Month: May 2020


MMS • Shane Hastie
Article originally posted on InfoQ. Visit InfoQ

Remote working is becoming normal for the tech industry, with most tech employees working remotely due to the ongoing impacts of COVID-19. Studies and surveys are trying to measure the impact on productivity that organisations are seeing as a result of the shift. The results are conflicting and illustrate the complexity of the times we find ourselves in.
By Shane Hastie
Presentation: What’s Your App Pulse? How We Built Metrics Observability in Large Enterprise Hybrid Clouds

MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Volkswagen is changing their working methods for software development, where they focus on regaining their own development skills and developing new products based on new technologies and methods. The technologies used are decided on by the teams independently.
Holger Urban gave a keynote on Volkswagen’s journey towards a software-driven company at OOP 2020 where he shared the challenges, opportunities and successes.
Volkswagen is transitioning their business from a car manufacturer to a mobility provider. Business demands have expanded, including needs from users and technology, which results in a high level of complexity, Urban said.
Volkswagen is building up in-house expertise and establishing a developer community in the company. Urban mentioned that they are working on a common code repository for developers.
InfoQ interviewed Holger Urban, one of the office leads of the Software Development Center in Wolfsburg, about the challenges Volkswagen is facing, the technology that they use, how Volkswagen develops software, and what they have learned on their journey.
InfoQ: What challenges is Volkswagen facing on its software development journey?
Holger Urban: We have several challenges. In the past and especially in the automotive industry, business demands have always required a strong response. Above all, these demands are costs, quality and time.
Nowadays there are also the additional factors of users and technology. The user cares about speed, functionality, and of course the usability of the product. On the technological side the requirements include stability, scaling and availability.
These challenges in connection with the size of the Volkswagen Group (currently 13 different brands) result in a high level of complexity. We also have many legacy systems that need to be replaced as we transition the business from a car manufacturer to a mobility provider. Enough challenges ;-)?
InfoQ: What kind of technologies does Volkswagen use? Why these?
Urban: Due to the size of our company, we naturally rely on a variety of technologies. In the SDCs (Software Development Centers) we rely on cloud solutions as the backbone of our development. For this we have our own development platform (VWS VW Cloud Services based on AWS).
The technologies used – such as programming languages, frameworks, tooling etc. – are decided on by the teams independently and we have had very good experience with this. Who knows the technologies better than the colleagues who use them every day?
InfoQ: How does Volkswagen do things? And why do they do them the way they do?
Urban: We started an initiative at Volkswagen called “back to tech”. Outsourcing has been a big issue for the past decade, which has led to us losing a lot of software development experts. With “back to tech” we have built our in-house expertise up a bit again in the last few years, but we are not done yet. It’s not about developing everything internally, but when it comes to core business knowledge, these projects should remain in-house.
With the SDC’s we want to establish a developer community in the company. What connects all developers is the code. For this reason, we are in the process of building a common code repository and giving every developer in the group access to this code. That doesn’t sound like rocket science, but in our complex environment it is quite a challenge, especially when it comes to working with external partners, which we still need.
I have spoken a lot about complex challenges and there isn’t of course only one way to solve them. We have developed several SDC types for this. I would like to go into more detail about one type. In cooperation with an external tech company, we started in Berlin with a method that relies heavily on the values of extreme programming (XP). Among other things, we rely on pairing, TDD (test driven development) and the balanced team. We have now extended this method to other locations such as Wolfsburg and Lisbon.
InfoQ: What have you learned on your journey?
Urban: We really learned a lot. First of all, it is important to have your own development skills again. Furthermore, it makes no sense to implement new functions for complex legacy systems. You have to make the hard cut and develop new products based on new technologies and methods (TDD). We have to put the User Experience at the heart of our products. We do not develop products for steering committees, but for our users. You always have to ask about the benefits and if no visible benefits, stop the product!
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

In this article, we demonstrate how Java developers can use the JSR-381 VisRec API to implement image classification or object detection with DJL’s pre-trained models in less than 10 lines of code.
By Xinyu Liu, Frank Liu, Frank Greco, Zoran Sevarac, Balaji Kamakoti
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ
The pika team released the second major iteration of Snowpack. Snowpack 2.0 self-describes as a build system for the modern web and claims start-up times below 50ms even in large projects. Snowpack 2.0 achieves its speed by eschewing bundles during development. Bundles may still be generated for production. Snowpack 2.0 ships with a set of Create Snowpack App (CSA) starter templates targeting miscellaneous stacks.
Snowpack’s release note explains the value added by the second iteration of Snowpack:
Snowpack 1.0 was designed for a simple mission: install npm packages to run directly in the browser [without] requiring the use of a bundler during development. […] Thousands of developers started using Snowpack to install their dependencies and build websites with less tooling.
Snowpack 2.0 is a build system designed for this new era of web development. Snowpack removes the bundler from your dev environment, leveraging native ES Module (ESM) syntax in the browser to serve built files directly. This isn’t just a faster tool, it’s a new approach to web build systems.
The release note proceeds to illustrate how Snowpack achieves constant build time (characteristic summarized as O(1) build time) by removing the bundling stage in development:
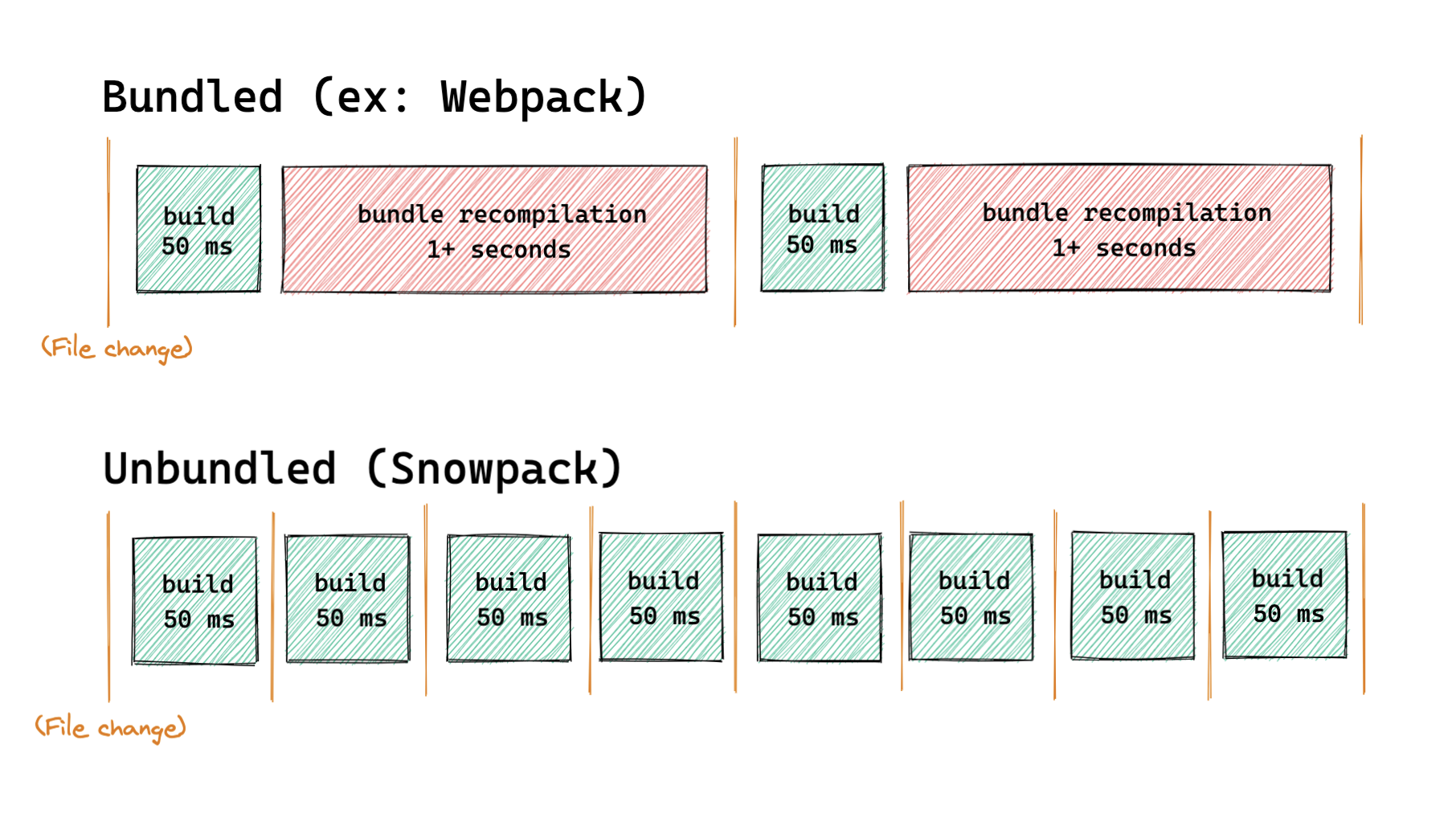
(Source: Release note)
The previous illustration shows that bundling is often a time-consuming task. This is so because bundling has O(n) complexity, i.e. the time to produce a bundle of entities is proportional to the number of entities being bundled. As bundling became more common in development in the last few years, bundlers have been performing an ever-larger list of tasks, including code-splitting, tree-shaking, and more. According to the release note, in some cases, bundling may be much slower (growing quadratically instead of linearly with the number of bundles entities), as the bundler may require a second pass over the entities.
Snowpack explains how it starts fast and remains fast in development:
Every file goes through a linear
input -> build -> outputbuild pipeline and then out to the browser (or the final build directory, if you’re building for production). Multi-file bundling becomes a single-file build step.
[…]
With no bundling work needed to start, your server spins up immediately. On your very first page load, Snowpack builds your first requested files and then caches them for future use. Even if your project contains a million different files, Snowpack will only every build files needed to load the current page. This is how Snowpack stays fast.
Snowpack includes a development server which offers TypeScript and JSX support, Hot Module Replacement (caveats apply), CSS modules, custom routing, proxy requests, and more. Non-js files (such as Svelte files) can be supported via plugins. Running snowpack build will generate a static production build which will be a working copy of the same development code. For optimized production builds, Snowpack 2.0 has official plugins for integration with other bundlers such as Webpack and Parcel.
