Month: November 2021

MMS • RSS
Posted on mongodb google news. Visit mongodb google news

- The shares of MongoDB Inc (NASDAQ: MDB) have received a $700 price target from Credit Suisse. These are the details.
The shares of MongoDB Inc (NASDAQ: MDB) – the leading modern and general-purpose database platform – have received a $700 price target from Credit Suisse. These are the details.
The shares of MongoDB Inc (NASDAQ: MDB) have received a $700 price target from Credit Suisse. And Credit Suisse analyst Phil Winslow initiated coverage of MongoDB with an “Outperform” rating and $700 price target.
Winslow noted that as developers continue to move away from tabular models to document models and multi-model databases, Winslow is expecting MongoDB to garner the lion’s share of the growth in this rapidly growing market.
MongoDB will be reporting its third quarter fiscal year 2022 financial results for the 3 months ended October 31, 2021 after the U.S. financial markets close on Monday, December 6, 2021.
Disclaimer: This content is intended for informational purposes. Before making any investment, you should do your own analysis.
Article originally posted on mongodb google news. Visit mongodb google news
Explainable AI is about to become mainstream: The AI audits are here – Impact of AI recruitment bias audit in New York city
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

A few weeks ago, I said that we will be increasingly faced with AI audits and that I hoped such regulation would be pragmatic. (Could AI audits end up like GDPR).
That post proved prophetic
The New York city council has passed a new bill which requires mandatory yearly audits against bias on race or gender for users of automated AI based hiring tools
Candidates can ask for an explanation or a human review
‘AI’ includes all technologies – from decision trees to neural networks
The regulation is needed and already, there is discussion about adding ageism and disabilities to this audit
I am almost sure that the EU will follow in this direction also
Here are my takes on this for data scientists:
- I guess the first implication is: pure deep learning as it stands is impacted since it’s not explainable (without additional strategies / techniques)
- The requirements for disclosure will make the whole process transparent and could have a greater impact than the regulation of algorithms. In other words, I always think that its easy to ‘regulate’ AI – when the AI is actually a reflection of human values and biases at a point in time
- Major companies like Amazon who recognise the limitation of automated hiring tools had already abandoned such tools because the tools were based on data that reflected their current employee pool (automatically introducing bias).
- I expect that this will become mainstream – not just for recruitment
- We will see an increase in certification especially from Cloud vendors for people who develop on data for AI dealing with people
On a personal note, being on the autism spectrum, the legislation is well meaning and helpful towards people with limitations and disabilities – but I still believe that data driven algorithms reflect biases in society – and its easier to regulate AI than to look at our own biases
That’s one of the reasons I think the current data-driven strategy is not the future.
In my research and teaching, I have moved a lot towards Bayesian strategies and techniques to complement deep learning (because they are more explainable)
The full legislation is HERE
Image source pixabay
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
“
Document Databases Market Research Report covers the present scenario and the growth prospects of Document Databases market for 2021-2028. The report covers the market landscape and its growth prospects over the coming years and discussion of the Leading Companies effective in this market. Document Databases Market has been prepared based on an in-depth market analysis with inputs from industry experts. To calculate the market size, the report considers the revenue generated from the sales of Document Databases globally
This report will help you take informed decisions, understand opportunities, plan effective business strategies, plan new projects, analyse drivers and restraints and give you a vision on the industry forecast. Further, Document Databases market report also covers the marketing strategies followed by top Document Databases players, distributor’s analysis, Document Databases marketing channels, potential buyers and Document Databases development history.
Request for Sample with Complete TOC and Figures & Graphs @ https://globalmarketvision.com/sample_request/130847
Major Market Players Profiled in the Report include:
Couchbase, MongoDB, Amazon, MarkLogic, Aerospike, Neo Technology, Basho Technologies, DataStax, Oracle, MapR Technologies.
Market Segmentation:
On the basis of type:
Key-Value, Column Oriented, Document Stored, Graph Based
On the basis of application:
BFSI, Retail, IT, Government, Healthcare, Education
The Document Databases Market Industry is intensely competitive and fragmented because of the presence of several established players participating in various marketing strategies to expand their market share. The vendors available in the market compete centered on price, quality, brand, product differentiation, and product portfolio. The vendors are increasingly emphasizing product customization through customer interaction.
Impact of COVID-19:
Document Databases Market report analyses the impact of Coronavirus (COVID-19) on the Document Databases industry. Since the COVID-19 virus outbreak in December 2020, the disease has spread to almost 180+ countries around the globe with the World Health Organization declaring it a public health emergency. The global impacts of the coronavirus disease 2020 (COVID-19) are already starting to be felt, and will significantly affect the Document Databases market in 2021.
The outbreak of COVID-19 has brought effects on many aspects, like flight cancellations; travel bans and quarantines; restaurants closed; all indoor events restricted; emergency declared in many countries; massive slowing of the supply chain; stock market unpredictability; falling business assurance, growing panic among the population, and uncertainty about future.
Reasons to Get this Report:
- Document Databases market opportunities and identify large possible modules according to comprehensive volume and value assessment.
- The report is created in a way that assists pursuers to get a complete Document Databases understanding of the general market scenario and also the essential industries.
- This report includes a detailed overview of Document Databases market trends and more in-depth research.
- Market landscape, current market trends, and shifting Document Databases technologies which may be helpful for the businesses that are competing in this market.
Table of Content:
Chapter 1: Introduction, market driving force product Objective of Study and Research Scope Document Databases market
Chapter 2: Exclusive Summary – the basic information of Document Databases Market.
Chapter 3: Displaying the Market Dynamics- Drivers, Trends and Challenges of Document Databases
Chapter 4: Presenting Document Databases Market Factor Analysis Porters Five Forces, Supply/Value Chain, PESTEL analysis, Market Entropy, Patent/Trademark Analysis.
