Month: December 2018

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
At the recent Connect() event, Microsoft announced the public preview of Python support in Azure Functions. Developers can build functions using Python 3.6, based upon the open-source Functions 2.0 runtime and publish them to a Consumption plan.
Since the general availability of Azure Function runtime 2.0, reported earlier in October on InfoQ, support for Python has been one of the top requests and was available through a private preview. Now it is generally available, and developers can start building functions useful for data manipulation, machine learning, scripting, and automation scenarios.
The Azure runtime 2.0 has a language worker model, providing support for non-.NET languages such as Java, and Python. Hence, developers can import existing .py scripts and modules, and start writing functions. Furthermore, with the requirement.txt file developers can configure additional dependencies for pip.
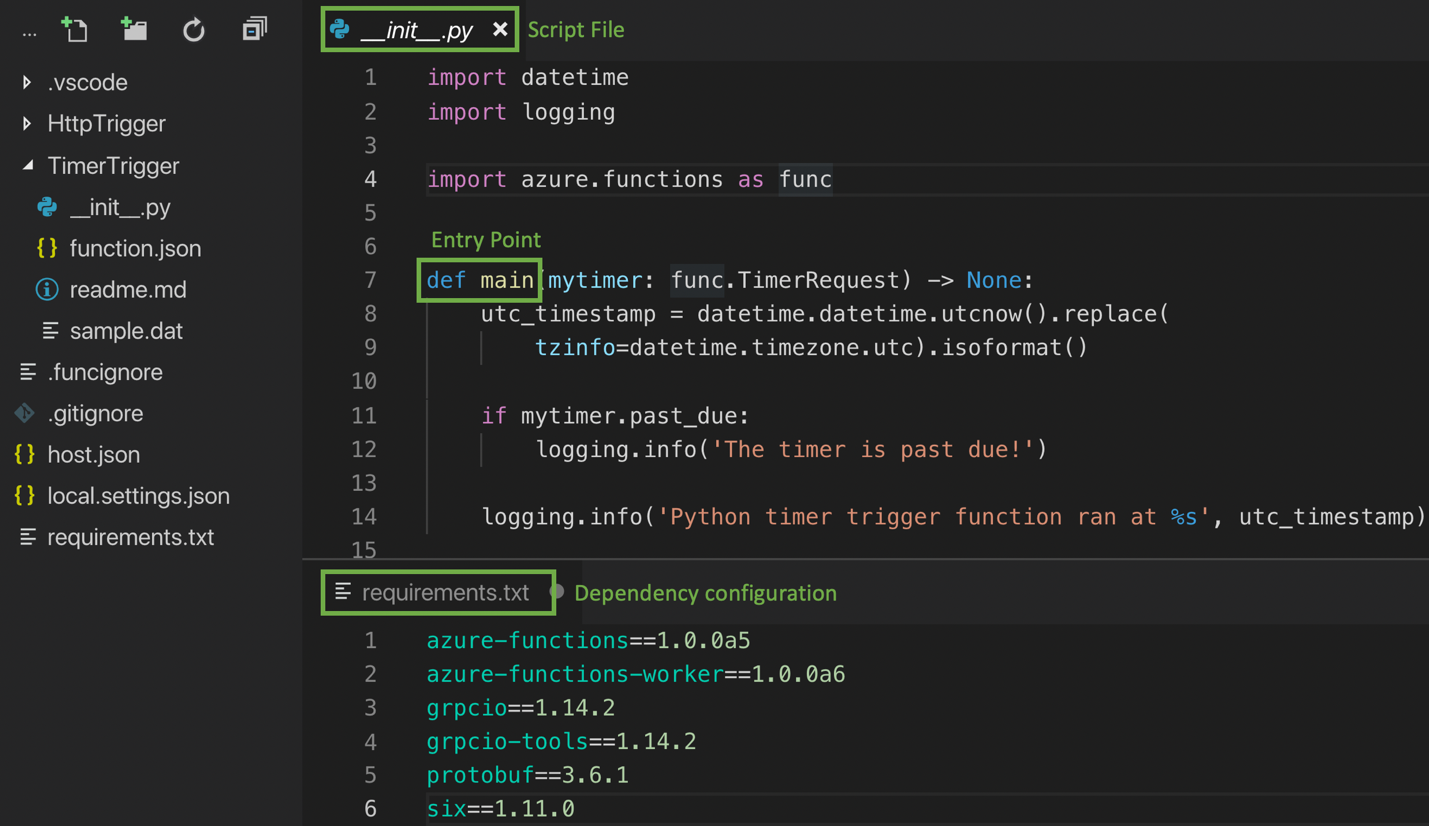
Source: https://azure.microsoft.com/en-us/blog/taking-a-closer-look-at-python-support-for-azure-functions/
With triggers and bindings available in the Azure Function programming model developers can configure an event that will trigger the function execution and any data sources that the function needs to orchestrate with. According to Asavari Tayal, Program Manager of the Azure Functions team at Microsoft, the preview release will support bindings to HTTP requests, timer events, Azure Storage, Cosmos DB, Service Bus, Event Hubs, and Event Grid. Once configured, developers can quickly retrieve data from these bindings or write back using the method attributes of your entry point function.
Developers familiar with Python do not have to learn any new tooling, they can debug and test functions locally using a Mac, Linux, or Windows machine. With the Azure Functions Core Tools (CLI) developers can get started quickly using trigger templates and publish directly to Azure, while the Azure platform will handle the build and configuration. Furthermore, developers can also use the Azure Functions extension for Visual Studio Code, including a Python extension, to benefit from auto-complete, IntelliSense, linting, and debugging for Python development, on any platform.
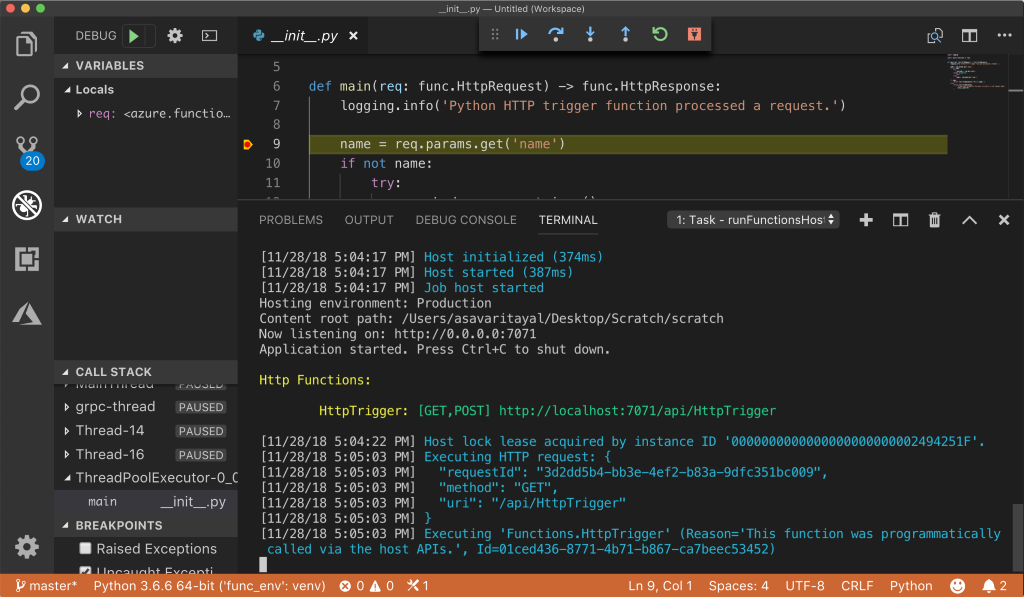
Source: https://azure.microsoft.com/en-us/blog/taking-a-closer-look-at-python-support-for-azure-functions/
Hosting of Azure Functions written in Python language can be either through a Consumption Plan or Service App Plan. Tayal explains in the blog post around the Python preview:
Underneath the covers, both hosting plans run your functions in a docker container based on the open source azure-function/python base image. The platform abstracts away the container, so you’re only responsible for providing your Python files and don’t need to worry about managing the underlying Azure Functions and Python runtime.
Lastly, with the support for Python 3.6, Microsoft is following competitor Amazon’s offering AWS Lambda, which already supports this Python version. By promoting more languages for running code on a Cloud platform both Microsoft and Amazon try to reach a wider audience.
Podcast: Charles Humble and Wes Reisz Take a Look Back at 2018 and Speculate on What 2019 Might Have in Store
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

In this podcast Charles Humble and Wes Reisz talk about autonomous vehicles, GDPR, quantum computing, microservices, AR/VR and more.
Key Takeaways
- Waymo vehicles are now allowed to be on the road in California running fully autonomous; they seem to be a long way ahead in terms of the number of autonomous miles they’ve driven, but there are something like 60 other companies in California approved to test autonomous vehicles.
- It seems reasonable to assume that considerably more regulation around privacy will appear over the next few years, as governments and regulators grapple with not only social media but also who owns the data from technology like AR glasses or self-driving cars.
- We’ve seen a huge amount of interest in the ethical implications of technology this year, with Uber getting into some regulatory trouble, and Facebook being co-opted by foreign governments for nefarious purposes. As software becomes more and more pervasive in people’s lives the ethical impact of what we all do becomes more and more profound.
- Researchers from IBM, the University of Waterloo, Canada, and the Technical University of Munich, Germany, have proved theoretically that quantum computers can solve certain problems faster than classical computers.
- We’re also seeing a lot of interest around human computer interaction – AR, VR, voice, neural interfaces. We had a presentation at QCon San Francisco from CTRL-labs, who are working on neural interfaces – in this case interpreting nerve signals – and they have working prototypes. Much like touch this could open up computing to another whole group of people.
Show Notes
- 02:13 Reisz: How do you keep your pulse on software?
- 02:16 Humble: One of the main methods I use to keep abreast of technology trends is through the software practitioners and news writers who contribute to InfoQ.com, both through their writing and when we meet at QCon conferences throughout the year. In addition to participating in the planning of some of the QCons, I attend developer meetups and other conferences.
- 03:28 Reisz: You’re hosting the Architectures You’ve Always Wondered About track at QCon London in March. What are some of the talks you have in there, so far?
- 03:34 Humble: The BBC is coming to talk about iPlayer, their catch-up service in the UK. A couple years ago, they talked about their microservices journey and moving to AWS. I’m hoping to get them to talk about the iPlayer client, written entirely in Javascript, and it’s a fascinating story.
- 04:06 We’ve got AirBnb coming, talking about their microservices journey and their experience running microservices in production.
- 04:19 John Graham-Cumming from Cloudflare will be talking about Cloudflare Workers, their Javascript-based, serverless execution environment.
- 04:33 There are a few others that aren’t quite confirmed yet, so I can’t discuss them, but it’s shaping up quite well. I’d like to get one more UK or London company, and maybe a Bay Area/Silicon Valley company to round it out.
- 04:48 Reisz: One of the things that stood out for me in 2018 was the pervasiveness of AI and how it’s affecting our lives now, and will be affecting our lives in the near future. One example is autonomous driving cars, and you can’t really talk about that without mentioning the Uber accident last March. It shows there’s lots of room for improvement here, but in 2016 there were approximately 34,000 deaths in North America alone from car accidents. Self-driving cars have a tremendous ability to make an impact on our daily lives.
- 05:48 Humble: I completely agree. The vast majority of accidents are caused by driver error, and eliminating that whole reason for accidents is a good thing. Ubiquitous autonomous vehicles are probably further away than many people imagine, but I do think that autonomy within certain constraints is still a big deal. There’s still a way to go, but there’s definitely a chance for these vehicles to save lives. There are also opportunities to help people with mobility issues, or live where there is a lack of public transportation. There will inevitably be accidents, but that shouldn’t make us blind to the fact that cars are pretty lethal anyway, and autonomous vehicles have the ability to improve that in a significant way.
- 07:18 Reisz: Fully autonomous vehicles catch the major headlines, but it’s going to augmenting people, especially in the short term. The human in the AI loop, where feedback allows the human to make better decisions.
- 07:43 Reisz: Waymo is now the first fully-autonomous car allowed to be on the roads in California, at least around Silicon Valley.
- 08:05 Humble: Waymo has done ten million autonomous miles, and a further seven billion simulated miles, since 2009. They seem to be a long way ahead in the amount of driving they have done, but there are about 60 other manufacturers that are approved to test autonomous vehicles in California. There is a lot of money and effort going on, just in the category of cars, but there is also work being done on trucks and drones.
- 09:04 Reisz: Another subject that’s been in the news, especially in Europe, is GDPR.
- 09:14 Humble: GDPR is the General Data Protection Regulation, announced by the European Union in April 2016, and came into effect a couple years later. There were some high profile companies that weren’t ready, including Pinterest’s Instapaper, Unroll.me, and Stardust. It’s a very complex piece of legislation, with the purpose of giving you the right to understand how your data is being used. We will need case law to understand how well it works in practice. It’s part of a movement by governments all over the western world to tackle the business of consumer data and privacy. We’ve seen bills passed in California and Vermont, and I think we’ll see more and more. Back to what we were just talking about, if you think the data that can be collected from social media records is a problem, imagine how much data we could collect from self-driving cars.
- 10:28 Reisz: Ford’s CEO was recently interviewed, and discussed the analytics they are doing around automobile financing as well as driving characteristics. He said about 100 million people have Ford vehicles, and there’s a huge case for monetizing those insights. If you add that to self-driving cars, it’s amazing the kind of insights we could potentially find from people’s habits.
- 11:04 Humble: I think we’re at a cusp in our industry of seeing a large quantity of legislation. Because we’ve been slow to put our own house in order, such as around ethically implications of software, it’s probably not a bad thing that legislators are starting to call attention to issue.
- 11:25 Humble: Something else that we’ve seen this year on InfoQ and at QCon was the ethical implications of technology. The broader point is, because software is becoming more ubiquitous in more people’s lives, the impacts you have if you’re working on software just become more profound. If one person throws litter out the car window, it doesn’t really matter, but if everyone does it, pretty soon the whole world is covered in rubbish. It’s the scale that is becoming interesting now.
- 12:30 Humble: In March, at QCon London, we had our ethics track, which was the first major conference that I know of that had an ethics track.
- 12:41 Reisz: As far as I know, that’s true. Ann Curry spun up a follow-on conference on ethics after that, but it was following QCon London.
- 13:05 Reisz: There was some news recently about Red Hat that I know you wanted to talk about.
- 13:09 Humble: Essentially IBM is acquiring Red Hat. Other than Oracle, IBM and Red Hat are two of the largest contributors to the Java platform. One thing that seems likely is that IBM will reduce the total number of people allocated to supporting Java. I also think it’s interesting in the general context of public clouds, because I think it’s something we can expect to see a bit more of in the next two or three years. Mergers and acquisitions in the cloud space are quite likely to happen. I wouldn’t be surprised if Oracle we to acquire somebody, or they could exit the public cloud business altogether. I have the sense that their cloud offering isn’t gaining enough traction in the market, and we’ve had some other companies exit the market (AT&T, Cisco, the former Hewlett-Packard), so there’s precedence.
- 14:07 Humble: I could be really contentious and say it’s quite interesting to see what Google does. Obviously, Google is one of the big players in the cloud space, but they’re quite a long way behind AWS, and they seem to be a long way behind Azure, as well. I wonder how much longer they will keep going. My guess is they will always have a bit of a niche with machine learning-type stuff, because of TensorFlow. Google almost invented the whole idea of cloud computing, and yet AWS, to me, seems to be very far ahead.
- 14:48 Reisz: Let’s put a pin in 2018 and look at 2019. What do you see as the major trends going forward into the coming year?
- 14:57 Humble: One of the things we talked about briefly last year was quantum computing. It’s still some way out, but it is still genuinely interesting.
- 15:07 Reisz: Before you go further, let’s level set. What is into quantum computing?
- 15:14 Humble: It’s very hard to describe in a small number of words. We published a series of articles by Holly Cummins of IBM (part one, part two, part three) which are brilliant, and are a much better explanation. Basically, quantum computers were purely theoretical twenty years ago, and they now exist. They exploit certain aspects of quantum mechanics. In particular superposition which has to do with spin and that an observed spin is in one of two states. The other bit has to do with shared properties of entanglement. You can observe one electron, and that tells you the state of the other electron, over long distances, up to 1.3km.
- 15:51 Humble: The key thing to understand is that quantum computers can deal with certain kinds of problems much faster or, in some cases, more effectively, than classical computers. In fact, we had a formal proof of that this year. You tend to hear it talked about a lot in the context of cryptography because we rely on asymmetric keys, and, in theory, quantum computers can break asymmetric keys, so we’ll need new ways of securing stuff. But there are several categories of problems, including financial risk management, logistics, or medical research, which require high levels of computing power.
- 16:55 Humble: There are several companies exploring this space. IBM has their Q machines, which you can access via IBM’s cloud, to run real experiments on real quantum computers. Google launched a Python open library called Cirq, and Microsoft has Q#.
- 17:30 Reisz: Are these all new languages to target quantum processors?
- 17:39 Humble: IBM has a Python library, as does Google. Python seems to be one of the languages being used, but Microsoft has created its own language in Q#. I don’t know how that will go, but I suspect we will need new languages to describe what we’re trying to do, and Python isn’t a bad place to start. I think it’s genuinely exciting that you can go to GitHub, download some code and then run it on real quantum computers in IBM’s data centers. For corporations, it also means you don’t have to invest in building and maintaining these complex machines, because you can just access them through the cloud.
- 19:29 Humble: What are some of the forward-looking things you’ve been thinking about? I know you’ve been thinking a lot about machine learning.
- 19:35 Reisz: What’s old is new might be a good way of phrasing things. Back in 2016 Netflix talked about Open Connect, and how they worked with ISPs to stage these boxes all around the world. Most of the content being served to clients all around the world was via this CDN. This facilitated the Netflix Everywhere deployment when content was made simultaneously available to 190 countries.
- 20:27 Reisz: I see the pattern of pushing logic out to the edge and taking it off the cloud resources. That’s particularly true for ML and AI. Mike Lee Williams of Cloudera, one of our committee members for QCon AI, released a report talking about federated machine learning. It ties some of the privacy concerns of GDPR into edge and machine learning. Federated learning allows you to use your phone or other IOT devices to run a machine learning algorithm using training data specific to that device, and then upload the model to a central server and then aggregate those models together.
- 21:36 Humble: So what does that mean and what are the benefits?
- 21:38 Reisz: It means taking some of the processing power off the centralized servers and pushing it down to edge devices. To handle the privacy implications, instead of uploading personal data, you keep the personal data local and only upload the trained model to the server.
- 22:03 There are some other interesting cases for edge computing outside machine learning. At QCon New York, Chick-Fil-A talked about what they’re doing with edge computing. Statistica said by 2025 there are going to be 75 billion IOT devices connected to the internet. I think it’s very compelling and forward-looking to start leveraging the edge, and being able to push machine learning and different functions down to those devices, and then aggregate them up.
- 22:48 Humble: We’ve known for a while that if you train models using big machines, that you can then push those models down to small devices to run them. Doing that the other way is really fascinating. The most recent Apple devices have a neural engine as part of the A12 chip, which is exactly for this idea of being able to run things and push it back up. In Apple’s case, it’s partly around privacy.
- 23:20 Humble: Something else we’re seeing with machine learning, as we’re putting the tooling into the hands of more developers, the applications we’re seeing are really fascinating. We know about use cases with image processing, such as interpreting radiology scans. Some of the opportunities with wearables are also compelling, like being able to combine wearable health tech with machine learning. We’re really just scratching the surface of what machine learning can do.
- 24:32 Humble: It would be remiss of us to not talk about microservices.
- 24:43 Reisz: Two or three years ago, when we talked about microservices at QCon, we were talking about how to decompose the monolith. Where do we set our bounded contexts? How do we decompose this thing into services? We were still asking, “What is ‘micro’ in a microservice?” Now I hear a lot more of the conversation being around how to operate microservices. How do we properly setup north-south and east-west communication among services? How do we properly secure things? How do we handle observability? When you get to a certain point with microservices, the discussion is now, “How do we enable this?”
- 25:27 Reisz: Kubernetes seems to have won the battle when it comes to orchestration. People are now building on top of Kubernetes as a given piece of infrastructure. We’re seeing a lot of work with service meshes. If cloud removed the undifferentiated heavy lifting of building apps on infrastructure, I think service meshes are starting to remove the undifferentiated heavy lifting in writing applications. It does dynamic routing. It gives you resilience with circuit breakers. It provides a best-in-class observability experience. Some of the names we hear about in that space are Envoy, Hashicorp’s Consul Connect, Bouyant’s Linkerd 2, and Istio. One interesting one is Cilium, which works in the kernel space, instead of the user space.
