Month: July 2021

MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Couchbase is out today with the general availability of its updated NoSQL database providing users with a series of new features that aim to narrow the gap between NoSQL and relational databases.
The Couchbase 7.0 release comes a week after the open source NoSQL database vendor had its IPO and is the first major update since the Couchbase 6.5 release that came out in October 2019.
The new version provides new SQL query capabilities including multi-document SQL ACID (atomicity, consistency, isolation and durability) transactions that provide more scalability and performance for users.
A key highlight of the Couchbase 7.0 release is what the vendor refers to as scopes and collections. The purpose of scopes and collection is to have a new type of organizing capability for the NoSQL database that mimics the tables and schema approach of a relational database.
Couchbase is what is known as a “schema-less database” and previously did not have a schema type of feature.
Features common to relational databases
The scopes and collections capabilities are key advancements, along with multiple document transactions, said Carl Olofson, an analyst at IDC.
When multiple applications develop document databases, those documents may contain overlapping data. When that happens, there must be a mechanism for coordinating the overlap.
With document collections, documents that are unique to an application and documents that are shared are handled together, which delivers the same simplicity as before, but without the duplication and synchronization problem.
With multi-document SQL ACID transactions, when an action occurs involving updates in multiple documents, that action either succeeds altogether, or fails altogether, keeping the data consistent, Olofson said.
“This [multi-document SQL ACID transactions] has been a common feature in relational databases for decades but adding it to document databases makes them capable of supporting the more sophisticated operations that business applications require,” Olofson said.
“The overall effect is to enable Couchbase to move up the food chain from being focused on end-user and edge data applications to a range of more complex business process-based transactions,” he said.
Bringing scopes and collections to the NoSQL database
Couchbase is positioning the “scope” as equivalent to a schema, while the “collection” is similar to a relational database table. Within the table are documents — the equivalent of rows within a relational database — and within the documents are data fields, which are akin to columns.
“We all have a very good sense of how our data is arranged inside a relational database. There’s an ontology for it with a database schema, table, rows and columns, that’s how data is arranged,” explained Ravi Mayuram, CTO of Couchbase. “So we wanted to offer an equivalent of that.”
Mayuram said that with scopes and collections in Couchbase 7.0 there is now a 1:1 mapping for data coming from an organization’s relational system to how it can be structured within Couchbase.
That type of mapping will ease migration from a relational database to Couchbase, he said.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

A latest study collated and published by Transparency Market Research (TMR) analyzes the historical and present-day scenario of the global AI in medical imaging market to accurately gauge its potential future development. The study presents detailed information about the important growth factors, restraints, and key trends that are creating the landscape for the future growth of the AI in medical imaging market, to identify the opportunistic avenues of the business potential for stakeholders. The report also provides insightful information about how the AI in medical imaging market will progress during the forecast period 2021 – 2031.
The report offers intricate dynamics about the different aspects of the AI in medical imaging market, which aids companies operating in the market in making strategic development decisions. TMR’s study also elaborates on the significant changes that are highly anticipated to configure the growth of the AI in medical imaging market during the forecast period. It also includes impact analysis of COVID-19 on the AI in medical imaging market. The global AI in medical imaging market report helps to estimate statistics related to the market progress in terms of value (US$ Mn).
The study covers a detailed segmentation of the AI in medical imaging market, along with key information and a competitive outlook. The report mentions the company profiles of key players currently dominating the AI in medical imaging market, wherein various development, expansion, and winning strategies practiced and executed by leading players have been presented in detail.
The research methodology adopted by analysts to compile the AI in medical imaging market report is based on detailed primary as well as secondary research. With the help of in-depth insights of industry-affiliated information that is obtained and legitimated by market-admissible sources, analysts have offered riveting observations and authentic forecasts of the AI in medical imaging market. During the primary research phase, analysts interviewed industry stakeholders, investors, brand managers, vice presidtmrents, and sales and marketing managers. On the basis of data obtained through the interviews of genuine sources, analysts have emphasized the changing scenario of the AI in medical imaging market. For secondary research, analysts scrutinized numerous annual report publications, white papers, and data of major countries of the world, industry association publications, and company websites to obtain the necessary understanding of the AI in medical imaging market.
