China’s push to AI as expressed in Kai Fu Lis book AI superpowers
- Learning from the success of CIFAR in Canada (as an organization in nurturing AI researchers)
- Learning from technical hubs for AI ex Israel BGU for Cyber security centre of excellence
- How should countries position for competitiveness (ex which domains should they focus their education system)
- Educating in emerging markets
- Using education to solve local problems in emerging markets
- Learning from the Russian school of education ie strong maths focus – Moscow state school 57
- The UAE world government summit and emphasis on AI
Reskilling – Content and techniques
- Methods of learning online – Online Education / Moocs
- Basic literacy in AI (finland)
- Awareness of potential of new intellectual property in AI
- Reskilling after job losses
- Awareness of the role of maths and science
- Awareness of algorithms
- Simplifying the tools of AI
- Educating about the potential to share and reuse code (ex github) which makes it easier to adopt new technologies
- Creating an awareness of robotics
- Educating about data (opportunities and risks)
- Educating for AI with an optimistic view of the future but making aware of the risks
- Adopting the Kaggle model (meritocracy based problem solving)
- Educating about how to rethink the learning process (ex by using forums such as stack overflow to find solutions)
People and community
- Teaching other professions about the value of AI (e doctors)
- Reskilling teachers
- Leveraging the skills of teachers post retirement age
- Encouraging more women to take up AI and also under-represented groups
- Academia as a hub for innovation – for example Technion
- Pushing the boundaries in AI for education ex trying radical methods of learning such as AI complementing the teacher
- How to inspire the next generation for AI – Young Data Scientist
Conclusion
To conclude, Educating for AI is multi-faceted – with both risks and opportunities.
The futures of whole countries are at stake. I expect much activity in this domain
Image source; shutterstock
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
My name is Aarti Parikh and today I’m here to talk about Go, and why it’s a really important language for enterprise development today. Everybody is being here in this room. It’s pretty crowded I think. It’s the largest audience I’ve ever spoken to. So I’m pretty excited to be here. I am a new engineering manager. Before that I mostly worked in startups. For the last three years I’ve been writing in Go. Then I started the two meetups that Ashley mentioned in Silicon Valley.
So rankings- let’s talk about the TIOBE index, which is the one where we saw skyrocket and then later it went down, but it’s going up again. Rankings matter. It is an indicator that the language is getting popular. Why is it getting popular? What is happening is that a lot of startups have adopted Go and they have found success with that. So Uber is pretty much Go with their microservices and all of that. There’s a lot of Go at segment, if you know, segment. So there are a lot of startups that were writing in Go and they found it really fast and they found productivity was high, and they also found that they were using less resources. As a result, performance, productivity and simplicity. So it’s been great.
Now enterprises are starting to pay attention. They’re like, ”Oh, we also want to do this. We can save money. And also we can find good developers.” People say history repeats herself. I don’t think it repeats itself. I think that we have all of these bad things that happen in history, and then in the next generation, we try to fix them in some way, but I don’t know if you actually fix them, or we make more of a mess or whatever. We’re doing something. So it happens in programming languages too. I love Mark Twain, so I have his quote up there.
Going back in history: this slide is actually going back to 1970. was alive, but I wasn’t writing code in 1970. But all these companies were writing business applications. So this is an enterprise application development pitch. Go is good for an enterprise application development. And so when we talk about that, we’re talking about invoicing and payroll and finance and all of those things, that business logic stuff, that was running on Cobol based systems on proprietary systems and then came the open systems, the open architecture and X3H6 and all of that. A lot of C and C++ was being written, but it wasn’t taking on for the business application needs.
There was this like, “Oh, this is causing, this is too hard or this has these problems”. This again, like Ashley said, isn’t about which language is great or what, which language is good for which system that you’re writing. If you’re writing low-level stuff, C, C++ were great, but they weren’t great for business applications. And that’s where Java’s timing in the early 2000s was perfect. I’ve written a lot of Java. I raised my children writing Java. But yes, my daughter’s taking AP computer science now and she has to study Java, so I’m helping her with recursion and all of that.
But why not C++? C++ is on the list of the most difficult programming languages in the world. It’s number 10, but I think Haskell is number one for me. I’ve tried to learn Haskell many times. I have several books on bookshelves of FP books. But it’s a hard language to learn. If you’re been doing application development and you are in the enterprise application development world, it’s not well-suited. Going back again, Java was like perfect for its time. At the time when Java came in, the early 2000 was late groundbreaking or like, “Oh we don’t have to deal with C makefiles and auto conference from bill tools and write for the compile for this and compile for that and all of that.” So it changed things and memory safety, which was the earlier talk today, was important in this area because Java was garbage collected and memory safe are no pointers.
Innovation & Growth Early Years
This is a little bit of history. I have some history with Java. I was young, I was really excited about coding and I was doing all of this stuff. Every time a new article would come on O’Reilly- O’Reilly was like our water cooler, just like hacker news is today. So we’re like, “Oh, this article came on hibernate and now everybody’s excited about hibernate.” And Gavin Newsome, I don’t know if anybody knows, remembers his name. Mark Flurry, who wrote Jay Boston, changed things because it was open source, and changed things from websphere. I don’t know if anybody here knows those names.
But extreme programming, anybody? Anybody read that book? Ken, back. Oh yes, that was groundbreaking. Wesley’s scary. That book like changed my life, because J unit and unit testing and all of the innovation that happened during the Java years was really amazing, at least it was for me. Then design patterns and we were all innovating on all of these things; dependency, injections, spraying- we’re still using spring. That is the sort of what enterprise application developers are using everywhere. Maven, how to do dependencies was beautiful. You had the Maven sitting locally on your local system and then you had all the layers.
I see the excitement around via SKO today, and it’s a little bit of history because the eclipse plugin architecture reminds me exactly of what we as code is today, because I wrote plugins in Eclipse. I was so into all of this. It was a good time. And I was promoted. I was an architect and it was like, “Hey, I have an A in my title.” I was an architect for a healthcare startup and I was writing a lot of abstractions, that was the thing. I loved it. So I was already abstract. We are already abstracted from the JVM. You don’t know what’s happening on the hardware. Then we’re writing frameworks upon frameworks. It was fun. It’s fun to write, “Hey, I can just do this and all of this stuff happens on its own.”
So that was sort of my story. But what happened as a result, was engineers on the ground floor who were coming in, they were like, “This is tedious. This is verbose. Why am I doing all of this factory builder, blah, blah, blah?” To write a thread in Java was like six lines of code and executed a thread factory, blah, blah, blah and then something inside. So it was crazy. I felt like it was like object-oriented programming, extreme object-oriented programming, and heavyweight frameworks. Startup times were slow. You would just be sitting. How many times he was sitting and just watching j boss startup. We had this discussion at PayPal, sitting in the audience. We talked about how Spring Boot came to the rescue but still, Java was slow. And for concurrency things, Java’s concurrency model is always threads map one-to-one, with Java threads. That was the limitation.
Don’t Underestimate Developer Happiness
Then I went to this conference and I met Dave Thomas and I read his book. Anyone, Dave Thomas, “Pragmatic Programmer”? Oh, my gosh. Only two, three people. So yes, Bruce Tate, he wrote this book, ”Seven Languages in Seven Weeks.” And he tweeted this outside, “Dave Thomas ruined Java for me.” I saw that and I was like, “That’s me. He ruined it for me too.” I read his book and then I read all of the Ruby books that came out and then it changed things for me. So my thing with enterprises- because this is an enterprise application developer conference- is that developer happiness matters. Don’t underestimate it. I was unhappy. I was like, “Hey, I wrote all of this stuff,” but I wanted to write in a fun language that me happy and Ruby made me happy. Ruby on Rails at the time, convention over configuration that was another huge growth that happened in the community.
This is the time that I also got involved in communities where I found the Ruby on Rails and Ruby community to be amazing. I was like, “Wow, this is a little group of really passionate people, writing stuff, doing stuff that they’re excited about.” That was a sort of my story. At PayPal, the story was node.js. So the VP who’s Org I work in, Geoff Harold, he’s kind of famous at PayPal for heralding this big change with node.js because Java- PayPal was all Java. Then he came and I sat with him once and he’s telling me his story, like, “You can’t tell this to anyone,” so I’m not going to tell his story. But how he brought about that change is really cool. So if you ever come to PayPal and have a one-on-one with him, you should talk to talk to him about that. He was able to bring about big change at PayPal, and that developer velocity at PayPal just like boomed. You look up the Java to node.js story. That was a big part of it. In my discussion with him, developer velocity mattered. We wanted to ship products fast because we wanted to keep up with the competition. Not only that, but you see your score and running and that’s important.
10 Years after the Rise of Dynamic Languages & Web Frameworks
But what happened after? I don’t know how many people in the audience follow Gary Bernhardt? Yes, he’s awesome. Yesterday he tweeted that he runs this conference Deconstruct Con, which is really cool. If you all get a chance to go there, and he does also live coding and all of this. He tweeted that, “Oh, my gosh, 10 years after the rise of these dynamic languages we’re seeing fatigue.” There’s all these security vulnerabilities in these things. There’s all this dependent NPM install downloads, the whole internet on my local laptop. It’s like, “Okay, this isn’t fun anymore. What was fun 10 years ago is not fun anymore.” We’re back to not being simple and fun anymore. More than that, I have this maze. This is the best image I could use to describe callback hell in my opinion.
Then, just as you’re in the node event loop or whatever, and you’re dealing with all of this, crazy, you can’t figure out how your code is working. So because you have a state machine always to deal with, with all of these callback things, and it’s not sequential like where you can just read your code and say, “Talk to Don, what’s happening?” You have to go on these code paths.
How Should I Change My Code to Gain More Performance in Multicore Environments?
So that’s what we’re facing right now, people were facing. Then the other thing, people who were close to the hardware, like the C, C++folks always know more than you always, because they’re close to the hardware. They’re like, “You’re writing all this code in scripting languages but you’re not using all the cores.” And that was the message that people were getting. “Hey, you’re node.js is single-threaded and you’re not using all the cores or global interpreter lock. How do you leverage that?” There was, of course, another framework, I think BM2 is what people use in the node world to scale on the different processes. But then again, framework. It’s not in the language itself where you could use all of the processors.
So that was kind of the unease with that. And then now we are here and this is not my slide. I have attributed this to the person who created it. But I thought this was a really neat slide. We were running on hardware. Then we went to okay, easy two instances or whatever. Then we were like, “Hey, we just need something, even simpler, or get pushed Blah and my code runs.” And now we’re like, “We just want to run something, and you all take care of all of the service, everything underneath. I just want my language to run. It doesn’t matter what I’m running. If I ship you a minor, you should be able to run in on your server, somewhere.” And so serverless, it’s not on.
I think that developers want this. They want even more simplicity. We’re going to this function as a service serverless. I’m sure like a lot of people were in. Serverless it’s this thing that people make fun of, but it’s really about developer experience, because as an engineer, if I’m a product developer, in product development teams- they’re called PD teams at PayPal – I just want to ship my code and I want to do a good job and I want the product to be good. So that’s what’s needed.
This is a code from Bala Natarajan. He heads all of bill, trust and release platforms at PayPal. It supports 4,000 developers and we have 2,500 microservices. It’s kind of crazy. One code I heard from someone in the platform team at PayPal says like, if we sneeze PayPal shivers. So this really small core team supports lots and lots of developers at PayPal. There’s a really great talk from our CTO from Google nest, where he talks about how PayPal operates at scale. So his thing is he’s kind of like, “You know, I have seen so much in my life, Aarti. Developers keep shifting with line. Every generation comes and they want more simplicity, simplicity.” And he saw that with node.js. He’s like, “We’re definitely seeing another shift now where things just run somewhere and backends are running, front ends are running and we just need to make this work for developers.” That’s the new paradigm. We need to simplify it to that. So I will end with that and I will take a quick water break.
Designers
It took me a while to get here, but I had to tell my journey, my story with Go. So the designers of Go, how the language was designed- it’s something when I tell people, they’re like, “Really?” They’re like, “Yes, the person who wrote UNIX also wrote Go.” That’s kind of a big deal. Somebody tweeted “Bell Lab refugees wrote Go”. I thought, I love that tweet. So yes, these people like performance. They like languages that are simple. Robin Grades, I was researching about him. It’s like, “Oh my God, he wrote everything”. He was in the JVM, he wrote the JavaScript V8 engine, also wrote the chubby locks over, the cluster thing that makes Google work, all of the Google clusters work, in borger whatever. He wrote that too. I was like, “Oh my God.” Then the face of the Go programming languages is Rob Pike. He’s like the brainchild. He was also on the original Unix team and a lot of the Go ideas come from Plan9, some of them. He also rode UTF-8. It’s not UTF-16 like JavaScript and windows and all of that. So it’s in UTF-8.
Those are the designers. So it comes from that place. It comes from people who cared about performance, simplicity and wanted things to run. I was on Rob Pike’s blog and I’ve read this blog like five, six times. I recommend you all read it too. The trigger for him for designing Go was, they were combining all of this C++ code in Google. And then he went to some meeting about C++, what they’re doing to improve. The discussion was, “Hey, we’re going to add these many features in C++.” He’s like, “Really? Do you not really care about developers at all?” So again, people that are asking me about Go, I was like, developer happiness. That’s what this talk is about. Developer happiness. So it matters all the way. People are unhappy and then go and build things in the languages they want.
I love to read like commentary on where ideas came from and I think that matters, because Go may not be the final destination. Who knows? I’m excited about Russ too and I’m excited about all this other stuff. But you want to know where ideas came from. To me it was really interesting, like, “Hey, we took C and we want to fix all this stuff.” But we were making it and it turned out to be something else. Then what they really wanted to do- because they were mostly programming in Python and C++. So that’s what Go kind of looks like.
Simple
So it’s simple. Go is a really simple language to start with. It has 25 keywords, low cognitive overload loop for everything. You don’t have seven different ways to do something. I remember submitting poll requests for Ruby programs and I would get 10 different comments. “Oh, you can concise it like this and you could put it in one line and you could tweak this.” And there’s nine different ways to do something. I’m spending most of the time making my code look pretty, versus understanding how my code actually runs, where it’s supposed to run. So I think that that changed. I could spend all my life making pretty code, but if I don’t understand how it’s operating, or that becomes more important if I want to scale my applications.
My punch line here was it feels like Ruby runs like Steve, but then I wrote, feels like scripting language. So I was a former Ruby programmer. I still have a complicated relationship with Ruby. I love Ruby. So readability was paramount to them. Then simple code is debuggable. You can go in the goal line code right now on GitHub and start reading a top down. It’s just fun. Hey, I can go and read the HTTP library. I don’t need no framework for it. I can go and read how Go channels are made. Even that code you can go and read, “Okay, this is H times track.” “Oh, that’s how it works,” so you can actually go and read the code and it’s readable. It’s top down, you can figure it out. So I love that part. It makes it very accessible for me.
And it can scale on large code bases where you have by large code bases. I’m an engine manager now, I work at an enterprise company. I have 10 developers on my team and then I’ll have a couple of interns. I have a couple of RCGs. Rohart is nodding his head, and there’ll be maybe a few senior developers, there will be one architect. You’re not in the startup world where everybody’s a senior developer You’re an enterprise company. So somebody coming into your code base needs to be able to read it. It’s a very different need than working at a startup where everybody’s a senior engineer and has built systems.
Stable
The other thing that enterprises need is stability. Stability of a language. I think this was really one of the big successes of Java, was it was always backward compatible. Every release they came out with, it was backward compatible. They had the deprecated flag that, “Okay, don’t use this, but if you use it, it’s still going to run. We’re going to make sure your code runs.” And that really mattered. I think that’s still the big success of Java, and the Go community is paying attention. So Go2 is in the works right now. One of the talks that I attended from Ian Wallace, who’s on the Go2 team was like, “We’re looking at that, we’re looking at the success of C with not that many changes, and the success of Java with not that many changes, and we want stability.” I think that was one of their things too, where they don’t add many changes in the language pack. So the focus for the Go team was, “Let’s make compiler performance. Let’s make runtime faster.” Performance, performance, performance; not waste time on language features.
