Month: November 2021
Podcast: James Clark on How Ballerina Handles Network Interaction, Data, and Concurrency

MMS • James Clark
Article originally posted on InfoQ. Visit InfoQ

Subscribe on:
Introductions
Hello, and welcome to The InfoQ Podcast. I’m Charles Humble, one of the co-hosts of the show, and editor-in-chief at cloud native consultancy firm Container Solutions. My guest this week is James Clark. James has been contributing to the open source community for nearly 20 years and is probably best known as a pioneer of SGML and XML. More recently, he’s been working for WSO2 which is an open source technology provider founded in 2005, where he is the lead designer for the Ballerina language. Ballerina is an open source programming language for the cloud that makes it easier to use, combine and create network services. It is, I think, a really interesting language that joins others, like Go and Rust and Dart, as being languages that have been developed for this cloud native era, and so it’s Ballerin, that will be the focus for this podcast. James, welcome to The InfoQ Podcast.
James Clark: Hello, thank you for having me. I think it’s actually nearly 30 years I’ve been doing this sort of thing, actually. I’m getting on a bit now.
Charles Humble: Is it 30?
James Clark: Yeah, I think it’s nearly 30 now.
How has the shift to cloud changed programming? [<a href="javascript:void(0);" onclick="seekTo(01,2001:20]
Charles Humble: Nearly 30 years, excellent. Well, there we are. So, I said in my introduction that Ballerina’s been conceived during this new cloud native era. So, how has the shift to cloud changed programming in your view?
James Clark: I think it changes, in a fairly big way, what are the main tasks that a program do? I started programming in the pre-cloud era and you think about how a program get things done in that era, you were having Perl and it was, you read files, you write files and you have APIs, but the APIs are calls to libraries. They’re called to maybe shared libraries or C libraries, they’re all on the same machine. So, APIs are library APIs and you get stuff done by writing files basically. Whereas in the cloud area, you get stuff done by consuming and providing network services and the APIs that matter are primarily network APIs. So, they’re sending network messages, typically HTTP, typically JSON. So, what an API is and what the main business of our program is very different.
I guess another aspect is concurrency in the traditional C world, if you like, most application programs don’t really need to worry about it. The operation system does, but the application program can just forget about it. Whereas in the cloud, it’s pretty pervasive. You’ve really got to think about it. You can’t completely hide concurrency from the application programmer.
What are the specific goals you have for Ballerina? [02:42]
Charles Humble: And then given that context, what is the specific goal or goals you have for Ballerina? What is it that you’re trying to accomplish with the language?
James Clark: This isn’t an academic exercise. So, it’s very much designed to be a pragmatic language and it’s not designed … we don’t want it to be a niche language. We have ambitious goals. We want it to be something that is capable of being a mainstream language. So, I guess the initial target is we want it to be a good way to do enterprise integration and you can start off with a narrow objective, which is we want it to be a good way to do enterprise integration. Good compared to the traditional way, which is an ESB plus some Java. So, basically the basic concept is okay, instead of having a DSL, typically a DSL, with XML syntax that has networky stuff that’s all about providing endpoints and messages and routing. Instead of having that plus Java, let’s just have one unified language that you can do it all in. You don’t have to have this two language, you don’t have to have this split, and you could just do it all in one unified way and in a way that works, is a good fit, for the needs of the cloud.
It feels very much like a language that’s been designed to favor ease of maintainability over speed of initial implementation. [03:56]
Charles Humble: When I first started looking at the language, one of the things I was struck by was that everything is very explicit. So, for example, there are no implicit conversions between integers and floating point values. An integer overflow causes a runtime exception and so on. It feels very much like a language that’s been designed to favor ease of maintainability over speed of initial implementation, initial typing. Would you agree with that? Is that a fair assessment?
James Clark: Absolutely. It’s a kind of, I mean, if I say enterprisey mindset, not everybody would understand that in a positive way. I mean, programs are read, I mean, real programs, that businesses rely, on serious programs, they have a long lifespan. You’ve got that crafty COBOL code that’s 20 or 30 years old. They’re read for years and decades, where being able to read it and understand it is far more important than being able to save a few key strikes when you’re typing it up.
So, it’s definitely a fundamental design goal of Ballerina to favor maintainability, favor explicitness, avoid surprises, and also to leverage familiarity and leverage what people know. The percentage of working programmers, who know one of JavaScript C, C#, Java, C++ is pretty high. So we want to leverage that so that if you know one of these languages and you look at a chunk of Ballerina code, you should have a pretty good idea what’s going on. I may not know every little tell of the semantics of the language, but you can look at it and even knowing zero Ballerina, you should have a reasonable sense of what’s going on. It should not be mysterious.
You don’t use the exceptions? [05:30]
Charles Humble: Right, and that shows up, for example, in the way you do error handling, you don’t use the exception method, which is common in languages like Java.
James Clark: I think there’s a significant trend in modern program languages, away from exceptions towards more explicit error handling, where you return error values. So, you see that in Go and in Rust, explicit error handling is explicit. You do have exceptional flow, which are panics, but those are for the really, truly exceptional case, but a regular error handling, and then it’s a normal part of network programming to have errors, that is dealt with explicitly. You see the control flow explicitly in the program, just like regular control flow. That again is a thing that’s a little bit more inconvenient to write, but the poor old maintenance programmer who’s coming to look at it can see what are the possible control flows and is going to have a much easier time not screwing up when they try and fix bugs,
Charles Humble: Right, yes. I found this really interesting because most of my professional programming was done in Java. Obviously Java has its concept of checked exceptions, which I think were trying to solve the same problem, but because they allow you to throw a runtime exception, most people do that. So the checked exceptions didn’t really work well but I think it’s trying to do the same sort of job.
James Clark: Yes, and the check exceptions are not quite the same. It shows you which are the possible exceptions, but it’s still, you don’t know when you call a function, when you see a function call there, you don’t see in the call that there is the possibility of it at throwing exceptions. You see that there is a possibility of checked exceptions, but it’s not explicit the syntax. So every time you see a function call, you got to go, “Oh, what are the possible exceptions that can throw, and how is this going to affect the flow of control in the function?” That just makes it harder to figure out what’s going on.
What is it that makes Ballerina distinct? [07:14]
Charles Humble: Now you’ve said that Ballerina isn’t a research language, it’s intended to be used in industry for real-world applications. And given that you haven’t invented any particularly new ideas from a language point of view, so what is it that makes it distinct?
James Clark: I mean, there are several different dimensions, but we’re starting off from the proposition that what we want to do is make the things that a program has to do today easy. So, consume provide network services, work with data, we want to make those easy.
That’s one dimension. Another dimension is that we are trying to provide an alternative to a combination of a DSL and Java. One of the things you can do with the DSL is you can have a graphical view and the graphical view that you get from the DSL, isn’t just the syntax, it’s not just a syntactic view, it is actually showing you meaningful things about the flow of messages that is possible within your application.
James Clark: So, one of the goals is that you should be able to take a Ballerina program and from that, have a graphical view that is not just syntactic, it’s not just giving you the classes or the functions. It is actually giving you real insight into how your application is interacting with the network. It does that by leveraging sequence diagrams.
I think part of WSO2’s experience doing enterprise integration for 15 years is that when you talk to customers and they want to explain how is this application supposed to be working? What they do is they sit down, they write a little sequence diagram, draw a little sequence track, and that gets everybody on the same page.
So, one of the key features in Ballerina is that you can click on it and you can look at every function as a sequence diagram, and you can see the flow of messages in that function. That deeply affects the syntax and it deeply affects the concurrency model, and that’s something you couldn’t graft onto any other program. So, when you get this, it’s a two-way model, so you can edit the sequence diagram, or you can edit the code and they’re two views of the same thing. You can always think of as an alternative syntax for the high level layers of the language.
The graphical representation is the actual Ballerina syntax tree [09:20]
Charles Humble: Right, yes. That I think, is really interesting, and it is something that I think is unique. So, the graphical representation is a graphical representation of the actual Ballerina syntax tree, meaning that there’s no abstraction, there’s no translation between the visualization and the code that runs on the platform. If you edit the diagram, you’re editing the code and vice versa. So, you can genuinely roundtrip between low code and normal code as it were.
James Clark: Exactly. There’s no possibility of them getting out of sync, as we are now.
Just for listeners, we are on a different continent, so there’s a little bit of a lag. But there’s no possibility with these two views of that getting out of sync and that comes from having thought about this. You couldn’t do this just by drawing a pretty layer on top of another language. It’s designed in and it’s designed into the concurrency model. The way we do concurrency is it’s somewhat limited and we know we need fancier stuff for the cases, it doesn’t handle. For cases it does handle, it provides a more controlled environment, you can really see what’s going on and there’s a much easier way to do things.
How does a network API differ from a traditional object-oriented API? [10:22]
James Clark: So, that’s possibly a unique thing, but I think there’s deeper stuff too, which goes back to the point about APIs. What is an API in a cloud era language? A cloud era language, it’s a network API. So, how does a network API differ from a traditional object-oriented API?