- 27:35 Humble: We’re also seeing some definite pushback against microservices.
- 27:38 Reisz: Microservices solve the specific problem of developer and deployment velocity, when people are stepping on each other’s toes. If you’re not having those problems, microservices may not be the right answer; monoliths are perfectly fine. You do hear counter-arguments from people now saying, “microservices were wrong for us.”
- 28:11 Reisz: At our heart as developers are languages. What trends are you seeing for languages in 2019, and is there a language of choice?
- 28:24 Humble: Java isn’t going anywhere. C# and .NET isn’t going anywhere, either. There’s still a tremendous amount of interest in those languages on InfoQ, and I think that will continue to be true. In terms of the other languages we’re seeing interest in, Go is one. We had a popular piece recently about Go and microservices at The Economist. We also see a lot of interest in Rust. If you’re doing anything that’s performance-sensitive, Rust is a pretty good alternative to C++. I’m personally very interested in Swift. My ten-year-old is a big fan of the iPad, and he wants to learn Swift, so I’ve been learning it with him. Kotlin, on the JVM space, is similar to Swift because it’s found its niche for doing mobile development. Python has also been growing really rapidly. It’s not new, about the same age as Java, but it’s really taking off, driven mostly by data science.
- 30:02 Reisz: I know you have an interest in augmented reality and virtual reality. What’s coming up in 2019 with AR and VR?
- 30:14 Humble: In AR, we don’t have the form factor, yet. I think it’s likely to be eyeglasses, but I don’t think anyone is quite ready with the tech. I don’t think Apple gets enough credit for building really small computers. If you think of AirPods or the Apple Pencil, they are really discrete computing devices that we don’t really think of as computers. That works well for the idea that if you’re going to build an AR device, it has to be small and discrete. There’s also the whole issue with privacy. We learned from Google Glass that you must have a strong privacy story if this stuff is going to work for you. I think we know where it’s going, but we aren’t there yet.
- 31:13 Humble: In more general terms, there’s so much happening around human-computer interaction, with voice, AR, and neural interfaces. Adam Berenzweig from CTRL-labs gave a presentation at QCon San Francisco talking about their wrist device that picks up nerve signals. I think that’s interesting because the same way that touch opened up computers to a class of people who couldn’t use them before, neural interfaces may be able to do that for people for whom touch isn’t an option. It can also be a benefit for everyday users who start to suffer from repetitive stress injuries, to allow alternative input options. That whole space is a long way out, but I find it all fascinating. In the same way we had the touchpad shift, I think there will be another shift coming.
Resources
Holly Cummins articles on Quantum Computing (part one, part two, part three)
Rethinking HCI with Neural Interfaces @CTRLlabsco
More about our podcasts
You can keep up-to-date with the podcasts via our RSS Feed, and they are available via SoundCloud and iTunes. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
Related Editorial
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

The past few years have seen a wave of travel companies member accounts compromised which have rocked the industry.
Cathay Pacific had 9.4M accounts compromised.
British Airways had 380,000 card payments breached.
Raddison hotels had up to 10% loyalty program accounts compromised.
Hyatt twice had malware embedded into payment systems that had a bunch of data compromised.
IHG had s string of hotels data compromised between 2016-2017
Marriot beat them all with 500M loyalty accounts compromised in a recent data breach.
While the worrying trend of personal data being accessible to hackers, unsavoury characters and the dark web continues to grow; there is potentially a much larger, scarier secret these companies are not disclosing to the public in the wake of the data leaks.
Has personally identifiable behavioural or consumer insights data been exposed?
What’s the big deal?
You may have heard the phrase data is the new oil, which implies that what businesses can extract from personal data is so rich and of high value that it’s what underpins the commercial models of technology companies.
Consumers are lead to believe that it’s their data which businesses are monetising, selling it off to advertisers, emailing you personalised offers, and displaying relevant advertisements. That is not entirely true.
Personal consumer data such as your name, email address, phone number etc. are details which you as an individual, own. The privacy protections around GDPR and other global privacy laws are in place to restrict how companies collect, store and share your personally identifiable information with third parties. The concept is to give you greater perceived control over what happens with your information. That is true.
If businesses are not selling access to your personal information to external parties, and yet data is touted as ‘the new oil’, then how the heck are big organisations generating revenue from data?
The real value of data and how it’s used to make you buy more products.
Data that you input into a website or app that is created by you is your data. That may include your name, email address, gender, date of birth, credit card numbers and so on. Let’s call the data ‘personal ownership’.
Traditional advertising and CRM targeting focus on basics such as – “let’s show advertisement X to all males between 24 and 30 years of age who live in Los Angeles”. Advertising in this way works – but it’s nothing compared to where the real money is in the business.
Next, we have dark data, which is the hidden, and often utilized data which can be how many failed logins a user has on a website, the number of times a user visits a site on any given day, what types of airline tickets they are searching for, what web browser or mobile phone they use, etc.
However, the real cash is in behavioural data. That is – knowing WHY a consumer clicks on a link or transacts with a brand. What was the intent, or the primary driving factor behind the engagement?
Consumers do not own their behavioural insights. These insights are derived from data science teams at the organisations who have invested time creating machine learning models to identify traits, trends and use success metrics to better predict future intent behaviour on similar consumers.
Now armed with the behavioural data, companies can hyper-personalised the content you see, the marketing emails you receive, and the prices displayed. In this sense, companies can provide the right incentive to the right person at the right time. The ‘How Big Data is Changing the way we fly‘ explains how some airlines are feeding in behavioural data into their internet booking engines.
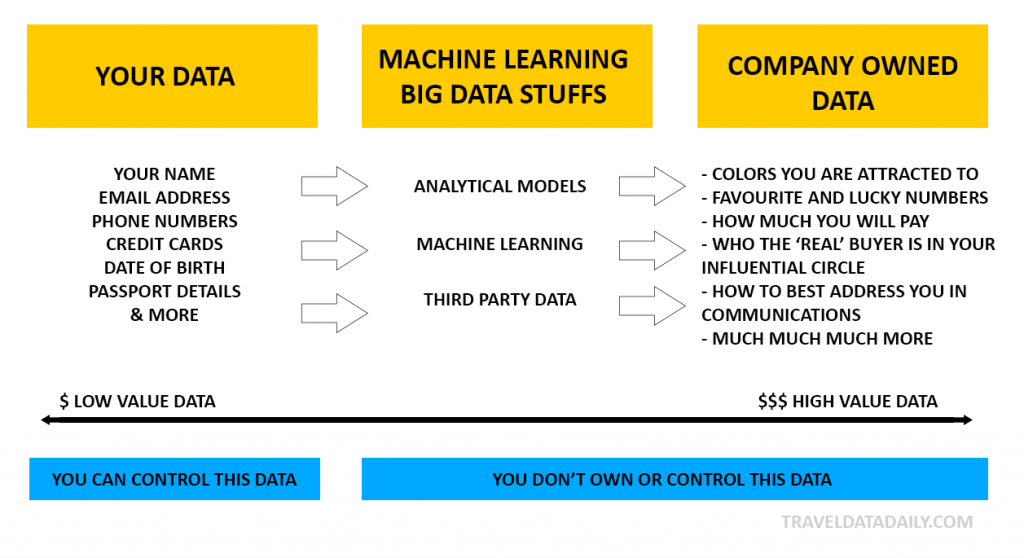
Your personal information, while interesting – is not that important. It’s an identifier of sorts and tells us who you are. As more is learned about who you are, what you click on, what you do and don’t interact with – you are segmented into multiple bucks of user behavioural types. Typically, organisations at this level of data analytics will not provide consumers with any algorithmic transparency.
Why is behavioural data valuable?
If a business knows what your primary drivers are in given situations, it’s possible to exploit your motivations and leverage them to drive a particular agenda.
In the 2015 movie ‘Focus’ starring Will Smith, his character is a clued-up con man who lives and dies by the game. Smith’s character in it for the long haul and keeps his eye on the ultimate long-term goal throughout the entire movie.
[Spoiler Alert] – The long-con involves a big-time gambler who has his day seeded with the ‘lucky’ number 55. Smith’s team position themselves in key areas of the gamblers life holding signs and objects with the number ‘55’ subtly placed everywhere. The number is plastered EVERYWHERE in the gamblers life before the final scenes. The branding for the number 55 is therefore implanted into the gamblers head in the leadup to the big event, and when it comes time to pick a number – guess which number he bets on?
In the 2016 US Federal elections, Cambridge Analytica came under scrutiny for assisting political campaigns by using Facebook behavioural data to drive users to specifically designed landing pages that would appeal to them.
One Facebook member may see “Trump supports the right to arms”, and another user may see “Trump to enforce stricter gun controls”. The entire concept was to garner support for Trump – but the messaging is delivered on an individual basis specifically to what motivates that person to click, engage or share.
Knowing what type (or segment) of user clicked on each link type let Cambridge Analytica know what important interests and motivations each Facebook user have, what made them click, share and like certain pages – even those not politically inclined.
Photograph: Cambridge Analytica
As you can see – the power of knowing behavioural influence data is supremely powerful. Many companies are training their models to be able to identify specific ‘look-a-like’ behavioural patterns, and this leads to a greater risk of your personally identifiable actionable insights (aka: all about you), being exposed when company data is leaked or compromised.
These companies don’t need to disclose if insights data is compromised in the same way they do if your personal information has been compromised. If leaks are disclosed to the public, the company also does not need to disclose what anonymization or transparency (if any) was involved in the modelling process.
Basic behavioural insights include:
– Which marketing channels a type of user is most likely to purchase via
– Which complimentary ancillary/upsells a user is most likely to purchase using propensity modelling
– Your favourite drink or meal on a flight
Advanced behavioural insights include:
– How to address a user in communication (Hello Name, Dear Name, etc..)
– Whether to target marketing communication directed to that user, or to the key person of influence in their buying circle (ie: target emails to the wife who may have ultimate influence over the husband who is seen as the frequent flyer)
– Your lucky numbers or other numbers which you have a strong affinity toward
KNOWING HOW TO MAKE A CONSUMER BUY YOUR PRODUCT, BY USING THE WHY A CONSUMER WILL BUY YOUR PRODUCT IS THE HOLY GRAIL OF MARKETING.
Getting to the HOW and WHY can be achieved after analysing key insights, which is extracted from, or the Dark Data are hidden within standard data sets, third party data, and consistent machine learning over time which looks for patterns in similar user types.
Should consumers be concerned their data has been exposed? Absolutely.
However, to understand the actual extent of the data breaches has on consumers, we need to know the full extent of every piece of data which was compromised.
Hotels and airlines ARE using your personal data to change your behaviour and drive specific transactional and non-transactional outcomes. While it can be a positive experience with highly personalised deals – it’s important to keep in mind that – you don’t own that data.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Hey, everybody. Thanks for coming. I appreciate everybody coming to the after lunch slot. It’s always a risky one because everybody else is pretty full and ready to nap, you know. But hopefully, we have a pretty fun presentation in store for you.
So today I’m going to be talking about connecting, managing, observing and securing microservices and that’s a big mouthful, and obviously any single one of those topics is more than enough for an hour-long talk so we’re going to be doing kind of a whirlwind tour of some of the problem space, the shape of some of the solutions to help connect manage, observe and secure services and then we’re going to do a deep dive into Istio itself which is the particular service mesh that I work on.
Intro
So just a little bit about me. You know, I’m one of the core contributors at Istio. Just left to help start a company that’s building on top of the project now. And before that, I worked on the project at Google.
So our high-level agenda: What is the problem? What’s the shape of the solution? What are some service meshes that are around that you could use today and then we’ll talk a little bit about maybe when one might be more appropriate than another. And then we’ll do the deep dive into Istio itself and in the end we’ll have a nice demo to show some of the functionality that I’m talking about.
The Problem
So this is kind of the motivating problem statement for service meshes in general and for a lot of technology that’s cloud data today. Our shift to a modern architecture leaves us unable to connect monitor, manage or secure. That’s the fundamental problem. And so what do I mean by this modern distributed architecture? We mean that we’re moving away from monoliths and into services. So there’s a lot more points of contact. Whereas before with the monolith I might have one or two front doors to get into the system, when I have a set of services there’s doors everywhere into various things.
We are deploying them into more dynamic environments. This is both a really good thing and a very painful thing. So these dynamic, you know, fluid scaling environments that cloud providers can give us are incredible. If you heard the talk that was in the ballroom I guess two before mine, that was a perfect intro. Andrew [McVeigh] talked about a lot of the challenges of building microservices at scale. And these dynamic environments are a key piece of that, things like Kubernetes and Mesos and Nomad and other orchestrators. Let you take use of this flexible capacity but the problem is you have to architect your entire system around this change that’s now introduced. With old style architectures, I worked trying to oil pipe one, and we ran five services. We had a service-oriented architecture but I could walk into our server room and I could point to each of the servers that ran our services. Right? And that doesn’t work when compute scales. You can’t go point to the box that runs it.
And then the final piece of this and in my opinion, this is actually the thing that causes the most developer pain, is that our applications are now composed with the network. And the network is really the glue that sticks our applications together, whereas before in the world of monoliths, we maybe had one process, one giant binary that we could debug through. And really this is a failure of tooling and this is a large part of the reason in my opinion that it’s so hard to move to micro service-based architectures because the tools that we’re used to using to diagnose problems really don’t apply in the same way because they don’t know how to navigate the network. How do I trace a request across a set of 10 services? You know, that’s hard to do. How do I trace a call through 10 processes on a single machine, is hard enough today with our tooling, and now you make them distributed and it’s an incredible amount of complexity to add. But we have to take on that complexity so that we can increase our velocity, move faster and actually ship features, right. So we have to take on that pain to achieve our business goals.
Connect
So what exactly are the things that I’m talking about when I say connect, manage, monitor and secure? When we talk about connections, we want to make an application developer not think about the network, and that’s really hard when now the network is the thing that glues all of your application together. Right? And today if you go and look at dead services you’ll see a lot of patterns like who has written a FOR loop to do retries? Yes. So who has gotten it wrong and then DOSed another service? And fixing that is a pain, right, because you have to go redeploy your code, and redeploying code is risky and hard. That’s never a good thing. So we want things like resiliency, things like retry, circuit breaking, timeouts, I want to do lame ducking, I want to not talk to a back end that’s giving me bad responses. And really I shouldn’t have to build that into my application.
Second big piece of connectivity is service discovery. How do I even know the things that I’m talking to and where they live? You know, and today there are solutions like DNS that are widely used that come with a lot of problems again, because we have this dynamic environment. DNS caches are kind of our enemy. How many people have had problems with DNS caching that results in request going to bad services that should be out of rotation?
And that could be hard to fix. And similarly, we want load balancing everywhere, because that’s really a key to building a robust and resilient system is being able to shift load easily. And ideally, we would like our load balancing to be client side. I would like my clients to be smart enough to be able to pick the right destination, because that means that I could have more efficient network topologies, right. If I have to run a middle proxy that does load balancing, it means that it becomes a point in my network where all this traffic has to flow through, and I would really like to keep traffic point to point where I can keep nice, simple, efficient networks, if I can. And so the client side load balancing is a really valuable tool to help with that.
Monitoring
Next, we want to do monitoring. This is just what’s going on. This gets really to the heart of where I think most of our developer pain is today, which is I have this thing, I have this system and it’s got all these moving parts. What’s it like, what’s it doing? And there we need metrics and we need logs and ideally, we want traces too so that we can actually look at the path of any particular request through our system.
And it’s not enough just to have metrics and logging. You really need consistent metrics and logging with similar dimensions, with the same semantics for those dimensions everywhere because when we have metrics for example that are ad hoc per service, it becomes impossible to build a higher level system on top of those metrics. If you use something like a service mesh that can give uniform metrics everywhere, it becomes possible to do things like build alerting on top of those predefined metrics that your entire organization can use. Hey, I’m spinning up a new service. I need to wire up alerts for it. You go, “Oh, cool. Here’s the templates already, you know. Here, we already have our metrics. You’re ready to go.”
And it really reduces the effort required to spin up new services, the effort required to monitor existing ones. This is one of the key features of a service mesh that we’ll come back to which is just this consistency because a different system is handling these core requirements rather than every individual application doing it.
Manage
We want to be able to manage the traffic in our system, and we want to manage not just where it goes, where it gets routed to but how it does that and really we want to be able to apply policy to that traffic. I want to be able to look at L7 attributes of a request and decide whether or not my application is going to serve that request or not. And there’s a ton of different use cases there. So you can think about maybe some API gateway use cases around things like coding, rate limiting, off. You can even phrase authn/z, you know. Is the service allowed to talk to another service is a perfect example of policy that applies to an entire fleet that you can use a service mesh to help you implement.
And when I talk about traffic control a lot of the industry today does L4 load balancing and L4 traffic control. So we really want to move that up to be application aware. I want to be able to make load balancing decisions based on application load on the health of my actual service. Not necessarily how much CPU or RAM or whatever it’s using because those may or may not actually be correlated depending on what my use case is.
Secure
And then a final big piece that we need now and this gets back to some of this decomposing of the monolith into individual pieces. Security becomes a lot harder. So before, typically, I would have one entry point into my monolith, and we can lock down and firewall everything else, and network traffic is locked down and I can apply network policies at L3 and L4 to make sure that things can’t talk to each other that should. The problem is all of that is focused on the network identity of a workload. What is the IP:port pair, what is the machine that’s running it? That’s what all of our network security is used to dealing with. Except that I just said, “Hey, we’re in this new dynamic environment where things change all the time.” And that IP and port that’s hosting one application may not be hosting at the next. That’s a lot for existing networking tooling to keep up with. If we look at some of the early CNI implementations in Kubernetes as an example, they suffered all kinds of problems with crashing kernels and that kind of thing because it was doing IP tables to update which hosts on the network were allowed to talk to each other ones.
And that was kind of an abuse of that system to provide a valuable feature set and since then a lot of CNI plugins have moved away from that model, but fundamentally a lot of the network level tooling that we’re used to dealing with is not built to cope with the higher rate of change of the applications today.
So we want to be able to assign an identity that is tied to the application, not to the host, the thing that’s running on the network. I want my identity and I want the policy that I write about what two services are allowed to talk to each other for example, to be in terms of the services and not in terms of the IP address that happens to host that service right now.
And then with the goal with moving away from that reachability is authorization model, right. Kind of in vogue today is the zero trust networks and Google’s Beyond Corp. That’s kind of the stuff that I’m talking about here, when we can start to move identity out of the network and into some higher level construct that’s tied to an application.
The Service Mesh
So, the goal of a service mesh is to move those four key areas out of your applications, out of thick frameworks and into something else. And that something else depends on which implementation you pick. A common service message today that people use is just Envoy proxies, right. So we write up some config for how Envoy is going to proxy for my service, and we put an Envoy beside every instance. And you can get a lot of the traffic control, you can get a lot of the resiliency features that I talked about, the telemetry out of that system.
You could do something like Linkerd which is again another service mesh that works in a similar way to what Envoy does now, where you put a proxy beside every single workload, it intercepts all the network traffic, and allows you to provide this feature set. And we’ll go into depth about how that architecture works and then how those things happen.
And then Istio is the third service mesh that provides these features that I talked about. One of the other key goals that I didn’t talk about in those four is the consistency. I want metrics, I want security, I want policy – each of those four categories I want to be consistent across all of my services. I want to retry policy to be consistent. All of that. I would like to be able to control it in one place and this is a key enabler for velocity. When we add in a service mesh, we can delegate another team to handle a lot of these cross-cutting concerns and move them out of the realm of concern of an application developer.
So a single central team can do things like manage the traffic health and the network health of your infrastructure, and individual developers don’t need to worry about that. It’s a huge force multiplier. Central control is a huge force multiplier to let an organization do more by moving things out of the view of developers.
And then finally another key feature of all of these systems are fast to change. Change on the order of config updates, not binary pushes. And that’s a really, really key feature just for that DOS use case that I talked about. I have on multiple occasions DOSed another service with a bad retry loop. It’s really nice to be able to push config to change that and not have to go get a release in and cut a new binary.
