Month: August 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Imagine an advanced fighter aircraft is patrolling a hostile conflict area and a bogie suddenly appears on radar accelerating aggressively at them. The pilot, with the assistance of an Artificial Intelligence co-pilot, has a fraction of a second to decide what action to take – ignore, avoid, flee, bluff, or attack. The costs associated with False Positive and False Negative are substantial – a wrong decision that could potentially provoke a war or lead to the death of the pilot. What is one to do…and why?

No one less than the Defense Advanced Research Projects Agency (DARPA) and the Department of Defense (DoD) are interested in not only applying AI to decide what to do in hostile, unstable and rapidly devolving environments but also want to understand why an AI model recommended a particular action.
Welcome to the world of Explainable Artificial Intelligence (XAI).
A McKinsey Quarterly article “What AI Can And Can’t Do (Yet) For Your Business” highlights the importance of XAI in achieveing AI mass adoption:
“Explainability is not a new issue for AI systems. But it has grown along with the success and adoption of deep learning, which has given rise both to more diverse and advanced applications and to more opaqueness. Larger and more complex models make it hard to explain, in human terms, why a certain decision was reached (and even harder when it was reached in real time). This is one reason that adoption of some AI tools remains low in application areas where explainability is useful or indeed required. Furthermore, as the application of AI expands, regulatory requirements could also drive the need for more explainable AI models.”
Being able to quantify the predictive contribution of a particular variable to the effectiveness of an analytic model is a critically important for the following reasons:
- XAI is a legal mandate in regulated verticals such as banking, insurance, telecommunications and others. XAI is critical in ensuring that there are no age, gender, race, disabilities or sexual orientation biases in decisions dictated by regulations such as the European General Data Protection Regulation (GDPR) and the Fair Credit Report Act (FCRA).
- XAI is critical for physicians, engineers, technicians, physicists, chemists, scientists and other specialists whose work is governed by the exactness of the model’s results, and who simply must understand and trust the models and modeling results.
- For AI to take hold in healthcare, it has to be explainable. This black-box paradox is particularly problematic in healthcare, where the method used to reach a conclusion is vitally important. Responsibility for making life and death decisions, physicians are unwilling to entrust those decisions to a black box.
Let’s drill into what DARPA is trying to achieve with their XAI initiative.
DARPA XAI Requirements
DARPA is an agency of the United States Department of Defense responsible for the development of emerging technologies for use by the military. DARPA is soliciting proposals to help address the XAI problem. Information about the research proposals and timeline can be found at “Explainable Artificial Intelligence (XAI)”.
The target persona of XAI is an end user who depends on decisions, recommendations, or actions produced by an AI system, and therefore needs to understand the rationale for the system’s decisions. To accomplish this, DARPA is pushing the concepts of an “Explainable AI Model” and an “Explanation Interface” (see Figure 1).
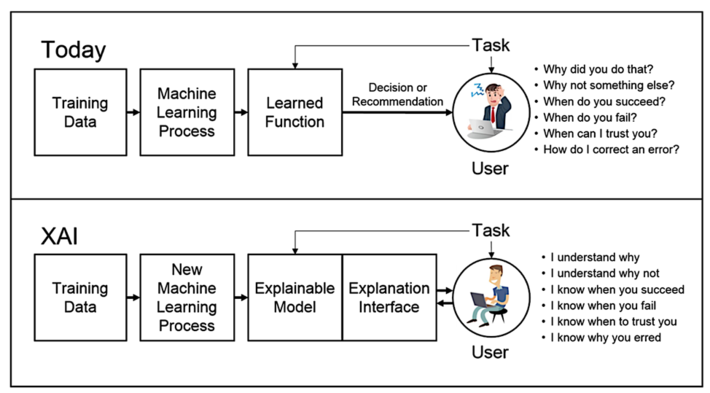
Figure 1: Explainable Artificial Intelligence (XAI)
Figure 1 presents three XAI research and development challenges:
- How to produce more explainable models? For this, DARPA envisions developing a range of new or modified machine learning and deep learning algorithms to produce more explainable models versus today’s black box deep learning algorithms.
- How to design the explanation interface? DARPA anticipates integrating state-of-the-art human-computer interaction (HCI) techniques (e.g., visualization, language understanding, language generation, and dialog management) with new principles, strategies, and techniques to generate more effective and human understandable explanations.
- How to understand the psychological requirements for effective explanations? DARPA plans to summarize, extend, and apply current psychological theories of explanation to assist both the XAI developers and evaluator.
These are bold but critically-important developments if we hope to foster public confidence in the use of AI in our daily lives (e.g., autonomous vehicles, personalized medicine, robotic machines, intelligent devices, precision agriculture, smart buildings and cities).
How Deep Learning Works
Deep learning systems are “trained” by analyzing massive amounts of labeled data to classify the data. These models are then used to predict the probability of matches to new data sets (cats, dogs, handwriting, pedestrians, tumors, cancer, plant diseases). Deep Learning goes through three stages to create their classification models.
Step 1: Training. A Neural Network is trainedby feeding thousands, if not millions, of labeled images into the Neural Network in order to create the weights and biases across the different neurons and connections between layers of neurons that are used to classify the images (see Figure 2).
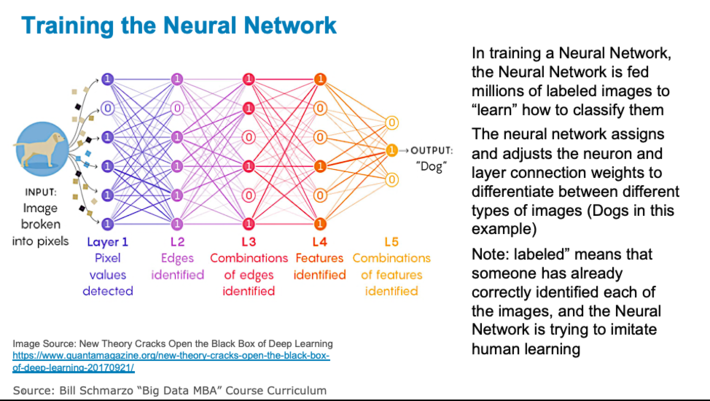
Figure 2: Training the Neural Network
Step 2: Testing.The Neural Network’s predictive effectiveness is testedby feeding new images into the Neural Network to see how effective the neural network is at classifying the new images (see Figure 3).
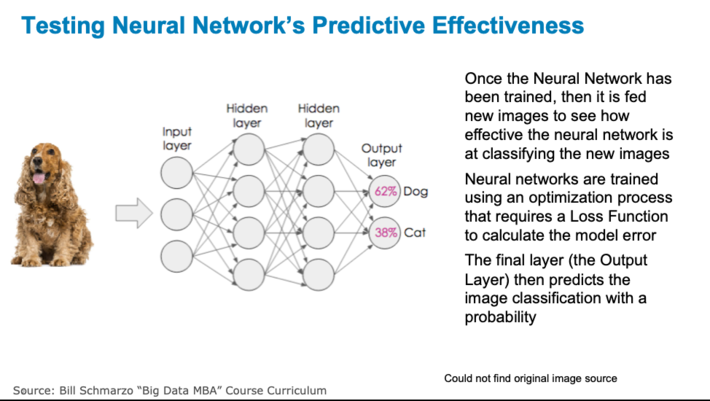
Figure 3: Testing Neural Network
Step 3: Learning. Learning or refining of the Neural Network model is driven by rippling learnings from the model errors in order to minimize the square of errors between expected versus actual results.
