Month: April 2022
Document Databases Software Market Biggest Innovation with Top Key Players – Energy Siren

MMS • RSS
Posted on mongodb google news. Visit mongodb google news

The Document Databases Software market is globally one of the leading markets involving innovative techniques development and extremely categorized sector. After a thorough investigation conducted over the industries under Document Databases Software market, the market report delivers in-depth information, based on the data related to export and import along with the ongoing industry trends in the global market. The report deeply observes the competitive structure of the Document Databases Software market worldwide. The Document Databases Software market report comprises the detailed summary of the various firms, manufacturers, organizations, and other competitive players that hold major count over the global market in terms of demand, sales, and revenue by providing reliable products and services to the customers worldwide.
Key Players Profiled In the Report Includes
The major players covered in the Document Databases Software report are MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis
Request A Sample Report + All Related Graphs & Charts @https://www.mraccuracyreports.com/report-sample/399125
The global Document Databases Software market report renders notable information about the Document Databases Software market by fragmenting the market into various segments. The global Document Databases Software market report delivers a comprehensive overview of the market’s global development including its features and forecast. It requires deep research studies and analytical power to understand the technology, ideas, methodologies, and theories involved in understanding the market.
Furthermore, the report presents complete analytical studies about the limitation and growth factors. The report provides a detailed summary of the Document Databases Software market’s current innovations and approaches, overall parameters, and specifications. The report also gives a complete study of the economic fluctuations in terms of supply and demand.
Document Databases Software Market
Cloud Based, Web Based.
Application as below
Large Enterprises, SMEs
Apart from this, the report includes the Document Databases Software market study based on geographical and regional location. Geographical Segmentation, On the basis of region, North America (United States, Canada), South America (Argentina, Chile, Brazil, etc.), Asia-Pacific (India, China, Japan, Singapore, Korea, etc.), Europe (UK, France, Germany, Italy, etc.), the Middle East & Africa (GCC Countries, South Africa, etc.) and the Rest of the world.
Key Points of Document Databases Software Market:
CAGR of the Document Databases Software market during the forecast period 2020-2026.
Accurate information on factors that will help in the growth of the market during the next six years.
Forecasts on future industry trends and changes in customer behavior.
Outlook of the market size and its contribution to the parent market.
The growth and current status of the market in the COVID-19 Pandemic Situation.
Analysis of the competitive landscape of the market and detailed information on the vendors.
A comprehensive description of the factors that will challenge the growth of market vendors.
The Document Databases Software global report indicates the status of the industry and regional and global basis with the help of graphs, diagrams, and figures to make it easy and better understandable.
Please click here today to buy full report @ https://www.mraccuracyreports.com/checkout/399125
The Document Databases Software Report Supports the Facts Below:
Industry Historical Demand Trends and Future Development Study – Document Databases Software Market Investors will make their business decisions based on historical and projected performance of the market Document Databases Software in terms of growth trends, revenue contribution, and Document Databases Software market growth rate. The report offers Document Databases Software industry analysis from 2016 to 2019, according to categories such as product type, applications/end-users and regions.
Market Drivers, Limits and Opportunities – The market is deeply evaluated by a current market situation such as market growth factors and constraints. In addition, here we can discuss the latest industry news and its impact on the Document Databases Software business.
Industry Chain Analysis – The study of industry chain structure incorporates details related to supplier’s and buyer’s information. Furthermore, the report classifies the top manufacturers of Document Databases Software business based on their production base, cost structure, Document Databases Software production process, spending on raw materials and labor outlay.
Future Project Expediency – The Document Databases Software market report includes a detailed explanation about the past and present trends of the market has been following along with its future analysis that may concern with the Document Databases Software market growth.
Note – To provide a more accurate market forecast, all our reports will be updated prior to delivery considering the impact of COVID-19.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Someone with a lot of money to spend has taken a bearish stance on MongoDB MDB.
And retail traders should know.
We noticed this today when the big position showed up on publicly available options history that we track here at Benzinga.
Whether this is an institution or just a wealthy individual, we don’t know. But when something this big happens with MDB, it often means somebody knows something is about to happen.
So how do we know what this whale just did?
Today, Benzinga‘s options scanner spotted 13 uncommon options trades for MongoDB.
This isn’t normal.
The overall sentiment of these big-money traders is split between 30% bullish and 69%, bearish.
Out of all of the special options we uncovered, 8 are puts, for a total amount of $304,030, and 5 are calls, for a total amount of $162,018.
What’s The Price Target?
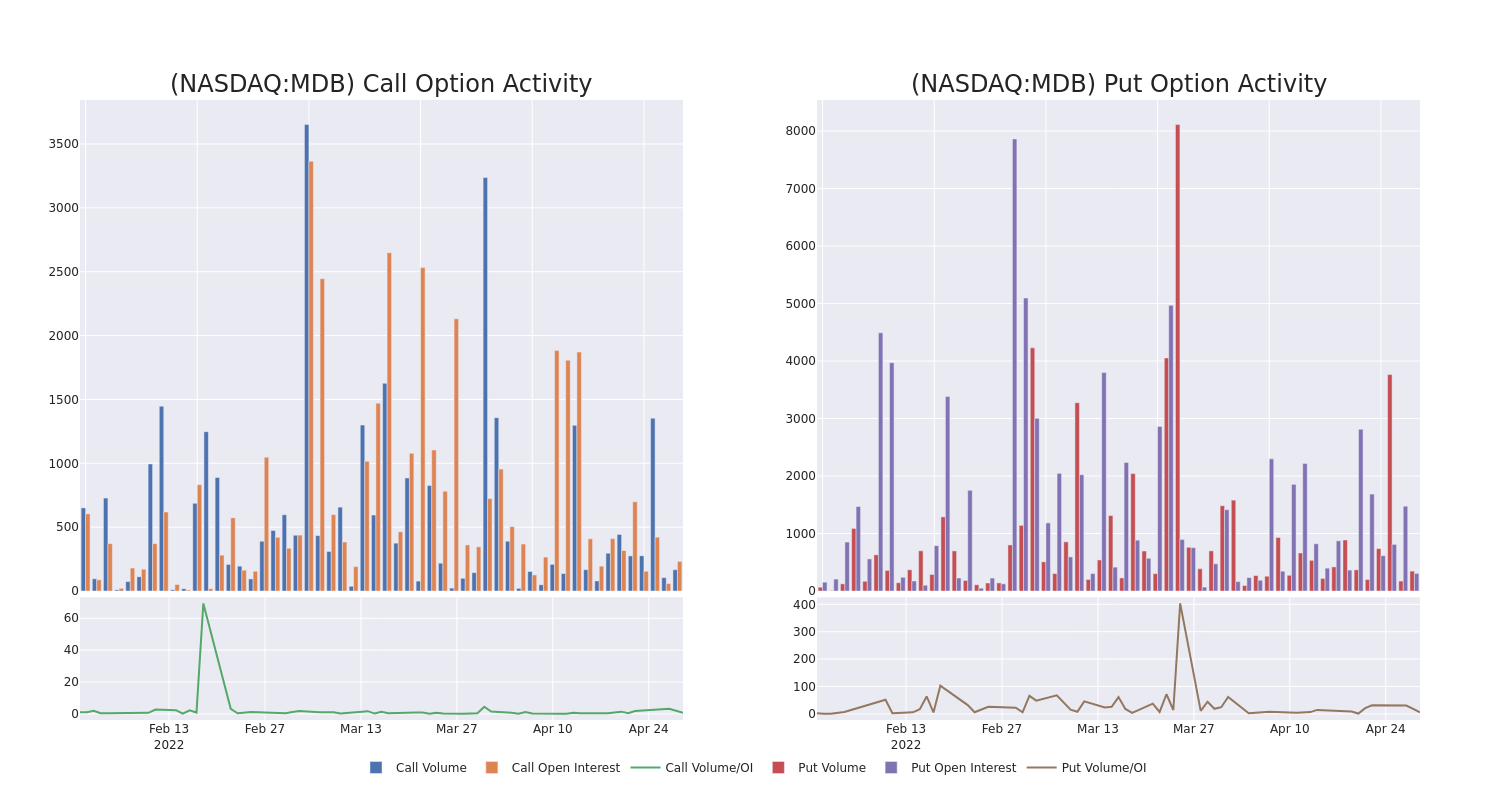
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $145.0 to $450.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $145.0 to $450.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | TRADE | BEARISH | 05/06/22 | $360.00 | $76.8K | 112 | 127 |
| MDB | CALL | SWEEP | NEUTRAL | 05/06/22 | $410.00 | $43.6K | 8 | 142 |
| MDB | PUT | TRADE | BULLISH | 05/06/22 | $360.00 | $42.1K | 112 | 163 |
| MDB | PUT | SWEEP | BEARISH | 01/20/23 | $440.00 | $34.5K | 33 | 0 |
| MDB | CALL | SWEEP | BEARISH | 05/06/22 | $410.00 | $34.1K | 8 | 0 |
Where Is MongoDB Standing Right Now?