Istio
So Istio is a platform that does that. It is a service mesh that implements a lot of this capability. And so let’s talk about kind of in detail how it works. So this is going to be our mental model. It’s real, it’s about as simple as it can be. A just wants to call B over the network. We don’t really have to care what. It can be HTTP rest request, it could be TCP bundle over TLS. It really doesn’t matter. It’s just a network call. If it’s a protocol that we can understand like HTTP for example, then we can get more interesting data about it to show the user and I’m going to demo a lot of this stuff. I’m going to demo a lot of the telemetry and that kind of thing in at the end of the talk and we’ll get to see some of what I’m talking about. But this is just our model.
How Istio Works
So how do we start to build this kind of mesh to get this functionality that I’ve talked about? The first thing that we’re going to do is put a proxy beside every single workload that’s deployed in our system. We call this a sidecar proxy. Istio uses Envoy as its proxy of choice. Envoy was specifically built with this use case in mind. So if we think about like a traditional nginx that we use for load balancing in our system, it has a very different set of requirements than a proxy that we’re going to put beside every single application. It’s a lot bigger, the rate of change is a lot slower, you’re handling substantially more traffic typically. You want to make a different set of tradeoffs somewhere when we’re building in this sidecar style model. We want a lighter weight proxy. Keeping the footprint small becomes very important. We want it to be highly dynamic because again that’s one of the big requirements of the system that we’re deploying into is that things change quickly. We need to be able to update the configuration of our proxies very quickly as well. And so Envoy was built by Matt Klein and the team at Lyft to address these particular use cases.
Secondly, then we need to start to get configuration into the system. So Istio has this component called Galley. It’s responsible for taking configuration, validating it and then distributing it to the other Istio components.
So we had these sidecars there. They actually need some config to do something. In our system, if we just have static sidecars that sit there it doesn’t give us a lot. So we deploy this Pilot component of Istio, which is responsible for understanding the topology of our deployment and what’s the network loop like, and pushing that information into the sidecar so they can actually do routing at runtime.
We want to perform policy at runtime like I mentioned. We want to be able to do things like service to service authentication. I want to do things like rate limiting. Ideally, I might even want to do things like end user off in Mixer. So that’s one of those things that invariably in every organization winds up being a library that you include. How do you handle your end user credentials? How do you authenticate them and how do you authorize them for access? Hopefully, all of your services do it the same way. And they probably use a library to do that. This is another key location where, hey, that’s logic that we can pull out and into our service mesh. Things that are horizontal that cut across our entire fleet, we can pull into our service mesh, implement at one time.
And if I have Mixer here, in this case, doing the off policy on the end user request, for example, I don’t need my application developers to worry about it. And this is one of the other kind of core features of a service mesh as opposed to other approaches to get this functionality, because service meshes are not necessarily new. There’s been things like Finagle that had been around for quite a while that Twitter uses. There’s Netflix and Hystrix and that family of things. Those are all very service mesh-like libraries and frameworks. The problem is they’re all language specific. Using a proxy to implement it, it being the network to the application lets you sidestep that language dependency so you can provide all this functionality in a language agnostic way.
And again, this is one of those things that helps boost developer productivity. It becomes one less hurdle to use a new language in your environment for example, because a lot of the core cross-cutting functionality which has traditionally been implemented as libraries can move out into a language agnostic format. Huge benefit.
And then finally there’s a component of Istio called Citadel that’s responsible for provisioning workload identity, that L7 identity that’s tied to the application. Citadel is responsible for provisioning that at runtime and that looks like a certificate. That’s an X509 cert and rotating it frequently.
So how does our request actually flow through the system? If we go back to the very beginning, A just wants to call B. We’ve set up all this machinery, these Envoy sidecars, the control plane is running static and A is used to call the B. So the first thing that happens is that locally the client sidecar traps that request. That can be done in a variety of ways but so far Istio typically uses IP tables to do this redirect. And so it traps all the traffic in and out. Envoy then inspects that request that looks at the metadata, the L7 request. If this is an HTTP call we’ll look at the host header to determine routing. And Envoy then takes this opportunity to make a client-side routing decision, and picks the B instance that we’re actually going to send the request to. And Pilot ahead of time programmed all this data into the Envoy. So any given Envoy in the context of a request knows all the other endpoints and can make an immediate decision and route. We don’t need to do DNS lookups, we’re not out of path. You can then immediately route.
So we pick a B. We forward our call to B. We don’t necessarily know that there’s a client-side Envoy or server side Envoy in this case. We don’t know that there’s a sidecar there or not. Part of the goal of the system is to be transparent. But in this case, we do have one that catches it on the other side.
Now receiving – this is where I want to apply policy. So this is actually in request path. I’m going to block. I’m going to go talk to Mixer and I’m going to say, “Hey, here’s this request that I just got. Here’s the bundle of the data about it. Do I let it through or not? Make a decision.” And this is the point where you can do things like implement your own authn/z. If you’re doing things like a header based token for off that’s easy enough to pull that out of the request and do authentication or authorization. You can do things like rate limiting here. Again, anything you might want central control over is a good fit for policy in Istio.
And Mixer makes a thumbs up, thumbs down decision. That’s really at the end of the day. Envoy says, “Do I let it through or not?” And Mixer just replies with “yes”, “no” and a cache key. So obviously it would be prohibitively expensive to call out to Mixer for every single request that comes into the system because that doubles the traffic in your system, that’s not feasible. And so, instead, it turns out that a lot of service-to-service communication, and even end-user-to-service communication has a lot of properties that make it very cacheable. Typically any given client has a very high temporal locality. If you’re going to access my API, you’re probably going to access it a whole bunch in a short amount of time and then you’re going to go away and not come back for a long time. And then you’re going to come back and access it a whole bunch.
Very admitable to caching and you can actually see cached rates, above 90%. So rather than doubling the traffic in your system by making these policy calls instead, you’re talking about a much smaller increase, maybe 10%.
So Mixer gives a thumbs up. We say, “Yes, cool. Let the request through.” And so the sidecar there will send the request back into the application that’s behind it. The application will do whatever business logic it needs to build its response. Maybe that’s calling other services down the graph, maybe it’s going to a database. Maybe it just has the answer in hand.
But it will send that response back. And then asynchronously and out of band, both the client and the server side sidecar will report back telemetry. And that’s awesome because it means that we get a complete picture of what happened from the client’s perspective and from the server’s perspective which is massive for debugging. It’s so frustrating, we typically only ever have the server side metrics. As somebody that’s producing a service, I always worked on back-end services myself. I always had my server-side metrics and there’s so many times the problem is either in the middle or on the client. Having a single system that gives us both sides of that is massive for debugging. It’s so awesome.
Architecture
So here’s a little bit nicer picture of the architecture that we just walked through with all of the components labeled. And again like I said, Pilot is for config to the sidecars, Mixer is for telemetry and for policy, Citadel is for identity and Galley is for configuring everything.
Demo
So with that we’re actually going to dive into a demo, and I’m going to just kind of show you some of what I’m talking about with the service mesh and we’ll see some of the telemetry, we’ll see some of the traffic control. So let me frame our demo. If anybody has played with Istio before, you’ve seen the bookinfo app. It is the canonical test application that we use for Istio. And this is what the deployment looks like. We have a product page that’s the UI that renders a book. It calls the detail service to get some details about the book, and it calls some version of the review service to get a review for that book.
Finally, two of the reviews calls the rating service. So this is what we’re just going to deploy. I’ll just do [inaudible] and apply in a second. Where we’re going with it is we’re going to use Istio to split it up and deploy it across clusters. So this is a use case that I’ve had quite a few different users talk about, which is we need to deploy it across availability zones as an HA requirement for example. That’s a pretty frequent one. I need to run in two availability zones as an HA setup and that’s a blocker for my merger and acquisition, for example.
So what we’re going to do is go from this setup to that setup with no errors. We should see a 100% 200s the entire time and it should be seamless, the application. We’re not going to touch the applications that are deployed at all.
So with luck, it’ll go smoothly. […] Let me go to my cheat sheet real quick and make sure that I’m set up correctly. So just real quick so that everybody can see what I’m doing. I’m just going to alias throughout this presentation. I’m going to use KA and KB because I’m going to be typing and to type coop control in the context is ridiculous. So KA goes to cluster A, KB goes to cluster B.
And then let’s go ahead and get Istio. Istio, I’ve already installed actually. Sorry you can never type when you’re on stage. And so just to prove that I’ve installed this ahead of time already. So this is just a stock Istio installed. This is actually the Istio demo script. One small change that I’ll touch on later is I do have a core DNS deployed and we’ll get into that. And KB is the same. So if I grab this, we can see the same and notice we have just this one external IP address. That’s our ingress into the remote cluster. So that’s our proxy that’s running ingress.
So let’s go ahead and deploy the book info in the cluster A. Again this is just the standard stock Istio looking for deployment and similarly … (This is a proof that you know the demo is live is that something breaks. Sorry. One second.) I tried to bypass some of my setup. So all I did was just run a little script that went and pulled the IP addresses that we’re going to need later for me, and wrote them into some files including … Sorry about that. So now let’s verify that our product page was actually deployed successfully. All right, so we’re deployed. We’re there. We have our ingress.
Sorry about this, guys. It’s fun debugging. Let me pull up the ingress. Actually it did work before, I promise. So we’re just going to do this by hand to verify, and then we can do the nuclear option which is just blow up the pod. (So sorry about that.) And then there’s one more little bit of setup that we’re going to do if I find my script. This is all because I didn’t correctly tear down my cluster last time. I’ll go into detail about what this is in a second but I’m just doing this to set up things.
We’re using the CW tool that we’re using is this a tool that produces Istio config for us. And we’ll dive in detail what it does. But this now gets everything working. So we have book info with reviews. Awesome. We’re at the start of the demo now. So let’s go ahead and start driving some traffic to the deployment. I’m going to show you some stats in a second. So all I’m going to do is just start a loop that’s just curling the websites, we get some traffic in the background. And then I am also going to go ahead and set up Grafana to run. So in the Istio demo deployments, Istio ships with a Grafana dashboard that lets us see all these consistent metrics that I talked about.
One more command. You can tell that this is a fresh demo. This is the first time giving this particular demo. Awesome. This one’s not on me. This is the port forward. Now we get our Grafana dashboards. So this is the stock Istio dashboard so if you’ve looked at Istio before you would see it. And here we can clearly see the set of services that we’ve deployed. We can see the small amount of traffic that we’re sending to it right now – about 10. And then we can go and look at any individual service that we have deployed. Again, this is the advantage of having these pre-canned metrics that are homogenous everywhere. I can do things like define one dashboard that plugs into those metrics that provides useful and interesting data like total request volume, the success rate, our latencies, these critical metrics for actually diagnosing the health of a service. Out of the box without having to add them to the application itself. And we can see both the client side and the server side. We don’t have any … sorry, I guess we do in this case.
So these dashboards, awesome, free, out of the box. We’re now in this state. So let’s go ahead and start to migrate things over. So if we’re moving to this end destination, step one is going to be just to migrate details over first. So we’ll go incrementally one service at a time. We’ll ship them over and the big thing that we want to watch, we can actually see our global success rate. This is aggregate any 500 across the entire system will trigger something there. So we expect that to stay at a 100 as we do our traffic shifting. And then let’s go ahead and start doing that. So the first thing that we’re going to do is deploy the detail service into our second cluster.
And if we get the service we see it’s deployed. Now let’s talk about the CW tool that I was going to demo. So Istio gives us the tools in hand to shift this stuff around basically playing some shell games with how names resolve. The problem is it’s the config to write this, to do these kinds of traffic shifts and Istio’s super tedious to write. It’s exactly the same every single time but it’s multiple config documents that you need to produce together. So the CW tool that we’re going to be using, it’s called Cardimapal, is something that my team built, and all it does is just generate the Istio config for a couple of different use cases. The reason I’m talking about it now is because in order to generate this config, we need a little bit of auxiliary data. So the first thing that we need is a representation of our clusters. So I mentioned before that we have A and B.
Here is our A and B clusters and in particular, these addresses are those IP addresses of the ingresses that I talked about earlier. So we’re going to communicate between our clusters over the internet via the ingress, and we can rely on Istio TLS to keep that secure. So Citadel provisions identities. Those identities are used to do mutual TLS between workloads. So we can over the internet just go in through the ingress and that’s fine. We sub the same route of trust ahead of time and so the workloads trust each other, and we can just do TLS all the way through. Not need to worry about setting up a VPN or any other kind of complicated setup that we might have to do otherwise.
The second thing that we need is a small representation of the service. Enough to be able to generate some configuration to talk to it. Here’s the name, the product page service, how we call it, the ports. And this backends bit here lines up with the clusters in A. So if I had product page deployed in B for example or I just deployed details into B, I can go ahead and add this as a backend.
So all I’m doing is updating this little model of our detail service and I’m saying, “Hey, it’s deployed both into cluster A and it’s deployed into cluster B. And it’s the details that default Kubernetes service name. That’s the actual address of the service in the cluster. And so now we can go and generate some of that tedious config to wire up our cluster so that this ingress works, details us here and then we’ll wire up some config on A side to let it know that cluster B exists.
So this time we’ll say, “Hey, Cardimapal generate config for cluster B and I care about the detail service.” So this just spat out a bunch of yammo. Let me pull it over somewhere where we can actually look and see what it does. So there’s three key pieces of config that we have here. The first is our gateway. How do we actually get into this detail service? And this just says, “Hey, run on the normal SEO gateway and use the details like global name.” This is going to be the name I expect a client to call with this global name to ingress.
I defined routing for that. I say, “Hey, by the way, at that gateway that we created, if you see these two hosts go ahead and just send it to the detail service.” I had a typo here in my services And then finally we have a service entry that just says, “Hey, by the way …”
By the way, this service entry, I’m going to define this name, these two names and just resolve them to the Kubernetes service really. So it’s just basically playing a shell game, creating a new name for our Kubernetes service. And our application already talks to this thing. And the reason that we want to do this that we want to decouple naming from the Kubernetes names is it allows us to do things like shift traffic between clusters. The problem is that Kubernetes names are scoped to a cluster. And so, if I immediately want to begin to do things across clusters, I need some different naming domain where I can’t get conflicts. And so that’s why we’re playing a little bit of a shell game with some of the names here. We’re using this global service rather than the full Kubernetes service name. And that’s also why we’re running core DNS in our clusters so that we can resolve these new names that we’re creating.
So let’s go ahead and do that. Let me verify that I actually saved this correctly so we don’t wind up with reviews on there like last time. Details, details everywhere. Ratings, ratings, reviews. So the same config that I just walked through. We’re just going to keep it and apply it. We didn’t create our namespace. Excellent. So now I can take this. I can prove to you that our ingress works real quick. So I’m going to curl the detail service and I’m going to set that host header. We have the same problem that we had in the other one so let’s just kill the pod real quick. Sorry, and again this is just a little bit of setup. It’s not typical that you have to go delete your ingress pod to get config to apply.
So we got a 404 which we would expect because we didn’t set our host header but as soon as we set our host header, suddenly we can do routing normally and we can get our details. Great. So we have set up this. Now we want to add our keyed link.
And the way that we’re going to do that is go update our representation. So I want to move details. I really don’t want to model details being in A. I want to shift it over to cluster B. So I’m going to go back to my model with my services. I just deleted it out and now we are only in cluster B. And we can see that we actually generate now a different set of config for cluster A. So I said, “Hey, details moved. The config to talk to details is now a little different.” It actually points to this IP address for the remote cluster. So we say, “Hey, if you want to resolve that details name go over to the royal cluster.”
So we can just go ahead and apply that. And then the last thing we have to do is you remember that virtual service that I showed you here? This is currently in our cluster and it says, “Hey, when you see details send it to the local service.” Clearly, I don’t want that anymore, because I just said, “Hey, no. I want to move it over to the remote.” So let’s go ahead and delete this virtual service. And this is just some Istio config and what we’ll see here is if we come and look at our cluster A we see that there’s traffic going in. If we look at cluster B we see that the only traffic was my couple curls. What we should see is when I remove this rule our traffic flop over because right now that rule says, “Keep the traffic local.”
And then let’s lead it in the right namespace. And so we just removed that config from cluster A. So now what we should see is traffic start is A still 100% success. This should still load. We’re still loading and we’re seeing reviews. And we see that traffic is actually starting to pick up. So we’re on our five minute delayed window for our metrics. So we can see the traffic picked up but our ops per second is still low. And we can dig into a little bit more detail here and we can see that in fact, traffic is picking up. And we can go back to our side that’s actually serving our UI and see that did it with actually no errors anywhere. So we didn’t drop any connections to anybody. We didn’t lose one of the user requests during that flop over. Everything just kind of flowed through the system.
So we’re running short on time now because, you know, it turns out the demo was a little bit more efficient when it works. I want to save some time for questions. So I apologize we didn’t get to dig in quite as much as I’d wanted to but hopefully we got to see a little bit of the telemetry out of the box that’s pretty useful. And we can see how we can apply pretty cool traffic shifts and make interesting things happen with just changing configuration. I didn’t have to touch any of those applications, we didn’t have to touch any of the code, it was all deployed and running the entire time and we were able to change it really without the applications noticing. And that’s a key feature for that philosophy. I want my ops team to be able to manage the cluster and my dev team not to have to care.
Questions and Answers
So questions? We got four minutes.
Man: So in your example, you were referring that saber A called Mixer to apply policies, and you said that there was no penalty you paid per request but then when invoke service B, there is again Envoy. So down the stream service there always calling Mixer to check enforcement?
Butcher: So the server side, Envoy will always call. You want policy to be enforced on the server side because you can’t trust the client applied policy. So we always hit on the server side. Logically, Mixer is called on every single request to a server but we cache. Does that answer the question?
Man 1: Yes.
Butcher: Perfect.
Man 2: In the instance you showed, is the same instance of Istio actually managing across two distinct Kubernetes clusters?
Butcher: That’s a great question. So and this gets into some of that Istio multi-cluster work. The answer is today what I demoed you does not actually. So these are two separate control playing instances with two separate config domains. In my opinion, that’s actually how you want to run Istio across clusters. So it really gets into what you mean by what’s a service mesh. The real answer is identity. These workloads can communicate with each other because they share a common identity domain. Because they have that common identity domain we can establish connections. It doesn’t really matter who’s configuring that. The fundamental piece is that there’s communication. And so we can have separate administrative domains. It’s still one mesh because we still have one set of identities.
Woman: So every time I make a call that Mixer is invoked. What keeps it from being the single point of failure?
Butcher: Yes, that’s a great question. So there are a couple of different things. So A, Envoys are doing caching. So you can think of Mixer in some senses as a centralized cache and then the Envoy as this kind of leaf cache notes. So the second piece is that Mixer itself can be horizontally scaled. So there’s not any one particular instance of it. There are many instances. I guess the short answer is Mixer can be a single point of failure if you configure things incorrectly, but in terms of actual scaling, it’s horizontally scaled so one instance going down is not going to kill anything. You can push bad policy that might cause a global outage and be a single point of failure. But outside of that, it tends to not be. So this architecture actually came out of Google. Google had a system of identical architecture for about the last four and a half years now. And actually what we’ve observed is that not only is it not a single point of failure, but it actually boost the client perceived availability of the backends that it’s in front of, because it acts as a distributed cache. And it turns out that it’s really, really easy to run a distributed cache at high availability and it’s really, really hard to run systems that make policy decisions at high availability.
So there are definitely failure modes in which it can be a single point of failure but in practice, we’ve actually observed it doing just the opposite and increasing the client perceived availability of a back end. And off is a perfect example. So today your off call -every single service should be calling your off service for every single request. And instead, you can reduce that by a factor of about 10X by having Mixer cache that and have that result reused. And that just works natively with how Mixer functions. It automatically does these caching of decisions.
See more presentations with transcripts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
I thought I would follow on my first blog posting with a follow-up on a claim in the post that going returns followed a truncated Cauchy distribution in three ways. The first way was to describe a proof and empirical evidence to support it in a population study. The second was to discuss the consequences by performing simulations so that financial modelers using things such as the Fama-French, CAPM or APT would understand the full consequences of that decision. The third was to discuss financial model building and the verification and validation of financial software for equity securities.
At the end of the blog posting is a link to an article that contains both a proof and a population study to test the distribution returns in the proof.
The proof is relatively simple. Returns are the product of the ratio of prices times the ratio of quantities. If the quantities are held constant, it is just the ratio of prices. Auction theory provides strategies for actors to choose a bid. Stocks are sold in a double auction. If there is nothing that keeps the market from being in equilibrium, prices should be driven to the equilibrium over time. Because it is sold in a double auction, the rational behavior is to bid your appraised value, its expected value.
If there are enough potential bidders and sellers, the distribution of prices should converge to normality due to the central limit theorem as the number of actors becomes very large. If there are no dividends or liquidity costs, or if we can ignore them or account for them separately, the prices will be distributed normally around the current and future equilibrium prices.
