Month: February 2022

MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

Version 4.0.0 of Apache Groovy introduces switch expressions, sealed types, built-in type checkers, built-in macro methods and incubating features such as records, JavaShell, POJO annotation, Groovy contracts, Groovy-Integrated Query and TOML support. This release also contains several smaller improvements and breaking changes due to features removed from this latest version.
Developers are encouraged to change their dependencies when upgrading to Groovy 4.0.0 as the Maven groupId has changed from org.codehaus.groovy to org.apache.groovy.
The Java Platform Module System (JPMS) doesn’t allow the same class and package name in multiple modules. Groovy 3 still provided duplicate versions of classes, however, those have been removed in Groovy 4 and new classes, such as groovy.xml.XmlSlurper, groovy.xml.XmlParser, groovy.ant.AntBuilder, groovy.test.GroovyTestCase should be used.
Switch expressions are now supported to complement the already existing switch statements:
def result = switch(i) {
case 0 -> 'January'
case 1 -> 'February'
//...
default -> throw new IllegalStateException('Invalid number of month')
}
A code block may be used for multiple statements:
case 0 -> { def month = 'January'; def year = Year.now().getValue();
month + " " + year }
The implementation of switch differs from Java as not all possible values need case branches. When a default branch is not supplied, Groovy implicitly adds a default branch, returning null.
Sealed classes may be created with the sealed keyword or the @Sealed annotation. Permitted subclasses are automatically detected when compiled at the same time. The permits clause can be used together with the sealed keyword and the permittedSubclasses attribute can be used together with the @Sealed annotation to explicitly define the permitted subclasses:
@Sealed(permittedSubclasses = [Dog, Cat]) interface Animal {}
@Singleton final class Dog implements Animal {
String toString() { 'Dog' }
}
@Singleton final class Cat implements Animal {
String toString() { 'Cat' }
}
sealed interface Animal permits Dog, Cat {}
@Singleton final class Dog implements Animal {
String toString() { 'Dog' }
}
@Singleton final class Cat implements Animal {
String toString() { 'Cat' }
}
Records, one of the new incubating features, are quite comparable to the existing @Immutable Groovy feature:
record Student(String firstName, String lastName) { }
The resulting class is implicitly final, with automatically generated firstName and lastName as private final fields, firstName() and lastName() methods, a default constructor with both arguments, a serialVersionUID of 0L and toString(), equals() and hashcode() methods.
Groovy provides built-in type checkers to either weaken type checking or strengthen type checking. This release introduces the groovy-typecheckers module which contains several type checkers. The @TypeChecked annotation may be used, after adding the dependency to the project, in order to verify if a regular expression is valid during compilation. The following expression misses the closing bracket which normally results in a runtime error:
@TypeChecked(extensions = 'groovy.typecheckers.RegexChecker')
def year() {
def year = '2022'
def matcher = year =~ /(d{4}/
}
However, the type checker displays the error during compilation:
Groovyc: [Static type checking] - Bad regex: Unclosed group near index 6
(d{4}
Comparable to type checkers, some macro methods are now available through the groovy-macro-library module such as the SV macro that creates a String from the variable names and values:
def studentName = "James"
def age = 42
def courses = ["Introduction to Java" , "Java Concurrency", "Data structures"]
println SV(studentName, age, courses)
studentName=James, age=42, courses=[Introduction to Java, Java Concurrency,
Data structures]
The NV macro creates a NamedValue which allows for further processing of the name and value:
def namedValue = NV(age)
assert namedValue instanceof NamedValue
assert namedValue.name == 'age' && namedValue.val == 42
The incubating JavaShell feature enables developers to run Java code snippets:
import org.apache.groovy.util.JavaShell
def student = 'record Student(String firstName, String lastName) {}'
Class studentClass = new JavaShell().compile('Student', student)
assert studentClass.newInstance("James", "Gosling")
.toString() == 'Student[firstName=James, lastName=Gosling]'
POJO annotation is another incubating feature that allows using Groovy as a pre-processor comparable to Lombok. The @POJO annotation indicates that the class is more of a POJO than an advanced Groovy object and needs the @CompileStatic annotation to be processed.
The groovy-contracts incubating module allows the specification of class-invariants, and pre- and post-conditions on classes and interfaces:
import groovy.contracts.*
@Invariant({ coursesCompleted >= 0 })
class Student {
int coursesCompleted = 0
boolean started = false
@Requires({ started })
@Ensures({ old.coursesCompleted < coursesCompleted })
def processCourses(newCoursesCompleted) {
coursesCompleted += newCoursesCompleted
}
}
An error message is shown whenever a precondition isn’t met, such as the started precondition which should be true:
def student = new Student()
student.processCourses(2)
org.apache.groovy.contracts.PreconditionViolation: <groovy.contracts.Requires>
Student.java.lang.Object processCourses(java.lang.Object)
started
|
false
Another error message is shown whenever the post-condition isn’t met such as when the number of processed courses declines:
def student = new Student()
student.setStarted(true)
student.processCourses(-2)
org.apache.groovy.contracts.PostconditionViolation: <groovy.contracts.Ensures>
Student.java.lang.Object processCourses(java.lang.Object)
old.coursesCompleted < coursesCompleted
| | | |
| 0 | -2
| false
The incubating Groovy-Integrated Query (GINQ or GQuery) feature allows querying collections such as lists, maps, custom domain objects, or other structured data, much like SQL:
from student in students
orderby student.age
where student.age > 20
select student.firstName, student.lastName, student.age
from student in students
leftjoin university in universities on student.university == university.name
select student.firstName, student.lastName, university.city
Support for TOML-based files, still in incubation, is provided with the groovy-toml module to build and parse an object graph:
def tomlBuilder = new TomlBuilder()
tomlBuilder.records {
student {
firstName 'James'
// ...
}
}
def tomlSlurper = new TomlSlurper()
def toml = tomlSlurper.parseText(tomlBuilder.toString())
assert 'James' == toml.records.student.firstName
Various smaller improvements were introduced such as caching the GString toString values to increase performance. Ranges could be specified as inclusive 1..10 or exclusive on the right 1..<10, now it’s also possible to be exclusive on the left 1<..10 or both 1<..<10. A leading zero for fractional values is now optional, so both .5 and 0.5 are now supported.
Groovy 4 has some breaking changes, such as the removal of the Antlr2 parser, and the generation of call-site based bytecode is no longer possible. Some modules such as groovy-jaxb and groovy-bsf have been removed. The groovy-all pom now includes the groovy-yaml module, while the groovy-testng module was removed.
The complete list of breaking changes and new features is available in the release notes.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ
Flix, an open-source programming language inspired by many programming languages, enables developers to write code in a functional, imperative or logic style. Flix looks like Scala, uses a type system based on Hindley-Milner and a concurrency model inspired by Go. The JVM language supports unique features such as the polymorphic effect system and Datalog constraints.
Flix programs are compiled to JVM bytecode and developers can use the Flix Visual Studio Code extension or evaluate the language by using the online playground.
The community develops the language based on a set of principles such as: no null value, private by default, no reflection, separation of pure and impure code, correctness over performance and no global state.
The following main function is considered impure as the println function has a side effect. The Flix compiler keeps track of the purity of each expression and guarantees that a pure expression doesn’t have side effects.
def main(_args: Array[String]): Int32 & Impure =
println("Hello world!");
0 // exit code
The Flix language supports Polymorphic Effects making it possible to distinguish between pure functional programs and programs with side effects. Functions are pure by default, or can explicitly be marked as pure:
def add(x: Int32, y: Int32): Int32 & Pure =
x + y;
Functions with side effects can be marked explicitly as impure:
def main(_args: Array[String]): Int32 & Impure =
println(add(21, 21));
0 // exit code
The compiler displays an error Impure function declared as pure whenever side effects are used in an explicitly marked Pure function:
def add(x: Int32, y: Int32): Int32 & Pure =
x + y;
println("Hello")
The separation of pure and impure code allows developers to reason about pure functions as if they are mathematical functions without side effects.
