Month: April 2020
Amazon Updates AWS Snowball Edge with Faster Hardware, OpsHub GUI, IAM, and AWS Systems Manager

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS Snowball is a part of the AWS Snow Family of edge computing and data transfer devices. Recently Amazon announced several updates for the Snowball Edge device option. It now has a graphical user interface with AWS OpsHub, 25% faster data transfer performance, and support for local Identity and Access Management (IAM), and AWS System Manager.
Amazon launched the first AWS Snowball device back in 2015 to enable enterprises to migrate large amounts of data from their local servers to AWS. A company could request a Snowball device, load the data up to a maximum of 50 TB, and then ship it to the nearest AWS facility. A Snowball Edge has a similar capability, and this device can also act as an edge computing platform for running applications in environments such as ships and factories.
One of the updates for AWS Snowball Edge includes AWS OpsHub, a new graphical user interface allowing customers to manage their Snowball devices. By downloading and installing on Windows or Mac, users can unlock devices and configure devices, use drag-and-drop operations to copy data, launch applications (EC2 AMIs), monitor device metrics, and automate routine operations. Details of these operations are available on the documentation page.
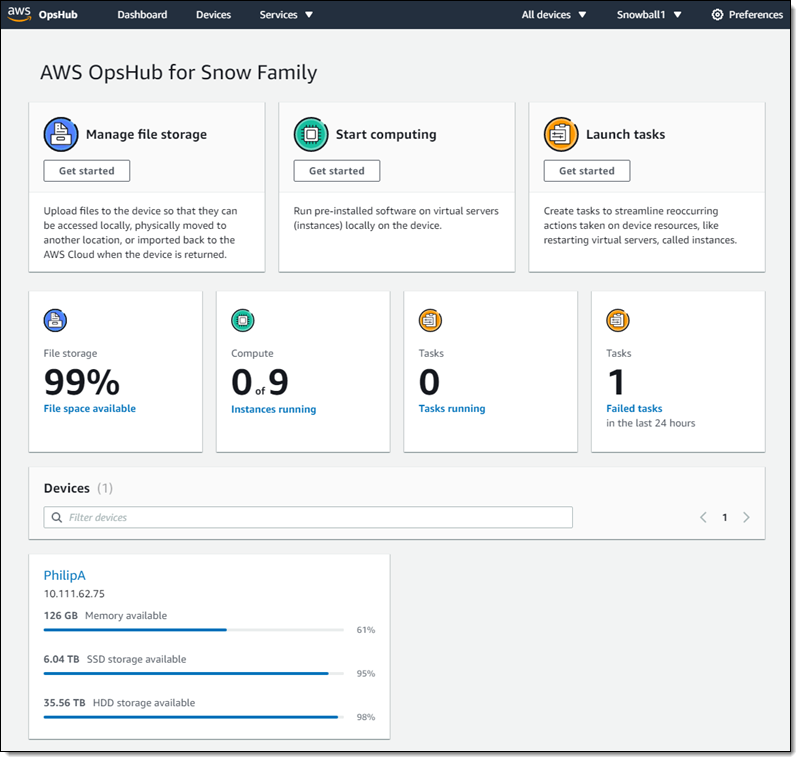
Source: https://aws.amazon.com/blogs/aws/aws-snowball-edge-update/
In addition to manageability improvements provided by the GUI, the public cloud vendor has optimized the device hardware by doubling the processing power and boosting data transfer speed by 25%. The newest so-called Snowball Edge Optimized devices features 40 vCPUs and 80 GB of memory, and the processor can run at 3.2 GHz, allowing this device to run more powerful EC2 instances. Also, Jeff Barr, Chief Evangelist for AWS, wrote in the blog post about the Snowball Edge Updates:
In addition to the 80 TB of storage for data processing and data transfer workloads, there’s now 1 TB of SATA SSD storage that is accessible to the EC2 instances that you launch on the device.
Note that users can order through the AWS Snowball Console cluster up to twelve Optimized Storage devices together. With this cluster, they can create a single S3-compatible bucket that can store nearly 1 petabyte of data, in addition to running AWS Lambda functions.
Furthermore, to enhance security for Snowball Edge Devices, Amazon brings support for local IAM. Users can now leverage user-based IAM policies to provide fine-grained control access to services and resources running on the Snowball Edge devices.
Rounding off the updates to Snowball Edge is the support for AWS Systems Manager, a service allowing users to automate frequent maintenance and deployment tasks. They can now write scripts in Python or PowerShell and execute them in AWS OpsHub. Moreover, these scripts can be any of the operations supported on the device.
The public cloud provider is not the only organisation in the Edge Computing space with its Snowball Edge device. Microsoft, for instance, offers Azure Stack appliances, which enterprises can deploy on-premise. Furthermore, Google has the Global Mobile Edge Cloud providing telco companies to run their applications in its main cloud data centers and also on its 100 plus edge locations.
Constellation Research Inc. analyst Holger Mueller told InfoQ:
Edge computing is critical for any next-generation application strategy and infrastructure in enterprises. Being able to use the same software assets on cloud infrastructure and at the edge is a significant factor to build applications faster – resulting in enterprise acceleration. As all hardware platforms, edge platforms need hardware refreshes, and that is what AWS is delivering right now.
AWS Snowball is available in almost all regions. Furthermore, pricing details for AWS Snowball is available through the pricing page.
MMS • Kate Sills
Article originally posted on InfoQ. Visit InfoQ

Transcript
Sills: Today I want to talk about making NPM install safe. Code has power. There’s this great quote from the structure and interpretation of computer programs and it says, “In effect, we conjure the spirits of the computer with our spells.” We conjure the spirits of the computer with our spells. As programmers, we have tremendous power, and this power can be used for good and it can be used for evil. Code can read our files, it can delete our files, it can send all of our data over the network, it can steal our identity, drain our bank account, and much more.
Introduction
So my name is Kate Sills, and I work for a startup called Agoric. There’s two things that you should know about Agoric. Number one, we’re building a smart contract framework that we hope can handle millions of dollars in assets. Number two, we’re doing it in JavaScript. This probably sounds like a terrible idea, and we’ll talk about how we’re able to actually do that.
