Month: April 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
It has been popularly noted that artificial intelligence would be like the ultimate version of Google. With recent advancements in research and technology, Artificial Intelligence (AI) and Machine Learning (ML) are slowly becoming a part of our routine.
The pace at which technology is growing is unfathomable. As these smart technologies engulf our life, staying updated with them is the need of the day. So, here’s Packt’s selection of finest books in artificial intelligence and machine learning that will help you have an edge in these fields:
Hands-On Reinforcement Learning with Python by Sudharsan Ravichandiran
Reinforcement Learning is the trending and one of the most promising branches of artificial intelligence. Hands-On Reinforcement learning with Python will help you master not only the basic reinforcement learning algorithms but also the advanced deep reinforcement learning algorithms. It is a hands-on guide enriched with examples to master deep reinforcement learning algorithms with Python.
Generative Adversarial Networks Cookbook by Josh Kalin
Now, simplify next-generation deep learning by implementing powerful generative models using Python, TensorFlow, and Keras. Developing Generative Adversarial Networks (GANs) is a complex task, and it is often hard to find a code that is easy to understand. This book leads you through eight different examples of modern GAN implementations, including CycleGAN, simGAN, DCGAN, and 2D image to 3D model generation.
Hands-On Machine Learning for Cybersecurity by Soma Halder and Sinan Ozdemir
Cyber threats today are one of the costliest losses that an organization can face. Get into the world of smart data security using machine learning algorithms and Python libraries. This book will show you the most efficient tools to solve the big problems that exist in the cybersecurity domain.
Hands-On Transfer Learning with Python by Dipanjan Sarkar, Raghav Bali, and Tamoghna Ghosh
Transfer learning is a machine learning technique where knowledge gained during training a set of problems can be used to solve other similar problems. The purpose of this book is two-fold; firstly, we focus on detailed coverage of deep learning (DL) and transfer learning, comparing and contrasting the two with easy-to-follow concepts and examples. The second area of focus is real-world examples and research problems using TensorFlow, Keras, and the Python ecosystem with hands-on examples.
Hands-On Meta Learning with Python by Sudharsan Ravichandiran
Meta learning is an exciting research trend in machine learning, which enables a model to understand the learning process. Unlike other ML paradigms, with meta learning, you can learn from small datasets faster. Explore a diverse set of meta-learning algorithms and techniques to enable human-like cognition for your machine learning models using various Python frameworks with Hands-On Meta Learning with Python.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
About the conference
Code Mesh LDN, the Alternative Programming Conference, focuses on promoting useful non-mainstream technologies to the software industry. The underlying theme is “the right tool for the job”, as opposed to automatically choosing the tool at hand.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Introduction
Automated machine learning is a fundamental shift to machine learning and data science. Data science as it stands today, is resource-intensive, expensive and challenging. It requires skills which are in high demand. Automated Machine learning may not quite lead to the beach lifestyle for the data scientist – but automated machine learning will fundamentally change the job of a data scientist. It’s an irony that AI / ML could replace many jobs – and the first it seems is that of the data scientist himself! But we have been there before. In the 90s and 2000 we had CASE tools. Managers loved them because they were supposed to replace those expensive Programmers. That has not happened. So, would automated machine learning be any different?
Automated machine learning solves a different problem. It does not advocate zero human intervention for data science (data in – model out). More specifically, automated machine learning solves three technical problems: feature engineering, model selection and hyperparameter tuning. We do not discuss these here because you can find a lot about them by searching the Web. Rather, we see how fast automated machine learning is advancing
Last week, Google launched an AI platform for collaborative machine learning. It points to how rapidly automated machine learning is moving. Here are some key takeaways which point to its rapid growith
How will the Data Scientist’s job change through automated machine learning?