Who Is Using Go?
A little bit about who’s using Go. I think this slide is important because people may know, may not know, that all of these things are written in Go. Docker is written in Go, Kubernetes is written in Go, etcd, [inaudible 00:22:30]. IPFS is an interesting project that I discovered, and it’s a good one. Hopefully one day I can contribute to something. It’s a fun project and it’s written in Go. All of Hashicorp stack is written in Go. Prometheus, OpenCensus, influx DB and so many other ones. Cockroach DB, Victus. Sogou is presenting here somewhere. It’s all written In Go.
Also these companies are writing in Go. PayPal has a bit of Go in the infrastructure side right now, mostly. But we have Go, we’re talking about Go. I have seen job postings from big companies looking to build Go framework teams very recently in the Bay Area. So I can’t name names, but they have also approached me, but I’m not going anywhere. But yes, Go is picking up everywhere. There are going to be go framework teams. There are going to be enterprise companies saying like, “Hey, we’re going to write microservices in Go.” So this isn’t just about infrastructure. I think it’s going to be more, that’s my thing.
Design
The design of Go, it’s natively compiled, statically typed, open source. I’ll say all these things- it’s on the slide, but I’ll say it again. It’s important because I had an interview and someone says, “Oh no, Go, is it really natively combined? There has to be a virtual machine somewhere.” They just couldn’t believe that it was natively compiled. This was an interview and it was a senior director asking me this question. It was pretty interesting. It has concurrency primitives built in. That’s one of the things that people love the most about Go. They’ll come, “Oh I came to learn Go because I want to learn about Go’s concurrency model.” So yes, that’s one of the things I talk about, in the next slides.
It’s a C-like language. I think I had a lot more slides with code, but the feedback I got from my mentor was don’t put code on slides so I removed them. But if you, later on, want to meet me in the hallway entrance, I can share some code. But it’s very simple. It reads like C. I mentioned about natively compiled. So this is a question; I think it’s an important question. At least this is how I learned, is through FAQs and not by reading. So Go has a really nice language specification. If you are one of those learners who learns from reading the whole specification packets in our forum and all of that, it’s there, go read it. I struggled, it was not easy for me, so I jumped around. Why is it so big? It’s because Go binaries include the Go runtime. It’s all packaged together. You’ve got everything in one single binary that’s running your Go code.
Compiler
The compiler, it’s fast. It’s really fast. Early, it was written in C. They ported it to Go, it’s still fast. It’s not as fast as the C one, but they admit it, but it’s still fast. They’re focused more on the runtime than the compiler for performance. There’s dependency cache and you can do Go Bill Myers, and you can cash your dependencies, statically linked to a single binary. So, for example, if you’re linking C libraries, for example, if you’re using Kafka and you have Liberty Kafka, you can link it with your Go binary and ship a single binary if you’re using the Kafka driver. I did that in a previous project and you can do that. You can dynamically link too, but you can statically link the binary. There are provisions to do that. I put this l slide for cross-compilation there because I feel like people really need to see that it does do all of this cross compilation across all these platforms and oasis.
So that’s one of the things, and there’s also support for assembly. So you can ride hand-coded assembly, and there’s a lot of poll requests that come from academia for the math libraries. If you’re watching the Go line GitHub, you’ll see that on the math libraries for sign costs down and all of those, a lot of that is in assembly and people are constantly tweaking, people- their domain, is constantly making it better, which is great, right, because we get a better language.
Data Oriented Design
Go is not object-oriented. It’s data-oriented. By data-oriented it has struts and it has methods that are outside of struts. They are not related; there is no class keyword in Go. There is no extends keyword in Go. So class extends- we don’t have that. We just have struts, like C, and we have methods that are outside of struts. So stayed in behavior is separate because it’s based on the data, the strut. Struts do a lot of other stuff too, like Go behind the scene does alignment and all of this stuff to make it compact, very much because they are coming from the C world. I don’t talk about it here because there’s so much to cover.
So Go uses interfaces to implement polymorphism. Again, like I mentioned, with methods you can implement multiple interfaces. It also prefers composition over inheritance, because we don’t do the inheritance tree. Encapsulation is done with three things. You’ve got the packages. Packages are not like Java namespaces, they’re more like libraries. They’re completely encapsulated. If you start thinking of them as Java namespaces, it’s trouble. If you think of them as libraries, like, “Hey, this needs to live independently off everything else,” then it works. It follows a very simple upper case convention for things that are exposed out of that package and things that are lower case or not. So it’s a very simple convention.
There’s also this concept of internal, which you don’t want it exposed at all, which is sort of protected I think. I don’t know which paradigm, but yes, so you wouldn’t be able to ask us those portions of a library that you’re using. You can embed struts inside Strut. So type reuse is through embedding struts inside struts.
Language Design (continued)
So language design. This is interesting because maybe you took a C-class in college and you have mostly written in Java or mostly written in languages that didn’t have pointers, you come to Go on, you’re like, “Oh, Go has pointers.” It has pointer semantics. These are not your seed pointer arithmetic thing. So don’t confuse the two. Pointer semantics is the same thing as Java references. Java is all pointer semantics. Everything is a pointer semantic in Java. Java doesn’t have value semantics, and that’s something that is a concept that I feel people should tell up front somewhere- maybe I’ll write a blog about it because it was a source of confusion for me too. I’m like, “Oh my God, these stars are scaring me. Pointers,” because I haven’t used pointers in awhile. It doesn’t like that.
Value semantics is really nothing. But if people who came from C++ know this, it’s just about copying something instead of using it as a reference. So that’s value semantics. Java doesn’t have value semantics, but there’s a GSR open for the next release of Java to have value semantics. Which is the next one, Java 11 or Java 12? Yes, that’s going to have that has a GSR open for adding value semantics. So look at pointer semantics as nothing but references, just like you are in your ordinary code. Use those more than where you need to pass references.
You can do low level stuff with pointers, I played a little bit with it. You can import the unsafe and access things inside that Strut with casting with unsafe. But don’t do that unless you have to. So one place where I’ve seen it is in Go’s binary serialization package, GAB. It’s called GAB, which is Go’s thing for like doing service to service. If you don’t want to use GRPC, if you’re writing everything in Go, you can use the GAB library, because to make it really efficient, Rob Pike had written it and he was using unsafe that to do all of the manipulation and make it fast. So that’s there.
cgo is an option. I have used cgo for image processing in a previous company. That’s the only place I needed to use it because there are some things, you’re going to write all of it in Go? For example, like FFmpeg. Who wants to write it in Go? That’s a hard library to port to Go. So you end up using cgo for those kinds of things, those libraries that provide those values. The other thing about Go, and I think it was in the previous talk mentioned too, about zero value. Go does that too. When you say new or make or you know any of these things, you’re not instantiating a class in Java. All you’re doing is you’re allocating memory for this variable and you’re zeroing out that memory.
So zero value is that you’re doing that because this whole zero value concept is interesting. I didn’t come from the C word, but the C people are really excited about it. I’m like, “Why are you always talking about is zero value?” I asked Bill. And Bill’s like, “Because C had this problem where it would allocate memory but it would not zero it.” So you could do bad things. You could access things inside and mess things up. So Go takes care of that for you. There’s a slight performance hit. You would never do this in C, because you’re writing firmware in C. You wouldn’t want to do anything with performance. But Go cares about data integrity first. So that matters. So things have to be accurate, consistent, efficient. That’s more important.
Testing
I’ll take a quick break again, sorry. So Go has testing built in. In the toolchain you’ve got Go test, you’ve got the benchmarking tests and I had a bunch of code associated with that. If anybody wants to look, I can talk about table-driven tasks and how Go does unit tests. There’s also how you can wrap a benchmark test, and test race conditions. I mentioned everything was a reference. So yes, you will run into race conditions. Go has a race detector in the testing toolchain built in, which you can run to detect these kinds of errors. There are also options for coverage, memory profiling, and other things. So it’s pretty good. To be honest, I still find it lacking straight up. I think we need a Go testing cookbook. Maybe someone will write a Go testing cookbook that’ll tell us how to do tests well. I still love the Java style of doing tests and their ways, so in a very systematic way. Ruby too had great testing frameworks. So I think this is an area where we could do more open source and contribute Go testing frameworks.
Concurrency
Concurrency. There are some really great talks about concurrency in Go. I saw all of them and I still didn’t understand concurrency in Go. And I finally get it, so it isn’t about running on all of these processors. It’s about multiple things. Concurrency is about out of order execution. If I go to a coffee shop and I ask for coffee and I pay the money, but there’s someone behind me and there are things that can happen in parallel inside the coffee shop. The things that can happen out of order; I can pay first or somebody’s doing something first. It isn’t about using all of the machines in the coffee shop for example. You can do certain things out of order, and actually you all should watch the talk- Samir Ajmani has a great talk on this, about concurrency, and he has this coffee example that really explains how concurrency works with channels and goroutines in Go. But it’s really about out of order execution.
Go gives you goroutines. They are lightweight userspace threads. Then Go has a cooperative scheduler that’s in the Go runtime, that’s managing these goroutines for you. The scheduler is deciding which goroutine is going to be run, which goroutine is blocking or whatever, and which goroutine needs the Cisco right now, so I need to go to the OS level. It’s managing all of that so you don’t have to do that. So it’s like a mix. It hits the sweet spot. So node.js had the event loop and was managing all [inaudible 00:36:44] io and working around this, I’m mumbling right now, but it wasn’t going to the OS level threads. But Go is doing all of that with this really amazing scheduler.
A lot has been written about the scheduler. There are some great talks. My favorite talk is by Kavya Joshi at Go for con. It’s called the scheduler saga. You must watch it. She’s amazing. She’s my hero. So yes, you must watch that talk, the scheduler saga. It explains how Go handles all of these. There’s a lot of literature on it too. A lot of great blog posts.
Channels
Where was I? Yes, this slide. I talked about goroutines. So you’ve got your threads. I talked about concurrencies, about out of order execution. So now how do I make sure what thing happens when? I need to signal. There are four things happening. There’s out of order execution happening, this thing happened, this thing happened, but I need to signal these and bring it all together. So the channels provide the mechanisms that allow the goroutines to communicate. And that comes from this old paper written by Tony H-O-A-R-E- you all can pronounce it in your heads- from 1978. Communicating sequential processes. It’s a great paper. That’s one of the talks that Go for con was also about, implementing the paper in the original language, which was done by Adrian Crockford. That’s also a great talk if you like the academic side of things. That’s a great talk to watch.
Channels are signaling semantics. I’m trying to signal what happens first. I’m orchestrating what’s happening. This is one of the patterns, and I’ve just picked one good example where I have a goroutine. In this example, I’m a manager and I’m hiring a new employee, and I want my employee to perform a task immediately when they’re hired. Then you need to wait for the result of their work. And so you need to wait because you need some paper from them before you continue. That’s what this orchestration is about, and this is the semantics here. So you make a channel, you run a goroutine, and then you’re waiting for something to land before you can exit this function.
Tooling
I’ll talk a little bit about go toolchain. A lot of people talk about toolchain and Go. It’s really, really well written because there’s a lot of good tooling built, in especially the Go format, gofmt or whatever. You don’t have to talk about tabs and spaces ever, ever again. There’s just one way to do formatting of all of your code, and you just do it to Go way, it’s in the toolchain, it’s there. There’s Go LinkedIn, there’s Go where, there are other things that the toolchain provides. But it also provides really powerful tools for profiling, memory and CPU and blocking. There are really some really great workshops. We had a workshop for women a couple of weeks ago where we did a Go tooling workshop, where Francesc went through and we worked through all of these examples and wrote code on the Go toolchain.
And then tracing: Go tool trace really helps you when you want to see when garbage collection is happening, how many goroutines are running, the GC pause or whatever, if you’re really into all of that. I wasn’t into that when I was doing Java, but if you’re into that now you can, and now I’m into everything. But it’s kind of fun that you can do this very easily and it’s built in. You don’t have to download a special framework or a library. It’s part of Go.
Error Handling
Error handling. Go does not have exceptions. There is no exception hierarchy. If you are like me and have written all this code path, with tons and tons of exceptions, it’s like, “Oh my gosh, that’s my main program. This is my exception program.” I used to write down like that. You had to, because that was the one way. You had checked exceptions. And I think that Java improved exceptions from C++ and it made them better. But it wasn’t like now where we’re taking it to the next level. I think with Go, errors are just values. You can do whatever you want with them. You have state and behavior.
Data structures – I’m going to go really, really fast now. Go has arrays, maps and slices, and if anything you should read about slices. Slices is the best thing ever. It just makes Go super fast. It’s contiguous chunks of memory. It’s not your dynamic array, it’s not your array list. I was confused forever. Think of slices as its own thing, and read up on it. Just leave the old paradigms when you start reading up on this. Go has this built in thing for if you want to do a pence and length and all of that. It’s in the library. It also has a rich standard library. All of the stuff is there. And you can read on it. I’m going to go really fast.
API development. This is at the heart of everything. I have written swagger and lots of Go swagger stuff. I have written REST stuff, web frameworks are there. GRPC. This is a quick example of chaining middleware and I put this in there because this is something that comes up that you have to do. I’m going to go much faster. This is a really important slide. So seven minutes. You should read up about the Go network polar. It’s really, really amazing. This is why Go’s network library is amazing. That’s why Cisco wants to use it and all these networking companies want to use it. It just does these amazing things. There are great blog posts on it. Underneath it just abstracts all the different operating systems. The community- we have Gopher slack, Golang mailing lists, Global conferences, WomenWhoGo.
The Future of Go
The future of Go. There’s stuff happening with Go 2. Generics is something that people miss, improved error handling, dependency management is something that the Go team is working on. And my last slide is for people who are writing Go frameworks. This is my pitch: please, please, please build for developer happiness. Don’t build top-down frameworks that make your developers unhappy. Build tooling that helps give developer autonomy.
These are the learning resources for Go that I use. My last slide is why I like Go. I feel like I’m a programmer again. I was writing business logic forever. I’ve lived in API land, and I feel like I can finally see what’s happening. I’m attached to what’s happening with systems and I’m very excited about learning more and doing more. There’s a great blog post that I would recommend, that’s called Go has Heralded the future for Rustin other systems languages. It’s an amazing post. Go has all these problems. It’s an easy-to-read blog post where there are pros and cons. But yes, this is where we’re going. This is what’s happening with the changes and things that are coming with Docker and containers and at Go. So thank you all for listening.
Questions & Answers
Participant 1: If Go does not have interfaces, what do you create that implements interfaces?
Parikh: Go has interfaces.
Participant 1: Yes, Go has interfaces. But I just think an interface is something that a class kind of uses, right?
Parikh: Yes. No. You have interfaces and then you have methods. When it’s implicit, if you implement those methods that the interface wants, then you have your implementation. So I’ll tell you what …
Participant 1: Where are those methods? Because that to me is a class.
Parikh: It’s not a class. It’s methods on the struts. I’ll show you. I’ll show you after. I can show you some code.
Moderator: We have something similar in Rust. So I know this and it is complicated to figure it out.
Parikh: It is. It’s way hard. I was like, “Oh my God, where are my classes. I was the same way.
Participant 2: A question about since the stock was at an enterprise applications, I just want to know what does Go support for working with databases?
Parikh: Yes. There is a database in the standard library, but there are also these abstractions that people have built on top of that, that you can sequel acts and all of that that you could use to streamline. You could use ORMs if you want. In one project I used ORMs and then the other project was a gaming company, high performance. And the CTO made us write all sequel by hand, which is a good thing. But yes, you could do both.
Participant 3: I was just wondering if it is a good prototyping language. I have a lot of systems engineers that just come up with some quick ideas.
Parikh: CLI is fun stuff. I want to teach my daughter Go this summer, because I want her to learn. She’s learned all this Java, but prototyping is perfect for that so you can see what’s happening.
See more presentations with transcripts
Uncategorized
Windows Virtual Desktop Public Preview on Azure: Q&A with Microsoft's Scott Manchester
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Windows Virtual Desktop (WVD) entered public preview on Azure. It’s an Azure service that allows Windows desktop and apps to be deployed and scaled easily. Most of the components necessary to be able to achieve this are managed in the cloud.