At Agoric, we’re at this intersection of cryptocurrencies and third-party JavaScript code, we use a lot of JavaScript packages. And it turns out that this intersection is just like A-plus target for attackers, just kind of like an Italian chef kiss his fingers type of situation. What exactly is going on here? NPM has some great stats. They say that there’s over 1.3 billion downloads of NPM packages on your average Tuesday. That’s a lot of downloads. JavaScript has this rich culture of code reuse. Here are some more stats from NPM. NPM says that there are over 800,000 packages in the NPM repository, making it the largest open-source code repository in the world. The modern web application, it has over 1,000 dependencies. If we look at something like create-react-app, which is just kind of this basic bundle of everything that you might need for your react application, that alone has over 1,700 dependencies. There’s a lot of code reuse going on here.
NPM has this great quote, they say that over 97% of the code in a modern web application comes from NPM, and an individual developer is only responsible for about 3% or so of what makes their application useful and unique. We can think of the time saved, the time that we saved by not having to reinvent the wheel. That’s hundreds of millions of hours of coding hours saved. I think this is a really beautiful example of the kind of cooperation that humankind is capable of. We should be proud, and NPM should be proud of everything that they’ve accomplished. We have this really rich civilization of code. We have specialization, we have experts, and we don’t have to build everything ourselves. As long as we can rely on package developers to be good people, we’re fine, but not everyone is good, and not everyone is good all the time. People make mistakes. What happens when things go bad?
When It Goes Bad
Using other people’s code is risky. It’s risky because whatever package we install can pretty much do whatever it wants. There are no restrictions and we may not find out what actually happens until it’s too late. In real life, we also have this rich ecosystem. We’re able to buy and use things that other people create. We don’t have to make our own clothes or grow our own food. Imagine if everything that you bought, all the interactions that you had over the course of the day, that coffee that you bought this morning, imagine that that could take over your life. That would be ridiculous. That would be absolutely absurd, but that’s the situation that we’re in right now with JavaScript packages. We can’t safely interact with the things that other people have made without it potentially ruining us.
Let’s look at how authority works in Node.js. I’m going to focus on Node.js for the most part here. By authority, I mean the ability to do things. Authority in node, it comes in the form of imports and through global variables. Whenever we require something or we import something, that’s a way that you can get authority. It turns out that anyone or anything can import modules, especially the node built-in modules, and they can use global variables. The effects of this use, it’s often opaque to the user. There’s no notification that says like, “Alert, alert, someone’s trying to access your file system.” The user can’t tell. The imports that happen in these dependencies, it can be many levels deep, which means that all packages are potentially risky because you think you’re installing something really simple, but it has dependencies, and those things have dependencies, and so forth. Node currently provides no mechanisms to prevent this kind of access.
To illustrate this, let’s imagine that we’re building a very simple web application, and we want to add a little excitement. Let’s say we install this package called addExcitement. What it’s doing is just adding an exclamation point to the end of whatever we pass in. We pass in the string, it adds an exclamation point. If you’re not familiar with this notation, this is just like a template literal. Our “hello” turns into “hello!” so it’s just string manipulation. It turns out the addExcitement could actually be written like this, and we would have no idea. We have the same functionality, so it works exactly the same from the outside, it looks exactly the same. From the user’s perspective, we get the same effects, but we’re also importing the file system. In node, one of the built-in modules is FS for the file system. We’re also importing HTTPS, which is another built-in node module.
What this attacker is able to do, they’re able to say fs.readfile, and they can basically read anything. Let’s say that my wallet private key there, that’s the path to our bitcoin private key. It’s able to read that and it’s able to send it over the network. This code is simplified quite a bit, but I think you can kind of see what’s going on here. Just through access to FS and just through access to HTTPS, any attacker through the installation of pretty much any package would be able to read our data and send it over the network. In the cryptocurrency world where we’re dealing with private keys, we’re dealing with lots of value, this is a really big problem. This is a really big deal.
Let’s go over the steps that it took to read any file. All we had to do, we had to get the user to install the package, or maybe we get another package to install our package as a dependency. Then step two, we import FS, the node built-in module for the file system. Then step three, we know, or we can even guess, there’s no penalties for guessing the file path. That’s it. That’s all we had to do. Like I was saying, we just had to import FS, and then that’s pretty much it. We just had to guess the file path and we had access.
A Pattern of Attacks
This is actually a very common pattern of attacks. You might have heard of the event-stream incident that happened last year. What happened was that there was an open-source JavaScript developer, Dominic Tarr, and he was, I think, managing over 100 open-source JavaScript packages at the time. A volunteer came up to him and said, “You know what? I’ll tell you what, I can take over the event-stream package for you. I’ll handle it, you don’t need to worry about that.” Dominic Tarr said, “Great. That’s fantastic. Thank you for doing that.” This volunteer made some changes. What they actually ended up doing to the event-stream package was adding a malicious dependency. This malicious dependency targeted a specific cryptocurrency wallet called BitPay, or Copay. What it did was that it tried to take the bitcoin private keys, send them over the network, exfiltrate them, and ultimately steal bitcoin.
We saw this pattern again this year. There was another package, the electron-native-notify package, and it also had a malicious dependency that tried to target cryptocurrency wallets. NPM was able to stop this attack, but I’m sure there’s going to be many attacks like this in the future. If we don’t do something to prevent it, we’re going to see this pattern again and again.
Solutions
What are the solutions? One of the solutions, this is a serious solution, companies are actually doing this, is to write everything yourself, believe it or not. Obviously, this isn’t a very good solution, and it’s not very practical for most of us out here. If I had to write everything myself, I wouldn’t get very much stuff done. We’d lose millions of coding hours that we’ve saved by reusing other people’s code. I don’t think this is a very practical solution.
Another solution that people have suggested is paying open-source maintainers, so at least there’s someone responsible for the security of the package. I think this is a good solution. I’m not against it. But even if someone is paid to maintain a package, there’s still no guarantee that they won’t be compromised, that they won’t make a mistake. I think we’ll see this attacks will happen, even if we start paying maintainers for their packages.
Lastly, the solution that people suggest is code audits. Code audits are great, but they’re not a panacea. They don’t solve everything. There are things that code audits miss. To provide an example of this, here’s some great code by David Gilbertson. What this code is actually doing, it’s doing a window.fetch, but it’s doing it in a really weird way. That “const i” at the top is just fetch just shifted over one character. Then “self” is just an alias for window. If you’re going through a code audit, imagine this is two dependencies deep, this package you’re just looking through, you’re never going to catch this. Code audits are great. Even if you have manual tools for that, you can maybe grep for the things that you think are dangerous, you might still be missing things.