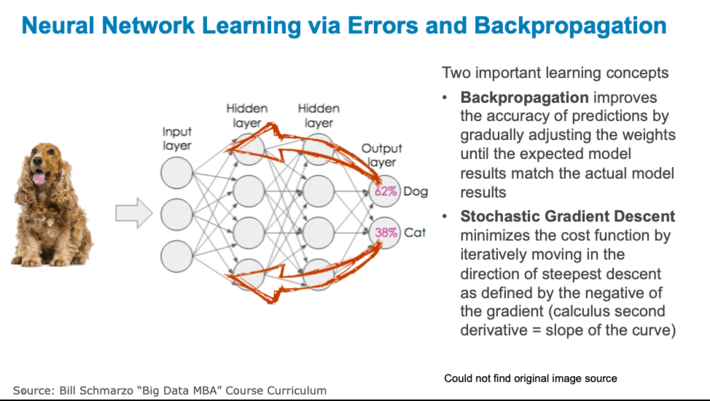
Figure 4: Learning and Refining the Model
As I covered in the blog “Neural Networks: Is Meta-learning the New Black?,” a neural network “learns” from the square of its errors using two important concepts:
- Backpropagation is a mathematically-based tool for improving the accuracy of predictions of neural networks by gradually adjusting the weights until the expected model results match the actual model results. Backpropagation solves the problem of finding the best weights to deliver the best expected results.
- Stochastic Gradient Descent is a mathematically-based optimization algorithm (think second derivative in calculus) used to minimize some cost function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient (slope). Gradient descent guides the updates being made to the weights of our neural network model by pushing the errors from the models results back into the weights.
In summary, we are propagating the total error backward through the connections in the network layer by layer, calculating the contribution (gradient) of each weight and bias to the total error in every layer, and then using gradient descent algorithm to optimize the weights and biases, and eventually minimizing the total error of the neural network (see Figure 5).
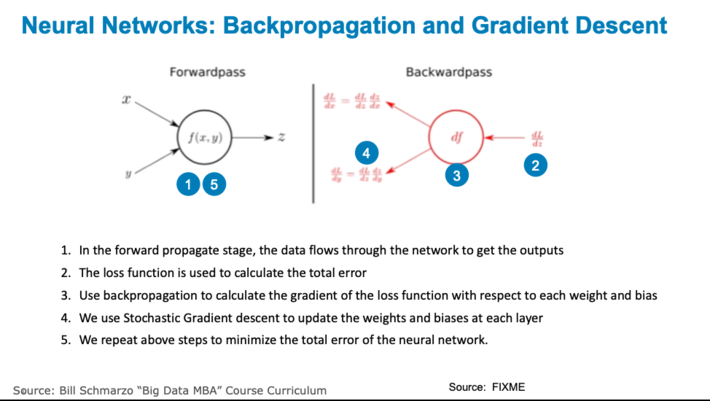
Figure 5: Neural Networks: Backpropagation and Gradient Descent
As powerful as Neural Networks are in analyzing and classifying data sets, the problem with a Neural Network in a world of XAI is that none of the variables and their associated weights are known, so it is impossible to explain why and how a deep learning model came up with its predictions.
Note as we discussed in the opening scenario, there are many scenarios where the costs of model failure – False Positives and False Negatives – can be significant, maybe even disastrous. Consequently, organizations must invest the time and effort to thoroughly detail the consequences of False Positives and False Negatives. See the blog “Using Confusion Matrices to Quantify the Cost of Being Wrong” for more details on understanding and quantifying the costs of False Positives and False Negatives.
USF Data Attribution Research Project
Building upon our industry-leading research at the University of San Francisco on the Economic Value of Data, we are following up on that research by exploring a mathematical formula that can calculate how much of the analytic model’s predictive results can be attributed to any one individual variable. This research not only helps to further advance the XAI thinking, but also provides invaluable guidance to organizations that are trying to:
- Determine the economic or financial value of a particular data set can help prioritize IT and business investments in data management efforts (e.g., governance, quality, accuracy, completeness, granularity, metadata) and data acquisition strategies.
- Determine how an organization accounts for the value of its data impacts an organization’s balance sheet and market capitalization.
Watch this space for more details on this research project.
I’m also overjoyed by the positive feedback that I have gotten on the release of my third book: “The Art of Thinking Like A Data Scientist”. This workbook is jammed with templates, worksheets, examples and hands-on exercises to help organizations become more effective at leveraging data and analytics to power your business models. I hope that you enjoy it as well.

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Artificial intelligence is changing the way that we interact with technology; eliminating unnecessary interfaces makes interaction with machines more humane, argued Agnieszka Walorska at ACE conference 2019. “I’m sure that we will soon have new design jobs that didn’t exist before – like virtual assistant personality designer for example”, she said.
The expectations towards customer experience have changed, and one factor that is becoming more and more important to this change is machine learning. Machine learning algorithms are used in most of the digital products we frequently use. The majority of customers expect personalization, which is getting better and better thanks to the use of algorithms, said Walorska. Most of us use Netflix, YouTube, Facebook, and Amazon, highly personalized products setting the standards for every other product to come.
Walorska mentioned that we’re also getting used to more and more sophisticated voice interfaces; interfaces that wouldn’t be possible without machine learning. Since humans invented computers, they had to communicate with them in a way that was understandable to machines, as the machines struggled and still struggle to understand our natural way of communication. The progress in machine learning and artificial intelligence makes it possible to do it the other way around – machines are getting better at “understanding” humans; not only their speech, but also their gestures, mimics and biology, said Walorska.
A more humane interaction would be one that would free us from screens, said Walorska. Currently, we are glued to our screens, averaging 3:15 hours a day on smartphones alone. Kids and teens aged 8 to 18 in the US spend an average of more than seven hours a day looking at screens. Walorska mentioned that anticipatory experiences that learn from our data, voice interfaces, sensors, and brain-computer interfaces have the potential to save some of this screen time. But they come at a cost: an even deeper knowledge of our behavioral data.
Walorska quoted Steve Jobs:
Most people make the mistake of thinking design is what it looks like. People think it’s this veneer – that the designers are handed this box and told, “Make it look good!” That’s not what we think design is. It’s not just what it looks like and feels like. Design is how it works.
She mentioned that this statement will increasingly characterize the job of the designer in the future, and expects that the role of designers and developers will become more and more similar. “To design interactions driven by algorithms we need to have at least a general understanding of the technology”, she said, “while designing digital experiences in the algorithmic age we are also facing difficult ethical questions: privacy, algorithmic bias, technology addiction.”
InfoQ interviewed Agnieszka Walorska, founder at Creative Construction, after her talk at ACE conference 2019:
InfoQ: What is the state of practice in dealing with empathy in user interfaces?
Agnieszka Walorska: One factor in defining how much we enjoy an interaction is empathy: when our counterpart recognizes when we are frustrated, slows down when we’re confused, speeds up when we’re impatient, etc. For a more humane experience empathy is necessary, and that’s something machines are not good at yet. That’s why interaction with software, even an intelligent one, is still pretty unsatisfying (unlike in the movie “Her”). To even approach human capability, intelligent assistants must recognize and adapt to the user’s state, whether that involves awareness, emotion, or comprehension.
While speech recognition is getting quite good (Amazon has patented an Echo feature that is going to identify a cold or sadness from the way the person is speaking) and recognition of gestures and facial expressions is becoming much more accurate (check the Microsoft Emotions API), there are very few computer systems that use verbal and visual information to recognize user state, and even fewer that change their behavior in response to perceived user states.
The question is, will it be possible in the foreseeable future for machines to react to them in the way humans would describe as empathetic, or will we still need humans for the tasks requiring empathy? I’d be fine with the latter – there still will be some things that we, as humans, are better at 😉
InfoQ: What are some of the possible consequences of artificially intelligent design in terms of our privacy and self-determination?
Walorska: We are seeing many consequences already. We find ourselves in a kind of “uncanny valley of algorithms”. The term “Uncanny Valley” originally refers to robotics. It states that the acceptance of robots and avatars depends on the degree of anthropomorphism. The bigger the similarity with human beings, the more we like them, at least up until a certain point, where the linearity stops and we perceive the humanoids as creepy.
We can apply the same to algorithms, I guess. We love personalization and prediction, as it gives us a better experience – until it’s just too good and we start wondering, “How do they know all this about us?”
The question of self-determination is even more difficult, as the line between guidance, recommendations and manipulation can be very thin. We tend to trust the recommendations of the technologies we use. We blindly follow Google Maps, shutting our brains down and not being able to orientate without it, we let YouTube autoplay video after video and spend hours scrolling through Facebook or Instagram feeds. We get more of what we already like or believe in, which can strengthen our already existing filter bubbles or nudge us towards becoming more radical in our opinions.