Treating the equilibrium as (0,0) in the error space and integrating around that point results in a Cauchy distribution for returns. To test this assertion a population study of all end-of-day trades in the CRSP universe from 1925-2013 was performed. Annual returns were tested using the Bayesian posterior probability and Bayes factors for each model.
For those not used to Bayesian testing, the simplest way to think about it would be to test every single observation under the truncated normal or log-normal model versus the truncated Cauchy model. Is a specific observation more likely to come from one distribution or another? A probability is assigned to every trade. The normal model was excluded with essentially a probability of zero of being valid.
Bayesian probabilities are different from Frequentist p-values. Frequentist p-values are the probability of seeing the data you saw given a null hypothesis is true. A Bayesian probability does not assume a hypothesis is true; rather it assumes the data is valid and assigns a probability to each hypothesis that it is true. It would provide a probability that data is normally distributed after truncation, log-normally distributed, and Cauchy distributed after truncation. The probability that the data is normally distributed with truncation is less than one with eight million six hundred thousand zeros in front of it when compared to the probability it follows a truncated Cauchy distribution.
That does not mean the data follows a truncated Cauchy distribution, although visual inspection will show it is close; it does imply that a normal distribution is an unbelievably poor approximation. The log-normal was excluded as its posterior didn’t integrate to one because it appears that the likelihood function would only maximize if the variance were infinite. Essentially, the uniform distribution over the log-reals would be as good an estimator as the log-normal.
To understand the consequences, I created a simulation of one thousand samples with each sample having ten thousand observations. Both were drawn from a Cauchy distribution, and a simple regression was performed to describe the relationship of one variable to another.
The regression was performed twice. The method of ordinary least squares (OLS) was used as is common for models such as the CAPM or Fama-French. A Bayesian regression with a Cauchy likelihood was also created, and the maximum a postiori (MAP) estimator was found given a flat prior.
Theoretically, any model that minimizes a squared loss function should not converge to the correct solution, whether statistical or through artificial intelligence. Instead, it should slowly map out the population density, though with each estimator claiming to be the true center. The sampling distribution of the mean is identical to the sampling distribution of the population.
Adding data doesn’t add information. A sample size of one or ten million will result in the same level of statistical power.
SIMULATIONS
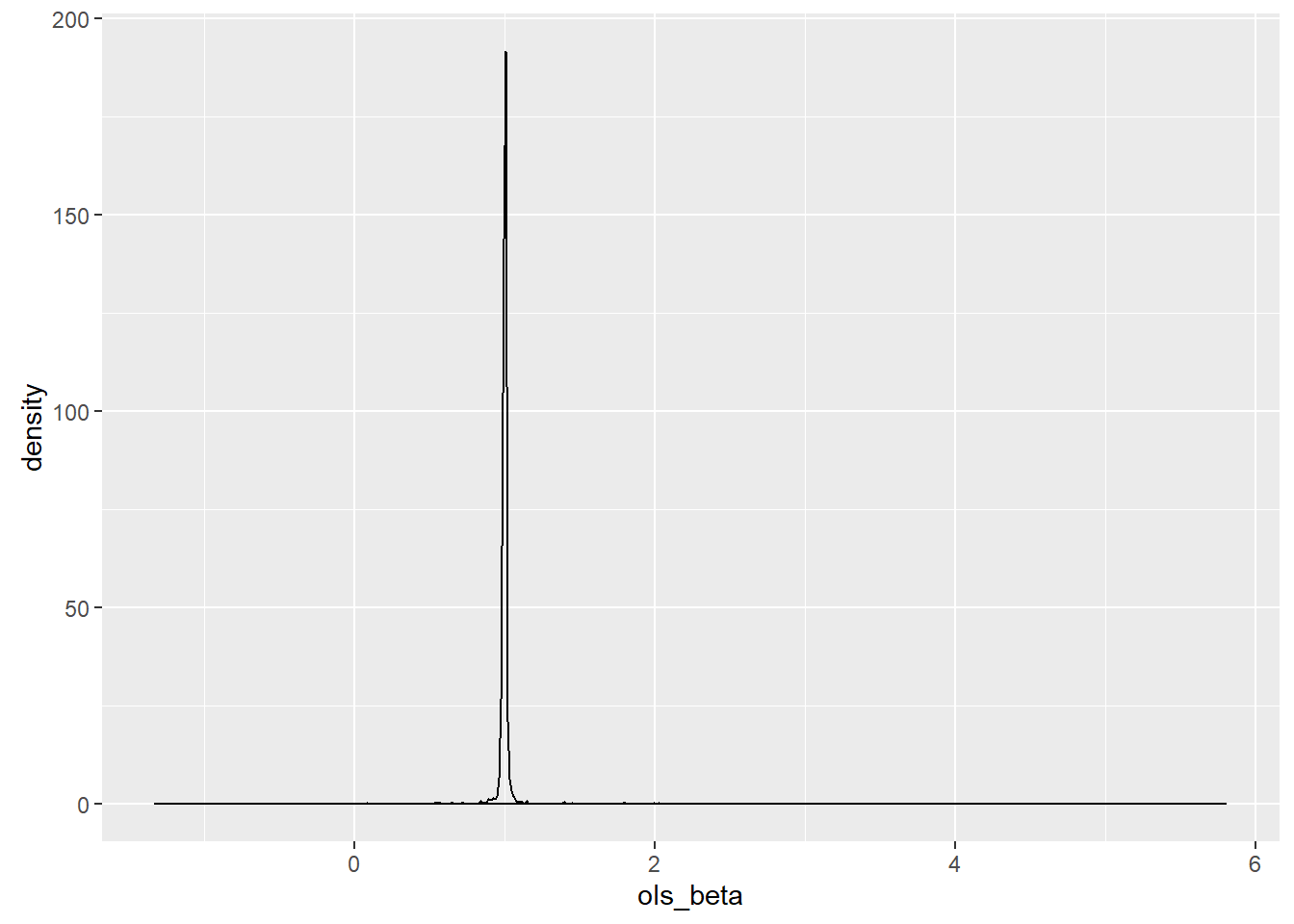
To see this, I mapped out one thousand point estimators using OLS and constructed a graph of it estimating its shape using kernel density estimation.
The sampling distribution of the Bayesian MAP estimator was also mapped and is seen here.
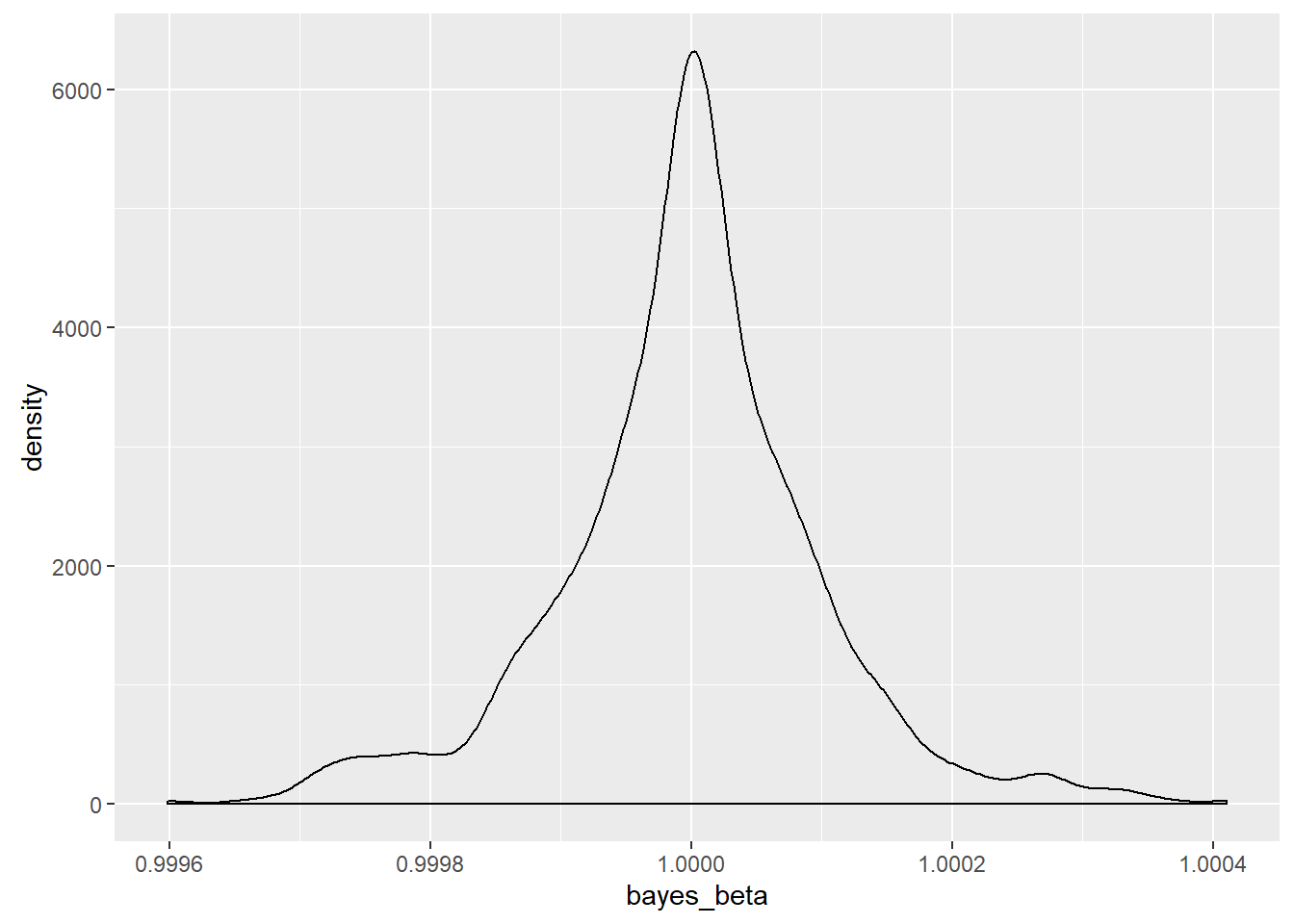
For this sample, the MAP estimator was 3,236,560.7 times more precise than the least squares estimator. The sample statistics for this case were
## ols_beta bayes_beta
## Minimum. : -1.3213 0.9996
## 1st Quarter.: 0.9969 0.9999
## Median : 1.0000 1.0000
## Mean : 1.0030 1.0000
## 3rd Quarter.: 1.0025 1.0001
## Maximum : 5.8004 1.0004
The range of the OLS estimates was 7.12 units wide while the MAP estimates had a range of 0.0008118. MCMC was not used for the Bayesian estimate because of the low dimensionality. Instead, a moving window was created that was designed to find the maximum value at a given scaling and to center the window on that point. The scale was then cut in half, and a fine screen was placed over the region. The window was then centered on the new maximum point, and the scaling was again halved for a total of twenty-one rescalings. While the estimator was biased, the bias is guaranteed to be less than 0.00000001 and so is meaningless for my purposes.
With a true value for the population parameter of one, the median of both estimators was correct, but the massive level of noise meant that the OLS estimator was often far away from the population parameter on a relative basis.
I constructed a joint sampling distribution to look at the quality of the sample. It appeared from the existence of islands of dense estimators that the sample chosen might not be a good sample, though we do not know if the real world is made up of good samples.
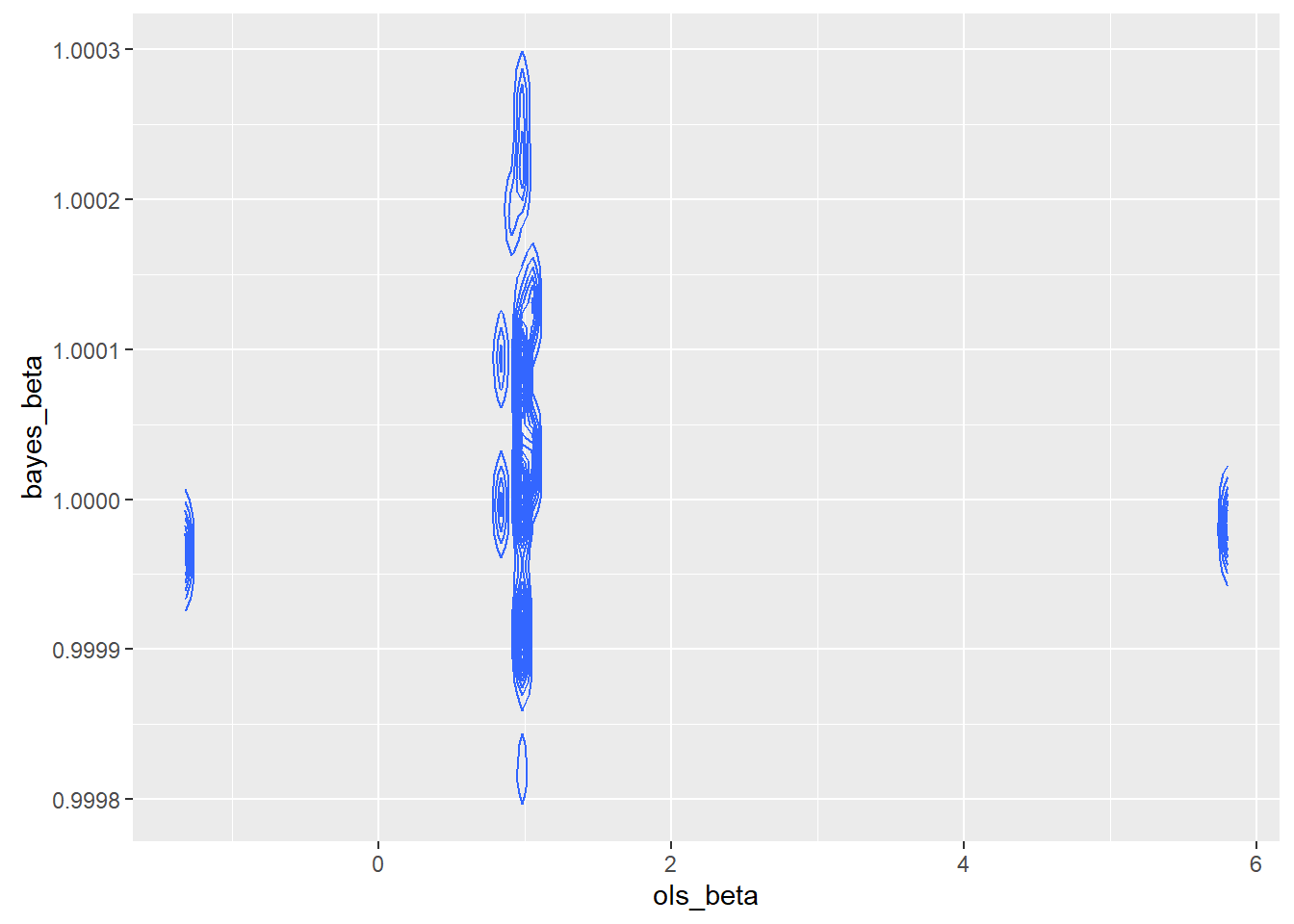
I zoomed in because I was concerned about what appeared to be little islands of probability.
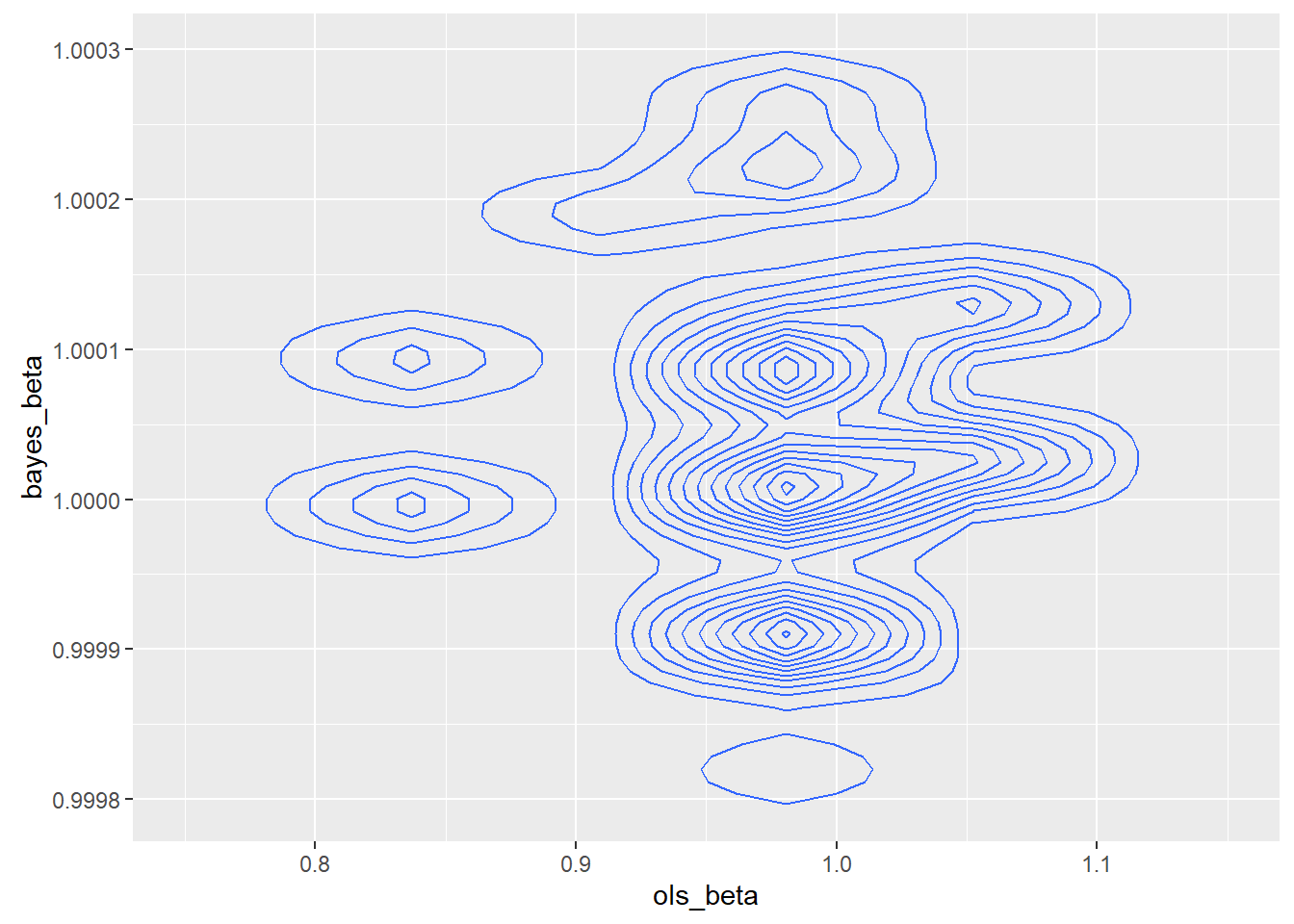
To test the impact of a possibly unusual sample, I drew a new sample of the same size with a different seed.