If we go back to the steps to read any file, we see that a lot of the solutions that have been proposed, they focus on number one. They focus on trying to only install packages that you trust, they focus on being able to trust the open-source developers. I think this is admirable. I don’t want to stop people from actually carrying out these solutions, but I think we should be focusing on step number two and step number three. What would happen when a malicious package tries to import FS and it just can’t, or it tries, it knows the file path, it knows the file name, and it just can’t use it, it can’t access those files? There’s this great quote from Alan Karp that kind of goes towards this point. He says, “The mistake is in asking, ‘How can we prevent attacks?’ when we should be asking, ‘How can we limit the damage that can be done when an attack succeeds?’ The former assumes infallibility; the latter recognizes that building systems is a human process”.
What We Need: Code Isolation
If we were actually able to focus on preventing the import of FS, and making sure that even if someone does know the file path, it’s of no use to them. How could we actually do that? So the solution is code isolation. It turns out that JavaScript is really good at isolation. This is kind of due to an accident of history. JavaScript has a clear separation between the pure computation and access to the outside world. If we sever that connection to the outside world, we can actually prevent access to a lot of harmful effects. This is not true necessarily of other languages. If you look at something like Java, it doesn’t have this clear separation. As JavaScript developers, we’re actually in a really good place to do code isolation.
In JavaScript, we already have the concept of a realm. Each webpage actually has its own realm. JavaScript that executes in one webpage, it can’t actually affect JavaScript that executes in another. A realm is basically the environment in which code gets executed. It consists of all of the objects that must exist before code starts running. These are objects like object, object.prototype, array.prototype.push. It also consists of the global object and the global scope. Historically, one way that people have isolated third-party code is to isolate it in a same-origin iframe, but using iframe is clunky. It would be great to be able to use realms to create new realms without the overhead of iframes.
That was the concept behind a TC39 standards proposal called realms. The question that they asked was, “What if we could actually create these realms without the overhead of the iframe and without the DOM?” What if we could do it in a very lightweight and easy way? Creating a new realm creates a new set of all these primordials, these objects that we get at the start of our code. It also creates a new global object and a new global scope. A realm is almost a perfect sandbox. When the code is isolated in a realm, it’s isolated from the rest of the world. And it has no abilities to cause effect in the world outside itself. Malicious code that runs in a realm can pretty much do no damage.
The realm API allows us to create another kind of realm, known as a featherweight compartment. Rather than duplicating all of the primordials, like array, object, prototype, that sort of thing, a featherweight compartment just shares them. This makes the compartment much lighter.
So realms is a proposal before TC39, the JavaScript Standards Committee right now. Right now it’s at stage two, which is still the draft stage. We’re looking for input on syntax and semantics, and everything like that. We’re really hoping to push it forward so that it becomes part of the standard JavaScript language. Even though it’s still at the proposal stage, there’s a shim, and so you can start using the shim now. Realms and realms shim was really a team effort between Agoric and Salesforce. Mark Miller from Agoric, JF and Caridy from Salesforce. JF was doing such a great job, we actually hired him at Agoric. It’s been really great. They’ve been building this shim and you’re actually able to use it now.
Let’s see if this will work. I wanted to try to show what happens when you use that same piece of code that I had showed you guys before with the fetch that was one character over. I’ll take the code that we saw earlier. Let’s just paste it into our console here. What this is doing, again, it’s doing a window.fetch. This is just showing that you can have a network call and not necessarily realize it. That works. We get a promise back and that promise resolves to the page data, so that worked. Now, if we take that same code, and we evaluate it inside a realm, it doesn’t work because window is actually not even defined at all. When it tries to find fetch on undefined, it just can’t. It doesn’t work.
We have these featherweight compartments. We’re sharing these primordials, but we still have a problem because we’re sharing these primordials. There’s a thing called prototype poisoning. What prototype poisoning actually does is that it allows people to reset the value of the objects that we get, these primordial. Here’s an example of the attack. In this attack, the attacker is taking array.prototype.map, and it’s saving the original functionality. From the user’s perspective, it all acts the same, it’s mapping over a function, it’s mapping over the array, but it’s, actually, in the background, also doing a network call. This is obviously a huge problem, and we don’t want this to happen. What we can do is we can use realms plus transitive freezing, or what we call harden. That turns into something that we call Secure ECMAScript or SES. When someone tries to make changes to the primordials, when they try to reset those values, it’s a frozen object. It’s just not able to do that.
Using SES is really easy. It’s a package right now. All you have to do is do an NPM install of SES. Then you require it. Then you just say makeSESRootRealm. Then whatever code it is that you want to evaluate, let’s say you have some third-party code, maybe it’s a dependency, maybe it’s like a plug-in architecture, so someone else’s code, you have to evaluate it, and then you can run it. There’s kind of a developer ergonomics issue right now where you have to stringify all of the code that you pass in. That’s one of the things that we’re working on. Importantly, you can evaluate it in a safe way.
You might be saying, “That’s really great. Isolation is great, but my code actually needs to do things. It needs access to the file system, it needs access to the network.” What do we do when our code actually needs a lot of authority?
POLA
There’s this thing called POLA. POLA stands for the Principle of Least Authority. You may have also heard this as the Principle of Least Privileged, but POLP doesn’t sound as great, so we’ll stick with POLA. What POLA means is that you should only grant the authority that’s needed, and no more. That means we have to eliminate ambient and excess authority. We’ll go into what those are.
What does ambient authority mean? Basically, ambient authority is easy access to things without explicit grants. In our example, with the addExcitement stringification, we saw that it had access to the file system and to the network. Both of those were just through importing node modules. There was no explicit grant of access there, the code was just able to get it. That’s an example of ambient authority.
We also should not have excess authority. In that example, in the addExcitement example, that code didn’t actually need any authority at all. It was just simple string manipulation. It shouldn’t have had access to the built-in node modules, or the file system in the network. When we rewrite it to work under POLA, it shouldn’t actually have the authority to do any of those things at all.
To illustrate this, let’s use an example. Let’s make a command line to-do app. It’s going to be really simple. It can add and display tasks. These tasks are just saved to a file, we’re not even going to try using a database. We’re going to use two JavaScript packages. These are really popular packages. One of them is called chalk, and one of them is minimist. They both have over 25 million downloads per week, so they’re very highly used. What chalk does is that it just adds color to our terminal. Whenever we console that log something, we can make it red, green, blue, purple, whatever it is that we want. What minimist does is that it parses the command line arguments, so it just makes it a little bit easier.
Here’s an example of how you might use it. It’s pretty simple. Let’s say we added todo=”pay bills”, we added todo=”do laundry”, we add another to-do to pack for QCon. Let’s make this priority high, because it’s really important. Then we can display them. The normal to-dos are in yellow, and our priority high to-dos are in red.