While one user questioned the no-bundling differentiating aspect of Snowpack (What means “no-bundling” really?) and failed to see the difference between Webpack and Snowpack besides the first-class support for ESM modules, the initial reactions on Twitter seem to be positive. The user chadhietela said:
Increasingly I believe the idea of O(1) builds is correct for development. Evergreen browser support + native imports demand a change in tools.
The full release note contains many more technicals details on Snowpack 2.0. The documentation site provides an overview of Snowpack behavior, concepts, configuration, tooling, plugins, and common recipes.
Snowpack is an open-source project with an MIT license. Contributions are welcome and should follow the contributing guidelines. Feedback can be given through the project’s GitHub repository.
MMS • Jason Chan
Article originally posted on InfoQ. Visit InfoQ

Transcript
Chan: We will talk about how security teams adapt to all the changes that are happening in the software engineering and software operations world. Frankly, that sounds like a really boring and dry topic. I’m going to try to make it entertaining by looking at it through the lens of movies and through entertainment, because that’s something that’s near and dear to my heart. I personally love movies. I do work at Netflix. We produce quite a lot of movies. I’m first going to ask you to get in our time machine and let’s travel back to the 1980s. I’m a child of the ’80s. I remember when the first video rental store opened up in my town. I grew up in Upstate New York. It was really neat because you’d go in. You wander the aisles. Every few weeks or so my parents would let us actually rent something, make popcorn and have a nice movie night at home. You don’t really see a lot of these movie rental stores around anymore, do you? I don’t.
This one is not my childhood store. This is in Eugene, Oregon, a place called Flicks & Pics. I used to live right down the street from it. It also closed. It’s interesting because this entire industry, the video rental store industry basically came to life and died off in the span of my lifetime, just really a few decades. It sounds like people are still watching movies. I know I do. Of course, we just do it in a different way. This is a bit of a dated stat. There was a day last year in January 2018, where people watched about 350 million hours of video in one day. That’s a lot of content. People clearly still like great storytelling. They like movies. They like to be entertained. We just do it in a different way.
It sounds obvious. We’re sitting here at a technology conference. We’re in San Francisco, in the middle of Silicon Valley. It’s 2019. It seems incredibly obvious that people would choose streaming over a video rental store. Why would I get in my car, drive to the store, pick something out, bring it home, watch it. Bring it back before I get a late fee. When I could just, in my pajamas, sit on the couch and just hit play. It feels like an objectively better experience. Hindsight is always 20/20. It seems obvious. There was really a set of trends that happened over a few decades that really brought forth an environment where streaming video could become a dominant mode of entertainment.
Secular Trends
I want to talk about these trends. We’re going to talk about what we refer to as secular trends. A secular trend is a long-term directional trend. It’s non-seasonal and non-cyclical. A good example is the automobile. After the car was invented, it pretty much was just up into the right in terms of adoption. People just buy more cars. Compare that to a seasonal trend. This is a good season if you think about, at least in the United States, eggnog. People don’t drink a lot of eggnog unless it’s a holiday. It’s pretty flat most of the year. Then you see a spike around the holidays. Goes back down, and just repeats year-over-year. That’s seasonal. Then secular is just one direction. The key to thinking about secular trends is that they have a pretty massive impact for incumbents and competitors in the space. Just going back to the car example, think about what happened to the horse and buggy industry after cars were invented. They also moved in one direction. It was a different direction.
Reliable Internet
First off, to be able to stream video on the internet, you need the internet. That makes sense. What we’re talking about here is reasonably priced, high bandwidth, reliable broadband to the home. Certainly, over the last few decades, that’s really increased. If you’re going to be sitting on the couch and you want to buy a movie, or rent a movie, or subscribe to a service like Netflix. You need to have some way to pay for it, so e-commerce. I don’t think anyone would doubt that e-commerce has exploded over the last couple decades. There’s so many different ways to pay. Mobile is an interesting one. People like to watch content at home, but more you see folks watching content on their mobile phones. I’m sure probably most of the folks in this room have some smartphone capable of watching content, carrying around with them.
Then last but not least, is this idea of a subscription economy, or what you might more generally call access versus ownership. Basically, the idea is if you have access to something, you don’t really feel the need to own it. For me, my best example would be music. I moved last year. I had probably about 500 or 600 CDs. I got rid of them during the move because I have Spotify. I have most of the music I need. I have felt no need to actually own the physical media. You put all these things together and then you have an environment where it makes sense for streaming video to be successful and to have these video rental stores go away.
Security Development Lifecycle Era
You’re asking, what does this have to do with security? I know that QCon is well known for having the most intelligent conference attendees of any conference. I’m sure many folks have already made a connection. It is very similar. Security has seen a number of these secular trends in the technology industry that is really forcing us to change. We’re going to get in another time travel machine, and we’re going to go to a different era. This year is the late ’90s, the early 2000s. At that time, I was a security consultant. I spent about three years doing security consulting for Microsoft. Does anybody remember late ’90s, early 2000s what the state of security in Microsoft software was? It wasn’t great. There were really serious security issues, so Nimbda, Code Red, SQL Slammer, very serious security issues. It actually got to the point where in 2002, Bill Gates, who was leading the company at the time, actually wrote one of the most famous memos in security history, what’s now known as the trustworthy computing memo. In that memo, he said, “As of now, Microsoft’s top priority is security.” Working in the industry and working for Microsoft at the time, it was really pretty inspiring. Because we felt, “Maybe there’s a light at the end of the tunnel. Maybe we’re going to get past this era of vulnerabilities in software.” Of course, that was 20 years ago. I think we still have vulnerabilities in software. There was a lot of energy and a lot of resource put behind guidance and tools to make software more secure. I refer to this era as the SDL era of security. SDL is an acronym for Security Development Lifecycle. It’s really a very seminal book in software security. It generally refers to this overall approach of how we were thinking about building secure software, again, in the late ’90s, early 2000s.
Then things started to change in terms of how we build software. The first one that I would note is just the amount of software that’s out there today, if you think about IoT, Internet of Things. How many IP addresses do you have in your house today versus 10 years ago, or 15 years ago? I’m not a big IoT person. I have a Fitbit scale. I have a Nest thermostat. I have a smartwatch. Think about how much software is in a Tesla. It’s pretty amazing just the sheer amount, the volume of software that we’re dealing with.
Software Delivery
Then, of course, the way that we deliver software. When I was working at Microsoft, we did security assessments on products like SQL Server and Microsoft Exchange, different operating systems. There was a time when software vendors actually put their software on these round things, called CDs or DVDs, and actually shipped them to their customers. The customers had to put them into a computer they owned in a data center that they also manage. That seems really unusual now. Of course, now, most software is delivered over the internet: web applications, APIs. Companies started to realize, “I don’t need to have this six month cycle of getting disks printed and shipped. I can change software pretty much every day.” Then that really brought along this idea of, how can we deliver software even faster? There’s this whole set, and I’m sure you’ve heard a bunch of it at the conference this week, all mechanisms to deliver software faster: continuous deployment, microservices, all these techniques. Again, secular trend, just growing over time. Then, of course, the cloud. If you think about the public cloud, how much easier it is to deploy software in the cloud versus procuring your own data centers and managing. Then last but not least, is open source. What I can do now is I can use an open-source operating system, open-source web server, UI framework. All I really need to worry about is the business logic I need. It really shortens the time to value.
Hourglass and Software Development
You add all these things together and you have a fundamentally different way of developing software. The comparison I like to use is I think of the hourglass as the way maybe we used to develop software and we used to think about software security. Think of the grains of sand as software. There’s only so much that can go through. We are well coordinated, there’s that little skinny part in the middle. That’s where security teams got involved. There was only so much you could do. There was only so much you could go through, very coordinated release trains. Then I think today, it’s more of an industrial sandpit. There’s way more software. It’s being developed, and distributed, and deployed, and operated in a highly decentralized way. Then when you say, in the SDL era, we were really building practices around the hourglass. How do we approach the industrial sandpit? That’s where we get to this slide. It’s intended to be a gravestone. It’s basically saying traditional application security is no longer applicable. This is really all of the practices that we had spent time developing, or have been basically made unusable because they just don’t match the scale and the speed of software today.
Then, what do we do about it? If we know software has changed in the way we develop and operate, what are we going to do about that? That’s what I want to spend the rest of the talk going through. I want to use some examples of some of the things that we’ve done at Netflix. Not thinking that folks are necessarily going to directly use that because I know every organization acts a little bit differently. I want to think more about what are some questions that security teams should be asking. What are some principles that we can start organizing around to be a little bit more successful in this new world? I want to try to keep it entertaining. I want to go back and think about examples of movies to match up to some of these technical examples.
This is the first movie, anybody recognize this one? “Dazed and confused,” this was pretty popular when I was growing up. It was basically about high school shenanigans and smoking a lot of pot. That’s not what we’re talking about now. I would say, “Dazed and Confused,” imagine yourself, you’re a software engineer. How does it feel to be on your first day at a new job? To me, I think “Dazed and Confused” is a good way to describe that. Because we hire people to do some software thing, maybe it’s to build a mobile app or some recommendations algorithm. It doesn’t really matter. We hire folks to do something, but then you have to understand a bunch more to actually be effective. There’s the basics around what does the infrastructure look like? How do we do deployments? There are all the non-functional requirements like performance and reliability. You got to figure out, how do you make changes? How do you do migrations? How do you upgrades? Then of course, last but not least, is security. You’ve created an environment. You’ve hired somebody, and probably paying them pretty well to do this thing in the middle. Then you’re making them figure out all this other stuff just to be effective and to be productive.
That’s the first principle I would ask security teams to think about, is really, how can you reduce the cognitive load for developers? I’m not a psychologist. I’m not a learning specialist. My general thought of cognitive load is, what is the set of things you need to have in your brain to get something done? I’ll ask you to pretend you don’t know what a square is. What the shape of a square is. I was going to explain that to you. I could do that in a number of ways. I could show you this. I could say here’s a square. Or I could show you that definition. They’re both correct. You understand what a square is. One of them was probably a little bit easier to use and a little bit easier to get your brain around.
That’s really what we want to focus on. There’s an interface between security teams and engineers, and we want to simplify how that works. There are a couple of questions that I think are important to ask. One is, are you trying to make your engineers, security experts? It’s a reasonable question. Do you want to train your engineers to become better at security? Then a separate question, which is somewhat related, do you want them to build and operate secure systems? At Netflix, we weigh very heavily to the second. I am not interested in making our general software engineers, security experts. If they’re passionate about security, great, but I look at my team’s job as enabling them to build and operate secure systems regardless of their knowledge of security. That’s a fundamental underlying principle of how we operate.