Datalog, a declarative logic programming language, may be seen as a query language such as SQL, but more advanced. Flix supports Datalog as a first-class citizen making it possible to use Datalog constraints as function arguments, returned from functions and stored in data structures. Flix may be used with Datalog to express fixpoint problems such as determining the ancestors:
def getParents(): #{ ParentOf(String, String) | r } = #{
ParentOf("Mother", "GrandMother").
ParentOf("Granddaughter", "Mother").
ParentOf("Grandson", "Mother").
}
def withAncestors(): #{ ParentOf(String, String),
AncestorOf(String, String) | r } = #{
AncestorOf(x, y) :- ParentOf(x, y).
AncestorOf(x, z) :- AncestorOf(x, y), AncestorOf(y, z).
}
def main(_args: Array[String]): Int32 & Impure =
query getParents(), withAncestors()
select (x, y) from AncestorOf(x, y) |> println;
0
This displays the following results:
[(Granddaughter, GrandMother), (Granddaughter, Mother),
(Grandson, GrandMother), (Grandson, Mother), (Mother, GrandMother)]
Flix provides built-in support for tuples and records as well as algebraic data types and pattern matching:
enum Shape {
case Circle(Int32), // circle radius
case Square(Int32), // side length
case Rectangle(Int32, Int32) // height and width
}
def area(s: Shape): Int32 = match s {
case Circle(r) => 3 * (r * r)
case Square(w) => w * w
case Rectangle(h, w) => h * w
}
def main(_args: Array[String]): Int32 & Impure =
println(area(Rectangle(2, 4)));
0 // exit code
The GitHub repository provides more examples for the various features.
InfoQ spoke to Magnus Madsen, assistant professor at the Department of Computer Science, Aarhus University in Denmark, and lead designer / developer of the Flix programming language.
InfoQ: What was the inspiration to create Flix?
Madsen: In the landscape of programming languages, I felt something was missing: a primarily functional language but with full support for imperative programming and with a twist of logic programming. A language at a unique point in the design space with the best ideas from OCaml, Haskell, and Scala.
I wanted a new language based on principles; clearly expressed ideas and design goals. Not just a mishmash of features. For me, a language should not try to be everything for everyone. Better to focus on a few core ideas and excel at those. Personally, I wanted a language that would be a joy to use with powerful features from functional programming: algebraic data types, pattern matching, and higher-order functions.
InfoQ: To what extent is Flix inspired by Scala?
Madsen: Flix draws a lot of inspiration from Haskell, OCaml, and Scala. We want to build on the solid ideas of these languages and go beyond them. The Flix syntax is inspired by Scala, i.e., it is based on keywords and braces, and will feel instantly familiar to many Scala programmers. The Flix type system is based on Hindley-Milner, the same expressive type system that powers OCaml and Haskell. Flix has type inference and will always infer the correct type within a function. While Scala has classes and objects, Flix has type classes borrowed from Haskell. Scala also has a form of type classes based on implicits. The type classes in Flix are closer to those in Haskell and integrate better with type inference.
InfoQ: Why create a new language rather than add capabilities to Scala?
Madsen: Scala is an excellent programming language that has pushed the boundaries of functional and object-oriented programming while maintaining great interoperability with Java.
With Flix, I wanted to go in a different direction and to start from a clean slate. In my experience, functional programming in Scala sometimes feels cumbersome due to limitations of Scala’s type inference. More importantly, I have become more and more convinced that object-oriented programming is a step in the wrong direction. In particular, I feel that the classic features (or values) of OOP – object identity, mutable state, and class inheritance – are not the right way to structure and think about programs.
At the time – and still today – I feel that programming languages with static type systems, despite their many benefits, have been on the retreat. I was afraid for a future with only JavaScript and Python, especially for large scale software development. But I recognize that these languages are attractive because of their flexibility and lack of ceremony. This has led me to conclude that future programming languages must invest heavily in expressive type systems with type inference – that way we can have the same flexibility while retaining the benefits of static type systems, e.g., type safety and better tool support for auto-complete and refactoring. But unfortunately, as it turns out, type inference and subtyping do not mix well.
For these reasons, Flix is not object-oriented. Nevertheless, Flix still supports many features programmers associate with OOP, including imperative programming with mutable data and records.
InfoQ: What are the most significant language features that you think Flix adds?
Madsen: We are actively working on Flix, but today we can identify three unique features that no other programming language currently has:
Flix has a type and effect system that separates pure and impure code. In Flix, every expression is either pure, impure, or effect polymorphic. A pure expression cannot have any side-effects and its evaluation always returns the same result. This is an ironclad guarantee enforced by the compiler. An impure expression may have side-effects. Finally, and most interestingly, for some expressions their purity depends on the purity of other expressions. For example, in a call to
List.map, the overall expression is pure if the function argument toList.mapis pure. We say that such functions are considered effect polymorphic.A Flix programmer (but typically a Flix library author) can use the type and effect system to write functions that are effect-aware. This is a type of meta-programming that enables a higher-order function (e.g.
Set.count) to reflect on the purity of its function argument(s). This knowledge enables support for automatic lazy or parallel evaluation. For example, in the Flix standard library, theSet.countfunction runs in parallel when passed a pure function, but runs sequentially when passed an impure function; to preserve the order of effects and to avoid any thread safety issues.Flix has support for first-class Datalog constraints. Datalog is a logic programming language, but can be thought of as a query language like SQL – but on steroids. Any SQL query is trivial to express in Datalog, but Datalog also makes it possible to write more complex queries on graphs. For example, a two-line Datalog program can be used to compute the shortest distance between two cities in a road network. Unlike some ORMs, the Datalog integration is seamless. There is no messy construction of strings or mapping of data types. Datalog queries use the same underlying data types as Flix. Finally, Datalog should not be used blindly, but for some computational problems, it is really a super-weapon.
InfoQ: For which type of applications do you think Flix is especially suited?
Madsen: We are designing Flix as a general-purpose programming language. Flix can be used where you would use Java, Kotlin, Scala, OCaml, or Haskell. We are taking a “batteries included” approach and the Flix standard library is now more than 30,000 lines of code with more than 2,000 functions. If the standard library lacks functionality, a programmer can always fall back on the Java library and/or on external JARs. We care a lot about correctness and stability. In particular, the Flix compiler and standard library have more than 12,500 manually written unit tests. Flix also comes with API documentation, a website, a “Programming Flix” manual, and a Visual Studio Code extension that implements most of the Language Server Protocol. We also have a nascent package manager.
InfoQ: What are your immediate goals for Flix – how big is the community currently?
Madsen: We are at a point where the language itself, the compiler, the standard library, and the documentation are ready for early adopters. We want software developers to start using Flix and we are ready to offer help via our Gitter channel. We are interested in feedback on the design to iterate and move forward. Flix is already used in production by a few companies. We would like to dramatically increase this number.
Now there are about 5-8 programmers actively working on Flix. A couple of programming language researchers, a PhD student, two student programmers, and several open-source contributors.
The Flix project is about a bit more than six years old. Most activity has happened in the last two years. The Flix compiler project consists of approximately 170,000 lines of code contributed by more than 40+ developers.
InfoQ: What language feature of Flix do you like most?
Madsen: Personally, I really like programming with algebraic data types, pattern matching, and functions. Flix’s concise syntax and type inference make it a breeze to write programs with these features. I find it convenient that, when needed, I can write messy imperative code without comprising the functional purity of the rest of my program. The effect system helps me structure my code into pure and impure parts. Usually, the core computation is pure whereas everything around it deals with the external world (e.g., files). I like that the type signature tells me almost everything I need to know about a function: the type of its arguments and return type, the type class instances that are required, and whether the function is pure or impure. Finally, while the Visual Studio Code extension is not yet perfect, it is still pleasant to use because it uses the real Flix compiler, i.e., I can trust that if VSCode says a program is error-free then the compiler agrees.
InfoQ: What part of Flix would you like to improve?
Madsen: In the last year we have made great progress on polishing the language, the compiler, and the standard library. Flix is ready for use, but there are still a few areas we would like to improve:
We hope to extend the Flix type and effect system to allow functions to use local mutation while remaining pure. For example, you could imagine a sorting function that internally uses a mutable array for in-place sorting, but to the outside appears as a pure function.