InfoQ: How does data science help us learn more about how customers are using our products?
Walorska: I cannot imagine a digital product in 2019 that doesn’t use analytics to learn about their customers. A good example is A/B testing or multivariate-testing like Optimizely, that not only identifies the interfaces that generate more desirable behaviours, but also automatically shows the better performing interfaces after reaching a significant sufficient number of interactions.
But it goes both ways – AI products need humans to understand more about customers. There have been many recent publications that describe how human employees are listening to Amazon Alexa or Google Assistant conversations to identify problems with interactions and make the products better (but also interfere with the privacy).
InfoQ: How do developments in AI impact the jobs of designers?
Walorska: You might have seen the analysis done by NPR titled, “Will Your Job Be Done by a Machine?” According to the study, designers are quite safe; the probability of machines taking over design in the next 20 years is just 8,2%. When you compare it to the 48,1% probability for developers, it actually looks quite good.
But aren’t we being too optimistic here? First of all – even if the job of a digital designer is a creative occupation, it’s also not free from all repetitive work. Every designer knows how uninspiring the job of the designer can be if he or she has to create 50 different formats of an advertising banner, or adjust the graphics for a mobile app so they look good in every resolution on every screen. And there are more tasks like these. Most designers probably wouldn’t mind if such tasks could be done by a machine – and this is already starting to happen. Every task that can be automated – will be automated.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
By the time I graduated university four years ago, I sensed that maybe I had missed out on something by not fitting any computer science or coding courses into my schedule.
“Computer Science: two words that still held every ounce of mystery when I received my diploma as they had when I first met a few of the guys who lived down the hall that were majoring in it. Wasn’t computer science just something you studied if you wanted to work in IT and ask befuddled office workers, “Have you tried turning it off and back on again?”
Soon after entering the professional working world, I understood that computer science was, in fact, a whole new way to work with information …
…
My math skills in high school were strong enough to be accepted into three top engineering schools—I had plans to pursue a career as a civil engineer. However, after my first year, I decided that pursuing a course of study that was so rooted in numbers and theory was cutting out the part of my personality that excels in approaching conflict with open eyes, gathering information and facts from multiple involved parties, and developing solutions with optimal outcomes for all stakeholders. Thus, in my second year at university, I pivoted out of engineering into Political Science, hitting a stride with a balanced curriculum of political theory and economics.
Needing a new outlet for my future work, I realized I didn’t need to look further than my own backyard –Harlem. There was (and still is!) a national need for quality public education to combat the systemic under-education of traditionally underserved minority communities, especially in urban areas. Charter schools looked like the solution to me, so I jumped aboard the train.
Over the last 4 years, I have worked at two district-sized charter systems in New York City–two systems that couldn’t be more different from each other in so many ways: Their metrics of success, rates of growth, ability to be self-reflective as an organization, office culture—you name it. I’ve been able to work in positions focused on performance of the organization and in positions that focused on the performance of the people that make the organization. No matter the approach, the goal is the same: offering kids the opportunity to become the first generation of college graduates in their families.
One thing I’ve learned is that numbers talk. If you can prove there is a problem area that has negative impact on the organization, or can show that a small positive occurrence could drive positive results if multiplied, leadership is often willing to devote the necessary resources. This understanding is what awakened and then sustained my interest to learn to paint pictures with information. I want to dig into the nitty gritty and uncover the drivers of the deepest impact. Unfortunately, my toolbox has been somewhat limited. Spreadsheets don’t make great brushes–but I have had the opportunity to play with some of the tools of a true artist.
…
For most people, finishing a graduate degree means you are done being tested forever. Not the teachers at our schools. My current role has me assessing the performance of teachers; and let me tell you, we’re tough graders. What helps me get comfortable with the rigor of our instructional staff assessments is the thought that, eventually, I will want the best-of-the-best teaching my kids. That, and we have some seriously sweet perks for teachers who knock it out of the park.
So, to capture all the great work these often-under-appreciated professionals are doing, I’ve learned a little SQL and figured out how to build a report in Tableau. It’s exciting to wrangle information together and present it, and the self-teaching that has accompanied learning these programs helps me relate to all of the students in our schools. Personally and professionally, I have always gained satisfaction when I can give someone a helpful answer; so imagine my appreciation for these newfound tools and the answers they could help me deliver.
These are the exciting days for me in the office, because it is when I am doing this work that I get back to learning and challenging my mind. I’ve been exposed to new concepts that have started to build off one another–basic data structures, data types, joins, etc. When I am given an assignment for a report to build, I open my small toolbox and get to work. And when I hit a groove in these projects, or when I hit a block that I eventually solve, I’m transported back in time. Once again, I am 10 years old, sitting on my living room floor, with my 12-gallon tub of LEGO pieces spread out in front of me, and the world is a blank slate for me to build upon. Just like sorting the parts out to build the next great structure, I can sort information into helpful piles and look for the piece that will bring everything together to complete my masterpiece.
There is a sense of freedom knowing that I have access to instruction manuals written by fellow builders, some master, some junior, all creators. I wanted to just glance at a picture to get an idea for a project, and when I needed to really follow some instructions step-by-step to get what was on the box—and believe me, I’ll be reading a lot of instructions for the time being! The first few steps along the path of learning Data Science—dabbling in SQL and Python, differentiating data by types, building math equations with pandas functions—have solidified this vision in my mind. It is incredibly exciting for me because I know that while today, I’m stacking big blocks to build rudimentary houses, soon I’ll be constructing spaceships.
P.S. Yes, I still have that 12-gallon tub of LEGOs.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Coming at the end of an eight-month development cycle, Project Marble, the latest release of Android Studio, refrains from adding new major features and opts instead for improving performance and memory efficiency.
Based on feedback from developers, Google Android Studio team tackled three core areas of Android official IDE: system health, feature polish, and bugs.
In the area of system health, Android Studio 3.5 includes a new infrastructure aimed to better detect performance problems and to improve the process to analyze developer feedback and bug reports. Thanks to these changes, Android Studio is now also able to detect when it needs more memory and to notify you to increase allocated memory on systems where it is available.
Speaking of performance improvements, Android 3.5 includes a number of significant changes, such as improved typing responsiveness with XML-formatted data and Kotlin; support for incremental builds for annotation processors such as Glide, AndroidX data binding, Dagger, Realm, and Kotlin; faster disk access on Windows systems; reduced CPU usage for the Android emulator; faster linting, and more.
Android Studio 3.5 removes Instant run, a feature aimed to speed up the edit-build-run cycle by directly modifying the APK and only relaunching the app or restarting the currently running activity if required. Instead, the latest Android Studio version provides a new feature called Apply changes, which does not tamper with the APK and uses instead platform-specific APIs available on Oreo and later Android versions to achieve the same result while ensuring more stability and consistency.
As a last note, Android Studio fixes over 600 bugs, 50 memory leaks, and 20 IDE hangs, with over 40 external contributions. For a full list of changes, do not miss the release notes. Android Studio 3.5 is available for download for Windows, Mac, and Linux. Previous versions can be updated from within the app itself.
Project Marble does not end Google effort to improve Android Studio performance and quality, remarked Google Android Studio team member Tor Norbye, and further polish and improvements are expected in next release, Android Studio 3.6.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Gluon has released beta support that enables JavaFX applications to run the same code across PC, Mac, iOS, and Android. As a result, developers can use a language and tools that they already know, managing one codebase per application instead of per device.
The toolchain expands on work done in 2015 by José Perada and Bruno Borges who produced a JavaFX game for Android called 2048FX. Gluon has also pushed for mobile Java since Java 9. For running on iOS, Gluon’s suite of tools includes a few notable aspects that are automated through a build pipeline:
- OpenJDK libraries are brought in as static libraries compiled for the target platform.
- OpenJFX is the graphical framework for user interaction, available for all target platforms.