As explained in the overview, users and admins can create a full desktop virtualization environment in their respective Azure subscription without having to spin up any additional servers.
As a first step, you grant the necessary permissions for querying the Azure Active Directory (AAD) for administrative and end-user tasks via the Windows Virtual Desktop consent page. Thereafter, using the Azure market place, you can create host pools, which are collections of identical virtual machines hosted in the respective users tenant environment. Then you can create app groups using Windows Virtual Desktop PowerShell module. The final step is to create role assignments.
The remote apps and desktops are now available remotely via the Windows Virtual Desktop web client and other clients.
Most of the infrastructure related tasks are managed by Microsoft in the cloud and some of these aspects, such as load balancing, can be configured via PowerShell commands.
The basic architecture diagram is as follows:

InfoQ caught up with Scott Manchester, group program manager at Microsoft for Windows Virtual Desktop, regarding the public preview on Azure announcement.
InfoQ: Developers who have spun up windows in the cloud are familiar with Remote Desktop Services (RDS) to connect to the VM. Using that as a starting point, can you explain some of the challenges for managing this at scale?
Scott Manchester: WVD greatly simplifies the management overhead of a virtualization deployment. All of the infrastructure is managed by Microsoft and we provide the tools to enable an IT admin to easily deploy and manage Remote Apps and Desktops.
InfoQ: What about other technologies in this space, like RemoteApp (for instance) which has shaped the architecture of WVD?
Manchester: Our customers typically have mixed environments and deploy both Apps and Desktops. With Windows Virtual Desktops, we are providing a unified approach to doing both – in the cloud. For our On-Premises customers who use RemoteApp as part of RDS deployments, this provides an optimized migration path to the cloud.
In the cloud, our earlier offering called Azure Remote App (ARA) only offered apps and it obscured the actual VMs from the customer. WVD is an entirely new approach that fills most of the technology gaps of ARA and brings a whole new experience with a no-compromise Windows Client multi-session OS.
InfoQ: How is Office 365 app usage streamlined (if any) on WVD? Can you talk about the acquisition of FSLogix and its role as part of the WVD public preview and architecture?
Manchester: FSLogix provides most of the enhancements of the Office experience with WVD by allowing user and app data to be dynamically mounted when a user logs into a non-persistent VM. The Office team has also made a number of enhancements to provide a better experience with virtualized environments (per user install of OneDrive, optimizations in the Outlook hydration process, Calendar hydrates after email and time of cache can be adjusted).
InfoQ: Most developers and architects avoid discussing licensing and costs. Can you provide a quick primer on what might be needed to getting started and any comments on costs?
Manchester: See the documents we published on this – WVD is the most cost effective solution as the management is provided via a number of entitlements and with the new Windows 10, multi-user no Remote Desktop Session Client Access License (RDS-CAL) is required.
InfoQ: Currently, printing on local printers and Multi-Factor Authentication (MFA) which is an essential requirement is cumbersome. What’s the plan to alleviate this?
Manchester: We have not introduced any new printing features, but we have partnered with ThinPrint to provide extended printing features with WVD. WVD Auth is based on AAD so all AAD policies can be applied such as MFA and CA.
InfoQ: Does the announcement in anyway concern Linux users or administrators? Is this purely a windows play for now? If so, can you comment if Linux desktops and servers are going to be part of the roadmap?
Manchester: We are developing a Linux client, but no announcement about Linux host support.
InfoQ: Currently this service is available only on Azure. Any plans to make this available in other environments, such as customer’s on-premises? Can you also talk about the shorter-term and longer-term roadmap including the 3rd party ecosystem?
Manchester: Nothing to announce on native support for WVD for hybrid. Our partnership with Citrix enables customers to leverage Citrix Cloud to deploy and manage on-prem and Azure resources.
In summary, WVD sometimes referred to as Desktop as a Service (DaaS), primarily alleviates the burden of having to scale and manage Windows desktops.
More detailed information on WVD including enabling AAD tenants is available in docs. A video of the announcement goes into some of the technical details. The pricing and licensing details is available in the pricing and licensing page. Finally, WVD could be a service to use to continue to transition out of Windows 7, since it offers free Extended Security Updates for an extended period.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Varda: I’m Kenton [Varda]. I’m going to tell you today about how we built a platform, a cloud compute platform designed for massive multi-tenancy without using virtual machines or containers, but instead using V8 isolates. Let me start by explaining what it is we were trying to solve here. So, Cloudflare operates a network of servers located in 165 locations worldwide and growing all the time. Historically what these servers could do if you put them in front your website, they’d act as a glorified HTTP proxy. They could give you HTTP cashing, they could give you detecting and blocking security threats, famously they give you DDoS mitigation.
But, a few years ago Cloudflare thought, well, it would be really cool if you could just run code on these machines, give us a piece of code to distribute, and have it run all those places and handle HTTP requests for your site directly there. This could be either to augment the functionality of Cloudflare itself to implement new features that we hadn’t implemented yet, or it could be to actually take entire applications and run them across the whole network such that you’re not really thinking about where it runs anymore. It’s just runs everywhere, kind of like what I feel like the cloud was supposed to be all along rather than choosing one or two locations.
But there’s a challenge in this, there’s a scalability challenge. It’s not the scalability challenge that we normally think about. Normally we think about scaling to traffic, the number of requests that we can handle per second. Scaling to traffic is actually really easy for Cloudflare, because every time we add a new location, it means we can handle more traffic, add more service to that location, can handle more traffic. It’s evenly distributed across the whole network, our architecture scales out very nicely.
But the kind of scalability I’m talking about here is scalability to the number of tenants, the number of applications that we can be hosting at one time. The challenge with this is that, again, we don’t want people to choose one or two or five locations where their software runs; we want it to run everywhere. We want everyone’s code running in every one of our locations. And some of our locations are not that big. Though some have lots and lots of computers, but others have maybe a dozen machines. How do you fit- we have 10 million customers- on a dozen machines? Turns out that the existing technologies for this, the existing server-side technologies, don’t live up to the task. What we really need is basically 100X efficiency gain in number of people we can host and 100X decrease in how many resources each one is using.
Quick intro on me. I worked for Google for a long time where I was best known for open-sourcing protocol buffers. I created version 2 which is the open-source version. After I left Google, I created Cap’n Proto as I mentioned, which is an alternative serialization and RPC framework. Then I founded a company called Sandstorm that was doing interesting things with decentralized web hosting or hosting of web applications and security around that. The company made some cool tech, but I kind of failed on the business side in a classic fashion in the couple of years ago. I was looking for something new. I talked to Cloudflare and they said, “Hey, well, we have this idea. We want people to run code on our edge. We’re not sure how we want to do it. Do you want to take this on?” I said, “Yes.”
Couple of warnings, this is actually the first time I’ve spoken at a conference, I’m not an experienced speaker, and I am also not a graphics designer. My slides, as the talk goes on, are going to get worse and worse, and you’re going to want to avert your vision at the end.
Efficiency
Getting back to efficiency, what kind of efficiency do we need here? Well, first of all, we need apps to be very small. We can’t be shipping around even 100-megabyte app images because we can’t fit enough of those on one machine to host the number of apps that we want. We want apps that are more like a megabyte or less in code size. We want the baseline memory usage, that is the amount of memory the app uses when it has just started up, and it’s not doing anything in particular, has to be very low so that we can fit many of them.
Context switching, this is interesting. In our environment because we have requests distributed across the whole world, although we need to host a lot of tenants in each location, each one of them is not going to be getting very much traffic, because they’re only going to be getting the traffic that originates in that local part of the world. So what that ends up meaning is that we are actually diffusing our traffic across all of the tenants on the machine, potentially every request handling tens of thousands of requests per second with a new tenant each time handling that request. That means that context switching overhead becomes a problem for us. It isn’t for basically anyone else. A big VM cloud provider will usually pin your VM to a core, and it just runs on that core and it doesn’t switch at all. We’re at the other end of the spectrum, to the point where even switching processes can be too much of a problem because of all the caches that get flushed in the CPU. So we need to potentially put lots of tenants in a single process.
Then finally, startup time. If we can get startup time to be really, really fast then we don’t have to worry as much about memory usage, because we can just kick out the tenants who aren’t currently handling traffic and start them back up again when they’re needed. Ideally, we’d like something that’s just a couple of milliseconds, so it’s not even perceptible that we’ve initiated a cold start when the request comes in.
Other Use Cases
Now, we’re not the only ones who need this stuff, just to give you an idea of some other use cases. If you have an API that you’re exposing to the world over the web, especially like a server-to-server kind of thing, the clients of that API might not like the latency incurred by going over the internet to talk to it. They might want to host their code directly on your servers in some way. If you wanted to give them the ability to do that, you probably aren’t going to give each of them a virtual machine or even anything heavyweight. You would like something very cheap.
If you’re doing big data processing, say you have a gigantic dataset and you have multiple untrusted third parties that want to do MapReduces over this. In big data processing, you cannot bring the data to the software, you have to bring the software to the data. So you need a very efficient way of taking some code from someone and spreading it across all of your machines where the data actually lives.
Another use case is something like web browsers, where people are browsing the internet, they download code from every site that they go to so that the site can be more interactive running locally. But, don’t we already have that? We’ve actually had that for quite some time, about 20 years now. So that’s interesting because we’ve been looking at the server technology and it’s too inefficient to work for this use case. But could it be that web browsers have already developed the technology that we need to solve our problem? It turns out that indeed they have.
Web browsers are optimized to start up code really, really fast because the user is sitting there waiting for it to start. They’re optimized to allow for application code to be relatively small so that it can download quickly. They’re optimized to have lots of separate sandboxes at the same time, not just for separate tabs but each iframe within a tab is potentially a different website and needs a sandbox. It may be an ad network, it may be the Facebook Like button. Those are all iframes. You don’t see it, but they’re all whole separate JavaScript contexts. And, of course, web browsers have been probably the most hostile security environment that exists for quite some time. If you can hack somebody’s web browser, you can do a lot of damage. All you have to do is convince someone to click on a bad link and potentially you can get into all their other websites and so on.
V8: Isolates and APIs
So, this led us to the conclusion that what we want is the technology from web browsers. In particular, we chose V8, which is the JavaScript execution engine from Google Chrome. It seems to have the most resources behind it, basically, which is why we chose it. Though some of the others might work well too. We found that this works great as an engine for extreme multi-tenancy.
Let’s go into the details a little bit. We’ve been using this word isolate instead of VMs or containers. We now have isolates. What is an isolate? It actually comes from part of the V8 embedder’s API. When you build around V8, you’re going to be using the C++ interface V8 as a library. It has a class called isolate, and what an isolate represents is one JavaScript execution environment. It’s what we used to call virtual machines like JVM, Java Virtual Machine. Now, the word virtual machine has these two meanings and most people mean something entirely different. So we use the word isolate instead.
Now, here’s why, or one reason why, isolates turn out to be so much more efficient. In virtual machines, the application brings its own kernel in its own operating system traditionally. You get huge images. With containers, they got so much more efficient because now the operating system kernel is shared between all of the tenants. The applications only need to bring their own code and any libraries and maybe language environments that they build on top of. So they got a lot smaller and less resource-intensive.
With isolates, we can go further. So now we have, traditionally, all these user space things that we can share between all of the tenants of our system. We have the JavaScript runtime, which includes a garbage collector and JIT compiler, some very complicated pieces of code. If we can have only one copy of that code instead of several, that helps a lot. We can provide high-level APIs instead of providing- in containers your API is the system call API that’s pretty low level. If we can do something much higher level, we can do things like have the same HTTP implementation shared between all of the tenants. Hopefully, they then only need to bring their own business logic, and not a big pile of dependencies.
But we don’t want to just go start inventing a bunch of our own new API’s for this. It turns out there are standards. So the browser, as we know, has APIs for things like HTTP requests, traditionally XML HTTP requests. But these days it’s better to use the fetch API. What you might not know is that the browser also has standardized APIs for acting as an HTTP server in the, what’s called the service worker standard, which lets you run scripts on the browser side that intercept HTTP requests. This turns out to be exactly what we want for our use case. So we didn’t have to develop any new APIs of our own. This is great because it means that this code, that runs on Cloudflare Worker, is potentially portable to other environments, especially if some of the other server list providers decide to also support standard APIs at some point.
This is an example here of a complete HTTP proxy server written in about 10 lines of code. And it actually does something useful. This server is checking for incoming requests whose URLs end with .jpg. And it is sending those requests to a different back-end than everything else, something you might see all the time. But what’s interesting is there are no imports, no require statements here. This is just using the built-in APIs in the platform and 10 lines of code and we get something useful. That’s how we make code footprint so much smaller.
A lot of people lately have been talking about web assembly. So with V8, we get web assembly for free. It’s part of V8. We’ve actually enabled this in Workers, so that means potentially with web assembly, the promise is now you can write in any language, not just JavaScript. There’s just a little problem with this currently, which is that now you’re back to shipping your own language runtime because potentially, every tenant has their own language that they want to use. So you see people, they want to use go, and so now they’re shipping the go garbage collector and the go green threads implementation, and all of the standard libraries for go. And it’s very large, and it goes over the various limits.
This is not solved yet but it will be. What we essentially need here is a way to do dynamic linking on web assembly modules, so that the go 1.11 runtime could be something that we share across multiple isolates. Then each one brings its own application code on top of that. The good news is we’re going to be working on that. If you go to Ashley Williams’s talk tomorrow, she’ll tell you all about what we’re going to be building on this to fix this.
Resource Management
You can start to see why this is part of the operating systems track. It’s looking a bit like an operating system. It’s about to look even more like an operating system. Another thing that we have to do: how do we figure out when to start up apps, make sure they don’t use too many resources, and so on? In a traditional operating system, you have a bunch of processes, they’re using memory. They kind of allocate the amount of memory that they want, and the operating system has to live with that and hope that everything fits in memory. Because if it doesn’t, then it has to take drastic measures. In Linux, there’s something called the oom killer, out of memory killer, that kicks in when you run out of memory, and it tries to choose the least important process and kill it. Doesn’t always choose correctly and it’s a problem because these processes have state.
In our environment, these isolates are essentially stateless. When they’re not actively handling a request, they don’t have any other state that’s important. We can kick them out at any time. So we end up with a completely different memory management strategy, which is we say, “Okay, we can set by configuration that we’re going to use eight gigabytes of memory. We’ll fill that up until it’s full, and then we’ll evict the least recently used isolate to make sure that we stay under that eight gigabytes.” It’s pretty neat to know exactly how much memory your server needs to use. Makes a lot of things easier.
Now we have this trade-off basically, between memory and CPU, because if we have too many customers cycling through too often, then we’ll be restarting isolates that we recently evicted too often. But it’s a sliding scale and we can monitor it over time. There’s not going to be an emergency where all of a sudden we’re out of space, and then we can bump up the memory when we see that there’s too much churn happening.
We need to make sure that an isolate can’t consume all of the resources on a system. There are a couple of ways that we do that. For CPU time, we actually limit each isolate to 50 milliseconds of CPU execution per request. The way we do that is the Linux timer create system call lets you set up to receive a signal when a certain amount of CPU time has gone by. Then from that signal handler, we can call a V8 function, called terminate execution, which will actually cancel execution wherever it is. If you have just a wild true open race close brace infinite loop, it can still cancel that. It essentially throws an uncatchable exception, and then we regain control and we can error out that request.
An isolate in JavaScript is a single-threaded thing. JavaScript is inherently a single threaded event driven language. So an isolate is only running on one thread at a time, other isolates can be on other threads. We don’t technically have to, but in our design, we never run more than one isolate on a thread at a time. We could have multiple isolates assigned to one thread and handle the events as they come in. But what we don’t want is for one isolate to be able to block another with a long computation and create latency for someone else, so we put them each on different threats.