Well, I think one of the big difference is that you want to do more in each network roundtrip, roundtrips are expensive. So, you have typically, the parameters to your network APIs are often complex structures. So, you’re sending data and whereas your object-oriented, maybe I might be set this, set that, and it’s a bouillon orient or something. You don’t do your network APIs like that and instead you want to send in each of your API calls, it’s a complex structure. Typically JSON, which has a deep nest, typically a tree structure. That’s one thing.
Another thing is that the different parts of your service are going to be in different languages. One of the beautiful things about microservices is you’re not constrained to use one language for everything. You don’t have to have a common API or anything. Each bit of your system can be written in whatever language is best suited for that bit. But that means that your messages, your data, the parameters if you like to your API, you want those to be data. You want them to be pure data. You don’t want them to be objects. You want to send around chunks of JSON that can be interpreted by whatever language each microservice is using. So, that means a lot of what you want to do in an integration language is deal with these data. It’s not objects, it’s just data. You want to take the message you got from one, and you want to transform it a bit, and you want to send it off to somewhere else, or you want to combine two of them together into another message and send it off to several different people. But instead it’s not the object oriented.
The object-oriented way is about combining code and data into objects and keeping the data hidden within the. Opposite of what you want to do when you’re dealing with network APIs, you want to expose the data. Well, it may be hidden within your servers, but you’re exposing the data in the messages that you’re sending, it’s very much exposed.
What is plain data? [12:24]
Charles Humble: Right, yes. I mean, you have this concept of plain data in ballerina. I was trying to think, I’m not quite sure where that term originates, but could you make you try and give us a bit of a definition of what plain data actually is in Ballerina?
James Clark: It’s a term that actually comes from, I think it’s a C++ term, POD, plain old data. It’s just data that doesn’t have any methods attached to it. It doesn’t make any assumptions as to how it’s going to be processed. It’s programming language independent, and it’s therefore inherently mobile. You can serialize it, you can copy it. It’s just data. If you’re going to try sending functions around, that’s not so easy.
Charles Humble: And then once you’ve got your plain data, you can presumably do things like deep copy, deep equality, serialization, de-serialization and so forth, right?
James Clark: All that happens for free. Also you can serialize it as JSON, you don’t to pre-agree … I mean, if you try to start serializing objects, then you need to agree with the recipient about what are the objects you going to send. You have to agree on what you’re going to call them, all that sort of stuff. But plain data is just much more flexible and has much less coupling and allows your services to be much more loosely coupled. Doesn’t create coupling between your services.
it’s a statically typed language, but the type system is primarily structural, as distinct from nominal, right? [13:34]
Charles Humble: And I think that’s kind of reflected in your type system as well. So, it’s a statically typed language, but you’ve got looser coupling than some other statically-typed languages, including things like Java that people are probably familiar with. You have built-in support for JSON and XML. But as I say, the type system is, it’s primarily structural, as distinct from nominal, right?
James Clark: Yes, it’s a structural type system. It works in some ways a little bit more like a schema language. You can almost think of the type system it’s really doing double duty, the type system. We are both using it to constrain how, or to check how, the operations have been done within the program. But we’re also using it to describe the network interfaces to the program. So you can take, when you write Ballerina types, those can also be used to generate schemas for the network interface. So you can generate graph drill schema, or open API from the types. You write the types once and those types are used both to generate that schema and also to manipulate, just like a regular type system within the program.
I think one of the things that makes life very difficult for a modern programmer is you have to continually switch between different worlds. They’ve got to be a bit of HTML, a bit of SQL, they’ve got all these different things and they have to manually switch gears being, “Okay, this is how it works in GraphQL, this is how it works in SQL. This is how it works in my languages type system and deal with the various infinite matches between them themselves. Whereas in Ballerina, you can just express the thing once in the Ballerina type and because it’s almost like a schema, you can map it onto your GraphQL type and you can use like a regular type system. It also has something called semantic subtyping, which means that you can think of a type as being a set of values and you can think of the subtype relationship as corresponding to the subset relationship between types, which is something that you see in some Cchema languages.
So, you can use Ballerina types to basically describe what’s on the wire. So, you can have features like say, the particular field is optional. That happens all the time in JSON, that you may or may not have this particular field in an object, but most type systems, you don’t have that. You have defaults, but that’s not the same thing. You’re able to describe what’s there. Or you can say, “You can just have this or this.” Again, that’s an absolutely basic thing when you think of it as a schema, but most languages don’t do that. You can’t say, “Well, it’s either this, or this.” You’ve got to say, “You’ve got to have some sort of type hierarchy or something.” I mean, TypeScript can do it, and probably TypeScript is the closest of mainstream languages in terms of how the type system works. Because again, what TypeScript is doing is it’s describing JavaScript values and JavaScript values are pretty close to JSON, so you can think of TypeScript as basically describing JSON values.
So in a way, it has some similarity to TypeScript. TypeScript is very much tied to JavaScript, which has a anything goes, free and easy, very dynamic view of the world. Whereas Ballerina is, trying to want to catch your errors. Eventually we want to be able to compile things into a nice excerptable. At the moment, current implementation is based on Java, but that’s not part of the language. That’s just the current implementation and we plan to have a native implementation where everything’s statically compiled.
Can you describe the support for lightweight threads – Strands. They are run time managed, logical threads of control, right? [16:37]
Charles Humble: I want to return briefly to the concurrency model. We talked about it in the context of the sequence diagrams, the visual aspects, but I’d like to talk a little bit more about the concurrency model in general. So, one thing is that you support lightweight threads. You refer to these as strands, and these are analogous, I think, to virtual threads in Java’s Project Loom, which we’ve talked about in a previous episode with Ron Pressler on the podcast, so I’ll link to that in the show notes. But basically, these strands are run time managed, logical threads of control, right?
James Clark: Exactly. They’re logical threads. I mean, it’s very fashionable these days to do everything with asynchronous programming, but I think that makes life awfully hard for the programmer, this whole async thing, and promises, and all that sort of stuff, is just a layer of complexity for the poor application programmer. I think a thread model, where you just present a very simple logical model to the programmer, and it’s up to the implementation to turn that into something efficient. I think that’s a better model for the programmer. Fundamentally, a threads is a better program model, I feel.
How do strands enable cooperative multitasking? [17:36]
Charles Humble: How do strands enable cooperative multitasking?
James Clark: Well, so strands, it’s as you say, it’s a logical thread. So, these things logically run concurrently. Whether they’re actually running on two threads or not, depends on whether the compiler can figure out that it’s safe to do so. So, if we have locking constructs and you haven’t used the locking construct, then the compiler will figure out that, “Okay, we can’t run these things in parallel.” So, it will switch between them, so you never get two things running on two different threads. So, the first data races can’t happen.
So in the worst case, it will just run on one thread. Typically when you do some IO, that logical strand will block waiting to do the IO and another logical thread will start running. Because in a lot of cases within network programming, it’s really the IO that really matters. So, so long as you can … if you got to go out and I don’t know, go to five different web services and get results from them and then compute your result from that, what’s important is you don’t do one, wait for that, then do the other one, wait for that. You want to be waiting at the same time. Whether you are actually using multiple cores is not such a big deal, it’s more about having the IO work in parallel.
A function can be defined by multiple named workers. Can you describe how that works? [18:44]
Charles Humble: Then to bring this back to the visual aspects, the concurrent operations in a function can be defined by multiple named workers. Can you describe that and how that works for us?
James Clark: Right, so within a function, and this is going back to the sequence diagram model, but at the top level within a function, you can have blocks that are named workers and those blocks run in parallel and they can exchange messages with each other and the messages are matched up at compile time to make sure that everyone … So, if you think of a sequence diagram, your arrows match up. So, the arrows in the sequence diagram, there’ll be a send in one block and a receive from the other block. In order to be able to build that sequence diagrams, you’ll check that the sends and the receives in each block match up.
It’s probably easier with a picture. I mean, a sequence diagram, you have a send and receiver and if one block is sending and one block is receiving, in order to be able to draw a diagram with an arrow from one to the other, you’ve got to have a send in one and receive in the other, or vice versa. So, that is part of the semantics of the language, that you can match those lines up. What the static checking does is check that your sends and receives do match up and so you can achieve every line has a send and receiver.
Which is a somewhat restrictive model, but when it applies to your problem, you detect a lot of problems at compile time that would not otherwise be detectable. You also get the diagram that actually gives you real insight into what your program is doing in terms of network interaction.
What’s next for Ballerina? [20:07]
Charles Humble: What’s next for Ballerina? What are you currently working on?
James Clark: Currently, we are working on getting the Java version. We’re just in the process of finishing up the beta for the major release, we have this rather … We call it Swan Lake, which is the first-
Charles Humble: Oh, I’m loving this.
James Clark: Yeah, next one’s going to be Nutcracker.
Charles Humble: Excellent, so you’re working away through all the Tchaikovsky ballets. You need a Sleeping Beauty and a Romeo and Juliet, I think.