One of the things that we think about are what are the functions that we can abstract so that general engineering teams don’t need to worry about them? I want to use an example from our studio engineering team. You may know, Netflix is a streaming service but we also produce a lot of our own content. We have essentially a studio. We create things like “BoJack Horseman,” which is my favorite Netflix original. That’s my recommendation of the day. We also produce things like “Stranger Things,” which is a really popular show that we have. The studio engineering team is really working on technology to make that better. If you’re at all familiar with the production process, like TV shows and movies, it’s a pretty antiquated process. It hasn’t changed a lot in the last 50 or 75 years. Very paper based, it’s very manual. It’s not real efficient.
The studio engineering team’s job is to really optimize production from what we call pitch to play. Pitch is when we get an idea. When somebody says I have an idea for a show. Play is when it’s actually on the service and you can click play. As you would imagine, there’s a lot of things that happen between those two words. There’s scheduling, and casting, and budgeting. There’s photography, and editing. There’s marketing, all stuff. Their job is to really innovate on this overall production process then make it more effective through technology to not only make an individual production more effective. To make it so we can produce a very large amount of content concurrently across the world.
Netflix Studio Apps – Zuul and Wall-E
Our studio apps work in a pretty standard way. They’re pretty standard line-of-business applications. The studio user could be a production assistant. They could be a creative executive, could be an accountant, something like that. They’re accessing on order of several dozen different applications to do the business of creating content. What we wanted to do was we wanted to allow these folks to be more effective and more efficient by abstracting some security functionality away. We actually did it through an existing open-source project that we had that our cloud gateway team created, which is called Zuul. Zuul is our main routing gateway. Zuul has been open source for some time. If you’ve ever used Netflix, your traffic goes through Zuul. Our bet was that we could repurpose this to improve the security of other line-of-business applications. We did that through a separate version of Zuul that we call Wall-E. We just inject it between the user and the applications.
The way Zuul works and hence the way Wall-E works is that it has a set of pre-filters and post-filters. Pre-filters are what happens to the traffic on the way in, post-filters on the way out. We just create a bunch of functionality that we plug in there. Things like authentication, authorization, logging, setting security headers on traffic on the way out. If you’re a studio engineering developer, all you need to do is publish your app with Wall-E. You don’t need to worry about any of these security features. Worry on how to create a more effective production app. We’ll worry about all the rest. That’s really the principle. We’re trying to get from point A to point B, as quickly as possible. We’re trying to make things simple for our developers.
Next example movie, does any recognize that one? I have seen “Inception” a couple times. I still probably couldn’t tell you what it’s actually about. It’s pretty confusing. The idea is there are these multiple levels of reality and dreams in the subconscious. You could potentially inject an idea into a different level and have it escape into reality. A key theme, though, is it’s very blurry. When is it reality? When is it a dream?
I’m going to take a massive leap and I’m going to compare these blurred lines to something that we’re seeing now in technology. That sees blurring lines between applications, and between software and infrastructure. If you’re familiar with different architectural patterns, like the monolith, when you’re building software in a monolith, you don’t really worry about the network because all your code is running on a single system. You move to microservices. You, as a software engineer, you have to care pretty deeply about the network conditions, because all your calls are going to be network calls. Think about immutable infrastructure. When you’re taking your operating system, your software, middleware, you’re packaging it as a single deployment artifact, and then deploying it that way. Pretty much everything is jumbled. Then of course, probably the ultimate is infrastructure as code. Where does software end and infrastructure begin?
This is important for security teams, because back in the SDL era, we had a bit more separation. You had network security teams, and they were working on network access control, and firewalls. You had app sec teams and they were working on threat modeling and code reviews, maybe a system security team that was working on hardening the operating system. Now it’s all been bundled together. Really, it’s a good opportunity. It seems it could be more confusing for security teams, but it’s actually this really nice opportunity to start to use that combination for leverage.
The Magic of IaaS
The example that I want to talk about is how we handle permissions in the cloud, in Amazon Web Services. Infrastructure as a Service, it’s neat to deploy an app in AWS, and to run it. You really start to unlock power and velocity when you start to use the other infrastructure services that your provider gives you. A good example, pretend you have some customer-facing application, and you need to email your customer. Back in the old days, when you manage your own infrastructure, you had to do all that yourself. You had to manage an SMTP relay. You had to handle deliverability, all those things. It has nothing to do with how your app actually works. Now with things like AWS, you just call an API and you send an email. Much simpler, much easier, you can focus on the business logic. Of course, from a security perspective, this is somewhat problematic. Because to be able to interact with those services, those instances, your applications in the middle, they need to have permissions. They need to have credentials to interact with AWS. That can be a problem, because if that system gets compromised, now your attacker has access to not just that system but potentially your entire cloud environment. What we’re trying to do is get the permissions that that instance have to be what we call least privilege, just the privileges that they need to do their thing.
Cloud Based Word Processor
Let’s go back to day one at a job. You’ve just started a new job. Your manager says, “I would love you to build a cloud based word processor.” I don’t know why, but that’s the assignment. They say, “We use AWS. Go ahead and use as much of AWS as you can to make this thing work.” You’re super excited because you’re like, “I get to focus just on the business logic. AWS is going to take care of it for me. Just go ahead and give me the permissions for AWS and I’ll go ahead and get started.” We’ll tell this story through a series of emojis. This emoji is a newspaper, because you might end up on the front page of the newspaper with this policy. You don’t need to know how AWS permissions work. Just know that as security folks when you’re looking at an authorization policy, and whenever you see asterisk or stars. That’s probably not a good thing.
This particular policy basically gives you complete rights to the entire AWS environment. That’s pretty problematic. You’re a responsible developer and you tell your security team, “I don’t need all those rights. I only need to use the storage mechanism.” They give you a little bit better policy because S3 is the AWS storage system. You still have more rights than you need because you can create storage containers. You can delete them. You can change all configurations. You say, “I only need a couple of APIs.” They make it a little bit better. There’s still room for improvement. Then they say, “Here we go.” Now this is where we need to be. This is a least privilege policy. You have only the permissions you need to the resources that you need to operate against. I know what you’re thinking. You’re like, “That’s easy. Let’s just do that for all the applications.” Unfortunately, if you’ve ever worked in a production environment, you know that it’s not that simple.
I’m going to use another little story here. This is “Goldilocks and the Three Bears.” Basically, Goldilocks is wandering around in the woods. She comes along the Three Bears cabin. She goes into the cabin uninvited. She’s hungry and there’s some breakfast on the table. She tries one, it’s too hot. She tries the other one, it’s too cold. She tries the third one, it’s just right. Then she just ate breakfast so she’s tired. There are three bedrooms. She goes and tries one of the beds, it’s too hard. She tries another bed, it’s too soft. She tries the third, it’s perfect. In this case, Goldilocks is the developer. She gets what she wants, ultimately. There’s a lot of collateral damage there. Put yourself in the bear’s shoes. Somebody just came in your house, ate all your food. They messed up your bed.
This is how it works in the real world. Because security teams what they typically do is they say, default deny. I’m not going to give you anything, tell me what you need. The problem is, when you’re a developer, and you’re innovating. You’re working on something. You’re not quite sure. You don’t know what you need. Then you say, “I need X.” Then the security team gives you X. You start doing your thing. Then you run into some roadblock because you don’t have access. You say, “Now I need Y.” They give you Y. Do it again, now I need Z. There’s this back and forth that is inefficient and is going to stifle innovation. It’s also going to create a bad relationship between your developers and your security teams.
AWS Provides Data about API Use
The nice thing about AWS is that it actually tells you how your cloud is being used. They have a service called CloudTrail that basically tells you how your systems are using the cloud. Then we could use this. We’ve been using AWS for a bit over a decade. We run many hundreds and thousands of applications in AWS. We’ve observed those, and we have a reasonable sense of how general apps want to interact with the cloud. Then what we do, if this is your day one, and you’re creating your cloud based word processor, we give you a base set of permissions. What you should know is that this set of permissions is a bit permissive. It’s more than you’re going to need. We start that way, because we think it’s a good trade-off between velocity and security.
I mentioned, we have data, we can see what’s being used. We just look at what your app is doing. We just observe. It doesn’t really matter what you think you need. What you might need. I think I need this particular API call. It doesn’t matter because we’re going to see what you actually need. Then we just remove any permissions that you’re not using. The nice thing here is you don’t need to ask for anything. It just happens. You don’t need to know what any of this is. You don’t need to know what CloudTrail is. What IAM is. You don’t need to know what policies are. You just do your thing. We’re trying to keep the developer from having to worry about this thing. We’ve actually open sourced this. If you use AWS and you think that might be useful, I would encourage you to take a look at Repokid.
I like to use this picture just to describe the principles that we’re trying to get to. I think this is an imagination of Hyperloop or something like that. I look at this, and I think, transparent. Because we have data, we’re using data to make our decisions. It’s high speed. It’s low friction. That’s the environment we’re trying to create to facilitate high-velocity, high-scale software development.
The last movie here, you don’t need to guess because I have neglected to cut out the title, but “The Purge.” Has anybody seen “The Purge?” It’s not going to win any Academy Awards. There are a few purges, but I like them. Basically, the idea with “The Purge” is there’s one day a year where there are no laws. Go out, kill, steal, whatever you want to do for one day of the year. It’s like anarchy. You’re thinking, what does anarchy have to do with software engineering?
Potential for Controlled Anarchy
There is the potential for some bits of what you might call anarchy, or at least distributed governance. Even think about microservices. When you adopt a microservices architecture or pattern, you’re basically saying you want teams to be able to operate independently. You want to move away from the central control. Then you have these operational patterns. You build it. You run it. Where, if you’re building software, you’re also running it. Instead of having a single ops team, you now have all different operational teams maybe doing things in different ways. You have polyglot. You have people using all different technologies. Because part of the promise of microservices is that, assuming you’ve maintained an API contract, you can iterate with whatever technology you want behind that. Then independent deployments, you’re no longer doing a single deployment. Everybody’s deploying when they want. What this does, it does intentionally decentralize governance because you’re trying to unlock velocity. It does make things more complicated for security teams. Now instead of having that single hourglass, that single place to keep an eye on things, you’ve got things all over the place.