The second sample was better behaved, though not so well behaved that a rational programmer would consider using least squares. The relative efficiency of the MAP over OLS was 366,981.6. In theory, the asymptotic relative efficiency of the MAP over OLS is infinite. The joint density was
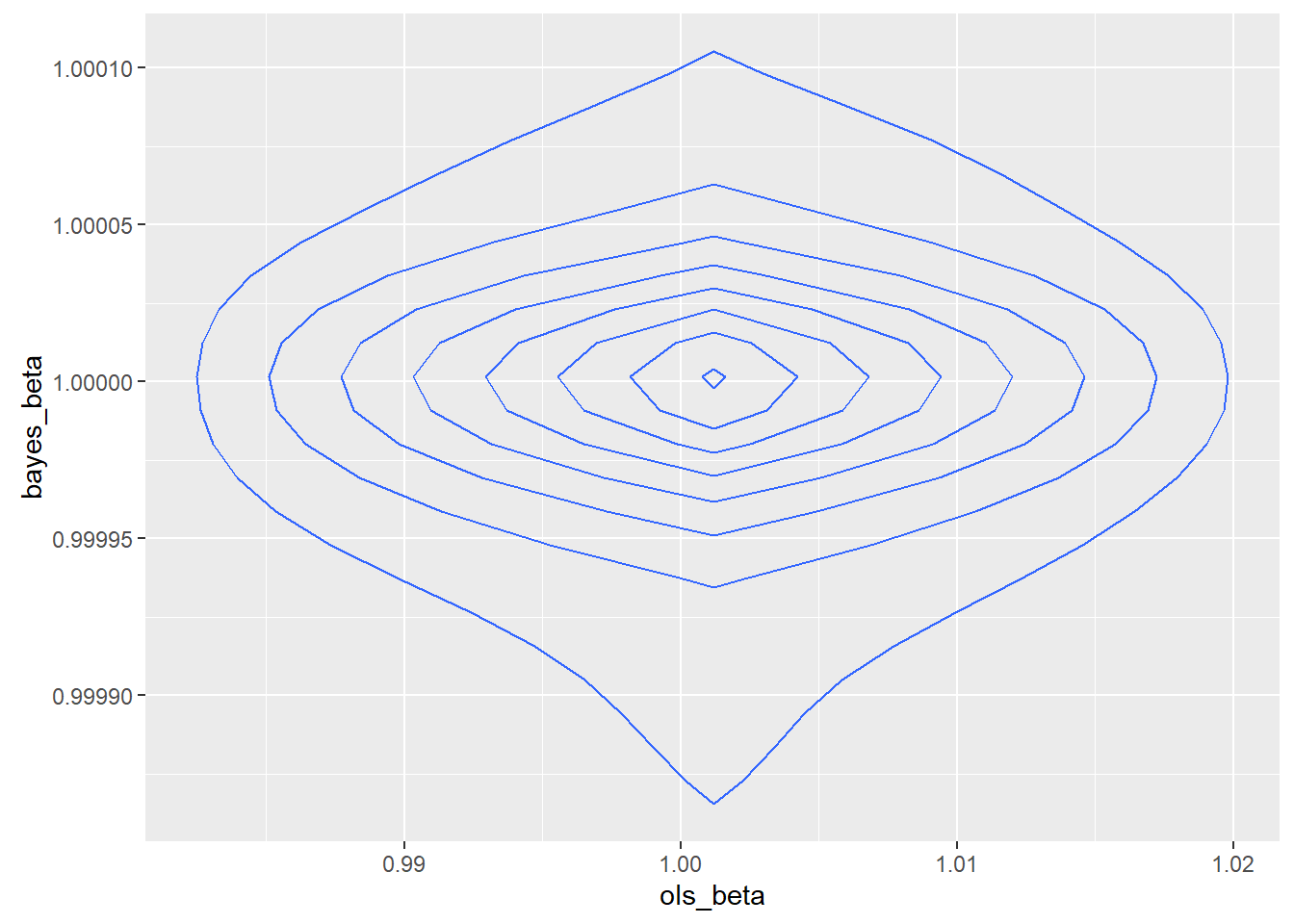
The summary statistics are
## ols_beta bayes_beta
## Mininum : 0.1906 0.9994
## 1st Quarter: 0.9972 1.0000
## Median : 1.0000 1.0000
## Mean : 1.0004 1.0000
## 3rd Quarter: 1.0029 1.0001
## Maximum : 2.2482 1.0005
A somewhat related question is the behavior of an estimator given only one sample.
The first sample of second set resulted in OLS estimates using R’s LM function,
## ## Call:## lm(formula = y[, 1] ~ 0 + x[, 1])
## ## Residuals:##
Minimum 1Q Median 3Q Max
-1985 -1 0 1 83433
## ## Coefficients:## Estimate Std. Error t value Pr(>|t|) ##
x[, 1] 1.000882 0.008043 124.4 <2e-16 *** ## —
## Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1## ##
Residual standard error: 837 on 9999 degrees of freedom##
Multiple R-squared: 0.6077, Adjusted R-squared: 0.6076 ##
F-statistic: 1.549e+04 on 1 and 9999 DF, p-value: < 2.2e-16
while the Bayesian parameter estimate was 1.000019 and a posterior density for β as appears in the below figure.
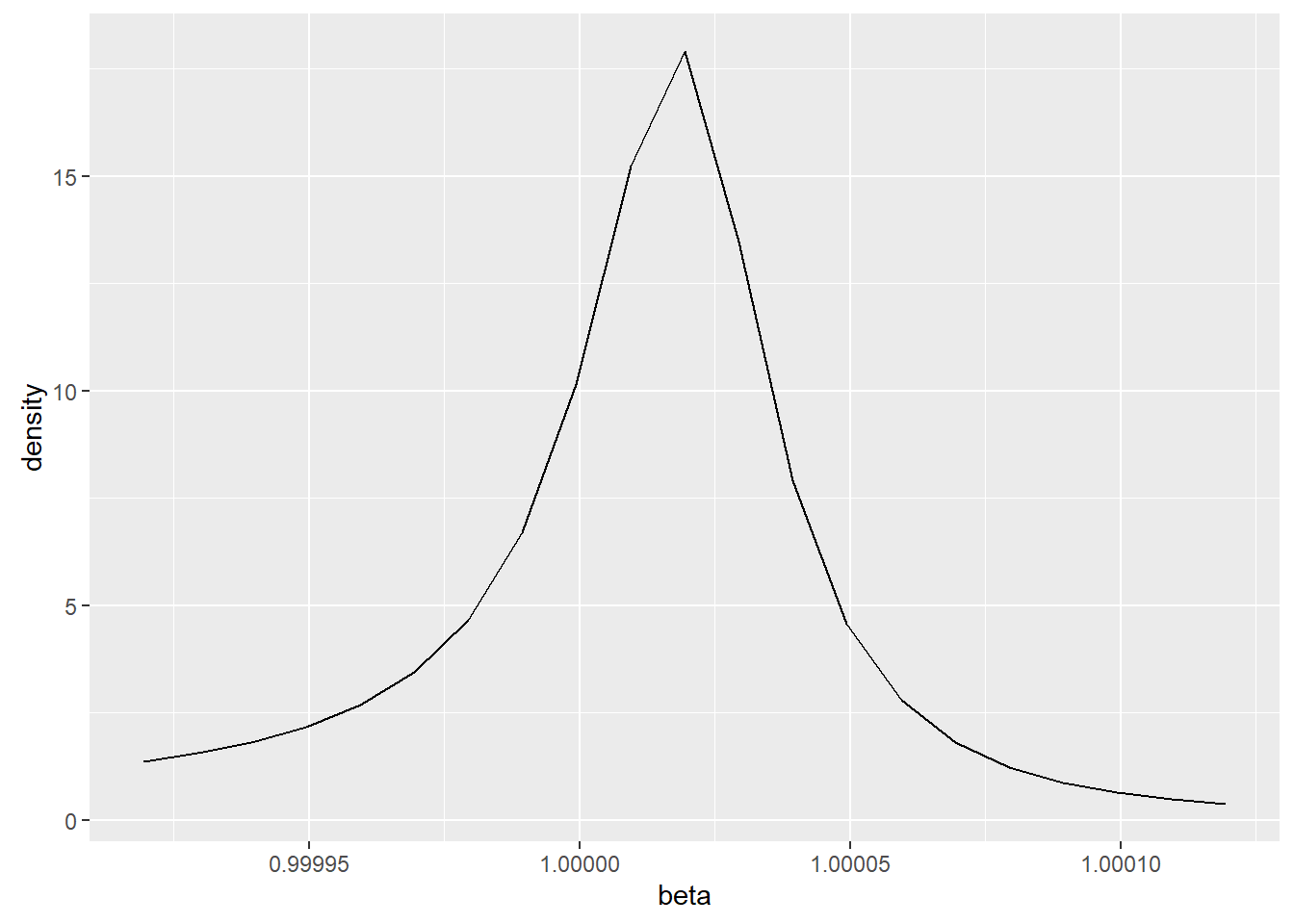
Specific Bayesian intervals were not calculated.
Although the residuals are approximately equal as the coefficients are approximately equal, the residuals have a sample standard deviation of 837, but an interquartile range of 2.04. Based on the assumption of a Cauchy distribution, there were no outliers or very few depending on how one categorized something as an outlier. Based on the assumption of a normal distribution roughly twenty percent of the residuals are outliers.
Just looking for statistical significance won’t provide warnings that something may be amiss.
Model Building
So, if models like the CAPM, APT or Fama-French do not follow using a Bayesian method of model construction, what could work?
The answer would be to go back to first principles. What things should impact returns and scaling?
One of the simplest and most obvious is the probability of bankruptcy, where bankruptcy is defined as the total loss shares by a court for the existing shareholders. Ignoring the causes of bankruptcy for a moment, if π(B) is the probability of bankruptcy, then the required return should be such that
dμ/dπ(B)>0.
Furthermore, since the variance of a Bernoulli trial maximizes at fifty percent, then the scale parameter should grow no less fast than the change in the scaling of the Bernoulli trial. If bankruptcy risk went from one percent to two percent, one would expect the scale parameter of the stock to go up no less than the increase in standard deviation for the risk in the underlying cash flow.
The author previously tested seventy-eight models of bankruptcy against a variety of fundamental and economic variables. Two of the models had approximately fifty-three percent and forty-seven percent of the posterior probability, while the remaining seventy-six model’s posterior probability summed to around one in one hundred and twenty-fifth of a percent.
These models of bankruptcy were highly non-linear, so a curved geometry in high dimensions is likely to be found in this narrow case.
To understand why, consider the accounting measure of current assets – current liabilities. Most bankruptcies are due to a cash crisis. Enron was still profitable under GAAP well after entering into bankruptcy.
However, this gap may indicate different bankruptcies risks at different levels, especially considering that other variables may interact with it. For example, a firm with just a small cushion of current assets over current liabilities will probably not have a particularly high risk of sudden failure. What about the other two extremes?
For a firm to carry a large negative gap, some other firm has to be underwriting their liabilities. That would usually be a bank. If a bank is underwriting their liabilities, then the bank has adjudged their risk of loss to be small. It implies that the bank has sufficient confidence in the business model to extend credit without the immediate ability to repay. Further, because banks love to place a mountain of protective covenants, the management of the bank is likely constrained from engaging in shenanigans as it is being monitored and prohibited from doing so.
On the other side of the gap, a large amount of current resources may have an indeterminate meaning. Other variables would need to be consulted. Is nobody buying their inventory? Is it a month before Black Friday and they have just accumulated an enormous inventory for a one day sale? Are they conserving cash expecting very bad times in the immediate future? Is the management just overly conservative?
The logic also could vary by firm. Some economic or accounting variables are of no interest to a firm. An electrical utility has no way to incentivize or materially influence the bulk of its demand. The weather is of far greater importance. It cannot control its revenue. A jeweler, on the other hand, may have a substantial influence on its revenue through careful pricing, marketing, and judicious credit terms. Revenue may have a very different meaning to a jeweler. Likewise, some products do not depend on economic circumstances to determine the amount purchased. Examples of this include goods such as toilet paper or aspirin. Model construction should involve thinking.
Imagine a set of two factors whose expected bankruptcy rate is a paraboloid. Will your neural network detect the mapping of those features onto returns or a decision function? What if the top of the paraboloid has extra bends in it? A good method to start the validation process is to simulate the conditions where the model is likely to have difficulties.
Ex-ante validation of mapping factors to decisions for neural networks should be more about the ability to map from a geometry onto another geometry. The mean-variance finance models were nice because they implied a relatively low dimensionality with linear, independent relationships.
The alternative test models should not be uncorrelated as there is high correlation among variables in finance. Rather, it should be a test of correlated but incorrect geometries.
Large-scale model building often implies grabbing large amounts of data with many variables and doing automated model selection. I have no argument with that, but I do recommend two things. First, remember that accounting and economic data are highly correlated by design. Second, remember that simple linear relationships may not may logical sense from a first principles perspective so be highly skeptical.
For the first, a handful of variables contain nearly all the independent information. The Pearson correlation among accounting entries in the COMPUSTAT universe range from .6 to .96 depending on the item. Adding variables doesn’t add much information.
For the second case, a simple mapping of believed associations and how they would impact mergers, bankruptcies, continued operations and dividends would be useful as well as how they would likely interact with each other to determine a rational polynomial or other function as the form.
As this is being done as software, that software should undergo a verification and validation (V&V) process.
Verification and validation differ slightly from the simple testing of software code in a couple of ways. If I write code and test it, I am not performing either verification or validation automatically.
In an ideal world, the individual performing the V&V would be independent of the person writing the code and of the person representing the customer, although that is an ideal. It is an extra cognitive step. The verifier is determining whether or not the software meets requirements. Simplified, is the software solving the problem intended to be solved? It has happened, more than once in the history of software development, that the designers and builders of software have interpreted communications from a customer differently than the customer intended. In the best of worlds, quite a bit of time is spent communicating between customer and builder clarifying what both parties are really talking about.
Validation, on the other hand, is a different animal. It is a check to determine if the proposed solution is a valid solution to the problem. It is here where financial economics and data science may get a bit sticky. Much depends upon how the question was asked. Saying “I used an econophysics approach to create the order entry system,” does not answer the question. Answering with “well, I cross-validated it,” also doesn’t answer the question of “does it solve the actual problem.” The cross-validation procedure, itself, is subject to V&V.
Are you solving the problem the customer feels needs to be addressed and is your solution a valid solution?
Imagine a human resource management system for pit traders that is designed to determine which employee will be on the floor. Behavioral economics notes that individuals that have lost money behave differently than those who were recently profitable. The goal is to create a mechanism to detect which traders should be on the floor. Mean-variance finance would imply that such an effect shouldn’t exist. The behavioral finance observation has been supported in the literature. The question is what theory to use, how to verify the solution and validate it.
The answer to that depends entirely on what the customer needs. Do they need to minimize the risk of any loss? Maximize dollar profits? Maximize percentage profits? Produce profits relative to some other measure? As behavioral finance is descriptive and not prescriptive, it may be the case that replacement traders will not improve performance. When considering which mechanism and measurement system to adopt, the question has to always go back to the question being asked of the data scientist.
The proposed calculus in the prior blog posting adds a new layer to mathematical finance. In it, there is a claim that returns, given that the firm would remain a going concern and ignoring dividends and liquidity costs, would converge to a truncated Cauchy distribution. That is quite a bit at odds with the standard assumption of a normal distribution being present or a log-normal distribution being present, but certainly in the literature since the 1960s.
Nonetheless, the assumption of normality or log-normality is built on models that presume that the parameters are known. If the assumption that the markets know the parameters is dropped, then a different result follows.
The primary existing models haven’t passed validations studies. The author believes it is due to the necessary assumption in the older calculus that the parameters were known. Dropping that assumption will create validation issues as everyone is on new ground. Caution is advised.
Future Posts
In my upcoming blog posts, I am going to cover the logarithmic transformation. It isn’t a free lunch to use. I am also going to cover additional issues with regression. However, my next blog posting will be on sex and the math of the stock market.
There is a grave danger in blind, large-scale analysis of ignoring the fact that we are modeling human behavior. Unfortunately, it is an economic discussion so it won’t be an interesting article on sex. Sex and food are simpler to discuss as low-level toy cases than questions of power or money. For reasons that are themselves fascinating, people spend hours or days analyzing what stock to pick, but minutes to figure out who to potentially have children with.
The entire reason managers are taught numerical methods is to prevent gut decisions. Leadership isn’t everything, management matters.
It takes leadership to convince people to climb a heavily defended hill, possibly to their death or dismemberment. No one will respond to a person with a clipboard letting them know they will get three extra points on his or her quarterly review if he or she takes the hill. They will follow a leader to certain death to defend their nation.
On the other hand, leadership will not get food, ammunition, clothing or equipment to their encampment on time and in the right quantities at the correct location. Only proper management and numerical analysis can do that. Data science can inform management decisions, so it is best to remember we are not, automatically, a logical species.
Also, before everyone runs for the door on the Fama-French model, I will present a defense of it that I hope will serve as both a warning and a cause to look deeper into their model. Fama and French were responding to the CAPM, not replacing it.
Up next, sex, data science, and the stock market…
For empirical verification of the above proof see the article at the Social Science Research Network.
References
Curtiss, J. H. (1941). On the distribution of the quotient of two chance variables. Annals of Mathematical Statistics, 12:409-421.
Davis, H. Z. and Peles, Y. C. (1993). Measuring equilibrating forces of financial ratios. The Accounting Review, 68(4):725-747.
Grice, J. S. and Dugan, M. T. (2001). The limitations of bankruptcy prediction models: Some cautions for the researcher. Review of Quantitative Finance and Accounting, 17:151-166. 10.1023/A:1017973604789.
Gurland, J. (1948). Inversion formulae for the distribution of ratios. The Annals of Mathematical Statistics, 19(2):228-237.
Harris, D. E. (2017). The distribution of returns. The Journal of Mathematical Finance, 7(3):769-804.
Hillegeist, S. A., Keating, E. K., Cram, D. P., and Lundstedt, K. G. (2004). Assessing the probability of bankruptcy. Review of Accounting Studies, 9:5-34.
Jaynes, E. T. (2003). Probability Theory: The Language of Science. Cambridge University Press, Cambridge.
Marsaglia, G. (1965). Ratios of normal variables and ratios of sums of uniform variables. Journal of the American Statistical Association, 60(309):193-204.
Nwogugu, M. (2007). Decision-making, risk and corporate governance: A critique of methodological issues in bankruptcy/recovery prediction models. Applied Mathematics and Computation, 185:178-196.
Sen, P. K. (1968). Estimates of the regression coefficient based on Kendall’s tau. Journal of the American Statistical Association, 63(324):1379-1389.
Shepard, L. E. and Collins, R. A. (1982). Why do farmers fail? Farm bankruptcies 1910-1978. American Journal of Agricultural Economics,64(4):609-615.
Sun, L. and Shenoy, P. P. (2007). Using Bayesian networks for bankruptcy prediction: Some methodological issues. Computing, Artificial Intelligence and Information Management, 180:738-753.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

“The internet is killing retail. Bookstores are just the first to go.” — quoted in this NYT article. Retail bookstores are in a death row; looks like it’s just a matter of time for those to be in the museum. eBooks are partly to blame, but with eBook sales leveling off recently, the remaining affect seems to be online book sales, dominated by, with no surpirse!, Amazon. So, exactly how long retail bookstores are going to survive? Is it going to be “Gradually and then suddenly”? Or could it be just 5 years from now? One might ask: “5 years? no way!!”. But imagine the Amazon effect just few years ago; or the Facebook effect in 2008.
To examine this I’ve got a nice time series dataset from the Census Bureau database. This is a monthly retail sales data (in millions $) from bookstores all across the country. Data are collected monthly as part of Monthly Retail Trade Survey and cover 26 years since 1992. A number of popular forecasting methods are out there but since the data has seasonality, I choose to run the Holt-Winter Exponential Smoothing (HW) — a popular forecasting method in machine learning field ( I also ran ARIMA, but the results are less definitive).
So what exactly does the forecast tell? The analysis shows that bookstore sales peaked around 2007, but since then the sales are going downhill. The HW forecasting predicts that the bookstores may at best survive another 15-20 years from now due to decline in retail sales. This roughly puts the lifeline around 2040.
Signs are everywhere. Book World is closing it’s stores. Barnes & Noble closed 10% of it’s stores in just the last 5/6 years and this February it shedded 1800 jobs. This will keep accelerating in the next few years. That said, some bookstores may well survive beyond 2040, but not as traditional stores, rather as antique books stores.
[For data, codes and further analysis on this topic visit my website. Follow me on Twitter for updates on new analysis. Photo credit: M Alam]
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Hello, everyone. I’m Hema Raghavan and as it introduced, I am head of the AI and machine learning for growth and notifications at LinkedIn. Prior to LinkedIn, I was at IBM Research and I’ve also worked at Yahoo Labs. I’ve worked in search, advertising, and more recently, recommender systems. And in today’s talk, I will be talking about building near realtime contextual recommendations for active communities on LinkedIn and that’s a mouthful of a title. So we’ll break that down out. First, I assume most of you here use the LinkedIn app. How many people use LinkedIn? Great. So we use LinkedIn for networking, for finding jobs, and so on. And what you’ll understand through this talk is also what it means to have an active profession community, how LinkedIn can help you build that active profession community, but also why near realtime platforms which can do contextual recommendations and all of that will start making sense by the end of this talk. So why you need a near realtime platform to do this.
Economic Opportunity for Every Member of the Global Workforce
So at LinkedIn, we have a very big vision, we are only part of the way there, our vision is to create economic opportunity for every member of the global workforce. The way we do this is we use AI and machine learning to connect the world’s professionals to make them more productive and successful. Note the keyword “connect” and connections are what drive most of our profession and careers. So many of us here are to learn, but we’re also here to connect with people. And that’s what propels our careers. And that’s the founding principle of LinkedIn. For LinkedIn’s connection engine or, you know, to build your connections in LinkedIn, one way to do it would be for every person you know, you potentially search, you look at their profile, and you actually hit connect. But for 10 years or so, we’ve had a critical recommender engine which actually helps people build their connections.