Chapter 5: Displaying the by Type, End User and Region 2014-2020
Chapter 6: Evaluating the leading manufacturers of Document Databases market which consists of its Competitive Landscape, Peer Group Analysis, BCG Matrix & Company Profile
Chapter 7: To evaluate the market by segments, by countries and by manufacturers with revenue share and sales by key countries in these various regions.
Chapter 8 & 9: Displaying the Appendix, Methodology and Data Source
Conclusion: At the end of Document Databases Market report, all the findings and estimation are given. It also includes major drivers, and opportunities along with regional analysis. Segment analysis is also providing in terms of type and application both.
Buy Now and Get Report To Email, Click Here: https://globalmarketvision.com/checkout/?currency=USD&type=single_user_license&report_id=130847
About Global Market Vision
Global Market Vision consists of an ambitious team of young, experienced people who focus on the details and provide the information as per customer’s needs. Information is vital in the business world, and we specialize in disseminating it. Our experts not only have in-depth expertise, but can also create a comprehensive report to help you develop your own business.
With our reports, you can make important tactical business decisions with the certainty that they are based on accurate and well-founded information. Our experts can dispel any concerns or doubts about our accuracy and help you differentiate between reliable and less reliable reports, reducing the risk of making decisions. We can make your decision-making process more precise and increase the probability of success of your goals.
Contact Us
George Miller | Business Development
Phone: +1-3105055739
Email: [email protected]
Global Market Vision
Website: www.globalmarketvision.com
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Karsten Silz
Article originally posted on InfoQ. Visit InfoQ

Microsoft has announced that they have signed the Java Specification Participation Agreement (JSPA) to officially join the Java Community Process (JCP), which governs the Java language evolution. This furthers Microsoft’s embrace of Java, such as providing its own downstream distribution of OpenJDK and offering continuous improvement with Java support in Visual Studio Code. Microsoft is also a strategic member of both the Eclipse Foundation and the Eclipse Adoptium Working Group.
Discussing the importance of Microsoft’s involvement in the Java community, Bruno Souza, principal consultant at Summa Technologies and president of the SouJava, an executive committee member of the JCP, stating:
The JCP is the place where we define and discuss the future of Java and where we need the collaboration of all the Java community. Microsoft has been an important part of this community, with their involvement in OpenJDK but also supporting Java User Groups and community events.
Microsoft highlighted that it has “more than 500,000 JVMs in production running hundreds of internal Microsoft systems” in its Azure cloud. This number does not include JVMs of Microsoft customers and has not increased since Microsoft first introduced Microsoft Build of OpenJDK in April 2021.
Mike Milinkovich, executive director of the Eclipse Foundation, commented on Microsoft’s announcement:
It is great to see Microsoft joining the Java Community Process and becoming a full-fledged member of the Java community. There is a lot of old history there, including the ghost of the J++ lawsuit that was settled 15 years ago. I see this as part of Microsoft’s overall strategy of making Azure the platform of choice for Java developers.
Azure was the biggest Microsoft business unit with 46% of overall revenue, up 36% year over year in its most recent earnings report. Microsoft does not break out Java revenue in its financial statements, but running Java applications does contribute to Azure.
Amazon, Microsoft’s most significant cloud rival, joined the JCP two years ago. Google is the other big cloud competitor who is also a member of the JCP.
Along with joining the JCP, Microsoft also announced that they endorse the two-year LTS release cadence proposed by Oracle just after the release of JDK 17. There had been no public update on this subject since September 21, 2021.
Microsoft also promoted the Microsoft Build of OpenJDK and highlighted its support for running Jakarta EE and Spring applications on Azure. It also acknowledged the recent 1.0 release of the Java Language Support in Visual Studio Code.
Earlier this year, the Adoptium Steering Committee formally approved the Adoptium Working Group Charter. Formerly known as AdoptOpenJDK, the group changed its name to Eclipse Adoptium after joining the Eclipse Foundation in June 2020. The Adoptium Working Group, stewards of the Adoptium project, will work in collaboration with the former AdoptOpenJDK Technical Steering Committee to provide the Java community with fully compatible, high-quality distributions of Java binaries based on OpenJDK source code.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

A recent research paper by a team at University of California, Riverside, shows the existence of previously overlooked side channels in the Linux kernels that can be exploited to attack DNS servers.
According to the researchers, the issue with DNS roots in its design, that never really took security as a key concern and that made it extremely hard to retrofit strong security features into it.
Despite its critical role, DNS has been a fragile part of the security chain. Historically, efficiency was the primary consideration of DNS, leading to the design of a single query and response over UDP, which is still the primary mechanism used today.
While DNS security features are available, including DNSSEC and DNS cookies, they are not widely deployed due to backward compatibility, say the researchers. Instead, the only approach to make DNS more secure has been the randomization of UDP ports, known as ephemeral ports, with the aim to makes it harder for an attacker to discover them.
As a result of this, several attacks to DNS have been discovered in the past, including the recent SAD DNS, a variant of DNS cache poisoning that allows an attacker to inject malicious DNS records into a DNS cache, thus redirecting any traffic to their own server and becoming a man-in-the-middle (MITM).
More recently, some of the researchers who first disclosed SAD DNS have uncovered side channels vulnerabilities that had gone undetected inside the Linux kernel for over a decade. Those vulnerabilities enable the use of ICMP probes to scan UDP ephemeral ports and allowed the researchers to develop new DNS cache poisoning attacks.
Specifically, the research focused on two types of ICMP error messages, ICMP fragment needed (or ICMP packet too big in IPv6) and ICMP redirect. As the researchers show, the Linux kernel processes those messages using shared resources that form side channels. What this means, roughly, is that an attacker can target a specific port where they send ICMP probes. If the targeted port is correct, this will cause some change in the shared resource state that can be observed indirectly, thus confirming the guess was right. For example, an attack could lower a server’s MTU, which would manifest itself in subsequent responses being fragmented.
The newly discovered side channels affect the most popular DNS software, say the researchers, including BIND, Unbound, and dnsmasq running on top of Linux. An estimated 13.85% of open resolvers are affected. Additionally, the researchers show an end-to-end attack against the latest BIND resolver and a home router only taking minutes to succeed.
