Month: October 2020
Podcast: Alois Reitbauer on Cloud Native Application Delivery, Keptn, and Observability

MMS • Alois Reitbauer
Article originally posted on InfoQ. Visit InfoQ

In this podcast, Alois Reitbauer sat down with InfoQ podcast co-host Daniel Bryant. Topics discussed included: the goals of the CNCF app delivery SIG; how cloud native continuous delivery tooling like Keptn can help engineers scale development and release processes; and the role of culture change, tooling, and adopting open standards, such as OpenTelemetry, within observability.
By Alois Reitbauer

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
If you have ever had a book self-published through Amazon or similar fulfillment houses, chances are good that the physical book did not exist prior to the order being placed. Instead, that book existed as a PDF file, image files for cover art and author photograph, perhaps with some additional XML-based metadata indicating production instructions, trim, paper specifications, and so forth.
When the order was placed, it was sent to a printer that likely was the length of a bowling alley, where the PDF was converted into a negative and then laser printed onto the continuous paper stock. This was then cut to a precise size that varied minutely from page to page depending upon the binding type, before being collated and glued into the binding.
At the end of the process, a newly printed book dropped onto a rolling platform and from there to a box, where it was potentially wrapped and deposited automatically before the whole box was closed, labeled, and passed to a shipping gurney. From beginning to end, the whole process likely took ten to fifteen minutes, and more than likely no human hands touched the book at any point in the process. There were no plates to change out, no prepress film being created, no specialized inking mixes prepared between runs. Such a book was not “printed” so much as “instantiated”, quite literally coming into existence only when needed.
It’s also worth noting here that the same book probably was “printed” to a Kindle or similar ebook format, but in that particular case, it remained a digital file. No trees were destroyed in the manufacture of the ebook.
Such print on demand capability has existed since the early 2000s, to the extent that most people generally do not even think much about how the physical book that they are reading came into existence. Yet this model of publishing represents a profound departure from manufacturing as it has existed for centuries, and is in the process of transforming the very nature of capitalism.

Shortly after these printing presses came online, there were a number of innovations with thermal molded plastic that made it possible to create certain types of objects to exquisite tolerances without actually requiring a physical mold. Ablative printing techniques had been developed during the 1990s and involved the use of lasers to cut away at materials based upon precise computerized instruction, working in much the same that a sculptor chips away at a block of granite to reveal the statue within.
Additive printing, on the other hand, made use of a combination of dot matrix printing and specialized lithographic gels that would be activated by two lasers acting in concert. The gels would harden at the point of intersection, then when done the whole would be flushed with reagents that removed the “ink” that hadn’t been fixed into place. Such a printing system solved one of the biggest problems of ablative printing in that it could build up an internal structure in layers, making it possible to create interconnected components with minimal physical assembly.
The primary limitation that additive printing faced was the fact that it worked well with plastics and other gels, but the physics of metals made such systems considerably more difficult to solve – and a great deal of assembly requires the use of metals for durability and strength. By 2018, however, this problem was increasingly finding solutions for various types of metals, primarily by using annealing processes that heated up the metals to sufficient temperatures to enable pliability in cutting and shaping.
What this means in practice is that we are entering the age of just in time production in which manufacturing exists primarily in the process of designing what is becoming known as a digital twin. While one can argue that this refers to the use of CAD/CAM like design files, there’s actually a much larger, more significant meaning here, one that gets right to the heart of an organization’s digital transformation. You can think of digital twins as the triumph of design over manufacturing, and data and metadata play an oversized role in this victory.