James Clark: Anyway, so we’re starting on Swan lake. The idea is going to be that really represents the language being mature, not language being perfect, there’s tons of stuff we can do, but we’ve got a fairly comprehensive set of language features, which we’re happy with. There’s plenty of stuff we want to do, but it’s a solid base and we’ll have a Java-based implementation that is a solid implementation of those features. So we’re just finishing that up.
I guess several things are going in parallel, but I think that the next thing is, which is what I’m working on, is doing a native implementation. So targeting LLVM, being able to use native executables that don’t have any dependency on Java. We’re also, which is interesting, doing it in Ballerina. So, we’re trying to write a Ballerina compiler in Ballerina.
This is not what Ballerina’s designed for. Obviously, Ballerina’s designed for writing relatively small programs to enterprise integration. So, using it to write a compiler is pushing it to its limits but I think that that’s good because it pushes the current implementation and it pushes the language. I think one of the goals of Ballerina is that you shouldn’t run into a wall. You should be able to start small and as your program grows, Ballerina will grow with you. I think if we can write a compiler in Ballerina, then adding whatever integration problem you need to solve, you can confident that Ballerina will have sufficient horsepower to be able to do it.
If listeners want to find out more about the language, where’s the best place for them to get started? [21:52]
Charles Humble: If listeners want to find out more about the language and maybe have a play with it and see what they think, where’s the best place for them to get started?
James Clark: The ballerina.io website.
Charles Humble: Nice, easy answer.
James Clark: Nice, easy answer. Everything’s linked to from that.
Charles Humble: Excellent. All right. I shall include a link to that in the show notes and with that, James, thank you very much indeed for joining me today on The InfoQ Podcast.
James Clark: Thank you for having me, I enjoyed our conversation.
Mentioned
QCon brings together the world’s most innovative senior software engineers across multiple domains to share their real-world implementation of emerging trends and practices.
Find practical inspiration (not product pitches) from software leaders deep in the trenches creating software, scaling architectures and fine-tuning their technical leadership
to help you make the right decisions. Save your spot now!
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

- UC San Diego team trained AI to construct a new model of the cell.
- Model detects new protein communities and predicts their functions.
- The technique revealed dozens of novel cell components.
A new study by UC San Diego researchers combined machine learning with protein imaging and biophysical association to create a map of subcellular components. The AI generated map, called Multi-Scale Integrated Cell (MuSIC), revealed 69 subcellular systems—around half of which are new, undocumented cell components. The technique, detailed in a November 24, 2021, article in Nature [1], resulted in a map that looks nothing like the cell diagrams in biology textbooks.
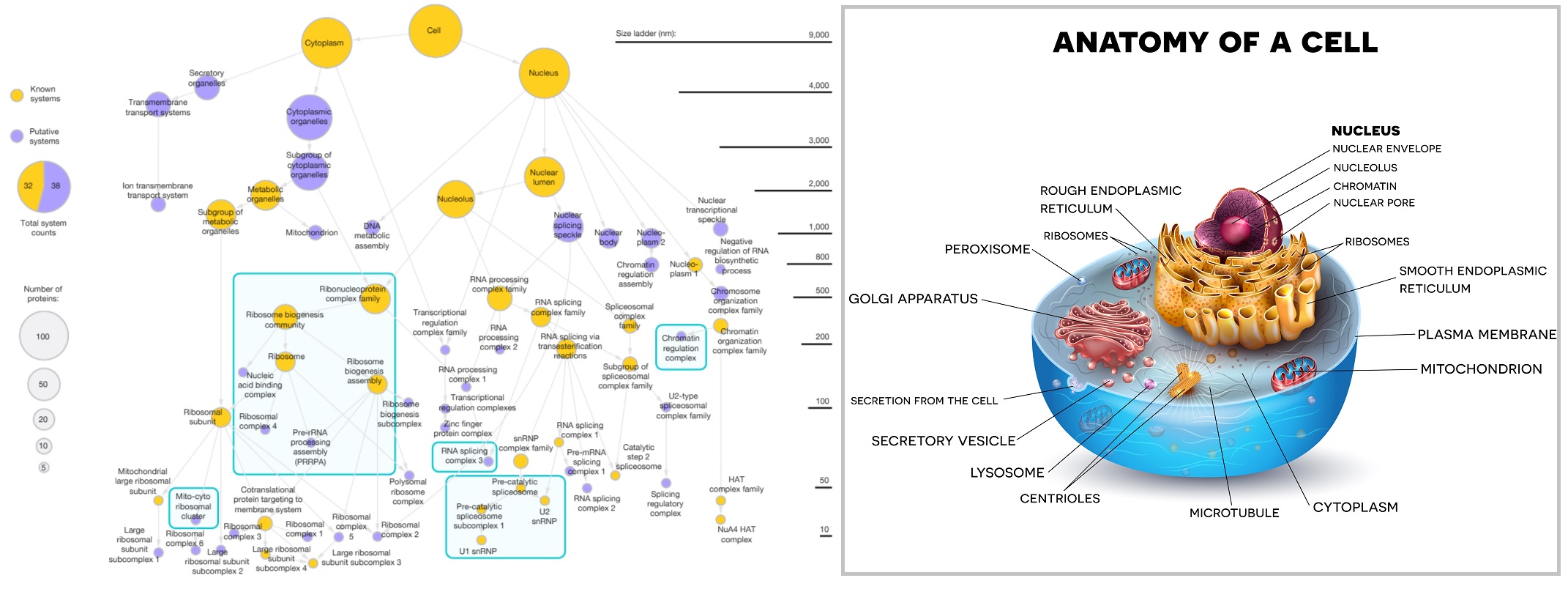
In the MuSIC image on the left, known cell components are in gold, new cell components are in purple, and arrows indicate containment of the lower system by the upper system. The system doesn’t map the cell component to a specific place, like those in the classic diagram on the right, partly because their locations are fluid, changing with cell type and situation [2]. In other words, the cell isn’t made up of neatly placed components suspended in intracellular fluid; there is a hierarchy of biological order, where a nested succession of processes determines the functional and spatial organization of cells [3].
Traditional imaging research tends to focus on physical size and distances between cellular components, but this new AI-based research suggests that protein interactions can give a complementary measure of intracellular distance. [1] If you think of intercellular organization as being like a small city, a whole host of inputs make up a dynamic object that’s much more than buildings and streets. For example, people’s movements are a function of factors like rush hour traffic, social interactions, or weather. In the same way, the full features of cells can’t be accurately described by a two-dimensional map; they are governed by a myriad of complex biological processes that occur within the cell walls.
Combining Traditional Techniques and AI
Finding a bridge to span the gap from nanometer to micron scale had—up until this recent study—eluded researchers in the biological sciences. “Turns out you can do it with artificial intelligence,” says Trey Ideker, PhD, one of the study leaders, in a UCSD press release [2].
Cellular components are usually mapped with either biophysical association or microscope imaging. Both techniques have their limitations: super-resolution microscopes, which can see inside cells with resolution better than 250 nanometers [4] are limited by the wavelength of the electron beam [5]; biochemistry techniques can map structures further down the nanometer scale, but still can’t see cell structures on the micron level (one micron is 1/1000th of a nanometer). The two approaches generate massive amounts of data with distinct qualities and resolutions that are usually analyzed separately [6]. With machine learning, the ability to analyze both sets of data comes into play. This new technique combines the traditional imaging methods with deep learning to map cell data from multiple sources, including cellular microscopy images.
The Procedure
The study began with a matched dataset of immunofluorescence cell images, including human embryonic kidney cells with 661 proteins. Deep neural networks embedded each protein and assigned them coordinates in reduced dimensions. Distances between the proteins was calculated and calibrated with a reference set of known cellular components of known or estimated diameter. A supervised ML model (random forest regression) was trained to estimate the distance of any protein pair from its embedded coordinates. After all the distances were analyzed, the MuSIC 1.0 hierarchy was created, with 69 protein communities—54% of which had never been categorized before.
The Future of Cell Maps
Ideker noted this pilot study looked at just 661 proteins from one cell type. The map is being developed to cover all human proteins, a huge task that may result in a unified map of cellular components or in separate maps for different cell types. Identification of new protein communities brings more promise to the hope of curing cancer and other diseases that start at the intercellular level. “Eventually we might be able to better understand the molecular basis of many diseases,” Ideker said, “…by comparing what’s different between healthy and diseased cells” [2].
References
Cell image: Adobe Creative Cloud [Licensed]
[1] A multi-scale map of cell structure fusing protein images and interactions
https://www.nature.com/articles/s41586-021-04115-9.epdf
[3] https://journals.asm.org/doi/full/10.1128/MMBR.69.4.544-564.2005
[4] https://news.mit.edu/2015/enlarged-brain-samples-easier-to-image-0115
[5] https://learn.genetics.utah.edu/content/cells/scale/
[6] https://www.biorxiv.org/content/10.1101/2020.06.21.163709v1?