This novel attack can be prevented by setting proper socket options, e.g. by instructing the OS not to accept the ICMP frag needed messages, which will eliminate the side-channel altogether; by randomizing the kernel shared caching structure itself; and by rejecting ICMP redirects.
As a consequence of the disclosure of this new vulnerability, the Linux kernel has been patched both for IPv4 and IPv6 to randomize the shared kernel structure. Additionally, BIND 9.16.20 sets IP_PMTUDISC_OMIT on IPv6 sockets.
MMS • Murali Krishna Ramanathan
Article originally posted on InfoQ. Visit InfoQ

Transcript
Ramanathan: I’m going to talk about my experiences with building Piranha and deploying it at Uber, to reduce stale feature flag debt. I will provide an introduction to feature flags, explain how they can introduce technical debt, and the challenges associated with handling the debt. Then, I’ll discuss our efforts in building Piranha to address this problem, and the results that we have observed over 3-plus years. I will conclude with the learnings from this process and provide an overview of potential future directions to this effort.
What Are Feature Flags?
Let us understand, what are feature flags using a simple code example. Here we have a code fragment, which contains a feature implementation, a flag API named, isEnabled, and a feature flag named, SHOW_CUSTOM_IMAGE. If this code is part of an app, the value of the flag is obtained at app startup from the server. Depending upon the value of the flag, the app behavior can change to exhibit the feature or not. Observe that the same version of the application can exhibit distinct behaviors by simply toggling the flag value. This powerful aspect of feature flags explains their enhanced use in software development.
Why Feature Flags?
Feature flags are quite useful. For example, we can have two different customers sitting in opposite corners of the world, using the same version of a food delivery app. The user in San Francisco may be rendered an image of granola berries, whereas a user in Malaysia and Bangalore may be shown an image of Idli Sambar. The ability to customize user experience can be seamlessly achieved using feature flags. This customization may be due to geography, the OS on which the app is used, the maturity of the build feature. Further, using feature flags, optimizes software development costs. These features can be reused and custom features can be modulated according to requirements. Without any additional effort, it is possible to provide numerous perspectives of the application to the user and iterate quickly towards an optimal solution.
Benefits of Feature Flags
Apart from being beneficial to provide customized user experience, feature flags play a critical role in doing A/B testing. Software development organizations may want to evaluate the value proposition between two features, and can potentially roll out an experiment using flags to get real world data.
Feature flags can also be used for gradually rolling out features, and can be used as yet another step in the software release process. This ensures that issues that are undetected with static analysis and internal automated testing can be detected before the feature is widely available to our users. Finally, they can also serve as kill switches, where globally available features can be turned off by simply turning on the kill switch. Given these benefits with feature flags, it is not surprising to observe the increased popularity among software developers and organizations.
Using Feature Flags
Using a feature flag in code, assuming the presence of a feature flag management system, is straightforward. It is done in three steps, define the flag. Here, a new flag, RIDES_NEW_FEATURE is defined. Use the flag by invoking the flag API with the appropriate flag. Here, isTreated on the previously defined flag is used to modulate the behavior of the application. Test the flag by decorating the tests appropriately. Here, a unit test has an annotation that tests the code with respect to the newly defined flag.
Code Base Evolution
Let us now understand the evolution of code with feature flags. Here we have our example corresponding to a feature flag, SHOW_CUSTOM_IMAGE. The, if branch, contains code related to when custom image is enabled, and the, else branch, corresponds to when the custom image feature is disabled. Subsequently, more code and additional features may be added. Here, a new feature flag, SHOW_CUSTOM_VIDEO, is added to differentiate between the presence and absence of custom video features. A code modification may restrict the custom image feature to only premium users, and a flag, PREMIUM_USER, to handle the scenario, may be added as shown in the code here.
Stale Feature Flags
With addition of more features and flags, it is only a matter of time before feature flags become stale. A flag is considered stale when the same branch executes across all executions. This can happen when the purpose of the flag is accomplished. For example, when A/B testing is complete, then one feature may be rolled out globally for all users and executions. Good software engineering practice demands that we delete code from the stale branch, the code region that will never be executed. Further, any other code artifact that is only reachable from this region needs to be deleted. Beyond production code deletions, related tests for stale feature flags need to be deleted too. Not deleting the code due to stale feature flags creates technical debt.
In our running example, assume after a period of time, the team decides to move SHOW_CUSTOM_IMAGE and SHOW_CUSTOM_VIDEO to 100% enabled and disabled respectively. Then, on each execution of the application, the appropriate conditions will be evaluated to true and false respectively as shown in the slide. The source code continues to carry references to these stale flags and the related debt code. The presence of this code makes it unnecessarily complex for developers to reason about the application logic. Consider the code region at the end of two if statements, a developer now has to reason about eight different paths reaching that region, when in reality they may just be two paths with the stale codes deleted.
Technical Debt
This additional complexity and technical debt can be reduced by cleaning up the code as shown here. Here, when the code is deleted, we observe that the custom image feature is only available for premium users, and the custom video feature is disabled for all users, vastly simplifying the code here. To further emphasize the problem due to stale flags beyond coding complexity, here is a real world example of a bug due to a stale feature flag, causing financial damage. The bug manifested due to repurposing a flag, triggering automated stock market trades, resulting in half a billion dollar losses in 2012. In general, technical debt due to stale feature flags causes multiple problems. This graph abstracts a control flow graph with nodes corresponding to the flag API and locations. In the presence of a stale branch, we see the presence of unnecessary code files, which affects application reliability due to reduced effectiveness of testing and analysis tools. Binary sizes are larger as they contain dead code, which cannot be removed by compiler optimizations, as the value of the flag is known only at runtime. There is additional costs associated with compiling and testing code due to stale feature flags. The payload or flags from server is unnecessarily high, carrying flag values that are either globally true or false. Finally, it increases overall coding complexity. By deleting code due to stale feature flags, we can reduce the technical debt and the corresponding disadvantages. The elephant in the room is the manual effort required to address this technical debt.