We want to extend the standard library with support for file I/O, interacting with the operating system, networking, and parsing (e.g., JSON) without having to rely on Java libraries.
We want to improve interoperability with Java without too many sacrifices.
InfoQ: Can you already tell us something about future directions for Flix?
Madsen: We want to under-promise and over-deliver. We prefer to talk about features that exist today and are ready for use. That said, Flix has recently received funding from Amazon Science and from DIREC for work on increasing the expressive power of type and effect systems, so that may offer a clue.
Madsen provided further insights in his session Designing a principled programming language on the Happy Path Programming podcast by Bruce Eckel and James Ward.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Databases are everywhere. These structured systems gather data in rows, columns, and fields which are used to record customer lists, product catalogs, items for sale, personnel data, medical records, telephone numbers, and much more.
Some databases are massive, while others are fairly small. But they all have to be managed. And that provides plenty of jobs across the IT and business landscape.
Each kind of database has its own database management system (DBMS). These software packages help organizations to define, format, manipulate, retrieve, and manage the data contained within a database. DBMS’s contain rules about the various field names, how records and files are structured, and so on.
Here are some of the top trends in the database job market:
1. SAP and Oracle
SAP and Oracle are two of the stalwarts of the enterprise database market. SAP offers multi-model processing within SAP HANA, which provides an immense amount of in-memory processing for high performance.
The latest version of Oracle Database 21c includes an Always Free tier of Oracle Autonomous Database. It contains immutable blockchain tables, In-Database JavaScript, native JSON binary data type, AutoML for in-database machine learning (ML), and persistent memory store. It also offers enhancements for in-memory, graph processing performance, sharding, multitenant, and security.
As the most popular database platforms in the world, Oracle and SAP skills open a great many employment doors into large and mid-sized enterprises.
2. New Generation Database Tools
In some ways, SAP and Oracle represent the older generation. Even though they have gone to great lengths to bring their platforms to the cloud, their heritage still manifests in terms of architectural complexity.
Small businesses working with large corporations often run into difficulties with such systems when it comes to getting accepted as a supplier. The data fields to be entered are as obscure as they are endless. Some give up and decide that learning such systems isn’t worth the hassle.
Enter a new wave of simpler and easy-to-use cloud-based databases. There are many of these, and they are growing in importance in the market. Those learning these skills could find themselves doing well within a specific market niche.
For example, Knack offers an online database to structure data with data types that make sense, like names and emails. It helps to connect data by linking related records together and extend it with special options like formulas and equations.
TeamDesk is another online database that aims to remove the complexity of running and maintaining one on-premises. Its templates make it easy to create a custom database despite lack of technical knowledge.
There are plenty of other platforms too.
3. Multi-Model Databases
According to SAP, multi-model databases are one of the trends in database software and management right now. As such, they represent plenty of job opportunities.
Multi-model databases offer a single, integrated data platform that can store, access, and process different types of data to carry out multiple tasks. With a multi-model database, you can unify various data types and models into a single solution, without having individual technologies for each specific purpose.
This is more beneficial than having individual technologies for each specific purpose. The resulting patchwork solutions can lead to silos that hamper business agility and innovation. A unified multi-model data platform can help overcome these challenges.
4. New Skills for Database Flexibility
The IT world is converging more and more. Not so long ago there were distinctly separate lines for telecommunications and data. Now, almost everything goes on one means of connection, resulting in disappearing land lines.
Similarly, storage, networking, compute, applications, and development used to be clearly separated disciplines within IT. Now, many are converging. Hyperconverged infrastructures have emerged.
As a result, database specialists are finding it harder to stick rigidly to their chosen area of interest. They are being asked to do more, even if that only goes as far as being knowledgeable in how the database interfaces with other systems. But increasingly, they are being required to possess wider skill sets such as security and storage.
For example, data mirroring as a means of protecting a database can lessen organizational risk and increase resiliency. By copying the database in real-time from one location to another, database administrators can ensure that if the primary copy of the database is lost, another one is immediately available.
“With cloud deployments, data mirroring takes on greater importance and particularly when core business applications like analytics and databases move to the cloud,” said Kirill Shoikhet, CTO of Excelero.
“Databases must have mirroring across availability zones. Technologies that can synchronously mirror while minimizing the number of round trips have an advantage, as cross-availability zones and regions means that there is some basic latency, due to the distance and physics.”
5. Current Favorites
As trends in database jobs rapidly change, it is smart to pay attention to reports about which technologies are best in terms of compensation.
Foote Partners’ “IT Skills and Certifications Pay Index” shows good news in general for the database job market. Pay rates as a whole have risen sharply over the past decade. But over the past six months, there are a few specific areas where salaries are surging. These include Amazon DynamoDB, data management, database management, data quality, MongoDB, PostgreSQL, NoSQL. HBase, and Oracle Forms.
Pay for those experienced in Apache HBase, for example, rose 25% in market value over a six-month span. This open-source NoSQL database runs atop the Hadoop Distributed File System and provides access in real time to large datasets.
Pay for pros working with Amazon DynamoDB also increased in value by 12.5%. It is another NoSQL database that supports the key-value and document data structures. It is part of Amazon Web Services and uses synchronous replication across multiple data centers to increase data durability and availability.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

NoSQL database vendor Couchbase is about to launch the third upgrade to its mobile database, with new features promising REST-based remote administration support for large multi-tenant edge applications.
The future release will allow developers to embed lightweight data storage directly into applications on mobile and other “edge” devices such as those in IoT setups.
The new system offers the advantage of giving developers a single, coherent database whether applications were hosted in the cloud or end-user or edge devices, one industry analyst said.
Couchbase is a document-oriented database that uses JSON. Wayne Carter, Couchbase’s vice president of engineering, said the approach was particularly suited to mobile and edge applications compared with relational databases.
“There is a fundamental difference at a consistency level,” he said. “Our database – and many other NoSQL systems – go for eventual consistency instead of immediate consistency. What this allows you to do is distributed.
“Any time you go distributed, that means you have a network connection between two parts of the system. And when there’s a network connection – if it’s down or slow – then your system will either be unavailable or slow.
“By relaxing consistency, you’re able to allow the systems to operate at their full speed and full availability at each independent distributed node in the system. In mobile and IoT, you’re dealing with fundamentally unreliable networks.”
Couchbase Mobile 3, in C, is set to be available for Ubuntu, Rasberry Pi, Debian, Windows 10, Android, iOS and macOS. Other operating systems will be supported in C#, Java, Swift and ObjC.
“Developers will be able to build applications on the same database, are using the same programming paradigms. They’re using the same simple, SQL interface that we have across all our entire database platform,” Carter said.
IDC estimates that the global market for so-called edge computing will reach $176bn in 2022, which is up nearly 15 per cent on 2021.
Dave McCarthy, IDC research vice president for cloud and edge infrastructure, told The Register that developers were driving demand for NoSQL databases.
“It’s somewhat in response to the pace of innovation that they are being asked to deliver on, plus the diversity of data types,” he said.
“More companies are adopting a NoSQL approach when they’re building modern applications, mainly because it frees the developer to have more flexibility in how they store data and how they use it.”
He said that the Couchbase mobile announcement offered both flexibility in deployment architectures and compatibility with existing environments.
“I think it’s developers that have already decided that this is a good approach for them and the way they want to develop applications, but they want more, they want to be able to extend that capability outside of these cloud environments into these more distributed deployment locations.”
Couchbase Mobile 3 deploys a Sync Gateway on the edge or mobile device, as well as the database itself, to allow developers to control how devices share data between devices and with a cloud-based system.
“The fact that it’s modular in such a way that both of those components can run directly on a mobile device itself enables a really unique scenario around peer-to-peer syncing between devices,” McCarthy said.
For example, an airline could digitise their pre-flight check process by embedding Couchbase onto tablets for recording inspections and synchronise across tablets in real-time, even disconnected from a central database, the company said.
“That’s novel and I think there’s a lot of scenarios like that, where it would be useful,” McCarthy said.