Get More Information about AI in Medical Imaging by TMR
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Following the close of its IPO, Couchbase has announced the general availability of Couchbase Server 7, which the company is calling a landmark release for its ability to bridge the best aspects of relational databases like ACID transactions with the flexibility of a modern database.
Couchbase announced the closing of its initial public offering of 9,589,999 shares of its common stock at a public offering price of $24 per share, which includes the full exercise by the underwriters of their option to purchase an additional 1,250,869 shares of common stock. Aggregate gross proceeds to Couchbase were approximately $230 million, before underwriting discounts, commissions, and estimated offering expenses. Couchbase’s common stock is listed on the Nasdaq Global Select Market under the ticker symbol “BASE.”
With Couchbase Server 7, enterprise development teams get one unified platform and no longer need to use one database for transactions and a separate database for developer agility and scale. This means that customers can simplify their database architectures, expand Couchbase usage into enterprise transactional applications and reduce operating costs through performance enhancements.
“With Couchbase Server 7, the relational versus NoSQL database debate is over. Modern developers no longer have to struggle with having multiple databases—a relational database for transactionality, and a NoSQL database for flexibility and scale,” said Ravi Mayuram, senior vice president of engineering and CTO, Couchbase. “We are delighted to be the first modern database-as-a-service provider to combine traditional relational database functionality like SQL and transactions with the flexibility and scalability of NoSQL. The data containment model and distributed SQL transactions introduced in Couchbase Server 7.0 give developers a familiar programming model on a distributed database. In addition, there are 30 other innovations covering query, search, eventing, analytics, and geo-replication. No other database has organically fused all of these capabilities in a single database. These innovations give developers an astonishing advantage to build modern enterprise applications for a connected world.”
According to Couchbase, there is an urgent need for a database platform that can support both developing and deploying new applications and also modernizing and upgrading existing ones. According to the company, Couchbase Server 7 eliminates the key friction points that have kept enterprises from modernizing their relational-based applications, giving them the flexibility to accelerate the development of modern business-critical applications.
Couchbase Server 7 highlights:
Customers no longer need both a relational database and also a NoSQL database. Couchbase now has multi-statement SQL transactions by fusing together transactions and high-volume interactions. For the first time, customers can do multi-document SQL ACID transactions with interactions in microseconds all within one unified database platform.
There are schema and table-like organizing structures, called “Scopes and Collections,” within the schemaless database. Customers add a table (the “Collection”) in Couchbase, while transactions are happening without having to add or modify the schema (the “Scope”) or take down the database for this upgrade. The new multi-level, dynamic data organizing structure allows the platform to match and migrate relational data models into Couchbase Server 7, and then inverts ongoing control of the data structures from the database administrator to the application developer, thereby improving their productivity.
Faster operational performance lowers the total cost of ownership facilitated by collection-level processing of data access, partitioning, and index isolation. Couchbase Server 7 also adds a configurable backup service. Datasets delivered to microservices are faster, index builds execute in parallel, and indexes are portable during data rebalancing. And finally, the query service adds a cost-based query optimizer to replace its former rules-based optimization.
For more information, visit www.couchbase.com.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Coming off a successful IPO last week that raised $200 million, Couchbase is getting back to business with the release of its 7.0 database. The highlights of Couchbase 7.0 include rounding out ACID transaction processing support; adding a new Scopes construct to add a relational skin to the document database; and various performance tweaks.
There’s little secret about the 7.0 release, which has been in public beta since last fall. The theme is overwhelmingly a pitch to the relational database world, part of Couchbase’s continued positioning as the most SQL-friendly document database. Transaction support, expanded in 7.0, came earlier in 6.5 that supported full commit and rollback for transactions spanning multiple documents, where you could invoke transactions using the Couchbase SDK or database API.
Among NoSQL document database players, Couchbase is not the first to get there: There are some parallels with the transaction support introduced in the next-to-most recent version of MongoDB. But in the 7.0 release, there is a real differentiation with MongoDB because now, Couchbase transactions are supported through its SQL-like language, awkwardly named N1QL. That means transactions are supported with common SQL SELECT, INSERT, UPDATE, DELETE, and MERGE statements.