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
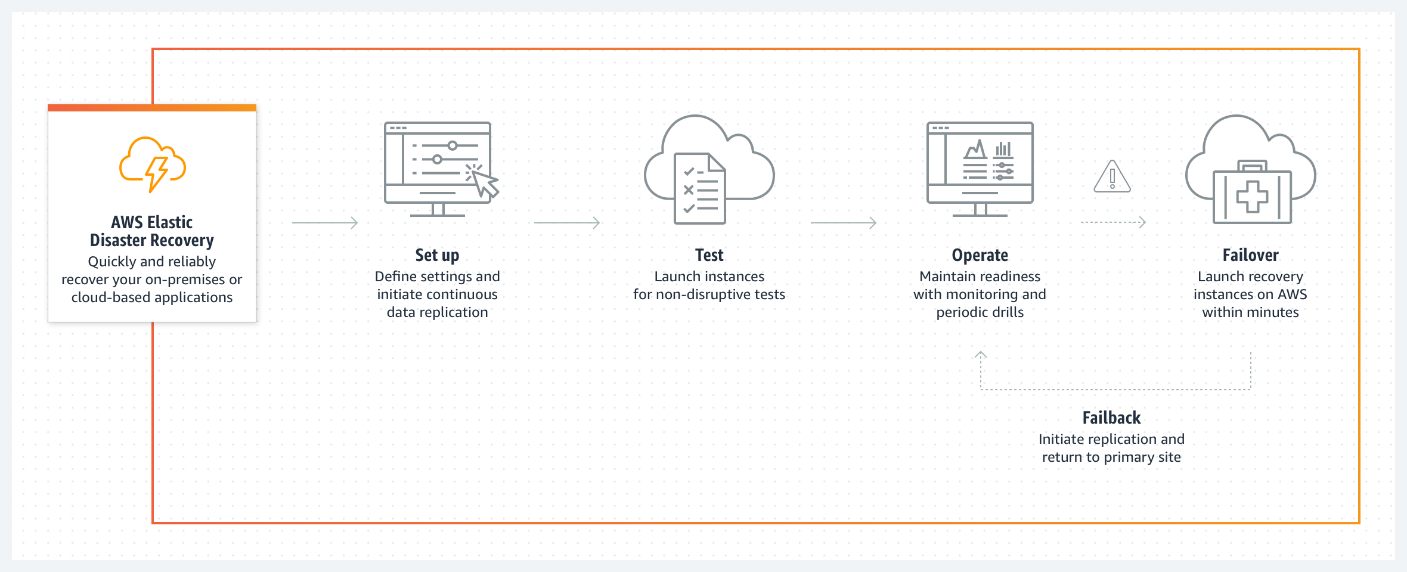
Recently AWS announced the general availability (GA) of AWS Elastic Disaster Recovery (AWS DRS). With this new service, organizations can minimize downtime and data loss through the fast, reliable recovery of on-premises and cloud-based applications.
AWS RDS is a fully scalable, cost-effective disaster recovery service for physical, virtual, and cloud servers, based on CloudEndure Disaster Recovery and now advised by the company as the recommended service for disaster recovery to AWS.
Customers can use AWS as an elastic recovery site instead of investing in on-premises disaster recovery infrastructure that sits idle until needed. Once configured, DRS keeps the customer’s operating systems, applications, and databases in a continual replication state. This enables them to accomplish recovery point objectives (RPOs) of seconds and recovery time objectives (RTOs) of minutes after a disaster. DRS, for example, permits recovery to a previous point of time in the event of a ransomware attack.
Source: https://aws.amazon.com/disaster-recovery/
Users can enable DRS using the AWS Elastic Disaster Recovery Console. In an AWS news blog, Steve Roberts, a developer advocate at AWS, explains that once the service is enabled, it continuously replicates block storage volumes from physical, virtual, or cloud-based servers – allowing support business RPOs measured in seconds. The recovery includes applications on AWS, including critical databases such as Oracle, MySQL, and SQL Server, and enterprise applications such as SAP, VMware vSphere, Microsoft Hyper-V, and cloud infrastructure. DRS orchestrates the recovery process for the servers on AWS to enable an RTO measured in minutes, allowing users to recover all their apps and databases that run on supported Windows and Linux operating systems.
The GA of AWS DRS follows the earlier release of AWS Application Migration Service (AWS MGN) as a successor to CloudEndure and the primary migration service for lift-and-shift migrations to AWS. In a Reddit thread, a respondent commented:
So, this is CloudEndure DR as if CloudEndure migration is to Application Migration Service.
And finally, note that AWS’s biggest competitor in the cloud, Microsoft, also offers disaster recovery services with Azure Backup, Site Recovery, and Archive Storage.
AWS DRS is currently available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (London) regions. Furthermore, additional details and guidance are available through the documentation page. Customers using the service are billed at an hourly rate per replicating source server, and more information on pricing details is on the pricing page.
MMS • Chris Smith
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Redgate Software runs a deliberate reteaming process to respond to new and changing needs of their business each year. Their approach has been to allow people to strongly influence where in the new team structure they will work, encouraging them to move towards the work they find most engaging.
- Aiming to maintain very stable teams might be an unrealistic and harmful goal for software development organizations. Teams naturally change all the time and very stable teams can stagnate and become silos of knowledge, harming the overall organization.
- Deliberately changingnup teams and giving people the opportunity to move towards the work they find most engaging has driven personal growth, staff engagement and cross-team collaboration at Redgate. It has also provided the organization with a responsive and popular process to decide team assignments.
- Redgate has been able to meet the team preferences for 97% of their engineering staff during their three years of reteaming. Each time around, a third of people have decided to move teams. This has had no detrimental effect on software delivery performance or customer satisfaction.
- As with any reorganization process, self-selection reteaming can generate anxiety for participant team members and managers. It’s paramount that leaders have a deep empathy for their people throughout and apply a process that reduces worry and uncertainty as much as possible.
Reteaming at Redgate
At Redgate Software, for each of the last three years we’ve run a deliberate reteaming process across our engineering organisation to alter how we invest the efforts of our teams and encourage our people to move towards the work they find most engaging. You might be wondering: why on earth would we do that?
Well, firstly, we have a business need to reteam every year – that is, change the composition and assignments of our development teams. Each year Redgate takes a step back to consider its strategy for its portfolio of products and solutions. That review is a catalyst for change, as the business often decides it wants to start-up new initiatives, reduce investment in some areas and increase in others. And they expect us to be agile and responsive to these changing needs. As a result, we need to reconfigure how our teams are assigned, which causes some change for people but also creates opportunities.
We’d also spotted that our longer-lived development teams were not talking to each other as much as we’d like. When teams did not need to change due to the strategy in their area persisting, they had a tendency towards siloization. Those teams had a strong mission and were self-sufficient, so they did not really need to collaborate with people outside the team very often. This meant that connections weren’t built between teams naturally.
Not only did that silozation limit our efforts to collaborate between teams, it also reduced the spread of good practice and expertise between teams and reduced personal development opportunities.
A self-selection approach
So, there were several drivers to deliberately reteam, but why apply a self-selection process? Broadly speaking, it’s because we believe that it aligns with our principles and helps provide fulfilling work for our people, which improves engagement and the organisation’s performance.
At Redgate we believe the best way to make software products is by engaging small teams empowered with clear purpose, freedom to act and a drive to learn. We believe this because we’ve seen it; teams who have had laser-like focus on an aim, decision-making authority and the space to get better at what they do, were the most engaged and effective.
If you have read Dan Pink’s seminal book Drive: The Surprising Truth About What Motivates Us, you might recognise that our beliefs echo what the author demonstrates are key to an engaged and motivated workforce — autonomy, mastery and purpose.
To remain true to our beliefs, Redgate needs to ensure that the goals and expectations of our teams are crystal clear, that we push authority to teams as much as we can, and we encourage people to grow. We also recognise that different people have different ambitions, preferences for work and views on what counts as personal development. We have a large portfolio of products, written in a variety of languages, structured in a variety of ways and that exist at various stages of the product life cycle. That’s a lot of variety, and people are going to favour some combinations over others. They may also see a change of combinations, moving to work on something they have never worked on before, as an opportunity for personal growth.
As we believe that paying attention to people’s drive to learn is important, we knew we should allow people to take on work that they are drawn towards, either because they feel it will suit them better, they want to gather new experience, or they like things just as they are.
In the past we’ve always allowed people to move teams — everyone could proactively talk to their line manager at any point to kick-off a process that would result in a team move – but that wasn’t enough. We needed to do more than just allow people to move. Team bonds are strong and it’s difficult to break the inertia of working in a team you are comfortable in. Instead, we need to make it really easy for people to move, by creating opportunities for a change, making it a truly reasonable thing to do, being clear on the options available and helping people move towards the work they find most motivational.
Hence, we decided to embark on our first self-selection reteaming process in December, 2018.
How we reteam
Our reteaming process has six stages: we share our plans for teams, we confirm leadership assignments, we encourage everyone to explore the team options that will be available to them, we ask those people to share their team preferences, we decide team assignments based on those preferences and, finally, we deliberately kick-off our new teams.