Let’s analyze the authority of this app. We have our command line to-do app, and it needs to use FS, of course, because it’s using a file as its data storage. It also needs to use minimist because minimist is passing the command line arguments. Minimist is pretty much a pure function, so it doesn’t need a lot of authority. You can see in the diagram, the authority that’s in red is kind of more dangerous, and the authority that’s in blue is relatively safe. Chalk, on the other hand, it does something interesting. It imports a package called supports-color. This needs to use process, which is a global variable. It also needs to use OS, which is a node built-in module. These are both a little dangerous. Let’s look at what they can do.
If you have access to process, you can actually call process.kill. You can kill any process that you know the idea of. You can send various signals as well. This is just great. This package that we installed, chalk, just to change the color of what was being printed in our terminal, it can actually kill processes on our machine. If you have access to OS, you’re able to set the priority of any process. All we needed to know was the process ID and we can set the priority. This is pretty crazy, but this is how the JavaScript package ecosystem works right now, where without us even knowing it, things that we install can do all of these things.
If we want to enforce POLA, we’re going to need to be able to attenuate access. We want to be able to attenuate access in two ways. We want to be able to take away our own access authority to FS, the file system, we want to attenuate chalk’s access to OS and process. I should point out here that this actually only makes sense once you’ve already achieved the confinement of running code in a realm, or under SES or Secure ECMAScript. If it’s not confined, then the code can basically do whatever it wants. You can try, but it’s not going to affect it at all.
Let’s attenuate our own access to FS. First, let’s check the file name. This is just a function that says, “If the path that we pass in as an argument is anything different than what we expect, let’s throw an error.” We can do that. We can use this function, checkFileName, in our attenuation. This is a pattern that you’ll see again and again in kind of the attenuation practice. What’s happening is that we take the original FS that we got from node, and we say, “You know what, we don’t actually need all of the properties on that object.” We can create our own new object, we can harden it, which is the transitive freezing, we can take the two methods that we actually want, the two methods that will be used by chalk, and we can redefine them. We can have a check kind of a guard in each of these methods for checkFileName. If it tries to access anything other than our to-do app file, it will throw an error. Then after we do that, we can basically just use the same functionality from the original FS, and just kind of pass it forward. You might ask, “Why do we actually want to restrict our own access? I’m writing this code, I trust myself.” People slip up, you may do something that compromises your computer. It’s just kind of part of the best practices to attenuate even your own access to things.
How do we attenuate chalk’s access to OS and process? First, let’s solve the ambient authority problem. Instead of chalk just being able to import OS, and to use the process variable, let’s just pass those in. Let’s take out the ability to just kind of ambiently access that authority. Let’s make sure that the only way that it can get it is by getting it passed in as an argument. We’ll change chalk, rewrite it just to take it in as an argument. We’ll do the same thing to supports-color too, this package that chalk uses.
We mentioned how chalk needs the OS built-in module. It turns out that the only thing that chalk needs from OS is just this release, which is just a string, like Win-32, what have you. It just needs to know the operating system release. The reason why it needs to know that is because there’s a certain kind of color of blue that doesn’t show up very well, I guess, on Windows computers. That’s why it needs this access, just because that certain color of blue won’t show up quite as well as another color of blue. That means that we can attenuate this. We can take all of the power that OS has, and we can take that original OS and just create a new object that only has that release property, and then just have it be the original OS release.
We can do the same thing to process. Chalk actually uses a bit more of process, but you can kind of see the same pattern here, where we take the original process object, and we just pick off a few properties that we need off of that object. There’s something else interesting that happens here. It turns out that we can actually lie. I’m using a Mac right now. My platform is not Win-32, but I can pass that along. This is also part of the windowing of authority. You don’t have to necessarily tell the truth to your JavaScript dependencies. This is a really important pattern in enforcing POLA.
If you’ve liked these patterns, if you liked attenuation and virtualization, you might really like a programming paradigm known as object capabilities. The main message of object capabilities is to don’t separate designation from authority. It’s an access control model that’s not identity based. You can think of object capabilities as using a key instead of a list of the people that are allowed to do things. It’s kind of like a car key in that way. What’s really great about object capabilities is that it makes it easy for us to enforce POLA, and to do it in creative ways. We can just give the authority that we need to people, and we don’t have to have complicated permission lists that are updated with who’s able to do what. We can just do it with objects. This also makes it really easy to reason about authority, because it turns out that the reference graph of objects, so like which objects have references to other objects, that’s also the authority graph. If we can see that this object, no matter what, it doesn’t have access to this, we know that there’s no access there. That makes it really, really easy to actually do a meaningful code audit.
If you’re interested in object capabilities, there’s this great post by Chip Morningstar at habitatchronicles.com. I really encourage you to check it out. Object capabilities help us to do some really cool things in enforcing POLA.
SES as Used Today
I want to go over how SES is used today. Like I said, it’s stage 2 proposal at TC39, SES/Realms. It’s still in progress, but there’s a shim for both SES and realms, and people have already started using it. First, Moddable. Moddable is a company that just does JavaScript for the Internet of Things. Your Whirlpool washing machine might have JavaScript running on it. They have this engine called XS. It is the only ECMAScript 2018 engine that’s optimized for embedded devices. They’ve been the first engine to implement SES or Secure ECMAScript. What’s really cool about this is that once they have that confinement, once they have the code isolation, they can actually allow users to safely install apps written in JavaScript on their own IoT devices. You can imagine you have your oven, your washer, your light bulb, and you’re able to control all those things with code that you write. The manufacturer can let you do that because it’s safe, because they’ve isolated your code, and they only allow you to do certain things like, for instance, make the light change color. That’s really cool. I think that’s really exciting.
Another company that’s been using realms and SES is MetaMask. MetaMask is one of the main Ethereum wallets. What they’re able to do is that they allow you to run Ethereum apps without having to run an Ethereum full node. They actually have over 200,000 JavaScript dependencies. I think some of those are duplicates, but they have a lot of code reuse. What they built was this product called LavaMoat, I think it’s a Browserify plugin, as well as a Webpack plugin at this point. What it does is it solves that JavaScript supply chain issue where you have all of your JavaScript dependencies, you have this build step, and you don’t know if it’s actually safe. What they do is that each of these JavaScript dependencies is put in its own realm, so that whatever you’re installing isn’t actually able to do very much. They also have a permissions list that’s very tightly confined. You have kind of like a declarative access file of what packages have access to what. If you use Browserify, or you use Webpack checkout LavaMoat.