Challenges with Stale Flag Cleanup
When we deep dived into this problem further at Uber, there were a number of challenges, both technical and process oriented. There was ambiguity pertaining to the liveness of the flag, as there was no easy way to denote the expiry date for a given feature flag. This raised questions pertaining to when the flag becomes stale. One possibility is that if a flag is rolled out 100%, one way, and its configuration has not been updated in a while, then it can be considered stale. That only serves as a heuristic because kill switches may satisfy this criterion, but can never be stale by definition. Second, because stale flags accumulated over time, and there was churn in the organization, cleaning up flags owned by former employees or teams was non-trivial, as knowledge pertaining to the current state of the flag and its usefulness in the code was unclear. Even in scenarios where there are about two problems that are not blockers, we observed that prioritizing code cleanup over feature development was always an ongoing discussion. Finally, the variation in coding style raised questions on how to build an automated refactoring solution to address this problem effectively.
Piranha: Automated Refactoring
At Uber, we try to address these challenges due to stale feature flags by building an automated code refactoring bot named Piranha. Piranha can be configured to accept feature flag APIs to support SDKs of various feature flag management systems. It accepts as input the source code that needs to be refactored along with information pertaining to the stale flag and the expected behavior. It automatically refactors the code using static analysis and generates a modified source code. Under the hood, it analyzes abstract syntax trees, and performs partial program evaluation based on the input stale flag and expected behavior. Using this, it rewrites the source by deleting unnecessary code due to stale feature flags, and then subsequently deletes any other additional code.
Piranha Pipelines
In our initial iterations, we noticed that building a standalone refactoring tool, while useful, was not the easiest way to gain traction among users. Therefore, we built a workflow surrounding refactoring to ensure that the effort required by the end user is minimal. For this purpose, we set up a weekly job that queries the flag management system for potential stale feature flags, and trigger Piranha accordingly. Piranha performs that refactoring on the latest version of the source to generate stale flag cleanup diffs, and assigns it to the appropriate engineers for review. Diffs are equivalent to GitHub PRs, and are used internally for reviewing code as part of the CI workflow. If the reviewing engineer considers the flag to be stale, and the code changes to be precise and complete, they stamp the diffs so that the changes are landed. If more changes are needed, beyond the automated cleanup, they make more changes on top of this diff, get it reviewed, and land the changes. If the flag is not stale, then they can provide this information so that the diff generation for this flag is snoozed.
Example of a Generated Diff
This slide shows a snapshot of a real Piranha diff that was landed in the main branch sometime back, where the red colored regions on the left correspond to deletion of code, you still do. I would like to emphasize here that the problem of stale flag deletion is peculiar, because the stale code is interspersed with useful code. This is in contrast to dead code in the traditional sense, which is usually associated with the specific functions, files are published.
Demo
I will now present a brief demo of triggering Piranha diff generation to clean up a stale flag. Here is a Jenkins job to run Piranha Swift for one flag. We want to clean up the flag named, demo_stale_feature flag for this demo. The expected behavior is treated. The generated diff needs to be reviewed, and for demo purposes, I will provide my LDAP. Building this will generate a diff. For this demo, I already created a diff as shown here. This diff is authored by piranha-bot, and the reviewer is my LDAP. There is a brief description on the purpose of this diff, and then the inputs used to generate the diff are listed, the flag name, the expected behavior, who the reviewer is. Then, specific processing instructions are provided to the reviewer to validate various aspects: flag is stale, cleanup is complete, it’s correct. If the diff should not be landed, then there are instructions pertaining to that also here. To handle merge conflicts, there is a link within the diff that can be used to refresh the diff.
This is followed by code changes which shows deletion of unnecessary code. The unit test code removes references to the flag. There is a code change that deletes the else branch, as shown here. Then there is deletion of the definition of the flag along with the accompanying comments. Then there is a deletion of field declaration because it was assigned the return of a flag API that invoked it on the stale feature flag. Then, related code deletion associated to that. The reviewer can review this diff, and if they are happy with it, they can simply accept the solution. There is a linked Jira task that contains a description pertaining to what the appropriate flag owner needs to do with the reference to the generated diff. While in this case, I have shown the demo by triggering a cleanup diff manually, the most common workflow is the automated workflow that generates diffs periodically.
Piranha Timeline for Cleanup
At Uber, Piranha has been used for more than three years to clean up code due to stale flags. This graph shows the number of cleaned-up stale flags versus time in months. The initial prototype was available from December 2017, and we enhanced the availability of Piranha to multiple languages over the course of a year, and set up the automated workflow. General availability was announced in October 2018. Seeing the positive results, we decided to document our experiences as a technical report and open sourced all variants in January 2020. Since open sourcing Piranha, we have seen increased usage to clean up stale flags. More recently, it has increased even further following an engineering-wide effort to clean up stale flags and improve overall code quality of our mobile apps. As can be observed from this graph, we have observed increased stickiness with time.
Code Deletion Using Piranha
We have now deleted more than a quarter million lines of code using the Piranha workflow. This roughly corresponds to approximately 5000 stale flags being deleted from our mobile code bases. This graph shows the distribution of diff counts on y-axis versus deleted lines per diff on the x-axis. A majority of the diffs contain code deletions between 11 to 30 lines, followed by code deletions with less than 10 lines. We also noticed a non-trivial fraction of diffs, where we see more than 500 lines deleted per diff.
