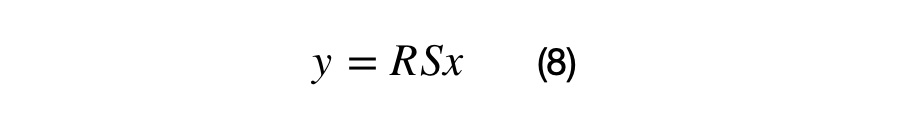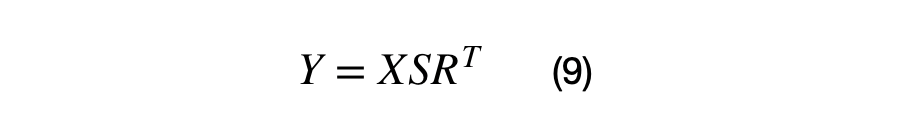Introduction
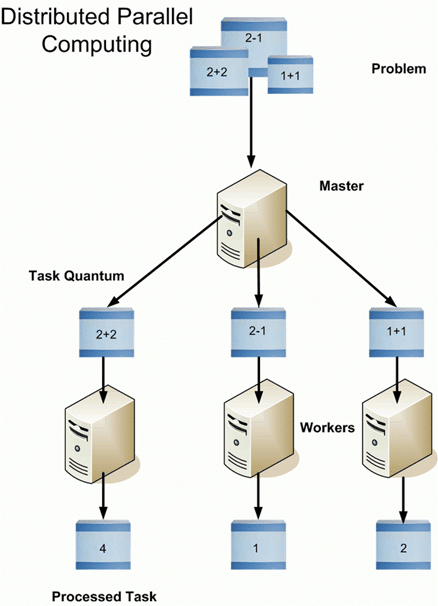
Hadoop is a software framework from Apache Software Foundation that is used to store and process Big Data. It has two main components; Hadoop Distributed File System (HDFS), its storage system and MapReduce, is its data processing framework. Hadoop has the capability to manage large datasets by distributing the dataset into smaller chunks across multiple machines and performing parallel computation on it .
Overview of HDFS
Hadoop is an essential component of the Big Data industry as it provides the most reliable storage layer, HDFS, which can scale massively. Companies like Yahoo and Facebook use HDFS to store their data.
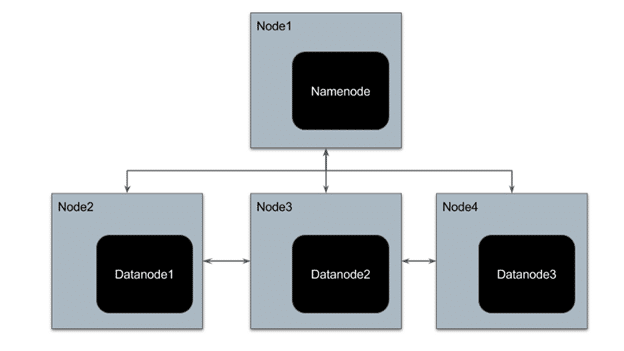
HDFS has a master-slave architecture where the master node is called NameNode and slave node is called DataNode. The NameNode and its DataNodes form a cluster. NameNode acts like an instructor to DataNode while the DataNodes store the actual data.
source: Hasura
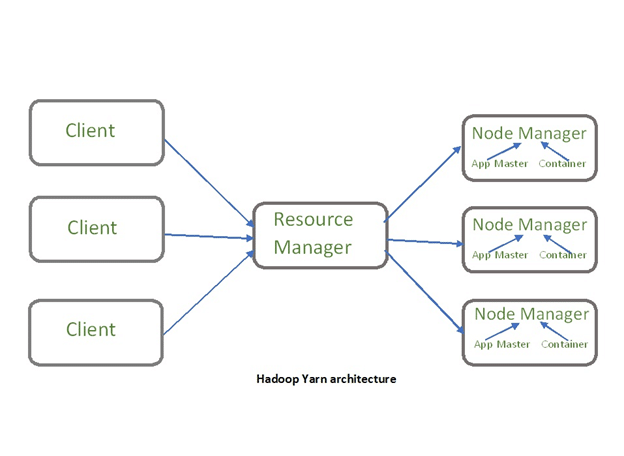
There is another component of Hadoop known as YARN. The idea of Yarn is to manage the resources and schedule/monitor jobs in Hadoop. Yarn has two main components, Resource Manager and Node Manager. The resource manager has the authority to allocate resources to various applications running in a cluster. The node manager is responsible for monitoring their resource usage (CPU, memory, disk) and reporting the same to the resource manager.