MetaMask has another product called MetaMask Snaps. They had this issue basically, where they had this very widely used Ethereum wallet, or this web plugin, and it was getting very political. All these different groups were saying, “We really want our latest functionality. We want it in this wallet so that people can use this.” It was getting really hard for them to figure out who they should prioritize first, and how someone would be displeased because they did someone else’s job first, things like that. They built this plugin architecture called Snaps that allows third parties to write their own custom behavior for MetaMask. For instance, this one group, StarkWare, has some custom crypto that they want to be able to sign transactions with. They can add that as a plugin.
Lastly, Salesforce, which has been one of the primary co-authors of realms. They’re using a version of realms right now in their Locker Service. This is an ecosystem of over 5 million developers. Their Locker Service is a plugin platform. You can create third-party apps, you can have people use them. You can have these apps installed all on the same web page. They have a DOM solution as well in addition to the realms. Because they’re handling a lot of business data, it’s really important that these third-party apps are safe.
I want to be clear about the limitations. SES is still a work in progress. We’re still solidifying the API. We’re still working on performance. Like I mentioned, there’s still some developer ergonomics issues. For instance, you have to stringify the modules to be able to use them right now. It’s stage 2 in the TC39 process.
Even while it’s a work in progress, SES is still able to provide nearly perfect code isolation. It’s scalable, it’s resilient, and it doesn’t depend on trust. It doesn’t depend on us being able to trust all these open-source developers. It enables object capability patterns like attenuation that I think are really powerful. Most importantly, it allows us to safely interact with other people’s code.
Here are the three repos, if you’re interested. There is the TC39 proposal realms repo. There’s the realm shim under Agoric, and also SES under Agoric. Please, take a look, play around with them. We would love your feedback, love your comments, love your POLA requests. We could definitely use your help.
Questions and Answers
Participant 1: I was wondering about the changes to the access object where basically you’re providing a slimmed-down version of access control things. It looks like you’re essentially depending on that third-party library to basically have dependency injection, right?
Sills: Yes, I guess you could say that.
Participant 1: I was just wondering how that would just practically work.
Sills: For that particular example, what I did is I forked the chalk and the supports-color code base, and then I modified it so that it was able to take those as arguments. Yes, it is kind of a dependency injection pattern. Ideally, what would happen is that everyone here would submit a PR to all of those JavaScript packages, and ask them to do it that way. Obviously, that’s a really hard transition. It’s a hard problem to solve. I think what we’ll see is that people who have very high security needs will fork those repos, make those changes, and then hopefully encouraged packages to do things more in that style.
Participant 2: You mentioned a few different methods of isolation. Which one would you recommend us to use right now?
Sills: First, I should mention that all of these things are still a work in progress, so they’re better than nothing. There are still security audits to go through and all of that. Realms alone, that’s what gets you the isolation. Then if you want to protect against the prototype poisoning, then you actually need to do the transitive hardening. SES or Secure ECMAScript is probably what you should be using right now, but again, it’s still going through the security audit, still a work in progress, so it’s better than nothing. We’ll hopefully have a 1.0 version to release soon.
Participant 3: How do you handle if a library you’re using changes its dependencies or changes how it uses its dependencies, and that causes bugs, because maybe it only cared about the OS version for one particular reason, and you know that reason, but now cares about it for other reasons? Now bugs happen in your app and you’re not sure if it’s your own source code or because of the dependency?
Sills: That’s a really good question. People have been building tools for that specifically. LavaMoat, which I mentioned, what they have is, the first time that you run an app, you can get a printout, basically, of all of the authority that’s being used. When I mentioned that the only thing that was being used in OS was release. You would kind of get a JSON printout of what everything is using. Then when you upgrade your dependencies, and you get a new version of that, if you do that same print out again, you’ll have different results. It allows you to see what authority is being asked for over what’s been asked for before. Hopefully, that’ll help you figure out some of those issues. I think notifying developers that their dependencies are actually asking for more authority is really important, and we don’t have that at all right now.
Moderator: That analysis through runtime analysis, not through static analysis, right?
Sills: Right.
See more presentations with transcripts
MMS • Ben Linders Paul Gibbons
Article originally posted on InfoQ. Visit InfoQ

In The Science of Organizational Change, Paul Gibbons challenges existing theories and tools of change management and debunks management myths. He explores going from a change management to a change-agility paradigm and provides 21st-century research on behavioral science, that affects topics such as project planning, change strategy, business-agility, and change leadership in a VUCA world.
By Ben Linders, Paul Gibbons
MMS • Erik Costlow
Article originally posted on InfoQ. Visit InfoQ
Maven 3.7.0 is slated to include a new wrapper designed to simplify portable builds between systems. This expands beyond maven’s typical dependency resolution to include resolution of the correct version of maven itself, removing the need to pre-configure most systems. As a result developers can more easily compile third party software projects and organizations can scale generic build nodes via continuous integration.
A large portion of the Java ecosystem uses Maven for two major parts: maven is a build system for compiling software, and maven central is a public repository of libraries so that the maven build system can obtain needed files. Without the maven build system, developers who want to work on a project must spend time learning a unique build system or setup for each project, thus taking time away from the work they set out to do. Instead, maven sets out to share a common structure to all projects — while some may complain about a lack of customization in maven’s pom.xml file, developers can learn one thing and then apply the same complaints and skillset to other projects without additional effort. Many maven plugins are also available that can customize activities across the build phases. Inspiration for the wrapper came from Gradle, with the wrapper project emphasizing the inspiration.
Maven to date has been very stable for users, is available on most systems or is easy to procure: but with many of the recent changes in Maven it will be easier for users to have a fully encapsulated build setup provided by the project. With the Maven Wrapper this is very easy to do and it’s a great idea borrowed from Gradle.
-Takari
All maven projects follow a similar folder structure and layout:
- pom.xml indicates that a project is based on maven and contains instructions on how to build it, the relationship between projects, and dependencies.
- src/main/java is the initial folder for custom code
- src/main/resources is the location for code-like files, such as documents or configuration
- src/main/java9 and similarly numbered folders indicate a multi-release JAR file, such as a library working on forwards-compatibility. These folders are less common, used mostly for libraries rather than applications that can specify their JRE version.
- src/test/java is the location of unit tests, code that will validate much of the project’s correctness
- target is the destination of compiled class files and other artifacts
Ultimately maven works by breaking software compilation into several needed phases, with key elements as follows:
- Someone configures a build system to have both a JDK and Maven.