Couchbase said “significant parts” of the source code for Mobile 3 is open source, licensed under BSL. More details are available here. ®
MongoDB Stock Bullish Momentum With A 5% Jump As Session Comes To An End Today | Via News
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
(VIANEWS) – Shares of MongoDB (NASDAQ: MDB) jumped 5.64% to $374.83 at 15:49 EST on Thursday, after five sequential sessions in a row of losses. NASDAQ is rising 2.33% to $13,341.11, after five consecutive sessions in a row of losses. This seems, up to now, an all-around up trend trading session today.
MongoDB’s last close was $354.81, 39.86% below its 52-week high of $590.00.
Volume
Today’s last reported volume for MongoDB is 989841 which is 12.45% below its average volume of 1130665.
The company’s growth estimates for the ongoing quarter and the next is a negative 19.4% and a negative 3%, respectively.
MongoDB’s Revenue

Year-on-year quarterly revenue growth grew by 43.7%, now sitting on 702.16M for the twelve trailing months.
Volatility
MongoDB’s last week, last month’s, and last quarter’s current intraday variation average was a negative 4.36%, a negative 0.88%, and a positive 4.10%, respectively.
MongoDB’s highest amplitude of average volatility was 4.36% (last week), 3.79% (last month), and 4.10% (last quarter), respectively.
Stock Price Classification
According to the stochastic oscillator, a useful indicator of overbought and oversold conditions,
MongoDB’s stock is considered to be overbought (>=80).
MongoDB’s Stock Yearly Top and Bottom Value
MongoDB’s stock is valued at $374.83 at 15:49 EST, way under its 52-week high of $590.00 and way higher than its 52-week low of $238.01.
MongoDB’s Moving Average
MongoDB’s worth is way below its 50-day moving average of $509.44 and below its 200-day moving average of $389.11.
Previous days news about MongoDB (MDB)
- Mongodb ventures wants to foster the next generation of data infrastructure companies. According to VentureBeat on Tuesday, 22 February, “Moreover, MongoDB Ventures is unusual in that it is not publicly disclosing the size of its fund – most VC funds, whether they are attached to a corporate entity or not, proactively quantify their investment ambitions. “, “More recently, MongoDB Ventures invested in Apollo’s $130 million series D round. “
More news about MongoDB (MDB).
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Data is a key element of success for enterprises, but without well-designed databases, data can easily be misinterpreted, siloed, or ignored.
Databases provide more than a repository to meet this data management need. They offer data storage, accessibility, analytics, and security.
The database market is one of the most dynamic in data science because companies are looking for new ways to manage their growing sets of valuable big data.
Read on to learn about what the database market looks like and how companies are shifting their expectations for database technology:
An Analysis of the Database Solutions Market
Also read: Database Trends
Database market
The database market continues to grow in both size and complexity. The in-memory database market grew to $5.2 billion in 2020 and is expected to surpass $12.1 billion by 2026, according to Mordor Intelligence.
For the greater database management system (DBMS) market, a similar growth trajectory is predicted. The DBMS market reached around $63.1 billion in 2020 and is projected to near $125.6 billion by 2026, according to Expert Market Research.
Growth in the database market is due partly to the role that database technologies are playing in corporate digital transformation efforts.
Enterprises are looking for increasingly integrated database solutions that can manage SQL and NoSQL data as needed. Companies are also investing in database technology to support data quality management and important tech initiatives, like cloud migration and machine learning (ML).
Although relational (SQL) and non-relational (NoSQL) are the most common types of databases, other types include object-oriented, hierarchical, key-value, cloud, and wide column databases.
Learn more about the Cloud Database Market.
Database features
Both standard database solutions and custom-designed solutions offer some core capabilities to users:
- Data retrieval and query management: When a user submits a query or searches for a specific kind of data, the DBMS uses the provided criteria to source and display the data in a selected format.
- Data editing and manipulation: Databases typically allow users to make manual edits to data sets, but they also frequently use automated guidelines and scanning to detect and correct errors.
- Automation: Beyond error and anomaly detection, DBMS solutions can automate security patching, platform upgrades, scaling, and data provisioning. Automation is often performed with some machine learning features.
- APIs and integrations: Database technology often comes with native integrations and API capabilities, making it possible for users to connect the database to other business applications.
- Performance monitoring: Databases use preprogrammed criteria and guidelines to find errors in data sets; in many cases, this technology integrates with other performance monitoring solutions.
- Data analytics: Databases typically include a dashboard where data visualization, reporting, and other analytics tools can be used to further understand stored data.
Learn more about machine learning: Machine Learning Market
Benefits of databases
Ensure data organization and searchability
Databases can organize structured and unstructured data on a single platform. Regardless of the silos where this data is normally stored, the database setup and its searchability make it easy for users to store, access, and maintain the quality of data.
Uncover business intelligence
Because databases focus on breaking down traditional business data silos and storing data in an easy-to-interpret format, this type of technology is frequently implemented to democratize data and make it easier to apply to greater business intelligence (BI) needs.
Enable data storage, backup, and security
Databases provide storage and backup solutions, but they also typically offer different security features, like automated patching, user access monitoring and management, and data policy application.
Allow multi-user access
Many database technologies are hosted in the cloud or designed for multiple users to access and use the tool. This democratizes the data for less technical teams and makes it possible for different departments to benefit from accessible data.
Establish data integrity management
When businesses use databases for master data management, they improve their data integrity management capabilities because they’ve invested in a single source of truth for ongoing business data changes.
Learn about Cloud Database Trends
Database use cases
Databases can be used to manage internal or external-facing data, and they’re not limited to any one department. In many scenarios, database management systems and other database technologies are used to integrate data from different platforms for interdepartmental goals and higher-level business needs.
To better understand how databases can aid in corporate data management, learn how two customers use two of the top products in this space:
“Our previous financial transactional system was extremely dated; it was an MS-DOS-based system. This was not a sustainable solution as it could not scale to future needs and there was no support for the product. We had to modernize rapidly and change our business to the digital age so we could scale to match our growth targets and also retain our customers (with ever more complex invoicing and reporting needs). We also needed to become more compliant in our reporting and risk management. SAP HANA allowed us to do all of this, so it was a great product.” -Model risk manager in miscellaneous services, review of SAP HANA at Gartner Peer Insights
“Db2 suits most of our applications as a backend RDBMS. This is our go-to choice as it’s scalable, secure, and highly available. Db2 is supported on-premise as well as in cloud-hosted formats. We can set up automatic backups and encryption to run on scheduled times. It’s easy to install Db2 in Windows as well as Linux machines. The transactions are quite fast and secure and can be rollbacked at any time if the temporal database feature is enabled. Db2 provides more control to the DBA to make the database more efficient for space and performance.” -Design and automation engineer in industrial manufacturing, review of IBM Db2 at Gartner Peer Insights
Database providers
When considering which database providers to work with, consider if they offer open- or closed-source solutions, if they provide any specialized features for your industry, and especially if they extend support services that your team will need for ongoing database maintenance.
Across different industrial standards and business use cases, the following database vendors are considered some of the best:
Read next: Top Data Management Platforms & Software
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

A database management system (DBMS) is software that allows organizations to create, maintain, organize, and control access to datasets. The DBMS is the framework by which an end user can access and run queries within a large database. It functions as a conduit between users, programs, and data.
Database management systems are widely used in a variety of major industries, such as the finance, media and entertainment, health care, pharmaceutical, service, and hospitality.
In this article, we will discuss the DBMS market as a whole, covering the growth and geographical spread of the market as well as the market-leading vendors offering DBMS and the features and benefits of using DBMS software.
DBMS Market
As the world increasingly runs on technology, the DBMS industry has evolved to handle increasing data needs from social media, e-commerce, and other high-tech sectors. The recent pandemic increased economic reliance on the internet and the use of data, driving the growth of the DBMS market.
North American, Western Europe, and Asia-Pacific countries such as Australia, China, and India, have been the top geographic consumers of this software. Countries with medium market maturity include Russia and South Korea, while demand is emerging from countries such as Colombia, Austria, and Slovakia.
The development of various formats of data, software-as-a-service (SaaS)-based DBMS, and the growing reliance on “big data” for marketing are great drivers of growth for database management systems.