source: GeeksforGeeks
To understand the Hadoop architecture in detail, refer this blog –
Advantages of Hadoop
1. Economical – Hadoop is an open source Apache product, so it is free software. It has hardware cost associated with it. It is cost effective as it uses commodity hardware that are cheap machines to store its datasets and not any specialized machine.
2. Scalable – Hadoop distributes large data sets across multiple machines of a cluster. New machines can be easily added to the nodes of a cluster and can scale to thousands of nodes storing thousands of terabytes of data.
3. Fault Tolerance – Hadoop, by default, stores 3 replicas of data across the nodes of a cluster. So if any node goes down, data can be retrieved from other nodes.
4. Fast – Since Hadoop processes distributed data parallelly, it can process large data sets much faster than the traditional systems. It is highly suitable for batch processing of data.
5. Flexibility – Hadoop can store structured, semi-structured as well as unstructured data. It can accept data in the form of textfile, images, CSV files, XML files, emails, etc
6. Data Locality – Traditionally, to process the data, the data was fetched from the location it is stored, to the location where the application is submitted; however, in Hadoop, the processing application goes to the location of data to perform computation. This reduces the delay in processing of data.
7. Compatibility – Most of the emerging big data tools can be easily integrated with Hadoop like Spark. They use Hadoop as a storage platform and work as its processing system.
Hadoop Deployment Methods
1. Standalone Mode – It is the default mode of configuration of Hadoop. It doesn’t use hdfs instead, it uses a local file system for both input and output. It is useful for debugging and testing.
2. Pseudo-Distributed Mode – It is also called a single node cluster where both NameNode and DataNode resides in the same machine. All the daemons run on the same machine in this mode. It produces a fully functioning cluster on a single machine.
3. Fully Distributed Mode – Hadoop runs on multiple nodes wherein there are separate nodes for master and slave daemons. The data is distributed among a cluster of machines providing a production environment.
Hadoop Installation on Windows 10
As a beginner, you might feel reluctant in performing cloud computing which requires subscriptions. While you can install a virtual machine as well in your system, it requires allocation of a large amount of RAM for it to function smoothly else it would hang constantly.
You can install Hadoop in your system as well which would be a feasible way to learn Hadoop.
We will be installing single node pseudo-distributed hadoop cluster on windows 10.
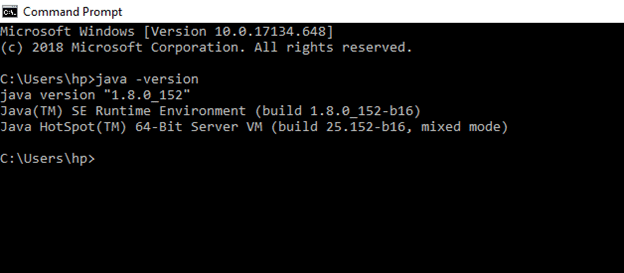
Prerequisite: To install Hadoop, you should have Java version 1.8 in your system.