Transaction support is distributed, fitting with Couchbase’s masterless architecture. But, as this is still an early release of transaction support, there are some limitations. Transaction work across multiple nodes, but at this point, not across multiple regions. Also, when transactions are updated, accompanying indexes remain eventually consistent. This is an area where Couchbase, along with MongoDB, Cosmos DB, DynamoDB trail counterparts like Google Cloud Spanner, CockroachDB, Yugabyte and others in the relational world.
We expect that in upcoming releases, Couchbase will further round out transaction support in alignment with its positioning as a distributed database, in conjunction with further enhancement of its Couchbase Cloud database service.
Another highlight of the new release is the addition of a Scopes construct that makes Couchbase look and act more like a relational database. It complements Collections, a common artifact in document databases, that Couchbase has in its own documentation. Both are logical projections or views of data that is physically stored as JSON documents. The technical definition is that Scopes can group multiple collections together, so that if Collections roughly correspond to relational tables, scopes correspond to schema. And with the scopes feature, Couchbase is supporting smart caching that can tier data either automatically or according to preset rules by the customer.
In essence, consider Couchbase scopes as the equivalent of materialized views in analytic database that provide virtualized rollups of data; the difference with scopes is that it can be used for transactional and analytic views such as CUBE functions.
Finally, no new release is complete without performance- or scale-enhancing tweaks. There are refinements for managing data access, partitioning, and index isolation at the collection level. A configurable backup service is being added where index builds can be performed in parallel, and made portable when rebalancing the cluster. And a more flexible query optimizer supersedes the former rules-based optimizer.
Couchbase is hardly a new player in the NoSQL document database space, and like most of its rivals, was long overshadowed by MongoDB. Traditionally, Couchbase positioned itself as the more scalable and SQL-friendly alternative, but MongoDB’s rise has been propelled by its developer-friendliness, especially with its tooling. In the current release, Couchbase has been playing up its appeal to the SQL relational world; we expect that in the future, it will shower more love to the JavaScript JSON community that made MongoDB what it is today.
There’s good historical reason why it’s taken Couchbase longer to gain momentum compared to better known rivals. In the early years, there was a forking of the original CouchDB project that was the ancestor of the Couchbase platform. IBM now owns the company that stuck with the other fork. And during those years, there was significant management turnover.
But over the past four years, the senior management team has stabilized. The reason we’re having this conversation now and why the IPO turned out better than expected can be summed up in two words: The cloud. The limitless scale of the cloud is a natural fit for distributed databases like Couchbase because it provides the environment where they can exploit their natural advantages over traditional, monolithic scale-up databases. For many startups that didn’t rapidly shoot to market leadership, the cloud could provide a second lease on life.
During the IPO, the company was able to raise the original share price. But it still has a ways to go. While MongoDB’s revenues has been coasting along at 40% annual growth rates, Couchbase’s has been roughly half that.
The company’s cloud offering has carved footholds on AWS and Azure, and we expect that Google Cloud will come in the near future. As we noted in our discussion of the cloud release, it is still not yet a one-stop shopping seamless experience, in that you have to book cloud infrastructure first from the cloud provider, then go to Couchbase for the actual service. That’s another item that we expect will be on the company’s short term to-do list.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Analytics Insight
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Keeping in touch and being cohesive as a distributed team is a challenge many face. Assigning stories from a product owner’s shared backlog helped a distributed team in doing non-stop delivery, as did giving all members of the team the authority to promote to production and back-out code at need. You need to give attention to the architecture to prevent creating similar or even duplicate micro-services at different locations.
Ola Chowning, a partner at Information Services Group, spoke about dealing with geographically distributed DevOps teams at DevOpsCon Berlin 2021.
Chowning presented a solution for teams to do non-stop delivery where they are distributed globally and across time-zones. The particular organization broke their DevOps team into “crews.” Each crew was in a different time-zone and was “assigned” different stories (tasks/work) from the shared backlog.
The “real” product owner of the team was aligned to the crew within their natural time zone – the counter crew within the team had a “proxy product owner”. This allowed the priority of work to continue to be set by a product owner or proxy out of a shared backlog, Chowning said.