- The build system launches a single job to compile the software in a lifecycle, some of which are:
- Clean: Cleans up all older artifacts, ensuring no side-effects from previous builds.
- Compile: builds the software project
- Package: converts the compiled project to a deployable artifact
- A deploy or custom runner phase
- The compiled code or application is then sent to the appropriate area for distribution.
The maven build wrapper makes an important improvement in step 1, removing the need to have Maven already present and configured on a system. While some development systems may benefit, the wrapper is not necessary for major Integrated Development Environments such as Apache NetBeans that already ship with an embedded Maven and full native support for Maven projects.
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

Oracle is well on their way to a Helidon 2.0 GA release scheduled for late Spring 2020. Helidon 2.0.0-M1, released in early February, and Helidon 2.0.0-M2, released in late March, have provided a host of new features including: support for reactive messaging; a new command-line tool, a new web client API for Helidon SE, GraalVM support for Helidon MP, and a new reactive database client.
By Michael Redlich

MMS • Alex Blewitt
Article originally posted on InfoQ. Visit InfoQ
The DNSSEC Root Key Signing Key ceremony 41 will take place tomorrow between 17:00-19:30 UTC on Thursday 23 April. However, unlike previous years, the keyholders will not be physically present, as reported last month by InfoQ. The ceremony’s process has been adapted after discussions with the keyholders and community, in light of the fact none of the keyholders can physically assemble at the key location in Virginia.
DNSSEC works by having a signed root-of-trust to the root keyservers, whose keys are signed by the root signing key, in a similar way that browsers use root Certificate Authorities. The DNSSEC root keys have a much higher blast radius, since they apply to all DNSSEC signed DNS zones; and so great care is taken in the root key signing ceremonies and the production of the root key material.
Every three months over the last decade, DNSSEC Root Key Signing Key ceremonies have taken place, hosted in securely held locations with members from around the globe coming to witness and participate in the ceremony. The event is recorded on video, and Root KSK Ceremony 41 will be available as a public stream on YouTube for those that want to observe and ask questions.
The normal process works by individual keyholders unlocking their own smartcard from a locked, on-site security deposit box. A hardware security module uses a quorum of those smartcards to generate the root key signing key. Because of travel restrictions caused by COVID-19, none of the keyholders will be physically present and so the ceremony has been adapted. There is a FAQ available specifically for this ceremony.
The physical safety deposit keys for those who cannot be present have been double packaged inside tamper evident casing and have physically been received by a number of individual “Trusted Community Representative” ICANN staff who are standing in as proxies for the keyholders who cannot be present. The tamper proof packages remain sealed, and will be vetted by each original keyholder over the video link to verify that the tamper seals are still intact, before authorising the unpacking of the contents. Once the tamper proof seals have been broken, the secondary containing package will be opened to reveal the safety deposit box key (though for security reasons, the physical key will not be visible on the video stream to avoid cloning attempts) to remove the hardware security module smartcard.
Once all the smartcards have been released from the security deposit boxes, and the root key signing keys generated, then the smartcards will be returned to the safety deposit boxes, relocked, and then the physical security box keys will be securely packaged inside a separate tamper evident box for their return to the keyholders.
To minimise travel and impact on the ICANN staff, a minimum of people will be physically present. In addition, the signing ceremony will take place in Los Angeles rather than the usual Virginia to minimise travel for those staff who are present to facilitate the ceremony and the signing steps.
To further minimise the impact of COVID-19 on future ceremonies, a full 9 months’ worth of root zone signatures are being generated at this ceremony. It is anticipated that this amount of breathing time will give normality a chance to resume before the next signing ceremony needs to take place; but since predicting the future is impossible, a future virtual signing ceremony may take place. If longer term impacts to global travel result, it may be that the ceremony needs to be adapted further, and discussions on that will take place towards the end of this year or next if needed.
To be (virtually) part of this unique DNSSEC signing ceremony, and to witness how secure key management protocols are enacted, watch the public YouTube stream on Thursday at 17:00 UTC.

MMS • Helen Beal
Article originally posted on InfoQ. Visit InfoQ

Alcide, a Kubernetes security platform, has announced the release of sKan, a command line tool that allows developers, DevOps and Kubernetes application builders access to the Alcide Security Platform. sKan enables developers to scan Kubernetes configuration and deployment files as part of their application development lifecycle including CI pipelines. Developers can scan their Kubernetes deployment files, Helm charts or Kustomized resources.
Alcide is a Kubernetes-native AI-driven security platform for cross Kubernetes aspects such as configuration risks, visibility across clusters, and run-time security events. It uses policies enforcement and a behavioural anomaly engine that detects anomalous and malicious network activity. Alcide sKan uses the same technology behind Alcide Advisor and Open Policy Agent (OPA) and is a software translation of DevSecOps culture in that it shifts security left to developers building Kubernetes-based applications.
Alcide sKan operates with Kubernetes application builders’ choice of deployment framework tooling; Helm charts, Kustomized resources or Kubernetes resource files (YAML/JSON). While scanning source code for security vulnerabilities may be considered a common practice today, possible configuration errors in Kubernetes environments can be overlooked and vulnerabilities can be unwittingly introduced to production. Alcide sKan provides developers with feedback on security issues, risk, hardening and best practices of Kubernetes deliverables, before committing code.
sKan covers a range of potential security risks that may concern Kubernetes application builders, such as verifying that deployment files are not configured to run privileged, they don’t introduce risks to Kubernetes worker nodes as well as RBAC sanitation checks and the identification of secret leaks. Alcide sKan presents insights for each detected risk. InfoQ asked Alcide’s CTO, Gadi Naor, about sKan:
InfoQ: How does a developer integrate sKan into their deployment pipeline?
Naor: Alcide sKan be captured in developer terms as a Kubernetes YAML/JSON resource linter.Anything you can do with a code linter in your pipeline would be something a developer can implement with sKan. SKan’s input options offer a number of integrations, such as developers can have sKan read an entire directory of Kubernetes resources, or render a Helm chart and pipe them via standard input into sKan or take Kustomized resources and pipe them via standard input into sKan. On the output end, developers can have sKan generate a report as JUnit or HTML and store it in the pipeline artefacts. Developers can also leverage sKan in commit hooks to validate certain assertions about Kubernetes configurations.
InfoQ: How are security considerations different in a Kubernetes environment?
Naor: Code scanners identify, report, and potentially fix issues found in programming languages. Kubernetes application configurations are effectively YAML/JSON files that declaratively specify how built code will run in Kubernetes. sKan essentially starts where YAML/JSON syntax validation ends.