At the core of such digital twins is the notion of a model. A model, in the most basic definition of the word, is a proxy for a thing or process. A runway model, for instance, is a person who is intended to be a proxy for the viewer, showing off how a given garment looks. An artist’s model is a stand-in or proxy for the image, scene, or illustration that an artist is producing. An architectural model is a simulation of how a given building will look like when constructed, and with 3D rendering technology, such models can appear quite life-like. Additionally, though, the models can also simulate more than appearance – they can simulate structural integrity, strain analysis, and even chemistry interactions. We create models of stars, black holes, and neutron stars based upon our understanding of physics, and models of disease spread in the case of epidemics.
Indeed, it can be argued that the primary role of a data scientist is to create and evaluate models. It is one of the reasons that data scientists are in such increasing demand, the ability to build models is one of the most pressing that any organization can have, especially as more and more of a company’s production exists in the form of digital twins.
There are several purposes for building such models: the most obvious is to reduce (or in some cases eliminate altogether) the cost of instantiation. If you create a model of a car, you can stress test the model, can get feedback from potential customers about what works and what doesn’t in its design, can determine whether there’s sufficient legroom or if the steering wheel is awkwardly placed, can test to see whether the trunk can actually hold various sized suitcases or packages, all without the cost of actually building it. You can test out gas consumption (or electricity consumption), can see what happens when it crashes, can even attempt to explode it. While such models aren’t perfect (nor are they uniform), they can often serve to significantly reduce the things that may go wrong with the car before it ever goes into production.
However, such models, such digital twins, also serve other purposes. All too often, decisions are made not on the basis of what the purchasers of the thing being represented want, but what a designer, or a marketing executive, or the CEO of a company feel the customer should get. When there was a significant production cost involved in instantiating the design, this often meant that there was a strong bias towards what the decision-maker greenlighting the production felt should work, rather than actually working with the stake-holders who would not only be purchasing but also using the product wanted. With 3D production increasingly becoming a reality, however, control is shifting from the producer to the consumer, and not just at the higher end of the market.
Consider automobile production. Currently, millions of cars are produced by automakers globally, but a significant number never get sold. They end up clogging lots, moving from dealerships to secondary markets to fleet sales, and eventually end up in the scrapyard. They don’t get sold primarily because they simply don’t represent the optimal combination of features at a given price point for the buyer.
The industry has, however, been changing their approach, pushing the consumer much closer to the design process before the car is actually even built. Colors, trim, engine type, seating, communications and entertainment systems, types of brakes, all of these and more can be can be changed. Increasingly, these changes are even making their way to the configuration of the chassis and carriage. This becomes possible because it is far easier to change the design of the digital twin than it is to change the physical entity, and that physical entity can then be “instantiated” within a few days of ordering it.
What are the benefits? You end up producing product upon demand, rather than in anticipation of it. This means that you need to invest in fewer materials, have smaller supply chains, produce less waste, and in general have a more committed customer. The downside, of course, is that you need fewer workers, have a much smaller sales infrastructure, and have to work harder to differentiate your product from your competitors. This is also happening now – it is becoming easier for a company such as Amazon to sell bespoke vehicles than ever before, because of that digitalization process.
This is in fact one of the primary dangers facing established players. Even today, many C-Suite managers see themselves in the automotive manufacturing space, or the aircraft production space, or the book publishing space. Yet ultimately, once you move to a stage where you have digital twins creating a proxy for the physical object, the actual instantiation – the manufacturing aspect – becomes very much a secondary concern.
Indeed, the central tenet of digital transformation is that everything simply becomes a publishing exercise. If I have the software product to build a car, then ultimately the cost of building that car involves purchasing the raw materials and the time on a 3D printer, then performing the final assembly. There is a growing “hobbyist’ segment of companies that can go from bespoke design to finished product in a few weeks. Ordinarily the volume of such production is low enough that it is likely tempting to ignore what’s going on, but between Covid-19 reshaping retail patterns, the diminishing spending power of Millennials and GenZers, and the changes being increasingly required by Climate Change, the bespoke digital twin is likely to eat into increasingly thin margins.
Put another way, existing established companies in many different sectors have managed to maintain their dominance both because they were large enough to dictate the language that described the models and because they could take advantage of the costs involved in manufacturing and production creating a major barrier to entry of new players. That’s now changing.