In a weekend post Charles Givre pointed out that AutoML came second in a Kaggle contest. This is indeed impressive(albeit a bit contrived). At the moment, I believe AutoML is not poised to address the top 10% of the solutions (which require skill and design) – but this development shows how far AutoML has come already
So, what can we expect of AutoML in the near future? Based on the Google AtoML announcement webinar which I watched – here are seven ways in which the Data Scientist’s job will change
- AutoML for research to create better / state of the art architectures like for imageenet
- Custom models by domains
- Applicable to solve 80% problems in domain
- Massively scale ML applications in the real world.
- An emphasis on transfer learning
- AutoML for time series
- AutoML for NLP
- Democratising Machine Learning – like spreadsheets(calculation) , SQL (data access)
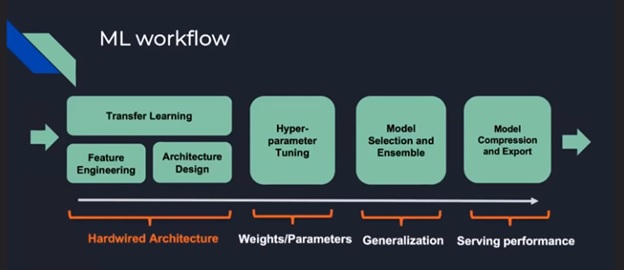
Image source: Google AtoML announcement webinar
Image source:Beach
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Today, on The InfoQ Podcast Wes talks with Cloudflare’s Ashley Williams. Ashley is a core team member of Rust and Rust Web Assembly teams. The two talk about Web Assembly and what it’s being used for today. In addition to talking about things like bootstrapping a Web Assembly app in Ashley’s preferred Rust toolchain (that she was core to creating) the two talk about the application edge, Wasi, Cloudflare Workers, and where she sees wasm/wasi going in relationship to the edge.
Key Takeaways
- Web Assembly (wasm) is a set of instructions or a low-level byte code that is a target for higher level languages. It was added to the browser because it was a portion of the web platform that many felt was just missing.
- Wasm is still a young technology. It performs really well for computationally intensive applications and also offers performance consistency (because it lacks a garbage collector).
- Bootstrapping an application using the Rust toolchain looks like: pull down a template, export a function using an attribute (defines that you want to access this function from JavaScript), and run a tool called wasm-pack (compiles it into Web Assembly and then runs a tool called wasm-bindgen that generated Rust types for Wasm). Then you can talk to that binary as if it was written in JavaScript in your code.
- Cloudflare workers allow JavaScript that you might have written for a server to be written and distributed at the application edge (or close to the end user). It uses a similar model as serverless architecture platforms.
- Interesting use cases such as A/B testing, DDoS prevention, server-side rendering, or traffic shaping can be done at the edge.
- Wasm is an approach to bringing full application experiences to the edge.
- Wasi (Web Assembly System Interface) is a standardized interface for running Web Assembly for places that are outside of the web. Fastly recently released a pure Web Assembly runtime for their edge that is built on top of Wasi called Lucet (allows access to lower level things at the edge like sockets and UDP).
- Zoom has a web client written in Web Assembly.
Show notes will follow shortly.
About QCon
QCon is a practitioner-driven conference designed for technical team leads, architects, and project managers who influence software innovation in their teams. QCon takes place 8 times per year in London, New York, San Francisco, Sao Paolo, Beijing, Guangzhou & Shanghai. QCon New York is at its 8th Edition and will take place Jun 24-26, 2019. 140+ expert practitioner speakers, 1000+ attendees and 18 tracks will cover topics driving the evolution of software development today. Visit qconnewyork.com to get more details.
More about our podcasts
You can keep up-to-date with the podcasts via our RSS Feed, and they are available via SoundCloud and Apple Podcasts. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Previous podcasts
Related Editorial
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Gaurav Sood, principal data scientist at Microsoft, recently spoke at the AnacondaCon 2019 Conference on how the sequence of characters in a person’s name can be used to predict that person’s race and ethnicity, using machine learning techniques.