- With a volume of 221,733, the price of MDB is down -1.64% at $371.47.
- RSI indicators hint that the underlying stock may be approaching oversold.
- Next earnings are expected to be released in 34 days.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for {d[company_name]}, Benzinga Progives you real-time options trades alerts.
Article originally posted on mongodb google news. Visit mongodb google news
QCon Plus, May 10th: Learn About the Latest Software Development Trends & Real World Best Practices
MMS • Ian Robins
Article originally posted on InfoQ. Visit InfoQ

The latest QCon Plus virtual event begins online in just over a week (May 10th). The online software development conference and learning path brings together innovative software practitioners who will share case studies and insights about real-world best practices and solutions in software development and tech leadership.
Join you peers to learn about the latest software delivery methodologies, technologies, and frameworks that will help you identify what you and your team should focus on to achieve your goals. You will leave the event with insights that will save you valuable time and give you assurances that you are adopting the right technologies, practices, and skills for your organization’s current challenges.
Top tracks not to miss as a Software Architect, Software Developer, Product Manager or a Team Lead
- Architectures You’ve Always Wondered About: Hosted by Eder Ignatowicz, Java Champion, Tech Lead, and Principal Software Engineer @RedHat.
- Building and Evolving APIs: Hosted by Wes Reisz, Technical Principal @thoughtworks & Creator/Co-host of #TheInfoQPodcast, previously Platform Architect @VMware
- Debug, Analyze & Optimise… in Production!: Hosted by Pierre Vincent, Head of SRE @weareglofox.
- Modern Data Pipelines & DataMesh: Hosted by Adi Polak, VP of DevEx @Treeverse
- Resilient Architectures: Hosted by Nicki Watt, CTO/CEO @OpenCredo
- Current Trends in Frontends: Hosted by Luca Mezzalira, Principal Solutions Architect @AWS
- Modern Java: Hosted by Holly Cummins, Senior Technical Staff Member & Innovation Leader @IBM
- Staff-Plus Engineer Path: Hosted by Fabiane Nardon, Data Scientist, Java Champion & CTO @tail_oficia
- Optimising for Speed & Flow: Hosted by Matthew Skelton, Founder and Head of Consulting @ConfluxHQ
Recommended Talks
Rob Donovan and Ioana Creanga talk about what happens behind the scenes when you pay with your card, and how Starling built their own card processor, integrating more traditional hardware with cloud-deployed micro-services. With speakers: Ioana Creanga, Engineer Lead for the Payments Processing Group @StarlingBank and Rob Donovan, Tech Lead @StarlingBank.
In this talk we are going to take a step back and go through a handful of skills that, when applied strategically, will help you amplify your impact. Hear about 5 behaviors that can improve your position in a team. Learn how to evaluate yourself to see if you are doing the right thing in your team. Speaker: Blanca Garcia Gil, Principal Engineer.
This talk will give you a peek into the day-to-day reality of working with a GraphQL API at scale, taking you on a journey through the API development process at Twitter. Michelle will share the unique challenges Twitter faces, plus the strategies and tooling they’ve built to handle these challenges. Speaker: Michelle Garrett, Software Engineer @Twitter.
In this talk, we review the current data landscape and discuss both technical and organizational ideas to avoid being overwhelmed by the current lack of consolidation in the data engineering world. We will discuss ideas from adopting open source APIs and open standards to more recent data management methodologies around operations, data sharing, and data products that enable us to create and maintain resilient and reliable data architectures. Speaker: Ismaël Mejía, Senior Cloud Advocate @Microsoft.
In this session, we will talk about fault isolation boundaries and ways to take advantage of fault isolation in AWS. We will then demonstrate initial tests you can use to ensure your system has successfully isolated faults within its architecture. Speaker: Jason Barto, Principal Solutions Architect @AWS.
In this talk, Anna Shipman, Technical Director for Customer Products at the Financial Times, will talk about her experience joining the FT to lead on FT.com a few years after launch; and share some of the things that she and my team implemented to stop the drift towards an unmaintainable system and another rebuild. Speaker: Anna Shipman, Technical Director for Customer Products @FinancialTimes
There are many ways to take part in QCon Plus. You have the opportunity to attend all the sessions live online or create a self-directed learning experience over 90 days to fit your schedule. Pick the learning pace that works best for you:
- Fully live experience: Immerse yourself in the full live experience spaced over a few hours a day across two weeks. Get your burning questions answered by our 80 software practitioner speakers in interactive Q&As, speaker hangouts, and in our QCon Plus Slack.
- A mix of live and on-demand access: Pick the sessions you would like to join live, connect with speakers and peers, and watch other talks on-demand over 90 days at a pace that suits you.
- All on-demand access for 90 days: A stress-free training environment. Create a self-directed learning experience over 3 months to fit around your schedule. Your all-access 90-day pass will unlock 60+ inspirational talks to watch at your own pace…as many times as you like.
- Start your learning path starting on May 10. Sign up.
Take advantage of the QCon Plus group discount.
Don’t let your friends and colleagues miss out. Attend as a team at QCon Plus and receive an additional complimentary ticket for every 4 regular conference tickets purchased. There’s no need to add attendee names yet. Order the tickets now and add names later. Once you have placed the order, we’ll send individual promo codes that each person can use to register.
Book your seat now and catch all sessions on-demand across 90 days! Attend QCon Plus Online Software Development Conference starting this May 10.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently, AWS announced the general availability of the second version of Amazon Aurora Serverless, an on-demand, auto-scaling configuration for Amazon Aurora. The second version is generally available for both Aurora PostgreSQL and MySQL, featuring the independent scaling of compute and storage.