Consider the first part of this assertion. Names are important. One of the realizations that has emerged in the last twenty years is that before two people or organizations can communicate with one another, they need to establish (and refine) the meanings of the language used to identify entities, processes, and relationships. An API, when you get right down to it, is a language used to interact with a system. The problem with trying to deal with intercommunication is that it is generally far easier to establish internal languages – the way that one organization defines its terms – than it is to create a common language. For a dominant organization in a given sector, this often also manifests as the desire to dominate the linguistic debate, as this puts the onus of changing the language (a timeconsuming and laborious process) into the hands of competitors.
However, this approach has also backfired spectacularly more often than not, especially when those competitors are willing to work with one another to weaken a dominant player. Most successful industry standards are pidgins – languages that capture 80-90% of the commonality in a given domain while providing a way to communicate about the remaining 10-20% that typifies the specialty of a given organization. This is the language of the digital twin, the way that you describe it, and the more that organizations subscribe to that language, the easier it is for those organizations to interchange digital twin components.
To put this into perspective, consider the growth of bespoke automobiles. One form of linguistic harmonization is the standardization of containment – the dimensions of a particular component, the location of ports for physical processes (pipes for fluids, air and wires) and electronic ones (the use of USB or similar communication ports), agreements on tolerances and so forth. With such ontologies in place, construction of a car’s digital twin becomes far easier. Moreover, by adhering to these standards, linguistic as well as dimensional, you still get specialization at a functional level (for instance, the performance of a battery) while at the same time being able to facilitate containment variations, especially with digital printing technology.
As an ontology emerges for automobile manufacturing, this facilitates “plug-and-play” at a macro-level. The barrier to entry for creating a vehicle drops dramatically, though likely not quite to the individual level (except for well-heeled enthusiasts). Ironically, this makes it possible for a designer to create a particular design that meets their criterion, and also makes it possible for that designer to sell or give that IP to others for license or reuse. Now, if history is any indication, that will likely initially lead to a lot of very badly designed cars, but over time, the bad designers will get winnowed out by long-tail market pressures.
Moreover, because it becomes possible to test digital twins in virtual environments, the market for digital wind-tunnels, simulators, stress analyzers and so forth will also rise. That is to say, just as programming has developed an agile methodology for testing, so too would manufacturing facilitate data agility that serves to validate designs. Lest this be seen as a pipe dream, consider that most contemporary game platforms can, with very little tweaking, be reconfigured for exactly this kind of simulation work, especially as GPUs increase in performance and available memory.
The same type of interoperability applies not just to the construction of components, but also to all aspects of resource metadata, especially with datasets. Ontologies provide ways to identify, locate and discover the schemas of datasets for everything from usage statistics to simulation parameters for training models. The design of that car (or airplane, or boat, or refrigerator) is simply one more digital file, transmissible in the same way that a movie or audio file is, and containing metadata that puts those resources into the broader context of the organization.
The long term impact on business is simple. Everything becomes a publishing company. Some companies will publish aircraft or automobiles. Others will publish enzymes or microbes, and still others will publish movies and video games. You still need subject matter expertise in the area that you are publishing into – a manufacturer of pastries will be ill-equipped to handle the publishing of engines, for instance, but overall you will see a convergence in the process, regardless of the end-product.
How long will this process take to play out? In some cases, it’s playing out now. Book publishing is almost completely virtual at this stage, and the distinction between the physical object and the digital twin comes down to whether instantiation takes place or not. The automotive industry is moving in this direction, and drone tech (especially for military drones) have been shifting this way for years.
On the other hand, entrenched companies with extensive supply chains will likely adopt such digital twins approaches relatively slowly, and more than likely only at a point where competitors make serious inroads into their core businesses (or the industries themselves are going through a significant economic shock). Automobiles are going through this now, as the combination of the pandemic, the shift towards electric vehicles, and changing demographics are all creating a massive glut in automobile production that will likely result in the collapse of internal combustion engine vehicle sales altogether over the next decade along with a rethinking of the ownership relationship with respect to vehicles.
Similarly, the aerospace industry faces an existential crisis as demand for new aircraft has dropped significantly in the wake of the pandemic. While aircraft production is still a very high-cost business, the ability to create digital twins – along with an emergence of programming ontologies that make interchange between companies much more feasible – has opened up the market to smaller, more agile competitors who can create bespoke aircraft much more quickly by distributing the overall workload and specializing in configurable subcomponents, many of which are produced via 3D printing techniques.