Learning about names helps with real-world use cases like fairness in lending of loans and user personalization. Sood talked about how precision and recall model evaluation metrics are enhanced by modeling the relationship between race/ethnicity and the sequence of characters in a name, using Long Short Term Memory (LSTM) Networks. Some of the data used for this analysis came from US Census Last Name Dataset, Florida voting registration data and Wikipedia data.
He also talked about how to capitalize the opportunities by using the following techniques:
- Patterns in names
- Use Bi-chars instead of Phonemes
- Patterns in communication networks
- Use a large corpus and learn context well
- Preserve a few hundred vectors and pass it to a model
InfoQ spoke with Sood about the conference talk and what we can learn from names using prediction modeling techniques.
InfoQ: Can you discuss how we can learn from names? What ML/DL algorithms can we use?
Gaurav Sood: Learning more about a person from their name is no different from tackling any other supervised ML problem. It all starts with getting (or creating) a large labeled corpus. For instance, one key innovation in ethnicolr is the training data—we use voting registration files to get a large labeled corpus. In another project on learning from names, I scraped Google Image Search results to build the training data for inferring the gender from a name.
Once you have the data, find ways to exploit patterns in the data to learn a model. The early ventures exploited the fact that names of different kinds of people began/ended differently. For instance, female names in India often end with an ‘a,’ and you can exploit that pattern to infer gender from Indian names. In ethnicolr, we generalize this intuition and use patterns in sequences of characters. (I am also working on exploiting sequences of sounds.) Like Ye et al., you could also rely on the fact that we correspond more frequently with co-ethnics and exploit email networks for building your models.
To exploit the patterns in the data, the full-range of DL/ML tools is available to you. Use what works best.
InfoQ: Can you talk about phonemes and bi-chars and how they helped in the data analysis?
Sood: A phoneme is a unit of speech in a language. (There are 39 phonemes in English. If you are looking to get intuition, on the CMU site you can decompose a large list of words into constituent phonemes.) Before the era of end-to-end DL, for audio transcription, we would first get phonemes from audio waves and then learn the relationship between sequences of phonemes and words.
Bi-chars are another (noisy but easy) way to represent sounds and structure in a word. And sequences of common bi-chars can capture our intuitions reasonably. For instance, “ashian” (think Kim Kardashian) is a common sequence in the last names of Armenians. And “ashian” can be broken down into the following bi-chars (as, sh, hi, ia, an) and we can learn to associate that sequence with the relevant race/ethnicity.
InfoQ: What all technologies did you use in this case study?
Sood: We used Python as the programming language, scikit-learn to split our names into bi-chars, and Tensorflow with Keras interface to learn the embeddings and to apply LSTM.
InfoQ: How can our readers learn more about your project and try it in their development environments?
Sood: The code for doing a plain vanilla version of the project and models are available on the website. If you want to get the intuition, the paper and presentation are likely to be of help. If you want to use the open-source package to answer a question, the code for our campaign contribution application may prove useful.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Naive Bayes is a deceptively simple way to find answers to probability questions that involve many inputs. For example, if you’re a website owner, you might be interested to know the probability that a visitor will make a purchase. That question has a lot of “what-ifs”, including time on page, pages visited, and prior visits. Naive Bayes essentially allows you to take the raw inputs (i.e. historical data), sort the data into more meaningful chunks, and input them into a formula.