Relational DBMSs, or RDBMSs, account for nearly 95% of the overall market currently. Due to the prevalence of open-source databases, the industry is expected to witness a 25–30% growth in 2022. Approximately one in four DBMS clients run on open-source databases, mainly companies in retail, e-commerce, and BFSI.
Predictions of an increasingly digital society, in which most shopping, socialization, and media consumption occurs online, have helped spur the reliance on DBMSs for increasing mounds of complex, interconnected data. The growing fields of data science, data modeling, and expansion of machine learning (ML) will also play a large part in the DBMS market as well.
DBMS Features
The DBMS enables the organization to retrieve and store of vital data through defined formats and structure. DBMS can be divided into different segments by relying on a variety of techniques, such as NoSQL, Hadoop, XML database system (XDBMS), RDBMS, object-relational database management (ORDBMS). Regarding deployment, DBMS software can be divided into cloud-based or on-premises servers.
DBMS software can manage data in a way that allows employees to work efficiently, whether taking calls at an office or developing a website from home. Enhanced data integrity, data backup, data integration, and data security are all top benefits of using a DBMS. Minimizing data redundancy is also a leading reason enterprise-level companies work with this software.
Benefits of DBMS
DBMS software has many advantages over the traditional file-based data management systems that existed before it. Data integrity is one of the core benefits offered by DBMS. Data that is consistent and accurate is important for organizations, as well as the ability to be able to maintain and communicate between different databases.
Data backup is a crucial element of DBMS software as well. While organizations in the past had to focus on backing up data consistently at predesignated intervals, the DBMS automates recovery and backup. This means that in the unfortunate event of a system failure or natural disaster, data loss is less of a concern.
Data security is another prime concern addressed by DBMS software. Cybersecurity is a growing threat that is getting bigger every year, and the importance of protecting sensitive consumer data is paramount.
Authorized users must be able to easily access databases. Yet, there must be a significant amount of protection against data breaches, meaning efficient user authentication is an important aspect. Integrity constraints protect data, consumers, and companies that rely on the use of DBMS systems.
A further benefit of DBMS software is better data integration. Because of the widespread use of DBMS software, people are now able to seamlessly manage data and communicate between different data sets. Data synchronization and data logs allow companies to get a greater insight into their own operations in order to enhance them.
Data inconsistency is a common problem that is minimized by the use of DBMS. Data inconsistency occurs between files when different versions of the same data have been saved in different files. Data redundancy is minimized through the use of a DBMS, synchronizing data changes between all users.
Other benefits of using a DBMS include faster data access which enables better decision making. Running data queries that are accurate and fast can empower leaders to make the best choices for their organization, driving successful marketing campaigns and making accurate revenue forecasts, for example.
DBMS Use Case
DBMS software has widespread use across different industries, depending on how organizations gather, store, and organize data. Tech companies rely on this software, especially when a product or service needs to be delivered in a customized way to hundreds of millions of customers to an even higher number of devices.
Hulu was in precisely this predicament. Their streaming media services were growing in leaps and bounds, and they needed to have the ability to scale while not compromising on the quality of experience they offered their customers.
The company signed a contract with Apache Cassandra, which helped them create a framework that allowed them to manage their inventory, create a customized experience for each user, and allow viewers to pause and resume watching movies and shows on different devices.
A well-managed DBMS software was the solution to all of these issues. At the time, Hulu was still a small company, but they were hungry for growth. Senior Software Development Lead Andres Rangel chose Cassandra because of its ability to address their needs.
“We needed something that could scale quickly and would be easy to maintain because we have a very small team,” Rangel says.
DBMS Providers
Oracle remains the most popular provider of database management systems, followed by Microsoft SQL and MySQL.
IBMDB2, SolarWinds Database Performance Analyzer, Amazon RDS, Hadoop, and Maria DB are all top market leaders in the DBMS market as well.
A number of open-source providers with some free features also remain competitive, such as Apache Cassandra and PostgreSQL.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
(VIANEWS) – The NASDAQ opens in less than two hours and MongoDB‘s pre-market value is already 5.58% down.
The last session, NASDAQ finished with MongoDB (MDB) falling 7.22% to $354.81. NASDAQ dropped 2.57% to $13,037.49, after five successive sessions in a row of losses, on what was an all-around negative trend trading session.
Volume
Today’s last reported volume for MongoDB is 1299490, 14.93% above its average volume of 1130665.
MongoDB’s last close was $354.81, 39.86% under its 52-week high of $590.00.
The company’s growth estimates for the current quarter and the next is a negative 19.4% and a negative 3%, respectively.
Volatility
MongoDB’s last day, last week, and last month’s current intraday variation average was 7.78%, 4.92%, and 3.88%, respectively.
MongoDB’s highest amplitude of average volatility was 10.43% (day), 7.37% (last week), and 6.25% (last month), respectively.
Previous days news about MongoDB
- Mongodb ventures wants to foster the next generation of data infrastructure companies. According to VentureBeat on Tuesday, 22 February, “In addition to investing, MongoDB Ventures will pair entrepreneurs with MongoDB executive mentors, support product and go-to-market initiatives, and provide exposure to partners and customers.”, “To kickstart its endeavors, MongoDB Ventures has confirmed two of its inaugural investments, though they actually predate today’s formal fund launch by quite some time. “
More news about MongoDB (MDB).
Article originally posted on mongodb google news. Visit mongodb google news
Insiders probably made the right decision selling US$31m worth of shares earlier this year …
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
By selling US$31m worth of MongoDB, Inc. (NASDAQ:MDB) stock at an average sell price of US$409 over the last year, insiders seemed to have made the most of their holdings. The company’s market worth decreased by US$3.7b over the past week after the stock price dropped 13%, although insiders were able to minimize their losses
While insider transactions are not the most important thing when it comes to long-term investing, we would consider it foolish to ignore insider transactions altogether.
View our latest analysis for MongoDB
MongoDB Insider Transactions Over The Last Year
The President, Dev Ittycheria, made the biggest insider sale in the last 12 months. That single transaction was for US$6.0m worth of shares at a price of US$517 each. We generally don’t like to see insider selling, but the lower the sale price, the more it concerns us. The silver lining is that this sell-down took place above the latest price (US$355). So it may not shed much light on insider confidence at current levels.
MongoDB insiders didn’t buy any shares over the last year. You can see a visual depiction of insider transactions (by companies and individuals) over the last 12 months, below. If you want to know exactly who sold, for how much, and when, simply click on the graph below!
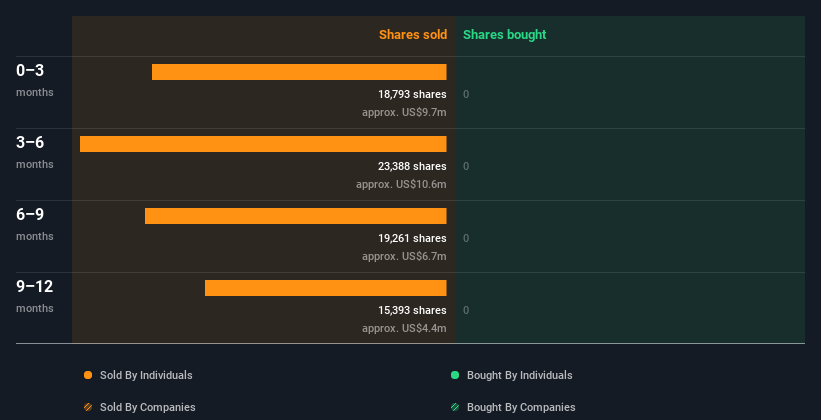
If you like to buy stocks that insiders are buying, rather than selling, then you might just love this free list of companies. (Hint: insiders have been buying them).
MongoDB Insiders Are Selling The Stock
The last three months saw significant insider selling at MongoDB. Specifically, insiders ditched US$9.7m worth of shares in that time, and we didn’t record any purchases whatsoever. This may suggest that some insiders think that the shares are not cheap.