The company released the first version of Amazon Aurora Serverless in August 2018 as a serverless database offering that automatically starts, scales, and shuts down capacity with per-second billing for applications with less predictable usage patterns. Customers could leverage this serverless option in Aurora by creating an endpoint through the AWS Management Console, and Aurora Serverless takes it from that point onward.
However, due to scale up/down speeds, failover time, and lack of Aurora provisioned cluster features flagged since the release, AWS released a second version in a preview that scales in a fraction of a second and introduces multi-AZ support, global databases, and read replicas. And now, this second version is generally available for the MySQL 8.0 and PostgreSQL 13 compatible editions of Amazon Aurora, including a new key feature according to the company with the separation of compute and storage. As a result, storage automatically scales as the amount of data in the database increases, and compute scales independently when needed (not every workload needs a constant amount of compute).
In an AWS press release on Amazon Aurora Serverless Version 2, Swami Sivasubramanian, Vice President of Databases, Analytics, and Machine Learning at AWS, said:
With the next generation of Amazon Aurora Serverless, it is now even easier for customers to leave the constraints of old-guard databases behind and enjoy the immense cost savings of scalable, on-demand capacity with all of the advanced capabilities in Amazon Aurora.
According to the User Guide of Amazon Aurora Serverless Version 2, the service is architected from the ground up to support serverless DB clusters that are instantly scalable. Furthermore, it is engineered to provide the same security and isolation as provisioned writers and readers. Additionally, the documentation provides the following explanation:
By using Aurora Serverless v2, you can create an Aurora DB cluster without being locked into a specific database capacity for each writer and reader. You specify the minimum and maximum capacity range. Aurora scales each Aurora Serverless v2 writer or reader in the cluster within that capacity range. By using a Multi-AZ cluster where each writer or reader can scale dynamically, you can take advantage of dynamic scaling and high availability. Aurora Serverless v2 scales the database resources automatically based on your minimum and maximum capacity specifications. Scaling is fast because most scaling events operations keep the writer or reader on the same host.
Marcia Villalba, a Senior Developer Advocate for Amazon Web Services, stated the following on the scaling down in an AWS News blog post:
For scaling down, Aurora Serverless v2 takes a more conservative approach. It scales down in steps until it reaches the required capacity needed for the workload. Scaling down too quickly can prematurely evict cached pages and decrease the buffer pool, which may affect the performance.
Lastly, Amazon Aurora Serverless capacity is measured in so-called Aurora Capacity Units (ACUs). Each ACU combines approximately two gibibytes (GiB) of memory, corresponding CPU, and networking. According to Villalba, with Aurora Serverless v2, the starting capacity can be as small as 0.5 ACU, and the maximum capacity supported is 128 ACU. In addition, it helps fine-grained increments as small as 0.5 ACU which allows the database capacity to match the workload needs closely.
However, AWS Serverless Hero, Jeremy Daly, made the following comment on Twitter about Aurora Serverless Version 2:
There are two major problems with Serverless Aurora v2 that fundamentally miss the mark of true #serverless(ness). One is the inability to auto-pause (as Mike mentions), and the other is the missing Data API. These might make it unusable (for now).
The second version of Amazon Aurora Serverless Version 2 is currently available in various regions in the Americas, Europa, Asia, and the Pacific. More details are available on the documentation pages, and pricing can be found on the pricing page.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Google has just introduced Android 13 Beta 1, aiming to improve privacy and security, as well as developer productivity. Alongside it, developers can start exploring the Privacy Sandbox Preview, a collection of technologies that improve user privacy while enabling personalized ads, says Google.
Android 13 Beta 1 introduces new, more granular permissions to access media files. In particular, whereas older Android version dumped all distinct media types under the same category, Android 13 explicitly differentiates three media file types: images and photos, videos, and audio files.
When the permissions are granted by the user, apps will have read access to the respective media file types. To simplify the experience for users, If an app requests READ_MEDIA_IMAGE and READ_MEDIA_VIDEO at the same time, the system displays a single dialog for granting both permissions.
Apps accessing shared media files will need to migrate to the new permission system if they want to keep working as expected on Android 13. For compatibility with previous Android versions, apps will also need to include the old READ_EXTERNAL_STORAGE permission for SDKs up to and including version 32.
Android 13 Beta 1 also improves support for determining the best audio format to use for an audio track. In particular a new getAudioDevicesForAttributes() allows developers to retrieve a list of devices that may be used to play the specified audio and getDirectProfilesForAttributes() tells whether an audio stream can be played directly.
Other upcoming features in Android 13 that were already available through developers previews include a new notification permission, support for color vector fonts, text conversion APIs, Bluetooth LE Audio, MIDI 2.0 over USB, and more.
The Privacy Sandbox for Android is roughly the equivalent to Apple’s App Tracking Transparency, a solution that allows users to prevent an app can track them using an advertisement ID.
Google approach focuses on preventing cross-tracking across different apps, while still granting an individual app effective means to present customized advertisements. In particular, those include Topics, Attribution Reporting, and FLEDGE on Android.
Our goal with the Privacy Sandbox on Android is to develop effective and privacy enhancing advertising solutions, where users know their privacy is protected, and developers and businesses have the tools to succeed on mobile.
The Topics API supports so called Interest-based advertising (IBA), where users are shown ads based on their interests as they can be inferred from the apps they have been using in the past. This differs from contextualized advertising in that ads are displayed based on content the user is currently consuming.
Attribution Reporting is similar to Apple’s ATT solution and aims to prevent the usage of cross-party identifiers such device IDs, advertising IDs, and so on, which can be easily used to track users. Every Ads publisher gets its own identifier which is then used to provide aggregate summaries about clicks and/or views to track conversion and fraud.
FLEDGE is a specific approach to what is commonly referred to as “remarketing” and “custom audience targeting”. For example, an app might want to show an Ad to a user who left some items in the shopping cart and remind them to complete the purchase. FLEDGE implements a bidding mechanism to make this possible without sharing user-related identifiers across providers. Instead, all user-related information is kept on the device itself and can be used by apps adopting FLEDGE to participate in the bid process.
As implied above, none of the above approaches have met any significant adoption, and it remains to be seen how well they will fare with the advertising industry. For this reason, the current Advertising ID will be supported for at least two years, says Google.
NoSQL Market Share, Size, Trends, Leading Companies, Growth, Opportunities and … – EIN News
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

SHERIDAN, WY, USA, April 28, 2022 /EINPresswire.com/ — According to IMARC Group’s latest report, titled “NoSQL Market: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2022-2027”, the global NoSQL market reached a value of US$ 5.5 Billion in 2021. Looking forward, IMARC Group expects the market to reach US$ 27.4 Billion by 2027, exhibiting a CAGR of 30.2% during 2022-2027.
We are regularly tracking the direct effect of COVID-19 on the market, along with the indirect influence of associated industries. These observations will be integrated into the report.
Request for a PDF sample of this report: https://www.imarcgroup.com/nosql-market/requestsample
Not only standardized query language (NoSQL) refers to a database that provides a mechanism for storage and retrieval of a massive volume of unstructured data. It makes use of real-time web applications and big data to enable schema-less data storage. The use of NoSQL has increased over the years as it offers high scalability, precise control, a straightforward design and convenient big data management. It can also accommodate data models, key-value, document, columnar, and graph formats. NoSQL utilizes flexible database tables compared to the relational database table, which aids in its prompt operations.