A strong product owner was critical to making this approach work well, and the organization saw teams without effective product owners quickly diverged into separate teams overall, which was less productive and was confusing for the business constituents as well. In these instances, they had to quickly address the product owner role, Chowning mentioned. proxy product owners, on the other hand, needed to lead within their crew and yet recognize the limits of their authority for larger decisions that required the product owner’s input.
This organization was in two different countries that had a natural time zone overlap – without that, they would have needed to create some form of overlap for the crews to stay in sync and to share work. Chowning mentioned that their method of essentially assigning work to a specific crew actually worked well; they had to pay attention to their architecture and rampant “micro-service sprawl,” as the different crews tended to create similar or even duplicate micro-services.
Each crew had their own work to do, but kept connected to the shared backlog and priority, shared releases and planning sessions. Chowning explained that crews made it a point to demand, and even schedule, crew sharing opportunities to make sure that the crews maintained some sense of togetherness, even as they worked on different tasks and in different time zones.
InfoQ interviewed Ola Chowning, about working in distributed teams.
InfoQ: What challenges do distributed teams face?
Ola Chowning: An important element of most DevOps teams is cultural integration; learning about and from each other, establishing the psychological safety within the team to fail in front of your peers, the proverbial finishing of each other’s sentences… it’s simply harder to establish this level of cultural cohesiveness when you are working in distributed teams.
Leaders are also challenged; how do they recognize when a team member needs help, needs to be prompted, or requires clearer direction without the body language cues or without any interaction at all, if they are in completely different time zones? As a leader, recognizing when to intervene, when to support, and when to engage is challenging when the team is delivering outside of view.
Trust becomes crucial between all team members. This particular organization is currently considering “time zone rotation” so that team members can establish working relationships and trust outside of their own normal working time group.
InfoQ: How did the crews feel about getting work assigned?
Chowning: They still used a product planning mind-set, and so bi-weekly they conducted a planning session where the crews were able to essentially volunteer for stories, tasks or work products. They also used these sessions to discuss how things were going, both within and between the crews.
This particular organization had some difficulty as one crew commonly had skills that the other did not (e.g., test automation), and so there was initially a bit of frustration that certain tasks always “went” to a specific crew. With their current trial of “time zone rotation”, they are looking to promote better skill sharing, and are focusing on minimizing those skill differences.
They share that they are able to act autonomously and with agility within their crew, but still struggle a bit across the team as a whole. Taking the time to clearly articulate the stories (or even story-lines) within a feature or epic, and then assigning specific stories to a crew while still measuring the overall feature, has helped to minimize the feeling of separation.
InfoQ: How does the culture of inclusion and empowerment work when the team is spread across the world?
Chowning: The non-stop delivery method was very useful to promote both empowerment (the crews had the authority to release code to production at will), as well as inclusion (particularly with their crew members as they effectively shared time zones and could chat and collaborate at will). Organizations can strive for inclusion in a variety of ways, but I believe the most useful practices measure inclusion, focus on it, and continuously improve it as a core feature of the team.
InfoQ: What have you learned about supporting online collaboration in distributed teams?
Chowning: Don’t expect this to come naturally to teams – you need to focus on it, include the team members in your initial approach and in continuously improving your practices. Leaders need to be constantly checking in with team members, monitoring their participation, eliciting feedback and enabling changes.
Video fatigue is a real thing. Scheduling a meeting instead of sending an email or chat is a real thing. Recognize where practices may not be working well and involve the team to improve them.
InfoQ: What are your suggestions for creating highly collaborative and empowered teams in a global, distributed environment?
Chowning: The core attributes remain the same – empower the team to make decisions, foster collaboration and diversity as the key to team enablement, establish psychological safety as necessary in a test-and-learn environment. Using digital tools that attempt to mimic physical proximity are not enough to bridge the gaps of being globally distributed, although they are certainly important.
You also need leaders to monitor and foster inclusion, check in with team members, even force some of the interactions that would have been natural with physical proximity. Most importantly, involve the team members in creating the best environment that allows them to thrive as a cohesive team.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Credible Markets has added a new key research reports covering NoSQL market. The study aims to provide global investors with a game-changing decision making tool covering key fundamentals of the NoSQL market. The research report will include total global revenues in the market with historical analysis, key figures including total revenues, total sales, key products, instrumental drivers, and challenges. The report data is derived from extensive primary and secondary information sources with a reliable in-depth overview of the NoSQL market. The research report relies on global governing bodies as primary sources of data, with independent analysis of the forecast, and objective estimations of the growth.