People You May Know
The product here is called People You May Know. It’s been there for over 10 years now and its mission is to connect our members to the people who matter most to them professionally. And this allows them to access opportunities in the LinkedIn ecosystem. The way we do this is we mine data sources which is the LinkedIn’s Economic Graph. The Economic Graph is not just the connection network, but it could also entail companies, schools, all these other nodes that you can have that you have links to. So we use AI and ML, and graph mining techniques to build algorithms on top of this graph and this is how we build our connections. And it’s intuitive why building a network is useful, but I’ll say a little more here. And the key is that by being connected, in some senses, you stay informed. We do that in workplaces, we do that in the actual physical world on LinkedIn. Your connections help you stay informed on the feed. So if someone shares something, someone’s reading an article, someone’s, you know, going to QCon and a bunch of your networks are going to QCon, you might discover that on the LinkedIn feed.
If you’re looking for a job, it’s actually again very clear why connections are useful. So for example, if you’re looking for a new job, most people reach out to their professional connections for a referral and that’s how connections help you advance your career. And then if you’re a hiring manager or even if you’re a tech lead which many of you in the audience are, if you want to ask a technical question, you might actually solve the problem faster by reaching out to someone in your network. So connections help you work smarter and of course, if you’re a recruiter or a hiring manager, the value proposition is obvious.
High Quality Relevant Connections Matter
Now, for LinkedIn, we’ve had connection data that we built over several years and the fact that high quality relevant connections matter is something we see in our data on many different metrics. So the graphs here actually show you three different metrics, the X axis here are the number of connections and then you’ll see the number of in-mails received, in-mails are often recruiter mails. But the number of opportunities that come to you actually increases with the number of connections you have. Messages can be recruiter messages, or they can be even just people asking for your advice or seeking out help. And then in general, the value for LinkedIn itself, like how many daily active users we have or how much engagement we have on our site increases as the member has more connections. So connections are critical and for growth at LinkedIn, and when I say growth, at LinkedIn, we use the term “growth” to mean to be the process of bringing users into LinkedIn. So not just signups, but taking them through the journey to when they actually engage with LinkedIn on a periodic cadence and as they understand what the value of LinkedIn is.
Developing a True North Metric
So growth is essentially grow in LinkedIn, but making sure that our members actually understand what the value of LinkedIn is. And in LinkedIn, one of the ways we approach our problems is to often think of a true north metric. So we will take this mission, right? For example, we have the larger vision of connecting people to an economic opportunity, but here within growth, we’re thinking about how do we bring people to the site and actually see value? So we typically define a metric a success criteria that actually measures the quality of how our product is doing for this value proposition. And we have moved on from, you know, real metrics. So a lot of companies do daily active users or monthly active users, but we often try to take something that’s more nuanced and just beyond role counts.
Once you’ve arrived at a true north metric, we often use data science and many of you saw the keynote this morning. So you’ll have a true north, but our data scientists will go in and actually say, “Hey, what are the products we can actually build to move this true north?” And then we have a large framework for A/B testing that lets us that lets us inform product decisions.
So the true north for the growth team is essentially to get engaged members with high quality connections because we think that’s the first stage, once you have that, you will get the value for LinkedIn. Towards this goal within the PYMK group, what they know they can drive, and this is established through correlation or causal analysis models, is they can drive the connections component. So the proposed metric would be PYMK invitations sent and accepted. So typically when you come into the recommendation engine, you may hit invite, invite, invite. Typical recommendation products would measure CTR and that would have just been how many invites you sent. But we really want to look at the downstream. So we want to see given an invitation, do you actually get an acceptance. So we look at the downstream impact and that’s what I meant by actually making sure that your metric makes sense. It’s not just something that is easy to move, but making sure that you send invitations and those invitations are accepted. And we monitor both. You certainly don’t want a large invitation volume and a very low connection volume or in an A/B test, you don’t want to be driving up invitation so much, but your connection accepts are not actually moving at the same rate. So metrics in some sense are the conscience of your product, they keep you honest, they keep you close to what value you bring.
Likewise, we also look at the recipient side. So for example, we will look at how many inbound invitations does a member get? So if you’re flooded with invitation request and you’re getting notifications, that’s a pretty bad experience. So we want to maintain a base rate for that as well and in our A/B tests, we will look at both invitations sent and received, and both the rates. So now, we define the metric. So how do we go about building a product like people you may know?
Connecting the World’s Professionals
And for this, I will take a small sample graph. And let’s say there’s a new user, Lucille, who comes in. Let’s say she’s just joined as an intern at a particular company, she’s a student, and her manager tells her that LinkedIn is the place to be and sends her a connection request which she accepts because you generally accept your manager’s connection request. And so, she’s built her first edge on the LinkedIn graph. Now, who do we recommend to Lucille so that she builds this network, right? Because if she has just one connection, she’s not really going to get a lot of value out of LinkedIn.
So in the limit, this becomes an N squared problem because we could recommend anyone to anyone. And right now, we have close to 600 million members on the graph and that’s just computationally infeasible. So a common heuristic that makes sense and it’s actually established in the social science literature is that friends of my friends are likely to be my friends. It’s homophily, there’s many different terms in the literature, in social science as well, and it works in the real world as well.
So with that, we can use the simple heuristic that we can look at Dominiq’s network. So that just brings the candidates from N squared down to four in this case and we say which of these members is, you know, a potential recommendation for Lucille? Now, this is a small enough problem that we can show all of them in a rank sorted list. But you can very well imagine that, if Lucille had 30 or 40 connections and each of them had hundreds of connections each, that would blow up, so you have a large candidate set and how you’re going to rank this.
So the second piece of intuition again very natural is that people I know share common connections. They may have common institutions, skills, so on and so forth. And we bring this into our models. So as we said, Lucille and Dominiq work at a given company. And so, let’s say Erick is another person at this company. So perhaps it makes sense that the top of this rank list is Erick and let’s say then, we recommend Erick to Lucille or Lucille to Eric, vice-a-versa. Depending on who comes to the site first, we can actually recommend one way or the other. And one sends invitation to the other, the other accepts it and this edge is built. So now, Lucille has started building her network.
Typical Playbook for Recommendation Systems
Now, this playbook for recommendation systems that there is candidate generation and then there is something that reranks those candidates appears everywhere because it appears in newsfeed ranking, it appears in search. So for those of you who work in search, you’ll typically have something that generate … it’s either heuristics or simpler models would generate a first class of candidates and then you may rerank it using maybe deeper models. And when I say deep, actually, something like deep learning can actually be applied there. You can actually put things which are computationally more expensive, more features. And so, the first layer focuses on recall, the second layer focuses on precision.
Candidate Generation
For graph algorithms and some of this even applies to follow recommendation like problems which appear in companies like Twitter or Pinterest, and so on, where you may actually navigate the graph, you’ll see a second degree network. And then you also have extensions like personalized page rank. Personalized page rank is actually fairly intuitive to understand. So it’s a random work algorithm. So given a starting node, it computes the probability of landing at a destination node. You might do a random work. So given a node, you might land at anyone of the neighbors and then you may jump from there to anyone of the other neighbors. And then if you did this a few times, where would you end up is what personalized page rank does. And it’s an extension of friends of friends essentially and it lets us go beyond the second degree network. And it really helps in the case when the initial candidate generation phase has very low liquidity, a small number of candidate sets. So for example, in the Lucille example when she had only one connection which was Dominiq, personalized page rank would have helped you to extend the candidate list to even perhaps a third degree network. But again, it’s not right up to N squared.
So once we have candidates from these graph algorithms, typically, scoring tries to predict the probability of a connection. And here we’re applying node features and node features are, you know, whether what skills a person may have, what school the person is at, the company, so on and so forth, the general propensity of the person to invite someone or accept an invite, and so on. And then we have features of the edges which could be common connections of the commonality of the schools, skills, so on and so forth. So you have all of this. You put this in your favorite decision tree or in a logistic regression, or whatever favorite model you have, and you have an output probability, and you use this for ranking.
PYMK Architecture
And as I said, PYMK has existed for a long time and for some of you who have attended some of the talks from the team and meetups, or other forums, you may have seen a typical architecture diagram. And this is often involved computing offline in batch. And in fact, PYMK actually, I’m kind of proud to say has been the birth place for a lot of LinkedIn’s open source architecture. So for example, Voldemort or some of the stereotypical examples that are in the Kafka paper for why Kafka was built and so on actually stem from PYMK.
So typically, candidate generations or this world friend of friend calculation, or personalized page rank is done in Hadoop, it could be MapReduce or in Spark. And then you do scoring and then you push to a key value store. And the key value store in today’s architecture is Venice which is a successor to Voldemort. Once you have data in your key value store, the keys are members and then when a member comes to the site, you look up the key on the member ID. We might apply some real-time signals. A very simple example of a real-time signal maybe the fact that Lucille just joined this company x, y, z. So then you can actually just rerank the candidates such that based on the context that she just joined this. Maybe she did a profile update half an hour ago. It could be a very simple real-time signal.
And then you do some rescoring and then you output the set of candidates. And then what you see back is once a member starts clicking, you generate tracking events and these go through Kafka back into our offline infrastructure. This is the offline tracked events I used for A/B testing, reporting, and back into our model training pipeline. So this cycle just continues and models can be run on a periodic basis. So the Netflix talk talked about auto-training pipelines that you want to run at a regular cadence and so on. And you can instrument all of that through an architecture like this.
Data Processed Grows Linearly
Now, what happens with a batch offline is that the data grows and it gets computationally heavier and heavier. And you’re precomputing, in that previous architecture, you’re precomputing for every member, many of which do not visit your site. So you have a large heavy computation and the fact the data process grows linearly is not a surprise. But at LinkedIn, for every member you add, that is every node you add to the graph, the number of edges and that’s for us it’s really the number edges that you’re processing, grow super linearly. So every edge creates a compounding effect on the second degree network or in the page rank like candidates that you’re generating. So that grows super linearly and this blows up our offline infrastructure.
Scalability of Batch Offline
To give you a little more of a window into why that happens, I’m just showing you a simple example with two tables. One is where you have the node features and you have a table with member IDs and a set of features, and then you have pair features. And pair features are really edge features. So you have a source and a destination. So two members and you have a set of features. And you do two joins. So you do a first join where the source ID is the same as the member ID and then you do a destination side join where you join it back to the member ID table. So you get this big fat table in the middle. You put that through your scoring and you get a result, and that’s when you get your probability of connect. But this table here is big. That’s where we are actually shuffling. Mid 2015, we were shuffling trillions of records in MapReduce and we just took lots of cost to serve initiatives. We started getting smarter and smarter about how we started doing joins.
Need Smart Joins
And we have a blog post about this, so you can actually see the algorithms we developed. So one of them was just getting smarter about how we partition the data and that’s what we call the 2D Hash Join algorithm and even triangle closing follows this pattern of this big middle, and that’s easy to see, because I already talked about how a single node compounds the number of computations. So you have this big fat middle and we had got smarter there where we did matrix multiplication.
So we started taking these jobs which would take several hours in our offline MapReduce, and in fact, we had the reputation in the company of being like, when the PYMK job is running on the Hadoop queue, nobody else can get anything done. So as we got smarter and smarter, so wanting to decrease cost to serve, we started doing these optimizations. We brought down some of our compute costs down to several tens of seconds and this was amazing.
Freshness Matters
But something we observed besides cost to serve was on metrics. Our PYMK sent and accepted lit up like, by huge numbers every time we did a cost to serve improvement. And so, we saw that freshness mattered. Now, why does freshness matter? So like, the fact that we just reduced cost to serve time and the index that we have, that’s key value store is just way more fresh like, instead of starting at a snapshot of the graph which was severed as old that it is actually much closer in time to where it is where the graph was when the user comes in, that it lit up our true north metrics was a mystery to us.
Why Near Real-Time PYMK
So we started actually digging deeper and deeper, and this is where our data science hat came on. And all our data showed us, in our analysis, that network building is contextual and it often involves people exploring a cohort or a subnetwork in a session. So what people would do is people don’t come and engage with PYMK even though it’s the second tab on LinkedIn on a daily basis. But when they come in, they’ll go click, click, click and they’ll build a network. And that context really matters. So if you’re connecting to your QCon network, you’re very likely that in the subsequent scrolls, if we show you people you’re meeting here, that you’re likely to connect. If I interleave one person from QCon with an old high school buddy, the odds are that’s not how network building works. And if you will analyze your LinkedIn network, it’s likely that you build subnetworks of these over time. This is just a mock example of someone who went to Stanford, built a network, and then perhaps worked at LinkedIn, Yahoo, and maybe some other places. And each of these subnetworks will probably build at a moment in time.
Near Real-Time Recommendation Platform: GAIA
So all of these intuitions including the cost to serve on our offline pipelines motivated us to try a proof of concept for a near realtime recommendation platform. So we have a pretty of mixed group of skill sets in the team. So the distributed systems people came in and they said, “You know what? I’m going to try doing this in memory.” So what they did was they built a snapshot of the graph on Hadoop, they pushed it to a large RAM machine so we would ingest the graph in memory, but every update that came to the draft, so every new connection that was made in the LinkedIn ecosystem made its way into GAIA through Kafka. So at any given point of time, this platform which we called GAIA had the true representation of the graph. The only latency being the Kafka latency. And our systems experts also built a very simple API where our data scientists would just write random walk like algorithms. They could bias these random walks to walk around the neighborhood of a school or the neighborhood of a company, or you could bias these random walks.
And after the deployment of GAIA, we actually saw the biggest site-wide improvement in connections that we had seen in the history of the product. So it’s your 10 years into the product, we were moving at a regular pace. So we were improving. We have never plateaued, but we actually saw one of the biggest improvements in the connections made. We also saw a bunch of other metrics especially signups. So the moment a user came in, we realized that the one of the first few screens they see is a PYMK. So then you actually have a more real representation of the graph, a more updated representation of the graph. And so, all of those metrics actually started moving in.
Now, one thing that came out is we had done all this analysis and we actually understood why a near real-time platform was helping. It started actually tickling our product partners’ minds to start thinking about different user experiences.
Conversational “Network Builder”
So for a long time, our product had been fairly static. So you would see PYMK recommendations as a rank list and you would just go click, click, click. But now, let’s take the example where let’s say Dominiq invites Lucille and then Lucille accepts. And then when she accepts, Dominiq gets a notification which says, “Congrats, we’re adding Lucille to your network.” And then in that subsequent screen, Dominiq sees Lucille’s first degree network. So you’re actually exploring that subnetwork in near real-time. So it actually weighted the product manager’s mind to actually start thinking of exploring subgraphs in near real-time.
Platforms Unlock New Product Experiences
Our India team always knew that people in India actually had a behavior of network building where in the third or fourth year of their university program, they would connect to alumni. And this is an inherent part of the culture for job seeking. People pay it forward. So basically, every group pays it back to the next group, in turn. And so, they said, “You know what? We’ll just start showing PYMK in batches of alumni.” And what GAIA allowed us to do was actually explore these alumni cohorts. So if I know which school I’m graduating from, it would actually explore that subnetwork of the graph in near real-time. So through all this, we actually discovered that context matters, near real-time context matters, and actually having a platform that was near real-time was really valuable. Not only from a cost to serve perspective, but also from how we shaped our product.
Active Professional Community
Now, this is why we’ve talked about edge building, but what good is an edge on its own if it doesn’t help you? So towards our goal of helping our members finding their dream careers, at LinkedIn, we believe that it’s important for a member to have an active professional community. What does an active professional community mean? It really means that when you look for help, you get the help you want. For example, if I have a question to ask about a paper on blockchain, someone in my network can actually help me answer that and is willing to help me answer that. Alternatively, if I have a question about machine learning, there may be some other subnetwork of mine that is actually relevant and is willing to help me. And we also find from the purpose of LinkedIn that building this active community where people are willing to share and then get feedback actually helps people share more. So actually talking about that a little bit more. So if I share and if I get no feedback at all, the odds that I’m going to put myself out there and ask for help is very little.
So actually what we find is that if we can steer edge buildings such that we know for sure that people will get the help they need, then we can actually make edge building or steer edge building in a way that we help people build these active communities. So let me explain that a little bit more. So this was the little graph that we built earlier and let’s now take an example of where Alice shares a post. And like in all social networks, this becomes an eligible candidate for the feed off all of Alice’s first degree network. Now, let’s assume Carol, Bob, and Erick come to the site maybe an hour later, they see this. This is how Facebook behaves, all your social networks behave in this manner. And let’s say Bob comments on the post and it does create for the viral cascades where Carol gets information that Alice is talking, Bob is commenting. It may actually propel Carol to comment more and this is the social behavior that you see on the network.
Biasing Connection Recommendations for an Active Community
Now, in this example, what happens is Lucille is kind of in a pocket where no information is going to her because she’s connected to Erick and Erick is a passive consumer. Erick consumes, but he doesn’t really share or comment, or do any of the social actions which actually create further information cascades. And Dominiq isn’t even coming to the site. So Lucille really has an empty feed at this point and she’s unlikely to see value from LinkedIn. So how could we potentially bias edge building so that Lucille actually sees some value for LinkedIn? And so, when we’re looking at candidate generation or scoring, we could potentially consider which of these candidates are likely to be Lucille’s active community. And this is what we mean in terms of actually helping build an active community. And towards that goal, perhaps connecting Lucille to Alice makes sense.
And so, a score ends up being more than just a probability of connect. It actually ends up being a probability of connection, it also includes the probability of a potential conversation between this edge, because we don’t want to just build passive edges that are never going to help you. And you can take this objective function to mean not just help in the context of feed, but it can be other kinds of help as well. And we tune these hyper-parameters using an online parameter selection framework. There’s more written about that in the literature.
Notifications
So that brings me to the end of the first half of my talk where I talked about building this graph, the graph that is LinkedIn. In the second half of my talk, I’m going to talk about the role of notifications and I said in growth, we think of growth as the general problem of showing you value for LinkedIn. And I will continue to use my running example of the simple graph to show you how notification is going to help. And again, I will show you why we need near real-time platforms and why we also need it to move from batch offline to near real-time for a similar problem.
So now, coming back to this example where Alice has an active community, she has people who give her feedback, so on and so forth, we have discovered that Dominiq was kind of passive. And what if this conversation or this share was really relevant to Dominiq and if he had actually seen it, it was super useful? We could potentially send Dominiq a notification saying that Alice shared this piece of content, you might want to look at it. Again, a lot of social networks do this. If this content, piece of content is very relevant to Dominiq’s interest which we can of course infer from Dominiq’s past behavior on other pieces of content and so on, it perhaps may motivate Dominiq to do another share and then that actually creates further viral cascades on the network. Maybe it prompts because Dominiq is the manager. Again, this is a behavior we often see is that if your manager comments on something, you feel like you’ve got to say something, too. So maybe Lucille is going to comment and then she suddenly becomes an active participant. She’s a new user, but she’s become an active participant for LinkedIn.
So we can shape these graph algorithms and even shape the notification problem to create these viral actions, and actually create pockets of conversations that are completely relevant to our users on LinkedIn. And we have many notifications that come off from LinkedIn, but one of them is the shared by your network notification and I’m going to use that as a running example in the rest of my talk.
The idea of a shared by your network notification is that a member never misses out on a conversation that is timely and important for them. This is what it looks like. It’s the third tab on your app. As I said, there are many different notifications, but the top one which actually says Dominiq shared an update is what it typically looks like.
As many of you know, we have many different ways of getting notifications today. We have Push which is probably the most invasive. It comes, the phones buzz, it catches your attention, it makes you feel like you need to react. There’s badging. So we can choose not to push, but just put that little red dot on your app saying “Hey, I’m missing out something.” We may send you an email which is the least invasive and then we may just send it to your tab. So there’s just many different ways. And so, we call these notifications channels. And you can think of them as just different places we can send you the notification.
And here’s a graph which actually shows the number of sessions that come from the mobile app. And I think from any of you who work in a consumer facing internet product, you probably see your app sessions are growing at a much faster rate than sessions that come from desktop and mobile. And this is great. So you have more channels, but it also leads to something like this because most of our apps start looking like this. It creates notification fatigue and in the worst case, a member may completely tune out, they may either disable notifications. So as I said, push notifications are a great way to get the user back in, but if you’re too noisy, they may just disable push or in the worst case, uninstall the app. And at that point, you’ve lost the user.