Insider Ownership of MongoDB
I like to look at how many shares insiders own in a company, to help inform my view of how aligned they are with insiders. I reckon it’s a good sign if insiders own a significant number of shares in the company. MongoDB insiders own about US$1.5b worth of shares (which is 6.2% of the company). This kind of significant ownership by insiders does generally increase the chance that the company is run in the interest of all shareholders.
So What Do The MongoDB Insider Transactions Indicate?
Insiders sold stock recently, but they haven’t been buying. Looking to the last twelve months, our data doesn’t show any insider buying. The company boasts high insider ownership, but we’re a little hesitant, given the history of share sales. So while it’s helpful to know what insiders are doing in terms of buying or selling, it’s also helpful to know the risks that a particular company is facing. While conducting our analysis, we found that MongoDB has 4 warning signs and it would be unwise to ignore them.
Of course, you might find a fantastic investment by looking elsewhere. So take a peek at this free list of interesting companies.
For the purposes of this article, insiders are those individuals who report their transactions to the relevant regulatory body. We currently account for open market transactions and private dispositions, but not derivative transactions.
Have feedback on this article? Concerned about the content? Get in touch with us directly. Alternatively, email editorial-team (at) simplywallst.com.
This article by Simply Wall St is general in nature. We provide commentary based on historical data and analyst forecasts only using an unbiased methodology and our articles are not intended to be financial advice. It does not constitute a recommendation to buy or sell any stock, and does not take account of your objectives, or your financial situation. We aim to bring you long-term focused analysis driven by fundamental data. Note that our analysis may not factor in the latest price-sensitive company announcements or qualitative material. Simply Wall St has no position in any stocks mentioned.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Sarah Wells Sangeeta Narayanan Nick Caldwell
Article originally posted on InfoQ. Visit InfoQ

Transcript
Shoup: Maybe we can briefly introduce everybody, and what you do.
Narayanan: I’m Sangeeta Narayanan. A director of engineering at Netflix. I lead an org focused on infrastructure and productivity and enablement tooling, targeted towards content creation use cases. I’ve been at Netflix for over 11 years now. Prior to that, been at a few startups.
Wells: I’m Sarah Wells. I work at the Financial Times. I am a technical director for an organization called Engineering Enablement. We’ve just set that up. It is things like platform teams, enabling teams, operational concerns, basically.
Caldwell: I’m Nick Caldwell, VP of Engineering for the consumer team at Twitter. The consumer team is all the fun parts of Twitter, so on timelines, the content creation stuff, and all the health systems. Also, on the board of a really great company called HubSpot. I’ve been on the board since January. Previously was VP of Engineering at Reddit, Chief Product Officer at Looker, and at Microsoft for a long time.
Helping Platform Teams Foster Customer Centricity, and Empathy
Shoup: The first one is, how to help platform teams foster a sense of customer centricity, customer focus and empathy for the teams. The particular thing we noted as we were preparing is, a lot of times the team that build a particular piece of platform-y software, don’t use it as much as you might imagine.
Narayanan: This one’s something we run into all the time. I look at it in a couple different ways. One is, as you pointed out, do you use what you build? The other is, how connected are you to the business and the end use case? If you think of a product, you have product managers who play that role. How do you do that in a platform or with smaller companies who likely don’t? When I think of tactics, a couple that I feel have worked well, that I’ve seen work well is embedding in this virtual squad model, go work with the product teams, see what it’s like, and that really helps build empathy. Our compute team does a great job of this, they have a liaison model. As an engineer, you have different customers, and one person is dedicated to understanding the use cases and business requirements for a particular group, for instance. That way, you have the continuity, and you have an internal evangelist in your infra team. A couple things that I’ve seen work.
Wells: All of those are great things. The things we’ve done additionally to that is, we actually look to recruit from our product teams into some of our teams that are building tools, because they’ve got that customer focus, and they know some of the problems. Additional to that, when I set up the precursor to my current group, doing reliability engineering, we agreed with our product teams that they would send people on secondment for three months at a time, we will get two people from a particular group. That was fantastic, because first of all, we can check things with them as we’re building them. They’re also fantastic evangelists for the stuff that we’ve built. We find that they continue to submit PRs for our code. They find ways to use our tools that we didn’t think about, but because they were embedded they’ve learned that and that’s fantastic.
Caldwell: Sarah took the best answer, which is having a thoughtful way to rotate people in and out. I’ve also used some other approaches maybe more directly connecting engineers in the platform. This works for any place in your org, but connecting folks with what’s going on in the design and research department, so they can directly hear output from research studies. Then, if not, having them sit directly in those sessions, then taking the output of those sessions and presenting them in all-hands, and forums like that. The biggest risk as a company scales is, particularly your platform team, like you’re going to be focusing too much downward instead of externally. You have to find ways to keep people connected.
The other thing is, we also have used at various places I’ve worked, NSAT reviews, or some way to basically have customers come in and get in your face and tell you what the problems are that can either be driven by PM or sales. The key thing is to have engineers hear that feedback, even if it’s raw and visceral, and they’ll take it away, and at least know why they’re doing what they’re doing. I don’t know if they’ll adjust their behavior, but help them stay connected to the customer, which was the thrust of this question.
Shoup: I often do another kind of embedding, which is have the platform team person go and sit with the product engineering team. I think you were talking about rotating the product engineering person into the platform team. To be super clear, both those models work. It also has second-order effects in terms of camaraderie and cross team collaboration, and stuff.
Narayanan: Something Sarah said, I thought this might be helpful sharing, because camaraderie embedding. I was talking about embedding platform folks in product. I think when Sarah said, that helps these people build a lasting relationship to where they’re contributing through PRs. One thing on the mental model that we use is, in one sense, you want to look at product teams as your customers, but you also want them to feel like they’re partners. It’s not just a customer provider SLA based relationship. It’s, we’re collectively trying to make things better. This mental shift of making them feel like partners, I think also helps.
How to Foster Collaboration & Knowledge Sharing Between Product Teams
Shoup: How do you foster collaboration and knowledge sharing between product teams, without it interfering with the flow of those respective teams?
Wells: I think it comes from your culture. If you’ve got a culture of people like to share what they’ve learned, and they like to talk about the cool stuff, then they’ll naturally do it. You need to try and default to things being open. If we’ve got fortnightly showcases for a particular group, we want anyone to be able to come along and see it too. If you could persuade people to write blog posts, I had a great comment from my colleague, Anna Shipman, that actually your blog post is as good for internal communication as it is for external. You have to write it really clearly because someone is going to be reading it without context. It’s a fantastic way to document stuff. You have to make time for it, but it pays off. For example, ft.com team, there was a blog post written about two years ago, and the architecture has changed a bit, but it’s still a really good explanation of why they made certain choices. They use it in their interview process. People always refer to it.
Caldwell: This only works for companies of a certain size. If your company is a certain size, you should encourage particularly tech leads or folks who are passionate in a particular area to form guilds, where they can meet and discuss topics. We have had guilds for ML, backend engineering, frontend engineering. Then the key thing is to not assume that those are unpaid positions, so reward them in different ways. The places I think that do the best job of this structure not only allow guilds to be formed, but provide them with funding, and then also to some extent, incentivize this behavior through job ladders in the promo process as well. The idea of contributing back to share knowledge base gets formally recognized not just in a fluffy way, but people tangibly benefit from it. That also works for mentoring and other techniques. Always back up the behaviors you want with incentives. Your culture over time is just the accumulation of your incentives and disincentives. Don’t just say you want something, come up with a system to actually reward it, or discourage the behavior you don’t want.
Narayanan: Huge plus one to incentives and culture. I think, tactically, maybe one thing I’ll throw out there is for enablement teams to also think, as part of their charter of being a builder of communities, we can create communities of practice. Maybe they’re the ones bringing all their users together, and they could play a role there.
Shoup: I love the point of connecting up with just performance management, career ladder or career growth. We all know, almost by definition, whatever you call it, like staff, principal, when you’re at the higher levels of individual contributorship, that’s a first order thing. That’s also a deal breaker, if it’s not there, like, “Randy seems to be fine at the typing that he does, but he’s not helping anybody else.” That’s a real thing.
Sharing Code and Components between Product Teams
How do we share code and components between product teams?