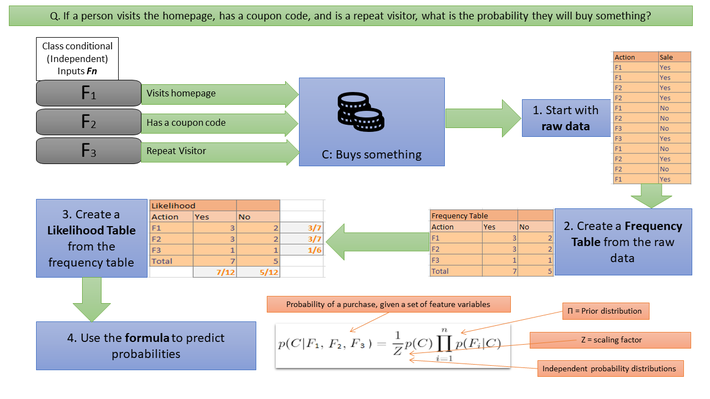
Click on the picture to zoom in
For more articles on naive Bayes, follow this link. For more concepts explained in one picture, follow this link.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
NGINX has released version 18 (R18) of NGINX Plus, their all-in-one load balancer, content cache, and web server. This release includes support for dynamic certificate loading, enhancements to their OpenID Connect implementation, and the ability to specify port ranges for virtual servers.
With support for dynamic certificate loading, SSL/TLS certificates can now be loaded on demand without needing to list them explicitly in the configuration files. NGINX Plus can now dynamically load the correct certifications based on the hostname provided by Server Name Indication (SNI) during the TLS handshake. This permits hosting multiple secure websites under a single server configuration.
In previous versions of NGINX Plus, each secure hostname would need its own server block in the configuration, statically specifying the certification and private key as files on disk. This also meant having to reload the configuration when adding new hostnames.
With this new feature, it is now possible to only have one server block in the configuration to securely host any number of sites:
server {
listen 443 ssl;
ssl_certificate /etc/ssl/$ssl_server_name.crt; # Lazy load from SNI
ssl_certificate_key /etc/ssl/$ssl_server_name.key; # ditto
ssl_protocols TLSv1.3 TLSv1.2 TLSv1.1;
ssl_prefer_server_ciphers on;
location / {
proxy_set_header Host $host;
proxy_pass http://my_backend;
}
}
With this setup the certificates will be lazy-loaded from disk as needed based on the value of the $ssl_server_name variable. The certificate and key will then be cached in memory in the filesystem cache. Any variable can be used there as long as its value is available during SNI (which happens before the request line and headers are read).
It is also possible to store SSL/TLS certificate data in memory (within the key-value store) instead of as files on disk. This allows for certificates to be programmatically installed via the Plus API. NGINX recommends this for either clustered deployments of Plus, as the certificate data will only need to be uploaded once for automatic propagation to occur, or for automating integrations with certificates issuers such as Hashicorp Vault.
In both cases a performance penalty will be incurred during the initial certificate loading. The certificate loading process only occurs during the TLS handshake, once the session is established the request processing will occur normally. According to NGINX, this penalty will cause the initial TLS handshake take 20 – 30% longer.
This release also includes improvements to the active health checks functionality. This release introduces the require directive to allow for testing the value of any variable, including both standard and user-defined variables. The require directive inside a match block permits checking that one or more variables must have a non-zero value for the test to pass.
Further improvements to health checks include allowing for termination of Layer 4 connections using the proxy_session_drop directive. Previously it was possible for established clients to experience a timeout if the server they were connected to was unhealthy. This was because the backend server health status was previously only considered when a new client attempted to establish a connection. The new proxy_session_drop directive will allow the connection to be immediately closed. With this directive enabled, a termination of connections can also be triggered by a failure of an active health check or the removal of the server from the upstream group (e.g. removal through DNS lookup).
Other features available in this release include:
- OpenID Connect implementation now has support for opaque session tokens, refresh tokens, and a logout URL
- NGINX Plus servers can now be configured to listen on a range of ports (i.e. 80-90)
- Key-value pairs can now be created directly with variables in configuration
For more details and additional features included in this release, please review the official announcement on the NGINX blog. NGINX Plus can be trialed as part of the NGINX Application Platform.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Lecture notes for the Statistical Machine Learning course taught at the Department of Information Technology, University of Uppsala (Sweden.) Updated in March 2019. Authors: Andreas Lindholm, Niklas Wahlström, Fredrik Lindsten, and Thomas B. Schön.