So the key problems for notification are to send the right message at the right time, on the right channel. And send as few notifications as possible. So there’s a nice class of problems that reside in the notification space. If your company isn’t using intelligence for notifications, I think it’s probably worth considering it. In the next part, I’ll just talk about the right message and later, I’ll talk about minimizing the total number of notifications. I’m happy to chat offline about getting the timing right or the channels right because each of them is a very deep and interesting problem.
Notifications also follows the typical label for recommendation systems. So you have candidate generation. At LinkedIn, we talked about shared by your network as an example, candidates generation can come from anywhere. For example, the jobs team may decide that there’s a set of jobs that you should actually see. We know you’re a job seeker and we’re going to send you the jobs that you’re interested in. If you’re a recruiter, maybe the corresponding product team has a set of candidate notifications that they want to notify you about, so on and so forth. So there’s a set of candidates. It’s different from the PYMK problem in that in PYMK, even the candidate generation is trying to solve one problem. In this case, candidates come from many different product or products all vying for your eyeballs and shared by your network is just one example of that.
Notification Ecosystem
Candidate generation can happen offline or it can happen in near real-time. We have both platforms at LinkedIn and often when a product decides that they want to send notifications, we’d often debate when whether it’s an offline use case or an online use case. And good example of an offline use case would be say, work anniversaries or birthdays. It’s interesting how chatty people get with their ex colleagues on the context of birthdays, but people just love that. They really engage with that form of notification because, you know, it’s that one way you’ve forgotten ex colleague but you get a notification which says, “Wish x, y, z happy birthday,” and then they’ll have a set of back and forth messages. And some people engage with that more than others. So you have to use intelligence to know whether, you know, that’s interesting or not to this given member.
So we have near real-time and offline platforms. Offline is useful in cases like the birthday notification because you know all the set of birthdays that are coming up. So you can batch process all of them offline, you can put smarter models. You know what’s coming, so you can actually decide to control volume early on. And then we have a centralized decision making system called air traffic controller (ATC) which essentially takes all the candidates and scores them. It also does the problems of message spacing. So it means it should not be sending you messages in the middle of the night, it should not be sending you messages at times that it has figured out are more disruptive to you, and it also tries to control volume because it has the picture of the entire universe. And then once ATC makes the decision, it can go to some UI and decoration services. ATC also makes the decision as to what channel the notification goes through, then correspondingly decoration happens. And all of this message, so these are not API calls, all of this happens through a series of Samza processors and message parsing happening through Kafka. So Concourse is a set of Samza processors which then push down to Kafka, then it goes down to ATC which is another set of Samza processors and so on, and so forth. The offline is still offline batch, but we have mechanisms to push from Hadoop into Kafka.
Batch Offline or Near Real-Time
So notifications can be, as I said, batch offline or near real-time and there’s value to either of the use cases. But in some cases and then the hypothesis is that especially in the case of breaking news or especially when our conversations are happening, people like to jump into the conversation when it’s happening especially in a professional context, which is why maybe a lot of you use Slack or, you know, similar messaging applications in your workplace. There’s some conversation that’s happening that’s just timely and you want to jump right in. It’s different from the email use case which is kind of batch. And for that, we hypothesized and this was a hypothesis we had over a year ago. And we said maybe for shared by your network especially for certain kinds of shared by your network, depending on the topic, depending on the news worthiness and so on, that decreasing the notification latency from hours, so it was a batch offline process, so going from hours to a few seconds can actually help build an active community. So this is the example where Dominiq gets the notification that this active conversation is happening in near real-time.
So we built Concourse. At LinkedIn, we like these fancy names, probably many of you do. We built our near real-time candidate generation platform. In this example, Alice creates a post and it goes through Concourse. So that generates an event in Kafka. Concourse is again a set of Samza processers that looks at it. The post, it looks at the content of the post, it looks at Alice’s first degree network and it decides which of her connections or which of her followers should get this as a notification. Remodeling back, it may look at behavioral signals between Alice and her first degree network. We may look at how often they interact and an affinity to the contact as well. So we talked about the fact that Dominiq perhaps really liked that topic and he was likely to share.
Results: Near Real-Time Candidate Generation
Concourse may choose to filter out some of the edges and then actually propagate the information to only some of the edges. Since they’re from Concourse, it goes down to ATC and as I mentioned, ATC does reranking, scoring, message spacing, and so on, and so forth. And again, once we moved the shared by your network notification from an offline use case to a near real-time use case, we saw one of our biggest improvements in sessions. So people really liked this super engaged behavior, getting the notification on time.
Scoring
So scoring the models look a little different. We look at the incremental probability of your visiting given the notification. We don’t just want to send you the notification because we say it’s relevant if you’re going to visit anyway and see that content on your feed. We don’t want to send you the notification. So that keeps the volume in some sense down. And then we model the expected value of the session. We don’t say you just come in or you just click, you hit or tap on the notification. What is the expected value? What’s the probability that you’re likely to do a share? And then once you do a share, more people are likely to comment and like, we try to estimate that downstream viral impact as well.
Notification Relevance Problems
And that brings me to the last problem in the notification space. I would spend a couple of minutes on it and really, this is also published work. It’s been published in KDD almost more than two years ago. But really, we formulate the volume minimization problem as minimizing the total volume of sends and then we subject it to multiple constraints. So this class of problems ends up being a little different from what you see in the standard machine learning literature which is estimating some kind of score. It’s actually a large scale LP solver, like a large scale linear program which says minimize the quantity, subject to some other constraints. And again, with the launch of the ATC volume optimization, we actually saw that we cut down our send volume. These charts are for email, but it applies for any channel. And we saw a huge reduction in the number of complaints. Now, in the email, you can see complaints, you can see unsubscribe. So you can actually, in A/B tests, measure these metrics and we saw huge reductions in this with very little page view loss or very little session loss.
Product Optimization
Now, with the launch of a near real-time platform, again in the notification space, it tickled our product manager’s minds. It’s like, “Hey, we have a near real-time platform.” So now, let’s just make sure that when you’ve sent this person a notification on something, let’s not waste real estate on the feed for the same item. So you can start to actually jointly optimizing your product across all of these different tabs, all of these different experiences, and having a near real-time view or having state in near real-time really helped.
Summary
So through both of these parts of the talk, what we learned was that online/nearline computations captivate the user in the moment, and it’s not just driving your metrics. But it also started shaping our product. So there’s this cycle between when we think of a product or we may start at a platform. In both cases, we actually moved the platform, it helped move our metrics and then it actually just changed our product. And we see this continuous cycle and we’ve learned that we just need all the people with all of these skill sets to just keep talking and keep iterating on ideas at the same time. So with that, I’m happy to take questions.
Questions and Answers
Man 1: Thank you for the talk. GAIA has the entire graph in memory or are you segmenting?
Raghavan: We have the entire graph in memory. These are beefy machines, but you can use some heuristics to prune certain kinds of nodes out of it.
Man 1: But you’re pruning nodes or attributes?
Raghavan: No, we don’t prune any attributes because we have fairly rich models. The heuristics we use often aim at pruning nodes.
Man 2: At LinkedIn, you also have the paid members and the unpaid members. Do you have the segmentation of the candidates that you’ve been talking about even in the modeling as well?
Raghavan: Not for our core consumer products, but certainly as a premium member, you get an experience. So for those products, you may have explicit tuning of the models. But, yes, not for the core.
Man 2: So no extra special notification for the premium members which come in?
Raghavan: Again, that’s a set of products that may send you a notification, but your PYMK is not going to be different. So we’re not going to tune your PYMK.
Man 3: Do you guys do embeddings of your users as well? And if so, have you considered doing things like KNN and other ways of actually comparing similarity of users?
Raghavan: Yes. So we do do embeddings. What I did cover is in those node features, I talked about human interpretable features, but definitely, some of those vectors are actually embeddings.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Thank you very much for attending. I know your time is very valuable, and I always value when people decide to take their time and listen to me present. So the talk today is, yes, reactive DDD, or domain-driven design. And so, where did the two ideas, the two concepts, approaches to software development overlap? I think that today we’re in a bit of a crisis in terms of the way that software is designed, the way it’s implemented. And, in my experience, over many years of software development, I found that it really doesn’t have to be the way that things are done today. And so, I want encourage you to take carefully and consider the information that I’m going to share with you and give it a try. It’s not difficult. It is emphasizing simplicity, and sometimes simplistic or simple doesn’t mean easy, but I don’t think that it’s overly complex to try to use these approaches.
Blocking
I think where most of us are, or have been for a long time, is in this mode. This is a blocking mode where, as you see, there’s a client and a server. Now when I’m discussing these two concepts, I’m not talking about a remote client and a remote server, I’m talking about two objects. And, as Rebecca Wirfs-Brock has pointed out in her writings about responsibility-driven design or development, you know, we talk about an object that provides a service, as a server object, and a client that uses that service or consumes that service as a client object. And so, what happens when this client requests a service of the server? Typically it blocks. This is no doubt, what you learned, whenever you started programming, in whatever phase of your career, you probably have always been working with blocking.
And this, generally speaking, is not well-suited on the large scale for the kinds of systems and the kinds of infrastructures that we work on these days. Also, this happens when we request a behavior of an object, and sometimes even requesting behavior is something that’s rarely done these days. And I’ll show you why I say that in a moment. But the HTTP request-response is often a blocking operation where a remote client will make a REST request to a remote-server service and, essentially, the request will block until a response is received. But sometimes, that’s quite a delayed or latent process. And then, of course, when we write something to the database or read something from the database, very often our connections to the database are synchronous. And you might add more to that.
Now there is an improvement today in that some of the frameworks, or web servers, or so forth, that are available are providing some asynchronicity or asynchrony to their request-response behavior. And also, you can get asynchronous database connection. So it’s not, you know, entirely a loss today, but it’s still not a widespread situation.
Anemic Domain Model
The other problem that we have today is largely software is implemented using an anemic domain model. This is where essentially a domain object, or what people liberally call domain object, really has no behavior, it just has data settings on it. So you can, in Java for example, call, “Set something,” “set something else,” and that’s sort of seen as the way that a service communicates with the domain object. This is problematic and, hopefully, I can show you that, when you consider a behavior-rich domain object, there’s actually much less code overall in a behavior-rich domain object than there is in an anemic object. And you can test the behavior-rich object, whereas testing an anemic object is quite difficult.
Imagine that, there aren’t just these seven attributes, on this Java object, that’s marked as an entity, it’s annotated as an entity, and it has an ID column and other columns. So essentially, what we’re doing with this object is we’re just using it to map data into a relational-database table, into a row. And that is, very often, how software is being designed these days. I would say, not 100% but it’s a very probably high number in the 90% of times software’s being developed this way. Now imagine that this object has 25 string attributes on it. Think of all the possible ways that a client could set data on this object incorrectly. How do you test that the client is not only perhaps setting the correct attributes but not setting the incorrect attributes? You could probably write a hundred different tests and not be confident that you’ve covered all the cases, nor is it really necessary if you’re using rich behavior.
Message Driven
I think that where we are headed today is a message driven architecture, message driven systems, message driven domain models even. And I think that this is highly necessary because most of the software that we see in the open today, in the wild, is blocking, it’s not using processors to the extent that they can be used. And message driven, even at the object level, can help to improve the overall throughput of the system because all cores, on a given server, can be used to a very high percentage of their capacity.
Event Driven
And this even includes event driven. So any kind of event can also serve as a message but this is where we actually create a concept, in our domain model that represents a happening that we care about and that happening is recorded as a fact. And that fact can be saved into a data source, and that fact can then be basically published out, or relayed to, or broadcast to other subsystems because they have some interest in it.
And what you see here is not just an event driven architecture but it’s also a reactive architecture. Because, as you can see, the controller, on the left-hand side, is sending a command message to what, in domain-driven design, we might call an aggregate. It’s basically an entity that has a very certain transactional boundary. And that command can then be processed and, if accepted, an event has emitted, that event can be persisted and even help to represent the entire state of the aggregate or entity. And then, notice how the commands are actually being queued at the bottom. So this is introducing the idea of an actor, this is using the actor model. So this is where command 1, 2, 3, and 4 are being sequentially processed by the actor, or this aggregate, this entity, but they’re only being processed one at a time in the order in which they occurred. Which means there’s a non-blocking and non-locking kind of environment where the actor doesn’t have to worry about concurrency violations.
OS/2
Now I want to tell you a story. Is this sort of an odd-looking coffee mug to you? Yes. So in I think it was early 1987, I was asked to co-author a book entitled “The Advanced C-Programmers Guide to OS/2.” And Microsoft Press was the publisher. If you know anything about OS/2, well, that explains a lot. But how many here have ever wanted to scare Bill Gates? Oh, come on. Yes. I mean, here’s what happened: I’m writing this book and I came up with this library, a message-based library that was using the OS/2 IPC facilities. And what I did is I created a character mode, desktop API basically, that sat on top of the OS/2 API. And it handled full windowing with asynchronous control, and all the windows actually, you know, weren’t going through a processing loop but actually reactive to the fact that a clock updated or reacting to anything. And without dragging this out further, basically, when Bill Gates found out about what I did, he said, “Shut it down. It might compete with Presentation Manager.” So my days with reactive and messaging, and so forth, goes quite a ways back. And it proves that you can scare people when you do the things that you want to do.
Reactive DDD
So one of the maybe problems that we faced with reactive today is that sometimes the reactive platform itself requires us to, if you’re optimally using the reactive platform, to even switch languages that you’re using. Can you model with fluency in that reactive system or platform? Do you have type safety in that platform? Is it testable type safety, is it testable model fluency? And so, what I suggest is don’t give up the languages. For example, if you’re working in Java on a regular basis, you don’t have to give up Java to get reactive benefits.
So when I talk about reactive DDD, this is what I’m referring to. And you probably, you know, could recognize these green blobs as, let’s say, microservices. You might immediately question that and say, “Well, there are too many entities in that for it to be a microservice.” Well, it depends on your definition of microservice. What I’m talking about here is a microservice as a domain-driven design-bounded context, which is not a monolith but it’s also, generally speaking, not a single entity type. So a relatively small model that is bounded away from other models because it has a specific set of language drivers. As in human language drivers, business language drivers that say, “Okay, the bounded context, on the far right, and the bounded context, on the far left, speak different languages.” And even if they use the same words, they can have subtle or entirely different meanings for those words and behaviors for that matter.
So this is what I’m referring to, with reactive DDD. And you see how I have a command model and a query model that are, what we would say, segregated from each other. This is talking about the CQRS pattern. It doesn’t mean though that to have a reactive DDD ecosystem with microservices that you must use the CQRS pattern, but we’ll find, in a few moments, that this can be very handy to use.
Fluent
So what is fluent? I don’t know how well you can see this definition from the back but fluent is a way of articulately expressing yourself. And I really have to reiterate that, by setting data on entities, you are not conveying the intention of why you were doing that. So just think about having an anemic entity that has, whatever, 25 different setter methods on it, maybe not so many but, in any case, you set five of those attributes through a setter method, what does that mean? Do you require your client to understand what that means? In essence, what you’re doing is you’re putting the burden of the client in conforming to your data model rather than the client understanding what the business language is.
Protocol
So when I talk about fluent, I’m talking about potentially creating a protocol, such as this one, a progress protocol. Actually that’s a mistake – that should say “proposal”, in case you’re editing my slides. And the proposal has the protocol of you can submit a proposal for a client with some expectations. You also have, in the protocol, that the pricing set by the expectations of the client, or defined by that in the proposal is denyPricing or it could be verifyPricing so the pricing is accepted. If it’s denyPricing, then we’re going to provide a suggestedPrice as a money. So notice how this is actually a fluent model, you are expressing the intent of the operations that are being performed on this domain object.
Ok, so it’s fluent. We can say, “proposal.submitFor(client, expectations).” Don’t you just like how that rolls off? Maybe if you just said it under your breath, you’d go, “Wow. That says it all, doesn’t it? It’s a proposal submitted for client expectations.” Yes, everybody knows exactly what we’re doing. So that’s fluent. And notice, you know, I tweeted about this last night, there’s no semicolon in this language. That’s a trick, there is. It’s Java, but I’ve put the semicolon on column 192. So yes, I’m emulating a semicolon-less language.
Now what’s interesting too is, not only can I have fluency in the domain model itself, but what if I could have fluency in the library or the tool set that I’m using? For example, if I have a stage where actors are playing, if I could say stage.actorOf(from(user ID), and then, I’m going to take that user and I’m going to, “Now use another actor, the user actor that I just looked up.” But I didn’t just look it up. It was looked up asynchronously and, therefore, I don’t know when that user may or may not be found. But when it is, then I can ask the user to, in essence, convey a new contact onto the user, new contact information for that user. And when that is finally done, I will “.andThenConsume” so I can use a restful response to, “Respond,” and, “Ok,” with the serialized user.
So there’s an idea of fluency in the library itself. Oh, and I forgot to mention why is the, “.otherwiseConsume,” there? Well, this is in case the user wasn’t found, what do you want to do in that case? “OtherwiseConsume.” And we then answer a response of not found, in our REST response. So imagine being able to have fluency, both in your API and in your domain model. It just sounds the way things work.
Reactive
The question is, “Is this reactive?” Yes, it is reactive because there’s this sort of invisible thing happening behind the scenes. When I, as we would say in Java normally, “Invoke this method,” when I invoke this method, this “submitFor” method is not just an invocation on the proposal actor itself, instead that “submitFor” invocation is reified into a message that is then delivered asynchronously to the proposal, which is an actor that is receiving messages asynchronously. And so, this is a command kind of message, we’re saying, “It’s an imperative,” we’re saying, “do this.” So, in fact, it is reactive, and yet, you don’t have to know intuitively, as the client, that you are working in a reactive environment, other than the fact that, as soon as you “submitFor,” you get control back. And it means that that actor will not have an immediate response for you. So what does that mean? Well, that’s why we have this “.andThenConsume,” method where we can consume the result if there is a result afterwards or we get essentially, another name for a future that causes this reactive response to be asynchronous, and you can deal with it asynchronously.
Type-Safe
Type-safe? Well, I think this is type-safe, so we’re going to use this proposal to “submitFor” a client from a clientID. And it has the expectations of “Summary,” “Description,” “Keywords,” “completedBy,” “steps,” and a “price”. So not only is this fluent and expressive but it’s type-safe. And what we’re leveraging here are, what are called, value objects, to express our ubiquitous language of domain-driven design but also, even at the creational point of view, we’re doing that very fluently. And it’s type-safe at every single attribute. So a summary has a specific type. And, if you’ve ever seen one of these API’s into a service method, you have to pass maybe 5 to 25 string parameters, you know, in one single method invocation. How do you get the order of those parameters correct? I mean I think it takes a genius to remember, just the order that those parameters are in. Or a very tired set of eyes. How do you actually accomplish that? So type=safety is an important thing.
Uncertainty
However, because actors work in a very reactive or asynchronous way, how do we know when the command will be fulfilled? Was it fulfilled? When does the event get emitted? Has it been permanently persisted to a data source? So when we go asynchronous concurrent parallel, we are introducing uncertainty. And the uncertainty is even introduced at the entire system level. So I was talking about the uncertainty that occurs inside a single bounded context, or a microservice, with that example of an actor, but, externally too, how are these events, for example, consumed around the entire system for a full-system solution? There’s uncertainty here. How do we deal with that? How do we model it? Well, I’m going to talk about that.
Model
So here we have a proposal, and notice that this proposal implements the proposal protocol. So this is the protocol that this proposal understands, and I showed you, a few slides ago, what that protocol is. And we happen to be an event-sourced kind of entity, so we’re using event sourcing. And if you don’t know about that, I won’t go into it a lot here, but you can look it up. It’s basically where the events that get emitted from this proposal, collectively and in order, represent the entire state of this proposal entity that has been built up over time. So notice that we have two attributes, client and expectations, these are the ones that have been put into our proposal through the, “.submitFor,” fluent method. But how is it that we deal with the uncertainty in this proposal? Well, we can use a progress. What is a progress? This was not passed in by the client but rather it’s an internal object that we’re going to transition as we know more, as we learn more about what has happened to this entity. So, for example ( I hate to rollback but just to make a point), when the proposal is submitted, eventually, we will get, for example, a denied pricing or a verified pricing because this proposal has some pricing information in it. And that will be verified by another bounded context because this is a pricing service and that verification is then, later, communicated. And when it is finally communicated, we’re going to transition this progress step by step. So focus in on the progress.