I’m going to use another comparison, another analogy to talk about this. I’m going to talk about eating. Have you gone to a tapas restaurant? This is a Spanish style of eating. I think it literally means small plates. If you’ve ever been to a tapas place, you usually go with people. You just hang out. You maybe order one thing. Then you have some wine or some sangria. Order a few more things. You might stay there a long time. The idea is that every time you go to a tapas restaurant, it’s probably going to be a little bit different of experience. It’s a very high-touch, a very custom eating experience. This is similar to how we were doing software security in the SDL world. It was very high-touch, very custom.
Then I would say compare your dining experience when you go to a tapas place, at least in the U.S. In the United States, have you ever been to a large wedding with maybe a couple hundred people? What is dinner like at that place? You don’t have a lot of choice. You have chicken, fish, vegetarian. There’s no substitution. You’re not going to interact a lot with the waitstaff, or with the servers. That’s what you need to do to be able to serve that many people all at the same time in a synchronized way. This is the approach. This is where I would say security teams need to go to. You need to think less custom, less bespoke, less tapas, and more large wedding. You got to think about scale, and you got to think about simplifying and standardizing.
Managing the Anarchy – The Security Paved Road
Let’s talk about how we do that. How we manage the anarchy at Netflix. We have a concept that we use at Netflix that’s called the paved road. We have a security paved road. The idea of a paved road is that we’re a central engineering team. We provide a bunch of solutions for common security problems like identity and logging, stuff like that. The idea is what the security paved road does is it clarifies what our recommendations are. It helps us evangelize these patterns. What we want to be able to do is in an automated way, observe whether or not you’re actually participating in these paved road solutions. Then use that as the means of interfacing with engineering teams. What it helps us do is uncover risk and reward folks that are actually doing a good thing. Say, we had 25 different paved road practices. We can measure how much adoption we have. You’re a team that’s only adopted two of those practices. We’re probably going to spend some time talking with you, whereas if you’re a team that’s adopted them all, we’re going to give you a pat on the back.
These are some example checks, things like AWS configurations. We want to make sure you’re using our identity service. We want to make sure you’re not storing secrets in code, those things. Another example I wanted to talk about, was what we call the quarterly change cycle. The quarterly change cycle is what we’re asking developers to do is commit to updating your code at least once a quarter. If you do that, if you push your code once a quarter, you’re going to automatically pull in all of the updates to the paved road components, all the upgrades, and library changes.
This is an example here. The quarterly change cycle has this idea of deprecations and blacklists. This is a service that my team runs called Gandalf. It’s an authorization service. You can probably guess what that’s saying there. Basically, what we’re doing is we’re publishing a deprecation. We’re saying, if you’re using this software version less than 0.16.0, you’re going to need to update it. You don’t need to update it manually. You just push your code. Then what we do is we have a burndown chart here. When we first published that deprecation, there’s a high degree of noncompliance. Then as teams deploy code over the quarter, you see it going down. There’s no specific interaction that we do. We just make our change available. We publish it as a deprecation. Teams automatically pick it up as they push code.
Security Brain
The other example I wanted to show is a tool that we built called Security Brain. The intent of Security Brain is to make our expectations very explicit for engineering teams that we work with, and also, to standardize the interface that we have with them. This is some screenshots from Security Brain. Basically, what you have is a per user view, or a per team view. You have all your applications in that view. It’s very clear what vulnerabilities have been identified in your application. You can click straight through to Jira, and see. It also has all of the practices that we recommend, and whether or not your application is actually using them. It’s very easy for you as an engineer to see, these are the things the security team wants me to do, and whether or not we’ve actually done them. Then it allows us as a security team to prioritize who we’re going to work with. We tend to go after the folks that are fairly low on the Security Brain score.
Our intent there is that most of the asks that we have are going to be standard. We really need to be careful about how much bespoke work we do, how much custom work we do. We do a fair amount of custom work. We really want to aim that towards the teams that are building the most critical systems. For the vast majority of engineering teams that are building less security sensitive systems, we still want to give them guidance, but we need to deliver in a standard way.
That’s the paved road. Really, a key there for us is to be able to gather data, to measure adoption, and to be able to use that as a standard way of interfacing with engineering teams so that we can get leverage.
Overall Takeaways
First is, we talked about secular trends. It’s really important for security teams and engineering teams in general to stay attuned to what’s going on. How do we need to adapt based on what we’re seeing? We don’t want to keep our mental models and never refresh them. Simplify, standardize, to me that’s a real key to working in high-velocity environments. We want to be transparent. I think it’s very important for security teams to be transparent. If I’m going to make a decision about something, then I want to make sure that I can explain why that’s being made. We talked about that with the AWS permissions. We want to measure adoption and uptake so we know who to target. Then finally, we need to be comfortable with trade-offs. We talked about tapas versus a wedding. You might like tapas more, but we know to scale you’re going to need to make some trade-offs.
Questions and Answers
Participant 1: In the Security Brain, you mentioned that you ask people to pick up new libraries that have patches once a quarter. Could you just do that for them? You could just go to their dependency declaration and say, upgrade this version of these libraries. It would prepare a CI/CD build, run some tests. It’d still be up to them to do the whole canary thing all the way through. Would you do something like that?
Chan: That’s essentially where the team is moving. Not necessarily the security team, but the engineering tools and services team. They’re moving to make it as simple as possible. You still want to give the team control over when it gets deployed. The idea is to make it as simple as possible. I think we’ve made good progress over the years. Although I think our deployment systems have always been pretty user friendly. They’re just becoming simpler and simpler, and even evolving to what you might think of as a more managed delivery approach where you can be quite hands-off.
Participant 1: The thing you mentioned, the Repokid. Yesterday, I was talking to this person who gave a talk about Terraform. The biggest issues we have in that world is the security IAMs. People just open the policy door. I actually thought about the same problem, which is claw back. Initially, be permissive: scan, observe, and claw back. Does Repokid work with the existing tooling that is in the language of infrastructures, such as Ansible, Terraform, Packer, that suite of widely deployed build tools?
Chan: It does not. It should probably be reasonably easy to modify that. The way it works, it’s a multi-stage process. Part of the process is we need to make sure every application in the environment is using its own unique identity, its own unique IAM role so that we can then accurately profile it. Then from there, what we’re really trying to do is, behind the scenes, mine the data that we have. Then as appropriate, swap out those policies. It doesn’t necessarily work with those tools. I imagine that it would be reasonably adaptable to that.
Moderator: If you were an organization that doesn’t do any of these, a blank field, where would you start from?
Chan: Is it an organization that has adopted what you might consider modern software engineering and operation?
Moderator: Yes. They don’t put a lot of attention on security.
Chan: They have a relatively low knowledge retention.
Moderator: Yes. What are your priorities there? From your experience, how do you decide where to start, to updating libraries quarterly, or to implementing some CI/CD processes?
Chan: At a high level, non-engineering specific, I would always start with making sure that the organization understands what is truly valuable in their environment, and what is the worst case scenario? Because I think security folks, you need to take a risk-based view because you can never do everything. Then speaking on the technical sides, I would probably focus on figuring out how to make sure I understand the environment. We think about asset inventory. Understanding what are you actually responsible for, and then figuring out how to make sure that stays updated, so patching or upgrades.
Moderator: DevOps, infrastructure as a code, patching all the time?
Chan: Yes. That’s one of the benefits that security teams have had from continuous deployment is that if you can make changes quickly in your environment, that’s a very important security feature because vulnerabilities happen. We want to be able to update quickly. Any mechanism that the organization has that allows you to push changes, or config, or new OS, those things are super beneficial and valuable to security.
See more presentations with transcripts
MMS • Roman Shaposhnik
Article originally posted on InfoQ. Visit InfoQ

Transcript
Shaposhnik: I think through the introduction, it’s pretty clear who I am. If you’re interested in talking to me about some of the other things that I do in the open source, feel free to do that. I happen to be very involved in Apache Software Foundation and Linux Foundation.
Edge Computing is ‘Cloud-Native’ IOT
Today, we will be talking about edge computing. Let’s start by defining the term, what is edge computing? I think we started a long time ago with IoT, Internet of Things. Then Cisco introduced this term called fog computing, which was telco-ish, IoT view. I think edge computing to me is very simple. It is basically cloud native IoT. It is when the small devices, I call them computers outside of data centers, they start to be treated by developers in a very cloud native way. People say, “We’ve been doing it for years. What’s different?” The difference is it’s all of the APIs and all of the things that we take for granted in the cloud and even in the private data center today. That actually took time to develop. We didn’t start with Kubernetes, and Docker, and orchestration tools, and mesh networks. We started with individual machines. We started with individual rackable servers. That’s basically what IoT is still, individual machines. The whole hope is that we can make it much better and much more exciting by applying some of the cloud native paradigms like liquid software, pipeline delivery, CI/CD, DevOps, that type of thing, but with the software running outside of your data center.
Edge Isn’t Your Gramp’s Embedded and/or IoT
When I talk about edge, let’s actually be very specific, because there are different types of edge. I will cover the edge I will not be talking about. Very specifically, let’s talk about the edge that’s very interesting to me, and I think it should be interesting to all of you. These are the type of devices that some people called deep edge, some people call enterprise edge. These are basically computers that are attached to some physical object. That physical object could be a moving vehicle. It could be a big turbine generating electricity. It could be a construction site. The point being is that something is happening in the real world and you either need to capture data about that something, or you need to drive the process of that something. Manufacturing is a really good example. You have your pipeline. You’re manufacturing your product. You need to control that process. You have a computer that is typically called industrial PC attached to it. Same deal with a construction site, or even your local McDonald’s. In McDonald’s, you want to orchestrate the experience of your customers. You have a little computer that’s attached to the cash register. You have a little computer that’s attached to the display, and all of that needs to be orchestrated.