The NoSQL research report will also study market share for major stakeholders in their global capacity as transformers of the global scale. This qualitative and quantitative analysis will include key product offerings, key differentiators, revenue share, market size, market status, and strategies. The report will also cover key agreements, collaborations, and global partnership soon to change dynamics of the market on a global scale.
Request for Sample with Complete TOC and Figures & Graphs @ https://crediblemarkets.com/sample-request/nosql-market-481760?utm_source=Amogh&utm_medium=SatPR
Top Key Players
SAP
MarkLogic
IBM Cloudant
MongoDB
Redis
MongoLab
Amazon Web Services
Basho Technologies
Google
MapR Technologies
Couchbase
AranogoDB
DataStax
Aerospike
Apache
CloudDB
MarkLogic
Oracle
RavenDB
Neo4j
Microsoft
By Types
Key-Value Store
Document Databases
Column Based Stores
Graph Database
By Applications
Retail
Online gaming
IT
Social network development
Web applications management
Government
BFSI
Healthcare
Education
Others
NoSQL Market: Regional Analysis Includes:
- Asia-Pacific (Vietnam, China, Malaysia, Japan, Philippines, Korea, Thailand, India, Indonesia, and Australia)
- Europe (Turkey, Germany, Russia UK, Italy, France, etc.)
- North America (the United States, Mexico, and Canada.)
- South America (Brazil etc.)
- The Middle East and Africa (GCC Countries and Egypt.)
Direct Purchase this Market Research Report Now @ https://crediblemarkets.com/reports/purchase/nosql-market-481760?license_type=single_user;utm_source=Amogh&utm_medium=SatPR
Some Point from Table of Content:
Global NoSQL Market Analysis, Key Company Profiles, Types, Applications and Forecast to 2027
Chapter 1 NoSQL Market – Research Scope
Chapter 2 NoSQL Market – Research Methodology
Chapter 3 NoSQL Market Forces
Chapter 4 NoSQL Market – By Geography
Chapter 5 NoSQL Market – By Trade Statistics
Chapter 6 NoSQL Market – By Type
Chapter 7 NoSQL Market – By Application
Chapter 8 North America NoSQL Market
Chapter 9 Europe NoSQL Market Analysis
Chapter 10 Asia-Pacific NoSQL Market Analysis
Chapter 11 Middle East and Africa NoSQL Market Analysis
Chapter 12 South America NoSQL Market Analysis
Chapter 13 Company Profiles
Chapter 14 Market Forecast – By Regions
Chapter 15 Market Forecast – By Type and Applications
Do You Have Any Query Or Specific Requirement? Ask to Our Industry Expert @ https://crediblemarkets.com/enquire-request/nosql-market-481760?utm_source=Amogh&utm_medium=SatPR
Report includes Competitor’s Landscape:
➊ Major trends and growth projections by region and country
➋ Key winning strategies followed by the competitors
➌ Who are the key competitors in this industry?
➍ What shall be the potential of this industry over the forecast tenure?
➎ What are the factors propelling the demand for the NoSQL?
➏ What are the opportunities that shall aid in significant proliferation of the market growth?
➐ What are the regional and country wise regulations that shall either hamper or boost the demand for NoSQL?
➑ How has the covid-19 impacted the growth of the market?
➒ Has the supply chain disruption caused changes in the entire value chain?
Contact Us
Credible Markets Analytics
99 Wall Street 2124 New York, NY 10005
Email: [email protected]
Follow Us: LinkedIn | Twitter | Facebook
MMS • Erik Costlow
Article originally posted on InfoQ. Visit InfoQ
GraalVM 21.2 has been released to speed up native compilation times, and improve integrations with JDK flight recorder as well as improve support for non-Java languages like Ruby and JavaScript.