Memory is interesting. V8 has a way for you to say, “I don’t want this isolate to use more than this amount of memory, please stop it at that point.” The problem is when you hit that limit, it aborts the process. That means we’ve aborted all the other isolates on the machine as well. So that’s not what we want. Instead, we end up having to do more of a monitoring approach. After each time we call into JavaScript when it returns, we check how much use space it is now using. If it’s gone a little bit over its limit, then we’ll do a soft eviction where it can continue handling in-flight requests. But for any new requests, we can just start up another isolate. If it goes way over then we’ll just kill it and cancel all the requests. This works in conjunction with the CPU time limit because generally, you can’t allocate a whole lot of data without spending some CPU time on that, at least not JavaScript objects. Then type trays are something different, but it’s a long story.
Another problem is we need to get our code, or the user’s code, to all the machines that run that code. It sure would be sad if we had achieved our 5 millisecond startup time only to spend 200 milliseconds waiting for some storage server to return the code to us before we could even execute it. So what we’re doing right now is actually we distribute the code to all of the machines in our fleet up front. We already had technology for this to distribute configuration changes to the edge, and we just said code is another kind of configuration, and threw it in there and it works. It takes about three seconds between when you upload your code and when it’s on every machine in our fleet.
And because the code footprint of each of these is so small, this is basically fine so far. We have enough disk space. Now, it may come to the point where we don’t at some point, and then we’ll have to make the tradeoff of deciding who gets slower startups because we need to store their code in a more central location. But it probably would be a per [inaudible 00:22:39] thing instead of every single machine thing, and so shouldn’t add too much latency.
Security
Let me get to the thing that everyone wants to ask me about, which is security. There’s a question as to whether V8 is secure enough for servers? You’ll see actually some security experts saying that it isn’t. Surprisingly enough, some people at Google saying that it isn’t. What do they mean by this? Well, here’s basically the problem. I said, my slides are going to get ugly, they’ve gotten ugly. It’s ugly not just visually but also for the content. V8 has these bugs. In this particular case, this is two lines of code from deep in the V8 optimizer where these two lines basically say that the function Math.Expm1, which calculates E to the power of x minus 1. I’m not good at math so I don’t know why you want that, but I’m sure there’s a reason. This line says to the optimizer that it returns either a plane number or NaN, not a number.
Turns out though that it can also return negative zero. For some reason, negative zero is not a plane number in V8 type system. As a result, people were able to exploit this one little error to completely break out of the V8 sandbox, by basically tricking the system into thinking something was a different type or triggering an optimization that shouldn’t have happened. The details are complicated and really interesting. If you want to know more, check out this blog post. It’s very understandable. You don’t need to know V8 details but this guy, Andrea Biondo, wrote it all up. It’s very interesting.
So that sounds pretty bad. You can imagine that there’s going to be lots of bugs like this in V8. It’s a big, complicated system. The assertion is that because of this,V8 is not trustworthy enough, whereas say, virtual machines and maybe containers are more trustworthy because they have a smaller attack surface. Well, here’s the thing, nothing is secure. Security is not an on or off thing. Everything has bugs. Virtual machines have bugs, kernels have bugs, hardware has bugs. We really need to be thinking about risk management, ways that we can account for the fact that there are going to be bugs and make sure that they have minimum impact.
The frequency of bug reports in V8, there are two ways to look at it that could make it bad or good. V8 has relatively more bugs reported against it than virtual machines. That’s bad because it’s showing that there’s a larger attack surface, there are more things to attack. But there’s also a good side to this, which means that there’s a lot of research being done. Actually, the vast majority of V8 bug reports that like I have access to before the rest of the world. I look at them and almost every single one of them is found by V8’s own fuzzing infrastructure, it’s found by Google essentially. They’ve put an amazing amount of effort into this. I just learned actually recently that not only does V8 have a bug bounty, where if you find a sandbox breakout, Google will pay you $15,000, maybe more- if you’re going to use it to exploit someone, you need to be getting more than that out of it, right? But they also have a bounty for fuzzers. If you write a new fuzzer and add it to their infrastructure, a new test case basically, and it finds bugs, they will pay you for those bugs.
That was really interesting to me, and people do this. Every now and then someone will submit a new fuzzer, and it’ll find a bunch of new things and they’ll get paid out, and this is awesome. How much has gone into this? On the other hand, like if you’re looking at a security solution and it has no bugs ever reported against it, you don’t want to use that. Because what that means is no one has looked, no one writes bug-free code. So this is why I’m feeling fairly comfortable about this.
Now let’s talk about risk management. How can we limit the damage caused when a bug happens? There are things that you may do in your browser today to protect yourself against browser bugs, and some of them apply to the server as well. Obvious one, you probably install Chrome updates as soon as they become available. Well, we can do something on the server that’s even better. We can see when the commit lands in the V8 repository, which happens before the Chrome update, and automate our build system so that we can get that out into production within hours automatically. We don’t even need some want to click.
Something that probably fewer of you do on the browser, but I’m sure a few of you, is use separate browser profiles for visiting suspicious sites, versus visiting your important sites. This is actually really easy to do in Chrome. There’s great user management also in other browsers as well, or some people prefer to just use separate browsers. But we can do something similar to this on the server. We don’t have the ability to spin up a process for every single tenant, but we can spin up a process, like one for enterprise users, one for established users who have been paying for a while, and one for free users when they come. We don’t currently have a free plan, but if we were to in the future. Then, we can put additional isolation around those, we can put those in a container or in a VM or whatever else we want. So that makes it pretty hard for an attacker to just sign up and get something good.
There are some things, some risk management things we can do on the server, that we cannot do so easily on the browser. One of them is we store every single piece of code that executes on our platform, because we do not allow you to call eval to evaluate code at runtime. You have to upload your code to us and then we distribute it. What that means is that if anyone tries to upload an attack, we now have a record of that attack. If it’s a zero-day that they have attacked, they have now burned their zero day, when we take a look at that code. We’ll submit it to Google, and then the person who uploaded won’t get their $15,000.
We can do a lot of monitoring. For example, we can watch for segfaults anywhere on any of our servers. They are rare, and when they happen, we raise an alert, we look at it. And we see in the crash report, it says what script was running. So we’re going to immediately look at that script, which we have available. Now, Chrome can’t really do this, because it can’t just upload any script it sees, because it’s potentially a privacy violation. They can’t investigate every crash report they get, because the browser is running on so many different pieces of hardware, some of which are just terrible. They get a constant stream of these crash reports. It can be terrible hardware, it could be that the user has installed malicious software already, and it’s trying to modify Chrome. That happens a lot and that causes a bunch of crash reports and all these other things. So they have a much harder time actually like looking for the attacks.
What about Spectre, speculative execution side channels? A couple of weeks ago, the V8 team at Google put out this paper that basically said that they cannot solve Spectre, and so, therefore, Chrome is moving towards isolating every site in its own process, instead of doing anything internally. In particular they said timers, timer mitigations, are useless. When this came out, we started getting a lot of people asking us .doesn’t that apply to Cloudflare? Ae you totally vulnerable to Spectre?
Well, here’s the thing. You have to be careful when you read this paper to understand what it is actually saying. It is saying that, “The V8 team has not been able to find anything else they can do, except for rely on process isolation.” It is not saying that process isolation solves the problem. The problem is if you go to the Intel side, there have been a bunch of different variants of Spectre found already. Each time it requires a custom fix. And miraculously so far, they’ve always been able to somehow fix it through some crazy thing they do in microcode or whatnot. Usually there’s a gigantic performance penalty, sometimes people say the performance penalty isn’t worth it.
But they’re not done. There are going to be more bugs, they’re just not found yet. We don’t know for sure if all of these bugs will have mitigations that are easy, and mitigations that are easier than buying new hardware. It’s kind of scary. When you talk to the people who have been researching a lot of this stuff, they’re like, “I don’t know. We could see a bug that breaks out of virtual machines and not have anything to do or anything we can do about it.”
But in Cloudflare’s case, we actually have some things we can do that basically nobody else can do. We’re taking an entirely different approach here. In our API, we have actually removed all timers from our API. We can do that because we don’t have any backwards compatibility legacy that we need to support, and because our API is at a much higher level, to the point where applications don’t usually need to time things. If you’re implementing say a new P threads library, you need access to a high position timer to do it well. or a new garbage collector, you need a high position timer for that. But we provide those in this platform. The application only does business logic stuff.
The application can still ask what time it is. It can call date.now, but the value that’s returned by that does not advance during execution. So it essentially tells you when the last network message was received. If you check it and then run a Spectre attack in a loop and then check it again, it returns the same value and the difference is zero, so you think that you just ran it infinite speed.
We also don’t provide any concurrency primitives because any kind of concurrency can usually be used to build a timer by comparing your own execution against whatever happens in the other thread. That’s another thing that browsers can’t do. They have this platform they need to support that already has explicit concurrency in it, and also has implicit concurrency in rendering. You start some rendering and then you do something, and then you check how much the rendering has progressed. In our platform, we can eliminate all of those.
Now, it is of course still possible to do remote timing. The client can send a request to their worker and see how long it takes to reply. That’s over the internet. There is noise in that. but noise doesn’t mean it’s impossible to attack. No amount of noise will prevent a Spectre attack. The Spectre attack just has to amplify itself until the point where the difference between a one bit and a zero bit is larger than the noise window. But the noise does lower the bandwidth of the attack. It can lower it far enough that now we have an opportunity to come in there and notice that something fishy is going on.
We can look for things like high cache misses or other telltale signs that someone is doing something fishy. Then we have this other superpower which is that because the isolates are stateless, we can just move them at that point to another process or to another machine, let them keep running. So if we have a false positive, that’s fine, the worker will continue to do its job. But now, we’ve taken the attackers and moved them away and everyone else is potentially safe. But this, as I said, it hasn’t been tried before. There’s a lot of research to do and we’re going to be working with some of the foremost researchers in speculative side channels to check our work here. There’ll be announcements about that soon, once we have the details worked out.
Big Picture
But I’m backing up a bit. We could just say, “Oh, there’s challenges here, it doesn’t work, let’s not do this.” But we can’t, because there’s too much value here. The history of computing, of server-side computing in particular, has been of getting to finer and finer granularity. Virtual machines started being used they weren’t thought of as secure. But virtual machines now enabled public cloud which is clearly incredibly valuable. Containers have had their naysayers, but they enable microservices, which are incredibly valuable as we saw in the keynote this morning. We can’t just say it doesn’t work. We have to solve the problems.
With isolate computing, we have the potential to handle every single event in the best place for that one event to be handled, whether that’s close to a user or that’s close to the data that it’s operating on. That’s going to change everything about how we develop servers. You’re not going to think about where your code runs anymore. It’s a lot less to think about, but then everything is going to be faster to. Imagine this. Imagine you have an app that uses some third-party API that’s also built on this infrastructure, and another API is built on other APIs, so you’ve got this whole stack of infrastructure. Imagine that can all actually run on the same machine, all on the same machine which itself is located in the cell tower that’s closest to the user. That would be amazing. That’s what we’re going for here.
Questions & Answers
Participant 1: Great talk, thank you. I have a question about utilization, I mean CPU utilization. If we talk about scenarios like proxies, then probably the isolates do not do anything most of the time, just waiting for a response from a remote system. So do you run thousands of these threads with isolates in parallel, or do you have threadbare core and so the CPU is almost free? The second question is related: do you have any accessory bar related to latency, like minimal or maximal latency before your screen will up in running?
Varda: As I said earlier, we start up a thread or we have different isolates running on different threads. We actually start a thread for each incoming HTTP connection, which are connections incoming from an engine X Server on the same machine. This is kind of a neat trick because engine X will only send one HTTP request on that connection at a time. So this is how we know that we only have one isolate executing at a time. But we can potentially have as many threads as are needed to handle the concurrent requests. The workers will usually be spending most of their time waiting for some back end, so not actually executing that whole time. Does that sort of answer your first question?
Participant 1: But then this case, you can go, I don’t know, 10 requests, which consume all the CPU and then other requests will be just waiting, and you’ll have high latency. I mean, how do you view CPU sharing between thousands of requests?
Varda: Right. First of all, you’re limited to 50 milliseconds per request, and we cancel them after that. But it’s still possible if there’s enough isolates and enough requests, you could run out of total CPU. Basically that’s a provisioning problem. We need to make sure that we have plenty of CPU capacity in all of our locations. When we don’t, when one location gets a little overloaded, what we do is we actually shift. Usually the free users we just shift them to other locations- the free users of our general service, there isn’t a free tier of workers yet. But that offloads CPU to other places without affecting any of the paying users in any way. So we’ve been doing that for a long time, it works pretty well. And then the second part of your question?
Participant 1: It was about latency, SLA’s.
Varda: So yes, SLAs, I don’t think we have a specific SLA for latency. Well, actually, I don’t know. That might be something that is someone else’s department. Okay, doesn’t have one, but it’s usually pretty good.
Participant 2: You mentioned in the beginning that customers can use this to augment Cloudflare functionality. You also mentioned that you store and inspect user’s code. What kind of protections do you have to allay customers fears that you will just steal that code essentially?
Varda: We look at code only for debugging and incident response purposes. We don’t dig through code to see what people are doing for fun. That’s not what we want to do. We have something called the Cloudflare app store, which actually lets you publish a worker for other people to install on their own sites. It’s being able to do it with workers is in beta right now. So this will be something that will ramp up soon. But then you sell that to other users, and we’d much rather have people selling their neat features that they built on Cloudflare to each other in this marketplace, than have us just build it ourselves. There’s so much more we can do that way. We’d rather focus on the core network platform and on building more servers, than trying to come up with everything under the sun that people can build on it.
Participant 3: All these tools that you’re creating, are they going to remain proprietary Cloudflare things for your platform? Or are you going to actually start to maybe open-source some of these tools for other people to use them to do similar things or to benefit from?
Varda: We don’t have specific plans yet, but I can tell you personally, I would very much like to start open-sourcing parts of this, probably in stages. We have this great glue layer that we use for binding APIs written in native code into JavaScript so they can be called. I would like to do that. Can’t make any announcements right now.
Participant 4: Is there any ability or thought about being able to store some sort of state on the edge? Because you’re basically just processing data as it passes through. Is there a future where you can do some sort of fancier processing right there?
Varda: Storing state on the edge. We have a number of projects that we’re working on with the goal of eventually every user’s data, if you build an application on Cloudflare storage, then every user’s data, every user of your application, their data should be stored at the closest location to them. I have this thought experiment I to think about, which is when people go to Mars, is the internet still going to work? Can you use web apps from Mars? On today’s model, no, because you’re going to wait for half an hour round trip to do every page load. But if we send a Cloudflare pop to Mars, and an application were written on Cloudflare storage, would people then be able to use it as long as they’re only collaborating with other people on Mars?
If we solve that problem, then we’ve also solved the problem of slow internet in New Zealand. So it’s important here too. But there are a number of efforts underway. One of the first ones that’s already in beta is called Workers KV. It’s fairly simple right now, it’s KV Store but it’s optimized for read-heavy workloads, not really for lots of writes from the edge. But there are things we’re working on that I’m very excited about but not ready to talk about yet, that will allow whole databases to be built on the edge.
Participant 5: Next question. Considering the fact that there are no free services at the moment, what are the other ways to get in touch with technology and to experiment with a little bit?
Varda: Great question. If you go to cloudflareworkers.com, you can actually play around with it just in your web browser. You write some code and it immediately runs, and it shows you what the result would be. That’s free. Then when you want to actually deploy it on your site, the cost is $5 per month minimum, and then it’s 50 cents per million requests. You get the first 10 million free. So it’s less expensive for a lot of people than Lambda.
Participant 6: Like you said, one of the awesome things about Cloudflare is it’s DDoS protection and handling some of the most hardcore traffic patterns on the internet. Now that we’re running JavaScript at the edge, in this controls computing environment, does your DDoS strategy change at all when you get tons, and tons, and tons of load?
Varda: The DDoS protection happens before Workers. Your Worker is protected. So that’s one part. There is, of course, an interesting new question here, which is could you use Workers to launch a DDoS on someone else? “Oh, now you’ve got 165 well-connected locations that can run your code and send last request someone.” Yes, we don’t let you do that. When people try, they get shut down really quick. That’s all I’ll say about that, because I have to stop.