What I’m not talking about, I’m not actually talking about two things. I’m not talking about Raspberry Pis. There’s definitely a lot of excitement about Raspberry Pis. It’s interesting because if you think about the original motivation for the Raspberry Pi, it was to give underprivileged kids access to computing. It was basically to replace your personal laptop or desktop with essentially a very inexpensive device. The fact that Raspberry Pis now find their way into pretty much every single personal IoT project, there’s almost a byproduct of how they designed the thing. I am yet to see Raspberry Pis being used for business, most of the time they just stop at the level of you personally doing something, or maybe you doing something with your friends, your hackerspace. Today, we’ll not be talking about any of that. The reason we’re not talking about that is because just like with container orchestration and Docker, you don’t really need those tools unless you actually do some level of production. You don’t really need those tools if you’re just tinkering. You don’t need Kubernetes to basically run your application if you’re just writing an application for yourself. You only need Kubernetes if that is something that actually generates some business. We will not be talking about Raspberry Pis. We’ll not be talking about telco edge, edge of the network, all of that.
Connected Device – Data at the Edge
Even this slice of the edge computing alone, given various estimations, represents a huge total addressable market. The biggest reason for that is the size of the data. These computers are connected to something that is in the real world. The data originates in the real world. The previous presentation today about self-driving vehicle from Uber is a perfect example of that. There’s so much data that the vehicle is gathering, even if it was legally allowed, it is completely impossible to transfer all of that data to the big cloud in the sky for any processing. You have to orchestrate that behavior on the edge. As practitioners, we actually have to figure out how to do that. I was a little bit underwhelmed that Uber is focusing more on the machine learning. I understand why, but I’m an infrastructure guy. Today, I will be talking to you about infrastructure, how to make those types of applications easily deployable.
The good news is the total addressable market. The bad news is that it’s a little bit of a situation like building the airplane while it’s in flight. I think it would be fair to say that edge computing today is where cloud computing was in 2006. 2006, Amazon was starting to introduce EC2. Everybody was saying, it’s crazy, it will never work. People at Netflix started doing microservices. Everybody says it’s crazy, it will never work. The rest is history. Edge computing is a little bit of that. My goal today is to give you enough understanding of the space, to give you enough understanding of the challenges in this space but also the opportunities in this space. Also, explain maybe a little bit of the vocabulary of this space so you can orient yourself. I cannot give you the tools. I cannot really give you something that you will be immediately productive at your workplace, the same way that I can talk about Kubernetes, or Kafka, or any other tool that’s fairly mature. Edge computing is just happening in front of our eyes. To me, that’s what makes it exciting.
Are You Ready to Live On The Edge?
In a way, when I say cloud native, to me, edge computing represents basically one final cloud that we’re building, because we’ve built a lot of the public clouds. There’s Google. There is Microsoft. There is obviously Amazon. All of these are essentially in the business of getting all of the applications that don’t have to have any physicality attached to them. What we’re trying to do is we’re trying to basically build a distributed cloud from the API perspective that will be executing on the equipment that doesn’t belong to the same people who run public clouds. Edge computing is where ownership belongs to somebody else, not the infrastructure provider. From any other perspective, it’s just the cloud. People always ask me, “If edge is just another cloud, can we actually reuse all of the software that we developed for the cloud and run it on these small computers”?
It used to be a challenge even to do that, because those computers used to be really small. The good news now is that the whole space of IoT bifurcated. The only constraint that you have from now on is power budget. It might still be the case that you have to count every single milliamp. If you’re in that type of a business, you’re doing essential Snowflake’s and bespoke things all the time. There’s really no commonality that I can give you because everything has to be so super tightly integrated, because you’re really in a very constrained power budget. Everything else where power is not a problem, it used to be that silicon cost used to be a problem, but that’s not the case anymore. Thanks to the economy of scale, you can basically get Raspberry Pi class devices for essentially a couple dozen bucks. It actually costs more to encase them in a way that would make them weatherproof than to actually produce the silicon.
The computers are actually pretty powerful. These are the type of computers we used to have in our data centers five years ago. Five years ago, public cloud existed. Five years ago, Kubernetes already existed. Docker definitely existed. The temptation is to take that software and run it at the edge. There have been numerous attempts to rub some Kubernetes on it because, obviously, that’s what we do. We try to reuse as much as possible. Pretty much every attempt of reusing the implementation that I know of failed. I can talk in greater details of why that is. APIs are still very useful. If you’re taking the implementation that Kubernetes gives you today, that will not work for two reasons. First of all, it will not work because of the network issues. All of those devices happen to be offline more than they are online. Kubernetes is not happy about that type of situation. Second of all, and this is where you need to start appreciating the differences of why edge is different, interestingly enough, in the data center, the game that Kubernetes and all of these orchestration technologies play is essentially a game of workload consolidation. You’re trying to run as many containers on as few servers as possible. The scalability requirements that we’re building the Kubernetes-like platforms with are essentially not as many servers and tons of containers and applications. On the edge, it’s exactly the reverse. On the edge, you basically have maybe half a dozen applications on each box, because boxes are ok, but they’re still 4, 8 gigs of memory. It’s not like your rackable server, but you have a lot of them.
Here’s one data point that was given to us by one of our biggest customers. There’s an industrial company called Siemens. That industrial company is in the business of managing and supporting industrial PCs that are attached to all things. Today, they have a challenge of managing 10 million of those industrial PCs. By various estimations, total number of servers inside of all of the Amazon data centers is single digit millions. That gives you a feel for what scale we should actually be building this for.
Finally, the economics of the edge is not the same as with the data center. All of these challenges essentially, make you think, we can reuse some of the principles that made cloud so successful and so developer friendly nowadays. We actually have to come up with slightly different implementations. My thesis is that the edge computing will be this really interesting, weird mix of traditional data center requirements, and actually mobile requirements. Because edge computing is like the original edge computing is this. Actually, the original edge computing, I would argue, is Microsoft Xbox. With this we really got our first taste for what an edge computing-like platform could look like. All of the things that made it so, the platforms, Android or iOS, the mobile device management approaches, cloud, Google Play Store or Google services, all of that will actually find its way into the edge. We have to think about, how will it look like? We also need to think about traditional data center architectures, like operating systems, hypervisors, all of that. I will try to outline and map out how Linux Foundation is trying to approach this space.
Challenges at the Edge
Edge is actually pretty diverse, not just in terms of the ownership, but also in terms of the hardware and applications. Today, let’s take industrial PCs. Pretty much all of them are running Windows. They’re all x86 based hardware running Windows. When I say Windows, I actually mean Windows XP. Yes, it exists. A lot of SCADA applications are still based on Windows XP. If you show up as a developer and start razzle-dazzling these customers with your cloud native microservices-based architectures, the first question that they’re going to ask you is, “It’s all great. This is the new stuff. What about my old stuff? I want to keep running my old stuff. Can you give me a platform that would be able to support my old stuff, while I am slowly rebuilding it in this new next-generation architecture?” That becomes one of the fundamental requirements.
Scale, we already talked about the geographic aspect of it and deployments and the maintenance. The security is also interesting. Edge computing, unlike data center is much closer to this. Because edge computing is physical, which means you cannot really rely on physical security to protect it. It’s not like there is a guy holding a machine gun in front of a data center, you cannot put that guy in front of every single edge computing device. You basically have to build your platform, very similarly to how iOS and Android are protecting all of your personal data. That’s not something that data center people are even thinking about, because in a data center, you have your physical security and you have your network security. We are done with that. On a perimeter, you pay a lot of attention to it, but within the data center, not so much.
Also, interestingly enough, what I like about edge is that edge is probably the hardest one to really succumb to a vendor lock-in. Because the diversity is such that not a single vendor like a big cloud provider can actually handle it all. Edge is driven a lot by system integrator companies, SIs. SIs are typically pretty vertical. There may be an SI that is specializing in industrial, in retail, this and that. That diversity is actually good news for us as developers because we will not see the same concentration of power like we’re seeing in the public cloud today, so I think it’s good for us.
Microsoft Xbox
A lot of what I will be covering, in this talk, I wanted to pitch this other talk that just was made publicly available, taken out. This is the first time ever that Microsoft Xbox team talked about how they develop the platform for Xbox. That was done about a month ago, maybe two months ago, first time ever. A lot of the same principles apply, which makes me happy because we thought about them independently. The tricks that they played are really fascinating. The challenges they faced are very similar to the edge. If you want to hear from somebody who can claim that they successfully developed an edge platform, listen to those guys. I’m talking about the platform that’s being developed. Mine can still fail, theirs is pretty successful.
From The People Who Brought You CNCF
Let’s switch gears a little bit and talk about how Linux Foundation got involved in all of this. I shouldn’t be the one to tell you that Cloud Native Compute Foundation has been super successful. In a way, I would say that Kubernetes was the first Google project that was successful precisely because of CNCF. I love Google, but they have a tendency of just throwing their open-source project over the wall and basically say, “If you like it, use it, if you don’t, not our problem.” Kubernetes was the first one where they actively tried to build a community. The fact that they went and donated it to Linux Foundation, and that was the anchor tenant for the Cloud Native Compute Foundation, I think made all the difference. Obviously, Linux Foundation itself was pretty happy about this outcome. They would like to do more of it.
The thought process went exactly like what I was talking about. When I say inside of data centers, I mean public cloud or your private data center. It doesn’t matter. It’s just a computer inside of a data center. For all of that, there’s basically a forum of technologists that can decide, what is the common set of best practices that we all need to apply to the space to be more productive, more effective? That’s CNCF, Cloud Native Compute Foundation. For all of the computers outside of data centers, it feels like we at least need to provide that type of forum even if we don’t really have an anchor tenant like Kubernetes still. We need to give people a chance to talk among themselves, because otherwise there is really no way for them to synchronize on how the technology gets developed. That’s LF EDGE.
LF EDGE
Linux Foundation Edge Initiative was announced, not that long ago, actually, this year. It was announced in January, February this year. My company, ZEDEDA, we ended up being one of the founding members. We donated our project. There are a lot of companies in the space that are now part of the LF EDGE, so if you’re interested, you can go to this lfedge.org website. The membership is pretty vast at this point. These are the premium members. There are also tons of general members. A lot of the good discussions are already happening within LF EDGE.
To give you a complete picture, what does LF EDGE cover? LF EDGE basically covers all of the computers outside of data centers. It starts with what we consider to be partial edge. A partial edge would be a quasi data center. It’s not quite a data center, but it looks almost like a data center if you squint. A good example of that would be a telco central office, a telco CO. It’s not really built to the same specification that a telco data center or a hyperscale data center would be built for, but a lot of technologies still apply. That’s definitely in scope for LF EDGE. Then we basically go to telco access points. These are already physical devices. We’re talking base stations. We’re talking 5G deployments. These are all of the things in the CD infrastructure, or any infrastructure that would have to run some compute on them. That’s definitely in scope for LF EDGE. Both of these are pretty dominated by telcos today, for good reason, because they’re probably the best example of that type of an edge computing.