Check your java version through this command on command prompt
If java is not installed in your system, then –
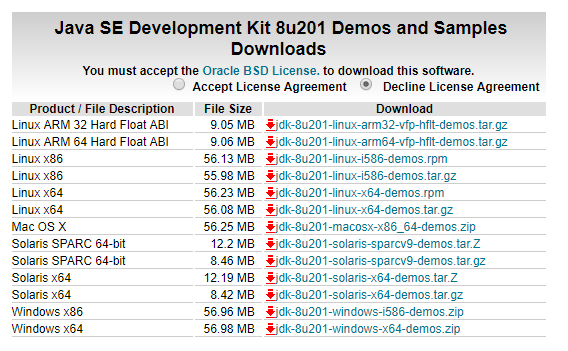
Go this link –
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Accept the license,
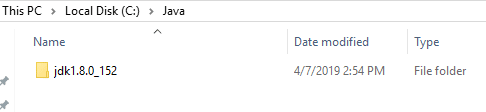
Download the file according to your operating system. Keep the java folder directly under the local disk directory (C:Javajdk1.8.0_152) rather than in Program Files (C:Program FilesJavajdk1.8.0_152) as it can create errors afterwards.
After downloading java version 1.8, download hadoop version 3.1 from this link –
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
Extract it to a folder.
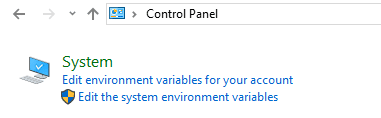
Setup System Environment Variables
Open control panel to edit the system environment variable
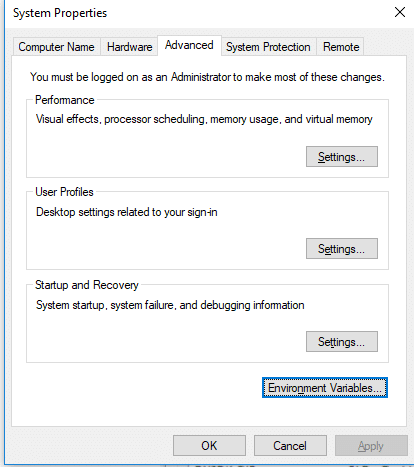
Go to environment variable in system properties
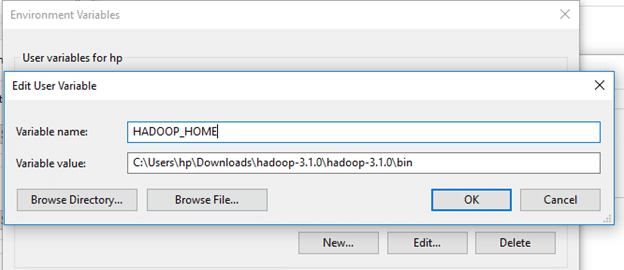
Create a new user variable. Put the Variable_name as HADOOP_HOME and Variable_value as the path of the bin folder where you extracted hadoop.
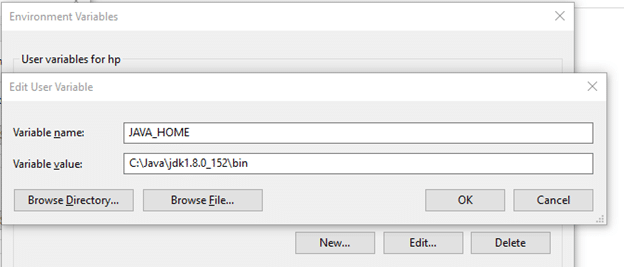
Likewise, create a new user variable with variable name as JAVA_HOME and variable value as the path of the bin folder in the Java directory.
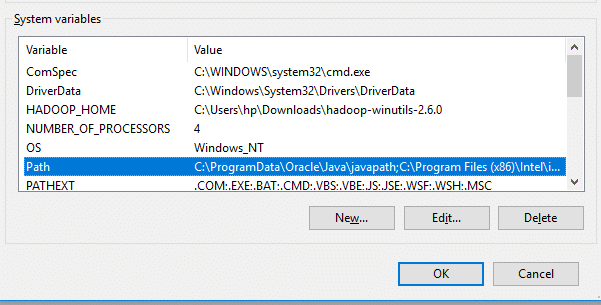
Now we need to set Hadoop bin directory and Java bin directory path in system variable path.