See more presentations with transcripts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Key points of this blog include:
- Digital Transformation sweeps aside traditional industry borders to create new sources of customer and operational value
- Unfortunately, Digital Transformation and “smart” initiatives are struggling, and organizations will need a more pragmatic approach to successful execution per Forrester research
- Organizations must define their “smart” initiatives from perspective of stakeholder journey maps that identify, validate, value and prioritize the use cases that support “smart”
- “Smart” spaces are comprised of interlocking subsystems that decompose into a series of use cases that are identified, validated and valued from the journey maps of your key stakeholders and constituents
- The Digital Transformation Journey Workbook identifies “smart” spaces and digital transformation requirements from perspectives of key stakeholders – the sources of economic value.
Digital Transformation sweeps aside traditional industry borders to create new sources of customer and operational value
Many organizations doom their “smart” spaces initiatives, and the supporting digital transformation, by ignoring the more holistic needs of the key stakeholders and constituents who start and extend their journeys beyond the self-inflicted four walls of your organization. Forrest proclaims in “Predictions 2019: Transformation Goes Pragmatic”, that 2019 represents a year when “smart” and Digital Transformation initiatives will translate into more pragmatic efforts with the aim of “putting points on the board[1]” (see Figure 1).

Figure 1: Digital Transformation Success will be guided with Pragmatic Approaches
Organizations are being challenged to create smart spaces – hospitals, trains, malls, universities, factories, hospitals, cities – but lack a pragmatic approach that 1) builds organizational and customer consensus around what to expect from “smart”, while 2) providing a pragmatic framework around which to identify, validate, value and prioritize the use cases (and the interaction between those use cases) that comprise “smart.”
“Smart” spaces are comprised of interlocking subsystems that decompose into a series of use cases that are identified, validated and valued from the journey maps of your key stakeholders and constituents
For example, a “smart” city initiative would include energy, water, transit, safety, security, recycling, events management, maintenance and operations subsystems which would decompose into use cases identified, validated, valued and prioritized from Resident, Employee and Commercial Business journey maps (see Figure 2).
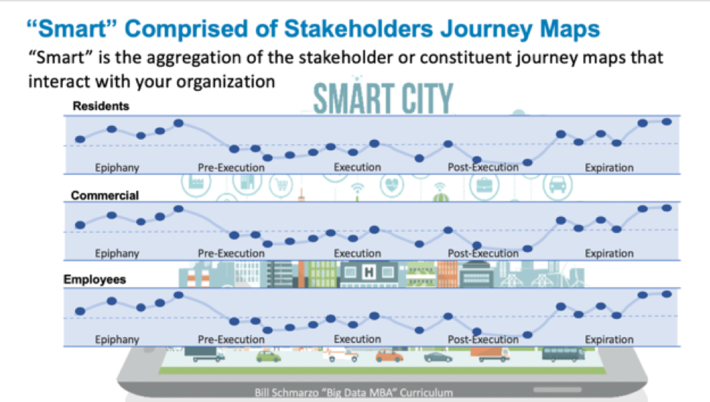
Figure 2: “Smart” is an Aggregation of Key Stakeholders’ Journey Maps
The Digital Transformation Journey Workbook will guide an organization’s “smart” initiative by 1) identifying the sources of customer and market value creation and 2) codifying the organization’s engines of customer and market value capture. The Digital Transformation Journey Workbook will help organizations start, execute and guide their continuously-learning “smart” initiatives, and the associated digital transformation, down the path to success by “putting points on the board” early and often.
Introduction to Digital Transformation
In several previous blogs, I introduced the Digital Transformation Journey (see Figure 3) as a process for:
- Identifying Sources of Value Creation. This is a customer-centric approached (think “outside-in”) to identify, validate, value and prioritize the sources of customer (and market) value creation by leveraging a Design Thinking technique called the “Customer Journey Mapping.”
- Identifying Processes/Engines of Value Capture. This is a production-centric approach (think “inside-out”) leveraging Michael Porter’s Value Chain Analysis methodology to identify the internal organizational capabilities necessary to capture the sources of value creation.
- Identifying Digital Assets. This is the Digital Solution Architecture that fuels the creation, sharing and reuse of the organization’s digital assets (decisions, metrics, KPI’s, analytics, data and apps).
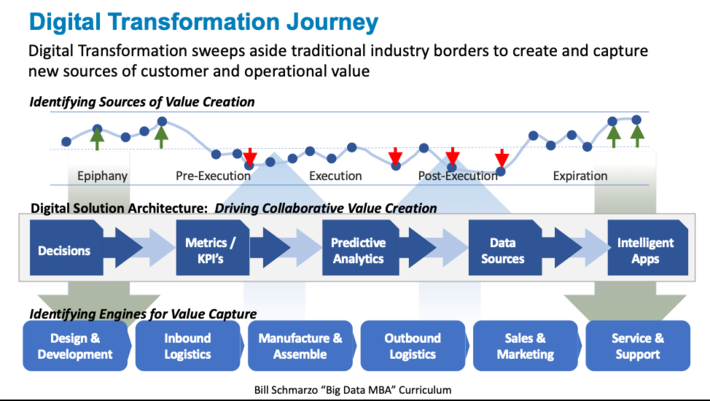
Figure 3: Digital Transformation Journey
See the following blogs for more details on Digital Transformation:
- “It’s Not Digital Transformation; It’s Digital “Business” Transformation! – Part I”
- “It’s Not Digital Transformation; It’s Digital “Business” Transformation – Part II”
- “It’s Not Digital Transformation; It’s Digital “Business” Transformation – Part III”
- “The Customer Journey Digital Transformation Workbook”
I will now introduce the “Digital Transformation Workbook” to identify, validate, value and prioritize the sources of customer and market value creation (use cases) and ascertain the digital assets necessary to capture these sources of customer and market value creation.
Digital Transformation Journey Workbook
The “Digital Transformation Journey Workbook” identifies the digital assets necessary to support an organization’s “smart” initiative. The Digital Transformation Journey Workbook is completed from the perspective of the key stakeholders that either impact or are impacted by the organization’s “smart” initiative (think Personas) and captures the digital assets (decisions, data, analytics, apps) necessary to enable the constituents to complete their “smart” journey and represent the sources of customer and market value creation.
Note: it probably seems strange that I’d designate “decisions” as digital assets, but decisions are the linkage point in monetizing the organization’s data, analytics and apps. Decisions by their nature are actionable, and when decisions are in support of an organization’s key business or operational initiatives, decisions can be a demonstrable source of value. Plus, a superior understanding of the decisions that your key constituents need to make provides a source of competitive advantage.
The Digital Transformation Workbook is comprised of two Design Canvases:
- The Smart Initiative Definition Canvascaptures the aggregated requirements for an organization’s smart initiative including the smart initiatives objectives, value proposition, potential impediments, and the KPI’s or metrics against which success will be measured. The Smart Initiative Definition Canvas also summarizes the aggregation of the supporting use cases and potential “intelligent” app requirements.
- The Customer Journey Design Canvasis created for each key stakeholder (think Personas) to ensure one has a holistic view of the “smart” spaces’ initiative requirements. The Customer Journey Design Canvas captures for each key stakeholder, their “journey” expectations, objectives, key decisions and metrics against which they will measure success across the 5 stages of their “journey”.
We will introduce the Digital Transformation Workbook via a “Smart” University initiative from the perspective of the student.
(1) Smart Initiative Definition Canvas
The Smart Initiative Definition Canvas defines the requirements for the “smart” places or things initiative. The Canvas captures the initiative’s business, operational, customer and society objectives, the potential impediments to successful implementation, the metrics and KPI’s that will be used to measure progress and success, the key stakeholders and constituents, the business entities around which we want to capture and monetize analytic insights, and top priority stakeholder use cases (see Figure 4).

Figure 4: Smart University Design Canvas
The Smart Initiative Definition Canvas in Figure 4 also captures the operational requirements from the perspective of the key stakeholders in the form of “Intelligent Apps”. It is likely that the “smart” initiatives operational requirements and the desired analytics-infused outcomes that students and faculty need will manifest themselves into“Intelligent” apps that provide the predictions and recommendations that guides the stakeholders and constituents’ journeys.
(2) Stakeholder Journey Map Canvas
The Stakeholder Journey Map Canvas defines the holistic customer journey from the perspective of each of the key stakeholders. The Stakeholder Journey Map Canvas includes the objectives of the journey, defining what a successful journey looks like and listing the potential impediments to a successful journey. The Stakeholder Journey Map Canvas also analyzes and determines the stakeholder’s business and operational requirements from the perspective of the following 5 stages:
- Stage 1: Epiphany. This is the moment that the stakeholder is aware that they want to or need to complete a specific event.
- Stage 2: Pre-Execution. This is the prerequisites that need to be completed prior to executing the event.
- Stage 3: This is the actual execution of the event.
- Stage 4: Post-Execution. This is everything required to wrap up after the execution of the event including any assessments and evaluations, and a cost-benefit assessment.
- Stage 5: This is the afterglow (event evaluations, social sharing) that occurs some period after the completion of the event.
Then for each of the 5 stages, we will capture 1) a description of that stage, 2) they key decisions or outcomes the stakeholder requires of that stage, and 3) the metrics or KPI’s which will measure stakeholder progress and ultimately a successful journey. The Stakeholder Journey Map Canvas will summarize the stakeholder’s operational requirements in the form of an “intelligent app”. The “Intelligent” apps requirements include the predictions and recommendations that the stakeholder needs to support the successful completion of their journey (see Figure 5).
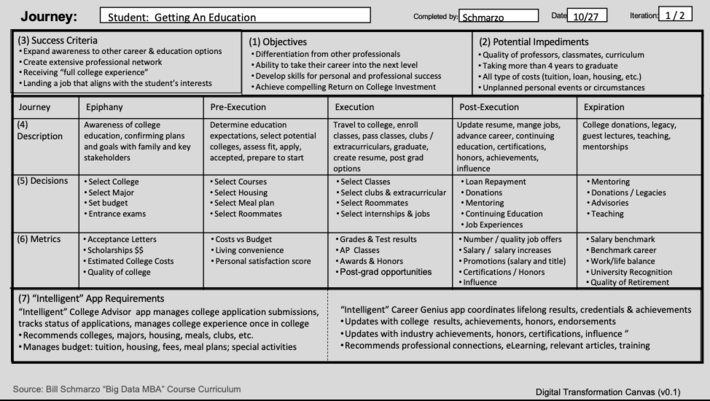
Figure 5: Student Journey Map Canvas
Creating “Intelligent” Apps
I’ve mentioned a couple times that the ultimate deliverable from the Stakeholder Journey Map Canvas are the intelligent apps that provide the recommendations that guides the stakeholder’s successful completion of their journey. Whether is supporting a family buying a home, or a person buying insurance, or a technician supporting plant operations, or an engineer building a car – the ultimate deliverable in these stakeholder journeys is to leverage data to provide analytics-infused recommendations that supports the successful completion of that journey.
Continuing our Smart University example from the perspective of the students, we identified two “intelligent” apps that would support the students’ more holistic, lifelong educational journey.
1) “Intelligent” College Advisor app (see Figure 6) which manages a student’s college application process and helps to manage college experience once in college including:
- Recommends potential colleges based upon the student’s interests and high school achievements, manages college application submissions, and tracks status of those applications
- Recommends majors/classes/lectures, housing options, meal plans, clubs, etc. based upon the student’s interests and college achievements
- Manages in-college budget including tuition payments, housing, fees, meal plans and special activities or events.
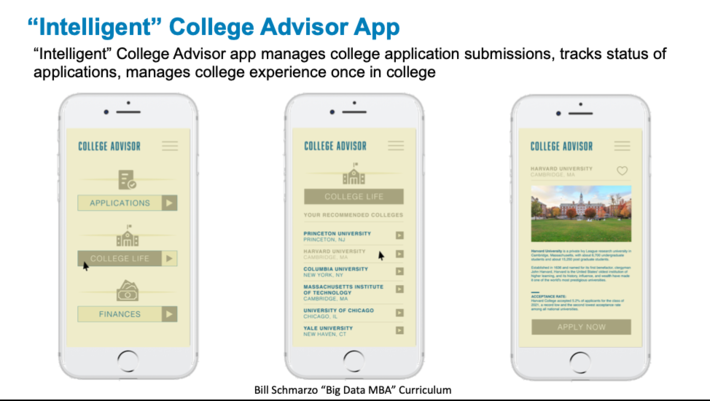
2) “Intelligent” Career Genius app coordinates one’s lifelong educational needs including:
- Updates with college results, honors, letters of recommendation and achievements
- Updates with job promotions, achievements, awards and honors (and no, achieving United 1K is NOT an achievement!)
- Updates with industry achievements, honors, certifications, achievements, endorsements, conference presentations and social influence
- Recommends professional connections, eLearning, relevant articles, training

Figure 7: “Intelligent” Career Genius App
Digital Transformation Workbook Summary
I plan on the further exploration and validation of the Digital Transformation Journey Workbook while teaching and lecturing at the National University of Ireland – Galway next week. I want to incorporate the perspective of the faculty as well as the students when I test this methodology. And eventually, I hope to find a couple of customers with whom I can test this methodology to combine digital transformation and customer journey maps to create “smart” spaces (Michael? Doug? Kevin?)
My hope for this workbook is that it cannot only provide a more holistic view of the requirements for “smart” by looking at it from the perspectives of the stakeholders, but can also make the initiative more actionable or real with the articulation of the analytic needs to support the creation of “intelligent” apps that guide the stakeholders’ through their related journeys.
[1]“Putting points on the board” is a sporting analogy for sports such as basketball, soccer or football that seek to win their sporting events by outscoring their opponents earlier and more often; it’s hard to win these sporting events if you are relying on scoring all of your points at the end of the game.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The latest release of Kubernetes, version 1.14, was released with production-level support for Windows nodes. The release also includes the addition of kustomize in kubectl, the kubectl plugin mechanism being moved to stable, and improved documentation for kubectl. This first release of 2019 has 10 features in total being moved into stable.
This releases sees Windows support being moved out of beta into full support. This includes being able to add Windows nodes as worker nodes and scheduling Windows containers. These improvements include support for Windows Server 2019 and as well as out of tree networking with Azure-CNI, OVN-Kubernetes, and Flannel. This brings Windows support for pods, service types, workload containers, and metrics to be more on par with what is offered for Linux containers.
Included in this release is the addition of kustomize, a declarative Resource Config authoring tool, into kubectl. Kustomize can be triggered either via the -k flag or using the kustomize subcommand. Kustomize allows for authoring and reuse of Resource Config by creating variants of a configuration using overlays that modify a common base configuration. Kustomize will continue to be developed in its own, Kubernetes maintained, repo and will be updated in kubectl prior to each Kubernetes release.
The kubectl plugin mechanism has also moved to stable as of this release. The plugin mechanism allows for publishing of custom kubectl subcommands in standalone binaries. This release sees the mechanism simplified and now modeled after the git plugin system.
To extend kubectl with a custom plugin a standalone executable file needs to be placed somewhere on the user’s $PATH. The executable must have the kubectl- name prefix, with the name suffix serving as the command name. For example, a plugin named kubectl-foo would be triggered by running kubectl foo. Note that plugins cannot overwrite nor enhance existing kubectl commands. Plugins can be written in any language or script that allows for command-line commands. A Go utility library has been created to assist with common plugin related tasks.
According to Aaron Crickenberger, senior test engineer at Google,
The thing I’m most proud of is that this release has the most stable enhancements of any release of Kubernetes. You have heard people talk about Kubernetes focusing on stability and maturity, and I think you’re starting to see the results of that play out with this release.
Other notable improvements in this release include:
- The documentation for kubectl has been rewritten to focus more on managing Resources using declarative Resource Config
- Locally attached storage is now available as a persistent volume source
- Process ID (PID) limiting is moving to beta. It is now possible to provide pod-to-pod PID isolation by defaulting the number of PIDs per pod
- Node-to-pod PID isolation by reserving the number of allocatable PIDs to user pods is now available as an alpha feature
- Pod priority and preemption allows Kubernetes scheduler to schedule Pods based on importance and also remove less important pods when the cluster is out of resources
- Pod Readiness Gates provide a point for external feedback on pod readiness
- Discovery has been removed from the APIs which allow for unauthenticated access by default.