- GraalVM in native mode provides the key runtime that is built for the target platform.
When combined through the javafxmobile plugin, the end result for iOS and Android is a native application in binary form. Unlike a typical Java application on a desktop or server, the iOS and Android applications are completely Ahead of Time (AOT) compiled, native, and do not use bytecode or Just In Time (JIT) compilation.
AOT compilation is used to provide direct access to the device and faster startup time. For server-based applications, Andrew Dinn has a technical analysis of why AOT is not necessarily faster than JIT. They are each options, and within Gluon’s stack, the choices favor AOT.
Gluon’s new release comes approximately two years after Shai Almog, CEO of Codename One, stated that “Gluon is dead as RoboVM is.” RoboVM was a similar project that ran JavaFX across mobile. That claim follows a similar path where technologists and reporters have made careers out of claiming that Java is dead (it isn’t). In 2016, Redmonk identified that saying “Java is dead,” is dead. Almog’s second claim regarding RoboVM was partially correct, as RoboVM was acquired by Xamarin, who was acquired by Microsoft, and integrated into the Visual Studio stack. While names have changed, the documentation and materials remain available.
Developers looking to build JavaFX applications for iOS can consult Gluon’s documentation. A separate tool, SceneBuilder, can be used to help design a user interface that will run across each platform. Visual libraries are available through many channels, where Jonathan Giles periodically aggregates and reports on JavaFX activity. Giles is the author of major libraries ControlsFX and Scenic View. ControlsFX is a suite of interactive visual components, and Scenic View is an analyzer that helps inspect running graphical layouts.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

The three pillars of observability are logs, metrics, and tracing. Most teams are able to handle logs and metrics, while proper tracing can still be a challenge. On this podcast, we talk with Yuri Shkuro, the creator of Jaeger, author of the book Mastering Distributed Tracing, and a software engineer at Uber, about how the Jaeger tracing backend implements the OpenTracing API to handle distributed tracing.
Key Takeaways
- Jaeger is an open-source tracing backend, developed at Uber. It also has a collection of libraries that implement the OpenTracing API.
- At a high level, Jaeger is very similar to Zipkin, but Jaeger has features not available in Zipkin, including adaptive sampling and advanced visualization tools in the UI.
- Tracing is less expensive than logging because data is sampled. It also gives you a complete view of the system. You can see a macro view of the transaction, and how it interacted with dozens of microservices, while still being able to drill down into the details of one service.
- If you have only a handful of services, you can probably get away with logging and metrics, but once the complexity increases to dozens, hundreds, or thousands of microservices, you must have tracing.
- Tracing does not work with a black box approach to the application. You can’t simply use a service mesh then add a tracing framework. You need correlation between a single request and all the subsequent requests that it generates. A service mesh still relies on the underlying components handling that correlation.
Subscribe on:
About QCon
QCon is a practitioner-driven conference designed for technical team leads, architects, and project managers who influence software innovation in their teams. QCon takes place 8 times per year in London, New York, San Francisco, Sao Paolo, Beijing, Guangzhou & Shanghai. QCon San Francisco is at its 13th Edition and will take place Nov 11-15, 2019. 140+ expert practitioner speakers, 1600+ attendees and 18 tracks will cover topics driving the evolution of software development today. Visit qconsf.com to get more details.
More about our podcasts
You can keep up-to-date with the podcasts via our RSS Feed, and they are available via SoundCloud, Apple Podcasts, Spotify, Overcast and the Google Podcast. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
Chrome 76 Shipped With PWA Installation, Stealthier Incognito Mode, Extension Tracking
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Google recently released Google Chrome 76. Chrome 76 makes it easier to install Progressive Web Apps (PWAs) on the desktop, disables a commonly used Incognito Mode detection technique, and allows users to track extension activities.
Users visiting web sites which meet the PWA installability criteria will see an install button in the omnibox. Clicking the button triggers a prompt to install the PWA.
PWA developers may listen for the appinstalled event and detect PWA installation. Additionally, PWA developers may also replace the default installation prompt with their own by listening for the beforeinstallprompt event. Google mentions a few patterns by which developers can promote their PWAs.
With Chrome 76, websites can no longer detect the Incognito Mode by making a FIleSystem API request, which is rejected in Incognito Mode. Some websites, like the New York Times, have used this technique to prevent visitors who are in incognito mode from bypassing their paywalls on the web or the limitations on the amount of free articles. Google recommends websites to require readers to log in rather working around the Incognito Mode:
Sites that wish to deter meter circumvention have options such as reducing the number of free articles someone can view before logging in, requiring free registration to view any content, or hardening their paywalls.
Our News teams support sites with meter strategies and recognize the goal of reducing meter circumvention, however any approach based on private browsing detection undermines the principles of Incognito Mode.
Chrome 76 also facilitates checking extension activities. The feature can be enabled by running Chrome with the --enable-extension-activity-logging flag. After doing so, users can navigate to the extension panel (Chrome menu > More tools > Extensions). By clicking on the Details tab for an extension, users should see a new View Activity log section, which leads to a History tab containing a list of activities performed by the extension. While the list of activities may be hard to comprehend for normal users, the list can be exported to a JSON file for careful examination.
Chrome 76 additionally implements 43 security fixes, features changes for web developers, such as Web Payments API improvements. Some web features are removed or deprecated, while the developer tools also benefit from additional functionalities.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
About the conference

Agile India is Asia’s Largest & Premier International Conference on Leading Edge Software Development Methods. Agile India is organized by Agile Software Community of India, a non-profit registered society founded in 2004 with a vision to evangelize new, better ways of building products that delights the users. Over the last 15 years, we’ve organized 58 conferences across 13 cities in India. We’ve hosted 1,100+ speakers from 38 countries, who have delivered 1,350+ sessions to 11,500+ attendees. We continue to be a non-profit, volunteer-run community conference.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Luu: Welcome, everyone to the session for machine learning for developers. This is the panel, we’re going to have a lot of interesting discussions. The theme of this panel that we’re going to be discussing is about how to apply machine learning to your application systems. We want to treat it from the beginner’s perspective. If I’m a software engineer, I’m new to machine learning, I heard it’s an awesome thing. I want to apply this to my application, in the system. How do I get started? How do I go about doing that? What should I be worrying about? How do I convince my management or my team? How do I do all that stuff? Those are the kind of questions that we’re going to be talking about.
The structure of this would be, we’ll do an introduction, I’ll seed the panel with some questions, and then I’ll turn it over to the questions from the audience after about 10 or 15 minutes. Let’s get to know all panel a little bit. We have Brad [Miro] from Google, and then we’ll have Jeff [Smith]. I want to let Brad [Miro] go first to do a quick intro about him. What do you do, and maybe some fun facts about you?
Miro: My name is Brad Miro. I’m a developer programs engineer at Google based here in New York City. A developer programs engineer is someone who splits their time between doing traditional software engineering and also reaching out to the community and speaking to developers and just learning about things that you like, things that you don’t like. The products that I specifically work on are in Google Cloud as well as open-source. I do a lot of work with TensorFlow and then also Spark on Google Cloud. That’s a little bit about me, and a fun fact is I can beatbox.
Smith: My name is Jeff [Smith]. I work at Facebook within our AI group, and I work specifically as an engineering manager supporting the PyTorch team. I spend most of my time really focused on users outside of Facebook, trying to understand where is the field of AI going and how can we get there together through open collaborations across companies, across research labs, and in open source.
Journeys in Machine Learning
Luu: I’m going to start with that first question. You guys have a lot of experience and have been working with machine learning and deep learning for a while. What is your journey like? How do you get started?
Smith: I think a little bit about my own personal journey, but I also think a lot about the teams I’ve been on. When I started working within the space of AI more than a decade ago, it was kind of a weird niche thing to do, and it was really strongly associated with academia, and I didn’t really know anyone else who had this job other than a couple of people sitting next to me. That’s changed a lot. A big part of how that has evolved is that a bunch of people who had strong technical skills in other domains of software engineering have started to realize that they can put those skills to use, within working within machine learning problems.