InfoQ: How does sKan operate alongside or integrate with tools that scan source code?
Naor: sKan complements source scanners, and would normally run alongside programming languages source scanners. sKan starts where YAML/JSON syntax validation ends; YAML/JSON files specify how built code will run in Kubernetes, and sKan analyses the Kubernetes application configurations and will identify and report security best practices.
InfoQ: How would sKan provide assurances and continuous compliance for security teams, architects and leadership?
Naor: sKan integrates with the same tools and platforms that code scanners integrate which means that sKan becomes a plug and play tool to the existing investments made into the tools that cover assurance, auditability and continuous compliance for the various stakeholders that consume those reports, such as architects and leadership. For example, CI pipeline artefacts and logs become the substance which is then exported to tools like Splunk, which provides the reports and auditability for a wider context and audience.
InfoQ: Please provide a couple of examples of actionable insights and the risks they may detect.
Naor: If a developer accidentally places a secret such as Slack Token or AWS Secret Key into Kubernetes deployment file such as StatefulSet, one suggestion made by sKan is to leverage Kubernetes secret resources, and the best practice is to wire secrets from secret stores in application runtime. Another example of a risk sKan may detect would be if a developer were to implement a cluster component and build it with excessive Kubernetes RBAC permissions; this is something that has potential to introduce a cluster-wide risk.
InfoQ: Is a full list of the potential security risks sKan looks for available?
Naor: sKan presently covers the following modules which each host multiple checks: Kubernetes pod security, RBAC privileges, misplaced secrets, service & Ingress controller and Isto meshconfig checks in addition to checks for Prometheus and Etcd operators, container image registries and admission controllers. sKan is powered by Alcide Advisor as well as Open-Policy-Agent, new modules and checks will be shipped on a regular basis from both in-house and the community.
InfoQ: How would it identify a secret leak?
Naor: Alcide sKan scans Kubernetes resources, rendered Helm Chart templates or rendered Kustomized resources, against a set of regular expressions. It’s quite comparable to how a GitHub Repository would be scanned for secret leaks, with a few important differences. For example, GitHub repository secret scanners scan files at rest; Alcide sKan processes resources after Kubernetes-specific transformations, and sKan points a developer to the Kubernetes specific root cause.
InfoQ: How does sKan bring dev and ops closer together?
Naor: Alcide sKan can be leveraged as a local tool for developers tasked to build Kubernetes-based applications, and enables them to build and ship secure components through Kubernetes; Ops would then need to run and operate those components. sKan helps to shape and form alignment between dev and ops by aligning the security quality of Kubernetes-based application deliverables with a set of high bar security standards and best practices.
For more information, please go here.
MMS • Joydip Kanjilal
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Caching is a technique for improving web application performance by temporarily storing requested data in memory for later reuse.
- Response caching refers to specifying cache-related headers on HTTP responses made by ASP.NET Core MVC actions.
- NCache is a cross-platform, open-source distributed caching framework from Alachisoft, built entirely using .NET.
- This article presents a discussion on how we can work with NCache and response caching middleware in ASP.NET Core.
NCache is a cross-platform, open-source distributed caching framework from Alachisoft. It is an extremely fast distributed caching framework that is linearly scalable. This article presents a discussion on how we can work with NCache and response caching middleware in ASP.NET Core.
Pre-requisites
You should have Visual Studio and ASP.NET Core installed in your system to work with the code examples discussed in this article. As of this writing, ASP.NET Core 3.0 has been released. You can download ASP.NET Core from here.
You can download Visual Studio 2019 from here.
What is caching and why is it needed?
Caching is a technique of storing the page output or application data across HTTP requests in the memory so that subsequent requests to the same piece of data or the page would be fetched from the memory. It improves application performance by faster page rendering and reduced consumption of the server’s resources. You can take advantage of caching for building applications that can scale and are high performant.
What is response caching and when should I use it?
Response caching enables you to cache the server responses of a request so that the subsequent requests can be served from the cache. It is a type of caching in which you would typically specify cache-related headers in the HTTP responses to let the clients know to cache responses. You can take advantage of the cache control header to set browser caching policies in requests that originate from the clients as well as responses that come from the server. As an example, cache-control: max-age=90 implies that the server response is valid for a period of 90 seconds. Once this time period elapses, the web browser should request a new version of the data.
The key benefits of response caching include reduced latency and network traffic, improved responsiveness, and hence improved performance. Proper usage of response caching can lower bandwidth requirements and improve the application’s performance.
You can take advantage of response caching to cache items that are static and have minimal chance of being modified, such as CSS, JavaScript files, etc.
Why use NCache as a response caching middleware?
You might need to leverage distributed caching if your web application has a high traffic. NCache is one of the best response caching middlewares available. NCache provides the following benefits as a distributed cache:
- 100% .NET—NCache is built in .NET and in .NET Core. It is one of the rare distributed caches available that is built entirely using .NET.
- Fast and scalable—NCache provides linear scalability and is very fast since it uses an in-memory distributed cache. Distributed caching is a concept in which the cached data might span multiple nodes or servers but within the same network hence enabling the cache to be scaled easily. The ability to scale linearly makes NCache a great choice when you experience performance challenges in your ASP.NET Core application during peak loads.
- High availability—One of the great features of NCache is its support for peer clustering architecture. NCache is capable of caching ASP.NET Core web pages using response caching so that there is no data loss when the cache server is down.
NCache provides several features, such as support for virtualization and containerization, asynchronous operations, cache locking, searchable cache, cache elasticity, cache administration and management, etc. You can find more about its features here.
Creating a new ASP.NET Core MVC application
To create a new ASP.NET Core MVC web application in Visual Studio 2019, follow the steps outlined below:
- Open the Visual Studio 2019 IDE
- Select the option “Create a new project”
- Select the option “ASP.NET Core Web Application” to specify the project type
- Click on “Next”
- Specify the project name and the location where you would like the new project to be saved
- Optionally, you can click on the option “Place solution and project in the same directory” checkbox
- Click on “Create”
- In the “Create a new ASP.NET Core Web Application” dialog window, select “Web Application (Model-View-Controller)” as the project template
- Select ASP.NET Core 3.0 from the DropDownList to specify the version of ASP.NET Core to be used
- Uncheck the “No Authentication,” “Configure for HTTPS,” and “Enable Docker Support” checkboxes since we wouldn’t be using any of these here
- Lastly, click on “Create”
Installing the NuGet packages
To work with NCache, you should install the following package(s) to your project via the NuGet Package Manager.
