

Introduction
Interactive notebooks are experiencing a rise in popularity. How do we know? They’re replacing PowerPoint in presentations, shared around organizations, and they’re even taking workload away from BI suites. Today there are many notebooks to choose from Jupyter, R Markdown, Apache Zeppelin, Spark Notebook and more. There are kernels/backends to multiple languages, such as Python, Julia, Scala, SQL, and others. Notebooks are typically used by data scientists for quick exploration tasks.
In this blog, we are going to learn about Jupyter notebooks and Google colab. We will learn about writing code in the notebooks and will focus on the basic features of notebooks. Before diving directly into writing code, let us familiarise ourselves with writing the code notebook style!
The Notebook way
Traditionally, notebooks have been used to document research and make results reproducible, simply by rerunning the notebook on source data. But why would one want to choose to use a notebook instead of a favorite IDE or command line? There are many limitations in the current browser-based notebook implementations, but what they do offer is an environment for exploration, collaboration, and visualization. Notebooks are typically used by data scientists for quick exploration tasks. In that regard, they offer a number of advantages over any local scripts or tools. Notebooks also tend to be set up in a cluster environment, allowing the data scientist to take advantage of computational resources beyond what is available on her laptop, and operate on the full data set without having to download a local copy.
Jupyter Notebooks
The Jupyter Notebook is an open source web application that you can use to create and share documents that contain live code, equations, visualizations, and text. Jupyter Notebook is maintained by the people at Project Jupyter.
Jupyter Notebooks are a spin-off project from the IPython project, which used to have an IPython Notebook project itself. The name, Jupyter, comes from the core supported programming languages that it supports: Julia, Python, and R. Jupyter ships with the IPython kernel, which allows you to write your programs in Python, but there are currently over 100 other kernels that you can also use.
Why Jupyter Notebooks
Jupyter notebooks are particularly useful as scientific lab books when you are doing computational physics and/or lots of data analysis using computational tools. This is because, with Jupyter notebooks, you can:
- Record the code you write in a notebook as you manipulate your data. This is useful to remember what you’ve done, repeat it if necessary, etc.
- Graphs and other figures are rendered directly in the notebook so there’s no more printing to paper, cutting and pasting as you would have with paper notebooks or copying and pasting as you would have with other electronic notebooks.
- You can have dynamic data visualizations, e.g. animations, which is simply not possible with a paper lab book.
- One can update the notebook (or parts thereof) with new data by re-running cells. You could also copy the cell and re-run the copy only if you want to retain a record of the previous attempt.
Google Colab
Colaboratory is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud. With Colaboratory you can write and execute code, save and share your analyses, and access powerful computing resources, all for free from your browser.
Why Google Colab
As the name suggests, Google Colab comes with collaboration backed in the product. In fact, it is a Jupyter notebook that leverages Google Docs collaboration features. It also runs on Google servers and you don’t need to install anything. Moreover, the notebooks are saved to your Google Drive account.
Some Extra Features
1. System Aliases
Jupyter includes shortcuts for common operations, such as ls and others.
2. Tab-Completion and Exploring Code
Colab provides tab completion to explore attributes of Python objects, as well as to quickly view documentation strings.
3. Exception Formatting
Exceptions are formatted nicely in Colab outputs
4. Rich, Interactive Outputs
Until now all of the generated outputs have been text, but they can be more interesting.
5. Integration with Drive
Colaboratory is integrated with Google Drive. It allows you to share, comment, and collaborate on the same document with multiple people:
Differences between Google Colab and Jupyter notebooks
1. Infrastructure
Google Colab runs on Google Cloud Platform ( GCP ). Hence it’s robust, flexible
2. Hardware
Google Colab recently added support for Tensor Processing Unit ( TPU ) apart from its existing GPU and CPU instances. So, it’s a big deal for all deep learning people.
3. Pricing
Despite being so good at hardware, the services provided by Google Colab are completely free. This makes it even more awesome.
4. Integration with Google Drive
Yes, this seems interesting as you can use your google drive as an interactive file system with Google Colab. This makes it easy to deal with larger files while computing your stuff.
5. Boon for Research and Startup Community
Perhaps this is the only tool available in the market which provides such a good PaaS for free to users. This is overwhelmingly helpful for startups, the research community and students in deep learning space
Working with Notebooks — The Cells Based Method
Jupyter Notebook supports adding rich content to its cells. In this section, you will get an overview of just some of the things you can do with your cells using Markup and Code.
Cell Types
There are technically four cell types: Code, Markdown, Raw NBConvert, and Heading.
The Heading cell type is no longer supported and will display a dialogue that says as much. Instead, you are supposed to use Markdown for your Headings.
The Raw NBConvert cell type is only intended for special use cases when using the nbconvert command line tool. Basically, it allows you to control the formatting in a very specific way when converting from a Notebook to another format.
The primary cell types that you will use are the Code and Markdown cell types. You have already learned how code cells work, so let’s learn how to style your text with Markdown.
Styling Your Text
Jupyter Notebook supports Markdown, which is a markup language that is a superset of HTML. This tutorial will cover some of the basics of what you can do with Markdown.
Set a new cell to Markdown and then add the following text to the cell:

When you run the cell, the output should look like this:

If you would prefer to bold your text, use a double underscore or double asterisk.
Headers
Creating headers in Markdown is also quite simple. You just have to use the humble pound sign. The more pound signs you use, the smaller the header. Jupyter Notebook even kind of previews it for you:

Then when you run the cell, you will end up with a nicely formatted header:

Creating Lists
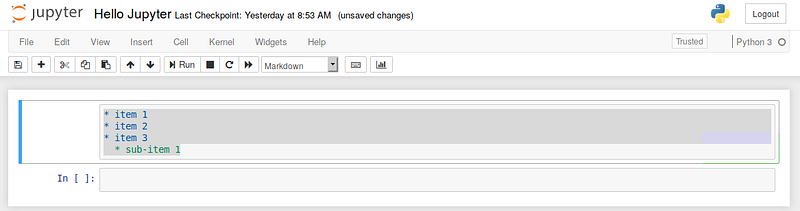
You can create a list (bullet points) by using dashes, plus signs, or asterisks. Here is an example:
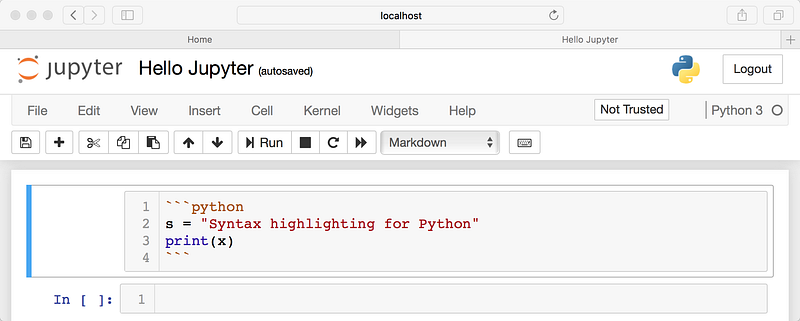
Code and Syntax Highlighting
If you want to insert a code example that you don’t want your end user to actually run, you can use Markdown to insert it. For inline code highlighting, just surround the code with backticks. If you want to insert a block of code, you can use triple backticks and also specify the programming language:
Useful Jupyter Notebook Extensions
Extensions are a very productive way of enhancing your productivity on Jupyter Notebooks. One of the best tools to install and use extensions I have found is ‘Nbextensions’. It takes two simple steps to install it on your machine (there are other methods as well but I found this the most convenient):
Step 1: Install it from pip:
|
1
|
pip install jupyter_contrib_nbextensions
|
Step 2: Install the associated JavaScript and CSS files:
|
1
|
jupyter contrib nbextension install —user
|
Once you’re done with this, you’ll see a ‘Nbextensions’ tab on the top of your Jupyter Notebook home. And voila! There are a collection of awesome extensions you can use for your projects.

Multi-user Notebooks
There is a thing called JupyterHub which is the proper way to host a multi-user notebook serverwhich might be useful for collaboration and could potentially be used for teaching. However, I have not investigated this in detail as there is no need for it yet. If lots of people start using jupyter notebooks, then we could look into whether JupyterHub would be of benefit. Work is also ongoing to facilitate real-time live collaboration by multiple users on the same notebook — more information is available here and here.
Summary
Jupyter notebooks are useful as a scientific research record, especially when you are digging about in your data using computational tools. In this lesson, we learned about Jupyter notebooks. To add, in Jupyter notebooks, we can either be in insert mode or escape mode. While in insert mode, we can edit the cells and undo changes within that cell with cmd + z on a mac or ctl + z on windows. In escape mode, we can add cells with b, delete a cell with x, and undo deletion of a cell with z. We can also change the type of a cell to markdown with m and to Python code with y. Furthermore, we can have our code in a cell executed, we need to press shift + enter. If we do not do this, then the variables that we assigned in Python are not going to be recognized by Python later on in our Jupyter notebook.
Jupyter notebooks/Google colab are more focused on making work reproducible and easier to understand. These notebooks find the usage in cases where you need story telling with your code!
Follow this link, if you are looking to learn more about data science online!
You can follow this link for our Big Data course!
Additionally, if you are having an interest in learning Data Science, click here to start
Furthermore, if you want to read more about data science, you can read our blogs here