What Piranha Users Think
Beyond quantitative statistics, we wanted to get the pulse of what Piranha users think about it and potential pain points that we can help address. For this purpose, we conducted an internal survey. We received responses from engineers developing feature flag based code across different languages: Java, Kotlin, Swift, and Objective-C. At least 70% of them have processed more than 5 Piranha diffs. Processing a Piranha diff involves a few things, checking whether the flag is really stale and can be cleaned up. Whether the generated code changes are precise and complete, any additional changes on top of that generated diff. We also received responses from an almost equal number of engineers who write code for Android and iOS apps respectively. We wanted to understand the average time taken to process a Piranha diff. We found approximately 75% of the respondents consider the processing of Piranha diff takes less than 30 minutes. In fact, 35% of the respondents thought that on average a Piranha diff takes less than 10 minutes to process. We also wanted to understand whether our approach to assign this to users was accurate. I’m sure that approximately 85% of users think that we get it right mostly or always. The response to the state of staleness of the flag shows that 90% of the diffs generated are to clean up stale flags. An automated workflow helps to reduce technical debt with reduced manual effort. The metadata corresponding to the stale state of flag and its owner also plays an important role in this process.
The Top 3 Pain Points
We also wanted to understand the top 3 pain points that users face while processing Piranha diffs. The top pain point according to our survey showed that processing diffs are affected when more manual cleanup is needed, because it requires context switching. This suggests refining the Piranha implementation to help reduce the manual effort. The required changes here range from handling simple patterns of coding to more challenging problems pertaining to determining unreachability of code regions. The second pain point corresponds to prioritizing the work related to cleanup, which can be addressed by setting up organizational initiatives. The third pain point was due to merge conflicts where cleanup diffs conflicted with each other due to changes in code regions. This was because of the time lag between diff generation and diff processing. We were able to resolve this by providing a refresh option within the diff, which updates the diff with a code cleanup on top of the latest version of the source, circumventing the problem. The remaining pain points were due to more info pertaining to the feature flag, and are being blocked by additional reviews due to operating on a mono repo code base. We also received free text feedback from a few users as seen here.
Learnings 1: Benefits of Automation
There have been many learnings with the usage of Piranha. We have noticed benefits due to automation, as it helped improve overall code quality and was able to reduce technical debt with minimal manual effort. Interestingly, we also noticed that the automation was able to detect many instances where flags were rolled out incorrectly, or not rolled out at all. These issues would not have been discovered in the absence of this workflow. Further, the automated cleanup handled complex refactorings seamlessly, where manual changes could potentially introduce errors. Finally, a surprising side effect of the Piranha workflow with regular usage was that it steered engineers into writing code in a specific manner, so that it becomes amenable to automated code cleanup. This ensured simplicity of feature flag related code, along with enabling better testing strategies.
Learnings 2: Automation vs. Motivation
The second set of learnings were on automation as compared to motivation. Initially, I found it quite surprising that even in instances where code cleanup was not complete, developers were happy to make changes on top of the diff to clean up code. The only downside was the slowing down of process due to additional manual effort. The second surprising aspect was that even when the code cleanup was complete, there were instances where the changes were not landed to the main branch. In these cases, organizational prioritization becomes important. It goes without saying that there are no replacements for a motivated engineer.
Learnings 3: Process Enablers
Finally, there are various aspects that ensured that technical debt due to feature flags is kept under control. Automated refactoring is one part, and there are other critical pieces. These include management of the ownership and the flag lifecycle, prioritizing source code quality, supporting infrastructure to validate the correctness of the changes, and review policies associated with automatically generated diffs. Integrating these aspects enables a better software developer experience with feature flags.
Open Questions in the Domain
While we had looked at reducing technical debt due to stale feature flags, there are still many open questions in this domain. What is the cost of adding a feature flag to code, given the complexities it introduces in the software development process? What are the costs incurred due to an incorrect rollout? There is additional developer complexity with the presence of feature flags. A more detailed investigation needs to be done to understand the software engineering cost of developing in code bases with many feature flags. Enabling 100% automated cleanup has many interesting technical challenges at the crossroads of static analysis and dynamic analysis, which merits further exploration. Then there is the question of performance. What are the runtime costs associated with widespread use of feature flags? Are there compiler optimizations that are disabled due to the presence of feature flags? Will they affect binary sizes and app execution times? Finally, how do we prioritize handling the software development costs related to feature flags and incentivize developers to address the technical debt associated with it, collectively?
Future Directions
Beyond the fundamental questions associated with flag based software development, there are many future directions of engineering work related to Piranha. Improving the automation by handling various coding patterns. Implementing deep cleaning of code, extending to other languages. Building code rewriting for applications beyond stale flag cleanup using this framework, correspond to one dimension of work. The second dimension is extending and applying Piranha workflows to various feature flag management systems, code review systems, and task management systems, which can help engineers tackle this problem in other software development organizations. The third dimension is the work on improving the flag tooling to simplify the software development process with feature flags. Working on the future directions requires more engineering work. Piranha is available as open source at this link, github.com/uber/piranha. We welcome engineering contributions to our efforts. In fact, Piranha variants for JavaScript and Go are completely external contributions.
Summary: Story of Piranha
In 2017, there were questions on designing solutions for handling stale flag debt. In 2019, Piranha was being used by users to clean up stale flags and was gaining popularity. In 2021, Piranha is now part of regular developer workflow. There are questions being asked on how we can improve automation rates with Piranha. This change in narrative from 2017 to 2021, summarizes the story of Piranha.
Questions and Answers
Losio: I’m really impressed by the numbers you mentioned, a quarter of a million lines already removed, 5000 stale flags. That’s quite an impressive number. I know that is a big company, but they’re huge numbers.
Have you explored using Piranha to basically clean up dead code, not just related to feature flags? Basically, outdated library, any other code? I noticed that your already partial addressing, is mainly targeted to stale feature flags, but I was wondering, what’s the direction there? What are the options?