Some of the common features I see of people who have successfully made a transition from working within software engineering to working within ML engineering specifically, is a focus on building a baseline of knowledge, focused on the real-world machine learning problems that they can solve, doing some independent studies, some dedicated classroom study. I’ve seen people do things like go back to Grad school or just read a couple of books, dive into projects head first. It really depends a lot on your career goals, but one of the messages I want to talk about in this panel and then in my talk later is that there are a whole lot of organizations collaborating, like Google, Facebook, Amazon, Microsoft, building things for you as a developer to get better at machine learning, to understand how to integrate it into your products, into solving problems that you’re working on. It’s a much more open door than it used to be, and I would encourage everyone to get started and talk about what your challenges are and what specific questions you have as someone new to the field.
Miro : I just want to piggyback off that. One thing that I am super excited about in the field generally right now is just the access to information that’s available. Jeff [Smith] mentioned books, but there are also so many online courses, both through via organizations such as like Coursera and Udacity. Some costs nothing to almost nothing. It’s the access that we have to all of this nowadays, it’s never been like this before. The fact that it’s available for you, it’s just great. There’s a lot of information available on the Internet and definitely go seek it out if you’re interested.
Luu: How did you get into your role?
Miro: I studied math and computer science in college and I guess I came at it from an approach where I liked math, I liked computer science. How can I do both? Machine learning is a perfect candidate for that. I think, fundamentally just the idea of building these algorithms that can teach themselves really fascinated me while I was in school. I actually held various software engineering jobs that weren’t necessarily doing machine learning, but just through taking online courses, just building toy models myself, and just really gaining an understanding. Some of it was at work too, just playing with some smaller data sets and seeing if I could derive any business value out of it. It was really just getting my hands dirty. Having the interest is definitely important, and I think nowadays as long as you’re at least interested, the means are there for you to continue to learn. That’s basically how it was for me. I just took online courses.
How to Get Started with Machine Learning
Luu: Awesome. I think this field has different types of roles, I can see data scientists, machine learning engineers, software engineers. It depends on what you’re interested in and where your background is, and there are different path to get there. I’m going to start with, imagine I’m a software engineer and focusing on building applications, services, backend, and so on, and I heard this awesome thing about machine learning and I want to see if I can apply it or introduce that into my application system. It’s a quite wide-open question. How do I get started? What do I need to know about? Maybe some of you have similar questions, but it’s quite daunting, it’s a big field. What do I do? Any thoughts?
Smith: It depends on how close you are to having what you think is the right opportunity to deploy machine learning technology within your application. Certainly, getting oriented and building some of that base knowledge through courses and books or whatever the case may be is a good start there. If you are, say, specifically motivated and, “I want to be able to do these things with the text of users interacting within my application. I want to understand things about it. I want to use that to make suggestions that help their experience.” That gives you a lot more focus, because frankly, the field of ML is really big. Being able to pick a domain where you can put things to use gives you focus and allows you to have a more targeted path in learning about what are the techniques in use.
Some of that’s going to be general knowledge, like deep learning is a general technique, but some of them is going to be really specific. Working with text is very different than working with audio, versus working with images. Having that sort of focus allows you to find the right resources. Some of those resources that you can find out there are the things like courses that are specific to those topics, but very often libraries as well. We’re getting to the point where it’s not just about, “Well, you have to solve all this yourself.” Libraries often contain functionality like pre-trained models which give you access to some of the best techniques in use developed through pioneering research, but now pre-trained sitting ready for you to use. You can get that available via various libraries. We, at PyTorch, have a tool called PyTorch Hub, which I’ll show you a little bit in a talk later, that gives you direct access to leading techniques for a given research problem in a pre-trained model that you just call on us, a one-liner, and say for torch.hub, load your model.
Miro: You definitely touched on this a lot, but I think something that’s really important when getting started with incorporating machine learning into a production or an enterprise environment is really figuring out where in the pipeline you are at with your organization. By that I mean, are you an organization that just wants to apply machine learning but doesn’t necessarily know where? Are you an organization that wants to apply machine learning but knows exactly how you want to do it? I think that needs to be the first step. I’ve personally worked at organizations who were on both sides of that who wanted to do machine learning, had no idea what or how, or and then organizations that did know what they wanted to do. Figure out where you are in that and then take the appropriate steps. In those two examples, if you know you want to do machine learning, you know you have a lot of data and you don’t necessarily have any ideas of what to do, one way to do it is go attend conferences like QCon and speak to other people who are actively doing this stuff and get ideas from them and see what other people in the industry are doing.
In a lot of cases, you’ll notice that a lot of problems are fundamentally the same across multiple organizations. By just going and speaking with people, you’ll generally be able to figure out ways that you can then do something similar in your own organization. If you do know what you want to do, yes, it’s going out and seeking that specific knowledge. If you have all those text data, you don’t necessarily know what to do, go learn about natural language processing, go learn about deep learning for texts. I think it’s really important to figure out where you are along and do you actually have the resources to do this? Because you can definitely get started doing this stuff just as a hobbyist or something, something simple. But to actually really add this stuff to production does take a lot of work and you need to make sure that you have all the appropriate steps in place if you really want to generate business value using machine learning.
Introducing Machine Learning to Teams & Management
Luu: Let’s talk a little bit more about the human side. I want to convince my team or the management to start adopting ML and stuff and doing applications. How should I go about doing that? What kind of risks should I be aware of? What other teams in the organization should I talk to in the journey of trying to introduce machine learning to the company itself?
Smith: I think that’s a really big topic. I’ll start with one that I think is pretty clear for almost everyone in the room; if you’re a software engineer inside a business or something like that, you probably need to have some concept of how is your investment going to make it out to production use case with live users. That’s going to be one of the biggest topics and really has been with the adoption of ML in general. I think people are afraid that someone’s just going to be sitting in the corner, spinning up a bunch of server bills, running Python and using up a bunch of GPUs and never delivering value.
Having an understanding of what is the infrastructure you’re going to use to take any sort of successful approach from research to production, I think is super important. That’s true whatever toolchain you use, whatever cloud you want to be on. That’s a story that’s gotten a lot better within the past few years, specifically within this field. That’s one of the things that I remember from the early part of my career; all I focused on was ML infrastructure. We just need all of these bits and pieces that we have to put together to build a model and take it out to production. These days, for the vast majority of use cases, you don’t necessarily need to reinvent the wheel for a lot of the things you need to do. Being able to build that picture, I think, can be a big part of convincing a larger organization, particularly if you’re thinking about when this is deployed, this is going to cost something to run a team that supports this live and production that has these servers. Being able to fill out that picture is a great way of establishing that there is a viable path from innovative ML techniques to user value.
Miro: I think one way to look at machine learning is, by nature it is very cool and very fun, but at the end of the day, it is also just another new thing that can help improve your business, just like how computers did when computers started to become mainstream in offices. It’s fundamentally just finding out how this can actually benefit you and bringing it down to the numbers, “Right now we have these systems in place and these people are doing this and it costs this much. If we have these automated systems, then it’ll cost us this much.”
There are definitely risks involved. Given that machine learning, fundamentally, are just statistical methods, you do need to weigh the costs of what happens if you have an unexpected result. Is that extremely detrimental to your business? Is that just a blip that you can just ignore? I think with something like machine learning, there are definitely risks associated with it that you absolutely should take into account before going into this. Again, that’s going to be completely situational.
Failed Machine Learning Projects
Luu: In your experience, have you encountered or seen examples where machine learning projects failed?
Smith: My answer is, too many, way too many. If I want to extract some commonalities from the situations in which I’ve seen ML fail, a lack of organizational alignment’s a big one. When we say that we want to build a product that, at its heart, a huge portion of its value is derived from machine learning, but then we start to impose business expectations on it that machine learning simply can’t do. There are limitations to the techniques. ML continues to amaze me every time I open up hacker news and someone’s achieved something new. It has specific properties as a technology, the same as databases do, as web servers do, and there are organizations where I’ve seen projects really fail and people be unhappy about that failure and not really learn from it, involve an over-commitment in spending a bunch of money to do something that couldn’t possibly conform to all of the expectations of a given business stakeholder, really wishing for a sort of magical technology, not really mapping to the constraints of what’s possible with true real-world machine learning.