Sharing plans
First, we share the context for the teams for the upcoming year with everyone in development, as soon as we can. This “big picture” is our newly-minted portfolio strategy and plans for the workstreams the company feels it needs. We also explain the overall reteaming process. As you might imagine, the process of setting the strategy for a product portfolio of over 20 products can take some time to set in stone. We aim to share plans as early as possible, when enough is certain to begin depending on it, but not all the questions are answered (we’ll need team leaders and teams to help us do that).
Confirming team leaders
Then we engage with the key leadership roles that support our teams – technical team leads, product designers and product managers – aiming to establish where they would prefer to work in service of the new strategy. Many team leaders decide to stay with their current teams, but some choose to move (or have to move if their team’s mission is no longer one the company wants to pursue). We get those team leadership roles settled first, looking to meet as many people’s preferences as possible. We do this first, not because they are the most important people to please, but because we need those folks to help us shape the details of the plan for the next year and support the rest of the engineering organisation in reteaming.
Defining what teams will be like
Next we aim to light-up the options people in our engineering teams have to consider for the next year. Our leadership teams, now confirmed in their areas for the coming year, provide the details on what life would be like in their team; what is their mission, what impact will they aim to have, what will they own, how will the team work, and so on. This information is of paramount importance for people who are deciding where they would like to play their part, and where they will feel most fulfilled.
Exploring team preferences
We run an open session for everyone to explore what life will be like on the teams and ask people to consider whether they would prefer to stay with their current team or move to another team. We say “prefer” rather than “choose” or “select,” because while we endeavour to meet as many people’s preferences as possible, we can’t guarantee that we can meet everyone’s selection.
Deciding team assignments, based on preferences
Next, we support everyone in confirming their team preferences. We have a coaching conversation with everyone one-on-one to help them explore and confirm their preferences. This is a big investment, a one-to-one conversation with everyone in the department, but it’s worth it. We ask people to tell us their 1st, 2nd and 3rd preferences for their team for the coming year and the reasoning behind those preferences. The department’s leadership team then takes a step back to see how people’s preferences line-up with the big picture we needed to create. We assemble a team structure that meets as many people’s preferences as possible while ensuring we have teams that can meet the needs of product strategies. We talk to everyone who has not been assigned to their first team preference (around 20% of people, as ~80% get their first preference) to ensure they understand why they are being asked to move their 2nd or 3rd preference team and confirm they are comfortable with that. Typically everyone is ok with that – getting your 2nd or even 3rd preference is not bad news.
Kicking-off the teams
Finally, we share the news on team assignments widely and kick-off the new teams. To form teams quickly, our team leaders have become well practiced at running workshops to share product histories, light-up plans and start to build trust in new groups.
The results
The first year went so well that we repeated it for the next two years. Now, reteaming is an annual event and I can’t imagine us taking an approach that does not give people a strong say on where they work.
Each year we have been able to assemble effective teams that have a clear purpose, are populated with people pleased to be there and are able to quickly get up-to-speed & deliver. We’ve proven to the business that we can respond with agility to the needs of the company and give people a stronger say over what they work on.
People ask me how much movement there actually has been across teams and enquire suspiciously as to whether Redgaters really do influence the process. I think the stats show that people have a really strong steer over team assignments. In the three years we’ve been trying this approach, 77%-83% of people have been placed into the team that was their first preference. Even more reassuringly, 97%-98% of people have been placed into a team that was one of their preferences (1st, 2nd or 3rd).
In the end, each time around a third of our team members move teams. Yep, that means two thirds stay in their teams, and that’s fine. It shows that our teams are, in general, good places to work and people feel happy and motivated where they are. That third of people moving across teams is hugely valuable too. That movement helps break down silos, building connections across the development organisation. It spreads knowledge and best practice, and it normalizes the process of moving teams. Each move represents someone choosing to take up a new challenge. Here’s an animation I like that illustrates just how much cross-pollination you get in a development organization if a third of people move teams each year.

Furthermore, each time we have done reteaming, software delivery performance has not been impacted materially. At Redgate we measure the Four Key Metrics of software delivery performance as described in the book Accelerate by Nicole Forsgren, Jez Humble and Gene Kim. They are: delivery lead time, deployment frequency, mean time to restore service and change fail rate. Those measures are stable during reteaming, registering only a slight dip in deployment frequency and lead time as team members move. This recovers within weeks and has no impact on the service we provide to our customers.
Improving through feedback
After each Annual Reteaming, we asked our development team members for their feedback. What they’ve told us has been broadly positive each time, but has also highlighted areas for improvement that we’ve been able to focus on in subsequent years. We’ve fine-tuned the process to make it as smooth and timely as possible for the organization, but also as comfortable as possible for our people. For instance, our first reteaming happened during December, which many people found difficult because they had holiday booked during that month, so they missed some of the context for decision-making and felt a bit rushed. Each year since, reteaming has taken place in January when virtually everyone is back at work and can fully engage in the activity.
What is absolutely clear from feedback each year is that people far prefer being consulted and involved in these kinds of team reorganizations than being moved around by arbitrary people moving a machine (we literally got that feedback on a sticky note after our first reteaming)!
We’ve learnt that there was a pent-up desire for people to move teams and that many do see changing teams as a personal development opportunity. We’ve gone from an organisation where people barely ever moved teams, to one where it’s an annual, regular activity.
But the main takeaway for me is that this approach works! It’s possible to give people a strong say over what team they are in and assemble an effective development organisation. We can do this repeatedly and in the open, staying true to our principle of providing people autonomy, mastery and purpose.
And in the last year we’ve also learned that we can do all this while everyone is working fully remote!
Obstacles to reteaming
As a software development community, we’ve been conditioned to believe that very stable teams are best. It’s wisdom to know that teams with stable membership perform better, that we should keep people together for predictability and that we don’t want to have to needlessly repeat our progress through the Tuckman model of “forming, storming, norming & performing” for each project. No one is going to criticise the notion of keeping teams the same – it’s a safe option for leaders! But there is a significant burden of proof for the leader who suggests deliberately changing teams as it’s counter-intuitive for most organisations.
So we need to get over that conventional wisdom, accept that teams do change (whether we like it or not), explain the benefits to the wider organisation and take the decision to harness reteaming to create opportunities for individuals and for teams to refresh themselves.
I think fear holds us back, too. For those in leadership positions, this approach can be really concerning – I know it was for me before we tried it – as it feels like we are losing control of the composition of our teams. We can catastrophize when faced with the notion of asking people to decide where they want to work, surmising that the process will be chaotic and that the result will be unfit for purpose, having been built without the wider context of the needs of the business or input from stakeholders. We’ll suppose that some of our teams will be totally abandoned, some will be oversubscribed and some will end up without the skills required to successful.
Some of our concerns might be well founded. Who is looking out for the needs of the org?
The needs of the work, the product or the business could get lost. Everyone might look after themselves and the overall goals will be missed. However, after three years we’ve found that our worst fears do not come to pass. Firstly, not everyone wants to change team during reteaming, so a core cohort of people remain in any given team. Secondly, if leaders are clear in specifying the minimal constraints on the composition of their team – for example, that the team needs two engineers who are proficient with React JavaScript library or experienced in leading usability interviews with customers – then people take this into consideration when considering their preferences. And finally, as we have a group of leaders who look to assemble preferences into a team structure that is fit for purpose, we are able to help shape the final outcome so that the needs of the business and our customers are also accommodated.
Self-selection reteaming can create anxiety in team members too. If we were to go to an extreme with this approach, people would have complete freedom to decide what team to join and when to join it, without the need to share intent or coordinate with anyone responsible for the overall organisation. This kind of approach can be characterized by a big self-selection ceremony, where you go along to a single event and sign up for a team on the spot, and everyone else does the same.
In those kinds of sessions, a significant cohort of people may not feel able to put themselves forward for the team they really want – perhaps those of us naturally a little more introverted, or people grappling with imposter syndrome or those who are neurodiverse. They may not have the confidence or the tools to get assigned to the team they prefer. Also, the pressure of attending that session and deciding during it where they will spend their working lives for the foreseeable future could be quite crippling for some. I think it might have been for me when I was a software developer.
Those folks might not get a choice and end up with whatever is left over. In my opinion, that kind of process, although aligning with principles of self-determination (autonomy, mastery and purpose), heavily disadvantages a significant cohort of people in software development.
But we can find a balance, applying an approach that meets the principles of self-determination, while ensuring the needs of the organisation and minimizing the anxiety of everyone involved. So ours is a curated process. We mindfully gather the preferences of people in the teams, providing support and space for them to consider the options, and assemble the teams considering wider context and utilizing the experience and insights from our software development leaders.
Benefits and drawbacks
I’ve found that stable teams are not the norm. More often than not, people leave and join teams, they leave and join companies and businesses decide to change what they spend their people’s time on. All that changes team composition, effectively meaning you have a new team to form.