The release simplifies the role of testing duplication between an application’s features when acting in HotSpot mode (a TCK compliant runtime) versus native image compilation (platform-native binary). The benefit to native compilation is lower startup time and memory, as well as the ability to run on different platforms like iOS and Android. Support for native testing appears as part of the Gradle and Maven plugins that run additional tests on an application to validate that the functionality of a native image matches the expectations of HotSpot mode. This test plugin offers similar functionality of tools like Quarkus that leverage GraalVM and Mandrel (RedHat’s GraalVM) testing when a native image is created. When native-compiling a Quarkus application, developers can leverage an additional @NativeImageTest annotation, extending an existing unit test class to run before and after native compilation. The duplicate testing occurs because the running application is slightly different: a failure before native compilation will prevent wasted time of compiling an incorrect application and a failed test after will demonstrate that functionality of the native version differs from the HotSpot version.
Developers of native applications can now monitor performance events through OpenJDK Flight Recorder using events that are written in Java, similar to what they would expect with these events on a HotSpot JDK. Custom events can then be viewed in tools like JDK Mission Control (the viewer companion to JFR) or major dashboard tools like New Relic One.
Additional performance improvements were made to the underlying polyglot languages, as GraalVM provides a common runtime and JIT that supports many languages at once. Through the Truffle language framework, GraalVM offers support to compile and run applications in Python, Ruby, R, Cuda, and many others.
The capabilities of GraalVM native compilation appear in a mix of different JVMs that enable developers and operators to take full advantage of different types of hardware:
- Standard HotSpot JVMs (the most common) offer just-in-time compilation with optimal peak performance to run across modern systems (x68/x86_64), cloud, and many embedded cases (various ARM chips).
- GraalVM/Mandrel offers a HotSpot mode as well as native compilation to run on mobile devices (iOS and Android) as well as favoring just-in-time compilation for ahead-of-time compilation on smaller ARM embedded devices.
- TornadoVM offers similar capabilities targeted more toward execution on GPUs rather than CPUs. TornadoVM shares some similar capabilities in concert with GraalVM, as both perform native compilation.
Developers interested in the new capabilities can download the latest GraalVM Community Edition or in future versions of RedHat Mandrel.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

This article is part of a new series featuring problems with solution, to help you hone your machine learning and pattern recognition skills. Try to solve this problem by yourself first, before looking at the solution. Today’s problem also has an intriguing mathematical appeal and solution: this allows you to check if your solution found using machine learning techniques, is correct or not. The level is for beginners.
The problem is as follows. Let X1, X2, X3 and so on be a sequence recursively defined by Xn+1 = Stdev(X1, …, Xn). Here X1, the initial condition, is a positive real number or random variable. Thus,
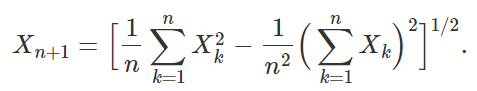
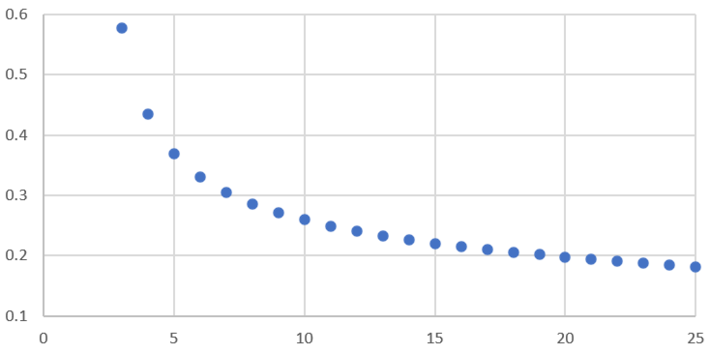
It is clear that Xn = An X1, where An is a number that does not depend on X1. So we can assume, without loss of generality, that X1 = 1. For instance, A1 = 1 and A2 = 0. The purpose here is to study the behavior of An (for large n) using simple model fitting techniques. I plotted the first few values of An, below. In the figure below, the X-axis represents n, and the Y-axis represents An. The question is: how to approximate An as a simple function of n? Of course, a linear regression won’t work. What about a polynomial regression?
The first 600 values of An are available here, as a text file.
Solution
A tool as basic as Excel is good enough to find the solution. However, if you use Excel, the built-in function Stdev has a correcting factor that needs to be taken care of. But you can just use the values of An available in my text file mentioned above, to avoid this problem.