Kubernetes 1.14 is available for download on GitHub or can be installed using kubeadm. Starting next week the Kubernetes blog will have a five part walkthrough of the major components of this release.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Podjarny: Thanks for coming back into the session. We’ll talk about the three phases of DevSecOps, and like the first talk in this track, not sure if you’ve noticed, I also have over 100 slides to get through in 40 minutes. So just brace yourself. A few words about me. I’m Guy Podjarny or @guypod [on Twitter]. I’m the CEO and co-founder of Snyk. If you haven’t heard of us, come check us out in the booth. I previously founded a work performance company called Blaze, it was acquired by Akamai, was CTO there for a bunch of years. In general, I’ve been in the security space since about ’97, and been working on Devops and Performance, member of the Velocity Programming Committee and the likes since about 2010. I’ve been doing a lot of this type of writing, speaking, and the likes.
What are we going to talk about? We all love DevOps. If you don’t love DevOps, you’re welcome to leave. Otherwise, we probably all love DevOps. But why? Why are we doing this? Come back a little bit to the core principles about what drove us here in the first place. There are a million definitions here, I’m going to choose mine. It’s totally self-serving here, which is, fundamentally, we use DevOps because of the speed. We use DevOps because it allows us to deliver value and adapt faster to market needs, faster and at scale. That’s the core principle, whether it is about efficiency internally, whether it’s about user value, understanding from a statement, from a customer to be able to deliver it to that person, or if it’s adjusting to market needs, because the market changes on us all the time in part because of DevOps technologies, and we need to be ready for it.
But what does doing DevOps mean? What is doing DevOps? Once again, google that and you’re going to get 70 different opinions from 50 people. I’m going to choose a specific trial here that says, when we talk about DevOps, you can split up what’s doing DevOps is into three core buckets. When somebody says they’re doing DevOps, what do they mean? They’re roughly in order of evolution- and I’ll use this as the scaffolding here for the rest of the talk- which is DevOps technologies, containers, and the likes, cloud, etc. DevOps methodologies, microservices, continuous integration, changing how we work. And last but not least, DevOps shared ownership, the idea that DevOps breaks the barriers, that it’s not something you throw over the wall, that it’s everyone’s problem to operate the software and it’s everybody’s responsibility that is of high quality.
Using this foundation, what does DevSecOps mean? DevSecOps is this buzzword that I sort of love and hate. I love it because it represents emotion that I believe in around changing the way we do security. I hate it because a buzzword cannot contain nuance. Everybody now uses it for all these substantially different purposes. We’re rolling with it, it’s the term as you are, just like DevOps is a very imperfect term. When you think about this, I’ll use the same formats to guide us through how do we think of a DevSecOps as, first, securing DevOps technologies, second, securing DevOps methodologies, or, rather, embedding security into DevOps methodologies, and again, last but not least, the notion of security or including security as part of this DevOps shared ownership. And hopefully, I give you some tools by the end of the talk to be able to assess somebody saying, “I’m doing DevSecOps,” or a thought of, “I want to do DevSecOps,” and maybe split that up into things that are a little bit more useful.
Securing DevOps Technologies
Let’s get going. Let’s start by talking about DevOps technologies. DevOps created a whole slew of these new technologies. Some of them they created. DevOps, this movement, just popularized the use of open source. It was there for many, many more years. But with this motion, it accelerated. It accelerated substantially. So cloud, containers, serverless more recently, open source libraries and component, the fact that we assemble software today, versus build it or write the code, a lot of these different technologies.
That creates two types of problems for security. Again, simplifying. The first problem is fairly technical, it’s fairly administrative, which is, security solutions oftentimes just simply don’t work in these new surroundings. You can’t just take the problem. The threats that they’re addressing are still relevant, but they just technically do not operate in this new setup. Let’s give a couple of examples. Web app firewalls. Who here uses a web app firewall? Fewer people than I would have hoped. Hopefully, some of you are using web app firewalls and just don’t know it. So web app firewalls sit in front of your application and they try to block attacks, somewhat successfully and sometimes not. Sometimes they block legitimate traffic. But as a whole, they try to block attacks that come into a site.
This is a visual from Imperva, maybe the leader in web app firewall, at least in the appliance side. It traditionally has been an appliance, maybe a VM, instead of an appliance that you put in front of it. That worked somewhat well, the Firewall and the web app firewall, but it really broke down when you start talking about cloud. How do you protect? In general, this is true to the appliance model, and specifically to a bunch of these appliance security controls, when they sit in front of an auto-scaling web application. How do you address that? I’m starting from the easy ones. Simple, right? Very easy to solve. This is an actual diagram from the Imperva website showing how you auto-scale the firewall. We joke a little bit, but these architectures are indeed fairly elaborate. But the one solution for that is the immediate, the very clear revolution, which is, “I’m just going to do the same thing my application does, and I will auto-scale in front of it.” And then the very same company actually also introduced a different solution, my clicker here in borderline, a different solution, which is the notion of introducing this as a service, so a different way to address that the cloud is to move to the cloud, to move your own services to the cloud, and then put yourself in the line of fire. So this is Imperva.
This is one way to adapt, it’s the same functionality. You still need a web app firewall as much as you needed a web app firewall in pre-DevOps and post-DevOps, but you need a different way to apply it. Because this new model comes in around being in the cloud, then that actually opens up an opportunity for other players that are already in the cloud and already knew how to be in the line of fire to your site to introduce capabilities, and then today, you actually see that in the web app firewall industry, some of the leaders are actually the CDNs, the Akamai, Cloudfare, those players that were already proxying your site, and now they can add this layer of protection which before wasn’t perceived as really the right place to deploy it.
So that was one aspect of cloud. Another troublemaker in the world of security and when it comes to DevOps technologies, is containers. Containers are very disruptive. They sit squarely in the twilight zone between application and infrastructure. I’ll give you a couple of examples about why containers cause security people some grief. One is endpoint protection. Endpoint protection is the broader term for an antivirus and malware protection and anti-exploits. Containers can be exploited just like everybody else. They don’t have superpowers, they can be exploited. If they’re exploited, you want to know. You know to know if there’s a virus on this, you want to know if it’s malicious. And yet, existing endpoint protection systems are very much designed to sit on baremetal, to sit maybe on VMs. They’re not really designed for these elements.
How do you do this? How do you identify malware or a virus inside your containers that we think about from a dev angle? So once again, adaptation. The web app firewall example is something that the industry has already embraced. This is more a work in progress for the industry. But you can see things like. This is Symantec, which is one of the leaders in endpoint protection. They introduced this cloud workload protection that has an agent that sits on the host machine of the containers. When you start getting into cloud situations, when you don’t have the host machine, you’re just running a container on some cloud platform like a Fargate or such, they’re a little bit in trouble. But it is adaptation. They run those and they scan them.
A different problem containers create from a security perspective is, how do you patch your servers when your container is so ad hoc and disposable? Patching servers is a very important practice today. The vast majority of exploits or of breaches happen because you have some system and it’s been unpatched. I say today, but really, for the last decade or two, that’s been the case. Unpatched servers are the primary cause for breaches. And yet, when you move into this container land, suddenly, it’s developers that push this container and it has the OS on it. The IT person or the person operating the servers, if they’re already an entity that is separate, sits there and says, “Okay, I found a vulnerability, what do I do?”
Suddenly, patching the system, even logging in and all that, is outside of their purview. It’s not something that they do, it’s development that does it. So this is happening right now where there’s a sequence of solutions that are able to adapt to this, it’s the same action around scanning an image. I used my own solution here in Snyk, but, really, there’s a sequence of them, there’s Clare, there are a bunch of commercial solutions out there that can scan an image and find vulnerabilities; the same scan that you might have done on your infrastructure, but now, we just adapt to running in a different surrounding, run on the container image.
The first challenge that we have is that security solutions that are logically valuable in the DevOps context need to adapt to the surrounding, and if you are using those technologies, you have to think about just being able to map out what are the security concerns, and apply them to your surrounding. This is one problem with DevOps technologies. The second problem with DevOps technologies is new risks that these technologies introduce. Every technology has pros and cons; they introduce strength, and they introduce weaknesses. That’s just it. It’s an axiom, it’s a truism.
Let’s take a look at a couple of those. Maybe the one that hits the news the most is these unsecured buckets. It’s not a brand-new problem from DevOps. You could have had public facing storage that was unsecured before cloud, but you didn’t, but now we do. We have tons and tons of them. That lends to a whole bunch of stories. Let me show you a couple, just because it’s fun. Uber. It’s so much fun to so pick on Uber in a security conference. Unfortunately, or fortunately, they give a lot of room to work with. In 2016, attackers accessed the details of about 600,000 Uber drivers, and some professional info- could be fairly sensitive professional info- of 57 million Uber users in the U.S. That’s pretty much anybody using Uber at the time in the U.S., and they leaked that information.
How did that happen? Well, a developer pushed S3 tokens into a private github.com repository. So they’re on the cloud in github.com. Somehow, we don’t know exactly how, attackers gained access to that repository, and went on to steal those tokens. There’s a side story here, which is Uber tried to bribe those people, pay them $100,000 through a supposed bug bounty program, tried to keep them silent. It’s a whole story here, less relevant to our talk, we’re going to keep that out. But basically, a developer pushed the token. This is actually a slightly better version than what happened to Uber in 2014, which is that a developer, hopefully, a different developer, pushed a secret URL to a public repository, public gist in this case, which was found and only 50,000 drivers’ information was leaked then.
You had an access key? You were lucky. I don’t know how many people get the Monty Python reference here. But at least they had an access key. If you look at the news, there’s a whole bunch of cases where there really wasn’t an access key at all. If you see Accenture, you see medical data, you see governmental data, these things just happen, it seems like we get desensitized to them. Just every week, there’s some bigger and bigger blow. Michael showed those are the beginning. This is a problem that has been amplified by the world of Devops and we have to address it. We have to address the security risk and introduce security solutions that monitor it.
A very close cousin to this problem is insecure configurations. We launched these databases, we launched very easily, Elastic, Mongo, a variety of others, and we need to secure them. They might be insecure. We see, once again, a whole bunch of these types of stories. I was waiting for the last minute to add to these titles, because I knew there were going to be some fresh ones. Dow Jones just now had 2.4 million high risk individuals, risk of fraud or money laundering and the likes leaked through an insecure elastic database. A very similar elastic database was also leaked from Rubrik, which is a big data backup- something ironic about it, you know, data backup system- that has exposed this database repository outside. And then not to pick on Elastic, there were actually 28,000 public instances of Mongo that were found a couple of years ago through Shodan, through the search engine, that exposed information, just used credentials that were the default credentials, and were exposed to the web.
These are types of problems that are new risks, and you need new security solutions to address this. Indeed, you see a couple of solutions come up. On one hand, you see cloud security configuration solutions that statically scan them. CloudCheckr is one example of it, I have a slightly grainy picture of them over here, that would scan your config and would find cases that you are indeed insecure, so you need to apply. If you’re going to use cloud configuration in mass, you need to apply those solutions. Then a different angle to the same problem comes from an expansion of an existing practice, which is scanning outside. Who here has heard of Nessus? Okay, some good hands. Nessus is a very old and true and awesome tool, that is an open source tool, that can scan a system and find problems by probing it to say, “Hey, do I see this thing installed? Maybe I tried to get in.” Tenable has a slightly more cloud-oriented, slightly broader version of that. I use Tenable and CloudCheckr. I’m really just using examples. Each of these things is a subset of an industry.
So this is cloud, it’s an example of a new security risk. You don’t think I’m going to continue without containers. Containers introduce their own world of security risks. Maybe the one that is most well-known is that of sandbox escaping. Containers are awesome. They’re very lightweight. They’re very quick. A part of the reason they’re so quick and easy to work with is because they’re not really, really fully isolated. Unlike a VM, they do leave some collaboration, some sharing of resources between containers that run on the same host. Then your risk is a malicious container, or a compromised container, jumps up to the host, and is able to affect neighboring containers. If that was a cloud instance, and a compromised container was compromising your own container, you wouldn’t find that so funny, right? It’s not something you want to do. We just had a recent reminder of this with a serious runC vulnerability, which kind of runs the container, that indeed did precisely that. It allowed a vulnerability that was very widespread in all those cloud providers as well, that allowed a malicious container to break out into the host, and get some group permissions on the host.
Once again, a whole set of companies come along, these are slightly more complicated problems. You actually see more startups kicking into the space, as opposed to adaptations from the bigger companies. As problems get more complex, it tends to be more startup realm than it is established companies. Twistlock, Aqua, and TrendMicro is veering into that. That’s probably the biggest company that I’d point out is making good strides here.
To summarize security, DevOps introduces all these different technologies, and these technologies create security challenges. When you think about securing the technologies, you have to think about two aspects. One is look at the security solutions you already have in place and think about whether they are still relevant in the context of DevOps and how do you apply them. And second, is think about these new technologies, and think about the security risks they introduce and think about what security solutions you want to apply there.
Security in DevOps Methodologies
This was technologies. Let’s go on to methodologies. DevOps also changes methodologies. If you haven’t noticed, the number of times people said microservices, and this like, microservice and CI, there must be some word bingo, buzzword bingo here, right? How many times does CI get told on the keynote? So let’s indeed look at these problems. I’m going to try the clicker again, see if it works for me this time.
CI/CD. So CI/CD is very interesting for security when you talk about security pipelines. In concept, it is a positive thing. It allows security automation. In practice, it’s harder. Let’s dig in. Security, conceptually, has worked in this methodology of saying, “These are the points in which I will audit. You run, you build your software in this waterfall model. Even if you are sort of forward-thinking and that point of time was not just before you ship, there were points in time in which you stopped and I will audit. So pause here, give me a couple of weeks, I’m going to audit.” And that’s really never been an awesome idea. But that’s been the way that security works. In fact, it still works in many places.
In CI/CD, you can’t stop, it’s continuous. That’s the whole notion here, there is no stopping, it just rolls out. The solution for that, conceptually, is CI/CD. It’s actually the same element, which is introduce automation in a continuous fashion that does security testing. You want this to be statically done and dynamic. You want to be able, from a security mindset, to explore the things that are being built as well as the systems that are being deployed that works, that is a solution kind of. So let’s dig into the three primary security capabilities that are actually being put into CI/CD.
The first one is static analysis. Static analysis means scan your code, it does something called taint flow analysis, which is it tries to theorize how data flows from a source, like a form field, through your database to a security sensitive sync, like a database call, and see if it hasn’t been sanitized in the process. It finds vulnerabilities, scans your code, finds vulnerabilities. Conceptually, great. Wouldn’t you want to just throw a thing, scan it in the build, find the vulnerabilities, and you’d fix? This isn’t same as a linter. Except security scans, static analysis, takes hours to run, hours or days to run, depending on the size of the code base. These are the modern tools that take that amount. Builds don’t take hours. If you introduce something that takes 10 minutes into the build, generally, there will be some outcry. If you introduce something that introduced hours into the build, the whole notion of a blameless culture might go out the window. There might be some challenges involved. So, this industry had to adapt, they started at a good place of automation, they had to adapt.
How do they adapt? Fundamentally, incremental scans. You run this massive scan over the weekend, that still takes its couple of days to run. But then what you do in the build is you run smaller scans that only test the Delta. These scans are not as comprehensive, but they’re good, they still would find some issues. This is static analysis. Side note, but important side note for static analysis: static analysis still has the challenge of the fact that it reports many, many, many false positives. So at the end of the day, running a test that is just flawed, that doesn’t give you the run results, is not great either. And that is a different challenge that static analysis industry is facing right now.