Wells: I feel you shouldn’t. I feel like you should share services, but as soon as you share code, you run into problems. Maybe libraries, but it has to be something that doesn’t change very often.
Caldwell: Very carefully. It’s something I always hear, because in an ideal world, this would be super easy. Particularly as your code base gets more mature and more complicated, it becomes harder for people to contribute. I think culturally, always aspire toward if some team is wanting to contribute into a code base that’s not in their local domain that we culturally encourage stewardship, and the ability for people to cross boundaries. What you don’t want to have happen is, if you don’t allow this, you create an unsustainable network of interdependencies that will prevent you from being able to ship with high velocity. You have to have some facility for teams to unblock themselves, rather than everyone just taking dependencies on each other. It’s easier said than done. Generally speaking, the larger the code base is, the bigger the company is, the less likely it is that team A is going to be able to effectively work in team B’s code base. Allowing internal mobility in the company and encouraging it is the most effective way I’ve seen this solve problems at scale. Rather than taking a cross team dependency, saying, can person on team A come and help out, even if temporarily, with team B’s code base. Not only unblocks the inter-team dependency, but it also shares knowledge.
Shoup: The idea of stewardship, like contributing in an internal open source model between the teams. That’s not exactly sharing components, that’s scratching my own itch, but it’s not the priorities of the team. When I ran App Engine, like that worked really well. Tying back, Nick, to one of your earlier points like, it was a line item on their promo packet that they contributed to this other thing. Just like an external open source project, you have to be super clear on, here are the contribution guidelines. We’ll read your PR, but we won’t necessarily merge it, and we expect the tests. There’s a bunch of good stuff there.
Dealing with High Management Resistance
Any hints on how to deal with high management resistance to change even if the organization in general is willing to change?
Wells: I think change works best if it does come down from the top. We used to do tech talks, and we used to invite people in to come and talk, and it would generally be connections we had. It is amazing how someone externally to the company coming in and saying the same thing you’ve been saying internally, can have an impact. Charity Majors came and gave a talk about observability, and literally for the next six months, engineers all over the place would say, Charity said we should do this. It’s like, this is great. Actually demonstrating that other people think this is an approach so that people feel, yes, actually, this is a standard thing. That can help.
Narayanan: I think the question maybe was also how to overcome management resistance. There’s definitely hearing from industry experts. I think this touches upon a topic that we were discussing in the prep, which was how to quantify the business impact of enablement teams. I think that’s where you start getting into management, because this is an indirect impact. I think Nick touched upon it in terms of NSAT scores and things like that. That’s a whole other area. There’s quantitative metrics and qualitative feedback. That’s what enablement team is looking at in general, and that they can’t make the case.
Caldwell: How you solve this depends where you sit in the org hierarchy, in terms of what levers you can pull. As a company gets larger, it will incur innovator’s dilemma that hits foundational teams, as well as the end user product services as well. You always have to reserve some capacity to allow people to innovate. My default assumption is that it will not be 100% of the people in my management chain will want to just be hyper change tolerant, because as a company gets bigger, you’re naturally disincentivized to do that. Where you go really wrong is if you don’t have any capacity to reserve for innovation at all.
From where I sit in the org, there’s two things I do. I always allow teams to spike ahead and experiment with new technologies or new experiences or new ways of working, and then bring that knowledge back to the core teams, and we can expand out. That way, you’re not relying on massive culture change from all of your managers. If you’re at a mid to large-size company, and you try and get all of your managers to be change tolerant at the same time, it will probably cause more trouble than it’s worth. There’s a reason it’s called change management, you have to manage it. That’s one thing.
The other thing is there are times when you cannot afford debate on change. If you have a burning platform problem, or if you have a competitor who is outpacing you, and if you have people in your team, who really just fundamentally want to do things the old way, that becomes personnel issue. You sit down with them and say, for this part of where we’re at in the business cycle, these are the behaviors that we need. Then I’ll let your imagination run to where that takes you. Sometimes you just have to make the call about what you need for a given moment in the business, and decide how patient you’re going to be to bring systems and people along with you.
Shoup: I’d love just to reinforce that, I think all of us have happening. If you’ve worked in a company that’s been around for a while, there’s definitely behaviors that were adaptive when we were small, and they’re not adaptive when they’re larger. Really, anybody that’s worked in an organization that’s grown substantially has had this situation. This doesn’t come from like, I want to fire this person. It comes from, let’s be all open and honest and transparent with each other about, everything you were doing was super awesome five years ago, and it’s not working now. We got a couple of options. A lot of times when you have that conversation very transparently with somebody, they’re like, I see that and I’m on. Or, I see that and, no, I want to go do another startup. We all know people that are the early stage seed startup people and they’re like, 25 people is too big. Then there are the people that are like, 10,000 people is too small.
Wells: For the Financial Times, it wasn’t, we’re growing massively, it was, we’re changing our culture. We’re adapting, and we’re going from 12 releases to the website a year to 30,000 changes last year. We’re releasing changes all the time. Moving to microservices, you need a different type of developer, both generally and on platform teams. Part of what you do is you look to recruit those when you have natural turnover, and some people who are in the team will make the transition because they see this and they say, “This is really cool. I want to learn it.” Some people will decide, it’s not for me, and they’ll leave. Then you have a few people who it’s not for them, and they don’t leave. That’s the more difficult thing. That’s where the incentives come in, because that’s the only way you can show this is the behavior we want. We did do a pretty big change and went from people who probably spent 80% of their time writing code. Then they committed it, and someone else packaged it up and deployed it. To people that do a lot of different things. That’s a massive change for people’s day to day work.
How Not To Structure or Organize Product Teams
Shoup: Anything you would highlight on how not to structure or organize product teams. Maybe you’ve encountered some team structures, which really don’t work, maybe related to team size, ownerships, lack of ownership, or team member to product ratios.
Caldwell: There’s an easy one for not to do, like the holacracy movement, which was popular a while ago. Anyone who’s been a manager just looked at that and was like, “This is bare idiocy. What are we talking about here?” I think it works first. There’s maybe one or two companies on the planet where that thing works. In general, as the company scales, you will need different organizational structures. An analog you might use is a cell splitting. In the smallest stage, it’s just one cell, everyone’s doing everything. Then it starts to split, and the two cells each have parallel functions, and so on. I generally think that there was periods and times when not having managers or having overly flat hierarchies was popular. We are, thankfully, out of that phase of whatever management philosophy, to a place where I think we’re approaching more reasonable, we call it at Twitter, full stack teams. Given a project, make sure that it has all of the resources, people, and personnel necessary to carry on to whatever that mission is. Then you can then stack related teams into aggregate groups who are all marching toward the same direction, and then upward into higher level products, and so on. If you think about it this way, you end up with a nice hierarchy of organization.
Then you can also think about across all of those product type teams, what shared capabilities you might need. Those tend to end up in your platform teams. Then you also might think about, what teams do you need to better understand your users? Those tend to be data science, or growth teams, or things like that that sit across all of your product teams. That standard framing is what I typically recommend to people. Then the main thing is, like org design also depends on the type of people that you’ve hired and the culture that you’ve built. How much freedom or independence versus top-down hierarchy you’re going to give people. All of this influences your org. Also, the product you’re building, your product organization is usually mapped in some way to how your org and your product is designed. All of this stuff is a mix. Hopefully, that’s good general guidance.
Narayanan: I think also, it’s important to be intentional about how we structure our teams. Sometimes if you’re not careful, you put something in place and you’re just drifting. That’s one thing. Then talking about incentivizing, let’s be clear, our product teams incentivize for velocity, nimbleness, and all of that. The platform team, what do you incentivize for long term leverage? Are they inherently at odds? How do we bridge them? I think I’ve seen challenges when we’re not clear about that. I think finding that balance and make it very clear. That’s the people part. If you have more infrastructure-y people in your product org, there’s tension there. Those are some things I would watch out for.