However, let’s say we did have a genuine long-lived stable team; then I think the drawbacks are that they can easily become siloed and stagnant. Unless we are very mindful, they can become stuck in a rut as a team, unable to see those issues or bring in new ideas. This can mean a lack of opportunity to learn other systems in the organization and/or other technologies – leading to disengagement. It can lead to people being stuck as experts, unable to ever move teams because there is just too much important knowledge in their heads. And silozation can lead to a lack of alignment and connectedness between other teams in the organisation.
Changing your teams up regularly can ameliorate those problems. However, there are drawbacks too. It obviously takes effort and time to create and run a process to do this, supporting teams and individuals along the way. For instance, a lot of thought goes into creating team charters, with leaders having to back brief strategy through them and think deeply about what they’d like their team to be like in the coming year. But, to be honest, I’ve found this to be a very useful thinking tool for leaders to deliberately work through.
Changing teams, or the prospect of having to change teams, can also cause anxiety. We learnt that via feedback from participants. In our post-activity survey, a significant proportion of people (39%) felt anxious about the reteaming process at some point. That’s even though we have always been very mindful of the stress that can be caused by organisational changes and why we offer things like 1–2–1 coaching conversation for every single person who is part of the reteaming process.
A sympathetic solution to the anxiety reported to some might be to say, “Ok, we’ll stop annual reteaming then”, but that wouldn’t be in service of a central principle we hold dear at Redgate — the ambition to give people autonomy, mastery and purpose. It also would not reflect the reality that reteaming, the changing and forming of teams, will always be necessary. Cancelling deliberate reteaming would also not help break down team silos, create personal development opportunities or spread good practice. No, self-selection reteaming is here to stay, but we should minimize the level of unnecessary anxiety (or dis-stress) caused by a reorganization process like reteaming.
In response to the aforementioned survey result, we’re going to set clearer expectations from the start of next year’s reteaming process that if someone’s preference is to stay in their current team (and that team is continuing on its current mission), then we’ll do our utmost to ensure they can stay in that team. In fact, this is what happened at our last reteaming – everyone who wanted to stay where they were stayed in their team. Our theory is that this important caveat will lessen the anxiety felt by those people who are very keen to stay. Again, we’ll ask for feedback following reteaming to see if that is borne out by the data.
The key point here is that, as with any reorganization process, self-selection reteaming can still generate anxiety for participants. It’s therefore paramount that leaders have a deep empathy for their people throughout, and are considerate of the uncertainty and worry that may be being created for some.
A self-selection reteaming process is not an easier way to change teams. It’s a tricky thing to convince an organisation to do; it takes effort to nurture the environment to support it and coach individuals to help them explore options. But we do think it’s a better way, as opposed to a traditional top-down approach.
How to start
For planning and running self-selection, I’d recommend reading Heidi Helfand’s book Dynamic Reteaming, to get a grounding on the subject and the full story of how and why we should embrace changing teams. We’ve also shared many more details of Redgate’s approach to reteaming on our blog – so I’d check out Reteaming at Redgate.
Your first reteaming process might sound like quite a risky venture for the organisation and management can fear losing control or catastrophize (I know I did). So, be mindful of that. Explain the longer-term benefits to the leadership of the organisation, highlighting if you are seeing some of the drawbacks of stagnant or siloed teams, but build in some safety to your proposed process. For instance, Redgate has those one-on-one coaching sessions and an explicit sanity check that the resulting organisation is fit for purpose before moving ahead with team moves. That way everyone is more comfortable and ready to engage with the idea.
I wouldn’t recommend copying Redgate’s process in its entirety though – it was built by us, for us, and is unlikely to fit the context or needs of your organisation. Rather, perhaps what we do will provide some inspiration and you can keep in mind our key principle – to give our people a strong influence over what team they are in and the work they do.
Conclusion
Three years down the line, Redgate has found that annual self-selection reteaming is an effective and empowering method of aligning with new company goals. The engineering organisation has proven to the business that it can respond with agility to the needs of the company, while giving people a stronger say over what they work on.
From an organization where people hardly ever moved, reteaming has now normalized the idea of people moving between teams for personal development and a renewed sense of purpose. The organisation has come to re-evaluate the traditional wisdom of aiming for very stable teams and recognises the virtues of deliberately and thoughtfully changing-up teams. This approach has helped Redgate nurture a development culture of engagement, resilience and opportunity.
References
- Drive: The Surprising Truth About What Motivates Us by Dan Pink
- Dynamic Reteaming: The Art and Wisdom of Changing Teams by Heidi Helfand
- Accelerate: The Science of Lean Software and Devops: Building and Scaling High Performing Technology Organizations by Nicole Forsgren, Jez Humble and Gene Kim
- “Reteaming at Redgate” articles by Chris Smith
About the Author
 Chris Smith is head of product delivery at Redgate. His job is to lead the software development teams that work on Redgate’s ingeniously simple database software, building teams with clarity of purpose, freedom to act and a drive to learn. For the last three years Smith has lead Redgate’s annual reteaming process which gives people a strong influence over which team they are part of, encouraging them to move towards the work they find most engaging
Chris Smith is head of product delivery at Redgate. His job is to lead the software development teams that work on Redgate’s ingeniously simple database software, building teams with clarity of purpose, freedom to act and a drive to learn. For the last three years Smith has lead Redgate’s annual reteaming process which gives people a strong influence over which team they are part of, encouraging them to move towards the work they find most engaging
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

With a virtually infinite pool of resources, cloud helps scale applications as desired for computing, storage, and networking to change the way they are deployed, monitored, and used by the end-users. You would agree that performance is the utmost factor in testing a web application as it directly impacts the end-user experience. And, it is vital to measure the performance of the applications in the cloud. It is a well-known fact that software testing is a critical part of the development process. So far, so great, but companies are now increasingly turning to test using cloud infrastructure. Why?
Performance testing in the cloud is different from that of traditional applications. It aims to measure the parameters such as system throughput & latency with changing number of parallel users accessing your application. This is across different load profiles and various other performance metrics. Allow me to explain with the following discussion. We will start with a look at some of the benefits of cloud performance testing:
- Scalability: A critical benefit of cloud performance testing is that it empowers employees with mobility which, in turn, means that cloud computing testing does not need to focus on investments in software as well as hardware.
- Ease of use: Despite the multitude of cloud computing subsets and forms, the fact remains that cloud performance testing is easy to configure, set up, and use.
- Reduced costs: When companies use the cloud as a platform for testing, they observe a lowered demand for not only installation setup but also a reduced need for focus on hardware maintenance.
Let us discuss cloud performance testing further, starting with a quick list of the different forms of such testing:
- Entire cloud
- Within a cloud
- Across clouds
There are different types of cloud performance testing as well and some of the most important types of those tests have been listed below.
- Stress test: Stress testing seeks to help testers pre-emptively identify any roadblocks and performance issues to enable the team to proactively take corrective action.
- Infrastructure test: This test involves isolating every component or layer of the application and then testing it to see if the app can deliver the expected or required performance. One of the key goals of such testing is to determine bugs and issues that could impede the system’s collective performance.
- Load test: Testers make use of a load test when they are trying to see if the system’s performance is streamlined and optimized when the system is simultaneously used by several users.
- Capacity test: The capacity test is what testing teams use to, first, determine and, then, establish the maximum load-bearing capacity or the most amount of traffic a given cloud computing solution can manage.
Let us wrap up this discussion with a quick look at some of the tools you can use for such testing:
- Jmeter: Jmeter, a Java-based testing app, helps testers analyze the app’s functional performance and can also be used to mimic heavy loads to gauge the server’s strength.
- Wireshark: A rather popular offering on this list, Wireshark is a network protocol analyzer that helps deal with issues such as latency issues, malicious activity, dropped packets, etc.
- SOASTA: Even though it is not only quick but also scalable, the SOASTA testing solution manages to be quite affordable. It allows testers to gauge the app’s load-bearing capacity and is simple and convenient to use.
- LoadStorm: A load testing solution, it enables low-cost testing of not only web apps but mobile apps as well.
Like for any other software, software performance testing for cloud-based offerings is quite an important aspect of the entire development process. Of course, to achieve the full range of benefits such testing has to offer, one must carefully strategize and execute their performance testing in cloud-based environments.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
![]() MongoDB (NASDAQ:MDB) is set to post its quarterly earnings results after the market closes on Monday, December 6th. Analysts expect MongoDB to post earnings of ($1.29) per share for the quarter. Individual that wish to register for the company’s earnings conference call can do so using this link.
MongoDB (NASDAQ:MDB) is set to post its quarterly earnings results after the market closes on Monday, December 6th. Analysts expect MongoDB to post earnings of ($1.29) per share for the quarter. Individual that wish to register for the company’s earnings conference call can do so using this link.