Ramanathan: We actually target Piranha for stale feature flags. Also, it’s a natural question, and we explored that problem of deleting dead code because that’s another major pain point for most organizations, but one of the benefits of automating stale flag cleanup versus dead code is, for stale flags, there are clear anchor points. There is a clear logical association for what constitutes dead code with respect to a feature flag. Whereas, dead code in generality can be spread across the entire code base, and now splitting it into multiple chunks, and then assigning it and making it compilable, and having it run tests successfully, is non-trivial. That’s one challenge. Then the second challenge is with stale feature flags, there are usually a specific owner associated with that single point of contact, but with general dead code, it’s not that trivial to find a specific point of contact, because that code could have been iterated upon by different folks. It probably falls within the purview of a team, and then trying to drive the cleanup with working with the team as opposed to working with the POC, is slightly harder and more challenging. We explored that. We have that in our roadmap, as you’ve seen, but haven’t fully solved that.
Losio: Actually, you already partially addressed my next question, “How do you define the owner of a feature?” That’s really major. How we interact with them in the sense that there are many scenarios where, how do you define if it’s really stale, or if something maybe would be rolled back, or something will be used again? Of course, yes, it’s a good point that there’s an owner. It’s the full engineering team, it’s not just the developer. Do you have any case where you really need to involve the product owner or to a further discussion if something can be removed?
Ramanathan: In fact, this entire workflow wherein we actually post diffs to the appropriate owner and let them review it falls under them. Because we have a heuristic of what probably is likely stale, and therefore we say, “This is a likely stale flag. We are going to do a cleanup.” Then the eventual cleanup decision has to be made by the engineer who actually implemented it, or in consultation with the team or in consultation with the PPM associated with the product. The final decision to actually land the changes are with the appropriate teams. We don’t make that decision further. We just simplify the process of actually bubbling up saying, “This flag has not been changed in configuration for some time now. It’s 100% rolled out one way or the other, therefore, this may be a candidate for cleanup. Here’s a change, which you can just do a click of a button and then you are done.” Whether you want to do it or not, that’s a decision that the team has to make.
Losio: Has Piranha made you rethink how you define a stale flag?
Ramanathan: It has in some sense. One of our recommendations is that when we create a flag, there needs to be an expiry date associated with the flag that needs to be defined by the owner so that way, for kill switches, the expiry date can sometime be in the future. Whereas for gradual rollout features, it can be time bound. This will also help workflow surrounding Piranha because we don’t need to make any heuristics associated with what could be considered stale, but rather use the information or the intent that the owner has specified as part of the management system to say, “This is a stale flag based on what you have recorded, and now, let’s clean this up.”
Losio: You just mentioned about coding styles and automation. How critical are specific coding styles at this point to enabling high automation rates in the way Piranha works.
Ramanathan: At Uber, we have actually noticed, cleanup is happening across Android and iOS apps, across multiple teams and multiple apps. It’s very interesting, like there are certain teams that follow a specific coding style. The style itself makes the cleanup much easier and more automatable. There are teams that may not necessarily follow such strategies. In those cases, we will have to over-engineer Piranha to handle those cases. What we have observed based on our users is that initially, certain code regions may not necessarily be cleaned up automatically completely. Then the engineers who are actually working on that, they quickly see what automation is doable by this bot. When they build new features and add new flags, they follow the guidelines that we have placed for creating the feature flag so that when it comes to deleting a test, it becomes much more easier by adding annotations, as opposed to not having a clear specification on what constitutes a stale code or not. Initially, there will be some amount of friction, but then eventually, with time, the coding style changes so that it makes it easy to integrate with the bot.
Losio: You’re basically saying that the code that has been written after Piranha was introduced, is somehow much easier to handle because the developer already knows that he wants to use that, so he’s already writing the code in a way that is going to be easier to clean up later. That’s really a self-fulfillment process that is really helping out there.
Ramanathan: Particularly this happens after three or four diffs of processing it. Then engineers are also like reviewers on other Piranha diffs for other teams because they may have some reviewing responsibilities for those. Then they also notice that there are certain diffs for Piranha, which are just landing access. Therefore, they actually invite those practices. In an earlier version of the Piranha workflow, we also had a link for the coding events associated with Piranha, and that actually had some traction, which influenced the coding style that we took.
Losio: What was the most common way to deal with those problems before Piranha? I understand what you’re addressing, I was wondering, if someone never had Piranha before, how were you basically working before that?
Ramanathan: There are multiple ways that tech debt due to feature flags was being handled earlier. One was the fix-it weeks. Yearly, there would be two or three fix-it weeks. The entire week the team sits and tries to get rid of the tech debt, which is essentially a lot of work during that period of time and not much getting done. That was one problem. Then tech debt keeps on accruing for every fix-it week, and it becomes much harder to reach completion. That’s one thing. Second was there was some automated tooling that was built upon just textual processing, like considering code as text, as opposed to ASTs. Then trying to rewrite code using Python scripts. This would work for very specific teams. It would be very brittle, because you have some additional spaces, or maybe assignments and reassignments, maybe additional comments, and suddenly, the entire script will fail, and you will not be able to even get the code to compile. It was not a foolproof point. What Piranha was able to do was use ASTs and partial program evaluation to actually ensure that we are able to do as much cleanup as feasible, and then provide the opportunity to actually add more engineering effort so that we can eventually reach 100% automation rate at some point in time in the future.
Losio: I understand as well that probably had a very positive impact as well on the morale of the team, because if I have to have an iteration, where I’m just basically working with technical debts, with cleaning up code. It’s probably not as exciting as maybe I have to merge some code or I have to fix something at the end, but where most of the job has already been addressed in a semi-automatic or automatic way. That’s right?
Ramanathan: That’s right. In fact, the initial variant of Piranha for Objective-C was compiled by the team reaching out to us saying, we have to stop all development work for the next two, three weeks, because we have a lot of nested feature flags, and just developing on this code base is becoming much more complex, and they wanted a tooling for that. We quickly whipped up a prototype. That’s how it took off also in some sense.
Losio: What’s the process of integrating Piranha with other third-party flag management systems?