Construction, likewise, is dealing with both the fallout due to the pandemic and the increasing abstractions that come from digital twins. The days when architects worked out details on paper blueprints are long gone, and digital twins of construction products are increasingly being designed with earthquake and weather testing, stress analysis, airflow and energy consumption and so forth. Combine this with the increasing capabilities inherent in 3D printing both full structures and custom components in concrete, carbon fiber and even (increasingly) metallic structures. There are still limitations; as with other large structure projects, the lack of specialized talent in this space is still an issue, and fabrication units are typically not yet built on a scale that makes them that useful for onsite construction.
Nonetheless, the benefits make achieving that scaling worthwhile. A 3D printed house can be designed, approved, tested, and “built” within three to four weeks, as opposed to six months to two years for traditional processes. Designs, similarly, can be bought or traded and modified, making it possible to create neighborhoods where there are significant variations between houses as opposed to the prefab two to three designs that tend to predominate in the US especially. Such constructs also can move significantly away from the traditional boxy structures that most houses have, both internally and externally, as materials can be shaped to best fit the design aesthetic rather than the inherent rectangular slabs that typifies most building construction.
Such constructs can also be set up to be self-aware, to the extent that sensors can be built into the infrastructure and viewscreens (themselves increasingly moving away from flatland shapes) can replace or augment the views of the outside world. In this sense, the digital twin of the instantiated house or building is able to interact with its physical counterpart, maintaining history (memory) while increasingly able to adapt to new requirements.

This feedback loop – the ability of the physical twin to affect the model – provides a look at where this technology is going. Print publishing, once upon a time, had been something where the preparation of the medium, the book or magazine or newspaper, occurred only in one direction – from digital to print. Today, the print resides primarily on phones or screens or tablets, and authors often provide live blog chapters that evolve in agile ways. You’re seeing the emergence of processors such as FPGAs that configure themselves programmatically, literally changing the nature of the processor itself in response to software code.
It’s not that hard, with the right forethought, to envision real world objects that can reconfigure themselves in the same way – buildings reconfiguring themselves for different uses or to adapt to environmental conditions, cars that can reconfigure its styling or even body shape, clothing that can change color or thermal profiles, aircraft that can be reconfigured for different uses within minutes, and so forth . This is reality in some places, though still piecemeal and one-offs, but the malleability of the digital twins – whether of office suites or jet engines – is the future of manufacturing.
The end state, likely still a few decades away, will be an economy built upon just-in-time replication and the importance of the virtual twin, where you are charged not for the finished product but the cost of the license to use a model, the material components, the “inks”, for same, and the processing to go from the former to the latter (and back), quite possibly with some form of remuneration for recycled source. Moreover, as this process continues, more and more of the digital twin carries the burden of existence (tools that “learn” a new configuration are able to adapt to that configuration at any time). The physical and the virtual become one.

Some may see the resulting society as utopian, others as dystopian, but what is increasingly unavoidable is the fact that this is the logical conclusion of the trends currently at work (for some inkling of what such a society may be like, I’d recommend reading The Diamond Age by Neal Stevenson, which I believe to be very prescient in this regard).
How Kids Channel Their Internal Data Scientist to Become Candy Optimization Machines on Halloween
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Ghostly greetings!
I believe everyone is born with the innate, curiosity-driven, explore-test-learn Data Science capability. At Halloween, kids naturally embrace a rapid exploration, rapid testing, failure-empowering “Scientific Method” to optimize their candy yield and logistical “Trick or Treating” algorithms.
So, what can we – as parents and teachers – provide to help nurture these budding data scientists? How can we prepare them for a future using data and analysis (analytics) to make informed operational, policy and life decisions?
Don’t be a scaredy cat and let’s talk about how we can get our kids ready for the future – by preparing them to embrace their inner data scientist.
Teach Your Students How to Use the Hypothesis Development Canvas
The Hypothesis Development Canvas is a design tool that succinctly defines the problem that one is trying to solve. The Hypothesis Development Canvas is a collaborative tool that captures the details about the hypothesis or problem that we are trying to solve, brainstorms the metrics and variables against which progress and success will be measured, identifies the stakeholders who either impact or are impacted by the targeted hypothesis, identifies and prioritizes the decisions that the stakeholders need to make in support of the targeted hypothesis (see Figure 2).