Edit Path in system variable
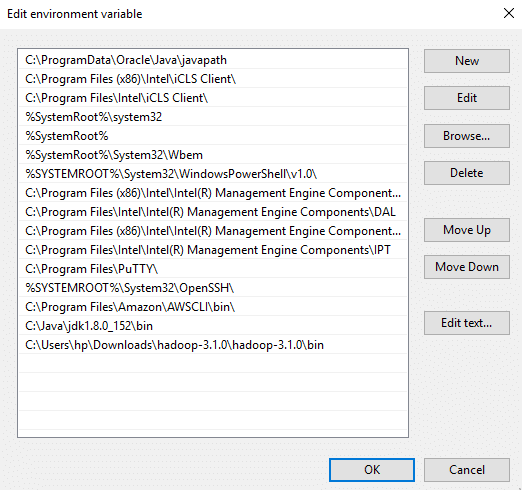
Click on New and add the bin directory path of Hadoop and Java in it.
Configurations
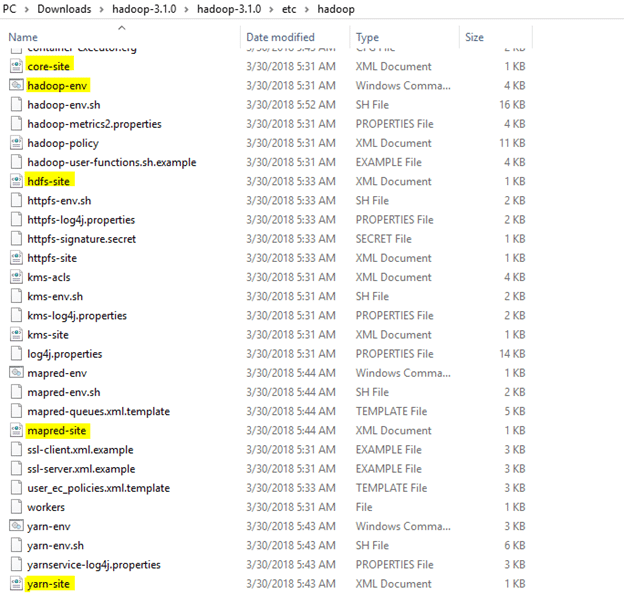
Now we need to edit some files located in the hadoop directory of the etc folder where we installed hadoop. The files that need to be edited have been highlighted.
1. Edit the file core-site.xml in the hadoop directory. Copy this xml property in the configuration in the file
|
|
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
|
2. Edit mapred-site.xml and copy this property in the cofiguration
|
|
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
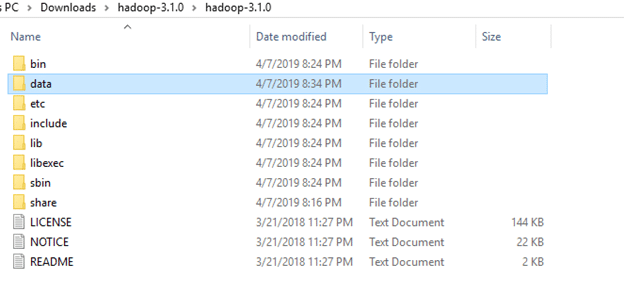
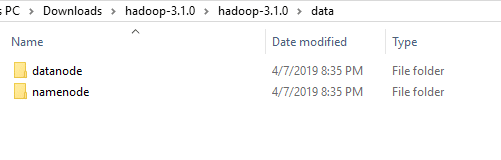
3. Create a folder ‘data’ in the hadoop directory
Create a folder with the name ‘datanode’ and a folder ‘namenode’ in this data directory
4. Edit the file hdfs-site.xml and add below property in the configuration
Note: The path of namenode and datanode across value would be the path of the datanode and namenode folders you just created.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>C:UsershpDownloadshadoop–3.1.0hadoop–3.1.0datanamenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> C:UsershpDownloadshadoop–3.1.0hadoop–3.1.0datadatanode</value>
</property>
</configuration>
|
5. Edit the file yarn-site.xml and add below property in the configuration
|
|
<configuration>
<property>
<name>yarn.nodemanager.aux–services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
|
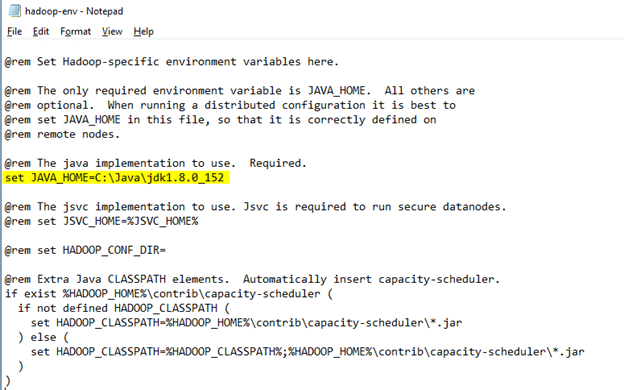
6. Edit hadoop-env.cmd and replace %JAVA_HOME% with the path of the java folder where your jdk 1.8 is installed
Hadoop needs windows OS specific files which does not come with default download of hadoop.