Miro: Honestly, most of the examples that I have fall into very a similar field. I’ve also seen other examples where the data just isn’t necessarily representative of the actual problem. To give you an example, this is not a project that I specifically worked on, but to give you an idea of what might happen is, let’s say you’re building a self-driving car and you only train the car when it’s good weather. You don’t want to be bothered driving the car in the rain because that’s no fun. Then what happens when you want to actually use the self-driving car in the rain? It has no data to actually reflect on, so it won’t necessarily be able to perform very well. It’s those sorts of things that when you’re actually building a data set to start training these models that you need to make sure that you account for all specific use cases. That can be hard, that that does require a lot of human intuition to be able to figure that out. I’ve definitely seen some projects falter and not necessarily be as effective because it just wasn’t representative of all of the use cases that it was trying to account for.
Resources for Learning about Machine Learning
Participant 1: Let me posit a slightly different scenario. Suppose I’m in a company that, for a good or bad reason, has no interest in machine learning, yet I realize that for my career development, this is something that I need to know. This is sort of a two-fold question. Since I have no business case to constrain my learning, how would you suggest I start? One of the things I know from just development in general, is what I don’t know I don’t know, is what’s really going to kill me, and what falls into that category?
Smith: I think there are a lot of educational resources that start with a very generalist focus. I think that’s not an uncommon scenario to say, “I have broad interests and I will specialize later.” In particular, I think I would echo a point that Brad [Miro] made earlier, which is there are resources that specifically introduce you to the concept of machine learning, and that deep learning, in particular, has proven to be a very successful variant of machine learning, but you can’t skip core concepts and not shoot yourself in the foot later. Concretely, the Andrew Ng classic course from Coursera is still one of the best foundations out there in terms of introducing the must-know concepts that allow you to go deeper, even if your specific interest is, “Well, I want to get up and running with deep learning models.”
Participant 1: See, that’s my point. I have no deep interest in doing anything except that I think it’s good for where I should go.
Miro: Something that I’m really interested in doing is just increasing knowledge about artificial intelligence and machine learning generally. The same Andrew Ng that Jeff [Smith] was mentioning, he has a famous quote. He says, “AI is the new electricity,” and in his mind, he believes that AI will be as impactful to your life as electricity is. In that sense, even if you’re not necessarily interested in business for business reasons, I think it’s just good to stay in the know about how this stuff is just changing society in general, because it’s only going to keep increasing. So the best way to do that would be following something like a TechCrunch or the InfoQ newsletter, those sorts of things, to just stay up-to-date on what’s happening in the world. Then even if you could do a search for just “machine learning in my industry”. You might be surprised. There might be some very edge corner cases that you may never have even thought of for actually impacting your industry.
Luu: I can share one specific resource that may be useful, it’s on deep learning and AI. There’s a new course there which starts at the beginning of the year. It’s called “AI for Everyone” It gives you a broad strip of AI at a very high level. I think that might be useful if you are in that kind of a situation.
Developing a Well-Developed System & Monitoring It
Participant 2: This is sort of related to that question about failure. You develop a system that is tested, it’s giving good results. What’s the state of monitoring for that? What’s the current situation or processes that you follow to say, “Ok, now we’re depending on this data to be right.” How do we know that it’s continuing to be right?
Miro: A lot of times when you’re building a system, these things do continue to grow and you do need to continuously be retraining them just to make sure that they are up-to-date. Testing with machine learning can definitely be a little tricky because it’s not as deterministic as it might be for more traditional systems. Make sure you’re doing tests and running, passing in a sample data, making sure that the output is correct, and then constantly retraining it and making sure that the real-world data that it’s working on is being represented appropriately as environments change.
Smith: I’ll add to that a little bit. A footnote that I have a lot of thoughts on this one and I put them in a book, it’s called “Machine Learning Systems,” which is unusually focused on production concerns like failure and monitoring. Some of the things I would call out that are uniquely different that I think Brad was referring to; he didn’t use the term, but in passing a concept drift when, in some respect, that the machine learning concept that your model has been built upon no longer conforms in the out of sample set, the real world, as opposed to what your machine learning system is trained on.
You’re absolutely right that monitoring has to be a key piece of that. It’s pretty integrated to how you serve your models, how easy that’s going to be. What is the infrastructure you sit on top of? That’s gotten a lot better, but it’s very toolchain specific at this point. One project I’m going to talk about later today is an example of something that comes out of our practice inside Facebook AI and our adaptive experimentation framework where we get into how can we understand the real-world behavior of a deployed machine learning model and how much does it match up with our simulations of what should be going on, and when should we detect some form of failure. It’s a super deep and complicated topic and we’re going to continue to see a lot of new approaches and platforms launched within that.
Luu: I’m going to add a little more in on that. I think machine learning model is kind of unique compared to your standard of microservices and whatnot. The performance in your model can degrade over time if they’re not being retrained with fresh data. That’s one thing I learned that’s quite unique.
Identifying Business Problems to Apply Machine Learning to
Participant 3: My question is – and maybe this may be just me – even after taking preliminary courses and things like that, I feel like I have a problem with getting a good intuition among the set of my company’s business problems; which ones can I actually apply machine learning to? I struggle to find out which ones could I actually do. I wonder if you have any thoughts on that?
Smith: One good heuristic I would usually use is how much data do we have. Are we in a data poor application? A further slice of that is actually how many labels do we have? Because this is where we get into supervised learning. Are we talking about labeled or unlabeled, versus data? Some business processes naturally produce labels. For example, fraud detection does that. If we detected fraud, with any sort of due diligence, we marked it as fraud, we have natural labels.
Some things don’t. You can imagine having a whole bunch of unlabeled text documents for various purposes or images or something like that. If you don’t have labels in a given case, you can do some really easy back of the napkin math around what that might cost you to do. There are great tools for getting labels for new training sets, but if you estimate based on, “This paper, I’m probably going to need something like a million labeled examples. I look and, yes, maybe we have a million examples, none of them are labeled. Can I afford to do that within realistic business constraints?” Those would be my first starting points for almost any business problem or idea.
Miro: Another way to look at this is, I’m going to do a plug here for Google cloud platform for instance. We have a lot of just prebuilt models and very easy-to-use products for just getting started with machine learning, and some of them are as simple as doing computer vision just with a simple API call. You send it a picture and it’ll tell you what’s in it. Potentially looking at what something like GCP is using or other companies out there, the actual business use cases that they’re looking to solve, you might see some of these and be like, “This could potentially be interesting to me.” Even if you don’t necessarily go and use the products, it might just give you an idea for some other products that some of these organizations are trying to solve.
Luu: Does your company have a data scientist team?
Participant 3: No, not yet.
Luu: Because I would suggest that you can go and talk to them, that you would ask what are they thinking, and then maybe pick their brain.
Participant 3: Yes. My company is healthcare-based and there’s just tons of information but it’s labeled, unlabeled.
Smith: One small detail though, which I’m sure you’re aware of but maybe the audience isn’t, is that the usage of data within a healthcare situation is obviously highly restricted and can be highly regulated. The techniques we have for understanding how machine learning models make decisions on data, and thus, in your case, on healthcare data, is a really complicated and difficult topic requiring a lot of technical depth to the work of how you would actually deploy something like that, I would presume. That might be a very specific concern in your organization around building up the skill set of people, even establishing the principles by which you would use data within a healthcare situation and the combination of automated reasoning. From talking with folks who’ve been able to successfully do things like that, it’s a super challenging intersection of business and technical problem.
Luu: Privacy, security concerns, and all that good stuff.
Miro: Don’t let that discourage you. There’s a lot of really cool work going on there.
Bringing the Agile World into Machine Learning
Participant 4: We’re experimenting with machine learning at our company. One of the things we want to avoid is getting into places where you research for five, six months, build a model and so on. How can we bring the Agile world into machine learning and start small and continuously improve, and not get into projects that who knows what will end up being?