NoSQL Market Trends and Drivers:
With the increasing penetration of the internet and smartphones, NoSQL databases are being adopted to support the expanding business data in the social networks, retail, and e-commerce sectors, which represents the major growth-inducing factor. The colossal amount of unstructured and semi-structured data generated by varied business needs and user preferences is also fueling the demand for NoSQL database systems for data management and analysis. Furthermore, the increasing implementation of big data analytics is expected to bolster the market in the future. Moreover, the integration of NoSQL systems into the Industry 4.0 offers lower costs, schema flexibility, high scalability and distributed computing.
NoSQL Market 2022-2027 Competitive Analysis and Segmentation:
Competitive Landscape With Key Players:
The competitive landscape of the NoSQL market has been studied in the report with the detailed profiles of the key players operating in the market.
Some of these key players include:
• Aerospike
• Amazon Web Services
• Apache Cassandra
• Basho Technologies
• Cisco Systems
• Couchbase, Inc
• Hypertable Inc.
• IBM
• MarkLogic
• Microsoft Corporation
• MongoDB Inc.
• Neo Technology Inc.
• Objectivity Inc.
• Oracle Corporation
Key Market Segmentation:
The report has segmented the global NoSQL market on the basis of database type, technology, vertical, application and region.
Breakup by Database Type:
• Key-Value Based Database
• Document Based Database
• Column Based Database
• Graph Based Database
Breakup by Technology:
• MySQL
• Database
• Oracle
• Relational Database Management Systems (RDBMS)
• ACID
• Metadata
• Hadoop
• Others
Breakup by Vertical:
• BFSI
• Healthcare
• Telecom
• Government
• Retail
• Others
Breakup by Application:
• Data Storage
• Metadata Store
• Cache Memory
• Distributed Data Depository
• e-Commerce
• Mobile Apps
• Web Applications
• Data Analytics
• Social Networking
• Others
Breakup by Region:
• North America
• Asia Pacific
• Europe
• Latin America
• Middle East and Africa
Ask Analyst for Customization and Explore Full Report with TOC & List of Figures: https://www.imarcgroup.com/request?type=report&id=2040&flag=C
Key Highlights of the Report:
• Market Performance (2016-2021)
• Market Outlook (2022-2027)
• Market Trends
• Market Drivers and Success Factors
• Impact of COVID-19
• Value Chain Analysis
• Comprehensive mapping of the competitive landscape
If you need specific information that is not currently within the scope of the report, we will provide it to you as a part of the customization.
About Us
IMARC Group is a leading market research company that offers management strategy and market research worldwide. We partner with clients in all sectors and regions to identify their highest-value opportunities, address their most critical challenges, and transform their businesses.
IMARC’s information products include major market, scientific, economic and technological developments for business leaders in pharmaceutical, industrial, and high technology organizations. Market forecasts and industry analysis for biotechnology, advanced materials, pharmaceuticals, food and beverage, travel and tourism, nanotechnology and novel processing methods are at the top of the company’s expertise.
Our offerings include comprehensive market intelligence in the form of research reports, production cost reports, feasibility studies, and consulting services. Our team, which includes experienced researchers and analysts from various industries, is dedicated to providing high-quality data and insights to our clientele, ranging from small and medium businesses to Fortune 1000 corporations.
Elena Anderson
IMARC Services Private Limited
+1 6317911145
email us here
![]()
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

New Jersey, USA,- The research report, which contains the highest level of information, is the main advantage of providing qualitative and quantitative elements of the Big Data and Analytics market. The Big Data and Analytics Market Research report contains an in-depth survey of the market and concludes with the exact value of revenue generation by each sector, country, region and company. Each aspect that may prove essential to making a ponderous decision is mentioned along with solutions and recommendations from experienced forecasters. The Big Data and Analyticss market Research report contains comprehensive information about the dynamics that affect the market valuation during the evaluation period. It also covers market scope, competitive environment and market segmentation.
Get | Download Sample Copy with TOC, Graphs & List of Figures@ https://www.marketresearchintellect.com/download-sample/?rid=349161
In addition to a dashboard view of the vendor landscape and important company profiles,medical disposable market competition analysis provides an encyclopedic examination of the market structure. The company’s stock analysis included in the study helps players improve their business tactics and compete well with key market participants in the medical disposable industry. The strength map prepared by our analysts allows you to get a quick view of the presence of several players in the global medical disposable market. The report also provides a footprint matrix of key players in the global medical disposable market. It dives deep into growth strategies,sales footprints,production footprints,product and application portfolios of prominent names in the medical disposable industry.
The major players covered in Big Data and Analytics Markets:
- Microsoft Corporation
- MongoDB
- Predikto
- Informatica
- CS
- Blue Yonder
- Azure
- Software AG
- Sensewaves
- TempoIQ
- SAP
- OT
- IBM Corp
- Cyber Group
- Splunk
Big Data and Analytics Market Breakdown by Type:
- Data Intergration
- Data Storage
Big Data and Analytics Market breakdown by application:
As part of our quantitative analysis, we have provided regional market forecasts by type and application, market sales forecasts and estimates by type, application and region by 2030, and global sales and production forecasts and estimates for Big Data and Analytics by 2030. For the qualitative analysis, we focused on political and regulatory scenarios, component benchmarking, technology landscape, important market topics as well as industry landscape and trends.
We have also focused on technological lead, profitability, company size, company valuation in relation to the industry and analysis of products and applications in relation to market growth and market share.
Get | Discount On The Purchase Of This Report @ https://www.marketresearchintellect.com/ask-for-discount/?rid=349161
Big Data and Analytics Market Report Scope
| Report Attribute | Details |
|---|---|
| Market size available for years | 2022 – 2030 |
| Base year considered | 2021 |
| Historical data | 2018 – 2021 |
| Forecast Period | 2022 – 2030 |
| Quantitative units | Revenue in USD million and CAGR from 2022 to 2030 |
| Segments Covered | Types, Applications, End-Users, and more. |
| Report Coverage | Revenue Forecast, Company Ranking, Competitive Landscape, Growth Factors, and Trends |
| Regional Scope | North America, Europe, Asia Pacific, Latin America, Middle East and Africa |
| Customization scope | Free report customization (equivalent up to 8 analysts working days) with purchase. Addition or alteration to country, regional & segment scope. |
| Pricing and purchase options | Avail of customized purchase options to meet your exact research needs. Explore purchase options |
Regional market analysis Big Data and Analytics can be represented as follows:
This part of the report assesses key regional and country-level markets on the basis of market size by type and application, key players, and market forecast.
The base of geography, the world market of Big Data and Analytics has segmented as follows:
-
- North America includes the United States, Canada, and Mexico
-
- Europe includes Germany, France, UK, Italy, Spain
-
- South America includes Colombia, Argentina, Nigeria, and Chile
-
- The Asia Pacific includes Japan, China, Korea, India, Saudi Arabia, and Southeast Asia
For More Information or Query or Customization Before Buying, Visit @ https://www.marketresearchintellect.com/product/global-big-data-and-analytics-market-size-and-forecast/
About Us: Market Research Intellect
Market Research Intellect provides syndicated and customized research reports to clients from various industries and organizations with the aim of delivering customized and in-depth research studies.
Our advanced analytical research solutions, custom consulting and in-depth data analysis cover a range of industries including Energy, Technology, Manufacturing and Construction, Chemicals and Materials, Food and Beverages. Etc
Our research studies help our clients to make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information without compromise.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi.