Then there are two other examples of edge. One that I will spend a lot of time talking about, we call it, for now, enterprise edge. This is basically all of those industrial PCs, IoT gateways. An example of the enterprise edge would be also a self-driving vehicle. Uber or Tesla building it would be also an example. Finally, there’s obviously consumer edge. This is all of your washers, and dryers, and your refrigerators, all of that is in scope for LF EDGE. Every single one of these areas basically has a project that was donated by one of the founding companies. HomeEdge is from Samsung, which is not surprising because they’re making all of these devices that you buy. Enterprise edge is us, ZEDEDA, and a few big enterprise companies like Dell, those types of guys. There’s project Akraino that’s dominated by telcos.
Interestingly enough, I have a friend of mine from Dell, Jason Shepherd, who keeps joking that this edge thing, it’s very similar to how this country was settled. Because it feels we’re now running away from the big hyperscale cloud providers, just like in the good old days people were running away for big businesses on the East Coast. The only place for us to actually build this exciting technology now is on the edge because everything else is dominated, and you have to join Google or Facebook to have a play in there. Go West, young man, go Edge.
These are the projects. I will be specifically talking about one of them, Edge Virtualization Engine. Check out the rest on the Linux Foundation website. I think you will find it very useful. Edge Virtualization Engine is what was donated by my company, ZEDEDA. We’re actually working very closely with Fledge. Fledge is a middleware that runs on top of the project EVE. EVE stands for Edge Virtualization Engine.
Edge Requirements
Specifically, what requirements does EVE try to address? We basically approach looking at these boxes essentially from the ground up. We feel that we have to take control pretty much from the BIOS level up. I will talk about why that is important, because a lot of the technology that you would find at the BIOS and board management level in the data center simply doesn’t exist on the edge. For those of you who know BMCs and iLOs, those things are not present on the edge for obvious reasons, because the control plane is not really to be had on the edge. Who are you going to talk to even if you have a BMC? Which creates an interesting challenge for how you can cut down on BIOS, and things like that. We feel that we need to start supporting hardware from the ground up. The hardware at the same time has to be zero touch. The experience of actually deploying the edge computing device should be as much similar to you buying a mobile device as possible. You get a device with an Android pre-installed. You turn it on, and you can run any applications that are compatible with an Android platform, so zero touch deployment.
We also feel that we need to run legacy applications. The legacy applications would include Windows XP. For Windows XP, you actually have to make sure that the application can access a floppy drive. That’s a requirement. You also need to run real-time operating systems for control processes. You need to basically do hard partitioning of the hardware to guarantee the real-time SLAs on these applications. You need to build it at IoT scale, but what it really means is it needs to be at the same scale that all of the services that support your mobile devices operate at. What it means is that when you talk about edge computing, just building a service, a control plane in a single data center is not good enough, because your customers will be all over the place, sometimes even in Antarctica, or in the middle of the ocean. That also happens. You have to figure that one out. The platform has to be built with zero trust, absolutely zero trust, because we all know the stories of hacks that happened at uranium enrichment plant at Iranian facilities. The attack vector was very simple. It was a physical attack vector. Those things will keep happening unless we secure the platforms, and make them trustworthy as much as possible.
Finally, and that’s where all of you come in, those platforms have to be made cloud native, in a sense that what APIs we give to developers to actually provide applications on top of them. Because if you look at the state of the industry today, and I already scared you at least a little bit with my Windows XP story, but Windows XP is actually a good story. The rest of the industry is still stuck in the embedded mindset. It’s not a good embedded mindset. It’s not like using Yocto or something. It’s using some god-awful, embedded operating system that the company purchased 12, 15, 20 years ago, where people cannot even use modern GCC to compile the binary. That’s the development experience in the edge and IoT today. I think it is only if we allow the same developers who built the cloud to actually develop for these platforms, it’s only then that edge computing will actually take off. Because we are artificially restricting the number of innovative people that can come to the platform by not allowing the same tools that allowed us to make cloud as successful as it is today.
App Deployment Is But the Tip of The Iceberg
I talked a lot about various things that we plan to tackle. As developers, when I talk about cloud native, people tend to really just focus and assume app deployments. They’re like, “Give me app deployments, and I’m done.” The trouble is, app deployments, the way we think about them in a data center is just the tip of the iceberg on the edge. My favorite example that I give to everyone is, even if you assume virtualization, on the edge you basically have to solve the following problem. Suppose you decided on Docker containers, and now there is one Docker container that needs to drive a certain process, and another Docker container that needs to get a certain set of data. The process and the data happened to be connected to the single GPIO. This is a single physical device that basically has a pin out. Now you’re in business of making sure that one container gets these two pins, and the other container gets those two pins. It’s not something that would even come up as a problem in a data center. Because in a data center, all of your IO is basically restricted to networking, maybe a little bit of GPU. That’s about it. Edge, is all about IO. All of that data that we’re trying to get access to and unlock, that is the data that we can only access through a reasonable IO.
A Complete Edge ‘Cloudification’ Proposal
There are a lot of interesting plumbing challenges that need to be solved first before we can even start deploying our Docker containers. Docker containers are great. I think the thesis that we have at LF EDGE, at least within the project EVE, is basically very similar to what you would see in a data center, but with a certain set of specific details attached to it. We feel that edge needs to be treated exactly like you treat your Kubernetes cluster edge. The physical nodes, like your pods will be out there. There will be a controller sitting typically in the cloud, or it can sit on-prem, either one. All of these devices will basically talk to the controller just like your pods talk to the Kubernetes controller. Then somebody deploying the applications would talk to the control through typically a Kubernetes-like API. It is very much guaranteed to be a Kubernetes-like API. I think the API itself is great. That’s very familiar to all of you. The question is, how do we build the layer that actually makes it all possible? That’s where the project EVE comes in.
Edge Infrastructure Challenges Solved with Edge Virtualization
If I were to go through EVE’s architecture, high level view, very quickly. It all starts with the hardware. Actually, it starts with the physical devices that you attach to the hardware. Then there needs to be some operating system that would allow you to do all of the above. That operating system needs to be open source. It needs to be Android of the edge type of an offering. That operating system will talk to the control plane. The control plane will sit in the cloud. On top of that offering of an operating system, you would be running your applications just like you do today in a data center, so a very typical, very familiar architecture.
Typically, your applications will talk to the big clouds in the sky from time to time, because that’s where the data ends up anyway. You need to help them do that. Because a lot of times, people will talk to me and say, “I’m deploying my edge application today using Docker.” I’m like, “That’s great.” They’re like, “Now we need to make sure that the traffic flows into this particular Amazon VPC. How can we do that?” It just so happens that now you have to read a lot of documentation, because there’s strongSwan involved, there’s IPsec. It’s not really configured by default. It’s like, how can we actually connect the big cloud in the sky with this last cloud that we’re building called edge computing? That has to come out of the box. These are essentially the requirements. That’s the high-level architecture. I will deep dive into one specific component, which is EVE today.
4 Pillars of Complete Edge ‘Cloudification’
What we’re trying to accomplish is, at the open-source layer, we need to standardize on two components. One is the runtime itself. The other one is the notion of an application. An application we’re now trying to standardize we’re calling that standard edge containers. The runtime is project EVE. At the top you basically have catalogs, and you have control planes. That’s where companies can innovate and monetize. I would expect a lot of big cloud providers to basically join LF EDGE and essentially start building their controller offerings. Just like Amazon today gives you a lot of managed services, that will be one of the services that they would give you.
EVE’s Architecture
Deep diving into project EVE. EVE today is based on the type-1 hypervisor, currently Xen. We actually just integrated patches for ACRN. ACRN is Intel’s type-1 hypervisor. It’s a pretty simple layered cake, very traditional virtualization architecture. I will explain why virtualization is involved. It’s hardware, a hypervisor, then there’s a bunch of microservices that are running on that hypervisor. Finally, you get to run your containers.
EVE Is Going To Be For the Edge What Android Is For Mobile
That is to say that we’re building the very same architecture that Android had to build for the mobile. The biggest difference being that Android built it in 2003. They essentially answered the same questions that we’re answering just in a different way, because those were different times. The hardware was different. The questions are still the same. The questions are, how can you do application and operating system sandboxing because you don’t want your applications to affect the operating system and vice versa? How do you do application bundling? How do you do application deployment? What hardware do you support? We are answering it more closely to a traditional virtualization play. Android basically did it through the sandboxing on top of JVM, because it made sense at the time. At the end of the day, I think Android also had this idea in mind that mobile platforms will only be successful if we invite all of the developers to actually develop for them. At the time developing for mobile was painful. It was that type of an embedded development experience. It’s god-awful compilers, tool chains from the ’80s. One of the key pieces of innovation of Android was like, let’s actually pick a language that everybody understands and can program in called Java. We’re essentially doing the same, but we’re saying, language nowadays doesn’t matter because we have this technology called Docker container. Language can be anything. It’s the same idea of opening it up to the biggest amount of people who can actually bring their workloads to the platform.
EVE: A Post-, Post-Modern OS
EVE happens to be a post-, post-modern operating system. When I say it like that, I’ve built a couple of operating systems. I used to work at Sun Microsystems for a long time. I’ve built a couple of those. I used to hack on plotnine. I spent a bit of time doing that. All throughout my career, an operating system wanted to be a point of aggregation for anything that you do, hence packaging, shared libraries. An operating system wanted to be that point, that skeleton on which you hang everything. What happened a few years ago with basically the help of virtualization and technologies like unikernels, and things like that, is that we no longer view an operating system as that central aggregation point. An operating system these days is basically just enough operating system to run my Docker engine. I don’t actually update my operating system, hence CoreOS. I don’t really care about my operating system that much. I care about it running a certain type of workload. That’s about it. That’s what I mean by post-, post-modern operating system. It is an operating system in support of a certain type of workload. In case of EVE, that workload happens to be edge container.