And if we look in at the progress, this is actually a value object, and what we’re going to do when the progress is verified for pricing, this is a side-effect-free behavior, which means it’s using roughly a functional approach, which says, “We’re not going to modify the progress in place. What we’re actually going to do is return a new progress that is created with the current state of this progress and, in addition to it, specification of, PricingVerified”. Now this proposal entity can know its current progress, it knows when it has completed a certain set of steps or when some are incomplete, and therefore, this modeling technique helps us to deal with or model the uncertainty. So you notice what we’re actually doing is we are not trying to model the uncertainty out, at the infrastructure level, and try to make everything look synchronous, and everything look ordered, and everything look non-duplicated and de-duplicated and so forth. What we’re actually doing is we’re saying, “Okay. We work in a distributed environment. We are going to model this for the distributed nature of our service. And as we do, we’re going to name something that is not necessarily part of the original idea of a proposal. And yet, we need to.” And so, it’s not necessarily the natural model or the real-world model but it is a useful model. And that is the goal of a model, as we know, it’s been said time and again that all models are wrong, some are useful, and that’s what we’re trying to accomplish here.
Microservices
Okay. So I’ve been touching a little bit on microservices and everybody wants to go microservices. But what is a microservice anyway? And I have a certain definition that I promote, and I don’t stand alone on this idea, although you’re free to examine the other approaches and determine what you like. So defining though the size of a microservice can be a pretty important thing. So if everybody else wants to go microservices, that means we want to go microservices. And just for what it’s worth, this is what the business wants. Right? And it’s not a joke. I mean, if you’re working for a profitable organization, and even non-profit organizations have to be profitable to exist, they want this. But you know what your job is? Your job is to convince them that this is what they want. Oh come on, you didn’t get that? I worked hard for that. Okay, these are microservices. The other is what? A big ball of mud. So what we’re going to do is define, get some definitions here what is a microservice? Legacy, this is legacy. Why do I say, “This is legacy?” Because it makes money. If it didn’t make money, it would be unplugged. Hopefully. The business would know better, “Oh man, we’re just dragging this thing around wherever we go. Now we need to go to the cloud, it’s not making any money. But let’s port it anyway, let’s lift and shift anyway.” No. So that’s what legacy means.
Oh, but this is legacy too. What’s the difference? Monolith. I hear people say, “Monolith,” and I just wish that they would sort of clarify because I think monolith is used, generally, in a very negative connotation. Not always, but, generally, what they’re talking about when they say, “Monolith,” is a big ball of mud. This is something that, you touch something, over here, and something, way over here, breaks and you have no explanation until maybe lots of research is done, and you have no idea. But this is actually a well-modularized monolith. And so, you could do a lot worse than a monolith, this may not scale or perform the way that you want it to, or need it to, I should say, but it’s a lot easier to reason about this kind of monolith. And so, you can imagine where you are using packages or namespaces, or whatever sort of language that you’re using, to separate out, within a single JAR file, the different modules. And as I’ll show you in a moment, there’s a good hint to what these modules might be. But I think that this is probably what most people are referring to when they talk about a legacy monolith, I think they really mean the big ball of mud.
And again, this is where things are so tangled, so ridiculous. I have a colleague here and friend, we’ve worked together, from time to time, and I remember I tell this story often. His team of architects roll out this UML diagram, but I’m pretty sure, Tom, that that UML diagram was 20-feet-long maybe. I don’t know. But, you could touch something over here and that, logically shown on the UML diagram, that’s real code running that could break something over here, and you had no idea why. And I’m not saying that that was Tom’s fault, it wasn’t. But that’s I think, you know, what we’re talking about when we say monolith, often.
A microservice. What is a microservice? Some people say it’s 100 lines of code. And, frankly, I think the person who takes credit for the term microservice and the conceptualizing of microservice, refers to a microservice as basically 100 lines of code. But should it be 400 instead, would that be good? Maybe 1,000 lines of code, is that a good microservice? I mean if you say 400, and it’s 450 lines, does that make it a bad microservice? I don’t know, but here’s what happens with that 100-line microservice is you start out off and basically these are just entities. So each microservice has a single entity type in it or at most a single entity type. And all of these entities, when something happens to them, they publish a message of some kind to a topic, let’s say, that’s Kafka, and then, any other microservice that is dependent on that message being sent through Kafka is consuming that. And now that we have a microservice’s architecture, the problem with this is, not so much right now today. As I see this, the problem happens over time.
Dependencies
And this is what happens. We start thinking about, “Okay now. That service A and service Z did this for it. Does service A still depend on service Z or maybe service Z isn’t even relevant anymore? Could we unplug it?” Oh man, this is hard. You know.
Now I know that things are improving with service meshes and the kind of logging that’s going on. But just ask yourself how long you could survive that kind of situation? I know I wouldn’t want to. That’s all that I’ll say, I can’t speak for you. And so, what some have done is they’ve said, “Hey, I got the solution. It only costs $400 a month to keep one of those microservices running. Let’s just keep it running, we’ll never unplug it. That way we don’t need to know what depends on it or if it still does anything relevant.” And so, this is what we end up with over time. So, you might say, “Well, that was unfair to draw all of those little microservices as a big ball of mud,” but I think, by my definition, this is just a distributed big ball of mud because you don’t understand it in the same way that you don’t understand the monolithic big ball of mud. And when you’re afraid to unplug something because you don’t have any idea if it’s still relevant, I don’t know, but I think I’d be worried about that. Whether it’s $400 a month or not, because this is what it amounts to. Four hundred dollars a month and it keeps growing.
Complex System
And so, what is a complex system? Now I’m not saying you would necessarily create two million or five million lines of code purely through microservices, but if you did, just think about it from this aspect. Two-million-lines-of-code system. That’s 20,000 microservices at $400 a month, that’s $8 million a month, $96 million a year. Or, let’s say, we’re up to 5 million lines of code, that’s 50,000 microservices. So all that I’m saying here is, before you jump down that path, think about it. And then, consider that a bounded context as a microservice may be the first best step for you. This is, again, not a monolith, but it’s not as small as a single entity type either. And can we still talk to Kafka topics or through Kafka topics? Sure, why not. But now, with roughly the same number of entities involved that we had in the first rendition of that distributed big ball of mud, what we’re talking about is seven bounded contexts, or microservices, rather than dozens of them. And growing.
Identify Strategic Drivers
So one of things that we need to accomplish is that we have to try to achieve strategic business advantage. And that is really the big job that DDD tries to solve or is intended to solve. And if you look here and you go back, in your mind, to that anemic client model, that anemic client model could be replaced with just a few methods, which is I can set a new address on that anemic model. I can set a new telephone number on that anemic model, it’s fluent, it’s explicit. The intention is revealed through the interface itself. But then, notice this additional method, “relocateTo.” This is also changing the address but it has a different use case, and the use case is that if this client has just purchased something on our ecommerce system or proposed a job request that some worker is going to consume and they said, “Oh, I just moved house, I need to change my address,” and they change the address. Now all downstream concerns can be aware that this client’s address has changed because this domain event is being sent out through to other microservices or bounded context who need to know this, who need to consume that nugget of factual knowledge that says, “We need to react to this. This is a reactive system.”
Explicit, Testable, Less Code
And notice that this client is now testable. And look, just a couple lines of code, “relocateTo,” yes indeed, is setting an address-value object but it’s also emitting an event, “ClientRelocated,” this is how the downstream knows. And you can imagine that, just in one or two tests here, “testThatClientRelocates,” we can assert that the client relocates in the way that we expect it to, and we can even assert that the domain event was emitted as part of the test acceptance.
Monolith to Microservices
So now, if you go back, in your mind, to that monolith, that was a well-structured modularized monolith, what if each of those were a bounded context? I just want to make that point because we’re going into a more complicated or complex part of this story, and that’s, “How do we get from there to there?” Well, if you have a monolith that is well-modularized as bounded context, getting to microservices can be a matter of breaking those apart. They should already be very loosely coupled, as you see from the interfaces between those bounded contexts or those modules, it’s already loosely coupled. And so, what we’re going to do is incur some network overhead latency and the uncertainty of network partitions and whatever it happens to be. But think about how much easier that is than this. Now, how do you get from the big ball of mud to one of these? Very, very carefully.
Sometimes there are these unavoidable situations like COBOL. COBOL happens, you know. And man, it happens in a big way. But one of the big problems with COBOL is you can no longer hire COBOL programmers, and companies are trying to hire them back as contractors out of retirement to maintain their systems. So when you’re in that situation or another sort of very languishing technology or a product that you’re leveraging for your applications and services, you’ve got to get out of there. But if you’re, say, using Java for the big ball of mud, or another currently-supported and well-supported language and platform you kind of have to tackle this like one bite at a time. And one bite at a time means that it’s change-driven, value-driven, test-driven. So you don’t just dive in and say, “Hey, manager, our team needs like 3 months to turn this monolith into microservices.” Now Andrew just said it took them 18 months to do that, at Hulu. So be careful about saying something like 3 months. But whatever number of months it takes, you’re probably better off trying to turn the big ball of mud, first, into a modularized monolith, and then, taking the steps over here. Because you can get away with it when the company, when the business says, “This needs to be done.”
Strangler
But another solution to this, when you really have to take the big step of, “Let’s get out of here now,” is an event-driven approach. And this is where you can strangle the big ball of mud one microservice at a time. And this is where basically there are a few approaches to this, one approach is use triggers. Put triggers in your database that, whenever a row is written into a table, whether that’s created or updated, you can cause a trigger to raise an event. And this is not the most explicit event because it’s sort of a little bit hidden where that happens, but it’s an event and the microservice strangulation can now start to consume those events. But notice that this microservice has to talk back with events to the big ball of mud because, if the user is using it directly, the big ball of mud needs to know what happened over there because you can’t entirely cut off every single client all at once. It just doesn’t work that way. So it’s strangling but it’s, you know, like one microservice at a time.
Another way to accomplish this is through a product called Debezium, it’s an open-source product that works with MySQL, Postgres, and maybe a few other databases. And it doesn’t currently support Oracle, so you can use Oracle’s GoldenGate. But this is basically a database commit log tailor that allows you to, in essence, pick off commits and turn those into events. And you accomplish the same thing but without triggers, and that’s a lot nicer approach to do, if you can. But I just want to make a statement here that I don’t think that publishing events to the outside world long-term through this kind of solution is the right way to go, but it’s a tool for the job that probably works or would work well with a strangler approach. But I don’t think that you want to design your new bounded context to publish events out to, you know, a topic or something by using an event log like this.
Restructuring
Restructuring. This is a different approach, it’s not really strangling, it is, in a way. But what you’re going to attempt to do is, potentially, find as many entities as you can that can just represent the things that happen in the domain model. Break those away, restructure them, and now, use that database commit log to project into a query model which is used for your user interface. Problem? Yes. Well, at least challenge, and that is that the command model and the query model are, eventually, consistent. But it could be that you’ll take more of the hit, in the UI, than in the application. So that’s another consideration. And then, as you sort of deconstruct that monolith, little by little, you can talk to the big ball of mud primarily through the command model, and the query model, and scale out your microservices a lot better than they were.
And ultimately, this is sort of where we want to end up. We want to have the microservices as bounded context. But I just have to say, this is hard. You really can’t just jump into this and say, “Oh, we’re going to be done in a few months.” It’s hard work. But I think as somebody said, “Sticking with the other way is even harder.”
Conclusions
I just wanted to kind of wrap up with a few thoughts about why reactive from maybe a completely different viewpoint. Almost nobody wanted to scare Bill Gates but who here is concerned about the ecology, you know, our environment? Anybody? Yes. Could I just mention cryptocurrency? More hands now. So Dave Farley recently tweeted that most industries would never tolerate a 50%, you know, loss of efficiency for ease of use, and yet, software developers do this all the time. And he said, “Anyone who does that is developing weird software.” And then, our Vlingo platform tweeted Donald Knuth saying, “Yes, that’s right. In fact, if you don’t know anything or enough about your hardware, any software that you create for it is going to be pretty weird.” So have in mind what we’re doing to the ecosystem of our Earth by all of these latent and blocking and inefficient pieces of software that we’re writing, and realize that we’re producing 1,000 X carbon dioxide overhead. And I’m not just here totally to appeal to this side, but there are factors than just performance and scalability to be aware of.
And so, ultimately, we want to rework into a reactive system, this is what I think makes a lot of sense. And I’m just going to tell you briefly about the platform, the open-source platform that I’m developing and we’re building a team around this effort, it’s called Vlingo. You can say, “V-lingo,” if you want to, but I say Vlingo, it seems to sound better. But we do support these actors as aggregates, we do support a reactive HTTP server. Very lightweight, all this stuff is under a megabyte of code, right about a megabyte of code right now in terms of Java bytecode. And Lattice, which is basically a grid or a compute grid that runs on top of clustering, within the platform, which is also all reactive. And Streams is being developed and should be released shortly.
So, you know, kick the tires, take a spin, it’s at github.com/vlingo
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Unity, maker of the eponymous game engine, continues to advance its AR Foundation project, which aims to make it easier for developers to create AR apps that runs both on iOS and Android. Its latest release adds support for ARKit’s ARWorldMap and Unity’s Lightweight Render Pipeline.
AR Foundation exposes a common API which aims to cover the core functionality of both Android ARCore and iOS ARKit thus making it possible to create AR apps for both platforms from a single code base. After providing support for a number of basic AR features in its first release, including plane detection, device position and orientation tracking, light estimation, and others, Unity is now adding more advanced features to its offerings.
One of those is support for ARKit ARWorldMap, which enables the creation of shared or persistent experience. Shared experience allow multiple users to see and interact with the same AR scene using different devices at the same time, with each user seeing the common virtual environment from their own perspective. ARWorldMap also makes it possible to create persistent AR experience that can be stored and recreated at some other point in time. Another ARKit feature that is now supported by AR Foundation is face tracking, which makes it possible to track the movement and expressions of the user’s face.
It is worth noting that both world map and face tracking support are for the time being exclusive to ARKit. Unity plans to add support for the equivalent ARCore features in the future but no detailed plan has been announced. You can see the list of currently supported features in the image below.
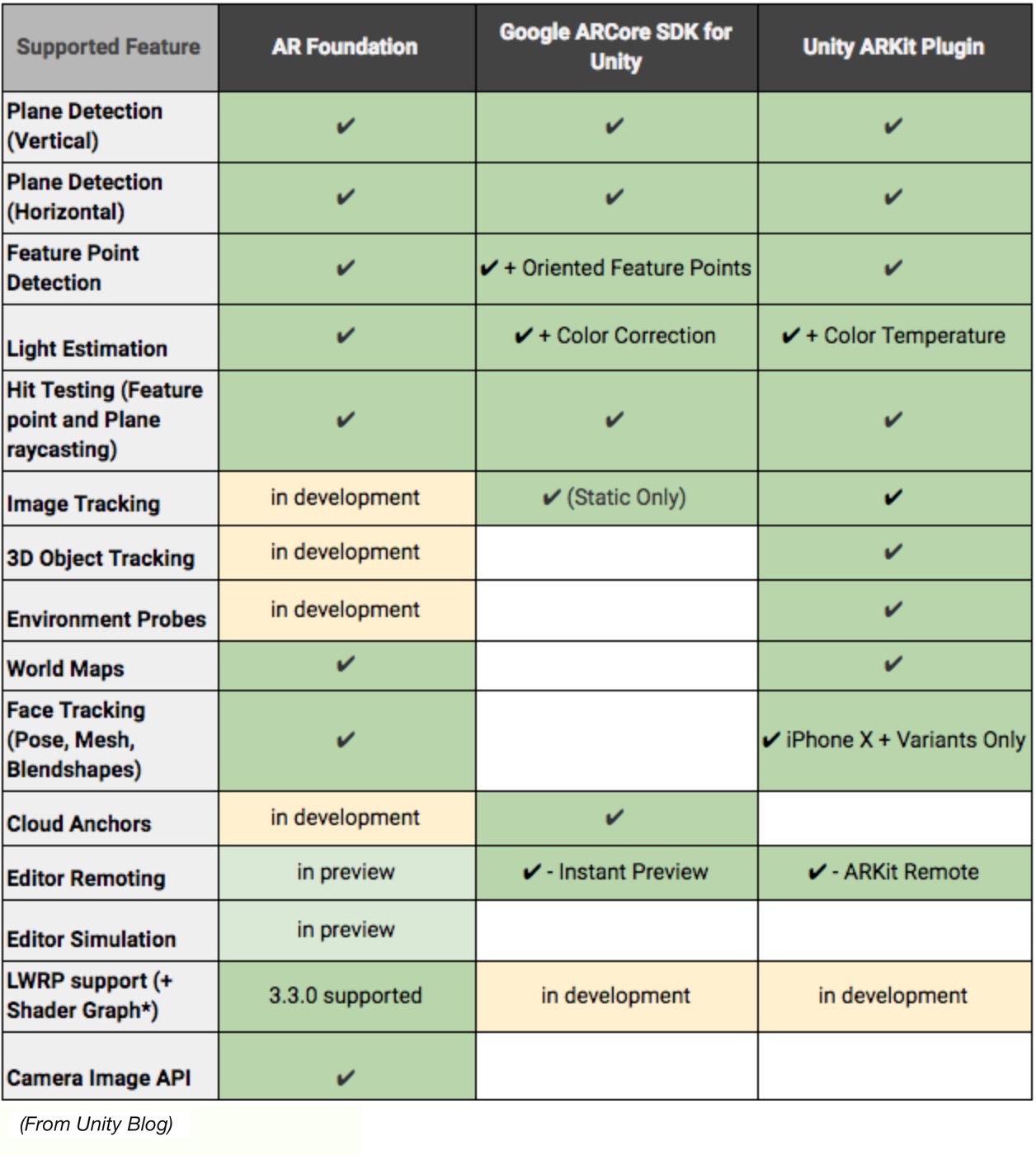
A new feature that is supported both on iOS and Android is Unity Lightweight Render Pipeline. This enables the creation of shaders using Unity’s shader graph, which provides a visual editor for shaders, and then use them in AR apps.
A couple of other features that Unity is working on for AR Foundation are remoting, which is the ability to stream sensor data from a mobile device to a desktop computer with the aim to speed-up development; and in-editor simulation, aiming to enable testing without using a real device. Both features are scheduled to be released during 2019.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Geoffrey Hinton dismissed the need for explainable AI. A range of experts have explained why he is wrong.
I actually tend to agree with Geoff.
Explainable AI is overrated and hyped by the media.
And I am glad someone of his stature is calling it out
To clarify, I am not saying that interpretability, transparency, and explainability are not important (and nor is Geoff Hinton for that matter)
A whole industry has sprung up with a business model of scaring everyone about AI being not explainable.
And they use words like discrimination which create a sense of shock-horror.
However, for starters – in most western countries – we already have laws against discrimination.
These are valid irrespective of medium (AI)
Now, let us look at interpretability itself.
Cassie Kozyrkov from Google rightly points out that “It all boils down to how you apply the algorithms. There’s nothing to argue about if you frame the discussion in terms of the project goals.”.
In the simplest sense, this could mean that if you need to provide explainability – you could run another algorithm (such as tree based algorithms) that can explain the result (for example can provide an explanation for the rejection of a loan)
Another great resource is Christoph molnar’s free book on interpretability
I highly recommend it because it shows how complex and multi-faceted the issue is
For example, the book talks about:
- There is no mathematical definition of interpretability.
- interpretability has a taxonomy
- Includes specific Aspects: Intrinsic or post hoc, Feature summary statistic , Feature summary visualization, Model internals (e.g. learned weights) , Data point, Intrinsically interpretable model, Model-specific or model-agnostic?, Local or global?
- Interpretability has a scope: Algorithm Transparency, Global, Holistic, Modular, Local, For a single prediction etc
- Evaluation of Interpretability: Application level evaluation (real task), Human level evaluation (simple task), Function level evaluation (proxy task)
- Properties of Explanation Methods: Expressive, Translucency, Portability, Algorithmic Complexity
- Properties of Individual Explanations: Accuracy, Fidelity, Consistency, Stability, Comprehensibility, Certainty, Degree of Importance, Novelty, Representativeness:
- Good Explanations are contrastive, selected, social, focus on the abnormal, are truthful, consistent with prior beliefs of the explainee, are general and probable.
Finally, Patrick Feris provides a good introduction to explainable ai and why we need it
By sharing these links, I hope we can elevate the level of discussion
To conclude, I believe that interpretability is context(project/problem) specific
There are many dimensions/ possible solutions to the problem when seen from a business perspective
Image source: trusted reviews