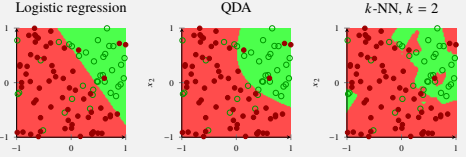
Source: page 61 in these lecture notes
Available as a PDF, here (original) or here (mirror).
Content
1 Introduction 7
1.1 What is machine learning all about?
1.2 Regression and classification
1.3 Overview of these lecture notes
1.4 Further reading
2 The regression problem and linear regression 11
2.1 The regression problem
2.2 The linear regression model
- Describe relationships — classical statistics
- Predicting future outputs — machine learning
2.3 Learning the model from training data
- Maximum likelihood
- Least squares and the normal equations
2.4 Nonlinear transformations of the inputs – creating more features
2.5 Qualitative input variables
2.6 Regularization
- Ridge regression
- LASSO
- General cost function regularization
2.7 Further reading
2.A Derivation of the normal equations
- A calculus approach
- A linear algebra approach
3 The classification problem and three parametric classifiers 25
3.1 The classification problem
3.2 Logistic regression
- Learning the logistic regression model from training data
- Decision boundaries for logistic regression
- Logistic regression for more than two classes
3.3 Linear and quadratic discriminant analysis (LDA & QDA)
- Using Gaussian approximations in Bayes’ theorem
- Using LDA and QDA in practice
3.4 Bayes’ classifier — a theoretical justification for turning p(y | x) into yb
- Bayes’ classifier
- Optimality of Bayes’ classifier
- Bayes’ classifier in practice: useless, but a source of inspiration
- Is it always good to predict according to Bayes’ classifier?
3.5 More on classification and classifiers
- Regularization
- Evaluating binary classifiers
4 Non-parametric methods for regression and classification: k-NN and trees 43
4.1 k-NN
- Decision boundaries for k-NN
- Choosing k
- Normalization
4.2 Trees
- Basics
- Training a classification tree
- Other splitting criteria
- Regression trees
5 How well does a method perform? 53
5.1 Expected new data error Enew: performance in production
5.2 Estimating Enew
- Etrain 6≈ Enew: We cannot estimate Enew from training data
- Etest ≈ Enew: We can estimate Enew from test data
- Cross-validation: Eval ≈ Enew without setting aside test data
5.3 Understanding Enew
- Enew = Etrain+ generalization error
- Enew = bias2 + variance + irreducible error
6 Ensemble methods 67
6.1 Bagging
- Variance reduction by averaging
- The bootstrap
6.2 Random forests
6.3 Boosting
- The conceptual idea
- Binary classification, margins, and exponential loss
- AdaBoost
- Boosting vs. bagging: base models and ensemble size
- Robust loss functions and gradient boosting
6.A Classification loss functions
7 Neural networks and deep learning 83
7.1 Neural networks for regression
- Generalized linear regression
- Two-layer neural network
- Matrix notation
- Deep neural network
- Learning the network from data
7.2 Neural networks for classification
- Learning classification networks from data
7.3 Convolutional neural networks
- Data representation of an image
- The convolutional layer
- Condensing information with strides
- Multiple channels
- Full CNN architecture
7.4 Training a neural network
- Initialization
- Stochastic gradient descent
- Learning rate
- Dropout
7.5 Perspective and further reading
A Probability theory 101
A.1 Random variables
- Marginalization
- Conditioning
A.2 Approximating an integral with a sum