Inside of EVE, there is a lot of moving parts. I will be talking about a few of those today. If you’re interested, we actually have a really good documentation, which I’m proud of, because most of the open source projects lack that aspect of it. Go to our GitHub if you want to read some of the other stuff, so it’s LF EDGE EVE, and click on the docs folder. There’s the whole design and implementation of EVE that would be available to you. Let’s quickly cover a few interesting bits and pieces. Here, I’m doing this hopefully to explain to you that what we’re building is legit, but also maybe generate some interest so you can help us build it. If anything like that sounds interesting to you just talk to me after the presentation, we can figure out what pull request and GitHub issues I can assign to you.
LF EDGE’s EVE Deep Dive
EVE was inspired by a few operating systems that I had privilege to be associated with, one is Qubes OS. How many of you do know about Qubes OS? That’s surprisingly few. You absolutely should check out Qubes OS. Qubes OS is the only operating system that Edward Snowden trusts. That’s what he’s running on his laptop, because that is the only one that he trusts. When he was escaping, his whole journey was Qubes OS that was running on his laptop. It’s not perfect, but it’s probably the best in terms of security thinking that I have seen in a long while.
Then there is Chrome OS. It’s basically this idea that you can take an operating system and make it available on devices that you don’t really manage. SmartOS was like Chrome OS or CoreOS, but derived from Solaris. EVE today is based on the type-1 hypervisor. People always ask me, why type-1? Why KVM is not allowed. The answer is simple. It’s that requirement for the real-time workloads. Yes, patches for the real-time Linux kernel exist. They are really tricky. If you’re talking about a pretty heterogeneous set of hardware, it’s actually really tricky to maintain this single view of guaranteeing that your scheduler in Linux kernel would really be real-time. We use type-1 hypervisors and an ACRN, our choice today. We’re running containers. We’re running VMs. We’re running unikernels. Basically, everything gets partitioned into its own domain by hypervisor but those domains can be super lightweight. With projects like Firecracker, that becomes faster and faster and pretty much indistinguishable from just starting a container.
DomU, basically where all of the microservices run, that is based on LinuxKit. LinuxKit is one of the most exciting projects in building specialized Linux-based distributions that I found in the last five years. It came out of Docker. It basically came out of Docker trying to build Docker Desktop. LinuxKit is how Docker manages that VM that happens to give you all of the Docker Desktop Services. It’s also based on Alpine Linux. We get a lot of Alpine Linux dependencies.
We’re driving towards unikernel architecture. Every single instance of a service will be running in its own domain. All of our stuff is implemented in Go. One of the really interesting projects that we’re looking at is called AtmanOS, which basically allows you to do this, see that line, GOOS equals Xen, and you just do, go build. AtmanOS figured out that you can create very little infrastructure to allow binary run without an operating system, because it so happens that Go is actually pretty good about sandboxing you. Go needs a few services from an operating system, like memory management, scheduling, and that’s about it. All of those services are provided directly by the hypervisor. You can actually do, go build, with GOOS Xen and have a binary that’s a unikernel.
Edge Containers
Finally, we’re actually trying to standardize edge containers, which is pretty exciting. We are trying to truly extend the OCI specification. There have been a few areas in the OCI that we’re looking at. Image specification itself doesn’t require much of a change. The biggest focus that we have is on registry support. We don’t actually need runtime specification because OCI had this problem that they needed to integrate with other tools. Remember, classical operating system, when all the classical operating systems were black box execution engine. We don’t need to integrate with anything but ourselves, hence runtime specification is not really needed. Good news is that there are actually a lot of the parallel efforts of extending the OCI into supporting different types of containers. Two that I would mention are Kata Containers, which are more traditional OCI, but also Singularity Containers, which came more from HPC and giving you access to hardware. Weaveworks is doing some of that same thing. Check them out. Obviously, Firecracker is pretty cool as a container execution environment that also gives you isolation of the hypervisor.
Top three goals that we have for edge containers are, basically allow you not only file system level composition, which is what a traditional container gives you. You can basically compose layers. We happen to be glorified tarball. You do everything at the level of the file system. You add this file, you remove that file. We’re also allowing you block-level composition. You can basically compose block-level devices, which allows you then to manage disks, VMs, unikernels, this and that. We allow you hardware mapping. You can basically associate how the hardware maps to a given container, not at the runtime level, but at the container level itself.
We still feel that the registry is the best thing that ever happened to Docker. The fact that you can produce a container is not interesting enough. The fact that you can share that container with everybody else, that is interesting. We feel that the registry basically has to take onto an ownership of managing as many artifacts as possible, which seems to be the trajectory of OCI anyway. Things like Helm charts and all the other things that you need for orchestration, I would love for them to exist in the registry. Because that becomes my single choke point for any deployment that then happens throughout my enterprise.
EVE’s Networking Is Intent Based
Eve’s networking is intent based. You will find that very familiar to any type of networking architecture that exists in VMware or any virtualization product, with a couple of exceptions. One is cloud network, which is, literally, intent is, connect me to that cloud. I don’t care how. I’m willing to give you my credentials but I need my traffic to flow into the Google, into Amazon, into Microsoft Cloud. Just make it happen. The way we do make it happen is each container or each VM, because everything is virtualized, basically gets a virtualized NIC, network interface card. What happens on the other side of that NIC? Think of it as basically one glorified sidecar, but instead of using the sidecar that has to communicate through the operating system. We communicate through the hypervisor. Basically, the VM is none the wiser of what happens to the traffic. All of that is configured by the system, which allows us really interesting tricks, like networking that Windows XP into the Amazon cloud. Otherwise, it would be impossible. You can install IPsec to Windows XP but it’s super tricky. Windows XP that just communicates over the virtualized NIC and the traffic happens to flow through IPsec and to Amazon cloud, that Windows XP instance, is none the wiser.
Another cool thing that we do networking-wise is called mesh network. It is basically based on the standard called LISP, which has an RFC 6830. It allows you to have a flat IPv6 overlay namespace where anything can see anything else. That IPv6 is true overlay. It doesn’t change if you move the device. What allows it to do is basically bypass all of the NetBoxes, and all of the things that may be in between this edge device and that edge device, so that they can directly communicate with each other. Think about it as one gigantic Skype or peer-to-peer system that allows everything to basically have a service mesh that is based on IPv6 instead of some interesting service discovery. That’s networking.
EVE’s Trust Model – Zero Trust
On trust, we’re basically building everything through the root-of-trust that’s rooted at the hardware element. On Intel most of the time it happens to be TPM. TPMs exist in pretty much every single system I’ve seen. Yet nobody but Microsoft seems to be using them. Why? Because the developer support still sucks. On Linux, it actually takes a lot of time to enable TPM and configure TPM. We’re virtualizing the TPM. We use it internally, but then the applications, the edge containers get the virtualized view of the TPM. We also deal with a lot of the crap that exists today in the modern x86 based system. Because a lot of people don’t realize it but there is a lot of processors and software that runs on your x86 system that you don’t know about. Your operating system, even your hypervisor is not the only piece of software. We’re trying to either disable it or make it manageable. Our management starts from the BIOS level up. Thanks to Qubes for pioneering this. Everything runs in its own domain. We’re even disaggregating device drivers. If you have a device driver for Bluetooth and it gets compromised, since it’s running in its own domain, that will not compromise the rest of the system. Stuff like that.
EVE’s Software Update Model
EVE’s software update model is super easy for applications. It’s your traditional cloud native deployment. You push to the cloud and the application happens to run. If you don’t like it, you push the next version. You can do canary deployments. You can do all of the stuff that you expect to see from Kubernetes. EVE itself needs to be updated. That’s where ideas from Chrome OS and CoreOS kick in. It’s pretty similar to what happens on your cell phone. It’s dual partitioned with multiple levels of fallback, lots of burn-in testing that we do. We’re trying to avoid the need for physical contact with edge nodes as much as possible, which means that a lot of things that would have you press a key would have to be simulated by us. That’s a whole tricky area of how to do that. That’s something that we also do in EVE. We are really big fans of the open-source BIOS reimplementation from coreboot, and especially u-root on top of coreboot. That allows us to basically have a complete open-source stack on everything from the BIOS level up.
Hardware-protected vTPM 2.0
The most interesting work that we’re doing with TPM, and I have to plug it because I get excited about every single time, we’re trying to basically do a hardware-protected vTPM, something that hasn’t been done before, even in the data center. There’s a group of us who is doing it, if you’re interested you can contact any one of us. TrenchBoot is the name of the project. There’s Dave Smith and LF EDGE in general.
Demo
Eve itself is actually super easy to develop. That’s the demo that I wanted to give, because it’s not a QCon without a demo. EVE is based on LinuxKit. There is a little makefile infrastructure that allows you to do all of the traditional operating system developer things. Basically, typing make run would allow you to manage the operating system, run the operating system. The only reason I’m mentioning this is because people get afraid a lot of times if I talk about operating system development and design, because there’s a little bit of a stigma. It’s like, “I need a real device. I need some J-Tech connector. I need a serial port to debug it.” No, with EVE, you can actually debug it all in the comfort of your terminal window on macOS.
The entire build system is Docker based. Basically, all of the artifacts in EVE get packaged as Docker containers. It’s actually super easy to develop within a single artifact. Because we’re developing edge containers in parallel, we are planning to start using that for the unikernel development as well, which might, interestingly enough, bifurcate and be its own project. Because, I think when it comes to unikernels, developers still don’t really have the tools. There’s a few available like UniK and a few others. There’s not, really, that same level of usefulness of the tools that Docker Desktop just gives me. We’re looking into that as well.
Key Takeaways
Edge computing today is where public cloud was in ’06. Sorry, I cannot give you ready-made tools, but I can invite you to actually build the tools with me and us at Linux Foundation. Edge computing is one final cloud that’s left. I think it’s the cloud that will never ever be taken away from us. By us, I mean people who actually run the actual physical hardware. Because you could tell, I’m an infrastructure guy. It sucked when people stopped buying servers and operating systems, and now everything just moved to the cloud. My refuge is edge. Edge computing is a huge total addressable market. As a founder of a startup company, I can assure you that there is tremendous amount of VC activity in the space. It’s a good place to be if you’re trying to build a company. Kubernetes as an implementation is dead, but long live Kubernetes as an API. That stays with us. Edge computing is a lot of fun. Just help us build either EVE, a super exciting project, or there are a few projects to pick in the LF EDGE in general.