So this is SAST. These are Gartner names, so apologies. DAST. Dynamic analysis, used to be called black box testing, is a different type of slide that I meant to animate. Assume these are bullets in automation. What does it do? It’s like an automated hacker. So you launched it against a running system, and it would go off and it would test as a black box, it would start probing it and trying to see if you can break in, run some SQL injection payloads, run some cross-site scripting payload. DAST, again, conceptually is automation, it’s a positive thing you want to run it. It should be a runnable in the build, but has two challenges. One, it requires a dedicated environment to run against. Some of you probably have a running environment where you run the build, and you deploy an environment and you test against that environment. That is something everybody wants to have, and most people don’t have, or most pipelines don’t have. That’s a challenge. And once again, it’s very, very long. It’s very, very long to complete.
What’s the adaptation here? All in all, don’t use DAST. It’s the adaptation that is happening, it just doesn’t get embraced into CI/CD too much. But maybe a slightly smarter way that is still finding its way, is this notion of IS, interactive application security testing, which means you instrument the application, you run your unit tests, and then the tool tries to deduce from what has been found whether there’s a security flaw or not. It learns your application through your unit tests, and then it just applies a security perspective to it. It’s not exactly DAST, but it’s similar. It’s less comprehensive, but it works within your unit tests that you’re already running. So very imperfect, this space is really struggling with these methodologies, but it might work.
In DAST, there’s an interesting alternate approach, which, as I said, like DAST is very much adapting to the space from a company called Detectify, that I kind of like their approach, which is they said, “You know what? It’s never going to be fast enough to run into build, you’re never going to have these environments that are your own. What we’re going to do is we’re going to be able to test your production or your staging environment as is.” So from the build, you kick off a scan from your build, but the scans come in at a band. They come async afterwards. We scan the application that has been deployed by your build system. That’s interesting. Pros and cons to it, just sort of sharing, I guess, the perspective that the industry is trying to do.
Then the last one that people do in the build is this SCA, software composition analysis, or scanning for open source vulnerabilities. This is the one that actually you see more adopted. I’m a little bit biased because this is the space I live in. But it’s just one of those things that is, indeed, more DevOpsy in its mindset. It’s a fast scan that explores which open source libraries you are using, and tells you if they are vulnerable or not. You might break the build if you find a library that has a vulnerability or some license problem. It’s fast, accurate, it’s kind of naturally CI/CD friendly. The number of conversations is like, “Hey, can you also do this for SAST?” That has been the sample of success. And now you’re trying to say, “Can I apply those other technology in a similar fashion?”
CI/CD is maybe the pillar of what is DevOps technology, what is DevOps like. What’s the one tech that really enabled – actually, I don’t know, maybe cloud, it’s hard. It’s definitely one of them, one of the key technologies that are there in DevOps. Another one that is very key, that amazingly has been marked as the sort of early or late majority in the slides this morning is microservices. What do we care about for security for microservices? Well, when you talk about security, monoliths are really convenient. They have a clear perimeter; their flexibility is limited. There’s a controlled flow, there’s this set of inputs, and there’s this set of outputs, and you might have a mess inside, but I don’t care. There are inputs and there are outputs, and the deploys are done in this one full unit that can be audited, and they can be tested.
Microservices are a mess. That’s generally true, but specifically, that’s true from a security perspective. Suddenly, there are all these disparate entities, they get deployed independently, what the hell is a perimeter at this point? The flow can change, data that yesterday went through these services today would go through these services. It’s a mess from a security perspective. You need solutions. You need some ways to address it. We’re getting into a world where my examples of what the solutions are, are increasingly thin, because it’s a world where the security world is slower, it’s more behind, but you see solutions like Aporeto’s monitoring of different microservices. So starting to say, from a monitoring perspective period, and security monitoring specifically, can I track data flows across those microservices and secure them? If I learned those, maybe I even apply some AI to it to understand what is normal, and I will flag anomalies. So just understand that you have to accept it and look in line, and also try to visualize that to the user.
A similar challenge happens with the deployment side. Before, you would have these wholesale deploys, and then in those wholesale deploys, you can install an agent that will do that type of monitoring. Today, as we talked about, developers deploy some Docker file, it has a bunch of content inside of it. You have to adapt your installation, some mundane bit, but it’s critical for its success. You see Signal Sciences, which actually do a lot of cool things. They just don’t have a lot of great screenshots for me to share here, around adapting to DevOps. One of the things as they say is, “Okay, install this agent, install the monitoring agent from a security perspective that they still require as a part of your Docker file.” Copy and contribute. So it means it’s a natural part of your application, at least the installation bit.
Security solutions have to adapt these new methodologies in order to stay relevant. The good news about these methodologies is that they also offer an opportunity. There’s this general conversation that happens around, is DevOps good for security, or is it bad for security? Oftentimes comes down to this- everything I described up until now was pain; it was the negatives from a security perspective. But these methodologies also present an opportunity to improve how we work. Let me show you some examples. Maybe the best example is around response. If you have this big VM, and you detected malware, what do you do? You have to alert things, you have to start containing things and all that. If it’s a contender, you just kill it, you know? You remove it, remove it from the equation, and the new one would spin up and unless your origin is malicious, that new one would not be compromised. That’s awesome. That’s a solution that is far more powerful than what we could do before. And indeed, Aqua, Twistlock, all these companies, when they do Sysdig, which is Sysdig Falco, which is an open source version of it, they do precisely that when they catch a violation.
Continuous deployment means faster patching. How many people here in this room had to handle the red carpets deploy when there was a problem? There’s a serious problem. Not many, but maybe the term is a little bit different. But there was some severe problem in production and you had to do an out of band deployment to get a thing deployed urgently, because there’s this severe security vulnerabilities. Now, guess what? You have a pipeline, it just goes straight to production, it is the paved road, so you want to embrace those. It makes us fast, it makes security teams fast.
As we talked about before, CI/CD is room for automation. There’s all this desire in security teams to apply constraints, to apply policies to be able to embed some of these security questions and necessities inside of our development process. CI/CD opens up the door to do it. It’s a home for this type of security testing. It’s great in that sense. Then maybe a slightly more modern version, which I’m personally a big fan of, is this notion of GitOps. When you talk about pipelines, many people in this room might have 15, 20, 100 different pipes or pipelines, different systems, different people run them, I don’t know how it works. Increasingly, those same organizations must have consolidated on a single GitHub, Bitbucket, Azure DevOps, one of those environments, GitLab, and more of those applications are actually running on that or are moving towards that single element.
GitOps or Git, actually, all these platforms of Git, most of it is not in the core Git protocol, actually allow us really interactive controls. They allow us to fail pull request. They allow us to open pull request with fixes and recommendations. They allow us to leave comments. So you can build automated or not automated security tools to just use that source as a review. I think security GitOps would be a big deal moving forward.
To summarize, security for DevOps methodologies is around, one, adapting, again, the existing security solution so they’d be able to run in these environments. You can’t just throw them out the window. They are valuable tools. You can, but you’d be exposed. The security risks that they tackle are real, and they’re just as real in this new world. But you have to adapt to them to these new surroundings. Then the second thing that the methodologies open up is opportunities, and you don’t want to just be chasing your tail. You also want to be looking forward and saying, “What can I do better now than what I did before?”
Include Security in DevOps Shared Ownership
The last section is, when you pause to think about everything I just described, a lot of that was also relevant for virtualization, for mobile security, those trends have also changed a lot of the technology stack and required security tools to adapt. But one of the things that’s interesting in DevOps that hasn’t happened as much in those others is this notion of shared ownership, is the changes to people, is the changes to culture.
That gets me to the last bit, which is maybe the most important one, which is the notion of including security in DevOps shared ownership. Let me tell you a story here. It sounds like the rabbit and the hare, or whatever, the turtle and the hare. The Syrian Electronic Army and the Financial Times. This is a story of an attack that happened a few years ago. A bunch of employees at the FT started receiving these phishing emails that had some seemingly CNN link that was actually a false link, just an HTML link that led to an attacker-controlled website. A subset of people clicked it and got redirected to some spoofed FT single sign-on page, a page that looked like the FT single sign-on page that was started, I think it was a Google single sign-on page, and a subset of those entered their passwords.
So some people at the FT get phished, and now they had their passwords. The attackers used those compromised accounts, and they emailed similar phishing emails from those FT addresses to other FT employees. Now you have better credibility because it’s coming from an internal FT address. They also adjusted them a little bit to the internal usage of it. So more users got compromised. This is my favorite part. IT finds out and they send this email to everybody that says, “Don’t click these links, you need to do it …” The attackers see the email, they’re in the inboxes. They see the email, and they send an identical email, an identical email. So it’s like you got the email twice. But if you click this one, it basically gets you to the attacker website. Genius.
Long story short, there’s been more evolution here. But long story short, the attackers gained access to a whole bunch of official Twitter accounts and blogs, they just wanted it for vanity, and to make statements, and the FT, being kind of a true journalistic entity, actually chased them down and wrote a story about this hack later on. But most of this information we know because of a great blog post by Andrew Betts, who’s a brilliant guy and a very security-conscious developer, maybe the most security-conscious developer I know, who wrote this post called “A Sobering Day,” well-named. It talks about how he was one of those people that got compromised. To an extent, he was actually a highly privileged user because he’s a developer. He’s a developer in a DevOps shop. So he has access to systems, he has access to a lot of things.
He writes in this post that “Developers might well think that they’d be wise to all this. And I thought I was.” When we think about this Nigerian prince scam, or these spelling mistakes written email, we don’t think about an email that looks like it’s coming from our IT department but is named – the email address is different, right? In fact, I interviewed this lady called Masha Sedova who used to run security education at Salesforce, and they ran this phishing test across Salesforce, and she was just sharing, who came out worst or best in it, the worst group was marketing. And before you laugh too hard, the second worst group was developers. To an extent, marketing can be excused, because it’s kind of their job to explore and to click all these links. They send the links as well. And developers, really generally do this because they think they’re better. We think we’re better, we think we’d be smarter, we’d identify the problem.
So in this world of DevOps, compromising a highly privileged developer is hitting the jackpot; that is a very, very good target for an attacker. You have to remember that DevOps makes developers more powerful than ever. You couple that with the fact that the pace of shipping code is skyrocketing. Also, with a very, very routine access from developers into production systems, into user data, you take all of that and you add to the fact that in a typical organization, there are 100 developers to 1 security person. I’m not sure about the 10 ops in there, there might be fewer ops per developer, but 100 to 1 is oftentimes a generous rate, definitely when you talk about application security. And you get to the inevitable conclusion that as developers, we cannot outsource security. You can’t have it be another team’s problem. It is core; nobody else can keep up, and that is just going to get more and more true.
What do we do about it from the context of DevOps? Well, first of all, the good news. We actually ran this survey and asked a whole bunch of developers, it’s dominantly developers that filled in the survey, and said, “Who’s responsible for security?” The biggest number was us. The biggest number was developers, 81% of the survey consensus thinks that developers should at least co-own security. You can see that the numbers don’t add to 100%, it was a multi-choice element, and developers is the one that really shine to the top. The other bit that came out is that 68% of users feel developers should own security in the container world, security responsibility of container images.
The intent is there, the responsibility of people feeling like they should do this, but there are two primary challenges. One is the tooling. Security tools are generally designed for security professionals. I know I’ve built some earlier on, AppScan and AppScan Developer Edition. It had developer in the name, but it wasn’t really for developers; it was an auditor tool integrated into Eclipse. So from a security perspective, we need to understand that integrating a security tool into IntelliJ- at the time it was Eclipse- doesn’t just make it a developer tool nor does running it in Jenkins. That doesn’t make it a good developer tool.
What does make a good developer tool from a security perspective or a developer tool in general? Well, great documentation, like that of Auth0. It’s not really a security solution, it’s a functionality solution. It’s about authentication, that a security conscious company that has amazing self-serve documentation. On that note, the ability to run things self-serve, like HashiCorp, Vault, which have great open source self-serve tooling. This is very much a security solution. This is a secret management system. And if you’re not using it, well, maybe you’re using one of the KMSes, but unless you’re doing that, I think it’s a very good choice.
It’s around educating for non-security experts, or PagerDuty on its own right, not necessarily a security company, but they do a lot of incident responses, including being used a lot for security purposes. When you look at the good developer tools, they have a lot of education out there that caters to people that have the typical developer knowledge. They don’t push content out there that assumes you’re a security expert. They push content out that assumes you’re a developer or you’re familiar with dev technologies, and they explain to you how to handle incident response, including security in it.
Then my favorite is actionability. Generally, a developer’s job is not to find issues; it is the fix them. That feels so trivial, except all security solutions just find issues, they just create work. Then you’re surprised that people hide under the desk when you walk around with this sort of bulk of issues that they need to fix. It’s not the mindset. The mindset should be one that helps fix the issues. You want to find or build, depending on whether it’s tools that you’re providing to your team, or vice versa, the security tools the developers will actually use, will actually embrace and consume it.
The second challenge, which is maybe the biggest challenge, is one of adoption. How do you get developers- the first one was more the onus on the security industry, how do you get developers to embrace security and security to embrace dev? Unfortunately, I don’t have a one, two, three list over here, but what I do have is some advice for people who know better than I do. I have the pleasure of running “The Secure Developer” podcast, and I’ve had some great people on the podcast that run security teams that have modern approaches to security, or that work with very modern developers.
I’ve picked a handful of them to just quote a few examples of how do they do it, how do they get their dev teams to embrace it, or vice versa? I have four of them. The first one is PagerDuty. I had the whole team there, Arup and two other folks. Again, these are hour-long, 30, 40-minute podcast. I hope you enjoy them if you go check it out. But I was saying, we have a phrase we like when our security team, which is, “We’re here to make it easy to do the right thing.” Their goal is ease of use. I love that notion. There’s how much you care about security, and there’s how easy it is, and you just need to make it easier or how hard it is. You just make it easier than how much you care. You can inch up how much you care, but you can really draw up how easy it is. One of the things that they do for that is that they actually treat security problems as operational problems. This is true to what they’re using the product as well. They use Chef, Splunk, AWS tooling and their own PagerDuty tooling to do that. So that’s good advice there.
Other advice comes from Optimizely. Kyle Randolph who was, I think, their first security hire, talked about giving out T-shirts. So they actually look at developers that do good things and they have this security hero T-shirt. Had Zack from One Medical talked about hoodie-driven security. They have hoodies that they give that are sort of a similar notion. They’re very exclusive, they’re high quality, and it makes people want them. Just sort of a simple social incentive. Once again, he makes a comment that is similar to that a PagerDuty, which is, they use a lot of Spinnaker as a security tool which is not a dedicated security tool, but it is very useful for them.
The New Relic CSO talks a lot about teams. He almost talked about the negative sentiment that you can do with this. He says you can turn off a developer very easily if you give them unactionable information, or something that they don’t understand, or don’t know how to fix it. So basically, if you just make it work for me, I generally don’t want to hear from you. It’s just that’s a natural human response. If you’re just creating work for me and you’re not helping me, you’re not my favorite person. That’s just a natural sentiment.
The Slack CSO, Geoff, talked about org structure. This is more a lesson for dev teams, maybe. Security was this delegated IT part of the company and actually moved to be a first-class citizen of the engineering organization. There, they can affect change much more effectively. And then the second thing he talked about was more the community bit and the Slack team and a bunch of others now, but I think they first started sending cakes and cookies to other competitor security teams that suffered a breach or in some tough states, just showing some solidarity, which I think is amazing.
So you want to look for ways to engage developers in security and vice versa. I’m kind of running out of time here. Just to say, including security in this DevOps shared ownership means, one, on the tooling and the tech side, find tools developers would actually use. And second is look for ways to engage developers and security and vice versa. To summarize, DevOps is all about delivering value and adapting to market needs faster and at scale. We do it for speed. And if you don’t address security, that’s going to get in your way, it’s going to nullify all of this value. What you want to do is you want to secure DevOps technologies, methodologies, and include security in this shared ownership.
Just to summarize what I’ve shown before, technologies imply adapting the existing security tools to these new tech stacks, and finding the new risks that they introduce and doing something about them. Methodologies means, once again, adapting to these new methodologies, but also tapping into the opportunities the new methodologies present for security. And then shared ownership means finding the perspectives that actually makes developer embrace security, both from a tooling perspective and from a security perspective.