Contact us:
Mr. Edwyne Fernandes
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Website: –https://www.marketresearchintellect.com/
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
(VIANEWS) – The NASDAQ ended the session with MongoDB jumping 4.88% to $377.56 on Thursday, after three successive sessions in a row of gains. NASDAQ jumped 3.06% to $12,871.53, after two consecutive sessions in a row of losses, on what was a very up trend trading session today.
Volume
Today’s last reported volume for MongoDB is 723129, 41.9% below its average volume of 1244810.
MongoDB’s last close was $359.98, 38.99% under its 52-week high of $590.00.
The company’s growth estimates for the current quarter and the next is a negative 19.4% and a negative 3%, respectively.
MongoDB’s Revenue

Year-on-year quarterly revenue growth grew by 43.7%, now sitting on 702.16M for the twelve trailing months.
Stock Price Classification
According to the stochastic oscillator, a useful indicator of overbought and oversold conditions,
MongoDB’s stock is considered to be overbought (>=80).
MongoDB’s Stock Yearly Top and Bottom Value
MongoDB’s stock is valued at $377.56 at 19:17 EST, way under its 52-week high of $590.00 and way higher than its 52-week low of $238.01.
MongoDB’s Moving Average
MongoDB’s value is way below its 50-day moving average of $509.44 and under its 200-day moving average of $389.11.
More news about MongoDB (MDB).


Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
AWS has added fast compute instances called I4i using Intel Xeon IceLake servers and 30TB of NVMe Nitro SSD storage.
These Nitro SSDs and the Xeons deliver up to 60 per cent lower I/O latency, 75 per cent lower latency variability compared to the prior I3 instances, and up to 30 per cent better compute price/performance. The processors have an all-core turbo frequency of 3.5GHz. There is a I41.32xlarge instance size with 128 vCPUs and 1,024GiB (1.1 TB) of storage using 8x 3,750MiB (3.9GB) Nitro SSDs – a total of 31.2TB of SSD capacity.
Yiftach Shoolman, co-founder and CTO of Redis, offered a testimonial: “Our testing shows I4i instances delivering an astonishing 2.9x higher query throughput than the previous generation I3 instances. We have also tested with various read and write mixes, and observed consistent and linearly scaling performance.”
Avi Kivity, co-founder and CTO of ScyllaDB, had similar to say: “When we tested I4i instances, we observed up to 2.7x increase in throughput per vCPU compared to I3 instances for reads. With an even mix of reads and writes, we observed 2.2x higher throughput per vCPU, with a 40 per cent reduction in average latency than I3 instances.”
The I4i.16xlarge and I4i.32xlarge instances give users control over C-states, and the I4i.32xlarge instances support non-uniform memory access (NUMA). All of the instances support AVX-512, and use Intel Total Memory. I4i instances give customers up to 75Gbit/sec of networking speed and 40Gbit/sec of bandwidth to Amazon’s EBS (Elastic Block Store). Overall, applications go faster for less money.

Nitro SSD
Intel says AWS’s Nitro System is a combination of dedicated hardware and lightweight hypervisor. The I4i instances deliver practically all compute and memory resources of the host hardware to instances.
AWS says a Nitro SSD has firmware inside responsible for implementing many lower-level functions, with designed-in operational telemetry and diagnostics. It has code to manage the instance-level storage to improve reliability and deliver consistent performance.
AWS says these SSDs are engineered to deliver maximum performance under a sustained, continuous load, with the firmware responsible for garbage collection and wear-leveling to even out Program-Erase cycles per cell over time. The firmware can also be updated, AWS says, at at cloud scale and at cloud speed – more often than commodity SSDs, at any rate.
Accelerated apps
The new instances, AWS says, “are designed to minimize latency and maximize transactions per second (TPS) on workloads that need very fast access to medium-sized datasets on local storage. This includes transactional databases such as MySQL, Oracle DB, and Microsoft SQL Server, as well as NoSQL databases: MongoDB, Couchbase, Aerospike, Redis, and the like. They are also an ideal fit for workloads that can benefit from very high compute performance per TB of storage such as data analytics and search engines.”
AWS customers can launch I4i instances today in the AWS US East (N Virginia), US East (Ohio), US West (Oregon), and Europe (Ireland) Regions (with more to come) in On-Demand and Spot form. Savings Plans and Reserved Instances are available, as are Dedicated Instances and Dedicated Hosts.
In order to take advantage of the performance benefits, customers must use recent AMIs that include current ENA drivers and support for NVMe 1.4. The I4i instance home page has more information.
MMS • Bryan Cantrill Laura Abbott Cliff Biffle
Article originally posted on InfoQ. Visit InfoQ

Transcript
Shamrell-Harrington: Welcome to a panel on Oxide Computing, which is a company that is building on Rust. I’m a principal engineer at Microsoft. I’m also a board director on the board of directors for the Rust Foundation, and I lead editing on, This Week in Rust.
Cantrill: I’m Bryan Cantrill, co-founder and CTO of Oxide Computer Company.
Abbott: I’m Laura. I am an engineer at Oxide Computer. A lot of my background has been with the Linux kernel. I’ve been at Oxide since January 2020. I’m very excited to be able to talk about my experience with Rust, and everything we’re doing at Oxide.
Biffle: I’m Cliff Biffle. I’m an engineer at Oxide. I’ve traded 20 years of doing silly things with C for now doing slightly less silly things with Rust.
Why Oxide Computing Was Founded, and Why Rust
Shamrell-Harrington: Can you tell us, what inspired the founding of Oxide Computing? Then, what inspired you to build so much on Rust?
Cantrill: Yes, like many companies, the foundation of Oxide was born out of frustration that the thing that we wanted in the world wasn’t being built. It felt very frustrating to Steve, Jessie, to me that the state of the art of the actual computer had not advanced that much from the perspective of those that needed to run their own compute in the data center. Indeed, those folks were being told that they didn’t exist, that everything was either going to the public cloud, or was going away. What we knew from our own experiences running a private cloud is that the folks were very much running on premises. Those folks felt pretty ignored by the market and the products really weren’t very good.
This is going to sound ridiculously trite. I knew we wanted to go do something together. We were beginning to think about what that old, I don’t know if it is mistreated Eleanor Roosevelt, I’ve always treated Eleanor Roosevelt, what would you do if you weren’t afraid of failing? The thing that we would do if we weren’t afraid of failing was start a computer company actually. That was the germ of the idea. As we talked to other technologists, we learned that a lot of other people saw the same problem that we saw. At the same time, I was beginning to fall in love with Rust. The three of us come from slightly different backgrounds. Laura and I actually are most similar in that we are historical C programmers. Cliff is coming from the perspective of C++ historically. I was discovering Rust out of something of desperation. It was like Rust or bust for me. I didn’t really know what was going to happen.
I had experimented in other languages and those weren’t going to be a fit for the software that I wanted to write. If it was not going to be Rust, I was going to have to find a way to componentize C better. It was like question mark, if Rust didn’t work out. As I got into Rust, it was really exciting actually. I had a blog entry about falling in love with Rust. To the point that when we started the company we wanted to have a tip of the hat in the name. Oxide is very much named because of what we saw happening with Rust.