Figure 2: Halloween “Treat or Treating” Candy Optimization Hypothesis Development Canvas
Having your students construct a Hypothesis Development Canvas for their Trick or Treating objectives is a great way to help our future data scientists understand the importance of preparation before actually putting science to the data. The Hypothesis Development Canvas in Figure 2 provides a “paint by the numbers” example for our future data scientists to thoroughly understand what they are trying to achieve, how they will measure success and how they can leverage data and analysis to optimize their key decisions to optimize their Halloween “Treat or Treating” endeavor. This canvas helps clarify the following before actually diving into the analysis that drives the event optimization, including:
- What is your Halloween candy gathering objectives? For example: “To gather and retain as much high-quality candy, within the allotted time period, as possible.”
- What are the metrics against which you will measure candy gathering progress and success? For example: “Maximize candy quality, optimize candy volume, minimize effort exerted to gather candy, minimize distance covered to gather candy.”
- Who are your key stakeholders who can help you achieve your objectives? For example: “Friends, parents, neighbors, siblings.”
- What are the key decisions that you need to make? For example:
- What outfit are you going to wear?
- What neighborhoods and residences are you going to target?
- When to start out and how long to go?
- With which friends are you going? (Be sure to leave your skeleton friend at home because he’s got no-body to go with.)
- What candies to your keep for yourself?
- What candies are offered up for the “Dad Tax”?
- What treats (raisins, apples) do you off load to your younger siblings?
- What data might one want to use to help optimize the above decisions? For example:
- Last Year’s Yield by Residence or Store
- New Neighbors
- Neighborhood Construction
- Weather
- Day of the Week (school night versus non-school night)
- Friends’ Neighborhood Recommendations
- Traffic
- Local Events
Note: one of the most important outcomes from the Hypothesis Development Canvas exercise is 1) the identification of the variables and metrics against which hypothesis progress and success will be measured, and 2) the identification, validating, valuation and prioritization of the key decisions that they need to make in support of the targeted hypothesis. Get these two items right, and your students are well down the path to becoming data scientists and serving up Frankenstein his favorite kind of potatoes: monster-mashed!
Kids’ Halloween Candy Optimization in Action!
Children are naturally able to optimize across multiple, sometimes conflicting variables – volume of candy, quality of candy, distance to travel between sources of candy, time to wait at the door to get their candy – in order to optimize their candy gathering decisions. So, while we as parents see a traditional neighborhood map such as Figure 3…
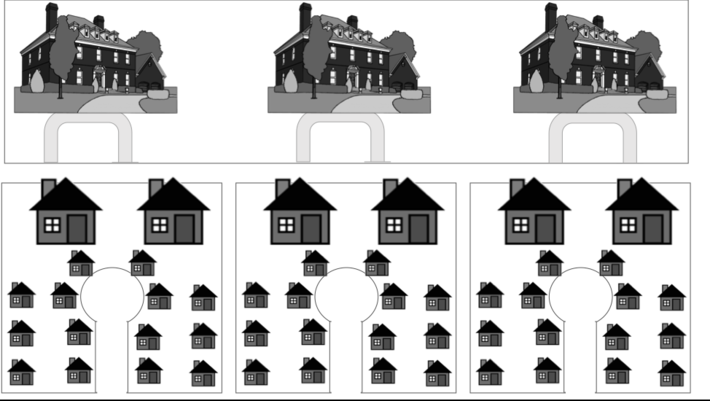
Figure 3: Traditional Neighborhood Map
…our children are applying their innate data science (data and analysis) skills to map out the candy gathering targets and their logistical paths that they believe will yield the best results given the metrics against which they will measure progress and success (see Figure 4).
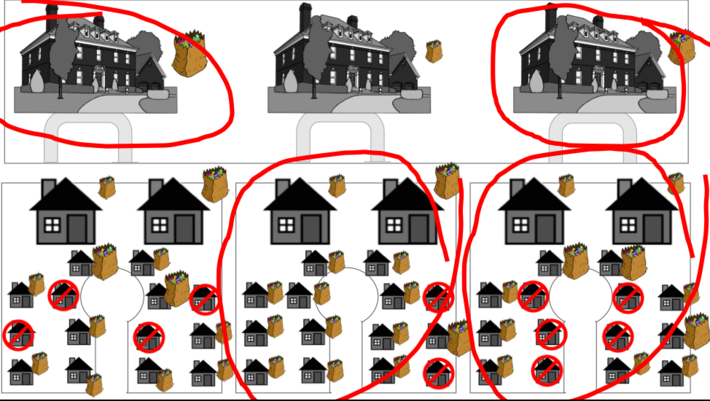
Figure 4: Optimized Candy Gathering Logistical Map
Kids’ Halloween Candy Optimization Homework Assignment
One last thing to help our future data scientists is a simple but effective homework assignment. In this exercise, we want to 1) help our students get comfortable optimizing across different metrics while 2) performing some rudimentary analytics to create a “score” that tells them the best neighborhoods to target for their candy optimization journey.
Figure 5 provides a simple spreadsheet that is designed to help students get comfortable playing with the data and the decision variable weights in order to make an informed decision about what neighborhoods they should target for their “Treat or Treating” venture.