One last point before I close off here, is that we actually have it backwards. I talked about these different things, but in practice, they don’t go that way, they go the other way. DevOps is first and foremost about people. It’s about the changes that we do in how we work, and everything else derives from that. So if you were to do one thing of all those things that I talked about, it would be the third. It would be embracing this DevOps shared ownership of security, and if you do that well, everything else will follow. Thank you.
See more presentations with transcripts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Installation and setup
Kafka and Prometheus JMX exporter
Kafka is an open-source stream-processing software platform written in Scala and Java. The general aim is to provide a unified, high-throughput, low-latency platform for real-time handling of data feeds. The storage layer of the software platform makes it extremely beneficial for businesses in terms of processing the streaming data. Moreover, Kafka is capable to connect to the external systems via Kafka Connect. Apache Kafka provides you with opportunities:
-
to subscribe to streams of records;
-
to publish data to any numbers of systems;
-
to store the streams of records;
-
to process the streams of records.
Prometheus JMX exporter is a collector, designed for scraping and exposing mBeans of a JMX target. It runs as a Java agent as well as an independent HTTP server. The JMX exporter can export from various applications and efficiently work with your matrix.
Installation
We’ll use Prometheus JMX exporter for scraping Kafka Broker, Kafka Consumer, and Kafka Producer metrics. Java and Zookeeper should be already installed and running.
- Download Kafka:
wget http://www-eu.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz -P /tmp/
sudo tar -zxvf /tmp/kafka_2.11-1.1.0.tgz -C /opt/
sudo ln -s /opt/kafka_2.11-1.1.0 /opt/kafka sudo mkdir /opt/kafka/prometheus/ - Download Prometheus JMX exporter:
sudo wget -P /opt/kafka/prometheus/ https://repo1.maven.org/maven2/io/prometheus/
jmx/jmx_prometheus_javaagent/0.3.0/jmx_prometheus_javaagent-0.3.0.jarsudo wget -P/opt/kafka/prometheus/https://raw.githubusercontent.com/prometheus/
jmx_exporter/master/example_configs/kafka-0-8-2.ym - Edit Prometheus JMX exporter config file. We’ll append it with Kafka Consumer and Kafka Producer scraping query:
- pattern : kafka.producer<type=producer-metrics, client-id=(.+)><>(.+):w*
name: kafka_producer_$- pattern : kafka.consumer<type=consumer-metrics, client-id=(.+)><>(.+):w*
name: kafka_consumer_$2- pattern : kafka.consumer<type=consumer-fetch-manager-metrics, client-id=(.+)><>(.+):w*
name: kafka_consumer_$2More accessible queries defined by Confluent here.
Run
Now, we are fully prepared to start Kafka’s services with Jolokia JVM agent. This material is just an example, so here we’ll run the console version of Kafka Consumer and Kafka Producer. But you can run Jolokia Agent with own consumer and producer based on JVM.
- Start Kafka Broker:
sudo KAFKA_HEAP_OPTS="-Xmx1000M -Xms1000M" KAFKA_OPTS="-javaagent:/opt/kafka/prometheus/jmx_prometheus_javaagent-0.3.0.jar=7071:/opt/kafka/
prometheus/kafka-0-8-2.yml"
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties - Start Kafka Consumer:
KAFKA_OPTS="-javaagent:/opt/kafka/prometheus/jmx_prometheus_javaagent-0.3.0.jar=7072:/
opt/kafka/prometheus/kafka-0-8-2.yml"
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 0.0.0.0:9092 --topic test --from-beginning - Start Kafka Producer:
KAFKA_OPTS="-javaagent:/opt/kafka/prometheus/jmx_prometheus_javaagent-0.3.0.jar=7073:/
opt/kafka/prometheus/kafka-0-8-2.yml"
/opt/kafka/bin/kafka-console-producer.sh --broker-list 0.0.0.0:9092 --topic test
Prometheus
Prometheus is an open-source time series monitoring solution with pull-model collecting storage, flexible query language, and high-throughput availability. Prometheus has a simple and powerful model allowing to carry out analysis of infrastructure performance. Prometheus text format allows the system to focus on core features. Thus, Prometheus proves to be very performative, efficient and easy to run.
Installation
- Create Prometheus directories:
sudo mkdir /etc/prometheus /var/lib/prometheus /var/log/prometheus /var/run/prometheus
- Download and install Prometheus:
wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz -P /tmp/
sudo tar -zxvf /tmp/prometheus-2.2.1.linux-amd64.tar.gz -C /tmp/
sudo cp /tmp/prometheus-2.2.1.linux-amd64/{prometheus,promtool} /usr/local/bin/
sudo chmod +x /usr/local/bin/{prometheus,promtool}
sudo cp /tmp/prometheus-2.2.1.linux-amd64/prometheus.yml /etc/prometheus/
sudo cp -r /tmp/prometheus-2.2.1.linux-amd64/{consoles,console_libraries} /etc/prometheus/ - Append /etc/prometheus/prometheus.yml for needed exporters:
- job_name: 'kafka-server'
static_configs:
- targets: ['127.0.0.1:7071']- job_name: 'kafka-consumer'
static_configs:
- targets: ['127.0.0.1:7072']- job_name: 'kafka-producer'
static_configs:
- targets: ['127.0.0.1:7073']- job_name: 'telegraf'
static_configs:
- targets: ['127.0.0.1:9200'] - Prometheus systemd service (/etc/systemd/system/prometheus.service):
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/local/bin/prometheus
--config.file /etc/prometheus/prometheus.yml
--storage.tsdb.path /var/lib/prometheus/
--web.console.templates=/etc/prometheus/consoles
--web.console.libraries=/etc/prometheus/console_libraries
[Install]
WantedBy=multi-user.target - Start Prometheus:
sudo systemctl enable prometheus.service && sudo service prometheus start
Telegraf
Telegraf is a powerful open-source data collecting agent written in Go. It collects performance metrics of the system and services. Telegraf provides opportunity to monitor, process and push data to many different services. This agent has some beneficial peculiarities making it a good choice in terms of data collecting and reporting:
- minimal memory footprint;
- easy and fast addition of the new outputs;
- a wide number of plugins for various services.
Installation
- Add an Influx repo:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" |
sudo tee /etc/apt/sources.list.d/influxdb.list - Install Telegraf:
sudo apt-get update && sudo apt-get install telegraf
- Change config: comment out InfluxDB output, and then append outputs list with Prometheus exporter.
listen = ":9200"
collectors_exclude = ["gocollector", "process"] - Run Telegraf:
sudo systemctl enable telegraf.service
sudo service telegraf start
Grafana
Grafana is a popular fully-featured open-source frontend dashboard solution. This is a visualization tool designed to work with a variety of data sources like Graphite, InfluxDB, Elasticsearch, etc. This solution allows the fast and easy development of dashboards for users. Key functional opportunities provided by Grafana are as follows:
- easy downloading and sharing smart dashboards;
- access to Grafana Cloud;
- use of diverse panels.
Installation
- Add Grafana repo:
curl https://packagecloud.io/gpg.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://packagecloud.io/grafana/stable/debian/ stretch main" |
sudo tee /etc/apt/sources.list.d/grafana.list - Install Grafana:
sudo apt-get update && sudo apt-get install grafana
- Run Grafana:
sudo systemctl enable grafana-server.servicesudo service grafana-server start
View metrics
Now, we’ll see metrics on Prometheus side and also prepare Grafana Dashboard.
Prometheus
Open http://localhost:9090/graph and start to explore with “kafka” prefix.
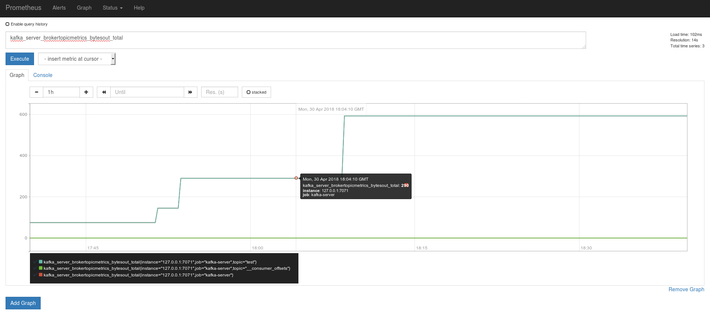
Grafana
Here’s the example dashboard for the system and Kafka monitoring:
Conclusion
In this article we attempted to compile short and comprehensive guide on the installation, setup and running of such monitoring solutions as Prometheus, Telegraf, and Grafana. These solutions prove to be very efficient in collecting metrics, preventing problems and keeping you alert in case of emergencies.
MMS • RSS
Article originally posted on MongoDB. Visit MongoDB
Former TradeWeb CISO and 20+ year cyber security expert will lead MongoDB security efforts
NEW YORK, March 29, 2019 (GLOBE NEWSWIRE) — MongoDB, Inc. (Nasdaq: MDB), the leading modern, general purpose database platform, today announced Lena Smart will be joining MongoDB as the company’s first Chief Information Security Officer.
Smart joins the company to oversee MongoDB’s ongoing product security efforts which include industry-leading standards for products and services and educational efforts around security best practices. She will be responsible for growing MongoDB’s global security team and evolving the company’s security approach to match ever-changing threat vectors in both on premise and cloud database environments. Smart will report to MongoDB CTO and co-founder Eliot Horowitz.
“Security is a top priority at MongoDB, especially as we scale MongoDB Atlas, our global cloud database platform, to more users in more geographies. We have made great strides in recent years to not only provide our customers with best in class security features but to also educate them in best practices for database security,” said Eliot Horowitz, CTO and co-founder, MongoDB. “I’m very excited to be adding Lena, a proven industry leader, as our first CISO to ensure that MongoDB security continues to evolve and improve even as our business continues to grow.”
With more than 20 years of cyber security leadership, Smart has a history of building out security teams for global enterprises and is a recognized security industry leader. Before joining MongoDB, she was the Global Chief Information Security Officer for the international fintech company, Tradeweb, where she was responsible for all aspects of cybersecurity. Previously, Smart served as CIO and Chief Security Officer for the New York Power Authority, the largest state power organization in the country, where she was responsible for physical and cyber security, overseeing a staff of more than 250.
Smart is an active member of the cyber security community. She is a founding partner of Cybersecurity at MIT Sloan (CAMS), formerly the Interdisciplinary Consortium for Improving Critical Infrastructure Cybersecurity, which allows security leaders in academia and the private sector to collaborate on tackling the most challenging security issues. She has previously served as a Sector Chief with FBI InfraGard.
“MongoDB is enjoying massive adoption in every industry in every part of the world, and I’m excited to be joining at such a critical moment in the company’s growth,” said Lena Smart, CISO, MongoDB. “As part of that growth, I am very excited to scale our security efforts with an engineering and security team that puts a premium on providing users with industry best security offerings and education.”
About MongoDB
MongoDB is the leading modern, general purpose database platform, designed to unleash the power of software and data for developers and the applications they build. Headquartered in New York, MongoDB has more than 13,000 customers in over 100 countries. The MongoDB database platform has been downloaded over 60 million times and there have been more than one million MongoDB University registrations.
Investor Relations
Brian Denyeau
ICR
646-277-1251
ir@mongodb.com
Media Relations
Mark Wheeler
MongoDB
866-237-8815 x7186
communications@mongodb.com
![]()
Source: MongoDB, Inc.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Beginning in 2015, Condé Nast created a natural-language-processing and content-analysis engine to improve the metadata around content created across their 22 brands. The new system has led to a 30% increase in click-through rates. Antonino Rau, a software engineer and technology manager at Condé Nast US, recently described the motivation behind the project, the system architecture, and the evolution of their NLP-as-a-service system named HAL in a two-part blog post, “Natural Language Processing and Content Analysis at Condé Nast“. According to the post, the goal was to replace simple categorization and tagging with a system that could “automatically ‘reverse engineer’ the knowledge that [their] world-class editors put in there.”
Named after HAL-9000 from the movie 2001: A Space Odyssey, HAL integrates with a proprietary content management system (CMS) called Copilot. Built using Java, HAL runs a set of analyzers using pre-trained or custom-trained models, both in-JVM and out-of-JVM.
HAL’s processing engine is built upon a parallelizable, direct acyclic graph to analyse and annotate content. This analyses different aspects of the content, extracting various features. For example, by analysing the content it may extract known people and then annotate the response with linked resources about the individual. Other features include topics and categories, or locations and news stories. All of these are annotated with additional pertinent information.
The results of the analysis are curated in a way inspired by Uber’s Michelangelo, to improve and train models, as well as making repeated calls to HAL for content that has remained static.
InfoQ caught up with Rau, to ask him about the work he’s done around HAL.
InfoQ: In your blog post, you say, “A few years ago, in 2015, we decided to go to the next level”. What was the driver to change how it worked? Were editors manually tagging their articles previously?
Antonino Rau: The main driver was to have automatic insights (topics, entities, etc…) on what the editors were producing for different use cases. This content intelligence would be then crossed with user behavior to build segments, recommendations, and other features. Yes, previously editors were manually tagging. After, they still have the possibility to remove automatic tags or add manual tags from a controlled vocabulary.
InfoQ: You decided to build your own natural language processing system in HAL. Did you look at third-party options? If so, what made you choose to build in-house?
Rau: Yes, we looked at third parties at that time, but we decided to use a mixture of custom and open source model because initially HAL was needed only for English and for that language there are plenty of open source, pre-trained models and we built custom models for only one language pretty easily for the features not supported by the OSS models. Very recently, November 2018, Condé decided to join Condé Nast US and Condé Nast International in a global platform, hence the need to support eight other languages. We are investigating the integration in HAL of third-party models to speed up the availability of HAL for all the Condé markets globally for all those languages. The nice part of HAL is that it acts also as an anti-corruption layer, so even if we integrate vendors, due to its framework, we can easily operate in a mixture of OSS, custom and vendors models/analyzers and still have the same abstracted and standardized output.
InfoQ: Why did you choose Java?
Rau: Running NLP models is very CPU and memory intensive. Moreover, from our benchmark, the best, in terms of features and performance, above-mentioned OSS models were available in Java. Finally, in terms of system performance and robustness for CPU and memory intensive apps, it seemed to us the best choice.
InfoQ: The design of HAL and the direct acyclic graph in particular is impressive in how it abstracts away for generic use. Were there many iterations before you decided on this approach? What other approaches did you consider?
Rau: Initially, it was a straight “pipe and filter” approach using the annotation model, which is pretty common in literature as mentioned in the blog post. But, then the more out-of-JVM analyzers we used, the more we noticed the fact that we could build a graph of analyzers passing annotations to each other to speed up and parallelize the processing.
InfoQ: Is anything you produced as open source for others to use?
Rau: Currently, no. Maybe in the future.
InfoQ: You mentioned the use of your in-house CMS called Copilot. Did having your own CMS help in producing HAL or do you think this could have been done with any CMS?
Rau: Copilot is backed by a set of APIs named Formation Platform. We realized that the right place for HAL was in the pipeline of the production of content, in this way the automatic enrichment is part of the content types and content models served by the APIs. But the reverse is also true, that one of the HAL components, the Copilot-linker, an instance of an Entity-linker, is mining daily Copilot content types like restaurants, people, venues, etc. to “learn” about the knowledge that the editors put in the system, so to automatically extract those entities from articles and propose links between them. So, I would say that in the context of Condé Nast, and publishers in general, content analysis and NLP are highly synergetic with the CMS. If the CMS is proprietary it is easier to make it part of the internal flow and hence streamline easily the downstream usage of this enrichment, but I guess one can augment also OSS CMS if there are extension points available at the right place.
InfoQ: What sort of volumes go through HAL?
Rau: Around 30 million requests per month. We process all the revisions with changed text and also content that is not from Condé sometime.
InfoQ: What metrics other than click-through rate do you measure and have there been any improvements in those metrics due to HAL?
Rau: HAL Topics Feature has been the most predictive features in Data Science Team predictive models, which has been used both for audience targeting and consumer subscription propensity.