MongoDB (NASDAQ:MDB) last posted its earnings results on Wednesday, September 1st. The company reported ($0.24) earnings per share for the quarter, beating the consensus estimate of ($0.39) by $0.15. The firm had revenue of $198.75 million during the quarter, compared to analyst estimates of $184.19 million. MongoDB had a negative net margin of 41.24% and a negative return on equity of 239.38%. The business’s quarterly revenue was up 43.7% on a year-over-year basis. During the same period in the previous year, the firm earned ($0.22) EPS. On average, analysts expect MongoDB to post $-5 EPS for the current fiscal year and $-5 EPS for the next fiscal year.
NASDAQ:MDB opened at $518.61 on Monday. The company has a debt-to-equity ratio of 1.69, a current ratio of 5.74 and a quick ratio of 5.74. The firm has a market cap of $34.32 billion, a price-to-earnings ratio of -109.64 and a beta of 0.64. The company has a 50 day moving average price of $509.45 and a 200-day moving average price of $415.50. MongoDB has a 1-year low of $238.01 and a 1-year high of $590.00.
A number of equities analysts have weighed in on the stock. Oppenheimer upped their price objective on shares of MongoDB from $400.00 to $470.00 and gave the stock an “outperform” rating in a research report on Friday, September 3rd. Piper Sandler upped their price objective on shares of MongoDB from $425.00 to $525.00 and gave the stock an “overweight” rating in a research report on Friday, September 3rd. Barclays upped their price objective on shares of MongoDB from $505.00 to $590.00 and gave the stock an “overweight” rating in a research report on Friday, September 17th. They noted that the move was a valuation call. Needham & Company LLC upped their price objective on shares of MongoDB from $415.00 to $534.00 and gave the stock a “buy” rating in a research report on Friday, September 3rd. Finally, UBS Group upped their price objective on shares of MongoDB from $300.00 to $450.00 and gave the stock a “neutral” rating in a research report on Friday, September 3rd. Four equities research analysts have rated the stock with a hold rating and thirteen have assigned a buy rating to the stock. Based on data from MarketBeat.com, the stock has an average rating of “Buy” and a consensus price target of $489.65.
(Ad)
Missed Out on Crypto Boom?
In other MongoDB news, CRO Cedric Pech sold 279 shares of the stock in a transaction dated Monday, October 4th. The shares were sold at an average price of $460.55, for a total transaction of $128,493.45. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is accessible through the SEC website. Also, insider Thomas Bull sold 2,500 shares of the stock in a transaction dated Wednesday, September 15th. The stock was sold at an average price of $501.02, for a total transaction of $1,252,550.00. Following the sale, the insider now directly owns 19,867 shares in the company, valued at approximately $9,953,764.34. The disclosure for this sale can be found here. Insiders sold 96,555 shares of company stock valued at $47,183,609 in the last three months. 7.40% of the stock is currently owned by insiders.
About MongoDB
MongoDB, Inc engages in the development and provision of a general purpose database platform. The firm’s products include MongoDB Enterprise Advanced, MongoDB Atlas and Community Server. It also offers professional services including consulting and training. The company was founded by Eliot Horowitz, Dwight A.
Recommended Story: What are the advantages of the Stochastic Momentum Index?

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to [email protected]
Should you invest $1,000 in MongoDB right now?
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.
Article originally posted on mongodb google news. Visit mongodb google news
Java News Roundup: Micronaut 3.2, Quarkus 2.5, JDK 18, Spring HATEOAS 1.4, JKDMon 17.0.14
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

It was a relatively quiet news week for the November 22nd, 2021 edition of the Java roundup featuring news from OpenJDK JEPs, JDK 18, Project Loom Build 18-loom+6-282, Spring HATEOAS 1.4, Micronaut 3.2, Quarkus 2.5.0, Apache Camel Quarkus 2.5.0 and JDKMon 17.0.14.
OpenJDK
After its review has concluded, JEP 419, Foreign Function & Memory API (Second Incubator), has been promoted from Proposed to Target to Targeted for JDK 18. This JEP evolves the first incubator, JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17, to incorporate improvements based on Java community feedback. Changes in this second incubator include: support for more carriers in memory access var handles such as boolean and MemoryAddress interface; a more general dereference API for the MemoryAddress and MemorySegment interfaces; a simpler API to obtain downcall methods handles such that passing a MemoryType enumeration is no longer necessary; and a new API to copy Java arrays to and from memory segments.
Similarly, JEP 420, Pattern Matching for switch (Second Preview), has been promoted from Proposed to Target to Targeted for JDK 18. This JEP allows a target switch expression to be tested against a number of patterns, each with a specific action, allowing complex data-oriented queries to be expressed concisely and safely. This is the second preview following JEP 406, Pattern Matching for switch (Preview), that was delivered in JDK 17. Enhancements include: an improvement in dominance checking that forces a constant case label to appear before a guarded pattern of the same type; and an exhaustiveness checking of the switch block is now more precise with sealed hierarchies.
Brian Goetz, Java language architect at Oracle, spoke to InfoQ in September 2017 when pattern matching was still in its proof-of-concept phase. Pattern matching for the instanceof operator, JEP 394, was delivered in JDK 16.
JDK 18
Build 25 of the JDK 18 early-access builds was made available this past week, featuring updates from Build 24 that include fixes to various issues. More details may be found in the release notes.
The feature set for JDK 18 currently stands as follows:
Developers are encouraged to report bugs via the Java Bug Database.
Project Loom
Build 18-loom+6-282 of Project Loom early-access builds was made available to the Java community and is based on Build 24 of the JDK 18 early access builds.
Spring Framework
After a couple of busy weeks for the Spring team, the only activity this past week was the release of Spring HATEOAS 1.4 with new features such as: support for level 4 URI templates; support for non-composite request parameter rendering; improved support for the HAL-FORMS media type; additional HTML input types; and dependency upgrades to Spring Framework 5.3.13 and Jackson 2.13.9. More details may be found in the changelog.
Micronaut
The Micronaut Foundation has released Micronaut 3.2 featuring support for GraalVM 21.3.0, Gradle Plugin 3.0.0, Kotlin 1.6.0, a host of HTTP features, and upgrades to some of their modules such as Micronaut Data, Micronaut Security, Micronaut Kubernetes, and Micronaut Elasticsearch. Further details may be found in the documentation.
Quarkus
Red Hat has released Quarkus 2.5.0.Final featuring: a dependency upgrade to Mandrel 21.3, a downstream distribution of GraalVM community edition; support for JPA entity listeners for Hibernate ORM in native mode; the ability to add HTTP headers to server responses using the quarkus.http.header property; and usability improvements in Quarkus extensions and the dev mode and testing infrastructure.
Apache Camel
Maintaining alignment with Quarkus, version 2.5.0 of Camel Quarkus was released featuring Quarkus 2.5.0.Final, Apache Camel 3.13.0, improved test coverage and documentation. More details may be found in the list of issues.
JDKMon
The latest version of JDKMon, a new tool that monitors and updates installed JDKs, has been made available to the Java community. Created by Gerrit Grunwald, principal engineer at Azul, version 17.0.14 ships with new features such as: automatically adding JDK distributions hosted by SDKMAN! and any corresponding Java folder to search paths, if available; and display a link to release details, if available, for any updates found.
MMS • Olimpiu Pop
Article originally posted on InfoQ. Visit InfoQ

The Covid-19 pandemic meant a rapid shift towards home offices for many employees, especially in the technology sector. “While experts have long predicted that the pandemic will end with a whimper, not a bang“, the talent and companies are trying to conclude the new normal will be in regards to the workplace. Some leaders insist that they will return to the office as soon as it is allowed, others want to be fully remote from now on, but most likely a hybrid approach will be the new normal for most of us.
As people understand their growing importance in a tightening job market, they tend to play hardball with the giants, negotiating for what they see as an improved way of living and working. So, companies are doing their best to accommodate what seems to be the new normal. Over the last two years, multiple studies were conducted by both private and public organisations.
A survey by the National Bureau of Economic Research involving more than thirty thousand Americans over multiple waves yielded three consequences of this massive shift towards remote work. First, employees will enjoy massive benefits from the extended telecommuting, especially those with higher earnings. Second, the Work From Home (WFH) policies will reduce spending in the major city centers by 5-10 percent. Third, the data on employer plans and the relative productivity implies a 5 percent productivity boost. Only one-fifth of this productivity gain will show up in the conventional productivity measures, as they do not capture the time savings from less commuting.
Similar conclusions come from an across-the-company study conducted by Microsoft to better understand the long term effects of remote work. Even though productivity hikes were observed, the study identified that it was harder for employees to acquire and share information across cooperation networks. This was caused mainly by collaboration webs becoming more static and siloed, and the preference for asynchronous communication.
Microsoft’s more than sixty thousand employees from all over the US were part of the study. As some individuals were already working remotely before the pandemic, it enabled them to separate the effects of company-wide remote work from other pandemic-related confounding factors. Rich data on the emails, calendars, instant messages, video/audio calls and workweek hours over the first half of 2020 were used to estimate the causal effects on collaboration and communication, as pointed by Microsoft’s researchers:
Based on previous research, we believe that the shift to less “rich” communication media may have made it more difficult for workers to convey and process complex information.