Figure 5: Rudimentary Neighborhood Scoring Algorithm
To calculate the Neighborhood Candy Gathering Optimization Score in the last column of Figure 5, the students need to do the following (indicated in red in Figure 5):
- Enter the names of their potential target Neighborhoods.
- Next, enter a weight for the relative importance of them of each of the 3 different variables (Variable 1: Amount of Candy, Variable 2: Quality of Candy, and Variable 3: Time to Gather Candy). We use a scale of 1 to 10 where 10 is your most important variable and 1 is your least important variable.
Note: Not all variables are of equal weight. Part of the data science process is making trade-offs between the weights assigned to the different variables. Because there probably isn’t an equal difference between the importance of the variables, feel free to use the full range of 1 to 10 to make a relative determination of the value of each variable vis-à-vis each other.
- Finally, for each neighborhood, enter a weight for how well you think that particular neighborhood does vis-à-vis each variable. For example: for Variable 1 (Amount of Candy), I felt that Mid Town and South Side would yield the highest volume of candy based upon previous experience and recommendations from friends (so both got 8’s out of 10), while I felt that Old Town would probably yield the lowest volume of candy based upon previous experience and recommendations from friends (so I gave Old Town a 2 out of 10).
Allow the students to play with the weights on the Variables and the Neighborhoods to see the impact that each has on the resulting Candy Optimization Score in the final column of the spreadsheet.
Extra credit: ask them what data they might want to gather in order to help them make even more informed, accurate weighting decisions.
Finally, the spreadsheet from Figure 5 can be pulled off of Google Docs: https://docs.google.com/spreadsheets/d/13fwmBLm5DPsDRNGqHvzI-9u5wWwJ9jT4azds6ksGLNo/edit?usp=sharing
Extra, extra credit: What do you get when you divide the circumference of your Jack-o’Lantern by its diameter?
Did you answer, Pumpkin Pi? Hehehe
Summary
Kids are natural data scientists; they have the natural curiosity to leverage data and basic analysis to make more informed decisions. But what are we as parents and teachers doing to nurture that innate, curiosity-driven, explore-test-learn Data Science capability. Help them by introducing them to a structured way to perform basic analysis – using the Hypothesis Development Canvas – and watch their natural curiosity, creativity and innovation cycle kick in.
In closing, I ‘witch’ you a Happy Halloween and have fun “Trick or Treating”, you crazy data scientists you!
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
For the last few years, I have read the free state of AI report
Here are the list of insights which I found interesting
The full report and the download link is at the end of this article
AI research is less open than you think: Only 15% of papers publish their code
Facebook’s PyTorch is fast outpacing Google’s TensorFlow in research papers, which tends to be a leading indicator of production use down the line
PyTorch is also more popular than TensorFlow in paper implementations on GitHub
Language models: Welcome to the Billion Parameter club
Huge models, large companies and massive training costs dominate the hottest area of AI today, NLP.
Bigger models, datasets and compute budgets clearly drive performance
Empirical scaling laws of neural language models show smooth power-law relationships, which means that as model performance increases, the model size and amount of computation has to increase more rapidly.
Tuning billions of model parameters costs millions of dollars
Based on variables released by Google et al., you’re paying circa $1 per 1,000 parameters. This means OpenAI’s 175B parameter GPT-3 could have cost tens of millions to train. Experts suggest the likely budget was $10M.
We’re rapidly approaching outrageous computational, economic, and environmental costs to gain incrementally smaller improvements in model performance
Without major new research breakthroughs, dropping the ImageNet error rate from 11.5% to 1% would require over one hundred billion billion dollars! Many practitioners feel that progress in mature areas of ML is stagnant.
A larger model needs less data than a smaller peer to achieve the same performance
This has implications for problems where training data samples are expensive to generate, which likely confers an advantage to large companies entering new domains with supervised learning-based models.
Even as deep learning consumes more data, it continues to get more efficient
Since 2012 the amount of compute needed to train a neural network to the same performance on ImageNet classification has been decreasing by a factor of 2 every 16 months.
A new generation of transformer language models are unlocking new NLP use-cases
GPT-3, T5, BART are driving a drastic improvement in the performance of transformer models for text-to-text tasks like translation, summarization, text generation, text to code.
NLP benchmarks take a beating: Over a dozen teams outrank the human GLUE baseline
It was only 12 months ago that the human GLUE benchmark was beat by 1 point. Now SuperGLUE is in sight.
What’s next after SuperGLUE? More challenging NLP benchmarks zero-in on knowledge