Questions and Answers
Participant 1: We see the clouds, AWS, Azure, and all that. Is there L2 connectivity? Are you using, for example, the AWS Direct Connect APIs, and for Azure, ExpressRoute? That’s what you’re doing?
Shaposhnik: Yes, exactly.
Participant 1: I belong to Aconex and we are delving into a similar thing, we already allow people to connect to the cloud. We’ll look deeper into this.
Shaposhnik: Absolutely. That’s exactly right. That’s why I’m saying it’s a different approach to running an operating system because I see a lot of companies trying to still integrate with Linux, which is great. There is a lot of business in that. What we’re saying is Linux itself doesn’t matter anymore. It’s the Docker container that matters. We’re extending it into the edge container. Docker container is an edge container. It almost doesn’t matter what an operating system is. We’re replacing all layers of it with this very built for purpose engine. While it’s still absolutely a valid approach to still say, “I need Yocto,” or some traditional Linux distribution that integrates with that. I think my only call to action would be, let’s build tools that would be applicable in both scenarios. That way we can help each other grow.
Participant 2: I know in your presentation you mentioned that edge is going to be more diverse. What’s your opinion on cloud providers extending to the edge through projects like Azure Sphere and Azure IoT Edge?
Shaposhnik: They will be doing it, no question about it. I think they will come from the cloud side. Remember that long range of what’s edge and what’s not edge. They will basically start addressing the issues at the CO, the central office. They will start addressing the issues at the maybe Mac access points. I don’t see them completely flipping and basically running on the deep edge. The reason for that is, business-wise, they’re not set up to do that. The only company that I see that potentially can do that is Microsoft. Because if you want to run on the deep edge, you need to develop and foster your ecosystem, the same way that Microsoft developed and fostered the ecosystem that made every single PC run Windows. Amazon and ecosystem don’t go together in the same sentence. Google is just confused. If anybody tackles it, that would be Microsoft, but they are distracted by so much of a low-hanging fruit in front of them just moving their traditional customers into the cloud, that I just don’t see them as applying effort in that space. It may happen in five years, but for now, running this company, at least I don’t see any of that happening.
Participant 3: What about drivers for sensors on these edge devices? It seems EVE abstracts the OS away from you, but in industrial, for instance, you need to detect things, so you need peripherals.
Shaposhnik: Correct. What about drivers? Because it’s a hypervisor based architecture, we can just assign the hardware directly to you. If you want to have that Windows XP based VM drive your hardware, we can do that. That’s not interesting, because we need software abstractions that will make it easier for developers to basically not think about it. That is the work that is a very nascent chunk of work. How do you provide software abstractions for a lot of things that we took for granted, like there’s a file in /dev someplace, and I do something with it through Yocto. Now we’re flipping it back and saying, “If I’m running a Docker container, what would be the most natural abstraction to a particular hardware resource?” A lot of times, surprisingly, to me, that abstraction happens to be a network socket. We can manage the driver on the other side of the hypervisor. Again, we will still run the driver in its own domain. To all of the containers that want to use it, we will basically present a nice software abstraction such as network socket.
See more presentations with transcripts
MMS • Jonathan Allen
Article originally posted on InfoQ. Visit InfoQ
One of the defining characteristics of “scripting” languages is they don’t need any boilerplate. The very first line of a file can be the declarations and statements as you would see inside a function. By contrast, a language like VB, C#, or Java requires a ‘main’ method of some sort contained within a class.
Mads Torgersen of Microsoft is proposing C# 9 adopt this capability. Proposal 3117, Top-level statements and functions would allow statements and functions to be declared in a file without the need for encompassing class. His justification from the previous incarnation of this proposal is,
The C# compiler currently understands a dialect of the language used for various scripting and interactive purposes. In this dialect, statements can be written at the top level (without enclosing member bodies) and non-virtual members (methods etc) can be written at the top level (without enclosing type declarations).
Usage of the scripting dialect has been relatively minor, and in some ways it hasn’t kept up with the “proper” C# language. However, usage is picking up through Try.NET and other technologies, and I am concerned with being stuck with two incompatible dialects of C#.
Currently the scripting version of C# isn’t heavily used, but Mads predicts that will change in the future,
Not only is there Try.NET, but data-science and machine learning scenarios are also growing, and those tend to benefit from a much more direct – interactive mode of working with live data.
Why then not just keep interactive/scripting C# separate? Because I think it is going to be useful to be able to roundtrip code between “experimentation” and “software development”.
Scenario 1
If scenario 1 of this proposal is adopted, executable statements would be allowed to appear before a namespace declaration. Any such statements would be compiled into a Main function in a class named Program. This function would support asynchronous operations.
If multiple files have executable statements outside of a namespace, then a compiler error will occur. Specifically, you would get multiple classes named Program with Main functions.
Scenario 2
Top-level functions would also be allowed under scenario 2. The functions can be declared within a namespace or globally. They would default to internal, though public would also be allowed. Consumers would see the function as belonging directly to the namespace. (This is already how functions work in Visual Basic modules.)
The implementation would be that a partial class is generated to wrap the members as static members. The class name would probably be unspeakable, and would be chosen in such a way that the same name wouldn’t be used twice in the same namespace across different assemblies. If any of the top-level members are public, the class would be public, and marked in such a way that a consuming assembly would know to expose the members directly.
Scenario 3
C# already has a scripting dialect, though it does differ from C# itself. The goal in this scenario isn’t to eliminate the scripting dialect, but rather move the two languages closer together. Mads elaborates,
If we want to add top level statements and functions to C#, we don’t want them to conflict with how those work in scripting. Rather we want to compile them in the requisite manner when necessary, but unify on the semantics of the features. This doesn’t fully eliminate the scripting dialect, as we would still need to deal with the special directives and “magic commands” that it requires, but at the minimum we do need to avoid the same syntax to not mean materially different things.
At this time, Mads is proposing that C# only focus on scenario 1,
You can squint and imagine a merged feature that serves all the scenarios. It would require a lot of design work, and some corners cut. I do not propose that. Instead I suggest that we fully embrace scenario 1, essentially fleshing out and slightly generalizing the feature sketched out for that scenario above.
He goes on to explain any functionality introduced by scenario 1 needs to be done in such a way that it will not prevent scenarios 2 and 3 from being implemented in the future.
Design Details
The first rule of Top-level Statements is only one file may contain them in a given project. Just as you can only have one “Main” function, having more than one file that contains naked statements will result in a compiler error.
The contents of the statements will dictate what the generated code looks like. There are four possibilities depending on whether or not await is used and if there is a return statement with an expression (e.g. return 5).
static void Main(string[] args)
static int Main(string[] args)
static Task Main(string[] args)
static Task<int> Main(string[] args)
Local functions are permitted using the same syntax one would use for local functions in normal methods.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

Pulumi announced the release of version 2.0 of their open source infrastructure as code platform. This release includes a new policy as code system called CrossGuard. Also included are improvements for moving pre-existing systems into Pulumi.
The policy as code system CrossGuard allows for declaring guardrails to enforce compliance while provisioning infrastructure. This facilitates adhering to best practices in the declaration and creation of infrastructure. These rules can be written in TypeScript, JavaScript, Node.js, or Python and can be applied to stacks written in any language supported by Pulumi.
Policies can be grouped together into policy packs. Each policy within a policy pack must have a unique name. When writing assertions it is recommended to write them in complete sentences while specifying the resource that is in violation. For example, a policy that prohibits S3 buckets from having public read could look like this:
new PolicyPack("policy-pack-typescript", {
policies: [{
name: "s3-no-public-read",
description: "Prohibits setting the publicRead or publicReadWrite permission on AWS S3 buckets.",
enforcementLevel: "mandatory",
validateResource: validateResourceOfType(aws.s3.Bucket, (bucket, args, reportViolation) => {
if (bucket.acl === "public-read" || bucket.acl === "public-read-write") {
reportViolation(
"You cannot set public-read or public-read-write on an S3 bucket. " +
"Read more about ACLs here: https://docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html");
}
}),
}],
});
This release also includes a set of pre-codified practices for AWS. AWSGuard is a configurable library that can be adopted and used within a policy pack. There are also example policy packs for AWS, Azure, Google Cloud, and Kubernetes. More details on CrossGuard can be found in the FAQ.
Also included within this update are three methods for adopting Pulumi for existing infrastructure. These are coexistence, importing, and conversion. Coexistence is to be used when there is already infrastructure provisioned but a full conversion into Pulumi isn’t desired. With coexistence the new infrastructure provisioned with Pulumi can coexist with the original infrastructure. Resource getters are available on every resource to allow for reading all the details from a resource from the cloud provider using its ID. Stack references allow for referencing the outputs of another Pulumi stack for use as an input to a stack. As a similar tool, external stack references allow for referencing outputs from a non-Pulumi stack as inputs to a Pulumi stack.
For example, it is possible to read data from the terraform.tfstate file. In this code, the AWS EC2 VPC and subnet IDs are read from the terraform.tfstate file and used to provision new EC2 instances:
import * as aws from "@pulumi/aws";
import * as terraform from "@pulumi/terraform";
// Reference the Terraform state file:
const networkState = new terraform.state.RemoteStateReference("network", {
backendType: "local",
path: "/path/to/terraform.tfstate",
});
// Read the VPC and subnet IDs into variables:
const vpcId = networkState.getOutput("vpc_id");
const publicSubnetIds = networkState.getOutput("public_subnet_ids");
// Now spin up servers in the first two subnets:
for (let i = 0; i < 2; i++) {
new aws.ec2.Instance(`instance-${i}`, {
ami: "ami-7172b611",
instanceType: "t2.medium",
subnetId: publicSubnetIds[i],
});
}
It is also possible to import existing infrastructure so that it is under the control of Pulumi. This differs from coexistence in that with importing, Pulumi will be able to modify and delete the infrastructure. Pulumi is able to import infrastructure regardless of how it was created, such as via the cloud provider’s console, from the CLI, or from Terraform.
Finally with conversion, it is possible to convert existing infrastructure as code into the equivalent Pulumi program structure. The primary conversion tool available at this time is tf2pulumi which converts Terraform HCL to Pulumi code. By default this will convert into TypeScript. To convert into Python instead, use tf2pulumi --target-language python.
More details about what is included in this release of Pulumi can be found in the official blog. A migration guide for migrating from version 1.0 is available. Pulumi open source is available for download from GitHub. Community Edition is also free for download and use on an individual basis.