Ramanathan: I think Piranha is configurable, as I mentioned. There are JSON files, like configuration files present in the code base itself. If you look at the GitHub code base, for each variant, we actually make it configurable so that for each of the feature flag API, you can specify whether it is treated. What behavior is expected? Whether it’s a testing API, or whether it’s an enabling API or a disabling API. Then, once that API is configured, you will be able to run Piranha with this tool. Typically, it could involve maybe 50 to 60 lines of JSON file updates to support 5 to 6 different APIs. This can be done for pretty much any feature flag management system. We only support something that’s available within Uber.
See more presentations with transcripts
MMS • Vasco Veloso
Article originally posted on InfoQ. Visit InfoQ

Daniel Orner published a recent article arguing that SOLID principles are still the foundation for modern software architecture. According to Daniel, while the practice of software development has changed in the past 20 years, SOLID principles are still the basis of good design. The author explains how they also apply to functional programming and microservices architecture, with examples.
SOLID is a mnemonic and acronym for five software design principles enumerated in 2000 by Robert C. Martin. According to the article’s author, these “SOLID principles are a time-tested rubric for creating good software” and can be adapted to modern software engineering practices.
The author points out some relevant developments in the software industry since the creation of the SOLID principles. Dynamically-typed languages and paradigms such as functional programming or metaprogramming have gained traction and are a common sight in software today. He adds that microservices and software-as-a-service made the monolithic deployment pattern less common and states that many principles governed by SOLID are no longer commonly used by as many programmers as before.
Other aspects of software design have not changed, the author says. People continue to write and modify code, it still is organised into modules, and there is still a need to define its visibility according to its intended user base.
The author proposes to reword the original SOLID principle definitions so that they become applicable to object-oriented (OOP), functional (FP), or multi-paradigm programming and, sometimes, to microservices-based systems.
The author restates the single responsibility principle as “each module should do one thing and do it well”. Besides OOP, the new definition is also applicable to functional programming and microservice design.
The open-closed principle becomes “you should be able to use and add to a module without rewriting it”. It is accomplished in FP by using “hook points” and is a natural characteristic of OOP.
The author defines the Liskov substitution principle as “you should be able to substitute one thing for another if those things are declared to behave the same way”. It now applies too to dynamic programming languages with the help of duck typing or filter functions.
As redefined by the author, the interface segregation principle becomes “don’t show your clients more than they need to see”. In other words, only document what your client needs to know. This definition is also applicable to microservices through separate deployments or separate documentation sets.
The definition of the dependency inversion principle remains the same: “depend upon abstractions, not concretions”. The author believes that abstraction is still an essential concept, applying to OOP, FP, and even microservices (using message passing instead of direct communication).
Other authors have different perspectives regarding microservices. Paulo Merson argues that SOLID principles are good for OOP but do not fully apply to microservices. Therefore, Paulo proposes a different set of principles for microservice design: IDEALS. These are: interface segregation, deployability, event-driven, availability over consistency, loose-coupling, and single responsibility.
NoSQL Industry Market: Worldwide Industry to Boost in the Period of 2020-2025 – AEResearch.net
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

The recent research report on NoSQL Industry market offers a meticulous analysis of all the crucial parameters such as primary growth determinants, impediments, and expansion opportunities to reveal the growth pattern of the industry over 20XX-20XX. It also delivers vivid details regarding the sizes and shares of the market segments, including the product landscape and application spectrum, as well as the regional segmentation.
Proceeding further, the document offers actionable insights into competitive arena, elaborating on emerging firms, leading companies, as well as new entrants in this domain. Moreover, it highlights the aftermath of COVID-19 pandemic on this vertical and provides a collection of tactics that will help business stay afloat amid the market turbulence.
Important pointers from COVID-19 case studies:
- COVID-19 pandemic effect on economic status at both regional and global level
- Corresponding importance of supply and demand amid the pandemic
- Industry scenario before and after the pandemic
Request Sample Copy of this Report @ https://www.aeresearch.net/request-sample/510614
Overview of the regional analysis:
- North America, Europe, Asia-Pacific, South America, Middle East & Africa, South East Asia are the top regional markets.
- Each region’s contribution to the overall industry progression is computed in the study.
- Sales, market share, and revenue of every geography are given.
Other important inclusions in the NoSQL Industry market report:
- The document segments the product landscape of NoSQL Industry market into Key-Value Store,Document Databases,Column Based Stores andGraph Database.
- The report encompasses industry share and revenue data of each product segment.
- Production patterns, industry share, and yearly growth rate of each product segment over the predicted time period are provided.
- The application scope of NoSQL Industry market is categorized into Retail,Online gaming,IT,Social network development,Web applications management,Government,BFSI,Healthcare,Education andOthers.
- Growth rate and market share estimates of each application segment over the forecast period are concluded with supporting statistics.
- Leading firms in NoSQL Industry market are IBM Cloudant,Microsoft,Basho Technologies,DataStax,MapR Technologies,Couchbase,CloudDB,Amazon Web Services,Redis,SAP,RavenDB,MongoDB,Aerospike,Neo4j,Google,MarkLogic,Oracle,AranogoDB,MarkLogic,Apache andMongoLab.
- Predominant trends and their effect on companies are presented to help in better understanding the competitive dynamics of this industry.
- Systematic inspection of industry supply chain is performed by appraising the leading vendors, raw material & equipment suppliers, and downstream clients.
- The study infers the benefits and drawbacks of investing in a new project via Porter’s Five Force assessment and SWOT analysis tools.
Major Points Covered in TOC:
Overview: Along with a broad overview of the global NoSQL Industry market, this section gives an overview of the report to give an idea about the nature and contents of the research study.
Analysis of Strategies of Leading Players: Market players can use this analysis to gain a competitive advantage over their competitors in the NoSQL Industry market.
Study on Key Market Trends: This section of the report offers a deeper analysis of the latest and future trends of the market.
Market Forecasts: Buyers of the report will have access to accurate and validated estimates of the total market size in terms of value and volume. The report also provides consumption, production, sales, and other forecasts for the NoSQL Industry market.
Regional Growth Analysis: All major regions and countries have been covered in the report. The regional analysis will help market players to tap into unexplored regional markets, prepare specific strategies for target regions, and compare the growth of all regional markets.