Wells: I think the key thing is, you don’t want teams that have to wait on other teams to make progress. There’s the whole thing in Accelerate, it’s like if you want to be loosely coupled. You want the team to have ownership of something, and to be able to make progress. You don’t want them to be sharing a test environment. You don’t want them to be going to a change board. You don’t want them to be waiting for someone else to approve a request for something to be provisioned. That structure means that you’re looking at the places where things get held up and trying to automate it, trying to simplify it. If you have some part of your estate where you’re not clear who owns it, that is going to cause you trouble, and you need to work out how that goes. That can be difficult because you will have some places where people want to make changes. If you’re at the FT, people probably want to put things on the website for various product reasons.
Application SRE Embedded in Agile or Product Teams vs. Platform SRE
Shoup: What’s the panel’s point of view on application SRE that is embedded in the agile teams or product teams versus platform SRE to provide cross cutting concerns as a service? Is this model viable? Choose a model or a third model?
Caldwell: It depends on your org. My preference is embedded, but that assumes that you have enough resourcing and that your central SRE org has enough shared tooling and capability to support embedded engineers. You may or may not be in that state. At Twitter, right now, all SREs are coming from a central model, we’re not embedded. I’ve worked at other places where we’ve managed to fully embed. One way to think about org structure and org design is like removing dependencies as a lever to very quickly improve your velocity. Embedding not just SREs but many functions is a way to accomplish that. To get to a point where you can embed, it does require your organization has reached certain levels of maturity.
Narayanan: I’d say that more strongly, totally in favor of embedding. I do feel like, to the point of maturity, yes. I do think that the enablement function does because it really rises in importance. I do feel like the industry is at a point to where there’s enough out there that you don’t have to build it all. You can get leverage from a relatively modest investment. I’m definitely a big fan of operate what you build.
Wells: I totally think you build it, you run it. We don’t really have an SRE model. Our website is running on Heroku. We’re outsourcing some of the work that you would do to create that platform for you. It’s quite conscious. It gives that team a lot of freedom. Making sure you have the skills in the team, whichever way around you want to do it. Either because you have someone embedded who can do the work, or you’ve got something where you can get it from a third party, or where your platform or enabling teams have made something that’s very simple, well documented, self-service, so that actually you don’t need someone to be there embedded because it’s really straightforward to do what you need. That’s the Holy Grail.
Showing the Value of Platform and Enabling Teams to the Overall Business
Shoup: How to show the value of platform teams and enabling teams to the overall business.
Narayanan: Think of your platform as a product. How would you, I’m not saying sell it, but what’s the value you’re bringing? That’s something you think about if you create a business and a product, so that mindset, I think you start with that. Then the tactics are, what are your KPIs? Often, you just gradually drift into building these things, “That’ll make this easier.” Then at some point, it’s like, ok, shaving the five minutes off of this, is that the place you’d invest? Having some KPIs. In all our businesses, you have all kinds of metrics and dashboards that execs are looking at, how many of us have the same level of rigor when it comes to our internal enablement team? Trying to do that after the fact gets harder. Having some sense of that, I think, is it.
Then we touched upon the other aspects, the qualitative feedback surveys, and interviews. I think UX, somebody brought that up, that’s the thing I personally have learned over the years. My customers are engineers, I don’t have to worry about this stuff. No DX, DevEx, so that matters. I cannot understate the value of culture, because we touched upon this with the management. At some point, you can make the case. At the end of the day, we’re able to say, it’s about freeing up capacity so our engineers can focus on business. There’s this indirect benefit as well, and have senior leadership buying into the culture. At the end of the day, we can have all the metrics, but I think the culture and the environment you create is huge.
Wells: I agree completely, the sales thing. I think, particularly infrastructure engineers don’t tend to write something that says, here’s this great thing we built, and this is what it does for you. Doing that, and thinking about how you’d sell that to someone who’s not another infrastructure engineer, I think is really valuable. In Randy’s talk, he talked about the fact you’re effectively competing with vendors. If you have a culture where someone could go out and get this from someone else, the fact that they vote for you, proves that you’re providing value. It’s a bit scary the thought of offering that. You should be able to meet the needs of the engineers in your organization better than anyone else can, because you have them right there that you can talk to and find out exactly what they need.
This is tangential, but we run an internal engineering conference once a year. A couple of years ago, we did a panel on how standardized should we be. If you talk to technical leadership, they were very much on the, we should all be free to make our own choices. It turned out that a lot of our engineers were like, please, could we just have some standard things we can use? Having that panel where there was a vote and hands went up, it had an amazing impact on what people thought. Feedback is great, but asking the question in public and having people see what other people think, is also good.
Caldwell: I think you have to be, as an engineering leader, a strong advocate for your platform teams, because they’re at a disadvantage compared to your user facing teams. Your user facing teams, when they ship something, it’s going to get multiplied by the external environment. Your customers are going to be high fiving the PMs, and that’s going to go all the way up to your C level. The odd thing is, if you think about the impact that platform teams have, it’s actually a greater impact. It touches every engineer in the company. It’s just, you don’t have that magnification layer. The way I think about this is if you treat your engineering organization as the customer, and then try and find ways to get those folks to celebrate your wins in the same way that an external customer might, then you can get the same celebratory feel when you ship a change. Then some of those changes are really dramatic. Right now at Twitter we’re moving a lot of our internal data tooling to GCP from some on-premise systems. We’re seeing order of magnitude improvement in our ability to understand data and our pipeline speeds, and so on. This stuff is just as valuable as the fact that we shipped Spaces last week. We just have to always keep in mind like, impact, who’s the customer? Then formalize getting quotes, or insert, or however you want to do it. Focus on making sure that that customer voice when they’re satisfied, is heard, and that gets broadcast throughout the entire company.
Never lose sight of incentives. It’s great to have high fives from customers, but you have to back it up with actual tangential rewards in your performance and review system. Just make sure that when you’re sitting in the promo committee, or however your company does it, that it is just as valuable to have change improvements on internal infrastructure as it is to ship customer facing features. That has to come from engineering leadership.
Shoup: I’ll just restate the problem. How do we prove to executives that there’s value to doing this platform investment. To everybody’s point, like, so much leverage. You add a marginal person to the platform team that should accelerate lots of other people’s work, how do we measure that? One thing to do is you can use the four key Accelerate metrics around deployment frequency, and lead time, and change failure rate, and MTTR, which I am actually doing my personal version of this quest. The other thing is, value it in terms of the stuff that the business cares about, which is people, money, and time. If one, hypothetically, would imagine that XYZ product team wants to achieve a certain goal, and ok, product team says this is going to take us 50 person months to get from here to there. Then you can have the conversation, let’s try to figure out what that 50 is, not because I want to argue down and beat you down. I trust your 50, but I bet I can make that 50 40, or 30, or 20, if we apply some engineering discipline to it. That’s the unlock. You do that a couple of times or all the time, and then it’s like, shouldn’t we be investing more in this leverage? Again, remember what your business cares about and your customers.
Failure Scenarios due to Company Changes
Do you have failure cases to talk about, maybe situations where people left because they didn’t follow the company change, or companies where changes were not easy?
Wells: Yes, absolutely. Any change that you do, you will have people who are up for it, you’ll have people who will come along the way once they see where it’s going, and you will have people who do not want to do it. You need to be very clear about what this change is and what it means, so that people can decide, this is not what I want to do. I’ve spoken to people in the past that I managed and had that conversation about, I think you would be happier in an organization that works like this. Obviously, eventually people can dig themselves in, but really, people who are motivated generally will go and find the thing that works for them.
Caldwell: You have to tell people the change you want and find people who are going to be supporters, and double down on them. You have to find people who are going to be detractors, and you have to ask them to do something else. Has this 100% worked in my career? No. I’ll give a very specific example. I used to work at Microsoft, and I once got marching orders from my upper management that we were going to take a bet on the Windows Mobile platform. I’ll just leave that dangling thread. I did all the above, found change agents. We took a bet on Windows Mobile, and then the whole platform dropped out from under us. People weren’t happy with it, so it led to another round of change management. As senior leaders, you’re constantly managing this change. It’s par for the course.
Narayanan: I think speaking of change, it’s probably worth understanding why someone is resistant to change. People fall in different cans. There’s some great literature out there. Sometimes we think about it’s not, are you in or are you out? It’s, how do you tackle this cohort versus this cohort? That’s something I would consider adding.
See more presentations with transcripts