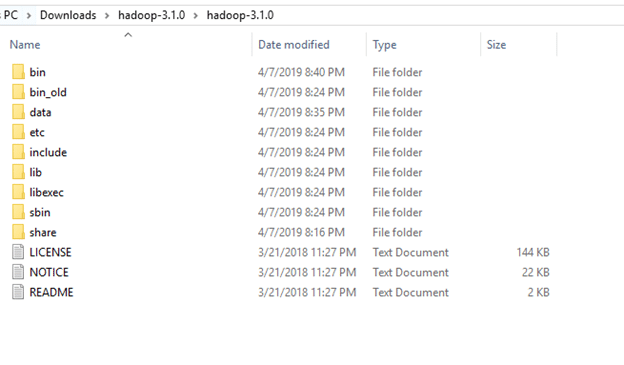
To include those files, replace the bin folder in hadoop directory with the bin folder provided in this github link.
https://github.com/s911415/apache-hadoop-3.1.0-winutils
Download it as zip file. Extract it and copy the bin folder in it. If you want to save the old bin folder, rename it like bin_old and paste the copied bin folder in that directory.
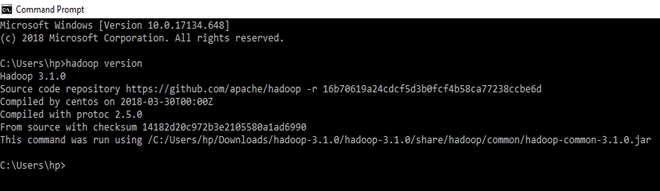
Check whether hadoop is successfully installed by running this command on cmd-
Since it doesn’t throw error and successfully shows the hadoop version, that means hadoop is successfully installed in the system.
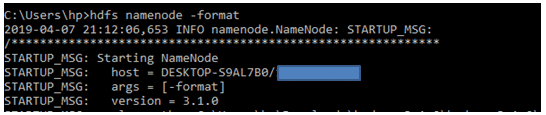
Format the NameNode
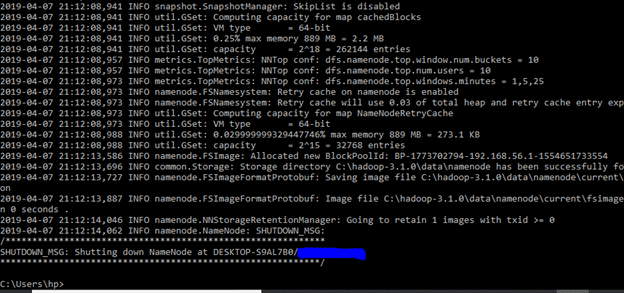
Formatting the NameNode is done once when hadoop is installed and not for running hadoop filesystem, else it will delete all the data inside HDFS. Run this command-
It would appear something like this –
Now change the directory in cmd to sbin folder of hadoop directory with this command,
(Note: Make sure you are writing the path as per your system)
|
|
cd C:UsershpDownloadshadoop–3.1.0hadoop–3.1.0sbin
|
Start namenode and datanode with this command –
Two more cmd windows will open for NameNode and DataNode
Now start yarn through this command-
Two more windows will open, one for yarn resource manager and one for yarn node manager.