B Unconstrained numerical optimization 105
B.1 A general iterative solution
B.2 Commonly used search directions
- Steepest descent direction
- Newton direction
- Quasi-Newton
B.3 Further reading
Bibliography
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
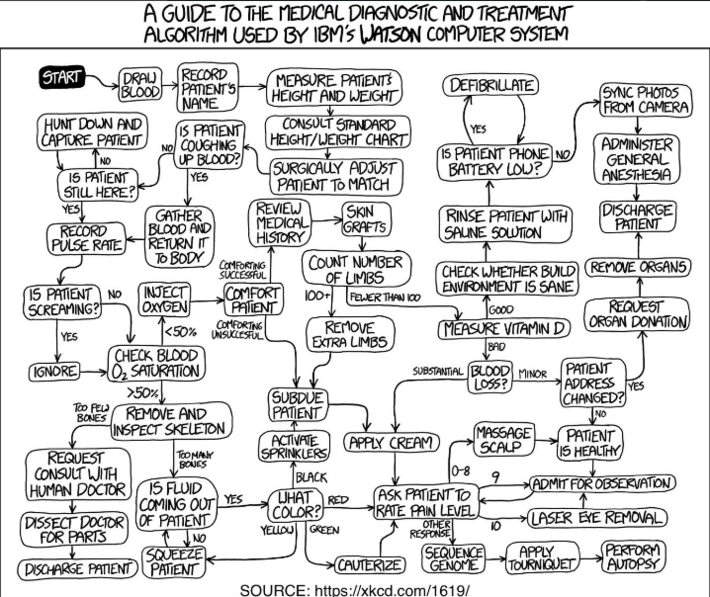
Interesting cartoon featuring the decision tree used in medical diagnosis. To see other cartoons about data science, follow this link.
W3C Publishes WebXR Draft Specification for Direct Web Interaction With Immersive Hardware
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The World Wide Web Consortium (W3C) recently published draft specifications for WebXR. The WebXR Device API seeks to provide “the interfaces necessary to enable developers to build compelling, comfortable, and safe immersive applications on the web across a wide variety of hardware form factors”.
WebXR is an API that allows developers to create XR experiences; a term which encompasses Augmented Reality (AR), Virtual Reality(VR) and newly-developed immersive technologies. The Immersive Web Community Group, the community behind the draft specification explains:
Since we don’t want to be limited to just one facet of VR or AR (or anything in between) we use “X”, not as part of an acronym but as an algebraic variable of sorts to indicate “Your Reality Here”. We’ve also heard it called “Extended Reality” and “Cross Reality”, which seem fine too, but really the X is whatever you want it to be!
A lot of VR developers build interactive virtual worlds in engines like Unreal and Unity. Programmers often write the underlying logic of those worlds in a language like C#. WebXR builds on, and seeks to supersede WebVR. The goal is to facilitate the development of Virtual Reality, Augmented Reality and other immersive technology applications by web developers fluent in JavaScript, and for a wide set of devices. Developers may thus make web apps that leverage both Android’s ARCore and iOS’s ARKit.
WebVR was first announced in 2016, with the goal to bring VR content to the web, by means of a wide range of headsets. According to the Immersive Web Community Group, the WebXR Device API has two new goals with respect to WebVR:
- To support a wider variety of user inputs, such as voice and gestures, giving users options for navigating and interacting in virtual spaces
- To establish a commontechnical foundation for development of AR experiences, letting creators integrate real-world media with contextual overlays that elevate the experience, on any API-supporting devices.
The current version of the API specifies key features, allowing to:
- Detect available VR/AR devices.
- Query the devices capabilities.
- Poll the device’s position and orientation.
- Display imagery on the device at the appropriate frame rate.
The WebXR draft specification additionally notes:
The WebXR Device API’s new features give rise to unique privacy, security, and comfort risks that user agents must take steps to mitigate, [such as gaze tracking, or finger printing].
While WebXR is still in its early stages, it is already supported by both Mozilla and Chrome — with caveats.
A list of supported devices include (but is not limited to):
Feedback and comments on the WebXR specification are welcome through Github issues. Discussions may also be found in the public-immersive-web@w3.org archives.