That said, it was a little bit assertive in that I didn’t know Rust all that well. We’d been on a couple of dates and we’d gotten along, and things seemed to be going well. Now we’re really talking about building a company around Rust. Going in with a bit of a question like, would Rust be a fit? That’s when Laura and Cliff both joined Oxide very early, and discovered pretty early on that Rust is going to be an even better fit than we thought it was going to be in even more places than we thought it was going to be. That was an exciting realization. I think it was really helpful to have Cliff in particular. Laura, I don’t know from your perspective, my perspective is we were newer to Rust and Cliff was coming in with a lot of Rust experience, and had been already in certain places, and was really able to show us that this is actually very viable.
Experience with Rust
Shamrell-Harrington: Can you tell us about your experience with Rust as you were going into Oxide and how your understanding may have evolved as a result of using it?
Biffle: I used to do firmware for a balloon internet project about 10 years ago. At the time we started in C and we had moved into C++ because we needed the ability to define some of our own abstractions, which was something C is a little weak at. Our move to C++ was always grudging. We actually were aware of Rust from 2013, or so on. It never quite seemed right until 2015, 2016 around the time of 1.0, it started to look like an actual contender with a lot of really thoughtful changes that for those of us on a bare metal, had real-time heapless programming environment were incredibly valuable. I had snuck Rust into some previous projects in areas where we needed high performance, high determinism computing. That had been very successful. The interesting thing was teaching Rust to new people and watching how different people’s language backgrounds affected it. Honestly, a lot of this got easier at the 2018 edition, which made a lot of improvements to how learnable and understandable the language was. Teaching the Rust language today is so much easier than in 2015 because they’ve rounded off all of these horrible corners and improved the ergonomics just so much. When I got to Oxide, it was exciting not to have to start with the hard sell.
Using Rust in Prod at Oxide
Shamrell-Harrington: Can you tell us what it was like to come to Oxide, and start using Rust to write production stuff?
Abbott: Oxide was the first time I’d ever written any serious Rust. I’d played around with it, and I’d been aware of Rust for a very long time. I’d also seen it evolve. I think for the most part that the biggest thing for me is just to get comfortable really, to learn how to work with Rust and be able to see exactly what it can do for me to solve the right kinds of problems. If you’re starting out, it does look fairly familiar to see. A lot of the constructs will be similar. If you’ve come from any programming language outside of C as well, you also see some very familiar things. I had somewhat of a background in programming languages with a lot of respect there. I felt like I was coming into a C background with some of my favorite PL features.
It was really nice to be able to pick up and just be able to get more comfortable. Also, it gave me the confidence to be able to write things and not be able to make various mistakes I would be making in C, especially with respect to memory safety, for example. I spent so much of my career in C then tracking down these bugs in C just to know that Rust can eliminate a lot of these types of errors, but with minimal performance overhead. It’s been fantastic to be able to work with. There’s definitely been a learning curve but I think that comes with any language. I think it’s been great to have everyone at Oxide be able to answer questions that’s helped me also be able to write more idiomatic Rust as well, to be able to get to know some of the nitty-gritty stuff. I’m really becoming a better Rust programmer at the same time.
Shamrell-Harrington: You are definitely a Rustacean. Once you write your first line of code, you become a Rustacean in my book.
Oxide’s Hubris Platform
I understand you’re writing an operating system in Rust for the hardware you all are building. Can you tell me more about that?
Biffle: Part of what attracted me to Oxide initially was that their firmware effort at the time I joined was based on Tock. We worked with Tock for several months, and increasingly it became apparent that what we needed was weird, and our application didn’t line up super well with what Tock provided, which is a bunch of nice stuff, but not the stuff we wanted. We made the difficult decision last summer to roll our own, and in recognition of how that sounds we called the platform Hubris. Have been building our firmware on top of it since then. It’s a fairly simple all Rust, microcontroller protected memory operating system.
Abbott: I think also, it’s sometimes pretty rare to be able to write stuff from first principles. We’ve gotten really a chance to be able to build up and also be able to, I think, build the abstractions, we as lower level software developers really want to see in the world in terms of being able to have stuff that’s nice to work with. Being able to build everything up in terms of also being able to figure out, how exactly do we write safe drivers? For example, that take advantage of Rust features to be able to have access to the hardware that let us do what we want to do, but also, again, be able to take advantage of all the great features that Rust provides and everything.
Part of this has also been a lot of work on trying to make sure this is also debuggable, because I think we all have stories about getting stuck debugging one of these things. Because as much as we all talk about Rust and all the joy it provides, it will still not take care of some classes of bugs, of course. We still have to be able to make sure we debug. We’ve spent a long time. Especially, Bryan has been really pushing to be able to make sure we have a good way to be able to debug Hubris with Humility, as Bryan called his debugging tool, to be able to help to get things going. I think it’s been a good experience to hopefully be able to really get things going, and be able to, again, see the change you want to be in the world.
Shamrell-Harrington: I understand there are some principles of operation for Oxide, which are very important. Can you tell us more about those?
Cantrill: Yes, I do think. Just to touch up on Hubris, because I just can’t resist to try to be here. I’ve had so much fun building with these two. It has been such a homecoming for me. I worked for a company called QNX back in the day, microkernel based operating system. Cliff won’t let me say Hubris is a microkernel. He’s calling it an email kernel. It feels like it’s more appropriate for Ozymandias and Hubris. One of the things that I particularly love about Hubris, certainly for me, one of the wisdom that Cliff brought was what things in Rust not to use. For example, Tock is an async heavy system. I think for us as relative newcomers to Rust, it’s like, interesting. With Cliff coming in with more wisdom, and more miles on the tires from a Rust perspective, it’s like, async, there are times to use it. There are reasons to use it. It also complicates a lot of the system. Hubris has multiple tasks that are broadly synchronous, and we can add asynchrony to that system when and where we need it. It’s much more often a synchrony as opposed to forced asynchrony. That’s been great.
Cliff was very adamant about using the memory protection unit. Obviously, we’re pro memory protection. Cliff, I don’t feel you get to have an argument with anybody about the memory protection unit. You might think to yourself, why would you need a memory protection? Why would you need to enable the memory protection unit in a memory safe language? I think one of the things that is an important eye opener about any system is your stack usage is always fundamentally unsafe at some level. Even in an all safe system, if your stack grows without bounds, if you don’t hit a memory protection boundary, you will hit somebody else. You will plow into somebody else and you will corrupt your system. Indeed, where you overflow your stack and corrupt someone else is some of the most pernicious corruption to find. Even in Hubris, some of the gnarliest bugs we’ve had have been from that exactly. Again, not that we weren’t converts to begin with, but anyone developing their own Rust based system who thinks that they can turn off the hardware memory protection unit is doing so at their peril.
Oxide’s Principles of Operation
On the principles and values, very important to us. Looking to start a company, one of the things, and Laura talks about this too, in terms of being the difference that we want to see in the world, we wanted to be the difference that we wanted to see in the world in terms of the way a company engages its employees. The way a company engages its customers. The way a company engages its community. The way a company engages its broader community. We feel that we can be a model in that regard. I think that part of that is being very upfront about what our principles are. To be clear, principles are unequivocal. Honesty, integrity, decency, those are our principles. Principles can’t be taken to a fault. You can’t have someone who’s like, just too much integrity in this person. They’re their absolute. Whereas values are things that are tradeoffs. We have got 15 values at Oxide, which feels like a lot, but it feels like it’s the coverage that we needed: courage, candor, curiosity, diversity, empathy, humor, optimism, resilience, rigor, responsibility, teamwork, thriftiness, transparency, urgency, and versatility.