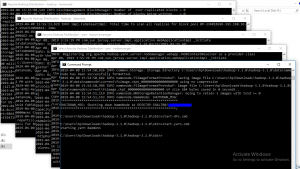
Note: Make sure all the 4 Apache Hadoop Distribution windows are up n running. If they are not running, you will see an error or a shutdown message. In that case, you need to debug the error.
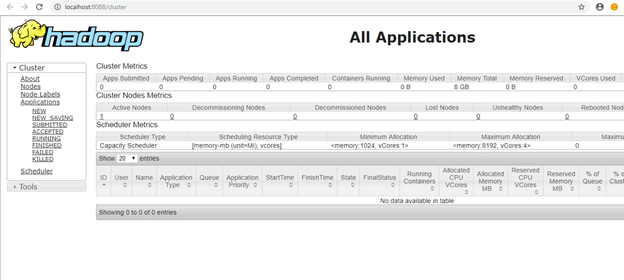
To access information about resource manager current jobs, successful and failed jobs, go to this link in browser-
http://localhost:8088/cluster
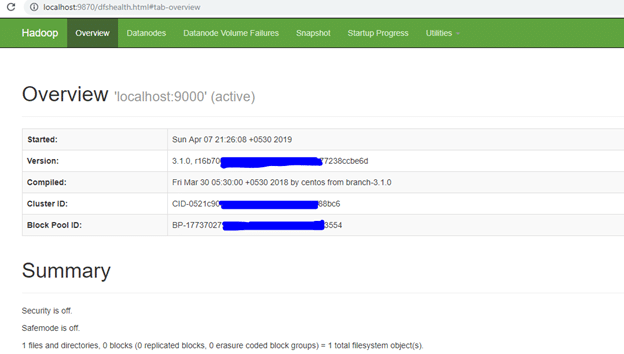
To check the details about the hdfs (namenode and datanode),
Open this link on browser-
http://localhost:9870/
Note: If you are using Hadoop version prior to 3.0.0 – Alpha 1, then use port http://localhost:50070/
Working with HDFS
I will be using a small text file in my local file system. To put it in hdfs using hdfs command line tool.
I will create a directory named ‘sample’ in my hadoop directory using the following command-

To verify if the directory is created in hdfs, we will use ‘ls’ command which will list the files present in hdfs –
Then I will copy a text file named ‘potatoes’ from my local file system to this folder that I just created in hdfs using copyFromLocal command-
|
|
hdfs dfs –copyFromLocal C:UsershpDownloadspotatoes.txt /sample
|
To verify if the file is copied to the folder, I will use ‘ls’ command by specifying the folder name which will read the list of files in that folder –
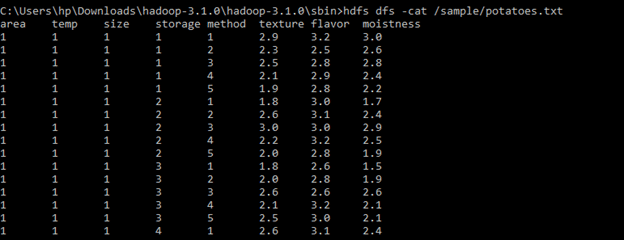
To view the contents of the file we copied, I will use cat command-
|
|
hdfs dfs –cat /sample/potatoes.txt
|
To Copy file from hdfs to local directory, I will use get command –
|
|
hdfs dfs –get /sample/potatoes.txt C:UsershpDesktoppriyanka
|
These were some basic hadoop commands. You can refer to this HDFS commands guide to learn more.
https://hadoop.apache.org/docs/r3.1.0/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
Hadoop MapReduce can be used to perform data processing activity. However, it possessed limitations due to which frameworks like Spark and Pig emerged and have gained popularity. A 200 lines of MapReduce code can be written with less than 10 lines of Pig code. Hadoop has various other components in its ecosystem like Hive, Sqoop, Oozie, and HBase. You can download these software as well in your windows system to perform data processing operations using cmd.
Follow this link, if you are looking to learn more about data science online.