Smith: I think this overlaps with some of the things we’ve footnoted a bit before. I’ll bring them up again. Pre-trained models are a great place to start. One way you might access a pre-trained model is from a service, from a cloud provider like Google or Amazon. Another way that you might use a pre-trained model in a different manner is to actually plug it into your application as part of its code in some way. We have support for doing this within PyTorch, ways to load existing models.
Some of these models are good examples of what do we know for sure that we can do pretty well, whether that’s around natural language understanding or object detection, something like that. You can work pretty fast from something like that. We’re talking about one-liners to load a preexisting model. Then basically you’re saying, “Here’s my data, apply it to the model and see what sort of results I get out.” It’s not the case that you have to be thinking in terms of, “We need to be sending three, six months of training models people before we have the slightest clue, does it apply to our data?” If you have the ability to start with something like a pre-trained model, whether it comes in the form of a service or just as an artifact in a line of code, I would encourage you to start there.
Luu: Have your team or company considered a crawl, walk, run, kind of approach to adopting or introducing machine learning?
Participant 4: Those are exactly the kind of things I’m interested in. We applied machine learning for fraud detection in online media, and those are not exactly off-the-shelf models, especially for our specialized data. What we’re looking for is how can we bring more systems that help us create models and get them in production and see value before we invest months. In fraud specifically, and in our field specifically, in three to six months your model might be relevant by then. How do you make this process of research and deployment and so on Agile?
How Do You Know You Have Enough Data for ML?
Participant 5: I actually have a data science team, which is kind of neat. We have to solve problems where we often don’t have much data. We may have one decision and we need to help automate that class of decision across a large body of problems. I know a lot of these examples when we talk about models being trained on millions of decisions. How do I deal with the fact that I often only have a few? Are there techniques that I can use to know for example that, “Maybe this decision isn’t something that we should even put through the algorithm. We’re going to have to handle with humans for now.” How do I know how much data is enough to really get good answers?
Luu: Can you share more about what’s the industry?
Participant 5: We work in a tax compliance, and so what we’ll often do is we’ll have to figure out, “How would you tax this object?” We may not have a ton of details about the object, and the tax decision may be very specific.
Miro: In my experience with a lot of these things, you just have to sometimes try. I imagine there’s a degree of text data that’s involved in your decision, and text specifically can sometimes be very difficult to work. I personally find that text is of the harder sub-disciplines to really apply to machine learning. A lot of it is just trying and just seeing can you actually pinpoint it? Maybe looking out and seeing if there are other organizations who have solved, maybe not the same problem, but similar problems, and how they were able to make those fine-grained decisions. That might be one way to do it.
I think there are also a lot of misconceptions out there on how machine learning is being used in a lot of organizations. In some cases, it is completely taking over the role of what humans are doing, but in a lot of cases, it’s also not. A lot there it’s done in tandem with the humans or for what’s called a human in the loop, where the machine learning might get you 80% of the way there, but you still do need a human, at least in today’s world, to do those last few steps.
Participant 5: Yes. We call that machine curation. Are there tools out there that can help with that? We’ve had to hand roll quite a lot, which is great, but it feels like this is something a lot of people are doing. I know that Stitch Fix, for example, has hundreds of people working in this, and I just am not aware of any tool that makes it easier and is open-source or well-managed startups.
Smith: Sorry, I’m just trying to understand the question. You’re talking about human in the loop doing the top supervision?
Participant 5: Is there something to make human in the loop?
Smith: Are we saying labeling an instance or are we saying something like overriding a business decision, like for fraud or something like that?
Participant 5: It’s more like I just want to quickly be able to see what the decisions of the model were and quickly decide whether they are good enough to move forward and that sort of thing. Something I need to put in the hands of an expert, not an engineer.
Smith: The point I was trying to get at is, you’re touching on a space where there are two possible scenarios, and if I heard you correctly, we’re talking about a domain expert who needs to make a human expertise decision about some set of data. Briefly, I’ll point to the other large problem of having humans in the loop, which is having any sort of human annotation of it does not require domain expertise. This is like, “This is a cat, this bounding box is a stop sign,” things like that.
There are a lot of startups chasing that and there’s a lot of open source tooling as well for being able to do that. When you’re talking about managing humans in the loop. I do know the problem that you’re talking about. I’m not sure that there’s a generic one-size-fits-all answer of actually having domain experts in the loop rather than someone on the expertise of, say, a mechanical Turgor. I’ve seen organizations do it and I can talk about some of the tips and tricks of how you make that happen, but I’ve never seen it done without some amount of architecture-specific integration, where you are the team which builds the technology, which controls that decision point. You need to be building that step in the business flow, and then producing the appropriate dashboard for the human to review, because it sounds very domain-specific.
Toolchain Selection and Polyglot Environments
Participant 6: This question’s related to toolchain selection. We tolerate a polyglot environment for our software engineers, all kinds of languages, run time environments, architectures and frameworks. Are there any gotchas or pitfalls with allowing that in terms of ML toolchain selection, and even all the infrastructure instances that we can then tie to that?
Smith: Yes, I think there are. It’s my personal opinion. I would say that compared to where machine learning was before the age of deep learning, there’s substantially less heterogeneity in people’s tech stacks, particularly within the field of deep learning. Deep learning is really enabled by hardware acceleration like GPUs and TPUs from Google, and there are just only so many ways to do that. I think you’re going to find that your toolchain is substantially narrower than for something like web application engineering, and that in particular, the more that you say, “Just use whatever random client-side language you want and then bind to whatever within any powerful deep learning framework,” you’re not necessarily going to have access to the full range of capabilities being provided by those technologies. I’m speaking generically here. I can talk a little bit more specifically about what it’s like with PyTorch later, but I think this is just a generic property of deep learning that has emerged.
Miro: I pretty much more or less agree. The advice I always tell people is find something you like that you know works and just stick with it. Specifically, TensorFlow, PyTorch, those generally tend to be two of the more popular ones, and they’re honestly both good. Pick one. They have a lot of overlap of what they can do so just pick one, learn it, and stick with it, it’s generally a safe bet.
Classifying in Isolation
Participant 7: I don’t know much about machine learning, I’m still trying to get started, but what I know of classification is, you’re trying to classify something in isolation, just itself. Is this label based on a model and some data set you have? Can you point me towards some examples or some research I could look at? If it’s just in isolation one thing, you maybe label it one way, but if over a time, some kind of time window, you’re seeing this over and over again, it becomes labeled something else? What is that considered? Also, positionally; if you have this network of nodes, where these events are happening in the nodes, changes labels. The field is security, if you’re trying to find a hacker who’s trying to hack a system. Certain things are benign, like someone actually doing a login, but based on the timeframe and some kind of sequence.
Miro: I think that that piggybacks nicely off of some of the conversations we were having earlier where a lot of the times, you do just need to keep retraining it and keeping up-to-date with what’s happening in the world. Jeff [Smith] mentioned using the term of concept drift, so just making sure that your models do continue to be accurate.
Smith: Yes. I think, depending on what you’re talking about, you may be talking about modeling retraining. You might not be though. If we imagine that we have some human-engineered features and they provide some sort of signal on what’s going on within real-world concept and you’re saying, if I heard you correctly, at T0 only one of these features is firing. At T1 more features are firing. At T2, even more features are firing. Those are multiple classification, so inference operations. You could even call these the same model, and different features extracted over time, is a common approach there. I think you also mentioned some stuff around graphs. Working with graphs is definitely a big sub-problem within machine learning. A lot of specific libraries you could look into. My personal favorite, no surprise, can be PyTorch BigGraph.
Fighting Fraud
Luu: What about a very interesting challenge and use case of fighting fraud? As you know, the techniques that are used are changing all the time. How do you keep up your models to keep up with the changes in terms of what they are doing? Talk about maybe some of the interesting developments in real-time training, for example. Any thoughts on that?