What we have found is, one, it has served to attract people to the company. When Laura and Cliff both came into the company, those values were important to them. The three of us share values. I think, almost just as importantly, when we diverge a bit, when we’ve got a different perspective, we can go back to those values, and help reason about some of those differences. From our perspective, this has been essential for the company. I can’t imagine anyone starting any endeavor without being upfront about those founding principles and values.
Oxide’s Values
Shamrell-Harrington: I do want to get Laura and Cliff’s perspective on the values.
Abbott: I was admittedly a little bit skeptical when I first heard about the values. A lot of companies out there say they have these types of values. I think more than anything, Oxide, I think has really been learning along the way about how exactly to hold itself accountable to those values and be able to go along the way. I really say this is a learning process, just because I think these are things we strive to be for. I think part of along the way is figuring out how to make sure we are going to go up, especially as we have grown as a company. When I joined Oxide, I think there were maybe not even 10 people and now we’re up to 30 or so. We certainly have a lot of people. I think part of figuring out what we do along the way is exactly how we have to go. I think more than anything, I think that transparency has really spoken to me about as we’ve made changes, as we’ve tried to do everything, I think that has really helped. One of the values that’s always struck me is in terms of being able to keep things going, so when we inevitably do make mistakes, we have a way to be able to find a path forward.
Biffle: I feel like one of the things that I’ve experienced, and I hear this a lot from applicants is that we’ve all got a corporate PTSD of various kinds, depending on where we’ve worked previously, or the stories we’ve heard. A lot of the process in evaluating a company is trying to figure out how they’re fronting, how they’re lying to you about their public image, and which of these things they espouse on their website that they just made up because they thought they sounded cool. They don’t reflect day to day operations. We try to put it really upfront with people that like, no, really, we take this list of things seriously. There’s a lot of things on the list, but they all stand alone. It really does produce a different environment both internally, but also when we’re trying to bring people in, and we can say “No, really, here’s the list. You can read the things we’ve said about it. We’re curious what you have to say about it, and let’s talk. Let’s actually engage on this.” It does produce a different kind of environment. It attracts very thoughtful people, and they’re all a joy to work with.
Shamrell-Harrington: That’s very Rust, thoughtful, technical excellence.
Features of Rust That Make Writing Code Difficult, at the Lowest Level
What are some of the features of Rust that you’ve found that make writing code at the lowest level still difficult at times? Examples I’ve seen, the standard alloc lib’s panic on out of memory exceptions, having control whether certain code is pageable or not.
Abbott: I like to start with just for my thing about learning how to do unsafe Rust, because I think probably the big thing, especially when you’re writing low level code, is that I think programmers, especially for when we’re here on safety, are like, “I can never use unsafe,” which is not actually true. The big thing about unsafe is that what it actually means to be doing things that are memory unsafe with respect to the guarantees that Rust can provide. That’s probably the trickiest thing I think is for me has been learning how exactly to use unsafe because things like especially accessing hardware is somewhat inherently unsafe in some respects. You have to be able to learn how to do that with respect. I think that’s probably been the biggest thing for me is especially learning how to write unsafe Rust as a Rust way as opposed to a C programmer would write Rust, which is not exactly the safest thing. Also learning exactly how to build these abstractions in such a way that they are narrow.
One nice thing about writing C is that it doesn’t have a great boundary in terms of module boundaries, in terms of say, this code goes here and this code goes here, whereas Rust I think is a lot tighter in terms of being able to contain things. I think, really being able to say, this code in particular is the stuff that’s unsafe, and what else can you derive from there. That’s been one of the biggest challenges I found. I think things have certainly gotten better. I think especially as far as where Rust needs to go, I think making sure that it’s somewhat easier and better specified about how to actually do some of that for some of this hardware movement is definitely a place that I think is getting better in area of growth.
Biffle: I think to start with the specific one that the thoughtful question poser raised. The standard library panicking on memory exhaustion isn’t really a problem for us, because we target libcore, which is a thoughtfully separated subset of the standard library that doesn’t assume the existence of a heap or threads or other platform dependent things. Our bare metal code, and I think most bare metal code targets either libcore, which has no heap and therefore cannot panic on memory exhaustion, or a combination of libcore and liballoc. The facilities in liballoc are a little more flexible in terms of allowing you to specify, particularly if you’re using unstable features, memory allocators that can fail.
In our case, we don’t dynamically allocate memory because that way lies unreliable software. The features that make Rust hardest at a very low level are the areas where Rust is bleeding edge in terms of programming language research. Even unsafe Rust is way more specifically defined than C, for example. Even in unsafe Rust, if you have two mutable references, they are not allowed to alias the same data structure. If you violate that, weird things are going to happen and you can’t violate that in safe Rust. We write a lot of unsafe Rust so we can totally violate that. The issues around initialized memory, it’s pretty common in bare metal things to be able to say like, “I created this Ethernet DMA buffer over here and I’m going to create a pointer to it because that’s how you get access to it.” Except that you forgot to initialize the memory and Rust requires that things be initialized before you reference them.
The compiler will make assumptions, like if you load a byte from that and say, is this zero? The compiler will say a constant yes, because it’s initialized to zero, you said right there. If you forgot to initialize it, your software is going to misbehave. There are a small set of patterns you learn to work around these, and these are also classes of behaviors that in C lead our software to misbehave. When you’re writing unsafe Rust, you have to do the job of keeping track of all of these things quite explicitly. I think that’s what’s posed a lot of overhead for particularly new systems programmers in Rust.
Cantrill: The presence of unsafe, though, also allows you to write. Between unsafe and asm! which I feel is another killer Rust feature, the asm! macro is really nice. It’s really in any operating system, but in much low level software, you’re going to have components that are actually in assembly. That has always been rocky in every language, in part because the machines themselves are rocky. When you’re trying to put an abstraction on something that really is not amenable to cross platform abstraction, because it’s not cross platform, it’s the actual machine. The asm! macro has been really delightful. Between asm! and unsafe, you can write effectively any code in Rust. If you can write it in C, you can write it in Rust, and that gives you a starting point where you can then begin to look at, now what am I doing? How can I pull that into more pneumatic Rust? How can I pull that into safer Rust?
This is where I think Laura and I have both benefited from Cliff’s wisdom where we would start off with something, it’s like, this is great. This works. I think actually I’ve noticed that you’ve got some soundness issues here, where this code as you’ve written it is fine but it could be extended in a way that’s unsound because of your use of unsafe here. Let’s actually brainstorm a way to make this safer, to prune down the unsafety. That gives you this really nice iterative path, because I think that one of the challenges of Rust that I feel that all Rust programmers have is that Rust challenges you to do it a better way, which is great. The downside of that is as a Rust programmer, you’re like, is there a better way to be doing this right now? Am I doing this the best way? There’s the sense of, there is a better, cleaner way to do this that I am not finding. That can slow you down a little bit.
Again, it’s been hugely helpful, to have Cliff tell us, “I have blessed you. This is a clean way to do it,” which feels liberating. I think you need that with Rust a little bit. It’s a strength of Rust, but it’s also a peril. Part of the reason you constantly search for that is because there often is a better way to do it. When you discover the better way to do it, you’re like, that’s so clean. That’s so nice. It’s so tight. It looks just like, why would you think of any other way to write it? It’s so satisfying. It’s such an endorphin rush as a programmer to be able to have that beautiful, tight, robust, safe code. At the same time, you have to hit this balancing act of knowing, no, actually, there’s going to have to be some unsafety here. This is a good starting point, and we can evolve it into something that’s better over time.