A multi-task language understanding challenge tests for world knowledge and problem solving ability across 57 tasks including maths, US history, law and more. GPT-3’s performance is lopsided with large knowledge gaps.
The transformer’s ability to generalise is remarkable. It can be thought of as a new layer type that is more powerful than convolutions because it can process sets of inputs and fuse information more globally.
For example, GPT-2 was trained on text but can be fed images in the form of a sequence of pixels to learn how to autocomplete images in an unsupervised manner.
Biology is experiencing its “AI moment”: Over 21,000 papers in 2020 alone
Publications involving AI methods (e.g. deep learning, NLP, computer vision, RL) in biology are growing >50% year-on-year since 2017. Papers published since 2019 account for 25% of all output since 2000.
From physical object recognition to “cell painting”: Decoding biology through images
Large labelled datasets offer huge potential for generating new biological knowledge about health and disease.
Deep learning on cellular microscopy accelerates biological discovery with drug screens
Embeddings from experimental data illuminate biological relationships and predict COVID-19 drug successes.
Ophthalmology advances as the sandbox for deep learning applied to medical imaging
After diagnosis of ‘wet’ age-related macular degeneration (exAMD) in one eye, a computer vision system can predict whether a patient’s second eye will convert from healthy to exAMD within six months. The system uses 3D eye scans and predicted semantic segmentation maps.
AI-based screening mammography reduces false positives and false negatives in two large, clinically-representative datasets from the US and UK
The AI system, an ensemble of three deep learning models operating on individual lesions, individual breasts and the full case, was trained to produce a cancer risk score between 0 and 1 for the entire mammography case. The system outperformed human radiologists and could generalise to US data when trained on UK data only.
Causal reasoning is a vital missing ingredient for applying AI to medical diagnosis
Existing AI approaches to diagnosis are purely associative, identifying diseases that are strongly correlated with a patient’s symptoms. The inability to disentangle correlation from causation can result in suboptimal or dangerous diagnoses.
Model explainability is an important area of AI safety: A new approach aims to incorporate causal structure between input features into model explanations
A flaw with Shapley values, one current approach to explainability, is that they assume the model’s input features are uncorrelated. Asymmetric Shapley Values (ASV) are proposed to incorporate this causal information.
Reinforcement learning helps ensure that molecules you discover in silico can actually be synthesized in the lab. This helps chemists avoid dead ends during drug discovery.
RL agent designs molecules using step-wise transitions defined by chemical reaction templates.
American institutions and corporations continue to dominate NeurIPS 2019 papers
Google, Stanford, CMU, MIT and Microsoft Research own the Top-5.
The same is true at ICML 2020: American organisations cement their leadership position
The top 20 most prolific organisations by ICML 2020 paper acceptances further cemented their position vs. ICML 2019. The chart below shows their Publication Index position gains vs. ICML 2019.
Demand outstrips supply for AI talent
Analysis of Indeed.com US data shows almost 3x more job postings than job views for AI-related roles. Job postings grew 12x faster than job viewings in the last from late 2016 to late 2018.
US states continue to legislate autonomous vehicles policies
Over half of all US states have enacted legislation to related to autonomous vehicles.
Even so, driverless cars are still not so driverless: Only 3 of 66 companies with AV testing permits in California are allowed to test without safety drivers since 2018
The rise of MLOps (DevOps for ML) signals an industry shift from technology R&D (how to build models) to operations (how to run models)
25% of the top-20 fastest growing GitHub projects in Q2 2020 concern ML infrastructure, tooling and operations. Google Search traffic for “MLOps” is now on an uptick for the first time.
As AI adoption grows, regulators give developers more to think about
External monitoring is transitioning from a focus on business metrics down to low-level model metrics. This creates challenges for AI application vendors including slower deployments, IP sharing, and more:
Berkshire Grey robotic installations are achieving millions of robotic picks per month
Supply chain operators realise a 70% reduction in direct labour as a result.
Algorithmic decision making: Regulatory pressure builds
Multiple countries and states start to wrestle with how to regulate the use of ML in decision making.
GPT-3, like GPT-2, still outputs biased predictions when prompted with topics of religion
Example from the GPT-3 (left) and GPT-2 (right) with prompts and the model’s predictions, which contain clear bias. Models trained on large volumes of language on the internet will reflect the bias in those datasets unless their developers make efforts to fix this. See our coverage in State of AI Report 2019 of how Google adapted their translation model to remove gender bias.
Free download link is at state of ai report
MMS • Aditya Kulkarni
Article originally posted on InfoQ. Visit InfoQ