The outcome of the research was reinforced also by a series of internal surveys, which indicate that Microsoft employees report that inclusion and support from the company is at an all time high, but even if they feel as productive as before, they are striving to find work-life balance, time to focus and time to collaborate. All of this, depending on each individual’s circumstances, can be balanced either by working from home or by going to the office. The seeming divergent needs for both flexibility and connection with others is what Microsoft’s CEO Satya Nadella calls the “Great Paradox.” Similar concerns are shared by other executives as well, GoFundMe’s Tim Cadogan declared in a Time Magazine article: “What I’m candidly more worried about is, people call it “going back to work,” which is not what it is. It’s not really going back. I think we are going forward to something that is different from anything we’ve seen to date, which is a hybrid work environment.”
Even though research and surveys suggest that productivity, support and inclusion increased during this time in the long run, the results could be exactly the opposite, as Microsoft’s researchers conclude:
We expect that the effects we observe on workers’ collaboration and communication patterns will impact productivity and, in the long-term, innovation.
Meanwhile Tim Cadogan thinks that even if he “doesn’t know the three or four rules” that will allow everybody to be an equal rights participant in hybrid conversations, he knows that work will not return to what it previously was: only from office work. In retrospect, Cadogan considers that remote work was simple in comparison to what hybrid will be:
Everyone’s got a screen, everyone’s on the same playing field.
Both formal and empirical studies show that work can continue in extraordinary circumstances as usual, or sometimes even better; and as during the pandemic the remote worker numbers in the US hiked from 5% to 37%, together with the growing importance of the need to address the “Great Paradox”. Satya Nadela says that solving the hybrid work paradox is the challenge of the decade for companies. That might be true, as many technology companies such as Twitter, Facebook, Square, Box, Slack and Quora have already announced longer term or even permanent remote work policies. And some scholars predict that in the future there will be an equilibrium between remote and in-office work, with employees spending around 20% of their time working from home, giving room for what is more and more often called hybrid-work. Aligned with academic studies are also plain thumbs-up, thumbs-down polls conducted on social media that yield similar results: people want flexibility. So, besides the insecurity and sorough that the Covid-19 pandemic brought on us, it accelerated what seemed to be a predictable trend: less time commuting.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

A few days before re:Invent 2021, AWS announced the general availability of Aurora MySQL 3 with MySQL 8.0 compatibility. The latest major MySQL version adds features such as common table expressions (CTEs), role-based authentication, invisible indexes and instant DDL previously lacking on Aurora.
The new major version introduces improvements to binary log replication, including multi-threaded replication (MTR), replication filtering and binary log transaction compression. Aditya Samant and Vlad Vlasceanu, database solution architects at AWS, explain how Aurora will keep closer compatibility with the MySQL Community Edition going forward:
Starting with Aurora MySQL 3, we will change this release strategy to follow MySQL Community Edition releases more closely. Each Aurora MySQL 3 release will be mapped to a corresponding MySQL 8.0 Community Edition release. For example, Aurora MySQL 3.01 maps to MySQL 8.0.23 and is wire-compatible with that specific Community Edition minor version. (…) Aurora MySQL 3 minor versions will not only continue to add Aurora-specific fixes and features, but will also maintain currency with MySQL 8.0 Community Edition to ensure all community bug fixes and features are continuously incorporated.
Customers already running a MySQL 8.0 database on RDS can migrate to Aurora MySQL 3 either restoring a RDS snapshot of the instance to Aurora or creating an Aurora read replica before promoting it to a standalone primary DB cluster to accept reads and writes.
MySQL 8.0 has been generally available for over 3 years, with Amazon RDS for MySQL supporting it since the end of 2018 and Amazon RDS Proxy introducing it recently. Pintu Panigrahi, senior software engineer at Zenefits, tweeted last summer:
Aurora MySQL 8.0 support is still a long pending request from a lot of AWS customers who are already or want to move into a DBaaS.
The lack of MySQL 8 compatibility triggered in the past threads on StackExchange and Reddit asking to be able to use features like functional indexes on Aurora, with Amazon announcing an optimistic coming soon at re:Invent 2020. Ben Bauer, database architect at Back Market, celebrates the announcement:
The wait was long but finally, we got AWS RDS Aurora MySQL 8.0 compatibility!
AWS is not the only cloud provider offering a managed MySQL 8.0, with both Azure Database for MySQL and Google Cloud SQL supporting the latest major version of MySQL. MySQL Database Service is the cloud offering by Oracle. Samant and Vlasceanu add a warning about long-term supported versions:
A long-term supported (LTS) version of Aurora MySQL 3 is coming. In the meantime, you should consider Aurora MySQL 2 (MySQL 5.7 compatible) if you need an LTS version of the database engine, where you can be assured that software updates are limited to security and bug fixes.
At launch, Aurora MySQL 3 provides compatibility with MySQL 8.0.23 and is available in all AWS Regions where Aurora is supported. There are no differences in pricing between major versions of Aurora.
Comprehensive report of NoSQL Software Market Projected to Gain Significant Value by 2026
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

The report named Global NoSQL Software Market 2021 by Company, Regions, Type, and Application, forecast to 2026 is a broad audit of the market size and patterns with values. The report is a thorough report on worldwide market investigation and experiences. The report is an arrangement of itemized market outline dependent on sorts, application, patterns and openings, consolidations and acquisitions, drivers and restrictions, and a world coming to. The report centers around the arising patterns in the worldwide and provincial spaces on all the huge segments, for example, market limit, cost, value, request and supply, creation, benefit, and serious scene. It offers a board translation of the worldwide NoSQL Software industry from a scope of data that is gathered through respectable and checked sources.
The latest NoSQL Software market research report offers a detailed scrutiny of all the factors that will drive or restrain the revenue flow over the analysis duration. Moreover, it emphasizes on the various sub-markets to identify all the remunerative opportunities in the business sphere, followed by a comprehensive examination of the competitive landscape.
According to expert analysts, the industry is anticipated to garner significant revenues over the analysis duration 2021-2026, registering XX% CAGR throughout.
Request Sample Copy of this Report @ https://www.aeresearch.net/request-sample/512595
Speaking of the recent updates, besides covering the latest acquisitions, partnerships and mergers of the major market players, the research literature underlines the impact of COVID-19 to comprehend the disruptions caused in the market sphere. It then recommends suitable strategies and contingency plans to assist companies to stand tall these in adverse times.
Key features of the NoSQL Software market report:
- Repercussions of the coronavirus pandemic on the industry progression
- Accounts of the total sales, overall returns, and market shares
- Major industry trends
- Remunerative prospects
- Growth rate assessments for the market
- Advantages and drawbacks associated with the use of direct and indirect sales channels
- A record of the chief distributors, dealers, and sellers
NoSQL Software market segments covered in the report:
Geographical fragmentation: North America, Europe, Asia-Pacific, South America, Middle East & Africa
- Market analysis at country and regional level
- Sales garnered, returns amassed, and industry shares occupied by each geography
- Assessment of revenue share and growth rate for each regional market over the forecast period
Product types:
- Cloud Based and Web Based
- Pricing pattern for each product type
- Market share estimation based on the sales and returns accumulated by each product segment
Application spectrum:
- E-Commerce
- Social Networking
- Data Analytics
- Data Storage and Others
- Evaluation of product pricing considering the application reach
- Revenue and sales gathered by each application type over the analysis period
Competitive dashboard:
- The major players covered in NoSQL Software are:
- MongoDB
- CouchDB
- Azure Cosmos DB
- Amazon
- RethinkDB
- ArangoDB
- OrientDB
- MarkLogic
- Couchbase
- SQL-RD
- RavenDB
- Redis and Microsoft
- Business overview of the enumerated companies
- Product and service offerings of the leading players
- Information on pricing models, total revenue, sales, gross margins, and market shares held by each company
- SWOT analysis of the major companies
- Analysis of rate of commercialization, market concentration ratio, and other major facets
- In-depth assessment of the business strategies implemented by the leading companies
Major Points Covered in Table of Contents:
- Overview of NoSQL Software Market
- Global Market Status and Forecast by Regions
- Global Market Status and Forecast by Types
- Global Market Status and Forecast by Downstream Industry
- Market Driving Factor Analysis
- Market Competition Status by Major Manufacturers
- Major Manufacturers Introduction and Market Data
- Upstream and Downstream Market Analysis
- Cost and Gross Margin Analysis
- Marketing Status Analysis
- Market Report Conclusion
- Research Methodology and Reference.
Report Answers Following Questions:
- Which regions will continue to remain the most profitable regional markets for NoSQL Software market players?
- Which factors will induce a change in the demand for NoSQL Software during the assessment period?
- How will changing trends impact the NoSQL Software market?
- How can market players capture the low-hanging opportunities in the NoSQL Software market in developed regions?
- Which companies are leading the NoSQL Software market?
- What are the winning strategies of stakeholders in the Surgical Lasers market to upscale their position in this landscape?
Request Customization on This Report @ https://www.aeresearch.net/request-for-customization/512595