Biffle: One of the key decisions in programming language ergonomics, which is a thing that happens whether people think about it or not, is languages encourage people to do certain things and not to do other things. This tension between doing it the obvious way and doing it the tight, elegant way exists in C and in assembly language. This is a universal tension. The unique thing about Rust is that there is a bunch of decisions in the language design that nudge you to be better, that nudge you up the rigor curve. For example, the fact that writing unsafe code simply takes more letters to type than safe code, because you have to write the word unsafe at the very least, that’s nudging you because nobody likes to type more. That’s nudging you toward maybe not doing that. It’s an interesting thing to experience.
Stack Overflow Checking
Shamrell-Harrington: Am I correct in inferring from Bryan’s comments earlier that you all don’t have Stack Overflow checking turned on?
Biffle: No, quite the contrary. Stack Overflows are quickly caught by the memory protection unit. We’re using MV7m primarily, which is an architecture for microcontrollers that doesn’t have built-in stack protection. We do also have some ARMv8-M processors, which have a native stack overflow protection. In both cases, there’s a memory protection unit that you can configure to cache these sort of things. If I can make a brief other shout out to the other thing you need to do with the memory protection unit to make Rust correct, you need to intercept null pointer dereferences. This is a problem C has had in embedded context too, because frequently compilers in their never ending quest to do what we say but better, will see a null pointer dereference and say, it’s a null pointer dereference. I don’t need to check that because it’s going to false, because that’s what happens on Unix. It doesn’t happen in most firmware. Check for stack overflows and restrict access to address zero, and you’re pretty much home free.
The Limitations of Rust
Shamrell-Harrington: What things do you not like about Rust? What frustrations do you experience?
Cantrill: Honestly, very few. I’ve always felt that you want to talk to someone not on their first day of learning a programming language, but on their 1000th day. Where do they feel about the 1000th today? For me, Rust on the 1000th day remains incredibly uplifting. I’m still discovering great things and the ability to make things better. Broadly, it is very good. I will say, one frustration I have, and this may just be an ideological difference, I definitely believe in consistent formatting.
I admire the approach that Rust format has taken, which is, we are going to reduce your program to its atomic particles. Then we’re going to reassemble those atomic particles in a way that passes the formatter, which is great, and it works almost all the time. It’s amazing that it works so frequently. The fact that this is my biggest issue shows how few big issues there are because this is a pretty small issue, where we want to structure code that fits the format rules, but is not exactly what it wants to see. It’s very hard to tell the thing, this is actually fitting the rules that you’ve outlined. You just don’t like it. You want to do it differently.
The specific example is where you’ve got functions that are returning things that other functions are going to operate on, and you have these long chain of functions. This gets into the details of the actual machine model on Cortex-M. We want to actually group these things by functional unit. This thing is like, actually, I want each of those on a separate line, and be like, yes, exactly. It’s like, big piece of vertical space. That’s the level of issue that you’re dealing with. That is actually quite literally my biggest frustration with Rust. That’s a very small frustration. We can definitely live.
Abbott: I’m going to simultaneously say Rust has fantastic compiler error messages. There have been a lot of work put in to be able to help you decode some of these. At the same time, especially as you start to write larger projects and write larger stuff, I think sometimes figuring out how to decode some of the error messages can be cryptic, especially when it comes to building larger libraries. This is something you run into especially with C. I think in particular, some of the Rust type things remind me of other obtuse errors from things like that. I think learning how to debug some of the Rust type of thing.
I think also the thorniest edges for me about Rust, tends to be around some of the tooling, which is not that it’s not great, but I think it’s just that errors I think we tend to run into, and especially in terms of trying to build like the thing. It’s another place to be able to learn how to do things, especially how cargo interacts with Rust. Cargo is a good build system, but at the same time it has its own quirks about how exactly to do things. I think especially for what we’ve been building, cross compiling, for example, that’s been a little bit of errors we’ve had to explore and learn about exactly for being able to build things. I think in particular we’ve had to find some rough edges about being able to split between host tools and tools that are supposed to go on target, things like that.
Rust, if you’re just being able to run it on your x86 desktop machine, I think there’s been a lot of work, and I think that’s pretty optimized for that. I think for a lot of what we’ve been doing with the embedded and cross compiling, I think there have been some rough edges. There’s certainly a lot of areas to be able to grow and fix things up there.
Biffle: Debug symbol generation in async code could be dramatically improved. If I’ve got a future that’s not currently being pulled, I can’t print its stack trace. That’s annoying. The technical pieces are there, but we haven’t put them together yet. There are some things missing from libcore that I need to write useful software, like floating point transcendental operations are missing from core. They’re in standard, because something-something, how LLVM models intrinsic something-something. That can be a little bit style crampy. We don’t use a lot of floating point at Oxide, but my personal projects definitely do. There’s a bunch of language features that I think are important that have been stuck in unstable for longer than I would like. Granted, I’m not getting in and doing the work to stabilize them. I don’t have a lot of room to talk. Like the never type. I would like to have the never type on stable. I would like the compiler to be faster at the same time, I get that that’s a really hard problem.
There are growth seams in the language that are sometimes a little more obvious than I’d like, for example, our notion of how to do errors has evolved as the language has evolved, not to the same degree as some other languages, but like the error trait. Is it right? Is it not? Do you use a crate to talk about errors, or do you use the standard library? You get different advice from different people. Cargo is limited in a lot of ways. It’s nice that the language comes with a build system. I’ve got a blog entry on why that’s an important thing. It’s also limited. Finally, the embedded ecosystem is almost entirely written in a way that assumes that you’re running in privilege mode with memory protection off. This can cause the code to be straight up incorrect if you violate either of those assumptions, which is not a Rust language thing so much, but you can’t really use a language without its libraries. I think that’s fair game.
Cantrill: It’s a good question to ask because I think asking people about the imperfections in the technology really assesses whether someone has gone deep enough into something to really use it. I would also caution that it’s a huge mistake to weaponize these imperfections, in that these are relatively small imperfections in a system that is broadly a fit for many different kinds of use cases.
Biffle: Clearly, we’ve looked at these imperfections and said, yes, we’re going to use this tool. Like my list of imperfections for any programming language is at least this long. These are imperfections that I can deal with personally. You may disagree. Maybe one of these really rubs you the wrong way.
Abbott: More than anything, we also know that there’s an abundant Rust community that is out there and really working to try and get things going. Some of these will also be problems we see now but we also realize that as things go down the line, we expect things to be able to continue to grow and build for everything.
Conclusion
Cantrill: If you are discovering Rust and you’re excited like, “I would love to contribute,” view these as opportunities to go to the coalface on all of these. I love Cliff’s example of getting the DWARF information on futures and being able to actually properly generate a stack trace. That’s a gritty problem, but like a lot of problems in Rust that the Rust community has, Rust community has tackled a lot of gritty problems. It’s a huge tribute to the Rust community. These are all the problems and imperfections that we have mentioned. Although there’s a good opportunity to make a real difference and to certainly ingratiate yourselves to the Oxide swag, to whomever solves these problems, for sure.
See more presentations with transcripts