Kubermatic, a German-based startup, introduced an open-source tool called KubeCarrier that automates lifecycle management of services, applications, and hardware using Kubernetes Operators. The goal of the tool is to provide scalability and repeatability to meet the organization’s requirements.
By Aditya Kulkarni
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Tesla has enabled new full-self driving features for certain customers. The new features include the ability to automatically steer the vehicle while on city streets, and Tesla plans to increase the price of the package by $2,000 in the near future.
By Anthony Alford
MMS • Adelina Turcu
Article originally posted on InfoQ. Visit InfoQ

As software developers ourselves, we designed QCon Plus to be practical, actionable, and software-focused. This is not just another virtual conference; it’s an online experience where senior software engineers, architects, and team leads connect, gather new ideas, and hear from software leaders that are constantly pushing the boundaries.
By Adelina Turcu
MMS • Erisan Olasheni
Article originally posted on InfoQ. Visit InfoQ

Deno is a simple, modern, and secure runtime for JavaScript and TypeScript applications built with the Chromium V8 JavaScript engine and Rust, created to avoid several pain points and regrets with Node.js. Deno was originally announced in 2018 and reached 1.0 in 2020, created by the original Node.js founder Ryan Dahl and other mindful contributors.
By Erisan Olasheni
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

Recently Microsoft launched its Azure Space initiative as a further push of cloud computing towards space. This initiative by the public cloud vendor consists of several products and partnerships to position Azure as a critical player in the space- and satellite-related connectivity and compute part of the cloud market.
By Steef-Jan Wiggers