Smith: I’m not an expert on fraud. I wrote one book chapter in which I worked through an example to try and understand some of the techniques in use, and I would say that the challenges you’re talking about there point me towards retraining; when you have a dynamic concept, it becomes an important capability to have. Depending on what you’re doing, training may have more or less wall clock time for you. This gets into really the whole story of your toolchain in your infrastructure. Do you have the velocity within your process to simply have an automatic job, which is constantly retraining or retraining at a sufficient cadence, that gets it retrained in sufficient time to allow you to adapt to a rapidly moving concept? Some of this gets into cost, because if you want to say, “I just want to run a cluster of many dozens of GPU servers all the time,” at some point, that maybe pushes against how much business value you’re providing for something like that.
Miro: To get Meta here, you might even be able to use machine learning to predict when you should be retraining your machine learning models. That might be one potential use case.
Biggest Triggers in the Last Few Years & Future of the Industry
Participant 8: What changed in the last three to five years that machine learning became vital and essential for the big companies? The core concepts like neural networks have been around for much longer. What was the biggest trigger or driver in the last few years? Then where do you see the industry heading in the next five to seven years?
Miro: I think the short answer is the hardware, just between the access to hardware and the cloud, just with hardware continuing to grow. I think that’s just been able to enable a lot of this. These neural networks are extremely computationally intensive. They just couldn’t necessarily work on computers from the ’90s and the early 2000s. I think we’re seeing a lot of advancements there. That being said, in terms of the next 5 to 10 years, we are bumping into physical limits of Moore’s law, Moore’s law being every two years the number of transistors double. The idea is that there are physical limitations of that, once we get down to the quantum level.
There are a lot of talks about quantum computing being used as another medium to continue to accelerate these things. You’re just seeing more research being done than ever before and actually improving these models. You’ll see improved models that are more reliable, might actually rely on less data for being able to retrain. Right now deep learning is really intensive, but there are things such as one-shot learning and zero-shot learning, that allow you to train your models on less data. I think we’re also going to see a lot there. We’re also just going to see a lot of new data in general in the world just as we continue to turn to the Internet for more and more things. It’s just going to be more data to train on.
Smith: I’m going to give an answer that overlaps a little bit there and really focus on the work of Yann LeCun, who’s the founder of Facebook AI, he works with us here in New York. I think most of the information he’s pointed at people and trying to understand where deep learning is today involves a couple of related breakthroughs in techniques like convolution, which he personally developed, and with Geoff Hinton and Yoshua Bengio, his Turing Award colleagues. Some of those techniques are substantially newer; convolution, LSTM, RNNs, are substantially newer than neural networks. Neural networks go back many decades but a lot of this work that constitutes what we call deep learning today is done by people who are still actively working today, just down the street sometimes.
A big part of what allowed that to become successful is that underlying GPU acceleration. Brad [Miro] was talking a little bit about the story of how CPUs progressed; GPUs are a massive leap forward, if you have the correct software techniques to be deployed on GPUs. In the transition from graphics processing units to a general-purpose GPUs, that got unlocked. Key parts of that involve software breakthroughs that have more recently been made, have been the development of things like the CUDA tech stack on Nvidia GPUs and similar technologies.
That also points towards what’s coming next, at least at the hardware level. We know that we have to continue to make breakthroughs in performance efficiency. One major area that Google’s invested in is in domain-specific architectures like the tensor processing unit, and I think that it’s clear that that’s going to be a very promising area. Something that we care a lot about within the PyTorch project is will we see better and better GPUs that get you to the next breakthrough, or do we need to continue to support things like domain-specific architectures like TPUs? We say both of those things right now.
Getting back to the actual computer science techniques that allow us to have the deep learning breakthrough, and again, stealing from Yann, a lot of Yann’s work today focuses on self-supervised learning. We’ve talked a little bit about the business problems of getting someone to pay for human labels and pay for human labels at the scale of millions or billions, and some of those things just start to become infeasible. There aren’t enough humans, there aren’t enough hours in the day for some of the problems we want to solve. Self-supervised learning, where we’re working in the absence of labels and having a deep learning networks learn how to supervise themselves, is a really promising area of research right now, and you can see a lot of interesting papers on that. I think some of the most interesting ones that we’ve released out of Facebook involved things like working on very large image data sets, where there are no labels available, or even within weekly supervised learning as a closely tech-related technique where you don’t really have labels, but you have some sort of information which guides you in that direction.
Luu: There’s a lot of research in Wii reinforcement learning as well, I believe.
Team Structuring around Machine Learning
Participant 9: I’m curious, just stepping back about team dynamics and how this really works at a practical level. I have a team in which none of us know anything about ML, but we have a lot of good use cases. We can learn, we can hire, but what do you see on teams as far as how the ML specialist interacts with the application designers and so forth? What’s the breakdown there?
Smith: You call out that you need different skills on a team to be able to solve a problem like that. Absolutely. You need to have some idea of what are the decisions and responsibilities you’re trying to bring someone in to take on. I would say that, speaking fairly generically, some of the unsuccessful teams I’ve seen in this respect hire as if they’re pursuing major research goals and are trying to develop novel techniques where their business context is, apply the existing techniques to the given business problem, and then you get a massive impedance mismatch. Maybe that’s at a personal level. Someone is, in fact, a researcher interested in novel algorithmics and then they’re asked to say, “Could I use this tool on this problem?” You get a shrug back and, “Sure. Probably,” which isn’t really the useful business work.
There are starting to be, I would say, structures within machine learning career paths that you’re going to see. You want to make sure that you, as you build a team, find people who are actually interested in the application of ML techniques to business problems. The good news is, thanks to a lot of educational resources and growth within even the higher educational system, there are more and more people who have the right knowledge and an interest in real-world business problems. As long as you’re setting that fit, I think you’ll have a much better intuition of how could this individual person and another person help your team, rather than just saying, “Well, I guess we need to hire someone to write papers in the corner and never deliver any value.”
Participant 9: Just to clarify, though, and again, I know it may be hard to answer at a general level, but thinking of it from an Agile point of view, “Ok, what kind of stories go to the ML engineer and in the broader scheme of developing this application?” How does that break down? How can you break down that work?
Miro: I think one way to look at it is just how you would look at any other engineering project where the machine learning, retraining the model or doing the machine learning specific things would – not to be profound – but that would go to the machine learning engineers; then the infrastructure, depending on how you set it up, might go to the ML engineers. It might go to the data engineers or the software engineers. Especially on the engineering side, there can sometimes be a lot of overlap in the responsibilities of the positions, as well as a lot of ambiguity into what they should be doing in the first place.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
IBM has open sourced the POWER Instruction Set Architecture (ISA), which is used in its Power Series chips and in many embedded devices by other manufacturers. In addition, the OpenPOWER Foundation will become part of The Linux Foundation to further open governance.
IBM created the OpenPOWER Foundation in 2013 with the aim to make it easier for server vendors to build customized servers based on IBM Power architecture. By joining the OpenPOWER Foundation, vendors had access to processor specifications, firmware, and software and were allowed to manufacture POWER processors or related chips under a liberal license. With IBM latest announcement, vendors can create chips using the POWER ISA without paying any royalties and have full access to the ISA definition. As IBM OpenPOWER general manager Ken King highlights, open sourcing the POWER ISA enables the creation of computers that are completely open source, from the foundation of the hardware, including the processor instruction set, firmware, boot code, and so on up to the software stack.
IBM is also contributing a softcore implementation of the POWER ISA, which is fully implemented using programmable logic on an FPGA architecture. This is especially relevant for embedded system manufacturers, which often need to integrate a processor along with other components on the same custom chip.
As mentioned, POWER-based chips are used mostly in high-end servers, including IBM recent POWER9 series, and in embedded devices. Nevertheless, OpenPOWER-based chips are also used in desktop-class workstations.
IBM POWER is not the only open-source ISA available to manufacturers. Besides 34-year-old MIPS, it is worth mentioning RISC-V, which has been seeing a growing adoption in the last year. The RISC-V architecture is mostly geared toward low-power IoT use cases, as opposed to POWER being used in high-performance scenarios, but Alibaba has recently come up with a high-performance RISC-V design and introduced a high-end RISC-V processor