Segmental Analysis: The report provides accurate and reliable forecasts of the market share of important segments of the NoSQL Industry market. Market participants can use this analysis to make strategic investments in key growth pockets of the market.
Key questions answered in the report:
- What will the market growth rate of NoSQL Industry market?
- What are the key factors driving the Global NoSQL Industry market?
- Who are the key manufacturers in market space?
- What are the market opportunities, market risk and market overview of the market?
- What are sales, revenue, and price analysis of top manufacturers of NoSQL Industry market?
- Who are the distributors, traders, and dealers of NoSQL Industry market?
- What are the NoSQL Industry market opportunities and threats faced by the vendors in the Global NoSQL Industry industries?
- What are sales, revenue, and price analysis by types and applications of the market?
- What are sales, revenue, and price analysis by regions of industries?
Request Customization on This Report @ https://www.aeresearch.net/request-for-customization/510614
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS Cloud Adoption Framework (CAF) is designed to help AWS customers build and execute a comprehensive plan for their digital transformation. And recently, the company announced the availability of version 3.0 of their CAF.
The new version includes what the company has learned since they released version 2.0, focusing on digital transformation and emphasizing data and analytics. It now identifies six groups of foundational perspectives (Business, People, Governance, Platform, Security, and Operations), totaling 47 discrete capabilities, up from 31 in the previous version. And from there, it identifies four transformation domains (Technology, Process, Organization, and Product) that must participate in a successful digital transformation.
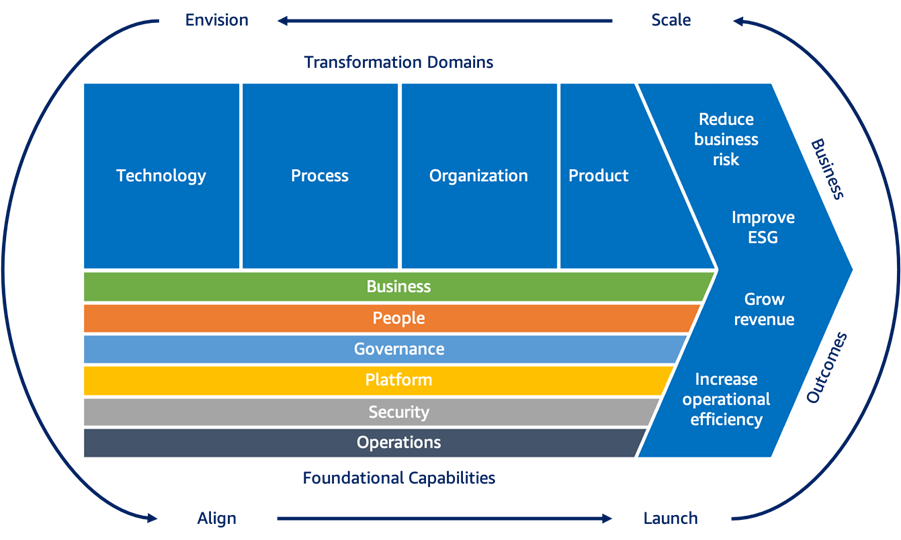
Source: https://aws.amazon.com/blogs/aws/aws-cloud-adoption-framework-caf-3-0-is-now-available/
The AWS CAF recommends a set of four iterative and incremental cloud transformation phases based on the transformation domains and foundational capabilities. These phases are:
- Envision phase provided through an interactive workshop led by a facilitator that will assist an organization in identifying transformation possibilities and laying the groundwork for their digital transformation.
- Align phase, which again is provided through a facilitator-led workshop to identify capability gaps across the foundational capabilities resulting in an action plan.
- Launch phase leading to the creation and delivery of production-ready pilot programs showing incremental business benefits.
- Scale phase to extend pilot projects to the desired scale while achieving the expected and desired business outcomes.
In an AWS CAF 101 blog post, Piyush Jalan, senior cloud consultant, concluded:
The AWS Cloud Adoption Framework demonstrates how businesses may learn to match their cloud strategies and goals with their business plans and goals. It assists companies in identifying gaps in their present organizational capabilities and developing work streams to fill those gaps.
Every significant public cloud provider offers a framework for adopting their respective platforms. AWS competitor Microsoft offers a cloud adoption framework for Azure, and also Google provides one. All these frameworks offer a way to align business and technology agendas with simplifying choices to move forward, indicate, and minimize risks before, during, and after deployment or migration to the cloud.
Charles Collier, director, Transformation & Strategy at Lucernys, stated in a tweet:
Moving to the #cloud is more and more common. However, it requires the right framework.
In addition, David das Neves, director at MediaMarktSaturn, tweeted referring to the three largest cloud providers and their cloud adoption frameworks:
IMHO, you need to pick the best out of them which matches YOUR, company, YOUR culture & YOUR strategy.
Lastly, more details on CAF are available on the landing page.
Inuit vs. MongoDB: Which Enterprise Software Stock is a Better Buy? By StockNews – Investing.com
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Threats related to data security, especially on cloud-based platforms, continue to hamper the enterprise software market’s growth. Nevertheless, the enterprise software market is still expected to grow rapidly in the coming months on increasing demand from almost every industry as part of widespread digital transformation efforts. Furthermore, the resurgence of COVID-19 cases is leading to a resurgence in hybrid working arrangements, which is benefitting the enterprise software industry. According to a Statista report, the worldwide enterprise software market is expected to grow at an 8.74% CAGR between 2021 – 2026. So, both INTU and MDB should benefit.
INTU’s shares have gained 15.8% in price over the past month, while MDB has returned 0.5%. Also, INTU’s 65.6% gains over the past nine months are significantly higher than MDB’s 27.4% returns. Furthermore, INTU is the clear winner with 80.1% gains versus MDB’s 41.3% returns in terms of their year-to-date performance.
Article originally posted on mongodb google news. Visit mongodb google news