Install-Package NCache.Microsoft.Extensions.Caching
Note that you should include the Alachisoft.NCache.Caching.Distributed assembly in your programs to be able to work with the types in the NCache library. The following statement shows how you can do this.
using Alachisoft.NCache.Caching.Distributed;
Response caching options in NCache
There are three ways in which you can implement response caching using NCache. These include the following:
- HTTP Based Caching—this is a type of response caching that caches the data at the web browser’s end. HTTP based caching can reduce the server hits since subsequent requests for a particular resource can be served from the cache.
- In-Memory Caching – this is another type of response caching strategy in which data is cached in the memory of the web server. Note that the data in the cache is cleared when the ASP.NET engine is restarted since this is an in-proc mode of caching. In-memory caching is fast since it resides within the address space of your application.
- Distributed Caching—this is yet another strategy used in response caching. A distributed cache is external to an application. In this strategy, the cache is distributed across several servers in a web farm. Any of the servers can respond to a request for data from the client. You can take advantage of NCache from Alachisoft to implement a distributed cache. If you are running your application in a load balanced multi-server environment, NCache can help you in distributed caching of the application’s data.
Add response caching services
You can take advantage of the AddResponseCaching() method in the Startup class’s ConfigureServices() method to configure response caching. Open the Startup.cs file and write the following code in the ConfigureServices method.
public void ConfigureServices(IServiceCollection services)
{
services.AddResponseCaching();
services.AddMvc();
}
Note that the response caching middleware is implicitly available in ASP.NET Core. The UseResponseCaching extension method is used to add the middleware to the request processing pipeline.
Lastly, call the UseResponseCaching() method to add the response caching middleware to the pipeline. Refer to the code snippet given below that shows how this can be achieved.
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
//Other code
app.UseResponseCaching();
}
Configure the response cache middleware
Response caching is a great feature in ASP.NET Core and is a built-in functionality. You can take advantage of it to reduce the number of requests a client makes to a web server. NCache can also be used as a response caching middleware. Let’s explore how this can be achieved.
To use NCache as a response cache middleware, you need to do the following:
- Specify the NCache settings in the Appsettings.json file
- Invoke the AddResponseCaching and AddNCacheDistributedCache methods in the ConfigureServices method of the Startup class.
You can configure NCache as a distributed cache in two ways:
- By specifying cache configuration in AppSettings.json
- By specifying cache configuration in IOptions
Specify cache configuration in AppSettings.json file
The following code snippet illustrates how you can specify cache configuration settings in the AppSettings.json file—a section named NCacheSettings has been added.
{
"NCacheSettings": {
"CacheName": "SpecifytheCacheNameHere",
"EnableLogs": "True",
"RequestTimeout": "60"
}
}
The ASP.NET Core IDistributedCache interface has been implemented in the NCache library. This allows you to use NCache as a response cache middleware in ASP.NET Core.
To use NCache as a NCache as your response cache middleware, write the following code in the ConfigureServices() method.
public void ConfigureServices(IServiceCollection services)
{
services.AddResponseCaching();
services.AddNCacheDistributedCache
(Configuration.GetSection("NCacheSettings"));
services.AddMvc();
}
Specify cache configuration in IOptions
You can also specify the NCache configuration details as IOptions as well. Refer to the code snippet given below to learnhow this can be achieved.
public void ConfigureServices(IServiceCollection services)
{
//Write code to add other services
services.AddMvc();
services.AddNCacheDistributedCache(options =>
{
options.CacheName = "SpecifytheCacheNameHere";
options.EnableLogs = true;
options.ExceptionsEnabled = true;
});
}
In the section that follows, we’ll examine how we can use NCache as a response caching middleware in the action methods.
Use response caching in the action methods
Assuming that you’ve configured the response caching middleware successfully, you can use the following code to take advantage of response caching in the action method.
public class HomeController : Controller
{
public IActionResult Index()
{
return View();
}
[ResponseCache(Duration = 60, Location = ResponseCacheLocation.None, NoStore = false)]
public IActionResult GetData()
{
//Write your code here
}
}
The Duration parameter is used to specify how long the data will remain in the cache. The ResponseCacheAttribute is used to specify the parameters in response caching. You can take advantage of the Location parameter to indicate if any client or intermediate proxy will cache the data. The possible values of the Location parameter are: ResponseCacheLocation.None, ResponseCacheLocation.Any, and ResponseCacheLocation.Client. If the value is ResponseCacheLocation.Any, it implies that the client or a proxy will cache the data. If the value is ResponseCacheLocation.Client, it implies that the client will cache the data. The NoStore parameter can have boolean values and if set to true, the Cache-Control header is set to no-store.
Use Distributed Cache Tag Helper
Now that NCache has been configured for response caching, you can specify the content that you would like to cache. To achieve this, you can take advantage of Distributed Cache Tag Helpers in ASP.NET Core.
The following code snippet illustrates how you can specify an item to remain in the cache forever.
<distributed-cache name="Key:A" >
<div>@DateTime.Now.ToString()</div>
</distributed-cache>
If you would like to set an expiry for a cached item, here’s what you need to write.
<distributed-cache name="Key:B" expires-after ="TimeSpan.FromSeconds(30)">
<div>@DateTime.Now.ToString()</div><br />
</distributed-cache>
The following code snippet illustrates how you can specify an item that will only be removed from cache if the “vary-by” value is changed.
<distributed-cache name="Key:C" vary-by ="test">
<div>@DateTime.Now.ToString()</div><br />
</distributed-cache>
Testing
To test the code examples given in the earlier section, you can create a new ASP.NET Core MVC application and write the following code in the Index.cshtml file:
<distributed-cache name="Key:A" >
<div>@DateTime.Now.ToString()</div>
</distributed-cache>
<distributed-cache name="Key:B" expires-after ="TimeSpan.FromSeconds(30)">
<div>@DateTime.Now.ToString()</div><br />
</distributed-cache>
<distributed-cache name="Key:C" vary-by ="test">
<div>@DateTime.Now.ToString()</div><br />
</distributed-cache>
When you execute the application you’ll observe that three DateTime values are displayed in the web browser. While the first and the third one doesn’t change, the second one changes the value after every 30 seconds.
Summary
Caching is a proven technique used in web applications to improve the performance and responsiveness. Response caching is a caching technique in which the response is served from the cache. ASP.NET Core provides support for response caching using the response caching middleware. For more information on NCache and how it can be used in ASP.NET Core, you can refer to the online documentation for NCache.