If you use Excel, you can try various types of trend lines to approximate the blue curve, and even compute the regression coefficients and the R-squared for each tested model. You will find very quickly that the power trend line is the best model by far, that is, An is very well approximated (for large values of n) by An = b n^c. Here n^c stands for n at power c; also, b and c are the regression coefficients. In other words, log An = log b + c log n (approximately).
What is very interesting, is that using some mathematics, you can actually compute the exact value of c. Indeed, c is solution of the equation c^2 = (2c + 1) (c + 1)^2, see here. This is a polynomial equation of degree 3, so the exact value of c can be computed. The approximation is c = -0.3522011. It is however very hard to get the exact value of b.
It would interesting to plot the residual error for each estimated value of An, and see if it shows some pattern. This could lead to a better approximation: An = b n^c (1 + d / n), with three parameters: b, c (unchanged) and d.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). He recently opened Paris Restaurant, in Anacortes. You can access Vincent’s articles and books, here.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

 What Does A Data-Driven Organization Look Like?There are fashions in technology that are every bit as ephemeral as fashions in the garment industry. For a while, all data was BIG DATA, then data warehouses were cool, then data lakes became the gotta-have look for the year. Data science had its heyday, and everyone had to stock up on PhDs, then knowledge graphs gained a brief bit of currency, like a particularly frilly collar or gold chains. DevOps was hot and everyone wanted to be a DevOps tech, then machine learning was hot and everyone became a machine learning guru. Yesterday we were arguing about whether R or Python was the next big thing, and today it’s shifted to AutoMLOps vs. AIOps. Everyone is currently chasing the holy grail of being data-driven companies, often with at best only a very faint idea about what that actually means. Every so often, it is worth stepping off the carousel and letting the brass ring go past, In general, data can be thought of as records of the events that take place around a person or an organization as they take place Some of this information is a record of the events themselves, such as sales transactions. Some of the data is contextual metadata that puts the events into perspective. It’s worth noting that some of this data has no relevance to you or your organization, which we refer to as noise, while other data does have relevance, which can be referred to as signal. Unfortunately, there is no explicit guide about what is noise and what is signal until you have a question or query to ask, and typically the biggest problem that most organizations face is that they tend to hold on to transactional data preferentially to metadata, despite the fact that it is frequently the latter that holds the answer to the queries, simply because transactional data is easiest to capture. Data analytics, at its core, is the art of knowing how to ask the right questions. Not surprisingly, data analytics is stochastic or probabilistic in nature because it is based upon the assumption that people and organizations that act a certain way in the past will continue to do so into the future. This is true, so long as the conditions that applied in the past also continue into the future, and because people’s behaviors have a certain degree of momentum, it is even somewhat true when the conditions change, at least for a little while. However, the future is notoriously fuzzy around inflection points, where events change in dramatic ways, and in those times a good data scientist is worth their Ph.D.-enhanced salaries. A data-driven organization then is one that both practices good “data hygiene” in the acquisition and preparation of data (typically by attempting to determine semantics or meaning in that data independent of the form of that data) as well as utilizes that data in order to not only read the tea leaves but also to change the behavior of that organization in response to changes in data. Failure to change when the model indicates that change is warranted makes everything else that happens in the data process moot – it is an exercise in adding process without using that process for something positive. In many respects, the goal of being data-driven, then, is to make the organization become aware in the same way that an animal is aware of its surroundings and can react when those surroundings change, or the way that a seasoned captain aboard a sailing ship can read the sky and know whether to unfurl the sails to catch favorable winds or to furl them to protect the ship from storms. A data-driven organization is one that is capable of discerning the signal from the noise and acting in response. All else is marketing. In media res, Kurt Cagle To subscribe to the DSC Newsletter, go to Data Science Central and become a member today. It’s free! Data Science Central Editorial CalendarDSC is looking for editorial content specifically in these areas for July, with these topics having higher priority than other incoming articles.
DSC Featured Articles
TechTarget Articles
Picture of the Week
 Building Blocks to Success
To make sure you keep getting these emails, please add mail@newsletter.datasciencecentral.com to your browser’s address book.
Join Data Science Central | Comprehensive Repository of Data Science and ML Resources
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge This email, and all related content, is published by Data Science Central, a division of TechTarget, Inc.
275 Grove Street, Newton, Massachusetts, 02466 US
|